
Ovis2
Collection
Our latest advancement in multi-modal large language models (MLLMs)
•
15 items
•
Updated
•
65

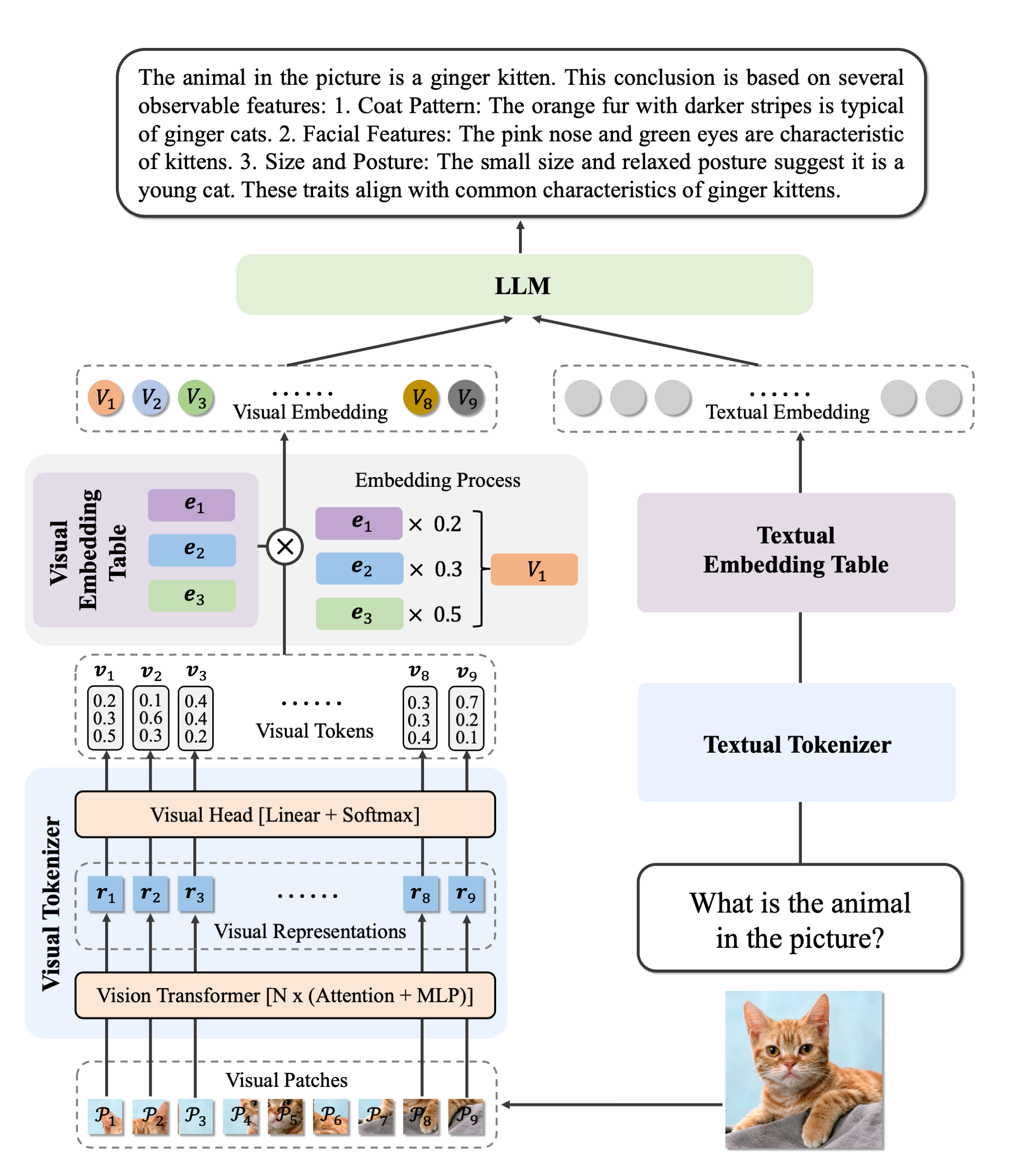
We are pleased to announce the release of Ovis2, our latest advancement in multi-modal large language models (MLLMs). Ovis2 inherits the innovative architectural design of the Ovis series, aimed at structurally aligning visual and textual embeddings. As the successor to Ovis1.6, Ovis2 incorporates significant improvements in both dataset curation and training methodologies.
Key Features:
Small Model Performance: Optimized training strategies enable small-scale models to achieve higher capability density, demonstrating cross-tier leading advantages.
Enhanced Reasoning Capabilities: Significantly strengthens Chain-of-Thought (CoT) reasoning abilities through the combination of instruction tuning and preference learning.
Video and Multi-Image Processing: Video and multi-image data are incorporated into training to enhance the ability to handle complex visual information across frames and images.
Multilingual Support and OCR: Enhances multilingual OCR beyond English and Chinese and improves structured data extraction from complex visual elements like tables and charts.
| Ovis MLLMs | ViT | LLM | Model Weights | Demo |
|---|---|---|---|---|
| Ovis2-1B | aimv2-large-patch14-448 | Qwen2.5-0.5B-Instruct | Huggingface | Space |
| Ovis2-2B | aimv2-large-patch14-448 | Qwen2.5-1.5B-Instruct | Huggingface | Space |
| Ovis2-4B | aimv2-huge-patch14-448 | Qwen2.5-3B-Instruct | Huggingface | Space |
| Ovis2-8B | aimv2-huge-patch14-448 | Qwen2.5-7B-Instruct | Huggingface | Space |
| Ovis2-16B | aimv2-huge-patch14-448 | Qwen2.5-14B-Instruct | Huggingface | Space |
| Ovis2-34B | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | Huggingface | - |
| Ovis2-2B-GPTQ-Int4 | aimv2-large-patch14-448 | Qwen2.5-1.5B-Instruct | Huggingface | - |
| Ovis2-4B-GPTQ-Int4 | aimv2-huge-patch14-448 | Qwen2.5-3B-Instruct | Huggingface | - |
| Ovis2-8B-GPTQ-Int4 | aimv2-huge-patch14-448 | Qwen2.5-7B-Instruct | Huggingface | - |
| Ovis2-16B-GPTQ-Int4 | aimv2-huge-patch14-448 | Qwen2.5-14B-Instruct | Huggingface | - |
| Ovis2-34B-GPTQ-Int4 | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | Huggingface | Space |
| Ovis2-34B-GPTQ-Int8 | aimv2-1B-patch14-448 | Qwen2.5-32B-Instruct | Huggingface | - |
We quantized Ovis2 with GPTQModel. Follow these steps to launch it.
Run the following commands to get a basic environment. Be sure to run with CUDA 12.1.
conda create -n <your_env_name> python=3.10
conda activate <your_env_name>
pip install torch==2.4.0 transformers==4.49.0 pillow==10.3.0
pip install flash-attn==2.7.0.post2 --no-build-isolation
pip install gptqmodel
pip install numpy==1.25.0
Below is a code snippet to run quantized Ovis2 series with multimodal inputs. For additional usage instructions, including inference wrapper and Gradio UI, please refer to Ovis GitHub.
import torch
from PIL import Image
from transformers import GenerationConfig
from gptqmodel import GPTQModel
# load model
# customize load device
load_device = "cuda:0"
torch.cuda.set_device(load_device)
# We take AIDC-AI/Ovis2-34B-GPTQ-Int4 as an example. Note that the code snippet is
# applicable to any GPTQ-quantized Ovis2 model.
model = GPTQModel.load("AIDC-AI/Ovis2-34B-GPTQ-Int4", device=load_device, trust_remote_code=True)
model.model.generation_config = GenerationConfig.from_pretrained("AIDC-AI/Ovis2-34B-GPTQ-Int4")
text_tokenizer = model.get_text_tokenizer()
visual_tokenizer = model.get_visual_tokenizer()
# For inference, quantization affects only the model loading part. The rest is the same
# as unquantized Ovis2 models. Here we show how to inference with single image input
# and without batching. For other input types and batch inference, please refer to
# https://huggingface.co/AIDC-AI/Ovis2-34B.
image_path = input("Enter image path: ")
images = [Image.open(image_path)]
max_partition = 9
text = input("Enter prompt: ")
query = f'<image>\n{text}'
# format conversation
prompt, input_ids, pixel_values = model.preprocess_inputs(query, images, max_partition=max_partition)
attention_mask = torch.ne(input_ids, text_tokenizer.pad_token_id)
input_ids = input_ids.unsqueeze(0).to(device=model.device)
attention_mask = attention_mask.unsqueeze(0).to(device=model.device)
if pixel_values is not None:
pixel_values = pixel_values.to(dtype=visual_tokenizer.dtype, device=visual_tokenizer.device)
pixel_values = [pixel_values]
# generate output
with torch.inference_mode():
gen_kwargs = dict(
max_new_tokens=1024,
do_sample=False,
top_p=None,
top_k=None,
temperature=None,
repetition_penalty=None,
eos_token_id=model.generation_config.eos_token_id,
pad_token_id=text_tokenizer.pad_token_id,
use_cache=True
)
output_ids = model.generate(input_ids, pixel_values=pixel_values, attention_mask=attention_mask, **gen_kwargs)[0]
output = text_tokenizer.decode(output_ids, skip_special_tokens=True)
print(f'Output:\n{output}')
We provide a demonstration code snippet for you to quantize your own fine-tuned Ovis2 model. Before running the code, you need to follow the ABOVE installation steps to obtain an environment for quantization.
import torch
from gptqmodel import QuantizeConfig, GPTQModel
model_path = "path/to/finetuned/model"
quantize_save_path = "path/to/save/quantized/model"
quantize_config = QuantizeConfig(
bits=4, # 4 or 8
group_size=128 # it is recommended to set the value to 128
)
model = GPTQModel.load(
model_path,
quantize_config,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
use_cache=False
)
model.model.llm.model.config.use_cache = False
model.model.config.llm_config.use_cache = False
# Data list for calibration, should be in the following format:
# Single Image/Multi-Image/Video: For video input, frames should be pre-selected and form
# a list, thus equaling multi-image input. See more on video input in
# https://huggingface.co/AIDC-AI/Ovis2-34B.
# data_list = [
# {
# "image": ["path/to/image(s)/of/this/sample", ...],
# "conversations": [
# {
# "from": "human",
# "value": "<image>\n[Your sample prompt]"
# # For multi-image input, the number of '<image>' marks should be equal
# # to the number of input images. For video input, the mark should be a
# # single '<video>'.
# },
# {
# "from": "gpt",
# "value": "[Your sample answer]"
# }
# ]
# },
# ...
# ]
#
# Pure Text
# data_list = [
# {
# "conversations": [
# {
# "from": "human",
# "value": "[Your sample prompt]"
# },
# {
# "from": "gpt",
# "value": "[Your sample answer]"
# }
# ]
# },
# ...
# ]
data_list = [...]
model.quantize(data_list, batch_size=1, calibration_enable_gpu_cache=True)
print(f"Quantized! Now Saving...")
model.save(quantize_save_path, max_shard_size='5GB')
print(f"ALL Done!")
We report the performance of the quantized Ovis2 series. OpenCompass results are evaluated with VLMEvalkit.


GPU peak memory consumption, tested by inferencing on 500 ChartQA samples:

If you find Ovis useful, please consider citing the paper
@article{lu2024ovis,
title={Ovis: Structural Embedding Alignment for Multimodal Large Language Model},
author={Shiyin Lu and Yang Li and Qing-Guo Chen and Zhao Xu and Weihua Luo and Kaifu Zhang and Han-Jia Ye},
year={2024},
journal={arXiv:2405.20797}
}
This project is licensed under the Apache License, Version 2.0 (SPDX-License-Identifier: Apache-2.0).
We used compliance-checking algorithms during the training process, to ensure the compliance of the trained model to the best of our ability. Due to the complexity of the data and the diversity of language model usage scenarios, we cannot guarantee that the model is completely free of copyright issues or improper content. If you believe anything infringes on your rights or generates improper content, please contact us, and we will promptly address the matter.
Base model
AIDC-AI/Ovis2-34B