

license: cc-by-nc-4.0
datasets:
- Salesforce/xlam-function-calling-60k
- MadeAgents/xlam-irrelevance-7.5k
base_model:
- Qwen/Qwen2.5-Coder-1.5B-Instruct
Hammer2.1-1.5b Function Calling Model
Introduction
Hammer refers to a series of lightweight Large Action Models. Currently, we are releasing Hammer 2.1 models (0.5B, 1.5B, 3B, and 7B) with strong function calling capability. These models are based on the Qwen 2.5 coder series and utilize function masking techniques and other advanced technologies. Hammer 2.5 series bring significant enhancements, while still maintaining the basic functionality of Hammer 2.0's Single-Turn interaction and further strengthening other capabilities.
Model Details
The Hammer 2.5 models, fine-tuned from the Qwen 2.5 coder series, inherit Hammer 2.0's advantages and are enhanced as follows:
- Multi-Step Function Calling: The assistant can perform multiple internal function calls to handle a single user request, actively planning and gathering information to fulfill complex tasks.
- Multi-Turn Function Calling: Enables continuous and context-aware interactions over multiple exchanges, with each turn potentially containing multiple steps, for a more natural conversation experience.
- Enhanced Irrelevant Information Inspection: Better at identifying when provided functions are irrelevant to a user query, by providing a non-function call response.
Evaluation
The evaluation results of Hammer 2.1 models on the Berkeley Function-Calling Leaderboard (BFCL-v3) are presented in the following table:
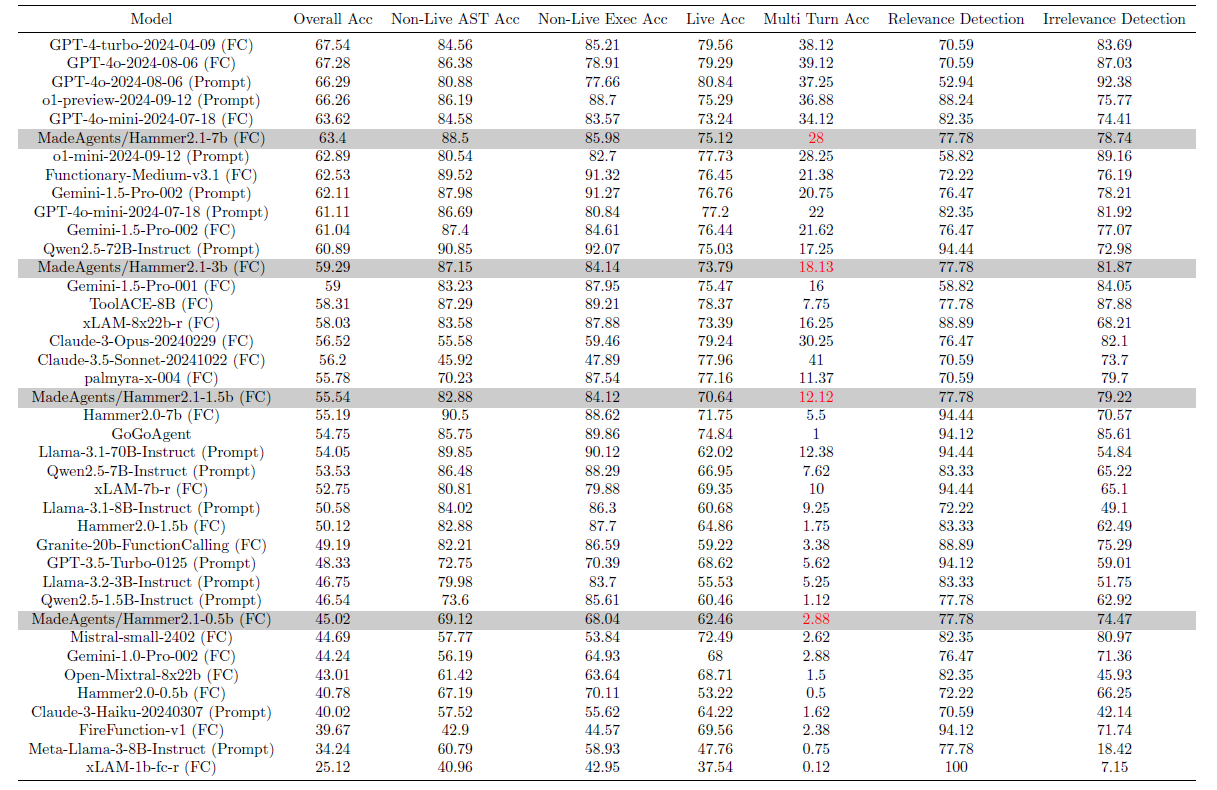
Our Hammer 2.1 series consistently achieves corresponding best performance at comparable scales. The 7B/3B/1.5B model outperform most function calling enchanced models.
In addition, we evaluated the Hammer 2.1 models on other academic benchmarks to further demonstrate the generalization ability of our models.
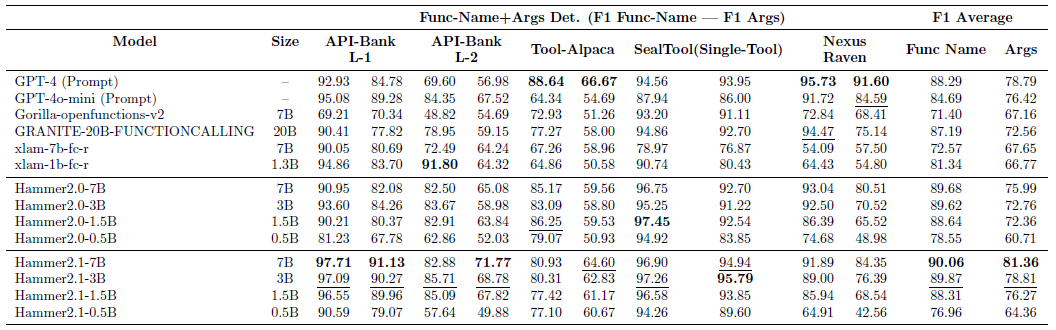
Hammer 2.1 models showcase highly stable performance, suggesting the robustness of Hammer 2.1 series. In contrast, the baseline approaches display varying levels of effectiveness.
Tuning Details
Thanks so much for your attention, a report with all the technical details leading to our models will be published soon.
Requiements
The code of Hammer 2.1 models have been in the latest Hugging face transformers and we advise you to install transformers>=4.34.0.
How to Use
Hammer2.1 models offer flexibility in deployment and usage, fully supporting both vLLM deployment and Hugging Face Transformers tool calling. For more detailed examples and use cases, please refer to the examples/README_USING.md in our repository. This is a simple example of how to use our model.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("MadeAgents/Hammer2.1-1.5b")
model = AutoModelForCausalLM.from_pretrained("MadeAgents/Hammer2.1-1.5b", torch_dtype=torch.bfloat16, device_map="auto")
# Example conversation
messages = [
{"role": "user", "content": "What's the weather like in New York?"},
{"role": "assistant","content": '```\n{"name": "get_weather", "arguments": {"location": "New York, NY ", "unit": "celsius"}\n```'},
{"role": "tool", "name": "get_weather", "content": '{"temperature": 72, "description": "Partly cloudy"}'},
{"role": "user", "content": "Now, search for the weather in San Francisco."}
]
# Example function definition (optional)
tools = [
{
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The unit of temperature to return"}
},
"required": ["location"]
}
},
{
"name": "respond",
"description": "When you are ready to respond, use this function. This function allows the assistant to formulate and deliver appropriate replies based on the input message and the context of the conversation. Generate a concise response for simple questions, and a more detailed response for complex questions.",
"parameters": {
"type": "object",
"properties": {
"message": {"type": "string", "description": "The content of the message to respond to."}
},
"required": ["message"]
}
}
]
inputs = tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, return_dict=True, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
out = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(out[0][len(inputs["input_ids"][0]):], skip_special_tokens=True))