{
"cells": [
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"# Video Subtitle Generation using Whisper and OpenVINO™\n",
"\n",
"[Whisper](https://openai.com/blog/whisper/) is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web. It is a multi-task model that can perform multilingual speech recognition as well as speech translation and language identification.\n",
"\n",
"\n",
"\n",
"You can find more information about this model in the [research paper](https://cdn.openai.com/papers/whisper.pdf), [OpenAI blog](https://openai.com/blog/whisper/), [model card](https://github.com/openai/whisper/blob/main/model-card.md) and GitHub [repository](https://github.com/openai/whisper).\n",
"\n",
"In this notebook, we will use Whisper with OpenVINO to generate subtitles in a sample video.\n",
"Notebook contains the following steps:\n",
"1. Download the model.\n",
"2. Instantiate the PyTorch model pipeline.\n",
"3. Convert model to OpenVINO IR, using model conversion API.\n",
"4. Run the Whisper pipeline with OpenVINO models.\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"\n",
"#### Table of contents:\n",
"\n",
"- [Prerequisites](#Prerequisites)\n",
"- [Instantiate model](#Instantiate-model)\n",
" - [Convert model to OpenVINO Intermediate Representation (IR) format.](#Convert-model-to-OpenVINO-Intermediate-Representation-(IR)-format.)\n",
" - [Convert Whisper Encoder to OpenVINO IR](#Convert-Whisper-Encoder-to-OpenVINO-IR)\n",
" - [Convert Whisper decoder to OpenVINO IR](#Convert-Whisper-decoder-to-OpenVINO-IR)\n",
"- [Prepare inference pipeline](#Prepare-inference-pipeline)\n",
" - [Select inference device](#Select-inference-device)\n",
"- [Run video transcription pipeline](#Run-video-transcription-pipeline)\n",
"- [Interactive demo](#Interactive-demo)\n",
"\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prerequisites\n",
"[back to top ⬆️](#Table-of-contents:)\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Install dependencies."
]
},
{
"cell_type": "code",
"execution_count": 1,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"%pip install -q \"openvino>=2023.1.0\"\n",
"%pip install -q \"python-ffmpeg<=1.0.16\" moviepy transformers --extra-index-url https://download.pytorch.org/whl/cpu\n",
"%pip install -q \"git+https://github.com/garywu007/pytube.git\"\n",
"%pip install -q \"gradio>=4.19\"\n",
"%pip install -q \"openai-whisper==20231117\" --extra-index-url https://download.pytorch.org/whl/cpu"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Instantiate model\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"Whisper is a Transformer based encoder-decoder model, also referred to as a sequence-to-sequence model. It maps a sequence of audio spectrogram features to a sequence of text tokens. First, the raw audio inputs are converted to a log-Mel spectrogram by action of the feature extractor. Then, the Transformer encoder encodes the spectrogram to form a sequence of encoder hidden states. Finally, the decoder autoregressively predicts text tokens, conditional on both the previous tokens and the encoder hidden states.\n",
"\n",
"You can see the model architecture in the diagram below:\n",
"\n",
"\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"There are several models of different sizes and capabilities trained by the authors of the model. In this tutorial, we will use the `base` model, but the same actions are also applicable to other models from Whisper family."
]
},
{
"cell_type": "code",
"execution_count": 2,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "84e419a30ba4427c8643d622348d6dda",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Dropdown(description='Model:', index=9, options=('tiny.en', 'tiny', 'base.en', 'base', 'small.en', 'small', 'm…"
]
},
"execution_count": 2,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from whisper import _MODELS\n",
"import ipywidgets as widgets\n",
"\n",
"model_id = widgets.Dropdown(\n",
" options=list(_MODELS),\n",
" value=\"large-v2\",\n",
" description=\"Model:\",\n",
" disabled=False,\n",
")\n",
"\n",
"model_id"
]
},
{
"cell_type": "code",
"execution_count": 3,
"metadata": {},
"outputs": [],
"source": [
"import whisper\n",
"\n",
"model = whisper.load_model(model_id.value, \"cpu\")\n",
"model.eval()\n",
"pass"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Convert model to OpenVINO Intermediate Representation (IR) format.\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"For best results with OpenVINO, it is recommended to convert the model to OpenVINO IR format. We need to provide initialized model object and example of inputs for shape inference. We will use `ov.convert_model` functionality to convert models. The `ov.convert_model` Python function returns an OpenVINO model ready to load on device and start making predictions. We can save it on disk for next usage with `ov.save_model`.\n"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Convert Whisper Encoder to OpenVINO IR\n",
"[back to top ⬆️](#Table-of-contents:)\n"
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"collapsed": false,
"jupyter": {
"outputs_hidden": false
}
},
"outputs": [],
"source": [
"from pathlib import Path\n",
"\n",
"WHISPER_ENCODER_OV = Path(f\"whisper_{model_id.value}_encoder.xml\")\n",
"WHISPER_DECODER_OV = Path(f\"whisper_{model_id.value}_decoder.xml\")"
]
},
{
"cell_type": "code",
"execution_count": 5,
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"import openvino as ov\n",
"\n",
"mel = torch.zeros((1, 80 if \"v3\" not in model_id.value else 128, 3000))\n",
"audio_features = model.encoder(mel)\n",
"if not WHISPER_ENCODER_OV.exists():\n",
" encoder_model = ov.convert_model(model.encoder, example_input=mel)\n",
" ov.save_model(encoder_model, WHISPER_ENCODER_OV)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Convert Whisper decoder to OpenVINO IR\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"To reduce computational complexity, the decoder uses cached key/value projections in attention modules from the previous steps. We need to modify this process for correct tracing."
]
},
{
"cell_type": "code",
"execution_count": 6,
"metadata": {},
"outputs": [],
"source": [
"import torch\n",
"from typing import Optional, Tuple\n",
"from functools import partial\n",
"\n",
"\n",
"def attention_forward(\n",
" attention_module,\n",
" x: torch.Tensor,\n",
" xa: Optional[torch.Tensor] = None,\n",
" mask: Optional[torch.Tensor] = None,\n",
" kv_cache: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,\n",
"):\n",
" \"\"\"\n",
" Override for forward method of decoder attention module with storing cache values explicitly.\n",
" Parameters:\n",
" attention_module: current attention module\n",
" x: input token ids.\n",
" xa: input audio features (Optional).\n",
" mask: mask for applying attention (Optional).\n",
" kv_cache: dictionary with cached key values for attention modules.\n",
" idx: idx for search in kv_cache.\n",
" Returns:\n",
" attention module output tensor\n",
" updated kv_cache\n",
" \"\"\"\n",
" q = attention_module.query(x)\n",
"\n",
" if xa is None:\n",
" # hooks, if installed (i.e. kv_cache is not None), will prepend the cached kv tensors;\n",
" # otherwise, perform key/value projections for self- or cross-attention as usual.\n",
" k = attention_module.key(x)\n",
" v = attention_module.value(x)\n",
" if kv_cache is not None:\n",
" k = torch.cat((kv_cache[0], k), dim=1)\n",
" v = torch.cat((kv_cache[1], v), dim=1)\n",
" kv_cache_new = (k, v)\n",
" else:\n",
" # for cross-attention, calculate keys and values once and reuse in subsequent calls.\n",
" k = attention_module.key(xa)\n",
" v = attention_module.value(xa)\n",
" kv_cache_new = (None, None)\n",
"\n",
" wv, qk = attention_module.qkv_attention(q, k, v, mask)\n",
" return attention_module.out(wv), kv_cache_new\n",
"\n",
"\n",
"def block_forward(\n",
" residual_block,\n",
" x: torch.Tensor,\n",
" xa: Optional[torch.Tensor] = None,\n",
" mask: Optional[torch.Tensor] = None,\n",
" kv_cache: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,\n",
"):\n",
" \"\"\"\n",
" Override for residual block forward method for providing kv_cache to attention module.\n",
" Parameters:\n",
" residual_block: current residual block.\n",
" x: input token_ids.\n",
" xa: input audio features (Optional).\n",
" mask: attention mask (Optional).\n",
" kv_cache: cache for storing attention key values.\n",
" Returns:\n",
" x: residual block output\n",
" kv_cache: updated kv_cache\n",
"\n",
" \"\"\"\n",
" x0, kv_cache = residual_block.attn(residual_block.attn_ln(x), mask=mask, kv_cache=kv_cache)\n",
" x = x + x0\n",
" if residual_block.cross_attn:\n",
" x1, _ = residual_block.cross_attn(residual_block.cross_attn_ln(x), xa)\n",
" x = x + x1\n",
" x = x + residual_block.mlp(residual_block.mlp_ln(x))\n",
" return x, kv_cache\n",
"\n",
"\n",
"# update forward functions\n",
"for idx, block in enumerate(model.decoder.blocks):\n",
" block.forward = partial(block_forward, block)\n",
" block.attn.forward = partial(attention_forward, block.attn)\n",
" if block.cross_attn:\n",
" block.cross_attn.forward = partial(attention_forward, block.cross_attn)\n",
"\n",
"\n",
"def decoder_forward(\n",
" decoder,\n",
" x: torch.Tensor,\n",
" xa: torch.Tensor,\n",
" kv_cache: Optional[Tuple[Tuple[torch.Tensor, torch.Tensor]]] = None,\n",
"):\n",
" \"\"\"\n",
" Override for decoder forward method.\n",
" Parameters:\n",
" x: torch.LongTensor, shape = (batch_size, <= n_ctx) the text tokens\n",
" xa: torch.Tensor, shape = (batch_size, n_mels, n_audio_ctx)\n",
" the encoded audio features to be attended on\n",
" kv_cache: Dict[str, torch.Tensor], attention modules hidden states cache from previous steps\n",
" \"\"\"\n",
" if kv_cache is not None:\n",
" offset = kv_cache[0][0].shape[1]\n",
" else:\n",
" offset = 0\n",
" kv_cache = [None for _ in range(len(decoder.blocks))]\n",
" x = decoder.token_embedding(x) + decoder.positional_embedding[offset : offset + x.shape[-1]]\n",
" x = x.to(xa.dtype)\n",
" kv_cache_upd = []\n",
"\n",
" for block, kv_block_cache in zip(decoder.blocks, kv_cache):\n",
" x, kv_block_cache_upd = block(x, xa, mask=decoder.mask, kv_cache=kv_block_cache)\n",
" kv_cache_upd.append(tuple(kv_block_cache_upd))\n",
"\n",
" x = decoder.ln(x)\n",
" logits = (x @ torch.transpose(decoder.token_embedding.weight.to(x.dtype), 1, 0)).float()\n",
"\n",
" return logits, tuple(kv_cache_upd)\n",
"\n",
"\n",
"# override decoder forward\n",
"model.decoder.forward = partial(decoder_forward, model.decoder)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"tokens = torch.ones((5, 3), dtype=torch.int64)\n",
"logits, kv_cache = model.decoder(tokens, audio_features, kv_cache=None)\n",
"\n",
"tokens = torch.ones((5, 1), dtype=torch.int64)\n",
"\n",
"if not WHISPER_DECODER_OV.exists():\n",
" decoder_model = ov.convert_model(model.decoder, example_input=(tokens, audio_features, kv_cache))\n",
" ov.save_model(decoder_model, WHISPER_DECODER_OV)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"The decoder model autoregressively predicts the next token guided by encoder hidden states and previously predicted sequence. This means that the shape of inputs which depends on the previous step (inputs for tokens and attention hidden states from previous step) are dynamic. For efficient utilization of memory, you define an upper bound for dynamic input shapes."
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prepare inference pipeline\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"The image below illustrates the pipeline of video transcribing using the Whisper model.\n",
"\n",
"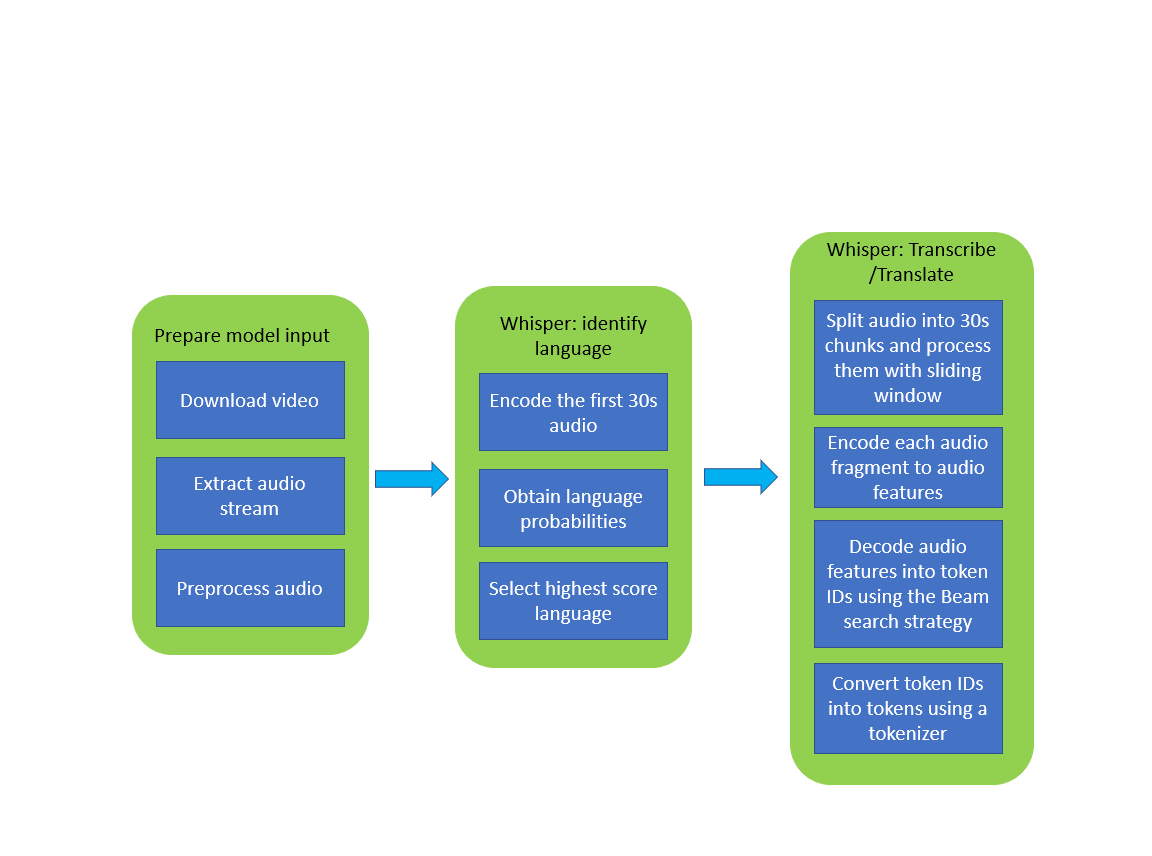\n",
"\n",
"To run the PyTorch Whisper model, we just need to call the `model.transcribe(audio, **parameters)` function. We will try to reuse original model pipeline for audio transcribing after replacing the original models with OpenVINO IR versions."
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"### Select inference device\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"select device from dropdown list for running inference using OpenVINO"
]
},
{
"cell_type": "code",
"execution_count": 8,
"metadata": {
"collapsed": false,
"jupyter": {
"outputs_hidden": false
}
},
"outputs": [],
"source": [
"core = ov.Core()"
]
},
{
"cell_type": "code",
"execution_count": 9,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "aaed5765ded34dfebfa13954e15860e7",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Dropdown(description='Device:', index=2, options=('CPU', 'GPU', 'AUTO'), value='AUTO')"
]
},
"execution_count": 9,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"import ipywidgets as widgets\n",
"\n",
"device = widgets.Dropdown(\n",
" options=core.available_devices + [\"AUTO\"],\n",
" value=\"AUTO\",\n",
" description=\"Device:\",\n",
" disabled=False,\n",
")\n",
"\n",
"device"
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"# Fetch `notebook_utils` module\n",
"import requests\n",
"\n",
"r = requests.get(\n",
" url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\",\n",
")\n",
"open(\"notebook_utils.py\", \"w\").write(r.text)\n",
"from notebook_utils import download_file\n",
"\n",
"if not Path(\"./utils.py\").exists():\n",
" download_file(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/whisper-subtitles-generation/utils.py\")\n",
"\n",
"from utils import (\n",
" patch_whisper_for_ov_inference,\n",
" OpenVINOAudioEncoder,\n",
" OpenVINOTextDecoder,\n",
")\n",
"\n",
"patch_whisper_for_ov_inference(model)\n",
"\n",
"model.encoder = OpenVINOAudioEncoder(core, WHISPER_ENCODER_OV, device=device.value)\n",
"model.decoder = OpenVINOTextDecoder(core, WHISPER_DECODER_OV, device=device.value)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Run video transcription pipeline\n",
"[back to top ⬆️](#Table-of-contents:)\n",
"\n",
"Now, we are ready to start transcription. We select a video from YouTube that we want to transcribe. Be patient, as downloading the video may take some time."
]
},
{
"cell_type": "code",
"execution_count": 11,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "5fa5aeaf42b14268b15396af3fec8ef2",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Text(value='https://youtu.be/kgL5LBM-hFI', description='Video:', placeholder='Type link for video')"
]
},
"execution_count": 11,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"import ipywidgets as widgets\n",
"\n",
"VIDEO_LINK = \"https://youtu.be/kgL5LBM-hFI\"\n",
"link = widgets.Text(\n",
" value=VIDEO_LINK,\n",
" placeholder=\"Type link for video\",\n",
" description=\"Video:\",\n",
" disabled=False,\n",
")\n",
"\n",
"link"
]
},
{
"cell_type": "code",
"execution_count": 12,
"metadata": {},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Downloading video https://youtu.be/kgL5LBM-hFI started\n",
"Video saved to downloaded_video.mp4\n"
]
}
],
"source": [
"from pytube import YouTube\n",
"\n",
"print(f\"Downloading video {link.value} started\")\n",
"\n",
"output_file = Path(\"downloaded_video.mp4\")\n",
"yt = YouTube(link.value)\n",
"yt.streams.get_highest_resolution().download(filename=output_file)\n",
"print(f\"Video saved to {output_file}\")"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [],
"source": [
"from utils import get_audio\n",
"\n",
"audio, duration = get_audio(output_file)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Select the task for the model:\n",
"\n",
"* **transcribe** - generate audio transcription in the source language (automatically detected).\n",
"* **translate** - generate audio transcription with translation to English language."
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "27c6ea25e4b1444887158695a655ad7b",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Select(description='Select task:', index=1, options=('transcribe', 'translate'), value='translate')"
]
},
"execution_count": 14,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"task = widgets.Select(\n",
" options=[\"transcribe\", \"translate\"],\n",
" value=\"translate\",\n",
" description=\"Select task:\",\n",
" disabled=False,\n",
")\n",
"task"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {},
"outputs": [],
"source": [
"transcription = model.transcribe(audio, task=task.value)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"\"The results will be saved in the `downloaded_video.srt` file. SRT is one of the most popular formats for storing subtitles and is compatible with many modern video players. This file can be used to embed transcription into videos during playback or by injecting them directly into video files using `ffmpeg`."
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {},
"outputs": [],
"source": [
"from utils import prepare_srt\n",
"\n",
"srt_lines = prepare_srt(transcription, filter_duration=duration)\n",
"# save transcription\n",
"with output_file.with_suffix(\".srt\").open(\"w\") as f:\n",
" f.writelines(srt_lines)"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"Now let us see the results."
]
},
{
"cell_type": "code",
"execution_count": 17,
"metadata": {},
"outputs": [
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "cbca661ad8284e418aaf94f42ed2621e",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"Video(value=b\"\\x00\\x00\\x00\\x18ftypmp42\\x00\\x00\\x00\\x00isommp42\\x00\\x00:'moov\\x00\\x00\\x00lmvhd...\", height='800…"
]
},
"execution_count": 17,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"widgets.Video.from_file(output_file, loop=False, width=800, height=800)"
]
},
{
"cell_type": "code",
"execution_count": 18,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"1\n",
"00:00:00,000 --> 00:00:05,000\n",
" What's that?\n",
"\n",
"2\n",
"00:00:05,000 --> 00:00:07,000\n",
" Wow.\n",
"\n",
"3\n",
"00:00:07,000 --> 00:00:10,000\n",
" Hello, humans.\n",
"\n",
"4\n",
"00:00:10,000 --> 00:00:15,000\n",
" Focus on me.\n",
"\n",
"5\n",
"00:00:15,000 --> 00:00:16,000\n",
" Focus on the guard.\n",
"\n",
"6\n",
"00:00:16,000 --> 00:00:20,000\n",
" Don't tell anyone what you've seen in here.\n",
"\n",
"7\n",
"00:00:20,000 --> 00:00:24,000\n",
" Have you seen what's in there?\n",
"\n",
"8\n",
"00:00:24,000 --> 00:00:30,000\n",
" Intel. This is where it all changes.\n",
"\n",
"\n"
]
}
],
"source": [
"print(\"\".join(srt_lines))"
]
},
{
"attachments": {},
"cell_type": "markdown",
"metadata": {},
"source": [
"## Interactive demo\n",
"[back to top ⬆️](#Table-of-contents:)\n"
]
},
{
"cell_type": "code",
"execution_count": 19,
"metadata": {
"test_replace": {
" demo.launch(debug=True)": " demo.launch()",
" demo.launch(share=True, debug=True)": " demo.launch(share=True)"
}
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"Running on local URL: http://127.0.0.1:7862\n",
"\n",
"To create a public link, set `share=True` in `launch()`.\n"
]
},
{
"data": {
"text/html": [
""
],
"text/plain": [
""
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Keyboard interruption in main thread... closing server.\n"
]
}
],
"source": [
"import gradio as gr\n",
"\n",
"\n",
"def transcribe(url, task):\n",
" output_file = Path(\"downloaded_video.mp4\")\n",
" yt = YouTube(url)\n",
" yt.streams.get_highest_resolution().download(filename=output_file)\n",
" audio, duration = get_audio(output_file)\n",
" transcription = model.transcribe(audio, task=task.lower())\n",
" srt_lines = prepare_srt(transcription, duration)\n",
" with output_file.with_suffix(\".srt\").open(\"w\") as f:\n",
" f.writelines(srt_lines)\n",
" return [str(output_file), str(output_file.with_suffix(\".srt\"))]\n",
"\n",
"\n",
"demo = gr.Interface(\n",
" transcribe,\n",
" [\n",
" gr.Textbox(label=\"YouTube URL\"),\n",
" gr.Radio([\"Transcribe\", \"Translate\"], value=\"Transcribe\"),\n",
" ],\n",
" \"video\",\n",
" examples=[[\"https://youtu.be/kgL5LBM-hFI\", \"Transcribe\"]],\n",
" allow_flagging=\"never\",\n",
")\n",
"try:\n",
" demo.launch(debug=True)\n",
"except Exception:\n",
" demo.launch(share=True, debug=True)\n",
"# if you are launching remotely, specify server_name and server_port\n",
"# demo.launch(server_name='your server name', server_port='server port in int')\n",
"# Read more in the docs: https://gradio.app/docs/"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.8.10"
},
"openvino_notebooks": {
"imageUrl": "https://user-images.githubusercontent.com/29454499/204548693-1304ef33-c790-490d-8a8b-d5766acb6254.png",
"tags": {
"categories": [
"Model Demos",
"AI Trends"
],
"libraries": [],
"other": [],
"tasks": [
"Speech Recognition"
]
}
},
"vscode": {
"interpreter": {
"hash": "916dbcbb3f70747c44a77c7bcd40155683ae19c65e1c03b4aa3499c5328201f1"
}
},
"widgets": {
"application/vnd.jupyter.widget-state+json": {
"state": {},
"version_major": 2,
"version_minor": 0
}
}
},
"nbformat": 4,
"nbformat_minor": 4
}