Zero GPU Spaces - Best of AI Models Development Using Shared Quota GPU for Inference
https://huggingface.co/spaces/awacke1/ZeroHot

AI Multimodal Media Workflows and Pipelines
Simple Graph: https://github.com/AaronCWacker/Yggdrasil/blob/main/Mermaid/MultimodalAIPipelines.md
Detail Graph: https://github.com/AaronCWacker/Yggdrasil/blob/main/Mermaid/MultimodalPipelinesDetail.md




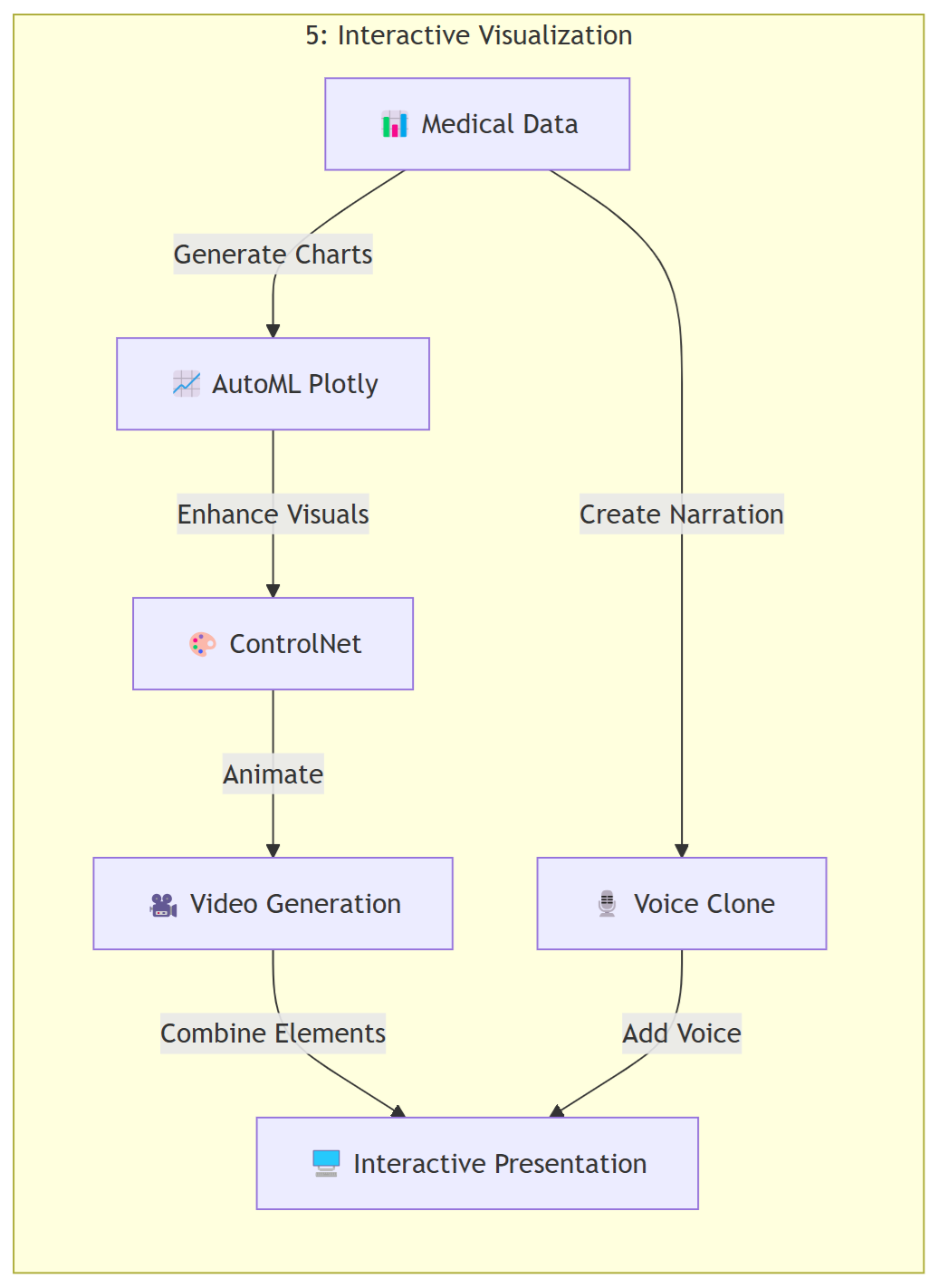
AI Pipeline Architecture Models for Multimodal Model Space Workflows
Zero GPU and GPU Spaces of note:
- https://huggingface.co/spaces/awacke1/midi-composer
- https://huggingface.co/spaces/awacke1/OpenDalleV1.1-GPU-Demo
- https://huggingface.co/spaces/awacke1/AudioFileGenerationWithSDAudio

- https://huggingface.co/spaces/multimodalart/stable-video-diffusion

- https://huggingface.co/spaces/mukaist/Midjourney

- https://huggingface.co/spaces/multimodalart/stable-cascade

- https://huggingface.co/spaces/stabilityai/stable-diffusion-3-medium
- https://huggingface.co/spaces/ehristoforu/dalle-3-xl-lora-v2

- https://huggingface.co/spaces/stabilityai/stable-diffusion-3.5-large

- https://huggingface.co/spaces/TencentARC/InstantMesh

- https://huggingface.co/spaces/playgroundai/playground-v2.5

- https://huggingface.co/spaces/jasperai/Flux.1-dev-Controlnet-Upscaler

- https://huggingface.co/spaces/akhaliq/anychat

- https://huggingface.co/spaces/awacke1/stable-video-diffusion
- https://huggingface.co/spaces/awacke1/GPT-4o-omni-text-audio-image-video
- https://huggingface.co/spaces/awacke1/Arxiv-Paper-Search-And-QA-RAG-Pattern
- https://huggingface.co/spaces/awacke1/AnthropicClaude3.5Sonnet-ACW
- https://huggingface.co/spaces/awacke1/MusicGenStreamFacebook
- https://huggingface.co/spaces/awacke1/AIKnowledgeTreeBuilder
- https://huggingface.co/spaces/awacke1/RescuerOfStolenBikes
- https://huggingface.co/spaces/awacke1/PDF-text-to-speech-Per-Page
- https://huggingface.co/spaces/awacke1/AzureCosmosDBUI
- https://huggingface.co/spaces/awacke1/MSGraphAPI
- https://huggingface.co/spaces/awacke1/RealTimeAsyncASR
- https://huggingface.co/spaces/awacke1/whisper-web
- https://huggingface.co/spaces/awacke1/MarkdownMagicEditor.md
- https://huggingface.co/spaces/awacke1/EZ-Voice-Clone-From-Long-Text
- https://huggingface.co/spaces/awacke1/Edge-TTS-Text-to-Speech
- https://huggingface.co/spaces/awacke1/StreamlitDotEdgeGraphViz-Images-SVG (Image button and rounded buttons)
- https://huggingface.co/spaces/awacke1/DynamicMapCreator2
- https://huggingface.co/spaces/awacke1/RealTimeAsyncASR
- https://huggingface.co/spaces/awacke1/realtime-whisper-webgpu
- https://huggingface.co/collections/Xenova/transformersjs-demos-64f9c4f49c099d93dbc611df
- https://huggingface.co/spaces/awacke1/Models-Datasets-Spaces-Search-Hub
- https://huggingface.co/spaces/awacke1/AutoMLUsingStreamlit-Plotly (CSV to Plotly Graph Objects)
- https://huggingface.co/spaces/awacke1/Multiplayer-Eval-App-Upvote
- https://huggingface.co/spaces/awacke1/AI-MovieMaker-Comedy
- https://huggingface.co/spaces/awacke1/Multiplayer-Image-Evaluate-Upvote
- https://huggingface.co/spaces/awacke1/Multiplayer-USMLE-Story-Voting-Evals
- https://huggingface.co/spaces/awacke1/Multiplayer-RLHF-Evals
- https://huggingface.co/spaces/awacke1/RLHF.Reinforce.Learn.With.Human.Feedback
- https://huggingface.co/spaces/awacke1/MultiuserFarmSimulator
- https://huggingface.co/spaces/awacke1/SocketIO-Multiplayer-DrawingGame
- https://huggingface.co/spaces/awacke1/Multiplayer-Self-Play-Sankey-Simulator
- https://huggingface.co/spaces/awacke1/Multiplayer-Action-Battle
- https://huggingface.co/spaces/awacke1/Multiplayer-Image-Character-Terrain
- https://huggingface.co/spaces/awacke1/MultiplayerMapMovement
- https://huggingface.co/spaces/awacke1/MultiplayerDiceGameFromGrok
- https://huggingface.co/spaces/awacke1/AaronWackerMusic
Architecture to AI Space
🤖 AI Types and Capabilities Classification
1. Foundation Models & Orchestrators 🎯
Large Language Models (LLMs)
- 🧠 General Purpose
- GPT-4 Omni
- Claude 3.5 Sonnet
- 📚 Domain-Specific
Mapped Spaces:
GPT-4o-omni-text-audio-image-videoAnthropicClaude3.5Sonnet-ACW
2. Content Generation 🎨
2.1 Image Generation
Static Images
- 🖼️ Text-to-Image
- Stable Diffusion 3
- DALL-E 3
- Midjourney
- 🔄 Image-to-Image
- ControlNet
- Stable Cascade
Mapped Spaces:
OpenDalleV1.1-GPU-Demostable-cascadestable-diffusion-3-mediumplaygroundai/playground-v2.5
2.2 Video Generation
Dynamic Content
- 🎥 Text-to-Video
- 🎬 Image-to-Video
Mapped Spaces:
stable-video-diffusionAI-MovieMaker-Comedy
2.3 Audio Generation
Sound Creation
- 🎵 Music Generation
- 🗣️ Text-to-Speech
- 🎙️ Voice Cloning
Mapped Spaces:
midi-composerAudioFileGenerationWithSDAudioMusicGenStreamFacebookEZ-Voice-Clone-From-Long-Text
3. Analysis & Understanding 🔍
3.1 Text Analysis
Document Processing
- 📄 RAG Systems
- 📚 Knowledge Extraction
Mapped Spaces:
Arxiv-Paper-Search-And-QA-RAG-PatternAIKnowledgeTreeBuilder
3.2 Speech Processing
Audio Analysis
- 🎤 Speech Recognition
- 📢 Speech Understanding
Mapped Spaces:
RealTimeAsyncASRwhisper-web
4. Visualization & Presentation 📊
4.1 Data Visualization
Chart Generation
- 📈 AutoML Plotting
- 🗺️ Mapping Tools
Mapped Spaces:
AutoMLUsingStreamlit-PlotlyDynamicMapCreator2
4.2 3D Visualization
3D Content
- 💠 Mesh Generation
- 🎮 Interactive 3D
Mapped Spaces:
5. Integration & Composition 🔄
5.1 Media Composition
Multi-modal Integration
- 🎬 Video Composition
- 🔊 Audio Mixing
Mapped Spaces:
Jasperai/Flux.1-dev-Controlnet-Upscaler
5.2 Interactive Systems
User Interaction
- 👥 Chat Interfaces
- 🤝 Multiplayer Systems
Mapped Spaces:
anychatMultiplayer-Eval-App-UpvoteSocketIO-Multiplayer-DrawingGame
6. Specialized Applications 🏥
6.1 Healthcare Specific
Medical Tools
- 📋 Training Material Generation
- 👨⚕️ Patient Communication
Mapped Spaces:
USMLE-Story-Voting-EvalsPDF-text-to-speech-Per-Page
6.2 Research Tools
Scientific Applications
- 📚 Literature Analysis
- 🔬 Data Processing
Mapped Spaces:
Models-Datasets-Spaces-Search-HubRLHF.Reinforce.Learn.With.Human.Feedback
AI Architecture Synopsis for GPU Spaces:
Below is a grouped synopsis of the provided dataset, highlighting common model families, tasks, and modalities. We’ve identified 10 thematic clusters, collapsed similar entries, and tallied their approximate counts. Each section includes representative examples and a brief summary:
1. Llama-Based Language Models 🦙📚
- Count: ~10+
- Examples:
- Llama 2 7B/13B Chat, Llama 3.2V 11B Cot, Llava Llama-3 8B, Llama-Vision-11B
- Note:
Models derived from or combined with LLaMA, often used for chat, reasoning, and multimodal tasks.
2. FLUX Models & Tools ⚡🖼
- Count: ~30+
- Examples:
- FLUXllama, FLUX.1 [dev], FLUX 8Steps LoRA, FLUX Prompt Generator, FLUX.1 Redux Dev
- Note:
A large ecosystem of FLUX-based image generation tools, LoRAs (Low-Rank Adapters), and control variations, emphasizing fast, high-quality image outputs and model refinements.
3. Stable Diffusion & Derivatives 🎨🏃
- Count: ~20+
- Examples:
- Stable Diffusion 3.5 Large, Stable Diffusion 3 Medium, Stable Audio Open, StableDelight, Stable Design
- Note:
Numerous text-to-image and image-to-image tools built on Stable Diffusion technology, including audio and video extensions. Often offer rapid generation and style customization.
4. TTS & Audio Generation/Processing 🎤🔊
- Count: ~25+
- Examples:
- F5-TTS, Spanish F5, Sound AI SFX, Multi Parler-TTS, Kokoro TTS, Voice Clone
- Note:
Text-to-speech models, voice cloning, audio upscaling, and SFX generation demos. Many support zero-shot voice cloning and multilingual options.
5. Video Generation & Editing 🎥⚡
- Count: ~20+
- Examples:
- Stable Video Diffusion, MMAudio — generating synchronized audio from video/text, Instant Video, Video Background Removal, Animagine XL 3.1
- Note:
Tools for creating or editing video content from text prompts, applying style transfers, removing backgrounds, and generating synchronized audio-visual experiences.
6. Image Editing, Inpainting & Upscaling 🖌️🔍
- Count: ~25+
- Examples:
- Diffusers Image Outpaint, Background Removal, Finegrain Image Enhancer, IC Light, InstantMesh, GiniGen Canvas, PhotoMaker V2
- Note:
A broad set of image refinement tools: removing backgrounds, outpainting, upscaling, enhancing clarity, inpainting, and object-specific edits.
7. Document Parsing, OCR & Retrieval 📄🔎
- Count: ~15+
- Examples:
- Document Parser, PDF to Markdown, OmniParser demo, DocLayout YOLO, Newborn Article Impact Predict, RAG-Chatbot
- Note:
Models dedicated to extracting information from documents, performing OCR, summarizing or querying text, and turning PDFs into searchable or structured formats.
8. Vision-Language & Multimodal Models 🧩👁
- Count: ~30+
- Examples:
- Qwen2-VL-7B, Llava Video, BLIP2, Florence 2, OpenGPT 4o, MMAudio, Paligemma2 Vqav2
- Note:
Models that combine text, images, audio, and sometimes video to answer questions, perform captioning, generate rich content, and handle complex multimodal tasks.
9. 3D Generation & Geometry Processing 🌐🦾
- Count: ~15+
- Examples:
- Make It Animatable, MeshAnything, 3D-GRAND, Unique3D, Shap-E, Instant Text-to-3D Mesh Demo
- Note:
Tools for converting images or text into 3D meshes, animating characters, and generating or refining 3D scenes. Often build on diffusion or 3D native generation methods.
10. Developer & Coding Tools 👨🏻💻🔧
- **Count:** ~10+
- **Examples:**
- *OpenCoder 8B Instruct*, *Code Review debug*, *Screenshot to HTML*, *Fake Data Generator (JSONL)*, *Beam Search Visualizer*
- **Note:**
A set of utilities for code generation, debugging, embeddings, dataset creation, and general developer-centric workflows.
Overall Synopsis
Common Models:
- LLaMA-based: Widely used for language and multimodal capabilities.
- Stable Diffusion & FLUX: Predominant for image, audio, and video generation tasks.
- TTS & Voice Conversion: Multiple frameworks offering multilingual and zero-shot cloning.
Common Terms:
- LoRA (Low-Rank Adaptation), ControlNet, Inpainting, Upscaling: Frequent technical keywords pointing to image refinements and personalization.
- RAG (Retrieval Augmented Generation), OCR, Document Parser: Indicative of text/data extraction and retrieval functionalities.
- Multimodal, Vision-Language, 3D Generation: Emphasizes integrating multiple data types (text, image, audio, video, 3D).
Common Modalities:
- Text-to-Image/Video/Audio conversions prevalent throughout.
- Image & Video Editing, Restoration, and Manipulation capabilities are abundant.
- Document, OCR, and Data Processing tasks show a strong presence.
Evolvable In:
Technology and Science:
Software and Systems: In computing, an "evolvable" system or software might refer to those that are designed with future changes in mind, incorporating modularity, scalability, and flexibility. For instance:
Evolvable APIs: Application Programming Interfaces (APIs) that are designed to evolve with changes in technology or user needs without breaking existing integrations.
Evolvable Hardware: Refers to hardware systems where the physical or functional aspects can be altered or improved, often through reconfigurable technology like FPGAs (Field-Programmable Gate Arrays).
Biological and Evolutionary Science: In biology, "evolvable" might describe organisms, traits, or genetic structures that have a high potential for evolutionary change due to variability, plasticity, or other mechanisms that aid in adaptation.
Machine Learning and AI: Here, "evolvable" could describe algorithms or models that can learn and adapt from data over time, improving their performance or changing their behavior based on new inputs or changes in the environment.
Business and Organizational Context:
Business Models: A company might be described as "evolvable" if it has the capability to adapt its business model to new market conditions, technologies, or consumer behaviors without losing its core identity or value proposition.
Organizational Structures: Refers to organizational designs that allow for change, learning, and growth, often through decentralized decision-making or agile methodologies.
Cultural and Philosophical Implications:
Ideas and Culture: Can describe ideas, cultures, or societal structures that are capable of changing, growing, or adapting in response to new knowledge, ethics, or external pressures.
