

Upload 8 files
Browse files- config.json +22 -0
- firefly-gan-vq-fsq-8x1024-21hz-generator.pth +3 -0
- merges.txt +0 -0
- model.jpeg +0 -0
- model.pth +3 -0
- tokenizer.json +0 -0
- tokenizer_config.json +112 -0
- vocab.json +0 -0
config.json
ADDED
|
@@ -0,0 +1,22 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"attention_qkv_bias": true,
|
| 3 |
+
"attention_qkv_bias_fast": false,
|
| 4 |
+
"codebook_size": 1024,
|
| 5 |
+
"dim": 1024,
|
| 6 |
+
"dropout": 0.1,
|
| 7 |
+
"head_dim": 64,
|
| 8 |
+
"initializer_range": 0.02,
|
| 9 |
+
"intermediate_size": 2816,
|
| 10 |
+
"intermediate_size_fast": 4096,
|
| 11 |
+
"max_seq_len": 4096,
|
| 12 |
+
"n_fast_layer": 4,
|
| 13 |
+
"n_head": 16,
|
| 14 |
+
"n_layer": 24,
|
| 15 |
+
"n_local_heads": 16,
|
| 16 |
+
"n_local_heads_fast": 2,
|
| 17 |
+
"norm_eps": 1e-06,
|
| 18 |
+
"num_codebooks": 8,
|
| 19 |
+
"rope_base": 1000000.0,
|
| 20 |
+
"tie_word_embeddings": false,
|
| 21 |
+
"vocab_size": 151936
|
| 22 |
+
}
|
firefly-gan-vq-fsq-8x1024-21hz-generator.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:01b81dbf753224a156c3fe139b88bf0b9a0f54b11bee864f95e66511c3ccd754
|
| 3 |
+
size 188518579
|
merges.txt
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
model.jpeg
ADDED
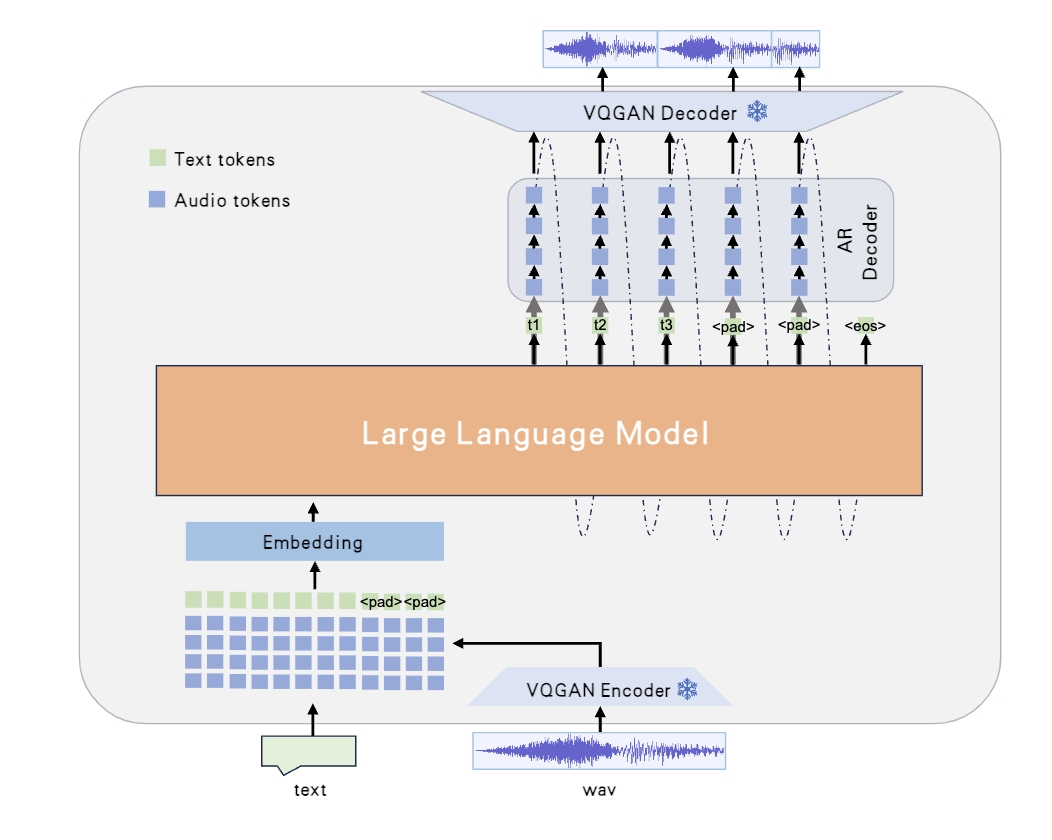
|
model.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:89318b6924451dce0cd7ee1b959192ad99c47d0868426c7fec2a66073ef2cb81
|
| 3 |
+
size 1068631972
|
tokenizer.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|
tokenizer_config.json
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"add_prefix_space": false,
|
| 3 |
+
"added_tokens_decoder": {
|
| 4 |
+
"151643": {
|
| 5 |
+
"content": "<|endoftext|>",
|
| 6 |
+
"lstrip": false,
|
| 7 |
+
"normalized": false,
|
| 8 |
+
"rstrip": false,
|
| 9 |
+
"single_word": false,
|
| 10 |
+
"special": true
|
| 11 |
+
},
|
| 12 |
+
"151644": {
|
| 13 |
+
"content": "<|im_start|>",
|
| 14 |
+
"lstrip": false,
|
| 15 |
+
"normalized": false,
|
| 16 |
+
"rstrip": false,
|
| 17 |
+
"single_word": false,
|
| 18 |
+
"special": true
|
| 19 |
+
},
|
| 20 |
+
"151645": {
|
| 21 |
+
"content": "<|im_end|>",
|
| 22 |
+
"lstrip": false,
|
| 23 |
+
"normalized": false,
|
| 24 |
+
"rstrip": false,
|
| 25 |
+
"single_word": false,
|
| 26 |
+
"special": true
|
| 27 |
+
},
|
| 28 |
+
"151646": {
|
| 29 |
+
"content": "<|begin_of_sequence|>",
|
| 30 |
+
"lstrip": false,
|
| 31 |
+
"normalized": false,
|
| 32 |
+
"rstrip": false,
|
| 33 |
+
"single_word": false,
|
| 34 |
+
"special": true
|
| 35 |
+
},
|
| 36 |
+
"151647": {
|
| 37 |
+
"content": "<|end_of_sequence|>",
|
| 38 |
+
"lstrip": false,
|
| 39 |
+
"normalized": false,
|
| 40 |
+
"rstrip": false,
|
| 41 |
+
"single_word": false,
|
| 42 |
+
"special": true
|
| 43 |
+
},
|
| 44 |
+
"151648": {
|
| 45 |
+
"content": "<|pad|>",
|
| 46 |
+
"lstrip": false,
|
| 47 |
+
"normalized": false,
|
| 48 |
+
"rstrip": false,
|
| 49 |
+
"single_word": false,
|
| 50 |
+
"special": true
|
| 51 |
+
},
|
| 52 |
+
"151649": {
|
| 53 |
+
"content": "<|semantic|>",
|
| 54 |
+
"lstrip": false,
|
| 55 |
+
"normalized": false,
|
| 56 |
+
"rstrip": false,
|
| 57 |
+
"single_word": false,
|
| 58 |
+
"special": true
|
| 59 |
+
},
|
| 60 |
+
"151650": {
|
| 61 |
+
"content": "<|mel|>",
|
| 62 |
+
"lstrip": false,
|
| 63 |
+
"normalized": false,
|
| 64 |
+
"rstrip": false,
|
| 65 |
+
"single_word": false,
|
| 66 |
+
"special": true
|
| 67 |
+
},
|
| 68 |
+
"151651": {
|
| 69 |
+
"content": "<|phoneme_start|>",
|
| 70 |
+
"lstrip": false,
|
| 71 |
+
"normalized": false,
|
| 72 |
+
"rstrip": false,
|
| 73 |
+
"single_word": false,
|
| 74 |
+
"special": true
|
| 75 |
+
},
|
| 76 |
+
"151652": {
|
| 77 |
+
"content": "<|phoneme_end|>",
|
| 78 |
+
"lstrip": false,
|
| 79 |
+
"normalized": false,
|
| 80 |
+
"rstrip": false,
|
| 81 |
+
"single_word": false,
|
| 82 |
+
"special": true
|
| 83 |
+
},
|
| 84 |
+
"151653": {
|
| 85 |
+
"content": "<|tts|>",
|
| 86 |
+
"lstrip": false,
|
| 87 |
+
"normalized": false,
|
| 88 |
+
"rstrip": false,
|
| 89 |
+
"single_word": false,
|
| 90 |
+
"special": true
|
| 91 |
+
},
|
| 92 |
+
"151654": {
|
| 93 |
+
"content": "<|sep|>",
|
| 94 |
+
"lstrip": false,
|
| 95 |
+
"normalized": false,
|
| 96 |
+
"rstrip": false,
|
| 97 |
+
"single_word": false,
|
| 98 |
+
"special": true
|
| 99 |
+
}
|
| 100 |
+
},
|
| 101 |
+
"additional_special_tokens": ["<|im_start|>", "<|im_end|>"],
|
| 102 |
+
"bos_token": null,
|
| 103 |
+
"chat_template": "{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system\nYou are a helpful assistant.<|im_end|>\n' }}{% endif %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}",
|
| 104 |
+
"clean_up_tokenization_spaces": false,
|
| 105 |
+
"eos_token": "<|im_end|>",
|
| 106 |
+
"errors": "replace",
|
| 107 |
+
"model_max_length": 32768,
|
| 108 |
+
"pad_token": "<|endoftext|>",
|
| 109 |
+
"split_special_tokens": false,
|
| 110 |
+
"tokenizer_class": "Qwen2Tokenizer",
|
| 111 |
+
"unk_token": null
|
| 112 |
+
}
|
vocab.json
ADDED
|
The diff for this file is too large to render.
See raw diff
|
|
|