
SpaceTimeGPT - Video Captioning Model
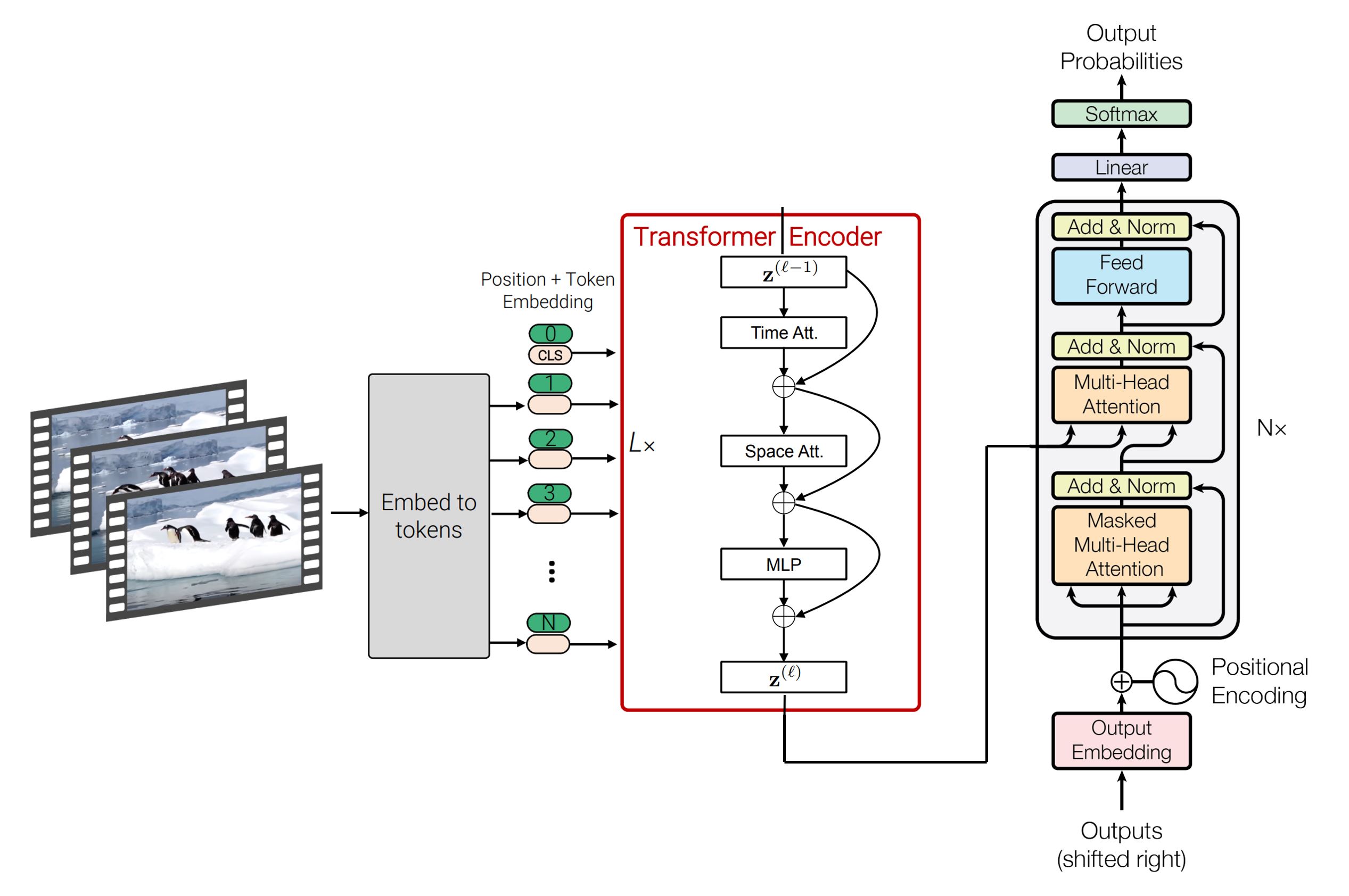
SpaceTimeGPT is a video description generation model capable of spatial and temporal reasoning. Given a video, eight frames are sampled and analyzed by the model. The output is a sentence description of the events that occured in the video, generated using autoregression.
Architecture and Training
Vision Encoder: timesformer-base-finetuned-k600
Text Decoder: gpt2
The encoder and decoder are initialized using pretrained weights for video classification and sentence completion, respectively. Encoder-decoder cross attention is used to unify the visual and linguistic domains. The model is fine-tuned end-to-end on the video captioning task. See GitHub repository for details.
Example Inference Code:
import av
import numpy as np
import torch
from transformers import AutoImageProcessor, AutoTokenizer, VisionEncoderDecoderModel
device = "cuda" if torch.cuda.is_available() else "cpu"
# load pretrained processor, tokenizer, and model
image_processor = AutoImageProcessor.from_pretrained("MCG-NJU/videomae-base")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = VisionEncoderDecoderModel.from_pretrained("Neleac/timesformer-gpt2-video-captioning").to(device)
# load video
video_path = "never_gonna_give_you_up.mp4"
container = av.open(video_path)
# extract evenly spaced frames from video
seg_len = container.streams.video[0].frames
clip_len = model.config.encoder.num_frames
indices = set(np.linspace(0, seg_len, num=clip_len, endpoint=False).astype(np.int64))
frames = []
container.seek(0)
for i, frame in enumerate(container.decode(video=0)):
if i in indices:
frames.append(frame.to_ndarray(format="rgb24"))
# generate caption
gen_kwargs = {
"min_length": 10,
"max_length": 20,
"num_beams": 8,
}
pixel_values = image_processor(frames, return_tensors="pt").pixel_values.to(device)
tokens = model.generate(pixel_values, **gen_kwargs)
caption = tokenizer.batch_decode(tokens, skip_special_tokens=True)[0]
print(caption) # A man and a woman are dancing on a stage in front of a mirror.
Author Information:
- Downloads last month
- 405
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support