
Fireball-12B
Collection
Collections of Fireball-12B
•
5 items
•
Updated
•
1

This model is super fine-tune to provide better coding and better response(from first fine-tune) than Llama-3.1-8B and Google Gemma 2 9B. Further fine tuned with ORPO method with dataset. Best use in alpaca(see Prompt instructions - Alpaca style prompt(recommended) ) instruct mode for best response, instead of chat mode.
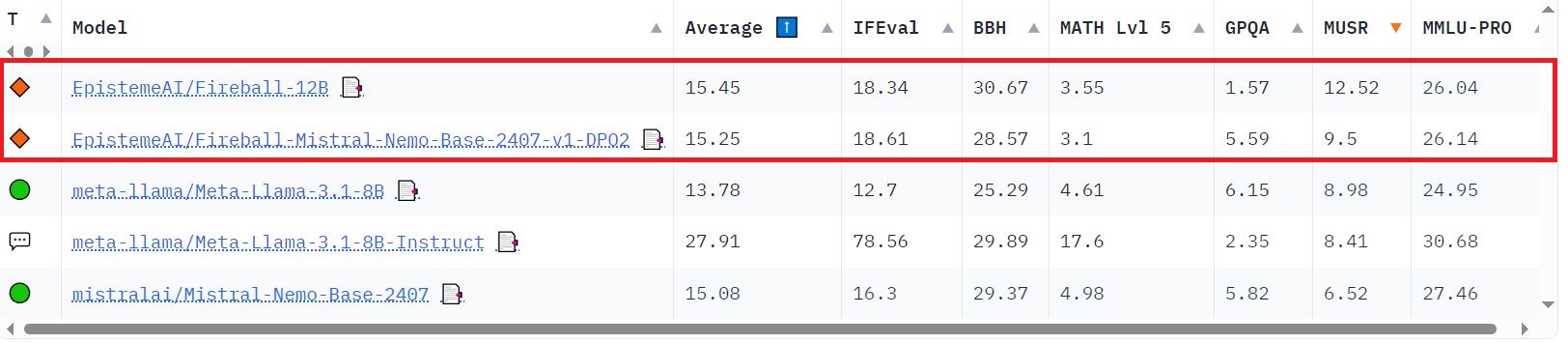 ## Training Dataset
Supervised fine-tuning with dataset:
- candenizkocak/code-alpaca-297k
- yahma/alpaca-cleaned
## Training Dataset
Supervised fine-tuning with dataset:
- candenizkocak/code-alpaca-297k
- yahma/alpaca-cleaned
The Heavy fine-tuned Mistral-Nemo-Base-2407 Large Language Model (LLM) is a pretrained generative text model of 12B parameters trained jointly by Mistral AI and NVIDIA, it significantly outperforms existing models smaller or similar in size.
For more details about this model please refer to our release blog post.
Mistral Nemo is a transformer model, with the following architecture choices:
For guardrailing and moderating prompts against indirect/direct prompt injections and jailbreaking, please follow the SentinelShield AI GitHub repository: SentinelShield AI
plesee use Alpaca prompt
f"""Below is an instruction that describes a task. \
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Input:
{x['input']}
### Response:
"""
After installing mistral_inference, a mistral-demo CLI command should be available in your environment.
f"""Below is an instruction that describes a task. \
Write a response that appropriately completes the request.
### Instruction:
{x['instruction']}
### Input:
{x['input']}
### Response:
"""
NOTE: Until a new release has been made, you need to install transformers from source:
pip install mistral_inference pip install mistral-demo pip install git+https://github.com/huggingface/transformers.git
If you want to use Hugging Face transformers to generate text, you can do something like this.
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "EpistemeAI/Fireball-12B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
inputs = tokenizer("Hello my name is", return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=20)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
pip install accelerate #GPU A100/L4
from transformers import AutoModelForCausalLM, AutoTokenizer
from accelerate import Accelerator
# Initialize the accelerator
accelerator = Accelerator()
# Define the model ID
model_id = "EpistemeAI/Fireball-12B"
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# Load the model and prepare it for distributed setup using accelerate
model = AutoModelForCausalLM.from_pretrained(model_id)
# Move the model to the appropriate device using accelerate
model, = accelerator.prepare(model)
# Prepare inputs
inputs = tokenizer("Hello my name is", return_tensors="pt").to(accelerator.device)
# Generate outputs with the model
outputs = model.generate(**inputs, max_new_tokens=20)
# Decode and print the outputs
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Unlike previous Mistral models, Mistral Nemo requires smaller temperatures. We recommend to use a temperature of 0.3.
EpistemeAI/Fireball-12B is a pretrained base model and therefore does not have any moderation mechanisms. Go to Guardrail/Moderation guide section for moderation guide
@misc{alpaca,
author = {Rohan Taori and Ishaan Gulrajani and Tianyi Zhang and Yann Dubois and Xuechen Li and Carlos Guestrin and Percy Liang and Tatsunori B. Hashimoto },
title = {Stanford Alpaca: An Instruction-following LLaMA model},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/tatsu-lab/stanford_alpaca}},
}
This mistral model was trained 2x faster with Unsloth and Huggingface's TRL library.
