
YAML Metadata
Warning:
empty or missing yaml metadata in repo card
(https://huggingface.co/docs/hub/model-cards#model-card-metadata)
Quantization made by Richard Erkhov.
Orpo-Llama-3.2-1B-40k - AWQ
- Model creator: https://huggingface.co/AdamLucek/
- Original model: https://huggingface.co/AdamLucek/Orpo-Llama-3.2-1B-40k/
Original model description:
library_name: transformers license: mit datasets: - mlabonne/orpo-dpo-mix-40k base_model: - meta-llama/Llama-3.2-1B pipeline_tag: text-generation
Orpo-Llama-3.2-1B-40k
AdamLucek/Orpo-Llama-3.2-1B-40k is an ORPO fine tuned version of meta-llama/Llama-3.2-1B on 1 epoch of mlabonne/orpo-dpo-mix-40k.
Trained for 11 hours on an A100 GPU with this training script
For full model details, refer to the base model page meta-llama/Llama-3.2-1B
Evaluations
In comparsion to AdamLucek/Orpo-Llama-3.2-1B-15k using lm-evaluation-harness.
| Benchmark | 15k Accuracy | 15k Normalized | 40k Accuracy | 40k Normalized | Notes |
|---|---|---|---|---|---|
| AGIEval | 22.14% | 21.01% | 23.57% | 23.26% | 0-Shot Average across multiple reasoning tasks |
| GPT4ALL | 51.15% | 54.38% | 51.63% | 55.00% | 0-Shot Average across all categories |
| TruthfulQA | 42.79% | N/A | 42.14% | N/A | MC2 accuracy |
| MMLU | 31.22% | N/A | 31.01% | N/A | 5-Shot Average across all categories |
| Winogrande | 61.72% | N/A | 61.12% | N/A | 0-shot evaluation |
| ARC Challenge | 32.94% | 36.01% | 33.36% | 37.63% | 0-shot evaluation |
| ARC Easy | 64.52% | 60.40% | 65.91% | 60.90% | 0-shot evaluation |
| BoolQ | 50.24% | N/A | 52.29% | N/A | 0-shot evaluation |
| PIQA | 75.46% | 74.37% | 75.63% | 75.19% | 0-shot evaluation |
| HellaSwag | 48.56% | 64.71% | 48.46% | 64.50% | 0-shot evaluation |
Using this Model
from transformers import AutoTokenizer
import transformers
import torch
# Load Model and Pipeline
model = "AdamLucek/Orpo-Llama-3.2-1B-40k"
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
# Load Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model)
# Generate Message
messages = [{"role": "user", "content": "What is a language model?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=1024, do_sample=True, temperature=0.3, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
Training Statistics
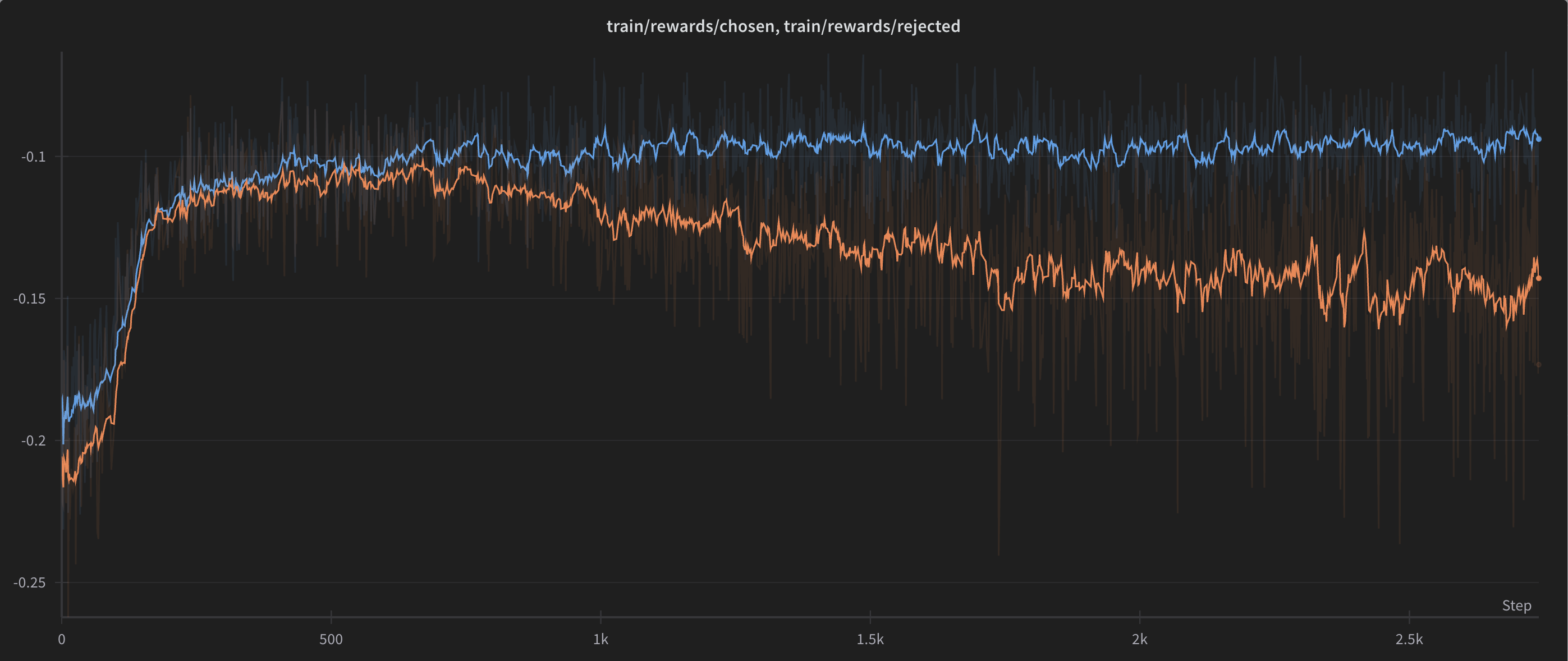


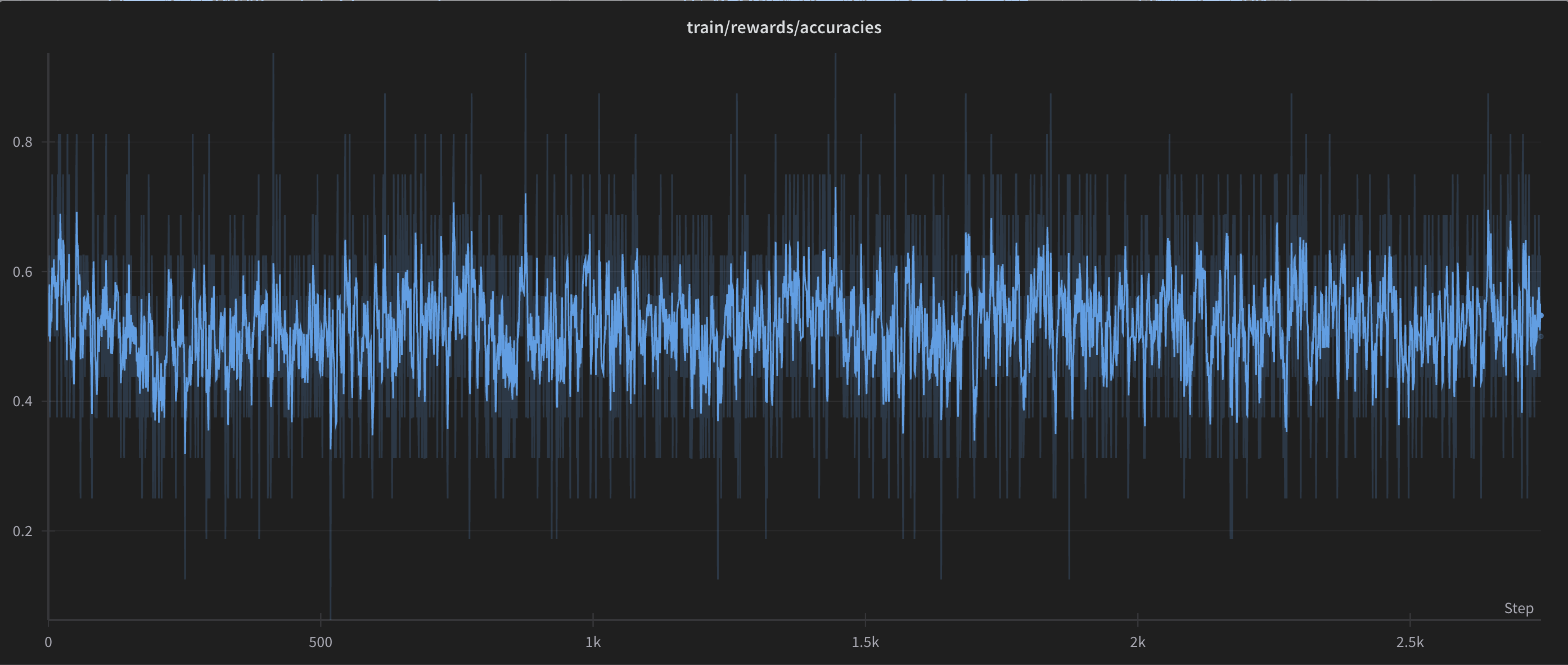
OpenLLM Leaderboard Metrics
| Tasks | Version | Filter | n-shot | Metric | Value | Stderr | ||
|---|---|---|---|---|---|---|---|---|
| leaderboard | N/A | |||||||
| - leaderboard_bbh | N/A | 0.3290 | ||||||
| - leaderboard_bbh_boolean_expressions | 1 | none | 3 | acc_norm | ↑ | 0.6840 | ± | 0.0295 |
| - leaderboard_bbh_causal_judgement | 1 | none | 3 | acc_norm | ↑ | 0.5134 | ± | 0.0366 |
| - leaderboard_bbh_date_understanding | 1 | none | 3 | acc_norm | ↑ | 0.1920 | ± | 0.0250 |
| - leaderboard_bbh_disambiguation_qa | 1 | none | 3 | acc_norm | ↑ | 0.3880 | ± | 0.0309 |
| - leaderboard_bbh_formal_fallacies | 1 | none | 3 | acc_norm | ↑ | 0.4680 | ± | 0.0316 |
| - leaderboard_bbh_geometric_shapes | 1 | none | 3 | acc_norm | ↑ | 0.0000 | ± | 0 |
| - leaderboard_bbh_hyperbaton | 1 | none | 3 | acc_norm | ↑ | 0.4840 | ± | 0.0317 |
| - leaderboard_bbh_logical_deduction_five_objects | 1 | none | 3 | acc_norm | ↑ | 0.2000 | ± | 0.0253 |
| - leaderboard_bbh_logical_deduction_seven_objects | 1 | none | 3 | acc_norm | ↑ | 0.1360 | ± | 0.0217 |
| - leaderboard_bbh_logical_deduction_three_objects | 1 | none | 3 | acc_norm | ↑ | 0.3440 | ± | 0.0301 |
| - leaderboard_bbh_movie_recommendation | 1 | none | 3 | acc_norm | ↑ | 0.2280 | ± | 0.0266 |
| - leaderboard_bbh_navigate | 1 | none | 3 | acc_norm | ↑ | 0.4200 | ± | 0.0313 |
| - leaderboard_bbh_object_counting | 1 | none | 3 | acc_norm | ↑ | 0.3880 | ± | 0.0309 |
| - leaderboard_bbh_penguins_in_a_table | 1 | none | 3 | acc_norm | ↑ | 0.1575 | ± | 0.0303 |
| - leaderboard_bbh_reasoning_about_colored_objects | 1 | none | 3 | acc_norm | ↑ | 0.1280 | ± | 0.0212 |
| - leaderboard_bbh_ruin_names | 1 | none | 3 | acc_norm | ↑ | 0.2000 | ± | 0.0253 |
| - leaderboard_bbh_salient_translation_error_detection | 1 | none | 3 | acc_norm | ↑ | 0.2280 | ± | 0.0266 |
| - leaderboard_bbh_snarks | 1 | none | 3 | acc_norm | ↑ | 0.5393 | ± | 0.0375 |
| - leaderboard_bbh_sports_understanding | 1 | none | 3 | acc_norm | ↑ | 0.5240 | ± | 0.0316 |
| - leaderboard_bbh_temporal_sequences | 1 | none | 3 | acc_norm | ↑ | 0.2000 | ± | 0.0253 |
| - leaderboard_bbh_tracking_shuffled_objects_five_objects | 1 | none | 3 | acc_norm | ↑ | 0.1640 | ± | 0.0235 |
| - leaderboard_bbh_tracking_shuffled_objects_seven_objects | 1 | none | 3 | acc_norm | ↑ | 0.1400 | ± | 0.0220 |
| - leaderboard_bbh_tracking_shuffled_objects_three_objects | 1 | none | 3 | acc_norm | ↑ | 0.3520 | ± | 0.0303 |
| - leaderboard_bbh_web_of_lies | 1 | none | 3 | acc_norm | ↑ | 0.4880 | ± | 0.0317 |
| - leaderboard_gpqa | N/A | 0.2482 | ||||||
| - leaderboard_gpqa_diamond | 1 | none | 0 | acc_norm | ↑ | 0.2576 | ± | 0.0312 |
| - leaderboard_gpqa_extended | 1 | none | 0 | acc_norm | ↑ | 0.2436 | ± | 0.0184 |
| - leaderboard_gpqa_main | 1 | none | 0 | acc_norm | ↑ | 0.2433 | ± | 0.0203 |
| - leaderboard_ifeval | 3 | none | 0 | inst_level_loose_acc | ↑ | 0.2962 | ± | N/A |
| none | 0 | inst_level_strict_acc | ↑ | 0.2842 | ± | N/A | ||
| none | 0 | prompt_level_loose_acc | ↑ | 0.1516 | ± | 0.0154 | ||
| none | 0 | prompt_level_strict_acc | ↑ | 0.1386 | ± | 0.0149 | ||
| - leaderboard_math_hard | N/A | |||||||
| - leaderboard_math_algebra_hard | 2 | none | 4 | exact_match | ↑ | 0.0000 | ± | 0 |
| - leaderboard_math_counting_and_prob_hard | 2 | none | 4 | exact_match | ↑ | 0.0000 | ± | 0 |
| - leaderboard_math_geometry_hard | 2 | none | 4 | exact_match | ↑ | 0.0000 | ± | 0 |
| - leaderboard_math_intermediate_algebra_hard | 2 | none | 4 | exact_match | ↑ | 0.0000 | ± | 0 |
| - leaderboard_math_num_theory_hard | 2 | none | 4 | exact_match | ↑ | 0.0000 | ± | 0 |
| - leaderboard_math_prealgebra_hard | 2 | none | 4 | exact_match | ↑ | 0.0000 | ± | 0 |
| - leaderboard_math_precalculus_hard | 2 | none | 4 | exact_match | ↑ | 0.0000 | ± | 0 |
| - leaderboard_mmlu_pro | 0.1 | none | 5 | acc | ↑ | 0.1222 | ± | 0.0030 |
| - leaderboard_musr | N/A | avg acc_norm | 0.3433 | |||||
| - leaderboard_musr_murder_mysteries | 1 | none | 0 | acc_norm | ↑ | 0.5120 | ± | 0.0317 |
| - leaderboard_musr_object_placements | 1 | none | 0 | acc_norm | ↑ | 0.2500 | ± | 0.0271 |
| - leaderboard_musr_team_allocation | 1 | none | 0 | acc_norm | ↑ | 0.2680 | ± | 0.0281 |
- Downloads last month
- 2