

license: apache-2.0
language:
- en
FILM-7B
💻 [Github Repo] • 📃 [Paper] • ⚓ [VaLProbing-32K]
FILM-7B is a 32K-context LLM that overcomes the lost-in-the-middle problem. It is trained from Mistral-7B-Instruct-v0.2 by applying Information-Intensie (In2) Training. FILM-7B achieves near-perfect performance on probing tasks, SOTA-level performance on real-world long-context tasks among ~7B size LLMs, and does not compromise the short-context performance.
Model Usage
The system tempelate for FILM-7B:
'''[INST] Below is a context and an instruction. Based on the information provided in the context, write a response for the instruction.
### Context:
{YOUR LONG CONTEXT}
### Instruction:
{YOUR QUESTION & INSTRUCTION} [/INST]
'''
Probing Results
To reproduce the results on our VaL Probing, see the guidance in https://github.com/microsoft/FILM/tree/main/VaLProbing.

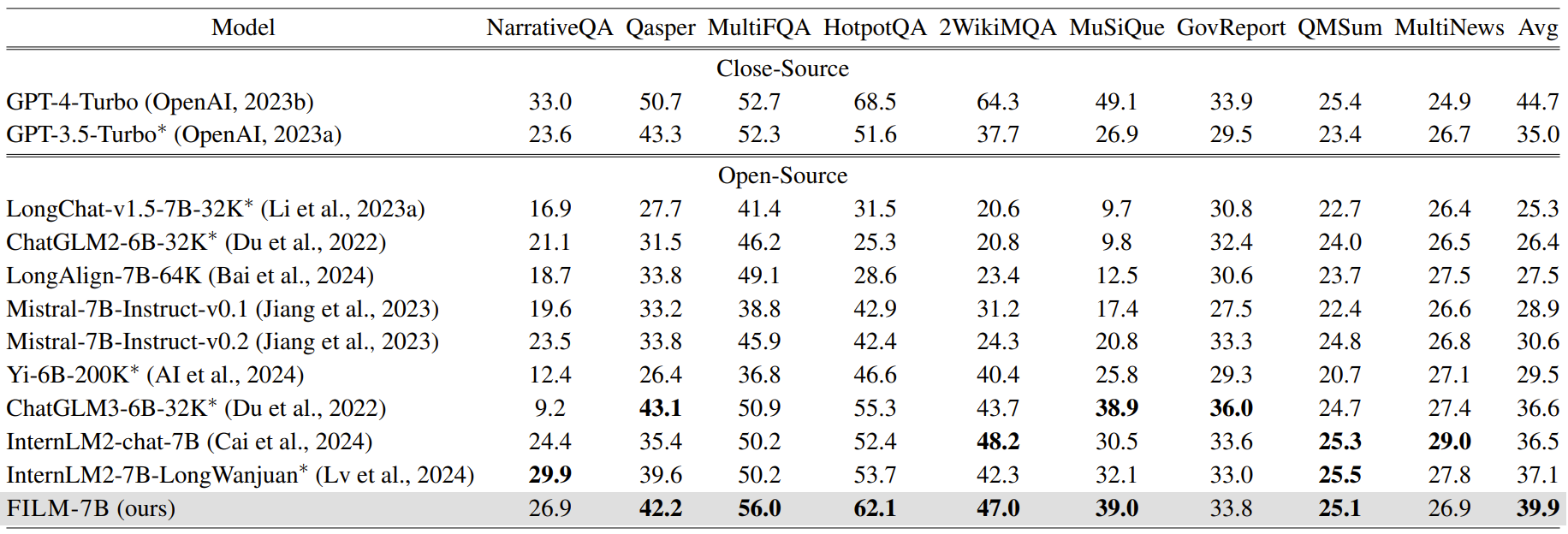
Real-World Long-Context Tasks
To reproduce the results on real-world long-context tasks, see the guidance in https://github.com/microsoft/FILM/tree/main/real_world_long.
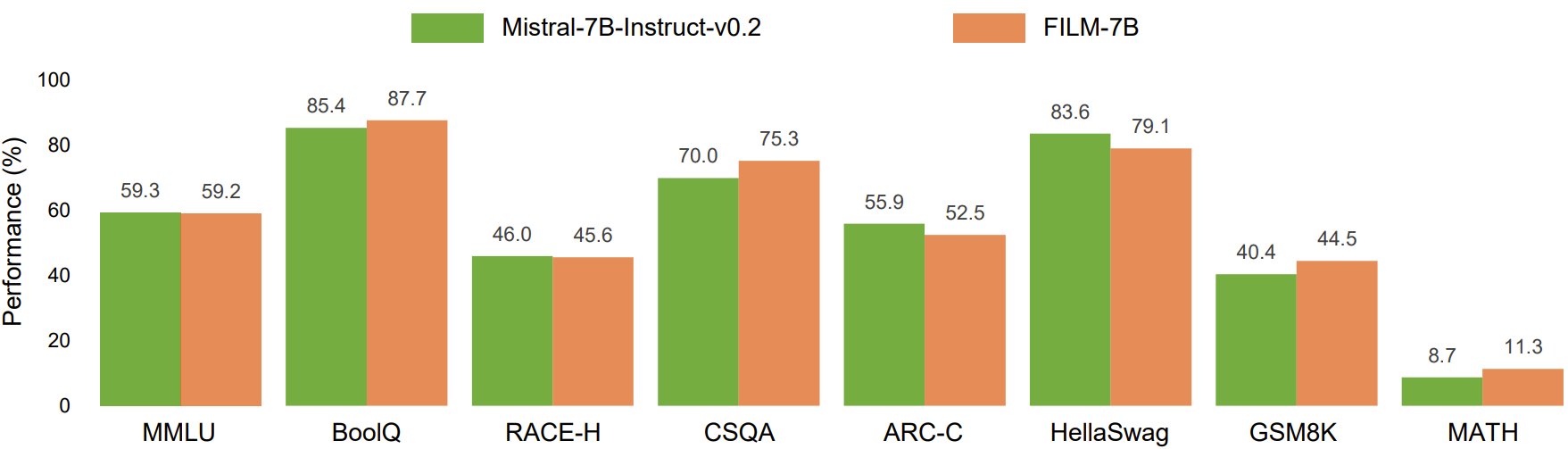
Short-Context Tasks
To reproduce the results on short-context tasks, see the guidance in https://github.com/microsoft/FILM/tree/main/short_tasks.
📝 Citation
@misc{an2024make,
title={Make Your LLM Fully Utilize the Context},
author={Shengnan An and Zexiong Ma and Zeqi Lin and Nanning Zheng and Jian-Guang Lou},
year={2024},
eprint={2404.16811},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Disclaimer: This model is strictly for research purposes, and not an official product or service from Microsoft.