
Breeze 2 Family
Collection
Llama-Breeze2 is a multi-modal language model family specifically intended for Traditional Chinese use. BreezyVoice is a Taiwan Mandarin TTS
•
6 items
•
Updated
•
18
🚀 Try out our interactive UI playground now! 🚀
Or visit one of these resources:
BreezyVoice: Adapting TTS for Taiwanese Mandarin with Enhanced Polyphone Disambiguation -- Challenges and Insights
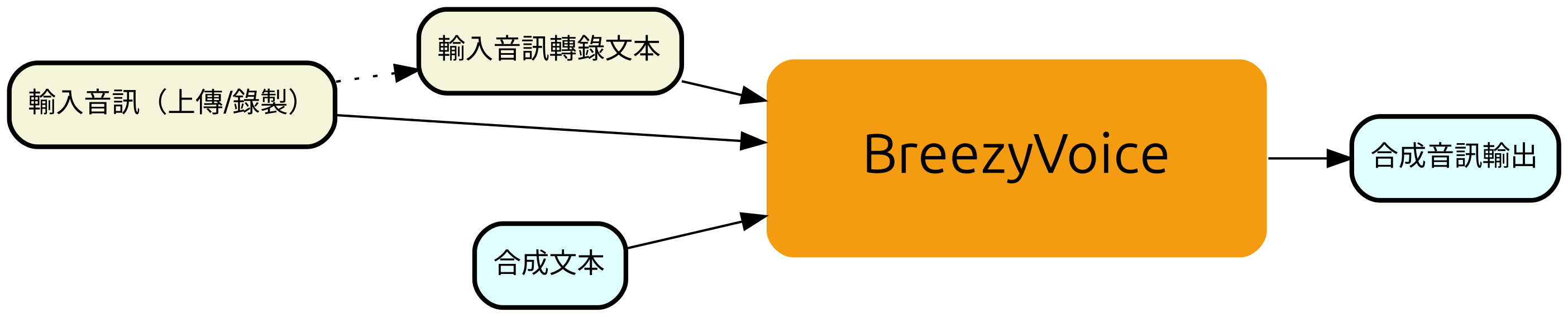
BreezyVoice is a voice-cloning text-to-speech system specifically adapted for Taiwanese Mandarin, highlighting phonetic control abilities via auxiliary 注音 (bopomofo) inputs. BreezyVoice is partially derived from CosyVoice
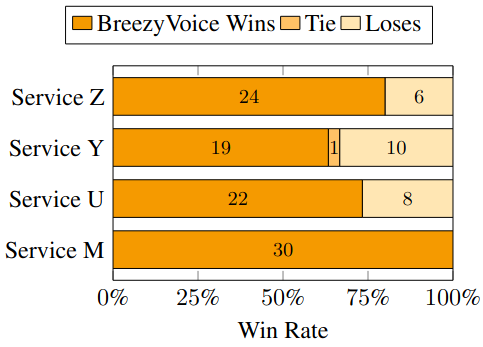
BreezyVoice outperforms competing commercial services in terms of naturalness.
BreezyVoice excels at code-switching scenarios.
| Code-Switching Term Category | BreezyVoice | Z | Y | U | M |
|---|---|---|---|---|---|
| General Words | 8 | 5 | 8 | 8 | 7 |
| Entities | 9 | 6 | 4 | 7 | 4 |
| Abbreviations | 9 | 8 | 6 | 6 | 7 |
| Toponyms | 3 | 3 | 7 | 3 | 4 |
| Full Sentences | 7 | 7 | 8 | 5 | 3 |
Running from GitHub following instructions automatically downloads the model for you
You can also run the model from a specified local path by cloning the model
git lfs install
git clone https://huggingface.co/MediaTek-Research/BreezyVoice
You can then use the model as outlined in the single_inference.py script on GitHub, specifying the local model path via the model_path parameter.
If you like our work, please cite:
@article{hsu2025breezyvoice,
title={BreezyVoice: Adapting TTS for Taiwanese Mandarin with Enhanced Polyphone Disambiguation--Challenges and Insights},
author={Hsu, Chan-Jan and Lin, Yi-Cheng and Lin, Chia-Chun and Chen, Wei-Chih and Chung, Ho Lam and Li, Chen-An and Chen, Yi-Chang and Yu, Chien-Yu and Lee, Ming-Ji and Chen, Chien-Cheng and others},
journal={arXiv preprint arXiv:2501.17790},
year={2025}
}
@article{hsu2025breeze,
title={The Breeze 2 Herd of Models: Traditional Chinese LLMs Based on Llama with Vision-Aware and Function-Calling Capabilities},
author={Hsu, Chan-Jan and Liu, Chia-Sheng and Chen, Meng-Hsi and Chen, Muxi and Hsu, Po-Chun and Chen, Yi-Chang and Shiu, Da-Shan},
journal={arXiv preprint arXiv:2501.13921},
year={2025}
}
@article{du2024cosyvoice,
title={Cosyvoice: A scalable multilingual zero-shot text-to-speech synthesizer based on supervised semantic tokens},
author={Du, Zhihao and Chen, Qian and Zhang, Shiliang and Hu, Kai and Lu, Heng and Yang, Yexin and Hu, Hangrui and Zheng, Siqi and Gu, Yue and Ma, Ziyang and others},
journal={arXiv preprint arXiv:2407.05407},
year={2024}
}