
Merge pull request #37 from seanpedrick-case/dev
Browse filesCan remove all redactions with same text on button, added more config options
- README.md +9 -8
- app.py +100 -87
- pyproject.toml +1 -1
- tools/config.py +76 -5
- tools/data_anonymise.py +18 -10
- tools/file_conversion.py +9 -10
- tools/file_redaction.py +31 -31
- tools/helper_functions.py +24 -33
- tools/redaction_review.py +14 -4
README.md
CHANGED
|
@@ -10,7 +10,7 @@ license: agpl-3.0
|
|
| 10 |
---
|
| 11 |
# Document redaction
|
| 12 |
|
| 13 |
-
version: 0.6.
|
| 14 |
|
| 15 |
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Please see the [User Guide](#user-guide) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 16 |
|
|
@@ -223,13 +223,13 @@ On the 'Review redactions' tab you have a visual interface that allows you to in
|
|
| 223 |
|
| 224 |
### Uploading documents for review
|
| 225 |
|
| 226 |
-
The top area has a file upload area where you can upload original, unredacted PDFs, alongside the '..._review_file.csv' that is produced by the redaction process. Once you have uploaded these two files, click the 'Review PDF
|
| 227 |
|
| 228 |
Optionally, you can also upload one of the '..._ocr_output.csv' files here that comes out of a redaction task, so that you can navigate the extracted text from the document.
|
| 229 |
|
| 230 |

|
| 231 |
|
| 232 |
-
You can upload the three review files in the box (unredacted document, '..._review_file.csv' and '..._ocr_output.csv' file) before clicking 'Review PDF
|
| 233 |
|
| 234 |

|
| 235 |
|
|
@@ -293,7 +293,7 @@ The table shows a list of all the suggested redactions in the document alongside
|
|
| 293 |
|
| 294 |
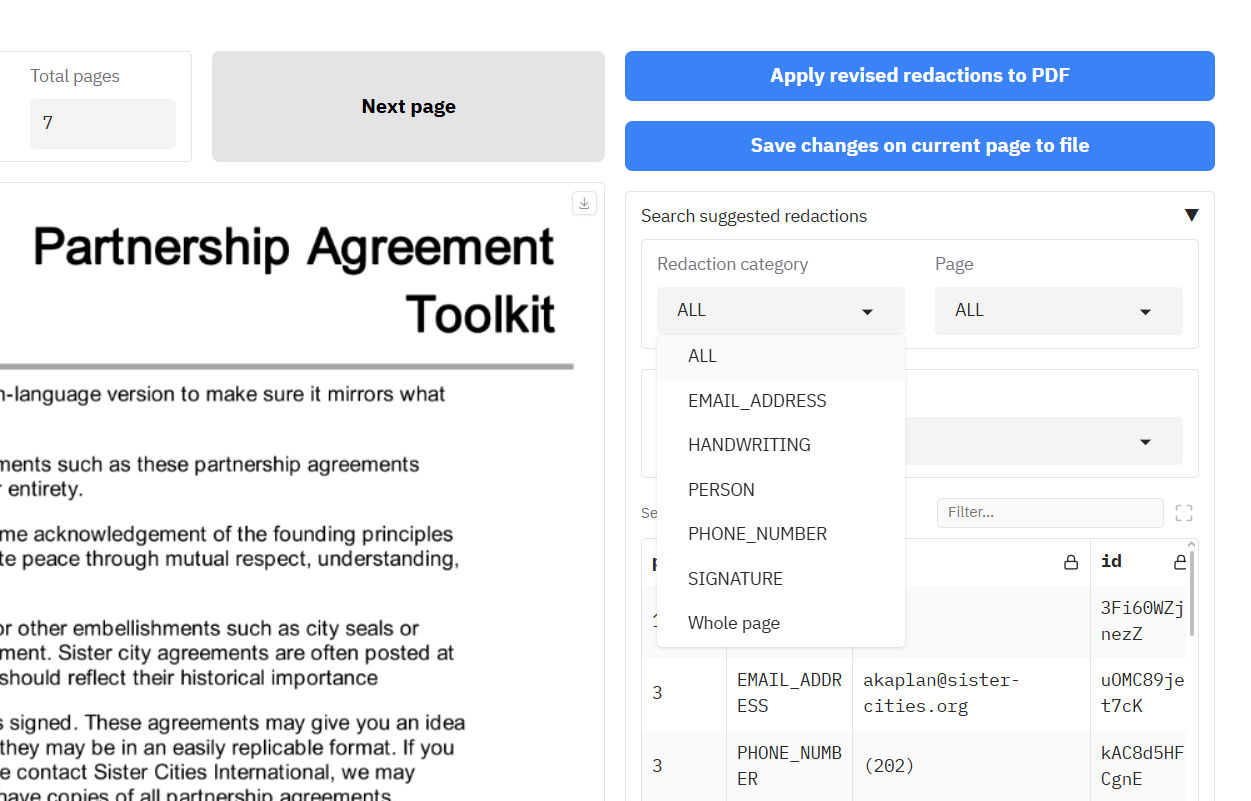
|
| 295 |
|
| 296 |
-
If you click on one of the rows in this table, you will be taken to the page of the redaction. Clicking on a redaction row on the same page
|
| 297 |
|
| 298 |

|
| 299 |
|
|
@@ -303,12 +303,13 @@ To filter the 'Search suggested redactions' table you can:
|
|
| 303 |
1. Click on one of the dropdowns (Redaction category, Page, Text), and select an option, or
|
| 304 |
2. Write text in the 'Filter' box just above the table. Click the blue box to apply the filter to the table.
|
| 305 |
|
| 306 |
-
Once you have filtered the table, you have a few options underneath on what you can do with the filtered rows:
|
| 307 |
|
| 308 |
-
- Click the
|
| 309 |
-
- Click the
|
|
|
|
| 310 |
|
| 311 |
-
**NOTE**: After excluding redactions using
|
| 312 |
|
| 313 |
If you made a mistake, click the 'Undo last element removal' button to restore the Search suggested redactions table to its previous state (can only undo the last action).
|
| 314 |
|
|
|
|
| 10 |
---
|
| 11 |
# Document redaction
|
| 12 |
|
| 13 |
+
version: 0.6.8
|
| 14 |
|
| 15 |
Redact personally identifiable information (PII) from documents (pdf, images), open text, or tabular data (xlsx/csv/parquet). Please see the [User Guide](#user-guide) for a walkthrough on how to use the app. Below is a very brief overview.
|
| 16 |
|
|
|
|
| 223 |
|
| 224 |
### Uploading documents for review
|
| 225 |
|
| 226 |
+
The top area has a file upload area where you can upload original, unredacted PDFs, alongside the '..._review_file.csv' that is produced by the redaction process. Once you have uploaded these two files, click the '**Review redactions based on original PDF...**' button to load in the files for review. This will allow you to visualise and modify the suggested redactions using the interface below.
|
| 227 |
|
| 228 |
Optionally, you can also upload one of the '..._ocr_output.csv' files here that comes out of a redaction task, so that you can navigate the extracted text from the document.
|
| 229 |
|
| 230 |

|
| 231 |
|
| 232 |
+
You can upload the three review files in the box (unredacted document, '..._review_file.csv' and '..._ocr_output.csv' file) before clicking '**Review redactions based on original PDF...**', as in the image below:
|
| 233 |
|
| 234 |

|
| 235 |
|
|
|
|
| 293 |
|
| 294 |

|
| 295 |
|
| 296 |
+
If you click on one of the rows in this table, you will be taken to the page of the redaction. Clicking on a redaction row on the same page will change the colour of redaction box to blue to help you locate it in the document viewer (just when using the app, not in redacted output PDFs).
|
| 297 |
|
| 298 |

|
| 299 |
|
|
|
|
| 303 |
1. Click on one of the dropdowns (Redaction category, Page, Text), and select an option, or
|
| 304 |
2. Write text in the 'Filter' box just above the table. Click the blue box to apply the filter to the table.
|
| 305 |
|
| 306 |
+
Once you have filtered the table, or selected a row from the table, you have a few options underneath on what you can do with the filtered rows:
|
| 307 |
|
| 308 |
+
- Click the **Exclude all redactions in table** button to remove all redactions visible in the table from the document. **Important:** ensure that you have clicked the blue tick icon next to the search box before doing this, or you will remove all redactions from the document. If you do end up doing this, click the 'Undo last element removal' button below to restore the redactions.
|
| 309 |
+
- Click the **Exclude specific redaction row** button to remove only the redaction from the last row you clicked on from the document. The currently selected row is visible below.
|
| 310 |
+
- Click the **Exclude all redactions with the same text as selected row** button to remove all redactions from the document that are exactly the same as the selected row text.
|
| 311 |
|
| 312 |
+
**NOTE**: After excluding redactions using any of the above options, click the 'Reset filters' button below to ensure that the dropdowns and table return to seeing all remaining redactions in the document.
|
| 313 |
|
| 314 |
If you made a mistake, click the 'Undo last element removal' button to restore the Search suggested redactions table to its previous state (can only undo the last action).
|
| 315 |
|
app.py
CHANGED
|
@@ -1,15 +1,13 @@
|
|
| 1 |
import os
|
| 2 |
-
import logging
|
| 3 |
import pandas as pd
|
| 4 |
import gradio as gr
|
| 5 |
from gradio_image_annotation import image_annotator
|
| 6 |
-
|
| 7 |
-
from tools.
|
| 8 |
-
from tools.
|
| 9 |
-
from tools.aws_functions import upload_file_to_s3, download_file_from_s3, upload_log_file_to_s3
|
| 10 |
from tools.file_redaction import choose_and_run_redactor
|
| 11 |
from tools.file_conversion import prepare_image_or_pdf, get_input_file_names
|
| 12 |
-
from tools.redaction_review import apply_redactions_to_review_df_and_files, update_all_page_annotation_object_based_on_previous_page, decrease_page, increase_page, update_annotator_object_and_filter_df, update_entities_df_recogniser_entities, update_entities_df_page, update_entities_df_text,
|
| 13 |
from tools.data_anonymise import anonymise_data_files
|
| 14 |
from tools.auth import authenticate_user
|
| 15 |
from tools.load_spacy_model_custom_recognisers import custom_entities
|
|
@@ -20,30 +18,7 @@ from tools.textract_batch_call import analyse_document_with_textract_api, poll_w
|
|
| 20 |
# Suppress downcasting warnings
|
| 21 |
pd.set_option('future.no_silent_downcasting', True)
|
| 22 |
|
| 23 |
-
|
| 24 |
-
|
| 25 |
-
full_comprehend_entity_list = ['BANK_ACCOUNT_NUMBER','BANK_ROUTING','CREDIT_DEBIT_NUMBER','CREDIT_DEBIT_CVV','CREDIT_DEBIT_EXPIRY','PIN','EMAIL','ADDRESS','NAME','PHONE','SSN','DATE_TIME','PASSPORT_NUMBER','DRIVER_ID','URL','AGE','USERNAME','PASSWORD','AWS_ACCESS_KEY','AWS_SECRET_KEY','IP_ADDRESS','MAC_ADDRESS','ALL','LICENSE_PLATE','VEHICLE_IDENTIFICATION_NUMBER','UK_NATIONAL_INSURANCE_NUMBER','CA_SOCIAL_INSURANCE_NUMBER','US_INDIVIDUAL_TAX_IDENTIFICATION_NUMBER','UK_UNIQUE_TAXPAYER_REFERENCE_NUMBER','IN_PERMANENT_ACCOUNT_NUMBER','IN_NREGA','INTERNATIONAL_BANK_ACCOUNT_NUMBER','SWIFT_CODE','UK_NATIONAL_HEALTH_SERVICE_NUMBER','CA_HEALTH_NUMBER','IN_AADHAAR','IN_VOTER_NUMBER', "CUSTOM_FUZZY"]
|
| 26 |
-
|
| 27 |
-
# Add custom spacy recognisers to the Comprehend list, so that local Spacy model can be used to pick up e.g. titles, streetnames, UK postcodes that are sometimes missed by comprehend
|
| 28 |
-
chosen_comprehend_entities.extend(custom_entities)
|
| 29 |
-
full_comprehend_entity_list.extend(custom_entities)
|
| 30 |
-
|
| 31 |
-
# Entities for local PII redaction option
|
| 32 |
-
chosen_redact_entities = ["TITLES", "PERSON", "PHONE_NUMBER", "EMAIL_ADDRESS", "STREETNAME", "UKPOSTCODE", "CUSTOM"]
|
| 33 |
-
|
| 34 |
-
full_entity_list = ["TITLES", "PERSON", "PHONE_NUMBER", "EMAIL_ADDRESS", "STREETNAME", "UKPOSTCODE", 'CREDIT_CARD', 'CRYPTO', 'DATE_TIME', 'IBAN_CODE', 'IP_ADDRESS', 'NRP', 'LOCATION', 'MEDICAL_LICENSE', 'URL', 'UK_NHS', 'CUSTOM', 'CUSTOM_FUZZY']
|
| 35 |
-
|
| 36 |
-
log_file_name = 'log.csv'
|
| 37 |
-
|
| 38 |
-
file_input_height = 200
|
| 39 |
-
|
| 40 |
-
if RUN_AWS_FUNCTIONS == "1":
|
| 41 |
-
default_ocr_val = textract_option
|
| 42 |
-
default_pii_detector = local_pii_detector
|
| 43 |
-
else:
|
| 44 |
-
default_ocr_val = text_ocr_option
|
| 45 |
-
default_pii_detector = local_pii_detector
|
| 46 |
-
|
| 47 |
SAVE_LOGS_TO_CSV = eval(SAVE_LOGS_TO_CSV)
|
| 48 |
SAVE_LOGS_TO_DYNAMODB = eval(SAVE_LOGS_TO_DYNAMODB)
|
| 49 |
|
|
@@ -55,6 +30,17 @@ if DYNAMODB_ACCESS_LOG_HEADERS: DYNAMODB_ACCESS_LOG_HEADERS = eval(DYNAMODB_ACCE
|
|
| 55 |
if DYNAMODB_FEEDBACK_LOG_HEADERS: DYNAMODB_FEEDBACK_LOG_HEADERS = eval(DYNAMODB_FEEDBACK_LOG_HEADERS)
|
| 56 |
if DYNAMODB_USAGE_LOG_HEADERS: DYNAMODB_USAGE_LOG_HEADERS = eval(DYNAMODB_USAGE_LOG_HEADERS)
|
| 57 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 58 |
# Create the gradio interface
|
| 59 |
app = gr.Blocks(theme = gr.themes.Base(), fill_width=True)
|
| 60 |
|
|
@@ -66,8 +52,7 @@ with app:
|
|
| 66 |
|
| 67 |
# Pymupdf doc and all image annotations objects need to be stored as State objects as they do not have a standard Gradio component equivalent
|
| 68 |
pdf_doc_state = gr.State([])
|
| 69 |
-
all_image_annotations_state = gr.State([])
|
| 70 |
-
|
| 71 |
|
| 72 |
all_decision_process_table_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="all_decision_process_table", visible=False, type="pandas", wrap=True)
|
| 73 |
review_file_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="review_file_df", visible=False, type="pandas", wrap=True)
|
|
@@ -105,11 +90,11 @@ with app:
|
|
| 105 |
backup_recogniser_entity_dataframe_base = gr.Dataframe(visible=False)
|
| 106 |
|
| 107 |
# Logging state
|
| 108 |
-
feedback_logs_state = gr.Textbox(label= "feedback_logs_state", value=FEEDBACK_LOGS_FOLDER +
|
| 109 |
feedback_s3_logs_loc_state = gr.Textbox(label= "feedback_s3_logs_loc_state", value=FEEDBACK_LOGS_FOLDER, visible=False)
|
| 110 |
-
access_logs_state = gr.Textbox(label= "access_logs_state", value=ACCESS_LOGS_FOLDER +
|
| 111 |
access_s3_logs_loc_state = gr.Textbox(label= "access_s3_logs_loc_state", value=ACCESS_LOGS_FOLDER, visible=False)
|
| 112 |
-
usage_logs_state = gr.Textbox(label= "usage_logs_state", value=USAGE_LOGS_FOLDER +
|
| 113 |
usage_s3_logs_loc_state = gr.Textbox(label= "usage_s3_logs_loc_state", value=USAGE_LOGS_FOLDER, visible=False)
|
| 114 |
|
| 115 |
session_hash_textbox = gr.Textbox(label= "session_hash_textbox", value="", visible=False)
|
|
@@ -172,8 +157,8 @@ with app:
|
|
| 172 |
s3_whole_document_textract_input_subfolder = gr.Textbox(label = "Default Textract whole_document S3 input folder", value=TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, visible=False)
|
| 173 |
s3_whole_document_textract_output_subfolder = gr.Textbox(label = "Default Textract whole_document S3 output folder", value=TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, visible=False)
|
| 174 |
successful_textract_api_call_number = gr.Number(precision=0, value=0, visible=False)
|
| 175 |
-
no_redaction_method_drop = gr.Radio(label = """Placeholder for no redaction method after downloading Textract outputs""", value =
|
| 176 |
-
textract_only_method_drop = gr.Radio(label="""Placeholder for Textract method after downloading Textract outputs""", value =
|
| 177 |
|
| 178 |
load_s3_whole_document_textract_logs_bool = gr.Textbox(label = "Load Textract logs or not", value=LOAD_PREVIOUS_TEXTRACT_JOBS_S3, visible=False)
|
| 179 |
s3_whole_document_textract_logs_subfolder = gr.Textbox(label = "Default Textract whole_document S3 input folder", value=TEXTRACT_JOBS_S3_LOC, visible=False)
|
|
@@ -190,6 +175,14 @@ with app:
|
|
| 190 |
all_line_level_ocr_results_df_placeholder = gr.Dataframe(visible=False)
|
| 191 |
cost_code_dataframe_base = gr.Dataframe(value=pd.DataFrame(), row_count = (0, "dynamic"), label="Cost codes", type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, show_search='filter', wrap=True, max_height=200, visible=False)
|
| 192 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 193 |
# Duplicate page detection
|
| 194 |
in_duplicate_pages_text = gr.Textbox(label="in_duplicate_pages_text", visible=False)
|
| 195 |
duplicate_pages_df = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="duplicate_pages_df", visible=False, type="pandas", wrap=True)
|
|
@@ -225,7 +218,7 @@ with app:
|
|
| 225 |
job_output_textbox = gr.Textbox(value="", label="Textract call outputs", visible=False)
|
| 226 |
job_input_textbox = gr.Textbox(value=TEXTRACT_JOBS_S3_INPUT_LOC, label="Textract call outputs", visible=False)
|
| 227 |
|
| 228 |
-
textract_job_output_file = gr.File(label="Textract job output files", height=
|
| 229 |
convert_textract_outputs_to_ocr_results = gr.Button("Placeholder - Convert Textract job outputs to OCR results (needs relevant document file uploaded above)", variant="secondary", visible=False)
|
| 230 |
|
| 231 |
###
|
|
@@ -248,15 +241,15 @@ with app:
|
|
| 248 |
###
|
| 249 |
with gr.Tab("Redact PDFs/images"):
|
| 250 |
with gr.Accordion("Redact document", open = True):
|
| 251 |
-
in_doc_files = gr.File(label="Choose a document or image file (PDF, JPG, PNG)", file_count= "multiple", file_types=['.pdf', '.jpg', '.png', '.json', '.zip'], height=
|
| 252 |
|
| 253 |
-
text_extract_method_radio = gr.Radio(label="""Choose text extraction method. Local options are lower quality but cost nothing - they may be worth a try if you are willing to spend some time reviewing outputs. AWS Textract has a cost per page - £2.66 ($3.50) per 1,000 pages with signature detection (default), £1.14 ($1.50) without. Change the settings in the tab below (AWS Textract signature detection) to change this.""", value =
|
| 254 |
|
| 255 |
with gr.Accordion("AWS Textract signature detection (default is on)", open = False):
|
| 256 |
handwrite_signature_checkbox = gr.CheckboxGroup(label="AWS Textract extraction settings", choices=["Extract handwriting", "Extract signatures"], value=["Extract handwriting", "Extract signatures"])
|
| 257 |
|
| 258 |
with gr.Row(equal_height=True):
|
| 259 |
-
pii_identification_method_drop = gr.Radio(label = """Choose personal information detection method. The local model is lower quality but costs nothing - it may be worth a try if you are willing to spend some time reviewing outputs, or if you are only interested in searching for custom search terms (see Redaction settings - custom deny list). AWS Comprehend has a cost of around £0.0075 ($0.01) per 10,000 characters.""", value =
|
| 260 |
|
| 261 |
if SHOW_COSTS == "True":
|
| 262 |
with gr.Accordion("Estimated costs and time taken. Note that costs shown only include direct usage of AWS services and do not include other running costs (e.g. storage, run-time costs)", open = True, visible=True):
|
|
@@ -303,7 +296,7 @@ with app:
|
|
| 303 |
|
| 304 |
with gr.Row():
|
| 305 |
redaction_output_summary_textbox = gr.Textbox(label="Output summary", scale=1)
|
| 306 |
-
output_file = gr.File(label="Output files", scale = 2)#, height=
|
| 307 |
latest_file_completed_text = gr.Number(value=0, label="Number of documents redacted", interactive=False, visible=False)
|
| 308 |
|
| 309 |
# Feedback elements are invisible until revealed by redaction action
|
|
@@ -318,8 +311,8 @@ with app:
|
|
| 318 |
with gr.Tab("Review redactions", id="tab_object_annotation"):
|
| 319 |
|
| 320 |
with gr.Accordion(label = "Review PDF redactions", open=True):
|
| 321 |
-
output_review_files = gr.File(label="Upload original PDF and 'review_file' csv here to review suggested redactions. The 'ocr_output' file can also be optionally provided for text search.", file_count='multiple', height=
|
| 322 |
-
upload_previous_review_file_btn = gr.Button("Review PDF and '
|
| 323 |
with gr.Row():
|
| 324 |
annotate_zoom_in = gr.Button("Zoom in", visible=False)
|
| 325 |
annotate_zoom_out = gr.Button("Zoom out", visible=False)
|
|
@@ -368,19 +361,18 @@ with app:
|
|
| 368 |
recogniser_entity_dropdown = gr.Dropdown(label="Redaction category", value="ALL", allow_custom_value=True)
|
| 369 |
page_entity_dropdown = gr.Dropdown(label="Page", value="ALL", allow_custom_value=True)
|
| 370 |
text_entity_dropdown = gr.Dropdown(label="Text", value="ALL", allow_custom_value=True)
|
| 371 |
-
|
|
|
|
| 372 |
|
| 373 |
-
with gr.Row(equal_height=True):
|
| 374 |
-
|
| 375 |
-
exclude_selected_btn = gr.Button(value="Exclude all items in table from redactions")
|
| 376 |
-
with gr.Row(equal_height=True):
|
| 377 |
-
reset_dropdowns_btn = gr.Button(value="Reset filters")
|
| 378 |
-
|
| 379 |
-
undo_last_removal_btn = gr.Button(value="Undo last element removal")
|
| 380 |
|
| 381 |
-
|
| 382 |
-
|
| 383 |
-
|
|
|
|
|
|
|
|
|
|
| 384 |
|
| 385 |
with gr.Accordion("Search all extracted text", open=True):
|
| 386 |
all_line_level_ocr_results_df = gr.Dataframe(value=pd.DataFrame(), headers=["page", "text"], col_count=(2, 'fixed'), row_count = (0, "dynamic"), label="All OCR results", visible=True, type="pandas", wrap=True, show_fullscreen_button=True, show_search='filter', show_label=False, show_copy_button=True, max_height=400)
|
|
@@ -396,12 +388,12 @@ with app:
|
|
| 396 |
###
|
| 397 |
with gr.Tab(label="Identify duplicate pages"):
|
| 398 |
with gr.Accordion("Identify duplicate pages to redact", open = True):
|
| 399 |
-
in_duplicate_pages = gr.File(label="Upload multiple 'ocr_output.csv' data files from redaction jobs here to compare", file_count="multiple", height=
|
| 400 |
with gr.Row():
|
| 401 |
duplicate_threshold_value = gr.Number(value=0.9, label="Minimum similarity to be considered a duplicate (maximum = 1)", scale =1)
|
| 402 |
find_duplicate_pages_btn = gr.Button(value="Identify duplicate pages", variant="primary", scale = 4)
|
| 403 |
|
| 404 |
-
duplicate_pages_out = gr.File(label="Duplicate pages analysis output", file_count="multiple", height=
|
| 405 |
|
| 406 |
###
|
| 407 |
# TEXT / TABULAR DATA TAB
|
|
@@ -411,13 +403,13 @@ with app:
|
|
| 411 |
with gr.Accordion("Redact open text", open = False):
|
| 412 |
in_text = gr.Textbox(label="Enter open text", lines=10)
|
| 413 |
with gr.Accordion("Upload xlsx or csv files", open = True):
|
| 414 |
-
in_data_files = gr.File(label="Choose Excel or csv files", file_count= "multiple", file_types=['.xlsx', '.xls', '.csv', '.parquet', '.csv.gz'], height=
|
| 415 |
|
| 416 |
in_excel_sheets = gr.Dropdown(choices=["Choose Excel sheets to anonymise"], multiselect = True, label="Select Excel sheets that you want to anonymise (showing sheets present across all Excel files).", visible=False, allow_custom_value=True)
|
| 417 |
|
| 418 |
in_colnames = gr.Dropdown(choices=["Choose columns to anonymise"], multiselect = True, label="Select columns that you want to anonymise (showing columns present across all files).")
|
| 419 |
|
| 420 |
-
pii_identification_method_drop_tabular = gr.Radio(label = "Choose PII detection method. AWS Comprehend has a cost of approximately $0.01 per 10,000 characters.", value =
|
| 421 |
|
| 422 |
with gr.Accordion("Anonymisation output format", open = False):
|
| 423 |
anon_strat = gr.Radio(choices=["replace with 'REDACTED'", "replace with <ENTITY_NAME>", "redact completely", "hash", "mask"], label="Select an anonymisation method.", value = "replace with 'REDACTED'") # , "encrypt", "fake_first_name" are also available, but are not currently included as not that useful in current form
|
|
@@ -443,13 +435,13 @@ with app:
|
|
| 443 |
with gr.Accordion("Custom allow, deny, and full page redaction lists", open = True):
|
| 444 |
with gr.Row():
|
| 445 |
with gr.Column():
|
| 446 |
-
in_allow_list = gr.File(label="Import allow list file - csv table with one column of a different word/phrase on each row (case insensitive). Terms in this file will not be redacted.", file_count="multiple", height=
|
| 447 |
in_allow_list_text = gr.Textbox(label="Custom allow list load status")
|
| 448 |
with gr.Column():
|
| 449 |
-
in_deny_list = gr.File(label="Import custom deny list - csv table with one column of a different word/phrase on each row (case insensitive). Terms in this file will always be redacted.", file_count="multiple", height=
|
| 450 |
in_deny_list_text = gr.Textbox(label="Custom deny list load status")
|
| 451 |
with gr.Column():
|
| 452 |
-
in_fully_redacted_list = gr.File(label="Import fully redacted pages list - csv table with one column of page numbers on each row. Page numbers in this file will be fully redacted.", file_count="multiple", height=
|
| 453 |
in_fully_redacted_list_text = gr.Textbox(label="Fully redacted page list load status")
|
| 454 |
with gr.Accordion("Manually modify custom allow, deny, and full page redaction lists (NOTE: you need to press Enter after modifying/adding an entry to the lists to apply them)", open = False):
|
| 455 |
with gr.Row():
|
|
@@ -458,8 +450,8 @@ with app:
|
|
| 458 |
in_fully_redacted_list_state = gr.Dataframe(value=pd.DataFrame(), headers=["fully_redacted_pages_list"], col_count=(1, "fixed"), row_count = (0, "dynamic"), label="Fully redacted pages", visible=True, type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, datatype='number', wrap=True)
|
| 459 |
|
| 460 |
with gr.Accordion("Select entity types to redact", open = True):
|
| 461 |
-
in_redact_entities = gr.Dropdown(value=
|
| 462 |
-
in_redact_comprehend_entities = gr.Dropdown(value=
|
| 463 |
|
| 464 |
with gr.Row():
|
| 465 |
max_fuzzy_spelling_mistakes_num = gr.Number(label="Maximum number of spelling mistakes allowed for fuzzy matching (CUSTOM_FUZZY entity).", value=1, minimum=0, maximum=9, precision=0)
|
|
@@ -478,8 +470,6 @@ with app:
|
|
| 478 |
aws_access_key_textbox = gr.Textbox(value='', label="AWS access key for account with permissions for AWS Textract and Comprehend", visible=True, type="password")
|
| 479 |
aws_secret_key_textbox = gr.Textbox(value='', label="AWS secret key for account with permissions for AWS Textract and Comprehend", visible=True, type="password")
|
| 480 |
|
| 481 |
-
|
| 482 |
-
|
| 483 |
with gr.Accordion("Log file outputs", open = False):
|
| 484 |
log_files_output = gr.File(label="Log file output", interactive=False)
|
| 485 |
|
|
@@ -492,7 +482,7 @@ with app:
|
|
| 492 |
all_output_files = gr.File(label="All files in output folder", file_count='multiple', file_types=['.csv'], interactive=False)
|
| 493 |
|
| 494 |
###
|
| 495 |
-
|
| 496 |
###
|
| 497 |
|
| 498 |
###
|
|
@@ -565,7 +555,6 @@ with app:
|
|
| 565 |
|
| 566 |
textract_job_detail_df.select(df_select_callback_textract_api, inputs=[textract_output_found_checkbox], outputs=[job_id_textbox, job_type_dropdown, selected_job_id_row])
|
| 567 |
|
| 568 |
-
|
| 569 |
convert_textract_outputs_to_ocr_results.click(replace_existing_pdf_input_for_whole_document_outputs, inputs = [s3_whole_document_textract_input_subfolder, doc_file_name_no_extension_textbox, output_folder_textbox, s3_whole_document_textract_default_bucket, in_doc_files, input_folder_textbox], outputs = [in_doc_files, doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 570 |
success(fn = prepare_image_or_pdf, inputs=[in_doc_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, first_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool_false, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base, local_ocr_output_found_checkbox]).\
|
| 571 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
|
@@ -587,17 +576,34 @@ with app:
|
|
| 587 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 588 |
|
| 589 |
# Page number controls
|
| 590 |
-
annotate_current_page.
|
| 591 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 592 |
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 593 |
|
| 594 |
-
annotation_last_page_button.click(fn=decrease_page, inputs=[annotate_current_page], outputs=[annotate_current_page, annotate_current_page_bottom])
|
| 595 |
-
|
|
|
|
|
|
|
| 596 |
|
| 597 |
-
|
| 598 |
-
|
|
|
|
|
|
|
| 599 |
|
| 600 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 601 |
|
| 602 |
# Apply page redactions
|
| 603 |
annotation_button_apply.click(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state], scroll_to_output=True)
|
|
@@ -613,7 +619,7 @@ with app:
|
|
| 613 |
text_entity_dropdown.select(update_entities_df_text, inputs=[text_entity_dropdown, recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown], outputs=[recogniser_entity_dataframe, recogniser_entity_dropdown, page_entity_dropdown])
|
| 614 |
|
| 615 |
# Clicking on a cell in the recogniser entity dataframe will take you to that page, and also highlight the target redaction box in blue
|
| 616 |
-
recogniser_entity_dataframe.select(
|
| 617 |
success(update_selected_review_df_row_colour, inputs=[selected_entity_dataframe_row, review_file_state, selected_entity_id, selected_entity_colour], outputs=[review_file_state, selected_entity_id, selected_entity_colour]).\
|
| 618 |
success(update_annotator_page_from_review_df, inputs=[review_file_state, images_pdf_state, page_sizes, all_image_annotations_state, annotator, selected_entity_dataframe_row, input_folder_textbox, doc_full_file_name_textbox], outputs=[annotator, all_image_annotations_state, annotate_current_page, page_sizes, review_file_state, annotate_previous_page])
|
| 619 |
|
|
@@ -621,25 +627,32 @@ with app:
|
|
| 621 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 622 |
|
| 623 |
# Exclude current selection from annotator and outputs
|
| 624 |
-
# Exclude only row
|
| 625 |
exclude_selected_row_btn.click(exclude_selected_items_from_redaction, inputs=[review_file_state, selected_entity_dataframe_row, images_pdf_state, page_sizes, all_image_annotations_state, recogniser_entity_dataframe_base], outputs=[review_file_state, all_image_annotations_state, recogniser_entity_dataframe_base, backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base]).\
|
| 626 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 627 |
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state]).\
|
| 628 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 629 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 630 |
# Exclude everything visible in table
|
| 631 |
exclude_selected_btn.click(exclude_selected_items_from_redaction, inputs=[review_file_state, recogniser_entity_dataframe, images_pdf_state, page_sizes, all_image_annotations_state, recogniser_entity_dataframe_base], outputs=[review_file_state, all_image_annotations_state, recogniser_entity_dataframe_base, backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base]).\
|
| 632 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 633 |
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state]).\
|
| 634 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
|
|
|
|
|
|
| 635 |
|
| 636 |
undo_last_removal_btn.click(undo_last_removal, inputs=[backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base], outputs=[review_file_state, all_image_annotations_state, recogniser_entity_dataframe_base]).\
|
| 637 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 638 |
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 639 |
-
|
| 640 |
-
|
| 641 |
-
|
| 642 |
-
# Review OCR text buttom
|
| 643 |
all_line_level_ocr_results_df.select(df_select_callback_ocr, inputs=[all_line_level_ocr_results_df], outputs=[annotate_current_page, selected_entity_dataframe_row])
|
| 644 |
reset_all_ocr_results_btn.click(reset_ocr_base_dataframe, inputs=[all_line_level_ocr_results_df_base], outputs=[all_line_level_ocr_results_df])
|
| 645 |
|
|
@@ -737,7 +750,7 @@ with app:
|
|
| 737 |
|
| 738 |
### ACCESS LOGS
|
| 739 |
# Log usernames and times of access to file (to know who is using the app when running on AWS)
|
| 740 |
-
access_callback = CSVLogger_custom(dataset_file_name=
|
| 741 |
access_callback.setup([session_hash_textbox, host_name_textbox], ACCESS_LOGS_FOLDER)
|
| 742 |
session_hash_textbox.change(lambda *args: access_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=ACCESS_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_ACCESS_LOG_HEADERS, replacement_headers=CSV_ACCESS_LOG_HEADERS), [session_hash_textbox, host_name_textbox], None, preprocess=False).\
|
| 743 |
success(fn = upload_log_file_to_s3, inputs=[access_logs_state, access_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
|
@@ -745,25 +758,25 @@ with app:
|
|
| 745 |
### FEEDBACK LOGS
|
| 746 |
if DISPLAY_FILE_NAMES_IN_LOGS == 'True':
|
| 747 |
# User submitted feedback for pdf redactions
|
| 748 |
-
pdf_callback = CSVLogger_custom(dataset_file_name=
|
| 749 |
pdf_callback.setup([pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], FEEDBACK_LOGS_FOLDER)
|
| 750 |
pdf_submit_feedback_btn.click(lambda *args: pdf_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], None, preprocess=False).\
|
| 751 |
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[pdf_further_details_text])
|
| 752 |
|
| 753 |
# User submitted feedback for data redactions
|
| 754 |
-
data_callback = CSVLogger_custom(dataset_file_name=
|
| 755 |
data_callback.setup([data_feedback_radio, data_further_details_text, data_full_file_name_textbox], FEEDBACK_LOGS_FOLDER)
|
| 756 |
data_submit_feedback_btn.click(lambda *args: data_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [data_feedback_radio, data_further_details_text, data_full_file_name_textbox], None, preprocess=False).\
|
| 757 |
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[data_further_details_text])
|
| 758 |
else:
|
| 759 |
# User submitted feedback for pdf redactions
|
| 760 |
-
pdf_callback = CSVLogger_custom(dataset_file_name=
|
| 761 |
pdf_callback.setup([pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], FEEDBACK_LOGS_FOLDER)
|
| 762 |
pdf_submit_feedback_btn.click(lambda *args: pdf_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [pdf_feedback_radio, pdf_further_details_text, placeholder_doc_file_name_no_extension_textbox_for_logs], None, preprocess=False).\
|
| 763 |
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[pdf_further_details_text])
|
| 764 |
|
| 765 |
# User submitted feedback for data redactions
|
| 766 |
-
data_callback = CSVLogger_custom(dataset_file_name=
|
| 767 |
data_callback.setup([data_feedback_radio, data_further_details_text, data_full_file_name_textbox], FEEDBACK_LOGS_FOLDER)
|
| 768 |
data_submit_feedback_btn.click(lambda *args: data_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [data_feedback_radio, data_further_details_text, placeholder_data_file_name_no_extension_textbox_for_logs], None, preprocess=False).\
|
| 769 |
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[data_further_details_text])
|
|
@@ -771,7 +784,7 @@ with app:
|
|
| 771 |
### USAGE LOGS
|
| 772 |
# Log processing usage - time taken for redaction queries, and also logs for queries to Textract/Comprehend
|
| 773 |
|
| 774 |
-
usage_callback = CSVLogger_custom(dataset_file_name=
|
| 775 |
|
| 776 |
if DISPLAY_FILE_NAMES_IN_LOGS == 'True':
|
| 777 |
usage_callback.setup([session_hash_textbox, doc_file_name_no_extension_textbox, data_full_file_name_textbox, total_pdf_page_count, actual_time_taken_number, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], USAGE_LOGS_FOLDER)
|
|
@@ -809,7 +822,7 @@ if __name__ == "__main__":
|
|
| 809 |
|
| 810 |
main(first_loop_state, latest_file_completed=0, redaction_output_summary_textbox="", output_file_list=None,
|
| 811 |
log_files_list=None, estimated_time=0, textract_metadata="", comprehend_query_num=0,
|
| 812 |
-
current_loop_page=0, page_break=False, pdf_doc_state = [], all_image_annotations = [], all_line_level_ocr_results_df = pd.DataFrame(), all_decision_process_table = pd.DataFrame(),
|
| 813 |
|
| 814 |
# AWS options - placeholder for possibility of storing data on s3 and retrieving it in app
|
| 815 |
# with gr.Tab(label="Advanced options"):
|
|
|
|
| 1 |
import os
|
|
|
|
| 2 |
import pandas as pd
|
| 3 |
import gradio as gr
|
| 4 |
from gradio_image_annotation import image_annotator
|
| 5 |
+
from tools.config import OUTPUT_FOLDER, INPUT_FOLDER, RUN_DIRECT_MODE, MAX_QUEUE_SIZE, DEFAULT_CONCURRENCY_LIMIT, MAX_FILE_SIZE, GRADIO_SERVER_PORT, ROOT_PATH, GET_DEFAULT_ALLOW_LIST, ALLOW_LIST_PATH, S3_ALLOW_LIST_PATH, FEEDBACK_LOGS_FOLDER, ACCESS_LOGS_FOLDER, USAGE_LOGS_FOLDER, REDACTION_LANGUAGE, GET_COST_CODES, COST_CODES_PATH, S3_COST_CODES_PATH, ENFORCE_COST_CODES, DISPLAY_FILE_NAMES_IN_LOGS, SHOW_COSTS, RUN_AWS_FUNCTIONS, DOCUMENT_REDACTION_BUCKET, SHOW_WHOLE_DOCUMENT_TEXTRACT_CALL_OPTIONS, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_BUCKET, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, SESSION_OUTPUT_FOLDER, LOAD_PREVIOUS_TEXTRACT_JOBS_S3, TEXTRACT_JOBS_S3_LOC, TEXTRACT_JOBS_LOCAL_LOC, HOST_NAME, DEFAULT_COST_CODE, OUTPUT_COST_CODES_PATH, OUTPUT_ALLOW_LIST_PATH, COGNITO_AUTH, SAVE_LOGS_TO_CSV, SAVE_LOGS_TO_DYNAMODB, ACCESS_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_ACCESS_LOG_HEADERS, CSV_ACCESS_LOG_HEADERS, FEEDBACK_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_FEEDBACK_LOG_HEADERS, CSV_FEEDBACK_LOG_HEADERS, USAGE_LOG_DYNAMODB_TABLE_NAME, DYNAMODB_USAGE_LOG_HEADERS, CSV_USAGE_LOG_HEADERS, TEXTRACT_JOBS_S3_INPUT_LOC, TEXTRACT_TEXT_EXTRACT_OPTION, NO_REDACTION_PII_OPTION, TEXT_EXTRACTION_MODELS, PII_DETECTION_MODELS, DEFAULT_TEXT_EXTRACTION_MODEL, DEFAULT_PII_DETECTION_MODEL, LOG_FILE_NAME, CHOSEN_COMPREHEND_ENTITIES, FULL_COMPREHEND_ENTITY_LIST, CHOSEN_REDACT_ENTITIES, FULL_ENTITY_LIST, FILE_INPUT_HEIGHT, TABULAR_PII_DETECTION_MODELS
|
| 6 |
+
from tools.helper_functions import put_columns_in_df, get_connection_params, reveal_feedback_buttons, custom_regex_load, reset_state_vars, load_in_default_allow_list, reset_review_vars, merge_csv_files, load_all_output_files, update_dataframe, check_for_existing_textract_file, load_in_default_cost_codes, enforce_cost_codes, calculate_aws_costs, calculate_time_taken, reset_base_dataframe, reset_ocr_base_dataframe, update_cost_code_dataframe_from_dropdown_select, check_for_existing_local_ocr_file, reset_data_vars, reset_aws_call_vars
|
| 7 |
+
from tools.aws_functions import download_file_from_s3, upload_log_file_to_s3
|
|
|
|
| 8 |
from tools.file_redaction import choose_and_run_redactor
|
| 9 |
from tools.file_conversion import prepare_image_or_pdf, get_input_file_names
|
| 10 |
+
from tools.redaction_review import apply_redactions_to_review_df_and_files, update_all_page_annotation_object_based_on_previous_page, decrease_page, increase_page, update_annotator_object_and_filter_df, update_entities_df_recogniser_entities, update_entities_df_page, update_entities_df_text, df_select_callback_dataframe_row, convert_df_to_xfdf, convert_xfdf_to_dataframe, reset_dropdowns, exclude_selected_items_from_redaction, undo_last_removal, update_selected_review_df_row_colour, update_all_entity_df_dropdowns, df_select_callback_cost, update_other_annotator_number_from_current, update_annotator_page_from_review_df, df_select_callback_ocr, df_select_callback_textract_api, get_all_rows_with_same_text
|
| 11 |
from tools.data_anonymise import anonymise_data_files
|
| 12 |
from tools.auth import authenticate_user
|
| 13 |
from tools.load_spacy_model_custom_recognisers import custom_entities
|
|
|
|
| 18 |
# Suppress downcasting warnings
|
| 19 |
pd.set_option('future.no_silent_downcasting', True)
|
| 20 |
|
| 21 |
+
# Convert string environment variables to string or list
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 22 |
SAVE_LOGS_TO_CSV = eval(SAVE_LOGS_TO_CSV)
|
| 23 |
SAVE_LOGS_TO_DYNAMODB = eval(SAVE_LOGS_TO_DYNAMODB)
|
| 24 |
|
|
|
|
| 30 |
if DYNAMODB_FEEDBACK_LOG_HEADERS: DYNAMODB_FEEDBACK_LOG_HEADERS = eval(DYNAMODB_FEEDBACK_LOG_HEADERS)
|
| 31 |
if DYNAMODB_USAGE_LOG_HEADERS: DYNAMODB_USAGE_LOG_HEADERS = eval(DYNAMODB_USAGE_LOG_HEADERS)
|
| 32 |
|
| 33 |
+
if CHOSEN_COMPREHEND_ENTITIES: CHOSEN_COMPREHEND_ENTITIES = eval(CHOSEN_COMPREHEND_ENTITIES)
|
| 34 |
+
if FULL_COMPREHEND_ENTITY_LIST: FULL_COMPREHEND_ENTITY_LIST = eval(FULL_COMPREHEND_ENTITY_LIST)
|
| 35 |
+
if CHOSEN_REDACT_ENTITIES: CHOSEN_REDACT_ENTITIES = eval(CHOSEN_REDACT_ENTITIES)
|
| 36 |
+
if FULL_ENTITY_LIST: FULL_ENTITY_LIST = eval(FULL_ENTITY_LIST)
|
| 37 |
+
|
| 38 |
+
# Add custom spacy recognisers to the Comprehend list, so that local Spacy model can be used to pick up e.g. titles, streetnames, UK postcodes that are sometimes missed by comprehend
|
| 39 |
+
CHOSEN_COMPREHEND_ENTITIES.extend(custom_entities)
|
| 40 |
+
FULL_COMPREHEND_ENTITY_LIST.extend(custom_entities)
|
| 41 |
+
|
| 42 |
+
FILE_INPUT_HEIGHT = int(FILE_INPUT_HEIGHT)
|
| 43 |
+
|
| 44 |
# Create the gradio interface
|
| 45 |
app = gr.Blocks(theme = gr.themes.Base(), fill_width=True)
|
| 46 |
|
|
|
|
| 52 |
|
| 53 |
# Pymupdf doc and all image annotations objects need to be stored as State objects as they do not have a standard Gradio component equivalent
|
| 54 |
pdf_doc_state = gr.State([])
|
| 55 |
+
all_image_annotations_state = gr.State([])
|
|
|
|
| 56 |
|
| 57 |
all_decision_process_table_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="all_decision_process_table", visible=False, type="pandas", wrap=True)
|
| 58 |
review_file_state = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="review_file_df", visible=False, type="pandas", wrap=True)
|
|
|
|
| 90 |
backup_recogniser_entity_dataframe_base = gr.Dataframe(visible=False)
|
| 91 |
|
| 92 |
# Logging state
|
| 93 |
+
feedback_logs_state = gr.Textbox(label= "feedback_logs_state", value=FEEDBACK_LOGS_FOLDER + LOG_FILE_NAME, visible=False)
|
| 94 |
feedback_s3_logs_loc_state = gr.Textbox(label= "feedback_s3_logs_loc_state", value=FEEDBACK_LOGS_FOLDER, visible=False)
|
| 95 |
+
access_logs_state = gr.Textbox(label= "access_logs_state", value=ACCESS_LOGS_FOLDER + LOG_FILE_NAME, visible=False)
|
| 96 |
access_s3_logs_loc_state = gr.Textbox(label= "access_s3_logs_loc_state", value=ACCESS_LOGS_FOLDER, visible=False)
|
| 97 |
+
usage_logs_state = gr.Textbox(label= "usage_logs_state", value=USAGE_LOGS_FOLDER + LOG_FILE_NAME, visible=False)
|
| 98 |
usage_s3_logs_loc_state = gr.Textbox(label= "usage_s3_logs_loc_state", value=USAGE_LOGS_FOLDER, visible=False)
|
| 99 |
|
| 100 |
session_hash_textbox = gr.Textbox(label= "session_hash_textbox", value="", visible=False)
|
|
|
|
| 157 |
s3_whole_document_textract_input_subfolder = gr.Textbox(label = "Default Textract whole_document S3 input folder", value=TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, visible=False)
|
| 158 |
s3_whole_document_textract_output_subfolder = gr.Textbox(label = "Default Textract whole_document S3 output folder", value=TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, visible=False)
|
| 159 |
successful_textract_api_call_number = gr.Number(precision=0, value=0, visible=False)
|
| 160 |
+
no_redaction_method_drop = gr.Radio(label = """Placeholder for no redaction method after downloading Textract outputs""", value = NO_REDACTION_PII_OPTION, choices=[NO_REDACTION_PII_OPTION], visible=False)
|
| 161 |
+
textract_only_method_drop = gr.Radio(label="""Placeholder for Textract method after downloading Textract outputs""", value = TEXTRACT_TEXT_EXTRACT_OPTION, choices=[TEXTRACT_TEXT_EXTRACT_OPTION], visible=False)
|
| 162 |
|
| 163 |
load_s3_whole_document_textract_logs_bool = gr.Textbox(label = "Load Textract logs or not", value=LOAD_PREVIOUS_TEXTRACT_JOBS_S3, visible=False)
|
| 164 |
s3_whole_document_textract_logs_subfolder = gr.Textbox(label = "Default Textract whole_document S3 input folder", value=TEXTRACT_JOBS_S3_LOC, visible=False)
|
|
|
|
| 175 |
all_line_level_ocr_results_df_placeholder = gr.Dataframe(visible=False)
|
| 176 |
cost_code_dataframe_base = gr.Dataframe(value=pd.DataFrame(), row_count = (0, "dynamic"), label="Cost codes", type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, show_search='filter', wrap=True, max_height=200, visible=False)
|
| 177 |
|
| 178 |
+
# Placeholder for selected entity dataframe row
|
| 179 |
+
selected_entity_id = gr.Textbox(value="", label="selected_entity_id", visible=False)
|
| 180 |
+
selected_entity_colour = gr.Textbox(value="", label="selected_entity_colour", visible=False)
|
| 181 |
+
selected_entity_dataframe_row_text = gr.Textbox(value="", label="selected_entity_dataframe_row_text", visible=False)
|
| 182 |
+
|
| 183 |
+
# This is an invisible dataframe that holds all items from the redaction outputs that have the same text as the selected row
|
| 184 |
+
recogniser_entity_dataframe_same_text = gr.Dataframe(pd.DataFrame(data={"page":[], "label":[], "text":[], "id":[]}), col_count=(4,"fixed"), type="pandas", label="Click table row to select and go to page", headers=["page", "label", "text", "id"], show_fullscreen_button=True, wrap=True, max_height=400, static_columns=[0,1,2,3], visible=False)
|
| 185 |
+
|
| 186 |
# Duplicate page detection
|
| 187 |
in_duplicate_pages_text = gr.Textbox(label="in_duplicate_pages_text", visible=False)
|
| 188 |
duplicate_pages_df = gr.Dataframe(value=pd.DataFrame(), headers=None, col_count=0, row_count = (0, "dynamic"), label="duplicate_pages_df", visible=False, type="pandas", wrap=True)
|
|
|
|
| 218 |
job_output_textbox = gr.Textbox(value="", label="Textract call outputs", visible=False)
|
| 219 |
job_input_textbox = gr.Textbox(value=TEXTRACT_JOBS_S3_INPUT_LOC, label="Textract call outputs", visible=False)
|
| 220 |
|
| 221 |
+
textract_job_output_file = gr.File(label="Textract job output files", height=FILE_INPUT_HEIGHT, visible=False)
|
| 222 |
convert_textract_outputs_to_ocr_results = gr.Button("Placeholder - Convert Textract job outputs to OCR results (needs relevant document file uploaded above)", variant="secondary", visible=False)
|
| 223 |
|
| 224 |
###
|
|
|
|
| 241 |
###
|
| 242 |
with gr.Tab("Redact PDFs/images"):
|
| 243 |
with gr.Accordion("Redact document", open = True):
|
| 244 |
+
in_doc_files = gr.File(label="Choose a document or image file (PDF, JPG, PNG)", file_count= "multiple", file_types=['.pdf', '.jpg', '.png', '.json', '.zip'], height=FILE_INPUT_HEIGHT)
|
| 245 |
|
| 246 |
+
text_extract_method_radio = gr.Radio(label="""Choose text extraction method. Local options are lower quality but cost nothing - they may be worth a try if you are willing to spend some time reviewing outputs. AWS Textract has a cost per page - £2.66 ($3.50) per 1,000 pages with signature detection (default), £1.14 ($1.50) without. Change the settings in the tab below (AWS Textract signature detection) to change this.""", value = DEFAULT_TEXT_EXTRACTION_MODEL, choices=TEXT_EXTRACTION_MODELS)
|
| 247 |
|
| 248 |
with gr.Accordion("AWS Textract signature detection (default is on)", open = False):
|
| 249 |
handwrite_signature_checkbox = gr.CheckboxGroup(label="AWS Textract extraction settings", choices=["Extract handwriting", "Extract signatures"], value=["Extract handwriting", "Extract signatures"])
|
| 250 |
|
| 251 |
with gr.Row(equal_height=True):
|
| 252 |
+
pii_identification_method_drop = gr.Radio(label = """Choose personal information detection method. The local model is lower quality but costs nothing - it may be worth a try if you are willing to spend some time reviewing outputs, or if you are only interested in searching for custom search terms (see Redaction settings - custom deny list). AWS Comprehend has a cost of around £0.0075 ($0.01) per 10,000 characters.""", value = DEFAULT_PII_DETECTION_MODEL, choices=PII_DETECTION_MODELS)
|
| 253 |
|
| 254 |
if SHOW_COSTS == "True":
|
| 255 |
with gr.Accordion("Estimated costs and time taken. Note that costs shown only include direct usage of AWS services and do not include other running costs (e.g. storage, run-time costs)", open = True, visible=True):
|
|
|
|
| 296 |
|
| 297 |
with gr.Row():
|
| 298 |
redaction_output_summary_textbox = gr.Textbox(label="Output summary", scale=1)
|
| 299 |
+
output_file = gr.File(label="Output files", scale = 2)#, height=FILE_INPUT_HEIGHT)
|
| 300 |
latest_file_completed_text = gr.Number(value=0, label="Number of documents redacted", interactive=False, visible=False)
|
| 301 |
|
| 302 |
# Feedback elements are invisible until revealed by redaction action
|
|
|
|
| 311 |
with gr.Tab("Review redactions", id="tab_object_annotation"):
|
| 312 |
|
| 313 |
with gr.Accordion(label = "Review PDF redactions", open=True):
|
| 314 |
+
output_review_files = gr.File(label="Upload original PDF and 'review_file' csv here to review suggested redactions. The 'ocr_output' file can also be optionally provided for text search.", file_count='multiple', height=FILE_INPUT_HEIGHT)
|
| 315 |
+
upload_previous_review_file_btn = gr.Button("Review redactions based on original PDF and 'review_file' csv provided above ('ocr_output' csv optional)", variant="secondary")
|
| 316 |
with gr.Row():
|
| 317 |
annotate_zoom_in = gr.Button("Zoom in", visible=False)
|
| 318 |
annotate_zoom_out = gr.Button("Zoom out", visible=False)
|
|
|
|
| 361 |
recogniser_entity_dropdown = gr.Dropdown(label="Redaction category", value="ALL", allow_custom_value=True)
|
| 362 |
page_entity_dropdown = gr.Dropdown(label="Page", value="ALL", allow_custom_value=True)
|
| 363 |
text_entity_dropdown = gr.Dropdown(label="Text", value="ALL", allow_custom_value=True)
|
| 364 |
+
reset_dropdowns_btn = gr.Button(value="Reset filters")
|
| 365 |
+
recogniser_entity_dataframe = gr.Dataframe(pd.DataFrame(data={"page":[], "label":[], "text":[], "id":[]}), col_count=(4,"fixed"), type="pandas", label="Click table row to select and go to page", headers=["page", "label", "text", "id"], show_fullscreen_button=True, wrap=True, max_height=400, static_columns=[0,1,2,3])
|
| 366 |
|
| 367 |
+
with gr.Row(equal_height=True):
|
| 368 |
+
exclude_selected_btn = gr.Button(value="Exclude all redactions in table")
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 369 |
|
| 370 |
+
with gr.Accordion("Selected redaction row", open=True):
|
| 371 |
+
selected_entity_dataframe_row = gr.Dataframe(pd.DataFrame(data={"page":[], "label":[], "text":[], "id":[]}), col_count=4, type="pandas", visible=True, headers=["page", "label", "text", "id"], wrap=True)
|
| 372 |
+
exclude_selected_row_btn = gr.Button(value="Exclude specific redaction row")
|
| 373 |
+
exclude_text_with_same_as_selected_row_btn = gr.Button(value="Exclude all redactions with same text as selected row")
|
| 374 |
+
|
| 375 |
+
undo_last_removal_btn = gr.Button(value="Undo last element removal", variant="primary")
|
| 376 |
|
| 377 |
with gr.Accordion("Search all extracted text", open=True):
|
| 378 |
all_line_level_ocr_results_df = gr.Dataframe(value=pd.DataFrame(), headers=["page", "text"], col_count=(2, 'fixed'), row_count = (0, "dynamic"), label="All OCR results", visible=True, type="pandas", wrap=True, show_fullscreen_button=True, show_search='filter', show_label=False, show_copy_button=True, max_height=400)
|
|
|
|
| 388 |
###
|
| 389 |
with gr.Tab(label="Identify duplicate pages"):
|
| 390 |
with gr.Accordion("Identify duplicate pages to redact", open = True):
|
| 391 |
+
in_duplicate_pages = gr.File(label="Upload multiple 'ocr_output.csv' data files from redaction jobs here to compare", file_count="multiple", height=FILE_INPUT_HEIGHT, file_types=['.csv'])
|
| 392 |
with gr.Row():
|
| 393 |
duplicate_threshold_value = gr.Number(value=0.9, label="Minimum similarity to be considered a duplicate (maximum = 1)", scale =1)
|
| 394 |
find_duplicate_pages_btn = gr.Button(value="Identify duplicate pages", variant="primary", scale = 4)
|
| 395 |
|
| 396 |
+
duplicate_pages_out = gr.File(label="Duplicate pages analysis output", file_count="multiple", height=FILE_INPUT_HEIGHT, file_types=['.csv'])
|
| 397 |
|
| 398 |
###
|
| 399 |
# TEXT / TABULAR DATA TAB
|
|
|
|
| 403 |
with gr.Accordion("Redact open text", open = False):
|
| 404 |
in_text = gr.Textbox(label="Enter open text", lines=10)
|
| 405 |
with gr.Accordion("Upload xlsx or csv files", open = True):
|
| 406 |
+
in_data_files = gr.File(label="Choose Excel or csv files", file_count= "multiple", file_types=['.xlsx', '.xls', '.csv', '.parquet', '.csv.gz'], height=FILE_INPUT_HEIGHT)
|
| 407 |
|
| 408 |
in_excel_sheets = gr.Dropdown(choices=["Choose Excel sheets to anonymise"], multiselect = True, label="Select Excel sheets that you want to anonymise (showing sheets present across all Excel files).", visible=False, allow_custom_value=True)
|
| 409 |
|
| 410 |
in_colnames = gr.Dropdown(choices=["Choose columns to anonymise"], multiselect = True, label="Select columns that you want to anonymise (showing columns present across all files).")
|
| 411 |
|
| 412 |
+
pii_identification_method_drop_tabular = gr.Radio(label = "Choose PII detection method. AWS Comprehend has a cost of approximately $0.01 per 10,000 characters.", value = DEFAULT_PII_DETECTION_MODEL, choices=TABULAR_PII_DETECTION_MODELS)
|
| 413 |
|
| 414 |
with gr.Accordion("Anonymisation output format", open = False):
|
| 415 |
anon_strat = gr.Radio(choices=["replace with 'REDACTED'", "replace with <ENTITY_NAME>", "redact completely", "hash", "mask"], label="Select an anonymisation method.", value = "replace with 'REDACTED'") # , "encrypt", "fake_first_name" are also available, but are not currently included as not that useful in current form
|
|
|
|
| 435 |
with gr.Accordion("Custom allow, deny, and full page redaction lists", open = True):
|
| 436 |
with gr.Row():
|
| 437 |
with gr.Column():
|
| 438 |
+
in_allow_list = gr.File(label="Import allow list file - csv table with one column of a different word/phrase on each row (case insensitive). Terms in this file will not be redacted.", file_count="multiple", height=FILE_INPUT_HEIGHT)
|
| 439 |
in_allow_list_text = gr.Textbox(label="Custom allow list load status")
|
| 440 |
with gr.Column():
|
| 441 |
+
in_deny_list = gr.File(label="Import custom deny list - csv table with one column of a different word/phrase on each row (case insensitive). Terms in this file will always be redacted.", file_count="multiple", height=FILE_INPUT_HEIGHT)
|
| 442 |
in_deny_list_text = gr.Textbox(label="Custom deny list load status")
|
| 443 |
with gr.Column():
|
| 444 |
+
in_fully_redacted_list = gr.File(label="Import fully redacted pages list - csv table with one column of page numbers on each row. Page numbers in this file will be fully redacted.", file_count="multiple", height=FILE_INPUT_HEIGHT)
|
| 445 |
in_fully_redacted_list_text = gr.Textbox(label="Fully redacted page list load status")
|
| 446 |
with gr.Accordion("Manually modify custom allow, deny, and full page redaction lists (NOTE: you need to press Enter after modifying/adding an entry to the lists to apply them)", open = False):
|
| 447 |
with gr.Row():
|
|
|
|
| 450 |
in_fully_redacted_list_state = gr.Dataframe(value=pd.DataFrame(), headers=["fully_redacted_pages_list"], col_count=(1, "fixed"), row_count = (0, "dynamic"), label="Fully redacted pages", visible=True, type="pandas", interactive=True, show_fullscreen_button=True, show_copy_button=True, datatype='number', wrap=True)
|
| 451 |
|
| 452 |
with gr.Accordion("Select entity types to redact", open = True):
|
| 453 |
+
in_redact_entities = gr.Dropdown(value=CHOSEN_REDACT_ENTITIES, choices=FULL_ENTITY_LIST, multiselect=True, label="Local PII identification model (click empty space in box for full list)")
|
| 454 |
+
in_redact_comprehend_entities = gr.Dropdown(value=CHOSEN_COMPREHEND_ENTITIES, choices=FULL_COMPREHEND_ENTITY_LIST, multiselect=True, label="AWS Comprehend PII identification model (click empty space in box for full list)")
|
| 455 |
|
| 456 |
with gr.Row():
|
| 457 |
max_fuzzy_spelling_mistakes_num = gr.Number(label="Maximum number of spelling mistakes allowed for fuzzy matching (CUSTOM_FUZZY entity).", value=1, minimum=0, maximum=9, precision=0)
|
|
|
|
| 470 |
aws_access_key_textbox = gr.Textbox(value='', label="AWS access key for account with permissions for AWS Textract and Comprehend", visible=True, type="password")
|
| 471 |
aws_secret_key_textbox = gr.Textbox(value='', label="AWS secret key for account with permissions for AWS Textract and Comprehend", visible=True, type="password")
|
| 472 |
|
|
|
|
|
|
|
| 473 |
with gr.Accordion("Log file outputs", open = False):
|
| 474 |
log_files_output = gr.File(label="Log file output", interactive=False)
|
| 475 |
|
|
|
|
| 482 |
all_output_files = gr.File(label="All files in output folder", file_count='multiple', file_types=['.csv'], interactive=False)
|
| 483 |
|
| 484 |
###
|
| 485 |
+
# UI INTERACTION
|
| 486 |
###
|
| 487 |
|
| 488 |
###
|
|
|
|
| 555 |
|
| 556 |
textract_job_detail_df.select(df_select_callback_textract_api, inputs=[textract_output_found_checkbox], outputs=[job_id_textbox, job_type_dropdown, selected_job_id_row])
|
| 557 |
|
|
|
|
| 558 |
convert_textract_outputs_to_ocr_results.click(replace_existing_pdf_input_for_whole_document_outputs, inputs = [s3_whole_document_textract_input_subfolder, doc_file_name_no_extension_textbox, output_folder_textbox, s3_whole_document_textract_default_bucket, in_doc_files, input_folder_textbox], outputs = [in_doc_files, doc_file_name_no_extension_textbox, doc_file_name_with_extension_textbox, doc_full_file_name_textbox, doc_file_name_textbox_list, total_pdf_page_count]).\
|
| 559 |
success(fn = prepare_image_or_pdf, inputs=[in_doc_files, text_extract_method_radio, latest_file_completed_text, redaction_output_summary_textbox, first_loop_state, annotate_max_pages, all_image_annotations_state, prepare_for_review_bool_false, in_fully_redacted_list_state, output_folder_textbox, input_folder_textbox, prepare_images_bool_false], outputs=[redaction_output_summary_textbox, prepared_pdf_state, images_pdf_state, annotate_max_pages, annotate_max_pages_bottom, pdf_doc_state, all_image_annotations_state, review_file_state, document_cropboxes, page_sizes, textract_output_found_checkbox, all_img_details_state, all_line_level_ocr_results_df_base, local_ocr_output_found_checkbox]).\
|
| 560 |
success(fn=check_for_existing_textract_file, inputs=[doc_file_name_no_extension_textbox, output_folder_textbox], outputs=[textract_output_found_checkbox]).\
|
|
|
|
| 576 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 577 |
|
| 578 |
# Page number controls
|
| 579 |
+
annotate_current_page.submit(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 580 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 581 |
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 582 |
|
| 583 |
+
annotation_last_page_button.click(fn=decrease_page, inputs=[annotate_current_page], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 584 |
+
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 585 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 586 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 587 |
|
| 588 |
+
annotation_next_page_button.click(fn=increase_page, inputs=[annotate_current_page, all_image_annotations_state], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 589 |
+
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 590 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 591 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 592 |
|
| 593 |
+
annotation_last_page_button_bottom.click(fn=decrease_page, inputs=[annotate_current_page], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 594 |
+
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 595 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 596 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 597 |
+
|
| 598 |
+
annotation_next_page_button_bottom.click(fn=increase_page, inputs=[annotate_current_page, all_image_annotations_state], outputs=[annotate_current_page, annotate_current_page_bottom]).\
|
| 599 |
+
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 600 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 601 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 602 |
+
|
| 603 |
+
annotate_current_page_bottom.submit(update_other_annotator_number_from_current, inputs=[annotate_current_page_bottom], outputs=[annotate_current_page]).\
|
| 604 |
+
success(update_all_page_annotation_object_based_on_previous_page, inputs = [annotator, annotate_current_page, annotate_previous_page, all_image_annotations_state, page_sizes], outputs = [all_image_annotations_state, annotate_previous_page, annotate_current_page_bottom]).\
|
| 605 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 606 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 607 |
|
| 608 |
# Apply page redactions
|
| 609 |
annotation_button_apply.click(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state], scroll_to_output=True)
|
|
|
|
| 619 |
text_entity_dropdown.select(update_entities_df_text, inputs=[text_entity_dropdown, recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown], outputs=[recogniser_entity_dataframe, recogniser_entity_dropdown, page_entity_dropdown])
|
| 620 |
|
| 621 |
# Clicking on a cell in the recogniser entity dataframe will take you to that page, and also highlight the target redaction box in blue
|
| 622 |
+
recogniser_entity_dataframe.select(df_select_callback_dataframe_row, inputs=[recogniser_entity_dataframe], outputs=[selected_entity_dataframe_row, selected_entity_dataframe_row_text]).\
|
| 623 |
success(update_selected_review_df_row_colour, inputs=[selected_entity_dataframe_row, review_file_state, selected_entity_id, selected_entity_colour], outputs=[review_file_state, selected_entity_id, selected_entity_colour]).\
|
| 624 |
success(update_annotator_page_from_review_df, inputs=[review_file_state, images_pdf_state, page_sizes, all_image_annotations_state, annotator, selected_entity_dataframe_row, input_folder_textbox, doc_full_file_name_textbox], outputs=[annotator, all_image_annotations_state, annotate_current_page, page_sizes, review_file_state, annotate_previous_page])
|
| 625 |
|
|
|
|
| 627 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state])
|
| 628 |
|
| 629 |
# Exclude current selection from annotator and outputs
|
| 630 |
+
# Exclude only selected row
|
| 631 |
exclude_selected_row_btn.click(exclude_selected_items_from_redaction, inputs=[review_file_state, selected_entity_dataframe_row, images_pdf_state, page_sizes, all_image_annotations_state, recogniser_entity_dataframe_base], outputs=[review_file_state, all_image_annotations_state, recogniser_entity_dataframe_base, backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base]).\
|
| 632 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 633 |
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state]).\
|
| 634 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 635 |
|
| 636 |
+
# Exclude all items with same text as selected row
|
| 637 |
+
exclude_text_with_same_as_selected_row_btn.click(get_all_rows_with_same_text, inputs=[recogniser_entity_dataframe_base, selected_entity_dataframe_row_text], outputs=[recogniser_entity_dataframe_same_text]).\
|
| 638 |
+
success(exclude_selected_items_from_redaction, inputs=[review_file_state, recogniser_entity_dataframe_same_text, images_pdf_state, page_sizes, all_image_annotations_state, recogniser_entity_dataframe_base], outputs=[review_file_state, all_image_annotations_state, recogniser_entity_dataframe_base, backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base]).\
|
| 639 |
+
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 640 |
+
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state]).\
|
| 641 |
+
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 642 |
+
|
| 643 |
# Exclude everything visible in table
|
| 644 |
exclude_selected_btn.click(exclude_selected_items_from_redaction, inputs=[review_file_state, recogniser_entity_dataframe, images_pdf_state, page_sizes, all_image_annotations_state, recogniser_entity_dataframe_base], outputs=[review_file_state, all_image_annotations_state, recogniser_entity_dataframe_base, backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base]).\
|
| 645 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 646 |
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state]).\
|
| 647 |
success(update_all_entity_df_dropdowns, inputs=[recogniser_entity_dataframe_base, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown], outputs=[recogniser_entity_dropdown, text_entity_dropdown, page_entity_dropdown])
|
| 648 |
+
|
| 649 |
+
|
| 650 |
|
| 651 |
undo_last_removal_btn.click(undo_last_removal, inputs=[backup_review_state, backup_image_annotations_state, backup_recogniser_entity_dataframe_base], outputs=[review_file_state, all_image_annotations_state, recogniser_entity_dataframe_base]).\
|
| 652 |
success(update_annotator_object_and_filter_df, inputs=[all_image_annotations_state, annotate_current_page, recogniser_entity_dropdown, page_entity_dropdown, text_entity_dropdown, recogniser_entity_dataframe_base, annotator_zoom_number, review_file_state, page_sizes, doc_full_file_name_textbox, input_folder_textbox], outputs = [annotator, annotate_current_page, annotate_current_page_bottom, annotate_previous_page, recogniser_entity_dropdown, recogniser_entity_dataframe, recogniser_entity_dataframe_base, text_entity_dropdown, page_entity_dropdown, page_sizes, all_image_annotations_state]).\
|
| 653 |
success(apply_redactions_to_review_df_and_files, inputs=[annotator, doc_full_file_name_textbox, pdf_doc_state, all_image_annotations_state, annotate_current_page, review_file_state, output_folder_textbox, do_not_save_pdf_state, page_sizes], outputs=[pdf_doc_state, all_image_annotations_state, output_review_files, log_files_output, review_file_state])
|
| 654 |
+
|
| 655 |
+
# Review OCR text button
|
|
|
|
|
|
|
| 656 |
all_line_level_ocr_results_df.select(df_select_callback_ocr, inputs=[all_line_level_ocr_results_df], outputs=[annotate_current_page, selected_entity_dataframe_row])
|
| 657 |
reset_all_ocr_results_btn.click(reset_ocr_base_dataframe, inputs=[all_line_level_ocr_results_df_base], outputs=[all_line_level_ocr_results_df])
|
| 658 |
|
|
|
|
| 750 |
|
| 751 |
### ACCESS LOGS
|
| 752 |
# Log usernames and times of access to file (to know who is using the app when running on AWS)
|
| 753 |
+
access_callback = CSVLogger_custom(dataset_file_name=LOG_FILE_NAME)
|
| 754 |
access_callback.setup([session_hash_textbox, host_name_textbox], ACCESS_LOGS_FOLDER)
|
| 755 |
session_hash_textbox.change(lambda *args: access_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=ACCESS_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_ACCESS_LOG_HEADERS, replacement_headers=CSV_ACCESS_LOG_HEADERS), [session_hash_textbox, host_name_textbox], None, preprocess=False).\
|
| 756 |
success(fn = upload_log_file_to_s3, inputs=[access_logs_state, access_s3_logs_loc_state], outputs=[s3_logs_output_textbox])
|
|
|
|
| 758 |
### FEEDBACK LOGS
|
| 759 |
if DISPLAY_FILE_NAMES_IN_LOGS == 'True':
|
| 760 |
# User submitted feedback for pdf redactions
|
| 761 |
+
pdf_callback = CSVLogger_custom(dataset_file_name=LOG_FILE_NAME)
|
| 762 |
pdf_callback.setup([pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], FEEDBACK_LOGS_FOLDER)
|
| 763 |
pdf_submit_feedback_btn.click(lambda *args: pdf_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], None, preprocess=False).\
|
| 764 |
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[pdf_further_details_text])
|
| 765 |
|
| 766 |
# User submitted feedback for data redactions
|
| 767 |
+
data_callback = CSVLogger_custom(dataset_file_name=LOG_FILE_NAME)
|
| 768 |
data_callback.setup([data_feedback_radio, data_further_details_text, data_full_file_name_textbox], FEEDBACK_LOGS_FOLDER)
|
| 769 |
data_submit_feedback_btn.click(lambda *args: data_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [data_feedback_radio, data_further_details_text, data_full_file_name_textbox], None, preprocess=False).\
|
| 770 |
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[data_further_details_text])
|
| 771 |
else:
|
| 772 |
# User submitted feedback for pdf redactions
|
| 773 |
+
pdf_callback = CSVLogger_custom(dataset_file_name=LOG_FILE_NAME)
|
| 774 |
pdf_callback.setup([pdf_feedback_radio, pdf_further_details_text, doc_file_name_no_extension_textbox], FEEDBACK_LOGS_FOLDER)
|
| 775 |
pdf_submit_feedback_btn.click(lambda *args: pdf_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [pdf_feedback_radio, pdf_further_details_text, placeholder_doc_file_name_no_extension_textbox_for_logs], None, preprocess=False).\
|
| 776 |
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[pdf_further_details_text])
|
| 777 |
|
| 778 |
# User submitted feedback for data redactions
|
| 779 |
+
data_callback = CSVLogger_custom(dataset_file_name=LOG_FILE_NAME)
|
| 780 |
data_callback.setup([data_feedback_radio, data_further_details_text, data_full_file_name_textbox], FEEDBACK_LOGS_FOLDER)
|
| 781 |
data_submit_feedback_btn.click(lambda *args: data_callback.flag(list(args), save_to_csv=SAVE_LOGS_TO_CSV, save_to_dynamodb=SAVE_LOGS_TO_DYNAMODB, dynamodb_table_name=FEEDBACK_LOG_DYNAMODB_TABLE_NAME, dynamodb_headers=DYNAMODB_FEEDBACK_LOG_HEADERS, replacement_headers=CSV_FEEDBACK_LOG_HEADERS), [data_feedback_radio, data_further_details_text, placeholder_data_file_name_no_extension_textbox_for_logs], None, preprocess=False).\
|
| 782 |
success(fn = upload_log_file_to_s3, inputs=[feedback_logs_state, feedback_s3_logs_loc_state], outputs=[data_further_details_text])
|
|
|
|
| 784 |
### USAGE LOGS
|
| 785 |
# Log processing usage - time taken for redaction queries, and also logs for queries to Textract/Comprehend
|
| 786 |
|
| 787 |
+
usage_callback = CSVLogger_custom(dataset_file_name=LOG_FILE_NAME)
|
| 788 |
|
| 789 |
if DISPLAY_FILE_NAMES_IN_LOGS == 'True':
|
| 790 |
usage_callback.setup([session_hash_textbox, doc_file_name_no_extension_textbox, data_full_file_name_textbox, total_pdf_page_count, actual_time_taken_number, textract_query_number, pii_identification_method_drop, comprehend_query_number, cost_code_choice_drop, handwrite_signature_checkbox, host_name_textbox, text_extract_method_radio, is_a_textract_api_call], USAGE_LOGS_FOLDER)
|
|
|
|
| 822 |
|
| 823 |
main(first_loop_state, latest_file_completed=0, redaction_output_summary_textbox="", output_file_list=None,
|
| 824 |
log_files_list=None, estimated_time=0, textract_metadata="", comprehend_query_num=0,
|
| 825 |
+
current_loop_page=0, page_break=False, pdf_doc_state = [], all_image_annotations = [], all_line_level_ocr_results_df = pd.DataFrame(), all_decision_process_table = pd.DataFrame(),CHOSEN_COMPREHEND_ENTITIES = CHOSEN_COMPREHEND_ENTITIES, CHOSEN_REDACT_ENTITIES = CHOSEN_REDACT_ENTITIES, handwrite_signature_checkbox = ["Extract handwriting", "Extract signatures"])
|
| 826 |
|
| 827 |
# AWS options - placeholder for possibility of storing data on s3 and retrieving it in app
|
| 828 |
# with gr.Tab(label="Advanced options"):
|
pyproject.toml
CHANGED
|
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
|
|
| 4 |
|
| 5 |
[project]
|
| 6 |
name = "doc_redaction"
|
| 7 |
-
version = "0.6.
|
| 8 |
description = "Redact PDF/image-based documents, or CSV/XLSX files using a Gradio-based GUI interface"
|
| 9 |
readme = "README.md"
|
| 10 |
requires-python = ">=3.10"
|
|
|
|
| 4 |
|
| 5 |
[project]
|
| 6 |
name = "doc_redaction"
|
| 7 |
+
version = "0.6.8"
|
| 8 |
description = "Redact PDF/image-based documents, or CSV/XLSX files using a Gradio-based GUI interface"
|
| 9 |
readme = "README.md"
|
| 10 |
requires-python = ">=3.10"
|
tools/config.py
CHANGED
|
@@ -204,7 +204,7 @@ if LOGGING == 'True':
|
|
| 204 |
# Configure logging
|
| 205 |
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
|
| 206 |
|
| 207 |
-
|
| 208 |
|
| 209 |
|
| 210 |
###
|
|
@@ -218,6 +218,80 @@ POPPLER_FOLDER = get_or_create_env_var('POPPLER_FOLDER', "") # If installing on
|
|
| 218 |
if TESSERACT_FOLDER: add_folder_to_path(TESSERACT_FOLDER)
|
| 219 |
if POPPLER_FOLDER: add_folder_to_path(POPPLER_FOLDER)
|
| 220 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 221 |
|
| 222 |
# Number of pages to loop through before breaking the function and restarting from the last finished page (not currently activated).
|
| 223 |
PAGE_BREAK_VALUE = get_or_create_env_var('PAGE_BREAK_VALUE', '99999')
|
|
@@ -232,9 +306,6 @@ RETURN_PDF_END_OF_REDACTION = get_or_create_env_var("RETURN_PDF_END_OF_REDACTION
|
|
| 232 |
|
| 233 |
COMPRESS_REDACTED_PDF = get_or_create_env_var("COMPRESS_REDACTED_PDF","False") # On low memory systems, the compression options in pymupdf can cause the app to crash if the PDF is longer than 500 pages or so. Setting this to False will save the PDF only with a basic cleaning option enabled
|
| 234 |
|
| 235 |
-
|
| 236 |
-
|
| 237 |
-
|
| 238 |
###
|
| 239 |
# APP RUN OPTIONS
|
| 240 |
###
|
|
@@ -269,7 +340,7 @@ S3_ALLOW_LIST_PATH = get_or_create_env_var('S3_ALLOW_LIST_PATH', '') # default_a
|
|
| 269 |
if ALLOW_LIST_PATH: OUTPUT_ALLOW_LIST_PATH = ALLOW_LIST_PATH
|
| 270 |
else: OUTPUT_ALLOW_LIST_PATH = 'config/default_allow_list.csv'
|
| 271 |
|
| 272 |
-
|
| 273 |
|
| 274 |
|
| 275 |
###
|
|
|
|
| 204 |
# Configure logging
|
| 205 |
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
|
| 206 |
|
| 207 |
+
LOG_FILE_NAME = get_or_create_env_var('LOG_FILE_NAME', 'log.csv')
|
| 208 |
|
| 209 |
|
| 210 |
###
|
|
|
|
| 218 |
if TESSERACT_FOLDER: add_folder_to_path(TESSERACT_FOLDER)
|
| 219 |
if POPPLER_FOLDER: add_folder_to_path(POPPLER_FOLDER)
|
| 220 |
|
| 221 |
+
# List of models to use for text extraction and PII detection
|
| 222 |
+
# Text extraction models
|
| 223 |
+
SELECTABLE_TEXT_EXTRACT_OPTION = get_or_create_env_var('SELECTABLE_TEXT_EXTRACT_OPTION', "Local model - selectable text")
|
| 224 |
+
TESSERACT_TEXT_EXTRACT_OPTION = get_or_create_env_var('TESSERACT_TEXT_EXTRACT_OPTION', "Local OCR model - PDFs without selectable text")
|
| 225 |
+
TEXTRACT_TEXT_EXTRACT_OPTION = get_or_create_env_var('TEXTRACT_TEXT_EXTRACT_OPTION', "AWS Textract service - all PDF types")
|
| 226 |
+
|
| 227 |
+
# PII detection models
|
| 228 |
+
NO_REDACTION_PII_OPTION = get_or_create_env_var('NO_REDACTION_PII_OPTION', "Only extract text (no redaction)")
|
| 229 |
+
LOCAL_PII_OPTION = get_or_create_env_var('LOCAL_PII_OPTION', "Local")
|
| 230 |
+
AWS_PII_OPTION = get_or_create_env_var('AWS_PII_OPTION', "AWS Comprehend")
|
| 231 |
+
|
| 232 |
+
SHOW_LOCAL_TEXT_EXTRACTION_OPTIONS = get_or_create_env_var('SHOW_LOCAL_TEXT_EXTRACTION_OPTIONS', 'True')
|
| 233 |
+
SHOW_AWS_TEXT_EXTRACTION_OPTIONS = get_or_create_env_var('SHOW_AWS_TEXT_EXTRACTION_OPTIONS', 'True')
|
| 234 |
+
|
| 235 |
+
# Show at least local options if everything mistakenly removed
|
| 236 |
+
if SHOW_LOCAL_TEXT_EXTRACTION_OPTIONS != "True" and SHOW_AWS_TEXT_EXTRACTION_OPTIONS != "True":
|
| 237 |
+
SHOW_LOCAL_TEXT_EXTRACTION_OPTIONS = "True"
|
| 238 |
+
|
| 239 |
+
local_model_options = []
|
| 240 |
+
aws_model_options = []
|
| 241 |
+
text_extraction_models = []
|
| 242 |
+
|
| 243 |
+
if SHOW_LOCAL_TEXT_EXTRACTION_OPTIONS == 'True':
|
| 244 |
+
local_model_options.append(SELECTABLE_TEXT_EXTRACT_OPTION)
|
| 245 |
+
local_model_options.append(TESSERACT_TEXT_EXTRACT_OPTION)
|
| 246 |
+
|
| 247 |
+
if SHOW_AWS_TEXT_EXTRACTION_OPTIONS == 'True':
|
| 248 |
+
aws_model_options.append(TEXTRACT_TEXT_EXTRACT_OPTION)
|
| 249 |
+
|
| 250 |
+
TEXT_EXTRACTION_MODELS = local_model_options + aws_model_options
|
| 251 |
+
|
| 252 |
+
SHOW_LOCAL_PII_DETECTION_OPTIONS = get_or_create_env_var('SHOW_LOCAL_PII_DETECTION_OPTIONS', 'True')
|
| 253 |
+
SHOW_AWS_PII_DETECTION_OPTIONS = get_or_create_env_var('SHOW_AWS_PII_DETECTION_OPTIONS', 'True')
|
| 254 |
+
|
| 255 |
+
if SHOW_LOCAL_PII_DETECTION_OPTIONS != "True" and SHOW_AWS_PII_DETECTION_OPTIONS != "True":
|
| 256 |
+
SHOW_LOCAL_PII_DETECTION_OPTIONS = "True"
|
| 257 |
+
|
| 258 |
+
local_model_options = [NO_REDACTION_PII_OPTION]
|
| 259 |
+
aws_model_options = []
|
| 260 |
+
pii_detection_models = []
|
| 261 |
+
|
| 262 |
+
if SHOW_LOCAL_PII_DETECTION_OPTIONS == 'True':
|
| 263 |
+
local_model_options.append(LOCAL_PII_OPTION)
|
| 264 |
+
|
| 265 |
+
if SHOW_AWS_PII_DETECTION_OPTIONS == 'True':
|
| 266 |
+
aws_model_options.append(AWS_PII_OPTION)
|
| 267 |
+
|
| 268 |
+
PII_DETECTION_MODELS = local_model_options + aws_model_options
|
| 269 |
+
|
| 270 |
+
if SHOW_AWS_TEXT_EXTRACTION_OPTIONS == "True":
|
| 271 |
+
DEFAULT_TEXT_EXTRACTION_MODEL = get_or_create_env_var('DEFAULT_TEXT_EXTRACTION_MODEL', TEXTRACT_TEXT_EXTRACT_OPTION)
|
| 272 |
+
else:
|
| 273 |
+
DEFAULT_TEXT_EXTRACTION_MODEL = get_or_create_env_var('DEFAULT_TEXT_EXTRACTION_MODEL', SELECTABLE_TEXT_EXTRACT_OPTION)
|
| 274 |
+
|
| 275 |
+
if SHOW_AWS_PII_DETECTION_OPTIONS == "True":
|
| 276 |
+
DEFAULT_PII_DETECTION_MODEL = get_or_create_env_var('DEFAULT_PII_DETECTION_MODEL', AWS_PII_OPTION)
|
| 277 |
+
else:
|
| 278 |
+
DEFAULT_PII_DETECTION_MODEL = get_or_create_env_var('DEFAULT_PII_DETECTION_MODEL', LOCAL_PII_OPTION)
|
| 279 |
+
|
| 280 |
+
# Create list of PII detection models for tabular redaction
|
| 281 |
+
TABULAR_PII_DETECTION_MODELS = PII_DETECTION_MODELS.copy()
|
| 282 |
+
if NO_REDACTION_PII_OPTION in TABULAR_PII_DETECTION_MODELS:
|
| 283 |
+
TABULAR_PII_DETECTION_MODELS.remove(NO_REDACTION_PII_OPTION)
|
| 284 |
+
|
| 285 |
+
# Entities for redaction
|
| 286 |
+
CHOSEN_COMPREHEND_ENTITIES = get_or_create_env_var('CHOSEN_COMPREHEND_ENTITIES', "['BANK_ACCOUNT_NUMBER','BANK_ROUTING','CREDIT_DEBIT_NUMBER','CREDIT_DEBIT_CVV','CREDIT_DEBIT_EXPIRY','PIN','EMAIL','ADDRESS','NAME','PHONE', 'PASSPORT_NUMBER','DRIVER_ID', 'USERNAME','PASSWORD', 'IP_ADDRESS','MAC_ADDRESS', 'LICENSE_PLATE','VEHICLE_IDENTIFICATION_NUMBER','UK_NATIONAL_INSURANCE_NUMBER', 'INTERNATIONAL_BANK_ACCOUNT_NUMBER','SWIFT_CODE','UK_NATIONAL_HEALTH_SERVICE_NUMBER']")
|
| 287 |
+
|
| 288 |
+
FULL_COMPREHEND_ENTITY_LIST = get_or_create_env_var('FULL_COMPREHEND_ENTITY_LIST', "['BANK_ACCOUNT_NUMBER','BANK_ROUTING','CREDIT_DEBIT_NUMBER','CREDIT_DEBIT_CVV','CREDIT_DEBIT_EXPIRY','PIN','EMAIL','ADDRESS','NAME','PHONE','SSN','DATE_TIME','PASSPORT_NUMBER','DRIVER_ID','URL','AGE','USERNAME','PASSWORD','AWS_ACCESS_KEY','AWS_SECRET_KEY','IP_ADDRESS','MAC_ADDRESS','ALL','LICENSE_PLATE','VEHICLE_IDENTIFICATION_NUMBER','UK_NATIONAL_INSURANCE_NUMBER','CA_SOCIAL_INSURANCE_NUMBER','US_INDIVIDUAL_TAX_IDENTIFICATION_NUMBER','UK_UNIQUE_TAXPAYER_REFERENCE_NUMBER','IN_PERMANENT_ACCOUNT_NUMBER','IN_NREGA','INTERNATIONAL_BANK_ACCOUNT_NUMBER','SWIFT_CODE','UK_NATIONAL_HEALTH_SERVICE_NUMBER','CA_HEALTH_NUMBER','IN_AADHAAR','IN_VOTER_NUMBER', 'CUSTOM_FUZZY']")
|
| 289 |
+
|
| 290 |
+
# Entities for local PII redaction option
|
| 291 |
+
CHOSEN_REDACT_ENTITIES = get_or_create_env_var('CHOSEN_REDACT_ENTITIES', "['TITLES', 'PERSON', 'PHONE_NUMBER', 'EMAIL_ADDRESS', 'STREETNAME', 'UKPOSTCODE', 'CUSTOM']")
|
| 292 |
+
|
| 293 |
+
FULL_ENTITY_LIST = get_or_create_env_var('FULL_ENTITY_LIST', "['TITLES', 'PERSON', 'PHONE_NUMBER', 'EMAIL_ADDRESS', 'STREETNAME', 'UKPOSTCODE', 'CREDIT_CARD', 'CRYPTO', 'DATE_TIME', 'IBAN_CODE', 'IP_ADDRESS', 'NRP', 'LOCATION', 'MEDICAL_LICENSE', 'URL', 'UK_NHS', 'CUSTOM', 'CUSTOM_FUZZY']")
|
| 294 |
+
|
| 295 |
|
| 296 |
# Number of pages to loop through before breaking the function and restarting from the last finished page (not currently activated).
|
| 297 |
PAGE_BREAK_VALUE = get_or_create_env_var('PAGE_BREAK_VALUE', '99999')
|
|
|
|
| 306 |
|
| 307 |
COMPRESS_REDACTED_PDF = get_or_create_env_var("COMPRESS_REDACTED_PDF","False") # On low memory systems, the compression options in pymupdf can cause the app to crash if the PDF is longer than 500 pages or so. Setting this to False will save the PDF only with a basic cleaning option enabled
|
| 308 |
|
|
|
|
|
|
|
|
|
|
| 309 |
###
|
| 310 |
# APP RUN OPTIONS
|
| 311 |
###
|
|
|
|
| 340 |
if ALLOW_LIST_PATH: OUTPUT_ALLOW_LIST_PATH = ALLOW_LIST_PATH
|
| 341 |
else: OUTPUT_ALLOW_LIST_PATH = 'config/default_allow_list.csv'
|
| 342 |
|
| 343 |
+
FILE_INPUT_HEIGHT = get_or_create_env_var('FILE_INPUT_HEIGHT', '200')
|
| 344 |
|
| 345 |
|
| 346 |
###
|
tools/data_anonymise.py
CHANGED
|
@@ -6,20 +6,16 @@ import time
|
|
| 6 |
import boto3
|
| 7 |
import botocore
|
| 8 |
import pandas as pd
|
| 9 |
-
from openpyxl import Workbook
|
| 10 |
-
|
| 11 |
from faker import Faker
|
| 12 |
from gradio import Progress
|
| 13 |
from typing import List, Dict, Any
|
| 14 |
-
|
| 15 |
from presidio_analyzer import AnalyzerEngine, BatchAnalyzerEngine, DictAnalyzerResult, RecognizerResult
|
| 16 |
from presidio_anonymizer import AnonymizerEngine, BatchAnonymizerEngine
|
| 17 |
-
from presidio_anonymizer.entities import OperatorConfig, ConflictResolutionStrategy
|
| 18 |
-
|
| 19 |
from tools.config import RUN_AWS_FUNCTIONS, AWS_ACCESS_KEY, AWS_SECRET_KEY, OUTPUT_FOLDER
|
| 20 |
from tools.helper_functions import get_file_name_without_type, read_file, detect_file_type
|
| 21 |
from tools.load_spacy_model_custom_recognisers import nlp_analyser, score_threshold, custom_word_list_recogniser, CustomWordFuzzyRecognizer, custom_entities
|
| 22 |
-
from tools.custom_image_analyser_engine import do_aws_comprehend_call
|
| 23 |
# Use custom version of analyze_dict to be able to track progress
|
| 24 |
from tools.presidio_analyzer_custom import analyze_dict
|
| 25 |
|
|
@@ -28,7 +24,7 @@ fake = Faker("en_UK")
|
|
| 28 |
def fake_first_name(x):
|
| 29 |
return fake.first_name()
|
| 30 |
|
| 31 |
-
def initial_clean(text):
|
| 32 |
#### Some of my cleaning functions
|
| 33 |
html_pattern_regex = r'<.*?>|&([a-z0-9]+|#[0-9]{1,6}|#x[0-9a-f]{1,6});|\xa0| '
|
| 34 |
html_start_pattern_end_dots_regex = r'<(.*?)\.\.'
|
|
@@ -49,7 +45,7 @@ def initial_clean(text):
|
|
| 49 |
|
| 50 |
return text
|
| 51 |
|
| 52 |
-
def process_recognizer_result(result, recognizer_result, data_row, dictionary_key, df_dict, keys_to_keep):
|
| 53 |
output = []
|
| 54 |
|
| 55 |
if hasattr(result, 'value'):
|
|
@@ -115,7 +111,7 @@ def generate_decision_process_output(analyzer_results: List[DictAnalyzerResult],
|
|
| 115 |
|
| 116 |
return decision_process_output_str
|
| 117 |
|
| 118 |
-
def anon_consistent_names(df):
|
| 119 |
# ## Pick out common names and replace them with the same person value
|
| 120 |
df_dict = df.to_dict(orient="list")
|
| 121 |
|
|
@@ -553,7 +549,19 @@ def anon_wrapper_func(
|
|
| 553 |
|
| 554 |
return out_file_paths, out_message, key_string, log_files_output_paths
|
| 555 |
|
| 556 |
-
def anonymise_script(df:pd.DataFrame,
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 557 |
'''
|
| 558 |
Conduct anonymisation of a dataframe using Presidio and/or AWS Comprehend if chosen.
|
| 559 |
'''
|
|
|
|
| 6 |
import boto3
|
| 7 |
import botocore
|
| 8 |
import pandas as pd
|
| 9 |
+
from openpyxl import Workbook
|
|
|
|
| 10 |
from faker import Faker
|
| 11 |
from gradio import Progress
|
| 12 |
from typing import List, Dict, Any
|
| 13 |
+
from presidio_anonymizer.entities import OperatorConfig, ConflictResolutionStrategy
|
| 14 |
from presidio_analyzer import AnalyzerEngine, BatchAnalyzerEngine, DictAnalyzerResult, RecognizerResult
|
| 15 |
from presidio_anonymizer import AnonymizerEngine, BatchAnonymizerEngine
|
|
|
|
|
|
|
| 16 |
from tools.config import RUN_AWS_FUNCTIONS, AWS_ACCESS_KEY, AWS_SECRET_KEY, OUTPUT_FOLDER
|
| 17 |
from tools.helper_functions import get_file_name_without_type, read_file, detect_file_type
|
| 18 |
from tools.load_spacy_model_custom_recognisers import nlp_analyser, score_threshold, custom_word_list_recogniser, CustomWordFuzzyRecognizer, custom_entities
|
|
|
|
| 19 |
# Use custom version of analyze_dict to be able to track progress
|
| 20 |
from tools.presidio_analyzer_custom import analyze_dict
|
| 21 |
|
|
|
|
| 24 |
def fake_first_name(x):
|
| 25 |
return fake.first_name()
|
| 26 |
|
| 27 |
+
def initial_clean(text:str) -> str:
|
| 28 |
#### Some of my cleaning functions
|
| 29 |
html_pattern_regex = r'<.*?>|&([a-z0-9]+|#[0-9]{1,6}|#x[0-9a-f]{1,6});|\xa0| '
|
| 30 |
html_start_pattern_end_dots_regex = r'<(.*?)\.\.'
|
|
|
|
| 45 |
|
| 46 |
return text
|
| 47 |
|
| 48 |
+
def process_recognizer_result(result:RecognizerResult, recognizer_result:RecognizerResult, data_row:int, dictionary_key:int, df_dict:Dict[str, List[Any]], keys_to_keep:List[str]) -> List[str]:
|
| 49 |
output = []
|
| 50 |
|
| 51 |
if hasattr(result, 'value'):
|
|
|
|
| 111 |
|
| 112 |
return decision_process_output_str
|
| 113 |
|
| 114 |
+
def anon_consistent_names(df:pd.DataFrame) -> pd.DataFrame:
|
| 115 |
# ## Pick out common names and replace them with the same person value
|
| 116 |
df_dict = df.to_dict(orient="list")
|
| 117 |
|
|
|
|
| 549 |
|
| 550 |
return out_file_paths, out_message, key_string, log_files_output_paths
|
| 551 |
|
| 552 |
+
def anonymise_script(df:pd.DataFrame,
|
| 553 |
+
anon_strat:str,
|
| 554 |
+
language:str,
|
| 555 |
+
chosen_redact_entities:List[str],
|
| 556 |
+
in_allow_list:List[str]=[],
|
| 557 |
+
in_deny_list:List[str]=[],
|
| 558 |
+
max_fuzzy_spelling_mistakes_num:int=0,
|
| 559 |
+
pii_identification_method:str="Local",
|
| 560 |
+
chosen_redact_comprehend_entities:List[str]=[],
|
| 561 |
+
comprehend_query_number:int=0,
|
| 562 |
+
comprehend_client:botocore.client.BaseClient="",
|
| 563 |
+
custom_entities:List[str]=custom_entities,
|
| 564 |
+
progress:Progress=Progress(track_tqdm=False)):
|
| 565 |
'''
|
| 566 |
Conduct anonymisation of a dataframe using Presidio and/or AWS Comprehend if chosen.
|
| 567 |
'''
|
tools/file_conversion.py
CHANGED
|
@@ -1,5 +1,4 @@
|
|
| 1 |
from pdf2image import convert_from_path, pdfinfo_from_path
|
| 2 |
-
|
| 3 |
from PIL import Image, ImageFile
|
| 4 |
import os
|
| 5 |
import re
|
|
@@ -14,7 +13,7 @@ import zipfile
|
|
| 14 |
from collections import defaultdict
|
| 15 |
from tqdm import tqdm
|
| 16 |
from gradio import Progress
|
| 17 |
-
from typing import List,
|
| 18 |
from concurrent.futures import ThreadPoolExecutor, as_completed
|
| 19 |
from pdf2image import convert_from_path
|
| 20 |
from PIL import Image
|
|
@@ -23,14 +22,14 @@ import random
|
|
| 23 |
import string
|
| 24 |
import warnings # To warn about potential type changes
|
| 25 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 26 |
IMAGE_NUM_REGEX = re.compile(r'_(\d+)\.png$')
|
| 27 |
|
| 28 |
pd.set_option('future.no_silent_downcasting', True)
|
| 29 |
|
| 30 |
-
from tools.config import OUTPUT_FOLDER, INPUT_FOLDER, IMAGES_DPI, LOAD_TRUNCATED_IMAGES, MAX_IMAGE_PIXELS, CUSTOM_BOX_COLOUR, COMPRESS_REDACTED_PDF
|
| 31 |
-
from tools.helper_functions import get_file_name_without_type, tesseract_ocr_option, text_ocr_option, textract_option, read_file
|
| 32 |
-
# from tools.aws_textract import load_and_convert_textract_json
|
| 33 |
-
|
| 34 |
image_dpi = float(IMAGES_DPI)
|
| 35 |
if not MAX_IMAGE_PIXELS: Image.MAX_IMAGE_PIXELS = None
|
| 36 |
else: Image.MAX_IMAGE_PIXELS = MAX_IMAGE_PIXELS
|
|
@@ -596,8 +595,8 @@ def prepare_image_or_pdf(
|
|
| 596 |
|
| 597 |
elif is_pdf_or_image(file_path): # Alternatively, if it's an image
|
| 598 |
# Check if the file is an image type and the user selected text ocr option
|
| 599 |
-
if file_extension in ['.jpg', '.jpeg', '.png'] and in_redact_method ==
|
| 600 |
-
in_redact_method =
|
| 601 |
|
| 602 |
# Convert image to a pymupdf document
|
| 603 |
pymupdf_doc = pymupdf.open() # Create a new empty document
|
|
@@ -765,13 +764,13 @@ def prepare_image_or_pdf(
|
|
| 765 |
|
| 766 |
# Must be something else, return with error message
|
| 767 |
else:
|
| 768 |
-
if in_redact_method ==
|
| 769 |
if is_pdf_or_image(file_path) == False:
|
| 770 |
out_message = "Please upload a PDF file or image file (JPG, PNG) for image analysis."
|
| 771 |
print(out_message)
|
| 772 |
raise Exception(out_message)
|
| 773 |
|
| 774 |
-
elif in_redact_method ==
|
| 775 |
if is_pdf(file_path) == False:
|
| 776 |
out_message = "Please upload a PDF file for text analysis."
|
| 777 |
print(out_message)
|
|
|
|
| 1 |
from pdf2image import convert_from_path, pdfinfo_from_path
|
|
|
|
| 2 |
from PIL import Image, ImageFile
|
| 3 |
import os
|
| 4 |
import re
|
|
|
|
| 13 |
from collections import defaultdict
|
| 14 |
from tqdm import tqdm
|
| 15 |
from gradio import Progress
|
| 16 |
+
from typing import List, Dict, Any
|
| 17 |
from concurrent.futures import ThreadPoolExecutor, as_completed
|
| 18 |
from pdf2image import convert_from_path
|
| 19 |
from PIL import Image
|
|
|
|
| 22 |
import string
|
| 23 |
import warnings # To warn about potential type changes
|
| 24 |
|
| 25 |
+
from tools.config import OUTPUT_FOLDER, INPUT_FOLDER, IMAGES_DPI, LOAD_TRUNCATED_IMAGES, MAX_IMAGE_PIXELS, CUSTOM_BOX_COLOUR, COMPRESS_REDACTED_PDF, TESSERACT_TEXT_EXTRACT_OPTION, SELECTABLE_TEXT_EXTRACT_OPTION, TEXTRACT_TEXT_EXTRACT_OPTION
|
| 26 |
+
from tools.helper_functions import get_file_name_without_type, read_file
|
| 27 |
+
# from tools.aws_textract import load_and_convert_textract_json
|
| 28 |
+
|
| 29 |
IMAGE_NUM_REGEX = re.compile(r'_(\d+)\.png$')
|
| 30 |
|
| 31 |
pd.set_option('future.no_silent_downcasting', True)
|
| 32 |
|
|
|
|
|
|
|
|
|
|
|
|
|
| 33 |
image_dpi = float(IMAGES_DPI)
|
| 34 |
if not MAX_IMAGE_PIXELS: Image.MAX_IMAGE_PIXELS = None
|
| 35 |
else: Image.MAX_IMAGE_PIXELS = MAX_IMAGE_PIXELS
|
|
|
|
| 595 |
|
| 596 |
elif is_pdf_or_image(file_path): # Alternatively, if it's an image
|
| 597 |
# Check if the file is an image type and the user selected text ocr option
|
| 598 |
+
if file_extension in ['.jpg', '.jpeg', '.png'] and in_redact_method == SELECTABLE_TEXT_EXTRACT_OPTION:
|
| 599 |
+
in_redact_method = TESSERACT_TEXT_EXTRACT_OPTION
|
| 600 |
|
| 601 |
# Convert image to a pymupdf document
|
| 602 |
pymupdf_doc = pymupdf.open() # Create a new empty document
|
|
|
|
| 764 |
|
| 765 |
# Must be something else, return with error message
|
| 766 |
else:
|
| 767 |
+
if in_redact_method == TESSERACT_TEXT_EXTRACT_OPTION or in_redact_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 768 |
if is_pdf_or_image(file_path) == False:
|
| 769 |
out_message = "Please upload a PDF file or image file (JPG, PNG) for image analysis."
|
| 770 |
print(out_message)
|
| 771 |
raise Exception(out_message)
|
| 772 |
|
| 773 |
+
elif in_redact_method == SELECTABLE_TEXT_EXTRACT_OPTION:
|
| 774 |
if is_pdf(file_path) == False:
|
| 775 |
out_message = "Please upload a PDF file for text analysis."
|
| 776 |
print(out_message)
|
tools/file_redaction.py
CHANGED
|
@@ -19,11 +19,11 @@ import gradio as gr
|
|
| 19 |
from gradio import Progress
|
| 20 |
from collections import defaultdict # For efficient grouping
|
| 21 |
|
| 22 |
-
from tools.config import OUTPUT_FOLDER, IMAGES_DPI, MAX_IMAGE_PIXELS, RUN_AWS_FUNCTIONS, AWS_ACCESS_KEY, AWS_SECRET_KEY, AWS_REGION, PAGE_BREAK_VALUE, MAX_TIME_VALUE, LOAD_TRUNCATED_IMAGES, INPUT_FOLDER, RETURN_PDF_END_OF_REDACTION
|
| 23 |
-
from tools.custom_image_analyser_engine import CustomImageAnalyzerEngine, OCRResult, combine_ocr_results, CustomImageRecognizerResult, run_page_text_redaction,
|
| 24 |
-
from tools.file_conversion import convert_annotation_json_to_review_df, redact_whole_pymupdf_page, redact_single_box,
|
| 25 |
from tools.load_spacy_model_custom_recognisers import nlp_analyser, score_threshold, custom_entities, custom_recogniser, custom_word_list_recogniser, CustomWordFuzzyRecognizer
|
| 26 |
-
from tools.helper_functions import get_file_name_without_type, clean_unicode_text
|
| 27 |
from tools.aws_textract import analyse_page_with_textract, json_to_ocrresult, load_and_convert_textract_json
|
| 28 |
|
| 29 |
ImageFile.LOAD_TRUNCATED_IMAGES = LOAD_TRUNCATED_IMAGES.lower() == "true"
|
|
@@ -242,7 +242,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 242 |
combined_out_message = combined_out_message + end_message
|
| 243 |
|
| 244 |
# Only send across review file if redaction has been done
|
| 245 |
-
if pii_identification_method !=
|
| 246 |
|
| 247 |
if len(review_out_file_paths) == 1:
|
| 248 |
#review_file_path = [x for x in out_file_paths if "review_file" in x]
|
|
@@ -262,12 +262,12 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 262 |
# Prepare documents and images as required if they don't already exist
|
| 263 |
prepare_images_flag = None # Determines whether to call prepare_image_or_pdf
|
| 264 |
|
| 265 |
-
if textract_output_found and text_extraction_method ==
|
| 266 |
print("Existing Textract outputs found, not preparing images or documents.")
|
| 267 |
prepare_images_flag = False
|
| 268 |
#return # No need to call `prepare_image_or_pdf`, exit early
|
| 269 |
|
| 270 |
-
elif text_extraction_method ==
|
| 271 |
print("Running text extraction analysis, not preparing images.")
|
| 272 |
prepare_images_flag = False
|
| 273 |
|
|
@@ -316,7 +316,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 316 |
combined_out_message = combined_out_message + "\n" + out_message
|
| 317 |
|
| 318 |
# Only send across review file if redaction has been done
|
| 319 |
-
if pii_identification_method !=
|
| 320 |
# If only pdf currently in review outputs, add on the latest review file
|
| 321 |
if len(review_out_file_paths) == 1:
|
| 322 |
#review_file_path = [x for x in out_file_paths if "review_file" in x]
|
|
@@ -361,7 +361,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 361 |
|
| 362 |
|
| 363 |
# Try to connect to AWS services directly only if RUN_AWS_FUNCTIONS environmental variable is 1, otherwise an environment variable or direct textbox input is needed.
|
| 364 |
-
if pii_identification_method ==
|
| 365 |
if aws_access_key_textbox and aws_secret_key_textbox:
|
| 366 |
print("Connecting to Comprehend using AWS access key and secret keys from user input.")
|
| 367 |
comprehend_client = boto3.client('comprehend',
|
|
@@ -384,7 +384,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 384 |
comprehend_client = ""
|
| 385 |
|
| 386 |
# Try to connect to AWS Textract Client if using that text extraction method
|
| 387 |
-
if text_extraction_method ==
|
| 388 |
if aws_access_key_textbox and aws_secret_key_textbox:
|
| 389 |
print("Connecting to Textract using AWS access key and secret keys from user input.")
|
| 390 |
textract_client = boto3.client('textract',
|
|
@@ -429,10 +429,10 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 429 |
pdf_file_name_with_ext = os.path.basename(file_path)
|
| 430 |
|
| 431 |
is_a_pdf = is_pdf(file_path) == True
|
| 432 |
-
if is_a_pdf == False and text_extraction_method ==
|
| 433 |
# If user has not submitted a pdf, assume it's an image
|
| 434 |
print("File is not a PDF, assuming that image analysis needs to be used.")
|
| 435 |
-
text_extraction_method =
|
| 436 |
else:
|
| 437 |
out_message = "No file selected"
|
| 438 |
print(out_message)
|
|
@@ -443,7 +443,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 443 |
review_file_path = orig_pdf_file_path + '_review_file.csv'
|
| 444 |
|
| 445 |
# Remove any existing review_file paths from the review file outputs
|
| 446 |
-
if text_extraction_method ==
|
| 447 |
|
| 448 |
#Analyse and redact image-based pdf or image
|
| 449 |
if is_pdf_or_image(file_path) == False:
|
|
@@ -490,7 +490,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 490 |
all_textract_request_metadata.extend(new_textract_request_metadata)
|
| 491 |
|
| 492 |
|
| 493 |
-
elif text_extraction_method ==
|
| 494 |
|
| 495 |
if is_pdf(file_path) == False:
|
| 496 |
out_message = "Please upload a PDF file for text analysis. If you have an image, select 'Image analysis'."
|
|
@@ -541,7 +541,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 541 |
|
| 542 |
|
| 543 |
# Save redacted file
|
| 544 |
-
if pii_identification_method !=
|
| 545 |
if RETURN_PDF_END_OF_REDACTION == True:
|
| 546 |
progress(0.9, "Saving redacted file")
|
| 547 |
|
|
@@ -589,7 +589,7 @@ def choose_and_run_redactor(file_paths:List[str],
|
|
| 589 |
|
| 590 |
review_file_state.to_csv(review_file_path, index=None)
|
| 591 |
|
| 592 |
-
if pii_identification_method !=
|
| 593 |
out_file_paths.append(review_file_path)
|
| 594 |
|
| 595 |
# Make a combined message for the file
|
|
@@ -1249,7 +1249,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1249 |
allow_list:List[str]=None,
|
| 1250 |
page_min:int=0,
|
| 1251 |
page_max:int=999,
|
| 1252 |
-
text_extraction_method:str=
|
| 1253 |
handwrite_signature_checkbox:List[str]=["Extract handwriting", "Extract signatures"],
|
| 1254 |
textract_request_metadata:list=[],
|
| 1255 |
current_loop_page:int=0,
|
|
@@ -1287,7 +1287,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1287 |
- allow_list (List[str], optional): A list of entity types to allow in the PDF. Defaults to None.
|
| 1288 |
- page_min (int, optional): The minimum page number to start redaction from. Defaults to 0.
|
| 1289 |
- page_max (int, optional): The maximum page number to end redaction at. Defaults to 999.
|
| 1290 |
-
- text_extraction_method (str, optional): The type of analysis to perform on the PDF. Defaults to
|
| 1291 |
- handwrite_signature_checkbox (List[str], optional): A list of options for redacting handwriting and signatures. Defaults to ["Extract handwriting", "Extract signatures"].
|
| 1292 |
- textract_request_metadata (list, optional): Metadata related to the redaction request. Defaults to an empty string.
|
| 1293 |
- page_break_return (bool, optional): Indicates if the function should return after a page break. Defaults to False.
|
|
@@ -1336,7 +1336,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1336 |
print(out_message)
|
| 1337 |
raise Exception(out_message)
|
| 1338 |
|
| 1339 |
-
if text_extraction_method ==
|
| 1340 |
out_message_warning = "Connection to AWS Textract service unsuccessful. Redaction will only continue if local AWS Textract results can be found."
|
| 1341 |
print(out_message_warning)
|
| 1342 |
#raise Exception(out_message)
|
|
@@ -1353,7 +1353,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1353 |
print("Page range:", str(page_min + 1), "to", str(page_max))
|
| 1354 |
|
| 1355 |
# If running Textract, check if file already exists. If it does, load in existing data
|
| 1356 |
-
if text_extraction_method ==
|
| 1357 |
textract_json_file_path = output_folder + file_name + "_textract.json"
|
| 1358 |
textract_data, is_missing, log_files_output_paths = load_and_convert_textract_json(textract_json_file_path, log_files_output_paths, page_sizes_df)
|
| 1359 |
original_textract_data = textract_data.copy()
|
|
@@ -1361,7 +1361,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1361 |
print("Successfully loaded in Textract analysis results from file")
|
| 1362 |
|
| 1363 |
# If running local OCR option, check if file already exists. If it does, load in existing data
|
| 1364 |
-
if text_extraction_method ==
|
| 1365 |
all_page_line_level_ocr_results_with_words_json_file_path = output_folder + file_name + "_ocr_results_with_words.json"
|
| 1366 |
all_page_line_level_ocr_results_with_words, is_missing, log_files_output_paths = load_and_convert_ocr_results_with_words_json(all_page_line_level_ocr_results_with_words_json_file_path, log_files_output_paths, page_sizes_df)
|
| 1367 |
original_all_page_line_level_ocr_results_with_words = all_page_line_level_ocr_results_with_words.copy()
|
|
@@ -1428,7 +1428,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1428 |
# Step 1: Perform OCR. Either with Tesseract, or with AWS Textract
|
| 1429 |
|
| 1430 |
# If using Tesseract
|
| 1431 |
-
if text_extraction_method ==
|
| 1432 |
|
| 1433 |
if all_page_line_level_ocr_results_with_words:
|
| 1434 |
# Find the first dict where 'page' matches
|
|
@@ -1452,7 +1452,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1452 |
all_page_line_level_ocr_results_with_words.append(page_line_level_ocr_results_with_words)
|
| 1453 |
|
| 1454 |
# Check if page exists in existing textract data. If not, send to service to analyse
|
| 1455 |
-
if text_extraction_method ==
|
| 1456 |
text_blocks = []
|
| 1457 |
|
| 1458 |
if not textract_data:
|
|
@@ -1527,7 +1527,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1527 |
|
| 1528 |
all_line_level_ocr_results_df_list.append(line_level_ocr_results_df)
|
| 1529 |
|
| 1530 |
-
if pii_identification_method !=
|
| 1531 |
# Step 2: Analyse text and identify PII
|
| 1532 |
if chosen_redact_entities or chosen_redact_comprehend_entities:
|
| 1533 |
|
|
@@ -1667,7 +1667,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1667 |
annotations_all_pages.append(page_image_annotations)
|
| 1668 |
|
| 1669 |
|
| 1670 |
-
if text_extraction_method ==
|
| 1671 |
if original_textract_data != textract_data:
|
| 1672 |
# Write the updated existing textract data back to the JSON file
|
| 1673 |
with open(textract_json_file_path, 'w') as json_file:
|
|
@@ -1676,7 +1676,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1676 |
if textract_json_file_path not in log_files_output_paths:
|
| 1677 |
log_files_output_paths.append(textract_json_file_path)
|
| 1678 |
|
| 1679 |
-
if text_extraction_method ==
|
| 1680 |
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1681 |
# Write the updated existing textract data back to the JSON file
|
| 1682 |
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
|
@@ -1715,7 +1715,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1715 |
progress.close(_tqdm=progress_bar)
|
| 1716 |
tqdm._instances.clear()
|
| 1717 |
|
| 1718 |
-
if text_extraction_method ==
|
| 1719 |
# Write the updated existing textract data back to the JSON file
|
| 1720 |
if original_textract_data != textract_data:
|
| 1721 |
with open(textract_json_file_path, 'w') as json_file:
|
|
@@ -1724,7 +1724,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1724 |
if textract_json_file_path not in log_files_output_paths:
|
| 1725 |
log_files_output_paths.append(textract_json_file_path)
|
| 1726 |
|
| 1727 |
-
if text_extraction_method ==
|
| 1728 |
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1729 |
# Write the updated existing textract data back to the JSON file
|
| 1730 |
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
|
@@ -1739,7 +1739,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1739 |
|
| 1740 |
return pymupdf_doc, all_pages_decision_process_table, log_files_output_paths, textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words
|
| 1741 |
|
| 1742 |
-
if text_extraction_method ==
|
| 1743 |
# Write the updated existing textract data back to the JSON file
|
| 1744 |
|
| 1745 |
if original_textract_data != textract_data:
|
|
@@ -1749,7 +1749,7 @@ def redact_image_pdf(file_path:str,
|
|
| 1749 |
if textract_json_file_path not in log_files_output_paths:
|
| 1750 |
log_files_output_paths.append(textract_json_file_path)
|
| 1751 |
|
| 1752 |
-
if text_extraction_method ==
|
| 1753 |
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1754 |
# Write the updated existing textract data back to the JSON file
|
| 1755 |
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
|
@@ -2095,7 +2095,7 @@ def redact_text_pdf(
|
|
| 2095 |
all_page_line_text_extraction_characters.extend(line_characters)
|
| 2096 |
|
| 2097 |
### REDACTION
|
| 2098 |
-
if pii_identification_method !=
|
| 2099 |
|
| 2100 |
if chosen_redact_entities or chosen_redact_comprehend_entities:
|
| 2101 |
page_redaction_bounding_boxes = run_page_text_redaction(
|
|
|
|
| 19 |
from gradio import Progress
|
| 20 |
from collections import defaultdict # For efficient grouping
|
| 21 |
|
| 22 |
+
from tools.config import OUTPUT_FOLDER, IMAGES_DPI, MAX_IMAGE_PIXELS, RUN_AWS_FUNCTIONS, AWS_ACCESS_KEY, AWS_SECRET_KEY, AWS_REGION, PAGE_BREAK_VALUE, MAX_TIME_VALUE, LOAD_TRUNCATED_IMAGES, INPUT_FOLDER, RETURN_PDF_END_OF_REDACTION, TESSERACT_TEXT_EXTRACT_OPTION, SELECTABLE_TEXT_EXTRACT_OPTION, TEXTRACT_TEXT_EXTRACT_OPTION, LOCAL_PII_OPTION, AWS_PII_OPTION, NO_REDACTION_PII_OPTION
|
| 23 |
+
from tools.custom_image_analyser_engine import CustomImageAnalyzerEngine, OCRResult, combine_ocr_results, CustomImageRecognizerResult, run_page_text_redaction, recreate_page_line_level_ocr_results_with_page
|
| 24 |
+
from tools.file_conversion import convert_annotation_json_to_review_df, redact_whole_pymupdf_page, redact_single_box, is_pdf, is_pdf_or_image, prepare_image_or_pdf, divide_coordinates_by_page_sizes, convert_annotation_data_to_dataframe, divide_coordinates_by_page_sizes, create_annotation_dicts_from_annotation_df, remove_duplicate_images_with_blank_boxes, fill_missing_ids, fill_missing_box_ids, load_and_convert_ocr_results_with_words_json, save_pdf_with_or_without_compression
|
| 25 |
from tools.load_spacy_model_custom_recognisers import nlp_analyser, score_threshold, custom_entities, custom_recogniser, custom_word_list_recogniser, CustomWordFuzzyRecognizer
|
| 26 |
+
from tools.helper_functions import get_file_name_without_type, clean_unicode_text
|
| 27 |
from tools.aws_textract import analyse_page_with_textract, json_to_ocrresult, load_and_convert_textract_json
|
| 28 |
|
| 29 |
ImageFile.LOAD_TRUNCATED_IMAGES = LOAD_TRUNCATED_IMAGES.lower() == "true"
|
|
|
|
| 242 |
combined_out_message = combined_out_message + end_message
|
| 243 |
|
| 244 |
# Only send across review file if redaction has been done
|
| 245 |
+
if pii_identification_method != NO_REDACTION_PII_OPTION:
|
| 246 |
|
| 247 |
if len(review_out_file_paths) == 1:
|
| 248 |
#review_file_path = [x for x in out_file_paths if "review_file" in x]
|
|
|
|
| 262 |
# Prepare documents and images as required if they don't already exist
|
| 263 |
prepare_images_flag = None # Determines whether to call prepare_image_or_pdf
|
| 264 |
|
| 265 |
+
if textract_output_found and text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 266 |
print("Existing Textract outputs found, not preparing images or documents.")
|
| 267 |
prepare_images_flag = False
|
| 268 |
#return # No need to call `prepare_image_or_pdf`, exit early
|
| 269 |
|
| 270 |
+
elif text_extraction_method == SELECTABLE_TEXT_EXTRACT_OPTION:
|
| 271 |
print("Running text extraction analysis, not preparing images.")
|
| 272 |
prepare_images_flag = False
|
| 273 |
|
|
|
|
| 316 |
combined_out_message = combined_out_message + "\n" + out_message
|
| 317 |
|
| 318 |
# Only send across review file if redaction has been done
|
| 319 |
+
if pii_identification_method != NO_REDACTION_PII_OPTION:
|
| 320 |
# If only pdf currently in review outputs, add on the latest review file
|
| 321 |
if len(review_out_file_paths) == 1:
|
| 322 |
#review_file_path = [x for x in out_file_paths if "review_file" in x]
|
|
|
|
| 361 |
|
| 362 |
|
| 363 |
# Try to connect to AWS services directly only if RUN_AWS_FUNCTIONS environmental variable is 1, otherwise an environment variable or direct textbox input is needed.
|
| 364 |
+
if pii_identification_method == AWS_PII_OPTION:
|
| 365 |
if aws_access_key_textbox and aws_secret_key_textbox:
|
| 366 |
print("Connecting to Comprehend using AWS access key and secret keys from user input.")
|
| 367 |
comprehend_client = boto3.client('comprehend',
|
|
|
|
| 384 |
comprehend_client = ""
|
| 385 |
|
| 386 |
# Try to connect to AWS Textract Client if using that text extraction method
|
| 387 |
+
if text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 388 |
if aws_access_key_textbox and aws_secret_key_textbox:
|
| 389 |
print("Connecting to Textract using AWS access key and secret keys from user input.")
|
| 390 |
textract_client = boto3.client('textract',
|
|
|
|
| 429 |
pdf_file_name_with_ext = os.path.basename(file_path)
|
| 430 |
|
| 431 |
is_a_pdf = is_pdf(file_path) == True
|
| 432 |
+
if is_a_pdf == False and text_extraction_method == SELECTABLE_TEXT_EXTRACT_OPTION:
|
| 433 |
# If user has not submitted a pdf, assume it's an image
|
| 434 |
print("File is not a PDF, assuming that image analysis needs to be used.")
|
| 435 |
+
text_extraction_method = TESSERACT_TEXT_EXTRACT_OPTION
|
| 436 |
else:
|
| 437 |
out_message = "No file selected"
|
| 438 |
print(out_message)
|
|
|
|
| 443 |
review_file_path = orig_pdf_file_path + '_review_file.csv'
|
| 444 |
|
| 445 |
# Remove any existing review_file paths from the review file outputs
|
| 446 |
+
if text_extraction_method == TESSERACT_TEXT_EXTRACT_OPTION or text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 447 |
|
| 448 |
#Analyse and redact image-based pdf or image
|
| 449 |
if is_pdf_or_image(file_path) == False:
|
|
|
|
| 490 |
all_textract_request_metadata.extend(new_textract_request_metadata)
|
| 491 |
|
| 492 |
|
| 493 |
+
elif text_extraction_method == SELECTABLE_TEXT_EXTRACT_OPTION:
|
| 494 |
|
| 495 |
if is_pdf(file_path) == False:
|
| 496 |
out_message = "Please upload a PDF file for text analysis. If you have an image, select 'Image analysis'."
|
|
|
|
| 541 |
|
| 542 |
|
| 543 |
# Save redacted file
|
| 544 |
+
if pii_identification_method != NO_REDACTION_PII_OPTION:
|
| 545 |
if RETURN_PDF_END_OF_REDACTION == True:
|
| 546 |
progress(0.9, "Saving redacted file")
|
| 547 |
|
|
|
|
| 589 |
|
| 590 |
review_file_state.to_csv(review_file_path, index=None)
|
| 591 |
|
| 592 |
+
if pii_identification_method != NO_REDACTION_PII_OPTION:
|
| 593 |
out_file_paths.append(review_file_path)
|
| 594 |
|
| 595 |
# Make a combined message for the file
|
|
|
|
| 1249 |
allow_list:List[str]=None,
|
| 1250 |
page_min:int=0,
|
| 1251 |
page_max:int=999,
|
| 1252 |
+
text_extraction_method:str=TESSERACT_TEXT_EXTRACT_OPTION,
|
| 1253 |
handwrite_signature_checkbox:List[str]=["Extract handwriting", "Extract signatures"],
|
| 1254 |
textract_request_metadata:list=[],
|
| 1255 |
current_loop_page:int=0,
|
|
|
|
| 1287 |
- allow_list (List[str], optional): A list of entity types to allow in the PDF. Defaults to None.
|
| 1288 |
- page_min (int, optional): The minimum page number to start redaction from. Defaults to 0.
|
| 1289 |
- page_max (int, optional): The maximum page number to end redaction at. Defaults to 999.
|
| 1290 |
+
- text_extraction_method (str, optional): The type of analysis to perform on the PDF. Defaults to TESSERACT_TEXT_EXTRACT_OPTION.
|
| 1291 |
- handwrite_signature_checkbox (List[str], optional): A list of options for redacting handwriting and signatures. Defaults to ["Extract handwriting", "Extract signatures"].
|
| 1292 |
- textract_request_metadata (list, optional): Metadata related to the redaction request. Defaults to an empty string.
|
| 1293 |
- page_break_return (bool, optional): Indicates if the function should return after a page break. Defaults to False.
|
|
|
|
| 1336 |
print(out_message)
|
| 1337 |
raise Exception(out_message)
|
| 1338 |
|
| 1339 |
+
if text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION and textract_client == "":
|
| 1340 |
out_message_warning = "Connection to AWS Textract service unsuccessful. Redaction will only continue if local AWS Textract results can be found."
|
| 1341 |
print(out_message_warning)
|
| 1342 |
#raise Exception(out_message)
|
|
|
|
| 1353 |
print("Page range:", str(page_min + 1), "to", str(page_max))
|
| 1354 |
|
| 1355 |
# If running Textract, check if file already exists. If it does, load in existing data
|
| 1356 |
+
if text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 1357 |
textract_json_file_path = output_folder + file_name + "_textract.json"
|
| 1358 |
textract_data, is_missing, log_files_output_paths = load_and_convert_textract_json(textract_json_file_path, log_files_output_paths, page_sizes_df)
|
| 1359 |
original_textract_data = textract_data.copy()
|
|
|
|
| 1361 |
print("Successfully loaded in Textract analysis results from file")
|
| 1362 |
|
| 1363 |
# If running local OCR option, check if file already exists. If it does, load in existing data
|
| 1364 |
+
if text_extraction_method == TESSERACT_TEXT_EXTRACT_OPTION:
|
| 1365 |
all_page_line_level_ocr_results_with_words_json_file_path = output_folder + file_name + "_ocr_results_with_words.json"
|
| 1366 |
all_page_line_level_ocr_results_with_words, is_missing, log_files_output_paths = load_and_convert_ocr_results_with_words_json(all_page_line_level_ocr_results_with_words_json_file_path, log_files_output_paths, page_sizes_df)
|
| 1367 |
original_all_page_line_level_ocr_results_with_words = all_page_line_level_ocr_results_with_words.copy()
|
|
|
|
| 1428 |
# Step 1: Perform OCR. Either with Tesseract, or with AWS Textract
|
| 1429 |
|
| 1430 |
# If using Tesseract
|
| 1431 |
+
if text_extraction_method == TESSERACT_TEXT_EXTRACT_OPTION:
|
| 1432 |
|
| 1433 |
if all_page_line_level_ocr_results_with_words:
|
| 1434 |
# Find the first dict where 'page' matches
|
|
|
|
| 1452 |
all_page_line_level_ocr_results_with_words.append(page_line_level_ocr_results_with_words)
|
| 1453 |
|
| 1454 |
# Check if page exists in existing textract data. If not, send to service to analyse
|
| 1455 |
+
if text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 1456 |
text_blocks = []
|
| 1457 |
|
| 1458 |
if not textract_data:
|
|
|
|
| 1527 |
|
| 1528 |
all_line_level_ocr_results_df_list.append(line_level_ocr_results_df)
|
| 1529 |
|
| 1530 |
+
if pii_identification_method != NO_REDACTION_PII_OPTION:
|
| 1531 |
# Step 2: Analyse text and identify PII
|
| 1532 |
if chosen_redact_entities or chosen_redact_comprehend_entities:
|
| 1533 |
|
|
|
|
| 1667 |
annotations_all_pages.append(page_image_annotations)
|
| 1668 |
|
| 1669 |
|
| 1670 |
+
if text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 1671 |
if original_textract_data != textract_data:
|
| 1672 |
# Write the updated existing textract data back to the JSON file
|
| 1673 |
with open(textract_json_file_path, 'w') as json_file:
|
|
|
|
| 1676 |
if textract_json_file_path not in log_files_output_paths:
|
| 1677 |
log_files_output_paths.append(textract_json_file_path)
|
| 1678 |
|
| 1679 |
+
if text_extraction_method == TESSERACT_TEXT_EXTRACT_OPTION:
|
| 1680 |
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1681 |
# Write the updated existing textract data back to the JSON file
|
| 1682 |
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
|
|
|
| 1715 |
progress.close(_tqdm=progress_bar)
|
| 1716 |
tqdm._instances.clear()
|
| 1717 |
|
| 1718 |
+
if text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 1719 |
# Write the updated existing textract data back to the JSON file
|
| 1720 |
if original_textract_data != textract_data:
|
| 1721 |
with open(textract_json_file_path, 'w') as json_file:
|
|
|
|
| 1724 |
if textract_json_file_path not in log_files_output_paths:
|
| 1725 |
log_files_output_paths.append(textract_json_file_path)
|
| 1726 |
|
| 1727 |
+
if text_extraction_method == TESSERACT_TEXT_EXTRACT_OPTION:
|
| 1728 |
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1729 |
# Write the updated existing textract data back to the JSON file
|
| 1730 |
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
|
|
|
| 1739 |
|
| 1740 |
return pymupdf_doc, all_pages_decision_process_table, log_files_output_paths, textract_request_metadata, annotations_all_pages, current_loop_page, page_break_return, all_line_level_ocr_results_df, comprehend_query_number, all_page_line_level_ocr_results, all_page_line_level_ocr_results_with_words
|
| 1741 |
|
| 1742 |
+
if text_extraction_method == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 1743 |
# Write the updated existing textract data back to the JSON file
|
| 1744 |
|
| 1745 |
if original_textract_data != textract_data:
|
|
|
|
| 1749 |
if textract_json_file_path not in log_files_output_paths:
|
| 1750 |
log_files_output_paths.append(textract_json_file_path)
|
| 1751 |
|
| 1752 |
+
if text_extraction_method == TESSERACT_TEXT_EXTRACT_OPTION:
|
| 1753 |
if original_all_page_line_level_ocr_results_with_words != all_page_line_level_ocr_results_with_words:
|
| 1754 |
# Write the updated existing textract data back to the JSON file
|
| 1755 |
with open(all_page_line_level_ocr_results_with_words_json_file_path, 'w') as json_file:
|
|
|
|
| 2095 |
all_page_line_text_extraction_characters.extend(line_characters)
|
| 2096 |
|
| 2097 |
### REDACTION
|
| 2098 |
+
if pii_identification_method != NO_REDACTION_PII_OPTION:
|
| 2099 |
|
| 2100 |
if chosen_redact_entities or chosen_redact_comprehend_entities:
|
| 2101 |
page_redaction_bounding_boxes = run_page_text_redaction(
|
tools/helper_functions.py
CHANGED
|
@@ -9,16 +9,7 @@ import unicodedata
|
|
| 9 |
from typing import List
|
| 10 |
from math import ceil
|
| 11 |
from gradio_image_annotation import image_annotator
|
| 12 |
-
from tools.config import CUSTOM_HEADER_VALUE, CUSTOM_HEADER, OUTPUT_FOLDER, INPUT_FOLDER, SESSION_OUTPUT_FOLDER, AWS_USER_POOL_ID, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, TEXTRACT_JOBS_S3_LOC, TEXTRACT_JOBS_LOCAL_LOC
|
| 13 |
-
|
| 14 |
-
# Names for options labels
|
| 15 |
-
text_ocr_option = "Local model - selectable text"
|
| 16 |
-
tesseract_ocr_option = "Local OCR model - PDFs without selectable text"
|
| 17 |
-
textract_option = "AWS Textract service - all PDF types"
|
| 18 |
-
|
| 19 |
-
no_redaction_option = "Only extract text (no redaction)"
|
| 20 |
-
local_pii_detector = "Local"
|
| 21 |
-
aws_pii_detector = "AWS Comprehend"
|
| 22 |
|
| 23 |
def reset_state_vars():
|
| 24 |
return [], pd.DataFrame(), pd.DataFrame(), 0, "", image_annotator(
|
|
@@ -438,9 +429,9 @@ def calculate_aws_costs(number_of_pages:str,
|
|
| 438 |
comprehend_unit_cost:float=0.0001,
|
| 439 |
comprehend_size_unit_average:float=250,
|
| 440 |
average_characters_per_page:float=2000,
|
| 441 |
-
|
| 442 |
-
|
| 443 |
-
|
| 444 |
'''
|
| 445 |
Calculate the approximate cost of submitting a document to AWS Textract and/or AWS Comprehend, assuming that Textract outputs do not already exist in the output folder.
|
| 446 |
|
|
@@ -457,9 +448,9 @@ def calculate_aws_costs(number_of_pages:str,
|
|
| 457 |
- comprehend_unit_cost (float, optional): Cost per 'unit' (300 character minimum) for identifying PII in text with AWS Comprehend.
|
| 458 |
- comprehend_size_unit_average (float, optional): Average size of a 'unit' of text passed to AWS Comprehend by the app through the batching process
|
| 459 |
- average_characters_per_page (float, optional): Average number of characters on an A4 page.
|
| 460 |
-
-
|
| 461 |
-
-
|
| 462 |
-
-
|
| 463 |
'''
|
| 464 |
text_extraction_cost = 0
|
| 465 |
pii_identification_cost = 0
|
|
@@ -467,14 +458,14 @@ def calculate_aws_costs(number_of_pages:str,
|
|
| 467 |
number_of_pages = int(number_of_pages)
|
| 468 |
|
| 469 |
if textract_output_found_checkbox != True:
|
| 470 |
-
if text_extract_method_radio ==
|
| 471 |
text_extraction_cost = number_of_pages * textract_page_cost
|
| 472 |
|
| 473 |
if "Extract signatures" in handwrite_signature_checkbox:
|
| 474 |
text_extraction_cost += (textract_signature_cost * number_of_pages)
|
| 475 |
|
| 476 |
-
if pii_identification_method !=
|
| 477 |
-
if pii_identification_method ==
|
| 478 |
comprehend_page_cost = ceil(average_characters_per_page / comprehend_size_unit_average) * comprehend_unit_cost
|
| 479 |
pii_identification_cost = comprehend_page_cost * number_of_pages
|
| 480 |
|
|
@@ -497,11 +488,11 @@ def calculate_time_taken(number_of_pages:str,
|
|
| 497 |
local_text_extraction_page_time:float=0.3,
|
| 498 |
local_pii_redaction_page_time:float=0.5,
|
| 499 |
local_ocr_extraction_page_time:float=1.5,
|
| 500 |
-
|
| 501 |
-
|
| 502 |
-
local_ocr_option:str=
|
| 503 |
-
|
| 504 |
-
|
| 505 |
'''
|
| 506 |
Calculate the approximate time to redact a document.
|
| 507 |
|
|
@@ -516,11 +507,11 @@ def calculate_time_taken(number_of_pages:str,
|
|
| 516 |
- local_text_redaction_page_time (float, optional): Approximate time to extract text on a page with the local text redaction option.
|
| 517 |
- local_pii_redaction_page_time (float, optional): Approximate time to redact text on a page with the local text redaction option.
|
| 518 |
- local_ocr_extraction_page_time (float, optional): Approximate time to extract text from a page with the local OCR redaction option.
|
| 519 |
-
-
|
| 520 |
-
-
|
| 521 |
- local_ocr_option (str, optional): String label for text_extract_method_radio for local OCR.
|
| 522 |
-
-
|
| 523 |
-
-
|
| 524 |
'''
|
| 525 |
calculated_time_taken = 0
|
| 526 |
page_conversion_time_taken = 0
|
|
@@ -530,22 +521,22 @@ def calculate_time_taken(number_of_pages:str,
|
|
| 530 |
number_of_pages = int(number_of_pages)
|
| 531 |
|
| 532 |
# Page preparation/conversion to image time
|
| 533 |
-
if (text_extract_method_radio !=
|
| 534 |
page_conversion_time_taken = number_of_pages * convert_page_time
|
| 535 |
|
| 536 |
# Page text extraction time
|
| 537 |
-
if text_extract_method_radio ==
|
| 538 |
if textract_output_found_checkbox != True:
|
| 539 |
page_extraction_time_taken = number_of_pages * textract_page_time
|
| 540 |
elif text_extract_method_radio == local_ocr_option:
|
| 541 |
if local_ocr_output_found_checkbox != True:
|
| 542 |
page_extraction_time_taken = number_of_pages * local_ocr_extraction_page_time
|
| 543 |
-
elif text_extract_method_radio ==
|
| 544 |
page_conversion_time_taken = number_of_pages * local_text_extraction_page_time
|
| 545 |
|
| 546 |
# Page redaction time
|
| 547 |
-
if pii_identification_method !=
|
| 548 |
-
if pii_identification_method ==
|
| 549 |
page_redaction_time_taken = number_of_pages * comprehend_page_time
|
| 550 |
else:
|
| 551 |
page_redaction_time_taken = number_of_pages * local_pii_redaction_page_time
|
|
|
|
| 9 |
from typing import List
|
| 10 |
from math import ceil
|
| 11 |
from gradio_image_annotation import image_annotator
|
| 12 |
+
from tools.config import CUSTOM_HEADER_VALUE, CUSTOM_HEADER, OUTPUT_FOLDER, INPUT_FOLDER, SESSION_OUTPUT_FOLDER, AWS_USER_POOL_ID, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_INPUT_SUBFOLDER, TEXTRACT_WHOLE_DOCUMENT_ANALYSIS_OUTPUT_SUBFOLDER, TEXTRACT_JOBS_S3_LOC, TEXTRACT_JOBS_LOCAL_LOC, SELECTABLE_TEXT_EXTRACT_OPTION, TESSERACT_TEXT_EXTRACT_OPTION, TEXTRACT_TEXT_EXTRACT_OPTION, NO_REDACTION_PII_OPTION, AWS_PII_OPTION
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 13 |
|
| 14 |
def reset_state_vars():
|
| 15 |
return [], pd.DataFrame(), pd.DataFrame(), 0, "", image_annotator(
|
|
|
|
| 429 |
comprehend_unit_cost:float=0.0001,
|
| 430 |
comprehend_size_unit_average:float=250,
|
| 431 |
average_characters_per_page:float=2000,
|
| 432 |
+
TEXTRACT_TEXT_EXTRACT_OPTION:str=TEXTRACT_TEXT_EXTRACT_OPTION,
|
| 433 |
+
NO_REDACTION_PII_OPTION:str=NO_REDACTION_PII_OPTION,
|
| 434 |
+
AWS_PII_OPTION:str=AWS_PII_OPTION):
|
| 435 |
'''
|
| 436 |
Calculate the approximate cost of submitting a document to AWS Textract and/or AWS Comprehend, assuming that Textract outputs do not already exist in the output folder.
|
| 437 |
|
|
|
|
| 448 |
- comprehend_unit_cost (float, optional): Cost per 'unit' (300 character minimum) for identifying PII in text with AWS Comprehend.
|
| 449 |
- comprehend_size_unit_average (float, optional): Average size of a 'unit' of text passed to AWS Comprehend by the app through the batching process
|
| 450 |
- average_characters_per_page (float, optional): Average number of characters on an A4 page.
|
| 451 |
+
- TEXTRACT_TEXT_EXTRACT_OPTION (str, optional): String label for the text_extract_method_radio button for AWS Textract.
|
| 452 |
+
- NO_REDACTION_PII_OPTION (str, optional): String label for pii_identification_method_drop for no redaction.
|
| 453 |
+
- AWS_PII_OPTION (str, optional): String label for pii_identification_method_drop for AWS Comprehend.
|
| 454 |
'''
|
| 455 |
text_extraction_cost = 0
|
| 456 |
pii_identification_cost = 0
|
|
|
|
| 458 |
number_of_pages = int(number_of_pages)
|
| 459 |
|
| 460 |
if textract_output_found_checkbox != True:
|
| 461 |
+
if text_extract_method_radio == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 462 |
text_extraction_cost = number_of_pages * textract_page_cost
|
| 463 |
|
| 464 |
if "Extract signatures" in handwrite_signature_checkbox:
|
| 465 |
text_extraction_cost += (textract_signature_cost * number_of_pages)
|
| 466 |
|
| 467 |
+
if pii_identification_method != NO_REDACTION_PII_OPTION:
|
| 468 |
+
if pii_identification_method == AWS_PII_OPTION:
|
| 469 |
comprehend_page_cost = ceil(average_characters_per_page / comprehend_size_unit_average) * comprehend_unit_cost
|
| 470 |
pii_identification_cost = comprehend_page_cost * number_of_pages
|
| 471 |
|
|
|
|
| 488 |
local_text_extraction_page_time:float=0.3,
|
| 489 |
local_pii_redaction_page_time:float=0.5,
|
| 490 |
local_ocr_extraction_page_time:float=1.5,
|
| 491 |
+
TEXTRACT_TEXT_EXTRACT_OPTION:str=TEXTRACT_TEXT_EXTRACT_OPTION,
|
| 492 |
+
SELECTABLE_TEXT_EXTRACT_OPTION:str=SELECTABLE_TEXT_EXTRACT_OPTION,
|
| 493 |
+
local_ocr_option:str=TESSERACT_TEXT_EXTRACT_OPTION,
|
| 494 |
+
NO_REDACTION_PII_OPTION:str=NO_REDACTION_PII_OPTION,
|
| 495 |
+
AWS_PII_OPTION:str=AWS_PII_OPTION):
|
| 496 |
'''
|
| 497 |
Calculate the approximate time to redact a document.
|
| 498 |
|
|
|
|
| 507 |
- local_text_redaction_page_time (float, optional): Approximate time to extract text on a page with the local text redaction option.
|
| 508 |
- local_pii_redaction_page_time (float, optional): Approximate time to redact text on a page with the local text redaction option.
|
| 509 |
- local_ocr_extraction_page_time (float, optional): Approximate time to extract text from a page with the local OCR redaction option.
|
| 510 |
+
- TEXTRACT_TEXT_EXTRACT_OPTION (str, optional): String label for the text_extract_method_radio button for AWS Textract.
|
| 511 |
+
- SELECTABLE_TEXT_EXTRACT_OPTION (str, optional): String label for text_extract_method_radio for text extraction.
|
| 512 |
- local_ocr_option (str, optional): String label for text_extract_method_radio for local OCR.
|
| 513 |
+
- NO_REDACTION_PII_OPTION (str, optional): String label for pii_identification_method_drop for no redaction.
|
| 514 |
+
- AWS_PII_OPTION (str, optional): String label for pii_identification_method_drop for AWS Comprehend.
|
| 515 |
'''
|
| 516 |
calculated_time_taken = 0
|
| 517 |
page_conversion_time_taken = 0
|
|
|
|
| 521 |
number_of_pages = int(number_of_pages)
|
| 522 |
|
| 523 |
# Page preparation/conversion to image time
|
| 524 |
+
if (text_extract_method_radio != SELECTABLE_TEXT_EXTRACT_OPTION) and (textract_output_found_checkbox != True):
|
| 525 |
page_conversion_time_taken = number_of_pages * convert_page_time
|
| 526 |
|
| 527 |
# Page text extraction time
|
| 528 |
+
if text_extract_method_radio == TEXTRACT_TEXT_EXTRACT_OPTION:
|
| 529 |
if textract_output_found_checkbox != True:
|
| 530 |
page_extraction_time_taken = number_of_pages * textract_page_time
|
| 531 |
elif text_extract_method_radio == local_ocr_option:
|
| 532 |
if local_ocr_output_found_checkbox != True:
|
| 533 |
page_extraction_time_taken = number_of_pages * local_ocr_extraction_page_time
|
| 534 |
+
elif text_extract_method_radio == SELECTABLE_TEXT_EXTRACT_OPTION:
|
| 535 |
page_conversion_time_taken = number_of_pages * local_text_extraction_page_time
|
| 536 |
|
| 537 |
# Page redaction time
|
| 538 |
+
if pii_identification_method != NO_REDACTION_PII_OPTION:
|
| 539 |
+
if pii_identification_method == AWS_PII_OPTION:
|
| 540 |
page_redaction_time_taken = number_of_pages * comprehend_page_time
|
| 541 |
else:
|
| 542 |
page_redaction_time_taken = number_of_pages * local_pii_redaction_page_time
|
tools/redaction_review.py
CHANGED
|
@@ -14,8 +14,8 @@ import pymupdf
|
|
| 14 |
from PIL import ImageDraw, Image
|
| 15 |
from datetime import datetime, timezone, timedelta
|
| 16 |
|
| 17 |
-
from tools.config import OUTPUT_FOLDER,
|
| 18 |
-
from tools.file_conversion import is_pdf, convert_annotation_json_to_review_df, convert_review_df_to_annotation_json, process_single_page_for_image_conversion, multiply_coordinates_by_page_sizes, convert_annotation_data_to_dataframe,
|
| 19 |
from tools.helper_functions import get_file_name_without_type, detect_file_type
|
| 20 |
from tools.file_redaction import redact_page_with_pymupdf
|
| 21 |
|
|
@@ -1040,7 +1040,7 @@ def reset_dropdowns(df:pd.DataFrame):
|
|
| 1040 |
|
| 1041 |
return recogniser_entities_drop, text_entities_drop, page_entities_drop
|
| 1042 |
|
| 1043 |
-
def
|
| 1044 |
|
| 1045 |
row_value_page = evt.row_value[0] # This is the page number value
|
| 1046 |
row_value_label = evt.row_value[1] # This is the label number value
|
|
@@ -1049,7 +1049,7 @@ def df_select_callback(df: pd.DataFrame, evt: gr.SelectData):
|
|
| 1049 |
|
| 1050 |
row_value_df = pd.DataFrame(data={"page":[row_value_page], "label":[row_value_label], "text":[row_value_text], "id":[row_value_id]})
|
| 1051 |
|
| 1052 |
-
return row_value_df
|
| 1053 |
|
| 1054 |
def df_select_callback_textract_api(df: pd.DataFrame, evt: gr.SelectData):
|
| 1055 |
|
|
@@ -1079,6 +1079,16 @@ def df_select_callback_ocr(df: pd.DataFrame, evt: gr.SelectData):
|
|
| 1079 |
|
| 1080 |
return row_value_page, row_value_df
|
| 1081 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1082 |
def update_selected_review_df_row_colour(
|
| 1083 |
redaction_row_selection: pd.DataFrame,
|
| 1084 |
review_df: pd.DataFrame,
|
|
|
|
| 14 |
from PIL import ImageDraw, Image
|
| 15 |
from datetime import datetime, timezone, timedelta
|
| 16 |
|
| 17 |
+
from tools.config import OUTPUT_FOLDER, MAX_IMAGE_PIXELS, INPUT_FOLDER, COMPRESS_REDACTED_PDF
|
| 18 |
+
from tools.file_conversion import is_pdf, convert_annotation_json_to_review_df, convert_review_df_to_annotation_json, process_single_page_for_image_conversion, multiply_coordinates_by_page_sizes, convert_annotation_data_to_dataframe, remove_duplicate_images_with_blank_boxes, fill_missing_ids, divide_coordinates_by_page_sizes, save_pdf_with_or_without_compression
|
| 19 |
from tools.helper_functions import get_file_name_without_type, detect_file_type
|
| 20 |
from tools.file_redaction import redact_page_with_pymupdf
|
| 21 |
|
|
|
|
| 1040 |
|
| 1041 |
return recogniser_entities_drop, text_entities_drop, page_entities_drop
|
| 1042 |
|
| 1043 |
+
def df_select_callback_dataframe_row(df: pd.DataFrame, evt: gr.SelectData):
|
| 1044 |
|
| 1045 |
row_value_page = evt.row_value[0] # This is the page number value
|
| 1046 |
row_value_label = evt.row_value[1] # This is the label number value
|
|
|
|
| 1049 |
|
| 1050 |
row_value_df = pd.DataFrame(data={"page":[row_value_page], "label":[row_value_label], "text":[row_value_text], "id":[row_value_id]})
|
| 1051 |
|
| 1052 |
+
return row_value_df, row_value_text
|
| 1053 |
|
| 1054 |
def df_select_callback_textract_api(df: pd.DataFrame, evt: gr.SelectData):
|
| 1055 |
|
|
|
|
| 1079 |
|
| 1080 |
return row_value_page, row_value_df
|
| 1081 |
|
| 1082 |
+
def get_all_rows_with_same_text(df: pd.DataFrame, text: str):
|
| 1083 |
+
'''
|
| 1084 |
+
Get all rows with the same text as the selected row
|
| 1085 |
+
'''
|
| 1086 |
+
if text:
|
| 1087 |
+
# Get all rows with the same text as the selected row
|
| 1088 |
+
return df[df["text"] == text]
|
| 1089 |
+
else:
|
| 1090 |
+
return pd.DataFrame(columns=["page", "label", "text", "id"])
|
| 1091 |
+
|
| 1092 |
def update_selected_review_df_row_colour(
|
| 1093 |
redaction_row_selection: pd.DataFrame,
|
| 1094 |
review_df: pd.DataFrame,
|