# Introduction
!!! warning
We assume no responsibility for any illegal use of the codebase. Please refer to the local laws regarding DMCA (Digital Millennium Copyright Act) and other relevant laws in your area.
This codebase and all models are released under the CC-BY-NC-SA-4.0 license.
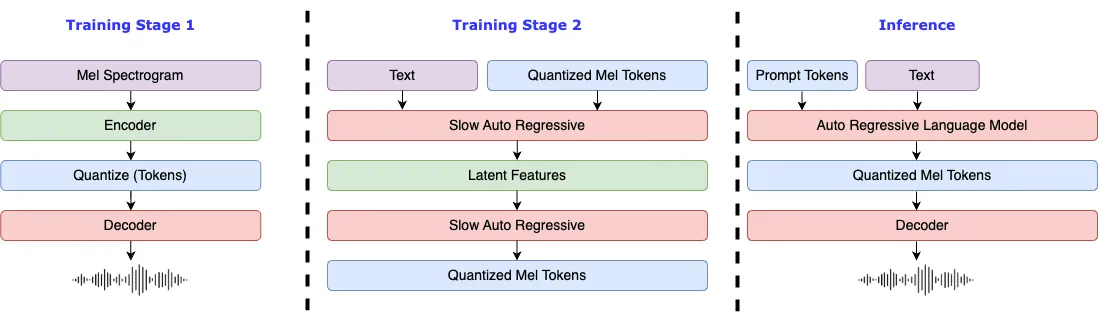
## Requirements
- GPU Memory: 4GB (for inference), 8GB (for fine-tuning)
- System: Linux, Windows
## Windows Setup
Professional Windows users may consider using WSL2 or Docker to run the codebase.
```bash
# Create a python 3.10 virtual environment, you can also use virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# Install pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
# Install fish-speech
pip3 install -e .
# (Enable acceleration) Install triton-windows
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
```
Non-professional Windows users can consider the following basic methods to run the project without a Linux environment (with model compilation capabilities, i.e., `torch.compile`):
1. Extract the project package.
2. Click `install_env.bat` to install the environment.
3. If you want to enable compilation acceleration, follow this step:
1. Download the LLVM compiler from the following links:
- [LLVM-17.0.6 (Official Site Download)](https://huggingface.co/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
- [LLVM-17.0.6 (Mirror Site Download)](https://hf-mirror.com/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
- After downloading `LLVM-17.0.6-win64.exe`, double-click to install, select an appropriate installation location, and most importantly, check the `Add Path to Current User` option to add the environment variable.
- Confirm that the installation is complete.
2. Download and install the Microsoft Visual C++ Redistributable to solve potential .dll missing issues:
- [MSVC++ 14.40.33810.0 Download](https://aka.ms/vs/17/release/vc_redist.x64.exe)
3. Download and install Visual Studio Community Edition to get MSVC++ build tools and resolve LLVM's header file dependencies:
- [Visual Studio Download](https://visualstudio.microsoft.com/zh-hans/downloads/)
- After installing Visual Studio Installer, download Visual Studio Community 2022.
- As shown below, click the `Modify` button and find the `Desktop development with C++` option to select and download.
4. Download and install [CUDA Toolkit 12.x](https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Windows&target_arch=x86_64)
4. Double-click `start.bat` to open the training inference WebUI management interface. If needed, you can modify the `API_FLAGS` as prompted below.
!!! info "Optional"
Want to start the inference WebUI?
Edit the `API_FLAGS.txt` file in the project root directory and modify the first three lines as follows:
```
--infer
# --api
# --listen ...
...
```
!!! info "Optional"
Want to start the API server?
Edit the `API_FLAGS.txt` file in the project root directory and modify the first three lines as follows:
```
# --infer
--api
--listen ...
...
```
!!! info "Optional"
Double-click `run_cmd.bat` to enter the conda/python command line environment of this project.
## Linux Setup
See [pyproject.toml](../../pyproject.toml) for details.
```bash
# Create a python 3.10 virtual environment, you can also use virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# Install pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# (Ubuntu / Debian User) Install sox + ffmpeg
apt install libsox-dev ffmpeg
# (Ubuntu / Debian User) Install pyaudio
apt install build-essential \
cmake \
libasound-dev \
portaudio19-dev \
libportaudio2 \
libportaudiocpp0
# Install fish-speech
pip3 install -e .[stable]
```
## macos setup
If you want to perform inference on MPS, please add the `--device mps` flag.
Please refer to [this PR](https://github.com/fishaudio/fish-speech/pull/461#issuecomment-2284277772) for a comparison of inference speeds.
!!! warning
The `compile` option is not officially supported on Apple Silicon devices, so there is no guarantee that inference speed will improve.
```bash
# create a python 3.10 virtual environment, you can also use virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# install pytorch
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# install fish-speech
pip install -e .[stable]
```
## Docker Setup
1. Install NVIDIA Container Toolkit:
To use GPU for model training and inference in Docker, you need to install NVIDIA Container Toolkit:
For Ubuntu users:
```bash
# Add repository
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# Install nvidia-container-toolkit
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# Restart Docker service
sudo systemctl restart docker
```
For users of other Linux distributions, please refer to: [NVIDIA Container Toolkit Install-guide](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html).
2. Pull and run the fish-speech image
```shell
# Pull the image
docker pull fishaudio/fish-speech:latest-dev
# Run the image
docker run -it \
--name fish-speech \
--gpus all \
-p 7860:7860 \
fishaudio/fish-speech:latest-dev \
zsh
# If you need to use a different port, please modify the -p parameter to YourPort:7860
```
3. Download model dependencies
Make sure you are in the terminal inside the docker container, then download the required `vqgan` and `llama` models from our huggingface repository.
```bash
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
```
4. Configure environment variables and access WebUI
In the terminal inside the docker container, enter `export GRADIO_SERVER_NAME="0.0.0.0"` to allow external access to the gradio service inside docker.
Then in the terminal inside the docker container, enter `python tools/webui.py` to start the WebUI service.
If you're using WSL or MacOS, visit [http://localhost:7860](http://localhost:7860) to open the WebUI interface.
If it's deployed on a server, replace localhost with your server's IP.
## Changelog
- 2024/09/10: Updated Fish-Speech to 1.4 version, with an increase in dataset size and a change in the quantizer's n_groups from 4 to 8.
- 2024/07/02: Updated Fish-Speech to 1.2 version, remove VITS Decoder, and greatly enhanced zero-shot ability.
- 2024/05/10: Updated Fish-Speech to 1.1 version, implement VITS decoder to reduce WER and improve timbre similarity.
- 2024/04/22: Finished Fish-Speech 1.0 version, significantly modified VQGAN and LLAMA models.
- 2023/12/28: Added `lora` fine-tuning support.
- 2023/12/27: Add `gradient checkpointing`, `causual sampling`, and `flash-attn` support.
- 2023/12/19: Updated webui and HTTP API.
- 2023/12/18: Updated fine-tuning documentation and related examples.
- 2023/12/17: Updated `text2semantic` model, supporting phoneme-free mode.
- 2023/12/13: Beta version released, includes VQGAN model and a language model based on LLAMA (phoneme support only).
## Acknowledgements
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
- [GPT VITS](https://github.com/innnky/gpt-vits)
- [MQTTS](https://github.com/b04901014/MQTTS)
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
- [Transformers](https://github.com/huggingface/transformers)
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)

