
license: mit
datasets:
- peiyi9979/Math-Shepherd
language:
- en
base_model:
- deepseek-ai/deepseek-math-7b-base
pipeline_tag: reinforcement-learning
Introduction
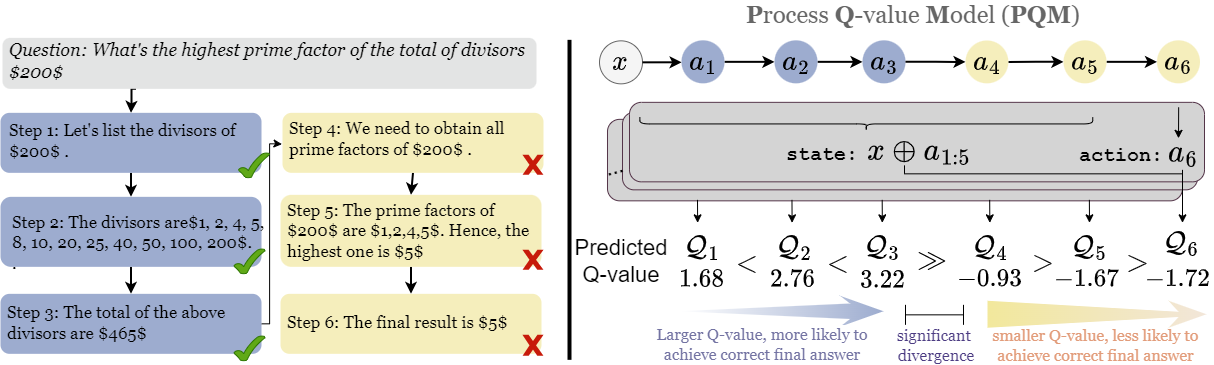
We present a new framework for PRM by framing it as a $Q$-value ranking problem, providing a theoretical basis for reward modeling that captures inter-dependencies among reasoning states. We also show that prior classification-based PRM can be cast as a special case under our framework. We validate its effectiveness through comprehensive experiments and ablation studies on a wide range of sampling policies, LLM backbones, and different test sets.
Checkpoints & Evaluation Data
We upload the sampling corpus of three policies to folder ./eval_data of current repository.
The checkpoints are model.safetensors in ./zeta-2 and ./zeta-4, corresponding to the two hyperparameter settings in our main experiments.
You can download them by huggingface-cli download Windy0822/PQM <filename> --local-dir <local path>