
LLaMA 3.1-8B Fine-Tuned on ChatDoctor Dataset
Model Overview
This model is a fine-tuned version of the LLaMA 3.1-8B model, trained on a curated selection of 1,122 samples from the ChatDoctor (HealthCareMagic-100k) dataset. It has been optimized for task related to medical consultations.
- Base Model: LLaMA 3.1-8B
- Fine-tuning Dataset: 1,122 samples from ChatDoctor dataset
- Output Format: GGUF (Grok-Generated Universal Format)
- Quantization: Q4_0 for efficient inference
Applications
This model is designed to assist in:
- Medical question-answering
- Providing health-related advice
- Assisting in basic diagnostic reasoning (non-clinical use)
Datasets
- Training Data: ChatDoctor-HealthCareMagic-100k
- Training Set: 900 samples
- Validation Set: 100 samples
- Test Set: 122 samples
Model Details
| Feature | Details |
|---|---|
| Model Type | Causal Language Model |
| Architecture | LLaMA 3.1-8B |
| Training Data | ChatDoctor (1,122 samples) |
| Quantization | Q4_0 |
| Deployment Format | GGUF |
Training Configuration
The model was fine-tuned with the following hyperparameters:
- Output Directory:
output_model - Per-Device Batch Size: 2
- Gradient Accumulation Steps: 16 (Effective batch size: 32)
- Learning Rate: 2e-4
- Scheduler: Cosine Annealing
- Optimizer: AdamW (paged with 32-bit precision)
- Number of Epochs: 16
- Evaluation Strategy: Per epoch
- Save Strategy: Per epoch
- Logging Steps: 1
- Mixed Precision: FP16
- Best Model Criteria:
eval_loss, withgreater_is_better=False
LoRA Hyperparameters
The fine-tuning process also included the following LoRA (Low-Rank Adaptation) configuration:
- Rank (r): 8
- Alpha: 16
- Dropout: 0.05
- Bias: None
- Task Type: Causal Language Modeling (CAUSAL_LM)
Validation was performed using a separate subset of the dataset. The final training and validation loss are as follows:
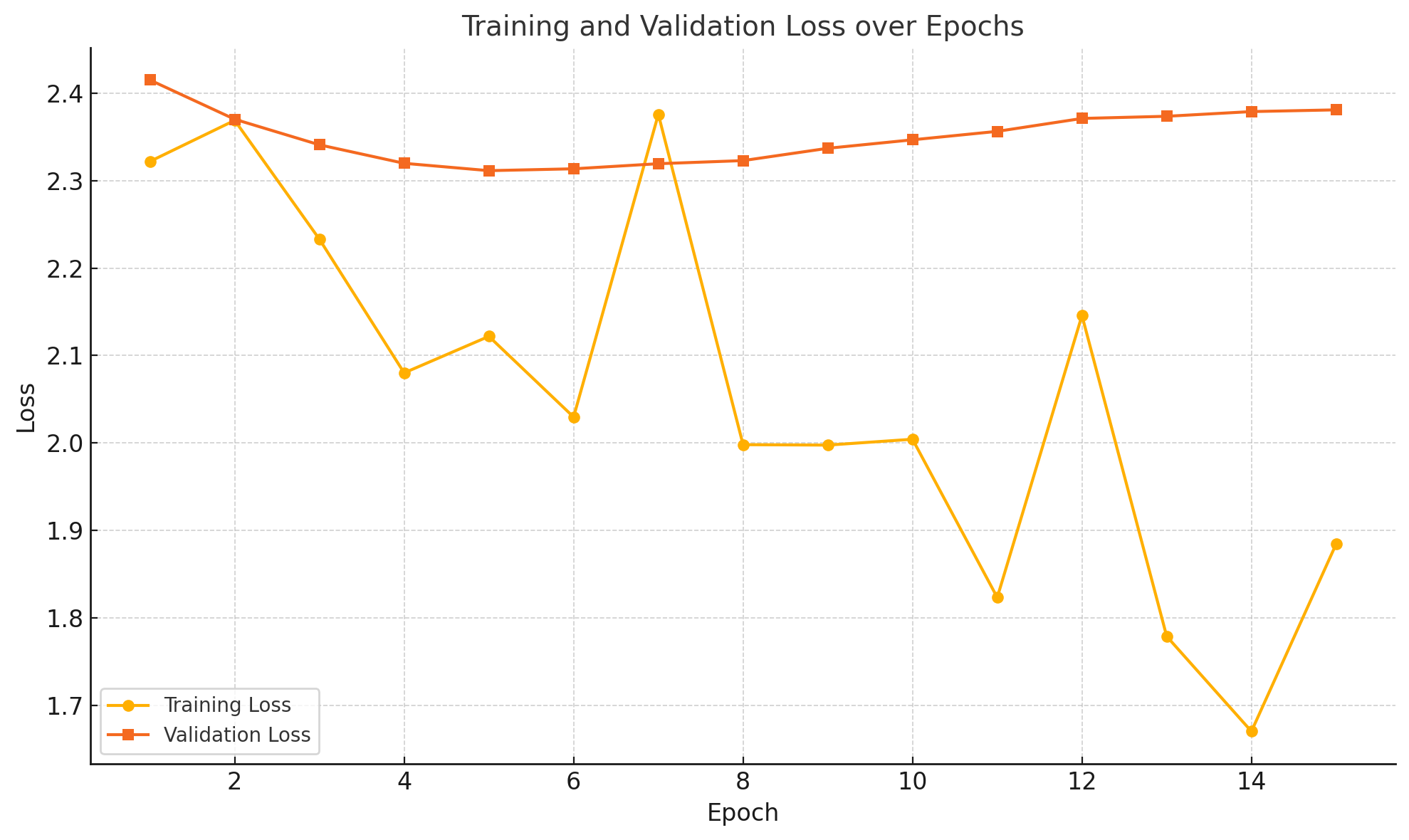
Evaluation Results
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Original Model | 0.1726 | 0.0148 | 0.0980 |
| Fine-Tuned Model | 0.2177 | 0.0337 | 0.1249 |
Usage
from transformers import AutoTokenizer, AutoModelForCausalLM
from bitsandbytes import BitsAndBytesConfig
model_id="Yassinj/Llama-3.1-8B_medical"
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
# Configure quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
bnb_4bit_use_double_quant=True
)
# Load model with quantization
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map="auto"
)
- Downloads last month
- 6
Hardware compatibility
Log In
to view the estimation
Inference Providers
NEW
This model isn't deployed by any Inference Provider.
🙋
Ask for provider support
Model tree for Yassinj/Llama-3.1-8B_medical
Base model
meta-llama/Meta-Llama-3-8B