Spaces:
Running

Running
Upload 186 files
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- assets/main_fig.png +0 -0
- configs/ground-truth-warmup/Base-COCO-PanopticSegmentation.yaml +60 -0
- configs/ground-truth-warmup/mask-adapter/mask_adapter_convnext_large_cocopan_eval_ade20k.yaml +40 -0
- configs/ground-truth-warmup/mask-adapter/mask_adapter_maft_convnext_base_cocostuff_eval_ade20k.yaml +40 -0
- configs/ground-truth-warmup/mask-adapter/mask_adapter_maft_convnext_large_cocostuff_eval_ade20k.yaml +40 -0
- configs/ground-truth-warmup/maskformer2_R50_bs16_50ep.yaml +45 -0
- configs/mixed-mask-training/fc-clip/Base-COCO-PanopticSegmentation.yaml +49 -0
- configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_a847.yaml +12 -0
- configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_ade20k.yaml +55 -0
- configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_coco.yaml +4 -0
- configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_pas20.yaml +12 -0
- configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_pc459.yaml +12 -0
- configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_pc59.yaml +12 -0
- configs/mixed-mask-training/fc-clip/maskformer2_R50_bs16_50ep.yaml +45 -0
- configs/mixed-mask-training/maftp/Base-COCO-PanopticSegmentation.yaml +62 -0
- configs/mixed-mask-training/maftp/maskformer2_R50_bs16_50ep.yaml +45 -0
- configs/mixed-mask-training/maftp/semantic/eval_a847.yaml +13 -0
- configs/mixed-mask-training/maftp/semantic/eval_pas20.yaml +12 -0
- configs/mixed-mask-training/maftp/semantic/eval_pas21.yaml +13 -0
- configs/mixed-mask-training/maftp/semantic/eval_pc459.yaml +12 -0
- configs/mixed-mask-training/maftp/semantic/eval_pc59.yaml +12 -0
- configs/mixed-mask-training/maftp/semantic/train_semantic_base_eval_a150.yaml +50 -0
- configs/mixed-mask-training/maftp/semantic/train_semantic_large_eval_a150.yaml +46 -0
- demo/demo.py +201 -0
- demo/images/000000000605.jpg +0 -0
- demo/images/000000001025.jpg +0 -0
- demo/images/000000290833.jpg +0 -0
- demo/images/ADE_val_00000739.jpg +0 -0
- demo/images/ADE_val_00000979.jpg +0 -0
- demo/images/ADE_val_00001200.jpg +0 -0
- demo/predictor.py +280 -0
- mask_adapter/.DS_Store +0 -0
- mask_adapter/__init__.py +44 -0
- mask_adapter/__pycache__/__init__.cpython-310.pyc +0 -0
- mask_adapter/__pycache__/__init__.cpython-38.pyc +0 -0
- mask_adapter/__pycache__/config.cpython-310.pyc +0 -0
- mask_adapter/__pycache__/config.cpython-38.pyc +0 -0
- mask_adapter/__pycache__/fcclip.cpython-310.pyc +0 -0
- mask_adapter/__pycache__/fcclip.cpython-38.pyc +0 -0
- mask_adapter/__pycache__/mask_adapter.cpython-310.pyc +0 -0
- mask_adapter/__pycache__/mask_adapter.cpython-38.pyc +0 -0
- mask_adapter/__pycache__/sam_maskadapter.cpython-310.pyc +0 -0
- mask_adapter/__pycache__/test_time_augmentation.cpython-310.pyc +0 -0
- mask_adapter/__pycache__/test_time_augmentation.cpython-38.pyc +0 -0
- mask_adapter/config.py +150 -0
- mask_adapter/data/.DS_Store +0 -0
- mask_adapter/data/__init__.py +16 -0
- mask_adapter/data/__pycache__/__init__.cpython-310.pyc +0 -0
- mask_adapter/data/__pycache__/__init__.cpython-38.pyc +0 -0
- mask_adapter/data/__pycache__/custom_dataset_dataloader.cpython-310.pyc +0 -0
assets/main_fig.png
ADDED
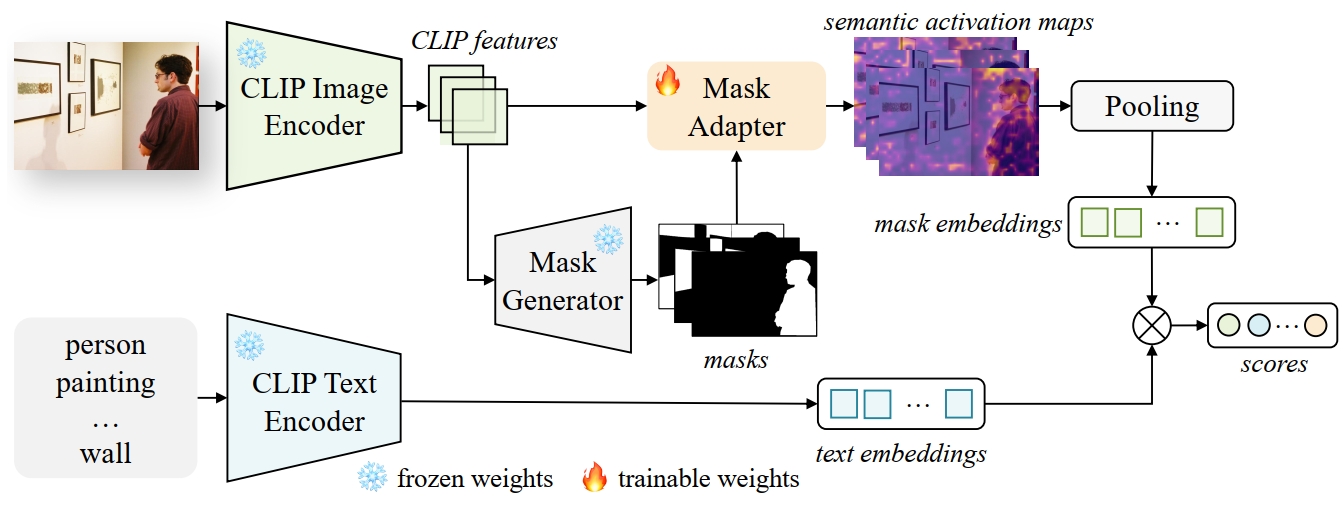
|
configs/ground-truth-warmup/Base-COCO-PanopticSegmentation.yaml
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL:
|
| 2 |
+
BACKBONE:
|
| 3 |
+
FREEZE_AT: 0
|
| 4 |
+
NAME: "build_resnet_backbone"
|
| 5 |
+
WEIGHTS: "detectron2://ImageNetPretrained/torchvision/R-50.pkl"
|
| 6 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 7 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 8 |
+
RESNETS:
|
| 9 |
+
DEPTH: 50
|
| 10 |
+
STEM_TYPE: "basic" # not used
|
| 11 |
+
STEM_OUT_CHANNELS: 64
|
| 12 |
+
STRIDE_IN_1X1: False
|
| 13 |
+
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 14 |
+
# NORM: "SyncBN"
|
| 15 |
+
RES5_MULTI_GRID: [1, 1, 1] # not used
|
| 16 |
+
|
| 17 |
+
SOLVER:
|
| 18 |
+
IMS_PER_BATCH: 8
|
| 19 |
+
BASE_LR: 0.0001
|
| 20 |
+
STEPS: (260231, 283888)
|
| 21 |
+
MAX_ITER: 295717
|
| 22 |
+
WARMUP_FACTOR: 1.0
|
| 23 |
+
WARMUP_ITERS: 10
|
| 24 |
+
CHECKPOINT_PERIOD: 10000
|
| 25 |
+
WEIGHT_DECAY: 0.05
|
| 26 |
+
OPTIMIZER: "ADAMW"
|
| 27 |
+
BACKBONE_MULTIPLIER: 0.1
|
| 28 |
+
CLIP_GRADIENTS:
|
| 29 |
+
ENABLED: True
|
| 30 |
+
CLIP_TYPE: "full_model"
|
| 31 |
+
CLIP_VALUE: 1.0
|
| 32 |
+
NORM_TYPE: 2.0
|
| 33 |
+
AMP:
|
| 34 |
+
ENABLED: True
|
| 35 |
+
INPUT:
|
| 36 |
+
IMAGE_SIZE: 768
|
| 37 |
+
MIN_SCALE: 0.1
|
| 38 |
+
MAX_SCALE: 2.0
|
| 39 |
+
FORMAT: "RGB"
|
| 40 |
+
MIN_SIZE_TRAIN: (1024,)
|
| 41 |
+
MAX_SIZE_TRAIN: 1024
|
| 42 |
+
DATASET_MAPPER_NAME: "coco_combine_lsj"
|
| 43 |
+
MASK_FORMAT: "bitmask"
|
| 44 |
+
COLOR_AUG_SSD: True
|
| 45 |
+
|
| 46 |
+
DATASETS:
|
| 47 |
+
TRAIN: ("openvocab_coco_2017_train_panoptic_with_sem_seg",)
|
| 48 |
+
TEST: ("openvocab_ade20k_panoptic_val",) # to evaluate instance and semantic performance as well
|
| 49 |
+
DATALOADER:
|
| 50 |
+
SAMPLER_TRAIN: "MultiDatasetSampler"
|
| 51 |
+
USE_DIFF_BS_SIZE: False
|
| 52 |
+
DATASET_RATIO: [1.0]
|
| 53 |
+
DATASET_BS: [2]
|
| 54 |
+
USE_RFS: [False]
|
| 55 |
+
NUM_WORKERS: 8
|
| 56 |
+
DATASET_ANN: ['mask']
|
| 57 |
+
ASPECT_RATIO_GROUPING: True
|
| 58 |
+
TEST:
|
| 59 |
+
EVAL_PERIOD: 10000
|
| 60 |
+
VERSION: 2
|
configs/ground-truth-warmup/mask-adapter/mask_adapter_convnext_large_cocopan_eval_ade20k.yaml
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ../maskformer2_R50_bs16_50ep.yaml
|
| 2 |
+
MODEL:
|
| 3 |
+
META_ARCHITECTURE: "MASK_Adapter"
|
| 4 |
+
MASK_ADAPTER:
|
| 5 |
+
NAME: "MASKAdapterHead"
|
| 6 |
+
MASK_IN_CHANNELS: 16
|
| 7 |
+
NUM_CHANNELS: 768
|
| 8 |
+
USE_CHECKPOINT: False
|
| 9 |
+
NUM_OUTPUT_MAPS: 16
|
| 10 |
+
# backbone part.
|
| 11 |
+
BACKBONE:
|
| 12 |
+
NAME: "CLIP"
|
| 13 |
+
WEIGHTS: ""
|
| 14 |
+
PIXEL_MEAN: [122.7709383, 116.7460125, 104.09373615]
|
| 15 |
+
PIXEL_STD: [68.5005327, 66.6321579, 70.32316305]
|
| 16 |
+
FC_CLIP:
|
| 17 |
+
CLIP_MODEL_NAME: "convnext_large_d_320"
|
| 18 |
+
CLIP_PRETRAINED_WEIGHTS: "laion2b_s29b_b131k_ft_soup"
|
| 19 |
+
EMBED_DIM: 768
|
| 20 |
+
GEOMETRIC_ENSEMBLE_ALPHA: -1.0
|
| 21 |
+
GEOMETRIC_ENSEMBLE_BETA: -1.0
|
| 22 |
+
MASK_FORMER:
|
| 23 |
+
NUM_OBJECT_QUERIES: 250
|
| 24 |
+
TEST:
|
| 25 |
+
SEMANTIC_ON: True
|
| 26 |
+
INSTANCE_ON: True
|
| 27 |
+
PANOPTIC_ON: True
|
| 28 |
+
OVERLAP_THRESHOLD: 0.8
|
| 29 |
+
OBJECT_MASK_THRESHOLD: 0.0
|
| 30 |
+
|
| 31 |
+
INPUT:
|
| 32 |
+
DATASET_MAPPER_NAME: "coco_panoptic_lsj"
|
| 33 |
+
|
| 34 |
+
DATALOADER:
|
| 35 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 36 |
+
|
| 37 |
+
DATASETS:
|
| 38 |
+
TRAIN: ("openvocab_coco_2017_train_panoptic_with_sem_seg",)
|
| 39 |
+
TEST: ("openvocab_ade20k_panoptic_val",)
|
| 40 |
+
OUTPUT_DIR: ./training/first-phase/fcclip-l-adapter
|
configs/ground-truth-warmup/mask-adapter/mask_adapter_maft_convnext_base_cocostuff_eval_ade20k.yaml
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ../maskformer2_R50_bs16_50ep.yaml
|
| 2 |
+
MODEL:
|
| 3 |
+
META_ARCHITECTURE: "MASK_Adapter"
|
| 4 |
+
MASK_ADAPTER:
|
| 5 |
+
NAME: "MASKAdapterHead"
|
| 6 |
+
MASK_IN_CHANNELS: 16
|
| 7 |
+
NUM_CHANNELS: 768
|
| 8 |
+
USE_CHECKPOINT: False
|
| 9 |
+
NUM_OUTPUT_MAPS: 16
|
| 10 |
+
TRAIN_MAFT: True
|
| 11 |
+
# backbone part.
|
| 12 |
+
BACKBONE:
|
| 13 |
+
NAME: "CLIP"
|
| 14 |
+
WEIGHTS: ""
|
| 15 |
+
PIXEL_MEAN: [122.7709383, 116.7460125, 104.09373615]
|
| 16 |
+
PIXEL_STD: [68.5005327, 66.6321579, 70.32316305]
|
| 17 |
+
FC_CLIP:
|
| 18 |
+
CLIP_MODEL_NAME: "convnext_base_w_320"
|
| 19 |
+
CLIP_PRETRAINED_WEIGHTS: "laion_aesthetic_s13b_b82k_augreg"
|
| 20 |
+
EMBED_DIM: 640
|
| 21 |
+
GEOMETRIC_ENSEMBLE_ALPHA: -1.0
|
| 22 |
+
GEOMETRIC_ENSEMBLE_BETA: -1.0
|
| 23 |
+
MASK_FORMER:
|
| 24 |
+
NUM_OBJECT_QUERIES: 250
|
| 25 |
+
TEST:
|
| 26 |
+
SEMANTIC_ON: True
|
| 27 |
+
INSTANCE_ON: True
|
| 28 |
+
PANOPTIC_ON: True
|
| 29 |
+
OVERLAP_THRESHOLD: 0.8
|
| 30 |
+
OBJECT_MASK_THRESHOLD: 0.0
|
| 31 |
+
|
| 32 |
+
INPUT:
|
| 33 |
+
DATASET_MAPPER_NAME: "mask_former_semantic"
|
| 34 |
+
|
| 35 |
+
DATASETS:
|
| 36 |
+
TRAIN: ("openvocab_coco_2017_train_stuff_sem_seg",)
|
| 37 |
+
TEST: ("openvocab_ade20k_panoptic_val",)
|
| 38 |
+
DATALOADER:
|
| 39 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 40 |
+
OUTPUT_DIR: ./training/first-phase/maft_b_adapter
|
configs/ground-truth-warmup/mask-adapter/mask_adapter_maft_convnext_large_cocostuff_eval_ade20k.yaml
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ../maskformer2_R50_bs16_50ep.yaml
|
| 2 |
+
MODEL:
|
| 3 |
+
META_ARCHITECTURE: "MASK_Adapter"
|
| 4 |
+
MASK_ADAPTER:
|
| 5 |
+
NAME: "MASKAdapterHead"
|
| 6 |
+
MASK_IN_CHANNELS: 16
|
| 7 |
+
NUM_CHANNELS: 768
|
| 8 |
+
USE_CHECKPOINT: False
|
| 9 |
+
NUM_OUTPUT_MAPS: 16
|
| 10 |
+
TRAIN_MAFT: True
|
| 11 |
+
# backbone part.
|
| 12 |
+
BACKBONE:
|
| 13 |
+
NAME: "CLIP"
|
| 14 |
+
WEIGHTS: ""
|
| 15 |
+
PIXEL_MEAN: [122.7709383, 116.7460125, 104.09373615]
|
| 16 |
+
PIXEL_STD: [68.5005327, 66.6321579, 70.32316305]
|
| 17 |
+
FC_CLIP:
|
| 18 |
+
CLIP_MODEL_NAME: "convnext_large_d_320"
|
| 19 |
+
CLIP_PRETRAINED_WEIGHTS: "laion2b_s29b_b131k_ft_soup"
|
| 20 |
+
EMBED_DIM: 768
|
| 21 |
+
GEOMETRIC_ENSEMBLE_ALPHA: -1.0
|
| 22 |
+
GEOMETRIC_ENSEMBLE_BETA: -1.0
|
| 23 |
+
MASK_FORMER:
|
| 24 |
+
NUM_OBJECT_QUERIES: 250
|
| 25 |
+
TEST:
|
| 26 |
+
SEMANTIC_ON: True
|
| 27 |
+
INSTANCE_ON: True
|
| 28 |
+
PANOPTIC_ON: True
|
| 29 |
+
OVERLAP_THRESHOLD: 0.8
|
| 30 |
+
OBJECT_MASK_THRESHOLD: 0.0
|
| 31 |
+
|
| 32 |
+
INPUT:
|
| 33 |
+
DATASET_MAPPER_NAME: "mask_former_semantic"
|
| 34 |
+
|
| 35 |
+
DATASETS:
|
| 36 |
+
TRAIN: ("openvocab_coco_2017_train_stuff_sem_seg",)
|
| 37 |
+
TEST: ("openvocab_ade20k_panoptic_val",)
|
| 38 |
+
DATALOADER:
|
| 39 |
+
SAMPLER_TRAIN: "TrainingSampler"
|
| 40 |
+
OUTPUT_DIR: ./training/first-phase/maft_l_adapter
|
configs/ground-truth-warmup/maskformer2_R50_bs16_50ep.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: Base-COCO-PanopticSegmentation.yaml
|
| 2 |
+
MODEL:
|
| 3 |
+
META_ARCHITECTURE: "MaskFormer"
|
| 4 |
+
SEM_SEG_HEAD:
|
| 5 |
+
NAME: "FCCLIPMASKHead"
|
| 6 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 7 |
+
IGNORE_VALUE: 255
|
| 8 |
+
NUM_CLASSES: 133
|
| 9 |
+
LOSS_WEIGHT: 1.0
|
| 10 |
+
CONVS_DIM: 256
|
| 11 |
+
MASK_DIM: 256
|
| 12 |
+
NORM: "GN"
|
| 13 |
+
# pixel decoder
|
| 14 |
+
PIXEL_DECODER_NAME: "MSDeformAttnPixelDecoder"
|
| 15 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 16 |
+
DEFORMABLE_TRANSFORMER_ENCODER_IN_FEATURES: ["res3", "res4", "res5"]
|
| 17 |
+
COMMON_STRIDE: 4
|
| 18 |
+
TRANSFORMER_ENC_LAYERS: 6
|
| 19 |
+
MASK_FORMER:
|
| 20 |
+
TRANSFORMER_DECODER_NAME: "MultiScaleMaskedTransformerDecoder"
|
| 21 |
+
TRANSFORMER_IN_FEATURE: "multi_scale_pixel_decoder"
|
| 22 |
+
DEEP_SUPERVISION: True
|
| 23 |
+
NO_OBJECT_WEIGHT: 0.1
|
| 24 |
+
CLASS_WEIGHT: 2.0
|
| 25 |
+
MASK_WEIGHT: 5.0
|
| 26 |
+
DICE_WEIGHT: 5.0
|
| 27 |
+
HIDDEN_DIM: 256
|
| 28 |
+
NUM_OBJECT_QUERIES: 100
|
| 29 |
+
NHEADS: 8
|
| 30 |
+
DROPOUT: 0.0
|
| 31 |
+
DIM_FEEDFORWARD: 2048
|
| 32 |
+
ENC_LAYERS: 0
|
| 33 |
+
PRE_NORM: False
|
| 34 |
+
ENFORCE_INPUT_PROJ: False
|
| 35 |
+
SIZE_DIVISIBILITY: 32
|
| 36 |
+
DEC_LAYERS: 10 # 9 decoder layers, add one for the loss on learnable query
|
| 37 |
+
TRAIN_NUM_POINTS: 12544
|
| 38 |
+
OVERSAMPLE_RATIO: 3.0
|
| 39 |
+
IMPORTANCE_SAMPLE_RATIO: 0.75
|
| 40 |
+
TEST:
|
| 41 |
+
SEMANTIC_ON: True
|
| 42 |
+
INSTANCE_ON: True
|
| 43 |
+
PANOPTIC_ON: True
|
| 44 |
+
OVERLAP_THRESHOLD: 0.8
|
| 45 |
+
OBJECT_MASK_THRESHOLD: 0.8
|
configs/mixed-mask-training/fc-clip/Base-COCO-PanopticSegmentation.yaml
ADDED
|
@@ -0,0 +1,49 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL:
|
| 2 |
+
BACKBONE:
|
| 3 |
+
FREEZE_AT: 0
|
| 4 |
+
NAME: "build_resnet_backbone"
|
| 5 |
+
WEIGHTS: "detectron2://ImageNetPretrained/torchvision/R-50.pkl"
|
| 6 |
+
PIXEL_MEAN: [123.675, 116.280, 103.530]
|
| 7 |
+
PIXEL_STD: [58.395, 57.120, 57.375]
|
| 8 |
+
RESNETS:
|
| 9 |
+
DEPTH: 50
|
| 10 |
+
STEM_TYPE: "basic" # not used
|
| 11 |
+
STEM_OUT_CHANNELS: 64
|
| 12 |
+
STRIDE_IN_1X1: False
|
| 13 |
+
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 14 |
+
# NORM: "SyncBN"
|
| 15 |
+
RES5_MULTI_GRID: [1, 1, 1] # not used
|
| 16 |
+
DATASETS:
|
| 17 |
+
TRAIN: ("openvocab_coco_2017_train_stuff_sem_seg",)
|
| 18 |
+
TEST: ("openvocab_ade20k_panoptic_val",) # to evaluate instance and semantic performance as well
|
| 19 |
+
SOLVER:
|
| 20 |
+
IMS_PER_BATCH: 18
|
| 21 |
+
BASE_LR: 0.0001
|
| 22 |
+
STEPS: (216859, 236574)
|
| 23 |
+
MAX_ITER: 246431
|
| 24 |
+
WARMUP_FACTOR: 1.0
|
| 25 |
+
WARMUP_ITERS: 10
|
| 26 |
+
WEIGHT_DECAY: 0.05
|
| 27 |
+
OPTIMIZER: "ADAMW"
|
| 28 |
+
BACKBONE_MULTIPLIER: 0.1
|
| 29 |
+
CLIP_GRADIENTS:
|
| 30 |
+
ENABLED: True
|
| 31 |
+
CLIP_TYPE: "full_model"
|
| 32 |
+
CLIP_VALUE: 1.0
|
| 33 |
+
NORM_TYPE: 2.0
|
| 34 |
+
AMP:
|
| 35 |
+
ENABLED: True
|
| 36 |
+
INPUT:
|
| 37 |
+
IMAGE_SIZE: 1024
|
| 38 |
+
MIN_SCALE: 0.1
|
| 39 |
+
MAX_SCALE: 2.0
|
| 40 |
+
MIN_SIZE_TEST: 896
|
| 41 |
+
MAX_SIZE_TEST: 896
|
| 42 |
+
FORMAT: "RGB"
|
| 43 |
+
DATASET_MAPPER_NAME: "coco_panoptic_lsj"
|
| 44 |
+
TEST:
|
| 45 |
+
EVAL_PERIOD: 5000
|
| 46 |
+
DATALOADER:
|
| 47 |
+
FILTER_EMPTY_ANNOTATIONS: True
|
| 48 |
+
NUM_WORKERS: 4
|
| 49 |
+
VERSION: 2
|
configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_a847.yaml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./fcclip_convnext_large_eval_ade20k.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_ade20k_full_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
OUTPUT_DIR: ./evaluation/fc-clip/a847
|
configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_ade20k.yaml
ADDED
|
@@ -0,0 +1,55 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ../maskformer2_R50_bs16_50ep.yaml
|
| 2 |
+
MODEL:
|
| 3 |
+
META_ARCHITECTURE: "FCCLIP"
|
| 4 |
+
SEM_SEG_HEAD:
|
| 5 |
+
NAME: "FCCLIPHead"
|
| 6 |
+
# backbone part.
|
| 7 |
+
MASK_ADAPTER:
|
| 8 |
+
NAME: "MASKAdapterHead"
|
| 9 |
+
MASK_IN_CHANNELS: 16
|
| 10 |
+
NUM_CHANNELS: 768
|
| 11 |
+
USE_CHECKPOINT: False
|
| 12 |
+
NUM_OUTPUT_MAPS: 16
|
| 13 |
+
MASK_THRESHOLD: 0.5
|
| 14 |
+
BACKBONE:
|
| 15 |
+
NAME: "CLIP"
|
| 16 |
+
WEIGHTS: ""
|
| 17 |
+
PIXEL_MEAN: [122.7709383, 116.7460125, 104.09373615]
|
| 18 |
+
PIXEL_STD: [68.5005327, 66.6321579, 70.32316305]
|
| 19 |
+
FC_CLIP:
|
| 20 |
+
CLIP_MODEL_NAME: "convnext_large_d_320"
|
| 21 |
+
CLIP_PRETRAINED_WEIGHTS: "laion2b_s29b_b131k_ft_soup"
|
| 22 |
+
EMBED_DIM: 768
|
| 23 |
+
GEOMETRIC_ENSEMBLE_ALPHA: 0.7
|
| 24 |
+
GEOMETRIC_ENSEMBLE_BETA: 0.9
|
| 25 |
+
MASK_FORMER:
|
| 26 |
+
NUM_OBJECT_QUERIES: 250
|
| 27 |
+
TEST:
|
| 28 |
+
SEMANTIC_ON: True
|
| 29 |
+
INSTANCE_ON: True
|
| 30 |
+
PANOPTIC_ON: True
|
| 31 |
+
OBJECT_MASK_THRESHOLD: 0.0
|
| 32 |
+
|
| 33 |
+
INPUT:
|
| 34 |
+
IMAGE_SIZE: 1024
|
| 35 |
+
MIN_SCALE: 0.1
|
| 36 |
+
MAX_SCALE: 2.0
|
| 37 |
+
COLOR_AUG_SSD: False
|
| 38 |
+
SOLVER:
|
| 39 |
+
IMS_PER_BATCH: 24
|
| 40 |
+
BASE_LR: 0.0001
|
| 41 |
+
WARMUP_FACTOR: 1.0
|
| 42 |
+
WARMUP_ITERS: 0
|
| 43 |
+
WEIGHT_DECAY: 0.05
|
| 44 |
+
STEPS: (86743, 94629)
|
| 45 |
+
MAX_ITER: 98572
|
| 46 |
+
CHECKPOINT_PERIOD: 3300
|
| 47 |
+
TEST:
|
| 48 |
+
EVAL_PERIOD: 3300
|
| 49 |
+
|
| 50 |
+
#SEED: 9782623
|
| 51 |
+
DATASETS:
|
| 52 |
+
TRAIN: ("openvocab_coco_2017_train_panoptic_with_sem_seg",)
|
| 53 |
+
TEST: ("openvocab_ade20k_panoptic_val",)
|
| 54 |
+
|
| 55 |
+
OUTPUT_DIR: ./evaluation/fc-clip/ade20k
|
configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_coco.yaml
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./fcclip_convnext_large_eval_ade20k.yaml
|
| 2 |
+
DATASETS:
|
| 3 |
+
TEST: ("openvocab_coco_2017_val_panoptic_with_sem_seg",)
|
| 4 |
+
OUTPUT_DIR: ./coco-test
|
configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_pas20.yaml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./fcclip_convnext_large_eval_ade20k.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_pascal20_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
OUTPUT_DIR: ./evaluation/fc-clip/pas20
|
configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_pc459.yaml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./fcclip_convnext_large_eval_ade20k.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_pascal_ctx459_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
OUTPUT_DIR: ./evaluation/fc-clip/pc459
|
configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_pc59.yaml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./fcclip_convnext_large_eval_ade20k.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_pascal_ctx59_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
OUTPUT_DIR: ./evaluation/fc-clip/pc59
|
configs/mixed-mask-training/fc-clip/maskformer2_R50_bs16_50ep.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: Base-COCO-PanopticSegmentation.yaml
|
| 2 |
+
MODEL:
|
| 3 |
+
META_ARCHITECTURE: "MaskFormer"
|
| 4 |
+
SEM_SEG_HEAD:
|
| 5 |
+
NAME: "MaskFormerHead"
|
| 6 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 7 |
+
IGNORE_VALUE: 255
|
| 8 |
+
NUM_CLASSES: 133
|
| 9 |
+
LOSS_WEIGHT: 1.0
|
| 10 |
+
CONVS_DIM: 256
|
| 11 |
+
MASK_DIM: 256
|
| 12 |
+
NORM: "GN"
|
| 13 |
+
# pixel decoder
|
| 14 |
+
PIXEL_DECODER_NAME: "MSDeformAttnPixelDecoder"
|
| 15 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 16 |
+
DEFORMABLE_TRANSFORMER_ENCODER_IN_FEATURES: ["res3", "res4", "res5"]
|
| 17 |
+
COMMON_STRIDE: 4
|
| 18 |
+
TRANSFORMER_ENC_LAYERS: 6
|
| 19 |
+
MASK_FORMER:
|
| 20 |
+
TRANSFORMER_DECODER_NAME: "MultiScaleMaskedTransformerDecoder"
|
| 21 |
+
TRANSFORMER_IN_FEATURE: "multi_scale_pixel_decoder"
|
| 22 |
+
DEEP_SUPERVISION: True
|
| 23 |
+
NO_OBJECT_WEIGHT: 0.1
|
| 24 |
+
CLASS_WEIGHT: 2.0
|
| 25 |
+
MASK_WEIGHT: 5.0
|
| 26 |
+
DICE_WEIGHT: 5.0
|
| 27 |
+
HIDDEN_DIM: 256
|
| 28 |
+
NUM_OBJECT_QUERIES: 100
|
| 29 |
+
NHEADS: 8
|
| 30 |
+
DROPOUT: 0.0
|
| 31 |
+
DIM_FEEDFORWARD: 2048
|
| 32 |
+
ENC_LAYERS: 0
|
| 33 |
+
PRE_NORM: False
|
| 34 |
+
ENFORCE_INPUT_PROJ: False
|
| 35 |
+
SIZE_DIVISIBILITY: 32
|
| 36 |
+
DEC_LAYERS: 10 # 9 decoder layers, add one for the loss on learnable query
|
| 37 |
+
TRAIN_NUM_POINTS: 12544
|
| 38 |
+
OVERSAMPLE_RATIO: 3.0
|
| 39 |
+
IMPORTANCE_SAMPLE_RATIO: 0.75
|
| 40 |
+
TEST:
|
| 41 |
+
SEMANTIC_ON: True
|
| 42 |
+
INSTANCE_ON: True
|
| 43 |
+
PANOPTIC_ON: True
|
| 44 |
+
OVERLAP_THRESHOLD: 0.8
|
| 45 |
+
OBJECT_MASK_THRESHOLD: 0.8
|
configs/mixed-mask-training/maftp/Base-COCO-PanopticSegmentation.yaml
ADDED
|
@@ -0,0 +1,62 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MODEL:
|
| 2 |
+
BACKBONE:
|
| 3 |
+
FREEZE_AT: 0
|
| 4 |
+
NAME: "CLIP"
|
| 5 |
+
# WEIGHTS: "detectron2://ImageNetPretrained/torchvision/R-50.pkl"
|
| 6 |
+
PIXEL_MEAN: [122.7709383, 116.7460125, 104.09373615]
|
| 7 |
+
PIXEL_STD: [68.5005327, 66.6321579, 70.32316305]
|
| 8 |
+
RESNETS:
|
| 9 |
+
DEPTH: 50
|
| 10 |
+
STEM_TYPE: "basic" # not used
|
| 11 |
+
STEM_OUT_CHANNELS: 64
|
| 12 |
+
STRIDE_IN_1X1: False
|
| 13 |
+
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 14 |
+
# NORM: "SyncBN"
|
| 15 |
+
RES5_MULTI_GRID: [1, 1, 1] # not used
|
| 16 |
+
DATASETS:
|
| 17 |
+
TRAIN: ("coco_2017_train_panoptic",)
|
| 18 |
+
TEST: ("coco_2017_val_panoptic_with_sem_seg",) # to evaluate instance and semantic performance as well
|
| 19 |
+
SOLVER:
|
| 20 |
+
IMS_PER_BATCH: 8
|
| 21 |
+
BASE_LR: 0.0001
|
| 22 |
+
BIAS_LR_FACTOR: 1.0
|
| 23 |
+
CHECKPOINT_PERIOD: 50000000
|
| 24 |
+
MAX_ITER: 55000
|
| 25 |
+
LR_SCHEDULER_NAME: WarmupPolyLR
|
| 26 |
+
MOMENTUM: 0.9
|
| 27 |
+
NESTEROV: false
|
| 28 |
+
OPTIMIZER: ADAMW
|
| 29 |
+
POLY_LR_CONSTANT_ENDING: 0.0
|
| 30 |
+
POLY_LR_POWER: 0.9
|
| 31 |
+
REFERENCE_WORLD_SIZE: 0
|
| 32 |
+
WARMUP_FACTOR: 1.0
|
| 33 |
+
WARMUP_ITERS: 10
|
| 34 |
+
WARMUP_METHOD: linear
|
| 35 |
+
WEIGHT_DECAY: 2.0e-05
|
| 36 |
+
#WEIGHT_DECAY: 0.05
|
| 37 |
+
WEIGHT_DECAY_BIAS: null
|
| 38 |
+
WEIGHT_DECAY_EMBED: 0.0
|
| 39 |
+
WEIGHT_DECAY_NORM: 0.0
|
| 40 |
+
STEPS: (327778, 355092)
|
| 41 |
+
BACKBONE_MULTIPLIER: 0.1
|
| 42 |
+
CLIP_GRADIENTS:
|
| 43 |
+
ENABLED: True
|
| 44 |
+
CLIP_TYPE: "full_model"
|
| 45 |
+
CLIP_VALUE: 1.0
|
| 46 |
+
NORM_TYPE: 2.0
|
| 47 |
+
AMP:
|
| 48 |
+
ENABLED: True
|
| 49 |
+
INPUT:
|
| 50 |
+
IMAGE_SIZE: 1024
|
| 51 |
+
MIN_SCALE: 0.1
|
| 52 |
+
MAX_SCALE: 2.0
|
| 53 |
+
MIN_SIZE_TEST: 896
|
| 54 |
+
MAX_SIZE_TEST: 896
|
| 55 |
+
FORMAT: "RGB"
|
| 56 |
+
DATASET_MAPPER_NAME: "coco_panoptic_lsj"
|
| 57 |
+
TEST:
|
| 58 |
+
EVAL_PERIOD: 5000
|
| 59 |
+
DATALOADER:
|
| 60 |
+
FILTER_EMPTY_ANNOTATIONS: True
|
| 61 |
+
NUM_WORKERS: 8
|
| 62 |
+
VERSION: 2
|
configs/mixed-mask-training/maftp/maskformer2_R50_bs16_50ep.yaml
ADDED
|
@@ -0,0 +1,45 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: Base-COCO-PanopticSegmentation.yaml
|
| 2 |
+
MODEL:
|
| 3 |
+
META_ARCHITECTURE: "MaskFormer"
|
| 4 |
+
SEM_SEG_HEAD:
|
| 5 |
+
NAME: "MaskFormerHead"
|
| 6 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 7 |
+
IGNORE_VALUE: 255
|
| 8 |
+
NUM_CLASSES: 133
|
| 9 |
+
LOSS_WEIGHT: 1.0
|
| 10 |
+
CONVS_DIM: 256
|
| 11 |
+
MASK_DIM: 256
|
| 12 |
+
NORM: "GN"
|
| 13 |
+
# pixel decoder
|
| 14 |
+
PIXEL_DECODER_NAME: "MSDeformAttnPixelDecoder"
|
| 15 |
+
IN_FEATURES: ["res2", "res3", "res4", "res5"]
|
| 16 |
+
DEFORMABLE_TRANSFORMER_ENCODER_IN_FEATURES: ["res3", "res4", "res5"]
|
| 17 |
+
COMMON_STRIDE: 4
|
| 18 |
+
TRANSFORMER_ENC_LAYERS: 6
|
| 19 |
+
MASK_FORMER:
|
| 20 |
+
TRANSFORMER_DECODER_NAME: "MultiScaleMaskedTransformerDecoder"
|
| 21 |
+
TRANSFORMER_IN_FEATURE: "multi_scale_pixel_decoder"
|
| 22 |
+
DEEP_SUPERVISION: True
|
| 23 |
+
NO_OBJECT_WEIGHT: 0.1
|
| 24 |
+
CLASS_WEIGHT: 2.0
|
| 25 |
+
MASK_WEIGHT: 5.0
|
| 26 |
+
DICE_WEIGHT: 5.0
|
| 27 |
+
HIDDEN_DIM: 256
|
| 28 |
+
NUM_OBJECT_QUERIES: 100
|
| 29 |
+
NHEADS: 8
|
| 30 |
+
DROPOUT: 0.0
|
| 31 |
+
DIM_FEEDFORWARD: 2048
|
| 32 |
+
ENC_LAYERS: 0
|
| 33 |
+
PRE_NORM: False
|
| 34 |
+
ENFORCE_INPUT_PROJ: False
|
| 35 |
+
SIZE_DIVISIBILITY: 32
|
| 36 |
+
DEC_LAYERS: 10 # 9 decoder layers, add one for the loss on learnable query
|
| 37 |
+
TRAIN_NUM_POINTS: 12544
|
| 38 |
+
OVERSAMPLE_RATIO: 3.0
|
| 39 |
+
IMPORTANCE_SAMPLE_RATIO: 0.75
|
| 40 |
+
TEST:
|
| 41 |
+
SEMANTIC_ON: True
|
| 42 |
+
INSTANCE_ON: False
|
| 43 |
+
PANOPTIC_ON: False
|
| 44 |
+
OBJECT_MASK_THRESHOLD: 0.2
|
| 45 |
+
OVERLAP_THRESHOLD: 0.7
|
configs/mixed-mask-training/maftp/semantic/eval_a847.yaml
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./eval.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_ade20k_full_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
OUTPUT_DIR: ./eval/a847
|
configs/mixed-mask-training/maftp/semantic/eval_pas20.yaml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./eval.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_pascal20_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
OUTPUT_DIR: ./eval/pas20
|
configs/mixed-mask-training/maftp/semantic/eval_pas21.yaml
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./eval.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_pascal21_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
OUTPUT_DIR: ./eval/pas21
|
configs/mixed-mask-training/maftp/semantic/eval_pc459.yaml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./eval.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_pascal_ctx459_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
OUTPUT_DIR: ./eval/pc459
|
configs/mixed-mask-training/maftp/semantic/eval_pc59.yaml
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
_BASE_: ./eval.yaml
|
| 2 |
+
|
| 3 |
+
MODEL:
|
| 4 |
+
MASK_FORMER:
|
| 5 |
+
TEST:
|
| 6 |
+
PANOPTIC_ON: False
|
| 7 |
+
INSTANCE_ON: False
|
| 8 |
+
|
| 9 |
+
DATASETS:
|
| 10 |
+
TEST: ("openvocab_pascal_ctx59_sem_seg_val",)
|
| 11 |
+
|
| 12 |
+
OUTPUT_DIR: ./eval/pc59
|
configs/mixed-mask-training/maftp/semantic/train_semantic_base_eval_a150.yaml
ADDED
|
@@ -0,0 +1,50 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# python train_net.py --config-file configs/semantic/train_semantic_base.yaml --num-gpus 8
|
| 2 |
+
|
| 3 |
+
_BASE_: ../maskformer2_R50_bs16_50ep.yaml
|
| 4 |
+
MODEL:
|
| 5 |
+
META_ARCHITECTURE: "MAFT_Plus" # FCCLIP MAFT_Plus
|
| 6 |
+
SEM_SEG_HEAD:
|
| 7 |
+
NAME: "FCCLIPHead"
|
| 8 |
+
NUM_CLASSES: 171
|
| 9 |
+
MASK_ADAPTER:
|
| 10 |
+
NAME: "MASKAdapterHead"
|
| 11 |
+
MASK_IN_CHANNELS: 16
|
| 12 |
+
NUM_CHANNELS: 768
|
| 13 |
+
USE_CHECKPOINT: False
|
| 14 |
+
NUM_OUTPUT_MAPS: 16
|
| 15 |
+
MASK_THRESHOLD: 0.5
|
| 16 |
+
FC_CLIP:
|
| 17 |
+
CLIP_MODEL_NAME: "convnext_base_w_320"
|
| 18 |
+
CLIP_PRETRAINED_WEIGHTS: "laion_aesthetic_s13b_b82k_augreg"
|
| 19 |
+
EMBED_DIM: 640
|
| 20 |
+
GEOMETRIC_ENSEMBLE_ALPHA: 0.7
|
| 21 |
+
GEOMETRIC_ENSEMBLE_BETA: 1.0
|
| 22 |
+
rc_weights: 0.1
|
| 23 |
+
MASK_FORMER:
|
| 24 |
+
TEST:
|
| 25 |
+
SEMANTIC_ON: True
|
| 26 |
+
INSTANCE_ON: False
|
| 27 |
+
PANOPTIC_ON: False
|
| 28 |
+
OBJECT_MASK_THRESHOLD: 0.0
|
| 29 |
+
cdt_params:
|
| 30 |
+
- 640
|
| 31 |
+
- 8
|
| 32 |
+
|
| 33 |
+
INPUT:
|
| 34 |
+
DATASET_MAPPER_NAME: "mask_former_semantic" # mask_former_semantic coco_panoptic_lsj
|
| 35 |
+
DATASETS:
|
| 36 |
+
TRAIN: ("openvocab_coco_2017_train_stuff_sem_seg",)
|
| 37 |
+
TEST: ('openvocab_ade20k_panoptic_val',)
|
| 38 |
+
|
| 39 |
+
SOLVER:
|
| 40 |
+
IMS_PER_BATCH: 24
|
| 41 |
+
BASE_LR: 0.0001
|
| 42 |
+
STEPS: (43371, 47314)
|
| 43 |
+
MAX_ITER: 49286
|
| 44 |
+
CHECKPOINT_PERIOD: 2500
|
| 45 |
+
TEST:
|
| 46 |
+
EVAL_PERIOD: 2500
|
| 47 |
+
INPUT:
|
| 48 |
+
DATASET_MAPPER_NAME: "mask_former_semantic" #
|
| 49 |
+
OUTPUT_DIR: ../evaluation/maftp-base/ade20k
|
| 50 |
+
|
configs/mixed-mask-training/maftp/semantic/train_semantic_large_eval_a150.yaml
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# python train_net.py --config-file configs/semantic/train_semantic_large.yaml --num-gpus 8
|
| 2 |
+
|
| 3 |
+
_BASE_: ../maskformer2_R50_bs16_50ep.yaml
|
| 4 |
+
MODEL:
|
| 5 |
+
META_ARCHITECTURE: "MAFT_Plus" # FCCLIP MAFT_Plus
|
| 6 |
+
SEM_SEG_HEAD:
|
| 7 |
+
NAME: "FCCLIPHead"
|
| 8 |
+
NUM_CLASSES: 171
|
| 9 |
+
MASK_ADAPTER:
|
| 10 |
+
NAME: "MASKAdapterHead"
|
| 11 |
+
MASK_IN_CHANNELS: 16
|
| 12 |
+
NUM_CHANNELS: 768
|
| 13 |
+
USE_CHECKPOINT: False
|
| 14 |
+
NUM_OUTPUT_MAPS: 16
|
| 15 |
+
MASK_THRESHOLD: 0.5
|
| 16 |
+
FC_CLIP:
|
| 17 |
+
CLIP_MODEL_NAME: "convnext_large_d_320"
|
| 18 |
+
CLIP_PRETRAINED_WEIGHTS: "laion2b_s29b_b131k_ft_soup"
|
| 19 |
+
EMBED_DIM: 768
|
| 20 |
+
GEOMETRIC_ENSEMBLE_ALPHA: 0.8
|
| 21 |
+
GEOMETRIC_ENSEMBLE_BETA: 1.0
|
| 22 |
+
rc_weights: 0.1
|
| 23 |
+
MASK_FORMER:
|
| 24 |
+
TEST:
|
| 25 |
+
SEMANTIC_ON: True
|
| 26 |
+
INSTANCE_ON: True
|
| 27 |
+
PANOPTIC_ON: True
|
| 28 |
+
OBJECT_MASK_THRESHOLD: 0.0
|
| 29 |
+
|
| 30 |
+
SOLVER:
|
| 31 |
+
IMS_PER_BATCH: 24
|
| 32 |
+
BASE_LR: 0.0001
|
| 33 |
+
STEPS: (43371, 47314)
|
| 34 |
+
MAX_ITER: 49286
|
| 35 |
+
CHECKPOINT_PERIOD: 2500
|
| 36 |
+
TEST:
|
| 37 |
+
EVAL_PERIOD: 2500
|
| 38 |
+
INPUT:
|
| 39 |
+
DATASET_MAPPER_NAME: "mask_former_semantic" # mask_former_semantic coco_panoptic_lsj
|
| 40 |
+
DATASETS:
|
| 41 |
+
TRAIN: ("openvocab_coco_2017_train_stuff_sem_seg",) # openvocab_coco_2017_train_panoptic_with_sem_seg
|
| 42 |
+
TEST: ('openvocab_ade20k_panoptic_val',)
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
OUTPUT_DIR: ../evaluation/maftp-large/ade20k
|
demo/demo.py
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This file may have been modified by Bytedance Ltd. and/or its affiliates (“Bytedance's Modifications”).
|
| 3 |
+
All Bytedance's Modifications are Copyright (year) Bytedance Ltd. and/or its affiliates.
|
| 4 |
+
|
| 5 |
+
Reference: https://github.com/facebookresearch/Mask2Former/blob/main/demo/demo.py
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import argparse
|
| 9 |
+
import glob
|
| 10 |
+
import multiprocessing as mp
|
| 11 |
+
import os
|
| 12 |
+
|
| 13 |
+
# fmt: off
|
| 14 |
+
import sys
|
| 15 |
+
sys.path.insert(1, os.path.join(sys.path[0], '..'))
|
| 16 |
+
# fmt: on
|
| 17 |
+
|
| 18 |
+
import tempfile
|
| 19 |
+
import time
|
| 20 |
+
import warnings
|
| 21 |
+
|
| 22 |
+
import cv2
|
| 23 |
+
import numpy as np
|
| 24 |
+
import tqdm
|
| 25 |
+
|
| 26 |
+
from detectron2.config import get_cfg
|
| 27 |
+
from detectron2.data.detection_utils import read_image
|
| 28 |
+
from detectron2.projects.deeplab import add_deeplab_config
|
| 29 |
+
from detectron2.utils.logger import setup_logger
|
| 30 |
+
|
| 31 |
+
from fcclip import add_maskformer2_config, add_fcclip_config, add_mask_adapter_config
|
| 32 |
+
from predictor import VisualizationDemo
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
# constants
|
| 36 |
+
WINDOW_NAME = "mask-adapter demo"
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
def setup_cfg(args):
|
| 40 |
+
# load config from file and command-line arguments
|
| 41 |
+
cfg = get_cfg()
|
| 42 |
+
add_deeplab_config(cfg)
|
| 43 |
+
add_maskformer2_config(cfg)
|
| 44 |
+
add_fcclip_config(cfg)
|
| 45 |
+
add_mask_adapter_config(cfg)
|
| 46 |
+
cfg.merge_from_file(args.config_file)
|
| 47 |
+
cfg.merge_from_list(args.opts)
|
| 48 |
+
cfg.freeze()
|
| 49 |
+
return cfg
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def get_parser():
|
| 53 |
+
parser = argparse.ArgumentParser(description="mask-adapter demo for builtin configs")
|
| 54 |
+
parser.add_argument(
|
| 55 |
+
"--config-file",
|
| 56 |
+
default="configs/mixed-mask-training/fc-clip/fcclip/fcclip_convnext_large_eval_ade20k.yaml",
|
| 57 |
+
metavar="FILE",
|
| 58 |
+
help="path to config file",
|
| 59 |
+
)
|
| 60 |
+
parser.add_argument("--webcam", action="store_true", help="Take inputs from webcam.")
|
| 61 |
+
parser.add_argument("--video-input", help="Path to video file.")
|
| 62 |
+
parser.add_argument(
|
| 63 |
+
"--input",
|
| 64 |
+
nargs="+",
|
| 65 |
+
help="A list of space separated input images; "
|
| 66 |
+
"or a single glob pattern such as 'directory/*.jpg'",
|
| 67 |
+
)
|
| 68 |
+
parser.add_argument(
|
| 69 |
+
"--output",
|
| 70 |
+
help="A file or directory to save output visualizations. "
|
| 71 |
+
"If not given, will show output in an OpenCV window.",
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
parser.add_argument(
|
| 75 |
+
"--confidence-threshold",
|
| 76 |
+
type=float,
|
| 77 |
+
default=0.5,
|
| 78 |
+
help="Minimum score for instance predictions to be shown",
|
| 79 |
+
)
|
| 80 |
+
parser.add_argument(
|
| 81 |
+
"--opts",
|
| 82 |
+
help="Modify config options using the command-line 'KEY VALUE' pairs",
|
| 83 |
+
default=[],
|
| 84 |
+
nargs=argparse.REMAINDER,
|
| 85 |
+
)
|
| 86 |
+
return parser
|
| 87 |
+
|
| 88 |
+
|
| 89 |
+
def test_opencv_video_format(codec, file_ext):
|
| 90 |
+
with tempfile.TemporaryDirectory(prefix="video_format_test") as dir:
|
| 91 |
+
filename = os.path.join(dir, "test_file" + file_ext)
|
| 92 |
+
writer = cv2.VideoWriter(
|
| 93 |
+
filename=filename,
|
| 94 |
+
fourcc=cv2.VideoWriter_fourcc(*codec),
|
| 95 |
+
fps=float(30),
|
| 96 |
+
frameSize=(10, 10),
|
| 97 |
+
isColor=True,
|
| 98 |
+
)
|
| 99 |
+
[writer.write(np.zeros((10, 10, 3), np.uint8)) for _ in range(30)]
|
| 100 |
+
writer.release()
|
| 101 |
+
if os.path.isfile(filename):
|
| 102 |
+
return True
|
| 103 |
+
return False
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
if __name__ == "__main__":
|
| 107 |
+
mp.set_start_method("spawn", force=True)
|
| 108 |
+
args = get_parser().parse_args()
|
| 109 |
+
setup_logger(name="fvcore")
|
| 110 |
+
logger = setup_logger()
|
| 111 |
+
logger.info("Arguments: " + str(args))
|
| 112 |
+
|
| 113 |
+
cfg = setup_cfg(args)
|
| 114 |
+
|
| 115 |
+
demo = VisualizationDemo(cfg)
|
| 116 |
+
|
| 117 |
+
if args.input:
|
| 118 |
+
if len(args.input) == 1:
|
| 119 |
+
args.input = glob.glob(os.path.expanduser(args.input[0]))
|
| 120 |
+
assert args.input, "The input path(s) was not found"
|
| 121 |
+
for path in tqdm.tqdm(args.input, disable=not args.output):
|
| 122 |
+
# use PIL, to be consistent with evaluation
|
| 123 |
+
img = read_image(path, format="BGR")
|
| 124 |
+
start_time = time.time()
|
| 125 |
+
predictions, visualized_output = demo.run_on_image(img)
|
| 126 |
+
logger.info(
|
| 127 |
+
"{}: {} in {:.2f}s".format(
|
| 128 |
+
path,
|
| 129 |
+
"detected {} instances".format(len(predictions["instances"]))
|
| 130 |
+
if "instances" in predictions
|
| 131 |
+
else "finished",
|
| 132 |
+
time.time() - start_time,
|
| 133 |
+
)
|
| 134 |
+
)
|
| 135 |
+
|
| 136 |
+
if args.output:
|
| 137 |
+
if os.path.isdir(args.output):
|
| 138 |
+
assert os.path.isdir(args.output), args.output
|
| 139 |
+
out_filename = os.path.join(args.output, os.path.basename(path))
|
| 140 |
+
else:
|
| 141 |
+
assert len(args.input) == 1, "Please specify a directory with args.output"
|
| 142 |
+
out_filename = args.output
|
| 143 |
+
visualized_output.save(out_filename)
|
| 144 |
+
else:
|
| 145 |
+
cv2.namedWindow(WINDOW_NAME, cv2.WINDOW_NORMAL)
|
| 146 |
+
cv2.imshow(WINDOW_NAME, visualized_output.get_image()[:, :, ::-1])
|
| 147 |
+
if cv2.waitKey(0) == 27:
|
| 148 |
+
break # esc to quit
|
| 149 |
+
elif args.webcam:
|
| 150 |
+
assert args.input is None, "Cannot have both --input and --webcam!"
|
| 151 |
+
assert args.output is None, "output not yet supported with --webcam!"
|
| 152 |
+
cam = cv2.VideoCapture(0)
|
| 153 |
+
for vis in tqdm.tqdm(demo.run_on_video(cam)):
|
| 154 |
+
cv2.namedWindow(WINDOW_NAME, cv2.WINDOW_NORMAL)
|
| 155 |
+
cv2.imshow(WINDOW_NAME, vis)
|
| 156 |
+
if cv2.waitKey(1) == 27:
|
| 157 |
+
break # esc to quit
|
| 158 |
+
cam.release()
|
| 159 |
+
cv2.destroyAllWindows()
|
| 160 |
+
elif args.video_input:
|
| 161 |
+
video = cv2.VideoCapture(args.video_input)
|
| 162 |
+
width = int(video.get(cv2.CAP_PROP_FRAME_WIDTH))
|
| 163 |
+
height = int(video.get(cv2.CAP_PROP_FRAME_HEIGHT))
|
| 164 |
+
frames_per_second = video.get(cv2.CAP_PROP_FPS)
|
| 165 |
+
num_frames = int(video.get(cv2.CAP_PROP_FRAME_COUNT))
|
| 166 |
+
basename = os.path.basename(args.video_input)
|
| 167 |
+
codec, file_ext = (
|
| 168 |
+
("x264", ".mkv") if test_opencv_video_format("x264", ".mkv") else ("mp4v", ".mp4")
|
| 169 |
+
)
|
| 170 |
+
if codec == ".mp4v":
|
| 171 |
+
warnings.warn("x264 codec not available, switching to mp4v")
|
| 172 |
+
if args.output:
|
| 173 |
+
if os.path.isdir(args.output):
|
| 174 |
+
output_fname = os.path.join(args.output, basename)
|
| 175 |
+
output_fname = os.path.splitext(output_fname)[0] + file_ext
|
| 176 |
+
else:
|
| 177 |
+
output_fname = args.output
|
| 178 |
+
assert not os.path.isfile(output_fname), output_fname
|
| 179 |
+
output_file = cv2.VideoWriter(
|
| 180 |
+
filename=output_fname,
|
| 181 |
+
# some installation of opencv may not support x264 (due to its license),
|
| 182 |
+
# you can try other format (e.g. MPEG)
|
| 183 |
+
fourcc=cv2.VideoWriter_fourcc(*codec),
|
| 184 |
+
fps=float(frames_per_second),
|
| 185 |
+
frameSize=(width, height),
|
| 186 |
+
isColor=True,
|
| 187 |
+
)
|
| 188 |
+
assert os.path.isfile(args.video_input)
|
| 189 |
+
for vis_frame in tqdm.tqdm(demo.run_on_video(video), total=num_frames):
|
| 190 |
+
if args.output:
|
| 191 |
+
output_file.write(vis_frame)
|
| 192 |
+
else:
|
| 193 |
+
cv2.namedWindow(basename, cv2.WINDOW_NORMAL)
|
| 194 |
+
cv2.imshow(basename, vis_frame)
|
| 195 |
+
if cv2.waitKey(1) == 27:
|
| 196 |
+
break # esc to quit
|
| 197 |
+
video.release()
|
| 198 |
+
if args.output:
|
| 199 |
+
output_file.release()
|
| 200 |
+
else:
|
| 201 |
+
cv2.destroyAllWindows()
|
demo/images/000000000605.jpg
ADDED

|
demo/images/000000001025.jpg
ADDED

|
demo/images/000000290833.jpg
ADDED

|
demo/images/ADE_val_00000739.jpg
ADDED

|
demo/images/ADE_val_00000979.jpg
ADDED

|
demo/images/ADE_val_00001200.jpg
ADDED

|
demo/predictor.py
ADDED
|
@@ -0,0 +1,280 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
This file may have been modified by Bytedance Ltd. and/or its affiliates (“Bytedance's Modifications”).
|
| 3 |
+
All Bytedance's Modifications are Copyright (year) Bytedance Ltd. and/or its affiliates.
|
| 4 |
+
|
| 5 |
+
Reference: https://github.com/facebookresearch/Mask2Former/blob/main/demo/predictor.py
|
| 6 |
+
"""
|
| 7 |
+
|
| 8 |
+
import atexit
|
| 9 |
+
import bisect
|
| 10 |
+
import multiprocessing as mp
|
| 11 |
+
from collections import deque
|
| 12 |
+
|
| 13 |
+
import cv2
|
| 14 |
+
import torch
|
| 15 |
+
import itertools
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
from detectron2.data import DatasetCatalog, MetadataCatalog
|
| 19 |
+
from detectron2.engine.defaults import DefaultPredictor as d2_defaultPredictor
|
| 20 |
+
from detectron2.utils.video_visualizer import VideoVisualizer
|
| 21 |
+
from detectron2.utils.visualizer import ColorMode, Visualizer, random_color
|
| 22 |
+
import detectron2.utils.visualizer as d2_visualizer
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
class DefaultPredictor(d2_defaultPredictor):
|
| 26 |
+
|
| 27 |
+
def set_metadata(self, metadata):
|
| 28 |
+
self.model.set_metadata(metadata)
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
class OpenVocabVisualizer(Visualizer):
|
| 32 |
+
def draw_panoptic_seg(self, panoptic_seg, segments_info, area_threshold=None, alpha=0.7):
|
| 33 |
+
"""
|
| 34 |
+
Draw panoptic prediction annotations or results.
|
| 35 |
+
|
| 36 |
+
Args:
|
| 37 |
+
panoptic_seg (Tensor): of shape (height, width) where the values are ids for each
|
| 38 |
+
segment.
|
| 39 |
+
segments_info (list[dict] or None): Describe each segment in `panoptic_seg`.
|
| 40 |
+
If it is a ``list[dict]``, each dict contains keys "id", "category_id".
|
| 41 |
+
If None, category id of each pixel is computed by
|
| 42 |
+
``pixel // metadata.label_divisor``.
|
| 43 |
+
area_threshold (int): stuff segments with less than `area_threshold` are not drawn.
|
| 44 |
+
|
| 45 |
+
Returns:
|
| 46 |
+
output (VisImage): image object with visualizations.
|
| 47 |
+
"""
|
| 48 |
+
pred = d2_visualizer._PanopticPrediction(panoptic_seg, segments_info, self.metadata)
|
| 49 |
+
|
| 50 |
+
if self._instance_mode == ColorMode.IMAGE_BW:
|
| 51 |
+
self.output.reset_image(self._create_grayscale_image(pred.non_empty_mask()))
|
| 52 |
+
# draw mask for all semantic segments first i.e. "stuff"
|
| 53 |
+
for mask, sinfo in pred.semantic_masks():
|
| 54 |
+
category_idx = sinfo["category_id"]
|
| 55 |
+
try:
|
| 56 |
+
mask_color = [x / 255 for x in self.metadata.stuff_colors[category_idx]]
|
| 57 |
+
except AttributeError:
|
| 58 |
+
mask_color = None
|
| 59 |
+
|
| 60 |
+
text = self.metadata.stuff_classes[category_idx].split(',')[0]
|
| 61 |
+
self.draw_binary_mask(
|
| 62 |
+
mask,
|
| 63 |
+
color=mask_color,
|
| 64 |
+
edge_color=d2_visualizer._OFF_WHITE,
|
| 65 |
+
text=text,
|
| 66 |
+
alpha=alpha,
|
| 67 |
+
area_threshold=area_threshold,
|
| 68 |
+
)
|
| 69 |
+
# draw mask for all instances second
|
| 70 |
+
all_instances = list(pred.instance_masks())
|
| 71 |
+
if len(all_instances) == 0:
|
| 72 |
+
return self.output
|
| 73 |
+
masks, sinfo = list(zip(*all_instances))
|
| 74 |
+
category_ids = [x["category_id"] for x in sinfo]
|
| 75 |
+
|
| 76 |
+
try:
|
| 77 |
+
scores = [x["score"] for x in sinfo]
|
| 78 |
+
except KeyError:
|
| 79 |
+
scores = None
|
| 80 |
+
stuff_classes = self.metadata.stuff_classes
|
| 81 |
+
stuff_classes = [x.split(',')[0] for x in stuff_classes]
|
| 82 |
+
labels = d2_visualizer._create_text_labels(
|
| 83 |
+
category_ids, scores, stuff_classes, [x.get("iscrowd", 0) for x in sinfo]
|
| 84 |
+
)
|
| 85 |
+
|
| 86 |
+
try:
|
| 87 |
+
colors = [
|
| 88 |
+
self._jitter([x / 255 for x in self.metadata.stuff_colors[c]]) for c in category_ids
|
| 89 |
+
]
|
| 90 |
+
except AttributeError:
|
| 91 |
+
colors = None
|
| 92 |
+
self.overlay_instances(masks=masks, labels=labels, assigned_colors=colors, alpha=alpha)
|
| 93 |
+
|
| 94 |
+
return self.output
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
class VisualizationDemo(object):
|
| 98 |
+
def __init__(self, cfg, instance_mode=ColorMode.IMAGE, parallel=False):
|
| 99 |
+
"""
|
| 100 |
+
Args:
|
| 101 |
+
cfg (CfgNode):
|
| 102 |
+
instance_mode (ColorMode):
|
| 103 |
+
parallel (bool): whether to run the model in different processes from visualization.
|
| 104 |
+
Useful since the visualization logic can be slow.
|
| 105 |
+
"""
|
| 106 |
+
|
| 107 |
+
coco_metadata = MetadataCatalog.get("openvocab_coco_2017_val_panoptic_with_sem_seg")
|
| 108 |
+
ade20k_metadata = MetadataCatalog.get("openvocab_ade20k_panoptic_val")
|
| 109 |
+
lvis_classes = open("./fcclip/data/datasets/lvis_1203_with_prompt_eng.txt", 'r').read().splitlines()
|
| 110 |
+
lvis_classes = [x[x.find(':')+1:] for x in lvis_classes]
|
| 111 |
+
lvis_colors = list(
|
| 112 |
+
itertools.islice(itertools.cycle(coco_metadata.stuff_colors), len(lvis_classes))
|
| 113 |
+
)
|
| 114 |
+
# rerrange to thing_classes, stuff_classes
|
| 115 |
+
coco_thing_classes = coco_metadata.thing_classes
|
| 116 |
+
coco_stuff_classes = [x for x in coco_metadata.stuff_classes if x not in coco_thing_classes]
|
| 117 |
+
coco_thing_colors = coco_metadata.thing_colors
|
| 118 |
+
coco_stuff_colors = [x for x in coco_metadata.stuff_colors if x not in coco_thing_colors]
|
| 119 |
+
ade20k_thing_classes = ade20k_metadata.thing_classes
|
| 120 |
+
ade20k_stuff_classes = [x for x in ade20k_metadata.stuff_classes if x not in ade20k_thing_classes]
|
| 121 |
+
ade20k_thing_colors = ade20k_metadata.thing_colors
|
| 122 |
+
ade20k_stuff_colors = [x for x in ade20k_metadata.stuff_colors if x not in ade20k_thing_colors]
|
| 123 |
+
|
| 124 |
+
user_classes = []
|
| 125 |
+
user_colors = [random_color(rgb=True, maximum=1) for _ in range(len(user_classes))]
|
| 126 |
+
|
| 127 |
+
stuff_classes = coco_stuff_classes + ade20k_stuff_classes
|
| 128 |
+
stuff_colors = coco_stuff_colors + ade20k_stuff_colors
|
| 129 |
+
thing_classes = user_classes + coco_thing_classes + ade20k_thing_classes + lvis_classes
|
| 130 |
+
thing_colors = user_colors + coco_thing_colors + ade20k_thing_colors + lvis_colors
|
| 131 |
+
|
| 132 |
+
thing_dataset_id_to_contiguous_id = {x: x for x in range(len(thing_classes))}
|
| 133 |
+
DatasetCatalog.register(
|
| 134 |
+
"openvocab_dataset", lambda x: []
|
| 135 |
+
)
|
| 136 |
+
self.metadata = MetadataCatalog.get("openvocab_dataset").set(
|
| 137 |
+
stuff_classes=thing_classes+stuff_classes,
|
| 138 |
+
stuff_colors=thing_colors+stuff_colors,
|
| 139 |
+
thing_dataset_id_to_contiguous_id=thing_dataset_id_to_contiguous_id,
|
| 140 |
+
)
|
| 141 |
+
#print("self.metadata:", self.metadata)
|
| 142 |
+
self.cpu_device = torch.device("cpu")
|
| 143 |
+
self.instance_mode = instance_mode
|
| 144 |
+
|
| 145 |
+
self.parallel = parallel
|
| 146 |
+
if parallel:
|
| 147 |
+
num_gpu = torch.cuda.device_count()
|
| 148 |
+
self.predictor = AsyncPredictor(cfg, num_gpus=num_gpu)
|
| 149 |
+
else:
|
| 150 |
+
self.predictor = DefaultPredictor(cfg)
|
| 151 |
+
self.predictor.set_metadata(self.metadata)
|
| 152 |
+
|
| 153 |
+
def run_on_image(self, image):
|
| 154 |
+
"""
|
| 155 |
+
Args:
|
| 156 |
+
image (np.ndarray): an image of shape (H, W, C) (in BGR order).
|
| 157 |
+
This is the format used by OpenCV.
|
| 158 |
+
Returns:
|
| 159 |
+
predictions (dict): the output of the model.
|
| 160 |
+
vis_output (VisImage): the visualized image output.
|
| 161 |
+
"""
|
| 162 |
+
vis_output = None
|
| 163 |
+
predictions = self.predictor(image)
|
| 164 |
+
# Convert image from OpenCV BGR format to Matplotlib RGB format.
|
| 165 |
+
image = image[:, :, ::-1]
|
| 166 |
+
visualizer = OpenVocabVisualizer(image, self.metadata, instance_mode=self.instance_mode)
|
| 167 |
+
if "panoptic_seg" in predictions:
|
| 168 |
+
panoptic_seg, segments_info = predictions["panoptic_seg"]
|
| 169 |
+
vis_output = visualizer.draw_panoptic_seg(
|
| 170 |
+
panoptic_seg.to(self.cpu_device), segments_info
|
| 171 |
+
)
|
| 172 |
+
else:
|
| 173 |
+
if "sem_seg" in predictions:
|
| 174 |
+
vis_output = visualizer.draw_sem_seg(
|
| 175 |
+
predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
|
| 176 |
+
)
|
| 177 |
+
if "instances" in predictions:
|
| 178 |
+
instances = predictions["instances"].to(self.cpu_device)
|
| 179 |
+
vis_output = visualizer.draw_instance_predictions(predictions=instances)
|
| 180 |
+
|
| 181 |
+
return predictions, vis_output
|
| 182 |
+
|
| 183 |
+
def _frame_from_video(self, video):
|
| 184 |
+
while video.isOpened():
|
| 185 |
+
success, frame = video.read()
|
| 186 |
+
if success:
|
| 187 |
+
yield frame
|
| 188 |
+
else:
|
| 189 |
+
break
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
class AsyncPredictor:
|
| 193 |
+
"""
|
| 194 |
+
A predictor that runs the model asynchronously, possibly on >1 GPUs.
|
| 195 |
+
Because rendering the visualization takes considerably amount of time,
|
| 196 |
+
this helps improve throughput a little bit when rendering videos.
|
| 197 |
+
"""
|
| 198 |
+
|
| 199 |
+
class _StopToken:
|
| 200 |
+
pass
|
| 201 |
+
|
| 202 |
+
class _PredictWorker(mp.Process):
|
| 203 |
+
def __init__(self, cfg, task_queue, result_queue):
|
| 204 |
+
self.cfg = cfg
|
| 205 |
+
self.task_queue = task_queue
|
| 206 |
+
self.result_queue = result_queue
|
| 207 |
+
super().__init__()
|
| 208 |
+
|
| 209 |
+
def run(self):
|
| 210 |
+
predictor = DefaultPredictor(self.cfg)
|
| 211 |
+
|
| 212 |
+
while True:
|
| 213 |
+
task = self.task_queue.get()
|
| 214 |
+
if isinstance(task, AsyncPredictor._StopToken):
|
| 215 |
+
break
|
| 216 |
+
idx, data = task
|
| 217 |
+
result = predictor(data)
|
| 218 |
+
self.result_queue.put((idx, result))
|
| 219 |
+
|
| 220 |
+
def __init__(self, cfg, num_gpus: int = 1):
|
| 221 |
+
"""
|
| 222 |
+
Args:
|
| 223 |
+
cfg (CfgNode):
|
| 224 |
+
num_gpus (int): if 0, will run on CPU
|
| 225 |
+
"""
|
| 226 |
+
num_workers = max(num_gpus, 1)
|
| 227 |
+
self.task_queue = mp.Queue(maxsize=num_workers * 3)
|
| 228 |
+
self.result_queue = mp.Queue(maxsize=num_workers * 3)
|
| 229 |
+
self.procs = []
|
| 230 |
+
for gpuid in range(max(num_gpus, 1)):
|
| 231 |
+
cfg = cfg.clone()
|
| 232 |
+
cfg.defrost()
|
| 233 |
+
cfg.MODEL.DEVICE = "cuda:{}".format(gpuid) if num_gpus > 0 else "cpu"
|
| 234 |
+
self.procs.append(
|
| 235 |
+
AsyncPredictor._PredictWorker(cfg, self.task_queue, self.result_queue)
|
| 236 |
+
)
|
| 237 |
+
|
| 238 |
+
self.put_idx = 0
|
| 239 |
+
self.get_idx = 0
|
| 240 |
+
self.result_rank = []
|
| 241 |
+
self.result_data = []
|
| 242 |
+
|
| 243 |
+
for p in self.procs:
|
| 244 |
+
p.start()
|
| 245 |
+
atexit.register(self.shutdown)
|
| 246 |
+
|
| 247 |
+
def put(self, image):
|
| 248 |
+
self.put_idx += 1
|
| 249 |
+
self.task_queue.put((self.put_idx, image))
|
| 250 |
+
|
| 251 |
+
def get(self):
|
| 252 |
+
self.get_idx += 1 # the index needed for this request
|
| 253 |
+
if len(self.result_rank) and self.result_rank[0] == self.get_idx:
|
| 254 |
+
res = self.result_data[0]
|
| 255 |
+
del self.result_data[0], self.result_rank[0]
|
| 256 |
+
return res
|
| 257 |
+
|
| 258 |
+
while True:
|
| 259 |
+
# make sure the results are returned in the correct order
|
| 260 |
+
idx, res = self.result_queue.get()
|
| 261 |
+
if idx == self.get_idx:
|
| 262 |
+
return res
|
| 263 |
+
insert = bisect.bisect(self.result_rank, idx)
|
| 264 |
+
self.result_rank.insert(insert, idx)
|
| 265 |
+
self.result_data.insert(insert, res)
|
| 266 |
+
|
| 267 |
+
def __len__(self):
|
| 268 |
+
return self.put_idx - self.get_idx
|
| 269 |
+
|
| 270 |
+
def __call__(self, image):
|
| 271 |
+
self.put(image)
|
| 272 |
+
return self.get()
|
| 273 |
+
|
| 274 |
+
def shutdown(self):
|
| 275 |
+
for _ in self.procs:
|
| 276 |
+
self.task_queue.put(AsyncPredictor._StopToken())
|
| 277 |
+
|
| 278 |
+
@property
|
| 279 |
+
def default_buffer_size(self):
|
| 280 |
+
return len(self.procs) * 5
|
mask_adapter/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
mask_adapter/__init__.py
ADDED
|
@@ -0,0 +1,44 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (2023) Bytedance Ltd. and/or its affiliates
|
| 3 |
+
|
| 4 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
you may not use this file except in compliance with the License.
|
| 6 |
+
You may obtain a copy of the License at
|
| 7 |
+
|
| 8 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
|
| 10 |
+
Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
See the License for the specific language governing permissions and
|
| 14 |
+
limitations under the License.
|
| 15 |
+
"""
|
| 16 |
+
from . import data # register all new datasets
|
| 17 |
+
from . import modeling
|
| 18 |
+
|
| 19 |
+
# config
|
| 20 |
+
from .config import add_maskformer2_config, add_fcclip_config, add_mask_adapter_config
|
| 21 |
+
|
| 22 |
+
# dataset loading
|
| 23 |
+
from .data.dataset_mappers.coco_instance_new_baseline_dataset_mapper import COCOInstanceNewBaselineDatasetMapper
|
| 24 |
+
from .data.dataset_mappers.coco_panoptic_new_baseline_dataset_mapper import COCOPanopticNewBaselineDatasetMapper
|
| 25 |
+
#from .data.dataset_mappers.grand_new_baseline_dataset_mapper import GrandNewBaselineDatasetMapper
|
| 26 |
+
from .data.dataset_mappers.mask_former_instance_dataset_mapper import (
|
| 27 |
+
MaskFormerInstanceDatasetMapper,
|
| 28 |
+
)
|
| 29 |
+
from .data.dataset_mappers.mask_former_panoptic_dataset_mapper import (
|
| 30 |
+
MaskFormerPanopticDatasetMapper,
|
| 31 |
+
)
|
| 32 |
+
from .data.dataset_mappers.mask_former_semantic_dataset_mapper import (
|
| 33 |
+
MaskFormerSemanticDatasetMapper,
|
| 34 |
+
)
|
| 35 |
+
from .data.dataset_mappers.coco_combine_new_baseline_dataset_mapper import (
|
| 36 |
+
COCOCombineNewBaselineDatasetMapper,
|
| 37 |
+
)
|
| 38 |
+
from .data.custom_dataset_dataloader import *
|
| 39 |
+
# models
|
| 40 |
+
from .mask_adapter import MASK_Adapter
|
| 41 |
+
from .test_time_augmentation import SemanticSegmentorWithTTA
|
| 42 |
+
|
| 43 |
+
# evaluation
|
| 44 |
+
from .evaluation.instance_evaluation import InstanceSegEvaluator
|
mask_adapter/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (1.88 kB). View file
|
|
|
mask_adapter/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (1.87 kB). View file
|
|
|
mask_adapter/__pycache__/config.cpython-310.pyc
ADDED
|
Binary file (3.74 kB). View file
|
|
|
mask_adapter/__pycache__/config.cpython-38.pyc
ADDED
|
Binary file (3.7 kB). View file
|
|
|
mask_adapter/__pycache__/fcclip.cpython-310.pyc
ADDED
|
Binary file (27.7 kB). View file
|
|
|
mask_adapter/__pycache__/fcclip.cpython-38.pyc
ADDED
|
Binary file (28.3 kB). View file
|
|
|
mask_adapter/__pycache__/mask_adapter.cpython-310.pyc
ADDED
|
Binary file (21.5 kB). View file
|
|
|
mask_adapter/__pycache__/mask_adapter.cpython-38.pyc
ADDED
|
Binary file (21.6 kB). View file
|
|
|
mask_adapter/__pycache__/sam_maskadapter.cpython-310.pyc
ADDED
|
Binary file (11.8 kB). View file
|
|
|
mask_adapter/__pycache__/test_time_augmentation.cpython-310.pyc
ADDED
|
Binary file (4.29 kB). View file
|
|
|
mask_adapter/__pycache__/test_time_augmentation.cpython-38.pyc
ADDED
|
Binary file (4.28 kB). View file
|
|
|
mask_adapter/config.py
ADDED
|
@@ -0,0 +1,150 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# -*- coding: utf-8 -*-
|
| 2 |
+
"""
|
| 3 |
+
This file may have been modified by Bytedance Ltd. and/or its affiliates (“Bytedance's Modifications”).
|
| 4 |
+
All Bytedance's Modifications are Copyright (year) Bytedance Ltd. and/or its affiliates.
|
| 5 |
+
|
| 6 |
+
Reference: https://github.com/facebookresearch/Mask2Former/blob/main/mask2former/config.py
|
| 7 |
+
"""
|
| 8 |
+
from detectron2.config import CfgNode as CN
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def add_maskformer2_config(cfg):
|
| 12 |
+
"""
|
| 13 |
+
Add config for MASK_FORMER.
|
| 14 |
+
"""
|
| 15 |
+
# NOTE: configs from original maskformer
|
| 16 |
+
# data config
|
| 17 |
+
# select the dataset mapper
|
| 18 |
+
cfg.INPUT.DATASET_MAPPER_NAME = "mask_former_semantic"
|
| 19 |
+
# Color augmentation
|
| 20 |
+
cfg.INPUT.COLOR_AUG_SSD = False
|
| 21 |
+
# We retry random cropping until no single category in semantic segmentation GT occupies more
|
| 22 |
+
# than `SINGLE_CATEGORY_MAX_AREA` part of the crop.
|
| 23 |
+
cfg.INPUT.CROP.SINGLE_CATEGORY_MAX_AREA = 1.0
|
| 24 |
+
# Pad image and segmentation GT in dataset mapper.
|
| 25 |
+
cfg.INPUT.SIZE_DIVISIBILITY = -1
|
| 26 |
+
|
| 27 |
+
# solver config
|
| 28 |
+
# weight decay on embedding
|
| 29 |
+
cfg.SOLVER.WEIGHT_DECAY_EMBED = 0.0
|
| 30 |
+
# optimizer
|
| 31 |
+
cfg.SOLVER.OPTIMIZER = "ADAMW"
|
| 32 |
+
cfg.SOLVER.BACKBONE_MULTIPLIER = 0.1
|
| 33 |
+
|
| 34 |
+
# mask_former model config
|
| 35 |
+
cfg.MODEL.MASK_FORMER = CN()
|
| 36 |
+
|
| 37 |
+
# loss
|
| 38 |
+
cfg.MODEL.MASK_FORMER.DEEP_SUPERVISION = True
|
| 39 |
+
cfg.MODEL.MASK_FORMER.NO_OBJECT_WEIGHT = 0.1
|
| 40 |
+
cfg.MODEL.MASK_FORMER.CLASS_WEIGHT = 1.0
|
| 41 |
+
cfg.MODEL.MASK_FORMER.DICE_WEIGHT = 1.0
|
| 42 |
+
cfg.MODEL.MASK_FORMER.MASK_WEIGHT = 20.0
|
| 43 |
+
|
| 44 |
+
# transformer config
|
| 45 |
+
cfg.MODEL.MASK_FORMER.NHEADS = 8
|
| 46 |
+
cfg.MODEL.MASK_FORMER.DROPOUT = 0.1
|
| 47 |
+
cfg.MODEL.MASK_FORMER.DIM_FEEDFORWARD = 2048
|
| 48 |
+
cfg.MODEL.MASK_FORMER.ENC_LAYERS = 0
|
| 49 |
+
cfg.MODEL.MASK_FORMER.DEC_LAYERS = 6
|
| 50 |
+
cfg.MODEL.MASK_FORMER.PRE_NORM = False
|
| 51 |
+
|
| 52 |
+
cfg.MODEL.MASK_FORMER.HIDDEN_DIM = 256
|
| 53 |
+
cfg.MODEL.MASK_FORMER.NUM_OBJECT_QUERIES = 100
|
| 54 |
+
|
| 55 |
+
cfg.MODEL.MASK_FORMER.TRANSFORMER_IN_FEATURE = "res5"
|
| 56 |
+
cfg.MODEL.MASK_FORMER.ENFORCE_INPUT_PROJ = False
|
| 57 |
+
|
| 58 |
+
# mask_former inference config
|
| 59 |
+
cfg.MODEL.MASK_FORMER.TEST = CN()
|
| 60 |
+
cfg.MODEL.MASK_FORMER.TEST.SEMANTIC_ON = True
|
| 61 |
+
cfg.MODEL.MASK_FORMER.TEST.INSTANCE_ON = False
|
| 62 |
+
cfg.MODEL.MASK_FORMER.TEST.PANOPTIC_ON = False
|
| 63 |
+
cfg.MODEL.MASK_FORMER.TEST.OBJECT_MASK_THRESHOLD = 0.0
|
| 64 |
+
cfg.MODEL.MASK_FORMER.TEST.OVERLAP_THRESHOLD = 0.0
|
| 65 |
+
cfg.MODEL.MASK_FORMER.TEST.SEM_SEG_POSTPROCESSING_BEFORE_INFERENCE = False
|
| 66 |
+
|
| 67 |
+
# Sometimes `backbone.size_divisibility` is set to 0 for some backbone (e.g. ResNet)
|
| 68 |
+
# you can use this config to override
|
| 69 |
+
cfg.MODEL.MASK_FORMER.SIZE_DIVISIBILITY = 32
|
| 70 |
+
|
| 71 |
+
# pixel decoder config
|
| 72 |
+
cfg.MODEL.SEM_SEG_HEAD.MASK_DIM = 256
|
| 73 |
+
# adding transformer in pixel decoder
|
| 74 |
+
cfg.MODEL.SEM_SEG_HEAD.TRANSFORMER_ENC_LAYERS = 0
|
| 75 |
+
# pixel decoder
|
| 76 |
+
cfg.MODEL.SEM_SEG_HEAD.PIXEL_DECODER_NAME = "BasePixelDecoder"
|
| 77 |
+
|
| 78 |
+
# swin transformer backbone
|
| 79 |
+
cfg.MODEL.SWIN = CN()
|
| 80 |
+
cfg.MODEL.SWIN.PRETRAIN_IMG_SIZE = 224
|
| 81 |
+
cfg.MODEL.SWIN.PATCH_SIZE = 4
|
| 82 |
+
cfg.MODEL.SWIN.EMBED_DIM = 96
|
| 83 |
+
cfg.MODEL.SWIN.DEPTHS = [2, 2, 6, 2]
|
| 84 |
+
cfg.MODEL.SWIN.NUM_HEADS = [3, 6, 12, 24]
|
| 85 |
+
cfg.MODEL.SWIN.WINDOW_SIZE = 7
|
| 86 |
+
cfg.MODEL.SWIN.MLP_RATIO = 4.0
|
| 87 |
+
cfg.MODEL.SWIN.QKV_BIAS = True
|
| 88 |
+
cfg.MODEL.SWIN.QK_SCALE = None
|
| 89 |
+
cfg.MODEL.SWIN.DROP_RATE = 0.0
|
| 90 |
+
cfg.MODEL.SWIN.ATTN_DROP_RATE = 0.0
|
| 91 |
+
cfg.MODEL.SWIN.DROP_PATH_RATE = 0.3
|
| 92 |
+
cfg.MODEL.SWIN.APE = False
|
| 93 |
+
cfg.MODEL.SWIN.PATCH_NORM = True
|
| 94 |
+
cfg.MODEL.SWIN.OUT_FEATURES = ["res2", "res3", "res4", "res5"]
|
| 95 |
+
cfg.MODEL.SWIN.USE_CHECKPOINT = False
|
| 96 |
+
|
| 97 |
+
# NOTE: maskformer2 extra configs
|
| 98 |
+
# transformer module
|
| 99 |
+
cfg.MODEL.MASK_FORMER.TRANSFORMER_DECODER_NAME = "MultiScaleMaskedTransformerDecoder"
|
| 100 |
+
|
| 101 |
+
# LSJ aug
|
| 102 |
+
cfg.INPUT.IMAGE_SIZE = 1024
|
| 103 |
+
cfg.INPUT.MIN_SCALE = 0.1
|
| 104 |
+
cfg.INPUT.MAX_SCALE = 2.0
|
| 105 |
+
|
| 106 |
+
# MSDeformAttn encoder configs
|
| 107 |
+
cfg.MODEL.SEM_SEG_HEAD.DEFORMABLE_TRANSFORMER_ENCODER_IN_FEATURES = ["res3", "res4", "res5"]
|
| 108 |
+
cfg.MODEL.SEM_SEG_HEAD.DEFORMABLE_TRANSFORMER_ENCODER_N_POINTS = 4
|
| 109 |
+
cfg.MODEL.SEM_SEG_HEAD.DEFORMABLE_TRANSFORMER_ENCODER_N_HEADS = 8
|
| 110 |
+
|
| 111 |
+
# point loss configs
|
| 112 |
+
# Number of points sampled during training for a mask point head.
|
| 113 |
+
cfg.MODEL.MASK_FORMER.TRAIN_NUM_POINTS = 112 * 112
|
| 114 |
+
# Oversampling parameter for PointRend point sampling during training. Parameter `k` in the
|
| 115 |
+
# original paper.
|
| 116 |
+
cfg.MODEL.MASK_FORMER.OVERSAMPLE_RATIO = 3.0
|
| 117 |
+
# Importance sampling parameter for PointRend point sampling during training. Parametr `beta` in
|
| 118 |
+
# the original paper.
|
| 119 |
+
cfg.MODEL.MASK_FORMER.IMPORTANCE_SAMPLE_RATIO = 0.75
|
| 120 |
+
|
| 121 |
+
|
| 122 |
+
def add_fcclip_config(cfg):
|
| 123 |
+
# FC-CLIP model config
|
| 124 |
+
cfg.MODEL.FC_CLIP = CN()
|
| 125 |
+
cfg.MODEL.FC_CLIP.CLIP_MODEL_NAME = "convnext_large_d_320"
|
| 126 |
+
cfg.MODEL.FC_CLIP.CLIP_PRETRAINED_WEIGHTS = "laion2b_s29b_b131k_ft_soup"
|
| 127 |
+
cfg.MODEL.FC_CLIP.EMBED_DIM = 768
|
| 128 |
+
cfg.MODEL.FC_CLIP.GEOMETRIC_ENSEMBLE_ALPHA = 0.4
|
| 129 |
+
cfg.MODEL.FC_CLIP.GEOMETRIC_ENSEMBLE_BETA = 0.8
|
| 130 |
+
cfg.MODEL.FC_CLIP.ENSEMBLE_ON_VALID_MASK = False
|
| 131 |
+
|
| 132 |
+
def add_mask_adapter_config(cfg):
|
| 133 |
+
# Mask-Adapter model config
|
| 134 |
+
cfg.MODEL.MASK_ADAPTER = CN()
|
| 135 |
+
cfg.MODEL.MASK_ADAPTER.MASK_IN_CHANNELS = 16
|
| 136 |
+
cfg.MODEL.MASK_ADAPTER.NUM_CHANNELS = 768
|
| 137 |
+
cfg.MODEL.MASK_ADAPTER.USE_CHECKPOINT = False
|
| 138 |
+
cfg.MODEL.MASK_ADAPTER.NUM_OUTPUT_MAPS = 16
|
| 139 |
+
|
| 140 |
+
cfg.MODEL.MASK_ADAPTER.MASK_THRESHOLD = 0.45
|
| 141 |
+
cfg.MODEL.MASK_ADAPTER.TRAIN_MAFT = False
|
| 142 |
+
|
| 143 |
+
cfg.MODEL.MASK_ADAPTER.NAME = "MASKAdapterHead"
|
| 144 |
+
|
| 145 |
+
cfg.DATALOADER.DATASET_RATIO = [1, 1]
|
| 146 |
+
cfg.DATALOADER.USE_DIFF_BS_SIZE = True
|
| 147 |
+
cfg.DATALOADER.DATASET_BS = [2, 2]
|
| 148 |
+
cfg.DATALOADER.USE_RFS = [False, False]
|
| 149 |
+
cfg.DATALOADER.MULTI_DATASET_GROUPING = True
|
| 150 |
+
cfg.DATALOADER.DATASET_ANN = ['box', 'box']
|
mask_adapter/data/.DS_Store
ADDED
|
Binary file (6.15 kB). View file
|
|
|
mask_adapter/data/__init__.py
ADDED
|
@@ -0,0 +1,16 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Copyright (2023) Bytedance Ltd. and/or its affiliates
|
| 3 |
+
|
| 4 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 5 |
+
you may not use this file except in compliance with the License.
|
| 6 |
+
You may obtain a copy of the License at
|
| 7 |
+
|
| 8 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 9 |
+
|
| 10 |
+
Unless required by applicable law or agreed to in writing, software
|
| 11 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 12 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 13 |
+
See the License for the specific language governing permissions and
|
| 14 |
+
limitations under the License.
|
| 15 |
+
"""
|
| 16 |
+
from . import datasets
|
mask_adapter/data/__pycache__/__init__.cpython-310.pyc
ADDED
|
Binary file (799 Bytes). View file
|
|
|
mask_adapter/data/__pycache__/__init__.cpython-38.pyc
ADDED
|
Binary file (792 Bytes). View file
|
|
|
mask_adapter/data/__pycache__/custom_dataset_dataloader.cpython-310.pyc
ADDED
|
Binary file (10.1 kB). View file
|
|
|