
Hammer2.1
Collection
Hammer: a series of lightweight language models with strong function calling capability
•
4 items
•
Updated
Hammer refers to a series of lightweight Large Action Models. Currently, we are releasing Hammer 2.1 models (0.5B, 1.5B, 3B, and 7B) with strong function calling capability. These models are based on the Qwen 2.5 coder series and utilize function masking techniques and other advanced technologies. Hammer 2.1 series bring significant enhancements, while still maintaining the basic functionality of Hammer 2.0's Single-Turn interaction and further strengthening other capabilities.
The Hammer 2.1 models, fine-tuned from the Qwen 2.5 coder series, inherit Hammer 2.0's advantages and are enhanced as follows:
The evaluation results of Hammer 2.1 models on the Berkeley Function-Calling Leaderboard (BFCL-v3) are presented in the following table:
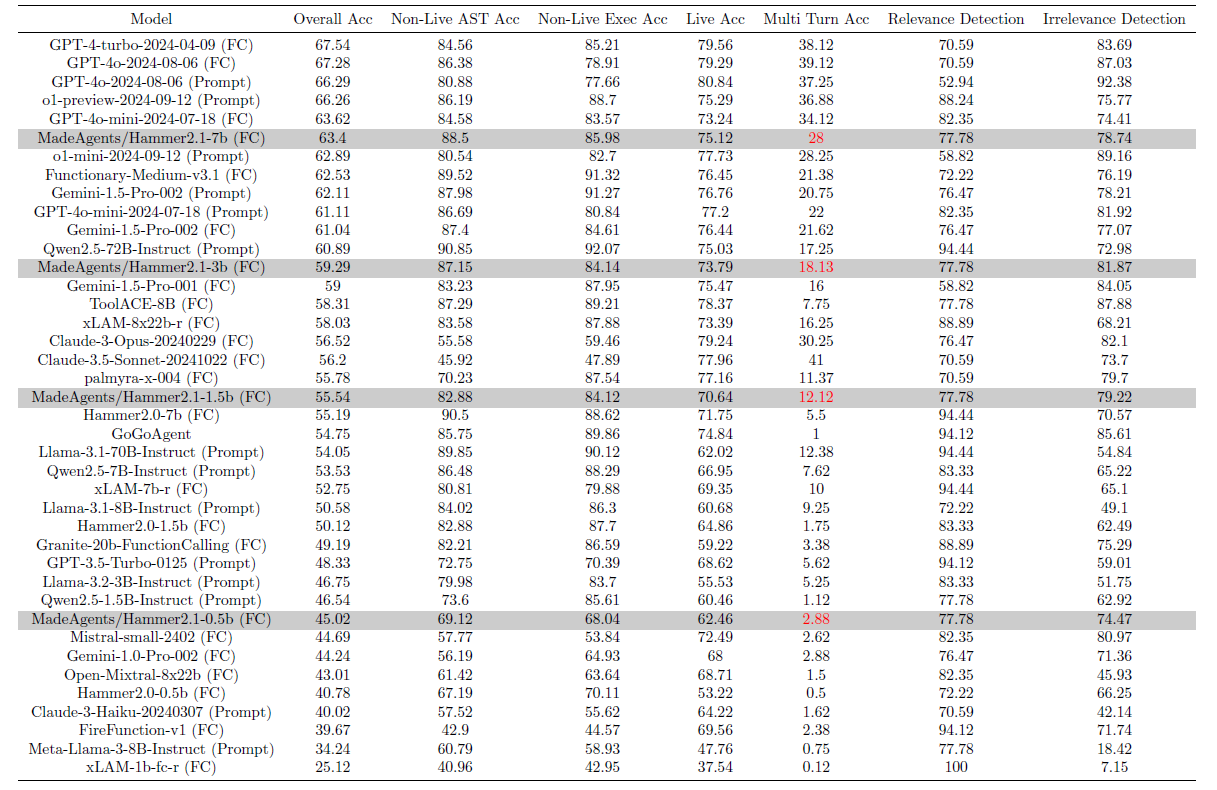
Our Hammer 2.1 series consistently achieves corresponding best performance at comparable scales. The 7B/3B/1.5B model outperform most function calling enchanced models.
In addition, we evaluated the Hammer 2.1 models on other academic benchmarks to further demonstrate the generalization ability of our models.
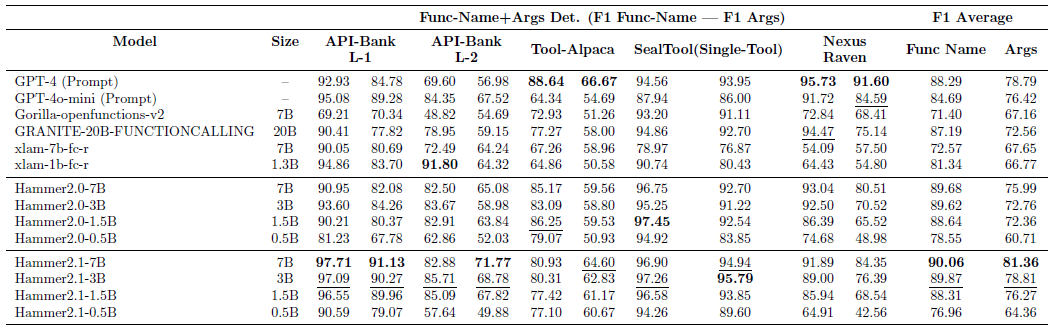
Hammer 2.1 models showcase highly stable performance, suggesting the robustness of Hammer 2.1 series. In contrast, the baseline approaches display varying levels of effectiveness.
The code of Hammer 2.1 models have been in the latest Hugging face transformers and we advise you to install transformers>=4.47.0.
Hammer models offer flexibility in deployment and usage, fully supporting both vLLM deployment and Hugging Face Transformers tool calling. Below are the specifics on how to make use of these features:
Before using vLLM, first clone the Hammer code repository and change directory to the 'Hammer':
git clone https://github.com/MadeAgents/Hammer.git
cd Hammer
vLLM offers efficient serving with lower latency. To serve the model with vLLM:
vllm serve MadeAgents/Hammer2.1-7b --host 0.0.0.0 --port 8000 --tensor-parallel-size 1
Once the model is served, you can use the following Hammer client to interact with it for function calling:
from client import HammerChatCompletion,HammerConfig
config = HammerConfig(base_url="http://localhost:8000/v1/", model="MadeAgents/Hammer2.1-7b")
llm = HammerChatCompletion.from_config(config)
# Example conversation
messages = [
{"role": "user", "content": "What's the weather like in New York?"},
{"role": "assistant","content": '```\n{"name": "get_weather", "arguments": {"location": "New York, NY ", "unit": "celsius"}\n```'},
{"role": "tool", "name": "get_weather", "content": '{"temperature": 72, "description": "Partly cloudy"}'},
{"role": "user", "content": "Now, search for the weather in San Francisco."}
]
# Example function definition (optional)
tools = [
{
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The unit of temperature to return"}
},
"required": ["location"]
}
},
{
"name": "respond",
"description": "When you are ready to respond, use this function. This function allows the assistant to formulate and deliver appropriate replies based on the input message and the context of the conversation. Generate a concise response for simple questions, and a more detailed response for complex questions.",
"parameters": {
"type": "object",
"properties": {
"message": {"type": "string", "description": "The content of the message to respond to."}
},
"required": ["message"]
}
}
]
response = llm.completion(messages, tools=tools)
print(response)
Hammer2.1 supports vllm’s built-in tool calling. This functionality requires vllm>=0.6. If you want to enable this functionality, please start vllm’s OpenAI-compatible service with:
vllm serve MadeAgents/Hammer2.1-7b --enable-auto-tool-choice --tool-call-parser hermes
And then use it in the same way you use GPT’s tool calling:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
"default": "celsius"
},
},
"required": ["location","format"],
},
}
},
{
"type": "function",
"function": {
"name": "get_n_day_weather_forecast",
"description": "Get an N-day weather forecast",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
"default": "celsius"
},
"num_days": {
"type": "integer",
"description": "The number of days to forecast",
"default": 1
}
},
"required": ["location", "format", "num_days"]
},
}
},
]
from openai import OpenAI
openai_api_key = "None"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
query = """What's the weather like today in San Francisco"""
chat_response = client.chat.completions.create(
model="MadeAgents/Hammer2.1-7b",
messages=[
{"role": "user", "content": query},],
tools = tools,
temperature=0
)
print(chat_response.choices[0].message.content)
Hammer2.1’s chat template also includes a tool calling template, meaning that you can use Hugging Face transformers’ tool calling support. This is a simple example of how to use our model using Transformers.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("MadeAgents/Hammer2.1-7b")
model = AutoModelForCausalLM.from_pretrained("MadeAgents/Hammer2.1-7b", torch_dtype=torch.bfloat16, device_map="auto")
# Example conversation
messages = [
{"role": "user", "content": "What's the weather like in New York?"},
{"role": "assistant","content": '```\n{"name": "get_weather", "arguments": {"location": "New York, NY ", "unit": "celsius"}\n```'},
{"role": "tool", "name": "get_weather", "content": '{"temperature": 72, "description": "Partly cloudy"}'},
{"role": "user", "content": "Now, search for the weather in San Francisco."}
]
# Example function definition (optional)
tools = [
{
"name": "get_weather",
"description": "Get the current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"], "description": "The unit of temperature to return"}
},
"required": ["location"]
}
},
{
"name": "respond",
"description": "When you are ready to respond, use this function. This function allows the assistant to formulate and deliver appropriate replies based on the input message and the context of the conversation. Generate a concise response for simple questions, and a more detailed response for complex questions.",
"parameters": {
"type": "object",
"properties": {
"message": {"type": "string", "description": "The content of the message to respond to."}
},
"required": ["message"]
}
}
]
inputs = tokenizer.apply_chat_template(messages, tools=tools, add_generation_prompt=True, return_dict=True, return_tensors="pt")
inputs = {k: v.to(model.device) for k, v in inputs.items()}
out = model.generate(**inputs, max_new_tokens=128)
print(tokenizer.decode(out[0][len(inputs["input_ids"][0]):], skip_special_tokens=True))