
🖲️ PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing
👉 Project PLM Website |
The PLM (Peripheral Language Model) series introduces a novel model architecture to peripheral computing by delivering powerful language capabilities within the constraints of resource-limited devices. Through modeling and system co-design strategy, PLM optimizes model performance and fits edge system requirements, PLM employs Multi-head Latent Attention and squared ReLU activation to achieve sparsity, significantly reducing memory footprint and computational demands. Coupled with a meticulously crafted training regimen using curated datasets and a Warmup-Stable-Decay-Constant learning rate scheduler, PLM demonstrates superior performance compared to existing small language models, all while maintaining the lowest activated parameters, making it ideally suited for deployment on diverse peripheral platforms like mobile phones and Raspberry Pis.
News
The paper "PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing" has been released!
PLM Roadmap

PLM Hightlight
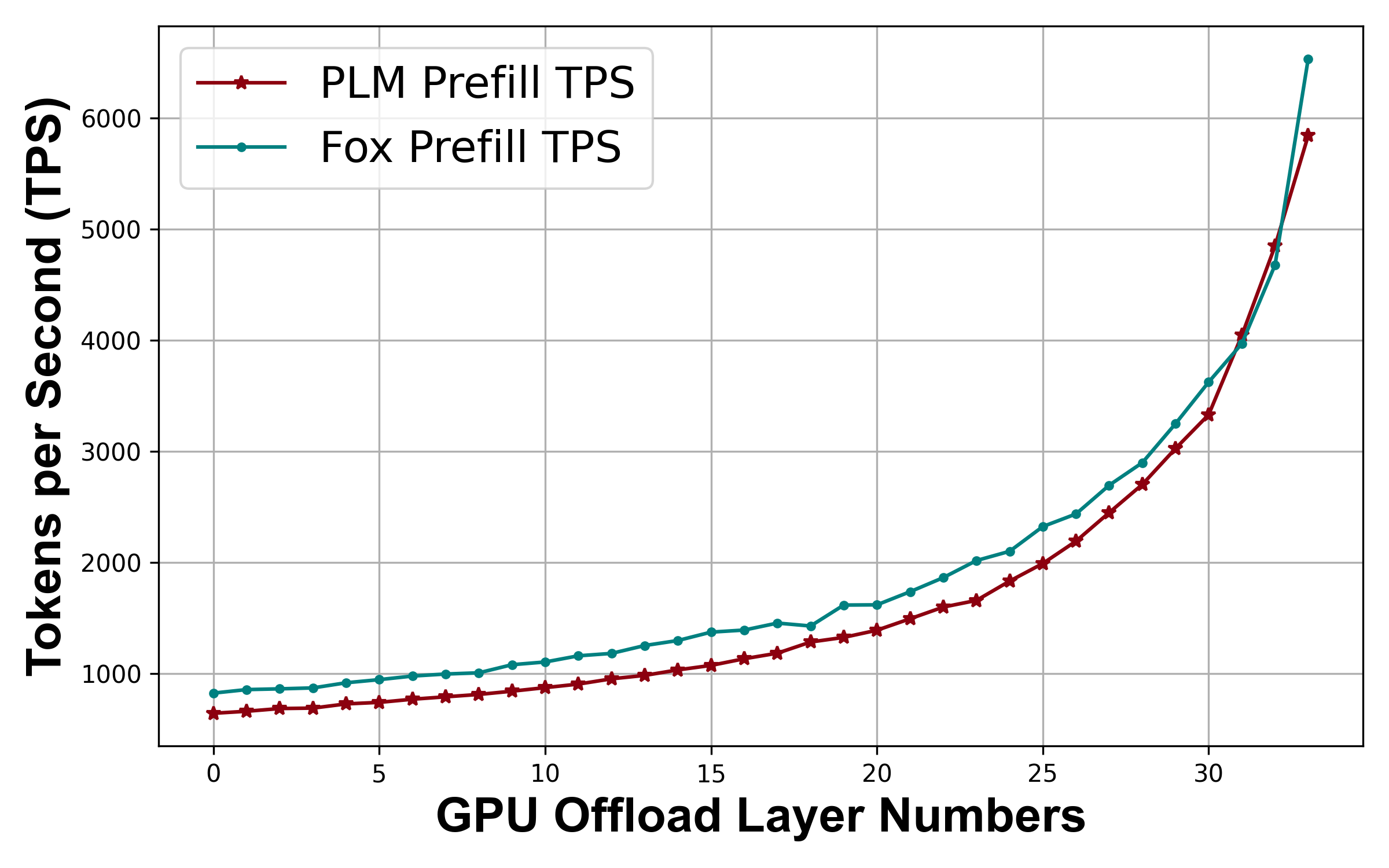
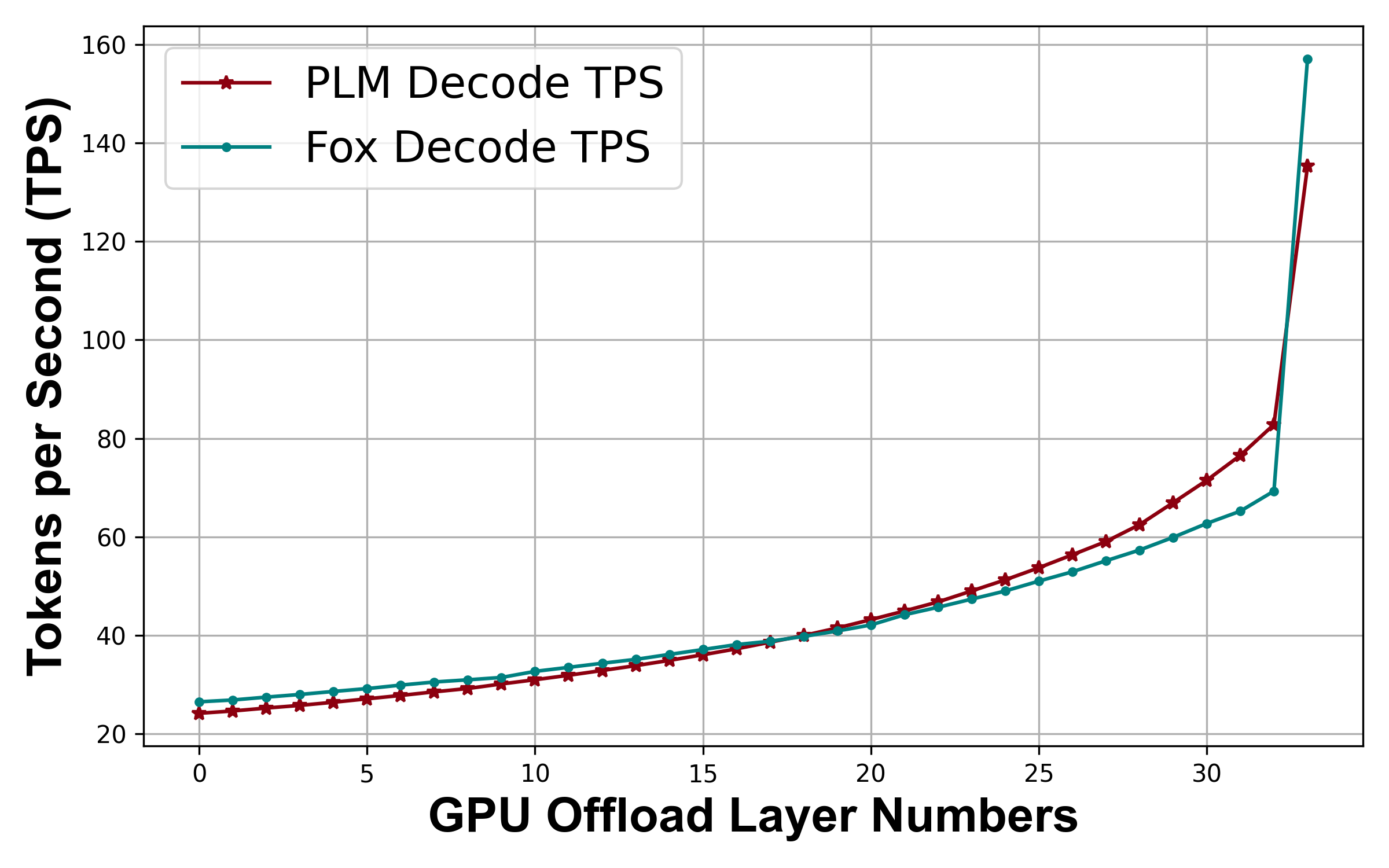
PLM demonstrates highly competitive performance along with a series of advantages stemming from its modeling and system co-design. These benefits include impressive inference speed, extreme sparsity, and reduced KV cache due to MLA, enabling it to outperform models with the same number of layers when handling long-context inference tasks at certain sequence lengths.
- Sparse (Less activated parameters but better performance)
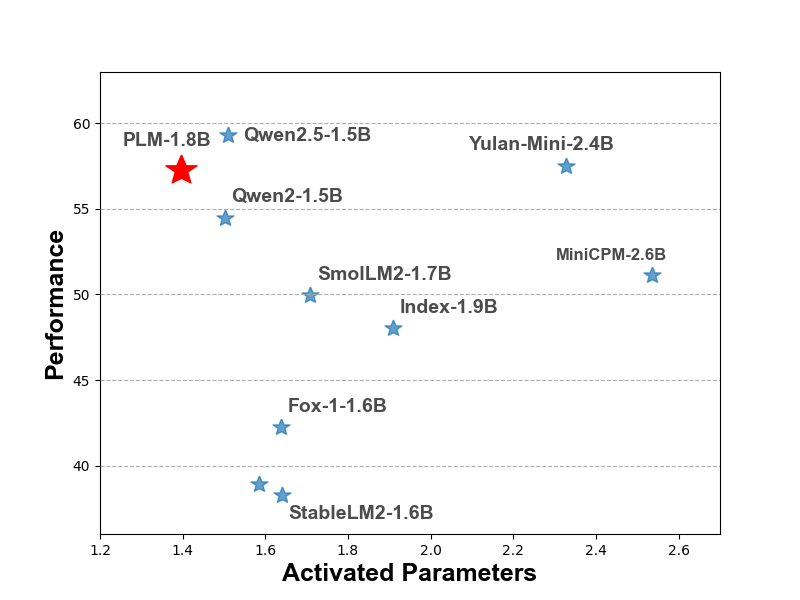
- High efficiency (Generate content with low latency while having a good quality)
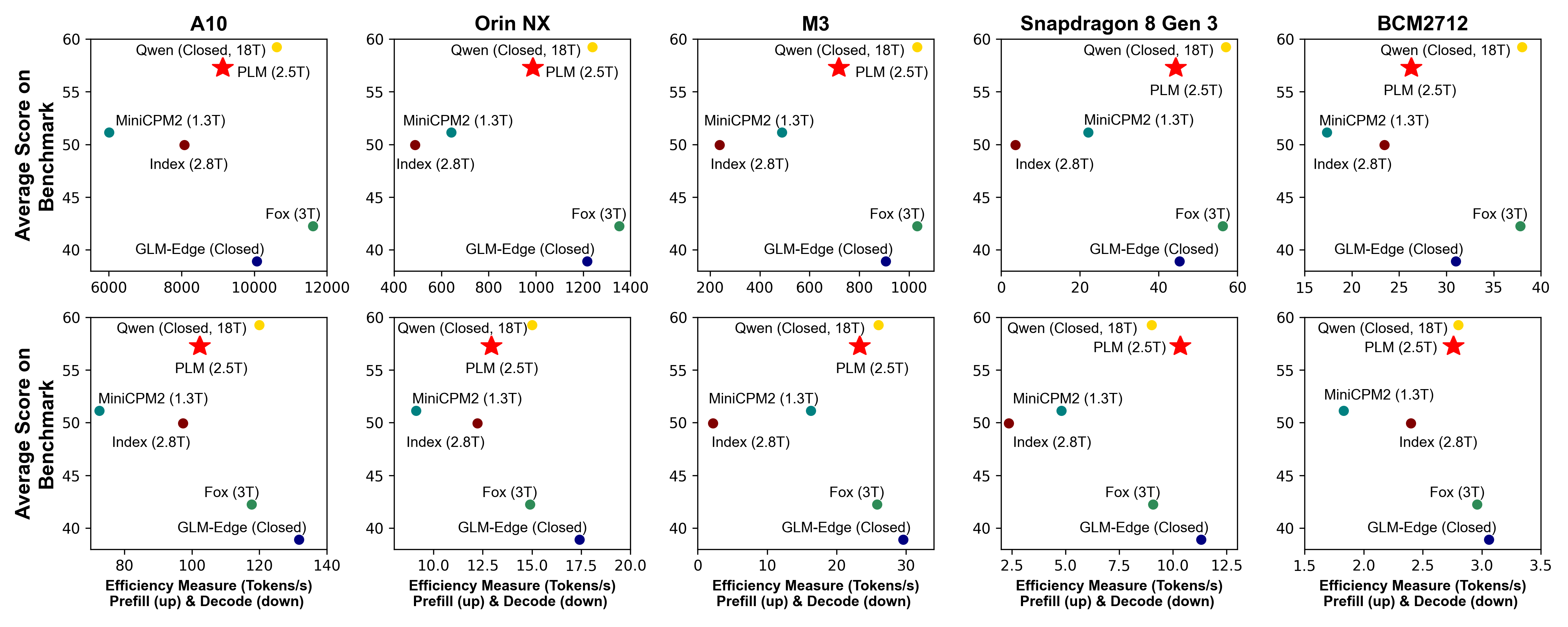
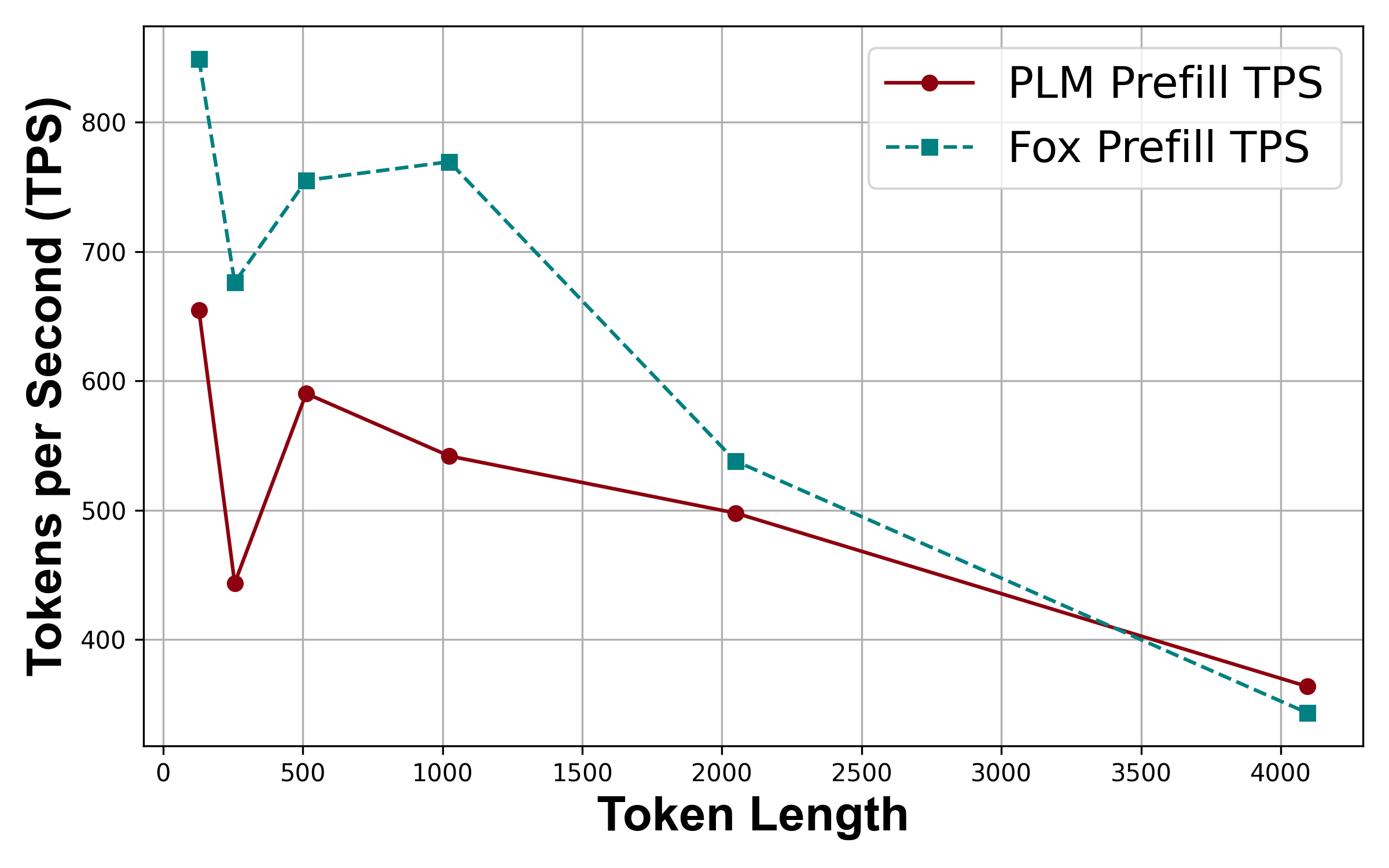
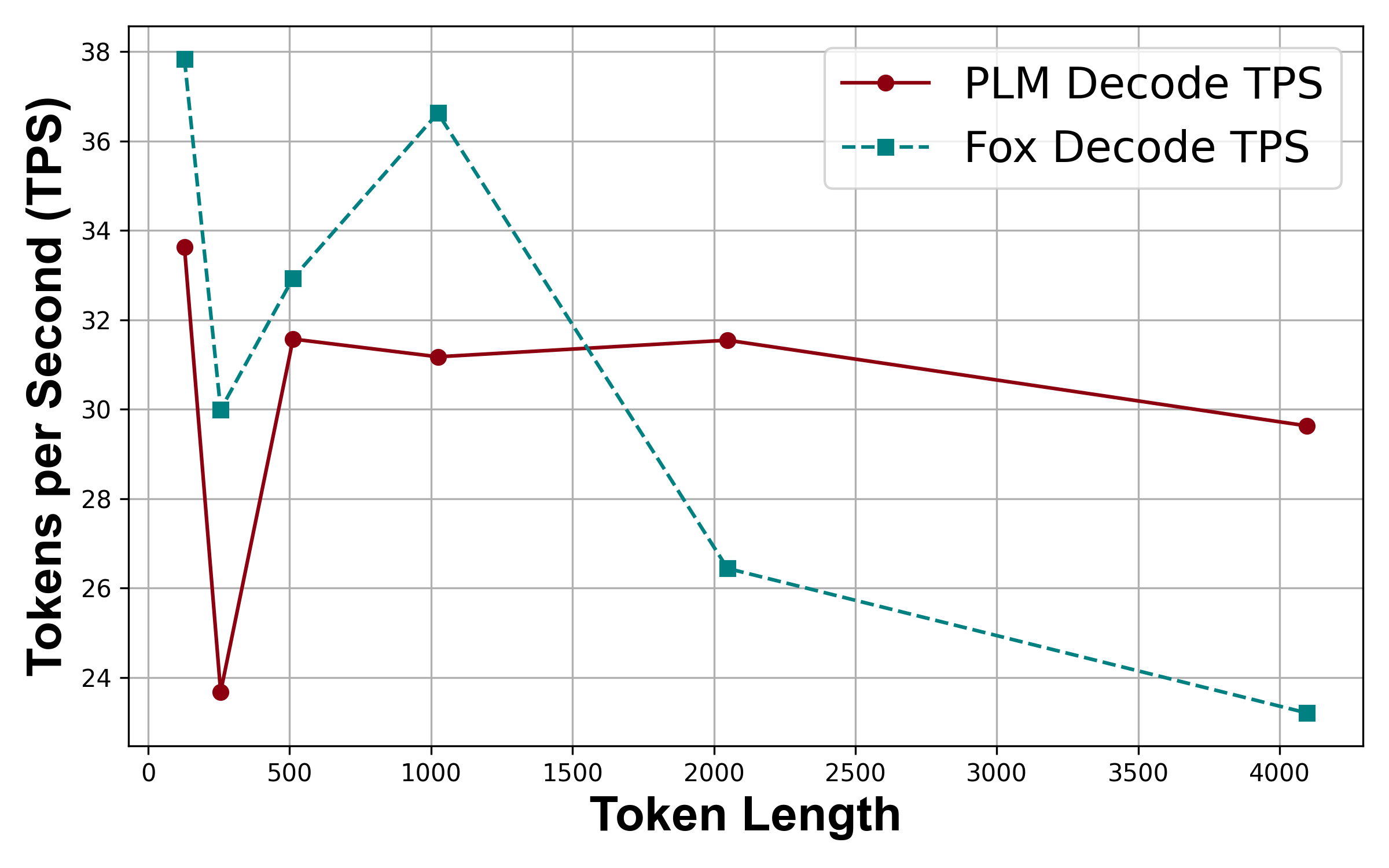
- Low kv-cache on long-context processing leads to a low latency when inference with long sequences.
 |
 |
- More efficiency when layer-wise loading.
 |
 |
Performance
PLM-1.8B is a strong and reliable model, particularly in basic knowledge understanding, coding and simple reasoning tasks.
| Benchmarks | PLM-Instruct | MiniCPM | Yulan-Mini | SmolLM2 | Qwen2.5 | Qwen2 | GLM-Edge |
|---|---|---|---|---|---|---|---|
| ARC-C | 51.14 | 43.86 | 50.51 | 50.29 | 53.41 | 43.90 | 24.15 |
| ARC-E | 78.18 | 55.51 | 69.87 | 77.78 | 79.13 | 62.21 | 36.83 |
| MMLU | 51.18 | 51.13 | 49.10 | 51.91 | 59.79 | 56.50 | 54.84 |
| CMMLU | 48.18 | 48.97 | 48.35 | 33.46 | 67.82 | 70.30 | 54.23 |
| C-Eval | 44.93 | 48.24 | 51.47 | 35.10 | 69.05 | 70.60 | 55.05 |
| GSM8K | 60.73 | 53.83 | 66.65 | 47.68 | 68.50 | 46.90 | 54.89 |
| MathQA | 33.23 | 30.59 | 34.84 | 34.30 | 35.14 | 31.66 | 33.94 |
| HumanEval | 64.60 | 50.00 | 61.60 | 23.35 | 37.20 | 34.80 | 1.21 |
| MBPP | 60.40 | 47.31 | 66.70 | 45.00 | 60.20 | 46.90 | 3.44 |
| BoolQ | 77.86 | 73.55 | 70.89 | 72.26 | 72.91 | 72.69 | 60.95 |
| Hellaswag | 68.17 | 53.06 | 71.47 | 71.48 | 67.73 | 65.41 | 29.39 |
| LogiQA | 30.12 | 31.64 | 29.65 | 29.65 | 31.03 | 31.02 | 22.73 |
| PIQA | 76.01 | 77.04 | 76.50 | 77.04 | 76.01 | 75.35 | 74.32 |
| Average | 57.29 (3rd) | 51.13 | 57.51 (2nd) | 49.95 | 59.84 (1st) | 54.48 | 38.92 |
How to use PLM
Here we introduce some methods to use PLM models.
Hugging Face
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("PLM-Team/PLM-1.8B-Instruct")
model = AutoModelForCausalLM.from_pretrained("PLM-Team/PLM-1.8B-Instruct", torch_dtype=torch.bfloat16)
# Input text
input_text = "Tell me something about reinforcement learning."
inputs = tokenizer(input_text, return_tensors="pt")
# Completion
output = model.generate(inputs["input_ids"], max_new_tokens=100)
print(tokenizer.decode(output[0], skip_special_tokens=True))
llama.cpp
The original contribution to the llama.cpp framwork is Si1w/llama.cpp. Here is the usage:
git clone https://github.com/Si1w/llama.cpp.git
cd llama.cpp
pip install -r requirements.txt
Then, we can build with CPU of GPU (e.g. Orin). The build is based on cmake.
- For CPU
cmake -B build
cmake --build build --config Release
- For GPU
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release
Don't forget to download the GGUF files of the PLM. We use the quantization methods in llama.cpp to generate the quantized PLM.
huggingface-cli download --resume-download PLM-Team/PLM-1.8B-Instruct-gguf --local-dir PLM-Team/PLM-1.8B-Instruct-gguf
After build the llama.cpp, we can use llama-cli script to launch the PLM.
./build/bin/llama-cli -m ./PLM-Team/PLM-1.8B-Instruct-gguf/PLM-1.8B-Instruct-Q8_0.gguf -cnv -p "hello!" -n 128
Future works
- Release vLLM, SGLang, and PowerInfer inference scripts for PLM.
- Release reasoning model trained on PLM.
- Release vision model based on PLM.
Acknowledgements
We sincerely thank Deepseek for its contributions to the community through the MLA architecture and the PowerInfer project for inspiring our model architecture design. We are grateful to Yixin Song, Yan Song, and Yang Li for their insightful suggestions throughout the project. We also acknowledge the ADC of the Hong Kong University of Science and Technology (Guangzhou) for providing essential computing resources. Finally, we extend our deepest appreciation to our team members for their dedication and contributions from September 2024 to the present.
License
The code in this repository is released under the MIT License. Limitations: While we strive to address safety concerns and promote the generation of ethical and lawful text, the probabilistic nature of language models may still produce unforeseen outputs. These may include biased, discriminatory, or otherwise harmful content. Users are advised not to disseminate such material. We disclaim any liability for consequences resulting from the distribution of harmful information.
Citation
If you find Project PLM helpful for your research or applications, please cite as follows:
@misc{deng2025plmefficientperipherallanguage,
title={PLM: Efficient Peripheral Language Models Hardware-Co-Designed for Ubiquitous Computing},
author={Cheng Deng and Luoyang Sun and Jiwen Jiang and Yongcheng Zeng and Xinjian Wu and Wenxin Zhao and Qingfa Xiao and Jiachuan Wang and Lei Chen and Lionel M. Ni and Haifeng Zhang and Jun Wang},
year={2025},
eprint={2503.12167},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2503.12167},
}
- Downloads last month
- 8