
distinct
Browse files- README.md +3 -1
- distinct.py +1 -1
README.md
CHANGED
|
@@ -77,7 +77,9 @@ Example of calculating original Distinct. This will return Distinct-1,2,and 3.
|
|
| 77 |
```
|
| 78 |
|
| 79 |
## Limitations and Bias
|
| 80 |
-
|
|
|
|
|
|
|
| 81 |
|
| 82 |
## Citation
|
| 83 |
```bibtex
|
|
|
|
| 77 |
```
|
| 78 |
|
| 79 |
## Limitations and Bias
|
| 80 |
+
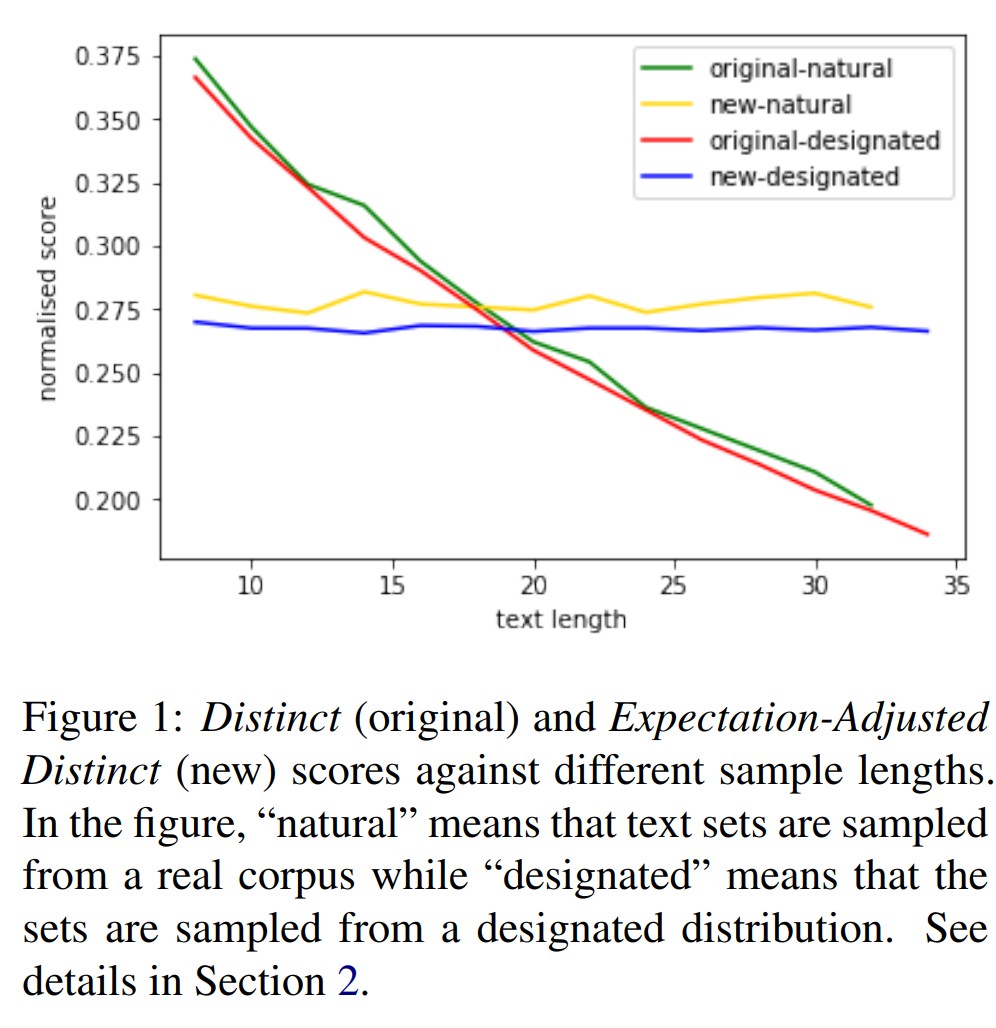
As EAD (Expectation-Adjusted-Distinct) is based on the idealized assumption that does not take language distribution into account, we further discuss this problem and propose a potential practical way of Expectation-Adjusted Distinct in real situations. Before applying EAD, it is necessary to explore the relationship between
|
| 81 |
+
score and text length (Figure 1) and check the performance of EAD on the training data. To our knowledge, if the training data is from large-scale open-domain sources such as OpenSubtitles and Reddit, EAD can maintain its value on different lengths. Hence, it can be directly used for evaluating models trained on these datasets. However, we found our experiments on datasets such as Twitter showed a decline in EAD on lengthier texts. This is
|
| 82 |
+
probably because input length limitations on these platforms (e.g. 280 words on Twitter), which induces users to say as much information as possible within a shorter length. In these situations, it is unfair to use EAD to evaluate methods that tend to generate lengthier texts.
|
| 83 |
|
| 84 |
## Citation
|
| 85 |
```bibtex
|
distinct.py
CHANGED
|
@@ -54,7 +54,7 @@ _DESCRIPTION = """\
|
|
| 54 |
Distinct metric is to calculate corpus-level diversity of language. We provide two versions of distinct score. Expectation-Adjusted-Distinct (EAD) is the default one, which removes
|
| 55 |
the biases of the original distinct score on lengthier sentences. Distinct is the original version.
|
| 56 |
|
| 57 |
-
 is the default one, which removes
|
| 55 |
the biases of the original distinct score on lengthier sentences. Distinct is the original version.
|
| 56 |
|
| 57 |
+
|
| 58 |
|
| 59 |
For the use of Expectation-Adjusted-Distinct, vocab_size is required.
|
| 60 |
|