|
--- |
|
license: other |
|
license_name: tencent-hunyuan-community |
|
license_link: LICENSE |
|
datasets: |
|
- trojblue/test-HunyuanVideo-anime-images |
|
language: |
|
- en |
|
base_model: |
|
- tencent/HunyuanVideo |
|
pipeline_tag: text-to-video |
|
tags: |
|
- hyvid |
|
- lora |
|
- gguf-comfy |
|
--- |
|
|
|
# **GGUF quantized hyvid with lora anime adapter** |
|
|
|
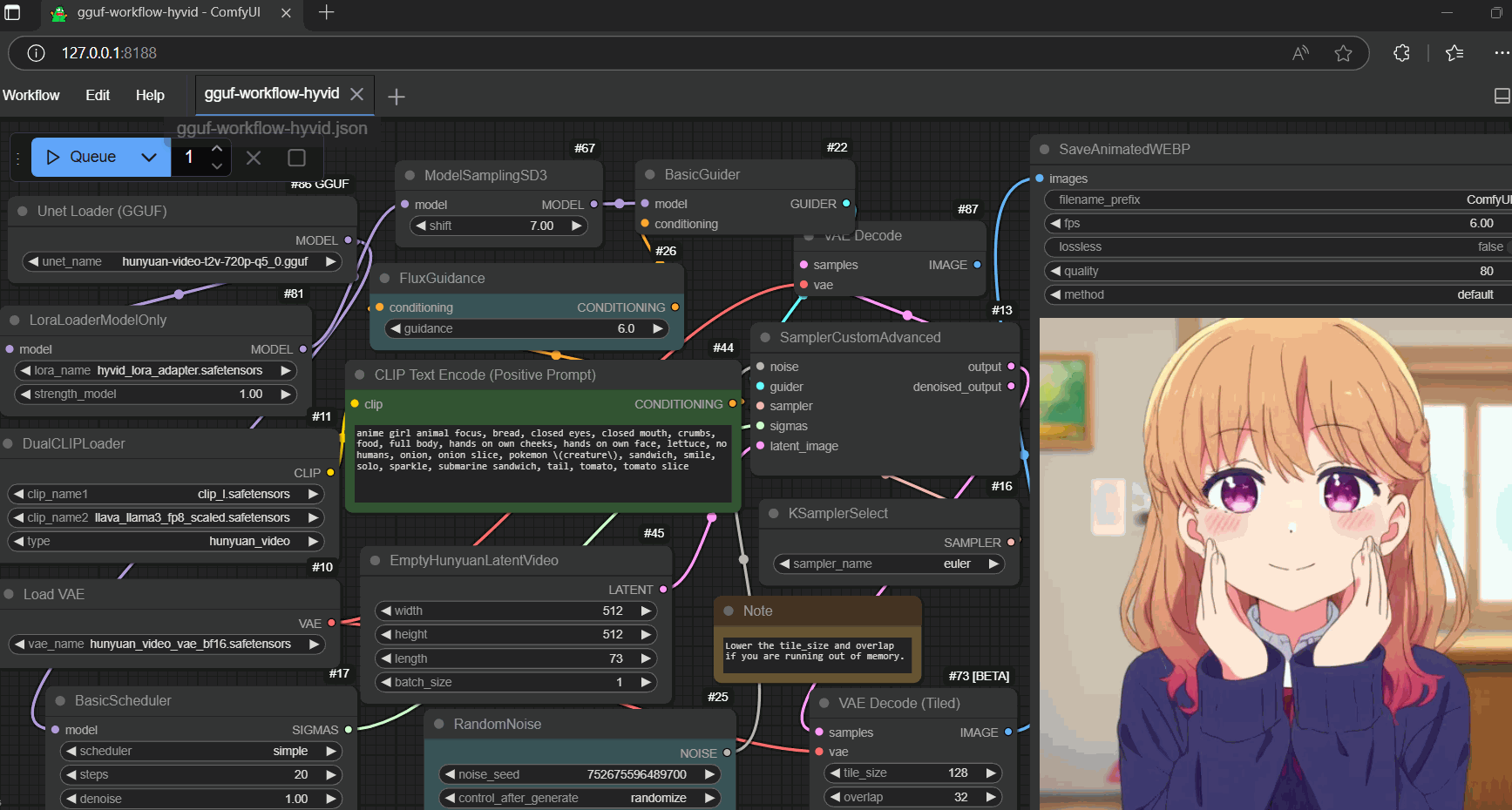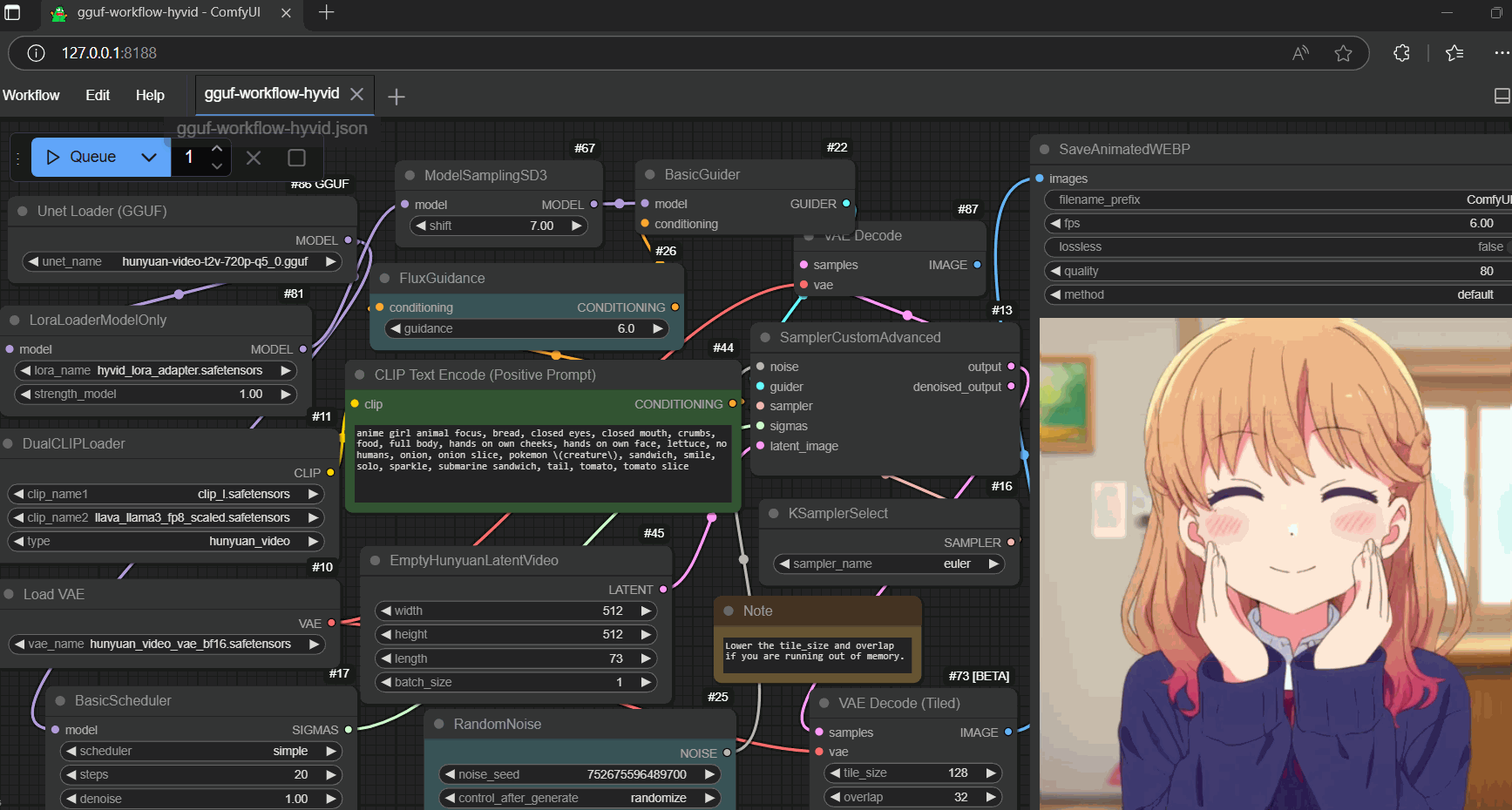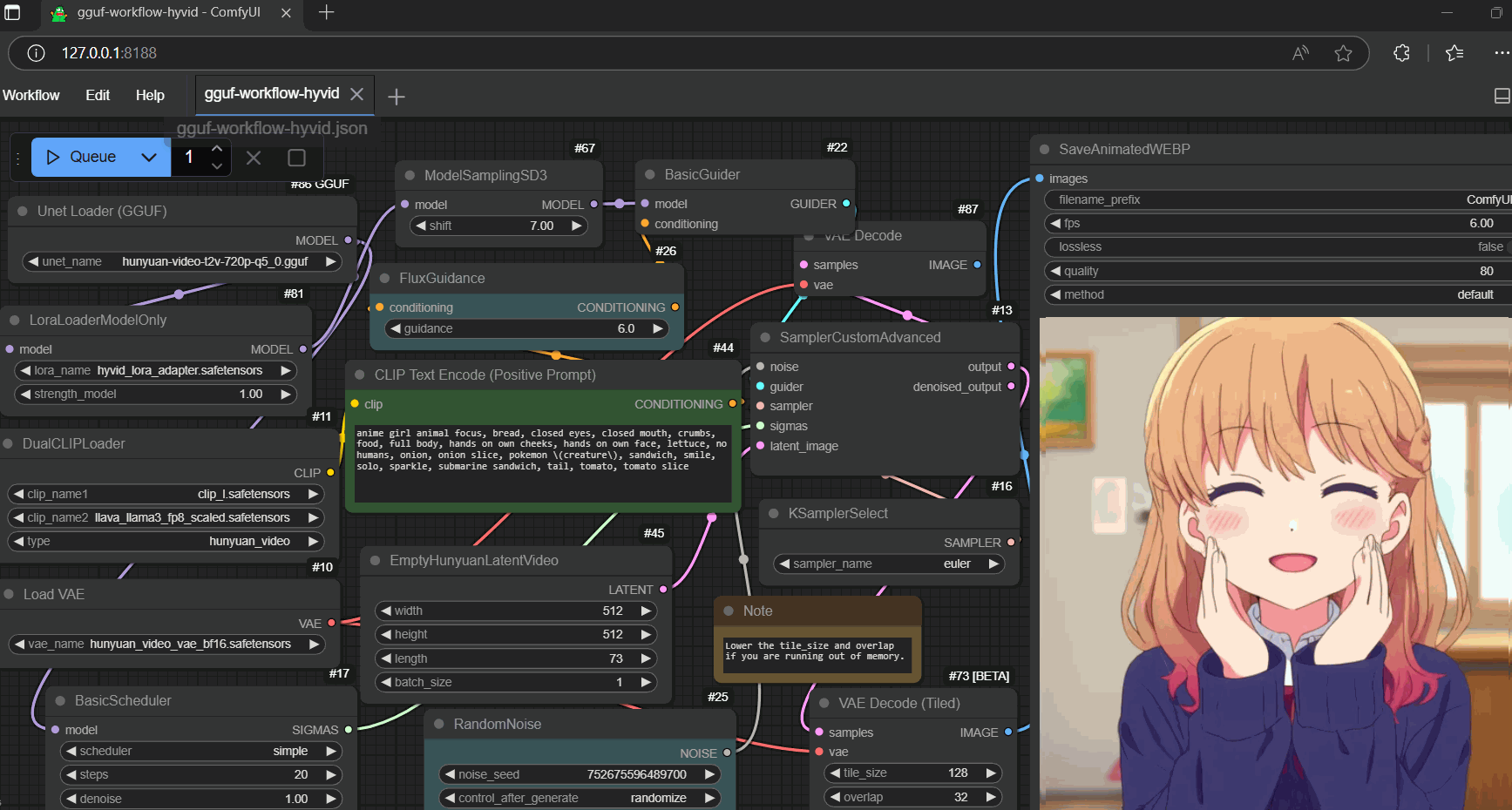 |
|
|
|
## Setup (once) |
|
- drag hyvid_lora_adapter.safetensors to > ./ComfyUI/models/loras |
|
- drag hunyuan-video-t2v-720p-q4_0.gguf to > ./ComfyUI/models/diffusion_models |
|
- drag clip_l.safetensors to > ./ComfyUI/models/text_encoders |
|
- drag llava_llama3_fp8_scaled.safetensors to > ./ComfyUI/models/text_encoders |
|
- drag hunyuan_video_vae_bf16.safetensors to > ./ComfyUI/models/vae |
|
|
|
## Run it straight (no installation needed way) |
|
- run the .bat file in the main directory (assuming you are using the gguf-comfy pack below) |
|
- drag the workflow json file (below) to > your browser |
|
|
|
### Workflows |
|
- example workflow for gguf (prepare two quantized files to switch while oom occurs) |
|
- example workflow for safetensors (fp8_scaled version is recommended) |
|
|
|
### References |
|
- base model from [tencent](https://huggingface.co/tencent/HunyuanVideo) |
|
- lora adapter from [trojblue](https://huggingface.co/trojblue/HunyuanVideo-lora-AnimeShots) |
|
- comfyui from [comfyanonymous](https://github.com/comfyanonymous/ComfyUI) |
|
- gguf node from [city96](https://github.com/city96/ComfyUI-GGUF) |
|
- gguf-comfy [pack](https://github.com/calcuis/gguf-comfy/releases) |
