{
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Sound Generation with AudioLDM2 and OpenVINO™\n",
"\n",
"[AudioLDM 2](https://huggingface.co/cvssp/audioldm2) is a latent text-to-audio diffusion model capable of generating realistic audio samples given any text input.\n",
"\n",
"AudioLDM 2 was proposed in the paper [AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining](https://arxiv.org/abs/2308.05734) by `Haohe Liu` et al.\n",
"\n",
"The model takes a text prompt as input and predicts the corresponding audio. It can generate text-conditional sound effects, human speech and music.\n",
"\n",
"\n",
"\n",
"In this tutorial we will try out the pipeline, convert the models backing it one by one and will run an interactive app with Gradio!\n",
"\n",
"\n",
"#### Table of contents:\n",
"\n",
"- [Prerequisites](#Prerequisites)\n",
"- [Instantiating Generation Pipeline](#Instantiating-Generation-Pipeline)\n",
"- [Convert models to OpenVINO Intermediate representation (IR) format](#Convert-models-to-OpenVINO-Intermediate-representation-(IR)-format)\n",
" - [CLAP Text Encoder Conversion](#CLAP-Text-Encoder-Conversion)\n",
" - [T5 Text Encoder Conversion](#T5-Text-Encoder-Conversion)\n",
" - [Projection model conversion](#Projection-model-conversion)\n",
" - [GPT-2 conversion](#GPT-2-conversion)\n",
" - [Vocoder conversion](#Vocoder-conversion)\n",
" - [UNet conversion](#UNet-conversion)\n",
" - [VAE Decoder conversion](#VAE-Decoder-conversion)\n",
"- [Select inference device for AudioLDM2 pipeline](#Select-inference-device-for-AudioLDM2-pipeline)\n",
"- [Adapt OpenVINO models to the original pipeline](#Adapt-OpenVINO-models-to-the-original-pipeline)\n",
"- [Try out the converted pipeline](#Try-out-the-converted-pipeline)\n",
"\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prerequisites\n",
"[back to top ⬆️](#Table-of-contents:)\n"
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"scrolled": true
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Note: you may need to restart the kernel to use updated packages.\n",
"Note: you may need to restart the kernel to use updated packages.\n"
]
}
],
"source": [
"%pip install -q accelerate \"diffusers>=0.21.0\" transformers \"torch>=2.1\" \"gradio>=4.19\" \"peft==0.6.2\" --extra-index-url https://download.pytorch.org/whl/cpu\n",
"%pip install -q \"openvino>=2024.0.0\""
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Instantiating Generation Pipeline \n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"\n",
"To work with [AudioLDM 2](https://huggingface.co/cvssp/audioldm2) by [`Centre for Vision, Speech and Signal Processing - University of Surrey`](https://www.surrey.ac.uk/centre-vision-speech-signal-processing), we will use [Hugging Face Diffusers package](https://github.com/huggingface/diffusers). Diffusers package exposes the `AudioLDM2Pipeline` class, simplifying the model instantiation and weights loading. The code below demonstrates how to create a `AudioLDM2Pipeline` and generate a text-conditioned sound sample."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "e73797b45858426181402e6848621847",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Loading pipeline components...: 0%| | 0/11 [00:00\n",
" \n",
" Your browser does not support the audio element.\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from collections import namedtuple\n",
"from functools import partial\n",
"import gc\n",
"from pathlib import Path\n",
"\n",
"from diffusers import AudioLDM2Pipeline\n",
"from IPython.display import Audio\n",
"import numpy as np\n",
"import openvino as ov\n",
"import torch\n",
"\n",
"MODEL_ID = \"cvssp/audioldm2\"\n",
"pipe = AudioLDM2Pipeline.from_pretrained(MODEL_ID)\n",
"\n",
"prompt = \"birds singing in the forest\"\n",
"negative_prompt = \"Low quality\"\n",
"audio = pipe(\n",
" prompt,\n",
" negative_prompt=negative_prompt,\n",
" num_inference_steps=150,\n",
" audio_length_in_s=3.0,\n",
").audios[0]\n",
"\n",
"sampling_rate = 16000\n",
"Audio(audio, rate=sampling_rate)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Convert models to OpenVINO Intermediate representation (IR) format \n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"\n",
"[Model conversion API](https://docs.openvino.ai/2024/openvino-workflow/model-preparation.html) enables direct conversion of PyTorch models backing the pipeline. We need to provide a model object, input data for model tracing to `ov.convert_model` function to obtain OpenVINO `ov.Model` object instance. Model can be saved on disk for next deployment using `ov.save_model` function.\n",
"\n",
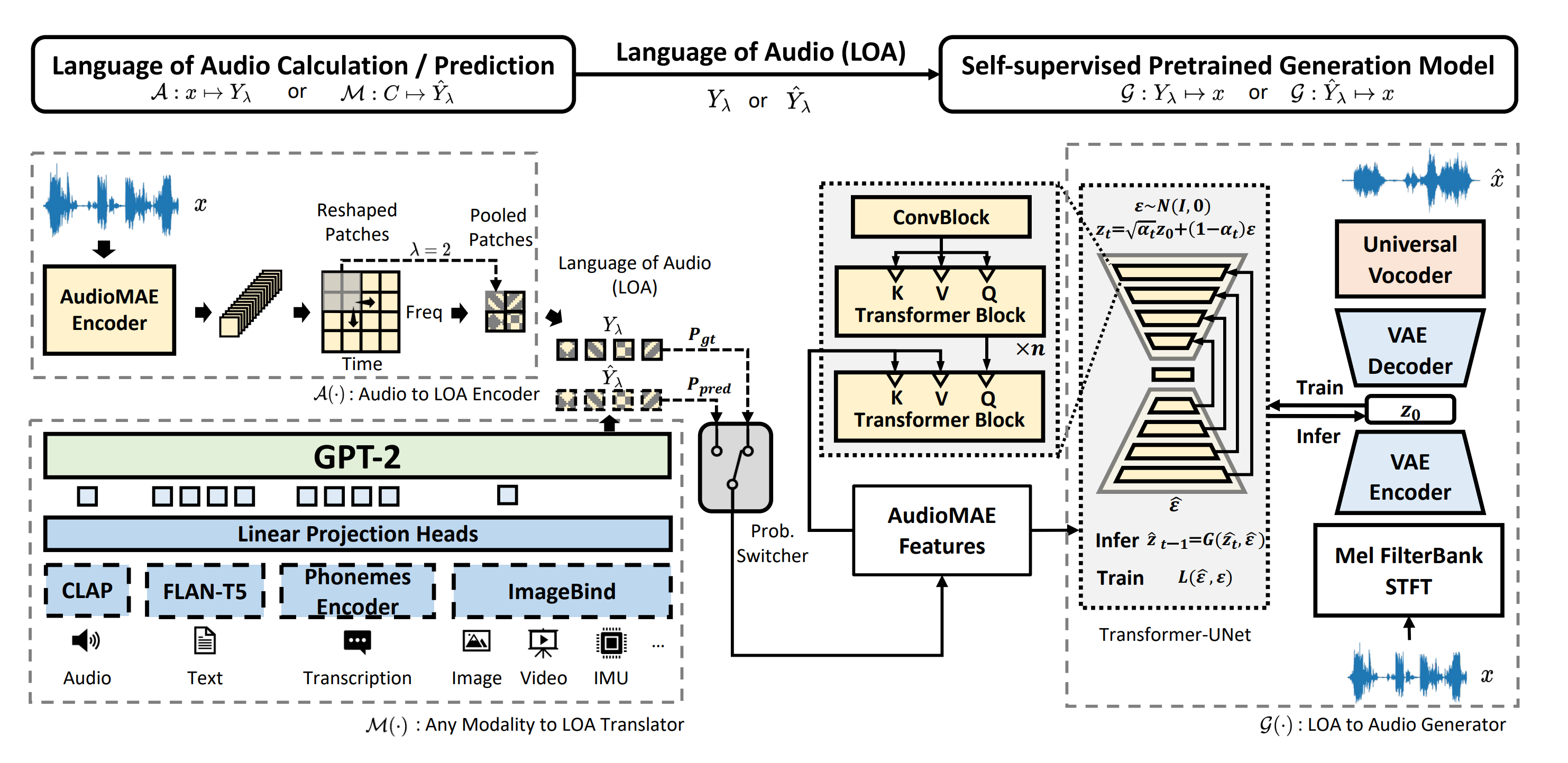
"The pipeline consists of seven important parts:\n",
"\n",
"* T5 and CLAP Text Encoders for creation condition to generate an sound from a text prompt.\n",
"* Projection model to merge outputs from the two text encoders.\n",
"* GPT-2 language model to generate a sequence of hidden-states conditioned on the projected outputs from the two text encoders.\n",
"* Vocoder to convert the mel-spectrogram latents to the final audio waveform.\n",
"* Unet for step-by-step denoising latent image representation.\n",
"* Autoencoder (VAE) for decoding latent space to image."
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"models_base_folder = Path(\"models\")\n",
"\n",
"\n",
"def cleanup_torchscript_cache():\n",
" \"\"\"\n",
" Helper for removing cached model representation\n",
" \"\"\"\n",
" torch._C._jit_clear_class_registry()\n",
" torch.jit._recursive.concrete_type_store = torch.jit._recursive.ConcreteTypeStore()\n",
" torch.jit._state._clear_class_state()"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### CLAP Text Encoder Conversion\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"First frozen text-encoder. AudioLDM2 uses the joint audio-text embedding model\n",
"[CLAP](https://huggingface.co/docs/transformers/model_doc/clap#transformers.CLAPTextModelWithProjection),\n",
"specifically the [`laion/clap-htsat-unfused`](https://huggingface.co/laion/clap-htsat-unfused) variant. The\n",
"text branch is used to encode the text prompt to a prompt embedding. The full audio-text model is used to\n",
"rank generated waveforms against the text prompt by computing similarity scores."
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Text Encoder will be loaded from clap_text_encoder.xml\n"
]
}
],
"source": [
"class ClapEncoderWrapper(torch.nn.Module):\n",
" def __init__(self, encoder):\n",
" super().__init__()\n",
" encoder.eval()\n",
" self.encoder = encoder\n",
"\n",
" def forward(self, input_ids, attention_mask):\n",
" return self.encoder.get_text_features(input_ids, attention_mask)\n",
"\n",
"\n",
"clap_text_encoder_ir_path = models_base_folder / \"clap_text_encoder.xml\"\n",
"\n",
"if not clap_text_encoder_ir_path.exists():\n",
" with torch.no_grad():\n",
" ov_model = ov.convert_model(\n",
" ClapEncoderWrapper(pipe.text_encoder), # model instance\n",
" example_input={\n",
" \"input_ids\": torch.ones((1, 512), dtype=torch.long),\n",
" \"attention_mask\": torch.ones((1, 512), dtype=torch.long),\n",
" }, # inputs for model tracing\n",
" )\n",
" ov.save_model(ov_model, clap_text_encoder_ir_path)\n",
" del ov_model\n",
" cleanup_torchscript_cache()\n",
" gc.collect()\n",
" print(\"Text Encoder successfully converted to IR\")\n",
"else:\n",
" print(f\"Text Encoder will be loaded from {clap_text_encoder_ir_path}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### T5 Text Encoder Conversion\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"As second frozen text-encoder, AudioLDM2 uses the [T5](https://huggingface.co/docs/transformers/model_doc/t5#transformers.T5EncoderModel), specifically the\n",
" [google/flan-t5-large](https://huggingface.co/google/flan-t5-large) variant.\n",
"\n",
"The text-encoder is responsible for transforming the input prompt, for example, \"birds singing in the forest\" into an embedding space that can be understood by the U-Net. It is usually a simple transformer-based encoder that maps a sequence of input tokens to a sequence of latent text embeddings.\n",
"\n",
"The input of the text encoder is tensor `input_ids`, which contains indexes of tokens from text processed by the tokenizer and padded to the maximum length accepted by the model. Model outputs are two tensors: `last_hidden_state` - hidden state from the last MultiHeadAttention layer in the model and `pooler_out` - pooled output for whole model hidden states."
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Text Encoder will be loaded from t5_text_encoder.xml\n"
]
}
],
"source": [
"t5_text_encoder_ir_path = models_base_folder / \"t5_text_encoder.xml\"\n",
"\n",
"if not t5_text_encoder_ir_path.exists():\n",
" pipe.text_encoder_2.eval()\n",
" with torch.no_grad():\n",
" ov_model = ov.convert_model(\n",
" pipe.text_encoder_2, # model instance\n",
" example_input=torch.ones((1, 7), dtype=torch.long), # inputs for model tracing\n",
" )\n",
" ov.save_model(ov_model, t5_text_encoder_ir_path)\n",
" del ov_model\n",
" cleanup_torchscript_cache()\n",
" gc.collect()\n",
" print(\"Text Encoder successfully converted to IR\")\n",
"else:\n",
" print(f\"Text Encoder will be loaded from {t5_text_encoder_ir_path}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Projection model conversion\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"A trained model used to linearly project the hidden-states from the first and second text encoder models and insert learned Start Of Sequence and End Of Sequence token embeddings. The projected hidden-states from the two text encoders are concatenated to give the input to the language model."
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The Projection Model will be loaded from projection_model.xml\n"
]
}
],
"source": [
"projection_model_ir_path = models_base_folder / \"projection_model.xml\"\n",
"\n",
"projection_model_inputs = {\n",
" \"hidden_states\": torch.randn((1, 1, 512), dtype=torch.float32),\n",
" \"hidden_states_1\": torch.randn((1, 7, 1024), dtype=torch.float32),\n",
" \"attention_mask\": torch.ones((1, 1), dtype=torch.int64),\n",
" \"attention_mask_1\": torch.ones((1, 7), dtype=torch.int64),\n",
"}\n",
"\n",
"if not projection_model_ir_path.exists():\n",
" pipe.projection_model.eval()\n",
" with torch.no_grad():\n",
" ov_model = ov.convert_model(\n",
" pipe.projection_model, # model instance\n",
" example_input=projection_model_inputs, # inputs for model tracing\n",
" )\n",
" ov.save_model(ov_model, projection_model_ir_path)\n",
" del ov_model\n",
" cleanup_torchscript_cache()\n",
" gc.collect()\n",
" print(\"The Projection Model successfully converted to IR\")\n",
"else:\n",
" print(f\"The Projection Model will be loaded from {projection_model_ir_path}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### GPT-2 conversion\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"[GPT-2](https://huggingface.co/gpt2) is an auto-regressive language model used to generate a sequence of hidden-states conditioned on the projected outputs from the two text encoders."
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The Projection Model will be loaded from language_model.xml\n"
]
}
],
"source": [
"language_model_ir_path = models_base_folder / \"language_model.xml\"\n",
"\n",
"language_model_inputs = {\n",
" \"inputs_embeds\": torch.randn((1, 12, 768), dtype=torch.float32),\n",
" \"attention_mask\": torch.ones((1, 12), dtype=torch.int64),\n",
"}\n",
"\n",
"if not language_model_ir_path.exists():\n",
" pipe.language_model.config.torchscript = True\n",
" pipe.language_model.eval()\n",
" pipe.language_model.__call__ = partial(\n",
" pipe.language_model.__call__,\n",
" kwargs={\"past_key_values\": None, \"use_cache\": False, \"return_dict\": False},\n",
" )\n",
" with torch.no_grad():\n",
" ov_model = ov.convert_model(\n",
" pipe.language_model, # model instance\n",
" example_input=language_model_inputs, # inputs for model tracing\n",
" )\n",
"\n",
" ov_model.inputs[0].get_node().set_partial_shape(ov.PartialShape([1, -1]))\n",
" ov_model.inputs[0].get_node().set_element_type(ov.Type.i64)\n",
" ov_model.inputs[1].get_node().set_partial_shape(ov.PartialShape([1, -1, 768]))\n",
" ov_model.inputs[1].get_node().set_element_type(ov.Type.f32)\n",
"\n",
" ov_model.validate_nodes_and_infer_types()\n",
"\n",
" ov.save_model(ov_model, language_model_ir_path)\n",
" del ov_model\n",
" cleanup_torchscript_cache()\n",
" gc.collect()\n",
" print(\"The Projection Model successfully converted to IR\")\n",
"else:\n",
" print(f\"The Projection Model will be loaded from {language_model_ir_path}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Vocoder conversion\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"[`SpeechT5 HiFi-GAN Vocoder`](https://huggingface.co/microsoft/speecht5_hifigan) is used to convert the mel-spectrogram latents to the final audio waveform."
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"The Vocoder will be loaded from vocoder.xml\n"
]
}
],
"source": [
"vocoder_ir_path = models_base_folder / \"vocoder.xml\"\n",
"\n",
"if not vocoder_ir_path.exists():\n",
" pipe.vocoder.eval()\n",
" with torch.no_grad():\n",
" ov_model = ov.convert_model(\n",
" pipe.vocoder, # model instance\n",
" example_input=torch.ones((1, 700, 64), dtype=torch.float32), # inputs for model tracing\n",
" )\n",
" ov.save_model(ov_model, vocoder_ir_path)\n",
" del ov_model\n",
" cleanup_torchscript_cache()\n",
" gc.collect()\n",
" print(\"The Vocoder successfully converted to IR\")\n",
"else:\n",
" print(f\"The Vocoder will be loaded from {vocoder_ir_path}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### UNet conversion \n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"\n",
"The UNet model is used to denoise the encoded audio latents. The process of UNet model conversion remains the same, like for original Stable Diffusion model."
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Unet will be loaded from unet.xml\n"
]
}
],
"source": [
"unet_ir_path = models_base_folder / \"unet.xml\"\n",
"\n",
"pipe.unet.eval()\n",
"unet_inputs = {\n",
" \"sample\": torch.randn((2, 8, 75, 16), dtype=torch.float32),\n",
" \"timestep\": torch.tensor(1, dtype=torch.int64),\n",
" \"encoder_hidden_states\": torch.randn((2, 8, 768), dtype=torch.float32),\n",
" \"encoder_hidden_states_1\": torch.randn((2, 7, 1024), dtype=torch.float32),\n",
" \"encoder_attention_mask_1\": torch.ones((2, 7), dtype=torch.int64),\n",
"}\n",
"\n",
"if not unet_ir_path.exists():\n",
" with torch.no_grad():\n",
" ov_model = ov.convert_model(pipe.unet, example_input=unet_inputs)\n",
"\n",
" ov_model.inputs[0].get_node().set_partial_shape(ov.PartialShape((2, 8, -1, 16)))\n",
" ov_model.inputs[2].get_node().set_partial_shape(ov.PartialShape((2, 8, 768)))\n",
" ov_model.inputs[3].get_node().set_partial_shape(ov.PartialShape((2, -1, 1024)))\n",
" ov_model.inputs[4].get_node().set_partial_shape(ov.PartialShape((2, -1)))\n",
" ov_model.validate_nodes_and_infer_types()\n",
"\n",
" ov.save_model(ov_model, unet_ir_path)\n",
"\n",
" del ov_model\n",
" cleanup_torchscript_cache()\n",
" gc.collect()\n",
" print(\"Unet successfully converted to IR\")\n",
"else:\n",
" print(f\"Unet will be loaded from {unet_ir_path}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### VAE Decoder conversion \n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"\n",
"The VAE model has two parts, an encoder, and a decoder. The encoder is used to convert the image into a low-dimensional latent representation, which will serve as the input to the U-Net model. The decoder, conversely, transforms the latent representation back into an image.\n",
"\n",
"During latent diffusion training, the encoder is used to get the latent representations (latents) of the images for the forward diffusion process, which applies more and more noise at each step. During inference, the denoised latents generated by the reverse diffusion process are converted back into images using the VAE decoder. During inference, we will see that we **only need the VAE decoder**. You can find instructions on how to convert the encoder part in a stable diffusion [notebook](../stable-diffusion-text-to-image/stable-diffusion-text-to-image.ipynb)."
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"VAE decoder will be loaded from vae.xml\n"
]
}
],
"source": [
"vae_ir_path = models_base_folder / \"vae.xml\"\n",
"\n",
"\n",
"class VAEDecoderWrapper(torch.nn.Module):\n",
" def __init__(self, vae):\n",
" super().__init__()\n",
" vae.eval()\n",
" self.vae = vae\n",
"\n",
" def forward(self, latents):\n",
" return self.vae.decode(latents)\n",
"\n",
"\n",
"if not vae_ir_path.exists():\n",
" vae_decoder = VAEDecoderWrapper(pipe.vae)\n",
" latents = torch.zeros((1, 8, 175, 16))\n",
"\n",
" vae_decoder.eval()\n",
" with torch.no_grad():\n",
" ov_model = ov.convert_model(vae_decoder, example_input=latents)\n",
" ov.save_model(ov_model, vae_ir_path)\n",
" del ov_model\n",
" cleanup_torchscript_cache()\n",
" gc.collect()\n",
" print(\"VAE decoder successfully converted to IR\")\n",
"else:\n",
" print(f\"VAE decoder will be loaded from {vae_ir_path}\")"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Select inference device for AudioLDM2 pipeline \n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"\n",
"select device from dropdown list for running inference using OpenVINO"
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "d3add09d5e08400db5da7d9a013cfd6c",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Dropdown(description='Device:', options=('CPU', 'AUTO'), value='CPU')"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"import ipywidgets as widgets\n",
"\n",
"core = ov.Core()\n",
"\n",
"device = widgets.Dropdown(\n",
" options=core.available_devices + [\"AUTO\"],\n",
" value=\"CPU\",\n",
" description=\"Device:\",\n",
" disabled=False,\n",
")\n",
"\n",
"device"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Adapt OpenVINO models to the original pipeline\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"Here we create wrapper classes for all three OpenVINO models that we want to embed in the original inference pipeline.\n",
"Here are some of the things to consider when adapting an OV model:\n",
" - Make sure that parameters passed by the original pipeline are forwarded to the compiled OV model properly; sometimes the OV model uses only a portion of the input arguments and some are ignored, sometimes you need to convert the argument to another data type or unwrap some data structures such as tuples or dictionaries.\n",
" - Do guarantee that the wrapper class returns results to the pipeline in an expected format. In the example below you can see how we pack OV model outputs into special named tuples to adapt them for the pipeline.\n",
" - Pay attention to the model method used in the original pipeline for calling the model - it may be not the `forward` method! Refer to the `OVClapEncoderWrapper` to see how we wrap OV model inference into the `get_text_features` method."
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [],
"source": [
"class OVClapEncoderWrapper:\n",
" def __init__(self, encoder_ir, config):\n",
" self.encoder = core.compile_model(encoder_ir, device.value)\n",
" self.config = config\n",
"\n",
" def get_text_features(self, input_ids, attention_mask, **_):\n",
" last_hidden_state = self.encoder([input_ids, attention_mask])[0]\n",
" return torch.from_numpy(last_hidden_state)\n",
"\n",
"\n",
"class OVT5EncoderWrapper:\n",
" def __init__(self, encoder_ir, config):\n",
" self.encoder = core.compile_model(encoder_ir, device.value)\n",
" self.config = config\n",
" self.dtype = self.config.torch_dtype\n",
"\n",
" def __call__(self, input_ids, **_):\n",
" last_hidden_state = self.encoder(input_ids)[0]\n",
" return torch.from_numpy(last_hidden_state)[None, ...]\n",
"\n",
"\n",
"class OVVocoderWrapper:\n",
" def __init__(self, vocoder_ir, config):\n",
" self.vocoder = core.compile_model(vocoder_ir, device.value)\n",
" self.config = config\n",
"\n",
" def __call__(self, mel_spectrogram, **_):\n",
" waveform = self.vocoder(mel_spectrogram)[0]\n",
" return torch.from_numpy(waveform)\n",
"\n",
"\n",
"class OVProjectionModelWrapper:\n",
" def __init__(self, proj_model_ir, config):\n",
" self.proj_model = core.compile_model(proj_model_ir, device.value)\n",
" self.config = config\n",
" self.output_type = namedtuple(\"ProjectionOutput\", [\"hidden_states\", \"attention_mask\"])\n",
"\n",
" def __call__(self, hidden_states, hidden_states_1, attention_mask, attention_mask_1, **_):\n",
" output = self.proj_model(\n",
" {\n",
" \"hidden_states\": hidden_states,\n",
" \"hidden_states_1\": hidden_states_1,\n",
" \"attention_mask\": attention_mask,\n",
" \"attention_mask_1\": attention_mask_1,\n",
" }\n",
" )\n",
" return self.output_type(torch.from_numpy(output[0]), torch.from_numpy(output[1]))\n",
"\n",
"\n",
"class OVUnetWrapper:\n",
" def __init__(self, unet_ir, config):\n",
" self.unet = core.compile_model(unet_ir, device.value)\n",
" self.config = config\n",
"\n",
" def __call__(self, sample, timestep, encoder_hidden_states, encoder_hidden_states_1, encoder_attention_mask_1, **_):\n",
" output = self.unet(\n",
" {\n",
" \"sample\": sample,\n",
" \"timestep\": timestep,\n",
" \"encoder_hidden_states\": encoder_hidden_states,\n",
" \"encoder_hidden_states_1\": encoder_hidden_states_1,\n",
" \"encoder_attention_mask_1\": encoder_attention_mask_1,\n",
" }\n",
" )\n",
" return (torch.from_numpy(output[0]),)\n",
"\n",
"\n",
"class OVVaeDecoderWrapper:\n",
" def __init__(self, vae_ir, config):\n",
" self.vae = core.compile_model(vae_ir, device.value)\n",
" self.config = config\n",
" self.output_type = namedtuple(\"VaeOutput\", [\"sample\"])\n",
"\n",
" def decode(self, latents, **_):\n",
" last_hidden_state = self.vae(latents)[0]\n",
" return self.output_type(torch.from_numpy(last_hidden_state))\n",
"\n",
"\n",
"def generate_language_model(gpt_2: ov.CompiledModel, inputs_embeds: torch.Tensor, attention_mask: torch.Tensor, max_new_tokens: int = 8, **_) -> torch.Tensor:\n",
" \"\"\"\n",
" Generates a sequence of hidden-states from the language model, conditioned on the embedding inputs.\n",
" \"\"\"\n",
" if not max_new_tokens:\n",
" max_new_tokens = 8\n",
" inputs_embeds = inputs_embeds.cpu().numpy()\n",
" attention_mask = attention_mask.cpu().numpy()\n",
" for _ in range(max_new_tokens):\n",
" # forward pass to get next hidden states\n",
" output = gpt_2({\"inputs_embeds\": inputs_embeds, \"attention_mask\": attention_mask})\n",
"\n",
" next_hidden_states = output[0]\n",
"\n",
" # Update the model input\n",
" inputs_embeds = np.concatenate([inputs_embeds, next_hidden_states[:, -1:, :]], axis=1)\n",
" attention_mask = np.concatenate([attention_mask, np.ones((attention_mask.shape[0], 1))], axis=1)\n",
" return torch.from_numpy(inputs_embeds[:, -max_new_tokens:, :])"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Now we initialize the wrapper objects and load them to the HF pipeline"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "21cfd11e143745ecb46967f0485cc6d8",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Loading pipeline components...: 0%| | 0/11 [00:00\n",
" \n",
" Your browser does not support the audio element.\n",
" \n",
" "
],
"text/plain": [
""
]
},
"execution_count": 15,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"pipe = AudioLDM2Pipeline.from_pretrained(MODEL_ID)\n",
"pipe.config.torchscript = True\n",
"pipe.config.return_dict = False\n",
"\n",
"np.random.seed(0)\n",
"torch.manual_seed(0)\n",
"\n",
"pipe.text_encoder = OVClapEncoderWrapper(clap_text_encoder_ir_path, pipe.text_encoder.config)\n",
"pipe.text_encoder_2 = OVT5EncoderWrapper(t5_text_encoder_ir_path, pipe.text_encoder_2.config)\n",
"pipe.projection_model = OVProjectionModelWrapper(projection_model_ir_path, pipe.projection_model.config)\n",
"pipe.vocoder = OVVocoderWrapper(vocoder_ir_path, pipe.vocoder.config)\n",
"pipe.unet = OVUnetWrapper(unet_ir_path, pipe.unet.config)\n",
"pipe.vae = OVVaeDecoderWrapper(vae_ir_path, pipe.vae.config)\n",
"\n",
"pipe.generate_language_model = partial(generate_language_model, core.compile_model(language_model_ir_path, device.value))\n",
"\n",
"gc.collect()\n",
"\n",
"prompt = \"birds singing in the forest\"\n",
"negative_prompt = \"Low quality\"\n",
"audio = pipe(\n",
" prompt,\n",
" negative_prompt=negative_prompt,\n",
" num_inference_steps=150,\n",
" audio_length_in_s=3.0,\n",
").audios[0]\n",
"\n",
"sampling_rate = 16000\n",
"Audio(audio, rate=sampling_rate)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Try out the converted pipeline\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"Now, we are ready to start generation. For improving the generation process, we also introduce an opportunity to provide a `negative prompt`. Technically, positive prompt steers the diffusion toward the output associated with it, while negative prompt steers the diffusion away from it.\n",
"The demo app below is created using [Gradio package](https://www.gradio.app/docs/interface)"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"import gradio as gr\n",
"\n",
"\n",
"def _generate(\n",
" prompt,\n",
" negative_prompt,\n",
" audio_length_in_s,\n",
" num_inference_steps,\n",
" _=gr.Progress(track_tqdm=True),\n",
"):\n",
" \"\"\"Gradio backing function.\"\"\"\n",
" audio_values = pipe(\n",
" prompt,\n",
" negative_prompt=negative_prompt,\n",
" num_inference_steps=num_inference_steps,\n",
" audio_length_in_s=audio_length_in_s,\n",
" )\n",
" waveform = audio_values[0].squeeze() * 2**15\n",
" return (sampling_rate, waveform.astype(np.int16))\n",
"\n",
"\n",
"demo = gr.Interface(\n",
" _generate,\n",
" inputs=[\n",
" gr.Textbox(label=\"Text Prompt\"),\n",
" gr.Textbox(label=\"Negative Prompt\", placeholder=\"Example: Low quality\"),\n",
" gr.Slider(\n",
" minimum=1.0,\n",
" maximum=15.0,\n",
" step=0.25,\n",
" value=7,\n",
" label=\"Audio Length (s)\",\n",
" ),\n",
" gr.Slider(label=\"Inference Steps\", step=5, value=150, minimum=50, maximum=250),\n",
" ],\n",
" outputs=[\"audio\"],\n",
" examples=[\n",
" [\"birds singing in the forest\", \"Low quality\", 7, 150],\n",
" [\"The sound of a hammer hitting a wooden surface\", \"\", 4, 200],\n",
" ],\n",
")\n",
"try:\n",
" demo.queue().launch(debug=True)\n",
"except Exception:\n",
" demo.queue().launch(share=True, debug=True)\n",
"\n",
"# If you are launching remotely, specify server_name and server_port\n",
"# EXAMPLE: `demo.launch(server_name=\"your server name\", server_port=\"server port in int\")`\n",
"# To learn more please refer to the Gradio docs: https://gradio.app/docs/"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.10"
},
"openvino_notebooks": {
"imageUrl": "https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/notebooks/sound-generation-audioldm2/sound-generation-audioldm2.png?raw=true",
"tags": {
"categories": [
"Model Demos",
"AI Trends"
],
"libraries": [],
"other": [],
"tasks": [
"Text-to-Audio"
]
}
},
"widgets": {
"application/vnd.jupyter.widget-state+json": {
"state": {},
"version_major": 2,
"version_minor": 0
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}