Spaces:
Running


Running
Vincentqyw
commited on
Commit
·
9223079
1
Parent(s):
71bbcb3
add: files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .gitattributes +1 -0
- .gitignore +19 -0
- .gitmodules +45 -0
- README.md +107 -12
- app.py +291 -0
- assets/demo.gif +3 -0
- assets/gui.jpg +0 -0
- datasets/.gitignore +0 -0
- datasets/lines/terrace0.JPG +0 -0
- datasets/lines/terrace1.JPG +0 -0
- datasets/sacre_coeur/README.md +3 -0
- datasets/sacre_coeur/mapping/02928139_3448003521.jpg +0 -0
- datasets/sacre_coeur/mapping/03903474_1471484089.jpg +0 -0
- datasets/sacre_coeur/mapping/10265353_3838484249.jpg +0 -0
- datasets/sacre_coeur/mapping/17295357_9106075285.jpg +0 -0
- datasets/sacre_coeur/mapping/32809961_8274055477.jpg +0 -0
- datasets/sacre_coeur/mapping/44120379_8371960244.jpg +0 -0
- datasets/sacre_coeur/mapping/51091044_3486849416.jpg +0 -0
- datasets/sacre_coeur/mapping/60584745_2207571072.jpg +0 -0
- datasets/sacre_coeur/mapping/71295362_4051449754.jpg +0 -0
- datasets/sacre_coeur/mapping/93341989_396310999.jpg +0 -0
- extra_utils/__init__.py +0 -0
- extra_utils/plotting.py +504 -0
- extra_utils/utils.py +182 -0
- extra_utils/visualize_util.py +642 -0
- hloc/__init__.py +31 -0
- hloc/extract_features.py +516 -0
- hloc/extractors/__init__.py +0 -0
- hloc/extractors/alike.py +52 -0
- hloc/extractors/cosplace.py +44 -0
- hloc/extractors/d2net.py +57 -0
- hloc/extractors/darkfeat.py +57 -0
- hloc/extractors/dedode.py +102 -0
- hloc/extractors/dir.py +76 -0
- hloc/extractors/disk.py +32 -0
- hloc/extractors/dog.py +131 -0
- hloc/extractors/example.py +58 -0
- hloc/extractors/fire.py +73 -0
- hloc/extractors/fire_local.py +90 -0
- hloc/extractors/lanet.py +53 -0
- hloc/extractors/netvlad.py +147 -0
- hloc/extractors/openibl.py +26 -0
- hloc/extractors/r2d2.py +61 -0
- hloc/extractors/rekd.py +53 -0
- hloc/extractors/superpoint.py +44 -0
- hloc/match_dense.py +384 -0
- hloc/match_features.py +389 -0
- hloc/matchers/__init__.py +3 -0
- hloc/matchers/adalam.py +69 -0
- hloc/matchers/aspanformer.py +76 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
*.gif filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,19 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
build/
|
| 2 |
+
|
| 3 |
+
lib/
|
| 4 |
+
bin/
|
| 5 |
+
|
| 6 |
+
cmake_modules/
|
| 7 |
+
cmake-build-debug/
|
| 8 |
+
.idea/
|
| 9 |
+
.vscode/
|
| 10 |
+
*.pyc
|
| 11 |
+
flagged
|
| 12 |
+
.ipynb_checkpoints
|
| 13 |
+
__pycache__
|
| 14 |
+
Untitled*
|
| 15 |
+
experiments
|
| 16 |
+
third_party/REKD
|
| 17 |
+
Dockerfile
|
| 18 |
+
hloc/matchers/dedode.py
|
| 19 |
+
gradio_cached_examples
|
.gitmodules
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[submodule "third_party/Roma"]
|
| 2 |
+
path = third_party/Roma
|
| 3 |
+
url = https://github.com/Vincentqyw/RoMa.git
|
| 4 |
+
[submodule "third_party/SuperGluePretrainedNetwork"]
|
| 5 |
+
path = third_party/SuperGluePretrainedNetwork
|
| 6 |
+
url = https://github.com/magicleap/SuperGluePretrainedNetwork.git
|
| 7 |
+
[submodule "third_party/SOLD2"]
|
| 8 |
+
path = third_party/SOLD2
|
| 9 |
+
url = https://github.com/cvg/SOLD2.git
|
| 10 |
+
[submodule "third_party/GlueStick"]
|
| 11 |
+
path = third_party/GlueStick
|
| 12 |
+
url = https://github.com/cvg/GlueStick.git
|
| 13 |
+
[submodule "third_party/ASpanFormer"]
|
| 14 |
+
path = third_party/ASpanFormer
|
| 15 |
+
url = https://github.com/Vincentqyw/ml-aspanformer.git
|
| 16 |
+
[submodule "third_party/TopicFM"]
|
| 17 |
+
path = third_party/TopicFM
|
| 18 |
+
url = https://github.com/Vincentqyw/TopicFM.git
|
| 19 |
+
[submodule "third_party/d2net"]
|
| 20 |
+
path = third_party/d2net
|
| 21 |
+
url = https://github.com/Vincentqyw/d2-net.git
|
| 22 |
+
[submodule "third_party/r2d2"]
|
| 23 |
+
path = third_party/r2d2
|
| 24 |
+
url = https://github.com/naver/r2d2.git
|
| 25 |
+
[submodule "third_party/DKM"]
|
| 26 |
+
path = third_party/DKM
|
| 27 |
+
url = https://github.com/Vincentqyw/DKM.git
|
| 28 |
+
[submodule "third_party/ALIKE"]
|
| 29 |
+
path = third_party/ALIKE
|
| 30 |
+
url = https://github.com/Shiaoming/ALIKE.git
|
| 31 |
+
[submodule "third_party/lanet"]
|
| 32 |
+
path = third_party/lanet
|
| 33 |
+
url = https://github.com/wangch-g/lanet.git
|
| 34 |
+
[submodule "third_party/LightGlue"]
|
| 35 |
+
path = third_party/LightGlue
|
| 36 |
+
url = https://github.com/cvg/LightGlue.git
|
| 37 |
+
[submodule "third_party/SGMNet"]
|
| 38 |
+
path = third_party/SGMNet
|
| 39 |
+
url = https://github.com/vdvchen/SGMNet.git
|
| 40 |
+
[submodule "third_party/DarkFeat"]
|
| 41 |
+
path = third_party/DarkFeat
|
| 42 |
+
url = https://github.com/THU-LYJ-Lab/DarkFeat.git
|
| 43 |
+
[submodule "third_party/DeDoDe"]
|
| 44 |
+
path = third_party/DeDoDe
|
| 45 |
+
url = https://github.com/Parskatt/DeDoDe.git
|
README.md
CHANGED
|
@@ -1,12 +1,107 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
| 4 |
-
|
| 5 |
-
|
| 6 |
-
|
| 7 |
-
|
| 8 |
-
|
| 9 |
-
|
| 10 |
-
|
| 11 |
-
|
| 12 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[![Contributors][contributors-shield]][contributors-url]
|
| 2 |
+
[![Forks][forks-shield]][forks-url]
|
| 3 |
+
[![Stargazers][stars-shield]][stars-url]
|
| 4 |
+
[![Issues][issues-shield]][issues-url]
|
| 5 |
+
|
| 6 |
+
<p align="center">
|
| 7 |
+
<h1 align="center"><br><ins>Image Matching WebUI</ins><br>find matches between 2 images</h1>
|
| 8 |
+
</p>
|
| 9 |
+
|
| 10 |
+
## Description
|
| 11 |
+
|
| 12 |
+
This simple tool efficiently matches image pairs using multiple famous image matching algorithms. The tool features a Graphical User Interface (GUI) designed using [gradio](https://gradio.app/). You can effortlessly select two images and a matching algorithm and obtain a precise matching result.
|
| 13 |
+
**Note**: the images source can be either local images or webcam images.
|
| 14 |
+
|
| 15 |
+
Here is a demo of the tool:
|
| 16 |
+
|
| 17 |
+

|
| 18 |
+
|
| 19 |
+
The tool currently supports various popular image matching algorithms, namely:
|
| 20 |
+
- [x] [LightGlue](https://github.com/cvg/LightGlue), ICCV 2023
|
| 21 |
+
- [x] [DeDoDe](https://github.com/Parskatt/DeDoDe), TBD
|
| 22 |
+
- [x] [DarkFeat](https://github.com/THU-LYJ-Lab/DarkFeat), AAAI 2023
|
| 23 |
+
- [ ] [ASTR](https://github.com/ASTR2023/ASTR), CVPR 2023
|
| 24 |
+
- [ ] [SEM](https://github.com/SEM2023/SEM), CVPR 2023
|
| 25 |
+
- [ ] [DeepLSD](https://github.com/cvg/DeepLSD), CVPR 2023
|
| 26 |
+
- [x] [GlueStick](https://github.com/cvg/GlueStick), ArXiv 2023
|
| 27 |
+
- [ ] [ConvMatch](https://github.com/SuhZhang/ConvMatch), AAAI 2023
|
| 28 |
+
- [x] [SOLD2](https://github.com/cvg/SOLD2), CVPR 2021
|
| 29 |
+
- [ ] [LineTR](https://github.com/yosungho/LineTR), RA-L 2021
|
| 30 |
+
- [x] [DKM](https://github.com/Parskatt/DKM), CVPR 2023
|
| 31 |
+
- [x] [RoMa](https://github.com/Vincentqyw/RoMa), Arxiv 2023
|
| 32 |
+
- [ ] [NCMNet](https://github.com/xinliu29/NCMNet), CVPR 2023
|
| 33 |
+
- [x] [TopicFM](https://github.com/Vincentqyw/TopicFM), AAAI 2023
|
| 34 |
+
- [x] [AspanFormer](https://github.com/Vincentqyw/ml-aspanformer), ECCV 2022
|
| 35 |
+
- [x] [LANet](https://github.com/wangch-g/lanet), ACCV 2022
|
| 36 |
+
- [ ] [LISRD](https://github.com/rpautrat/LISRD), ECCV 2022
|
| 37 |
+
- [ ] [REKD](https://github.com/bluedream1121/REKD), CVPR 2022
|
| 38 |
+
- [x] [ALIKE](https://github.com/Shiaoming/ALIKE), ArXiv 2022
|
| 39 |
+
- [x] [SGMNet](https://github.com/vdvchen/SGMNet), ICCV 2021
|
| 40 |
+
- [x] [SuperPoint](https://github.com/magicleap/SuperPointPretrainedNetwork), CVPRW 2018
|
| 41 |
+
- [x] [SuperGlue](https://github.com/magicleap/SuperGluePretrainedNetwork), CVPR 2020
|
| 42 |
+
- [x] [D2Net](https://github.com/Vincentqyw/d2-net), CVPR 2019
|
| 43 |
+
- [x] [R2D2](https://github.com/naver/r2d2), NeurIPS 2019
|
| 44 |
+
- [x] [DISK](https://github.com/cvlab-epfl/disk), NeurIPS 2020
|
| 45 |
+
- [ ] [Key.Net](https://github.com/axelBarroso/Key.Net), ICCV 2019
|
| 46 |
+
- [ ] [OANet](https://github.com/zjhthu/OANet), ICCV 2019
|
| 47 |
+
- [ ] [SOSNet](https://github.com/scape-research/SOSNet), CVPR 2019
|
| 48 |
+
- [x] [SIFT](https://docs.opencv.org/4.x/da/df5/tutorial_py_sift_intro.html), IJCV 2004
|
| 49 |
+
|
| 50 |
+
## How to use
|
| 51 |
+
|
| 52 |
+
### requirements
|
| 53 |
+
``` bash
|
| 54 |
+
git clone --recursive https://github.com/Vincentqyw/image-matching-webui.git
|
| 55 |
+
cd image-matching-webui
|
| 56 |
+
conda env create -f environment.yaml
|
| 57 |
+
conda activate imw
|
| 58 |
+
```
|
| 59 |
+
|
| 60 |
+
### run demo
|
| 61 |
+
``` bash
|
| 62 |
+
python3 ./app.py
|
| 63 |
+
```
|
| 64 |
+
then open http://localhost:7860 in your browser.
|
| 65 |
+
|
| 66 |
+

|
| 67 |
+
|
| 68 |
+
### Add your own feature / matcher
|
| 69 |
+
|
| 70 |
+
I provide an example to add local feature in [hloc/extractors/example.py](hloc/extractors/example.py). Then add feature settings in `confs` in file [hloc/extract_features.py](hloc/extract_features.py). Last step is adding some settings to `model_zoo` in file [extra_utils/utils.py](extra_utils/utils.py).
|
| 71 |
+
|
| 72 |
+
## Contributions welcome!
|
| 73 |
+
|
| 74 |
+
External contributions are very much welcome. Please follow the [PEP8 style guidelines](https://www.python.org/dev/peps/pep-0008/) using a linter like flake8 (reformat using command `python -m black .`). This is a non-exhaustive list of features that might be valuable additions:
|
| 75 |
+
|
| 76 |
+
- [x] add webcam support
|
| 77 |
+
- [x] add [line feature matching](https://github.com/Vincentqyw/LineSegmentsDetection) algorithms
|
| 78 |
+
- [x] example to add a new feature extractor / matcher
|
| 79 |
+
- [ ] ransac to filter outliers
|
| 80 |
+
- [ ] support export matches to colmap ([#issue 6](https://github.com/Vincentqyw/image-matching-webui/issues/6))
|
| 81 |
+
- [ ] add config file to set default parameters
|
| 82 |
+
- [ ] dynamically load models and reduce GPU overload
|
| 83 |
+
|
| 84 |
+
Adding local features / matchers as submodules is very easy. For example, to add the [GlueStick](https://github.com/cvg/GlueStick):
|
| 85 |
+
|
| 86 |
+
``` bash
|
| 87 |
+
git submodule add https://github.com/cvg/GlueStick.git third_party/GlueStick
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
If remote submodule repositories are updated, don't forget to pull submodules with `git submodule update --remote`, if you only want to update one submodule, use `git submodule update --remote third_party/GlueStick`.
|
| 91 |
+
|
| 92 |
+
## Resources
|
| 93 |
+
- [Image Matching: Local Features & Beyond](https://image-matching-workshop.github.io)
|
| 94 |
+
- [Long-term Visual Localization](https://www.visuallocalization.net)
|
| 95 |
+
|
| 96 |
+
## Acknowledgement
|
| 97 |
+
|
| 98 |
+
This code is built based on [Hierarchical-Localization](https://github.com/cvg/Hierarchical-Localization). We express our gratitude to the authors for their valuable source code.
|
| 99 |
+
|
| 100 |
+
[contributors-shield]: https://img.shields.io/github/contributors/Vincentqyw/image-matching-webui.svg?style=for-the-badge
|
| 101 |
+
[contributors-url]: https://github.com/Vincentqyw/image-matching-webui/graphs/contributors
|
| 102 |
+
[forks-shield]: https://img.shields.io/github/forks/Vincentqyw/image-matching-webui.svg?style=for-the-badge
|
| 103 |
+
[forks-url]: https://github.com/Vincentqyw/image-matching-webui/network/members
|
| 104 |
+
[stars-shield]: https://img.shields.io/github/stars/Vincentqyw/image-matching-webui.svg?style=for-the-badge
|
| 105 |
+
[stars-url]: https://github.com/Vincentqyw/image-matching-webui/stargazers
|
| 106 |
+
[issues-shield]: https://img.shields.io/github/issues/Vincentqyw/image-matching-webui.svg?style=for-the-badge
|
| 107 |
+
[issues-url]: https://github.com/Vincentqyw/image-matching-webui/issues
|
app.py
ADDED
|
@@ -0,0 +1,291 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import gradio as gr
|
| 3 |
+
|
| 4 |
+
from hloc import extract_features
|
| 5 |
+
from extra_utils.utils import (
|
| 6 |
+
matcher_zoo,
|
| 7 |
+
device,
|
| 8 |
+
match_dense,
|
| 9 |
+
match_features,
|
| 10 |
+
get_model,
|
| 11 |
+
get_feature_model,
|
| 12 |
+
display_matches
|
| 13 |
+
)
|
| 14 |
+
|
| 15 |
+
def run_matching(
|
| 16 |
+
match_threshold, extract_max_keypoints, keypoint_threshold, key, image0, image1
|
| 17 |
+
):
|
| 18 |
+
# image0 and image1 is RGB mode
|
| 19 |
+
if image0 is None or image1 is None:
|
| 20 |
+
raise gr.Error("Error: No images found! Please upload two images.")
|
| 21 |
+
|
| 22 |
+
model = matcher_zoo[key]
|
| 23 |
+
match_conf = model["config"]
|
| 24 |
+
# update match config
|
| 25 |
+
match_conf["model"]["match_threshold"] = match_threshold
|
| 26 |
+
match_conf["model"]["max_keypoints"] = extract_max_keypoints
|
| 27 |
+
|
| 28 |
+
matcher = get_model(match_conf)
|
| 29 |
+
if model["dense"]:
|
| 30 |
+
pred = match_dense.match_images(
|
| 31 |
+
matcher, image0, image1, match_conf["preprocessing"], device=device
|
| 32 |
+
)
|
| 33 |
+
del matcher
|
| 34 |
+
extract_conf = None
|
| 35 |
+
else:
|
| 36 |
+
extract_conf = model["config_feature"]
|
| 37 |
+
# update extract config
|
| 38 |
+
extract_conf["model"]["max_keypoints"] = extract_max_keypoints
|
| 39 |
+
extract_conf["model"]["keypoint_threshold"] = keypoint_threshold
|
| 40 |
+
extractor = get_feature_model(extract_conf)
|
| 41 |
+
pred0 = extract_features.extract(
|
| 42 |
+
extractor, image0, extract_conf["preprocessing"]
|
| 43 |
+
)
|
| 44 |
+
pred1 = extract_features.extract(
|
| 45 |
+
extractor, image1, extract_conf["preprocessing"]
|
| 46 |
+
)
|
| 47 |
+
pred = match_features.match_images(matcher, pred0, pred1)
|
| 48 |
+
del extractor
|
| 49 |
+
fig, num_inliers = display_matches(pred)
|
| 50 |
+
del pred
|
| 51 |
+
return (
|
| 52 |
+
fig,
|
| 53 |
+
{"matches number": num_inliers},
|
| 54 |
+
{"match_conf": match_conf, "extractor_conf": extract_conf},
|
| 55 |
+
)
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def ui_change_imagebox(choice):
|
| 59 |
+
return {"value": None, "source": choice, "__type__": "update"}
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def ui_reset_state(
|
| 63 |
+
match_threshold, extract_max_keypoints, keypoint_threshold, key, image0, image1
|
| 64 |
+
):
|
| 65 |
+
match_threshold = 0.2
|
| 66 |
+
extract_max_keypoints = 1000
|
| 67 |
+
keypoint_threshold = 0.015
|
| 68 |
+
key = list(matcher_zoo.keys())[0]
|
| 69 |
+
image0 = None
|
| 70 |
+
image1 = None
|
| 71 |
+
return (
|
| 72 |
+
match_threshold,
|
| 73 |
+
extract_max_keypoints,
|
| 74 |
+
keypoint_threshold,
|
| 75 |
+
key,
|
| 76 |
+
image0,
|
| 77 |
+
image1,
|
| 78 |
+
{"value": None, "source": "upload", "__type__": "update"},
|
| 79 |
+
{"value": None, "source": "upload", "__type__": "update"},
|
| 80 |
+
"upload",
|
| 81 |
+
None,
|
| 82 |
+
{},
|
| 83 |
+
{},
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
|
| 87 |
+
def run(config):
|
| 88 |
+
with gr.Blocks(
|
| 89 |
+
theme=gr.themes.Monochrome(), css="footer {visibility: hidden}"
|
| 90 |
+
) as app:
|
| 91 |
+
gr.Markdown(
|
| 92 |
+
"""
|
| 93 |
+
<p align="center">
|
| 94 |
+
<h1 align="center">Image Matching WebUI</h1>
|
| 95 |
+
</p>
|
| 96 |
+
"""
|
| 97 |
+
)
|
| 98 |
+
|
| 99 |
+
with gr.Row(equal_height=False):
|
| 100 |
+
with gr.Column():
|
| 101 |
+
with gr.Row():
|
| 102 |
+
matcher_list = gr.Dropdown(
|
| 103 |
+
choices=list(matcher_zoo.keys()),
|
| 104 |
+
value="disk+lightglue",
|
| 105 |
+
label="Matching Model",
|
| 106 |
+
interactive=True,
|
| 107 |
+
)
|
| 108 |
+
match_image_src = gr.Radio(
|
| 109 |
+
["upload", "webcam", "canvas"],
|
| 110 |
+
label="Image Source",
|
| 111 |
+
value="upload",
|
| 112 |
+
)
|
| 113 |
+
|
| 114 |
+
with gr.Row():
|
| 115 |
+
match_setting_threshold = gr.Slider(
|
| 116 |
+
minimum=0.0,
|
| 117 |
+
maximum=1,
|
| 118 |
+
step=0.001,
|
| 119 |
+
label="Match threshold",
|
| 120 |
+
value=0.1,
|
| 121 |
+
)
|
| 122 |
+
match_setting_max_features = gr.Slider(
|
| 123 |
+
minimum=10,
|
| 124 |
+
maximum=10000,
|
| 125 |
+
step=10,
|
| 126 |
+
label="Max number of features",
|
| 127 |
+
value=1000,
|
| 128 |
+
)
|
| 129 |
+
# TODO: add line settings
|
| 130 |
+
with gr.Row():
|
| 131 |
+
detect_keypoints_threshold = gr.Slider(
|
| 132 |
+
minimum=0,
|
| 133 |
+
maximum=1,
|
| 134 |
+
step=0.001,
|
| 135 |
+
label="Keypoint threshold",
|
| 136 |
+
value=0.015,
|
| 137 |
+
)
|
| 138 |
+
detect_line_threshold = gr.Slider(
|
| 139 |
+
minimum=0.1,
|
| 140 |
+
maximum=1,
|
| 141 |
+
step=0.01,
|
| 142 |
+
label="Line threshold",
|
| 143 |
+
value=0.2,
|
| 144 |
+
)
|
| 145 |
+
# matcher_lists = gr.Radio(
|
| 146 |
+
# ["NN-mutual", "Dual-Softmax"],
|
| 147 |
+
# label="Matcher mode",
|
| 148 |
+
# value="NN-mutual",
|
| 149 |
+
# )
|
| 150 |
+
with gr.Row():
|
| 151 |
+
input_image0 = gr.Image(
|
| 152 |
+
label="Image 0",
|
| 153 |
+
type="numpy",
|
| 154 |
+
interactive=True,
|
| 155 |
+
image_mode="RGB",
|
| 156 |
+
)
|
| 157 |
+
input_image1 = gr.Image(
|
| 158 |
+
label="Image 1",
|
| 159 |
+
type="numpy",
|
| 160 |
+
interactive=True,
|
| 161 |
+
image_mode="RGB",
|
| 162 |
+
)
|
| 163 |
+
|
| 164 |
+
with gr.Row():
|
| 165 |
+
button_reset = gr.Button(label="Reset", value="Reset")
|
| 166 |
+
button_run = gr.Button(
|
| 167 |
+
label="Run Match", value="Run Match", variant="primary"
|
| 168 |
+
)
|
| 169 |
+
|
| 170 |
+
with gr.Accordion("Open for More!", open=False):
|
| 171 |
+
gr.Markdown(
|
| 172 |
+
f"""
|
| 173 |
+
<h3>Supported Algorithms</h3>
|
| 174 |
+
{", ".join(matcher_zoo.keys())}
|
| 175 |
+
"""
|
| 176 |
+
)
|
| 177 |
+
|
| 178 |
+
# collect inputs
|
| 179 |
+
inputs = [
|
| 180 |
+
match_setting_threshold,
|
| 181 |
+
match_setting_max_features,
|
| 182 |
+
detect_keypoints_threshold,
|
| 183 |
+
matcher_list,
|
| 184 |
+
input_image0,
|
| 185 |
+
input_image1,
|
| 186 |
+
]
|
| 187 |
+
|
| 188 |
+
# Add some examples
|
| 189 |
+
with gr.Row():
|
| 190 |
+
examples = [
|
| 191 |
+
[
|
| 192 |
+
0.1,
|
| 193 |
+
2000,
|
| 194 |
+
0.015,
|
| 195 |
+
"disk+lightglue",
|
| 196 |
+
"datasets/sacre_coeur/mapping/71295362_4051449754.jpg",
|
| 197 |
+
"datasets/sacre_coeur/mapping/93341989_396310999.jpg",
|
| 198 |
+
],
|
| 199 |
+
[
|
| 200 |
+
0.1,
|
| 201 |
+
2000,
|
| 202 |
+
0.015,
|
| 203 |
+
"loftr",
|
| 204 |
+
"datasets/sacre_coeur/mapping/03903474_1471484089.jpg",
|
| 205 |
+
"datasets/sacre_coeur/mapping/02928139_3448003521.jpg",
|
| 206 |
+
],
|
| 207 |
+
[
|
| 208 |
+
0.1,
|
| 209 |
+
2000,
|
| 210 |
+
0.015,
|
| 211 |
+
"disk",
|
| 212 |
+
"datasets/sacre_coeur/mapping/10265353_3838484249.jpg",
|
| 213 |
+
"datasets/sacre_coeur/mapping/51091044_3486849416.jpg",
|
| 214 |
+
],
|
| 215 |
+
[
|
| 216 |
+
0.1,
|
| 217 |
+
2000,
|
| 218 |
+
0.015,
|
| 219 |
+
"topicfm",
|
| 220 |
+
"datasets/sacre_coeur/mapping/44120379_8371960244.jpg",
|
| 221 |
+
"datasets/sacre_coeur/mapping/93341989_396310999.jpg",
|
| 222 |
+
],
|
| 223 |
+
[
|
| 224 |
+
0.1,
|
| 225 |
+
2000,
|
| 226 |
+
0.015,
|
| 227 |
+
"superpoint+superglue",
|
| 228 |
+
"datasets/sacre_coeur/mapping/17295357_9106075285.jpg",
|
| 229 |
+
"datasets/sacre_coeur/mapping/44120379_8371960244.jpg",
|
| 230 |
+
],
|
| 231 |
+
]
|
| 232 |
+
# Example inputs
|
| 233 |
+
gr.Examples(
|
| 234 |
+
examples=examples,
|
| 235 |
+
inputs=inputs,
|
| 236 |
+
outputs=[],
|
| 237 |
+
fn=run_matching,
|
| 238 |
+
cache_examples=False,
|
| 239 |
+
label="Examples (click one of the images below to Run Match)",
|
| 240 |
+
)
|
| 241 |
+
|
| 242 |
+
with gr.Column():
|
| 243 |
+
output_mkpts = gr.Image(label="Keypoints Matching", type="numpy")
|
| 244 |
+
matches_result_info = gr.JSON(label="Matches Statistics")
|
| 245 |
+
matcher_info = gr.JSON(label="Match info")
|
| 246 |
+
|
| 247 |
+
# callbacks
|
| 248 |
+
match_image_src.change(
|
| 249 |
+
fn=ui_change_imagebox, inputs=match_image_src, outputs=input_image0
|
| 250 |
+
)
|
| 251 |
+
match_image_src.change(
|
| 252 |
+
fn=ui_change_imagebox, inputs=match_image_src, outputs=input_image1
|
| 253 |
+
)
|
| 254 |
+
|
| 255 |
+
# collect outputs
|
| 256 |
+
outputs = [
|
| 257 |
+
output_mkpts,
|
| 258 |
+
matches_result_info,
|
| 259 |
+
matcher_info,
|
| 260 |
+
]
|
| 261 |
+
# button callbacks
|
| 262 |
+
button_run.click(fn=run_matching, inputs=inputs, outputs=outputs)
|
| 263 |
+
|
| 264 |
+
# Reset images
|
| 265 |
+
reset_outputs = [
|
| 266 |
+
match_setting_threshold,
|
| 267 |
+
match_setting_max_features,
|
| 268 |
+
detect_keypoints_threshold,
|
| 269 |
+
matcher_list,
|
| 270 |
+
input_image0,
|
| 271 |
+
input_image1,
|
| 272 |
+
input_image0,
|
| 273 |
+
input_image1,
|
| 274 |
+
match_image_src,
|
| 275 |
+
output_mkpts,
|
| 276 |
+
matches_result_info,
|
| 277 |
+
matcher_info,
|
| 278 |
+
]
|
| 279 |
+
button_reset.click(fn=ui_reset_state, inputs=inputs, outputs=reset_outputs)
|
| 280 |
+
|
| 281 |
+
app.launch(share=True)
|
| 282 |
+
|
| 283 |
+
|
| 284 |
+
if __name__ == "__main__":
|
| 285 |
+
parser = argparse.ArgumentParser()
|
| 286 |
+
parser.add_argument(
|
| 287 |
+
"--config_path", type=str, default="config.yaml", help="configuration file path"
|
| 288 |
+
)
|
| 289 |
+
args = parser.parse_args()
|
| 290 |
+
config = None
|
| 291 |
+
run(config)
|
assets/demo.gif
ADDED

|
Git LFS Details
|
assets/gui.jpg
ADDED
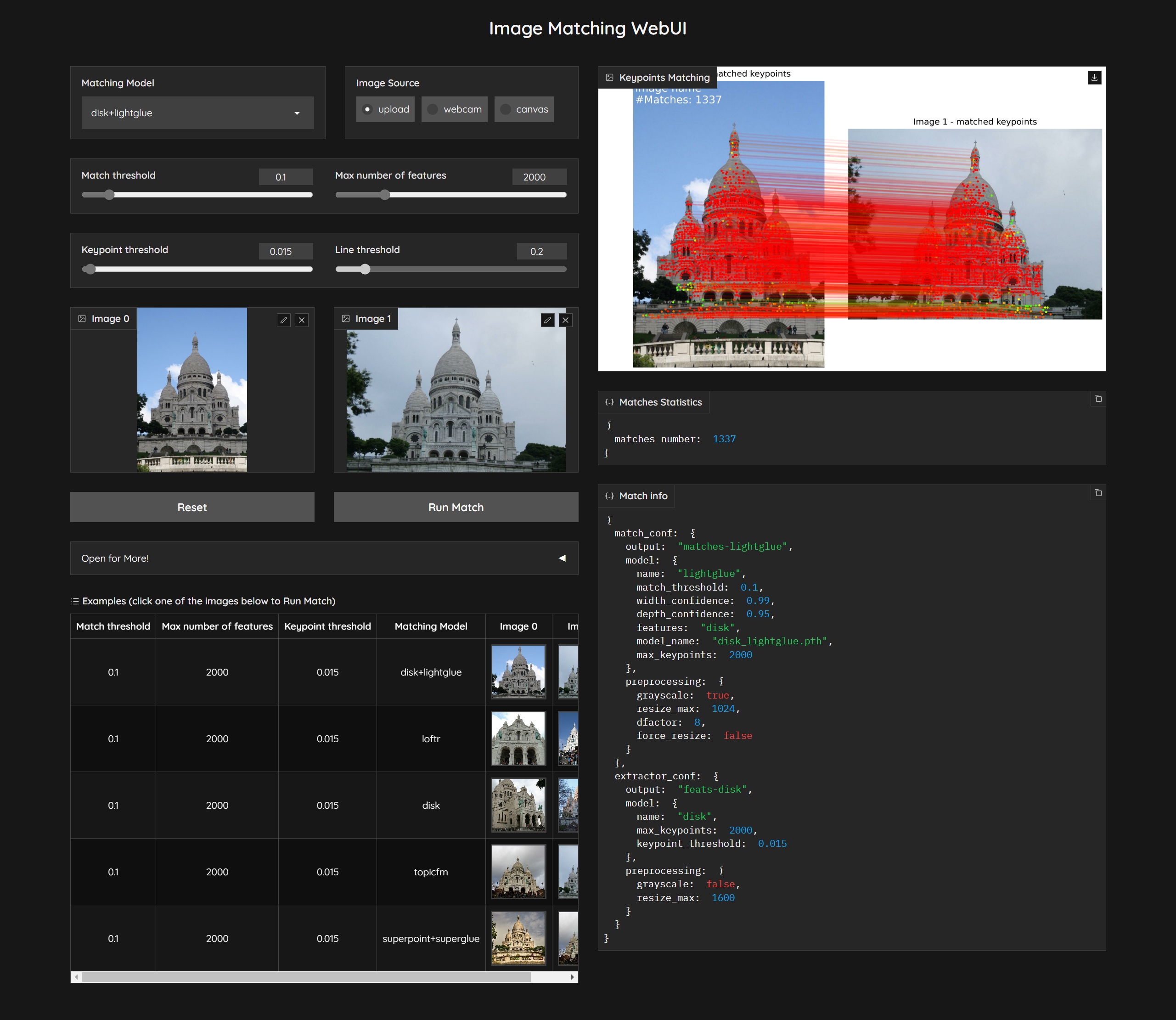
|
datasets/.gitignore
ADDED
|
File without changes
|
datasets/lines/terrace0.JPG
ADDED

|
datasets/lines/terrace1.JPG
ADDED

|
datasets/sacre_coeur/README.md
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Sacre Coeur demo
|
| 2 |
+
|
| 3 |
+
We provide here a subset of images depicting the Sacre Coeur. These images were obtained from the [Image Matching Challenge 2021](https://www.cs.ubc.ca/research/image-matching-challenge/2021/data/) and were originally collected by the [Yahoo Flickr Creative Commons 100M (YFCC) dataset](https://multimediacommons.wordpress.com/yfcc100m-core-dataset/).
|
datasets/sacre_coeur/mapping/02928139_3448003521.jpg
ADDED

|
datasets/sacre_coeur/mapping/03903474_1471484089.jpg
ADDED

|
datasets/sacre_coeur/mapping/10265353_3838484249.jpg
ADDED

|
datasets/sacre_coeur/mapping/17295357_9106075285.jpg
ADDED

|
datasets/sacre_coeur/mapping/32809961_8274055477.jpg
ADDED

|
datasets/sacre_coeur/mapping/44120379_8371960244.jpg
ADDED

|
datasets/sacre_coeur/mapping/51091044_3486849416.jpg
ADDED

|
datasets/sacre_coeur/mapping/60584745_2207571072.jpg
ADDED

|
datasets/sacre_coeur/mapping/71295362_4051449754.jpg
ADDED

|
datasets/sacre_coeur/mapping/93341989_396310999.jpg
ADDED

|
extra_utils/__init__.py
ADDED
|
File without changes
|
extra_utils/plotting.py
ADDED
|
@@ -0,0 +1,504 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import bisect
|
| 2 |
+
import numpy as np
|
| 3 |
+
import matplotlib.pyplot as plt
|
| 4 |
+
import matplotlib, os, cv2
|
| 5 |
+
import matplotlib.cm as cm
|
| 6 |
+
from PIL import Image
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
import torch
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def _compute_conf_thresh(data):
|
| 12 |
+
dataset_name = data["dataset_name"][0].lower()
|
| 13 |
+
if dataset_name == "scannet":
|
| 14 |
+
thr = 5e-4
|
| 15 |
+
elif dataset_name == "megadepth":
|
| 16 |
+
thr = 1e-4
|
| 17 |
+
else:
|
| 18 |
+
raise ValueError(f"Unknown dataset: {dataset_name}")
|
| 19 |
+
return thr
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
# --- VISUALIZATION --- #
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def make_matching_figure(
|
| 26 |
+
img0,
|
| 27 |
+
img1,
|
| 28 |
+
mkpts0,
|
| 29 |
+
mkpts1,
|
| 30 |
+
color,
|
| 31 |
+
titles=None,
|
| 32 |
+
kpts0=None,
|
| 33 |
+
kpts1=None,
|
| 34 |
+
text=[],
|
| 35 |
+
dpi=75,
|
| 36 |
+
path=None,
|
| 37 |
+
pad=0,
|
| 38 |
+
):
|
| 39 |
+
# draw image pair
|
| 40 |
+
# assert mkpts0.shape[0] == mkpts1.shape[0], f'mkpts0: {mkpts0.shape[0]} v.s. mkpts1: {mkpts1.shape[0]}'
|
| 41 |
+
fig, axes = plt.subplots(1, 2, figsize=(10, 6), dpi=dpi)
|
| 42 |
+
axes[0].imshow(img0) # , cmap='gray')
|
| 43 |
+
axes[1].imshow(img1) # , cmap='gray')
|
| 44 |
+
for i in range(2): # clear all frames
|
| 45 |
+
axes[i].get_yaxis().set_ticks([])
|
| 46 |
+
axes[i].get_xaxis().set_ticks([])
|
| 47 |
+
for spine in axes[i].spines.values():
|
| 48 |
+
spine.set_visible(False)
|
| 49 |
+
if titles is not None:
|
| 50 |
+
axes[i].set_title(titles[i])
|
| 51 |
+
|
| 52 |
+
plt.tight_layout(pad=pad)
|
| 53 |
+
|
| 54 |
+
if kpts0 is not None:
|
| 55 |
+
assert kpts1 is not None
|
| 56 |
+
axes[0].scatter(kpts0[:, 0], kpts0[:, 1], c="w", s=5)
|
| 57 |
+
axes[1].scatter(kpts1[:, 0], kpts1[:, 1], c="w", s=5)
|
| 58 |
+
|
| 59 |
+
# draw matches
|
| 60 |
+
if mkpts0.shape[0] != 0 and mkpts1.shape[0] != 0:
|
| 61 |
+
fig.canvas.draw()
|
| 62 |
+
transFigure = fig.transFigure.inverted()
|
| 63 |
+
fkpts0 = transFigure.transform(axes[0].transData.transform(mkpts0))
|
| 64 |
+
fkpts1 = transFigure.transform(axes[1].transData.transform(mkpts1))
|
| 65 |
+
fig.lines = [
|
| 66 |
+
matplotlib.lines.Line2D(
|
| 67 |
+
(fkpts0[i, 0], fkpts1[i, 0]),
|
| 68 |
+
(fkpts0[i, 1], fkpts1[i, 1]),
|
| 69 |
+
transform=fig.transFigure,
|
| 70 |
+
c=color[i],
|
| 71 |
+
linewidth=2,
|
| 72 |
+
)
|
| 73 |
+
for i in range(len(mkpts0))
|
| 74 |
+
]
|
| 75 |
+
|
| 76 |
+
# freeze the axes to prevent the transform to change
|
| 77 |
+
axes[0].autoscale(enable=False)
|
| 78 |
+
axes[1].autoscale(enable=False)
|
| 79 |
+
|
| 80 |
+
axes[0].scatter(mkpts0[:, 0], mkpts0[:, 1], c=color[..., :3], s=4)
|
| 81 |
+
axes[1].scatter(mkpts1[:, 0], mkpts1[:, 1], c=color[..., :3], s=4)
|
| 82 |
+
|
| 83 |
+
# put txts
|
| 84 |
+
txt_color = "k" if img0[:100, :200].mean() > 200 else "w"
|
| 85 |
+
fig.text(
|
| 86 |
+
0.01,
|
| 87 |
+
0.99,
|
| 88 |
+
"\n".join(text),
|
| 89 |
+
transform=fig.axes[0].transAxes,
|
| 90 |
+
fontsize=15,
|
| 91 |
+
va="top",
|
| 92 |
+
ha="left",
|
| 93 |
+
color=txt_color,
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
# save or return figure
|
| 97 |
+
if path:
|
| 98 |
+
plt.savefig(str(path), bbox_inches="tight", pad_inches=0)
|
| 99 |
+
plt.close()
|
| 100 |
+
else:
|
| 101 |
+
return fig
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
def _make_evaluation_figure(data, b_id, alpha="dynamic"):
|
| 105 |
+
b_mask = data["m_bids"] == b_id
|
| 106 |
+
conf_thr = _compute_conf_thresh(data)
|
| 107 |
+
|
| 108 |
+
img0 = (data["image0"][b_id][0].cpu().numpy() * 255).round().astype(np.int32)
|
| 109 |
+
img1 = (data["image1"][b_id][0].cpu().numpy() * 255).round().astype(np.int32)
|
| 110 |
+
kpts0 = data["mkpts0_f"][b_mask].cpu().numpy()
|
| 111 |
+
kpts1 = data["mkpts1_f"][b_mask].cpu().numpy()
|
| 112 |
+
|
| 113 |
+
# for megadepth, we visualize matches on the resized image
|
| 114 |
+
if "scale0" in data:
|
| 115 |
+
kpts0 = kpts0 / data["scale0"][b_id].cpu().numpy()[[1, 0]]
|
| 116 |
+
kpts1 = kpts1 / data["scale1"][b_id].cpu().numpy()[[1, 0]]
|
| 117 |
+
|
| 118 |
+
epi_errs = data["epi_errs"][b_mask].cpu().numpy()
|
| 119 |
+
correct_mask = epi_errs < conf_thr
|
| 120 |
+
precision = np.mean(correct_mask) if len(correct_mask) > 0 else 0
|
| 121 |
+
n_correct = np.sum(correct_mask)
|
| 122 |
+
n_gt_matches = int(data["conf_matrix_gt"][b_id].sum().cpu())
|
| 123 |
+
recall = 0 if n_gt_matches == 0 else n_correct / (n_gt_matches)
|
| 124 |
+
# recall might be larger than 1, since the calculation of conf_matrix_gt
|
| 125 |
+
# uses groundtruth depths and camera poses, but epipolar distance is used here.
|
| 126 |
+
|
| 127 |
+
# matching info
|
| 128 |
+
if alpha == "dynamic":
|
| 129 |
+
alpha = dynamic_alpha(len(correct_mask))
|
| 130 |
+
color = error_colormap(epi_errs, conf_thr, alpha=alpha)
|
| 131 |
+
|
| 132 |
+
text = [
|
| 133 |
+
f"#Matches {len(kpts0)}",
|
| 134 |
+
f"Precision({conf_thr:.2e}) ({100 * precision:.1f}%): {n_correct}/{len(kpts0)}",
|
| 135 |
+
f"Recall({conf_thr:.2e}) ({100 * recall:.1f}%): {n_correct}/{n_gt_matches}",
|
| 136 |
+
]
|
| 137 |
+
|
| 138 |
+
# make the figure
|
| 139 |
+
figure = make_matching_figure(img0, img1, kpts0, kpts1, color, text=text)
|
| 140 |
+
return figure
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
def _make_confidence_figure(data, b_id):
|
| 144 |
+
# TODO: Implement confidence figure
|
| 145 |
+
raise NotImplementedError()
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
def make_matching_figures(data, config, mode="evaluation"):
|
| 149 |
+
"""Make matching figures for a batch.
|
| 150 |
+
|
| 151 |
+
Args:
|
| 152 |
+
data (Dict): a batch updated by PL_LoFTR.
|
| 153 |
+
config (Dict): matcher config
|
| 154 |
+
Returns:
|
| 155 |
+
figures (Dict[str, List[plt.figure]]
|
| 156 |
+
"""
|
| 157 |
+
assert mode in ["evaluation", "confidence"] # 'confidence'
|
| 158 |
+
figures = {mode: []}
|
| 159 |
+
for b_id in range(data["image0"].size(0)):
|
| 160 |
+
if mode == "evaluation":
|
| 161 |
+
fig = _make_evaluation_figure(
|
| 162 |
+
data, b_id, alpha=config.TRAINER.PLOT_MATCHES_ALPHA
|
| 163 |
+
)
|
| 164 |
+
elif mode == "confidence":
|
| 165 |
+
fig = _make_confidence_figure(data, b_id)
|
| 166 |
+
else:
|
| 167 |
+
raise ValueError(f"Unknown plot mode: {mode}")
|
| 168 |
+
figures[mode].append(fig)
|
| 169 |
+
return figures
|
| 170 |
+
|
| 171 |
+
|
| 172 |
+
def dynamic_alpha(
|
| 173 |
+
n_matches, milestones=[0, 300, 1000, 2000], alphas=[1.0, 0.8, 0.4, 0.2]
|
| 174 |
+
):
|
| 175 |
+
if n_matches == 0:
|
| 176 |
+
return 1.0
|
| 177 |
+
ranges = list(zip(alphas, alphas[1:] + [None]))
|
| 178 |
+
loc = bisect.bisect_right(milestones, n_matches) - 1
|
| 179 |
+
_range = ranges[loc]
|
| 180 |
+
if _range[1] is None:
|
| 181 |
+
return _range[0]
|
| 182 |
+
return _range[1] + (milestones[loc + 1] - n_matches) / (
|
| 183 |
+
milestones[loc + 1] - milestones[loc]
|
| 184 |
+
) * (_range[0] - _range[1])
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def error_colormap(err, thr, alpha=1.0):
|
| 188 |
+
assert alpha <= 1.0 and alpha > 0, f"Invaid alpha value: {alpha}"
|
| 189 |
+
x = 1 - np.clip(err / (thr * 2), 0, 1)
|
| 190 |
+
return np.clip(
|
| 191 |
+
np.stack([2 - x * 2, x * 2, np.zeros_like(x), np.ones_like(x) * alpha], -1),
|
| 192 |
+
0,
|
| 193 |
+
1,
|
| 194 |
+
)
|
| 195 |
+
|
| 196 |
+
|
| 197 |
+
np.random.seed(1995)
|
| 198 |
+
color_map = np.arange(100)
|
| 199 |
+
np.random.shuffle(color_map)
|
| 200 |
+
|
| 201 |
+
|
| 202 |
+
def draw_topics(
|
| 203 |
+
data, img0, img1, saved_folder="viz_topics", show_n_topics=8, saved_name=None
|
| 204 |
+
):
|
| 205 |
+
|
| 206 |
+
topic0, topic1 = data["topic_matrix"]["img0"], data["topic_matrix"]["img1"]
|
| 207 |
+
hw0_c, hw1_c = data["hw0_c"], data["hw1_c"]
|
| 208 |
+
hw0_i, hw1_i = data["hw0_i"], data["hw1_i"]
|
| 209 |
+
# print(hw0_i, hw1_i)
|
| 210 |
+
scale0, scale1 = hw0_i[0] // hw0_c[0], hw1_i[0] // hw1_c[0]
|
| 211 |
+
if "scale0" in data:
|
| 212 |
+
scale0 *= data["scale0"][0]
|
| 213 |
+
else:
|
| 214 |
+
scale0 = (scale0, scale0)
|
| 215 |
+
if "scale1" in data:
|
| 216 |
+
scale1 *= data["scale1"][0]
|
| 217 |
+
else:
|
| 218 |
+
scale1 = (scale1, scale1)
|
| 219 |
+
|
| 220 |
+
n_topics = topic0.shape[-1]
|
| 221 |
+
# mask0_nonzero = topic0[0].sum(dim=-1, keepdim=True) > 0
|
| 222 |
+
# mask1_nonzero = topic1[0].sum(dim=-1, keepdim=True) > 0
|
| 223 |
+
theta0 = topic0[0].sum(dim=0)
|
| 224 |
+
theta0 /= theta0.sum().float()
|
| 225 |
+
theta1 = topic1[0].sum(dim=0)
|
| 226 |
+
theta1 /= theta1.sum().float()
|
| 227 |
+
# top_topic0 = torch.argsort(theta0, descending=True)[:show_n_topics]
|
| 228 |
+
# top_topic1 = torch.argsort(theta1, descending=True)[:show_n_topics]
|
| 229 |
+
top_topics = torch.argsort(theta0 * theta1, descending=True)[:show_n_topics]
|
| 230 |
+
# print(sum_topic0, sum_topic1)
|
| 231 |
+
|
| 232 |
+
topic0 = topic0[0].argmax(
|
| 233 |
+
dim=-1, keepdim=True
|
| 234 |
+
) # .float() / (n_topics - 1) #* 255 + 1 #
|
| 235 |
+
# topic0[~mask0_nonzero] = -1
|
| 236 |
+
topic1 = topic1[0].argmax(
|
| 237 |
+
dim=-1, keepdim=True
|
| 238 |
+
) # .float() / (n_topics - 1) #* 255 + 1
|
| 239 |
+
# topic1[~mask1_nonzero] = -1
|
| 240 |
+
label_img0, label_img1 = torch.zeros_like(topic0) - 1, torch.zeros_like(topic1) - 1
|
| 241 |
+
for i, k in enumerate(top_topics):
|
| 242 |
+
label_img0[topic0 == k] = color_map[k]
|
| 243 |
+
label_img1[topic1 == k] = color_map[k]
|
| 244 |
+
|
| 245 |
+
# print(hw0_c, scale0)
|
| 246 |
+
# print(hw1_c, scale1)
|
| 247 |
+
# map_topic0 = F.fold(label_img0.unsqueeze(0), hw0_i, kernel_size=scale0, stride=scale0)
|
| 248 |
+
map_topic0 = (
|
| 249 |
+
label_img0.float().view(hw0_c).cpu().numpy()
|
| 250 |
+
) # map_topic0.squeeze(0).squeeze(0).cpu().numpy()
|
| 251 |
+
map_topic0 = cv2.resize(
|
| 252 |
+
map_topic0, (int(hw0_c[1] * scale0[0]), int(hw0_c[0] * scale0[1]))
|
| 253 |
+
)
|
| 254 |
+
# map_topic1 = F.fold(label_img1.unsqueeze(0), hw1_i, kernel_size=scale1, stride=scale1)
|
| 255 |
+
map_topic1 = (
|
| 256 |
+
label_img1.float().view(hw1_c).cpu().numpy()
|
| 257 |
+
) # map_topic1.squeeze(0).squeeze(0).cpu().numpy()
|
| 258 |
+
map_topic1 = cv2.resize(
|
| 259 |
+
map_topic1, (int(hw1_c[1] * scale1[0]), int(hw1_c[0] * scale1[1]))
|
| 260 |
+
)
|
| 261 |
+
|
| 262 |
+
# show image0
|
| 263 |
+
if saved_name is None:
|
| 264 |
+
return map_topic0, map_topic1
|
| 265 |
+
|
| 266 |
+
if not os.path.exists(saved_folder):
|
| 267 |
+
os.makedirs(saved_folder)
|
| 268 |
+
path_saved_img0 = os.path.join(saved_folder, "{}_0.png".format(saved_name))
|
| 269 |
+
plt.imshow(img0)
|
| 270 |
+
masked_map_topic0 = np.ma.masked_where(map_topic0 < 0, map_topic0)
|
| 271 |
+
plt.imshow(
|
| 272 |
+
masked_map_topic0,
|
| 273 |
+
cmap=plt.cm.jet,
|
| 274 |
+
vmin=0,
|
| 275 |
+
vmax=n_topics - 1,
|
| 276 |
+
alpha=0.3,
|
| 277 |
+
interpolation="bilinear",
|
| 278 |
+
)
|
| 279 |
+
# plt.show()
|
| 280 |
+
plt.axis("off")
|
| 281 |
+
plt.savefig(path_saved_img0, bbox_inches="tight", pad_inches=0, dpi=250)
|
| 282 |
+
plt.close()
|
| 283 |
+
|
| 284 |
+
path_saved_img1 = os.path.join(saved_folder, "{}_1.png".format(saved_name))
|
| 285 |
+
plt.imshow(img1)
|
| 286 |
+
masked_map_topic1 = np.ma.masked_where(map_topic1 < 0, map_topic1)
|
| 287 |
+
plt.imshow(
|
| 288 |
+
masked_map_topic1,
|
| 289 |
+
cmap=plt.cm.jet,
|
| 290 |
+
vmin=0,
|
| 291 |
+
vmax=n_topics - 1,
|
| 292 |
+
alpha=0.3,
|
| 293 |
+
interpolation="bilinear",
|
| 294 |
+
)
|
| 295 |
+
plt.axis("off")
|
| 296 |
+
plt.savefig(path_saved_img1, bbox_inches="tight", pad_inches=0, dpi=250)
|
| 297 |
+
plt.close()
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
def draw_topicfm_demo(
|
| 301 |
+
data,
|
| 302 |
+
img0,
|
| 303 |
+
img1,
|
| 304 |
+
mkpts0,
|
| 305 |
+
mkpts1,
|
| 306 |
+
mcolor,
|
| 307 |
+
text,
|
| 308 |
+
show_n_topics=8,
|
| 309 |
+
topic_alpha=0.3,
|
| 310 |
+
margin=5,
|
| 311 |
+
path=None,
|
| 312 |
+
opencv_display=False,
|
| 313 |
+
opencv_title="",
|
| 314 |
+
):
|
| 315 |
+
topic_map0, topic_map1 = draw_topics(data, img0, img1, show_n_topics=show_n_topics)
|
| 316 |
+
|
| 317 |
+
mask_tm0, mask_tm1 = np.expand_dims(topic_map0 >= 0, axis=-1), np.expand_dims(
|
| 318 |
+
topic_map1 >= 0, axis=-1
|
| 319 |
+
)
|
| 320 |
+
|
| 321 |
+
topic_cm0, topic_cm1 = cm.jet(topic_map0 / 99.0), cm.jet(topic_map1 / 99.0)
|
| 322 |
+
topic_cm0 = cv2.cvtColor(topic_cm0[..., :3].astype(np.float32), cv2.COLOR_RGB2BGR)
|
| 323 |
+
topic_cm1 = cv2.cvtColor(topic_cm1[..., :3].astype(np.float32), cv2.COLOR_RGB2BGR)
|
| 324 |
+
overlay0 = (mask_tm0 * topic_cm0 + (1 - mask_tm0) * img0).astype(np.float32)
|
| 325 |
+
overlay1 = (mask_tm1 * topic_cm1 + (1 - mask_tm1) * img1).astype(np.float32)
|
| 326 |
+
|
| 327 |
+
cv2.addWeighted(overlay0, topic_alpha, img0, 1 - topic_alpha, 0, overlay0)
|
| 328 |
+
cv2.addWeighted(overlay1, topic_alpha, img1, 1 - topic_alpha, 0, overlay1)
|
| 329 |
+
|
| 330 |
+
overlay0, overlay1 = (overlay0 * 255).astype(np.uint8), (overlay1 * 255).astype(
|
| 331 |
+
np.uint8
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
h0, w0 = img0.shape[:2]
|
| 335 |
+
h1, w1 = img1.shape[:2]
|
| 336 |
+
h, w = h0 * 2 + margin * 2, w0 * 2 + margin
|
| 337 |
+
out_fig = 255 * np.ones((h, w, 3), dtype=np.uint8)
|
| 338 |
+
out_fig[:h0, :w0] = overlay0
|
| 339 |
+
if h0 >= h1:
|
| 340 |
+
start = (h0 - h1) // 2
|
| 341 |
+
out_fig[start : (start + h1), (w0 + margin) : (w0 + margin + w1)] = overlay1
|
| 342 |
+
else:
|
| 343 |
+
start = (h1 - h0) // 2
|
| 344 |
+
out_fig[:h0, (w0 + margin) : (w0 + margin + w1)] = overlay1[
|
| 345 |
+
start : (start + h0)
|
| 346 |
+
]
|
| 347 |
+
|
| 348 |
+
step_h = h0 + margin * 2
|
| 349 |
+
out_fig[step_h : step_h + h0, :w0] = (img0 * 255).astype(np.uint8)
|
| 350 |
+
if h0 >= h1:
|
| 351 |
+
start = step_h + (h0 - h1) // 2
|
| 352 |
+
out_fig[start : start + h1, (w0 + margin) : (w0 + margin + w1)] = (
|
| 353 |
+
img1 * 255
|
| 354 |
+
).astype(np.uint8)
|
| 355 |
+
else:
|
| 356 |
+
start = (h1 - h0) // 2
|
| 357 |
+
out_fig[step_h : step_h + h0, (w0 + margin) : (w0 + margin + w1)] = (
|
| 358 |
+
img1[start : start + h0] * 255
|
| 359 |
+
).astype(np.uint8)
|
| 360 |
+
|
| 361 |
+
# draw matching lines, this is inspried from https://raw.githubusercontent.com/magicleap/SuperGluePretrainedNetwork/master/models/utils.py
|
| 362 |
+
mkpts0, mkpts1 = np.round(mkpts0).astype(int), np.round(mkpts1).astype(int)
|
| 363 |
+
mcolor = (np.array(mcolor[:, [2, 1, 0]]) * 255).astype(int)
|
| 364 |
+
|
| 365 |
+
for (x0, y0), (x1, y1), c in zip(mkpts0, mkpts1, mcolor):
|
| 366 |
+
c = c.tolist()
|
| 367 |
+
cv2.line(
|
| 368 |
+
out_fig,
|
| 369 |
+
(x0, y0 + step_h),
|
| 370 |
+
(x1 + margin + w0, y1 + step_h + (h0 - h1) // 2),
|
| 371 |
+
color=c,
|
| 372 |
+
thickness=1,
|
| 373 |
+
lineType=cv2.LINE_AA,
|
| 374 |
+
)
|
| 375 |
+
# display line end-points as circles
|
| 376 |
+
cv2.circle(out_fig, (x0, y0 + step_h), 2, c, -1, lineType=cv2.LINE_AA)
|
| 377 |
+
cv2.circle(
|
| 378 |
+
out_fig,
|
| 379 |
+
(x1 + margin + w0, y1 + step_h + (h0 - h1) // 2),
|
| 380 |
+
2,
|
| 381 |
+
c,
|
| 382 |
+
-1,
|
| 383 |
+
lineType=cv2.LINE_AA,
|
| 384 |
+
)
|
| 385 |
+
|
| 386 |
+
# Scale factor for consistent visualization across scales.
|
| 387 |
+
sc = min(h / 960.0, 2.0)
|
| 388 |
+
|
| 389 |
+
# Big text.
|
| 390 |
+
Ht = int(30 * sc) # text height
|
| 391 |
+
txt_color_fg = (255, 255, 255)
|
| 392 |
+
txt_color_bg = (0, 0, 0)
|
| 393 |
+
for i, t in enumerate(text):
|
| 394 |
+
cv2.putText(
|
| 395 |
+
out_fig,
|
| 396 |
+
t,
|
| 397 |
+
(int(8 * sc), Ht + step_h * i),
|
| 398 |
+
cv2.FONT_HERSHEY_DUPLEX,
|
| 399 |
+
1.0 * sc,
|
| 400 |
+
txt_color_bg,
|
| 401 |
+
2,
|
| 402 |
+
cv2.LINE_AA,
|
| 403 |
+
)
|
| 404 |
+
cv2.putText(
|
| 405 |
+
out_fig,
|
| 406 |
+
t,
|
| 407 |
+
(int(8 * sc), Ht + step_h * i),
|
| 408 |
+
cv2.FONT_HERSHEY_DUPLEX,
|
| 409 |
+
1.0 * sc,
|
| 410 |
+
txt_color_fg,
|
| 411 |
+
1,
|
| 412 |
+
cv2.LINE_AA,
|
| 413 |
+
)
|
| 414 |
+
|
| 415 |
+
if path is not None:
|
| 416 |
+
cv2.imwrite(str(path), out_fig)
|
| 417 |
+
|
| 418 |
+
if opencv_display:
|
| 419 |
+
cv2.imshow(opencv_title, out_fig)
|
| 420 |
+
cv2.waitKey(1)
|
| 421 |
+
|
| 422 |
+
return out_fig
|
| 423 |
+
|
| 424 |
+
|
| 425 |
+
def fig2im(fig):
|
| 426 |
+
fig.canvas.draw()
|
| 427 |
+
w, h = fig.canvas.get_width_height()
|
| 428 |
+
buf_ndarray = np.frombuffer(fig.canvas.tostring_rgb(), dtype="u1")
|
| 429 |
+
im = buf_ndarray.reshape(h, w, 3)
|
| 430 |
+
return im
|
| 431 |
+
|
| 432 |
+
|
| 433 |
+
def draw_matches(
|
| 434 |
+
mkpts0, mkpts1, img0, img1, conf, titles=None, dpi=150, path=None, pad=0.5
|
| 435 |
+
):
|
| 436 |
+
thr = 5e-4
|
| 437 |
+
thr = 0.5
|
| 438 |
+
color = error_colormap(conf, thr, alpha=0.1)
|
| 439 |
+
text = [
|
| 440 |
+
f"image name",
|
| 441 |
+
f"#Matches: {len(mkpts0)}",
|
| 442 |
+
]
|
| 443 |
+
if path:
|
| 444 |
+
fig2im(
|
| 445 |
+
make_matching_figure(
|
| 446 |
+
img0,
|
| 447 |
+
img1,
|
| 448 |
+
mkpts0,
|
| 449 |
+
mkpts1,
|
| 450 |
+
color,
|
| 451 |
+
titles=titles,
|
| 452 |
+
text=text,
|
| 453 |
+
path=path,
|
| 454 |
+
dpi=dpi,
|
| 455 |
+
pad=pad,
|
| 456 |
+
)
|
| 457 |
+
)
|
| 458 |
+
else:
|
| 459 |
+
return fig2im(
|
| 460 |
+
make_matching_figure(
|
| 461 |
+
img0,
|
| 462 |
+
img1,
|
| 463 |
+
mkpts0,
|
| 464 |
+
mkpts1,
|
| 465 |
+
color,
|
| 466 |
+
titles=titles,
|
| 467 |
+
text=text,
|
| 468 |
+
pad=pad,
|
| 469 |
+
dpi=dpi,
|
| 470 |
+
)
|
| 471 |
+
)
|
| 472 |
+
|
| 473 |
+
|
| 474 |
+
def draw_image_pairs(img0, img1, text=[], dpi=75, path=None, pad=0.5):
|
| 475 |
+
# draw image pair
|
| 476 |
+
fig, axes = plt.subplots(1, 2, figsize=(10, 6), dpi=dpi)
|
| 477 |
+
axes[0].imshow(img0) # , cmap='gray')
|
| 478 |
+
axes[1].imshow(img1) # , cmap='gray')
|
| 479 |
+
for i in range(2): # clear all frames
|
| 480 |
+
axes[i].get_yaxis().set_ticks([])
|
| 481 |
+
axes[i].get_xaxis().set_ticks([])
|
| 482 |
+
for spine in axes[i].spines.values():
|
| 483 |
+
spine.set_visible(False)
|
| 484 |
+
plt.tight_layout(pad=pad)
|
| 485 |
+
|
| 486 |
+
# put txts
|
| 487 |
+
txt_color = "k" if img0[:100, :200].mean() > 200 else "w"
|
| 488 |
+
fig.text(
|
| 489 |
+
0.01,
|
| 490 |
+
0.99,
|
| 491 |
+
"\n".join(text),
|
| 492 |
+
transform=fig.axes[0].transAxes,
|
| 493 |
+
fontsize=15,
|
| 494 |
+
va="top",
|
| 495 |
+
ha="left",
|
| 496 |
+
color=txt_color,
|
| 497 |
+
)
|
| 498 |
+
|
| 499 |
+
# save or return figure
|
| 500 |
+
if path:
|
| 501 |
+
plt.savefig(str(path), bbox_inches="tight", pad_inches=0)
|
| 502 |
+
plt.close()
|
| 503 |
+
else:
|
| 504 |
+
return fig2im(fig)
|
extra_utils/utils.py
ADDED
|
@@ -0,0 +1,182 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import numpy as np
|
| 3 |
+
import cv2
|
| 4 |
+
from hloc import matchers, extractors
|
| 5 |
+
from hloc.utils.base_model import dynamic_load
|
| 6 |
+
from hloc import match_dense, match_features, extract_features
|
| 7 |
+
from .plotting import draw_matches, fig2im
|
| 8 |
+
from .visualize_util import plot_images, plot_color_line_matches
|
| 9 |
+
|
| 10 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def get_model(match_conf):
|
| 14 |
+
Model = dynamic_load(matchers, match_conf["model"]["name"])
|
| 15 |
+
model = Model(match_conf["model"]).eval().to(device)
|
| 16 |
+
return model
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
def get_feature_model(conf):
|
| 20 |
+
Model = dynamic_load(extractors, conf["model"]["name"])
|
| 21 |
+
model = Model(conf["model"]).eval().to(device)
|
| 22 |
+
return model
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def display_matches(pred: dict):
|
| 26 |
+
img0 = pred["image0_orig"]
|
| 27 |
+
img1 = pred["image1_orig"]
|
| 28 |
+
|
| 29 |
+
num_inliers = 0
|
| 30 |
+
if "keypoints0_orig" in pred.keys() and "keypoints1_orig" in pred.keys():
|
| 31 |
+
mkpts0 = pred["keypoints0_orig"]
|
| 32 |
+
mkpts1 = pred["keypoints1_orig"]
|
| 33 |
+
num_inliers = len(mkpts0)
|
| 34 |
+
if "mconf" in pred.keys():
|
| 35 |
+
mconf = pred["mconf"]
|
| 36 |
+
else:
|
| 37 |
+
mconf = np.ones(len(mkpts0))
|
| 38 |
+
fig_mkpts = draw_matches(
|
| 39 |
+
mkpts0,
|
| 40 |
+
mkpts1,
|
| 41 |
+
img0,
|
| 42 |
+
img1,
|
| 43 |
+
mconf,
|
| 44 |
+
dpi=300,
|
| 45 |
+
titles=["Image 0 - matched keypoints", "Image 1 - matched keypoints"],
|
| 46 |
+
)
|
| 47 |
+
fig = fig_mkpts
|
| 48 |
+
if "line0_orig" in pred.keys() and "line1_orig" in pred.keys():
|
| 49 |
+
# lines
|
| 50 |
+
mtlines0 = pred["line0_orig"]
|
| 51 |
+
mtlines1 = pred["line1_orig"]
|
| 52 |
+
num_inliers = len(mtlines0)
|
| 53 |
+
fig_lines = plot_images(
|
| 54 |
+
[img0.squeeze(), img1.squeeze()],
|
| 55 |
+
["Image 0 - matched lines", "Image 1 - matched lines"],
|
| 56 |
+
dpi=300,
|
| 57 |
+
)
|
| 58 |
+
fig_lines = plot_color_line_matches([mtlines0, mtlines1], lw=2)
|
| 59 |
+
fig_lines = fig2im(fig_lines)
|
| 60 |
+
|
| 61 |
+
# keypoints
|
| 62 |
+
mkpts0 = pred["line_keypoints0_orig"]
|
| 63 |
+
mkpts1 = pred["line_keypoints1_orig"]
|
| 64 |
+
|
| 65 |
+
if mkpts0 is not None and mkpts1 is not None:
|
| 66 |
+
num_inliers = len(mkpts0)
|
| 67 |
+
if "mconf" in pred.keys():
|
| 68 |
+
mconf = pred["mconf"]
|
| 69 |
+
else:
|
| 70 |
+
mconf = np.ones(len(mkpts0))
|
| 71 |
+
fig_mkpts = draw_matches(mkpts0, mkpts1, img0, img1, mconf, dpi=300)
|
| 72 |
+
fig_lines = cv2.resize(fig_lines, (fig_mkpts.shape[1], fig_mkpts.shape[0]))
|
| 73 |
+
fig = np.concatenate([fig_mkpts, fig_lines], axis=0)
|
| 74 |
+
else:
|
| 75 |
+
fig = fig_lines
|
| 76 |
+
return fig, num_inliers
|
| 77 |
+
|
| 78 |
+
|
| 79 |
+
# Matchers collections
|
| 80 |
+
matcher_zoo = {
|
| 81 |
+
"gluestick": {"config": match_dense.confs["gluestick"], "dense": True},
|
| 82 |
+
"sold2": {"config": match_dense.confs["sold2"], "dense": True},
|
| 83 |
+
# 'dedode-sparse': {
|
| 84 |
+
# 'config': match_dense.confs['dedode_sparse'],
|
| 85 |
+
# 'dense': True # dense mode, we need 2 images
|
| 86 |
+
# },
|
| 87 |
+
"loftr": {"config": match_dense.confs["loftr"], "dense": True},
|
| 88 |
+
"topicfm": {"config": match_dense.confs["topicfm"], "dense": True},
|
| 89 |
+
"aspanformer": {"config": match_dense.confs["aspanformer"], "dense": True},
|
| 90 |
+
"dedode": {
|
| 91 |
+
"config": match_features.confs["Dual-Softmax"],
|
| 92 |
+
"config_feature": extract_features.confs["dedode"],
|
| 93 |
+
"dense": False,
|
| 94 |
+
},
|
| 95 |
+
"superpoint+superglue": {
|
| 96 |
+
"config": match_features.confs["superglue"],
|
| 97 |
+
"config_feature": extract_features.confs["superpoint_max"],
|
| 98 |
+
"dense": False,
|
| 99 |
+
},
|
| 100 |
+
"superpoint+lightglue": {
|
| 101 |
+
"config": match_features.confs["superpoint-lightglue"],
|
| 102 |
+
"config_feature": extract_features.confs["superpoint_max"],
|
| 103 |
+
"dense": False,
|
| 104 |
+
},
|
| 105 |
+
"disk": {
|
| 106 |
+
"config": match_features.confs["NN-mutual"],
|
| 107 |
+
"config_feature": extract_features.confs["disk"],
|
| 108 |
+
"dense": False,
|
| 109 |
+
},
|
| 110 |
+
"disk+dualsoftmax": {
|
| 111 |
+
"config": match_features.confs["Dual-Softmax"],
|
| 112 |
+
"config_feature": extract_features.confs["disk"],
|
| 113 |
+
"dense": False,
|
| 114 |
+
},
|
| 115 |
+
"superpoint+dualsoftmax": {
|
| 116 |
+
"config": match_features.confs["Dual-Softmax"],
|
| 117 |
+
"config_feature": extract_features.confs["superpoint_max"],
|
| 118 |
+
"dense": False,
|
| 119 |
+
},
|
| 120 |
+
"disk+lightglue": {
|
| 121 |
+
"config": match_features.confs["disk-lightglue"],
|
| 122 |
+
"config_feature": extract_features.confs["disk"],
|
| 123 |
+
"dense": False,
|
| 124 |
+
},
|
| 125 |
+
"superpoint+mnn": {
|
| 126 |
+
"config": match_features.confs["NN-mutual"],
|
| 127 |
+
"config_feature": extract_features.confs["superpoint_max"],
|
| 128 |
+
"dense": False,
|
| 129 |
+
},
|
| 130 |
+
"sift+sgmnet": {
|
| 131 |
+
"config": match_features.confs["sgmnet"],
|
| 132 |
+
"config_feature": extract_features.confs["sift"],
|
| 133 |
+
"dense": False,
|
| 134 |
+
},
|
| 135 |
+
"sosnet": {
|
| 136 |
+
"config": match_features.confs["NN-mutual"],
|
| 137 |
+
"config_feature": extract_features.confs["sosnet"],
|
| 138 |
+
"dense": False,
|
| 139 |
+
},
|
| 140 |
+
"hardnet": {
|
| 141 |
+
"config": match_features.confs["NN-mutual"],
|
| 142 |
+
"config_feature": extract_features.confs["hardnet"],
|
| 143 |
+
"dense": False,
|
| 144 |
+
},
|
| 145 |
+
"d2net": {
|
| 146 |
+
"config": match_features.confs["NN-mutual"],
|
| 147 |
+
"config_feature": extract_features.confs["d2net-ss"],
|
| 148 |
+
"dense": False,
|
| 149 |
+
},
|
| 150 |
+
"d2net-ms": {
|
| 151 |
+
"config": match_features.confs["NN-mutual"],
|
| 152 |
+
"config_feature": extract_features.confs["d2net-ms"],
|
| 153 |
+
"dense": False,
|
| 154 |
+
},
|
| 155 |
+
"alike": {
|
| 156 |
+
"config": match_features.confs["NN-mutual"],
|
| 157 |
+
"config_feature": extract_features.confs["alike"],
|
| 158 |
+
"dense": False,
|
| 159 |
+
},
|
| 160 |
+
"lanet": {
|
| 161 |
+
"config": match_features.confs["NN-mutual"],
|
| 162 |
+
"config_feature": extract_features.confs["lanet"],
|
| 163 |
+
"dense": False,
|
| 164 |
+
},
|
| 165 |
+
"r2d2": {
|
| 166 |
+
"config": match_features.confs["NN-mutual"],
|
| 167 |
+
"config_feature": extract_features.confs["r2d2"],
|
| 168 |
+
"dense": False,
|
| 169 |
+
},
|
| 170 |
+
"darkfeat": {
|
| 171 |
+
"config": match_features.confs["NN-mutual"],
|
| 172 |
+
"config_feature": extract_features.confs["darkfeat"],
|
| 173 |
+
"dense": False,
|
| 174 |
+
},
|
| 175 |
+
"sift": {
|
| 176 |
+
"config": match_features.confs["NN-mutual"],
|
| 177 |
+
"config_feature": extract_features.confs["sift"],
|
| 178 |
+
"dense": False,
|
| 179 |
+
},
|
| 180 |
+
"roma": {"config": match_dense.confs["roma"], "dense": True},
|
| 181 |
+
"DKMv3": {"config": match_dense.confs["dkm"], "dense": True},
|
| 182 |
+
}
|
extra_utils/visualize_util.py
ADDED
|
@@ -0,0 +1,642 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
""" Organize some frequently used visualization functions. """
|
| 2 |
+
import cv2
|
| 3 |
+
import numpy as np
|
| 4 |
+
import matplotlib
|
| 5 |
+
import matplotlib.pyplot as plt
|
| 6 |
+
import copy
|
| 7 |
+
import seaborn as sns
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
# Plot junctions onto the image (return a separate copy)
|
| 11 |
+
def plot_junctions(input_image, junctions, junc_size=3, color=None):
|
| 12 |
+
"""
|
| 13 |
+
input_image: can be 0~1 float or 0~255 uint8.
|
| 14 |
+
junctions: Nx2 or 2xN np array.
|
| 15 |
+
junc_size: the size of the plotted circles.
|
| 16 |
+
"""
|
| 17 |
+
# Create image copy
|
| 18 |
+
image = copy.copy(input_image)
|
| 19 |
+
# Make sure the image is converted to 255 uint8
|
| 20 |
+
if image.dtype == np.uint8:
|
| 21 |
+
pass
|
| 22 |
+
# A float type image ranging from 0~1
|
| 23 |
+
elif image.dtype in [np.float32, np.float64, np.float] and image.max() <= 2.0:
|
| 24 |
+
image = (image * 255.0).astype(np.uint8)
|
| 25 |
+
# A float type image ranging from 0.~255.
|
| 26 |
+
elif image.dtype in [np.float32, np.float64, np.float] and image.mean() > 10.0:
|
| 27 |
+
image = image.astype(np.uint8)
|
| 28 |
+
else:
|
| 29 |
+
raise ValueError(
|
| 30 |
+
"[Error] Unknown image data type. Expect 0~1 float or 0~255 uint8."
|
| 31 |
+
)
|
| 32 |
+
|
| 33 |
+
# Check whether the image is single channel
|
| 34 |
+
if len(image.shape) == 2 or ((len(image.shape) == 3) and (image.shape[-1] == 1)):
|
| 35 |
+
# Squeeze to H*W first
|
| 36 |
+
image = image.squeeze()
|
| 37 |
+
|
| 38 |
+
# Stack to channle 3
|
| 39 |
+
image = np.concatenate([image[..., None] for _ in range(3)], axis=-1)
|
| 40 |
+
|
| 41 |
+
# Junction dimensions should be N*2
|
| 42 |
+
if not len(junctions.shape) == 2:
|
| 43 |
+
raise ValueError("[Error] junctions should be 2-dim array.")
|
| 44 |
+
|
| 45 |
+
# Always convert to N*2
|
| 46 |
+
if junctions.shape[-1] != 2:
|
| 47 |
+
if junctions.shape[0] == 2:
|
| 48 |
+
junctions = junctions.T
|
| 49 |
+
else:
|
| 50 |
+
raise ValueError("[Error] At least one of the two dims should be 2.")
|
| 51 |
+
|
| 52 |
+
# Round and convert junctions to int (and check the boundary)
|
| 53 |
+
H, W = image.shape[:2]
|
| 54 |
+
junctions = (np.round(junctions)).astype(np.int)
|
| 55 |
+
junctions[junctions < 0] = 0
|
| 56 |
+
junctions[junctions[:, 0] >= H, 0] = H - 1 # (first dim) max bounded by H-1
|
| 57 |
+
junctions[junctions[:, 1] >= W, 1] = W - 1 # (second dim) max bounded by W-1
|
| 58 |
+
|
| 59 |
+
# Iterate through all the junctions
|
| 60 |
+
num_junc = junctions.shape[0]
|
| 61 |
+
if color is None:
|
| 62 |
+
color = (0, 255.0, 0)
|
| 63 |
+
for idx in range(num_junc):
|
| 64 |
+
# Fetch one junction
|
| 65 |
+
junc = junctions[idx, :]
|
| 66 |
+
cv2.circle(
|
| 67 |
+
image, tuple(np.flip(junc)), radius=junc_size, color=color, thickness=3
|
| 68 |
+
)
|
| 69 |
+
|
| 70 |
+
return image
|
| 71 |
+
|
| 72 |
+
|
| 73 |
+
# Plot line segements given junctions and line adjecent map
|
| 74 |
+
def plot_line_segments(
|
| 75 |
+
input_image,
|
| 76 |
+
junctions,
|
| 77 |
+
line_map,
|
| 78 |
+
junc_size=3,
|
| 79 |
+
color=(0, 255.0, 0),
|
| 80 |
+
line_width=1,
|
| 81 |
+
plot_survived_junc=True,
|
| 82 |
+
):
|
| 83 |
+
"""
|
| 84 |
+
input_image: can be 0~1 float or 0~255 uint8.
|
| 85 |
+
junctions: Nx2 or 2xN np array.
|
| 86 |
+
line_map: NxN np array
|
| 87 |
+
junc_size: the size of the plotted circles.
|
| 88 |
+
color: color of the line segments (can be string "random")
|
| 89 |
+
line_width: width of the drawn segments.
|
| 90 |
+
plot_survived_junc: whether we only plot the survived junctions.
|
| 91 |
+
"""
|
| 92 |
+
# Create image copy
|
| 93 |
+
image = copy.copy(input_image)
|
| 94 |
+
# Make sure the image is converted to 255 uint8
|
| 95 |
+
if image.dtype == np.uint8:
|
| 96 |
+
pass
|
| 97 |
+
# A float type image ranging from 0~1
|
| 98 |
+
elif image.dtype in [np.float32, np.float64, np.float] and image.max() <= 2.0:
|
| 99 |
+
image = (image * 255.0).astype(np.uint8)
|
| 100 |
+
# A float type image ranging from 0.~255.
|
| 101 |
+
elif image.dtype in [np.float32, np.float64, np.float] and image.mean() > 10.0:
|
| 102 |
+
image = image.astype(np.uint8)
|
| 103 |
+
else:
|
| 104 |
+
raise ValueError(
|
| 105 |
+
"[Error] Unknown image data type. Expect 0~1 float or 0~255 uint8."
|
| 106 |
+
)
|
| 107 |
+
|
| 108 |
+
# Check whether the image is single channel
|
| 109 |
+
if len(image.shape) == 2 or ((len(image.shape) == 3) and (image.shape[-1] == 1)):
|
| 110 |
+
# Squeeze to H*W first
|
| 111 |
+
image = image.squeeze()
|
| 112 |
+
|
| 113 |
+
# Stack to channle 3
|
| 114 |
+
image = np.concatenate([image[..., None] for _ in range(3)], axis=-1)
|
| 115 |
+
|
| 116 |
+
# Junction dimensions should be 2
|
| 117 |
+
if not len(junctions.shape) == 2:
|
| 118 |
+
raise ValueError("[Error] junctions should be 2-dim array.")
|
| 119 |
+
|
| 120 |
+
# Always convert to N*2
|
| 121 |
+
if junctions.shape[-1] != 2:
|
| 122 |
+
if junctions.shape[0] == 2:
|
| 123 |
+
junctions = junctions.T
|
| 124 |
+
else:
|
| 125 |
+
raise ValueError("[Error] At least one of the two dims should be 2.")
|
| 126 |
+
|
| 127 |
+
# line_map dimension should be 2
|
| 128 |
+
if not len(line_map.shape) == 2:
|
| 129 |
+
raise ValueError("[Error] line_map should be 2-dim array.")
|
| 130 |
+
|
| 131 |
+
# Color should be "random" or a list or tuple with length 3
|
| 132 |
+
if color != "random":
|
| 133 |
+
if not (isinstance(color, tuple) or isinstance(color, list)):
|
| 134 |
+
raise ValueError("[Error] color should have type list or tuple.")
|
| 135 |
+
else:
|
| 136 |
+
if len(color) != 3:
|
| 137 |
+
raise ValueError(
|
| 138 |
+
"[Error] color should be a list or tuple with length 3."
|
| 139 |
+
)
|
| 140 |
+
|
| 141 |
+
# Make a copy of the line_map
|
| 142 |
+
line_map_tmp = copy.copy(line_map)
|
| 143 |
+
|
| 144 |
+
# Parse line_map back to segment pairs
|
| 145 |
+
segments = np.zeros([0, 4])
|
| 146 |
+
for idx in range(junctions.shape[0]):
|
| 147 |
+
# if no connectivity, just skip it
|
| 148 |
+
if line_map_tmp[idx, :].sum() == 0:
|
| 149 |
+
continue
|
| 150 |
+
# record the line segment
|
| 151 |
+
else:
|
| 152 |
+
for idx2 in np.where(line_map_tmp[idx, :] == 1)[0]:
|
| 153 |
+
p1 = np.flip(junctions[idx, :]) # Convert to xy format
|
| 154 |
+
p2 = np.flip(junctions[idx2, :]) # Convert to xy format
|
| 155 |
+
segments = np.concatenate(
|
| 156 |
+
(segments, np.array([p1[0], p1[1], p2[0], p2[1]])[None, ...]),
|
| 157 |
+
axis=0,
|
| 158 |
+
)
|
| 159 |
+
|
| 160 |
+
# Update line_map
|
| 161 |
+
line_map_tmp[idx, idx2] = 0
|
| 162 |
+
line_map_tmp[idx2, idx] = 0
|
| 163 |
+
|
| 164 |
+
# Draw segment pairs
|
| 165 |
+
for idx in range(segments.shape[0]):
|
| 166 |
+
seg = np.round(segments[idx, :]).astype(np.int)
|
| 167 |
+
# Decide the color
|
| 168 |
+
if color != "random":
|
| 169 |
+
color = tuple(color)
|
| 170 |
+
else:
|
| 171 |
+
color = tuple(
|
| 172 |
+
np.random.rand(
|
| 173 |
+
3,
|
| 174 |
+
)
|
| 175 |
+
)
|
| 176 |
+
cv2.line(
|
| 177 |
+
image, tuple(seg[:2]), tuple(seg[2:]), color=color, thickness=line_width
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
# Also draw the junctions
|
| 181 |
+
if not plot_survived_junc:
|
| 182 |
+
num_junc = junctions.shape[0]
|
| 183 |
+
for idx in range(num_junc):
|
| 184 |
+
# Fetch one junction
|
| 185 |
+
junc = junctions[idx, :]
|
| 186 |
+
cv2.circle(
|
| 187 |
+
image,
|
| 188 |
+
tuple(np.flip(junc)),
|
| 189 |
+
radius=junc_size,
|
| 190 |
+
color=(0, 255.0, 0),
|
| 191 |
+
thickness=3,
|
| 192 |
+
)
|
| 193 |
+
# Only plot the junctions which are part of a line segment
|
| 194 |
+
else:
|
| 195 |
+
for idx in range(segments.shape[0]):
|
| 196 |
+
seg = np.round(segments[idx, :]).astype(np.int) # Already in HW format.
|
| 197 |
+
cv2.circle(
|
| 198 |
+
image,
|
| 199 |
+
tuple(seg[:2]),
|
| 200 |
+
radius=junc_size,
|
| 201 |
+
color=(0, 255.0, 0),
|
| 202 |
+
thickness=3,
|
| 203 |
+
)
|
| 204 |
+
cv2.circle(
|
| 205 |
+
image,
|
| 206 |
+
tuple(seg[2:]),
|
| 207 |
+
radius=junc_size,
|
| 208 |
+
color=(0, 255.0, 0),
|
| 209 |
+
thickness=3,
|
| 210 |
+
)
|
| 211 |
+
|
| 212 |
+
return image
|
| 213 |
+
|
| 214 |
+
|
| 215 |
+
# Plot line segments given Nx4 or Nx2x2 line segments
|
| 216 |
+
def plot_line_segments_from_segments(
|
| 217 |
+
input_image, line_segments, junc_size=3, color=(0, 255.0, 0), line_width=1
|
| 218 |
+
):
|
| 219 |
+
# Create image copy
|
| 220 |
+
image = copy.copy(input_image)
|
| 221 |
+
# Make sure the image is converted to 255 uint8
|
| 222 |
+
if image.dtype == np.uint8:
|
| 223 |
+
pass
|
| 224 |
+
# A float type image ranging from 0~1
|
| 225 |
+
elif image.dtype in [np.float32, np.float64, np.float] and image.max() <= 2.0:
|
| 226 |
+
image = (image * 255.0).astype(np.uint8)
|
| 227 |
+
# A float type image ranging from 0.~255.
|
| 228 |
+
elif image.dtype in [np.float32, np.float64, np.float] and image.mean() > 10.0:
|
| 229 |
+
image = image.astype(np.uint8)
|
| 230 |
+
else:
|
| 231 |
+
raise ValueError(
|
| 232 |
+
"[Error] Unknown image data type. Expect 0~1 float or 0~255 uint8."
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
# Check whether the image is single channel
|
| 236 |
+
if len(image.shape) == 2 or ((len(image.shape) == 3) and (image.shape[-1] == 1)):
|
| 237 |
+
# Squeeze to H*W first
|
| 238 |
+
image = image.squeeze()
|
| 239 |
+
|
| 240 |
+
# Stack to channle 3
|
| 241 |
+
image = np.concatenate([image[..., None] for _ in range(3)], axis=-1)
|
| 242 |
+
|
| 243 |
+
# Check the if line_segments are in (1) Nx4, or (2) Nx2x2.
|
| 244 |
+
H, W, _ = image.shape
|
| 245 |
+
# (1) Nx4 format
|
| 246 |
+
if len(line_segments.shape) == 2 and line_segments.shape[-1] == 4:
|
| 247 |
+
# Round to int32
|
| 248 |
+
line_segments = line_segments.astype(np.int32)
|
| 249 |
+
|
| 250 |
+
# Clip H dimension
|
| 251 |
+
line_segments[:, 0] = np.clip(line_segments[:, 0], a_min=0, a_max=H - 1)
|
| 252 |
+
line_segments[:, 2] = np.clip(line_segments[:, 2], a_min=0, a_max=H - 1)
|
| 253 |
+
|
| 254 |
+
# Clip W dimension
|
| 255 |
+
line_segments[:, 1] = np.clip(line_segments[:, 1], a_min=0, a_max=W - 1)
|
| 256 |
+
line_segments[:, 3] = np.clip(line_segments[:, 3], a_min=0, a_max=W - 1)
|
| 257 |
+
|
| 258 |
+
# Convert to Nx2x2 format
|
| 259 |
+
line_segments = np.concatenate(
|
| 260 |
+
[
|
| 261 |
+
np.expand_dims(line_segments[:, :2], axis=1),
|
| 262 |
+
np.expand_dims(line_segments[:, 2:], axis=1),
|
| 263 |
+
],
|
| 264 |
+
axis=1,
|
| 265 |
+
)
|
| 266 |
+
|
| 267 |
+
# (2) Nx2x2 format
|
| 268 |
+
elif len(line_segments.shape) == 3 and line_segments.shape[-1] == 2:
|
| 269 |
+
# Round to int32
|
| 270 |
+
line_segments = line_segments.astype(np.int32)
|
| 271 |
+
|
| 272 |
+
# Clip H dimension
|
| 273 |
+
line_segments[:, :, 0] = np.clip(line_segments[:, :, 0], a_min=0, a_max=H - 1)
|
| 274 |
+
line_segments[:, :, 1] = np.clip(line_segments[:, :, 1], a_min=0, a_max=W - 1)
|
| 275 |
+
|
| 276 |
+
else:
|
| 277 |
+
raise ValueError(
|
| 278 |
+
"[Error] line_segments should be either Nx4 or Nx2x2 in HW format."
|
| 279 |
+
)
|
| 280 |
+
|
| 281 |
+
# Draw segment pairs (all segments should be in HW format)
|
| 282 |
+
image = image.copy()
|
| 283 |
+
for idx in range(line_segments.shape[0]):
|
| 284 |
+
seg = np.round(line_segments[idx, :, :]).astype(np.int32)
|
| 285 |
+
# Decide the color
|
| 286 |
+
if color != "random":
|
| 287 |
+
color = tuple(color)
|
| 288 |
+
else:
|
| 289 |
+
color = tuple(
|
| 290 |
+
np.random.rand(
|
| 291 |
+
3,
|
| 292 |
+
)
|
| 293 |
+
)
|
| 294 |
+
cv2.line(
|
| 295 |
+
image,
|
| 296 |
+
tuple(np.flip(seg[0, :])),
|
| 297 |
+
tuple(np.flip(seg[1, :])),
|
| 298 |
+
color=color,
|
| 299 |
+
thickness=line_width,
|
| 300 |
+
)
|
| 301 |
+
|
| 302 |
+
# Also draw the junctions
|
| 303 |
+
cv2.circle(
|
| 304 |
+
image,
|
| 305 |
+
tuple(np.flip(seg[0, :])),
|
| 306 |
+
radius=junc_size,
|
| 307 |
+
color=(0, 255.0, 0),
|
| 308 |
+
thickness=3,
|
| 309 |
+
)
|
| 310 |
+
cv2.circle(
|
| 311 |
+
image,
|
| 312 |
+
tuple(np.flip(seg[1, :])),
|
| 313 |
+
radius=junc_size,
|
| 314 |
+
color=(0, 255.0, 0),
|
| 315 |
+
thickness=3,
|
| 316 |
+
)
|
| 317 |
+
|
| 318 |
+
return image
|
| 319 |
+
|
| 320 |
+
|
| 321 |
+
# Additional functions to visualize multiple images at the same time,
|
| 322 |
+
# e.g. for line matching
|
| 323 |
+
def plot_images(imgs, titles=None, cmaps="gray", dpi=100, size=5, pad=0.5):
|
| 324 |
+
"""Plot a set of images horizontally.
|
| 325 |
+
Args:
|
| 326 |
+
imgs: a list of NumPy or PyTorch images, RGB (H, W, 3) or mono (H, W).
|
| 327 |
+
titles: a list of strings, as titles for each image.
|
| 328 |
+
cmaps: colormaps for monochrome images.
|
| 329 |
+
"""
|
| 330 |
+
n = len(imgs)
|
| 331 |
+
if not isinstance(cmaps, (list, tuple)):
|
| 332 |
+
cmaps = [cmaps] * n
|
| 333 |
+
# figsize = (size*n, size*3/4) if size is not None else None
|
| 334 |
+
figsize = (size * n, size * 6 / 5) if size is not None else None
|
| 335 |
+
fig, ax = plt.subplots(1, n, figsize=figsize, dpi=dpi)
|
| 336 |
+
|
| 337 |
+
if n == 1:
|
| 338 |
+
ax = [ax]
|
| 339 |
+
for i in range(n):
|
| 340 |
+
ax[i].imshow(imgs[i], cmap=plt.get_cmap(cmaps[i]))
|
| 341 |
+
ax[i].get_yaxis().set_ticks([])
|
| 342 |
+
ax[i].get_xaxis().set_ticks([])
|
| 343 |
+
ax[i].set_axis_off()
|
| 344 |
+
for spine in ax[i].spines.values(): # remove frame
|
| 345 |
+
spine.set_visible(False)
|
| 346 |
+
if titles:
|
| 347 |
+
ax[i].set_title(titles[i])
|
| 348 |
+
fig.tight_layout(pad=pad)
|
| 349 |
+
return fig
|
| 350 |
+
|
| 351 |
+
|
| 352 |
+
def plot_keypoints(kpts, colors="lime", ps=4):
|
| 353 |
+
"""Plot keypoints for existing images.
|
| 354 |
+
Args:
|
| 355 |
+
kpts: list of ndarrays of size (N, 2).
|
| 356 |
+
colors: string, or list of list of tuples (one for each keypoints).
|
| 357 |
+
ps: size of the keypoints as float.
|
| 358 |
+
"""
|
| 359 |
+
if not isinstance(colors, list):
|
| 360 |
+
colors = [colors] * len(kpts)
|
| 361 |
+
axes = plt.gcf().axes
|
| 362 |
+
for a, k, c in zip(axes, kpts, colors):
|
| 363 |
+
a.scatter(k[:, 0], k[:, 1], c=c, s=ps, linewidths=0)
|
| 364 |
+
|
| 365 |
+
|
| 366 |
+
def plot_matches(kpts0, kpts1, color=None, lw=1.5, ps=4, indices=(0, 1), a=1.0):
|
| 367 |
+
"""Plot matches for a pair of existing images.
|
| 368 |
+
Args:
|
| 369 |
+
kpts0, kpts1: corresponding keypoints of size (N, 2).
|
| 370 |
+
color: color of each match, string or RGB tuple. Random if not given.
|
| 371 |
+
lw: width of the lines.
|
| 372 |
+
ps: size of the end points (no endpoint if ps=0)
|
| 373 |
+
indices: indices of the images to draw the matches on.
|
| 374 |
+
a: alpha opacity of the match lines.
|
| 375 |
+
"""
|
| 376 |
+
fig = plt.gcf()
|
| 377 |
+
ax = fig.axes
|
| 378 |
+
assert len(ax) > max(indices)
|
| 379 |
+
ax0, ax1 = ax[indices[0]], ax[indices[1]]
|
| 380 |
+
fig.canvas.draw()
|
| 381 |
+
|
| 382 |
+
assert len(kpts0) == len(kpts1)
|
| 383 |
+
if color is None:
|
| 384 |
+
color = matplotlib.cm.hsv(np.random.rand(len(kpts0))).tolist()
|
| 385 |
+
elif len(color) > 0 and not isinstance(color[0], (tuple, list)):
|
| 386 |
+
color = [color] * len(kpts0)
|
| 387 |
+
|
| 388 |
+
if lw > 0:
|
| 389 |
+
# transform the points into the figure coordinate system
|
| 390 |
+
transFigure = fig.transFigure.inverted()
|
| 391 |
+
fkpts0 = transFigure.transform(ax0.transData.transform(kpts0))
|
| 392 |
+
fkpts1 = transFigure.transform(ax1.transData.transform(kpts1))
|
| 393 |
+
fig.lines += [
|
| 394 |
+
matplotlib.lines.Line2D(
|
| 395 |
+
(fkpts0[i, 0], fkpts1[i, 0]),
|
| 396 |
+
(fkpts0[i, 1], fkpts1[i, 1]),
|
| 397 |
+
zorder=1,
|
| 398 |
+
transform=fig.transFigure,
|
| 399 |
+
c=color[i],
|
| 400 |
+
linewidth=lw,
|
| 401 |
+
alpha=a,
|
| 402 |
+
)
|
| 403 |
+
for i in range(len(kpts0))
|
| 404 |
+
]
|
| 405 |
+
|
| 406 |
+
# freeze the axes to prevent the transform to change
|
| 407 |
+
ax0.autoscale(enable=False)
|
| 408 |
+
ax1.autoscale(enable=False)
|
| 409 |
+
|
| 410 |
+
if ps > 0:
|
| 411 |
+
ax0.scatter(kpts0[:, 0], kpts0[:, 1], c=color, s=ps, zorder=2)
|
| 412 |
+
ax1.scatter(kpts1[:, 0], kpts1[:, 1], c=color, s=ps, zorder=2)
|
| 413 |
+
|
| 414 |
+
|
| 415 |
+
def plot_lines(
|
| 416 |
+
lines, line_colors="orange", point_colors="cyan", ps=4, lw=2, indices=(0, 1)
|
| 417 |
+
):
|
| 418 |
+
"""Plot lines and endpoints for existing images.
|
| 419 |
+
Args:
|
| 420 |
+
lines: list of ndarrays of size (N, 2, 2).
|
| 421 |
+
colors: string, or list of list of tuples (one for each keypoints).
|
| 422 |
+
ps: size of the keypoints as float pixels.
|
| 423 |
+
lw: line width as float pixels.
|
| 424 |
+
indices: indices of the images to draw the matches on.
|
| 425 |
+
"""
|
| 426 |
+
if not isinstance(line_colors, list):
|
| 427 |
+
line_colors = [line_colors] * len(lines)
|
| 428 |
+
if not isinstance(point_colors, list):
|
| 429 |
+
point_colors = [point_colors] * len(lines)
|
| 430 |
+
|
| 431 |
+
fig = plt.gcf()
|
| 432 |
+
ax = fig.axes
|
| 433 |
+
assert len(ax) > max(indices)
|
| 434 |
+
axes = [ax[i] for i in indices]
|
| 435 |
+
fig.canvas.draw()
|
| 436 |
+
|
| 437 |
+
# Plot the lines and junctions
|
| 438 |
+
for a, l, lc, pc in zip(axes, lines, line_colors, point_colors):
|
| 439 |
+
for i in range(len(l)):
|
| 440 |
+
line = matplotlib.lines.Line2D(
|
| 441 |
+
(l[i, 0, 0], l[i, 1, 0]),
|
| 442 |
+
(l[i, 0, 1], l[i, 1, 1]),
|
| 443 |
+
zorder=1,
|
| 444 |
+
c=lc,
|
| 445 |
+
linewidth=lw,
|
| 446 |
+
)
|
| 447 |
+
a.add_line(line)
|
| 448 |
+
pts = l.reshape(-1, 2)
|
| 449 |
+
a.scatter(pts[:, 0], pts[:, 1], c=pc, s=ps, linewidths=0, zorder=2)
|
| 450 |
+
|
| 451 |
+
return fig
|
| 452 |
+
|
| 453 |
+
|
| 454 |
+
def plot_line_matches(kpts0, kpts1, color=None, lw=1.5, indices=(0, 1), a=1.0):
|
| 455 |
+
"""Plot matches for a pair of existing images, parametrized by their middle point.
|
| 456 |
+
Args:
|
| 457 |
+
kpts0, kpts1: corresponding middle points of the lines of size (N, 2).
|
| 458 |
+
color: color of each match, string or RGB tuple. Random if not given.
|
| 459 |
+
lw: width of the lines.
|
| 460 |
+
indices: indices of the images to draw the matches on.
|
| 461 |
+
a: alpha opacity of the match lines.
|
| 462 |
+
"""
|
| 463 |
+
fig = plt.gcf()
|
| 464 |
+
ax = fig.axes
|
| 465 |
+
assert len(ax) > max(indices)
|
| 466 |
+
ax0, ax1 = ax[indices[0]], ax[indices[1]]
|
| 467 |
+
fig.canvas.draw()
|
| 468 |
+
|
| 469 |
+
assert len(kpts0) == len(kpts1)
|
| 470 |
+
if color is None:
|
| 471 |
+
color = matplotlib.cm.hsv(np.random.rand(len(kpts0))).tolist()
|
| 472 |
+
elif len(color) > 0 and not isinstance(color[0], (tuple, list)):
|
| 473 |
+
color = [color] * len(kpts0)
|
| 474 |
+
|
| 475 |
+
if lw > 0:
|
| 476 |
+
# transform the points into the figure coordinate system
|
| 477 |
+
transFigure = fig.transFigure.inverted()
|
| 478 |
+
fkpts0 = transFigure.transform(ax0.transData.transform(kpts0))
|
| 479 |
+
fkpts1 = transFigure.transform(ax1.transData.transform(kpts1))
|
| 480 |
+
fig.lines += [
|
| 481 |
+
matplotlib.lines.Line2D(
|
| 482 |
+
(fkpts0[i, 0], fkpts1[i, 0]),
|
| 483 |
+
(fkpts0[i, 1], fkpts1[i, 1]),
|
| 484 |
+
zorder=1,
|
| 485 |
+
transform=fig.transFigure,
|
| 486 |
+
c=color[i],
|
| 487 |
+
linewidth=lw,
|
| 488 |
+
alpha=a,
|
| 489 |
+
)
|
| 490 |
+
for i in range(len(kpts0))
|
| 491 |
+
]
|
| 492 |
+
|
| 493 |
+
# freeze the axes to prevent the transform to change
|
| 494 |
+
ax0.autoscale(enable=False)
|
| 495 |
+
ax1.autoscale(enable=False)
|
| 496 |
+
|
| 497 |
+
|
| 498 |
+
def plot_color_line_matches(lines, correct_matches=None, lw=2, indices=(0, 1)):
|
| 499 |
+
"""Plot line matches for existing images with multiple colors.
|
| 500 |
+
Args:
|
| 501 |
+
lines: list of ndarrays of size (N, 2, 2).
|
| 502 |
+
correct_matches: bool array of size (N,) indicating correct matches.
|
| 503 |
+
lw: line width as float pixels.
|
| 504 |
+
indices: indices of the images to draw the matches on.
|
| 505 |
+
"""
|
| 506 |
+
n_lines = len(lines[0])
|
| 507 |
+
colors = sns.color_palette("husl", n_colors=n_lines)
|
| 508 |
+
np.random.shuffle(colors)
|
| 509 |
+
alphas = np.ones(n_lines)
|
| 510 |
+
# If correct_matches is not None, display wrong matches with a low alpha
|
| 511 |
+
if correct_matches is not None:
|
| 512 |
+
alphas[~np.array(correct_matches)] = 0.2
|
| 513 |
+
|
| 514 |
+
fig = plt.gcf()
|
| 515 |
+
ax = fig.axes
|
| 516 |
+
assert len(ax) > max(indices)
|
| 517 |
+
axes = [ax[i] for i in indices]
|
| 518 |
+
fig.canvas.draw()
|
| 519 |
+
|
| 520 |
+
# Plot the lines
|
| 521 |
+
for a, l in zip(axes, lines):
|
| 522 |
+
# Transform the points into the figure coordinate system
|
| 523 |
+
transFigure = fig.transFigure.inverted()
|
| 524 |
+
endpoint0 = transFigure.transform(a.transData.transform(l[:, 0]))
|
| 525 |
+
endpoint1 = transFigure.transform(a.transData.transform(l[:, 1]))
|
| 526 |
+
fig.lines += [
|
| 527 |
+
matplotlib.lines.Line2D(
|
| 528 |
+
(endpoint0[i, 0], endpoint1[i, 0]),
|
| 529 |
+
(endpoint0[i, 1], endpoint1[i, 1]),
|
| 530 |
+
zorder=1,
|
| 531 |
+
transform=fig.transFigure,
|
| 532 |
+
c=colors[i],
|
| 533 |
+
alpha=alphas[i],
|
| 534 |
+
linewidth=lw,
|
| 535 |
+
)
|
| 536 |
+
for i in range(n_lines)
|
| 537 |
+
]
|
| 538 |
+
|
| 539 |
+
return fig
|
| 540 |
+
|
| 541 |
+
|
| 542 |
+
def plot_color_lines(lines, correct_matches, wrong_matches, lw=2, indices=(0, 1)):
|
| 543 |
+
"""Plot line matches for existing images with multiple colors:
|
| 544 |
+
green for correct matches, red for wrong ones, and blue for the rest.
|
| 545 |
+
Args:
|
| 546 |
+
lines: list of ndarrays of size (N, 2, 2).
|
| 547 |
+
correct_matches: list of bool arrays of size N with correct matches.
|
| 548 |
+
wrong_matches: list of bool arrays of size (N,) with correct matches.
|
| 549 |
+
lw: line width as float pixels.
|
| 550 |
+
indices: indices of the images to draw the matches on.
|
| 551 |
+
"""
|
| 552 |
+
# palette = sns.color_palette()
|
| 553 |
+
palette = sns.color_palette("hls", 8)
|
| 554 |
+
blue = palette[5] # palette[0]
|
| 555 |
+
red = palette[0] # palette[3]
|
| 556 |
+
green = palette[2] # palette[2]
|
| 557 |
+
colors = [np.array([blue] * len(l)) for l in lines]
|
| 558 |
+
for i, c in enumerate(colors):
|
| 559 |
+
c[np.array(correct_matches[i])] = green
|
| 560 |
+
c[np.array(wrong_matches[i])] = red
|
| 561 |
+
|
| 562 |
+
fig = plt.gcf()
|
| 563 |
+
ax = fig.axes
|
| 564 |
+
assert len(ax) > max(indices)
|
| 565 |
+
axes = [ax[i] for i in indices]
|
| 566 |
+
fig.canvas.draw()
|
| 567 |
+
|
| 568 |
+
# Plot the lines
|
| 569 |
+
for a, l, c in zip(axes, lines, colors):
|
| 570 |
+
# Transform the points into the figure coordinate system
|
| 571 |
+
transFigure = fig.transFigure.inverted()
|
| 572 |
+
endpoint0 = transFigure.transform(a.transData.transform(l[:, 0]))
|
| 573 |
+
endpoint1 = transFigure.transform(a.transData.transform(l[:, 1]))
|
| 574 |
+
fig.lines += [
|
| 575 |
+
matplotlib.lines.Line2D(
|
| 576 |
+
(endpoint0[i, 0], endpoint1[i, 0]),
|
| 577 |
+
(endpoint0[i, 1], endpoint1[i, 1]),
|
| 578 |
+
zorder=1,
|
| 579 |
+
transform=fig.transFigure,
|
| 580 |
+
c=c[i],
|
| 581 |
+
linewidth=lw,
|
| 582 |
+
)
|
| 583 |
+
for i in range(len(l))
|
| 584 |
+
]
|
| 585 |
+
|
| 586 |
+
|
| 587 |
+
def plot_subsegment_matches(lines, subsegments, lw=2, indices=(0, 1)):
|
| 588 |
+
"""Plot line matches for existing images with multiple colors and
|
| 589 |
+
highlight the actually matched subsegments.
|
| 590 |
+
Args:
|
| 591 |
+
lines: list of ndarrays of size (N, 2, 2).
|
| 592 |
+
subsegments: list of ndarrays of size (N, 2, 2).
|
| 593 |
+
lw: line width as float pixels.
|
| 594 |
+
indices: indices of the images to draw the matches on.
|
| 595 |
+
"""
|
| 596 |
+
n_lines = len(lines[0])
|
| 597 |
+
colors = sns.cubehelix_palette(
|
| 598 |
+
start=2, rot=-0.2, dark=0.3, light=0.7, gamma=1.3, hue=1, n_colors=n_lines
|
| 599 |
+
)
|
| 600 |
+
|
| 601 |
+
fig = plt.gcf()
|
| 602 |
+
ax = fig.axes
|
| 603 |
+
assert len(ax) > max(indices)
|
| 604 |
+
axes = [ax[i] for i in indices]
|
| 605 |
+
fig.canvas.draw()
|
| 606 |
+
|
| 607 |
+
# Plot the lines
|
| 608 |
+
for a, l, ss in zip(axes, lines, subsegments):
|
| 609 |
+
# Transform the points into the figure coordinate system
|
| 610 |
+
transFigure = fig.transFigure.inverted()
|
| 611 |
+
|
| 612 |
+
# Draw full line
|
| 613 |
+
endpoint0 = transFigure.transform(a.transData.transform(l[:, 0]))
|
| 614 |
+
endpoint1 = transFigure.transform(a.transData.transform(l[:, 1]))
|
| 615 |
+
fig.lines += [
|
| 616 |
+
matplotlib.lines.Line2D(
|
| 617 |
+
(endpoint0[i, 0], endpoint1[i, 0]),
|
| 618 |
+
(endpoint0[i, 1], endpoint1[i, 1]),
|
| 619 |
+
zorder=1,
|
| 620 |
+
transform=fig.transFigure,
|
| 621 |
+
c="red",
|
| 622 |
+
alpha=0.7,
|
| 623 |
+
linewidth=lw,
|
| 624 |
+
)
|
| 625 |
+
for i in range(n_lines)
|
| 626 |
+
]
|
| 627 |
+
|
| 628 |
+
# Draw matched subsegment
|
| 629 |
+
endpoint0 = transFigure.transform(a.transData.transform(ss[:, 0]))
|
| 630 |
+
endpoint1 = transFigure.transform(a.transData.transform(ss[:, 1]))
|
| 631 |
+
fig.lines += [
|
| 632 |
+
matplotlib.lines.Line2D(
|
| 633 |
+
(endpoint0[i, 0], endpoint1[i, 0]),
|
| 634 |
+
(endpoint0[i, 1], endpoint1[i, 1]),
|
| 635 |
+
zorder=1,
|
| 636 |
+
transform=fig.transFigure,
|
| 637 |
+
c=colors[i],
|
| 638 |
+
alpha=1,
|
| 639 |
+
linewidth=lw,
|
| 640 |
+
)
|
| 641 |
+
for i in range(n_lines)
|
| 642 |
+
]
|
hloc/__init__.py
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
from packaging import version
|
| 3 |
+
|
| 4 |
+
__version__ = "1.3"
|
| 5 |
+
|
| 6 |
+
formatter = logging.Formatter(
|
| 7 |
+
fmt="[%(asctime)s %(name)s %(levelname)s] %(message)s", datefmt="%Y/%m/%d %H:%M:%S"
|
| 8 |
+
)
|
| 9 |
+
handler = logging.StreamHandler()
|
| 10 |
+
handler.setFormatter(formatter)
|
| 11 |
+
handler.setLevel(logging.INFO)
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger("hloc")
|
| 14 |
+
logger.setLevel(logging.INFO)
|
| 15 |
+
logger.addHandler(handler)
|
| 16 |
+
logger.propagate = False
|
| 17 |
+
|
| 18 |
+
try:
|
| 19 |
+
import pycolmap
|
| 20 |
+
except ImportError:
|
| 21 |
+
logger.warning("pycolmap is not installed, some features may not work.")
|
| 22 |
+
else:
|
| 23 |
+
minimal_version = version.parse("0.3.0")
|
| 24 |
+
found_version = version.parse(getattr(pycolmap, "__version__"))
|
| 25 |
+
if found_version < minimal_version:
|
| 26 |
+
logger.warning(
|
| 27 |
+
"hloc now requires pycolmap>=%s but found pycolmap==%s, "
|
| 28 |
+
"please upgrade with `pip install --upgrade pycolmap`",
|
| 29 |
+
minimal_version,
|
| 30 |
+
found_version,
|
| 31 |
+
)
|
hloc/extract_features.py
ADDED
|
@@ -0,0 +1,516 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import torch
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
from typing import Dict, List, Union, Optional
|
| 5 |
+
import h5py
|
| 6 |
+
from types import SimpleNamespace
|
| 7 |
+
import cv2
|
| 8 |
+
import numpy as np
|
| 9 |
+
from tqdm import tqdm
|
| 10 |
+
import pprint
|
| 11 |
+
import collections.abc as collections
|
| 12 |
+
import PIL.Image
|
| 13 |
+
import torchvision.transforms.functional as F
|
| 14 |
+
from . import extractors, logger
|
| 15 |
+
from .utils.base_model import dynamic_load
|
| 16 |
+
from .utils.parsers import parse_image_lists
|
| 17 |
+
from .utils.io import read_image, list_h5_names
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
"""
|
| 21 |
+
A set of standard configurations that can be directly selected from the command
|
| 22 |
+
line using their name. Each is a dictionary with the following entries:
|
| 23 |
+
- output: the name of the feature file that will be generated.
|
| 24 |
+
- model: the model configuration, as passed to a feature extractor.
|
| 25 |
+
- preprocessing: how to preprocess the images read from disk.
|
| 26 |
+
"""
|
| 27 |
+
confs = {
|
| 28 |
+
"superpoint_aachen": {
|
| 29 |
+
"output": "feats-superpoint-n4096-r1024",
|
| 30 |
+
"model": {
|
| 31 |
+
"name": "superpoint",
|
| 32 |
+
"nms_radius": 3,
|
| 33 |
+
"max_keypoints": 4096,
|
| 34 |
+
"keypoint_threshold": 0.005,
|
| 35 |
+
},
|
| 36 |
+
"preprocessing": {
|
| 37 |
+
"grayscale": True,
|
| 38 |
+
"force_resize": True,
|
| 39 |
+
"resize_max": 1600,
|
| 40 |
+
"width": 640,
|
| 41 |
+
"height": 480,
|
| 42 |
+
"dfactor": 8,
|
| 43 |
+
},
|
| 44 |
+
},
|
| 45 |
+
# Resize images to 1600px even if they are originally smaller.
|
| 46 |
+
# Improves the keypoint localization if the images are of good quality.
|
| 47 |
+
"superpoint_max": {
|
| 48 |
+
"output": "feats-superpoint-n4096-rmax1600",
|
| 49 |
+
"model": {
|
| 50 |
+
"name": "superpoint",
|
| 51 |
+
"nms_radius": 3,
|
| 52 |
+
"max_keypoints": 4096,
|
| 53 |
+
"keypoint_threshold": 0.005,
|
| 54 |
+
},
|
| 55 |
+
"preprocessing": {
|
| 56 |
+
"grayscale": True,
|
| 57 |
+
"force_resize": True,
|
| 58 |
+
"resize_max": 1600,
|
| 59 |
+
"width": 640,
|
| 60 |
+
"height": 480,
|
| 61 |
+
"dfactor": 8,
|
| 62 |
+
},
|
| 63 |
+
},
|
| 64 |
+
"superpoint_inloc": {
|
| 65 |
+
"output": "feats-superpoint-n4096-r1600",
|
| 66 |
+
"model": {
|
| 67 |
+
"name": "superpoint",
|
| 68 |
+
"nms_radius": 4,
|
| 69 |
+
"max_keypoints": 4096,
|
| 70 |
+
"keypoint_threshold": 0.005,
|
| 71 |
+
},
|
| 72 |
+
"preprocessing": {
|
| 73 |
+
"grayscale": True,
|
| 74 |
+
"resize_max": 1600,
|
| 75 |
+
},
|
| 76 |
+
},
|
| 77 |
+
"r2d2": {
|
| 78 |
+
"output": "feats-r2d2-n5000-r1024",
|
| 79 |
+
"model": {
|
| 80 |
+
"name": "r2d2",
|
| 81 |
+
"max_keypoints": 5000,
|
| 82 |
+
"reliability_threshold": 0.7,
|
| 83 |
+
"repetability_threshold": 0.7,
|
| 84 |
+
},
|
| 85 |
+
"preprocessing": {
|
| 86 |
+
"grayscale": False,
|
| 87 |
+
"force_resize": True,
|
| 88 |
+
"resize_max": 1600,
|
| 89 |
+
"width": 640,
|
| 90 |
+
"height": 480,
|
| 91 |
+
"dfactor": 8,
|
| 92 |
+
},
|
| 93 |
+
},
|
| 94 |
+
"d2net-ss": {
|
| 95 |
+
"output": "feats-d2net-ss",
|
| 96 |
+
"model": {
|
| 97 |
+
"name": "d2net",
|
| 98 |
+
"multiscale": False,
|
| 99 |
+
},
|
| 100 |
+
"preprocessing": {
|
| 101 |
+
"grayscale": False,
|
| 102 |
+
"resize_max": 1600,
|
| 103 |
+
},
|
| 104 |
+
},
|
| 105 |
+
"d2net-ms": {
|
| 106 |
+
"output": "feats-d2net-ms",
|
| 107 |
+
"model": {
|
| 108 |
+
"name": "d2net",
|
| 109 |
+
"multiscale": True,
|
| 110 |
+
},
|
| 111 |
+
"preprocessing": {
|
| 112 |
+
"grayscale": False,
|
| 113 |
+
"resize_max": 1600,
|
| 114 |
+
},
|
| 115 |
+
},
|
| 116 |
+
"rootsift": {
|
| 117 |
+
"output": "feats-sift",
|
| 118 |
+
"model": {
|
| 119 |
+
"name": "dog",
|
| 120 |
+
"max_keypoints": 5000,
|
| 121 |
+
},
|
| 122 |
+
"preprocessing": {
|
| 123 |
+
"grayscale": True,
|
| 124 |
+
"force_resize": True,
|
| 125 |
+
"resize_max": 1600,
|
| 126 |
+
"width": 640,
|
| 127 |
+
"height": 480,
|
| 128 |
+
"dfactor": 8,
|
| 129 |
+
},
|
| 130 |
+
},
|
| 131 |
+
"sift": {
|
| 132 |
+
"output": "feats-sift",
|
| 133 |
+
"model": {
|
| 134 |
+
"name": "dog",
|
| 135 |
+
"descriptor": "sift",
|
| 136 |
+
"max_keypoints": 5000,
|
| 137 |
+
},
|
| 138 |
+
"preprocessing": {
|
| 139 |
+
"grayscale": True,
|
| 140 |
+
"force_resize": True,
|
| 141 |
+
"resize_max": 1600,
|
| 142 |
+
"width": 640,
|
| 143 |
+
"height": 480,
|
| 144 |
+
"dfactor": 8,
|
| 145 |
+
},
|
| 146 |
+
},
|
| 147 |
+
"sosnet": {
|
| 148 |
+
"output": "feats-sosnet",
|
| 149 |
+
"model": {"name": "dog", "descriptor": "sosnet"},
|
| 150 |
+
"preprocessing": {
|
| 151 |
+
"grayscale": True,
|
| 152 |
+
"resize_max": 1600,
|
| 153 |
+
"force_resize": True,
|
| 154 |
+
"width": 640,
|
| 155 |
+
"height": 480,
|
| 156 |
+
"dfactor": 8,
|
| 157 |
+
},
|
| 158 |
+
},
|
| 159 |
+
"hardnet": {
|
| 160 |
+
"output": "feats-hardnet",
|
| 161 |
+
"model": {"name": "dog", "descriptor": "hardnet"},
|
| 162 |
+
"preprocessing": {
|
| 163 |
+
"grayscale": True,
|
| 164 |
+
"resize_max": 1600,
|
| 165 |
+
"force_resize": True,
|
| 166 |
+
"width": 640,
|
| 167 |
+
"height": 480,
|
| 168 |
+
"dfactor": 8,
|
| 169 |
+
},
|
| 170 |
+
},
|
| 171 |
+
"disk": {
|
| 172 |
+
"output": "feats-disk",
|
| 173 |
+
"model": {
|
| 174 |
+
"name": "disk",
|
| 175 |
+
"max_keypoints": 5000,
|
| 176 |
+
},
|
| 177 |
+
"preprocessing": {
|
| 178 |
+
"grayscale": False,
|
| 179 |
+
"resize_max": 1600,
|
| 180 |
+
},
|
| 181 |
+
},
|
| 182 |
+
"alike": {
|
| 183 |
+
"output": "feats-alike",
|
| 184 |
+
"model": {
|
| 185 |
+
"name": "alike",
|
| 186 |
+
"max_keypoints": 5000,
|
| 187 |
+
"use_relu": True,
|
| 188 |
+
"multiscale": False,
|
| 189 |
+
"detection_threshold": 0.5,
|
| 190 |
+
"top_k": -1,
|
| 191 |
+
"sub_pixel": False,
|
| 192 |
+
},
|
| 193 |
+
"preprocessing": {
|
| 194 |
+
"grayscale": False,
|
| 195 |
+
"resize_max": 1600,
|
| 196 |
+
},
|
| 197 |
+
},
|
| 198 |
+
"lanet": {
|
| 199 |
+
"output": "feats-lanet",
|
| 200 |
+
"model": {
|
| 201 |
+
"name": "lanet",
|
| 202 |
+
"keypoint_threshold": 0.1,
|
| 203 |
+
"max_keypoints": 5000,
|
| 204 |
+
},
|
| 205 |
+
"preprocessing": {
|
| 206 |
+
"grayscale": False,
|
| 207 |
+
"resize_max": 1600,
|
| 208 |
+
},
|
| 209 |
+
},
|
| 210 |
+
"darkfeat": {
|
| 211 |
+
"output": "feats-darkfeat-n5000-r1024",
|
| 212 |
+
"model": {
|
| 213 |
+
"name": "darkfeat",
|
| 214 |
+
"max_keypoints": 5000,
|
| 215 |
+
"reliability_threshold": 0.7,
|
| 216 |
+
"repetability_threshold": 0.7,
|
| 217 |
+
},
|
| 218 |
+
"preprocessing": {
|
| 219 |
+
"grayscale": False,
|
| 220 |
+
"force_resize": True,
|
| 221 |
+
"resize_max": 1600,
|
| 222 |
+
"width": 640,
|
| 223 |
+
"height": 480,
|
| 224 |
+
"dfactor": 8,
|
| 225 |
+
},
|
| 226 |
+
},
|
| 227 |
+
"dedode": {
|
| 228 |
+
"output": "feats-dedode-n5000-r1024",
|
| 229 |
+
"model": {
|
| 230 |
+
"name": "dedode",
|
| 231 |
+
"max_keypoints": 5000,
|
| 232 |
+
},
|
| 233 |
+
"preprocessing": {
|
| 234 |
+
"grayscale": False,
|
| 235 |
+
"force_resize": True,
|
| 236 |
+
"resize_max": 1024,
|
| 237 |
+
"width": 768,
|
| 238 |
+
"height": 768,
|
| 239 |
+
"dfactor": 8,
|
| 240 |
+
},
|
| 241 |
+
},
|
| 242 |
+
"example": {
|
| 243 |
+
"output": "feats-example-n5000-r1024",
|
| 244 |
+
"model": {
|
| 245 |
+
"name": "example",
|
| 246 |
+
"keypoint_threshold": 0.1,
|
| 247 |
+
"max_keypoints": 2000,
|
| 248 |
+
"model_name": "model.pth",
|
| 249 |
+
},
|
| 250 |
+
"preprocessing": {
|
| 251 |
+
"grayscale": False,
|
| 252 |
+
"force_resize": True,
|
| 253 |
+
"resize_max": 1024,
|
| 254 |
+
"width": 768,
|
| 255 |
+
"height": 768,
|
| 256 |
+
"dfactor": 8,
|
| 257 |
+
},
|
| 258 |
+
},
|
| 259 |
+
# Global descriptors
|
| 260 |
+
"dir": {
|
| 261 |
+
"output": "global-feats-dir",
|
| 262 |
+
"model": {"name": "dir"},
|
| 263 |
+
"preprocessing": {"resize_max": 1024},
|
| 264 |
+
},
|
| 265 |
+
"netvlad": {
|
| 266 |
+
"output": "global-feats-netvlad",
|
| 267 |
+
"model": {"name": "netvlad"},
|
| 268 |
+
"preprocessing": {"resize_max": 1024},
|
| 269 |
+
},
|
| 270 |
+
"openibl": {
|
| 271 |
+
"output": "global-feats-openibl",
|
| 272 |
+
"model": {"name": "openibl"},
|
| 273 |
+
"preprocessing": {"resize_max": 1024},
|
| 274 |
+
},
|
| 275 |
+
"cosplace": {
|
| 276 |
+
"output": "global-feats-cosplace",
|
| 277 |
+
"model": {"name": "cosplace"},
|
| 278 |
+
"preprocessing": {"resize_max": 1024},
|
| 279 |
+
},
|
| 280 |
+
}
|
| 281 |
+
|
| 282 |
+
|
| 283 |
+
def resize_image(image, size, interp):
|
| 284 |
+
if interp.startswith("cv2_"):
|
| 285 |
+
interp = getattr(cv2, "INTER_" + interp[len("cv2_") :].upper())
|
| 286 |
+
h, w = image.shape[:2]
|
| 287 |
+
if interp == cv2.INTER_AREA and (w < size[0] or h < size[1]):
|
| 288 |
+
interp = cv2.INTER_LINEAR
|
| 289 |
+
resized = cv2.resize(image, size, interpolation=interp)
|
| 290 |
+
elif interp.startswith("pil_"):
|
| 291 |
+
interp = getattr(PIL.Image, interp[len("pil_") :].upper())
|
| 292 |
+
resized = PIL.Image.fromarray(image.astype(np.uint8))
|
| 293 |
+
resized = resized.resize(size, resample=interp)
|
| 294 |
+
resized = np.asarray(resized, dtype=image.dtype)
|
| 295 |
+
else:
|
| 296 |
+
raise ValueError(f"Unknown interpolation {interp}.")
|
| 297 |
+
return resized
|
| 298 |
+
|
| 299 |
+
|
| 300 |
+
class ImageDataset(torch.utils.data.Dataset):
|
| 301 |
+
default_conf = {
|
| 302 |
+
"globs": ["*.jpg", "*.png", "*.jpeg", "*.JPG", "*.PNG"],
|
| 303 |
+
"grayscale": False,
|
| 304 |
+
"resize_max": None,
|
| 305 |
+
"force_resize": False,
|
| 306 |
+
"interpolation": "cv2_area", # pil_linear is more accurate but slower
|
| 307 |
+
}
|
| 308 |
+
|
| 309 |
+
def __init__(self, root, conf, paths=None):
|
| 310 |
+
self.conf = conf = SimpleNamespace(**{**self.default_conf, **conf})
|
| 311 |
+
self.root = root
|
| 312 |
+
|
| 313 |
+
if paths is None:
|
| 314 |
+
paths = []
|
| 315 |
+
for g in conf.globs:
|
| 316 |
+
paths += list(Path(root).glob("**/" + g))
|
| 317 |
+
if len(paths) == 0:
|
| 318 |
+
raise ValueError(f"Could not find any image in root: {root}.")
|
| 319 |
+
paths = sorted(list(set(paths)))
|
| 320 |
+
self.names = [i.relative_to(root).as_posix() for i in paths]
|
| 321 |
+
logger.info(f"Found {len(self.names)} images in root {root}.")
|
| 322 |
+
else:
|
| 323 |
+
if isinstance(paths, (Path, str)):
|
| 324 |
+
self.names = parse_image_lists(paths)
|
| 325 |
+
elif isinstance(paths, collections.Iterable):
|
| 326 |
+
self.names = [p.as_posix() if isinstance(p, Path) else p for p in paths]
|
| 327 |
+
else:
|
| 328 |
+
raise ValueError(f"Unknown format for path argument {paths}.")
|
| 329 |
+
|
| 330 |
+
for name in self.names:
|
| 331 |
+
if not (root / name).exists():
|
| 332 |
+
raise ValueError(f"Image {name} does not exists in root: {root}.")
|
| 333 |
+
|
| 334 |
+
def __getitem__(self, idx):
|
| 335 |
+
name = self.names[idx]
|
| 336 |
+
image = read_image(self.root / name, self.conf.grayscale)
|
| 337 |
+
image = image.astype(np.float32)
|
| 338 |
+
size = image.shape[:2][::-1]
|
| 339 |
+
|
| 340 |
+
if self.conf.resize_max and (
|
| 341 |
+
self.conf.force_resize or max(size) > self.conf.resize_max
|
| 342 |
+
):
|
| 343 |
+
scale = self.conf.resize_max / max(size)
|
| 344 |
+
size_new = tuple(int(round(x * scale)) for x in size)
|
| 345 |
+
image = resize_image(image, size_new, self.conf.interpolation)
|
| 346 |
+
|
| 347 |
+
if self.conf.grayscale:
|
| 348 |
+
image = image[None]
|
| 349 |
+
else:
|
| 350 |
+
image = image.transpose((2, 0, 1)) # HxWxC to CxHxW
|
| 351 |
+
image = image / 255.0
|
| 352 |
+
|
| 353 |
+
data = {
|
| 354 |
+
"image": image,
|
| 355 |
+
"original_size": np.array(size),
|
| 356 |
+
}
|
| 357 |
+
return data
|
| 358 |
+
|
| 359 |
+
def __len__(self):
|
| 360 |
+
return len(self.names)
|
| 361 |
+
|
| 362 |
+
|
| 363 |
+
def extract(model, image_0, conf):
|
| 364 |
+
default_conf = {
|
| 365 |
+
"grayscale": True,
|
| 366 |
+
"resize_max": 1024,
|
| 367 |
+
"dfactor": 8,
|
| 368 |
+
"cache_images": False,
|
| 369 |
+
"force_resize": False,
|
| 370 |
+
"width": 320,
|
| 371 |
+
"height": 240,
|
| 372 |
+
"interpolation": "cv2_area",
|
| 373 |
+
}
|
| 374 |
+
conf = SimpleNamespace(**{**default_conf, **conf})
|
| 375 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 376 |
+
|
| 377 |
+
def preprocess(image: np.ndarray, conf: SimpleNamespace):
|
| 378 |
+
image = image.astype(np.float32, copy=False)
|
| 379 |
+
size = image.shape[:2][::-1]
|
| 380 |
+
scale = np.array([1.0, 1.0])
|
| 381 |
+
if conf.resize_max:
|
| 382 |
+
scale = conf.resize_max / max(size)
|
| 383 |
+
if scale < 1.0:
|
| 384 |
+
size_new = tuple(int(round(x * scale)) for x in size)
|
| 385 |
+
image = resize_image(image, size_new, "cv2_area")
|
| 386 |
+
scale = np.array(size) / np.array(size_new)
|
| 387 |
+
if conf.force_resize:
|
| 388 |
+
image = resize_image(image, (conf.width, conf.height), "cv2_area")
|
| 389 |
+
size_new = (conf.width, conf.height)
|
| 390 |
+
scale = np.array(size) / np.array(size_new)
|
| 391 |
+
if conf.grayscale:
|
| 392 |
+
assert image.ndim == 2, image.shape
|
| 393 |
+
image = image[None]
|
| 394 |
+
else:
|
| 395 |
+
image = image.transpose((2, 0, 1)) # HxWxC to CxHxW
|
| 396 |
+
image = torch.from_numpy(image / 255.0).float()
|
| 397 |
+
|
| 398 |
+
# assure that the size is divisible by dfactor
|
| 399 |
+
size_new = tuple(
|
| 400 |
+
map(lambda x: int(x // conf.dfactor * conf.dfactor), image.shape[-2:])
|
| 401 |
+
)
|
| 402 |
+
image = F.resize(image, size=size_new, antialias=True)
|
| 403 |
+
input_ = image.to(device, non_blocking=True)[None]
|
| 404 |
+
data = {
|
| 405 |
+
"image": input_,
|
| 406 |
+
"image_orig": image_0,
|
| 407 |
+
"original_size": np.array(size),
|
| 408 |
+
"size": np.array(image.shape[1:][::-1]),
|
| 409 |
+
}
|
| 410 |
+
return data
|
| 411 |
+
|
| 412 |
+
# convert to grayscale if needed
|
| 413 |
+
if len(image_0.shape) == 3 and conf.grayscale:
|
| 414 |
+
image0 = cv2.cvtColor(image_0, cv2.COLOR_RGB2GRAY)
|
| 415 |
+
else:
|
| 416 |
+
image0 = image_0
|
| 417 |
+
# comment following lines, image is always RGB mode
|
| 418 |
+
# if not conf.grayscale and len(image_0.shape) == 3:
|
| 419 |
+
# image0 = image_0[:, :, ::-1] # BGR to RGB
|
| 420 |
+
data = preprocess(image0, conf)
|
| 421 |
+
pred = model({"image": data["image"]})
|
| 422 |
+
pred["image_size"] = original_size = data["original_size"]
|
| 423 |
+
pred = {**pred, **data}
|
| 424 |
+
return pred
|
| 425 |
+
|
| 426 |
+
|
| 427 |
+
@torch.no_grad()
|
| 428 |
+
def main(
|
| 429 |
+
conf: Dict,
|
| 430 |
+
image_dir: Path,
|
| 431 |
+
export_dir: Optional[Path] = None,
|
| 432 |
+
as_half: bool = True,
|
| 433 |
+
image_list: Optional[Union[Path, List[str]]] = None,
|
| 434 |
+
feature_path: Optional[Path] = None,
|
| 435 |
+
overwrite: bool = False,
|
| 436 |
+
) -> Path:
|
| 437 |
+
logger.info(
|
| 438 |
+
"Extracting local features with configuration:" f"\n{pprint.pformat(conf)}"
|
| 439 |
+
)
|
| 440 |
+
|
| 441 |
+
dataset = ImageDataset(image_dir, conf["preprocessing"], image_list)
|
| 442 |
+
if feature_path is None:
|
| 443 |
+
feature_path = Path(export_dir, conf["output"] + ".h5")
|
| 444 |
+
feature_path.parent.mkdir(exist_ok=True, parents=True)
|
| 445 |
+
skip_names = set(
|
| 446 |
+
list_h5_names(feature_path) if feature_path.exists() and not overwrite else ()
|
| 447 |
+
)
|
| 448 |
+
dataset.names = [n for n in dataset.names if n not in skip_names]
|
| 449 |
+
if len(dataset.names) == 0:
|
| 450 |
+
logger.info("Skipping the extraction.")
|
| 451 |
+
return feature_path
|
| 452 |
+
|
| 453 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 454 |
+
Model = dynamic_load(extractors, conf["model"]["name"])
|
| 455 |
+
model = Model(conf["model"]).eval().to(device)
|
| 456 |
+
|
| 457 |
+
loader = torch.utils.data.DataLoader(
|
| 458 |
+
dataset, num_workers=1, shuffle=False, pin_memory=True
|
| 459 |
+
)
|
| 460 |
+
for idx, data in enumerate(tqdm(loader)):
|
| 461 |
+
name = dataset.names[idx]
|
| 462 |
+
pred = model({"image": data["image"].to(device, non_blocking=True)})
|
| 463 |
+
pred = {k: v[0].cpu().numpy() for k, v in pred.items()}
|
| 464 |
+
|
| 465 |
+
pred["image_size"] = original_size = data["original_size"][0].numpy()
|
| 466 |
+
if "keypoints" in pred:
|
| 467 |
+
size = np.array(data["image"].shape[-2:][::-1])
|
| 468 |
+
scales = (original_size / size).astype(np.float32)
|
| 469 |
+
pred["keypoints"] = (pred["keypoints"] + 0.5) * scales[None] - 0.5
|
| 470 |
+
if "scales" in pred:
|
| 471 |
+
pred["scales"] *= scales.mean()
|
| 472 |
+
# add keypoint uncertainties scaled to the original resolution
|
| 473 |
+
uncertainty = getattr(model, "detection_noise", 1) * scales.mean()
|
| 474 |
+
|
| 475 |
+
if as_half:
|
| 476 |
+
for k in pred:
|
| 477 |
+
dt = pred[k].dtype
|
| 478 |
+
if (dt == np.float32) and (dt != np.float16):
|
| 479 |
+
pred[k] = pred[k].astype(np.float16)
|
| 480 |
+
|
| 481 |
+
with h5py.File(str(feature_path), "a", libver="latest") as fd:
|
| 482 |
+
try:
|
| 483 |
+
if name in fd:
|
| 484 |
+
del fd[name]
|
| 485 |
+
grp = fd.create_group(name)
|
| 486 |
+
for k, v in pred.items():
|
| 487 |
+
grp.create_dataset(k, data=v)
|
| 488 |
+
if "keypoints" in pred:
|
| 489 |
+
grp["keypoints"].attrs["uncertainty"] = uncertainty
|
| 490 |
+
except OSError as error:
|
| 491 |
+
if "No space left on device" in error.args[0]:
|
| 492 |
+
logger.error(
|
| 493 |
+
"Out of disk space: storing features on disk can take "
|
| 494 |
+
"significant space, did you enable the as_half flag?"
|
| 495 |
+
)
|
| 496 |
+
del grp, fd[name]
|
| 497 |
+
raise error
|
| 498 |
+
|
| 499 |
+
del pred
|
| 500 |
+
|
| 501 |
+
logger.info("Finished exporting features.")
|
| 502 |
+
return feature_path
|
| 503 |
+
|
| 504 |
+
|
| 505 |
+
if __name__ == "__main__":
|
| 506 |
+
parser = argparse.ArgumentParser()
|
| 507 |
+
parser.add_argument("--image_dir", type=Path, required=True)
|
| 508 |
+
parser.add_argument("--export_dir", type=Path, required=True)
|
| 509 |
+
parser.add_argument(
|
| 510 |
+
"--conf", type=str, default="superpoint_aachen", choices=list(confs.keys())
|
| 511 |
+
)
|
| 512 |
+
parser.add_argument("--as_half", action="store_true")
|
| 513 |
+
parser.add_argument("--image_list", type=Path)
|
| 514 |
+
parser.add_argument("--feature_path", type=Path)
|
| 515 |
+
args = parser.parse_args()
|
| 516 |
+
main(confs[args.conf], args.image_dir, args.export_dir, args.as_half)
|
hloc/extractors/__init__.py
ADDED
|
File without changes
|
hloc/extractors/alike.py
ADDED
|
@@ -0,0 +1,52 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import subprocess
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from ..utils.base_model import BaseModel
|
| 7 |
+
|
| 8 |
+
alike_path = Path(__file__).parent / "../../third_party/ALIKE"
|
| 9 |
+
sys.path.append(str(alike_path))
|
| 10 |
+
from alike import ALike as Alike_
|
| 11 |
+
from alike import configs
|
| 12 |
+
|
| 13 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
class Alike(BaseModel):
|
| 17 |
+
default_conf = {
|
| 18 |
+
"model_name": "alike-t", # 'alike-t', 'alike-s', 'alike-n', 'alike-l'
|
| 19 |
+
"use_relu": True,
|
| 20 |
+
"multiscale": False,
|
| 21 |
+
"max_keypoints": 1000,
|
| 22 |
+
"detection_threshold": 0.5,
|
| 23 |
+
"top_k": -1,
|
| 24 |
+
"sub_pixel": False,
|
| 25 |
+
}
|
| 26 |
+
|
| 27 |
+
required_inputs = ["image"]
|
| 28 |
+
|
| 29 |
+
def _init(self, conf):
|
| 30 |
+
self.net = Alike_(
|
| 31 |
+
**configs[conf["model_name"]],
|
| 32 |
+
device=device,
|
| 33 |
+
top_k=conf["top_k"],
|
| 34 |
+
scores_th=conf["detection_threshold"],
|
| 35 |
+
n_limit=conf["max_keypoints"],
|
| 36 |
+
)
|
| 37 |
+
|
| 38 |
+
def _forward(self, data):
|
| 39 |
+
image = data["image"]
|
| 40 |
+
image = image.permute(0, 2, 3, 1).squeeze()
|
| 41 |
+
image = image.cpu().numpy() * 255.0
|
| 42 |
+
pred = self.net(image, sub_pixel=self.conf["sub_pixel"])
|
| 43 |
+
|
| 44 |
+
keypoints = pred["keypoints"]
|
| 45 |
+
descriptors = pred["descriptors"]
|
| 46 |
+
scores = pred["scores"]
|
| 47 |
+
|
| 48 |
+
return {
|
| 49 |
+
"keypoints": torch.from_numpy(keypoints)[None],
|
| 50 |
+
"scores": torch.from_numpy(scores)[None],
|
| 51 |
+
"descriptors": torch.from_numpy(descriptors.T)[None],
|
| 52 |
+
}
|
hloc/extractors/cosplace.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Code for loading models trained with CosPlace as a global features extractor
|
| 3 |
+
for geolocalization through image retrieval.
|
| 4 |
+
Multiple models are available with different backbones. Below is a summary of
|
| 5 |
+
models available (backbone : list of available output descriptors
|
| 6 |
+
dimensionality). For example you can use a model based on a ResNet50 with
|
| 7 |
+
descriptors dimensionality 1024.
|
| 8 |
+
ResNet18: [32, 64, 128, 256, 512]
|
| 9 |
+
ResNet50: [32, 64, 128, 256, 512, 1024, 2048]
|
| 10 |
+
ResNet101: [32, 64, 128, 256, 512, 1024, 2048]
|
| 11 |
+
ResNet152: [32, 64, 128, 256, 512, 1024, 2048]
|
| 12 |
+
VGG16: [ 64, 128, 256, 512]
|
| 13 |
+
|
| 14 |
+
CosPlace paper: https://arxiv.org/abs/2204.02287
|
| 15 |
+
"""
|
| 16 |
+
|
| 17 |
+
import torch
|
| 18 |
+
import torchvision.transforms as tvf
|
| 19 |
+
|
| 20 |
+
from ..utils.base_model import BaseModel
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
class CosPlace(BaseModel):
|
| 24 |
+
default_conf = {"backbone": "ResNet50", "fc_output_dim": 2048}
|
| 25 |
+
required_inputs = ["image"]
|
| 26 |
+
|
| 27 |
+
def _init(self, conf):
|
| 28 |
+
self.net = torch.hub.load(
|
| 29 |
+
"gmberton/CosPlace",
|
| 30 |
+
"get_trained_model",
|
| 31 |
+
backbone=conf["backbone"],
|
| 32 |
+
fc_output_dim=conf["fc_output_dim"],
|
| 33 |
+
).eval()
|
| 34 |
+
|
| 35 |
+
mean = [0.485, 0.456, 0.406]
|
| 36 |
+
std = [0.229, 0.224, 0.225]
|
| 37 |
+
self.norm_rgb = tvf.Normalize(mean=mean, std=std)
|
| 38 |
+
|
| 39 |
+
def _forward(self, data):
|
| 40 |
+
image = self.norm_rgb(data["image"])
|
| 41 |
+
desc = self.net(image)
|
| 42 |
+
return {
|
| 43 |
+
"global_descriptor": desc,
|
| 44 |
+
}
|
hloc/extractors/d2net.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import subprocess
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from ..utils.base_model import BaseModel
|
| 7 |
+
|
| 8 |
+
d2net_path = Path(__file__).parent / "../../third_party/d2net"
|
| 9 |
+
sys.path.append(str(d2net_path))
|
| 10 |
+
from lib.model_test import D2Net as _D2Net
|
| 11 |
+
from lib.pyramid import process_multiscale
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
class D2Net(BaseModel):
|
| 15 |
+
default_conf = {
|
| 16 |
+
"model_name": "d2_tf.pth",
|
| 17 |
+
"checkpoint_dir": d2net_path / "models",
|
| 18 |
+
"use_relu": True,
|
| 19 |
+
"multiscale": False,
|
| 20 |
+
}
|
| 21 |
+
required_inputs = ["image"]
|
| 22 |
+
|
| 23 |
+
def _init(self, conf):
|
| 24 |
+
model_file = conf["checkpoint_dir"] / conf["model_name"]
|
| 25 |
+
if not model_file.exists():
|
| 26 |
+
model_file.parent.mkdir(exist_ok=True)
|
| 27 |
+
cmd = [
|
| 28 |
+
"wget",
|
| 29 |
+
"https://dsmn.ml/files/d2-net/" + conf["model_name"],
|
| 30 |
+
"-O",
|
| 31 |
+
str(model_file),
|
| 32 |
+
]
|
| 33 |
+
subprocess.run(cmd, check=True)
|
| 34 |
+
|
| 35 |
+
self.net = _D2Net(
|
| 36 |
+
model_file=model_file, use_relu=conf["use_relu"], use_cuda=False
|
| 37 |
+
)
|
| 38 |
+
|
| 39 |
+
def _forward(self, data):
|
| 40 |
+
image = data["image"]
|
| 41 |
+
image = image.flip(1) # RGB -> BGR
|
| 42 |
+
norm = image.new_tensor([103.939, 116.779, 123.68])
|
| 43 |
+
image = image * 255 - norm.view(1, 3, 1, 1) # caffe normalization
|
| 44 |
+
|
| 45 |
+
if self.conf["multiscale"]:
|
| 46 |
+
keypoints, scores, descriptors = process_multiscale(image, self.net)
|
| 47 |
+
else:
|
| 48 |
+
keypoints, scores, descriptors = process_multiscale(
|
| 49 |
+
image, self.net, scales=[1]
|
| 50 |
+
)
|
| 51 |
+
keypoints = keypoints[:, [1, 0]] # (x, y) and remove the scale
|
| 52 |
+
|
| 53 |
+
return {
|
| 54 |
+
"keypoints": torch.from_numpy(keypoints)[None],
|
| 55 |
+
"scores": torch.from_numpy(scores)[None],
|
| 56 |
+
"descriptors": torch.from_numpy(descriptors.T)[None],
|
| 57 |
+
}
|
hloc/extractors/darkfeat.py
ADDED
|
@@ -0,0 +1,57 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import subprocess
|
| 4 |
+
import logging
|
| 5 |
+
|
| 6 |
+
from ..utils.base_model import BaseModel
|
| 7 |
+
|
| 8 |
+
logger = logging.getLogger(__name__)
|
| 9 |
+
|
| 10 |
+
darkfeat_path = Path(__file__).parent / "../../third_party/DarkFeat"
|
| 11 |
+
sys.path.append(str(darkfeat_path))
|
| 12 |
+
from darkfeat import DarkFeat as DarkFeat_
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class DarkFeat(BaseModel):
|
| 16 |
+
default_conf = {
|
| 17 |
+
"model_name": "DarkFeat.pth",
|
| 18 |
+
"max_keypoints": 1000,
|
| 19 |
+
"detection_threshold": 0.5,
|
| 20 |
+
"sub_pixel": False,
|
| 21 |
+
}
|
| 22 |
+
weight_urls = {
|
| 23 |
+
"DarkFeat.pth": "https://drive.google.com/uc?id=1Thl6m8NcmQ7zSAF-1_xaFs3F4H8UU6HX&confirm=t",
|
| 24 |
+
}
|
| 25 |
+
proxy = "http://localhost:1080"
|
| 26 |
+
required_inputs = ["image"]
|
| 27 |
+
|
| 28 |
+
def _init(self, conf):
|
| 29 |
+
model_path = darkfeat_path / "checkpoints" / conf["model_name"]
|
| 30 |
+
link = self.weight_urls[conf["model_name"]]
|
| 31 |
+
if not model_path.exists():
|
| 32 |
+
model_path.parent.mkdir(exist_ok=True)
|
| 33 |
+
cmd_wo_proxy = ["gdown", link, "-O", str(model_path)]
|
| 34 |
+
cmd = ["gdown", link, "-O", str(model_path), "--proxy", self.proxy]
|
| 35 |
+
logger.info(f"Downloading the DarkFeat model with `{cmd_wo_proxy}`.")
|
| 36 |
+
try:
|
| 37 |
+
subprocess.run(cmd_wo_proxy, check=True)
|
| 38 |
+
except subprocess.CalledProcessError as e:
|
| 39 |
+
logger.info(f"Downloading the DarkFeat model with `{cmd}`.")
|
| 40 |
+
try:
|
| 41 |
+
subprocess.run(cmd, check=True)
|
| 42 |
+
except subprocess.CalledProcessError as e:
|
| 43 |
+
logger.error(f"Failed to download the DarkFeat model.")
|
| 44 |
+
raise e
|
| 45 |
+
|
| 46 |
+
self.net = DarkFeat_(model_path)
|
| 47 |
+
|
| 48 |
+
def _forward(self, data):
|
| 49 |
+
pred = self.net({"image": data["image"]})
|
| 50 |
+
keypoints = pred["keypoints"]
|
| 51 |
+
descriptors = pred["descriptors"]
|
| 52 |
+
scores = pred["scores"]
|
| 53 |
+
return {
|
| 54 |
+
"keypoints": keypoints[None], # 1 x N x 2
|
| 55 |
+
"scores": scores[None], # 1 x N
|
| 56 |
+
"descriptors": descriptors[None], # 1 x 128 x N
|
| 57 |
+
}
|
hloc/extractors/dedode.py
ADDED
|
@@ -0,0 +1,102 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import subprocess
|
| 4 |
+
import logging
|
| 5 |
+
import torch
|
| 6 |
+
from PIL import Image
|
| 7 |
+
from ..utils.base_model import BaseModel
|
| 8 |
+
import torchvision.transforms as transforms
|
| 9 |
+
|
| 10 |
+
dedode_path = Path(__file__).parent / "../../third_party/DeDoDe"
|
| 11 |
+
sys.path.append(str(dedode_path))
|
| 12 |
+
|
| 13 |
+
from DeDoDe import dedode_detector_L, dedode_descriptor_B
|
| 14 |
+
from DeDoDe.utils import to_pixel_coords
|
| 15 |
+
|
| 16 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 17 |
+
logger = logging.getLogger(__name__)
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class DeDoDe(BaseModel):
|
| 21 |
+
default_conf = {
|
| 22 |
+
"name": "dedode",
|
| 23 |
+
"model_detector_name": "dedode_detector_L.pth",
|
| 24 |
+
"model_descriptor_name": "dedode_descriptor_B.pth",
|
| 25 |
+
"max_keypoints": 2000,
|
| 26 |
+
"match_threshold": 0.2,
|
| 27 |
+
"dense": False, # Now fixed to be false
|
| 28 |
+
}
|
| 29 |
+
required_inputs = [
|
| 30 |
+
"image",
|
| 31 |
+
]
|
| 32 |
+
weight_urls = {
|
| 33 |
+
"dedode_detector_L.pth": "https://github.com/Parskatt/DeDoDe/releases/download/dedode_pretrained_models/dedode_detector_L.pth",
|
| 34 |
+
"dedode_descriptor_B.pth": "https://github.com/Parskatt/DeDoDe/releases/download/dedode_pretrained_models/dedode_descriptor_B.pth",
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
# Initialize the line matcher
|
| 38 |
+
def _init(self, conf):
|
| 39 |
+
model_detector_path = dedode_path / "pretrained" / conf["model_detector_name"]
|
| 40 |
+
model_descriptor_path = (
|
| 41 |
+
dedode_path / "pretrained" / conf["model_descriptor_name"]
|
| 42 |
+
)
|
| 43 |
+
|
| 44 |
+
self.normalizer = transforms.Normalize(
|
| 45 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 46 |
+
)
|
| 47 |
+
# Download the model.
|
| 48 |
+
if not model_detector_path.exists():
|
| 49 |
+
model_detector_path.parent.mkdir(exist_ok=True)
|
| 50 |
+
link = self.weight_urls[conf["model_detector_name"]]
|
| 51 |
+
cmd = ["wget", link, "-O", str(model_detector_path)]
|
| 52 |
+
logger.info(f"Downloading the DeDoDe detector model with `{cmd}`.")
|
| 53 |
+
subprocess.run(cmd, check=True)
|
| 54 |
+
|
| 55 |
+
if not model_descriptor_path.exists():
|
| 56 |
+
model_descriptor_path.parent.mkdir(exist_ok=True)
|
| 57 |
+
link = self.weight_urls[conf["model_descriptor_name"]]
|
| 58 |
+
cmd = ["wget", link, "-O", str(model_descriptor_path)]
|
| 59 |
+
logger.info(f"Downloading the DeDoDe descriptor model with `{cmd}`.")
|
| 60 |
+
subprocess.run(cmd, check=True)
|
| 61 |
+
|
| 62 |
+
logger.info(f"Loading DeDoDe model...")
|
| 63 |
+
|
| 64 |
+
# load the model
|
| 65 |
+
weights_detector = torch.load(model_detector_path, map_location="cpu")
|
| 66 |
+
weights_descriptor = torch.load(model_descriptor_path, map_location="cpu")
|
| 67 |
+
self.detector = dedode_detector_L(weights=weights_detector)
|
| 68 |
+
self.descriptor = dedode_descriptor_B(weights=weights_descriptor)
|
| 69 |
+
logger.info(f"Load DeDoDe model done.")
|
| 70 |
+
|
| 71 |
+
def _forward(self, data):
|
| 72 |
+
"""
|
| 73 |
+
data: dict, keys: {'image0','image1'}
|
| 74 |
+
image shape: N x C x H x W
|
| 75 |
+
color mode: RGB
|
| 76 |
+
"""
|
| 77 |
+
img0 = self.normalizer(data["image"].squeeze()).float()[None]
|
| 78 |
+
H_A, W_A = img0.shape[2:]
|
| 79 |
+
|
| 80 |
+
# step 1: detect keypoints
|
| 81 |
+
detections_A = None
|
| 82 |
+
batch_A = {"image": img0}
|
| 83 |
+
if self.conf["dense"]:
|
| 84 |
+
detections_A = self.detector.detect_dense(batch_A)
|
| 85 |
+
else:
|
| 86 |
+
detections_A = self.detector.detect(
|
| 87 |
+
batch_A, num_keypoints=self.conf["max_keypoints"]
|
| 88 |
+
)
|
| 89 |
+
keypoints_A, P_A = detections_A["keypoints"], detections_A["confidence"]
|
| 90 |
+
|
| 91 |
+
# step 2: describe keypoints
|
| 92 |
+
# dim: 1 x N x 256
|
| 93 |
+
description_A = self.descriptor.describe_keypoints(batch_A, keypoints_A)[
|
| 94 |
+
"descriptions"
|
| 95 |
+
]
|
| 96 |
+
keypoints_A = to_pixel_coords(keypoints_A, H_A, W_A)
|
| 97 |
+
|
| 98 |
+
return {
|
| 99 |
+
"keypoints": keypoints_A, # 1 x N x 2
|
| 100 |
+
"descriptors": description_A.permute(0, 2, 1), # 1 x 256 x N
|
| 101 |
+
"scores": P_A, # 1 x N
|
| 102 |
+
}
|
hloc/extractors/dir.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import torch
|
| 4 |
+
from zipfile import ZipFile
|
| 5 |
+
import os
|
| 6 |
+
import sklearn
|
| 7 |
+
import gdown
|
| 8 |
+
|
| 9 |
+
from ..utils.base_model import BaseModel
|
| 10 |
+
|
| 11 |
+
sys.path.append(str(Path(__file__).parent / "../../third_party/deep-image-retrieval"))
|
| 12 |
+
os.environ["DB_ROOT"] = "" # required by dirtorch
|
| 13 |
+
|
| 14 |
+
from dirtorch.utils import common # noqa: E402
|
| 15 |
+
from dirtorch.extract_features import load_model # noqa: E402
|
| 16 |
+
|
| 17 |
+
# The DIR model checkpoints (pickle files) include sklearn.decomposition.pca,
|
| 18 |
+
# which has been deprecated in sklearn v0.24
|
| 19 |
+
# and must be explicitly imported with `from sklearn.decomposition import PCA`.
|
| 20 |
+
# This is a hacky workaround to maintain forward compatibility.
|
| 21 |
+
sys.modules["sklearn.decomposition.pca"] = sklearn.decomposition._pca
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
class DIR(BaseModel):
|
| 25 |
+
default_conf = {
|
| 26 |
+
"model_name": "Resnet-101-AP-GeM",
|
| 27 |
+
"whiten_name": "Landmarks_clean",
|
| 28 |
+
"whiten_params": {
|
| 29 |
+
"whitenp": 0.25,
|
| 30 |
+
"whitenv": None,
|
| 31 |
+
"whitenm": 1.0,
|
| 32 |
+
},
|
| 33 |
+
"pooling": "gem",
|
| 34 |
+
"gemp": 3,
|
| 35 |
+
}
|
| 36 |
+
required_inputs = ["image"]
|
| 37 |
+
|
| 38 |
+
dir_models = {
|
| 39 |
+
"Resnet-101-AP-GeM": "https://docs.google.com/uc?export=download&id=1UWJGDuHtzaQdFhSMojoYVQjmCXhIwVvy",
|
| 40 |
+
}
|
| 41 |
+
|
| 42 |
+
def _init(self, conf):
|
| 43 |
+
checkpoint = Path(torch.hub.get_dir(), "dirtorch", conf["model_name"] + ".pt")
|
| 44 |
+
if not checkpoint.exists():
|
| 45 |
+
checkpoint.parent.mkdir(exist_ok=True, parents=True)
|
| 46 |
+
link = self.dir_models[conf["model_name"]]
|
| 47 |
+
gdown.download(str(link), str(checkpoint) + ".zip", quiet=False)
|
| 48 |
+
zf = ZipFile(str(checkpoint) + ".zip", "r")
|
| 49 |
+
zf.extractall(checkpoint.parent)
|
| 50 |
+
zf.close()
|
| 51 |
+
os.remove(str(checkpoint) + ".zip")
|
| 52 |
+
|
| 53 |
+
self.net = load_model(checkpoint, False) # first load on CPU
|
| 54 |
+
if conf["whiten_name"]:
|
| 55 |
+
assert conf["whiten_name"] in self.net.pca
|
| 56 |
+
|
| 57 |
+
def _forward(self, data):
|
| 58 |
+
image = data["image"]
|
| 59 |
+
assert image.shape[1] == 3
|
| 60 |
+
mean = self.net.preprocess["mean"]
|
| 61 |
+
std = self.net.preprocess["std"]
|
| 62 |
+
image = image - image.new_tensor(mean)[:, None, None]
|
| 63 |
+
image = image / image.new_tensor(std)[:, None, None]
|
| 64 |
+
|
| 65 |
+
desc = self.net(image)
|
| 66 |
+
desc = desc.unsqueeze(0) # batch dimension
|
| 67 |
+
if self.conf["whiten_name"]:
|
| 68 |
+
pca = self.net.pca[self.conf["whiten_name"]]
|
| 69 |
+
desc = common.whiten_features(
|
| 70 |
+
desc.cpu().numpy(), pca, **self.conf["whiten_params"]
|
| 71 |
+
)
|
| 72 |
+
desc = torch.from_numpy(desc)
|
| 73 |
+
|
| 74 |
+
return {
|
| 75 |
+
"global_descriptor": desc,
|
| 76 |
+
}
|
hloc/extractors/disk.py
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import kornia
|
| 2 |
+
|
| 3 |
+
from ..utils.base_model import BaseModel
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
class DISK(BaseModel):
|
| 7 |
+
default_conf = {
|
| 8 |
+
"weights": "depth",
|
| 9 |
+
"max_keypoints": None,
|
| 10 |
+
"nms_window_size": 5,
|
| 11 |
+
"detection_threshold": 0.0,
|
| 12 |
+
"pad_if_not_divisible": True,
|
| 13 |
+
}
|
| 14 |
+
required_inputs = ["image"]
|
| 15 |
+
|
| 16 |
+
def _init(self, conf):
|
| 17 |
+
self.model = kornia.feature.DISK.from_pretrained(conf["weights"])
|
| 18 |
+
|
| 19 |
+
def _forward(self, data):
|
| 20 |
+
image = data["image"]
|
| 21 |
+
features = self.model(
|
| 22 |
+
image,
|
| 23 |
+
n=self.conf["max_keypoints"],
|
| 24 |
+
window_size=self.conf["nms_window_size"],
|
| 25 |
+
score_threshold=self.conf["detection_threshold"],
|
| 26 |
+
pad_if_not_divisible=self.conf["pad_if_not_divisible"],
|
| 27 |
+
)
|
| 28 |
+
return {
|
| 29 |
+
"keypoints": [f.keypoints for f in features],
|
| 30 |
+
"scores": [f.detection_scores for f in features],
|
| 31 |
+
"descriptors": [f.descriptors.t() for f in features],
|
| 32 |
+
}
|
hloc/extractors/dog.py
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import kornia
|
| 2 |
+
from kornia.feature.laf import laf_from_center_scale_ori, extract_patches_from_pyramid
|
| 3 |
+
import numpy as np
|
| 4 |
+
import torch
|
| 5 |
+
import pycolmap
|
| 6 |
+
|
| 7 |
+
from ..utils.base_model import BaseModel
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
EPS = 1e-6
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
def sift_to_rootsift(x):
|
| 14 |
+
x = x / (np.linalg.norm(x, ord=1, axis=-1, keepdims=True) + EPS)
|
| 15 |
+
x = np.sqrt(x.clip(min=EPS))
|
| 16 |
+
x = x / (np.linalg.norm(x, axis=-1, keepdims=True) + EPS)
|
| 17 |
+
return x
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class DoG(BaseModel):
|
| 21 |
+
default_conf = {
|
| 22 |
+
"options": {
|
| 23 |
+
"first_octave": 0,
|
| 24 |
+
"peak_threshold": 0.01,
|
| 25 |
+
},
|
| 26 |
+
"descriptor": "rootsift",
|
| 27 |
+
"max_keypoints": -1,
|
| 28 |
+
"patch_size": 32,
|
| 29 |
+
"mr_size": 12,
|
| 30 |
+
}
|
| 31 |
+
required_inputs = ["image"]
|
| 32 |
+
detection_noise = 1.0
|
| 33 |
+
max_batch_size = 1024
|
| 34 |
+
|
| 35 |
+
def _init(self, conf):
|
| 36 |
+
if conf["descriptor"] == "sosnet":
|
| 37 |
+
self.describe = kornia.feature.SOSNet(pretrained=True)
|
| 38 |
+
elif conf["descriptor"] == "hardnet":
|
| 39 |
+
self.describe = kornia.feature.HardNet(pretrained=True)
|
| 40 |
+
elif conf["descriptor"] not in ["sift", "rootsift"]:
|
| 41 |
+
raise ValueError(f'Unknown descriptor: {conf["descriptor"]}')
|
| 42 |
+
|
| 43 |
+
self.sift = None # lazily instantiated on the first image
|
| 44 |
+
self.device = torch.device("cpu")
|
| 45 |
+
|
| 46 |
+
def to(self, *args, **kwargs):
|
| 47 |
+
device = kwargs.get("device")
|
| 48 |
+
if device is None:
|
| 49 |
+
match = [a for a in args if isinstance(a, (torch.device, str))]
|
| 50 |
+
if len(match) > 0:
|
| 51 |
+
device = match[0]
|
| 52 |
+
if device is not None:
|
| 53 |
+
self.device = torch.device(device)
|
| 54 |
+
return super().to(*args, **kwargs)
|
| 55 |
+
|
| 56 |
+
def _forward(self, data):
|
| 57 |
+
image = data["image"]
|
| 58 |
+
image_np = image.cpu().numpy()[0, 0]
|
| 59 |
+
assert image.shape[1] == 1
|
| 60 |
+
assert image_np.min() >= -EPS and image_np.max() <= 1 + EPS
|
| 61 |
+
|
| 62 |
+
if self.sift is None:
|
| 63 |
+
use_gpu = pycolmap.has_cuda and self.device.type == "cuda"
|
| 64 |
+
options = {**self.conf["options"]}
|
| 65 |
+
if self.conf["descriptor"] == "rootsift":
|
| 66 |
+
options["normalization"] = pycolmap.Normalization.L1_ROOT
|
| 67 |
+
else:
|
| 68 |
+
options["normalization"] = pycolmap.Normalization.L2
|
| 69 |
+
self.sift = pycolmap.Sift(
|
| 70 |
+
options=pycolmap.SiftExtractionOptions(options),
|
| 71 |
+
device=getattr(pycolmap.Device, "cuda" if use_gpu else "cpu"),
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
keypoints, scores, descriptors = self.sift.extract(image_np)
|
| 75 |
+
scales = keypoints[:, 2]
|
| 76 |
+
oris = np.rad2deg(keypoints[:, 3])
|
| 77 |
+
|
| 78 |
+
if self.conf["descriptor"] in ["sift", "rootsift"]:
|
| 79 |
+
# We still renormalize because COLMAP does not normalize well,
|
| 80 |
+
# maybe due to numerical errors
|
| 81 |
+
if self.conf["descriptor"] == "rootsift":
|
| 82 |
+
descriptors = sift_to_rootsift(descriptors)
|
| 83 |
+
descriptors = torch.from_numpy(descriptors)
|
| 84 |
+
elif self.conf["descriptor"] in ("sosnet", "hardnet"):
|
| 85 |
+
center = keypoints[:, :2] + 0.5
|
| 86 |
+
laf_scale = scales * self.conf["mr_size"] / 2
|
| 87 |
+
laf_ori = -oris
|
| 88 |
+
lafs = laf_from_center_scale_ori(
|
| 89 |
+
torch.from_numpy(center)[None],
|
| 90 |
+
torch.from_numpy(laf_scale)[None, :, None, None],
|
| 91 |
+
torch.from_numpy(laf_ori)[None, :, None],
|
| 92 |
+
).to(image.device)
|
| 93 |
+
patches = extract_patches_from_pyramid(
|
| 94 |
+
image, lafs, PS=self.conf["patch_size"]
|
| 95 |
+
)[0]
|
| 96 |
+
descriptors = patches.new_zeros((len(patches), 128))
|
| 97 |
+
if len(patches) > 0:
|
| 98 |
+
for start_idx in range(0, len(patches), self.max_batch_size):
|
| 99 |
+
end_idx = min(len(patches), start_idx + self.max_batch_size)
|
| 100 |
+
descriptors[start_idx:end_idx] = self.describe(
|
| 101 |
+
patches[start_idx:end_idx]
|
| 102 |
+
)
|
| 103 |
+
else:
|
| 104 |
+
raise ValueError(f'Unknown descriptor: {self.conf["descriptor"]}')
|
| 105 |
+
|
| 106 |
+
keypoints = torch.from_numpy(keypoints[:, :2]) # keep only x, y
|
| 107 |
+
scales = torch.from_numpy(scales)
|
| 108 |
+
oris = torch.from_numpy(oris)
|
| 109 |
+
scores = torch.from_numpy(scores)
|
| 110 |
+
if self.conf["max_keypoints"] != -1:
|
| 111 |
+
# TODO: check that the scores from PyCOLMAP are 100% correct,
|
| 112 |
+
# follow https://github.com/mihaidusmanu/pycolmap/issues/8
|
| 113 |
+
max_number = (
|
| 114 |
+
scores.shape[0]
|
| 115 |
+
if scores.shape[0] < self.conf["max_keypoints"]
|
| 116 |
+
else self.conf["max_keypoints"]
|
| 117 |
+
)
|
| 118 |
+
values, indices = torch.topk(scores, max_number)
|
| 119 |
+
keypoints = keypoints[indices]
|
| 120 |
+
scales = scales[indices]
|
| 121 |
+
oris = oris[indices]
|
| 122 |
+
scores = scores[indices]
|
| 123 |
+
descriptors = descriptors[indices]
|
| 124 |
+
|
| 125 |
+
return {
|
| 126 |
+
"keypoints": keypoints[None],
|
| 127 |
+
"scales": scales[None],
|
| 128 |
+
"oris": oris[None],
|
| 129 |
+
"scores": scores[None],
|
| 130 |
+
"descriptors": descriptors.T[None],
|
| 131 |
+
}
|
hloc/extractors/example.py
ADDED
|
@@ -0,0 +1,58 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import subprocess
|
| 4 |
+
import torch
|
| 5 |
+
import logging
|
| 6 |
+
|
| 7 |
+
from ..utils.base_model import BaseModel
|
| 8 |
+
|
| 9 |
+
example_path = Path(__file__).parent / "../../third_party/example"
|
| 10 |
+
sys.path.append(str(example_path))
|
| 11 |
+
|
| 12 |
+
# import some modules here
|
| 13 |
+
|
| 14 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 15 |
+
logger = logging.getLogger(__name__)
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class Example(BaseModel):
|
| 19 |
+
# change to your default configs
|
| 20 |
+
default_conf = {
|
| 21 |
+
"name": "example",
|
| 22 |
+
"keypoint_threshold": 0.1,
|
| 23 |
+
"max_keypoints": 2000,
|
| 24 |
+
"model_name": "model.pth",
|
| 25 |
+
}
|
| 26 |
+
required_inputs = ["image"]
|
| 27 |
+
|
| 28 |
+
def _init(self, conf):
|
| 29 |
+
|
| 30 |
+
# set checkpoints paths if needed
|
| 31 |
+
model_path = example_path / "checkpoints" / f'{conf["model_name"]}'
|
| 32 |
+
if not model_path.exists():
|
| 33 |
+
logger.info(f"No model found at {model_path}")
|
| 34 |
+
|
| 35 |
+
# init model
|
| 36 |
+
self.net = callable
|
| 37 |
+
# self.net = ExampleNet(is_test=True)
|
| 38 |
+
state_dict = torch.load(model_path, map_location="cpu")
|
| 39 |
+
self.net.load_state_dict(state_dict["model_state"])
|
| 40 |
+
logger.info(f"Load example model done.")
|
| 41 |
+
|
| 42 |
+
def _forward(self, data):
|
| 43 |
+
# data: dict, keys: 'image'
|
| 44 |
+
# image color mode: RGB
|
| 45 |
+
# image value range in [0, 1]
|
| 46 |
+
image = data["image"]
|
| 47 |
+
|
| 48 |
+
# B: batch size, N: number of keypoints
|
| 49 |
+
# keypoints shape: B x N x 2, type: torch tensor
|
| 50 |
+
# scores shape: B x N, type: torch tensor
|
| 51 |
+
# descriptors shape: B x 128 x N, type: torch tensor
|
| 52 |
+
keypoints, scores, descriptors = self.net(image)
|
| 53 |
+
|
| 54 |
+
return {
|
| 55 |
+
"keypoints": keypoints,
|
| 56 |
+
"scores": scores,
|
| 57 |
+
"descriptors": descriptors,
|
| 58 |
+
}
|
hloc/extractors/fire.py
ADDED
|
@@ -0,0 +1,73 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
import subprocess
|
| 3 |
+
import logging
|
| 4 |
+
import sys
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision.transforms as tvf
|
| 7 |
+
|
| 8 |
+
from ..utils.base_model import BaseModel
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger(__name__)
|
| 11 |
+
fire_path = Path(__file__).parent / "../../third_party/fire"
|
| 12 |
+
sys.path.append(str(fire_path))
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
import fire_network
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class FIRe(BaseModel):
|
| 19 |
+
default_conf = {
|
| 20 |
+
"global": True,
|
| 21 |
+
"asmk": False,
|
| 22 |
+
"model_name": "fire_SfM_120k.pth",
|
| 23 |
+
"scales": [2.0, 1.414, 1.0, 0.707, 0.5, 0.353, 0.25], # default params
|
| 24 |
+
"features_num": 1000, # TODO:not supported now
|
| 25 |
+
"asmk_name": "asmk_codebook.bin", # TODO:not supported now
|
| 26 |
+
"config_name": "eval_fire.yml",
|
| 27 |
+
}
|
| 28 |
+
required_inputs = ["image"]
|
| 29 |
+
|
| 30 |
+
# Models exported using
|
| 31 |
+
fire_models = {
|
| 32 |
+
"fire_SfM_120k.pth": "http://download.europe.naverlabs.com/ComputerVision/FIRe/official/fire.pth",
|
| 33 |
+
"fire_imagenet.pth": "http://download.europe.naverlabs.com/ComputerVision/FIRe/pretraining/fire_imagenet.pth",
|
| 34 |
+
}
|
| 35 |
+
|
| 36 |
+
def _init(self, conf):
|
| 37 |
+
|
| 38 |
+
assert conf["model_name"] in self.fire_models.keys()
|
| 39 |
+
# Config paths
|
| 40 |
+
model_path = fire_path / "model" / conf["model_name"]
|
| 41 |
+
|
| 42 |
+
# Download the model.
|
| 43 |
+
if not model_path.exists():
|
| 44 |
+
model_path.parent.mkdir(exist_ok=True)
|
| 45 |
+
link = self.fire_models[conf["model_name"]]
|
| 46 |
+
cmd = ["wget", link, "-O", str(model_path)]
|
| 47 |
+
logger.info(f"Downloading the FIRe model with `{cmd}`.")
|
| 48 |
+
subprocess.run(cmd, check=True)
|
| 49 |
+
|
| 50 |
+
logger.info(f"Loading fire model...")
|
| 51 |
+
|
| 52 |
+
# Load net
|
| 53 |
+
state = torch.load(model_path)
|
| 54 |
+
state["net_params"]["pretrained"] = None
|
| 55 |
+
net = fire_network.init_network(**state["net_params"])
|
| 56 |
+
net.load_state_dict(state["state_dict"])
|
| 57 |
+
self.net = net
|
| 58 |
+
|
| 59 |
+
self.norm_rgb = tvf.Normalize(
|
| 60 |
+
**dict(zip(["mean", "std"], net.runtime["mean_std"]))
|
| 61 |
+
)
|
| 62 |
+
|
| 63 |
+
# params
|
| 64 |
+
self.scales = conf["scales"]
|
| 65 |
+
|
| 66 |
+
def _forward(self, data):
|
| 67 |
+
|
| 68 |
+
image = self.norm_rgb(data["image"])
|
| 69 |
+
|
| 70 |
+
# Feature extraction.
|
| 71 |
+
desc = self.net.forward_global(image, scales=self.scales)
|
| 72 |
+
|
| 73 |
+
return {"global_descriptor": desc}
|
hloc/extractors/fire_local.py
ADDED
|
@@ -0,0 +1,90 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
import subprocess
|
| 3 |
+
import logging
|
| 4 |
+
import sys
|
| 5 |
+
import torch
|
| 6 |
+
import torchvision.transforms as tvf
|
| 7 |
+
|
| 8 |
+
from ..utils.base_model import BaseModel
|
| 9 |
+
|
| 10 |
+
logger = logging.getLogger(__name__)
|
| 11 |
+
fire_path = Path(__file__).parent / "../../third_party/fire"
|
| 12 |
+
|
| 13 |
+
sys.path.append(str(fire_path))
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
import fire_network
|
| 17 |
+
from lib.how.how.stages.evaluate import eval_asmk_fire, load_dataset_fire
|
| 18 |
+
|
| 19 |
+
from lib.asmk import asmk
|
| 20 |
+
from asmk import io_helpers, asmk_method, kernel as kern_pkg
|
| 21 |
+
|
| 22 |
+
EPS = 1e-6
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class FIRe(BaseModel):
|
| 26 |
+
default_conf = {
|
| 27 |
+
"global": True,
|
| 28 |
+
"asmk": False,
|
| 29 |
+
"model_name": "fire_SfM_120k.pth",
|
| 30 |
+
"scales": [2.0, 1.414, 1.0, 0.707, 0.5, 0.353, 0.25], # default params
|
| 31 |
+
"features_num": 1000,
|
| 32 |
+
"asmk_name": "asmk_codebook.bin",
|
| 33 |
+
"config_name": "eval_fire.yml",
|
| 34 |
+
}
|
| 35 |
+
required_inputs = ["image"]
|
| 36 |
+
|
| 37 |
+
# Models exported using
|
| 38 |
+
fire_models = {
|
| 39 |
+
"fire_SfM_120k.pth": "http://download.europe.naverlabs.com/ComputerVision/FIRe/official/fire.pth",
|
| 40 |
+
"fire_imagenet.pth": "http://download.europe.naverlabs.com/ComputerVision/FIRe/pretraining/fire_imagenet.pth",
|
| 41 |
+
}
|
| 42 |
+
|
| 43 |
+
def _init(self, conf):
|
| 44 |
+
|
| 45 |
+
assert conf["model_name"] in self.fire_models.keys()
|
| 46 |
+
|
| 47 |
+
# Config paths
|
| 48 |
+
model_path = fire_path / "model" / conf["model_name"]
|
| 49 |
+
config_path = fire_path / conf["config_name"]
|
| 50 |
+
asmk_bin_path = fire_path / "model" / conf["asmk_name"]
|
| 51 |
+
|
| 52 |
+
# Download the model.
|
| 53 |
+
if not model_path.exists():
|
| 54 |
+
model_path.parent.mkdir(exist_ok=True)
|
| 55 |
+
link = self.fire_models[conf["model_name"]]
|
| 56 |
+
cmd = ["wget", link, "-O", str(model_path)]
|
| 57 |
+
logger.info(f"Downloading the FIRe model with `{cmd}`.")
|
| 58 |
+
subprocess.run(cmd, check=True)
|
| 59 |
+
|
| 60 |
+
logger.info(f"Loading fire model...")
|
| 61 |
+
|
| 62 |
+
# Load net
|
| 63 |
+
state = torch.load(model_path)
|
| 64 |
+
state["net_params"]["pretrained"] = None
|
| 65 |
+
net = fire_network.init_network(**state["net_params"])
|
| 66 |
+
net.load_state_dict(state["state_dict"])
|
| 67 |
+
self.net = net
|
| 68 |
+
|
| 69 |
+
self.norm_rgb = tvf.Normalize(
|
| 70 |
+
**dict(zip(["mean", "std"], net.runtime["mean_std"]))
|
| 71 |
+
)
|
| 72 |
+
|
| 73 |
+
# params
|
| 74 |
+
self.scales = conf["scales"]
|
| 75 |
+
self.features_num = conf["features_num"]
|
| 76 |
+
|
| 77 |
+
def _forward(self, data):
|
| 78 |
+
|
| 79 |
+
image = self.norm_rgb(data["image"])
|
| 80 |
+
|
| 81 |
+
local_desc = self.net.forward_local(
|
| 82 |
+
image, features_num=self.features_num, scales=self.scales
|
| 83 |
+
)
|
| 84 |
+
|
| 85 |
+
logger.info(f"output[0].shape = {local_desc[0].shape}\n")
|
| 86 |
+
|
| 87 |
+
return {
|
| 88 |
+
# 'global_descriptor': desc
|
| 89 |
+
"local_descriptor": local_desc
|
| 90 |
+
}
|
hloc/extractors/lanet.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import subprocess
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from ..utils.base_model import BaseModel
|
| 7 |
+
|
| 8 |
+
lanet_path = Path(__file__).parent / "../../third_party/lanet"
|
| 9 |
+
sys.path.append(str(lanet_path))
|
| 10 |
+
from network_v0.model import PointModel
|
| 11 |
+
|
| 12 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class LANet(BaseModel):
|
| 16 |
+
default_conf = {
|
| 17 |
+
"model_name": "v0",
|
| 18 |
+
"keypoint_threshold": 0.1,
|
| 19 |
+
}
|
| 20 |
+
required_inputs = ["image"]
|
| 21 |
+
|
| 22 |
+
def _init(self, conf):
|
| 23 |
+
model_path = lanet_path / "checkpoints" / f'PointModel_{conf["model_name"]}.pth'
|
| 24 |
+
if not model_path.exists():
|
| 25 |
+
print(f"No model found at {model_path}")
|
| 26 |
+
self.net = PointModel(is_test=True)
|
| 27 |
+
state_dict = torch.load(model_path, map_location="cpu")
|
| 28 |
+
self.net.load_state_dict(state_dict["model_state"])
|
| 29 |
+
|
| 30 |
+
def _forward(self, data):
|
| 31 |
+
image = data["image"]
|
| 32 |
+
keypoints, scores, descriptors = self.net(image)
|
| 33 |
+
_, _, Hc, Wc = descriptors.shape
|
| 34 |
+
|
| 35 |
+
# Scores & Descriptors
|
| 36 |
+
kpts_score = (
|
| 37 |
+
torch.cat([keypoints, scores], dim=1).view(3, -1).t().cpu().detach().numpy()
|
| 38 |
+
)
|
| 39 |
+
descriptors = (
|
| 40 |
+
descriptors.view(256, Hc, Wc).view(256, -1).t().cpu().detach().numpy()
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
# Filter based on confidence threshold
|
| 44 |
+
descriptors = descriptors[kpts_score[:, 0] > self.conf["keypoint_threshold"], :]
|
| 45 |
+
kpts_score = kpts_score[kpts_score[:, 0] > self.conf["keypoint_threshold"], :]
|
| 46 |
+
keypoints = kpts_score[:, 1:]
|
| 47 |
+
scores = kpts_score[:, 0]
|
| 48 |
+
|
| 49 |
+
return {
|
| 50 |
+
"keypoints": torch.from_numpy(keypoints)[None],
|
| 51 |
+
"scores": torch.from_numpy(scores)[None],
|
| 52 |
+
"descriptors": torch.from_numpy(descriptors.T)[None],
|
| 53 |
+
}
|
hloc/extractors/netvlad.py
ADDED
|
@@ -0,0 +1,147 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from pathlib import Path
|
| 2 |
+
import subprocess
|
| 3 |
+
import logging
|
| 4 |
+
import numpy as np
|
| 5 |
+
import torch
|
| 6 |
+
import torch.nn as nn
|
| 7 |
+
import torch.nn.functional as F
|
| 8 |
+
import torchvision.models as models
|
| 9 |
+
from scipy.io import loadmat
|
| 10 |
+
|
| 11 |
+
from ..utils.base_model import BaseModel
|
| 12 |
+
|
| 13 |
+
logger = logging.getLogger(__name__)
|
| 14 |
+
|
| 15 |
+
EPS = 1e-6
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
class NetVLADLayer(nn.Module):
|
| 19 |
+
def __init__(self, input_dim=512, K=64, score_bias=False, intranorm=True):
|
| 20 |
+
super().__init__()
|
| 21 |
+
self.score_proj = nn.Conv1d(input_dim, K, kernel_size=1, bias=score_bias)
|
| 22 |
+
centers = nn.parameter.Parameter(torch.empty([input_dim, K]))
|
| 23 |
+
nn.init.xavier_uniform_(centers)
|
| 24 |
+
self.register_parameter("centers", centers)
|
| 25 |
+
self.intranorm = intranorm
|
| 26 |
+
self.output_dim = input_dim * K
|
| 27 |
+
|
| 28 |
+
def forward(self, x):
|
| 29 |
+
b = x.size(0)
|
| 30 |
+
scores = self.score_proj(x)
|
| 31 |
+
scores = F.softmax(scores, dim=1)
|
| 32 |
+
diff = x.unsqueeze(2) - self.centers.unsqueeze(0).unsqueeze(-1)
|
| 33 |
+
desc = (scores.unsqueeze(1) * diff).sum(dim=-1)
|
| 34 |
+
if self.intranorm:
|
| 35 |
+
# From the official MATLAB implementation.
|
| 36 |
+
desc = F.normalize(desc, dim=1)
|
| 37 |
+
desc = desc.view(b, -1)
|
| 38 |
+
desc = F.normalize(desc, dim=1)
|
| 39 |
+
return desc
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
class NetVLAD(BaseModel):
|
| 43 |
+
default_conf = {"model_name": "VGG16-NetVLAD-Pitts30K", "whiten": True}
|
| 44 |
+
required_inputs = ["image"]
|
| 45 |
+
|
| 46 |
+
# Models exported using
|
| 47 |
+
# https://github.com/uzh-rpg/netvlad_tf_open/blob/master/matlab/net_class2struct.m.
|
| 48 |
+
dir_models = {
|
| 49 |
+
"VGG16-NetVLAD-Pitts30K": "https://cvg-data.inf.ethz.ch/hloc/netvlad/Pitts30K_struct.mat",
|
| 50 |
+
"VGG16-NetVLAD-TokyoTM": "https://cvg-data.inf.ethz.ch/hloc/netvlad/TokyoTM_struct.mat",
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
def _init(self, conf):
|
| 54 |
+
assert conf["model_name"] in self.dir_models.keys()
|
| 55 |
+
|
| 56 |
+
# Download the checkpoint.
|
| 57 |
+
checkpoint = Path(torch.hub.get_dir(), "netvlad", conf["model_name"] + ".mat")
|
| 58 |
+
if not checkpoint.exists():
|
| 59 |
+
checkpoint.parent.mkdir(exist_ok=True, parents=True)
|
| 60 |
+
link = self.dir_models[conf["model_name"]]
|
| 61 |
+
cmd = ["wget", link, "-O", str(checkpoint)]
|
| 62 |
+
logger.info(f"Downloading the NetVLAD model with `{cmd}`.")
|
| 63 |
+
subprocess.run(cmd, check=True)
|
| 64 |
+
|
| 65 |
+
# Create the network.
|
| 66 |
+
# Remove classification head.
|
| 67 |
+
backbone = list(models.vgg16().children())[0]
|
| 68 |
+
# Remove last ReLU + MaxPool2d.
|
| 69 |
+
self.backbone = nn.Sequential(*list(backbone.children())[:-2])
|
| 70 |
+
|
| 71 |
+
self.netvlad = NetVLADLayer()
|
| 72 |
+
|
| 73 |
+
if conf["whiten"]:
|
| 74 |
+
self.whiten = nn.Linear(self.netvlad.output_dim, 4096)
|
| 75 |
+
|
| 76 |
+
# Parse MATLAB weights using https://github.com/uzh-rpg/netvlad_tf_open
|
| 77 |
+
mat = loadmat(checkpoint, struct_as_record=False, squeeze_me=True)
|
| 78 |
+
|
| 79 |
+
# CNN weights.
|
| 80 |
+
for layer, mat_layer in zip(self.backbone.children(), mat["net"].layers):
|
| 81 |
+
if isinstance(layer, nn.Conv2d):
|
| 82 |
+
w = mat_layer.weights[0] # Shape: S x S x IN x OUT
|
| 83 |
+
b = mat_layer.weights[1] # Shape: OUT
|
| 84 |
+
# Prepare for PyTorch - enforce float32 and right shape.
|
| 85 |
+
# w should have shape: OUT x IN x S x S
|
| 86 |
+
# b should have shape: OUT
|
| 87 |
+
w = torch.tensor(w).float().permute([3, 2, 0, 1])
|
| 88 |
+
b = torch.tensor(b).float()
|
| 89 |
+
# Update layer weights.
|
| 90 |
+
layer.weight = nn.Parameter(w)
|
| 91 |
+
layer.bias = nn.Parameter(b)
|
| 92 |
+
|
| 93 |
+
# NetVLAD weights.
|
| 94 |
+
score_w = mat["net"].layers[30].weights[0] # D x K
|
| 95 |
+
# centers are stored as opposite in official MATLAB code
|
| 96 |
+
center_w = -mat["net"].layers[30].weights[1] # D x K
|
| 97 |
+
# Prepare for PyTorch - make sure it is float32 and has right shape.
|
| 98 |
+
# score_w should have shape K x D x 1
|
| 99 |
+
# center_w should have shape D x K
|
| 100 |
+
score_w = torch.tensor(score_w).float().permute([1, 0]).unsqueeze(-1)
|
| 101 |
+
center_w = torch.tensor(center_w).float()
|
| 102 |
+
# Update layer weights.
|
| 103 |
+
self.netvlad.score_proj.weight = nn.Parameter(score_w)
|
| 104 |
+
self.netvlad.centers = nn.Parameter(center_w)
|
| 105 |
+
|
| 106 |
+
# Whitening weights.
|
| 107 |
+
if conf["whiten"]:
|
| 108 |
+
w = mat["net"].layers[33].weights[0] # Shape: 1 x 1 x IN x OUT
|
| 109 |
+
b = mat["net"].layers[33].weights[1] # Shape: OUT
|
| 110 |
+
# Prepare for PyTorch - make sure it is float32 and has right shape
|
| 111 |
+
w = torch.tensor(w).float().squeeze().permute([1, 0]) # OUT x IN
|
| 112 |
+
b = torch.tensor(b.squeeze()).float() # Shape: OUT
|
| 113 |
+
# Update layer weights.
|
| 114 |
+
self.whiten.weight = nn.Parameter(w)
|
| 115 |
+
self.whiten.bias = nn.Parameter(b)
|
| 116 |
+
|
| 117 |
+
# Preprocessing parameters.
|
| 118 |
+
self.preprocess = {
|
| 119 |
+
"mean": mat["net"].meta.normalization.averageImage[0, 0],
|
| 120 |
+
"std": np.array([1, 1, 1], dtype=np.float32),
|
| 121 |
+
}
|
| 122 |
+
|
| 123 |
+
def _forward(self, data):
|
| 124 |
+
image = data["image"]
|
| 125 |
+
assert image.shape[1] == 3
|
| 126 |
+
assert image.min() >= -EPS and image.max() <= 1 + EPS
|
| 127 |
+
image = torch.clamp(image * 255, 0.0, 255.0) # Input should be 0-255.
|
| 128 |
+
mean = self.preprocess["mean"]
|
| 129 |
+
std = self.preprocess["std"]
|
| 130 |
+
image = image - image.new_tensor(mean).view(1, -1, 1, 1)
|
| 131 |
+
image = image / image.new_tensor(std).view(1, -1, 1, 1)
|
| 132 |
+
|
| 133 |
+
# Feature extraction.
|
| 134 |
+
descriptors = self.backbone(image)
|
| 135 |
+
b, c, _, _ = descriptors.size()
|
| 136 |
+
descriptors = descriptors.view(b, c, -1)
|
| 137 |
+
|
| 138 |
+
# NetVLAD layer.
|
| 139 |
+
descriptors = F.normalize(descriptors, dim=1) # Pre-normalization.
|
| 140 |
+
desc = self.netvlad(descriptors)
|
| 141 |
+
|
| 142 |
+
# Whiten if needed.
|
| 143 |
+
if hasattr(self, "whiten"):
|
| 144 |
+
desc = self.whiten(desc)
|
| 145 |
+
desc = F.normalize(desc, dim=1) # Final L2 normalization.
|
| 146 |
+
|
| 147 |
+
return {"global_descriptor": desc}
|
hloc/extractors/openibl.py
ADDED
|
@@ -0,0 +1,26 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
import torchvision.transforms as tvf
|
| 3 |
+
|
| 4 |
+
from ..utils.base_model import BaseModel
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
class OpenIBL(BaseModel):
|
| 8 |
+
default_conf = {
|
| 9 |
+
"model_name": "vgg16_netvlad",
|
| 10 |
+
}
|
| 11 |
+
required_inputs = ["image"]
|
| 12 |
+
|
| 13 |
+
def _init(self, conf):
|
| 14 |
+
self.net = torch.hub.load(
|
| 15 |
+
"yxgeee/OpenIBL", conf["model_name"], pretrained=True
|
| 16 |
+
).eval()
|
| 17 |
+
mean = [0.48501960784313836, 0.4579568627450961, 0.4076039215686255]
|
| 18 |
+
std = [0.00392156862745098, 0.00392156862745098, 0.00392156862745098]
|
| 19 |
+
self.norm_rgb = tvf.Normalize(mean=mean, std=std)
|
| 20 |
+
|
| 21 |
+
def _forward(self, data):
|
| 22 |
+
image = self.norm_rgb(data["image"])
|
| 23 |
+
desc = self.net(image)
|
| 24 |
+
return {
|
| 25 |
+
"global_descriptor": desc,
|
| 26 |
+
}
|
hloc/extractors/r2d2.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import torchvision.transforms as tvf
|
| 4 |
+
|
| 5 |
+
from ..utils.base_model import BaseModel
|
| 6 |
+
|
| 7 |
+
r2d2_path = Path(__file__).parent / "../../third_party/r2d2"
|
| 8 |
+
sys.path.append(str(r2d2_path))
|
| 9 |
+
from extract import load_network, NonMaxSuppression, extract_multiscale
|
| 10 |
+
|
| 11 |
+
|
| 12 |
+
class R2D2(BaseModel):
|
| 13 |
+
default_conf = {
|
| 14 |
+
"model_name": "r2d2_WASF_N16.pt",
|
| 15 |
+
"max_keypoints": 5000,
|
| 16 |
+
"scale_factor": 2**0.25,
|
| 17 |
+
"min_size": 256,
|
| 18 |
+
"max_size": 1024,
|
| 19 |
+
"min_scale": 0,
|
| 20 |
+
"max_scale": 1,
|
| 21 |
+
"reliability_threshold": 0.7,
|
| 22 |
+
"repetability_threshold": 0.7,
|
| 23 |
+
}
|
| 24 |
+
required_inputs = ["image"]
|
| 25 |
+
|
| 26 |
+
def _init(self, conf):
|
| 27 |
+
model_fn = r2d2_path / "models" / conf["model_name"]
|
| 28 |
+
self.norm_rgb = tvf.Normalize(
|
| 29 |
+
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
|
| 30 |
+
)
|
| 31 |
+
self.net = load_network(model_fn)
|
| 32 |
+
self.detector = NonMaxSuppression(
|
| 33 |
+
rel_thr=conf["reliability_threshold"],
|
| 34 |
+
rep_thr=conf["repetability_threshold"],
|
| 35 |
+
)
|
| 36 |
+
|
| 37 |
+
def _forward(self, data):
|
| 38 |
+
img = data["image"]
|
| 39 |
+
img = self.norm_rgb(img)
|
| 40 |
+
|
| 41 |
+
xys, desc, scores = extract_multiscale(
|
| 42 |
+
self.net,
|
| 43 |
+
img,
|
| 44 |
+
self.detector,
|
| 45 |
+
scale_f=self.conf["scale_factor"],
|
| 46 |
+
min_size=self.conf["min_size"],
|
| 47 |
+
max_size=self.conf["max_size"],
|
| 48 |
+
min_scale=self.conf["min_scale"],
|
| 49 |
+
max_scale=self.conf["max_scale"],
|
| 50 |
+
)
|
| 51 |
+
idxs = scores.argsort()[-self.conf["max_keypoints"] or None :]
|
| 52 |
+
xy = xys[idxs, :2]
|
| 53 |
+
desc = desc[idxs].t()
|
| 54 |
+
scores = scores[idxs]
|
| 55 |
+
|
| 56 |
+
pred = {
|
| 57 |
+
"keypoints": xy[None],
|
| 58 |
+
"descriptors": desc[None],
|
| 59 |
+
"scores": scores[None],
|
| 60 |
+
}
|
| 61 |
+
return pred
|
hloc/extractors/rekd.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import subprocess
|
| 4 |
+
import torch
|
| 5 |
+
|
| 6 |
+
from ..utils.base_model import BaseModel
|
| 7 |
+
|
| 8 |
+
rekd_path = Path(__file__).parent / "../../third_party/REKD"
|
| 9 |
+
sys.path.append(str(rekd_path))
|
| 10 |
+
from training.model.REKD import REKD as REKD_
|
| 11 |
+
|
| 12 |
+
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
class REKD(BaseModel):
|
| 16 |
+
default_conf = {
|
| 17 |
+
"model_name": "v0",
|
| 18 |
+
"keypoint_threshold": 0.1,
|
| 19 |
+
}
|
| 20 |
+
required_inputs = ["image"]
|
| 21 |
+
|
| 22 |
+
def _init(self, conf):
|
| 23 |
+
model_path = rekd_path / "checkpoints" / f'PointModel_{conf["model_name"]}.pth'
|
| 24 |
+
if not model_path.exists():
|
| 25 |
+
print(f"No model found at {model_path}")
|
| 26 |
+
self.net = REKD_(is_test=True)
|
| 27 |
+
state_dict = torch.load(model_path, map_location="cpu")
|
| 28 |
+
self.net.load_state_dict(state_dict["model_state"])
|
| 29 |
+
|
| 30 |
+
def _forward(self, data):
|
| 31 |
+
image = data["image"]
|
| 32 |
+
keypoints, scores, descriptors = self.net(image)
|
| 33 |
+
_, _, Hc, Wc = descriptors.shape
|
| 34 |
+
|
| 35 |
+
# Scores & Descriptors
|
| 36 |
+
kpts_score = (
|
| 37 |
+
torch.cat([keypoints, scores], dim=1).view(3, -1).t().cpu().detach().numpy()
|
| 38 |
+
)
|
| 39 |
+
descriptors = (
|
| 40 |
+
descriptors.view(256, Hc, Wc).view(256, -1).t().cpu().detach().numpy()
|
| 41 |
+
)
|
| 42 |
+
|
| 43 |
+
# Filter based on confidence threshold
|
| 44 |
+
descriptors = descriptors[kpts_score[:, 0] > self.conf["keypoint_threshold"], :]
|
| 45 |
+
kpts_score = kpts_score[kpts_score[:, 0] > self.conf["keypoint_threshold"], :]
|
| 46 |
+
keypoints = kpts_score[:, 1:]
|
| 47 |
+
scores = kpts_score[:, 0]
|
| 48 |
+
|
| 49 |
+
return {
|
| 50 |
+
"keypoints": torch.from_numpy(keypoints)[None],
|
| 51 |
+
"scores": torch.from_numpy(scores)[None],
|
| 52 |
+
"descriptors": torch.from_numpy(descriptors.T)[None],
|
| 53 |
+
}
|
hloc/extractors/superpoint.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
from pathlib import Path
|
| 3 |
+
import torch
|
| 4 |
+
|
| 5 |
+
from ..utils.base_model import BaseModel
|
| 6 |
+
|
| 7 |
+
sys.path.append(str(Path(__file__).parent / "../../third_party"))
|
| 8 |
+
from SuperGluePretrainedNetwork.models import superpoint # noqa E402
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
# The original keypoint sampling is incorrect. We patch it here but
|
| 12 |
+
# we don't fix it upstream to not impact exisiting evaluations.
|
| 13 |
+
def sample_descriptors_fix_sampling(keypoints, descriptors, s: int = 8):
|
| 14 |
+
"""Interpolate descriptors at keypoint locations"""
|
| 15 |
+
b, c, h, w = descriptors.shape
|
| 16 |
+
keypoints = (keypoints + 0.5) / (keypoints.new_tensor([w, h]) * s)
|
| 17 |
+
keypoints = keypoints * 2 - 1 # normalize to (-1, 1)
|
| 18 |
+
descriptors = torch.nn.functional.grid_sample(
|
| 19 |
+
descriptors, keypoints.view(b, 1, -1, 2), mode="bilinear", align_corners=False
|
| 20 |
+
)
|
| 21 |
+
descriptors = torch.nn.functional.normalize(
|
| 22 |
+
descriptors.reshape(b, c, -1), p=2, dim=1
|
| 23 |
+
)
|
| 24 |
+
return descriptors
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
class SuperPoint(BaseModel):
|
| 28 |
+
default_conf = {
|
| 29 |
+
"nms_radius": 4,
|
| 30 |
+
"keypoint_threshold": 0.005,
|
| 31 |
+
"max_keypoints": -1,
|
| 32 |
+
"remove_borders": 4,
|
| 33 |
+
"fix_sampling": False,
|
| 34 |
+
}
|
| 35 |
+
required_inputs = ["image"]
|
| 36 |
+
detection_noise = 2.0
|
| 37 |
+
|
| 38 |
+
def _init(self, conf):
|
| 39 |
+
if conf["fix_sampling"]:
|
| 40 |
+
superpoint.sample_descriptors = sample_descriptors_fix_sampling
|
| 41 |
+
self.net = superpoint.SuperPoint(conf)
|
| 42 |
+
|
| 43 |
+
def _forward(self, data):
|
| 44 |
+
return self.net(data)
|
hloc/match_dense.py
ADDED
|
@@ -0,0 +1,384 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import numpy as np
|
| 2 |
+
import torch
|
| 3 |
+
import torchvision.transforms.functional as F
|
| 4 |
+
from types import SimpleNamespace
|
| 5 |
+
from .extract_features import read_image, resize_image
|
| 6 |
+
import cv2
|
| 7 |
+
|
| 8 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 9 |
+
|
| 10 |
+
confs = {
|
| 11 |
+
# Best quality but loads of points. Only use for small scenes
|
| 12 |
+
"loftr": {
|
| 13 |
+
"output": "matches-loftr",
|
| 14 |
+
"model": {
|
| 15 |
+
"name": "loftr",
|
| 16 |
+
"weights": "outdoor",
|
| 17 |
+
"max_keypoints": 2000,
|
| 18 |
+
"match_threshold": 0.2,
|
| 19 |
+
},
|
| 20 |
+
"preprocessing": {
|
| 21 |
+
"grayscale": True,
|
| 22 |
+
"resize_max": 1024,
|
| 23 |
+
"dfactor": 8,
|
| 24 |
+
"width": 640,
|
| 25 |
+
"height": 480,
|
| 26 |
+
"force_resize": True,
|
| 27 |
+
},
|
| 28 |
+
"max_error": 1, # max error for assigned keypoints (in px)
|
| 29 |
+
"cell_size": 1, # size of quantization patch (max 1 kp/patch)
|
| 30 |
+
},
|
| 31 |
+
# Semi-scalable loftr which limits detected keypoints
|
| 32 |
+
"loftr_aachen": {
|
| 33 |
+
"output": "matches-loftr_aachen",
|
| 34 |
+
"model": {
|
| 35 |
+
"name": "loftr",
|
| 36 |
+
"weights": "outdoor",
|
| 37 |
+
"max_keypoints": 2000,
|
| 38 |
+
"match_threshold": 0.2,
|
| 39 |
+
},
|
| 40 |
+
"preprocessing": {"grayscale": True, "resize_max": 1024, "dfactor": 8},
|
| 41 |
+
"max_error": 2, # max error for assigned keypoints (in px)
|
| 42 |
+
"cell_size": 8, # size of quantization patch (max 1 kp/patch)
|
| 43 |
+
},
|
| 44 |
+
# Use for matching superpoint feats with loftr
|
| 45 |
+
"loftr_superpoint": {
|
| 46 |
+
"output": "matches-loftr_aachen",
|
| 47 |
+
"model": {
|
| 48 |
+
"name": "loftr",
|
| 49 |
+
"weights": "outdoor",
|
| 50 |
+
"max_keypoints": 2000,
|
| 51 |
+
"match_threshold": 0.2,
|
| 52 |
+
},
|
| 53 |
+
"preprocessing": {"grayscale": True, "resize_max": 1024, "dfactor": 8},
|
| 54 |
+
"max_error": 4, # max error for assigned keypoints (in px)
|
| 55 |
+
"cell_size": 4, # size of quantization patch (max 1 kp/patch)
|
| 56 |
+
},
|
| 57 |
+
# Use topicfm for matching feats
|
| 58 |
+
"topicfm": {
|
| 59 |
+
"output": "matches-topicfm",
|
| 60 |
+
"model": {
|
| 61 |
+
"name": "topicfm",
|
| 62 |
+
"weights": "outdoor",
|
| 63 |
+
"max_keypoints": 2000,
|
| 64 |
+
"match_threshold": 0.2,
|
| 65 |
+
},
|
| 66 |
+
"preprocessing": {
|
| 67 |
+
"grayscale": True,
|
| 68 |
+
"force_resize": True,
|
| 69 |
+
"resize_max": 1024,
|
| 70 |
+
"dfactor": 8,
|
| 71 |
+
"width": 640,
|
| 72 |
+
"height": 480,
|
| 73 |
+
},
|
| 74 |
+
},
|
| 75 |
+
# Use topicfm for matching feats
|
| 76 |
+
"aspanformer": {
|
| 77 |
+
"output": "matches-aspanformer",
|
| 78 |
+
"model": {
|
| 79 |
+
"name": "aspanformer",
|
| 80 |
+
"weights": "outdoor",
|
| 81 |
+
"max_keypoints": 2000,
|
| 82 |
+
"match_threshold": 0.2,
|
| 83 |
+
},
|
| 84 |
+
"preprocessing": {
|
| 85 |
+
"grayscale": True,
|
| 86 |
+
"force_resize": True,
|
| 87 |
+
"resize_max": 1024,
|
| 88 |
+
"width": 640,
|
| 89 |
+
"height": 480,
|
| 90 |
+
"dfactor": 8,
|
| 91 |
+
},
|
| 92 |
+
},
|
| 93 |
+
"dkm": {
|
| 94 |
+
"output": "matches-dkm",
|
| 95 |
+
"model": {
|
| 96 |
+
"name": "dkm",
|
| 97 |
+
"weights": "outdoor",
|
| 98 |
+
"max_keypoints": 2000,
|
| 99 |
+
"match_threshold": 0.2,
|
| 100 |
+
},
|
| 101 |
+
"preprocessing": {
|
| 102 |
+
"grayscale": False,
|
| 103 |
+
"force_resize": True,
|
| 104 |
+
"resize_max": 1024,
|
| 105 |
+
"width": 80,
|
| 106 |
+
"height": 60,
|
| 107 |
+
"dfactor": 8,
|
| 108 |
+
},
|
| 109 |
+
},
|
| 110 |
+
"roma": {
|
| 111 |
+
"output": "matches-roma",
|
| 112 |
+
"model": {
|
| 113 |
+
"name": "roma",
|
| 114 |
+
"weights": "outdoor",
|
| 115 |
+
"max_keypoints": 2000,
|
| 116 |
+
"match_threshold": 0.2,
|
| 117 |
+
},
|
| 118 |
+
"preprocessing": {
|
| 119 |
+
"grayscale": False,
|
| 120 |
+
"force_resize": True,
|
| 121 |
+
"resize_max": 1024,
|
| 122 |
+
"width": 320,
|
| 123 |
+
"height": 240,
|
| 124 |
+
"dfactor": 8,
|
| 125 |
+
},
|
| 126 |
+
},
|
| 127 |
+
"dedode_sparse": {
|
| 128 |
+
"output": "matches-dedode",
|
| 129 |
+
"model": {
|
| 130 |
+
"name": "dedode",
|
| 131 |
+
"max_keypoints": 2000,
|
| 132 |
+
"match_threshold": 0.2,
|
| 133 |
+
"dense": False,
|
| 134 |
+
},
|
| 135 |
+
"preprocessing": {
|
| 136 |
+
"grayscale": False,
|
| 137 |
+
"force_resize": True,
|
| 138 |
+
"resize_max": 1024,
|
| 139 |
+
"width": 768,
|
| 140 |
+
"height": 768,
|
| 141 |
+
"dfactor": 8,
|
| 142 |
+
},
|
| 143 |
+
},
|
| 144 |
+
"sold2": {
|
| 145 |
+
"output": "matches-sold2",
|
| 146 |
+
"model": {
|
| 147 |
+
"name": "sold2",
|
| 148 |
+
"max_keypoints": 2000,
|
| 149 |
+
"match_threshold": 0.2,
|
| 150 |
+
},
|
| 151 |
+
"preprocessing": {
|
| 152 |
+
"grayscale": True,
|
| 153 |
+
"force_resize": True,
|
| 154 |
+
"resize_max": 1024,
|
| 155 |
+
"width": 640,
|
| 156 |
+
"height": 480,
|
| 157 |
+
"dfactor": 8,
|
| 158 |
+
},
|
| 159 |
+
},
|
| 160 |
+
"gluestick": {
|
| 161 |
+
"output": "matches-gluestick",
|
| 162 |
+
"model": {
|
| 163 |
+
"name": "gluestick",
|
| 164 |
+
"use_lines": True,
|
| 165 |
+
"max_keypoints": 1000,
|
| 166 |
+
"max_lines": 300,
|
| 167 |
+
"force_num_keypoints": False,
|
| 168 |
+
},
|
| 169 |
+
"preprocessing": {
|
| 170 |
+
"grayscale": True,
|
| 171 |
+
"force_resize": True,
|
| 172 |
+
"resize_max": 1024,
|
| 173 |
+
"width": 640,
|
| 174 |
+
"height": 480,
|
| 175 |
+
"dfactor": 8,
|
| 176 |
+
},
|
| 177 |
+
},
|
| 178 |
+
}
|
| 179 |
+
|
| 180 |
+
|
| 181 |
+
def scale_keypoints(kpts, scale):
|
| 182 |
+
if np.any(scale != 1.0):
|
| 183 |
+
kpts *= kpts.new_tensor(scale)
|
| 184 |
+
return kpts
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
def scale_lines(lines, scale):
|
| 188 |
+
if np.any(scale != 1.0):
|
| 189 |
+
lines *= lines.new_tensor(scale)
|
| 190 |
+
return lines
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
def match(model, path_0, path_1, conf):
|
| 194 |
+
default_conf = {
|
| 195 |
+
"grayscale": True,
|
| 196 |
+
"resize_max": 1024,
|
| 197 |
+
"dfactor": 8,
|
| 198 |
+
"cache_images": False,
|
| 199 |
+
"force_resize": False,
|
| 200 |
+
"width": 320,
|
| 201 |
+
"height": 240,
|
| 202 |
+
}
|
| 203 |
+
|
| 204 |
+
def preprocess(image: np.ndarray):
|
| 205 |
+
image = image.astype(np.float32, copy=False)
|
| 206 |
+
size = image.shape[:2][::-1]
|
| 207 |
+
scale = np.array([1.0, 1.0])
|
| 208 |
+
if conf.resize_max:
|
| 209 |
+
scale = conf.resize_max / max(size)
|
| 210 |
+
if scale < 1.0:
|
| 211 |
+
size_new = tuple(int(round(x * scale)) for x in size)
|
| 212 |
+
image = resize_image(image, size_new, "cv2_area")
|
| 213 |
+
scale = np.array(size) / np.array(size_new)
|
| 214 |
+
if conf.force_resize:
|
| 215 |
+
size = image.shape[:2][::-1]
|
| 216 |
+
image = resize_image(image, (conf.width, conf.height), "cv2_area")
|
| 217 |
+
size_new = (conf.width, conf.height)
|
| 218 |
+
scale = np.array(size) / np.array(size_new)
|
| 219 |
+
if conf.grayscale:
|
| 220 |
+
assert image.ndim == 2, image.shape
|
| 221 |
+
image = image[None]
|
| 222 |
+
else:
|
| 223 |
+
image = image.transpose((2, 0, 1)) # HxWxC to CxHxW
|
| 224 |
+
image = torch.from_numpy(image / 255.0).float()
|
| 225 |
+
# assure that the size is divisible by dfactor
|
| 226 |
+
size_new = tuple(
|
| 227 |
+
map(lambda x: int(x // conf.dfactor * conf.dfactor), image.shape[-2:])
|
| 228 |
+
)
|
| 229 |
+
image = F.resize(image, size=size_new, antialias=True)
|
| 230 |
+
scale = np.array(size) / np.array(size_new)[::-1]
|
| 231 |
+
return image, scale
|
| 232 |
+
|
| 233 |
+
conf = SimpleNamespace(**{**default_conf, **conf})
|
| 234 |
+
image0 = read_image(path_0, conf.grayscale)
|
| 235 |
+
image1 = read_image(path_1, conf.grayscale)
|
| 236 |
+
image0, scale0 = preprocess(image0)
|
| 237 |
+
image1, scale1 = preprocess(image1)
|
| 238 |
+
image0 = image0.to(device)[None]
|
| 239 |
+
image1 = image1.to(device)[None]
|
| 240 |
+
pred = model({"image0": image0, "image1": image1})
|
| 241 |
+
|
| 242 |
+
# Rescale keypoints and move to cpu
|
| 243 |
+
kpts0, kpts1 = pred["keypoints0"], pred["keypoints1"]
|
| 244 |
+
kpts0 = scale_keypoints(kpts0 + 0.5, scale0) - 0.5
|
| 245 |
+
kpts1 = scale_keypoints(kpts1 + 0.5, scale1) - 0.5
|
| 246 |
+
|
| 247 |
+
ret = {
|
| 248 |
+
"image0": image0.squeeze().cpu().numpy(),
|
| 249 |
+
"image1": image1.squeeze().cpu().numpy(),
|
| 250 |
+
"keypoints0": kpts0.cpu().numpy(),
|
| 251 |
+
"keypoints1": kpts1.cpu().numpy(),
|
| 252 |
+
}
|
| 253 |
+
if "mconf" in pred.keys():
|
| 254 |
+
ret["mconf"] = pred["mconf"].cpu().numpy()
|
| 255 |
+
return ret
|
| 256 |
+
|
| 257 |
+
|
| 258 |
+
@torch.no_grad()
|
| 259 |
+
def match_images(model, image_0, image_1, conf, device="cpu"):
|
| 260 |
+
default_conf = {
|
| 261 |
+
"grayscale": True,
|
| 262 |
+
"resize_max": 1024,
|
| 263 |
+
"dfactor": 8,
|
| 264 |
+
"cache_images": False,
|
| 265 |
+
"force_resize": False,
|
| 266 |
+
"width": 320,
|
| 267 |
+
"height": 240,
|
| 268 |
+
}
|
| 269 |
+
|
| 270 |
+
def preprocess(image: np.ndarray):
|
| 271 |
+
image = image.astype(np.float32, copy=False)
|
| 272 |
+
size = image.shape[:2][::-1]
|
| 273 |
+
scale = np.array([1.0, 1.0])
|
| 274 |
+
if conf.resize_max:
|
| 275 |
+
scale = conf.resize_max / max(size)
|
| 276 |
+
if scale < 1.0:
|
| 277 |
+
size_new = tuple(int(round(x * scale)) for x in size)
|
| 278 |
+
image = resize_image(image, size_new, "cv2_area")
|
| 279 |
+
scale = np.array(size) / np.array(size_new)
|
| 280 |
+
if conf.force_resize:
|
| 281 |
+
size = image.shape[:2][::-1]
|
| 282 |
+
image = resize_image(image, (conf.width, conf.height), "cv2_area")
|
| 283 |
+
size_new = (conf.width, conf.height)
|
| 284 |
+
scale = np.array(size) / np.array(size_new)
|
| 285 |
+
if conf.grayscale:
|
| 286 |
+
assert image.ndim == 2, image.shape
|
| 287 |
+
image = image[None]
|
| 288 |
+
else:
|
| 289 |
+
image = image.transpose((2, 0, 1)) # HxWxC to CxHxW
|
| 290 |
+
image = torch.from_numpy(image / 255.0).float()
|
| 291 |
+
|
| 292 |
+
# assure that the size is divisible by dfactor
|
| 293 |
+
size_new = tuple(
|
| 294 |
+
map(lambda x: int(x // conf.dfactor * conf.dfactor), image.shape[-2:])
|
| 295 |
+
)
|
| 296 |
+
image = F.resize(image, size=size_new)
|
| 297 |
+
scale = np.array(size) / np.array(size_new)[::-1]
|
| 298 |
+
return image, scale
|
| 299 |
+
|
| 300 |
+
conf = SimpleNamespace(**{**default_conf, **conf})
|
| 301 |
+
|
| 302 |
+
if len(image_0.shape) == 3 and conf.grayscale:
|
| 303 |
+
image0 = cv2.cvtColor(image_0, cv2.COLOR_RGB2GRAY)
|
| 304 |
+
else:
|
| 305 |
+
image0 = image_0
|
| 306 |
+
if len(image_0.shape) == 3 and conf.grayscale:
|
| 307 |
+
image1 = cv2.cvtColor(image_1, cv2.COLOR_RGB2GRAY)
|
| 308 |
+
else:
|
| 309 |
+
image1 = image_1
|
| 310 |
+
|
| 311 |
+
# comment following lines, image is always RGB mode
|
| 312 |
+
# if not conf.grayscale and len(image0.shape) == 3:
|
| 313 |
+
# image0 = image0[:, :, ::-1] # BGR to RGB
|
| 314 |
+
# if not conf.grayscale and len(image1.shape) == 3:
|
| 315 |
+
# image1 = image1[:, :, ::-1] # BGR to RGB
|
| 316 |
+
|
| 317 |
+
image0, scale0 = preprocess(image0)
|
| 318 |
+
image1, scale1 = preprocess(image1)
|
| 319 |
+
image0 = image0.to(device)[None]
|
| 320 |
+
image1 = image1.to(device)[None]
|
| 321 |
+
pred = model({"image0": image0, "image1": image1})
|
| 322 |
+
|
| 323 |
+
s0 = np.array(image_0.shape[:2][::-1]) / np.array(image0.shape[-2:][::-1])
|
| 324 |
+
s1 = np.array(image_1.shape[:2][::-1]) / np.array(image1.shape[-2:][::-1])
|
| 325 |
+
|
| 326 |
+
# Rescale keypoints and move to cpu
|
| 327 |
+
if "keypoints0" in pred.keys() and "keypoints1" in pred.keys():
|
| 328 |
+
kpts0, kpts1 = pred["keypoints0"], pred["keypoints1"]
|
| 329 |
+
kpts0_origin = scale_keypoints(kpts0 + 0.5, s0) - 0.5
|
| 330 |
+
kpts1_origin = scale_keypoints(kpts1 + 0.5, s1) - 0.5
|
| 331 |
+
|
| 332 |
+
ret = {
|
| 333 |
+
"image0": image0.squeeze().cpu().numpy(),
|
| 334 |
+
"image1": image1.squeeze().cpu().numpy(),
|
| 335 |
+
"image0_orig": image_0,
|
| 336 |
+
"image1_orig": image_1,
|
| 337 |
+
"keypoints0": kpts0.cpu().numpy(),
|
| 338 |
+
"keypoints1": kpts1.cpu().numpy(),
|
| 339 |
+
"keypoints0_orig": kpts0_origin.cpu().numpy(),
|
| 340 |
+
"keypoints1_orig": kpts1_origin.cpu().numpy(),
|
| 341 |
+
"original_size0": np.array(image_0.shape[:2][::-1]),
|
| 342 |
+
"original_size1": np.array(image_1.shape[:2][::-1]),
|
| 343 |
+
"new_size0": np.array(image0.shape[-2:][::-1]),
|
| 344 |
+
"new_size1": np.array(image1.shape[-2:][::-1]),
|
| 345 |
+
"scale0": s0,
|
| 346 |
+
"scale1": s1,
|
| 347 |
+
}
|
| 348 |
+
if "mconf" in pred.keys():
|
| 349 |
+
ret["mconf"] = pred["mconf"].cpu().numpy()
|
| 350 |
+
if "lines0" in pred.keys() and "lines1" in pred.keys():
|
| 351 |
+
if "keypoints0" in pred.keys() and "keypoints1" in pred.keys():
|
| 352 |
+
kpts0, kpts1 = pred["keypoints0"], pred["keypoints1"]
|
| 353 |
+
kpts0_origin = scale_keypoints(kpts0 + 0.5, s0) - 0.5
|
| 354 |
+
kpts1_origin = scale_keypoints(kpts1 + 0.5, s1) - 0.5
|
| 355 |
+
kpts0_origin = kpts0_origin.cpu().numpy()
|
| 356 |
+
kpts1_origin = kpts1_origin.cpu().numpy()
|
| 357 |
+
else:
|
| 358 |
+
kpts0_origin, kpts1_origin = None, None # np.zeros([0]), np.zeros([0])
|
| 359 |
+
lines0, lines1 = pred["lines0"], pred["lines1"]
|
| 360 |
+
lines0_raw, lines1_raw = pred["raw_lines0"], pred["raw_lines1"]
|
| 361 |
+
|
| 362 |
+
lines0_raw = torch.from_numpy(lines0_raw.copy())
|
| 363 |
+
lines1_raw = torch.from_numpy(lines1_raw.copy())
|
| 364 |
+
lines0_raw = scale_lines(lines0_raw + 0.5, s0) - 0.5
|
| 365 |
+
lines1_raw = scale_lines(lines1_raw + 0.5, s1) - 0.5
|
| 366 |
+
|
| 367 |
+
lines0 = torch.from_numpy(lines0.copy())
|
| 368 |
+
lines1 = torch.from_numpy(lines1.copy())
|
| 369 |
+
lines0 = scale_lines(lines0 + 0.5, s0) - 0.5
|
| 370 |
+
lines1 = scale_lines(lines1 + 0.5, s1) - 0.5
|
| 371 |
+
|
| 372 |
+
ret = {
|
| 373 |
+
"image0_orig": image_0,
|
| 374 |
+
"image1_orig": image_1,
|
| 375 |
+
"line0": lines0_raw.cpu().numpy(),
|
| 376 |
+
"line1": lines1_raw.cpu().numpy(),
|
| 377 |
+
"line0_orig": lines0.cpu().numpy(),
|
| 378 |
+
"line1_orig": lines1.cpu().numpy(),
|
| 379 |
+
"line_keypoints0_orig": kpts0_origin,
|
| 380 |
+
"line_keypoints1_orig": kpts1_origin,
|
| 381 |
+
}
|
| 382 |
+
del pred
|
| 383 |
+
torch.cuda.empty_cache()
|
| 384 |
+
return ret
|
hloc/match_features.py
ADDED
|
@@ -0,0 +1,389 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
from typing import Union, Optional, Dict, List, Tuple
|
| 3 |
+
from pathlib import Path
|
| 4 |
+
import pprint
|
| 5 |
+
from queue import Queue
|
| 6 |
+
from threading import Thread
|
| 7 |
+
from functools import partial
|
| 8 |
+
from tqdm import tqdm
|
| 9 |
+
import h5py
|
| 10 |
+
import torch
|
| 11 |
+
|
| 12 |
+
from . import matchers, logger
|
| 13 |
+
from .utils.base_model import dynamic_load
|
| 14 |
+
from .utils.parsers import names_to_pair, names_to_pair_old, parse_retrieval
|
| 15 |
+
import numpy as np
|
| 16 |
+
|
| 17 |
+
"""
|
| 18 |
+
A set of standard configurations that can be directly selected from the command
|
| 19 |
+
line using their name. Each is a dictionary with the following entries:
|
| 20 |
+
- output: the name of the match file that will be generated.
|
| 21 |
+
- model: the model configuration, as passed to a feature matcher.
|
| 22 |
+
"""
|
| 23 |
+
confs = {
|
| 24 |
+
"superglue": {
|
| 25 |
+
"output": "matches-superglue",
|
| 26 |
+
"model": {
|
| 27 |
+
"name": "superglue",
|
| 28 |
+
"weights": "outdoor",
|
| 29 |
+
"sinkhorn_iterations": 50,
|
| 30 |
+
"match_threshold": 0.2,
|
| 31 |
+
},
|
| 32 |
+
"preprocessing": {
|
| 33 |
+
"grayscale": True,
|
| 34 |
+
"resize_max": 1024,
|
| 35 |
+
"dfactor": 8,
|
| 36 |
+
"force_resize": False,
|
| 37 |
+
},
|
| 38 |
+
},
|
| 39 |
+
"superglue-fast": {
|
| 40 |
+
"output": "matches-superglue-it5",
|
| 41 |
+
"model": {
|
| 42 |
+
"name": "superglue",
|
| 43 |
+
"weights": "outdoor",
|
| 44 |
+
"sinkhorn_iterations": 5,
|
| 45 |
+
"match_threshold": 0.2,
|
| 46 |
+
},
|
| 47 |
+
},
|
| 48 |
+
"superpoint-lightglue": {
|
| 49 |
+
"output": "matches-lightglue",
|
| 50 |
+
"model": {
|
| 51 |
+
"name": "lightglue",
|
| 52 |
+
"match_threshold": 0.2,
|
| 53 |
+
"width_confidence": 0.99, # for point pruning
|
| 54 |
+
"depth_confidence": 0.95, # for early stopping,
|
| 55 |
+
"features": "superpoint",
|
| 56 |
+
"model_name": "superpoint_lightglue.pth",
|
| 57 |
+
},
|
| 58 |
+
"preprocessing": {
|
| 59 |
+
"grayscale": True,
|
| 60 |
+
"resize_max": 1024,
|
| 61 |
+
"dfactor": 8,
|
| 62 |
+
"force_resize": False,
|
| 63 |
+
},
|
| 64 |
+
},
|
| 65 |
+
"disk-lightglue": {
|
| 66 |
+
"output": "matches-lightglue",
|
| 67 |
+
"model": {
|
| 68 |
+
"name": "lightglue",
|
| 69 |
+
"match_threshold": 0.2,
|
| 70 |
+
"width_confidence": 0.99, # for point pruning
|
| 71 |
+
"depth_confidence": 0.95, # for early stopping,
|
| 72 |
+
"features": "disk",
|
| 73 |
+
"model_name": "disk_lightglue.pth",
|
| 74 |
+
},
|
| 75 |
+
"preprocessing": {
|
| 76 |
+
"grayscale": True,
|
| 77 |
+
"resize_max": 1024,
|
| 78 |
+
"dfactor": 8,
|
| 79 |
+
"force_resize": False,
|
| 80 |
+
},
|
| 81 |
+
},
|
| 82 |
+
"sgmnet": {
|
| 83 |
+
"output": "matches-sgmnet",
|
| 84 |
+
"model": {
|
| 85 |
+
"name": "sgmnet",
|
| 86 |
+
"seed_top_k": [256, 256],
|
| 87 |
+
"seed_radius_coe": 0.01,
|
| 88 |
+
"net_channels": 128,
|
| 89 |
+
"layer_num": 9,
|
| 90 |
+
"head": 4,
|
| 91 |
+
"seedlayer": [0, 6],
|
| 92 |
+
"use_mc_seeding": True,
|
| 93 |
+
"use_score_encoding": False,
|
| 94 |
+
"conf_bar": [1.11, 0.1],
|
| 95 |
+
"sink_iter": [10, 100],
|
| 96 |
+
"detach_iter": 1000000,
|
| 97 |
+
"match_threshold": 0.2,
|
| 98 |
+
},
|
| 99 |
+
"preprocessing": {
|
| 100 |
+
"grayscale": True,
|
| 101 |
+
"resize_max": 1024,
|
| 102 |
+
"dfactor": 8,
|
| 103 |
+
"force_resize": False,
|
| 104 |
+
},
|
| 105 |
+
},
|
| 106 |
+
"NN-superpoint": {
|
| 107 |
+
"output": "matches-NN-mutual-dist.7",
|
| 108 |
+
"model": {
|
| 109 |
+
"name": "nearest_neighbor",
|
| 110 |
+
"do_mutual_check": True,
|
| 111 |
+
"distance_threshold": 0.7,
|
| 112 |
+
"match_threshold": 0.2,
|
| 113 |
+
},
|
| 114 |
+
},
|
| 115 |
+
"NN-ratio": {
|
| 116 |
+
"output": "matches-NN-mutual-ratio.8",
|
| 117 |
+
"model": {
|
| 118 |
+
"name": "nearest_neighbor",
|
| 119 |
+
"do_mutual_check": True,
|
| 120 |
+
"ratio_threshold": 0.8,
|
| 121 |
+
"match_threshold": 0.2,
|
| 122 |
+
},
|
| 123 |
+
},
|
| 124 |
+
"NN-mutual": {
|
| 125 |
+
"output": "matches-NN-mutual",
|
| 126 |
+
"model": {
|
| 127 |
+
"name": "nearest_neighbor",
|
| 128 |
+
"do_mutual_check": True,
|
| 129 |
+
"match_threshold": 0.2,
|
| 130 |
+
},
|
| 131 |
+
},
|
| 132 |
+
"Dual-Softmax": {
|
| 133 |
+
"output": "matches-Dual-Softmax",
|
| 134 |
+
"model": {
|
| 135 |
+
"name": "dual_softmax",
|
| 136 |
+
"do_mutual_check": True,
|
| 137 |
+
"match_threshold": 0.2, # TODO
|
| 138 |
+
},
|
| 139 |
+
},
|
| 140 |
+
"adalam": {
|
| 141 |
+
"output": "matches-adalam",
|
| 142 |
+
"model": {
|
| 143 |
+
"name": "adalam",
|
| 144 |
+
"match_threshold": 0.2,
|
| 145 |
+
},
|
| 146 |
+
},
|
| 147 |
+
}
|
| 148 |
+
|
| 149 |
+
|
| 150 |
+
class WorkQueue:
|
| 151 |
+
def __init__(self, work_fn, num_threads=1):
|
| 152 |
+
self.queue = Queue(num_threads)
|
| 153 |
+
self.threads = [
|
| 154 |
+
Thread(target=self.thread_fn, args=(work_fn,)) for _ in range(num_threads)
|
| 155 |
+
]
|
| 156 |
+
for thread in self.threads:
|
| 157 |
+
thread.start()
|
| 158 |
+
|
| 159 |
+
def join(self):
|
| 160 |
+
for thread in self.threads:
|
| 161 |
+
self.queue.put(None)
|
| 162 |
+
for thread in self.threads:
|
| 163 |
+
thread.join()
|
| 164 |
+
|
| 165 |
+
def thread_fn(self, work_fn):
|
| 166 |
+
item = self.queue.get()
|
| 167 |
+
while item is not None:
|
| 168 |
+
work_fn(item)
|
| 169 |
+
item = self.queue.get()
|
| 170 |
+
|
| 171 |
+
def put(self, data):
|
| 172 |
+
self.queue.put(data)
|
| 173 |
+
|
| 174 |
+
|
| 175 |
+
class FeaturePairsDataset(torch.utils.data.Dataset):
|
| 176 |
+
def __init__(self, pairs, feature_path_q, feature_path_r):
|
| 177 |
+
self.pairs = pairs
|
| 178 |
+
self.feature_path_q = feature_path_q
|
| 179 |
+
self.feature_path_r = feature_path_r
|
| 180 |
+
|
| 181 |
+
def __getitem__(self, idx):
|
| 182 |
+
name0, name1 = self.pairs[idx]
|
| 183 |
+
data = {}
|
| 184 |
+
with h5py.File(self.feature_path_q, "r") as fd:
|
| 185 |
+
grp = fd[name0]
|
| 186 |
+
for k, v in grp.items():
|
| 187 |
+
data[k + "0"] = torch.from_numpy(v.__array__()).float()
|
| 188 |
+
# some matchers might expect an image but only use its size
|
| 189 |
+
data["image0"] = torch.empty((1,) + tuple(grp["image_size"])[::-1])
|
| 190 |
+
with h5py.File(self.feature_path_r, "r") as fd:
|
| 191 |
+
grp = fd[name1]
|
| 192 |
+
for k, v in grp.items():
|
| 193 |
+
data[k + "1"] = torch.from_numpy(v.__array__()).float()
|
| 194 |
+
data["image1"] = torch.empty((1,) + tuple(grp["image_size"])[::-1])
|
| 195 |
+
return data
|
| 196 |
+
|
| 197 |
+
def __len__(self):
|
| 198 |
+
return len(self.pairs)
|
| 199 |
+
|
| 200 |
+
|
| 201 |
+
def writer_fn(inp, match_path):
|
| 202 |
+
pair, pred = inp
|
| 203 |
+
with h5py.File(str(match_path), "a", libver="latest") as fd:
|
| 204 |
+
if pair in fd:
|
| 205 |
+
del fd[pair]
|
| 206 |
+
grp = fd.create_group(pair)
|
| 207 |
+
matches = pred["matches0"][0].cpu().short().numpy()
|
| 208 |
+
grp.create_dataset("matches0", data=matches)
|
| 209 |
+
if "matching_scores0" in pred:
|
| 210 |
+
scores = pred["matching_scores0"][0].cpu().half().numpy()
|
| 211 |
+
grp.create_dataset("matching_scores0", data=scores)
|
| 212 |
+
|
| 213 |
+
|
| 214 |
+
def main(
|
| 215 |
+
conf: Dict,
|
| 216 |
+
pairs: Path,
|
| 217 |
+
features: Union[Path, str],
|
| 218 |
+
export_dir: Optional[Path] = None,
|
| 219 |
+
matches: Optional[Path] = None,
|
| 220 |
+
features_ref: Optional[Path] = None,
|
| 221 |
+
overwrite: bool = False,
|
| 222 |
+
) -> Path:
|
| 223 |
+
|
| 224 |
+
if isinstance(features, Path) or Path(features).exists():
|
| 225 |
+
features_q = features
|
| 226 |
+
if matches is None:
|
| 227 |
+
raise ValueError(
|
| 228 |
+
"Either provide both features and matches as Path" " or both as names."
|
| 229 |
+
)
|
| 230 |
+
else:
|
| 231 |
+
if export_dir is None:
|
| 232 |
+
raise ValueError(
|
| 233 |
+
"Provide an export_dir if features is not" f" a file path: {features}."
|
| 234 |
+
)
|
| 235 |
+
features_q = Path(export_dir, features + ".h5")
|
| 236 |
+
if matches is None:
|
| 237 |
+
matches = Path(export_dir, f'{features}_{conf["output"]}_{pairs.stem}.h5')
|
| 238 |
+
|
| 239 |
+
if features_ref is None:
|
| 240 |
+
features_ref = features_q
|
| 241 |
+
match_from_paths(conf, pairs, matches, features_q, features_ref, overwrite)
|
| 242 |
+
|
| 243 |
+
return matches
|
| 244 |
+
|
| 245 |
+
|
| 246 |
+
def find_unique_new_pairs(pairs_all: List[Tuple[str]], match_path: Path = None):
|
| 247 |
+
"""Avoid to recompute duplicates to save time."""
|
| 248 |
+
pairs = set()
|
| 249 |
+
for i, j in pairs_all:
|
| 250 |
+
if (j, i) not in pairs:
|
| 251 |
+
pairs.add((i, j))
|
| 252 |
+
pairs = list(pairs)
|
| 253 |
+
if match_path is not None and match_path.exists():
|
| 254 |
+
with h5py.File(str(match_path), "r", libver="latest") as fd:
|
| 255 |
+
pairs_filtered = []
|
| 256 |
+
for i, j in pairs:
|
| 257 |
+
if (
|
| 258 |
+
names_to_pair(i, j) in fd
|
| 259 |
+
or names_to_pair(j, i) in fd
|
| 260 |
+
or names_to_pair_old(i, j) in fd
|
| 261 |
+
or names_to_pair_old(j, i) in fd
|
| 262 |
+
):
|
| 263 |
+
continue
|
| 264 |
+
pairs_filtered.append((i, j))
|
| 265 |
+
return pairs_filtered
|
| 266 |
+
return pairs
|
| 267 |
+
|
| 268 |
+
|
| 269 |
+
@torch.no_grad()
|
| 270 |
+
def match_from_paths(
|
| 271 |
+
conf: Dict,
|
| 272 |
+
pairs_path: Path,
|
| 273 |
+
match_path: Path,
|
| 274 |
+
feature_path_q: Path,
|
| 275 |
+
feature_path_ref: Path,
|
| 276 |
+
overwrite: bool = False,
|
| 277 |
+
) -> Path:
|
| 278 |
+
logger.info(
|
| 279 |
+
"Matching local features with configuration:" f"\n{pprint.pformat(conf)}"
|
| 280 |
+
)
|
| 281 |
+
|
| 282 |
+
if not feature_path_q.exists():
|
| 283 |
+
raise FileNotFoundError(f"Query feature file {feature_path_q}.")
|
| 284 |
+
if not feature_path_ref.exists():
|
| 285 |
+
raise FileNotFoundError(f"Reference feature file {feature_path_ref}.")
|
| 286 |
+
match_path.parent.mkdir(exist_ok=True, parents=True)
|
| 287 |
+
|
| 288 |
+
assert pairs_path.exists(), pairs_path
|
| 289 |
+
pairs = parse_retrieval(pairs_path)
|
| 290 |
+
pairs = [(q, r) for q, rs in pairs.items() for r in rs]
|
| 291 |
+
pairs = find_unique_new_pairs(pairs, None if overwrite else match_path)
|
| 292 |
+
if len(pairs) == 0:
|
| 293 |
+
logger.info("Skipping the matching.")
|
| 294 |
+
return
|
| 295 |
+
|
| 296 |
+
device = "cuda" if torch.cuda.is_available() else "cpu"
|
| 297 |
+
Model = dynamic_load(matchers, conf["model"]["name"])
|
| 298 |
+
model = Model(conf["model"]).eval().to(device)
|
| 299 |
+
|
| 300 |
+
dataset = FeaturePairsDataset(pairs, feature_path_q, feature_path_ref)
|
| 301 |
+
loader = torch.utils.data.DataLoader(
|
| 302 |
+
dataset, num_workers=5, batch_size=1, shuffle=False, pin_memory=True
|
| 303 |
+
)
|
| 304 |
+
writer_queue = WorkQueue(partial(writer_fn, match_path=match_path), 5)
|
| 305 |
+
|
| 306 |
+
for idx, data in enumerate(tqdm(loader, smoothing=0.1)):
|
| 307 |
+
data = {
|
| 308 |
+
k: v if k.startswith("image") else v.to(device, non_blocking=True)
|
| 309 |
+
for k, v in data.items()
|
| 310 |
+
}
|
| 311 |
+
pred = model(data)
|
| 312 |
+
pair = names_to_pair(*pairs[idx])
|
| 313 |
+
writer_queue.put((pair, pred))
|
| 314 |
+
writer_queue.join()
|
| 315 |
+
logger.info("Finished exporting matches.")
|
| 316 |
+
|
| 317 |
+
|
| 318 |
+
def scale_keypoints(kpts, scale):
|
| 319 |
+
if np.any(scale != 1.0):
|
| 320 |
+
kpts *= kpts.new_tensor(scale)
|
| 321 |
+
return kpts
|
| 322 |
+
|
| 323 |
+
|
| 324 |
+
@torch.no_grad()
|
| 325 |
+
def match_images(model, feat0, feat1):
|
| 326 |
+
# forward pass to match keypoints
|
| 327 |
+
desc0 = feat0["descriptors"][0]
|
| 328 |
+
desc1 = feat1["descriptors"][0]
|
| 329 |
+
if len(desc0.shape) == 2:
|
| 330 |
+
desc0 = desc0.unsqueeze(0)
|
| 331 |
+
if len(desc1.shape) == 2:
|
| 332 |
+
desc1 = desc1.unsqueeze(0)
|
| 333 |
+
pred = model(
|
| 334 |
+
{
|
| 335 |
+
"image0": feat0["image"],
|
| 336 |
+
"keypoints0": feat0["keypoints"][0],
|
| 337 |
+
"scores0": feat0["scores"][0].unsqueeze(0),
|
| 338 |
+
"descriptors0": desc0,
|
| 339 |
+
"image1": feat1["image"],
|
| 340 |
+
"keypoints1": feat1["keypoints"][0],
|
| 341 |
+
"scores1": feat1["scores"][0].unsqueeze(0),
|
| 342 |
+
"descriptors1": desc1,
|
| 343 |
+
}
|
| 344 |
+
)
|
| 345 |
+
pred = {
|
| 346 |
+
k: v.cpu().detach()[0] if isinstance(v, torch.Tensor) else v
|
| 347 |
+
for k, v in pred.items()
|
| 348 |
+
}
|
| 349 |
+
kpts0, kpts1 = (
|
| 350 |
+
feat0["keypoints"][0].cpu().numpy(),
|
| 351 |
+
feat1["keypoints"][0].cpu().numpy(),
|
| 352 |
+
)
|
| 353 |
+
matches, confid = pred["matches0"], pred["matching_scores0"]
|
| 354 |
+
# Keep the matching keypoints.
|
| 355 |
+
valid = matches > -1
|
| 356 |
+
mkpts0 = kpts0[valid]
|
| 357 |
+
mkpts1 = kpts1[matches[valid]]
|
| 358 |
+
mconfid = confid[valid]
|
| 359 |
+
# rescale the keypoints to their original size
|
| 360 |
+
s0 = feat0["original_size"] / feat0["size"]
|
| 361 |
+
s1 = feat1["original_size"] / feat1["size"]
|
| 362 |
+
kpts0_origin = scale_keypoints(torch.from_numpy(mkpts0 + 0.5), s0) - 0.5
|
| 363 |
+
kpts1_origin = scale_keypoints(torch.from_numpy(mkpts1 + 0.5), s1) - 0.5
|
| 364 |
+
ret = {
|
| 365 |
+
"image0_orig": feat0["image_orig"],
|
| 366 |
+
"image1_orig": feat1["image_orig"],
|
| 367 |
+
"keypoints0": kpts0,
|
| 368 |
+
"keypoints1": kpts1,
|
| 369 |
+
"keypoints0_orig": kpts0_origin.numpy(),
|
| 370 |
+
"keypoints1_orig": kpts1_origin.numpy(),
|
| 371 |
+
"mconf": mconfid,
|
| 372 |
+
}
|
| 373 |
+
del feat0, feat1, desc0, desc1, kpts0, kpts1, kpts0_origin, kpts1_origin
|
| 374 |
+
torch.cuda.empty_cache()
|
| 375 |
+
|
| 376 |
+
return ret
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
if __name__ == "__main__":
|
| 380 |
+
parser = argparse.ArgumentParser()
|
| 381 |
+
parser.add_argument("--pairs", type=Path, required=True)
|
| 382 |
+
parser.add_argument("--export_dir", type=Path)
|
| 383 |
+
parser.add_argument("--features", type=str, default="feats-superpoint-n4096-r1024")
|
| 384 |
+
parser.add_argument("--matches", type=Path)
|
| 385 |
+
parser.add_argument(
|
| 386 |
+
"--conf", type=str, default="superglue", choices=list(confs.keys())
|
| 387 |
+
)
|
| 388 |
+
args = parser.parse_args()
|
| 389 |
+
main(confs[args.conf], args.pairs, args.features, args.export_dir)
|
hloc/matchers/__init__.py
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
def get_matcher(matcher):
|
| 2 |
+
mod = __import__(f"{__name__}.{matcher}", fromlist=[""])
|
| 3 |
+
return getattr(mod, "Model")
|
hloc/matchers/adalam.py
ADDED
|
@@ -0,0 +1,69 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import torch
|
| 2 |
+
|
| 3 |
+
from ..utils.base_model import BaseModel
|
| 4 |
+
|
| 5 |
+
from kornia.feature.adalam import AdalamFilter
|
| 6 |
+
from kornia.utils.helpers import get_cuda_device_if_available
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
class AdaLAM(BaseModel):
|
| 10 |
+
# See https://kornia.readthedocs.io/en/latest/_modules/kornia/feature/adalam/adalam.html.
|
| 11 |
+
default_conf = {
|
| 12 |
+
"area_ratio": 100,
|
| 13 |
+
"search_expansion": 4,
|
| 14 |
+
"ransac_iters": 128,
|
| 15 |
+
"min_inliers": 6,
|
| 16 |
+
"min_confidence": 200,
|
| 17 |
+
"orientation_difference_threshold": 30,
|
| 18 |
+
"scale_rate_threshold": 1.5,
|
| 19 |
+
"detected_scale_rate_threshold": 5,
|
| 20 |
+
"refit": True,
|
| 21 |
+
"force_seed_mnn": True,
|
| 22 |
+
"device": get_cuda_device_if_available(),
|
| 23 |
+
}
|
| 24 |
+
required_inputs = [
|
| 25 |
+
"image0",
|
| 26 |
+
"image1",
|
| 27 |
+
"descriptors0",
|
| 28 |
+
"descriptors1",
|
| 29 |
+
"keypoints0",
|
| 30 |
+
"keypoints1",
|
| 31 |
+
"scales0",
|
| 32 |
+
"scales1",
|
| 33 |
+
"oris0",
|
| 34 |
+
"oris1",
|
| 35 |
+
]
|
| 36 |
+
|
| 37 |
+
def _init(self, conf):
|
| 38 |
+
self.adalam = AdalamFilter(conf)
|
| 39 |
+
|
| 40 |
+
def _forward(self, data):
|
| 41 |
+
assert data["keypoints0"].size(0) == 1
|
| 42 |
+
if data["keypoints0"].size(1) < 2 or data["keypoints1"].size(1) < 2:
|
| 43 |
+
matches = torch.zeros(
|
| 44 |
+
(0, 2), dtype=torch.int64, device=data["keypoints0"].device
|
| 45 |
+
)
|
| 46 |
+
else:
|
| 47 |
+
matches = self.adalam.match_and_filter(
|
| 48 |
+
data["keypoints0"][0],
|
| 49 |
+
data["keypoints1"][0],
|
| 50 |
+
data["descriptors0"][0].T,
|
| 51 |
+
data["descriptors1"][0].T,
|
| 52 |
+
data["image0"].shape[2:],
|
| 53 |
+
data["image1"].shape[2:],
|
| 54 |
+
data["oris0"][0],
|
| 55 |
+
data["oris1"][0],
|
| 56 |
+
data["scales0"][0],
|
| 57 |
+
data["scales1"][0],
|
| 58 |
+
)
|
| 59 |
+
matches_new = torch.full(
|
| 60 |
+
(data["keypoints0"].size(1),),
|
| 61 |
+
-1,
|
| 62 |
+
dtype=torch.int64,
|
| 63 |
+
device=data["keypoints0"].device,
|
| 64 |
+
)
|
| 65 |
+
matches_new[matches[:, 0]] = matches[:, 1]
|
| 66 |
+
return {
|
| 67 |
+
"matches0": matches_new.unsqueeze(0),
|
| 68 |
+
"matching_scores0": torch.zeros(matches_new.size(0)).unsqueeze(0),
|
| 69 |
+
}
|
hloc/matchers/aspanformer.py
ADDED
|
@@ -0,0 +1,76 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import sys
|
| 2 |
+
import torch
|
| 3 |
+
from ..utils.base_model import BaseModel
|
| 4 |
+
from ..utils import do_system
|
| 5 |
+
from pathlib import Path
|
| 6 |
+
import subprocess
|
| 7 |
+
import logging
|
| 8 |
+
|
| 9 |
+
logger = logging.getLogger(__name__)
|
| 10 |
+
|
| 11 |
+
sys.path.append(str(Path(__file__).parent / "../../third_party"))
|
| 12 |
+
from ASpanFormer.src.ASpanFormer.aspanformer import ASpanFormer as _ASpanFormer
|
| 13 |
+
from ASpanFormer.src.config.default import get_cfg_defaults
|
| 14 |
+
from ASpanFormer.src.utils.misc import lower_config
|
| 15 |
+
from ASpanFormer.demo import demo_utils
|
| 16 |
+
|
| 17 |
+
aspanformer_path = Path(__file__).parent / "../../third_party/ASpanFormer"
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
class ASpanFormer(BaseModel):
|
| 21 |
+
default_conf = {
|
| 22 |
+
"weights": "outdoor",
|
| 23 |
+
"match_threshold": 0.2,
|
| 24 |
+
"config_path": aspanformer_path / "configs/aspan/outdoor/aspan_test.py",
|
| 25 |
+
"model_name": "weights_aspanformer.tar",
|
| 26 |
+
}
|
| 27 |
+
required_inputs = ["image0", "image1"]
|
| 28 |
+
proxy = "http://localhost:1080"
|
| 29 |
+
aspanformer_models = {
|
| 30 |
+
"weights_aspanformer.tar": "https://drive.google.com/uc?id=1eavM9dTkw9nbc-JqlVVfGPU5UvTTfc6k&confirm=t"
|
| 31 |
+
}
|
| 32 |
+
|
| 33 |
+
def _init(self, conf):
|
| 34 |
+
model_path = aspanformer_path / "weights" / Path(conf["weights"] + ".ckpt")
|
| 35 |
+
# Download the model.
|
| 36 |
+
if not model_path.exists():
|
| 37 |
+
# model_path.parent.mkdir(exist_ok=True)
|
| 38 |
+
tar_path = aspanformer_path / conf["model_name"]
|
| 39 |
+
if not tar_path.exists():
|
| 40 |
+
link = self.aspanformer_models[conf["model_name"]]
|
| 41 |
+
cmd = ["gdown", link, "-O", str(tar_path), "--proxy", self.proxy]
|
| 42 |
+
cmd_wo_proxy = ["gdown", link, "-O", str(tar_path)]
|
| 43 |
+
logger.info(f"Downloading the Aspanformer model with `{cmd_wo_proxy}`.")
|
| 44 |
+
try:
|
| 45 |
+
subprocess.run(cmd_wo_proxy, check=True)
|
| 46 |
+
except subprocess.CalledProcessError as e:
|
| 47 |
+
logger.info(f"Downloading the Aspanformer model with `{cmd}`.")
|
| 48 |
+
try:
|
| 49 |
+
subprocess.run(cmd, check=True)
|
| 50 |
+
except subprocess.CalledProcessError as e:
|
| 51 |
+
logger.error(f"Failed to download the Aspanformer model.")
|
| 52 |
+
raise e
|
| 53 |
+
|
| 54 |
+
do_system(f"cd {str(aspanformer_path)} & tar -xvf {str(tar_path)}")
|
| 55 |
+
|
| 56 |
+
logger.info(f"Loading Aspanformer model...")
|
| 57 |
+
|
| 58 |
+
config = get_cfg_defaults()
|
| 59 |
+
config.merge_from_file(conf["config_path"])
|
| 60 |
+
_config = lower_config(config)
|
| 61 |
+
self.net = _ASpanFormer(config=_config["aspan"])
|
| 62 |
+
weight_path = model_path
|
| 63 |
+
state_dict = torch.load(str(weight_path), map_location="cpu")["state_dict"]
|
| 64 |
+
self.net.load_state_dict(state_dict, strict=False)
|
| 65 |
+
|
| 66 |
+
def _forward(self, data):
|
| 67 |
+
data_ = {
|
| 68 |
+
"image0": data["image0"],
|
| 69 |
+
"image1": data["image1"],
|
| 70 |
+
}
|
| 71 |
+
self.net(data_, online_resize=True)
|
| 72 |
+
corr0 = data_["mkpts0_f"]
|
| 73 |
+
corr1 = data_["mkpts1_f"]
|
| 74 |
+
pred = {}
|
| 75 |
+
pred["keypoints0"], pred["keypoints1"] = corr0, corr1
|
| 76 |
+
return pred
|