Spaces:
Sleeping

Sleeping
Commit
·
3b1a154
0
Parent(s):
making workflows
Browse files- PDF_chat.png +0 -0
- README.md +40 -0
- app.py +142 -0
- requirements.txt +12 -0
PDF_chat.png
ADDED

|
README.md
ADDED
|
@@ -0,0 +1,40 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
title: Chat With Documents
|
| 3 |
+
emoji: 🦀
|
| 4 |
+
colorFrom: green
|
| 5 |
+
colorTo: red
|
| 6 |
+
sdk: streamlit
|
| 7 |
+
sdk_version: 1.31.0
|
| 8 |
+
app_file: app.py
|
| 9 |
+
pinned: false
|
| 10 |
+
---
|
| 11 |
+
|
| 12 |
+
# qp-ai-assessment
|
| 13 |
+
Contextual Chat Bot
|
| 14 |
+
|
| 15 |
+
Simple Contextual Chat Bot
|
| 16 |
+
1. Read a long PDF/ Word Document.
|
| 17 |
+
2. Build a chat bot that will use the document as a context to answer the question.
|
| 18 |
+
3. If the answer is not found in the document - it should say I don't know the answer.
|
| 19 |
+
|
| 20 |
+
Advanced Challenge:
|
| 21 |
+
- Break down the document into multiple chunks/ paragraphs.
|
| 22 |
+
- Store them in a vector database like pinecone.
|
| 23 |
+
- When you ask a question find out the top 3 chunks that will likely have the answer to the question using semantic similarity search.
|
| 24 |
+
|
| 25 |
+
#**System Design**
|
| 26 |
+
|
| 27 |
+
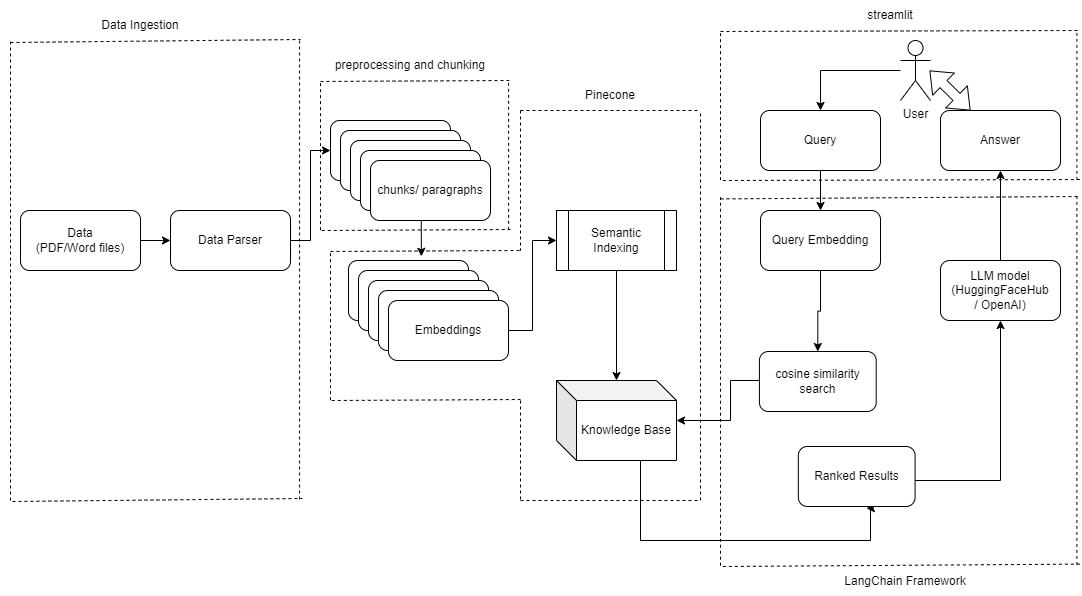
|
| 28 |
+
|
| 29 |
+
#**Required Packages**
|
| 30 |
+
1. Langchain : LangChain is a framework for developing applications powered by language models. [Docs](https://python.langchain.com/docs/get_started/introduction)
|
| 31 |
+
2. Pinecone : Pinecone makes it easy to provide long-term memory for high-performance AI applications. It’s a managed, cloud-native vector database with a simple API and no infrastructure hassles. Pinecone serves fresh, filtered query results with low latency at the scale of billions of vectors. [Docs](https://docs.pinecone.io/docs/quickstart)
|
| 32 |
+
3. Sentence_transformers : SentenceTransformers is a Python framework for state-of-the-art sentence, text and image embeddings. The initial work is described in our paper Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. [Docs](https://www.sbert.net/)
|
| 33 |
+
4. pdf2image : pdf2image is a python module that wraps the pdftoppm and pdftocairo utilities to convert PDF into images. [Docs](https://pdf2image.readthedocs.io/en/latest/overview.html)
|
| 34 |
+
5. pypdf2 : PyPDF2 is a free and open source pure-python PDF library capable of splitting, merging, cropping, and transforming the pages of PDF files. It can also add custom data, viewing options, and passwords to PDF files. PyPDF2 can retrieve text and metadata from PDFs as well.[Docs](https://pdf2image.readthedocs.io/en/latest/overview.html)
|
| 35 |
+
6. transformers : Transformers provides APIs and tools to easily download and train state-of-the-art pretrained models. Using pretrained models can reduce your compute costs, carbon footprint, and save you the time and resources required to train a model from scratch. [Docs](https://huggingface.co/docs/transformers/en/index)
|
| 36 |
+
|
| 37 |
+
#**Limitations**
|
| 38 |
+
1. Embedding : As the project has made use of readily available huggingface embeddings, it has max dimension of 768. We can make use of alternate embeddings such as HuggingFaceInstructEmbeddings, Ollama embeddings which are open-source or OpenAI embeddings.
|
| 39 |
+
2. LLM : Making use of llm which has more parameter and was trained more data can also provide optimal results.
|
| 40 |
+
|
app.py
ADDED
|
@@ -0,0 +1,142 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import os
|
| 2 |
+
import pinecone
|
| 3 |
+
|
| 4 |
+
from langchain.chains import RetrievalQA, ConversationalRetrievalChain
|
| 5 |
+
from langchain_community.embeddings import HuggingFaceEmbeddings
|
| 6 |
+
from langchain_community.llms import HuggingFaceHub
|
| 7 |
+
|
| 8 |
+
from PyPDF2 import PdfReader
|
| 9 |
+
from langchain.text_splitter import CharacterTextSplitter, RecursiveCharacterTextSplitter
|
| 10 |
+
from langchain_community.vectorstores import Pinecone
|
| 11 |
+
from langchain_community.chat_message_histories import StreamlitChatMessageHistory
|
| 12 |
+
|
| 13 |
+
import streamlit as st
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
st.set_page_config(page_title="chatbot")
|
| 17 |
+
st.title("Chat with Documents")
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
num_of_top_selection = 3
|
| 21 |
+
CHUNK_SIZE = 500
|
| 22 |
+
CHUNK_OVERLAP = 50
|
| 23 |
+
embedding_dim = 768
|
| 24 |
+
|
| 25 |
+
# Initialize Pinecone
|
| 26 |
+
pc = pinecone.Pinecone(api_key=os.environ.getattribute("PINECONE_API_KEY"))
|
| 27 |
+
index_name = "qp-ai-assessment"
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
def recreate_index():
|
| 31 |
+
# Check if the index exists, and delete it if it does
|
| 32 |
+
existing_indexes = pc.list_indexes().names()
|
| 33 |
+
print(existing_indexes)
|
| 34 |
+
if index_name in existing_indexes:
|
| 35 |
+
pc.delete_index(index_name)
|
| 36 |
+
print(f"Deleted existing index: {index_name}")
|
| 37 |
+
|
| 38 |
+
# Create a new index
|
| 39 |
+
pc.create_index(
|
| 40 |
+
name=index_name,
|
| 41 |
+
metric='cosine',
|
| 42 |
+
dimension=embedding_dim,
|
| 43 |
+
spec=pinecone.PodSpec(os.environ.getattribute("PINECONE_ENV")) # 1536 dim of text-embedding-ada-002
|
| 44 |
+
)
|
| 45 |
+
print(f"Created new index: {index_name}")
|
| 46 |
+
|
| 47 |
+
def load_documents(pdf_docs):
|
| 48 |
+
text = ""
|
| 49 |
+
for pdf in pdf_docs:
|
| 50 |
+
pdf_reader = PdfReader(pdf)
|
| 51 |
+
for page in pdf_reader.pages:
|
| 52 |
+
text += page.extract_text()
|
| 53 |
+
return text
|
| 54 |
+
|
| 55 |
+
|
| 56 |
+
def split_documents(documents):
|
| 57 |
+
text_splitter = RecursiveCharacterTextSplitter(chunk_size=CHUNK_SIZE, chunk_overlap=CHUNK_OVERLAP)
|
| 58 |
+
texts = text_splitter.split_text(documents)
|
| 59 |
+
return text_splitter.create_documents(texts)
|
| 60 |
+
|
| 61 |
+
|
| 62 |
+
def embeddings_on_pinecone(texts):
|
| 63 |
+
# Use HuggingFace embeddings for transforming text into numerical vectors
|
| 64 |
+
embeddings = HuggingFaceEmbeddings()
|
| 65 |
+
vectordb = Pinecone.from_documents(texts, embeddings, index_name=st.session_state.pinecone_index)
|
| 66 |
+
retriever = vectordb.as_retriever(search_kwargs={'k': num_of_top_selection})
|
| 67 |
+
return retriever
|
| 68 |
+
|
| 69 |
+
def query_llm(retriever, query):
|
| 70 |
+
#llm = OpenAIChat(openai_api_key=st.session_state.openai_api_key)
|
| 71 |
+
llm = HuggingFaceHub(repo_id="google/flan-t5-xxl", model_kwargs={"temperature":0.5, "max_length":512})
|
| 72 |
+
qa_chain = ConversationalRetrievalChain.from_llm(
|
| 73 |
+
llm=llm,
|
| 74 |
+
retriever=retriever,
|
| 75 |
+
return_source_documents=True,
|
| 76 |
+
)
|
| 77 |
+
result = qa_chain({'question': query, 'chat_history': st.session_state.messages})
|
| 78 |
+
result = result['answer']
|
| 79 |
+
st.session_state.messages.append((query, result))
|
| 80 |
+
return result
|
| 81 |
+
|
| 82 |
+
def input_fields():
|
| 83 |
+
#
|
| 84 |
+
with st.sidebar:
|
| 85 |
+
#
|
| 86 |
+
# if "openai_api_key" in st.secrets:
|
| 87 |
+
# st.session_state.openai_api_key = st.secrets.openai_api_key
|
| 88 |
+
# else:
|
| 89 |
+
# st.session_state.openai_api_key = st.text_input("OpenAI API key", type="password")
|
| 90 |
+
|
| 91 |
+
st.session_state.pinecone_api_key = os.environ.getattribute("PINECONE_API_KEY")
|
| 92 |
+
# st.text_input("Pinecone API key", type="password")
|
| 93 |
+
st.session_state.pinecone_env = os.environ.getattribute("PINECONE_ENV")
|
| 94 |
+
# st.text_input("Pinecone environment")
|
| 95 |
+
st.session_state.pinecone_index = index_name
|
| 96 |
+
# st.text_input("Pinecone index name")
|
| 97 |
+
st.session_state.source_docs = st.file_uploader(label="Upload Documents", type="pdf", accept_multiple_files=True)
|
| 98 |
+
#
|
| 99 |
+
|
| 100 |
+
|
| 101 |
+
def process_documents():
|
| 102 |
+
|
| 103 |
+
if not st.session_state.pinecone_api_key or not st.session_state.pinecone_env or not st.session_state.pinecone_index or not st.session_state.source_docs:
|
| 104 |
+
st.warning(f"Please upload the documents and provide the missing fields.")
|
| 105 |
+
else:
|
| 106 |
+
try:
|
| 107 |
+
# for source_doc in st.session_state.source_docs:
|
| 108 |
+
if st.session_state.source_docs:
|
| 109 |
+
#
|
| 110 |
+
# recreate_index()
|
| 111 |
+
|
| 112 |
+
documents = load_documents(st.session_state.source_docs)
|
| 113 |
+
|
| 114 |
+
#
|
| 115 |
+
texts = split_documents(documents)
|
| 116 |
+
#
|
| 117 |
+
st.session_state.retriever = embeddings_on_pinecone(texts)
|
| 118 |
+
except Exception as e:
|
| 119 |
+
st.error(f"An error occurred: {e}")
|
| 120 |
+
|
| 121 |
+
def boot():
|
| 122 |
+
#
|
| 123 |
+
input_fields()
|
| 124 |
+
#
|
| 125 |
+
st.button("Submit Documents", on_click=process_documents)
|
| 126 |
+
#
|
| 127 |
+
if "messages" not in st.session_state:
|
| 128 |
+
st.session_state.messages = []
|
| 129 |
+
#
|
| 130 |
+
for message in st.session_state.messages:
|
| 131 |
+
st.chat_message('human').write(message[0])
|
| 132 |
+
st.chat_message('ai').write(message[1])
|
| 133 |
+
#
|
| 134 |
+
if query := st.chat_input():
|
| 135 |
+
st.chat_message("human").write(query)
|
| 136 |
+
response = query_llm(st.session_state.retriever, query)
|
| 137 |
+
st.chat_message("ai").write(response)
|
| 138 |
+
|
| 139 |
+
if __name__ == '__main__':
|
| 140 |
+
#
|
| 141 |
+
boot()
|
| 142 |
+
|
requirements.txt
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
langchain
|
| 2 |
+
langchain-community
|
| 3 |
+
PyPDF2
|
| 4 |
+
streamlit
|
| 5 |
+
tiktoken
|
| 6 |
+
pinecone-client
|
| 7 |
+
sentence-transformers==2.2.2
|
| 8 |
+
accelerate
|
| 9 |
+
transformers
|
| 10 |
+
huggingface-hub
|
| 11 |
+
python-docx
|
| 12 |
+
textract
|