Spaces:
Runtime error

Runtime error
Commit
·
dbaf842
1
Parent(s):
a25de9b
Test1
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +10 -0
- .gitignore +6 -0
- LICENSE +21 -0
- app.py +19 -0
- assets/.DS_Store +0 -0
- assets/comparison.jpg +3 -0
- assets/embeddings_sd_1.4/cat.pt +3 -0
- assets/embeddings_sd_1.4/dog.pt +3 -0
- assets/embeddings_sd_1.4/horse.pt +3 -0
- assets/embeddings_sd_1.4/zebra.pt +3 -0
- assets/grid_cat2dog.jpg +3 -0
- assets/grid_dog2cat.jpg +3 -0
- assets/grid_horse2zebra.jpg +3 -0
- assets/grid_tree2fall.jpg +3 -0
- assets/grid_zebra2horse.jpg +3 -0
- assets/main.gif +3 -0
- assets/method.jpeg +3 -0
- assets/results_real.jpg +3 -0
- assets/results_syn.jpg +3 -0
- assets/results_teaser.jpg +0 -0
- assets/test_images/cats/cat_1.png +0 -0
- assets/test_images/cats/cat_2.png +0 -0
- assets/test_images/cats/cat_3.png +0 -0
- assets/test_images/cats/cat_4.png +0 -0
- assets/test_images/cats/cat_5.png +0 -0
- assets/test_images/cats/cat_6.png +0 -0
- assets/test_images/cats/cat_7.png +0 -0
- assets/test_images/cats/cat_8.png +0 -0
- assets/test_images/cats/cat_9.png +0 -0
- assets/test_images/dogs/dog_1.png +0 -0
- assets/test_images/dogs/dog_2.png +0 -0
- assets/test_images/dogs/dog_3.png +0 -0
- assets/test_images/dogs/dog_4.png +0 -0
- assets/test_images/dogs/dog_5.png +0 -0
- assets/test_images/dogs/dog_6.png +0 -0
- assets/test_images/dogs/dog_7.png +0 -0
- assets/test_images/dogs/dog_8.png +0 -0
- assets/test_images/dogs/dog_9.png +0 -0
- environment.yml +23 -0
- output/test_cat/edit/cat_1.png +0 -0
- output/test_cat/inversion/cat_1.pt +3 -0
- output/test_cat/prompt/cat_1.txt +1 -0
- output/test_cat/reconstruction/cat_1.png +0 -0
- output/test_cat2/edit/cat_1.png +0 -0
- output/test_cat2/reconstruction/cat_1.png +0 -0
- requirements.txt +11 -0
- src/edit_real.py +65 -0
- src/edit_synthetic.py +52 -0
- src/inversion.py +64 -0
- src/make_edit_direction.py +61 -0
.gitattributes
CHANGED
|
@@ -32,3 +32,13 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 32 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 33 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
assets/comparison.jpg filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
assets/grid_cat2dog.jpg filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
assets/grid_dog2cat.jpg filter=lfs diff=lfs merge=lfs -text
|
| 38 |
+
assets/grid_horse2zebra.jpg filter=lfs diff=lfs merge=lfs -text
|
| 39 |
+
assets/grid_tree2fall.jpg filter=lfs diff=lfs merge=lfs -text
|
| 40 |
+
assets/grid_zebra2horse.jpg filter=lfs diff=lfs merge=lfs -text
|
| 41 |
+
assets/main.gif filter=lfs diff=lfs merge=lfs -text
|
| 42 |
+
assets/method.jpeg filter=lfs diff=lfs merge=lfs -text
|
| 43 |
+
assets/results_real.jpg filter=lfs diff=lfs merge=lfs -text
|
| 44 |
+
assets/results_syn.jpg filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
output
|
| 2 |
+
scripts
|
| 3 |
+
src/folder_*.py
|
| 4 |
+
src/ig_*.py
|
| 5 |
+
assets/edit_sentences
|
| 6 |
+
src/utils/edit_pipeline_spatial.py
|
LICENSE
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023 pix2pixzero
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
app.py
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import gradio as gr
|
| 3 |
+
|
| 4 |
+
def update(name):
|
| 5 |
+
os.system('''python src/inversion.py \
|
| 6 |
+
--input_image "assets/test_images/cats/cat_1.png" \
|
| 7 |
+
--results_folder "output/test_cat"
|
| 8 |
+
''')
|
| 9 |
+
return f"Inverted!"
|
| 10 |
+
|
| 11 |
+
with gr.Blocks() as demo:
|
| 12 |
+
gr.Markdown("Start typing below and then click **Run** to see the output.")
|
| 13 |
+
with gr.Row():
|
| 14 |
+
inp = gr.Textbox(placeholder="Do you want to invert?")
|
| 15 |
+
out = gr.Textbox()
|
| 16 |
+
btn = gr.Button("Run")
|
| 17 |
+
btn.click(fn=update, inputs=inp, outputs=out)
|
| 18 |
+
|
| 19 |
+
demo.launch()
|
assets/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
assets/comparison.jpg
ADDED

|
Git LFS Details
|
assets/embeddings_sd_1.4/cat.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:aa9441dc014d5e86567c5ef165e10b50d2a7b3a68d90686d0cd1006792adf334
|
| 3 |
+
size 237300
|
assets/embeddings_sd_1.4/dog.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:becf079d61d7f35727bcc0d8506ddcdcddb61e62d611840ff3d18eca7fb6338c
|
| 3 |
+
size 237300
|
assets/embeddings_sd_1.4/horse.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:c5d499299544d11371f84674761292b0512055ef45776c700c0b0da164cbf6c7
|
| 3 |
+
size 118949
|
assets/embeddings_sd_1.4/zebra.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:a29f6a11d91f3a276e27326b7623fae9d61a3d253ad430bb868bd40fb7e02fec
|
| 3 |
+
size 118949
|
assets/grid_cat2dog.jpg
ADDED

|
Git LFS Details
|
assets/grid_dog2cat.jpg
ADDED

|
Git LFS Details
|
assets/grid_horse2zebra.jpg
ADDED

|
Git LFS Details
|
assets/grid_tree2fall.jpg
ADDED

|
Git LFS Details
|
assets/grid_zebra2horse.jpg
ADDED

|
Git LFS Details
|
assets/main.gif
ADDED

|
Git LFS Details
|
assets/method.jpeg
ADDED

|
Git LFS Details
|
assets/results_real.jpg
ADDED

|
Git LFS Details
|
assets/results_syn.jpg
ADDED

|
Git LFS Details
|
assets/results_teaser.jpg
ADDED
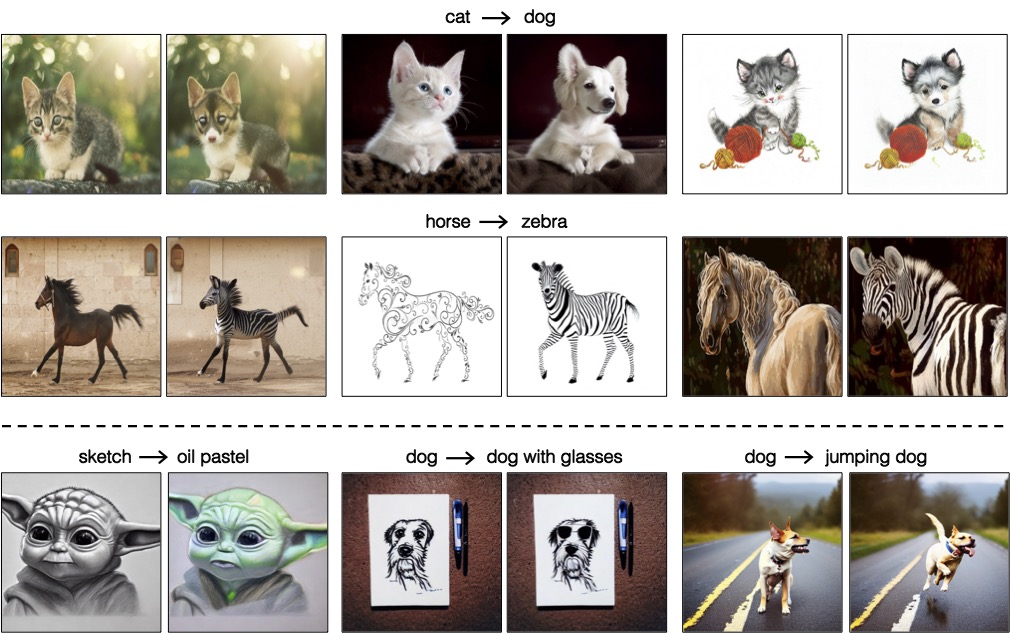
|
assets/test_images/cats/cat_1.png
ADDED

|
assets/test_images/cats/cat_2.png
ADDED

|
assets/test_images/cats/cat_3.png
ADDED

|
assets/test_images/cats/cat_4.png
ADDED

|
assets/test_images/cats/cat_5.png
ADDED

|
assets/test_images/cats/cat_6.png
ADDED

|
assets/test_images/cats/cat_7.png
ADDED

|
assets/test_images/cats/cat_8.png
ADDED

|
assets/test_images/cats/cat_9.png
ADDED

|
assets/test_images/dogs/dog_1.png
ADDED

|
assets/test_images/dogs/dog_2.png
ADDED

|
assets/test_images/dogs/dog_3.png
ADDED

|
assets/test_images/dogs/dog_4.png
ADDED

|
assets/test_images/dogs/dog_5.png
ADDED

|
assets/test_images/dogs/dog_6.png
ADDED

|
assets/test_images/dogs/dog_7.png
ADDED

|
assets/test_images/dogs/dog_8.png
ADDED

|
assets/test_images/dogs/dog_9.png
ADDED

|
environment.yml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: pix2pix-zero
|
| 2 |
+
channels:
|
| 3 |
+
- pytorch
|
| 4 |
+
- nvidia
|
| 5 |
+
- defaults
|
| 6 |
+
dependencies:
|
| 7 |
+
- pip
|
| 8 |
+
- pytorch-cuda=11.6
|
| 9 |
+
- torchvision
|
| 10 |
+
- pytorch
|
| 11 |
+
- pip:
|
| 12 |
+
- accelerate
|
| 13 |
+
- diffusers
|
| 14 |
+
- einops
|
| 15 |
+
- gradio
|
| 16 |
+
- ipython
|
| 17 |
+
- numpy
|
| 18 |
+
- opencv-python-headless
|
| 19 |
+
- pillow
|
| 20 |
+
- psutil
|
| 21 |
+
- tqdm
|
| 22 |
+
- transformers
|
| 23 |
+
- salesforce-lavis
|
output/test_cat/edit/cat_1.png
ADDED

|
output/test_cat/inversion/cat_1.pt
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1fd7cd2554d2d695841ede6038f7906b50085841706a2f62429ee32c08a0dc85
|
| 3 |
+
size 66283
|
output/test_cat/prompt/cat_1.txt
ADDED
|
@@ -0,0 +1 @@
|
|
|
|
|
|
|
| 1 |
+
a dog with his paws on top of a ball, painting
|
output/test_cat/reconstruction/cat_1.png
ADDED

|
output/test_cat2/edit/cat_1.png
ADDED

|
output/test_cat2/reconstruction/cat_1.png
ADDED

|
requirements.txt
ADDED
|
@@ -0,0 +1,11 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
accelerate
|
| 2 |
+
diffusers
|
| 3 |
+
einops
|
| 4 |
+
numpy
|
| 5 |
+
opencv-python-headless
|
| 6 |
+
pillow
|
| 7 |
+
psutil
|
| 8 |
+
transformers
|
| 9 |
+
tqdm
|
| 10 |
+
pytorch
|
| 11 |
+
salesforce-lavis
|
src/edit_real.py
ADDED
|
@@ -0,0 +1,65 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, pdb
|
| 2 |
+
|
| 3 |
+
import argparse
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import requests
|
| 7 |
+
from PIL import Image
|
| 8 |
+
|
| 9 |
+
from diffusers import DDIMScheduler
|
| 10 |
+
from utils.ddim_inv import DDIMInversion
|
| 11 |
+
from utils.edit_directions import construct_direction
|
| 12 |
+
from utils.edit_pipeline import EditingPipeline
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
if __name__=="__main__":
|
| 16 |
+
parser = argparse.ArgumentParser()
|
| 17 |
+
parser.add_argument('--inversion', required=True)
|
| 18 |
+
parser.add_argument('--prompt', type=str, required=True)
|
| 19 |
+
parser.add_argument('--task_name', type=str, default='cat2dog')
|
| 20 |
+
parser.add_argument('--results_folder', type=str, default='output/test_cat')
|
| 21 |
+
parser.add_argument('--num_ddim_steps', type=int, default=50)
|
| 22 |
+
parser.add_argument('--model_path', type=str, default='CompVis/stable-diffusion-v1-4')
|
| 23 |
+
parser.add_argument('--xa_guidance', default=0.1, type=float)
|
| 24 |
+
parser.add_argument('--negative_guidance_scale', default=5.0, type=float)
|
| 25 |
+
parser.add_argument('--use_float_16', action='store_true')
|
| 26 |
+
|
| 27 |
+
args = parser.parse_args()
|
| 28 |
+
|
| 29 |
+
os.makedirs(os.path.join(args.results_folder, "edit"), exist_ok=True)
|
| 30 |
+
os.makedirs(os.path.join(args.results_folder, "reconstruction"), exist_ok=True)
|
| 31 |
+
|
| 32 |
+
if args.use_float_16:
|
| 33 |
+
torch_dtype = torch.float16
|
| 34 |
+
else:
|
| 35 |
+
torch_dtype = torch.float32
|
| 36 |
+
|
| 37 |
+
# if the inversion is a folder, the prompt should also be a folder
|
| 38 |
+
assert (os.path.isdir(args.inversion)==os.path.isdir(args.prompt)), "If the inversion is a folder, the prompt should also be a folder"
|
| 39 |
+
if os.path.isdir(args.inversion):
|
| 40 |
+
l_inv_paths = sorted(glob(os.path.join(args.inversion, "*.pt")))
|
| 41 |
+
l_bnames = [os.path.basename(x) for x in l_inv_paths]
|
| 42 |
+
l_prompt_paths = [os.path.join(args.prompt, x.replace(".pt",".txt")) for x in l_bnames]
|
| 43 |
+
else:
|
| 44 |
+
l_inv_paths = [args.inversion]
|
| 45 |
+
l_prompt_paths = [args.prompt]
|
| 46 |
+
|
| 47 |
+
# Make the editing pipeline
|
| 48 |
+
pipe = EditingPipeline.from_pretrained(args.model_path, torch_dtype=torch_dtype).to("cuda")
|
| 49 |
+
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
for inv_path, prompt_path in zip(l_inv_paths, l_prompt_paths):
|
| 53 |
+
prompt_str = open(prompt_path).read().strip()
|
| 54 |
+
rec_pil, edit_pil = pipe(prompt_str,
|
| 55 |
+
num_inference_steps=args.num_ddim_steps,
|
| 56 |
+
x_in=torch.load(inv_path).unsqueeze(0),
|
| 57 |
+
edit_dir=construct_direction(args.task_name),
|
| 58 |
+
guidance_amount=args.xa_guidance,
|
| 59 |
+
guidance_scale=args.negative_guidance_scale,
|
| 60 |
+
negative_prompt=prompt_str # use the unedited prompt for the negative prompt
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
bname = os.path.basename(args.inversion).split(".")[0]
|
| 64 |
+
edit_pil[0].save(os.path.join(args.results_folder, f"edit/{bname}.png"))
|
| 65 |
+
rec_pil[0].save(os.path.join(args.results_folder, f"reconstruction/{bname}.png"))
|
src/edit_synthetic.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, pdb
|
| 2 |
+
|
| 3 |
+
import argparse
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import requests
|
| 7 |
+
from PIL import Image
|
| 8 |
+
|
| 9 |
+
from diffusers import DDIMScheduler
|
| 10 |
+
from utils.edit_directions import construct_direction
|
| 11 |
+
from utils.edit_pipeline import EditingPipeline
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
if __name__=="__main__":
|
| 15 |
+
parser = argparse.ArgumentParser()
|
| 16 |
+
parser.add_argument('--prompt_str', type=str, required=True)
|
| 17 |
+
parser.add_argument('--random_seed', default=0)
|
| 18 |
+
parser.add_argument('--task_name', type=str, default='cat2dog')
|
| 19 |
+
parser.add_argument('--results_folder', type=str, default='output/test_cat')
|
| 20 |
+
parser.add_argument('--num_ddim_steps', type=int, default=50)
|
| 21 |
+
parser.add_argument('--model_path', type=str, default='CompVis/stable-diffusion-v1-4')
|
| 22 |
+
parser.add_argument('--xa_guidance', default=0.15, type=float)
|
| 23 |
+
parser.add_argument('--negative_guidance_scale', default=5.0, type=float)
|
| 24 |
+
parser.add_argument('--use_float_16', action='store_true')
|
| 25 |
+
args = parser.parse_args()
|
| 26 |
+
|
| 27 |
+
os.makedirs(args.results_folder, exist_ok=True)
|
| 28 |
+
|
| 29 |
+
if args.use_float_16:
|
| 30 |
+
torch_dtype = torch.float16
|
| 31 |
+
else:
|
| 32 |
+
torch_dtype = torch.float32
|
| 33 |
+
|
| 34 |
+
# make the input noise map
|
| 35 |
+
torch.cuda.manual_seed(args.random_seed)
|
| 36 |
+
x = torch.randn((1,4,64,64), device="cuda")
|
| 37 |
+
|
| 38 |
+
# Make the editing pipeline
|
| 39 |
+
pipe = EditingPipeline.from_pretrained(args.model_path, torch_dtype=torch_dtype).to("cuda")
|
| 40 |
+
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
|
| 41 |
+
|
| 42 |
+
rec_pil, edit_pil = pipe(args.prompt_str,
|
| 43 |
+
num_inference_steps=args.num_ddim_steps,
|
| 44 |
+
x_in=x,
|
| 45 |
+
edit_dir=construct_direction(args.task_name),
|
| 46 |
+
guidance_amount=args.xa_guidance,
|
| 47 |
+
guidance_scale=args.negative_guidance_scale,
|
| 48 |
+
negative_prompt="" # use the empty string for the negative prompt
|
| 49 |
+
)
|
| 50 |
+
|
| 51 |
+
edit_pil[0].save(os.path.join(args.results_folder, f"edit.png"))
|
| 52 |
+
rec_pil[0].save(os.path.join(args.results_folder, f"reconstruction.png"))
|
src/inversion.py
ADDED
|
@@ -0,0 +1,64 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, pdb
|
| 2 |
+
|
| 3 |
+
import argparse
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import requests
|
| 7 |
+
from PIL import Image
|
| 8 |
+
|
| 9 |
+
from lavis.models import load_model_and_preprocess
|
| 10 |
+
|
| 11 |
+
from utils.ddim_inv import DDIMInversion
|
| 12 |
+
from utils.scheduler import DDIMInverseScheduler
|
| 13 |
+
|
| 14 |
+
if __name__=="__main__":
|
| 15 |
+
parser = argparse.ArgumentParser()
|
| 16 |
+
parser.add_argument('--input_image', type=str, default='assets/test_images/cat_a.png')
|
| 17 |
+
parser.add_argument('--results_folder', type=str, default='output/test_cat')
|
| 18 |
+
parser.add_argument('--num_ddim_steps', type=int, default=50)
|
| 19 |
+
parser.add_argument('--model_path', type=str, default='CompVis/stable-diffusion-v1-4')
|
| 20 |
+
parser.add_argument('--use_float_16', action='store_true')
|
| 21 |
+
args = parser.parse_args()
|
| 22 |
+
|
| 23 |
+
# make the output folders
|
| 24 |
+
os.makedirs(os.path.join(args.results_folder, "inversion"), exist_ok=True)
|
| 25 |
+
os.makedirs(os.path.join(args.results_folder, "prompt"), exist_ok=True)
|
| 26 |
+
|
| 27 |
+
if args.use_float_16:
|
| 28 |
+
torch_dtype = torch.float16
|
| 29 |
+
else:
|
| 30 |
+
torch_dtype = torch.float32
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
# load the BLIP model
|
| 34 |
+
model_blip, vis_processors, _ = load_model_and_preprocess(name="blip_caption", model_type="base_coco", is_eval=True, device=torch.device("cuda"))
|
| 35 |
+
# make the DDIM inversion pipeline
|
| 36 |
+
pipe = DDIMInversion.from_pretrained(args.model_path, torch_dtype=torch_dtype).to("cuda")
|
| 37 |
+
pipe.scheduler = DDIMInverseScheduler.from_config(pipe.scheduler.config)
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
# if the input is a folder, collect all the images as a list
|
| 41 |
+
if os.path.isdir(args.input_image):
|
| 42 |
+
l_img_paths = sorted(glob(os.path.join(args.input_image, "*.png")))
|
| 43 |
+
else:
|
| 44 |
+
l_img_paths = [args.input_image]
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
for img_path in l_img_paths:
|
| 48 |
+
bname = os.path.basename(args.input_image).split(".")[0]
|
| 49 |
+
img = Image.open(args.input_image).resize((512,512), Image.Resampling.LANCZOS)
|
| 50 |
+
# generate the caption
|
| 51 |
+
_image = vis_processors["eval"](img).unsqueeze(0).cuda()
|
| 52 |
+
prompt_str = model_blip.generate({"image": _image})[0]
|
| 53 |
+
x_inv, x_inv_image, x_dec_img = pipe(
|
| 54 |
+
prompt_str,
|
| 55 |
+
guidance_scale=1,
|
| 56 |
+
num_inversion_steps=args.num_ddim_steps,
|
| 57 |
+
img=img,
|
| 58 |
+
torch_dtype=torch_dtype
|
| 59 |
+
)
|
| 60 |
+
# save the inversion
|
| 61 |
+
torch.save(x_inv[0], os.path.join(args.results_folder, f"inversion/{bname}.pt"))
|
| 62 |
+
# save the prompt string
|
| 63 |
+
with open(os.path.join(args.results_folder, f"prompt/{bname}.txt"), "w") as f:
|
| 64 |
+
f.write(prompt_str)
|
src/make_edit_direction.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os, pdb
|
| 2 |
+
|
| 3 |
+
import argparse
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import requests
|
| 7 |
+
from PIL import Image
|
| 8 |
+
|
| 9 |
+
from diffusers import DDIMScheduler
|
| 10 |
+
from utils.edit_pipeline import EditingPipeline
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
## convert sentences to sentence embeddings
|
| 14 |
+
def load_sentence_embeddings(l_sentences, tokenizer, text_encoder, device="cuda"):
|
| 15 |
+
with torch.no_grad():
|
| 16 |
+
l_embeddings = []
|
| 17 |
+
for sent in l_sentences:
|
| 18 |
+
text_inputs = tokenizer(
|
| 19 |
+
sent,
|
| 20 |
+
padding="max_length",
|
| 21 |
+
max_length=tokenizer.model_max_length,
|
| 22 |
+
truncation=True,
|
| 23 |
+
return_tensors="pt",
|
| 24 |
+
)
|
| 25 |
+
text_input_ids = text_inputs.input_ids
|
| 26 |
+
prompt_embeds = text_encoder(text_input_ids.to(device), attention_mask=None)[0]
|
| 27 |
+
l_embeddings.append(prompt_embeds)
|
| 28 |
+
return torch.concatenate(l_embeddings, dim=0).mean(dim=0).unsqueeze(0)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
if __name__=="__main__":
|
| 32 |
+
parser = argparse.ArgumentParser()
|
| 33 |
+
parser.add_argument('--file_source_sentences', required=True)
|
| 34 |
+
parser.add_argument('--file_target_sentences', required=True)
|
| 35 |
+
parser.add_argument('--output_folder', required=True)
|
| 36 |
+
parser.add_argument('--model_path', type=str, default='CompVis/stable-diffusion-v1-4')
|
| 37 |
+
args = parser.parse_args()
|
| 38 |
+
|
| 39 |
+
# load the model
|
| 40 |
+
pipe = EditingPipeline.from_pretrained(args.model_path, torch_dtype=torch.float16).to("cuda")
|
| 41 |
+
bname_src = os.path.basename(args.file_source_sentences).strip(".txt")
|
| 42 |
+
outf_src = os.path.join(args.output_folder, bname_src+".pt")
|
| 43 |
+
if os.path.exists(outf_src):
|
| 44 |
+
print(f"Skipping source file {outf_src} as it already exists")
|
| 45 |
+
else:
|
| 46 |
+
with open(args.file_source_sentences, "r") as f:
|
| 47 |
+
l_sents = [x.strip() for x in f.readlines()]
|
| 48 |
+
mean_emb = load_sentence_embeddings(l_sents, pipe.tokenizer, pipe.text_encoder, device="cuda")
|
| 49 |
+
print(mean_emb.shape)
|
| 50 |
+
torch.save(mean_emb, outf_src)
|
| 51 |
+
|
| 52 |
+
bname_tgt = os.path.basename(args.file_target_sentences).strip(".txt")
|
| 53 |
+
outf_tgt = os.path.join(args.output_folder, bname_tgt+".pt")
|
| 54 |
+
if os.path.exists(outf_tgt):
|
| 55 |
+
print(f"Skipping target file {outf_tgt} as it already exists")
|
| 56 |
+
else:
|
| 57 |
+
with open(args.file_target_sentences, "r") as f:
|
| 58 |
+
l_sents = [x.strip() for x in f.readlines()]
|
| 59 |
+
mean_emb = load_sentence_embeddings(l_sents, pipe.tokenizer, pipe.text_encoder, device="cuda")
|
| 60 |
+
print(mean_emb.shape)
|
| 61 |
+
torch.save(mean_emb, outf_tgt)
|