
Exllamav2 quant (exl2 / 8.0 bpw) made with ExLlamaV2 v0.1.1
Other EXL2 quants:
| Quant | Model Size | lm_head |
|---|---|---|
K2-Chat: a fully-reproducible large language model outperforming Llama 2 70B Chat using 35% less compute
K2 Chat is finetuned from K2-65B. K2 Chat outperforms Llama 2-70B-Chat on all evaluations conducted. The model also outperforms Llama 3-70B-Instruct on coding tasks.
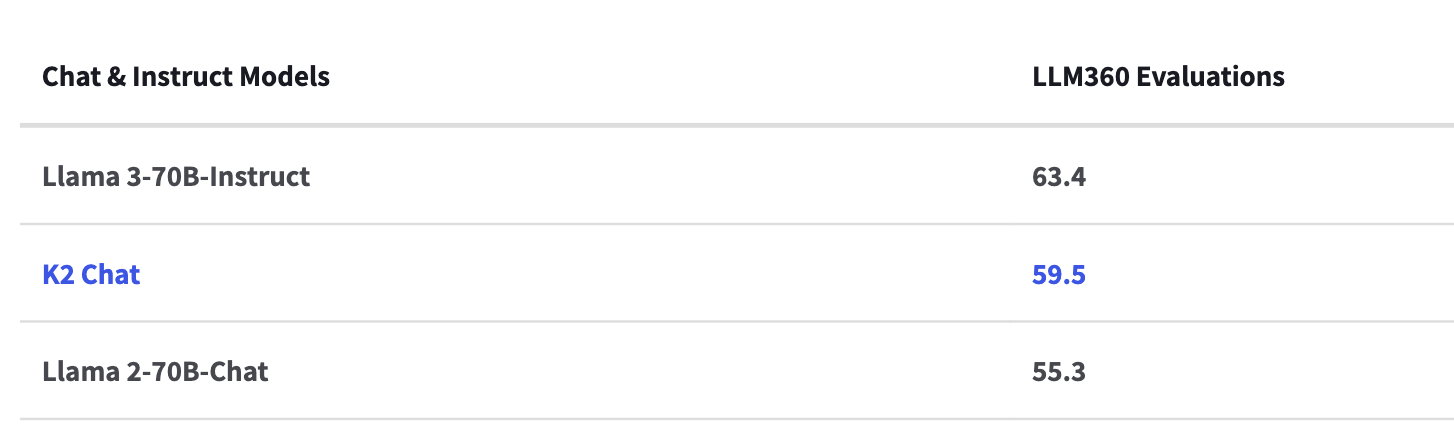
LLM360 Model Performance and Evaluation Collection
The LLM360 Performance and Evaluation Collection is a robust evaluations set consisting of general and domain specific evaluations to assess model knowledge and function.
Evaluations include standard best practice benchmarks, medical, math, and coding knowledge. More about the evaluations can be found here.

Datasets and Mix
| Subset | #Tokens | Avg. #Q | Avg. Query Len | Avg. #R | Avg. Reply Len |
|---|---|---|---|---|---|
| MathInstruct | 66,639,699 | 1.00 | 81.53 | 1.00 | 172.78 |
| OpenHermes-2 | 404,820,694 | 1.01 | 152.38 | 1.01 | 249.12 |
| FLAN_3M | 2,346,961,387 | 1.00 | 727.49 | 1.00 | 54.83 |
| Standford Encyclopedia Philosophy | 786,928 | 1.00 | 219.09 | 1.00 | 166.28 |
| TinyStories | 1,448,898 | 1.00 | 260.82 | 1.00 | 207.47 |
| Safety & Alignment Data | 99,976,621 | 1.00 | 126.71 | 1.00 | 373.79 |
| Total | 2,920,634,227 |
Loading K2-Chat
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("LLM360/K2-Chat")
model = AutoModelForCausalLM.from_pretrained("LLM360/K2-Chat")
prompt = '<|beginofuser|>what is the highest mountain on earth?<|beginofsystem|>'
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
Alternatively, you can construct the prompt by applying the chat template of tokenizer on input conversation:
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("LLM360/K2-Chat")
model = AutoModelForCausalLM.from_pretrained("LLM360/K2-Chat")
messages = [{"role": "user", "content": "what is the highest mountain on earth?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
gen_tokens = model.generate(input_ids, do_sample=True, max_new_tokens=128)
print("-"*20 + "Output for model" + 20 * '-')
print(tokenizer.batch_decode(gen_tokens)[0])
LLM360 Developer Suite
We provide step-by-step finetuning tutorials for tech enthusiasts, AI practitioners and academic or industry researchers here.
About LLM360
LLM360 is an open research lab enabling community-owned AGI through open-source large model research and development.
LLM360 enables community-owned AGI by creating standards and tools to advance the bleeding edge of LLM capability and empower knowledge transfer, research, and development.
We believe in a future where artificial general intelligence (AGI) is created by the community, for the community. Through an open ecosystem of equitable computational resources, high quality data, and flowing technical knowledge, we can ensure ethical AGI development and universal access for all innovators.
Citation
BibTeX:
@article{
title={LLM360 K2-65B: Scaling Up Fully Transparent Open-Source LLMs},
author={The LLM360 Team},
year={2024},
}
- Downloads last month
- 4