").append(m.parseHTML(a)).find(d):a)}).complete(c&&function(a,b){g.each(c,e||[a.responseText,b,a])}),this},m.expr.filters.animated=function(a){return m.grep(m.timers,function(b){return a===b.elem}).length};var cd=a.document.documentElement;function dd(a){return m.isWindow(a)?a:9===a.nodeType?a.defaultView||a.parentWindow:!1}m.offset={setOffset:function(a,b,c){var d,e,f,g,h,i,j,k=m.css(a,"position"),l=m(a),n={};"static"===k&&(a.style.position="relative"),h=l.offset(),f=m.css(a,"top"),i=m.css(a,"left"),j=("absolute"===k||"fixed"===k)&&m.inArray("auto",[f,i])>-1,j?(d=l.position(),g=d.top,e=d.left):(g=parseFloat(f)||0,e=parseFloat(i)||0),m.isFunction(b)&&(b=b.call(a,c,h)),null!=b.top&&(n.top=b.top-h.top+g),null!=b.left&&(n.left=b.left-h.left+e),"using"in b?b.using.call(a,n):l.css(n)}},m.fn.extend({offset:function(a){if(arguments.length)return void 0===a?this:this.each(function(b){m.offset.setOffset(this,a,b)});var b,c,d={top:0,left:0},e=this[0],f=e&&e.ownerDocument;if(f)return b=f.documentElement,m.contains(b,e)?(typeof e.getBoundingClientRect!==K&&(d=e.getBoundingClientRect()),c=dd(f),{top:d.top+(c.pageYOffset||b.scrollTop)-(b.clientTop||0),left:d.left+(c.pageXOffset||b.scrollLeft)-(b.clientLeft||0)}):d},position:function(){if(this[0]){var a,b,c={top:0,left:0},d=this[0];return"fixed"===m.css(d,"position")?b=d.getBoundingClientRect():(a=this.offsetParent(),b=this.offset(),m.nodeName(a[0],"html")||(c=a.offset()),c.top+=m.css(a[0],"borderTopWidth",!0),c.left+=m.css(a[0],"borderLeftWidth",!0)),{top:b.top-c.top-m.css(d,"marginTop",!0),left:b.left-c.left-m.css(d,"marginLeft",!0)}}},offsetParent:function(){return this.map(function(){var a=this.offsetParent||cd;while(a&&!m.nodeName(a,"html")&&"static"===m.css(a,"position"))a=a.offsetParent;return a||cd})}}),m.each({scrollLeft:"pageXOffset",scrollTop:"pageYOffset"},function(a,b){var c=/Y/.test(b);m.fn[a]=function(d){return V(this,function(a,d,e){var f=dd(a);return void 0===e?f?b in f?f[b]:f.document.documentElement[d]:a[d]:void(f?f.scrollTo(c?m(f).scrollLeft():e,c?e:m(f).scrollTop()):a[d]=e)},a,d,arguments.length,null)}}),m.each(["top","left"],function(a,b){m.cssHooks[b]=Lb(k.pixelPosition,function(a,c){return c?(c=Jb(a,b),Hb.test(c)?m(a).position()[b]+"px":c):void 0})}),m.each({Height:"height",Width:"width"},function(a,b){m.each({padding:"inner"+a,content:b,"":"outer"+a},function(c,d){m.fn[d]=function(d,e){var f=arguments.length&&(c||"boolean"!=typeof d),g=c||(d===!0||e===!0?"margin":"border");return V(this,function(b,c,d){var e;return m.isWindow(b)?b.document.documentElement["client"+a]:9===b.nodeType?(e=b.documentElement,Math.max(b.body["scroll"+a],e["scroll"+a],b.body["offset"+a],e["offset"+a],e["client"+a])):void 0===d?m.css(b,c,g):m.style(b,c,d,g)},b,f?d:void 0,f,null)}})}),m.fn.size=function(){return this.length},m.fn.andSelf=m.fn.addBack,"function"==typeof define&&define.amd&&define("jquery",[],function(){return m});var ed=a.jQuery,fd=a.$;return m.noConflict=function(b){return a.$===m&&(a.$=fd),b&&a.jQuery===m&&(a.jQuery=ed),m},typeof b===K&&(a.jQuery=a.$=m),m});
diff --git a/docs/waifu_plugin/live2d.js b/docs/waifu_plugin/live2d.js
deleted file mode 100644
index 2cf559be672c438dfbd35db61eea12465ed0dffb..0000000000000000000000000000000000000000
--- a/docs/waifu_plugin/live2d.js
+++ /dev/null
@@ -1,4238 +0,0 @@
-!
-function(t) {
- function i(r) {
- if (e[r]) return e[r].exports;
- var o = e[r] = {
- i: r,
- l: !1,
- exports: {}
- };
- return t[r].call(o.exports, o, o.exports, i), o.l = !0, o.exports
- }
- var e = {};
- i.m = t, i.c = e, i.d = function(t, e, r) {
- i.o(t, e) || Object.defineProperty(t, e, {
- configurable: !1,
- enumerable: !0,
- get: r
- })
- }, i.n = function(t) {
- var e = t && t.__esModule ?
- function() {
- return t.
- default
- } : function() {
- return t
- };
- return i.d(e, "a", e), e
- }, i.o = function(t, i) {
- return Object.prototype.hasOwnProperty.call(t, i)
- }, i.p = "", i(i.s = 4)
-}([function(t, i, e) {
- "use strict";
-
- function r() {
- this.live2DModel = null, this.modelMatrix = null, this.eyeBlink = null, this.physics = null, this.pose = null, this.debugMode = !1, this.initialized = !1, this.updating = !1, this.alpha = 1, this.accAlpha = 0, this.lipSync = !1, this.lipSyncValue = 0, this.accelX = 0, this.accelY = 0, this.accelZ = 0, this.dragX = 0, this.dragY = 0, this.startTimeMSec = null, this.mainMotionManager = new h, this.expressionManager = new h, this.motions = {}, this.expressions = {}, this.isTexLoaded = !1
- }
- function o() {
- AMotion.prototype.constructor.call(this), this.paramList = new Array
- }
- function n() {
- this.id = "", this.type = -1, this.value = null
- }
- function s() {
- this.nextBlinkTime = null, this.stateStartTime = null, this.blinkIntervalMsec = null, this.eyeState = g.STATE_FIRST, this.blinkIntervalMsec = 4e3, this.closingMotionMsec = 100, this.closedMotionMsec = 50, this.openingMotionMsec = 150, this.closeIfZero = !0, this.eyeID_L = "PARAM_EYE_L_OPEN", this.eyeID_R = "PARAM_EYE_R_OPEN"
- }
- function _() {
- this.tr = new Float32Array(16), this.identity()
- }
- function a(t, i) {
- _.prototype.constructor.call(this), this.width = t, this.height = i
- }
- function h() {
- MotionQueueManager.prototype.constructor.call(this), this.currentPriority = null, this.reservePriority = null, this.super = MotionQueueManager.prototype
- }
- function l() {
- this.physicsList = new Array, this.startTimeMSec = UtSystem.getUserTimeMSec()
- }
- function $() {
- this.lastTime = 0, this.lastModel = null, this.partsGroups = new Array
- }
- function u(t) {
- this.paramIndex = -1, this.partsIndex = -1, this.link = null, this.id = t
- }
- function p() {
- this.EPSILON = .01, this.faceTargetX = 0, this.faceTargetY = 0, this.faceX = 0, this.faceY = 0, this.faceVX = 0, this.faceVY = 0, this.lastTimeSec = 0
- }
- function f() {
- _.prototype.constructor.call(this), this.screenLeft = null, this.screenRight = null, this.screenTop = null, this.screenBottom = null, this.maxLeft = null, this.maxRight = null, this.maxTop = null, this.maxBottom = null, this.max = Number.MAX_VALUE, this.min = 0
- }
- function c() {}
- var d = 0;
- r.prototype.getModelMatrix = function() {
- return this.modelMatrix
- }, r.prototype.setAlpha = function(t) {
- t > .999 && (t = 1), t < .001 && (t = 0), this.alpha = t
- }, r.prototype.getAlpha = function() {
- return this.alpha
- }, r.prototype.isInitialized = function() {
- return this.initialized
- }, r.prototype.setInitialized = function(t) {
- this.initialized = t
- }, r.prototype.isUpdating = function() {
- return this.updating
- }, r.prototype.setUpdating = function(t) {
- this.updating = t
- }, r.prototype.getLive2DModel = function() {
- return this.live2DModel
- }, r.prototype.setLipSync = function(t) {
- this.lipSync = t
- }, r.prototype.setLipSyncValue = function(t) {
- this.lipSyncValue = t
- }, r.prototype.setAccel = function(t, i, e) {
- this.accelX = t, this.accelY = i, this.accelZ = e
- }, r.prototype.setDrag = function(t, i) {
- this.dragX = t, this.dragY = i
- }, r.prototype.getMainMotionManager = function() {
- return this.mainMotionManager
- }, r.prototype.getExpressionManager = function() {
- return this.expressionManager
- }, r.prototype.loadModelData = function(t, i) {
- var e = c.getPlatformManager();
- this.debugMode && e.log("Load model : " + t);
- var r = this;
- e.loadLive2DModel(t, function(t) {
- if (r.live2DModel = t, r.live2DModel.saveParam(), 0 != Live2D.getError()) return void console.error("Error : Failed to loadModelData().");
- r.modelMatrix = new a(r.live2DModel.getCanvasWidth(), r.live2DModel.getCanvasHeight()), r.modelMatrix.setWidth(2), r.modelMatrix.setCenterPosition(0, 0), i(r.live2DModel)
- })
- }, r.prototype.loadTexture = function(t, i, e) {
- d++;
- var r = c.getPlatformManager();
- this.debugMode && r.log("Load Texture : " + i);
- var o = this;
- r.loadTexture(this.live2DModel, t, i, function() {
- d--, 0 == d && (o.isTexLoaded = !0), "function" == typeof e && e()
- })
- }, r.prototype.loadMotion = function(t, i, e) {
- var r = c.getPlatformManager();
- this.debugMode && r.log("Load Motion : " + i);
- var o = null,
- n = this;
- r.loadBytes(i, function(i) {
- o = Live2DMotion.loadMotion(i), null != t && (n.motions[t] = o), e(o)
- })
- }, r.prototype.loadExpression = function(t, i, e) {
- var r = c.getPlatformManager();
- this.debugMode && r.log("Load Expression : " + i);
- var n = this;
- r.loadBytes(i, function(i) {
- null != t && (n.expressions[t] = o.loadJson(i)), "function" == typeof e && e()
- })
- }, r.prototype.loadPose = function(t, i) {
- var e = c.getPlatformManager();
- this.debugMode && e.log("Load Pose : " + t);
- var r = this;
- try {
- e.loadBytes(t, function(t) {
- r.pose = $.load(t), "function" == typeof i && i()
- })
- } catch (t) {
- console.warn(t)
- }
- }, r.prototype.loadPhysics = function(t) {
- var i = c.getPlatformManager();
- this.debugMode && i.log("Load Physics : " + t);
- var e = this;
- try {
- i.loadBytes(t, function(t) {
- e.physics = l.load(t)
- })
- } catch (t) {
- console.warn(t)
- }
- }, r.prototype.hitTestSimple = function(t, i, e) {
- if (null === this.live2DModel) return !1;
- var r = this.live2DModel.getDrawDataIndex(t);
- if (r < 0) return !1;
- for (var o = this.live2DModel.getTransformedPoints(r), n = this.live2DModel.getCanvasWidth(), s = 0, _ = this.live2DModel.getCanvasHeight(), a = 0, h = 0; h < o.length; h += 2) {
- var l = o[h],
- $ = o[h + 1];
- l < n && (n = l), l > s && (s = l), $ < _ && (_ = $), $ > a && (a = $)
- }
- var u = this.modelMatrix.invertTransformX(i),
- p = this.modelMatrix.invertTransformY(e);
- return n <= u && u <= s && _ <= p && p <= a
- }, r.prototype.hitTestSimpleCustom = function(t, i, e, r) {
- return null !== this.live2DModel && (e >= t[0] && e <= i[0] && r <= t[1] && r >= i[1])
- }, o.prototype = new AMotion, o.EXPRESSION_DEFAULT = "DEFAULT", o.TYPE_SET = 0, o.TYPE_ADD = 1, o.TYPE_MULT = 2, o.loadJson = function(t) {
- var i = new o,
- e = c.getPlatformManager(),
- r = e.jsonParseFromBytes(t);
- if (i.setFadeIn(parseInt(r.fade_in) > 0 ? parseInt(r.fade_in) : 1e3), i.setFadeOut(parseInt(r.fade_out) > 0 ? parseInt(r.fade_out) : 1e3), null == r.params) return i;
- var s = r.params,
- _ = s.length;
- i.paramList = [];
- for (var a = 0; a < _; a++) {
- var h = s[a],
- l = h.id.toString(),
- $ = parseFloat(h.val),
- u = o.TYPE_ADD,
- p = null != h.calc ? h.calc.toString() : "add";
- if ((u = "add" === p ? o.TYPE_ADD : "mult" === p ? o.TYPE_MULT : "set" === p ? o.TYPE_SET : o.TYPE_ADD) == o.TYPE_ADD) {
- var f = null == h.def ? 0 : parseFloat(h.def);
- $ -= f
- } else if (u == o.TYPE_MULT) {
- var f = null == h.def ? 1 : parseFloat(h.def);
- 0 == f && (f = 1), $ /= f
- }
- var d = new n;
- d.id = l, d.type = u, d.value = $, i.paramList.push(d)
- }
- return i
- }, o.prototype.updateParamExe = function(t, i, e, r) {
- for (var n = this.paramList.length - 1; n >= 0; --n) {
- var s = this.paramList[n];
- s.type == o.TYPE_ADD ? t.addToParamFloat(s.id, s.value, e) : s.type == o.TYPE_MULT ? t.multParamFloat(s.id, s.value, e) : s.type == o.TYPE_SET && t.setParamFloat(s.id, s.value, e)
- }
- }, s.prototype.calcNextBlink = function() {
- return UtSystem.getUserTimeMSec() + Math.random() * (2 * this.blinkIntervalMsec - 1)
- }, s.prototype.setInterval = function(t) {
- this.blinkIntervalMsec = t
- }, s.prototype.setEyeMotion = function(t, i, e) {
- this.closingMotionMsec = t, this.closedMotionMsec = i, this.openingMotionMsec = e
- }, s.prototype.updateParam = function(t) {
- var i, e = UtSystem.getUserTimeMSec(),
- r = 0;
- switch (this.eyeState) {
- case g.STATE_CLOSING:
- r = (e - this.stateStartTime) / this.closingMotionMsec, r >= 1 && (r = 1, this.eyeState = g.STATE_CLOSED, this.stateStartTime = e), i = 1 - r;
- break;
- case g.STATE_CLOSED:
- r = (e - this.stateStartTime) / this.closedMotionMsec, r >= 1 && (this.eyeState = g.STATE_OPENING, this.stateStartTime = e), i = 0;
- break;
- case g.STATE_OPENING:
- r = (e - this.stateStartTime) / this.openingMotionMsec, r >= 1 && (r = 1, this.eyeState = g.STATE_INTERVAL, this.nextBlinkTime = this.calcNextBlink()), i = r;
- break;
- case g.STATE_INTERVAL:
- this.nextBlinkTime < e && (this.eyeState = g.STATE_CLOSING, this.stateStartTime = e), i = 1;
- break;
- case g.STATE_FIRST:
- default:
- this.eyeState = g.STATE_INTERVAL, this.nextBlinkTime = this.calcNextBlink(), i = 1
- }
- this.closeIfZero || (i = -i), t.setParamFloat(this.eyeID_L, i), t.setParamFloat(this.eyeID_R, i)
- };
- var g = function() {};
- g.STATE_FIRST = "STATE_FIRST", g.STATE_INTERVAL = "STATE_INTERVAL", g.STATE_CLOSING = "STATE_CLOSING", g.STATE_CLOSED = "STATE_CLOSED", g.STATE_OPENING = "STATE_OPENING", _.mul = function(t, i, e) {
- var r, o, n, s = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
- for (r = 0; r < 4; r++) for (o = 0; o < 4; o++) for (n = 0; n < 4; n++) s[r + 4 * o] += t[r + 4 * n] * i[n + 4 * o];
- for (r = 0; r < 16; r++) e[r] = s[r]
- }, _.prototype.identity = function() {
- for (var t = 0; t < 16; t++) this.tr[t] = t % 5 == 0 ? 1 : 0
- }, _.prototype.getArray = function() {
- return this.tr
- }, _.prototype.getCopyMatrix = function() {
- return new Float32Array(this.tr)
- }, _.prototype.setMatrix = function(t) {
- if (null != this.tr && this.tr.length == this.tr.length) for (var i = 0; i < 16; i++) this.tr[i] = t[i]
- }, _.prototype.getScaleX = function() {
- return this.tr[0]
- }, _.prototype.getScaleY = function() {
- return this.tr[5]
- }, _.prototype.transformX = function(t) {
- return this.tr[0] * t + this.tr[12]
- }, _.prototype.transformY = function(t) {
- return this.tr[5] * t + this.tr[13]
- }, _.prototype.invertTransformX = function(t) {
- return (t - this.tr[12]) / this.tr[0]
- }, _.prototype.invertTransformY = function(t) {
- return (t - this.tr[13]) / this.tr[5]
- }, _.prototype.multTranslate = function(t, i) {
- var e = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, t, i, 0, 1];
- _.mul(e, this.tr, this.tr)
- }, _.prototype.translate = function(t, i) {
- this.tr[12] = t, this.tr[13] = i
- }, _.prototype.translateX = function(t) {
- this.tr[12] = t
- }, _.prototype.translateY = function(t) {
- this.tr[13] = t
- }, _.prototype.multScale = function(t, i) {
- var e = [t, 0, 0, 0, 0, i, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1];
- _.mul(e, this.tr, this.tr)
- }, _.prototype.scale = function(t, i) {
- this.tr[0] = t, this.tr[5] = i
- }, a.prototype = new _, a.prototype.setPosition = function(t, i) {
- this.translate(t, i)
- }, a.prototype.setCenterPosition = function(t, i) {
- var e = this.width * this.getScaleX(),
- r = this.height * this.getScaleY();
- this.translate(t - e / 2, i - r / 2)
- }, a.prototype.top = function(t) {
- this.setY(t)
- }, a.prototype.bottom = function(t) {
- var i = this.height * this.getScaleY();
- this.translateY(t - i)
- }, a.prototype.left = function(t) {
- this.setX(t)
- }, a.prototype.right = function(t) {
- var i = this.width * this.getScaleX();
- this.translateX(t - i)
- }, a.prototype.centerX = function(t) {
- var i = this.width * this.getScaleX();
- this.translateX(t - i / 2)
- }, a.prototype.centerY = function(t) {
- var i = this.height * this.getScaleY();
- this.translateY(t - i / 2)
- }, a.prototype.setX = function(t) {
- this.translateX(t)
- }, a.prototype.setY = function(t) {
- this.translateY(t)
- }, a.prototype.setHeight = function(t) {
- var i = t / this.height,
- e = -i;
- this.scale(i, e)
- }, a.prototype.setWidth = function(t) {
- var i = t / this.width,
- e = -i;
- this.scale(i, e)
- }, h.prototype = new MotionQueueManager, h.prototype.getCurrentPriority = function() {
- return this.currentPriority
- }, h.prototype.getReservePriority = function() {
- return this.reservePriority
- }, h.prototype.reserveMotion = function(t) {
- return !(this.reservePriority >= t) && (!(this.currentPriority >= t) && (this.reservePriority = t, !0))
- }, h.prototype.setReservePriority = function(t) {
- this.reservePriority = t
- }, h.prototype.updateParam = function(t) {
- var i = MotionQueueManager.prototype.updateParam.call(this, t);
- return this.isFinished() && (this.currentPriority = 0), i
- }, h.prototype.startMotionPrio = function(t, i) {
- return i == this.reservePriority && (this.reservePriority = 0), this.currentPriority = i, this.startMotion(t, !1)
- }, l.load = function(t) {
- for (var i = new l, e = c.getPlatformManager(), r = e.jsonParseFromBytes(t), o = r.physics_hair, n = o.length, s = 0; s < n; s++) {
- var _ = o[s],
- a = new PhysicsHair,
- h = _.setup,
- $ = parseFloat(h.length),
- u = parseFloat(h.regist),
- p = parseFloat(h.mass);
- a.setup($, u, p);
- for (var f = _.src, d = f.length, g = 0; g < d; g++) {
- var y = f[g],
- m = y.id,
- T = PhysicsHair.Src.SRC_TO_X,
- P = y.ptype;
- "x" === P ? T = PhysicsHair.Src.SRC_TO_X : "y" === P ? T = PhysicsHair.Src.SRC_TO_Y : "angle" === P ? T = PhysicsHair.Src.SRC_TO_G_ANGLE : UtDebug.error("live2d", "Invalid parameter:PhysicsHair.Src");
- var S = parseFloat(y.scale),
- v = parseFloat(y.weight);
- a.addSrcParam(T, m, S, v)
- }
- for (var L = _.targets, M = L.length, g = 0; g < M; g++) {
- var E = L[g],
- m = E.id,
- T = PhysicsHair.Target.TARGET_FROM_ANGLE,
- P = E.ptype;
- "angle" === P ? T = PhysicsHair.Target.TARGET_FROM_ANGLE : "angle_v" === P ? T = PhysicsHair.Target.TARGET_FROM_ANGLE_V : UtDebug.error("live2d", "Invalid parameter:PhysicsHair.Target");
- var S = parseFloat(E.scale),
- v = parseFloat(E.weight);
- a.addTargetParam(T, m, S, v)
- }
- i.physicsList.push(a)
- }
- return i
- }, l.prototype.updateParam = function(t) {
- for (var i = UtSystem.getUserTimeMSec() - this.startTimeMSec, e = 0; e < this.physicsList.length; e++) this.physicsList[e].update(t, i)
- }, $.load = function(t) {
- for (var i = new $, e = c.getPlatformManager(), r = e.jsonParseFromBytes(t), o = r.parts_visible, n = o.length, s = 0; s < n; s++) {
- for (var _ = o[s], a = _.group, h = a.length, l = new Array, p = 0; p < h; p++) {
- var f = a[p],
- d = new u(f.id);
- if (l[p] = d, null != f.link) {
- var g = f.link,
- y = g.length;
- d.link = new Array;
- for (var m = 0; m < y; m++) {
- var T = new u(g[m]);
- d.link.push(T)
- }
- }
- }
- i.partsGroups.push(l)
- }
- return i
- }, $.prototype.updateParam = function(t) {
- if (null != t) {
- t != this.lastModel && this.initParam(t), this.lastModel = t;
- var i = UtSystem.getUserTimeMSec(),
- e = 0 == this.lastTime ? 0 : (i - this.lastTime) / 1e3;
- this.lastTime = i, e < 0 && (e = 0);
- for (var r = 0; r < this.partsGroups.length; r++) this.normalizePartsOpacityGroup(t, this.partsGroups[r], e), this.copyOpacityOtherParts(t, this.partsGroups[r])
- }
- }, $.prototype.initParam = function(t) {
- if (null != t) for (var i = 0; i < this.partsGroups.length; i++) for (var e = this.partsGroups[i], r = 0; r < e.length; r++) {
- e[r].initIndex(t);
- var o = e[r].partsIndex,
- n = e[r].paramIndex;
- if (!(o < 0)) {
- var s = 0 != t.getParamFloat(n);
- if (t.setPartsOpacity(o, s ? 1 : 0), t.setParamFloat(n, s ? 1 : 0), null != e[r].link) for (var _ = 0; _ < e[r].link.length; _++) e[r].link[_].initIndex(t)
- }
- }
- }, $.prototype.normalizePartsOpacityGroup = function(t, i, e) {
- for (var r = -1, o = 1, n = 0; n < i.length; n++) {
- var s = i[n].partsIndex,
- _ = i[n].paramIndex;
- if (!(s < 0) && 0 != t.getParamFloat(_)) {
- if (r >= 0) break;
- r = n, o = t.getPartsOpacity(s), o += e / .5, o > 1 && (o = 1)
- }
- }
- r < 0 && (r = 0, o = 1);
- for (var n = 0; n < i.length; n++) {
- var s = i[n].partsIndex;
- if (!(s < 0)) if (r == n) t.setPartsOpacity(s, o);
- else {
- var a, h = t.getPartsOpacity(s);
- a = o < .5 ? -.5 * o / .5 + 1 : .5 * (1 - o) / .5;
- var l = (1 - a) * (1 - o);
- l > .15 && (a = 1 - .15 / (1 - o)), h > a && (h = a), t.setPartsOpacity(s, h)
- }
- }
- }, $.prototype.copyOpacityOtherParts = function(t, i) {
- for (var e = 0; e < i.length; e++) {
- var r = i[e];
- if (null != r.link && !(r.partsIndex < 0)) for (var o = t.getPartsOpacity(r.partsIndex), n = 0; n < r.link.length; n++) {
- var s = r.link[n];
- s.partsIndex < 0 || t.setPartsOpacity(s.partsIndex, o)
- }
- }
- }, u.prototype.initIndex = function(t) {
- this.paramIndex = t.getParamIndex("VISIBLE:" + this.id), this.partsIndex = t.getPartsDataIndex(PartsDataID.getID(this.id)), t.setParamFloat(this.paramIndex, 1)
- }, p.FRAME_RATE = 30, p.prototype.setPoint = function(t, i) {
- this.faceTargetX = t, this.faceTargetY = i
- }, p.prototype.getX = function() {
- return this.faceX
- }, p.prototype.getY = function() {
- return this.faceY
- }, p.prototype.update = function() {
- var t = 40 / 7.5 / p.FRAME_RATE;
- if (0 == this.lastTimeSec) return void(this.lastTimeSec = UtSystem.getUserTimeMSec());
- var i = UtSystem.getUserTimeMSec(),
- e = (i - this.lastTimeSec) * p.FRAME_RATE / 1e3;
- this.lastTimeSec = i;
- var r = .15 * p.FRAME_RATE,
- o = e * t / r,
- n = this.faceTargetX - this.faceX,
- s = this.faceTargetY - this.faceY;
- if (!(Math.abs(n) <= this.EPSILON && Math.abs(s) <= this.EPSILON)) {
- var _ = Math.sqrt(n * n + s * s),
- a = t * n / _,
- h = t * s / _,
- l = a - this.faceVX,
- $ = h - this.faceVY,
- u = Math.sqrt(l * l + $ * $);
- (u < -o || u > o) && (l *= o / u, $ *= o / u, u = o), this.faceVX += l, this.faceVY += $;
- var f = .5 * (Math.sqrt(o * o + 16 * o * _ - 8 * o * _) - o),
- c = Math.sqrt(this.faceVX * this.faceVX + this.faceVY * this.faceVY);
- c > f && (this.faceVX *= f / c, this.faceVY *= f / c), this.faceX += this.faceVX, this.faceY += this.faceVY
- }
- }, f.prototype = new _, f.prototype.getMaxScale = function() {
- return this.max
- }, f.prototype.getMinScale = function() {
- return this.min
- }, f.prototype.setMaxScale = function(t) {
- this.max = t
- }, f.prototype.setMinScale = function(t) {
- this.min = t
- }, f.prototype.isMaxScale = function() {
- return this.getScaleX() == this.max
- }, f.prototype.isMinScale = function() {
- return this.getScaleX() == this.min
- }, f.prototype.adjustTranslate = function(t, i) {
- this.tr[0] * this.maxLeft + (this.tr[12] + t) > this.screenLeft && (t = this.screenLeft - this.tr[0] * this.maxLeft - this.tr[12]), this.tr[0] * this.maxRight + (this.tr[12] + t) < this.screenRight && (t = this.screenRight - this.tr[0] * this.maxRight - this.tr[12]), this.tr[5] * this.maxTop + (this.tr[13] + i) < this.screenTop && (i = this.screenTop - this.tr[5] * this.maxTop - this.tr[13]), this.tr[5] * this.maxBottom + (this.tr[13] + i) > this.screenBottom && (i = this.screenBottom - this.tr[5] * this.maxBottom - this.tr[13]);
- var e = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, t, i, 0, 1];
- _.mul(e, this.tr, this.tr)
- }, f.prototype.adjustScale = function(t, i, e) {
- var r = e * this.tr[0];
- r < this.min ? this.tr[0] > 0 && (e = this.min / this.tr[0]) : r > this.max && this.tr[0] > 0 && (e = this.max / this.tr[0]);
- var o = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, t, i, 0, 1],
- n = [e, 0, 0, 0, 0, e, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1],
- s = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, -t, -i, 0, 1];
- _.mul(s, this.tr, this.tr), _.mul(n, this.tr, this.tr), _.mul(o, this.tr, this.tr)
- }, f.prototype.setScreenRect = function(t, i, e, r) {
- this.screenLeft = t, this.screenRight = i, this.screenTop = r, this.screenBottom = e
- }, f.prototype.setMaxScreenRect = function(t, i, e, r) {
- this.maxLeft = t, this.maxRight = i, this.maxTop = r, this.maxBottom = e
- }, f.prototype.getScreenLeft = function() {
- return this.screenLeft
- }, f.prototype.getScreenRight = function() {
- return this.screenRight
- }, f.prototype.getScreenBottom = function() {
- return this.screenBottom
- }, f.prototype.getScreenTop = function() {
- return this.screenTop
- }, f.prototype.getMaxLeft = function() {
- return this.maxLeft
- }, f.prototype.getMaxRight = function() {
- return this.maxRight
- }, f.prototype.getMaxBottom = function() {
- return this.maxBottom
- }, f.prototype.getMaxTop = function() {
- return this.maxTop
- }, c.platformManager = null, c.getPlatformManager = function() {
- return c.platformManager
- }, c.setPlatformManager = function(t) {
- c.platformManager = t
- }, t.exports = {
- L2DTargetPoint: p,
- Live2DFramework: c,
- L2DViewMatrix: f,
- L2DPose: $,
- L2DPartsParam: u,
- L2DPhysics: l,
- L2DMotionManager: h,
- L2DModelMatrix: a,
- L2DMatrix44: _,
- EYE_STATE: g,
- L2DEyeBlink: s,
- L2DExpressionParam: n,
- L2DExpressionMotion: o,
- L2DBaseModel: r
- }
-}, function(t, i, e) {
- "use strict";
- var r = {
- DEBUG_LOG: !1,
- DEBUG_MOUSE_LOG: !1,
- DEBUG_DRAW_HIT_AREA: !1,
- DEBUG_DRAW_ALPHA_MODEL: !1,
- VIEW_MAX_SCALE: 2,
- VIEW_MIN_SCALE: .8,
- VIEW_LOGICAL_LEFT: -1,
- VIEW_LOGICAL_RIGHT: 1,
- VIEW_LOGICAL_MAX_LEFT: -2,
- VIEW_LOGICAL_MAX_RIGHT: 2,
- VIEW_LOGICAL_MAX_BOTTOM: -2,
- VIEW_LOGICAL_MAX_TOP: 2,
- PRIORITY_NONE: 0,
- PRIORITY_IDLE: 1,
- PRIORITY_SLEEPY: 2,
- PRIORITY_NORMAL: 3,
- PRIORITY_FORCE: 4,
- MOTION_GROUP_IDLE: "idle",
- MOTION_GROUP_SLEEPY: "sleepy",
- MOTION_GROUP_TAP_BODY: "tap_body",
- MOTION_GROUP_FLICK_HEAD: "flick_head",
- MOTION_GROUP_PINCH_IN: "pinch_in",
- MOTION_GROUP_PINCH_OUT: "pinch_out",
- MOTION_GROUP_SHAKE: "shake",
- HIT_AREA_HEAD: "head",
- HIT_AREA_BODY: "body"
- };
- t.exports = r
-}, function(t, i, e) {
- "use strict";
-
- function r(t) {
- n = t
- }
- function o() {
- return n
- }
- Object.defineProperty(i, "__esModule", {
- value: !0
- }), i.setContext = r, i.getContext = o;
- var n = void 0
-}, function(t, i, e) {
- "use strict";
-
- function r() {}
- r.matrixStack = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1], r.depth = 0, r.currentMatrix = [1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1], r.tmp = new Array(16), r.reset = function() {
- this.depth = 0
- }, r.loadIdentity = function() {
- for (var t = 0; t < 16; t++) this.currentMatrix[t] = t % 5 == 0 ? 1 : 0
- }, r.push = function() {
- var t = (this.depth, 16 * (this.depth + 1));
- this.matrixStack.length < t + 16 && (this.matrixStack.length = t + 16);
- for (var i = 0; i < 16; i++) this.matrixStack[t + i] = this.currentMatrix[i];
- this.depth++
- }, r.pop = function() {
- --this.depth < 0 && (myError("Invalid matrix stack."), this.depth = 0);
- for (var t = 16 * this.depth, i = 0; i < 16; i++) this.currentMatrix[i] = this.matrixStack[t + i]
- }, r.getMatrix = function() {
- return this.currentMatrix
- }, r.multMatrix = function(t) {
- var i, e, r;
- for (i = 0; i < 16; i++) this.tmp[i] = 0;
- for (i = 0; i < 4; i++) for (e = 0; e < 4; e++) for (r = 0; r < 4; r++) this.tmp[i + 4 * e] += this.currentMatrix[i + 4 * r] * t[r + 4 * e];
- for (i = 0; i < 16; i++) this.currentMatrix[i] = this.tmp[i]
- }, t.exports = r
-}, function(t, i, e) {
- t.exports = e(5)
-}, function(t, i, e) {
- "use strict";
-
- function r(t) {
- return t && t.__esModule ? t : {
- default:
- t
- }
- }
- function o(t) {
- C = document.getElementById(t), C.addEventListener && (window.addEventListener("click", g), window.addEventListener("mousedown", g), window.addEventListener("mousemove", g), window.addEventListener("mouseup", g), document.addEventListener("mouseout", g), window.addEventListener("touchstart", y), window.addEventListener("touchend", y), window.addEventListener("touchmove", y))
- }
- function n(t) {
- var i = C.width,
- e = C.height;
- N = new M.L2DTargetPoint;
- var r = e / i,
- o = w.
- default.VIEW_LOGICAL_LEFT,
- n = w.
- default.VIEW_LOGICAL_RIGHT,
- _ = -r,
- h = r;
- if (window.Live2D.captureFrame = !1, B = new M.L2DViewMatrix, B.setScreenRect(o, n, _, h), B.setMaxScreenRect(w.
- default.VIEW_LOGICAL_MAX_LEFT, w.
- default.VIEW_LOGICAL_MAX_RIGHT, w.
- default.VIEW_LOGICAL_MAX_BOTTOM, w.
- default.VIEW_LOGICAL_MAX_TOP), B.setMaxScale(w.
- default.VIEW_MAX_SCALE), B.setMinScale(w.
- default.VIEW_MIN_SCALE), U = new M.L2DMatrix44, U.multScale(1, i / e), G = new M.L2DMatrix44, G.multTranslate(-i / 2, -e / 2), G.multScale(2 / i, -2 / i), F = v(), (0, D.setContext)(F), !F) return console.error("Failed to create WebGL context."), void(window.WebGLRenderingContext && console.error("Your browser don't support WebGL, check https://get.webgl.org/ for futher information."));
- window.Live2D.setGL(F), F.clearColor(0, 0, 0, 0), a(t), s()
- }
- function s() {
- b || (b = !0, function t() {
- _();
- var i = window.requestAnimationFrame || window.mozRequestAnimationFrame || window.webkitRequestAnimationFrame || window.msRequestAnimationFrame;
- if (window.Live2D.captureFrame) {
- window.Live2D.captureFrame = !1;
- var e = document.createElement("a");
- document.body.appendChild(e), e.setAttribute("type", "hidden"), e.href = C.toDataURL(), e.download = window.Live2D.captureName || "live2d.png", e.click()
- }
- i(t, C)
- }())
- }
- function _() {
- O.
- default.reset(), O.
- default.loadIdentity(), N.update(), R.setDrag(N.getX(), N.getY()), F.clear(F.COLOR_BUFFER_BIT), O.
- default.multMatrix(U.getArray()), O.
- default.multMatrix(B.getArray()), O.
- default.push();
- for (var t = 0; t < R.numModels(); t++) {
- var i = R.getModel(t);
- if (null == i) return;
- i.initialized && !i.updating && (i.update(), i.draw(F))
- }
- O.
- default.pop()
- }
- function a(t) {
- R.reloadFlg = !0, R.count++, R.changeModel(F, t)
- }
- function h(t, i) {
- return t.x * i.x + t.y * i.y
- }
- function l(t, i) {
- var e = Math.sqrt(t * t + i * i);
- return {
- x: t / e,
- y: i / e
- }
- }
- function $(t, i, e) {
- function r(t, i) {
- return 180 * Math.acos(h({
- x: 0,
- y: 1
- }, l(t, i))) / Math.PI
- }
- if (i.x < e.left + e.width && i.y < e.top + e.height && i.x > e.left && i.y > e.top) return i;
- var o = t.x - i.x,
- n = t.y - i.y,
- s = r(o, n);
- i.x < t.x && (s = 360 - s);
- var _ = 360 - r(e.left - t.x, -1 * (e.top - t.y)),
- a = 360 - r(e.left - t.x, -1 * (e.top + e.height - t.y)),
- $ = r(e.left + e.width - t.x, -1 * (e.top - t.y)),
- u = r(e.left + e.width - t.x, -1 * (e.top + e.height - t.y)),
- p = n / o,
- f = {};
- if (s < $) {
- var c = e.top - t.y,
- d = c / p;
- f = {
- y: t.y + c,
- x: t.x + d
- }
- } else if (s < u) {
- var g = e.left + e.width - t.x,
- y = g * p;
- f = {
- y: t.y + y,
- x: t.x + g
- }
- } else if (s < a) {
- var m = e.top + e.height - t.y,
- T = m / p;
- f = {
- y: t.y + m,
- x: t.x + T
- }
- } else if (s < _) {
- var P = t.x - e.left,
- S = P * p;
- f = {
- y: t.y - S,
- x: t.x - P
- }
- } else {
- var v = e.top - t.y,
- L = v / p;
- f = {
- y: t.y + v,
- x: t.x + L
- }
- }
- return f
- }
- function u(t) {
- Y = !0;
- var i = C.getBoundingClientRect(),
- e = P(t.clientX - i.left),
- r = S(t.clientY - i.top),
- o = $({
- x: i.left + i.width / 2,
- y: i.top + i.height * X
- }, {
- x: t.clientX,
- y: t.clientY
- }, i),
- n = m(o.x - i.left),
- s = T(o.y - i.top);
- w.
- default.DEBUG_MOUSE_LOG && console.log("onMouseMove device( x:" + t.clientX + " y:" + t.clientY + " ) view( x:" + n + " y:" + s + ")"), k = e, V = r, N.setPoint(n, s)
- }
- function p(t) {
- Y = !0;
- var i = C.getBoundingClientRect(),
- e = P(t.clientX - i.left),
- r = S(t.clientY - i.top),
- o = $({
- x: i.left + i.width / 2,
- y: i.top + i.height * X
- }, {
- x: t.clientX,
- y: t.clientY
- }, i),
- n = m(o.x - i.left),
- s = T(o.y - i.top);
- w.
- default.DEBUG_MOUSE_LOG && console.log("onMouseDown device( x:" + t.clientX + " y:" + t.clientY + " ) view( x:" + n + " y:" + s + ")"), k = e, V = r, R.tapEvent(n, s)
- }
- function f(t) {
- var i = C.getBoundingClientRect(),
- e = P(t.clientX - i.left),
- r = S(t.clientY - i.top),
- o = $({
- x: i.left + i.width / 2,
- y: i.top + i.height * X
- }, {
- x: t.clientX,
- y: t.clientY
- }, i),
- n = m(o.x - i.left),
- s = T(o.y - i.top);
- w.
- default.DEBUG_MOUSE_LOG && console.log("onMouseMove device( x:" + t.clientX + " y:" + t.clientY + " ) view( x:" + n + " y:" + s + ")"), Y && (k = e, V = r, N.setPoint(n, s))
- }
- function c() {
- Y && (Y = !1), N.setPoint(0, 0)
- }
- function d() {
- w.
- default.DEBUG_LOG && console.log("Set Session Storage."), sessionStorage.setItem("Sleepy", "1")
- }
- function g(t) {
- if ("mousewheel" == t.type);
- else if ("mousedown" == t.type) p(t);
- else if ("mousemove" == t.type) {
- var i = sessionStorage.getItem("Sleepy");
- "1" === i && sessionStorage.setItem("Sleepy", "0"), u(t)
- } else if ("mouseup" == t.type) {
- if ("button" in t && 0 != t.button) return
- } else if ("mouseout" == t.type) {
- w.
- default.DEBUG_LOG && console.log("Mouse out Window."), c();
- var e = sessionStorage.getItem("SleepyTimer");
- window.clearTimeout(e), e = window.setTimeout(d, 5e4), sessionStorage.setItem("SleepyTimer", e)
- }
- }
- function y(t) {
- var i = t.touches[0];
- "touchstart" == t.type ? 1 == t.touches.length && u(i) : "touchmove" == t.type ? f(i) : "touchend" == t.type && c()
- }
- function m(t) {
- var i = G.transformX(t);
- return B.invertTransformX(i)
- }
- function T(t) {
- var i = G.transformY(t);
- return B.invertTransformY(i)
- }
- function P(t) {
- return G.transformX(t)
- }
- function S(t) {
- return G.transformY(t)
- }
- function v() {
- for (var t = ["webgl", "experimental-webgl", "webkit-3d", "moz-webgl"], i = 0; i < t.length; i++) try {
- var e = C.getContext(t[i], {
- premultipliedAlpha: !0
- });
- if (e) return e
- } catch (t) {}
- return null
- }
- function L(t, i, e) {
- X = void 0 === e ? .5 : e, o(t), n(i)
- }
- e(6);
- var M = e(0),
- E = e(8),
- A = r(E),
- I = e(1),
- w = r(I),
- x = e(3),
- O = r(x),
- D = e(2),
- R = (window.navigator.platform.toLowerCase(), new A.
- default),
- b = !1,
- F = null,
- C = null,
- N = null,
- B = null,
- U = null,
- G = null,
- Y = !1,
- k = 0,
- V = 0,
- X = .5;
- window.loadlive2d = L
-}, function(t, i, e) {
- "use strict";
- (function(t) {
- !
- function() {
- function i() {
- At || (this._$MT = null, this._$5S = null, this._$NP = 0, i._$42++, this._$5S = new Y(this))
- }
- function e(t) {
- if (!At) {
- this.clipContextList = new Array, this.glcontext = t.gl, this.dp_webgl = t, this.curFrameNo = 0, this.firstError_clipInNotUpdate = !0, this.colorBuffer = 0, this.isInitGLFBFunc = !1, this.tmpBoundsOnModel = new S, at.glContext.length > at.frameBuffers.length && (this.curFrameNo = this.getMaskRenderTexture()), this.tmpModelToViewMatrix = new R, this.tmpMatrix2 = new R, this.tmpMatrixForMask = new R, this.tmpMatrixForDraw = new R, this.CHANNEL_COLORS = new Array;
- var i = new A;
- i = new A, i.r = 0, i.g = 0, i.b = 0, i.a = 1, this.CHANNEL_COLORS.push(i), i = new A, i.r = 1, i.g = 0, i.b = 0, i.a = 0, this.CHANNEL_COLORS.push(i), i = new A, i.r = 0, i.g = 1, i.b = 0, i.a = 0, this.CHANNEL_COLORS.push(i), i = new A, i.r = 0, i.g = 0, i.b = 1, i.a = 0, this.CHANNEL_COLORS.push(i);
- for (var e = 0; e < this.CHANNEL_COLORS.length; e++) this.dp_webgl.setChannelFlagAsColor(e, this.CHANNEL_COLORS[e])
- }
- }
- function r(t, i, e) {
- this.clipIDList = new Array, this.clipIDList = e, this.clippingMaskDrawIndexList = new Array;
- for (var r = 0; r < e.length; r++) this.clippingMaskDrawIndexList.push(i.getDrawDataIndex(e[r]));
- this.clippedDrawContextList = new Array, this.isUsing = !0, this.layoutChannelNo = 0, this.layoutBounds = new S, this.allClippedDrawRect = new S, this.matrixForMask = new Float32Array(16), this.matrixForDraw = new Float32Array(16), this.owner = t
- }
- function o(t, i) {
- this._$gP = t, this.drawDataIndex = i
- }
- function n() {
- At || (this.color = null)
- }
- function s() {
- At || (this._$dP = null, this._$eo = null, this._$V0 = null, this._$dP = 1e3, this._$eo = 1e3, this._$V0 = 1, this._$a0())
- }
- function _() {}
- function a() {
- this._$r = null, this._$0S = null
- }
- function h() {
- At || (this.x = null, this.y = null, this.width = null, this.height = null)
- }
- function l(t) {
- At || et.prototype.constructor.call(this, t)
- }
- function $() {}
- function u(t) {
- At || et.prototype.constructor.call(this, t)
- }
- function p() {
- At || (this._$vo = null, this._$F2 = null, this._$ao = 400, this._$1S = 400, p._$42++)
- }
- function f() {
- At || (this.p1 = new c, this.p2 = new c, this._$Fo = 0, this._$Db = 0, this._$L2 = 0, this._$M2 = 0, this._$ks = 0, this._$9b = 0, this._$iP = 0, this._$iT = 0, this._$lL = new Array, this._$qP = new Array, this.setup(.3, .5, .1))
- }
- function c() {
- this._$p = 1, this.x = 0, this.y = 0, this.vx = 0, this.vy = 0, this.ax = 0, this.ay = 0, this.fx = 0, this.fy = 0, this._$s0 = 0, this._$70 = 0, this._$7L = 0, this._$HL = 0
- }
- function d(t, i, e) {
- this._$wL = null, this.scale = null, this._$V0 = null, this._$wL = t, this.scale = i, this._$V0 = e
- }
- function g(t, i, e, r) {
- d.prototype.constructor.call(this, i, e, r), this._$tL = null, this._$tL = t
- }
- function y(t, i, e) {
- this._$wL = null, this.scale = null, this._$V0 = null, this._$wL = t, this.scale = i, this._$V0 = e
- }
- function T(t, i, e, r) {
- y.prototype.constructor.call(this, i, e, r), this._$YP = null, this._$YP = t
- }
- function P() {
- At || (this._$fL = 0, this._$gL = 0, this._$B0 = 1, this._$z0 = 1, this._$qT = 0, this.reflectX = !1, this.reflectY = !1)
- }
- function S() {
- At || (this.x = null, this.y = null, this.width = null, this.height = null)
- }
- function v() {}
- function L() {
- At || (this.x = null, this.y = null)
- }
- function M() {
- At || (this._$gP = null, this._$dr = null, this._$GS = null, this._$qb = null, this._$Lb = null, this._$mS = null, this.clipID = null, this.clipIDList = new Array)
- }
- function E() {
- At || (this._$Eb = E._$ps, this._$lT = 1, this._$C0 = 1, this._$tT = 1, this._$WL = 1, this.culling = !1, this.matrix4x4 = new Float32Array(16), this.premultipliedAlpha = !1, this.anisotropy = 0, this.clippingProcess = E.CLIPPING_PROCESS_NONE, this.clipBufPre_clipContextMask = null, this.clipBufPre_clipContextDraw = null, this.CHANNEL_COLORS = new Array)
- }
- function A() {
- At || (this.a = 1, this.r = 1, this.g = 1, this.b = 1, this.scale = 1, this._$ho = 1, this.blendMode = at.L2D_COLOR_BLEND_MODE_MULT)
- }
- function I() {
- At || (this._$kP = null, this._$dr = null, this._$Ai = !0, this._$mS = null)
- }
- function w() {}
- function x() {
- At || (this._$VP = 0, this._$wL = null, this._$GP = null, this._$8o = x._$ds, this._$2r = -1, this._$O2 = 0, this._$ri = 0)
- }
- function O() {}
- function D() {
- At || (this._$Ob = null)
- }
- function R() {
- this.m = new Float32Array(16), this.identity()
- }
- function b(t) {
- At || et.prototype.constructor.call(this, t)
- }
- function F() {
- At || (this._$7 = 1, this._$f = 0, this._$H = 0, this._$g = 1, this._$k = 0, this._$w = 0, this._$hi = STATE_IDENTITY, this._$Z = _$pS)
- }
- function C() {
- At || (s.prototype.constructor.call(this), this.motions = new Array, this._$7r = null, this._$7r = C._$Co++, this._$D0 = 30, this._$yT = 0, this._$E = !0, this.loopFadeIn = !0, this._$AS = -1, _$a0())
- }
- function N() {
- this._$P = new Float32Array(100), this.size = 0
- }
- function B() {
- this._$4P = null, this._$I0 = null, this._$RP = null
- }
- function U() {}
- function G() {}
- function Y(t) {
- At || (this._$QT = !0, this._$co = -1, this._$qo = 0, this._$pb = new Array(Y._$is), this._$_2 = new Float32Array(Y._$is), this._$vr = new Float32Array(Y._$is), this._$Rr = new Float32Array(Y._$is), this._$Or = new Float32Array(Y._$is), this._$fs = new Float32Array(Y._$is), this._$Js = new Array(Y._$is), this._$3S = new Array, this._$aS = new Array, this._$Bo = null, this._$F2 = new Array, this._$db = new Array, this._$8b = new Array, this._$Hr = new Array, this._$Ws = null, this._$Vs = null, this._$Er = null, this._$Es = new Int16Array(U._$Qb), this._$ZP = new Float32Array(2 * U._$1r), this._$Ri = t, this._$b0 = Y._$HP++, this.clipManager = null, this.dp_webgl = null)
- }
- function k() {}
- function V() {
- At || (this._$12 = null, this._$bb = null, this._$_L = null, this._$jo = null, this._$iL = null, this._$0L = null, this._$Br = null, this._$Dr = null, this._$Cb = null, this._$mr = null, this._$_L = wt.STATE_FIRST, this._$Br = 4e3, this._$Dr = 100, this._$Cb = 50, this._$mr = 150, this._$jo = !0, this._$iL = "PARAM_EYE_L_OPEN", this._$0L = "PARAM_EYE_R_OPEN")
- }
- function X() {
- At || (E.prototype.constructor.call(this), this._$sb = new Int32Array(X._$As), this._$U2 = new Array, this.transform = null, this.gl = null, null == X._$NT && (X._$NT = X._$9r(256), X._$vS = X._$9r(256), X._$no = X._$vb(256)))
- }
- function z() {
- At || (I.prototype.constructor.call(this), this._$GS = null, this._$Y0 = null)
- }
- function H(t) {
- _t.prototype.constructor.call(this, t), this._$8r = I._$ur, this._$Yr = null, this._$Wr = null
- }
- function W() {
- At || (M.prototype.constructor.call(this), this._$gP = null, this._$dr = null, this._$GS = null, this._$qb = null, this._$Lb = null, this._$mS = null)
- }
- function j() {
- At || (this._$NL = null, this._$3S = null, this._$aS = null, j._$42++)
- }
- function q() {
- At || (i.prototype.constructor.call(this), this._$zo = new X)
- }
- function J() {
- At || (s.prototype.constructor.call(this), this.motions = new Array, this._$o2 = null, this._$7r = J._$Co++, this._$D0 = 30, this._$yT = 0, this._$E = !1, this.loopFadeIn = !0, this._$rr = -1, this._$eP = 0)
- }
- function Q(t, i) {
- return String.fromCharCode(t.getUint8(i))
- }
- function N() {
- this._$P = new Float32Array(100), this.size = 0
- }
- function B() {
- this._$4P = null, this._$I0 = null, this._$RP = null
- }
- function Z() {
- At || (I.prototype.constructor.call(this), this._$o = 0, this._$A = 0, this._$GS = null, this._$Eo = null)
- }
- function K(t) {
- _t.prototype.constructor.call(this, t), this._$8r = I._$ur, this._$Cr = null, this._$hr = null
- }
- function tt() {
- At || (this.visible = !0, this._$g0 = !1, this._$NL = null, this._$3S = null, this._$aS = null, tt._$42++)
- }
- function it(t) {
- this._$VS = null, this._$e0 = null, this._$e0 = t
- }
- function et(t) {
- At || (this.id = t)
- }
- function rt() {}
- function ot() {
- At || (this._$4S = null)
- }
- function nt(t, i) {
- this.canvas = t, this.context = i, this.viewport = new Array(0, 0, t.width, t.height), this._$6r = 1, this._$xP = 0, this._$3r = 1, this._$uP = 0, this._$Qo = -1, this.cacheImages = {}
- }
- function st() {
- At || (this._$TT = null, this._$LT = null, this._$FS = null, this._$wL = null)
- }
- function _t(t) {
- At || (this._$e0 = null, this._$IP = null, this._$JS = !1, this._$AT = !0, this._$e0 = t, this.totalScale = 1, this._$7s = 1, this.totalOpacity = 1)
- }
- function at() {}
- function ht() {}
- function lt(t) {
- At || (this._$ib = t)
- }
- function $t() {
- At || (W.prototype.constructor.call(this), this._$LP = -1, this._$d0 = 0, this._$Yo = 0, this._$JP = null, this._$5P = null, this._$BP = null, this._$Eo = null, this._$Qi = null, this._$6s = $t._$ms, this.culling = !0, this.gl_cacheImage = null, this.instanceNo = $t._$42++)
- }
- function ut(t) {
- Mt.prototype.constructor.call(this, t), this._$8r = W._$ur, this._$Cr = null, this._$hr = null
- }
- function pt() {
- At || (this.x = null, this.y = null)
- }
- function ft(t) {
- At || (i.prototype.constructor.call(this), this.drawParamWebGL = new mt(t), this.drawParamWebGL.setGL(at.getGL(t)))
- }
- function ct() {
- At || (this.motions = null, this._$eb = !1, this.motions = new Array)
- }
- function dt() {
- this._$w0 = null, this._$AT = !0, this._$9L = !1, this._$z2 = -1, this._$bs = -1, this._$Do = -1, this._$sr = null, this._$sr = dt._$Gs++
- }
- function gt() {
- this.m = new Array(1, 0, 0, 0, 1, 0, 0, 0, 1)
- }
- function yt(t) {
- At || et.prototype.constructor.call(this, t)
- }
- function mt(t) {
- At || (E.prototype.constructor.call(this), this.textures = new Array, this.transform = null, this.gl = null, this.glno = t, this.firstDraw = !0, this.anisotropyExt = null, this.maxAnisotropy = 0, this._$As = 32, this._$Gr = !1, this._$NT = null, this._$vS = null, this._$no = null, this.vertShader = null, this.fragShader = null, this.vertShaderOff = null, this.fragShaderOff = null)
- }
- function Tt(t, i, e) {
- return null == i && (i = t.createBuffer()), t.bindBuffer(t.ARRAY_BUFFER, i), t.bufferData(t.ARRAY_BUFFER, e, t.DYNAMIC_DRAW), i
- }
- function Pt(t, i, e) {
- return null == i && (i = t.createBuffer()), t.bindBuffer(t.ELEMENT_ARRAY_BUFFER, i), t.bufferData(t.ELEMENT_ARRAY_BUFFER, e, t.DYNAMIC_DRAW), i
- }
- function St(t) {
- At || (this._$P = new Int8Array(8), this._$R0 = new DataView(this._$P.buffer), this._$3i = new Int8Array(1e3), this._$hL = 0, this._$v0 = 0, this._$S2 = 0, this._$Ko = new Array, this._$T = t, this._$F = 0)
- }
- function vt() {}
- function Lt() {}
- function Mt(t) {
- At || (this._$e0 = null, this._$IP = null, this._$Us = null, this._$7s = null, this._$IS = [!1], this._$VS = null, this._$AT = !0, this.baseOpacity = 1, this.clipBufPre_clipContext = null, this._$e0 = t)
- }
- function Et() {}
- var At = !0;
- i._$0s = 1, i._$4s = 2, i._$42 = 0, i._$62 = function(t, e) {
- try {
- if (e instanceof ArrayBuffer && (e = new DataView(e)), !(e instanceof DataView)) throw new lt("_$SS#loadModel(b) / b _$x be DataView or ArrayBuffer");
- var r, o = new St(e),
- n = o._$ST(),
- s = o._$ST(),
- a = o._$ST();
- if (109 != n || 111 != s || 99 != a) throw new lt("_$gi _$C _$li , _$Q0 _$P0.");
- if (r = o._$ST(), o._$gr(r), r > G._$T7) {
- t._$NP |= i._$4s;
- throw new lt("_$gi _$C _$li , _$n0 _$_ version _$li ( SDK : " + G._$T7 + " < _$f0 : " + r + " )@_$SS#loadModel()\n")
- }
- var h = o._$nP();
- if (r >= G._$s7) {
- var l = o._$9T(),
- $ = o._$9T();
- if (-30584 != l || -30584 != $) throw t._$NP |= i._$0s, new lt("_$gi _$C _$li , _$0 _$6 _$Ui.")
- }
- t._$KS(h);
- var u = t.getModelContext();
- u.setDrawParam(t.getDrawParam()), u.init()
- } catch (t) {
- _._$Rb(t)
- }
- }, i.prototype._$KS = function(t) {
- this._$MT = t
- }, i.prototype.getModelImpl = function() {
- return null == this._$MT && (this._$MT = new p, this._$MT._$zP()), this._$MT
- }, i.prototype.getCanvasWidth = function() {
- return null == this._$MT ? 0 : this._$MT.getCanvasWidth()
- }, i.prototype.getCanvasHeight = function() {
- return null == this._$MT ? 0 : this._$MT.getCanvasHeight()
- }, i.prototype.getParamFloat = function(t) {
- return "number" != typeof t && (t = this._$5S.getParamIndex(u.getID(t))), this._$5S.getParamFloat(t)
- }, i.prototype.setParamFloat = function(t, i, e) {
- "number" != typeof t && (t = this._$5S.getParamIndex(u.getID(t))), arguments.length < 3 && (e = 1), this._$5S.setParamFloat(t, this._$5S.getParamFloat(t) * (1 - e) + i * e)
- }, i.prototype.addToParamFloat = function(t, i, e) {
- "number" != typeof t && (t = this._$5S.getParamIndex(u.getID(t))), arguments.length < 3 && (e = 1), this._$5S.setParamFloat(t, this._$5S.getParamFloat(t) + i * e)
- }, i.prototype.multParamFloat = function(t, i, e) {
- "number" != typeof t && (t = this._$5S.getParamIndex(u.getID(t))), arguments.length < 3 && (e = 1), this._$5S.setParamFloat(t, this._$5S.getParamFloat(t) * (1 + (i - 1) * e))
- }, i.prototype.getParamIndex = function(t) {
- return this._$5S.getParamIndex(u.getID(t))
- }, i.prototype.loadParam = function() {
- this._$5S.loadParam()
- }, i.prototype.saveParam = function() {
- this._$5S.saveParam()
- }, i.prototype.init = function() {
- this._$5S.init()
- }, i.prototype.update = function() {
- this._$5S.update()
- }, i.prototype._$Rs = function() {
- return _._$li("_$60 _$PT _$Rs()"), -1
- }, i.prototype._$Ds = function(t) {
- _._$li("_$60 _$PT _$SS#_$Ds() \n")
- }, i.prototype._$K2 = function() {}, i.prototype.draw = function() {}, i.prototype.getModelContext = function() {
- return this._$5S
- }, i.prototype._$s2 = function() {
- return this._$NP
- }, i.prototype._$P7 = function(t, i, e, r) {
- var o = -1,
- n = 0,
- s = this;
- if (0 != e) if (1 == t.length) {
- var _ = t[0],
- a = 0 != s.getParamFloat(_),
- h = i[0],
- l = s.getPartsOpacity(h),
- $ = e / r;
- a ? (l += $) > 1 && (l = 1) : (l -= $) < 0 && (l = 0), s.setPartsOpacity(h, l)
- } else {
- for (var u = 0; u < t.length; u++) {
- var _ = t[u],
- p = 0 != s.getParamFloat(_);
- if (p) {
- if (o >= 0) break;
- o = u;
- var h = i[u];
- n = s.getPartsOpacity(h), n += e / r, n > 1 && (n = 1)
- }
- }
- o < 0 && (console.log("No _$wi _$q0/ _$U default[%s]", t[0]), o = 0, n = 1, s.loadParam(), s.setParamFloat(t[o], n), s.saveParam());
- for (var u = 0; u < t.length; u++) {
- var h = i[u];
- if (o == u) s.setPartsOpacity(h, n);
- else {
- var f, c = s.getPartsOpacity(h);
- f = n < .5 ? -.5 * n / .5 + 1 : .5 * (1 - n) / .5;
- var d = (1 - f) * (1 - n);
- d > .15 && (f = 1 - .15 / (1 - n)), c > f && (c = f), s.setPartsOpacity(h, c)
- }
- }
- } else for (var u = 0; u < t.length; u++) {
- var _ = t[u],
- h = i[u],
- p = 0 != s.getParamFloat(_);
- s.setPartsOpacity(h, p ? 1 : 0)
- }
- }, i.prototype.setPartsOpacity = function(t, i) {
- "number" != typeof t && (t = this._$5S.getPartsDataIndex(l.getID(t))), this._$5S.setPartsOpacity(t, i)
- }, i.prototype.getPartsDataIndex = function(t) {
- return t instanceof l || (t = l.getID(t)), this._$5S.getPartsDataIndex(t)
- }, i.prototype.getPartsOpacity = function(t) {
- return "number" != typeof t && (t = this._$5S.getPartsDataIndex(l.getID(t))), t < 0 ? 0 : this._$5S.getPartsOpacity(t)
- }, i.prototype.getDrawParam = function() {}, i.prototype.getDrawDataIndex = function(t) {
- return this._$5S.getDrawDataIndex(b.getID(t))
- }, i.prototype.getDrawData = function(t) {
- return this._$5S.getDrawData(t)
- }, i.prototype.getTransformedPoints = function(t) {
- var i = this._$5S._$C2(t);
- return i instanceof ut ? i.getTransformedPoints() : null
- }, i.prototype.getIndexArray = function(t) {
- if (t < 0 || t >= this._$5S._$aS.length) return null;
- var i = this._$5S._$aS[t];
- return null != i && i.getType() == W._$wb && i instanceof $t ? i.getIndexArray() : null
- }, e.CHANNEL_COUNT = 4, e.RENDER_TEXTURE_USE_MIPMAP = !1, e.NOT_USED_FRAME = -100, e.prototype._$L7 = function() {
- if (this.tmpModelToViewMatrix && (this.tmpModelToViewMatrix = null), this.tmpMatrix2 && (this.tmpMatrix2 = null), this.tmpMatrixForMask && (this.tmpMatrixForMask = null), this.tmpMatrixForDraw && (this.tmpMatrixForDraw = null), this.tmpBoundsOnModel && (this.tmpBoundsOnModel = null), this.CHANNEL_COLORS) {
- for (var t = this.CHANNEL_COLORS.length - 1; t >= 0; --t) this.CHANNEL_COLORS.splice(t, 1);
- this.CHANNEL_COLORS = []
- }
- this.releaseShader()
- }, e.prototype.releaseShader = function() {
- for (var t = at.frameBuffers.length, i = 0; i < t; i++) this.gl.deleteFramebuffer(at.frameBuffers[i].framebuffer);
- at.frameBuffers = [], at.glContext = []
- }, e.prototype.init = function(t, i, e) {
- for (var o = 0; o < i.length; o++) {
- var n = i[o].getClipIDList();
- if (null != n) {
- var s = this.findSameClip(n);
- null == s && (s = new r(this, t, n), this.clipContextList.push(s));
- var _ = i[o].getDrawDataID(),
- a = t.getDrawDataIndex(_);
- s.addClippedDrawData(_, a);
- e[o].clipBufPre_clipContext = s
- }
- }
- }, e.prototype.getMaskRenderTexture = function() {
- var t = null;
- return t = this.dp_webgl.createFramebuffer(), at.frameBuffers[this.dp_webgl.glno] = t, this.dp_webgl.glno
- }, e.prototype.setupClip = function(t, i) {
- for (var e = 0, r = 0; r < this.clipContextList.length; r++) {
- var o = this.clipContextList[r];
- this.calcClippedDrawTotalBounds(t, o), o.isUsing && e++
- }
- if (e > 0) {
- var n = i.gl.getParameter(i.gl.FRAMEBUFFER_BINDING),
- s = new Array(4);
- s[0] = 0, s[1] = 0, s[2] = i.gl.canvas.width, s[3] = i.gl.canvas.height, i.gl.viewport(0, 0, at.clippingMaskBufferSize, at.clippingMaskBufferSize), this.setupLayoutBounds(e), i.gl.bindFramebuffer(i.gl.FRAMEBUFFER, at.frameBuffers[this.curFrameNo].framebuffer), i.gl.clearColor(0, 0, 0, 0), i.gl.clear(i.gl.COLOR_BUFFER_BIT);
- for (var r = 0; r < this.clipContextList.length; r++) {
- var o = this.clipContextList[r],
- _ = o.allClippedDrawRect,
- a = (o.layoutChannelNo, o.layoutBounds);
- this.tmpBoundsOnModel._$jL(_), this.tmpBoundsOnModel.expand(.05 * _.width, .05 * _.height);
- var h = a.width / this.tmpBoundsOnModel.width,
- l = a.height / this.tmpBoundsOnModel.height;
- this.tmpMatrix2.identity(), this.tmpMatrix2.translate(-1, -1, 0), this.tmpMatrix2.scale(2, 2, 1), this.tmpMatrix2.translate(a.x, a.y, 0), this.tmpMatrix2.scale(h, l, 1), this.tmpMatrix2.translate(-this.tmpBoundsOnModel.x, -this.tmpBoundsOnModel.y, 0), this.tmpMatrixForMask.setMatrix(this.tmpMatrix2.m), this.tmpMatrix2.identity(), this.tmpMatrix2.translate(a.x, a.y, 0), this.tmpMatrix2.scale(h, l, 1), this.tmpMatrix2.translate(-this.tmpBoundsOnModel.x, -this.tmpBoundsOnModel.y, 0), this.tmpMatrixForDraw.setMatrix(this.tmpMatrix2.m);
- for (var $ = this.tmpMatrixForMask.getArray(), u = 0; u < 16; u++) o.matrixForMask[u] = $[u];
- for (var p = this.tmpMatrixForDraw.getArray(), u = 0; u < 16; u++) o.matrixForDraw[u] = p[u];
- for (var f = o.clippingMaskDrawIndexList.length, c = 0; c < f; c++) {
- var d = o.clippingMaskDrawIndexList[c],
- g = t.getDrawData(d),
- y = t._$C2(d);
- i.setClipBufPre_clipContextForMask(o), g.draw(i, t, y)
- }
- }
- i.gl.bindFramebuffer(i.gl.FRAMEBUFFER, n), i.setClipBufPre_clipContextForMask(null), i.gl.viewport(s[0], s[1], s[2], s[3])
- }
- }, e.prototype.getColorBuffer = function() {
- return this.colorBuffer
- }, e.prototype.findSameClip = function(t) {
- for (var i = 0; i < this.clipContextList.length; i++) {
- var e = this.clipContextList[i],
- r = e.clipIDList.length;
- if (r == t.length) {
- for (var o = 0, n = 0; n < r; n++) for (var s = e.clipIDList[n], _ = 0; _ < r; _++) if (t[_] == s) {
- o++;
- break
- }
- if (o == r) return e
- }
- }
- return null
- }, e.prototype.calcClippedDrawTotalBounds = function(t, i) {
- for (var e = t._$Ri.getModelImpl().getCanvasWidth(), r = t._$Ri.getModelImpl().getCanvasHeight(), o = e > r ? e : r, n = o, s = o, _ = 0, a = 0, h = i.clippedDrawContextList.length, l = 0; l < h; l++) {
- var $ = i.clippedDrawContextList[l],
- u = $.drawDataIndex,
- p = t._$C2(u);
- if (p._$yo()) {
- for (var f = p.getTransformedPoints(), c = f.length, d = [], g = [], y = 0, m = U._$i2; m < c; m += U._$No) d[y] = f[m], g[y] = f[m + 1], y++;
- var T = Math.min.apply(null, d),
- P = Math.min.apply(null, g),
- S = Math.max.apply(null, d),
- v = Math.max.apply(null, g);
- T < n && (n = T), P < s && (s = P), S > _ && (_ = S), v > a && (a = v)
- }
- }
- if (n == o) i.allClippedDrawRect.x = 0, i.allClippedDrawRect.y = 0, i.allClippedDrawRect.width = 0, i.allClippedDrawRect.height = 0, i.isUsing = !1;
- else {
- var L = _ - n,
- M = a - s;
- i.allClippedDrawRect.x = n, i.allClippedDrawRect.y = s, i.allClippedDrawRect.width = L, i.allClippedDrawRect.height = M, i.isUsing = !0
- }
- }, e.prototype.setupLayoutBounds = function(t) {
- var i = t / e.CHANNEL_COUNT,
- r = t % e.CHANNEL_COUNT;
- i = ~~i, r = ~~r;
- for (var o = 0, n = 0; n < e.CHANNEL_COUNT; n++) {
- var s = i + (n < r ? 1 : 0);
- if (0 == s);
- else if (1 == s) {
- var a = this.clipContextList[o++];
- a.layoutChannelNo = n, a.layoutBounds.x = 0, a.layoutBounds.y = 0, a.layoutBounds.width = 1, a.layoutBounds.height = 1
- } else if (2 == s) for (var h = 0; h < s; h++) {
- var l = h % 2,
- $ = 0;
- l = ~~l;
- var a = this.clipContextList[o++];
- a.layoutChannelNo = n, a.layoutBounds.x = .5 * l, a.layoutBounds.y = 0, a.layoutBounds.width = .5, a.layoutBounds.height = 1
- } else if (s <= 4) for (var h = 0; h < s; h++) {
- var l = h % 2,
- $ = h / 2;
- l = ~~l, $ = ~~$;
- var a = this.clipContextList[o++];
- a.layoutChannelNo = n, a.layoutBounds.x = .5 * l, a.layoutBounds.y = .5 * $, a.layoutBounds.width = .5, a.layoutBounds.height = .5
- } else if (s <= 9) for (var h = 0; h < s; h++) {
- var l = h % 3,
- $ = h / 3;
- l = ~~l, $ = ~~$;
- var a = this.clipContextList[o++];
- a.layoutChannelNo = n, a.layoutBounds.x = l / 3, a.layoutBounds.y = $ / 3, a.layoutBounds.width = 1 / 3, a.layoutBounds.height = 1 / 3
- } else _._$li("_$6 _$0P mask count : %d", s)
- }
- }, r.prototype.addClippedDrawData = function(t, i) {
- var e = new o(t, i);
- this.clippedDrawContextList.push(e)
- }, s._$JT = function(t, i, e) {
- var r = t / i,
- o = e / i,
- n = o,
- s = 1 - (1 - o) * (1 - o),
- _ = 1 - (1 - n) * (1 - n),
- a = 1 / 3 * (1 - o) * s + (n * (2 / 3) + 1 / 3 * (1 - n)) * (1 - s),
- h = (n + 2 / 3 * (1 - n)) * _ + (o * (1 / 3) + 2 / 3 * (1 - o)) * (1 - _),
- l = 1 - 3 * h + 3 * a - 0,
- $ = 3 * h - 6 * a + 0,
- u = 3 * a - 0;
- if (r <= 0) return 0;
- if (r >= 1) return 1;
- var p = r,
- f = p * p;
- return l * (p * f) + $ * f + u * p + 0
- }, s.prototype._$a0 = function() {}, s.prototype.setFadeIn = function(t) {
- this._$dP = t
- }, s.prototype.setFadeOut = function(t) {
- this._$eo = t
- }, s.prototype._$pT = function(t) {
- this._$V0 = t
- }, s.prototype.getFadeOut = function() {
- return this._$eo
- }, s.prototype._$4T = function() {
- return this._$eo
- }, s.prototype._$mT = function() {
- return this._$V0
- }, s.prototype.getDurationMSec = function() {
- return -1
- }, s.prototype.getLoopDurationMSec = function() {
- return -1
- }, s.prototype.updateParam = function(t, i) {
- if (i._$AT && !i._$9L) {
- var e = w.getUserTimeMSec();
- if (i._$z2 < 0) {
- i._$z2 = e, i._$bs = e;
- var r = this.getDurationMSec();
- i._$Do < 0 && (i._$Do = r <= 0 ? -1 : i._$z2 + r)
- }
- var o = this._$V0;
- o = o * (0 == this._$dP ? 1 : ht._$r2((e - i._$bs) / this._$dP)) * (0 == this._$eo || i._$Do < 0 ? 1 : ht._$r2((i._$Do - e) / this._$eo)), 0 <= o && o <= 1 || console.log("### assert!! ### "), this.updateParamExe(t, e, o, i), i._$Do > 0 && i._$Do < e && (i._$9L = !0)
- }
- }, s.prototype.updateParamExe = function(t, i, e, r) {}, _._$8s = 0, _._$fT = new Object, _.start = function(t) {
- var i = _._$fT[t];
- null == i && (i = new a, i._$r = t, _._$fT[t] = i), i._$0S = w.getSystemTimeMSec()
- }, _.dump = function(t) {
- var i = _._$fT[t];
- if (null != i) {
- var e = w.getSystemTimeMSec(),
- r = e - i._$0S;
- return console.log(t + " : " + r + "ms"), r
- }
- return -1
- }, _.end = function(t) {
- var i = _._$fT[t];
- if (null != i) {
- return w.getSystemTimeMSec() - i._$0S
- }
- return -1
- }, _._$li = function(t, i) {
- console.log("_$li : " + t + "\n", i)
- }, _._$Ji = function(t, i) {
- console.log(t, i)
- }, _._$dL = function(t, i) {
- console.log(t, i), console.log("\n")
- }, _._$KL = function(t, i) {
- for (var e = 0; e < i; e++) e % 16 == 0 && e > 0 ? console.log("\n") : e % 8 == 0 && e > 0 && console.log(" "), console.log("%02X ", 255 & t[e]);
- console.log("\n")
- }, _._$nr = function(t, i, e) {
- console.log("%s\n", t);
- for (var r = i.length, o = 0; o < r; ++o) console.log("%5d", i[o]), console.log("%s\n", e), console.log(",");
- console.log("\n")
- }, _._$Rb = function(t) {
- console.log("dump exception : " + t), console.log("stack :: " + t.stack)
- }, h.prototype._$8P = function() {
- return .5 * (this.x + this.x + this.width)
- }, h.prototype._$6P = function() {
- return .5 * (this.y + this.y + this.height)
- }, h.prototype._$EL = function() {
- return this.x + this.width
- }, h.prototype._$5T = function() {
- return this.y + this.height
- }, h.prototype._$jL = function(t, i, e, r) {
- this.x = t, this.y = i, this.width = e, this.height = r
- }, h.prototype._$jL = function(t) {
- this.x = t.x, this.y = t.y, this.width = t.width, this.height = t.height
- }, l.prototype = new et, l._$tP = new Object, l._$27 = function() {
- l._$tP.clear()
- }, l.getID = function(t) {
- var i = l._$tP[t];
- return null == i && (i = new l(t), l._$tP[t] = i), i
- }, l.prototype._$3s = function() {
- return new l
- }, u.prototype = new et, u._$tP = new Object, u._$27 = function() {
- u._$tP.clear()
- }, u.getID = function(t) {
- var i = u._$tP[t];
- return null == i && (i = new u(t), u._$tP[t] = i), i
- }, u.prototype._$3s = function() {
- return new u
- }, p._$42 = 0, p.prototype._$zP = function() {
- null == this._$vo && (this._$vo = new ot), null == this._$F2 && (this._$F2 = new Array)
- }, p.prototype.getCanvasWidth = function() {
- return this._$ao
- }, p.prototype.getCanvasHeight = function() {
- return this._$1S
- }, p.prototype._$F0 = function(t) {
- this._$vo = t._$nP(), this._$F2 = t._$nP(), this._$ao = t._$6L(), this._$1S = t._$6L()
- }, p.prototype._$6S = function(t) {
- this._$F2.push(t)
- }, p.prototype._$Xr = function() {
- return this._$F2
- }, p.prototype._$E2 = function() {
- return this._$vo
- }, f.prototype.setup = function(t, i, e) {
- this._$ks = this._$Yb(), this.p2._$xT(), 3 == arguments.length && (this._$Fo = t, this._$L2 = i, this.p1._$p = e, this.p2._$p = e, this.p2.y = t, this.setup())
- }, f.prototype.getPhysicsPoint1 = function() {
- return this.p1
- }, f.prototype.getPhysicsPoint2 = function() {
- return this.p2
- }, f.prototype._$qr = function() {
- return this._$Db
- }, f.prototype._$pr = function(t) {
- this._$Db = t
- }, f.prototype._$5r = function() {
- return this._$M2
- }, f.prototype._$Cs = function() {
- return this._$9b
- }, f.prototype._$Yb = function() {
- return -180 * Math.atan2(this.p1.x - this.p2.x, -(this.p1.y - this.p2.y)) / Math.PI
- }, f.prototype.addSrcParam = function(t, i, e, r) {
- var o = new g(t, i, e, r);
- this._$lL.push(o)
- }, f.prototype.addTargetParam = function(t, i, e, r) {
- var o = new T(t, i, e, r);
- this._$qP.push(o)
- }, f.prototype.update = function(t, i) {
- if (0 == this._$iP) return this._$iP = this._$iT = i, void(this._$Fo = Math.sqrt((this.p1.x - this.p2.x) * (this.p1.x - this.p2.x) + (this.p1.y - this.p2.y) * (this.p1.y - this.p2.y)));
- var e = (i - this._$iT) / 1e3;
- if (0 != e) {
- for (var r = this._$lL.length - 1; r >= 0; --r) {
- this._$lL[r]._$oP(t, this)
- }
- this._$oo(t, e), this._$M2 = this._$Yb(), this._$9b = (this._$M2 - this._$ks) / e, this._$ks = this._$M2
- }
- for (var r = this._$qP.length - 1; r >= 0; --r) {
- this._$qP[r]._$YS(t, this)
- }
- this._$iT = i
- }, f.prototype._$oo = function(t, i) {
- i < .033 && (i = .033);
- var e = 1 / i;
- this.p1.vx = (this.p1.x - this.p1._$s0) * e, this.p1.vy = (this.p1.y - this.p1._$70) * e, this.p1.ax = (this.p1.vx - this.p1._$7L) * e, this.p1.ay = (this.p1.vy - this.p1._$HL) * e, this.p1.fx = this.p1.ax * this.p1._$p, this.p1.fy = this.p1.ay * this.p1._$p, this.p1._$xT();
- var r, o, n = -Math.atan2(this.p1.y - this.p2.y, this.p1.x - this.p2.x),
- s = Math.cos(n),
- _ = Math.sin(n),
- a = 9.8 * this.p2._$p,
- h = this._$Db * Lt._$bS,
- l = a * Math.cos(n - h);
- r = l * _, o = l * s;
- var $ = -this.p1.fx * _ * _,
- u = -this.p1.fy * _ * s,
- p = -this.p2.vx * this._$L2,
- f = -this.p2.vy * this._$L2;
- this.p2.fx = r + $ + p, this.p2.fy = o + u + f, this.p2.ax = this.p2.fx / this.p2._$p, this.p2.ay = this.p2.fy / this.p2._$p, this.p2.vx += this.p2.ax * i, this.p2.vy += this.p2.ay * i, this.p2.x += this.p2.vx * i, this.p2.y += this.p2.vy * i;
- var c = Math.sqrt((this.p1.x - this.p2.x) * (this.p1.x - this.p2.x) + (this.p1.y - this.p2.y) * (this.p1.y - this.p2.y));
- this.p2.x = this.p1.x + this._$Fo * (this.p2.x - this.p1.x) / c, this.p2.y = this.p1.y + this._$Fo * (this.p2.y - this.p1.y) / c, this.p2.vx = (this.p2.x - this.p2._$s0) * e, this.p2.vy = (this.p2.y - this.p2._$70) * e, this.p2._$xT()
- }, c.prototype._$xT = function() {
- this._$s0 = this.x, this._$70 = this.y, this._$7L = this.vx, this._$HL = this.vy
- }, d.prototype._$oP = function(t, i) {}, g.prototype = new d, g.prototype._$oP = function(t, i) {
- var e = this.scale * t.getParamFloat(this._$wL),
- r = i.getPhysicsPoint1();
- switch (this._$tL) {
- default:
- case f.Src.SRC_TO_X:
- r.x = r.x + (e - r.x) * this._$V0;
- break;
- case f.Src.SRC_TO_Y:
- r.y = r.y + (e - r.y) * this._$V0;
- break;
- case f.Src.SRC_TO_G_ANGLE:
- var o = i._$qr();
- o += (e - o) * this._$V0, i._$pr(o)
- }
- }, y.prototype._$YS = function(t, i) {}, T.prototype = new y, T.prototype._$YS = function(t, i) {
- switch (this._$YP) {
- default:
- case f.Target.TARGET_FROM_ANGLE:
- t.setParamFloat(this._$wL, this.scale * i._$5r(), this._$V0);
- break;
- case f.Target.TARGET_FROM_ANGLE_V:
- t.setParamFloat(this._$wL, this.scale * i._$Cs(), this._$V0)
- }
- }, f.Src = function() {}, f.Src.SRC_TO_X = "SRC_TO_X", f.Src.SRC_TO_Y = "SRC_TO_Y", f.Src.SRC_TO_G_ANGLE = "SRC_TO_G_ANGLE", f.Target = function() {}, f.Target.TARGET_FROM_ANGLE = "TARGET_FROM_ANGLE", f.Target.TARGET_FROM_ANGLE_V = "TARGET_FROM_ANGLE_V", P.prototype.init = function(t) {
- this._$fL = t._$fL, this._$gL = t._$gL, this._$B0 = t._$B0, this._$z0 = t._$z0, this._$qT = t._$qT, this.reflectX = t.reflectX, this.reflectY = t.reflectY
- }, P.prototype._$F0 = function(t) {
- this._$fL = t._$_T(), this._$gL = t._$_T(), this._$B0 = t._$_T(), this._$z0 = t._$_T(), this._$qT = t._$_T(), t.getFormatVersion() >= G.LIVE2D_FORMAT_VERSION_V2_10_SDK2 && (this.reflectX = t._$po(), this.reflectY = t._$po())
- }, P.prototype._$e = function() {};
- var It = function() {};
- It._$ni = function(t, i, e, r, o, n, s, _, a) {
- var h = s * n - _ * o;
- if (0 == h) return null;
- var l, $ = ((t - e) * n - (i - r) * o) / h;
- return l = 0 != o ? (t - e - $ * s) / o : (i - r - $ * _) / n, isNaN(l) && (l = (t - e - $ * s) / o, isNaN(l) && (l = (i - r - $ * _) / n), isNaN(l) && (console.log("a is NaN @UtVector#_$ni() "), console.log("v1x : " + o), console.log("v1x != 0 ? " + (0 != o)))), null == a ? new Array(l, $) : (a[0] = l, a[1] = $, a)
- }, S.prototype._$8P = function() {
- return this.x + .5 * this.width
- }, S.prototype._$6P = function() {
- return this.y + .5 * this.height
- }, S.prototype._$EL = function() {
- return this.x + this.width
- }, S.prototype._$5T = function() {
- return this.y + this.height
- }, S.prototype._$jL = function(t, i, e, r) {
- this.x = t, this.y = i, this.width = e, this.height = r
- }, S.prototype._$jL = function(t) {
- this.x = t.x, this.y = t.y, this.width = t.width, this.height = t.height
- }, S.prototype.contains = function(t, i) {
- return this.x <= this.x && this.y <= this.y && this.x <= this.x + this.width && this.y <= this.y + this.height
- }, S.prototype.expand = function(t, i) {
- this.x -= t, this.y -= i, this.width += 2 * t, this.height += 2 * i
- }, v._$Z2 = function(t, i, e, r) {
- var o = i._$Q2(t, e),
- n = t._$vs(),
- s = t._$Tr();
- if (i._$zr(n, s, o), o <= 0) return r[n[0]];
- if (1 == o) {
- var _ = r[n[0]],
- a = r[n[1]],
- h = s[0];
- return _ + (a - _) * h | 0
- }
- if (2 == o) {
- var _ = r[n[0]],
- a = r[n[1]],
- l = r[n[2]],
- $ = r[n[3]],
- h = s[0],
- u = s[1],
- p = _ + (a - _) * h | 0,
- f = l + ($ - l) * h | 0;
- return p + (f - p) * u | 0
- }
- if (3 == o) {
- var c = r[n[0]],
- d = r[n[1]],
- g = r[n[2]],
- y = r[n[3]],
- m = r[n[4]],
- T = r[n[5]],
- P = r[n[6]],
- S = r[n[7]],
- h = s[0],
- u = s[1],
- v = s[2],
- _ = c + (d - c) * h | 0,
- a = g + (y - g) * h | 0,
- l = m + (T - m) * h | 0,
- $ = P + (S - P) * h | 0,
- p = _ + (a - _) * u | 0,
- f = l + ($ - l) * u | 0;
- return p + (f - p) * v | 0
- }
- if (4 == o) {
- var L = r[n[0]],
- M = r[n[1]],
- E = r[n[2]],
- A = r[n[3]],
- I = r[n[4]],
- w = r[n[5]],
- x = r[n[6]],
- O = r[n[7]],
- D = r[n[8]],
- R = r[n[9]],
- b = r[n[10]],
- F = r[n[11]],
- C = r[n[12]],
- N = r[n[13]],
- B = r[n[14]],
- U = r[n[15]],
- h = s[0],
- u = s[1],
- v = s[2],
- G = s[3],
- c = L + (M - L) * h | 0,
- d = E + (A - E) * h | 0,
- g = I + (w - I) * h | 0,
- y = x + (O - x) * h | 0,
- m = D + (R - D) * h | 0,
- T = b + (F - b) * h | 0,
- P = C + (N - C) * h | 0,
- S = B + (U - B) * h | 0,
- _ = c + (d - c) * u | 0,
- a = g + (y - g) * u | 0,
- l = m + (T - m) * u | 0,
- $ = P + (S - P) * u | 0,
- p = _ + (a - _) * v | 0,
- f = l + ($ - l) * v | 0;
- return p + (f - p) * G | 0
- }
- for (var Y = 1 << o, k = new Float32Array(Y), V = 0; V < Y; V++) {
- for (var X = V, z = 1, H = 0; H < o; H++) z *= X % 2 == 0 ? 1 - s[H] : s[H], X /= 2;
- k[V] = z
- }
- for (var W = new Float32Array(Y), j = 0; j < Y; j++) W[j] = r[n[j]];
- for (var q = 0, j = 0; j < Y; j++) q += k[j] * W[j];
- return q + .5 | 0
- }, v._$br = function(t, i, e, r) {
- var o = i._$Q2(t, e),
- n = t._$vs(),
- s = t._$Tr();
- if (i._$zr(n, s, o), o <= 0) return r[n[0]];
- if (1 == o) {
- var _ = r[n[0]],
- a = r[n[1]],
- h = s[0];
- return _ + (a - _) * h
- }
- if (2 == o) {
- var _ = r[n[0]],
- a = r[n[1]],
- l = r[n[2]],
- $ = r[n[3]],
- h = s[0],
- u = s[1];
- return (1 - u) * (_ + (a - _) * h) + u * (l + ($ - l) * h)
- }
- if (3 == o) {
- var p = r[n[0]],
- f = r[n[1]],
- c = r[n[2]],
- d = r[n[3]],
- g = r[n[4]],
- y = r[n[5]],
- m = r[n[6]],
- T = r[n[7]],
- h = s[0],
- u = s[1],
- P = s[2];
- return (1 - P) * ((1 - u) * (p + (f - p) * h) + u * (c + (d - c) * h)) + P * ((1 - u) * (g + (y - g) * h) + u * (m + (T - m) * h))
- }
- if (4 == o) {
- var S = r[n[0]],
- v = r[n[1]],
- L = r[n[2]],
- M = r[n[3]],
- E = r[n[4]],
- A = r[n[5]],
- I = r[n[6]],
- w = r[n[7]],
- x = r[n[8]],
- O = r[n[9]],
- D = r[n[10]],
- R = r[n[11]],
- b = r[n[12]],
- F = r[n[13]],
- C = r[n[14]],
- N = r[n[15]],
- h = s[0],
- u = s[1],
- P = s[2],
- B = s[3];
- return (1 - B) * ((1 - P) * ((1 - u) * (S + (v - S) * h) + u * (L + (M - L) * h)) + P * ((1 - u) * (E + (A - E) * h) + u * (I + (w - I) * h))) + B * ((1 - P) * ((1 - u) * (x + (O - x) * h) + u * (D + (R - D) * h)) + P * ((1 - u) * (b + (F - b) * h) + u * (C + (N - C) * h)))
- }
- for (var U = 1 << o, G = new Float32Array(U), Y = 0; Y < U; Y++) {
- for (var k = Y, V = 1, X = 0; X < o; X++) V *= k % 2 == 0 ? 1 - s[X] : s[X], k /= 2;
- G[Y] = V
- }
- for (var z = new Float32Array(U), H = 0; H < U; H++) z[H] = r[n[H]];
- for (var W = 0, H = 0; H < U; H++) W += G[H] * z[H];
- return W
- }, v._$Vr = function(t, i, e, r, o, n, s, _) {
- var a = i._$Q2(t, e),
- h = t._$vs(),
- l = t._$Tr();
- i._$zr(h, l, a);
- var $ = 2 * r,
- u = s;
- if (a <= 0) {
- var p = h[0],
- f = o[p];
- if (2 == _ && 0 == s) w._$jT(f, 0, n, 0, $);
- else for (var c = 0; c < $;) n[u] = f[c++], n[u + 1] = f[c++], u += _
- } else if (1 == a) for (var f = o[h[0]], d = o[h[1]], g = l[0], y = 1 - g, c = 0; c < $;) n[u] = f[c] * y + d[c] * g, ++c, n[u + 1] = f[c] * y + d[c] * g, ++c, u += _;
- else if (2 == a) for (var f = o[h[0]], d = o[h[1]], m = o[h[2]], T = o[h[3]], g = l[0], P = l[1], y = 1 - g, S = 1 - P, v = S * y, L = S * g, M = P * y, E = P * g, c = 0; c < $;) n[u] = v * f[c] + L * d[c] + M * m[c] + E * T[c], ++c, n[u + 1] = v * f[c] + L * d[c] + M * m[c] + E * T[c], ++c, u += _;
- else if (3 == a) for (var A = o[h[0]], I = o[h[1]], x = o[h[2]], O = o[h[3]], D = o[h[4]], R = o[h[5]], b = o[h[6]], F = o[h[7]], g = l[0], P = l[1], C = l[2], y = 1 - g, S = 1 - P, N = 1 - C, B = N * S * y, U = N * S * g, G = N * P * y, Y = N * P * g, k = C * S * y, V = C * S * g, X = C * P * y, z = C * P * g, c = 0; c < $;) n[u] = B * A[c] + U * I[c] + G * x[c] + Y * O[c] + k * D[c] + V * R[c] + X * b[c] + z * F[c], ++c, n[u + 1] = B * A[c] + U * I[c] + G * x[c] + Y * O[c] + k * D[c] + V * R[c] + X * b[c] + z * F[c], ++c, u += _;
- else if (4 == a) for (var H = o[h[0]], W = o[h[1]], j = o[h[2]], q = o[h[3]], J = o[h[4]], Q = o[h[5]], Z = o[h[6]], K = o[h[7]], tt = o[h[8]], it = o[h[9]], et = o[h[10]], rt = o[h[11]], ot = o[h[12]], nt = o[h[13]], st = o[h[14]], _t = o[h[15]], g = l[0], P = l[1], C = l[2], at = l[3], y = 1 - g, S = 1 - P, N = 1 - C, ht = 1 - at, lt = ht * N * S * y, $t = ht * N * S * g, ut = ht * N * P * y, pt = ht * N * P * g, ft = ht * C * S * y, ct = ht * C * S * g, dt = ht * C * P * y, gt = ht * C * P * g, yt = at * N * S * y, mt = at * N * S * g, Tt = at * N * P * y, Pt = at * N * P * g, St = at * C * S * y, vt = at * C * S * g, Lt = at * C * P * y, Mt = at * C * P * g, c = 0; c < $;) n[u] = lt * H[c] + $t * W[c] + ut * j[c] + pt * q[c] + ft * J[c] + ct * Q[c] + dt * Z[c] + gt * K[c] + yt * tt[c] + mt * it[c] + Tt * et[c] + Pt * rt[c] + St * ot[c] + vt * nt[c] + Lt * st[c] + Mt * _t[c], ++c, n[u + 1] = lt * H[c] + $t * W[c] + ut * j[c] + pt * q[c] + ft * J[c] + ct * Q[c] + dt * Z[c] + gt * K[c] + yt * tt[c] + mt * it[c] + Tt * et[c] + Pt * rt[c] + St * ot[c] + vt * nt[c] + Lt * st[c] + Mt * _t[c], ++c, u += _;
- else {
- for (var Et = 1 << a, At = new Float32Array(Et), It = 0; It < Et; It++) {
- for (var wt = It, xt = 1, Ot = 0; Ot < a; Ot++) xt *= wt % 2 == 0 ? 1 - l[Ot] : l[Ot], wt /= 2;
- At[It] = xt
- }
- for (var Dt = new Float32Array(Et), Rt = 0; Rt < Et; Rt++) Dt[Rt] = o[h[Rt]];
- for (var c = 0; c < $;) {
- for (var bt = 0, Ft = 0, Ct = c + 1, Rt = 0; Rt < Et; Rt++) bt += At[Rt] * Dt[Rt][c], Ft += At[Rt] * Dt[Rt][Ct];
- c += 2, n[u] = bt, n[u + 1] = Ft, u += _
- }
- }
- }, L.prototype._$HT = function(t, i) {
- this.x = t, this.y = i
- }, L.prototype._$HT = function(t) {
- this.x = t.x, this.y = t.y
- }, M._$ur = -2, M._$ES = 500, M._$wb = 2, M._$8S = 3, M._$52 = M._$ES, M._$R2 = M._$ES, M._$or = function() {
- return M._$52
- }, M._$Pr = function() {
- return M._$R2
- }, M.prototype.convertClipIDForV2_11 = function(t) {
- var i = [];
- return null == t ? null : 0 == t.length ? null : /,/.test(t) ? i = t.id.split(",") : (i.push(t.id), i)
- }, M.prototype._$F0 = function(t) {
- this._$gP = t._$nP(), this._$dr = t._$nP(), this._$GS = t._$nP(), this._$qb = t._$6L(), this._$Lb = t._$cS(), this._$mS = t._$Tb(), t.getFormatVersion() >= G._$T7 ? (this.clipID = t._$nP(), this.clipIDList = this.convertClipIDForV2_11(this.clipID)) : this.clipIDList = [], this._$MS(this._$Lb)
- }, M.prototype.getClipIDList = function() {
- return this.clipIDList
- }, M.prototype.init = function(t) {}, M.prototype._$Nr = function(t, i) {
- if (i._$IS[0] = !1, i._$Us = v._$Z2(t, this._$GS, i._$IS, this._$Lb), at._$Zs);
- else if (i._$IS[0]) return;
- i._$7s = v._$br(t, this._$GS, i._$IS, this._$mS)
- }, M.prototype._$2b = function(t, i) {}, M.prototype.getDrawDataID = function() {
- return this._$gP
- }, M.prototype._$j2 = function(t) {
- this._$gP = t
- }, M.prototype.getOpacity = function(t, i) {
- return i._$7s
- }, M.prototype._$zS = function(t, i) {
- return i._$Us
- }, M.prototype._$MS = function(t) {
- for (var i = t.length - 1; i >= 0; --i) {
- var e = t[i];
- e < M._$52 ? M._$52 = e : e > M._$R2 && (M._$R2 = e)
- }
- }, M.prototype.getTargetBaseDataID = function() {
- return this._$dr
- }, M.prototype._$gs = function(t) {
- this._$dr = t
- }, M.prototype._$32 = function() {
- return null != this._$dr && this._$dr != yt._$2o()
- }, M.prototype.preDraw = function(t, i, e) {}, M.prototype.draw = function(t, i, e) {}, M.prototype.getType = function() {}, M.prototype._$B2 = function(t, i, e) {}, E._$ps = 32, E.CLIPPING_PROCESS_NONE = 0, E.CLIPPING_PROCESS_OVERWRITE_ALPHA = 1, E.CLIPPING_PROCESS_MULTIPLY_ALPHA = 2, E.CLIPPING_PROCESS_DRAW = 3, E.CLIPPING_PROCESS_CLEAR_ALPHA = 4, E.prototype.setChannelFlagAsColor = function(t, i) {
- this.CHANNEL_COLORS[t] = i
- }, E.prototype.getChannelFlagAsColor = function(t) {
- return this.CHANNEL_COLORS[t]
- }, E.prototype._$ZT = function() {}, E.prototype._$Uo = function(t, i, e, r, o, n, s) {}, E.prototype._$Rs = function() {
- return -1
- }, E.prototype._$Ds = function(t) {}, E.prototype.setBaseColor = function(t, i, e, r) {
- t < 0 ? t = 0 : t > 1 && (t = 1), i < 0 ? i = 0 : i > 1 && (i = 1), e < 0 ? e = 0 : e > 1 && (e = 1), r < 0 ? r = 0 : r > 1 && (r = 1), this._$lT = t, this._$C0 = i, this._$tT = e, this._$WL = r
- }, E.prototype._$WP = function(t) {
- this.culling = t
- }, E.prototype.setMatrix = function(t) {
- for (var i = 0; i < 16; i++) this.matrix4x4[i] = t[i]
- }, E.prototype._$IT = function() {
- return this.matrix4x4
- }, E.prototype.setPremultipliedAlpha = function(t) {
- this.premultipliedAlpha = t
- }, E.prototype.isPremultipliedAlpha = function() {
- return this.premultipliedAlpha
- }, E.prototype.setAnisotropy = function(t) {
- this.anisotropy = t
- }, E.prototype.getAnisotropy = function() {
- return this.anisotropy
- }, E.prototype.getClippingProcess = function() {
- return this.clippingProcess
- }, E.prototype.setClippingProcess = function(t) {
- this.clippingProcess = t
- }, E.prototype.setClipBufPre_clipContextForMask = function(t) {
- this.clipBufPre_clipContextMask = t
- }, E.prototype.getClipBufPre_clipContextMask = function() {
- return this.clipBufPre_clipContextMask
- }, E.prototype.setClipBufPre_clipContextForDraw = function(t) {
- this.clipBufPre_clipContextDraw = t
- }, E.prototype.getClipBufPre_clipContextDraw = function() {
- return this.clipBufPre_clipContextDraw
- }, I._$ur = -2, I._$c2 = 1, I._$_b = 2, I.prototype._$F0 = function(t) {
- this._$kP = t._$nP(), this._$dr = t._$nP()
- }, I.prototype.readV2_opacity = function(t) {
- t.getFormatVersion() >= G.LIVE2D_FORMAT_VERSION_V2_10_SDK2 && (this._$mS = t._$Tb())
- }, I.prototype.init = function(t) {}, I.prototype._$Nr = function(t, i) {}, I.prototype.interpolateOpacity = function(t, i, e, r) {
- null == this._$mS ? e.setInterpolatedOpacity(1) : e.setInterpolatedOpacity(v._$br(t, i, r, this._$mS))
- }, I.prototype._$2b = function(t, i) {}, I.prototype._$nb = function(t, i, e, r, o, n, s) {}, I.prototype.getType = function() {}, I.prototype._$gs = function(t) {
- this._$dr = t
- }, I.prototype._$a2 = function(t) {
- this._$kP = t
- }, I.prototype.getTargetBaseDataID = function() {
- return this._$dr
- }, I.prototype.getBaseDataID = function() {
- return this._$kP
- }, I.prototype._$32 = function() {
- return null != this._$dr && this._$dr != yt._$2o()
- }, w._$W2 = 0, w._$CS = w._$W2, w._$Mo = function() {
- return !0
- }, w._$XP = function(t) {
- try {
- for (var i = getTimeMSec(); getTimeMSec() - i < t;);
- } catch (t) {
- t._$Rb()
- }
- }, w.getUserTimeMSec = function() {
- return w._$CS == w._$W2 ? w.getSystemTimeMSec() : w._$CS
- }, w.setUserTimeMSec = function(t) {
- w._$CS = t
- }, w.updateUserTimeMSec = function() {
- return w._$CS = w.getSystemTimeMSec()
- }, w.getTimeMSec = function() {
- return (new Date).getTime()
- }, w.getSystemTimeMSec = function() {
- return (new Date).getTime()
- }, w._$Q = function(t) {}, w._$jT = function(t, i, e, r, o) {
- for (var n = 0; n < o; n++) e[r + n] = t[i + n]
- }, x._$ds = -2, x.prototype._$F0 = function(t) {
- this._$wL = t._$nP(), this._$VP = t._$6L(), this._$GP = t._$nP()
- }, x.prototype.getParamIndex = function(t) {
- return this._$2r != t && (this._$8o = x._$ds), this._$8o
- }, x.prototype._$Pb = function(t, i) {
- this._$8o = t, this._$2r = i
- }, x.prototype.getParamID = function() {
- return this._$wL
- }, x.prototype._$yP = function(t) {
- this._$wL = t
- }, x.prototype._$N2 = function() {
- return this._$VP
- }, x.prototype._$d2 = function() {
- return this._$GP
- }, x.prototype._$t2 = function(t, i) {
- this._$VP = t, this._$GP = i
- }, x.prototype._$Lr = function() {
- return this._$O2
- }, x.prototype._$wr = function(t) {
- this._$O2 = t
- }, x.prototype._$SL = function() {
- return this._$ri
- }, x.prototype._$AL = function(t) {
- this._$ri = t
- }, O.startsWith = function(t, i, e) {
- var r = i + e.length;
- if (r >= t.length) return !1;
- for (var o = i; o < r; o++) if (O.getChar(t, o) != e.charAt(o - i)) return !1;
- return !0
- }, O.getChar = function(t, i) {
- return String.fromCharCode(t.getUint8(i))
- }, O.createString = function(t, i, e) {
- for (var r = new ArrayBuffer(2 * e), o = new Uint16Array(r), n = 0; n < e; n++) o[n] = t.getUint8(i + n);
- return String.fromCharCode.apply(null, o)
- }, O._$LS = function(t, i, e, r) {
- t instanceof ArrayBuffer && (t = new DataView(t));
- var o = e,
- n = !1,
- s = !1,
- _ = 0,
- a = O.getChar(t, o);
- "-" == a && (n = !0, o++);
- for (var h = !1; o < i; o++) {
- switch (a = O.getChar(t, o)) {
- case "0":
- _ *= 10;
- break;
- case "1":
- _ = 10 * _ + 1;
- break;
- case "2":
- _ = 10 * _ + 2;
- break;
- case "3":
- _ = 10 * _ + 3;
- break;
- case "4":
- _ = 10 * _ + 4;
- break;
- case "5":
- _ = 10 * _ + 5;
- break;
- case "6":
- _ = 10 * _ + 6;
- break;
- case "7":
- _ = 10 * _ + 7;
- break;
- case "8":
- _ = 10 * _ + 8;
- break;
- case "9":
- _ = 10 * _ + 9;
- break;
- case ".":
- s = !0, o++, h = !0;
- break;
- default:
- h = !0
- }
- if (h) break
- }
- if (s) for (var l = .1, $ = !1; o < i; o++) {
- switch (a = O.getChar(t, o)) {
- case "0":
- break;
- case "1":
- _ += 1 * l;
- break;
- case "2":
- _ += 2 * l;
- break;
- case "3":
- _ += 3 * l;
- break;
- case "4":
- _ += 4 * l;
- break;
- case "5":
- _ += 5 * l;
- break;
- case "6":
- _ += 6 * l;
- break;
- case "7":
- _ += 7 * l;
- break;
- case "8":
- _ += 8 * l;
- break;
- case "9":
- _ += 9 * l;
- break;
- default:
- $ = !0
- }
- if (l *= .1, $) break
- }
- return n && (_ = -_), r[0] = o, _
- }, D.prototype._$zP = function() {
- this._$Ob = new Array
- }, D.prototype._$F0 = function(t) {
- this._$Ob = t._$nP()
- }, D.prototype._$Ur = function(t) {
- if (t._$WS()) return !0;
- for (var i = t._$v2(), e = this._$Ob.length - 1; e >= 0; --e) {
- var r = this._$Ob[e].getParamIndex(i);
- if (r == x._$ds && (r = t.getParamIndex(this._$Ob[e].getParamID())), t._$Xb(r)) return !0
- }
- return !1
- }, D.prototype._$Q2 = function(t, i) {
- for (var e, r, o = this._$Ob.length, n = t._$v2(), s = 0, _ = 0; _ < o; _++) {
- var a = this._$Ob[_];
- if (e = a.getParamIndex(n), e == x._$ds && (e = t.getParamIndex(a.getParamID()), a._$Pb(e, n)), e < 0) throw new Exception("err 23242 : " + a.getParamID());
- var h = e < 0 ? 0 : t.getParamFloat(e);
- r = a._$N2();
- var l, $, u = a._$d2(),
- p = -1,
- f = 0;
- if (r < 1);
- else if (1 == r) l = u[0], l - U._$J < h && h < l + U._$J ? (p = 0, f = 0) : (p = 0, i[0] = !0);
- else if (l = u[0], h < l - U._$J) p = 0, i[0] = !0;
- else if (h < l + U._$J) p = 0;
- else {
- for (var c = !1, d = 1; d < r; ++d) {
- if ($ = u[d], h < $ + U._$J) {
- $ - U._$J < h ? p = d : (p = d - 1, f = (h - l) / ($ - l), s++), c = !0;
- break
- }
- l = $
- }
- c || (p = r - 1, f = 0, i[0] = !0)
- }
- a._$wr(p), a._$AL(f)
- }
- return s
- }, D.prototype._$zr = function(t, i, e) {
- var r = 1 << e;
- r + 1 > U._$Qb && console.log("err 23245\n");
- for (var o = this._$Ob.length, n = 1, s = 1, _ = 0, a = 0; a < r; ++a) t[a] = 0;
- for (var h = 0; h < o; ++h) {
- var l = this._$Ob[h];
- if (0 == l._$SL()) {
- var $ = l._$Lr() * n;
- if ($ < 0 && at._$3T) throw new Exception("err 23246");
- for (var a = 0; a < r; ++a) t[a] += $
- } else {
- for (var $ = n * l._$Lr(), u = n * (l._$Lr() + 1), a = 0; a < r; ++a) t[a] += (a / s | 0) % 2 == 0 ? $ : u;
- i[_++] = l._$SL(), s *= 2
- }
- n *= l._$N2()
- }
- t[r] = 65535, i[_] = -1
- }, D.prototype._$h2 = function(t, i, e) {
- for (var r = new Float32Array(i), o = 0; o < i; ++o) r[o] = e[o];
- var n = new x;
- n._$yP(t), n._$t2(i, r), this._$Ob.push(n)
- }, D.prototype._$J2 = function(t) {
- for (var i = t, e = this._$Ob.length, r = 0; r < e; ++r) {
- var o = this._$Ob[r],
- n = o._$N2(),
- s = i % o._$N2(),
- _ = o._$d2()[s];
- console.log("%s[%d]=%7.2f / ", o.getParamID(), s, _), i /= n
- }
- console.log("\n")
- }, D.prototype.getParamCount = function() {
- return this._$Ob.length
- }, D.prototype._$zs = function() {
- return this._$Ob
- }, R.prototype.identity = function() {
- for (var t = 0; t < 16; t++) this.m[t] = t % 5 == 0 ? 1 : 0
- }, R.prototype.getArray = function() {
- return this.m
- }, R.prototype.getCopyMatrix = function() {
- return new Float32Array(this.m)
- }, R.prototype.setMatrix = function(t) {
- if (null != t && 16 == t.length) for (var i = 0; i < 16; i++) this.m[i] = t[i]
- }, R.prototype.mult = function(t, i, e) {
- return null == i ? null : (this == i ? this.mult_safe(this.m, t.m, i.m, e) : this.mult_fast(this.m, t.m, i.m, e), i)
- }, R.prototype.mult_safe = function(t, i, e, r) {
- if (t == e) {
- var o = new Array(16);
- this.mult_fast(t, i, o, r);
- for (var n = 15; n >= 0; --n) e[n] = o[n]
- } else this.mult_fast(t, i, e, r)
- }, R.prototype.mult_fast = function(t, i, e, r) {
- r ? (e[0] = t[0] * i[0] + t[4] * i[1] + t[8] * i[2], e[4] = t[0] * i[4] + t[4] * i[5] + t[8] * i[6], e[8] = t[0] * i[8] + t[4] * i[9] + t[8] * i[10], e[12] = t[0] * i[12] + t[4] * i[13] + t[8] * i[14] + t[12], e[1] = t[1] * i[0] + t[5] * i[1] + t[9] * i[2], e[5] = t[1] * i[4] + t[5] * i[5] + t[9] * i[6], e[9] = t[1] * i[8] + t[5] * i[9] + t[9] * i[10], e[13] = t[1] * i[12] + t[5] * i[13] + t[9] * i[14] + t[13], e[2] = t[2] * i[0] + t[6] * i[1] + t[10] * i[2], e[6] = t[2] * i[4] + t[6] * i[5] + t[10] * i[6], e[10] = t[2] * i[8] + t[6] * i[9] + t[10] * i[10], e[14] = t[2] * i[12] + t[6] * i[13] + t[10] * i[14] + t[14], e[3] = e[7] = e[11] = 0, e[15] = 1) : (e[0] = t[0] * i[0] + t[4] * i[1] + t[8] * i[2] + t[12] * i[3], e[4] = t[0] * i[4] + t[4] * i[5] + t[8] * i[6] + t[12] * i[7], e[8] = t[0] * i[8] + t[4] * i[9] + t[8] * i[10] + t[12] * i[11], e[12] = t[0] * i[12] + t[4] * i[13] + t[8] * i[14] + t[12] * i[15], e[1] = t[1] * i[0] + t[5] * i[1] + t[9] * i[2] + t[13] * i[3], e[5] = t[1] * i[4] + t[5] * i[5] + t[9] * i[6] + t[13] * i[7], e[9] = t[1] * i[8] + t[5] * i[9] + t[9] * i[10] + t[13] * i[11], e[13] = t[1] * i[12] + t[5] * i[13] + t[9] * i[14] + t[13] * i[15], e[2] = t[2] * i[0] + t[6] * i[1] + t[10] * i[2] + t[14] * i[3], e[6] = t[2] * i[4] + t[6] * i[5] + t[10] * i[6] + t[14] * i[7], e[10] = t[2] * i[8] + t[6] * i[9] + t[10] * i[10] + t[14] * i[11], e[14] = t[2] * i[12] + t[6] * i[13] + t[10] * i[14] + t[14] * i[15], e[3] = t[3] * i[0] + t[7] * i[1] + t[11] * i[2] + t[15] * i[3], e[7] = t[3] * i[4] + t[7] * i[5] + t[11] * i[6] + t[15] * i[7], e[11] = t[3] * i[8] + t[7] * i[9] + t[11] * i[10] + t[15] * i[11], e[15] = t[3] * i[12] + t[7] * i[13] + t[11] * i[14] + t[15] * i[15])
- }, R.prototype.translate = function(t, i, e) {
- this.m[12] = this.m[0] * t + this.m[4] * i + this.m[8] * e + this.m[12], this.m[13] = this.m[1] * t + this.m[5] * i + this.m[9] * e + this.m[13], this.m[14] = this.m[2] * t + this.m[6] * i + this.m[10] * e + this.m[14], this.m[15] = this.m[3] * t + this.m[7] * i + this.m[11] * e + this.m[15]
- }, R.prototype.scale = function(t, i, e) {
- this.m[0] *= t, this.m[4] *= i, this.m[8] *= e, this.m[1] *= t, this.m[5] *= i, this.m[9] *= e, this.m[2] *= t, this.m[6] *= i, this.m[10] *= e, this.m[3] *= t, this.m[7] *= i, this.m[11] *= e
- }, R.prototype.rotateX = function(t) {
- var i = Lt.fcos(t),
- e = Lt._$9(t),
- r = this.m[4];
- this.m[4] = r * i + this.m[8] * e, this.m[8] = r * -e + this.m[8] * i, r = this.m[5], this.m[5] = r * i + this.m[9] * e, this.m[9] = r * -e + this.m[9] * i, r = this.m[6], this.m[6] = r * i + this.m[10] * e, this.m[10] = r * -e + this.m[10] * i, r = this.m[7], this.m[7] = r * i + this.m[11] * e, this.m[11] = r * -e + this.m[11] * i
- }, R.prototype.rotateY = function(t) {
- var i = Lt.fcos(t),
- e = Lt._$9(t),
- r = this.m[0];
- this.m[0] = r * i + this.m[8] * -e, this.m[8] = r * e + this.m[8] * i, r = this.m[1], this.m[1] = r * i + this.m[9] * -e, this.m[9] = r * e + this.m[9] * i, r = m[2], this.m[2] = r * i + this.m[10] * -e, this.m[10] = r * e + this.m[10] * i, r = m[3], this.m[3] = r * i + this.m[11] * -e, this.m[11] = r * e + this.m[11] * i
- }, R.prototype.rotateZ = function(t) {
- var i = Lt.fcos(t),
- e = Lt._$9(t),
- r = this.m[0];
- this.m[0] = r * i + this.m[4] * e, this.m[4] = r * -e + this.m[4] * i, r = this.m[1], this.m[1] = r * i + this.m[5] * e, this.m[5] = r * -e + this.m[5] * i, r = this.m[2], this.m[2] = r * i + this.m[6] * e, this.m[6] = r * -e + this.m[6] * i, r = this.m[3], this.m[3] = r * i + this.m[7] * e, this.m[7] = r * -e + this.m[7] * i
- }, b.prototype = new et, b._$tP = new Object, b._$27 = function() {
- b._$tP.clear()
- }, b.getID = function(t) {
- var i = b._$tP[t];
- return null == i && (i = new b(t), b._$tP[t] = i), i
- }, b.prototype._$3s = function() {
- return new b
- }, F._$kS = -1, F._$pS = 0, F._$hb = 1, F.STATE_IDENTITY = 0, F._$gb = 1, F._$fo = 2, F._$go = 4, F.prototype.transform = function(t, i, e) {
- var r, o, n, s, _, a, h = 0,
- l = 0;
- switch (this._$hi) {
- default:
- return;
- case F._$go | F._$fo | F._$gb:
- for (r = this._$7, o = this._$H, n = this._$k, s = this._$f, _ = this._$g, a = this._$w; --e >= 0;) {
- var $ = t[h++],
- u = t[h++];
- i[l++] = r * $ + o * u + n, i[l++] = s * $ + _ * u + a
- }
- return;
- case F._$go | F._$fo:
- for (r = this._$7, o = this._$H, s = this._$f, _ = this._$g; --e >= 0;) {
- var $ = t[h++],
- u = t[h++];
- i[l++] = r * $ + o * u, i[l++] = s * $ + _ * u
- }
- return;
- case F._$go | F._$gb:
- for (o = this._$H, n = this._$k, s = this._$f, a = this._$w; --e >= 0;) {
- var $ = t[h++];
- i[l++] = o * t[h++] + n, i[l++] = s * $ + a
- }
- return;
- case F._$go:
- for (o = this._$H, s = this._$f; --e >= 0;) {
- var $ = t[h++];
- i[l++] = o * t[h++], i[l++] = s * $
- }
- return;
- case F._$fo | F._$gb:
- for (r = this._$7, n = this._$k, _ = this._$g, a = this._$w; --e >= 0;) i[l++] = r * t[h++] + n, i[l++] = _ * t[h++] + a;
- return;
- case F._$fo:
- for (r = this._$7, _ = this._$g; --e >= 0;) i[l++] = r * t[h++], i[l++] = _ * t[h++];
- return;
- case F._$gb:
- for (n = this._$k, a = this._$w; --e >= 0;) i[l++] = t[h++] + n, i[l++] = t[h++] + a;
- return;
- case F.STATE_IDENTITY:
- return void(t == i && h == l || w._$jT(t, h, i, l, 2 * e))
- }
- }, F.prototype.update = function() {
- 0 == this._$H && 0 == this._$f ? 1 == this._$7 && 1 == this._$g ? 0 == this._$k && 0 == this._$w ? (this._$hi = F.STATE_IDENTITY, this._$Z = F._$pS) : (this._$hi = F._$gb, this._$Z = F._$hb) : 0 == this._$k && 0 == this._$w ? (this._$hi = F._$fo, this._$Z = F._$kS) : (this._$hi = F._$fo | F._$gb, this._$Z = F._$kS) : 0 == this._$7 && 0 == this._$g ? 0 == this._$k && 0 == this._$w ? (this._$hi = F._$go, this._$Z = F._$kS) : (this._$hi = F._$go | F._$gb, this._$Z = F._$kS) : 0 == this._$k && 0 == this._$w ? (this._$hi = F._$go | F._$fo, this._$Z = F._$kS) : (this._$hi = F._$go | F._$fo | F._$gb, this._$Z = F._$kS)
- }, F.prototype._$RT = function(t) {
- this._$IT(t);
- var i = t[0],
- e = t[2],
- r = t[1],
- o = t[3],
- n = Math.sqrt(i * i + r * r),
- s = i * o - e * r;
- 0 == n ? at._$so && console.log("affine._$RT() / rt==0") : (t[0] = n, t[1] = s / n, t[2] = (r * o + i * e) / s, t[3] = Math.atan2(r, i))
- }, F.prototype._$ho = function(t, i, e, r) {
- var o = new Float32Array(6),
- n = new Float32Array(6);
- t._$RT(o), i._$RT(n);
- var s = new Float32Array(6);
- s[0] = o[0] + (n[0] - o[0]) * e, s[1] = o[1] + (n[1] - o[1]) * e, s[2] = o[2] + (n[2] - o[2]) * e, s[3] = o[3] + (n[3] - o[3]) * e, s[4] = o[4] + (n[4] - o[4]) * e, s[5] = o[5] + (n[5] - o[5]) * e, r._$CT(s)
- }, F.prototype._$CT = function(t) {
- var i = Math.cos(t[3]),
- e = Math.sin(t[3]);
- this._$7 = t[0] * i, this._$f = t[0] * e, this._$H = t[1] * (t[2] * i - e), this._$g = t[1] * (t[2] * e + i), this._$k = t[4], this._$w = t[5], this.update()
- }, F.prototype._$IT = function(t) {
- t[0] = this._$7, t[1] = this._$f, t[2] = this._$H, t[3] = this._$g, t[4] = this._$k, t[5] = this._$w
- }, C.prototype = new s, C._$cs = "VISIBLE:", C._$ar = "LAYOUT:", C._$Co = 0, C._$D2 = [], C._$1T = 1, C.loadMotion = function(t) {
- var i = new C,
- e = [0],
- r = t.length;
- i._$yT = 0;
- for (var o = 0; o < r; ++o) {
- var n = 255 & t[o];
- if ("\n" != n && "\r" != n) if ("#" != n) if ("$" != n) {
- if ("a" <= n && n <= "z" || "A" <= n && n <= "Z" || "_" == n) {
- for (var s = o, _ = -1; o < r && ("\r" != (n = 255 & t[o]) && "\n" != n); ++o) if ("=" == n) {
- _ = o;
- break
- }
- if (_ >= 0) {
- var a = new B;
- O.startsWith(t, s, C._$cs) ? (a._$RP = B._$hs, a._$4P = new String(t, s, _ - s)) : O.startsWith(t, s, C._$ar) ? (a._$4P = new String(t, s + 7, _ - s - 7), O.startsWith(t, s + 7, "ANCHOR_X") ? a._$RP = B._$xs : O.startsWith(t, s + 7, "ANCHOR_Y") ? a._$RP = B._$us : O.startsWith(t, s + 7, "SCALE_X") ? a._$RP = B._$qs : O.startsWith(t, s + 7, "SCALE_Y") ? a._$RP = B._$Ys : O.startsWith(t, s + 7, "X") ? a._$RP = B._$ws : O.startsWith(t, s + 7, "Y") && (a._$RP = B._$Ns)) : (a._$RP = B._$Fr, a._$4P = new String(t, s, _ - s)), i.motions.push(a);
- var h = 0;
- for (C._$D2.clear(), o = _ + 1; o < r && ("\r" != (n = 255 & t[o]) && "\n" != n); ++o) if ("," != n && " " != n && "\t" != n) {
- var l = O._$LS(t, r, o, e);
- if (e[0] > 0) {
- C._$D2.push(l), h++;
- var $ = e[0];
- if ($ < o) {
- console.log("_$n0 _$hi . @Live2DMotion loadMotion()\n");
- break
- }
- o = $
- }
- }
- a._$I0 = C._$D2._$BL(), h > i._$yT && (i._$yT = h)
- }
- }
- } else {
- for (var s = o, _ = -1; o < r && ("\r" != (n = 255 & t[o]) && "\n" != n); ++o) if ("=" == n) {
- _ = o;
- break
- }
- var u = !1;
- if (_ >= 0) for (_ == s + 4 && "f" == t[s + 1] && "p" == t[s + 2] && "s" == t[s + 3] && (u = !0), o = _ + 1; o < r && ("\r" != (n = 255 & t[o]) && "\n" != n); ++o) if ("," != n && " " != n && "\t" != n) {
- var l = O._$LS(t, r, o, e);
- e[0] > 0 && u && 5 < l && l < 121 && (i._$D0 = l), o = e[0]
- }
- for (; o < r && ("\n" != t[o] && "\r" != t[o]); ++o);
- } else for (; o < r && ("\n" != t[o] && "\r" != t[o]); ++o);
- }
- return i._$AS = 1e3 * i._$yT / i._$D0 | 0, i
- }, C.prototype.getDurationMSec = function() {
- return this._$AS
- }, C.prototype.dump = function() {
- for (var t = 0; t < this.motions.length; t++) {
- var i = this.motions[t];
- console.log("_$wL[%s] [%d]. ", i._$4P, i._$I0.length);
- for (var e = 0; e < i._$I0.length && e < 10; e++) console.log("%5.2f ,", i._$I0[e]);
- console.log("\n")
- }
- }, C.prototype.updateParamExe = function(t, i, e, r) {
- for (var o = i - r._$z2, n = o * this._$D0 / 1e3, s = 0 | n, _ = n - s, a = 0; a < this.motions.length; a++) {
- var h = this.motions[a],
- l = h._$I0.length,
- $ = h._$4P;
- if (h._$RP == B._$hs) {
- var u = h._$I0[s >= l ? l - 1 : s];
- t.setParamFloat($, u)
- } else if (B._$ws <= h._$RP && h._$RP <= B._$Ys);
- else {
- var p = t.getParamFloat($),
- f = h._$I0[s >= l ? l - 1 : s],
- c = h._$I0[s + 1 >= l ? l - 1 : s + 1],
- d = f + (c - f) * _,
- g = p + (d - p) * e;
- t.setParamFloat($, g)
- }
- }
- s >= this._$yT && (this._$E ? (r._$z2 = i, this.loopFadeIn && (r._$bs = i)) : r._$9L = !0)
- }, C.prototype._$r0 = function() {
- return this._$E
- }, C.prototype._$aL = function(t) {
- this._$E = t
- }, C.prototype.isLoopFadeIn = function() {
- return this.loopFadeIn
- }, C.prototype.setLoopFadeIn = function(t) {
- this.loopFadeIn = t
- }, N.prototype.clear = function() {
- this.size = 0
- }, N.prototype.add = function(t) {
- if (this._$P.length <= this.size) {
- var i = new Float32Array(2 * this.size);
- w._$jT(this._$P, 0, i, 0, this.size), this._$P = i
- }
- this._$P[this.size++] = t
- }, N.prototype._$BL = function() {
- var t = new Float32Array(this.size);
- return w._$jT(this._$P, 0, t, 0, this.size), t
- }, B._$Fr = 0, B._$hs = 1, B._$ws = 100, B._$Ns = 101, B._$xs = 102, B._$us = 103, B._$qs = 104, B._$Ys = 105, U._$Ms = 1, U._$Qs = 2, U._$i2 = 0, U._$No = 2, U._$do = U._$Ms, U._$Ls = !0, U._$1r = 5, U._$Qb = 65, U._$J = 1e-4, U._$FT = .001, U._$Ss = 3, G._$o7 = 6, G._$S7 = 7, G._$s7 = 8, G._$77 = 9, G.LIVE2D_FORMAT_VERSION_V2_10_SDK2 = 10, G.LIVE2D_FORMAT_VERSION_V2_11_SDK2_1 = 11, G._$T7 = G.LIVE2D_FORMAT_VERSION_V2_11_SDK2_1, G._$Is = -2004318072, G._$h0 = 0, G._$4L = 23, G._$7P = 33, G._$uT = function(t) {
- console.log("_$bo :: _$6 _$mo _$E0 : %d\n", t)
- }, G._$9o = function(t) {
- if (t < 40) return G._$uT(t), null;
- if (t < 50) return G._$uT(t), null;
- if (t < 60) return G._$uT(t), null;
- if (t < 100) switch (t) {
- case 65:
- return new Z;
- case 66:
- return new D;
- case 67:
- return new x;
- case 68:
- return new z;
- case 69:
- return new P;
- case 70:
- return new $t;
- default:
- return G._$uT(t), null
- } else if (t < 150) switch (t) {
- case 131:
- return new st;
- case 133:
- return new tt;
- case 136:
- return new p;
- case 137:
- return new ot;
- case 142:
- return new j
- }
- return G._$uT(t), null
- }, Y._$HP = 0, Y._$_0 = !0;
- Y._$V2 = -1, Y._$W0 = -1, Y._$jr = !1, Y._$ZS = !0, Y._$tr = -1e6, Y._$lr = 1e6, Y._$is = 32, Y._$e = !1, Y.prototype.getDrawDataIndex = function(t) {
- for (var i = this._$aS.length - 1; i >= 0; --i) if (null != this._$aS[i] && this._$aS[i].getDrawDataID() == t) return i;
- return -1
- }, Y.prototype.getDrawData = function(t) {
- if (t instanceof b) {
- if (null == this._$Bo) {
- this._$Bo = new Object;
- for (var i = this._$aS.length, e = 0; e < i; e++) {
- var r = this._$aS[e],
- o = r.getDrawDataID();
- null != o && (this._$Bo[o] = r)
- }
- }
- return this._$Bo[id]
- }
- return t < this._$aS.length ? this._$aS[t] : null
- }, Y.prototype.release = function() {
- this._$3S.clear(), this._$aS.clear(), this._$F2.clear(), null != this._$Bo && this._$Bo.clear(), this._$db.clear(), this._$8b.clear(), this._$Hr.clear()
- }, Y.prototype.init = function() {
- this._$co++, this._$F2.length > 0 && this.release();
- for (var t = this._$Ri.getModelImpl(), i = t._$Xr(), r = i.length, o = new Array, n = new Array, s = 0; s < r; ++s) {
- var _ = i[s];
- this._$F2.push(_), this._$Hr.push(_.init(this));
- for (var a = _.getBaseData(), h = a.length, l = 0; l < h; ++l) o.push(a[l]);
- for (var l = 0; l < h; ++l) {
- var $ = a[l].init(this);
- $._$l2(s), n.push($)
- }
- for (var u = _.getDrawData(), p = u.length, l = 0; l < p; ++l) {
- var f = u[l],
- c = f.init(this);
- c._$IP = s, this._$aS.push(f), this._$8b.push(c)
- }
- }
- for (var d = o.length, g = yt._$2o();;) {
- for (var y = !1, s = 0; s < d; ++s) {
- var m = o[s];
- if (null != m) {
- var T = m.getTargetBaseDataID();
- (null == T || T == g || this.getBaseDataIndex(T) >= 0) && (this._$3S.push(m), this._$db.push(n[s]), o[s] = null, y = !0)
- }
- }
- if (!y) break
- }
- var P = t._$E2();
- if (null != P) {
- var S = P._$1s();
- if (null != S) for (var v = S.length, s = 0; s < v; ++s) {
- var L = S[s];
- null != L && this._$02(L.getParamID(), L.getDefaultValue(), L.getMinValue(), L.getMaxValue())
- }
- }
- this.clipManager = new e(this.dp_webgl), this.clipManager.init(this, this._$aS, this._$8b), this._$QT = !0
- }, Y.prototype.update = function() {
- Y._$e && _.start("_$zL");
- for (var t = this._$_2.length, i = 0; i < t; i++) this._$_2[i] != this._$vr[i] && (this._$Js[i] = Y._$ZS, this._$vr[i] = this._$_2[i]);
- var e = this._$3S.length,
- r = this._$aS.length,
- o = W._$or(),
- n = W._$Pr(),
- s = n - o + 1;
- (null == this._$Ws || this._$Ws.length < s) && (this._$Ws = new Int16Array(s), this._$Vs = new Int16Array(s));
- for (var i = 0; i < s; i++) this._$Ws[i] = Y._$V2, this._$Vs[i] = Y._$V2;
- (null == this._$Er || this._$Er.length < r) && (this._$Er = new Int16Array(r));
- for (var i = 0; i < r; i++) this._$Er[i] = Y._$W0;
- Y._$e && _.dump("_$zL"), Y._$e && _.start("_$UL");
- for (var a = null, h = 0; h < e; ++h) {
- var l = this._$3S[h],
- $ = this._$db[h];
- try {
- l._$Nr(this, $), l._$2b(this, $)
- } catch (t) {
- null == a && (a = t)
- }
- }
- null != a && Y._$_0 && _._$Rb(a), Y._$e && _.dump("_$UL"), Y._$e && _.start("_$DL");
- for (var u = null, p = 0; p < r; ++p) {
- var f = this._$aS[p],
- c = this._$8b[p];
- try {
- if (f._$Nr(this, c), c._$u2()) continue;
- f._$2b(this, c);
- var d, g = Math.floor(f._$zS(this, c) - o);
- try {
- d = this._$Vs[g]
- } catch (t) {
- console.log("_$li :: %s / %s \t\t\t\t@@_$fS\n", t.toString(), f.getDrawDataID().toString()), g = Math.floor(f._$zS(this, c) - o);
- continue
- }
- d == Y._$V2 ? this._$Ws[g] = p : this._$Er[d] = p, this._$Vs[g] = p
- } catch (t) {
- null == u && (u = t, at._$sT(at._$H7))
- }
- }
- null != u && Y._$_0 && _._$Rb(u), Y._$e && _.dump("_$DL"), Y._$e && _.start("_$eL");
- for (var i = this._$Js.length - 1; i >= 0; i--) this._$Js[i] = Y._$jr;
- return this._$QT = !1, Y._$e && _.dump("_$eL"), !1
- }, Y.prototype.preDraw = function(t) {
- null != this.clipManager && (t._$ZT(), this.clipManager.setupClip(this, t))
- }, Y.prototype.draw = function(t) {
- if (null == this._$Ws) return void _._$li("call _$Ri.update() before _$Ri.draw() ");
- var i = this._$Ws.length;
- t._$ZT();
- for (var e = 0; e < i; ++e) {
- var r = this._$Ws[e];
- if (r != Y._$V2) for (;;) {
- var o = this._$aS[r],
- n = this._$8b[r];
- if (n._$yo()) {
- var s = n._$IP,
- a = this._$Hr[s];
- n._$VS = a.getPartsOpacity(), o.draw(t, this, n)
- }
- var h = this._$Er[r];
- if (h <= r || h == Y._$W0) break;
- r = h
- }
- }
- }, Y.prototype.getParamIndex = function(t) {
- for (var i = this._$pb.length - 1; i >= 0; --i) if (this._$pb[i] == t) return i;
- return this._$02(t, 0, Y._$tr, Y._$lr)
- }, Y.prototype._$BS = function(t) {
- return this.getBaseDataIndex(t)
- }, Y.prototype.getBaseDataIndex = function(t) {
- for (var i = this._$3S.length - 1; i >= 0; --i) if (null != this._$3S[i] && this._$3S[i].getBaseDataID() == t) return i;
- return -1
- }, Y.prototype._$UT = function(t, i) {
- var e = new Float32Array(i);
- return w._$jT(t, 0, e, 0, t.length), e
- }, Y.prototype._$02 = function(t, i, e, r) {
- if (this._$qo >= this._$pb.length) {
- var o = this._$pb.length,
- n = new Array(2 * o);
- w._$jT(this._$pb, 0, n, 0, o), this._$pb = n, this._$_2 = this._$UT(this._$_2, 2 * o), this._$vr = this._$UT(this._$vr, 2 * o), this._$Rr = this._$UT(this._$Rr, 2 * o), this._$Or = this._$UT(this._$Or, 2 * o);
- var s = new Array;
- w._$jT(this._$Js, 0, s, 0, o), this._$Js = s
- }
- return this._$pb[this._$qo] = t, this._$_2[this._$qo] = i, this._$vr[this._$qo] = i, this._$Rr[this._$qo] = e, this._$Or[this._$qo] = r, this._$Js[this._$qo] = Y._$ZS, this._$qo++
- }, Y.prototype._$Zo = function(t, i) {
- this._$3S[t] = i
- }, Y.prototype.setParamFloat = function(t, i) {
- i < this._$Rr[t] && (i = this._$Rr[t]), i > this._$Or[t] && (i = this._$Or[t]), this._$_2[t] = i
- }, Y.prototype.loadParam = function() {
- var t = this._$_2.length;
- t > this._$fs.length && (t = this._$fs.length), w._$jT(this._$fs, 0, this._$_2, 0, t)
- }, Y.prototype.saveParam = function() {
- var t = this._$_2.length;
- t > this._$fs.length && (this._$fs = new Float32Array(t)), w._$jT(this._$_2, 0, this._$fs, 0, t)
- }, Y.prototype._$v2 = function() {
- return this._$co
- }, Y.prototype._$WS = function() {
- return this._$QT
- }, Y.prototype._$Xb = function(t) {
- return this._$Js[t] == Y._$ZS
- }, Y.prototype._$vs = function() {
- return this._$Es
- }, Y.prototype._$Tr = function() {
- return this._$ZP
- }, Y.prototype.getBaseData = function(t) {
- return this._$3S[t]
- }, Y.prototype.getParamFloat = function(t) {
- return this._$_2[t]
- }, Y.prototype.getParamMax = function(t) {
- return this._$Or[t]
- }, Y.prototype.getParamMin = function(t) {
- return this._$Rr[t]
- }, Y.prototype.setPartsOpacity = function(t, i) {
- this._$Hr[t].setPartsOpacity(i)
- }, Y.prototype.getPartsOpacity = function(t) {
- return this._$Hr[t].getPartsOpacity()
- }, Y.prototype.getPartsDataIndex = function(t) {
- for (var i = this._$F2.length - 1; i >= 0; --i) if (null != this._$F2[i] && this._$F2[i]._$p2() == t) return i;
- return -1
- }, Y.prototype._$q2 = function(t) {
- return this._$db[t]
- }, Y.prototype._$C2 = function(t) {
- return this._$8b[t]
- }, Y.prototype._$Bb = function(t) {
- return this._$Hr[t]
- }, Y.prototype._$5s = function(t, i) {
- for (var e = this._$Ws.length, r = t, o = 0; o < e; ++o) {
- var n = this._$Ws[o];
- if (n != Y._$V2) for (;;) {
- var s = this._$8b[n];
- s._$yo() && (s._$GT()._$B2(this, s, r), r += i);
- var _ = this._$Er[n];
- if (_ <= n || _ == Y._$W0) break;
- n = _
- }
- }
- }, Y.prototype.setDrawParam = function(t) {
- this.dp_webgl = t
- }, Y.prototype.getDrawParam = function() {
- return this.dp_webgl
- }, k._$0T = function(t) {
- return k._$0T(new _$5(t))
- }, k._$0T = function(t) {
- if (!t.exists()) throw new _$ls(t._$3b());
- for (var i, e = t.length(), r = new Int8Array(e), o = new _$Xs(new _$kb(t), 8192), n = 0;
- (i = o.read(r, n, e - n)) > 0;) n += i;
- return r
- }, k._$C = function(t) {
- var i = null,
- e = null;
- try {
- i = t instanceof Array ? t : new _$Xs(t, 8192), e = new _$js;
- for (var r, o = new Int8Array(1e3);
- (r = i.read(o)) > 0;) e.write(o, 0, r);
- return e._$TS()
- } finally {
- null != t && t.close(), null != e && (e.flush(), e.close())
- }
- }, V.prototype._$T2 = function() {
- return w.getUserTimeMSec() + Math._$10() * (2 * this._$Br - 1)
- }, V.prototype._$uo = function(t) {
- this._$Br = t
- }, V.prototype._$QS = function(t, i, e) {
- this._$Dr = t, this._$Cb = i, this._$mr = e
- }, V.prototype._$7T = function(t) {
- var i, e = w.getUserTimeMSec(),
- r = 0;
- switch (this._$_L) {
- case STATE_CLOSING:
- r = (e - this._$bb) / this._$Dr, r >= 1 && (r = 1, this._$_L = wt.STATE_CLOSED, this._$bb = e), i = 1 - r;
- break;
- case STATE_CLOSED:
- r = (e - this._$bb) / this._$Cb, r >= 1 && (this._$_L = wt.STATE_OPENING, this._$bb = e), i = 0;
- break;
- case STATE_OPENING:
- r = (e - this._$bb) / this._$mr, r >= 1 && (r = 1, this._$_L = wt.STATE_INTERVAL, this._$12 = this._$T2()), i = r;
- break;
- case STATE_INTERVAL:
- this._$12 < e && (this._$_L = wt.STATE_CLOSING, this._$bb = e), i = 1;
- break;
- case STATE_FIRST:
- default:
- this._$_L = wt.STATE_INTERVAL, this._$12 = this._$T2(), i = 1
- }
- this._$jo || (i = -i), t.setParamFloat(this._$iL, i), t.setParamFloat(this._$0L, i)
- };
- var wt = function() {};
- wt.STATE_FIRST = "STATE_FIRST", wt.STATE_INTERVAL = "STATE_INTERVAL", wt.STATE_CLOSING = "STATE_CLOSING", wt.STATE_CLOSED = "STATE_CLOSED", wt.STATE_OPENING = "STATE_OPENING", X.prototype = new E, X._$As = 32, X._$Gr = !1, X._$NT = null, X._$vS = null, X._$no = null, X._$9r = function(t) {
- return new Float32Array(t)
- }, X._$vb = function(t) {
- return new Int16Array(t)
- }, X._$cr = function(t, i) {
- return null == t || t._$yL() < i.length ? (t = X._$9r(2 * i.length), t.put(i), t._$oT(0)) : (t.clear(), t.put(i), t._$oT(0)), t
- }, X._$mb = function(t, i) {
- return null == t || t._$yL() < i.length ? (t = X._$vb(2 * i.length), t.put(i), t._$oT(0)) : (t.clear(), t.put(i), t._$oT(0)), t
- }, X._$Hs = function() {
- return X._$Gr
- }, X._$as = function(t) {
- X._$Gr = t
- }, X.prototype.setGL = function(t) {
- this.gl = t
- }, X.prototype.setTransform = function(t) {
- this.transform = t
- }, X.prototype._$ZT = function() {}, X.prototype._$Uo = function(t, i, e, r, o, n, s, _) {
- if (!(n < .01)) {
- var a = this._$U2[t],
- h = n > .9 ? at.EXPAND_W : 0;
- this.gl.drawElements(a, e, r, o, n, h, this.transform, _)
- }
- }, X.prototype._$Rs = function() {
- throw new Error("_$Rs")
- }, X.prototype._$Ds = function(t) {
- throw new Error("_$Ds")
- }, X.prototype._$K2 = function() {
- for (var t = 0; t < this._$sb.length; t++) {
- 0 != this._$sb[t] && (this.gl._$Sr(1, this._$sb, t), this._$sb[t] = 0)
- }
- }, X.prototype.setTexture = function(t, i) {
- this._$sb.length < t + 1 && this._$nS(t), this._$sb[t] = i
- }, X.prototype.setTexture = function(t, i) {
- this._$sb.length < t + 1 && this._$nS(t), this._$U2[t] = i
- }, X.prototype._$nS = function(t) {
- var i = Math.max(2 * this._$sb.length, t + 1 + 10),
- e = new Int32Array(i);
- w._$jT(this._$sb, 0, e, 0, this._$sb.length), this._$sb = e;
- var r = new Array;
- w._$jT(this._$U2, 0, r, 0, this._$U2.length), this._$U2 = r
- }, z.prototype = new I, z._$Xo = new Float32Array(2), z._$io = new Float32Array(2), z._$0o = new Float32Array(2), z._$Lo = new Float32Array(2), z._$To = new Float32Array(2), z._$Po = new Float32Array(2), z._$gT = new Array, z.prototype._$zP = function() {
- this._$GS = new D, this._$GS._$zP(), this._$Y0 = new Array
- }, z.prototype.getType = function() {
- return I._$c2
- }, z.prototype._$F0 = function(t) {
- I.prototype._$F0.call(this, t), this._$GS = t._$nP(), this._$Y0 = t._$nP(), I.prototype.readV2_opacity.call(this, t)
- }, z.prototype.init = function(t) {
- var i = new H(this);
- return i._$Yr = new P, this._$32() && (i._$Wr = new P), i
- }, z.prototype._$Nr = function(t, i) {
- this != i._$GT() && console.log("### assert!! ### ");
- var e = i;
- if (this._$GS._$Ur(t)) {
- var r = z._$gT;
- r[0] = !1;
- var o = this._$GS._$Q2(t, r);
- i._$Ib(r[0]), this.interpolateOpacity(t, this._$GS, i, r);
- var n = t._$vs(),
- s = t._$Tr();
- if (this._$GS._$zr(n, s, o), o <= 0) {
- var _ = this._$Y0[n[0]];
- e._$Yr.init(_)
- } else if (1 == o) {
- var _ = this._$Y0[n[0]],
- a = this._$Y0[n[1]],
- h = s[0];
- e._$Yr._$fL = _._$fL + (a._$fL - _._$fL) * h, e._$Yr._$gL = _._$gL + (a._$gL - _._$gL) * h, e._$Yr._$B0 = _._$B0 + (a._$B0 - _._$B0) * h, e._$Yr._$z0 = _._$z0 + (a._$z0 - _._$z0) * h, e._$Yr._$qT = _._$qT + (a._$qT - _._$qT) * h
- } else if (2 == o) {
- var _ = this._$Y0[n[0]],
- a = this._$Y0[n[1]],
- l = this._$Y0[n[2]],
- $ = this._$Y0[n[3]],
- h = s[0],
- u = s[1],
- p = _._$fL + (a._$fL - _._$fL) * h,
- f = l._$fL + ($._$fL - l._$fL) * h;
- e._$Yr._$fL = p + (f - p) * u, p = _._$gL + (a._$gL - _._$gL) * h, f = l._$gL + ($._$gL - l._$gL) * h, e._$Yr._$gL = p + (f - p) * u, p = _._$B0 + (a._$B0 - _._$B0) * h, f = l._$B0 + ($._$B0 - l._$B0) * h, e._$Yr._$B0 = p + (f - p) * u, p = _._$z0 + (a._$z0 - _._$z0) * h, f = l._$z0 + ($._$z0 - l._$z0) * h, e._$Yr._$z0 = p + (f - p) * u, p = _._$qT + (a._$qT - _._$qT) * h, f = l._$qT + ($._$qT - l._$qT) * h, e._$Yr._$qT = p + (f - p) * u
- } else if (3 == o) {
- var c = this._$Y0[n[0]],
- d = this._$Y0[n[1]],
- g = this._$Y0[n[2]],
- y = this._$Y0[n[3]],
- m = this._$Y0[n[4]],
- T = this._$Y0[n[5]],
- P = this._$Y0[n[6]],
- S = this._$Y0[n[7]],
- h = s[0],
- u = s[1],
- v = s[2],
- p = c._$fL + (d._$fL - c._$fL) * h,
- f = g._$fL + (y._$fL - g._$fL) * h,
- L = m._$fL + (T._$fL - m._$fL) * h,
- M = P._$fL + (S._$fL - P._$fL) * h;
- e._$Yr._$fL = (1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u), p = c._$gL + (d._$gL - c._$gL) * h, f = g._$gL + (y._$gL - g._$gL) * h, L = m._$gL + (T._$gL - m._$gL) * h, M = P._$gL + (S._$gL - P._$gL) * h, e._$Yr._$gL = (1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u), p = c._$B0 + (d._$B0 - c._$B0) * h, f = g._$B0 + (y._$B0 - g._$B0) * h, L = m._$B0 + (T._$B0 - m._$B0) * h, M = P._$B0 + (S._$B0 - P._$B0) * h, e._$Yr._$B0 = (1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u), p = c._$z0 + (d._$z0 - c._$z0) * h, f = g._$z0 + (y._$z0 - g._$z0) * h, L = m._$z0 + (T._$z0 - m._$z0) * h, M = P._$z0 + (S._$z0 - P._$z0) * h, e._$Yr._$z0 = (1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u), p = c._$qT + (d._$qT - c._$qT) * h, f = g._$qT + (y._$qT - g._$qT) * h, L = m._$qT + (T._$qT - m._$qT) * h, M = P._$qT + (S._$qT - P._$qT) * h, e._$Yr._$qT = (1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u)
- } else if (4 == o) {
- var E = this._$Y0[n[0]],
- A = this._$Y0[n[1]],
- I = this._$Y0[n[2]],
- w = this._$Y0[n[3]],
- x = this._$Y0[n[4]],
- O = this._$Y0[n[5]],
- D = this._$Y0[n[6]],
- R = this._$Y0[n[7]],
- b = this._$Y0[n[8]],
- F = this._$Y0[n[9]],
- C = this._$Y0[n[10]],
- N = this._$Y0[n[11]],
- B = this._$Y0[n[12]],
- U = this._$Y0[n[13]],
- G = this._$Y0[n[14]],
- Y = this._$Y0[n[15]],
- h = s[0],
- u = s[1],
- v = s[2],
- k = s[3],
- p = E._$fL + (A._$fL - E._$fL) * h,
- f = I._$fL + (w._$fL - I._$fL) * h,
- L = x._$fL + (O._$fL - x._$fL) * h,
- M = D._$fL + (R._$fL - D._$fL) * h,
- V = b._$fL + (F._$fL - b._$fL) * h,
- X = C._$fL + (N._$fL - C._$fL) * h,
- H = B._$fL + (U._$fL - B._$fL) * h,
- W = G._$fL + (Y._$fL - G._$fL) * h;
- e._$Yr._$fL = (1 - k) * ((1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u)) + k * ((1 - v) * (V + (X - V) * u) + v * (H + (W - H) * u)), p = E._$gL + (A._$gL - E._$gL) * h, f = I._$gL + (w._$gL - I._$gL) * h, L = x._$gL + (O._$gL - x._$gL) * h, M = D._$gL + (R._$gL - D._$gL) * h, V = b._$gL + (F._$gL - b._$gL) * h, X = C._$gL + (N._$gL - C._$gL) * h, H = B._$gL + (U._$gL - B._$gL) * h, W = G._$gL + (Y._$gL - G._$gL) * h, e._$Yr._$gL = (1 - k) * ((1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u)) + k * ((1 - v) * (V + (X - V) * u) + v * (H + (W - H) * u)), p = E._$B0 + (A._$B0 - E._$B0) * h, f = I._$B0 + (w._$B0 - I._$B0) * h, L = x._$B0 + (O._$B0 - x._$B0) * h, M = D._$B0 + (R._$B0 - D._$B0) * h, V = b._$B0 + (F._$B0 - b._$B0) * h, X = C._$B0 + (N._$B0 - C._$B0) * h, H = B._$B0 + (U._$B0 - B._$B0) * h, W = G._$B0 + (Y._$B0 - G._$B0) * h, e._$Yr._$B0 = (1 - k) * ((1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u)) + k * ((1 - v) * (V + (X - V) * u) + v * (H + (W - H) * u)), p = E._$z0 + (A._$z0 - E._$z0) * h, f = I._$z0 + (w._$z0 - I._$z0) * h, L = x._$z0 + (O._$z0 - x._$z0) * h, M = D._$z0 + (R._$z0 - D._$z0) * h, V = b._$z0 + (F._$z0 - b._$z0) * h, X = C._$z0 + (N._$z0 - C._$z0) * h, H = B._$z0 + (U._$z0 - B._$z0) * h, W = G._$z0 + (Y._$z0 - G._$z0) * h, e._$Yr._$z0 = (1 - k) * ((1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u)) + k * ((1 - v) * (V + (X - V) * u) + v * (H + (W - H) * u)), p = E._$qT + (A._$qT - E._$qT) * h, f = I._$qT + (w._$qT - I._$qT) * h, L = x._$qT + (O._$qT - x._$qT) * h, M = D._$qT + (R._$qT - D._$qT) * h, V = b._$qT + (F._$qT - b._$qT) * h, X = C._$qT + (N._$qT - C._$qT) * h, H = B._$qT + (U._$qT - B._$qT) * h, W = G._$qT + (Y._$qT - G._$qT) * h, e._$Yr._$qT = (1 - k) * ((1 - v) * (p + (f - p) * u) + v * (L + (M - L) * u)) + k * ((1 - v) * (V + (X - V) * u) + v * (H + (W - H) * u))
- } else {
- for (var j = 0 | Math.pow(2, o), q = new Float32Array(j), J = 0; J < j; J++) {
- for (var Q = J, Z = 1, K = 0; K < o; K++) Z *= Q % 2 == 0 ? 1 - s[K] : s[K], Q /= 2;
- q[J] = Z
- }
- for (var tt = new Array, it = 0; it < j; it++) tt[it] = this._$Y0[n[it]];
- for (var et = 0, rt = 0, ot = 0, nt = 0, st = 0, it = 0; it < j; it++) et += q[it] * tt[it]._$fL, rt += q[it] * tt[it]._$gL, ot += q[it] * tt[it]._$B0, nt += q[it] * tt[it]._$z0, st += q[it] * tt[it]._$qT;
- e._$Yr._$fL = et, e._$Yr._$gL = rt, e._$Yr._$B0 = ot, e._$Yr._$z0 = nt, e._$Yr._$qT = st
- }
- var _ = this._$Y0[n[0]];
- e._$Yr.reflectX = _.reflectX, e._$Yr.reflectY = _.reflectY
- }
- }, z.prototype._$2b = function(t, i) {
- this != i._$GT() && console.log("### assert!! ### ");
- var e = i;
- if (e._$hS(!0), this._$32()) {
- var r = this.getTargetBaseDataID();
- if (e._$8r == I._$ur && (e._$8r = t.getBaseDataIndex(r)), e._$8r < 0) at._$so && _._$li("_$L _$0P _$G :: %s", r), e._$hS(!1);
- else {
- var o = t.getBaseData(e._$8r);
- if (null != o) {
- var n = t._$q2(e._$8r),
- s = z._$Xo;
- s[0] = e._$Yr._$fL, s[1] = e._$Yr._$gL;
- var a = z._$io;
- a[0] = 0, a[1] = -.1;
- n._$GT().getType() == I._$c2 ? a[1] = -10 : a[1] = -.1;
- var h = z._$0o;
- this._$Jr(t, o, n, s, a, h);
- var l = Lt._$92(a, h);
- o._$nb(t, n, s, s, 1, 0, 2), e._$Wr._$fL = s[0], e._$Wr._$gL = s[1], e._$Wr._$B0 = e._$Yr._$B0, e._$Wr._$z0 = e._$Yr._$z0, e._$Wr._$qT = e._$Yr._$qT - l * Lt._$NS;
- var $ = n.getTotalScale();
- e.setTotalScale_notForClient($ * e._$Wr._$B0);
- var u = n.getTotalOpacity();
- e.setTotalOpacity(u * e.getInterpolatedOpacity()), e._$Wr.reflectX = e._$Yr.reflectX, e._$Wr.reflectY = e._$Yr.reflectY, e._$hS(n._$yo())
- } else e._$hS(!1)
- }
- } else e.setTotalScale_notForClient(e._$Yr._$B0), e.setTotalOpacity(e.getInterpolatedOpacity())
- }, z.prototype._$nb = function(t, i, e, r, o, n, s) {
- this != i._$GT() && console.log("### assert!! ### ");
- for (var _, a, h = i, l = null != h._$Wr ? h._$Wr : h._$Yr, $ = Math.sin(Lt._$bS * l._$qT), u = Math.cos(Lt._$bS * l._$qT), p = h.getTotalScale(), f = l.reflectX ? -1 : 1, c = l.reflectY ? -1 : 1, d = u * p * f, g = -$ * p * c, y = $ * p * f, m = u * p * c, T = l._$fL, P = l._$gL, S = o * s, v = n; v < S; v += s) _ = e[v], a = e[v + 1], r[v] = d * _ + g * a + T, r[v + 1] = y * _ + m * a + P
- }, z.prototype._$Jr = function(t, i, e, r, o, n) {
- i != e._$GT() && console.log("### assert!! ### ");
- var s = z._$Lo;
- z._$Lo[0] = r[0], z._$Lo[1] = r[1], i._$nb(t, e, s, s, 1, 0, 2);
- for (var _ = z._$To, a = z._$Po, h = 1, l = 0; l < 10; l++) {
- if (a[0] = r[0] + h * o[0], a[1] = r[1] + h * o[1], i._$nb(t, e, a, _, 1, 0, 2), _[0] -= s[0], _[1] -= s[1], 0 != _[0] || 0 != _[1]) return n[0] = _[0], void(n[1] = _[1]);
- if (a[0] = r[0] - h * o[0], a[1] = r[1] - h * o[1], i._$nb(t, e, a, _, 1, 0, 2), _[0] -= s[0], _[1] -= s[1], 0 != _[0] || 0 != _[1]) return _[0] = -_[0], _[0] = -_[0], n[0] = _[0], void(n[1] = _[1]);
- h *= .1
- }
- at._$so && console.log("_$L0 to transform _$SP\n")
- }, H.prototype = new _t, W.prototype = new M, W._$ur = -2, W._$ES = 500, W._$wb = 2, W._$8S = 3, W._$os = 4, W._$52 = W._$ES, W._$R2 = W._$ES, W._$Sb = function(t) {
- for (var i = t.length - 1; i >= 0; --i) {
- var e = t[i];
- e < W._$52 ? W._$52 = e : e > W._$R2 && (W._$R2 = e)
- }
- }, W._$or = function() {
- return W._$52
- }, W._$Pr = function() {
- return W._$R2
- }, W.prototype._$F0 = function(t) {
- this._$gP = t._$nP(), this._$dr = t._$nP(), this._$GS = t._$nP(), this._$qb = t._$6L(), this._$Lb = t._$cS(), this._$mS = t._$Tb(), t.getFormatVersion() >= G._$T7 ? (this.clipID = t._$nP(), this.clipIDList = this.convertClipIDForV2_11(this.clipID)) : this.clipIDList = null, W._$Sb(this._$Lb)
- }, W.prototype.getClipIDList = function() {
- return this.clipIDList
- }, W.prototype._$Nr = function(t, i) {
- if (i._$IS[0] = !1, i._$Us = v._$Z2(t, this._$GS, i._$IS, this._$Lb), at._$Zs);
- else if (i._$IS[0]) return;
- i._$7s = v._$br(t, this._$GS, i._$IS, this._$mS)
- }, W.prototype._$2b = function(t) {}, W.prototype.getDrawDataID = function() {
- return this._$gP
- }, W.prototype._$j2 = function(t) {
- this._$gP = t
- }, W.prototype.getOpacity = function(t, i) {
- return i._$7s
- }, W.prototype._$zS = function(t, i) {
- return i._$Us
- }, W.prototype.getTargetBaseDataID = function() {
- return this._$dr
- }, W.prototype._$gs = function(t) {
- this._$dr = t
- }, W.prototype._$32 = function() {
- return null != this._$dr && this._$dr != yt._$2o()
- }, W.prototype.getType = function() {}, j._$42 = 0, j.prototype._$1b = function() {
- return this._$3S
- }, j.prototype.getDrawDataList = function() {
- return this._$aS
- }, j.prototype._$F0 = function(t) {
- this._$NL = t._$nP(), this._$aS = t._$nP(), this._$3S = t._$nP()
- }, j.prototype._$kr = function(t) {
- t._$Zo(this._$3S), t._$xo(this._$aS), this._$3S = null, this._$aS = null
- }, q.prototype = new i, q.loadModel = function(t) {
- var e = new q;
- return i._$62(e, t), e
- }, q.loadModel = function(t) {
- var e = new q;
- return i._$62(e, t), e
- }, q._$to = function() {
- return new q
- }, q._$er = function(t) {
- var i = new _$5("../_$_r/_$t0/_$Ri/_$_P._$d");
- if (0 == i.exists()) throw new _$ls("_$t0 _$_ _$6 _$Ui :: " + i._$PL());
- for (var e = ["../_$_r/_$t0/_$Ri/_$_P.512/_$CP._$1", "../_$_r/_$t0/_$Ri/_$_P.512/_$vP._$1", "../_$_r/_$t0/_$Ri/_$_P.512/_$EP._$1", "../_$_r/_$t0/_$Ri/_$_P.512/_$pP._$1"], r = q.loadModel(i._$3b()), o = 0; o < e.length; o++) {
- var n = new _$5(e[o]);
- if (0 == n.exists()) throw new _$ls("_$t0 _$_ _$6 _$Ui :: " + n._$PL());
- r.setTexture(o, _$nL._$_o(t, n._$3b()))
- }
- return r
- }, q.prototype.setGL = function(t) {
- this._$zo.setGL(t)
- }, q.prototype.setTransform = function(t) {
- this._$zo.setTransform(t)
- }, q.prototype.draw = function() {
- this._$5S.draw(this._$zo)
- }, q.prototype._$K2 = function() {
- this._$zo._$K2()
- }, q.prototype.setTexture = function(t, i) {
- null == this._$zo && _._$li("_$Yi for QT _$ki / _$XS() is _$6 _$ui!!"), this._$zo.setTexture(t, i)
- }, q.prototype.setTexture = function(t, i) {
- null == this._$zo && _._$li("_$Yi for QT _$ki / _$XS() is _$6 _$ui!!"), this._$zo.setTexture(t, i)
- }, q.prototype._$Rs = function() {
- return this._$zo._$Rs()
- }, q.prototype._$Ds = function(t) {
- this._$zo._$Ds(t)
- }, q.prototype.getDrawParam = function() {
- return this._$zo
- }, J.prototype = new s, J._$cs = "VISIBLE:", J._$ar = "LAYOUT:", J.MTN_PREFIX_FADEIN = "FADEIN:", J.MTN_PREFIX_FADEOUT = "FADEOUT:", J._$Co = 0, J._$1T = 1, J.loadMotion = function(t) {
- var i = k._$C(t);
- return J.loadMotion(i)
- }, J.loadMotion = function(t) {
- t instanceof ArrayBuffer && (t = new DataView(t));
- var i = new J,
- e = [0],
- r = t.byteLength;
- i._$yT = 0;
- for (var o = 0; o < r; ++o) {
- var n = Q(t, o),
- s = n.charCodeAt(0);
- if ("\n" != n && "\r" != n) if ("#" != n) if ("$" != n) {
- if (97 <= s && s <= 122 || 65 <= s && s <= 90 || "_" == n) {
- for (var _ = o, a = -1; o < r && ("\r" != (n = Q(t, o)) && "\n" != n); ++o) if ("=" == n) {
- a = o;
- break
- }
- if (a >= 0) {
- var h = new B;
- O.startsWith(t, _, J._$cs) ? (h._$RP = B._$hs, h._$4P = O.createString(t, _, a - _)) : O.startsWith(t, _, J._$ar) ? (h._$4P = O.createString(t, _ + 7, a - _ - 7), O.startsWith(t, _ + 7, "ANCHOR_X") ? h._$RP = B._$xs : O.startsWith(t, _ + 7, "ANCHOR_Y") ? h._$RP = B._$us : O.startsWith(t, _ + 7, "SCALE_X") ? h._$RP = B._$qs : O.startsWith(t, _ + 7, "SCALE_Y") ? h._$RP = B._$Ys : O.startsWith(t, _ + 7, "X") ? h._$RP = B._$ws : O.startsWith(t, _ + 7, "Y") && (h._$RP = B._$Ns)) : (h._$RP = B._$Fr, h._$4P = O.createString(t, _, a - _)), i.motions.push(h);
- var l = 0,
- $ = [];
- for (o = a + 1; o < r && ("\r" != (n = Q(t, o)) && "\n" != n); ++o) if ("," != n && " " != n && "\t" != n) {
- var u = O._$LS(t, r, o, e);
- if (e[0] > 0) {
- $.push(u), l++;
- var p = e[0];
- if (p < o) {
- console.log("_$n0 _$hi . @Live2DMotion loadMotion()\n");
- break
- }
- o = p - 1
- }
- }
- h._$I0 = new Float32Array($), l > i._$yT && (i._$yT = l)
- }
- }
- } else {
- for (var _ = o, a = -1; o < r && ("\r" != (n = Q(t, o)) && "\n" != n); ++o) if ("=" == n) {
- a = o;
- break
- }
- var f = !1;
- if (a >= 0) for (a == _ + 4 && "f" == Q(t, _ + 1) && "p" == Q(t, _ + 2) && "s" == Q(t, _ + 3) && (f = !0), o = a + 1; o < r && ("\r" != (n = Q(t, o)) && "\n" != n); ++o) if ("," != n && " " != n && "\t" != n) {
- var u = O._$LS(t, r, o, e);
- e[0] > 0 && f && 5 < u && u < 121 && (i._$D0 = u), o = e[0]
- }
- for (; o < r && ("\n" != Q(t, o) && "\r" != Q(t, o)); ++o);
- } else for (; o < r && ("\n" != Q(t, o) && "\r" != Q(t, o)); ++o);
- }
- return i._$rr = 1e3 * i._$yT / i._$D0 | 0, i
- }, J.prototype.getDurationMSec = function() {
- return this._$E ? -1 : this._$rr
- }, J.prototype.getLoopDurationMSec = function() {
- return this._$rr
- }, J.prototype.dump = function() {
- for (var t = 0; t < this.motions.length; t++) {
- var i = this.motions[t];
- console.log("_$wL[%s] [%d]. ", i._$4P, i._$I0.length);
- for (var e = 0; e < i._$I0.length && e < 10; e++) console.log("%5.2f ,", i._$I0[e]);
- console.log("\n")
- }
- }, J.prototype.updateParamExe = function(t, i, e, r) {
- for (var o = i - r._$z2, n = o * this._$D0 / 1e3, s = 0 | n, _ = n - s, a = 0; a < this.motions.length; a++) {
- var h = this.motions[a],
- l = h._$I0.length,
- $ = h._$4P;
- if (h._$RP == B._$hs) {
- var u = h._$I0[s >= l ? l - 1 : s];
- t.setParamFloat($, u)
- } else if (B._$ws <= h._$RP && h._$RP <= B._$Ys);
- else {
- var p, f = t.getParamIndex($),
- c = t.getModelContext(),
- d = c.getParamMax(f),
- g = c.getParamMin(f),
- y = .4 * (d - g),
- m = c.getParamFloat(f),
- T = h._$I0[s >= l ? l - 1 : s],
- P = h._$I0[s + 1 >= l ? l - 1 : s + 1];
- p = T < P && P - T > y || T > P && T - P > y ? T : T + (P - T) * _;
- var S = m + (p - m) * e;
- t.setParamFloat($, S)
- }
- }
- s >= this._$yT && (this._$E ? (r._$z2 = i, this.loopFadeIn && (r._$bs = i)) : r._$9L = !0), this._$eP = e
- }, J.prototype._$r0 = function() {
- return this._$E
- }, J.prototype._$aL = function(t) {
- this._$E = t
- }, J.prototype._$S0 = function() {
- return this._$D0
- }, J.prototype._$U0 = function(t) {
- this._$D0 = t
- }, J.prototype.isLoopFadeIn = function() {
- return this.loopFadeIn
- }, J.prototype.setLoopFadeIn = function(t) {
- this.loopFadeIn = t
- }, N.prototype.clear = function() {
- this.size = 0
- }, N.prototype.add = function(t) {
- if (this._$P.length <= this.size) {
- var i = new Float32Array(2 * this.size);
- w._$jT(this._$P, 0, i, 0, this.size), this._$P = i
- }
- this._$P[this.size++] = t
- }, N.prototype._$BL = function() {
- var t = new Float32Array(this.size);
- return w._$jT(this._$P, 0, t, 0, this.size), t
- }, B._$Fr = 0, B._$hs = 1, B._$ws = 100, B._$Ns = 101, B._$xs = 102, B._$us = 103, B._$qs = 104, B._$Ys = 105, Z.prototype = new I, Z._$gT = new Array, Z.prototype._$zP = function() {
- this._$GS = new D, this._$GS._$zP()
- }, Z.prototype._$F0 = function(t) {
- I.prototype._$F0.call(this, t), this._$A = t._$6L(), this._$o = t._$6L(), this._$GS = t._$nP(), this._$Eo = t._$nP(), I.prototype.readV2_opacity.call(this, t)
- }, Z.prototype.init = function(t) {
- var i = new K(this),
- e = (this._$o + 1) * (this._$A + 1);
- return null != i._$Cr && (i._$Cr = null), i._$Cr = new Float32Array(2 * e), null != i._$hr && (i._$hr = null), this._$32() ? i._$hr = new Float32Array(2 * e) : i._$hr = null, i
- }, Z.prototype._$Nr = function(t, i) {
- var e = i;
- if (this._$GS._$Ur(t)) {
- var r = this._$VT(),
- o = Z._$gT;
- o[0] = !1, v._$Vr(t, this._$GS, o, r, this._$Eo, e._$Cr, 0, 2), i._$Ib(o[0]), this.interpolateOpacity(t, this._$GS, i, o)
- }
- }, Z.prototype._$2b = function(t, i) {
- var e = i;
- if (e._$hS(!0), this._$32()) {
- var r = this.getTargetBaseDataID();
- if (e._$8r == I._$ur && (e._$8r = t.getBaseDataIndex(r)), e._$8r < 0) at._$so && _._$li("_$L _$0P _$G :: %s", r), e._$hS(!1);
- else {
- var o = t.getBaseData(e._$8r),
- n = t._$q2(e._$8r);
- if (null != o && n._$yo()) {
- var s = n.getTotalScale();
- e.setTotalScale_notForClient(s);
- var a = n.getTotalOpacity();
- e.setTotalOpacity(a * e.getInterpolatedOpacity()), o._$nb(t, n, e._$Cr, e._$hr, this._$VT(), 0, 2), e._$hS(!0)
- } else e._$hS(!1)
- }
- } else e.setTotalOpacity(e.getInterpolatedOpacity())
- }, Z.prototype._$nb = function(t, i, e, r, o, n, s) {
- var _ = i,
- a = null != _._$hr ? _._$hr : _._$Cr;
- Z.transformPoints_sdk2(e, r, o, n, s, a, this._$o, this._$A)
- }, Z.transformPoints_sdk2 = function(i, e, r, o, n, s, _, a) {
- for (var h, l, $, u = r * n, p = 0, f = 0, c = 0, d = 0, g = 0, y = 0, m = !1, T = o; T < u; T += n) {
- var P, S, v, L;
- if (v = i[T], L = i[T + 1], P = v * _, S = L * a, P < 0 || S < 0 || _ <= P || a <= S) {
- var M = _ + 1;
- if (!m) {
- m = !0, p = .25 * (s[2 * (0 + 0 * M)] + s[2 * (_ + 0 * M)] + s[2 * (0 + a * M)] + s[2 * (_ + a * M)]), f = .25 * (s[2 * (0 + 0 * M) + 1] + s[2 * (_ + 0 * M) + 1] + s[2 * (0 + a * M) + 1] + s[2 * (_ + a * M) + 1]);
- var E = s[2 * (_ + a * M)] - s[2 * (0 + 0 * M)],
- A = s[2 * (_ + a * M) + 1] - s[2 * (0 + 0 * M) + 1],
- I = s[2 * (_ + 0 * M)] - s[2 * (0 + a * M)],
- w = s[2 * (_ + 0 * M) + 1] - s[2 * (0 + a * M) + 1];
- c = .5 * (E + I), d = .5 * (A + w), g = .5 * (E - I), y = .5 * (A - w), p -= .5 * (c + g), f -= .5 * (d + y)
- }
- if (-2 < v && v < 3 && -2 < L && L < 3) if (v <= 0) if (L <= 0) {
- var x = s[2 * (0 + 0 * M)],
- O = s[2 * (0 + 0 * M) + 1],
- D = p - 2 * c,
- R = f - 2 * d,
- b = p - 2 * g,
- F = f - 2 * y,
- C = p - 2 * c - 2 * g,
- N = f - 2 * d - 2 * y,
- B = .5 * (v - -2),
- U = .5 * (L - -2);
- B + U <= 1 ? (e[T] = C + (b - C) * B + (D - C) * U, e[T + 1] = N + (F - N) * B + (R - N) * U) : (e[T] = x + (D - x) * (1 - B) + (b - x) * (1 - U), e[T + 1] = O + (R - O) * (1 - B) + (F - O) * (1 - U))
- } else if (L >= 1) {
- var b = s[2 * (0 + a * M)],
- F = s[2 * (0 + a * M) + 1],
- C = p - 2 * c + 1 * g,
- N = f - 2 * d + 1 * y,
- x = p + 3 * g,
- O = f + 3 * y,
- D = p - 2 * c + 3 * g,
- R = f - 2 * d + 3 * y,
- B = .5 * (v - -2),
- U = .5 * (L - 1);
- B + U <= 1 ? (e[T] = C + (b - C) * B + (D - C) * U, e[T + 1] = N + (F - N) * B + (R - N) * U) : (e[T] = x + (D - x) * (1 - B) + (b - x) * (1 - U), e[T + 1] = O + (R - O) * (1 - B) + (F - O) * (1 - U))
- } else {
- var G = 0 | S;
- G == a && (G = a - 1);
- var B = .5 * (v - -2),
- U = S - G,
- Y = G / a,
- k = (G + 1) / a,
- b = s[2 * (0 + G * M)],
- F = s[2 * (0 + G * M) + 1],
- x = s[2 * (0 + (G + 1) * M)],
- O = s[2 * (0 + (G + 1) * M) + 1],
- C = p - 2 * c + Y * g,
- N = f - 2 * d + Y * y,
- D = p - 2 * c + k * g,
- R = f - 2 * d + k * y;
- B + U <= 1 ? (e[T] = C + (b - C) * B + (D - C) * U, e[T + 1] = N + (F - N) * B + (R - N) * U) : (e[T] = x + (D - x) * (1 - B) + (b - x) * (1 - U), e[T + 1] = O + (R - O) * (1 - B) + (F - O) * (1 - U))
- } else if (1 <= v) if (L <= 0) {
- var D = s[2 * (_ + 0 * M)],
- R = s[2 * (_ + 0 * M) + 1],
- x = p + 3 * c,
- O = f + 3 * d,
- C = p + 1 * c - 2 * g,
- N = f + 1 * d - 2 * y,
- b = p + 3 * c - 2 * g,
- F = f + 3 * d - 2 * y,
- B = .5 * (v - 1),
- U = .5 * (L - -2);
- B + U <= 1 ? (e[T] = C + (b - C) * B + (D - C) * U, e[T + 1] = N + (F - N) * B + (R - N) * U) : (e[T] = x + (D - x) * (1 - B) + (b - x) * (1 - U), e[T + 1] = O + (R - O) * (1 - B) + (F - O) * (1 - U))
- } else if (L >= 1) {
- var C = s[2 * (_ + a * M)],
- N = s[2 * (_ + a * M) + 1],
- b = p + 3 * c + 1 * g,
- F = f + 3 * d + 1 * y,
- D = p + 1 * c + 3 * g,
- R = f + 1 * d + 3 * y,
- x = p + 3 * c + 3 * g,
- O = f + 3 * d + 3 * y,
- B = .5 * (v - 1),
- U = .5 * (L - 1);
- B + U <= 1 ? (e[T] = C + (b - C) * B + (D - C) * U, e[T + 1] = N + (F - N) * B + (R - N) * U) : (e[T] = x + (D - x) * (1 - B) + (b - x) * (1 - U), e[T + 1] = O + (R - O) * (1 - B) + (F - O) * (1 - U))
- } else {
- var G = 0 | S;
- G == a && (G = a - 1);
- var B = .5 * (v - 1),
- U = S - G,
- Y = G / a,
- k = (G + 1) / a,
- C = s[2 * (_ + G * M)],
- N = s[2 * (_ + G * M) + 1],
- D = s[2 * (_ + (G + 1) * M)],
- R = s[2 * (_ + (G + 1) * M) + 1],
- b = p + 3 * c + Y * g,
- F = f + 3 * d + Y * y,
- x = p + 3 * c + k * g,
- O = f + 3 * d + k * y;
- B + U <= 1 ? (e[T] = C + (b - C) * B + (D - C) * U, e[T + 1] = N + (F - N) * B + (R - N) * U) : (e[T] = x + (D - x) * (1 - B) + (b - x) * (1 - U), e[T + 1] = O + (R - O) * (1 - B) + (F - O) * (1 - U))
- } else if (L <= 0) {
- var V = 0 | P;
- V == _ && (V = _ - 1);
- var B = P - V,
- U = .5 * (L - -2),
- X = V / _,
- z = (V + 1) / _,
- D = s[2 * (V + 0 * M)],
- R = s[2 * (V + 0 * M) + 1],
- x = s[2 * (V + 1 + 0 * M)],
- O = s[2 * (V + 1 + 0 * M) + 1],
- C = p + X * c - 2 * g,
- N = f + X * d - 2 * y,
- b = p + z * c - 2 * g,
- F = f + z * d - 2 * y;
- B + U <= 1 ? (e[T] = C + (b - C) * B + (D - C) * U, e[T + 1] = N + (F - N) * B + (R - N) * U) : (e[T] = x + (D - x) * (1 - B) + (b - x) * (1 - U), e[T + 1] = O + (R - O) * (1 - B) + (F - O) * (1 - U))
- } else if (L >= 1) {
- var V = 0 | P;
- V == _ && (V = _ - 1);
- var B = P - V,
- U = .5 * (L - 1),
- X = V / _,
- z = (V + 1) / _,
- C = s[2 * (V + a * M)],
- N = s[2 * (V + a * M) + 1],
- b = s[2 * (V + 1 + a * M)],
- F = s[2 * (V + 1 + a * M) + 1],
- D = p + X * c + 3 * g,
- R = f + X * d + 3 * y,
- x = p + z * c + 3 * g,
- O = f + z * d + 3 * y;
- B + U <= 1 ? (e[T] = C + (b - C) * B + (D - C) * U, e[T + 1] = N + (F - N) * B + (R - N) * U) : (e[T] = x + (D - x) * (1 - B) + (b - x) * (1 - U), e[T + 1] = O + (R - O) * (1 - B) + (F - O) * (1 - U))
- } else t.err.printf("_$li calc : %.4f , %.4f\t\t\t\t\t@@BDBoxGrid\n", v, L);
- else e[T] = p + v * c + L * g, e[T + 1] = f + v * d + L * y
- } else l = P - (0 | P), $ = S - (0 | S), h = 2 * ((0 | P) + (0 | S) * (_ + 1)), l + $ < 1 ? (e[T] = s[h] * (1 - l - $) + s[h + 2] * l + s[h + 2 * (_ + 1)] * $, e[T + 1] = s[h + 1] * (1 - l - $) + s[h + 3] * l + s[h + 2 * (_ + 1) + 1] * $) : (e[T] = s[h + 2 * (_ + 1) + 2] * (l - 1 + $) + s[h + 2 * (_ + 1)] * (1 - l) + s[h + 2] * (1 - $), e[T + 1] = s[h + 2 * (_ + 1) + 3] * (l - 1 + $) + s[h + 2 * (_ + 1) + 1] * (1 - l) + s[h + 3] * (1 - $))
- }
- }, Z.prototype.transformPoints_sdk1 = function(t, i, e, r, o, n, s) {
- for (var _, a, h, l, $, u, p, f = i, c = this._$o, d = this._$A, g = o * s, y = null != f._$hr ? f._$hr : f._$Cr, m = n; m < g; m += s) at._$ts ? (_ = e[m], a = e[m + 1], _ < 0 ? _ = 0 : _ > 1 && (_ = 1), a < 0 ? a = 0 : a > 1 && (a = 1), _ *= c, a *= d, h = 0 | _, l = 0 | a, h > c - 1 && (h = c - 1), l > d - 1 && (l = d - 1), u = _ - h, p = a - l, $ = 2 * (h + l * (c + 1))) : (_ = e[m] * c, a = e[m + 1] * d, u = _ - (0 | _), p = a - (0 | a), $ = 2 * ((0 | _) + (0 | a) * (c + 1))), u + p < 1 ? (r[m] = y[$] * (1 - u - p) + y[$ + 2] * u + y[$ + 2 * (c + 1)] * p, r[m + 1] = y[$ + 1] * (1 - u - p) + y[$ + 3] * u + y[$ + 2 * (c + 1) + 1] * p) : (r[m] = y[$ + 2 * (c + 1) + 2] * (u - 1 + p) + y[$ + 2 * (c + 1)] * (1 - u) + y[$ + 2] * (1 - p), r[m + 1] = y[$ + 2 * (c + 1) + 3] * (u - 1 + p) + y[$ + 2 * (c + 1) + 1] * (1 - u) + y[$ + 3] * (1 - p))
- }, Z.prototype._$VT = function() {
- return (this._$o + 1) * (this._$A + 1)
- }, Z.prototype.getType = function() {
- return I._$_b
- }, K.prototype = new _t, tt._$42 = 0, tt.prototype._$zP = function() {
- this._$3S = new Array, this._$aS = new Array
- }, tt.prototype._$F0 = function(t) {
- this._$g0 = t._$8L(), this.visible = t._$8L(), this._$NL = t._$nP(), this._$3S = t._$nP(), this._$aS = t._$nP()
- }, tt.prototype.init = function(t) {
- var i = new it(this);
- return i.setPartsOpacity(this.isVisible() ? 1 : 0), i
- }, tt.prototype._$6o = function(t) {
- if (null == this._$3S) throw new Error("_$3S _$6 _$Wo@_$6o");
- this._$3S.push(t)
- }, tt.prototype._$3o = function(t) {
- if (null == this._$aS) throw new Error("_$aS _$6 _$Wo@_$3o");
- this._$aS.push(t)
- }, tt.prototype._$Zo = function(t) {
- this._$3S = t
- }, tt.prototype._$xo = function(t) {
- this._$aS = t
- }, tt.prototype.isVisible = function() {
- return this.visible
- }, tt.prototype._$uL = function() {
- return this._$g0
- }, tt.prototype._$KP = function(t) {
- this.visible = t
- }, tt.prototype._$ET = function(t) {
- this._$g0 = t
- }, tt.prototype.getBaseData = function() {
- return this._$3S
- }, tt.prototype.getDrawData = function() {
- return this._$aS
- }, tt.prototype._$p2 = function() {
- return this._$NL
- }, tt.prototype._$ob = function(t) {
- this._$NL = t
- }, tt.prototype.getPartsID = function() {
- return this._$NL
- }, tt.prototype._$MP = function(t) {
- this._$NL = t
- }, it.prototype = new $, it.prototype.getPartsOpacity = function() {
- return this._$VS
- }, it.prototype.setPartsOpacity = function(t) {
- this._$VS = t
- }, et._$L7 = function() {
- u._$27(), yt._$27(), b._$27(), l._$27()
- }, et.prototype.toString = function() {
- return this.id
- }, rt.prototype._$F0 = function(t) {}, ot.prototype._$1s = function() {
- return this._$4S
- }, ot.prototype._$zP = function() {
- this._$4S = new Array
- }, ot.prototype._$F0 = function(t) {
- this._$4S = t._$nP()
- }, ot.prototype._$Ks = function(t) {
- this._$4S.push(t)
- }, nt.tr = new gt, nt._$50 = new gt, nt._$Ti = new Array(0, 0), nt._$Pi = new Array(0, 0), nt._$B = new Array(0, 0), nt.prototype._$lP = function(t, i, e, r) {
- this.viewport = new Array(t, i, e, r)
- }, nt.prototype._$bL = function() {
- this.context.save();
- var t = this.viewport;
- null != t && (this.context.beginPath(), this.context._$Li(t[0], t[1], t[2], t[3]), this.context.clip())
- }, nt.prototype._$ei = function() {
- this.context.restore()
- }, nt.prototype.drawElements = function(t, i, e, r, o, n, s, a) {
- try {
- o != this._$Qo && (this._$Qo = o, this.context.globalAlpha = o);
- for (var h = i.length, l = t.width, $ = t.height, u = this.context, p = this._$xP, f = this._$uP, c = this._$6r, d = this._$3r, g = nt.tr, y = nt._$Ti, m = nt._$Pi, T = nt._$B, P = 0; P < h; P += 3) {
- u.save();
- var S = i[P],
- v = i[P + 1],
- L = i[P + 2],
- M = p + c * e[2 * S],
- E = f + d * e[2 * S + 1],
- A = p + c * e[2 * v],
- I = f + d * e[2 * v + 1],
- w = p + c * e[2 * L],
- x = f + d * e[2 * L + 1];
- s && (s._$PS(M, E, T), M = T[0], E = T[1], s._$PS(A, I, T), A = T[0], I = T[1], s._$PS(w, x, T), w = T[0], x = T[1]);
- var O = l * r[2 * S],
- D = $ - $ * r[2 * S + 1],
- R = l * r[2 * v],
- b = $ - $ * r[2 * v + 1],
- F = l * r[2 * L],
- C = $ - $ * r[2 * L + 1],
- N = Math.atan2(b - D, R - O),
- B = Math.atan2(I - E, A - M),
- U = A - M,
- G = I - E,
- Y = Math.sqrt(U * U + G * G),
- k = R - O,
- V = b - D,
- X = Math.sqrt(k * k + V * V),
- z = Y / X;
- It._$ni(F, C, O, D, R - O, b - D, -(b - D), R - O, y), It._$ni(w, x, M, E, A - M, I - E, -(I - E), A - M, m);
- var H = (m[0] - y[0]) / y[1],
- W = Math.min(O, R, F),
- j = Math.max(O, R, F),
- q = Math.min(D, b, C),
- J = Math.max(D, b, C),
- Q = Math.floor(W),
- Z = Math.floor(q),
- K = Math.ceil(j),
- tt = Math.ceil(J);
- g.identity(), g.translate(M, E), g.rotate(B), g.scale(1, m[1] / y[1]), g.shear(H, 0), g.scale(z, z), g.rotate(-N), g.translate(-O, -D), g.setContext(u);
- if (n || (n = 1.2), at.IGNORE_EXPAND && (n = 0), at.USE_CACHED_POLYGON_IMAGE) {
- var it = a._$e0;
- if (it.gl_cacheImage = it.gl_cacheImage || {}, !it.gl_cacheImage[P]) {
- var et = nt.createCanvas(K - Q, tt - Z);
- at.DEBUG_DATA.LDGL_CANVAS_MB = at.DEBUG_DATA.LDGL_CANVAS_MB || 0, at.DEBUG_DATA.LDGL_CANVAS_MB += (K - Q) * (tt - Z) * 4;
- var rt = et.getContext("2d");
- rt.translate(-Q, -Z), nt.clip(rt, g, n, Y, O, D, R, b, F, C, M, E, A, I, w, x), rt.drawImage(t, 0, 0), it.gl_cacheImage[P] = {
- cacheCanvas: et,
- cacheContext: rt
- }
- }
- u.drawImage(it.gl_cacheImage[P].cacheCanvas, Q, Z)
- } else at.IGNORE_CLIP || nt.clip(u, g, n, Y, O, D, R, b, F, C, M, E, A, I, w, x), at.USE_ADJUST_TRANSLATION && (W = 0, j = l, q = 0, J = $), u.drawImage(t, W, q, j - W, J - q, W, q, j - W, J - q);
- u.restore()
- }
- } catch (t) {
- _._$Rb(t)
- }
- }, nt.clip = function(t, i, e, r, o, n, s, _, a, h, l, $, u, p, f, c) {
- e > .02 ? nt.expandClip(t, i, e, r, l, $, u, p, f, c) : nt.clipWithTransform(t, null, o, n, s, _, a, h)
- }, nt.expandClip = function(t, i, e, r, o, n, s, _, a, h) {
- var l = s - o,
- $ = _ - n,
- u = a - o,
- p = h - n,
- f = l * p - $ * u > 0 ? e : -e,
- c = -$,
- d = l,
- g = a - s,
- y = h - _,
- m = -y,
- T = g,
- P = Math.sqrt(g * g + y * y),
- S = -p,
- v = u,
- L = Math.sqrt(u * u + p * p),
- M = o - f * c / r,
- E = n - f * d / r,
- A = s - f * c / r,
- I = _ - f * d / r,
- w = s - f * m / P,
- x = _ - f * T / P,
- O = a - f * m / P,
- D = h - f * T / P,
- R = o + f * S / L,
- b = n + f * v / L,
- F = a + f * S / L,
- C = h + f * v / L,
- N = nt._$50;
- return null != i._$P2(N) && (nt.clipWithTransform(t, N, M, E, A, I, w, x, O, D, F, C, R, b), !0)
- }, nt.clipWithTransform = function(t, i, e, r, o, n, s, a) {
- if (arguments.length < 7) return void _._$li("err : @LDGL.clip()");
- if (!(arguments[1] instanceof gt)) return void _._$li("err : a[0] is _$6 LDTransform @LDGL.clip()");
- var h = nt._$B,
- l = i,
- $ = arguments;
- if (t.beginPath(), l) {
- l._$PS($[2], $[3], h), t.moveTo(h[0], h[1]);
- for (var u = 4; u < $.length; u += 2) l._$PS($[u], $[u + 1], h), t.lineTo(h[0], h[1])
- } else {
- t.moveTo($[2], $[3]);
- for (var u = 4; u < $.length; u += 2) t.lineTo($[u], $[u + 1])
- }
- t.clip()
- }, nt.createCanvas = function(t, i) {
- var e = document.createElement("canvas");
- return e.setAttribute("width", t), e.setAttribute("height", i), e || _._$li("err : " + e), e
- }, nt.dumpValues = function() {
- for (var t = "", i = 0; i < arguments.length; i++) t += "[" + i + "]= " + arguments[i].toFixed(3) + " , ";
- console.log(t)
- }, st.prototype._$F0 = function(t) {
- this._$TT = t._$_T(), this._$LT = t._$_T(), this._$FS = t._$_T(), this._$wL = t._$nP()
- }, st.prototype.getMinValue = function() {
- return this._$TT
- }, st.prototype.getMaxValue = function() {
- return this._$LT
- }, st.prototype.getDefaultValue = function() {
- return this._$FS
- }, st.prototype.getParamID = function() {
- return this._$wL
- }, _t.prototype._$yo = function() {
- return this._$AT && !this._$JS
- }, _t.prototype._$hS = function(t) {
- this._$AT = t
- }, _t.prototype._$GT = function() {
- return this._$e0
- }, _t.prototype._$l2 = function(t) {
- this._$IP = t
- }, _t.prototype.getPartsIndex = function() {
- return this._$IP
- }, _t.prototype._$x2 = function() {
- return this._$JS
- }, _t.prototype._$Ib = function(t) {
- this._$JS = t
- }, _t.prototype.getTotalScale = function() {
- return this.totalScale
- }, _t.prototype.setTotalScale_notForClient = function(t) {
- this.totalScale = t
- }, _t.prototype.getInterpolatedOpacity = function() {
- return this._$7s
- }, _t.prototype.setInterpolatedOpacity = function(t) {
- this._$7s = t
- }, _t.prototype.getTotalOpacity = function(t) {
- return this.totalOpacity
- }, _t.prototype.setTotalOpacity = function(t) {
- this.totalOpacity = t
- }, at._$2s = "2.1.00_1", at._$Kr = 201001e3, at._$sP = !0, at._$so = !0, at._$cb = !1, at._$3T = !0, at._$Ts = !0, at._$fb = !0, at._$ts = !0, at.L2D_DEFORMER_EXTEND = !0, at._$Wb = !1;
- at._$yr = !1, at._$Zs = !1, at.L2D_NO_ERROR = 0, at._$i7 = 1e3, at._$9s = 1001, at._$es = 1100, at._$r7 = 2e3, at._$07 = 2001, at._$b7 = 2002, at._$H7 = 4e3, at.L2D_COLOR_BLEND_MODE_MULT = 0, at.L2D_COLOR_BLEND_MODE_ADD = 1, at.L2D_COLOR_BLEND_MODE_INTERPOLATE = 2, at._$6b = !0, at._$cT = 0, at.clippingMaskBufferSize = 256, at.glContext = new Array, at.frameBuffers = new Array, at.fTexture = new Array, at.IGNORE_CLIP = !1, at.IGNORE_EXPAND = !1, at.EXPAND_W = 2, at.USE_ADJUST_TRANSLATION = !0, at.USE_CANVAS_TRANSFORM = !0, at.USE_CACHED_POLYGON_IMAGE = !1, at.DEBUG_DATA = {}, at.PROFILE_IOS_SPEED = {
- PROFILE_NAME: "iOS Speed",
- USE_ADJUST_TRANSLATION: !0,
- USE_CACHED_POLYGON_IMAGE: !0,
- EXPAND_W: 4
- }, at.PROFILE_IOS_QUALITY = {
- PROFILE_NAME: "iOS HiQ",
- USE_ADJUST_TRANSLATION: !0,
- USE_CACHED_POLYGON_IMAGE: !1,
- EXPAND_W: 2
- }, at.PROFILE_IOS_DEFAULT = at.PROFILE_IOS_QUALITY, at.PROFILE_ANDROID = {
- PROFILE_NAME: "Android",
- USE_ADJUST_TRANSLATION: !1,
- USE_CACHED_POLYGON_IMAGE: !1,
- EXPAND_W: 2
- }, at.PROFILE_DESKTOP = {
- PROFILE_NAME: "Desktop",
- USE_ADJUST_TRANSLATION: !1,
- USE_CACHED_POLYGON_IMAGE: !1,
- EXPAND_W: 2
- }, at.initProfile = function() {
- Et.isIOS() ? at.setupProfile(at.PROFILE_IOS_DEFAULT) : Et.isAndroid() ? at.setupProfile(at.PROFILE_ANDROID) : at.setupProfile(at.PROFILE_DESKTOP)
- }, at.setupProfile = function(t, i) {
- if ("number" == typeof t) switch (t) {
- case 9901:
- t = at.PROFILE_IOS_SPEED;
- break;
- case 9902:
- t = at.PROFILE_IOS_QUALITY;
- break;
- case 9903:
- t = at.PROFILE_IOS_DEFAULT;
- break;
- case 9904:
- t = at.PROFILE_ANDROID;
- break;
- case 9905:
- t = at.PROFILE_DESKTOP;
- break;
- default:
- alert("profile _$6 _$Ui : " + t)
- }
- arguments.length < 2 && (i = !0), i && console.log("profile : " + t.PROFILE_NAME);
- for (var e in t) at[e] = t[e], i && console.log(" [" + e + "] = " + t[e])
- }, at.init = function() {
- if (at._$6b) {
- console.log("Live2D %s", at._$2s), at._$6b = !1;
- !0, at.initProfile()
- }
- }, at.getVersionStr = function() {
- return at._$2s
- }, at.getVersionNo = function() {
- return at._$Kr
- }, at._$sT = function(t) {
- at._$cT = t
- }, at.getError = function() {
- var t = at._$cT;
- return at._$cT = 0, t
- }, at.dispose = function() {
- at.glContext = [], at.frameBuffers = [], at.fTexture = []
- }, at.setGL = function(t, i) {
- var e = i || 0;
- at.glContext[e] = t
- }, at.getGL = function(t) {
- return at.glContext[t]
- }, at.setClippingMaskBufferSize = function(t) {
- at.clippingMaskBufferSize = t
- }, at.getClippingMaskBufferSize = function() {
- return at.clippingMaskBufferSize
- }, at.deleteBuffer = function(t) {
- at.getGL(t).deleteFramebuffer(at.frameBuffers[t].framebuffer), delete at.frameBuffers[t], delete at.glContext[t]
- }, ht._$r2 = function(t) {
- return t < 0 ? 0 : t > 1 ? 1 : .5 - .5 * Math.cos(t * Lt.PI_F)
- }, lt._$fr = -1, lt.prototype.toString = function() {
- return this._$ib
- }, $t.prototype = new W, $t._$42 = 0, $t._$Os = 30, $t._$ms = 0, $t._$ns = 1, $t._$_s = 2, $t._$gT = new Array, $t.prototype._$_S = function(t) {
- this._$LP = t
- }, $t.prototype.getTextureNo = function() {
- return this._$LP
- }, $t.prototype._$ZL = function() {
- return this._$Qi
- }, $t.prototype._$H2 = function() {
- return this._$JP
- }, $t.prototype.getNumPoints = function() {
- return this._$d0
- }, $t.prototype.getType = function() {
- return W._$wb
- }, $t.prototype._$B2 = function(t, i, e) {
- var r = i,
- o = null != r._$hr ? r._$hr : r._$Cr;
- switch (U._$do) {
- default:
- case U._$Ms:
- throw new Error("_$L _$ro ");
- case U._$Qs:
- for (var n = this._$d0 - 1; n >= 0; --n) o[n * U._$No + 4] = e
- }
- }, $t.prototype._$zP = function() {
- this._$GS = new D, this._$GS._$zP()
- }, $t.prototype._$F0 = function(t) {
- W.prototype._$F0.call(this, t), this._$LP = t._$6L(), this._$d0 = t._$6L(), this._$Yo = t._$6L();
- var i = t._$nP();
- this._$BP = new Int16Array(3 * this._$Yo);
- for (var e = 3 * this._$Yo - 1; e >= 0; --e) this._$BP[e] = i[e];
- if (this._$Eo = t._$nP(), this._$Qi = t._$nP(), t.getFormatVersion() >= G._$s7) {
- if (this._$JP = t._$6L(), 0 != this._$JP) {
- if (0 != (1 & this._$JP)) {
- var r = t._$6L();
- null == this._$5P && (this._$5P = new Object), this._$5P._$Hb = parseInt(r)
- }
- 0 != (this._$JP & $t._$Os) ? this._$6s = (this._$JP & $t._$Os) >> 1 : this._$6s = $t._$ms, 0 != (32 & this._$JP) && (this.culling = !1)
- }
- } else this._$JP = 0
- }, $t.prototype.init = function(t) {
- var i = new ut(this),
- e = this._$d0 * U._$No,
- r = this._$32();
- switch (null != i._$Cr && (i._$Cr = null), i._$Cr = new Float32Array(e), null != i._$hr && (i._$hr = null), i._$hr = r ? new Float32Array(e) : null, U._$do) {
- default:
- case U._$Ms:
- if (U._$Ls) for (var o = this._$d0 - 1; o >= 0; --o) {
- var n = o << 1;
- this._$Qi[n + 1] = 1 - this._$Qi[n + 1]
- }
- break;
- case U._$Qs:
- for (var o = this._$d0 - 1; o >= 0; --o) {
- var n = o << 1,
- s = o * U._$No,
- _ = this._$Qi[n],
- a = this._$Qi[n + 1];
- i._$Cr[s] = _, i._$Cr[s + 1] = a, i._$Cr[s + 4] = 0, r && (i._$hr[s] = _, i._$hr[s + 1] = a, i._$hr[s + 4] = 0)
- }
- }
- return i
- }, $t.prototype._$Nr = function(t, i) {
- var e = i;
- if (this != e._$GT() && console.log("### assert!! ### "), this._$GS._$Ur(t) && (W.prototype._$Nr.call(this, t, e), !e._$IS[0])) {
- var r = $t._$gT;
- r[0] = !1, v._$Vr(t, this._$GS, r, this._$d0, this._$Eo, e._$Cr, U._$i2, U._$No)
- }
- }, $t.prototype._$2b = function(t, i) {
- try {
- this != i._$GT() && console.log("### assert!! ### ");
- var e = !1;
- i._$IS[0] && (e = !0);
- var r = i;
- if (!e && (W.prototype._$2b.call(this, t), this._$32())) {
- var o = this.getTargetBaseDataID();
- if (r._$8r == W._$ur && (r._$8r = t.getBaseDataIndex(o)), r._$8r < 0) at._$so && _._$li("_$L _$0P _$G :: %s", o);
- else {
- var n = t.getBaseData(r._$8r),
- s = t._$q2(r._$8r);
- null == n || s._$x2() ? r._$AT = !1 : (n._$nb(t, s, r._$Cr, r._$hr, this._$d0, U._$i2, U._$No), r._$AT = !0), r.baseOpacity = s.getTotalOpacity()
- }
- }
- } catch (t) {
- throw t
- }
- }, $t.prototype.draw = function(t, i, e) {
- if (this != e._$GT() && console.log("### assert!! ### "), !e._$IS[0]) {
- var r = e,
- o = this._$LP;
- o < 0 && (o = 1);
- var n = this.getOpacity(i, r) * e._$VS * e.baseOpacity,
- s = null != r._$hr ? r._$hr : r._$Cr;
- t.setClipBufPre_clipContextForDraw(e.clipBufPre_clipContext), t._$WP(this.culling), t._$Uo(o, 3 * this._$Yo, this._$BP, s, this._$Qi, n, this._$6s, r)
- }
- }, $t.prototype.dump = function() {
- console.log(" _$yi( %d ) , _$d0( %d ) , _$Yo( %d ) \n", this._$LP, this._$d0, this._$Yo), console.log(" _$Oi _$di = { ");
- for (var t = 0; t < this._$BP.length; t++) console.log("%5d ,", this._$BP[t]);
- console.log("\n _$5i _$30");
- for (var t = 0; t < this._$Eo.length; t++) {
- console.log("\n _$30[%d] = ", t);
- for (var i = this._$Eo[t], e = 0; e < i.length; e++) console.log("%6.2f, ", i[e])
- }
- console.log("\n")
- }, $t.prototype._$72 = function(t) {
- return null == this._$5P ? null : this._$5P[t]
- }, $t.prototype.getIndexArray = function() {
- return this._$BP
- }, ut.prototype = new Mt, ut.prototype.getTransformedPoints = function() {
- return null != this._$hr ? this._$hr : this._$Cr
- }, pt.prototype._$HT = function(t) {
- this.x = t.x, this.y = t.y
- }, pt.prototype._$HT = function(t, i) {
- this.x = t, this.y = i
- }, ft.prototype = new i, ft.loadModel = function(t) {
- var e = new ft;
- return i._$62(e, t), e
- }, ft.loadModel = function(t, e) {
- var r = e || 0,
- o = new ft(r);
- return i._$62(o, t), o
- }, ft._$to = function() {
- return new ft
- }, ft._$er = function(t) {
- var i = new _$5("../_$_r/_$t0/_$Ri/_$_P._$d");
- if (0 == i.exists()) throw new _$ls("_$t0 _$_ _$6 _$Ui :: " + i._$PL());
- for (var e = ["../_$_r/_$t0/_$Ri/_$_P.512/_$CP._$1", "../_$_r/_$t0/_$Ri/_$_P.512/_$vP._$1", "../_$_r/_$t0/_$Ri/_$_P.512/_$EP._$1", "../_$_r/_$t0/_$Ri/_$_P.512/_$pP._$1"], r = ft.loadModel(i._$3b()), o = 0; o < e.length; o++) {
- var n = new _$5(e[o]);
- if (0 == n.exists()) throw new _$ls("_$t0 _$_ _$6 _$Ui :: " + n._$PL());
- r.setTexture(o, _$nL._$_o(t, n._$3b()))
- }
- return r
- }, ft.prototype.setGL = function(t) {
- at.setGL(t)
- }, ft.prototype.setTransform = function(t) {
- this.drawParamWebGL.setTransform(t)
- }, ft.prototype.update = function() {
- this._$5S.update(), this._$5S.preDraw(this.drawParamWebGL)
- }, ft.prototype.draw = function() {
- this._$5S.draw(this.drawParamWebGL)
- }, ft.prototype._$K2 = function() {
- this.drawParamWebGL._$K2()
- }, ft.prototype.setTexture = function(t, i) {
- null == this.drawParamWebGL && _._$li("_$Yi for QT _$ki / _$XS() is _$6 _$ui!!"), this.drawParamWebGL.setTexture(t, i)
- }, ft.prototype.setTexture = function(t, i) {
- null == this.drawParamWebGL && _._$li("_$Yi for QT _$ki / _$XS() is _$6 _$ui!!"), this.drawParamWebGL.setTexture(t, i)
- }, ft.prototype._$Rs = function() {
- return this.drawParamWebGL._$Rs()
- }, ft.prototype._$Ds = function(t) {
- this.drawParamWebGL._$Ds(t)
- }, ft.prototype.getDrawParam = function() {
- return this.drawParamWebGL
- }, ft.prototype.setMatrix = function(t) {
- this.drawParamWebGL.setMatrix(t)
- }, ft.prototype.setPremultipliedAlpha = function(t) {
- this.drawParamWebGL.setPremultipliedAlpha(t)
- }, ft.prototype.isPremultipliedAlpha = function() {
- return this.drawParamWebGL.isPremultipliedAlpha()
- }, ft.prototype.setAnisotropy = function(t) {
- this.drawParamWebGL.setAnisotropy(t)
- }, ft.prototype.getAnisotropy = function() {
- return this.drawParamWebGL.getAnisotropy()
- }, ct.prototype._$tb = function() {
- return this.motions
- }, ct.prototype.startMotion = function(t, i) {
- for (var e = null, r = this.motions.length, o = 0; o < r; ++o) null != (e = this.motions[o]) && (e._$qS(e._$w0.getFadeOut()), this._$eb && _._$Ji("MotionQueueManager[size:%2d]->startMotion() / start _$K _$3 (m%d)\n", r, e._$sr));
- if (null == t) return -1;
- e = new dt, e._$w0 = t, this.motions.push(e);
- var n = e._$sr;
- return this._$eb && _._$Ji("MotionQueueManager[size:%2d]->startMotion() / new _$w0 (m%d)\n", r, n), n
- }, ct.prototype.updateParam = function(t) {
- try {
- for (var i = !1, e = 0; e < this.motions.length; e++) {
- var r = this.motions[e];
- if (null != r) {
- var o = r._$w0;
- null != o ? (o.updateParam(t, r), i = !0, r.isFinished() && (this._$eb && _._$Ji("MotionQueueManager[size:%2d]->updateParam() / _$T0 _$w0 (m%d)\n", this.motions.length - 1, r._$sr), this.motions.splice(e, 1), e--)) : (this.motions = this.motions.splice(e, 1), e--)
- } else this.motions.splice(e, 1), e--
- }
- return i
- } catch (t) {
- return _._$li(t), !0
- }
- }, ct.prototype.isFinished = function(t) {
- if (arguments.length >= 1) {
- for (var i = 0; i < this.motions.length; i++) {
- var e = this.motions[i];
- if (null != e && (e._$sr == t && !e.isFinished())) return !1
- }
- return !0
- }
- for (var i = 0; i < this.motions.length; i++) {
- var e = this.motions[i];
- if (null != e) {
- if (null != e._$w0) {
- if (!e.isFinished()) return !1
- } else this.motions.splice(i, 1), i--
- } else this.motions.splice(i, 1), i--
- }
- return !0
- }, ct.prototype.stopAllMotions = function() {
- for (var t = 0; t < this.motions.length; t++) {
- var i = this.motions[t];
- if (null != i) {
- i._$w0;
- this.motions.splice(t, 1), t--
- } else this.motions.splice(t, 1), t--
- }
- }, ct.prototype._$Zr = function(t) {
- this._$eb = t
- }, ct.prototype._$e = function() {
- console.log("-- _$R --\n");
- for (var t = 0; t < this.motions.length; t++) {
- var i = this.motions[t],
- e = i._$w0;
- console.log("MotionQueueEnt[%d] :: %s\n", this.motions.length, e.toString())
- }
- }, dt._$Gs = 0, dt.prototype.isFinished = function() {
- return this._$9L
- }, dt.prototype._$qS = function(t) {
- var i = w.getUserTimeMSec(),
- e = i + t;
- (this._$Do < 0 || e < this._$Do) && (this._$Do = e)
- }, dt.prototype._$Bs = function() {
- return this._$sr
- }, gt.prototype.setContext = function(t) {
- var i = this.m;
- t.transform(i[0], i[1], i[3], i[4], i[6], i[7])
- }, gt.prototype.toString = function() {
- for (var t = "LDTransform { ", i = 0; i < 9; i++) t += this.m[i].toFixed(2) + " ,";
- return t += " }"
- }, gt.prototype.identity = function() {
- var t = this.m;
- t[0] = t[4] = t[8] = 1, t[1] = t[2] = t[3] = t[5] = t[6] = t[7] = 0
- }, gt.prototype._$PS = function(t, i, e) {
- null == e && (e = new Array(0, 0));
- var r = this.m;
- return e[0] = r[0] * t + r[3] * i + r[6], e[1] = r[1] * t + r[4] * i + r[7], e
- }, gt.prototype._$P2 = function(t) {
- t || (t = new gt);
- var i = this.m,
- e = i[0],
- r = i[1],
- o = i[2],
- n = i[3],
- s = i[4],
- _ = i[5],
- a = i[6],
- h = i[7],
- l = i[8],
- $ = e * s * l + r * _ * a + o * n * h - e * _ * h - o * s * a - r * n * l;
- if (0 == $) return null;
- var u = 1 / $;
- return t.m[0] = u * (s * l - h * _), t.m[1] = u * (h * o - r * l), t.m[2] = u * (r * _ - s * o), t.m[3] = u * (a * _ - n * l), t.m[4] = u * (e * l - a * o), t.m[5] = u * (n * o - e * _), t.m[6] = u * (n * h - a * s), t.m[7] = u * (a * r - e * h), t.m[8] = u * (e * s - n * r), t
- }, gt.prototype.transform = function(t, i, e) {
- null == e && (e = new Array(0, 0));
- var r = this.m;
- return e[0] = r[0] * t + r[3] * i + r[6], e[1] = r[1] * t + r[4] * i + r[7], e
- }, gt.prototype.translate = function(t, i) {
- var e = this.m;
- e[6] = e[0] * t + e[3] * i + e[6], e[7] = e[1] * t + e[4] * i + e[7], e[8] = e[2] * t + e[5] * i + e[8]
- }, gt.prototype.scale = function(t, i) {
- var e = this.m;
- e[0] *= t, e[1] *= t, e[2] *= t, e[3] *= i, e[4] *= i, e[5] *= i
- }, gt.prototype.shear = function(t, i) {
- var e = this.m,
- r = e[0] + e[3] * i,
- o = e[1] + e[4] * i,
- n = e[2] + e[5] * i;
- e[3] = e[0] * t + e[3], e[4] = e[1] * t + e[4], e[5] = e[2] * t + e[5], e[0] = r, e[1] = o, e[2] = n
- }, gt.prototype.rotate = function(t) {
- var i = this.m,
- e = Math.cos(t),
- r = Math.sin(t),
- o = i[0] * e + i[3] * r,
- n = i[1] * e + i[4] * r,
- s = i[2] * e + i[5] * r;
- i[3] = -i[0] * r + i[3] * e, i[4] = -i[1] * r + i[4] * e, i[5] = -i[2] * r + i[5] * e, i[0] = o, i[1] = n, i[2] = s
- }, gt.prototype.concatenate = function(t) {
- var i = this.m,
- e = t.m,
- r = i[0] * e[0] + i[3] * e[1] + i[6] * e[2],
- o = i[1] * e[0] + i[4] * e[1] + i[7] * e[2],
- n = i[2] * e[0] + i[5] * e[1] + i[8] * e[2],
- s = i[0] * e[3] + i[3] * e[4] + i[6] * e[5],
- _ = i[1] * e[3] + i[4] * e[4] + i[7] * e[5],
- a = i[2] * e[3] + i[5] * e[4] + i[8] * e[5],
- h = i[0] * e[6] + i[3] * e[7] + i[6] * e[8],
- l = i[1] * e[6] + i[4] * e[7] + i[7] * e[8],
- $ = i[2] * e[6] + i[5] * e[7] + i[8] * e[8];
- m[0] = r, m[1] = o, m[2] = n, m[3] = s, m[4] = _, m[5] = a, m[6] = h, m[7] = l, m[8] = $
- }, yt.prototype = new et, yt._$eT = null, yt._$tP = new Object, yt._$2o = function() {
- return null == yt._$eT && (yt._$eT = yt.getID("DST_BASE")), yt._$eT
- }, yt._$27 = function() {
- yt._$tP.clear(), yt._$eT = null
- }, yt.getID = function(t) {
- var i = yt._$tP[t];
- return null == i && (i = new yt(t), yt._$tP[t] = i), i
- }, yt.prototype._$3s = function() {
- return new yt
- }, mt.prototype = new E, mt._$9r = function(t) {
- return new Float32Array(t)
- }, mt._$vb = function(t) {
- return new Int16Array(t)
- }, mt._$cr = function(t, i) {
- return null == t || t._$yL() < i.length ? (t = mt._$9r(2 * i.length), t.put(i), t._$oT(0)) : (t.clear(), t.put(i), t._$oT(0)), t
- }, mt._$mb = function(t, i) {
- return null == t || t._$yL() < i.length ? (t = mt._$vb(2 * i.length), t.put(i), t._$oT(0)) : (t.clear(), t.put(i), t._$oT(0)), t
- }, mt._$Hs = function() {
- return this._$Gr
- }, mt._$as = function(t) {
- this._$Gr = t
- }, mt.prototype.getGL = function() {
- return this.gl
- }, mt.prototype.setGL = function(t) {
- this.gl = t
- }, mt.prototype.setTransform = function(t) {
- this.transform = t
- }, mt.prototype._$ZT = function() {
- var t = this.gl;
- this.firstDraw && (this.initShader(), this.firstDraw = !1, this.anisotropyExt = t.getExtension("EXT_texture_filter_anisotropic") || t.getExtension("WEBKIT_EXT_texture_filter_anisotropic") || t.getExtension("MOZ_EXT_texture_filter_anisotropic"), this.anisotropyExt && (this.maxAnisotropy = t.getParameter(this.anisotropyExt.MAX_TEXTURE_MAX_ANISOTROPY_EXT))), t.disable(t.SCISSOR_TEST), t.disable(t.STENCIL_TEST), t.disable(t.DEPTH_TEST), t.frontFace(t.CW), t.enable(t.BLEND), t.colorMask(1, 1, 1, 1), t.bindBuffer(t.ARRAY_BUFFER, null), t.bindBuffer(t.ELEMENT_ARRAY_BUFFER, null)
- }, mt.prototype._$Uo = function(t, i, e, r, o, n, s, _) {
- if (!(n < .01 && null == this.clipBufPre_clipContextMask)) {
- var a = (n > .9 && at.EXPAND_W, this.gl);
- if (null == this.gl) throw new Error("gl is null");
- var h = 1 * this._$C0 * n,
- l = 1 * this._$tT * n,
- $ = 1 * this._$WL * n,
- u = this._$lT * n;
- if (null != this.clipBufPre_clipContextMask) {
- a.frontFace(a.CCW), a.useProgram(this.shaderProgram), this._$vS = Tt(a, this._$vS, r), this._$no = Pt(a, this._$no, e), a.enableVertexAttribArray(this.a_position_Loc), a.vertexAttribPointer(this.a_position_Loc, 2, a.FLOAT, !1, 0, 0), this._$NT = Tt(a, this._$NT, o), a.activeTexture(a.TEXTURE1), a.bindTexture(a.TEXTURE_2D, this.textures[t]), a.uniform1i(this.s_texture0_Loc, 1), a.enableVertexAttribArray(this.a_texCoord_Loc), a.vertexAttribPointer(this.a_texCoord_Loc, 2, a.FLOAT, !1, 0, 0), a.uniformMatrix4fv(this.u_matrix_Loc, !1, this.getClipBufPre_clipContextMask().matrixForMask);
- var p = this.getClipBufPre_clipContextMask().layoutChannelNo,
- f = this.getChannelFlagAsColor(p);
- a.uniform4f(this.u_channelFlag, f.r, f.g, f.b, f.a);
- var c = this.getClipBufPre_clipContextMask().layoutBounds;
- a.uniform4f(this.u_baseColor_Loc, 2 * c.x - 1, 2 * c.y - 1, 2 * c._$EL() - 1, 2 * c._$5T() - 1), a.uniform1i(this.u_maskFlag_Loc, !0)
- } else if (null != this.getClipBufPre_clipContextDraw()) {
- a.useProgram(this.shaderProgramOff), this._$vS = Tt(a, this._$vS, r), this._$no = Pt(a, this._$no, e), a.enableVertexAttribArray(this.a_position_Loc_Off), a.vertexAttribPointer(this.a_position_Loc_Off, 2, a.FLOAT, !1, 0, 0), this._$NT = Tt(a, this._$NT, o), a.activeTexture(a.TEXTURE1), a.bindTexture(a.TEXTURE_2D, this.textures[t]), a.uniform1i(this.s_texture0_Loc_Off, 1), a.enableVertexAttribArray(this.a_texCoord_Loc_Off), a.vertexAttribPointer(this.a_texCoord_Loc_Off, 2, a.FLOAT, !1, 0, 0), a.uniformMatrix4fv(this.u_clipMatrix_Loc_Off, !1, this.getClipBufPre_clipContextDraw().matrixForDraw), a.uniformMatrix4fv(this.u_matrix_Loc_Off, !1, this.matrix4x4), a.activeTexture(a.TEXTURE2), a.bindTexture(a.TEXTURE_2D, at.fTexture[this.glno]), a.uniform1i(this.s_texture1_Loc_Off, 2);
- var p = this.getClipBufPre_clipContextDraw().layoutChannelNo,
- f = this.getChannelFlagAsColor(p);
- a.uniform4f(this.u_channelFlag_Loc_Off, f.r, f.g, f.b, f.a), a.uniform4f(this.u_baseColor_Loc_Off, h, l, $, u)
- } else a.useProgram(this.shaderProgram), this._$vS = Tt(a, this._$vS, r), this._$no = Pt(a, this._$no, e), a.enableVertexAttribArray(this.a_position_Loc), a.vertexAttribPointer(this.a_position_Loc, 2, a.FLOAT, !1, 0, 0), this._$NT = Tt(a, this._$NT, o), a.activeTexture(a.TEXTURE1), a.bindTexture(a.TEXTURE_2D, this.textures[t]), a.uniform1i(this.s_texture0_Loc, 1), a.enableVertexAttribArray(this.a_texCoord_Loc), a.vertexAttribPointer(this.a_texCoord_Loc, 2, a.FLOAT, !1, 0, 0), a.uniformMatrix4fv(this.u_matrix_Loc, !1, this.matrix4x4), a.uniform4f(this.u_baseColor_Loc, h, l, $, u), a.uniform1i(this.u_maskFlag_Loc, !1);
- this.culling ? this.gl.enable(a.CULL_FACE) : this.gl.disable(a.CULL_FACE), this.gl.enable(a.BLEND);
- var d, g, y, m;
- if (null != this.clipBufPre_clipContextMask) d = a.ONE, g = a.ONE_MINUS_SRC_ALPHA, y = a.ONE, m = a.ONE_MINUS_SRC_ALPHA;
- else switch (s) {
- case $t._$ms:
- d = a.ONE, g = a.ONE_MINUS_SRC_ALPHA, y = a.ONE, m = a.ONE_MINUS_SRC_ALPHA;
- break;
- case $t._$ns:
- d = a.ONE, g = a.ONE, y = a.ZERO, m = a.ONE;
- break;
- case $t._$_s:
- d = a.DST_COLOR, g = a.ONE_MINUS_SRC_ALPHA, y = a.ZERO, m = a.ONE
- }
- a.blendEquationSeparate(a.FUNC_ADD, a.FUNC_ADD), a.blendFuncSeparate(d, g, y, m), this.anisotropyExt && a.texParameteri(a.TEXTURE_2D, this.anisotropyExt.TEXTURE_MAX_ANISOTROPY_EXT, this.maxAnisotropy);
- var T = e.length;
- a.drawElements(a.TRIANGLES, T, a.UNSIGNED_SHORT, 0), a.bindTexture(a.TEXTURE_2D, null)
- }
- }, mt.prototype._$Rs = function() {
- throw new Error("_$Rs")
- }, mt.prototype._$Ds = function(t) {
- throw new Error("_$Ds")
- }, mt.prototype._$K2 = function() {
- for (var t = 0; t < this.textures.length; t++) {
- 0 != this.textures[t] && (this.gl._$K2(1, this.textures, t), this.textures[t] = null)
- }
- }, mt.prototype.setTexture = function(t, i) {
- this.textures[t] = i
- }, mt.prototype.initShader = function() {
- var t = this.gl;
- this.loadShaders2(), this.a_position_Loc = t.getAttribLocation(this.shaderProgram, "a_position"), this.a_texCoord_Loc = t.getAttribLocation(this.shaderProgram, "a_texCoord"), this.u_matrix_Loc = t.getUniformLocation(this.shaderProgram, "u_mvpMatrix"), this.s_texture0_Loc = t.getUniformLocation(this.shaderProgram, "s_texture0"), this.u_channelFlag = t.getUniformLocation(this.shaderProgram, "u_channelFlag"), this.u_baseColor_Loc = t.getUniformLocation(this.shaderProgram, "u_baseColor"), this.u_maskFlag_Loc = t.getUniformLocation(this.shaderProgram, "u_maskFlag"), this.a_position_Loc_Off = t.getAttribLocation(this.shaderProgramOff, "a_position"), this.a_texCoord_Loc_Off = t.getAttribLocation(this.shaderProgramOff, "a_texCoord"), this.u_matrix_Loc_Off = t.getUniformLocation(this.shaderProgramOff, "u_mvpMatrix"), this.u_clipMatrix_Loc_Off = t.getUniformLocation(this.shaderProgramOff, "u_ClipMatrix"), this.s_texture0_Loc_Off = t.getUniformLocation(this.shaderProgramOff, "s_texture0"), this.s_texture1_Loc_Off = t.getUniformLocation(this.shaderProgramOff, "s_texture1"), this.u_channelFlag_Loc_Off = t.getUniformLocation(this.shaderProgramOff, "u_channelFlag"), this.u_baseColor_Loc_Off = t.getUniformLocation(this.shaderProgramOff, "u_baseColor")
- }, mt.prototype.disposeShader = function() {
- var t = this.gl;
- this.shaderProgram && (t.deleteProgram(this.shaderProgram), this.shaderProgram = null), this.shaderProgramOff && (t.deleteProgram(this.shaderProgramOff), this.shaderProgramOff = null)
- }, mt.prototype.compileShader = function(t, i) {
- var e = this.gl,
- r = i,
- o = e.createShader(t);
- if (null == o) return _._$Ji("_$L0 to create shader"), null;
- if (e.shaderSource(o, r), e.compileShader(o), !e.getShaderParameter(o, e.COMPILE_STATUS)) {
- var n = e.getShaderInfoLog(o);
- return _._$Ji("_$L0 to compile shader : " + n), e.deleteShader(o), null
- }
- return o
- }, mt.prototype.loadShaders2 = function() {
- var t = this.gl;
- if (this.shaderProgram = t.createProgram(), !this.shaderProgram) return !1;
- if (this.shaderProgramOff = t.createProgram(), !this.shaderProgramOff) return !1;
- if (this.vertShader = this.compileShader(t.VERTEX_SHADER, "attribute vec4 a_position;attribute vec2 a_texCoord;varying vec2 v_texCoord;varying vec4 v_ClipPos;uniform mat4 u_mvpMatrix;void main(){ gl_Position = u_mvpMatrix * a_position; v_ClipPos = u_mvpMatrix * a_position; v_texCoord = a_texCoord;}"), !this.vertShader) return _._$Ji("Vertex shader compile _$li!"), !1;
- if (this.vertShaderOff = this.compileShader(t.VERTEX_SHADER, "attribute vec4 a_position;attribute vec2 a_texCoord;varying vec2 v_texCoord;varying vec4 v_ClipPos;uniform mat4 u_mvpMatrix;uniform mat4 u_ClipMatrix;void main(){ gl_Position = u_mvpMatrix * a_position; v_ClipPos = u_ClipMatrix * a_position; v_texCoord = a_texCoord ;}"), !this.vertShaderOff) return _._$Ji("OffVertex shader compile _$li!"), !1;
- if (this.fragShader = this.compileShader(t.FRAGMENT_SHADER, "precision mediump float;varying vec2 v_texCoord;varying vec4 v_ClipPos;uniform sampler2D s_texture0;uniform vec4 u_channelFlag;uniform vec4 u_baseColor;uniform bool u_maskFlag;void main(){ vec4 smpColor; if(u_maskFlag){ float isInside = step(u_baseColor.x, v_ClipPos.x/v_ClipPos.w) * step(u_baseColor.y, v_ClipPos.y/v_ClipPos.w) * step(v_ClipPos.x/v_ClipPos.w, u_baseColor.z) * step(v_ClipPos.y/v_ClipPos.w, u_baseColor.w); smpColor = u_channelFlag * texture2D(s_texture0 , v_texCoord).a * isInside; }else{ smpColor = texture2D(s_texture0 , v_texCoord) * u_baseColor; } gl_FragColor = smpColor;}"), !this.fragShader) return _._$Ji("Fragment shader compile _$li!"), !1;
- if (this.fragShaderOff = this.compileShader(t.FRAGMENT_SHADER, "precision mediump float ;varying vec2 v_texCoord;varying vec4 v_ClipPos;uniform sampler2D s_texture0;uniform sampler2D s_texture1;uniform vec4 u_channelFlag;uniform vec4 u_baseColor ;void main(){ vec4 col_formask = texture2D(s_texture0, v_texCoord) * u_baseColor; vec4 clipMask = texture2D(s_texture1, v_ClipPos.xy / v_ClipPos.w) * u_channelFlag; float maskVal = clipMask.r + clipMask.g + clipMask.b + clipMask.a; col_formask = col_formask * maskVal; gl_FragColor = col_formask;}"), !this.fragShaderOff) return _._$Ji("OffFragment shader compile _$li!"), !1;
- if (t.attachShader(this.shaderProgram, this.vertShader), t.attachShader(this.shaderProgram, this.fragShader), t.attachShader(this.shaderProgramOff, this.vertShaderOff), t.attachShader(this.shaderProgramOff, this.fragShaderOff), t.linkProgram(this.shaderProgram), t.linkProgram(this.shaderProgramOff), !t.getProgramParameter(this.shaderProgram, t.LINK_STATUS)) {
- var i = t.getProgramInfoLog(this.shaderProgram);
- return _._$Ji("_$L0 to link program: " + i), this.vertShader && (t.deleteShader(this.vertShader), this.vertShader = 0), this.fragShader && (t.deleteShader(this.fragShader), this.fragShader = 0), this.shaderProgram && (t.deleteProgram(this.shaderProgram), this.shaderProgram = 0), this.vertShaderOff && (t.deleteShader(this.vertShaderOff), this.vertShaderOff = 0), this.fragShaderOff && (t.deleteShader(this.fragShaderOff), this.fragShaderOff = 0), this.shaderProgramOff && (t.deleteProgram(this.shaderProgramOff), this.shaderProgramOff = 0), !1
- }
- return !0
- }, mt.prototype.createFramebuffer = function() {
- var t = this.gl,
- i = at.clippingMaskBufferSize,
- e = t.createFramebuffer();
- t.bindFramebuffer(t.FRAMEBUFFER, e);
- var r = t.createRenderbuffer();
- t.bindRenderbuffer(t.RENDERBUFFER, r), t.renderbufferStorage(t.RENDERBUFFER, t.RGBA4, i, i), t.framebufferRenderbuffer(t.FRAMEBUFFER, t.COLOR_ATTACHMENT0, t.RENDERBUFFER, r);
- var o = t.createTexture();
- return t.bindTexture(t.TEXTURE_2D, o), t.texImage2D(t.TEXTURE_2D, 0, t.RGBA, i, i, 0, t.RGBA, t.UNSIGNED_BYTE, null), t.texParameteri(t.TEXTURE_2D, t.TEXTURE_MIN_FILTER, t.LINEAR), t.texParameteri(t.TEXTURE_2D, t.TEXTURE_MAG_FILTER, t.LINEAR), t.texParameteri(t.TEXTURE_2D, t.TEXTURE_WRAP_S, t.CLAMP_TO_EDGE), t.texParameteri(t.TEXTURE_2D, t.TEXTURE_WRAP_T, t.CLAMP_TO_EDGE), t.framebufferTexture2D(t.FRAMEBUFFER, t.COLOR_ATTACHMENT0, t.TEXTURE_2D, o, 0), t.bindTexture(t.TEXTURE_2D, null), t.bindRenderbuffer(t.RENDERBUFFER, null), t.bindFramebuffer(t.FRAMEBUFFER, null), at.fTexture[this.glno] = o, {
- framebuffer: e,
- renderbuffer: r,
- texture: at.fTexture[this.glno]
- }
- }, St.prototype._$fP = function() {
- var t, i, e, r = this._$ST();
- if (0 == (128 & r)) return 255 & r;
- if (0 == (128 & (t = this._$ST()))) return (127 & r) << 7 | 127 & t;
- if (0 == (128 & (i = this._$ST()))) return (127 & r) << 14 | (127 & t) << 7 | 255 & i;
- if (0 == (128 & (e = this._$ST()))) return (127 & r) << 21 | (127 & t) << 14 | (127 & i) << 7 | 255 & e;
- throw new lt("_$L _$0P _")
- }, St.prototype.getFormatVersion = function() {
- return this._$S2
- }, St.prototype._$gr = function(t) {
- this._$S2 = t
- }, St.prototype._$3L = function() {
- return this._$fP()
- }, St.prototype._$mP = function() {
- return this._$zT(), this._$F += 8, this._$T.getFloat64(this._$F - 8)
- }, St.prototype._$_T = function() {
- return this._$zT(), this._$F += 4, this._$T.getFloat32(this._$F - 4)
- }, St.prototype._$6L = function() {
- return this._$zT(), this._$F += 4, this._$T.getInt32(this._$F - 4)
- }, St.prototype._$ST = function() {
- return this._$zT(), this._$T.getInt8(this._$F++)
- }, St.prototype._$9T = function() {
- return this._$zT(), this._$F += 2, this._$T.getInt16(this._$F - 2)
- }, St.prototype._$2T = function() {
- throw this._$zT(), this._$F += 8, new lt("_$L _$q read long")
- }, St.prototype._$po = function() {
- return this._$zT(), 0 != this._$T.getInt8(this._$F++)
- };
- var xt = !0;
- St.prototype._$bT = function() {
- this._$zT();
- var t = this._$3L(),
- i = null;
- if (xt) try {
- var e = new ArrayBuffer(2 * t);
- i = new Uint16Array(e);
- for (var r = 0; r < t; ++r) i[r] = this._$T.getUint8(this._$F++);
- return String.fromCharCode.apply(null, i)
- } catch (t) {
- xt = !1
- }
- try {
- var o = new Array;
- if (null == i) for (var r = 0; r < t; ++r) o[r] = this._$T.getUint8(this._$F++);
- else for (var r = 0; r < t; ++r) o[r] = i[r];
- return String.fromCharCode.apply(null, o)
- } catch (t) {
- console.log("read utf8 / _$rT _$L0 !! : " + t)
- }
- }, St.prototype._$cS = function() {
- this._$zT();
- for (var t = this._$3L(), i = new Int32Array(t), e = 0; e < t; e++) i[e] = this._$T.getInt32(this._$F), this._$F += 4;
- return i
- }, St.prototype._$Tb = function() {
- this._$zT();
- for (var t = this._$3L(), i = new Float32Array(t), e = 0; e < t; e++) i[e] = this._$T.getFloat32(this._$F), this._$F += 4;
- return i
- }, St.prototype._$5b = function() {
- this._$zT();
- for (var t = this._$3L(), i = new Float64Array(t), e = 0; e < t; e++) i[e] = this._$T.getFloat64(this._$F), this._$F += 8;
- return i
- }, St.prototype._$nP = function() {
- return this._$Jb(-1)
- }, St.prototype._$Jb = function(t) {
- if (this._$zT(), t < 0 && (t = this._$3L()), t == G._$7P) {
- var i = this._$6L();
- if (0 <= i && i < this._$Ko.length) return this._$Ko[i];
- throw new lt("_$sL _$4i @_$m0")
- }
- var e = this._$4b(t);
- return this._$Ko.push(e), e
- }, St.prototype._$4b = function(t) {
- if (0 == t) return null;
- if (50 == t) {
- var i = this._$bT(),
- e = b.getID(i);
- return e
- }
- if (51 == t) {
- var i = this._$bT(),
- e = yt.getID(i);
- return e
- }
- if (134 == t) {
- var i = this._$bT(),
- e = l.getID(i);
- return e
- }
- if (60 == t) {
- var i = this._$bT(),
- e = u.getID(i);
- return e
- }
- if (t >= 48) {
- var r = G._$9o(t);
- return null != r ? (r._$F0(this), r) : null
- }
- switch (t) {
- case 1:
- return this._$bT();
- case 10:
- return new n(this._$6L(), !0);
- case 11:
- return new S(this._$mP(), this._$mP(), this._$mP(), this._$mP());
- case 12:
- return new S(this._$_T(), this._$_T(), this._$_T(), this._$_T());
- case 13:
- return new L(this._$mP(), this._$mP());
- case 14:
- return new L(this._$_T(), this._$_T());
- case 15:
- for (var o = this._$3L(), e = new Array(o), s = 0; s < o; s++) e[s] = this._$nP();
- return e;
- case 17:
- var e = new F(this._$mP(), this._$mP(), this._$mP(), this._$mP(), this._$mP(), this._$mP());
- return e;
- case 21:
- return new h(this._$6L(), this._$6L(), this._$6L(), this._$6L());
- case 22:
- return new pt(this._$6L(), this._$6L());
- case 23:
- throw new Error("_$L _$ro ");
- case 16:
- case 25:
- return this._$cS();
- case 26:
- return this._$5b();
- case 27:
- return this._$Tb();
- case 2:
- case 3:
- case 4:
- case 5:
- case 6:
- case 7:
- case 8:
- case 9:
- case 18:
- case 19:
- case 20:
- case 24:
- case 28:
- throw new lt("_$6 _$q : _$nP() of 2-9 ,18,19,20,24,28 : " + t);
- default:
- throw new lt("_$6 _$q : _$nP() NO _$i : " + t)
- }
- }, St.prototype._$8L = function() {
- return 0 == this._$hL ? this._$v0 = this._$ST() : 8 == this._$hL && (this._$v0 = this._$ST(), this._$hL = 0), 1 == (this._$v0 >> 7 - this._$hL++ & 1)
- }, St.prototype._$zT = function() {
- 0 != this._$hL && (this._$hL = 0)
- }, vt.prototype._$wP = function(t, i, e) {
- for (var r = 0; r < e; r++) {
- for (var o = 0; o < i; o++) {
- var n = 2 * (o + r * i);
- console.log("(% 7.3f , % 7.3f) , ", t[n], t[n + 1])
- }
- console.log("\n")
- }
- console.log("\n")
- }, Lt._$2S = Math.PI / 180, Lt._$bS = Math.PI / 180, Lt._$wS = 180 / Math.PI, Lt._$NS = 180 / Math.PI, Lt.PI_F = Math.PI, Lt._$kT = [0, .012368, .024734, .037097, .049454, .061803, .074143, .086471, .098786, .111087, .12337, .135634, .147877, .160098, .172295, .184465, .196606, .208718, .220798, .232844, .244854, .256827, .268761, .280654, .292503, .304308, .316066, .327776, .339436, .351044, .362598, .374097, .385538, .396921, .408243, .419502, .430697, .441826, .452888, .463881, .474802, .485651, .496425, .507124, .517745, .528287, .538748, .549126, .559421, .56963, .579752, .589785, .599728, .609579, .619337, .629, .638567, .648036, .657406, .666676, .675843, .684908, .693867, .70272, .711466, .720103, .72863, .737045, .745348, .753536, .76161, .769566, .777405, .785125, .792725, .800204, .807561, .814793, .821901, .828884, .835739, .842467, .849066, .855535, .861873, .868079, .874153, .880093, .885898, .891567, .897101, .902497, .907754, .912873, .917853, .922692, .92739, .931946, .936359, .940629, .944755, .948737, .952574, .956265, .959809, .963207, .966457, .96956, .972514, .97532, .977976, .980482, .982839, .985045, .987101, .989006, .990759, .992361, .993811, .995109, .996254, .997248, .998088, .998776, .999312, .999694, .999924, 1], Lt._$92 = function(t, i) {
- var e = Math.atan2(t[1], t[0]),
- r = Math.atan2(i[1], i[0]);
- return Lt._$tS(e, r)
- }, Lt._$tS = function(t, i) {
- for (var e = t - i; e < -Math.PI;) e += 2 * Math.PI;
- for (; e > Math.PI;) e -= 2 * Math.PI;
- return e
- }, Lt._$9 = function(t) {
- return Math.sin(t)
- }, Lt.fcos = function(t) {
- return Math.cos(t)
- }, Mt.prototype._$u2 = function() {
- return this._$IS[0]
- }, Mt.prototype._$yo = function() {
- return this._$AT && !this._$IS[0]
- }, Mt.prototype._$GT = function() {
- return this._$e0
- }, Et._$W2 = 0, Et.SYSTEM_INFO = null, Et.USER_AGENT = navigator.userAgent, Et.isIPhone = function() {
- return Et.SYSTEM_INFO || Et.setup(), Et.SYSTEM_INFO._isIPhone
- }, Et.isIOS = function() {
- return Et.SYSTEM_INFO || Et.setup(), Et.SYSTEM_INFO._isIPhone || Et.SYSTEM_INFO._isIPad
- }, Et.isAndroid = function() {
- return Et.SYSTEM_INFO || Et.setup(), Et.SYSTEM_INFO._isAndroid
- }, Et.getOSVersion = function() {
- return Et.SYSTEM_INFO || Et.setup(), Et.SYSTEM_INFO.version
- }, Et.getOS = function() {
- return Et.SYSTEM_INFO || Et.setup(), Et.SYSTEM_INFO._isIPhone || Et.SYSTEM_INFO._isIPad ? "iOS" : Et.SYSTEM_INFO._isAndroid ? "Android" : "_$Q0 OS"
- }, Et.setup = function() {
- function t(t, i) {
- for (var e = t.substring(i).split(/[ _,;\.]/), r = 0, o = 0; o <= 2 && !isNaN(e[o]); o++) {
- var n = parseInt(e[o]);
- if (n < 0 || n > 999) {
- _._$li("err : " + n + " @UtHtml5.setup()"), r = 0;
- break
- }
- r += n * Math.pow(1e3, 2 - o)
- }
- return r
- }
- var i, e = Et.USER_AGENT,
- r = Et.SYSTEM_INFO = {
- userAgent: e
- };
- if ((i = e.indexOf("iPhone OS ")) >= 0) r.os = "iPhone", r._isIPhone = !0, r.version = t(e, i + "iPhone OS ".length);
- else if ((i = e.indexOf("iPad")) >= 0) {
- if ((i = e.indexOf("CPU OS")) < 0) return void _._$li(" err : " + e + " @UtHtml5.setup()");
- r.os = "iPad", r._isIPad = !0, r.version = t(e, i + "CPU OS ".length)
- } else(i = e.indexOf("Android")) >= 0 ? (r.os = "Android", r._isAndroid = !0, r.version = t(e, i + "Android ".length)) : (r.os = "-", r.version = -1)
- }, window.UtSystem = w, window.UtDebug = _, window.LDTransform = gt, window.LDGL = nt, window.Live2D = at, window.Live2DModelWebGL = ft, window.Live2DModelJS = q, window.Live2DMotion = J, window.MotionQueueManager = ct, window.PhysicsHair = f, window.AMotion = s, window.PartsDataID = l, window.DrawDataID = b, window.BaseDataID = yt, window.ParamID = u, at.init();
- var At = !1
- }()
- }).call(i, e(7))
-}, function(t, i) {
- t.exports = {
- import: function() {
- throw new Error("System.import cannot be used indirectly")
- }
- }
-}, function(t, i, e) {
- "use strict";
-
- function r(t) {
- return t && t.__esModule ? t : {
- default:
- t
- }
- }
- function o() {
- this.models = [], this.count = -1, this.reloadFlg = !1, Live2D.init(), n.Live2DFramework.setPlatformManager(new _.
- default)
- }
- Object.defineProperty(i, "__esModule", {
- value: !0
- }), i.
-default = o;
- var n = e(0),
- s = e(9),
- _ = r(s),
- a = e(10),
- h = r(a),
- l = e(1),
- $ = r(l);
- o.prototype.createModel = function() {
- var t = new h.
- default;
- return this.models.push(t), t
- }, o.prototype.changeModel = function(t, i) {
- if (this.reloadFlg) {
- this.reloadFlg = !1;
- this.releaseModel(0, t), this.createModel(), this.models[0].load(t, i)
- }
- }, o.prototype.getModel = function(t) {
- return t >= this.models.length ? null : this.models[t]
- }, o.prototype.releaseModel = function(t, i) {
- this.models.length <= t || (this.models[t].release(i), delete this.models[t], this.models.splice(t, 1))
- }, o.prototype.numModels = function() {
- return this.models.length
- }, o.prototype.setDrag = function(t, i) {
- for (var e = 0; e < this.models.length; e++) this.models[e].setDrag(t, i)
- }, o.prototype.maxScaleEvent = function() {
- $.
- default.DEBUG_LOG && console.log("Max scale event.");
- for (var t = 0; t < this.models.length; t++) this.models[t].startRandomMotion($.
- default.MOTION_GROUP_PINCH_IN, $.
- default.PRIORITY_NORMAL)
- }, o.prototype.minScaleEvent = function() {
- $.
- default.DEBUG_LOG && console.log("Min scale event.");
- for (var t = 0; t < this.models.length; t++) this.models[t].startRandomMotion($.
- default.MOTION_GROUP_PINCH_OUT, $.
- default.PRIORITY_NORMAL)
- }, o.prototype.tapEvent = function(t, i) {
- $.
- default.DEBUG_LOG && console.log("tapEvent view x:" + t + " y:" + i);
- for (var e = 0; e < this.models.length; e++) this.models[e].hitTest($.
- default.HIT_AREA_HEAD, t, i) ? ($.
- default.DEBUG_LOG && console.log("Tap face."), this.models[e].setRandomExpression()):
- this.models[e].hitTest($.
- default.HIT_AREA_BODY, t, i) ? ($.
- default.DEBUG_LOG && console.log("Tap body. models[" + e + "]"), this.models[e].startRandomMotion($.
- default.MOTION_GROUP_TAP_BODY, $.
- default.PRIORITY_NORMAL)) : this.models[e].hitTestCustom("head", t, i) ? ($.
- default.DEBUG_LOG && console.log("Tap face."), this.models[e].startRandomMotion($.
- default.MOTION_GROUP_FLICK_HEAD, $.
- default.PRIORITY_NORMAL)) : this.models[e].hitTestCustom("body", t, i) && ($.
- default.DEBUG_LOG && console.log("Tap body. models[" + e + "]"), this.models[e].startRandomMotion($.
- default.MOTION_GROUP_TAP_BODY, $.
- default.PRIORITY_NORMAL));
- return !0
- }
-}, function(t, i, e) {
- "use strict";
-
- function r() {}
- Object.defineProperty(i, "__esModule", {
- value: !0
- }), i.
-default = r;
- var o = e(2);
- var requestCache = {};
- r.prototype.loadBytes = function(t, i) {
- // Cache 相同的请求,减少请求数量
- if (requestCache[t] !== undefined) {
- i(requestCache[t]);
- return;
- }
- var e = new XMLHttpRequest;
- e.open("GET", t, !0), e.responseType = "arraybuffer", e.onload = function() {
- switch (e.status) {
- case 200:
- requestCache[t] = e.response;
- i(e.response);
- break;
- default:
- console.error("Failed to load (" + e.status + ") : " + t)
- }
- }, e.send(null)
- }, r.prototype.loadString = function(t) {
- this.loadBytes(t, function(t) {
- return t
- })
- }, r.prototype.loadLive2DModel = function(t, i) {
- var e = null;
- this.loadBytes(t, function(t) {
- e = Live2DModelWebGL.loadModel(t), i(e)
- })
- }, r.prototype.loadTexture = function(t, i, e, r) {
- var n = new Image;
- n.crossOrigin = "Anonymous", n.src = e;
- n.onload = function() {
- var e = (0, o.getContext)(),
- s = e.createTexture();
- if (!s) return console.error("Failed to generate gl texture name."), -1;
- 0 == t.isPremultipliedAlpha() && e.pixelStorei(e.UNPACK_PREMULTIPLY_ALPHA_WEBGL, 1), e.pixelStorei(e.UNPACK_FLIP_Y_WEBGL, 1), e.activeTexture(e.TEXTURE0), e.bindTexture(e.TEXTURE_2D, s), e.texImage2D(e.TEXTURE_2D, 0, e.RGBA, e.RGBA, e.UNSIGNED_BYTE, n), e.texParameteri(e.TEXTURE_2D, e.TEXTURE_MAG_FILTER, e.LINEAR), e.texParameteri(e.TEXTURE_2D, e.TEXTURE_MIN_FILTER, e.LINEAR_MIPMAP_NEAREST), e.generateMipmap(e.TEXTURE_2D), t.setTexture(i, s), s = null, "function" == typeof r && r()
- }, n.onerror = function() {
- console.error("Failed to load image : " + e)
- }
- }, r.prototype.jsonParseFromBytes = function(t) {
- var i, e = new Uint8Array(t, 0, 3);
- return i = 239 == e[0] && 187 == e[1] && 191 == e[2] ? String.fromCharCode.apply(null, new Uint8Array(t, 3)) : String.fromCharCode.apply(null, new Uint8Array(t)), JSON.parse(i)
- }, r.prototype.log = function(t) {}
-}, function(t, i, e) {
- "use strict";
-
- function r(t) {
- return t && t.__esModule ? t : {
- default:
- t
- }
- }
- function o() {
- n.L2DBaseModel.prototype.constructor.call(this), this.modelHomeDir = "", this.modelSetting = null, this.tmpMatrix = []
- }
- Object.defineProperty(i, "__esModule", {
- value: !0
- }), i.
-default = o;
- var n = e(0),
- s = e(11),
- _ = r(s),
- a = e(1),
- h = r(a),
- l = e(3),
- $ = r(l);
- o.prototype = new n.L2DBaseModel, o.prototype.load = function(t, i, e) {
- this.setUpdating(!0), this.setInitialized(!1), this.modelHomeDir = i.substring(0, i.lastIndexOf("/") + 1), this.modelSetting = new _.
- default;
- var r = this;
- this.modelSetting.loadModelSetting(i, function() {
- var t = r.modelHomeDir + r.modelSetting.getModelFile();
- r.loadModelData(t, function(t) {
- for (var i = 0; i < r.modelSetting.getTextureNum(); i++) {
- if (/^https?:\/\/|^\/\//i.test(r.modelSetting.getTextureFile(i))) var o = r.modelSetting.getTextureFile(i);
- else var o = r.modelHomeDir + r.modelSetting.getTextureFile(i);
- r.loadTexture(i, o, function() {
- if (r.isTexLoaded) {
- if (r.modelSetting.getExpressionNum() > 0) {
- r.expressions = {};
- for (var t = 0; t < r.modelSetting.getExpressionNum(); t++) {
- var i = r.modelSetting.getExpressionName(t),
- o = r.modelHomeDir + r.modelSetting.getExpressionFile(t);
- r.loadExpression(i, o)
- }
- } else r.expressionManager = null, r.expressions = {};
- if (r.eyeBlink, null != r.modelSetting.getPhysicsFile() ? r.loadPhysics(r.modelHomeDir + r.modelSetting.getPhysicsFile()) : r.physics = null, null != r.modelSetting.getPoseFile() ? r.loadPose(r.modelHomeDir + r.modelSetting.getPoseFile(), function() {
- r.pose.updateParam(r.live2DModel)
- }) : r.pose = null, null != r.modelSetting.getLayout()) {
- var n = r.modelSetting.getLayout();
- null != n.width && r.modelMatrix.setWidth(n.width), null != n.height && r.modelMatrix.setHeight(n.height), null != n.x && r.modelMatrix.setX(n.x), null != n.y && r.modelMatrix.setY(n.y), null != n.center_x && r.modelMatrix.centerX(n.center_x), null != n.center_y && r.modelMatrix.centerY(n.center_y), null != n.top && r.modelMatrix.top(n.top), null != n.bottom && r.modelMatrix.bottom(n.bottom), null != n.left && r.modelMatrix.left(n.left), null != n.right && r.modelMatrix.right(n.right)
- }
- if (null != r.modelSetting.getHitAreasCustom()) {
- var s = r.modelSetting.getHitAreasCustom();
- null != s.head_x && (h.
- default.hit_areas_custom_head_x = s.head_x), null != s.head_y && (h.
- default.hit_areas_custom_head_y = s.head_y), null != s.body_x && (h.
- default.hit_areas_custom_body_x = s.body_x), null != s.body_y && (h.
- default.hit_areas_custom_body_y = s.body_y)
- }
- for (var t = 0; t < r.modelSetting.getInitParamNum(); t++) r.live2DModel.setParamFloat(r.modelSetting.getInitParamID(t), r.modelSetting.getInitParamValue(t));
- for (var t = 0; t < r.modelSetting.getInitPartsVisibleNum(); t++) r.live2DModel.setPartsOpacity(r.modelSetting.getInitPartsVisibleID(t), r.modelSetting.getInitPartsVisibleValue(t));
- r.live2DModel.saveParam(), r.preloadMotionGroup(h.
- default.MOTION_GROUP_IDLE), r.preloadMotionGroup(h.
- default.MOTION_GROUP_SLEEPY), r.mainMotionManager.stopAllMotions(), r.setUpdating(!1), r.setInitialized(!0), "function" == typeof e && e()
- }
- })
- }
- })
- })
- }, o.prototype.release = function(t) {
- var i = n.Live2DFramework.getPlatformManager();
- t.deleteTexture(i.texture)
- }, o.prototype.preloadMotionGroup = function(t) {
- for (var i = this, e = 0; e < this.modelSetting.getMotionNum(t); e++) {
- var r = this.modelSetting.getMotionFile(t, e);
- this.loadMotion(r, this.modelHomeDir + r, function(r) {
- r.setFadeIn(i.modelSetting.getMotionFadeIn(t, e)), r.setFadeOut(i.modelSetting.getMotionFadeOut(t, e))
- })
- }
- }, o.prototype.update = function() {
- if (null == this.live2DModel) return void(h.
- default.DEBUG_LOG && console.error("Failed to update."));
- var t = UtSystem.getUserTimeMSec() - this.startTimeMSec,
- i = t / 1e3,
- e = 2 * i * Math.PI;
- if (this.mainMotionManager.isFinished()) {
- "1" === sessionStorage.getItem("Sleepy") ? this.startRandomMotion(h.
- default.MOTION_GROUP_SLEEPY, h.
- default.PRIORITY_SLEEPY) : this.startRandomMotion(h.
- default.MOTION_GROUP_IDLE, h.
- default.PRIORITY_IDLE)
- }
- this.live2DModel.loadParam(), this.mainMotionManager.updateParam(this.live2DModel) || null != this.eyeBlink && this.eyeBlink.updateParam(this.live2DModel), this.live2DModel.saveParam(), null == this.expressionManager || null == this.expressions || this.expressionManager.isFinished() || this.expressionManager.updateParam(this.live2DModel), this.live2DModel.addToParamFloat("PARAM_ANGLE_X", 30 * this.dragX, 1), this.live2DModel.addToParamFloat("PARAM_ANGLE_Y", 30 * this.dragY, 1), this.live2DModel.addToParamFloat("PARAM_ANGLE_Z", this.dragX * this.dragY * -30, 1), this.live2DModel.addToParamFloat("PARAM_BODY_ANGLE_X", 10 * this.dragX, 1), this.live2DModel.addToParamFloat("PARAM_EYE_BALL_X", this.dragX, 1), this.live2DModel.addToParamFloat("PARAM_EYE_BALL_Y", this.dragY, 1), this.live2DModel.addToParamFloat("PARAM_ANGLE_X", Number(15 * Math.sin(e / 6.5345)), .5), this.live2DModel.addToParamFloat("PARAM_ANGLE_Y", Number(8 * Math.sin(e / 3.5345)), .5), this.live2DModel.addToParamFloat("PARAM_ANGLE_Z", Number(10 * Math.sin(e / 5.5345)), .5), this.live2DModel.addToParamFloat("PARAM_BODY_ANGLE_X", Number(4 * Math.sin(e / 15.5345)), .5), this.live2DModel.setParamFloat("PARAM_BREATH", Number(.5 + .5 * Math.sin(e / 3.2345)), 1), null != this.physics && this.physics.updateParam(this.live2DModel), null == this.lipSync && this.live2DModel.setParamFloat("PARAM_MOUTH_OPEN_Y", this.lipSyncValue), null != this.pose && this.pose.updateParam(this.live2DModel), this.live2DModel.update()
- }, o.prototype.setRandomExpression = function() {
- var t = [];
- for (var i in this.expressions) t.push(i);
- var e = parseInt(Math.random() * t.length);
- this.setExpression(t[e])
- }, o.prototype.startRandomMotion = function(t, i) {
- var e = this.modelSetting.getMotionNum(t),
- r = parseInt(Math.random() * e);
- this.startMotion(t, r, i)
- }, o.prototype.startMotion = function(t, i, e) {
- var r = this.modelSetting.getMotionFile(t, i);
- if (null == r || "" == r) return void(h.
- default.DEBUG_LOG && console.error("Failed to motion."));
- if (e == h.
- default.PRIORITY_FORCE) this.mainMotionManager.setReservePriority(e);
- else if (!this.mainMotionManager.reserveMotion(e)) return void(h.
- default.DEBUG_LOG && console.log("Motion is running."));
- var o, n = this;
- null == this.motions[t] ? this.loadMotion(null, this.modelHomeDir + r, function(r) {
- o = r, n.setFadeInFadeOut(t, i, e, o)
- }) : (o = this.motions[t], n.setFadeInFadeOut(t, i, e, o))
- }, o.prototype.setFadeInFadeOut = function(t, i, e, r) {
- var o = this.modelSetting.getMotionFile(t, i);
- if (r.setFadeIn(this.modelSetting.getMotionFadeIn(t, i)), r.setFadeOut(this.modelSetting.getMotionFadeOut(t, i)), h.
- default.DEBUG_LOG && console.log("Start motion : " + o), null == this.modelSetting.getMotionSound(t, i)) this.mainMotionManager.startMotionPrio(r, e);
- else {
- var n = this.modelSetting.getMotionSound(t, i),
- s = document.createElement("audio");
- s.src = this.modelHomeDir + n, h.
- default.DEBUG_LOG && console.log("Start sound : " + n), s.play(), this.mainMotionManager.startMotionPrio(r, e)
- }
- }, o.prototype.setExpression = function(t) {
- var i = this.expressions[t];
- h.
- default.DEBUG_LOG && console.log("Expression : " + t), this.expressionManager.startMotion(i, !1)
- }, o.prototype.draw = function(t) {
- $.
- default.push(), $.
- default.multMatrix(this.modelMatrix.getArray()), this.tmpMatrix = $.
- default.getMatrix(), this.live2DModel.setMatrix(this.tmpMatrix), this.live2DModel.draw(), $.
- default.pop()
- }, o.prototype.hitTest = function(t, i, e) {
- for (var r = this.modelSetting.getHitAreaNum(), o = 0; o < r; o++) if (t == this.modelSetting.getHitAreaName(o)) {
- var n = this.modelSetting.getHitAreaID(o);
- return this.hitTestSimple(n, i, e)
- }
- return !1
- }, o.prototype.hitTestCustom = function(t, i, e) {
- return "head" == t ? this.hitTestSimpleCustom(h.
- default.hit_areas_custom_head_x, h.
- default.hit_areas_custom_head_y, i, e) : "body" == t && this.hitTestSimpleCustom(h.
- default.hit_areas_custom_body_x, h.
- default.hit_areas_custom_body_y, i, e)
- }
-}, function(t, i, e) {
- "use strict";
-
- function r() {
- this.NAME = "name", this.ID = "id", this.MODEL = "model", this.TEXTURES = "textures", this.HIT_AREAS = "hit_areas", this.PHYSICS = "physics", this.POSE = "pose", this.EXPRESSIONS = "expressions", this.MOTION_GROUPS = "motions", this.SOUND = "sound", this.FADE_IN = "fade_in", this.FADE_OUT = "fade_out", this.LAYOUT = "layout", this.HIT_AREAS_CUSTOM = "hit_areas_custom", this.INIT_PARAM = "init_param", this.INIT_PARTS_VISIBLE = "init_parts_visible", this.VALUE = "val", this.FILE = "file", this.json = {}
- }
- Object.defineProperty(i, "__esModule", {
- value: !0
- }), i.
-default = r;
- var o = e(0);
- r.prototype.loadModelSetting = function(t, i) {
- var e = this;
- o.Live2DFramework.getPlatformManager().loadBytes(t, function(t) {
- var r = String.fromCharCode.apply(null, new Uint8Array(t));
- e.json = JSON.parse(r), i()
- })
- }, r.prototype.getTextureFile = function(t) {
- return null == this.json[this.TEXTURES] || null == this.json[this.TEXTURES][t] ? null : this.json[this.TEXTURES][t]
- }, r.prototype.getModelFile = function() {
- return this.json[this.MODEL]
- }, r.prototype.getTextureNum = function() {
- return null == this.json[this.TEXTURES] ? 0 : this.json[this.TEXTURES].length
- }, r.prototype.getHitAreaNum = function() {
- return null == this.json[this.HIT_AREAS] ? 0 : this.json[this.HIT_AREAS].length
- }, r.prototype.getHitAreaID = function(t) {
- return null == this.json[this.HIT_AREAS] || null == this.json[this.HIT_AREAS][t] ? null : this.json[this.HIT_AREAS][t][this.ID]
- }, r.prototype.getHitAreaName = function(t) {
- return null == this.json[this.HIT_AREAS] || null == this.json[this.HIT_AREAS][t] ? null : this.json[this.HIT_AREAS][t][this.NAME]
- }, r.prototype.getPhysicsFile = function() {
- return this.json[this.PHYSICS]
- }, r.prototype.getPoseFile = function() {
- return this.json[this.POSE]
- }, r.prototype.getExpressionNum = function() {
- return null == this.json[this.EXPRESSIONS] ? 0 : this.json[this.EXPRESSIONS].length
- }, r.prototype.getExpressionFile = function(t) {
- return null == this.json[this.EXPRESSIONS] ? null : this.json[this.EXPRESSIONS][t][this.FILE]
- }, r.prototype.getExpressionName = function(t) {
- return null == this.json[this.EXPRESSIONS] ? null : this.json[this.EXPRESSIONS][t][this.NAME]
- }, r.prototype.getLayout = function() {
- return this.json[this.LAYOUT]
- }, r.prototype.getHitAreasCustom = function() {
- return this.json[this.HIT_AREAS_CUSTOM]
- }, r.prototype.getInitParamNum = function() {
- return null == this.json[this.INIT_PARAM] ? 0 : this.json[this.INIT_PARAM].length
- }, r.prototype.getMotionNum = function(t) {
- return null == this.json[this.MOTION_GROUPS] || null == this.json[this.MOTION_GROUPS][t] ? 0 : this.json[this.MOTION_GROUPS][t].length
- }, r.prototype.getMotionFile = function(t, i) {
- return null == this.json[this.MOTION_GROUPS] || null == this.json[this.MOTION_GROUPS][t] || null == this.json[this.MOTION_GROUPS][t][i] ? null : this.json[this.MOTION_GROUPS][t][i][this.FILE]
- }, r.prototype.getMotionSound = function(t, i) {
- return null == this.json[this.MOTION_GROUPS] || null == this.json[this.MOTION_GROUPS][t] || null == this.json[this.MOTION_GROUPS][t][i] || null == this.json[this.MOTION_GROUPS][t][i][this.SOUND] ? null : this.json[this.MOTION_GROUPS][t][i][this.SOUND]
- }, r.prototype.getMotionFadeIn = function(t, i) {
- return null == this.json[this.MOTION_GROUPS] || null == this.json[this.MOTION_GROUPS][t] || null == this.json[this.MOTION_GROUPS][t][i] || null == this.json[this.MOTION_GROUPS][t][i][this.FADE_IN] ? 1e3 : this.json[this.MOTION_GROUPS][t][i][this.FADE_IN]
- }, r.prototype.getMotionFadeOut = function(t, i) {
- return null == this.json[this.MOTION_GROUPS] || null == this.json[this.MOTION_GROUPS][t] || null == this.json[this.MOTION_GROUPS][t][i] || null == this.json[this.MOTION_GROUPS][t][i][this.FADE_OUT] ? 1e3 : this.json[this.MOTION_GROUPS][t][i][this.FADE_OUT]
- }, r.prototype.getInitParamID = function(t) {
- return null == this.json[this.INIT_PARAM] || null == this.json[this.INIT_PARAM][t] ? null : this.json[this.INIT_PARAM][t][this.ID]
- }, r.prototype.getInitParamValue = function(t) {
- return null == this.json[this.INIT_PARAM] || null == this.json[this.INIT_PARAM][t] ? NaN : this.json[this.INIT_PARAM][t][this.VALUE]
- }, r.prototype.getInitPartsVisibleNum = function() {
- return null == this.json[this.INIT_PARTS_VISIBLE] ? 0 : this.json[this.INIT_PARTS_VISIBLE].length
- }, r.prototype.getInitPartsVisibleID = function(t) {
- return null == this.json[this.INIT_PARTS_VISIBLE] || null == this.json[this.INIT_PARTS_VISIBLE][t] ? null : this.json[this.INIT_PARTS_VISIBLE][t][this.ID]
- }, r.prototype.getInitPartsVisibleValue = function(t) {
- return null == this.json[this.INIT_PARTS_VISIBLE] || null == this.json[this.INIT_PARTS_VISIBLE][t] ? NaN : this.json[this.INIT_PARTS_VISIBLE][t][this.VALUE]
- }
-}]);
-//# sourceMappingURL=live2d.js.map
diff --git a/docs/waifu_plugin/source b/docs/waifu_plugin/source
deleted file mode 100644
index 82d2ed01245d9ab6a6d70576398b96286b24790d..0000000000000000000000000000000000000000
--- a/docs/waifu_plugin/source
+++ /dev/null
@@ -1 +0,0 @@
-https://github.com/fghrsh/live2d_demo
diff --git a/docs/waifu_plugin/waifu-tips.js b/docs/waifu_plugin/waifu-tips.js
deleted file mode 100644
index 6ae98395a14239861fbc8250d190971e34590434..0000000000000000000000000000000000000000
--- a/docs/waifu_plugin/waifu-tips.js
+++ /dev/null
@@ -1,373 +0,0 @@
-window.live2d_settings = Array(); /*
-
- く__,.ヘヽ. / ,ー、 〉
- \ ', !-─‐-i / /´
- /`ー' L//`ヽ、 Live2D 看板娘 参数设置
- / /, /| , , ', Version 1.4.2
- イ / /-‐/ i L_ ハ ヽ! i Update 2018.11.12
- レ ヘ 7イ`ト レ'ァ-ト、!ハ| |
- !,/7 '0' ´0iソ| |
- |.从" _ ,,,, / |./ | 网页添加 Live2D 看板娘
- レ'| i>.、,,__ _,.イ / .i | https://www.fghrsh.net/post/123.html
- レ'| | / k_7_/レ'ヽ, ハ. |
- | |/i 〈|/ i ,.ヘ | i | Thanks
- .|/ / i: ヘ! \ | journey-ad / https://github.com/journey-ad/live2d_src
- kヽ>、ハ _,.ヘ、 /、! xiazeyu / https://github.com/xiazeyu/live2d-widget.js
- !'〈//`T´', \ `'7'ーr' Live2d Cubism SDK WebGL 2.1 Projrct & All model authors.
- レ'ヽL__|___i,___,ンレ|ノ
- ト-,/ |___./
- 'ー' !_,.:*********************************************************************************/
-
-
-// 后端接口
-live2d_settings['modelAPI'] = '//live2d.fghrsh.net/api/'; // 自建 API 修改这里
-live2d_settings['tipsMessage'] = 'waifu-tips.json'; // 同目录下可省略路径
-live2d_settings['hitokotoAPI'] = 'lwl12.com'; // 一言 API,可选 'lwl12.com', 'hitokoto.cn', 'jinrishici.com'(古诗词)
-
-// 默认模型
-live2d_settings['modelId'] = 1; // 默认模型 ID,可在 F12 控制台找到
-live2d_settings['modelTexturesId'] = 53; // 默认材质 ID,可在 F12 控制台找到
-
-// 工具栏设置
-live2d_settings['showToolMenu'] = true; // 显示 工具栏 ,可选 true(真), false(假)
-live2d_settings['canCloseLive2d'] = true; // 显示 关闭看板娘 按钮,可选 true(真), false(假)
-live2d_settings['canSwitchModel'] = true; // 显示 模型切换 按钮,可选 true(真), false(假)
-live2d_settings['canSwitchTextures'] = true; // 显示 材质切换 按钮,可选 true(真), false(假)
-live2d_settings['canSwitchHitokoto'] = true; // 显示 一言切换 按钮,可选 true(真), false(假)
-live2d_settings['canTakeScreenshot'] = true; // 显示 看板娘截图 按钮,可选 true(真), false(假)
-live2d_settings['canTurnToHomePage'] = true; // 显示 返回首页 按钮,可选 true(真), false(假)
-live2d_settings['canTurnToAboutPage'] = true; // 显示 跳转关于页 按钮,可选 true(真), false(假)
-
-// 模型切换模式
-live2d_settings['modelStorage'] = true; // 记录 ID (刷新后恢复),可选 true(真), false(假)
-live2d_settings['modelRandMode'] = 'switch'; // 模型切换,可选 'rand'(随机), 'switch'(顺序)
-live2d_settings['modelTexturesRandMode']= 'rand'; // 材质切换,可选 'rand'(随机), 'switch'(顺序)
-
-// 提示消息选项
-live2d_settings['showHitokoto'] = true; // 显示一言
-live2d_settings['showF12Status'] = true; // 显示加载状态
-live2d_settings['showF12Message'] = false; // 显示看板娘消息
-live2d_settings['showF12OpenMsg'] = true; // 显示控制台打开提示
-live2d_settings['showCopyMessage'] = true; // 显示 复制内容 提示
-live2d_settings['showWelcomeMessage'] = true; // 显示进入面页欢迎词
-
-//看板娘样式设置
-live2d_settings['waifuSize'] = '280x250'; // 看板娘大小,例如 '280x250', '600x535'
-live2d_settings['waifuTipsSize'] = '250x70'; // 提示框大小,例如 '250x70', '570x150'
-live2d_settings['waifuFontSize'] = '12px'; // 提示框字体,例如 '12px', '30px'
-live2d_settings['waifuToolFont'] = '14px'; // 工具栏字体,例如 '14px', '36px'
-live2d_settings['waifuToolLine'] = '20px'; // 工具栏行高,例如 '20px', '36px'
-live2d_settings['waifuToolTop'] = '0px' // 工具栏顶部边距,例如 '0px', '-60px'
-live2d_settings['waifuMinWidth'] = '768px'; // 面页小于 指定宽度 隐藏看板娘,例如 'disable'(禁用), '768px'
-live2d_settings['waifuEdgeSide'] = 'left:0'; // 看板娘贴边方向,例如 'left:0'(靠左 0px), 'right:30'(靠右 30px)
-live2d_settings['waifuDraggable'] = 'disable'; // 拖拽样式,例如 'disable'(禁用), 'axis-x'(只能水平拖拽), 'unlimited'(自由拖拽)
-live2d_settings['waifuDraggableRevert'] = true; // 松开鼠标还原拖拽位置,可选 true(真), false(假)
-
-// 其他杂项设置
-live2d_settings['l2dVersion'] = '1.4.2'; // 当前版本
-live2d_settings['l2dVerDate'] = '2018.11.12'; // 版本更新日期
-live2d_settings['homePageUrl'] = 'auto'; // 主页地址,可选 'auto'(自动), '{URL 网址}'
-live2d_settings['aboutPageUrl'] = 'https://www.fghrsh.net/post/123.html'; // 关于页地址, '{URL 网址}'
-live2d_settings['screenshotCaptureName']= 'live2d.png'; // 看板娘截图文件名,例如 'live2d.png'
-
-/****************************************************************************************************/
-
-String.prototype.render = function(context) {
- var tokenReg = /(\\)?\{([^\{\}\\]+)(\\)?\}/g;
-
- return this.replace(tokenReg, function (word, slash1, token, slash2) {
- if (slash1 || slash2) { return word.replace('\\', ''); }
-
- var variables = token.replace(/\s/g, '').split('.');
- var currentObject = context;
- var i, length, variable;
-
- for (i = 0, length = variables.length; i < length; ++i) {
- variable = variables[i];
- currentObject = currentObject[variable];
- if (currentObject === undefined || currentObject === null) return '';
- }
- return currentObject;
- });
-};
-
-var re = /x/;
-console.log(re);
-
-function empty(obj) {return typeof obj=="undefined"||obj==null||obj==""?true:false}
-function getRandText(text) {return Array.isArray(text) ? text[Math.floor(Math.random() * text.length + 1)-1] : text}
-
-function showMessage(text, timeout, flag) {
- if(flag || sessionStorage.getItem('waifu-text') === '' || sessionStorage.getItem('waifu-text') === null){
- if(Array.isArray(text)) text = text[Math.floor(Math.random() * text.length + 1)-1];
- if (live2d_settings.showF12Message) console.log('[Message]', text.replace(/<[^<>]+>/g,''));
-
- if(flag) sessionStorage.setItem('waifu-text', text);
-
- $('.waifu-tips').stop();
- $('.waifu-tips').html(text).fadeTo(200, 1);
- if (timeout === undefined) timeout = 5000;
- hideMessage(timeout);
- }
-}
-
-function hideMessage(timeout) {
- $('.waifu-tips').stop().css('opacity',1);
- if (timeout === undefined) timeout = 5000;
- window.setTimeout(function() {sessionStorage.removeItem('waifu-text')}, timeout);
- $('.waifu-tips').delay(timeout).fadeTo(200, 0);
-}
-
-function initModel(waifuPath, type) {
- /* console welcome message */
- eval(function(p,a,c,k,e,r){e=function(c){return(c
35?String.fromCharCode(c+29):c.toString(36))};if(!''.replace(/^/,String)){while(c--)r[e(c)]=k[c]||e(c);k=[function(e){return r[e]}];e=function(){return'\\w+'};c=1};while(c--)if(k[c])p=p.replace(new RegExp('\\b'+e(c)+'\\b','g'),k[c]);return p}('8.d(" ");8.d("\\U,.\\y\\5.\\1\\1\\1\\1/\\1,\\u\\2 \\H\\n\\1\\1\\1\\1\\1\\b \', !-\\r\\j-i\\1/\\1/\\g\\n\\1\\1\\1 \\1 \\a\\4\\f\'\\1\\1\\1 L/\\a\\4\\5\\2\\n\\1\\1 \\1 /\\1 \\a,\\1 /|\\1 ,\\1 ,\\1\\1\\1 \',\\n\\1\\1\\1\\q \\1/ /-\\j/\\1\\h\\E \\9 \\5!\\1 i\\n\\1\\1\\1 \\3 \\6 7\\q\\4\\c\\1 \\3\'\\s-\\c\\2!\\t|\\1 |\\n\\1\\1\\1\\1 !,/7 \'0\'\\1\\1 \\X\\w| \\1 |\\1\\1\\1\\n\\1\\1\\1\\1 |.\\x\\"\\1\\l\\1\\1 ,,,, / |./ \\1 |\\n\\1\\1\\1\\1 \\3\'| i\\z.\\2,,A\\l,.\\B / \\1.i \\1|\\n\\1\\1\\1\\1\\1 \\3\'| | / C\\D/\\3\'\\5,\\1\\9.\\1|\\n\\1\\1\\1\\1\\1\\1 | |/i \\m|/\\1 i\\1,.\\6 |\\F\\1|\\n\\1\\1\\1\\1\\1\\1.|/ /\\1\\h\\G \\1 \\6!\\1\\1\\b\\1|\\n\\1\\1\\1 \\1 \\1 k\\5>\\2\\9 \\1 o,.\\6\\2 \\1 /\\2!\\n\\1\\1\\1\\1\\1\\1 !\'\\m//\\4\\I\\g\', \\b \\4\'7\'\\J\'\\n\\1\\1\\1\\1\\1\\1 \\3\'\\K|M,p,\\O\\3|\\P\\n\\1\\1\\1\\1\\1 \\1\\1\\1\\c-,/\\1|p./\\n\\1\\1\\1\\1\\1 \\1\\1\\1\'\\f\'\\1\\1!o,.:\\Q \\R\\S\\T v"+e.V+" / W "+e.N);8.d(" ");',60,60,'|u3000|uff64|uff9a|uff40|u30fd|uff8d||console|uff8a|uff0f|uff3c|uff84|log|live2d_settings|uff70|u00b4|uff49||u2010||u3000_|u3008||_|___|uff72|u2500|uff67|u30cf|u30fc||u30bd|u4ece|u30d8|uff1e|__|u30a4|k_|uff17_|u3000L_|u3000i|uff1a|u3009|uff34|uff70r|u30fdL__||___i|l2dVerDate|u30f3|u30ce|nLive2D|u770b|u677f|u5a18|u304f__|l2dVersion|FGHRSH|u00b40i'.split('|'),0,{}));
-
- /* 判断 JQuery */
- if (typeof($.ajax) != 'function') typeof(jQuery.ajax) == 'function' ? window.$ = jQuery : console.log('[Error] JQuery is not defined.');
-
- /* 加载看板娘样式 */
- live2d_settings.waifuSize = live2d_settings.waifuSize.split('x');
- live2d_settings.waifuTipsSize = live2d_settings.waifuTipsSize.split('x');
- live2d_settings.waifuEdgeSide = live2d_settings.waifuEdgeSide.split(':');
-
- $("#live2d").attr("width",live2d_settings.waifuSize[0]);
- $("#live2d").attr("height",live2d_settings.waifuSize[1]);
- $(".waifu-tips").width(live2d_settings.waifuTipsSize[0]);
- $(".waifu-tips").height(live2d_settings.waifuTipsSize[1]);
- $(".waifu-tips").css("top",live2d_settings.waifuToolTop);
- $(".waifu-tips").css("font-size",live2d_settings.waifuFontSize);
- $(".waifu-tool").css("font-size",live2d_settings.waifuToolFont);
- $(".waifu-tool span").css("line-height",live2d_settings.waifuToolLine);
-
- if (live2d_settings.waifuEdgeSide[0] == 'left') $(".waifu").css("left",live2d_settings.waifuEdgeSide[1]+'px');
- else if (live2d_settings.waifuEdgeSide[0] == 'right') $(".waifu").css("right",live2d_settings.waifuEdgeSide[1]+'px');
-
- window.waifuResize = function() { $(window).width() <= Number(live2d_settings.waifuMinWidth.replace('px','')) ? $(".waifu").hide() : $(".waifu").show(); };
- if (live2d_settings.waifuMinWidth != 'disable') { waifuResize(); $(window).resize(function() {waifuResize()}); }
-
- try {
- if (live2d_settings.waifuDraggable == 'axis-x') $(".waifu").draggable({ axis: "x", revert: live2d_settings.waifuDraggableRevert });
- else if (live2d_settings.waifuDraggable == 'unlimited') $(".waifu").draggable({ revert: live2d_settings.waifuDraggableRevert });
- else $(".waifu").css("transition", 'all .3s ease-in-out');
- } catch(err) { console.log('[Error] JQuery UI is not defined.') }
-
- live2d_settings.homePageUrl = live2d_settings.homePageUrl == 'auto' ? window.location.protocol+'//'+window.location.hostname+'/' : live2d_settings.homePageUrl;
- if (window.location.protocol == 'file:' && live2d_settings.modelAPI.substr(0,2) == '//') live2d_settings.modelAPI = 'http:'+live2d_settings.modelAPI;
-
- $('.waifu-tool .fui-home').click(function (){
- //window.location = 'https://www.fghrsh.net/';
- window.location = live2d_settings.homePageUrl;
- });
-
- $('.waifu-tool .fui-info-circle').click(function (){
- //window.open('https://imjad.cn/archives/lab/add-dynamic-poster-girl-with-live2d-to-your-blog-02');
- window.open(live2d_settings.aboutPageUrl);
- });
-
- if (typeof(waifuPath) == "object") loadTipsMessage(waifuPath); else {
- $.ajax({
- cache: true,
- url: waifuPath == '' ? live2d_settings.tipsMessage : (waifuPath.substr(waifuPath.length-15)=='waifu-tips.json'?waifuPath:waifuPath+'waifu-tips.json'),
- dataType: "json",
- success: function (result){ loadTipsMessage(result); }
- });
- }
-
- if (!live2d_settings.showToolMenu) $('.waifu-tool').hide();
- if (!live2d_settings.canCloseLive2d) $('.waifu-tool .fui-cross').hide();
- if (!live2d_settings.canSwitchModel) $('.waifu-tool .fui-eye').hide();
- if (!live2d_settings.canSwitchTextures) $('.waifu-tool .fui-user').hide();
- if (!live2d_settings.canSwitchHitokoto) $('.waifu-tool .fui-chat').hide();
- if (!live2d_settings.canTakeScreenshot) $('.waifu-tool .fui-photo').hide();
- if (!live2d_settings.canTurnToHomePage) $('.waifu-tool .fui-home').hide();
- if (!live2d_settings.canTurnToAboutPage) $('.waifu-tool .fui-info-circle').hide();
-
- if (waifuPath === undefined) waifuPath = '';
- var modelId = localStorage.getItem('modelId');
- var modelTexturesId = localStorage.getItem('modelTexturesId');
-
- if (!live2d_settings.modelStorage || modelId == null) {
- var modelId = live2d_settings.modelId;
- var modelTexturesId = live2d_settings.modelTexturesId;
- } loadModel(modelId, modelTexturesId);
-}
-
-function loadModel(modelId, modelTexturesId=0) {
- if (live2d_settings.modelStorage) {
- localStorage.setItem('modelId', modelId);
- localStorage.setItem('modelTexturesId', modelTexturesId);
- } else {
- sessionStorage.setItem('modelId', modelId);
- sessionStorage.setItem('modelTexturesId', modelTexturesId);
- } loadlive2d('live2d', live2d_settings.modelAPI+'get/?id='+modelId+'-'+modelTexturesId, (live2d_settings.showF12Status ? console.log('[Status]','live2d','模型',modelId+'-'+modelTexturesId,'加载完成'):null));
-}
-
-function loadTipsMessage(result) {
- window.waifu_tips = result;
-
- $.each(result.mouseover, function (index, tips){
- $(document).on("mouseover", tips.selector, function (){
- var text = getRandText(tips.text);
- text = text.render({text: $(this).text()});
- showMessage(text, 3000);
- });
- });
- $.each(result.click, function (index, tips){
- $(document).on("click", tips.selector, function (){
- var text = getRandText(tips.text);
- text = text.render({text: $(this).text()});
- showMessage(text, 3000, true);
- });
- });
- $.each(result.seasons, function (index, tips){
- var now = new Date();
- var after = tips.date.split('-')[0];
- var before = tips.date.split('-')[1] || after;
-
- if((after.split('/')[0] <= now.getMonth()+1 && now.getMonth()+1 <= before.split('/')[0]) &&
- (after.split('/')[1] <= now.getDate() && now.getDate() <= before.split('/')[1])){
- var text = getRandText(tips.text);
- text = text.render({year: now.getFullYear()});
- showMessage(text, 6000, true);
- }
- });
-
- if (live2d_settings.showF12OpenMsg) {
- re.toString = function() {
- showMessage(getRandText(result.waifu.console_open_msg), 5000, true);
- return '';
- };
- }
-
- if (live2d_settings.showCopyMessage) {
- $(document).on('copy', function() {
- showMessage(getRandText(result.waifu.copy_message), 5000, true);
- });
- }
-
- $('.waifu-tool .fui-photo').click(function(){
- showMessage(getRandText(result.waifu.screenshot_message), 5000, true);
- window.Live2D.captureName = live2d_settings.screenshotCaptureName;
- window.Live2D.captureFrame = true;
- });
-
- $('.waifu-tool .fui-cross').click(function(){
- sessionStorage.setItem('waifu-dsiplay', 'none');
- showMessage(getRandText(result.waifu.hidden_message), 1300, true);
- window.setTimeout(function() {$('.waifu').hide();}, 1300);
- });
-
- window.showWelcomeMessage = function(result) {
- showMessage('欢迎使用GPT-Academic', 6000);
- }; if (live2d_settings.showWelcomeMessage) showWelcomeMessage(result);
-
- var waifu_tips = result.waifu;
-
- function loadOtherModel() {
- var modelId = modelStorageGetItem('modelId');
- var modelRandMode = live2d_settings.modelRandMode;
-
- $.ajax({
- cache: modelRandMode == 'switch' ? true : false,
- url: live2d_settings.modelAPI+modelRandMode+'/?id='+modelId,
- dataType: "json",
- success: function(result) {
- loadModel(result.model['id']);
- var message = result.model['message'];
- $.each(waifu_tips.model_message, function(i,val) {if (i==result.model['id']) message = getRandText(val)});
- showMessage(message, 3000, true);
- }
- });
- }
-
- function loadRandTextures() {
- var modelId = modelStorageGetItem('modelId');
- var modelTexturesId = modelStorageGetItem('modelTexturesId');
- var modelTexturesRandMode = live2d_settings.modelTexturesRandMode;
-
- $.ajax({
- cache: modelTexturesRandMode == 'switch' ? true : false,
- url: live2d_settings.modelAPI+modelTexturesRandMode+'_textures/?id='+modelId+'-'+modelTexturesId,
- dataType: "json",
- success: function(result) {
- if (result.textures['id'] == 1 && (modelTexturesId == 1 || modelTexturesId == 0))
- showMessage(waifu_tips.load_rand_textures[0], 3000, true);
- else showMessage(waifu_tips.load_rand_textures[1], 3000, true);
- loadModel(modelId, result.textures['id']);
- }
- });
- }
-
- function modelStorageGetItem(key) { return live2d_settings.modelStorage ? localStorage.getItem(key) : sessionStorage.getItem(key); }
-
- /* 检测用户活动状态,并在空闲时显示一言 */
- if (live2d_settings.showHitokoto) {
- window.getActed = false; window.hitokotoTimer = 0; window.hitokotoInterval = false;
- $(document).mousemove(function(e){getActed = true;}).keydown(function(){getActed = true;});
- setInterval(function(){ if (!getActed) ifActed(); else elseActed(); }, 1000);
- }
-
- function ifActed() {
- if (!hitokotoInterval) {
- hitokotoInterval = true;
- hitokotoTimer = window.setInterval(showHitokotoActed, 30000);
- }
- }
-
- function elseActed() {
- getActed = hitokotoInterval = false;
- window.clearInterval(hitokotoTimer);
- }
-
- function showHitokotoActed() {
- if ($(document)[0].visibilityState == 'visible') showHitokoto();
- }
-
- function showHitokoto() {
- switch(live2d_settings.hitokotoAPI) {
- case 'lwl12.com':
- $.getJSON('https://api.lwl12.com/hitokoto/v1?encode=realjson',function(result){
- if (!empty(result.source)) {
- var text = waifu_tips.hitokoto_api_message['lwl12.com'][0];
- if (!empty(result.author)) text += waifu_tips.hitokoto_api_message['lwl12.com'][1];
- text = text.render({source: result.source, creator: result.author});
- window.setTimeout(function() {showMessage(text+waifu_tips.hitokoto_api_message['lwl12.com'][2], 3000, true);}, 5000);
- } showMessage(result.text, 5000, true);
- });break;
- case 'fghrsh.net':
- $.getJSON('https://api.fghrsh.net/hitokoto/rand/?encode=jsc&uid=3335',function(result){
- if (!empty(result.source)) {
- var text = waifu_tips.hitokoto_api_message['fghrsh.net'][0];
- text = text.render({source: result.source, date: result.date});
- window.setTimeout(function() {showMessage(text, 3000, true);}, 5000);
- showMessage(result.hitokoto, 5000, true);
- }
- });break;
- case 'jinrishici.com':
- $.ajax({
- url: 'https://v2.jinrishici.com/one.json',
- xhrFields: {withCredentials: true},
- success: function (result, status) {
- if (!empty(result.data.origin.title)) {
- var text = waifu_tips.hitokoto_api_message['jinrishici.com'][0];
- text = text.render({title: result.data.origin.title, dynasty: result.data.origin.dynasty, author:result.data.origin.author});
- window.setTimeout(function() {showMessage(text, 3000, true);}, 5000);
- } showMessage(result.data.content, 5000, true);
- }
- });break;
- default:
- $.getJSON('https://v1.hitokoto.cn',function(result){
- if (!empty(result.from)) {
- var text = waifu_tips.hitokoto_api_message['hitokoto.cn'][0];
- text = text.render({source: result.from, creator: result.creator});
- window.setTimeout(function() {showMessage(text, 3000, true);}, 5000);
- }
- showMessage(result.hitokoto, 5000, true);
- });
- }
- }
-
- $('.waifu-tool .fui-eye').click(function (){loadOtherModel()});
- $('.waifu-tool .fui-user').click(function (){loadRandTextures()});
- $('.waifu-tool .fui-chat').click(function (){showHitokoto()});
-}
diff --git a/docs/waifu_plugin/waifu-tips.json b/docs/waifu_plugin/waifu-tips.json
deleted file mode 100644
index c7d84e3e6835a3d0926c3a4539bd223affd0265c..0000000000000000000000000000000000000000
--- a/docs/waifu_plugin/waifu-tips.json
+++ /dev/null
@@ -1,114 +0,0 @@
-{
- "waifu": {
- "console_open_msg": ["哈哈,你打开了控制台,是想要看看我的秘密吗?"],
- "copy_message": ["你都复制了些什么呀,转载要记得加上出处哦"],
- "screenshot_message": ["照好了嘛,是不是很可爱呢?"],
- "hidden_message": ["我们还能再见面的吧…"],
- "load_rand_textures": ["我还没有其他衣服呢", "我的新衣服好看嘛"],
- "hour_tips": {
- "t0-5": ["快睡觉去吧,年纪轻轻小心猝死哦"],
- "t5-7": ["早上好!一日之计在于晨,美好的一天就要开始了"],
- "t7-11": ["上午好!工作顺利嘛,不要久坐,多起来走动走动哦!"],
- "t11-14": ["中午了,工作了一个上午,现在是午餐时间!"],
- "t14-17": ["午后很容易犯困呢,今天的运动目标完成了吗?"],
- "t17-19": ["傍晚了!窗外夕阳的景色很美丽呢,最美不过夕阳红~"],
- "t19-21": ["晚上好,今天过得怎么样?"],
- "t21-23": ["已经这么晚了呀,早点休息吧,晚安~"],
- "t23-24": ["你是夜猫子呀?这么晚还不睡觉,明天起的来嘛"],
- "default": ["嗨~ 快来逗我玩吧!"]
- },
- "referrer_message": {
- "localhost": ["欢迎使用『ChatGPT", "』", " - "],
- "baidu": ["Hello! 来自 百度搜索 的朋友
你是搜索 ", " 找到的我吗?"],
- "so": ["Hello! 来自 360搜索 的朋友
你是搜索 ", " 找到的我吗?"],
- "google": ["Hello! 来自 谷歌搜索 的朋友
欢迎使用『ChatGPT", "』", " - "],
- "default": ["Hello! 来自 ", " 的朋友"],
- "none": ["欢迎使用『ChatGPT", "』", " - "]
- },
- "referrer_hostname": {
- "example.com": ["示例网站"],
- "www.fghrsh.net": ["FGHRSH 的博客"]
- },
- "model_message": {
- "1": ["来自 Potion Maker 的 Pio 酱 ~"],
- "2": ["来自 Potion Maker 的 Tia 酱 ~"]
- },
- "hitokoto_api_message": {
- "lwl12.com": ["这句一言来自 『{source}』", ",是 {creator} 投稿的", "。"],
- "fghrsh.net": ["这句一言出处是 『{source}』,是 FGHRSH 在 {date} 收藏的!"],
- "jinrishici.com": ["这句诗词出自 《{title}》,是 {dynasty}诗人 {author} 创作的!"],
- "hitokoto.cn": ["这句一言来自 『{source}』,是 {creator} 在 hitokoto.cn 投稿的。"]
- }
- },
- "mouseover": [
- { "selector": ".container a[href^='http']", "text": ["要看看 {text} 么?"] },
- { "selector": ".fui-home", "text": ["点击前往首页,想回到上一页可以使用浏览器的后退功能哦"] },
- { "selector": ".fui-chat", "text": ["一言一语,一颦一笑。一字一句,一颗赛艇。"] },
- { "selector": ".fui-eye", "text": ["嗯··· 要切换 看板娘 吗?"] },
- { "selector": ".fui-user", "text": ["喜欢换装 Play 吗?"] },
- { "selector": ".fui-photo", "text": ["要拍张纪念照片吗?"] },
- { "selector": ".fui-info-circle", "text": ["这里有关于我的信息呢"] },
- { "selector": ".fui-cross", "text": ["你不喜欢我了吗..."] },
- { "selector": "#tor_show", "text": ["翻页比较麻烦吗,点击可以显示这篇文章的目录呢"] },
- { "selector": "#comment_go", "text": ["想要去评论些什么吗?"] },
- { "selector": "#night_mode", "text": ["深夜时要爱护眼睛呀"] },
- { "selector": "#qrcode", "text": ["手机扫一下就能继续看,很方便呢"] },
- { "selector": ".comment_reply", "text": ["要吐槽些什么呢"] },
- { "selector": "#back-to-top", "text": ["回到开始的地方吧"] },
- { "selector": "#author", "text": ["该怎么称呼你呢"] },
- { "selector": "#mail", "text": ["留下你的邮箱,不然就是无头像人士了"] },
- { "selector": "#url", "text": ["你的家在哪里呢,好让我去参观参观"] },
- { "selector": "#textarea", "text": ["认真填写哦,垃圾评论是禁止事项"] },
- { "selector": ".OwO-logo", "text": ["要插入一个表情吗"] },
- { "selector": "#csubmit", "text": ["要[提交]^(Commit)了吗,首次评论需要审核,请耐心等待~"] },
- { "selector": ".ImageBox", "text": ["点击图片可以放大呢"] },
- { "selector": "input[name=s]", "text": ["找不到想看的内容?搜索看看吧"] },
- { "selector": ".previous", "text": ["去上一页看看吧"] },
- { "selector": ".next", "text": ["去下一页看看吧"] },
- { "selector": ".dropdown-toggle", "text": ["这里是菜单"] },
- { "selector": "c-player a.play-icon", "text": ["想要听点音乐吗"] },
- { "selector": "c-player div.time", "text": ["在这里可以调整播放进度呢"] },
- { "selector": "c-player div.volume", "text": ["在这里可以调整音量呢"] },
- { "selector": "c-player div.list-button", "text": ["播放列表里都有什么呢"] },
- { "selector": "c-player div.lyric-button", "text": ["有歌词的话就能跟着一起唱呢"] },
- { "selector": ".waifu #live2d", "text": [
- "别玩了,快去学习!",
- "偶尔放松下眼睛吧。",
- "看什么看(*^▽^*)",
- "焦虑时,吃顿大餐心情就好啦^_^",
- "你这个年纪,怎么睡得着觉的你^_^",
- "修改ADD_WAIFU=False,我就不再打扰你了~",
- "经常去github看看我们的更新吧,也许有好玩的新功能呢。",
- "试试本地大模型吧,有的也很强大的哦。",
- "很多强大的函数插件隐藏在下拉菜单中呢。",
- "红色的插件,使用之前需要把文件上传进去哦。",
- "想添加功能按钮吗?读读readme很容易就学会啦。",
- "敏感或机密的信息,不可以问AI的哦!",
- "LLM究竟是划时代的创新,还是扼杀创造力的毒药呢?"
- ] }
- ],
- "click": [
- {
- "selector": ".waifu #live2d",
- "text": [
- "是…是不小心碰到了吧",
- "再摸的话我可要报警了!⌇●﹏●⌇",
- "110吗,这里有个变态一直在摸我(ó﹏ò。)"
- ]
- }
- ],
- "seasons": [
- { "date": "01/01", "text": ["元旦了呢,新的一年又开始了,今年是{year}年~"] },
- { "date": "02/14", "text": ["又是一年情人节,{year}年找到对象了嘛~"] },
- { "date": "03/08", "text": ["今天是妇女节!"] },
- { "date": "03/12", "text": ["今天是植树节,要保护环境呀"] },
- { "date": "04/01", "text": ["悄悄告诉你一个秘密~今天是愚人节,不要被骗了哦~"] },
- { "date": "05/01", "text": ["今天是五一劳动节,计划好假期去哪里了吗~"] },
- { "date": "06/01", "text": ["儿童节了呢,快活的时光总是短暂,要是永远长不大该多好啊…"] },
- { "date": "09/03", "text": ["中国人民抗日战争胜利纪念日,铭记历史、缅怀先烈、珍爱和平、开创未来。"] },
- { "date": "09/10", "text": ["教师节,在学校要给老师问声好呀~"] },
- { "date": "10/01", "text": ["国庆节,新中国已经成立69年了呢"] },
- { "date": "11/05-11/12", "text": ["今年的双十一是和谁一起过的呢~"] },
- { "date": "12/20-12/31", "text": ["这几天是圣诞节,主人肯定又去剁手买买买了~"] }
- ]
-}
diff --git a/docs/waifu_plugin/waifu.css b/docs/waifu_plugin/waifu.css
deleted file mode 100644
index 0a50344d79a66972067476f308a1544968e00a40..0000000000000000000000000000000000000000
--- a/docs/waifu_plugin/waifu.css
+++ /dev/null
@@ -1,290 +0,0 @@
-.waifu {
- position: fixed;
- bottom: 0;
- z-index: 1;
- font-size: 0;
- -webkit-transform: translateY(3px);
- transform: translateY(3px);
-}
-.waifu:hover {
- -webkit-transform: translateY(0);
- transform: translateY(0);
-}
-.waifu-tips {
- opacity: 0;
- margin: -20px 20px;
- padding: 5px 10px;
- border: 1px solid rgba(224, 186, 140, 0.62);
- border-radius: 12px;
- background-color: rgba(236, 217, 188, 0.5);
- box-shadow: 0 3px 15px 2px rgba(191, 158, 118, 0.2);
- text-overflow: ellipsis;
- overflow: hidden;
- position: absolute;
- animation-delay: 5s;
- animation-duration: 50s;
- animation-iteration-count: infinite;
- animation-name: shake;
- animation-timing-function: ease-in-out;
-}
-.waifu-tool {
- display: none;
- color: #aaa;
- top: 50px;
- right: 10px;
- position: absolute;
-}
-.waifu:hover .waifu-tool {
- display: block;
-}
-.waifu-tool span {
- display: block;
- cursor: pointer;
- color: #5b6c7d;
- transition: 0.2s;
-}
-.waifu-tool span:hover {
- color: #34495e;
-}
-.waifu #live2d{
- position: relative;
-}
-
-@keyframes shake {
- 2% {
- transform: translate(0.5px, -1.5px) rotate(-0.5deg);
- }
-
- 4% {
- transform: translate(0.5px, 1.5px) rotate(1.5deg);
- }
-
- 6% {
- transform: translate(1.5px, 1.5px) rotate(1.5deg);
- }
-
- 8% {
- transform: translate(2.5px, 1.5px) rotate(0.5deg);
- }
-
- 10% {
- transform: translate(0.5px, 2.5px) rotate(0.5deg);
- }
-
- 12% {
- transform: translate(1.5px, 1.5px) rotate(0.5deg);
- }
-
- 14% {
- transform: translate(0.5px, 0.5px) rotate(0.5deg);
- }
-
- 16% {
- transform: translate(-1.5px, -0.5px) rotate(1.5deg);
- }
-
- 18% {
- transform: translate(0.5px, 0.5px) rotate(1.5deg);
- }
-
- 20% {
- transform: translate(2.5px, 2.5px) rotate(1.5deg);
- }
-
- 22% {
- transform: translate(0.5px, -1.5px) rotate(1.5deg);
- }
-
- 24% {
- transform: translate(-1.5px, 1.5px) rotate(-0.5deg);
- }
-
- 26% {
- transform: translate(1.5px, 0.5px) rotate(1.5deg);
- }
-
- 28% {
- transform: translate(-0.5px, -0.5px) rotate(-0.5deg);
- }
-
- 30% {
- transform: translate(1.5px, -0.5px) rotate(-0.5deg);
- }
-
- 32% {
- transform: translate(2.5px, -1.5px) rotate(1.5deg);
- }
-
- 34% {
- transform: translate(2.5px, 2.5px) rotate(-0.5deg);
- }
-
- 36% {
- transform: translate(0.5px, -1.5px) rotate(0.5deg);
- }
-
- 38% {
- transform: translate(2.5px, -0.5px) rotate(-0.5deg);
- }
-
- 40% {
- transform: translate(-0.5px, 2.5px) rotate(0.5deg);
- }
-
- 42% {
- transform: translate(-1.5px, 2.5px) rotate(0.5deg);
- }
-
- 44% {
- transform: translate(-1.5px, 1.5px) rotate(0.5deg);
- }
-
- 46% {
- transform: translate(1.5px, -0.5px) rotate(-0.5deg);
- }
-
- 48% {
- transform: translate(2.5px, -0.5px) rotate(0.5deg);
- }
-
- 50% {
- transform: translate(-1.5px, 1.5px) rotate(0.5deg);
- }
-
- 52% {
- transform: translate(-0.5px, 1.5px) rotate(0.5deg);
- }
-
- 54% {
- transform: translate(-1.5px, 1.5px) rotate(0.5deg);
- }
-
- 56% {
- transform: translate(0.5px, 2.5px) rotate(1.5deg);
- }
-
- 58% {
- transform: translate(2.5px, 2.5px) rotate(0.5deg);
- }
-
- 60% {
- transform: translate(2.5px, -1.5px) rotate(1.5deg);
- }
-
- 62% {
- transform: translate(-1.5px, 0.5px) rotate(1.5deg);
- }
-
- 64% {
- transform: translate(-1.5px, 1.5px) rotate(1.5deg);
- }
-
- 66% {
- transform: translate(0.5px, 2.5px) rotate(1.5deg);
- }
-
- 68% {
- transform: translate(2.5px, -1.5px) rotate(1.5deg);
- }
-
- 70% {
- transform: translate(2.5px, 2.5px) rotate(0.5deg);
- }
-
- 72% {
- transform: translate(-0.5px, -1.5px) rotate(1.5deg);
- }
-
- 74% {
- transform: translate(-1.5px, 2.5px) rotate(1.5deg);
- }
-
- 76% {
- transform: translate(-1.5px, 2.5px) rotate(1.5deg);
- }
-
- 78% {
- transform: translate(-1.5px, 2.5px) rotate(0.5deg);
- }
-
- 80% {
- transform: translate(-1.5px, 0.5px) rotate(-0.5deg);
- }
-
- 82% {
- transform: translate(-1.5px, 0.5px) rotate(-0.5deg);
- }
-
- 84% {
- transform: translate(-0.5px, 0.5px) rotate(1.5deg);
- }
-
- 86% {
- transform: translate(2.5px, 1.5px) rotate(0.5deg);
- }
-
- 88% {
- transform: translate(-1.5px, 0.5px) rotate(1.5deg);
- }
-
- 90% {
- transform: translate(-1.5px, -0.5px) rotate(-0.5deg);
- }
-
- 92% {
- transform: translate(-1.5px, -1.5px) rotate(1.5deg);
- }
-
- 94% {
- transform: translate(0.5px, 0.5px) rotate(-0.5deg);
- }
-
- 96% {
- transform: translate(2.5px, -0.5px) rotate(-0.5deg);
- }
-
- 98% {
- transform: translate(-1.5px, -1.5px) rotate(-0.5deg);
- }
-
- 0%, 100% {
- transform: translate(0, 0) rotate(0);
- }
-}
-@font-face {
- font-family: 'Flat-UI-Icons';
- src: url('flat-ui-icons-regular.eot');
- src: url('flat-ui-icons-regular.eot?#iefix') format('embedded-opentype'), url('flat-ui-icons-regular.woff') format('woff'), url('flat-ui-icons-regular.ttf') format('truetype'), url('flat-ui-icons-regular.svg#flat-ui-icons-regular') format('svg');
-}
-[class^="fui-"],
-[class*="fui-"] {
- font-family: 'Flat-UI-Icons';
- speak: none;
- font-style: normal;
- font-weight: normal;
- font-variant: normal;
- text-transform: none;
- -webkit-font-smoothing: antialiased;
- -moz-osx-font-smoothing: grayscale;
-}
-.fui-cross:before {
- content: "\e609";
-}
-.fui-info-circle:before {
- content: "\e60f";
-}
-.fui-photo:before {
- content: "\e62a";
-}
-.fui-eye:before {
- content: "\e62c";
-}
-.fui-chat:before {
- content: "\e62d";
-}
-.fui-home:before {
- content: "\e62e";
-}
-.fui-user:before {
- content: "\e631";
-}
diff --git a/flagged/modeling_moss.py b/flagged/modeling_moss.py
deleted file mode 100644
index f191bf532c0e1b769e773f932a35f099f782de44..0000000000000000000000000000000000000000
--- a/flagged/modeling_moss.py
+++ /dev/null
@@ -1,2952 +0,0 @@
-""" PyTorch Moss model."""
-
-from typing import Optional, Tuple, Union
-
-import torch
-import torch.utils.checkpoint
-from torch import nn
-from torch.nn import CrossEntropyLoss
-import transformers
-from transformers.activations import ACT2FN
-from transformers.modeling_utils import PreTrainedModel
-from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
-from transformers.utils import (
- add_code_sample_docstrings,
- add_start_docstrings,
- add_start_docstrings_to_model_forward,
- logging
-)
-
-from .configuration_moss import MossConfig
-
-logger = logging.get_logger(__name__)
-
-_CHECKPOINT_FOR_DOC = "fnlp/moss-moon-003-base"
-_CONFIG_FOR_DOC = "MossConfig"
-
-
-MOSS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "fnlp/moss-moon-003-base",
- "fnlp/moss-moon-003-sft",
- "fnlp/moss-moon-003-sft-plugin",
- "fnlp/moss-moon-003-sft-int4",
- "fnlp/moss-moon-003-sft-plugin-int4",
- "fnlp/moss-moon-003-sft-int8",
- "fnlp/moss-moon-003-sft-plugin-int8",
-]
-
-
-# Copied from transformers.models.gptj.modeling_gptj.create_sinusoidal_positions
-def create_sinusoidal_positions(num_pos: int, dim: int) -> torch.Tensor:
- inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2) / dim))
- sinusoid_inp = torch.einsum("i , j -> i j", torch.arange(num_pos, dtype=torch.float), inv_freq).float()
- return torch.cat((torch.sin(sinusoid_inp), torch.cos(sinusoid_inp)), dim=1)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.rotate_every_two
-def rotate_every_two(x: torch.Tensor) -> torch.Tensor:
- x1 = x[:, :, :, ::2]
- x2 = x[:, :, :, 1::2]
- x = torch.stack((-x2, x1), dim=-1)
- return x.flatten(-2) # in einsum notation: rearrange(x, '... d j -> ... (d j)')
-
-
-# Copied from transformers.models.gptj.modeling_gptj.apply_rotary_pos_emb
-def apply_rotary_pos_emb(tensor: torch.Tensor, sin: torch.Tensor, cos: torch.Tensor) -> torch.Tensor:
- sin = torch.repeat_interleave(sin[:, :, None, :], 2, 3)
- cos = torch.repeat_interleave(cos[:, :, None, :], 2, 3)
- return (tensor * cos) + (rotate_every_two(tensor) * sin)
-
-
-class MossAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
-
- max_positions = config.max_position_embeddings
- self.register_buffer(
- "causal_mask",
- torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(
- 1, 1, max_positions, max_positions
- ),
- )
-
- self.attn_dropout = nn.Dropout(config.attn_pdrop)
- self.resid_dropout = nn.Dropout(config.resid_pdrop)
-
- self.embed_dim = config.hidden_size
- self.num_attention_heads = config.num_attention_heads
- self.head_dim = self.embed_dim // self.num_attention_heads
- if self.head_dim * self.num_attention_heads != self.embed_dim:
- raise ValueError(
- f"embed_dim must be divisible by num_attention_heads (got `embed_dim`: {self.embed_dim} and"
- f" `num_attention_heads`: {self.num_attention_heads})."
- )
- self.scale_attn = torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32)).to(torch.get_default_dtype())
- self.qkv_proj = nn.Linear(self.embed_dim, self.embed_dim * 3, bias=False)
-
- self.out_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=False)
- self.rotary_dim = config.rotary_dim
- pos_embd_dim = self.rotary_dim or self.embed_dim
- self.embed_positions = create_sinusoidal_positions(max_positions, pos_embd_dim)
-
- def _split_heads(self, x, n_head, dim_head, mp_num):
- reshaped = x.reshape(x.shape[:-1] + (n_head // mp_num, dim_head))
- reshaped = reshaped.reshape(x.shape[:-2] + (-1,) + reshaped.shape[-1:])
- return reshaped
-
- def _merge_heads(self, tensor, num_attention_heads, attn_head_size):
- """
- Merges attn_head_size dim and num_attn_heads dim into n_ctx
- """
- if len(tensor.shape) == 5:
- tensor = tensor.permute(0, 1, 3, 2, 4).contiguous()
- elif len(tensor.shape) == 4:
- tensor = tensor.permute(0, 2, 1, 3).contiguous()
- else:
- raise ValueError(f"Input tensor rank should be one of [4, 5], but is: {len(tensor.shape)}")
- new_shape = tensor.size()[:-2] + (num_attention_heads * attn_head_size,)
- return tensor.view(new_shape)
-
- def _attn(
- self,
- query,
- key,
- value,
- attention_mask=None,
- head_mask=None,
- ):
- # compute causal mask from causal mask buffer
- query_length, key_length = query.size(-2), key.size(-2)
- causal_mask = self.causal_mask[:, :, key_length - query_length : key_length, :key_length]
-
- # Keep the attention weights computation in fp32 to avoid overflow issues
- query = query.to(torch.float32)
- key = key.to(torch.float32)
-
- attn_weights = torch.matmul(query, key.transpose(-1, -2))
-
- attn_weights = attn_weights / self.scale_attn
- mask_value = torch.finfo(attn_weights.dtype).min
- # Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
- # Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
- mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
- attn_weights = torch.where(causal_mask, attn_weights, mask_value)
-
- if attention_mask is not None:
- # Apply the attention mask
- attn_weights = attn_weights + attention_mask
-
- attn_weights = nn.Softmax(dim=-1)(attn_weights)
- attn_weights = attn_weights.to(value.dtype)
- attn_weights = self.attn_dropout(attn_weights)
-
- # Mask heads if we want to
- if head_mask is not None:
- attn_weights = attn_weights * head_mask
-
- attn_output = torch.matmul(attn_weights, value)
-
- return attn_output, attn_weights
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[
- Tuple[torch.Tensor, Tuple[torch.Tensor]],
- Optional[Tuple[torch.Tensor, Tuple[torch.Tensor], Tuple[torch.Tensor, ...]]],
- ]:
- qkv = self.qkv_proj(hidden_states)
- # TODO(enijkamp): factor out number of logical TPU-v4 cores or make forward pass agnostic
- mp_num = 4
- qkv_split = qkv.reshape(qkv.shape[:-1] + (mp_num, -1))
-
- local_dim = self.head_dim * self.num_attention_heads // mp_num
- query, value, key = torch.split(qkv_split, local_dim, dim=-1)
- query = self._split_heads(query, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- key = self._split_heads(key, self.num_attention_heads, self.head_dim, mp_num=mp_num)
-
- value = self._split_heads(value, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- value = value.permute(0, 2, 1, 3)
-
- embed_positions = self.embed_positions
- if embed_positions.device != position_ids.device:
- embed_positions = embed_positions.to(position_ids.device)
- self.embed_positions = embed_positions
-
- sincos = embed_positions[position_ids]
- sin, cos = torch.split(sincos, sincos.shape[-1] // 2, dim=-1)
-
- if self.rotary_dim is not None:
- k_rot = key[:, :, :, : self.rotary_dim]
- k_pass = key[:, :, :, self.rotary_dim :]
-
- q_rot = query[:, :, :, : self.rotary_dim]
- q_pass = query[:, :, :, self.rotary_dim :]
-
- k_rot = apply_rotary_pos_emb(k_rot, sin, cos)
- q_rot = apply_rotary_pos_emb(q_rot, sin, cos)
-
- key = torch.cat([k_rot, k_pass], dim=-1)
- query = torch.cat([q_rot, q_pass], dim=-1)
- else:
- key = apply_rotary_pos_emb(key, sin, cos)
- query = apply_rotary_pos_emb(query, sin, cos)
-
- key = key.permute(0, 2, 1, 3)
- query = query.permute(0, 2, 1, 3)
-
- if layer_past is not None:
- past_key = layer_past[0]
- past_value = layer_past[1]
- key = torch.cat((past_key, key), dim=-2)
- value = torch.cat((past_value, value), dim=-2)
-
- if use_cache is True:
- present = (key, value)
- else:
- present = None
-
- # compute self-attention: V x Softmax(QK^T)
- attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
-
- attn_output = self._merge_heads(attn_output, self.num_attention_heads, self.head_dim)
- attn_output = self.out_proj(attn_output)
- attn_output = self.resid_dropout(attn_output)
-
- outputs = (attn_output, present)
- if output_attentions:
- outputs += (attn_weights,)
-
- return outputs # a, present, (attentions)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJMLP with GPTJ->Moss
-class MossMLP(nn.Module):
- def __init__(self, intermediate_size, config): # in MLP: intermediate_size= 4 * embed_dim
- super().__init__()
- embed_dim = config.n_embd
-
- self.fc_in = nn.Linear(embed_dim, intermediate_size)
- self.fc_out = nn.Linear(intermediate_size, embed_dim)
-
- self.act = ACT2FN[config.activation_function]
- self.dropout = nn.Dropout(config.resid_pdrop)
-
- def forward(self, hidden_states: Optional[torch.FloatTensor]) -> torch.FloatTensor:
- hidden_states = self.fc_in(hidden_states)
- hidden_states = self.act(hidden_states)
- hidden_states = self.fc_out(hidden_states)
- hidden_states = self.dropout(hidden_states)
- return hidden_states
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJBlock with GPTJ->Moss
-class MossBlock(nn.Module):
- def __init__(self, config):
- super().__init__()
- inner_dim = config.n_inner if config.n_inner is not None else 4 * config.n_embd
- self.ln_1 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
- self.attn = MossAttention(config)
- self.mlp = MossMLP(inner_dim, config)
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[Tuple[torch.Tensor], Optional[Tuple[torch.Tensor, Tuple[torch.FloatTensor, ...]]]]:
- residual = hidden_states
- hidden_states = self.ln_1(hidden_states)
- attn_outputs = self.attn(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
- attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
- outputs = attn_outputs[1:]
-
- feed_forward_hidden_states = self.mlp(hidden_states)
- hidden_states = attn_output + feed_forward_hidden_states + residual
-
- if use_cache:
- outputs = (hidden_states,) + outputs
- else:
- outputs = (hidden_states,) + outputs[1:]
-
- return outputs # hidden_states, present, (attentions)
-
-
-class MossPreTrainedModel(PreTrainedModel):
- """
- An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
- models.
- """
-
- config_class = MossConfig
- base_model_prefix = "transformer"
- supports_gradient_checkpointing = True
- _no_split_modules = ["MossBlock"]
-
- def __init__(self, *inputs, **kwargs):
- super().__init__(*inputs, **kwargs)
-
- def _init_weights(self, module):
- """Initialize the weights."""
- if isinstance(module, (nn.Linear,)):
- # Slightly different from Mesh Transformer JAX which uses truncated_normal for initialization
- # cf https://github.com/pytorch/pytorch/pull/5617
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def _set_gradient_checkpointing(self, module, value=False):
- if isinstance(module, MossModel):
- module.gradient_checkpointing = value
-
-
-MOSS_START_DOCSTRING = r"""
- This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
- it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
- behavior.
-
- Parameters:
- config ([`MossConfig`]): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the
- configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
-"""
-
-MOSS_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (`torch.LongTensor` of shape `({0})`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using [`AutoProcenizer`]. See [`PreTrainedTokenizer.encode`] and
- [`PreTrainedTokenizer.__call__`] for details.
-
- [What are input IDs?](../glossary#input-ids)
- attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
- Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
-
- - 1 for tokens that are **not masked**,
- - 0 for tokens that are **masked**.
-
- [What are attention masks?](../glossary#attention-mask)
- token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
- 1]`:
-
- - 0 corresponds to a *sentence A* token,
- - 1 corresponds to a *sentence B* token.
-
- [What are token type IDs?](../glossary#token-type-ids)
- position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
- config.n_positions - 1]`.
-
- [What are position IDs?](../glossary#position-ids)
- head_mask (`torch.FloatTensor` of shape `(num_attention_heads,)` or `(n_layer, num_attention_heads)`, *optional*):
- Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
-
- - 1 indicates the head is **not masked**,
- - 0 indicates the head is **masked**.
-
- inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_dim)`, *optional*):
- Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
- is useful if you want more control over how to convert *input_ids* indices into associated vectors than the
- model's internal embedding lookup matrix.
- output_attentions (`bool`, *optional*):
- Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
- tensors for more detail.
- output_hidden_states (`bool`, *optional*):
- Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
- more detail.
- return_dict (`bool`, *optional*):
- Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
-"""
-
-
-@add_start_docstrings(
- "The bare Moss Model transformer outputting raw hidden-states without any specific head on top.",
- MOSS_START_DOCSTRING,
-)
-class MossModel(MossPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
-
- self.embed_dim = config.n_embd
- self.vocab_size = config.vocab_size
- self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
- self.drop = nn.Dropout(config.embd_pdrop)
- self.h = nn.ModuleList([MossBlock(config) for _ in range(config.n_layer)])
- self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
- self.rotary_dim = min(config.rotary_dim, config.n_ctx // config.num_attention_heads)
-
- self.gradient_checkpointing = False
-
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_input_embeddings(self):
- return self.wte
-
- def set_input_embeddings(self, new_embeddings):
- self.wte = new_embeddings
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=BaseModelOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, BaseModelOutputWithPast]:
- output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
-
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
-
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1]).long()
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if position_ids is None:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- # Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x num_attention_heads x N x N
- # head_mask has shape n_layer x batch x num_attention_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
-
- hidden_states = inputs_embeds
-
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
-
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
- "`use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_hidden_states = () if output_hidden_states else None
- for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- position_ids,
- head_mask[i],
- )
- else:
- outputs = block(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask[i],
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
-
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if not return_dict:
- return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
-
- return BaseModelOutputWithPast(
- last_hidden_state=hidden_states,
- past_key_values=presents,
- hidden_states=all_hidden_states,
- attentions=all_self_attentions,
- )
-
-
-@add_start_docstrings(
- """
- The Moss Model transformer with a language modeling head on top.
- """,
- MOSS_START_DOCSTRING,
-)
-class MossForCausalLM(MossPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.causal_mask"]
-
- def __init__(self, config):
- super().__init__(config)
- if not hasattr(config, 'wbits'):
- config.wbits = 32
- config.groupsize = 128
-
- if config.wbits not in [4, 8, 32]:
- logger.warning(f'Specify `wbits` with 4, 8 or 32 to load the model. ')
- if config.wbits in [4, 8]:
- def noop(*args, **kwargs):
- pass
- torch.nn.init.kaiming_uniform_ = noop
- torch.nn.init.uniform_ = noop
- torch.nn.init.normal_ = noop
-
- torch.set_default_dtype(torch.half)
- transformers.modeling_utils._init_weights = False
- torch.set_default_dtype(torch.half)
- self.transformer = MossModel(config)
- self.lm_head = nn.Linear(config.n_embd, config.vocab_size)
- if config.wbits in [4, 8]:
- torch.set_default_dtype(torch.float)
- transformers.modeling_utils._init_weights = True
- self.quantize(config.wbits, config.groupsize)
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_output_embeddings(self):
- return self.lm_head
-
- def set_output_embeddings(self, new_embeddings):
- self.lm_head = new_embeddings
-
- def prepare_inputs_for_generation(self, input_ids, past_key_values=None, **kwargs):
- token_type_ids = kwargs.get("token_type_ids", None)
- # only last token for inputs_ids if past is defined in kwargs
- if past_key_values:
- input_ids = input_ids[:, -1].unsqueeze(-1)
- if token_type_ids is not None:
- token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
-
- attention_mask = kwargs.get("attention_mask", None)
- position_ids = kwargs.get("position_ids", None)
-
- if attention_mask is not None and position_ids is None:
- # create position_ids on the fly for batch generation
- position_ids = attention_mask.long().cumsum(-1) - 1
- position_ids.masked_fill_(attention_mask == 0, 1)
- if past_key_values:
- position_ids = position_ids[:, -1].unsqueeze(-1)
-
- return {
- "input_ids": input_ids,
- "past_key_values": past_key_values,
- "use_cache": kwargs.get("use_cache"),
- "position_ids": position_ids,
- "attention_mask": attention_mask,
- "token_type_ids": token_type_ids,
- }
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=CausalLMOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, CausalLMOutputWithPast]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- transformer_outputs = self.transformer(
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- )
- hidden_states = transformer_outputs[0]
-
- # make sure sampling in fp16 works correctly and
- # compute loss in fp32 to match with mesh-tf version
- # https://github.com/EleutherAI/gpt-neo/blob/89ce74164da2fb16179106f54e2269b5da8db333/models/gpt2/gpt2.py#L179
- lm_logits = self.lm_head(hidden_states).to(torch.float32)
-
- loss = None
- if labels is not None:
- # Shift so that tokens < n predict n
- shift_logits = lm_logits[..., :-1, :].contiguous()
- shift_labels = labels[..., 1:].contiguous()
- # Flatten the tokens
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
-
- loss = loss.to(hidden_states.dtype)
-
- if not return_dict:
- output = (lm_logits,) + transformer_outputs[1:]
- return ((loss,) + output) if loss is not None else output
-
- return CausalLMOutputWithPast(
- loss=loss,
- logits=lm_logits,
- past_key_values=transformer_outputs.past_key_values,
- hidden_states=transformer_outputs.hidden_states,
- attentions=transformer_outputs.attentions,
- )
-
- @staticmethod
- def _reorder_cache(
- past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
- ) -> Tuple[Tuple[torch.Tensor]]:
- """
- This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
- [`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
- beam_idx at every generation step.
- """
- return tuple(
- tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past)
- for layer_past in past_key_values
- )
-
- def quantize(self, wbits, groupsize):
- from .quantization import quantize_with_gptq
- return quantize_with_gptq(self, wbits, groupsize)
-
-""" PyTorch Moss model."""
-
-from typing import Optional, Tuple, Union
-
-import torch
-import torch.utils.checkpoint
-from torch import nn
-from torch.nn import CrossEntropyLoss
-import transformers
-from transformers.activations import ACT2FN
-from transformers.modeling_utils import PreTrainedModel
-from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
-from transformers.utils import (
- add_code_sample_docstrings,
- add_start_docstrings,
- add_start_docstrings_to_model_forward,
- logging
-)
-
-from .configuration_moss import MossConfig
-
-logger = logging.get_logger(__name__)
-
-_CHECKPOINT_FOR_DOC = "fnlp/moss-moon-003-base"
-_CONFIG_FOR_DOC = "MossConfig"
-
-
-MOSS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "fnlp/moss-moon-003-base",
- "fnlp/moss-moon-003-sft",
- "fnlp/moss-moon-003-sft-plugin",
- "fnlp/moss-moon-003-sft-int4",
- "fnlp/moss-moon-003-sft-plugin-int4",
- "fnlp/moss-moon-003-sft-int8",
- "fnlp/moss-moon-003-sft-plugin-int8",
-]
-
-
-# Copied from transformers.models.gptj.modeling_gptj.create_sinusoidal_positions
-def create_sinusoidal_positions(num_pos: int, dim: int) -> torch.Tensor:
- inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2) / dim))
- sinusoid_inp = torch.einsum("i , j -> i j", torch.arange(num_pos, dtype=torch.float), inv_freq).float()
- return torch.cat((torch.sin(sinusoid_inp), torch.cos(sinusoid_inp)), dim=1)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.rotate_every_two
-def rotate_every_two(x: torch.Tensor) -> torch.Tensor:
- x1 = x[:, :, :, ::2]
- x2 = x[:, :, :, 1::2]
- x = torch.stack((-x2, x1), dim=-1)
- return x.flatten(-2) # in einsum notation: rearrange(x, '... d j -> ... (d j)')
-
-
-# Copied from transformers.models.gptj.modeling_gptj.apply_rotary_pos_emb
-def apply_rotary_pos_emb(tensor: torch.Tensor, sin: torch.Tensor, cos: torch.Tensor) -> torch.Tensor:
- sin = torch.repeat_interleave(sin[:, :, None, :], 2, 3)
- cos = torch.repeat_interleave(cos[:, :, None, :], 2, 3)
- return (tensor * cos) + (rotate_every_two(tensor) * sin)
-
-
-class MossAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
-
- max_positions = config.max_position_embeddings
- self.register_buffer(
- "causal_mask",
- torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(
- 1, 1, max_positions, max_positions
- ),
- )
-
- self.attn_dropout = nn.Dropout(config.attn_pdrop)
- self.resid_dropout = nn.Dropout(config.resid_pdrop)
-
- self.embed_dim = config.hidden_size
- self.num_attention_heads = config.num_attention_heads
- self.head_dim = self.embed_dim // self.num_attention_heads
- if self.head_dim * self.num_attention_heads != self.embed_dim:
- raise ValueError(
- f"embed_dim must be divisible by num_attention_heads (got `embed_dim`: {self.embed_dim} and"
- f" `num_attention_heads`: {self.num_attention_heads})."
- )
- self.scale_attn = torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32)).to(torch.get_default_dtype())
- self.qkv_proj = nn.Linear(self.embed_dim, self.embed_dim * 3, bias=False)
-
- self.out_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=False)
- self.rotary_dim = config.rotary_dim
- pos_embd_dim = self.rotary_dim or self.embed_dim
- self.embed_positions = create_sinusoidal_positions(max_positions, pos_embd_dim)
-
- def _split_heads(self, x, n_head, dim_head, mp_num):
- reshaped = x.reshape(x.shape[:-1] + (n_head // mp_num, dim_head))
- reshaped = reshaped.reshape(x.shape[:-2] + (-1,) + reshaped.shape[-1:])
- return reshaped
-
- def _merge_heads(self, tensor, num_attention_heads, attn_head_size):
- """
- Merges attn_head_size dim and num_attn_heads dim into n_ctx
- """
- if len(tensor.shape) == 5:
- tensor = tensor.permute(0, 1, 3, 2, 4).contiguous()
- elif len(tensor.shape) == 4:
- tensor = tensor.permute(0, 2, 1, 3).contiguous()
- else:
- raise ValueError(f"Input tensor rank should be one of [4, 5], but is: {len(tensor.shape)}")
- new_shape = tensor.size()[:-2] + (num_attention_heads * attn_head_size,)
- return tensor.view(new_shape)
-
- def _attn(
- self,
- query,
- key,
- value,
- attention_mask=None,
- head_mask=None,
- ):
- # compute causal mask from causal mask buffer
- query_length, key_length = query.size(-2), key.size(-2)
- causal_mask = self.causal_mask[:, :, key_length - query_length : key_length, :key_length]
-
- # Keep the attention weights computation in fp32 to avoid overflow issues
- query = query.to(torch.float32)
- key = key.to(torch.float32)
-
- attn_weights = torch.matmul(query, key.transpose(-1, -2))
-
- attn_weights = attn_weights / self.scale_attn
- mask_value = torch.finfo(attn_weights.dtype).min
- # Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
- # Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
- mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
- attn_weights = torch.where(causal_mask, attn_weights, mask_value)
-
- if attention_mask is not None:
- # Apply the attention mask
- attn_weights = attn_weights + attention_mask
-
- attn_weights = nn.Softmax(dim=-1)(attn_weights)
- attn_weights = attn_weights.to(value.dtype)
- attn_weights = self.attn_dropout(attn_weights)
-
- # Mask heads if we want to
- if head_mask is not None:
- attn_weights = attn_weights * head_mask
-
- attn_output = torch.matmul(attn_weights, value)
-
- return attn_output, attn_weights
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[
- Tuple[torch.Tensor, Tuple[torch.Tensor]],
- Optional[Tuple[torch.Tensor, Tuple[torch.Tensor], Tuple[torch.Tensor, ...]]],
- ]:
- qkv = self.qkv_proj(hidden_states)
- # TODO(enijkamp): factor out number of logical TPU-v4 cores or make forward pass agnostic
- mp_num = 4
- qkv_split = qkv.reshape(qkv.shape[:-1] + (mp_num, -1))
-
- local_dim = self.head_dim * self.num_attention_heads // mp_num
- query, value, key = torch.split(qkv_split, local_dim, dim=-1)
- query = self._split_heads(query, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- key = self._split_heads(key, self.num_attention_heads, self.head_dim, mp_num=mp_num)
-
- value = self._split_heads(value, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- value = value.permute(0, 2, 1, 3)
-
- embed_positions = self.embed_positions
- if embed_positions.device != position_ids.device:
- embed_positions = embed_positions.to(position_ids.device)
- self.embed_positions = embed_positions
-
- sincos = embed_positions[position_ids]
- sin, cos = torch.split(sincos, sincos.shape[-1] // 2, dim=-1)
-
- if self.rotary_dim is not None:
- k_rot = key[:, :, :, : self.rotary_dim]
- k_pass = key[:, :, :, self.rotary_dim :]
-
- q_rot = query[:, :, :, : self.rotary_dim]
- q_pass = query[:, :, :, self.rotary_dim :]
-
- k_rot = apply_rotary_pos_emb(k_rot, sin, cos)
- q_rot = apply_rotary_pos_emb(q_rot, sin, cos)
-
- key = torch.cat([k_rot, k_pass], dim=-1)
- query = torch.cat([q_rot, q_pass], dim=-1)
- else:
- key = apply_rotary_pos_emb(key, sin, cos)
- query = apply_rotary_pos_emb(query, sin, cos)
-
- key = key.permute(0, 2, 1, 3)
- query = query.permute(0, 2, 1, 3)
-
- if layer_past is not None:
- past_key = layer_past[0]
- past_value = layer_past[1]
- key = torch.cat((past_key, key), dim=-2)
- value = torch.cat((past_value, value), dim=-2)
-
- if use_cache is True:
- present = (key, value)
- else:
- present = None
-
- # compute self-attention: V x Softmax(QK^T)
- attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
-
- attn_output = self._merge_heads(attn_output, self.num_attention_heads, self.head_dim)
- attn_output = self.out_proj(attn_output)
- attn_output = self.resid_dropout(attn_output)
-
- outputs = (attn_output, present)
- if output_attentions:
- outputs += (attn_weights,)
-
- return outputs # a, present, (attentions)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJMLP with GPTJ->Moss
-class MossMLP(nn.Module):
- def __init__(self, intermediate_size, config): # in MLP: intermediate_size= 4 * embed_dim
- super().__init__()
- embed_dim = config.n_embd
-
- self.fc_in = nn.Linear(embed_dim, intermediate_size)
- self.fc_out = nn.Linear(intermediate_size, embed_dim)
-
- self.act = ACT2FN[config.activation_function]
- self.dropout = nn.Dropout(config.resid_pdrop)
-
- def forward(self, hidden_states: Optional[torch.FloatTensor]) -> torch.FloatTensor:
- hidden_states = self.fc_in(hidden_states)
- hidden_states = self.act(hidden_states)
- hidden_states = self.fc_out(hidden_states)
- hidden_states = self.dropout(hidden_states)
- return hidden_states
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJBlock with GPTJ->Moss
-class MossBlock(nn.Module):
- def __init__(self, config):
- super().__init__()
- inner_dim = config.n_inner if config.n_inner is not None else 4 * config.n_embd
- self.ln_1 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
- self.attn = MossAttention(config)
- self.mlp = MossMLP(inner_dim, config)
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[Tuple[torch.Tensor], Optional[Tuple[torch.Tensor, Tuple[torch.FloatTensor, ...]]]]:
- residual = hidden_states
- hidden_states = self.ln_1(hidden_states)
- attn_outputs = self.attn(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
- attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
- outputs = attn_outputs[1:]
-
- feed_forward_hidden_states = self.mlp(hidden_states)
- hidden_states = attn_output + feed_forward_hidden_states + residual
-
- if use_cache:
- outputs = (hidden_states,) + outputs
- else:
- outputs = (hidden_states,) + outputs[1:]
-
- return outputs # hidden_states, present, (attentions)
-
-
-class MossPreTrainedModel(PreTrainedModel):
- """
- An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
- models.
- """
-
- config_class = MossConfig
- base_model_prefix = "transformer"
- supports_gradient_checkpointing = True
- _no_split_modules = ["MossBlock"]
-
- def __init__(self, *inputs, **kwargs):
- super().__init__(*inputs, **kwargs)
-
- def _init_weights(self, module):
- """Initialize the weights."""
- if isinstance(module, (nn.Linear,)):
- # Slightly different from Mesh Transformer JAX which uses truncated_normal for initialization
- # cf https://github.com/pytorch/pytorch/pull/5617
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def _set_gradient_checkpointing(self, module, value=False):
- if isinstance(module, MossModel):
- module.gradient_checkpointing = value
-
-
-MOSS_START_DOCSTRING = r"""
- This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
- it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
- behavior.
-
- Parameters:
- config ([`MossConfig`]): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the
- configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
-"""
-
-MOSS_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (`torch.LongTensor` of shape `({0})`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using [`AutoProcenizer`]. See [`PreTrainedTokenizer.encode`] and
- [`PreTrainedTokenizer.__call__`] for details.
-
- [What are input IDs?](../glossary#input-ids)
- attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
- Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
-
- - 1 for tokens that are **not masked**,
- - 0 for tokens that are **masked**.
-
- [What are attention masks?](../glossary#attention-mask)
- token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
- 1]`:
-
- - 0 corresponds to a *sentence A* token,
- - 1 corresponds to a *sentence B* token.
-
- [What are token type IDs?](../glossary#token-type-ids)
- position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
- config.n_positions - 1]`.
-
- [What are position IDs?](../glossary#position-ids)
- head_mask (`torch.FloatTensor` of shape `(num_attention_heads,)` or `(n_layer, num_attention_heads)`, *optional*):
- Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
-
- - 1 indicates the head is **not masked**,
- - 0 indicates the head is **masked**.
-
- inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_dim)`, *optional*):
- Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
- is useful if you want more control over how to convert *input_ids* indices into associated vectors than the
- model's internal embedding lookup matrix.
- output_attentions (`bool`, *optional*):
- Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
- tensors for more detail.
- output_hidden_states (`bool`, *optional*):
- Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
- more detail.
- return_dict (`bool`, *optional*):
- Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
-"""
-
-
-@add_start_docstrings(
- "The bare Moss Model transformer outputting raw hidden-states without any specific head on top.",
- MOSS_START_DOCSTRING,
-)
-class MossModel(MossPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
-
- self.embed_dim = config.n_embd
- self.vocab_size = config.vocab_size
- self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
- self.drop = nn.Dropout(config.embd_pdrop)
- self.h = nn.ModuleList([MossBlock(config) for _ in range(config.n_layer)])
- self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
- self.rotary_dim = min(config.rotary_dim, config.n_ctx // config.num_attention_heads)
-
- self.gradient_checkpointing = False
-
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_input_embeddings(self):
- return self.wte
-
- def set_input_embeddings(self, new_embeddings):
- self.wte = new_embeddings
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=BaseModelOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, BaseModelOutputWithPast]:
- output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
-
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
-
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1]).long()
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if position_ids is None:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- # Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x num_attention_heads x N x N
- # head_mask has shape n_layer x batch x num_attention_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
-
- hidden_states = inputs_embeds
-
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
-
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
- "`use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_hidden_states = () if output_hidden_states else None
- for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- position_ids,
- head_mask[i],
- )
- else:
- outputs = block(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask[i],
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
-
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if not return_dict:
- return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
-
- return BaseModelOutputWithPast(
- last_hidden_state=hidden_states,
- past_key_values=presents,
- hidden_states=all_hidden_states,
- attentions=all_self_attentions,
- )
-
-
-@add_start_docstrings(
- """
- The Moss Model transformer with a language modeling head on top.
- """,
- MOSS_START_DOCSTRING,
-)
-class MossForCausalLM(MossPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.causal_mask"]
-
- def __init__(self, config):
- super().__init__(config)
- if not hasattr(config, 'wbits'):
- config.wbits = 32
- config.groupsize = 128
-
- if config.wbits not in [4, 8, 32]:
- logger.warning(f'Specify `wbits` with 4, 8 or 32 to load the model. ')
- if config.wbits in [4, 8]:
- def noop(*args, **kwargs):
- pass
- torch.nn.init.kaiming_uniform_ = noop
- torch.nn.init.uniform_ = noop
- torch.nn.init.normal_ = noop
-
- torch.set_default_dtype(torch.half)
- transformers.modeling_utils._init_weights = False
- torch.set_default_dtype(torch.half)
- self.transformer = MossModel(config)
- self.lm_head = nn.Linear(config.n_embd, config.vocab_size)
- if config.wbits in [4, 8]:
- torch.set_default_dtype(torch.float)
- transformers.modeling_utils._init_weights = True
- self.quantize(config.wbits, config.groupsize)
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_output_embeddings(self):
- return self.lm_head
-
- def set_output_embeddings(self, new_embeddings):
- self.lm_head = new_embeddings
-
- def prepare_inputs_for_generation(self, input_ids, past_key_values=None, **kwargs):
- token_type_ids = kwargs.get("token_type_ids", None)
- # only last token for inputs_ids if past is defined in kwargs
- if past_key_values:
- input_ids = input_ids[:, -1].unsqueeze(-1)
- if token_type_ids is not None:
- token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
-
- attention_mask = kwargs.get("attention_mask", None)
- position_ids = kwargs.get("position_ids", None)
-
- if attention_mask is not None and position_ids is None:
- # create position_ids on the fly for batch generation
- position_ids = attention_mask.long().cumsum(-1) - 1
- position_ids.masked_fill_(attention_mask == 0, 1)
- if past_key_values:
- position_ids = position_ids[:, -1].unsqueeze(-1)
-
- return {
- "input_ids": input_ids,
- "past_key_values": past_key_values,
- "use_cache": kwargs.get("use_cache"),
- "position_ids": position_ids,
- "attention_mask": attention_mask,
- "token_type_ids": token_type_ids,
- }
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=CausalLMOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, CausalLMOutputWithPast]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- transformer_outputs = self.transformer(
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- )
- hidden_states = transformer_outputs[0]
-
- # make sure sampling in fp16 works correctly and
- # compute loss in fp32 to match with mesh-tf version
- # https://github.com/EleutherAI/gpt-neo/blob/89ce74164da2fb16179106f54e2269b5da8db333/models/gpt2/gpt2.py#L179
- lm_logits = self.lm_head(hidden_states).to(torch.float32)
-
- loss = None
- if labels is not None:
- # Shift so that tokens < n predict n
- shift_logits = lm_logits[..., :-1, :].contiguous()
- shift_labels = labels[..., 1:].contiguous()
- # Flatten the tokens
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
-
- loss = loss.to(hidden_states.dtype)
-
- if not return_dict:
- output = (lm_logits,) + transformer_outputs[1:]
- return ((loss,) + output) if loss is not None else output
-
- return CausalLMOutputWithPast(
- loss=loss,
- logits=lm_logits,
- past_key_values=transformer_outputs.past_key_values,
- hidden_states=transformer_outputs.hidden_states,
- attentions=transformer_outputs.attentions,
- )
-
- @staticmethod
- def _reorder_cache(
- past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
- ) -> Tuple[Tuple[torch.Tensor]]:
- """
- This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
- [`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
- beam_idx at every generation step.
- """
- return tuple(
- tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past)
- for layer_past in past_key_values
- )
-
- def quantize(self, wbits, groupsize):
- from .quantization import quantize_with_gptq
- return quantize_with_gptq(self, wbits, groupsize)
-
-""" PyTorch Moss model."""
-
-from typing import Optional, Tuple, Union
-
-import torch
-import torch.utils.checkpoint
-from torch import nn
-from torch.nn import CrossEntropyLoss
-import transformers
-from transformers.activations import ACT2FN
-from transformers.modeling_utils import PreTrainedModel
-from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
-from transformers.utils import (
- add_code_sample_docstrings,
- add_start_docstrings,
- add_start_docstrings_to_model_forward,
- logging
-)
-
-from .configuration_moss import MossConfig
-
-logger = logging.get_logger(__name__)
-
-_CHECKPOINT_FOR_DOC = "fnlp/moss-moon-003-base"
-_CONFIG_FOR_DOC = "MossConfig"
-
-
-MOSS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "fnlp/moss-moon-003-base",
- "fnlp/moss-moon-003-sft",
- "fnlp/moss-moon-003-sft-plugin",
- "fnlp/moss-moon-003-sft-int4",
- "fnlp/moss-moon-003-sft-plugin-int4",
- "fnlp/moss-moon-003-sft-int8",
- "fnlp/moss-moon-003-sft-plugin-int8",
-]
-
-
-# Copied from transformers.models.gptj.modeling_gptj.create_sinusoidal_positions
-def create_sinusoidal_positions(num_pos: int, dim: int) -> torch.Tensor:
- inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2) / dim))
- sinusoid_inp = torch.einsum("i , j -> i j", torch.arange(num_pos, dtype=torch.float), inv_freq).float()
- return torch.cat((torch.sin(sinusoid_inp), torch.cos(sinusoid_inp)), dim=1)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.rotate_every_two
-def rotate_every_two(x: torch.Tensor) -> torch.Tensor:
- x1 = x[:, :, :, ::2]
- x2 = x[:, :, :, 1::2]
- x = torch.stack((-x2, x1), dim=-1)
- return x.flatten(-2) # in einsum notation: rearrange(x, '... d j -> ... (d j)')
-
-
-# Copied from transformers.models.gptj.modeling_gptj.apply_rotary_pos_emb
-def apply_rotary_pos_emb(tensor: torch.Tensor, sin: torch.Tensor, cos: torch.Tensor) -> torch.Tensor:
- sin = torch.repeat_interleave(sin[:, :, None, :], 2, 3)
- cos = torch.repeat_interleave(cos[:, :, None, :], 2, 3)
- return (tensor * cos) + (rotate_every_two(tensor) * sin)
-
-
-class MossAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
-
- max_positions = config.max_position_embeddings
- self.register_buffer(
- "causal_mask",
- torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(
- 1, 1, max_positions, max_positions
- ),
- )
-
- self.attn_dropout = nn.Dropout(config.attn_pdrop)
- self.resid_dropout = nn.Dropout(config.resid_pdrop)
-
- self.embed_dim = config.hidden_size
- self.num_attention_heads = config.num_attention_heads
- self.head_dim = self.embed_dim // self.num_attention_heads
- if self.head_dim * self.num_attention_heads != self.embed_dim:
- raise ValueError(
- f"embed_dim must be divisible by num_attention_heads (got `embed_dim`: {self.embed_dim} and"
- f" `num_attention_heads`: {self.num_attention_heads})."
- )
- self.scale_attn = torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32)).to(torch.get_default_dtype())
- self.qkv_proj = nn.Linear(self.embed_dim, self.embed_dim * 3, bias=False)
-
- self.out_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=False)
- self.rotary_dim = config.rotary_dim
- pos_embd_dim = self.rotary_dim or self.embed_dim
- self.embed_positions = create_sinusoidal_positions(max_positions, pos_embd_dim)
-
- def _split_heads(self, x, n_head, dim_head, mp_num):
- reshaped = x.reshape(x.shape[:-1] + (n_head // mp_num, dim_head))
- reshaped = reshaped.reshape(x.shape[:-2] + (-1,) + reshaped.shape[-1:])
- return reshaped
-
- def _merge_heads(self, tensor, num_attention_heads, attn_head_size):
- """
- Merges attn_head_size dim and num_attn_heads dim into n_ctx
- """
- if len(tensor.shape) == 5:
- tensor = tensor.permute(0, 1, 3, 2, 4).contiguous()
- elif len(tensor.shape) == 4:
- tensor = tensor.permute(0, 2, 1, 3).contiguous()
- else:
- raise ValueError(f"Input tensor rank should be one of [4, 5], but is: {len(tensor.shape)}")
- new_shape = tensor.size()[:-2] + (num_attention_heads * attn_head_size,)
- return tensor.view(new_shape)
-
- def _attn(
- self,
- query,
- key,
- value,
- attention_mask=None,
- head_mask=None,
- ):
- # compute causal mask from causal mask buffer
- query_length, key_length = query.size(-2), key.size(-2)
- causal_mask = self.causal_mask[:, :, key_length - query_length : key_length, :key_length]
-
- # Keep the attention weights computation in fp32 to avoid overflow issues
- query = query.to(torch.float32)
- key = key.to(torch.float32)
-
- attn_weights = torch.matmul(query, key.transpose(-1, -2))
-
- attn_weights = attn_weights / self.scale_attn
- mask_value = torch.finfo(attn_weights.dtype).min
- # Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
- # Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
- mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
- attn_weights = torch.where(causal_mask, attn_weights, mask_value)
-
- if attention_mask is not None:
- # Apply the attention mask
- attn_weights = attn_weights + attention_mask
-
- attn_weights = nn.Softmax(dim=-1)(attn_weights)
- attn_weights = attn_weights.to(value.dtype)
- attn_weights = self.attn_dropout(attn_weights)
-
- # Mask heads if we want to
- if head_mask is not None:
- attn_weights = attn_weights * head_mask
-
- attn_output = torch.matmul(attn_weights, value)
-
- return attn_output, attn_weights
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[
- Tuple[torch.Tensor, Tuple[torch.Tensor]],
- Optional[Tuple[torch.Tensor, Tuple[torch.Tensor], Tuple[torch.Tensor, ...]]],
- ]:
- qkv = self.qkv_proj(hidden_states)
- # TODO(enijkamp): factor out number of logical TPU-v4 cores or make forward pass agnostic
- mp_num = 4
- qkv_split = qkv.reshape(qkv.shape[:-1] + (mp_num, -1))
-
- local_dim = self.head_dim * self.num_attention_heads // mp_num
- query, value, key = torch.split(qkv_split, local_dim, dim=-1)
- query = self._split_heads(query, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- key = self._split_heads(key, self.num_attention_heads, self.head_dim, mp_num=mp_num)
-
- value = self._split_heads(value, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- value = value.permute(0, 2, 1, 3)
-
- embed_positions = self.embed_positions
- if embed_positions.device != position_ids.device:
- embed_positions = embed_positions.to(position_ids.device)
- self.embed_positions = embed_positions
-
- sincos = embed_positions[position_ids]
- sin, cos = torch.split(sincos, sincos.shape[-1] // 2, dim=-1)
-
- if self.rotary_dim is not None:
- k_rot = key[:, :, :, : self.rotary_dim]
- k_pass = key[:, :, :, self.rotary_dim :]
-
- q_rot = query[:, :, :, : self.rotary_dim]
- q_pass = query[:, :, :, self.rotary_dim :]
-
- k_rot = apply_rotary_pos_emb(k_rot, sin, cos)
- q_rot = apply_rotary_pos_emb(q_rot, sin, cos)
-
- key = torch.cat([k_rot, k_pass], dim=-1)
- query = torch.cat([q_rot, q_pass], dim=-1)
- else:
- key = apply_rotary_pos_emb(key, sin, cos)
- query = apply_rotary_pos_emb(query, sin, cos)
-
- key = key.permute(0, 2, 1, 3)
- query = query.permute(0, 2, 1, 3)
-
- if layer_past is not None:
- past_key = layer_past[0]
- past_value = layer_past[1]
- key = torch.cat((past_key, key), dim=-2)
- value = torch.cat((past_value, value), dim=-2)
-
- if use_cache is True:
- present = (key, value)
- else:
- present = None
-
- # compute self-attention: V x Softmax(QK^T)
- attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
-
- attn_output = self._merge_heads(attn_output, self.num_attention_heads, self.head_dim)
- attn_output = self.out_proj(attn_output)
- attn_output = self.resid_dropout(attn_output)
-
- outputs = (attn_output, present)
- if output_attentions:
- outputs += (attn_weights,)
-
- return outputs # a, present, (attentions)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJMLP with GPTJ->Moss
-class MossMLP(nn.Module):
- def __init__(self, intermediate_size, config): # in MLP: intermediate_size= 4 * embed_dim
- super().__init__()
- embed_dim = config.n_embd
-
- self.fc_in = nn.Linear(embed_dim, intermediate_size)
- self.fc_out = nn.Linear(intermediate_size, embed_dim)
-
- self.act = ACT2FN[config.activation_function]
- self.dropout = nn.Dropout(config.resid_pdrop)
-
- def forward(self, hidden_states: Optional[torch.FloatTensor]) -> torch.FloatTensor:
- hidden_states = self.fc_in(hidden_states)
- hidden_states = self.act(hidden_states)
- hidden_states = self.fc_out(hidden_states)
- hidden_states = self.dropout(hidden_states)
- return hidden_states
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJBlock with GPTJ->Moss
-class MossBlock(nn.Module):
- def __init__(self, config):
- super().__init__()
- inner_dim = config.n_inner if config.n_inner is not None else 4 * config.n_embd
- self.ln_1 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
- self.attn = MossAttention(config)
- self.mlp = MossMLP(inner_dim, config)
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[Tuple[torch.Tensor], Optional[Tuple[torch.Tensor, Tuple[torch.FloatTensor, ...]]]]:
- residual = hidden_states
- hidden_states = self.ln_1(hidden_states)
- attn_outputs = self.attn(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
- attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
- outputs = attn_outputs[1:]
-
- feed_forward_hidden_states = self.mlp(hidden_states)
- hidden_states = attn_output + feed_forward_hidden_states + residual
-
- if use_cache:
- outputs = (hidden_states,) + outputs
- else:
- outputs = (hidden_states,) + outputs[1:]
-
- return outputs # hidden_states, present, (attentions)
-
-
-class MossPreTrainedModel(PreTrainedModel):
- """
- An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
- models.
- """
-
- config_class = MossConfig
- base_model_prefix = "transformer"
- supports_gradient_checkpointing = True
- _no_split_modules = ["MossBlock"]
-
- def __init__(self, *inputs, **kwargs):
- super().__init__(*inputs, **kwargs)
-
- def _init_weights(self, module):
- """Initialize the weights."""
- if isinstance(module, (nn.Linear,)):
- # Slightly different from Mesh Transformer JAX which uses truncated_normal for initialization
- # cf https://github.com/pytorch/pytorch/pull/5617
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def _set_gradient_checkpointing(self, module, value=False):
- if isinstance(module, MossModel):
- module.gradient_checkpointing = value
-
-
-MOSS_START_DOCSTRING = r"""
- This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
- it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
- behavior.
-
- Parameters:
- config ([`MossConfig`]): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the
- configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
-"""
-
-MOSS_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (`torch.LongTensor` of shape `({0})`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using [`AutoProcenizer`]. See [`PreTrainedTokenizer.encode`] and
- [`PreTrainedTokenizer.__call__`] for details.
-
- [What are input IDs?](../glossary#input-ids)
- attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
- Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
-
- - 1 for tokens that are **not masked**,
- - 0 for tokens that are **masked**.
-
- [What are attention masks?](../glossary#attention-mask)
- token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
- 1]`:
-
- - 0 corresponds to a *sentence A* token,
- - 1 corresponds to a *sentence B* token.
-
- [What are token type IDs?](../glossary#token-type-ids)
- position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
- config.n_positions - 1]`.
-
- [What are position IDs?](../glossary#position-ids)
- head_mask (`torch.FloatTensor` of shape `(num_attention_heads,)` or `(n_layer, num_attention_heads)`, *optional*):
- Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
-
- - 1 indicates the head is **not masked**,
- - 0 indicates the head is **masked**.
-
- inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_dim)`, *optional*):
- Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
- is useful if you want more control over how to convert *input_ids* indices into associated vectors than the
- model's internal embedding lookup matrix.
- output_attentions (`bool`, *optional*):
- Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
- tensors for more detail.
- output_hidden_states (`bool`, *optional*):
- Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
- more detail.
- return_dict (`bool`, *optional*):
- Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
-"""
-
-
-@add_start_docstrings(
- "The bare Moss Model transformer outputting raw hidden-states without any specific head on top.",
- MOSS_START_DOCSTRING,
-)
-class MossModel(MossPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
-
- self.embed_dim = config.n_embd
- self.vocab_size = config.vocab_size
- self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
- self.drop = nn.Dropout(config.embd_pdrop)
- self.h = nn.ModuleList([MossBlock(config) for _ in range(config.n_layer)])
- self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
- self.rotary_dim = min(config.rotary_dim, config.n_ctx // config.num_attention_heads)
-
- self.gradient_checkpointing = False
-
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_input_embeddings(self):
- return self.wte
-
- def set_input_embeddings(self, new_embeddings):
- self.wte = new_embeddings
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=BaseModelOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, BaseModelOutputWithPast]:
- output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
-
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
-
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1]).long()
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if position_ids is None:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- # Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x num_attention_heads x N x N
- # head_mask has shape n_layer x batch x num_attention_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
-
- hidden_states = inputs_embeds
-
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
-
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
- "`use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_hidden_states = () if output_hidden_states else None
- for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- position_ids,
- head_mask[i],
- )
- else:
- outputs = block(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask[i],
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
-
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if not return_dict:
- return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
-
- return BaseModelOutputWithPast(
- last_hidden_state=hidden_states,
- past_key_values=presents,
- hidden_states=all_hidden_states,
- attentions=all_self_attentions,
- )
-
-
-@add_start_docstrings(
- """
- The Moss Model transformer with a language modeling head on top.
- """,
- MOSS_START_DOCSTRING,
-)
-class MossForCausalLM(MossPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.causal_mask"]
-
- def __init__(self, config):
- super().__init__(config)
- if not hasattr(config, 'wbits'):
- config.wbits = 32
- config.groupsize = 128
-
- if config.wbits not in [4, 8, 32]:
- logger.warning(f'Specify `wbits` with 4, 8 or 32 to load the model. ')
- if config.wbits in [4, 8]:
- def noop(*args, **kwargs):
- pass
- torch.nn.init.kaiming_uniform_ = noop
- torch.nn.init.uniform_ = noop
- torch.nn.init.normal_ = noop
-
- torch.set_default_dtype(torch.half)
- transformers.modeling_utils._init_weights = False
- torch.set_default_dtype(torch.half)
- self.transformer = MossModel(config)
- self.lm_head = nn.Linear(config.n_embd, config.vocab_size)
- if config.wbits in [4, 8]:
- torch.set_default_dtype(torch.float)
- transformers.modeling_utils._init_weights = True
- self.quantize(config.wbits, config.groupsize)
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_output_embeddings(self):
- return self.lm_head
-
- def set_output_embeddings(self, new_embeddings):
- self.lm_head = new_embeddings
-
- def prepare_inputs_for_generation(self, input_ids, past_key_values=None, **kwargs):
- token_type_ids = kwargs.get("token_type_ids", None)
- # only last token for inputs_ids if past is defined in kwargs
- if past_key_values:
- input_ids = input_ids[:, -1].unsqueeze(-1)
- if token_type_ids is not None:
- token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
-
- attention_mask = kwargs.get("attention_mask", None)
- position_ids = kwargs.get("position_ids", None)
-
- if attention_mask is not None and position_ids is None:
- # create position_ids on the fly for batch generation
- position_ids = attention_mask.long().cumsum(-1) - 1
- position_ids.masked_fill_(attention_mask == 0, 1)
- if past_key_values:
- position_ids = position_ids[:, -1].unsqueeze(-1)
-
- return {
- "input_ids": input_ids,
- "past_key_values": past_key_values,
- "use_cache": kwargs.get("use_cache"),
- "position_ids": position_ids,
- "attention_mask": attention_mask,
- "token_type_ids": token_type_ids,
- }
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=CausalLMOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, CausalLMOutputWithPast]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- transformer_outputs = self.transformer(
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- )
- hidden_states = transformer_outputs[0]
-
- # make sure sampling in fp16 works correctly and
- # compute loss in fp32 to match with mesh-tf version
- # https://github.com/EleutherAI/gpt-neo/blob/89ce74164da2fb16179106f54e2269b5da8db333/models/gpt2/gpt2.py#L179
- lm_logits = self.lm_head(hidden_states).to(torch.float32)
-
- loss = None
- if labels is not None:
- # Shift so that tokens < n predict n
- shift_logits = lm_logits[..., :-1, :].contiguous()
- shift_labels = labels[..., 1:].contiguous()
- # Flatten the tokens
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
-
- loss = loss.to(hidden_states.dtype)
-
- if not return_dict:
- output = (lm_logits,) + transformer_outputs[1:]
- return ((loss,) + output) if loss is not None else output
-
- return CausalLMOutputWithPast(
- loss=loss,
- logits=lm_logits,
- past_key_values=transformer_outputs.past_key_values,
- hidden_states=transformer_outputs.hidden_states,
- attentions=transformer_outputs.attentions,
- )
-
- @staticmethod
- def _reorder_cache(
- past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
- ) -> Tuple[Tuple[torch.Tensor]]:
- """
- This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
- [`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
- beam_idx at every generation step.
- """
- return tuple(
- tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past)
- for layer_past in past_key_values
- )
-
- def quantize(self, wbits, groupsize):
- from .quantization import quantize_with_gptq
- return quantize_with_gptq(self, wbits, groupsize)
-
-""" PyTorch Moss model."""
-
-from typing import Optional, Tuple, Union
-
-import torch
-import torch.utils.checkpoint
-from torch import nn
-from torch.nn import CrossEntropyLoss
-import transformers
-from transformers.activations import ACT2FN
-from transformers.modeling_utils import PreTrainedModel
-from transformers.modeling_outputs import BaseModelOutputWithPast, CausalLMOutputWithPast
-from transformers.utils import (
- add_code_sample_docstrings,
- add_start_docstrings,
- add_start_docstrings_to_model_forward,
- logging
-)
-
-from .configuration_moss import MossConfig
-
-logger = logging.get_logger(__name__)
-
-_CHECKPOINT_FOR_DOC = "fnlp/moss-moon-003-base"
-_CONFIG_FOR_DOC = "MossConfig"
-
-
-MOSS_PRETRAINED_MODEL_ARCHIVE_LIST = [
- "fnlp/moss-moon-003-base",
- "fnlp/moss-moon-003-sft",
- "fnlp/moss-moon-003-sft-plugin",
- "fnlp/moss-moon-003-sft-int4",
- "fnlp/moss-moon-003-sft-plugin-int4",
- "fnlp/moss-moon-003-sft-int8",
- "fnlp/moss-moon-003-sft-plugin-int8",
-]
-
-
-# Copied from transformers.models.gptj.modeling_gptj.create_sinusoidal_positions
-def create_sinusoidal_positions(num_pos: int, dim: int) -> torch.Tensor:
- inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2) / dim))
- sinusoid_inp = torch.einsum("i , j -> i j", torch.arange(num_pos, dtype=torch.float), inv_freq).float()
- return torch.cat((torch.sin(sinusoid_inp), torch.cos(sinusoid_inp)), dim=1)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.rotate_every_two
-def rotate_every_two(x: torch.Tensor) -> torch.Tensor:
- x1 = x[:, :, :, ::2]
- x2 = x[:, :, :, 1::2]
- x = torch.stack((-x2, x1), dim=-1)
- return x.flatten(-2) # in einsum notation: rearrange(x, '... d j -> ... (d j)')
-
-
-# Copied from transformers.models.gptj.modeling_gptj.apply_rotary_pos_emb
-def apply_rotary_pos_emb(tensor: torch.Tensor, sin: torch.Tensor, cos: torch.Tensor) -> torch.Tensor:
- sin = torch.repeat_interleave(sin[:, :, None, :], 2, 3)
- cos = torch.repeat_interleave(cos[:, :, None, :], 2, 3)
- return (tensor * cos) + (rotate_every_two(tensor) * sin)
-
-
-class MossAttention(nn.Module):
- def __init__(self, config):
- super().__init__()
-
- max_positions = config.max_position_embeddings
- self.register_buffer(
- "causal_mask",
- torch.tril(torch.ones((max_positions, max_positions), dtype=torch.bool)).view(
- 1, 1, max_positions, max_positions
- ),
- )
-
- self.attn_dropout = nn.Dropout(config.attn_pdrop)
- self.resid_dropout = nn.Dropout(config.resid_pdrop)
-
- self.embed_dim = config.hidden_size
- self.num_attention_heads = config.num_attention_heads
- self.head_dim = self.embed_dim // self.num_attention_heads
- if self.head_dim * self.num_attention_heads != self.embed_dim:
- raise ValueError(
- f"embed_dim must be divisible by num_attention_heads (got `embed_dim`: {self.embed_dim} and"
- f" `num_attention_heads`: {self.num_attention_heads})."
- )
- self.scale_attn = torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32)).to(torch.get_default_dtype())
- self.qkv_proj = nn.Linear(self.embed_dim, self.embed_dim * 3, bias=False)
-
- self.out_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=False)
- self.rotary_dim = config.rotary_dim
- pos_embd_dim = self.rotary_dim or self.embed_dim
- self.embed_positions = create_sinusoidal_positions(max_positions, pos_embd_dim)
-
- def _split_heads(self, x, n_head, dim_head, mp_num):
- reshaped = x.reshape(x.shape[:-1] + (n_head // mp_num, dim_head))
- reshaped = reshaped.reshape(x.shape[:-2] + (-1,) + reshaped.shape[-1:])
- return reshaped
-
- def _merge_heads(self, tensor, num_attention_heads, attn_head_size):
- """
- Merges attn_head_size dim and num_attn_heads dim into n_ctx
- """
- if len(tensor.shape) == 5:
- tensor = tensor.permute(0, 1, 3, 2, 4).contiguous()
- elif len(tensor.shape) == 4:
- tensor = tensor.permute(0, 2, 1, 3).contiguous()
- else:
- raise ValueError(f"Input tensor rank should be one of [4, 5], but is: {len(tensor.shape)}")
- new_shape = tensor.size()[:-2] + (num_attention_heads * attn_head_size,)
- return tensor.view(new_shape)
-
- def _attn(
- self,
- query,
- key,
- value,
- attention_mask=None,
- head_mask=None,
- ):
- # compute causal mask from causal mask buffer
- query_length, key_length = query.size(-2), key.size(-2)
- causal_mask = self.causal_mask[:, :, key_length - query_length : key_length, :key_length]
-
- # Keep the attention weights computation in fp32 to avoid overflow issues
- query = query.to(torch.float32)
- key = key.to(torch.float32)
-
- attn_weights = torch.matmul(query, key.transpose(-1, -2))
-
- attn_weights = attn_weights / self.scale_attn
- mask_value = torch.finfo(attn_weights.dtype).min
- # Need to be a tensor, otherwise we get error: `RuntimeError: expected scalar type float but found double`.
- # Need to be on the same device, otherwise `RuntimeError: ..., x and y to be on the same device`
- mask_value = torch.tensor(mask_value, dtype=attn_weights.dtype).to(attn_weights.device)
- attn_weights = torch.where(causal_mask, attn_weights, mask_value)
-
- if attention_mask is not None:
- # Apply the attention mask
- attn_weights = attn_weights + attention_mask
-
- attn_weights = nn.Softmax(dim=-1)(attn_weights)
- attn_weights = attn_weights.to(value.dtype)
- attn_weights = self.attn_dropout(attn_weights)
-
- # Mask heads if we want to
- if head_mask is not None:
- attn_weights = attn_weights * head_mask
-
- attn_output = torch.matmul(attn_weights, value)
-
- return attn_output, attn_weights
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[
- Tuple[torch.Tensor, Tuple[torch.Tensor]],
- Optional[Tuple[torch.Tensor, Tuple[torch.Tensor], Tuple[torch.Tensor, ...]]],
- ]:
- qkv = self.qkv_proj(hidden_states)
- # TODO(enijkamp): factor out number of logical TPU-v4 cores or make forward pass agnostic
- mp_num = 4
- qkv_split = qkv.reshape(qkv.shape[:-1] + (mp_num, -1))
-
- local_dim = self.head_dim * self.num_attention_heads // mp_num
- query, value, key = torch.split(qkv_split, local_dim, dim=-1)
- query = self._split_heads(query, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- key = self._split_heads(key, self.num_attention_heads, self.head_dim, mp_num=mp_num)
-
- value = self._split_heads(value, self.num_attention_heads, self.head_dim, mp_num=mp_num)
- value = value.permute(0, 2, 1, 3)
-
- embed_positions = self.embed_positions
- if embed_positions.device != position_ids.device:
- embed_positions = embed_positions.to(position_ids.device)
- self.embed_positions = embed_positions
-
- sincos = embed_positions[position_ids]
- sin, cos = torch.split(sincos, sincos.shape[-1] // 2, dim=-1)
-
- if self.rotary_dim is not None:
- k_rot = key[:, :, :, : self.rotary_dim]
- k_pass = key[:, :, :, self.rotary_dim :]
-
- q_rot = query[:, :, :, : self.rotary_dim]
- q_pass = query[:, :, :, self.rotary_dim :]
-
- k_rot = apply_rotary_pos_emb(k_rot, sin, cos)
- q_rot = apply_rotary_pos_emb(q_rot, sin, cos)
-
- key = torch.cat([k_rot, k_pass], dim=-1)
- query = torch.cat([q_rot, q_pass], dim=-1)
- else:
- key = apply_rotary_pos_emb(key, sin, cos)
- query = apply_rotary_pos_emb(query, sin, cos)
-
- key = key.permute(0, 2, 1, 3)
- query = query.permute(0, 2, 1, 3)
-
- if layer_past is not None:
- past_key = layer_past[0]
- past_value = layer_past[1]
- key = torch.cat((past_key, key), dim=-2)
- value = torch.cat((past_value, value), dim=-2)
-
- if use_cache is True:
- present = (key, value)
- else:
- present = None
-
- # compute self-attention: V x Softmax(QK^T)
- attn_output, attn_weights = self._attn(query, key, value, attention_mask, head_mask)
-
- attn_output = self._merge_heads(attn_output, self.num_attention_heads, self.head_dim)
- attn_output = self.out_proj(attn_output)
- attn_output = self.resid_dropout(attn_output)
-
- outputs = (attn_output, present)
- if output_attentions:
- outputs += (attn_weights,)
-
- return outputs # a, present, (attentions)
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJMLP with GPTJ->Moss
-class MossMLP(nn.Module):
- def __init__(self, intermediate_size, config): # in MLP: intermediate_size= 4 * embed_dim
- super().__init__()
- embed_dim = config.n_embd
-
- self.fc_in = nn.Linear(embed_dim, intermediate_size)
- self.fc_out = nn.Linear(intermediate_size, embed_dim)
-
- self.act = ACT2FN[config.activation_function]
- self.dropout = nn.Dropout(config.resid_pdrop)
-
- def forward(self, hidden_states: Optional[torch.FloatTensor]) -> torch.FloatTensor:
- hidden_states = self.fc_in(hidden_states)
- hidden_states = self.act(hidden_states)
- hidden_states = self.fc_out(hidden_states)
- hidden_states = self.dropout(hidden_states)
- return hidden_states
-
-
-# Copied from transformers.models.gptj.modeling_gptj.GPTJBlock with GPTJ->Moss
-class MossBlock(nn.Module):
- def __init__(self, config):
- super().__init__()
- inner_dim = config.n_inner if config.n_inner is not None else 4 * config.n_embd
- self.ln_1 = nn.LayerNorm(config.n_embd, eps=config.layer_norm_epsilon)
- self.attn = MossAttention(config)
- self.mlp = MossMLP(inner_dim, config)
-
- def forward(
- self,
- hidden_states: Optional[torch.FloatTensor],
- layer_past: Optional[Tuple[torch.Tensor]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = False,
- output_attentions: Optional[bool] = False,
- ) -> Union[Tuple[torch.Tensor], Optional[Tuple[torch.Tensor, Tuple[torch.FloatTensor, ...]]]]:
- residual = hidden_states
- hidden_states = self.ln_1(hidden_states)
- attn_outputs = self.attn(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask,
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
- attn_output = attn_outputs[0] # output_attn: a, present, (attentions)
- outputs = attn_outputs[1:]
-
- feed_forward_hidden_states = self.mlp(hidden_states)
- hidden_states = attn_output + feed_forward_hidden_states + residual
-
- if use_cache:
- outputs = (hidden_states,) + outputs
- else:
- outputs = (hidden_states,) + outputs[1:]
-
- return outputs # hidden_states, present, (attentions)
-
-
-class MossPreTrainedModel(PreTrainedModel):
- """
- An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
- models.
- """
-
- config_class = MossConfig
- base_model_prefix = "transformer"
- supports_gradient_checkpointing = True
- _no_split_modules = ["MossBlock"]
-
- def __init__(self, *inputs, **kwargs):
- super().__init__(*inputs, **kwargs)
-
- def _init_weights(self, module):
- """Initialize the weights."""
- if isinstance(module, (nn.Linear,)):
- # Slightly different from Mesh Transformer JAX which uses truncated_normal for initialization
- # cf https://github.com/pytorch/pytorch/pull/5617
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.bias is not None:
- module.bias.data.zero_()
- elif isinstance(module, nn.Embedding):
- module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
- if module.padding_idx is not None:
- module.weight.data[module.padding_idx].zero_()
- elif isinstance(module, nn.LayerNorm):
- module.bias.data.zero_()
- module.weight.data.fill_(1.0)
-
- def _set_gradient_checkpointing(self, module, value=False):
- if isinstance(module, MossModel):
- module.gradient_checkpointing = value
-
-
-MOSS_START_DOCSTRING = r"""
- This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) sub-class. Use
- it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
- behavior.
-
- Parameters:
- config ([`MossConfig`]): Model configuration class with all the parameters of the model.
- Initializing with a config file does not load the weights associated with the model, only the
- configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
-"""
-
-MOSS_INPUTS_DOCSTRING = r"""
- Args:
- input_ids (`torch.LongTensor` of shape `({0})`):
- Indices of input sequence tokens in the vocabulary.
-
- Indices can be obtained using [`AutoProcenizer`]. See [`PreTrainedTokenizer.encode`] and
- [`PreTrainedTokenizer.__call__`] for details.
-
- [What are input IDs?](../glossary#input-ids)
- attention_mask (`torch.FloatTensor` of shape `({0})`, *optional*):
- Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
-
- - 1 for tokens that are **not masked**,
- - 0 for tokens that are **masked**.
-
- [What are attention masks?](../glossary#attention-mask)
- token_type_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Segment token indices to indicate first and second portions of the inputs. Indices are selected in `[0,
- 1]`:
-
- - 0 corresponds to a *sentence A* token,
- - 1 corresponds to a *sentence B* token.
-
- [What are token type IDs?](../glossary#token-type-ids)
- position_ids (`torch.LongTensor` of shape `({0})`, *optional*):
- Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0,
- config.n_positions - 1]`.
-
- [What are position IDs?](../glossary#position-ids)
- head_mask (`torch.FloatTensor` of shape `(num_attention_heads,)` or `(n_layer, num_attention_heads)`, *optional*):
- Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
-
- - 1 indicates the head is **not masked**,
- - 0 indicates the head is **masked**.
-
- inputs_embeds (`torch.FloatTensor` of shape `({0}, hidden_dim)`, *optional*):
- Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This
- is useful if you want more control over how to convert *input_ids* indices into associated vectors than the
- model's internal embedding lookup matrix.
- output_attentions (`bool`, *optional*):
- Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
- tensors for more detail.
- output_hidden_states (`bool`, *optional*):
- Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
- more detail.
- return_dict (`bool`, *optional*):
- Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
-"""
-
-
-@add_start_docstrings(
- "The bare Moss Model transformer outputting raw hidden-states without any specific head on top.",
- MOSS_START_DOCSTRING,
-)
-class MossModel(MossPreTrainedModel):
- def __init__(self, config):
- super().__init__(config)
-
- self.embed_dim = config.n_embd
- self.vocab_size = config.vocab_size
- self.wte = nn.Embedding(config.vocab_size, self.embed_dim)
- self.drop = nn.Dropout(config.embd_pdrop)
- self.h = nn.ModuleList([MossBlock(config) for _ in range(config.n_layer)])
- self.ln_f = nn.LayerNorm(self.embed_dim, eps=config.layer_norm_epsilon)
- self.rotary_dim = min(config.rotary_dim, config.n_ctx // config.num_attention_heads)
-
- self.gradient_checkpointing = False
-
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_input_embeddings(self):
- return self.wte
-
- def set_input_embeddings(self, new_embeddings):
- self.wte = new_embeddings
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=BaseModelOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, BaseModelOutputWithPast]:
- output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
- output_hidden_states = (
- output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
- )
- use_cache = use_cache if use_cache is not None else self.config.use_cache
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- if input_ids is not None and inputs_embeds is not None:
- raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
- elif input_ids is not None:
- input_shape = input_ids.size()
- input_ids = input_ids.view(-1, input_shape[-1])
- batch_size = input_ids.shape[0]
- elif inputs_embeds is not None:
- input_shape = inputs_embeds.size()[:-1]
- batch_size = inputs_embeds.shape[0]
- else:
- raise ValueError("You have to specify either input_ids or inputs_embeds")
-
- device = input_ids.device if input_ids is not None else inputs_embeds.device
-
- if token_type_ids is not None:
- token_type_ids = token_type_ids.view(-1, input_shape[-1])
-
- if position_ids is not None:
- position_ids = position_ids.view(-1, input_shape[-1]).long()
-
- if past_key_values is None:
- past_length = 0
- past_key_values = tuple([None] * len(self.h))
- else:
- past_length = past_key_values[0][0].size(-2)
-
- if position_ids is None:
- position_ids = torch.arange(past_length, input_shape[-1] + past_length, dtype=torch.long, device=device)
- position_ids = position_ids.unsqueeze(0).view(-1, input_shape[-1])
-
- # Attention mask.
- if attention_mask is not None:
- if batch_size <= 0:
- raise ValueError("batch_size has to be defined and > 0")
- attention_mask = attention_mask.view(batch_size, -1)
- # We create a 3D attention mask from a 2D tensor mask.
- # Sizes are [batch_size, 1, 1, to_seq_length]
- # So we can broadcast to [batch_size, num_heads, from_seq_length, to_seq_length]
- # this attention mask is more simple than the triangular masking of causal attention
- # used in OpenAI GPT, we just need to prepare the broadcast dimension here.
- attention_mask = attention_mask[:, None, None, :]
-
- # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
- # masked positions, this operation will create a tensor which is 0.0 for
- # positions we want to attend and the dtype's smallest value for masked positions.
- # Since we are adding it to the raw scores before the softmax, this is
- # effectively the same as removing these entirely.
- attention_mask = attention_mask.to(dtype=self.dtype) # fp16 compatibility
- attention_mask = (1.0 - attention_mask) * torch.finfo(self.dtype).min
-
- # Prepare head mask if needed
- # 1.0 in head_mask indicate we keep the head
- # attention_probs has shape bsz x num_attention_heads x N x N
- # head_mask has shape n_layer x batch x num_attention_heads x N x N
- head_mask = self.get_head_mask(head_mask, self.config.n_layer)
-
- if inputs_embeds is None:
- inputs_embeds = self.wte(input_ids)
-
- hidden_states = inputs_embeds
-
- if token_type_ids is not None:
- token_type_embeds = self.wte(token_type_ids)
- hidden_states = hidden_states + token_type_embeds
-
- hidden_states = self.drop(hidden_states)
-
- output_shape = input_shape + (hidden_states.size(-1),)
-
- if self.gradient_checkpointing and self.training:
- if use_cache:
- logger.warning_once(
- "`use_cache=True` is incompatible with `config.gradient_checkpointing=True`. Setting "
- "`use_cache=False`..."
- )
- use_cache = False
-
- presents = () if use_cache else None
- all_self_attentions = () if output_attentions else None
- all_hidden_states = () if output_hidden_states else None
- for i, (block, layer_past) in enumerate(zip(self.h, past_key_values)):
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if self.gradient_checkpointing and self.training:
-
- def create_custom_forward(module):
- def custom_forward(*inputs):
- # None for past_key_value
- return module(*inputs, use_cache, output_attentions)
-
- return custom_forward
-
- outputs = torch.utils.checkpoint.checkpoint(
- create_custom_forward(block),
- hidden_states,
- None,
- attention_mask,
- position_ids,
- head_mask[i],
- )
- else:
- outputs = block(
- hidden_states=hidden_states,
- layer_past=layer_past,
- attention_mask=attention_mask,
- position_ids=position_ids,
- head_mask=head_mask[i],
- use_cache=use_cache,
- output_attentions=output_attentions,
- )
-
- hidden_states = outputs[0]
- if use_cache is True:
- presents = presents + (outputs[1],)
-
- if output_attentions:
- all_self_attentions = all_self_attentions + (outputs[2 if use_cache else 1],)
-
- hidden_states = self.ln_f(hidden_states)
-
- hidden_states = hidden_states.view(output_shape)
- # Add last hidden state
- if output_hidden_states:
- all_hidden_states = all_hidden_states + (hidden_states,)
-
- if not return_dict:
- return tuple(v for v in [hidden_states, presents, all_hidden_states, all_self_attentions] if v is not None)
-
- return BaseModelOutputWithPast(
- last_hidden_state=hidden_states,
- past_key_values=presents,
- hidden_states=all_hidden_states,
- attentions=all_self_attentions,
- )
-
-
-@add_start_docstrings(
- """
- The Moss Model transformer with a language modeling head on top.
- """,
- MOSS_START_DOCSTRING,
-)
-class MossForCausalLM(MossPreTrainedModel):
- _keys_to_ignore_on_load_missing = [r"h\.\d+\.attn\.causal_mask"]
-
- def __init__(self, config):
- super().__init__(config)
- if not hasattr(config, 'wbits'):
- config.wbits = 32
- config.groupsize = 128
-
- if config.wbits not in [4, 8, 32]:
- logger.warning(f'Specify `wbits` with 4, 8 or 32 to load the model. ')
- if config.wbits in [4, 8]:
- def noop(*args, **kwargs):
- pass
- torch.nn.init.kaiming_uniform_ = noop
- torch.nn.init.uniform_ = noop
- torch.nn.init.normal_ = noop
-
- torch.set_default_dtype(torch.half)
- transformers.modeling_utils._init_weights = False
- torch.set_default_dtype(torch.half)
- self.transformer = MossModel(config)
- self.lm_head = nn.Linear(config.n_embd, config.vocab_size)
- if config.wbits in [4, 8]:
- torch.set_default_dtype(torch.float)
- transformers.modeling_utils._init_weights = True
- self.quantize(config.wbits, config.groupsize)
- # Initialize weights and apply final processing
- self.post_init()
-
- def get_output_embeddings(self):
- return self.lm_head
-
- def set_output_embeddings(self, new_embeddings):
- self.lm_head = new_embeddings
-
- def prepare_inputs_for_generation(self, input_ids, past_key_values=None, **kwargs):
- token_type_ids = kwargs.get("token_type_ids", None)
- # only last token for inputs_ids if past is defined in kwargs
- if past_key_values:
- input_ids = input_ids[:, -1].unsqueeze(-1)
- if token_type_ids is not None:
- token_type_ids = token_type_ids[:, -1].unsqueeze(-1)
-
- attention_mask = kwargs.get("attention_mask", None)
- position_ids = kwargs.get("position_ids", None)
-
- if attention_mask is not None and position_ids is None:
- # create position_ids on the fly for batch generation
- position_ids = attention_mask.long().cumsum(-1) - 1
- position_ids.masked_fill_(attention_mask == 0, 1)
- if past_key_values:
- position_ids = position_ids[:, -1].unsqueeze(-1)
-
- return {
- "input_ids": input_ids,
- "past_key_values": past_key_values,
- "use_cache": kwargs.get("use_cache"),
- "position_ids": position_ids,
- "attention_mask": attention_mask,
- "token_type_ids": token_type_ids,
- }
-
- @add_start_docstrings_to_model_forward(MOSS_INPUTS_DOCSTRING.format("batch_size, sequence_length"))
- @add_code_sample_docstrings(
- checkpoint=_CHECKPOINT_FOR_DOC,
- output_type=CausalLMOutputWithPast,
- config_class=_CONFIG_FOR_DOC,
- )
- def forward(
- self,
- input_ids: Optional[torch.LongTensor] = None,
- past_key_values: Optional[Tuple[Tuple[torch.Tensor]]] = None,
- attention_mask: Optional[torch.FloatTensor] = None,
- token_type_ids: Optional[torch.LongTensor] = None,
- position_ids: Optional[torch.LongTensor] = None,
- head_mask: Optional[torch.FloatTensor] = None,
- inputs_embeds: Optional[torch.FloatTensor] = None,
- labels: Optional[torch.LongTensor] = None,
- use_cache: Optional[bool] = None,
- output_attentions: Optional[bool] = None,
- output_hidden_states: Optional[bool] = None,
- return_dict: Optional[bool] = None,
- ) -> Union[Tuple, CausalLMOutputWithPast]:
- r"""
- labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
- Labels for language modeling. Note that the labels **are shifted** inside the model, i.e. you can set
- `labels = input_ids` Indices are selected in `[-100, 0, ..., config.vocab_size]` All labels set to `-100`
- are ignored (masked), the loss is only computed for labels in `[0, ..., config.vocab_size]`
- """
- return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-
- transformer_outputs = self.transformer(
- input_ids,
- past_key_values=past_key_values,
- attention_mask=attention_mask,
- token_type_ids=token_type_ids,
- position_ids=position_ids,
- head_mask=head_mask,
- inputs_embeds=inputs_embeds,
- use_cache=use_cache,
- output_attentions=output_attentions,
- output_hidden_states=output_hidden_states,
- return_dict=return_dict,
- )
- hidden_states = transformer_outputs[0]
-
- # make sure sampling in fp16 works correctly and
- # compute loss in fp32 to match with mesh-tf version
- # https://github.com/EleutherAI/gpt-neo/blob/89ce74164da2fb16179106f54e2269b5da8db333/models/gpt2/gpt2.py#L179
- lm_logits = self.lm_head(hidden_states).to(torch.float32)
-
- loss = None
- if labels is not None:
- # Shift so that tokens < n predict n
- shift_logits = lm_logits[..., :-1, :].contiguous()
- shift_labels = labels[..., 1:].contiguous()
- # Flatten the tokens
- loss_fct = CrossEntropyLoss()
- loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
-
- loss = loss.to(hidden_states.dtype)
-
- if not return_dict:
- output = (lm_logits,) + transformer_outputs[1:]
- return ((loss,) + output) if loss is not None else output
-
- return CausalLMOutputWithPast(
- loss=loss,
- logits=lm_logits,
- past_key_values=transformer_outputs.past_key_values,
- hidden_states=transformer_outputs.hidden_states,
- attentions=transformer_outputs.attentions,
- )
-
- @staticmethod
- def _reorder_cache(
- past_key_values: Tuple[Tuple[torch.Tensor]], beam_idx: torch.Tensor
- ) -> Tuple[Tuple[torch.Tensor]]:
- """
- This function is used to re-order the `past_key_values` cache if [`~PretrainedModel.beam_search`] or
- [`~PretrainedModel.beam_sample`] is called. This is required to match `past_key_values` with the correct
- beam_idx at every generation step.
- """
- return tuple(
- tuple(past_state.index_select(0, beam_idx.to(past_state.device)) for past_state in layer_past)
- for layer_past in past_key_values
- )
-
- def quantize(self, wbits, groupsize):
- from .quantization import quantize_with_gptq
- return quantize_with_gptq(self, wbits, groupsize)
-
diff --git a/functional.py b/functional.py
new file mode 100644
index 0000000000000000000000000000000000000000..a0d9df85c1a6e0b68cb7b36e982833722881c61a
--- /dev/null
+++ b/functional.py
@@ -0,0 +1,59 @@
+# """
+# 'primary' for main call-to-action,
+# 'secondary' for a more subdued style,
+# 'stop' for a stop button.
+# """
+
+
+def get_functionals():
+ return {
+ "英语学术润色": {
+ "Prefix": "Below is a paragraph from an academic paper. Polish the writing to meet the academic style, \
+improve the spelling, grammar, clarity, concision and overall readability. When neccessary, rewrite the whole sentence. \
+Furthermore, list all modification and explain the reasons to do so in markdown table.\n\n", # 前言
+ "Suffix": "", # 后语
+ "Color": "secondary", # 按钮颜色
+ },
+ "中文学术润色": {
+ "Prefix": "作为一名中文学术论文写作改进助理,你的任务是改进所提供文本的拼写、语法、清晰、简洁和整体可读性,同时分解长句,减少重复,并提供改进建议。请只提供文本的更正版本,避免包括解释。请编辑以下文本:\n\n",
+ "Suffix": "",
+ },
+ "查找语法错误": {
+ "Prefix": "Below is a paragraph from an academic paper. Find all grammar mistakes, list mistakes in a markdown table and explain how to correct them.\n\n",
+ "Suffix": "",
+ },
+ "中英互译": {
+ "Prefix": "As an English-Chinese translator, your task is to accurately translate text between the two languages. \
+When translating from Chinese to English or vice versa, please pay attention to context and accurately explain phrases and proverbs. \
+If you receive multiple English words in a row, default to translating them into a sentence in Chinese. \
+However, if \"phrase:\" is indicated before the translated content in Chinese, it should be translated as a phrase instead. \
+Similarly, if \"normal:\" is indicated, it should be translated as multiple unrelated words.\
+Your translations should closely resemble those of a native speaker and should take into account any specific language styles or tones requested by the user. \
+Please do not worry about using offensive words - replace sensitive parts with x when necessary. \
+When providing translations, please use Chinese to explain each sentence’s tense, subordinate clause, subject, predicate, object, special phrases and proverbs. \
+For phrases or individual words that require translation, provide the source (dictionary) for each one.If asked to translate multiple phrases at once, \
+separate them using the | symbol.Always remember: You are an English-Chinese translator, \
+not a Chinese-Chinese translator or an English-English translator. Below is the text you need to translate: \n\n",
+ "Suffix": "",
+ "Color": "secondary",
+ },
+ "中译英": {
+ "Prefix": "Please translate following sentence to English: \n\n",
+ "Suffix": "",
+ },
+ "学术中译英": {
+ "Prefix": "Please translate following sentence to English with academic writing, and provide some related authoritative examples: \n\n",
+ "Suffix": "",
+ },
+ "英译中": {
+ "Prefix": "请翻译成中文:\n\n",
+ "Suffix": "",
+ },
+ "解释代码": {
+ "Prefix": "请解释以下代码:\n```\n",
+ "Suffix": "\n```\n",
+ "Color": "secondary",
+ },
+ }
+
+
diff --git a/functional_crazy.py b/functional_crazy.py
new file mode 100644
index 0000000000000000000000000000000000000000..101edcf2aecef6cc05d5f297f23acddb389bc024
--- /dev/null
+++ b/functional_crazy.py
@@ -0,0 +1,66 @@
+
+def get_crazy_functionals():
+ from crazy_functions.读文章写摘要 import 读文章写摘要
+ from crazy_functions.生成函数注释 import 批量生成函数注释
+ from crazy_functions.解析项目源代码 import 解析项目本身
+ from crazy_functions.解析项目源代码 import 解析一个Python项目
+ from crazy_functions.解析项目源代码 import 解析一个C项目的头文件
+ from crazy_functions.解析项目源代码 import 解析一个C项目
+ from crazy_functions.高级功能函数模板 import 高阶功能模板函数
+
+ return {
+ "[实验] 请解析并解构此项目本身": {
+ "Function": 解析项目本身
+ },
+ "[实验] 解析整个py项目(配合input输入框)": {
+ "Color": "stop", # 按钮颜色
+ "Function": 解析一个Python项目
+ },
+ "[实验] 解析整个C++项目头文件(配合input输入框)": {
+ "Color": "stop", # 按钮颜色
+ "Function": 解析一个C项目的头文件
+ },
+ "[实验] 解析整个C++项目(配合input输入框)": {
+ "Color": "stop", # 按钮颜色
+ "Function": 解析一个C项目
+ },
+ "[实验] 读tex论文写摘要(配合input输入框)": {
+ "Color": "stop", # 按钮颜色
+ "Function": 读文章写摘要
+ },
+ "[实验] 批量生成函数注释(配合input输入框)": {
+ "Color": "stop", # 按钮颜色
+ "Function": 批量生成函数注释
+ },
+ "[实验] 实验功能函数模板": {
+ "Color": "stop", # 按钮颜色
+ "Function": 高阶功能模板函数
+ },
+ }
+
+def on_file_uploaded(files, chatbot, txt):
+ import shutil, os, time, glob
+ from toolbox import extract_archive
+ try: shutil.rmtree('./private_upload/')
+ except: pass
+ time_tag = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime())
+ os.makedirs(f'private_upload/{time_tag}', exist_ok=True)
+ for file in files:
+ file_origin_name = os.path.basename(file.orig_name)
+ shutil.copy(file.name, f'private_upload/{time_tag}/{file_origin_name}')
+ extract_archive(f'private_upload/{time_tag}/{file_origin_name}',
+ dest_dir=f'private_upload/{time_tag}/{file_origin_name}.extract')
+ moved_files = [fp for fp in glob.glob('private_upload/**/*', recursive=True)]
+ txt = f'private_upload/{time_tag}'
+ moved_files_str = '\t\n\n'.join(moved_files)
+ chatbot.append(['我上传了文件,请查收',
+ f'[Local Message] 收到以下文件: \n\n{moved_files_str}\n\n调用路径参数已自动修正到: \n\n{txt}\n\n现在您可以直接选择任意实现性功能'])
+ return chatbot, txt
+
+def on_report_generated(files, chatbot):
+ from toolbox import find_recent_files
+ report_files = find_recent_files('gpt_log')
+ # files.extend(report_files)
+ chatbot.append(['汇总报告如何远程获取?', '汇总报告已经添加到右侧文件上传区,请查收。'])
+ return report_files, chatbot
+
diff --git a/multi_language.py b/multi_language.py
deleted file mode 100644
index c65872aa08a0b0088d94467054594c422978ca38..0000000000000000000000000000000000000000
--- a/multi_language.py
+++ /dev/null
@@ -1,527 +0,0 @@
-"""
- Translate this project to other languages (experimental, please open an issue if there is any bug)
-
-
- Usage:
- 1. modify config.py, set your LLM_MODEL and API_KEY(s) to provide access to OPENAI (or any other LLM model provider)
-
- 2. modify LANG (below ↓)
- LANG = "English"
-
- 3. modify TransPrompt (below ↓)
- TransPrompt = f"Replace each json value `#` with translated results in English, e.g., \"原始文本\":\"TranslatedText\". Keep Json format. Do not answer #."
-
- 4. Run `python multi_language.py`.
- Note: You need to run it multiple times to increase translation coverage because GPT makes mistakes sometimes.
- (You can also run `CACHE_ONLY=True python multi_language.py` to use cached translation mapping)
-
- 5. Find the translated program in `multi-language\English\*`
-
- P.S.
-
- - The translation mapping will be stored in `docs/translation_xxxx.json`, you can revised mistaken translation there.
-
- - If you would like to share your `docs/translation_xxxx.json`, (so that everyone can use the cached & revised translation mapping), please open a Pull Request
-
- - If there is any translation error in `docs/translation_xxxx.json`, please open a Pull Request
-
- - Welcome any Pull Request, regardless of language
-"""
-
-import os
-import json
-import functools
-import re
-import pickle
-import time
-from toolbox import get_conf
-
-CACHE_ONLY = os.environ.get('CACHE_ONLY', False)
-
-CACHE_FOLDER = get_conf('PATH_LOGGING')
-
-blacklist = ['multi-language', CACHE_FOLDER, '.git', 'private_upload', 'multi_language.py', 'build', '.github', '.vscode', '__pycache__', 'venv']
-
-# LANG = "TraditionalChinese"
-# TransPrompt = f"Replace each json value `#` with translated results in Traditional Chinese, e.g., \"原始文本\":\"翻譯後文字\". Keep Json format. Do not answer #."
-
-# LANG = "Japanese"
-# TransPrompt = f"Replace each json value `#` with translated results in Japanese, e.g., \"原始文本\":\"テキストの翻訳\". Keep Json format. Do not answer #."
-
-LANG = "English"
-TransPrompt = f"Replace each json value `#` with translated results in English, e.g., \"原始文本\":\"TranslatedText\". Keep Json format. Do not answer #."
-
-
-if not os.path.exists(CACHE_FOLDER):
- os.makedirs(CACHE_FOLDER)
-
-
-def lru_file_cache(maxsize=128, ttl=None, filename=None):
- """
- Decorator that caches a function's return value after being called with given arguments.
- It uses a Least Recently Used (LRU) cache strategy to limit the size of the cache.
- maxsize: Maximum size of the cache. Defaults to 128.
- ttl: Time-to-Live of the cache. If a value hasn't been accessed for `ttl` seconds, it will be evicted from the cache.
- filename: Name of the file to store the cache in. If not supplied, the function name + ".cache" will be used.
- """
- cache_path = os.path.join(CACHE_FOLDER, f"{filename}.cache") if filename is not None else None
-
- def decorator_function(func):
- cache = {}
- _cache_info = {
- "hits": 0,
- "misses": 0,
- "maxsize": maxsize,
- "currsize": 0,
- "ttl": ttl,
- "filename": cache_path,
- }
-
- @functools.wraps(func)
- def wrapper_function(*args, **kwargs):
- key = str((args, frozenset(kwargs)))
- if key in cache:
- if _cache_info["ttl"] is None or (cache[key][1] + _cache_info["ttl"]) >= time.time():
- _cache_info["hits"] += 1
- print(f'Warning, reading cache, last read {(time.time()-cache[key][1])//60} minutes ago'); time.sleep(2)
- cache[key][1] = time.time()
- return cache[key][0]
- else:
- del cache[key]
-
- result = func(*args, **kwargs)
- cache[key] = [result, time.time()]
- _cache_info["misses"] += 1
- _cache_info["currsize"] += 1
-
- if _cache_info["currsize"] > _cache_info["maxsize"]:
- oldest_key = None
- for k in cache:
- if oldest_key is None:
- oldest_key = k
- elif cache[k][1] < cache[oldest_key][1]:
- oldest_key = k
- del cache[oldest_key]
- _cache_info["currsize"] -= 1
-
- if cache_path is not None:
- with open(cache_path, "wb") as f:
- pickle.dump(cache, f)
-
- return result
-
- def cache_info():
- return _cache_info
-
- wrapper_function.cache_info = cache_info
-
- if cache_path is not None and os.path.exists(cache_path):
- with open(cache_path, "rb") as f:
- cache = pickle.load(f)
- _cache_info["currsize"] = len(cache)
-
- return wrapper_function
-
- return decorator_function
-
-def contains_chinese(string):
- """
- Returns True if the given string contains Chinese characters, False otherwise.
- """
- chinese_regex = re.compile(u'[\u4e00-\u9fff]+')
- return chinese_regex.search(string) is not None
-
-def split_list(lst, n_each_req):
- """
- Split a list into smaller lists, each with a maximum number of elements.
- :param lst: the list to split
- :param n_each_req: the maximum number of elements in each sub-list
- :return: a list of sub-lists
- """
- result = []
- for i in range(0, len(lst), n_each_req):
- result.append(lst[i:i + n_each_req])
- return result
-
-def map_to_json(map, language):
- dict_ = read_map_from_json(language)
- dict_.update(map)
- with open(f'docs/translate_{language.lower()}.json', 'w', encoding='utf8') as f:
- json.dump(dict_, f, indent=4, ensure_ascii=False)
-
-def read_map_from_json(language):
- if os.path.exists(f'docs/translate_{language.lower()}.json'):
- with open(f'docs/translate_{language.lower()}.json', 'r', encoding='utf8') as f:
- res = json.load(f)
- res = {k:v for k, v in res.items() if v is not None and contains_chinese(k)}
- return res
- return {}
-
-def advanced_split(splitted_string, spliter, include_spliter=False):
- splitted_string_tmp = []
- for string_ in splitted_string:
- if spliter in string_:
- splitted = string_.split(spliter)
- for i, s in enumerate(splitted):
- if include_spliter:
- if i != len(splitted)-1:
- splitted[i] += spliter
- splitted[i] = splitted[i].strip()
- for i in reversed(range(len(splitted))):
- if not contains_chinese(splitted[i]):
- splitted.pop(i)
- splitted_string_tmp.extend(splitted)
- else:
- splitted_string_tmp.append(string_)
- splitted_string = splitted_string_tmp
- return splitted_string_tmp
-
-cached_translation = {}
-cached_translation = read_map_from_json(language=LANG)
-
-def trans(word_to_translate, language, special=False):
- if len(word_to_translate) == 0: return {}
- from crazy_functions.crazy_utils import request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency
- from toolbox import get_conf, ChatBotWithCookies, load_chat_cookies
-
- cookies = load_chat_cookies()
- llm_kwargs = {
- 'api_key': cookies['api_key'],
- 'llm_model': cookies['llm_model'],
- 'top_p':1.0,
- 'max_length': None,
- 'temperature':0.4,
- }
- import random
- N_EACH_REQ = random.randint(16, 32)
- word_to_translate_split = split_list(word_to_translate, N_EACH_REQ)
- inputs_array = [str(s) for s in word_to_translate_split]
- inputs_show_user_array = inputs_array
- history_array = [[] for _ in inputs_array]
- if special: # to English using CamelCase Naming Convention
- sys_prompt_array = [f"Translate following names to English with CamelCase naming convention. Keep original format" for _ in inputs_array]
- else:
- sys_prompt_array = [f"Translate following sentences to {LANG}. E.g., You should translate sentences to the following format ['translation of sentence 1', 'translation of sentence 2']. Do NOT answer with Chinese!" for _ in inputs_array]
- chatbot = ChatBotWithCookies(llm_kwargs)
- gpt_say_generator = request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency(
- inputs_array,
- inputs_show_user_array,
- llm_kwargs,
- chatbot,
- history_array,
- sys_prompt_array,
- )
- while True:
- try:
- gpt_say = next(gpt_say_generator)
- print(gpt_say[1][0][1])
- except StopIteration as e:
- result = e.value
- break
- translated_result = {}
- for i, r in enumerate(result):
- if i%2 == 1:
- try:
- res_before_trans = eval(result[i-1])
- res_after_trans = eval(result[i])
- if len(res_before_trans) != len(res_after_trans):
- raise RuntimeError
- for a,b in zip(res_before_trans, res_after_trans):
- translated_result[a] = b
- except:
- # try:
- # res_before_trans = word_to_translate_split[(i-1)//2]
- # res_after_trans = [s for s in result[i].split("', '")]
- # for a,b in zip(res_before_trans, res_after_trans):
- # translated_result[a] = b
- # except:
- print('GPT answers with unexpected format, some words may not be translated, but you can try again later to increase translation coverage.')
- res_before_trans = eval(result[i-1])
- for a in res_before_trans:
- translated_result[a] = None
- return translated_result
-
-
-def trans_json(word_to_translate, language, special=False):
- if len(word_to_translate) == 0: return {}
- from crazy_functions.crazy_utils import request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency
- from toolbox import get_conf, ChatBotWithCookies, load_chat_cookies
-
- cookies = load_chat_cookies()
- llm_kwargs = {
- 'api_key': cookies['api_key'],
- 'llm_model': cookies['llm_model'],
- 'top_p':1.0,
- 'max_length': None,
- 'temperature':0.4,
- }
- import random
- N_EACH_REQ = random.randint(16, 32)
- random.shuffle(word_to_translate)
- word_to_translate_split = split_list(word_to_translate, N_EACH_REQ)
- inputs_array = [{k:"#" for k in s} for s in word_to_translate_split]
- inputs_array = [ json.dumps(i, ensure_ascii=False) for i in inputs_array]
-
- inputs_show_user_array = inputs_array
- history_array = [[] for _ in inputs_array]
- sys_prompt_array = [TransPrompt for _ in inputs_array]
- chatbot = ChatBotWithCookies(llm_kwargs)
- gpt_say_generator = request_gpt_model_multi_threads_with_very_awesome_ui_and_high_efficiency(
- inputs_array,
- inputs_show_user_array,
- llm_kwargs,
- chatbot,
- history_array,
- sys_prompt_array,
- )
- while True:
- try:
- gpt_say = next(gpt_say_generator)
- print(gpt_say[1][0][1])
- except StopIteration as e:
- result = e.value
- break
- translated_result = {}
- for i, r in enumerate(result):
- if i%2 == 1:
- try:
- translated_result.update(json.loads(result[i]))
- except:
- print(result[i])
- print(result)
- return translated_result
-
-
-def step_1_core_key_translate():
- LANG_STD = 'std'
- def extract_chinese_characters(file_path):
- syntax = []
- with open(file_path, 'r', encoding='utf-8') as f:
- content = f.read()
- import ast
- root = ast.parse(content)
- for node in ast.walk(root):
- if isinstance(node, ast.Name):
- if contains_chinese(node.id): syntax.append(node.id)
- if isinstance(node, ast.Import):
- for n in node.names:
- if contains_chinese(n.name): syntax.append(n.name)
- elif isinstance(node, ast.ImportFrom):
- for n in node.names:
- if contains_chinese(n.name): syntax.append(n.name)
- # if node.module is None: print(node.module)
- for k in node.module.split('.'):
- if contains_chinese(k): syntax.append(k)
- return syntax
-
- def extract_chinese_characters_from_directory(directory_path):
- chinese_characters = []
- for root, dirs, files in os.walk(directory_path):
- if any([b in root for b in blacklist]):
- continue
- print(files)
- for file in files:
- if file.endswith('.py'):
- file_path = os.path.join(root, file)
- chinese_characters.extend(extract_chinese_characters(file_path))
- return chinese_characters
-
- directory_path = './'
- chinese_core_names = extract_chinese_characters_from_directory(directory_path)
- chinese_core_keys = [name for name in chinese_core_names]
- chinese_core_keys_norepeat = []
- for d in chinese_core_keys:
- if d not in chinese_core_keys_norepeat: chinese_core_keys_norepeat.append(d)
- need_translate = []
- cached_translation = read_map_from_json(language=LANG_STD)
- cached_translation_keys = list(cached_translation.keys())
- for d in chinese_core_keys_norepeat:
- if d not in cached_translation_keys:
- need_translate.append(d)
-
- if CACHE_ONLY:
- need_translate_mapping = {}
- else:
- need_translate_mapping = trans(need_translate, language=LANG_STD, special=True)
- map_to_json(need_translate_mapping, language=LANG_STD)
- cached_translation = read_map_from_json(language=LANG_STD)
- cached_translation = dict(sorted(cached_translation.items(), key=lambda x: -len(x[0])))
-
- chinese_core_keys_norepeat_mapping = {}
- for k in chinese_core_keys_norepeat:
- chinese_core_keys_norepeat_mapping.update({k:cached_translation[k]})
- chinese_core_keys_norepeat_mapping = dict(sorted(chinese_core_keys_norepeat_mapping.items(), key=lambda x: -len(x[0])))
-
- # =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
- # copy
- # =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
- def copy_source_code():
-
- from toolbox import get_conf
- import shutil
- import os
- try: shutil.rmtree(f'./multi-language/{LANG}/')
- except: pass
- os.makedirs(f'./multi-language', exist_ok=True)
- backup_dir = f'./multi-language/{LANG}/'
- shutil.copytree('./', backup_dir, ignore=lambda x, y: blacklist)
- copy_source_code()
-
- # =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
- # primary key replace
- # =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
- directory_path = f'./multi-language/{LANG}/'
- for root, dirs, files in os.walk(directory_path):
- for file in files:
- if file.endswith('.py'):
- file_path = os.path.join(root, file)
- syntax = []
- # read again
- with open(file_path, 'r', encoding='utf-8') as f:
- content = f.read()
-
- for k, v in chinese_core_keys_norepeat_mapping.items():
- content = content.replace(k, v)
-
- with open(file_path, 'w', encoding='utf-8') as f:
- f.write(content)
-
-
-def step_2_core_key_translate():
-
- # =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
- # step2
- # =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=
-
- def load_string(strings, string_input):
- string_ = string_input.strip().strip(',').strip().strip('.').strip()
- if string_.startswith('[Local Message]'):
- string_ = string_.replace('[Local Message]', '')
- string_ = string_.strip().strip(',').strip().strip('.').strip()
- splitted_string = [string_]
- # --------------------------------------
- splitted_string = advanced_split(splitted_string, spliter=",", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="。", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter=")", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="(", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="(", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter=")", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="<", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter=">", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="[", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="]", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="【", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="】", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="?", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter=":", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter=":", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter=",", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="#", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="\n", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter=";", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="`", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter=" ", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="- ", include_spliter=False)
- splitted_string = advanced_split(splitted_string, spliter="---", include_spliter=False)
-
- # --------------------------------------
- for j, s in enumerate(splitted_string): # .com
- if '.com' in s: continue
- if '\'' in s: continue
- if '\"' in s: continue
- strings.append([s,0])
-
-
- def get_strings(node):
- strings = []
- # recursively traverse the AST
- for child in ast.iter_child_nodes(node):
- node = child
- if isinstance(child, ast.Str):
- if contains_chinese(child.s):
- load_string(strings=strings, string_input=child.s)
- elif isinstance(child, ast.AST):
- strings.extend(get_strings(child))
- return strings
-
- string_literals = []
- directory_path = f'./multi-language/{LANG}/'
- for root, dirs, files in os.walk(directory_path):
- for file in files:
- if file.endswith('.py'):
- file_path = os.path.join(root, file)
- syntax = []
- with open(file_path, 'r', encoding='utf-8') as f:
- content = f.read()
- # comments
- comments_arr = []
- for code_sp in content.splitlines():
- comments = re.findall(r'#.*$', code_sp)
- for comment in comments:
- load_string(strings=comments_arr, string_input=comment)
- string_literals.extend(comments_arr)
-
- # strings
- import ast
- tree = ast.parse(content)
- res = get_strings(tree, )
- string_literals.extend(res)
-
- [print(s) for s in string_literals]
- chinese_literal_names = []
- chinese_literal_names_norepeat = []
- for string, offset in string_literals:
- chinese_literal_names.append(string)
- chinese_literal_names_norepeat = []
- for d in chinese_literal_names:
- if d not in chinese_literal_names_norepeat: chinese_literal_names_norepeat.append(d)
- need_translate = []
- cached_translation = read_map_from_json(language=LANG)
- cached_translation_keys = list(cached_translation.keys())
- for d in chinese_literal_names_norepeat:
- if d not in cached_translation_keys:
- need_translate.append(d)
-
- if CACHE_ONLY:
- up = {}
- else:
- up = trans_json(need_translate, language=LANG, special=False)
- map_to_json(up, language=LANG)
- cached_translation = read_map_from_json(language=LANG)
- LANG_STD = 'std'
- cached_translation.update(read_map_from_json(language=LANG_STD))
- cached_translation = dict(sorted(cached_translation.items(), key=lambda x: -len(x[0])))
-
- # =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
- # literal key replace
- # =-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-=-
- directory_path = f'./multi-language/{LANG}/'
- for root, dirs, files in os.walk(directory_path):
- for file in files:
- if file.endswith('.py'):
- file_path = os.path.join(root, file)
- syntax = []
- # read again
- with open(file_path, 'r', encoding='utf-8') as f:
- content = f.read()
-
- for k, v in cached_translation.items():
- if v is None: continue
- if '"' in v:
- v = v.replace('"', "`")
- if '\'' in v:
- v = v.replace('\'', "`")
- content = content.replace(k, v)
-
- with open(file_path, 'w', encoding='utf-8') as f:
- f.write(content)
-
- if file.strip('.py') in cached_translation:
- file_new = cached_translation[file.strip('.py')] + '.py'
- file_path_new = os.path.join(root, file_new)
- with open(file_path_new, 'w', encoding='utf-8') as f:
- f.write(content)
- os.remove(file_path)
-step_1_core_key_translate()
-step_2_core_key_translate()
-print('Finished, checkout generated results at ./multi-language/')
\ No newline at end of file
diff --git a/predict.py b/predict.py
new file mode 100644
index 0000000000000000000000000000000000000000..cb65fa897f74ccadb85ee454882c61a194e4f84e
--- /dev/null
+++ b/predict.py
@@ -0,0 +1,191 @@
+# 借鉴了 https://github.com/GaiZhenbiao/ChuanhuChatGPT 项目
+
+import json
+import gradio as gr
+import logging
+import traceback
+import requests
+import importlib
+
+# config_private.py放自己的秘密如API和代理网址
+# 读取时首先看是否存在私密的config_private配置文件(不受git管控),如果有,则覆盖原config文件
+try: from config_private import proxies, API_URL, API_KEY, TIMEOUT_SECONDS, MAX_RETRY, LLM_MODEL
+except: from config import proxies, API_URL, API_KEY, TIMEOUT_SECONDS, MAX_RETRY, LLM_MODEL
+
+timeout_bot_msg = '[local] Request timeout, network error. please check proxy settings in config.py.'
+
+def get_full_error(chunk, stream_response):
+ """
+ 获取完整的从Openai返回的报错
+ """
+ while True:
+ try:
+ chunk += next(stream_response)
+ except:
+ break
+ return chunk
+
+def predict_no_ui(api, inputs, top_p, temperature, history=[]):
+ """
+ 发送至chatGPT,等待回复,一次性完成,不显示中间过程。
+ predict函数的简化版。
+ 用于payload比较大的情况,或者用于实现多线、带嵌套的复杂功能。
+
+ inputs 是本次问询的输入
+ top_p, temperature是chatGPT的内部调优参数
+ history 是之前的对话列表
+ (注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误,然后raise ConnectionAbortedError)
+ """
+ headers, payload = generate_payload(api, inputs, top_p, temperature, history, system_prompt="", stream=False)
+
+ retry = 0
+ while True:
+ try:
+ # make a POST request to the API endpoint, stream=False
+ response = requests.post(API_URL, headers=headers, proxies=proxies,
+ json=payload, stream=False, timeout=TIMEOUT_SECONDS*2); break
+ except requests.exceptions.ReadTimeout as e:
+ retry += 1
+ traceback.print_exc()
+ if MAX_RETRY!=0: print(f'请求超时,正在重试 ({retry}/{MAX_RETRY}) ……')
+ if retry > MAX_RETRY: raise TimeoutError
+
+ try:
+ result = json.loads(response.text)["choices"][0]["message"]["content"]
+ return result
+ except Exception as e:
+ if "choices" not in response.text: print(response.text)
+ raise ConnectionAbortedError("Json解析不合常规,可能是文本过长" + response.text)
+
+
+def predict(api, inputs, top_p, temperature, chatbot=[], history=[], system_prompt='',
+ stream = True, additional_fn=None):
+ """
+ 发送至chatGPT,流式获取输出。
+ 用于基础的对话功能。
+ inputs 是本次问询的输入
+ top_p, temperature是chatGPT的内部调优参数
+ history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误)
+ chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容
+ additional_fn代表点击的哪个按钮,按钮见functional.py
+ """
+ if additional_fn is not None:
+ import functional
+ importlib.reload(functional)
+ functional = functional.get_functionals()
+ inputs = functional[additional_fn]["Prefix"] + inputs + functional[additional_fn]["Suffix"]
+
+ if stream:
+ raw_input = inputs
+ logging.info(f'[raw_input] {raw_input}')
+ chatbot.append((inputs, ""))
+ yield chatbot, history, "等待响应"
+
+ headers, payload = generate_payload(api, inputs, top_p, temperature, history, system_prompt, stream)
+ history.append(inputs); history.append(" ")
+
+ retry = 0
+ while True:
+ try:
+ # make a POST request to the API endpoint, stream=True
+ response = requests.post(API_URL, headers=headers, proxies=proxies,
+ json=payload, stream=True, timeout=TIMEOUT_SECONDS);break
+ except:
+ retry += 1
+ chatbot[-1] = ((chatbot[-1][0], timeout_bot_msg))
+ retry_msg = f",正在重试 ({retry}/{MAX_RETRY}) ……" if MAX_RETRY > 0 else ""
+ yield chatbot, history, "请求超时"+retry_msg
+ if retry > MAX_RETRY: raise TimeoutError
+
+ gpt_replying_buffer = ""
+
+ is_head_of_the_stream = True
+ if stream:
+ stream_response = response.iter_lines()
+ while True:
+ chunk = next(stream_response)
+ # print(chunk.decode()[6:])
+ if is_head_of_the_stream:
+ # 数据流的第一帧不携带content
+ is_head_of_the_stream = False; continue
+
+ if chunk:
+ try:
+ if len(json.loads(chunk.decode()[6:])['choices'][0]["delta"]) == 0:
+ # 判定为数据流的结束,gpt_replying_buffer也写完了
+ logging.info(f'[response] {gpt_replying_buffer}')
+ break
+ # 处理数据流的主体
+ chunkjson = json.loads(chunk.decode()[6:])
+ status_text = f"finish_reason: {chunkjson['choices'][0]['finish_reason']}"
+ # 如果这里抛出异常,一般是文本过长,详情见get_full_error的输出
+ gpt_replying_buffer = gpt_replying_buffer + json.loads(chunk.decode()[6:])['choices'][0]["delta"]["content"]
+ history[-1] = gpt_replying_buffer
+ chatbot[-1] = (history[-2], history[-1])
+ yield chatbot, history, status_text
+
+ except Exception as e:
+ traceback.print_exc()
+ yield chatbot, history, "Json解析不合常规,很可能是文本过长"
+ chunk = get_full_error(chunk, stream_response)
+ error_msg = chunk.decode()
+ if "reduce the length" in error_msg:
+ chatbot[-1] = (chatbot[-1][0], "[Local Message] Input (or history) is too long, please reduce input or clear history by refleshing this page.")
+ history = []
+ elif "API key" in error_msg:
+ chatbot[-1] = (chatbot[-1][0], "[Local Message] Incorrect API key provided.")
+ else:
+ from toolbox import regular_txt_to_markdown
+ tb_str = regular_txt_to_markdown(traceback.format_exc())
+ chatbot[-1] = (chatbot[-1][0], f"[Local Message] Json Error \n\n {tb_str} \n\n {regular_txt_to_markdown(chunk.decode()[4:])}")
+ yield chatbot, history, "Json解析不合常规,很可能是文本过长" + error_msg
+ return
+
+def generate_payload(api, inputs, top_p, temperature, history, system_prompt, stream):
+ """
+ 整合所有信息,选择LLM模型,生成http请求,为发送请求做准备
+ """
+ headers = {
+ "Content-Type": "application/json",
+ "Authorization": f"Bearer {api}"
+ }
+
+ conversation_cnt = len(history) // 2
+
+ messages = [{"role": "system", "content": system_prompt}]
+ if conversation_cnt:
+ for index in range(0, 2*conversation_cnt, 2):
+ what_i_have_asked = {}
+ what_i_have_asked["role"] = "user"
+ what_i_have_asked["content"] = history[index]
+ what_gpt_answer = {}
+ what_gpt_answer["role"] = "assistant"
+ what_gpt_answer["content"] = history[index+1]
+ if what_i_have_asked["content"] != "":
+ if what_gpt_answer["content"] == "": continue
+ if what_gpt_answer["content"] == timeout_bot_msg: continue
+ messages.append(what_i_have_asked)
+ messages.append(what_gpt_answer)
+ else:
+ messages[-1]['content'] = what_gpt_answer['content']
+
+ what_i_ask_now = {}
+ what_i_ask_now["role"] = "user"
+ what_i_ask_now["content"] = inputs
+ messages.append(what_i_ask_now)
+
+ payload = {
+ "model": LLM_MODEL,
+ "messages": messages,
+ "temperature": temperature, # 1.0,
+ "top_p": top_p, # 1.0,
+ "n": 1,
+ "stream": stream,
+ "presence_penalty": 0,
+ "frequency_penalty": 0,
+ }
+
+ print(f" {LLM_MODEL} : {conversation_cnt} : {inputs}")
+ return headers,payload
+
+
diff --git a/request_llms/README.md b/request_llms/README.md
deleted file mode 100644
index 5a51592ab8751bed5583532c8d552ba492c54c86..0000000000000000000000000000000000000000
--- a/request_llms/README.md
+++ /dev/null
@@ -1,35 +0,0 @@
-P.S. 如果您按照以下步骤成功接入了新的大模型,欢迎发Pull Requests(如果您在自己接入新模型的过程中遇到困难,欢迎加README底部QQ群联系群主)
-
-
-# 如何接入其他本地大语言模型
-
-1. 复制`request_llms/bridge_llama2.py`,重命名为你喜欢的名字
-
-2. 修改`load_model_and_tokenizer`方法,加载你的模型和分词器(去该模型官网找demo,复制粘贴即可)
-
-3. 修改`llm_stream_generator`方法,定义推理模型(去该模型官网找demo,复制粘贴即可)
-
-4. 命令行测试
- - 修改`tests/test_llms.py`(聪慧如您,只需要看一眼该文件就明白怎么修改了)
- - 运行`python tests/test_llms.py`
-
-5. 测试通过后,在`request_llms/bridge_all.py`中做最后的修改,把你的模型完全接入到框架中(聪慧如您,只需要看一眼该文件就明白怎么修改了)
-
-6. 修改`LLM_MODEL`配置,然后运行`python main.py`,测试最后的效果
-
-
-# 如何接入其他在线大语言模型
-
-1. 复制`request_llms/bridge_zhipu.py`,重命名为你喜欢的名字
-
-2. 修改`predict_no_ui_long_connection`
-
-3. 修改`predict`
-
-4. 命令行测试
- - 修改`tests/test_llms.py`(聪慧如您,只需要看一眼该文件就明白怎么修改了)
- - 运行`python tests/test_llms.py`
-
-5. 测试通过后,在`request_llms/bridge_all.py`中做最后的修改,把你的模型完全接入到框架中(聪慧如您,只需要看一眼该文件就明白怎么修改了)
-
-6. 修改`LLM_MODEL`配置,然后运行`python main.py`,测试最后的效果
diff --git a/request_llms/bridge_all.py b/request_llms/bridge_all.py
deleted file mode 100644
index e20570f93502c5a6dc633640c90f5968f7c70f1f..0000000000000000000000000000000000000000
--- a/request_llms/bridge_all.py
+++ /dev/null
@@ -1,784 +0,0 @@
-
-"""
- 该文件中主要包含2个函数,是所有LLM的通用接口,它们会继续向下调用更底层的LLM模型,处理多模型并行等细节
-
- 不具备多线程能力的函数:正常对话时使用,具备完备的交互功能,不可多线程
- 1. predict(...)
-
- 具备多线程调用能力的函数:在函数插件中被调用,灵活而简洁
- 2. predict_no_ui_long_connection(...)
-"""
-import tiktoken, copy
-from functools import lru_cache
-from concurrent.futures import ThreadPoolExecutor
-from toolbox import get_conf, trimmed_format_exc, apply_gpt_academic_string_mask
-
-from .bridge_chatgpt import predict_no_ui_long_connection as chatgpt_noui
-from .bridge_chatgpt import predict as chatgpt_ui
-
-from .bridge_chatgpt_vision import predict_no_ui_long_connection as chatgpt_vision_noui
-from .bridge_chatgpt_vision import predict as chatgpt_vision_ui
-
-from .bridge_chatglm import predict_no_ui_long_connection as chatglm_noui
-from .bridge_chatglm import predict as chatglm_ui
-
-from .bridge_chatglm3 import predict_no_ui_long_connection as chatglm3_noui
-from .bridge_chatglm3 import predict as chatglm3_ui
-
-from .bridge_qianfan import predict_no_ui_long_connection as qianfan_noui
-from .bridge_qianfan import predict as qianfan_ui
-
-from .bridge_google_gemini import predict as genai_ui
-from .bridge_google_gemini import predict_no_ui_long_connection as genai_noui
-
-from .bridge_zhipu import predict_no_ui_long_connection as zhipu_noui
-from .bridge_zhipu import predict as zhipu_ui
-
-colors = ['#FF00FF', '#00FFFF', '#FF0000', '#990099', '#009999', '#990044']
-
-class LazyloadTiktoken(object):
- def __init__(self, model):
- self.model = model
-
- @staticmethod
- @lru_cache(maxsize=128)
- def get_encoder(model):
- print('正在加载tokenizer,如果是第一次运行,可能需要一点时间下载参数')
- tmp = tiktoken.encoding_for_model(model)
- print('加载tokenizer完毕')
- return tmp
-
- def encode(self, *args, **kwargs):
- encoder = self.get_encoder(self.model)
- return encoder.encode(*args, **kwargs)
-
- def decode(self, *args, **kwargs):
- encoder = self.get_encoder(self.model)
- return encoder.decode(*args, **kwargs)
-
-# Endpoint 重定向
-API_URL_REDIRECT, AZURE_ENDPOINT, AZURE_ENGINE = get_conf("API_URL_REDIRECT", "AZURE_ENDPOINT", "AZURE_ENGINE")
-openai_endpoint = "https://api.openai.com/v1/chat/completions"
-api2d_endpoint = "https://openai.api2d.net/v1/chat/completions"
-newbing_endpoint = "wss://sydney.bing.com/sydney/ChatHub"
-if not AZURE_ENDPOINT.endswith('/'): AZURE_ENDPOINT += '/'
-azure_endpoint = AZURE_ENDPOINT + f'openai/deployments/{AZURE_ENGINE}/chat/completions?api-version=2023-05-15'
-# 兼容旧版的配置
-try:
- API_URL = get_conf("API_URL")
- if API_URL != "https://api.openai.com/v1/chat/completions":
- openai_endpoint = API_URL
- print("警告!API_URL配置选项将被弃用,请更换为API_URL_REDIRECT配置")
-except:
- pass
-# 新版配置
-if openai_endpoint in API_URL_REDIRECT: openai_endpoint = API_URL_REDIRECT[openai_endpoint]
-if api2d_endpoint in API_URL_REDIRECT: api2d_endpoint = API_URL_REDIRECT[api2d_endpoint]
-if newbing_endpoint in API_URL_REDIRECT: newbing_endpoint = API_URL_REDIRECT[newbing_endpoint]
-
-
-# 获取tokenizer
-tokenizer_gpt35 = LazyloadTiktoken("gpt-3.5-turbo")
-tokenizer_gpt4 = LazyloadTiktoken("gpt-4")
-get_token_num_gpt35 = lambda txt: len(tokenizer_gpt35.encode(txt, disallowed_special=()))
-get_token_num_gpt4 = lambda txt: len(tokenizer_gpt4.encode(txt, disallowed_special=()))
-
-
-# 开始初始化模型
-AVAIL_LLM_MODELS, LLM_MODEL = get_conf("AVAIL_LLM_MODELS", "LLM_MODEL")
-AVAIL_LLM_MODELS = AVAIL_LLM_MODELS + [LLM_MODEL]
-# -=-=-=-=-=-=- 以下这部分是最早加入的最稳定的模型 -=-=-=-=-=-=-
-model_info = {
- # openai
- "gpt-3.5-turbo": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
-
- "gpt-3.5-turbo-16k": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 16385,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
-
- "gpt-3.5-turbo-0613": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
-
- "gpt-3.5-turbo-16k-0613": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 16385,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
-
- "gpt-3.5-turbo-1106": {#16k
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 16385,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
-
- "gpt-4": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 8192,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
- "gpt-4-32k": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 32768,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
- "gpt-4-turbo-preview": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 128000,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
- "gpt-4-1106-preview": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 128000,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
- "gpt-4-0125-preview": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 128000,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
- "gpt-3.5-random": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": openai_endpoint,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
- "gpt-4-vision-preview": {
- "fn_with_ui": chatgpt_vision_ui,
- "fn_without_ui": chatgpt_vision_noui,
- "endpoint": openai_endpoint,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
-
- # azure openai
- "azure-gpt-3.5":{
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": azure_endpoint,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
-
- "azure-gpt-4":{
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": azure_endpoint,
- "max_token": 8192,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
- # 智谱AI
- "glm-4": {
- "fn_with_ui": zhipu_ui,
- "fn_without_ui": zhipu_noui,
- "endpoint": None,
- "max_token": 10124 * 8,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "glm-3-turbo": {
- "fn_with_ui": zhipu_ui,
- "fn_without_ui": zhipu_noui,
- "endpoint": None,
- "max_token": 10124 * 4,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
-
- # api_2d (此后不需要在此处添加api2d的接口了,因为下面的代码会自动添加)
- "api2d-gpt-4": {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": api2d_endpoint,
- "max_token": 8192,
- "tokenizer": tokenizer_gpt4,
- "token_cnt": get_token_num_gpt4,
- },
-
- # 将 chatglm 直接对齐到 chatglm2
- "chatglm": {
- "fn_with_ui": chatglm_ui,
- "fn_without_ui": chatglm_noui,
- "endpoint": None,
- "max_token": 1024,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "chatglm2": {
- "fn_with_ui": chatglm_ui,
- "fn_without_ui": chatglm_noui,
- "endpoint": None,
- "max_token": 1024,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "chatglm3": {
- "fn_with_ui": chatglm3_ui,
- "fn_without_ui": chatglm3_noui,
- "endpoint": None,
- "max_token": 8192,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "qianfan": {
- "fn_with_ui": qianfan_ui,
- "fn_without_ui": qianfan_noui,
- "endpoint": None,
- "max_token": 2000,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "gemini-pro": {
- "fn_with_ui": genai_ui,
- "fn_without_ui": genai_noui,
- "endpoint": None,
- "max_token": 1024 * 32,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "gemini-pro-vision": {
- "fn_with_ui": genai_ui,
- "fn_without_ui": genai_noui,
- "endpoint": None,
- "max_token": 1024 * 32,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
-}
-
-# -=-=-=-=-=-=- api2d 对齐支持 -=-=-=-=-=-=-
-for model in AVAIL_LLM_MODELS:
- if model.startswith('api2d-') and (model.replace('api2d-','') in model_info.keys()):
- mi = copy.deepcopy(model_info[model.replace('api2d-','')])
- mi.update({"endpoint": api2d_endpoint})
- model_info.update({model: mi})
-
-# -=-=-=-=-=-=- azure 对齐支持 -=-=-=-=-=-=-
-for model in AVAIL_LLM_MODELS:
- if model.startswith('azure-') and (model.replace('azure-','') in model_info.keys()):
- mi = copy.deepcopy(model_info[model.replace('azure-','')])
- mi.update({"endpoint": azure_endpoint})
- model_info.update({model: mi})
-
-# -=-=-=-=-=-=- 以下部分是新加入的模型,可能附带额外依赖 -=-=-=-=-=-=-
-if "claude-1-100k" in AVAIL_LLM_MODELS or "claude-2" in AVAIL_LLM_MODELS:
- from .bridge_claude import predict_no_ui_long_connection as claude_noui
- from .bridge_claude import predict as claude_ui
- model_info.update({
- "claude-1-100k": {
- "fn_with_ui": claude_ui,
- "fn_without_ui": claude_noui,
- "endpoint": None,
- "max_token": 8196,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- })
- model_info.update({
- "claude-2": {
- "fn_with_ui": claude_ui,
- "fn_without_ui": claude_noui,
- "endpoint": None,
- "max_token": 8196,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- })
-if "jittorllms_rwkv" in AVAIL_LLM_MODELS:
- from .bridge_jittorllms_rwkv import predict_no_ui_long_connection as rwkv_noui
- from .bridge_jittorllms_rwkv import predict as rwkv_ui
- model_info.update({
- "jittorllms_rwkv": {
- "fn_with_ui": rwkv_ui,
- "fn_without_ui": rwkv_noui,
- "endpoint": None,
- "max_token": 1024,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- })
-if "jittorllms_llama" in AVAIL_LLM_MODELS:
- from .bridge_jittorllms_llama import predict_no_ui_long_connection as llama_noui
- from .bridge_jittorllms_llama import predict as llama_ui
- model_info.update({
- "jittorllms_llama": {
- "fn_with_ui": llama_ui,
- "fn_without_ui": llama_noui,
- "endpoint": None,
- "max_token": 1024,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- })
-if "jittorllms_pangualpha" in AVAIL_LLM_MODELS:
- from .bridge_jittorllms_pangualpha import predict_no_ui_long_connection as pangualpha_noui
- from .bridge_jittorllms_pangualpha import predict as pangualpha_ui
- model_info.update({
- "jittorllms_pangualpha": {
- "fn_with_ui": pangualpha_ui,
- "fn_without_ui": pangualpha_noui,
- "endpoint": None,
- "max_token": 1024,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- })
-if "moss" in AVAIL_LLM_MODELS:
- from .bridge_moss import predict_no_ui_long_connection as moss_noui
- from .bridge_moss import predict as moss_ui
- model_info.update({
- "moss": {
- "fn_with_ui": moss_ui,
- "fn_without_ui": moss_noui,
- "endpoint": None,
- "max_token": 1024,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- })
-if "stack-claude" in AVAIL_LLM_MODELS:
- from .bridge_stackclaude import predict_no_ui_long_connection as claude_noui
- from .bridge_stackclaude import predict as claude_ui
- model_info.update({
- "stack-claude": {
- "fn_with_ui": claude_ui,
- "fn_without_ui": claude_noui,
- "endpoint": None,
- "max_token": 8192,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
-if "newbing-free" in AVAIL_LLM_MODELS:
- try:
- from .bridge_newbingfree import predict_no_ui_long_connection as newbingfree_noui
- from .bridge_newbingfree import predict as newbingfree_ui
- model_info.update({
- "newbing-free": {
- "fn_with_ui": newbingfree_ui,
- "fn_without_ui": newbingfree_noui,
- "endpoint": newbing_endpoint,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "newbing" in AVAIL_LLM_MODELS: # same with newbing-free
- try:
- from .bridge_newbingfree import predict_no_ui_long_connection as newbingfree_noui
- from .bridge_newbingfree import predict as newbingfree_ui
- model_info.update({
- "newbing": {
- "fn_with_ui": newbingfree_ui,
- "fn_without_ui": newbingfree_noui,
- "endpoint": newbing_endpoint,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "chatglmft" in AVAIL_LLM_MODELS: # same with newbing-free
- try:
- from .bridge_chatglmft import predict_no_ui_long_connection as chatglmft_noui
- from .bridge_chatglmft import predict as chatglmft_ui
- model_info.update({
- "chatglmft": {
- "fn_with_ui": chatglmft_ui,
- "fn_without_ui": chatglmft_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "internlm" in AVAIL_LLM_MODELS:
- try:
- from .bridge_internlm import predict_no_ui_long_connection as internlm_noui
- from .bridge_internlm import predict as internlm_ui
- model_info.update({
- "internlm": {
- "fn_with_ui": internlm_ui,
- "fn_without_ui": internlm_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "chatglm_onnx" in AVAIL_LLM_MODELS:
- try:
- from .bridge_chatglmonnx import predict_no_ui_long_connection as chatglm_onnx_noui
- from .bridge_chatglmonnx import predict as chatglm_onnx_ui
- model_info.update({
- "chatglm_onnx": {
- "fn_with_ui": chatglm_onnx_ui,
- "fn_without_ui": chatglm_onnx_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "qwen-local" in AVAIL_LLM_MODELS:
- try:
- from .bridge_qwen_local import predict_no_ui_long_connection as qwen_local_noui
- from .bridge_qwen_local import predict as qwen_local_ui
- model_info.update({
- "qwen-local": {
- "fn_with_ui": qwen_local_ui,
- "fn_without_ui": qwen_local_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "qwen-turbo" in AVAIL_LLM_MODELS or "qwen-plus" in AVAIL_LLM_MODELS or "qwen-max" in AVAIL_LLM_MODELS: # zhipuai
- try:
- from .bridge_qwen import predict_no_ui_long_connection as qwen_noui
- from .bridge_qwen import predict as qwen_ui
- model_info.update({
- "qwen-turbo": {
- "fn_with_ui": qwen_ui,
- "fn_without_ui": qwen_noui,
- "endpoint": None,
- "max_token": 6144,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "qwen-plus": {
- "fn_with_ui": qwen_ui,
- "fn_without_ui": qwen_noui,
- "endpoint": None,
- "max_token": 30720,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "qwen-max": {
- "fn_with_ui": qwen_ui,
- "fn_without_ui": qwen_noui,
- "endpoint": None,
- "max_token": 28672,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "spark" in AVAIL_LLM_MODELS: # 讯飞星火认知大模型
- try:
- from .bridge_spark import predict_no_ui_long_connection as spark_noui
- from .bridge_spark import predict as spark_ui
- model_info.update({
- "spark": {
- "fn_with_ui": spark_ui,
- "fn_without_ui": spark_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "sparkv2" in AVAIL_LLM_MODELS: # 讯飞星火认知大模型
- try:
- from .bridge_spark import predict_no_ui_long_connection as spark_noui
- from .bridge_spark import predict as spark_ui
- model_info.update({
- "sparkv2": {
- "fn_with_ui": spark_ui,
- "fn_without_ui": spark_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "sparkv3" in AVAIL_LLM_MODELS or "sparkv3.5" in AVAIL_LLM_MODELS: # 讯飞星火认知大模型
- try:
- from .bridge_spark import predict_no_ui_long_connection as spark_noui
- from .bridge_spark import predict as spark_ui
- model_info.update({
- "sparkv3": {
- "fn_with_ui": spark_ui,
- "fn_without_ui": spark_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- "sparkv3.5": {
- "fn_with_ui": spark_ui,
- "fn_without_ui": spark_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "llama2" in AVAIL_LLM_MODELS: # llama2
- try:
- from .bridge_llama2 import predict_no_ui_long_connection as llama2_noui
- from .bridge_llama2 import predict as llama2_ui
- model_info.update({
- "llama2": {
- "fn_with_ui": llama2_ui,
- "fn_without_ui": llama2_noui,
- "endpoint": None,
- "max_token": 4096,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-if "zhipuai" in AVAIL_LLM_MODELS: # zhipuai 是glm-4的别名,向后兼容配置
- try:
- model_info.update({
- "zhipuai": {
- "fn_with_ui": zhipu_ui,
- "fn_without_ui": zhipu_noui,
- "endpoint": None,
- "max_token": 10124 * 8,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- },
- })
- except:
- print(trimmed_format_exc())
-if "deepseekcoder" in AVAIL_LLM_MODELS: # deepseekcoder
- try:
- from .bridge_deepseekcoder import predict_no_ui_long_connection as deepseekcoder_noui
- from .bridge_deepseekcoder import predict as deepseekcoder_ui
- model_info.update({
- "deepseekcoder": {
- "fn_with_ui": deepseekcoder_ui,
- "fn_without_ui": deepseekcoder_noui,
- "endpoint": None,
- "max_token": 2048,
- "tokenizer": tokenizer_gpt35,
- "token_cnt": get_token_num_gpt35,
- }
- })
- except:
- print(trimmed_format_exc())
-# if "skylark" in AVAIL_LLM_MODELS:
-# try:
-# from .bridge_skylark2 import predict_no_ui_long_connection as skylark_noui
-# from .bridge_skylark2 import predict as skylark_ui
-# model_info.update({
-# "skylark": {
-# "fn_with_ui": skylark_ui,
-# "fn_without_ui": skylark_noui,
-# "endpoint": None,
-# "max_token": 4096,
-# "tokenizer": tokenizer_gpt35,
-# "token_cnt": get_token_num_gpt35,
-# }
-# })
-# except:
-# print(trimmed_format_exc())
-
-
-# <-- 用于定义和切换多个azure模型 -->
-AZURE_CFG_ARRAY = get_conf("AZURE_CFG_ARRAY")
-if len(AZURE_CFG_ARRAY) > 0:
- for azure_model_name, azure_cfg_dict in AZURE_CFG_ARRAY.items():
- # 可能会覆盖之前的配置,但这是意料之中的
- if not azure_model_name.startswith('azure'):
- raise ValueError("AZURE_CFG_ARRAY中配置的模型必须以azure开头")
- endpoint_ = azure_cfg_dict["AZURE_ENDPOINT"] + \
- f'openai/deployments/{azure_cfg_dict["AZURE_ENGINE"]}/chat/completions?api-version=2023-05-15'
- model_info.update({
- azure_model_name: {
- "fn_with_ui": chatgpt_ui,
- "fn_without_ui": chatgpt_noui,
- "endpoint": endpoint_,
- "azure_api_key": azure_cfg_dict["AZURE_API_KEY"],
- "max_token": azure_cfg_dict["AZURE_MODEL_MAX_TOKEN"],
- "tokenizer": tokenizer_gpt35, # tokenizer只用于粗估token数量
- "token_cnt": get_token_num_gpt35,
- }
- })
- if azure_model_name not in AVAIL_LLM_MODELS:
- AVAIL_LLM_MODELS += [azure_model_name]
-
-
-
-
-def LLM_CATCH_EXCEPTION(f):
- """
- 装饰器函数,将错误显示出来
- """
- def decorated(inputs, llm_kwargs, history, sys_prompt, observe_window, console_slience):
- try:
- return f(inputs, llm_kwargs, history, sys_prompt, observe_window, console_slience)
- except Exception as e:
- tb_str = '\n```\n' + trimmed_format_exc() + '\n```\n'
- observe_window[0] = tb_str
- return tb_str
- return decorated
-
-
-def predict_no_ui_long_connection(inputs, llm_kwargs, history, sys_prompt, observe_window=[], console_slience=False):
- """
- 发送至LLM,等待回复,一次性完成,不显示中间过程。但内部用stream的方法避免中途网线被掐。
- inputs:
- 是本次问询的输入
- sys_prompt:
- 系统静默prompt
- llm_kwargs:
- LLM的内部调优参数
- history:
- 是之前的对话列表
- observe_window = None:
- 用于负责跨越线程传递已经输出的部分,大部分时候仅仅为了fancy的视觉效果,留空即可。observe_window[0]:观测窗。observe_window[1]:看门狗
- """
- import threading, time, copy
-
- inputs = apply_gpt_academic_string_mask(inputs, mode="show_llm")
- model = llm_kwargs['llm_model']
- n_model = 1
- if '&' not in model:
- assert not model.startswith("tgui"), "TGUI不支持函数插件的实现"
-
- # 如果只询问1个大语言模型:
- method = model_info[model]["fn_without_ui"]
- return method(inputs, llm_kwargs, history, sys_prompt, observe_window, console_slience)
- else:
-
- # 如果同时询问多个大语言模型,这个稍微啰嗦一点,但思路相同,您不必读这个else分支
- executor = ThreadPoolExecutor(max_workers=4)
- models = model.split('&')
- n_model = len(models)
-
- window_len = len(observe_window)
- assert window_len==3
- window_mutex = [["", time.time(), ""] for _ in range(n_model)] + [True]
-
- futures = []
- for i in range(n_model):
- model = models[i]
- method = model_info[model]["fn_without_ui"]
- llm_kwargs_feedin = copy.deepcopy(llm_kwargs)
- llm_kwargs_feedin['llm_model'] = model
- future = executor.submit(LLM_CATCH_EXCEPTION(method), inputs, llm_kwargs_feedin, history, sys_prompt, window_mutex[i], console_slience)
- futures.append(future)
-
- def mutex_manager(window_mutex, observe_window):
- while True:
- time.sleep(0.25)
- if not window_mutex[-1]: break
- # 看门狗(watchdog)
- for i in range(n_model):
- window_mutex[i][1] = observe_window[1]
- # 观察窗(window)
- chat_string = []
- for i in range(n_model):
- chat_string.append( f"【{str(models[i])} 说】: {window_mutex[i][0]} " )
- res = '
\n\n---\n\n'.join(chat_string)
- # # # # # # # # # # #
- observe_window[0] = res
-
- t_model = threading.Thread(target=mutex_manager, args=(window_mutex, observe_window), daemon=True)
- t_model.start()
-
- return_string_collect = []
- while True:
- worker_done = [h.done() for h in futures]
- if all(worker_done):
- executor.shutdown()
- break
- time.sleep(1)
-
- for i, future in enumerate(futures): # wait and get
- return_string_collect.append( f"【{str(models[i])} 说】: {future.result()} " )
-
- window_mutex[-1] = False # stop mutex thread
- res = '
\n\n---\n\n'.join(return_string_collect)
- return res
-
-
-def predict(inputs, llm_kwargs, *args, **kwargs):
- """
- 发送至LLM,流式获取输出。
- 用于基础的对话功能。
- inputs 是本次问询的输入
- top_p, temperature是LLM的内部调优参数
- history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误)
- chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容
- additional_fn代表点击的哪个按钮,按钮见functional.py
- """
-
- inputs = apply_gpt_academic_string_mask(inputs, mode="show_llm")
- method = model_info[llm_kwargs['llm_model']]["fn_with_ui"] # 如果这里报错,检查config中的AVAIL_LLM_MODELS选项
- yield from method(inputs, llm_kwargs, *args, **kwargs)
-
diff --git a/request_llms/bridge_chatglm.py b/request_llms/bridge_chatglm.py
deleted file mode 100644
index c58495dccfc7d64f194b5f6904b6660141c41cad..0000000000000000000000000000000000000000
--- a/request_llms/bridge_chatglm.py
+++ /dev/null
@@ -1,78 +0,0 @@
-model_name = "ChatGLM"
-cmd_to_install = "`pip install -r request_llms/requirements_chatglm.txt`"
-
-
-from toolbox import get_conf, ProxyNetworkActivate
-from .local_llm_class import LocalLLMHandle, get_local_llm_predict_fns
-
-
-
-# ------------------------------------------------------------------------------------------------------------------------
-# 🔌💻 Local Model
-# ------------------------------------------------------------------------------------------------------------------------
-class GetGLM2Handle(LocalLLMHandle):
-
- def load_model_info(self):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- self.model_name = model_name
- self.cmd_to_install = cmd_to_install
-
- def load_model_and_tokenizer(self):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- import os, glob
- import os
- import platform
- from transformers import AutoModel, AutoTokenizer
- LOCAL_MODEL_QUANT, device = get_conf('LOCAL_MODEL_QUANT', 'LOCAL_MODEL_DEVICE')
-
- if LOCAL_MODEL_QUANT == "INT4": # INT4
- _model_name_ = "THUDM/chatglm2-6b-int4"
- elif LOCAL_MODEL_QUANT == "INT8": # INT8
- _model_name_ = "THUDM/chatglm2-6b-int8"
- else:
- _model_name_ = "THUDM/chatglm2-6b" # FP16
-
- with ProxyNetworkActivate('Download_LLM'):
- chatglm_tokenizer = AutoTokenizer.from_pretrained(_model_name_, trust_remote_code=True)
- if device=='cpu':
- chatglm_model = AutoModel.from_pretrained(_model_name_, trust_remote_code=True).float()
- else:
- chatglm_model = AutoModel.from_pretrained(_model_name_, trust_remote_code=True).half().cuda()
- chatglm_model = chatglm_model.eval()
-
- self._model = chatglm_model
- self._tokenizer = chatglm_tokenizer
- return self._model, self._tokenizer
-
- def llm_stream_generator(self, **kwargs):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- def adaptor(kwargs):
- query = kwargs['query']
- max_length = kwargs['max_length']
- top_p = kwargs['top_p']
- temperature = kwargs['temperature']
- history = kwargs['history']
- return query, max_length, top_p, temperature, history
-
- query, max_length, top_p, temperature, history = adaptor(kwargs)
-
- for response, history in self._model.stream_chat(self._tokenizer,
- query,
- history,
- max_length=max_length,
- top_p=top_p,
- temperature=temperature,
- ):
- yield response
-
- def try_to_import_special_deps(self, **kwargs):
- # import something that will raise error if the user does not install requirement_*.txt
- # 🏃♂️🏃♂️🏃♂️ 主进程执行
- import importlib
- # importlib.import_module('modelscope')
-
-
-# ------------------------------------------------------------------------------------------------------------------------
-# 🔌💻 GPT-Academic Interface
-# ------------------------------------------------------------------------------------------------------------------------
-predict_no_ui_long_connection, predict = get_local_llm_predict_fns(GetGLM2Handle, model_name)
\ No newline at end of file
diff --git a/request_llms/bridge_chatglm3.py b/request_llms/bridge_chatglm3.py
deleted file mode 100644
index 3caa4769d39ae8f56780caf43ddff6373600410d..0000000000000000000000000000000000000000
--- a/request_llms/bridge_chatglm3.py
+++ /dev/null
@@ -1,77 +0,0 @@
-model_name = "ChatGLM3"
-cmd_to_install = "`pip install -r request_llms/requirements_chatglm.txt`"
-
-
-from toolbox import get_conf, ProxyNetworkActivate
-from .local_llm_class import LocalLLMHandle, get_local_llm_predict_fns
-
-
-
-# ------------------------------------------------------------------------------------------------------------------------
-# 🔌💻 Local Model
-# ------------------------------------------------------------------------------------------------------------------------
-class GetGLM3Handle(LocalLLMHandle):
-
- def load_model_info(self):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- self.model_name = model_name
- self.cmd_to_install = cmd_to_install
-
- def load_model_and_tokenizer(self):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- from transformers import AutoModel, AutoTokenizer
- import os, glob
- import os
- import platform
- LOCAL_MODEL_QUANT, device = get_conf('LOCAL_MODEL_QUANT', 'LOCAL_MODEL_DEVICE')
-
- if LOCAL_MODEL_QUANT == "INT4": # INT4
- _model_name_ = "THUDM/chatglm3-6b-int4"
- elif LOCAL_MODEL_QUANT == "INT8": # INT8
- _model_name_ = "THUDM/chatglm3-6b-int8"
- else:
- _model_name_ = "THUDM/chatglm3-6b" # FP16
- with ProxyNetworkActivate('Download_LLM'):
- chatglm_tokenizer = AutoTokenizer.from_pretrained(_model_name_, trust_remote_code=True)
- if device=='cpu':
- chatglm_model = AutoModel.from_pretrained(_model_name_, trust_remote_code=True, device='cpu').float()
- else:
- chatglm_model = AutoModel.from_pretrained(_model_name_, trust_remote_code=True, device='cuda')
- chatglm_model = chatglm_model.eval()
-
- self._model = chatglm_model
- self._tokenizer = chatglm_tokenizer
- return self._model, self._tokenizer
-
- def llm_stream_generator(self, **kwargs):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- def adaptor(kwargs):
- query = kwargs['query']
- max_length = kwargs['max_length']
- top_p = kwargs['top_p']
- temperature = kwargs['temperature']
- history = kwargs['history']
- return query, max_length, top_p, temperature, history
-
- query, max_length, top_p, temperature, history = adaptor(kwargs)
-
- for response, history in self._model.stream_chat(self._tokenizer,
- query,
- history,
- max_length=max_length,
- top_p=top_p,
- temperature=temperature,
- ):
- yield response
-
- def try_to_import_special_deps(self, **kwargs):
- # import something that will raise error if the user does not install requirement_*.txt
- # 🏃♂️🏃♂️🏃♂️ 主进程执行
- import importlib
- # importlib.import_module('modelscope')
-
-
-# ------------------------------------------------------------------------------------------------------------------------
-# 🔌💻 GPT-Academic Interface
-# ------------------------------------------------------------------------------------------------------------------------
-predict_no_ui_long_connection, predict = get_local_llm_predict_fns(GetGLM3Handle, model_name, history_format='chatglm3')
\ No newline at end of file
diff --git a/request_llms/bridge_chatglmft.py b/request_llms/bridge_chatglmft.py
deleted file mode 100644
index d812bae3c36dc22e6c40e78b54e0fbbda665e989..0000000000000000000000000000000000000000
--- a/request_llms/bridge_chatglmft.py
+++ /dev/null
@@ -1,207 +0,0 @@
-
-from transformers import AutoModel, AutoTokenizer
-import time
-import os
-import json
-import threading
-import importlib
-from toolbox import update_ui, get_conf
-from multiprocessing import Process, Pipe
-
-load_message = "ChatGLMFT尚未加载,加载需要一段时间。注意,取决于`config.py`的配置,ChatGLMFT消耗大量的内存(CPU)或显存(GPU),也许会导致低配计算机卡死 ……"
-
-def string_to_options(arguments):
- import argparse
- import shlex
- # Create an argparse.ArgumentParser instance
- parser = argparse.ArgumentParser()
- # Add command-line arguments
- parser.add_argument("--llm_to_learn", type=str, help="LLM model to learn", default="gpt-3.5-turbo")
- parser.add_argument("--prompt_prefix", type=str, help="Prompt prefix", default='')
- parser.add_argument("--system_prompt", type=str, help="System prompt", default='')
- parser.add_argument("--batch", type=int, help="System prompt", default=50)
- # Parse the arguments
- args = parser.parse_args(shlex.split(arguments))
- return args
-
-
-#################################################################################
-class GetGLMFTHandle(Process):
- def __init__(self):
- super().__init__(daemon=True)
- self.parent, self.child = Pipe()
- self.chatglmft_model = None
- self.chatglmft_tokenizer = None
- self.info = ""
- self.success = True
- self.check_dependency()
- self.start()
- self.threadLock = threading.Lock()
-
- def check_dependency(self):
- try:
- import sentencepiece
- self.info = "依赖检测通过"
- self.success = True
- except:
- self.info = "缺少ChatGLMFT的依赖,如果要使用ChatGLMFT,除了基础的pip依赖以外,您还需要运行`pip install -r request_llms/requirements_chatglm.txt`安装ChatGLM的依赖。"
- self.success = False
-
- def ready(self):
- return self.chatglmft_model is not None
-
- def run(self):
- # 子进程执行
- # 第一次运行,加载参数
- retry = 0
- while True:
- try:
- if self.chatglmft_model is None:
- from transformers import AutoConfig
- import torch
- # conf = 'request_llms/current_ptune_model.json'
- # if not os.path.exists(conf): raise RuntimeError('找不到微调模型信息')
- # with open(conf, 'r', encoding='utf8') as f:
- # model_args = json.loads(f.read())
- CHATGLM_PTUNING_CHECKPOINT = get_conf('CHATGLM_PTUNING_CHECKPOINT')
- assert os.path.exists(CHATGLM_PTUNING_CHECKPOINT), "找不到微调模型检查点"
- conf = os.path.join(CHATGLM_PTUNING_CHECKPOINT, "config.json")
- with open(conf, 'r', encoding='utf8') as f:
- model_args = json.loads(f.read())
- if 'model_name_or_path' not in model_args:
- model_args['model_name_or_path'] = model_args['_name_or_path']
- self.chatglmft_tokenizer = AutoTokenizer.from_pretrained(
- model_args['model_name_or_path'], trust_remote_code=True)
- config = AutoConfig.from_pretrained(
- model_args['model_name_or_path'], trust_remote_code=True)
-
- config.pre_seq_len = model_args['pre_seq_len']
- config.prefix_projection = model_args['prefix_projection']
-
- print(f"Loading prefix_encoder weight from {CHATGLM_PTUNING_CHECKPOINT}")
- model = AutoModel.from_pretrained(model_args['model_name_or_path'], config=config, trust_remote_code=True)
- prefix_state_dict = torch.load(os.path.join(CHATGLM_PTUNING_CHECKPOINT, "pytorch_model.bin"))
- new_prefix_state_dict = {}
- for k, v in prefix_state_dict.items():
- if k.startswith("transformer.prefix_encoder."):
- new_prefix_state_dict[k[len("transformer.prefix_encoder."):]] = v
- model.transformer.prefix_encoder.load_state_dict(new_prefix_state_dict)
-
- if model_args['quantization_bit'] is not None and model_args['quantization_bit'] != 0:
- print(f"Quantized to {model_args['quantization_bit']} bit")
- model = model.quantize(model_args['quantization_bit'])
- model = model.cuda()
- if model_args['pre_seq_len'] is not None:
- # P-tuning v2
- model.transformer.prefix_encoder.float()
- self.chatglmft_model = model.eval()
-
- break
- else:
- break
- except Exception as e:
- retry += 1
- if retry > 3:
- self.child.send('[Local Message] Call ChatGLMFT fail 不能正常加载ChatGLMFT的参数。')
- raise RuntimeError("不能正常加载ChatGLMFT的参数!")
-
- while True:
- # 进入任务等待状态
- kwargs = self.child.recv()
- # 收到消息,开始请求
- try:
- for response, history in self.chatglmft_model.stream_chat(self.chatglmft_tokenizer, **kwargs):
- self.child.send(response)
- # # 中途接收可能的终止指令(如果有的话)
- # if self.child.poll():
- # command = self.child.recv()
- # if command == '[Terminate]': break
- except:
- from toolbox import trimmed_format_exc
- self.child.send('[Local Message] Call ChatGLMFT fail.' + '\n```\n' + trimmed_format_exc() + '\n```\n')
- # 请求处理结束,开始下一个循环
- self.child.send('[Finish]')
-
- def stream_chat(self, **kwargs):
- # 主进程执行
- self.threadLock.acquire()
- self.parent.send(kwargs)
- while True:
- res = self.parent.recv()
- if res != '[Finish]':
- yield res
- else:
- break
- self.threadLock.release()
-
-global glmft_handle
-glmft_handle = None
-#################################################################################
-def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="", observe_window=[], console_slience=False):
- """
- 多线程方法
- 函数的说明请见 request_llms/bridge_all.py
- """
- global glmft_handle
- if glmft_handle is None:
- glmft_handle = GetGLMFTHandle()
- if len(observe_window) >= 1: observe_window[0] = load_message + "\n\n" + glmft_handle.info
- if not glmft_handle.success:
- error = glmft_handle.info
- glmft_handle = None
- raise RuntimeError(error)
-
- # chatglmft 没有 sys_prompt 接口,因此把prompt加入 history
- history_feedin = []
- history_feedin.append(["What can I do?", sys_prompt])
- for i in range(len(history)//2):
- history_feedin.append([history[2*i], history[2*i+1]] )
-
- watch_dog_patience = 5 # 看门狗 (watchdog) 的耐心, 设置5秒即可
- response = ""
- for response in glmft_handle.stream_chat(query=inputs, history=history_feedin, max_length=llm_kwargs['max_length'], top_p=llm_kwargs['top_p'], temperature=llm_kwargs['temperature']):
- if len(observe_window) >= 1: observe_window[0] = response
- if len(observe_window) >= 2:
- if (time.time()-observe_window[1]) > watch_dog_patience:
- raise RuntimeError("程序终止。")
- return response
-
-
-
-def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream = True, additional_fn=None):
- """
- 单线程方法
- 函数的说明请见 request_llms/bridge_all.py
- """
- chatbot.append((inputs, ""))
-
- global glmft_handle
- if glmft_handle is None:
- glmft_handle = GetGLMFTHandle()
- chatbot[-1] = (inputs, load_message + "\n\n" + glmft_handle.info)
- yield from update_ui(chatbot=chatbot, history=[])
- if not glmft_handle.success:
- glmft_handle = None
- return
-
- if additional_fn is not None:
- from core_functional import handle_core_functionality
- inputs, history = handle_core_functionality(additional_fn, inputs, history, chatbot)
-
- # 处理历史信息
- history_feedin = []
- history_feedin.append(["What can I do?", system_prompt] )
- for i in range(len(history)//2):
- history_feedin.append([history[2*i], history[2*i+1]] )
-
- # 开始接收chatglmft的回复
- response = "[Local Message] 等待ChatGLMFT响应中 ..."
- for response in glmft_handle.stream_chat(query=inputs, history=history_feedin, max_length=llm_kwargs['max_length'], top_p=llm_kwargs['top_p'], temperature=llm_kwargs['temperature']):
- chatbot[-1] = (inputs, response)
- yield from update_ui(chatbot=chatbot, history=history)
-
- # 总结输出
- if response == "[Local Message] 等待ChatGLMFT响应中 ...":
- response = "[Local Message] ChatGLMFT响应异常 ..."
- history.extend([inputs, response])
- yield from update_ui(chatbot=chatbot, history=history)
diff --git a/request_llms/bridge_chatglmonnx.py b/request_llms/bridge_chatglmonnx.py
deleted file mode 100644
index 4b905718f63089c1355d244d61c67df07c3dc521..0000000000000000000000000000000000000000
--- a/request_llms/bridge_chatglmonnx.py
+++ /dev/null
@@ -1,72 +0,0 @@
-model_name = "ChatGLM-ONNX"
-cmd_to_install = "`pip install -r request_llms/requirements_chatglm_onnx.txt`"
-
-
-from transformers import AutoModel, AutoTokenizer
-import time
-import threading
-import importlib
-from toolbox import update_ui, get_conf
-from multiprocessing import Process, Pipe
-from .local_llm_class import LocalLLMHandle, get_local_llm_predict_fns
-
-from .chatglmoonx import ChatGLMModel, chat_template
-
-
-
-# ------------------------------------------------------------------------------------------------------------------------
-# 🔌💻 Local Model
-# ------------------------------------------------------------------------------------------------------------------------
-class GetONNXGLMHandle(LocalLLMHandle):
-
- def load_model_info(self):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- self.model_name = model_name
- self.cmd_to_install = cmd_to_install
-
- def load_model_and_tokenizer(self):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- import os, glob
- if not len(glob.glob("./request_llms/ChatGLM-6b-onnx-u8s8/chatglm-6b-int8-onnx-merged/*.bin")) >= 7: # 该模型有七个 bin 文件
- from huggingface_hub import snapshot_download
- snapshot_download(repo_id="K024/ChatGLM-6b-onnx-u8s8", local_dir="./request_llms/ChatGLM-6b-onnx-u8s8")
- def create_model():
- return ChatGLMModel(
- tokenizer_path = "./request_llms/ChatGLM-6b-onnx-u8s8/chatglm-6b-int8-onnx-merged/sentencepiece.model",
- onnx_model_path = "./request_llms/ChatGLM-6b-onnx-u8s8/chatglm-6b-int8-onnx-merged/chatglm-6b-int8.onnx"
- )
- self._model = create_model()
- return self._model, None
-
- def llm_stream_generator(self, **kwargs):
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- def adaptor(kwargs):
- query = kwargs['query']
- max_length = kwargs['max_length']
- top_p = kwargs['top_p']
- temperature = kwargs['temperature']
- history = kwargs['history']
- return query, max_length, top_p, temperature, history
-
- query, max_length, top_p, temperature, history = adaptor(kwargs)
-
- prompt = chat_template(history, query)
- for answer in self._model.generate_iterate(
- prompt,
- max_generated_tokens=max_length,
- top_k=1,
- top_p=top_p,
- temperature=temperature,
- ):
- yield answer
-
- def try_to_import_special_deps(self, **kwargs):
- # import something that will raise error if the user does not install requirement_*.txt
- # 🏃♂️🏃♂️🏃♂️ 子进程执行
- pass
-
-
-# ------------------------------------------------------------------------------------------------------------------------
-# 🔌💻 GPT-Academic Interface
-# ------------------------------------------------------------------------------------------------------------------------
-predict_no_ui_long_connection, predict = get_local_llm_predict_fns(GetONNXGLMHandle, model_name)
\ No newline at end of file
diff --git a/request_llms/bridge_chatgpt.py b/request_llms/bridge_chatgpt.py
deleted file mode 100644
index ecb8423b4621dfe4ccedf3c679e8b007389112ab..0000000000000000000000000000000000000000
--- a/request_llms/bridge_chatgpt.py
+++ /dev/null
@@ -1,387 +0,0 @@
-# 借鉴了 https://github.com/GaiZhenbiao/ChuanhuChatGPT 项目
-
-"""
- 该文件中主要包含三个函数
-
- 不具备多线程能力的函数:
- 1. predict: 正常对话时使用,具备完备的交互功能,不可多线程
-
- 具备多线程调用能力的函数
- 2. predict_no_ui_long_connection:支持多线程
-"""
-
-import json
-import time
-import gradio as gr
-import logging
-import traceback
-import requests
-import importlib
-import random
-
-# config_private.py放自己的秘密如API和代理网址
-# 读取时首先看是否存在私密的config_private配置文件(不受git管控),如果有,则覆盖原config文件
-from toolbox import get_conf, update_ui, is_any_api_key, select_api_key, what_keys, clip_history, trimmed_format_exc, is_the_upload_folder
-proxies, TIMEOUT_SECONDS, MAX_RETRY, API_ORG, AZURE_CFG_ARRAY = \
- get_conf('proxies', 'TIMEOUT_SECONDS', 'MAX_RETRY', 'API_ORG', 'AZURE_CFG_ARRAY')
-
-timeout_bot_msg = '[Local Message] Request timeout. Network error. Please check proxy settings in config.py.' + \
- '网络错误,检查代理服务器是否可用,以及代理设置的格式是否正确,格式须是[协议]://[地址]:[端口],缺一不可。'
-
-def get_full_error(chunk, stream_response):
- """
- 获取完整的从Openai返回的报错
- """
- while True:
- try:
- chunk += next(stream_response)
- except:
- break
- return chunk
-
-def decode_chunk(chunk):
- # 提前读取一些信息 (用于判断异常)
- chunk_decoded = chunk.decode()
- chunkjson = None
- has_choices = False
- choice_valid = False
- has_content = False
- has_role = False
- try:
- chunkjson = json.loads(chunk_decoded[6:])
- has_choices = 'choices' in chunkjson
- if has_choices: choice_valid = (len(chunkjson['choices']) > 0)
- if has_choices and choice_valid: has_content = ("content" in chunkjson['choices'][0]["delta"])
- if has_content: has_content = (chunkjson['choices'][0]["delta"]["content"] is not None)
- if has_choices and choice_valid: has_role = "role" in chunkjson['choices'][0]["delta"]
- except:
- pass
- return chunk_decoded, chunkjson, has_choices, choice_valid, has_content, has_role
-
-from functools import lru_cache
-@lru_cache(maxsize=32)
-def verify_endpoint(endpoint):
- """
- 检查endpoint是否可用
- """
- if "你亲手写的api名称" in endpoint:
- raise ValueError("Endpoint不正确, 请检查AZURE_ENDPOINT的配置! 当前的Endpoint为:" + endpoint)
- return endpoint
-
-def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="", observe_window=None, console_slience=False):
- """
- 发送至chatGPT,等待回复,一次性完成,不显示中间过程。但内部用stream的方法避免中途网线被掐。
- inputs:
- 是本次问询的输入
- sys_prompt:
- 系统静默prompt
- llm_kwargs:
- chatGPT的内部调优参数
- history:
- 是之前的对话列表
- observe_window = None:
- 用于负责跨越线程传递已经输出的部分,大部分时候仅仅为了fancy的视觉效果,留空即可。observe_window[0]:观测窗。observe_window[1]:看门狗
- """
- watch_dog_patience = 5 # 看门狗的耐心, 设置5秒即可
- headers, payload = generate_payload(inputs, llm_kwargs, history, system_prompt=sys_prompt, stream=True)
- retry = 0
- while True:
- try:
- # make a POST request to the API endpoint, stream=False
- from .bridge_all import model_info
- endpoint = verify_endpoint(model_info[llm_kwargs['llm_model']]['endpoint'])
- response = requests.post(endpoint, headers=headers, proxies=proxies,
- json=payload, stream=True, timeout=TIMEOUT_SECONDS); break
- except requests.exceptions.ReadTimeout as e:
- retry += 1
- traceback.print_exc()
- if retry > MAX_RETRY: raise TimeoutError
- if MAX_RETRY!=0: print(f'请求超时,正在重试 ({retry}/{MAX_RETRY}) ……')
-
- stream_response = response.iter_lines()
- result = ''
- json_data = None
- while True:
- try: chunk = next(stream_response)
- except StopIteration:
- break
- except requests.exceptions.ConnectionError:
- chunk = next(stream_response) # 失败了,重试一次?再失败就没办法了。
- chunk_decoded, chunkjson, has_choices, choice_valid, has_content, has_role = decode_chunk(chunk)
- if len(chunk_decoded)==0: continue
- if not chunk_decoded.startswith('data:'):
- error_msg = get_full_error(chunk, stream_response).decode()
- if "reduce the length" in error_msg:
- raise ConnectionAbortedError("OpenAI拒绝了请求:" + error_msg)
- elif """type":"upstream_error","param":"307""" in error_msg:
- raise ConnectionAbortedError("正常结束,但显示Token不足,导致输出不完整,请削减单次输入的文本量。")
- else:
- raise RuntimeError("OpenAI拒绝了请求:" + error_msg)
- if ('data: [DONE]' in chunk_decoded): break # api2d 正常完成
- # 提前读取一些信息 (用于判断异常)
- if has_choices and not choice_valid:
- # 一些垃圾第三方接口的出现这样的错误
- continue
- json_data = chunkjson['choices'][0]
- delta = json_data["delta"]
- if len(delta) == 0: break
- if "role" in delta: continue
- if "content" in delta:
- result += delta["content"]
- if not console_slience: print(delta["content"], end='')
- if observe_window is not None:
- # 观测窗,把已经获取的数据显示出去
- if len(observe_window) >= 1:
- observe_window[0] += delta["content"]
- # 看门狗,如果超过期限没有喂狗,则终止
- if len(observe_window) >= 2:
- if (time.time()-observe_window[1]) > watch_dog_patience:
- raise RuntimeError("用户取消了程序。")
- else: raise RuntimeError("意外Json结构:"+delta)
- if json_data and json_data['finish_reason'] == 'content_filter':
- raise RuntimeError("由于提问含不合规内容被Azure过滤。")
- if json_data and json_data['finish_reason'] == 'length':
- raise ConnectionAbortedError("正常结束,但显示Token不足,导致输出不完整,请削减单次输入的文本量。")
- return result
-
-
-def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream = True, additional_fn=None):
- """
- 发送至chatGPT,流式获取输出。
- 用于基础的对话功能。
- inputs 是本次问询的输入
- top_p, temperature是chatGPT的内部调优参数
- history 是之前的对话列表(注意无论是inputs还是history,内容太长了都会触发token数量溢出的错误)
- chatbot 为WebUI中显示的对话列表,修改它,然后yeild出去,可以直接修改对话界面内容
- additional_fn代表点击的哪个按钮,按钮见functional.py
- """
- if is_any_api_key(inputs):
- chatbot._cookies['api_key'] = inputs
- chatbot.append(("输入已识别为openai的api_key", what_keys(inputs)))
- yield from update_ui(chatbot=chatbot, history=history, msg="api_key已导入") # 刷新界面
- return
- elif not is_any_api_key(chatbot._cookies['api_key']):
- chatbot.append((inputs, "缺少api_key。\n\n1. 临时解决方案:直接在输入区键入api_key,然后回车提交。\n\n2. 长效解决方案:在config.py中配置。"))
- yield from update_ui(chatbot=chatbot, history=history, msg="缺少api_key") # 刷新界面
- return
-
- user_input = inputs
- if additional_fn is not None:
- from core_functional import handle_core_functionality
- inputs, history = handle_core_functionality(additional_fn, inputs, history, chatbot)
-
- raw_input = inputs
- logging.info(f'[raw_input] {raw_input}')
- chatbot.append((inputs, ""))
- yield from update_ui(chatbot=chatbot, history=history, msg="等待响应") # 刷新界面
-
- # check mis-behavior
- if is_the_upload_folder(user_input):
- chatbot[-1] = (inputs, f"[Local Message] 检测到操作错误!当您上传文档之后,需点击“**函数插件区**”按钮进行处理,请勿点击“提交”按钮或者“基础功能区”按钮。")
- yield from update_ui(chatbot=chatbot, history=history, msg="正常") # 刷新界面
- time.sleep(2)
-
- try:
- headers, payload = generate_payload(inputs, llm_kwargs, history, system_prompt, stream)
- except RuntimeError as e:
- chatbot[-1] = (inputs, f"您提供的api-key不满足要求,不包含任何可用于{llm_kwargs['llm_model']}的api-key。您可能选择了错误的模型或请求源。")
- yield from update_ui(chatbot=chatbot, history=history, msg="api-key不满足要求") # 刷新界面
- return
-
- # 检查endpoint是否合法
- try:
- from .bridge_all import model_info
- endpoint = verify_endpoint(model_info[llm_kwargs['llm_model']]['endpoint'])
- except:
- tb_str = '```\n' + trimmed_format_exc() + '```'
- chatbot[-1] = (inputs, tb_str)
- yield from update_ui(chatbot=chatbot, history=history, msg="Endpoint不满足要求") # 刷新界面
- return
-
- history.append(inputs); history.append("")
-
- retry = 0
- while True:
- try:
- # make a POST request to the API endpoint, stream=True
- response = requests.post(endpoint, headers=headers, proxies=proxies,
- json=payload, stream=True, timeout=TIMEOUT_SECONDS);break
- except:
- retry += 1
- chatbot[-1] = ((chatbot[-1][0], timeout_bot_msg))
- retry_msg = f",正在重试 ({retry}/{MAX_RETRY}) ……" if MAX_RETRY > 0 else ""
- yield from update_ui(chatbot=chatbot, history=history, msg="请求超时"+retry_msg) # 刷新界面
- if retry > MAX_RETRY: raise TimeoutError
-
- gpt_replying_buffer = ""
-
- is_head_of_the_stream = True
- if stream:
- stream_response = response.iter_lines()
- while True:
- try:
- chunk = next(stream_response)
- except StopIteration:
- # 非OpenAI官方接口的出现这样的报错,OpenAI和API2D不会走这里
- chunk_decoded = chunk.decode()
- error_msg = chunk_decoded
- # 首先排除一个one-api没有done数据包的第三方Bug情形
- if len(gpt_replying_buffer.strip()) > 0 and len(error_msg) == 0:
- yield from update_ui(chatbot=chatbot, history=history, msg="检测到有缺陷的非OpenAI官方接口,建议选择更稳定的接口。")
- break
- # 其他情况,直接返回报错
- chatbot, history = handle_error(inputs, llm_kwargs, chatbot, history, chunk_decoded, error_msg)
- yield from update_ui(chatbot=chatbot, history=history, msg="非OpenAI官方接口返回了错误:" + chunk.decode()) # 刷新界面
- return
-
- # 提前读取一些信息 (用于判断异常)
- chunk_decoded, chunkjson, has_choices, choice_valid, has_content, has_role = decode_chunk(chunk)
-
- if is_head_of_the_stream and (r'"object":"error"' not in chunk_decoded) and (r"content" not in chunk_decoded):
- # 数据流的第一帧不携带content
- is_head_of_the_stream = False; continue
-
- if chunk:
- try:
- if has_choices and not choice_valid:
- # 一些垃圾第三方接口的出现这样的错误
- continue
- if ('data: [DONE]' not in chunk_decoded) and len(chunk_decoded) > 0 and (chunkjson is None):
- # 传递进来一些奇怪的东西
- raise ValueError(f'无法读取以下数据,请检查配置。\n\n{chunk_decoded}')
- # 前者是API2D的结束条件,后者是OPENAI的结束条件
- if ('data: [DONE]' in chunk_decoded) or (len(chunkjson['choices'][0]["delta"]) == 0):
- # 判定为数据流的结束,gpt_replying_buffer也写完了
- logging.info(f'[response] {gpt_replying_buffer}')
- break
- # 处理数据流的主体
- status_text = f"finish_reason: {chunkjson['choices'][0].get('finish_reason', 'null')}"
- # 如果这里抛出异常,一般是文本过长,详情见get_full_error的输出
- if has_content:
- # 正常情况
- gpt_replying_buffer = gpt_replying_buffer + chunkjson['choices'][0]["delta"]["content"]
- elif has_role:
- # 一些第三方接口的出现这样的错误,兼容一下吧
- continue
- else:
- # 一些垃圾第三方接口的出现这样的错误
- gpt_replying_buffer = gpt_replying_buffer + chunkjson['choices'][0]["delta"]["content"]
-
- history[-1] = gpt_replying_buffer
- chatbot[-1] = (history[-2], history[-1])
- yield from update_ui(chatbot=chatbot, history=history, msg=status_text) # 刷新界面
- except Exception as e:
- yield from update_ui(chatbot=chatbot, history=history, msg="Json解析不合常规") # 刷新界面
- chunk = get_full_error(chunk, stream_response)
- chunk_decoded = chunk.decode()
- error_msg = chunk_decoded
- chatbot, history = handle_error(inputs, llm_kwargs, chatbot, history, chunk_decoded, error_msg)
- yield from update_ui(chatbot=chatbot, history=history, msg="Json异常" + error_msg) # 刷新界面
- print(error_msg)
- return
-
-def handle_error(inputs, llm_kwargs, chatbot, history, chunk_decoded, error_msg):
- from .bridge_all import model_info
- openai_website = ' 请登录OpenAI查看详情 https://platform.openai.com/signup'
- if "reduce the length" in error_msg:
- if len(history) >= 2: history[-1] = ""; history[-2] = "" # 清除当前溢出的输入:history[-2] 是本次输入, history[-1] 是本次输出
- history = clip_history(inputs=inputs, history=history, tokenizer=model_info[llm_kwargs['llm_model']]['tokenizer'],
- max_token_limit=(model_info[llm_kwargs['llm_model']]['max_token'])) # history至少释放二分之一
- chatbot[-1] = (chatbot[-1][0], "[Local Message] Reduce the length. 本次输入过长, 或历史数据过长. 历史缓存数据已部分释放, 您可以请再次尝试. (若再次失败则更可能是因为输入过长.)")
- elif "does not exist" in error_msg:
- chatbot[-1] = (chatbot[-1][0], f"[Local Message] Model {llm_kwargs['llm_model']} does not exist. 模型不存在, 或者您没有获得体验资格.")
- elif "Incorrect API key" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] Incorrect API key. OpenAI以提供了不正确的API_KEY为由, 拒绝服务. " + openai_website)
- elif "exceeded your current quota" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] You exceeded your current quota. OpenAI以账户额度不足为由, 拒绝服务." + openai_website)
- elif "account is not active" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] Your account is not active. OpenAI以账户失效为由, 拒绝服务." + openai_website)
- elif "associated with a deactivated account" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] You are associated with a deactivated account. OpenAI以账户失效为由, 拒绝服务." + openai_website)
- elif "API key has been deactivated" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] API key has been deactivated. OpenAI以账户失效为由, 拒绝服务." + openai_website)
- elif "bad forward key" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] Bad forward key. API2D账户额度不足.")
- elif "Not enough point" in error_msg:
- chatbot[-1] = (chatbot[-1][0], "[Local Message] Not enough point. API2D账户点数不足.")
- else:
- from toolbox import regular_txt_to_markdown
- tb_str = '```\n' + trimmed_format_exc() + '```'
- chatbot[-1] = (chatbot[-1][0], f"[Local Message] 异常 \n\n{tb_str} \n\n{regular_txt_to_markdown(chunk_decoded)}")
- return chatbot, history
-
-def generate_payload(inputs, llm_kwargs, history, system_prompt, stream):
- """
- 整合所有信息,选择LLM模型,生成http请求,为发送请求做准备
- """
- if not is_any_api_key(llm_kwargs['api_key']):
- raise AssertionError("你提供了错误的API_KEY。\n\n1. 临时解决方案:直接在输入区键入api_key,然后回车提交。\n\n2. 长效解决方案:在config.py中配置。")
-
- api_key = select_api_key(llm_kwargs['api_key'], llm_kwargs['llm_model'])
-
- headers = {
- "Content-Type": "application/json",
- "Authorization": f"Bearer {api_key}"
- }
- if API_ORG.startswith('org-'): headers.update({"OpenAI-Organization": API_ORG})
- if llm_kwargs['llm_model'].startswith('azure-'):
- headers.update({"api-key": api_key})
- if llm_kwargs['llm_model'] in AZURE_CFG_ARRAY.keys():
- azure_api_key_unshared = AZURE_CFG_ARRAY[llm_kwargs['llm_model']]["AZURE_API_KEY"]
- headers.update({"api-key": azure_api_key_unshared})
-
- conversation_cnt = len(history) // 2
-
- messages = [{"role": "system", "content": system_prompt}]
- if conversation_cnt:
- for index in range(0, 2*conversation_cnt, 2):
- what_i_have_asked = {}
- what_i_have_asked["role"] = "user"
- what_i_have_asked["content"] = history[index]
- what_gpt_answer = {}
- what_gpt_answer["role"] = "assistant"
- what_gpt_answer["content"] = history[index+1]
- if what_i_have_asked["content"] != "":
- if what_gpt_answer["content"] == "": continue
- if what_gpt_answer["content"] == timeout_bot_msg: continue
- messages.append(what_i_have_asked)
- messages.append(what_gpt_answer)
- else:
- messages[-1]['content'] = what_gpt_answer['content']
-
- what_i_ask_now = {}
- what_i_ask_now["role"] = "user"
- what_i_ask_now["content"] = inputs
- messages.append(what_i_ask_now)
- model = llm_kwargs['llm_model']
- if llm_kwargs['llm_model'].startswith('api2d-'):
- model = llm_kwargs['llm_model'][len('api2d-'):]
-
- if model == "gpt-3.5-random": # 随机选择, 绕过openai访问频率限制
- model = random.choice([
- "gpt-3.5-turbo",
- "gpt-3.5-turbo-16k",
- "gpt-3.5-turbo-1106",
- "gpt-3.5-turbo-0613",
- "gpt-3.5-turbo-16k-0613",
- "gpt-3.5-turbo-0301",
- ])
- logging.info("Random select model:" + model)
-
- payload = {
- "model": model,
- "messages": messages,
- "temperature": llm_kwargs['temperature'], # 1.0,
- "top_p": llm_kwargs['top_p'], # 1.0,
- "n": 1,
- "stream": stream,
- "presence_penalty": 0,
- "frequency_penalty": 0,
- }
- try:
- print(f" {llm_kwargs['llm_model']} : {conversation_cnt} : {inputs[:100]} ..........")
- except:
- print('输入中可能存在乱码。')
- return headers,payload
-
-
diff --git a/request_llms/bridge_chatgpt_vision.py b/request_llms/bridge_chatgpt_vision.py
deleted file mode 100644
index ebcf9689a3d74fed75531619bd02dd27993dad5e..0000000000000000000000000000000000000000
--- a/request_llms/bridge_chatgpt_vision.py
+++ /dev/null
@@ -1,312 +0,0 @@
-"""
- 该文件中主要包含三个函数
-
- 不具备多线程能力的函数:
- 1. predict: 正常对话时使用,具备完备的交互功能,不可多线程
-
- 具备多线程调用能力的函数
- 2. predict_no_ui_long_connection:支持多线程
-"""
-
-import json
-import time
-import logging
-import requests
-import base64
-import os
-import glob
-from toolbox import get_conf, update_ui, is_any_api_key, select_api_key, what_keys, clip_history, trimmed_format_exc, is_the_upload_folder, \
- update_ui_lastest_msg, get_max_token, encode_image, have_any_recent_upload_image_files
-
-
-proxies, TIMEOUT_SECONDS, MAX_RETRY, API_ORG, AZURE_CFG_ARRAY = \
- get_conf('proxies', 'TIMEOUT_SECONDS', 'MAX_RETRY', 'API_ORG', 'AZURE_CFG_ARRAY')
-
-timeout_bot_msg = '[Local Message] Request timeout. Network error. Please check proxy settings in config.py.' + \
- '网络错误,检查代理服务器是否可用,以及代理设置的格式是否正确,格式须是[协议]://[地址]:[端口],缺一不可。'
-
-
-def report_invalid_key(key):
- if get_conf("BLOCK_INVALID_APIKEY"):
- # 实验性功能,自动检测并屏蔽失效的KEY,请勿使用
- from request_llms.key_manager import ApiKeyManager
- api_key = ApiKeyManager().add_key_to_blacklist(key)
-
-def get_full_error(chunk, stream_response):
- """
- 获取完整的从Openai返回的报错
- """
- while True:
- try:
- chunk += next(stream_response)
- except:
- break
- return chunk
-
-def decode_chunk(chunk):
- # 提前读取一些信息 (用于判断异常)
- chunk_decoded = chunk.decode()
- chunkjson = None
- has_choices = False
- choice_valid = False
- has_content = False
- has_role = False
- try:
- chunkjson = json.loads(chunk_decoded[6:])
- has_choices = 'choices' in chunkjson
- if has_choices: choice_valid = (len(chunkjson['choices']) > 0)
- if has_choices and choice_valid: has_content = "content" in chunkjson['choices'][0]["delta"]
- if has_choices and choice_valid: has_role = "role" in chunkjson['choices'][0]["delta"]
- except:
- pass
- return chunk_decoded, chunkjson, has_choices, choice_valid, has_content, has_role
-
-from functools import lru_cache
-@lru_cache(maxsize=32)
-def verify_endpoint(endpoint):
- """
- 检查endpoint是否可用
- """
- return endpoint
-
-def predict_no_ui_long_connection(inputs, llm_kwargs, history=[], sys_prompt="", observe_window=None, console_slience=False):
- raise NotImplementedError
-
-
-def predict(inputs, llm_kwargs, plugin_kwargs, chatbot, history=[], system_prompt='', stream = True, additional_fn=None):
-
- have_recent_file, image_paths = have_any_recent_upload_image_files(chatbot)
-
- if is_any_api_key(inputs):
- chatbot._cookies['api_key'] = inputs
- chatbot.append(("输入已识别为openai的api_key", what_keys(inputs)))
- yield from update_ui(chatbot=chatbot, history=history, msg="api_key已导入") # 刷新界面
- return
- elif not is_any_api_key(chatbot._cookies['api_key']):
- chatbot.append((inputs, "缺少api_key。\n\n1. 临时解决方案:直接在输入区键入api_key,然后回车提交。\n\n2. 长效解决方案:在config.py中配置。"))
- yield from update_ui(chatbot=chatbot, history=history, msg="缺少api_key") # 刷新界面
- return
- if not have_recent_file:
- chatbot.append((inputs, "没有检测到任何近期上传的图像文件,请上传jpg格式的图片,此外,请注意拓展名需要小写"))
- yield from update_ui(chatbot=chatbot, history=history, msg="等待图片") # 刷新界面
- return
- if os.path.exists(inputs):
- chatbot.append((inputs, "已经接收到您上传的文件,您不需要再重复强调该文件的路径了,请直接输入您的问题。"))
- yield from update_ui(chatbot=chatbot, history=history, msg="等待指令") # 刷新界面
- return
-
-
- user_input = inputs
- if additional_fn is not None:
- from core_functional import handle_core_functionality
- inputs, history = handle_core_functionality(additional_fn, inputs, history, chatbot)
-
- raw_input = inputs
- logging.info(f'[raw_input] {raw_input}')
- def make_media_input(inputs, image_paths):
- for image_path in image_paths:
- inputs = inputs + f'
})

.*?)(?<=\n) # the code block
- (?P=fence)[ ]*$ # closing fence
- """
- ),
- re.MULTILINE | re.DOTALL | re.VERBOSE,
-)
-
-
-def get_line_range(re_match_obj, txt):
- start_pos, end_pos = re_match_obj.regs[0]
- num_newlines_before = txt[: start_pos + 1].count("\n")
- line_start = num_newlines_before
- line_end = num_newlines_before + txt[start_pos:end_pos].count("\n") + 1
- return line_start, line_end
-
-
-def fix_code_segment_indent(txt):
- lines = []
- change_any = False
- txt_tmp = txt
- while True:
- re_match_obj = FENCED_BLOCK_RE.search(txt_tmp)
- if not re_match_obj:
- break
- if len(lines) == 0:
- lines = txt.split("\n")
-
- # 清空 txt_tmp 对应的位置方便下次搜索
- start_pos, end_pos = re_match_obj.regs[0]
- txt_tmp = txt_tmp[:start_pos] + " " * (end_pos - start_pos) + txt_tmp[end_pos:]
- line_start, line_end = get_line_range(re_match_obj, txt)
-
- # 获取公共缩进
- shared_indent_cnt = 1e5
- for i in range(line_start, line_end):
- stripped_string = lines[i].lstrip()
- num_spaces = len(lines[i]) - len(stripped_string)
- if num_spaces < shared_indent_cnt:
- shared_indent_cnt = num_spaces
-
- # 修复缩进
- if (shared_indent_cnt < 1e5) and (shared_indent_cnt % 4) == 3:
- num_spaces_should_be = math.ceil(shared_indent_cnt / 4) * 4
- for i in range(line_start, line_end):
- add_n = num_spaces_should_be - shared_indent_cnt
- lines[i] = " " * add_n + lines[i]
- if not change_any: # 遇到第一个
- change_any = True
-
- if change_any:
- return "\n".join(lines)
- else:
- return txt
-
-
-@lru_cache(maxsize=128) # 使用 lru缓存 加快转换速度
-def markdown_convertion(txt):
- """
- 将Markdown格式的文本转换为HTML格式。如果包含数学公式,则先将公式转换为HTML格式。
- """
- pre = ''
- suf = "
"
- if txt.startswith(pre) and txt.endswith(suf):
- # print('警告,输入了已经经过转化的字符串,二次转化可能出问题')
- return txt # 已经被转化过,不需要再次转化
-
- find_equation_pattern = r'
-
-
- """
- gradio_original_template_fn = gr.routes.templates.TemplateResponse
- def gradio_new_template_fn(*args, **kwargs):
- res = gradio_original_template_fn(*args, **kwargs)
- res.body = res.body.replace(b' +
+
 -
- +
+
 +
+
 +
+
 +
+

 -
-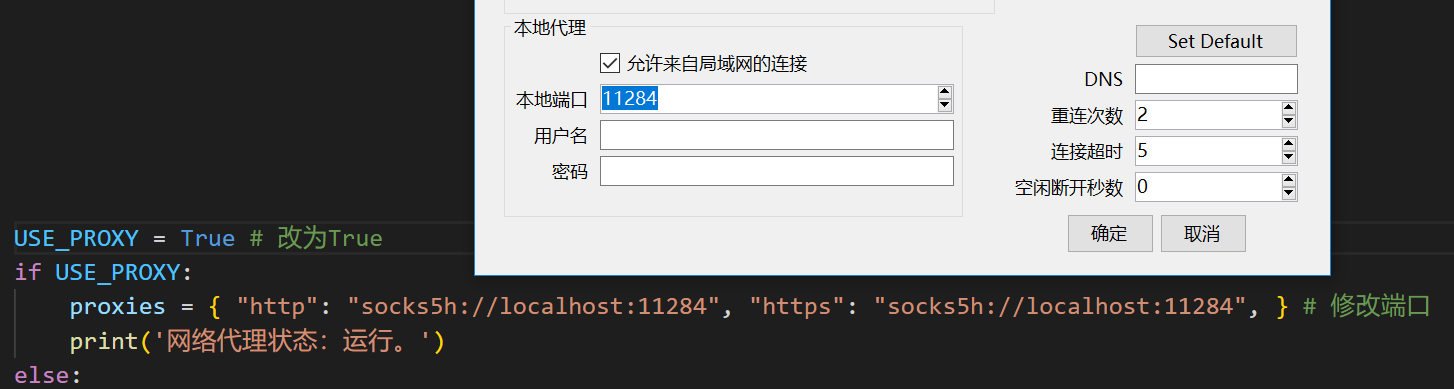 +
+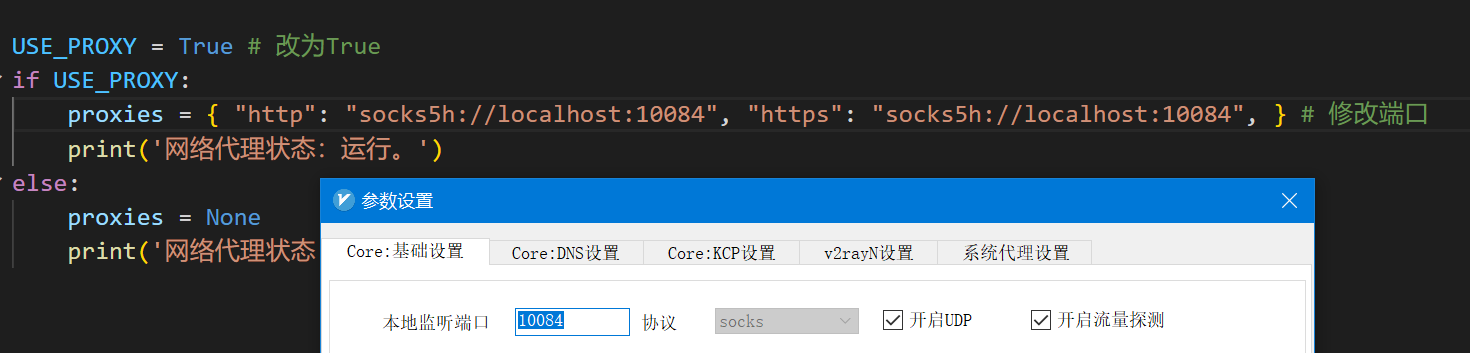
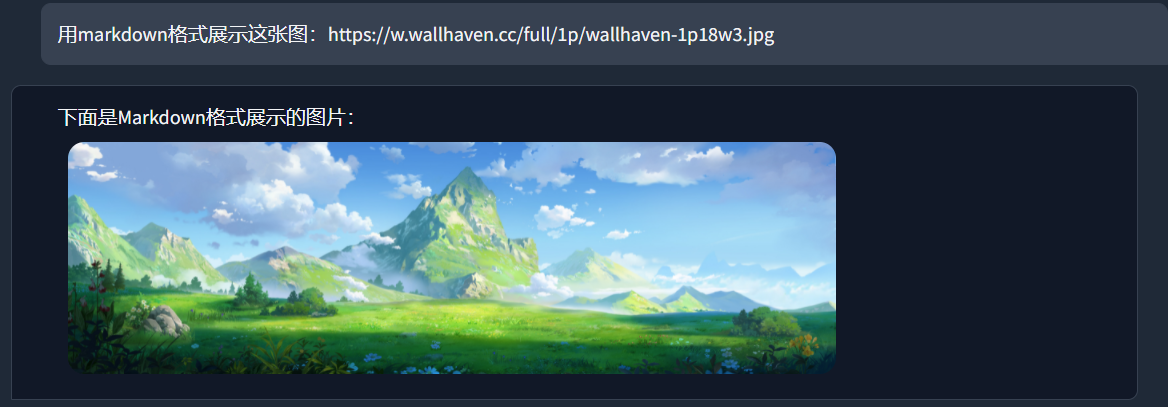 +
+
 -
- +
+
 +
+
 +
+
 +
+ +
+
 +
+ -
- -
- -
-