

license: apache-2.0
datasets:
- BUT-FIT/BUT-LCC
- BUT-FIT/adult_content_classifier_dataset
language:
- cs
Introduction
CSMPT7b is a large Czech language model continously pretrained on 272b training tokens from English MPT7b model. Model was pretrained on ~67b token Large Czech Collection using Czech tokenizer, obtained using our vocabulary swap method (see below). Training was done on Karolina cluster.
BUT LM Model Roster
Latest Updates
- 01/10/2024 We released BenCzechMark, the first Czech evaluation suite for fair open-weights model comparison.
- 18/04/2024 We released all our training checkpoints (in MosaicML format & packed using ZPAQ) at czechllm.fit.vutbr.cz/csmpt7b/checkpoints/
- 06/05/2024 We released small manually annotated dataset of adult content. We used classifier trained on this dataset for filtering our corpus.
Evaluation
Dev eval at CS-HellaSwag (automatically translated HellaSwag benchmark).
| Model | CS-HellaSwag Accuracy |
|---|---|
| mistral7b | 0.4992 |
| csmpt@130k steps [released] | 0.5004 |
| csmpt@100k steps | 0.4959 |
| csmpt@75k steps | 0.4895 |
| csmpt@50k steps | 0.4755 |
| csmpt@26,5k steps | 0.4524 |
However, we ran validation over the course of training on CS-Hellaswag, and after 100k steps, the improvements were very noisy if any. The improvement over mistral7b is not significant.
Loss
We encountered loss spikes during training. As the model always recovered, and our budget for training 7b model was very constrained, we kept on training. We observed such loss spikes before in our ablations. In these ablations (with GPT-2 small), we found these to be
- (a) influenced by learning rate, the lower the learning rate, less they appear, as it gets higher, they start to appear, and with too high learning rate, the training might diverge on such loss spike.
- (b) in preliminary ablations, they only appear for continuously pretrained models. While we do not know why do they appear, we hypothesize this might be linked to theory on Adam instability in time-domain correlation of update vectors. However such instabilities were previously observed only for much larger models (larger than 65b).
Corpora
The model was trained on 3 corpora, which were hot-swapped during the training. These were collected/filtered during the course of training.
- Corpus #1 was the same we used for our Czech GPT-2 training (15,621,685,248 tokens).
- Corpus #2 contained 67,981,934,592 tokens, coming mostly from HPLT and CulturaX corpora.
- Corpus #3 (with 66,035,515,392 tokens) is Corpus #2 after we removed proportions of the unappropriate content (which avoided our other checks) through linear classifier.
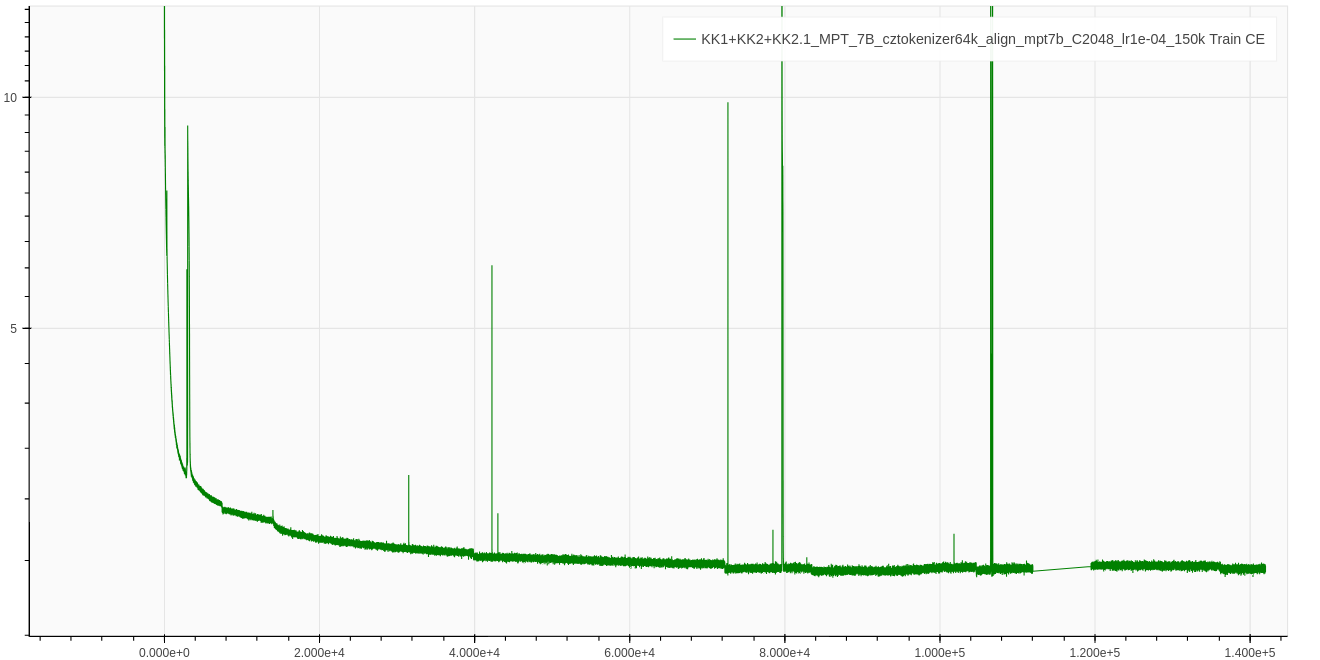 Figure 1: Training loss.
Figure 1: Training loss.
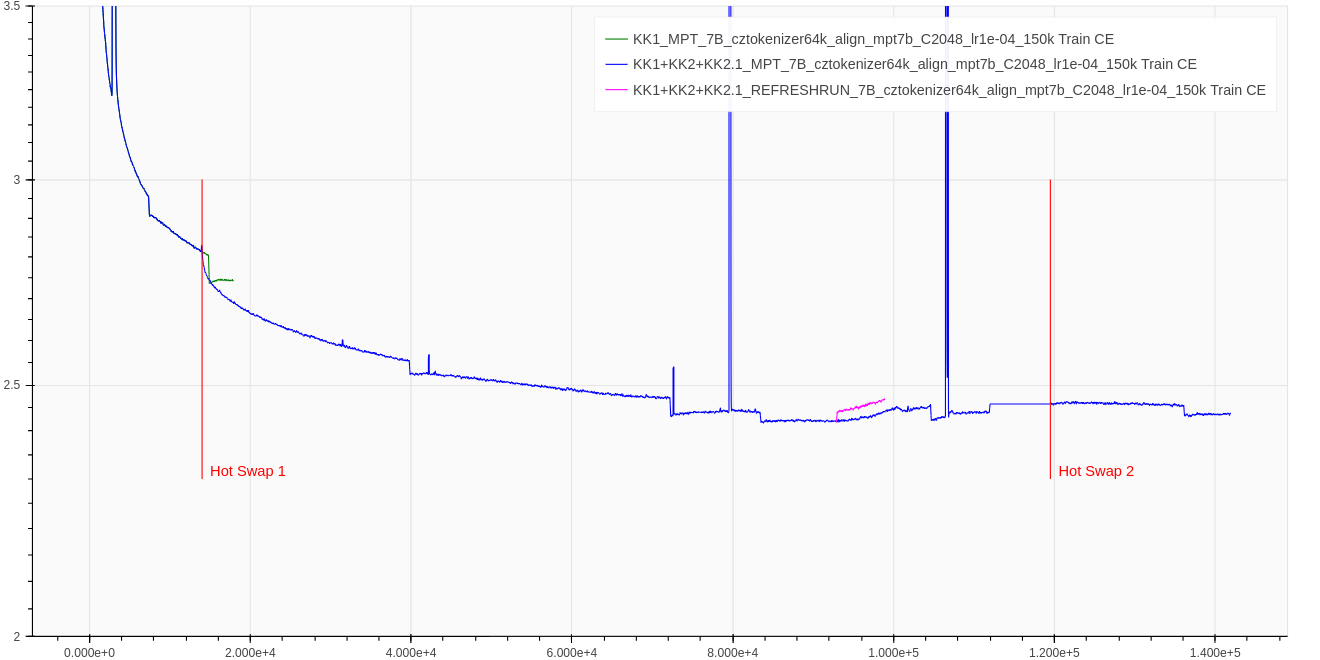 Figure 2: Training loss closeup. We mark two hotswap places, where the training corpus #1 was switched for internal-corpus #2 and internal-corpus #2.1 respectively. The flat region between 112k steps and 119.5k steps is caused by missing data---due to an accident, we lost these logs.
Figure 2: Training loss closeup. We mark two hotswap places, where the training corpus #1 was switched for internal-corpus #2 and internal-corpus #2.1 respectively. The flat region between 112k steps and 119.5k steps is caused by missing data---due to an accident, we lost these logs.
In Figure 3 (but also marked in Figure 2), we perform two ablations:
- (a) After first hot swap, we continued training on the corpus #1 for a while. Result: The fact that test loss is slightly better, signifies the slight difference between distribution of corpus #1 and corpus #2.
- (b) On step 94,000, the training loss stopped decreasing, increased, and around step 120,000 (near hot swap #2) started decreasing again. To ablate whether this was an effect of hot-swap, we resume training from step 93,000 using corpus #3.The optimizer states were reinitialized. Result: Neither corpus #3, nor optimizier state reinitialization seems to mitigate the issue of local divergence at step 94,000.
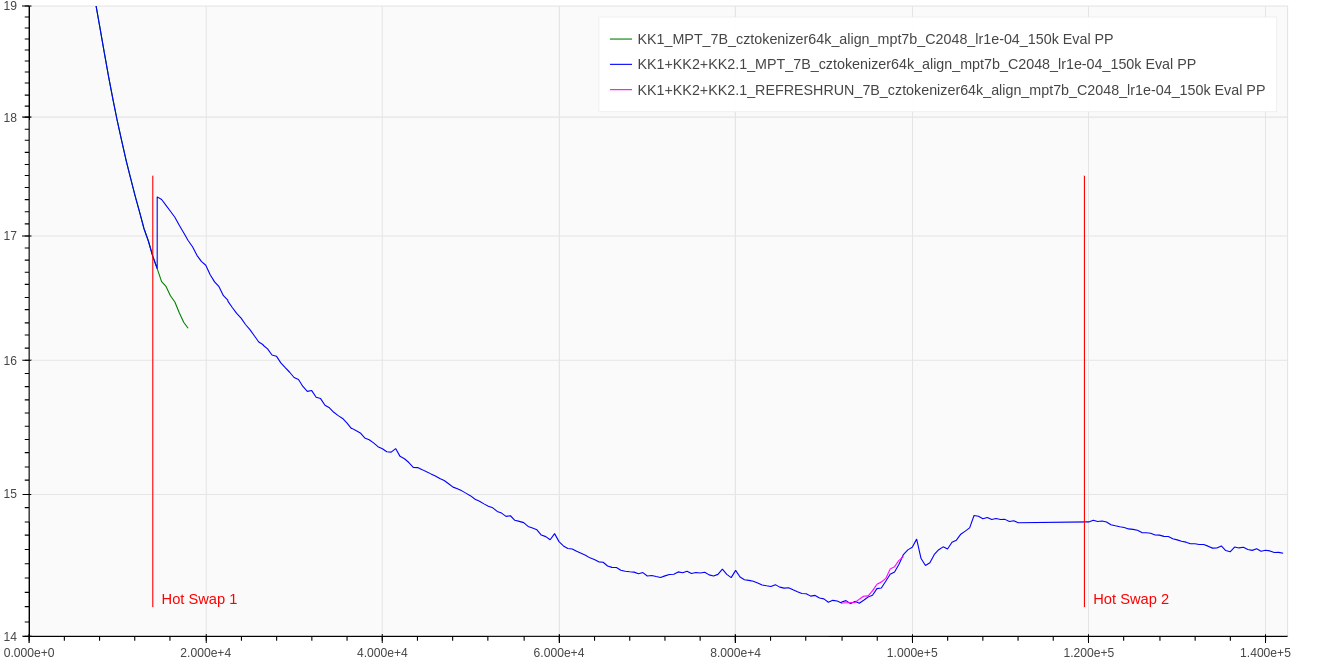 Figure 3: Test loss closeup, testing performed on split of internal-corpus #1. See Figure 2 description for ablation explanation.
Figure 3: Test loss closeup, testing performed on split of internal-corpus #1. See Figure 2 description for ablation explanation.
Training Method
Vocabulary Swap
To transfer knowledge from English model to Czech, we developed a simple method that (i) aligns several tokens between two vocabularies and (ii) copies the embeddings from original language to new language.
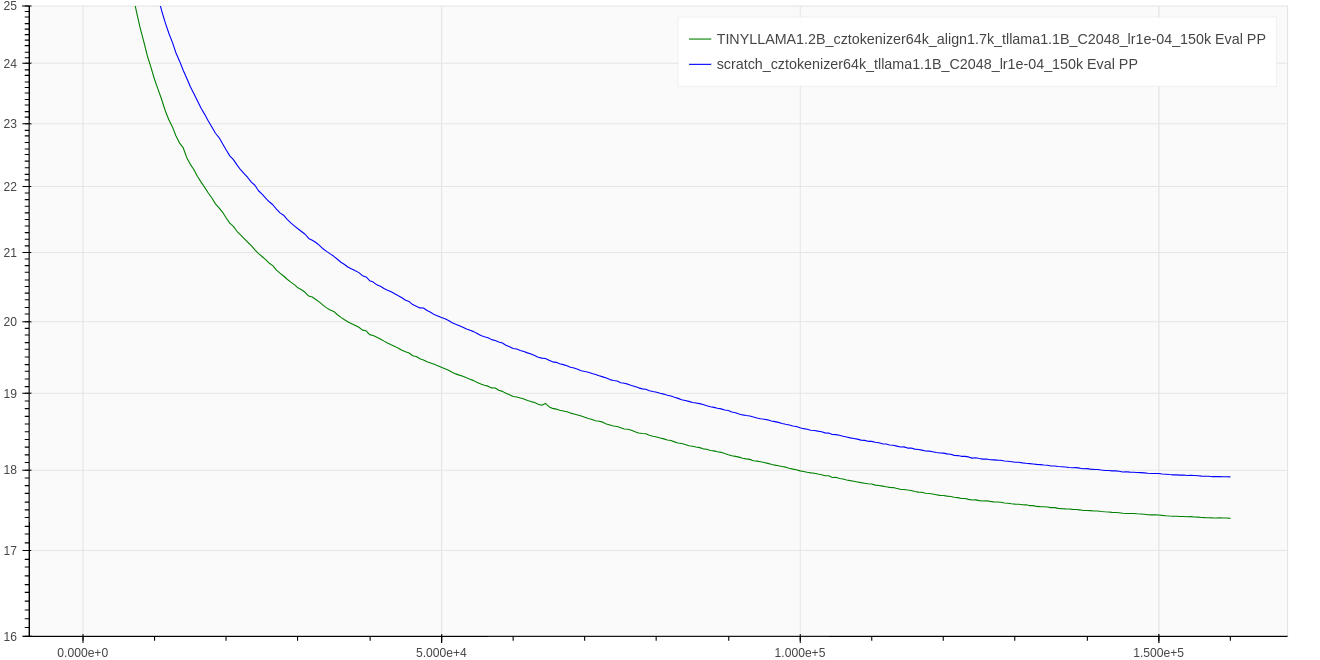 Figure 4: Test perplexity over the course of training for vocabulary swap (swapping 1.7K tokens) method on TinyLLAMA. Our method (green curve) vs TinyLLAMA training from scratch (blue curve).
Figure 4: Test perplexity over the course of training for vocabulary swap (swapping 1.7K tokens) method on TinyLLAMA. Our method (green curve) vs TinyLLAMA training from scratch (blue curve).
We also verify that finetuning from English to Czech is beneficial for MPT-7B model, compared from training a new model, at least on the first 10K steps. The training also seems to be more stable (notice yellow spike around 10k steps).
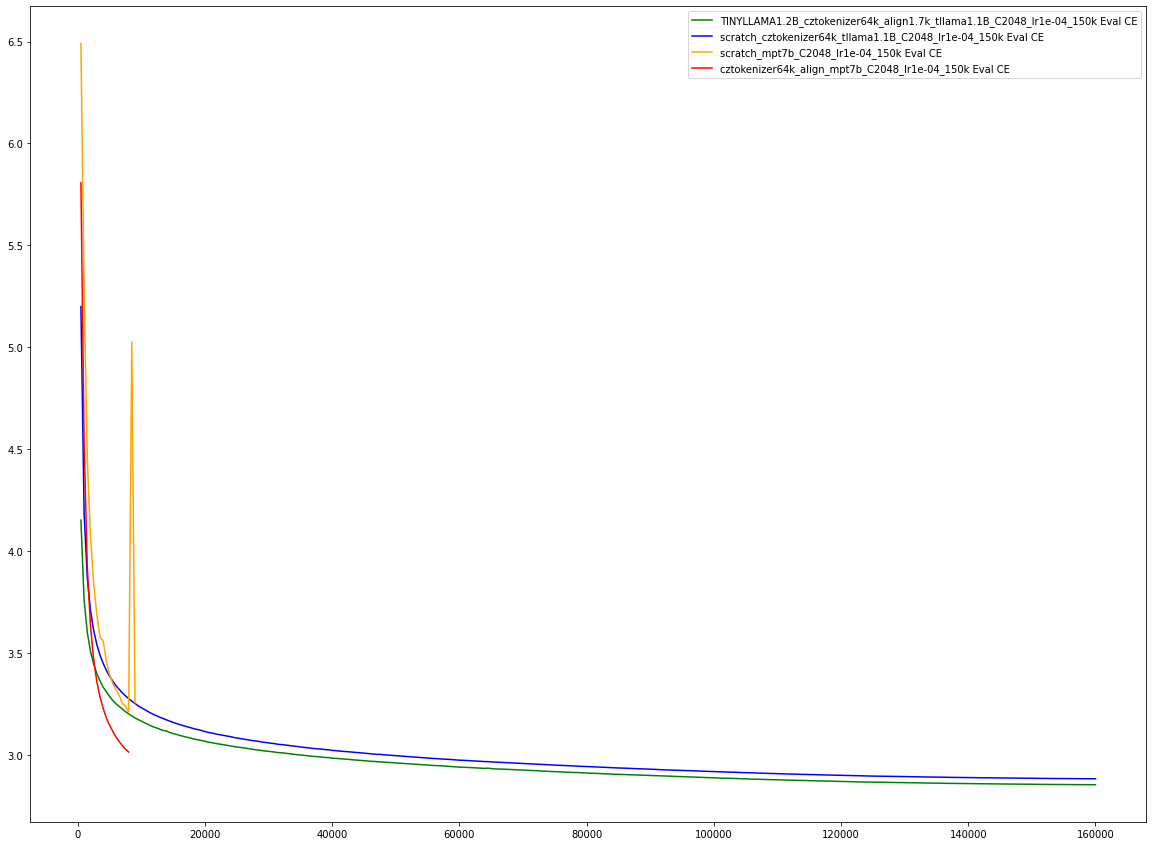 Figure 5: Test cross-entropy over the course of training on CSMPT7B (yellow-red). Comparison with TinyLLAMA (blue-green). Our method (red&green curve) vs training from scratch (yellow&blue curve).
Figure 5: Test cross-entropy over the course of training on CSMPT7B (yellow-red). Comparison with TinyLLAMA (blue-green). Our method (red&green curve) vs training from scratch (yellow&blue curve).
The vocabulary swap was done the same way as our Czech-GPT-2 model (check it out for comprehensive description.) For CSMPT7b, we managed to align 4,177 english tokens with corresponding czech tokens.
Hyperparameters
Not mentioned hyperparameters were kept the same as for MPT.
| Name | Value | Note |
|---|---|---|
| training sw | llm-foundry | We've done some minor patching (e.g., to allow DDP sync over file) |
| dataset_type | Concat | Sequences at the model's input were concatenated up to $max_seq_len, divided by EOS token. |
| tokenizer_size | 64k | Same as in Czech-GPT-2 |
| max_seq_len | 2048 | |
| batch_size | 1024 | |
| learning_rate | 1.0e-4 | |
| optimizer | LionW | |
| optimizer_betas | 0.9/0.95 | |
| optimizer_weight_decay | 0 | |
| optimizer_eps | 1.0e-08 | |
| gradient_clipping_max_norm | 1.0 | |
| attn_impl | flash2 | we used triton flash-attn 1 implementation for initial ~60k steps |
| positional_encoding | alibi | |
| fsdp | FULL_SHARD | (we had implementation issues with hybrid sharding in llm-foundry) |
| precision | bf16 | |
| scheduler | cosine | |
| scheduler_warmup | 100 steps | |
| scheduler_steps | 170,000 | |
| scheduler_alpha | 0.1 | So LR on last step is 0.1*(vanilla LR) |
Usage
How to Setup Environment
pip install transformers==4.37.2 torch==2.1.2 einops==0.7.0
# be sure to install right flash-attn, we use torch compiled with CUDA 12.1, no ABI, python 3.9, Linux x86_64 architecture
pip install https://github.com/Dao-AILab/flash-attention/releases/download/v2.5.3/flash_attn-2.5.3+cu122torch2.1cxx11abiFALSE-cp39-cp39-linux_x86_64.whl
Running the Code
import torch
import transformers
from transformers import pipeline
name = 'BUT-FIT/csmpt7b'
config = transformers.AutoConfig.from_pretrained(name, trust_remote_code=True)
config.init_device = 'cuda:0' # For fast initialization directly on GPU!
model = transformers.AutoModelForCausalLM.from_pretrained(
name,
config=config,
torch_dtype=torch.bfloat16, # Load model weights in bfloat16
trust_remote_code=True
)
tokenizer = transformers.AutoTokenizer.from_pretrained(name, trust_remote_code=True)
pipe = pipeline('text-generation', model=model, tokenizer=tokenizer, device='cuda:0')
with torch.autocast('cuda', dtype=torch.bfloat16):
print(
pipe('Nejznámějším českým spisovatelem ',
max_new_tokens=100,
top_p=0.95,
repetition_penalty=1.0,
do_sample=True,
use_cache=True))
Training Data
We release most (95.79%) of our training data corpus as BUT-Large Czech Collection.
Our Release Plan
| Stage | Description | Date |
|---|---|---|
| 1 | 'Best' model + training data | 13.03.2024 |
| 2 | All checkpoints + training code | 10.04.2024 Checkpoints are released. Code won't be released. We've used LLM foundry with slight adjustments, but the version is outdated now. |
| 3 | Benczechmark a collection of Czech datasets for few-shot LLM evaluation Get in touch if you want to contribute! | 01.10.2024 |
| 4 | Preprint Publication |
Getting in Touch
For further questions, email to [email protected].
Disclaimer
This is a probabilistic model, it can output stochastic information. Authors are not responsible for the model outputs. Use at your own risk.
Acknowledgement
This work was supported by NAKI III program of Ministry of Culture Czech Republic, project semANT ---
"Sémantický průzkumník textového kulturního dědictví" grant no. DH23P03OVV060 and
by the Ministry of Education, Youth and Sports of the Czech Republic through the e-INFRA CZ (ID:90254).
Citation
@article{benczechmark,
author = {Martin Fajčík, Martin Dočekal, Jan Doležal, Karel Beneš, Michal Hradiš},
title = {BenCzechMark: Machine Language Understanding Benchmark for Czech Language},
journal = {arXiv preprint arXiv:insert-arxiv-number-here},
year = {2024},
eprint = {insert-arxiv-number-here},
archivePrefix = {arXiv},
primaryClass = {cs.CL},
}