
Qwen2.5-MegaScience
Collection
Qwen2.5-MegaScience
•
3 items
•
Updated
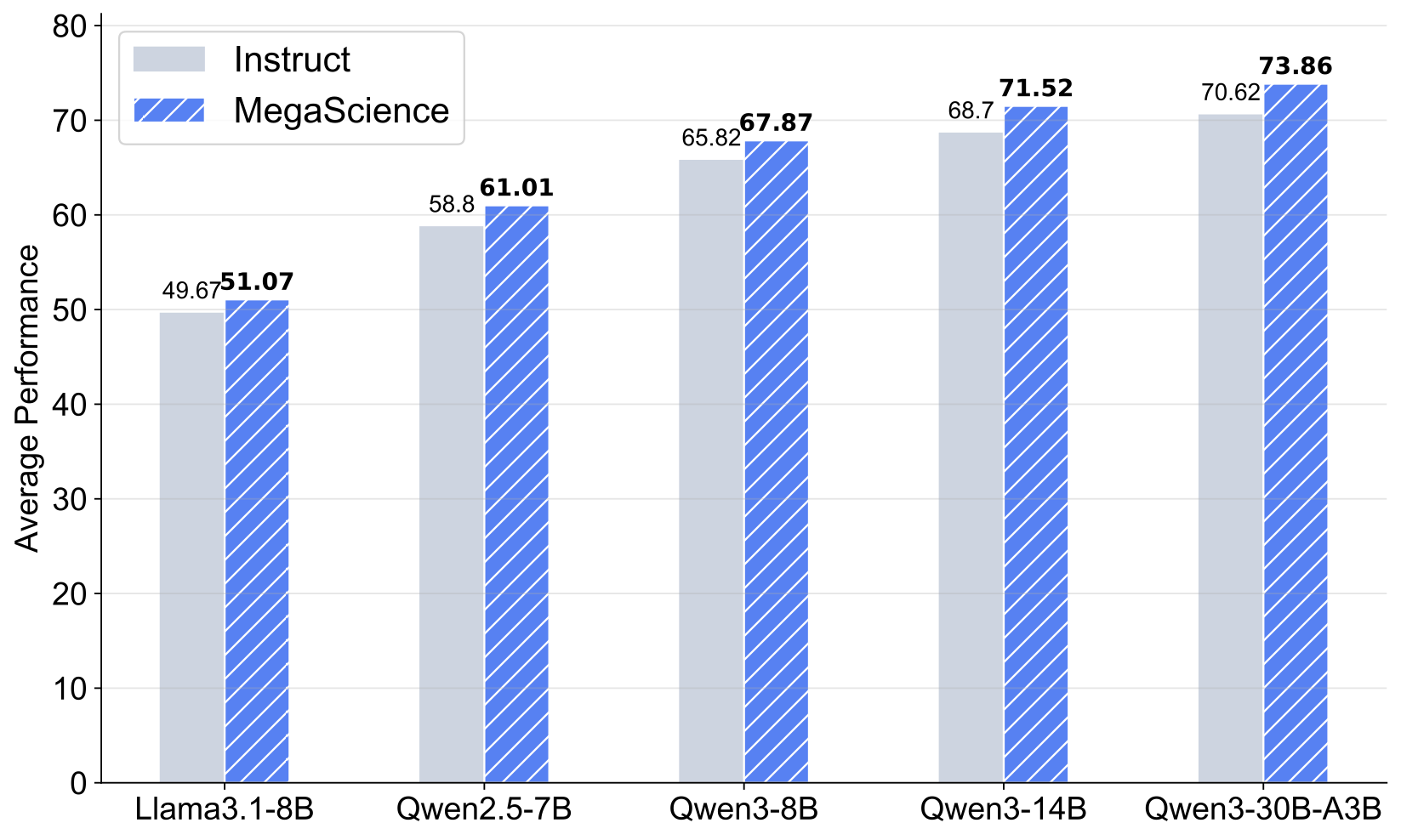
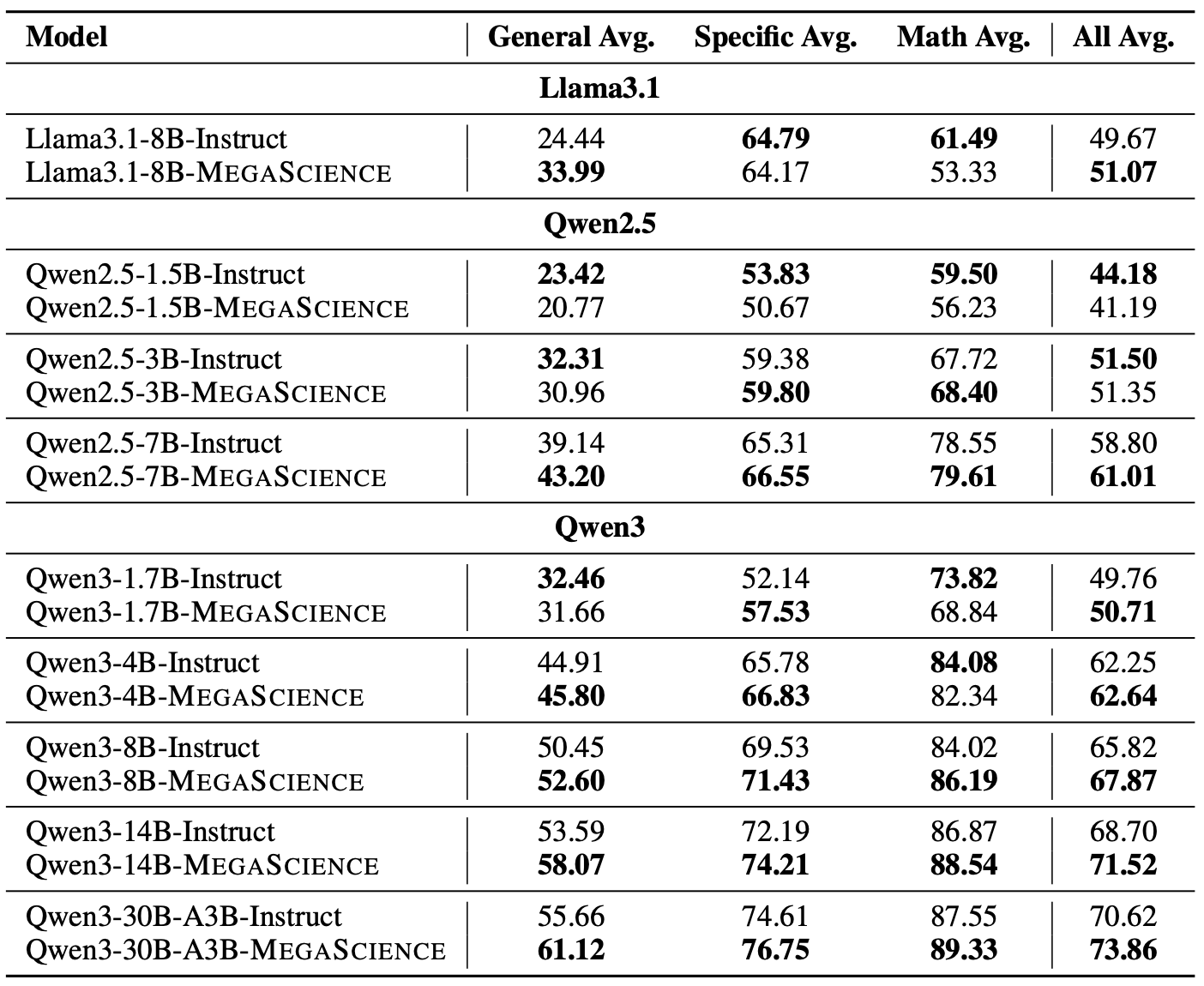
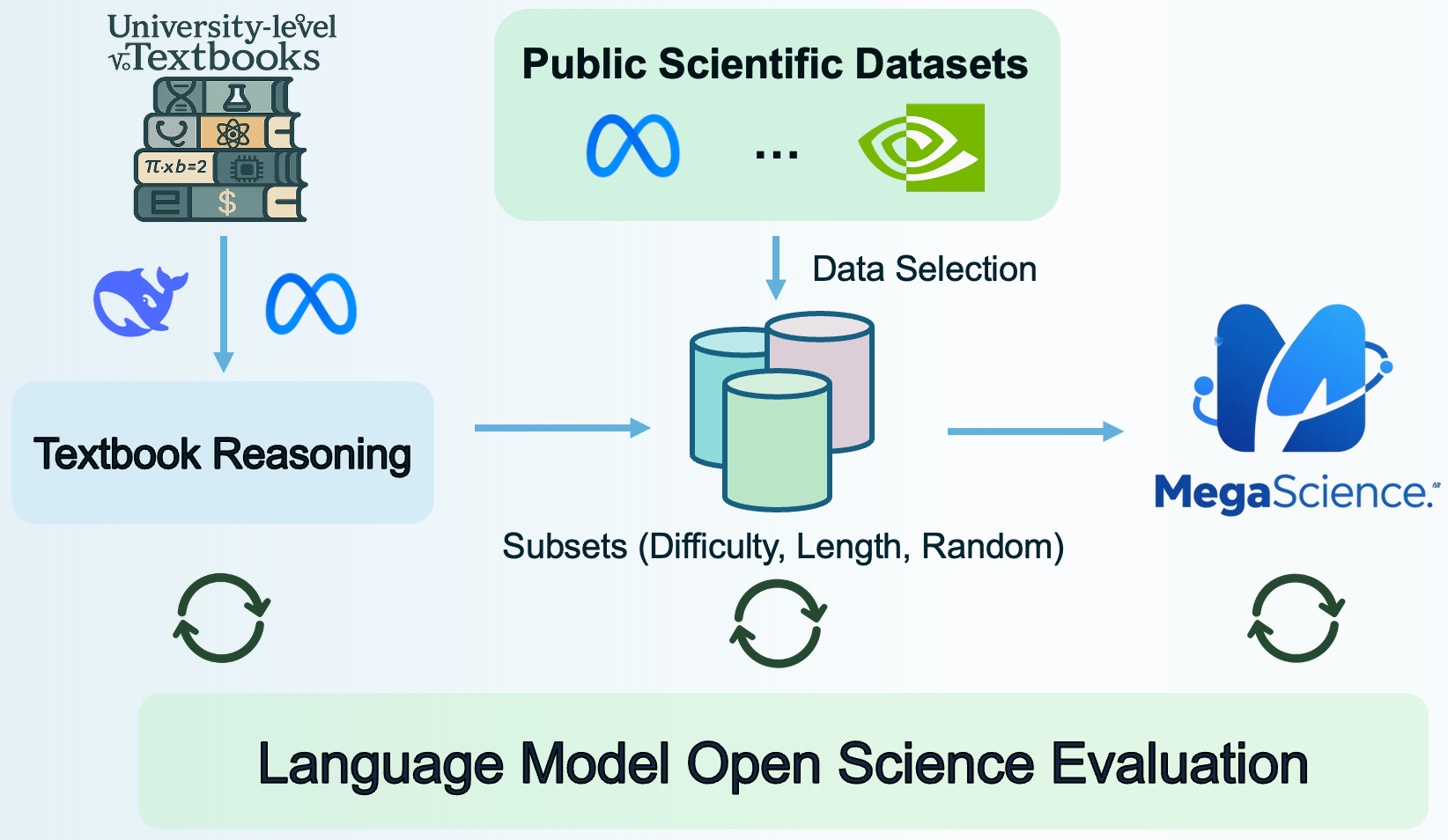
Scientific reasoning is critical for developing AI scientists and supporting human researchers in advancing the frontiers of natural science discovery. This work introduces TextbookReasoning, an open dataset featuring truthful reference answers extracted from 12k university-level scientific textbooks, comprising 650k reasoning questions. It further presents MegaScience, a large-scale mixture of high-quality open-source datasets totaling 1.25 million instances, developed through systematic ablation studies. Models trained on MegaScience demonstrate superior performance and training efficiency, significantly outperforming corresponding official instruct models, especially for larger and stronger base models.
Find the code and more details on the MegaScience GitHub repository.
You can use this model directly with the transformers library:
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "MegaScience/Qwen2.5-7B-MegaScience"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # or torch.float16 if bfloat16 is not supported
device_map="auto"
)
messages = [
{"role": "user", "content": "What is the capital of France?"},
]
text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
model_inputs = tokenizer(text, return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=256
)
generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(generated_text)
Check out our paper for more details. If you use our dataset or find our work useful, please cite
@article{fan2025megascience,
title={MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning},
author={Fan, Run-Ze and Wang, Zengzhi and Liu, Pengfei},
year={2025},
journal={arXiv preprint arXiv:2507.16812},
url={https://arxiv.org/abs/2507.16812}
}