# Introdução
!!! warning
Não nos responsabilizamos por qualquer uso ilegal do código-fonte. Consulte as leis locais sobre DMCA (Digital Millennium Copyright Act) e outras leis relevantes em sua região.
Este repositório de código e os modelos são distribuídos sob a licença CC-BY-NC-SA-4.0.
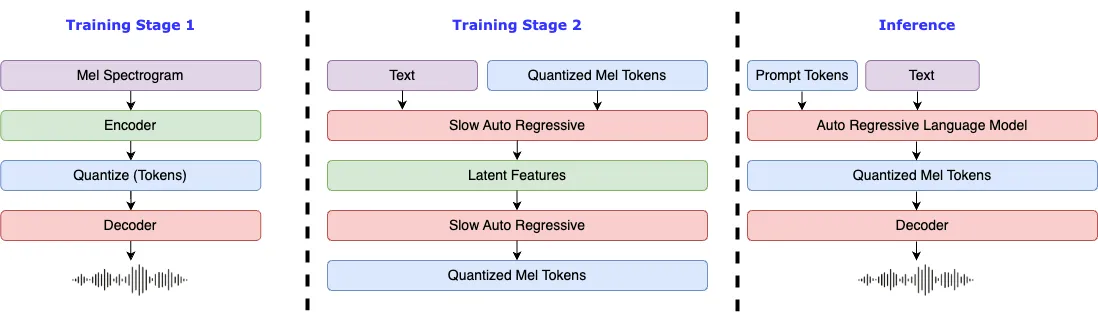
## Requisitos
- Memória da GPU: 4GB (para inferência), 8GB (para ajuste fino)
- Sistema: Linux, Windows
## Configuração do Windows
Usuários profissionais do Windows podem considerar o uso do WSL2 ou Docker para executar a base de código.
```bash
# Crie um ambiente virtual Python 3.10, também é possível usar o virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# Instale o pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu121
# Instale o fish-speech
pip3 install -e .
# (Ativar aceleração) Instalar triton-windows
pip install https://github.com/AnyaCoder/fish-speech/releases/download/v0.1.0/triton_windows-0.1.0-py3-none-any.whl
```
Usuários não profissionais do Windows podem considerar os seguintes métodos básicos para executar o projeto sem um ambiente Linux (com capacidades de compilação de modelo, ou seja, `torch.compile`):
1. Extraia o pacote do projeto.
2. Clique em `install_env.bat` para instalar o ambiente.
3. Se você quiser ativar a aceleração de compilação, siga estas etapas:
1. Baixe o compilador LLVM nos seguintes links:
- [LLVM-17.0.6 (Download do site oficial)](https://huggingface.co/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
- [LLVM-17.0.6 (Download do site espelho)](https://hf-mirror.com/fishaudio/fish-speech-1/resolve/main/LLVM-17.0.6-win64.exe?download=true)
- Após baixar o `LLVM-17.0.6-win64.exe`, clique duas vezes para instalar, selecione um local de instalação apropriado e, o mais importante, marque a opção `Add Path to Current User` para adicionar a variável de ambiente.
- Confirme que a instalação foi concluída.
2. Baixe e instale o Microsoft Visual C++ Redistributable para resolver possíveis problemas de arquivos .dll ausentes:
- [Download do MSVC++ 14.40.33810.0](https://aka.ms/vs/17/release/vc_redist.x64.exe)
3. Baixe e instale o Visual Studio Community Edition para obter as ferramentas de compilação do MSVC++ e resolver as dependências dos arquivos de cabeçalho do LLVM:
- [Download do Visual Studio](https://visualstudio.microsoft.com/pt-br/downloads/)
- Após instalar o Visual Studio Installer, baixe o Visual Studio Community 2022.
- Conforme mostrado abaixo, clique no botão `Modificar`, encontre a opção `Desenvolvimento de área de trabalho com C++` e selecione para fazer o download.
4. Baixe e instale o [CUDA Toolkit 12.x](https://developer.nvidia.com/cuda-12-1-0-download-archive?target_os=Windows&target_arch=x86_64)
4. Clique duas vezes em `start.bat` para abrir a interface de gerenciamento WebUI de inferência de treinamento. Se necessário, você pode modificar as `API_FLAGS` conforme mostrado abaixo.
!!! info "Opcional"
Você quer iniciar o WebUI de inferência?
Edite o arquivo `API_FLAGS.txt` no diretório raiz do projeto e modifique as três primeiras linhas como segue:
```
--infer
# --api
# --listen ...
...
```
!!! info "Opcional"
Você quer iniciar o servidor de API?
Edite o arquivo `API_FLAGS.txt` no diretório raiz do projeto e modifique as três primeiras linhas como segue:
```
# --infer
--api
--listen ...
...
```
!!! info "Opcional"
Clique duas vezes em `run_cmd.bat` para entrar no ambiente de linha de comando conda/python deste projeto.
## Configuração para Linux
Para mais detalhes, consulte [pyproject.toml](../../pyproject.toml).
```bash
# Crie um ambiente virtual python 3.10, você também pode usar virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# Instale o pytorch
pip3 install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# Para os Usuário do Ubuntu / Debian: Instale o sox + ffmpeg
apt install libsox-dev ffmpeg
# Para os Usuário do Ubuntu / Debian: Instale o pyaudio
apt install build-essential \
cmake \
libasound-dev \
portaudio19-dev \
libportaudio2 \
libportaudiocpp0
# Instale o fish-speech
pip3 install -e .[stable]
```
## Configuração para macos
Se você quiser realizar inferências no MPS, adicione a flag `--device mps`.
Para uma comparação das velocidades de inferência, consulte [este PR](https://github.com/fishaudio/fish-speech/pull/461#issuecomment-2284277772).
!!! aviso
A opção `compile` não é oficialmente suportada em dispositivos Apple Silicon, então não há garantia de que a velocidade de inferência irá melhorar.
```bash
# create a python 3.10 virtual environment, you can also use virtualenv
conda create -n fish-speech python=3.10
conda activate fish-speech
# install pytorch
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1
# install fish-speech
pip install -e .[stable]
```
## Configuração do Docker
1. Instale o NVIDIA Container Toolkit:
Para usar a GPU com Docker para treinamento e inferência de modelos, você precisa instalar o NVIDIA Container Toolkit:
Para usuários Ubuntu:
```bash
# Adicione o repositório remoto
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
# Instale o nvidia-container-toolkit
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# Reinicie o serviço Docker
sudo systemctl restart docker
```
Para usuários de outras distribuições Linux, consulte o guia de instalação: [NVIDIA Container Toolkit Install-guide](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html).
2. Baixe e execute a imagem fish-speech
```shell
# Baixe a imagem
docker pull fishaudio/fish-speech:latest-dev
# Execute a imagem
docker run -it \
--name fish-speech \
--gpus all \
-p 7860:7860 \
fishaudio/fish-speech:latest-dev \
zsh
# Se precisar usar outra porta, modifique o parâmetro -p para YourPort:7860
```
3. Baixe as dependências do modelo
Certifique-se de estar no terminal do contêiner Docker e, em seguida, baixe os modelos necessários `vqgan` e `llama` do nosso repositório HuggingFace.
```bash
huggingface-cli download fishaudio/fish-speech-1.4 --local-dir checkpoints/fish-speech-1.4
```
4. Configure as variáveis de ambiente e acesse a WebUI
No terminal do contêiner Docker, digite `export GRADIO_SERVER_NAME="0.0.0.0"` para permitir o acesso externo ao serviço gradio dentro do Docker.
Em seguida, no terminal do contêiner Docker, digite `python tools/webui.py` para iniciar o serviço WebUI.
Se estiver usando WSL ou MacOS, acesse [http://localhost:7860](http://localhost:7860) para abrir a interface WebUI.
Se estiver implantando em um servidor, substitua localhost pelo IP do seu servidor.
## Histórico de Alterações
- 10/09/2024: Fish-Speech atualizado para a versão 1.4, aumentado o tamanho do conjunto de dados, quantizer n_groups 4 -> 8.
- 02/07/2024: Fish-Speech atualizado para a versão 1.2, removido o Decodificador VITS e aprimorado consideravelmente a capacidade de zero-shot.
- 10/05/2024: Fish-Speech atualizado para a versão 1.1, implementado o decodificador VITS para reduzir a WER e melhorar a similaridade de timbre.
- 22/04/2024: Finalizada a versão 1.0 do Fish-Speech, modificados significativamente os modelos VQGAN e LLAMA.
- 28/12/2023: Adicionado suporte para ajuste fino `lora`.
- 27/12/2023: Adicionado suporte para `gradient checkpointing`, `causual sampling` e `flash-attn`.
- 19/12/2023: Atualizada a interface web e a API HTTP.
- 18/12/2023: Atualizada a documentação de ajuste fino e exemplos relacionados.
- 17/12/2023: Atualizado o modelo `text2semantic`, suportando o modo sem fonemas.
- 13/12/2023: Versão beta lançada, incluindo o modelo VQGAN e um modelo de linguagem baseado em LLAMA (suporte apenas a fonemas).
## Agradecimentos
- [VITS2 (daniilrobnikov)](https://github.com/daniilrobnikov/vits2)
- [Bert-VITS2](https://github.com/fishaudio/Bert-VITS2)
- [GPT VITS](https://github.com/innnky/gpt-vits)
- [MQTTS](https://github.com/b04901014/MQTTS)
- [GPT Fast](https://github.com/pytorch-labs/gpt-fast)
- [Transformers](https://github.com/huggingface/transformers)
- [GPT-SoVITS](https://github.com/RVC-Boss/GPT-SoVITS)

