Spaces:
No application file


No application file
Upload 32 files
Browse files- DenseAV/.gitignore +5 -0
- DenseAV/LICENSE +22 -0
- DenseAV/README.md +172 -0
- DenseAV/__init__.py +0 -0
- DenseAV/demo.ipynb +0 -0
- DenseAV/denseav/__init__.py +0 -0
- DenseAV/denseav/aggregators.py +517 -0
- DenseAV/denseav/aligners.py +300 -0
- DenseAV/denseav/configs/av_align.yaml +125 -0
- DenseAV/denseav/constants.py +12 -0
- DenseAV/denseav/data/AVDatasets.py +1249 -0
- DenseAV/denseav/data/__init__.py +0 -0
- DenseAV/denseav/data/make_tarballs.py +108 -0
- DenseAV/denseav/eval_utils.py +135 -0
- DenseAV/denseav/evaluate.py +87 -0
- DenseAV/denseav/featurizers/AudioMAE.py +570 -0
- DenseAV/denseav/featurizers/CAVMAE.py +1082 -0
- DenseAV/denseav/featurizers/CLIP.py +50 -0
- DenseAV/denseav/featurizers/DAVENet.py +162 -0
- DenseAV/denseav/featurizers/DINO.py +451 -0
- DenseAV/denseav/featurizers/DINOv2.py +49 -0
- DenseAV/denseav/featurizers/Hubert.py +70 -0
- DenseAV/denseav/featurizers/ImageBind.py +2033 -0
- DenseAV/denseav/featurizers/__init__.py +0 -0
- DenseAV/denseav/plotting.py +244 -0
- DenseAV/denseav/saved_models.py +262 -0
- DenseAV/denseav/shared.py +739 -0
- DenseAV/denseav/train.py +1222 -0
- DenseAV/gradio_app.py +196 -0
- DenseAV/hubconf.py +25 -0
- DenseAV/samples/puppies.mp4 +3 -0
- DenseAV/setup.py +37 -0
DenseAV/.gitignore
ADDED
|
@@ -0,0 +1,5 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Created by .ignore support plugin (hsz.mobi)
|
| 2 |
+
results/attention/*
|
| 3 |
+
results/features/*
|
| 4 |
+
|
| 5 |
+
.env
|
DenseAV/LICENSE
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) Mark Hamilton. All rights reserved.
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a
|
| 6 |
+
copy of this software and associated documentation files (the
|
| 7 |
+
"Software"), to deal in the Software without restriction, including
|
| 8 |
+
without limitation the rights to use, copy, modify, merge, publish,
|
| 9 |
+
distribute, sublicense, and/or sell copies of the Software, and to
|
| 10 |
+
permit persons to whom the Software is furnished to do so, subject to
|
| 11 |
+
the following conditions:
|
| 12 |
+
|
| 13 |
+
The above copyright notice and this permission notice shall be included
|
| 14 |
+
in all copies or substantial portions of the Software.
|
| 15 |
+
|
| 16 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS
|
| 17 |
+
OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
|
| 18 |
+
MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND
|
| 19 |
+
NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE
|
| 20 |
+
LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION
|
| 21 |
+
OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION
|
| 22 |
+
WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
|
DenseAV/README.md
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
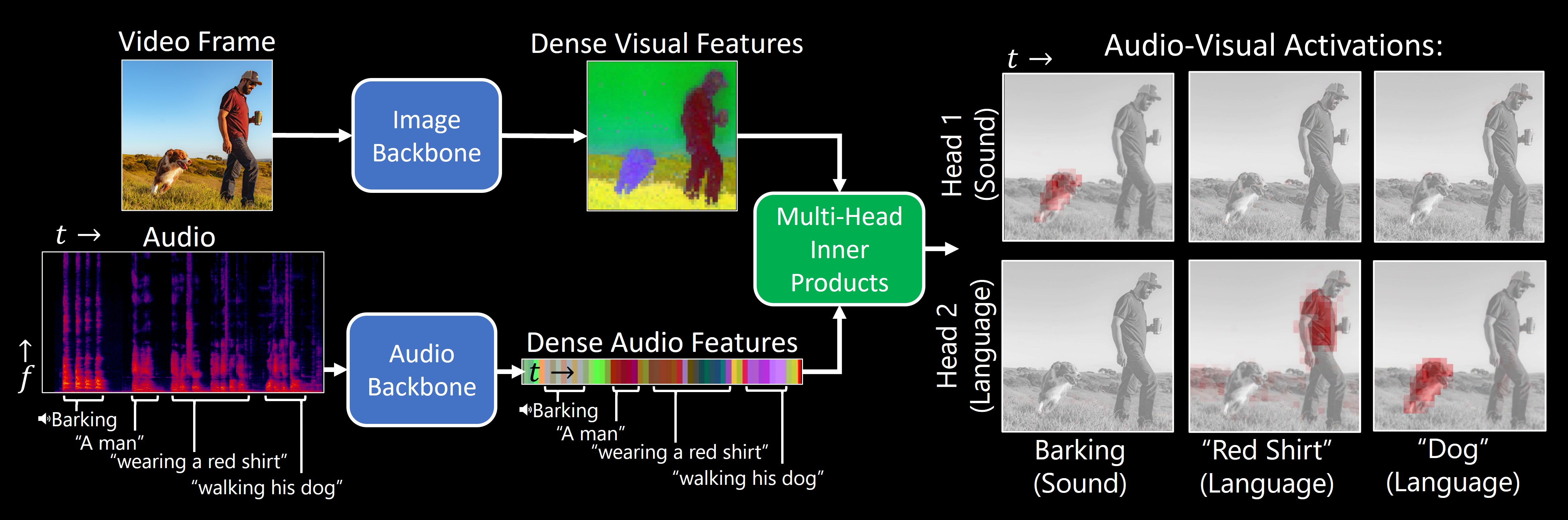
# Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language
|
| 2 |
+
### CVPR 2024
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
[](https://aka.ms/denseav) [](https://arxiv.org/abs/2406.05629) [](https://colab.research.google.com/github/mhamilton723/DenseAV/blob/main/demo.ipynb)
|
| 6 |
+
|
| 7 |
+
[](https://huggingface.co/spaces/mhamilton723/DenseAV)
|
| 8 |
+
|
| 9 |
+
[//]: # ([](https://huggingface.co/papers/2403.10516))
|
| 10 |
+
[](https://paperswithcode.com/sota/speech-prompted-semantic-segmentation-on?p=separating-the-chirp-from-the-chat-self)
|
| 11 |
+
[](https://paperswithcode.com/sota/sound-prompted-semantic-segmentation-on?p=separating-the-chirp-from-the-chat-self)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
[Mark Hamilton](https://mhamilton.net/),
|
| 15 |
+
[Andrew Zisserman](https://www.robots.ox.ac.uk/~az/),
|
| 16 |
+
[John R. Hershey](https://research.google/people/john-hershey/),
|
| 17 |
+
[William T. Freeman](https://billf.mit.edu/about/bio)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
**TL;DR**:Our model, DenseAV, learns the meaning of words and the location of sounds (visual grounding) without supervision or text.
|
| 22 |
+
|
| 23 |
+
https://github.com/mhamilton723/DenseAV/assets/6456637/ba908ab5-9618-42f9-8d7a-30ecb009091f
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
## Contents
|
| 27 |
+
<!--ts-->
|
| 28 |
+
* [Install](#install)
|
| 29 |
+
* [Model Zoo](#model-zoo)
|
| 30 |
+
* [Getting Datasets](#getting-atasets)
|
| 31 |
+
* [Evaluate Models](#evaluate-models)
|
| 32 |
+
* [Train a Model](#train-model)
|
| 33 |
+
* [Local Gradio Demo](#local-gradio-demo)
|
| 34 |
+
* [Coming Soon](coming-soon)
|
| 35 |
+
* [Citation](#citation)
|
| 36 |
+
* [Contact](#contact)
|
| 37 |
+
<!--te-->
|
| 38 |
+
|
| 39 |
+
## Install
|
| 40 |
+
|
| 41 |
+
To use DenseAV locally clone the repository:
|
| 42 |
+
|
| 43 |
+
```shell script
|
| 44 |
+
git clone https://github.com/mhamilton723/DenseAV.git
|
| 45 |
+
cd DenseAV
|
| 46 |
+
pip install -e .
|
| 47 |
+
```
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
## Model Zoo
|
| 51 |
+
|
| 52 |
+
To see examples of pretrained model usage please see our [Collab notebook](https://colab.research.google.com/github/mhamilton723/DenseAV/blob/main/demo.ipynb). We currently supply the following pretrained models:
|
| 53 |
+
|
| 54 |
+
| Model Name | Checkpoint | Torch Hub Repository | Torch Hub Name |
|
| 55 |
+
|-------------------------------|----------------------------------------------------------------------------------------------------------------------------------|----------------------|--------------------|
|
| 56 |
+
| Sound | [Download](https://marhamilresearch4.blob.core.windows.net/denseav-public/hub/denseav_sound.ckpt) | mhamilton723/DenseAV | sound |
|
| 57 |
+
| Language | [Download](https://marhamilresearch4.blob.core.windows.net/denseav-public/hub/denseav_language.ckpt) | mhamilton723/DenseAV | language |
|
| 58 |
+
| Sound + Language (Two Headed) | [Download](https://marhamilresearch4.blob.core.windows.net/denseav-public/hub/denseav_2head.ckpt) | mhamilton723/DenseAV | sound_and_language |
|
| 59 |
+
|
| 60 |
+
For example, to load the model trained on both sound and language:
|
| 61 |
+
|
| 62 |
+
```python
|
| 63 |
+
model = torch.hub.load("mhamilton723/DenseAV", 'sound_and_language')
|
| 64 |
+
```
|
| 65 |
+
|
| 66 |
+
### Load from HuggingFace
|
| 67 |
+
|
| 68 |
+
```python
|
| 69 |
+
from denseav.train import LitAVAligner
|
| 70 |
+
|
| 71 |
+
model1 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-sound")
|
| 72 |
+
model2 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-language")
|
| 73 |
+
model3 = LitAVAligner.from_pretrained("mhamilton723/DenseAV-sound-language")
|
| 74 |
+
```
|
| 75 |
+
|
| 76 |
+
|
| 77 |
+
## Getting Datasets
|
| 78 |
+
|
| 79 |
+
Our code assumes that all data lives in a common directory on your system, in these examples we use `/path/to/your/data`. Our code will often reference this directory as the `data_root`
|
| 80 |
+
|
| 81 |
+
### Speech and Sound Prompted ADE20K
|
| 82 |
+
|
| 83 |
+
To download our new Speech and Sound prompted ADE20K Dataset:
|
| 84 |
+
|
| 85 |
+
```bash
|
| 86 |
+
cd /path/to/your/data
|
| 87 |
+
wget https://marhamilresearch4.blob.core.windows.net/denseav-public/datasets/ADE20KSoundPrompted.zip
|
| 88 |
+
unzip ADE20KSoundPrompted.zip
|
| 89 |
+
wget https://marhamilresearch4.blob.core.windows.net/denseav-public/datasets/ADE20KSpeechPrompted.zip
|
| 90 |
+
unzip ADE20KSpeechPrompted.zip
|
| 91 |
+
```
|
| 92 |
+
|
| 93 |
+
### Places Audio
|
| 94 |
+
|
| 95 |
+
First download the places audio dataset from its [original source](https://groups.csail.mit.edu/sls/downloads/placesaudio/downloads.cgi).
|
| 96 |
+
|
| 97 |
+
To run the code the data will need to be processed to be of the form:
|
| 98 |
+
|
| 99 |
+
```
|
| 100 |
+
[Instructions coming soon]
|
| 101 |
+
```
|
| 102 |
+
|
| 103 |
+
### Audioset
|
| 104 |
+
|
| 105 |
+
Because of copyright issues we cannot make [Audioset](https://research.google.com/audioset/dataset/index.html) easily availible to download.
|
| 106 |
+
First download this dataset through appropriate means. [This other project](https://github.com/ktonal/audioset-downloader) appears to make this simple.
|
| 107 |
+
|
| 108 |
+
To run the code the data will need to be processed to be of the form:
|
| 109 |
+
|
| 110 |
+
```
|
| 111 |
+
[Instructions coming soon]
|
| 112 |
+
```
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
## Evaluate Models
|
| 116 |
+
|
| 117 |
+
To evaluate a trained model first clone the repository for
|
| 118 |
+
[local development](#local-development). Then run
|
| 119 |
+
|
| 120 |
+
```shell
|
| 121 |
+
cd featup
|
| 122 |
+
python evaluate.py
|
| 123 |
+
```
|
| 124 |
+
|
| 125 |
+
After evaluation, see the results in tensorboard's hparams tab.
|
| 126 |
+
|
| 127 |
+
```shell
|
| 128 |
+
cd ../logs/evaluate
|
| 129 |
+
tensorboard --logdir .
|
| 130 |
+
```
|
| 131 |
+
|
| 132 |
+
Then visit [https://localhost:6006](https://localhost:6006) and click on hparams to browse results. We report "advanced" speech metrics and "basic" sound metrics in our paper.
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
## Train a Model
|
| 136 |
+
|
| 137 |
+
```shell
|
| 138 |
+
cd denseav
|
| 139 |
+
python train.py
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
## Local Gradio Demo
|
| 143 |
+
|
| 144 |
+
To run our [HuggingFace Spaces hosted DenseAV demo](https://huggingface.co/spaces/mhamilton723/FeatUp) locally first install DenseAV for local development. Then run:
|
| 145 |
+
|
| 146 |
+
```shell
|
| 147 |
+
python gradio_app.py
|
| 148 |
+
```
|
| 149 |
+
|
| 150 |
+
Wait a few seconds for the demo to spin up, then navigate to [http://localhost:7860/](http://localhost:7860/) to view the demo.
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
## Coming Soon:
|
| 154 |
+
|
| 155 |
+
- Bigger models!
|
| 156 |
+
|
| 157 |
+
## Citation
|
| 158 |
+
|
| 159 |
+
```
|
| 160 |
+
@misc{hamilton2024separating,
|
| 161 |
+
title={Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language},
|
| 162 |
+
author={Mark Hamilton and Andrew Zisserman and John R. Hershey and William T. Freeman},
|
| 163 |
+
year={2024},
|
| 164 |
+
eprint={2406.05629},
|
| 165 |
+
archivePrefix={arXiv},
|
| 166 |
+
primaryClass={cs.CV}
|
| 167 |
+
}
|
| 168 |
+
```
|
| 169 |
+
|
| 170 |
+
## Contact
|
| 171 |
+
|
| 172 |
+
For feedback, questions, or press inquiries please contact [Mark Hamilton](mailto:[email protected])
|
DenseAV/__init__.py
ADDED
|
File without changes
|
DenseAV/demo.ipynb
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
DenseAV/denseav/__init__.py
ADDED
|
File without changes
|
DenseAV/denseav/aggregators.py
ADDED
|
@@ -0,0 +1,517 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from abc import abstractmethod
|
| 2 |
+
|
| 3 |
+
import math
|
| 4 |
+
import torch
|
| 5 |
+
import torch.nn as nn
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
from tqdm import tqdm
|
| 8 |
+
|
| 9 |
+
from denseav.constants import *
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
@torch.jit.script
|
| 13 |
+
def masked_mean(x: torch.Tensor, mask: torch.Tensor, dim: int):
|
| 14 |
+
mask = mask.to(x)
|
| 15 |
+
return (x * mask).sum(dim, keepdim=True) / mask.sum(dim, keepdim=True).clamp_min(.001)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
@torch.jit.script
|
| 19 |
+
def masked_max(x: torch.Tensor, mask: torch.Tensor, dim: int):
|
| 20 |
+
mask = mask.to(torch.bool)
|
| 21 |
+
eps = 1e7
|
| 22 |
+
# eps = torch.finfo(x.dtype).max
|
| 23 |
+
return (x - (~mask) * eps).max(dim, keepdim=True).values
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def masked_lse(x: torch.Tensor, mask: torch.Tensor, dim: int, temp):
|
| 27 |
+
x = x.to(torch.float32)
|
| 28 |
+
mask = mask.to(torch.float32)
|
| 29 |
+
x_masked = (x - (1 - mask) * torch.finfo(x.dtype).max)
|
| 30 |
+
return (torch.logsumexp(x_masked * temp, dim, keepdim=True) - torch.log(mask.sum(dim, keepdim=True))) / temp
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
class BaseAggregator(torch.nn.Module):
|
| 34 |
+
|
| 35 |
+
def __init__(self, nonneg_sim, mask_silence, num_heads, head_agg, use_cls):
|
| 36 |
+
super().__init__()
|
| 37 |
+
|
| 38 |
+
self.nonneg_sim = nonneg_sim
|
| 39 |
+
self.mask_silence = mask_silence
|
| 40 |
+
self.num_heads = num_heads
|
| 41 |
+
self.head_agg = head_agg
|
| 42 |
+
self.use_cls = use_cls
|
| 43 |
+
|
| 44 |
+
@abstractmethod
|
| 45 |
+
def _agg_sim(self, sim, mask):
|
| 46 |
+
pass
|
| 47 |
+
|
| 48 |
+
def prepare_sims(self, sim, mask, agg_sim, agg_heads):
|
| 49 |
+
sim_size = sim.shape
|
| 50 |
+
assert len(mask.shape) == 2
|
| 51 |
+
assert len(sim_size) in {6, 7}, f"sim has wrong number of dimensions: {sim.shape}"
|
| 52 |
+
pairwise = len(sim_size) == 6
|
| 53 |
+
|
| 54 |
+
if self.mask_silence:
|
| 55 |
+
mask = mask
|
| 56 |
+
else:
|
| 57 |
+
mask = torch.ones_like(mask)
|
| 58 |
+
|
| 59 |
+
if self.nonneg_sim:
|
| 60 |
+
sim = sim.clamp_min(0)
|
| 61 |
+
|
| 62 |
+
if pairwise:
|
| 63 |
+
head_dim = 1
|
| 64 |
+
else:
|
| 65 |
+
head_dim = 2
|
| 66 |
+
|
| 67 |
+
if self.head_agg == "max_elementwise" and agg_heads:
|
| 68 |
+
sim = sim.max(head_dim, keepdim=True).values
|
| 69 |
+
|
| 70 |
+
if agg_sim:
|
| 71 |
+
sim = self._agg_sim(sim, mask)
|
| 72 |
+
|
| 73 |
+
if agg_heads:
|
| 74 |
+
if self.head_agg == "sum" or self.head_agg == "max_elementwise":
|
| 75 |
+
sim = sim.sum(head_dim)
|
| 76 |
+
elif self.head_agg == "max":
|
| 77 |
+
sim = sim.max(head_dim).values
|
| 78 |
+
else:
|
| 79 |
+
raise ValueError(f"Unknown head_agg: {self.head_agg}")
|
| 80 |
+
|
| 81 |
+
return sim
|
| 82 |
+
|
| 83 |
+
def _get_full_sims(self, preds, raw, agg_sim, agg_heads):
|
| 84 |
+
if agg_sim or agg_heads or raw:
|
| 85 |
+
assert (agg_sim or agg_heads) != raw, "Cannot have raw on at the same time as agg_sim or agg_heads"
|
| 86 |
+
|
| 87 |
+
audio_feats = preds[AUDIO_FEATS]
|
| 88 |
+
audio_mask = preds[AUDIO_MASK]
|
| 89 |
+
image_feats = preds[IMAGE_FEATS]
|
| 90 |
+
|
| 91 |
+
b1, c2, f, t1 = audio_feats.shape
|
| 92 |
+
b2, t2 = audio_mask.shape
|
| 93 |
+
d, c1, h, w = image_feats.shape
|
| 94 |
+
assert b1 == b2 and c1 == c2 and t1 == t2
|
| 95 |
+
assert c1 % self.num_heads == 0
|
| 96 |
+
new_c = c1 // self.num_heads
|
| 97 |
+
audio_feats = audio_feats.reshape(b1, self.num_heads, new_c, f, t1)
|
| 98 |
+
image_feats = image_feats.reshape(d, self.num_heads, new_c, h, w)
|
| 99 |
+
raw_sims = torch.einsum(
|
| 100 |
+
"akcft,vkchw->avkhwft",
|
| 101 |
+
audio_feats.to(torch.float32),
|
| 102 |
+
image_feats.to(torch.float32))
|
| 103 |
+
|
| 104 |
+
if self.use_cls:
|
| 105 |
+
audio_cls = preds[AUDIO_CLS].reshape(b1, self.num_heads, new_c)
|
| 106 |
+
image_cls = preds[IMAGE_CLS].reshape(d, self.num_heads, new_c)
|
| 107 |
+
cls_sims = torch.einsum(
|
| 108 |
+
"akc,vkc->avk",
|
| 109 |
+
audio_cls.to(torch.float32),
|
| 110 |
+
image_cls.to(torch.float32))
|
| 111 |
+
raw_sims += cls_sims.reshape(b1, d, self.num_heads, 1, 1, 1, 1)
|
| 112 |
+
|
| 113 |
+
if raw:
|
| 114 |
+
return raw_sims
|
| 115 |
+
else:
|
| 116 |
+
return self.prepare_sims(raw_sims, audio_mask, agg_sim, agg_heads)
|
| 117 |
+
|
| 118 |
+
def get_pairwise_sims(self, preds, raw, agg_sim, agg_heads):
|
| 119 |
+
if agg_sim or agg_heads or raw:
|
| 120 |
+
assert (agg_sim or agg_heads) != raw, "Cannot have raw on at the same time as agg_sim or agg_heads"
|
| 121 |
+
|
| 122 |
+
audio_feats = preds[AUDIO_FEATS]
|
| 123 |
+
audio_mask = preds[AUDIO_MASK]
|
| 124 |
+
image_feats = preds[IMAGE_FEATS]
|
| 125 |
+
|
| 126 |
+
a1, c1, f, t1 = audio_feats.shape
|
| 127 |
+
a2, t2 = audio_mask.shape
|
| 128 |
+
|
| 129 |
+
assert c1 % self.num_heads == 0
|
| 130 |
+
new_c = c1 // self.num_heads
|
| 131 |
+
audio_feats = audio_feats.reshape(a1, self.num_heads, new_c, f, t1)
|
| 132 |
+
|
| 133 |
+
if len(image_feats.shape) == 5:
|
| 134 |
+
print("Using similarity for video, should only be called during plotting")
|
| 135 |
+
v, vt, c2, h, w = image_feats.shape
|
| 136 |
+
image_feats = image_feats.reshape(v, vt, self.num_heads, new_c, h, w)
|
| 137 |
+
raw_sims = torch.einsum(
|
| 138 |
+
"bkcft,bskchw,bt->bskhwft",
|
| 139 |
+
audio_feats.to(torch.float32),
|
| 140 |
+
image_feats.to(torch.float32),
|
| 141 |
+
audio_mask.to(torch.float32))
|
| 142 |
+
|
| 143 |
+
if self.use_cls:
|
| 144 |
+
audio_cls = preds[AUDIO_CLS].reshape(v, self.num_heads, new_c)
|
| 145 |
+
image_cls = preds[IMAGE_CLS].reshape(v, vt, self.num_heads, new_c)
|
| 146 |
+
cls_sims = torch.einsum(
|
| 147 |
+
"bkc,bskc->bsk",
|
| 148 |
+
audio_cls.to(torch.float32),
|
| 149 |
+
image_cls.to(torch.float32))
|
| 150 |
+
raw_sims += cls_sims.reshape(v, vt, self.num_heads, 1, 1, 1, 1)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
elif len(image_feats.shape) == 4:
|
| 154 |
+
v, c2, h, w = image_feats.shape
|
| 155 |
+
image_feats = image_feats.reshape(v, self.num_heads, new_c, h, w)
|
| 156 |
+
raw_sims = torch.einsum(
|
| 157 |
+
"bkcft,bkchw,bt->bkhwft",
|
| 158 |
+
audio_feats.to(torch.float32),
|
| 159 |
+
image_feats.to(torch.float32),
|
| 160 |
+
audio_mask.to(torch.float32))
|
| 161 |
+
|
| 162 |
+
if self.use_cls:
|
| 163 |
+
audio_cls = preds[AUDIO_CLS].reshape(v, self.num_heads, new_c)
|
| 164 |
+
image_cls = preds[IMAGE_CLS].reshape(v, self.num_heads, new_c)
|
| 165 |
+
cls_sims = torch.einsum(
|
| 166 |
+
"bkc,bkc->bk",
|
| 167 |
+
audio_cls.to(torch.float32),
|
| 168 |
+
image_cls.to(torch.float32))
|
| 169 |
+
raw_sims += cls_sims.reshape(v, self.num_heads, 1, 1, 1, 1)
|
| 170 |
+
else:
|
| 171 |
+
raise ValueError(f"Improper image shape: {image_feats.shape}")
|
| 172 |
+
|
| 173 |
+
assert a1 == a2 and c2 == c2 and t1 == t2
|
| 174 |
+
|
| 175 |
+
if raw:
|
| 176 |
+
return raw_sims
|
| 177 |
+
else:
|
| 178 |
+
return self.prepare_sims(raw_sims, audio_mask, agg_sim, agg_heads)
|
| 179 |
+
|
| 180 |
+
def forward(self, preds, agg_heads):
|
| 181 |
+
return self._get_full_sims(
|
| 182 |
+
preds, raw=False, agg_sim=True, agg_heads=agg_heads)
|
| 183 |
+
|
| 184 |
+
def forward_batched(self, preds, agg_heads, batch_size):
|
| 185 |
+
new_preds = {k: v for k, v in preds.items()}
|
| 186 |
+
big_image_feats = new_preds.pop(IMAGE_FEATS)
|
| 187 |
+
if self.use_cls:
|
| 188 |
+
big_image_cls = new_preds.pop(IMAGE_CLS)
|
| 189 |
+
|
| 190 |
+
n = big_image_feats.shape[0]
|
| 191 |
+
n_steps = math.ceil(n / batch_size)
|
| 192 |
+
outputs = []
|
| 193 |
+
for step in tqdm(range(n_steps), "Calculating Sim", leave=False):
|
| 194 |
+
new_preds[IMAGE_FEATS] = big_image_feats[step * batch_size:(step + 1) * batch_size].cuda()
|
| 195 |
+
if self.use_cls:
|
| 196 |
+
new_preds[IMAGE_CLS] = big_image_cls[step * batch_size:(step + 1) * batch_size].cuda()
|
| 197 |
+
|
| 198 |
+
sim = self.forward(new_preds, agg_heads=agg_heads)
|
| 199 |
+
outputs.append(sim.cpu())
|
| 200 |
+
return torch.cat(outputs, dim=1)
|
| 201 |
+
|
| 202 |
+
|
| 203 |
+
class ImageThenAudioAggregator(BaseAggregator):
|
| 204 |
+
|
| 205 |
+
def __init__(self, image_agg_type, audio_agg_type, nonneg_sim, mask_silence, num_heads, head_agg, use_cls):
|
| 206 |
+
super().__init__(nonneg_sim, mask_silence, num_heads, head_agg, use_cls)
|
| 207 |
+
if image_agg_type == "max":
|
| 208 |
+
self.image_agg = lambda x, dim: x.max(dim=dim, keepdim=True).values
|
| 209 |
+
elif image_agg_type == "avg":
|
| 210 |
+
self.image_agg = lambda x, dim: x.mean(dim=dim, keepdim=True)
|
| 211 |
+
else:
|
| 212 |
+
raise ValueError(f"Unknown image_agg_type {image_agg_type}")
|
| 213 |
+
|
| 214 |
+
if audio_agg_type == "max":
|
| 215 |
+
self.time_agg = masked_max
|
| 216 |
+
elif audio_agg_type == "avg":
|
| 217 |
+
self.time_agg = masked_mean
|
| 218 |
+
else:
|
| 219 |
+
raise ValueError(f"Unknown audio_agg_type {audio_agg_type}")
|
| 220 |
+
|
| 221 |
+
self.freq_agg = lambda x, dim: x.mean(dim=dim, keepdim=True)
|
| 222 |
+
|
| 223 |
+
def _agg_sim(self, sim, mask):
|
| 224 |
+
sim_shape = sim.shape
|
| 225 |
+
new_mask_shape = [1] * len(sim_shape)
|
| 226 |
+
new_mask_shape[0] = sim_shape[0]
|
| 227 |
+
new_mask_shape[-1] = sim_shape[-1]
|
| 228 |
+
mask = mask.reshape(new_mask_shape)
|
| 229 |
+
sim = self.image_agg(sim, -3)
|
| 230 |
+
sim = self.image_agg(sim, -4)
|
| 231 |
+
sim = self.freq_agg(sim, -2)
|
| 232 |
+
sim = self.time_agg(sim, mask, -1)
|
| 233 |
+
return sim.squeeze(-1).squeeze(-1).squeeze(-1).squeeze(-1)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
class PairedAggregator(BaseAggregator):
|
| 237 |
+
|
| 238 |
+
def __init__(self, nonneg_sim, mask_silence, num_heads, head_agg, use_cls):
|
| 239 |
+
super().__init__(nonneg_sim, mask_silence, num_heads, head_agg, use_cls)
|
| 240 |
+
self.image_agg_max = lambda x, dim: x.max(dim=dim, keepdim=True).values
|
| 241 |
+
self.image_agg_mean = lambda x, dim: x.mean(dim=dim, keepdim=True)
|
| 242 |
+
|
| 243 |
+
self.time_agg_max = masked_max
|
| 244 |
+
self.time_agg_mean = masked_mean
|
| 245 |
+
|
| 246 |
+
self.freq_agg = lambda x, dim: x.mean(dim=dim, keepdim=True)
|
| 247 |
+
|
| 248 |
+
def _agg_sim(self, sim, mask):
|
| 249 |
+
sim_shape = sim.shape
|
| 250 |
+
new_mask_shape = [1] * len(sim_shape)
|
| 251 |
+
new_mask_shape[0] = sim_shape[0]
|
| 252 |
+
new_mask_shape[-1] = sim_shape[-1]
|
| 253 |
+
mask = mask.reshape(new_mask_shape)
|
| 254 |
+
|
| 255 |
+
sim_1 = self.image_agg_max(sim, -3)
|
| 256 |
+
sim_1 = self.image_agg_max(sim_1, -4)
|
| 257 |
+
sim_1 = self.freq_agg(sim_1, -2)
|
| 258 |
+
sim_1 = self.time_agg_mean(sim_1, mask, -1)
|
| 259 |
+
|
| 260 |
+
sim_2 = self.freq_agg(sim, -2)
|
| 261 |
+
sim_2 = self.time_agg_max(sim_2, mask, -1)
|
| 262 |
+
sim_2 = self.image_agg_mean(sim_2, -3)
|
| 263 |
+
sim_2 = self.image_agg_mean(sim_2, -4)
|
| 264 |
+
|
| 265 |
+
sim = 1 / 2 * (sim_1 + sim_2)
|
| 266 |
+
|
| 267 |
+
return sim.squeeze(-1).squeeze(-1).squeeze(-1).squeeze(-1)
|
| 268 |
+
|
| 269 |
+
|
| 270 |
+
|
| 271 |
+
class CAVMAEAggregator(BaseAggregator):
|
| 272 |
+
|
| 273 |
+
def __init__(self, *args, **kwargs):
|
| 274 |
+
super().__init__(False, False, 1, "sum", False)
|
| 275 |
+
|
| 276 |
+
def _get_full_sims(self, preds, raw, agg_sim, agg_heads):
|
| 277 |
+
if agg_sim:
|
| 278 |
+
audio_feats = preds[AUDIO_FEATS]
|
| 279 |
+
image_feats = preds[IMAGE_FEATS]
|
| 280 |
+
pool_audio_feats = F.normalize(audio_feats.mean(dim=[-1, -2]), dim=1)
|
| 281 |
+
pool_image_feats = F.normalize(image_feats.mean(dim=[-1, -2]), dim=1)
|
| 282 |
+
sims = torch.einsum(
|
| 283 |
+
"bc,dc->bd",
|
| 284 |
+
pool_audio_feats.to(torch.float32),
|
| 285 |
+
pool_image_feats.to(torch.float32))
|
| 286 |
+
if agg_heads:
|
| 287 |
+
return sims
|
| 288 |
+
else:
|
| 289 |
+
return sims.unsqueeze(-1)
|
| 290 |
+
|
| 291 |
+
else:
|
| 292 |
+
return BaseAggregator._get_full_sims(self, preds, raw, agg_sim, agg_heads)
|
| 293 |
+
|
| 294 |
+
def get_pairwise_sims(self, preds, raw, agg_sim, agg_heads):
|
| 295 |
+
if agg_sim:
|
| 296 |
+
audio_feats = preds[AUDIO_FEATS]
|
| 297 |
+
image_feats = preds[IMAGE_FEATS]
|
| 298 |
+
pool_audio_feats = F.normalize(audio_feats.mean(dim=[-1, -2]), dim=1)
|
| 299 |
+
pool_image_feats = F.normalize(image_feats.mean(dim=[-1, -2]), dim=1)
|
| 300 |
+
sims = torch.einsum(
|
| 301 |
+
"bc,bc->b",
|
| 302 |
+
pool_audio_feats.to(torch.float32),
|
| 303 |
+
pool_image_feats.to(torch.float32))
|
| 304 |
+
if agg_heads:
|
| 305 |
+
return sims
|
| 306 |
+
else:
|
| 307 |
+
return sims.unsqueeze(-1)
|
| 308 |
+
|
| 309 |
+
else:
|
| 310 |
+
return BaseAggregator.get_pairwise_sims(self, preds, raw, agg_sim, agg_heads)
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
class ImageBindAggregator(BaseAggregator):
|
| 314 |
+
|
| 315 |
+
def __init__(self, num_heads, *args, **kwargs):
|
| 316 |
+
super().__init__(False, False, num_heads, "sum", False)
|
| 317 |
+
|
| 318 |
+
def _get_full_sims(self, preds, raw, agg_sim, agg_heads):
|
| 319 |
+
if agg_sim:
|
| 320 |
+
sims = torch.einsum(
|
| 321 |
+
"bc,dc->bd",
|
| 322 |
+
preds[AUDIO_CLS].to(torch.float32),
|
| 323 |
+
preds[IMAGE_CLS].to(torch.float32))
|
| 324 |
+
if agg_heads:
|
| 325 |
+
return sims
|
| 326 |
+
else:
|
| 327 |
+
sims = sims.unsqueeze(-1)
|
| 328 |
+
return sims.repeat(*([1] * (sims.dim() - 1)), self.num_heads)
|
| 329 |
+
|
| 330 |
+
|
| 331 |
+
else:
|
| 332 |
+
return BaseAggregator._get_full_sims(self, preds, raw, agg_sim, agg_heads)
|
| 333 |
+
|
| 334 |
+
def get_pairwise_sims(self, preds, raw, agg_sim, agg_heads):
|
| 335 |
+
if agg_sim:
|
| 336 |
+
sims = torch.einsum(
|
| 337 |
+
"bc,dc->b",
|
| 338 |
+
preds[AUDIO_CLS].to(torch.float32),
|
| 339 |
+
preds[IMAGE_CLS].to(torch.float32))
|
| 340 |
+
if agg_heads:
|
| 341 |
+
return sims
|
| 342 |
+
else:
|
| 343 |
+
sims = sims.unsqueeze(-1)
|
| 344 |
+
return sims.repeat(*([1] * (sims.dim() - 1)), self.num_heads)
|
| 345 |
+
|
| 346 |
+
else:
|
| 347 |
+
return BaseAggregator.get_pairwise_sims(self, preds, raw, agg_sim, agg_heads)
|
| 348 |
+
|
| 349 |
+
def forward_batched(self, preds, agg_heads, batch_size):
|
| 350 |
+
return self.forward(preds, agg_heads)
|
| 351 |
+
|
| 352 |
+
|
| 353 |
+
class SimPool(nn.Module):
|
| 354 |
+
def __init__(self, dim, num_heads=1, qkv_bias=False, qk_scale=None, gamma=None, use_beta=False):
|
| 355 |
+
super().__init__()
|
| 356 |
+
self.num_heads = num_heads
|
| 357 |
+
head_dim = dim // num_heads
|
| 358 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 359 |
+
|
| 360 |
+
self.norm_patches = nn.LayerNorm(dim, eps=1e-6)
|
| 361 |
+
|
| 362 |
+
self.wq = nn.Linear(dim, dim, bias=qkv_bias)
|
| 363 |
+
self.wk = nn.Linear(dim, dim, bias=qkv_bias)
|
| 364 |
+
|
| 365 |
+
if gamma is not None:
|
| 366 |
+
self.gamma = torch.tensor([gamma])
|
| 367 |
+
if use_beta:
|
| 368 |
+
self.beta = nn.Parameter(torch.tensor([0.0]))
|
| 369 |
+
self.eps = torch.tensor([1e-6])
|
| 370 |
+
|
| 371 |
+
self.gamma = gamma
|
| 372 |
+
self.use_beta = use_beta
|
| 373 |
+
|
| 374 |
+
def prepare_input(self, x):
|
| 375 |
+
if len(x.shape) == 3: # Transformer
|
| 376 |
+
# Input tensor dimensions:
|
| 377 |
+
# x: (B, N, d), where B is batch size, N are patch tokens, d is depth (channels)
|
| 378 |
+
B, N, d = x.shape
|
| 379 |
+
gap_cls = x.mean(-2) # (B, N, d) -> (B, d)
|
| 380 |
+
gap_cls = gap_cls.unsqueeze(1) # (B, d) -> (B, 1, d)
|
| 381 |
+
return gap_cls, x
|
| 382 |
+
if len(x.shape) == 4: # CNN
|
| 383 |
+
# Input tensor dimensions:
|
| 384 |
+
# x: (B, d, H, W), where B is batch size, d is depth (channels), H is height, and W is width
|
| 385 |
+
B, d, H, W = x.shape
|
| 386 |
+
gap_cls = x.mean([-2, -1]) # (B, d, H, W) -> (B, d)
|
| 387 |
+
x = x.reshape(B, d, H * W).permute(0, 2, 1) # (B, d, H, W) -> (B, d, H*W) -> (B, H*W, d)
|
| 388 |
+
gap_cls = gap_cls.unsqueeze(1) # (B, d) -> (B, 1, d)
|
| 389 |
+
return gap_cls, x
|
| 390 |
+
else:
|
| 391 |
+
raise ValueError(f"Unsupported number of dimensions in input tensor: {len(x.shape)}")
|
| 392 |
+
|
| 393 |
+
def forward(self, x):
|
| 394 |
+
self.eps = self.eps.to(x.device)
|
| 395 |
+
# Prepare input tensor and perform GAP as initialization
|
| 396 |
+
gap_cls, x = self.prepare_input(x)
|
| 397 |
+
|
| 398 |
+
# Prepare queries (q), keys (k), and values (v)
|
| 399 |
+
q, k, v = gap_cls, self.norm_patches(x), self.norm_patches(x)
|
| 400 |
+
|
| 401 |
+
# Extract dimensions after normalization
|
| 402 |
+
Bq, Nq, dq = q.shape
|
| 403 |
+
Bk, Nk, dk = k.shape
|
| 404 |
+
Bv, Nv, dv = v.shape
|
| 405 |
+
|
| 406 |
+
# Check dimension consistency across batches and channels
|
| 407 |
+
assert Bq == Bk == Bv
|
| 408 |
+
assert dq == dk == dv
|
| 409 |
+
|
| 410 |
+
# Apply linear transformation for queries and keys then reshape
|
| 411 |
+
qq = self.wq(q).reshape(Bq, Nq, self.num_heads, dq // self.num_heads).permute(0, 2, 1,
|
| 412 |
+
3) # (Bq, Nq, dq) -> (B, num_heads, Nq, dq/num_heads)
|
| 413 |
+
kk = self.wk(k).reshape(Bk, Nk, self.num_heads, dk // self.num_heads).permute(0, 2, 1,
|
| 414 |
+
3) # (Bk, Nk, dk) -> (B, num_heads, Nk, dk/num_heads)
|
| 415 |
+
|
| 416 |
+
vv = v.reshape(Bv, Nv, self.num_heads, dv // self.num_heads).permute(0, 2, 1,
|
| 417 |
+
3) # (Bv, Nv, dv) -> (B, num_heads, Nv, dv/num_heads)
|
| 418 |
+
|
| 419 |
+
# Compute attention scores
|
| 420 |
+
attn = (qq @ kk.transpose(-2, -1)) * self.scale
|
| 421 |
+
# Apply softmax for normalization
|
| 422 |
+
attn = attn.softmax(dim=-1)
|
| 423 |
+
|
| 424 |
+
# If gamma scaling is used
|
| 425 |
+
if self.gamma is not None:
|
| 426 |
+
# Apply gamma scaling on values and compute the weighted sum using attention scores
|
| 427 |
+
x = torch.pow(attn @ torch.pow((vv - vv.min() + self.eps), self.gamma),
|
| 428 |
+
1 / self.gamma) # (B, num_heads, Nv, dv/num_heads) -> (B, 1, 1, d)
|
| 429 |
+
# If use_beta, add a learnable translation
|
| 430 |
+
if self.use_beta:
|
| 431 |
+
x = x + self.beta
|
| 432 |
+
else:
|
| 433 |
+
# Compute the weighted sum using attention scores
|
| 434 |
+
x = (attn @ vv).transpose(1, 2).reshape(Bq, Nq, dq)
|
| 435 |
+
|
| 436 |
+
return x.squeeze()
|
| 437 |
+
|
| 438 |
+
|
| 439 |
+
|
| 440 |
+
class SimPoolAggregator(BaseAggregator):
|
| 441 |
+
|
| 442 |
+
def __init__(self, num_heads, dim, *args, **kwargs):
|
| 443 |
+
super().__init__(False, False, num_heads, "sum", False)
|
| 444 |
+
self.pool = SimPool(dim, gamma=1.25)
|
| 445 |
+
|
| 446 |
+
def _get_full_sims(self, preds, raw, agg_sim, agg_heads):
|
| 447 |
+
if agg_sim:
|
| 448 |
+
device = self.pool.wq.weight.data.device
|
| 449 |
+
pooled_audio = self.pool(preds[AUDIO_FEATS].to(torch.float32).to(device))
|
| 450 |
+
pooled_image = self.pool(preds[IMAGE_FEATS].to(torch.float32).to(device))
|
| 451 |
+
|
| 452 |
+
sims = torch.einsum(
|
| 453 |
+
"bc,dc->bd",
|
| 454 |
+
pooled_audio,
|
| 455 |
+
pooled_image)
|
| 456 |
+
if agg_heads:
|
| 457 |
+
return sims
|
| 458 |
+
else:
|
| 459 |
+
sims = sims.unsqueeze(-1)
|
| 460 |
+
return sims.repeat(*([1] * (sims.dim() - 1)), self.num_heads)
|
| 461 |
+
|
| 462 |
+
|
| 463 |
+
else:
|
| 464 |
+
return BaseAggregator._get_full_sims(self, preds, raw, agg_sim, agg_heads)
|
| 465 |
+
|
| 466 |
+
def get_pairwise_sims(self, preds, raw, agg_sim, agg_heads):
|
| 467 |
+
if agg_sim:
|
| 468 |
+
device = self.pool.wq.weight.data.device
|
| 469 |
+
pooled_audio = self.pool(preds[AUDIO_FEATS].to(torch.float32).to(device))
|
| 470 |
+
pooled_image = self.pool(preds[IMAGE_FEATS].to(torch.float32).to(device))
|
| 471 |
+
|
| 472 |
+
sims = torch.einsum(
|
| 473 |
+
"bc,dc->b",
|
| 474 |
+
pooled_audio,
|
| 475 |
+
pooled_image)
|
| 476 |
+
if agg_heads:
|
| 477 |
+
return sims
|
| 478 |
+
else:
|
| 479 |
+
sims = sims.unsqueeze(-1)
|
| 480 |
+
return sims.repeat(*([1] * (sims.dim() - 1)), self.num_heads)
|
| 481 |
+
|
| 482 |
+
else:
|
| 483 |
+
return BaseAggregator.get_pairwise_sims(self, preds, raw, agg_sim, agg_heads)
|
| 484 |
+
|
| 485 |
+
def forward_batched(self, preds, agg_heads, batch_size):
|
| 486 |
+
return self.forward(preds, agg_heads)
|
| 487 |
+
|
| 488 |
+
|
| 489 |
+
|
| 490 |
+
def get_aggregator(sim_agg_type, nonneg_sim, mask_silence, num_heads, head_agg, use_cls, dim):
|
| 491 |
+
shared_args = dict(
|
| 492 |
+
nonneg_sim=nonneg_sim,
|
| 493 |
+
mask_silence=mask_silence,
|
| 494 |
+
num_heads=num_heads,
|
| 495 |
+
head_agg=head_agg,
|
| 496 |
+
use_cls=use_cls,
|
| 497 |
+
)
|
| 498 |
+
|
| 499 |
+
if sim_agg_type == "paired":
|
| 500 |
+
agg1 = PairedAggregator(**shared_args)
|
| 501 |
+
elif sim_agg_type == "misa":
|
| 502 |
+
agg1 = ImageThenAudioAggregator("max", "avg", **shared_args)
|
| 503 |
+
elif sim_agg_type == "mima":
|
| 504 |
+
agg1 = ImageThenAudioAggregator("max", "max", **shared_args)
|
| 505 |
+
elif sim_agg_type == "sisa":
|
| 506 |
+
agg1 = ImageThenAudioAggregator("avg", "avg", **shared_args)
|
| 507 |
+
elif sim_agg_type == "cavmae":
|
| 508 |
+
agg1 = CAVMAEAggregator()
|
| 509 |
+
elif sim_agg_type == "imagebind":
|
| 510 |
+
agg1 = ImageBindAggregator(num_heads=shared_args["num_heads"])
|
| 511 |
+
elif sim_agg_type == "simpool":
|
| 512 |
+
agg1 = SimPoolAggregator(num_heads=shared_args["num_heads"], dim=dim)
|
| 513 |
+
else:
|
| 514 |
+
raise ValueError(f"Unknown loss_type {sim_agg_type}")
|
| 515 |
+
|
| 516 |
+
return agg1
|
| 517 |
+
|
DenseAV/denseav/aligners.py
ADDED
|
@@ -0,0 +1,300 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from functools import partial
|
| 2 |
+
|
| 3 |
+
import torch
|
| 4 |
+
import torch.nn.functional as F
|
| 5 |
+
from torch.nn import ModuleList
|
| 6 |
+
|
| 7 |
+
from denseav.featurizers.DINO import Block
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
class ChannelNorm(torch.nn.Module):
|
| 11 |
+
|
| 12 |
+
def __init__(self, dim, *args, **kwargs):
|
| 13 |
+
super().__init__(*args, **kwargs)
|
| 14 |
+
self.norm = torch.nn.LayerNorm(dim, eps=1e-4)
|
| 15 |
+
|
| 16 |
+
def forward_spatial(self, x):
|
| 17 |
+
return self.norm(x.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
|
| 18 |
+
|
| 19 |
+
def forward(self, x, cls):
|
| 20 |
+
return self.forward_spatial(x), self.forward_cls(cls)
|
| 21 |
+
|
| 22 |
+
def forward_cls(self, cls):
|
| 23 |
+
if cls is not None:
|
| 24 |
+
return self.norm(cls)
|
| 25 |
+
else:
|
| 26 |
+
return None
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def id_conv(dim, strength=.9):
|
| 30 |
+
conv = torch.nn.Conv2d(dim, dim, 1, padding="same")
|
| 31 |
+
start_w = conv.weight.data
|
| 32 |
+
conv.weight.data = torch.nn.Parameter(
|
| 33 |
+
torch.eye(dim, device=start_w.device).unsqueeze(-1).unsqueeze(-1) * strength + start_w * (1 - strength))
|
| 34 |
+
conv.bias.data = torch.nn.Parameter(conv.bias.data * (1 - strength))
|
| 35 |
+
return conv
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
class LinearAligner(torch.nn.Module):
|
| 39 |
+
def __init__(self, in_dim, out_dim, use_norm=True):
|
| 40 |
+
super().__init__()
|
| 41 |
+
self.in_dim = in_dim
|
| 42 |
+
self.out_dim = out_dim
|
| 43 |
+
if use_norm:
|
| 44 |
+
self.norm = ChannelNorm(in_dim)
|
| 45 |
+
else:
|
| 46 |
+
self.norm = Identity2()
|
| 47 |
+
|
| 48 |
+
if in_dim == out_dim:
|
| 49 |
+
self.layer = id_conv(in_dim, 0)
|
| 50 |
+
else:
|
| 51 |
+
self.layer = torch.nn.Conv2d(in_dim, out_dim, kernel_size=1, stride=1)
|
| 52 |
+
|
| 53 |
+
self.cls_layer = torch.nn.Linear(in_dim, out_dim)
|
| 54 |
+
|
| 55 |
+
def forward(self, spatial, cls):
|
| 56 |
+
norm_spatial, norm_cls = self.norm(spatial, cls)
|
| 57 |
+
|
| 58 |
+
if cls is not None:
|
| 59 |
+
aligned_cls = self.cls_layer(cls)
|
| 60 |
+
else:
|
| 61 |
+
aligned_cls = None
|
| 62 |
+
|
| 63 |
+
return self.layer(norm_spatial), aligned_cls
|
| 64 |
+
|
| 65 |
+
class IdLinearAligner(torch.nn.Module):
|
| 66 |
+
def __init__(self, in_dim, out_dim):
|
| 67 |
+
super().__init__()
|
| 68 |
+
self.in_dim = in_dim
|
| 69 |
+
self.out_dim = out_dim
|
| 70 |
+
assert self.out_dim == self.in_dim
|
| 71 |
+
self.layer = id_conv(in_dim, 1.0)
|
| 72 |
+
def forward(self, spatial, cls):
|
| 73 |
+
return self.layer(spatial), cls
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class FrequencyAvg(torch.nn.Module):
|
| 77 |
+
def __init__(self):
|
| 78 |
+
super().__init__()
|
| 79 |
+
|
| 80 |
+
def forward(self, spatial, cls):
|
| 81 |
+
return spatial.mean(2, keepdim=True), cls
|
| 82 |
+
|
| 83 |
+
|
| 84 |
+
class LearnedTimePool(torch.nn.Module):
|
| 85 |
+
def __init__(self, dim, width, maxpool):
|
| 86 |
+
super().__init__()
|
| 87 |
+
self.dim = dim
|
| 88 |
+
self.width = width
|
| 89 |
+
self.norm = ChannelNorm(dim)
|
| 90 |
+
if maxpool:
|
| 91 |
+
self.layer = torch.nn.Sequential(
|
| 92 |
+
torch.nn.Conv2d(dim, dim, kernel_size=width, stride=1, padding="same"),
|
| 93 |
+
torch.nn.MaxPool2d(kernel_size=(1, width), stride=(1, width))
|
| 94 |
+
)
|
| 95 |
+
else:
|
| 96 |
+
self.layer = torch.nn.Conv2d(dim, dim, kernel_size=(1, width), stride=(1, width))
|
| 97 |
+
|
| 98 |
+
def forward(self, spatial, cls):
|
| 99 |
+
norm_spatial, norm_cls = self.norm(spatial, cls)
|
| 100 |
+
return self.layer(norm_spatial), norm_cls
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class LearnedTimePool2(torch.nn.Module):
|
| 104 |
+
def __init__(self, in_dim, out_dim, width, maxpool, use_cls_layer):
|
| 105 |
+
super().__init__()
|
| 106 |
+
self.in_dim = in_dim
|
| 107 |
+
self.out_dim = out_dim
|
| 108 |
+
self.width = width
|
| 109 |
+
|
| 110 |
+
if maxpool:
|
| 111 |
+
self.layer = torch.nn.Sequential(
|
| 112 |
+
torch.nn.Conv2d(in_dim, out_dim, kernel_size=width, stride=1, padding="same"),
|
| 113 |
+
torch.nn.MaxPool2d(kernel_size=(1, width), stride=(1, width))
|
| 114 |
+
)
|
| 115 |
+
else:
|
| 116 |
+
self.layer = torch.nn.Conv2d(in_dim, out_dim, kernel_size=(1, width), stride=(1, width))
|
| 117 |
+
|
| 118 |
+
self.use_cls_layer = use_cls_layer
|
| 119 |
+
if use_cls_layer:
|
| 120 |
+
self.cls_layer = torch.nn.Linear(in_dim, out_dim)
|
| 121 |
+
|
| 122 |
+
def forward(self, spatial, cls):
|
| 123 |
+
|
| 124 |
+
if cls is not None:
|
| 125 |
+
if self.use_cls_layer:
|
| 126 |
+
aligned_cls = self.cls_layer(cls)
|
| 127 |
+
else:
|
| 128 |
+
aligned_cls = cls
|
| 129 |
+
else:
|
| 130 |
+
aligned_cls = None
|
| 131 |
+
|
| 132 |
+
return self.layer(spatial), aligned_cls
|
| 133 |
+
|
| 134 |
+
|
| 135 |
+
class Sequential2(torch.nn.Module):
|
| 136 |
+
|
| 137 |
+
def __init__(self, *modules):
|
| 138 |
+
super().__init__()
|
| 139 |
+
self.mod_list = ModuleList(modules)
|
| 140 |
+
|
| 141 |
+
def forward(self, x, y):
|
| 142 |
+
results = (x, y)
|
| 143 |
+
for m in self.mod_list:
|
| 144 |
+
results = m(*results)
|
| 145 |
+
return results
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
class ProgressiveGrowing(torch.nn.Module):
|
| 149 |
+
|
| 150 |
+
def __init__(self, stages, phase_lengths):
|
| 151 |
+
super().__init__()
|
| 152 |
+
self.stages = torch.nn.ModuleList(stages)
|
| 153 |
+
self.phase_lengths = torch.tensor(phase_lengths)
|
| 154 |
+
assert len(self.phase_lengths) + 1 == len(self.stages)
|
| 155 |
+
self.phase_boundaries = self.phase_lengths.cumsum(0)
|
| 156 |
+
self.register_buffer('phase', torch.tensor([1]))
|
| 157 |
+
|
| 158 |
+
def maybe_change_phase(self, global_step):
|
| 159 |
+
needed_phase = (global_step >= self.phase_boundaries).to(torch.int64).sum().item() + 1
|
| 160 |
+
if needed_phase != self.phase.item():
|
| 161 |
+
print(f"Changing aligner phase to {needed_phase}")
|
| 162 |
+
self.phase.copy_(torch.tensor([needed_phase]).to(self.phase.device))
|
| 163 |
+
return True
|
| 164 |
+
else:
|
| 165 |
+
return False
|
| 166 |
+
|
| 167 |
+
def parameters(self, recurse: bool = True):
|
| 168 |
+
phase = self.phase.item()
|
| 169 |
+
used_stages = self.stages[:phase]
|
| 170 |
+
print(f"Progressive Growing at stage {phase}")
|
| 171 |
+
all_params = []
|
| 172 |
+
for stage in used_stages:
|
| 173 |
+
all_params.extend(stage.parameters(recurse))
|
| 174 |
+
return iter(all_params)
|
| 175 |
+
|
| 176 |
+
def forward(self, spatial, cls):
|
| 177 |
+
pipeline = Sequential2(*self.stages[:self.phase.item()])
|
| 178 |
+
return pipeline(spatial, cls)
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
class Identity2(torch.nn.Module):
|
| 182 |
+
|
| 183 |
+
def __init__(self):
|
| 184 |
+
super().__init__()
|
| 185 |
+
|
| 186 |
+
def forward(self, x, y):
|
| 187 |
+
return x, y
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
class SelfAttentionAligner(torch.nn.Module):
|
| 191 |
+
|
| 192 |
+
def __init__(self, dim):
|
| 193 |
+
super().__init__()
|
| 194 |
+
self.dim = dim
|
| 195 |
+
|
| 196 |
+
self.num_heads = 6
|
| 197 |
+
if dim % self.num_heads != 0:
|
| 198 |
+
self.padding = self.num_heads - (dim % self.num_heads)
|
| 199 |
+
else:
|
| 200 |
+
self.padding = 0
|
| 201 |
+
|
| 202 |
+
self.block = Block(
|
| 203 |
+
dim + self.padding,
|
| 204 |
+
num_heads=self.num_heads,
|
| 205 |
+
mlp_ratio=4,
|
| 206 |
+
qkv_bias=True,
|
| 207 |
+
qk_scale=None,
|
| 208 |
+
drop=0.0,
|
| 209 |
+
attn_drop=0.0,
|
| 210 |
+
drop_path=0.0,
|
| 211 |
+
norm_layer=partial(torch.nn.LayerNorm, eps=1e-4))
|
| 212 |
+
|
| 213 |
+
def forward(self, spatial, cls):
|
| 214 |
+
padded_feats = F.pad(spatial, [0, 0, 0, 0, self.padding, 0])
|
| 215 |
+
|
| 216 |
+
B, C, H, W = padded_feats.shape
|
| 217 |
+
proj_feats = padded_feats.reshape(B, C, H * W).permute(0, 2, 1)
|
| 218 |
+
|
| 219 |
+
if cls is not None:
|
| 220 |
+
assert len(cls.shape) == 2
|
| 221 |
+
padded_cls = F.pad(cls, [self.padding, 0])
|
| 222 |
+
proj_feats = torch.cat([padded_cls.unsqueeze(1), proj_feats], dim=1)
|
| 223 |
+
|
| 224 |
+
aligned_feat, attn, qkv = self.block(proj_feats, return_qkv=True)
|
| 225 |
+
|
| 226 |
+
if cls is not None:
|
| 227 |
+
aligned_cls = aligned_feat[:, 0, :]
|
| 228 |
+
aligned_spatial = aligned_feat[:, 1:, :]
|
| 229 |
+
else:
|
| 230 |
+
aligned_cls = None
|
| 231 |
+
aligned_spatial = aligned_feat
|
| 232 |
+
|
| 233 |
+
aligned_spatial = aligned_spatial.reshape(B, H, W, self.dim + self.padding).permute(0, 3, 1, 2)
|
| 234 |
+
|
| 235 |
+
aligned_spatial = aligned_spatial[:, self.padding:, :, :]
|
| 236 |
+
if aligned_cls is not None:
|
| 237 |
+
aligned_cls = aligned_cls[:, self.padding:]
|
| 238 |
+
|
| 239 |
+
return aligned_spatial, aligned_cls
|
| 240 |
+
|
| 241 |
+
|
| 242 |
+
def get_aligner(aligner_type, in_dim, out_dim, **kwargs):
|
| 243 |
+
if aligner_type is None:
|
| 244 |
+
return Identity2()
|
| 245 |
+
|
| 246 |
+
if "prog" in aligner_type:
|
| 247 |
+
phase_length = kwargs["phase_length"]
|
| 248 |
+
|
| 249 |
+
if aligner_type == "image_linear":
|
| 250 |
+
return LinearAligner(in_dim, out_dim)
|
| 251 |
+
elif aligner_type == "image_idlinear":
|
| 252 |
+
return IdLinearAligner(in_dim, out_dim)
|
| 253 |
+
elif aligner_type == "image_linear_no_norm":
|
| 254 |
+
return LinearAligner(in_dim, out_dim, use_norm=False)
|
| 255 |
+
elif aligner_type == "image_id":
|
| 256 |
+
return Identity2()
|
| 257 |
+
elif aligner_type == "image_norm":
|
| 258 |
+
return ChannelNorm(in_dim)
|
| 259 |
+
elif aligner_type == "audio_linear":
|
| 260 |
+
return Sequential2(
|
| 261 |
+
LinearAligner(in_dim, out_dim),
|
| 262 |
+
FrequencyAvg())
|
| 263 |
+
elif aligner_type == "audio_sa":
|
| 264 |
+
return Sequential2(
|
| 265 |
+
LinearAligner(in_dim, out_dim),
|
| 266 |
+
FrequencyAvg(),
|
| 267 |
+
SelfAttentionAligner(out_dim)
|
| 268 |
+
)
|
| 269 |
+
elif aligner_type == "audio_sa_sa":
|
| 270 |
+
return Sequential2(
|
| 271 |
+
FrequencyAvg(),
|
| 272 |
+
LinearAligner(in_dim, out_dim),
|
| 273 |
+
SelfAttentionAligner(out_dim),
|
| 274 |
+
SelfAttentionAligner(out_dim)
|
| 275 |
+
)
|
| 276 |
+
elif aligner_type == "audio_3_3_pool":
|
| 277 |
+
return Sequential2(
|
| 278 |
+
LinearAligner(in_dim, out_dim),
|
| 279 |
+
FrequencyAvg(),
|
| 280 |
+
LearnedTimePool(out_dim, 3, False),
|
| 281 |
+
LearnedTimePool(out_dim, 3, False),
|
| 282 |
+
)
|
| 283 |
+
elif aligner_type == "audio_sa_3_3_pool":
|
| 284 |
+
return Sequential2(
|
| 285 |
+
LinearAligner(in_dim, out_dim),
|
| 286 |
+
FrequencyAvg(),
|
| 287 |
+
LearnedTimePool(out_dim, 3, False),
|
| 288 |
+
LearnedTimePool(out_dim, 3, False),
|
| 289 |
+
SelfAttentionAligner(out_dim)
|
| 290 |
+
)
|
| 291 |
+
elif aligner_type == "audio_sa_3_3_pool_2":
|
| 292 |
+
return Sequential2(
|
| 293 |
+
FrequencyAvg(),
|
| 294 |
+
ChannelNorm(in_dim),
|
| 295 |
+
LearnedTimePool2(in_dim, out_dim, 3, False, True),
|
| 296 |
+
LearnedTimePool2(out_dim, out_dim, 3, False, False),
|
| 297 |
+
SelfAttentionAligner(out_dim)
|
| 298 |
+
)
|
| 299 |
+
else:
|
| 300 |
+
raise ValueError(f"Unknown aligner type {aligner_type}")
|
DenseAV/denseav/configs/av_align.yaml
ADDED
|
@@ -0,0 +1,125 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Model args
|
| 2 |
+
|
| 3 |
+
code_dim: 384
|
| 4 |
+
image_model_type: "dino8"
|
| 5 |
+
image_model_token_type: "token"
|
| 6 |
+
image_aligner_type: "image_linear"
|
| 7 |
+
image_pool_width: 2
|
| 8 |
+
|
| 9 |
+
audio_model_type: "hubert"
|
| 10 |
+
audio_aligner_type: "audio_sa_3_3_pool_2"
|
| 11 |
+
audio_pool_width: 1
|
| 12 |
+
|
| 13 |
+
learn_audio_cls: True
|
| 14 |
+
|
| 15 |
+
#code_dim: 1024
|
| 16 |
+
#image_model_type: "imagebind"
|
| 17 |
+
#image_model_token_type: "token"
|
| 18 |
+
#image_aligner_type: "image_linear"
|
| 19 |
+
#image_pool_width: 1
|
| 20 |
+
#
|
| 21 |
+
#audio_model_type: "imagebind"
|
| 22 |
+
#audio_aligner_type: "audio_sa"
|
| 23 |
+
#audio_pool_width: 1
|
| 24 |
+
#
|
| 25 |
+
#learn_audio_cls: False
|
| 26 |
+
|
| 27 |
+
audio_lora: False
|
| 28 |
+
audio_lora_rank: 8
|
| 29 |
+
image_lora: True
|
| 30 |
+
image_lora_rank: 8
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
spatial_dropout: 0.0
|
| 34 |
+
channel_dropout: 0.0
|
| 35 |
+
|
| 36 |
+
quad_mixup: 0.1
|
| 37 |
+
bg_mixup: 0.0
|
| 38 |
+
patch_mixup: 0.0
|
| 39 |
+
mixup_weight: 0.1
|
| 40 |
+
|
| 41 |
+
sim_agg_type: "misa"
|
| 42 |
+
sim_agg_heads: 1
|
| 43 |
+
sim_use_cls: False
|
| 44 |
+
|
| 45 |
+
cal_init: 1.0
|
| 46 |
+
cal_balance_weight: 0.1
|
| 47 |
+
nonneg_sim: False
|
| 48 |
+
nonneg_pressure: 0.01
|
| 49 |
+
silence_l1: 0.01
|
| 50 |
+
silence_l2: 0.0
|
| 51 |
+
tv_weight: 0.01
|
| 52 |
+
specialization_weight: 0.05
|
| 53 |
+
head_agg: "max_elementwise"
|
| 54 |
+
disentangle_weight: 0.0
|
| 55 |
+
|
| 56 |
+
norm_vectors: False
|
| 57 |
+
|
| 58 |
+
neg_audio: true
|
| 59 |
+
neg_audio_weight: 0.01
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
pretrain_steps: 3000
|
| 63 |
+
pretrain_lr: .5e-4
|
| 64 |
+
|
| 65 |
+
# Loss args
|
| 66 |
+
lr: .5e-4
|
| 67 |
+
lr_warmup: 1000
|
| 68 |
+
|
| 69 |
+
#lr_warmup: 100
|
| 70 |
+
|
| 71 |
+
lr_schedule: ~
|
| 72 |
+
lr_cycle_length: 50000
|
| 73 |
+
|
| 74 |
+
optimizer: "adam"
|
| 75 |
+
gradient_clipping: 10.0
|
| 76 |
+
adaptive_clipping: True
|
| 77 |
+
gather_tensors: True
|
| 78 |
+
loss_type: "nce"
|
| 79 |
+
loss_leak: 0.0
|
| 80 |
+
loss_margin: 0.0
|
| 81 |
+
mask_silence: true
|
| 82 |
+
extra_audio_masking: true
|
| 83 |
+
max_steps: 1000001
|
| 84 |
+
|
| 85 |
+
finetune_image_model: False
|
| 86 |
+
finetune_audio_model: True
|
| 87 |
+
|
| 88 |
+
# Checkpointing args
|
| 89 |
+
load_strict: true
|
| 90 |
+
starting_weights: ~
|
| 91 |
+
auto_resume: false
|
| 92 |
+
grouping_name: "foo"
|
| 93 |
+
resume_prefix: "imagebind_exp2"
|
| 94 |
+
|
| 95 |
+
# Data Args
|
| 96 |
+
#dataset_name: "sample-audio"
|
| 97 |
+
dataset_name: "places-audio"
|
| 98 |
+
#dataset_name: "mixed"
|
| 99 |
+
#dataset_name: "audio-set-full"
|
| 100 |
+
use_extra_val_sets: true
|
| 101 |
+
batch_size: 10
|
| 102 |
+
load_size: 224
|
| 103 |
+
image_aug: true
|
| 104 |
+
audio_aug: false
|
| 105 |
+
|
| 106 |
+
audio_level: false
|
| 107 |
+
|
| 108 |
+
memory_buffer_size: 0
|
| 109 |
+
|
| 110 |
+
val_check_interval: 10000 #0
|
| 111 |
+
use_cached_embs: false
|
| 112 |
+
num_workers: 12
|
| 113 |
+
num_gpus: 4
|
| 114 |
+
num_sanity_val_steps: 0 #-1
|
| 115 |
+
seed: 0
|
| 116 |
+
|
| 117 |
+
# Env args
|
| 118 |
+
output_root: '../'
|
| 119 |
+
pytorch_data_dir: '/pytorch-data/'
|
| 120 |
+
submitting_to_aml: false
|
| 121 |
+
|
| 122 |
+
hydra:
|
| 123 |
+
run:
|
| 124 |
+
dir: "."
|
| 125 |
+
output_subdir: ~
|
DenseAV/denseav/constants.py
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
IMAGE_INPUT = "frames"
|
| 3 |
+
IMAGE_FEATS = "image_feats"
|
| 4 |
+
IMAGE_CLS = "image_cls"
|
| 5 |
+
IMAGE_MASK = "image_masks"
|
| 6 |
+
|
| 7 |
+
AUDIO_FEATS = "audio_feats"
|
| 8 |
+
AUDIO_CLS = "audio_cls"
|
| 9 |
+
AUDIO_MASK = "audio_mask"
|
| 10 |
+
AUDIO_POS_MASK = "audio_pos_mask"
|
| 11 |
+
|
| 12 |
+
DATA_SOURCE = "source"
|
DenseAV/denseav/data/AVDatasets.py
ADDED
|
@@ -0,0 +1,1249 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import os
|
| 3 |
+
from abc import ABC, abstractmethod
|
| 4 |
+
from glob import glob
|
| 5 |
+
from os.path import join
|
| 6 |
+
from pathlib import Path
|
| 7 |
+
from typing import List, Set
|
| 8 |
+
|
| 9 |
+
import audioread
|
| 10 |
+
import numpy as np
|
| 11 |
+
import pandas as pd
|
| 12 |
+
import pytorch_lightning as pl
|
| 13 |
+
import torch
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
import torchaudio
|
| 16 |
+
import torchvision.transforms as T
|
| 17 |
+
from PIL import Image
|
| 18 |
+
from torch.utils.data import Dataset, DataLoader, default_collate, Subset, ConcatDataset
|
| 19 |
+
from tqdm import tqdm
|
| 20 |
+
|
| 21 |
+
from denseav.constants import AUDIO_MASK, AUDIO_POS_MASK, IMAGE_MASK, IMAGE_INPUT
|
| 22 |
+
from denseav.data.make_tarballs import untar_all
|
| 23 |
+
from denseav.shared import norm, prep_waveform
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
def sample_choice(choices, probs):
|
| 27 |
+
# Check that probabilities sum to 1 and are non-negative
|
| 28 |
+
assert sum(probs) == 1, "Probabilities must sum to 1"
|
| 29 |
+
assert all(p >= 0 for p in probs), "Probabilities cannot be negative"
|
| 30 |
+
|
| 31 |
+
# Convert probs to a tensor
|
| 32 |
+
probs_tensor = torch.tensor(probs)
|
| 33 |
+
|
| 34 |
+
# Sample a choice according to the probabilities
|
| 35 |
+
index = torch.multinomial(probs_tensor, 1).item()
|
| 36 |
+
|
| 37 |
+
# Return the sampled choice
|
| 38 |
+
return choices[index]
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def grid_frames(frames):
|
| 42 |
+
top_row = torch.cat([frames[0], frames[1]], dim=2)
|
| 43 |
+
bottom_row = torch.cat([frames[2], frames[3]], dim=2)
|
| 44 |
+
return torch.cat([top_row, bottom_row], dim=3)
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def create_mixed_image(pos_frame, neg_frame, patch_size):
|
| 48 |
+
# Step 1: Check that patch_size evenly divides the image dimensions
|
| 49 |
+
b, c, h, w = pos_frame.shape
|
| 50 |
+
assert h % patch_size == 0 and w % patch_size == 0, "Patch size must evenly divide image dimensions"
|
| 51 |
+
|
| 52 |
+
# Step 2: Create a random binary mask with the same number of patches as the image
|
| 53 |
+
mask = torch.randint(0, 2, (b, 1, h // patch_size, w // patch_size))
|
| 54 |
+
|
| 55 |
+
# Step 3: Create a new image using patches from pos_frame and neg_frame according to the mask
|
| 56 |
+
# Upscale the mask to the size of the image
|
| 57 |
+
mask_upscaled = F.interpolate(mask.to(torch.float32), scale_factor=patch_size)
|
| 58 |
+
|
| 59 |
+
# Use the mask to create a mixed frame
|
| 60 |
+
mixed_frame = mask_upscaled * pos_frame + (1 - mask_upscaled) * neg_frame
|
| 61 |
+
|
| 62 |
+
return mixed_frame, mask_upscaled
|
| 63 |
+
|
| 64 |
+
|
| 65 |
+
class AVDataset(ABC, Dataset):
|
| 66 |
+
|
| 67 |
+
@abstractmethod
|
| 68 |
+
def _dataset_folder(self) -> str:
|
| 69 |
+
pass
|
| 70 |
+
|
| 71 |
+
@abstractmethod
|
| 72 |
+
def _load_info(self, split) -> pd.DataFrame:
|
| 73 |
+
"""
|
| 74 |
+
This function should return a dataframe with at least a column "id"
|
| 75 |
+
@return:
|
| 76 |
+
"""
|
| 77 |
+
pass
|
| 78 |
+
|
| 79 |
+
@abstractmethod
|
| 80 |
+
def _missing_threshold(self) -> float:
|
| 81 |
+
pass
|
| 82 |
+
|
| 83 |
+
@abstractmethod
|
| 84 |
+
def default_target_length(self) -> int:
|
| 85 |
+
pass
|
| 86 |
+
|
| 87 |
+
def target_length(self):
|
| 88 |
+
if self.override_target_length is not None:
|
| 89 |
+
return self.override_target_length
|
| 90 |
+
else:
|
| 91 |
+
return self.default_target_length()
|
| 92 |
+
|
| 93 |
+
def _frame_root(self) -> str:
|
| 94 |
+
return join(self.root, "frames", self.split)
|
| 95 |
+
|
| 96 |
+
def _video_root(self) -> str:
|
| 97 |
+
return join(self.root, "videos", self.split)
|
| 98 |
+
|
| 99 |
+
def _audio_root(self) -> str:
|
| 100 |
+
return join(self.root, "audio", self.split)
|
| 101 |
+
|
| 102 |
+
def _semseg_root(self) -> str:
|
| 103 |
+
return join(self.root, "annotations", self.split)
|
| 104 |
+
|
| 105 |
+
def _embed_root(self) -> str:
|
| 106 |
+
return join(self.root, "embedding", self.audio_embed_model, self.split)
|
| 107 |
+
|
| 108 |
+
def _label_root(self) -> str:
|
| 109 |
+
return join(self.root, "pseudo-labels")
|
| 110 |
+
|
| 111 |
+
def _hn_root(self) -> str:
|
| 112 |
+
return join(self.root, "hard_negatives")
|
| 113 |
+
|
| 114 |
+
def _all_video_files(self) -> Set[str]:
|
| 115 |
+
return set(str(p) for p in Path(join(self._video_root())).rglob('*'))
|
| 116 |
+
|
| 117 |
+
def _all_frame_files(self) -> Set[str]:
|
| 118 |
+
return set(str(p) for p in Path(join(self._frame_root())).rglob('*'))
|
| 119 |
+
|
| 120 |
+
def _all_audio_files(self) -> Set[str]:
|
| 121 |
+
return set(str(p) for p in Path(join(self._audio_root())).rglob('*'))
|
| 122 |
+
|
| 123 |
+
def _all_embed_files(self) -> Set[str]:
|
| 124 |
+
return set(str(p) for p in Path(join(self._embed_root())).rglob('*'))
|
| 125 |
+
|
| 126 |
+
def _get_frame_files(self, row) -> List[str]:
|
| 127 |
+
return [self._frame_root() + "/" + row["id"] + f"_{i}.jpg" for i in range(self._expected_num_frames())]
|
| 128 |
+
|
| 129 |
+
def _get_semseg_file(self, row) -> str:
|
| 130 |
+
raise NotImplementedError("Class has not implemented _get_semseg_files")
|
| 131 |
+
|
| 132 |
+
def _get_audio_file(self, row) -> str:
|
| 133 |
+
return self._audio_root() + "/" + row["id"] + ".mp3"
|
| 134 |
+
|
| 135 |
+
def _get_video_file(self, row) -> str:
|
| 136 |
+
return self._video_root() + "/" + row["id"] + ".mp4"
|
| 137 |
+
|
| 138 |
+
def _get_embed_file(self, row) -> str:
|
| 139 |
+
return self._embed_root() + "/" + row["id"] + ".npz"
|
| 140 |
+
|
| 141 |
+
def _add_files_to_metadata(self, df) -> pd.DataFrame:
|
| 142 |
+
tqdm.pandas()
|
| 143 |
+
|
| 144 |
+
if self.use_audio_embed:
|
| 145 |
+
df["embed_file"] = df.progress_apply(self._get_embed_file, axis=1)
|
| 146 |
+
|
| 147 |
+
if self.use_audio or self.use_spec:
|
| 148 |
+
df["audio_file"] = df.progress_apply(self._get_audio_file, axis=1)
|
| 149 |
+
|
| 150 |
+
if self.use_frames:
|
| 151 |
+
df["frame_files"] = df.progress_apply(self._get_frame_files, axis=1)
|
| 152 |
+
|
| 153 |
+
if self.use_semseg:
|
| 154 |
+
df["semseg_file"] = df.progress_apply(self._get_semseg_file, axis=1)
|
| 155 |
+
|
| 156 |
+
df = self._filter_valid_metadata(df)
|
| 157 |
+
|
| 158 |
+
if self.use_hn:
|
| 159 |
+
loaded = np.load(join(self._hn_root(), "original", f"{self.split}_hard_negatives.npz"))
|
| 160 |
+
df["hn0"] = [t for t in torch.tensor(loaded["indices_0"])]
|
| 161 |
+
df["hn1"] = [t for t in torch.tensor(loaded["indices_1"])]
|
| 162 |
+
|
| 163 |
+
return df
|
| 164 |
+
|
| 165 |
+
def _split_name(self, split):
|
| 166 |
+
return split
|
| 167 |
+
|
| 168 |
+
def _filter_valid_metadata(self, df: pd.DataFrame) -> pd.DataFrame:
|
| 169 |
+
|
| 170 |
+
print("MY_DIR ", list(glob(join(self.root, "*"))))
|
| 171 |
+
if self.use_audio_embed:
|
| 172 |
+
missing_embed_files = set(df['embed_file']) - self.all_embed_files
|
| 173 |
+
valid_audio = ~df['embed_file'].isin(missing_embed_files)
|
| 174 |
+
print("ALL EMBED ", len(self.all_embed_files))
|
| 175 |
+
elif self.use_audio or self.use_spec:
|
| 176 |
+
missing_audio_files = set(df['audio_file']) - self.all_audio_files
|
| 177 |
+
valid_audio = ~df['audio_file'].isin(missing_audio_files)
|
| 178 |
+
print("ALL AUDIO ", len(self.all_audio_files))
|
| 179 |
+
|
| 180 |
+
if self.use_frames:
|
| 181 |
+
missing_frame_files = set(
|
| 182 |
+
item for sublist in df['frame_files'].tolist() for item in sublist) - self.all_frame_files
|
| 183 |
+
valid_frames = df['frame_files'].apply(lambda x: not any(file in missing_frame_files for file in x))
|
| 184 |
+
print("ALL FRAMES ", len(self.all_frame_files))
|
| 185 |
+
df["is_valid"] = valid_audio & valid_frames
|
| 186 |
+
else:
|
| 187 |
+
df["is_valid"] = valid_audio
|
| 188 |
+
|
| 189 |
+
percent_missing = (1 - (df["is_valid"].sum() / len(df)))
|
| 190 |
+
|
| 191 |
+
assert percent_missing <= self._missing_threshold(), \
|
| 192 |
+
f"Too many missing files: %{round(percent_missing * 100.0, 2)}"
|
| 193 |
+
assert len(df) > 0, "No files found"
|
| 194 |
+
return df[df["is_valid"]]
|
| 195 |
+
|
| 196 |
+
def __init__(
|
| 197 |
+
self,
|
| 198 |
+
root: str,
|
| 199 |
+
split: str = "train",
|
| 200 |
+
use_frames=False,
|
| 201 |
+
frame_transform=None,
|
| 202 |
+
use_audio=False,
|
| 203 |
+
use_spec=False,
|
| 204 |
+
use_audio_embed=False,
|
| 205 |
+
use_hn=False,
|
| 206 |
+
use_caption=False,
|
| 207 |
+
use_semseg=False,
|
| 208 |
+
neg_audio=False,
|
| 209 |
+
use_davenet_spec=False,
|
| 210 |
+
use_fnac_spec=False,
|
| 211 |
+
n_label_frames=196,
|
| 212 |
+
label_transform=None,
|
| 213 |
+
audio_embed_model="hubert",
|
| 214 |
+
n_frames=1,
|
| 215 |
+
audio_transform=None,
|
| 216 |
+
audio_aug=False,
|
| 217 |
+
spec_transform=None,
|
| 218 |
+
spec_mel_bins=128,
|
| 219 |
+
spec_mean=-6.6268077,
|
| 220 |
+
spec_std=5.358466,
|
| 221 |
+
sample_rate=16000,
|
| 222 |
+
override_target_length=None,
|
| 223 |
+
use_tags=False,
|
| 224 |
+
extra_audio_masking=False,
|
| 225 |
+
audio_level=False,
|
| 226 |
+
quad_mixup=0.0,
|
| 227 |
+
bg_mixup=0.0,
|
| 228 |
+
patch_mixup=0.0,
|
| 229 |
+
patch_size=8,
|
| 230 |
+
):
|
| 231 |
+
super(AVDataset).__init__()
|
| 232 |
+
self.pytorch_data_dir = root
|
| 233 |
+
self.split = self._split_name(split)
|
| 234 |
+
self.root = join(root, self._dataset_folder())
|
| 235 |
+
self.use_frames = use_frames
|
| 236 |
+
self.frame_transform = frame_transform
|
| 237 |
+
self.use_audio = use_audio
|
| 238 |
+
self.use_spec = use_spec
|
| 239 |
+
self.use_audio_embed = use_audio_embed
|
| 240 |
+
self.use_davenet_spec = use_davenet_spec
|
| 241 |
+
self.use_fnac_spec = use_fnac_spec
|
| 242 |
+
self.use_hn = use_hn
|
| 243 |
+
self.use_caption = use_caption
|
| 244 |
+
self.label_transform = label_transform
|
| 245 |
+
self.audio_embed_model = audio_embed_model
|
| 246 |
+
self.audio_aug = audio_aug
|
| 247 |
+
self.n_frames = n_frames
|
| 248 |
+
self.audio_transform = audio_transform
|
| 249 |
+
self.spec_transform = spec_transform
|
| 250 |
+
self.spec_mel_bins = spec_mel_bins
|
| 251 |
+
self.spec_mean = spec_mean
|
| 252 |
+
self.spec_std = spec_std
|
| 253 |
+
self.use_semseg = use_semseg
|
| 254 |
+
self.override_target_length = override_target_length
|
| 255 |
+
self.use_tags = use_tags
|
| 256 |
+
self.extra_audio_masking = extra_audio_masking
|
| 257 |
+
self.neg_audio = neg_audio
|
| 258 |
+
self.audio_level = audio_level
|
| 259 |
+
|
| 260 |
+
self.quad_mixup = quad_mixup
|
| 261 |
+
self.bg_mixup = bg_mixup
|
| 262 |
+
self.patch_mixup = patch_mixup
|
| 263 |
+
self.patch_size = patch_size
|
| 264 |
+
|
| 265 |
+
self.sample_rate = sample_rate
|
| 266 |
+
self.n_label_frames = n_label_frames
|
| 267 |
+
|
| 268 |
+
if self.use_audio_embed:
|
| 269 |
+
self.all_embed_files = self._all_embed_files()
|
| 270 |
+
|
| 271 |
+
if self.use_audio or self.use_spec:
|
| 272 |
+
self.all_audio_files = self._all_audio_files()
|
| 273 |
+
|
| 274 |
+
if self.use_frames:
|
| 275 |
+
self.all_frame_files = self._all_frame_files()
|
| 276 |
+
|
| 277 |
+
self.metadata = self._add_files_to_metadata(self._load_info(self.split))
|
| 278 |
+
|
| 279 |
+
assert len(self.metadata) > 0
|
| 280 |
+
|
| 281 |
+
def __len__(self):
|
| 282 |
+
return len(self.metadata)
|
| 283 |
+
|
| 284 |
+
@abstractmethod
|
| 285 |
+
def _expected_num_frames(self) -> int:
|
| 286 |
+
pass
|
| 287 |
+
|
| 288 |
+
def get_audio_mask(self, real_length, padded_length, target_size):
|
| 289 |
+
if not isinstance(real_length, torch.Tensor):
|
| 290 |
+
real_length = torch.tensor(real_length)
|
| 291 |
+
padded_length = torch.tensor(padded_length)
|
| 292 |
+
|
| 293 |
+
n_frames = ((real_length / padded_length) * target_size).to(torch.int64)
|
| 294 |
+
oh = F.one_hot(n_frames, num_classes=target_size + 1)
|
| 295 |
+
if len(oh.shape) == 1:
|
| 296 |
+
oh = oh.unsqueeze(0)
|
| 297 |
+
return (1 - torch.cumsum(oh, dim=1))[:, :-1].to(torch.bool)
|
| 298 |
+
|
| 299 |
+
def _base_get_item(self, item):
|
| 300 |
+
id = self.metadata["id"].iloc[item]
|
| 301 |
+
data_dict = {"metadata": {"id": id, "index": item}}
|
| 302 |
+
|
| 303 |
+
if self.use_tags and "tags" in self.metadata:
|
| 304 |
+
tags = torch.tensor(self.metadata["tags"].iloc[item])
|
| 305 |
+
tag_oh = torch.zeros(self.num_tags, dtype=torch.float32)
|
| 306 |
+
tag_oh[tags] += 1
|
| 307 |
+
data_dict["tags"] = tag_oh
|
| 308 |
+
|
| 309 |
+
if self.use_audio or self.use_spec:
|
| 310 |
+
audio_file = self.metadata["audio_file"].iloc[item]
|
| 311 |
+
data_dict["metadata"]["audio_file"] = audio_file
|
| 312 |
+
loaded_waveform, obs_sr = torchaudio.load(audio_file)
|
| 313 |
+
loaded_waveform = loaded_waveform[0]
|
| 314 |
+
|
| 315 |
+
if self.neg_audio:
|
| 316 |
+
neg_audio_file = self.metadata["audio_file"].iloc[torch.randint(0, len(self), size=(1,)).item()]
|
| 317 |
+
data_dict["metadata"]["neg_audio_file"] = neg_audio_file
|
| 318 |
+
neg_waveform, neg_obs_sr = torchaudio.load(neg_audio_file)
|
| 319 |
+
neg_waveform = neg_waveform[0]
|
| 320 |
+
else:
|
| 321 |
+
neg_waveform, neg_obs_sr = None, None
|
| 322 |
+
|
| 323 |
+
(waveform,
|
| 324 |
+
spectrogram,
|
| 325 |
+
audio_length,
|
| 326 |
+
total_length,
|
| 327 |
+
original_length,
|
| 328 |
+
mask,
|
| 329 |
+
pos_mask) = prep_waveform(
|
| 330 |
+
loaded_waveform,
|
| 331 |
+
obs_sr,
|
| 332 |
+
self.target_length(),
|
| 333 |
+
self.spec_mel_bins,
|
| 334 |
+
self.spec_mean,
|
| 335 |
+
self.spec_std,
|
| 336 |
+
self.sample_rate,
|
| 337 |
+
self.use_spec,
|
| 338 |
+
False,
|
| 339 |
+
self.extra_audio_masking,
|
| 340 |
+
neg_waveform,
|
| 341 |
+
neg_obs_sr,
|
| 342 |
+
self.audio_level,
|
| 343 |
+
self.audio_aug
|
| 344 |
+
)
|
| 345 |
+
|
| 346 |
+
if self.spec_transform is not None and spectrogram is not None:
|
| 347 |
+
spectrogram = self.spec_transform(spectrogram)
|
| 348 |
+
|
| 349 |
+
if self.audio_transform is not None:
|
| 350 |
+
waveform = self.audio_transform(waveform)
|
| 351 |
+
|
| 352 |
+
data_dict["audio"] = waveform
|
| 353 |
+
data_dict[AUDIO_MASK] = mask
|
| 354 |
+
data_dict[AUDIO_POS_MASK] = pos_mask
|
| 355 |
+
data_dict["audio_length"] = audio_length
|
| 356 |
+
data_dict["original_length"] = original_length
|
| 357 |
+
data_dict["total_length"] = total_length
|
| 358 |
+
if spectrogram is not None:
|
| 359 |
+
data_dict["spec"] = spectrogram
|
| 360 |
+
|
| 361 |
+
if mask.mean() < .04:
|
| 362 |
+
return None
|
| 363 |
+
|
| 364 |
+
if self.use_davenet_spec:
|
| 365 |
+
from data.DavenetUtilities import davenet_load_audio
|
| 366 |
+
audio_file = self.metadata["audio_file"].iloc[item]
|
| 367 |
+
spec, n_frames = davenet_load_audio(audio_file)
|
| 368 |
+
data_dict["davenet_spec"] = spec
|
| 369 |
+
|
| 370 |
+
if self.use_fnac_spec:
|
| 371 |
+
from featurizers.FNACAVL import load_spectrogram as fnac_load_spectrogram
|
| 372 |
+
audio_file = self.metadata["audio_file"].iloc[item]
|
| 373 |
+
data_dict["fnac_spec"] = fnac_load_spectrogram(audio_file, 3)
|
| 374 |
+
|
| 375 |
+
if self.use_audio_embed:
|
| 376 |
+
loaded = np.load(self.metadata["embed_file"].iloc[item])
|
| 377 |
+
data_dict["audio_emb"] = loaded["feat"]
|
| 378 |
+
data_dict["audio_length"] = loaded["audio_length"]
|
| 379 |
+
data_dict["total_length"] = loaded["total_length"]
|
| 380 |
+
data_dict["original_length"] = loaded["original_length"]
|
| 381 |
+
data_dict[AUDIO_MASK] = self.get_audio_mask(
|
| 382 |
+
data_dict["audio_length"],
|
| 383 |
+
data_dict["total_length"],
|
| 384 |
+
data_dict["audio_emb"].shape[-1]) \
|
| 385 |
+
.squeeze().to(torch.float32)
|
| 386 |
+
data_dict[AUDIO_POS_MASK] = data_dict[AUDIO_MASK].to(torch.float32)
|
| 387 |
+
|
| 388 |
+
if self.use_frames:
|
| 389 |
+
|
| 390 |
+
def get_frames(item):
|
| 391 |
+
file_group = self.metadata["frame_files"].iloc[item]
|
| 392 |
+
if self.n_frames is not None:
|
| 393 |
+
selected_frames = torch.randperm(len(file_group))[:self.n_frames]
|
| 394 |
+
file_group = [file_group[i] for i in selected_frames]
|
| 395 |
+
data_dict["metadata"]["frame_files"] = file_group
|
| 396 |
+
images = [Image.open(file).convert("RGB") for file in file_group]
|
| 397 |
+
|
| 398 |
+
if self.frame_transform is not None:
|
| 399 |
+
images = torch.cat([self.frame_transform(img).unsqueeze(0) for img in images], dim=0)
|
| 400 |
+
|
| 401 |
+
return images, file_group
|
| 402 |
+
|
| 403 |
+
no_mixup = 1.0 - (self.bg_mixup + self.quad_mixup + self.patch_mixup)
|
| 404 |
+
|
| 405 |
+
mixup_type = sample_choice(
|
| 406 |
+
["quad", "bg", "patch", None],
|
| 407 |
+
[self.quad_mixup, self.bg_mixup, self.patch_mixup, no_mixup]
|
| 408 |
+
)
|
| 409 |
+
|
| 410 |
+
if mixup_type == "quad":
|
| 411 |
+
indices = [item] + torch.randint(0, len(self), size=(3,)).numpy().tolist()
|
| 412 |
+
frames_and_files = [get_frames(i) for i in indices]
|
| 413 |
+
file_group = frames_and_files[0][1]
|
| 414 |
+
perm = torch.randperm(4)
|
| 415 |
+
all_frames = [F.interpolate(frames_and_files[i][0], scale_factor=0.5, mode="bilinear") for i in
|
| 416 |
+
perm]
|
| 417 |
+
b, c, h, w = all_frames[0].shape
|
| 418 |
+
indices = [indices[p] for p in perm]
|
| 419 |
+
masks = [(torch.ones(b, 1, h, w) if index == item else torch.zeros(b, 1, h, w)) for index in
|
| 420 |
+
indices]
|
| 421 |
+
|
| 422 |
+
data_dict[IMAGE_INPUT] = grid_frames(all_frames)
|
| 423 |
+
data_dict[IMAGE_MASK] = grid_frames(masks)
|
| 424 |
+
elif mixup_type == "bg":
|
| 425 |
+
neg_item = torch.randint(0, len(self), size=(1,)).item()
|
| 426 |
+
neg_frame, _ = get_frames(neg_item)
|
| 427 |
+
pos_frame, file_group = get_frames(item)
|
| 428 |
+
|
| 429 |
+
b, c, h, w = neg_frame.shape
|
| 430 |
+
neg_mask = torch.zeros(b, 1, h, w)
|
| 431 |
+
pos_mask = torch.ones(b, 1, h, w)
|
| 432 |
+
|
| 433 |
+
if torch.rand(1).item() > 0.5:
|
| 434 |
+
bg_frame = neg_frame
|
| 435 |
+
bg_mask = neg_mask
|
| 436 |
+
fg_frame = F.interpolate(pos_frame, scale_factor=0.5, mode="bilinear")
|
| 437 |
+
fg_mask = F.interpolate(pos_mask, scale_factor=0.5, mode="bilinear")
|
| 438 |
+
else:
|
| 439 |
+
bg_frame = pos_frame
|
| 440 |
+
bg_mask = pos_mask
|
| 441 |
+
fg_frame = F.interpolate(neg_frame, scale_factor=0.5, mode="bilinear")
|
| 442 |
+
fg_mask = F.interpolate(neg_mask, scale_factor=0.5, mode="bilinear")
|
| 443 |
+
|
| 444 |
+
start_h = torch.randint(0, h // 2, size=(1,))
|
| 445 |
+
start_w = torch.randint(0, w // 2, size=(1,))
|
| 446 |
+
bg_frame[:, :, start_h:start_h + fg_frame.shape[2], start_w:start_w + fg_frame.shape[3]] = fg_frame
|
| 447 |
+
bg_mask[:, :, start_h:start_h + fg_frame.shape[2], start_w:start_w + fg_frame.shape[3]] = fg_mask
|
| 448 |
+
|
| 449 |
+
data_dict["frames"] = bg_frame
|
| 450 |
+
data_dict["image_masks"] = bg_mask
|
| 451 |
+
|
| 452 |
+
elif mixup_type == "patch":
|
| 453 |
+
neg_item = torch.randint(0, len(self), size=(1,)).item()
|
| 454 |
+
neg_frame, _ = get_frames(neg_item)
|
| 455 |
+
pos_frame, file_group = get_frames(item)
|
| 456 |
+
frames, masks = create_mixed_image(pos_frame, neg_frame, self.patch_size)
|
| 457 |
+
data_dict["frames"] = frames
|
| 458 |
+
data_dict["image_masks"] = masks
|
| 459 |
+
|
| 460 |
+
elif mixup_type is None:
|
| 461 |
+
frames, file_group = get_frames(item)
|
| 462 |
+
|
| 463 |
+
data_dict["frames"] = frames
|
| 464 |
+
b, c, h, w = frames.shape
|
| 465 |
+
data_dict["image_masks"] = torch.ones(b, 1, h, w)
|
| 466 |
+
else:
|
| 467 |
+
raise ValueError(f"Unknown mixup type {mixup_type}")
|
| 468 |
+
|
| 469 |
+
if "original_length" in data_dict:
|
| 470 |
+
if self._expected_num_frames() == 1:
|
| 471 |
+
frame_nums = torch.tensor([0])
|
| 472 |
+
else:
|
| 473 |
+
frame_nums = torch.tensor([
|
| 474 |
+
int(f.split("/")[-1].split("_")[-1].split(".")[0]) for f in file_group])
|
| 475 |
+
|
| 476 |
+
data_dict["frame_nums"] = frame_nums
|
| 477 |
+
frame_fracs = ((frame_nums + .5) / (self._expected_num_frames()))
|
| 478 |
+
frame_position = (frame_fracs * data_dict["original_length"]) / data_dict["total_length"]
|
| 479 |
+
data_dict["frame_position"] = frame_position
|
| 480 |
+
|
| 481 |
+
if self.use_caption:
|
| 482 |
+
if "word" in self.metadata:
|
| 483 |
+
words = self.metadata["word"].iloc[item]
|
| 484 |
+
start = self.metadata["start"].iloc[item]
|
| 485 |
+
end = self.metadata["end"].iloc[item]
|
| 486 |
+
if isinstance(words, float):
|
| 487 |
+
words = [""]
|
| 488 |
+
start = [0.0]
|
| 489 |
+
end = [-1.0]
|
| 490 |
+
|
| 491 |
+
data_dict["caption"] = {
|
| 492 |
+
"words": words,
|
| 493 |
+
"start": start,
|
| 494 |
+
"end": end,
|
| 495 |
+
}
|
| 496 |
+
if "text" in self.metadata:
|
| 497 |
+
data_dict["text"] = self.metadata["text"].iloc[item]
|
| 498 |
+
|
| 499 |
+
if self.use_semseg:
|
| 500 |
+
semseg_path = join(self._semseg_root(), self.metadata["semseg_file"].iloc[item])
|
| 501 |
+
semseg = Image.open(semseg_path)
|
| 502 |
+
if self.label_transform is not None:
|
| 503 |
+
semseg = np.array(self.label_transform(semseg))
|
| 504 |
+
data_dict["semseg"] = semseg
|
| 505 |
+
data_dict["metadata"]["semseg_file"] = semseg_path
|
| 506 |
+
|
| 507 |
+
# if hasattr(self, "num_classes"):
|
| 508 |
+
# data_dict["num_pixels_per_class"] = F.one_hot(
|
| 509 |
+
# torch.tensor(semseg).to(torch.int64), self.num_classes() + 1).sum(dim=[0, 1])
|
| 510 |
+
|
| 511 |
+
return data_dict
|
| 512 |
+
|
| 513 |
+
def __getitem__(self, item):
|
| 514 |
+
try:
|
| 515 |
+
data_dict = self._base_get_item(item)
|
| 516 |
+
if self.use_hn:
|
| 517 |
+
indices = torch.cat([self.metadata["hn0"].iloc[item], self.metadata["hn1"].iloc[item]], dim=0)
|
| 518 |
+
neg_index = indices[torch.randint(0, indices.shape[0], (1,))]
|
| 519 |
+
negative_dict = self._base_get_item(neg_index)
|
| 520 |
+
data_dict["negatives"] = negative_dict
|
| 521 |
+
return data_dict
|
| 522 |
+
except (audioread.exceptions.NoBackendError, EOFError) as e:
|
| 523 |
+
# raise e
|
| 524 |
+
bad_path = self.metadata["audio_file"].iloc[item]
|
| 525 |
+
print(e)
|
| 526 |
+
print(f"Removing bad audio file {bad_path}")
|
| 527 |
+
# os.remove(bad_path)
|
| 528 |
+
return None
|
| 529 |
+
except ValueError as e:
|
| 530 |
+
# raise e
|
| 531 |
+
bad_path = self.metadata["audio_file"].iloc[item]
|
| 532 |
+
if "Input signal length=0" in str(e):
|
| 533 |
+
print(e)
|
| 534 |
+
print(f"Removing bad file {bad_path} due to input signal length=0")
|
| 535 |
+
# os.remove(bad_path)
|
| 536 |
+
return None
|
| 537 |
+
except OSError as e:
|
| 538 |
+
# raise e
|
| 539 |
+
bad_paths = self.metadata["frame_files"].iloc[item]
|
| 540 |
+
for bad_path in bad_paths:
|
| 541 |
+
print(e)
|
| 542 |
+
print(f"Removing bad frame file {bad_path}")
|
| 543 |
+
return None
|
| 544 |
+
except RuntimeError as e:
|
| 545 |
+
# raise e
|
| 546 |
+
bad_path = self.metadata["audio_file"].iloc[item]
|
| 547 |
+
print(e)
|
| 548 |
+
print(f"Removing bad audio file {bad_path}")
|
| 549 |
+
# os.remove(bad_path)
|
| 550 |
+
return None
|
| 551 |
+
|
| 552 |
+
|
| 553 |
+
class PlacesAudio(AVDataset):
|
| 554 |
+
|
| 555 |
+
def _load_info(self, split) -> pd.DataFrame:
|
| 556 |
+
df = pd.read_json(join(os.path.dirname(self._audio_root()), "metadata", f"{split}.json"))
|
| 557 |
+
df["id"] = df["data"].apply(lambda d: d["wav"][5:-4])
|
| 558 |
+
|
| 559 |
+
if self.use_caption:
|
| 560 |
+
if split == "train":
|
| 561 |
+
word_df = pd.read_json(
|
| 562 |
+
join(os.path.dirname(self._audio_root()), "metadata", f"word-alignment-{split}.json")
|
| 563 |
+
)
|
| 564 |
+
else:
|
| 565 |
+
word_df = pd.read_csv(
|
| 566 |
+
join(os.path.dirname(self._audio_root()), "metadata", f"word-alignment-{split}.csv")) \
|
| 567 |
+
.groupby("id").aggregate(lambda g: list(g)).reset_index().drop("Unnamed: 0", axis=1)
|
| 568 |
+
df = pd.merge(df, word_df, on="id", how="outer")
|
| 569 |
+
return df
|
| 570 |
+
|
| 571 |
+
def _missing_threshold(self) -> float:
|
| 572 |
+
# return 0.0
|
| 573 |
+
return 0.97 # TODO fix
|
| 574 |
+
|
| 575 |
+
def _expected_num_frames(self):
|
| 576 |
+
return 1
|
| 577 |
+
|
| 578 |
+
def default_target_length(self) -> int:
|
| 579 |
+
return 20
|
| 580 |
+
|
| 581 |
+
def _frame_root(self) -> str:
|
| 582 |
+
return join(os.path.dirname(self.root), "places_subset")
|
| 583 |
+
|
| 584 |
+
def _audio_root(self) -> str:
|
| 585 |
+
return join(self.root, "wavs")
|
| 586 |
+
|
| 587 |
+
def _embed_root(self) -> str:
|
| 588 |
+
return join(self.root, "embedding", self.audio_embed_model)
|
| 589 |
+
|
| 590 |
+
def _dataset_folder(self) -> str:
|
| 591 |
+
return "PlacesAudio_400k_distro"
|
| 592 |
+
|
| 593 |
+
def _get_audio_file(self, row) -> str:
|
| 594 |
+
return join(self._audio_root(), row["id"] + ".wav")
|
| 595 |
+
|
| 596 |
+
def _get_frame_files(self, row) -> List[str]:
|
| 597 |
+
return [join(self._frame_root(), row["data"]["image"])]
|
| 598 |
+
|
| 599 |
+
def _get_embed_file(self, row) -> str:
|
| 600 |
+
return join(self._embed_root(), row["id"] + ".npz")
|
| 601 |
+
|
| 602 |
+
|
| 603 |
+
class AudioSet(AVDataset):
|
| 604 |
+
def _expected_num_frames(self):
|
| 605 |
+
return 10
|
| 606 |
+
|
| 607 |
+
def default_target_length(self) -> int:
|
| 608 |
+
return 20
|
| 609 |
+
|
| 610 |
+
def _dataset_folder(self) -> str:
|
| 611 |
+
return "audioset-raw"
|
| 612 |
+
|
| 613 |
+
def _missing_threshold(self) -> float:
|
| 614 |
+
if self.split == "val" or self.split == "test":
|
| 615 |
+
return 0.02
|
| 616 |
+
else:
|
| 617 |
+
return 0.17
|
| 618 |
+
|
| 619 |
+
def train_seg_file(self):
|
| 620 |
+
return "unbalanced_train_segments.csv"
|
| 621 |
+
|
| 622 |
+
def _load_info(self, split) -> pd.DataFrame:
|
| 623 |
+
if split == "train":
|
| 624 |
+
df = pd.read_csv(join(self.root, "metadata", self.train_seg_file()))
|
| 625 |
+
elif split == "val" or split == "test":
|
| 626 |
+
df = pd.read_csv(join(self.root, "metadata", "eval_segments_subset.csv"))
|
| 627 |
+
else:
|
| 628 |
+
raise ValueError(f"Unknown split {split}")
|
| 629 |
+
|
| 630 |
+
labels = pd.read_csv(join(self.root, "metadata", "class_labels_indices.csv"))
|
| 631 |
+
mid_to_index = dict(zip(labels["mid"], labels["index"]))
|
| 632 |
+
df["tags"] = df["positive_labels"].apply(lambda l: [mid_to_index[e] for e in l.strip('"').split(",")])
|
| 633 |
+
|
| 634 |
+
self.num_tags = max(*[i for k, i in mid_to_index.items()]) + 1
|
| 635 |
+
df["id"] = df.apply(lambda r: f"{r.YTID}_{r.start_seconds}_{r.end_seconds}", axis=1)
|
| 636 |
+
return df
|
| 637 |
+
|
| 638 |
+
def _frame_root(self) -> str:
|
| 639 |
+
return join(self.root, "frames")
|
| 640 |
+
|
| 641 |
+
def _audio_root(self) -> str:
|
| 642 |
+
return join(self.root, "audio")
|
| 643 |
+
|
| 644 |
+
def _all_frame_files(self) -> Set[str]:
|
| 645 |
+
frame_files = set()
|
| 646 |
+
|
| 647 |
+
for entry in os.scandir(self._frame_root()):
|
| 648 |
+
if entry.is_file():
|
| 649 |
+
frame_files.add(entry.path)
|
| 650 |
+
elif entry.is_dir():
|
| 651 |
+
for subentry in os.scandir(entry.path):
|
| 652 |
+
if subentry.is_file():
|
| 653 |
+
frame_files.add(subentry.path)
|
| 654 |
+
|
| 655 |
+
return frame_files
|
| 656 |
+
|
| 657 |
+
def _all_audio_files(self) -> Set[str]:
|
| 658 |
+
return set(entry.path for entry in os.scandir(self._audio_root()) if entry.is_file())
|
| 659 |
+
|
| 660 |
+
def _all_embed_files(self) -> Set[str]:
|
| 661 |
+
return set(entry.path for entry in os.scandir(self._embed_root()) if entry.is_file())
|
| 662 |
+
|
| 663 |
+
def _embed_root(self) -> str:
|
| 664 |
+
return join(self.root, "embedding", self.audio_embed_model)
|
| 665 |
+
|
| 666 |
+
def prefix(self):
|
| 667 |
+
return ""
|
| 668 |
+
|
| 669 |
+
def _get_audio_file(self, row) -> str:
|
| 670 |
+
return f"{self.root}/audio/{self.prefix()}{row.id}.mp3"
|
| 671 |
+
|
| 672 |
+
def _get_frame_files(self, row) -> List[str]:
|
| 673 |
+
return [f"{self.root}/frames/frame_{fn}/{self.prefix()}{row.id}.jpg" for fn in range(10)]
|
| 674 |
+
|
| 675 |
+
def _get_embed_file(self, row) -> str:
|
| 676 |
+
return f"{self.root}/embedding/{self.audio_embed_model}/{self.prefix()}{row.id}.npz"
|
| 677 |
+
|
| 678 |
+
|
| 679 |
+
class AudioSetEval(AudioSet):
|
| 680 |
+
|
| 681 |
+
def _dataset_folder(self) -> str:
|
| 682 |
+
return "audioset-eval"
|
| 683 |
+
|
| 684 |
+
def _get_frame_files(self, row) -> List[str]:
|
| 685 |
+
base_path = f"{self.root}/frames/{self.prefix()}{row.id}_"
|
| 686 |
+
return [base_path + f"{fn}.jpg" for fn in range(10)]
|
| 687 |
+
|
| 688 |
+
def prefix(self):
|
| 689 |
+
return ""
|
| 690 |
+
|
| 691 |
+
|
| 692 |
+
class ADE20K(AVDataset):
|
| 693 |
+
|
| 694 |
+
def _split_name(self, split):
|
| 695 |
+
if split == "val":
|
| 696 |
+
return "validation"
|
| 697 |
+
elif split == "train":
|
| 698 |
+
return "training"
|
| 699 |
+
else:
|
| 700 |
+
raise ValueError(f"Unknown split name {split}")
|
| 701 |
+
|
| 702 |
+
def _load_info(self, split) -> pd.DataFrame:
|
| 703 |
+
df = pd.read_json(join(self.root, "metadata_with_caption_dedup.json"))
|
| 704 |
+
df["id"] = df["image"]
|
| 705 |
+
df = df[df["image"].apply(lambda f: f.split("/")[0] == split)]
|
| 706 |
+
|
| 707 |
+
if self.use_caption:
|
| 708 |
+
df["word"] = df["caption"].apply(lambda c: c["words"])
|
| 709 |
+
df["start"] = df["caption"].apply(lambda c: c["start"])
|
| 710 |
+
df["end"] = df["caption"].apply(lambda c: c["end"])
|
| 711 |
+
df["text"] = df["word"].apply(lambda l: " ".join(l))
|
| 712 |
+
return df
|
| 713 |
+
|
| 714 |
+
def _missing_threshold(self) -> float:
|
| 715 |
+
return 0.03
|
| 716 |
+
|
| 717 |
+
def _expected_num_frames(self):
|
| 718 |
+
return 1
|
| 719 |
+
|
| 720 |
+
def default_target_length(self) -> int:
|
| 721 |
+
return 20
|
| 722 |
+
|
| 723 |
+
def _dataset_folder(self) -> str:
|
| 724 |
+
return "ADE20K"
|
| 725 |
+
|
| 726 |
+
def _frame_root(self) -> str:
|
| 727 |
+
return join(self.root, "frames")
|
| 728 |
+
|
| 729 |
+
def _audio_root(self) -> str:
|
| 730 |
+
return join(self.root, "audio")
|
| 731 |
+
|
| 732 |
+
def _semseg_root(self) -> str:
|
| 733 |
+
return join(self.root, "annotations")
|
| 734 |
+
|
| 735 |
+
def _embed_root(self) -> str:
|
| 736 |
+
return join(self.root, "embedding", self.audio_embed_model)
|
| 737 |
+
|
| 738 |
+
def _get_audio_file(self, row) -> str:
|
| 739 |
+
return join(self._audio_root(), row["audio"])
|
| 740 |
+
|
| 741 |
+
def _get_frame_files(self, row) -> List[str]:
|
| 742 |
+
return [join(self._frame_root(), row["image"])]
|
| 743 |
+
|
| 744 |
+
def _get_semseg_file(self, row) -> str:
|
| 745 |
+
return join(self._semseg_root(), row["seg"])
|
| 746 |
+
|
| 747 |
+
def _get_embed_file(self, row) -> str:
|
| 748 |
+
return join(self._embed_root(), row["image"].replace(".jpg", ".npz"))
|
| 749 |
+
|
| 750 |
+
def num_classes(self):
|
| 751 |
+
return 3662
|
| 752 |
+
|
| 753 |
+
|
| 754 |
+
class ADE20KPromptedBase(AVDataset):
|
| 755 |
+
|
| 756 |
+
def _expected_num_frames(self):
|
| 757 |
+
return 1
|
| 758 |
+
|
| 759 |
+
def default_target_length(self) -> int:
|
| 760 |
+
return 20
|
| 761 |
+
|
| 762 |
+
def _frame_root(self) -> str:
|
| 763 |
+
return join(self.root, "frames")
|
| 764 |
+
|
| 765 |
+
def _audio_root(self) -> str:
|
| 766 |
+
return join(self.root, "audio")
|
| 767 |
+
|
| 768 |
+
def _semseg_root(self) -> str:
|
| 769 |
+
return join(self.root, "annotations")
|
| 770 |
+
|
| 771 |
+
def _embed_root(self) -> str:
|
| 772 |
+
return join(self.root, "embedding", self.audio_embed_model)
|
| 773 |
+
|
| 774 |
+
def _get_frame_files(self, row) -> List[str]:
|
| 775 |
+
return [join(self._frame_root(), row["image_location"])]
|
| 776 |
+
|
| 777 |
+
def _get_semseg_file(self, row) -> str:
|
| 778 |
+
return join(self._semseg_root(), row["image_location"].replace(".jpg", "_seg.png"))
|
| 779 |
+
|
| 780 |
+
def _get_embed_file(self, row) -> str:
|
| 781 |
+
return join(self._embed_root(), row["image_location"].replace(".jpg", ".npz"))
|
| 782 |
+
|
| 783 |
+
def num_classes(self):
|
| 784 |
+
return 3662
|
| 785 |
+
|
| 786 |
+
def _missing_threshold(self) -> float:
|
| 787 |
+
return 0.0
|
| 788 |
+
|
| 789 |
+
|
| 790 |
+
class ADE20KSpeechPrompted(ADE20KPromptedBase):
|
| 791 |
+
|
| 792 |
+
def _get_audio_file(self, row) -> str:
|
| 793 |
+
return join(self._audio_root(), row["speech_prompt_file"].split("/")[-1])
|
| 794 |
+
|
| 795 |
+
def _dataset_folder(self) -> str:
|
| 796 |
+
return "ADE20KSpeechPrompted"
|
| 797 |
+
|
| 798 |
+
def _audio_root(self) -> str:
|
| 799 |
+
# return join(self.root, "audio-noise-10") # TODO Remove
|
| 800 |
+
return join(self.root, "audio") # TODO Remove
|
| 801 |
+
|
| 802 |
+
def _load_info(self, split) -> pd.DataFrame:
|
| 803 |
+
df = pd.read_csv(join(self.root, "prompted_segmentation.csv"))
|
| 804 |
+
df = df[df["speech_prompt_file"].apply(lambda s: isinstance(s, str))]
|
| 805 |
+
df = df[df["ade_class_id"].apply(lambda id: id != 0)]
|
| 806 |
+
df["id"] = df["image_location"]
|
| 807 |
+
return df
|
| 808 |
+
|
| 809 |
+
|
| 810 |
+
class ADE20KSoundPrompted(ADE20KPromptedBase):
|
| 811 |
+
|
| 812 |
+
def _get_audio_file(self, row) -> str:
|
| 813 |
+
return join(self._audio_root(), row["vggsound_file"].split("/")[-1])
|
| 814 |
+
|
| 815 |
+
def _dataset_folder(self) -> str:
|
| 816 |
+
return "ADE20KSoundPrompted"
|
| 817 |
+
|
| 818 |
+
def _load_info(self, split) -> pd.DataFrame:
|
| 819 |
+
df = pd.read_csv(join(self.root, "prompted_segmentation.csv"))
|
| 820 |
+
df = df[df["vggsound_file"].apply(lambda s: isinstance(s, str))]
|
| 821 |
+
df = df[df["ade_class_id"].apply(lambda id: id != 0)]
|
| 822 |
+
df["id"] = df["image_location"]
|
| 823 |
+
return df
|
| 824 |
+
|
| 825 |
+
|
| 826 |
+
class PlacesAndAudioSet(Dataset):
|
| 827 |
+
|
| 828 |
+
def __init__(self, **kwargs):
|
| 829 |
+
self.ds1 = PlacesAudio(**kwargs, n_frames=1)
|
| 830 |
+
self.ds2 = AudioSet(**kwargs, n_frames=1)
|
| 831 |
+
|
| 832 |
+
def __len__(self):
|
| 833 |
+
return len(self.ds1)
|
| 834 |
+
|
| 835 |
+
def __getitem__(self, item):
|
| 836 |
+
if torch.rand(1).item() > .5:
|
| 837 |
+
d = self.ds2[torch.randint(0, len(self.ds2) - 1, size=(1,)).item()]
|
| 838 |
+
if d is not None:
|
| 839 |
+
d["source"] = 1
|
| 840 |
+
else:
|
| 841 |
+
d = self.ds1[item]
|
| 842 |
+
if d is not None:
|
| 843 |
+
d["source"] = 0
|
| 844 |
+
return d
|
| 845 |
+
|
| 846 |
+
|
| 847 |
+
class AVDataModule(pl.LightningDataModule):
|
| 848 |
+
def __init__(self,
|
| 849 |
+
dataset_name,
|
| 850 |
+
load_size,
|
| 851 |
+
image_aug,
|
| 852 |
+
audio_aug,
|
| 853 |
+
extra_audio_masking,
|
| 854 |
+
audio_model_type,
|
| 855 |
+
pytorch_data_dir,
|
| 856 |
+
use_cached_embs,
|
| 857 |
+
batch_size,
|
| 858 |
+
num_workers,
|
| 859 |
+
audio_level,
|
| 860 |
+
neg_audio,
|
| 861 |
+
data_for_plotting,
|
| 862 |
+
use_original_val_set,
|
| 863 |
+
use_extra_val_sets,
|
| 864 |
+
quad_mixup,
|
| 865 |
+
bg_mixup,
|
| 866 |
+
patch_mixup,
|
| 867 |
+
patch_size,
|
| 868 |
+
**kwargs):
|
| 869 |
+
|
| 870 |
+
super().__init__()
|
| 871 |
+
self.dataset_name = dataset_name
|
| 872 |
+
self.load_size = load_size
|
| 873 |
+
self.image_aug = image_aug
|
| 874 |
+
self.audio_aug = audio_aug
|
| 875 |
+
self.extra_audio_masking = extra_audio_masking
|
| 876 |
+
self.audio_model_type = audio_model_type
|
| 877 |
+
self.pytorch_data_dir = pytorch_data_dir
|
| 878 |
+
self.use_cached_embs = use_cached_embs
|
| 879 |
+
self.batch_size = batch_size
|
| 880 |
+
self.num_workers = num_workers
|
| 881 |
+
self.data_for_plotting = data_for_plotting
|
| 882 |
+
self.audio_level = audio_level
|
| 883 |
+
self.neg_audio = neg_audio
|
| 884 |
+
|
| 885 |
+
self.quad_mixup = quad_mixup
|
| 886 |
+
self.bg_mixup = bg_mixup
|
| 887 |
+
self.patch_mixup = patch_mixup
|
| 888 |
+
self.patch_size = patch_size
|
| 889 |
+
|
| 890 |
+
self.loader_args = dict(
|
| 891 |
+
num_workers=self.num_workers,
|
| 892 |
+
batch_size=self.batch_size,
|
| 893 |
+
)
|
| 894 |
+
self.save_hyperparameters()
|
| 895 |
+
self.extra_args = kwargs
|
| 896 |
+
|
| 897 |
+
self.use_original_val_set = use_original_val_set
|
| 898 |
+
self.use_extra_val_sets = use_extra_val_sets
|
| 899 |
+
|
| 900 |
+
def maybe_unpack(self, remove_source):
|
| 901 |
+
targets = [
|
| 902 |
+
(
|
| 903 |
+
join(self.pytorch_data_dir, "audioset-subset", "frame_archives"),
|
| 904 |
+
join(self.pytorch_data_dir, "audioset-subset", "frames"),
|
| 905 |
+
1
|
| 906 |
+
),
|
| 907 |
+
(
|
| 908 |
+
join(self.pytorch_data_dir, "audioset-raw", "frame_archives"),
|
| 909 |
+
join(self.pytorch_data_dir, "audioset-raw", "frames"),
|
| 910 |
+
4
|
| 911 |
+
),
|
| 912 |
+
(
|
| 913 |
+
join(self.pytorch_data_dir, "audioset-raw", "audio_archives"),
|
| 914 |
+
join(self.pytorch_data_dir, "audioset-raw", "audio"),
|
| 915 |
+
1
|
| 916 |
+
),
|
| 917 |
+
|
| 918 |
+
]
|
| 919 |
+
|
| 920 |
+
for (archive_dir, target_dir, n_parts) in targets:
|
| 921 |
+
if not os.path.exists(target_dir) and os.path.exists(archive_dir):
|
| 922 |
+
print(f"Could not find {target_dir}, attempting to unpack archives")
|
| 923 |
+
if os.path.exists(archive_dir):
|
| 924 |
+
untar_all(archive_dir, target_dir, remove_source)
|
| 925 |
+
else:
|
| 926 |
+
raise RuntimeError(f"Could not find archive folder: {archive_dir}")
|
| 927 |
+
|
| 928 |
+
def get_dataset_by_name(self, name, stage, data_for_plotting, n_frames=None):
|
| 929 |
+
|
| 930 |
+
if name == "vggss":
|
| 931 |
+
resize_op = T.Resize((self.load_size, self.load_size), Image.BILINEAR)
|
| 932 |
+
else:
|
| 933 |
+
resize_op = T.Resize(self.load_size, Image.BILINEAR)
|
| 934 |
+
|
| 935 |
+
img_transform = T.Compose([
|
| 936 |
+
resize_op,
|
| 937 |
+
T.CenterCrop(self.load_size),
|
| 938 |
+
T.ToTensor(),
|
| 939 |
+
norm])
|
| 940 |
+
|
| 941 |
+
if self.image_aug:
|
| 942 |
+
train_img_transform = T.Compose([
|
| 943 |
+
T.RandomResizedCrop(self.load_size),
|
| 944 |
+
T.RandomHorizontalFlip(),
|
| 945 |
+
T.ColorJitter(.2, .2, .2, .2),
|
| 946 |
+
T.RandomGrayscale(),
|
| 947 |
+
T.ToTensor(),
|
| 948 |
+
norm])
|
| 949 |
+
val_img_transform = img_transform
|
| 950 |
+
else:
|
| 951 |
+
train_img_transform = img_transform
|
| 952 |
+
val_img_transform = img_transform
|
| 953 |
+
|
| 954 |
+
if self.audio_aug:
|
| 955 |
+
train_audio_aug = True
|
| 956 |
+
val_audio_aug = False
|
| 957 |
+
else:
|
| 958 |
+
train_audio_aug = False
|
| 959 |
+
val_audio_aug = False
|
| 960 |
+
|
| 961 |
+
if self.audio_model_type == "hubert":
|
| 962 |
+
from featurizers.Hubert import HubertAudioTransform
|
| 963 |
+
audio_transform = HubertAudioTransform()
|
| 964 |
+
else:
|
| 965 |
+
audio_transform = None
|
| 966 |
+
|
| 967 |
+
if self.audio_model_type == "passt":
|
| 968 |
+
sample_rate = 32000
|
| 969 |
+
else:
|
| 970 |
+
sample_rate = 16000
|
| 971 |
+
|
| 972 |
+
if not self.use_cached_embs:
|
| 973 |
+
if self.audio_model_type == "hubert":
|
| 974 |
+
self.extra_args["use_audio"] = True
|
| 975 |
+
elif self.audio_model_type in {"audiomae", "audiomae-finetuned", "cavmae", "cavmae-mixed", "imagebind"}:
|
| 976 |
+
self.extra_args["use_spec"] = True
|
| 977 |
+
elif self.audio_model_type == "davenet":
|
| 978 |
+
self.extra_args["use_audio"] = True
|
| 979 |
+
self.extra_args["use_davenet_spec"] = True
|
| 980 |
+
elif self.audio_model_type == "fnac":
|
| 981 |
+
self.extra_args["use_audio"] = True
|
| 982 |
+
self.extra_args["use_fnac_spec"] = True
|
| 983 |
+
else:
|
| 984 |
+
raise ValueError(f"Unknown audio model type {self.audio_model_type}")
|
| 985 |
+
|
| 986 |
+
if self.audio_model_type == "cavmae" or self.audio_model_type == "cavmae-mixed":
|
| 987 |
+
self.extra_args["spec_mean"] = -5.081
|
| 988 |
+
self.extra_args["spec_std"] = 4.4849
|
| 989 |
+
elif self.audio_model_type == "imagebind":
|
| 990 |
+
self.extra_args["spec_mean"] = -4.268
|
| 991 |
+
self.extra_args["spec_std"] = 9.138
|
| 992 |
+
|
| 993 |
+
# if self.audio_model_type in {"audiomae", "audiomae-finetune", "cavmae"} \
|
| 994 |
+
# and "override_target_length" not in self.extra_args:
|
| 995 |
+
if "override_target_length" not in self.extra_args:
|
| 996 |
+
self.extra_args["override_target_length"] = 10
|
| 997 |
+
|
| 998 |
+
data_args = dict(
|
| 999 |
+
root=self.pytorch_data_dir,
|
| 1000 |
+
use_frames=True,
|
| 1001 |
+
audio_transform=audio_transform,
|
| 1002 |
+
sample_rate=sample_rate,
|
| 1003 |
+
audio_level=self.audio_level,
|
| 1004 |
+
**self.extra_args
|
| 1005 |
+
)
|
| 1006 |
+
|
| 1007 |
+
if n_frames is not None:
|
| 1008 |
+
data_args["n_frames"] = n_frames
|
| 1009 |
+
|
| 1010 |
+
train_args = dict(
|
| 1011 |
+
frame_transform=train_img_transform,
|
| 1012 |
+
extra_audio_masking=self.extra_audio_masking,
|
| 1013 |
+
neg_audio=self.neg_audio,
|
| 1014 |
+
quad_mixup=self.quad_mixup,
|
| 1015 |
+
bg_mixup=self.bg_mixup,
|
| 1016 |
+
patch_mixup=self.patch_mixup,
|
| 1017 |
+
patch_size=self.patch_size,
|
| 1018 |
+
audio_aug=train_audio_aug
|
| 1019 |
+
)
|
| 1020 |
+
val_args = dict(
|
| 1021 |
+
frame_transform=val_img_transform,
|
| 1022 |
+
audio_aug=val_audio_aug
|
| 1023 |
+
)
|
| 1024 |
+
|
| 1025 |
+
if data_for_plotting:
|
| 1026 |
+
val_args["use_audio"] = True
|
| 1027 |
+
val_args["use_spec"] = True
|
| 1028 |
+
|
| 1029 |
+
if "ade" in name:
|
| 1030 |
+
label_transform = T.Compose([
|
| 1031 |
+
T.Resize(self.load_size, Image.NEAREST),
|
| 1032 |
+
T.CenterCrop(self.load_size),
|
| 1033 |
+
prep_ade_label
|
| 1034 |
+
])
|
| 1035 |
+
else:
|
| 1036 |
+
label_transform = T.Compose([
|
| 1037 |
+
T.Resize(self.load_size, Image.NEAREST),
|
| 1038 |
+
T.CenterCrop(self.load_size)
|
| 1039 |
+
])
|
| 1040 |
+
|
| 1041 |
+
val_args["use_audio"] = True
|
| 1042 |
+
val_args["label_transform"] = label_transform
|
| 1043 |
+
|
| 1044 |
+
if name == "places-audio":
|
| 1045 |
+
dataset_constructor = PlacesAudio
|
| 1046 |
+
elif name == "mixed-full":
|
| 1047 |
+
dataset_constructor = PlacesAndAudioSet
|
| 1048 |
+
elif name == "audio-set-full":
|
| 1049 |
+
dataset_constructor = AudioSet
|
| 1050 |
+
elif name == "audio-set-eval":
|
| 1051 |
+
dataset_constructor = AudioSetEval
|
| 1052 |
+
elif name == "ade":
|
| 1053 |
+
val_args["use_semseg"] = True
|
| 1054 |
+
dataset_constructor = ADE20K
|
| 1055 |
+
elif name == "ade-speech-prompted":
|
| 1056 |
+
val_args["use_semseg"] = True
|
| 1057 |
+
dataset_constructor = ADE20KSpeechPrompted
|
| 1058 |
+
elif name == "ade-sound-prompted":
|
| 1059 |
+
val_args["use_semseg"] = True
|
| 1060 |
+
dataset_constructor = ADE20KSoundPrompted
|
| 1061 |
+
else:
|
| 1062 |
+
raise ValueError(f"Unknown dataset name {name}")
|
| 1063 |
+
|
| 1064 |
+
data_args["use_audio_embed"] = self.use_cached_embs
|
| 1065 |
+
data_args["audio_embed_model"] = self.audio_model_type
|
| 1066 |
+
|
| 1067 |
+
if stage == "full":
|
| 1068 |
+
val_dataset = dataset_constructor(split="val", **{**data_args, **val_args})
|
| 1069 |
+
train_dataset = dataset_constructor(split="train", **{**data_args, **val_args})
|
| 1070 |
+
return ConcatDataset([train_dataset, val_dataset])
|
| 1071 |
+
elif stage == "fit":
|
| 1072 |
+
return dataset_constructor(split="train", **{**data_args, **train_args})
|
| 1073 |
+
elif stage == "validate":
|
| 1074 |
+
return dataset_constructor(split="val", **{**data_args, **val_args})
|
| 1075 |
+
else:
|
| 1076 |
+
raise ValueError(f"Unknown stage: {stage}")
|
| 1077 |
+
|
| 1078 |
+
def _maybe_subset(self, dataset, length):
|
| 1079 |
+
if len(dataset) > length and self.dataset_name not in {"ade-sound-prompted", "ade-speech-prompted", "vggss"}:
|
| 1080 |
+
print("Using a subset of validation data")
|
| 1081 |
+
return Subset(dataset, generate_subset(len(dataset), length))
|
| 1082 |
+
else:
|
| 1083 |
+
print("Not using val subset")
|
| 1084 |
+
return dataset
|
| 1085 |
+
|
| 1086 |
+
def _make_val_datasets(self):
|
| 1087 |
+
val_sets = []
|
| 1088 |
+
if self.use_original_val_set:
|
| 1089 |
+
val_sets.append(self._maybe_subset(self.get_dataset_by_name(
|
| 1090 |
+
self.dataset_name, "validate", self.data_for_plotting), 1000))
|
| 1091 |
+
|
| 1092 |
+
if self.use_extra_val_sets:
|
| 1093 |
+
val_sets.append(self._maybe_subset(self.get_dataset_by_name(
|
| 1094 |
+
"places-audio", "validate", self.data_for_plotting), 1000))
|
| 1095 |
+
val_sets.append(self._maybe_subset(self.get_dataset_by_name(
|
| 1096 |
+
"audio-set-eval", "validate", False, n_frames=1), 1000))
|
| 1097 |
+
val_sets.append(self.get_dataset_by_name(
|
| 1098 |
+
"ade-speech-prompted", "validate", True))
|
| 1099 |
+
val_sets.append(self.get_dataset_by_name(
|
| 1100 |
+
"ade-sound-prompted", "validate", self.data_for_plotting))
|
| 1101 |
+
|
| 1102 |
+
return val_sets
|
| 1103 |
+
|
| 1104 |
+
def setup(self, stage: str):
|
| 1105 |
+
if stage == "full":
|
| 1106 |
+
self.full_dataset = self.get_dataset_by_name(self.dataset_name, stage, self.data_for_plotting)
|
| 1107 |
+
elif stage == "fit":
|
| 1108 |
+
self.train_dataset = self.get_dataset_by_name(self.dataset_name, stage, self.data_for_plotting)
|
| 1109 |
+
self.val_datasets = self._make_val_datasets()
|
| 1110 |
+
elif stage == "validate":
|
| 1111 |
+
self.val_datasets = self._make_val_datasets()
|
| 1112 |
+
else:
|
| 1113 |
+
raise ValueError(f"Unknown stage: {stage}")
|
| 1114 |
+
|
| 1115 |
+
def train_dataloader(self):
|
| 1116 |
+
return DataLoader(self.train_dataset, shuffle=True, **self.loader_args, collate_fn=custom_coallate)
|
| 1117 |
+
|
| 1118 |
+
def subsampled_train_dataloader(self, k=5000):
|
| 1119 |
+
if len(self.train_dataset) > k:
|
| 1120 |
+
ds = Subset(self.train_dataset, generate_subset(len(self.train_dataset), k))
|
| 1121 |
+
else:
|
| 1122 |
+
ds = self.train_dataset
|
| 1123 |
+
|
| 1124 |
+
return DataLoader(ds, shuffle=True, **self.loader_args, collate_fn=custom_coallate)
|
| 1125 |
+
|
| 1126 |
+
def val_dataloader(self):
|
| 1127 |
+
return [
|
| 1128 |
+
DataLoader(dataset, shuffle=False, **self.loader_args, collate_fn=custom_coallate)
|
| 1129 |
+
for dataset in self.val_datasets
|
| 1130 |
+
]
|
| 1131 |
+
|
| 1132 |
+
def full_dataloader(self):
|
| 1133 |
+
return DataLoader(self.full_dataset, shuffle=False, **self.loader_args, collate_fn=custom_coallate)
|
| 1134 |
+
|
| 1135 |
+
|
| 1136 |
+
def generate_subset(n, batch, seed=0):
|
| 1137 |
+
np.random.seed(seed)
|
| 1138 |
+
return np.random.permutation(n)[:batch]
|
| 1139 |
+
|
| 1140 |
+
|
| 1141 |
+
def prep_ade_label(img):
|
| 1142 |
+
seg = np.array(img)
|
| 1143 |
+
class_labels = (seg[:, :, 0] / 10).astype(np.int32) * 256 + (seg[:, :, 1].astype(np.int32))
|
| 1144 |
+
return class_labels
|
| 1145 |
+
|
| 1146 |
+
|
| 1147 |
+
def maybe_replace(e, not_none):
|
| 1148 |
+
if e is not None:
|
| 1149 |
+
return e
|
| 1150 |
+
else:
|
| 1151 |
+
print("Warning found a None in the dataset indicitive of a loading failure, replacing it with another item")
|
| 1152 |
+
return not_none[0]
|
| 1153 |
+
|
| 1154 |
+
|
| 1155 |
+
empty_caption = {
|
| 1156 |
+
"words": [],
|
| 1157 |
+
"start": [],
|
| 1158 |
+
"end": [],
|
| 1159 |
+
}
|
| 1160 |
+
|
| 1161 |
+
|
| 1162 |
+
def custom_coallate(l):
|
| 1163 |
+
if l is None:
|
| 1164 |
+
return l
|
| 1165 |
+
|
| 1166 |
+
not_none = [e for e in l if e is not None]
|
| 1167 |
+
assert len(not_none) > 0
|
| 1168 |
+
|
| 1169 |
+
l = [maybe_replace(e, not_none) for e in l]
|
| 1170 |
+
|
| 1171 |
+
to_merge = {}
|
| 1172 |
+
|
| 1173 |
+
def pop_or_default(dict, k, default):
|
| 1174 |
+
if k in dict:
|
| 1175 |
+
return dict.pop(k)
|
| 1176 |
+
else:
|
| 1177 |
+
print(f"WARNING: Could not find {k}, using {default}")
|
| 1178 |
+
return default
|
| 1179 |
+
|
| 1180 |
+
if "caption" in l[0]:
|
| 1181 |
+
to_merge["caption"] = [pop_or_default(l[i], "caption", empty_caption) for i in range(len(l))]
|
| 1182 |
+
|
| 1183 |
+
if "text" in l[0]:
|
| 1184 |
+
to_merge["text"] = [pop_or_default(l[i], "text", "") for i in range(len(l))]
|
| 1185 |
+
|
| 1186 |
+
result = default_collate(l)
|
| 1187 |
+
|
| 1188 |
+
return {**result, **to_merge}
|
| 1189 |
+
|
| 1190 |
+
|
| 1191 |
+
if __name__ == "__main__":
|
| 1192 |
+
|
| 1193 |
+
from featurizers.Hubert import HubertAudioTransform
|
| 1194 |
+
|
| 1195 |
+
pytorch_data_dir = "/pytorch-data"
|
| 1196 |
+
dataset_constructor = PlacesAudio
|
| 1197 |
+
split = "val"
|
| 1198 |
+
|
| 1199 |
+
img_transform = T.Compose([
|
| 1200 |
+
T.Resize(224, Image.BILINEAR),
|
| 1201 |
+
T.CenterCrop(224),
|
| 1202 |
+
T.ToTensor(),
|
| 1203 |
+
norm])
|
| 1204 |
+
|
| 1205 |
+
video_transform = T.Compose([
|
| 1206 |
+
T.Resize(224, Image.BILINEAR),
|
| 1207 |
+
T.CenterCrop(224),
|
| 1208 |
+
norm])
|
| 1209 |
+
|
| 1210 |
+
label_transform = T.Compose([
|
| 1211 |
+
T.Resize(224, Image.NEAREST),
|
| 1212 |
+
T.CenterCrop(224)
|
| 1213 |
+
])
|
| 1214 |
+
|
| 1215 |
+
audio_transform = HubertAudioTransform()
|
| 1216 |
+
|
| 1217 |
+
data_args = dict(
|
| 1218 |
+
root=pytorch_data_dir,
|
| 1219 |
+
frame_transform=img_transform,
|
| 1220 |
+
use_frames=True,
|
| 1221 |
+
use_spec=True,
|
| 1222 |
+
use_audio=True,
|
| 1223 |
+
use_caption=False,
|
| 1224 |
+
use_semseg=False,
|
| 1225 |
+
label_transform=label_transform,
|
| 1226 |
+
audio_transform=audio_transform,
|
| 1227 |
+
use_audio_embed=False,
|
| 1228 |
+
audio_embed_model="audiomae",
|
| 1229 |
+
extra_audio_masking=False,
|
| 1230 |
+
neg_audio=False,
|
| 1231 |
+
override_target_length=10,
|
| 1232 |
+
audio_level=False,
|
| 1233 |
+
quad_mixup=.3,
|
| 1234 |
+
patch_mixup=.3,
|
| 1235 |
+
bg_mixup=.3,
|
| 1236 |
+
)
|
| 1237 |
+
|
| 1238 |
+
|
| 1239 |
+
def return_datasets(dataset_constructor, split):
|
| 1240 |
+
dataset = dataset_constructor(split=split, **data_args)
|
| 1241 |
+
return dataset
|
| 1242 |
+
|
| 1243 |
+
|
| 1244 |
+
train_ds = return_datasets(dataset_constructor, split)
|
| 1245 |
+
|
| 1246 |
+
print(len(train_ds))
|
| 1247 |
+
train_loader = DataLoader(train_ds, batch_size=1, shuffle=False, num_workers=36, collate_fn=custom_coallate)
|
| 1248 |
+
for batch in tqdm(train_loader):
|
| 1249 |
+
pass
|
DenseAV/denseav/data/__init__.py
ADDED
|
File without changes
|
DenseAV/denseav/data/make_tarballs.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import glob
|
| 2 |
+
import os
|
| 3 |
+
import tarfile
|
| 4 |
+
from glob import glob
|
| 5 |
+
from io import BytesIO
|
| 6 |
+
from os.path import join
|
| 7 |
+
|
| 8 |
+
from torch.utils.data import Dataset, DataLoader
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
from pathlib import Path
|
| 11 |
+
|
| 12 |
+
from denseav.shared import batch
|
| 13 |
+
|
| 14 |
+
import tempfile
|
| 15 |
+
import shutil
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class Tarballer(Dataset):
|
| 19 |
+
|
| 20 |
+
def __init__(self, source, target, n):
|
| 21 |
+
source_path = Path(source)
|
| 22 |
+
self.frames = [f.relative_to(source_path) for f in source_path.rglob('*') if f.is_file()]
|
| 23 |
+
assert (len(self.frames) > 0)
|
| 24 |
+
self.source = source
|
| 25 |
+
self.target_dir = target
|
| 26 |
+
self.batched = list(batch(self.frames, n))
|
| 27 |
+
os.makedirs(self.target_dir, exist_ok=True)
|
| 28 |
+
|
| 29 |
+
def __len__(self):
|
| 30 |
+
return len(self.batched)
|
| 31 |
+
|
| 32 |
+
def __getitem__(self, item):
|
| 33 |
+
with tarfile.open(join(self.target_dir, f"{item}.tar"), "w") as tar:
|
| 34 |
+
for relpath in self.batched[item]:
|
| 35 |
+
abs_path = os.path.join(self.source, str(relpath)) # Convert to string here
|
| 36 |
+
with open(abs_path, "rb") as file:
|
| 37 |
+
file_content = file.read()
|
| 38 |
+
info = tarfile.TarInfo(name=str(relpath)) # Convert to string here
|
| 39 |
+
info.size = len(file_content)
|
| 40 |
+
tar.addfile(info, fileobj=BytesIO(file_content))
|
| 41 |
+
|
| 42 |
+
return 0
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
class UnTarballer:
|
| 46 |
+
|
| 47 |
+
def __init__(self, archive_dir, target_dir, remove_source=False):
|
| 48 |
+
self.tarballs = sorted(glob(join(archive_dir, "*.tar")))
|
| 49 |
+
self.target_dir = target_dir
|
| 50 |
+
self.remove_source = remove_source # New flag to determine if source tarball should be removed
|
| 51 |
+
os.makedirs(self.target_dir, exist_ok=True)
|
| 52 |
+
|
| 53 |
+
def __len__(self):
|
| 54 |
+
return len(self.tarballs)
|
| 55 |
+
|
| 56 |
+
def __getitem__(self, item):
|
| 57 |
+
with tarfile.open(self.tarballs[item], "r") as tar:
|
| 58 |
+
# Create a unique temporary directory inside the target directory
|
| 59 |
+
with tempfile.TemporaryDirectory(dir=self.target_dir) as tmpdirname:
|
| 60 |
+
tar.extractall(tmpdirname) # Extract to the temporary directory
|
| 61 |
+
|
| 62 |
+
# Move contents from temporary directory to final target directory
|
| 63 |
+
for src_dir, dirs, files in os.walk(tmpdirname):
|
| 64 |
+
dst_dir = src_dir.replace(tmpdirname, self.target_dir, 1)
|
| 65 |
+
os.makedirs(dst_dir, exist_ok=True)
|
| 66 |
+
for file_ in files:
|
| 67 |
+
src_file = os.path.join(src_dir, file_)
|
| 68 |
+
dst_file = os.path.join(dst_dir, file_)
|
| 69 |
+
shutil.move(src_file, dst_file)
|
| 70 |
+
|
| 71 |
+
# Remove the source tarball if the flag is set to True
|
| 72 |
+
if self.remove_source:
|
| 73 |
+
os.remove(self.tarballs[item])
|
| 74 |
+
|
| 75 |
+
return 0
|
| 76 |
+
|
| 77 |
+
def untar_all(archive_dir, target_dir, remove_source):
|
| 78 |
+
loader = DataLoader(UnTarballer(archive_dir, target_dir, remove_source), num_workers=24)
|
| 79 |
+
for _ in tqdm(loader):
|
| 80 |
+
pass
|
| 81 |
+
|
| 82 |
+
|
| 83 |
+
if __name__ == "__main__":
|
| 84 |
+
# loader = DataLoader(Tarballer(
|
| 85 |
+
# join("/pytorch-data", "audioset-raw", "audio"),
|
| 86 |
+
# join("/pytorch-data", "audioset-raw", "audio_archives")
|
| 87 |
+
# ), num_workers=24)
|
| 88 |
+
|
| 89 |
+
# loader = DataLoader(Tarballer(
|
| 90 |
+
# join("/pytorch-data", "audioset-raw", "frames"),
|
| 91 |
+
# join("/pytorch-data", "audioset-raw", "frame_archives"),
|
| 92 |
+
# 5000
|
| 93 |
+
# ), num_workers=24)
|
| 94 |
+
|
| 95 |
+
# loader = DataLoader(Tarballer(
|
| 96 |
+
# join("/pytorch-data", "ADE20KLabels"),
|
| 97 |
+
# join("/pytorch-data", "ADE20KLabelsAr"),
|
| 98 |
+
# 100
|
| 99 |
+
# ), num_workers=24)
|
| 100 |
+
#
|
| 101 |
+
# for _ in tqdm(loader):
|
| 102 |
+
# pass
|
| 103 |
+
#
|
| 104 |
+
# #
|
| 105 |
+
#
|
| 106 |
+
untar_all(
|
| 107 |
+
join("/pytorch-data", "audioset-raw", "frame_archives"),
|
| 108 |
+
join("/pytorch-data", "audioset-raw", "frames_4"))
|
DenseAV/denseav/eval_utils.py
ADDED
|
@@ -0,0 +1,135 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import json
|
| 2 |
+
from collections import defaultdict
|
| 3 |
+
|
| 4 |
+
import matplotlib.pyplot as plt
|
| 5 |
+
import numpy as np
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
from torchmetrics.functional.classification import binary_average_precision
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
|
| 11 |
+
from constants import *
|
| 12 |
+
from denseav.shared import unnorm, remove_axes
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def prep_heatmap(sims, masks, h, w):
|
| 16 |
+
masks = masks.to(torch.float32)
|
| 17 |
+
hm = torch.einsum("bhwt,bt->bhw", sims, masks) / masks.sum(-1).reshape(-1, 1, 1)
|
| 18 |
+
hm -= hm.min()
|
| 19 |
+
hm /= hm.max()
|
| 20 |
+
return F.interpolate(hm.unsqueeze(1), (h, w), mode="bilinear").squeeze(1)
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def iou(prediction, target):
|
| 24 |
+
prediction = prediction > 0.0
|
| 25 |
+
target = target > 0.5
|
| 26 |
+
intersection = torch.logical_and(prediction, target).sum().float()
|
| 27 |
+
union = torch.logical_or(prediction, target).sum().float()
|
| 28 |
+
if union == 0:
|
| 29 |
+
return 1.0
|
| 30 |
+
return (intersection / union).item() # Convert to Python scalar
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def multi_iou(prediction, target, k=20):
|
| 34 |
+
prediction = torch.tensor(prediction)
|
| 35 |
+
target = torch.tensor(target)
|
| 36 |
+
target = target > 0.5
|
| 37 |
+
|
| 38 |
+
thresholds = torch.linspace(prediction.min(), prediction.max(), k)
|
| 39 |
+
hard_pred = prediction.unsqueeze(0) > thresholds.reshape(k, 1, 1, 1, 1)
|
| 40 |
+
target = torch.broadcast_to(target.unsqueeze(0), hard_pred.shape)
|
| 41 |
+
|
| 42 |
+
# Calculate IoU for each threshold
|
| 43 |
+
intersection = torch.logical_and(hard_pred, target).sum(dim=(1, 2, 3, 4)).float()
|
| 44 |
+
union = torch.logical_or(hard_pred, target).sum(dim=(1, 2, 3, 4)).float()
|
| 45 |
+
union = torch.where(union == 0, torch.tensor(1.0), union) # Avoid division by zero
|
| 46 |
+
iou_scores = intersection / union
|
| 47 |
+
|
| 48 |
+
# Find the best IoU and corresponding threshold
|
| 49 |
+
best_iou, best_idx = torch.max(iou_scores, dim=0)
|
| 50 |
+
# best_threshold = thresholds[best_idx]
|
| 51 |
+
# print(best_threshold)
|
| 52 |
+
return best_iou # , best_threshold.item()
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def get_paired_heatmaps(
|
| 56 |
+
model,
|
| 57 |
+
results,
|
| 58 |
+
class_ids,
|
| 59 |
+
timing,
|
| 60 |
+
class_names=None):
|
| 61 |
+
sims = model.sim_agg.get_pairwise_sims(
|
| 62 |
+
results,
|
| 63 |
+
raw=False,
|
| 64 |
+
agg_sim=False,
|
| 65 |
+
agg_heads=True
|
| 66 |
+
).squeeze(1).mean(-2)
|
| 67 |
+
|
| 68 |
+
prompt_classes = torch.tensor(list(class_ids))
|
| 69 |
+
gt = results["semseg"] == prompt_classes.reshape(-1, 1, 1)
|
| 70 |
+
basic_masks = results[AUDIO_MASK] # BxT
|
| 71 |
+
_, fullh, fullw = gt.shape
|
| 72 |
+
basic_heatmaps = prep_heatmap(sims, basic_masks, fullh, fullw)
|
| 73 |
+
|
| 74 |
+
if timing is not None:
|
| 75 |
+
prompt_timing = np.array(list(timing))
|
| 76 |
+
raw_timing = torch.tensor([json.loads(t) for t in prompt_timing])
|
| 77 |
+
timing = torch.clone(raw_timing)
|
| 78 |
+
timing[:, 0] -= .2
|
| 79 |
+
timing[:, 1] += .2
|
| 80 |
+
total_length = (results['total_length'] / 16000)[0]
|
| 81 |
+
fracs = timing / total_length
|
| 82 |
+
bounds = basic_masks.shape[1] * fracs
|
| 83 |
+
bounds[:, 0] = bounds[:, 0].floor()
|
| 84 |
+
bounds[:, 1] = bounds[:, 1].ceil()
|
| 85 |
+
bounds = bounds.to(torch.int64)
|
| 86 |
+
advanced_masks = (F.one_hot(bounds, basic_masks.shape[1]).cumsum(-1).sum(-2) == 1).to(basic_masks)
|
| 87 |
+
advanced_heatmaps = prep_heatmap(sims, advanced_masks, fullh, fullw)
|
| 88 |
+
|
| 89 |
+
metrics = defaultdict(list)
|
| 90 |
+
unique_classes = torch.unique(prompt_classes)
|
| 91 |
+
|
| 92 |
+
should_plot = class_names is not None
|
| 93 |
+
|
| 94 |
+
if should_plot:
|
| 95 |
+
prompt_names = np.array(list(class_names))
|
| 96 |
+
|
| 97 |
+
for prompt_class in tqdm(unique_classes):
|
| 98 |
+
subset = torch.where(prompt_classes == prompt_class)[0]
|
| 99 |
+
gt_subset = gt[subset]
|
| 100 |
+
basic_subset = basic_heatmaps[subset]
|
| 101 |
+
metrics["basic_ap"].append(binary_average_precision(basic_subset.flatten(), gt_subset.flatten()))
|
| 102 |
+
metrics["basic_iou"].append(multi_iou(basic_subset.flatten(), gt_subset.flatten()))
|
| 103 |
+
|
| 104 |
+
if timing is not None:
|
| 105 |
+
advanced_subset = advanced_heatmaps[subset]
|
| 106 |
+
metrics["advanced_ap"].append(binary_average_precision(advanced_subset.flatten(), gt_subset.flatten()))
|
| 107 |
+
metrics["advanced_iou"].append(multi_iou(advanced_subset.flatten(), gt_subset.flatten()))
|
| 108 |
+
|
| 109 |
+
if should_plot:
|
| 110 |
+
prompt_class_subset = prompt_classes[subset]
|
| 111 |
+
name_subset = prompt_names[subset]
|
| 112 |
+
print(prompt_class, name_subset, prompt_class_subset)
|
| 113 |
+
n_imgs = min(len(subset), 5)
|
| 114 |
+
if n_imgs > 1:
|
| 115 |
+
fig, axes = plt.subplots(n_imgs, 5, figsize=(4 * 5, n_imgs * 3))
|
| 116 |
+
frame_subset = unnorm(results[IMAGE_INPUT][subset].squeeze(1)).permute(0, 2, 3, 1)
|
| 117 |
+
semseg_subset = results["semseg"][subset]
|
| 118 |
+
for img_num in range(n_imgs):
|
| 119 |
+
axes[img_num, 0].imshow(frame_subset[img_num])
|
| 120 |
+
axes[img_num, 1].imshow(basic_subset[img_num])
|
| 121 |
+
axes[img_num, 2].imshow(advanced_subset[img_num])
|
| 122 |
+
axes[img_num, 3].imshow(gt_subset[img_num])
|
| 123 |
+
axes[img_num, 4].imshow(semseg_subset[img_num], cmap="tab20", interpolation='none')
|
| 124 |
+
|
| 125 |
+
axes[0, 0].set_title("Image")
|
| 126 |
+
class_name = name_subset[0].split(",")[0]
|
| 127 |
+
axes[0, 1].set_title(f"{class_name} Basic Heatmap")
|
| 128 |
+
axes[0, 2].set_title(f"{class_name} Advanced Heatmap")
|
| 129 |
+
axes[0, 3].set_title("True Mask")
|
| 130 |
+
axes[0, 4].set_title("True Seg")
|
| 131 |
+
remove_axes(axes)
|
| 132 |
+
plt.tight_layout()
|
| 133 |
+
plt.show()
|
| 134 |
+
|
| 135 |
+
return metrics, unique_classes
|
DenseAV/denseav/evaluate.py
ADDED
|
@@ -0,0 +1,87 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from os.path import join
|
| 2 |
+
import hydra
|
| 3 |
+
from omegaconf import DictConfig, OmegaConf
|
| 4 |
+
from pytorch_lightning import Trainer
|
| 5 |
+
from pytorch_lightning import seed_everything
|
| 6 |
+
from pytorch_lightning.loggers import TensorBoardLogger
|
| 7 |
+
from denseav.data.AVDatasets import AVDataModule
|
| 8 |
+
from denseav.shared import load_trained_model
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
@hydra.main(config_path="configs", config_name="av_align.yaml")
|
| 12 |
+
def my_app(cfg: DictConfig) -> None:
|
| 13 |
+
from saved_models import saved_model_dict
|
| 14 |
+
|
| 15 |
+
seed_everything(0)
|
| 16 |
+
print(OmegaConf.to_yaml(cfg))
|
| 17 |
+
|
| 18 |
+
models_to_eval = [
|
| 19 |
+
"denseav_language",
|
| 20 |
+
"denseav_sound",
|
| 21 |
+
]
|
| 22 |
+
|
| 23 |
+
checkpoint_dir = "../checkpoints"
|
| 24 |
+
saved_models = saved_model_dict(checkpoint_dir)
|
| 25 |
+
for model_name in models_to_eval:
|
| 26 |
+
model_info = saved_models[model_name]
|
| 27 |
+
extra_data_args = model_info["data_args"] if "data_args" in model_info else {}
|
| 28 |
+
model_info["extra_args"]["output_root"] = "../"
|
| 29 |
+
model_info["extra_args"]["neg_audio"] = False
|
| 30 |
+
model_info["extra_args"]["image_mixup"] = 0.0
|
| 31 |
+
|
| 32 |
+
model = load_trained_model(join(checkpoint_dir, model_info["chkpt_name"]), model_info["extra_args"])
|
| 33 |
+
model.set_full_train(True)
|
| 34 |
+
|
| 35 |
+
if model.image_model_type == "dinov2":
|
| 36 |
+
load_size = cfg.load_size * 2
|
| 37 |
+
else:
|
| 38 |
+
load_size = cfg.load_size
|
| 39 |
+
|
| 40 |
+
if model.image_model_type == "davenet":
|
| 41 |
+
batch_size = cfg.batch_size // 2
|
| 42 |
+
elif model.image_model_type == "imagebind":
|
| 43 |
+
batch_size = cfg.batch_size
|
| 44 |
+
else:
|
| 45 |
+
batch_size = cfg.batch_size
|
| 46 |
+
|
| 47 |
+
print(load_size)
|
| 48 |
+
|
| 49 |
+
data_args = dict(
|
| 50 |
+
dataset_name=cfg.dataset_name,
|
| 51 |
+
load_size=load_size,
|
| 52 |
+
image_aug=cfg.image_aug,
|
| 53 |
+
audio_aug=cfg.audio_aug,
|
| 54 |
+
audio_model_type=model.audio_model_type,
|
| 55 |
+
pytorch_data_dir=cfg.pytorch_data_dir,
|
| 56 |
+
use_cached_embs=model.use_cached_embs,
|
| 57 |
+
batch_size=batch_size,
|
| 58 |
+
num_workers=cfg.num_workers,
|
| 59 |
+
extra_audio_masking=False,
|
| 60 |
+
use_original_val_set=False,
|
| 61 |
+
use_extra_val_sets=True,
|
| 62 |
+
use_caption=True,
|
| 63 |
+
data_for_plotting=False,
|
| 64 |
+
n_frames=None,
|
| 65 |
+
audio_level=False,
|
| 66 |
+
neg_audio=False,
|
| 67 |
+
quad_mixup=0.0,
|
| 68 |
+
bg_mixup=0.0,
|
| 69 |
+
patch_mixup=0.0,
|
| 70 |
+
patch_size=8,
|
| 71 |
+
)
|
| 72 |
+
data_args = {**data_args, **extra_data_args}
|
| 73 |
+
|
| 74 |
+
datamodule = AVDataModule(**data_args)
|
| 75 |
+
log_dir = join(cfg.output_root, "logs", "evaluate", model_name)
|
| 76 |
+
print(log_dir)
|
| 77 |
+
tb_logger = TensorBoardLogger(log_dir, default_hp_metric=False)
|
| 78 |
+
trainer = Trainer(
|
| 79 |
+
accelerator='gpu',
|
| 80 |
+
strategy="ddp",
|
| 81 |
+
devices=cfg.num_gpus,
|
| 82 |
+
logger=tb_logger)
|
| 83 |
+
trainer.validate(model, datamodule)
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
if __name__ == "__main__":
|
| 87 |
+
my_app()
|
DenseAV/denseav/featurizers/AudioMAE.py
ADDED
|
@@ -0,0 +1,570 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import os
|
| 3 |
+
import warnings
|
| 4 |
+
from functools import partial
|
| 5 |
+
|
| 6 |
+
import numpy as np
|
| 7 |
+
import torch
|
| 8 |
+
import torch.nn as nn
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import torchaudio
|
| 11 |
+
from timm.models.layers import to_2tuple
|
| 12 |
+
from torch.utils.data import Dataset
|
| 13 |
+
from torchaudio.functional import resample
|
| 14 |
+
import pickle
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
|
| 18 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 19 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 20 |
+
def norm_cdf(x):
|
| 21 |
+
# Computes standard normal cumulative distribution function
|
| 22 |
+
return (1. + math.erf(x / math.sqrt(2.))) / 2.
|
| 23 |
+
|
| 24 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 25 |
+
warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 26 |
+
"The distribution of values may be incorrect.",
|
| 27 |
+
stacklevel=2)
|
| 28 |
+
|
| 29 |
+
with torch.no_grad():
|
| 30 |
+
# Values are generated by using a truncated uniform distribution and
|
| 31 |
+
# then using the inverse CDF for the normal distribution.
|
| 32 |
+
# Get upper and lower cdf values
|
| 33 |
+
l = norm_cdf((a - mean) / std)
|
| 34 |
+
u = norm_cdf((b - mean) / std)
|
| 35 |
+
|
| 36 |
+
# Uniformly fill tensor with values from [l, u], then translate to
|
| 37 |
+
# [2l-1, 2u-1].
|
| 38 |
+
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 39 |
+
|
| 40 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 41 |
+
# standard normal
|
| 42 |
+
tensor.erfinv_()
|
| 43 |
+
|
| 44 |
+
# Transform to proper mean, std
|
| 45 |
+
tensor.mul_(std * math.sqrt(2.))
|
| 46 |
+
tensor.add_(mean)
|
| 47 |
+
|
| 48 |
+
# Clamp to ensure it's in the proper range
|
| 49 |
+
tensor.clamp_(min=a, max=b)
|
| 50 |
+
return tensor
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
|
| 54 |
+
# type: (Tensor, float, float, float, float) -> Tensor
|
| 55 |
+
r"""Fills the input Tensor with values drawn from a truncated
|
| 56 |
+
normal distribution. The values are effectively drawn from the
|
| 57 |
+
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
|
| 58 |
+
with values outside :math:`[a, b]` redrawn until they are within
|
| 59 |
+
the bounds. The method used for generating the random values works
|
| 60 |
+
best when :math:`a \leq \text{mean} \leq b`.
|
| 61 |
+
Args:
|
| 62 |
+
tensor: an n-dimensional `torch.Tensor`
|
| 63 |
+
mean: the mean of the normal distribution
|
| 64 |
+
std: the standard deviation of the normal distribution
|
| 65 |
+
a: the minimum cutoff value
|
| 66 |
+
b: the maximum cutoff value
|
| 67 |
+
Examples:
|
| 68 |
+
>>> w = torch.empty(3, 5)
|
| 69 |
+
>>> nn.init.trunc_normal_(w)
|
| 70 |
+
"""
|
| 71 |
+
return _no_grad_trunc_normal_(tensor, mean, std, a, b)
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
class Mlp(nn.Module):
|
| 75 |
+
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
|
| 76 |
+
super().__init__()
|
| 77 |
+
out_features = out_features or in_features
|
| 78 |
+
hidden_features = hidden_features or in_features
|
| 79 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 80 |
+
self.act = act_layer()
|
| 81 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 82 |
+
self.drop = nn.Dropout(drop)
|
| 83 |
+
|
| 84 |
+
def forward(self, x):
|
| 85 |
+
x = self.fc1(x)
|
| 86 |
+
x = self.act(x)
|
| 87 |
+
x = self.drop(x)
|
| 88 |
+
x = self.fc2(x)
|
| 89 |
+
x = self.drop(x)
|
| 90 |
+
return x
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
class Attention(nn.Module):
|
| 94 |
+
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
|
| 95 |
+
super().__init__()
|
| 96 |
+
self.num_heads = num_heads
|
| 97 |
+
head_dim = dim // num_heads
|
| 98 |
+
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
|
| 99 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 100 |
+
|
| 101 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 102 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 103 |
+
self.proj = nn.Linear(dim, dim)
|
| 104 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 105 |
+
|
| 106 |
+
def forward(self, x):
|
| 107 |
+
B, N, C = x.shape
|
| 108 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 109 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
|
| 110 |
+
|
| 111 |
+
attn = (q @ k.transpose(-2, -1)) * self.scale
|
| 112 |
+
attn = attn.softmax(dim=-1)
|
| 113 |
+
attn = self.attn_drop(attn)
|
| 114 |
+
|
| 115 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 116 |
+
x = self.proj(x)
|
| 117 |
+
x = self.proj_drop(x)
|
| 118 |
+
return x
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def drop_path(x, drop_prob: float = 0., training: bool = False):
|
| 122 |
+
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
|
| 123 |
+
|
| 124 |
+
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
|
| 125 |
+
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
|
| 126 |
+
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
|
| 127 |
+
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
|
| 128 |
+
'survival rate' as the argument.
|
| 129 |
+
|
| 130 |
+
"""
|
| 131 |
+
if drop_prob == 0. or not training:
|
| 132 |
+
return x
|
| 133 |
+
keep_prob = 1 - drop_prob
|
| 134 |
+
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
|
| 135 |
+
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
|
| 136 |
+
random_tensor.floor_() # binarize
|
| 137 |
+
output = x.div(keep_prob) * random_tensor
|
| 138 |
+
return output
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class DropPath(nn.Module):
|
| 142 |
+
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
|
| 143 |
+
"""
|
| 144 |
+
|
| 145 |
+
def __init__(self, drop_prob=None):
|
| 146 |
+
super(DropPath, self).__init__()
|
| 147 |
+
self.drop_prob = drop_prob
|
| 148 |
+
|
| 149 |
+
def forward(self, x):
|
| 150 |
+
return drop_path(x, self.drop_prob, self.training)
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class Block(nn.Module):
|
| 154 |
+
|
| 155 |
+
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
|
| 156 |
+
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
|
| 157 |
+
super().__init__()
|
| 158 |
+
self.norm1 = norm_layer(dim)
|
| 159 |
+
self.attn = Attention(
|
| 160 |
+
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
|
| 161 |
+
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
|
| 162 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
| 163 |
+
self.norm2 = norm_layer(dim)
|
| 164 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 165 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
|
| 166 |
+
|
| 167 |
+
def forward(self, x):
|
| 168 |
+
x = x + self.drop_path(self.attn(self.norm1(x)))
|
| 169 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 170 |
+
return x
|
| 171 |
+
|
| 172 |
+
|
| 173 |
+
class PatchEmbed(nn.Module):
|
| 174 |
+
""" Image to Patch Embedding
|
| 175 |
+
"""
|
| 176 |
+
|
| 177 |
+
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
|
| 178 |
+
super().__init__()
|
| 179 |
+
img_size = to_2tuple(img_size)
|
| 180 |
+
patch_size = to_2tuple(patch_size)
|
| 181 |
+
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
|
| 182 |
+
self.patch_hw = (img_size[1] // patch_size[1], img_size[0] // patch_size[0])
|
| 183 |
+
self.img_size = img_size
|
| 184 |
+
self.patch_size = patch_size
|
| 185 |
+
self.num_patches = num_patches
|
| 186 |
+
|
| 187 |
+
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
|
| 188 |
+
|
| 189 |
+
def forward(self, x):
|
| 190 |
+
B, C, H, W = x.shape
|
| 191 |
+
# FIXME look at relaxing size constraints
|
| 192 |
+
# assert H == self.img_size[0] and W == self.img_size[1], \
|
| 193 |
+
# f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
|
| 194 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 195 |
+
return x
|
| 196 |
+
|
| 197 |
+
|
| 198 |
+
class HybridEmbed(nn.Module):
|
| 199 |
+
""" CNN Feature Map Embedding
|
| 200 |
+
Extract feature map from CNN, flatten, project to embedding dim.
|
| 201 |
+
"""
|
| 202 |
+
|
| 203 |
+
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
|
| 204 |
+
super().__init__()
|
| 205 |
+
assert isinstance(backbone, nn.Module)
|
| 206 |
+
img_size = to_2tuple(img_size)
|
| 207 |
+
self.img_size = img_size
|
| 208 |
+
self.backbone = backbone
|
| 209 |
+
if feature_size is None:
|
| 210 |
+
with torch.no_grad():
|
| 211 |
+
# FIXME this is hacky, but most reliable way of determining the exact dim of the output feature
|
| 212 |
+
# map for all networks, the feature metadata has reliable channel and stride info, but using
|
| 213 |
+
# stride to calc feature dim requires info about padding of each stage that isn't captured.
|
| 214 |
+
training = backbone.training
|
| 215 |
+
if training:
|
| 216 |
+
backbone.eval()
|
| 217 |
+
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))[-1]
|
| 218 |
+
feature_size = o.shape[-2:]
|
| 219 |
+
feature_dim = o.shape[1]
|
| 220 |
+
backbone.train(training)
|
| 221 |
+
else:
|
| 222 |
+
feature_size = to_2tuple(feature_size)
|
| 223 |
+
feature_dim = self.backbone.feature_info.channels()[-1]
|
| 224 |
+
self.num_patches = feature_size[0] * feature_size[1]
|
| 225 |
+
self.proj = nn.Linear(feature_dim, embed_dim)
|
| 226 |
+
|
| 227 |
+
def forward(self, x):
|
| 228 |
+
x = self.backbone(x)[-1]
|
| 229 |
+
x = x.flatten(2).transpose(1, 2)
|
| 230 |
+
x = self.proj(x)
|
| 231 |
+
return x
|
| 232 |
+
|
| 233 |
+
|
| 234 |
+
class TimmVisionTransformer(nn.Module):
|
| 235 |
+
""" Vision Transformer with support for patch or hybrid CNN input stage
|
| 236 |
+
"""
|
| 237 |
+
|
| 238 |
+
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
|
| 239 |
+
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
|
| 240 |
+
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm):
|
| 241 |
+
super().__init__()
|
| 242 |
+
self.num_classes = num_classes
|
| 243 |
+
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
|
| 244 |
+
|
| 245 |
+
if hybrid_backbone is not None:
|
| 246 |
+
self.patch_embed = HybridEmbed(
|
| 247 |
+
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
|
| 248 |
+
else:
|
| 249 |
+
self.patch_embed = PatchEmbed(
|
| 250 |
+
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
|
| 251 |
+
num_patches = self.patch_embed.num_patches
|
| 252 |
+
|
| 253 |
+
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 254 |
+
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
|
| 255 |
+
self.pos_drop = nn.Dropout(p=drop_rate)
|
| 256 |
+
|
| 257 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
|
| 258 |
+
self.blocks = nn.ModuleList([
|
| 259 |
+
Block(
|
| 260 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 261 |
+
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
|
| 262 |
+
for i in range(depth)])
|
| 263 |
+
self.norm = norm_layer(embed_dim)
|
| 264 |
+
|
| 265 |
+
# NOTE as per official impl, we could have a pre-logits representation dense layer + tanh here
|
| 266 |
+
# self.repr = nn.Linear(embed_dim, representation_size)
|
| 267 |
+
# self.repr_act = nn.Tanh()
|
| 268 |
+
|
| 269 |
+
# Classifier head
|
| 270 |
+
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 271 |
+
|
| 272 |
+
trunc_normal_(self.pos_embed, std=.02)
|
| 273 |
+
trunc_normal_(self.cls_token, std=.02)
|
| 274 |
+
self.apply(self._init_weights)
|
| 275 |
+
|
| 276 |
+
def _init_weights(self, m):
|
| 277 |
+
if isinstance(m, nn.Linear):
|
| 278 |
+
trunc_normal_(m.weight, std=.02)
|
| 279 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 280 |
+
nn.init.constant_(m.bias, 0)
|
| 281 |
+
elif isinstance(m, nn.LayerNorm):
|
| 282 |
+
nn.init.constant_(m.bias, 0)
|
| 283 |
+
nn.init.constant_(m.weight, 1.0)
|
| 284 |
+
|
| 285 |
+
@torch.jit.ignore
|
| 286 |
+
def no_weight_decay(self):
|
| 287 |
+
return {'pos_embed', 'cls_token'}
|
| 288 |
+
|
| 289 |
+
def get_classifier(self):
|
| 290 |
+
return self.head
|
| 291 |
+
|
| 292 |
+
def reset_classifier(self, num_classes, global_pool=''):
|
| 293 |
+
self.num_classes = num_classes
|
| 294 |
+
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 295 |
+
|
| 296 |
+
def forward_features(self, x):
|
| 297 |
+
B = x.shape[0]
|
| 298 |
+
x = self.patch_embed(x)
|
| 299 |
+
|
| 300 |
+
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
|
| 301 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 302 |
+
x = x + self.pos_embed
|
| 303 |
+
x = self.pos_drop(x)
|
| 304 |
+
|
| 305 |
+
for blk in self.blocks:
|
| 306 |
+
x = blk(x)
|
| 307 |
+
|
| 308 |
+
x = self.norm(x)
|
| 309 |
+
return x[:, 0]
|
| 310 |
+
|
| 311 |
+
def forward(self, x):
|
| 312 |
+
x = self.forward_features(x)
|
| 313 |
+
x = self.head(x)
|
| 314 |
+
return x
|
| 315 |
+
|
| 316 |
+
|
| 317 |
+
class VisionTransformer(TimmVisionTransformer):
|
| 318 |
+
""" Vision Transformer with support for global average pooling
|
| 319 |
+
"""
|
| 320 |
+
|
| 321 |
+
def __init__(self, **kwargs):
|
| 322 |
+
super(VisionTransformer, self).__init__(**kwargs)
|
| 323 |
+
norm_layer = kwargs['norm_layer']
|
| 324 |
+
embed_dim = kwargs['embed_dim']
|
| 325 |
+
self.fc_norm = norm_layer(embed_dim)
|
| 326 |
+
del self.norm # remove the original norm
|
| 327 |
+
|
| 328 |
+
def interpolate_pos_encoding(self, x, embed):
|
| 329 |
+
new_patches = x.shape[1]
|
| 330 |
+
old_patches = embed.shape[1]
|
| 331 |
+
|
| 332 |
+
w = 8
|
| 333 |
+
h = int(new_patches / w)
|
| 334 |
+
if new_patches == old_patches:
|
| 335 |
+
return embed
|
| 336 |
+
|
| 337 |
+
dim = x.shape[-1]
|
| 338 |
+
pos_embed = nn.functional.interpolate(
|
| 339 |
+
embed.reshape(1, 64, 8, dim).permute(0, 3, 1, 2),
|
| 340 |
+
size=(h, w),
|
| 341 |
+
mode='bicubic',
|
| 342 |
+
)
|
| 343 |
+
pos_embed = pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
|
| 344 |
+
return pos_embed
|
| 345 |
+
|
| 346 |
+
def forward(self, x):
|
| 347 |
+
B = x.shape[0]
|
| 348 |
+
x = self.patch_embed(x)
|
| 349 |
+
|
| 350 |
+
x = x + self.interpolate_pos_encoding(x, self.pos_embed[:, 1:, :])
|
| 351 |
+
|
| 352 |
+
cls_token = self.cls_token + self.pos_embed[:, :1, :]
|
| 353 |
+
cls_tokens = cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
|
| 354 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 355 |
+
x = self.pos_drop(x)
|
| 356 |
+
|
| 357 |
+
for blk in self.blocks:
|
| 358 |
+
x = blk(x)
|
| 359 |
+
|
| 360 |
+
# x = x[:, 1:, :].mean(dim=1) # global pool without cls token
|
| 361 |
+
# outcome = self.fc_norm(x)
|
| 362 |
+
|
| 363 |
+
return x[:, 1:, :].reshape(B, -1, 8, 768).permute(0, 3, 2, 1), x[:, 0]
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
class NewPatchEmbed(nn.Module):
|
| 367 |
+
""" Flexible Image to Patch Embedding
|
| 368 |
+
"""
|
| 369 |
+
|
| 370 |
+
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, stride=10):
|
| 371 |
+
super().__init__()
|
| 372 |
+
img_size = to_2tuple(img_size)
|
| 373 |
+
patch_size = to_2tuple(patch_size)
|
| 374 |
+
stride = to_2tuple(stride)
|
| 375 |
+
self.img_size = img_size
|
| 376 |
+
self.patch_size = patch_size
|
| 377 |
+
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride) # with overlapped patches
|
| 378 |
+
_, _, h, w = self.get_output_shape(img_size) # n, emb_dim, h, w
|
| 379 |
+
self.patch_hw = (h, w)
|
| 380 |
+
self.num_patches = h * w
|
| 381 |
+
|
| 382 |
+
def get_output_shape(self, img_size):
|
| 383 |
+
# todo: don't be lazy..
|
| 384 |
+
return self.proj(torch.randn(1, 1, img_size[0], img_size[1])).shape
|
| 385 |
+
|
| 386 |
+
def forward(self, x):
|
| 387 |
+
x = self.proj(x)
|
| 388 |
+
x = x.flatten(2).transpose(1, 2)
|
| 389 |
+
return x
|
| 390 |
+
|
| 391 |
+
|
| 392 |
+
def pca(image_feats_list, dim=3, fit_pca=None):
|
| 393 |
+
from sklearn.decomposition import PCA
|
| 394 |
+
|
| 395 |
+
device = image_feats_list[0].device
|
| 396 |
+
|
| 397 |
+
def flatten(tensor, target_size=None):
|
| 398 |
+
if target_size is not None and fit_pca is None:
|
| 399 |
+
F.interpolate(tensor, (target_size, target_size), mode="bilinear")
|
| 400 |
+
B, C, H, W = tensor.shape
|
| 401 |
+
return feats.permute(1, 0, 2, 3).reshape(C, B * H * W).permute(1, 0).detach().cpu()
|
| 402 |
+
|
| 403 |
+
if len(image_feats_list) > 1 and fit_pca is None:
|
| 404 |
+
target_size = image_feats_list[0].shape[2]
|
| 405 |
+
else:
|
| 406 |
+
target_size = None
|
| 407 |
+
|
| 408 |
+
flattened_feats = []
|
| 409 |
+
for feats in image_feats_list:
|
| 410 |
+
flattened_feats.append(flatten(feats, target_size))
|
| 411 |
+
x = torch.cat(flattened_feats, dim=0)
|
| 412 |
+
|
| 413 |
+
if fit_pca is None:
|
| 414 |
+
fit_pca = PCA(n_components=dim, svd_solver="arpack").fit(np.nan_to_num(x.detach().numpy()))
|
| 415 |
+
|
| 416 |
+
reduced_feats = []
|
| 417 |
+
for feats in image_feats_list:
|
| 418 |
+
x_red = torch.from_numpy(fit_pca.transform(flatten(feats)))
|
| 419 |
+
x_red -= x_red.min(dim=0, keepdim=True).values
|
| 420 |
+
x_red /= x_red.max(dim=0, keepdim=True).values
|
| 421 |
+
B, C, H, W = feats.shape
|
| 422 |
+
reduced_feats.append(x_red.reshape(B, H, W, dim).permute(0, 3, 1, 2).to(device))
|
| 423 |
+
|
| 424 |
+
return reduced_feats, fit_pca
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
class AudiosetDataset(Dataset):
|
| 428 |
+
def __init__(self, audio_conf):
|
| 429 |
+
self.audio_conf = audio_conf
|
| 430 |
+
self.melbins = self.audio_conf.get('num_mel_bins')
|
| 431 |
+
self.dataset = self.audio_conf.get('dataset')
|
| 432 |
+
self.norm_mean = self.audio_conf.get('mean')
|
| 433 |
+
self.norm_std = self.audio_conf.get('std')
|
| 434 |
+
|
| 435 |
+
print('Dataset: {}, mean {:.3f} and std {:.3f}'.format(self.dataset, self.norm_mean, self.norm_std))
|
| 436 |
+
print(f'size of dataset {self.__len__()}')
|
| 437 |
+
|
| 438 |
+
def _wav2fbank(self, filename):
|
| 439 |
+
sample_rate = 16000
|
| 440 |
+
target_length = 10
|
| 441 |
+
waveform, obs_sr = torchaudio.load(filename)
|
| 442 |
+
waveform = waveform[0]
|
| 443 |
+
if obs_sr != sample_rate:
|
| 444 |
+
waveform = resample(waveform, obs_sr, sample_rate)
|
| 445 |
+
|
| 446 |
+
original_length = waveform.shape[0]
|
| 447 |
+
padding = target_length * sample_rate - original_length
|
| 448 |
+
|
| 449 |
+
if padding > 0:
|
| 450 |
+
m = torch.nn.ZeroPad2d((0, padding))
|
| 451 |
+
waveform = m(waveform)
|
| 452 |
+
else:
|
| 453 |
+
waveform = waveform[:target_length * sample_rate]
|
| 454 |
+
|
| 455 |
+
|
| 456 |
+
waveform = waveform - waveform.mean()
|
| 457 |
+
|
| 458 |
+
# 498 128, 998, 128
|
| 459 |
+
fbank = torchaudio.compliance.kaldi.fbank(
|
| 460 |
+
waveform.unsqueeze(0),
|
| 461 |
+
htk_compat=True,
|
| 462 |
+
sample_frequency=sample_rate,
|
| 463 |
+
use_energy=False,
|
| 464 |
+
window_type='hanning',
|
| 465 |
+
num_mel_bins=128,
|
| 466 |
+
dither=0.0,
|
| 467 |
+
frame_shift=10)
|
| 468 |
+
|
| 469 |
+
normed_fbank = (fbank - self.norm_mean) / (self.norm_std * 2)
|
| 470 |
+
|
| 471 |
+
return normed_fbank
|
| 472 |
+
|
| 473 |
+
def __getitem__(self, index):
|
| 474 |
+
datum = {"wav": "../../samples/example.wav"}
|
| 475 |
+
fbank = self._wav2fbank(datum['wav'])
|
| 476 |
+
fbank = fbank.transpose(0, 1).unsqueeze(0) # 1, 128, 1024 (...,freq,time)
|
| 477 |
+
fbank = torch.transpose(fbank.squeeze(), 0, 1) # time, freq
|
| 478 |
+
# the output fbank shape is [time_frame_num, frequency_bins], e.g., [1024, 128]
|
| 479 |
+
return fbank.unsqueeze(0)
|
| 480 |
+
|
| 481 |
+
def __len__(self):
|
| 482 |
+
return 1
|
| 483 |
+
|
| 484 |
+
|
| 485 |
+
class AudioMAE(nn.Module):
|
| 486 |
+
|
| 487 |
+
def __init__(self, output_path, finetuned):
|
| 488 |
+
super().__init__()
|
| 489 |
+
# build model
|
| 490 |
+
model = VisionTransformer(
|
| 491 |
+
patch_size=16,
|
| 492 |
+
embed_dim=768,
|
| 493 |
+
depth=12,
|
| 494 |
+
num_heads=12,
|
| 495 |
+
mlp_ratio=4,
|
| 496 |
+
qkv_bias=True,
|
| 497 |
+
norm_layer=partial(nn.LayerNorm, eps=1e-6),
|
| 498 |
+
num_classes=527,
|
| 499 |
+
drop_path_rate=0.1)
|
| 500 |
+
|
| 501 |
+
img_size = (1024, 128) # 1024, 128
|
| 502 |
+
emb_dim = 768
|
| 503 |
+
model.patch_embed = NewPatchEmbed(
|
| 504 |
+
img_size=img_size, patch_size=(16, 16), in_chans=1, embed_dim=emb_dim, stride=16)
|
| 505 |
+
num_patches = model.patch_embed.num_patches
|
| 506 |
+
model.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, emb_dim), requires_grad=False)
|
| 507 |
+
|
| 508 |
+
if finetuned:
|
| 509 |
+
fn = "audiomae_finetuned.pth"
|
| 510 |
+
else:
|
| 511 |
+
fn = "audiomae.pth"
|
| 512 |
+
|
| 513 |
+
checkpoint = torch.load(os.path.join(output_path, 'models', fn), map_location='cpu')
|
| 514 |
+
|
| 515 |
+
checkpoint_model = checkpoint['model']
|
| 516 |
+
state_dict = model.state_dict()
|
| 517 |
+
for k in ['head.weight', 'head.bias']:
|
| 518 |
+
if k in checkpoint_model and checkpoint_model[k].shape != state_dict[k].shape:
|
| 519 |
+
print(f"Removing key {k} from pretrained checkpoint")
|
| 520 |
+
del checkpoint_model[k]
|
| 521 |
+
msg = model.load_state_dict(checkpoint_model, strict=False)
|
| 522 |
+
print(msg)
|
| 523 |
+
|
| 524 |
+
model = model.eval()
|
| 525 |
+
self.model = model
|
| 526 |
+
self.config = dict(output_path=output_path, finetuned=finetuned)
|
| 527 |
+
|
| 528 |
+
def forward(self, audio, include_cls):
|
| 529 |
+
patch_tokens, cls_token = self.model(audio)
|
| 530 |
+
|
| 531 |
+
if include_cls:
|
| 532 |
+
return patch_tokens, cls_token
|
| 533 |
+
else:
|
| 534 |
+
return patch_tokens
|
| 535 |
+
|
| 536 |
+
|
| 537 |
+
if __name__ == '__main__':
|
| 538 |
+
import os
|
| 539 |
+
|
| 540 |
+
device = torch.device("cuda:2")
|
| 541 |
+
|
| 542 |
+
torch.manual_seed(0)
|
| 543 |
+
np.random.seed(0)
|
| 544 |
+
|
| 545 |
+
model = AudioMAE("../../", True).to(device)
|
| 546 |
+
|
| 547 |
+
audio_conf_val = {
|
| 548 |
+
'num_mel_bins': 128,
|
| 549 |
+
'target_length': 1024,
|
| 550 |
+
'dataset': "audioset",
|
| 551 |
+
'mode': 'val',
|
| 552 |
+
'mean': -4.2677393,
|
| 553 |
+
'std': 4.5689974,
|
| 554 |
+
}
|
| 555 |
+
|
| 556 |
+
dataset = AudiosetDataset(audio_conf=audio_conf_val)
|
| 557 |
+
|
| 558 |
+
batch = dataset[0].unsqueeze(0).to(device)
|
| 559 |
+
|
| 560 |
+
embeddings = model(batch, include_cls=False)
|
| 561 |
+
|
| 562 |
+
import matplotlib.pyplot as plt
|
| 563 |
+
|
| 564 |
+
with torch.no_grad():
|
| 565 |
+
[pca_feats], _ = pca([embeddings])
|
| 566 |
+
plt.imshow(pca_feats.cpu().squeeze(0).permute(1, 2, 0))
|
| 567 |
+
plt.show()
|
| 568 |
+
print("here")
|
| 569 |
+
|
| 570 |
+
print("here")
|
DenseAV/denseav/featurizers/CAVMAE.py
ADDED
|
@@ -0,0 +1,1082 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
|
| 3 |
+
import numpy as np
|
| 4 |
+
import timm
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
import torchaudio
|
| 9 |
+
import torchvision.transforms as T
|
| 10 |
+
from PIL import Image
|
| 11 |
+
from timm.models.layers import to_2tuple, DropPath
|
| 12 |
+
from timm.models.vision_transformer import Mlp, PatchEmbed, Block
|
| 13 |
+
import os
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class Attention(nn.Module):
|
| 17 |
+
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
|
| 18 |
+
super().__init__()
|
| 19 |
+
self.num_heads = num_heads
|
| 20 |
+
head_dim = dim // num_heads
|
| 21 |
+
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
|
| 22 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 23 |
+
|
| 24 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 25 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 26 |
+
self.proj = nn.Linear(dim, dim)
|
| 27 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 28 |
+
|
| 29 |
+
def forward(self, x):
|
| 30 |
+
B, N, C = x.shape
|
| 31 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 32 |
+
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
|
| 33 |
+
|
| 34 |
+
attn = (q @ k.transpose(-2, -1)) * self.scale
|
| 35 |
+
attn = attn.softmax(dim=-1)
|
| 36 |
+
attn = self.attn_drop(attn)
|
| 37 |
+
|
| 38 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 39 |
+
x = self.proj(x)
|
| 40 |
+
x = self.proj_drop(x)
|
| 41 |
+
return x
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
def get_2d_sincos_pos_embed(embed_dim, grid_h_size, grid_w_size, cls_token=False):
|
| 45 |
+
"""
|
| 46 |
+
grid_size: int of the grid height and width
|
| 47 |
+
return:
|
| 48 |
+
pos_embed: [grid_size*grid_size, embed_dim] or [1+grid_size*grid_size, embed_dim] (w/ or w/o cls_token)
|
| 49 |
+
"""
|
| 50 |
+
grid_h = np.arange(grid_h_size, dtype=float)
|
| 51 |
+
grid_w = np.arange(grid_w_size, dtype=float)
|
| 52 |
+
grid = np.meshgrid(grid_w, grid_h) # here w goes first
|
| 53 |
+
grid = np.stack(grid, axis=0)
|
| 54 |
+
|
| 55 |
+
grid = grid.reshape([2, 1, grid_w_size, grid_h_size])
|
| 56 |
+
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
|
| 57 |
+
if cls_token:
|
| 58 |
+
pos_embed = np.concatenate([np.zeros([1, embed_dim]), pos_embed], axis=0)
|
| 59 |
+
return pos_embed
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
|
| 63 |
+
assert embed_dim % 2 == 0
|
| 64 |
+
|
| 65 |
+
# use half of dimensions to encode grid_h
|
| 66 |
+
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
|
| 67 |
+
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
|
| 68 |
+
|
| 69 |
+
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
|
| 70 |
+
return emb
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
|
| 74 |
+
"""
|
| 75 |
+
embed_dim: output dimension for each position
|
| 76 |
+
pos: a list of positions to be encoded: size (M,)
|
| 77 |
+
out: (M, D)
|
| 78 |
+
"""
|
| 79 |
+
assert embed_dim % 2 == 0
|
| 80 |
+
omega = np.arange(embed_dim // 2, dtype=float)
|
| 81 |
+
omega /= embed_dim / 2.
|
| 82 |
+
omega = 1. / 10000 ** omega # (D/2,)
|
| 83 |
+
|
| 84 |
+
pos = pos.reshape(-1) # (M,)
|
| 85 |
+
out = np.einsum('m,d->md', pos, omega) # (M, D/2), outer product
|
| 86 |
+
|
| 87 |
+
emb_sin = np.sin(out) # (M, D/2)
|
| 88 |
+
emb_cos = np.cos(out) # (M, D/2)
|
| 89 |
+
|
| 90 |
+
emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
|
| 91 |
+
return emb
|
| 92 |
+
|
| 93 |
+
|
| 94 |
+
# --------------------------------------------------------
|
| 95 |
+
# Interpolate position embeddings for high-resolution
|
| 96 |
+
# References:
|
| 97 |
+
# DeiT: https://github.com/facebookresearch/deit
|
| 98 |
+
# --------------------------------------------------------
|
| 99 |
+
def interpolate_pos_embed(model, checkpoint_model):
|
| 100 |
+
if 'pos_embed' in checkpoint_model:
|
| 101 |
+
pos_embed_checkpoint = checkpoint_model['pos_embed']
|
| 102 |
+
embedding_size = pos_embed_checkpoint.shape[-1]
|
| 103 |
+
num_patches = model.patch_embed.num_patches
|
| 104 |
+
num_extra_tokens = model.pos_embed.shape[-2] - num_patches
|
| 105 |
+
# height (== width) for the checkpoint position embedding
|
| 106 |
+
orig_size = int((pos_embed_checkpoint.shape[-2] - num_extra_tokens) ** 0.5)
|
| 107 |
+
# height (== width) for the new position embedding
|
| 108 |
+
new_size = int(num_patches ** 0.5)
|
| 109 |
+
# class_token and dist_token are kept unchanged
|
| 110 |
+
if orig_size != new_size:
|
| 111 |
+
print("Position interpolate from %dx%d to %dx%d" % (orig_size, orig_size, new_size, new_size))
|
| 112 |
+
extra_tokens = pos_embed_checkpoint[:, :num_extra_tokens]
|
| 113 |
+
# only the position tokens are interpolated
|
| 114 |
+
pos_tokens = pos_embed_checkpoint[:, num_extra_tokens:]
|
| 115 |
+
pos_tokens = pos_tokens.reshape(-1, orig_size, orig_size, embedding_size).permute(0, 3, 1, 2)
|
| 116 |
+
pos_tokens = torch.nn.functional.interpolate(
|
| 117 |
+
pos_tokens, size=(new_size, new_size), mode='bicubic', align_corners=False)
|
| 118 |
+
pos_tokens = pos_tokens.permute(0, 2, 3, 1).flatten(1, 2)
|
| 119 |
+
new_pos_embed = torch.cat((extra_tokens, pos_tokens), dim=1)
|
| 120 |
+
checkpoint_model['pos_embed'] = new_pos_embed
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
class PatchEmbed(nn.Module):
|
| 124 |
+
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
|
| 125 |
+
super().__init__()
|
| 126 |
+
|
| 127 |
+
img_size = to_2tuple(img_size)
|
| 128 |
+
patch_size = to_2tuple(patch_size)
|
| 129 |
+
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
|
| 130 |
+
self.img_size = img_size
|
| 131 |
+
self.patch_size = patch_size
|
| 132 |
+
self.num_patches = num_patches
|
| 133 |
+
|
| 134 |
+
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
|
| 135 |
+
|
| 136 |
+
def forward(self, x):
|
| 137 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 138 |
+
return x
|
| 139 |
+
|
| 140 |
+
|
| 141 |
+
class Block(nn.Module):
|
| 142 |
+
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
|
| 143 |
+
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
|
| 144 |
+
super().__init__()
|
| 145 |
+
self.norm1 = norm_layer(dim)
|
| 146 |
+
self.norm1_a = norm_layer(dim)
|
| 147 |
+
self.norm1_v = norm_layer(dim)
|
| 148 |
+
self.attn = Attention(
|
| 149 |
+
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
|
| 150 |
+
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
|
| 151 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
| 152 |
+
self.norm2 = norm_layer(dim)
|
| 153 |
+
self.norm2_a = norm_layer(dim)
|
| 154 |
+
self.norm2_v = norm_layer(dim)
|
| 155 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 156 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
|
| 157 |
+
|
| 158 |
+
def forward(self, x, modality=None):
|
| 159 |
+
if modality == None:
|
| 160 |
+
x = x + self.drop_path(self.attn(self.norm1(x)))
|
| 161 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 162 |
+
elif modality == 'a':
|
| 163 |
+
x = x + self.drop_path(self.attn(self.norm1_a(x)))
|
| 164 |
+
x = x + self.drop_path(self.mlp(self.norm2_a(x)))
|
| 165 |
+
elif modality == 'v':
|
| 166 |
+
x = x + self.drop_path(self.attn(self.norm1_v(x)))
|
| 167 |
+
x = x + self.drop_path(self.mlp(self.norm2_v(x)))
|
| 168 |
+
return x
|
| 169 |
+
|
| 170 |
+
|
| 171 |
+
# our main proposed model, for pretraining only, for finetuning, use CAVMAEFT class
|
| 172 |
+
class CAVMAE(nn.Module):
|
| 173 |
+
""" CAV-MAE Model
|
| 174 |
+
"""
|
| 175 |
+
|
| 176 |
+
def __init__(self, img_size=224, audio_length=1024, patch_size=16, in_chans=3,
|
| 177 |
+
embed_dim=768, modality_specific_depth=11, num_heads=12,
|
| 178 |
+
decoder_embed_dim=512, decoder_depth=8, decoder_num_heads=16,
|
| 179 |
+
mlp_ratio=4., norm_layer=nn.LayerNorm, norm_pix_loss=False, tr_pos=False):
|
| 180 |
+
super().__init__()
|
| 181 |
+
print('A CAV-MAE Model')
|
| 182 |
+
print('Use norm_pix_loss: ', norm_pix_loss)
|
| 183 |
+
print('Learnable Positional Embedding: ', tr_pos)
|
| 184 |
+
|
| 185 |
+
# the encoder part
|
| 186 |
+
# overide the timm package
|
| 187 |
+
timm.models.vision_transformer.PatchEmbed = PatchEmbed
|
| 188 |
+
timm.models.vision_transformer.Block = Block
|
| 189 |
+
|
| 190 |
+
self.patch_embed_a = PatchEmbed(img_size, patch_size, 1, embed_dim)
|
| 191 |
+
self.patch_embed_v = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
|
| 192 |
+
|
| 193 |
+
self.patch_embed_a.num_patches = int(audio_length * 128 / 256)
|
| 194 |
+
print('Number of Audio Patches: {:d}, Visual Patches: {:d}'.format(self.patch_embed_a.num_patches,
|
| 195 |
+
self.patch_embed_v.num_patches))
|
| 196 |
+
|
| 197 |
+
self.modality_a = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 198 |
+
self.modality_v = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 199 |
+
|
| 200 |
+
self.pos_embed_a = nn.Parameter(torch.zeros(1, self.patch_embed_a.num_patches, embed_dim),
|
| 201 |
+
requires_grad=tr_pos) # fixed sin-cos embedding
|
| 202 |
+
self.pos_embed_v = nn.Parameter(torch.zeros(1, self.patch_embed_v.num_patches, embed_dim),
|
| 203 |
+
requires_grad=tr_pos) # fixed sin-cos embedding
|
| 204 |
+
|
| 205 |
+
# audio-branch
|
| 206 |
+
self.blocks_a = nn.ModuleList(
|
| 207 |
+
[Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer) for i in
|
| 208 |
+
range(modality_specific_depth)])
|
| 209 |
+
# visual-branch
|
| 210 |
+
self.blocks_v = nn.ModuleList(
|
| 211 |
+
[Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer) for i in
|
| 212 |
+
range(modality_specific_depth)])
|
| 213 |
+
# unified branch
|
| 214 |
+
self.blocks_u = nn.ModuleList(
|
| 215 |
+
[Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer) for i in
|
| 216 |
+
range(12 - modality_specific_depth)])
|
| 217 |
+
|
| 218 |
+
# independent normalization layer for audio, visual, and audio-visual
|
| 219 |
+
self.norm_a, self.norm_v, self.norm = norm_layer(embed_dim), norm_layer(embed_dim), norm_layer(embed_dim)
|
| 220 |
+
|
| 221 |
+
# the decoder part
|
| 222 |
+
# Project to lower dimension for the decoder
|
| 223 |
+
self.decoder_embed = nn.Linear(embed_dim, decoder_embed_dim, bias=True)
|
| 224 |
+
|
| 225 |
+
# token used for masking
|
| 226 |
+
self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
|
| 227 |
+
|
| 228 |
+
self.decoder_modality_a = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
|
| 229 |
+
self.decoder_modality_v = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))
|
| 230 |
+
|
| 231 |
+
self.decoder_pos_embed_a = nn.Parameter(torch.zeros(1, self.patch_embed_a.num_patches, decoder_embed_dim),
|
| 232 |
+
requires_grad=tr_pos) # fixed sin-cos embedding
|
| 233 |
+
self.decoder_pos_embed_v = nn.Parameter(torch.zeros(1, self.patch_embed_v.num_patches, decoder_embed_dim),
|
| 234 |
+
requires_grad=tr_pos) # fixed sin-cos embedding
|
| 235 |
+
|
| 236 |
+
self.decoder_blocks = nn.ModuleList(
|
| 237 |
+
[Block(decoder_embed_dim, decoder_num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer)
|
| 238 |
+
for i in range(decoder_depth)])
|
| 239 |
+
|
| 240 |
+
self.decoder_norm = norm_layer(decoder_embed_dim)
|
| 241 |
+
|
| 242 |
+
# project channel is different for two modality, use two projection head
|
| 243 |
+
self.decoder_pred_a = nn.Linear(decoder_embed_dim, patch_size ** 2 * 1, bias=True) # decoder to patch
|
| 244 |
+
self.decoder_pred_v = nn.Linear(decoder_embed_dim, patch_size ** 2 * in_chans, bias=True) # decoder to patch
|
| 245 |
+
|
| 246 |
+
self.norm_pix_loss = norm_pix_loss
|
| 247 |
+
|
| 248 |
+
self.initialize_weights()
|
| 249 |
+
|
| 250 |
+
print('Audio Positional Embedding Shape:', self.pos_embed_a.shape)
|
| 251 |
+
print('Visual Positional Embedding Shape:', self.pos_embed_v.shape)
|
| 252 |
+
|
| 253 |
+
def initialize_weights(self):
|
| 254 |
+
# initialize (and freeze) pos_embed by sin-cos embedding, opt the cls token, add by myself
|
| 255 |
+
pos_embed_a = get_2d_sincos_pos_embed(self.pos_embed_a.shape[-1], 8, int(self.patch_embed_a.num_patches / 8),
|
| 256 |
+
cls_token=False)
|
| 257 |
+
self.pos_embed_a.data.copy_(torch.from_numpy(pos_embed_a).float().unsqueeze(0))
|
| 258 |
+
|
| 259 |
+
pos_embed_v = get_2d_sincos_pos_embed(self.pos_embed_v.shape[-1], int(self.patch_embed_v.num_patches ** .5),
|
| 260 |
+
int(self.patch_embed_v.num_patches ** .5), cls_token=False)
|
| 261 |
+
self.pos_embed_v.data.copy_(torch.from_numpy(pos_embed_v).float().unsqueeze(0))
|
| 262 |
+
|
| 263 |
+
decoder_pos_embed_a = get_2d_sincos_pos_embed(self.decoder_pos_embed_a.shape[-1], 8,
|
| 264 |
+
int(self.patch_embed_a.num_patches / 8), cls_token=False)
|
| 265 |
+
self.decoder_pos_embed_a.data.copy_(torch.from_numpy(decoder_pos_embed_a).float().unsqueeze(0))
|
| 266 |
+
|
| 267 |
+
decoder_pos_embed_v = get_2d_sincos_pos_embed(self.decoder_pos_embed_v.shape[-1],
|
| 268 |
+
int(self.patch_embed_v.num_patches ** .5),
|
| 269 |
+
int(self.patch_embed_v.num_patches ** .5), cls_token=False)
|
| 270 |
+
self.decoder_pos_embed_v.data.copy_(torch.from_numpy(decoder_pos_embed_v).float().unsqueeze(0))
|
| 271 |
+
|
| 272 |
+
# initialize patch_embed like nn.Linear (instead of nn.Conv2d)
|
| 273 |
+
w = self.patch_embed_a.proj.weight.data
|
| 274 |
+
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
|
| 275 |
+
w = self.patch_embed_v.proj.weight.data
|
| 276 |
+
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
|
| 277 |
+
|
| 278 |
+
# timm's trunc_normal_(std=.02) is effectively normal_(std=0.02) as cutoff is too big (2.)
|
| 279 |
+
torch.nn.init.normal_(self.modality_a, std=.02)
|
| 280 |
+
torch.nn.init.normal_(self.modality_v, std=.02)
|
| 281 |
+
torch.nn.init.normal_(self.decoder_modality_a, std=.02)
|
| 282 |
+
torch.nn.init.normal_(self.decoder_modality_v, std=.02)
|
| 283 |
+
torch.nn.init.normal_(self.mask_token, std=.02)
|
| 284 |
+
|
| 285 |
+
# initialize nn.Linear and nn.LayerNorm
|
| 286 |
+
self.apply(self._init_weights)
|
| 287 |
+
|
| 288 |
+
def _init_weights(self, m):
|
| 289 |
+
if isinstance(m, nn.Linear):
|
| 290 |
+
# we use xavier_uniform following official JAX ViT:
|
| 291 |
+
torch.nn.init.xavier_uniform_(m.weight)
|
| 292 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 293 |
+
nn.init.constant_(m.bias, 0)
|
| 294 |
+
elif isinstance(m, nn.LayerNorm):
|
| 295 |
+
nn.init.constant_(m.bias, 0)
|
| 296 |
+
nn.init.constant_(m.weight, 1.0)
|
| 297 |
+
|
| 298 |
+
def patchify(self, imgs, c, h, w, p=16):
|
| 299 |
+
"""
|
| 300 |
+
imgs: (N, 3, H, W)
|
| 301 |
+
x: (N, L, patch_size**2 *3)
|
| 302 |
+
"""
|
| 303 |
+
x = imgs.reshape(shape=(imgs.shape[0], c, h, p, w, p))
|
| 304 |
+
x = torch.einsum('nchpwq->nhwpqc', x)
|
| 305 |
+
x = x.reshape(shape=(imgs.shape[0], h * w, p ** 2 * c))
|
| 306 |
+
return x
|
| 307 |
+
|
| 308 |
+
def unpatchify(self, x, c, h, w, p=16):
|
| 309 |
+
"""
|
| 310 |
+
x: (N, L, patch_size**2 *3)
|
| 311 |
+
imgs: (N, 3, H, W)
|
| 312 |
+
"""
|
| 313 |
+
assert h * w == x.shape[1]
|
| 314 |
+
|
| 315 |
+
x = x.reshape(shape=(x.shape[0], h, w, p, p, c))
|
| 316 |
+
x = torch.einsum('nhwpqc->nchpwq', x)
|
| 317 |
+
imgs = x.reshape(shape=(x.shape[0], c, h * p, w * p))
|
| 318 |
+
return imgs
|
| 319 |
+
|
| 320 |
+
def random_masking_unstructured(self, x, mask_ratio):
|
| 321 |
+
"""
|
| 322 |
+
Perform per-sample random masking by per-sample shuffling.
|
| 323 |
+
Per-sample shuffling is done by argsort random noise.
|
| 324 |
+
x: [N, L, D], sequence
|
| 325 |
+
"""
|
| 326 |
+
N, L, D = x.shape # batch, length, dim
|
| 327 |
+
len_keep = int(L * (1 - mask_ratio))
|
| 328 |
+
|
| 329 |
+
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
|
| 330 |
+
|
| 331 |
+
# sort noise for each sample
|
| 332 |
+
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
|
| 333 |
+
ids_restore = torch.argsort(ids_shuffle, dim=1)
|
| 334 |
+
|
| 335 |
+
# keep the first subset
|
| 336 |
+
ids_keep = ids_shuffle[:, :len_keep]
|
| 337 |
+
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
|
| 338 |
+
|
| 339 |
+
# generate the binary mask: 0 is keep, 1 is remove
|
| 340 |
+
mask = torch.ones([N, L], device=x.device)
|
| 341 |
+
mask[:, :len_keep] = 0
|
| 342 |
+
# unshuffle to get the binary mask
|
| 343 |
+
mask = torch.gather(mask, dim=1, index=ids_restore)
|
| 344 |
+
|
| 345 |
+
return x_masked, mask, ids_restore
|
| 346 |
+
|
| 347 |
+
def random_masking_structured(self, x, mask_ratio, t=64, f=8, mode='time'):
|
| 348 |
+
"""
|
| 349 |
+
Perform per-sample random masking by per-sample shuffling.
|
| 350 |
+
Per-sample shuffling is done by argsort random noise.
|
| 351 |
+
x: [N, L, D], sequence
|
| 352 |
+
"""
|
| 353 |
+
N, L, D = x.shape # batch, length, dim
|
| 354 |
+
len_keep = int(L * (1 - mask_ratio))
|
| 355 |
+
|
| 356 |
+
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
|
| 357 |
+
assert L == f * t
|
| 358 |
+
noise = noise.reshape(N, f, t) # the audio patch is in shape [f,t], not [t,f]
|
| 359 |
+
if mode == 'time':
|
| 360 |
+
for i in range(N):
|
| 361 |
+
mask_t_list = random.sample(range(t), int(t * mask_ratio))
|
| 362 |
+
for k in mask_t_list:
|
| 363 |
+
noise[i, :, k] = 1.1 # large value will be removed
|
| 364 |
+
elif mode == 'freq':
|
| 365 |
+
for i in range(N):
|
| 366 |
+
mask_f_list = random.sample(range(f), int(f * mask_ratio))
|
| 367 |
+
for k in mask_f_list:
|
| 368 |
+
noise[i, k, :] = 1.1 # large value will be removed
|
| 369 |
+
elif mode == 'tf':
|
| 370 |
+
for i in range(N):
|
| 371 |
+
mask_t_list = random.sample(range(t), int(t * mask_ratio * 0.7))
|
| 372 |
+
for k in mask_t_list:
|
| 373 |
+
noise[i, :, k] = 1.1 # large value will be removed
|
| 374 |
+
for i in range(N):
|
| 375 |
+
mask_f_list = random.sample(range(f), int(f * mask_ratio * 0.7))
|
| 376 |
+
for k in mask_f_list:
|
| 377 |
+
noise[i, k, :] = 1.1 # large value will be removed
|
| 378 |
+
noise = noise.reshape(N, L)
|
| 379 |
+
|
| 380 |
+
# sort noise for each sample, only need to manuplate these two ids_shuffle, ids_restore
|
| 381 |
+
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
|
| 382 |
+
ids_restore = torch.argsort(ids_shuffle, dim=1)
|
| 383 |
+
|
| 384 |
+
# keep the first subset
|
| 385 |
+
ids_keep = ids_shuffle[:, :len_keep]
|
| 386 |
+
x_masked = torch.gather(x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D))
|
| 387 |
+
|
| 388 |
+
# generate the binary mask: 0 is keep, 1 is remove
|
| 389 |
+
mask = torch.ones([N, L], device=x.device)
|
| 390 |
+
mask[:, :len_keep] = 0
|
| 391 |
+
# unshuffle to get the binary mask
|
| 392 |
+
mask = torch.gather(mask, dim=1, index=ids_restore)
|
| 393 |
+
|
| 394 |
+
return x_masked, mask, ids_restore
|
| 395 |
+
|
| 396 |
+
def forward_encoder(self, a, v, mask_ratio_a, mask_ratio_v, mask_mode='unstructured'):
|
| 397 |
+
# embed patches
|
| 398 |
+
a = a.unsqueeze(1)
|
| 399 |
+
a = a.transpose(2, 3)
|
| 400 |
+
a = self.patch_embed_a(a)
|
| 401 |
+
a = a + self.pos_embed_a
|
| 402 |
+
a = a + self.modality_a
|
| 403 |
+
|
| 404 |
+
v = self.patch_embed_v(v)
|
| 405 |
+
v = v + self.pos_embed_v
|
| 406 |
+
v = v + self.modality_v
|
| 407 |
+
|
| 408 |
+
# by default, we always use unstructured masking
|
| 409 |
+
if mask_mode == 'unstructured':
|
| 410 |
+
a, mask_a, ids_restore_a = self.random_masking_unstructured(a, mask_ratio_a)
|
| 411 |
+
# in ablation study, we tried time/freq/tf masking. mode in ['freq', 'time', 'tf']
|
| 412 |
+
else:
|
| 413 |
+
a, mask_a, ids_restore_a = self.random_masking_structured(a, mask_ratio_a, t=64, f=8, mode=mask_mode)
|
| 414 |
+
|
| 415 |
+
# visual branch always use unstructured masking
|
| 416 |
+
v, mask_v, ids_restore_v = self.random_masking_unstructured(v, mask_ratio_v)
|
| 417 |
+
|
| 418 |
+
# audio and visual stream, independent blocks
|
| 419 |
+
for blk in self.blocks_a:
|
| 420 |
+
a = blk(a)
|
| 421 |
+
|
| 422 |
+
for blk in self.blocks_v:
|
| 423 |
+
v = blk(v)
|
| 424 |
+
|
| 425 |
+
x = torch.cat((a, v), dim=1)
|
| 426 |
+
|
| 427 |
+
# unified stream, shared blocks_u, but independent normalization layers
|
| 428 |
+
for blk in self.blocks_u:
|
| 429 |
+
x = blk(x)
|
| 430 |
+
x = self.norm(x)
|
| 431 |
+
|
| 432 |
+
for blk in self.blocks_u:
|
| 433 |
+
ca = blk(a, 'a')
|
| 434 |
+
ca = self.norm_a(ca)
|
| 435 |
+
|
| 436 |
+
for blk in self.blocks_u:
|
| 437 |
+
cv = blk(v, 'v')
|
| 438 |
+
cv = self.norm_v(cv)
|
| 439 |
+
|
| 440 |
+
return x, mask_a, ids_restore_a, mask_v, ids_restore_v, ca, cv
|
| 441 |
+
|
| 442 |
+
def forward_decoder(self, x, mask_a, ids_restore_a, mask_v, ids_restore_v):
|
| 443 |
+
|
| 444 |
+
x = self.decoder_embed(x)
|
| 445 |
+
|
| 446 |
+
# append mask tokens to sequence
|
| 447 |
+
# mask_tokens_a in shape [B, #a_mask_token, mask_token_dim], get the number of masked samples from mask_a[0], which is the first example of the batch, all samples should have same number of masked tokens
|
| 448 |
+
mask_tokens_a = self.mask_token.repeat(x.shape[0], int(mask_a[0].sum()), 1)
|
| 449 |
+
a_ = torch.cat([x[:, :self.patch_embed_a.num_patches - int(mask_a[0].sum()), :], mask_tokens_a],
|
| 450 |
+
dim=1) # no cls token
|
| 451 |
+
a_ = torch.gather(a_, dim=1, index=ids_restore_a.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
|
| 452 |
+
|
| 453 |
+
# similar for the visual modality
|
| 454 |
+
mask_tokens_v = self.mask_token.repeat(x.shape[0], int(mask_v[0].sum()), 1)
|
| 455 |
+
v_ = torch.cat([x[:, self.patch_embed_a.num_patches - int(mask_a[0].sum()):, :], mask_tokens_v],
|
| 456 |
+
dim=1) # no cls token
|
| 457 |
+
v_ = torch.gather(v_, dim=1, index=ids_restore_v.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
|
| 458 |
+
|
| 459 |
+
# concatenate audio and visual tokens
|
| 460 |
+
x = torch.cat([a_, v_], dim=1)
|
| 461 |
+
|
| 462 |
+
decoder_pos_embed = torch.cat([self.decoder_pos_embed_a, self.decoder_pos_embed_v], dim=1)
|
| 463 |
+
x = x + decoder_pos_embed
|
| 464 |
+
|
| 465 |
+
# add modality indication tokens
|
| 466 |
+
x[:, 0:self.patch_embed_a.num_patches, :] = x[:, 0:self.patch_embed_a.num_patches, :] + self.decoder_modality_a
|
| 467 |
+
x[:, self.patch_embed_a.num_patches:, :] = x[:, self.patch_embed_a.num_patches:, :] + self.decoder_modality_v
|
| 468 |
+
|
| 469 |
+
# apply Transformer blocks
|
| 470 |
+
for blk in self.decoder_blocks:
|
| 471 |
+
x = blk(x)
|
| 472 |
+
x = self.decoder_norm(x)
|
| 473 |
+
|
| 474 |
+
# predictor projection
|
| 475 |
+
x_a = self.decoder_pred_a(x[:, :self.patch_embed_a.num_patches, :])
|
| 476 |
+
x_v = self.decoder_pred_v(x[:, self.patch_embed_a.num_patches:, :])
|
| 477 |
+
|
| 478 |
+
# return audio and video tokens
|
| 479 |
+
return x_a, x_v
|
| 480 |
+
|
| 481 |
+
def forward_contrastive(self, audio_rep, video_rep, bidirect_contrast=False):
|
| 482 |
+
# calculate nce loss for mean-visual representation and mean-audio representation
|
| 483 |
+
|
| 484 |
+
audio_rep = torch.nn.functional.normalize(audio_rep, dim=-1)
|
| 485 |
+
video_rep = torch.nn.functional.normalize(video_rep, dim=-1)
|
| 486 |
+
|
| 487 |
+
total = torch.mm(audio_rep, torch.transpose(video_rep, 0, 1)) / 0.05
|
| 488 |
+
|
| 489 |
+
# by default we use single directional
|
| 490 |
+
if bidirect_contrast == False:
|
| 491 |
+
nce = -torch.mean(torch.diag(torch.nn.functional.log_softmax(total, dim=0)))
|
| 492 |
+
c_acc = torch.sum(torch.eq(torch.argmax(torch.nn.functional.softmax(total, dim=0), dim=0),
|
| 493 |
+
torch.arange(0, total.shape[0], device=audio_rep.device))) / total.shape[0]
|
| 494 |
+
return nce, c_acc
|
| 495 |
+
else:
|
| 496 |
+
nce_1 = -torch.mean(torch.diag(torch.nn.functional.log_softmax(total, dim=0)))
|
| 497 |
+
nce_2 = -torch.mean(torch.diag(torch.nn.functional.log_softmax(total.t(), dim=0)))
|
| 498 |
+
c_acc_1 = torch.sum(torch.eq(torch.argmax(torch.nn.functional.softmax(total, dim=0), dim=0),
|
| 499 |
+
torch.arange(0, total.shape[0], device=audio_rep.device))) / total.shape[0]
|
| 500 |
+
c_acc_2 = torch.sum(torch.eq(torch.argmax(torch.nn.functional.softmax(total.t(), dim=0), dim=0),
|
| 501 |
+
torch.arange(0, total.shape[0], device=audio_rep.device))) / total.shape[0]
|
| 502 |
+
nce = (nce_1 + nce_2) / 2
|
| 503 |
+
c_acc = (c_acc_1 + c_acc_2) / 2
|
| 504 |
+
return nce, c_acc
|
| 505 |
+
|
| 506 |
+
def forward_mae_loss(self, input, pred, mask, modality):
|
| 507 |
+
if modality == 'a':
|
| 508 |
+
# for audio, need to adjust the shape
|
| 509 |
+
input = input.unsqueeze(1)
|
| 510 |
+
input = input.transpose(2, 3)
|
| 511 |
+
target = self.patchify(input, 1, int(input.shape[2] / self.patch_embed_a.patch_size[0]),
|
| 512 |
+
int(input.shape[3] / self.patch_embed_a.patch_size[1]), 16)
|
| 513 |
+
elif modality == 'v':
|
| 514 |
+
target = self.patchify(input, 3, int(input.shape[2] / self.patch_embed_v.patch_size[0]),
|
| 515 |
+
int(input.shape[3] / self.patch_embed_v.patch_size[1]), 16)
|
| 516 |
+
|
| 517 |
+
# patch-wise normalization might minorly improve the classification performance, but will make the model lose inpainting function
|
| 518 |
+
if self.norm_pix_loss:
|
| 519 |
+
mean = target.mean(dim=-1, keepdim=True)
|
| 520 |
+
var = target.var(dim=-1, keepdim=True)
|
| 521 |
+
target = (target - mean) / (var + 1.e-6) ** .5
|
| 522 |
+
|
| 523 |
+
loss = (pred - target) ** 2
|
| 524 |
+
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
|
| 525 |
+
|
| 526 |
+
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
|
| 527 |
+
return loss
|
| 528 |
+
|
| 529 |
+
def forward(self, audio, imgs, mask_ratio_a=0.75, mask_ratio_v=0.75, mae_loss_weight=1., contrast_loss_weight=0.01,
|
| 530 |
+
mask_mode='unstructured'):
|
| 531 |
+
# latent is used for reconstruction (mae), latent_c_{a,v} are used for contrastive learning
|
| 532 |
+
latent, mask_a, ids_restore_a, mask_v, ids_restore_v, latent_c_a, latent_c_v = self.forward_encoder(audio, imgs,
|
| 533 |
+
mask_ratio_a,
|
| 534 |
+
mask_ratio_v,
|
| 535 |
+
mask_mode=mask_mode)
|
| 536 |
+
# if mae loss is used
|
| 537 |
+
if mae_loss_weight != 0:
|
| 538 |
+
pred_a, pred_v = self.forward_decoder(latent, mask_a, ids_restore_a, mask_v, ids_restore_v)
|
| 539 |
+
loss_mae_a = self.forward_mae_loss(audio, pred_a, mask_a, 'a')
|
| 540 |
+
loss_mae_v = self.forward_mae_loss(imgs, pred_v, mask_v, 'v')
|
| 541 |
+
loss_mae = mae_loss_weight * (loss_mae_a + loss_mae_v)
|
| 542 |
+
else:
|
| 543 |
+
loss_mae_a, loss_mae_v, loss_mae = torch.tensor(0.0, device=audio.device), torch.tensor(0.0,
|
| 544 |
+
device=audio.device), torch.tensor(
|
| 545 |
+
0.0, device=audio.device)
|
| 546 |
+
|
| 547 |
+
# if contrastive loss is used
|
| 548 |
+
if contrast_loss_weight != 0:
|
| 549 |
+
# note this is single directional
|
| 550 |
+
loss_c, c_acc = self.forward_contrastive(latent_c_a.mean(dim=1), latent_c_v.mean(dim=1))
|
| 551 |
+
loss_c = contrast_loss_weight * loss_c
|
| 552 |
+
else:
|
| 553 |
+
loss_c, c_acc = torch.tensor(0.0, device=audio.device), torch.tensor(0.0, device=audio.device)
|
| 554 |
+
|
| 555 |
+
loss = loss_mae + loss_c
|
| 556 |
+
|
| 557 |
+
return loss, loss_mae, loss_mae_a, loss_mae_v, loss_c, mask_a, mask_v, c_acc
|
| 558 |
+
|
| 559 |
+
# used only for inpainting, ignore if inpainting is not of interest
|
| 560 |
+
def forward_inpaint(self, audio, imgs, mask_ratio_a=0.75, mask_ratio_v=0.75, mask_mode='unstructured'):
|
| 561 |
+
latent, mask_a, ids_restore_a, mask_v, ids_restore_v, latent_c_a, latent_c_v = self.forward_encoder(audio, imgs,
|
| 562 |
+
mask_ratio_a,
|
| 563 |
+
mask_ratio_v,
|
| 564 |
+
mask_mode=mask_mode)
|
| 565 |
+
pred_a, pred_v = self.forward_decoder(latent, mask_a, ids_restore_a, mask_v, ids_restore_v) # [N, L, p*p*3]
|
| 566 |
+
loss_pixel_a = self.forward_mae_loss(audio, pred_a, mask_a, 'a')
|
| 567 |
+
loss_pixel_v = self.forward_mae_loss(imgs, pred_v, mask_v, 'v')
|
| 568 |
+
return pred_a, pred_v, mask_a, mask_v, loss_pixel_a, loss_pixel_v
|
| 569 |
+
|
| 570 |
+
# used for retrieval, ignore if retrieval is not of interest
|
| 571 |
+
def forward_feat(self, a, v):
|
| 572 |
+
# embed patches
|
| 573 |
+
a = a.unsqueeze(1)
|
| 574 |
+
a = a.transpose(2, 3)
|
| 575 |
+
a = self.patch_embed_a(a)
|
| 576 |
+
a = a + self.pos_embed_a
|
| 577 |
+
a = a + self.modality_a
|
| 578 |
+
|
| 579 |
+
v = self.patch_embed_v(v)
|
| 580 |
+
v = v + self.pos_embed_v
|
| 581 |
+
v = v + self.modality_v
|
| 582 |
+
|
| 583 |
+
# the modality-specific stream
|
| 584 |
+
for blk in self.blocks_a:
|
| 585 |
+
a = blk(a)
|
| 586 |
+
|
| 587 |
+
for blk in self.blocks_v:
|
| 588 |
+
v = blk(v)
|
| 589 |
+
|
| 590 |
+
# use modality specific normalization,
|
| 591 |
+
for blk in self.blocks_u:
|
| 592 |
+
a = blk(a, 'a')
|
| 593 |
+
a = self.norm_a(a)
|
| 594 |
+
|
| 595 |
+
for blk in self.blocks_u:
|
| 596 |
+
v = blk(v, 'v')
|
| 597 |
+
v = self.norm_v(v)
|
| 598 |
+
return a, v
|
| 599 |
+
|
| 600 |
+
def forward_audio(self, a):
|
| 601 |
+
# embed patches
|
| 602 |
+
a = a.unsqueeze(1)
|
| 603 |
+
a = a.transpose(2, 3)
|
| 604 |
+
a = self.patch_embed_a(a)
|
| 605 |
+
a = a + self.pos_embed_a
|
| 606 |
+
a = a + self.modality_a
|
| 607 |
+
|
| 608 |
+
# the modality-specific stream
|
| 609 |
+
for blk in self.blocks_a:
|
| 610 |
+
a = blk(a)
|
| 611 |
+
|
| 612 |
+
# use modality specific normalization,
|
| 613 |
+
for blk in self.blocks_u:
|
| 614 |
+
a = blk(a, 'a')
|
| 615 |
+
a = self.norm_a(a)
|
| 616 |
+
|
| 617 |
+
return a.reshape(a.shape[0], 128 // 16, 1024 // 16, 768).permute(0, 3, 1, 2)
|
| 618 |
+
|
| 619 |
+
def forward_video(self, v):
|
| 620 |
+
v = self.patch_embed_v(v)
|
| 621 |
+
v = v + self.pos_embed_v
|
| 622 |
+
v = v + self.modality_v
|
| 623 |
+
|
| 624 |
+
for blk in self.blocks_v:
|
| 625 |
+
v = blk(v)
|
| 626 |
+
|
| 627 |
+
for blk in self.blocks_u:
|
| 628 |
+
v = blk(v, 'v')
|
| 629 |
+
v = self.norm_v(v)
|
| 630 |
+
return v.reshape(v.shape[0], 224 // 16, 224 // 16, 768).permute(0, 3, 1, 2)
|
| 631 |
+
|
| 632 |
+
|
| 633 |
+
# the finetuned CAV-MAE model
|
| 634 |
+
class CAVMAEFT(nn.Module):
|
| 635 |
+
def __init__(self, label_dim, img_size=224, audio_length=1024, patch_size=16, in_chans=3,
|
| 636 |
+
embed_dim=768, modality_specific_depth=11, num_heads=12, mlp_ratio=4., norm_layer=nn.LayerNorm,
|
| 637 |
+
norm_pix_loss=False, tr_pos=True):
|
| 638 |
+
super().__init__()
|
| 639 |
+
timm.models.vision_transformer.Block = Block
|
| 640 |
+
print('Use norm_pix_loss: ', norm_pix_loss)
|
| 641 |
+
|
| 642 |
+
timm.models.vision_transformer.PatchEmbed = PatchEmbed
|
| 643 |
+
timm.models.vision_transformer.Block = Block
|
| 644 |
+
|
| 645 |
+
self.patch_embed_a = PatchEmbed(img_size, patch_size, 1, embed_dim)
|
| 646 |
+
self.patch_embed_v = PatchEmbed(img_size, patch_size, in_chans, embed_dim)
|
| 647 |
+
|
| 648 |
+
self.patch_embed_a.num_patches = int(audio_length * 128 / 256)
|
| 649 |
+
print('Number of Audio Patches: {:d}, Visual Patches: {:d}'.format(self.patch_embed_a.num_patches,
|
| 650 |
+
self.patch_embed_v.num_patches))
|
| 651 |
+
|
| 652 |
+
self.modality_a = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 653 |
+
self.modality_v = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 654 |
+
|
| 655 |
+
self.pos_embed_a = nn.Parameter(torch.zeros(1, self.patch_embed_a.num_patches, embed_dim),
|
| 656 |
+
requires_grad=tr_pos) # fixed sin-cos embedding
|
| 657 |
+
self.pos_embed_v = nn.Parameter(torch.zeros(1, self.patch_embed_v.num_patches, embed_dim),
|
| 658 |
+
requires_grad=tr_pos) # fixed sin-cos embedding
|
| 659 |
+
|
| 660 |
+
self.blocks_a = nn.ModuleList(
|
| 661 |
+
[Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer) for i in
|
| 662 |
+
range(modality_specific_depth)])
|
| 663 |
+
self.blocks_v = nn.ModuleList(
|
| 664 |
+
[Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer) for i in
|
| 665 |
+
range(modality_specific_depth)])
|
| 666 |
+
self.blocks_u = nn.ModuleList(
|
| 667 |
+
[Block(embed_dim, num_heads, mlp_ratio, qkv_bias=True, qk_scale=None, norm_layer=norm_layer) for i in
|
| 668 |
+
range(12 - modality_specific_depth)])
|
| 669 |
+
|
| 670 |
+
self.norm_a = norm_layer(embed_dim)
|
| 671 |
+
self.norm_v = norm_layer(embed_dim)
|
| 672 |
+
self.norm = norm_layer(embed_dim)
|
| 673 |
+
|
| 674 |
+
self.mlp_head = nn.Sequential(nn.LayerNorm(embed_dim), nn.Linear(embed_dim, label_dim))
|
| 675 |
+
|
| 676 |
+
self.initialize_weights()
|
| 677 |
+
|
| 678 |
+
print('Audio Positional Embedding Shape:', self.pos_embed_a.shape)
|
| 679 |
+
print('Visual Positional Embedding Shape:', self.pos_embed_v.shape)
|
| 680 |
+
|
| 681 |
+
def get_patch_num(self, input_shape, stride):
|
| 682 |
+
test_input = torch.zeros(1, 1, input_shape[0], input_shape[1])
|
| 683 |
+
test_proj = torch.nn.Conv2d(1, 4, kernel_size=(16, 16), stride=(stride, stride))
|
| 684 |
+
test_output = test_proj(test_input)
|
| 685 |
+
print(test_output.shape)
|
| 686 |
+
return test_output.shape[2], test_output[3], test_output[2] * test_output[2]
|
| 687 |
+
|
| 688 |
+
def initialize_weights(self):
|
| 689 |
+
pos_embed_a = get_2d_sincos_pos_embed(self.pos_embed_a.shape[-1], 8, int(self.patch_embed_a.num_patches / 8),
|
| 690 |
+
cls_token=False)
|
| 691 |
+
self.pos_embed_a.data.copy_(torch.from_numpy(pos_embed_a).float().unsqueeze(0))
|
| 692 |
+
|
| 693 |
+
pos_embed_v = get_2d_sincos_pos_embed(self.pos_embed_v.shape[-1], int(self.patch_embed_v.num_patches ** .5),
|
| 694 |
+
int(self.patch_embed_v.num_patches ** .5), cls_token=False)
|
| 695 |
+
self.pos_embed_v.data.copy_(torch.from_numpy(pos_embed_v).float().unsqueeze(0))
|
| 696 |
+
|
| 697 |
+
w = self.patch_embed_a.proj.weight.data
|
| 698 |
+
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
|
| 699 |
+
w = self.patch_embed_v.proj.weight.data
|
| 700 |
+
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
|
| 701 |
+
|
| 702 |
+
torch.nn.init.normal_(self.modality_a, std=.02)
|
| 703 |
+
torch.nn.init.normal_(self.modality_v, std=.02)
|
| 704 |
+
|
| 705 |
+
self.apply(self._init_weights)
|
| 706 |
+
|
| 707 |
+
def _init_weights(self, m):
|
| 708 |
+
if isinstance(m, nn.Linear):
|
| 709 |
+
# we use xavier_uniform following official JAX ViT:
|
| 710 |
+
torch.nn.init.xavier_uniform_(m.weight)
|
| 711 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 712 |
+
nn.init.constant_(m.bias, 0)
|
| 713 |
+
elif isinstance(m, nn.LayerNorm):
|
| 714 |
+
nn.init.constant_(m.bias, 0)
|
| 715 |
+
nn.init.constant_(m.weight, 1.0)
|
| 716 |
+
|
| 717 |
+
def forward(self, a, v, mode):
|
| 718 |
+
# multi-modal fine-tuning, our default method for fine-tuning
|
| 719 |
+
if mode == 'multimodal':
|
| 720 |
+
a = a.unsqueeze(1)
|
| 721 |
+
a = a.transpose(2, 3)
|
| 722 |
+
a = self.patch_embed_a(a)
|
| 723 |
+
a = a + self.pos_embed_a
|
| 724 |
+
a = a + self.modality_a
|
| 725 |
+
|
| 726 |
+
v = self.patch_embed_v(v)
|
| 727 |
+
v = v + self.pos_embed_v
|
| 728 |
+
v = v + self.modality_v
|
| 729 |
+
|
| 730 |
+
for blk in self.blocks_a:
|
| 731 |
+
a = blk(a)
|
| 732 |
+
|
| 733 |
+
for blk in self.blocks_v:
|
| 734 |
+
v = blk(v)
|
| 735 |
+
|
| 736 |
+
x = torch.cat((a, v), dim=1)
|
| 737 |
+
|
| 738 |
+
for blk in self.blocks_u:
|
| 739 |
+
x = blk(x)
|
| 740 |
+
x = self.norm(x)
|
| 741 |
+
|
| 742 |
+
x = x.mean(dim=1)
|
| 743 |
+
x = self.mlp_head(x)
|
| 744 |
+
return x
|
| 745 |
+
|
| 746 |
+
# finetune with only audio (and inference with only audio when the model is finetuned with only audio)
|
| 747 |
+
elif mode == 'audioonly':
|
| 748 |
+
a = a.unsqueeze(1)
|
| 749 |
+
a = a.transpose(2, 3)
|
| 750 |
+
a = self.patch_embed_a(a)
|
| 751 |
+
a = a + self.pos_embed_a
|
| 752 |
+
a = a + self.modality_a
|
| 753 |
+
|
| 754 |
+
for blk in self.blocks_a:
|
| 755 |
+
a = blk(a)
|
| 756 |
+
|
| 757 |
+
# note here uses the 'a' normalization, it is used in both training and inference, so it is fine
|
| 758 |
+
for blk in self.blocks_u:
|
| 759 |
+
a = blk(a, 'a')
|
| 760 |
+
a = self.norm_a(a)
|
| 761 |
+
x = a.mean(dim=1)
|
| 762 |
+
x = self.mlp_head(x)
|
| 763 |
+
return x
|
| 764 |
+
|
| 765 |
+
# finetune with only image (and inference with only audio when the model is finetuned with only image)
|
| 766 |
+
elif mode == 'videoonly':
|
| 767 |
+
v = self.patch_embed_v(v)
|
| 768 |
+
v = v + self.pos_embed_v
|
| 769 |
+
v = v + self.modality_v
|
| 770 |
+
|
| 771 |
+
for blk in self.blocks_v:
|
| 772 |
+
v = blk(v)
|
| 773 |
+
|
| 774 |
+
# note here uses the 'v' normalization, it is used in both training and inference, so it is fine
|
| 775 |
+
for blk in self.blocks_u:
|
| 776 |
+
v = blk(v, 'v')
|
| 777 |
+
v = self.norm_v(v)
|
| 778 |
+
x = v.mean(dim=1)
|
| 779 |
+
x = self.mlp_head(x)
|
| 780 |
+
return x
|
| 781 |
+
|
| 782 |
+
# used in case that the model is finetuned with both modality, but in inference only audio is given
|
| 783 |
+
elif mode == 'missingaudioonly':
|
| 784 |
+
a = a.unsqueeze(1)
|
| 785 |
+
a = a.transpose(2, 3)
|
| 786 |
+
a = self.patch_embed_a(a)
|
| 787 |
+
a = a + self.pos_embed_a
|
| 788 |
+
a = a + self.modality_a
|
| 789 |
+
|
| 790 |
+
for blk in self.blocks_a:
|
| 791 |
+
a = blk(a)
|
| 792 |
+
|
| 793 |
+
# two forward passes to the block_u, one with modality-specific normalization, another with unified normalization
|
| 794 |
+
u = a
|
| 795 |
+
for blk in self.blocks_u:
|
| 796 |
+
u = blk(u) # note here use unified normalization
|
| 797 |
+
u = self.norm(u)
|
| 798 |
+
u = u.mean(dim=1)
|
| 799 |
+
|
| 800 |
+
for blk in self.blocks_u:
|
| 801 |
+
a = blk(a, 'a') # note here use modality-specific normalization
|
| 802 |
+
a = self.norm_a(a)
|
| 803 |
+
a = a.mean(dim=1)
|
| 804 |
+
|
| 805 |
+
# average the output of the two forward passes
|
| 806 |
+
x = (u + a) / 2
|
| 807 |
+
x = self.mlp_head(x)
|
| 808 |
+
return x
|
| 809 |
+
|
| 810 |
+
# used in case that the model is fine-tuned with both modality, but in inference only image is given
|
| 811 |
+
elif mode == 'missingvideoonly':
|
| 812 |
+
v = self.patch_embed_v(v)
|
| 813 |
+
v = v + self.pos_embed_v
|
| 814 |
+
v = v + self.modality_v
|
| 815 |
+
|
| 816 |
+
for blk in self.blocks_v:
|
| 817 |
+
v = blk(v)
|
| 818 |
+
|
| 819 |
+
# two forward passes to the block_u, one with modality-specific normalization, another with unified normalization
|
| 820 |
+
u = v
|
| 821 |
+
for blk in self.blocks_u:
|
| 822 |
+
u = blk(u) # note here use unified normalization
|
| 823 |
+
u = self.norm(u)
|
| 824 |
+
u = u.mean(dim=1)
|
| 825 |
+
|
| 826 |
+
for blk in self.blocks_u:
|
| 827 |
+
v = blk(v, 'v') # note here use modality-specific normalization
|
| 828 |
+
v = self.norm_v(v)
|
| 829 |
+
v = v.mean(dim=1)
|
| 830 |
+
|
| 831 |
+
# average the output of the two forward passes
|
| 832 |
+
x = (u + v) / 2
|
| 833 |
+
x = self.mlp_head(x)
|
| 834 |
+
return x
|
| 835 |
+
|
| 836 |
+
# for retrieval
|
| 837 |
+
def forward_feat(self, a, v, mode='av'):
|
| 838 |
+
# return both audio and visual
|
| 839 |
+
if mode == 'av':
|
| 840 |
+
a = a.unsqueeze(1)
|
| 841 |
+
a = a.transpose(2, 3)
|
| 842 |
+
a = self.patch_embed_a(a)
|
| 843 |
+
a = a + self.pos_embed_a
|
| 844 |
+
a = a + self.modality_a
|
| 845 |
+
|
| 846 |
+
v = self.patch_embed_v(v)
|
| 847 |
+
v = v + self.pos_embed_v
|
| 848 |
+
v = v + self.modality_v
|
| 849 |
+
|
| 850 |
+
for blk in self.blocks_a:
|
| 851 |
+
a = blk(a)
|
| 852 |
+
|
| 853 |
+
for blk in self.blocks_v:
|
| 854 |
+
v = blk(v)
|
| 855 |
+
|
| 856 |
+
for blk in self.blocks_u:
|
| 857 |
+
a = blk(a, 'a')
|
| 858 |
+
a = self.norm_a(a)
|
| 859 |
+
|
| 860 |
+
for blk in self.blocks_u:
|
| 861 |
+
v = blk(v, 'v')
|
| 862 |
+
|
| 863 |
+
v = self.norm_v(v)
|
| 864 |
+
return a, v
|
| 865 |
+
|
| 866 |
+
# return only audio
|
| 867 |
+
if mode == 'a':
|
| 868 |
+
a = a.unsqueeze(1)
|
| 869 |
+
a = a.transpose(2, 3)
|
| 870 |
+
a = self.patch_embed_a(a)
|
| 871 |
+
a = a + self.pos_embed_a
|
| 872 |
+
a = a + self.modality_a
|
| 873 |
+
|
| 874 |
+
for blk in self.blocks_a:
|
| 875 |
+
a = blk(a)
|
| 876 |
+
|
| 877 |
+
for blk in self.blocks_u:
|
| 878 |
+
a = blk(a, 'a')
|
| 879 |
+
|
| 880 |
+
a = self.norm_a(a)
|
| 881 |
+
return a
|
| 882 |
+
|
| 883 |
+
|
| 884 |
+
def _wav2fbank(filename):
|
| 885 |
+
waveform, sr = torchaudio.load(filename)
|
| 886 |
+
waveform = torchaudio.functional.resample(
|
| 887 |
+
waveform, orig_freq=sr, new_freq=16000
|
| 888 |
+
)
|
| 889 |
+
|
| 890 |
+
waveform = waveform - waveform.mean()
|
| 891 |
+
waveform
|
| 892 |
+
print(sr)
|
| 893 |
+
|
| 894 |
+
fbank = torchaudio.compliance.kaldi.fbank(
|
| 895 |
+
waveform,
|
| 896 |
+
htk_compat=True,
|
| 897 |
+
sample_frequency=sr,
|
| 898 |
+
use_energy=False,
|
| 899 |
+
window_type='hanning',
|
| 900 |
+
num_mel_bins=128,
|
| 901 |
+
dither=0.0,
|
| 902 |
+
frame_shift=10)
|
| 903 |
+
|
| 904 |
+
target_length = 1024
|
| 905 |
+
n_frames = fbank.shape[0]
|
| 906 |
+
|
| 907 |
+
p = target_length - n_frames
|
| 908 |
+
|
| 909 |
+
# cut and pad
|
| 910 |
+
if p > 0:
|
| 911 |
+
m = torch.nn.ZeroPad2d((0, 0, 0, p))
|
| 912 |
+
fbank = m(fbank)
|
| 913 |
+
elif p < 0:
|
| 914 |
+
fbank = fbank[0:target_length, :]
|
| 915 |
+
|
| 916 |
+
return fbank
|
| 917 |
+
|
| 918 |
+
|
| 919 |
+
def pca(image_feats_list, dim=3, fit_pca=None):
|
| 920 |
+
from sklearn.decomposition import PCA
|
| 921 |
+
|
| 922 |
+
device = image_feats_list[0].device
|
| 923 |
+
|
| 924 |
+
def flatten(tensor, target_size=None):
|
| 925 |
+
if target_size is not None and fit_pca is None:
|
| 926 |
+
F.interpolate(tensor, (target_size, target_size), mode="bilinear")
|
| 927 |
+
B, C, H, W = tensor.shape
|
| 928 |
+
return feats.permute(1, 0, 2, 3).reshape(C, B * H * W).permute(1, 0).detach().cpu()
|
| 929 |
+
|
| 930 |
+
if len(image_feats_list) > 1 and fit_pca is None:
|
| 931 |
+
target_size = image_feats_list[0].shape[2]
|
| 932 |
+
else:
|
| 933 |
+
target_size = None
|
| 934 |
+
|
| 935 |
+
flattened_feats = []
|
| 936 |
+
for feats in image_feats_list:
|
| 937 |
+
flattened_feats.append(flatten(feats, target_size))
|
| 938 |
+
x = torch.cat(flattened_feats, dim=0)
|
| 939 |
+
|
| 940 |
+
if fit_pca is None:
|
| 941 |
+
fit_pca = PCA(n_components=dim).fit(x)
|
| 942 |
+
|
| 943 |
+
reduced_feats = []
|
| 944 |
+
for feats in image_feats_list:
|
| 945 |
+
x_red = torch.from_numpy(fit_pca.transform(flatten(feats)))
|
| 946 |
+
x_red -= x_red.min(dim=0, keepdim=True).values
|
| 947 |
+
x_red /= x_red.max(dim=0, keepdim=True).values
|
| 948 |
+
B, C, H, W = feats.shape
|
| 949 |
+
reduced_feats.append(x_red.reshape(B, H, W, dim).permute(0, 3, 1, 2).to(device))
|
| 950 |
+
|
| 951 |
+
return reduced_feats, fit_pca
|
| 952 |
+
|
| 953 |
+
|
| 954 |
+
class CAVMAEAudioFeaturizer(nn.Module):
|
| 955 |
+
|
| 956 |
+
def __init__(self, output_path, model_name="base", model=None):
|
| 957 |
+
super().__init__()
|
| 958 |
+
if model is not None:
|
| 959 |
+
self.model = model
|
| 960 |
+
else:
|
| 961 |
+
if model_name == "base":
|
| 962 |
+
model_path = os.path.join(output_path, 'models/audio_model.21.pth')
|
| 963 |
+
else:
|
| 964 |
+
raise ValueError(f"Unknown model type {model_name}")
|
| 965 |
+
|
| 966 |
+
audio_model = CAVMAE(
|
| 967 |
+
audio_length=1024,
|
| 968 |
+
modality_specific_depth=11,
|
| 969 |
+
norm_pix_loss=True,
|
| 970 |
+
tr_pos=False)
|
| 971 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 972 |
+
mdl_weight = torch.load(model_path, map_location=device)
|
| 973 |
+
audio_model = torch.nn.DataParallel(audio_model)
|
| 974 |
+
audio_model.load_state_dict(mdl_weight, strict=True)
|
| 975 |
+
self.model = audio_model.module.cuda()
|
| 976 |
+
|
| 977 |
+
def forward(self, audio, include_cls):
|
| 978 |
+
cls_token = None
|
| 979 |
+
patch_tokens = self.model.forward_audio(audio.squeeze(1))
|
| 980 |
+
|
| 981 |
+
if include_cls:
|
| 982 |
+
return patch_tokens, cls_token
|
| 983 |
+
else:
|
| 984 |
+
return patch_tokens
|
| 985 |
+
|
| 986 |
+
|
| 987 |
+
class CAVMAEImageFeaturizer(nn.Module):
|
| 988 |
+
|
| 989 |
+
def __init__(self, output_path, model=None, model_name="base"):
|
| 990 |
+
super().__init__()
|
| 991 |
+
if model is not None:
|
| 992 |
+
self.model: CAVMAE = model
|
| 993 |
+
else:
|
| 994 |
+
if model_name == "base":
|
| 995 |
+
model_path = os.path.join(output_path, 'models/audio_model.21.pth')
|
| 996 |
+
else:
|
| 997 |
+
raise ValueError(f"Unknown model type {model_name}")
|
| 998 |
+
|
| 999 |
+
audio_model = CAVMAE(
|
| 1000 |
+
audio_length=1024,
|
| 1001 |
+
modality_specific_depth=11,
|
| 1002 |
+
norm_pix_loss=True,
|
| 1003 |
+
tr_pos=False)
|
| 1004 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 1005 |
+
mdl_weight = torch.load(model_path, map_location=device)
|
| 1006 |
+
audio_model = torch.nn.DataParallel(audio_model)
|
| 1007 |
+
audio_model.load_state_dict(mdl_weight, strict=True)
|
| 1008 |
+
self.model: CAVMAE = audio_model.module.cuda()
|
| 1009 |
+
|
| 1010 |
+
def forward(self, image, include_cls):
|
| 1011 |
+
cls_token = None
|
| 1012 |
+
patch_tokens = self.model.forward_video(image)
|
| 1013 |
+
|
| 1014 |
+
if include_cls:
|
| 1015 |
+
return patch_tokens, cls_token
|
| 1016 |
+
else:
|
| 1017 |
+
return patch_tokens
|
| 1018 |
+
|
| 1019 |
+
|
| 1020 |
+
if __name__ == "__main__":
|
| 1021 |
+
model_path = os.path.join("../../", 'models/audio_model.21.pth')
|
| 1022 |
+
audio_model = CAVMAE(
|
| 1023 |
+
audio_length=1024,
|
| 1024 |
+
modality_specific_depth=11,
|
| 1025 |
+
norm_pix_loss=True,
|
| 1026 |
+
tr_pos=False)
|
| 1027 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 1028 |
+
mdl_weight = torch.load(model_path, map_location=device)
|
| 1029 |
+
audio_model = torch.nn.DataParallel(audio_model)
|
| 1030 |
+
audio_model.load_state_dict(mdl_weight, strict=True)
|
| 1031 |
+
model: CAVMAE = audio_model.module.cuda()
|
| 1032 |
+
|
| 1033 |
+
image_paths = ["../../samples/dog_image.jpg", "../../samples/car_image.jpg", "../../samples/bird_image.jpg"]
|
| 1034 |
+
audio_paths = ["../../samples/dog_audio.wav", "../../samples/car_audio.wav", "../../samples/bird_audio.wav"]
|
| 1035 |
+
|
| 1036 |
+
images = []
|
| 1037 |
+
audios = []
|
| 1038 |
+
|
| 1039 |
+
for image_path in image_paths:
|
| 1040 |
+
image = Image.open(image_path).convert("RGB")
|
| 1041 |
+
preprocess = T.Compose([
|
| 1042 |
+
T.Resize(224, interpolation=Image.BICUBIC),
|
| 1043 |
+
T.CenterCrop(224),
|
| 1044 |
+
T.ToTensor(),
|
| 1045 |
+
T.Normalize(
|
| 1046 |
+
mean=[0.4850, 0.4560, 0.4060],
|
| 1047 |
+
std=[0.2290, 0.2240, 0.2250]
|
| 1048 |
+
)])
|
| 1049 |
+
images.append(preprocess(image).unsqueeze(0).cuda())
|
| 1050 |
+
|
| 1051 |
+
for audio_path in audio_paths:
|
| 1052 |
+
a = _wav2fbank(audio_path).cuda().unsqueeze(0)
|
| 1053 |
+
a = (a + 5.081) / (4.4849)
|
| 1054 |
+
audios.append(a)
|
| 1055 |
+
|
| 1056 |
+
audio_feats, image_feats = model.forward_feat(
|
| 1057 |
+
torch.cat(audios, dim=0), torch.cat(images, dim=0))
|
| 1058 |
+
|
| 1059 |
+
audio_feats = F.normalize(audio_feats.mean(1), dim=1)
|
| 1060 |
+
image_feats = F.normalize(image_feats.mean(1), dim=1)
|
| 1061 |
+
|
| 1062 |
+
sims = torch.einsum("bc,dc->bd", image_feats, audio_feats)
|
| 1063 |
+
print(sims)
|
| 1064 |
+
|
| 1065 |
+
print("here")
|
| 1066 |
+
|
| 1067 |
+
# a_feat = F.normalize(a_feat, dim=1)
|
| 1068 |
+
# v_feat = F.normalize(v_feat, dim=1)
|
| 1069 |
+
|
| 1070 |
+
# [red_v_feat, red_a_feat], fit_pca = pca([v_feat, a_feat])
|
| 1071 |
+
#
|
| 1072 |
+
# [red_v_feat], fit_pca = pca([v_feat])
|
| 1073 |
+
# [red_a_feat], fit_pca = pca([a_feat])
|
| 1074 |
+
#
|
| 1075 |
+
# import matplotlib.pyplot as plt
|
| 1076 |
+
#
|
| 1077 |
+
# fig, ax = plt.subplots(1, 2, figsize=(2 * 5, 5))
|
| 1078 |
+
# ax[0].imshow(red_v_feat[0].permute(1, 2, 0).cpu())
|
| 1079 |
+
# ax[1].imshow(red_a_feat[0].permute(1, 2, 0).cpu())
|
| 1080 |
+
# plt.tight_layout()
|
| 1081 |
+
# plt.show()
|
| 1082 |
+
# print("here")
|
DenseAV/denseav/featurizers/CLIP.py
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import clip
|
| 2 |
+
import torch
|
| 3 |
+
from torch import nn
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class CLIPFeaturizer(nn.Module):
|
| 7 |
+
|
| 8 |
+
def __init__(self):
|
| 9 |
+
super().__init__()
|
| 10 |
+
self.model, self.preprocess = clip.load("ViT-B/16", device="cpu")
|
| 11 |
+
self.model.eval().cuda()
|
| 12 |
+
self.config = {}
|
| 13 |
+
|
| 14 |
+
def get_cls_token(self, img):
|
| 15 |
+
return self.model.encode_image(img).to(torch.float32)
|
| 16 |
+
|
| 17 |
+
def forward(self, img, include_cls):
|
| 18 |
+
features = self.model.get_visual_features(img, include_cls)
|
| 19 |
+
new_features = []
|
| 20 |
+
for i in range(2):
|
| 21 |
+
t = features[i]
|
| 22 |
+
if isinstance(t, torch.Tensor):
|
| 23 |
+
new_features.append(t.to(torch.float32))
|
| 24 |
+
else:
|
| 25 |
+
new_features.append(t)
|
| 26 |
+
|
| 27 |
+
return new_features
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
if __name__ == "__main__":
|
| 31 |
+
import torchvision.transforms as T
|
| 32 |
+
from PIL import Image
|
| 33 |
+
from shared import norm, crop_to_divisor
|
| 34 |
+
|
| 35 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 36 |
+
|
| 37 |
+
image = Image.open("../samples/lex1.jpg")
|
| 38 |
+
load_size = 224 # * 3
|
| 39 |
+
transform = T.Compose([
|
| 40 |
+
T.Resize(load_size, Image.BILINEAR),
|
| 41 |
+
# T.CenterCrop(load_size),
|
| 42 |
+
T.ToTensor(),
|
| 43 |
+
lambda x: crop_to_divisor(x, 16),
|
| 44 |
+
norm])
|
| 45 |
+
|
| 46 |
+
model = CLIPFeaturizer().cuda()
|
| 47 |
+
|
| 48 |
+
results = model(transform(image).cuda().unsqueeze(0))
|
| 49 |
+
|
| 50 |
+
print(clip.available_models())
|
DenseAV/denseav/featurizers/DAVENet.py
ADDED
|
@@ -0,0 +1,162 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Author: David Harwath
|
| 2 |
+
import torch
|
| 3 |
+
import torch.nn as nn
|
| 4 |
+
import torch.nn.functional
|
| 5 |
+
import torch.nn.functional
|
| 6 |
+
import torch.nn.functional as F
|
| 7 |
+
import torch.utils.model_zoo as model_zoo
|
| 8 |
+
import torchvision.models as imagemodels
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
class Davenet(nn.Module):
|
| 12 |
+
def __init__(self, embedding_dim=1024):
|
| 13 |
+
super(Davenet, self).__init__()
|
| 14 |
+
self.embedding_dim = embedding_dim
|
| 15 |
+
self.batchnorm1 = nn.BatchNorm2d(1)
|
| 16 |
+
self.conv1 = nn.Conv2d(1, 128, kernel_size=(40, 1), stride=(1, 1), padding=(0, 0))
|
| 17 |
+
self.conv2 = nn.Conv2d(128, 256, kernel_size=(1, 11), stride=(1, 1), padding=(0, 5))
|
| 18 |
+
self.conv3 = nn.Conv2d(256, 512, kernel_size=(1, 17), stride=(1, 1), padding=(0, 8))
|
| 19 |
+
self.conv4 = nn.Conv2d(512, 512, kernel_size=(1, 17), stride=(1, 1), padding=(0, 8))
|
| 20 |
+
self.conv5 = nn.Conv2d(512, embedding_dim, kernel_size=(1, 17), stride=(1, 1), padding=(0, 8))
|
| 21 |
+
self.pool = nn.MaxPool2d(kernel_size=(1, 3), stride=(1, 2), padding=(0, 1))
|
| 22 |
+
|
| 23 |
+
def forward(self, x):
|
| 24 |
+
if x.dim() == 3:
|
| 25 |
+
x = x.unsqueeze(1)
|
| 26 |
+
x = self.batchnorm1(x)
|
| 27 |
+
x = F.relu(self.conv1(x))
|
| 28 |
+
x = F.relu(self.conv2(x))
|
| 29 |
+
x = self.pool(x)
|
| 30 |
+
x = F.relu(self.conv3(x))
|
| 31 |
+
x = self.pool(x)
|
| 32 |
+
x = F.relu(self.conv4(x))
|
| 33 |
+
x = self.pool(x)
|
| 34 |
+
x = F.relu(self.conv5(x))
|
| 35 |
+
x = self.pool(x)
|
| 36 |
+
x = x.squeeze(2)
|
| 37 |
+
return x
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
class Resnet18(imagemodels.ResNet):
|
| 41 |
+
def __init__(self, embedding_dim=1024, pretrained=False):
|
| 42 |
+
super(Resnet18, self).__init__(imagemodels.resnet.BasicBlock, [2, 2, 2, 2])
|
| 43 |
+
if pretrained:
|
| 44 |
+
self.load_state_dict(model_zoo.load_url(imagemodels.resnet.model_urls['resnet18']))
|
| 45 |
+
self.avgpool = None
|
| 46 |
+
self.fc = None
|
| 47 |
+
self.embedder = nn.Conv2d(512, embedding_dim, kernel_size=1, stride=1, padding=0)
|
| 48 |
+
self.embedding_dim = embedding_dim
|
| 49 |
+
self.pretrained = pretrained
|
| 50 |
+
|
| 51 |
+
def forward(self, x):
|
| 52 |
+
x = self.conv1(x)
|
| 53 |
+
x = self.bn1(x)
|
| 54 |
+
x = self.relu(x)
|
| 55 |
+
x = self.maxpool(x)
|
| 56 |
+
x = self.layer1(x)
|
| 57 |
+
x = self.layer2(x)
|
| 58 |
+
x = self.layer3(x)
|
| 59 |
+
x = self.layer4(x)
|
| 60 |
+
x = self.embedder(x)
|
| 61 |
+
return x
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class Resnet34(imagemodels.ResNet):
|
| 65 |
+
def __init__(self, embedding_dim=1024, pretrained=False):
|
| 66 |
+
super(Resnet34, self).__init__(imagemodels.resnet.BasicBlock, [3, 4, 6, 3])
|
| 67 |
+
if pretrained:
|
| 68 |
+
self.load_state_dict(model_zoo.load_url(imagemodels.resnet.model_urls['resnet34']))
|
| 69 |
+
self.avgpool = None
|
| 70 |
+
self.fc = None
|
| 71 |
+
self.embedder = nn.Conv2d(512, embedding_dim, kernel_size=1, stride=1, padding=0)
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
x = self.conv1(x)
|
| 75 |
+
x = self.bn1(x)
|
| 76 |
+
x = self.relu(x)
|
| 77 |
+
x = self.maxpool(x)
|
| 78 |
+
x = self.layer1(x)
|
| 79 |
+
x = self.layer2(x)
|
| 80 |
+
x = self.layer3(x)
|
| 81 |
+
x = self.layer4(x)
|
| 82 |
+
x = self.embedder(x)
|
| 83 |
+
return x
|
| 84 |
+
|
| 85 |
+
|
| 86 |
+
class Resnet50(imagemodels.ResNet):
|
| 87 |
+
def __init__(self, embedding_dim=1024, pretrained=False):
|
| 88 |
+
super(Resnet50, self).__init__(imagemodels.resnet.Bottleneck, [3, 4, 6, 3])
|
| 89 |
+
if pretrained:
|
| 90 |
+
self.load_state_dict(model_zoo.load_url(imagemodels.resnet.model_urls['resnet50']))
|
| 91 |
+
self.avgpool = None
|
| 92 |
+
self.fc = None
|
| 93 |
+
self.embedder = nn.Conv2d(2048, embedding_dim, kernel_size=1, stride=1, padding=0)
|
| 94 |
+
|
| 95 |
+
def forward(self, x):
|
| 96 |
+
x = self.conv1(x)
|
| 97 |
+
x = self.bn1(x)
|
| 98 |
+
x = self.relu(x)
|
| 99 |
+
x = self.maxpool(x)
|
| 100 |
+
x = self.layer1(x)
|
| 101 |
+
x = self.layer2(x)
|
| 102 |
+
x = self.layer3(x)
|
| 103 |
+
x = self.layer4(x)
|
| 104 |
+
x = self.embedder(x)
|
| 105 |
+
return x
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
class VGG16(nn.Module):
|
| 109 |
+
def __init__(self, embedding_dim=1024, pretrained=False):
|
| 110 |
+
super(VGG16, self).__init__()
|
| 111 |
+
seed_model = imagemodels.__dict__['vgg16'](pretrained=pretrained).features
|
| 112 |
+
seed_model = nn.Sequential(*list(seed_model.children())[:-1]) # remove final maxpool
|
| 113 |
+
last_layer_index = len(list(seed_model.children()))
|
| 114 |
+
seed_model.add_module(str(last_layer_index),
|
| 115 |
+
nn.Conv2d(512, embedding_dim, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)))
|
| 116 |
+
self.image_model = seed_model
|
| 117 |
+
|
| 118 |
+
def forward(self, x):
|
| 119 |
+
x = self.image_model(x)
|
| 120 |
+
return x
|
| 121 |
+
|
| 122 |
+
|
| 123 |
+
def prep(dict):
|
| 124 |
+
return {k.replace("module.", ""): v for k, v in dict.items()}
|
| 125 |
+
|
| 126 |
+
|
| 127 |
+
class DavenetAudioFeaturizer(nn.Module):
|
| 128 |
+
|
| 129 |
+
def __init__(self):
|
| 130 |
+
super().__init__()
|
| 131 |
+
self.audio_model = Davenet()
|
| 132 |
+
self.audio_model.load_state_dict(prep(torch.load("../models/davenet_pt_audio.pth")))
|
| 133 |
+
|
| 134 |
+
def forward(self, audio, include_cls):
|
| 135 |
+
patch_tokens = self.audio_model(audio).unsqueeze(2)
|
| 136 |
+
|
| 137 |
+
if include_cls:
|
| 138 |
+
return patch_tokens, None
|
| 139 |
+
else:
|
| 140 |
+
return patch_tokens
|
| 141 |
+
|
| 142 |
+
def get_last_params(self):
|
| 143 |
+
return []
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
class DavenetImageFeaturizer(nn.Module):
|
| 147 |
+
|
| 148 |
+
def __init__(self):
|
| 149 |
+
super().__init__()
|
| 150 |
+
self.image_model = VGG16()
|
| 151 |
+
self.image_model.load_state_dict(prep(torch.load("../models/davenet_pt_image.pth")))
|
| 152 |
+
|
| 153 |
+
def forward(self, image, include_cls):
|
| 154 |
+
patch_tokens = self.image_model(image)
|
| 155 |
+
|
| 156 |
+
if include_cls:
|
| 157 |
+
return patch_tokens, None
|
| 158 |
+
else:
|
| 159 |
+
return patch_tokens
|
| 160 |
+
|
| 161 |
+
def get_last_params(self):
|
| 162 |
+
return []
|
DenseAV/denseav/featurizers/DINO.py
ADDED
|
@@ -0,0 +1,451 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import math
|
| 2 |
+
import warnings
|
| 3 |
+
from functools import partial
|
| 4 |
+
|
| 5 |
+
import timm
|
| 6 |
+
import torch
|
| 7 |
+
import torch.nn as nn
|
| 8 |
+
|
| 9 |
+
eps = 1e-4
|
| 10 |
+
|
| 11 |
+
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
|
| 12 |
+
# Cut & paste from PyTorch official master until it's in a few official releases - RW
|
| 13 |
+
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
|
| 14 |
+
def norm_cdf(x):
|
| 15 |
+
# Computes standard normal cumulative distribution function
|
| 16 |
+
return (1. + math.erf(x / math.sqrt(2.))) / 2.
|
| 17 |
+
|
| 18 |
+
if (mean < a - 2 * std) or (mean > b + 2 * std):
|
| 19 |
+
warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
|
| 20 |
+
"The distribution of values may be incorrect.",
|
| 21 |
+
stacklevel=2)
|
| 22 |
+
|
| 23 |
+
with torch.no_grad():
|
| 24 |
+
# Values are generated by using a truncated uniform distribution and
|
| 25 |
+
# then using the inverse CDF for the normal distribution.
|
| 26 |
+
# Get upper and lower cdf values
|
| 27 |
+
l = norm_cdf((a - mean) / std)
|
| 28 |
+
u = norm_cdf((b - mean) / std)
|
| 29 |
+
|
| 30 |
+
# Uniformly fill tensor with values from [l, u], then translate to
|
| 31 |
+
# [2l-1, 2u-1].
|
| 32 |
+
tensor.uniform_(2 * l - 1, 2 * u - 1)
|
| 33 |
+
|
| 34 |
+
# Use inverse cdf transform for normal distribution to get truncated
|
| 35 |
+
# standard normal
|
| 36 |
+
tensor.erfinv_()
|
| 37 |
+
|
| 38 |
+
# Transform to proper mean, std
|
| 39 |
+
tensor.mul_(std * math.sqrt(2.))
|
| 40 |
+
tensor.add_(mean)
|
| 41 |
+
|
| 42 |
+
# Clamp to ensure it's in the proper range
|
| 43 |
+
tensor.clamp_(min=a, max=b)
|
| 44 |
+
return tensor
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
|
| 48 |
+
# type: (Tensor, float, float, float, float) -> Tensor
|
| 49 |
+
return _no_grad_trunc_normal_(tensor, mean, std, a, b)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
|
| 53 |
+
def drop_path(x, drop_prob: float = 0., training: bool = False):
|
| 54 |
+
if drop_prob == 0. or not training:
|
| 55 |
+
return x
|
| 56 |
+
keep_prob = 1 - drop_prob
|
| 57 |
+
shape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNets
|
| 58 |
+
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
|
| 59 |
+
random_tensor.floor_() # binarize
|
| 60 |
+
output = x.div(keep_prob) * random_tensor
|
| 61 |
+
return output
|
| 62 |
+
|
| 63 |
+
|
| 64 |
+
class DropPath(nn.Module):
|
| 65 |
+
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
|
| 66 |
+
"""
|
| 67 |
+
|
| 68 |
+
def __init__(self, drop_prob=None):
|
| 69 |
+
super(DropPath, self).__init__()
|
| 70 |
+
self.drop_prob = drop_prob
|
| 71 |
+
|
| 72 |
+
def forward(self, x):
|
| 73 |
+
return drop_path(x, self.drop_prob, self.training)
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
class Mlp(nn.Module):
|
| 77 |
+
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
|
| 78 |
+
super().__init__()
|
| 79 |
+
out_features = out_features or in_features
|
| 80 |
+
hidden_features = hidden_features or in_features
|
| 81 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 82 |
+
self.act = act_layer()
|
| 83 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 84 |
+
self.drop = nn.Dropout(drop)
|
| 85 |
+
|
| 86 |
+
def forward(self, x):
|
| 87 |
+
x = self.fc1(x)
|
| 88 |
+
x = self.act(x)
|
| 89 |
+
x = self.drop(x)
|
| 90 |
+
x = self.fc2(x)
|
| 91 |
+
x = self.drop(x)
|
| 92 |
+
return x
|
| 93 |
+
|
| 94 |
+
|
| 95 |
+
class Attention(nn.Module):
|
| 96 |
+
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
|
| 97 |
+
super().__init__()
|
| 98 |
+
self.num_heads = num_heads
|
| 99 |
+
head_dim = dim // num_heads
|
| 100 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 101 |
+
|
| 102 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 103 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 104 |
+
self.proj = nn.Linear(dim, dim)
|
| 105 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 106 |
+
|
| 107 |
+
def forward(self, x, return_qkv=False):
|
| 108 |
+
B, N, C = x.shape
|
| 109 |
+
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
|
| 110 |
+
q, k, v = qkv[0], qkv[1], qkv[2]
|
| 111 |
+
|
| 112 |
+
attn = (q @ k.transpose(-2, -1)) * self.scale
|
| 113 |
+
attn = attn.softmax(dim=-1)
|
| 114 |
+
attn = self.attn_drop(attn)
|
| 115 |
+
|
| 116 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 117 |
+
x = self.proj(x)
|
| 118 |
+
x = self.proj_drop(x)
|
| 119 |
+
return x, attn, qkv
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
class Block(nn.Module):
|
| 123 |
+
def __init__(self, dim,
|
| 124 |
+
num_heads,
|
| 125 |
+
mlp_ratio=4.,
|
| 126 |
+
qkv_bias=False,
|
| 127 |
+
qk_scale=None,
|
| 128 |
+
drop=0.,
|
| 129 |
+
attn_drop=0.,
|
| 130 |
+
drop_path=0.,
|
| 131 |
+
act_layer=nn.GELU,
|
| 132 |
+
norm_layer=nn.LayerNorm):
|
| 133 |
+
super().__init__()
|
| 134 |
+
self.norm1 = norm_layer(dim)
|
| 135 |
+
self.attn = Attention(
|
| 136 |
+
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
|
| 137 |
+
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
|
| 138 |
+
self.norm2 = norm_layer(dim)
|
| 139 |
+
mlp_hidden_dim = int(dim * mlp_ratio)
|
| 140 |
+
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
|
| 141 |
+
|
| 142 |
+
def forward(self, x, return_attention=False, return_qkv=False):
|
| 143 |
+
y, attn, qkv = self.attn(self.norm1(x))
|
| 144 |
+
if return_attention:
|
| 145 |
+
return attn
|
| 146 |
+
x = x + self.drop_path(y)
|
| 147 |
+
x = x + self.drop_path(self.mlp(self.norm2(x)))
|
| 148 |
+
if return_qkv:
|
| 149 |
+
return x, attn, qkv
|
| 150 |
+
return x
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class PatchEmbed(nn.Module):
|
| 154 |
+
""" Image to Patch Embedding
|
| 155 |
+
"""
|
| 156 |
+
|
| 157 |
+
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
|
| 158 |
+
super().__init__()
|
| 159 |
+
num_patches = (img_size // patch_size) * (img_size // patch_size)
|
| 160 |
+
self.img_size = img_size
|
| 161 |
+
self.patch_size = patch_size
|
| 162 |
+
self.num_patches = num_patches
|
| 163 |
+
|
| 164 |
+
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
|
| 165 |
+
|
| 166 |
+
def forward(self, x):
|
| 167 |
+
B, C, H, W = x.shape
|
| 168 |
+
x = self.proj(x).flatten(2).transpose(1, 2)
|
| 169 |
+
return x
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
class VisionTransformer(nn.Module):
|
| 173 |
+
""" Vision Transformer """
|
| 174 |
+
|
| 175 |
+
def __init__(self,
|
| 176 |
+
img_size=[224],
|
| 177 |
+
patch_size=16,
|
| 178 |
+
in_chans=3,
|
| 179 |
+
num_classes=0,
|
| 180 |
+
embed_dim=768,
|
| 181 |
+
depth=12,
|
| 182 |
+
num_heads=12,
|
| 183 |
+
mlp_ratio=4.,
|
| 184 |
+
qkv_bias=False,
|
| 185 |
+
qk_scale=None,
|
| 186 |
+
drop_rate=0.,
|
| 187 |
+
attn_drop_rate=0.,
|
| 188 |
+
drop_path_rate=0.,
|
| 189 |
+
norm_layer=nn.LayerNorm,
|
| 190 |
+
**kwargs):
|
| 191 |
+
super().__init__()
|
| 192 |
+
|
| 193 |
+
self.num_features = self.embed_dim = embed_dim
|
| 194 |
+
|
| 195 |
+
self.patch_embed = PatchEmbed(
|
| 196 |
+
img_size=img_size[0], patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
|
| 197 |
+
num_patches = self.patch_embed.num_patches
|
| 198 |
+
|
| 199 |
+
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
|
| 200 |
+
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
|
| 201 |
+
self.pos_drop = nn.Dropout(p=drop_rate)
|
| 202 |
+
|
| 203 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
|
| 204 |
+
self.blocks = nn.ModuleList([
|
| 205 |
+
Block(
|
| 206 |
+
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
|
| 207 |
+
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
|
| 208 |
+
for i in range(depth)])
|
| 209 |
+
self.norm = norm_layer(embed_dim)
|
| 210 |
+
|
| 211 |
+
# Classifier head
|
| 212 |
+
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
|
| 213 |
+
|
| 214 |
+
trunc_normal_(self.pos_embed, std=.02)
|
| 215 |
+
trunc_normal_(self.cls_token, std=.02)
|
| 216 |
+
self.apply(self._init_weights)
|
| 217 |
+
|
| 218 |
+
def _init_weights(self, m):
|
| 219 |
+
if isinstance(m, nn.Linear):
|
| 220 |
+
trunc_normal_(m.weight, std=.02)
|
| 221 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 222 |
+
nn.init.constant_(m.bias, 0)
|
| 223 |
+
elif isinstance(m, nn.LayerNorm):
|
| 224 |
+
nn.init.constant_(m.bias, 0)
|
| 225 |
+
nn.init.constant_(m.weight, 1.0)
|
| 226 |
+
|
| 227 |
+
def interpolate_pos_encoding(self, x, w, h):
|
| 228 |
+
npatch = x.shape[1] - 1
|
| 229 |
+
N = self.pos_embed.shape[1] - 1
|
| 230 |
+
if npatch == N and w == h:
|
| 231 |
+
return self.pos_embed
|
| 232 |
+
class_pos_embed = self.pos_embed[:, 0]
|
| 233 |
+
patch_pos_embed = self.pos_embed[:, 1:]
|
| 234 |
+
dim = x.shape[-1]
|
| 235 |
+
w0 = w // self.patch_embed.patch_size
|
| 236 |
+
h0 = h // self.patch_embed.patch_size
|
| 237 |
+
# we add a small number to avoid floating point error in the interpolation
|
| 238 |
+
# see discussion at https://github.com/facebookresearch/dino/issues/8
|
| 239 |
+
w0, h0 = w0 + 0.1, h0 + 0.1
|
| 240 |
+
patch_pos_embed = nn.functional.interpolate(
|
| 241 |
+
patch_pos_embed.reshape(1, int(math.sqrt(N)), int(math.sqrt(N)), dim).permute(0, 3, 1, 2),
|
| 242 |
+
scale_factor=(w0 / math.sqrt(N), h0 / math.sqrt(N)),
|
| 243 |
+
mode='bicubic',
|
| 244 |
+
)
|
| 245 |
+
assert int(w0) == patch_pos_embed.shape[-2] and int(h0) == patch_pos_embed.shape[-1]
|
| 246 |
+
patch_pos_embed = patch_pos_embed.permute(0, 2, 3, 1).reshape(1, -1, dim)
|
| 247 |
+
return torch.cat((class_pos_embed.unsqueeze(0), patch_pos_embed), dim=1)
|
| 248 |
+
|
| 249 |
+
def prepare_tokens(self, x):
|
| 250 |
+
B, nc, w, h = x.shape
|
| 251 |
+
x = self.patch_embed(x) # patch linear embedding
|
| 252 |
+
|
| 253 |
+
# add the [CLS] token to the embed patch tokens
|
| 254 |
+
cls_tokens = self.cls_token.expand(B, -1, -1)
|
| 255 |
+
x = torch.cat((cls_tokens, x), dim=1)
|
| 256 |
+
|
| 257 |
+
# add positional encoding to each token
|
| 258 |
+
x = x + self.interpolate_pos_encoding(x, w, h)
|
| 259 |
+
|
| 260 |
+
return self.pos_drop(x)
|
| 261 |
+
|
| 262 |
+
def forward(self, x):
|
| 263 |
+
x = self.prepare_tokens(x)
|
| 264 |
+
for blk in self.blocks:
|
| 265 |
+
x = blk(x)
|
| 266 |
+
x = self.norm(x)
|
| 267 |
+
return x[:, 0]
|
| 268 |
+
|
| 269 |
+
def forward_feats(self, x):
|
| 270 |
+
x = self.prepare_tokens(x)
|
| 271 |
+
for blk in self.blocks:
|
| 272 |
+
x = blk(x)
|
| 273 |
+
x = self.norm(x)
|
| 274 |
+
return x
|
| 275 |
+
|
| 276 |
+
def get_intermediate_feat(self, x, n=1, norm=True):
|
| 277 |
+
x = self.prepare_tokens(x)
|
| 278 |
+
# we return the output tokens from the `n` last blocks
|
| 279 |
+
feat = []
|
| 280 |
+
attns = []
|
| 281 |
+
qkvs = []
|
| 282 |
+
for i, blk in enumerate(self.blocks):
|
| 283 |
+
x, attn, qkv = blk(x, return_qkv=True)
|
| 284 |
+
if len(self.blocks) - i <= n:
|
| 285 |
+
if norm:
|
| 286 |
+
feat.append(self.norm(x))
|
| 287 |
+
else:
|
| 288 |
+
feat.append(x)
|
| 289 |
+
qkvs.append(qkv)
|
| 290 |
+
attns.append(attn)
|
| 291 |
+
return feat, attns, qkvs
|
| 292 |
+
|
| 293 |
+
def get_last_selfattention(self, x):
|
| 294 |
+
x = self.prepare_tokens(x)
|
| 295 |
+
for i, blk in enumerate(self.blocks):
|
| 296 |
+
if i < len(self.blocks) - 1:
|
| 297 |
+
x = blk(x)
|
| 298 |
+
else:
|
| 299 |
+
# return attention of the last block
|
| 300 |
+
return blk(x, return_attention=True)
|
| 301 |
+
|
| 302 |
+
def get_intermediate_layers(self, x, n=1):
|
| 303 |
+
x = self.prepare_tokens(x)
|
| 304 |
+
# we return the output tokens from the `n` last blocks
|
| 305 |
+
output = []
|
| 306 |
+
for i, blk in enumerate(self.blocks):
|
| 307 |
+
x = blk(x)
|
| 308 |
+
if len(self.blocks) - i <= n:
|
| 309 |
+
output.append(self.norm(x))
|
| 310 |
+
return output
|
| 311 |
+
|
| 312 |
+
|
| 313 |
+
def vit_tiny(patch_size=16, **kwargs):
|
| 314 |
+
model = VisionTransformer(
|
| 315 |
+
patch_size=patch_size, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4,
|
| 316 |
+
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=eps), **kwargs)
|
| 317 |
+
return model
|
| 318 |
+
|
| 319 |
+
|
| 320 |
+
def vit_small(patch_size=16, **kwargs):
|
| 321 |
+
model = VisionTransformer(
|
| 322 |
+
patch_size=patch_size, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4,
|
| 323 |
+
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=eps), **kwargs)
|
| 324 |
+
return model
|
| 325 |
+
|
| 326 |
+
|
| 327 |
+
def vit_base(patch_size=16, **kwargs):
|
| 328 |
+
model = VisionTransformer(
|
| 329 |
+
patch_size=patch_size, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4,
|
| 330 |
+
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=eps), **kwargs)
|
| 331 |
+
return model
|
| 332 |
+
|
| 333 |
+
|
| 334 |
+
class DINOHead(nn.Module):
|
| 335 |
+
def __init__(self, in_dim, out_dim, use_bn=False, norm_last_layer=True, nlayers=3, hidden_dim=2048,
|
| 336 |
+
bottleneck_dim=256):
|
| 337 |
+
super().__init__()
|
| 338 |
+
nlayers = max(nlayers, 1)
|
| 339 |
+
if nlayers == 1:
|
| 340 |
+
self.mlp = nn.Linear(in_dim, bottleneck_dim)
|
| 341 |
+
else:
|
| 342 |
+
layers = [nn.Linear(in_dim, hidden_dim)]
|
| 343 |
+
if use_bn:
|
| 344 |
+
layers.append(nn.BatchNorm1d(hidden_dim))
|
| 345 |
+
layers.append(nn.GELU())
|
| 346 |
+
for _ in range(nlayers - 2):
|
| 347 |
+
layers.append(nn.Linear(hidden_dim, hidden_dim))
|
| 348 |
+
if use_bn:
|
| 349 |
+
layers.append(nn.BatchNorm1d(hidden_dim))
|
| 350 |
+
layers.append(nn.GELU())
|
| 351 |
+
layers.append(nn.Linear(hidden_dim, bottleneck_dim))
|
| 352 |
+
self.mlp = nn.Sequential(*layers)
|
| 353 |
+
self.apply(self._init_weights)
|
| 354 |
+
self.last_layer = nn.utils.weight_norm(nn.Linear(bottleneck_dim, out_dim, bias=False))
|
| 355 |
+
self.last_layer.weight_g.data.fill_(1)
|
| 356 |
+
if norm_last_layer:
|
| 357 |
+
self.last_layer.weight_g.requires_grad = False
|
| 358 |
+
|
| 359 |
+
def _init_weights(self, m):
|
| 360 |
+
if isinstance(m, nn.Linear):
|
| 361 |
+
trunc_normal_(m.weight, std=.02)
|
| 362 |
+
if isinstance(m, nn.Linear) and m.bias is not None:
|
| 363 |
+
nn.init.constant_(m.bias, 0)
|
| 364 |
+
|
| 365 |
+
def forward(self, x):
|
| 366 |
+
x = self.mlp(x)
|
| 367 |
+
x = nn.functional.normalize(x, dim=-1, p=2)
|
| 368 |
+
x = self.last_layer(x)
|
| 369 |
+
return x
|
| 370 |
+
|
| 371 |
+
|
| 372 |
+
|
| 373 |
+
class DINOFeaturizer(nn.Module):
|
| 374 |
+
|
| 375 |
+
def __init__(self, arch, patch_size, feat_type):
|
| 376 |
+
super().__init__()
|
| 377 |
+
self.arch = arch
|
| 378 |
+
self.patch_size = patch_size
|
| 379 |
+
self.feat_type = feat_type
|
| 380 |
+
|
| 381 |
+
self.config = {
|
| 382 |
+
"arch": arch,
|
| 383 |
+
"patch_size": patch_size,
|
| 384 |
+
"feat_type": feat_type
|
| 385 |
+
}
|
| 386 |
+
|
| 387 |
+
self.model = vit_small(
|
| 388 |
+
patch_size=patch_size,
|
| 389 |
+
num_classes=0)
|
| 390 |
+
|
| 391 |
+
if "3d-dino" in arch:
|
| 392 |
+
state_dict = torch.load("../models/3d-dino-co3d.pth")["teacher"]
|
| 393 |
+
state_dict = {k.replace("module.", "").replace("backbone.", ""): v for k, v in state_dict.items()}
|
| 394 |
+
state_dict = {k: v for k, v in state_dict.items() if "head." not in k}
|
| 395 |
+
elif "iarpa-dino" in arch:
|
| 396 |
+
state_dict = torch.load("../models/dino_iarpa.pth")["teacher"]
|
| 397 |
+
state_dict = {k.replace("module.", "").replace("backbone.", ""): v for k, v in state_dict.items()}
|
| 398 |
+
state_dict = {k: v for k, v in state_dict.items() if "head." not in k}
|
| 399 |
+
elif "chk-dino" in arch:
|
| 400 |
+
state_dict = torch.load("../models/dino_deitsmall16_pretrain_full_checkpoint.pth")["teacher"]
|
| 401 |
+
state_dict = {k.replace("module.", "").replace("backbone.", ""): v for k, v in state_dict.items()}
|
| 402 |
+
state_dict = {k: v for k, v in state_dict.items() if "head." not in k}
|
| 403 |
+
elif "ft_dino" in arch:
|
| 404 |
+
arch = "_".join(arch.split("_")[:-1])
|
| 405 |
+
state_dict = torch.load("../models/{}.pth".format(arch))["teacher"]
|
| 406 |
+
state_dict = {k.replace("module.", "").replace("backbone.", ""): v for k, v in state_dict.items()}
|
| 407 |
+
state_dict = {k: v for k, v in state_dict.items() if "head." not in k}
|
| 408 |
+
elif "dino" in arch:
|
| 409 |
+
state_dict = torch.hub.load('facebookresearch/dino:main', self.arch).state_dict()
|
| 410 |
+
else: # model from timm -- load weights from timm to dino model (enables working on arbitrary size images).
|
| 411 |
+
temp_model = timm.create_model(self.arch, pretrained=True)
|
| 412 |
+
state_dict = temp_model.state_dict()
|
| 413 |
+
del state_dict['head.weight']
|
| 414 |
+
del state_dict['head.bias']
|
| 415 |
+
|
| 416 |
+
self.model.load_state_dict(state_dict, strict=True)
|
| 417 |
+
|
| 418 |
+
if arch == "vit_small":
|
| 419 |
+
self.n_feats = 384
|
| 420 |
+
else:
|
| 421 |
+
self.n_feats = 768
|
| 422 |
+
|
| 423 |
+
def get_cls_token(self, img):
|
| 424 |
+
return self.model.forward(img)
|
| 425 |
+
|
| 426 |
+
def forward(self, img, n=1, include_cls=False):
|
| 427 |
+
assert (img.shape[2] % self.patch_size == 0)
|
| 428 |
+
assert (img.shape[3] % self.patch_size == 0)
|
| 429 |
+
|
| 430 |
+
feat, attn, qkv = self.model.get_intermediate_feat(img, n=n)
|
| 431 |
+
feat, attn, qkv = feat[0], attn[0], qkv[0]
|
| 432 |
+
|
| 433 |
+
feat_h = img.shape[2] // self.patch_size
|
| 434 |
+
feat_w = img.shape[3] // self.patch_size
|
| 435 |
+
|
| 436 |
+
if self.feat_type == "token":
|
| 437 |
+
image_feat = feat[:, 1:, :].reshape(feat.shape[0], feat_h, feat_w, -1).permute(0, 3, 1, 2)
|
| 438 |
+
cls_feat = feat[:, 0, :]
|
| 439 |
+
elif self.feat_type == "key":
|
| 440 |
+
x = qkv[1, :, :, 1:, :] # remove cls token
|
| 441 |
+
desc = x.permute(0, 2, 3, 1).flatten(start_dim=-2, end_dim=-1)
|
| 442 |
+
image_feat = desc.reshape(desc.shape[0], feat_h, feat_w, desc.shape[2]) \
|
| 443 |
+
.permute(0, 3, 1, 2)
|
| 444 |
+
cls_feat = None
|
| 445 |
+
else:
|
| 446 |
+
raise ValueError("Unknown feat type:{}".format(self.feat_type))
|
| 447 |
+
|
| 448 |
+
if include_cls:
|
| 449 |
+
return image_feat, cls_feat
|
| 450 |
+
|
| 451 |
+
return image_feat
|
DenseAV/denseav/featurizers/DINOv2.py
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
class DINOv2Featurizer(nn.Module):
|
| 6 |
+
|
| 7 |
+
def __init__(self):
|
| 8 |
+
super().__init__()
|
| 9 |
+
self.model = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14').cuda()
|
| 10 |
+
# self.model = torch.hub.load('facebookresearch/dinov2', 'dinov2_vitb14_reg')
|
| 11 |
+
self.model.eval()
|
| 12 |
+
self.config = {}
|
| 13 |
+
|
| 14 |
+
def get_cls_token(self, img):
|
| 15 |
+
pass
|
| 16 |
+
|
| 17 |
+
def forward(self, img, include_cls):
|
| 18 |
+
feature_dict = self.model.forward_features(img)
|
| 19 |
+
_, _, h, w = img.shape
|
| 20 |
+
new_h, new_w = h // 14, w // 14
|
| 21 |
+
b, _, c = feature_dict["x_norm_patchtokens"].shape
|
| 22 |
+
spatial_tokens = feature_dict["x_norm_patchtokens"].permute(0, 2, 1).reshape(b, c, new_h, new_w)
|
| 23 |
+
|
| 24 |
+
if include_cls:
|
| 25 |
+
return spatial_tokens, feature_dict["x_norm_clstoken"]
|
| 26 |
+
else:
|
| 27 |
+
return spatial_tokens
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
if __name__ == "__main__":
|
| 31 |
+
import torchvision.transforms as T
|
| 32 |
+
from PIL import Image
|
| 33 |
+
from shared import norm, crop_to_divisor
|
| 34 |
+
|
| 35 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 36 |
+
|
| 37 |
+
image = Image.open("../../samples/dog_man_1_crop.jpg")
|
| 38 |
+
load_size = 224 # * 3
|
| 39 |
+
transform = T.Compose([
|
| 40 |
+
T.Resize(load_size, Image.BILINEAR),
|
| 41 |
+
T.CenterCrop(load_size),
|
| 42 |
+
T.ToTensor(),
|
| 43 |
+
norm])
|
| 44 |
+
|
| 45 |
+
model = DINOv2Featurizer().cuda()
|
| 46 |
+
|
| 47 |
+
results = model(transform(image).cuda().unsqueeze(0), include_cls=False)
|
| 48 |
+
|
| 49 |
+
print(results.shape)
|
DenseAV/denseav/featurizers/Hubert.py
ADDED
|
@@ -0,0 +1,70 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torch.nn as nn
|
| 3 |
+
from transformers import Wav2Vec2Processor, HubertModel, HubertConfig
|
| 4 |
+
from transformers.pytorch_utils import Conv1D
|
| 5 |
+
|
| 6 |
+
class HubertAudioTransform():
|
| 7 |
+
|
| 8 |
+
def __init__(self):
|
| 9 |
+
self.processor = Wav2Vec2Processor.from_pretrained("facebook/hubert-large-ls960-ft")
|
| 10 |
+
|
| 11 |
+
def __call__(self, audio):
|
| 12 |
+
return self.processor(audio, return_tensors="pt", sampling_rate=16000).input_values.squeeze(0)
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def copy_conv(l):
|
| 16 |
+
new_l = Conv1D()
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
class Hubert(nn.Module):
|
| 20 |
+
def __init__(self):
|
| 21 |
+
super().__init__()
|
| 22 |
+
model1 = HubertModel.from_pretrained("facebook/hubert-large-ls960-ft")
|
| 23 |
+
config = model1.config
|
| 24 |
+
del model1
|
| 25 |
+
config.layer_norm_eps = 1e-4
|
| 26 |
+
self.model = HubertModel.from_pretrained("facebook/hubert-large-ls960-ft", config=config)
|
| 27 |
+
self.config = dict()
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def forward(self, audio, include_cls):
|
| 31 |
+
outputs = self.model(audio)
|
| 32 |
+
# outputs = deepspeed.checkpointing.checkpoint(self.model, audio)
|
| 33 |
+
|
| 34 |
+
patch_tokens = outputs.last_hidden_state.permute(0, 2, 1).unsqueeze(2)
|
| 35 |
+
|
| 36 |
+
# return patch_tokens
|
| 37 |
+
if include_cls:
|
| 38 |
+
return patch_tokens, None
|
| 39 |
+
else:
|
| 40 |
+
return patch_tokens
|
| 41 |
+
|
| 42 |
+
def get_last_params(self):
|
| 43 |
+
return self.model.encoder.layers[-1].parameters()
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
if __name__ == "__main__":
|
| 47 |
+
import librosa
|
| 48 |
+
from shared import pca, remove_axes
|
| 49 |
+
import matplotlib.pyplot as plt
|
| 50 |
+
from pytorch_lightning import seed_everything
|
| 51 |
+
|
| 52 |
+
audio, _ = librosa.load("../../samples/example.wav", sr=16000)
|
| 53 |
+
audio = torch.from_numpy(audio).unsqueeze(0).to("cuda")
|
| 54 |
+
|
| 55 |
+
model = Hubert().to("cuda")
|
| 56 |
+
embeddings = model.forward(audio, include_cls=False)
|
| 57 |
+
|
| 58 |
+
print(embeddings.shape)
|
| 59 |
+
seed_everything(0)
|
| 60 |
+
|
| 61 |
+
with torch.no_grad():
|
| 62 |
+
[pca_feats], _ = pca([embeddings])
|
| 63 |
+
pca_feats = torch.broadcast_to(
|
| 64 |
+
pca_feats, (pca_feats.shape[0], pca_feats.shape[1], 25, pca_feats.shape[3]))
|
| 65 |
+
fig, axes = plt.subplots(2, 1, figsize=(10, 7))
|
| 66 |
+
axes[1].imshow(pca_feats.cpu().squeeze(0).permute(1, 2, 0))
|
| 67 |
+
remove_axes(axes)
|
| 68 |
+
plt.tight_layout()
|
| 69 |
+
plt.show()
|
| 70 |
+
print("here")
|
DenseAV/denseav/featurizers/ImageBind.py
ADDED
|
@@ -0,0 +1,2033 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import gzip
|
| 2 |
+
import html
|
| 3 |
+
import io
|
| 4 |
+
import logging
|
| 5 |
+
import math
|
| 6 |
+
import os
|
| 7 |
+
from functools import lru_cache
|
| 8 |
+
from functools import partial
|
| 9 |
+
from types import SimpleNamespace
|
| 10 |
+
from typing import Callable, List
|
| 11 |
+
from typing import Optional
|
| 12 |
+
|
| 13 |
+
import einops
|
| 14 |
+
import ftfy
|
| 15 |
+
import numpy as np
|
| 16 |
+
import regex as re
|
| 17 |
+
import torch
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
import torch.nn.functional as F
|
| 20 |
+
import torch.utils.checkpoint as checkpoint
|
| 21 |
+
import torchaudio
|
| 22 |
+
import torchvision.transforms as T
|
| 23 |
+
from PIL import Image
|
| 24 |
+
from timm.models.layers import DropPath, trunc_normal_
|
| 25 |
+
from torchvision import transforms
|
| 26 |
+
import matplotlib.pyplot as plt
|
| 27 |
+
from iopath.common.file_io import g_pathmgr
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class Attention(nn.Module):
|
| 31 |
+
def __init__(
|
| 32 |
+
self,
|
| 33 |
+
dim,
|
| 34 |
+
num_heads=8,
|
| 35 |
+
qkv_bias=False,
|
| 36 |
+
qk_scale=None,
|
| 37 |
+
attn_drop=0.0,
|
| 38 |
+
proj_drop=0.0,
|
| 39 |
+
):
|
| 40 |
+
super().__init__()
|
| 41 |
+
self.num_heads = num_heads
|
| 42 |
+
head_dim = dim // num_heads
|
| 43 |
+
# NOTE scale factor was wrong in my original version,
|
| 44 |
+
# can set manually to be compat with prev weights
|
| 45 |
+
self.scale = qk_scale or head_dim ** -0.5
|
| 46 |
+
|
| 47 |
+
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
|
| 48 |
+
self.attn_drop = nn.Dropout(attn_drop)
|
| 49 |
+
self.proj = nn.Linear(dim, dim)
|
| 50 |
+
self.proj_drop = nn.Dropout(proj_drop)
|
| 51 |
+
|
| 52 |
+
def forward(self, x):
|
| 53 |
+
B, N, C = x.shape
|
| 54 |
+
qkv = (
|
| 55 |
+
self.qkv(x)
|
| 56 |
+
.reshape(B, N, 3, self.num_heads, C // self.num_heads)
|
| 57 |
+
.permute(2, 0, 3, 1, 4)
|
| 58 |
+
)
|
| 59 |
+
q, k, v = (
|
| 60 |
+
qkv[0],
|
| 61 |
+
qkv[1],
|
| 62 |
+
qkv[2],
|
| 63 |
+
) # make torchscript happy (cannot use tensor as tuple)
|
| 64 |
+
|
| 65 |
+
attn = (q @ k.transpose(-2, -1)) * self.scale
|
| 66 |
+
attn = attn.softmax(dim=-1)
|
| 67 |
+
attn = self.attn_drop(attn)
|
| 68 |
+
|
| 69 |
+
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
|
| 70 |
+
x = self.proj(x)
|
| 71 |
+
x = self.proj_drop(x)
|
| 72 |
+
return x
|
| 73 |
+
|
| 74 |
+
|
| 75 |
+
class Mlp(nn.Module):
|
| 76 |
+
def __init__(
|
| 77 |
+
self,
|
| 78 |
+
in_features,
|
| 79 |
+
hidden_features=None,
|
| 80 |
+
out_features=None,
|
| 81 |
+
act_layer=nn.GELU,
|
| 82 |
+
drop=0.0,
|
| 83 |
+
):
|
| 84 |
+
super().__init__()
|
| 85 |
+
out_features = out_features or in_features
|
| 86 |
+
hidden_features = hidden_features or in_features
|
| 87 |
+
self.fc1 = nn.Linear(in_features, hidden_features)
|
| 88 |
+
self.act = act_layer()
|
| 89 |
+
self.fc2 = nn.Linear(hidden_features, out_features)
|
| 90 |
+
self.drop = nn.Dropout(drop)
|
| 91 |
+
|
| 92 |
+
def forward(self, x):
|
| 93 |
+
x = self.fc1(x)
|
| 94 |
+
x = self.act(x)
|
| 95 |
+
x = self.drop(x)
|
| 96 |
+
x = self.fc2(x)
|
| 97 |
+
x = self.drop(x)
|
| 98 |
+
return x
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
class MultiheadAttention(nn.MultiheadAttention):
|
| 102 |
+
def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
|
| 103 |
+
return super().forward(x, x, x, need_weights=False, attn_mask=attn_mask)[0]
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
class ViTAttention(Attention):
|
| 107 |
+
def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
|
| 108 |
+
assert attn_mask is None
|
| 109 |
+
return super().forward(x)
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class BlockWithMasking(nn.Module):
|
| 113 |
+
def __init__(
|
| 114 |
+
self,
|
| 115 |
+
dim: int,
|
| 116 |
+
attn_target: Callable,
|
| 117 |
+
mlp_ratio: int = 4,
|
| 118 |
+
act_layer: Callable = nn.GELU,
|
| 119 |
+
norm_layer: Callable = nn.LayerNorm,
|
| 120 |
+
ffn_dropout_rate: float = 0.0,
|
| 121 |
+
drop_path: float = 0.0,
|
| 122 |
+
layer_scale_type: str = None,
|
| 123 |
+
layer_scale_init_value: float = 1e-4,
|
| 124 |
+
):
|
| 125 |
+
super().__init__()
|
| 126 |
+
|
| 127 |
+
assert not isinstance(
|
| 128 |
+
attn_target, nn.Module
|
| 129 |
+
), "attn_target should be a Callable. Otherwise attn_target is shared across blocks!"
|
| 130 |
+
self.attn = attn_target()
|
| 131 |
+
if drop_path > 0.0:
|
| 132 |
+
self.drop_path = DropPath(drop_path)
|
| 133 |
+
else:
|
| 134 |
+
self.drop_path = nn.Identity()
|
| 135 |
+
self.norm_1 = norm_layer(dim)
|
| 136 |
+
mlp_hidden_dim = int(mlp_ratio * dim)
|
| 137 |
+
self.mlp = Mlp(
|
| 138 |
+
in_features=dim,
|
| 139 |
+
hidden_features=mlp_hidden_dim,
|
| 140 |
+
act_layer=act_layer,
|
| 141 |
+
drop=ffn_dropout_rate,
|
| 142 |
+
)
|
| 143 |
+
self.norm_2 = norm_layer(dim)
|
| 144 |
+
self.layer_scale_type = layer_scale_type
|
| 145 |
+
if self.layer_scale_type is not None:
|
| 146 |
+
assert self.layer_scale_type in [
|
| 147 |
+
"per_channel",
|
| 148 |
+
"scalar",
|
| 149 |
+
], f"Found Layer scale type {self.layer_scale_type}"
|
| 150 |
+
if self.layer_scale_type == "per_channel":
|
| 151 |
+
# one gamma value per channel
|
| 152 |
+
gamma_shape = [1, 1, dim]
|
| 153 |
+
elif self.layer_scale_type == "scalar":
|
| 154 |
+
# single gamma value for all channels
|
| 155 |
+
gamma_shape = [1, 1, 1]
|
| 156 |
+
# two gammas: for each part of the fwd in the encoder
|
| 157 |
+
self.layer_scale_gamma1 = nn.Parameter(
|
| 158 |
+
torch.ones(size=gamma_shape) * layer_scale_init_value,
|
| 159 |
+
requires_grad=True,
|
| 160 |
+
)
|
| 161 |
+
self.layer_scale_gamma2 = nn.Parameter(
|
| 162 |
+
torch.ones(size=gamma_shape) * layer_scale_init_value,
|
| 163 |
+
requires_grad=True,
|
| 164 |
+
)
|
| 165 |
+
|
| 166 |
+
def forward(self, x: torch.Tensor, attn_mask: torch.Tensor):
|
| 167 |
+
if self.layer_scale_type is None:
|
| 168 |
+
x = x + self.drop_path(self.attn(self.norm_1(x), attn_mask))
|
| 169 |
+
x = x + self.drop_path(self.mlp(self.norm_2(x)))
|
| 170 |
+
else:
|
| 171 |
+
x = (
|
| 172 |
+
x
|
| 173 |
+
+ self.drop_path(self.attn(self.norm_1(x), attn_mask))
|
| 174 |
+
* self.layer_scale_gamma1
|
| 175 |
+
)
|
| 176 |
+
x = x + self.drop_path(self.mlp(self.norm_2(x))) * self.layer_scale_gamma2
|
| 177 |
+
return x
|
| 178 |
+
|
| 179 |
+
|
| 180 |
+
_LAYER_NORM = partial(nn.LayerNorm, eps=1e-6)
|
| 181 |
+
|
| 182 |
+
|
| 183 |
+
class SimpleTransformer(nn.Module):
|
| 184 |
+
def __init__(
|
| 185 |
+
self,
|
| 186 |
+
attn_target: Callable,
|
| 187 |
+
embed_dim: int,
|
| 188 |
+
num_blocks: int,
|
| 189 |
+
block: Callable = BlockWithMasking,
|
| 190 |
+
pre_transformer_layer: Callable = None,
|
| 191 |
+
post_transformer_layer: Callable = None,
|
| 192 |
+
drop_path_rate: float = 0.0,
|
| 193 |
+
drop_path_type: str = "progressive",
|
| 194 |
+
norm_layer: Callable = _LAYER_NORM,
|
| 195 |
+
mlp_ratio: int = 4,
|
| 196 |
+
ffn_dropout_rate: float = 0.0,
|
| 197 |
+
layer_scale_type: str = None, # from cait; possible values are None, "per_channel", "scalar"
|
| 198 |
+
layer_scale_init_value: float = 1e-4, # from cait; float
|
| 199 |
+
weight_init_style: str = "jax", # possible values jax or pytorch
|
| 200 |
+
):
|
| 201 |
+
"""
|
| 202 |
+
Simple Transformer with the following features
|
| 203 |
+
1. Supports masked attention
|
| 204 |
+
2. Supports DropPath
|
| 205 |
+
3. Supports LayerScale
|
| 206 |
+
4. Supports Dropout in Attention and FFN
|
| 207 |
+
5. Makes few assumptions about the input except that it is a Tensor
|
| 208 |
+
"""
|
| 209 |
+
super().__init__()
|
| 210 |
+
self.pre_transformer_layer = pre_transformer_layer
|
| 211 |
+
if drop_path_type == "progressive":
|
| 212 |
+
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_blocks)]
|
| 213 |
+
elif drop_path_type == "uniform":
|
| 214 |
+
dpr = [drop_path_rate for i in range(num_blocks)]
|
| 215 |
+
else:
|
| 216 |
+
raise ValueError(f"Unknown drop_path_type: {drop_path_type}")
|
| 217 |
+
|
| 218 |
+
self.blocks = nn.Sequential(
|
| 219 |
+
*[
|
| 220 |
+
block(
|
| 221 |
+
dim=embed_dim,
|
| 222 |
+
attn_target=attn_target,
|
| 223 |
+
mlp_ratio=mlp_ratio,
|
| 224 |
+
ffn_dropout_rate=ffn_dropout_rate,
|
| 225 |
+
drop_path=dpr[i],
|
| 226 |
+
norm_layer=norm_layer,
|
| 227 |
+
layer_scale_type=layer_scale_type,
|
| 228 |
+
layer_scale_init_value=layer_scale_init_value,
|
| 229 |
+
)
|
| 230 |
+
for i in range(num_blocks)
|
| 231 |
+
]
|
| 232 |
+
)
|
| 233 |
+
self.post_transformer_layer = post_transformer_layer
|
| 234 |
+
self.weight_init_style = weight_init_style
|
| 235 |
+
self.apply(self._init_weights)
|
| 236 |
+
|
| 237 |
+
def _init_weights(self, m):
|
| 238 |
+
if isinstance(m, nn.Linear):
|
| 239 |
+
if self.weight_init_style == "jax":
|
| 240 |
+
# Based on MAE and official Jax ViT implementation
|
| 241 |
+
torch.nn.init.xavier_uniform_(m.weight)
|
| 242 |
+
elif self.weight_init_style == "pytorch":
|
| 243 |
+
# PyTorch ViT uses trunc_normal_
|
| 244 |
+
trunc_normal_(m.weight, std=0.02)
|
| 245 |
+
|
| 246 |
+
if m.bias is not None:
|
| 247 |
+
nn.init.constant_(m.bias, 0)
|
| 248 |
+
elif isinstance(m, (nn.LayerNorm)):
|
| 249 |
+
nn.init.constant_(m.bias, 0)
|
| 250 |
+
nn.init.constant_(m.weight, 1.0)
|
| 251 |
+
|
| 252 |
+
def forward(
|
| 253 |
+
self,
|
| 254 |
+
tokens: torch.Tensor,
|
| 255 |
+
attn_mask: torch.Tensor = None,
|
| 256 |
+
use_checkpoint: bool = False,
|
| 257 |
+
checkpoint_every_n: int = 1,
|
| 258 |
+
checkpoint_blk_ids: List[int] = None,
|
| 259 |
+
):
|
| 260 |
+
"""
|
| 261 |
+
Inputs
|
| 262 |
+
- tokens: data of shape N x L x D (or L x N x D depending on the attention implementation)
|
| 263 |
+
- attn: mask of shape L x L
|
| 264 |
+
|
| 265 |
+
Output
|
| 266 |
+
- x: data of shape N x L x D (or L x N x D depending on the attention implementation)
|
| 267 |
+
"""
|
| 268 |
+
if self.pre_transformer_layer:
|
| 269 |
+
tokens = self.pre_transformer_layer(tokens)
|
| 270 |
+
if use_checkpoint and checkpoint_blk_ids is None:
|
| 271 |
+
checkpoint_blk_ids = [
|
| 272 |
+
blk_id
|
| 273 |
+
for blk_id in range(len(self.blocks))
|
| 274 |
+
if blk_id % checkpoint_every_n == 0
|
| 275 |
+
]
|
| 276 |
+
if checkpoint_blk_ids:
|
| 277 |
+
checkpoint_blk_ids = set(checkpoint_blk_ids)
|
| 278 |
+
for blk_id, blk in enumerate(self.blocks):
|
| 279 |
+
if use_checkpoint and blk_id in checkpoint_blk_ids:
|
| 280 |
+
tokens = checkpoint.checkpoint(
|
| 281 |
+
blk, tokens, attn_mask, use_reentrant=False
|
| 282 |
+
)
|
| 283 |
+
else:
|
| 284 |
+
tokens = blk(tokens, attn_mask=attn_mask)
|
| 285 |
+
if self.post_transformer_layer:
|
| 286 |
+
tokens = self.post_transformer_layer(tokens)
|
| 287 |
+
return tokens
|
| 288 |
+
|
| 289 |
+
|
| 290 |
+
def get_sinusoid_encoding_table(n_position, d_hid):
|
| 291 |
+
"""Sinusoid position encoding table"""
|
| 292 |
+
|
| 293 |
+
# TODO: make it with torch instead of numpy
|
| 294 |
+
def get_position_angle_vec(position):
|
| 295 |
+
return [
|
| 296 |
+
position / np.power(10000, 2 * (hid_j // 2) / d_hid)
|
| 297 |
+
for hid_j in range(d_hid)
|
| 298 |
+
]
|
| 299 |
+
|
| 300 |
+
sinusoid_table = np.array(
|
| 301 |
+
[get_position_angle_vec(pos_i) for pos_i in range(n_position)]
|
| 302 |
+
)
|
| 303 |
+
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # dim 2i
|
| 304 |
+
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # dim 2i+1
|
| 305 |
+
|
| 306 |
+
return torch.FloatTensor(sinusoid_table).unsqueeze(0)
|
| 307 |
+
|
| 308 |
+
|
| 309 |
+
def interpolate_pos_encoding_2d(target_spatial_size, pos_embed):
|
| 310 |
+
N = pos_embed.shape[1]
|
| 311 |
+
if N == target_spatial_size:
|
| 312 |
+
return pos_embed
|
| 313 |
+
dim = pos_embed.shape[-1]
|
| 314 |
+
# nn.functional.interpolate doesn't work with bfloat16 so we cast to float32
|
| 315 |
+
pos_embed, updated = cast_if_src_dtype(pos_embed, torch.bfloat16, torch.float32)
|
| 316 |
+
pos_embed = nn.functional.interpolate(
|
| 317 |
+
pos_embed.reshape(1, int(math.sqrt(N)), int(math.sqrt(N)), dim).permute(
|
| 318 |
+
0, 3, 1, 2
|
| 319 |
+
),
|
| 320 |
+
scale_factor=math.sqrt(target_spatial_size / N),
|
| 321 |
+
mode="bicubic",
|
| 322 |
+
)
|
| 323 |
+
if updated:
|
| 324 |
+
pos_embed, _ = cast_if_src_dtype(pos_embed, torch.float32, torch.bfloat16)
|
| 325 |
+
pos_embed = pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
|
| 326 |
+
return pos_embed
|
| 327 |
+
|
| 328 |
+
|
| 329 |
+
def interpolate_pos_encoding(
|
| 330 |
+
npatch_per_img,
|
| 331 |
+
pos_embed,
|
| 332 |
+
patches_layout,
|
| 333 |
+
input_shape=None,
|
| 334 |
+
first_patch_idx=1,
|
| 335 |
+
):
|
| 336 |
+
assert first_patch_idx == 0 or first_patch_idx == 1, "there is 1 CLS token or none"
|
| 337 |
+
N = pos_embed.shape[1] - first_patch_idx # since it's 1 if cls_token exists
|
| 338 |
+
if npatch_per_img == N:
|
| 339 |
+
return pos_embed
|
| 340 |
+
|
| 341 |
+
# assert (
|
| 342 |
+
# patches_layout[-1] == patches_layout[-2]
|
| 343 |
+
# ), "Interpolation of pos embed not supported for non-square layouts"
|
| 344 |
+
|
| 345 |
+
class_emb = pos_embed[:, :first_patch_idx]
|
| 346 |
+
pos_embed = pos_embed[:, first_patch_idx:]
|
| 347 |
+
|
| 348 |
+
if input_shape is None or patches_layout[0] == 1:
|
| 349 |
+
# simple 2D pos embedding, no temporal component
|
| 350 |
+
pos_embed = interpolate_pos_encoding_2d(npatch_per_img, pos_embed)
|
| 351 |
+
elif patches_layout[0] > 1:
|
| 352 |
+
# pos embed has a temporal component
|
| 353 |
+
assert len(input_shape) == 4, "temporal interpolation not supported"
|
| 354 |
+
# we only support 2D interpolation in this case
|
| 355 |
+
num_frames = patches_layout[0]
|
| 356 |
+
num_spatial_tokens = patches_layout[1] * patches_layout[2]
|
| 357 |
+
pos_embed = pos_embed.view(1, num_frames, num_spatial_tokens, -1)
|
| 358 |
+
# interpolate embedding for zeroth frame
|
| 359 |
+
pos_embed = interpolate_pos_encoding_2d(
|
| 360 |
+
npatch_per_img, pos_embed[0, 0, ...].unsqueeze(0)
|
| 361 |
+
)
|
| 362 |
+
else:
|
| 363 |
+
raise ValueError("This type of interpolation isn't implemented")
|
| 364 |
+
|
| 365 |
+
return torch.cat((class_emb, pos_embed), dim=1)
|
| 366 |
+
|
| 367 |
+
|
| 368 |
+
def _get_pos_embedding(
|
| 369 |
+
npatch_per_img,
|
| 370 |
+
pos_embed,
|
| 371 |
+
patches_layout,
|
| 372 |
+
input_shape,
|
| 373 |
+
first_patch_idx=1,
|
| 374 |
+
):
|
| 375 |
+
pos_embed = interpolate_pos_encoding(
|
| 376 |
+
npatch_per_img,
|
| 377 |
+
pos_embed,
|
| 378 |
+
patches_layout,
|
| 379 |
+
input_shape=input_shape,
|
| 380 |
+
first_patch_idx=first_patch_idx,
|
| 381 |
+
)
|
| 382 |
+
return pos_embed
|
| 383 |
+
|
| 384 |
+
|
| 385 |
+
class VerboseNNModule(nn.Module):
|
| 386 |
+
"""
|
| 387 |
+
Wrapper around nn.Module that prints registered buffers and parameter names.
|
| 388 |
+
"""
|
| 389 |
+
|
| 390 |
+
@staticmethod
|
| 391 |
+
def get_readable_tensor_repr(name: str, tensor: torch.Tensor) -> str:
|
| 392 |
+
st = (
|
| 393 |
+
"("
|
| 394 |
+
+ name
|
| 395 |
+
+ "): "
|
| 396 |
+
+ "tensor("
|
| 397 |
+
+ str(tuple(tensor[1].shape))
|
| 398 |
+
+ ", requires_grad="
|
| 399 |
+
+ str(tensor[1].requires_grad)
|
| 400 |
+
+ ")\n"
|
| 401 |
+
)
|
| 402 |
+
return st
|
| 403 |
+
|
| 404 |
+
def extra_repr(self) -> str:
|
| 405 |
+
named_modules = set()
|
| 406 |
+
for p in self.named_modules():
|
| 407 |
+
named_modules.update([p[0]])
|
| 408 |
+
named_modules = list(named_modules)
|
| 409 |
+
|
| 410 |
+
string_repr = ""
|
| 411 |
+
for p in self.named_parameters():
|
| 412 |
+
name = p[0].split(".")[0]
|
| 413 |
+
if name not in named_modules:
|
| 414 |
+
string_repr += self.get_readable_tensor_repr(name, p)
|
| 415 |
+
|
| 416 |
+
for p in self.named_buffers():
|
| 417 |
+
name = p[0].split(".")[0]
|
| 418 |
+
string_repr += self.get_readable_tensor_repr(name, p)
|
| 419 |
+
|
| 420 |
+
return string_repr
|
| 421 |
+
|
| 422 |
+
|
| 423 |
+
class PatchEmbedGeneric(nn.Module):
|
| 424 |
+
"""
|
| 425 |
+
PatchEmbed from Hydra
|
| 426 |
+
"""
|
| 427 |
+
|
| 428 |
+
def __init__(self, proj_stem, norm_layer: Optional[nn.Module] = None):
|
| 429 |
+
super().__init__()
|
| 430 |
+
|
| 431 |
+
if len(proj_stem) > 1:
|
| 432 |
+
self.proj = nn.Sequential(*proj_stem)
|
| 433 |
+
else:
|
| 434 |
+
# Special case to be able to load pre-trained models that were
|
| 435 |
+
# trained with a standard stem
|
| 436 |
+
self.proj = proj_stem[0]
|
| 437 |
+
self.norm_layer = norm_layer
|
| 438 |
+
|
| 439 |
+
def get_patch_layout(self, img_size):
|
| 440 |
+
with torch.no_grad():
|
| 441 |
+
dummy_img = torch.zeros(
|
| 442 |
+
[
|
| 443 |
+
1,
|
| 444 |
+
]
|
| 445 |
+
+ img_size
|
| 446 |
+
)
|
| 447 |
+
dummy_out = self.proj(dummy_img)
|
| 448 |
+
embed_dim = dummy_out.shape[1]
|
| 449 |
+
patches_layout = tuple(dummy_out.shape[2:])
|
| 450 |
+
num_patches = np.prod(patches_layout)
|
| 451 |
+
return patches_layout, num_patches, embed_dim
|
| 452 |
+
|
| 453 |
+
def forward(self, x):
|
| 454 |
+
x = self.proj(x)
|
| 455 |
+
# B C (T) H W -> B (T)HW C
|
| 456 |
+
x = x.flatten(2).transpose(1, 2)
|
| 457 |
+
if self.norm_layer is not None:
|
| 458 |
+
x = self.norm_layer(x)
|
| 459 |
+
return x
|
| 460 |
+
|
| 461 |
+
|
| 462 |
+
class SpatioTemporalPosEmbeddingHelper(VerboseNNModule):
|
| 463 |
+
def __init__(
|
| 464 |
+
self,
|
| 465 |
+
patches_layout: List,
|
| 466 |
+
num_patches: int,
|
| 467 |
+
num_cls_tokens: int,
|
| 468 |
+
embed_dim: int,
|
| 469 |
+
learnable: bool,
|
| 470 |
+
) -> None:
|
| 471 |
+
super().__init__()
|
| 472 |
+
self.num_cls_tokens = num_cls_tokens
|
| 473 |
+
self.patches_layout = patches_layout
|
| 474 |
+
self.num_patches = num_patches
|
| 475 |
+
self.num_tokens = num_cls_tokens + num_patches
|
| 476 |
+
self.learnable = learnable
|
| 477 |
+
if self.learnable:
|
| 478 |
+
self.pos_embed = nn.Parameter(torch.zeros(1, self.num_tokens, embed_dim))
|
| 479 |
+
trunc_normal_(self.pos_embed, std=0.02)
|
| 480 |
+
else:
|
| 481 |
+
self.register_buffer(
|
| 482 |
+
"pos_embed", get_sinusoid_encoding_table(self.num_tokens, embed_dim)
|
| 483 |
+
)
|
| 484 |
+
|
| 485 |
+
def get_pos_embedding(self, vision_input, all_vision_tokens):
|
| 486 |
+
input_shape = vision_input.shape
|
| 487 |
+
pos_embed = _get_pos_embedding(
|
| 488 |
+
all_vision_tokens.size(1) - self.num_cls_tokens,
|
| 489 |
+
pos_embed=self.pos_embed,
|
| 490 |
+
patches_layout=self.patches_layout,
|
| 491 |
+
input_shape=input_shape,
|
| 492 |
+
first_patch_idx=self.num_cls_tokens,
|
| 493 |
+
)
|
| 494 |
+
return pos_embed
|
| 495 |
+
|
| 496 |
+
|
| 497 |
+
class RGBDTPreprocessor(VerboseNNModule):
|
| 498 |
+
def __init__(
|
| 499 |
+
self,
|
| 500 |
+
rgbt_stem: PatchEmbedGeneric,
|
| 501 |
+
depth_stem: PatchEmbedGeneric,
|
| 502 |
+
img_size: List = (3, 224, 224),
|
| 503 |
+
num_cls_tokens: int = 1,
|
| 504 |
+
pos_embed_fn: Callable = None,
|
| 505 |
+
use_type_embed: bool = False,
|
| 506 |
+
init_param_style: str = "openclip",
|
| 507 |
+
) -> None:
|
| 508 |
+
super().__init__()
|
| 509 |
+
stem = rgbt_stem if rgbt_stem is not None else depth_stem
|
| 510 |
+
(
|
| 511 |
+
self.patches_layout,
|
| 512 |
+
self.num_patches,
|
| 513 |
+
self.embed_dim,
|
| 514 |
+
) = stem.get_patch_layout(img_size)
|
| 515 |
+
self.rgbt_stem = rgbt_stem
|
| 516 |
+
self.depth_stem = depth_stem
|
| 517 |
+
self.use_pos_embed = pos_embed_fn is not None
|
| 518 |
+
self.use_type_embed = use_type_embed
|
| 519 |
+
self.num_cls_tokens = num_cls_tokens
|
| 520 |
+
|
| 521 |
+
if self.use_pos_embed:
|
| 522 |
+
self.pos_embedding_helper = pos_embed_fn(
|
| 523 |
+
patches_layout=self.patches_layout,
|
| 524 |
+
num_cls_tokens=num_cls_tokens,
|
| 525 |
+
num_patches=self.num_patches,
|
| 526 |
+
embed_dim=self.embed_dim,
|
| 527 |
+
)
|
| 528 |
+
if self.num_cls_tokens > 0:
|
| 529 |
+
self.cls_token = nn.Parameter(
|
| 530 |
+
torch.zeros(1, self.num_cls_tokens, self.embed_dim)
|
| 531 |
+
)
|
| 532 |
+
if self.use_type_embed:
|
| 533 |
+
self.type_embed = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
|
| 534 |
+
|
| 535 |
+
self.init_parameters(init_param_style)
|
| 536 |
+
|
| 537 |
+
@torch.no_grad()
|
| 538 |
+
def init_parameters(self, init_param_style):
|
| 539 |
+
if init_param_style == "openclip":
|
| 540 |
+
# OpenCLIP style initialization
|
| 541 |
+
scale = self.embed_dim ** -0.5
|
| 542 |
+
if self.use_pos_embed:
|
| 543 |
+
nn.init.normal_(self.pos_embedding_helper.pos_embed)
|
| 544 |
+
self.pos_embedding_helper.pos_embed *= scale
|
| 545 |
+
|
| 546 |
+
if self.num_cls_tokens > 0:
|
| 547 |
+
nn.init.normal_(self.cls_token)
|
| 548 |
+
self.cls_token *= scale
|
| 549 |
+
elif init_param_style == "vit":
|
| 550 |
+
self.cls_token.data.fill_(0)
|
| 551 |
+
else:
|
| 552 |
+
raise ValueError(f"Unknown init {init_param_style}")
|
| 553 |
+
|
| 554 |
+
if self.use_type_embed:
|
| 555 |
+
nn.init.normal_(self.type_embed)
|
| 556 |
+
|
| 557 |
+
def get_pos_emb_2(self, input, stem):
|
| 558 |
+
patches = stem.proj(input)
|
| 559 |
+
target_size = patches.shape[-2:]
|
| 560 |
+
original_size = list(self.pos_embedding_helper.patches_layout)[-2:]
|
| 561 |
+
|
| 562 |
+
orig_ce = self.pos_embedding_helper.pos_embed[:, 0, :]
|
| 563 |
+
orig_pe = ((self.pos_embedding_helper.pos_embed[:, 1:, :]
|
| 564 |
+
.reshape(1, *original_size, self.embed_dim))
|
| 565 |
+
.permute(0, 3, 1, 2))
|
| 566 |
+
|
| 567 |
+
new_pe = F.interpolate(orig_pe, size=target_size, mode="bicubic")
|
| 568 |
+
|
| 569 |
+
new_full_pe = torch.cat([orig_ce.unsqueeze(1), new_pe.permute(0, 2, 3, 1).reshape(1, -1, self.embed_dim)],
|
| 570 |
+
dim=1)
|
| 571 |
+
|
| 572 |
+
return new_full_pe
|
| 573 |
+
|
| 574 |
+
def tokenize_input_and_cls_pos(self, input, stem, mask):
|
| 575 |
+
# tokens is of shape B x L x D
|
| 576 |
+
tokens = stem(input)
|
| 577 |
+
assert tokens.ndim == 3
|
| 578 |
+
assert tokens.shape[2] == self.embed_dim
|
| 579 |
+
B = tokens.shape[0]
|
| 580 |
+
if self.num_cls_tokens > 0:
|
| 581 |
+
class_tokens = self.cls_token.expand(
|
| 582 |
+
B, -1, -1
|
| 583 |
+
) # stole class_tokens impl from Phil Wang, thanks
|
| 584 |
+
tokens = torch.cat((class_tokens, tokens), dim=1)
|
| 585 |
+
if self.use_pos_embed:
|
| 586 |
+
pos_embed = self.pos_embedding_helper.get_pos_embedding(input, tokens)
|
| 587 |
+
# pos_embed = self.get_pos_emb_2(input, stem)
|
| 588 |
+
tokens = tokens + pos_embed
|
| 589 |
+
if self.use_type_embed:
|
| 590 |
+
tokens = tokens + self.type_embed.expand(B, -1, -1)
|
| 591 |
+
return tokens
|
| 592 |
+
|
| 593 |
+
def forward(self, vision=None, depth=None, patch_mask=None):
|
| 594 |
+
if patch_mask is not None:
|
| 595 |
+
raise NotImplementedError()
|
| 596 |
+
|
| 597 |
+
if vision is not None:
|
| 598 |
+
vision_tokens = self.tokenize_input_and_cls_pos(
|
| 599 |
+
vision, self.rgbt_stem, patch_mask
|
| 600 |
+
)
|
| 601 |
+
|
| 602 |
+
if depth is not None:
|
| 603 |
+
depth_tokens = self.tokenize_input_and_cls_pos(
|
| 604 |
+
depth, self.depth_stem, patch_mask
|
| 605 |
+
)
|
| 606 |
+
|
| 607 |
+
# aggregate tokens
|
| 608 |
+
if vision is not None and depth is not None:
|
| 609 |
+
final_tokens = vision_tokens + depth_tokens
|
| 610 |
+
else:
|
| 611 |
+
final_tokens = vision_tokens if vision is not None else depth_tokens
|
| 612 |
+
return_dict = {
|
| 613 |
+
"trunk": {
|
| 614 |
+
"tokens": final_tokens,
|
| 615 |
+
},
|
| 616 |
+
"head": {},
|
| 617 |
+
}
|
| 618 |
+
return return_dict
|
| 619 |
+
|
| 620 |
+
|
| 621 |
+
class AudioPreprocessor(RGBDTPreprocessor):
|
| 622 |
+
def __init__(self, audio_stem: PatchEmbedGeneric, **kwargs) -> None:
|
| 623 |
+
super().__init__(rgbt_stem=audio_stem, depth_stem=None, **kwargs)
|
| 624 |
+
|
| 625 |
+
def forward(self, audio=None):
|
| 626 |
+
return super().forward(vision=audio)
|
| 627 |
+
|
| 628 |
+
|
| 629 |
+
class ThermalPreprocessor(RGBDTPreprocessor):
|
| 630 |
+
def __init__(self, thermal_stem: PatchEmbedGeneric, **kwargs) -> None:
|
| 631 |
+
super().__init__(rgbt_stem=thermal_stem, depth_stem=None, **kwargs)
|
| 632 |
+
|
| 633 |
+
def forward(self, thermal=None):
|
| 634 |
+
return super().forward(vision=thermal)
|
| 635 |
+
|
| 636 |
+
|
| 637 |
+
def build_causal_attention_mask(context_length):
|
| 638 |
+
# lazily create causal attention mask, with full attention between the vision tokens
|
| 639 |
+
# pytorch uses additive attention mask; fill with -inf
|
| 640 |
+
mask = torch.empty(context_length, context_length, requires_grad=False)
|
| 641 |
+
mask.fill_(float("-inf"))
|
| 642 |
+
mask.triu_(1) # zero out the lower diagonal
|
| 643 |
+
return mask
|
| 644 |
+
|
| 645 |
+
|
| 646 |
+
class TextPreprocessor(VerboseNNModule):
|
| 647 |
+
def __init__(
|
| 648 |
+
self,
|
| 649 |
+
vocab_size: int,
|
| 650 |
+
context_length: int,
|
| 651 |
+
embed_dim: int,
|
| 652 |
+
causal_masking: bool,
|
| 653 |
+
supply_seq_len_to_head: bool = True,
|
| 654 |
+
num_cls_tokens: int = 0,
|
| 655 |
+
init_param_style: str = "openclip",
|
| 656 |
+
) -> None:
|
| 657 |
+
super().__init__()
|
| 658 |
+
self.vocab_size = vocab_size
|
| 659 |
+
self.context_length = context_length
|
| 660 |
+
self.token_embedding = nn.Embedding(vocab_size, embed_dim)
|
| 661 |
+
self.pos_embed = nn.Parameter(
|
| 662 |
+
torch.empty(1, self.context_length + num_cls_tokens, embed_dim)
|
| 663 |
+
)
|
| 664 |
+
self.causal_masking = causal_masking
|
| 665 |
+
if self.causal_masking:
|
| 666 |
+
mask = build_causal_attention_mask(self.context_length)
|
| 667 |
+
# register the mask as a buffer, so it can be moved to the right device
|
| 668 |
+
self.register_buffer("mask", mask)
|
| 669 |
+
|
| 670 |
+
self.supply_seq_len_to_head = supply_seq_len_to_head
|
| 671 |
+
self.num_cls_tokens = num_cls_tokens
|
| 672 |
+
self.embed_dim = embed_dim
|
| 673 |
+
if num_cls_tokens > 0:
|
| 674 |
+
assert self.causal_masking is False, "Masking + CLS token isn't implemented"
|
| 675 |
+
self.cls_token = nn.Parameter(
|
| 676 |
+
torch.zeros(1, self.num_cls_tokens, embed_dim)
|
| 677 |
+
)
|
| 678 |
+
|
| 679 |
+
self.init_parameters(init_param_style)
|
| 680 |
+
|
| 681 |
+
@torch.no_grad()
|
| 682 |
+
def init_parameters(self, init_param_style="openclip"):
|
| 683 |
+
# OpenCLIP style initialization
|
| 684 |
+
nn.init.normal_(self.token_embedding.weight, std=0.02)
|
| 685 |
+
nn.init.normal_(self.pos_embed, std=0.01)
|
| 686 |
+
|
| 687 |
+
if init_param_style == "openclip":
|
| 688 |
+
# OpenCLIP style initialization
|
| 689 |
+
scale = self.embed_dim ** -0.5
|
| 690 |
+
if self.num_cls_tokens > 0:
|
| 691 |
+
nn.init.normal_(self.cls_token)
|
| 692 |
+
self.cls_token *= scale
|
| 693 |
+
elif init_param_style == "vit":
|
| 694 |
+
self.cls_token.data.fill_(0)
|
| 695 |
+
else:
|
| 696 |
+
raise ValueError(f"Unknown init {init_param_style}")
|
| 697 |
+
|
| 698 |
+
def forward(self, text):
|
| 699 |
+
# text tokens are of shape B x L x D
|
| 700 |
+
text_tokens = self.token_embedding(text)
|
| 701 |
+
# concat CLS tokens if any
|
| 702 |
+
if self.num_cls_tokens > 0:
|
| 703 |
+
B = text_tokens.shape[0]
|
| 704 |
+
class_tokens = self.cls_token.expand(
|
| 705 |
+
B, -1, -1
|
| 706 |
+
) # stole class_tokens impl from Phil Wang, thanks
|
| 707 |
+
text_tokens = torch.cat((class_tokens, text_tokens), dim=1)
|
| 708 |
+
text_tokens = text_tokens + self.pos_embed
|
| 709 |
+
return_dict = {
|
| 710 |
+
"trunk": {
|
| 711 |
+
"tokens": text_tokens,
|
| 712 |
+
},
|
| 713 |
+
"head": {},
|
| 714 |
+
}
|
| 715 |
+
# Compute sequence length after adding CLS tokens
|
| 716 |
+
if self.supply_seq_len_to_head:
|
| 717 |
+
text_lengths = text.argmax(dim=-1)
|
| 718 |
+
return_dict["head"] = {
|
| 719 |
+
"seq_len": text_lengths,
|
| 720 |
+
}
|
| 721 |
+
if self.causal_masking:
|
| 722 |
+
return_dict["trunk"].update({"attn_mask": self.mask})
|
| 723 |
+
return return_dict
|
| 724 |
+
|
| 725 |
+
|
| 726 |
+
class Im2Video(nn.Module):
|
| 727 |
+
"""Convert an image into a trivial video."""
|
| 728 |
+
|
| 729 |
+
def __init__(self, time_dim=2):
|
| 730 |
+
super().__init__()
|
| 731 |
+
self.time_dim = time_dim
|
| 732 |
+
|
| 733 |
+
def forward(self, x):
|
| 734 |
+
if x.ndim == 4:
|
| 735 |
+
# B, C, H, W -> B, C, T, H, W
|
| 736 |
+
return x.unsqueeze(self.time_dim)
|
| 737 |
+
elif x.ndim == 5:
|
| 738 |
+
return x
|
| 739 |
+
else:
|
| 740 |
+
raise ValueError(f"Dimension incorrect {x.shape}")
|
| 741 |
+
|
| 742 |
+
|
| 743 |
+
class PadIm2Video(Im2Video):
|
| 744 |
+
def __init__(self, ntimes, pad_type, time_dim=2):
|
| 745 |
+
super().__init__(time_dim=time_dim)
|
| 746 |
+
assert ntimes > 0
|
| 747 |
+
assert pad_type in ["zero", "repeat"]
|
| 748 |
+
self.ntimes = ntimes
|
| 749 |
+
self.pad_type = pad_type
|
| 750 |
+
|
| 751 |
+
def forward(self, x):
|
| 752 |
+
x = super().forward(x)
|
| 753 |
+
if x.shape[self.time_dim] == 1:
|
| 754 |
+
if self.pad_type == "repeat":
|
| 755 |
+
new_shape = [1] * len(x.shape)
|
| 756 |
+
new_shape[self.time_dim] = self.ntimes
|
| 757 |
+
x = x.repeat(new_shape)
|
| 758 |
+
elif self.pad_type == "zero":
|
| 759 |
+
padarg = [0, 0] * len(x.shape)
|
| 760 |
+
padarg[2 * self.time_dim + 1] = self.ntimes - x.shape[self.time_dim]
|
| 761 |
+
x = nn.functional.pad(x, padarg)
|
| 762 |
+
return x
|
| 763 |
+
|
| 764 |
+
|
| 765 |
+
# Modified from github.com/openai/CLIP
|
| 766 |
+
@lru_cache()
|
| 767 |
+
def bytes_to_unicode():
|
| 768 |
+
"""
|
| 769 |
+
Returns list of utf-8 byte and a corresponding list of unicode strings.
|
| 770 |
+
The reversible bpe codes work on unicode strings.
|
| 771 |
+
This means you need a large # of unicode characters in your vocab if you want to avoid UNKs.
|
| 772 |
+
When you're at something like a 10B token dataset you end up needing around 5K for decent coverage.
|
| 773 |
+
This is a signficant percentage of your normal, say, 32K bpe vocab.
|
| 774 |
+
To avoid that, we want lookup tables between utf-8 bytes and unicode strings.
|
| 775 |
+
And avoids mapping to whitespace/control characters the bpe code barfs on.
|
| 776 |
+
"""
|
| 777 |
+
bs = (
|
| 778 |
+
list(range(ord("!"), ord("~") + 1))
|
| 779 |
+
+ list(range(ord("¡"), ord("¬") + 1))
|
| 780 |
+
+ list(range(ord("®"), ord("ÿ") + 1))
|
| 781 |
+
)
|
| 782 |
+
cs = bs[:]
|
| 783 |
+
n = 0
|
| 784 |
+
for b in range(2 ** 8):
|
| 785 |
+
if b not in bs:
|
| 786 |
+
bs.append(b)
|
| 787 |
+
cs.append(2 ** 8 + n)
|
| 788 |
+
n += 1
|
| 789 |
+
cs = [chr(n) for n in cs]
|
| 790 |
+
return dict(zip(bs, cs))
|
| 791 |
+
|
| 792 |
+
|
| 793 |
+
def get_pairs(word):
|
| 794 |
+
"""Return set of symbol pairs in a word.
|
| 795 |
+
Word is represented as tuple of symbols (symbols being variable-length strings).
|
| 796 |
+
"""
|
| 797 |
+
pairs = set()
|
| 798 |
+
prev_char = word[0]
|
| 799 |
+
for char in word[1:]:
|
| 800 |
+
pairs.add((prev_char, char))
|
| 801 |
+
prev_char = char
|
| 802 |
+
return pairs
|
| 803 |
+
|
| 804 |
+
|
| 805 |
+
def basic_clean(text):
|
| 806 |
+
text = ftfy.fix_text(text)
|
| 807 |
+
text = html.unescape(html.unescape(text))
|
| 808 |
+
return text.strip()
|
| 809 |
+
|
| 810 |
+
|
| 811 |
+
def whitespace_clean(text):
|
| 812 |
+
text = re.sub(r"\s+", " ", text)
|
| 813 |
+
text = text.strip()
|
| 814 |
+
return text
|
| 815 |
+
|
| 816 |
+
|
| 817 |
+
class SimpleTokenizer(object):
|
| 818 |
+
def __init__(self, bpe_path: str, context_length=77):
|
| 819 |
+
self.byte_encoder = bytes_to_unicode()
|
| 820 |
+
self.byte_decoder = {v: k for k, v in self.byte_encoder.items()}
|
| 821 |
+
|
| 822 |
+
with g_pathmgr.open(bpe_path, "rb") as fh:
|
| 823 |
+
bpe_bytes = io.BytesIO(fh.read())
|
| 824 |
+
merges = gzip.open(bpe_bytes).read().decode("utf-8").split("\n")
|
| 825 |
+
merges = merges[1: 49152 - 256 - 2 + 1]
|
| 826 |
+
merges = [tuple(merge.split()) for merge in merges]
|
| 827 |
+
vocab = list(bytes_to_unicode().values())
|
| 828 |
+
vocab = vocab + [v + "</w>" for v in vocab]
|
| 829 |
+
for merge in merges:
|
| 830 |
+
vocab.append("".join(merge))
|
| 831 |
+
vocab.extend(["<|startoftext|>", "<|endoftext|>"])
|
| 832 |
+
self.encoder = dict(zip(vocab, range(len(vocab))))
|
| 833 |
+
self.decoder = {v: k for k, v in self.encoder.items()}
|
| 834 |
+
self.bpe_ranks = dict(zip(merges, range(len(merges))))
|
| 835 |
+
self.cache = {
|
| 836 |
+
"<|startoftext|>": "<|startoftext|>",
|
| 837 |
+
"<|endoftext|>": "<|endoftext|>",
|
| 838 |
+
}
|
| 839 |
+
self.pat = re.compile(
|
| 840 |
+
r"""<\|startoftext\|>|<\|endoftext\|>|'s|'t|'re|'ve|'m|'ll|'d|[\p{L}]+|[\p{N}]|[^\s\p{L}\p{N}]+""",
|
| 841 |
+
re.IGNORECASE,
|
| 842 |
+
)
|
| 843 |
+
self.context_length = context_length
|
| 844 |
+
|
| 845 |
+
def bpe(self, token):
|
| 846 |
+
if token in self.cache:
|
| 847 |
+
return self.cache[token]
|
| 848 |
+
word = tuple(token[:-1]) + (token[-1] + "</w>",)
|
| 849 |
+
pairs = get_pairs(word)
|
| 850 |
+
|
| 851 |
+
if not pairs:
|
| 852 |
+
return token + "</w>"
|
| 853 |
+
|
| 854 |
+
while True:
|
| 855 |
+
bigram = min(pairs, key=lambda pair: self.bpe_ranks.get(pair, float("inf")))
|
| 856 |
+
if bigram not in self.bpe_ranks:
|
| 857 |
+
break
|
| 858 |
+
first, second = bigram
|
| 859 |
+
new_word = []
|
| 860 |
+
i = 0
|
| 861 |
+
while i < len(word):
|
| 862 |
+
try:
|
| 863 |
+
j = word.index(first, i)
|
| 864 |
+
new_word.extend(word[i:j])
|
| 865 |
+
i = j
|
| 866 |
+
except:
|
| 867 |
+
new_word.extend(word[i:])
|
| 868 |
+
break
|
| 869 |
+
|
| 870 |
+
if word[i] == first and i < len(word) - 1 and word[i + 1] == second:
|
| 871 |
+
new_word.append(first + second)
|
| 872 |
+
i += 2
|
| 873 |
+
else:
|
| 874 |
+
new_word.append(word[i])
|
| 875 |
+
i += 1
|
| 876 |
+
new_word = tuple(new_word)
|
| 877 |
+
word = new_word
|
| 878 |
+
if len(word) == 1:
|
| 879 |
+
break
|
| 880 |
+
else:
|
| 881 |
+
pairs = get_pairs(word)
|
| 882 |
+
word = " ".join(word)
|
| 883 |
+
self.cache[token] = word
|
| 884 |
+
return word
|
| 885 |
+
|
| 886 |
+
def encode(self, text):
|
| 887 |
+
bpe_tokens = []
|
| 888 |
+
text = whitespace_clean(basic_clean(text)).lower()
|
| 889 |
+
for token in re.findall(self.pat, text):
|
| 890 |
+
token = "".join(self.byte_encoder[b] for b in token.encode("utf-8"))
|
| 891 |
+
bpe_tokens.extend(
|
| 892 |
+
self.encoder[bpe_token] for bpe_token in self.bpe(token).split(" ")
|
| 893 |
+
)
|
| 894 |
+
return bpe_tokens
|
| 895 |
+
|
| 896 |
+
def decode(self, tokens):
|
| 897 |
+
text = "".join([self.decoder[token] for token in tokens])
|
| 898 |
+
text = (
|
| 899 |
+
bytearray([self.byte_decoder[c] for c in text])
|
| 900 |
+
.decode("utf-8", errors="replace")
|
| 901 |
+
.replace("</w>", " ")
|
| 902 |
+
)
|
| 903 |
+
return text
|
| 904 |
+
|
| 905 |
+
def __call__(self, texts, context_length=None):
|
| 906 |
+
if not context_length:
|
| 907 |
+
context_length = self.context_length
|
| 908 |
+
|
| 909 |
+
if isinstance(texts, str):
|
| 910 |
+
texts = [texts]
|
| 911 |
+
|
| 912 |
+
sot_token = self.encoder["<|startoftext|>"]
|
| 913 |
+
eot_token = self.encoder["<|endoftext|>"]
|
| 914 |
+
all_tokens = [[sot_token] + self.encode(text) + [eot_token] for text in texts]
|
| 915 |
+
result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
|
| 916 |
+
|
| 917 |
+
for i, tokens in enumerate(all_tokens):
|
| 918 |
+
tokens = tokens[:context_length]
|
| 919 |
+
result[i, : len(tokens)] = torch.tensor(tokens)
|
| 920 |
+
|
| 921 |
+
if len(result) == 1:
|
| 922 |
+
return result[0]
|
| 923 |
+
return result
|
| 924 |
+
|
| 925 |
+
|
| 926 |
+
class Normalize(nn.Module):
|
| 927 |
+
def __init__(self, dim: int) -> None:
|
| 928 |
+
super().__init__()
|
| 929 |
+
self.dim = dim
|
| 930 |
+
|
| 931 |
+
def forward(self, x):
|
| 932 |
+
return torch.nn.functional.normalize(x, dim=self.dim, p=2)
|
| 933 |
+
|
| 934 |
+
|
| 935 |
+
class LearnableLogitScaling(nn.Module):
|
| 936 |
+
def __init__(
|
| 937 |
+
self,
|
| 938 |
+
logit_scale_init: float = 1 / 0.07,
|
| 939 |
+
learnable: bool = True,
|
| 940 |
+
max_logit_scale: float = 100,
|
| 941 |
+
) -> None:
|
| 942 |
+
super().__init__()
|
| 943 |
+
self.max_logit_scale = max_logit_scale
|
| 944 |
+
self.logit_scale_init = logit_scale_init
|
| 945 |
+
self.learnable = learnable
|
| 946 |
+
log_logit_scale = torch.ones([]) * np.log(self.logit_scale_init)
|
| 947 |
+
if learnable:
|
| 948 |
+
self.log_logit_scale = nn.Parameter(log_logit_scale)
|
| 949 |
+
else:
|
| 950 |
+
self.register_buffer("log_logit_scale", log_logit_scale)
|
| 951 |
+
|
| 952 |
+
def forward(self, x):
|
| 953 |
+
return torch.clip(self.log_logit_scale.exp(), max=self.max_logit_scale) * x
|
| 954 |
+
|
| 955 |
+
def extra_repr(self):
|
| 956 |
+
st = f"logit_scale_init={self.logit_scale_init},learnable={self.learnable}, max_logit_scale={self.max_logit_scale}"
|
| 957 |
+
return st
|
| 958 |
+
|
| 959 |
+
|
| 960 |
+
class EinOpsRearrange(nn.Module):
|
| 961 |
+
def __init__(self, rearrange_expr: str, **kwargs) -> None:
|
| 962 |
+
super().__init__()
|
| 963 |
+
self.rearrange_expr = rearrange_expr
|
| 964 |
+
self.kwargs = kwargs
|
| 965 |
+
|
| 966 |
+
def forward(self, x):
|
| 967 |
+
assert isinstance(x, torch.Tensor)
|
| 968 |
+
return einops.rearrange(x, self.rearrange_expr, **self.kwargs)
|
| 969 |
+
|
| 970 |
+
|
| 971 |
+
class IMUPreprocessor(VerboseNNModule):
|
| 972 |
+
def __init__(
|
| 973 |
+
self,
|
| 974 |
+
kernel_size: int,
|
| 975 |
+
imu_stem: PatchEmbedGeneric,
|
| 976 |
+
embed_dim: int,
|
| 977 |
+
img_size: List = (6, 2000),
|
| 978 |
+
num_cls_tokens: int = 1,
|
| 979 |
+
pos_embed_fn: Callable = None,
|
| 980 |
+
init_param_style: str = "openclip",
|
| 981 |
+
) -> None:
|
| 982 |
+
super().__init__()
|
| 983 |
+
stem = imu_stem
|
| 984 |
+
self.imu_stem = imu_stem
|
| 985 |
+
self.embed_dim = embed_dim
|
| 986 |
+
self.use_pos_embed = pos_embed_fn is not None
|
| 987 |
+
self.num_cls_tokens = num_cls_tokens
|
| 988 |
+
self.kernel_size = kernel_size
|
| 989 |
+
self.pos_embed = nn.Parameter(
|
| 990 |
+
torch.empty(1, (img_size[1] // kernel_size) + num_cls_tokens, embed_dim)
|
| 991 |
+
)
|
| 992 |
+
|
| 993 |
+
if self.num_cls_tokens > 0:
|
| 994 |
+
self.cls_token = nn.Parameter(
|
| 995 |
+
torch.zeros(1, self.num_cls_tokens, self.embed_dim)
|
| 996 |
+
)
|
| 997 |
+
|
| 998 |
+
self.init_parameters(init_param_style)
|
| 999 |
+
|
| 1000 |
+
@torch.no_grad()
|
| 1001 |
+
def init_parameters(self, init_param_style):
|
| 1002 |
+
nn.init.normal_(self.pos_embed, std=0.01)
|
| 1003 |
+
|
| 1004 |
+
if init_param_style == "openclip":
|
| 1005 |
+
# OpenCLIP style initialization
|
| 1006 |
+
scale = self.embed_dim ** -0.5
|
| 1007 |
+
|
| 1008 |
+
if self.num_cls_tokens > 0:
|
| 1009 |
+
nn.init.normal_(self.cls_token)
|
| 1010 |
+
self.cls_token *= scale
|
| 1011 |
+
elif init_param_style == "vit":
|
| 1012 |
+
self.cls_token.data.fill_(0)
|
| 1013 |
+
else:
|
| 1014 |
+
raise ValueError(f"Unknown init {init_param_style}")
|
| 1015 |
+
|
| 1016 |
+
def tokenize_input_and_cls_pos(self, input, stem):
|
| 1017 |
+
# tokens is of shape B x L x D
|
| 1018 |
+
tokens = stem.norm_layer(stem.proj(input))
|
| 1019 |
+
assert tokens.ndim == 3
|
| 1020 |
+
assert tokens.shape[2] == self.embed_dim
|
| 1021 |
+
B = tokens.shape[0]
|
| 1022 |
+
if self.num_cls_tokens > 0:
|
| 1023 |
+
class_tokens = self.cls_token.expand(
|
| 1024 |
+
B, -1, -1
|
| 1025 |
+
) # stole class_tokens impl from Phil Wang, thanks
|
| 1026 |
+
tokens = torch.cat((class_tokens, tokens), dim=1)
|
| 1027 |
+
if self.use_pos_embed:
|
| 1028 |
+
tokens = tokens + self.pos_embed
|
| 1029 |
+
return tokens
|
| 1030 |
+
|
| 1031 |
+
def forward(self, imu):
|
| 1032 |
+
# Patchify
|
| 1033 |
+
imu = imu.unfold(
|
| 1034 |
+
-1,
|
| 1035 |
+
self.kernel_size,
|
| 1036 |
+
self.kernel_size,
|
| 1037 |
+
).permute(0, 2, 1, 3)
|
| 1038 |
+
imu = imu.reshape(imu.size(0), imu.size(1), -1)
|
| 1039 |
+
|
| 1040 |
+
imu_tokens = self.tokenize_input_and_cls_pos(
|
| 1041 |
+
imu,
|
| 1042 |
+
self.imu_stem,
|
| 1043 |
+
)
|
| 1044 |
+
|
| 1045 |
+
return_dict = {
|
| 1046 |
+
"trunk": {
|
| 1047 |
+
"tokens": imu_tokens,
|
| 1048 |
+
},
|
| 1049 |
+
"head": {},
|
| 1050 |
+
}
|
| 1051 |
+
return return_dict
|
| 1052 |
+
|
| 1053 |
+
|
| 1054 |
+
def cast_if_src_dtype(
|
| 1055 |
+
tensor: torch.Tensor, src_dtype: torch.dtype, tgt_dtype: torch.dtype
|
| 1056 |
+
):
|
| 1057 |
+
updated = False
|
| 1058 |
+
if tensor.dtype == src_dtype:
|
| 1059 |
+
tensor = tensor.to(dtype=tgt_dtype)
|
| 1060 |
+
updated = True
|
| 1061 |
+
return tensor, updated
|
| 1062 |
+
|
| 1063 |
+
|
| 1064 |
+
class QuickGELU(nn.Module):
|
| 1065 |
+
# From https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/clip/model.py#L166
|
| 1066 |
+
def forward(self, x: torch.Tensor):
|
| 1067 |
+
return x * torch.sigmoid(1.702 * x)
|
| 1068 |
+
|
| 1069 |
+
|
| 1070 |
+
class SelectElement(nn.Module):
|
| 1071 |
+
def __init__(self, index) -> None:
|
| 1072 |
+
super().__init__()
|
| 1073 |
+
self.index = index
|
| 1074 |
+
|
| 1075 |
+
def forward(self, x):
|
| 1076 |
+
assert x.ndim >= 3
|
| 1077 |
+
return x[:, self.index, ...]
|
| 1078 |
+
|
| 1079 |
+
|
| 1080 |
+
class ReshapeSpatial(nn.Module):
|
| 1081 |
+
def __init__(self, shape) -> None:
|
| 1082 |
+
super().__init__()
|
| 1083 |
+
self.h, self.w = shape
|
| 1084 |
+
|
| 1085 |
+
def forward(self, x):
|
| 1086 |
+
assert x.ndim >= 3
|
| 1087 |
+
return x[:, 1:, ...].reshape(x.shape[0], self.h, self.w, -1), x[:, 0, :]
|
| 1088 |
+
|
| 1089 |
+
|
| 1090 |
+
class ReshapeAudio(nn.Module):
|
| 1091 |
+
def __init__(self, shape) -> None:
|
| 1092 |
+
super().__init__()
|
| 1093 |
+
self.h, self.w = shape
|
| 1094 |
+
|
| 1095 |
+
def forward(self, x):
|
| 1096 |
+
assert x.ndim == 3
|
| 1097 |
+
return x[:, 1:, :].reshape(-1, 5, self.h, self.w, x.shape[-1]), x[:, 0, :]
|
| 1098 |
+
|
| 1099 |
+
|
| 1100 |
+
class ApplyTwice(nn.Module):
|
| 1101 |
+
def __init__(self, module) -> None:
|
| 1102 |
+
super().__init__()
|
| 1103 |
+
self.module = module
|
| 1104 |
+
|
| 1105 |
+
def forward(self, pair):
|
| 1106 |
+
return self.module(pair[0]), self.module(pair[1])
|
| 1107 |
+
|
| 1108 |
+
|
| 1109 |
+
class SelectEOSAndProject(nn.Module):
|
| 1110 |
+
"""
|
| 1111 |
+
Text Pooling used in OpenCLIP
|
| 1112 |
+
"""
|
| 1113 |
+
|
| 1114 |
+
def __init__(self, proj: nn.Module) -> None:
|
| 1115 |
+
super().__init__()
|
| 1116 |
+
self.proj = proj
|
| 1117 |
+
|
| 1118 |
+
def forward(self, x, seq_len):
|
| 1119 |
+
assert x.ndim == 3
|
| 1120 |
+
# x is of shape B x L x D
|
| 1121 |
+
# take features from the eot embedding (eot_token is the highest number in each sequence)
|
| 1122 |
+
x = x[torch.arange(x.shape[0]), seq_len]
|
| 1123 |
+
x = self.proj(x)
|
| 1124 |
+
return x
|
| 1125 |
+
|
| 1126 |
+
|
| 1127 |
+
ModalityType = SimpleNamespace(
|
| 1128 |
+
VISION="vision",
|
| 1129 |
+
TEXT="text",
|
| 1130 |
+
AUDIO="audio",
|
| 1131 |
+
THERMAL="thermal",
|
| 1132 |
+
DEPTH="depth",
|
| 1133 |
+
IMU="imu",
|
| 1134 |
+
)
|
| 1135 |
+
|
| 1136 |
+
|
| 1137 |
+
class ImageBindModel(nn.Module):
|
| 1138 |
+
def __init__(
|
| 1139 |
+
self,
|
| 1140 |
+
video_frames=2,
|
| 1141 |
+
kernel_size=(2, 14, 14),
|
| 1142 |
+
audio_kernel_size=16,
|
| 1143 |
+
audio_stride=10,
|
| 1144 |
+
out_embed_dim=768,
|
| 1145 |
+
vision_embed_dim=1024,
|
| 1146 |
+
vision_num_blocks=24,
|
| 1147 |
+
vision_num_heads=16,
|
| 1148 |
+
audio_embed_dim=768,
|
| 1149 |
+
audio_num_blocks=12,
|
| 1150 |
+
audio_num_heads=12,
|
| 1151 |
+
audio_num_mel_bins=128,
|
| 1152 |
+
audio_target_len=204,
|
| 1153 |
+
audio_drop_path=0.1,
|
| 1154 |
+
text_embed_dim=768,
|
| 1155 |
+
text_num_blocks=12,
|
| 1156 |
+
text_num_heads=12,
|
| 1157 |
+
depth_embed_dim=384,
|
| 1158 |
+
depth_kernel_size=16,
|
| 1159 |
+
depth_num_blocks=12,
|
| 1160 |
+
depth_num_heads=8,
|
| 1161 |
+
depth_drop_path=0.0,
|
| 1162 |
+
thermal_embed_dim=768,
|
| 1163 |
+
thermal_kernel_size=16,
|
| 1164 |
+
thermal_num_blocks=12,
|
| 1165 |
+
thermal_num_heads=12,
|
| 1166 |
+
thermal_drop_path=0.0,
|
| 1167 |
+
imu_embed_dim=512,
|
| 1168 |
+
imu_kernel_size=8,
|
| 1169 |
+
imu_num_blocks=6,
|
| 1170 |
+
imu_num_heads=8,
|
| 1171 |
+
imu_drop_path=0.7,
|
| 1172 |
+
):
|
| 1173 |
+
super().__init__()
|
| 1174 |
+
|
| 1175 |
+
self.modality_preprocessors = self._create_modality_preprocessors(
|
| 1176 |
+
video_frames,
|
| 1177 |
+
vision_embed_dim,
|
| 1178 |
+
kernel_size,
|
| 1179 |
+
text_embed_dim,
|
| 1180 |
+
audio_embed_dim,
|
| 1181 |
+
audio_kernel_size,
|
| 1182 |
+
audio_stride,
|
| 1183 |
+
audio_num_mel_bins,
|
| 1184 |
+
audio_target_len,
|
| 1185 |
+
depth_embed_dim,
|
| 1186 |
+
depth_kernel_size,
|
| 1187 |
+
thermal_embed_dim,
|
| 1188 |
+
thermal_kernel_size,
|
| 1189 |
+
imu_embed_dim,
|
| 1190 |
+
)
|
| 1191 |
+
|
| 1192 |
+
self.modality_trunks = self._create_modality_trunks(
|
| 1193 |
+
vision_embed_dim,
|
| 1194 |
+
vision_num_blocks,
|
| 1195 |
+
vision_num_heads,
|
| 1196 |
+
text_embed_dim,
|
| 1197 |
+
text_num_blocks,
|
| 1198 |
+
text_num_heads,
|
| 1199 |
+
audio_embed_dim,
|
| 1200 |
+
audio_num_blocks,
|
| 1201 |
+
audio_num_heads,
|
| 1202 |
+
audio_drop_path,
|
| 1203 |
+
depth_embed_dim,
|
| 1204 |
+
depth_num_blocks,
|
| 1205 |
+
depth_num_heads,
|
| 1206 |
+
depth_drop_path,
|
| 1207 |
+
thermal_embed_dim,
|
| 1208 |
+
thermal_num_blocks,
|
| 1209 |
+
thermal_num_heads,
|
| 1210 |
+
thermal_drop_path,
|
| 1211 |
+
imu_embed_dim,
|
| 1212 |
+
imu_num_blocks,
|
| 1213 |
+
imu_num_heads,
|
| 1214 |
+
imu_drop_path,
|
| 1215 |
+
)
|
| 1216 |
+
|
| 1217 |
+
self.modality_heads = self._create_modality_heads(
|
| 1218 |
+
out_embed_dim,
|
| 1219 |
+
vision_embed_dim,
|
| 1220 |
+
text_embed_dim,
|
| 1221 |
+
audio_embed_dim,
|
| 1222 |
+
depth_embed_dim,
|
| 1223 |
+
thermal_embed_dim,
|
| 1224 |
+
imu_embed_dim,
|
| 1225 |
+
)
|
| 1226 |
+
|
| 1227 |
+
self.modality_postprocessors = self._create_modality_postprocessors(
|
| 1228 |
+
out_embed_dim
|
| 1229 |
+
)
|
| 1230 |
+
|
| 1231 |
+
def _create_modality_preprocessors(
|
| 1232 |
+
self,
|
| 1233 |
+
video_frames=2,
|
| 1234 |
+
vision_embed_dim=1024,
|
| 1235 |
+
kernel_size=(2, 14, 14),
|
| 1236 |
+
text_embed_dim=768,
|
| 1237 |
+
audio_embed_dim=768,
|
| 1238 |
+
audio_kernel_size=16,
|
| 1239 |
+
audio_stride=10,
|
| 1240 |
+
audio_num_mel_bins=128,
|
| 1241 |
+
audio_target_len=204,
|
| 1242 |
+
depth_embed_dim=768,
|
| 1243 |
+
depth_kernel_size=16,
|
| 1244 |
+
thermal_embed_dim=768,
|
| 1245 |
+
thermal_kernel_size=16,
|
| 1246 |
+
imu_embed_dim=512,
|
| 1247 |
+
):
|
| 1248 |
+
rgbt_stem = PatchEmbedGeneric(
|
| 1249 |
+
proj_stem=[
|
| 1250 |
+
PadIm2Video(pad_type="repeat", ntimes=2),
|
| 1251 |
+
nn.Conv3d(
|
| 1252 |
+
in_channels=3,
|
| 1253 |
+
kernel_size=kernel_size,
|
| 1254 |
+
out_channels=vision_embed_dim,
|
| 1255 |
+
stride=kernel_size,
|
| 1256 |
+
bias=False,
|
| 1257 |
+
),
|
| 1258 |
+
]
|
| 1259 |
+
)
|
| 1260 |
+
rgbt_preprocessor = RGBDTPreprocessor(
|
| 1261 |
+
img_size=[3, video_frames, 224, 224],
|
| 1262 |
+
num_cls_tokens=1,
|
| 1263 |
+
pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
|
| 1264 |
+
rgbt_stem=rgbt_stem,
|
| 1265 |
+
depth_stem=None,
|
| 1266 |
+
)
|
| 1267 |
+
|
| 1268 |
+
text_preprocessor = TextPreprocessor(
|
| 1269 |
+
context_length=77,
|
| 1270 |
+
vocab_size=49408,
|
| 1271 |
+
embed_dim=text_embed_dim,
|
| 1272 |
+
causal_masking=True,
|
| 1273 |
+
)
|
| 1274 |
+
|
| 1275 |
+
audio_stem = PatchEmbedGeneric(
|
| 1276 |
+
proj_stem=[
|
| 1277 |
+
nn.Conv2d(
|
| 1278 |
+
in_channels=1,
|
| 1279 |
+
kernel_size=audio_kernel_size,
|
| 1280 |
+
stride=audio_stride,
|
| 1281 |
+
out_channels=audio_embed_dim,
|
| 1282 |
+
bias=False,
|
| 1283 |
+
),
|
| 1284 |
+
],
|
| 1285 |
+
norm_layer=nn.LayerNorm(normalized_shape=audio_embed_dim),
|
| 1286 |
+
)
|
| 1287 |
+
audio_preprocessor = AudioPreprocessor(
|
| 1288 |
+
img_size=[1, audio_num_mel_bins, audio_target_len],
|
| 1289 |
+
num_cls_tokens=1,
|
| 1290 |
+
pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
|
| 1291 |
+
audio_stem=audio_stem,
|
| 1292 |
+
)
|
| 1293 |
+
|
| 1294 |
+
# depth_stem = PatchEmbedGeneric(
|
| 1295 |
+
# [
|
| 1296 |
+
# nn.Conv2d(
|
| 1297 |
+
# kernel_size=depth_kernel_size,
|
| 1298 |
+
# in_channels=1,
|
| 1299 |
+
# out_channels=depth_embed_dim,
|
| 1300 |
+
# stride=depth_kernel_size,
|
| 1301 |
+
# bias=False,
|
| 1302 |
+
# ),
|
| 1303 |
+
# ],
|
| 1304 |
+
# norm_layer=nn.LayerNorm(normalized_shape=depth_embed_dim),
|
| 1305 |
+
# )
|
| 1306 |
+
#
|
| 1307 |
+
# depth_preprocessor = RGBDTPreprocessor(
|
| 1308 |
+
# img_size=[1, 224, 224],
|
| 1309 |
+
# num_cls_tokens=1,
|
| 1310 |
+
# pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
|
| 1311 |
+
# rgbt_stem=None,
|
| 1312 |
+
# depth_stem=depth_stem,
|
| 1313 |
+
# )
|
| 1314 |
+
#
|
| 1315 |
+
# thermal_stem = PatchEmbedGeneric(
|
| 1316 |
+
# [
|
| 1317 |
+
# nn.Conv2d(
|
| 1318 |
+
# kernel_size=thermal_kernel_size,
|
| 1319 |
+
# in_channels=1,
|
| 1320 |
+
# out_channels=thermal_embed_dim,
|
| 1321 |
+
# stride=thermal_kernel_size,
|
| 1322 |
+
# bias=False,
|
| 1323 |
+
# ),
|
| 1324 |
+
# ],
|
| 1325 |
+
# norm_layer=nn.LayerNorm(normalized_shape=thermal_embed_dim),
|
| 1326 |
+
# )
|
| 1327 |
+
# thermal_preprocessor = ThermalPreprocessor(
|
| 1328 |
+
# img_size=[1, 224, 224],
|
| 1329 |
+
# num_cls_tokens=1,
|
| 1330 |
+
# pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
|
| 1331 |
+
# thermal_stem=thermal_stem,
|
| 1332 |
+
# )
|
| 1333 |
+
#
|
| 1334 |
+
# imu_stem = PatchEmbedGeneric(
|
| 1335 |
+
# [
|
| 1336 |
+
# nn.Linear(
|
| 1337 |
+
# in_features=48,
|
| 1338 |
+
# out_features=imu_embed_dim,
|
| 1339 |
+
# bias=False,
|
| 1340 |
+
# ),
|
| 1341 |
+
# ],
|
| 1342 |
+
# norm_layer=nn.LayerNorm(normalized_shape=imu_embed_dim),
|
| 1343 |
+
# )
|
| 1344 |
+
#
|
| 1345 |
+
# imu_preprocessor = IMUPreprocessor(
|
| 1346 |
+
# img_size=[6, 2000],
|
| 1347 |
+
# num_cls_tokens=1,
|
| 1348 |
+
# kernel_size=8,
|
| 1349 |
+
# embed_dim=imu_embed_dim,
|
| 1350 |
+
# pos_embed_fn=partial(SpatioTemporalPosEmbeddingHelper, learnable=True),
|
| 1351 |
+
# imu_stem=imu_stem,
|
| 1352 |
+
# )
|
| 1353 |
+
|
| 1354 |
+
modality_preprocessors = {
|
| 1355 |
+
ModalityType.VISION: rgbt_preprocessor,
|
| 1356 |
+
ModalityType.TEXT: text_preprocessor,
|
| 1357 |
+
ModalityType.AUDIO: audio_preprocessor,
|
| 1358 |
+
# ModalityType.DEPTH: depth_preprocessor,
|
| 1359 |
+
# ModalityType.THERMAL: thermal_preprocessor,
|
| 1360 |
+
# ModalityType.IMU: imu_preprocessor,
|
| 1361 |
+
}
|
| 1362 |
+
|
| 1363 |
+
return nn.ModuleDict(modality_preprocessors)
|
| 1364 |
+
|
| 1365 |
+
def _create_modality_trunks(
|
| 1366 |
+
self,
|
| 1367 |
+
vision_embed_dim=1024,
|
| 1368 |
+
vision_num_blocks=24,
|
| 1369 |
+
vision_num_heads=16,
|
| 1370 |
+
text_embed_dim=768,
|
| 1371 |
+
text_num_blocks=12,
|
| 1372 |
+
text_num_heads=12,
|
| 1373 |
+
audio_embed_dim=768,
|
| 1374 |
+
audio_num_blocks=12,
|
| 1375 |
+
audio_num_heads=12,
|
| 1376 |
+
audio_drop_path=0.0,
|
| 1377 |
+
depth_embed_dim=768,
|
| 1378 |
+
depth_num_blocks=12,
|
| 1379 |
+
depth_num_heads=12,
|
| 1380 |
+
depth_drop_path=0.0,
|
| 1381 |
+
thermal_embed_dim=768,
|
| 1382 |
+
thermal_num_blocks=12,
|
| 1383 |
+
thermal_num_heads=12,
|
| 1384 |
+
thermal_drop_path=0.0,
|
| 1385 |
+
imu_embed_dim=512,
|
| 1386 |
+
imu_num_blocks=6,
|
| 1387 |
+
imu_num_heads=8,
|
| 1388 |
+
imu_drop_path=0.7,
|
| 1389 |
+
):
|
| 1390 |
+
def instantiate_trunk(
|
| 1391 |
+
embed_dim, num_blocks, num_heads, pre_transformer_ln, add_bias_kv, drop_path
|
| 1392 |
+
):
|
| 1393 |
+
return SimpleTransformer(
|
| 1394 |
+
embed_dim=embed_dim,
|
| 1395 |
+
num_blocks=num_blocks,
|
| 1396 |
+
ffn_dropout_rate=0.0,
|
| 1397 |
+
drop_path_rate=drop_path,
|
| 1398 |
+
attn_target=partial(
|
| 1399 |
+
MultiheadAttention,
|
| 1400 |
+
embed_dim=embed_dim,
|
| 1401 |
+
num_heads=num_heads,
|
| 1402 |
+
bias=True,
|
| 1403 |
+
add_bias_kv=add_bias_kv,
|
| 1404 |
+
),
|
| 1405 |
+
pre_transformer_layer=nn.Sequential(
|
| 1406 |
+
nn.LayerNorm(embed_dim, eps=1e-6)
|
| 1407 |
+
if pre_transformer_ln
|
| 1408 |
+
else nn.Identity(),
|
| 1409 |
+
EinOpsRearrange("b l d -> l b d"),
|
| 1410 |
+
),
|
| 1411 |
+
post_transformer_layer=EinOpsRearrange("l b d -> b l d"),
|
| 1412 |
+
)
|
| 1413 |
+
|
| 1414 |
+
modality_trunks = {}
|
| 1415 |
+
modality_trunks[ModalityType.VISION] = instantiate_trunk(
|
| 1416 |
+
vision_embed_dim,
|
| 1417 |
+
vision_num_blocks,
|
| 1418 |
+
vision_num_heads,
|
| 1419 |
+
pre_transformer_ln=True,
|
| 1420 |
+
add_bias_kv=False,
|
| 1421 |
+
drop_path=0.0,
|
| 1422 |
+
)
|
| 1423 |
+
modality_trunks[ModalityType.TEXT] = instantiate_trunk(
|
| 1424 |
+
text_embed_dim,
|
| 1425 |
+
text_num_blocks,
|
| 1426 |
+
text_num_heads,
|
| 1427 |
+
pre_transformer_ln=False,
|
| 1428 |
+
add_bias_kv=False,
|
| 1429 |
+
drop_path=0.0,
|
| 1430 |
+
)
|
| 1431 |
+
modality_trunks[ModalityType.AUDIO] = instantiate_trunk(
|
| 1432 |
+
audio_embed_dim,
|
| 1433 |
+
audio_num_blocks,
|
| 1434 |
+
audio_num_heads,
|
| 1435 |
+
pre_transformer_ln=False,
|
| 1436 |
+
add_bias_kv=True,
|
| 1437 |
+
drop_path=audio_drop_path,
|
| 1438 |
+
)
|
| 1439 |
+
# modality_trunks[ModalityType.DEPTH] = instantiate_trunk(
|
| 1440 |
+
# depth_embed_dim,
|
| 1441 |
+
# depth_num_blocks,
|
| 1442 |
+
# depth_num_heads,
|
| 1443 |
+
# pre_transformer_ln=False,
|
| 1444 |
+
# add_bias_kv=True,
|
| 1445 |
+
# drop_path=depth_drop_path,
|
| 1446 |
+
# )
|
| 1447 |
+
# modality_trunks[ModalityType.THERMAL] = instantiate_trunk(
|
| 1448 |
+
# thermal_embed_dim,
|
| 1449 |
+
# thermal_num_blocks,
|
| 1450 |
+
# thermal_num_heads,
|
| 1451 |
+
# pre_transformer_ln=False,
|
| 1452 |
+
# add_bias_kv=True,
|
| 1453 |
+
# drop_path=thermal_drop_path,
|
| 1454 |
+
# )
|
| 1455 |
+
# modality_trunks[ModalityType.IMU] = instantiate_trunk(
|
| 1456 |
+
# imu_embed_dim,
|
| 1457 |
+
# imu_num_blocks,
|
| 1458 |
+
# imu_num_heads,
|
| 1459 |
+
# pre_transformer_ln=False,
|
| 1460 |
+
# add_bias_kv=True,
|
| 1461 |
+
# drop_path=imu_drop_path,
|
| 1462 |
+
# )
|
| 1463 |
+
|
| 1464 |
+
return nn.ModuleDict(modality_trunks)
|
| 1465 |
+
|
| 1466 |
+
def _create_modality_heads(
|
| 1467 |
+
self,
|
| 1468 |
+
out_embed_dim,
|
| 1469 |
+
vision_embed_dim,
|
| 1470 |
+
text_embed_dim,
|
| 1471 |
+
audio_embed_dim,
|
| 1472 |
+
depth_embed_dim,
|
| 1473 |
+
thermal_embed_dim,
|
| 1474 |
+
imu_embed_dim,
|
| 1475 |
+
):
|
| 1476 |
+
modality_heads = {}
|
| 1477 |
+
|
| 1478 |
+
modality_heads[ModalityType.VISION] = nn.Sequential(
|
| 1479 |
+
nn.LayerNorm(normalized_shape=vision_embed_dim, eps=1e-6),
|
| 1480 |
+
SelectElement(index=0),
|
| 1481 |
+
nn.Linear(vision_embed_dim, out_embed_dim, bias=False),
|
| 1482 |
+
)
|
| 1483 |
+
|
| 1484 |
+
modality_heads[ModalityType.TEXT] = SelectEOSAndProject(
|
| 1485 |
+
proj=nn.Sequential(
|
| 1486 |
+
nn.LayerNorm(normalized_shape=text_embed_dim, eps=1e-6),
|
| 1487 |
+
nn.Linear(text_embed_dim, out_embed_dim, bias=False),
|
| 1488 |
+
)
|
| 1489 |
+
)
|
| 1490 |
+
|
| 1491 |
+
modality_heads[ModalityType.AUDIO] = nn.Sequential(
|
| 1492 |
+
nn.LayerNorm(normalized_shape=audio_embed_dim, eps=1e-6),
|
| 1493 |
+
SelectElement(index=0),
|
| 1494 |
+
nn.Linear(audio_embed_dim, out_embed_dim, bias=False),
|
| 1495 |
+
)
|
| 1496 |
+
|
| 1497 |
+
# modality_heads[ModalityType.DEPTH] = nn.Sequential(
|
| 1498 |
+
# nn.LayerNorm(normalized_shape=depth_embed_dim, eps=1e-6),
|
| 1499 |
+
# SelectElement(index=0),
|
| 1500 |
+
# nn.Linear(depth_embed_dim, out_embed_dim, bias=False),
|
| 1501 |
+
# )
|
| 1502 |
+
#
|
| 1503 |
+
# modality_heads[ModalityType.THERMAL] = nn.Sequential(
|
| 1504 |
+
# nn.LayerNorm(normalized_shape=thermal_embed_dim, eps=1e-6),
|
| 1505 |
+
# SelectElement(index=0),
|
| 1506 |
+
# nn.Linear(thermal_embed_dim, out_embed_dim, bias=False),
|
| 1507 |
+
# )
|
| 1508 |
+
#
|
| 1509 |
+
# modality_heads[ModalityType.IMU] = nn.Sequential(
|
| 1510 |
+
# nn.LayerNorm(normalized_shape=imu_embed_dim, eps=1e-6),
|
| 1511 |
+
# SelectElement(index=0),
|
| 1512 |
+
# nn.Dropout(p=0.5),
|
| 1513 |
+
# nn.Linear(imu_embed_dim, out_embed_dim, bias=False),
|
| 1514 |
+
# )
|
| 1515 |
+
|
| 1516 |
+
return nn.ModuleDict(modality_heads)
|
| 1517 |
+
|
| 1518 |
+
def _create_modality_postprocessors(self, out_embed_dim):
|
| 1519 |
+
modality_postprocessors = {}
|
| 1520 |
+
|
| 1521 |
+
modality_postprocessors[ModalityType.VISION] = Normalize(dim=-1)
|
| 1522 |
+
modality_postprocessors[ModalityType.TEXT] = nn.Sequential(
|
| 1523 |
+
Normalize(dim=-1), LearnableLogitScaling(learnable=True)
|
| 1524 |
+
)
|
| 1525 |
+
modality_postprocessors[ModalityType.AUDIO] = nn.Sequential(
|
| 1526 |
+
Normalize(dim=-1),
|
| 1527 |
+
LearnableLogitScaling(logit_scale_init=20.0, learnable=False),
|
| 1528 |
+
)
|
| 1529 |
+
# modality_postprocessors[ModalityType.DEPTH] = nn.Sequential(
|
| 1530 |
+
# Normalize(dim=-1),
|
| 1531 |
+
# LearnableLogitScaling(logit_scale_init=5.0, learnable=False),
|
| 1532 |
+
# )
|
| 1533 |
+
# modality_postprocessors[ModalityType.THERMAL] = nn.Sequential(
|
| 1534 |
+
# Normalize(dim=-1),
|
| 1535 |
+
# LearnableLogitScaling(logit_scale_init=10.0, learnable=False),
|
| 1536 |
+
# )
|
| 1537 |
+
# modality_postprocessors[ModalityType.IMU] = nn.Sequential(
|
| 1538 |
+
# Normalize(dim=-1),
|
| 1539 |
+
# LearnableLogitScaling(logit_scale_init=5.0, learnable=False),
|
| 1540 |
+
# )
|
| 1541 |
+
|
| 1542 |
+
return nn.ModuleDict(modality_postprocessors)
|
| 1543 |
+
|
| 1544 |
+
def forward(self, inputs):
|
| 1545 |
+
outputs = {}
|
| 1546 |
+
for modality_key, modality_value in inputs.items():
|
| 1547 |
+
reduce_list = (
|
| 1548 |
+
modality_value.ndim >= 5
|
| 1549 |
+
) # Audio and Video inputs consist of multiple clips
|
| 1550 |
+
if reduce_list:
|
| 1551 |
+
B, S = modality_value.shape[:2]
|
| 1552 |
+
modality_value = modality_value.reshape(
|
| 1553 |
+
B * S, *modality_value.shape[2:]
|
| 1554 |
+
)
|
| 1555 |
+
|
| 1556 |
+
if modality_value is not None:
|
| 1557 |
+
modality_value = self.modality_preprocessors[modality_key](
|
| 1558 |
+
**{modality_key: modality_value}
|
| 1559 |
+
)
|
| 1560 |
+
trunk_inputs = modality_value["trunk"]
|
| 1561 |
+
head_inputs = modality_value["head"]
|
| 1562 |
+
modality_value = self.modality_trunks[modality_key](**trunk_inputs)
|
| 1563 |
+
modality_value = self.modality_heads[modality_key](
|
| 1564 |
+
modality_value, **head_inputs
|
| 1565 |
+
)
|
| 1566 |
+
modality_value = self.modality_postprocessors[modality_key](
|
| 1567 |
+
modality_value
|
| 1568 |
+
)
|
| 1569 |
+
|
| 1570 |
+
if reduce_list:
|
| 1571 |
+
modality_value = modality_value.reshape(B, S, -1)
|
| 1572 |
+
modality_value = modality_value.mean(dim=1)
|
| 1573 |
+
|
| 1574 |
+
outputs[modality_key] = modality_value
|
| 1575 |
+
|
| 1576 |
+
return outputs
|
| 1577 |
+
|
| 1578 |
+
def reconfigure_head(self, k, v):
|
| 1579 |
+
if k == ModalityType.AUDIO:
|
| 1580 |
+
return torch.nn.Sequential(v[0], v[2])
|
| 1581 |
+
elif k == ModalityType.VISION:
|
| 1582 |
+
return torch.nn.Sequential(v[0], v[2])
|
| 1583 |
+
else:
|
| 1584 |
+
return v
|
| 1585 |
+
|
| 1586 |
+
def forward_features(self, inputs):
|
| 1587 |
+
outputs = {}
|
| 1588 |
+
|
| 1589 |
+
reconfigured_heads = {k: self.reconfigure_head(k, v) for k, v in self.modality_heads.items()}
|
| 1590 |
+
|
| 1591 |
+
for modality_key, modality_value in inputs.items():
|
| 1592 |
+
reduce_list = (
|
| 1593 |
+
modality_value.ndim >= 5
|
| 1594 |
+
) # Audio and Video inputs consist of multiple clips
|
| 1595 |
+
if reduce_list:
|
| 1596 |
+
B, S = modality_value.shape[:2]
|
| 1597 |
+
modality_value = modality_value.reshape(
|
| 1598 |
+
B * S, *modality_value.shape[2:]
|
| 1599 |
+
)
|
| 1600 |
+
|
| 1601 |
+
if modality_value is not None:
|
| 1602 |
+
modality_value = self.modality_preprocessors[modality_key](
|
| 1603 |
+
**{modality_key: modality_value}
|
| 1604 |
+
)
|
| 1605 |
+
trunk_inputs = modality_value["trunk"]
|
| 1606 |
+
head_inputs = modality_value["head"]
|
| 1607 |
+
modality_value = self.modality_trunks[modality_key](**trunk_inputs)
|
| 1608 |
+
modality_value = reconfigured_heads[modality_key](
|
| 1609 |
+
modality_value, **head_inputs
|
| 1610 |
+
)
|
| 1611 |
+
modality_value = self.modality_postprocessors[modality_key](
|
| 1612 |
+
modality_value
|
| 1613 |
+
)
|
| 1614 |
+
if modality_key == ModalityType.AUDIO:
|
| 1615 |
+
modality_value = ReshapeAudio((12, 19))(modality_value)
|
| 1616 |
+
elif modality_key == ModalityType.VISION:
|
| 1617 |
+
modality_value = ReshapeSpatial((16, 16))(modality_value)
|
| 1618 |
+
|
| 1619 |
+
outputs[modality_key] = modality_value
|
| 1620 |
+
|
| 1621 |
+
return outputs
|
| 1622 |
+
|
| 1623 |
+
|
| 1624 |
+
def imagebind_huge(output_path, pretrained=False):
|
| 1625 |
+
model = ImageBindModel(
|
| 1626 |
+
vision_embed_dim=1280,
|
| 1627 |
+
vision_num_blocks=32,
|
| 1628 |
+
vision_num_heads=16,
|
| 1629 |
+
text_embed_dim=1024,
|
| 1630 |
+
text_num_blocks=24,
|
| 1631 |
+
text_num_heads=16,
|
| 1632 |
+
out_embed_dim=1024,
|
| 1633 |
+
audio_drop_path=0.1,
|
| 1634 |
+
imu_drop_path=0.7,
|
| 1635 |
+
)
|
| 1636 |
+
|
| 1637 |
+
if pretrained:
|
| 1638 |
+
path = os.path.join(output_path, 'models/imagebind_huge.pth')
|
| 1639 |
+
|
| 1640 |
+
if not os.path.exists(path):
|
| 1641 |
+
print(f"Downloading imagebind weights to {path} ...")
|
| 1642 |
+
os.makedirs(os.path.dirname(path), exist_ok=True)
|
| 1643 |
+
torch.hub.download_url_to_file(
|
| 1644 |
+
"https://dl.fbaipublicfiles.com/imagebind/imagebind_huge.pth",
|
| 1645 |
+
path,
|
| 1646 |
+
progress=True,
|
| 1647 |
+
)
|
| 1648 |
+
|
| 1649 |
+
model.load_state_dict(torch.load(path), strict=False)
|
| 1650 |
+
|
| 1651 |
+
return model
|
| 1652 |
+
|
| 1653 |
+
|
| 1654 |
+
DEFAULT_AUDIO_FRAME_SHIFT_MS = 10 # in milliseconds
|
| 1655 |
+
|
| 1656 |
+
|
| 1657 |
+
def waveform2melspec(waveform, sample_rate, num_mel_bins, target_length):
|
| 1658 |
+
# Based on https://github.com/YuanGongND/ast/blob/d7d8b4b8e06cdaeb6c843cdb38794c1c7692234c/src/dataloader.py#L102
|
| 1659 |
+
waveform -= waveform.mean()
|
| 1660 |
+
fbank = torchaudio.compliance.kaldi.fbank(
|
| 1661 |
+
waveform,
|
| 1662 |
+
htk_compat=True,
|
| 1663 |
+
sample_frequency=sample_rate,
|
| 1664 |
+
use_energy=False,
|
| 1665 |
+
window_type="hanning",
|
| 1666 |
+
num_mel_bins=num_mel_bins,
|
| 1667 |
+
dither=0.0,
|
| 1668 |
+
frame_length=25,
|
| 1669 |
+
frame_shift=DEFAULT_AUDIO_FRAME_SHIFT_MS,
|
| 1670 |
+
)
|
| 1671 |
+
# Convert to [mel_bins, num_frames] shape
|
| 1672 |
+
fbank = fbank.transpose(0, 1)
|
| 1673 |
+
# Pad to target_length
|
| 1674 |
+
n_frames = fbank.size(1)
|
| 1675 |
+
p = target_length - n_frames
|
| 1676 |
+
# if p is too large (say >20%), flash a warning
|
| 1677 |
+
if abs(p) / n_frames > 0.2:
|
| 1678 |
+
logging.warning(
|
| 1679 |
+
"Large gap between audio n_frames(%d) and "
|
| 1680 |
+
"target_length (%d). Is the audio_target_length "
|
| 1681 |
+
"setting correct?",
|
| 1682 |
+
n_frames,
|
| 1683 |
+
target_length,
|
| 1684 |
+
)
|
| 1685 |
+
# cut and pad
|
| 1686 |
+
if p > 0:
|
| 1687 |
+
fbank = torch.nn.functional.pad(fbank, (0, p), mode="constant", value=0)
|
| 1688 |
+
elif p < 0:
|
| 1689 |
+
fbank = fbank[:, 0:target_length]
|
| 1690 |
+
# Convert to [1, mel_bins, num_frames] shape, essentially like a 1
|
| 1691 |
+
# channel image
|
| 1692 |
+
fbank = fbank.unsqueeze(0)
|
| 1693 |
+
return fbank
|
| 1694 |
+
|
| 1695 |
+
|
| 1696 |
+
def get_clip_timepoints(clip_sampler, duration):
|
| 1697 |
+
# Read out all clips in this video
|
| 1698 |
+
all_clips_timepoints = []
|
| 1699 |
+
is_last_clip = False
|
| 1700 |
+
end = 0.0
|
| 1701 |
+
while not is_last_clip:
|
| 1702 |
+
start, end, _, _, is_last_clip = clip_sampler(end, duration, annotation=None)
|
| 1703 |
+
all_clips_timepoints.append((start, end))
|
| 1704 |
+
return all_clips_timepoints
|
| 1705 |
+
|
| 1706 |
+
|
| 1707 |
+
def load_and_transform_vision_data(image_paths, device):
|
| 1708 |
+
if image_paths is None:
|
| 1709 |
+
return None
|
| 1710 |
+
|
| 1711 |
+
image_ouputs = []
|
| 1712 |
+
for image_path in image_paths:
|
| 1713 |
+
data_transform = transforms.Compose(
|
| 1714 |
+
[
|
| 1715 |
+
transforms.Resize(
|
| 1716 |
+
224, interpolation=transforms.InterpolationMode.BICUBIC
|
| 1717 |
+
),
|
| 1718 |
+
transforms.CenterCrop(224),
|
| 1719 |
+
transforms.ToTensor(),
|
| 1720 |
+
transforms.Normalize(
|
| 1721 |
+
mean=(0.48145466, 0.4578275, 0.40821073),
|
| 1722 |
+
std=(0.26862954, 0.26130258, 0.27577711),
|
| 1723 |
+
),
|
| 1724 |
+
]
|
| 1725 |
+
)
|
| 1726 |
+
with open(image_path, "rb") as fopen:
|
| 1727 |
+
image = Image.open(fopen).convert("RGB")
|
| 1728 |
+
|
| 1729 |
+
image = data_transform(image).to(device)
|
| 1730 |
+
image_ouputs.append(image)
|
| 1731 |
+
return torch.stack(image_ouputs, dim=0)
|
| 1732 |
+
|
| 1733 |
+
|
| 1734 |
+
def load_and_transform_audio_data(
|
| 1735 |
+
audio_paths,
|
| 1736 |
+
device,
|
| 1737 |
+
num_mel_bins=128,
|
| 1738 |
+
target_length=204,
|
| 1739 |
+
sample_rate=16000,
|
| 1740 |
+
clip_duration=2,
|
| 1741 |
+
clips_per_video=3,
|
| 1742 |
+
mean=-4.268,
|
| 1743 |
+
std=9.138,
|
| 1744 |
+
):
|
| 1745 |
+
from pytorchvideo.data.clip_sampling import ConstantClipsPerVideoSampler
|
| 1746 |
+
|
| 1747 |
+
if audio_paths is None:
|
| 1748 |
+
return None
|
| 1749 |
+
|
| 1750 |
+
audio_outputs = []
|
| 1751 |
+
clip_sampler = ConstantClipsPerVideoSampler(
|
| 1752 |
+
clip_duration=clip_duration, clips_per_video=clips_per_video
|
| 1753 |
+
)
|
| 1754 |
+
|
| 1755 |
+
for audio_path in audio_paths:
|
| 1756 |
+
waveform, sr = torchaudio.load(audio_path)
|
| 1757 |
+
if sample_rate != sr:
|
| 1758 |
+
waveform = torchaudio.functional.resample(
|
| 1759 |
+
waveform, orig_freq=sr, new_freq=sample_rate
|
| 1760 |
+
)
|
| 1761 |
+
all_clips_timepoints = get_clip_timepoints(
|
| 1762 |
+
clip_sampler, waveform.size(1) / sample_rate
|
| 1763 |
+
)
|
| 1764 |
+
all_clips = []
|
| 1765 |
+
for clip_timepoints in all_clips_timepoints:
|
| 1766 |
+
waveform_clip = waveform[
|
| 1767 |
+
:,
|
| 1768 |
+
int(clip_timepoints[0] * sample_rate): int(
|
| 1769 |
+
clip_timepoints[1] * sample_rate
|
| 1770 |
+
),
|
| 1771 |
+
]
|
| 1772 |
+
waveform_melspec = waveform2melspec(
|
| 1773 |
+
waveform_clip, sample_rate, num_mel_bins, target_length
|
| 1774 |
+
)
|
| 1775 |
+
all_clips.append(waveform_melspec)
|
| 1776 |
+
|
| 1777 |
+
normalize = transforms.Normalize(mean=mean, std=std)
|
| 1778 |
+
all_clips = [normalize(ac).to(device) for ac in all_clips]
|
| 1779 |
+
|
| 1780 |
+
all_clips = torch.stack(all_clips, dim=0)
|
| 1781 |
+
audio_outputs.append(all_clips)
|
| 1782 |
+
|
| 1783 |
+
return torch.stack(audio_outputs, dim=0)
|
| 1784 |
+
|
| 1785 |
+
|
| 1786 |
+
class UnNormalize(object):
|
| 1787 |
+
def __init__(self, mean, std):
|
| 1788 |
+
self.mean = mean
|
| 1789 |
+
self.std = std
|
| 1790 |
+
|
| 1791 |
+
def __call__(self, image):
|
| 1792 |
+
image2 = torch.clone(image)
|
| 1793 |
+
for t, m, s in zip(image2, self.mean, self.std):
|
| 1794 |
+
t.mul_(s).add_(m)
|
| 1795 |
+
return image2
|
| 1796 |
+
|
| 1797 |
+
|
| 1798 |
+
norm = T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
|
| 1799 |
+
unnorm = UnNormalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
|
| 1800 |
+
|
| 1801 |
+
|
| 1802 |
+
class TorchPCA(object):
|
| 1803 |
+
|
| 1804 |
+
def __init__(self, n_components):
|
| 1805 |
+
self.n_components = n_components
|
| 1806 |
+
|
| 1807 |
+
def fit(self, X):
|
| 1808 |
+
self.mean_ = X.mean(dim=0)
|
| 1809 |
+
unbiased = X - self.mean_.unsqueeze(0)
|
| 1810 |
+
U, S, V = torch.pca_lowrank(unbiased, q=self.n_components, center=False, niter=4)
|
| 1811 |
+
self.components_ = V.T
|
| 1812 |
+
self.singular_values_ = S
|
| 1813 |
+
return self
|
| 1814 |
+
|
| 1815 |
+
def transform(self, X):
|
| 1816 |
+
t0 = X - self.mean_.unsqueeze(0)
|
| 1817 |
+
projected = t0 @ self.components_.T
|
| 1818 |
+
return projected
|
| 1819 |
+
|
| 1820 |
+
|
| 1821 |
+
def pca(image_feats_list, dim=3, fit_pca=None):
|
| 1822 |
+
# from sklearn.decomposition import PCA
|
| 1823 |
+
|
| 1824 |
+
device = image_feats_list[0].device
|
| 1825 |
+
|
| 1826 |
+
def flatten(tensor, target_size=None):
|
| 1827 |
+
if target_size is not None and fit_pca is None:
|
| 1828 |
+
F.interpolate(tensor, (target_size, target_size), mode="bilinear")
|
| 1829 |
+
B, C, H, W = tensor.shape
|
| 1830 |
+
return feats.permute(1, 0, 2, 3).reshape(C, B * H * W).permute(1, 0).detach().cpu()
|
| 1831 |
+
|
| 1832 |
+
if len(image_feats_list) > 1 and fit_pca is None:
|
| 1833 |
+
target_size = image_feats_list[0].shape[2]
|
| 1834 |
+
else:
|
| 1835 |
+
target_size = None
|
| 1836 |
+
|
| 1837 |
+
flattened_feats = []
|
| 1838 |
+
for feats in image_feats_list:
|
| 1839 |
+
flattened_feats.append(flatten(feats, target_size))
|
| 1840 |
+
x = torch.cat(flattened_feats, dim=0)
|
| 1841 |
+
|
| 1842 |
+
if fit_pca is None:
|
| 1843 |
+
# fit_pca = PCA(n_components=dim, svd_solver='arpack').fit(np.nan_to_num(x.detach().numpy()))
|
| 1844 |
+
fit_pca = TorchPCA(n_components=dim).fit(x)
|
| 1845 |
+
|
| 1846 |
+
reduced_feats = []
|
| 1847 |
+
for feats in image_feats_list:
|
| 1848 |
+
# x_red = torch.from_numpy(fit_pca.transform(flatten(feats)))
|
| 1849 |
+
x_red = fit_pca.transform(flatten(feats))
|
| 1850 |
+
x_red -= x_red.min(dim=0, keepdim=True).values
|
| 1851 |
+
x_red /= x_red.max(dim=0, keepdim=True).values
|
| 1852 |
+
B, C, H, W = feats.shape
|
| 1853 |
+
reduced_feats.append(x_red.reshape(B, H, W, dim).permute(0, 3, 1, 2).to(device))
|
| 1854 |
+
|
| 1855 |
+
return reduced_feats, fit_pca
|
| 1856 |
+
|
| 1857 |
+
|
| 1858 |
+
def my_load_audio(audio_file):
|
| 1859 |
+
loaded_waveform, obs_sr = torchaudio.load(audio_file)
|
| 1860 |
+
loaded_waveform = loaded_waveform[0]
|
| 1861 |
+
|
| 1862 |
+
neg_waveform, neg_obs_sr = None, None
|
| 1863 |
+
from data.AVDatasets import prep_waveform
|
| 1864 |
+
|
| 1865 |
+
(waveform,
|
| 1866 |
+
spectrogram,
|
| 1867 |
+
audio_length,
|
| 1868 |
+
total_length,
|
| 1869 |
+
original_length,
|
| 1870 |
+
mask,
|
| 1871 |
+
pos_mask) = prep_waveform(
|
| 1872 |
+
loaded_waveform,
|
| 1873 |
+
obs_sr,
|
| 1874 |
+
10,
|
| 1875 |
+
128,
|
| 1876 |
+
-4.268,
|
| 1877 |
+
9.138,
|
| 1878 |
+
16000,
|
| 1879 |
+
True,
|
| 1880 |
+
False,
|
| 1881 |
+
False,
|
| 1882 |
+
neg_waveform,
|
| 1883 |
+
neg_obs_sr,
|
| 1884 |
+
False,
|
| 1885 |
+
)
|
| 1886 |
+
|
| 1887 |
+
patch_size = 204
|
| 1888 |
+
n_tiles = spectrogram.shape[1] // patch_size
|
| 1889 |
+
assert n_tiles == 5
|
| 1890 |
+
|
| 1891 |
+
patches = []
|
| 1892 |
+
for i in range(n_tiles):
|
| 1893 |
+
patches.append(spectrogram[:, i * patch_size:(i + 1) * patch_size, :])
|
| 1894 |
+
|
| 1895 |
+
patches = torch.cat(patches, dim=0).permute(0, 2, 1).unsqueeze(1)
|
| 1896 |
+
return patches
|
| 1897 |
+
|
| 1898 |
+
|
| 1899 |
+
class ImageBindImageFeaturizer(nn.Module):
|
| 1900 |
+
|
| 1901 |
+
def __init__(self, output_path, model=None):
|
| 1902 |
+
super().__init__()
|
| 1903 |
+
if model is not None:
|
| 1904 |
+
self.model = model
|
| 1905 |
+
else:
|
| 1906 |
+
self.model = imagebind_huge(output_path, pretrained=True).cuda()
|
| 1907 |
+
|
| 1908 |
+
def forward(self, image, include_cls):
|
| 1909 |
+
inputs = {
|
| 1910 |
+
ModalityType.VISION: image,
|
| 1911 |
+
}
|
| 1912 |
+
|
| 1913 |
+
patch_tokens, cls_tokens = self.model.forward_features(inputs)[ModalityType.VISION]
|
| 1914 |
+
patch_tokens = patch_tokens.permute(0, 3, 1, 2)
|
| 1915 |
+
|
| 1916 |
+
if include_cls:
|
| 1917 |
+
return patch_tokens, cls_tokens
|
| 1918 |
+
else:
|
| 1919 |
+
return patch_tokens
|
| 1920 |
+
|
| 1921 |
+
|
| 1922 |
+
class ImageBindAudioFeaturizer(nn.Module):
|
| 1923 |
+
|
| 1924 |
+
def __init__(self, output_path, model=None):
|
| 1925 |
+
super().__init__()
|
| 1926 |
+
if model is not None:
|
| 1927 |
+
self.model = model
|
| 1928 |
+
else:
|
| 1929 |
+
self.model = imagebind_huge(output_path, pretrained=True).cuda()
|
| 1930 |
+
|
| 1931 |
+
def forward(self, spec, include_cls):
|
| 1932 |
+
|
| 1933 |
+
patch_size = 204
|
| 1934 |
+
n_tiles = spec.shape[2] // patch_size
|
| 1935 |
+
assert n_tiles == 5
|
| 1936 |
+
|
| 1937 |
+
patches = []
|
| 1938 |
+
for i in range(n_tiles):
|
| 1939 |
+
patches.append(spec[:, :, i * patch_size:(i + 1) * patch_size, :])
|
| 1940 |
+
|
| 1941 |
+
patches = torch.cat(patches, dim=1).permute(0, 1, 3, 2).unsqueeze(2)
|
| 1942 |
+
|
| 1943 |
+
inputs = {
|
| 1944 |
+
ModalityType.AUDIO: patches,
|
| 1945 |
+
}
|
| 1946 |
+
|
| 1947 |
+
patch_tokens, cls_token = self.model.forward_features(inputs)[ModalityType.AUDIO]
|
| 1948 |
+
|
| 1949 |
+
patch_tokens = patch_tokens.permute(0, 4, 2, 1, 3)
|
| 1950 |
+
b, c, h, p, w = patch_tokens.shape
|
| 1951 |
+
patch_tokens = patch_tokens.reshape(b, c, h, w * p)
|
| 1952 |
+
|
| 1953 |
+
cls_token = cls_token.reshape(b, p, -1).mean(1)
|
| 1954 |
+
|
| 1955 |
+
if include_cls:
|
| 1956 |
+
return patch_tokens, cls_token
|
| 1957 |
+
else:
|
| 1958 |
+
return patch_tokens
|
| 1959 |
+
|
| 1960 |
+
|
| 1961 |
+
if __name__ == "__main__":
|
| 1962 |
+
image_paths = ["../../samples/dog_image.jpg", "../../samples/car_image.jpg", "../../samples/bird_image.jpg"]
|
| 1963 |
+
audio_paths = ["../../samples/dog_audio.wav", "../../samples/car_audio.wav", "../../samples/bird_audio.wav"]
|
| 1964 |
+
|
| 1965 |
+
device = "cuda:0" if torch.cuda.is_available() else "cpu"
|
| 1966 |
+
|
| 1967 |
+
# Instantiate model
|
| 1968 |
+
model = imagebind_huge("../../", pretrained=True)
|
| 1969 |
+
model.eval()
|
| 1970 |
+
model.to(device)
|
| 1971 |
+
|
| 1972 |
+
audio_inputs = torch.cat([my_load_audio(af).unsqueeze(0) for af in audio_paths], dim=0).cuda()
|
| 1973 |
+
# Load data
|
| 1974 |
+
inputs = {
|
| 1975 |
+
ModalityType.VISION: load_and_transform_vision_data(image_paths, device),
|
| 1976 |
+
# ModalityType.AUDIO: load_and_transform_audio_data(audio_paths, device, clip_duration=2, clips_per_video=5),
|
| 1977 |
+
ModalityType.AUDIO: audio_inputs,
|
| 1978 |
+
|
| 1979 |
+
}
|
| 1980 |
+
|
| 1981 |
+
with torch.no_grad():
|
| 1982 |
+
embeddings = model.forward_features(inputs)
|
| 1983 |
+
cls_tokens = model.forward(inputs)
|
| 1984 |
+
|
| 1985 |
+
audio_cls_token = embeddings["audio"][1].reshape(3, 5, -1).mean(1)
|
| 1986 |
+
|
| 1987 |
+
sims1 = torch.einsum(
|
| 1988 |
+
"bc,dc->bd",
|
| 1989 |
+
embeddings["vision"][1],
|
| 1990 |
+
audio_cls_token)
|
| 1991 |
+
|
| 1992 |
+
print(torch.softmax(sims1, dim=1).cpu().numpy())
|
| 1993 |
+
#
|
| 1994 |
+
# sims2 = torch.einsum(
|
| 1995 |
+
# "bc,dc->bd",
|
| 1996 |
+
# embeddings["vision"].mean(1).mean(1),
|
| 1997 |
+
# embeddings["audio"].mean(1).mean(1).mean(1)
|
| 1998 |
+
# )
|
| 1999 |
+
#
|
| 2000 |
+
# print(torch.softmax(sims2, dim=1).cpu().numpy())
|
| 2001 |
+
#
|
| 2002 |
+
#
|
| 2003 |
+
# img_num = 0
|
| 2004 |
+
# img_feats = F.normalize(embeddings["vision"].permute(0, 3, 1, 2), dim=1)
|
| 2005 |
+
# [red_img_feats], fit_pca = pca([img_feats])
|
| 2006 |
+
#
|
| 2007 |
+
# fig, axes = plt.subplots(2, 2, figsize=(4 * 2, 4 * 2))
|
| 2008 |
+
# axes[0][0].imshow(unnorm(inputs["vision"][0].unsqueeze(0))[0].permute(1, 2, 0).detach().cpu())
|
| 2009 |
+
# axes[0][1].imshow(unnorm(inputs["vision"][1].unsqueeze(0))[0].permute(1, 2, 0).detach().cpu())
|
| 2010 |
+
# axes[1][0].imshow(red_img_feats[0].permute(1, 2, 0).detach().cpu())
|
| 2011 |
+
# axes[1][1].imshow(red_img_feats[1].permute(1, 2, 0).detach().cpu())
|
| 2012 |
+
# plt.tight_layout()
|
| 2013 |
+
# plt.show()
|
| 2014 |
+
#
|
| 2015 |
+
audio_embs = F.normalize(embeddings["audio"][0], dim=-1)
|
| 2016 |
+
b, n, h, w, c = audio_embs.shape
|
| 2017 |
+
|
| 2018 |
+
audio_embs = audio_embs.permute(0, 4, 2, 1, 3).reshape(b, c, h, w * n)
|
| 2019 |
+
|
| 2020 |
+
b, n, c, h, w = inputs["audio"].shape
|
| 2021 |
+
audio_inputs = inputs["audio"].permute(0, 2, 3, 1, 4).reshape(b, c, h, w * n)
|
| 2022 |
+
|
| 2023 |
+
print("here")
|
| 2024 |
+
|
| 2025 |
+
for img_num in range(3):
|
| 2026 |
+
[red_audio], fit_pca = pca([audio_embs[img_num].unsqueeze(0)])
|
| 2027 |
+
fig, axes = plt.subplots(2, 1, figsize=(10 * 1, 4 * 2))
|
| 2028 |
+
axes[0].imshow(audio_inputs[img_num, 0].detach().cpu())
|
| 2029 |
+
axes[1].imshow(red_audio[0].permute(1, 2, 0).detach().cpu())
|
| 2030 |
+
plt.tight_layout()
|
| 2031 |
+
plt.show()
|
| 2032 |
+
|
| 2033 |
+
print("here")
|
DenseAV/denseav/featurizers/__init__.py
ADDED
|
File without changes
|
DenseAV/denseav/plotting.py
ADDED
|
@@ -0,0 +1,244 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from collections import defaultdict
|
| 3 |
+
|
| 4 |
+
import matplotlib.colors as mcolors
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
import numpy as np
|
| 7 |
+
import scipy.io.wavfile as wavfile
|
| 8 |
+
import torch
|
| 9 |
+
import torch.nn.functional as F
|
| 10 |
+
import torchvision
|
| 11 |
+
from moviepy.editor import VideoFileClip, AudioFileClip
|
| 12 |
+
from base64 import b64encode
|
| 13 |
+
from denseav.shared import pca
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def write_video_with_audio(video_frames, audio_array, video_fps, audio_fps, output_path):
|
| 17 |
+
"""
|
| 18 |
+
Writes video frames and audio to a specified path.
|
| 19 |
+
|
| 20 |
+
Parameters:
|
| 21 |
+
- video_frames: torch.Tensor of shape (num_frames, height, width, channels)
|
| 22 |
+
- audio_array: torch.Tensor of shape (num_samples, num_channels)
|
| 23 |
+
- video_fps: int, frames per second of the video
|
| 24 |
+
- audio_fps: int, sample rate of the audio
|
| 25 |
+
- output_path: str, path to save the final video with audio
|
| 26 |
+
"""
|
| 27 |
+
os.makedirs(os.path.dirname(output_path), exist_ok=True)
|
| 28 |
+
|
| 29 |
+
temp_video_path = output_path.replace('.mp4', '_temp.mp4')
|
| 30 |
+
temp_audio_path = output_path.replace('.mp4', '_temp_audio.wav')
|
| 31 |
+
video_options = {
|
| 32 |
+
'crf': '23',
|
| 33 |
+
'preset': 'slow',
|
| 34 |
+
'bit_rate': '1000k'}
|
| 35 |
+
|
| 36 |
+
if audio_array is not None:
|
| 37 |
+
torchvision.io.write_video(
|
| 38 |
+
filename=temp_video_path,
|
| 39 |
+
video_array=video_frames,
|
| 40 |
+
fps=video_fps,
|
| 41 |
+
options=video_options
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
wavfile.write(temp_audio_path, audio_fps, audio_array.cpu().to(torch.float64).permute(1, 0).numpy())
|
| 45 |
+
video_clip = VideoFileClip(temp_video_path)
|
| 46 |
+
audio_clip = AudioFileClip(temp_audio_path)
|
| 47 |
+
final_clip = video_clip.set_audio(audio_clip)
|
| 48 |
+
final_clip.write_videofile(output_path, codec='libx264', verbose=False)
|
| 49 |
+
os.remove(temp_video_path)
|
| 50 |
+
os.remove(temp_audio_path)
|
| 51 |
+
else:
|
| 52 |
+
torchvision.io.write_video(
|
| 53 |
+
filename=output_path,
|
| 54 |
+
video_array=video_frames,
|
| 55 |
+
fps=video_fps,
|
| 56 |
+
options=video_options
|
| 57 |
+
)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
def alpha_blend_layers(layers):
|
| 61 |
+
blended_image = layers[0]
|
| 62 |
+
for layer in layers[1:]:
|
| 63 |
+
rgb1, alpha1 = blended_image[:, :3, :, :], blended_image[:, 3:4, :, :]
|
| 64 |
+
rgb2, alpha2 = layer[:, :3, :, :], layer[:, 3:4, :, :]
|
| 65 |
+
alpha_out = alpha2 + alpha1 * (1 - alpha2)
|
| 66 |
+
rgb_out = (rgb2 * alpha2 + rgb1 * alpha1 * (1 - alpha2)) / alpha_out.clamp(min=1e-7)
|
| 67 |
+
blended_image = torch.cat([rgb_out, alpha_out], dim=1)
|
| 68 |
+
return (blended_image[:, :3] * 255).clamp(0, 255).to(torch.uint8).permute(0, 2, 3, 1)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
def _prep_sims_for_plotting(sim_by_head, frames):
|
| 72 |
+
with torch.no_grad():
|
| 73 |
+
results = defaultdict(list)
|
| 74 |
+
n_frames, _, vh, vw = frames.shape
|
| 75 |
+
|
| 76 |
+
sims = sim_by_head.max(dim=1).values
|
| 77 |
+
|
| 78 |
+
n_audio_feats = sims.shape[-1]
|
| 79 |
+
for frame_num in range(n_frames):
|
| 80 |
+
selected_audio_feat = int((frame_num / n_frames) * n_audio_feats)
|
| 81 |
+
|
| 82 |
+
selected_sim = F.interpolate(
|
| 83 |
+
sims[frame_num, :, :, selected_audio_feat].unsqueeze(0).unsqueeze(0),
|
| 84 |
+
size=(vh, vw),
|
| 85 |
+
mode="bicubic")
|
| 86 |
+
|
| 87 |
+
results["sims_all"].append(selected_sim)
|
| 88 |
+
|
| 89 |
+
for head in range(sim_by_head.shape[1]):
|
| 90 |
+
selected_sim = F.interpolate(
|
| 91 |
+
sim_by_head[frame_num, head, :, :, selected_audio_feat].unsqueeze(0).unsqueeze(0),
|
| 92 |
+
size=(vh, vw),
|
| 93 |
+
mode="bicubic")
|
| 94 |
+
results[f"sims_{head + 1}"].append(selected_sim)
|
| 95 |
+
|
| 96 |
+
results = {k: torch.cat(v, dim=0) for k, v in results.items()}
|
| 97 |
+
return results
|
| 98 |
+
|
| 99 |
+
|
| 100 |
+
def get_plasma_with_alpha():
|
| 101 |
+
plasma = plt.cm.plasma(np.linspace(0, 1, 256))
|
| 102 |
+
alphas = np.linspace(0, 1, 256)
|
| 103 |
+
plasma_with_alpha = np.zeros((256, 4))
|
| 104 |
+
plasma_with_alpha[:, 0:3] = plasma[:, 0:3]
|
| 105 |
+
plasma_with_alpha[:, 3] = alphas
|
| 106 |
+
return mcolors.ListedColormap(plasma_with_alpha)
|
| 107 |
+
|
| 108 |
+
|
| 109 |
+
def get_inferno_with_alpha_2(alpha=0.5, k=30):
|
| 110 |
+
k_fraction = k / 100.0
|
| 111 |
+
custom_cmap = np.zeros((256, 4))
|
| 112 |
+
threshold_index = int(k_fraction * 256)
|
| 113 |
+
custom_cmap[:threshold_index, :3] = 0 # RGB values for black
|
| 114 |
+
custom_cmap[:threshold_index, 3] = alpha # Alpha value
|
| 115 |
+
remaining_inferno = plt.cm.inferno(np.linspace(0, 1, 256 - threshold_index))
|
| 116 |
+
custom_cmap[threshold_index:, :3] = remaining_inferno[:, :3]
|
| 117 |
+
custom_cmap[threshold_index:, 3] = alpha # Alpha value
|
| 118 |
+
return mcolors.ListedColormap(custom_cmap)
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def get_inferno_with_alpha():
|
| 122 |
+
plasma = plt.cm.inferno(np.linspace(0, 1, 256))
|
| 123 |
+
alphas = np.linspace(0, 1, 256)
|
| 124 |
+
plasma_with_alpha = np.zeros((256, 4))
|
| 125 |
+
plasma_with_alpha[:, 0:3] = plasma[:, 0:3]
|
| 126 |
+
plasma_with_alpha[:, 3] = alphas
|
| 127 |
+
return mcolors.ListedColormap(plasma_with_alpha)
|
| 128 |
+
|
| 129 |
+
|
| 130 |
+
red_cmap = mcolors.LinearSegmentedColormap('RedMap', segmentdata={
|
| 131 |
+
'red': [(0.0, 1.0, 1.0), (1.0, 1.0, 1.0)],
|
| 132 |
+
'green': [(0.0, 0.0, 0.0), (1.0, 0.0, 0.0)],
|
| 133 |
+
'blue': [(0.0, 0.0, 0.0), (1.0, 0.0, 0.0)],
|
| 134 |
+
'alpha': [(0.0, 0.0, 0.0), (1.0, 1.0, 1.0)]
|
| 135 |
+
})
|
| 136 |
+
|
| 137 |
+
blue_cmap = mcolors.LinearSegmentedColormap('BlueMap', segmentdata={
|
| 138 |
+
'red': [(0.0, 0.0, 0.0), (1.0, 0.0, 0.0)],
|
| 139 |
+
'green': [(0.0, 0.0, 0.0), (1.0, 0.0, 0.0)],
|
| 140 |
+
'blue': [(0.0, 1.0, 1.0), (1.0, 1.0, 1.0)],
|
| 141 |
+
'alpha': [(0.0, 0.0, 0.0), (1.0, 1.0, 1.0)]
|
| 142 |
+
})
|
| 143 |
+
|
| 144 |
+
|
| 145 |
+
def plot_attention_video(sims_by_head, frames, audio, video_fps, audio_fps, output_filename):
|
| 146 |
+
prepped_sims = _prep_sims_for_plotting(sims_by_head, frames)
|
| 147 |
+
n_frames, _, vh, vw = frames.shape
|
| 148 |
+
sims_all = prepped_sims["sims_all"].clamp_min(0)
|
| 149 |
+
sims_all -= sims_all.min()
|
| 150 |
+
sims_all = sims_all / sims_all.max()
|
| 151 |
+
cmap = get_inferno_with_alpha()
|
| 152 |
+
layer1 = torch.cat([frames, torch.ones(n_frames, 1, vh, vw)], axis=1)
|
| 153 |
+
layer2 = torch.tensor(cmap(sims_all.squeeze().detach().cpu())).permute(0, 3, 1, 2)
|
| 154 |
+
write_video_with_audio(
|
| 155 |
+
alpha_blend_layers([layer1, layer2]),
|
| 156 |
+
audio,
|
| 157 |
+
video_fps,
|
| 158 |
+
audio_fps,
|
| 159 |
+
output_filename)
|
| 160 |
+
|
| 161 |
+
|
| 162 |
+
def plot_2head_attention_video(sims_by_head, frames, audio, video_fps, audio_fps, output_filename):
|
| 163 |
+
prepped_sims = _prep_sims_for_plotting(sims_by_head, frames)
|
| 164 |
+
sims_1 = prepped_sims["sims_1"]
|
| 165 |
+
sims_2 = prepped_sims["sims_2"]
|
| 166 |
+
|
| 167 |
+
n_frames, _, vh, vw = frames.shape
|
| 168 |
+
|
| 169 |
+
mask = sims_1 > sims_2
|
| 170 |
+
sims_1 *= mask
|
| 171 |
+
sims_2 *= (~mask)
|
| 172 |
+
|
| 173 |
+
sims_1 = sims_1.clamp_min(0)
|
| 174 |
+
sims_1 -= sims_1.min()
|
| 175 |
+
sims_1 = sims_1 / sims_1.max()
|
| 176 |
+
|
| 177 |
+
sims_2 = sims_2.clamp_min(0)
|
| 178 |
+
sims_2 -= sims_2.min()
|
| 179 |
+
sims_2 = sims_2 / sims_2.max()
|
| 180 |
+
|
| 181 |
+
layer1 = torch.cat([frames, torch.ones(n_frames, 1, vh, vw)], axis=1)
|
| 182 |
+
layer2_head1 = torch.tensor(red_cmap(sims_1.squeeze().detach().cpu())).permute(0, 3, 1, 2)
|
| 183 |
+
layer2_head2 = torch.tensor(blue_cmap(sims_2.squeeze().detach().cpu())).permute(0, 3, 1, 2)
|
| 184 |
+
|
| 185 |
+
write_video_with_audio(
|
| 186 |
+
alpha_blend_layers([layer1, layer2_head1, layer2_head2]),
|
| 187 |
+
audio,
|
| 188 |
+
video_fps,
|
| 189 |
+
audio_fps,
|
| 190 |
+
output_filename)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def plot_feature_video(image_feats,
|
| 194 |
+
audio_feats,
|
| 195 |
+
frames,
|
| 196 |
+
audio,
|
| 197 |
+
video_fps,
|
| 198 |
+
audio_fps,
|
| 199 |
+
video_filename,
|
| 200 |
+
audio_filename):
|
| 201 |
+
with torch.no_grad():
|
| 202 |
+
image_feats_ = image_feats.cpu()
|
| 203 |
+
audio_feats_ = audio_feats.cpu()
|
| 204 |
+
[red_img_feats, red_audio_feats], _ = pca([
|
| 205 |
+
image_feats_,
|
| 206 |
+
audio_feats_, # .tile(image_feats_.shape[0], 1, 1, 1)
|
| 207 |
+
])
|
| 208 |
+
_, _, vh, vw = frames.shape
|
| 209 |
+
red_img_feats = F.interpolate(red_img_feats, size=(vh, vw), mode="bicubic")
|
| 210 |
+
red_audio_feats = red_audio_feats[0].unsqueeze(0)
|
| 211 |
+
red_audio_feats = F.interpolate(red_audio_feats, size=(50, red_img_feats.shape[0]), mode="bicubic")
|
| 212 |
+
|
| 213 |
+
write_video_with_audio(
|
| 214 |
+
(red_img_feats.permute(0, 2, 3, 1) * 255).clamp(0, 255).to(torch.uint8),
|
| 215 |
+
audio,
|
| 216 |
+
video_fps,
|
| 217 |
+
audio_fps,
|
| 218 |
+
video_filename)
|
| 219 |
+
|
| 220 |
+
red_audio_feats_expanded = red_audio_feats.tile(red_img_feats.shape[0], 1, 1, 1)
|
| 221 |
+
red_audio_feats_expanded = F.interpolate(red_audio_feats_expanded, scale_factor=6, mode="bicubic")
|
| 222 |
+
for i in range(red_img_feats.shape[0]):
|
| 223 |
+
center_index = i * 6
|
| 224 |
+
min_index = max(center_index - 2, 0)
|
| 225 |
+
max_index = min(center_index + 2, red_audio_feats_expanded.shape[-1])
|
| 226 |
+
red_audio_feats_expanded[i, :, :, min_index:max_index] = 1
|
| 227 |
+
|
| 228 |
+
write_video_with_audio(
|
| 229 |
+
(red_audio_feats_expanded.permute(0, 2, 3, 1) * 255).clamp(0, 255).to(torch.uint8),
|
| 230 |
+
audio,
|
| 231 |
+
video_fps,
|
| 232 |
+
audio_fps,
|
| 233 |
+
audio_filename)
|
| 234 |
+
|
| 235 |
+
|
| 236 |
+
def display_video_in_notebook(path):
|
| 237 |
+
from IPython.display import HTML, display
|
| 238 |
+
mp4 = open(path, 'rb').read()
|
| 239 |
+
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
|
| 240 |
+
display(HTML("""
|
| 241 |
+
<video width=400 controls>
|
| 242 |
+
<source src="%s" type="video/mp4">
|
| 243 |
+
</video>
|
| 244 |
+
""" % data_url))
|
DenseAV/denseav/saved_models.py
ADDED
|
@@ -0,0 +1,262 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import re
|
| 3 |
+
from os.path import join
|
| 4 |
+
|
| 5 |
+
import torch
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def get_latest(name, checkpoint_dir, extra_args=None):
|
| 10 |
+
if extra_args is None:
|
| 11 |
+
extra_args = dict()
|
| 12 |
+
files = os.listdir(join(checkpoint_dir, name))
|
| 13 |
+
steps = torch.tensor([int(f.split("step=")[-1].split(".")[0]) for f in files])
|
| 14 |
+
selected = files[steps.argmax()]
|
| 15 |
+
return dict(
|
| 16 |
+
chkpt_name=os.path.join(name, selected),
|
| 17 |
+
extra_args=extra_args)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
DS_PARAM_REGEX = r'_forward_module\.(.+)'
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
def convert_deepspeed_checkpoint(deepspeed_ckpt_path: str, pl_ckpt_path: str = None):
|
| 24 |
+
'''
|
| 25 |
+
Creates a PyTorch Lightning checkpoint from the DeepSpeed checkpoint directory, while patching
|
| 26 |
+
in parameters which are improperly loaded by the DeepSpeed conversion utility.
|
| 27 |
+
deepspeed_ckpt_path: Path to the DeepSpeed checkpoint folder.
|
| 28 |
+
pl_ckpt_path: Path to the reconstructed PyTorch Lightning checkpoint. If not specified, will be
|
| 29 |
+
placed in the same directory as the DeepSpeed checkpoint directory with the same name but
|
| 30 |
+
a .pt extension.
|
| 31 |
+
Returns: path to the converted checkpoint.
|
| 32 |
+
'''
|
| 33 |
+
from pytorch_lightning.utilities.deepspeed import convert_zero_checkpoint_to_fp32_state_dict
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
if not (deepspeed_ckpt_path.endswith('.ckpt') and os.path.isdir(deepspeed_ckpt_path)):
|
| 37 |
+
raise ValueError(
|
| 38 |
+
'args.ckpt_dir should point to the checkpoint directory'
|
| 39 |
+
' output by DeepSpeed (e.g. "last.ckpt" or "epoch=4-step=39150.ckpt").'
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
# Convert state dict to PyTorch format
|
| 43 |
+
if not pl_ckpt_path:
|
| 44 |
+
pl_ckpt_path = f'{deepspeed_ckpt_path[:-4]}pt' # .ckpt --> .pt
|
| 45 |
+
|
| 46 |
+
if not os.path.exists(pl_ckpt_path):
|
| 47 |
+
convert_zero_checkpoint_to_fp32_state_dict(deepspeed_ckpt_path, pl_ckpt_path)
|
| 48 |
+
|
| 49 |
+
# Patch in missing parameters that failed to be converted by DeepSpeed utility
|
| 50 |
+
pl_ckpt = _merge_deepspeed_weights(deepspeed_ckpt_path, pl_ckpt_path)
|
| 51 |
+
torch.save(pl_ckpt, pl_ckpt_path)
|
| 52 |
+
|
| 53 |
+
return pl_ckpt_path
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def get_optim_files(checkpoint_dir):
|
| 57 |
+
files = sorted([f for f in os.listdir(checkpoint_dir) if "optim" in f])
|
| 58 |
+
return [join(checkpoint_dir, f) for f in files]
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def get_model_state_file(checkpoint_dir, zero_stage):
|
| 62 |
+
f = [f for f in os.listdir(checkpoint_dir) if "model_states" in f][0]
|
| 63 |
+
return join(checkpoint_dir, f)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def _merge_deepspeed_weights(deepspeed_ckpt_path: str, fp32_ckpt_path: str):
|
| 67 |
+
'''
|
| 68 |
+
Merges tensors with keys in the DeepSpeed checkpoint but not in the fp32_checkpoint
|
| 69 |
+
into the fp32 state dict.
|
| 70 |
+
deepspeed_ckpt_path: Path to the DeepSpeed checkpoint folder.
|
| 71 |
+
fp32_ckpt_path: Path to the reconstructed
|
| 72 |
+
'''
|
| 73 |
+
from pytorch_lightning.utilities.deepspeed import ds_checkpoint_dir
|
| 74 |
+
|
| 75 |
+
|
| 76 |
+
# This first part is based on pytorch_lightning.utilities.deepspeed.convert_zero_checkpoint_to_fp32_state_dict
|
| 77 |
+
checkpoint_dir = ds_checkpoint_dir(deepspeed_ckpt_path)
|
| 78 |
+
optim_files = get_optim_files(checkpoint_dir)
|
| 79 |
+
optim_state = torch.load(optim_files[0], map_location='cpu')
|
| 80 |
+
zero_stage = optim_state["optimizer_state_dict"]["zero_stage"]
|
| 81 |
+
deepspeed_model_file = get_model_state_file(checkpoint_dir, zero_stage)
|
| 82 |
+
|
| 83 |
+
# Start adding all parameters from DeepSpeed ckpt to generated PyTorch Lightning ckpt
|
| 84 |
+
ds_ckpt = torch.load(deepspeed_model_file, map_location='cpu')
|
| 85 |
+
ds_sd = ds_ckpt['module']
|
| 86 |
+
|
| 87 |
+
fp32_ckpt = torch.load(fp32_ckpt_path, map_location='cpu')
|
| 88 |
+
fp32_sd = fp32_ckpt['state_dict']
|
| 89 |
+
|
| 90 |
+
for k, v in ds_sd.items():
|
| 91 |
+
try:
|
| 92 |
+
match = re.match(DS_PARAM_REGEX, k)
|
| 93 |
+
param_name = match.group(1)
|
| 94 |
+
except:
|
| 95 |
+
print(f'Failed to extract parameter from DeepSpeed key {k}')
|
| 96 |
+
continue
|
| 97 |
+
|
| 98 |
+
v = v.to(torch.float32)
|
| 99 |
+
if param_name not in fp32_sd:
|
| 100 |
+
print(f'Adding parameter {param_name} from DeepSpeed state_dict to fp32_sd')
|
| 101 |
+
fp32_sd[param_name] = v
|
| 102 |
+
else:
|
| 103 |
+
assert torch.allclose(v, fp32_sd[param_name].to(torch.float32), atol=1e-2)
|
| 104 |
+
|
| 105 |
+
return fp32_ckpt
|
| 106 |
+
|
| 107 |
+
|
| 108 |
+
def get_version_and_step(f, i):
|
| 109 |
+
step = f.split("step=")[-1].split(".")[0]
|
| 110 |
+
if "-v" in step:
|
| 111 |
+
[step, version] = step.split("-v")
|
| 112 |
+
else:
|
| 113 |
+
step, version = step, 0
|
| 114 |
+
|
| 115 |
+
return int(version), int(step), i
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
def get_latest_ds(name, extra_args=None):
|
| 119 |
+
if extra_args is None:
|
| 120 |
+
extra_args = dict()
|
| 121 |
+
files = os.listdir(f"../checkpoints/{name}")
|
| 122 |
+
latest = sorted([get_version_and_step(f, i) for i, f in enumerate(files)], reverse=True)[0]
|
| 123 |
+
selected = files[latest[-1]]
|
| 124 |
+
# print(f"Selecting file: {selected}")
|
| 125 |
+
ds_chkpt = join(name, selected)
|
| 126 |
+
reg_chkpt = join(name + "_fp32", selected)
|
| 127 |
+
reg_chkpt_path = join("../checkpoints", reg_chkpt)
|
| 128 |
+
if not os.path.exists(reg_chkpt_path):
|
| 129 |
+
os.makedirs(os.path.dirname(reg_chkpt_path), exist_ok=True)
|
| 130 |
+
print(f"Checkpoint {reg_chkpt} does not exist, converting from deepspeed")
|
| 131 |
+
convert_deepspeed_checkpoint(join("../checkpoints", ds_chkpt), reg_chkpt_path)
|
| 132 |
+
return dict(
|
| 133 |
+
chkpt_name=reg_chkpt,
|
| 134 |
+
extra_args=extra_args)
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
def get_all_models_in_dir(name, checkpoint_dir, extra_args=None):
|
| 138 |
+
ret = {}
|
| 139 |
+
for model_dir in os.listdir(join(checkpoint_dir, name)):
|
| 140 |
+
full_name = f"{name}/{model_dir}/train"
|
| 141 |
+
# print(f'"{full_name}",')
|
| 142 |
+
ret[full_name] = get_latest(full_name, checkpoint_dir, extra_args)
|
| 143 |
+
return ret
|
| 144 |
+
|
| 145 |
+
|
| 146 |
+
def saved_model_dict(checkpoint_dir):
|
| 147 |
+
model_info = {
|
| 148 |
+
|
| 149 |
+
**get_all_models_in_dir(
|
| 150 |
+
"9-5-23-mixed",
|
| 151 |
+
checkpoint_dir,
|
| 152 |
+
extra_args=dict(
|
| 153 |
+
mixup_weight=0.0,
|
| 154 |
+
sim_use_cls=False,
|
| 155 |
+
audio_pool_width=1,
|
| 156 |
+
memory_buffer_size=0,
|
| 157 |
+
loss_leak=0.0)
|
| 158 |
+
),
|
| 159 |
+
|
| 160 |
+
**get_all_models_in_dir(
|
| 161 |
+
"1-23-24-rebuttal-heads",
|
| 162 |
+
checkpoint_dir,
|
| 163 |
+
extra_args=dict(
|
| 164 |
+
loss_leak=0.0)
|
| 165 |
+
),
|
| 166 |
+
|
| 167 |
+
**get_all_models_in_dir(
|
| 168 |
+
"11-8-23",
|
| 169 |
+
checkpoint_dir,
|
| 170 |
+
extra_args=dict(loss_leak=0.0)),
|
| 171 |
+
|
| 172 |
+
**get_all_models_in_dir(
|
| 173 |
+
"10-30-23-3",
|
| 174 |
+
checkpoint_dir,
|
| 175 |
+
extra_args=dict(loss_leak=0.0)),
|
| 176 |
+
|
| 177 |
+
"davenet": dict(
|
| 178 |
+
chkpt_name=None,
|
| 179 |
+
extra_args=dict(
|
| 180 |
+
audio_blur=1,
|
| 181 |
+
image_model_type="davenet",
|
| 182 |
+
image_aligner_type=None,
|
| 183 |
+
audio_model_type="davenet",
|
| 184 |
+
audio_aligner_type=None,
|
| 185 |
+
audio_input="davenet_spec",
|
| 186 |
+
use_cached_embs=False,
|
| 187 |
+
dropout=False,
|
| 188 |
+
sim_agg_heads=1,
|
| 189 |
+
nonneg_sim=False,
|
| 190 |
+
audio_lora=False,
|
| 191 |
+
image_lora=False,
|
| 192 |
+
norm_vectors=False,
|
| 193 |
+
),
|
| 194 |
+
data_args=dict(
|
| 195 |
+
use_cached_embs=False,
|
| 196 |
+
use_davenet_spec=True,
|
| 197 |
+
override_target_length=20,
|
| 198 |
+
audio_model_type="davenet",
|
| 199 |
+
),
|
| 200 |
+
),
|
| 201 |
+
|
| 202 |
+
"cavmae": dict(
|
| 203 |
+
chkpt_name=None,
|
| 204 |
+
extra_args=dict(
|
| 205 |
+
audio_blur=1,
|
| 206 |
+
image_model_type="cavmae",
|
| 207 |
+
image_aligner_type=None,
|
| 208 |
+
audio_model_type="cavmae",
|
| 209 |
+
audio_aligner_type=None,
|
| 210 |
+
audio_input="spec",
|
| 211 |
+
use_cached_embs=False,
|
| 212 |
+
sim_agg_heads=1,
|
| 213 |
+
dropout=False,
|
| 214 |
+
nonneg_sim=False,
|
| 215 |
+
audio_lora=False,
|
| 216 |
+
image_lora=False,
|
| 217 |
+
norm_vectors=False,
|
| 218 |
+
learn_audio_cls=False,
|
| 219 |
+
sim_agg_type="cavmae",
|
| 220 |
+
),
|
| 221 |
+
data_args=dict(
|
| 222 |
+
use_cached_embs=False,
|
| 223 |
+
use_davenet_spec=True,
|
| 224 |
+
audio_model_type="cavmae",
|
| 225 |
+
override_target_length=10,
|
| 226 |
+
),
|
| 227 |
+
),
|
| 228 |
+
|
| 229 |
+
"imagebind": dict(
|
| 230 |
+
chkpt_name=None,
|
| 231 |
+
extra_args=dict(
|
| 232 |
+
audio_blur=1,
|
| 233 |
+
image_model_type="imagebind",
|
| 234 |
+
image_aligner_type=None,
|
| 235 |
+
audio_model_type="imagebind",
|
| 236 |
+
audio_aligner_type=None,
|
| 237 |
+
audio_input="spec",
|
| 238 |
+
use_cached_embs=False,
|
| 239 |
+
sim_agg_heads=1,
|
| 240 |
+
dropout=False,
|
| 241 |
+
nonneg_sim=False,
|
| 242 |
+
audio_lora=False,
|
| 243 |
+
image_lora=False,
|
| 244 |
+
norm_vectors=False,
|
| 245 |
+
learn_audio_cls=False,
|
| 246 |
+
sim_agg_type="imagebind",
|
| 247 |
+
),
|
| 248 |
+
data_args=dict(
|
| 249 |
+
use_cached_embs=False,
|
| 250 |
+
use_davenet_spec=True,
|
| 251 |
+
audio_model_type="imagebind",
|
| 252 |
+
override_target_length=10,
|
| 253 |
+
),
|
| 254 |
+
),
|
| 255 |
+
|
| 256 |
+
}
|
| 257 |
+
|
| 258 |
+
model_info["denseav_language"] = model_info["10-30-23-3/places_base/train"]
|
| 259 |
+
model_info["denseav_sound"] = model_info["11-8-23/hubert_1h_asf_cls_full_image_train_small_lr/train"]
|
| 260 |
+
model_info["denseav_2head"] = model_info["1-23-24-rebuttal-heads/mixed-2h/train"]
|
| 261 |
+
|
| 262 |
+
return model_info
|
DenseAV/denseav/shared.py
ADDED
|
@@ -0,0 +1,739 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import random
|
| 2 |
+
from collections import defaultdict, deque
|
| 3 |
+
from typing import Any
|
| 4 |
+
|
| 5 |
+
import math
|
| 6 |
+
import matplotlib.pyplot as plt
|
| 7 |
+
import numpy as np
|
| 8 |
+
import torch
|
| 9 |
+
import torch.distributed as dist
|
| 10 |
+
import torch.nn.functional as F
|
| 11 |
+
import torchaudio
|
| 12 |
+
import torchvision.transforms as T
|
| 13 |
+
from PIL import Image
|
| 14 |
+
from torch.utils.data import Dataset
|
| 15 |
+
from torchaudio.functional import resample
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class UnNormalize(object):
|
| 19 |
+
def __init__(self, mean, std):
|
| 20 |
+
self.mean = mean
|
| 21 |
+
self.std = std
|
| 22 |
+
|
| 23 |
+
def __call__(self, image):
|
| 24 |
+
image2 = torch.clone(image)
|
| 25 |
+
for t, m, s in zip(image2, self.mean, self.std):
|
| 26 |
+
t.mul_(s).add_(m)
|
| 27 |
+
return image2
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
class SliceDataset(Dataset):
|
| 31 |
+
|
| 32 |
+
def __init__(self, ds, start, end):
|
| 33 |
+
self.ds = ds
|
| 34 |
+
self.start = start
|
| 35 |
+
self.end = end
|
| 36 |
+
|
| 37 |
+
def __len__(self):
|
| 38 |
+
return self.end - self.start
|
| 39 |
+
|
| 40 |
+
def __getitem__(self, item):
|
| 41 |
+
return self.ds[item + self.start]
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
class SubsetDataset(Dataset):
|
| 45 |
+
|
| 46 |
+
def __init__(self, ds, subset):
|
| 47 |
+
self.ds = ds
|
| 48 |
+
self.subset = subset
|
| 49 |
+
|
| 50 |
+
def __len__(self):
|
| 51 |
+
return len(self.subset)
|
| 52 |
+
|
| 53 |
+
def __getitem__(self, item):
|
| 54 |
+
return self.ds[self.subset[item]]
|
| 55 |
+
|
| 56 |
+
|
| 57 |
+
norm = T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
|
| 58 |
+
unnorm = UnNormalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
|
| 59 |
+
|
| 60 |
+
|
| 61 |
+
def crop_to_divisor(x, patch_size):
|
| 62 |
+
if len(x.shape) == 3:
|
| 63 |
+
C, H, W = x.shape
|
| 64 |
+
return x[:, :(patch_size * (H // patch_size)), :(patch_size * (W // patch_size))]
|
| 65 |
+
elif len(x.shape) == 4:
|
| 66 |
+
B, C, H, W = x.shape
|
| 67 |
+
return x[:, :, :(patch_size * (H // patch_size)), :(patch_size * (W // patch_size))]
|
| 68 |
+
else:
|
| 69 |
+
raise ValueError("x should have 3 or 4 dimensions")
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
def _remove_axes(ax):
|
| 73 |
+
ax.xaxis.set_major_formatter(plt.NullFormatter())
|
| 74 |
+
ax.yaxis.set_major_formatter(plt.NullFormatter())
|
| 75 |
+
ax.set_xticks([])
|
| 76 |
+
ax.set_yticks([])
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
def remove_axes(axes):
|
| 80 |
+
if len(axes.shape) == 2:
|
| 81 |
+
for ax1 in axes:
|
| 82 |
+
for ax in ax1:
|
| 83 |
+
_remove_axes(ax)
|
| 84 |
+
else:
|
| 85 |
+
for ax in axes:
|
| 86 |
+
_remove_axes(ax)
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def get_image_featurizer(name, token_type="key", **kwargs):
|
| 90 |
+
name = name.lower()
|
| 91 |
+
|
| 92 |
+
if name == "vit":
|
| 93 |
+
from denseav.featurizers.DINO import DINOFeaturizer
|
| 94 |
+
patch_size = 16
|
| 95 |
+
model = DINOFeaturizer("vit_small_patch16_224", patch_size, token_type)
|
| 96 |
+
dim = 384
|
| 97 |
+
elif name == "dino16":
|
| 98 |
+
from denseav.featurizers.DINO import DINOFeaturizer
|
| 99 |
+
patch_size = 16
|
| 100 |
+
model = DINOFeaturizer("dino_vits16", patch_size, token_type)
|
| 101 |
+
dim = 384
|
| 102 |
+
elif name == "dino8":
|
| 103 |
+
from denseav.featurizers.DINO import DINOFeaturizer
|
| 104 |
+
patch_size = 8
|
| 105 |
+
model = DINOFeaturizer("dino_vits8", patch_size, token_type)
|
| 106 |
+
dim = 384
|
| 107 |
+
elif name == "clip":
|
| 108 |
+
from denseav.featurizers.CLIP import CLIPFeaturizer
|
| 109 |
+
patch_size = 16
|
| 110 |
+
model = CLIPFeaturizer()
|
| 111 |
+
dim = 512
|
| 112 |
+
elif name == "cavmae":
|
| 113 |
+
from denseav.featurizers.CAVMAE import CAVMAEImageFeaturizer
|
| 114 |
+
model = CAVMAEImageFeaturizer(kwargs["output_root"], model=kwargs.get("model"))
|
| 115 |
+
dim = 768
|
| 116 |
+
patch_size = 16
|
| 117 |
+
elif name == "fnac":
|
| 118 |
+
from denseav.featurizers.FNACAVL import FNACImageFeaturizer
|
| 119 |
+
model = FNACImageFeaturizer(kwargs["output_root"], model=kwargs.get("model"))
|
| 120 |
+
dim = 512
|
| 121 |
+
patch_size = 16
|
| 122 |
+
elif name == "imagebind":
|
| 123 |
+
from denseav.featurizers.ImageBind import ImageBindImageFeaturizer
|
| 124 |
+
model = ImageBindImageFeaturizer(kwargs["output_root"], model=kwargs.get("model"))
|
| 125 |
+
dim = 1024
|
| 126 |
+
patch_size = 16
|
| 127 |
+
elif name == "resnet50":
|
| 128 |
+
from torchvision import models
|
| 129 |
+
model = models.resnet50(pretrained=True)
|
| 130 |
+
model = torch.nn.Sequential(*list(model.children())[:-2])
|
| 131 |
+
patch_size = 1
|
| 132 |
+
dim = 2048
|
| 133 |
+
elif name == "davenet":
|
| 134 |
+
from fdenseav.eaturizers.DAVENet import DavenetImageFeaturizer
|
| 135 |
+
model = DavenetImageFeaturizer()
|
| 136 |
+
patch_size = 1
|
| 137 |
+
dim = 1024
|
| 138 |
+
elif name == "dinov2":
|
| 139 |
+
from denseav.featurizers.DINOv2 import DINOv2Featurizer
|
| 140 |
+
model = DINOv2Featurizer()
|
| 141 |
+
patch_size = 14
|
| 142 |
+
dim = 768
|
| 143 |
+
else:
|
| 144 |
+
raise ValueError("unknown model: {}".format(name))
|
| 145 |
+
return model, patch_size, dim
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def get_audio_featurizer(name, **kwargs):
|
| 149 |
+
if name == "davenet":
|
| 150 |
+
from denseav.featurizers.DAVENet import DavenetAudioFeaturizer
|
| 151 |
+
model = DavenetAudioFeaturizer()
|
| 152 |
+
dim = 1024
|
| 153 |
+
elif name == "dino8":
|
| 154 |
+
model, _, dim = get_image_featurizer("dino8")
|
| 155 |
+
elif name == "hubert":
|
| 156 |
+
from denseav.featurizers.Hubert import Hubert
|
| 157 |
+
model = Hubert()
|
| 158 |
+
dim = 1024
|
| 159 |
+
elif name == "cavmae":
|
| 160 |
+
from denseav.featurizers.CAVMAE import CAVMAEAudioFeaturizer
|
| 161 |
+
model = CAVMAEAudioFeaturizer(kwargs["output_root"], model=kwargs.get("model"))
|
| 162 |
+
dim = 768
|
| 163 |
+
elif name == "imagebind":
|
| 164 |
+
from denseav.featurizers.ImageBind import ImageBindAudioFeaturizer
|
| 165 |
+
model = ImageBindAudioFeaturizer(kwargs["output_root"], model=kwargs.get("model"))
|
| 166 |
+
dim = 1024
|
| 167 |
+
elif name == "audiomae":
|
| 168 |
+
from denseav.featurizers.AudioMAE import AudioMAE
|
| 169 |
+
model = AudioMAE(kwargs["output_root"], False)
|
| 170 |
+
dim = 768
|
| 171 |
+
elif name == "audiomae-finetuned":
|
| 172 |
+
from denseav.featurizers.AudioMAE import AudioMAE
|
| 173 |
+
model = AudioMAE(kwargs["output_root"], True)
|
| 174 |
+
dim = 768
|
| 175 |
+
else:
|
| 176 |
+
raise ValueError("Unknown audio model type")
|
| 177 |
+
|
| 178 |
+
return model, dim
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def load_img(image_path, transform):
|
| 182 |
+
return transform(Image.open(image_path)).unsqueeze(0)
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
def pytorch_to_pil(tensor):
|
| 186 |
+
return Image.fromarray((unnorm(tensor).permute(0, 2, 3, 1).cpu() * 255)
|
| 187 |
+
.clamp(0, 255).to(torch.uint8).detach().numpy()[0])
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
def _get_random_window(waveform, mask, min_size, max_size):
|
| 191 |
+
effective_size = mask.sum().to(torch.int64)
|
| 192 |
+
if effective_size <= min_size:
|
| 193 |
+
return waveform, mask
|
| 194 |
+
else:
|
| 195 |
+
window_size = min(torch.randint(low=min_size, high=min(effective_size, max_size), size=()), waveform.shape[0])
|
| 196 |
+
if window_size == waveform.shape[0]:
|
| 197 |
+
window_start = 0
|
| 198 |
+
else:
|
| 199 |
+
window_start = torch.randint(low=0, high=effective_size - window_size, size=())
|
| 200 |
+
|
| 201 |
+
new_waveform = torch.zeros_like(waveform)
|
| 202 |
+
new_mask = torch.zeros_like(mask)
|
| 203 |
+
new_waveform[window_start:window_start + window_size] = waveform[window_start:window_start + window_size]
|
| 204 |
+
new_mask[window_start:window_start + window_size] = mask[window_start:window_start + window_size]
|
| 205 |
+
return new_waveform, new_mask
|
| 206 |
+
|
| 207 |
+
|
| 208 |
+
def _splice_clips(clip1, clip2, loc, easing_size):
|
| 209 |
+
assert loc >= 0 and loc < len(clip1), "Invalid location"
|
| 210 |
+
assert easing_size > 0 and easing_size <= len(clip2), "Invalid easing size"
|
| 211 |
+
|
| 212 |
+
try:
|
| 213 |
+
assert loc + clip2.shape[0] < clip1.shape[0]
|
| 214 |
+
except Exception as e:
|
| 215 |
+
print(loc, clip2.shape[0], clip1.shape[0])
|
| 216 |
+
raise e
|
| 217 |
+
|
| 218 |
+
# Split clip1 into three parts: before splice, easing region, after splice
|
| 219 |
+
before_splice = clip1[:loc]
|
| 220 |
+
after_splice = clip1[loc + clip2.shape[0]:]
|
| 221 |
+
|
| 222 |
+
# Compute the fading weights for the easing region
|
| 223 |
+
# fade_in_weights = torch.cos(torch.linspace(1, 0, easing_size, device=clip1.device))
|
| 224 |
+
fade_in_weights = 0.5 * (1 + torch.cos(math.pi * torch.linspace(0, 1, easing_size)))
|
| 225 |
+
fade_out_weights = 1 - fade_in_weights
|
| 226 |
+
|
| 227 |
+
clip1_ease = torch.cat([
|
| 228 |
+
fade_in_weights,
|
| 229 |
+
torch.zeros(clip2.shape[0] - easing_size * 2),
|
| 230 |
+
fade_out_weights,
|
| 231 |
+
])
|
| 232 |
+
|
| 233 |
+
mask = torch.cat([torch.ones(loc), clip1_ease, torch.ones(clip1.shape[0] - (loc + clip2.shape[0]))])
|
| 234 |
+
|
| 235 |
+
# Apply fading weights to clip1 and clip2 within the easing region
|
| 236 |
+
splice = clip1_ease * clip1[loc:loc + clip2.shape[0]] + (1 - clip1_ease) * clip2
|
| 237 |
+
|
| 238 |
+
# Concatenate all parts back together
|
| 239 |
+
spliced_clip = torch.cat((before_splice, splice, after_splice))
|
| 240 |
+
|
| 241 |
+
return spliced_clip, mask
|
| 242 |
+
|
| 243 |
+
|
| 244 |
+
def _generate_random_subset(waveform, low, high):
|
| 245 |
+
length = len(waveform)
|
| 246 |
+
|
| 247 |
+
# If waveform is smaller than low or has zero length, return unmodified
|
| 248 |
+
if length < low or length == 0:
|
| 249 |
+
return waveform
|
| 250 |
+
|
| 251 |
+
# Generate random start index within valid range
|
| 252 |
+
start = random.randint(0, length - low)
|
| 253 |
+
|
| 254 |
+
# Generate random subset size within valid range
|
| 255 |
+
subset_size = random.randint(low, min(high, length - start))
|
| 256 |
+
|
| 257 |
+
# Extract the random subset from the waveform
|
| 258 |
+
subset = waveform[start: start + subset_size]
|
| 259 |
+
|
| 260 |
+
return subset
|
| 261 |
+
|
| 262 |
+
|
| 263 |
+
def level_audio(waveform):
|
| 264 |
+
waveform -= waveform.mean()
|
| 265 |
+
waveform /= waveform.abs.max().valus.clamp_min(.0001)
|
| 266 |
+
return waveform
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
def prep_waveform(waveform,
|
| 270 |
+
obs_sr,
|
| 271 |
+
target_length,
|
| 272 |
+
spec_mel_bins,
|
| 273 |
+
spec_mean,
|
| 274 |
+
spec_std,
|
| 275 |
+
sample_rate,
|
| 276 |
+
return_spec,
|
| 277 |
+
random_clip,
|
| 278 |
+
extra_audio_masking,
|
| 279 |
+
neg_waveform,
|
| 280 |
+
neg_obs_sr,
|
| 281 |
+
audio_level,
|
| 282 |
+
audio_aug,
|
| 283 |
+
):
|
| 284 |
+
if obs_sr != sample_rate:
|
| 285 |
+
waveform = resample(waveform, obs_sr, sample_rate)
|
| 286 |
+
if audio_level:
|
| 287 |
+
waveform = level_audio(waveform)
|
| 288 |
+
|
| 289 |
+
if neg_obs_sr is not None and neg_obs_sr != sample_rate:
|
| 290 |
+
neg_waveform = resample(neg_waveform, neg_obs_sr, sample_rate)
|
| 291 |
+
if audio_level:
|
| 292 |
+
neg_waveform = level_audio(neg_waveform)
|
| 293 |
+
|
| 294 |
+
if neg_obs_sr is not None: # and random.random() > .5:
|
| 295 |
+
neg_waveform_clip = _generate_random_subset(neg_waveform, sample_rate, sample_rate * 4)
|
| 296 |
+
if waveform.shape[0] - neg_waveform_clip.shape[0] > 0:
|
| 297 |
+
start = random.randint(0, waveform.shape[0] - neg_waveform_clip.shape[0] - 1)
|
| 298 |
+
easing = max(int(neg_waveform_clip.shape[0] * 1 / 4), sample_rate // 2)
|
| 299 |
+
easing = min(int(neg_waveform_clip.shape[0] * 1 / 2), easing)
|
| 300 |
+
waveform, pos_mask = _splice_clips(waveform, neg_waveform_clip, start, easing_size=easing)
|
| 301 |
+
else:
|
| 302 |
+
waveform, pos_mask = waveform, torch.ones_like(waveform)
|
| 303 |
+
else:
|
| 304 |
+
waveform, pos_mask = waveform, torch.ones_like(waveform)
|
| 305 |
+
|
| 306 |
+
mask = torch.ones_like(waveform)
|
| 307 |
+
original_length = waveform.shape[0]
|
| 308 |
+
|
| 309 |
+
if target_length == 10:
|
| 310 |
+
target_samples = 164200 # Result is 1024 after spec
|
| 311 |
+
else:
|
| 312 |
+
target_samples = int(target_length * sample_rate)
|
| 313 |
+
|
| 314 |
+
padding = target_samples - original_length
|
| 315 |
+
|
| 316 |
+
if padding > 0:
|
| 317 |
+
p = torch.nn.ZeroPad2d((0, padding))
|
| 318 |
+
waveform = p(waveform)
|
| 319 |
+
mask = p(mask)
|
| 320 |
+
pos_mask = p(pos_mask)
|
| 321 |
+
else:
|
| 322 |
+
if random_clip:
|
| 323 |
+
start = torch.randint(0, waveform.shape[0] - target_samples, size=())
|
| 324 |
+
else:
|
| 325 |
+
start = 0
|
| 326 |
+
end = start + target_samples
|
| 327 |
+
waveform = waveform[start:end]
|
| 328 |
+
mask = mask[start:end]
|
| 329 |
+
pos_mask = pos_mask[start:end]
|
| 330 |
+
|
| 331 |
+
audio_length = min(original_length, target_samples)
|
| 332 |
+
total_length = target_samples
|
| 333 |
+
|
| 334 |
+
if extra_audio_masking:
|
| 335 |
+
min_size = sample_rate // 2
|
| 336 |
+
max_size = total_length
|
| 337 |
+
if original_length > min_size and random.random() > .5:
|
| 338 |
+
waveform, mask = _get_random_window(waveform, mask, min_size, max_size)
|
| 339 |
+
|
| 340 |
+
if audio_aug:
|
| 341 |
+
import torchaudio_augmentations as AA
|
| 342 |
+
from torchvision.transforms import RandomApply, Compose
|
| 343 |
+
|
| 344 |
+
transform = Compose([
|
| 345 |
+
RandomApply([AA.PolarityInversion()], p=0.5),
|
| 346 |
+
RandomApply([AA.Noise(min_snr=0.001, max_snr=0.005)], p=0.2),
|
| 347 |
+
RandomApply([AA.Gain()], p=0.2),
|
| 348 |
+
RandomApply([AA.HighLowPass(sample_rate=sample_rate)], p=0.2),
|
| 349 |
+
RandomApply([AA.PitchShift(n_samples=waveform.shape[-1], sample_rate=sample_rate)], p=0.2),
|
| 350 |
+
RandomApply([AA.Reverb(sample_rate=sample_rate)], p=0.2)
|
| 351 |
+
])
|
| 352 |
+
waveform = transform(waveform.unsqueeze(0)).squeeze(0)
|
| 353 |
+
|
| 354 |
+
if return_spec:
|
| 355 |
+
spectrogram = torchaudio.compliance.kaldi.fbank(
|
| 356 |
+
waveform.unsqueeze(0) - waveform.mean(),
|
| 357 |
+
htk_compat=True,
|
| 358 |
+
sample_frequency=sample_rate,
|
| 359 |
+
use_energy=False,
|
| 360 |
+
window_type='hanning',
|
| 361 |
+
num_mel_bins=spec_mel_bins,
|
| 362 |
+
dither=0.0,
|
| 363 |
+
frame_shift=10)
|
| 364 |
+
|
| 365 |
+
spectrogram = ((spectrogram - spec_mean) / spec_std).unsqueeze(0)
|
| 366 |
+
else:
|
| 367 |
+
spectrogram = None
|
| 368 |
+
|
| 369 |
+
if mask.mean() < .04:
|
| 370 |
+
print(f"Bad entry: {mask.mean()}")
|
| 371 |
+
|
| 372 |
+
return waveform, spectrogram, audio_length, total_length, original_length, mask, pos_mask
|
| 373 |
+
|
| 374 |
+
|
| 375 |
+
class ToTargetTensor(object):
|
| 376 |
+
def __call__(self, target):
|
| 377 |
+
return torch.as_tensor(np.array(target), dtype=torch.int64).unsqueeze(0)
|
| 378 |
+
|
| 379 |
+
|
| 380 |
+
def show_heatmap(ax,
|
| 381 |
+
image,
|
| 382 |
+
heatmap,
|
| 383 |
+
cmap="bwr",
|
| 384 |
+
color=False,
|
| 385 |
+
center=False,
|
| 386 |
+
show_negative=False,
|
| 387 |
+
cax=None,
|
| 388 |
+
vmax=None,
|
| 389 |
+
vmin=None):
|
| 390 |
+
frame = []
|
| 391 |
+
|
| 392 |
+
if color:
|
| 393 |
+
frame.append(ax.imshow(image))
|
| 394 |
+
else:
|
| 395 |
+
bw = np.dot(np.array(image)[..., :3] / 255, [0.2989, 0.5870, 0.1140])
|
| 396 |
+
bw = np.ones_like(image) * np.expand_dims(bw, -1)
|
| 397 |
+
frame.append(ax.imshow(bw))
|
| 398 |
+
|
| 399 |
+
if center:
|
| 400 |
+
heatmap -= heatmap.mean()
|
| 401 |
+
|
| 402 |
+
if not show_negative:
|
| 403 |
+
heatmap = heatmap.clamp_min(0)
|
| 404 |
+
|
| 405 |
+
heatmap = F.interpolate(heatmap.unsqueeze(0).unsqueeze(0), (image.shape[0], image.shape[1])) \
|
| 406 |
+
.squeeze(0).squeeze(0)
|
| 407 |
+
|
| 408 |
+
if vmax is None:
|
| 409 |
+
vmax = np.abs(heatmap).max()
|
| 410 |
+
if vmin is None:
|
| 411 |
+
vmin = -vmax
|
| 412 |
+
|
| 413 |
+
hm = ax.imshow(heatmap, alpha=.5, cmap=cmap, vmax=vmax, vmin=vmin)
|
| 414 |
+
if cax is not None:
|
| 415 |
+
plt.colorbar(hm, cax=cax, orientation='vertical')
|
| 416 |
+
|
| 417 |
+
frame.extend([hm])
|
| 418 |
+
return frame
|
| 419 |
+
|
| 420 |
+
|
| 421 |
+
class TorchPCA(object):
|
| 422 |
+
|
| 423 |
+
def __init__(self, n_components):
|
| 424 |
+
self.n_components = n_components
|
| 425 |
+
|
| 426 |
+
def fit(self, X):
|
| 427 |
+
self.mean_ = X.mean(dim=0)
|
| 428 |
+
unbiased = X - self.mean_.unsqueeze(0)
|
| 429 |
+
U, S, V = torch.pca_lowrank(unbiased, q=self.n_components, center=False, niter=4)
|
| 430 |
+
self.components_ = V.T
|
| 431 |
+
self.singular_values_ = S
|
| 432 |
+
return self
|
| 433 |
+
|
| 434 |
+
def transform(self, X):
|
| 435 |
+
t0 = X - self.mean_.unsqueeze(0)
|
| 436 |
+
projected = t0 @ self.components_.T
|
| 437 |
+
return projected
|
| 438 |
+
|
| 439 |
+
|
| 440 |
+
def pca(image_feats_list, dim=3, fit_pca=None):
|
| 441 |
+
device = image_feats_list[0].device
|
| 442 |
+
|
| 443 |
+
def flatten(tensor, target_size=None):
|
| 444 |
+
if target_size is not None and fit_pca is None:
|
| 445 |
+
F.interpolate(tensor, (target_size, target_size), mode="bilinear")
|
| 446 |
+
B, C, H, W = tensor.shape
|
| 447 |
+
return feats.permute(1, 0, 2, 3).reshape(C, B * H * W).permute(1, 0).detach().cpu()
|
| 448 |
+
|
| 449 |
+
if len(image_feats_list) > 1 and fit_pca is None:
|
| 450 |
+
target_size = image_feats_list[0].shape[2]
|
| 451 |
+
else:
|
| 452 |
+
target_size = None
|
| 453 |
+
|
| 454 |
+
flattened_feats = []
|
| 455 |
+
for feats in image_feats_list:
|
| 456 |
+
flattened_feats.append(flatten(feats, target_size))
|
| 457 |
+
x = torch.cat(flattened_feats, dim=0)
|
| 458 |
+
|
| 459 |
+
if fit_pca is None:
|
| 460 |
+
# fit_pca = PCA(n_components=dim, svd_solver='arpack').fit(np.nan_to_num(x.detach().numpy()))
|
| 461 |
+
fit_pca = TorchPCA(n_components=dim).fit(x)
|
| 462 |
+
|
| 463 |
+
reduced_feats = []
|
| 464 |
+
for feats in image_feats_list:
|
| 465 |
+
# x_red = torch.from_numpy(fit_pca.transform(flatten(feats)))
|
| 466 |
+
x_red = fit_pca.transform(flatten(feats))
|
| 467 |
+
x_red -= x_red.min(dim=0, keepdim=True).values
|
| 468 |
+
x_red /= x_red.max(dim=0, keepdim=True).values
|
| 469 |
+
B, C, H, W = feats.shape
|
| 470 |
+
reduced_feats.append(x_red.reshape(B, H, W, dim).permute(0, 3, 1, 2).to(device))
|
| 471 |
+
|
| 472 |
+
return reduced_feats, fit_pca
|
| 473 |
+
|
| 474 |
+
|
| 475 |
+
def merge_col(fig, axes, col):
|
| 476 |
+
gs = axes[0, col].get_gridspec()
|
| 477 |
+
for ax in axes[:, col]:
|
| 478 |
+
ax.remove()
|
| 479 |
+
return fig.add_subplot(gs[:, col])
|
| 480 |
+
|
| 481 |
+
|
| 482 |
+
def visualize_av_features(
|
| 483 |
+
audio,
|
| 484 |
+
video,
|
| 485 |
+
feat_a,
|
| 486 |
+
feat_v,
|
| 487 |
+
att_a,
|
| 488 |
+
n_frames,
|
| 489 |
+
norm_before_pca=True,
|
| 490 |
+
axes=None,
|
| 491 |
+
fig=None,
|
| 492 |
+
modify_fig=True,
|
| 493 |
+
video_time=0,
|
| 494 |
+
fit_pca=None
|
| 495 |
+
):
|
| 496 |
+
assert (len(audio.shape) == 3) # C, F, T
|
| 497 |
+
assert (len(video.shape) == 4) # T, C, H, W
|
| 498 |
+
assert (len(feat_a.shape) == 2) # C, T
|
| 499 |
+
assert (len(feat_v.shape) == 4) # T, C, H, W
|
| 500 |
+
assert (len(att_a.shape) == 2) # F, T
|
| 501 |
+
|
| 502 |
+
ac, af, at = audio.shape
|
| 503 |
+
fac, fat = feat_a.shape
|
| 504 |
+
|
| 505 |
+
if modify_fig:
|
| 506 |
+
if axes is None:
|
| 507 |
+
fig, axes = plt.subplots(3, 3, figsize=(5 * 3, 5))
|
| 508 |
+
fig.tight_layout()
|
| 509 |
+
|
| 510 |
+
bigax1 = merge_col(fig, axes, 0)
|
| 511 |
+
bigax2 = merge_col(fig, axes, 1)
|
| 512 |
+
_remove_axes(bigax1)
|
| 513 |
+
_remove_axes(bigax2)
|
| 514 |
+
remove_axes(axes[:, 2])
|
| 515 |
+
else:
|
| 516 |
+
bigax1 = fig.axes[-2]
|
| 517 |
+
bigax2 = fig.axes[-1]
|
| 518 |
+
|
| 519 |
+
frame_v = unnorm(video).permute(0, 2, 3, 1).detach().cpu()
|
| 520 |
+
frame_v -= frame_v.min()
|
| 521 |
+
frame_v /= frame_v.max()
|
| 522 |
+
|
| 523 |
+
frame_a = audio.detach().cpu()
|
| 524 |
+
frame_a -= frame_a.min()
|
| 525 |
+
frame_a /= frame_a.max()
|
| 526 |
+
|
| 527 |
+
if norm_before_pca:
|
| 528 |
+
[red_feat_v], fit_pca = pca([F.normalize(feat_v, dim=1)], fit_pca=fit_pca)
|
| 529 |
+
[red_feat_a], _ = pca([F.normalize(feat_a.unsqueeze(0).unsqueeze(-1), dim=1)], fit_pca=fit_pca)
|
| 530 |
+
else:
|
| 531 |
+
[red_feat_v], fit_pca = pca([feat_v], fit_pca=fit_pca)
|
| 532 |
+
[red_feat_a], _ = pca([feat_a.unsqueeze(0).unsqueeze(-1)], fit_pca=fit_pca)
|
| 533 |
+
|
| 534 |
+
red_feat_v = red_feat_v.permute(0, 2, 3, 1).detach().cpu()
|
| 535 |
+
red_feat_a = red_feat_a.permute(0, 2, 3, 1)[0].detach().cpu()
|
| 536 |
+
|
| 537 |
+
if red_feat_a.shape[0] == 1:
|
| 538 |
+
new_height = int((frame_a.shape[0] / frame_a.shape[1]) * red_feat_a.shape[1])
|
| 539 |
+
red_feat_a = torch.broadcast_to(
|
| 540 |
+
red_feat_a, (new_height, red_feat_a.shape[1], red_feat_a.shape[2]))
|
| 541 |
+
plt_att_a = torch.broadcast_to(att_a, (new_height, att_a.shape[1]))
|
| 542 |
+
else:
|
| 543 |
+
plt_att_a = att_a
|
| 544 |
+
|
| 545 |
+
frac_signal = n_frames / fat
|
| 546 |
+
n_at = int(at * frac_signal)
|
| 547 |
+
|
| 548 |
+
return [bigax1.imshow(frame_v[video_time]),
|
| 549 |
+
bigax2.imshow(red_feat_v[video_time]),
|
| 550 |
+
axes[0, 2].imshow(frame_a[:, :n_at]),
|
| 551 |
+
axes[0, 2].set_title("Spectrogram"),
|
| 552 |
+
axes[1, 2].imshow(red_feat_a[:, :n_frames]),
|
| 553 |
+
axes[1, 2].set_title("Audio Features"),
|
| 554 |
+
axes[2, 2].imshow(plt_att_a[:, :n_frames], vmin=0),
|
| 555 |
+
axes[2, 2].set_title("Audio Attention")], fig, fit_pca
|
| 556 |
+
|
| 557 |
+
|
| 558 |
+
def create_label_tensor(labels, starts, ends, max_time, n_steps):
|
| 559 |
+
assert isinstance(starts, torch.Tensor)
|
| 560 |
+
assert isinstance(ends, torch.Tensor)
|
| 561 |
+
|
| 562 |
+
ends[ends < 0] = max_time
|
| 563 |
+
fps = n_steps / max_time
|
| 564 |
+
times = (torch.arange(0, n_steps, device=labels.device, dtype=torch.float32) + .5) / fps
|
| 565 |
+
after_start = starts.unsqueeze(1) <= times.unsqueeze(0)
|
| 566 |
+
before_end = ends.unsqueeze(1) >= times.unsqueeze(0)
|
| 567 |
+
# Find when you are inside of a word
|
| 568 |
+
in_word = (after_start * before_end)
|
| 569 |
+
# Find which word you are inside of
|
| 570 |
+
word_to_use = in_word.to(torch.float32).argmax(0)
|
| 571 |
+
# Get the label for that word, or mask out the label if in no word
|
| 572 |
+
final_labels = labels[word_to_use] * in_word.any(0).reshape(-1, 1, 1)
|
| 573 |
+
return final_labels
|
| 574 |
+
|
| 575 |
+
|
| 576 |
+
def generate_subset(n, batch, seed=0):
|
| 577 |
+
np.random.seed(seed)
|
| 578 |
+
return np.random.permutation(n)[:batch]
|
| 579 |
+
|
| 580 |
+
|
| 581 |
+
def channel_blur(t, window=5, std_dev=1):
|
| 582 |
+
tb, tc, th, tw = t.shape
|
| 583 |
+
x = torch.linspace(-2, 2, window, device=t.device, dtype=torch.float32)
|
| 584 |
+
k = torch.exp((-x ** 2 / (2 * std_dev ** 2)))
|
| 585 |
+
k = k / k.sum()
|
| 586 |
+
pad = window // 2
|
| 587 |
+
t_pad = F.pad(t, [0, 0, 0, 0, pad, pad], mode="replicate")
|
| 588 |
+
tpb, tpc, tph, tpw = t_pad.shape
|
| 589 |
+
flattened_t = t_pad.permute(0, 2, 3, 1).reshape(tpb * tph * tpw, 1, -1)
|
| 590 |
+
return F.conv1d(flattened_t, k.reshape(1, 1, window)).reshape(tpb, tph, tpw, tc).permute(0, 3, 1, 2)
|
| 591 |
+
|
| 592 |
+
|
| 593 |
+
def time_blur(t, window=5, std_dev=1):
|
| 594 |
+
tb, tc, tt = t.shape
|
| 595 |
+
with torch.no_grad():
|
| 596 |
+
x = torch.linspace(-2, 2, window, device=t.device, dtype=torch.float32)
|
| 597 |
+
k = torch.exp((-x ** 2 / (2 * std_dev ** 2)))
|
| 598 |
+
k = k / k.sum()
|
| 599 |
+
k = k.reshape(1, 1, window).detach()
|
| 600 |
+
pad = window // 2
|
| 601 |
+
t_pad = F.pad(t, [pad, pad], mode="replicate")
|
| 602 |
+
return F.conv1d(t_pad.reshape(tb * tc, 1, -1), k).reshape(tb, tc, tt)
|
| 603 |
+
|
| 604 |
+
|
| 605 |
+
def create_model_from_cfg(clazz, cfg, extra_args):
|
| 606 |
+
import inspect
|
| 607 |
+
expected_args = inspect.getfullargspec(clazz.__init__).args[1:]
|
| 608 |
+
new_args = {k: v for k, v in {**cfg, **extra_args}.items() if k in expected_args}
|
| 609 |
+
return clazz(**new_args)
|
| 610 |
+
|
| 611 |
+
|
| 612 |
+
def load_trained_model(chkpt_dir, extra_args, strict=True):
|
| 613 |
+
from train_av_alignment import LitAVAligner
|
| 614 |
+
model = LitAVAligner.load_from_checkpoint(chkpt_dir, **extra_args, strict=strict).cuda()
|
| 615 |
+
return model
|
| 616 |
+
|
| 617 |
+
|
| 618 |
+
def flatten(l):
|
| 619 |
+
return [item for sublist in l for item in sublist]
|
| 620 |
+
|
| 621 |
+
|
| 622 |
+
def flatten_preds(preds):
|
| 623 |
+
results = {}
|
| 624 |
+
for k in preds[0].keys():
|
| 625 |
+
if k == "caption_labels":
|
| 626 |
+
continue
|
| 627 |
+
if isinstance(preds[0][k], torch.Tensor):
|
| 628 |
+
results[k] = torch.cat([p[k] for p in preds], dim=0)
|
| 629 |
+
if "caption" in preds[0]:
|
| 630 |
+
results["caption"] = flatten([p["caption"] for p in preds])
|
| 631 |
+
|
| 632 |
+
if "metadata" in preds[0]:
|
| 633 |
+
results["frame_files"] = flatten([list(p["metadata"]["frame_files"][0]) for p in preds])
|
| 634 |
+
results["audio_file"] = flatten([list(p["metadata"]["audio_file"]) for p in preds])
|
| 635 |
+
results["id"] = flatten([list(p["metadata"]["id"]) for p in preds])
|
| 636 |
+
results["index"] = torch.tensor(flatten([list(p["metadata"]["index"]) for p in preds]))
|
| 637 |
+
|
| 638 |
+
return results
|
| 639 |
+
|
| 640 |
+
|
| 641 |
+
def batch(iterable, n=1):
|
| 642 |
+
l = len(iterable)
|
| 643 |
+
for ndx in range(0, l, n):
|
| 644 |
+
yield iterable[ndx:min(ndx + n, l)]
|
| 645 |
+
|
| 646 |
+
|
| 647 |
+
class GatherLayer(torch.autograd.Function):
|
| 648 |
+
"""Gather tensors from all process, supporting backward propagation."""
|
| 649 |
+
|
| 650 |
+
@staticmethod
|
| 651 |
+
def jvp(ctx: Any, *grad_inputs: Any) -> Any:
|
| 652 |
+
pass
|
| 653 |
+
|
| 654 |
+
@staticmethod
|
| 655 |
+
def forward(ctx, inputs):
|
| 656 |
+
ctx.save_for_backward(inputs)
|
| 657 |
+
output = [torch.zeros_like(inputs) for _ in range(dist.get_world_size())]
|
| 658 |
+
dist.all_gather(output, inputs)
|
| 659 |
+
return tuple(output)
|
| 660 |
+
|
| 661 |
+
@staticmethod
|
| 662 |
+
def backward(ctx, *grads):
|
| 663 |
+
(inputs,) = ctx.saved_tensors
|
| 664 |
+
grad_out = torch.zeros_like(inputs)
|
| 665 |
+
grad_out[:] = grads[dist.get_rank()]
|
| 666 |
+
return grad_out
|
| 667 |
+
|
| 668 |
+
|
| 669 |
+
class RollingAvg:
|
| 670 |
+
|
| 671 |
+
def __init__(self, length, nonzero=False):
|
| 672 |
+
self.length = length
|
| 673 |
+
self.nonzero = nonzero
|
| 674 |
+
self.metrics = defaultdict(lambda: deque(maxlen=self.length))
|
| 675 |
+
|
| 676 |
+
def add(self, name, metric):
|
| 677 |
+
if self.nonzero and metric == 0:
|
| 678 |
+
return
|
| 679 |
+
if isinstance(metric, torch.Tensor):
|
| 680 |
+
metric = metric.detach()
|
| 681 |
+
|
| 682 |
+
self.metrics[name].append(metric)
|
| 683 |
+
|
| 684 |
+
def get(self, name):
|
| 685 |
+
with torch.no_grad():
|
| 686 |
+
return torch.tensor(list(self.metrics[name])).mean()
|
| 687 |
+
|
| 688 |
+
def get_all(self):
|
| 689 |
+
return {k: self.get(k) for k in self.metrics.keys()}
|
| 690 |
+
|
| 691 |
+
def add_all(self, values):
|
| 692 |
+
for k, v in values.items():
|
| 693 |
+
self.add(k, v)
|
| 694 |
+
|
| 695 |
+
def logall(self, log_func):
|
| 696 |
+
for k in self.metrics.keys():
|
| 697 |
+
log_func(k, self.get(k))
|
| 698 |
+
|
| 699 |
+
|
| 700 |
+
def gaussian_kernel(k, sigma):
|
| 701 |
+
kernel = torch.tensor([math.exp(-0.5 * (x - (k // 2)) ** 2 / sigma ** 2) for x in range(k)], dtype=torch.float32)
|
| 702 |
+
kernel /= kernel.sum() # Normalize the kernel
|
| 703 |
+
return kernel
|
| 704 |
+
|
| 705 |
+
|
| 706 |
+
def blur_dim(t, window=5, std_dev=1, dim=-1):
|
| 707 |
+
shape = t.shape
|
| 708 |
+
n_dims = len(shape)
|
| 709 |
+
|
| 710 |
+
# Create the Gaussian kernel
|
| 711 |
+
with torch.no_grad():
|
| 712 |
+
x = torch.linspace(-2, 2, window, device=t.device, dtype=torch.float32)
|
| 713 |
+
k = torch.exp(-x ** 2 / (2 * std_dev ** 2))
|
| 714 |
+
k = k / k.sum()
|
| 715 |
+
k = k.view(1, 1, window).detach()
|
| 716 |
+
|
| 717 |
+
# Calculate padding
|
| 718 |
+
pad = window // 2
|
| 719 |
+
|
| 720 |
+
# Move the target dimension to the end
|
| 721 |
+
permute_order = list(range(n_dims))
|
| 722 |
+
permute_order.append(permute_order.pop(dim))
|
| 723 |
+
t_permuted = t.permute(permute_order)
|
| 724 |
+
|
| 725 |
+
# Flatten all dimensions except the last one
|
| 726 |
+
new_shape = (-1, t_permuted.size(-1))
|
| 727 |
+
t_flattened = t_permuted.reshape(new_shape)
|
| 728 |
+
|
| 729 |
+
# Pad the tensor
|
| 730 |
+
t_padded = F.pad(t_flattened.unsqueeze(1), (pad, pad), mode="replicate")
|
| 731 |
+
|
| 732 |
+
# Apply convolution
|
| 733 |
+
blurred = F.conv1d(t_padded, k)
|
| 734 |
+
|
| 735 |
+
# Reshape back to original
|
| 736 |
+
blurred = blurred.squeeze(1).reshape(*t_permuted.shape)
|
| 737 |
+
blurred = blurred.permute([permute_order.index(i) for i in range(n_dims)])
|
| 738 |
+
|
| 739 |
+
return blurred
|
DenseAV/denseav/train.py
ADDED
|
@@ -0,0 +1,1222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
from collections import deque
|
| 3 |
+
from itertools import combinations
|
| 4 |
+
from os.path import join
|
| 5 |
+
|
| 6 |
+
import hydra
|
| 7 |
+
import numpy as np
|
| 8 |
+
import pytorch_lightning as pl
|
| 9 |
+
import torch
|
| 10 |
+
import torch.distributed as dist
|
| 11 |
+
import torch.nn.functional as F
|
| 12 |
+
from omegaconf import DictConfig, OmegaConf
|
| 13 |
+
from peft import get_peft_model, LoraConfig
|
| 14 |
+
from pytorch_lightning import Trainer
|
| 15 |
+
from pytorch_lightning import seed_everything
|
| 16 |
+
from pytorch_lightning.callbacks import LearningRateMonitor, ModelCheckpoint
|
| 17 |
+
from pytorch_lightning.loggers import TensorBoardLogger
|
| 18 |
+
from pytorch_lightning.utilities import grad_norm
|
| 19 |
+
from torch.optim.lr_scheduler import CosineAnnealingWarmRestarts, SequentialLR, LambdaLR
|
| 20 |
+
from torchmetrics.functional.classification import binary_average_precision
|
| 21 |
+
|
| 22 |
+
from huggingface_hub import PyTorchModelHubMixin
|
| 23 |
+
|
| 24 |
+
from denseav.aggregators import get_aggregator
|
| 25 |
+
from denseav.aligners import get_aligner, ProgressiveGrowing
|
| 26 |
+
from denseav.constants import *
|
| 27 |
+
from denseav.data.AVDatasets import AVDataModule
|
| 28 |
+
from denseav.shared import flatten_preds, GatherLayer, \
|
| 29 |
+
get_image_featurizer, get_audio_featurizer, RollingAvg, create_model_from_cfg
|
| 30 |
+
|
| 31 |
+
torch.multiprocessing.set_sharing_strategy('file_system')
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def _imposter_indices_helper(true_indices: torch.Tensor, samples: torch.Tensor):
|
| 35 |
+
mask = (true_indices == samples).to(torch.int64)
|
| 36 |
+
n = mask.shape[0]
|
| 37 |
+
|
| 38 |
+
if not mask.any():
|
| 39 |
+
return samples
|
| 40 |
+
else:
|
| 41 |
+
new_samples = torch.randint(0, n, size=(n,), device=true_indices.device)
|
| 42 |
+
comb_samples = mask * new_samples + (1 - mask) * samples
|
| 43 |
+
return _imposter_indices_helper(true_indices, comb_samples)
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def imposter_indices(n, device):
|
| 47 |
+
return _imposter_indices_helper(
|
| 48 |
+
torch.arange(0, n, device=device),
|
| 49 |
+
torch.randint(0, n, size=(n,), device=device))
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def get_sim_per_row(image_outputs, audio_outputs, n_frames, sim_type):
|
| 53 |
+
max_t = audio_outputs.shape[-1]
|
| 54 |
+
oh = F.one_hot(n_frames - 1, num_classes=max_t)
|
| 55 |
+
audio_mask = 1 - torch.cumsum(oh, dim=1)
|
| 56 |
+
audio_mask = F.pad(audio_mask, [1, 0], value=1)[:, :max_t].to(audio_outputs.dtype)
|
| 57 |
+
|
| 58 |
+
full_sim = torch.einsum("bct,bchw->bthw", audio_outputs, image_outputs)
|
| 59 |
+
expanded_am = audio_mask.unsqueeze(-1).unsqueeze(-1)
|
| 60 |
+
|
| 61 |
+
if sim_type.endswith("mi"):
|
| 62 |
+
offset = 10 * (full_sim.max() - full_sim.min())
|
| 63 |
+
full_sim = (full_sim - ((1 - expanded_am) * offset)).max(1, keepdim=True).values
|
| 64 |
+
|
| 65 |
+
if sim_type.startswith("mi"):
|
| 66 |
+
full_sim = full_sim.max(-1, keepdim=True).values.max(-2, keepdim=True).values
|
| 67 |
+
|
| 68 |
+
if sim_type.endswith("sa"):
|
| 69 |
+
full_sim = (full_sim * (expanded_am / expanded_am.sum(1, keepdim=True).clamp_min(1))).sum(1, keepdim=True)
|
| 70 |
+
|
| 71 |
+
return full_sim.mean(dim=[1, 2, 3])
|
| 72 |
+
|
| 73 |
+
|
| 74 |
+
def sampled_margin_rank_loss(image_outputs, audio_outputs, n_frames, sim_type, margin=1.):
|
| 75 |
+
"""
|
| 76 |
+
Computes the triplet margin ranking loss for each anchor image/caption pair
|
| 77 |
+
The impostor image/caption is randomly sampled from the minibatch
|
| 78 |
+
"""
|
| 79 |
+
assert (image_outputs.dim() == 4)
|
| 80 |
+
assert (audio_outputs.dim() == 3)
|
| 81 |
+
n = image_outputs.size(0)
|
| 82 |
+
imp_ind_i = imposter_indices(n, image_outputs.device)
|
| 83 |
+
imp_ind_a = imposter_indices(n, image_outputs.device)
|
| 84 |
+
true_sim = get_sim_per_row(image_outputs, audio_outputs, n_frames, sim_type)
|
| 85 |
+
imp_sim_i = get_sim_per_row(image_outputs[imp_ind_i], audio_outputs, n_frames, sim_type)
|
| 86 |
+
imp_sim_a = get_sim_per_row(image_outputs, audio_outputs[imp_ind_a], n_frames[imp_ind_a], sim_type)
|
| 87 |
+
a2i_loss = (margin + imp_sim_i - true_sim).clamp_min(0)
|
| 88 |
+
i2a_loss = (margin + imp_sim_a - true_sim).clamp_min(0)
|
| 89 |
+
return (a2i_loss + i2a_loss).mean() / 2
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
class SimilarityCalibrator(torch.nn.Module):
|
| 93 |
+
|
| 94 |
+
def __init__(self, cal_init, max_w=100, min_w=.01, subtract_mean=True, use_bias=False):
|
| 95 |
+
super().__init__()
|
| 96 |
+
self.max_w = max_w
|
| 97 |
+
self.min_w = min_w
|
| 98 |
+
self.w = torch.nn.Parameter(torch.tensor([cal_init]).log())
|
| 99 |
+
|
| 100 |
+
self.use_bias = use_bias
|
| 101 |
+
if self.use_bias:
|
| 102 |
+
self.b = torch.nn.Parameter(torch.tensor([0.0]))
|
| 103 |
+
|
| 104 |
+
self.subtract_mean = subtract_mean
|
| 105 |
+
|
| 106 |
+
def get_w(self):
|
| 107 |
+
return torch.exp(self.w).clamp_max(self.max_w).clamp_min(self.min_w)
|
| 108 |
+
|
| 109 |
+
def forward(self, x):
|
| 110 |
+
sims = self.get_w() * x
|
| 111 |
+
|
| 112 |
+
if self.use_bias:
|
| 113 |
+
sims = sims + self.b
|
| 114 |
+
|
| 115 |
+
if self.subtract_mean:
|
| 116 |
+
return sims - sims.mean()
|
| 117 |
+
else:
|
| 118 |
+
return sims
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
class SpatialDropout(torch.nn.Module):
|
| 122 |
+
|
| 123 |
+
def __init__(self, p, *args, **kwargs):
|
| 124 |
+
super().__init__(*args, **kwargs)
|
| 125 |
+
self.p = p
|
| 126 |
+
|
| 127 |
+
def forward(self, x):
|
| 128 |
+
b, c, h, w = x.shape
|
| 129 |
+
dropout = torch.rand((b, 1, h, w), dtype=x.dtype, device=x.device) > self.p
|
| 130 |
+
|
| 131 |
+
if self.training:
|
| 132 |
+
return x * dropout
|
| 133 |
+
else:
|
| 134 |
+
return x
|
| 135 |
+
|
| 136 |
+
|
| 137 |
+
class LitAVAligner(pl.LightningModule, PyTorchModelHubMixin, repo_url="https://github.com/mhamilton723/DenseAV", license="mit", tags=["denseav"]):
|
| 138 |
+
def __init__(self,
|
| 139 |
+
code_dim,
|
| 140 |
+
image_model_type,
|
| 141 |
+
image_model_token_type,
|
| 142 |
+
image_aligner_type,
|
| 143 |
+
image_pool_width,
|
| 144 |
+
audio_model_type,
|
| 145 |
+
audio_aligner_type,
|
| 146 |
+
audio_pool_width,
|
| 147 |
+
audio_lora,
|
| 148 |
+
audio_lora_rank,
|
| 149 |
+
image_lora,
|
| 150 |
+
image_lora_rank,
|
| 151 |
+
gradient_clipping,
|
| 152 |
+
learn_audio_cls,
|
| 153 |
+
silence_l1,
|
| 154 |
+
silence_l2,
|
| 155 |
+
tv_weight,
|
| 156 |
+
nonneg_sim,
|
| 157 |
+
nonneg_pressure,
|
| 158 |
+
pretrain_lr,
|
| 159 |
+
lr,
|
| 160 |
+
lr_warmup,
|
| 161 |
+
lr_schedule,
|
| 162 |
+
lr_cycle_length,
|
| 163 |
+
optimizer,
|
| 164 |
+
gather_tensors,
|
| 165 |
+
sim_agg_type,
|
| 166 |
+
sim_agg_heads,
|
| 167 |
+
sim_use_cls,
|
| 168 |
+
disentangle_weight,
|
| 169 |
+
norm_vectors,
|
| 170 |
+
cal_init,
|
| 171 |
+
cal_balance_weight,
|
| 172 |
+
loss_type,
|
| 173 |
+
loss_margin,
|
| 174 |
+
mask_silence,
|
| 175 |
+
finetune_image_model,
|
| 176 |
+
finetune_audio_model,
|
| 177 |
+
use_cached_embs,
|
| 178 |
+
output_root,
|
| 179 |
+
neg_audio,
|
| 180 |
+
neg_audio_weight,
|
| 181 |
+
head_agg,
|
| 182 |
+
adaptive_clipping,
|
| 183 |
+
specialization_weight,
|
| 184 |
+
spatial_dropout,
|
| 185 |
+
channel_dropout,
|
| 186 |
+
mixup_weight,
|
| 187 |
+
memory_buffer_size,
|
| 188 |
+
loss_leak,
|
| 189 |
+
):
|
| 190 |
+
super().__init__()
|
| 191 |
+
|
| 192 |
+
self.code_dim = code_dim
|
| 193 |
+
self.image_model_type = image_model_type
|
| 194 |
+
self.image_model_token_type = image_model_token_type
|
| 195 |
+
self.image_aligner_type = image_aligner_type
|
| 196 |
+
self.image_pool_width = image_pool_width
|
| 197 |
+
self.audio_model_type = audio_model_type
|
| 198 |
+
self.audio_aligner_type = audio_aligner_type
|
| 199 |
+
self.audio_pool_width = audio_pool_width
|
| 200 |
+
|
| 201 |
+
self.gradient_clipping = gradient_clipping
|
| 202 |
+
self.learn_audio_cls = learn_audio_cls
|
| 203 |
+
self.silence_l1 = silence_l1
|
| 204 |
+
self.silence_l2 = silence_l2
|
| 205 |
+
|
| 206 |
+
self.tv_weight = tv_weight
|
| 207 |
+
self.nonneg_sim = nonneg_sim
|
| 208 |
+
self.nonneg_pressure = nonneg_pressure
|
| 209 |
+
self.pretrain_lr = pretrain_lr
|
| 210 |
+
self.lr = lr
|
| 211 |
+
self.lr_warmup = lr_warmup
|
| 212 |
+
self.lr_schedule = lr_schedule
|
| 213 |
+
self.lr_cycle_length = lr_cycle_length
|
| 214 |
+
self.optimizer = optimizer
|
| 215 |
+
self.gather_tensors = gather_tensors
|
| 216 |
+
self.sim_agg_type = sim_agg_type
|
| 217 |
+
self.sim_agg_heads = sim_agg_heads
|
| 218 |
+
self.sim_use_cls = sim_use_cls
|
| 219 |
+
self.disentangle_weight = disentangle_weight
|
| 220 |
+
|
| 221 |
+
self.norm_vectors = norm_vectors
|
| 222 |
+
self.cal_init = cal_init
|
| 223 |
+
self.cal_balance_weight = cal_balance_weight
|
| 224 |
+
self.loss_type = loss_type
|
| 225 |
+
self.loss_margin = loss_margin
|
| 226 |
+
self.mask_silence = mask_silence
|
| 227 |
+
self.finetune_image_model = finetune_image_model
|
| 228 |
+
self.finetune_audio_model = finetune_audio_model
|
| 229 |
+
self.use_cached_embs = use_cached_embs
|
| 230 |
+
self.output_root = output_root
|
| 231 |
+
self.audio_lora = audio_lora
|
| 232 |
+
self.audio_lora_rank = audio_lora_rank
|
| 233 |
+
self.image_lora = image_lora
|
| 234 |
+
self.image_lora_rank = image_lora_rank
|
| 235 |
+
self.neg_audio = neg_audio
|
| 236 |
+
self.neg_audio_weight = neg_audio_weight
|
| 237 |
+
self.head_agg = head_agg
|
| 238 |
+
|
| 239 |
+
self.adaptive_clipping = adaptive_clipping
|
| 240 |
+
self.specialization_weight = specialization_weight
|
| 241 |
+
self.spatial_dropout = spatial_dropout
|
| 242 |
+
self.channel_dropout = channel_dropout
|
| 243 |
+
self.mixup_weight = mixup_weight
|
| 244 |
+
|
| 245 |
+
self.memory_buffer_size = memory_buffer_size
|
| 246 |
+
self.memory_buffer = deque(maxlen=self.memory_buffer_size)
|
| 247 |
+
self.loss_leak = loss_leak
|
| 248 |
+
|
| 249 |
+
self.full_train = False # Added by me
|
| 250 |
+
|
| 251 |
+
if self.audio_model_type in {"audiomae", "audiomae-finetuned", "cavmae", "cavmae-mixed", "imagebind"}:
|
| 252 |
+
self.audio_input = "spec"
|
| 253 |
+
elif self.audio_model_type == "davenet":
|
| 254 |
+
self.audio_input = "davenet_spec"
|
| 255 |
+
elif self.audio_model_type == "fnac":
|
| 256 |
+
self.audio_input = "fnac_spec"
|
| 257 |
+
else:
|
| 258 |
+
self.audio_input = "audio"
|
| 259 |
+
|
| 260 |
+
extra_model_args = dict(output_root=output_root)
|
| 261 |
+
|
| 262 |
+
self.image_model, _, self.image_feat_dim = get_image_featurizer(
|
| 263 |
+
image_model_type, token_type=self.image_model_token_type, **extra_model_args)
|
| 264 |
+
|
| 265 |
+
self.image_model.eval()
|
| 266 |
+
if not self.finetune_image_model:
|
| 267 |
+
for param in self.image_model.parameters():
|
| 268 |
+
param.requires_grad = False
|
| 269 |
+
|
| 270 |
+
if image_model_type in {"cavmae", "cavmae-mixed", "imagebind", "fnac"}:
|
| 271 |
+
extra_model_args["model"] = self.image_model.model
|
| 272 |
+
|
| 273 |
+
if use_cached_embs:
|
| 274 |
+
_, self.audio_feat_dim = get_audio_featurizer(audio_model_type, **extra_model_args)
|
| 275 |
+
else:
|
| 276 |
+
self.audio_model, self.audio_feat_dim = get_audio_featurizer(audio_model_type, **extra_model_args)
|
| 277 |
+
|
| 278 |
+
self.audio_model.eval()
|
| 279 |
+
if not self.finetune_audio_model:
|
| 280 |
+
for param in self.audio_model.parameters():
|
| 281 |
+
param.requires_grad = False
|
| 282 |
+
|
| 283 |
+
if self.image_lora:
|
| 284 |
+
if self.image_model_type in {"sam", "dino8", "dinov2", "cavmae", "cavmae-mixed"}:
|
| 285 |
+
target_modules = ["qkv"]
|
| 286 |
+
elif self.image_model_type == "clip":
|
| 287 |
+
target_modules = ["out_proj"]
|
| 288 |
+
elif self.image_model_type == "imagebind":
|
| 289 |
+
target_modules = ["out_proj", "fc1", "fc2"]
|
| 290 |
+
else:
|
| 291 |
+
target_modules = ["q", "k", "v"]
|
| 292 |
+
|
| 293 |
+
peft_config = LoraConfig(
|
| 294 |
+
target_modules=target_modules,
|
| 295 |
+
inference_mode=False,
|
| 296 |
+
r=image_lora_rank,
|
| 297 |
+
lora_alpha=32,
|
| 298 |
+
lora_dropout=0.1
|
| 299 |
+
)
|
| 300 |
+
self.image_model = get_peft_model(self.image_model, peft_config)
|
| 301 |
+
self.image_model.print_trainable_parameters()
|
| 302 |
+
|
| 303 |
+
if self.audio_lora:
|
| 304 |
+
if self.audio_model_type == "hubert":
|
| 305 |
+
target_modules = ["q_proj", "k_proj", "v_proj"]
|
| 306 |
+
else:
|
| 307 |
+
target_modules = ["q", "k", "v"]
|
| 308 |
+
|
| 309 |
+
peft_config = LoraConfig(
|
| 310 |
+
inference_mode=False,
|
| 311 |
+
target_modules=target_modules,
|
| 312 |
+
r=audio_lora_rank,
|
| 313 |
+
lora_alpha=32,
|
| 314 |
+
lora_dropout=0.1
|
| 315 |
+
)
|
| 316 |
+
self.audio_model = get_peft_model(self.audio_model, peft_config)
|
| 317 |
+
self.audio_model.print_trainable_parameters()
|
| 318 |
+
|
| 319 |
+
shared_aligner_args = dict(out_dim=self.code_dim)
|
| 320 |
+
|
| 321 |
+
self.audio_aligner = get_aligner(
|
| 322 |
+
self.audio_aligner_type, self.audio_feat_dim, **shared_aligner_args)
|
| 323 |
+
self.image_aligner = get_aligner(
|
| 324 |
+
self.image_aligner_type, self.image_feat_dim, **shared_aligner_args)
|
| 325 |
+
|
| 326 |
+
if self.loss_type == "nce":
|
| 327 |
+
self.sim_cal = SimilarityCalibrator(self.cal_init, subtract_mean=True, use_bias=False)
|
| 328 |
+
else:
|
| 329 |
+
self.sim_cal = SimilarityCalibrator(self.cal_init, subtract_mean=False, use_bias=True)
|
| 330 |
+
|
| 331 |
+
if self.learn_audio_cls:
|
| 332 |
+
self.audio_cls = torch.nn.Parameter(torch.randn(self.audio_feat_dim))
|
| 333 |
+
|
| 334 |
+
if self.spatial_dropout > 0.0:
|
| 335 |
+
self.spatial_dropout_layer = SpatialDropout(self.spatial_dropout)
|
| 336 |
+
|
| 337 |
+
if self.channel_dropout > 0.0:
|
| 338 |
+
self.channel_dropout_layer = torch.nn.Dropout2d(self.channel_dropout)
|
| 339 |
+
|
| 340 |
+
self.sim_agg = get_aggregator(
|
| 341 |
+
self.sim_agg_type,
|
| 342 |
+
self.nonneg_sim,
|
| 343 |
+
self.mask_silence,
|
| 344 |
+
self.sim_agg_heads,
|
| 345 |
+
self.head_agg,
|
| 346 |
+
self.sim_use_cls,
|
| 347 |
+
dim=self.image_feat_dim
|
| 348 |
+
)
|
| 349 |
+
|
| 350 |
+
self.hparams_logged = False
|
| 351 |
+
self.rolling_avg = RollingAvg(50)
|
| 352 |
+
self.grad_avg = RollingAvg(50, nonzero=True)
|
| 353 |
+
|
| 354 |
+
self.save_hyperparameters()
|
| 355 |
+
|
| 356 |
+
def set_full_train(self, full_train):
|
| 357 |
+
self.full_train = full_train
|
| 358 |
+
|
| 359 |
+
def prep_feats(self, feats, is_audio):
|
| 360 |
+
|
| 361 |
+
if not is_audio and self.training and self.image_pool_width > 1:
|
| 362 |
+
feats = torch.nn.AvgPool2d(self.image_pool_width)(feats)
|
| 363 |
+
|
| 364 |
+
if is_audio and self.training and self.audio_pool_width > 1:
|
| 365 |
+
feats = torch.nn.AvgPool2d((1, self.audio_pool_width))(feats)
|
| 366 |
+
|
| 367 |
+
if self.norm_vectors:
|
| 368 |
+
feats = F.normalize(feats, dim=1)
|
| 369 |
+
|
| 370 |
+
return feats
|
| 371 |
+
|
| 372 |
+
def on_before_optimizer_step(self, optimizer, optimizer_idx):
|
| 373 |
+
norms = grad_norm(self, norm_type=2)
|
| 374 |
+
avg_grads = self.grad_avg.get_all()
|
| 375 |
+
params = {
|
| 376 |
+
f"grad_2.0_norm/{name}": p
|
| 377 |
+
for name, p in self.named_parameters()
|
| 378 |
+
if p.grad is not None
|
| 379 |
+
}
|
| 380 |
+
|
| 381 |
+
if self.adaptive_clipping:
|
| 382 |
+
for k in norms.keys():
|
| 383 |
+
if k in params:
|
| 384 |
+
avg_grad = max(avg_grads.get(k, norms[k]), 1e-5)
|
| 385 |
+
if self.global_step > 10 and norms[k] > avg_grad * 5:
|
| 386 |
+
print(f"Bad grad for {k}: {norms[k]} scaling to {avg_grad * 5}")
|
| 387 |
+
torch.nn.utils.clip_grad_norm_(params[k], avg_grad * 5)
|
| 388 |
+
norms[k] = avg_grad * 5
|
| 389 |
+
|
| 390 |
+
if norms[k] > self.gradient_clipping:
|
| 391 |
+
# print(f"Bad grad for {k}: {norms[k]} scaling to {self.gradient_clipping}")
|
| 392 |
+
torch.nn.utils.clip_grad_norm_(params[k], self.gradient_clipping)
|
| 393 |
+
|
| 394 |
+
# self.grad_avg.add_all(norms)
|
| 395 |
+
# self.log_dict(norms)
|
| 396 |
+
|
| 397 |
+
def interpolate_mask(self, mask, target_length, discrete):
|
| 398 |
+
b, t = mask.shape
|
| 399 |
+
|
| 400 |
+
mask = F.interpolate(mask.reshape(b, 1, 1, t), (1, target_length), mode="bilinear") \
|
| 401 |
+
.reshape(b, target_length)
|
| 402 |
+
|
| 403 |
+
if discrete:
|
| 404 |
+
mask = mask > 0.01
|
| 405 |
+
sums = mask.sum(1)
|
| 406 |
+
all_zeros = torch.where(sums == 0)[0]
|
| 407 |
+
if len(all_zeros) > 0:
|
| 408 |
+
print("Fixing a bad mask")
|
| 409 |
+
for entry in all_zeros:
|
| 410 |
+
mask[entry, torch.randint(0, target_length - 1, size=())] = True
|
| 411 |
+
else:
|
| 412 |
+
return mask
|
| 413 |
+
return mask
|
| 414 |
+
|
| 415 |
+
def forward_audio(self, batch):
|
| 416 |
+
if self.use_cached_embs:
|
| 417 |
+
audio_feats = batch["audio_emb"]
|
| 418 |
+
if "audio_cls" in batch:
|
| 419 |
+
audio_cls = batch["audio_cls"]
|
| 420 |
+
else:
|
| 421 |
+
audio_cls = None
|
| 422 |
+
else:
|
| 423 |
+
audio = batch[self.audio_input]
|
| 424 |
+
|
| 425 |
+
if self.full_train:
|
| 426 |
+
audio_feats, audio_cls = self.audio_model(audio, include_cls=True)
|
| 427 |
+
else:
|
| 428 |
+
with torch.no_grad():
|
| 429 |
+
audio_feats, audio_cls = self.audio_model(audio, include_cls=True)
|
| 430 |
+
|
| 431 |
+
mask = batch[AUDIO_MASK] if AUDIO_MASK in batch else torch.ones_like(audio)
|
| 432 |
+
pos_mask = batch[AUDIO_POS_MASK] if AUDIO_POS_MASK in batch else torch.ones_like(audio)
|
| 433 |
+
|
| 434 |
+
if self.learn_audio_cls:
|
| 435 |
+
assert audio_cls is None
|
| 436 |
+
audio_cls = torch.broadcast_to(self.audio_cls.unsqueeze(0), (audio_feats.shape[0], audio_feats.shape[1]))
|
| 437 |
+
|
| 438 |
+
aligned_audio_feats, aligned_audio_cls = self.audio_aligner(audio_feats, audio_cls)
|
| 439 |
+
|
| 440 |
+
if self.channel_dropout > 0.0:
|
| 441 |
+
aligned_audio_feats = self.channel_dropout_layer(aligned_audio_feats)
|
| 442 |
+
|
| 443 |
+
aligned_audio_feats = self.prep_feats(aligned_audio_feats, is_audio=True)
|
| 444 |
+
audio_mask = self.interpolate_mask(mask, aligned_audio_feats.shape[-1], True)
|
| 445 |
+
audio_pos_mask = self.interpolate_mask(pos_mask, aligned_audio_feats.shape[-1], False)
|
| 446 |
+
|
| 447 |
+
ret = {
|
| 448 |
+
AUDIO_MASK: audio_mask,
|
| 449 |
+
AUDIO_POS_MASK: audio_pos_mask,
|
| 450 |
+
AUDIO_FEATS: aligned_audio_feats,
|
| 451 |
+
}
|
| 452 |
+
|
| 453 |
+
if aligned_audio_cls is not None:
|
| 454 |
+
ret[AUDIO_CLS] = aligned_audio_cls
|
| 455 |
+
|
| 456 |
+
return ret
|
| 457 |
+
|
| 458 |
+
# @autocast(device_type="cuda", enabled=False)
|
| 459 |
+
def forward_image(self, batch, max_batch_size=None):
|
| 460 |
+
|
| 461 |
+
with torch.no_grad():
|
| 462 |
+
image = batch[IMAGE_INPUT]
|
| 463 |
+
b, nf, c, h, w = image.shape
|
| 464 |
+
image = image.reshape(b * nf, c, h, w)
|
| 465 |
+
|
| 466 |
+
if max_batch_size is None:
|
| 467 |
+
max_batch_size = image.shape[0]
|
| 468 |
+
|
| 469 |
+
chunks = [image[i:i + max_batch_size] for i in range(0, image.shape[0], max_batch_size)]
|
| 470 |
+
|
| 471 |
+
all_image_feats = []
|
| 472 |
+
all_image_cls = []
|
| 473 |
+
|
| 474 |
+
for chunk in chunks:
|
| 475 |
+
if self.full_train:
|
| 476 |
+
image_feats, image_cls = self.image_model(chunk, include_cls=True)
|
| 477 |
+
else:
|
| 478 |
+
with torch.no_grad():
|
| 479 |
+
image_feats, image_cls = self.image_model(chunk, include_cls=True)
|
| 480 |
+
|
| 481 |
+
aligned_image_feats, aligned_image_cls = self.image_aligner(image_feats, image_cls)
|
| 482 |
+
|
| 483 |
+
all_image_feats.append(aligned_image_feats)
|
| 484 |
+
all_image_cls.append(aligned_image_cls)
|
| 485 |
+
|
| 486 |
+
# Stitch the chunks back together
|
| 487 |
+
aligned_image_feats = torch.cat(all_image_feats, dim=0)
|
| 488 |
+
aligned_image_cls = torch.cat(all_image_cls, dim=0)
|
| 489 |
+
|
| 490 |
+
if self.channel_dropout > 0.0:
|
| 491 |
+
aligned_image_feats = self.channel_dropout_layer(aligned_image_feats)
|
| 492 |
+
|
| 493 |
+
if self.spatial_dropout > 0.0:
|
| 494 |
+
aligned_image_feats = self.spatial_dropout_layer(aligned_image_feats)
|
| 495 |
+
|
| 496 |
+
aligned_image_feats = self.prep_feats(aligned_image_feats, is_audio=False)
|
| 497 |
+
ret = {IMAGE_FEATS: aligned_image_feats}
|
| 498 |
+
|
| 499 |
+
if IMAGE_MASK in batch:
|
| 500 |
+
with torch.no_grad():
|
| 501 |
+
mask = batch[IMAGE_MASK]
|
| 502 |
+
mask = mask.reshape(b * nf, 1, h, w)
|
| 503 |
+
b, c, h, w = aligned_image_feats.shape
|
| 504 |
+
mask = F.adaptive_avg_pool2d(mask.to(aligned_image_feats), output_size=(h, w))
|
| 505 |
+
ret[IMAGE_MASK] = mask
|
| 506 |
+
|
| 507 |
+
if aligned_image_cls is not None:
|
| 508 |
+
ret[IMAGE_CLS] = aligned_image_cls
|
| 509 |
+
|
| 510 |
+
return ret
|
| 511 |
+
|
| 512 |
+
def forward(self, batch):
|
| 513 |
+
audio_feat_dict = self.forward_audio(batch)
|
| 514 |
+
image_feat_dict = self.forward_image(batch)
|
| 515 |
+
return {**image_feat_dict, **audio_feat_dict}
|
| 516 |
+
|
| 517 |
+
def contrast_loss(self, sims):
|
| 518 |
+
b = sims.shape[0]
|
| 519 |
+
sims = sims - torch.eye(b, b, device=sims.device) * self.loss_margin
|
| 520 |
+
sims_1 = sims
|
| 521 |
+
sims_2 = sims.permute(1, 0)
|
| 522 |
+
|
| 523 |
+
if self.loss_leak > 0.0:
|
| 524 |
+
id = torch.eye(sims_1.shape[0], sims_1.shape[1], device=sims.device, dtype=sims.dtype)
|
| 525 |
+
label_mask = id * (1 - self.loss_leak)
|
| 526 |
+
label_mask += (1 - id) * self.loss_leak / (sims_1.shape[0] - 1)
|
| 527 |
+
label_mask /= label_mask.sum(dim=1, keepdim=True)
|
| 528 |
+
else:
|
| 529 |
+
label_mask = torch.eye(sims_1.shape[0], sims_1.shape[1], device=sims.device, dtype=sims.dtype)
|
| 530 |
+
|
| 531 |
+
labels = torch.arange(0, sims.shape[0], device=sims.device)
|
| 532 |
+
self.rolling_avg.add(f"acc/1", (sims.argmax(dim=1) == labels).to(sims).mean())
|
| 533 |
+
self.rolling_avg.add(f"acc/2", (sims.argmax(dim=0) == labels).to(sims).mean())
|
| 534 |
+
|
| 535 |
+
if self.loss_type == "margin":
|
| 536 |
+
margin_loss_tensor = (sims - torch.diag(sims)).clamp_min(0)
|
| 537 |
+
margin_loss = margin_loss_tensor.mean()
|
| 538 |
+
self.rolling_avg.add(f"loss/frac_nonzero", (margin_loss_tensor > 0).to(sims).mean())
|
| 539 |
+
self.rolling_avg.add(f"loss/margin", margin_loss)
|
| 540 |
+
return margin_loss
|
| 541 |
+
elif self.loss_type == "ce":
|
| 542 |
+
ce_loss = 1 / 2 * F.cross_entropy(sims_1, labels) + \
|
| 543 |
+
1 / 2 * F.cross_entropy(sims_2, labels)
|
| 544 |
+
self.rolling_avg.add(f"loss/ce", ce_loss)
|
| 545 |
+
return ce_loss
|
| 546 |
+
elif self.loss_type == "bce":
|
| 547 |
+
bce_loss = F.binary_cross_entropy_with_logits(sims_1.flatten(), label_mask.flatten())
|
| 548 |
+
self.rolling_avg.add(f"loss/bce", bce_loss)
|
| 549 |
+
return bce_loss
|
| 550 |
+
elif self.loss_type == "nce":
|
| 551 |
+
nce_loss = 1 / 2 * (-F.log_softmax(sims_1, dim=-1) * label_mask).sum(1).mean() + \
|
| 552 |
+
1 / 2 * (-F.log_softmax(sims_2, dim=-1) * label_mask).sum(1).mean()
|
| 553 |
+
self.rolling_avg.add(f"loss/nce", nce_loss)
|
| 554 |
+
return nce_loss
|
| 555 |
+
else:
|
| 556 |
+
raise ValueError(f"Unknown loss type {self.loss_type}")
|
| 557 |
+
|
| 558 |
+
def loss(self, preds):
|
| 559 |
+
image_feats = preds[IMAGE_FEATS]
|
| 560 |
+
audio_feats = preds[AUDIO_FEATS]
|
| 561 |
+
audio_mask = preds[AUDIO_MASK]
|
| 562 |
+
image_mask = preds[IMAGE_MASK]
|
| 563 |
+
audio_pos_mask = preds[AUDIO_POS_MASK]
|
| 564 |
+
if DATA_SOURCE in preds:
|
| 565 |
+
source = preds[DATA_SOURCE].to(torch.int64)
|
| 566 |
+
else:
|
| 567 |
+
source = None
|
| 568 |
+
|
| 569 |
+
uncal_sims = self.sim_agg(preds, agg_heads=True)
|
| 570 |
+
sims = self.sim_cal(uncal_sims)
|
| 571 |
+
|
| 572 |
+
_mask = 1 - torch.eye(sims.shape[0], device=sims.device)
|
| 573 |
+
self.log(f"sim/pos", torch.diag(sims).mean())
|
| 574 |
+
self.log(f"sim/neg", (sims * _mask).sum() / (_mask.sum()))
|
| 575 |
+
self.log(f"sim/uncal_pos", torch.diag(uncal_sims).mean())
|
| 576 |
+
self.log(f"sim/uncal_neg", (uncal_sims * _mask).sum() / (_mask.sum()))
|
| 577 |
+
|
| 578 |
+
b, c, h, w = image_feats.shape
|
| 579 |
+
b, c, f, t = audio_feats.shape
|
| 580 |
+
n_samples = 250
|
| 581 |
+
|
| 582 |
+
nh = self.sim_agg_heads
|
| 583 |
+
image_feats_by_head = image_feats.reshape(b, self.sim_agg_heads, c // nh, h, w)
|
| 584 |
+
audio_feats_by_head = audio_feats.reshape(b, self.sim_agg_heads, c // nh, f, t)
|
| 585 |
+
|
| 586 |
+
def maybe_clamp(t):
|
| 587 |
+
return t.clamp_min(0) if self.nonneg_sim else t
|
| 588 |
+
|
| 589 |
+
paired_sim_raw = self.sim_agg.get_pairwise_sims(preds, raw=True, agg_sim=False, agg_heads=False)
|
| 590 |
+
paired_sim = maybe_clamp(paired_sim_raw)
|
| 591 |
+
|
| 592 |
+
loss = 0.0
|
| 593 |
+
|
| 594 |
+
if self.nonneg_pressure:
|
| 595 |
+
afb, afk, afc, aff, aft = audio_feats_by_head.shape
|
| 596 |
+
ifb, ifk, ifc, ifh, ifw = image_feats_by_head.shape
|
| 597 |
+
assert (afb == ifb)
|
| 598 |
+
|
| 599 |
+
device = audio_feats_by_head.device
|
| 600 |
+
random_b = torch.randint(0, afb, size=(n_samples,), device=device)
|
| 601 |
+
random_t = torch.randint(0, aft, size=(n_samples,), device=device)
|
| 602 |
+
random_f = torch.randint(0, aff, size=(n_samples,), device=device)
|
| 603 |
+
random_h = torch.randint(0, ifh, size=(n_samples,), device=device)
|
| 604 |
+
random_w = torch.randint(0, ifw, size=(n_samples,), device=device)
|
| 605 |
+
|
| 606 |
+
random_audio_feats = audio_feats_by_head[random_b, :, :, random_f, random_t]
|
| 607 |
+
random_image_feats = image_feats_by_head[random_b, :, :, random_h, random_w]
|
| 608 |
+
random_sim_raw = torch.einsum("bkc,dkc->bdk", random_audio_feats, random_image_feats)
|
| 609 |
+
|
| 610 |
+
nonneg_loss = random_sim_raw.clamp_max(0).square().mean()
|
| 611 |
+
self.rolling_avg.add(f"loss/nonneg", nonneg_loss)
|
| 612 |
+
loss += nonneg_loss * self.nonneg_pressure
|
| 613 |
+
|
| 614 |
+
if self.silence_l1 > 0 or self.silence_l2 > 0:
|
| 615 |
+
masked_b, masked_t = torch.where(~audio_mask)
|
| 616 |
+
if len(masked_b) > n_samples:
|
| 617 |
+
subset = torch.randperm(len(masked_b))[:n_samples]
|
| 618 |
+
masked_b = masked_b[subset]
|
| 619 |
+
masked_t = masked_t[subset]
|
| 620 |
+
|
| 621 |
+
if len(masked_b) == n_samples:
|
| 622 |
+
silent_audio_feats = audio_feats_by_head[masked_b, :, :, :, masked_t].mean(-1) # d k c
|
| 623 |
+
silence_tensor = maybe_clamp(
|
| 624 |
+
torch.einsum("bkchw,dkc->bkdhw", image_feats_by_head, silent_audio_feats))
|
| 625 |
+
|
| 626 |
+
silence_l1_loss = silence_tensor.abs().mean()
|
| 627 |
+
self.rolling_avg.add(f"loss/silence_l1", silence_l1_loss)
|
| 628 |
+
loss += silence_l1_loss * self.silence_l1
|
| 629 |
+
|
| 630 |
+
silence_l2_loss = silence_tensor.square().mean()
|
| 631 |
+
self.rolling_avg.add(f"loss/silence_l2", silence_l2_loss)
|
| 632 |
+
loss += silence_l2_loss * self.silence_l2
|
| 633 |
+
else:
|
| 634 |
+
pass
|
| 635 |
+
|
| 636 |
+
if self.neg_audio_weight > 0 and self.neg_audio:
|
| 637 |
+
b, t = audio_pos_mask.shape
|
| 638 |
+
negative_weight = ((1 - audio_pos_mask) * audio_mask.to(sims)).reshape(b, 1, 1, 1, 1, t)
|
| 639 |
+
negative_weight = torch.broadcast_to(negative_weight, paired_sim.shape)
|
| 640 |
+
if negative_weight.sum() > 0:
|
| 641 |
+
neg_audio_loss = (paired_sim.square() * negative_weight).sum() \
|
| 642 |
+
/ negative_weight.sum().clamp_min(0.1)
|
| 643 |
+
self.rolling_avg.add(f"loss/neg_audio", neg_audio_loss)
|
| 644 |
+
self.rolling_avg.add(f"loss/neg_weight_avg", negative_weight.mean())
|
| 645 |
+
loss += neg_audio_loss * self.neg_audio_weight
|
| 646 |
+
else:
|
| 647 |
+
print("WARNING: No negative samples found in batch")
|
| 648 |
+
|
| 649 |
+
if self.tv_weight > 0:
|
| 650 |
+
tv_loss = (paired_sim[:, :, :, :, :, 1:] - paired_sim[:, :, :, :, :, :-1]).square().mean()
|
| 651 |
+
self.rolling_avg.add(f"loss/tv", tv_loss)
|
| 652 |
+
loss += tv_loss * self.tv_weight
|
| 653 |
+
|
| 654 |
+
self.log(f"cal/w", self.sim_cal.get_w())
|
| 655 |
+
if self.cal_balance_weight > 0.0:
|
| 656 |
+
cal_balance = (np.log(self.cal_init) - torch.log(self.sim_cal.get_w().clamp_min(.00000001))) \
|
| 657 |
+
.clamp_min(0).square().mean()
|
| 658 |
+
self.rolling_avg.add(f"loss/cal_balance", cal_balance)
|
| 659 |
+
loss += cal_balance * self.cal_balance_weight
|
| 660 |
+
|
| 661 |
+
if self.disentangle_weight > 0.0:
|
| 662 |
+
assert source is not None
|
| 663 |
+
assert self.sim_agg_heads % 2 == 0
|
| 664 |
+
|
| 665 |
+
dilation = self.sim_agg_heads // 2
|
| 666 |
+
sources_oh = F.one_hot(source, num_classes=2)
|
| 667 |
+
b, h = sources_oh.shape
|
| 668 |
+
sources_mask = 1 - torch.broadcast_to(sources_oh.unsqueeze(-1), (b, h, dilation)) \
|
| 669 |
+
.reshape(b, h * dilation).to(paired_sim)
|
| 670 |
+
disentangle_loss = torch.einsum("bkhwft,bk->bhwft", paired_sim, sources_mask).square().mean()
|
| 671 |
+
self.rolling_avg.add(f"loss/disentangle", disentangle_loss)
|
| 672 |
+
loss += disentangle_loss * self.disentangle_weight
|
| 673 |
+
|
| 674 |
+
if self.specialization_weight > 0.0 and self.sim_agg_heads > 1:
|
| 675 |
+
total_specialization_loss = 0.0
|
| 676 |
+
combos = list(combinations(range(self.sim_agg_heads), 2))
|
| 677 |
+
for i, j in combos:
|
| 678 |
+
specialization_loss_pair = (paired_sim[:, i].abs() * paired_sim[:, j].abs()).mean()
|
| 679 |
+
total_specialization_loss += specialization_loss_pair
|
| 680 |
+
avg_specialization_loss = total_specialization_loss / len(combos)
|
| 681 |
+
self.rolling_avg.add(f"loss/specialize", avg_specialization_loss)
|
| 682 |
+
loss += avg_specialization_loss * self.specialization_weight
|
| 683 |
+
|
| 684 |
+
if self.mixup_weight > 0.0:
|
| 685 |
+
b, _, h, w = image_mask.shape
|
| 686 |
+
neg_img_mask = torch.broadcast_to(
|
| 687 |
+
1 - image_mask.to(paired_sim).reshape(b, 1, h, w, 1, 1),
|
| 688 |
+
paired_sim.shape)
|
| 689 |
+
image_mixup_loss = (paired_sim * neg_img_mask).square().sum() / neg_img_mask.sum().clamp_min(0.1)
|
| 690 |
+
self.rolling_avg.add(f"loss/image_mixup", image_mixup_loss)
|
| 691 |
+
loss += image_mixup_loss * self.mixup_weight
|
| 692 |
+
|
| 693 |
+
sims = sims
|
| 694 |
+
loss += self.contrast_loss(sims)
|
| 695 |
+
self.rolling_avg.add(f"loss/total", loss)
|
| 696 |
+
|
| 697 |
+
return loss
|
| 698 |
+
|
| 699 |
+
def setup_hparams(self):
|
| 700 |
+
recalls = ['A_r1', 'A_r5', 'A_r10', 'I_r1', 'I_r5', 'I_r10']
|
| 701 |
+
|
| 702 |
+
if self.trainer.datamodule.use_extra_val_sets:
|
| 703 |
+
datasets = ["Places", "AudioSet"]
|
| 704 |
+
else:
|
| 705 |
+
datasets = ["Val"]
|
| 706 |
+
|
| 707 |
+
heads = ["total"]
|
| 708 |
+
|
| 709 |
+
metric_names = [
|
| 710 |
+
"hp/speech_basic_ap", "hp/speech_advanced_ap", "hp/sound_basic_ap",
|
| 711 |
+
"hp/speech_basic_iou", "hp/speech_advanced_iou", "hp/sound_basic_iou",
|
| 712 |
+
]
|
| 713 |
+
for dataset in datasets:
|
| 714 |
+
for head in heads:
|
| 715 |
+
for recall in recalls:
|
| 716 |
+
metric_names.append(f"hp/{dataset}/{head}/{recall}")
|
| 717 |
+
|
| 718 |
+
if self.sim_agg_heads == 2:
|
| 719 |
+
metric_names.extend(["hp/ap_dis", "hp/act_dis"])
|
| 720 |
+
|
| 721 |
+
if hasattr(self.trainer, "datamodule"):
|
| 722 |
+
all_hparams = {**self.hparams, **self.trainer.datamodule.hparams}
|
| 723 |
+
else:
|
| 724 |
+
all_hparams = self.hparams
|
| 725 |
+
|
| 726 |
+
starting_values = {n: torch.nan for n in metric_names}
|
| 727 |
+
self.logger.log_hyperparams(all_hparams, starting_values)
|
| 728 |
+
|
| 729 |
+
def on_train_start(self):
|
| 730 |
+
self.setup_hparams()
|
| 731 |
+
self.hparams_logged = True
|
| 732 |
+
|
| 733 |
+
def on_train_batch_start(self, batch, batch_idx):
|
| 734 |
+
remake_optimizers = False
|
| 735 |
+
|
| 736 |
+
if isinstance(self.image_aligner, ProgressiveGrowing):
|
| 737 |
+
should_remake = self.image_aligner.maybe_change_phase(self.global_step)
|
| 738 |
+
remake_optimizers = remake_optimizers or should_remake
|
| 739 |
+
if isinstance(self.audio_aligner, ProgressiveGrowing):
|
| 740 |
+
should_remake = self.audio_aligner.maybe_change_phase(self.global_step)
|
| 741 |
+
remake_optimizers = remake_optimizers or should_remake
|
| 742 |
+
|
| 743 |
+
if remake_optimizers:
|
| 744 |
+
raise NotImplementedError()
|
| 745 |
+
|
| 746 |
+
def _combine_preds(self, all_preds):
|
| 747 |
+
temp = {}
|
| 748 |
+
new_preds = {}
|
| 749 |
+
|
| 750 |
+
# Collect tensors for each key into lists
|
| 751 |
+
for d in all_preds:
|
| 752 |
+
for key, value in d.items():
|
| 753 |
+
if isinstance(value, torch.Tensor):
|
| 754 |
+
if key not in temp:
|
| 755 |
+
temp[key] = []
|
| 756 |
+
temp[key].append(value)
|
| 757 |
+
|
| 758 |
+
# Concatenate all tensors for each key using a single call to torch.cat
|
| 759 |
+
for key, tensor_list in temp.items():
|
| 760 |
+
new_preds[key] = torch.cat(tensor_list)
|
| 761 |
+
return new_preds
|
| 762 |
+
|
| 763 |
+
def training_step(self, batch, batch_idx):
|
| 764 |
+
assert batch[IMAGE_INPUT].shape[1] == 1
|
| 765 |
+
|
| 766 |
+
preds = self.forward(batch)
|
| 767 |
+
if DATA_SOURCE in batch:
|
| 768 |
+
preds[DATA_SOURCE] = batch[DATA_SOURCE]
|
| 769 |
+
|
| 770 |
+
if self.trainer.world_size > 1 and self.gather_tensors:
|
| 771 |
+
for k, v in preds.items():
|
| 772 |
+
new_v = v.contiguous()
|
| 773 |
+
preds[k] = torch.cat(GatherLayer.apply(new_v), dim=0)
|
| 774 |
+
|
| 775 |
+
if self.memory_buffer_size > 0:
|
| 776 |
+
new_preds = self._combine_preds(list(self.memory_buffer) + [preds])
|
| 777 |
+
else:
|
| 778 |
+
new_preds = preds
|
| 779 |
+
|
| 780 |
+
loss = self.loss(new_preds)
|
| 781 |
+
|
| 782 |
+
if self.memory_buffer_size > 0:
|
| 783 |
+
self.memory_buffer.append(self._recursive_detach(preds, gather=False))
|
| 784 |
+
|
| 785 |
+
if self.trainer.is_global_zero and self.global_step % 50 == 1:
|
| 786 |
+
writer = self.logger.experiment
|
| 787 |
+
self.rolling_avg.logall(lambda k, v: writer.add_scalar(k, v, global_step=self.global_step))
|
| 788 |
+
|
| 789 |
+
if self.trainer.scaler is not None:
|
| 790 |
+
self.log("loss_scale", self.trainer.scaler.get_scale())
|
| 791 |
+
|
| 792 |
+
if self.global_step % 10000 == 0 and self.global_step > 0:
|
| 793 |
+
print("RESETTING TFEVENT FILE")
|
| 794 |
+
self.logger.experiment.close()
|
| 795 |
+
self.logger.experiment._get_file_writer()
|
| 796 |
+
|
| 797 |
+
return loss
|
| 798 |
+
|
| 799 |
+
def on_validation_start(self) -> None:
|
| 800 |
+
if not self.hparams_logged:
|
| 801 |
+
self.setup_hparams()
|
| 802 |
+
self.hparams_logged = True
|
| 803 |
+
|
| 804 |
+
def _auto_gather(self, t):
|
| 805 |
+
if t.dtype == torch.bool:
|
| 806 |
+
t = t.to(torch.float)
|
| 807 |
+
|
| 808 |
+
if self.trainer.num_devices == 1:
|
| 809 |
+
return t.cpu()
|
| 810 |
+
|
| 811 |
+
t = torch.clone(t).contiguous()
|
| 812 |
+
if self.trainer.is_global_zero:
|
| 813 |
+
gather_list = [torch.zeros_like(t) for _ in range(dist.get_world_size())]
|
| 814 |
+
dist.gather(t, gather_list)
|
| 815 |
+
return torch.cat(gather_list, dim=0).cpu()
|
| 816 |
+
else:
|
| 817 |
+
dist.gather(t)
|
| 818 |
+
|
| 819 |
+
def validation_step(self, batch, batch_idx, dataloader_idx=0):
|
| 820 |
+
|
| 821 |
+
with torch.no_grad():
|
| 822 |
+
preds = self.forward(batch)
|
| 823 |
+
|
| 824 |
+
ret = {}
|
| 825 |
+
for k in preds.keys():
|
| 826 |
+
if k in preds:
|
| 827 |
+
ret[k] = self._auto_gather(preds[k])
|
| 828 |
+
|
| 829 |
+
batch_keys = [IMAGE_INPUT, "spec", "semseg", "num_pixels_per_class", 'total_length']
|
| 830 |
+
for k in batch_keys:
|
| 831 |
+
if k in batch:
|
| 832 |
+
ret[k] = self._auto_gather(batch[k])
|
| 833 |
+
|
| 834 |
+
if "metadata" in batch:
|
| 835 |
+
if isinstance(batch["metadata"]["id"], torch.Tensor):
|
| 836 |
+
ret["id"] = self._auto_gather(batch["metadata"]["id"])
|
| 837 |
+
ret["index"] = self._auto_gather(batch["metadata"]["index"])
|
| 838 |
+
|
| 839 |
+
return ret
|
| 840 |
+
|
| 841 |
+
def _calc_recalls(self, sim):
|
| 842 |
+
top_10_a = sim.topk(10, 0).indices == torch.arange(sim.shape[0]).unsqueeze(0)
|
| 843 |
+
top_10_i = (sim.topk(10, 1).indices == torch.arange(sim.shape[0]).unsqueeze(1)).permute(1, 0)
|
| 844 |
+
a_recall = lambda p: top_10_a[0:p].any(0).to(sim).mean()
|
| 845 |
+
i_recall = lambda p: top_10_i[0:p].any(0).to(sim).mean()
|
| 846 |
+
return {'A_r1': a_recall(1),
|
| 847 |
+
'A_r5': a_recall(5),
|
| 848 |
+
'A_r10': a_recall(10),
|
| 849 |
+
'I_r1': i_recall(1),
|
| 850 |
+
'I_r5': i_recall(5),
|
| 851 |
+
'I_r10': i_recall(10)}
|
| 852 |
+
|
| 853 |
+
def calc_recalls(self, preds, dataset):
|
| 854 |
+
sim = self.sim_agg.forward_batched(
|
| 855 |
+
preds=preds,
|
| 856 |
+
agg_heads=False,
|
| 857 |
+
batch_size=4,
|
| 858 |
+
).cpu()
|
| 859 |
+
|
| 860 |
+
all_metrics = dict()
|
| 861 |
+
for k, v in self._calc_recalls(sim.sum(-1)).items():
|
| 862 |
+
all_metrics[f"hp/{dataset}/total/" + k] = v
|
| 863 |
+
|
| 864 |
+
return all_metrics
|
| 865 |
+
|
| 866 |
+
def retrieval_validation(self, outputs, dataset_name):
|
| 867 |
+
if len(outputs) == 0:
|
| 868 |
+
return
|
| 869 |
+
|
| 870 |
+
if self.trainer.is_global_zero:
|
| 871 |
+
results = flatten_preds(outputs)
|
| 872 |
+
if not self.trainer.sanity_checking:
|
| 873 |
+
print(results[IMAGE_FEATS].shape[0])
|
| 874 |
+
# assert (results[IMAGE_FEATS].shape[0] == 1000)
|
| 875 |
+
results[IMAGE_FEATS] = results[IMAGE_FEATS].cpu()
|
| 876 |
+
results[AUDIO_FEATS] = results[AUDIO_FEATS].cuda()
|
| 877 |
+
if self.sim_use_cls:
|
| 878 |
+
results[AUDIO_CLS] = results[AUDIO_CLS].cuda()
|
| 879 |
+
results[AUDIO_CLS] = results[AUDIO_CLS].cuda()
|
| 880 |
+
|
| 881 |
+
results[AUDIO_MASK] = results[AUDIO_MASK].cuda()
|
| 882 |
+
|
| 883 |
+
recalls = self.calc_recalls(results, dataset_name)
|
| 884 |
+
|
| 885 |
+
results[IMAGE_FEATS] = results[IMAGE_FEATS].cuda()
|
| 886 |
+
|
| 887 |
+
writer = self.logger.experiment
|
| 888 |
+
print("here")
|
| 889 |
+
for name, v in recalls.items():
|
| 890 |
+
writer.add_scalar(f"{name}", v, self.global_step + 1)
|
| 891 |
+
|
| 892 |
+
def semseg_validation(self, speech_preds, sound_preds):
|
| 893 |
+
|
| 894 |
+
if self.trainer.is_global_zero:
|
| 895 |
+
from eval_utils import get_paired_heatmaps
|
| 896 |
+
def prep_preds(preds, loader):
|
| 897 |
+
results = flatten_preds(preds)
|
| 898 |
+
metadata = loader.dataset.metadata
|
| 899 |
+
ordered_metadata = metadata.iloc[results["index"].numpy(), :].copy()
|
| 900 |
+
ordered_metadata["order"] = range(len(ordered_metadata))
|
| 901 |
+
return results, ordered_metadata
|
| 902 |
+
|
| 903 |
+
[_, _, speech_loader, sound_loader] = self.trainer.val_dataloaders
|
| 904 |
+
speech_results, speech_metadata = prep_preds(speech_preds, speech_loader)
|
| 905 |
+
sound_results, sound_metadata = prep_preds(sound_preds, sound_loader)
|
| 906 |
+
|
| 907 |
+
self.sound_metrics, unique_sound_indices = get_paired_heatmaps(
|
| 908 |
+
self, sound_results, sound_metadata["ade_class_id"], None)
|
| 909 |
+
|
| 910 |
+
self.speech_metrics, unique_word_indices = get_paired_heatmaps(
|
| 911 |
+
self, speech_results, speech_metadata["ade_class_id"], speech_metadata["timing"])
|
| 912 |
+
|
| 913 |
+
writer = self.logger.experiment
|
| 914 |
+
|
| 915 |
+
all_metrics = {
|
| 916 |
+
**{"sound_" + k: v for k, v in self.sound_metrics.items()},
|
| 917 |
+
**{"speech_" + k: v for k, v in self.speech_metrics.items()},
|
| 918 |
+
}
|
| 919 |
+
|
| 920 |
+
for k, v in all_metrics.items():
|
| 921 |
+
writer.add_scalar(f"hp/{k}", torch.tensor(v).mean(), self.global_step + 1)
|
| 922 |
+
|
| 923 |
+
def disentangle_validation(self, word_preds, sound_preds):
|
| 924 |
+
|
| 925 |
+
if len(word_preds) == 0 or len(sound_preds) == 0:
|
| 926 |
+
return
|
| 927 |
+
|
| 928 |
+
if self.trainer.is_global_zero:
|
| 929 |
+
word_preds = flatten_preds(word_preds)
|
| 930 |
+
sound_preds = flatten_preds(sound_preds)
|
| 931 |
+
|
| 932 |
+
word_scores = self.sim_agg.get_pairwise_sims(
|
| 933 |
+
word_preds,
|
| 934 |
+
raw=False,
|
| 935 |
+
agg_sim=True,
|
| 936 |
+
agg_heads=False,
|
| 937 |
+
)
|
| 938 |
+
|
| 939 |
+
sound_scores = self.sim_agg.get_pairwise_sims(
|
| 940 |
+
sound_preds,
|
| 941 |
+
raw=False,
|
| 942 |
+
agg_sim=True,
|
| 943 |
+
agg_heads=False,
|
| 944 |
+
)
|
| 945 |
+
|
| 946 |
+
all_scores = torch.cat([word_scores, sound_scores], dim=0)
|
| 947 |
+
all_scores -= all_scores.min(dim=0, keepdim=True).values
|
| 948 |
+
all_scores /= all_scores.max(dim=0, keepdim=True).values.clamp_min(.0001)
|
| 949 |
+
|
| 950 |
+
is_words = torch.cat([
|
| 951 |
+
torch.ones(word_scores.shape[0]),
|
| 952 |
+
torch.zeros(sound_scores.shape[0])], dim=0).to(torch.bool)
|
| 953 |
+
|
| 954 |
+
assert all_scores.shape[1] == 2
|
| 955 |
+
ap_matrix = torch.zeros(2, 2)
|
| 956 |
+
act_matrix = torch.zeros(2, 2)
|
| 957 |
+
|
| 958 |
+
for head in range(2):
|
| 959 |
+
# writer.add_histogram(f"h{head}_all_scores", all_scores[:, head])
|
| 960 |
+
for dataset_num in range(2):
|
| 961 |
+
if dataset_num == 0:
|
| 962 |
+
labels = is_words
|
| 963 |
+
else:
|
| 964 |
+
labels = ~is_words
|
| 965 |
+
|
| 966 |
+
ap_matrix[head, dataset_num] = binary_average_precision(
|
| 967 |
+
all_scores[:, head].cpu(), labels.to(torch.int64).cpu())
|
| 968 |
+
|
| 969 |
+
act_matrix[head, dataset_num] = 1 - (all_scores[:, head][labels]).mean()
|
| 970 |
+
|
| 971 |
+
ap_dis = max(.5 * (ap_matrix[0, 0] + ap_matrix[1, 1]),
|
| 972 |
+
.5 * (ap_matrix[0, 1] + ap_matrix[1, 0]))
|
| 973 |
+
|
| 974 |
+
act_dis = max(.5 * (act_matrix[0, 0] + act_matrix[1, 1]),
|
| 975 |
+
.5 * (act_matrix[0, 1] + act_matrix[1, 0]))
|
| 976 |
+
|
| 977 |
+
print("AP", ap_matrix)
|
| 978 |
+
print("AP dis", ap_dis)
|
| 979 |
+
print("Act", act_matrix)
|
| 980 |
+
print("Act dis", act_dis)
|
| 981 |
+
|
| 982 |
+
writer = self.logger.experiment
|
| 983 |
+
writer.add_scalar("hp/ap_dis", ap_dis, self.global_step + 1)
|
| 984 |
+
writer.add_scalar("hp/act_dis", act_dis, self.global_step + 1)
|
| 985 |
+
|
| 986 |
+
def validation_epoch_end(self, outputs) -> None:
|
| 987 |
+
print("Val end")
|
| 988 |
+
with torch.no_grad():
|
| 989 |
+
if self.trainer.datamodule.use_extra_val_sets:
|
| 990 |
+
if self.sim_agg_heads == 2:
|
| 991 |
+
self.disentangle_validation(outputs[0], outputs[1])
|
| 992 |
+
self.retrieval_validation(outputs[0], "Places")
|
| 993 |
+
self.retrieval_validation(outputs[1], "AudioSet")
|
| 994 |
+
self.semseg_validation(outputs[2], outputs[3])
|
| 995 |
+
|
| 996 |
+
else:
|
| 997 |
+
print("HERE!")
|
| 998 |
+
self.retrieval_validation(outputs, "Val")
|
| 999 |
+
|
| 1000 |
+
writer = self.logger.experiment
|
| 1001 |
+
writer.flush()
|
| 1002 |
+
|
| 1003 |
+
def _recursive_detach(self, obj, gather=True):
|
| 1004 |
+
if isinstance(obj, torch.Tensor):
|
| 1005 |
+
if gather:
|
| 1006 |
+
return self._auto_gather(obj)
|
| 1007 |
+
else:
|
| 1008 |
+
obj.detach()
|
| 1009 |
+
elif isinstance(obj, dict):
|
| 1010 |
+
return {k: self._recursive_detach(v, gather) for k, v in obj.items()}
|
| 1011 |
+
elif isinstance(obj, list):
|
| 1012 |
+
return [self._recursive_detach(v, gather) for v in obj]
|
| 1013 |
+
else:
|
| 1014 |
+
return obj
|
| 1015 |
+
|
| 1016 |
+
def predict_step(self, batch, batch_idx: int, dataloader_idx: int = 0):
|
| 1017 |
+
with torch.no_grad():
|
| 1018 |
+
predictions = {}
|
| 1019 |
+
for k, v in batch.items():
|
| 1020 |
+
predictions[k] = self._recursive_detach(v)
|
| 1021 |
+
for k, v in self.forward(batch).items():
|
| 1022 |
+
predictions[k] = self._auto_gather(v)
|
| 1023 |
+
|
| 1024 |
+
return predictions
|
| 1025 |
+
|
| 1026 |
+
def _configure_optimizers(self, full_train, lr):
|
| 1027 |
+
params = [
|
| 1028 |
+
*self.audio_aligner.parameters(),
|
| 1029 |
+
*self.image_aligner.parameters(),
|
| 1030 |
+
*self.sim_cal.parameters(),
|
| 1031 |
+
*self.sim_agg.parameters()
|
| 1032 |
+
]
|
| 1033 |
+
|
| 1034 |
+
if (self.finetune_image_model or self.image_lora) and full_train:
|
| 1035 |
+
params.extend(self.image_model.parameters())
|
| 1036 |
+
|
| 1037 |
+
if (self.finetune_audio_model or self.audio_lora) and full_train:
|
| 1038 |
+
params.extend(self.audio_model.parameters())
|
| 1039 |
+
|
| 1040 |
+
if self.learn_audio_cls:
|
| 1041 |
+
params.append(self.audio_cls)
|
| 1042 |
+
|
| 1043 |
+
last_epoch = self.global_step - 1
|
| 1044 |
+
if self.optimizer == "adam":
|
| 1045 |
+
opt = torch.optim.Adam(params, lr=lr, eps=1e-7)
|
| 1046 |
+
elif self.optimizer == "nadam":
|
| 1047 |
+
opt = torch.optim.NAdam(params, lr=lr, eps=1e-7)
|
| 1048 |
+
else:
|
| 1049 |
+
raise ValueError(f"Unknown optimizer {self.optimizer}")
|
| 1050 |
+
|
| 1051 |
+
if self.lr_schedule == "sgdr":
|
| 1052 |
+
scheduler = CosineAnnealingWarmRestarts(
|
| 1053 |
+
opt, self.lr_cycle_length, 2, eta_min=lr * 2e-2, last_epoch=last_epoch)
|
| 1054 |
+
else:
|
| 1055 |
+
scheduler = LambdaLR(opt, lr_lambda=lambda step: 1.0, last_epoch=last_epoch)
|
| 1056 |
+
|
| 1057 |
+
if self.lr_warmup > 0:
|
| 1058 |
+
warmup = LambdaLR(
|
| 1059 |
+
opt,
|
| 1060 |
+
lr_lambda=lambda step: min(max(float(step), 0.0) / self.lr_warmup, 1.0),
|
| 1061 |
+
last_epoch=last_epoch,
|
| 1062 |
+
)
|
| 1063 |
+
scheduler = SequentialLR(
|
| 1064 |
+
opt,
|
| 1065 |
+
schedulers=[warmup, scheduler],
|
| 1066 |
+
milestones=[self.lr_warmup],
|
| 1067 |
+
last_epoch=last_epoch)
|
| 1068 |
+
|
| 1069 |
+
scheduler = {"scheduler": scheduler, "interval": "step"}
|
| 1070 |
+
|
| 1071 |
+
return [opt], [scheduler]
|
| 1072 |
+
|
| 1073 |
+
def configure_optimizers(self):
|
| 1074 |
+
if self.full_train:
|
| 1075 |
+
return self._configure_optimizers(self.full_train, self.lr)
|
| 1076 |
+
else:
|
| 1077 |
+
return self._configure_optimizers(self.full_train, self.pretrain_lr)
|
| 1078 |
+
|
| 1079 |
+
|
| 1080 |
+
@hydra.main(config_path="configs", config_name="av_align.yaml", version_base=None)
|
| 1081 |
+
def my_app(cfg: DictConfig) -> None:
|
| 1082 |
+
print(OmegaConf.to_yaml(cfg))
|
| 1083 |
+
seed_everything(cfg.seed, workers=True)
|
| 1084 |
+
|
| 1085 |
+
exp_name = f"{cfg.resume_prefix}"
|
| 1086 |
+
|
| 1087 |
+
if cfg.image_model_type == "dino8":
|
| 1088 |
+
patch_size = 8 * cfg.image_pool_width
|
| 1089 |
+
elif cfg.image_model_type == "cavmae":
|
| 1090 |
+
patch_size = 16 * cfg.image_pool_width
|
| 1091 |
+
elif cfg.image_model_type == "imagebind":
|
| 1092 |
+
patch_size = 16 * cfg.image_pool_width
|
| 1093 |
+
elif cfg.image_model_type == "clip":
|
| 1094 |
+
patch_size = 16 * cfg.image_pool_width
|
| 1095 |
+
elif cfg.image_model_type == "cavmae-mixed":
|
| 1096 |
+
patch_size = 16 * cfg.image_pool_width
|
| 1097 |
+
elif cfg.image_model_type == "dinov2":
|
| 1098 |
+
patch_size = 14 * cfg.image_pool_width
|
| 1099 |
+
else:
|
| 1100 |
+
raise ValueError(f"Unknown patch size for model {cfg.image_model_type}")
|
| 1101 |
+
|
| 1102 |
+
datamodule = AVDataModule(
|
| 1103 |
+
dataset_name=cfg.dataset_name,
|
| 1104 |
+
load_size=cfg.load_size,
|
| 1105 |
+
image_aug=cfg.image_aug,
|
| 1106 |
+
audio_aug=cfg.audio_aug,
|
| 1107 |
+
extra_audio_masking=cfg.extra_audio_masking,
|
| 1108 |
+
audio_model_type=cfg.audio_model_type,
|
| 1109 |
+
pytorch_data_dir=cfg.pytorch_data_dir,
|
| 1110 |
+
use_cached_embs=cfg.use_cached_embs,
|
| 1111 |
+
batch_size=cfg.batch_size,
|
| 1112 |
+
num_workers=cfg.num_workers,
|
| 1113 |
+
audio_level=cfg.audio_level,
|
| 1114 |
+
neg_audio=cfg.neg_audio,
|
| 1115 |
+
use_original_val_set=not cfg.use_extra_val_sets,
|
| 1116 |
+
use_extra_val_sets=cfg.use_extra_val_sets,
|
| 1117 |
+
data_for_plotting=False,
|
| 1118 |
+
quad_mixup=cfg.quad_mixup,
|
| 1119 |
+
bg_mixup=cfg.bg_mixup,
|
| 1120 |
+
patch_mixup=cfg.patch_mixup,
|
| 1121 |
+
patch_size=patch_size
|
| 1122 |
+
)
|
| 1123 |
+
datamodule.maybe_unpack(remove_source=cfg.submitting_to_aml)
|
| 1124 |
+
|
| 1125 |
+
aligner = create_model_from_cfg(LitAVAligner, cfg, {})
|
| 1126 |
+
|
| 1127 |
+
if cfg.starting_weights is not None:
|
| 1128 |
+
loaded = torch.load(join(cfg.output_root, cfg.starting_weights), map_location='cpu')
|
| 1129 |
+
state = loaded["state_dict"]
|
| 1130 |
+
aligner.load_state_dict(state, strict=cfg.load_strict)
|
| 1131 |
+
del state
|
| 1132 |
+
del loaded
|
| 1133 |
+
|
| 1134 |
+
if cfg.num_gpus > 1:
|
| 1135 |
+
# strategy = "ddp_sharded" # _find_unused_parameters_true"
|
| 1136 |
+
strategy = "ddp" # _find_unused_parameters_true"
|
| 1137 |
+
else:
|
| 1138 |
+
strategy = "auto"
|
| 1139 |
+
|
| 1140 |
+
if cfg.dataset_name in {"places-audio", "mixed", "audio-set", "mixed-full"}:
|
| 1141 |
+
val_args = dict(check_val_every_n_epoch=2)
|
| 1142 |
+
elif cfg.dataset_name in {"dolphin"}:
|
| 1143 |
+
val_args = dict(check_val_every_n_epoch=5)
|
| 1144 |
+
else:
|
| 1145 |
+
val_args = dict(val_check_interval=10000)
|
| 1146 |
+
|
| 1147 |
+
# val_args = dict(val_check_interval=1000)
|
| 1148 |
+
|
| 1149 |
+
def maybe_get_ckpt(ckpt_dir):
|
| 1150 |
+
if cfg.auto_resume and os.path.exists(ckpt_dir):
|
| 1151 |
+
print(f"Attempting to resume from {ckpt_dir}")
|
| 1152 |
+
candidates = os.listdir(ckpt_dir)
|
| 1153 |
+
assert (len(candidates) == 1)
|
| 1154 |
+
return join(ckpt_dir, candidates[0])
|
| 1155 |
+
elif cfg.auto_resume:
|
| 1156 |
+
print(f"Could not find checkpoint at {ckpt_dir}")
|
| 1157 |
+
return None
|
| 1158 |
+
else:
|
| 1159 |
+
return None
|
| 1160 |
+
|
| 1161 |
+
log_dir = join(cfg.output_root, "logs", cfg.grouping_name, exp_name)
|
| 1162 |
+
ckpt_dir = join(cfg.output_root, "checkpoints", cfg.grouping_name, exp_name)
|
| 1163 |
+
|
| 1164 |
+
import gc
|
| 1165 |
+
torch.cuda.empty_cache()
|
| 1166 |
+
gc.collect()
|
| 1167 |
+
|
| 1168 |
+
def run_exp(aligner, full_train):
|
| 1169 |
+
trainer_args = dict(
|
| 1170 |
+
accelerator='gpu',
|
| 1171 |
+
strategy=strategy,
|
| 1172 |
+
devices=cfg.num_gpus,
|
| 1173 |
+
num_sanity_val_steps=cfg.num_sanity_val_steps,
|
| 1174 |
+
log_every_n_steps=50,
|
| 1175 |
+
reload_dataloaders_every_n_epochs=10,
|
| 1176 |
+
precision="16",
|
| 1177 |
+
# profiler="simple",
|
| 1178 |
+
# precision="bf16",
|
| 1179 |
+
max_steps=cfg.max_steps,
|
| 1180 |
+
**val_args)
|
| 1181 |
+
|
| 1182 |
+
aligner.set_full_train(full_train)
|
| 1183 |
+
if full_train:
|
| 1184 |
+
suffix = "train"
|
| 1185 |
+
else:
|
| 1186 |
+
suffix = "pretrain"
|
| 1187 |
+
trainer_args["max_steps"] = cfg.pretrain_steps
|
| 1188 |
+
|
| 1189 |
+
print(f"Starting {suffix} phase")
|
| 1190 |
+
|
| 1191 |
+
logger = TensorBoardLogger(join(log_dir, suffix), default_hp_metric=False)
|
| 1192 |
+
callbacks = [
|
| 1193 |
+
ModelCheckpoint(join(ckpt_dir, suffix), every_n_epochs=1),
|
| 1194 |
+
LearningRateMonitor(logging_interval='step'),
|
| 1195 |
+
]
|
| 1196 |
+
Trainer(logger=logger,
|
| 1197 |
+
callbacks=callbacks,
|
| 1198 |
+
**trainer_args).fit(
|
| 1199 |
+
aligner,
|
| 1200 |
+
datamodule=datamodule,
|
| 1201 |
+
ckpt_path=maybe_get_ckpt(join(ckpt_dir, suffix)))
|
| 1202 |
+
|
| 1203 |
+
train_chkpt = maybe_get_ckpt(join(ckpt_dir, "train"))
|
| 1204 |
+
|
| 1205 |
+
gc.collect()
|
| 1206 |
+
if torch.cuda.is_available():
|
| 1207 |
+
torch.cuda.empty_cache()
|
| 1208 |
+
|
| 1209 |
+
if cfg.pretrain_steps > 0 and train_chkpt is None:
|
| 1210 |
+
print("---"*10)
|
| 1211 |
+
print("Setup with full_train = False")
|
| 1212 |
+
run_exp(aligner, full_train=False)
|
| 1213 |
+
print("---"*10)
|
| 1214 |
+
else:
|
| 1215 |
+
print("---"*10)
|
| 1216 |
+
print("Setup with full_train = False")
|
| 1217 |
+
run_exp(aligner, full_train=True)
|
| 1218 |
+
print("---"*10)
|
| 1219 |
+
|
| 1220 |
+
|
| 1221 |
+
if __name__ == "__main__":
|
| 1222 |
+
my_app()
|
DenseAV/gradio_app.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import csv
|
| 2 |
+
import os
|
| 3 |
+
import tempfile
|
| 4 |
+
|
| 5 |
+
import gradio as gr
|
| 6 |
+
import requests
|
| 7 |
+
import torch
|
| 8 |
+
import torchvision
|
| 9 |
+
import torchvision.transforms as T
|
| 10 |
+
from PIL import Image
|
| 11 |
+
from featup.util import norm
|
| 12 |
+
from torchaudio.functional import resample
|
| 13 |
+
|
| 14 |
+
from denseav.train import LitAVAligner
|
| 15 |
+
from denseav.plotting import plot_attention_video, plot_2head_attention_video, plot_feature_video
|
| 16 |
+
from denseav.shared import norm, crop_to_divisor, blur_dim
|
| 17 |
+
from os.path import join
|
| 18 |
+
|
| 19 |
+
if __name__ == "__main__":
|
| 20 |
+
|
| 21 |
+
mode = "local"
|
| 22 |
+
|
| 23 |
+
if mode == "local":
|
| 24 |
+
sample_videos_dir = "samples"
|
| 25 |
+
else:
|
| 26 |
+
os.environ['TORCH_HOME'] = '/tmp/.cache'
|
| 27 |
+
os.environ['HF_HOME'] = '/tmp/.cache'
|
| 28 |
+
os.environ['HF_DATASETS_CACHE'] = '/tmp/.cache'
|
| 29 |
+
os.environ['TRANSFORMERS_CACHE'] = '/tmp/.cache'
|
| 30 |
+
os.environ['GRADIO_EXAMPLES_CACHE'] = '/tmp/gradio_cache'
|
| 31 |
+
sample_videos_dir = "/tmp/samples"
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def download_video(url, save_path):
|
| 35 |
+
response = requests.get(url)
|
| 36 |
+
with open(save_path, 'wb') as file:
|
| 37 |
+
file.write(response.content)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
base_url = "https://marhamilresearch4.blob.core.windows.net/denseav-public/samples/"
|
| 41 |
+
sample_videos_urls = {
|
| 42 |
+
"puppies.mp4": base_url + "puppies.mp4",
|
| 43 |
+
"peppers.mp4": base_url + "peppers.mp4",
|
| 44 |
+
"boat.mp4": base_url + "boat.mp4",
|
| 45 |
+
"elephant2.mp4": base_url + "elephant2.mp4",
|
| 46 |
+
|
| 47 |
+
}
|
| 48 |
+
|
| 49 |
+
# Ensure the directory for sample videos exists
|
| 50 |
+
os.makedirs(sample_videos_dir, exist_ok=True)
|
| 51 |
+
|
| 52 |
+
# Download each sample video
|
| 53 |
+
for filename, url in sample_videos_urls.items():
|
| 54 |
+
save_path = os.path.join(sample_videos_dir, filename)
|
| 55 |
+
# Download the video if it doesn't already exist
|
| 56 |
+
if not os.path.exists(save_path):
|
| 57 |
+
print(f"Downloading {filename}...")
|
| 58 |
+
download_video(url, save_path)
|
| 59 |
+
else:
|
| 60 |
+
print(f"{filename} already exists. Skipping download.")
|
| 61 |
+
|
| 62 |
+
csv.field_size_limit(100000000)
|
| 63 |
+
options = ['language', "sound-language", "sound"]
|
| 64 |
+
load_size = 224
|
| 65 |
+
plot_size = 224
|
| 66 |
+
|
| 67 |
+
video_input = gr.Video(label="Choose a video to featurize", height=480)
|
| 68 |
+
model_option = gr.Radio(options, value="language", label='Choose a model')
|
| 69 |
+
|
| 70 |
+
video_output1 = gr.Video(label="Audio Video Attention", height=480)
|
| 71 |
+
video_output2 = gr.Video(label="Multi-Head Audio Video Attention (Only Availible for sound_and_language)",
|
| 72 |
+
height=480)
|
| 73 |
+
video_output3 = gr.Video(label="Visual Features", height=480)
|
| 74 |
+
|
| 75 |
+
models = {o: LitAVAligner.from_pretrained(f"mhamilton723/DenseAV-{o}") for o in options}
|
| 76 |
+
|
| 77 |
+
|
| 78 |
+
def process_video(video, model_option):
|
| 79 |
+
model = models[model_option].cuda()
|
| 80 |
+
|
| 81 |
+
original_frames, audio, info = torchvision.io.read_video(video, end_pts=10, pts_unit='sec')
|
| 82 |
+
sample_rate = 16000
|
| 83 |
+
|
| 84 |
+
if info["audio_fps"] != sample_rate:
|
| 85 |
+
audio = resample(audio, info["audio_fps"], sample_rate)
|
| 86 |
+
audio = audio[0].unsqueeze(0)
|
| 87 |
+
|
| 88 |
+
img_transform = T.Compose([
|
| 89 |
+
T.Resize(load_size, Image.BILINEAR),
|
| 90 |
+
lambda x: crop_to_divisor(x, 8),
|
| 91 |
+
lambda x: x.to(torch.float32) / 255,
|
| 92 |
+
norm])
|
| 93 |
+
|
| 94 |
+
frames = torch.cat([img_transform(f.permute(2, 0, 1)).unsqueeze(0) for f in original_frames], axis=0)
|
| 95 |
+
|
| 96 |
+
plotting_img_transform = T.Compose([
|
| 97 |
+
T.Resize(plot_size, Image.BILINEAR),
|
| 98 |
+
lambda x: crop_to_divisor(x, 8),
|
| 99 |
+
lambda x: x.to(torch.float32) / 255])
|
| 100 |
+
|
| 101 |
+
frames_to_plot = plotting_img_transform(original_frames.permute(0, 3, 1, 2))
|
| 102 |
+
|
| 103 |
+
with torch.no_grad():
|
| 104 |
+
audio_feats = model.forward_audio({"audio": audio.cuda()})
|
| 105 |
+
audio_feats = {k: v.cpu() for k, v in audio_feats.items()}
|
| 106 |
+
image_feats = model.forward_image({"frames": frames.unsqueeze(0).cuda()}, max_batch_size=2)
|
| 107 |
+
image_feats = {k: v.cpu() for k, v in image_feats.items()}
|
| 108 |
+
|
| 109 |
+
sim_by_head = model.sim_agg.get_pairwise_sims(
|
| 110 |
+
{**image_feats, **audio_feats},
|
| 111 |
+
raw=False,
|
| 112 |
+
agg_sim=False,
|
| 113 |
+
agg_heads=False
|
| 114 |
+
).mean(dim=-2).cpu()
|
| 115 |
+
|
| 116 |
+
sim_by_head = blur_dim(sim_by_head, window=3, dim=-1)
|
| 117 |
+
print(sim_by_head.shape)
|
| 118 |
+
|
| 119 |
+
temp_video_path_1 = tempfile.mktemp(suffix='.mp4')
|
| 120 |
+
|
| 121 |
+
plot_attention_video(
|
| 122 |
+
sim_by_head,
|
| 123 |
+
frames_to_plot,
|
| 124 |
+
audio,
|
| 125 |
+
info["video_fps"],
|
| 126 |
+
sample_rate,
|
| 127 |
+
temp_video_path_1)
|
| 128 |
+
|
| 129 |
+
if model_option == "sound_and_language":
|
| 130 |
+
temp_video_path_2 = tempfile.mktemp(suffix='.mp4')
|
| 131 |
+
|
| 132 |
+
plot_2head_attention_video(
|
| 133 |
+
sim_by_head,
|
| 134 |
+
frames_to_plot,
|
| 135 |
+
audio,
|
| 136 |
+
info["video_fps"],
|
| 137 |
+
sample_rate,
|
| 138 |
+
temp_video_path_2)
|
| 139 |
+
|
| 140 |
+
else:
|
| 141 |
+
temp_video_path_2 = None
|
| 142 |
+
|
| 143 |
+
temp_video_path_3 = tempfile.mktemp(suffix='.mp4')
|
| 144 |
+
temp_video_path_4 = tempfile.mktemp(suffix='.mp4')
|
| 145 |
+
|
| 146 |
+
plot_feature_video(
|
| 147 |
+
image_feats["image_feats"].cpu(),
|
| 148 |
+
audio_feats['audio_feats'].cpu(),
|
| 149 |
+
frames_to_plot,
|
| 150 |
+
audio,
|
| 151 |
+
info["video_fps"],
|
| 152 |
+
sample_rate,
|
| 153 |
+
temp_video_path_3,
|
| 154 |
+
temp_video_path_4,
|
| 155 |
+
)
|
| 156 |
+
# return temp_video_path_1, temp_video_path_2, temp_video_path_3, temp_video_path_4
|
| 157 |
+
|
| 158 |
+
return temp_video_path_1, temp_video_path_2, temp_video_path_3
|
| 159 |
+
|
| 160 |
+
|
| 161 |
+
with gr.Blocks() as demo:
|
| 162 |
+
with gr.Column():
|
| 163 |
+
gr.Markdown("## Visualizing Sound and Language with DenseAV")
|
| 164 |
+
gr.Markdown(
|
| 165 |
+
"This demo allows you to explore the inner attention maps of DenseAV's dense multi-head contrastive operator.")
|
| 166 |
+
with gr.Row():
|
| 167 |
+
with gr.Column(scale=1):
|
| 168 |
+
model_option.render()
|
| 169 |
+
with gr.Column(scale=3):
|
| 170 |
+
video_input.render()
|
| 171 |
+
with gr.Row():
|
| 172 |
+
submit_button = gr.Button("Submit")
|
| 173 |
+
with gr.Row():
|
| 174 |
+
gr.Examples(
|
| 175 |
+
examples=[
|
| 176 |
+
[join(sample_videos_dir, "puppies.mp4"), "sound_and_language"],
|
| 177 |
+
[join(sample_videos_dir, "peppers.mp4"), "language"],
|
| 178 |
+
[join(sample_videos_dir, "elephant2.mp4"), "language"],
|
| 179 |
+
[join(sample_videos_dir, "boat.mp4"), "language"]
|
| 180 |
+
|
| 181 |
+
],
|
| 182 |
+
inputs=[video_input, model_option]
|
| 183 |
+
)
|
| 184 |
+
with gr.Row():
|
| 185 |
+
video_output1.render()
|
| 186 |
+
video_output2.render()
|
| 187 |
+
video_output3.render()
|
| 188 |
+
|
| 189 |
+
submit_button.click(fn=process_video, inputs=[video_input, model_option],
|
| 190 |
+
outputs=[video_output1, video_output2, video_output3])
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
if mode == "local":
|
| 194 |
+
demo.launch(server_name="0.0.0.0", server_port=6006, debug=True)
|
| 195 |
+
else:
|
| 196 |
+
demo.launch(server_name="0.0.0.0", server_port=7860, debug=True)
|
DenseAV/hubconf.py
ADDED
|
@@ -0,0 +1,25 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# hubconf.py
|
| 2 |
+
from denseav.train import LitAVAligner
|
| 3 |
+
|
| 4 |
+
dependencies = ['torch', 'torchvision', 'PIL', 'denseav'] # List any dependencies here
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def _load_base(model_name):
|
| 8 |
+
model = LitAVAligner.load_from_checkpoint(
|
| 9 |
+
f"https://marhamilresearch4.blob.core.windows.net/denseav-public/hub/{model_name}.ckpt",
|
| 10 |
+
**{'loss_leak': 0.0, 'use_cached_embs': False},
|
| 11 |
+
strict=True)
|
| 12 |
+
model.set_full_train(True)
|
| 13 |
+
return model
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def sound_and_language():
|
| 17 |
+
return _load_base("denseav_2head")
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
def language():
|
| 21 |
+
return _load_base("denseav_language")
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
def sound():
|
| 25 |
+
return _load_base("denseav_sound")
|
DenseAV/samples/puppies.mp4
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d4bc5049010142b9a4364afea7da15d4e9736d95cfc9a365c2658c69ba409d56
|
| 3 |
+
size 7534432
|
DenseAV/setup.py
ADDED
|
@@ -0,0 +1,37 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from setuptools import setup, find_packages
|
| 2 |
+
|
| 3 |
+
setup(
|
| 4 |
+
name='denseav',
|
| 5 |
+
version='0.1.0',
|
| 6 |
+
packages=find_packages(),
|
| 7 |
+
install_requires=[
|
| 8 |
+
'torch',
|
| 9 |
+
'kornia',
|
| 10 |
+
'omegaconf',
|
| 11 |
+
'pytorch-lightning',
|
| 12 |
+
'torchvision',
|
| 13 |
+
'tqdm',
|
| 14 |
+
'torchmetrics',
|
| 15 |
+
'scikit-learn',
|
| 16 |
+
'numpy',
|
| 17 |
+
'matplotlib',
|
| 18 |
+
'timm==0.4.12',
|
| 19 |
+
'moviepy',
|
| 20 |
+
'hydra-core',
|
| 21 |
+
'peft==0.5.0',
|
| 22 |
+
'av',
|
| 23 |
+
'audioread'
|
| 24 |
+
],
|
| 25 |
+
author='Mark Hamilton',
|
| 26 |
+
author_email='[email protected]',
|
| 27 |
+
description='Offical code for the CVPR 2024 Paper: Separating the "Chirp" from the "Chat": Self-supervised Visual Grounding of Sound and Language',
|
| 28 |
+
long_description=open('README.md').read(),
|
| 29 |
+
long_description_content_type='text/markdown',
|
| 30 |
+
url='https://github.com/mhamilton723/DenseAV',
|
| 31 |
+
classifiers=[
|
| 32 |
+
'Programming Language :: Python :: 3',
|
| 33 |
+
'License :: OSI Approved :: MIT License',
|
| 34 |
+
'Operating System :: OS Independent',
|
| 35 |
+
],
|
| 36 |
+
python_requires='>=3.6'
|
| 37 |
+
)
|