---
license: mit
pipeline_tag: image-text-to-text
library_name: transformers
tags:
- 3d-scene-understanding
- scene-graph
- multimodal
- vlm
- llama
- vision-language-model
---
# 3DGraphLLM
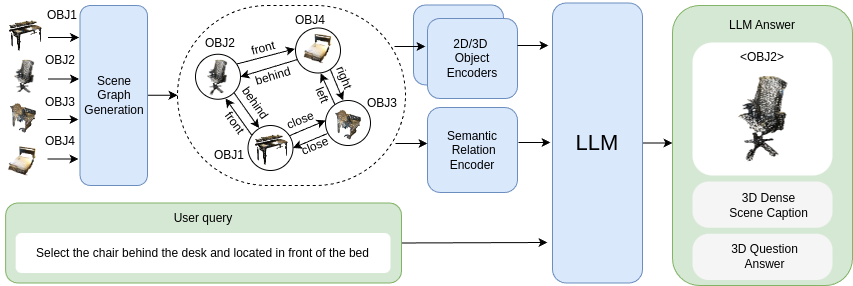
3DGraphLLM is a model that combines semantic graphs and large language models for 3D scene understanding. It aims to improve 3D vision-language tasks by explicitly incorporating semantic relationships into a learnable representation of a 3D scene graph, which is then used as input to LLMs.
This model was presented in the paper:
[**3DGraphLLM: Combining Semantic Graphs and Large Language Models for 3D Scene Understanding**](https://huggingface.co/papers/2412.18450)
The official code is publicly available at: [https://github.com/CognitiveAISystems/3DGraphLLM](https://github.com/CognitiveAISystems/3DGraphLLM)
## Abstract
A 3D scene graph represents a compact scene model by capturing both the objects present and the semantic relationships between them, making it a promising structure for robotic applications. To effectively interact with users, an embodied intelligent agent should be able to answer a wide range of natural language queries about the surrounding 3D environment. Large Language Models (LLMs) are beneficial solutions for user-robot interaction due to their natural language understanding and reasoning abilities. Recent methods for learning scene representations have shown that adapting these representations to the 3D world can significantly improve the quality of LLM responses. However, existing methods typically rely only on geometric information, such as object coordinates, and overlook the rich semantic relationships between objects. In this work, we propose 3DGraphLLM, a method for constructing a learnable representation of a 3D scene graph that explicitly incorporates semantic relationships. This representation is used as input to LLMs for performing 3D vision-language tasks. In our experiments on popular ScanRefer, Multi3DRefer, ScanQA, Sqa3D, and Scan2cap datasets, we demonstrate that our approach outperforms baselines that do not leverage semantic relationships between objects.
## Model Details
We provide our best checkpoint that uses [Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) as an LLM, [Mask3D](https://github.com/JonasSchult/Mask3D) 3D instance segmentation to get scene graph nodes, [VL-SAT](https://github.com/wz7in/CVPR2023-VLSAT) to encode semantic relations [Uni3D](https://github.com/baaivision/Uni3D) as 3D object encoder, and [DINOv2](https://github.com/facebookresearch/dinov2) as 2D object encoder.
## Performance
Semantic relations boost LLM performance on 3D Referred Object Grounding and Dense Scene Captioning tasks.
| | [ScanRefer](https://github.com/daveredrum/ScanRefer) | | [Multi3dRefer](https://github.com/3dlg-hcvc/M3DRef-CLIP) | | [Scan2Cap](https://github.com/daveredrum/Scan2Cap) | | [ScanQA](https://github.com/ATR-DBI/ScanQA) | | [SQA3D](https://github.com/SilongYong/SQA3D) |
|:----: |:---------: |:-------: |:------: |:------: |:---------: |:----------: |:------------: |:------: |:-----: |
| | Acc@0.25 | Acc@0.5 | F1@0.25 | F1@0.5 | CIDEr@0.5 | B-4@0.5 | CIDEr | B-4 | EM |
| [Chat-Scene](https://github.com/ZzZZCHS/Chat-Scene/tree/dev) | 55.5 | 50.2 | 57.1 | 52.3 | 77.1 | 36.3 | **87.7** | **14.3** | 54.6 |
| 3DGraphLLM Vicuna-1.5 | 58.6 | 53.0 | 61.9 | 57.3 | 79.2 | 34.7 | 91.2 | 13.7 | 55.1 |
| **3DGraphLLM LLAMA3-8B** | **62.4** | **56.6** | **64.7** | **59.9** | **81.0** | **36.5** | 88.8 | 15.9 | **55.9** |
## Usage
For detailed instructions on environment preparation, downloading LLM backbones, data preprocessing, training, and inference, please refer to the [official GitHub repository](https://github.com/CognitiveAISystems/3DGraphLLM).
You can run their interactive demo by following the instructions on their GitHub, or try the simplified command below:
```bash
bash demo/run_demo.sh
```
This will prompt you to ask different queries about Scene 435 of ScanNet.
## Citation
If you find 3DGraphLLM helpful, please consider citing our work as:
```
@misc{zemskova20243dgraphllm,
title={3DGraphLLM: Combining Semantic Graphs and Large Language Models for 3D Scene Understanding},
author={Tatiana Zemskova and Dmitry Yudin},
year={2024},
eprint={2412.18450},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2412.18450},
}
```
## Acknowledgement
Thanks to the open source of the following projects:
[Chat-Scene](https://github.com/ZzZZCHS/Chat-Scene/tree/dev)
## Contact
If you have any questions about the project, please open an issue in the [GitHub repository](https://github.com/CognitiveAISystems/3DGraphLLM) or send an email to [Tatiana Zemskova](zemskova@airi.net).