
File size: 10,758 Bytes
aa58d72 b36cb68 d34c84d aa58d72 b36cb68 d34c84d aa58d72 d34c84d aa58d72 a078535 aa58d72 b36cb68 5bac540 0aa722c d5275af b36cb68 aa58d72 a078535 aa58d72 a078535 aa58d72 7d23e9e b36cb68 aa58d72 3526756 aa58d72 3526756 aa58d72 428d5ca b36cb68 428d5ca b36cb68 79175b4 b36cb68 aa58d72 b36cb68 428d5ca aa58d72 79175b4 aa58d72 b36cb68 aa58d72 d34c84d |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 |
---
language:
- zh
- en
license: other
tags:
- glm
- chatglm
- thudm
license_name: glm-4
license_link: https://huggingface.co/THUDM/glm-4-9b-chat-1m/blob/main/LICENSE
inference: false
model-index:
- name: glm-4-9b-chat-1m
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: ENEM Challenge (No Images)
type: eduagarcia/enem_challenge
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 73.62
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: BLUEX (No Images)
type: eduagarcia-temp/BLUEX_without_images
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 61.89
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: OAB Exams
type: eduagarcia/oab_exams
split: train
args:
num_few_shot: 3
metrics:
- type: acc
value: 54.44
name: accuracy
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Assin2 RTE
type: assin2
split: test
args:
num_few_shot: 15
metrics:
- type: f1_macro
value: 93.79
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Assin2 STS
type: eduagarcia/portuguese_benchmark
split: test
args:
num_few_shot: 15
metrics:
- type: pearson
value: 81.07
name: pearson
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: FaQuAD NLI
type: ruanchaves/faquad-nli
split: test
args:
num_few_shot: 15
metrics:
- type: f1_macro
value: 76.27
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HateBR Binary
type: ruanchaves/hatebr
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 82.28
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: PT Hate Speech Binary
type: hate_speech_portuguese
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 70.27
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: tweetSentBR
type: eduagarcia/tweetsentbr_fewshot
split: test
args:
num_few_shot: 25
metrics:
- type: f1_macro
value: 73.25
name: f1-macro
source:
url: https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard?query=THUDM/glm-4-9b-chat-1m
name: Open Portuguese LLM Leaderboard
---
# GLM-4-9B-Chat-1M
Read this in [English](README_en.md).
**2024/08/12, 本仓库代码已更新并使用 `transforemrs>=4.44.0`, 请及时更新依赖。**
**2024/07/24,我们发布了与长文本相关的最新技术解读,关注 [这里](https://medium.com/@ChatGLM/glm-long-scaling-pre-trained-model-contexts-to-millions-caa3c48dea85) 查看我们在训练 GLM-4-9B 开源模型中关于长文本技术的技术报告**
## 模型介绍
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。
在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出较高的性能。
除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K
上下文)等高级功能。
本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。我们还推出了支持 1M 上下文长度(约 200 万中文字符)的模型。
## 评测结果
### 长文本
在 1M 的上下文长度下进行[大海捞针实验](https://github.com/LargeWorldModel/LWM/blob/main/scripts/eval_needle.py),结果如下:
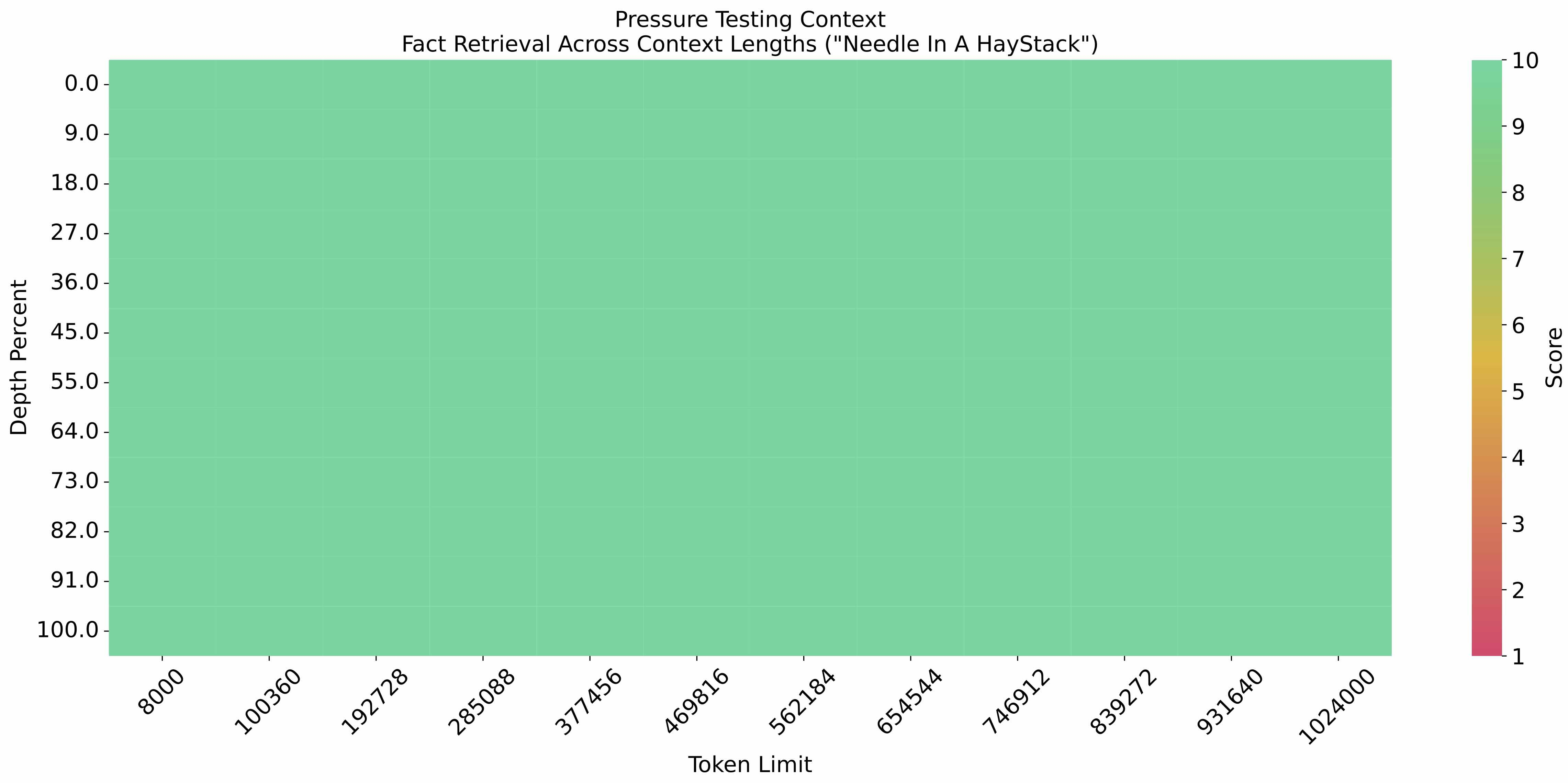
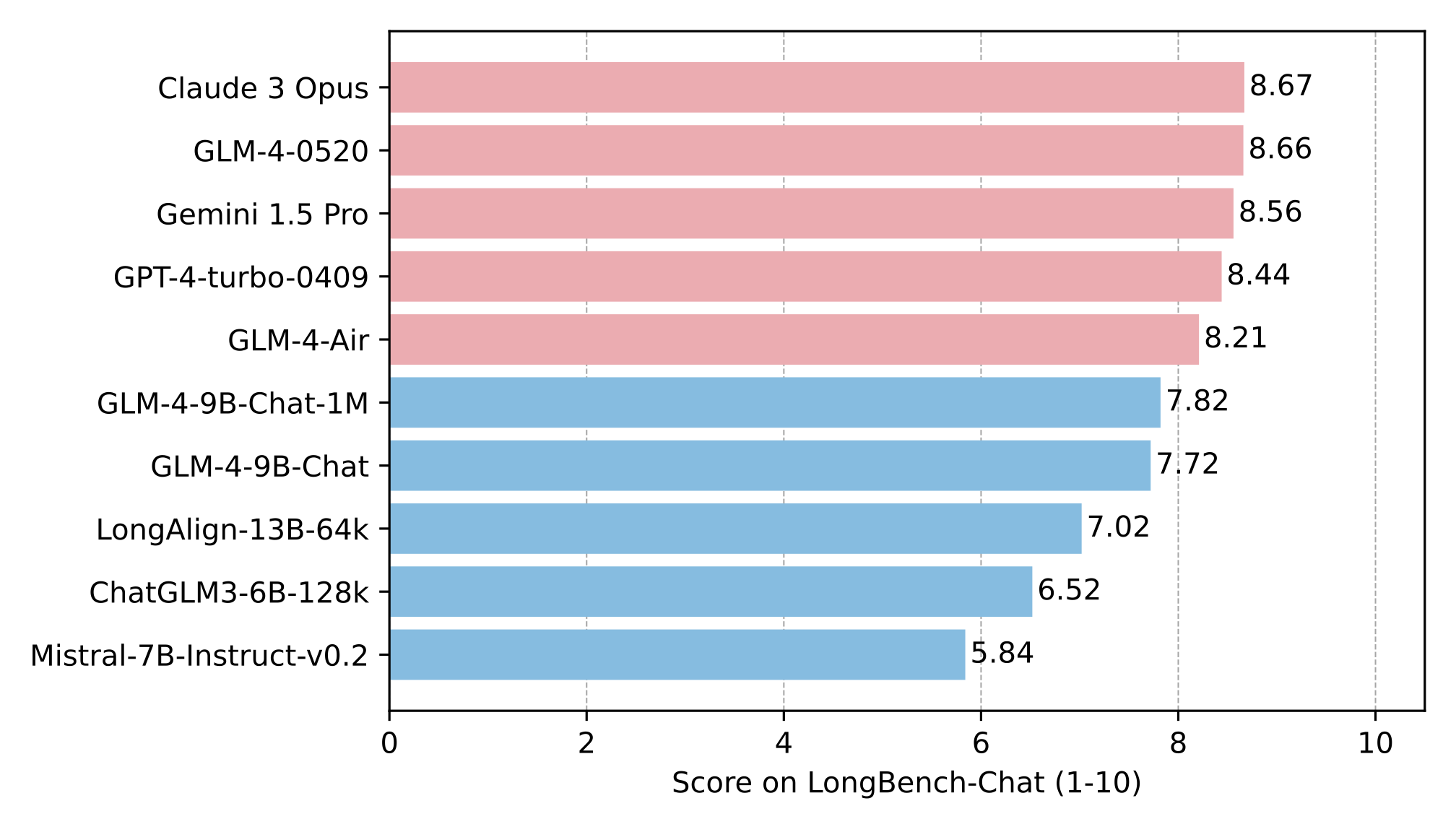
在 LongBench-Chat 上对长文本能力进行了进一步评测,结果如下:
**本仓库是 GLM-4-9B-Chat-1M 的模型仓库,支持`1M`上下文长度。**
## 运行模型
**更多推理代码和依赖信息,请访问我们的 [github](https://github.com/THUDM/GLM-4)。**
**请严格按照[依赖](https://github.com/THUDM/GLM-4/blob/main/basic_demo/requirements.txt)安装,否则无法正常运行。**
使用 transformers 后端进行推理:
```python
import torch
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
)
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat-1m",trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat-1m",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
使用 VLLM后端进行推理:
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat-1M
# max_model_len, tp_size = 1048576, 4
# GLM-4-9B-Chat
# If you encounter OOM, it is recommended to reduce max_model_len or increase tp_size
max_model_len, tp_size = 131072, 1
model_name = "THUDM/glm-4-9b-chat-1m"
prompt = [{"role": "user", "content": "hello"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# GLM-4-9B-Chat-1M If you encounter OOM phenomenon, it is recommended to enable the following parameters
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
```
## 协议
GLM-4 模型的权重的使用则需要遵循 [LICENSE](LICENSE)。
## 引用
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
```
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
```
# Open Portuguese LLM Leaderboard Evaluation Results
Detailed results can be found [here](https://huggingface.co/datasets/eduagarcia-temp/llm_pt_leaderboard_raw_results/tree/main/THUDM/glm-4-9b-chat-1m) and on the [🚀 Open Portuguese LLM Leaderboard](https://huggingface.co/spaces/eduagarcia/open_pt_llm_leaderboard)
| Metric | Value |
|--------------------------|--------|
|Average |**74.1**|
|ENEM Challenge (No Images)| 73.62|
|BLUEX (No Images) | 61.89|
|OAB Exams | 54.44|
|Assin2 RTE | 93.79|
|Assin2 STS | 81.07|
|FaQuAD NLI | 76.27|
|HateBR Binary | 82.28|
|PT Hate Speech Binary | 70.27|
|tweetSentBR | 73.25|
|