

Upload folder using huggingface_hub
Browse files- .gitattributes +2 -0
- Abacus-Q4_Q_M.gguf +3 -0
- Abacus-Q8_0.gguf +3 -0
- README.md +113 -3
- images/middlespan_1.png +0 -0
- images/middlespan_2.png +0 -0
- images/picture_1.PNG +0 -0
- images/tuili.png +0 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,5 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
Abacus-Q4_Q_M.gguf filter=lfs diff=lfs merge=lfs -text
|
| 37 |
+
Abacus-Q8_0.gguf filter=lfs diff=lfs merge=lfs -text
|
Abacus-Q4_Q_M.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:6f163b8dac3d4a3aa4ad41d4208a5ef7e09c0953262045db382fd6aecc09b9bc
|
| 3 |
+
size 1802418400
|
Abacus-Q8_0.gguf
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:b8aaa86ed72d86f86ae9c01e9849b5ee448ee79b644aaab1011ae94fb38946a3
|
| 3 |
+
size 2898590720
|
README.md
CHANGED
|
@@ -1,3 +1,113 @@
|
|
| 1 |
-
|
| 2 |
-
|
| 3 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<!-- markdownlint-disable first-line-h1 -->
|
| 2 |
+
<!-- markdownlint-disable html -->
|
| 3 |
+
<!-- markdownlint-disable no-duplicate-header -->
|
| 4 |
+
|
| 5 |
+
<div align="center">
|
| 6 |
+
<img src="./images/picture_1.PNG" width="40%" alt="Abacus" />
|
| 7 |
+
</div>
|
| 8 |
+
<hr>
|
| 9 |
+
<div align="center" style="line-height: 1;">
|
| 10 |
+
<!-- <a href="" target="_blank" style="margin: 2px;">
|
| 11 |
+
<img alt="Homepage" src="https://img.shields.io/badge/Abacus-Homepage-blue?style=flat-square&logo=homeadvisor" style="display: inline-block; vertical-align: middle;"/>
|
| 12 |
+
</a> -->
|
| 13 |
+
<!-- <a href="https://mp.weixin.qq.com/s/T24_U-aR1WuwQh9iDjCWCg" target="_blank" style="margin: 2px;">
|
| 14 |
+
<img alt="Blog" src="https://img.shields.io/badge/Abacus-blog-red?style=flat-square&logo=blogger" style="display: inline-block; vertical-align: middle;"/>
|
| 15 |
+
</a> -->
|
| 16 |
+
<a href="https://mp.weixin.qq.com/s/T24_U-aR1WuwQh9iDjCWCg" target="_blank" style="margin: 2px;">
|
| 17 |
+
<img alt="Wechat" src="https://img.shields.io/badge/Abacus-Wechat-%23368B13?logo=wechat&logoColor=%23368B13" style="display: inline-block; vertical-align: middle;"/>
|
| 18 |
+
</a>
|
| 19 |
+
|
| 20 |
+
<a href="https://github.com/HIT-SCIR/Abacus" target="_blank" style="margin: 2px;">
|
| 21 |
+
<img alt="Github" src="https://img.shields.io/badge/Abacus-GitHub-black?logo=github&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
|
| 22 |
+
</a>
|
| 23 |
+
<a href="LICENSE" style="margin: 2px;">
|
| 24 |
+
<img alt="Code License" src="https://img.shields.io/badge/License-Apache_2.0-green.svg" style="display: inline-block; vertical-align: middle;"/>
|
| 25 |
+
</a>
|
| 26 |
+
</div>
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
---
|
| 30 |
+
|
| 31 |
+
- [1 引言](#1-引言)
|
| 32 |
+
- [2 模型下载](#2-模型下载)
|
| 33 |
+
- [3 模型评价](#3-模型评价)
|
| 34 |
+
- [代码补全能力](#代码补全能力)
|
| 35 |
+
- [4 面向代码补全的预训练](#4-面向代码补全的预训练)
|
| 36 |
+
- [预训练数据组成](#预训练数据组成)
|
| 37 |
+
- [5 推理阶段数据格式](#5-推理阶段数据格式)
|
| 38 |
+
- [6.开源协议](#6开源协议)
|
| 39 |
+
- [7.参考资料](#7参考资料)
|
| 40 |
+
|
| 41 |
+
## 1 引言
|
| 42 |
+
“珠算”是哈工大赛尔实验室研发的代码大模型,在3B以下模型中展现了出色的Python代码生成能力。为了更加便捷地调用珠算辅助编程开发,我们推出了[基于珠算的VSCode(Visual Studio Code)插件](https://marketplace.visualstudio.com/items?itemName=HIT-SCIR.abacus)。插件运行时,插件的代码上下文会以请求的方式发至后端,由后端模型分析代码上下文并生成生成适合当前场景的代码建议。为了支持这种任务形式,需要训练后端模型的代码补全(Fill in the Middle, FIM)能力。我们借鉴已有的研究工作,设计了能够有效提高“珠算”大模型代码补全能力的训练方法,使模型在[HumanEval-Infilling测试集](https://github.com/openai/human-eval-infilling)上取得了最优的性能。
|
| 43 |
+
## 2 模型下载
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
<div align="center">
|
| 47 |
+
|
| 48 |
+
|模型名称|文件大小|下载地址|备注|
|
| 49 |
+
|:---:|:---:|:---:|:---:|
|
| 50 |
+
|Abacus-FIM|5GB|[🤗HuggingFace](https://huggingface.co/HIT-SCIR/Abacus-FIM)<br>[ModelScope](https://www.modelscope.cn/models/HIT-SCIR/Abacus-FIM)|Abacus代码补全版模型|
|
| 51 |
+
</div>
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
## 3 模型评价
|
| 56 |
+
#### 代码补全能力
|
| 57 |
+
模型代码补全能力的评估主要基于[HumanEval-Infilling测试集](https://github.com/openai/human-eval-infilling)中的Multi-line模式,此模式将HumanEval数据集[2]提供的标准答案随机挖去若干行代码,令模型补全代码,然后测试其正确率。各个模型使用PSM格式进行推理,**珠算大模型取得了最优的结果**。
|
| 58 |
+
<div align="center">
|
| 59 |
+
|
| 60 |
+
| 模型名称 | HumanEval-Infilling |
|
| 61 |
+
|:-----------------------:|:-----------:|
|
| 62 |
+
| stable-code-3B | 0.480 |
|
| 63 |
+
| granite-3b-code-base | 0.507 |
|
| 64 |
+
| qwen2.5-Coder-1.5B | 0.336 |
|
| 65 |
+
| deepseek-coder-1.3b | 0.527 |
|
| 66 |
+
| codegemma-1.1-2b | 0.538 |
|
| 67 |
+
| CodeLlama-7b-hf | 0.494 |
|
| 68 |
+
| Abacus-2.7B(珠算) | **0.540** |
|
| 69 |
+
</div>
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
## 4 面向代码补全的预训练
|
| 73 |
+
有别于预训练阶段常见的Causal Language Model形式(根据前文预测下一个词),代码补全任务的输入不仅包含前文,同时还包含待补全位置的后文。因此,基于Causal Language Model训练的模型直接构建插件未能充分利用已有信息,存在较大局限性。为此,我们借鉴已有的研究工作[1],设计了能够有效提高代码补全能力的训练方法。
|
| 74 |
+
#### 预训练数据组成
|
| 75 |
+
如下图所示,为了让模型更好地理解代码上下文,训练数据的格式被重构为特殊的格式。首先,从代码文件中随机选取一段代码作为${code}_{middle}$,作为训练模型、使模型预测的中间代码片段。选择的方法随机地从以下两种方法中采取一种:
|
| 76 |
+
①使用随机位置作为${code}_{middle}$的起始位置,选取该位置所在行剩余的某一token的末尾作为终止位置,这有利于增强模型补全单行内代码的能力,如下图所示。
|
| 77 |
+
<p align="center">
|
| 78 |
+
<img width="100%" src="./images/middlespan_1.png">
|
| 79 |
+
</p>
|
| 80 |
+
|
| 81 |
+
②使用随机位置作为${code}_{middle}$的起始位置,选取该位置之后的若干行的末尾作为终止位置,这有利于增强模型补全多行代码的能力,如下图所示。
|
| 82 |
+
<p align="center">
|
| 83 |
+
<img width="100%" src="./images/middlespan_2.png">
|
| 84 |
+
</p>
|
| 85 |
+
|
| 86 |
+
将${code}_{middle}$之前的代码作为${code}_{prefix}$,之后的代码作为${code}_{suffix}$。这样,代码就被分为了${code}_{prefix}$、${code}_{middle}$、${code}_{suffix}$三个部分。随后,<fim_prefix>、<fim_suffix>、<fim_middle>作为特殊token加入了词表,用来分隔代码的三部分。预训练数据中混入了两种此类数据,它们仅在结构上有略微不同。45%的数据被替换为了PSM(prefix-suffix-middle)格式:
|
| 87 |
+
$$<fim\_prefix>{code}_{prefix}<fim\_suffix>{code}_{suffix}<fim\_middle>{code}_{middle}$$
|
| 88 |
+
另外45%数据被替换为了SPM格式:
|
| 89 |
+
$$<fim\_prefix><fim\_suffix>{code}_{suffix}<fim\_middle>{code}_{prefix}{code}_{middle}$$
|
| 90 |
+
|
| 91 |
+
值得注意的是,SPM格式可以视为将${code}_{prefix}$移到<fim_middle>后面的PSM格式,两种数据格式本质上是相同的。PSM格式更加自然直观,而SPM格式通过将${code}_{prefix}$和${code}_{middle}$放在一起,使模型能够更好地处理${code}_{prefix}$末尾处的token。研究工作[1]指出这样的训练数据格式与比例有助于提高模型的代码补全性能。
|
| 92 |
+
|
| 93 |
+
此外,考虑到补全任务存在输入只包含前文而没有后文的情况,剩余的10%数据被替换为了
|
| 94 |
+
$$<fim\_prefix>{code}_{prefix}<fim\_suffix><fim\_middle>{code}_{middle}$$
|
| 95 |
+
其中,${code}_{prefix}$与${code}_{middle}$是代码数据随机切分的前后部分。上述形式保留了代码补全任务的数据格式的同时,兼顾了只基于前文预测的模式。
|
| 96 |
+
|
| 97 |
+
## 5 推理阶段数据格式
|
| 98 |
+
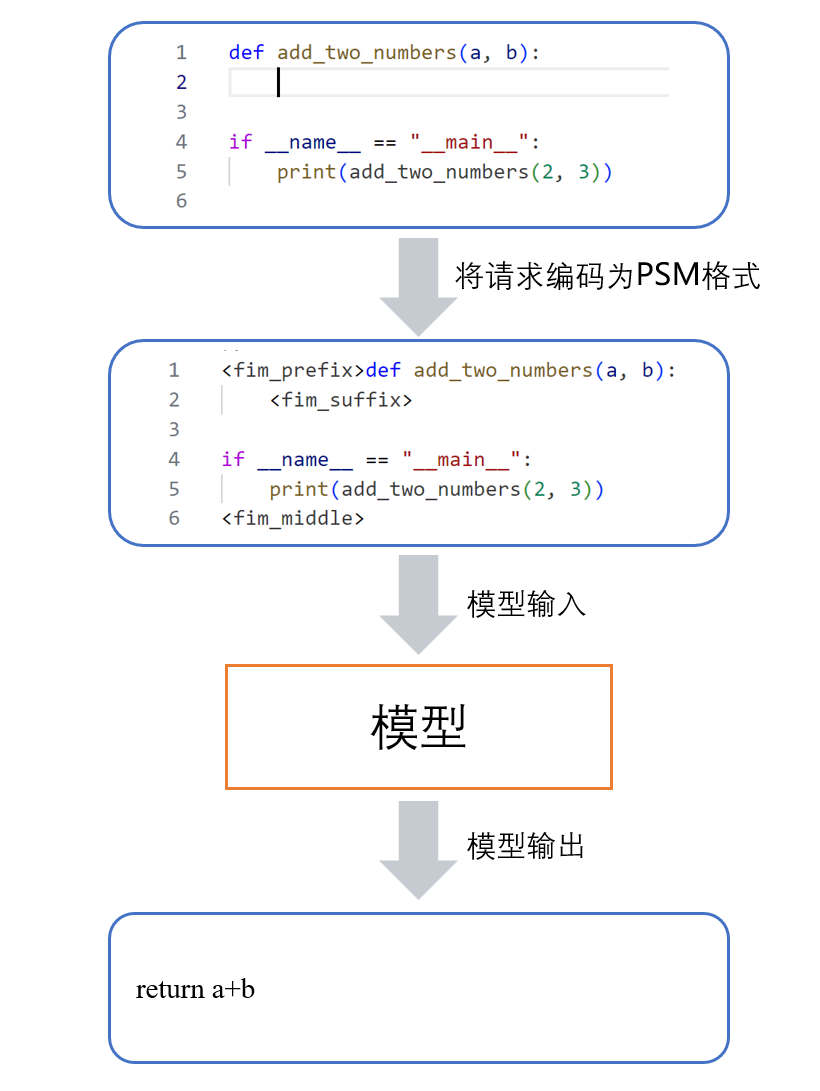
在推理阶段,模型仍然使用特殊的数据格式进行推理,我们采用了测试效果更佳的PSM格式。在实际使用中,插件通过读取用户代码编辑器中的内容和光标位置,整理为以PSM格式表示的代码上下文,作为prompt提供给模型进行推理。如下图所示,模型获得了位于特殊token<fim_prefix>、<fim_suffix>之后的代码上下文,即可自回归地在<fim_middle>后输出补全的代码。
|
| 99 |
+
<p align="center">
|
| 100 |
+
<img width="100%" src="./images/tuili.png">
|
| 101 |
+
</p>
|
| 102 |
+
|
| 103 |
+
|
| 104 |
+
## 6.开源协议
|
| 105 |
+
对本仓库源码的使用遵循开源许可协议 [Apache 2.0](LICENSE)。
|
| 106 |
+
|
| 107 |
+
珠算支持商用。如果将珠算模型或其衍生品用作商业用途,请您按照如下方式联系许可方,以进行登记并向许可方申请书面授权:联系邮箱:<[email protected]>。
|
| 108 |
+
|
| 109 |
+
## 7.参考资料
|
| 110 |
+
\[1\] BAVARIAN M, JUN H, TEZAK N, 等. Efficient Training of Language Models to Fill in the Middle[A/OL]. arXiv, 2022[2024-11-22]. http://arxiv.org/abs/2207.14255. DOI:10.48550/arXiv.2207.14255.
|
| 111 |
+
|
| 112 |
+
[1]:http://arxiv.org/abs/2207.14255
|
| 113 |
+
|
images/middlespan_1.png
ADDED

|
images/middlespan_2.png
ADDED

|
images/picture_1.PNG
ADDED

|
images/tuili.png
ADDED
|