Upload 17 files
Browse files- all_results.json +12 -0
- config.json +39 -0
- eval_results.json +8 -0
- finetuning_args.json +13 -0
- generation_config.json +6 -0
- merges.txt +0 -0
- pytorch_model.bin +3 -0
- special_tokens_map.json +6 -0
- tokenizer.json +0 -0
- tokenizer_config.json +10 -0
- train_results.json +7 -0
- trainer_log.jsonl +0 -0
- trainer_state.json +0 -0
- training_args.bin +3 -0
- training_eval_loss.png +0 -0
- training_loss.png +0 -0
- vocab.json +0 -0
all_results.json
ADDED
|
@@ -0,0 +1,12 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_loss": 1.5822535753250122,
|
| 4 |
+
"eval_runtime": 82.4784,
|
| 5 |
+
"eval_samples_per_second": 36.373,
|
| 6 |
+
"eval_steps_per_second": 4.547,
|
| 7 |
+
"perplexity": 4.865909157317248,
|
| 8 |
+
"train_loss": 1.6966034523956515,
|
| 9 |
+
"train_runtime": 1526476.5703,
|
| 10 |
+
"train_samples_per_second": 10.809,
|
| 11 |
+
"train_steps_per_second": 0.042
|
| 12 |
+
}
|
config.json
ADDED
|
@@ -0,0 +1,39 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "gpt2",
|
| 3 |
+
"activation_function": "gelu_new",
|
| 4 |
+
"architectures": [
|
| 5 |
+
"GPT2LMHeadModel"
|
| 6 |
+
],
|
| 7 |
+
"attn_pdrop": 0.1,
|
| 8 |
+
"bos_token_id": 50256,
|
| 9 |
+
"embd_pdrop": 0.1,
|
| 10 |
+
"eos_token_id": 50256,
|
| 11 |
+
"initializer_range": 0.02,
|
| 12 |
+
"layer_norm_epsilon": 1e-05,
|
| 13 |
+
"model_type": "gpt2",
|
| 14 |
+
"n_ctx": 1024,
|
| 15 |
+
"n_embd": 768,
|
| 16 |
+
"n_head": 12,
|
| 17 |
+
"n_inner": null,
|
| 18 |
+
"n_layer": 12,
|
| 19 |
+
"n_positions": 1024,
|
| 20 |
+
"reorder_and_upcast_attn": false,
|
| 21 |
+
"resid_pdrop": 0.1,
|
| 22 |
+
"scale_attn_by_inverse_layer_idx": false,
|
| 23 |
+
"scale_attn_weights": true,
|
| 24 |
+
"summary_activation": null,
|
| 25 |
+
"summary_first_dropout": 0.1,
|
| 26 |
+
"summary_proj_to_labels": true,
|
| 27 |
+
"summary_type": "cls_index",
|
| 28 |
+
"summary_use_proj": true,
|
| 29 |
+
"task_specific_params": {
|
| 30 |
+
"text-generation": {
|
| 31 |
+
"do_sample": true,
|
| 32 |
+
"max_length": 50
|
| 33 |
+
}
|
| 34 |
+
},
|
| 35 |
+
"torch_dtype": "float32",
|
| 36 |
+
"transformers_version": "4.31.0",
|
| 37 |
+
"use_cache": true,
|
| 38 |
+
"vocab_size": 50257
|
| 39 |
+
}
|
eval_results.json
ADDED
|
@@ -0,0 +1,8 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"eval_loss": 1.5822535753250122,
|
| 4 |
+
"eval_runtime": 82.4784,
|
| 5 |
+
"eval_samples_per_second": 36.373,
|
| 6 |
+
"eval_steps_per_second": 4.547,
|
| 7 |
+
"perplexity": 4.865909157317248
|
| 8 |
+
}
|
finetuning_args.json
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"finetuning_type": "full",
|
| 3 |
+
"lora_alpha": 32.0,
|
| 4 |
+
"lora_dropout": 0.1,
|
| 5 |
+
"lora_rank": 8,
|
| 6 |
+
"lora_target": [
|
| 7 |
+
"q_proj",
|
| 8 |
+
"v_proj"
|
| 9 |
+
],
|
| 10 |
+
"name_module_trainable": "mlp",
|
| 11 |
+
"num_hidden_layers": 32,
|
| 12 |
+
"num_layer_trainable": 3
|
| 13 |
+
}
|
generation_config.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_from_model_config": true,
|
| 3 |
+
"bos_token_id": 50256,
|
| 4 |
+
"eos_token_id": 50256,
|
| 5 |
+
"transformers_version": "4.31.0"
|
| 6 |
+
}
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
pytorch_model.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:ca142655688e8263fab4d4e8085d26fa7a1b30d32346a4c5d7622b835cf2ce1f
|
| 3 |
+
size 497805085
|
special_tokens_map.json
ADDED
|
@@ -0,0 +1,6 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"bos_token": "<|endoftext|>",
|
| 3 |
+
"eos_token": "<|endoftext|>",
|
| 4 |
+
"pad_token": "<|endoftext|>",
|
| 5 |
+
"unk_token": "<|endoftext|>"
|
| 6 |
+
}
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"bos_token": "<|endoftext|>",
|
| 4 |
+
"clean_up_tokenization_spaces": true,
|
| 5 |
+
"eos_token": "<|endoftext|>",
|
| 6 |
+
"model_max_length": 1024,
|
| 7 |
+
"padding_side": "left",
|
| 8 |
+
"tokenizer_class": "GPT2Tokenizer",
|
| 9 |
+
"unk_token": "<|endoftext|>"
|
| 10 |
+
}
|
train_results.json
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"epoch": 1.0,
|
| 3 |
+
"train_loss": 1.6966034523956515,
|
| 4 |
+
"train_runtime": 1526476.5703,
|
| 5 |
+
"train_samples_per_second": 10.809,
|
| 6 |
+
"train_steps_per_second": 0.042
|
| 7 |
+
}
|
trainer_log.jsonl
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
trainer_state.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
training_args.bin
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:60bdbe4ae5fe8312f27710f885d8ceeaba21a05addc110064a91b3fdec4c19dd
|
| 3 |
+
size 3374
|
training_eval_loss.png
ADDED
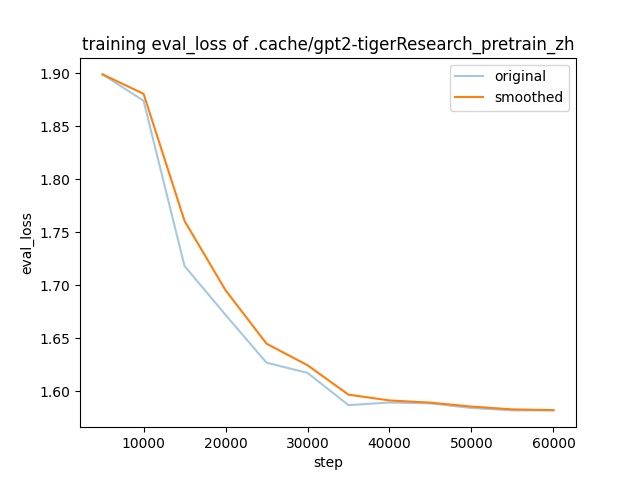
|
training_loss.png
ADDED
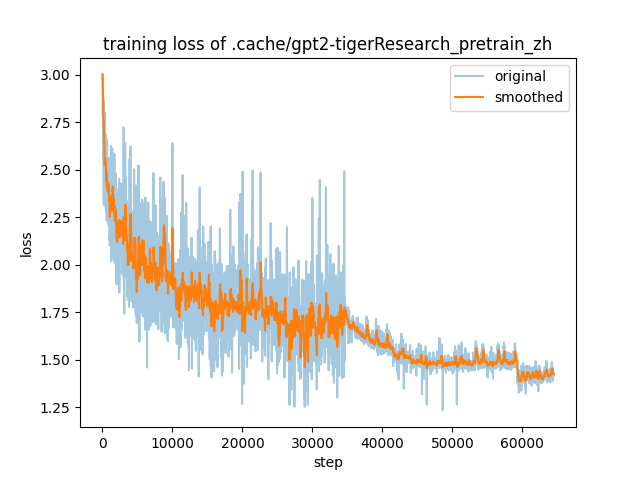
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|