



Deprecation Notice: This model is deprecated and will no longer receive updates.
Simply make AI models cheaper, smaller, faster, and greener!
- Give a thumbs up if you like this model!
- Contact us and tell us which model to compress next here.
- Request access to easily compress your own AI models here.
- Read the documentations to know more here
- Join Pruna AI community on Discord here to share feedback/suggestions or get help.
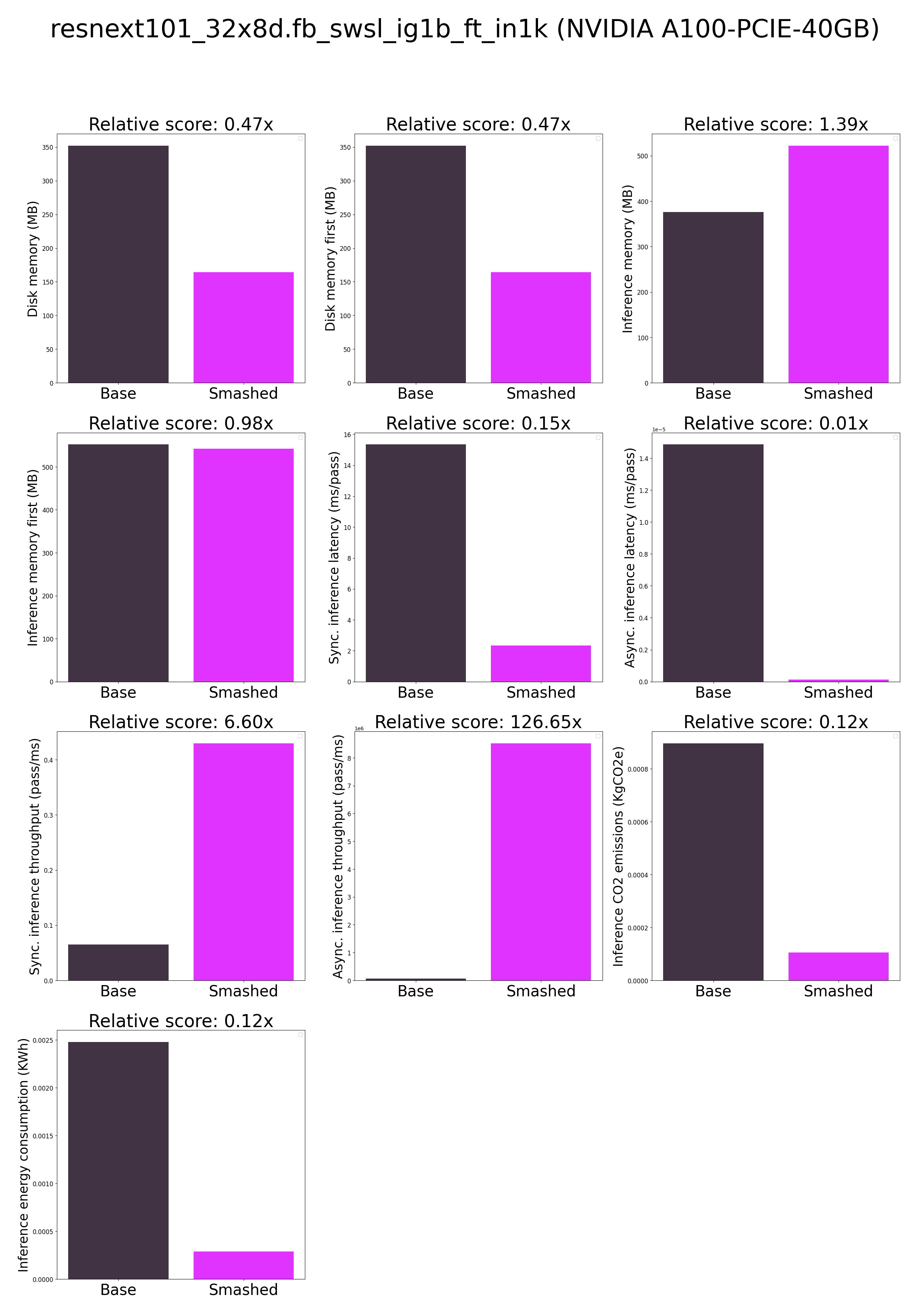
Results
Frequently Asked Questions
- How does the compression work? The model is compressed by combining quantization, xformers, jit, cuda graphs, triton.
- How does the model quality change? The quality of the model output might slightly vary compared to the base model.
- How is the model efficiency evaluated? These results were obtained on NVIDIA A100-PCIE-40GB with configuration described in
model/smash_config.json and are obtained after a hardware warmup. The smashed model is directly compared to the original base model. Efficiency results may vary in other settings (e.g. other hardware, image size, batch size, ...). We recommend to directly run them in the use-case conditions to know if the smashed model can benefit you.
- What is the model format? We used a custom Pruna model format based on pickle to make models compatible with the compression methods. We provide a tutorial to run models in dockers in the documentation here if needed.
- What is the naming convention for Pruna Huggingface models? We take the original model name and append "turbo", "tiny", or "green" if the smashed model has a measured inference speed, inference memory, or inference energy consumption which is less than 90% of the original base model.
- How to compress my own models? You can request premium access to more compression methods and tech support for your specific use-cases here.
- What are "first" metrics? Results mentioning "first" are obtained after the first run of the model. The first run might take more memory or be slower than the subsequent runs due cuda overheads.
- What are "Sync" and "Async" metrics? "Sync" metrics are obtained by syncing all GPU processes and stop measurement when all of them are executed. "Async" metrics are obtained without syncing all GPU processes and stop when the model output can be used by the CPU. We provide both metrics since both could be relevant depending on the use-case. We recommend to test the efficiency gains directly in your use-cases.
Setup
You can run the smashed model with these steps:
- Check that you have linux, python 3.10, and cuda 12.1.0 requirements installed. For cuda, check with
nvcc --version and install with conda install nvidia/label/cuda-12.1.0::cuda.
- Install the
pruna-engine available here on Pypi. It might take up to 15 minutes to install.pip install pruna-engine[gpu]==0.7.1 --extra-index-url https://pypi.nvidia.com --extra-index-url https://pypi.ngc.nvidia.com --extra-index-url https://prunaai.pythonanywhere.com/
- Download the model files using one of these three options.
- Option 1 - Use command line interface (CLI):
mkdir resnext101_32x8d.fb_swsl_ig1b_ft_in1k-turbo-green-smashed
huggingface-cli download PrunaAI/resnext101_32x8d.fb_swsl_ig1b_ft_in1k-turbo-green-smashed --local-dir resnext101_32x8d.fb_swsl_ig1b_ft_in1k-turbo-green-smashed --local-dir-use-symlinks False
- Option 2 - Use Python:
import subprocess
repo_name = "resnext101_32x8d.fb_swsl_ig1b_ft_in1k-turbo-green-smashed"
subprocess.run(["mkdir", repo_name])
subprocess.run(["huggingface-cli", "download", 'PrunaAI/'+ repo_name, "--local-dir", repo_name, "--local-dir-use-symlinks", "False"])
- Option 3 - Download them manually on the HuggingFace model page.
- Load & run the model.
from pruna_engine.PrunaModel import PrunaModel
model_path = "resnext101_32x8d.fb_swsl_ig1b_ft_in1k-turbo-green-smashed/model"
smashed_model = PrunaModel.load_model(model_path)
import torch; image = torch.rand(1, 3, 224, 224).to('cuda')
smashed_model(image)
Configurations
The configuration info are in model/smash_config.json.
Credits & License
The license of the smashed model follows the license of the original model. Please check the license of the original model resnext101_32x8d.fb_swsl_ig1b_ft_in1k before using this model which provided the base model. The license of the pruna-engine is here on Pypi.
Want to compress other models?
- Contact us and tell us which model to compress next here.
- Request access to easily compress your own AI models here.


