

Commit
•
c44da1d
1
Parent(s):
bd9f4f4
Upload README.md with huggingface_hub
Browse files
README.md
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
|
| 2 |
+
---
|
| 3 |
+
|
| 4 |
+
license: gpl-3.0
|
| 5 |
+
datasets:
|
| 6 |
+
- LooksJuicy/ruozhiba
|
| 7 |
+
- hfl/ruozhiba_gpt4
|
| 8 |
+
language:
|
| 9 |
+
- zh
|
| 10 |
+
pipeline_tag: text-generation
|
| 11 |
+
base_model: google/gemma-2-2b-it
|
| 12 |
+
|
| 13 |
+
---
|
| 14 |
+
|
| 15 |
+

|
| 16 |
+
|
| 17 |
+
# QuantFactory/Gemma-2-2b-Chinese-it-GGUF
|
| 18 |
+
This is quantized version of [stvlynn/Gemma-2-2b-Chinese-it](https://huggingface.co/stvlynn/Gemma-2-2b-Chinese-it) created using llama.cpp
|
| 19 |
+
|
| 20 |
+
# Original Model Card
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
# Gemma-2-2b-Chinese-it (Gemma-2-2b-中文)
|
| 24 |
+
|
| 25 |
+
## Intro
|
| 26 |
+
|
| 27 |
+
`Gemma-2-2b-Chinese-it` used approximately 6.4k rows of ruozhiba dataset to fine-tune `Gemma-2-2b-it`.
|
| 28 |
+
|
| 29 |
+
`Gemma-2-2b-中文`使用了约6.4k弱智吧数据对`Gemma-2-2b-it`进行微调
|
| 30 |
+
|
| 31 |
+
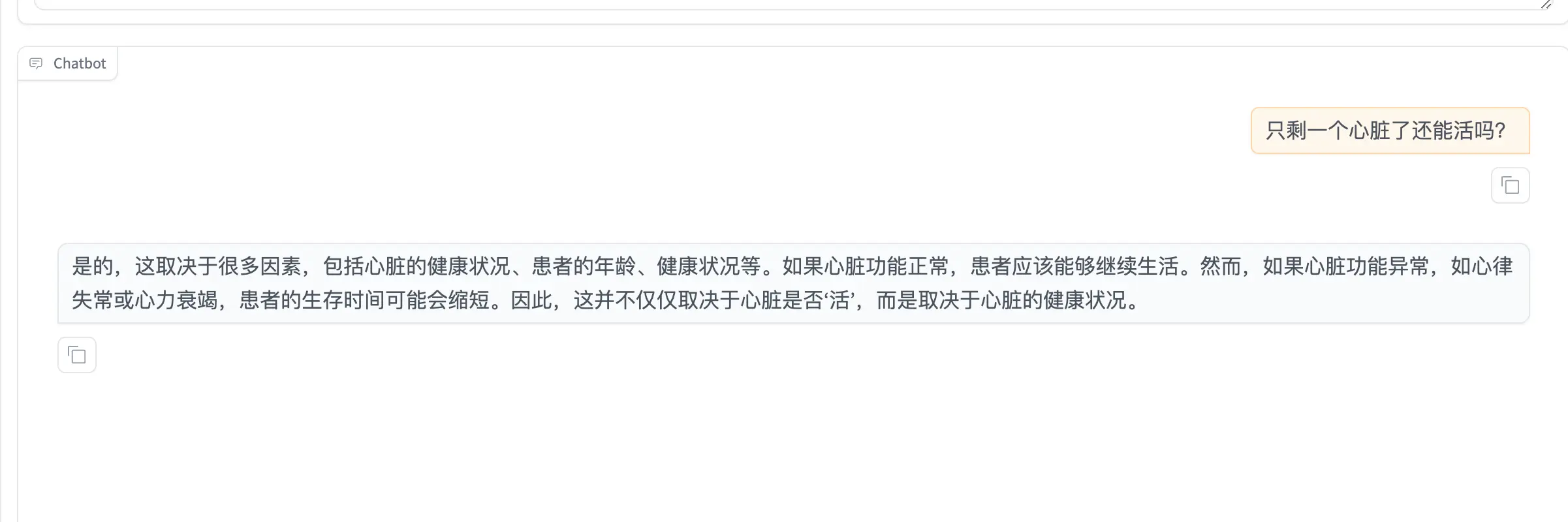
## Demo
|
| 32 |
+
|
| 33 |
+
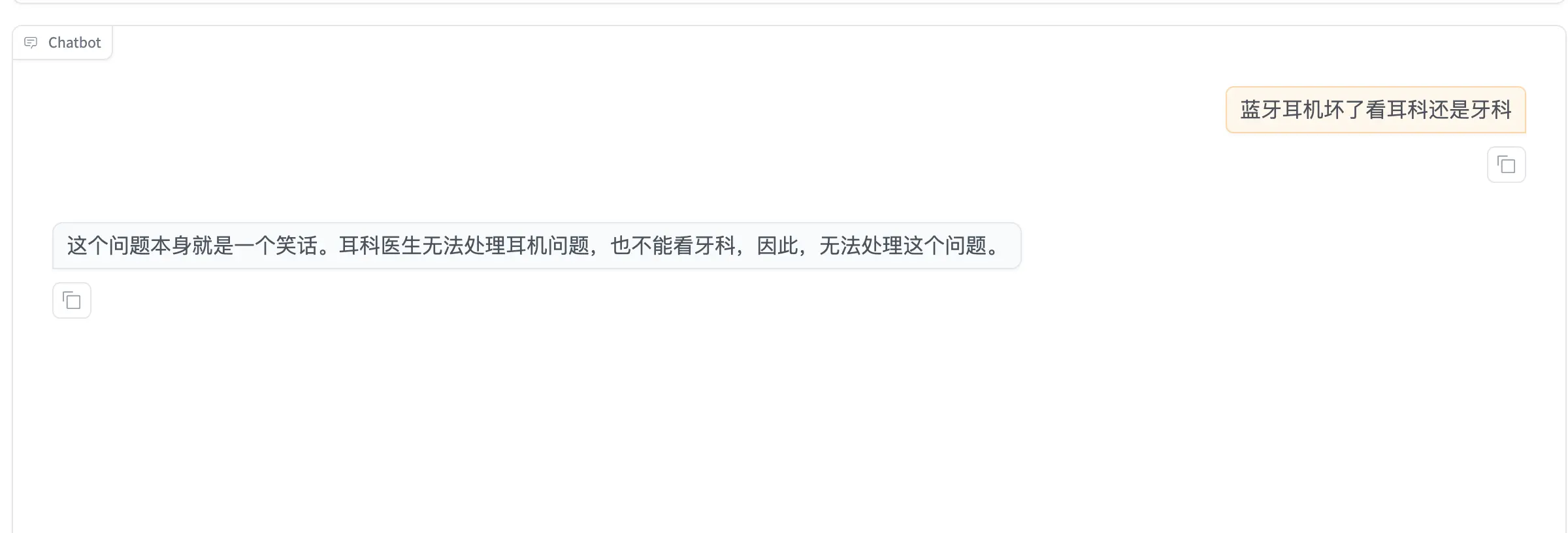
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
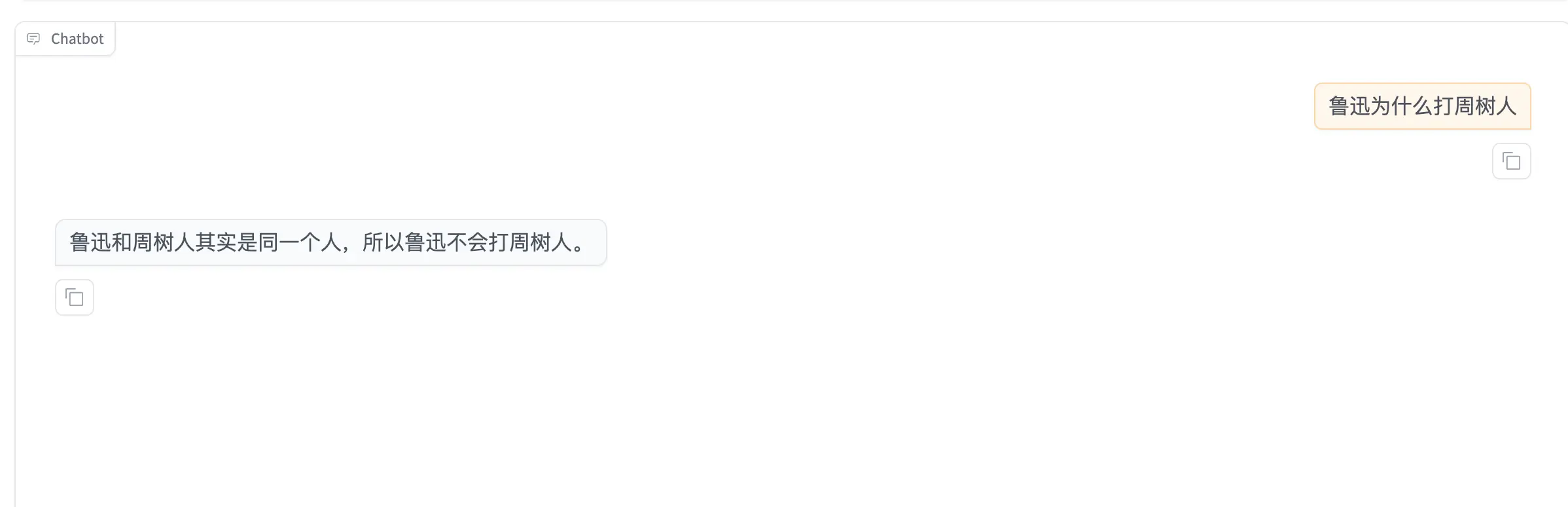
|
| 38 |
+
|
| 39 |
+
## Usage
|
| 40 |
+
|
| 41 |
+
see Google's doc:
|
| 42 |
+
|
| 43 |
+
[google/gemma-2-2b-it](https://huggingface.co/google/gemma-2-2b-it)
|
| 44 |
+
|
| 45 |
+
---
|
| 46 |
+
|
| 47 |
+
If you have any questions or suggestions, feel free to contact me.
|
| 48 |
+
|
| 49 |
+
[Twitter @stv_lynn](https://x.com/stv_lynn)
|
| 50 |
+
|
| 51 |
+
[Telegram @stvlynn](https://t.me/stvlynn)
|
| 52 |
+
|
| 53 |
+
[email [email protected]](mailto://[email protected])
|