

· Baka-Diffusion ·
· MBW Resources ·
· မင်္ဂလာပါ/Hello ·
Baka-Diffusion is a latent diffusion model based on series of finetuned / U-Net Block merges made to push the limits of SD1.x based models. Our models uses the Danbooru Tagging system
⚠️ Disclaimer
You are responsible for the content you generate, whether it is NSFW or SFW. The AI models do not contain explicit visual content that can be accessed easily.
⚒️ Model synopsis
Due to the nature of U-Net Block merging, some models function differently in CFG Scales. It is generally preferred to use the models in this repository with CFG 3-9. above this range are usable, but you may encounter artifacting, visible leftover noise, or color burn.
Baka-Diffusion[General]
Baka-Diffusion[General] was created with the idea of being a blank canvas; Without heavy focus on stylization, I wanted to make something compatible with most LoRA/LyCORIS models, but with coherency that would outperform [S3D]. To achieve that I've used some inference tricks as well as becoming an Inference rat in the process. Issues such as burned gens when having a long prompt are gone. CFG is also much more stable in this release.


Baka-Diffusion[S3D]
Baka-Diffusion[S3D] aims to bring a subtle 3D textured look and mimic natural lighting, diverging from the typical anime-style lighting seen in regular Baka-Diffusion models. It's specifically designed for higher resolutions, preferring 600x896 over the traditional 512x768. This model works well with low rank networks like LoRA / LyCORIS models, ensuring compatibility and versatility.

negative settings: (worst quality, low quality:1.2), lowres, bad anatomy,
🔧 Inference tricks
To become an inference rat such as myself, You will need these !
"Why is Hosioka recommending people to use a textual inversion alongside the model? is he stupid?"
Using a very light weight negative textual inversion such as SimpleNegativeV1 by Aikimi does wonders to your model's overall coherency without sacrificing the style. Thank you very much Aikimi!.
Here is my preset for FreeU, steering the model toward aesthetically pleasing generations, Also gives the model ZeroTerminalSNR effect when it comes being able to generate much lighter and darker images.
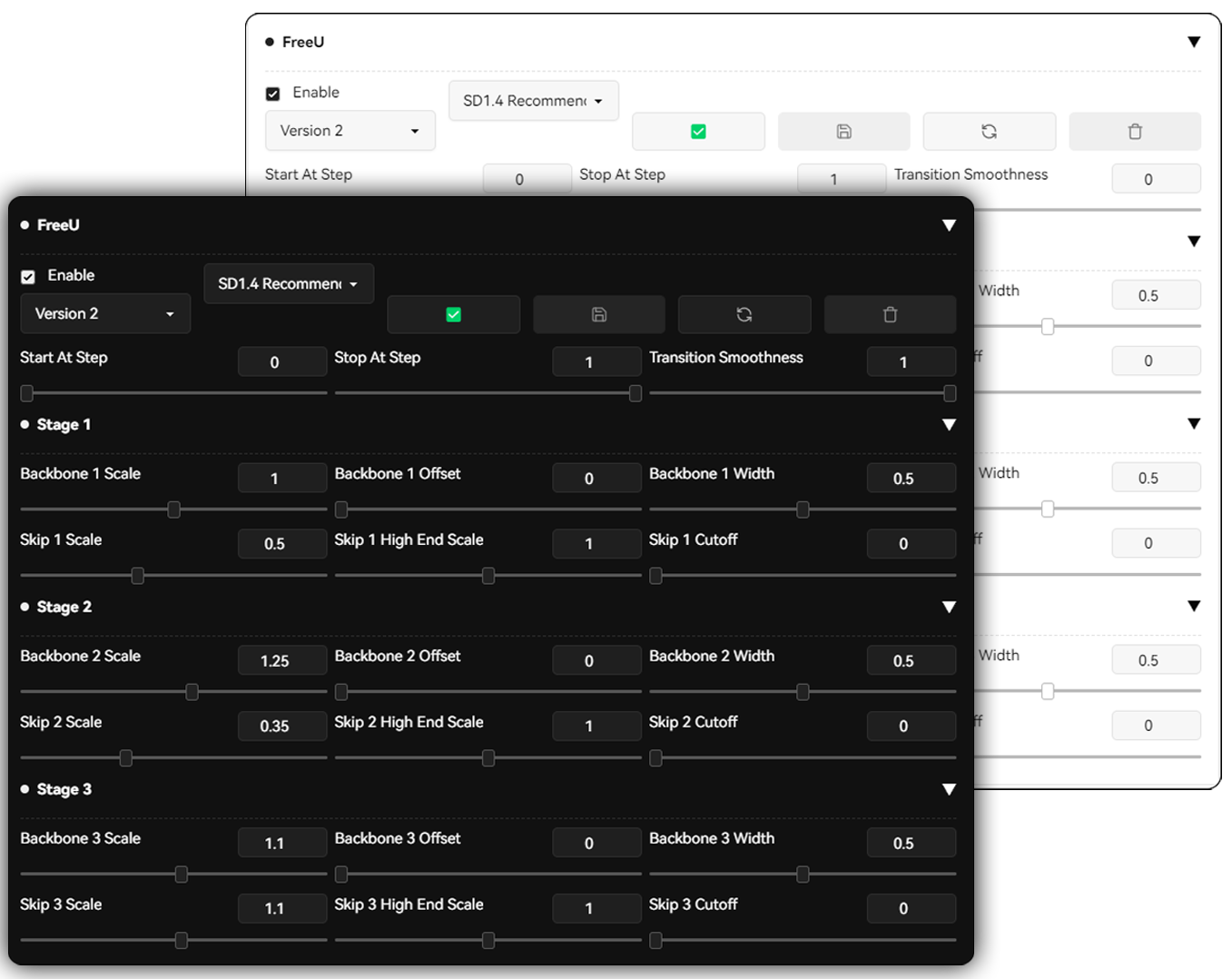 Transition smoothness is optional.
Transition smoothness is optional.
📝 Notes and Findings
Toggle to read
Training a standalone aesthetic model within this architecture seems nearly impossible without compromising anatomy quality. Even with a carefully curated dataset, the model doesn't converge into a high-quality aesthetic model. Instead, it appears to converge into an output that represents the average of all the training images, even when efforts are made to maintain a uniform dataset. I wonder if this issue is inherent to the nature of illustrations themselves. Unlike training a model focused on realism, which only requires high-quality data, training a weeb model with an aesthetic focus turns out to be a pain in the rear.
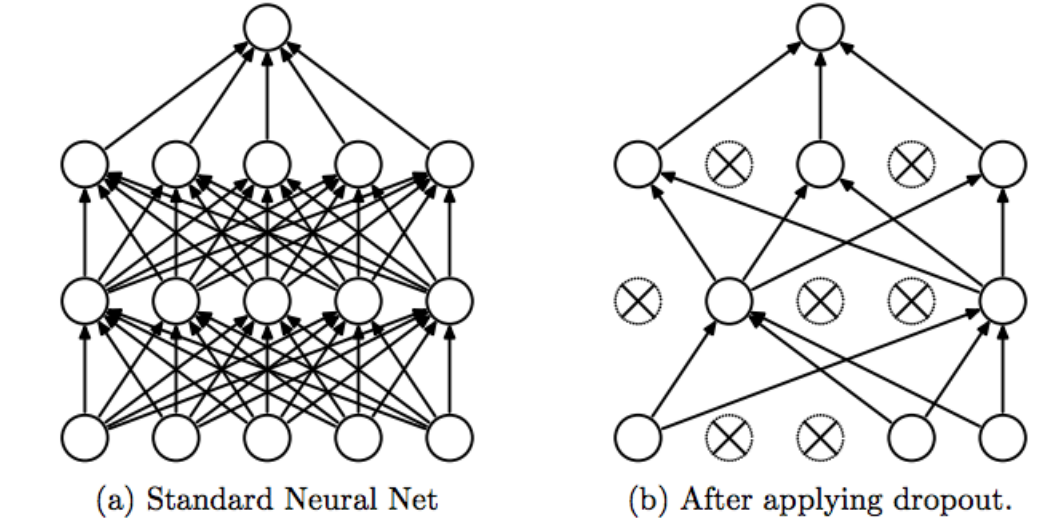
Now on the topic of trainers. Everyone use either Kohya or EveryDream2 for finetuning. Based on my experiences with both, Kohya falls short in full fine-tuning, whereas EveryDream2 excels in this aspect. Each trainer has features I wish to see combined into one. For example, EveryDream2 allows the freezing of layers in the text encoder to retain parent data while training the rest. On the other hand, Kohya has Neuron Dropout, a feature that can compel layer(X) to learn what layer(Y) excels at. On the surface, both trainers have their strengths and weaknesses. Each excels in certain features but also falls short in other aspects.
For example, if OUT5 is proficient in learning faces but IN00 isn't, Network Dropout enables you to instruct OUT5 to take a temporary break while IN00 focuses on mastering the skill of drawing a face. This approach compels the targeted layer(X) to improve in areas where it is weak, while temporarily halting other layers to prevent them from learning at the same pace and overfitting. Idiot proofy infographic below.
Lastly, I've decided to step back from creating any more models. I want to take a break and wait a few more years until open-source diffusion matures. I'll still be around, occasionally making gens and low-rank adapters. Thank you for using Baka-Diffusion!
🔗 Credits!
- Erasing : https://github.com/rohitgandikota/erasing
- Runtime Block Merge : https://github.com/ashen-sensored/sd-webui-runtime-block-merge
- Super Merger : https://github.com/hako-mikan/sd-webui-supermerger
- KL-F8 Anime2 VAE : https://huggingface.co/hakurei/waifu-diffusion-v1-4/blob/main/vae/kl-f8-anime2.ckpt
- SimpleNegative : https://civitai.com/models/87243?modelVersionId=92840
- (You)
📝 License
This project under the CC BY-NC 4.0 License.
2021 me just wanted to generate some drill haired waifus.... How did it come to this... Anyhow, I hope everyone enjoyed my work.
- Downloads last month
- 57