

1 引言
“珠算”是哈工大赛尔实验室研发的代码大模型,在3B以下模型中展现了出色的Python代码生成能力。为了更加便捷地调用珠算辅助编程开发,我们推出了基于珠算的VSCode(Visual Studio Code)插件。插件运行时,插件的代码上下文会以请求的方式发至后端,由后端模型分析代码上下文并生成生成适合当前场景的代码建议。为了支持这种任务形式,需要训练后端模型的代码补全(Fill in the Middle, FIM)能力。我们借鉴已有的研究工作,设计了能够有效提高“珠算”大模型代码补全能力的训练方法,使模型在HumanEval-Infilling测试集上取得了最优的性能。
2 模型下载
| 模型名称 | 文件大小 | 下载地址 | 备注 |
|---|---|---|---|
| Abacus-FIM | 5GB | 🤗HuggingFace ModelScope |
Abacus代码补全版模型 |
3 模型评价
代码补全能力
模型代码补全能力的评估主要基于HumanEval-Infilling测试集中的Multi-line模式,此模式将HumanEval数据集[2]提供的标准答案随机挖去若干行代码,令模型补全代码,然后测试其正确率。各个模型使用PSM格式进行推理,珠算大模型取得了最优的结果。
| 模型名称 | HumanEval-Infilling |
|---|---|
| stable-code-3B | 0.480 |
| granite-3b-code-base | 0.507 |
| qwen2.5-Coder-1.5B | 0.336 |
| deepseek-coder-1.3b | 0.527 |
| codegemma-1.1-2b | 0.538 |
| CodeLlama-7b-hf | 0.494 |
| Abacus-2.7B(珠算) | 0.540 |
4 面向代码补全的预训练
有别于预训练阶段常见的Causal Language Model形式(根据前文预测下一个词),代码补全任务的输入不仅包含前文,同时还包含待补全位置的后文。因此,基于Causal Language Model训练的模型直接构建插件未能充分利用已有信息,存在较大局限性。为此,我们借鉴已有的研究工作1,设计了能够有效提高代码补全能力的训练方法。
预训练数据组成
如下图所示,为了让模型更好地理解代码上下文,训练数据的格式被重构为特殊的格式。首先,从代码文件中随机选取一段代码作为${code}{middle}$,作为训练模型、使模型预测的中间代码片段。选择的方法随机地从以下两种方法中采取一种: ①使用随机位置作为${code}{middle}$的起始位置,选取该位置所在行剩余的某一token的末尾作为终止位置,这有利于增强模型补全单行内代码的能力,如下图所示。

②使用随机位置作为${code}_{middle}$的起始位置,选取该位置之后的若干行的末尾作为终止位置,这有利于增强模型补全多行代码的能力,如下图所示。

将${code}{middle}$之前的代码作为${code}{prefix}$,之后的代码作为${code}{suffix}$。这样,代码就被分为了${code}{prefix}$、${code}{middle}$、${code}{suffix}$三个部分。随后,、、作为特殊token加入了词表,用来分隔代码的三部分。预训练数据中混入了两种此类数据,它们仅在结构上有略微不同。45%的数据被替换为了PSM(prefix-suffix-middle)格式: 另外45%数据被替换为了SPM格式:
值得注意的是,SPM格式可以视为将${code}{prefix}$移到后面的PSM格式,两种数据格式本质上是相同的。PSM格式更加自然直观,而SPM格式通过将${code}{prefix}$和${code}{middle}$放在一起,使模型能够更好地处理${code}{prefix}$末尾处的token。研究工作1指出这样的训练数据格式与比例有助于提高模型的代码补全性能。
此外,考虑到补全任务存在输入只包含前文而没有后文的情况,剩余的10%数据被替换为了 其中,${code}{prefix}$与${code}{middle}$是代码数据随机切分的前后部分。上述形式保留了代码补全任务的数据格式的同时,兼顾了只基于前文预测的模式。
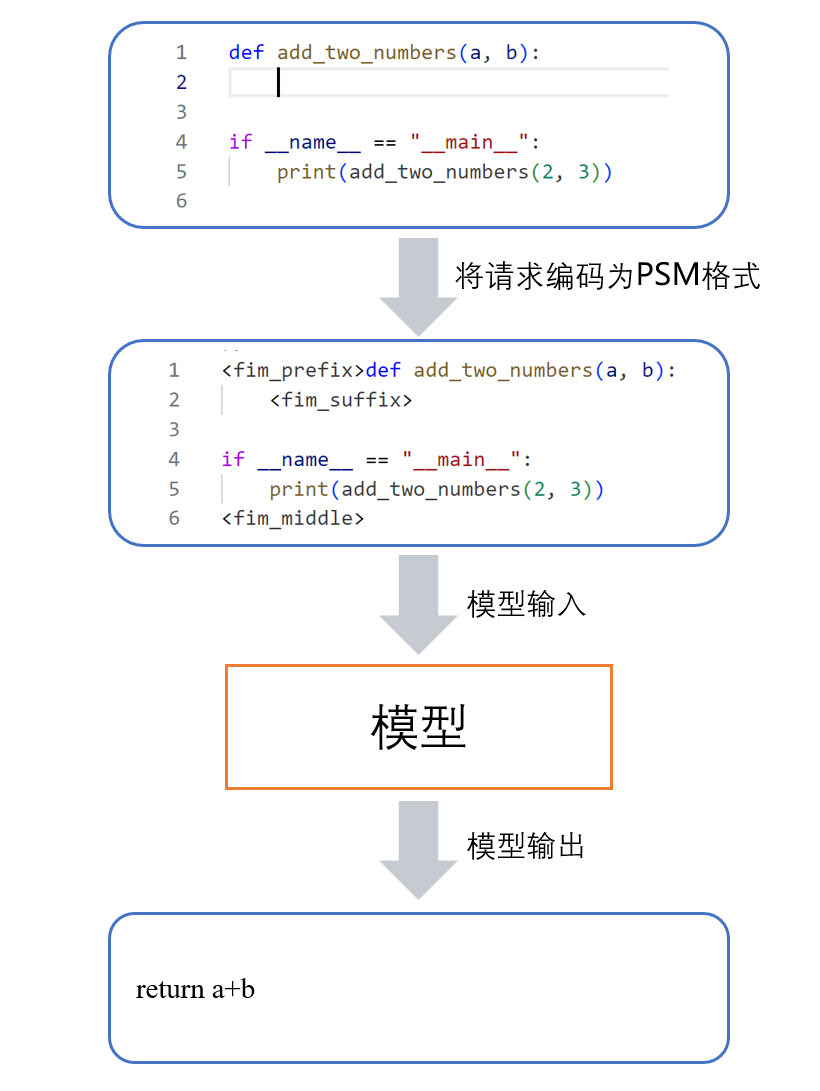
5 推理阶段数据格式
在推理阶段,模型仍然使用特殊的数据格式进行推理,我们采用了测试效果更佳的PSM格式。在实际使用中,插件通过读取用户代码编辑器中的内容和光标位置,整理为以PSM格式表示的代码上下文,作为prompt提供给模型进行推理。如下图所示,模型获得了位于特殊token、之后的代码上下文,即可自回归地在后输出补全的代码。
6.开源协议
对本仓库源码的使用遵循开源许可协议 Apache 2.0。
珠算支持商用。如果将珠算模型或其衍生品用作商业用途,请您按照如下方式联系许可方,以进行登记并向许可方申请书面授权:联系邮箱:[email protected]。
7.参考资料
[1] BAVARIAN M, JUN H, TEZAK N, 等. Efficient Training of Language Models to Fill in the Middle[A/OL]. arXiv, 2022[2024-11-22]. http://arxiv.org/abs/2207.14255. DOI:10.48550/arXiv.2207.14255.
- Downloads last month
- 79