

metadata
license: other
license_name: glm-4
license_link: https://huggingface.co/THUDM/glm-4-9b-chat-1m/blob/main/LICENSE
language:
- zh
- en
tags:
- glm
- chatglm
- thudm
inference: false
GLM-4-9B-Chat-1M
GLM-4-9B 是智谱 AI 推出的最新一代预训练模型 GLM-4 系列中的开源版本。 在语义、数学、推理、代码和知识等多方面的数据集测评中,GLM-4-9B 及其人类偏好对齐的版本 GLM-4-9B-Chat 均表现出较高的性能。 除了能进行多轮对话,GLM-4-9B-Chat 还具备网页浏览、代码执行、自定义工具调用(Function Call)和长文本推理(支持最大 128K 上下文)等高级功能。 本代模型增加了多语言支持,支持包括日语,韩语,德语在内的 26 种语言。我们还推出了支持 1M 上下文长度(约 200 万中文字符)的模型。
评测结果
长文本
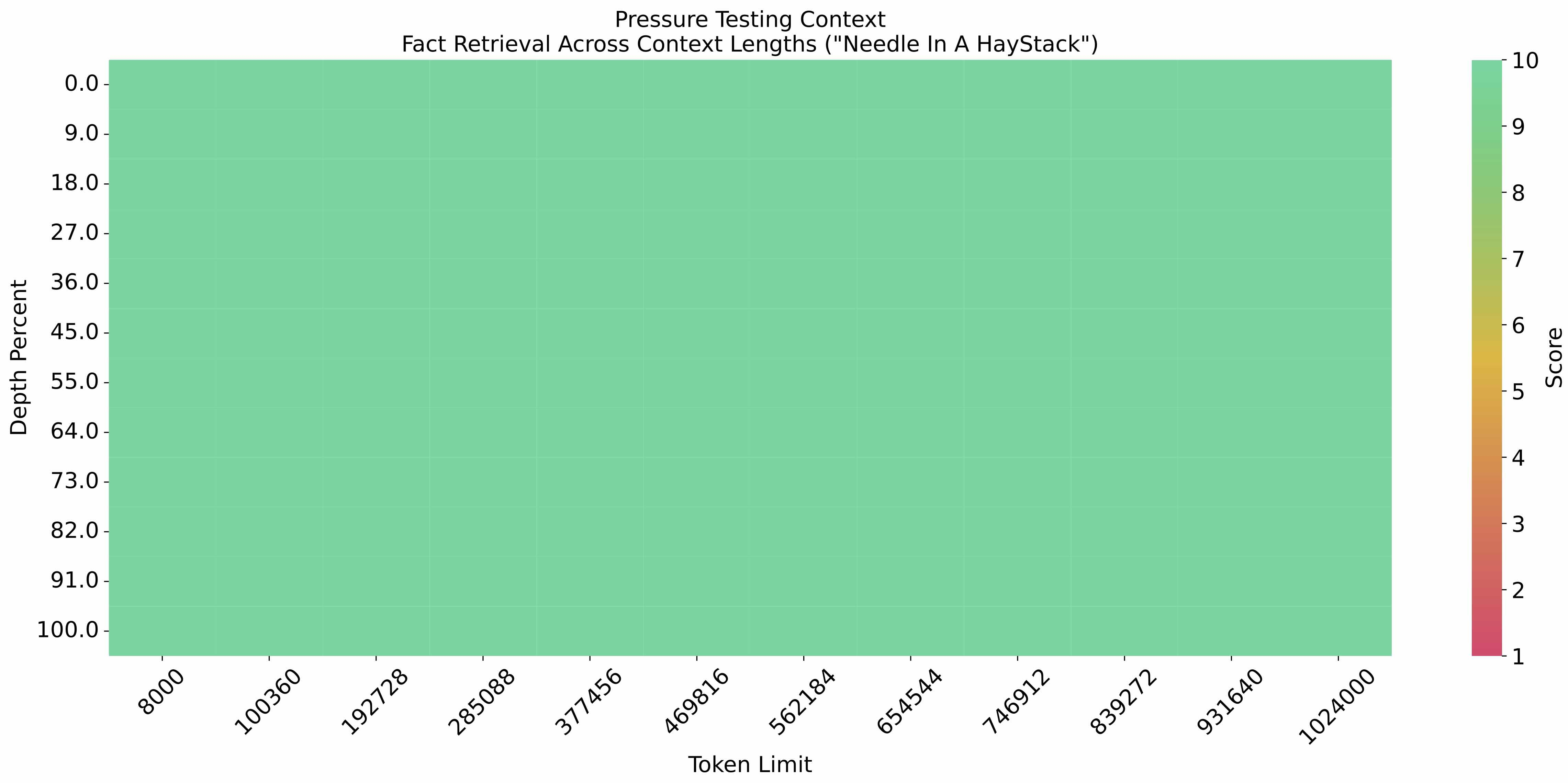
在 1M 的上下文长度下进行大海捞针实验,结果如下:
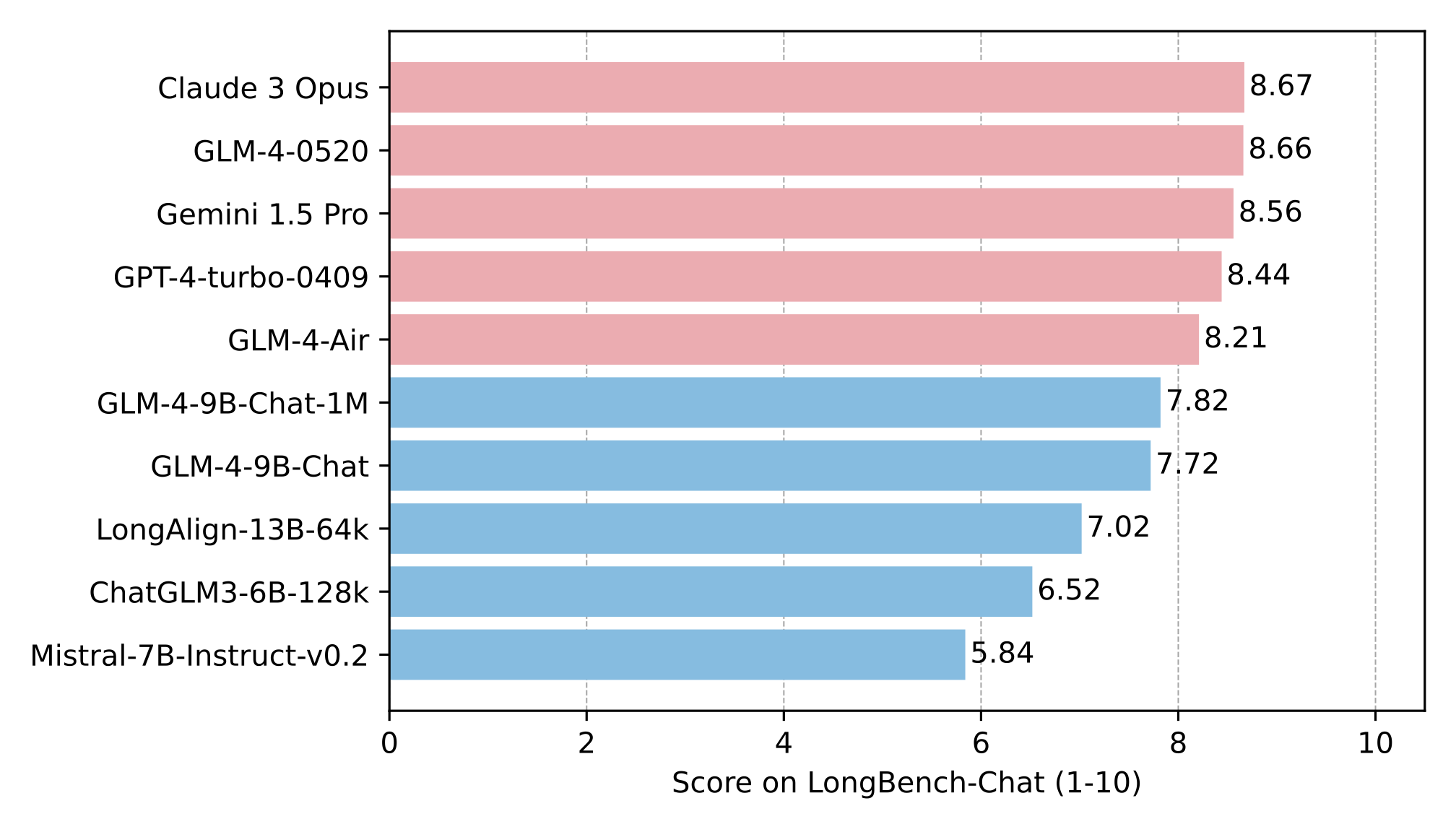
在 LongBench-Chat 上对长文本能力进行了进一步评测,结果如下:
本仓库是 GLM-4-9B-Chat-1M 的模型仓库,支持1M上下文长度。
运行模型
使用 transformers 后端进行推理:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained("THUDM/glm-4-9b-chat-1m",trust_remote_code=True)
query = "你好"
inputs = tokenizer.apply_chat_template([{"role": "user", "content": query}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
)
inputs = inputs.to(device)
model = AutoModelForCausalLM.from_pretrained(
"THUDM/glm-4-9b-chat-1m",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True
).to(device).eval()
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
使用 VLLM后端进行推理:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat-1M
# 如果遇见 OOM 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size = 1048576, 4
model_name = "THUDM/glm-4-9b-chat-1m"
prompt = [{"role": "user", "content": "你好"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# GLM-4-9B-Chat-1M 如果遇见 OOM 现象,建议开启下述参数
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
协议
GLM-4 模型的权重的使用则需要遵循 LICENSE。
Rhe use of the GLM-4 model weights needs to comply with the LICENSE.
引用
如果你觉得我们的工作有帮助的话,请考虑引用下列论文。
@article{zeng2022glm,
title={Glm-130b: An open bilingual pre-trained model},
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
journal={arXiv preprint arXiv:2210.02414},
year={2022}
}
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}