#Import and install libraries
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import load_model
import tensorflow_text as tf_text
import tensorflow_hub as hub
import gradio as gr
#Import model
model = tf.keras.models.load_model('detect_LLM_colab_method2')
#Function that predicts for a given text
def LLM_text(Text):
prediction = model.predict([Text])
output_text = 'Your text is {}% likely to be a LLM generated.'.format(round(prediction[0][0]*100, 2))
return output_text
project_heading = '
AI-generated Text Detection Engine
'
project_details_HTML = '''
Project Summary
Project Summary:
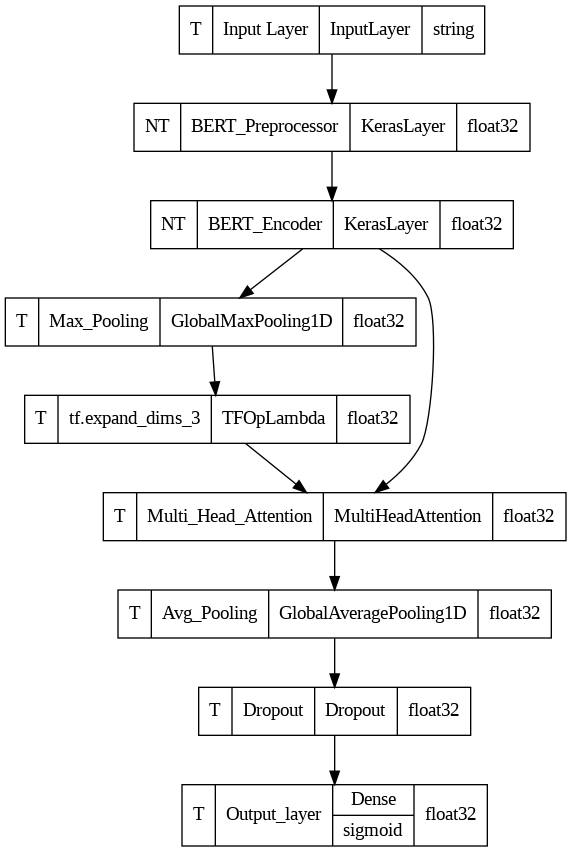
This project aims to develop a model for distinguishing between human-generated and language model-generated text, with evaluation based on the area under the ROC curve. We utilised the BERT encoder for text embeddings and incorporated a custom architecture featuring a Multi-Head Attention layer. Challenges included handling overfitting the training dataset and handling of long text sequences. These obstacles were overcome through careful architectural design, troubleshooting, sequential processing of text input, and leveraging the pre-trained BERT embeddings. The model achieved promising results, demonstrating its effectiveness in discerning language model-generated text.
Used transfer learning to build a Neural Network on top of BERT, the model had 23,63,137 trainable parameters, where BERT's parameters were not trainable.
Refer to the image below for more architectural details:
Fig: AI text detection model Architecture
'''
with gr.Blocks() as demo:
gr.HTML(project_heading)
with gr.Row():
inp = gr.Textbox(placeholder="What is your name?", label = 'Enter your text here!')
out = gr.Textbox(label = 'Prediction')
btn = gr.Button("Run")
btn.click(fn=LLM_text, inputs=inp, outputs=out)
with gr.Row():
#gr.Markdown("Our project aimed to develop a model for distinguishing between human-generated and language model-generated text, with evaluation based on the area under the ROC curve. We utilized the BERT encoder for text embeddings and incorporated a custom architecture featuring a Multi-Head Attention layer. Challenges included handling input preprocessing, addressing model loading issues, and optimizing for ROC AUC on the test set. These obstacles were overcome through careful architectural design, troubleshooting, and leveraging pre-trained BERT embeddings. The model achieved promising results, demonstrating its effectiveness in discerning language model-generated text.")
gr.HTML(project_details_HTML)
demo.launch()