
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
sequence | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/10535 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10535/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10535/comments | https://api.github.com/repos/huggingface/transformers/issues/10535/events | https://github.com/huggingface/transformers/issues/10535 | 822,826,159 | MDU6SXNzdWU4MjI4MjYxNTk= | 10,535 | tensorflow model convert onnx | {
"login": "Zjq9409",
"id": 62974595,
"node_id": "MDQ6VXNlcjYyOTc0NTk1",
"avatar_url": "https://avatars.githubusercontent.com/u/62974595?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Zjq9409",
"html_url": "https://github.com/Zjq9409",
"followers_url": "https://api.github.com/users/Zjq9409/followers",
"following_url": "https://api.github.com/users/Zjq9409/following{/other_user}",
"gists_url": "https://api.github.com/users/Zjq9409/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Zjq9409/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Zjq9409/subscriptions",
"organizations_url": "https://api.github.com/users/Zjq9409/orgs",
"repos_url": "https://api.github.com/users/Zjq9409/repos",
"events_url": "https://api.github.com/users/Zjq9409/events{/privacy}",
"received_events_url": "https://api.github.com/users/Zjq9409/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"and when I upgrade transformers version to 4.3.3, onnx version is 1.8.1,another error occurred:\r\nTraceback (most recent call last):\r\n File \"test_segment.py\", line 104, in <module>\r\n session = onnxruntime.InferenceSession(output_model_path, sess_options, providers=['CPUExecutionProvider'])\r\n File \"/usr/lib64/python3.6/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py\", line 206, in __init__\r\n self._create_inference_session(providers, provider_options)\r\n File \"/usr/lib64/python3.6/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py\", line 226, in _create_inference_session\r\n sess = C.InferenceSession(session_options, self._model_path, True, self._read_config_from_model)\r\nonnxruntime.capi.onnxruntime_pybind11_state.Fail: [ONNXRuntimeError] : 1 : FAIL : Load model from onnx_tf/segment.onnx failed:Fatal error: BroadcastTo is not a registered function/op",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | I use this code to transfer TFBertModel to onnx:
”convert(framework="tf", model=model, tokenizer=tokenizer, output=Path("onnx_tf/segment.onnx"), opset=12)”
and the output log as follows:
`Using framework TensorFlow: 2.2.0, keras2onnx: 1.7.0
Found input input_ids with shape: {0: 'batch', 1: 'sequence'}
Found input token_type_ids with shape: {0: 'batch', 1: 'sequence'}
Found input attention_mask with shape: {0: 'batch', 1: 'sequence'}
Found output output_0 with shape: {0: 'batch'}
Found output output_1 with shape: {0: 'batch', 1: 'sequence'}
Found output output_2 with shape: {0: 'batch', 1: 'sequence'}
Found output output_3 with shape: {0: 'batch', 1: 'sequence'}
Found output output_4 with shape: {0: 'batch', 1: 'sequence'}
Found output output_5 with shape: {0: 'batch', 1: 'sequence'}
Found output output_6 with shape: {0: 'batch', 1: 'sequence'}
Found output output_7 with shape: {0: 'batch', 1: 'sequence'}
Found output output_8 with shape: {0: 'batch', 1: 'sequence'}
Found output output_9 with shape: {0: 'batch', 1: 'sequence'}
Found output output_10 with shape: {0: 'batch', 1: 'sequence'}
Found output output_11 with shape: {0: 'batch', 1: 'sequence'}
Found output output_12 with shape: {0: 'batch', 1: 'sequence'}
Found output output_13 with shape: {0: 'batch', 1: 'sequence'}`
but,I run the output onnx,an error is occured as follows:
logits = session.run(None, inputs_onnx)
File "/usr/lib64/python3.6/site-packages/onnxruntime/capi/onnxruntime_inference_collection.py", line 124, in run
return self._sess.run(output_names, input_feed, run_options)
onnxruntime.capi.onnxruntime_pybind11_state.InvalidArgument: [ONNXRuntimeError] : 2 : INVALID_ARGUMENT : Invalid Feed Input Name:token_type_ids:0
transformers 3.0.2 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10535/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10535/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10534 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10534/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10534/comments | https://api.github.com/repos/huggingface/transformers/issues/10534/events | https://github.com/huggingface/transformers/pull/10534 | 822,739,024 | MDExOlB1bGxSZXF1ZXN0NTg1MzE0MjM3 | 10,534 | VisualBERT | {
"login": "gchhablani",
"id": 29076344,
"node_id": "MDQ6VXNlcjI5MDc2MzQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/29076344?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gchhablani",
"html_url": "https://github.com/gchhablani",
"followers_url": "https://api.github.com/users/gchhablani/followers",
"following_url": "https://api.github.com/users/gchhablani/following{/other_user}",
"gists_url": "https://api.github.com/users/gchhablani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gchhablani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gchhablani/subscriptions",
"organizations_url": "https://api.github.com/users/gchhablani/orgs",
"repos_url": "https://api.github.com/users/gchhablani/repos",
"events_url": "https://api.github.com/users/gchhablani/events{/privacy}",
"received_events_url": "https://api.github.com/users/gchhablani/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] | closed | false | null | [] | [
"Hi @gchhablani \r\n\r\nThis is great! You can ping me if you need any help with this model.\r\n\r\n\r\nAlso, we have now added a step-by-step doc for how to add a model, you can find it here \r\nhttps://huggingface.co/transformers/add_new_model.html\r\n\r\nAlso have a look at the `cookiecutter` tool, which will help you generate lots of boilerplate code.\r\nhttps://github.com/huggingface/transformers/tree/master/templates/adding_a_new_model",
"Hi @patil-suraj\r\n\r\nThanks a lot.\r\n\r\nI wanted to add this model in 2020, but I faced a lot of issues and got busy with some other work. Seems like the code structure has changed quite a bit after that. I'll check the shared links and get back.",
"Hi @patil-suraj,\r\n\r\nI have started adding some code. For comparison, you can see: https://github.com/uclanlp/visualbert/blob/master/pytorch_pretrained_bert/modeling.py.\r\n\r\nPlease look at the `VisualBertEmbeddings` and `VisualBertModel`. I have checked these using dummy tensors. I am adding/fixing other kinds of down-stream models. Please tell me if you think this is going in the right direction, and if there are any things that to need to be kept in mind.\r\n\r\nI skipped testing the original repository for now, they don't have an entry point, and require a bunch of installs for loading /handling the dataset(s) which are huge.\r\n\r\nThere are several different checkpoints, even for the pre-trained models (with different embedding dimensions, etc.). For each we'll have to make a separate checkpoint, I guess.\r\n\r\nIn addition, I was wondering if we want to provide encoder-decoder features (`cross-attention`, `past_key_value`, etc.). I don't think it has been used in the original code, but it will certainly be a nice feature to have in case we have some task in the future which involves generation of text given an image and a text (probably there is something already).\r\n\r\nThanks :)",
"Hi @patil-suraj\r\n\r\nI would appreciate some feedback :) It'll help me know if I am going in the right direction,\r\n\r\nThanks,\r\nGunjan",
"Hey @gchhablani \r\n\r\nI'm thinking about this and will get back to you tomorrow :)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Unstale",
"Hi @LysandreJik \r\nThanks for reviewing.\r\n\r\nI'll make the suggested changes in a few (4-5) hours.\r\n\r\nThe `position_embeddings_type` is not exactly being used by the authors. They use absolute embeddings. They do have an `embedding_strategy_type` argument but it is unused and kept as `'plain'`.\r\n\r\nYes, almost all of it is copied from BERT. The new additions are the embeddings and the model classes.\r\n\r\nInitially, I did have plans to add actual examples and notebooks initially in the same PR :stuck_out_tongue: I guess I'll work on it now.",
"@LysandreJik Do you wanna take a final look?",
":') Thanks a lot for all your help @patil-suraj @LysandreJik @sgugger @patrickvonplaten\r\n\r\nEdit:\r\nI will be working on another PR soon to add more/better examples, and to use the `SimpleDetector` as used by the original authors. Probably will also attempt to create `TF`/`Flax` models.",
"The PR looks awesome! I still think however that we should add `get_visual_embeddings` with a Processor in this PR to have it complete. @gchhablani @patil-suraj - do you think it would be too time-consuming to add a `VisualBERTFeatureExtractor` here? Just don't really think people will be able to run an example after we merge it at the moment",
"@patrickvonplaten here `visual_embeddings` comes from a cnn backbone (ResNet) or object detection model. So I don't think\r\n we can add `VisualBERTFeatureExtractor`. The plan is to add the cnn model and a demo notebook in `research_projects` dir in a follow-up a PR.",
"> @patrickvonplaten here `visual_embeddings` comes from a cnn backbone (ResNet) or object detection model. So I don't think\r\n> we can add `VisualBERTFeatureExtractor`. The plan is to add the cnn model and a demo notebook in `research_projects` dir in a follow-up a PR.\r\n\r\nOk! Do we have another model that could give us those embeddings? ViT maybe?",
"@patrickvonplaten, I am not sure about ViT as I haven't used or read about it yet. The VisualBERT authors used Detectron-based (MaskRCNN with FPN-ResNet-101 backbone) features for 3 out of 4 tasks. Each \"token\" is actually an object detected and the token features/embeddings from the detectron classifier layer. In case of VCR task, they use a ResNet on given box coordinates. \r\n\r\nUnless ViT has/is an extractor similar to this, if we could use ViT, it'd be very different from the original and might not work with the provided pre-trained weights. :/\r\n",
"Adding a common Fast/Faster/MaskRCNN feature extractor, however, will help with LXMERT/VisualBERT and other models I'm planning to contribute in the future - ViLBERT (#11986), VL-BERT, (and possibly MCAN). \r\n\r\n**Edit**: There's already an example for LXMERT: https://github.com/huggingface/transformers/blob/master/examples/research_projects/lxmert/modeling_frcnn.py which I'll build upon.",
"Ok! Good to merge for me then",
"maybe not promote it yet",
"@patrickvonplaten Yes, won't be promoted before adding an example.\r\n\r\nThe plan forward is to add a detector and example notebook in `research_projects` dir in a follow-up PR.\r\n\r\nVerified that all slow tests are passing :)\r\n\r\nMerging!",
"Great model addition @gchhablani. Small note: can you fix the code examples of the HTML page?\r\n\r\nCurrently they look like this:\r\n\r\n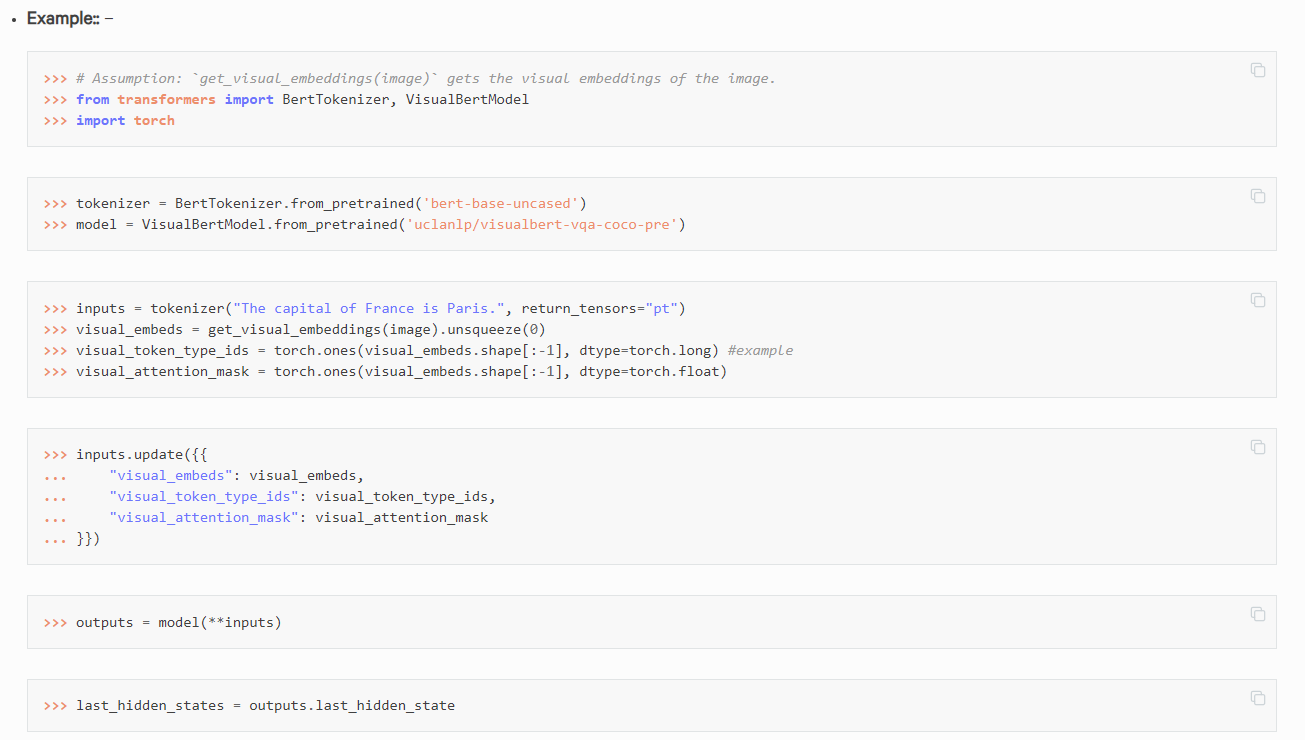\r\n\r\nThe Returns: statement should be below the Example: statement in `modeling_visual_bert.py`. Sorry for nitpicking ;) "
] | 1,614 | 1,622 | 1,622 | CONTRIBUTOR | null | This PR adds VisualBERT (See Closed Issue #5095). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10534/reactions",
"total_count": 4,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 4,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10534/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10534",
"html_url": "https://github.com/huggingface/transformers/pull/10534",
"diff_url": "https://github.com/huggingface/transformers/pull/10534.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10534.patch",
"merged_at": 1622637788000
} |
https://api.github.com/repos/huggingface/transformers/issues/10533 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10533/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10533/comments | https://api.github.com/repos/huggingface/transformers/issues/10533/events | https://github.com/huggingface/transformers/issues/10533 | 822,734,299 | MDU6SXNzdWU4MjI3MzQyOTk= | 10,533 | RAG with RAY workers keep repetitive copies of knowledge base as .nfs files until the process is done. | {
"login": "shamanez",
"id": 16892570,
"node_id": "MDQ6VXNlcjE2ODkyNTcw",
"avatar_url": "https://avatars.githubusercontent.com/u/16892570?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shamanez",
"html_url": "https://github.com/shamanez",
"followers_url": "https://api.github.com/users/shamanez/followers",
"following_url": "https://api.github.com/users/shamanez/following{/other_user}",
"gists_url": "https://api.github.com/users/shamanez/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shamanez/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shamanez/subscriptions",
"organizations_url": "https://api.github.com/users/shamanez/orgs",
"repos_url": "https://api.github.com/users/shamanez/repos",
"events_url": "https://api.github.com/users/shamanez/events{/privacy}",
"received_events_url": "https://api.github.com/users/shamanez/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I don't know what those .nfs are used for in Ray, is it safe to remove them @amogkam ?"
] | 1,614 | 1,617 | 1,617 | CONTRIBUTOR | null |
As mentioned in [this PR](https://github.com/huggingface/transformers/pull/10410), I update the **my_knowledge_dataset** object all the time. I save the new my_knowledge_dataset in the same place by removing previously saved stuff. But still, I see there are always some hidden files left. Please check the screenshot below.


I did some checks and found that these .nfs files being used by RAY. But my local KB is 30GB, so I do not want to add a .nfs file in every iteration. Is there a way to get over this?
@amogkam
@lhoestq
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10533/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10533/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10532 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10532/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10532/comments | https://api.github.com/repos/huggingface/transformers/issues/10532/events | https://github.com/huggingface/transformers/issues/10532 | 822,728,018 | MDU6SXNzdWU4MjI3MjgwMTg= | 10,532 | Calling Inference API returns input text | {
"login": "gstranger",
"id": 36181416,
"node_id": "MDQ6VXNlcjM2MTgxNDE2",
"avatar_url": "https://avatars.githubusercontent.com/u/36181416?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gstranger",
"html_url": "https://github.com/gstranger",
"followers_url": "https://api.github.com/users/gstranger/followers",
"following_url": "https://api.github.com/users/gstranger/following{/other_user}",
"gists_url": "https://api.github.com/users/gstranger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gstranger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gstranger/subscriptions",
"organizations_url": "https://api.github.com/users/gstranger/orgs",
"repos_url": "https://api.github.com/users/gstranger/repos",
"events_url": "https://api.github.com/users/gstranger/events{/privacy}",
"received_events_url": "https://api.github.com/users/gstranger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Could you try to add `\"max_length\": 200` to your payload ? (also cc @Narsil )",
"Hi @gstranger ,\r\n\r\nCan you reproduce the problem locally ? It could be that your model simply produces EOS token with high probability (leading to having the exact same prompt as output)\r\n\r\nIf not, do you mind telling us your username by DM `[email protected]` so we can investigate this issue ?",
"Hello @Narsil ,\r\n\r\nWhen I run the same model locally, without either `max_length` or `min_length` I receive additional output, typically it will generate about 20-40 tokens. Also @patrickvonplaten when I add either that parameter or the `min_length` parameter the model still returns in less than a second with the same input text. I've sent an email with additional information. ",
"Hi @gstranger,\r\n\r\nIt does seem like a `max_length`. Your config defines it as `20` which is not long enough for the prompt that gets automatically added (because it's a transfo-xl model): https://github.com/huggingface/transformers/blob/master/src/transformers/pipelines/text_generation.py#L23\r\n\r\nYou can override both `max_length` and `prefix` within the config to override the default `transfo-xl` behavior (depending on how it was trained it might lead to significant perf boost, or loss).\r\n\r\nBy default the API will read the config first. Replying also with more information by email with more information. Just sharing here so that the community can get help too.\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | - `transformers` version: 4.4.0dev0
- Platform: MACosx
- Python version: 3.7
- PyTorch version (GPU?): N/A
- Tensorflow version (GPU?): N/A
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
Library:
@patrickvonplaten
@LysandreJik
@sgugger
## Information
Model I am using (Bert, XLNet ...): TransformerXL
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Upload private model to hub
2. Follow the tutorial around calling the Inference API (pasted below)
I've trained a `TransformerXLLMHeadModel` and am using the equivalent tokenizer class `TransfoXLTokenizer` on a custom dataset. I've saved both of these classes and have verified that loading the directory using the Auto classes succeeds and that the model and tokenizer are usable. When attempting to call the Inference API, I only get back my input text.
### Specific code from tutorial
```python
import json
import requests
API_TOKEN = "api_1234"
API_URL = "https://api-inference.huggingface.co/models/private/model"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
def query(payload):
data = json.dumps(payload)
response = requests.request("POST", API_URL, headers=headers, data=data)
return json.loads(response.content.decode("utf-8"))
data = query({"inputs": "Begin 8Bars ", "temperature": .85, "num_return_sequences": 5})
# data = [{'generated_text': 'Begin First '}]
```
## Expected behavior
When calling the Inference API on my private model I would expect it to return additional output rather than just my input text.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10532/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10532/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10531 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10531/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10531/comments | https://api.github.com/repos/huggingface/transformers/issues/10531/events | https://github.com/huggingface/transformers/pull/10531 | 822,720,356 | MDExOlB1bGxSZXF1ZXN0NTg1Mjk4NTYy | 10,531 | Typo correction. | {
"login": "cliang1453",
"id": 14855272,
"node_id": "MDQ6VXNlcjE0ODU1Mjcy",
"avatar_url": "https://avatars.githubusercontent.com/u/14855272?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cliang1453",
"html_url": "https://github.com/cliang1453",
"followers_url": "https://api.github.com/users/cliang1453/followers",
"following_url": "https://api.github.com/users/cliang1453/following{/other_user}",
"gists_url": "https://api.github.com/users/cliang1453/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cliang1453/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cliang1453/subscriptions",
"organizations_url": "https://api.github.com/users/cliang1453/orgs",
"repos_url": "https://api.github.com/users/cliang1453/repos",
"events_url": "https://api.github.com/users/cliang1453/events{/privacy}",
"received_events_url": "https://api.github.com/users/cliang1453/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | # What does this PR do?
Fix a typo: DEBERTA_PRETRAINED_MODEL_ARCHIVE_LIST => DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST in line 31.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #10529
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10531/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10531/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10531",
"html_url": "https://github.com/huggingface/transformers/pull/10531",
"diff_url": "https://github.com/huggingface/transformers/pull/10531.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10531.patch",
"merged_at": 1614976030000
} |
https://api.github.com/repos/huggingface/transformers/issues/10530 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10530/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10530/comments | https://api.github.com/repos/huggingface/transformers/issues/10530/events | https://github.com/huggingface/transformers/issues/10530 | 822,713,227 | MDU6SXNzdWU4MjI3MTMyMjc= | 10,530 | Test/Predict on summarization task | {
"login": "zyxnlp",
"id": 31751455,
"node_id": "MDQ6VXNlcjMxNzUxNDU1",
"avatar_url": "https://avatars.githubusercontent.com/u/31751455?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zyxnlp",
"html_url": "https://github.com/zyxnlp",
"followers_url": "https://api.github.com/users/zyxnlp/followers",
"following_url": "https://api.github.com/users/zyxnlp/following{/other_user}",
"gists_url": "https://api.github.com/users/zyxnlp/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zyxnlp/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zyxnlp/subscriptions",
"organizations_url": "https://api.github.com/users/zyxnlp/orgs",
"repos_url": "https://api.github.com/users/zyxnlp/repos",
"events_url": "https://api.github.com/users/zyxnlp/events{/privacy}",
"received_events_url": "https://api.github.com/users/zyxnlp/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\ncould you please ask questions related to training of models on the [forum](https://discuss.huggingface.co/)?\r\n\r\nAll questions related to fine-tuning a model for summarization on CNN can be found [here](https://discuss.huggingface.co/search?q=summarization%20cnn) for example. \r\n\r\n",
"> Hi,\r\n> \r\n> could you please ask questions related to training of models on the [forum](https://discuss.huggingface.co/)?\r\n> \r\n> All questions related to fine-tuning a model for summarization on CNN can be found [here](https://discuss.huggingface.co/search?q=summarization%20cnn) for example.\r\n\r\n@NielsRogge Oh, thank you for your reminder, that really helped!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0.dev0
- Platform: Linux-5.3.0-53-generic-x86_64-with-glibc2.10
- Python version: 3.8.3
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
@patrickvonplaten, @patil-suraj
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
- maintained examples using bart: @patrickvonplaten, @patil-suraj
## Information
Model I am using (Bart):
The problem arises when using:
* [ ] only have train and eval example, do not have test/predict example script
* [ ] my own modified scripts: (give details below)
* [ ] CUDA_VISIBLE_DEVICES=2,3 python examples/seq2seq/run_seq2seq.py \
--model_name_or_path /home/yxzhou/experiment/ASBG/output/xsum_bart_large/ \
--do_predict \
--task summarization \
--dataset_name xsum \
--output_dir /home/yxzhou/experiment/ASBG/output/xsum_bart_large/test/ \
--num_beams 1 \
The tasks I am working on is:
* [ ] CNNDAILYMAIL , XSUM
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
Use the above script to test on CNNDAILYMAIL and XSUM dataset, the program seems will be always stuck at training_step (e.g., 26/709)
Could you please kindly provide a test/predict example script of the summarization task (e.g., XSUM). Thank you so much! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10530/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10530/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10529 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10529/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10529/comments | https://api.github.com/repos/huggingface/transformers/issues/10529/events | https://github.com/huggingface/transformers/issues/10529 | 822,685,396 | MDU6SXNzdWU4MjI2ODUzOTY= | 10,529 | Typo in deberta_v2/__init__.py | {
"login": "cliang1453",
"id": 14855272,
"node_id": "MDQ6VXNlcjE0ODU1Mjcy",
"avatar_url": "https://avatars.githubusercontent.com/u/14855272?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cliang1453",
"html_url": "https://github.com/cliang1453",
"followers_url": "https://api.github.com/users/cliang1453/followers",
"following_url": "https://api.github.com/users/cliang1453/following{/other_user}",
"gists_url": "https://api.github.com/users/cliang1453/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cliang1453/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cliang1453/subscriptions",
"organizations_url": "https://api.github.com/users/cliang1453/orgs",
"repos_url": "https://api.github.com/users/cliang1453/repos",
"events_url": "https://api.github.com/users/cliang1453/events{/privacy}",
"received_events_url": "https://api.github.com/users/cliang1453/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"That's correct! Do you want to open a PR to fix it?"
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | https://github.com/huggingface/transformers/blob/c503a1c15ec1b11e69a3eaaf06edfa87c05a2849/src/transformers/models/deberta_v2/__init__.py#L31
Should be '' DEBERTA_V2_PRETRAINED_MODEL_ARCHIVE_LIST ''. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10529/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10529/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10528 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10528/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10528/comments | https://api.github.com/repos/huggingface/transformers/issues/10528/events | https://github.com/huggingface/transformers/issues/10528 | 822,678,374 | MDU6SXNzdWU4MjI2NzgzNzQ= | 10,528 | Different vocab_size between model and tokenizer of mT5 | {
"login": "cih9088",
"id": 11530592,
"node_id": "MDQ6VXNlcjExNTMwNTky",
"avatar_url": "https://avatars.githubusercontent.com/u/11530592?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cih9088",
"html_url": "https://github.com/cih9088",
"followers_url": "https://api.github.com/users/cih9088/followers",
"following_url": "https://api.github.com/users/cih9088/following{/other_user}",
"gists_url": "https://api.github.com/users/cih9088/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cih9088/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cih9088/subscriptions",
"organizations_url": "https://api.github.com/users/cih9088/orgs",
"repos_url": "https://api.github.com/users/cih9088/repos",
"events_url": "https://api.github.com/users/cih9088/events{/privacy}",
"received_events_url": "https://api.github.com/users/cih9088/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! This is a duplicate of https://github.com/huggingface/transformers/issues/4875, https://github.com/huggingface/transformers/issues/10144 and https://github.com/huggingface/transformers/issues/9247\r\n\r\n@patrickvonplaten, maybe we could do something about this in the docs? In the docs we recommend doing this:\r\n```py\r\nmodel.resize_token_embedding(len(tokenizer))\r\n```\r\nbut this is unfortunately false for T5!",
"@LysandreJik @cih9088 , actually I think doing: \r\n\r\n```python\r\nmodel.resize_token_embedding(len(tokenizer))\r\n```\r\n\r\nis fine -> it shouldn't throw an error & logically it should also be correct...Can you try it out?\r\n",
"```python\r\nmodel.resize_token_embedding(len(tokenizer))\r\n```\r\nThis works perfectly fine but here is the thing.\r\n\r\nOne might add the `model.resize_token_embedding(len(tokenizer))` in their code and use other configuration packages such as `hydra` from Facebook to train models with additional tokens or without them dynamically at runtime.\r\nHe would naturally think that `vocab_size` of tokenizer (no tokens added) and `vocab_size` of model are the same because other models are.\r\nEventually, he fine-tunes the `google/mt5-base` model without added tokens but because of `model.resize_token_embedding(len(tokenizer))`, model he will fine-tune is not the same with `google/mt5-base`.\r\nAfter training, he wants to load the trained model to test but the model complains about inconsistent embedding size between a loaded model which is `google/mt5-base`, and the trained model which has a smaller size of token embedding.\r\n\r\nOf course, we could resize token embedding before loading model, but what matters is inconsistency with other models I think.\r\nI reckon that people would not very much care about how the dictionary is composed in tokenizer. Maybe we add some dummy tokens to the tokenizer to keep consistency with other huggingface models or add documentation about it (I could not find any).\r\n\r\nWhat do you think?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"\r\n> Hello! This is a duplicate of #4875, #10144 and #9247\r\n> \r\n> @patrickvonplaten, maybe we could do something about this in the docs? In the docs we recommend doing this:\r\n> \r\n> ```python\r\n> model.resize_token_embedding(len(tokenizer))\r\n> ```\r\n> \r\n> but this is unfortunately false for T5!\r\n\r\nWhat is the correct way to resize_token_embedding for T5/mT5?"
] | 1,614 | 1,628 | 1,619 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.1.1
- Platform: ubuntu 18.04
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1
### Who can help
@patrickvonplaten
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## To reproduce
Steps to reproduce the behavior:
```python
from transformers import AutoModelForSeq2SeqLM
from transformers import AutoTokenizer
mt5s = ['google/mt5-base', 'google/mt5-small', 'google/mt5-large', 'google/mt5-xl', 'google/mt5-xxl']
for mt5 in mt5s:
model = AutoModelForSeq2SeqLM.from_pretrained(mt5)
tokenizer = AutoTokenizer.from_pretrained(mt5)
print()
print(mt5)
print(f"tokenizer vocab: {tokenizer.vocab_size}, model vocab: {model.config.vocab_size}")
```
This is problematic in case when one addes some (special) tokens to tokenizer and resizes the token embedding of the model with `model.resize_token_embedding(len(tokenizer))`
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
vocab_size for model and tokenizer should be the same?
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10528/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10528/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10527 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10527/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10527/comments | https://api.github.com/repos/huggingface/transformers/issues/10527/events | https://github.com/huggingface/transformers/pull/10527 | 822,658,264 | MDExOlB1bGxSZXF1ZXN0NTg1MjQ3NjE0 | 10,527 | Refactoring checkpoint names for multiple models | {
"login": "danielpatrickhug",
"id": 38571110,
"node_id": "MDQ6VXNlcjM4NTcxMTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/38571110?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielpatrickhug",
"html_url": "https://github.com/danielpatrickhug",
"followers_url": "https://api.github.com/users/danielpatrickhug/followers",
"following_url": "https://api.github.com/users/danielpatrickhug/following{/other_user}",
"gists_url": "https://api.github.com/users/danielpatrickhug/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danielpatrickhug/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danielpatrickhug/subscriptions",
"organizations_url": "https://api.github.com/users/danielpatrickhug/orgs",
"repos_url": "https://api.github.com/users/danielpatrickhug/repos",
"events_url": "https://api.github.com/users/danielpatrickhug/events{/privacy}",
"received_events_url": "https://api.github.com/users/danielpatrickhug/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"...The test pasts on my local machine, I ran make test, style, quality, fixup. I dont know why this failed..",
"I just rebased the PR to ensure that the tests pass. We'll merge if all is green!",
"Thanks guys"
] | 1,614 | 1,615 | 1,614 | CONTRIBUTOR | null | Hi, @sgugger reupload without datasets dir and added tf_modeling files, removed extra decorator in distilbert.
Linked to #10193, this PR refactors the checkpoint names in one private constant.
one note: longformer_tf has two checkpoints "allenai/longformer-base-4096" & "allenai/longformer-large-4096-finetuned-triviaqa". I set the checkpoint constant to "allenai/longformer-base-4096" and left the one decorator with "allenai/longformer-large-4096-finetuned-triviaqa".
Fixes #10193
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10527/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10527/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10527",
"html_url": "https://github.com/huggingface/transformers/pull/10527",
"diff_url": "https://github.com/huggingface/transformers/pull/10527.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10527.patch",
"merged_at": 1614985615000
} |
https://api.github.com/repos/huggingface/transformers/issues/10526 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10526/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10526/comments | https://api.github.com/repos/huggingface/transformers/issues/10526/events | https://github.com/huggingface/transformers/pull/10526 | 822,581,103 | MDExOlB1bGxSZXF1ZXN0NTg1MTgzMjYy | 10,526 | Fix Adafactor documentation (recommend correct settings) | {
"login": "jsrozner",
"id": 1113285,
"node_id": "MDQ6VXNlcjExMTMyODU=",
"avatar_url": "https://avatars.githubusercontent.com/u/1113285?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jsrozner",
"html_url": "https://github.com/jsrozner",
"followers_url": "https://api.github.com/users/jsrozner/followers",
"following_url": "https://api.github.com/users/jsrozner/following{/other_user}",
"gists_url": "https://api.github.com/users/jsrozner/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jsrozner/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jsrozner/subscriptions",
"organizations_url": "https://api.github.com/users/jsrozner/orgs",
"repos_url": "https://api.github.com/users/jsrozner/repos",
"events_url": "https://api.github.com/users/jsrozner/events{/privacy}",
"received_events_url": "https://api.github.com/users/jsrozner/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"Is this part correct?\r\n\r\n> Recommended T5 finetuning settings:\r\n> - Scheduled LR warm-up to fixed LR\r\n> - disable relative updates\r\n> - use clip threshold: https://arxiv.org/abs/2004.14546\r\n\r\nIn particular:\r\n- are we supposed to do scheduled LR? adafactor handles this no?\r\n- we *should not* disable relative updates\r\n- i don't know what clip threshold means in this context",
"@sshleifer can you accept this documentation change?",
"No but @stas00 can!",
"@jsrozner, thank you for the PR. \r\n\r\nReading https://github.com/huggingface/transformers/issues/7789 it appears that the `Recommended T5 finetuning settings` are invalid.\r\n\r\nSo if we are fixing this, in addition to changing the example the prose above it should be synced as well. \r\n\r\nI don't know where the original recommendation came from - do you by chance have a source we could point to for the corrected recommendation? If you know that is, if not, please don't worry.\r\n\r\nThank you.\r\n\r\n",
"I receive the following error when using this the \"recommended way\":\r\n```{python}\r\nTraceback (most recent call last):\r\n File \"./folder_aws/transformers/examples/seq2seq/run_seq2seq.py\", line 759, in <module>\r\n main()\r\n File \"./folder_aws/transformers/examples/seq2seq/run_seq2seq.py\", line 651, in main\r\n train_result = trainer.train(resume_from_checkpoint=checkpoint)\r\n File \"/home/alejandro.vaca/SpainAI_Hackaton_2020/folder_aws/transformers/src/transformers/trainer.py\", line 909, in train\r\n self.create_optimizer_and_scheduler(num_training_steps=max_steps)\r\n File \"/home/alejandro.vaca/SpainAI_Hackaton_2020/folder_aws/transformers/src/transformers/trainer.py\", line 660, in create_optimizer_and_scheduler\r\n self.optimizer = optimizer_cls(optimizer_grouped_parameters, **optimizer_kwargs)\r\n File \"/home/alejandro.vaca/SpainAI_Hackaton_2020/folder_aws/transformers/src/transformers/optimization.py\", line 452, in __init__\r\n raise ValueError(\"warmup_init requires relative_step=True\")\r\nValueError: warmup_init requires relative_step=True\r\n```\r\n\r\nFollowing this example in documentation:\r\n\r\n```{python}\r\nAdafactor(model.parameters(), lr=1e-3, relative_step=False, warmup_init=True)\r\n```\r\n@sshleifer @stas00 @jsrozner ",
"@alexvaca0, what was the command line you run when you received this error?\r\n\r\nHF Trainer doesn't set `warmup_init=True`. Unless you modified the script?\r\n\r\nhttps://github.com/huggingface/transformers/blob/21e86f99e6b91af2e4df3790ba6c781e85fa0eb5/src/transformers/trainer.py#L649-L651\r\n\r\nIt is possible that the whole conflict comes from misunderstanding how this optimizer has to be used?\r\n\r\n> To use a manual (external) learning rate schedule you should set `scale_parameter=False` and `relative_step=False`.\r\n\r\nwhich is what the Trainer does at the moment. \r\n\r\nand:\r\n> relative_step (:obj:`bool`, `optional`, defaults to :obj:`True`):\r\n> If True, time-dependent learning rate is computed instead of external learning rate\r\n\r\nIs it possible that you are trying to use both an external and the internal scheduler at the same time?\r\n\r\nIt'd help a lot of you could show us the code that breaks, (perhaps on colab?) and how you invoke it. Basically, help us reproduce it.\r\n\r\nThank you.",
"Hi, @stas00 , first thank you very much for looking into it so fast. I forgot to say it, but yes, I changed the code in Trainer because I was trying to use the recommended settings for training T5 (I mean, setting an external learning rate with warmup_init = True as in the documentation. `Training without LR warmup or clip threshold is not recommended. Additional optimizer operations like gradient clipping should not be used alongside Adafactor.` From your answer, I understand that Trainer was designed for using Adam, as it uses the external learning rate scheduler and doesn't let you pass None as learning rate. Is there a workaround to be able to use the Trainer class with Adafactor following Adafactor settings recommended in the documentation? I'd also like to try using Adafactor without specifying the learning rate, would that be possible? I think maybe this documentation causes a little bit of confusion, because when you set the parameters specified in it `Adafactor(model.parameters(), lr=1e-3, relative_step=False, warmup_init=True)` it breaks. \r\n\r\n\r\n",
"OK, so first, as @jsrozner PR goes and others commented, the current recommendation appears to be invalid.\r\n\r\nSo we want to gather all the different combinations that work and identify which of them provides the best outcome. I originally replied to this PR asking if someone knows of an authoritative paper we could copy the recommendation from - i.e. finding someone who already did the quality studies, so that we won't have it. So I'm all ears if any of you knows of such source.\r\n\r\nNow to your commentary, @alexvaca0, while HF trainer has Adam as the default it has `--adafactor` which enables it in the mode with using the external scheduler. Surely, we could change the Trainer to skip the external scheduler (or perhaps simpler feeding it some no-op scheduler) and instead use this recommendation if @sgugger agrees with that. But we first need to see that it provides a better outcome in the general case. Or alternatively to make `--adafactor` configurable so it could support more than just one way.\r\n\r\nFor me personally I want to understand first the different combinations, what are the impacts and how many of those combinations should we expose through the Trainer. e.g. like apex optimization level, we could have named combos `--adafactor setup1`, `--adafactor setup2` and would activate the corresponding configuration. But first let's compile the list of desirable combos.\r\n\r\nWould any of the current participants be interested in taking a lead on that? I'm asking you since you are already trying to get the best outcome with your data and so are best positioned to judge which combinations work the best for what situation.\r\n\r\nOnce we compiled the data it'd be trivial to update the documented recommendation and potentially extend HF Trainer to support more than one setting for Adafactor.\r\n\r\n",
"I only ported the `--adafactor` option s it was implemented for the `Seq2SeqTrainer` to keep the commands using it working as they were. The `Trainer` does not have vocation to support all the optimizers and all their possible setups, just one sensible default that works well, that is the reason you can:\r\n- pass an `optimizer` at init\r\n- subclass and override `create_optimizer`.\r\n\r\nIn retrospect, I shouldn't have ported the Adafactor option and it should have stayed just in the script using it.",
"Thank you for your feedback, @sgugger. \r\n\r\nSo let's leave the trainer as it is and let's then solve this for Adafactor as just an optimizer and then document the best combinations. ",
"Per my comment on #7789, I observed that \r\n> I can confirm that `Adafactor(lr=1e-3, relative_step=False, warmup_init=False)` seems to break training (i.e. I observe no learning over 4 epochs, whereas `Adafactor(model.parameters(), relative_step=True, warmup_init=True, lr=None)` works well (much better than adam)\r\n\r\nGiven that relative_step and warmup_init must take on the same value, it seems like there is only one configuration that is working?\r\n\r\nBut, this is also confusing (see my comment above): https://github.com/huggingface/transformers/pull/10526#issuecomment-791012771\r\n\r\n> > Recommended T5 finetuning settings:\r\n> > - Scheduled LR warm-up to fixed LR\r\n> > - disable relative updates\r\n> > - use clip threshold: https://arxiv.org/abs/2004.14546\r\n> \r\n> In particular:\r\n> - are we supposed to do scheduled LR? adafactor handles this no?\r\n> - we *should not* disable relative updates\r\n> - i don't know what clip threshold means in this context\r\n",
"I first validated that HF `Adafactor` is 100% identical to the latest [fairseq version](https://github.com/pytorch/fairseq/blob/5273bbb7c18a9b147e3f0cfc97121cc945a962bd/fairseq/optim/adafactor.py).\r\n\r\nI then tried to find out the source of these recommendations and found:\r\n\r\n1. https://discuss.huggingface.co/t/t5-finetuning-tips/684/3\r\n```\r\nlr=0.001, scale_parameter=False, relative_step=False\r\n```\r\n2. https://discuss.huggingface.co/t/t5-finetuning-tips/684/22 which is your comment @jsrozner where you propose that the opposite combination works well:\r\n\r\n```\r\nlr=None, relative_step=True, warmup_init=True\r\n```\r\n\r\nIf both found to be working, I propose we solve this conundrum by documenting this as following:\r\n```\r\n Recommended T5 finetuning settings (https://discuss.huggingface.co/t/t5-finetuning-tips/684/3):\r\n\r\n - Scheduled LR warm-up to fixed LR\r\n - disable relative updates\r\n - scale_parameter=False\r\n - use clip threshold: https://arxiv.org/abs/2004.14546\r\n\r\n Example::\r\n\r\n Adafactor(model.parameters(), scale_parameter=False, relative_step=False, warmup_init=False, lr=1e-3)\r\n\r\n Others reported the following combination to work well::\r\n\r\n Adafactor(model.parameters(), scale_parameter=False, relative_step=True, warmup_init=True, lr=None)\r\n\r\n - Training without LR warmup or clip threshold is not recommended. Additional optimizer operations like\r\n gradient clipping should not be used alongside Adafactor.\r\n```\r\n\r\nhttps://discuss.huggingface.co/t/t5-finetuning-tips/684/22 Also highly recommends to turn `scale_parameter=False` - so I added that to the documentation and the example above in both cases. Please correct me if I'm wrong.\r\n\r\nAnd @jsrozner's correction in this PR is absolutely right to the point.\r\n\r\nPlease let me know if my proposal makes sense, in particular I'd like your validation, @jsrozner, since I added your alternative proposal. And don't have any other voices to agree or disagree with it.\r\n\r\nThank you!\r\n\r\n\r\n\r\n\r\n",
"> Is this part correct?\r\n> \r\n> > ```\r\n> > Recommended T5 finetuning settings:\r\n> > - Scheduled LR warm-up to fixed LR\r\n> > - disable relative updates\r\n> > - use clip threshold: https://arxiv.org/abs/2004.14546\r\n> > ```\r\n> \r\n> In particular:\r\n> \r\n> * are we supposed to do scheduled LR? adafactor handles this no?\r\n\r\nsee my last comment - it depends on whether we use the external LR scheduler or not.\r\n\r\n> * we _should not_ disable relative updates\r\n\r\nsee my last comment - it depends on `warmup_init`'s value\r\n\r\n> * i don't know what clip threshold means in this context\r\n\r\nthis?\r\n```\r\n def __init__(\r\n [....]\r\n clip_threshold=1.0,\r\n```",
"I'm running some experiments, playing around with Adafactor parameters. I'll post here which configuration has best results. From T5 paper, they used the following parameters for fine-tuning: Adafactor with *constant* lr 1e-3, with batch size 128, if I understood the paper well. Therefore, I find it appropriate the documentation changes mentioned above, leaving the recommendations from the paper while mentioning other configs that have worked well for other users. In my case, for example, the configuration from the paper doesn't work very well and I quickly overfit. ",
"Finally, I'm trying to understand the confusing:\r\n```\r\n - use clip threshold: https://arxiv.org/abs/2004.14546\r\n [...]\r\n gradient clipping should not be used alongside Adafactor.\r\n```\r\n\r\nAs the paper explains these are 2 different types of clipping.\r\n\r\nSince the code is:\r\n```\r\nupdate.div_((self._rms(update) / group[\"clip_threshold\"]).clamp_(min=1.0))\r\n```\r\nthis probably means that the default `clip_threshold=1.0` is in effect disables clip threshold. \r\n\r\nI can't find any mentioning of clip threshold in https://arxiv.org/abs/2004.14546 - is this a wrong paper? Perhaps it needed to link to the original paper https://arxiv.org/abs/1804.04235 where clipping is actually discussed? I think it's the param `d` in the latter paper and it proposes to get the best results with `d=1.0` without learning rate warmup:\r\n\r\npage 5 from https://arxiv.org/pdf/1804.04235:\r\n> We added update clipping to the previously described fast-\r\n> decay experiments. For the experiment without learning rate\r\n> warmup, update clipping with d = 1 significantly amelio-\r\n> rated the instability problem – see Table 2 (A) vs. (H). With\r\n> d = 2, the instability was not improved. Update clipping\r\n> did not significantly affect the experiments with warmup\r\n> (with no instability problems).\r\n\r\nSo I will change the doc to a non-ambiguous:\r\n\r\n`use clip_threshold=1.0 `",
"OK, so here is the latest proposal. I re-organized the notes:\r\n\r\n```\r\n Recommended T5 finetuning settings (https://discuss.huggingface.co/t/t5-finetuning-tips/684/3):\r\n\r\n - Training without LR warmup or clip_threshold is not recommended. \r\n * use scheduled LR warm-up to fixed LR\r\n * use clip_threshold=1.0 (https://arxiv.org/abs/1804.04235)\r\n - Disable relative updates\r\n - Use scale_parameter=False\r\n - Additional optimizer operations like gradient clipping should not be used alongside Adafactor\r\n\r\n Example::\r\n\r\n Adafactor(model.parameters(), scale_parameter=False, relative_step=False, warmup_init=False, lr=1e-3)\r\n\r\n Others reported the following combination to work well::\r\n\r\n Adafactor(model.parameters(), scale_parameter=False, relative_step=True, warmup_init=True, lr=None)\r\n```\r\n\r\nI added these into this PR, please have a look.\r\n",
"Let's just wait to hear from both @jsrozner and @alexvaca0 to ensure that my edits are valid before merging.",
"I observed that `Adafactor(lr=1e-3, relative_step=False, warmup_init=False)` failed to lead to any learning. I guess this is because I didn't change `scale_parameter` to False? I can try rerunning with scale_param false.\r\n\r\nAnd when I ran with `Adafactor(model.parameters(), relative_step=True, warmup_init=True, lr=None)`, I *did not* set `scale_parameter=False`. Before adding the \"others seem to have success with ...\" bit, we should check on the effect of scale_parameter.\r\n\r\nRegarding clip_threshold - just confirming that the comment is correct that when using adafactor we should *not* have any other gradient clipping (e.g. `nn.utils.clip_grad_norm_()`)?\r\n\r\nSemi-related per @alexvaca0, regarding T5 paper's recommended batch_size: is the 128 recommendation agnostic to the length of input sequences? Or is there a target number of tokens per batch that would be optimal? (E.g. input sequences of max length 10 tokens vs input sequences of max length 100 tokens -- should we expect 128 to work optimally for both?)\r\n\r\nBut most importantly, shouldn't we change the defaults so that a call to `Adafactor(model.paramaters())` == `Adafactor(model.parameters(), scale_parameter=False, relative_step=False, warmup_init=False, lr=1e-3)`\r\n\r\ni.e, we default to what we suggest?",
"> I observed that Adafactor(lr=1e-3, relative_step=False, warmup_init=False) failed to lead to any learning. I guess this is because I didn't change scale_parameter to False? I can try rerunning with scale_param false.\r\n\r\nYes, please and thank you!\r\n\r\n\r\n\r\n\r\n> Regarding clip_threshold - just confirming that the comment is correct that when using adafactor we should not have any other gradient clipping (e.g. nn.utils.clip_grad_norm_())?\r\n\r\nThank you for validating this, @jsrozner \r\n\r\nIs the current incarnation of the doc clear wrt this subject matter or should we add an explicit example?\r\n\r\nOne thing I'm concerned about is that the Trainer doesn't validate this and will happily run `clip_grad_norm` with Adafactor\r\n\r\nMight we need to add to:\r\n\r\nhttps://github.com/huggingface/transformers/blob/9f8fa4e9730b8e658bcd5625610cc70f3a019818/src/transformers/trainer.py#L649-L651\r\n\r\n```\r\nif self.args.max_grad_norm:\r\n raise ValueError(\"don't use max_grad_norm with adafactor\")\r\n```\r\n\r\n\r\n> But most importantly, shouldn't we change the defaults so that a call to Adafactor(model.paramaters()) == `Adafactor(model.parameters(), scale_parameter=False, relative_step=False, warmup_init=False, lr=1e-3)`\r\n\r\nSince we copied the code verbatim from fairseq, it might be a good idea to keep the defaults the same? I'm not attached to either way. @sgugger what do you think?\r\n\r\nedit: I don't think we can/should since it may break people's code that relies on the current defaults.",
"> > Regarding clip_threshold - just confirming that the comment is correct that when using adafactor we should not have any other gradient clipping (e.g. nn.utils.clip_grad_norm_())?\r\n> \r\n> Thank you for validating this, @jsrozner\r\n\r\nSorry, I didn't validate this. I wanted to confirm with you all that this is correct.\r\n\r\n> > But most importantly, shouldn't we change the defaults so that a call to Adafactor(model.paramaters()) == `Adafactor(model.parameters(), scale_parameter=False, relative_step=False, warmup_init=False, lr=1e-3)`\r\n> \r\n> Since we copied the code verbatim from fairseq, it might be a good idea to keep the defaults the same? I'm not attached to either way. @sgugger what do you think?\r\n\r\nAlternative is to not provide defaults for these values and force the user to read documentation and decide what he/she wants. Can provide the default implementation as well as Adafactor's recommended settings\r\n\r\n",
"> I'm running some experiments, playing around with Adafactor parameters. I'll post here which configuration has best results. From T5 paper, they used the following parameters for fine-tuning: Adafactor with _constant_ lr 1e-3, with batch size 128, if I understood the paper well. Therefore, I find it appropriate the documentation changes mentioned above, leaving the recommendations from the paper while mentioning other configs that have worked well for other users. In my case, for example, the configuration from the paper doesn't work very well and I quickly overfit.\r\n\r\n@alexvaca0 \r\nWhat set of adafactor params did you find work well when you were finetuning t5?",
"> Sorry, I didn't validate this. I wanted to confirm with you all that this is correct.\r\n\r\nI meant validating as in reading over and checking that it makes sense. So all is good. Thank you for extra clarification so we were on the same page, @jsrozner \r\n \r\n> Alternative is to not provide defaults for these values and force the user to read documentation and decide what he/she wants. Can provide the default implementation as well as Adafactor's recommended settings\r\n\r\nas I appended to my initial comment, this would be a breaking change. So if it's crucial that we do that, this would need to happen in the next major release.\r\n",
"Or maybe add a warning message that indicates that default params may not be optimal? It will be logged only a single time at optimizer init so not too annoying.\r\n\r\n`log.warning('Initializing Adafactor. If you are using default settings, it is recommended that you read the documentation to ensure that these are optimal for your use case.)`",
"But we now changed it propose two different ways - which one is the recommended one? The one used by the Trainer?\r\n\r\nSince it's pretty clear that there is more than one way, surely the user will find their way to the doc if they aren't happy with the results.\r\n\r\n",
"I ran my model under three different adafactor setups:\r\n\r\n```python\r\n optimizer = Adafactor(self.model.parameters(),\r\n relative_step=True,\r\n warmup_init=True)\r\n```\r\n```python\r\noptimizer = Adafactor(self.model.parameters(),\r\n relative_step=True,\r\n warmup_init=True,\r\n scale_parameter=False)\r\n```\r\n```python\r\n optimizer = Adafactor(self.model.parameters(),\r\n lr=1e-3,\r\n relative_step=False,\r\n warmup_init=False,\r\n scale_parameter=False)\r\n```\r\n\r\nI track exact match and NLL on the dev set. Epochs are tracked at the bottom. They start at 11 because of how I'm doing things. (i.e. x=11 => epoch=1)\r\n\r\nNote that I'm training a t5-small model on 80,000 examples, so maybe there's some variability with the sort of model we're training?\r\n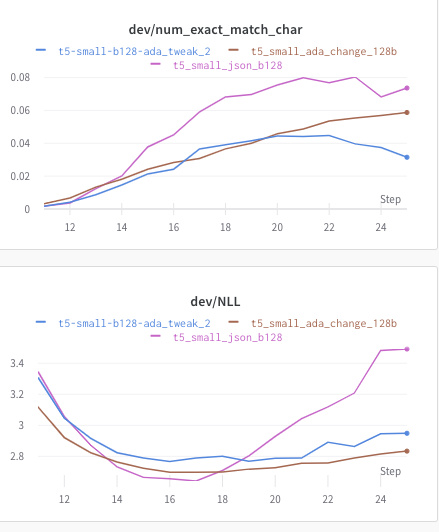\r\n\r\n(Image works if you navigate to the link, but seems not to appear?)\r\n\r\npurple is (1)\r\nblue is (2) and by far the worst (i.e. shows that scale_param should be set to True if we are using relative_step)\r\nbrown is (3)\r\n\r\nIn particular, it looks like scale_param should be True for the setting under \" Others reported the following combination to work well::\"\r\n\r\nOn the other hand, it looks like for a t5-large model, (3) does better than (1) (although I also had substantially different batch sizes). ",
"Thank you, @jsrozner, for running these experiments and the analysis.\r\n\r\nSo basically we should adjust \" Others reported the following combination to work well::\" to `scale_param=True`, correct? \r\n\r\nInterestingly we end up with 2 almost total opposites.",
"@jsrozner Batch size and learning rate configuration go hand in hand, therefore it's difficult to know about your last reflexion, as having different different batch sizes lead to different gradient estimations (in particular, the lower the batch size, the worse your gradient estimation is), the larger your batch size, the larger your learning rate can be without negatively affecting performance. \r\nFor the rest of the experiments, thanks a lot, the comparison is very clear and this will be very helpful for those of us who want to have some \"default\" parameters to start from. I see a clear advantage to leave the learning rate as None, as when setting an external learning rate we typically have to make experiments to find the optimal one for that concrete problem, so if it provides results similar or better to the ones provided by the paper's recommended parameters, I'd go with that as default. \r\nI hope I can have my experiments done soon, which will be with t5-large probably, to see if they coincide with your findings.",
"OK, let's merge this and if we need to make updates for any new findings we will do it then. ",
"Although I didn't really run an experiment, I have found that my settings for adafactor (relative step, warmup, scale all true) do well when training t5-large, also.\r\n\r\n@alexvaca0 please post your results when you have them!"
] | 1,614 | 1,617 | 1,617 | CONTRIBUTOR | null | This PR fixes documentation to reflect optimal settings for Adafactor:
- fix an impossible arg combination erroneously proposed in the example
- use the correct link to the adafactor paper where `clip_treshold` is discussed
- document the recommended `scale_parameter=False`
- add other recommended settings combinations, which are quite different from the original
- re-org notes
- make the errors less ambiguous
Fixes #7789
@sgugger
(edited by @stas00 to reflect it's pre-merge state as the PR evolved since it's original submission) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10526/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10526/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10526",
"html_url": "https://github.com/huggingface/transformers/pull/10526",
"diff_url": "https://github.com/huggingface/transformers/pull/10526.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10526.patch",
"merged_at": 1617249818000
} |
https://api.github.com/repos/huggingface/transformers/issues/10525 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10525/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10525/comments | https://api.github.com/repos/huggingface/transformers/issues/10525/events | https://github.com/huggingface/transformers/issues/10525 | 822,490,543 | MDU6SXNzdWU4MjI0OTA1NDM= | 10,525 | fine-tune Pegasus with xsum using Colab but generation results have no difference | {
"login": "harrywang",
"id": 595772,
"node_id": "MDQ6VXNlcjU5NTc3Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/595772?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/harrywang",
"html_url": "https://github.com/harrywang",
"followers_url": "https://api.github.com/users/harrywang/followers",
"following_url": "https://api.github.com/users/harrywang/following{/other_user}",
"gists_url": "https://api.github.com/users/harrywang/gists{/gist_id}",
"starred_url": "https://api.github.com/users/harrywang/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harrywang/subscriptions",
"organizations_url": "https://api.github.com/users/harrywang/orgs",
"repos_url": "https://api.github.com/users/harrywang/repos",
"events_url": "https://api.github.com/users/harrywang/events{/privacy}",
"received_events_url": "https://api.github.com/users/harrywang/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\ncould you please ask this question on the [forum](https://discuss.huggingface.co/)? We're happy to help you there!\r\n\r\nQuestions regarding training of models are a perfect use case for the forum :) for example, [here](https://discuss.huggingface.co/search?q=pegasus) you can find all questions related to fine-tuning PEGASUS.",
"@NielsRogge thanks a lot! I will post the question in forum 😄🤝",
"I think this issue can be closed - I used another input text and the generated text is different - I guess the fine-tuned model is different but for some input text, the generated result is exactly the same as the large model - interesting to know why though :)."
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | Hi. I tried to fine-tune pegasus large with xsum dataset using Colab (Pro). I was able to finish the fine-tuning with batch size 1, and 2000 epochs in about 40 minutes (larger batch size crashed colab). The working Colab notebook I used is shared at https://colab.research.google.com/drive/1RyUsYDAo6bA1RZICMb-FxYLszBcDY81X?usp=sharing
However, the generated summary seems to be the same for the pegasus large model (https://huggingface.co/google/pegasus-large) and the fine-tuned model. But the generated result using pegasus xsum model (https://huggingface.co/google/pegasus-xsum) is different and much better.
The training loss is already 0 and I am not sure what I have done wrong. Any help and pointers are highly appreciated.
@sshleifer
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10525/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10525/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10524 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10524/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10524/comments | https://api.github.com/repos/huggingface/transformers/issues/10524/events | https://github.com/huggingface/transformers/pull/10524 | 822,424,501 | MDExOlB1bGxSZXF1ZXN0NTg1MDUxNzcw | 10,524 | Change/remove default maximum length in run_glue.py | {
"login": "aditya-malte",
"id": 20294625,
"node_id": "MDQ6VXNlcjIwMjk0NjI1",
"avatar_url": "https://avatars.githubusercontent.com/u/20294625?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aditya-malte",
"html_url": "https://github.com/aditya-malte",
"followers_url": "https://api.github.com/users/aditya-malte/followers",
"following_url": "https://api.github.com/users/aditya-malte/following{/other_user}",
"gists_url": "https://api.github.com/users/aditya-malte/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aditya-malte/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aditya-malte/subscriptions",
"organizations_url": "https://api.github.com/users/aditya-malte/orgs",
"repos_url": "https://api.github.com/users/aditya-malte/repos",
"events_url": "https://api.github.com/users/aditya-malte/events{/privacy}",
"received_events_url": "https://api.github.com/users/aditya-malte/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"@sgugger Can you review this extremely simple PR",
"Hi there. The default is actually the same as the legacy script and I don't see any reason to change it. It provides the results given in the README which are consistent with the paper.\r\n\r\nAlso a default of 512 won't work with models that have a smaller max_length like distilbert.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Oh. Yeah, I didn’t know distilbert had a smaller max_len. I’d seen max_len at least greater than or equal to 512 until now. "
] | 1,614 | 1,618 | 1,618 | NONE | null | I propose one of the following:
1) A vast majority of models have maximum sequence length as 512. 128 as a maximum length is very misleading because of this reason and hence I suggest we revise it to 512.
2) Totally remove this variable and set maximum length only based on model’s maximum length. The tokenizers library used in this example already has code to take the minimum of (max_seq_length, max_model_seq_length). Why not just remove this redundancy and directly set it based on the model’s largest acceptable sequence length
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10524/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10524/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10524",
"html_url": "https://github.com/huggingface/transformers/pull/10524",
"diff_url": "https://github.com/huggingface/transformers/pull/10524.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10524.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10523 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10523/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10523/comments | https://api.github.com/repos/huggingface/transformers/issues/10523/events | https://github.com/huggingface/transformers/issues/10523 | 822,408,968 | MDU6SXNzdWU4MjI0MDg5Njg= | 10,523 | BERT as encoder - position ids | {
"login": "md975",
"id": 25549182,
"node_id": "MDQ6VXNlcjI1NTQ5MTgy",
"avatar_url": "https://avatars.githubusercontent.com/u/25549182?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/md975",
"html_url": "https://github.com/md975",
"followers_url": "https://api.github.com/users/md975/followers",
"following_url": "https://api.github.com/users/md975/following{/other_user}",
"gists_url": "https://api.github.com/users/md975/gists{/gist_id}",
"starred_url": "https://api.github.com/users/md975/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/md975/subscriptions",
"organizations_url": "https://api.github.com/users/md975/orgs",
"repos_url": "https://api.github.com/users/md975/repos",
"events_url": "https://api.github.com/users/md975/events{/privacy}",
"received_events_url": "https://api.github.com/users/md975/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! In the documentation you pointed to, you'll see that there is the `kwargs` argument, which accepts any keyword argument. The doc says:\r\n\r\n```\r\n(optional) Remaining dictionary of keyword arguments. Keyword arguments come in two flavors:\r\n\r\nWithout a prefix which will be input as **encoder_kwargs for the encoder forward function.\r\n\r\nWith a decoder_ prefix which will be input as **decoder_kwargs for the decoder forward function.\r\n```\r\n\r\nHave you tried passing `position_ids` to the `__call__` method of your model instantiated with the `EncoderDecoderModel.from_encoder_decoder_pretrained`? It should work!",
"Thanks so much!"
] | 1,614 | 1,614 | 1,614 | NONE | null | Hello,
I have an EncoderDecoderModel.from_encoder_decoder_pretrained which is using BERT as both the decoder and encoder.
I would like to adjust position_ids for the encoder input, however, looking at [this documentation](https://huggingface.co/transformers/model_doc/encoderdecoder.html#transformers.EncoderDecoderModel.forward) it seems like there is no such argument.
How can I do this?
Sorry if this is an obvious question, I'm new to this stuff.
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10523/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10523/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10522 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10522/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10522/comments | https://api.github.com/repos/huggingface/transformers/issues/10522/events | https://github.com/huggingface/transformers/issues/10522 | 822,389,034 | MDU6SXNzdWU4MjIzODkwMzQ= | 10,522 | Inconsistent API output for Q&A models between eager mode and torchscripted | {
"login": "HamidShojanazeri",
"id": 9162336,
"node_id": "MDQ6VXNlcjkxNjIzMzY=",
"avatar_url": "https://avatars.githubusercontent.com/u/9162336?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/HamidShojanazeri",
"html_url": "https://github.com/HamidShojanazeri",
"followers_url": "https://api.github.com/users/HamidShojanazeri/followers",
"following_url": "https://api.github.com/users/HamidShojanazeri/following{/other_user}",
"gists_url": "https://api.github.com/users/HamidShojanazeri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/HamidShojanazeri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/HamidShojanazeri/subscriptions",
"organizations_url": "https://api.github.com/users/HamidShojanazeri/orgs",
"repos_url": "https://api.github.com/users/HamidShojanazeri/repos",
"events_url": "https://api.github.com/users/HamidShojanazeri/events{/privacy}",
"received_events_url": "https://api.github.com/users/HamidShojanazeri/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"`torchscript` does not support anything else than tuple outputs, so you can't rely on the attributes when using it and transformers automatically sets `return_dict=False` in this case.\r\n\r\nYou need to access to the output fields with indices.",
"@sgugger Thanks for the explanations.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | CONTRIBUTOR | null | ## Environment info
- `transformers` version: 4.3.3
- Platform: Linux-5.4.0-1037-aws-x86_64-with-glibc2.10
- Python version:3.8.6
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?):
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
## Information
@sgugger I am using question-answering models from auto class, have tried, Bert-base/Roberta-base/distilbert-base-cased-distilled-squad.
The problem arises when using:
Accessing the start and end logits through the output of the model is inconsistent between eager mode and Torchscripted(traced) model. For the eager mode, it is possible to use "outputs.start_logits, outputs.end_logits" however for
Torchscripted model, it returns a tuple, as it was in older version (i.e. 2.10).
## To reproduce
```
import transformers
import os
import torch
from transformers import (AutoModelForSequenceClassification, AutoTokenizer, AutoModelForQuestionAnswering,
AutoModelForTokenClassification, AutoConfig)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pretrained_model_name = 'distilbert-base-cased-distilled-squad'
max_length = 30
config_torchscript = AutoConfig.from_pretrained(pretrained_model_name,torchscript=True)
model_torchscript = AutoModelForQuestionAnswering.from_pretrained(pretrained_model_name,config=config_torchscript)
tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name,do_lower_case=True)
config = AutoConfig.from_pretrained(pretrained_model_name)
model = AutoModelForQuestionAnswering.from_pretrained(pretrained_model_name,config=config)
dummy_input = "This is a dummy input for torch jit trace"
inputs = tokenizer.encode_plus(dummy_input,max_length = int(max_length),pad_to_max_length = True, add_special_tokens = True, return_tensors = 'pt')
input_ids = inputs["input_ids"].to(device)
model.to(device).eval()
model_torchscript.to(device).eval()
traced_model = torch.jit.trace(model_torchscript, [input_ids])
outputs = model(input_ids)
print(outputs.start_logits, outputs.end_logits)
print("******************************* eager mode passed **************")
traced_outputs = traced_model(input_ids)
print(traced_outputs.start_logits, traced_outputs.end_logits)
print("******************************* traced mode passed **************")
```
Steps to reproduce the behavior:
1. install transformers.
2. Run the above code snippet
## Expected behavior
Being able to access the start and end logits consistently between eager and torchscript mode.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10522/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10522/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10521 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10521/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10521/comments | https://api.github.com/repos/huggingface/transformers/issues/10521/events | https://github.com/huggingface/transformers/pull/10521 | 822,248,710 | MDExOlB1bGxSZXF1ZXN0NTg0OTA0NTQy | 10,521 | Removes overwrites for output_dir | {
"login": "philschmid",
"id": 32632186,
"node_id": "MDQ6VXNlcjMyNjMyMTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/32632186?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/philschmid",
"html_url": "https://github.com/philschmid",
"followers_url": "https://api.github.com/users/philschmid/followers",
"following_url": "https://api.github.com/users/philschmid/following{/other_user}",
"gists_url": "https://api.github.com/users/philschmid/gists{/gist_id}",
"starred_url": "https://api.github.com/users/philschmid/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/philschmid/subscriptions",
"organizations_url": "https://api.github.com/users/philschmid/orgs",
"repos_url": "https://api.github.com/users/philschmid/repos",
"events_url": "https://api.github.com/users/philschmid/events{/privacy}",
"received_events_url": "https://api.github.com/users/philschmid/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | MEMBER | null | # What does this PR do?
This PR removes the overwrites of the `output_dir` when running training on `SageMaker` and it removes the automatic save if `output_dir` is `None`.
The overwrites have been removed since it prevents saving checkpoints to a different dir like `opt/ml/checkpoints` impossible and it is not the "transformers" way. We can keep it the same as running training somewhere else and provide documentation on what you need to do. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10521/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10521/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10521",
"html_url": "https://github.com/huggingface/transformers/pull/10521",
"diff_url": "https://github.com/huggingface/transformers/pull/10521.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10521.patch",
"merged_at": 1614874358000
} |
https://api.github.com/repos/huggingface/transformers/issues/10520 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10520/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10520/comments | https://api.github.com/repos/huggingface/transformers/issues/10520/events | https://github.com/huggingface/transformers/issues/10520 | 822,244,488 | MDU6SXNzdWU4MjIyNDQ0ODg= | 10,520 | Unable to translate Arabic to many other languages in MBart-50 | {
"login": "lecidhugo",
"id": 52243817,
"node_id": "MDQ6VXNlcjUyMjQzODE3",
"avatar_url": "https://avatars.githubusercontent.com/u/52243817?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lecidhugo",
"html_url": "https://github.com/lecidhugo",
"followers_url": "https://api.github.com/users/lecidhugo/followers",
"following_url": "https://api.github.com/users/lecidhugo/following{/other_user}",
"gists_url": "https://api.github.com/users/lecidhugo/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lecidhugo/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lecidhugo/subscriptions",
"organizations_url": "https://api.github.com/users/lecidhugo/orgs",
"repos_url": "https://api.github.com/users/lecidhugo/repos",
"events_url": "https://api.github.com/users/lecidhugo/events{/privacy}",
"received_events_url": "https://api.github.com/users/lecidhugo/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
}
] | [
"Hi @lecidhugo \r\n\r\nThank you for reporting this. Is this for one particular example or is it happening for all examples?",
"Hi @patil-suraj,\r\nThank you for your reply.\r\nIndeed, it is for all examples and for many languages",
"Thanks. I'll look into it next week.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Unstale\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,621 | 1,621 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0.dev0
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.7.1+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patrickvonplaten
## Information
Model I am using (Bert, XLNet ...): Mbart-50
The problem arises when using:
* [ X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ X] an official GLUE/SQUaD task: (give the name)
* [ ] my own task or dataset: (give details below)
## To reproduce
```
# translate Arabic to Hindi
article_ar = "الأمين العام للأمم المتحدة يقول إنه لا يوجد حل عسكري في سوريا."
tokenizer.src_lang = "ar_AR"
encoded_ar = tokenizer(article_ar, return_tensors="pt")
generated_tokens = model.generate(
**encoded_ar,
forced_bos_token_id=tokenizer.lang_code_to_id["hi_IN"]
)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
```
**Result: ['Secretary of the United Nations says there is no military solution to Syria.']**
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
The result should be in Hindi, but it weirdly it is in English. Arabic --> Hindi is an example. But if you test Arabic -->xx_XX you will obtain the same behavior except for a few ones (such as `fr_XX` or `de_DE`)
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10520/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10520/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10519 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10519/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10519/comments | https://api.github.com/repos/huggingface/transformers/issues/10519/events | https://github.com/huggingface/transformers/issues/10519 | 822,237,938 | MDU6SXNzdWU4MjIyMzc5Mzg= | 10,519 | Adding option to truncation from beginning instead of end, for both longest_first and longest_second | {
"login": "jatinganhotra",
"id": 307606,
"node_id": "MDQ6VXNlcjMwNzYwNg==",
"avatar_url": "https://avatars.githubusercontent.com/u/307606?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jatinganhotra",
"html_url": "https://github.com/jatinganhotra",
"followers_url": "https://api.github.com/users/jatinganhotra/followers",
"following_url": "https://api.github.com/users/jatinganhotra/following{/other_user}",
"gists_url": "https://api.github.com/users/jatinganhotra/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jatinganhotra/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jatinganhotra/subscriptions",
"organizations_url": "https://api.github.com/users/jatinganhotra/orgs",
"repos_url": "https://api.github.com/users/jatinganhotra/repos",
"events_url": "https://api.github.com/users/jatinganhotra/events{/privacy}",
"received_events_url": "https://api.github.com/users/jatinganhotra/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] | open | false | null | [] | [
"Previous mention of this idea\r\nhttps://github.com/huggingface/transformers/issues/4476#issuecomment-677823688",
"Here's my workaround (from the previous issue): https://github.com/huggingface/transformers/issues/4476#issuecomment-951445067",
"May be of interest to @SaulLu @NielsRogge ",
"This is indeed a feature that is requested and would make sense to have!\r\n\r\nTo my knowledge @NielsRogge has started a [PR to add this feature](https://github.com/huggingface/transformers/pull/12913). Unfortunately, the feature requires development also in the Tokenizers library and nobody has yet got the bandwidth to support [the dedicated issue](https://github.com/huggingface/tokenizers/issues/779) for this feature.",
"> the feature requires development\r\n\r\nLinks provided show that only fast tokenizers are stopping this (\"requested and would make sense to have\" feature) to be implemented (\"since july.... July, Karl!\"). May this be implemented for ordinary tokenizers faster, and for faster tokenizers later, when they solve dedicated issues?\r\n\r\nIn my opinion, having left truncation for \"slow\" tokenizers now, is better than not having one at all (or in distant future releases). It is awaited (https://github.com/huggingface/transformers/issues/4476#event-3364051747) for more than a year now at least.",
"Seems this was added in #14947 about a month ago, so hopefully it will be in a near-future release!"
] | 1,614 | 1,645 | null | NONE | null | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
The current [truncation strategies](https://huggingface.co/transformers/preprocessing.html#everything-you-always-wanted-to-know-about-padding-and-truncation) only provide truncation from end of the input sentence. This may be enough for most cases, but is not applicable for dialog tasks.
Say, you are concatenating an input dialog context to BERT. If the input length > max_length (256/ 512), then the tokens are truncated from the ending i.e. the most recent utterances in the dialog.
In some cases, you want the most recent utterances to be included in the input and if truncation needs to be done, then the oldest utterances be truncated i.e. truncation from the beginning.
This can be done manually in own code base outside of Transformers library, but it's not ideal.
Truncation outside of model will be done most likely on full words to truncate from beginning and fit them to model max length (say you truncate from beginning and reduce input to 254 words). But, these words will be converted to subwords when fed to BertTokenizer and the final input will be > 256, thus resulting in words being dropped from the last utterance again.
To do this properly outside of the Transformers library, one would need to instantiate the same Tokenizer object, tokenize each input and then truncate from beginning, then convert ids back to tokens and then either reconstruct the input from the truncated tokenized version or skip the tokenizer call inside the Transformers library.
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
## Your contribution
<!-- Is there any way that you could help, e.g. by submitting a PR?
Make sure to read the CONTRIBUTING.MD readme:
https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10519/reactions",
"total_count": 9,
"+1": 9,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10519/timeline | null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10518 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10518/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10518/comments | https://api.github.com/repos/huggingface/transformers/issues/10518/events | https://github.com/huggingface/transformers/issues/10518 | 822,225,056 | MDU6SXNzdWU4MjIyMjUwNTY= | 10,518 | Converting models for tensoflowjs (node) | {
"login": "ierezell",
"id": 30974685,
"node_id": "MDQ6VXNlcjMwOTc0Njg1",
"avatar_url": "https://avatars.githubusercontent.com/u/30974685?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ierezell",
"html_url": "https://github.com/ierezell",
"followers_url": "https://api.github.com/users/ierezell/followers",
"following_url": "https://api.github.com/users/ierezell/following{/other_user}",
"gists_url": "https://api.github.com/users/ierezell/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ierezell/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ierezell/subscriptions",
"organizations_url": "https://api.github.com/users/ierezell/orgs",
"repos_url": "https://api.github.com/users/ierezell/repos",
"events_url": "https://api.github.com/users/ierezell/events{/privacy}",
"received_events_url": "https://api.github.com/users/ierezell/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1834083927,
"node_id": "MDU6TGFiZWwxODM0MDgzOTI3",
"url": "https://api.github.com/repos/huggingface/transformers/labels/External",
"name": "External",
"color": "fbca04",
"default": false,
"description": "Using the library with external tools (onnx, tflite, ...)"
}
] | closed | false | null | [] | [
"Hello!\r\n\r\nThanks for reporting this issue! Did you try to convert your H5 file to be able to use it with `tensorflowjs_converter --input_format keras path/to/my_model.h5 path/to/tfjs_target_dir`? You can also have a SavedModel version with:\r\n\r\n1. `model = TFAutoModel.from_pretrained(\"distilbert-base-uncased\")`\r\n2. `model.save_pretrained(path, saved_model=True)`\r\n\r\nH5 and SavedModel conversion process are nicely explained in https://www.tensorflow.org/js/tutorials/conversion/import_keras and https://www.tensorflow.org/js/tutorials/conversion/import_saved_model",
"Hi @jplu thanks for the fast reply ! \r\n\r\nYes I used the `tensorflowjs_converter` to convert the H5 huggingFace model to a TFJS layerModel (.json).\r\n\r\nIf not using a h5 but a savedModel I don't know how to then use it in tensorflowJS.... all my researches seems to indicate that a savedModel can only do inference but i would like to finetune it. \r\n\r\nMy goal is just to finetune Bert in nodejs (could be with other framework than tfjs if you know some (like pytorch node bindings or some fancy framework but I found nothing that allow training))\r\n\r\n## Attempts : \r\n\r\n### HuggingFace : \r\n1. Load model with huggingFace : `model = TFAutoModel.from_pretrained(model_name)`\r\n2. Save it (H5 format) : `model.save_pretrained(path_saved)`\r\n3. convert it to tfjs.json Layer format : \r\n```python\r\ndispatch_keras_h5_to_tfjs_layers_model_conversion(\r\n h5_path='path_saved/tf_model.h5',\r\n output_dir=my_tfjs_output_dir\r\n)\r\n```\r\n(`dispatch_keras_h5_to_tfjs_layers_model_conversion` is the function called when using `tensorflowjs_convert`, i'm calling it from python code)\r\n4. try to load it in nodejs : `const bert = await tf.loadLayersModel('file://${my_tfjs_output_dir}/model.json')`\r\n5. Get the error `UnhandledPromiseRejectionWarning: TypeError: Cannot read property 'model_config' of null`\r\n\r\n### Keras or tfjs saving (to have the `model_config`)\r\n1. Load model with huggingFace : `model = TFAutoModel.from_pretrained(model_name)`\r\n2. Save it (H5 format) : \r\n```python\r\ntf.keras.models.save_model(\r\n model=model,\r\n filepath=path_saved,\r\n signatures=tf.function(model.call).get_concrete_function([\r\n tf.TensorSpec([1, 512], tf.int32, name=\"input_ids\"),\r\n tf.TensorSpec([1, 512], tf.int32, name=\"attention_mask\")\r\n ]),\r\n save_format='h5'\r\n)\r\n```\r\nor \r\n`tfjs.converters.save_keras_model( model, path_saved)`\r\n3. Get the error `Saving the model to HDF5 format requires the model to be a Functional model or a Sequential model.`\r\n\r\n### Other formats : \r\n1. Load model with huggingFace : `model = TFAutoModel.from_pretrained(model_name)`\r\n2. Save it (SavedModel format) : `model.save_pretrained(path_saved)`\r\n4. try to load it in nodejs : `const bert = await tf.node.loadSavedModel(path_saved, ['serve'], \"serving_default\")`\r\n5. Cannot train it or use it in another model with `this._clf = tf.sequential(); this._clf.add(bert);`\r\n\r\n#### GraphModel or onnx model are for inference only \r\n\r\nSorry for this (too) long reply. \r\n\r\nThanks for your help (I guess many people try to attempt the same), \r\n\r\nHave a great day ",
"Indeed you cannot train or fine tune a SavedModel in other envs than Python.\r\n\r\nCurrently to load a model you are forced to have the config file because it is required as an argument to init a model. Then the H5 as well. Furthermore, the TF implementations are using subclass models which are not compliant with most of the internal TF process (such as what you are trying to do in your described process when saving a model).\r\n\r\nThen, I suggest you to fine tune your model in Python, create a SavedModel, and then use it in JS as described in the link I shared. Sorry for the inconvenience.",
"Okay so SOA is training custom models in tfjs but finetunning is almost impossible. It's what I thought but I'm glad you confirmed it. \r\n\r\nDo you know any other solutions that would allow me to finetune a model in a webstack (nodejs / typescript) ?\r\nI'm still hoping that one day pytorch will have node bindings... \r\n\r\nThanks again for your time. \r\nI guess we can close the issue.",
"> Do you know any other solutions that would allow me to finetune a model in a webstack (nodejs / typescript) ?\r\n\r\nNo, sorry this is not really my domain. And sorry again for the inconvenience on this."
] | 1,614 | 1,615 | 1,615 | CONTRIBUTOR | null | ## Environment info
- `transformers` version: 4.3.3
- Platform: Linux-5.11.2-zen1-1-zen-x86_64-with-glibc2.2.5
- Python version: 3.8.8 (also 3.9.2 but tensorflowjs is not available in 3.9.2)
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
- tensorflow: @jplu
## Information
Model I am using (Bert, XLNet ...): Any tensorflow ones
The problem arises when using:
* [X] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
1. Load a tensforflow model (e.g : `model = TFAutoModel.from_pretrained("distilbert-base-uncased")`)
2. Convert it to H5 with `model.save_pretrained(path)`
3. Try to load it in tensorflowjs and get `UnhandledPromiseRejectionWarning: TypeError: Cannot read property 'model_config' of null`
## Expected behavior
Be able to load a model in the LayerModel format as it's the only one which allows finetuning.
## More informations.
I know the question was already posted in https://github.com/huggingface/transformers/issues/4073
I need to do finetuning so onnx, graphModels & cie should be avoided.
Seems that the H5 model just need the config file which seems saved on the side with the custom HF script.
I went to read some issues on tensorflowjs (exemple : [this](https://github.com/tensorflow/tfjs/issues/2455) or [that](https://github.com/tensorflow/tfjs/issues/931)) and the problem is that the HF model contains only the weights and not the architecture. The goal would be to adapt the `save_pretrained` function to save the architecture as well. I guess it's complex because of the `Saving the model to HDF5 format requires the model to be a Functional model or a Sequential model.` error in described bellow.
Seems also that only H5 model can be converted to a trainable LayerModel.
I'm willing to work on a PR or to help as i'm working on a web stack (nodejs) and I need this.
I made a drawing of all models (that I'm aware of) to summarize loading converting :
## Also tried :
Use the nodejs `tf.node.loadSavedModel` which return only a saved model which I cannot use as the base structure with something like :
```
const bert = await tf.loadLayersModel(`file://${this._bert_model_path}/model.json`)
this._clf = tf.sequential();
this._clf.add(bert); // Raise Error
this._clf.add(tf.layers.dense({ units: 768, useBias: true }));
etc...
this._clf.compile(....)
this._clf.train(...)
```
Look for other libraries to train models (libtorch : incomplete, onnx training: only in python etc..)
Should I also write an issue on tensorflowjs ?
Thanks in advance for you time and have a great day. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10518/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/10518/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10517 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10517/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10517/comments | https://api.github.com/repos/huggingface/transformers/issues/10517/events | https://github.com/huggingface/transformers/pull/10517 | 822,203,753 | MDExOlB1bGxSZXF1ZXN0NTg0ODY2NzM3 | 10,517 | Not always consider a local model a checkpoint in run_glue | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | COLLABORATOR | null | # What does this PR do?
In the `run_glue` script, a local model is automatically considered a checkpoint (which is there to enable users to do --model_path_or_name path_to_specific_checkpoint`) but when using a local model, it can crash if the number of labels is different (cf #10502). This PR fixes that by checking the number of labels inside the potential checkpoint before passing it to the `Trainer`. Another possible fix is to check for the presence of files like `trainer_state.json` (but this only works if the checkpoint was created with a recent version of Transformers).
Fixes #10502
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10517/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10517/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10517",
"html_url": "https://github.com/huggingface/transformers/pull/10517",
"diff_url": "https://github.com/huggingface/transformers/pull/10517.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10517.patch",
"merged_at": 1614874299000
} |
https://api.github.com/repos/huggingface/transformers/issues/10514 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10514/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10514/comments | https://api.github.com/repos/huggingface/transformers/issues/10514/events | https://github.com/huggingface/transformers/issues/10514 | 822,101,612 | MDU6SXNzdWU4MjIxMDE2MTI= | 10,514 | Bug in Hosted inference API | {
"login": "hhou435",
"id": 59219579,
"node_id": "MDQ6VXNlcjU5MjE5NTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/59219579?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/hhou435",
"html_url": "https://github.com/hhou435",
"followers_url": "https://api.github.com/users/hhou435/followers",
"following_url": "https://api.github.com/users/hhou435/following{/other_user}",
"gists_url": "https://api.github.com/users/hhou435/gists{/gist_id}",
"starred_url": "https://api.github.com/users/hhou435/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/hhou435/subscriptions",
"organizations_url": "https://api.github.com/users/hhou435/orgs",
"repos_url": "https://api.github.com/users/hhou435/repos",
"events_url": "https://api.github.com/users/hhou435/events{/privacy}",
"received_events_url": "https://api.github.com/users/hhou435/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | CONTRIBUTOR | null | Hello,I found that when I use the Hosted inference API, there will be some problems.
Some inference results show the entire sentence, but other inference results only show the mask token.
For example the model [uer/roberta-base-word-chinese-cluecorpussmall](https://huggingface.co/uer/roberta-base-word-chinese-cluecorpussmall).
When I input "中国的首都是北[MASK]",the results are:


Thanks
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10514/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10514/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10513 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10513/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10513/comments | https://api.github.com/repos/huggingface/transformers/issues/10513/events | https://github.com/huggingface/transformers/pull/10513 | 822,081,918 | MDExOlB1bGxSZXF1ZXN0NTg0NzY0MDkz | 10,513 | Add Vision Transformer + ViTFeatureExtractor | {
"login": "NielsRogge",
"id": 48327001,
"node_id": "MDQ6VXNlcjQ4MzI3MDAx",
"avatar_url": "https://avatars.githubusercontent.com/u/48327001?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/NielsRogge",
"html_url": "https://github.com/NielsRogge",
"followers_url": "https://api.github.com/users/NielsRogge/followers",
"following_url": "https://api.github.com/users/NielsRogge/following{/other_user}",
"gists_url": "https://api.github.com/users/NielsRogge/gists{/gist_id}",
"starred_url": "https://api.github.com/users/NielsRogge/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/NielsRogge/subscriptions",
"organizations_url": "https://api.github.com/users/NielsRogge/orgs",
"repos_url": "https://api.github.com/users/NielsRogge/repos",
"events_url": "https://api.github.com/users/NielsRogge/events{/privacy}",
"received_events_url": "https://api.github.com/users/NielsRogge/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @NielsRogge \r\n\r\n\r\n> Add and improve tests. Currently I have defined the following tests: test_modeling_vit.py, test_feature_extraction_vit.py. However, for the former, since ViT does not use input_ids/input_embeds, some tests are failing, so I wonder whether it should use all tests defined in test_modeling_common.py. For the latter, I also need some help in creating random inputs to test the feature extractor on.\r\n\r\n\r\nSome common modeling test depend on the specific parameter names, (`input_ids`, `input_embeds`). You could just override such tests in your test class and use the correct parameter names. For example the `test_forward_signature` test\r\nexpects `inputs_ids`, so it should be overridden in your class to expect `input_values`. \r\n\r\nAlso, the tests for `input_embeds` (for example `test_inputs_embeds`) can be skipped since `ViT` does not use those. Agin just overrides the test and use `pass` in the method body.\r\n\r\nYou could use the modeling tests of `Wav2Vec2` and `Speech2Text` for reference since those models also use different parameter names.",
"I like the overall design `ViTFeatureExtractor`. Regrading the import `ViTFeatureExtractor`\r\nI think it should be always imported in the __init__ files, and instead, `ViTFeatureExtractor` could check for `torchvision` and raise if it’s not installed. Otherwise, the TF tests on CI will fail because they won’t be able to import `ViTFeatureExtractor` as we don’t install `torchvision` in TF tests.\r\n\r\nWe should also add the `torchvision` and `PIL` dependency in the setup.py file as `extras[\"vision\"]` and also add it in `config.yaml` for CI",
"Thanks for the reviews, addressed most of the comments. To do:\r\n\r\n- [x] rename `self.self` to `self.attention` and update conversion script accordingly\r\n- [x] convert more models, place them under the google namespace\r\n- [x] add model cards\r\n- [x] add 1,000 ImageNet class names to config",
"I've addressed all comments. Most important updates:\r\n\r\n* moved the ImageNet id to classes dict to a new file under transformers.utils named `imagenet_classes`.py.\r\n* added a warning to the `__call__` method of `ViTFeatureExtractor` to indicate that NumPy arrays and PyTorch tensors are converted to PIL images when resizing, so it's most efficient to pass in PIL images. \r\n\r\nThe remaining comments which are still open have to do with styling. I seem to have some issues with `make style`. The max_length is set to 119, so not sure what's causing this."
] | 1,614 | 1,617 | 1,617 | CONTRIBUTOR | null | # What does this PR do?
This PR includes 2 things:
* it adds the [Vision Transformer (ViT)](https://arxiv.org/abs/2010.11929) by Google Brain. ViT is a Transformer encoder trained on ImageNet. It is capable of classifying images, by placing a linear classification head on top of the final hidden state of the [CLS] token. I converted the weights from the [timm](https://github.com/rwightman/pytorch-image-models) repository, which already took care of converting the weights of the original implementation (which is written in JAX) into PyTorch. Once this model is added, we can also add [DeIT](https://ai.facebook.com/blog/data-efficient-image-transformers-a-promising-new-technique-for-image-classification/) (Data-efficient Image Transformers) by Facebook AI, which improve upon ViT.
* it provides a design for the `ViTFeatureExtractor` class, which can be used to prepare images for the model. It inherits from `FeatureExtractionMixin` and defines a `__call__` method. It currently accepts 3 types of inputs: PIL images, Numpy arrays and PyTorch tensors. It defines 2 transformations using `torchvision`: resizing + normalization. It then returns a `BatchFeature` object with 1 key, namely `pixel_values`.
Demo notebook of combination of `ViTForImageClassification` + `ViTFeatureExtractor`: https://colab.research.google.com/drive/16TCM-tJ1Mfhs00Qas063kWZmAtVJcOeP?usp=sharing
Compared to NLP models (which accept `input_ids`, `attention_mask` and `token_type_ids`), this model only accepts `pixel_values`. The model itself then converts these pixel values into patches (in case of ViT) in the `ViTEmbeddings` class.
## Help needed
Would be great if you can help me with the following tasks:
- [x] Add and improve tests. Currently I have defined the following tests: `test_modeling_vit.py`, `test_feature_extraction_vit.py`. However, for the former, since ViT does not use `input_ids`/`input_embeds`, some tests are failing, so I wonder whether it should use all tests defined in `test_modeling_common.py`. For the latter, I also need some help in creating random inputs to test the feature extractor on.
- [x] Add support for `head_mask` in the forward of `ViTModel`. Possibly remove `attention_mask`?
- [x] Run `make fix-copies` (doesn't work right now for me on Windows)
- [x] Remove the `is_decoder` logic from `modeling_vit.py` (since the model was created using the CookieCutter template). I assume that things such as `past_key_values` are not required for an encoder-only model.
## Who can review?
@patrickvonplaten @LysandreJik @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10513/reactions",
"total_count": 2,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10513/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10513",
"html_url": "https://github.com/huggingface/transformers/pull/10513",
"diff_url": "https://github.com/huggingface/transformers/pull/10513.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10513.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10512 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10512/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10512/comments | https://api.github.com/repos/huggingface/transformers/issues/10512/events | https://github.com/huggingface/transformers/issues/10512 | 821,998,125 | MDU6SXNzdWU4MjE5OTgxMjU= | 10,512 | Dynamic batch size for Seq2SeqTrainer | {
"login": "clang88",
"id": 71783092,
"node_id": "MDQ6VXNlcjcxNzgzMDky",
"avatar_url": "https://avatars.githubusercontent.com/u/71783092?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/clang88",
"html_url": "https://github.com/clang88",
"followers_url": "https://api.github.com/users/clang88/followers",
"following_url": "https://api.github.com/users/clang88/following{/other_user}",
"gists_url": "https://api.github.com/users/clang88/gists{/gist_id}",
"starred_url": "https://api.github.com/users/clang88/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/clang88/subscriptions",
"organizations_url": "https://api.github.com/users/clang88/orgs",
"repos_url": "https://api.github.com/users/clang88/repos",
"events_url": "https://api.github.com/users/clang88/events{/privacy}",
"received_events_url": "https://api.github.com/users/clang88/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Pinging @patil-suraj and @sgugger ",
"Hi @clang88 \r\n\r\nThe goal of the examples scripts is to keep them minimal and simple and I'm not sure if we want to support this immediately. \r\n\r\nFor now, you could use the `--group_by_length` argument which will group the long sequences together to avoid varying lengths and minimize the number of padding tokens.\r\n\r\nAlso to train large models, I would recommend you take a look at `fairscale/deepspeed` integration. Check this [blog post](https://huggingface.co/blog/zero-deepspeed-fairscale) for how to use `fairscale/deepspeed` with `Trainer` \r\n\r\n@sgugger think we could add a `MaxTokensSampler` for this in case we want to support this. ",
"Hi @patil-suraj,\r\n\r\nthank you for the quick reply! \r\n\r\nI will take a look at the `fairscale/deepspeed` integration!\r\n\r\nAs for `--group_by_length`: this will only work correctly if I use trainer with a `data_collator`, am I correct? I have been already experimenting with that approach, but am having some trouble during the evaluation phase with `custom_metrics`. For whatever reason, the labels passed to the function by the trainer appear to be padded with the default of -100, even though I am passing `label_pad_token_id=` of 0 (for mT5) or 1 (for mBART) in the collator. I am aware this is a whole other issue, but maybe you are aware of any potential solutions for this?\r\n\r\nThat said, I am sure `max_tokens_per_batch` would a be a great asset, as `group_by_length` does not fix the underlying issue of having batches with very long sentences that go OOM. For now I am just truncating my dataset with `max_length`, but that clearly leads to less than ideal performance of the fine-tuned model.",
"> think we could add a MaxTokensSampler for this in case we want to support this\r\n\r\nIt's a whole batch sampler that would be needed, since it results in batch size not being constant. And it would need the same version as a distributed batch sampler. This is a lot of work for a very specific use case, so we could accept a PR on an example in a research project first.\r\n\r\nOf course there is still the possibility of one user using the implementation from FAIR as was done in the old `finetune` script.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,650 | 1,619 | NONE | null | # 🚀 Feature request
In Fairseq it is possible to forego setting a constant batch-size in favor of a dynamic batch size with --max_tokens. This ensures that a batch always consists of at max N=max_tokens tokens. Fairseq tries to get to max_tokens by adding samples to the batch until N = max_tokens or just below.
I believe @sshleifer has implemented this for finetune.py here: #7030
Is it possible to add "--max_tokens_per_batch N" as a trainer argument to Seq2SeqTrainer?
## Motivation
This would an invaluable help when training/fine-tuning large models on data sequences (like sentences) of varying length. Long sequences/sentences might lead to OOM-Errors with a fixed batch-size. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10512/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10512/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10511 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10511/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10511/comments | https://api.github.com/repos/huggingface/transformers/issues/10511/events | https://github.com/huggingface/transformers/issues/10511 | 821,778,075 | MDU6SXNzdWU4MjE3NzgwNzU= | 10,511 | Why the positional embeddings in bert are not inplemented by sin/cos as the original paper said? Are these embeddings trainable? | {
"login": "SeaEagleI",
"id": 38852917,
"node_id": "MDQ6VXNlcjM4ODUyOTE3",
"avatar_url": "https://avatars.githubusercontent.com/u/38852917?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SeaEagleI",
"html_url": "https://github.com/SeaEagleI",
"followers_url": "https://api.github.com/users/SeaEagleI/followers",
"following_url": "https://api.github.com/users/SeaEagleI/following{/other_user}",
"gists_url": "https://api.github.com/users/SeaEagleI/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SeaEagleI/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SeaEagleI/subscriptions",
"organizations_url": "https://api.github.com/users/SeaEagleI/orgs",
"repos_url": "https://api.github.com/users/SeaEagleI/repos",
"events_url": "https://api.github.com/users/SeaEagleI/events{/privacy}",
"received_events_url": "https://api.github.com/users/SeaEagleI/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"BERT uses absolute position embeddings by default. The sin/cos embeddings are from the original Transformer paper IRRC. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | https://github.com/huggingface/transformers/blob/948b730f9777174335812cf76de2a9dd9e4cf20e/src/transformers/models/bert/modeling_bert.py#L172 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10511/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10511/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10510 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10510/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10510/comments | https://api.github.com/repos/huggingface/transformers/issues/10510/events | https://github.com/huggingface/transformers/issues/10510 | 821,759,868 | MDU6SXNzdWU4MjE3NTk4Njg= | 10,510 | Error in run_squad.py with BartForQuestionAnswering model | {
"login": "nrjvarshney",
"id": 19836137,
"node_id": "MDQ6VXNlcjE5ODM2MTM3",
"avatar_url": "https://avatars.githubusercontent.com/u/19836137?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nrjvarshney",
"html_url": "https://github.com/nrjvarshney",
"followers_url": "https://api.github.com/users/nrjvarshney/followers",
"following_url": "https://api.github.com/users/nrjvarshney/following{/other_user}",
"gists_url": "https://api.github.com/users/nrjvarshney/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nrjvarshney/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nrjvarshney/subscriptions",
"organizations_url": "https://api.github.com/users/nrjvarshney/orgs",
"repos_url": "https://api.github.com/users/nrjvarshney/repos",
"events_url": "https://api.github.com/users/nrjvarshney/events{/privacy}",
"received_events_url": "https://api.github.com/users/nrjvarshney/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello! Could you provide all the information required in the issue template?\r\n\r\nThank you! ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | I am using the BartForQuestionAnswering model and getting the following error during evaluation
`Evaluating: 0%| | 0/315 [00:10<?, ?it/s]
Traceback (most recent call last):
File "../run_squad.py", line 831, in <module>
main()
File "../run_squad.py", line 820, in main
result = evaluate(args, model, tokenizer, prefix=global_step)
File "../run_squad.py", line 325, in evaluate
output = [to_list(output[i]) for output in outputs.to_tuple()]
File "../run_squad.py", line 325, in <listcomp>
output = [to_list(output[i]) for output in outputs.to_tuple()]
File "../run_squad.py", line 73, in to_list
return tensor.detach().cpu().tolist()
AttributeError: 'tuple' object has no attribute 'detach'`
It works perfectly fine with the bert-base-uncased model but fails in case of BART model.
What could resolve this issue?
Thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10510/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10510/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10509 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10509/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10509/comments | https://api.github.com/repos/huggingface/transformers/issues/10509/events | https://github.com/huggingface/transformers/pull/10509 | 821,678,601 | MDExOlB1bGxSZXF1ZXN0NTg0NDI2Nzk1 | 10,509 | Stale Bot | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The `GITHUB_TOKEN` got rate-limited, unfortunately. The PR should be good to go, I'll try to run it again tomorrow night."
] | 1,614 | 1,614 | 1,614 | MEMBER | null | Adds a stale bot based on GitHub Actions.
This bot is slightly different than the previous one in that it comments that it is closing the issue and closes it immediately, rather than waiting 7 days. From what I've seen up to now, this shouldn't be an issue at all.
I've commented out the code for now so that it doesn't actually close issues, but you can take a look at which would be closed [here](https://github.com/huggingface/transformers/runs/2027394567?check_suite_focus=true). Will un-comment the code before merging. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10509/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10509/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10509",
"html_url": "https://github.com/huggingface/transformers/pull/10509",
"diff_url": "https://github.com/huggingface/transformers/pull/10509.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10509.patch",
"merged_at": 1614980510000
} |
https://api.github.com/repos/huggingface/transformers/issues/10508 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10508/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10508/comments | https://api.github.com/repos/huggingface/transformers/issues/10508/events | https://github.com/huggingface/transformers/issues/10508 | 821,607,609 | MDU6SXNzdWU4MjE2MDc2MDk= | 10,508 | Loading tapas model into pipeline from directory gives different result | {
"login": "mchari",
"id": 30506151,
"node_id": "MDQ6VXNlcjMwNTA2MTUx",
"avatar_url": "https://avatars.githubusercontent.com/u/30506151?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mchari",
"html_url": "https://github.com/mchari",
"followers_url": "https://api.github.com/users/mchari/followers",
"following_url": "https://api.github.com/users/mchari/following{/other_user}",
"gists_url": "https://api.github.com/users/mchari/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mchari/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mchari/subscriptions",
"organizations_url": "https://api.github.com/users/mchari/orgs",
"repos_url": "https://api.github.com/users/mchari/repos",
"events_url": "https://api.github.com/users/mchari/events{/privacy}",
"received_events_url": "https://api.github.com/users/mchari/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I noticed that the size of pytorch_model.bin that was downloaded into .cache is of size 442791751. When I save_pretrained() the model, the size is 442792154. \r\nIf I copy the first model into the model directory, I get valid results....",
"Hello! You're using `'google/tapas-base'` in order to initialize weights, why don't you use the variant fine-tuned on WTQ like in the configuration and tokenizer? \r\n\r\nUnless you're using a fine-tuned version, you won't benefit from the best possible predictions, like you have seen here.",
"@LysandreJik , I fixed that typo and changed it to \r\nmodel = TapasForQuestionAnswering.from_pretrained('google/tapas-base-finetuned-wtq', config=config), but I get the same discrepancy in results.\r\nI am trying to figure out why I get no results when I load the model from a directory(that was generated as above).",
"I'm running your code and I get some sensible results:\r\n\r\n```py\r\nfrom transformers import TapasConfig,TapasTokenizer,TapasForQuestionAnswering\r\nimport torch\r\nconfig = TapasConfig.from_pretrained('google/tapas-base-finetuned-wtq',from_pt=True)\r\nmodel = TapasForQuestionAnswering.from_pretrained('google/tapas-base-finetuned-wtq', config=config)\r\ntokenizer=TapasTokenizer.from_pretrained(\"google/tapas-base-finetuned-wtq\",from_pt=True)\r\nimport sys\r\n\r\noutdir = \"tmp\"\r\n\r\nmodel.save_pretrained(outdir)\r\ntokenizer.save_pretrained(outdir)\r\nconfig.save_pretrained(outdir)\r\n\r\nfrom transformers import pipeline\r\n\r\nnlp = pipeline(task=\"table-question-answering\",framework=\"pt\",model=outdir, tokenizer=outdir)\r\n#nlp = pipeline(task=\"table-question-answering\")\r\n\r\nimport pandas as pd\r\n\r\ndata= { \"actors\": [\"brad pitt\", \"leonardo di caprio\", \"george clooney\"],\r\n \"age\": [\"56\", \"45\", \"59\"],\r\n \"number of movies\": [\"87\", \"53\", \"69\"],\r\n \"date of birth\": [\"7 february 1967\", \"10 june 1996\", \"28 november 1967\"]\r\n}\r\n\r\nimport numpy as np\r\ntable = pd.DataFrame.from_dict(data)\r\nprint(np.shape(table))\r\nresult = nlp(query=[\"How many movies has Brad Pitt acted in\",\"What is Leonardo di caprio's age\"],table=table)\r\n\r\nprint(result)\r\n```\r\n\r\nResults in:\r\n```\r\n[{'answer': 'SUM > 87', 'coordinates': [(0, 2)], 'cells': ['87'], 'aggregator': 'SUM'}, {'answer': 'AVERAGE > 45', 'coordinates': [(1, 1)], 'cells': ['45'], 'aggregator': 'AVERAGE'}]\r\n```\r\n\r\nThe aggregator are a bit off but the results are correct. Brad Pitt has played in 87 movies and Leonardo di Caprio is 45.",
"I did additionally specify `tokenizer=outdir`, could that be the source of your issue?",
"@LysandreJik , that was it ! \r\nI will look into the code, but any insight into why tokenizer=outdir needs to be specified (for this pipeline task only) ?",
"@LysandreJik , what is the size of your pytorch_model.bin in outdir ?\r\n",
"The tokenizer needs to be specified for every pipeline tasks. You should always specify the checkpoint for the tokenizer as well as for the model. The size is `442.79 MB`!"
] | 1,614 | 1,614 | 1,614 | NONE | null | Hi,
I am using the following versions of these packages :
transformers = 4.3.2
pytorch = 1.6.0
I am using the following code to download and save a pretrained model:
```py
from transformers import TapasConfig,TapasTokenizer,TapasForQuestionAnswering
import torch
config = TapasConfig.from_pretrained('google/tapas-base-finetuned-wtq',from_pt=True)
model = TapasForQuestionAnswering.from_pretrained('google/tapas-base', config=config)
tokenizer=TapasTokenizer.from_pretrained("google/tapas-base-finetuned-wtq",from_pt=True)
import sys
outdir = sys.argv[1]
model.save_pretrained(outdir)
tokenizer.save_pretrained(outdir)
config.save_pretrained(outdir)
```
When I then feed the model directory into pipeline, I don't get any result for the table illustrated in the documentation....
If I let pipeline download the model on-the-fly, I get results. Here is the code to feed model directory into pipeline...
```py
import sys
from transformers import pipeline
nlp = pipeline(task="table-question-answering",framework="pt",model="tapas_model_dir")
#nlp = pipeline(task="table-question-answering")
import pandas as pd
data= { "actors": ["brad pitt", "leonardo di caprio", "george clooney"],
"age": ["56", "45", "59"],
"number of movies": ["87", "53", "69"],
"date of birth": ["7 february 1967", "10 june 1996", "28 november 1967"]
}
import numpy as np
table = pd.DataFrame.from_dict(data)
print(np.shape(table))
result = nlp(query=["How many movies has Brad Pitt acted in","What is Leonardo di caprio's age"],table=table)
print(result)
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10508/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10508/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10507 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10507/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10507/comments | https://api.github.com/repos/huggingface/transformers/issues/10507/events | https://github.com/huggingface/transformers/issues/10507 | 821,440,855 | MDU6SXNzdWU4MjE0NDA4NTU= | 10,507 | 'Trainer' object has no attribute 'log_metrics' | {
"login": "fatihbeyhan",
"id": 48058209,
"node_id": "MDQ6VXNlcjQ4MDU4MjA5",
"avatar_url": "https://avatars.githubusercontent.com/u/48058209?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/fatihbeyhan",
"html_url": "https://github.com/fatihbeyhan",
"followers_url": "https://api.github.com/users/fatihbeyhan/followers",
"following_url": "https://api.github.com/users/fatihbeyhan/following{/other_user}",
"gists_url": "https://api.github.com/users/fatihbeyhan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/fatihbeyhan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/fatihbeyhan/subscriptions",
"organizations_url": "https://api.github.com/users/fatihbeyhan/orgs",
"repos_url": "https://api.github.com/users/fatihbeyhan/repos",
"events_url": "https://api.github.com/users/fatihbeyhan/events{/privacy}",
"received_events_url": "https://api.github.com/users/fatihbeyhan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, this is a duplicate, see #10446 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | I was trying to use run_mlm.py to fine-tune roberta-large with a custom dataset on Google Colab.
!python /content/transformers/examples/language-modeling/run_mlm.py \
--model_name_or_path roberta-large \
--train_file /content/traincorpus.txt \
--validation_file /content/devcorpus.txt \
--do_train \
--do_eval \
--per_device_train_batch_size 2 \
--output_dir finetunedmodel \
--overwrite_output_dir True
I am able to train the model however at the end I can not see the evaluation due to an error:
Traceback (most recent call last):
File "/content/transformers/examples/language-modeling/run_mlm.py", line 442, in <module>
main()
File "/content/transformers/examples/language-modeling/run_mlm.py", line 416, in main
trainer.log_metrics("train", metrics)
AttributeError: 'Trainer' object has no attribute 'log_metrics'
There is nothing extra on colab env. I wasn't getting this error a week ago or something. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10507/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10507/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10506 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10506/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10506/comments | https://api.github.com/repos/huggingface/transformers/issues/10506/events | https://github.com/huggingface/transformers/pull/10506 | 821,437,320 | MDExOlB1bGxSZXF1ZXN0NTg0MjI3NDc3 | 10,506 | [WIP][BIGBIRD] Add new conversion | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,651 | 1,614 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10506/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10506/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10506",
"html_url": "https://github.com/huggingface/transformers/pull/10506",
"diff_url": "https://github.com/huggingface/transformers/pull/10506.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10506.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10505 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10505/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10505/comments | https://api.github.com/repos/huggingface/transformers/issues/10505/events | https://github.com/huggingface/transformers/pull/10505 | 821,402,116 | MDExOlB1bGxSZXF1ZXN0NTg0MTk4Nzk4 | 10,505 | Remove unsupported methods from ModelOutput doc | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | COLLABORATOR | null | # What does this PR do?
As said in the title :-)
Fixes #10469 | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10505/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10505/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10505",
"html_url": "https://github.com/huggingface/transformers/pull/10505",
"diff_url": "https://github.com/huggingface/transformers/pull/10505.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10505.patch",
"merged_at": 1614801318000
} |
https://api.github.com/repos/huggingface/transformers/issues/10504 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10504/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10504/comments | https://api.github.com/repos/huggingface/transformers/issues/10504/events | https://github.com/huggingface/transformers/pull/10504 | 821,390,036 | MDExOlB1bGxSZXF1ZXN0NTg0MTg5MTI4 | 10,504 | Rework TPU checkpointing in Trainer | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Tested on TPUs and all worked well (training, checkpointing, reloading from checkpoint, evaluating a saved model), so I will merge this."
] | 1,614 | 1,614 | 1,614 | COLLABORATOR | null | # What does this PR do?
This PR rewors a tiny bit the checkpointing mechanism in the `Trainer` and `PreTrainedModel` to get rid of the hack that stored something in the config (which was then forever present if the user decided to share their model on the hub).
The main problem is that the save on TPU has to be called on all processes because there is a synchronization inside (so if we only execute it in one process, the other do not reach the synchronization point and everything hangs). At the same time, the config should only be saved on one process to avoid race conditions. So this PR solves the problem by adding two new arguments to `save_pretrained`: `is_main` and `_save_function`. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10504/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10504/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10504",
"html_url": "https://github.com/huggingface/transformers/pull/10504",
"diff_url": "https://github.com/huggingface/transformers/pull/10504.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10504.patch",
"merged_at": 1614876371000
} |
https://api.github.com/repos/huggingface/transformers/issues/10503 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10503/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10503/comments | https://api.github.com/repos/huggingface/transformers/issues/10503/events | https://github.com/huggingface/transformers/issues/10503 | 821,388,301 | MDU6SXNzdWU4MjEzODgzMDE= | 10,503 | Fine tuning a pipeline | {
"login": "thiziri",
"id": 17499919,
"node_id": "MDQ6VXNlcjE3NDk5OTE5",
"avatar_url": "https://avatars.githubusercontent.com/u/17499919?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/thiziri",
"html_url": "https://github.com/thiziri",
"followers_url": "https://api.github.com/users/thiziri/followers",
"following_url": "https://api.github.com/users/thiziri/following{/other_user}",
"gists_url": "https://api.github.com/users/thiziri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/thiziri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/thiziri/subscriptions",
"organizations_url": "https://api.github.com/users/thiziri/orgs",
"repos_url": "https://api.github.com/users/thiziri/repos",
"events_url": "https://api.github.com/users/thiziri/events{/privacy}",
"received_events_url": "https://api.github.com/users/thiziri/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! I'm sorry, I don't understand what you mean exactly. A pipeline uses a model and a tokenizer under the hood, do you mean you want to fine-tune the model used underneath, and use that fine-tuned model?\r\n\r\nIf that is so, it is simple: any model/tokenizer can be loaded in the pipeline via local path/hub identifier. I invite you to read the [documentation of the pipelines](https://huggingface.co/transformers/main_classes/pipelines.html#transformers.pipeline), especially the `model` and `tokenizer` arguments.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | # 🚀 Feature request
<!-- A clear and concise description of the feature proposal.
Please provide a link to the paper and code in case they exist. -->
[Already asked](https://github.com/huggingface/transformers/issues/8127)
## Motivation
<!-- Please outline the motivation for the proposal. Is your feature request
related to a problem? e.g., I'm always frustrated when [...]. If this is related
to another GitHub issue, please link here too. -->
I would like to fine-tune a pipeline using a model (pre-trained or fine-tuned).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10503/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10503/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10502 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10502/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10502/comments | https://api.github.com/repos/huggingface/transformers/issues/10502/events | https://github.com/huggingface/transformers/issues/10502 | 821,329,792 | MDU6SXNzdWU4MjEzMjk3OTI= | 10,502 | GLUE benchmark crashes with MNLI and STSB | {
"login": "lucadiliello",
"id": 23355969,
"node_id": "MDQ6VXNlcjIzMzU1OTY5",
"avatar_url": "https://avatars.githubusercontent.com/u/23355969?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lucadiliello",
"html_url": "https://github.com/lucadiliello",
"followers_url": "https://api.github.com/users/lucadiliello/followers",
"following_url": "https://api.github.com/users/lucadiliello/following{/other_user}",
"gists_url": "https://api.github.com/users/lucadiliello/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lucadiliello/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lucadiliello/subscriptions",
"organizations_url": "https://api.github.com/users/lucadiliello/orgs",
"repos_url": "https://api.github.com/users/lucadiliello/repos",
"events_url": "https://api.github.com/users/lucadiliello/events{/privacy}",
"received_events_url": "https://api.github.com/users/lucadiliello/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! Actually I think you touched the base of the issue for MNLI, I would guess it has to do with the number of labels. When you do the following:\r\n```py\r\n>>> from transformers import RobertaForMaskedLM, RobertaConfig, RobertaTokenizer\r\n>>> tok = RobertaTokenizer.from_pretrained('roberta-base')\r\n>>> config = RobertaConfig.from_pretrained('roberta-base')\r\n>>> model = RobertaForMaskedLM(config=config)\r\n>>> model.save_pretrained('tmp_model')\r\n>>> from transformers import RobertaForSequenceClassification\r\n>>> model = RobertaForSequenceClassification.from_pretrained(\"tmp_model\")\r\n```\r\n\r\nYou'll see that the sequence classification model you've loaded has 2 labels, whereas MNLI is a 3-way classification:\r\n```py\r\n>>> model.classifier.out_proj\r\nLinear(in_features=768, out_features=2, bias=True)\r\n```\r\n\r\nI don't get any such errors when changing the configuration initialization to the following:\r\n```py\r\n>>> config = RobertaConfig.from_pretrained('roberta-base', num_labels=3)\r\n```\r\n\r\nRegarding the STS-B issue, I think this is an issue that was recently solved on `master`. Can you try pulling the `master` branch once again and letting me know if it fixes your issue? If not, I'll try and check what's happening.",
"> Hi! Actually I think you touched the base of the issue for MNLI, I would guess it has to do with the number of labels. When you do the following:\r\n> \r\n> ```python\r\n> >>> from transformers import RobertaForMaskedLM, RobertaConfig, RobertaTokenizer\r\n> >>> tok = RobertaTokenizer.from_pretrained('roberta-base')\r\n> >>> config = RobertaConfig.from_pretrained('roberta-base')\r\n> >>> model = RobertaForMaskedLM(config=config)\r\n> >>> model.save_pretrained('tmp_model')\r\n> >>> from transformers import RobertaForSequenceClassification\r\n> >>> model = RobertaForSequenceClassification.from_pretrained(\"tmp_model\")\r\n> ```\r\n> \r\n> You'll see that the sequence classification model you've loaded has 2 labels, whereas MNLI is a 3-way classification:\r\n> \r\n> ```python\r\n> >>> model.classifier.out_proj\r\n> Linear(in_features=768, out_features=2, bias=True)\r\n> ```\r\n> \r\n> I don't get any such errors when changing the configuration initialization to the following:\r\n> \r\n> ```python\r\n> >>> config = RobertaConfig.from_pretrained('roberta-base', num_labels=3)\r\n> ```\r\nI didn't have this problem on branch `v4.0.1-release` because the `num_labels` parameter was set automatically. I didn't have to set the exact number of label for each GLUE task. In fact, the script computes them automatically, but for some reason the error still happens.\r\n\r\n> Regarding the STS-B issue, I think this is an issue that was recently solved on `master`. Can you try pulling the `master` branch once again and letting me know if it fixes your issue? If not, I'll try and check what's happening.\r\n\r\nError still present on master (`4.4.0.dev0`).",
"cc @sgugger for knowledge regarding the MNLI issue."
] | 1,614 | 1,614 | 1,614 | NONE | null | ## Environment info
- `transformers` version: 4.4.0.dev0
- Platform: Linux-5.8.0-44-generic-x86_64-with-glibc2.10
- Python version: 3.8.5
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: no, running only on CPU or single GPU
### Who can help
Tags: @patrickvonplaten @LysandreJik
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [X] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: GLUE
* [ ] my own task or dataset:
## To reproduce
Steps to reproduce the behaviour:
Create model with a very recent version of transformers:
```
>>> from transformers import RobertaForMaskedLM, RobertaConfig, RobertaTokenizer
>>> tok = RobertaTokenizer.from_pretrained('roberta-base')
>>> config = RobertaConfig.from_pretrained('roberta-base')
>>> model = RobertaForMaskedLM(config=config)
>>> tok.save_pretrained('tmp_model')
('tmp_model/tokenizer_config.json', 'tmp_model/special_tokens_map.json', 'tmp_model/vocab.json', 'tmp_model/merges.txt', 'tmp_model/added_tokens.json')
>>> model.save_pretrained('tmp_model')
```
Run GLUE benchmark on MNLI:
```
python ./examples/text-classification/run_glue.py \
--model_name_or_path tmp_model \
--task_name MNLI \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--learning_rate 1e-5 \
--num_train_epochs 1 \
--output_dir TMP/
```
or on STSB:
```
python ./examples/text-classification/run_glue.py \
--model_name_or_path tmp_model \
--task_name STSB \
--do_train \
--do_eval \
--max_seq_length 128 \
--per_device_train_batch_size 32 \
--per_device_eval_batch_size 32 \
--learning_rate 1e-5 \
--num_train_epochs 1 \
--output_dir TMP/
```
### Error logs
MNLI:
> Traceback (most recent call last):
> File "./examples/text-classification/run_glue.py", line 480, in <module>
> main()
> File "./examples/text-classification/run_glue.py", line 415, in main
> train_result = trainer.train(resume_from_checkpoint=checkpoint)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/transformers/trainer.py", line 1048, in train
> tr_loss += self.training_step(model, inputs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/transformers/trainer.py", line 1432, in training_step
> loss = self.compute_loss(model, inputs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/transformers/trainer.py", line 1464, in compute_loss
> outputs = model(**inputs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
> result = self.forward(*input, **kwargs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/transformers/models/roberta/modeling_roberta.py", line 1168, in forward
> loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
> result = self.forward(*input, **kwargs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/modules/loss.py", line 961, in forward
> return F.cross_entropy(input, target, weight=self.weight,
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/functional.py", line 2468, in cross_entropy
> return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/functional.py", line 2264, in nll_loss
> ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
> IndexError: Target 2 is out of bounds.
The problem seems to be related to the incorrect initialisation of the classification head. However, with some prints I noticed that the shape of the classification head was `hidden_size x 3`, so I do not really understand where the problem comes from...
STSB:
> Traceback (most recent call last):
> File "./examples/text-classification/run_glue.py", line 480, in <module>
> main()
> File "./examples/text-classification/run_glue.py", line 415, in main
> train_result = trainer.train(resume_from_checkpoint=checkpoint)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/transformers/trainer.py", line 1048, in train
> tr_loss += self.training_step(model, inputs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/transformers/trainer.py", line 1432, in training_step
> loss = self.compute_loss(model, inputs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/transformers/trainer.py", line 1464, in compute_loss
> outputs = model(**inputs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
> result = self.forward(*input, **kwargs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/transformers/models/roberta/modeling_roberta.py", line 1168, in forward
> loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
> result = self.forward(*input, **kwargs)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/modules/loss.py", line 961, in forward
> return F.cross_entropy(input, target, weight=self.weight,
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/functional.py", line 2468, in cross_entropy
> return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)
> File "/home/lucadiliello/anaconda3/envs/tmp/lib/python3.8/site-packages/torch/nn/functional.py", line 2264, in nll_loss
> ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)
> RuntimeError: expected scalar type Long but found Float
Here the problem seems to be related to the `dtype` of the targets.
Interestingly, loading an old model like `bert-base-cased` or `roberta-base` does not raise errors....
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10502/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10502/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10501 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10501/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10501/comments | https://api.github.com/repos/huggingface/transformers/issues/10501/events | https://github.com/huggingface/transformers/pull/10501 | 821,271,936 | MDExOlB1bGxSZXF1ZXN0NTg0MDkxMzkw | 10,501 | [ProphetNet] Bart-like Refactor | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | MEMBER | null | # What does this PR do?
This PR refactors ProphetNet similar to Bart in that it moves the time dimension to be always at the 2nd place and the batch dimensions always in the first place. Also, the cache is refactored to consists of tuples instead of a dict.
The model is thereby very much aligned with Bart (I cannot really add any " # Copied from" statements though because the weight names are different).
The PR is in spirit very similar to https://github.com/huggingface/transformers/pull/8900.
I've verified that all slow tests pass. In the next step, I want to make a short notebook, verifying that ProphetNet can be trained since there have been some issues on training: #9804
# Benchmarking
The PR doesn't change compute or memory complexity:
On this PR:
```
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
microsoft/prophetnet-large-unc 8 8 0.029
microsoft/prophetnet-large-unc 8 32 0.044
microsoft/prophetnet-large-unc 8 128 0.175
microsoft/prophetnet-large-unc 8 512 N/A
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
microsoft/prophetnet-large-unc 8 8 2562
microsoft/prophetnet-large-unc 8 32 2756
microsoft/prophetnet-large-unc 8 128 3628
microsoft/prophetnet-large-unc 8 512 N/A
--------------------------------------------------------------------------------
```
on master:
```
==================== INFERENCE - SPEED - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Time in s
--------------------------------------------------------------------------------
microsoft/prophetnet-large-unc 8 8 0.027
microsoft/prophetnet-large-unc 8 32 0.044
microsoft/prophetnet-large-unc 8 128 0.172
microsoft/prophetnet-large-unc 8 512 N/A
--------------------------------------------------------------------------------
==================== INFERENCE - MEMORY - RESULT ====================
--------------------------------------------------------------------------------
Model Name Batch Size Seq Length Memory in MB
--------------------------------------------------------------------------------
microsoft/prophetnet-large-unc 8 8 2562
microsoft/prophetnet-large-unc 8 32 2768
microsoft/prophetnet-large-unc 8 128 3740
microsoft/prophetnet-large-unc 8 512 N/A
--------------------------------------------------------------------------------
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10501/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10501/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10501",
"html_url": "https://github.com/huggingface/transformers/pull/10501",
"diff_url": "https://github.com/huggingface/transformers/pull/10501.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10501.patch",
"merged_at": 1614889632000
} |
https://api.github.com/repos/huggingface/transformers/issues/10500 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10500/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10500/comments | https://api.github.com/repos/huggingface/transformers/issues/10500/events | https://github.com/huggingface/transformers/issues/10500 | 821,233,169 | MDU6SXNzdWU4MjEyMzMxNjk= | 10,500 | Fine tune of speaker embeddings model | {
"login": "karthikgali",
"id": 12197213,
"node_id": "MDQ6VXNlcjEyMTk3MjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/12197213?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/karthikgali",
"html_url": "https://github.com/karthikgali",
"followers_url": "https://api.github.com/users/karthikgali/followers",
"following_url": "https://api.github.com/users/karthikgali/following{/other_user}",
"gists_url": "https://api.github.com/users/karthikgali/gists{/gist_id}",
"starred_url": "https://api.github.com/users/karthikgali/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/karthikgali/subscriptions",
"organizations_url": "https://api.github.com/users/karthikgali/orgs",
"repos_url": "https://api.github.com/users/karthikgali/repos",
"events_url": "https://api.github.com/users/karthikgali/events{/privacy}",
"received_events_url": "https://api.github.com/users/karthikgali/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi! I think this is more of a question for `pyannote` rather than for `transformers`?",
"cc'ing @hbredin for visibility :)",
"Thanks @julien-c for the ping.\r\n\r\n@karthikgali please open an issue or discussion in [pyannote.audio Github repo](https://github.com/pyannote/pyannote-audio) instead.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | # 🚀 Feature request
Provide a way to fine tune the X-vector speaker embeddings model using our own custom dataset. (https://huggingface.co/hbredin/SpeakerEmbedding-XVectorMFCC-VoxCeleb)
## Motivation
This will help in finetuning the model for new domain/speakers.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10500/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10500/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10499 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10499/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10499/comments | https://api.github.com/repos/huggingface/transformers/issues/10499/events | https://github.com/huggingface/transformers/issues/10499 | 821,231,779 | MDU6SXNzdWU4MjEyMzE3Nzk= | 10,499 | f"The model '{self.model.__class__.__name__}' is not supported for {self.task}. Supported models are {supported_models}", | {
"login": "loretoparisi",
"id": 163333,
"node_id": "MDQ6VXNlcjE2MzMzMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/163333?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/loretoparisi",
"html_url": "https://github.com/loretoparisi",
"followers_url": "https://api.github.com/users/loretoparisi/followers",
"following_url": "https://api.github.com/users/loretoparisi/following{/other_user}",
"gists_url": "https://api.github.com/users/loretoparisi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/loretoparisi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/loretoparisi/subscriptions",
"organizations_url": "https://api.github.com/users/loretoparisi/orgs",
"repos_url": "https://api.github.com/users/loretoparisi/repos",
"events_url": "https://api.github.com/users/loretoparisi/events{/privacy}",
"received_events_url": "https://api.github.com/users/loretoparisi/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi there, \r\n\r\nYou should use the `AutoModelForQuestionAnswering` class to load a QA model, the `AutoModel` class just loads the base model and doesn't load the task-specific head, which is the reason for this error.\r\n\r\nIn general, always use the task-specific auto classes to load task-specific architectures.",
"@patil-suraj confirmed, it works \r\n\r\n```python\r\ntokenizer = AutoTokenizer.from_pretrained(\r\n 'mrm8488/bert-italian-finedtuned-squadv1-it-alfa',\r\n cache_dir=os.getenv(\"cache_dir\", \"model\"))\r\nmodel = AutoModelForQuestionAnswering.from_pretrained(\r\n 'mrm8488/bert-italian-finedtuned-squadv1-it-alfa',\r\n cache_dir=os.getenv(\"cache_dir\", \"model\"))\r\n\r\nnlp_qa_bert = pipeline(\r\n 'question-answering',\r\n model=model,\r\n tokenizer=tokenizer)\r\n```"
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | ## Context
I have used the official example for Q&A [here](https://huggingface.co/dbmdz/bert-base-italian-cased), but slightly modified the `Pipeline` to use the `model` and `tokenizer` objects from pretrained model as exaplained [here](https://huggingface.co/transformers/main_classes/pipelines.html#the-pipeline-abstraction). This because I need a `cache_dir` that currently is not supported by `Pipeline` object.
## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.3
- Platform: Linux-4.19.121-linuxkit-x86_64-with-debian-10.1
- Python version: 3.7.4
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: <NO>
- Using distributed or parallel set-up in script?: <NO>
### Who can help
Model:
https://huggingface.co/dbmdz/bert-base-italian-cased
@patrickvonplaten, @patil-suraj
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: (translation)
* [ ] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
```python
question = 'Quale filosofia seguì Marco Aurelio ?'
context = 'Marco Aurelio era un imperatore romano che praticava lo stoicismo come filosofia di vita .'
tokenizer = AutoTokenizer.from_pretrained(
'mrm8488/bert-italian-finedtuned-squadv1-it-alfa',
cache_dir=os.getenv("cache_dir", "model"))
model = AutoModel.from_pretrained(
'mrm8488/bert-italian-finedtuned-squadv1-it-alfa',
cache_dir=os.getenv("cache_dir", "model"))
nlp_qa_bert = pipeline(
'question-answering',
model=model,
tokenizer=tokenizer)
out = nlp_qa_bert({
'question': question,
'context': context
})
print(out)
````
ERROR:
```
Traceback (most recent call last):
File "qa/run.py", line 26, in <module>
tokenizer=tokenizer)
File "/usr/local/lib/python3.7/site-packages/transformers/pipelines/__init__.py", line 418, in pipeline
return task_class(model=model, tokenizer=tokenizer, modelcard=modelcard, framework=framework, task=task, **kwargs)
File "/usr/local/lib/python3.7/site-packages/transformers/pipelines/question_answering.py", line 135, in __init__
TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING if self.framework == "tf" else MODEL_FOR_QUESTION_ANSWERING_MAPPING
File "/usr/local/lib/python3.7/site-packages/transformers/pipelines/base.py", line 577, in check_model_type
f"The model '{self.model.__class__.__name__}' is not supported for {self.task}. Supported models are {supported_models}",
transformers.pipelines.base.PipelineException: The model 'BertModel' is not supported for question-answering. Supported models are ['ConvBertForQuestionAnswering', 'LEDForQuestionAnswering', 'DistilBertForQuestionAnswering', 'AlbertForQuestionAnswering', 'CamembertForQuestionAnswering', 'BartForQuestionAnswering', 'MBartForQuestionAnswering', 'LongformerForQuestionAnswering', 'XLMRobertaForQuestionAnswering', 'RobertaForQuestionAnswering', 'SqueezeBertForQuestionAnswering', 'BertForQuestionAnswering', 'XLNetForQuestionAnsweringSimple', 'FlaubertForQuestionAnsweringSimple', 'MobileBertForQuestionAnswering', 'XLMForQuestionAnsweringSimple', 'ElectraForQuestionAnswering', 'ReformerForQuestionAnswering', 'FunnelForQuestionAnswering', 'LxmertForQuestionAnswering', 'MPNetForQuestionAnswering', 'DebertaForQuestionAnswering', 'DebertaV2ForQuestionAnswering', 'IBertForQuestionAnswering']
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
no error
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10499/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10499/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10498 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10498/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10498/comments | https://api.github.com/repos/huggingface/transformers/issues/10498/events | https://github.com/huggingface/transformers/issues/10498 | 820,987,812 | MDU6SXNzdWU4MjA5ODc4MTI= | 10,498 | DeBERTa Fast Tokenizer | {
"login": "brandenchan",
"id": 33759007,
"node_id": "MDQ6VXNlcjMzNzU5MDA3",
"avatar_url": "https://avatars.githubusercontent.com/u/33759007?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/brandenchan",
"html_url": "https://github.com/brandenchan",
"followers_url": "https://api.github.com/users/brandenchan/followers",
"following_url": "https://api.github.com/users/brandenchan/following{/other_user}",
"gists_url": "https://api.github.com/users/brandenchan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/brandenchan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/brandenchan/subscriptions",
"organizations_url": "https://api.github.com/users/brandenchan/orgs",
"repos_url": "https://api.github.com/users/brandenchan/repos",
"events_url": "https://api.github.com/users/brandenchan/events{/privacy}",
"received_events_url": "https://api.github.com/users/brandenchan/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
},
{
"id": 2392046359,
"node_id": "MDU6TGFiZWwyMzkyMDQ2MzU5",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20Second%20Issue",
"name": "Good Second Issue",
"color": "dd935a",
"default": false,
"description": "Issues that are more difficult to do than \"Good First\" issues - give it a try if you want!"
}
] | closed | false | null | [] | [
"Hi @brandenchan ,\r\n\r\nI think it should be easier with version 2 of DeBERTa, because they use a \"normal\" sentence piece model now:\r\n\r\nhttps://github.com/huggingface/transformers/pull/10018\r\n\r\nSo having a fast alternative would be great. \r\n\r\n(The new 128k vocab size should really boost performance on QA tasks!)\r\n\r\n",
"Indeed, this would be a very nice addition and way easier to implement than for the first DeBERTa. I'm adding the `Good Second Issue` label so that a community member may work on it. @brandenchan or @stefan-it feel free to take it too if you feel like it!",
"Hi, I am looking for my first open source contribution. May I take this if its still available?",
"Yes, of course! Thank you!",
"@ShubhamSanghvi Maybe wait until #10703 is merged.",
"Hi, as far as I understand I will have to add tokenizer files for debarta_v2 to implement the fast tokenizer? \r\n\r\nMay I know how could I get the tokenizer files for deberta_v2 models and how to upload them to the intended destinations, which I believe should be (for deberta-v2-xlarge) :\r\n\r\nhttps://huggingface.co/microsoft/deberta-v2-xlarge/resolve/main/\r\n\r\nThanks, Shubham",
"@ShubhamSanghvi Do you only want to implement the fast tokenizer for DebertaV2 or also for Deberta? \r\n\r\n> May I know how could I get the tokenizer files for deberta_v2 models \r\n\r\nI think this is what you have to figure out. I would check the other models that have a slow sentencepiece tokenizer.\r\n\r\n> how to upload them to the intended destinations, which I believe should be (for deberta-v2-xlarge) \r\n\r\nYou can not upload them there. Upload them to some kind of a public cloud and request an upload.\r\n\r\n\r\n\r\n\r\n",
"@ShubhamSanghvi Are you planning to create a PR for this issue soon?\r\n",
"Hi @mansimane, I am currently working on it. I am hoping to get it done by next week. "
] | 1,614 | 1,619 | 1,619 | CONTRIBUTOR | null | Hi, I am interested in using the DeBERTa model that was recently implemented here and incorporating it into [FARM](https://github.com/deepset-ai/FARM) so that it can also be used in open-domain QA settings through [Haystack](https://github.com/deepset-ai/haystack).
Just wondering why there's only a Slow Tokenizer implemented for DeBERTa and wondering if there are plans to create the Fast Tokenizer too. Thanks in advance!
Hi @stefan-it! Wondering if you might have any insight on this? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10498/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10498/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10497 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10497/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10497/comments | https://api.github.com/repos/huggingface/transformers/issues/10497/events | https://github.com/huggingface/transformers/issues/10497 | 820,925,931 | MDU6SXNzdWU4MjA5MjU5MzE= | 10,497 | Wav2Vec fine code | {
"login": "idanmoradarthas",
"id": 14873156,
"node_id": "MDQ6VXNlcjE0ODczMTU2",
"avatar_url": "https://avatars.githubusercontent.com/u/14873156?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/idanmoradarthas",
"html_url": "https://github.com/idanmoradarthas",
"followers_url": "https://api.github.com/users/idanmoradarthas/followers",
"following_url": "https://api.github.com/users/idanmoradarthas/following{/other_user}",
"gists_url": "https://api.github.com/users/idanmoradarthas/gists{/gist_id}",
"starred_url": "https://api.github.com/users/idanmoradarthas/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/idanmoradarthas/subscriptions",
"organizations_url": "https://api.github.com/users/idanmoradarthas/orgs",
"repos_url": "https://api.github.com/users/idanmoradarthas/repos",
"events_url": "https://api.github.com/users/idanmoradarthas/events{/privacy}",
"received_events_url": "https://api.github.com/users/idanmoradarthas/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hey @idanmoradarthas, \r\n\r\nI will soon release a notebook, that will explain in-detail how to fine-tune a Wav2Vec2 model (~1week). \r\n\r\nIt's quite time consuming for me to debug user-specific code, such as `convert_to_dataset_torch`, so I can only give you some tips here:\r\n\r\n- Try to convert your dataset to PyTorch tensors istead of `np.ndarray`'s. This means you should change all of your lines that do:\r\n```processor(row[\"speech\"], sampling_rate=16000)``` to ```processor(row[\"speech\"], sampling_rate=16000, return_tensors=\"pt\")```",
"Thanks =)",
"with self.processor.as_target_processor():\r\n labels_batch = self.processor.pad(\r\ni use this command in order to encode labels but i got number 3 instead of all letters in sentence\r\nHow can i solve this issue?",
"Hey @kasrasehat,\r\n\r\nCould you please open a new issue? ",
"@patrickvonplaten sure"
] | 1,614 | 1,651 | 1,614 | NONE | null | # 🚀 Feature request
@patrickvonplaten
Hi, I have the following data set I want to use to fine tune Wav2Vec:
[cv-valid-train.zip](https://github.com/huggingface/transformers/files/6074839/cv-valid-train.zip)
I'm using the current transformers library from github (4.4.0 dev).
And I wrote the following code based on the code in the PR https://github.com/huggingface/transformers/pull/10145:
1. ctc_trainer.py
```python
from typing import Dict, Union, Any
import torch
from transformers import Trainer
class CTCTrainer(Trainer):
def training_step(self, model: torch.nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:
"""
Perform a training step on a batch of inputs.
Subclass and override to inject custom behavior.
Args:
model (:obj:`nn.Module`):
The model to train.
inputs (:obj:`Dict[str, Union[torch.Tensor, Any]]`):
The inputs and targets of the model.
The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
argument :obj:`labels`. Check your model's documentation for all accepted arguments.
Return:
:obj:`torch.Tensor`: The tensor with training loss on this batch.
"""
model.train()
inputs = self._prepare_inputs(inputs)
loss = self.compute_loss(model, inputs)
if self.args.n_gpu > 1:
if model.module.config.ctc_loss_reduction == "mean":
loss = loss.mean()
elif model.module.config.ctc_loss_reduction == "sum":
loss = loss.sum() / (inputs["labels"] >= 0).sum()
else:
raise ValueError(f"{model.config.ctc_loss_reduction} is not valid. Choose one of ['mean', 'sum']")
if self.args.gradient_accumulation_steps > 1:
loss = loss / self.args.gradient_accumulation_steps
loss.backward()
return loss.detach()
```
2. data_collector.py
```python
from dataclasses import dataclass
from typing import Union, Optional, List, Dict
import torch
from transformers import Wav2Vec2Processor
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
max_length_labels (:obj:`int`, `optional`):
Maximum length of the ``labels`` returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
max_length: Optional[int] = None
max_length_labels: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lenghts and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
with self.processor.as_target_processor():
labels_batch = self.processor.pad(
label_features,
padding=self.padding,
max_length=self.max_length_labels,
pad_to_multiple_of=self.pad_to_multiple_of_labels,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
```
3. fine tune model.py
```python
from pathlib import Path
import datasets
import librosa
import numpy
import pandas
import torch
from sklearn.model_selection import train_test_split
from torch.utils.data import TensorDataset
from tqdm import tqdm
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor, TrainingArguments
from ctc_trainer import CTCTrainer
from data_collector import DataCollatorCTCWithPadding
def map_to_array(batch):
input_audio, _ = librosa.load(
Path("__file__").parents[0].joinpath(batch["filename"]), sr=16000)
return input_audio
def convert_to_dataset_torch(x: pandas.DataFrame, y: pandas.DataFrame) -> TensorDataset:
input_values = []
labels = []
for _, row in tqdm(x.iterrows(), total=x.shape[0]):
input_values.append(row["input_values"])
for _, row in tqdm(y.iterrows(), total=y.shape[0]):
labels.append(row["labels"])
return TensorDataset(torch.cat(input_values, dim=0), torch.cat(labels, dim=0))
if __name__ == '__main__':
dataset = pandas.read_csv(Path(__file__).parents[0].joinpath("cv-valid-train.csv"))
X_train, X_test, y_train, y_test = train_test_split(dataset[["filename"]], dataset[["text"]], test_size=0.2,
random_state=42)
X_train, X_validation, y_train, y_validation = train_test_split(X_train, y_train, test_size=0.2, random_state=42)
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-base-960h")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-base-960h")
wer_metric = datasets.load_metric("wer")
X_train["speech"] = X_train.apply(map_to_array, axis=1)
X_train["input_values"] = X_train.apply(lambda row: processor(row["speech"], sampling_rate=16000).input_values,
axis=1)
X_validation["speech"] = X_validation.apply(map_to_array, axis=1)
X_validation["input_values"] = X_validation.apply(
lambda row: processor(row["speech"], sampling_rate=16000).input_values,
axis=1)
X_test["speech"] = X_test.apply(map_to_array, axis=1)
X_test["input_values"] = X_test.apply(lambda row: processor(row["speech"], sampling_rate=16000).input_values,
axis=1)
with processor.as_target_processor():
y_train["labels"] = y_train.apply(lambda row: processor(row["text"]).input_ids, axis=1)
y_validation["labels"] = y_validation.apply(lambda row: processor(row["text"]).input_ids, axis=1)
y_test["labels"] = y_test.apply(lambda row: processor(row["text"]).input_ids, axis=1)
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = numpy.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = 0
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=2, # total number of training epochs
per_device_train_batch_size=16, # batch size per device during training
per_device_eval_batch_size=64, # batch size for evaluation
warmup_steps=500, # number of warmup steps for learning rate scheduler
weight_decay=0.01, # strength of weight decay
logging_dir='./logs', # directory for storing logs
logging_steps=10,
)
trainer = CTCTrainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=convert_to_dataset_torch(X_train, y_train),
eval_dataset=convert_to_dataset_torch(X_validation, y_validation),
tokenizer=processor.feature_extractor,
)
trainer.train()
```
I'm unable in the method ```convert_to_dataset_torch``` to create TensorDataset. I get the following error:
TypeError: expected Tensor as element 0 in argument 0, but got numpy.ndarray
1. How can I convert the 2d numpy to torch?
2. How can I control argument such n_gpu and gradient_accumulation_steps?
4. What is model.module.config.ctc_loss_reduction, How It can be controled, and what is best for ASR task?
3. Is there any remorks over the code? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10497/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10497/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10496 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10496/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10496/comments | https://api.github.com/repos/huggingface/transformers/issues/10496/events | https://github.com/huggingface/transformers/pull/10496 | 820,891,613 | MDExOlB1bGxSZXF1ZXN0NTgzNzc2Mzk3 | 10,496 | [T5] Fix speed degradation bug t5 | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> Looks good to me!\r\n> \r\n> Some of the other library models also use this trick (BART-like models), we should also investigate those.\r\n\r\nGood point - yeah, let me fix this in this PR actually"
] | 1,614 | 1,614 | 1,614 | MEMBER | null | # What does this PR do?
Checking every value of a tensor for `inf` is expensive. This was added to T5 to allow for fp16 training, but should then also be used when the model is in fp16 to not slow down normal fp32 mode.
Using @dsgissin script:
```python
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')
print(f"Using device: {device}")
t5_tokenizer = T5TokenizerFast.from_pretrained('t5-base')
t5_model = T5ForConditionalGeneration.from_pretrained('t5-base')
t5_model = t5_model.to(device)
t5_input_ids = t5_tokenizer("summarize: studies have shown that owning a dog is good for you ", return_tensors="pt").input_ids # Batch size 1
t5_input_ids = t5_input_ids.to(device)
import time
import numpy as np
N = 100
times = []
for _ in range(N):
start = time.time()
t5_outputs = t5_model.generate(t5_input_ids)
end = time.time()
times.append(end-start)
print(f"transformers version: {transformers_version}")
print(f"torch version: {torch_version}")
print(f"{1000*np.mean(times):.0f} ms \u00B1 {1000*np.std(times):.2f} ms per loop (mean \u00B1 std of {N} runs)")
```
with:
- Python 3.8.5
- PyTorch 1.7.1
- CUDA 11.1 on a NVIDIA V100 GPU
The time was improved from:
```441 ms ± 41.67 ms per loop (mean ± std of 100 runs)```
to
```388 ms ± 44.75 ms per loop (mean ± std of 100 runs)``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10496/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10496/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10496",
"html_url": "https://github.com/huggingface/transformers/pull/10496",
"diff_url": "https://github.com/huggingface/transformers/pull/10496.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10496.patch",
"merged_at": 1614764561000
} |
https://api.github.com/repos/huggingface/transformers/issues/10495 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10495/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10495/comments | https://api.github.com/repos/huggingface/transformers/issues/10495/events | https://github.com/huggingface/transformers/issues/10495 | 820,861,772 | MDU6SXNzdWU4MjA4NjE3NzI= | 10,495 | Albert quantized | {
"login": "Zjq9409",
"id": 62974595,
"node_id": "MDQ6VXNlcjYyOTc0NTk1",
"avatar_url": "https://avatars.githubusercontent.com/u/62974595?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Zjq9409",
"html_url": "https://github.com/Zjq9409",
"followers_url": "https://api.github.com/users/Zjq9409/followers",
"following_url": "https://api.github.com/users/Zjq9409/following{/other_user}",
"gists_url": "https://api.github.com/users/Zjq9409/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Zjq9409/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Zjq9409/subscriptions",
"organizations_url": "https://api.github.com/users/Zjq9409/orgs",
"repos_url": "https://api.github.com/users/Zjq9409/repos",
"events_url": "https://api.github.com/users/Zjq9409/events{/privacy}",
"received_events_url": "https://api.github.com/users/Zjq9409/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | I use onnxruntime to optimize and quantize transformers model 'albert-base-v2' ,but the quantized result is different from original result,so,Does it support transformers albert quantized right now? | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10495/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10495/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10494 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10494/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10494/comments | https://api.github.com/repos/huggingface/transformers/issues/10494/events | https://github.com/huggingface/transformers/pull/10494 | 820,763,109 | MDExOlB1bGxSZXF1ZXN0NTgzNjY3NDE4 | 10,494 | [Wav2Vec2] Improve SpecAugment function by converting numpy based fun… | {
"login": "punitvara",
"id": 9531144,
"node_id": "MDQ6VXNlcjk1MzExNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/9531144?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/punitvara",
"html_url": "https://github.com/punitvara",
"followers_url": "https://api.github.com/users/punitvara/followers",
"following_url": "https://api.github.com/users/punitvara/following{/other_user}",
"gists_url": "https://api.github.com/users/punitvara/gists{/gist_id}",
"starred_url": "https://api.github.com/users/punitvara/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/punitvara/subscriptions",
"organizations_url": "https://api.github.com/users/punitvara/orgs",
"repos_url": "https://api.github.com/users/punitvara/repos",
"events_url": "https://api.github.com/users/punitvara/events{/privacy}",
"received_events_url": "https://api.github.com/users/punitvara/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"We need to run benchmark tests to see by how much the speed improved both on CPU and GPU",
"@patrickvonplaten Can you please help with above comments ?",
"Hey @punitvara,\r\n\r\nAt the moment, I sadly don't have the time to handle the big chunk of the PR. It would be great if you could try to:\r\n\r\n1) Find a way to benchmark your new function on GPU and show that it yields a speed-up in the forward pass compared to the old function\r\n\r\n2) Try out some advanced PyTorch indexing to replace the for loops.\r\n\r\nTaking a look at those PRs should help you: https://github.com/huggingface/transformers/pull/9600, https://github.com/huggingface/transformers/pull/9453, https://github.com/huggingface/transformers/pull/6064",
"Closing due to inactivity. Sorry @punitvara, I saw a lot of interest from other people to open a PR and this one seems to have stalled. Feel free to re-open it and give it a second shot if you want :-) ",
"I got busy into some other work. I will try to work on different issue. If you get any PR, feel free to merge it "
] | 1,614 | 1,618 | 1,618 | NONE | null | …ction to pytorch based function
Implements #10459
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10494/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10494/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10494",
"html_url": "https://github.com/huggingface/transformers/pull/10494",
"diff_url": "https://github.com/huggingface/transformers/pull/10494.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10494.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10493 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10493/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10493/comments | https://api.github.com/repos/huggingface/transformers/issues/10493/events | https://github.com/huggingface/transformers/pull/10493 | 820,756,455 | MDExOlB1bGxSZXF1ZXN0NTgzNjYxMjAx | 10,493 | Generate can return cross-attention weights too | {
"login": "Mehrad0711",
"id": 28717374,
"node_id": "MDQ6VXNlcjI4NzE3Mzc0",
"avatar_url": "https://avatars.githubusercontent.com/u/28717374?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Mehrad0711",
"html_url": "https://github.com/Mehrad0711",
"followers_url": "https://api.github.com/users/Mehrad0711/followers",
"following_url": "https://api.github.com/users/Mehrad0711/following{/other_user}",
"gists_url": "https://api.github.com/users/Mehrad0711/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Mehrad0711/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Mehrad0711/subscriptions",
"organizations_url": "https://api.github.com/users/Mehrad0711/orgs",
"repos_url": "https://api.github.com/users/Mehrad0711/repos",
"events_url": "https://api.github.com/users/Mehrad0711/events{/privacy}",
"received_events_url": "https://api.github.com/users/Mehrad0711/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi, I tried to keep the code changes to a minimum. Thus, I avoided adding another argument for returning cross-attention weights and used `output_attentions` to check instead. \r\nAlso in docstrings, for `decoder_attentions` the shape is mentioned as `(batch_size*num_return_sequences, num_heads, generated_length,\r\n sequence_length)`, although it seems that the shape is always `(batch_size*num_return_sequences, num_heads, 1, 1)`. `generated_length` is 1 as the code returns tuples per generated token and `sequence_length` is 1 since it's decoder self-attentions.\r\nSimilarly for `cross_attentions` the shape should be `(batch_size, num_heads, 1, input_sequence_length)`. Are there any examples where this is not True?\r\n\r\nPlease let me know what you think. Thanks!",
"> Hi, I tried to keep the code changes to a minimum. Thus, I avoided adding another argument for returning cross-attention weights and used `output_attentions` to check instead.\r\n> Also in docstrings, for `decoder_attentions` the shape is mentioned as `(batch_size*num_return_sequences, num_heads, generated_length, sequence_length)`, although it seems that the shape is always `(batch_size*num_return_sequences, num_heads, 1, 1)`. `generated_length` is 1 as the code returns tuples per generated token and `sequence_length` is 1 since it's decoder self-attentions.\r\n> Similarly for `cross_attentions` the shape should be `(batch_size, num_heads, 1, input_sequence_length)`. Are there any examples where this is not True?\r\n> \r\n> Please let me know what you think. Thanks!\r\n\r\nRegarding the `decoder_attentions` shape -> it's just the first attentions that is of shape `batch_size, num_heads, 1, 1`. Then it goes up to `..., 2, 2`, `..., 3, 3` etc. However if `use_cache` is enabled, then the shape is `...1, 1`, `...1, 2`, `....1, 3`.\r\n\r\nCheck this example:\r\n\r\n```python\r\nfrom transformers import BartForConditionalGeneration\r\nimport torch\r\n\r\nbart = BartForConditionalGeneration.from_pretrained(\"facebook/bart-large-cnn\")\r\nbart.config.max_length = 5 \r\nbart.config.num_beams = 1\r\n\r\noutputs_use_cache = bart.generate(torch.tensor([ 10 * [0]]), return_dict_in_generate=True, output_attentions=True)\r\noutputs_no_cache = bart.generate(torch.tensor([ 10 * [0]]), return_dict_in_generate=True, output_attentions=True, use_cache=False)\r\n\r\n# outputs_no_cache.decoder_attentions[1][0].shape gives (1, 16, 2, 2)\r\n# outputs_use_cache.decoder_attentions[1][0].shape gives (1, 16, 1, 2)\r\n```",
"> Regarding the decoder_attentions shape -> it's just the first attentions that is of shape batch_size, num_heads, 1, 1. Then it goes up to ..., 2, 2, ..., 3, 3 etc. However if use_cache is enabled, then the shape is ...1, 1, ...1, 2, ....1, 3.\r\n\r\nThanks for the example! It makes sense now.",
"Thanks for the great work. But I am still a bit confused about getting the cross-attention or encode-decoder attention if I am not mistaken the cross attention. Any hint would be great. Maybe it would be like \r\n\r\n```\r\n# outputs_no_cache.cross_attentions[1][0]\r\n# outputs_use_cache.cross_attentions[1][0]\r\n```\r\n\r\nThanks! @Mehrad0711 ",
"hi @xwuShirley \r\n\r\nYes, you are right. You can access the cross attentions using \r\n`outputs. cross_attentions`"
] | 1,614 | 1,615 | 1,614 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #10335
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [X] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [X] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [X] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patrickvonplaten
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10493/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10493/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10493",
"html_url": "https://github.com/huggingface/transformers/pull/10493",
"diff_url": "https://github.com/huggingface/transformers/pull/10493.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10493.patch",
"merged_at": 1614760022000
} |
https://api.github.com/repos/huggingface/transformers/issues/10492 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10492/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10492/comments | https://api.github.com/repos/huggingface/transformers/issues/10492/events | https://github.com/huggingface/transformers/issues/10492 | 820,745,341 | MDU6SXNzdWU4MjA3NDUzNDE= | 10,492 | Model Weights Fail to Load from Pre-Trained Model when Using `tf.name_scope` | {
"login": "EhsanM4t1qbit",
"id": 38892437,
"node_id": "MDQ6VXNlcjM4ODkyNDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/38892437?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/EhsanM4t1qbit",
"html_url": "https://github.com/EhsanM4t1qbit",
"followers_url": "https://api.github.com/users/EhsanM4t1qbit/followers",
"following_url": "https://api.github.com/users/EhsanM4t1qbit/following{/other_user}",
"gists_url": "https://api.github.com/users/EhsanM4t1qbit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/EhsanM4t1qbit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/EhsanM4t1qbit/subscriptions",
"organizations_url": "https://api.github.com/users/EhsanM4t1qbit/orgs",
"repos_url": "https://api.github.com/users/EhsanM4t1qbit/repos",
"events_url": "https://api.github.com/users/EhsanM4t1qbit/events{/privacy}",
"received_events_url": "https://api.github.com/users/EhsanM4t1qbit/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello!\n\nYou cannot load a model inside a namescope. This is the expected behavior because all the names are forced insides the h5 file. To use the model you have to load it outside your defined namescope and then use it inside.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.0
- Platform: Darwin-19.2.0-x86_64-i386-64bit
- Python version: 3.6.6
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): 2.3.1 (False)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
@LysandreJik @jplu
I can't load the pre-trained weights from BERT or Roberta when using a `tf.name_scope`.
Without defining a name scope, the code runs as expected.
```
text_model= TFBertModel.from_pretrained('bert-base-uncased')
Some layers from the model checkpoint at bert-base-uncased were not used when initializing TFBertModel: ['nsp___cls', 'mlm___cls']
- This IS expected if you are initializing TFBertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFBertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
All the layers of TFBertModel were initialized from the model checkpoint at bert-base-uncased.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFBertModel for predictions without further training.
```
By adding a name_scope, however, I'll get a warning, indicating that the pre-trained weights are not loaded.
```
import tensorflow as tf
from transformers import TFBertModel
with tf.name_scope("Model"):
text_model_2 = TFBertModel.from_pretrained('bert-base-uncased')
Some layers from the model checkpoint at bert-base-uncased were not used when initializing TFBertModel: ['nsp___cls', 'mlm___cls', 'bert/encoder/layer_._2/attention/self/key/bias:0', 'bert/encoder/layer_._7/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._4/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._6/attention/output/dense/kernel:0', 'bert/encoder/layer_._9/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._6/attention/self/key/bias:0', 'bert/encoder/layer_._5/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._3/output/LayerNorm/gamma:0', 'bert/encoder/layer_._5/attention/self/value/kernel:0', 'bert/encoder/layer_._9/attention/self/key/bias:0', 'bert/encoder/layer_._6/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._7/intermediate/dense/bias:0', 'bert/encoder/layer_._4/attention/self/value/kernel:0', 'bert/encoder/layer_._11/attention/self/key/bias:0', 'bert/encoder/layer_._5/attention/self/key/bias:0', 'bert/encoder/layer_._4/attention/self/query/bias:0', 'bert/encoder/layer_._7/output/dense/kernel:0', 'bert/encoder/layer_._8/output/dense/bias:0', 'bert/encoder/layer_._8/intermediate/dense/bias:0', 'bert/encoder/layer_._9/output/LayerNorm/gamma:0', 'bert/encoder/layer_._2/attention/self/key/kernel:0', 'bert/encoder/layer_._0/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._1/intermediate/dense/bias:0', 'bert/encoder/layer_._4/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._1/attention/self/key/kernel:0', 'bert/encoder/layer_._1/attention/self/query/kernel:0', 'bert/encoder/layer_._1/attention/output/dense/bias:0', 'bert/encoder/layer_._6/output/dense/kernel:0', 'bert/encoder/layer_._8/attention/self/key/kernel:0', 'bert/encoder/layer_._8/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._5/output/LayerNorm/beta:0', 'bert/encoder/layer_._1/attention/self/value/bias:0', 'bert/encoder/layer_._11/output/dense/kernel:0', 'bert/encoder/layer_._8/attention/output/dense/bias:0', 'bert/encoder/layer_._6/intermediate/dense/kernel:0', 'bert/encoder/layer_._8/attention/self/value/kernel:0', 'bert/encoder/layer_._7/attention/self/value/kernel:0', 'bert/encoder/layer_._11/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._5/attention/self/value/bias:0', 'bert/encoder/layer_._9/attention/output/dense/kernel:0', 'bert/encoder/layer_._1/attention/self/key/bias:0', 'bert/encoder/layer_._4/attention/output/dense/bias:0', 'bert/encoder/layer_._1/intermediate/dense/kernel:0', 'bert/encoder/layer_._6/output/LayerNorm/gamma:0', 'bert/encoder/layer_._2/intermediate/dense/kernel:0', 'bert/encoder/layer_._4/attention/self/query/kernel:0', 'bert/encoder/layer_._4/output/LayerNorm/gamma:0', 'bert/encoder/layer_._0/attention/self/query/bias:0', 'bert/encoder/layer_._11/attention/output/dense/bias:0', 'bert/encoder/layer_._2/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._10/attention/self/value/bias:0', 'bert/encoder/layer_._2/intermediate/dense/bias:0', 'bert/encoder/layer_._9/output/LayerNorm/beta:0', 'bert/encoder/layer_._0/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._3/attention/output/dense/bias:0', 'bert/encoder/layer_._2/attention/self/value/kernel:0', 'bert/encoder/layer_._3/output/dense/kernel:0', 'bert/encoder/layer_._1/attention/self/query/bias:0', 'bert/encoder/layer_._6/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._10/attention/output/dense/kernel:0', 'bert/encoder/layer_._3/intermediate/dense/kernel:0', 'bert/encoder/layer_._4/output/dense/kernel:0', 'bert/encoder/layer_._6/attention/self/key/kernel:0', 'bert/encoder/layer_._0/output/LayerNorm/beta:0', 'bert/encoder/layer_._7/attention/self/query/kernel:0', 'bert/encoder/layer_._1/output/dense/kernel:0', 'bert/encoder/layer_._0/output/dense/bias:0', 'bert/encoder/layer_._8/attention/output/dense/kernel:0', 'bert/encoder/layer_._11/attention/self/query/kernel:0', 'bert/encoder/layer_._9/attention/self/value/kernel:0', 'bert/encoder/layer_._2/attention/self/query/kernel:0', 'bert/encoder/layer_._4/intermediate/dense/bias:0', 'bert/encoder/layer_._4/intermediate/dense/kernel:0', 'bert/encoder/layer_._0/attention/self/key/kernel:0', 'bert/encoder/layer_._8/attention/self/query/bias:0', 'bert/encoder/layer_._5/attention/output/dense/bias:0', 'bert/encoder/layer_._10/attention/output/dense/bias:0', 'bert/encoder/layer_._11/attention/self/key/kernel:0', 'bert/encoder/layer_._2/output/LayerNorm/gamma:0', 'bert/encoder/layer_._10/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._3/attention/self/query/kernel:0', 'bert/encoder/layer_._10/intermediate/dense/kernel:0', 'bert/encoder/layer_._10/attention/self/query/bias:0', 'bert/encoder/layer_._7/output/LayerNorm/beta:0', 'bert/encoder/layer_._6/intermediate/dense/bias:0', 'bert/encoder/layer_._3/attention/self/key/kernel:0', 'bert/encoder/layer_._8/intermediate/dense/kernel:0', 'bert/encoder/layer_._5/intermediate/dense/kernel:0', 'bert/encoder/layer_._6/output/dense/bias:0', 'bert/encoder/layer_._0/attention/self/query/kernel:0', 'bert/encoder/layer_._6/attention/self/query/bias:0', 'bert/encoder/layer_._7/attention/output/dense/kernel:0', 'bert/encoder/layer_._8/output/LayerNorm/beta:0', 'bert/encoder/layer_._9/attention/self/query/bias:0', 'bert/encoder/layer_._3/output/dense/bias:0', 'bert/encoder/layer_._11/intermediate/dense/bias:0', 'bert/encoder/layer_._4/attention/output/dense/kernel:0', 'bert/encoder/layer_._6/output/LayerNorm/beta:0', 'bert/encoder/layer_._5/output/dense/kernel:0', 'bert/encoder/layer_._3/attention/self/value/kernel:0', 'bert/encoder/layer_._8/output/LayerNorm/gamma:0', 'bert/encoder/layer_._1/attention/output/dense/kernel:0', 'bert/encoder/layer_._11/output/dense/bias:0', 'bert/encoder/layer_._0/output/LayerNorm/gamma:0', 'bert/encoder/layer_._10/output/LayerNorm/beta:0', 'bert/encoder/layer_._0/intermediate/dense/bias:0', 'bert/encoder/layer_._9/output/dense/bias:0', 'bert/encoder/layer_._2/attention/self/value/bias:0', 'bert/encoder/layer_._5/output/LayerNorm/gamma:0', 'bert/encoder/layer_._1/output/dense/bias:0', 'bert/encoder/layer_._0/attention/self/value/kernel:0', 'bert/encoder/layer_._7/attention/output/dense/bias:0', 'bert/encoder/layer_._10/output/dense/bias:0', 'bert/encoder/layer_._11/attention/self/value/kernel:0', 'bert/encoder/layer_._3/intermediate/dense/bias:0', 'bert/encoder/layer_._8/attention/self/query/kernel:0', 'bert/encoder/layer_._10/intermediate/dense/bias:0', 'bert/encoder/layer_._6/attention/self/value/kernel:0', 'bert/encoder/layer_._5/attention/output/dense/kernel:0', 'bert/encoder/layer_._9/intermediate/dense/kernel:0', 'bert/encoder/layer_._4/attention/self/value/bias:0', 'bert/encoder/layer_._4/output/dense/bias:0', 'bert/encoder/layer_._5/attention/output/LayerNorm/beta:0', 'bert/embeddings/LayerNorm/gamma:0', 'bert/embeddings/position_embeddings/embeddings:0', 'bert/encoder/layer_._4/attention/self/key/kernel:0', 'bert/encoder/layer_._7/attention/self/query/bias:0', 'bert/encoder/layer_._10/attention/self/query/kernel:0', 'bert/encoder/layer_._10/attention/self/key/kernel:0', 'bert/encoder/layer_._11/attention/self/value/bias:0', 'bert/encoder/layer_._2/attention/self/query/bias:0', 'bert/encoder/layer_._4/attention/self/key/bias:0', 'bert/encoder/layer_._7/attention/self/key/kernel:0', 'bert/encoder/layer_._11/intermediate/dense/kernel:0', 'bert/encoder/layer_._3/attention/self/value/bias:0', 'bert/pooler/dense/kernel:0', 'bert/encoder/layer_._2/output/dense/bias:0', 'bert/encoder/layer_._7/intermediate/dense/kernel:0', 'bert/encoder/layer_._8/attention/self/key/bias:0', 'bert/embeddings/word_embeddings/weight:0', 'bert/encoder/layer_._11/output/LayerNorm/beta:0', 'bert/encoder/layer_._9/attention/self/value/bias:0', 'bert/embeddings/token_type_embeddings/embeddings:0', 'bert/encoder/layer_._1/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._6/attention/self/value/bias:0', 'bert/pooler/dense/bias:0', 'bert/encoder/layer_._8/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._1/output/LayerNorm/gamma:0', 'bert/encoder/layer_._9/intermediate/dense/bias:0', 'bert/encoder/layer_._1/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._9/output/dense/kernel:0', 'bert/encoder/layer_._0/output/dense/kernel:0', 'bert/encoder/layer_._3/output/LayerNorm/beta:0', 'bert/encoder/layer_._7/output/LayerNorm/gamma:0', 'bert/encoder/layer_._11/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._3/attention/output/dense/kernel:0', 'bert/encoder/layer_._3/attention/self/key/bias:0', 'bert/encoder/layer_._10/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._2/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._6/attention/output/dense/bias:0', 'bert/encoder/layer_._7/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._0/intermediate/dense/kernel:0', 'bert/encoder/layer_._10/attention/self/value/kernel:0', 'bert/encoder/layer_._5/attention/self/key/kernel:0', 'bert/encoder/layer_._10/attention/self/key/bias:0', 'bert/encoder/layer_._9/attention/self/key/kernel:0', 'bert/encoder/layer_._1/attention/self/value/kernel:0', 'bert/encoder/layer_._7/output/dense/bias:0', 'bert/encoder/layer_._11/output/LayerNorm/gamma:0', 'bert/encoder/layer_._0/attention/self/key/bias:0', 'bert/encoder/layer_._3/attention/output/LayerNorm/beta:0', 'bert/encoder/layer_._11/attention/output/dense/kernel:0', 'bert/encoder/layer_._7/attention/self/key/bias:0', 'bert/encoder/layer_._3/attention/output/LayerNorm/gamma:0', 'bert/encoder/layer_._10/output/dense/kernel:0', 'bert/encoder/layer_._10/output/LayerNorm/gamma:0', 'bert/encoder/layer_._5/output/dense/bias:0', 'bert/encoder/layer_._9/attention/output/dense/bias:0', 'bert/encoder/layer_._11/attention/self/query/bias:0', 'bert/encoder/layer_._2/output/LayerNorm/beta:0', 'bert/encoder/layer_._7/attention/self/value/bias:0', 'bert/encoder/layer_._1/output/LayerNorm/beta:0', 'bert/encoder/layer_._5/intermediate/dense/bias:0', 'bert/embeddings/LayerNorm/beta:0', 'bert/encoder/layer_._9/attention/self/query/kernel:0', 'bert/encoder/layer_._2/output/dense/kernel:0', 'bert/encoder/layer_._0/attention/output/dense/kernel:0', 'bert/encoder/layer_._2/attention/output/dense/bias:0', 'bert/encoder/layer_._4/output/LayerNorm/beta:0', 'bert/encoder/layer_._0/attention/self/value/bias:0', 'bert/encoder/layer_._8/output/dense/kernel:0', 'bert/encoder/layer_._2/attention/output/dense/kernel:0', 'bert/encoder/layer_._6/attention/self/query/kernel:0', 'bert/encoder/layer_._0/attention/output/dense/bias:0', 'bert/encoder/layer_._3/attention/self/query/bias:0', 'bert/encoder/layer_._5/attention/self/query/bias:0', 'bert/encoder/layer_._5/attention/self/query/kernel:0', 'bert/encoder/layer_._8/attention/self/value/bias:0', 'bert/encoder/layer_._9/attention/output/LayerNorm/gamma:0']
- This IS expected if you are initializing TFBertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing TFBertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
All the layers of TFBertModel were initialized from the model checkpoint at bert-base-uncased.
If your task is similar to the task the model of the checkpoint was trained on, you can already use TFBertModel for predictions without further training.
```
The problem I think is rooted in https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_tf_utils.py#L487. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10492/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10492/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10491 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10491/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10491/comments | https://api.github.com/repos/huggingface/transformers/issues/10491/events | https://github.com/huggingface/transformers/issues/10491 | 820,605,250 | MDU6SXNzdWU4MjA2MDUyNTA= | 10,491 | ONNX Training for Transformers | {
"login": "harsha070",
"id": 29897928,
"node_id": "MDQ6VXNlcjI5ODk3OTI4",
"avatar_url": "https://avatars.githubusercontent.com/u/29897928?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/harsha070",
"html_url": "https://github.com/harsha070",
"followers_url": "https://api.github.com/users/harsha070/followers",
"following_url": "https://api.github.com/users/harsha070/following{/other_user}",
"gists_url": "https://api.github.com/users/harsha070/gists{/gist_id}",
"starred_url": "https://api.github.com/users/harsha070/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/harsha070/subscriptions",
"organizations_url": "https://api.github.com/users/harsha070/orgs",
"repos_url": "https://api.github.com/users/harsha070/repos",
"events_url": "https://api.github.com/users/harsha070/events{/privacy}",
"received_events_url": "https://api.github.com/users/harsha070/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Is it possible to pretrain bert with ONNX?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,621 | 1,621 | NONE | null | # 🚀 Feature request
Is there a script for ONNX training of transformers on glue tasks ? If so, did anyone benchmark the training times ? If not, I can contribute.
## Motivation
Faster training.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10491/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10491/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10490 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10490/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10490/comments | https://api.github.com/repos/huggingface/transformers/issues/10490/events | https://github.com/huggingface/transformers/issues/10490 | 820,484,414 | MDU6SXNzdWU4MjA0ODQ0MTQ= | 10,490 | Pipeline's QnA and run_qa predictions do not match | {
"login": "oersoy1",
"id": 4379212,
"node_id": "MDQ6VXNlcjQzNzkyMTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4379212?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/oersoy1",
"html_url": "https://github.com/oersoy1",
"followers_url": "https://api.github.com/users/oersoy1/followers",
"following_url": "https://api.github.com/users/oersoy1/following{/other_user}",
"gists_url": "https://api.github.com/users/oersoy1/gists{/gist_id}",
"starred_url": "https://api.github.com/users/oersoy1/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/oersoy1/subscriptions",
"organizations_url": "https://api.github.com/users/oersoy1/orgs",
"repos_url": "https://api.github.com/users/oersoy1/repos",
"events_url": "https://api.github.com/users/oersoy1/events{/privacy}",
"received_events_url": "https://api.github.com/users/oersoy1/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Just to be sure I understand completely the problem since I don't see the F1s for the full results obtained via pipeline, which is producing the best results? `pipeline` or `run_qa`? Or are they different but overall comparable?",
"`run_qa.py` produces the better results. They are different on about 3000 records, 2700 of those are off by a character or so, 300 are off by a larger margin, sometimes different answers, 12 records Null (pipeline) vs Not-Null (run_qa) (false negative). And that is on SQuAD. I see a wider gap on custom datasets. \"Comparable\" is a subjective word so I perhaps should not comment on that. In my opinion they need to match. What we get out of run_qa.py in batch for a dataset should be the same for record i, meaning when we pass the same query and context to the model, the script and the module should deterministically return the same answer. The problem might not be exactly in the predictions but rather in the post prediction functions. ",
"@sgugger Hi, any update on this? Did you all get a chance to look into the problem? by the way, after I wrote the message above, I realized \"better\" is also subjective. I would prefer a 5 token answer to a 1 token answer for instance depending on the question and context. As I mentioned pipeline does not clean up the answer as well, punctuation gets carried over. Looking at custom validation sets I can tell the F1 score is lower for Pipelines, which I did it pretty much manually by writing custom code as I had a smaller set. If there is a way to take the pipeline predictions and calculate a F1 score against the ground truths in SQuAD, I would be happy to do that and return you a result. But again, that would be just SQuAD. better or worse, the answers don't match. Maybe the problem is in run_qa.py and this is an opportunity to get that fixed. Thanks in advance. ",
"The problem is that neither is easily fixable. For backward compatibility reason we can't change the way the qa pipeline works out of the blue. We are trying to think of having some \"pipeline configs\" to be able to switch behaviors in pre or post processing but it won't be added overnight.\r\n\r\nOverall this is going to take some time to solve.",
"@sgugger thank you for the acknowledgement and clarification that there indeed is a difference. I was not at least dreaming stuff up. \r\n\r\nHere is what I ended up doing: I gutted out `run_qa.py` and created a custom inference code using the evaluation functions in that script. Now my model answers match obviously but I ended up with a different problem. When I pass **a single** query/context pair to my custom question answerer, the latency increased by about 10x. I profiled my code and lo and behold the problem is in the data prep part that is written with `datasets` and seems like is optimized for batch processing during training, meaning there is a cost incurred in the upstream processing before the prediction.\r\n\r\nSo now I am caught between a rock and a hard place as the model does not produce the same answers if I use the `pipeline` and I have a latency issue for single inference with the `run_qa.py` code.. Is it possible to summarize the problem with `pipeline` so that maybe I can write some code to patch that configurable part into it? That would go a long way. Merci beaucoup!\r\n\r\nPS: I also noted 2 other main differences between these two inference codes. \r\n\r\n1) I don't see where we can incorporate a null threshold in the `pipeline` function. I actually benefit up to 2-3 points for F1 on my custom dataset with a threshold. \r\n2) The pipeline can take multiple query/context pairs but it loops through them one at a time, so if I pass a batch of 16, I get 16x latency. \r\n\r\nI am thinking about entering separate issues as I can't see any open issues regarding them. Please let me know if I have overlooked or you all have incorporated some of this recently. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hi @sgugger @oersoy1,\r\n\r\nI am facing the same issue. The pipeline predictions are not the same as run_qa.py predictions. Please let me know if there is any update or work around for the same. "
] | 1,614 | 1,652 | 1,619 | NONE | null | ## Environment info
- `transformers` version: 4.3.0 or 4.4.0dev (tested in both versions)
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.7.1+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
pipelines: @LysandreJik
maintained examples (run_qa.py): @sgugger, @patil-suraj
## Information
I have noticed that the `pipeline("question-answering)` and `run_qa.py `evaluation functions (prediction + post_process) not only are built differently but also yield different results affecting the precision/recall numbers, `pipeline` being the worse performer. I ran the test on 2 different environments and got the same results. Given the same exact model, the module and the script may affect precision/recall numbers up to 5%. The issue may manifest itself only in a set with negatives as I have not run a test on a set where negatives are not possible.
The problem arises when using:
* [X] the official example scripts:
`run_qa.py` and `pipeline`
The tasks I am working on is:
* [X] an official GLUE/SQUaD task: SQuAD V2
## To reproduce
Steps to reproduce the behavior:
1. Take any QnA model and execute `run_qa.py`on the SQuAD V2 validation set
2. Get predictions on the same set via `pipeline` with the same model and parameters
3. Compare
Here is my notebook to follow the logic and see the results on a particular QnA model.
[Colab Notebook](https://colab.research.google.com/drive/1GMetvI6e0pkUPUHiNX6f46_TBO0LUKre?usp=sharing
)
## Expected behavior
The results need to match. `run_qa.py` code appears to be optimized for training and evaluation at training. Most researchers report QnA model performance on a script like this. The inference module `pipeline` should match what `run_qa.py` is producing.
### more observations:
1. Pipeline produces more NULL answers than `run_qa` (Highest Concern)
2. About half the non-null answers do not match exactly (45%). Most of those are off by a character or so
3. More than negligible number of records do not match closely
4. pipeline produces shorter answers,
5. pipeline does not take care of apostrophe cases
6. pipeline answers may be in separate places in the context.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10490/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10490/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10489 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10489/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10489/comments | https://api.github.com/repos/huggingface/transformers/issues/10489/events | https://github.com/huggingface/transformers/pull/10489 | 820,418,410 | MDExOlB1bGxSZXF1ZXN0NTgzMzY1MzYw | 10,489 | Fix typos | {
"login": "WybeKoper",
"id": 40920213,
"node_id": "MDQ6VXNlcjQwOTIwMjEz",
"avatar_url": "https://avatars.githubusercontent.com/u/40920213?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/WybeKoper",
"html_url": "https://github.com/WybeKoper",
"followers_url": "https://api.github.com/users/WybeKoper/followers",
"following_url": "https://api.github.com/users/WybeKoper/following{/other_user}",
"gists_url": "https://api.github.com/users/WybeKoper/gists{/gist_id}",
"starred_url": "https://api.github.com/users/WybeKoper/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/WybeKoper/subscriptions",
"organizations_url": "https://api.github.com/users/WybeKoper/orgs",
"repos_url": "https://api.github.com/users/WybeKoper/repos",
"events_url": "https://api.github.com/users/WybeKoper/events{/privacy}",
"received_events_url": "https://api.github.com/users/WybeKoper/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | # What does this PR do?
I fixed a couple of typos in comments.
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10489/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10489/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10489",
"html_url": "https://github.com/huggingface/transformers/pull/10489",
"diff_url": "https://github.com/huggingface/transformers/pull/10489.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10489.patch",
"merged_at": 1614761245000
} |
https://api.github.com/repos/huggingface/transformers/issues/10488 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10488/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10488/comments | https://api.github.com/repos/huggingface/transformers/issues/10488/events | https://github.com/huggingface/transformers/pull/10488 | 820,403,249 | MDExOlB1bGxSZXF1ZXN0NTgzMzUzMTE2 | 10,488 | Smp grad accum | {
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | COLLABORATOR | null | # What does this PR do?
This PR adds support for gradient accumulation in `SageMakerTrainer`. It has been tested on the glue script with success (with and without gradient accumulation passed along). | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10488/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10488/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10488",
"html_url": "https://github.com/huggingface/transformers/pull/10488",
"diff_url": "https://github.com/huggingface/transformers/pull/10488.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10488.patch",
"merged_at": 1614791610000
} |
https://api.github.com/repos/huggingface/transformers/issues/10487 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10487/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10487/comments | https://api.github.com/repos/huggingface/transformers/issues/10487/events | https://github.com/huggingface/transformers/pull/10487 | 820,394,352 | MDExOlB1bGxSZXF1ZXN0NTgzMzQ1Nzg3 | 10,487 | remap MODEL_FOR_QUESTION_ANSWERING_MAPPING classes to names auto-generated file | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | As discussed in https://github.com/huggingface/transformers/issues/10467 currently Trainer loads `models.auto.modeling_auto` which loads **all** modeling files, which is absolutely not needed most of the time. At times it could have unwanted side-effects, loading modeling files that require some 3rd party modules that could be a problem.
Similar to the autogenerated 3rd party version numbers look up dict, this PR autogenerates the names of the classes dict for `MODEL_FOR_QUESTION_ANSWERING_MAPPING` which can then be quickly loaded.
This of course can be extended in the future to generate other structures if need be.
@sgugger, @LysandreJik
Fixes: https://github.com/huggingface/transformers/issues/10467
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10487/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10487/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10487",
"html_url": "https://github.com/huggingface/transformers/pull/10487",
"diff_url": "https://github.com/huggingface/transformers/pull/10487.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10487.patch",
"merged_at": 1614790440000
} |
https://api.github.com/repos/huggingface/transformers/issues/10486 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10486/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10486/comments | https://api.github.com/repos/huggingface/transformers/issues/10486/events | https://github.com/huggingface/transformers/issues/10486 | 820,336,870 | MDU6SXNzdWU4MjAzMzY4NzA= | 10,486 | Trainer not logging to WandB in SageMaker | {
"login": "alexf-a",
"id": 12577961,
"node_id": "MDQ6VXNlcjEyNTc3OTYx",
"avatar_url": "https://avatars.githubusercontent.com/u/12577961?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/alexf-a",
"html_url": "https://github.com/alexf-a",
"followers_url": "https://api.github.com/users/alexf-a/followers",
"following_url": "https://api.github.com/users/alexf-a/following{/other_user}",
"gists_url": "https://api.github.com/users/alexf-a/gists{/gist_id}",
"starred_url": "https://api.github.com/users/alexf-a/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/alexf-a/subscriptions",
"organizations_url": "https://api.github.com/users/alexf-a/orgs",
"repos_url": "https://api.github.com/users/alexf-a/repos",
"events_url": "https://api.github.com/users/alexf-a/events{/privacy}",
"received_events_url": "https://api.github.com/users/alexf-a/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Are you sure `wandb` is installed in the container you are using for training? There can't be any report if it's not installed and initialized.",
"Yup, it's installed. Here is the requirements file that goes into the container\r\n\r\n```\r\nboto3==1.16.32\r\npeewee==3.13.3\r\npandas==1.0.5\r\ntorch==1.6.0\r\nnumpy==1.18.2\r\ntransformers==4.3.0\r\nwandb==0.10.20\r\nbotocore==1.19.37\r\nsrsly==1.0.2\r\npsycopg2_binary==2.8.5\r\nscikit_learn==0.23.2\r\nuvloop==0.14.0\r\n./prodigy-1.10.5-cp36.cp37.cp38-cp36m.cp37m.cp38-linux_x86_64.whl\r\nhttps://github.com/explosion/spacy-models/releases/download/en_core_web_md-2.3.1/en_core_web_md-2.3.1.tar.gz\r\n```\r\nI also upload my API key from a separate file. \r\n\r\nAlso, if I manually call \r\n`wandb.log({\"Some metric\":\"This will appear\"})`\r\n\r\nThen it shows up in the run's dashboard. The only information that doesn't show up is the automatic logging that the Trainer is supposed to do. ",
"Could you share the training script you are using?",
"I can't share the full script, but it's something like \r\n\r\n```\r\nimport wandb\r\nfrom transformers import (\r\n AutoConfig,\r\n AutoModelForSequenceClassification,\r\n HfArgumentParser,\r\n Trainer,\r\n TrainingArguments,\r\n)\r\n\r\nclass ModelArguments:\r\n#Declare arguments here\r\n\r\nclass DataTrainingArguments:\r\n#Declare more arguments\r\n\r\nparser = HfArgumentParser((ModelArguments, DataTrainingArguments))\r\nmodel_args, data_args, training_args = parser.parse_args_into_dataclasses()\r\n\r\n#Assuming I have the config already\r\nmodel = AutoModelForSequenceClassification.from_pretrained(\r\n model_args.model_name_or_path,\r\n config=config\r\n )\r\n\r\n#train_data, eval_data = get data from a remote host\r\n\r\ntrainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n train_dataset=train_data,\r\n eval_dataset=eval_data,\r\n )\r\n\r\ntrainer.train()\r\n\r\nwandb.log({\"Fake Metric\":\"This will show up\"})\r\n```\r\nWhen I run on SageMaker, I can see from the console logs and the post-training evaluation that it has been training. \r\n\r\n",
"It would be interesting to have the result of \r\n```\r\nfrom transformers.integrations import get_available_reporting_integrations\r\nprint(get_available_reporting_integrations())\r\n```\r\nto check whether or not `wandb` is listed.\r\n\r\nAnother thing you can do is force the reporting to wandb with adding `report_to = [\"wand\"]` in your hyperparameters.",
"Got this from the integrations print\r\n`['wandb']`\r\nAlso, tried to force the reporting to WandB. It's a bit tricky to pass lists into the SageMaker Estimator as a hyperparam, so I just tried to force the reporting in my script\r\n\r\n```\r\n parser = HfArgumentParser((ModelArguments, DataTrainingArguments))\r\n model_args, data_args, training_args = parser.parse_args_into_dataclasses()\r\n training_args.report_to = [\"wandb\"]\r\n data_args.report_to = [\"wandb\"]\r\n```\r\nStill getting the same result",
"Curiouser and curiouser. So it is detected an added but doesn't log anything. @borisdayma do you have some idea of why theWandbCallback would not log anything in a training launched on SageMaker?",
"I'm not sure but now I'm feeling the curiousest!\r\nThere is actually some W&B documentation with specific setup instructions for Sagemaker: see [here](https://docs.wandb.ai/integrations/sagemaker)",
"I'm feeling pretty curious too...already followed the instructions with the secrents.env file. ",
"Could you add somewhere in the methods of [`WandbCallback`](https://github.com/huggingface/transformers/blob/395ffcd757103ed2ccc888e48d90fd2ccb4d506f/src/transformers/integrations.py#L510) some `print` statements just to see if they are being called at all?\r\n\r\nYou could just copy that file in your local folder and import from it.",
"I cloned the repo, added the` print `statements, imported the `WandbCallback` and added it to the `Trainer` callbacks.\r\n\r\nI am seeing some `print` statements, but...no logs to WandB dashboard :( ",
"That's progress!\r\nCan you add some maybe just after the calls to `wandb.log` and maybe also print `wandb.run.id`?",
"Got some interesting results.\r\n\r\nI added\r\n\r\n```\r\n def on_train_begin(self, args, state, control, model=None, **kwargs):\r\n print(\"TESTING WANDB: BEGINNING TRAINING\")\r\n wandb.log({\"Begining training\": \"Please appear\"})\r\n ...\r\n```\r\nand ran it locally (in the CLI on a Notebook instance). I got:\r\n\r\n`NameError: name 'wandb' is not defined`\r\n\r\nIf I run this code in the callbacks init function:\r\n\r\n\r\n```\r\n def __init__(self):\r\n print(\"TESTING WANDB: INITIALIZING CALLBACK\")\r\n has_wandb = is_wandb_available()\r\n assert has_wandb, \"WandbCallback requires wandb to be installed. Run `pip install wandb`.\"\r\n if not has_wandb:\r\n print(\"NO WEIGHTS AND BIASES!!!!!!!!\")\r\n if has_wandb:\r\n import wandb\r\n\r\n wandb.ensure_configured()\r\n if wandb.api.api_key is None:\r\n has_wandb = False\r\n logger.warning(\r\n \"W&B installed but not logged in. Run `wandb login` or set the WANDB_API_KEY env variable.\"\r\n )\r\n self._wandb = None\r\n else:\r\n self._wandb = wandb\r\n self._initialized = False\r\n # log outputs\r\n self._log_model = os.getenv(\"WANDB_LOG_MODEL\", \"FALSE\").upper() in ENV_VARS_TRUE_VALUES.union({\"TRUE\"})\r\n```\r\n`\"NO WEIGHTS AND BIASES!!!!!!!!\"` does not print.\r\n\r\nIf `wandb` gets imported, shouldn't the log statements work? Not sure if this is a separate issue from the SageMaker one. ",
"Very interesting!\r\nWhat if you ignore the second check and just set `self._wandb = wandb`",
"Same error! ",
"Does [this example](https://github.com/wandb/examples/tree/master/examples/pytorch/pytorch-cifar10-sagemaker) work for you?",
"Yup",
"Maybe can you try to log directly something to even before using the `Trainer`?\r\n\r\n```python\r\nimport wandb\r\nwandb.init()\r\nwandb.log({'val': 1})\r\n```\r\n\r\nThat way we will see if it comes from your wandb setup in Sagemaker or HF.",
"I do already do that actually, and it does appear! I successfully log a couple of charts before and after training. ",
"In your code where you set `self._wandb`, can you try to do something like `self._wandb.log({'test_value': 1})`",
"This works! \r\n\r\nI have regular training logs and the test_value logged when the callback's int function is like this:\r\n\r\n```\r\n def __init__(self):\r\n print(\"TESTING WANDB: INITIALIZING CALLBACK\")\r\n has_wandb = is_wandb_available()\r\n assert has_wandb, \"WandbCallback requires wandb to be installed. Run `pip install wandb`.\"\r\n if has_wandb:\r\n import wandb\r\n\r\n wandb.ensure_configured()\r\n '''\r\n if wandb.api.api_key is None:\r\n has_wandb = False\r\n logger.warning(\r\n \"W&B installed but not logged in. Run `wandb login` or set the WANDB_API_KEY env variable.\"\r\n )\r\n self._wandb = None\r\n else:\r\n '''\r\n self._wandb = wandb\r\n self._wandb.log({'test_value': 1})\r\n self._initialized = False\r\n # log outputs\r\n self._log_model = os.getenv(\"WANDB_LOG_MODEL\", \"FALSE\").upper() in ENV_VARS_TRUE_VALUES.union({\"TRUE\"})\r\n```\r\n\r\nHowever, if I do not pass in the modified version of WandbCallback the problem resumes. ",
"This is very strange...\r\nSo just adding the `log` statement makes it work and it stops working if you remove it?",
"It looks like what makes the difference is commenting out this portion\r\n\r\n```\r\n '''\r\n if wandb.api.api_key is None:\r\n has_wandb = False\r\n logger.warning(\r\n \"W&B installed but not logged in. Run `wandb login` or set the WANDB_API_KEY env variable.\"\r\n )\r\n self._wandb = None\r\n else:\r\n '''\r\n```\r\nAnd then passing the modified callback in explicitly in the Trainer. \r\n\r\nI believe that the NameError above was because I was calling `wandb.log`, instead of `self._wandb.log`",
"This should now be fixed on the master branch of `transformers`. Let me know if you still have any issue @alexf-a ",
"It is still happening! It looks like the WandB API key is not getting properly loaded from the secrets.env. If I run this code, it works\r\n\r\n``` \r\n with open(\"./secrets.env\", \"r\") as secrets_f:\r\n wandb_api_key = secrets_f.read().replace('\\n', '').split(\"=\")[1]\r\n os.environ[\"WANDB_API_KEY\"] = wandb_api_key \r\n\r\n```",
"Hey @alexf-a we'll work on a patch in the next release that handles the sagemaker case. Until then if you just add this code before you instantiate your trainer it should work.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,620 | 1,620 | NONE | null | - `transformers` version: 4.3.0
- wandb version: 0.10.20
- Platform: SageMaker hosted training with PyTorch estimator.
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
@stas00 @sgugger
I am using a SageMaker training environment to train `BertForSequenceClassification`. To do this, I'm passing the model into a `Trainer` instance and calling `trainer.train()`.
To train in SageMaker, I am using a PyTorch estimator:
```
estimator = PyTorch(
entry_point='train_classifier.py',
source_dir='./',
role=role,
sagemaker_session=sagemaker_session,
hyperparameters=hp,
subnets=subnets,
security_group_ids=sec_groups,
framework_version='1.6.0',
py_version='py3',
instance_count=1,
instance_type=instance_type,
dependencies=[ '../lib', '../db_conn'],
use_spot_instances=False,
volume_size=100,
#max_wait=max_wait_time_secs
)
estimator.fit()
```
I have tried this with different p2 and p3 instances.
In EC2 or in a SageMaker notebook, this does automated logging of training loss and evaluation loss and metrics to WandB. With the estimator, I get no training logs.
Anything that I manually log to WandB appears in my dashboard. The only info that doesn't show up is whatever used to get logged by the Trainer.
I tried `os.environ["WANDB_DISALBED"] = "false"` in my training script, no luck.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10486/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10486/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10485 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10485/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10485/comments | https://api.github.com/repos/huggingface/transformers/issues/10485/events | https://github.com/huggingface/transformers/issues/10485 | 820,324,145 | MDU6SXNzdWU4MjAzMjQxNDU= | 10,485 | Constrained decoding? | {
"login": "kailashkarthiks",
"id": 78363282,
"node_id": "MDQ6VXNlcjc4MzYzMjgy",
"avatar_url": "https://avatars.githubusercontent.com/u/78363282?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kailashkarthiks",
"html_url": "https://github.com/kailashkarthiks",
"followers_url": "https://api.github.com/users/kailashkarthiks/followers",
"following_url": "https://api.github.com/users/kailashkarthiks/following{/other_user}",
"gists_url": "https://api.github.com/users/kailashkarthiks/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kailashkarthiks/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kailashkarthiks/subscriptions",
"organizations_url": "https://api.github.com/users/kailashkarthiks/orgs",
"repos_url": "https://api.github.com/users/kailashkarthiks/repos",
"events_url": "https://api.github.com/users/kailashkarthiks/events{/privacy}",
"received_events_url": "https://api.github.com/users/kailashkarthiks/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I think you should take a look at `prefix_allowed_tokens_fn` on the [`generate` method](https://huggingface.co/transformers/main_classes/model.html?highlight=generate#transformers.generation_utils.GenerationMixin.generate). \r\n\r\nIt let's you create a function to constrain the generation based on previously generated tokens. It is inspired by this paper: [Autoregressive Entity Retrieval](https://arxiv.org/abs/2010.00904).",
"thanks! Is there a way to have more generic callbacks that can possibly access the beams (for instance, if I want to do custom scoring/tracking/modification to the entries in the beam)?\r\n\r\nIf not, would that be a useful PR to submit?",
"So you mean to access the different beams so that generations is conditioned to not just the current beam so far but also the others? \r\nYou probably should look at transformers.LogitsProcessor in:\r\nhttps://github.com/huggingface/transformers/blob/1750e629006bb6989aef5b4e141f3477f891a098/src/transformers/generation_utils.py#L555-L629\r\n\r\n which deals with the constraints and scoring of tokens at generation. Perhaps what you described could be introduced in a similar fashion as `prefix_allowed_tokens_fn`.\r\n\r\nRegarding a PR I am not the best to say, I would first make sure if what you aim for can be done within the existing functionality. ",
"I did take a look at `LogitsProcessor` and might be able to work with that - thanks!",
"@kailashkarthiks Hi, I am also interested in performing constrained decoding with seq2seq language models like BART. I was wondering if you made any progress on this, and if yes, would you be able to share your findings or code? Thank you!"
] | 1,614 | 1,623 | 1,614 | NONE | null | Is it possible to implement constraints on the beam during decoding using a seq2seq model? [NeuroLogic Decoding](https://arxiv.org/abs/2010.12884), [Constrained Abstractive Summarization](https://arxiv.org/abs/2010.12723)
I see that there is a Callback feature in the library - but AFAIK it only lets modify the training state and not the beam. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10485/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10485/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10484 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10484/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10484/comments | https://api.github.com/repos/huggingface/transformers/issues/10484/events | https://github.com/huggingface/transformers/issues/10484 | 820,311,946 | MDU6SXNzdWU4MjAzMTE5NDY= | 10,484 | Corrupted Relative Attention in T5 Decoder | {
"login": "Slash0BZ",
"id": 6762144,
"node_id": "MDQ6VXNlcjY3NjIxNDQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/6762144?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Slash0BZ",
"html_url": "https://github.com/Slash0BZ",
"followers_url": "https://api.github.com/users/Slash0BZ/followers",
"following_url": "https://api.github.com/users/Slash0BZ/following{/other_user}",
"gists_url": "https://api.github.com/users/Slash0BZ/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Slash0BZ/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Slash0BZ/subscriptions",
"organizations_url": "https://api.github.com/users/Slash0BZ/orgs",
"repos_url": "https://api.github.com/users/Slash0BZ/repos",
"events_url": "https://api.github.com/users/Slash0BZ/events{/privacy}",
"received_events_url": "https://api.github.com/users/Slash0BZ/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | {
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
] | [
"Uploaded full dataset and trained model: https://drive.google.com/drive/u/1/folders/1A7PIG1E98uuGUi8mDA2m_6T_oQp8XDhF\r\n\r\nYou can reproduce the issue by simply evaluating the test set using the trained model and observe the behavior with the aforementioned sets of decoder input ids. I suspect the issue is the same during the training process (which makes it converge to zero). I don't think I am doing anything wrong in the code, but please let me know. Thanks!",
"Hey @Slash0BZ,\r\n\r\nHmm, this might actually be very difficult to debug since 2.11 is quite outdated by now :-/.\r\n\r\n2 things:\r\n\r\n1) I'm very confident that in the decoder the causal mask is always enabled, so that tokens have **no** access to future tokens -> they should not be able to learn to \"cheat\". See this line (in 2.11 version): https://github.com/huggingface/transformers/blob/b42586ea560a20dcadb78472a6b4596f579e9043/src/transformers/modeling_t5.py#L707 if you follow the function definition you see that a causal mask is generated if the model is a decoder `self.config.is_decoder is True` - see: https://github.com/huggingface/transformers/blob/b42586ea560a20dcadb78472a6b4596f579e9043/src/transformers/modeling_utils.py#L192\r\n\r\n2) There was a bug in the relative positional encoding that was fixed in this PR: https://github.com/huggingface/transformers/pull/8518 . In this PR I also made sure that the original T5 and our T5 implementation give the exact same results.",
"Hi @patrickvonplaten, thank you for the quick response! Sorry about the version issue, 2.11.0 was the latest when I conducted all experiments for a paper under review.\r\n\r\nI understand how the causal mask is created, and I can confirm it is working, but it cannot explain what I see. Below is what I did (recap: 2024 and 2062 are two vocab ids I used for the binary tag, 1525 and 10 represent \"answer:\")\r\n\r\nwith `decoder_input_ids = [0, 1525, 10, 2062]`, inside the decoder (T5Stack), I printed input_ids, which is of size [16, 31] and of content `[0, 1525, 10, 2062, 0, ... 0]`. The extended_attention_mask is of size [16, 1, 31, 31] and of content (at position 2) `[0, 0, 0, -10000, -10000, ... -10000]`. Is everything here behaving as expected (i.e., should the first few masks be 0?) Under this, the prediction of an instance using a trained model at position 2 is 2062. \r\n\r\nHowever, if I change the decoder_input_ids to `[0, 1525, 10, 2024]` (different binary vocab), the **same** model's prediction on the **same** instance at position 2 becomes 2024, showing that it sees what the input is at position 3, or at least it changed with different position 3 inputs. \r\n\r\nBelow is how I got the prediction at position 2, using the lm_logits directly from the forward() function in a T5ForConditionalGeneration. Please let me know if you spot any issues with it.\r\n\r\n outputs = model(\r\n input_ids=inputs['input_ids'],\r\n attention_mask=inputs['attention_mask'],\r\n decoder_input_ids=inputs['decoder_input_ids'],\r\n # lm_labels=inputs['lm_labels'],\r\n decoder_attention_mask=inputs['decoder_attention_mask'],\r\n use_cache=False,\r\n )[0].cpu().numpy()\r\n ids = []\r\n for output in outputs:\r\n arr = []\r\n binary_tags = [2024, 2062]\r\n for val in binary_tags:\r\n arr.append(output[2][val])\r\n argmax_idx = int(np.argmax(np.array(arr)))\r\nThanks again for your help. I understand how difficult it is to look at previous versions, but I need to figure out if all experiments need to be re-done. ",
"Hmm, the `extended_attention_mask` looks correct to me. Position 2 is allowed to attend to itself and to position 0 & 1.\r\n\r\nAlso, I ran the following code snippet both on current master and on 2.11 and it passes -> showing that the attention mask works correctly:\r\n\r\n```python\r\nfrom transformers import T5ForConditionalGeneration\r\nimport torch\r\n\r\nmodel = T5ForConditionalGeneration.from_pretrained('t5-small')\r\n\r\ninput_ids = torch.tensor([list(range(30))], dtype=torch.long)\r\ndecoder_input_ids = torch.ones((1, 4), dtype=torch.long)\r\n\r\n\r\n# take output at position 2\r\nlogits_at_2 = model(input_ids, decoder_input_ids=decoder_input_ids)[0][:, 2]\r\n\r\ndecoder_input_ids[:, 3] = 10\r\n\r\n# take output at position 2 having changed the decoder_input_ids\r\nlogits_at_2_same = model(input_ids, decoder_input_ids=decoder_input_ids)[0][:, 2]\r\n\r\nassert abs(logits_at_2.sum().item() - logits_at_2_same.sum().item()) < 1e-3, \"Error\"\r\n```",
"Thanks, @patrickvonplaten . Following your snippet, this is how you can reproduce my issue (please give it a try, it has been bugging me for weeks): \r\n\r\n```\r\nfrom transformers import T5ForConditionalGeneration\r\nimport torch\r\nimport numpy as np\r\n\r\nmodel = T5ForConditionalGeneration.from_pretrained(\"trained_model\")\r\n\r\ninput_ids = torch.tensor([list(range(30))], dtype=torch.long)\r\ndecoder_input_ids = torch.tensor([[0, 1525, 10, 2024]])\r\n\r\nlogits_at_2 = model(input_ids, decoder_input_ids=decoder_input_ids)[0][:, 2]\r\nprint(np.argmax(logits_at_2[0].detach().cpu().numpy()))\r\n\r\ndecoder_input_ids = torch.tensor([[0, 1525, 10, 2062]])\r\n\r\nlogits_at_2_same = model(input_ids, decoder_input_ids=decoder_input_ids)[0][:, 2]\r\nprint(np.argmax(logits_at_2_same[0].detach().cpu().numpy()))\r\n\r\nassert abs(logits_at_2.sum().item() - logits_at_2_same.sum().item()) < 1e-3, \"Error\"\r\n```\r\n\r\nWhere trained_model can be downloaded here: https://drive.google.com/drive/u/1/folders/1A7PIG1E98uuGUi8mDA2m_6T_oQp8XDhF\r\nIt has the same config as a T5-large, just different learned weights.\r\n\r\nUnder my local env (2.11.0), it prints 2024 and 2062, and triggers the assertion error.\r\n\r\nGiven this, it seems that something corrupted during the training process, and somehow the learned weights let the model to look at future inputs. Do you have any suggestions?",
"@patrickvonplaten I just tried the latest Huggingface version with the snippet above using my trained model, and it also triggers the assertion error. Seems like something interesting is going on with certain model weights. ",
"Interesting, so our causal mask actually doesn't fully force \"attending-to-next-tokens\" to be impossible -> it just gives it a very large negative number before softmax (-10000) so that after softmax this value should be zero. Maybe your model has incredibly high activations that can somehow overturn the -10000. Could you maybe try the following:\r\n\r\n- Replace our setting of -10000 with `-float(\"inf\")`. Then the script above should definitely not yield an assertion error anymore",
"Thanks @patrickvonplaten . I tried what you said, -float(\"inf\") doesn't work because it makes the logits \"NaN\". So I tried -999999 and the predictions are now valid. Now that we know what the issue is, here are some of my concerns:\r\n\r\n- Does this only affect some \"extreme\" experiments or it affects all experiments more or less? i.e., is that attention value fine as long as it stays below zero, or it's later used continuously?\r\n- In my personal view, something has to be done more than this method to create the masks. I found this issue initially when doing a valid experiment studying numerical relations, and the model easily found this \"cheating\" way out within the first 1k steps. I suspect this issue might have affected people's experiments such as studying scrambled word orders, adding noises, etc., just without them knowing. This applies to both pre-trained Google T5 and random-initialized T5 (tried both). \r\n\r\nPlease let me know. Thanks again for your help!",
"Thanks for trying it out! Hmm, yeah I've never heard of such an issue before, so I assume that it will only affect the \"extreme\" experiments. But T5 tends to have very extreme values, which is also why we (so far) managed to run T5 only partly in fp16 mode. \r\n\r\nWe usually like to use -10000 as the masking value because it makes the model `fp16` compatible...Not really sure what to do here -> we could change the masking values to `-inf` in general if such errors occur more often. Also pinging @LysandreJik @sgugger @patil-suraj here. Have you guys heard of a case before where the model learned to cheat the `-10000` masking value? ",
"We use https://github.com/allenai/allennlp/blob/f091cb9cd92e767f55659b2b59f0ffb75bc613be/allennlp/nn/util.py#L239, which ultimately boils down to using this value: `torch.finfo(tensor.dtype).min`.",
"@patrickvonplaten, yes, the `-10000` can totally cheat the value. We've seen that in the past in cases where the output values are passed through an argmax while the probability distribution is very uniform.\r\n\r\nWe've kept `-10000` to stay as close as possible to the original BERT implementation, and we recommend to use as few padding tokens as possible for this not to have an effect (while keeping in mind that the -10000 should keep values very very small and should have a minimal impact).\r\n\r\n@dirkgr's solution is definitely more robust and I don't think switching the -10000 value to be lower would change anyone's workflow, so I wouldn't be opposed to switching.",
"@patrickvonplaten I never faced this issue in my T5 experiments but it does seem possible that -10000 can cause some issues because while investigating the fp16 issue we have seen that T5 produces large activation values.\r\n\r\nAnd I agree with @dirkgr solution.",
"Hi @patil-suraj @patrickvonplaten @sgugger I am experiencing similar issues with mt5, and I am getting nan always with fp16 mode, you mentioned you partly made T5 work with fp16, do you mind telling me how you managed it? I am having really a hard time with mT5 model + fp16 thanks a lot all ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Putting this on my ToDo-List as it seems to be quite important actually",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,652 | 1,623 | NONE | null | ## Environment info
platform: Mac/Ubuntu 14
transformers==2.11.0
torch==1.4.0 (GPU)
python 3.6
I know this is an old version but it supports important experiments in a paper under review. Would appreciate to know what's wrong. I checked the commit log and I don't think any following commits resolve it.
### Who can help
@patrickvonplaten (through slack) @patil-suraj (mentioned below)
Please let me know if there is anything else I can provide!
Thank you!
## Information
I made an artificial binary classification data where the input sequences are near-randomly generated tokens from the T5 vocab. The output sequences are balanced “`answer: correct/restaurant`” (two binary tag words randomly selected). A data sample [can be found here](https://github.com/Slash0BZ/t5-investigation/blob/main/sample_data.txt) in format (`input_seq \t output_seq`). The custom data reader parses this data with T5Tokenizer and is_pretokenized=True ([see here](https://github.com/Slash0BZ/t5-investigation/blob/main/train_t5.py#L129))
I feed the [T5ForConditionalGeneration model (v.2.11.0)](https://github.com/Slash0BZ/t5-investigation/blob/main/overrides.py#L60) with input_ids, lm_labels, and their corresponding attention_masks during training. The model should not learn anything because the sequences are near-random, but in reality, it converges to a zero loss, meaning that the lm_logits from decoder actually attend to future inputs (after `shift_right()`) and knows the label. During evaluation where I hide the binary tag, the model always predicts positive.
## To reproduce
Steps to reproduce the behavior:
1. Use the code in this repo: https://github.com/Slash0BZ/t5-investigation
2. Ran with sample data. I have tried both pre-trained T5-large and also randomly initialized T5-Large ([written like this](https://github.com/Slash0BZ/t5-investigation/blob/main/train_t5.py#L258))
I am not sure if the training data size affects the result. I ran with a training size of 5M. I am happy to provide the full data and a trained model if actual experiments are needed.
## Expected behavior
The training loss converges to near-zero and the lm_logits reflects predictions the same as the output sequence during training. However, in evaluation where the data reader hides the binary tag in the output sequence ([achieve through only providing "answer:" in decoder_input_ids](https://github.com/Slash0BZ/t5-investigation/blob/main/overrides.py#L46)), the prediction is uniform.
I also tried to change the decoder_input_ids. When it is [0, 1525, 10, 2024], the prediction at position 2 is 2024. When it is [0, 1525, 10, 2062], the prediction at position 2 is 2062.
Notes: 1525->"answer", 10->":", 2024->"correct", 2062->"restaurant"
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10484/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10484/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10483 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10483/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10483/comments | https://api.github.com/repos/huggingface/transformers/issues/10483/events | https://github.com/huggingface/transformers/pull/10483 | 820,281,236 | MDExOlB1bGxSZXF1ZXN0NTgzMjUwNzEy | 10,483 | add shift on BartForCausalLM | {
"login": "voidful",
"id": 10904842,
"node_id": "MDQ6VXNlcjEwOTA0ODQy",
"avatar_url": "https://avatars.githubusercontent.com/u/10904842?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/voidful",
"html_url": "https://github.com/voidful",
"followers_url": "https://api.github.com/users/voidful/followers",
"following_url": "https://api.github.com/users/voidful/following{/other_user}",
"gists_url": "https://api.github.com/users/voidful/gists{/gist_id}",
"starred_url": "https://api.github.com/users/voidful/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/voidful/subscriptions",
"organizations_url": "https://api.github.com/users/voidful/orgs",
"repos_url": "https://api.github.com/users/voidful/repos",
"events_url": "https://api.github.com/users/voidful/events{/privacy}",
"received_events_url": "https://api.github.com/users/voidful/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,615 | 1,615 | CONTRIBUTOR | null | # What does this PR do?
Fixes #10480
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@patil-suraj
@patrickvonplaten
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10483/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10483/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10483",
"html_url": "https://github.com/huggingface/transformers/pull/10483",
"diff_url": "https://github.com/huggingface/transformers/pull/10483.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10483.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10482 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10482/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10482/comments | https://api.github.com/repos/huggingface/transformers/issues/10482/events | https://github.com/huggingface/transformers/issues/10482 | 820,258,586 | MDU6SXNzdWU4MjAyNTg1ODY= | 10,482 | [examples] should all examples support the predict stage? | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1936351150,
"node_id": "MDU6TGFiZWwxOTM2MzUxMTUw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Examples",
"name": "Examples",
"color": "d4c5f9",
"default": false,
"description": "Which is related to examples in general"
}
] | closed | false | {
"login": "bhadreshpsavani",
"id": 26653468,
"node_id": "MDQ6VXNlcjI2NjUzNDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhadreshpsavani",
"html_url": "https://github.com/bhadreshpsavani",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}",
"gists_url": "https://api.github.com/users/bhadreshpsavani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhadreshpsavani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhadreshpsavani/subscriptions",
"organizations_url": "https://api.github.com/users/bhadreshpsavani/orgs",
"repos_url": "https://api.github.com/users/bhadreshpsavani/repos",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhadreshpsavani/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "bhadreshpsavani",
"id": 26653468,
"node_id": "MDQ6VXNlcjI2NjUzNDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhadreshpsavani",
"html_url": "https://github.com/bhadreshpsavani",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}",
"gists_url": "https://api.github.com/users/bhadreshpsavani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhadreshpsavani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhadreshpsavani/subscriptions",
"organizations_url": "https://api.github.com/users/bhadreshpsavani/orgs",
"repos_url": "https://api.github.com/users/bhadreshpsavani/repos",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhadreshpsavani/received_events",
"type": "User",
"site_admin": false
}
] | [
"I think we should have it on all scripts except the language-modeling ones -> it doesn't make much sense there.",
"@bhadreshpsavani, please feel free to make this part of your project or not. Please do not feel obliged as you can see a small need quickly expands into a much bigger one.\r\n\r\nIf not, then completing https://github.com/huggingface/transformers/issues/10437 would be a fantastic contribution. And I will then label it to be open to anybody else who would like to contribute.\r\n\r\nThank you!",
"Sure @stas00,\r\nI will take this. Actually, I would love to contribute more. I really enjoy contributing to this community.",
"Excellent! If you run into any puzzles please don't hesitate to ask.\r\n\r\nThank you!",
"Hi @stas00,\r\nIn the QA examples for the test dataset, should we keep The preprocessing same as evaluate dataset preprocessing?\r\nDo we need to apply any additional post-processing as well at the end?",
"Yes, that would be needed.",
"Hi, @stas00 and @sgugger, \r\n\r\nAdding predict function for the `run_qa` example is slightly complicated. \r\nIn the eval section itself, we are generating two files `predictions.json` and `nbest_predictions.json` using `postprocess_qa_predictions` \r\n from `utils_qa`. In Predict function also the same file will be generated and override the same files which will not be very good behavior.\r\n\r\nIn the predict function currently `trainer.predict()` calculates metrics but metrics calculation might not require in case of `predict()` right? \r\n\r\nThis issue might take a longer time for me to complete may be few weeks, is it fine?",
"> In Predict function also the same file will be generated and override the same files which will not be very good behavior.\r\n\r\nThis is simple: add `eval_` prefix for eval outputs and `test_` for predict.\r\n\r\nrelated: eventually we will rename the latter prefix, but for now this is the convention used in all examples. Please see: https://github.com/huggingface/transformers/issues/10165\r\n\r\n> In the predict function currently trainer.predict() calculates metrics but metrics calculation might not require in case of predict() right?\r\n\r\nWe always want the metrics for each stage, since now we report speed and memory usage, so for the quality metrics see what makes sense to report there - typically similar to eval.\r\n\r\n> This issue might take a longer time for me to complete may be few weeks, is it fine?\r\n\r\nYes, of course, thank you for giving us heads up and the clarity of your needs, @bhadreshpsavani ",
"Hi @stas00,\r\n\r\nWhen I run the evaluation on [example for question answering](https://github.com/bhadreshpsavani/UnderstandingNLP/blob/master/Check_Pretrained_Model_on_SQUAD2.ipynb),\r\n\r\nI was getting below error,\r\n```\r\nTraceback (most recent call last):\r\n File \"./transformers/examples/question-answering/run_qa.py\", line 546, in <module>\r\n main()\r\n File \"./transformers/examples/question-answering/run_qa.py\", line 531, in main\r\n metrics = trainer.evaluate()\r\n File \"/content/transformers/examples/question-answering/trainer_qa.py\", line 63, in evaluate\r\n metrics = self.compute_metrics(eval_preds)\r\n File \"./transformers/examples/question-answering/run_qa.py\", line 492, in compute_metrics\r\n return metric.compute(predictions=p.predictions, references=p.label_ids)\r\n File \"/usr/local/lib/python3.7/dist-packages/datasets/metric.py\", line 403, in compute\r\n output = self._compute(predictions=predictions, references=references, **kwargs)\r\n File \"/root/.cache/huggingface/modules/datasets_modules/metrics/squad/c0855591f1a2c2af8b7949e3146b9c86a6b7f536b4154019b03472639d310181/squad.py\", line 109, in _compute\r\n score = evaluate(dataset=dataset, predictions=pred_dict)\r\n File \"/root/.cache/huggingface/modules/datasets_modules/metrics/squad/c0855591f1a2c2af8b7949e3146b9c86a6b7f536b4154019b03472639d310181/evaluate.py\", line 68, in evaluate\r\n exact_match += metric_max_over_ground_truths(exact_match_score, prediction, ground_truths)\r\n File \"/root/.cache/huggingface/modules/datasets_modules/metrics/squad/c0855591f1a2c2af8b7949e3146b9c86a6b7f536b4154019b03472639d310181/evaluate.py\", line 53, in metric_max_over_ground_truths\r\n return max(scores_for_ground_truths)\r\nValueError: max() arg is an empty sequence\r\n```\r\nWhile calculating metrics at the end,\r\nI could not found anything to resolve this!\r\n\r\n\r\n",
"I am able to reproduce it - will have a look shortly. Thank you for the notebook - makes it super-easy to reproduce!\r\n\r\nBTW, I recommend you use `--max_val_samples 10` or similar to make your testing much faster ;)",
"OK, so we have a case of a broken dataset and the metrics evaluation code that doesn't check if the input data is valid.\r\n\r\nWhile ideally the eval code should be robust against an occasional corrupted input, the dataset should not have broken entries, observe the kind of data it evaluates against (`ground_truths`) \r\n\r\n```\r\n[{'answers': {'answer_start': [159, 159, 159, 159], 'text': ['France', 'France', 'France', 'France']}, 'id': '56ddde6b9a695914005b9628'},\r\n{'answers': {'answer_start': [94, 87, 94, 94], 'text': ['10th and 11th centuries', 'in the 10th and 11th centuries', '10th and 11th centuries', '10th and 11th centuries']}, 'id': '56ddde6b9a695914005b9629'},\r\n\r\n {'answers': {'answer_start': [], 'text': []}, 'id': '5ad39d53604f3c001a3fe8d1'},\r\n {'answers': {'answer_start': [], 'text': []}, 'id': '5ad39d53604f3c001a3fe8d2'},\r\n {'answers': {'answer_start': [], 'text': []}, 'id': '5ad39d53604f3c001a3fe8d3'},\r\n {'answers': {'answer_start': [], 'text': []}, 'id': '5ad39d53604f3c001a3fe8d4'}, \r\n```\r\n- and it has a ton of those - so this is a big problem on the dataset-level.\r\n\r\nHaving a quick look at the viewer:\r\nhttps://huggingface.co/datasets/viewer/?dataset=squad_v2\r\nI don't immediately see missing answers (scroll horizontally to the right to see it), but it doesn't mean anything.\r\n\r\nWhich most likely means that either the dataset conversion from the original to `datasets` format is borked, or there is some odd bug in the dataloader. But most likely it's the former. that is I'd debug this first and validate that it generates the answers correctly:\r\nhttps://github.com/huggingface/datasets/blob/b51cb81e736b86103089a584daa6e43db3c88bb5/datasets/squad_v2/squad_v2.py#L101\r\n\r\n\r\nif so then proceed to where they are loaded in the script and debug there, and so on - until you find a place where some of the records disappear in what it appears more than half of samples. There you will find the bug.\r\n\r\nPlease let me know if you'd like to try to investigate this and whether my suggestion at how to potentially approach this is clear. If it sounds too complicated please don't hesitate to say so and we will find another way to resolve this. Either way works.\r\n\r\nMeanwhile you can also try with a different model/dataset pair and see if it works there, which would also help isolate the problem. (if another dataset works then we know for sure the issue lies with `squad_v2`.",
"Hi @stas00,\r\nFor `squad_v1` = `squad` it is working fine.\r\n\r\nBut when i run the following script,\r\n```\r\n!python ./transformers/examples/question-answering/run_qa.py \\\r\n--model_name_or_path distilbert-base-uncased \\\r\n--train_file ./transformers/tests/fixtures/tests_samples/SQUAD/sample.json \\\r\n--validation_file ./transformers/tests/fixtures/tests_samples/SQUAD/sample.json \\\r\n--do_eval \\\r\n--max_val_sample 10 \\\r\n--per_device_train_batch_size 12 \\\r\n--learning_rate 3e-5 \\\r\n--num_train_epochs 2 \\\r\n--max_seq_length 384 \\\r\n--doc_stride 128 \\\r\n--output_dir /tmp/debug_squad/\r\n```\r\nwhich again data, I got the same error\r\n\r\nIn the earlier error logs it is giving like this for this issue,\r\n```\r\nFile \"/root/.cache/huggingface/modules/datasets_modules/metrics/squad/c0855591f1a2c2af8b7949e3146b9c86a6b7f536b4154019b03472639d310181/squad.py\", line 109, in _compute\r\n```\r\nBut for the squad_v2 dataset, it should be like this, \r\n```\r\n\"/root/.cache/huggingface/modules/datasets_modules/metrics/squad_v2/c0855591f1a2c2af8b7949e3146b9c86a6b7f536b4154019b03472639d310181/squad_v2.py\", line 109, in _compute\r\n```\r\ni mean it is picking wrong metrics somehow",
"OK, I found this in `run_qa.py`:\r\n```\r\n version_2_with_negative: bool = field(\r\n default=False, metadata={\"help\": \"If true, some of the examples do not have an answer.\"}\r\n )\r\n```\r\n\r\nThat is add: `--version_2_with_negative` to the cl args and it does:\r\n```\r\n metric = load_metric(\"squad_v2\" if data_args.version_2_with_negative else \"squad\")\r\n```\r\n\r\nExcept it's broken too:\r\n```\r\nexamples/question-answering/run_qa.py --model_name_or_path ktrapeznikov/albert-xlarge-v2-squad-v2 --dataset_name squad_v2 --do_eval --per_device_train_batch_size 12 --learning_rate 3e-5 --num_train_epochs 2 --max_seq_length 384 --doc_stride 128 --output_dir /tmp/debug_squad/ --max_val_samples 10 --version_2_with_negative\r\nTraceback (most recent call last): | 0/11873 [00:00<?, ?it/s]\r\n File \"examples/question-answering/run_qa.py\", line 553, in <module>\r\n main()\r\n File \"examples/question-answering/run_qa.py\", line 538, in main\r\n metrics = trainer.evaluate()\r\n File \"/mnt/nvme1/code/huggingface/transformers-master/examples/question-answering/trainer_qa.py\", line 62, in evaluate\r\n eval_preds = self.post_process_function(eval_examples, eval_dataset, output.predictions)\r\n File \"examples/question-answering/run_qa.py\", line 475, in post_processing_function\r\n predictions = postprocess_qa_predictions(\r\n File \"/mnt/nvme1/code/huggingface/transformers-master/examples/question-answering/utils_qa.py\", line 159, in postprocess_qa_predictions\r\n null_score = min_null_prediction[\"score\"]\r\nTypeError: 'NoneType' object is not subscriptable\r\n```\r\nthis fails with the same error:\r\n```\r\npython ./examples/question-answering/run_qa.py --model_name_or_path distilbert-base-uncased --train_file tests/fixtures/tests_samples/SQUAD/sample.json --validation_file tests/fixtures/tests_samples/SQUAD/sample.json --do_eval --max_val_sample 10 --per_device_train_batch_size 12 --learning_rate 3e-5 --num_train_epochs 2 --max_seq_length 384 --doc_stride 128 --output_dir /tmp/debug_squad/ --version_2_with_negative\r\n```\r\n\r\nSo it looks like this feature is half-baked, and ideally we should have a test for it.\r\n\r\nLet me know if you're ok to investigate this new issue.\r\n\r\nPlus ideally `run_qa.py` should signal the user that if the dataset has missing answers it should bail and recommend using `--version_2_with_negative`.\r\n\r\n(and the choice of this flag's name could probably be improved too to be more intuitive at what it does, but that's another story)\r\n",
"Sure @stas00,\r\n\r\nI can investigate this issue.\r\n\r\nOne more thing currently `run_qa.py` only supports `squad_v1` and `squad_v2` datasets completely, right? Shouldn't it support all the different question-answering datasets of the reading comprehension task? I mean preprocessing and postprocessing might be different for all the tasks but the concept is the same for all the tasks. Please correct me if I am wrong.\r\n\r\nI tried narrativeQA it was not supporting that one.",
"Awesome!\r\n\r\n> One more thing currently run_qa.py only supports squad_v1 and squad_v2 datasets completely, right? Shouldn't it support all the different question-answering datasets of the reading comprehension task? I mean preprocessing and postprocessing might be different for all the tasks but the concept is the same for all the tasks. Please correct me if I am wrong.\r\n\r\nHonestly, I have no idea as I didn't write it. \r\n\r\n@sgugger, @patrickvonplaten, do we want `run_qa.py` to support more than `squad_v1` and `squad_v2` datasets? Thank you!",
"Like all other examples, the script is given as just that, an example. As said in the main README under \"Why shouldn't I use Transformers?\":\r\n```\r\nWhile we strive to present as many use cases as possible, the scripts in our examples folder are just that: examples. It is expected that they won't work out-of-the box on your specific problem and that you will be required to change a few lines of code to adapt them to your needs.\r\n```\r\n\r\nSo like all other example scripts, the `run_qa` script will support any dataset that is structured the same way as the original dataset that was used with it (squad) but if the user wants the script to work on another dataset structured differently they will need to tweak it to their needs.",
"Hi @stas00 and @sgugger,\r\n\r\nI figured the cause for that squad2 issue while using `max_sample_*` arguments, I fixed it locally. The cause of the error was in the below line\r\nhttps://github.com/huggingface/transformers/blob/5f19c07a704eca4db376b56f950b729dcaa73039/examples/question-answering/run_qa.py#L493\r\n\r\nIt uses entire data for reference while it should use only `max_sample_*` data only.\r\n\r\nI tried to fix it by below code,\r\n```python\r\nif training_args.do_eval:\r\n if \"validation\" not in datasets:\r\n raise ValueError(\"--do_eval requires a validation dataset\")\r\n eval_examples = datasets[\"validation\"]\r\n if data_args.max_val_samples is not None:\r\n # We will select sample from whole data\r\n eval_examples = eval_examples.select(range(data_args.max_val_samples))\r\n # Validation Feature Creation\r\n eval_dataset = eval_examples.map(\r\n prepare_validation_features,\r\n batched=True,\r\n num_proc=data_args.preprocessing_num_workers,\r\n remove_columns=column_names,\r\n load_from_cache_file=not data_args.overwrite_cache,\r\n )\r\n if data_args.max_val_samples is not None:\r\n # During Feature creation dataset samples might increase, we will select required samples again\r\n eval_dataset = eval_dataset.select(range(data_args.max_val_samples))\r\n```\r\nand I used `eval_examples ` instead `datasets[\"validation\"]` in the above-mentioned line, This is working fine for data I tested, but as we know after applying `prepare_validation_features`, `eval_dataset ` and `eval_examples` might not have the same data (length will be same but because of sliding window example and feature might not be representing the same item)\r\n\r\nFor `max_val_samples=10` these changes are working fine so I added predict/test method, It seems to be working fine.\r\n\r\nhttps://github.com/huggingface/transformers/blob/5f19c07a704eca4db376b56f950b729dcaa73039/examples/question-answering/utils_qa.py#L214-L226\r\n\r\ni modified in below lines,\r\n```python\r\n prediction_file = os.path.join(\r\n output_dir, \"predictions.json\" if prefix is None else f\"{prefix}_predictions.json\"\r\n )\r\n nbest_file = os.path.join(\r\n output_dir, \"nbest_predictions.json\" if prefix is None else f\"{prefix}_nbest_predictions.json\"\r\n )\r\n if version_2_with_negative:\r\n null_odds_file = os.path.join(\r\n output_dir, \"null_odds.json\" if prefix is None else f\"{prefix}_null_odds_{prefix}.json\"\r\n```\r\nbecause while passing prefix and running it I was getting error like `string can't have json attribute`\r\nit will save test and eval files like `test_predictions.json` and `eval_predictions.json`\r\n ",
"Good job getting to the root of the issue, I hadn't thought of that when you added the `max_sample_xxx` but this task uses a subclass of the main `Trainer` that does require the original `eval_examples`.\r\n\r\nThe fix you propose appears good to me and you should definitely make a PR with it as soon as you can :-)\r\n\r\nFor the predicting stage, note that the subclass of the `Trainer` will require a test_dataset and test_examples to work (basically to interpret the predictions of the model as spans of the original texts, the `Trainer` needs the original texts). I do think adding a `--do_predict` to `run_qa` is going to be a bit complex so should be treated separately so my advise would be to:\r\n\r\n1. make a PR with the fix for evaluation in run_qa/run_qa_beam_search when `max_val_samples` is passed\r\n2. make a PR to add predict in all but run_qa/run_qa_beam_search scripts (when it makes sense of course)\r\n3. make a PR to add predict in run_qa/run_qa_beam_search\r\n\r\nLet me know if that makes sense to you and if you need any help along the way (or don't want to do one of those steps yourself).",
"Really awesome, @bhadreshpsavani! Glad you were able to find out the cause!",
"I gone through the traceback(stack trace) by running example with different stage combination and figured the root. Since I wrote earlier code about max_sample and the error was related I was able to find it!\r\n\r\nThanks @stas00 and @sgugger for your constant guidance, Now opensource contribution don't seems very difficult like earlier!\r\n\r\nNow I need to figure out for two more examples `run_swag.py` and `run_xlni.py`, all the other examples has predict if we ignore language modeling examples",
"Hi @sgugger,\r\n\r\nFor `run_swag.py` and `run_xlni.py` changes are still remaining",
"Hi @stas00,\r\n\r\nI was working to update `run_swag.py` and I got logs like for test metrics, \r\n```\r\nINFO|trainer_pt_utils.py:656] 2021-03-21 20:56:40,939 >> ***** test metrics *****\r\n[INFO|trainer_pt_utils.py:661] 2021-03-21 20:56:40,939 >> eval_accuracy = 1.0\r\n[INFO|trainer_pt_utils.py:661] 2021-03-21 20:56:40,939 >> eval_loss = 0.2582\r\n[INFO|trainer_pt_utils.py:661] 2021-03-21 20:56:40,939 >> eval_runtime = 4.1585\r\n[INFO|trainer_pt_utils.py:661] 2021-03-21 20:56:40,941 >> eval_samples_per_second = 2.405\r\n[INFO|trainer_pt_utils.py:661] 2021-03-21 20:56:40,941 >> test_mem_cpu_alloc_delta = 0MB\r\n[INFO|trainer_pt_utils.py:661] 2021-03-21 20:56:40,941 >> test_mem_cpu_peaked_delta = 0MB\r\n[INFO|trainer_pt_utils.py:661] 2021-03-21 20:56:40,941 >> test_samples = 10\r\n```\r\nI think we need to write `trainer_swag.py` because even predictions files need to be saved like `test_prediction.json` / `eval_prediction.json`.",
"If I understood your correctly you suggest to write `MultipleChoiceTrainer` subclass.\r\n\r\nIf so unlike the `question-answering` folder that has 2 scripts, `multiple-choice` has only one script so one way is to add it directly in `run_swag.py` or if there is a convention then as you suggest as `trainer_mc.py`. I think follow you instinct and then we can decide at PR point whether to have it in a separate file. ",
"Hi, @stas00 @sgugger,\r\n\r\nThe changes are ready for both examples, `run_xlni.py` works perfectly.\r\n\r\n`run_swag.py` has an issue after adding changes of predict,\r\n```\r\npython ./examples/multiple-choice/run_swag.py --model_name_or_path distilbert-base-uncased --do_train --do_eval --do_predict --max_train_samples 5 --max_val_samples 5 --max_test_samples 5 --learning_rate 5e-5 --num_train_epochs 3 --output_dir D:/tmp/swag_base --per_gpu_eval_batch_size=16 --per_device_train_batch_size=16 --overwrite_output\r\n```\r\nit gives the following error while prediction,\r\n```\r\nTraceback (most recent call last):\r\n File \"./examples/multiple-choice/run_swag.py\", line 481, in <module>\r\n main()\r\n File \"./examples/multiple-choice/run_swag.py\", line 466, in main\r\n predictions, labels, metrics = trainer.predict(test_dataset=test_dataset)\r\n File \"d:\\transformers\\src\\transformers\\trainer.py\", line 1762, in predict\r\n output = self.prediction_loop(\r\n File \"d:\\transformers\\src\\transformers\\trainer.py\", line 1829, in prediction_loop\r\n loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)\r\n File \"d:\\transformers\\src\\transformers\\trainer.py\", line 1943, in prediction_step\r\n loss, outputs = self.compute_loss(model, inputs, return_outputs=True)\r\n File \"d:\\transformers\\src\\transformers\\trainer.py\", line 1504, in compute_loss\r\n outputs = model(**inputs)\r\n File \"C:\\Users\\Bhadr\\Miniconda3\\envs\\trans-env2\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"d:\\transformers\\src\\transformers\\models\\distilbert\\modeling_distilbert.py\", line 929, in forward\r\n loss = loss_fct(reshaped_logits, labels)\r\n File \"C:\\Users\\Bhadr\\Miniconda3\\envs\\trans-env2\\lib\\site-packages\\torch\\nn\\modules\\module.py\", line 889, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"C:\\Users\\Bhadr\\Miniconda3\\envs\\trans-env2\\lib\\site-packages\\torch\\nn\\modules\\loss.py\", line 1047, in forward\r\n return F.cross_entropy(input, target, weight=self.weight,\r\n File \"C:\\Users\\Bhadr\\Miniconda3\\envs\\trans-env2\\lib\\site-packages\\torch\\nn\\functional.py\", line 2690, in cross_entropy\r\n return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)\r\n File \"C:\\Users\\Bhadr\\Miniconda3\\envs\\trans-env2\\lib\\site-packages\\torch\\nn\\functional.py\", line 2385, in nll_loss\r\n ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)\r\nIndexError: Target -1 is out of bounds.\r\n```\r\nThe problem is with test dataset,\r\n```python\r\ndataset = load_dataset(\"swag\", \"regular\")\r\npd.Series(dataset['test']['label']).value_counts()\r\n\"\"\"\r\nOutput:\r\n-1 20005\r\ndtype: int64\r\n\"\"\"\r\n```\r\nIt should have label In range(0, 3) like eval dataset not -1,\r\n```python\r\npd.Series(dataset['validation']['label']).value_counts()\r\n\"\"\"\r\nOutput:\r\n2 5038\r\n1 5029\r\n3 5006\r\n0 4933\r\ndtype: int64\r\n\"\"\"\r\n```\r\nI am not sure how can we fix this since it's with the dataset and this example is for only swag. when we pass the sample data present in `tests/fixtures/tests_samples/swag/sample.json` it works fine since it has label 0.\r\n\r\nThere is another small issue that needs to be fixed as well in the `trainer.py`\r\nhttps://github.com/huggingface/transformers/blob/a8d4d6776dd8a759324d0f57c60e8a738e7977a4/src/transformers/trainer.py#L1724-L1726\r\nBecause of this current test files are being saved with eval prefix, the issue that I mentioned in my previous comment.\r\nIt should be `metric_key_prefix: str = \"test\"`.\r\n\r\nPlease correct me if I am wrong.\r\n",
"I'm not sure we need the predict stage for `run_swag`, especially if the test dataset is \"broken\".",
"Filing an Issue with https://github.com/huggingface/datasets/issues and meanwhile using the local test file for the \r\nREADME.md?\r\n\r\n> There is another small issue that needs to be fixed as well in the trainer.py\r\n\r\nIndeed. In the default value and also the docstring - I'd say please make a separate PR for that as it's a standalone bug.\r\n\r\nAnd then we will eventually take care of https://github.com/huggingface/transformers/issues/10165 but for now let's use `test`.",
"Hi @stas00,\r\nThe original [dataset](https://github.com/rowanz/swagaf/tree/master/data) doesn't have a label in the test dataset so it's using `-1` as a label. \r\n\r\n`meanwhile using the local test file for the\r\nREADME.md` - I don't understand this part, can you please tell me a bit more about this?\r\n\r\nI will create a PR with `run_xlni.py`, Please let me know if we need to add changes for `run_swag` (On sample test data predict is working fine)",
"I see, they made a real \"test\" split where the target is unknown ;)\r\n\r\n> meanwhile using the local test file for the README.md - I don't understand this part, can you please tell me a bit more about this?\r\n\r\nI meant that perhaps the example in `README.md` (and test if we add any) could use a test dataset that we know has the labels, (like tests/fixtures/tests_samples/swag/sample.json it) does it make sense? And indicate that the swag dataset's `test` split can't be used here because it doesn't have labels.\r\n\r\nThis is just an idea.\r\n\r\nAlternatively, we could create a new dataset derived from the original swag, but whose test does have the labels. So basically take train+eval splits, merge them, re-splice them into train+eval+test. But perhaps this is a much larger project and perhaps it's not worth the effort.\r\n\r\nThat's why I thought that for the exemplification feeding it a known to have labels test dataset split would be sufficient.\r\n\r\nThe other approach suggested by @sgugger is not to have the predict stage in the first place. and perhaps documenting in the script why it's missing.\r\n\r\nBottom line - if you can think of a way that works for you to make it happen, then please go for it. If not, let's just leave a comment in place of what could be the predict stage.",
"Hi @stas00,\r\n\r\nI made a typo in `qa_util.py` \r\nhttps://github.com/huggingface/transformers/blob/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/question-answering/utils_qa.py#L225\r\nI forget to remove the second prefix, I will fix it.\r\n\r\n> Alternatively, we could create a new dataset derived from the original swag, but whose test does have the labels. So basically take train+eval splits, merge them, re-splice them into train+eval+test. But perhaps this is a much larger project and perhaps it's not worth the effort.\r\n\r\nI like this idea, I don't think this will take much time, It will hardly take few minutes. I worked on the dataset today at my work and it's really cool! The modifying dataset is very easy. Perhaps we can add one modified version of mrpc with your suggestion and add it to the huggingface datasets. \r\n",
"@sgugger, do you think it's a reasonable approach to re-make the dataset as I suggested so that it has a test split that has labels and then we can easier support the `predict` section in this example."
] | 1,614 | 1,620 | 1,616 | CONTRIBUTOR | null | This is part of the ongoing effort to sync the example scripts.
In https://github.com/huggingface/transformers/issues/10437#issuecomment-789090858 it was flagged that some scripts have test/predict, whereas others don't.
Should we:
A. have all scripts have train/eval/predict
B. only have predict where it's desired
@sgugger, @patil-suraj, @LysandreJik | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10482/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10482/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10481 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10481/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10481/comments | https://api.github.com/repos/huggingface/transformers/issues/10481/events | https://github.com/huggingface/transformers/pull/10481 | 820,115,813 | MDExOlB1bGxSZXF1ZXN0NTgzMTEzNjgx | 10,481 | feat(docs): navigate with left/right arrow keys | {
"login": "ydcjeff",
"id": 32727188,
"node_id": "MDQ6VXNlcjMyNzI3MTg4",
"avatar_url": "https://avatars.githubusercontent.com/u/32727188?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydcjeff",
"html_url": "https://github.com/ydcjeff",
"followers_url": "https://api.github.com/users/ydcjeff/followers",
"following_url": "https://api.github.com/users/ydcjeff/following{/other_user}",
"gists_url": "https://api.github.com/users/ydcjeff/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydcjeff/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydcjeff/subscriptions",
"organizations_url": "https://api.github.com/users/ydcjeff/orgs",
"repos_url": "https://api.github.com/users/ydcjeff/repos",
"events_url": "https://api.github.com/users/ydcjeff/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydcjeff/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Enables docs navigation with left/right arrow keys. It can be useful for the ones who navigate with keyboard a lot.
More info : https://github.com/sphinx-doc/sphinx/pull/2064
You can try here : https://174105-155220641-gh.circle-artifacts.com/0/docs/_build/html/index.html
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10481/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10481/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10481",
"html_url": "https://github.com/huggingface/transformers/pull/10481",
"diff_url": "https://github.com/huggingface/transformers/pull/10481.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10481.patch",
"merged_at": 1614788233000
} |
https://api.github.com/repos/huggingface/transformers/issues/10480 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10480/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10480/comments | https://api.github.com/repos/huggingface/transformers/issues/10480/events | https://github.com/huggingface/transformers/issues/10480 | 819,978,837 | MDU6SXNzdWU4MTk5Nzg4Mzc= | 10,480 | Different result in AutoModelForCausalLM | {
"login": "voidful",
"id": 10904842,
"node_id": "MDQ6VXNlcjEwOTA0ODQy",
"avatar_url": "https://avatars.githubusercontent.com/u/10904842?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/voidful",
"html_url": "https://github.com/voidful",
"followers_url": "https://api.github.com/users/voidful/followers",
"following_url": "https://api.github.com/users/voidful/following{/other_user}",
"gists_url": "https://api.github.com/users/voidful/gists{/gist_id}",
"starred_url": "https://api.github.com/users/voidful/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/voidful/subscriptions",
"organizations_url": "https://api.github.com/users/voidful/orgs",
"repos_url": "https://api.github.com/users/voidful/repos",
"events_url": "https://api.github.com/users/voidful/events{/privacy}",
"received_events_url": "https://api.github.com/users/voidful/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @voidful \r\n\r\nThe reason we need to shift labels in roberta because the `labels` start with the `decoder_start_token_id` (`pad` or `bos`),\r\nwhich are then passed directly to the decoder as `decoder_input_ids`, which is the reason we need to shift the `labels` when calculating the loss\r\n\r\nNow in BART, `decoder_input_ids` are prepared inside the model by pretending the `labels` with `decoder_start_token_id`, so we don't need to shift the labels there\r\nhttps://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/src/transformers/models/bart/modeling_bart.py#L1274\r\n\r\nHope this clears the difference.",
"> Hi @voidful\r\n> \r\n> The reason we need to shift labels in roberta because the `labels` start with the `decoder_start_token_id` (`pad` or `bos`),\r\n> which are then passed directly to the decoder as `decoder_input_ids`, which is the reason we need to shift the `labels` when calculating the loss\r\n> \r\n> Now in BART, `decoder_input_ids` are prepared inside the model by pretending the `labels` with `decoder_start_token_id`, so we don't need to shift the labels there\r\n> \r\n> https://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/src/transformers/models/bart/modeling_bart.py#L1274\r\n> \r\n> Hope this clears the difference.\r\n\r\nI got your point, but it seems to be apply on BartForConditionalGeneration, \r\nhttps://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/src/transformers/models/bart/modeling_bart.py#L1272\r\n\r\nMaybe we can apply same strategy on BartForCausalLM:\r\nhttps://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/src/transformers/models/bart/modeling_bart.py#L1594",
"Oh, I missed your point, great catch!\r\n\r\nFeel free to open PR to add the same strategy to `BartForCausalLM`, i.e prepare `decoder_input_ids` using the `shift_tokens_right` and pass them as the `input_ids` to the decoder.\r\n\r\ncc @patrickvonplaten ",
"Hmm, I'm not 100% whether everybody is on the same page here. `BartForCausalLM` was mostly created to be used in combination with `EncoderDecoderModel` and not as a standalone model. Also, Roberta requires both `input_ids` and `labels` as an input to correctly calculate the loss - the difference is just that that `input_ids` should be equal to `labels` with the labels being shifted under-the-hood. This is not the same thing as the `shift_tokens_right` function, which fully generates the `decoder_input_ids` from the labels...\r\n\r\nI think I would be fine with changing the behavior of `BartForCausalLM` so that `labels==input_ids` can be input to the function, even if this would be a slight breaking change. It would align `BartForCausalLM` closer with `RobertaForCausalm, GPT2LMHeadModel, ...` which would then also allow `EncoderDecoderModel` to have a general `shift_tokens` function.\r\n\r\nDoes this make sense?",
"`BartForCausalLM` does accept `labels==input_id`, in general, all the decoders in `EncoderDecoder` accept that and that's what we have documented, pass the same input as `labels` and `decoder_input_ids`.\r\n\r\nThe reason I suggested using `shift_tokens_right`, because BART uses `eos` as `decoder_start_token` which the `shift_tokens_right` function handles. This is different from `RobertaForCausalm, GPT2LMHeadModel ...`"
] | 1,614 | 1,615 | 1,615 | CONTRIBUTOR | null | # 🚀 Feature request
Models inside AutoModelForCausalLM have different behavior on loss calculation.
In BartForCausalLM
there is no shift in loss calculation
https://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/src/transformers/models/bart/modeling_bart.py#L1745
```
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.config.vocab_size), labels.view(-1))
```
In RobertaForCausalLM
A shift is applied before loss calculation
https://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/src/transformers/models/roberta/modeling_roberta.py#L944
```
# we are doing next-token prediction; shift prediction scores and input ids by one
shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
labels = labels[:, 1:].contiguous()
loss_fct = CrossEntropyLoss()
lm_loss = loss_fct(shifted_prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
```
## Motivation
I found a mistake when I switched the config from Roberta to BART in AutoModelForCausalLM. It turns out to be different labeling in loss. So, It would be nice to make CausalLM models handle label in the same way, either shift or not.
## Your contribution
I can make a PR to make sure that all the models will have a shift prediction. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10480/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10480/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10479 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10479/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10479/comments | https://api.github.com/repos/huggingface/transformers/issues/10479/events | https://github.com/huggingface/transformers/issues/10479 | 819,925,876 | MDU6SXNzdWU4MTk5MjU4NzY= | 10,479 | Question regarding training of BartForConditionalGeneration | {
"login": "bnaman50",
"id": 5251592,
"node_id": "MDQ6VXNlcjUyNTE1OTI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5251592?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bnaman50",
"html_url": "https://github.com/bnaman50",
"followers_url": "https://api.github.com/users/bnaman50/followers",
"following_url": "https://api.github.com/users/bnaman50/following{/other_user}",
"gists_url": "https://api.github.com/users/bnaman50/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bnaman50/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bnaman50/subscriptions",
"organizations_url": "https://api.github.com/users/bnaman50/orgs",
"repos_url": "https://api.github.com/users/bnaman50/repos",
"events_url": "https://api.github.com/users/bnaman50/events{/privacy}",
"received_events_url": "https://api.github.com/users/bnaman50/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"~Please ask on discuss.huggingface.co so that others can see your answer!~",
"Thanks for the prompt reply, @sshleifer. I wasn't aware of the discussion page. \r\nIn that case, should I close the issue since it is just a query question?\r\n\r\nThanks, \r\nNaman",
"- I got confused. This is a reasonable place for this post. Sorry.\r\n- Bart fine-tuned with no weights frozen, but this can be very slow.\r\n`self.lm_head` is tied (the same parameter as) to self.encoder.embed_tokens and self.decoder.embed_tokens.\r\n- I would recommend fine-tuning on your dataset with only the encoder frozen.\r\n- `final-logits-bias` doesn't matter it's all 0s and frozen.",
"Thanks for your quick response. This is super-helpful to me. \r\n\r\nI have one more question related to the training process. \r\n\r\nMy understanding is that BartModel (bart-base) was trained with two input sequences just like Google Bert (sadly, details are not given in the original paper. They only mention the difference in the objective function). On the other hand, BartForConditionalGeneration was trained (fine-tuned) for the summarization task i.e. single input and single input. \r\n\r\nIn my current task, I am trying, to do *constraint summarization using multi-document*. Ideally, I would want my model to take **two different inputs** \r\n```\r\ninput_encodings = self.tokenizer.batch_encode_plus(list(zip(example_batch['inp1'], example_batch['inp2'])), padding='max_length', truncation=True)\r\n```\r\nbut I feel this kind of fine-tuning will be harder given my smaller dataset and the change in training regime. \r\n\r\nThe other option is simply **concatenating the two documents** and passing it as one sequence \r\n```\r\n## comb_inp is a list of concatenated inputs from example_batch\r\ninput_encodings = self.tokenizer.batch_encode_plus(comb_inp, padding='max_length', truncation=True)\r\n``` \r\n\r\nIn your opinion, which one makes more sense? Your feedback and comments would be hugely appreciated in this case?\r\n\r\nP.S. - I am using your distilled-bart model for fine-tuning since it is smaller version 😇\r\n\r\nThanks, \r\nNaman\r\n",
"- I would try concatenating. \r\n- I would also grid search evaluation parameters (min_length, max_length, num_beam, length_penalty). \r\n- I would evaluate a few distillbart/distill-pegasus variants before any fine-tuning to decide which to start from.\r\n",
"Hey @sshleifer, \r\n\r\nI was thinking of using the default hyper-parameters used during the training as a starting point. I could find the default settings for BART model ([here](https://github.com/pytorch/fairseq/blob/master/examples/bart/README.summarization.md)) but not for distilled BART. I even looked at the paper but the values are missing over there as well. Would it be possible for you to provide me/refer me with/to the default settings that you used to train the model. \r\n\r\nThanks, \r\nNaman ",
"all the scripts have been moved to the [research_projects](https://github.com/huggingface/transformers/blob/master/examples/research_projects/seq2seq-distillation/) directory.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Hey @sshleifer, I was trying to fine-tune the `distill-pegasus-cnn-16-4` [model](https://huggingface.co/sshleifer/distill-pegasus-cnn-16-4) provided by you but I am not sure of the hyper-parameters and the corresponding file is also not avaialble in the [`research_projects/seq2seq_distillation`](https://github.com/huggingface/transformers/tree/master/examples/research_projects/seq2seq-distillation) directory. Could you please share the hyper-parameters that you used to train this model (and achieve the results shown in Table 5 from your [paper](https://arxiv.org/pdf/2010.13002.pdf))?\r\n\r\nThanks a lot!\r\nNaman",
"To clarify, you are trying to reproduce `distill-pegasus-cnn-16-4`, rather than finetune it further?\r\n\r\n\r\n1) Make a student using make_student.py or get one from model hub.\r\n2) guessing the train command from memory.\r\nI think it should be a combination of `train_distilbart_cnn.sh` and `train_pegasus_xsum.sh`.\r\n- You definitely want `max_target_length=142, --adafactor, --freeze-embeds --freeze-encoder`. \r\n- I think fp16 will not work.\r\n\r\n\r\nSo roughly...\r\n```bash\r\npython finetune.py \\\r\n --learning_rate=1e-4 \\\r\n --do_train \\\r\n --do_predict \\\r\n --n_val 1000 \\\r\n --val_check_interval 0.25 \\\r\n --max_target_length 142 \\\r\n --freeze_embeds --label_smoothing 0.1 --adafactor \\\r\n\t--eval_beams 2 \\\r\n\t--freeze-encoder \\\r\n\t--sortish_sampler \\\r\n\t--model_name_or_path $YOUR_STUDENT \\\r\n \"$@\"\r\n```\r\n3) Copy the `config.json` for `distill-pegasus-cnn-16-4` to increase rouge score of trained student model.\r\n\r\n\r\nHope that helps, and sorry for not having a definitive answer.\r\n",
"Hey @sshleifer , \r\n\r\nSorry, I think I phrased the question wrongly. I am trying to finetune the `distill-pegasus` model on my own dataset since the original pegasus model is huge and is taking a lot of time. I was simply hoping if you could provide me the hyper-parameters like you have provided for `distill-bart` models for CNN/DailyMail dataset ([here](https://github.com/huggingface/transformers/blob/master/examples/research_projects/seq2seq-distillation/train_distilbart_cnn.sh)).\r\nWould I be able to use the hyper-parameters that you provided above?\r\n\r\nThanks, \r\nNaman",
"Yes",
"Hello, \r\n\r\n@[sshleifer](https://github.com/sshleifer) how can I freeze only the first two layer from the encoder (I am using BART), and how can I change the dropout of some layers also in BART?\r\n\r\nThank you",
"Hey @JessicaLopezEspejel , \r\n\r\n`model.get_encoder().layers` will give you a list (`torch.nn.modules.container.ModuleList` to be precise) of layers in encoder, and you can freeze the required layers using the `freeze_params` function provided in the `utils.py` file. I have included a small code snippet for your reference. Hope this helps!\r\n\r\n```\r\nfrom torch import nn\r\nfrom transformers import AutoTokenizer, AutoModel\r\n\r\ndef freeze_params(model: nn.Module):\r\n \"\"\"Set requires_grad=False for each of model.parameters()\"\"\"\r\n for par in model.parameters():\r\n par.requires_grad = False\r\n\r\nmodel = AutoModel.from_pretrained(\"facebook/bart-large\")\r\nenc_layers = model.get_encoder().layers\r\nfreeze_params(enc_layers[0]) # freeze layer 0\r\ndropout = enc_layers[0].dropout # return dropout value for layer 0\r\nenc_layers[0].dropout = 0.5 # set dropout value for layer 0\r\n```\r\n\r\nThanks, \r\nNaman\r\n\r\n",
"Than you so much @bnaman50 , I will try it. "
] | 1,614 | 1,651 | 1,620 | NONE | null | Hello Guys,
I am trying to fine-tune the BART summarization model but due to the lack of big dataset, having some difficulties with the fine-tuning.
Thus, I decided to look at the trainig process of BartForConditionalGeneration model in detail. I came across this article, [Introducing BART](https://sshleifer.github.io/blog_v2/jupyter/2020/03/12/bart.html) from one of the engineers, @sshleifer, at HuggingFace. It says that BartModel was directly fine-tuned for the summarisation task without **any new randomly initialized heads**.
**My question is about this fine-tuning process, especially on CNN-DailyMail dataset. Do you guys fine-tune the entire Bart model or only the decoder or something else?**
I looked at the example [fine-tuning script](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_seq2seq.py) provided on the GitHub but I didn't find anything related to freezing some part of the model.
I also tried to look at the source code of the BartForConditionalGeneration model and observed the following -
Its just adds a [linear layer](https://github.com/huggingface/transformers/blob/master/src/transformers/models/bart/modeling_bart.py#L1207) on top of the BartModel (copy-pasting the `__init__` code here for quick reference).
```
self.model = BartModel(config)
self.register_buffer("final_logits_bias", torch.zeros((1, self.model.shared.num_embeddings)))
self.lm_head = nn.Linear(config.d_model, self.model.shared.num_embeddings, bias=False)
```
At first, I thought these are the new parameters that are being introduced and thus, being trained. Therefore, I tried the following code to check the number of trainable parameters while keeping the endoer and decoder fixed -
```
from transformers import BartModel, BartForConditionalGeneration, BartTokenizer
def freeze_params(model):
for par in model.parameters():
par.requires_grad = False
model_sum = BartForConditionalGeneration.from_pretrained('facebook/bart-large')
freeze_params(model_sum.get_encoder()) ## freeze the encoder
freeze_params(model_sum.get_decoder()) ## freeze the decoder
model_sum.train() ## set the train mode
train_p = [p for p in model_sum.parameters() if p.requires_grad] ## get the trainable params
print(f'Length of train params in Summarization Model : {len(train_p)}')
```
But this code shows that the list is empty. One thing I can do is to explictly set the `requires_grad=True` for the paramters in the `model_sum.lm_head` and only fine-tune these parameters. But I am curious to understand the original training/fine-tuning process. **It would be of great help to me if you guys could answer my question.**
P.S. - Love the HuggingFace library.
Thanks,
<br />
Naman | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10479/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10479/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10478 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10478/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10478/comments | https://api.github.com/repos/huggingface/transformers/issues/10478/events | https://github.com/huggingface/transformers/issues/10478 | 819,911,664 | MDU6SXNzdWU4MTk5MTE2NjQ= | 10,478 | generate() decoder_input_ids padding | {
"login": "LittlePea13",
"id": 26126169,
"node_id": "MDQ6VXNlcjI2MTI2MTY5",
"avatar_url": "https://avatars.githubusercontent.com/u/26126169?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LittlePea13",
"html_url": "https://github.com/LittlePea13",
"followers_url": "https://api.github.com/users/LittlePea13/followers",
"following_url": "https://api.github.com/users/LittlePea13/following{/other_user}",
"gists_url": "https://api.github.com/users/LittlePea13/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LittlePea13/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LittlePea13/subscriptions",
"organizations_url": "https://api.github.com/users/LittlePea13/orgs",
"repos_url": "https://api.github.com/users/LittlePea13/repos",
"events_url": "https://api.github.com/users/LittlePea13/events{/privacy}",
"received_events_url": "https://api.github.com/users/LittlePea13/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The issue was discussed at https://github.com/huggingface/transformers/pull/10552, and this is expected behaviour. If one wants to generate using `decoder_input_ids` with different lengths, the suggested approach is to use `padding_side` as `left` on the tokenizer.\r\nFor a custom solution if one wants to preserve the same results as if there was no padding, see code changes in https://github.com/huggingface/transformers/pull/10552.",
"I hope it is okay, that I ask a follow up question here, because I feel it might be highly related (also to [this](https://github.com/huggingface/transformers/pull/10552#issuecomment-801246652) comment about non-identical outputs with & without padding). If not I would be happy over any pointers were to ask this question.\r\n\r\nI am using an BERT encoder-decoder model as per the example [here](https://huggingface.co/transformers/model_doc/encoderdecoder.html#encoderdecodermodel) and want to condition the decoder output on some know sequence. The known sequence is of varying length, tokenized and `left` padded, exactly as described above.\r\n\r\nTo exactly match the training regime (which never contains padding before the first token), I was wondering whether there is a way to pass an additional padding mask for the `decoder_input_ids`, e.g. a `decoder_attention_mask` of size `(batch x max_known_seq_len)`?",
"Hi @l-salewski \r\n\r\nAs I mentioned in the PR comment, it would be better to group the sequence of similar length into a batch then pass them to generate otherwise call `generate` for each example.\r\n\r\nAlso it's possible to pass `decoder_attention_mask`, its shape need to be `[bath, current_seq_length]`",
"Hi @patil-suraj,\r\nthank you for getting back to me! Grouping of similar length seems to be an approximate solution, but e.g. my test set is relatively small and exhibits sentences of many different lengths. Running each example individually on the other hand may be quite slow.\r\n\r\nUsing `decoder_attention_mask` is what I did in the end. I had to overwrite the `prepare_inputs_for_generation` function, such that if a `decoder_attention_mask` is passed, it overrules the generated one:\r\n```python\r\ndef prepare_inputs_for_generation(\r\n self, input_ids, past=None, attention_mask=None, use_cache=None, encoder_outputs=None, **kwargs\r\n):\r\n decoder_inputs = self.decoder.prepare_inputs_for_generation(input_ids, past=past)\r\n decoder_attention_mask = decoder_inputs[\"attention_mask\"] if \"attention_mask\" in decoder_inputs else None\r\n\r\n # if we have been passed an attention mask, use it to overrule the generated one\r\n if \"decoder_attention_mask\" in kwargs:\r\n initial_decoder_attention_mask = kwargs.pop(\"decoder_attention_mask\")\r\n initial_sequence_length = initial_decoder_attention_mask.size(1)\r\n decoder_attention_mask[:,:initial_sequence_length] = initial_decoder_attention_mask\r\n\r\n\r\n input_dict = {\r\n \"attention_mask\": attention_mask,\r\n \"decoder_attention_mask\": decoder_attention_mask,\r\n \"decoder_input_ids\": decoder_inputs[\"input_ids\"],\r\n \"encoder_outputs\": encoder_outputs,\r\n \"past_key_values\": decoder_inputs[\"past_key_values\"],\r\n \"use_cache\": use_cache,\r\n **kwargs,\r\n }\r\n return input_dict\r\n```\r\n Furthermore, I overwrite `_expand_inputs_for_generation` from the beam search such that the `decoder_attention_mask` is also expanded for each of the beams:\r\n```python\r\n@staticmethod\r\ndef _expand_inputs_for_generation(\r\n input_ids: torch.LongTensor,\r\n expand_size: int = 1,\r\n is_encoder_decoder: bool = False,\r\n attention_mask: torch.LongTensor = None,\r\n encoder_outputs: ModelOutput = None,\r\n **model_kwargs,\r\n) -> Tuple[torch.LongTensor, Dict[str, Any]]:\r\n expanded_return_idx = (\r\n torch.arange(input_ids.shape[0]).view(-1, 1).repeat(1, expand_size).view(-1).to(input_ids.device)\r\n )\r\n input_ids = input_ids.index_select(0, expanded_return_idx)\r\n\r\n if \"token_type_ids\" in model_kwargs:\r\n token_type_ids = model_kwargs[\"token_type_ids\"]\r\n model_kwargs[\"token_type_ids\"] = token_type_ids\r\n \r\n # this has been added to the original method\r\n if \"decoder_attention_mask\" in model_kwargs:\r\n model_kwargs[\"decoder_attention_mask\"] = model_kwargs[\"decoder_attention_mask\"].index_select(0, expanded_return_idx)\r\n\r\n if attention_mask is not None:\r\n model_kwargs[\"attention_mask\"] = attention_mask.index_select(0, expanded_return_idx)\r\n\r\n if is_encoder_decoder:\r\n assert encoder_outputs is not None\r\n encoder_outputs[\"last_hidden_state\"] = encoder_outputs.last_hidden_state.index_select(\r\n 0, expanded_return_idx.to(encoder_outputs.last_hidden_state.device)\r\n )\r\n model_kwargs[\"encoder_outputs\"] = encoder_outputs\r\n return input_ids, model_kwargs\r\n```\r\nTo exactly match the training setting, I tokenize the known inputs, prepend a `[CLS]` token to each and extend the `decoder_attention_mask` with a 1 column to the left such that it also attends to the `[CLS]` token:\r\n```python\r\n# Combine a CLS Column with the forced input\r\nkwargs[\"decoder_input_ids\"] = torch.cat([\r\n torch.zeros_like(forced_input.input_ids)[:,:1]+self.tokenizer.cls_token_id,\r\n forced_input.input_ids],\r\n dim=1)\r\n# Attend to the CLS column, but not the PAD tokens of the forced input\r\nkwargs[\"decoder_attention_mask\"] = torch.cat([\r\n torch.ones_like(forced_input.attention_mask)[:,:1],\r\n forced_input.attention_mask],\r\n dim=1)\r\n```\r\nThen `**kwargs` is passed to `generate`. Overall this approach works flawlessly as it reduces the overhead (e.g. no organizing batches or looping over batches) from the user perspective. I just tokenize the known inputs separately add the `[CLS]` token as described above and that is it."
] | 1,614 | 1,618 | 1,616 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.4.0.dev0
- Platform: Linux-5.4.0-66-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes (but unrelevant)
- Using distributed or parallel set-up in script?: No
### Who can help
As it is a generation issue:
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
But also may benefit from better documentation:
Documentation: @sgugger
## Information
When using the `generate()` method from `generation_utils` for Bart (although other models will probably behave the same by checking the code), I am using `decoder_input_ids` to inform of the first tokens each sample in the batch should start with. Although not stated in the documentation (see [post in HF forum](https://discuss.huggingface.co/t/generate-continuation-for-seq2seq-models/)), `generate()` can take `decoder_input_ids` as the forward method would.
This works fine with batch size equal to one or if the `decoder_input_ids` would all have same length and not require padding. However, when padding is involved, the `generate` method does not ignore the padding tokens in order to generate text for each sample in the batch, generating instead after the padding tokens in `decoder_input_ids`.
## To reproduce
Steps to reproduce the behavior:
1. Load your favorite bart model for generation.
2. Prepare your `inputs_ids` for the encoder and the `decoder_input_ids` for your decoder, using sequences of different length.
3. Check the generated text.
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
```
from transformers import AutoConfig, AutoModelForSeq2SeqLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("sshleifer/distilbart-cnn-6-6")
model = AutoModelForSeq2SeqLM.from_pretrained("sshleifer/distilbart-cnn-6-6")
model.to("cuda:0")
model.eval()
inputs_text = ['Hugging Face is taking its first step into machine translation this week with the release of more than 1,000 models. Researchers trained models using unsupervised learning and the Open Parallel Corpus (OPUS). OPUS is a project undertaken by the University of Helsinki and global partners to gather and open-source a wide variety of language data sets, particularly for low resource languages. Low resource languages are those with less training data than more commonly used languages like English.', 'Hugging Face has announced the close of a $15 million series A funding round led by Lux Capital, with participation from Salesforce chief scientist Richard Socher and OpenAI CTO Greg Brockman, as well as Betaworks and A.Capital.']
decoder_text = ['</s><s>Hugging Face released', '</s><s>Hugging Face closed a']
inputs = tokenizer(inputs_text, return_tensors = 'pt', padding=True)
inputs_decoder = tokenizer(decoder_text, return_tensors = 'pt', padding=True, add_special_tokens = False)
generated_tokens = model.generate(inputs['input_ids'].to(model.device),
attention_mask=inputs['attention_mask'].to(model.device),
decoder_input_ids = inputs_decoder['input_ids'].to(model.device))
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=False)
print('\n'.join(decoded_preds), '\n')
Output:
</s><s>Hugging Face released<pad> models using unsupervised learning and the Open Parallel Corpus (OPUS) Low resource languages are those with less training data than more commonly used languages like English. The project was undertaken by the University of Helsinki and global partners to gather and open-source a wide variety of language data sets.</s>
</s><s>Hugging Face closed a $15 million series A funding round led by Lux Capital. Salesforce chief scientist Richard Socher and OpenAI CTO Greg Brockman participated. Betaworks and A.Capital also took part in the round, with participation from Betaworkorks.</s><pad><pad><pad><pad><pad><pad><pad>
```
In the first generated sentence, the `<pad>` token after released is kept, and would be worse if there was a higher length difference between the decoder inputs.
## Expected behavior
If one gives as `decoder_input_ids` same length sentences, for instance, we remove the a from "Hugging Face closed a":
```
decoder_text = ['</s><s>Hugging Face released', '</s><s>Hugging Face closed']
inputs = tokenizer(inputs_text, return_tensors = 'pt', padding=True)
inputs_decoder = tokenizer(decoder_text, return_tensors = 'pt', padding=True, add_special_tokens = False)
generated_tokens = model.generate(inputs['input_ids'].to(model.device),
attention_mask=inputs['attention_mask'].to(model.device),
decoder_input_ids = inputs_decoder['input_ids'].to(model.device))
decoded_preds = tokenizer.batch_decode(generated_tokens, skip_special_tokens=False)
print('\n'.join(decoded_preds), '\n')
Output:
</s><s>Hugging Face released its first step into machine translation this week. Researchers trained models using unsupervised learning and the Open Parallel Corpus (OPUS) OPUS is a project undertaken by the University of Helsinki and global partners. Low resource languages are those with less training data than more commonly used languages like English.</s>
</s><s>Hugging Face closed a $15 million series A funding round led by Lux Capital. Salesforce chief scientist Richard Socher and OpenAI CTO Greg Brockman were involved. Betaworks and A.Capital also participated in the round, which will take place in New York City.</s><pad><pad><pad><pad><pad>
```
Then the output does not include any `<pad>` token in between the generated text. It would be nice if this would be the same for different length in the decoder_input_ids (ie. ignore the `<pad>` tokens).
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10478/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
} | https://api.github.com/repos/huggingface/transformers/issues/10478/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10477 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10477/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10477/comments | https://api.github.com/repos/huggingface/transformers/issues/10477/events | https://github.com/huggingface/transformers/issues/10477 | 819,872,806 | MDU6SXNzdWU4MTk4NzI4MDY= | 10,477 | Facing NCCL error on Multi-GPU training(on single machine) using run_glue.py script | {
"login": "aditya-malte",
"id": 20294625,
"node_id": "MDQ6VXNlcjIwMjk0NjI1",
"avatar_url": "https://avatars.githubusercontent.com/u/20294625?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/aditya-malte",
"html_url": "https://github.com/aditya-malte",
"followers_url": "https://api.github.com/users/aditya-malte/followers",
"following_url": "https://api.github.com/users/aditya-malte/following{/other_user}",
"gists_url": "https://api.github.com/users/aditya-malte/gists{/gist_id}",
"starred_url": "https://api.github.com/users/aditya-malte/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/aditya-malte/subscriptions",
"organizations_url": "https://api.github.com/users/aditya-malte/orgs",
"repos_url": "https://api.github.com/users/aditya-malte/repos",
"events_url": "https://api.github.com/users/aditya-malte/events{/privacy}",
"received_events_url": "https://api.github.com/users/aditya-malte/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"cc @sgugger ",
"This seems like a problem in your environment install for NCCL: if your script can run on two GPUs there is nothing in the code to change to make it run on four GPUs so this is not a bug in the training script or transformers. I have never seen that particular NCCL error so I'm afraid I can't really help debugging it.",
"Thanks for the quick reply. \r\nYeah, it’s strange that it works on 2 GPUs but not on 4. Will check again and let you know.",
"@sgugger just to clarify:\r\nThe system has 4 GPUs. It’s only the nproc_per_node argument I’m changing (from 1 to 2,4,etc.). \r\nJust want to ensure I’ve not misunderstood the cause of the error. Right?",
"Yes I understood that. The PyTorch launcher is going to spawn a different number of processes depending on the number your pass, which in turn will use the number of GPUs specified (and the others are idle).",
"Thanks. Just wanted to confirm that. Will try reinstalling the environment and update if I find the solution.\r\n",
"Hi @sgugger,\r\nGood news, the issue seems to have been an environment issue.\r\nThanks for the instant help",
"I still meet the same problem, could you please tell me how to solve it?"
] | 1,614 | 1,628 | 1,614 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.2
- Platform: Linux-4.19.0-14-cloud-amd64-x86_64-with-debian-buster-sid
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.0 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: 4xTesla T4 (GCP)
- Using distributed or parallel set-up in script?: torch.distributed.launch
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): DistilRoberta
The problem arises when using:
* [*] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [*] my own task or dataset: (give details below)
Regression task with a single output, using BertForSequenceClassification
## To reproduce
Steps to reproduce the behavior:
1.python -m torch.distributed.launch --nproc_per_node 4 /home/run_glue.py --train_file /home/data/train.csv --validation_file /home/data/dev.csv --test_file /home/data/test.csv --model_name_or_path distilroberta-base --output_dir /home/model --num_train_epochs 5 --per_device_train_batch_size 1 --per_device_eval_batch_size 16 --do_train --do_eval --fp16 --gradient_accumulation_steps 2 --do_predict --logging_steps 100 --evaluation_strategy steps --save_steps 100 --overwrite_output_dir
File "/opt/conda/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 442, in init_process_group
732793de051f:1895:1925 [1] NCCL INFO transport/shm.cc:101 -> 2
732793de051f:1895:1925 [1] NCCL INFO transport.cc:30 -> 2
732793de051f:1895:1925 [1] NCCL INFO transport.cc:49 -> 2
732793de051f:1895:1925 [1] NCCL INFO init.cc:766 -> 2
732793de051f:1895:1925 [1] NCCL INFO init.cc:840 -> 2
732793de051f:1895:1925 [1] NCCL INFO group.cc:73 -> 2 [Async thread]
barrier()
File "/opt/conda/lib/python3.7/site-packages/torch/distributed/distributed_c10d.py", line 1947, in barrier
Traceback (most recent call last):
File "/home/run_text_classification.py", line 480, in <module>
work = _default_pg.barrier()
RuntimeError: NCCL error in: /opt/conda/conda-bld/pytorch_1603729138878/work/torch/lib/c10d/ProcessGroupNCCL.cpp:784, unhandled system error, NCCL version 2.7.8
main()
File "/home/run_text_classification.py", line 163, in main
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
File "/opt/conda/lib/python3.7/site-packages/transformers/hf_argparser.py", line 180, in parse_args_into_dataclasses
obj = dtype(**inputs)
File "<string>", line 60, in __init__
File "/opt/conda/lib/python3.7/site-packages/transformers/training_args.py", line 478, in __post_init__
if is_torch_available() and self.device.type != "cuda" and self.fp16:
File "/opt/conda/lib/python3.7/site-packages/transformers/file_utils.py", line 1346, in wrapper
return func(*args, **kwargs)
File "/opt/conda/lib/python3.7/site-packages/transformers/training_args.py", line 583, in device
return self._setup_devices
732793de051f:1897:1927 [3] include/shm.h:28 NCCL WARN Call to posix_fallocate failed : No space left on device
File "/opt/conda/lib/python3.7/site-packages/transformers/file_utils.py", line 1336, in __get__
732793de051f:1897:1927 [3] NCCL INFO include/shm.h:41 -> 2
732793de051f:1897:1927 [3] include/shm.h:48 NCCL WARN Error while creating shared memory segment nccl-shm-recv-b3d54cebe4167a34-0-2-3 (size 9637888)
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Expected model training to proceed smoothly using 4xGPU. When I run the said script with nproc_per_node=1(or even 2), it runs smoothly but setting it as 4 gives strange errors.
After updating to 1.9.0 I face a different error:
RuntimeError: NCCL error in: /pytorch/torch/lib/c10d/ProcessGroupNCCL.cpp:832, unhandled system error, NCCL version 2.7.8 ncclSystemError: System call (socket, malloc, munmap, etc) failed.
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10477/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10477/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10476 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10476/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10476/comments | https://api.github.com/repos/huggingface/transformers/issues/10476/events | https://github.com/huggingface/transformers/issues/10476 | 819,804,301 | MDU6SXNzdWU4MTk4MDQzMDE= | 10,476 | The size of CoNLL-2003 is not consistant with the official release. | {
"login": "h-peng17",
"id": 39556019,
"node_id": "MDQ6VXNlcjM5NTU2MDE5",
"avatar_url": "https://avatars.githubusercontent.com/u/39556019?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/h-peng17",
"html_url": "https://github.com/h-peng17",
"followers_url": "https://api.github.com/users/h-peng17/followers",
"following_url": "https://api.github.com/users/h-peng17/following{/other_user}",
"gists_url": "https://api.github.com/users/h-peng17/gists{/gist_id}",
"starred_url": "https://api.github.com/users/h-peng17/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/h-peng17/subscriptions",
"organizations_url": "https://api.github.com/users/h-peng17/orgs",
"repos_url": "https://api.github.com/users/h-peng17/repos",
"events_url": "https://api.github.com/users/h-peng17/events{/privacy}",
"received_events_url": "https://api.github.com/users/h-peng17/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi there, \r\n\r\nThe training scripts load the dataset using the `datasets` library, so this issue is related to the `datasets` lib, you can open it in that repo https://github.com/huggingface/datasets.",
"Thank you!"
] | 1,614 | 1,614 | 1,614 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:
- Platform: -
- Python version: -
- PyTorch version (GPU?): -
- Tensorflow version (GPU?): -
- Using GPU in script?: -
- Using distributed or parallel set-up in script?: -
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->@sgugger, @patil-suraj
## Information
Model I am using (Bert, XLNet ...):
The problem arises when using:
* [ ] the official example scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: CoNLL-2003
## To reproduce
Steps to reproduce the behavior:
1. just run the code
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
The official release of CoNLL-2003 is:
# train 14987
# dev 3466
# test 3684
While CoNLL-2003 in datasets is:
# train 14041
# dev 3250
# test 3453
Wish for your reply~ Thank you!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10476/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10476/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10475 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10475/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10475/comments | https://api.github.com/repos/huggingface/transformers/issues/10475/events | https://github.com/huggingface/transformers/pull/10475 | 819,699,425 | MDExOlB1bGxSZXF1ZXN0NTgyNzY5OTAy | 10,475 | Fixes compatibility bug when using grouped beam search and constrained decoding together | {
"login": "mnschmit",
"id": 2377507,
"node_id": "MDQ6VXNlcjIzNzc1MDc=",
"avatar_url": "https://avatars.githubusercontent.com/u/2377507?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mnschmit",
"html_url": "https://github.com/mnschmit",
"followers_url": "https://api.github.com/users/mnschmit/followers",
"following_url": "https://api.github.com/users/mnschmit/following{/other_user}",
"gists_url": "https://api.github.com/users/mnschmit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mnschmit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mnschmit/subscriptions",
"organizations_url": "https://api.github.com/users/mnschmit/orgs",
"repos_url": "https://api.github.com/users/mnschmit/repos",
"events_url": "https://api.github.com/users/mnschmit/events{/privacy}",
"received_events_url": "https://api.github.com/users/mnschmit/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Thanks a lot!"
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | Fixes #10415
## Who can review?
@patrickvonplaten | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10475/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10475/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10475",
"html_url": "https://github.com/huggingface/transformers/pull/10475",
"diff_url": "https://github.com/huggingface/transformers/pull/10475.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10475.patch",
"merged_at": 1614670914000
} |
https://api.github.com/repos/huggingface/transformers/issues/10474 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10474/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10474/comments | https://api.github.com/repos/huggingface/transformers/issues/10474/events | https://github.com/huggingface/transformers/issues/10474 | 819,696,766 | MDU6SXNzdWU4MTk2OTY3NjY= | 10,474 | Continue pre-training using the example code "run_mlm.py" | {
"login": "pavlion",
"id": 35861990,
"node_id": "MDQ6VXNlcjM1ODYxOTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/35861990?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pavlion",
"html_url": "https://github.com/pavlion",
"followers_url": "https://api.github.com/users/pavlion/followers",
"following_url": "https://api.github.com/users/pavlion/following{/other_user}",
"gists_url": "https://api.github.com/users/pavlion/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pavlion/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pavlion/subscriptions",
"organizations_url": "https://api.github.com/users/pavlion/orgs",
"repos_url": "https://api.github.com/users/pavlion/repos",
"events_url": "https://api.github.com/users/pavlion/events{/privacy}",
"received_events_url": "https://api.github.com/users/pavlion/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi there,\r\n\r\nthe `run_mlm` script expects an unlabeled text dataset, i.e a dataset with the column `text` in it, if there is no `text` column then it assumes that the first column is the text column.\r\n\r\nHere `sst2` is a classification dataset and the first column is `idx`. \r\nSo you could change the script and directly hardcode the `text_column_name`, which is `sentence` for `sst2`.\r\nhttps://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/examples/language-modeling/run_mlm.py#L304\r\n\r\n And also pass the `--line_by_line` argument.",
"Thanks for your prompt and accurate reply.\r\nThis does help!\r\n\r\nBut I notice that the line_by_line argument is not needed as long as the `text_column_name` is hard-coded in that line.\r\nAnyways, thanks!"
] | 1,614 | 1,615 | 1,615 | NONE | null | ## Environment info
- `transformers` version: 4.3.3
- Platform: Linux-5.4.0-65-generic-x86_64-with-glibc2.10 (Ubuntu 18.04)
- Python version: 3.8.8
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
- tokenizers: @LysandreJik
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
## Information
Model I am using (Bert, XLNet ...): albert-xlarge-v2
The problem arises when using:
transformers/examples/language-modeling/run_mlm.py
(https://github.com/huggingface/transformers/blob/master/examples/language-modeling/run_mlm.py)
The tasks I am working on is:
continue pre-training on a specific dataset (glue/sst2)
## To reproduce
Steps to reproduce the behavior:
```=
CUDA_VISIBLE_DEVICES=0 python run_mlm.py \
--model_name_or_path albert-xlarge-v2 \
--dataset_name "glue" \
--dataset_config_name "sst2" \
--do_train \
--do_eval \
--output_dir ckpt/pre_training/glue
```
### Error message
```=
Traceback (most recent call last):
File "src/run_mlm.py", line 447, in <module>
main()
File "src/run_mlm.py", line 353, in main
tokenized_datasets = datasets.map(
File "/home/robotlab/anaconda3/envs/thesis/lib/python3.8/site-packages/datasets/dataset_dict.py", line 369, in map
{
File "/home/robotlab/anaconda3/envs/thesis/lib/python3.8/site-packages/datasets/dataset_dict.py", line 370, in <dictcomp>
k: dataset.map(
File "/home/robotlab/anaconda3/envs/thesis/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1120, in map
update_data = does_function_return_dict(test_inputs, test_indices)
File "/home/robotlab/anaconda3/envs/thesis/lib/python3.8/site-packages/datasets/arrow_dataset.py", line 1091, in does_function_return_dict
function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "src/run_mlm.py", line 351, in tokenize_function
return tokenizer(examples[text_column_name], return_special_tokens_mask=True)
File "/home/robotlab/anaconda3/envs/thesis/lib/python3.8/site-packages/transformers/tokenization_utils_base.py", line 2286, in __call__
assert isinstance(text, str) or (
AssertionError: text input must of type `str` (single example), `List[str]` (batch or single pretokenized example) or `List[List[str]]` (batch of pretokenized exampl
es).
```
I skipped the message that relates to the model, as there's no problem with the loading of the model.
Dataset is successfully downloaded. There's a warning above the assertion error
```=
03/02/2021 14:03:44 - WARNING - datasets.builder - Reusing dataset glue (/home/robotlab/.cache/huggingface/datasets/glue/sst2/1.0.0/7c99657241149a24692c402a5c3f34d
4c9f1df5ac2e4c3759fadea38f6cb29c4)
```
## Expected behavior
When I continue pre-training on other datasets such as 'ag_news', 'dbpedia_14', 'imdb', there's no error and everything is fine.
There are also no "dataset_config_name" in these three datasets.
However, there's no error when I use `dataset_name=wikitext` and `dataset_config_name=wikitext-2-raw-v1` in `run_mlm.py`
Judging from the error message above,
it seems like the data format of the SST-2 is wrong so that the datasets can not handled the data correctly.
Any suggestion is highly appreciated!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10474/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10474/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10473 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10473/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10473/comments | https://api.github.com/repos/huggingface/transformers/issues/10473/events | https://github.com/huggingface/transformers/issues/10473 | 819,660,963 | MDU6SXNzdWU4MTk2NjA5NjM= | 10,473 | Issue with converting my own BERT TF2 checkpoint to PyTorch and loading the converted PyTorch checkpoint for training | {
"login": "jalajthanaki",
"id": 12840374,
"node_id": "MDQ6VXNlcjEyODQwMzc0",
"avatar_url": "https://avatars.githubusercontent.com/u/12840374?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jalajthanaki",
"html_url": "https://github.com/jalajthanaki",
"followers_url": "https://api.github.com/users/jalajthanaki/followers",
"following_url": "https://api.github.com/users/jalajthanaki/following{/other_user}",
"gists_url": "https://api.github.com/users/jalajthanaki/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jalajthanaki/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jalajthanaki/subscriptions",
"organizations_url": "https://api.github.com/users/jalajthanaki/orgs",
"repos_url": "https://api.github.com/users/jalajthanaki/repos",
"events_url": "https://api.github.com/users/jalajthanaki/events{/privacy}",
"received_events_url": "https://api.github.com/users/jalajthanaki/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"You've converted them successfully in PyTorch, so you should be left with a `pytorch_model.bin` alongside a `config.json`, is that right?\r\n\r\nI recommend reading the [quicktour entry related to using models](https://huggingface.co/transformers/quicktour.html#using-the-model) in order to get a sense of how one can load a model in PyTorch.",
"Hi @LysandreJik, Thank you for replying on this thread. \r\n\r\n> You've converted them successfully in PyTorch, so you should be left with a pytorch_model.bin alongside a config.json, is that right? \r\n\r\nYes, I have pytorch_model.bin file but the point is: it is not single serialised file like [this](https://huggingface.co/bert-base-uncased/blob/main/pytorch_model.bin) but I can unzip that exported bin file which I have generated using [convert_bert_original_tf2_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/blob/master/src/transformers/models/bert/convert_bert_original_tf2_checkpoint_to_pytorch.py) script and I can see the three main components which I posted in snapshot earlier. Ideally, I should have single serialised pytorch_model.bin, right? \r\n\r\nI have checked the same with original BERT model and tried to convert it from TF2 to PyTorch there also I have bert-model.bin file but I can unzip that bert-model.bin and it also have three components present inside the bin. See the snapshots. \r\n\r\nSnapshot 1: My exported bin file\r\n\r\n\r\nSnapshot 2: I can unzip this bin file\r\n\r\n\r\nSnapshot 3: I can see the three components \r\n\r\n\r\nIs this expected or Am I missing something?\r\n\r\nBasically my goal here is to make sure that I'm converting the my own BERT model which is trained using TF2 to PyTorch in bug-free manner.\r\n\r\nThanks you again for sharing the documentation link I will try that and post my further questions. \r\n\r\nThanks,",
"That is the way PyTorch works. See the documentation for [torch.save](https://pytorch.org/docs/stable/generated/torch.save.html).\r\n\r\nIt states:\r\n\r\n> The 1.6 release of PyTorch switched torch.save to use a new zipfile-based file format. torch.load still retains the ability to load files in the old format. If for any reason you want torch.save to use the old format, pass the kwarg _use_new_zipfile_serialization=False.",
"Thank you so much @LysandreJik for your help now I have one single .bin file. Closing this issue. I will reopen if needed. "
] | 1,614 | 1,615 | 1,615 | NONE | null | Hi,
I’m using huggingface to train my own bert model. I have checkpoints which are in TensorFlow2 and I have converted them successfully in PyTorch. The checkpoint conversion script has created **_.bin_** file which is having following subdirectories and pkl file.

I wanted to gain some more information on the following points:
- Am’I doing the conversation of TensorFlow checkpoint to PyTorch checkpoint correct? I can see the pre-trained bert-base-uncased model which is hosted on hugging face model repository is just having single [pytorch_model.bin](https://huggingface.co/bert-base-uncased/blob/main/pytorch_model.bin) file.
- How I can load this custom BERT-PyTorch model’s checkpoint using [modeling_bert.py](https://github.com/huggingface/transformers/blob/master/src/transformers/models/bert/modeling_bert.py) script?
Any help or suggestions will be helpful.
Thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10473/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10473/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10472 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10472/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10472/comments | https://api.github.com/repos/huggingface/transformers/issues/10472/events | https://github.com/huggingface/transformers/issues/10472 | 819,621,689 | MDU6SXNzdWU4MTk2MjE2ODk= | 10,472 | Needed a feature to convert facebook mbart many - many model to ONNX runtime inorder to reduce the inference time | {
"login": "Vimal0307",
"id": 41289592,
"node_id": "MDQ6VXNlcjQxMjg5NTky",
"avatar_url": "https://avatars.githubusercontent.com/u/41289592?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Vimal0307",
"html_url": "https://github.com/Vimal0307",
"followers_url": "https://api.github.com/users/Vimal0307/followers",
"following_url": "https://api.github.com/users/Vimal0307/following{/other_user}",
"gists_url": "https://api.github.com/users/Vimal0307/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Vimal0307/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vimal0307/subscriptions",
"organizations_url": "https://api.github.com/users/Vimal0307/orgs",
"repos_url": "https://api.github.com/users/Vimal0307/repos",
"events_url": "https://api.github.com/users/Vimal0307/events{/privacy}",
"received_events_url": "https://api.github.com/users/Vimal0307/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | We need a feature which makes the facebook mbart many - many model to convert to ONNX runtime which reduces the inference time, current mbart many-many model takes 9 secs to translate and we need to quantize it further to reduce the inference time | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10472/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10472/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10471 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10471/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10471/comments | https://api.github.com/repos/huggingface/transformers/issues/10471/events | https://github.com/huggingface/transformers/issues/10471 | 819,614,899 | MDU6SXNzdWU4MTk2MTQ4OTk= | 10,471 | Question: change location of cache datasets | {
"login": "ioana-blue",
"id": 17202292,
"node_id": "MDQ6VXNlcjE3MjAyMjky",
"avatar_url": "https://avatars.githubusercontent.com/u/17202292?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ioana-blue",
"html_url": "https://github.com/ioana-blue",
"followers_url": "https://api.github.com/users/ioana-blue/followers",
"following_url": "https://api.github.com/users/ioana-blue/following{/other_user}",
"gists_url": "https://api.github.com/users/ioana-blue/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ioana-blue/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ioana-blue/subscriptions",
"organizations_url": "https://api.github.com/users/ioana-blue/orgs",
"repos_url": "https://api.github.com/users/ioana-blue/repos",
"events_url": "https://api.github.com/users/ioana-blue/events{/privacy}",
"received_events_url": "https://api.github.com/users/ioana-blue/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"One more thing (maybe this is a bug): why are the datasets stuff cached in ~/.cache/huggingface/datasets when I have both the env var set up AND I specify a cache dir with --cache_dir when I run my scripts? The pretrained models go in the --cache_dir specified but the datasets don't. This is confusing (and maybe buggy?)",
"I wonder if this has something to do with newer versions of the library. I remember at the last upgrade I had to install the package `datasets` separately, which I didn't have to do before. Is there a way to specify a cache for the `datasets` and it's separate than the model one?\r\n",
"I'll have to look into this more, but I'm doing an educated guess that there is probably a way to send the cache_dir to the datasets api. In any case, I would like to learn how to change the cache dir globally, if at all possible. Thanks!",
"I'm guessing HF_HOME is what I'm looking for... ",
"Yes, that worked. Closing. "
] | 1,614 | 1,614 | 1,614 | NONE | null | This is not a bug, it's a question. I don't have too much space allowed in my home dir and I have to store most stuff elsewhere. I noticed that the library caches a lot of stuff under ~/.cache/huggingface (in particular under datasets). How do I change the location of the cache dir? I have `export TRANSFORMERS_CACHE=...` in my run script but that doesn't seem to be it.
I started using some large datasets and whatever caching happens because of these datasets is causing a disk quota issue. I hope it's possible to change the location of the cache dir.
Thanks! | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10471/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10471/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10470 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10470/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10470/comments | https://api.github.com/repos/huggingface/transformers/issues/10470/events | https://github.com/huggingface/transformers/issues/10470 | 819,554,879 | MDU6SXNzdWU4MTk1NTQ4Nzk= | 10,470 | (Sorry I can not visit the forum) BORT question: pre-training-using-knowledge-distillation is better than pre-training-only for downstream tasks? | {
"login": "guotong1988",
"id": 4702353,
"node_id": "MDQ6VXNlcjQ3MDIzNTM=",
"avatar_url": "https://avatars.githubusercontent.com/u/4702353?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/guotong1988",
"html_url": "https://github.com/guotong1988",
"followers_url": "https://api.github.com/users/guotong1988/followers",
"following_url": "https://api.github.com/users/guotong1988/following{/other_user}",
"gists_url": "https://api.github.com/users/guotong1988/gists{/gist_id}",
"starred_url": "https://api.github.com/users/guotong1988/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/guotong1988/subscriptions",
"organizations_url": "https://api.github.com/users/guotong1988/orgs",
"repos_url": "https://api.github.com/users/guotong1988/repos",
"events_url": "https://api.github.com/users/guotong1988/events{/privacy}",
"received_events_url": "https://api.github.com/users/guotong1988/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"https://github.com/alexa/bort/issues/10"
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | The paper shows the MLM accuarcy comparision.

What is the **downstream tasks'** performance comparison for pre-training-using-knowledge-distillation and pre-training-only to the end?
Thank you very much. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10470/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10470/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10469 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10469/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10469/comments | https://api.github.com/repos/huggingface/transformers/issues/10469/events | https://github.com/huggingface/transformers/issues/10469 | 819,526,454 | MDU6SXNzdWU4MTk1MjY0NTQ= | 10,469 | The described function in docs was not implemented in source code | {
"login": "yww211",
"id": 32888325,
"node_id": "MDQ6VXNlcjMyODg4MzI1",
"avatar_url": "https://avatars.githubusercontent.com/u/32888325?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yww211",
"html_url": "https://github.com/yww211",
"followers_url": "https://api.github.com/users/yww211/followers",
"following_url": "https://api.github.com/users/yww211/following{/other_user}",
"gists_url": "https://api.github.com/users/yww211/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yww211/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yww211/subscriptions",
"organizations_url": "https://api.github.com/users/yww211/orgs",
"repos_url": "https://api.github.com/users/yww211/repos",
"events_url": "https://api.github.com/users/yww211/events{/privacy}",
"received_events_url": "https://api.github.com/users/yww211/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Ah, indeed! cc @sgugger"
] | 1,614 | 1,614 | 1,614 | NONE | null | https://github.com/huggingface/transformers/blob/0c2325198fd638e5d1f0c7dcbdd8bf7f14c0ff7d/src/transformers/file_utils.py#L1512
The method of `update` in `ModelOutput` described as below,
https://huggingface.co/transformers/main_classes/output.html?highlight=modeloutput#transformers.file_utils.ModelOutput.update
but the source code will raise an exception when try to use it, which disagree with the docs. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10469/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10469/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10468 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10468/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10468/comments | https://api.github.com/repos/huggingface/transformers/issues/10468/events | https://github.com/huggingface/transformers/issues/10468 | 819,416,755 | MDU6SXNzdWU4MTk0MTY3NTU= | 10,468 | run_ner.py training data file format | {
"login": "pranav-s",
"id": 9393002,
"node_id": "MDQ6VXNlcjkzOTMwMDI=",
"avatar_url": "https://avatars.githubusercontent.com/u/9393002?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/pranav-s",
"html_url": "https://github.com/pranav-s",
"followers_url": "https://api.github.com/users/pranav-s/followers",
"following_url": "https://api.github.com/users/pranav-s/following{/other_user}",
"gists_url": "https://api.github.com/users/pranav-s/gists{/gist_id}",
"starred_url": "https://api.github.com/users/pranav-s/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/pranav-s/subscriptions",
"organizations_url": "https://api.github.com/users/pranav-s/orgs",
"repos_url": "https://api.github.com/users/pranav-s/repos",
"events_url": "https://api.github.com/users/pranav-s/events{/privacy}",
"received_events_url": "https://api.github.com/users/pranav-s/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @pranav-s \r\n\r\nWe only support the `json` and `csv` files in the examples. To convert your text files to the `json` format, you could use this `datasets` script as references, which converts the `conll` text files to the `datasets` format.\r\nhttps://github.com/huggingface/datasets/blob/master/datasets/conll2003/conll2003.py ",
"Hi @pranav-s,\r\nI found this script from `test_examples.py` file,\r\n```\r\nrun_ner.py\r\n --model_name_or_path bert-base-uncased\r\n --train_file tests/fixtures/tests_samples/conll/sample.json\r\n --validation_file tests/fixtures/tests_samples/conll/sample.json\r\n --output_dir {tmp_dir}\r\n --overwrite_output_dir\r\n --do_train\r\n --do_eval\r\n --warmup_steps=2\r\n --learning_rate=2e-4\r\n --per_device_train_batch_size=2\r\n --per_device_eval_batch_size=2\r\n --num_train_epochs=2\r\n```\r\nat this path `tests/fixtures/tests_samples/conll/sample.json` you can find an example file which is having required input format",
"Thank you @bhadreshpsavani and @patil-suraj . This was helpful.",
"Thank you @bhadreshpsavani . You saved my life!"
] | 1,614 | 1,624 | 1,614 | NONE | null | # 🚀 Feature request
Would it be possible to support text files as input files for the run_ner.py script similar to what was supported in examples/legacy/token-classification/run_ner.py ? This, I believe is the CoNLL-2003 format. The current version of the run_ner.py script in /examples/token-classification appears to support only json and csv format for training input. Could someone also tell me where I can find example files for aforementioned json and csv files ? Looking at some example files would help me format my labeled data in the required format if supporting text files is not possible.
## Motivation
I have some training data formatted as text files with one token and label per line and would like to use that as input to the run_ner.py script if possible. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10468/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10468/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10467 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10467/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10467/comments | https://api.github.com/repos/huggingface/transformers/issues/10467/events | https://github.com/huggingface/transformers/issues/10467 | 819,398,254 | MDU6SXNzdWU4MTkzOTgyNTQ= | 10,467 | modeling files loaded when they aren't being asked to be loaded | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I'm not sure there is a way to workaround `Trainer` loading all models since it needs the `MODEL_FOR_QUESTION_ANSWERING_MAPPING` to get the names of the labels (those models have different label names that are not `labels`). The auto models then loads every model in the lib, which we can't work around without rewriting the module and its logic from scratch.",
"If I look at the code it's just:\r\n\r\n```\r\nMODEL_FOR_QUESTION_ANSWERING_MAPPING = OrderedDict(\r\n [\r\n # Model for Question Answering mapping\r\n (ConvBertConfig, ConvBertForQuestionAnswering),\r\n (LEDConfig, LEDForQuestionAnswering),\r\n (DistilBertConfig, DistilBertForQuestionAnswering),\r\n (AlbertConfig, AlbertForQuestionAnswering),\r\n[...]\r\n (IBertConfig, IBertForQuestionAnswering),\r\n ]\r\n```\r\n\r\nwhy does it need to load all models in order to access this dict?\r\n\r\nI understand that it is doing it now, but why can't it be in a separate file which doesn't load all models? e.g. in `trainer.py`:\r\n```\r\nfrom .models.auto.modeling_auto_maps_only import MODEL_FOR_QUESTION_ANSWERING_MAPPING\r\n```\r\nand inside `models.auto.modeling_auto_maps`\r\n```\r\nfrom .models.auto.modeling_auto_maps_only import MODEL_FOR_QUESTION_ANSWERING_MAPPING\r\n```\r\n\r\nAh, right, because it doesn't know what those symbols are without loading all these models... duh!\r\n\r\nOk, so what you're saying it could have been done in a different way that doesn't require loading models - e.g. class names as strings but it'd require a big redesign.",
"OK, so since we are auto-generating code anyway during `make style`, we could autogenerate a simple dict with:\r\n```\r\nQA_model_classes = (\r\n 'transformers.models.albert.modeling_albert.AlbertForQuestionAnswering', \r\n 'transformers.models.led.modeling_albert.LEDForQuestionAnswering', \r\n ...\r\n)\r\n```\r\nand then in trainer:\r\n```\r\n default_label_names = (\r\n [\"start_positions\", \"end_positions\"]\r\n if self.model.__class__ in QA_model_classes\r\n else [\"labels\"]\r\n )\r\n```\r\nand there is no longer a need to load all models.",
"That would probably work yes."
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | ```
File "/gpfsdswork/projects/rech/ajs/uiz98zp/stas/transformers-master/src/transformers/trainer_seq2seq.py", line 22, in <module>
from .trainer import Trainer
File "/gpfsdswork/projects/rech/ajs/uiz98zp/stas/transformers-master/src/transformers/trainer.py", line 65, in <module>
from .trainer import Trainer
File "/gpfsdswork/projects/rech/ajs/uiz98zp/stas/transformers-master/src/transformers/trainer.py", line 65, in <module>
from .models.auto.modeling_auto import MODEL_FOR_QUESTION_ANSWERING_MAPPING
File "/gpfsdswork/projects/rech/ajs/uiz98zp/stas/transformers-master/src/transformers/models/auto/modeling_auto.py", line 214, in <module>
from .models.auto.modeling_auto import MODEL_FOR_QUESTION_ANSWERING_MAPPING
File "/gpfsdswork/projects/rech/ajs/uiz98zp/stas/transformers-master/src/transformers/models/auto/modeling_auto.py", line 214, in <module>
from ..tapas.modeling_tapas import (
from ..tapas.modeling_tapas import ( File "/gpfsdswork/projects/rech/ajs/uiz98zp/stas/transformers-master/src/transformers/models/tapas/modeling_tapas.py", line 51, in <module>
File "/gpfsdswork/projects/rech/ajs/uiz98zp/stas/transformers-master/src/transformers/models/tapas/modeling_tapas.py", line 51, in <module>
from torch_scatter import scatter
File "/gpfslocalsup/pub/anaconda-py3/2020.02/envs/pytorch-gpu-1.7.1/lib/python3.7/site-packages/torch_scatter/__init__.py", line 12, in <module>
```
Do we have to load `models/tapas/modeling_tapas.py` when we aren't using `tapas`?
There is some unrelated problem that gets triggered by this model loading `torch_scatter`, which is a 3rd party module.
I figured out the solution to the problem it triggered (binary incompatible `torch_scatter`), but still it might be a good idea not to pre-load model files until they are needed.
@LysandreJik, @sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10467/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10467/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10466 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10466/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10466/comments | https://api.github.com/repos/huggingface/transformers/issues/10466/events | https://github.com/huggingface/transformers/pull/10466 | 819,370,887 | MDExOlB1bGxSZXF1ZXN0NTgyNDg5Nzgz | 10,466 | Fix the bug in constructing the all_hidden_states of DeBERTa v2 | {
"login": "felixgwu",
"id": 7753366,
"node_id": "MDQ6VXNlcjc3NTMzNjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/7753366?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/felixgwu",
"html_url": "https://github.com/felixgwu",
"followers_url": "https://api.github.com/users/felixgwu/followers",
"following_url": "https://api.github.com/users/felixgwu/following{/other_user}",
"gists_url": "https://api.github.com/users/felixgwu/gists{/gist_id}",
"starred_url": "https://api.github.com/users/felixgwu/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/felixgwu/subscriptions",
"organizations_url": "https://api.github.com/users/felixgwu/orgs",
"repos_url": "https://api.github.com/users/felixgwu/repos",
"events_url": "https://api.github.com/users/felixgwu/events{/privacy}",
"received_events_url": "https://api.github.com/users/felixgwu/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
This PR fixes the bug in constructing the `all_hidden_states` of DeBERTa v2. In the master branch, it keeps appending `hidden_states` to `all_hidden_states` which comes from the inputs and is never updated in each layer. This would make `all_hidden_states` a list of duplicated elements. Instead, it should append `output_states` (which is the counterpart of the `hidden_states` in DeBERTa v1) to `all_hidden_states` because it is the real output of each layer.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10466/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10466/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10466",
"html_url": "https://github.com/huggingface/transformers/pull/10466",
"diff_url": "https://github.com/huggingface/transformers/pull/10466.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10466.patch",
"merged_at": 1614791121000
} |
https://api.github.com/repos/huggingface/transformers/issues/10465 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10465/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10465/comments | https://api.github.com/repos/huggingface/transformers/issues/10465/events | https://github.com/huggingface/transformers/issues/10465 | 819,364,229 | MDU6SXNzdWU4MTkzNjQyMjk= | 10,465 | Tflite conversion error for TFMT5ForConditionalGeneration model | {
"login": "abhijeetchauhan",
"id": 11993662,
"node_id": "MDQ6VXNlcjExOTkzNjYy",
"avatar_url": "https://avatars.githubusercontent.com/u/11993662?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/abhijeetchauhan",
"html_url": "https://github.com/abhijeetchauhan",
"followers_url": "https://api.github.com/users/abhijeetchauhan/followers",
"following_url": "https://api.github.com/users/abhijeetchauhan/following{/other_user}",
"gists_url": "https://api.github.com/users/abhijeetchauhan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/abhijeetchauhan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/abhijeetchauhan/subscriptions",
"organizations_url": "https://api.github.com/users/abhijeetchauhan/orgs",
"repos_url": "https://api.github.com/users/abhijeetchauhan/repos",
"events_url": "https://api.github.com/users/abhijeetchauhan/events{/privacy}",
"received_events_url": "https://api.github.com/users/abhijeetchauhan/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello!\r\n\r\nCurrently, most of the TF models are not compliant with TFLite. Sorry for the inconvenience, if you want to help on this, you can propose a PR to fix this, this will be more than welcome!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: Version: 4.4.0.dev0
- Platform: Not sure what this means
- Python version: 3
- PyTorch version (GPU?):
- Tensorflow version (GPU?):'2.4.1'
- Using GPU in script?:No
- Using distributed or parallel set-up in script?:No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people. -->
t5: @patrickvonplaten
tensorflow: @jplu
## Information
Model I am using (Bert, XLNet ...): TFMT5ForConditionalGeneration (it is already trained)
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
converting the model to tflite
```
config = AutoConfig.from_pretrained(
model_path
# output_attentions=True,
# output_hidden_states=True,
# use_cache=True,
# return_dict=True
)
tokenizer = AutoTokenizer.from_pretrained(
model_path
)
model = TFMT5ForConditionalGeneration.from_pretrained(
model_path,
from_pt=True,
config=config
)
conc_func = model.serving.get_concrete_function()
converter = tf.lite.TFLiteConverter.from_concrete_functions([conc_func])
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS,
tf.lite.OpsSet.SELECT_TF_OPS]
tflite_model = converter.convert()
print("Converted successfully")
```
## To reproduce
Steps to reproduce the behavior:
1.run the above script on TFMT5ForConditionalGeneration model
2. will get the follow error
```
Exception: /home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/tensorflow/python/ops/array_ops.py:1047:0: error: 'tf.Reshape' op requires 'shape' to have at most one dynamic dimension, but got multiple dynamic dimensions at indices 0 and 3
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/tensorflow/python/util/dispatch.py:201:0: note: called from
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/transformers/models/t5/modeling_tf_t5.py:703:0: note: called from
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/tensorflow/python/autograph/operators/control_flow.py:1218:0: note: called from
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/tensorflow/python/autograph/operators/control_flow.py:1165:0: note: called from
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/transformers/models/t5/modeling_tf_t5.py:702:0: note: called from
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/tensorflow/python/autograph/operators/control_flow.py:1218:0: note: called from
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/tensorflow/python/autograph/operators/control_flow.py:1165:0: note: called from
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/transformers/models/t5/modeling_tf_t5.py:694:0: note: called from
/home/python_user/.pyenv/versions/3.7.2/lib/python3.7/site-packages/tensorflow/python/keras/engine/base_layer.py:1012:0: note: called from
```
When I inspected : t5/modeling_tf_t5.py:703: i got
Line number: code
```
702: if num_dims_encoder_attention_mask == 2:
703: encoder_extended_attention_mask = inputs["encoder_attention_mask"][:, None, None, :]
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
convert the model to tflite successfully
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10465/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10465/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10464 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10464/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10464/comments | https://api.github.com/repos/huggingface/transformers/issues/10464/events | https://github.com/huggingface/transformers/pull/10464 | 819,153,496 | MDExOlB1bGxSZXF1ZXN0NTgyMjk5ODMy | 10,464 | [Deepspeed] Allow HF optimizer and scheduler to be passed to deepspeed | {
"login": "cli99",
"id": 17418037,
"node_id": "MDQ6VXNlcjE3NDE4MDM3",
"avatar_url": "https://avatars.githubusercontent.com/u/17418037?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/cli99",
"html_url": "https://github.com/cli99",
"followers_url": "https://api.github.com/users/cli99/followers",
"following_url": "https://api.github.com/users/cli99/following{/other_user}",
"gists_url": "https://api.github.com/users/cli99/gists{/gist_id}",
"starred_url": "https://api.github.com/users/cli99/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/cli99/subscriptions",
"organizations_url": "https://api.github.com/users/cli99/orgs",
"repos_url": "https://api.github.com/users/cli99/repos",
"events_url": "https://api.github.com/users/cli99/events{/privacy}",
"received_events_url": "https://api.github.com/users/cli99/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2659267025,
"node_id": "MDU6TGFiZWwyNjU5MjY3MDI1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/DeepSpeed",
"name": "DeepSpeed",
"color": "4D34F7",
"default": false,
"description": ""
}
] | closed | false | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
] | [
"OK, 2 tests added and no, this doesn't work w/o neither the default optimizer nor the default scheduler. e.g. if you comment out the `del ` lines in the tests then we are using DS optim/sched and things are back to normal.\r\n\r\nI didn't have time to investigate as it's late, so just sharing the outputs at the moment - will look closer tomorrow. I think both are issues on the DeepSpeed side, but I could be wrong.\r\n\r\nAlso note that the normal CI doesn't run these tests, so green doesn't say anything about those. \r\n\r\n```\r\npytest -sv examples/tests/deepspeed/test_deepspeed.py -k test_hf_native_scheduler\r\n\r\nexamples/tests/deepspeed/test_deepspeed.py:103:\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\nsrc/transformers/trainer.py:917: in train\r\n model, optimizer, lr_scheduler = init_deepspeed(self, num_training_steps=max_steps)\r\nsrc/transformers/integrations.py:351: in init_deepspeed\r\n trainer.create_scheduler(num_training_steps=num_training_steps)\r\nsrc/transformers/trainer.py:685: in create_scheduler\r\n self.lr_scheduler = get_scheduler(\r\nsrc/transformers/optimization.py:266: in get_scheduler\r\n return schedule_func(optimizer, num_warmup_steps=num_warmup_steps, num_training_steps=num_training_steps)\r\nsrc/transformers/optimization.py:98: in get_linear_schedule_with_warmup\r\n return LambdaLR(optimizer, lr_lambda, last_epoch)\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n\r\nself = <torch.optim.lr_scheduler.LambdaLR object at 0x7fd86fb0a160>, optimizer = None\r\nlr_lambda = <function get_linear_schedule_with_warmup.<locals>.lr_lambda at 0x7fd86fafc160>, last_epoch = -1, verbose = False\r\n\r\n def __init__(self, optimizer, lr_lambda, last_epoch=-1, verbose=False):\r\n self.optimizer = optimizer\r\n\r\n if not isinstance(lr_lambda, list) and not isinstance(lr_lambda, tuple):\r\n> self.lr_lambdas = [lr_lambda] * len(optimizer.param_groups)\r\nE AttributeError: 'NoneType' object has no attribute 'param_groups'\r\n\r\n/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/optim/lr_scheduler.py:197: AttributeError\r\n````\r\n\r\n\r\n```\r\npytest -sv examples/tests/deepspeed/test_deepspeed.py -k test_hf_native_optimizer\r\n\r\nexamples/tests/deepspeed/test_deepspeed.py:91: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\nsrc/transformers/trainer.py:917: in train\r\n model, optimizer, lr_scheduler = init_deepspeed(self, num_training_steps=max_steps)\r\nsrc/transformers/integrations.py:384: in init_deepspeed\r\n model, optimizer, _, lr_scheduler = deepspeed.initialize(\r\n../../github/00optimize/DeepSpeed/deepspeed/__init__.py:110: in initialize\r\n engine = DeepSpeedEngine(args=args,\r\n../../github/00optimize/DeepSpeed/deepspeed/runtime/engine.py:174: in __init__\r\n self._configure_optimizer(optimizer, model_parameters)\r\n../../github/00optimize/DeepSpeed/deepspeed/runtime/engine.py:570: in _configure_optimizer\r\n self.optimizer = self._configure_zero_optimizer(basic_optimizer)\r\n../../github/00optimize/DeepSpeed/deepspeed/runtime/engine.py:691: in _configure_zero_optimizer\r\n optimizer = FP16_DeepSpeedZeroOptimizer(\r\n../../github/00optimize/DeepSpeed/deepspeed/runtime/zero/stage2.py:239: in __init__\r\n flatten_dense_tensors_aligned(\r\n../../github/00optimize/DeepSpeed/deepspeed/runtime/zero/stage2.py:74: in flatten_dense_tensors_aligned\r\n return _flatten_dense_tensors(padded_tensor_list)\r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _\r\n\r\ntensors = []\r\n\r\n def _flatten_dense_tensors(tensors):\r\n \"\"\"Flatten dense tensors into a contiguous 1D buffer. Assume tensors are of\r\n same dense type.\r\n \r\n Since inputs are dense, the resulting tensor will be a concatenated 1D\r\n buffer. Element-wise operation on this buffer will be equivalent to\r\n operating individually.\r\n \r\n Args:\r\n tensors (Iterable[Tensor]): dense tensors to flatten.\r\n\r\n Returns:\r\n A contiguous 1D buffer containing input tensors.\r\n \"\"\"\r\n if len(tensors) == 1:\r\n return tensors[0].contiguous().view(-1)\r\n> flat = torch.cat([t.contiguous().view(-1) for t in tensors], dim=0)\r\nE RuntimeError: There were no tensor arguments to this function (e.g., you passed an empty list of Tensors), but no fallback function is registered for schema aten::_cat. This usually means that this function requires a non-empty list of Tensors. Available functions are [CPU, CUDA, QuantizedCPU, BackendSelect, Named, AutogradOther, AutogradCPU, AutogradCUDA, AutogradXLA, AutogradNestedTensor, UNKNOWN_TENSOR_TYPE_ID, AutogradPrivateUse1, AutogradPrivateUse2, AutogradPrivateUse3, Tracer, Autocast, Batched, VmapMode].\r\nE\r\nE CPU: registered at /pytorch/build/aten/src/ATen/RegisterCPU.cpp:5925 [kernel]\r\nE CUDA: registered at /pytorch/build/aten/src/ATen/RegisterCUDA.cpp:7100 [kernel]\r\nE QuantizedCPU: registered at /pytorch/build/aten/src/ATen/RegisterQuantizedCPU.cpp:641 [kernel]\r\nE BackendSelect: fallthrough registered at /pytorch/aten/src/ATen/core/BackendSelectFallbackKernel.cpp:3 [backend fallback]\r\nE Named: registered at /pytorch/aten/src/ATen/core/NamedRegistrations.cpp:7 [backend fallback]\r\nE AutogradOther: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE AutogradCPU: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE AutogradCUDA: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE AutogradXLA: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE AutogradNestedTensor: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE UNKNOWN_TENSOR_TYPE_ID: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE AutogradPrivateUse1: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE AutogradPrivateUse2: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE AutogradPrivateUse3: registered at /pytorch/torch/csrc/autograd/generated/VariableType_2.cpp:9161 [autograd kernel]\r\nE Tracer: registered at /pytorch/torch/csrc/autograd/generated/TraceType_2.cpp:10551 [kernel]\r\nE Autocast: registered at /pytorch/aten/src/ATen/autocast_mode.cpp:254 [kernel]\r\nE Batched: registered at /pytorch/aten/src/ATen/BatchingRegistrations.cpp:1016 [backend fallback]\r\nE VmapMode: fallthrough registered at /pytorch/aten/src/ATen/VmapModeRegistrations.cpp:33 [backend fallback]\r\n\r\n/home/stas/anaconda3/envs/main-38/lib/python3.8/site-packages/torch/_utils.py:259: RuntimeError\r\n```",
"OK, so I had a look at the first failing test. \r\n\r\nThese 2 can't be separated the way it was done, since the optimizer is needed to init the scheduler. But we don't have it yet if it's Deepspeed that creates the optimizer. So we have a chicken-n-egg problem here. Unless deepspeed provides a new API to handle that.\r\n\r\nSo probably at the moment we can only support one of: 1, 2, 3 and not 4.\r\n\r\n1. DS scheduler + DS optimizer\r\n2. HF scheduler + HF optimizer\r\n3. DS scheduler + HF optimizer\r\n4. HF scheduler + DS optimizer\r\n\r\nNote I added a new test for the combo 2 and renamed all tests to match, so now we have:\r\n```\r\npytest -sv examples/tests/deepspeed/test_deepspeed.py -k test_hf_scheduler_hf_optimizer\r\npytest -sv examples/tests/deepspeed/test_deepspeed.py -k test_ds_scheduler_hf_optimizer\r\npytest -sv examples/tests/deepspeed/test_deepspeed.py -k test_hf_scheduler_ds_optimizer\r\n```",
"This deepspeed PR https://github.com/microsoft/DeepSpeed/pull/827 fixes the issues. The following tests would pass.\r\nDS scheduler + DS optimizer\r\nHF scheduler + HF optimizer\r\nDS scheduler + HF optimizer \r\n\r\nShall we put a check in HF to disallow the case HF scheduler + DS optimizer?",
"I tested with your https://github.com/microsoft/DeepSpeed/pull/827 PR tree and indeed \r\n\r\n```\r\npytest -sv examples/tests/deepspeed/test_deepspeed.py -k test_hf_scheduler_hf_optimizer\r\npytest -sv examples/tests/deepspeed/test_deepspeed.py -k test_ds_scheduler_hf_optimizer\r\n```\r\n\r\nnow pass. awesome!\r\n\r\n> Shall we put a check in HF to disallow the case HF scheduler + DS optimizer?\r\n\r\nCorrect! Please let me know if you will be taking care of it or you'd rather me finish this up. Either way works.\r\n\r\nAlso will need to update the docs to reflect this new more flexible reality. I can take care of that.\r\n\r\nWe will need to wait for a new release from your side to commit this PR and add a requirement for that new version. I already have this check setup in another PR waiting for this new release: https://github.com/huggingface/transformers/pull/9624\r\n\r\nThere is another PR by @jeffra today that also needs a new release first before we can update our tree.",
"Great. Can you please add the check for the case HF scheduler + DS optimizer? Since you are updating the docs, I think it makes more sense for you to do it. I will work with @jeffra to push the deepspeed PRs into the new release. Thanks.",
"@cli99, I made further changes to your original code\r\n\r\n1. as @jeffra suggested we can't use HF optimizer with offload enabled - so coded to defend against that\r\n2. I realized my original design was flawed and that the user could end up with a mismatch between cl args and the ds config, so I recoded the optimizer/scheduler config sections to override ds config with cl args where needed.\r\n\r\nPlease let me know if I broke anything in your original plan. I have also updated the docs extensively. They look a bit scary at the moment and will need a rework down the road.\r\n\r\nMy main goal here is to prevent from user getting subtle errors, so setting command line arguments to override DS config. Hope it makes sense.\r\n\r\n",
"@sgugger, I made more doc updates - if you get a chance please kindly skim over them? Thank you!\r\n\r\nI think we will merge this on Monday when deepspeed==0.3.13 is planned to be released.",
"@stas00 I'll let you merge when you are ready (since you followed this more closely than me). It looks good to merge to me :-)\r\nThanks for your contribution @cli99!",
"I'm on top of this - we are waiting for a new DeepSpeed release required by this PR. Thank you, @sgugger "
] | 1,614 | 1,615 | 1,615 | CONTRIBUTOR | null | # Use HF optimizer and/or scheduler unless specified in deepspeed config
If HF is already creating an optimizer and LR scheduler, we should not try to match that config/implementation in a ds_config.json instead we pass it to deepspeed.initialize(..., lr_scheduler=hf_lr_scheduler)
* [x] This PR checks if ds_config has an optimizer or scheduler, if it does not, calls `create_optimizer` or `create_cheduler` (after splitting it) to create an optimizer or scheduler. Then HF optimizer and scheduler are passed it to deepspeed.initialize().
DeepSpeed can handle any optimizer and scheduler if these are passed directly to deepspeed.initialize() as an object.
Due to the chicken-n-egg init problem, the valid combinations are:
| Combos | HF Scheduler | DS Scheduler |
|--------------|--------------|--------------|
| HF Optimizer | Yes | Yes |
| DS Optimizer | No | Yes |
but if `cpu_offload` is used all bets are off - we can only use DS optim/sched.
----------
added by @stas00 below:
Added:
* [x] make init_deepspeed support config dict, besides the config file - this makes the testing much easier
* [x] add tests for this PR using this new feature of passing the dict
* [x] various small clean ups
* [x] update the docs
* [x] check for `cpu_offload` - add test
* [x] recode the config overrides to have one true source of values
* [x] tweak one not working test
**blocking event: waiting for a new release 0.3.13 from DeepSpeed.**
@sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10464/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10464/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10464",
"html_url": "https://github.com/huggingface/transformers/pull/10464",
"diff_url": "https://github.com/huggingface/transformers/pull/10464.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10464.patch",
"merged_at": 1615935069000
} |
https://api.github.com/repos/huggingface/transformers/issues/10463 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10463/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10463/comments | https://api.github.com/repos/huggingface/transformers/issues/10463/events | https://github.com/huggingface/transformers/issues/10463 | 819,153,223 | MDU6SXNzdWU4MTkxNTMyMjM= | 10,463 | Script for squad_v2 for custom data not working | {
"login": "BatMrE",
"id": 48859022,
"node_id": "MDQ6VXNlcjQ4ODU5MDIy",
"avatar_url": "https://avatars.githubusercontent.com/u/48859022?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BatMrE",
"html_url": "https://github.com/BatMrE",
"followers_url": "https://api.github.com/users/BatMrE/followers",
"following_url": "https://api.github.com/users/BatMrE/following{/other_user}",
"gists_url": "https://api.github.com/users/BatMrE/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BatMrE/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BatMrE/subscriptions",
"organizations_url": "https://api.github.com/users/BatMrE/orgs",
"repos_url": "https://api.github.com/users/BatMrE/repos",
"events_url": "https://api.github.com/users/BatMrE/events{/privacy}",
"received_events_url": "https://api.github.com/users/BatMrE/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"hi @BatMrE \r\n\r\ncould you try the new `run_qa.py` example script and let us know if you still face the issue. You can find the new script here \r\nhttps://github.com/huggingface/transformers/tree/master/examples/question-answering",
"> hi @BatMrE\r\n> \r\n> could you try the new `run_qa.py` example script and let us know if you still face the issue. You can find the new script here\r\n> https://github.com/huggingface/transformers/tree/master/examples/question-answering\r\n\r\n```\r\n[INFO|tokenization_utils_base.py:1786] 2021-03-02 18:56:09,448 >> loading file https://huggingface.co/bert-base-uncased/resolve/main/vocab.txt from cache at /root/.cache/huggingface/transformers/45c3f7a79a80e1cf0a489e5c62b43f173c15db47864303a55d623bb3c96f72a5.d789d64ebfe299b0e416afc4a169632f903f693095b4629a7ea271d5a0cf2c99\r\n[INFO|tokenization_utils_base.py:1786] 2021-03-02 18:56:09,448 >> loading file https://huggingface.co/bert-base-uncased/resolve/main/tokenizer.json from cache at /root/.cache/huggingface/transformers/534479488c54aeaf9c3406f647aa2ec13648c06771ffe269edabebd4c412da1d.7f2721073f19841be16f41b0a70b600ca6b880c8f3df6f3535cbc704371bdfa4\r\n[INFO|modeling_utils.py:1027] 2021-03-02 18:56:09,548 >> loading weights file https://huggingface.co/bert-base-uncased/resolve/main/pytorch_model.bin from cache at /root/.cache/huggingface/transformers/a8041bf617d7f94ea26d15e218abd04afc2004805632abc0ed2066aa16d50d04.faf6ea826ae9c5867d12b22257f9877e6b8367890837bd60f7c54a29633f7f2f\r\n[WARNING|modeling_utils.py:1135] 2021-03-02 18:56:14,139 >> Some weights of the model checkpoint at bert-base-uncased were not used when initializing BertForQuestionAnswering: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias']\r\n- This IS expected if you are initializing BertForQuestionAnswering from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).\r\n- This IS NOT expected if you are initializing BertForQuestionAnswering from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).\r\n[WARNING|modeling_utils.py:1146] 2021-03-02 18:56:14,139 >> Some weights of BertForQuestionAnswering were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['qa_outputs.weight', 'qa_outputs.bias']\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\n 1% 3/227 [00:01<02:25, 1.54ba/s]thread '<unnamed>' panicked at 'assertion failed: stride < max_len', /__w/tokenizers/tokenizers/tokenizers/src/tokenizer/encoding.rs:322:9\r\nnote: run with `RUST_BACKTRACE=1` environment variable to display a backtrace\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | **Environment info**
transformers version: 4.3.3
Platform: Linux-4.15.0-91-generic-x86_64-with-debian-buster-sid
Python version: 3.7.6
Using GPU in script?: True
Using distributed or parallel set-up in script?: True
**Who can help**
@gowtham1997 @patil-suraj
I am running the script from docs to train and evaluate squad_v2 data with custom arguments.
My dataset is as per the structure of squad format with every keys and values properly.
[colabJson2.zip](https://github.com/huggingface/transformers/files/6063805/colabJson2.zip)
```
python run_qa.py \
--model_name_or_path bert-base-uncased \
--version_2_with_negative\
--train_file=/content/colabJson.json \
--validation_file=/content/dev-v2.0.json \
--do_train \
--do_eval \
--per_device_train_batch_size 12 \
--learning_rate 3e-5 \
--num_train_epochs 2 \
--max_seq_length 384 \
--doc_stride 128 \
--output_dir /content/debug_squad_16
```
Output of the script i am getting error as
```
Traceback (most recent call last):
File "run_qa.py", line 507, in <module>
main()
File "run_qa.py", line 230, in main
datasets = load_dataset(extension, data_files=data_files, field="data")
File "/usr/local/lib/python3.7/dist-packages/datasets/load.py", line 750, in load_dataset
ds = builder_instance.as_dataset(split=split, ignore_verifications=ignore_verifications, in_memory=keep_in_memory)
File "/usr/local/lib/python3.7/dist-packages/datasets/builder.py", line 740, in as_dataset
map_tuple=True,
File "/usr/local/lib/python3.7/dist-packages/datasets/utils/py_utils.py", line 234, in map_nested
_single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)
File "/usr/local/lib/python3.7/dist-packages/datasets/utils/py_utils.py", line 234, in <listcomp>
_single_map_nested((function, obj, types, None, True)) for obj in tqdm(iterable, disable=disable_tqdm)
File "/usr/local/lib/python3.7/dist-packages/datasets/utils/py_utils.py", line 172, in _single_map_nested
return function(data_struct)
File "/usr/local/lib/python3.7/dist-packages/datasets/builder.py", line 757, in _build_single_dataset
in_memory=in_memory,
File "/usr/local/lib/python3.7/dist-packages/datasets/builder.py", line 831, in _as_dataset
return Dataset(**dataset_kwargs)
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 250, in __init__
self.info.features, self.info.features.type, inferred_features, inferred_features.type
ValueError: External features info don't match the dataset:
Got
{'title': Value(dtype='string', id=None), 'paragraphs': [{'qas': [{'question': Value(dtype='string', id=None), 'id': Value(dtype='string', id=None), 'answers': [{'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int64', id=None)}], 'is_impossible': Value(dtype='bool', id=None), 'plausible_answers': [{'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int64', id=None)}]}], 'context': Value(dtype='string', id=None)}]}
with type
struct<paragraphs: list<item: struct<context: string, qas: list<item: struct<answers: list<item: struct<answer_start: int64, text: string>>, id: string, is_impossible: bool, plausible_answers: list<item: struct<answer_start: int64, text: string>>, question: string>>>>, title: string>
but expected something like
{'title': Value(dtype='string', id=None), 'paragraphs': [{'context': Value(dtype='string', id=None), 'qas': [{'answers': [{'text': Value(dtype='string', id=None), 'answer_start': Value(dtype='int64', id=None)}], 'question': Value(dtype='string', id=None), 'id': Value(dtype='string', id=None)}]}]}
with type
struct<paragraphs: list<item: struct<context: string, qas: list<item: struct<answers: list<item: struct<answer_start: int64, text: string>>, id: string, question: string>>>>, title: string>
```
In my dataset I don't have any field as **plausible_answers**, **is_impossible** ..
how to match it with expected format when it is already in that format | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10463/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10463/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10462 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10462/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10462/comments | https://api.github.com/repos/huggingface/transformers/issues/10462/events | https://github.com/huggingface/transformers/pull/10462 | 819,074,896 | MDExOlB1bGxSZXF1ZXN0NTgyMjM0NTkz | 10,462 | Add I-BERT to README | {
"login": "LysandreJik",
"id": 30755778,
"node_id": "MDQ6VXNlcjMwNzU1Nzc4",
"avatar_url": "https://avatars.githubusercontent.com/u/30755778?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/LysandreJik",
"html_url": "https://github.com/LysandreJik",
"followers_url": "https://api.github.com/users/LysandreJik/followers",
"following_url": "https://api.github.com/users/LysandreJik/following{/other_user}",
"gists_url": "https://api.github.com/users/LysandreJik/gists{/gist_id}",
"starred_url": "https://api.github.com/users/LysandreJik/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/LysandreJik/subscriptions",
"organizations_url": "https://api.github.com/users/LysandreJik/orgs",
"repos_url": "https://api.github.com/users/LysandreJik/repos",
"events_url": "https://api.github.com/users/LysandreJik/events{/privacy}",
"received_events_url": "https://api.github.com/users/LysandreJik/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | MEMBER | null | This PR adds I-BERT to the readme, it was forgotten. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10462/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10462/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10462",
"html_url": "https://github.com/huggingface/transformers/pull/10462",
"diff_url": "https://github.com/huggingface/transformers/pull/10462.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10462.patch",
"merged_at": 1614618751000
} |
https://api.github.com/repos/huggingface/transformers/issues/10461 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10461/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10461/comments | https://api.github.com/repos/huggingface/transformers/issues/10461/events | https://github.com/huggingface/transformers/pull/10461 | 819,008,600 | MDExOlB1bGxSZXF1ZXN0NTgyMTc5NjY4 | 10,461 | pass correct head mask to cross-attention layer | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I see, then this looks a bit confusing to me, other seq2seq models (BART, Marian, BlendSmall) pass `encoder_layer_head_mask` to cross attention\r\n\r\nhttps://github.com/huggingface/transformers/blob/9248e27037ce7f7c9359802e6fdf819a1e227a18/src/transformers/models/bart/modeling_bart.py#L419\r\n\r\nhttps://github.com/huggingface/transformers/blob/9248e27037ce7f7c9359802e6fdf819a1e227a18/src/transformers/models/marian/modeling_marian.py#L438 \r\n\r\nhttps://github.com/huggingface/transformers/blob/9248e27037ce7f7c9359802e6fdf819a1e227a18/src/transformers/models/blenderbot_small/modeling_blenderbot_small.py#L421",
"> s looks a bit confusing to me, other seq2seq models (BART, Marian, BlendSmall) pass `encoder_layer_head_mask` to cross attention\r\n\r\nI would argue that they are wrong then :D (cc @stancld - maybe do you have more insight here?)",
"@patil-suraj @patrickvonplaten - What a coincidence... I was discussing this topic with my PhD supervisor this morning and I think the most proper way how to handle head masking for cross attention is to introduce a separate cross-attention head mask tensor to disentangle the cross-attention effect from the self-attention one?",
"I guess this would actually be the cleanest option! At the moment the cross-attention layer the exact same shape as the decoder self-attention layer -> so I think we can use the same mask for now and maybe improve it later with a `cross-attention head mask`. Using the `encoder_layer_head_mask` however could lead to errors IMO - so this option is just wrong to me",
"I can create a new issue and can have a look at this cross-attention `head_mask` at the weekend :)",
"That would be great @stancld! I will close this PR."
] | 1,614 | 1,614 | 1,614 | MEMBER | null | # What does this PR do?
MBart, Blender, and Pegaus models decoder layers pass `layer_head_mask` head mask to cross attention layer, which is incorrect. This PR passes the correct `encoder_layer_head_mask` to cross-attention layer. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10461/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10461/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10461",
"html_url": "https://github.com/huggingface/transformers/pull/10461",
"diff_url": "https://github.com/huggingface/transformers/pull/10461.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10461.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10460 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10460/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10460/comments | https://api.github.com/repos/huggingface/transformers/issues/10460/events | https://github.com/huggingface/transformers/issues/10460 | 818,923,860 | MDU6SXNzdWU4MTg5MjM4NjA= | 10,460 | How to Reduce the inference time of Facebook/many to many model? | {
"login": "sankarsiva123",
"id": 58412261,
"node_id": "MDQ6VXNlcjU4NDEyMjYx",
"avatar_url": "https://avatars.githubusercontent.com/u/58412261?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sankarsiva123",
"html_url": "https://github.com/sankarsiva123",
"followers_url": "https://api.github.com/users/sankarsiva123/followers",
"following_url": "https://api.github.com/users/sankarsiva123/following{/other_user}",
"gists_url": "https://api.github.com/users/sankarsiva123/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sankarsiva123/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sankarsiva123/subscriptions",
"organizations_url": "https://api.github.com/users/sankarsiva123/orgs",
"repos_url": "https://api.github.com/users/sankarsiva123/repos",
"events_url": "https://api.github.com/users/sankarsiva123/events{/privacy}",
"received_events_url": "https://api.github.com/users/sankarsiva123/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | Facebook/many to many model takes 9s on cpu to translate , how to reduce the inference time on cpu ?
It will be helpful if an method is suggested . | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10460/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10460/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10459 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10459/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10459/comments | https://api.github.com/repos/huggingface/transformers/issues/10459/events | https://github.com/huggingface/transformers/issues/10459 | 818,920,048 | MDU6SXNzdWU4MTg5MjAwNDg= | 10,459 | [Wav2Vec2] Improve SpecAugment function by converting numpy based function to pytorch based function | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 1990918270,
"node_id": "MDU6TGFiZWwxOTkwOTE4Mjcw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Good%20First%20Issue",
"name": "Good First Issue",
"color": "bbf794",
"default": false,
"description": ""
}
] | closed | false | null | [] | [
"@patrickvonplaten You mean it function definition will become def _compute_mask_indices(\r\n shape: Tuple[int, int],\r\n mask_prob: float,\r\n mask_length: int,\r\n attention_mask: Optional[torch.Tensor] = None,\r\n min_masks: int = 0,\r\n) -> torch.tensor:\r\n\r\n?? Of course internal working also needs to be changed according. Just trying to learn what need to be done",
"essentially all `np....` operations should be replaced by `torch....` operations :-) ",
"```\r\ndef _compute_mask_indices(\r\n shape: Tuple[int, int],\r\n mask_prob: float,\r\n mask_length: int,\r\n attention_mask: Optional[torch.Tensor] = None,\r\n min_masks: int = 0,\r\n) -> torch.tensor:\r\n\r\nbsz, all_sz = shape\r\n#mask = np.full((bsz, all_sz), False)\r\nmask = torch.Tensor(bsz, all_sz).fill_(False)\r\n\r\nall_num_mask = int(\r\n # add a random number for probabilistic rounding\r\n mask_prob * all_sz / float(mask_length)\r\n + torch.rand()\r\n )\r\nall_num_mask = max(min_masks, all_num_mask)\r\n\r\n mask_idcs = []\r\n padding_mask = attention_mask.ne(1) if attention_mask is not None else None\r\n\r\n for i in range(bsz):\r\n if padding_mask is not None:\r\n sz = all_sz - padding_mask[i].long().sum().item()\r\n num_mask = int(\r\n # add a random number for probabilistic rounding\r\n mask_prob * sz / float(mask_length)\r\n + torch.rand()\r\n )\r\n num_mask = max(min_masks, num_mask)\r\n else:\r\n sz = all_sz\r\n num_mask = all_num_mask\r\n\r\n lengths = torch.Tensor(num_mask).fill_(mask_length)\r\n\r\n if sum(lengths) == 0:\r\n lengths[0] = min(mask_length, sz - 1)\r\n\r\n min_len = min(lengths)\r\n if sz - min_len <= num_mask:\r\n min_len = sz - num_mask - 1\r\n\r\n #mask_idc = np.random.choice(sz - min_len, num_mask, replace=False)\r\n mask_idc = torch.randperm(sz - min_len)[:num_mask]\r\n #mask_idc = np.asarray([mask_idc[j] + offset for j in range(len(mask_idc)) for offset in range(lengths[j])])\r\n mask_idc = torch.from_numpy(np.asarray([mask_idc[j] + offset for j in range(len(mask_idc)) for offset in range(lengths[j])]))\r\n #mask_idcs.append(np.unique(mask_idc[mask_idc < sz]))\r\n mask_idcs.append(torch.unique(mask_idc[mask_idc < sz]))\r\n\r\n min_len = min([len(m) for m in mask_idcs])\r\n for i, mask_idc in enumerate(mask_idcs):\r\n if len(mask_idc) > min_len:\r\n #mask_idc = np.random.choice(mask_idc, min_len, replace=False)\r\n mask_idc = torch.randperm(mask_idc)[:min_len]\r\n mask[i, mask_idc] = True\r\n\r\n return mask\r\n\r\n```",
"Can you guide me if I am doing anything wrong above ? ",
"This looks nice already - do you want to open a PR for this? \r\n\r\nIt would be ideal to replace the `for ....` loops with pure PyTorch vector operations as well",
"yes sure. Let me try. I will send PR tomorrow. Bit late to work on it for now.",
"@patrickvonplaten Can you please help pass all checks. I have ran \"make style\", \"make fixup\" and did respective changes. But make quality is failing on master itself. Do you have any suggestion for code improvement ? ",
"@patrickvonplaten \r\nHello. I am Master 1student in japan.\r\nI want to fine tuning with local small data.\r\nShould I fix this your code???\r\nhttps://github.com/huggingface/transformers/blob/master/examples/research_projects/wav2vec2/run_asr.py\r\n\r\nSorry for low level question.\r\n\r\np.s. Is it okay to ask such a question here?",
"> @patrickvonplaten\r\n> Hello. I am Master 1student in japan.\r\n> I want to fine tuning with local small data.\r\n> Should I fix this your code???\r\n> https://github.com/huggingface/transformers/blob/master/examples/research_projects/wav2vec2/run_asr.py\r\n> \r\n> Sorry for low level question.\r\n> \r\n> p.s. Is it okay to ask such a question here?\r\n\r\nI'll open-source an explicit notebook on how to fine-tune Wav2Vec2 in a ~1,2 weeks under the hugging face blog. If you haven't seen it by then, please ping me here again.",
"Hi @patrickvonplaten. I'd like to contribute to this issue. Is it still open?",
"Hey @amalad,\r\n\r\nYes the PR is still open since the other PR mentioned here seems to be stuck - feel free to open a new one :-)",
"Since Pytorch has no equivalent function to `np.random.choice`, there're only workarounds. Some [discussions](https://github.com/pytorch/pytorch/issues/16897) about this issue.\r\n\r\nAnyway here's my take.\r\n\r\n```python3\r\nimport torch\r\nfrom typing import Optional, Tuple\r\nimport random\r\n\r\ndef _compute_specaugment_mask_indices(\r\n shape: Tuple[int, int],\r\n mask_prob: float,\r\n mask_length: int,\r\n attention_mask: Optional[torch.Tensor] = None,\r\n min_masks: int = 0,\r\n) -> torch.Tensor:\r\n \"\"\"\r\n Computes random mask spans for a given shape\r\n\r\n Args:\r\n shape: the the shape for which to compute masks.\r\n should be of size 2 where first element is batch size and 2nd is timesteps\r\n attention_mask: optional padding mask of the same size as shape, which will prevent masking padded elements\r\n mask_prob: probability for each token to be chosen as start of the span to be masked. this will be multiplied by\r\n number of timesteps divided by length of mask span to mask approximately this percentage of all elements.\r\n however due to overlaps, the actual number will be smaller (unless no_overlap is True)\r\n mask_length: size of the mask\r\n min_masks: minimum number of masked spans\r\n\r\n Adapted from `fairseq's data_utils.py\r\n <https://github.com/pytorch/fairseq/blob/e0788f7007a8473a76db573985031f3c94201e79/fairseq/data/data_utils.py#L376>`__.\r\n \"\"\"\r\n bsz, all_sz = shape\r\n mask = torch.full((bsz, all_sz), False)\r\n\r\n all_num_mask = int(\r\n # add a random number for probabilistic rounding\r\n mask_prob * all_sz / float(mask_length)\r\n + random.random()\r\n )\r\n\r\n all_num_mask = max(min_masks, all_num_mask)\r\n if all_num_mask == 0:\r\n return mask\r\n\r\n mask_idcs = []\r\n padding_mask = attention_mask.ne(1) if attention_mask is not None else None\r\n\r\n for i in range(bsz):\r\n if padding_mask is not None:\r\n sz = all_sz - padding_mask[i].long().sum().item()\r\n num_mask = int(\r\n # add a random number for probabilistic rounding\r\n mask_prob * sz / float(mask_length)\r\n + random.random()\r\n )\r\n num_mask = max(min_masks, num_mask)\r\n else:\r\n sz = all_sz\r\n num_mask = all_num_mask\r\n\r\n lengths = torch.full([num_mask], mask_length)\r\n\r\n if sum(lengths) == 0:\r\n lengths[0] = min(mask_length, sz - 1)\r\n\r\n min_len = int(min(lengths)) if not lengths.nelement() == 0 else 0\r\n if sz - min_len <= num_mask:\r\n min_len = sz - num_mask - 1\r\n\r\n #mask_idc = torch.randint(sz - min_len, [num_mask]) # TODO: should sample w/o replacement\r\n mask_idc = random.sample(range(sz - min_len), num_mask)\r\n mask_idc = torch.Tensor([mask_idc[j] + offset for j in range(num_mask) for offset in range(lengths[j])])\r\n mask_idcs.append(torch.unique(mask_idc[mask_idc < sz]))\r\n\r\n min_len = min([len(m) for m in mask_idcs])\r\n for i, mask_idc in enumerate(mask_idcs):\r\n if len(mask_idc) > min_len:\r\n mask_idc = mask_idc.gather(dim=0, index=torch.multinomial(mask_idc, min_len, replacement=False))\r\n mask[i, mask_idc.long()] = True\r\n\r\n return mask\r\n```",
"Hey @chutaklee, \r\n\r\nThis looks nice! Could you maybe open a PR for it and measure the speed improvement when training on a GPU? :-)",
"Hi, @patrickvonplaten can I still work on this issue? or Is @chutaklee working on it? Actually, I have been working with fairseq's wav2vec and would like to give this issue a go.",
"@01-vyom Hi Vyom, I'm stuck at vectorizing the mask generation. So feel free to try it.",
"Feel free to give it a go @01-vyom :-)",
"@patrickvonplaten Made a PR."
] | 1,614 | 1,621 | 1,621 | MEMBER | null | # 🚀 Feature request
As can be seen here: https://github.com/huggingface/transformers/blob/11655fafdd42eb56ad94e09ecd84d4dc2d1041ae/src/transformers/models/wav2vec2/modeling_wav2vec2.py#L47,
the function `_compute_mask_indices` (responsible for spec augment) of Wav2Vec2 is written in numpy which means that the function is not GPU compatible.
The function could simply be rewritten in PyTorch, which should make training on GPU faster.
This "Good First Issue" is about converting `_compute_mask_indices` to PyTorch while keeping the same functionality.
## Your contribution
I'm happy to guide the contributor through the PR!
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10459/reactions",
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10459/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10458 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10458/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10458/comments | https://api.github.com/repos/huggingface/transformers/issues/10458/events | https://github.com/huggingface/transformers/pull/10458 | 818,742,216 | MDExOlB1bGxSZXF1ZXN0NTgxOTU0NTQw | 10,458 | Work towards fixing Flax tests | {
"login": "avital",
"id": 37586,
"node_id": "MDQ6VXNlcjM3NTg2",
"avatar_url": "https://avatars.githubusercontent.com/u/37586?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/avital",
"html_url": "https://github.com/avital",
"followers_url": "https://api.github.com/users/avital/followers",
"following_url": "https://api.github.com/users/avital/following{/other_user}",
"gists_url": "https://api.github.com/users/avital/gists{/gist_id}",
"starred_url": "https://api.github.com/users/avital/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/avital/subscriptions",
"organizations_url": "https://api.github.com/users/avital/orgs",
"repos_url": "https://api.github.com/users/avital/repos",
"events_url": "https://api.github.com/users/avital/events{/privacy}",
"received_events_url": "https://api.github.com/users/avital/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"/cc @patrickvonplaten for review",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"Think this issue has been resolved :-)",
"Yes :)"
] | 1,614 | 1,618 | 1,618 | CONTRIBUTOR | null | I still get failures that seem due to missing HTTP artifacts, e.g.
E OSError: Can't load weights for 'roberta-large'. Make sure that:
E
E - 'roberta-large' is a correct model identifier listed on 'https://huggingface.co/models'
E
E - or 'roberta-large' is the correct path to a directory containing a file named pytorch_model.bin.
This is the command I used to run tests:
RUN_SLOW=true python -m pytest -k flax -n 8 --dist=loadfile -rA -s --make-reports=tests_flax ./tests/ | tee tests_output.txt
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests? (<-- this PR fixes existing tests)
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10458/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10458/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10458",
"html_url": "https://github.com/huggingface/transformers/pull/10458",
"diff_url": "https://github.com/huggingface/transformers/pull/10458.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10458.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10457 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10457/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10457/comments | https://api.github.com/repos/huggingface/transformers/issues/10457/events | https://github.com/huggingface/transformers/pull/10457 | 818,656,840 | MDExOlB1bGxSZXF1ZXN0NTgxODgyNzQy | 10,457 | [Wav2Vec2] Remove unused config | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Removes unused config variable
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10457/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10457/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10457",
"html_url": "https://github.com/huggingface/transformers/pull/10457",
"diff_url": "https://github.com/huggingface/transformers/pull/10457.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10457.patch",
"merged_at": 1614591012000
} |
https://api.github.com/repos/huggingface/transformers/issues/10456 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10456/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10456/comments | https://api.github.com/repos/huggingface/transformers/issues/10456/events | https://github.com/huggingface/transformers/issues/10456 | 818,607,680 | MDU6SXNzdWU4MTg2MDc2ODA= | 10,456 | How to Improve inference time of facebook/mbart many to many model? | {
"login": "Vimal0307",
"id": 41289592,
"node_id": "MDQ6VXNlcjQxMjg5NTky",
"avatar_url": "https://avatars.githubusercontent.com/u/41289592?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Vimal0307",
"html_url": "https://github.com/Vimal0307",
"followers_url": "https://api.github.com/users/Vimal0307/followers",
"following_url": "https://api.github.com/users/Vimal0307/following{/other_user}",
"gists_url": "https://api.github.com/users/Vimal0307/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Vimal0307/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vimal0307/subscriptions",
"organizations_url": "https://api.github.com/users/Vimal0307/orgs",
"repos_url": "https://api.github.com/users/Vimal0307/repos",
"events_url": "https://api.github.com/users/Vimal0307/events{/privacy}",
"received_events_url": "https://api.github.com/users/Vimal0307/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello, thanks for opening an issue! We try to keep the github issues for bugs/feature requests.\r\nCould you ask your question on the [forum](https://discusss.huggingface.co) instead?\r\n\r\nThanks!"
] | 1,614 | 1,614 | 1,614 | NONE | null | If we tried to run translation service on facebook mbart many to many on cpu it take 9 secs to translate, how do we reduce the inference time further | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10456/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10456/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10455 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10455/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10455/comments | https://api.github.com/repos/huggingface/transformers/issues/10455/events | https://github.com/huggingface/transformers/pull/10455 | 818,584,632 | MDExOlB1bGxSZXF1ZXN0NTgxODIyMTk0 | 10,455 | [Wav2Vec2FeatureExtractor] smal fixes | {
"login": "patil-suraj",
"id": 27137566,
"node_id": "MDQ6VXNlcjI3MTM3NTY2",
"avatar_url": "https://avatars.githubusercontent.com/u/27137566?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patil-suraj",
"html_url": "https://github.com/patil-suraj",
"followers_url": "https://api.github.com/users/patil-suraj/followers",
"following_url": "https://api.github.com/users/patil-suraj/following{/other_user}",
"gists_url": "https://api.github.com/users/patil-suraj/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patil-suraj/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patil-suraj/subscriptions",
"organizations_url": "https://api.github.com/users/patil-suraj/orgs",
"repos_url": "https://api.github.com/users/patil-suraj/repos",
"events_url": "https://api.github.com/users/patil-suraj/events{/privacy}",
"received_events_url": "https://api.github.com/users/patil-suraj/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | MEMBER | null | # What does this PR do?
This PR adds the `return_attention_mask` argument to `Wav2Vec2FeatureExtractor.__call__` method. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10455/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10455/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10455",
"html_url": "https://github.com/huggingface/transformers/pull/10455",
"diff_url": "https://github.com/huggingface/transformers/pull/10455.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10455.patch",
"merged_at": 1614610192000
} |
https://api.github.com/repos/huggingface/transformers/issues/10454 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10454/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10454/comments | https://api.github.com/repos/huggingface/transformers/issues/10454/events | https://github.com/huggingface/transformers/issues/10454 | 818,574,613 | MDU6SXNzdWU4MTg1NzQ2MTM= | 10,454 | How can I make the logging utils log to a file as well? | {
"login": "howardlau1999",
"id": 5250490,
"node_id": "MDQ6VXNlcjUyNTA0OTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/5250490?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/howardlau1999",
"html_url": "https://github.com/howardlau1999",
"followers_url": "https://api.github.com/users/howardlau1999/followers",
"following_url": "https://api.github.com/users/howardlau1999/following{/other_user}",
"gists_url": "https://api.github.com/users/howardlau1999/gists{/gist_id}",
"starred_url": "https://api.github.com/users/howardlau1999/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/howardlau1999/subscriptions",
"organizations_url": "https://api.github.com/users/howardlau1999/orgs",
"repos_url": "https://api.github.com/users/howardlau1999/repos",
"events_url": "https://api.github.com/users/howardlau1999/events{/privacy}",
"received_events_url": "https://api.github.com/users/howardlau1999/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I just realize that I can enable the propagation and add the file handler to logging.root",
"> I just realize that I can enable the propagation and add the file handler to logging.root\r\n\r\nhow? can you please provide the example code, if possible.",
"> > I just realize that I can enable the propagation and add the file handler to logging.root\r\n> \r\n> how? can you please provide the example code, if possible.\r\n\r\n@sid8491 add this piece of code at the beginning of your script\r\n```python\r\nfile_formatter = logging.Formatter(fmt=\"%(asctime)s - %(levelname)s - %(name)s - %(message)s\",\r\n datefmt=\"%m/%d/%Y %H:%M:%S\", )\r\nfile_handler = logging.FileHandler(\r\n os.path.join(training_args.output_dir, f\"log.{os.getpid()}.{training_args.local_rank}.txt\"))\r\nfile_handler.setFormatter(file_formatter)\r\nlogging.root.addHandler(file_handler)\r\n```",
"@howardlau1999 Thank you for providing the solution. However, after I set it up this way, I found that the log in the main.py script can be logged to the file properly. However, the logs in other python scripts (such as trainer.py) are not logged to the file. In addition, everything is fine to be logged in the command line. Have you encountered this situation?"
] | 1,614 | 1,694 | 1,614 | NONE | null | # 🚀 Feature request
I want to make the logging utils log to a file in addition to the console. But I can't find an API that lets me add a handler to the logging utils.
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10454/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10454/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10453 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10453/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10453/comments | https://api.github.com/repos/huggingface/transformers/issues/10453/events | https://github.com/huggingface/transformers/issues/10453 | 818,565,627 | MDU6SXNzdWU4MTg1NjU2Mjc= | 10,453 | pytorch Albert quantization error | {
"login": "Zjq9409",
"id": 62974595,
"node_id": "MDQ6VXNlcjYyOTc0NTk1",
"avatar_url": "https://avatars.githubusercontent.com/u/62974595?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Zjq9409",
"html_url": "https://github.com/Zjq9409",
"followers_url": "https://api.github.com/users/Zjq9409/followers",
"following_url": "https://api.github.com/users/Zjq9409/following{/other_user}",
"gists_url": "https://api.github.com/users/Zjq9409/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Zjq9409/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Zjq9409/subscriptions",
"organizations_url": "https://api.github.com/users/Zjq9409/orgs",
"repos_url": "https://api.github.com/users/Zjq9409/repos",
"events_url": "https://api.github.com/users/Zjq9409/events{/privacy}",
"received_events_url": "https://api.github.com/users/Zjq9409/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I also meet the bug,I find that self.dense has been through prune_linear_layer() and return a nn.Linear as it should be,\r\n```\r\n>>> m = torch.nn.Linear(1,2)\r\n>>> m.weight.t\r\n<built-in method t of Parameter object at 0x7fcb7c3a45f0>\r\n>>> m.weight.t()\r\ntensor([[-0.0714, 0.7815]], grad_fn=<TBackward>)\r\n```\r\nbut I can not find a way to fix it\r\nIf the maintainer answer your question,@me pls,thanks a lot!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | I use huggingface transformers 'albert_chinese_base',but in pytorch quantization,The following problem occurred:
File "test_simple.py", line 186, in <module>
model_pt_quantized(input_ids=model_inputs["input_ids"], token_type_ids=model_inputs["token_type_ids"], attention_mask=model_inputs["attention_mask"])
File "/work/runtime/torch/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/work/runtime/torch/lib/python3.6/site-packages/transformers/modeling_albert.py", line 563, in forward
output_hidden_states=output_hidden_states,
File "/work/runtime/torch/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/work/runtime/torch/lib/python3.6/site-packages/transformers/modeling_albert.py", line 346, in forward
output_hidden_states,
File "/work/runtime/torch/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/work/runtime/torch/lib/python3.6/site-packages/transformers/modeling_albert.py", line 299, in forward
layer_output = albert_layer(hidden_states, attention_mask, head_mask[layer_index], output_attentions)
File "/work/runtime/torch/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/work/runtime/torch/lib/python3.6/site-packages/transformers/modeling_albert.py", line 277, in forward
attention_output = self.attention(hidden_states, attention_mask, head_mask, output_attentions)
File "/work/runtime/torch/lib64/python3.6/site-packages/torch/nn/modules/module.py", line 722, in _call_impl
result = self.forward(*input, **kwargs)
File "/work/runtime/torch/lib/python3.6/site-packages/transformers/modeling_albert.py", line 251, in forward
self.dense.weight.t()
AttributeError: 'function' object has no attribute 't' | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10453/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10453/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10452 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10452/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10452/comments | https://api.github.com/repos/huggingface/transformers/issues/10452/events | https://github.com/huggingface/transformers/issues/10452 | 818,557,358 | MDU6SXNzdWU4MTg1NTczNTg= | 10,452 | BartForConditionalGeneration breaks with label smoothing loss | {
"login": "mingruimingrui",
"id": 18568364,
"node_id": "MDQ6VXNlcjE4NTY4MzY0",
"avatar_url": "https://avatars.githubusercontent.com/u/18568364?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/mingruimingrui",
"html_url": "https://github.com/mingruimingrui",
"followers_url": "https://api.github.com/users/mingruimingrui/followers",
"following_url": "https://api.github.com/users/mingruimingrui/following{/other_user}",
"gists_url": "https://api.github.com/users/mingruimingrui/gists{/gist_id}",
"starred_url": "https://api.github.com/users/mingruimingrui/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/mingruimingrui/subscriptions",
"organizations_url": "https://api.github.com/users/mingruimingrui/orgs",
"repos_url": "https://api.github.com/users/mingruimingrui/repos",
"events_url": "https://api.github.com/users/mingruimingrui/events{/privacy}",
"received_events_url": "https://api.github.com/users/mingruimingrui/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Another possible solution would be to change the behavior of `PreTrainedTokenizer.prepare_seq2seq_batch`, by adding something like a `return_decoder_input_ids` flag.\r\n\r\nPros\r\n- Backward compatibility also maintained\r\n- Only a handful of changes has to be made\r\n\r\nCons\r\n- This change can complicate matters for non-autoregressive sequence generation\r\n- A additional cost on serialization and I/O is incurred by having more tensors to pass from data loader workers and send to GPU.",
"Hi @mingruimingrui \r\n\r\nYou are right. But this issue has already been fixed on master. The default `DataCollatorForSeq2Seq` now prepares `decoder_input_ids` when label smoothing is enabled. All seq2seq models now have `prepare_decoder_input_ids_from_labels` method, which let's you prepare `decoder_input_ids` outside of the model. So you can directly pass `decoder_input_ids` to the model and drop `labels` when using label smoothing.",
"Hi @patil-suraj \r\n\r\nI see but just a little bit of nit-picking regarding this solution...\r\nMainly because I really can't excuse the passing of the entire model to DataCollator.\r\nUnder PyTorch, both Dataset and DataCollator should be passable to python subprocesses.\r\nBut a trainable model moved to the GPU would likely not work well with python multiprocessing.\r\nAlso worth mentioning is the breaking of backward compatibility.",
"That's a great point! Pinging @sgugger here.\r\n\r\n> Also worth mentioning is the breaking of backward compatibility.\r\n\r\nI'm not sure what's breaking backward compatibility here.\r\n\r\nAnd regarding the previous comments\r\n\r\n> Another possible solution would be to change the behavior of PreTrainedTokenizer.prepare_seq2seq_batch, by adding something like a return_decoder_input_ids flag.\r\n\r\nThis method is now deprecated and will be removed in v5 so we don't encourage using this method.\r\n\r\n> A possible way to fix this would be to shift smooth label loss into the loss computation of each model rather than in Trainer\r\n\r\nWe generally tend to avoid any training-specific code in model files, the model classes are just responsible for doing a forward pass and computing the loss. Most of the training-related functionality will be handled by `Trainer` or the training scripts.",
"> I'm not sure what's breaking backward compatibility here.\r\n\r\nAh, this is my bad! I was thinking that since `DataCollatorForSeq2Seq` may not work well with multiprocessing.\r\nScripts currently using `transformers<=4.3.3` may be affected when updating to `transformers>4.3.3`.\r\nBut in `transformers<=4.3.3`, there is no model attribute.",
"> We generally tend to avoid any training-specific code in model files, the model classes are just responsible for doing a forward pass and computing the loss. Most of the training-related functionality will be handled by `Trainer` or the training scripts.\r\n\r\nI agree, adding unrelated functionalities makes a class overloaded and code hard to read.\r\nThough it can be argued that the computation of loss is also a training-related function.",
"I don't think the multiprocessing will create copies of the models, it will just pass along the reference to it. Did you see GPU memory usage be multiplied by number of processes? I jsut tried your snippet of code and added the model to the data collator:\r\n```\r\ndata_collator = DataCollatorForSeq2Seq(tokenizer, model=model)\r\n```\r\nand I didn't see any change in GPU memory use with 1 or 4 workers in the dataloader.",
"@sgugger \r\n\r\nThe reason I discourage is practice is because it seemed to encourage the usage of model-related components in the `DataCollator`. Passing references of model parameters to python subprocesses is completely fine but special care has to be taken to not use them (in the subprocess) or the terribly descriptive `RuntimeError: CUDA error: initialization error` can be encountered.\r\n\r\nGPU memory usage was not my concern in this issue. Similar to what you had mentioned, pickling of PyTorch tensors passes only a reference to the original tensor so GPU memory usage would not increase due to this behavior.",
"We only use the method of the model ot generate decoder input IDs, not the actual model, so I think it's completely fine in this case. Passing the method from the model would be way weirder in terms of user API.",
"I see, it's a fair point. Implementing the feature this way also ensures that DataCollator performs all required preprocessing for training data input. Closing issue."
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | ## Environment info
- `transformers` version: 4.3.3
- The other parameters are irrelevant
### Who can help
@patrickvonplaten @sgugger
## Information
I apologize for not using the provided template for this issue.
By generating entries with `PreTrainedTokenizer.prepare_seq2seq_batch`, collating with `DataCollatorForSeq2Seq` and
training a `BartForConditionalGeneration` with `Seq2SeqTrainer`, I ran into this particular error message.
```txt
Traceback (most recent call last):
File "playground.py", line 42, in <module>
trainer.train()
File "/Users/mingrui.wang/miniconda3/envs/bert/lib/python3.7/site-packages/transformers/trainer.py", line 940, in train
tr_loss += self.training_step(model, inputs)
File "/Users/mingrui.wang/miniconda3/envs/bert/lib/python3.7/site-packages/transformers/trainer.py", line 1304, in training_step
loss = self.compute_loss(model, inputs)
File "/Users/mingrui.wang/miniconda3/envs/bert/lib/python3.7/site-packages/transformers/trainer.py", line 1341, in compute_loss
loss = self.label_smoother(outputs, labels)
File "/Users/mingrui.wang/miniconda3/envs/bert/lib/python3.7/site-packages/transformers/trainer_pt_utils.py", line 398, in __call__
nll_loss = log_probs.gather(dim=-1, index=labels)
RuntimeError: Size does not match at dimension 1 expected index [1, 7, 1] to be smaller than src [1, 5, 50265] apart from dimension 2
```
Provided is a script to replicate the error
```python
from torch.utils.data import Dataset
from transformers import (BartForConditionalGeneration, BartTokenizer,
BatchEncoding, DataCollatorForSeq2Seq,
PreTrainedTokenizer, Seq2SeqTrainer,
TrainingArguments)
class DummySeq2SeqDataset(Dataset):
def __init__(self, tokenizer: PreTrainedTokenizer):
self.tokenizer = tokenizer
self.data = [
("Hello world!", "Hallo welt!"),
]
def __len__(self):
return len(self.data)
def __getitem__(self, index: int) -> BatchEncoding:
src_text, tgt_text = self.data[index]
return self.tokenizer.prepare_seq2seq_batch(
src_text, tgt_text,
return_token_type_ids=False
)
train_args = TrainingArguments(output_dir='tmp', label_smoothing_factor=0.1)
tokenizer = BartTokenizer.from_pretrained('facebook/bart-base')
model = BartForConditionalGeneration.from_pretrained('facebook/bart-base')
train_dataset = DummySeq2SeqDataset(tokenizer)
data_collator = DataCollatorForSeq2Seq(tokenizer)
trainer = Seq2SeqTrainer(
model=model,
args=train_args,
data_collator=data_collator,
train_dataset=train_dataset,
tokenizer=tokenizer,
)
trainer.train()
```
## Source of problem
The problem lies with the interaction between `BartForConditionalGeneration` and how label-smoothing is implemented in `Trainer`.
`BartForConditionalGeneration.forward` is highly tied to `labels`, since it's also used to generate `decoder_input_ids`.
In the behavior of label-smoothing as implemented in the `Trainer` class, the following is currently being done.
https://github.com/huggingface/transformers/blob/3c733f320870261ea948049505a30c30fd6ea23a/src/transformers/trainer.py#L1447-L1469
The whoopsie is that `labels` is removed from the arguments passed to `BartForConditionalGeneration.forward`. Computation of logits then defaulted to using `input_ids` as `decoder_input_ids`.
## Possible solutions
A possible way to fix this would be to shift smooth label loss into the loss computation of each model rather than in `Trainer`. Doing it this way comes with its own set of pros and cons.
Pros
- Backward compatibility can be completely maintained
- Removes the little bit of code smell where true training loss is not reflected in `model.forward` when `label_smoothing > 0`.
Cons
- Complicates configuration
- label_smoothing loss defined in model config rather than training args
- Requires changes in many places in this repository (albeit, they are the same exact set of changes) | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10452/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10452/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10451 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10451/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10451/comments | https://api.github.com/repos/huggingface/transformers/issues/10451/events | https://github.com/huggingface/transformers/issues/10451 | 818,451,998 | MDU6SXNzdWU4MTg0NTE5OTg= | 10,451 | BART for generating sequence of length more than 1024 tokens | {
"login": "silentghoul-spec",
"id": 58596410,
"node_id": "MDQ6VXNlcjU4NTk2NDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/58596410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/silentghoul-spec",
"html_url": "https://github.com/silentghoul-spec",
"followers_url": "https://api.github.com/users/silentghoul-spec/followers",
"following_url": "https://api.github.com/users/silentghoul-spec/following{/other_user}",
"gists_url": "https://api.github.com/users/silentghoul-spec/gists{/gist_id}",
"starred_url": "https://api.github.com/users/silentghoul-spec/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/silentghoul-spec/subscriptions",
"organizations_url": "https://api.github.com/users/silentghoul-spec/orgs",
"repos_url": "https://api.github.com/users/silentghoul-spec/repos",
"events_url": "https://api.github.com/users/silentghoul-spec/events{/privacy}",
"received_events_url": "https://api.github.com/users/silentghoul-spec/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi @silentghoul-spec \r\n\r\nfor BART the maximum sequence length is 1024, so it can't process text larger than 1024 tokens.\r\nYou could use the `LED` model for long document summarization, here's a notebook which demonstrates how to use LED https://github.com/patrickvonplaten/notebooks/blob/master/Fine_tune_Longformer_Encoder_Decoder_(LED)_for_Summarization_on_pubmed.ipynb \r\n\r\nAlso please use the forum https://discuss.huggingface.co/ to ask such questions first",
"Thanks, @patil-suraj ,\r\nI wondered why it has a token limit of 1024 as the original paper https://arxiv.org/pdf/1910.13461.pdf didn't have any mentioned limit as such. I guess it's because BART model cards currently available were trained with encoder having a limit of 1024 tokens. \r\nBtw thanks for pointing me to discussion forums; I will use them for further discussions."
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | I was using pretraining code given in transformers/examples/seq2seq to finetune on my custom dataset containing summaries of the text of greater than 1024 tokens. But I am getting an error regarding index out of bounds error. Is it possible to fine-tune BART to generate summaries of more than 1024 tokens? I have added log file for reference.
[v100job.txt](https://github.com/huggingface/transformers/files/6059178/v100job.txt)
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10451/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10451/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10450 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10450/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10450/comments | https://api.github.com/repos/huggingface/transformers/issues/10450/events | https://github.com/huggingface/transformers/issues/10450 | 818,271,504 | MDU6SXNzdWU4MTgyNzE1MDQ= | 10,450 | OSError: Error no file named ['pytorch_model.bin', 'tf_model.h5'] When I try to use my model | {
"login": "MLDovakin",
"id": 78375175,
"node_id": "MDQ6VXNlcjc4Mzc1MTc1",
"avatar_url": "https://avatars.githubusercontent.com/u/78375175?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MLDovakin",
"html_url": "https://github.com/MLDovakin",
"followers_url": "https://api.github.com/users/MLDovakin/followers",
"following_url": "https://api.github.com/users/MLDovakin/following{/other_user}",
"gists_url": "https://api.github.com/users/MLDovakin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MLDovakin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MLDovakin/subscriptions",
"organizations_url": "https://api.github.com/users/MLDovakin/orgs",
"repos_url": "https://api.github.com/users/MLDovakin/repos",
"events_url": "https://api.github.com/users/MLDovakin/events{/privacy}",
"received_events_url": "https://api.github.com/users/MLDovakin/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Please check if the `pytorch_model.bin` file is available in your cloned repo. I can see that file on the hub, so there might have been some mistake when cloning the repo.",
"@patil-suraj when cloning the repository, this file is located in the folder\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored.",
"> Please check if the `pytorch_model.bin` file is available in your cloned repo. I can see that file on the hub, so there might have been some mistake when cloning the repo.\r\n\r\nThanks!🥰 It solves my problem, some files' name were changed after downloaded🤕"
] | 1,614 | 1,651 | 1,618 | NONE | null | an error occurred while importing my model from a folder. I cloned my repository and wanted to use the model, I got an error
https://huggingface.co/Fidlobabovic/beta-kvantorium-simple-small
Do I need to change files in my repository? What should I fix in code or model files?
#7370
#9667
````
from transformers import pipeline
nlp = pipeline("question-answering", model='/content/beta-kvantorium-simple-small', tokenizer='/content/beta-kvantorium-simple-small')
context = r"""
Цель текущего контроля и аттестаций - выявление уровня обученности, развития способностей обучающихся, приобретенных компетенций и их соответствие прогнозируемым результатам дополнительной общеобразовательной программы.
"""
print(nlp(question="Какая Цель текущего контроля аттестаций?", context=context))
-> 1046 state_dict = torch.load(resolved_archive_file, map_location="cpu")
1047 except Exception:
9 frames
UnpicklingError: invalid load key, 'v'.
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
OSError: Unable to load weights from pytorch checkpoint file for '/content/beta-kvantorium-simple-small' at '/content/beta-kvantorium-simple-small/pytorch_model.bin'If you tried to load a PyTorch model from a TF 2.0 checkpoint, please set from_tf=True.
During handling of the above exception, another exception occurred:
OSError Traceback (most recent call last)
/usr/local/lib/python3.7/dist-packages/transformers/modeling_tf_utils.py in from_pretrained(cls, pretrained_model_name_or_path, *model_args, **kwargs)
1183 raise EnvironmentError(
1184 "Error no file named {} found in directory {} or `from_pt` set to False".format(
-> 1185 [WEIGHTS_NAME, TF2_WEIGHTS_NAME], pretrained_model_name_or_path
1186 )
1187 )
OSError: Error no file named ['pytorch_model.bin', 'tf_model.h5'] found in directory /content/beta-kvantorium-simple-small or `from_pt` set to False
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10450/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10450/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10449 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10449/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10449/comments | https://api.github.com/repos/huggingface/transformers/issues/10449/events | https://github.com/huggingface/transformers/issues/10449 | 818,270,454 | MDU6SXNzdWU4MTgyNzA0NTQ= | 10,449 | pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed. | {
"login": "yigit353",
"id": 852489,
"node_id": "MDQ6VXNlcjg1MjQ4OQ==",
"avatar_url": "https://avatars.githubusercontent.com/u/852489?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yigit353",
"html_url": "https://github.com/yigit353",
"followers_url": "https://api.github.com/users/yigit353/followers",
"following_url": "https://api.github.com/users/yigit353/following{/other_user}",
"gists_url": "https://api.github.com/users/yigit353/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yigit353/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yigit353/subscriptions",
"organizations_url": "https://api.github.com/users/yigit353/orgs",
"repos_url": "https://api.github.com/users/yigit353/repos",
"events_url": "https://api.github.com/users/yigit353/events{/privacy}",
"received_events_url": "https://api.github.com/users/yigit353/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I think this means you have a label outside of boundaries from the error message but I can't be sure: `CUDA error: device-side assert triggered` are very tricky since they are thrown not when they appear but when there is a synchronization between all the CUDA processes.\r\n\r\nThe very best way to debug those errors is to try to run a few batches on the CPU to get a better error message. I can try to look into this later on but your model is not public (in the command you give us to repro) and you said it worked for other models?",
"> I think this means you have a label outside of boundaries from the error message but I can't be sure: `CUDA error: device-side assert triggered` are very tricky since they are thrown not when they appear but when there is a synchronization between all the CUDA processes.\r\n\r\nAfter running with a single CPU and no GPU I got this more explanatory error:\r\n```\r\n 0%| | 0/229 [00:00<?, ?it/s]Traceback (most recent call last):\r\n File \"/okyanus/users/ctantug/transformers/examples/token-classification/run_ner.py\", line 471, in <module>\r\n main()\r\n File \"/okyanus/users/ctantug/transformers/examples/token-classification/run_ner.py\", line 405, in main\r\n train_result = trainer.train(resume_from_checkpoint=checkpoint)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/transformers/trainer.py\", line 940, in train\r\n tr_loss += self.training_step(model, inputs)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/transformers/trainer.py\", line 1304, in training_step\r\n loss = self.compute_loss(model, inputs)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/transformers/trainer.py\", line 1334, in compute_loss\r\n outputs = model(**inputs)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/modules/module.py\", line 727, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/transformers/models/bert/modeling_bert.py\", line 1708, in forward\r\n loss = loss_fct(active_logits, active_labels)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/modules/module.py\", line 727, in _call_impl\r\n result = self.forward(*input, **kwargs)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/modules/loss.py\", line 962, in forward\r\n ignore_index=self.ignore_index, reduction=self.reduction)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/functional.py\", line 2471, in cross_entropy\r\n return nll_loss(log_softmax(input, 1), target, weight, None, ignore_index, None, reduction)\r\n File \"/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/functional.py\", line 2267, in nll_loss\r\n ret = torch._C._nn.nll_loss(input, target, weight, _Reduction.get_enum(reduction), ignore_index)\r\nIndexError: Target 9 is out of bounds.\r\n```\r\n> The very best way to debug those errors is to try to run a few batches on the CPU to get a better error message. I can try to look into this later on but your model is not public (in the command you give us to repro) and you said it worked for other models?\r\n\r\nThe model is not public yet, indeed. I will make them public if necessary. The model successfully performed the NER task (which is nearly the same considering the data structure). However, failed at PoS tagging (which has only different labels).",
"So the problem is indeed with the labels -> here you have a label with an index of 9 and you should print the value of `num_labels` in the script, but it looks like it's less than this from the error. I think the datasets should be fixed somehow.\r\n\r\nIt may be that your validation dataset has a label the training dataset did not have, which then causes this issue. In that case you should either make sure that label is present in the training set too or remove the samples with that label in your evaluation dataset.",
"These are my active labels:\r\n```\r\nActivate labels: tensor([-100, 9, 4, 7, 12, -100, -100, -100, 7, 0, 8, 7,\r\n -100, -100, 12, -100, 11, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 0, 2, -100, 0, 7, -100, 11,\r\n 7, -100, 7, 12, -100, 12, 2, -100, 7, -100, 1, 8,\r\n 7, 3, -100, 11, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 7, -100, -100,\r\n 1, 0, 7, 11, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, 10, -100, -100, -100, 10, -100, 0, 12, -100, -100, -100,\r\n 11, 9, 0, -100, 7, -100, -100, 7, 12, -100, -100, 11,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 7, -100, 11, 7, -100, -100, -100,\r\n 11, 7, -100, -100, -100, 11, 7, -100, -100, 12, 8, 7,\r\n 11, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 4, 9, 9,\r\n 1, 2, -100, 12, -100, -100, -100, 0, 3, 11, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, 2, 7, 7, -100, 12, 11, 4, 12, -100, 11, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 2, 12, -100, 12, -100, 11, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 8, 7, -100,\r\n 12, -100, -100, 12, -100, 1, 12, 11, 8, 7, 2, 12,\r\n -100, 7, 3, 9, 11, 4, 7, -100, 9, 8, 7, 12,\r\n -100, -100, -100, 11, 2, 0, -100, -100, 0, -100, 11, 12,\r\n -100, 12, -100, 1, 0, 12, 12, 0, -100, 3, 11, -100,\r\n -100, 10, -100, -100, 11, 0, 7, -100, 7, 1, 2, 0,\r\n -100, -100, 12, -100, 5, 7, 11, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 7, -100, 7, 7, 12, -100, 11,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 10, -100, 4,\r\n 11, 7, -100, 10, -100, -100, 10, -100, -100, -100, -100, 0,\r\n 7, -100, 12, 12, -100, -100, 4, 12, -100, 12, -100, 11,\r\n 7, -100, -100, -100, 12, 11, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, 0, 7, 12, -100, 11, 12, -100, -100, 11, 12, -100,\r\n 11, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 10, 7, -100, -100, -100, 12, 11,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 0, -100, -100,\r\n 7, 12, -100, 11, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, 10, 9, 7, 12, 11, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100])\r\n```\r\nAnd the targets:\r\n```\r\ntarget: tensor([-100, 9, 4, 7, 12, -100, -100, -100, 7, 0, 8, 7,\r\n -100, -100, 12, -100, 11, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 0, 2, -100, 0, 7, -100, 11,\r\n 7, -100, 7, 12, -100, 12, 2, -100, 7, -100, 1, 8,\r\n 7, 3, -100, 11, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 7, -100, -100,\r\n 1, 0, 7, 11, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, 10, -100, -100, -100, 10, -100, 0, 12, -100, -100, -100,\r\n 11, 9, 0, -100, 7, -100, -100, 7, 12, -100, -100, 11,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 7, -100, 11, 7, -100, -100, -100,\r\n 11, 7, -100, -100, -100, 11, 7, -100, -100, 12, 8, 7,\r\n 11, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 4, 9, 9,\r\n 1, 2, -100, 12, -100, -100, -100, 0, 3, 11, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, 2, 7, 7, -100, 12, 11, 4, 12, -100, 11, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 2, 12, -100, 12, -100, 11, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 8, 7, -100,\r\n 12, -100, -100, 12, -100, 1, 12, 11, 8, 7, 2, 12,\r\n -100, 7, 3, 9, 11, 4, 7, -100, 9, 8, 7, 12,\r\n -100, -100, -100, 11, 2, 0, -100, -100, 0, -100, 11, 12,\r\n -100, 12, -100, 1, 0, 12, 12, 0, -100, 3, 11, -100,\r\n -100, 10, -100, -100, 11, 0, 7, -100, 7, 1, 2, 0,\r\n -100, -100, 12, -100, 5, 7, 11, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 7, -100, 7, 7, 12, -100, 11,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 10, -100, 4,\r\n 11, 7, -100, 10, -100, -100, 10, -100, -100, -100, -100, 0,\r\n 7, -100, 12, 12, -100, -100, 4, 12, -100, 12, -100, 11,\r\n 7, -100, -100, -100, 12, 11, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, 0, 7, 12, -100, 11, 12, -100, -100, 11, 12, -100,\r\n 11, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, 10, 7, -100, -100, -100, 12, 11,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, 0, -100, -100,\r\n 7, 12, -100, 11, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, 10, 9, 7, 12, 11, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,\r\n -100, -100, -100, -100])\r\n\r\n```",
"I have already checked the number of labels first thing. That's why it surprised me that it is not the problem. I also run the script without eval. \r\n```\r\n03/01/2021 17:45:18 - INFO - __main__ - Label list ['ADJ', 'ADP', 'ADV', 'AUX', 'CCONJ', 'DET', 'INTJ', 'NOUN', 'NUM', 'PRON', 'PROPN', 'PUNCT', 'VERB', 'X']\r\n03/01/2021 17:45:18 - INFO - __main__ - Label to id {'ADJ': 0, 'ADP': 1, 'ADV': 2, 'AUX': 3, 'CCONJ': 4, 'DET': 5, 'INTJ': 6, 'NOUN': 7, 'NUM': 8, 'PRON': 9, 'PROPN': 10, 'PUNCT': 11, 'VERB': 12, 'X': 13}\r\n03/01/2021 17:45:18 - INFO - __main__ - Num labels 14\r\n```\r\nWhat might be another cause of this?",
"Solved it! Turns out in my config.json (which is copied from another PyTorch checkpoint) should also change the `label2id` and `id2label`. That was totally unexpected. In order to match 14 labels I changed the config file as follows:\r\n```\r\n{\r\n ...\r\n \"architectures\": [\r\n \"BertForTokenClassification\"\r\n ],\r\n \"id2label\": {\r\n \"0\": \"LABEL_0\",\r\n \"1\": \"LABEL_1\",\r\n \"2\": \"LABEL_2\",\r\n \"3\": \"LABEL_3\",\r\n \"4\": \"LABEL_4\",\r\n \"5\": \"LABEL_5\",\r\n \"6\": \"LABEL_6\",\r\n \"7\": \"LABEL_7\",\r\n \"8\": \"LABEL_8\",\r\n \"9\": \"LABEL_9\",\r\n \"10\": \"LABEL_10\",\r\n \"11\": \"LABEL_11\",\r\n \"12\": \"LABEL_12\",\r\n \"13\": \"LABEL_13\"\r\n },\r\n \r\n \"label2id\": {\r\n \"LABEL_0\": 0,\r\n \"LABEL_1\": 1,\r\n \"LABEL_2\": 2,\r\n \"LABEL_3\": 3,\r\n \"LABEL_4\": 4,\r\n \"LABEL_5\": 5,\r\n \"LABEL_6\": 6,\r\n \"LABEL_7\": 7,\r\n \"LABEL_8\": 8,\r\n \"LABEL_9\": 9,\r\n \"LABEL_10\": 10, \r\n \"LABEL_11\": 11, \r\n \"LABEL_12\": 12, \r\n \"LABEL_13\": 13\r\n },\r\n ...\r\n}\r\n```\r\nThank you anyways."
] | 1,614 | 1,614 | 1,614 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.3
- Platform: Linux-5.4.0-65-generic-x86_64-with-debian-buster-sid
- Python version: 3.7.9
- PyTorch version (GPU?): 1.7.1 (False)
- Tensorflow version (GPU?): 2.5.0-dev20210225 (False)
- Using GPU in script?: 2 V100 32GB
- Using distributed or parallel set-up in script?: parallel
### Who can help
@LysandreJik @sgugger @n1t0
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
I used `run_ner.py` from examples.
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
PoS Tagging task with the datasets: https://github.com/yigit353/turkish-bert-itu/tree/main/imst
## To reproduce
Steps to reproduce the behavior:
1. Converted a BERT TensorFlow 1 checkpoint pre-trained from scratch using a custom corpus and vocabulary with the original Google's BERT run_pretraining.py via `transformers-cli convert`
2. Used the datasets in this repo (I just uploaded them there): https://github.com/yigit353/turkish-bert-itu/tree/main/imst
3. Used run_ner.py on the dataset with the following code:
```bash
python3 "$USER_ROOT/$LIB_DIR/run_ner.py" \
--task_name=pos \
--model_name_or_path "$USER_ROOT/$BERT_DIR/$TORCH_DIR" \
--train_file "$USER_ROOT/$DATA_DIR/tr_imst-ud-train.conllu.json" \
--validation_file "$USER_ROOT/$DATA_DIR/tr_imst-ud-dev.conllu.json" \
--output_dir "$USER_ROOT/$DATA_DIR/$OUTPUT_DIR-$SEED" \
--per_device_train_batch_size=$BATCH_SIZE \
--num_train_epochs=$NUM_EPOCHS \
--overwrite_cache=True \
--do_train \
--do_eval \
--seed=$SEED \
--fp16
```
4. It worked good with NER datasets (which is parallel to PoS dataset) here: https://github.com/yigit353/turkish-bert-itu/tree/main/datasets/ner
5. It also worked with the PyTorch model (both with PoS and NER without errors or warnings): https://huggingface.co/dbmdz/bert-base-turkish-cased
I also receive the following warning for NER and POS datasets:
`thread '<unnamed>' panicked at 'no entry found for key', /__w/tokenizers/tokenizers/tokenizers/src/models/mod.rs:36:66`
However, NER task worked nonetheless with this script:
```bash
python3 "$USER_ROOT/$LIB_DIR/run_ner.py" \
--model_name_or_path "$USER_ROOT/$BERT_DIR/$OUT_DIR/$TORCH_OUT_DIR" \
--train_file "$USER_ROOT/$DATA_DIR/tr-data3/train.json" \
--validation_file "$USER_ROOT/$DATA_DIR/tr-data3/dev.json" \
--output_dir "$USER_ROOT/$DATA_DIR/$OUTPUT_DIR-$SEED" \
--per_device_train_batch_size=$BATCH_SIZE \
--num_train_epochs=$NUM_EPOCHS \
--do_train \
--do_eval \
--fp16`
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
```
[INFO|trainer.py:837] 2021-02-28 16:04:10,685 >> ***** Running training *****
[INFO|trainer.py:838] 2021-02-28 16:04:10,685 >> Num examples = 3664
[INFO|trainer.py:839] 2021-02-28 16:04:10,685 >> Num Epochs = 10
[INFO|trainer.py:840] 2021-02-28 16:04:10,685 >> Instantaneous batch size per device = 16
[INFO|trainer.py:841] 2021-02-28 16:04:10,685 >> Total train batch size (w. parallel, distributed & accumulation) = 32
[INFO|trainer.py:842] 2021-02-28 16:04:10,685 >> Gradient Accumulation steps = 1
[INFO|trainer.py:843] 2021-02-28 16:04:10,685 >> Total optimization steps = 1150
0%| | 0/1150 [00:00<?, ?it/s]/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/_functions.py:64: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.
warnings.warn('Was asked to gather along dimension 0, but all '
Traceback (most recent call last):
File "/okyanus/users/ctantug/transformers/examples/token-classification/run_ner.py", line 466, in <module>
main()
File "/okyanus/users/ctantug/transformers/examples/token-classification/run_ner.py", line 400, in main
train_result = trainer.train(resume_from_checkpoint=checkpoint)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/transformers/trainer.py", line 940, in train
tr_loss += self.training_step(model, inputs)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/transformers/trainer.py", line 1302, in training_step
loss = self.compute_loss(model, inputs)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/transformers/trainer.py", line 1334, in compute_loss
outputs = model(**inputs)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 162, in forward
return self.gather(outputs, self.output_device)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/data_parallel.py", line 174, in gather
return gather(outputs, output_device, dim=self.dim)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 68, in gather
res = gather_map(outputs)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 62, in gather_map
for k in out))
File "<string>", line 7, in __init__
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/transformers/file_utils.py", line 1413, in __post_init__
for element in iterator:
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 62, in <genexpr>
for k in out))
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/scatter_gather.py", line 55, in gather_map
return Gather.apply(target_device, dim, *outputs)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/_functions.py", line 71, in forward
return comm.gather(inputs, ctx.dim, ctx.target_device)
File "/okyanus/users/ctantug/.conda/envs/py37/lib/python3.7/site-packages/torch/nn/parallel/comm.py", line 230, in gather
return torch._C._gather(tensors, dim, destination)
RuntimeError: CUDA error: device-side assert triggered
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [2,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [5,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [9,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [12,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [14,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [1,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [4,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [14,0,0] Assertion `t >= 0 && t < n_classes` failed.
/pytorch/aten/src/THCUNN/ClassNLLCriterion.cu:108: cunn_ClassNLLCriterion_updateOutput_kernel: block: [0,0,0], thread: [16,0,0] Assertion `t >= 0 && t < n_classes` failed.
```
The stack trace always gives a different error location. | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10449/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10449/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10448 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10448/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10448/comments | https://api.github.com/repos/huggingface/transformers/issues/10448/events | https://github.com/huggingface/transformers/issues/10448 | 818,261,426 | MDU6SXNzdWU4MTgyNjE0MjY= | 10,448 | When I try to import my model I run into an error "TypeError: PyMetaspace.__new__() got an unexpected keyword argument: str_rep" | {
"login": "MLDovakin",
"id": 78375175,
"node_id": "MDQ6VXNlcjc4Mzc1MTc1",
"avatar_url": "https://avatars.githubusercontent.com/u/78375175?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MLDovakin",
"html_url": "https://github.com/MLDovakin",
"followers_url": "https://api.github.com/users/MLDovakin/followers",
"following_url": "https://api.github.com/users/MLDovakin/following{/other_user}",
"gists_url": "https://api.github.com/users/MLDovakin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MLDovakin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MLDovakin/subscriptions",
"organizations_url": "https://api.github.com/users/MLDovakin/orgs",
"repos_url": "https://api.github.com/users/MLDovakin/repos",
"events_url": "https://api.github.com/users/MLDovakin/events{/privacy}",
"received_events_url": "https://api.github.com/users/MLDovakin/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Maybe @n1t0 knows what might be happening here.",
"@n1t0 LysandreJik spoked call you ",
"Dose this problem fixed? I also got the same problem, I trained a SentencePieceBPETokenizer, use save() api to persist it as a tokenizer.json file, but got this error while loading. \r\n\r\nI dig into the rust code, and found that Metaspace is defined as a struct with three attributes but the constructor only accept two. I tried to modify the json file and remove the one not in the constructor method, but got another error: \r\n\r\n`Exception: data did not match any variant of untagged enum PyPreTokenizerTypeWrapper at line 1 column 1449\r\n`\r\nBelow is the content around char 1449:\r\n`\r\nlse, \"normalized\": false}], \"normalizer\": {\"type\": \"NFKC\"}, \"pre_tokenizer\": {\"type\": \"Metaspace\", \"replacement\": \"\\\\u2581\", \"add_prefix_space\": true}, \"post_processor\": null, \"decoder\": {\"type\": \"Meta\r\n`",
"This has been fixed in the latest version of tokenizers (`0.10.2`)"
] | 1,614 | 1,617 | 1,617 | NONE | null | In the Hugging Face repository I have my own model Fidlobabovic / beta-kvantorium-simple-small
https://huggingface.co/Fidlobabovic/beta-kvantorium-simple-small/tree/main
#7370
#10148
When I try to import it, I get an error. What can I do to fix it? Overwrite model files or rename them? What should I write for this?
````
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("Fidlobabovic/beta-kvantorium-simple-small")
model = AutoModelForMaskedLM.from_pretrained("Fidlobabovic/beta-kvantorium-simple-small")
TypeError Traceback (most recent call last)
<ipython-input-5-3f4375d4cdf7> in <module>()
1 from transformers import AutoTokenizer, AutoModelForMaskedLM
2
----> 3 tokenizer = AutoTokenizer.from_pretrained("Fidlobabovic/beta-kvantorium-simple-small")
4
5 model = AutoModelForMaskedLM.from_pretrained("Fidlobabovic/beta-kvantorium-simple-small")
4 frames
/usr/local/lib/python3.7/dist-packages/transformers/models/gpt2/tokenization_gpt2_fast.py in __init__(self, vocab_file, merges_file, tokenizer_file, unk_token, bos_token, eos_token, add_prefix_space, **kwargs)
150 pre_tok_class = getattr(pre_tokenizers, pre_tok_state.pop("type"))
151 pre_tok_state["add_prefix_space"] = add_prefix_space
--> 152 self.backend_tokenizer.pre_tokenizer = pre_tok_class(**pre_tok_state)
153
154 self.add_prefix_space = add_prefix_space
TypeError: PyMetaspace.__new__() got an unexpected keyword argument: str_rep
```` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10448/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10448/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10447 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10447/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10447/comments | https://api.github.com/repos/huggingface/transformers/issues/10447/events | https://github.com/huggingface/transformers/issues/10447 | 818,255,178 | MDU6SXNzdWU4MTgyNTUxNzg= | 10,447 | changing the way checkpoint is done in the new release | {
"login": "dorost1234",
"id": 79165106,
"node_id": "MDQ6VXNlcjc5MTY1MTA2",
"avatar_url": "https://avatars.githubusercontent.com/u/79165106?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dorost1234",
"html_url": "https://github.com/dorost1234",
"followers_url": "https://api.github.com/users/dorost1234/followers",
"following_url": "https://api.github.com/users/dorost1234/following{/other_user}",
"gists_url": "https://api.github.com/users/dorost1234/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dorost1234/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dorost1234/subscriptions",
"organizations_url": "https://api.github.com/users/dorost1234/orgs",
"repos_url": "https://api.github.com/users/dorost1234/repos",
"events_url": "https://api.github.com/users/dorost1234/events{/privacy}",
"received_events_url": "https://api.github.com/users/dorost1234/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I am not sure if I understand this correctly, how would the `Trainer` know if the last model is different from the actual last checkpoint, and if the model is only saved when the best eval accuracy reached, how would you save the last model to `save_path_folder`?\r\n\r\nAlso if you are saving the last model (and optimizer/scheduler) to some other directory, you could always pass that path as the `model_name_or_path` and change the `--output_dir` so the `Trainer` won't load the last checkpoint ",
"cc @sgugger ",
"> lets assume you train the model with limit of 1 checkpoint and then you checkpoint only when the best eval accuracy is achieved, then if library loads the model from the last checkpoint, this is not training from the place training is stopped, and this can goes back a lot in time, since the last checkpoint is not necessarily the last model we need to load from, and this is only the last model with best accuracy.\r\n\r\nYes, you should not use a `save_total_limit` of 1 in conjunction with metric tracking (such as `load_bst_model_at_end=True`) or accept you won't be able to resume training from the last checkpoint. If you want to restart from scratch, you should just pass `--overwrite_output_dir`.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | Hi
Currently HuggingFace library checks the path for the latest checkpoint and then starts the training from there, this approach is not working due to following reason:
- lets assume you train the model with limit of 1 checkpoint and then you checkpoint only when the best eval accuracy is achieved, then if library loads the model from the last checkpoint, this is not training from the place training is stopped, and this can goes back a lot in time, since the last checkpoint is not necessarily the last model we need to load from, and this is only the last model with best accuracy.
To solve the issue, in addition to the checkpoint folders, one needs to introduce a "save_path_folder", and then when resuming the model trainining, loading from this path and not from last checkpoint folder anymore.
Please let me know if any part is not clear. thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10447/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10447/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10446 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10446/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10446/comments | https://api.github.com/repos/huggingface/transformers/issues/10446/events | https://github.com/huggingface/transformers/issues/10446 | 818,248,865 | MDU6SXNzdWU4MTgyNDg4NjU= | 10,446 | AttributeError: 'Trainer' object has no attribute 'log_metrics' | {
"login": "MariaFjodorowa",
"id": 32707120,
"node_id": "MDQ6VXNlcjMyNzA3MTIw",
"avatar_url": "https://avatars.githubusercontent.com/u/32707120?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MariaFjodorowa",
"html_url": "https://github.com/MariaFjodorowa",
"followers_url": "https://api.github.com/users/MariaFjodorowa/followers",
"following_url": "https://api.github.com/users/MariaFjodorowa/following{/other_user}",
"gists_url": "https://api.github.com/users/MariaFjodorowa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MariaFjodorowa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MariaFjodorowa/subscriptions",
"organizations_url": "https://api.github.com/users/MariaFjodorowa/orgs",
"repos_url": "https://api.github.com/users/MariaFjodorowa/repos",
"events_url": "https://api.github.com/users/MariaFjodorowa/events{/privacy}",
"received_events_url": "https://api.github.com/users/MariaFjodorowa/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi there. As is mentioned at the very beginning of the [examples README](https://github.com/huggingface/transformers/tree/master/examples#important-note), running the examples requires an install from source.\r\n\r\nIf you want the examples associated with v4.3.3, you can find them [here](https://github.com/huggingface/transformers/tree/v4.3.3/examples)."
] | 1,614 | 1,614 | 1,614 | NONE | null | ## Environment info
- `transformers` version: 4.3.3
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.7.1+cu101 (True)
- Tensorflow version (GPU?): 2.4.1 (True)
- Using GPU in script?: True
- Using distributed or parallel set-up in script?: False
### Who can help
@sgugger
## Information
Model I am using (Bert, XLNet ...): Bert
The problem arises when using:
* [x] the official example scripts: (give details below)
* [ ] my own modified scripts: (give details below)
`examples/language-modeling/run_mlm.py`
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
Just a usual txt file with texts line by line.
Logging on the epoch's end of mlm training fails:
```
Traceback (most recent call last):
File "examples/language-modeling/run_mlm.py", line 442, in <module>
main()
File "examples/language-modeling/run_mlm.py", line 416, in main
trainer.log_metrics("train", metrics)
AttributeError: 'Trainer' object has no attribute 'log_metrics'
```
## To reproduce
Steps to reproduce the behavior:
```
pip install transformers
cd transformers
python examples/language-modeling/run_mlm.py \
--model_name_or_path Geotrend/bert-base-ru-cased \
--train_file <path to train file> \
--validation_file <path to validation file> \
--do_train \
--do_eval \
--num_train_epochs 1 \
--output_dir <path to output dir> \
--save_steps 10000 \
--line_by_line True
```
## Expected behavior
It works after checkout to the previous commit, [b01483f](https://github.com/huggingface/transformers/commit/b01483faa0cfb57369cbce153c671dbe48cc0638) :
```
02/28/2021 14:00:45 - INFO - __main__ - ***** Train results *****
02/28/2021 14:00:45 - INFO - __main__ - epoch = 1.0
02/28/2021 14:00:45 - INFO - __main__ - train_runtime = 1091.7453
02/28/2021 14:00:45 - INFO - __main__ - train_samples_per_second = 70.642
02/28/2021 14:00:45 - INFO - __main__ - *** Evaluate ***
[INFO|trainer.py:1600] 2021-02-28 14:00:45,719 >> ***** Running Evaluation *****
[INFO|trainer.py:1601] 2021-02-28 14:00:45,719 >> Num examples = 154244
[INFO|trainer.py:1602] 2021-02-28 14:00:45,719 >> Batch size = 8
100% 19281/19281 [06:56<00:00, 46.28it/s]
02/28/2021 14:07:42 - INFO - __main__ - ***** Eval results *****
02/28/2021 14:07:42 - INFO - __main__ - perplexity = 4.859176983612205
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10446/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10446/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10445 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10445/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10445/comments | https://api.github.com/repos/huggingface/transformers/issues/10445/events | https://github.com/huggingface/transformers/pull/10445 | 818,238,354 | MDExOlB1bGxSZXF1ZXN0NTgxNTQwMjI4 | 10,445 | [IBert] Correct link to paper | {
"login": "patrickvonplaten",
"id": 23423619,
"node_id": "MDQ6VXNlcjIzNDIzNjE5",
"avatar_url": "https://avatars.githubusercontent.com/u/23423619?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/patrickvonplaten",
"html_url": "https://github.com/patrickvonplaten",
"followers_url": "https://api.github.com/users/patrickvonplaten/followers",
"following_url": "https://api.github.com/users/patrickvonplaten/following{/other_user}",
"gists_url": "https://api.github.com/users/patrickvonplaten/gists{/gist_id}",
"starred_url": "https://api.github.com/users/patrickvonplaten/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/patrickvonplaten/subscriptions",
"organizations_url": "https://api.github.com/users/patrickvonplaten/orgs",
"repos_url": "https://api.github.com/users/patrickvonplaten/repos",
"events_url": "https://api.github.com/users/patrickvonplaten/events{/privacy}",
"received_events_url": "https://api.github.com/users/patrickvonplaten/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | MEMBER | null | # What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10445/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10445/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10445",
"html_url": "https://github.com/huggingface/transformers/pull/10445",
"diff_url": "https://github.com/huggingface/transformers/pull/10445.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10445.patch",
"merged_at": 1614528230000
} |
https://api.github.com/repos/huggingface/transformers/issues/10444 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10444/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10444/comments | https://api.github.com/repos/huggingface/transformers/issues/10444/events | https://github.com/huggingface/transformers/issues/10444 | 818,182,424 | MDU6SXNzdWU4MTgxODI0MjQ= | 10,444 | TypeError: can only concatenate str (not "int") to str | {
"login": "omerarshad",
"id": 16164105,
"node_id": "MDQ6VXNlcjE2MTY0MTA1",
"avatar_url": "https://avatars.githubusercontent.com/u/16164105?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/omerarshad",
"html_url": "https://github.com/omerarshad",
"followers_url": "https://api.github.com/users/omerarshad/followers",
"following_url": "https://api.github.com/users/omerarshad/following{/other_user}",
"gists_url": "https://api.github.com/users/omerarshad/gists{/gist_id}",
"starred_url": "https://api.github.com/users/omerarshad/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/omerarshad/subscriptions",
"organizations_url": "https://api.github.com/users/omerarshad/orgs",
"repos_url": "https://api.github.com/users/omerarshad/repos",
"events_url": "https://api.github.com/users/omerarshad/events{/privacy}",
"received_events_url": "https://api.github.com/users/omerarshad/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hi,\r\n\r\nif the `text_column` and `summary_column` arguments are not specified when running the script, it is assumed that the first column in a csv file contains the full text and the second column the corresponding summaries. From the error message, it seems your csv file has integers in the first column. ",
"done with this but now this error:\r\n",
" File \"run_seq2seq.py\", line 645, in <module>\r\n main()\r\n File \"run_seq2seq.py\", line 518, in main\r\n pad_to_multiple_of=8 if training_args.fp16 else None,\r\nTypeError: __init__() got an unexpected keyword argument 'model'",
"This is because the `DataCollatorForSeq2Seq` now adds a new `model` argument. Upgrading to master will fix this issue.\r\n\r\nAlso, as is mentioned at the very beginning of the [examples README,](https://github.com/huggingface/transformers/tree/master/examples#important-note) running the examples requires an install from source.\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | While running run_seq2seq.py for summarization task on my own CSV, i get following error:
All the weights of BartForConditionalGeneration were initialized from the model checkpoint at sshleifer/distilbart-cnn-12-6.
If your task is similar to the task the model of the checkpoint was trained on, you can already use BartForConditionalGeneration for predictions without further training.
Traceback (most recent call last):
File "/content/transformers/examples/seq2seq/run_seq2seq.py", line 645, in <module>
main()
File "/content/transformers/examples/seq2seq/run_seq2seq.py", line 476, in main
load_from_cache_file=not data_args.overwrite_cache,
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 1120, in map
update_data = does_function_return_dict(test_inputs, test_indices)
File "/usr/local/lib/python3.7/dist-packages/datasets/arrow_dataset.py", line 1091, in does_function_return_dict
function(*fn_args, indices, **fn_kwargs) if with_indices else function(*fn_args, **fn_kwargs)
File "/content/transformers/examples/seq2seq/run_seq2seq.py", line 448, in preprocess_function
inputs = [prefix + inp for inp in inputs]
File "/content/transformers/examples/seq2seq/run_seq2seq.py", line 448, in <listcomp>
inputs = [prefix + inp for inp in inputs]
TypeError: can only concatenate str (not "int") to str
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10444/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10444/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10443 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10443/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10443/comments | https://api.github.com/repos/huggingface/transformers/issues/10443/events | https://github.com/huggingface/transformers/pull/10443 | 818,169,051 | MDExOlB1bGxSZXF1ZXN0NTgxNDg4MzMy | 10,443 | Adds terms to Glossary | {
"login": "darigovresearch",
"id": 30328618,
"node_id": "MDQ6VXNlcjMwMzI4NjE4",
"avatar_url": "https://avatars.githubusercontent.com/u/30328618?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/darigovresearch",
"html_url": "https://github.com/darigovresearch",
"followers_url": "https://api.github.com/users/darigovresearch/followers",
"following_url": "https://api.github.com/users/darigovresearch/following{/other_user}",
"gists_url": "https://api.github.com/users/darigovresearch/gists{/gist_id}",
"starred_url": "https://api.github.com/users/darigovresearch/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/darigovresearch/subscriptions",
"organizations_url": "https://api.github.com/users/darigovresearch/orgs",
"repos_url": "https://api.github.com/users/darigovresearch/repos",
"events_url": "https://api.github.com/users/darigovresearch/events{/privacy}",
"received_events_url": "https://api.github.com/users/darigovresearch/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | # What does this PR do?
Wanted a definition of what a transformer is since it is not in the glossary, @cronoik provided one that required two other terms so this pull request makes those changes so more people can understand if they are new to the field.
Previous discussion can be found here - https://github.com/huggingface/transformers/issues/9078
- transformer: self-attention based deep learning model architecture.
- self-attention: each element of the input finds out which other elements of the input they should attend to.
- deep learning: machine learning algorithms which uses neural networks with several layers.
Any improvements/corrections to the definitions are welcome.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Merging this pull request would resolve Issue https://github.com/huggingface/transformers/issues/9078
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors which may be interested in your PR.
@sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10443/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10443/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10443",
"html_url": "https://github.com/huggingface/transformers/pull/10443",
"diff_url": "https://github.com/huggingface/transformers/pull/10443.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10443.patch",
"merged_at": 1614518875000
} |
https://api.github.com/repos/huggingface/transformers/issues/10442 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10442/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10442/comments | https://api.github.com/repos/huggingface/transformers/issues/10442/events | https://github.com/huggingface/transformers/issues/10442 | 818,149,242 | MDU6SXNzdWU4MTgxNDkyNDI= | 10,442 | Bug in Electra Example | {
"login": "david-waterworth",
"id": 5028974,
"node_id": "MDQ6VXNlcjUwMjg5NzQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/5028974?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/david-waterworth",
"html_url": "https://github.com/david-waterworth",
"followers_url": "https://api.github.com/users/david-waterworth/followers",
"following_url": "https://api.github.com/users/david-waterworth/following{/other_user}",
"gists_url": "https://api.github.com/users/david-waterworth/gists{/gist_id}",
"starred_url": "https://api.github.com/users/david-waterworth/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/david-waterworth/subscriptions",
"organizations_url": "https://api.github.com/users/david-waterworth/orgs",
"repos_url": "https://api.github.com/users/david-waterworth/repos",
"events_url": "https://api.github.com/users/david-waterworth/events{/privacy}",
"received_events_url": "https://api.github.com/users/david-waterworth/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Ah, good point! I'll edit it now, thanks for letting us know.",
"Just fixed it in [hf@cf81dc](https://huggingface.co/google/electra-small-discriminator/commit/cf81dc100ac08ff43eb688cb1e3e7d69a822f359), I added you as a co-author too.",
"Thanks @LysandreJik, out of interest did you get the same results as me - the model doesn't appear to have identified the fake token? I'll do some more investigation and perhaps post in the forum but it seems that no matter what I do it always retuns zeros? Also really the example should demonstrate the model working :)"
] | 1,614 | 1,614 | 1,614 | NONE | null | The description for Electra (https://huggingface.co/google/electra-small-discriminator) contains code the example below. The last line fails, I think instead of predictions.tolist() it should be predictions.squeeze() as predictions is 1xN
Also the example doesn't seem to detect the corrupted tokens.
```
from transformers import ElectraForPreTraining, ElectraTokenizerFast
import torch
discriminator = ElectraForPreTraining.from_pretrained("google/electra-small-discriminator")
tokenizer = ElectraTokenizerFast.from_pretrained("google/electra-small-discriminator")
sentence = "The quick brown fox jumps over the lazy dog"
fake_sentence = "The quick brown fox fake over the lazy dog"
fake_tokens = tokenizer.tokenize(fake_sentence)
fake_inputs = tokenizer.encode(fake_sentence, return_tensors="pt")
discriminator_outputs = discriminator(fake_inputs)
predictions = torch.round((torch.sign(discriminator_outputs[0]) + 1) / 2)
[print("%7s" % token, end="") for token in fake_tokens]
[print("%7s" % int(prediction), end="") for prediction in predictions.tolist()]
``` | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10442/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10442/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10441 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10441/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10441/comments | https://api.github.com/repos/huggingface/transformers/issues/10441/events | https://github.com/huggingface/transformers/issues/10441 | 818,128,276 | MDU6SXNzdWU4MTgxMjgyNzY= | 10,441 | TypeError: __init__() got an unexpected keyword argument 'model' in `run_seq2seq.py` example when using on our own files | {
"login": "amirveyseh",
"id": 7426897,
"node_id": "MDQ6VXNlcjc0MjY4OTc=",
"avatar_url": "https://avatars.githubusercontent.com/u/7426897?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amirveyseh",
"html_url": "https://github.com/amirveyseh",
"followers_url": "https://api.github.com/users/amirveyseh/followers",
"following_url": "https://api.github.com/users/amirveyseh/following{/other_user}",
"gists_url": "https://api.github.com/users/amirveyseh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amirveyseh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amirveyseh/subscriptions",
"organizations_url": "https://api.github.com/users/amirveyseh/orgs",
"repos_url": "https://api.github.com/users/amirveyseh/repos",
"events_url": "https://api.github.com/users/amirveyseh/events{/privacy}",
"received_events_url": "https://api.github.com/users/amirveyseh/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I have the same exact problem. Even if you skip that part, it keeps happening in other parts of the code. It seems that file hasn't been updated with the last changes.",
"any solution for this? issue persists",
"This is because of the old version of `transformers`, upgrading to master should resolve this issue. Also always install transformers from source to use examples.",
"I had the same issue. Upgrading to master solved the issue. \r\n\r\nI have a somewhat related question: \r\nCurrently, the metrics are logged at the end of the training.\r\nThe output right now looks like: \r\n```\r\n***** train metrics *****\r\n epoch = 3.0\r\n init_mem_cpu_alloc_delta = 7MB\r\n init_mem_cpu_peaked_delta = 0MB\r\n init_mem_gpu_alloc_delta = 230MB\r\n init_mem_gpu_peaked_delta = 0MB\r\n train_mem_cpu_alloc_delta = 0MB\r\n train_mem_cpu_peaked_delta = 1MB\r\n train_mem_gpu_alloc_delta = 696MB\r\n train_mem_gpu_peaked_delta = 4220MB\r\n train_runtime = 16.6234\r\n train_samples = 100\r\n train_samples_per_second = 2.346\r\n02/28/2021 13:29:32 - INFO - __main__ - *** Evaluate ***\r\n***** Running Evaluation *****\r\n Num examples = 10\r\n Batch size = 8\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:02<00:00, 1.29s/it]\r\n***** eval metrics *****\r\n epoch = 3.0\r\n eval_gen_len = 61.9\r\n eval_loss = 3.8083\r\n eval_mem_cpu_alloc_delta = 1MB\r\n eval_mem_cpu_peaked_delta = 0MB\r\n eval_mem_gpu_alloc_delta = 0MB\r\n eval_mem_gpu_peaked_delta = 896MB\r\n eval_rouge1 = 11.4663\r\n eval_rouge2 = 1.0712\r\n eval_rougeL = 9.2587\r\n eval_rougeLsum = 9.6266\r\n eval_runtime = 4.7684\r\n eval_samples = 10\r\n eval_samples_per_second = 2.097\r\n```\r\nI was wondering if there an easier way of getting metrics (say rouge score/loss) for each epoch so that we can see how the training is going and plot the loss? One solution that I could think of was writing a custom callback function with `on_epoch_end`. Just wondering if there's an easier solution?\r\n",
"There is,\r\nyou could set the `evaluation_strategy` and `logging_strategy` argument to `epoch`, which will tell the trainer to evaluate and log after each epoch. If it doesn't feel free to createe another issue."
] | 1,614 | 1,614 | 1,614 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: 4.3.3
- Platform: Linux-4.15.0-109-generic-x86_64-with-debian-buster-sid
- Python version: 3.6.13
- PyTorch version (GPU?): 1.7.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
@patil-suraj
## Information
I am using `run_seq2seq.py` in `transformers/examples/seq2seq`
The problem arises when using:
* the official example scripts:
when I run the following:
```
python run_seq2seq.py \
--model_name_or_path t5-small \
--do_train \
--do_eval \
--task summarization \
--train_file train.csv \
--validation_file test.csv \
--output_dir output \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate \
--max_train_samples 500 \
--max_val_samples 500
```
I get the following error:
```
Traceback (most recent call last):
File "run_seq2seq.py", line 645, in <module>
main()
File "run_seq2seq.py", line 518, in main
pad_to_multiple_of=8 if training_args.fp16 else None,
TypeError: __init__() got an unexpected keyword argument 'model'
```
The tasks I am working on is:
* my own task or dataset:
I take the examples provided in the README file for the custom CSV file. Specifically, I have two files `train.csv` and `test.csv` in the same directory as `run_seq2seq.py` with the following content:
```
text,summary
"I'm sitting here in a boring room. It's just another rainy Sunday afternoon. I'm wasting my time I got nothing to do. I'm hanging around I'm waiting for you. But nothing ever happens. And I wonder","I'm sitting in a room where I'm waiting for something to happen"
"I see trees so green, red roses too. I see them bloom for me and you. And I think to myself what a wonderful world. I see skies so blue and clouds so white. The bright blessed day, the dark sacred night. And I think to myself what a wonderful world.","I'm a gardener and I'm a big fan of flowers."
"Christmas time is here. Happiness and cheer. Fun for all that children call. Their favorite time of the year. Snowflakes in the air. Carols everywhere. Olden times and ancient rhymes. Of love and dreams to share","It's that time of year again."
```
## To reproduce
Steps to reproduce the behavior:
1. I copy and paste the file `run_seq2seq.py` located [here](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_seq2seq.py) into a directory.
2. I create two files named `train.csv` and `test.csv` in the same directory the file `run_seq2seq.py` is located.
3. I run the command provided above.
Here's the full terminal output:
```
02/27/2021 21:10:36 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 4distributed training: False, 16-bits training: False
02/27/2021 21:10:36 - INFO - __main__ - Training/evaluation parameters Seq2SeqTrainingArguments(output_dir='output', overwrite_output_dir=True, do_train=True, do_eval=True, do_predict=False, evaluation_strategy=<EvaluationStrategy.NO: 'no'>, prediction_loss_only=False, per_device_train_batch_size=4, per_device_eval_batch_size=4, per_gpu_train_batch_size=None, per_gpu_eval_batch_size=None, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=5e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=3.0, max_steps=-1, lr_scheduler_type=<SchedulerType.LINEAR: 'linear'>, warmup_steps=0, logging_dir='runs/Feb27_21-10-36_legendary1', logging_first_step=False, logging_steps=500, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level='O1', fp16_backend='auto', local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=500, dataloader_num_workers=0, past_index=-1, run_name='output', disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=False, deepspeed=None, label_smoothing_factor=0.0, adafactor=False, group_by_length=False, report_to=['tensorboard'], ddp_find_unused_parameters=None, dataloader_pin_memory=True, sortish_sampler=False, predict_with_generate=True)
02/27/2021 21:10:36 - WARNING - datasets.builder - Using custom data configuration default-40a1a8e44205ddce
Downloading and preparing dataset csv/default (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /home/users/apouranb/.cache/huggingface/datasets/csv/default-40a1a8e44205ddce/0.0.0/965b6429be0fc05f975b608ce64e1fa941cc8fb4f30629b523d2390f3c0e1a93...
Dataset csv downloaded and prepared to /home/users/apouranb/.cache/huggingface/datasets/csv/default-40a1a8e44205ddce/0.0.0/965b6429be0fc05f975b608ce64e1fa941cc8fb4f30629b523d2390f3c0e1a93. Subsequent calls will reuse this data.
https://huggingface.co/t5-small/resolve/main/config.json not found in cache or force_download set to True, downloading to /home/users/apouranb/.cache/huggingface/transformers/tmpgh87jvjl
Downloading: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.20k/1.20k [00:00<00:00, 843kB/s]
storing https://huggingface.co/t5-small/resolve/main/config.json in cache at /home/users/apouranb/.cache/huggingface/transformers/fe501e8fd6425b8ec93df37767fcce78ce626e34cc5edc859c662350cf712e41.406701565c0afd9899544c1cb8b93185a76f00b31e5ce7f6e18bbaef02241985
creating metadata file for /home/users/apouranb/.cache/huggingface/transformers/fe501e8fd6425b8ec93df37767fcce78ce626e34cc5edc859c662350cf712e41.406701565c0afd9899544c1cb8b93185a76f00b31e5ce7f6e18bbaef02241985
loading configuration file https://huggingface.co/t5-small/resolve/main/config.json from cache at /home/users/apouranb/.cache/huggingface/transformers/fe501e8fd6425b8ec93df37767fcce78ce626e34cc5edc859c662350cf712e41.406701565c0afd9899544c1cb8b93185a76f00b31e5ce7f6e18bbaef02241985
Model config T5Config {
"architectures": [
"T5WithLMHeadModel"
],
"d_ff": 2048,
"d_kv": 64,
"d_model": 512,
"decoder_start_token_id": 0,
"dropout_rate": 0.1,
"eos_token_id": 1,
"feed_forward_proj": "relu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"layer_norm_epsilon": 1e-06,
"model_type": "t5",
"n_positions": 512,
"num_decoder_layers": 6,
"num_heads": 8,
"num_layers": 6,
"output_past": true,
"pad_token_id": 0,
"relative_attention_num_buckets": 32,
"task_specific_params": {
"summarization": {
"early_stopping": true,
"length_penalty": 2.0,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
},
"transformers_version": "4.3.3",
"use_cache": true,
"vocab_size": 32128
}
loading configuration file https://huggingface.co/t5-small/resolve/main/config.json from cache at /home/users/apouranb/.cache/huggingface/transformers/fe501e8fd6425b8ec93df37767fcce78ce626e34cc5edc859c662350cf712e41.406701565c0afd9899544c1cb8b93185a76f00b31e5ce7f6e18bbaef02241985
Model config T5Config {
"architectures": [
"T5WithLMHeadModel"
],
"d_ff": 2048,
"d_kv": 64,
"d_model": 512,
"decoder_start_token_id": 0,
"dropout_rate": 0.1,
"eos_token_id": 1,
"feed_forward_proj": "relu",
"initializer_factor": 1.0,
"is_encoder_decoder": true,
"layer_norm_epsilon": 1e-06,
"model_type": "t5",
"n_positions": 512,
"num_decoder_layers": 6,
"num_heads": 8,
"num_layers": 6,
"output_past": true,
"pad_token_id": 0,
"relative_attention_num_buckets": 32,
"task_specific_params": {
"summarization": {
"early_stopping": true,
"length_penalty": 2.0,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
},
"transformers_version": "4.3.3",
"use_cache": true,
"vocab_size": 32128
}
https://huggingface.co/t5-small/resolve/main/spiece.model not found in cache or force_download set to True, downloading to /home/users/apouranb/.cache/huggingface/transformers/tmpuwh13b51
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 792k/792k [00:00<00:00, 2.15MB/s]
storing https://huggingface.co/t5-small/resolve/main/spiece.model in cache at /home/users/apouranb/.cache/huggingface/transformers/65fc04e21f45f61430aea0c4fedffac16a4d20d78b8e6601d8d996ebefefecd2.3b69006860e7b5d0a63ffdddc01ddcd6b7c318a6f4fd793596552c741734c62d
creating metadata file for /home/users/apouranb/.cache/huggingface/transformers/65fc04e21f45f61430aea0c4fedffac16a4d20d78b8e6601d8d996ebefefecd2.3b69006860e7b5d0a63ffdddc01ddcd6b7c318a6f4fd793596552c741734c62d
https://huggingface.co/t5-small/resolve/main/tokenizer.json not found in cache or force_download set to True, downloading to /home/users/apouranb/.cache/huggingface/transformers/tmpt45yih6q
Downloading: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1.39M/1.39M [00:00<00:00, 3.50MB/s]
storing https://huggingface.co/t5-small/resolve/main/tokenizer.json in cache at /home/users/apouranb/.cache/huggingface/transformers/06779097c78e12f47ef67ecb728810c2ae757ee0a9efe9390c6419783d99382d.8627f1bd5d270a9fd2e5a51c8bec3223896587cc3cfe13edeabb0992ab43c529
creating metadata file for /home/users/apouranb/.cache/huggingface/transformers/06779097c78e12f47ef67ecb728810c2ae757ee0a9efe9390c6419783d99382d.8627f1bd5d270a9fd2e5a51c8bec3223896587cc3cfe13edeabb0992ab43c529
loading file https://huggingface.co/t5-small/resolve/main/spiece.model from cache at /home/users/apouranb/.cache/huggingface/transformers/65fc04e21f45f61430aea0c4fedffac16a4d20d78b8e6601d8d996ebefefecd2.3b69006860e7b5d0a63ffdddc01ddcd6b7c318a6f4fd793596552c741734c62d
loading file https://huggingface.co/t5-small/resolve/main/tokenizer.json from cache at /home/users/apouranb/.cache/huggingface/transformers/06779097c78e12f47ef67ecb728810c2ae757ee0a9efe9390c6419783d99382d.8627f1bd5d270a9fd2e5a51c8bec3223896587cc3cfe13edeabb0992ab43c529
https://huggingface.co/t5-small/resolve/main/pytorch_model.bin not found in cache or force_download set to True, downloading to /home/users/apouranb/.cache/huggingface/transformers/tmpqjragsda
Downloading: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 242M/242M [00:03<00:00, 73.1MB/s]
storing https://huggingface.co/t5-small/resolve/main/pytorch_model.bin in cache at /home/users/apouranb/.cache/huggingface/transformers/fee5a3a0ae379232608b6eed45d2d7a0d2966b9683728838412caccc41b4b0ed.ddacdc89ec88482db20c676f0861a336f3d0409f94748c209847b49529d73885
creating metadata file for /home/users/apouranb/.cache/huggingface/transformers/fee5a3a0ae379232608b6eed45d2d7a0d2966b9683728838412caccc41b4b0ed.ddacdc89ec88482db20c676f0861a336f3d0409f94748c209847b49529d73885
loading weights file https://huggingface.co/t5-small/resolve/main/pytorch_model.bin from cache at /home/users/apouranb/.cache/huggingface/transformers/fee5a3a0ae379232608b6eed45d2d7a0d2966b9683728838412caccc41b4b0ed.ddacdc89ec88482db20c676f0861a336f3d0409f94748c209847b49529d73885
All model checkpoint weights were used when initializing T5ForConditionalGeneration.
All the weights of T5ForConditionalGeneration were initialized from the model checkpoint at t5-small.
If your task is similar to the task the model of the checkpoint was trained on, you can already use T5ForConditionalGeneration for predictions without further training.
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 161.24ba/s]
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 383.81ba/s]
Traceback (most recent call last):
File "run_seq2seq.py", line 645, in <module>
main()
File "run_seq2seq.py", line 518, in main
pad_to_multiple_of=8 if training_args.fp16 else None,
TypeError: __init__() got an unexpected keyword argument 'model'
```
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10441/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10441/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10440 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10440/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10440/comments | https://api.github.com/repos/huggingface/transformers/issues/10440/events | https://github.com/huggingface/transformers/pull/10440 | 818,113,275 | MDExOlB1bGxSZXF1ZXN0NTgxNDQ2MzQw | 10,440 | Checkpoint refactoring for Multiple Models | {
"login": "danielpatrickhug",
"id": 38571110,
"node_id": "MDQ6VXNlcjM4NTcxMTEw",
"avatar_url": "https://avatars.githubusercontent.com/u/38571110?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/danielpatrickhug",
"html_url": "https://github.com/danielpatrickhug",
"followers_url": "https://api.github.com/users/danielpatrickhug/followers",
"following_url": "https://api.github.com/users/danielpatrickhug/following{/other_user}",
"gists_url": "https://api.github.com/users/danielpatrickhug/gists{/gist_id}",
"starred_url": "https://api.github.com/users/danielpatrickhug/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/danielpatrickhug/subscriptions",
"organizations_url": "https://api.github.com/users/danielpatrickhug/orgs",
"repos_url": "https://api.github.com/users/danielpatrickhug/repos",
"events_url": "https://api.github.com/users/danielpatrickhug/events{/privacy}",
"received_events_url": "https://api.github.com/users/danielpatrickhug/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"> Thanks a lot for the PR!\r\n> \r\n> We can do the TF models in another PR, I'm completely fine with that. Regarding your other comments:\r\n> \r\n> * funnel is a special case indeed, so it's fine to leave it as it for now.\r\n> * for squeezebert, you can just use \"squeezebert/squeezebert-uncased\" everywhere\r\n> * for gpt I didn't see two checkpoints, just one.\r\n> * for distilbert, the duplicate `add_code_ample` decorator should be removed.\r\n> \r\n> One last thing, you added a `datasets` submodule in your PR that you should remove before we can merge it.\r\n\r\noo sorry about that Ill remove the datasets and clean up the rest, so GPT2 has 2 checkpoints(\"gpt2\" and for sequence classification..\r\n```\r\n @add_code_sample_docstrings(\r\n tokenizer_class=_TOKENIZER_FOR_DOC,\r\n checkpoint=\"microsoft/dialogrpt\",\r\n output_type=SequenceClassifierOutputWithPast,\r\n config_class=_CONFIG_FOR_DOC,\r\n )\r\n```",
"Ok for GPT2, you can leave this checkpoint and just refactor the traditional \"gpt2\" in the other places then.",
"Oh no, it looks like the rebase messed with GitHub and the diff. Do you think you could close this PR and open a fresh one on your branch?\r\n\r\nAlso, for the next step #10424 contains an example of what I was envisioning for the \"# Copied from\", if it still interests you to work on this part in a second stage. The PR needs to be merged before you work on it because there is some fixes in our check_copies script inside.",
" sure no problem, Ill include the TF modeling files as well in the next pull request."
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | Hi, thank you for providing an example @sgugger
Linked to #10193, this PR refactors the checkpoint names in one private constant.
A couple notes:
- I refactored most of the modeling files, however I excluded the modeling_tf_*.py files for now.
- The bare Distilbert foward pass has two add_code_sample_docstrings decorators, I wanted to check for confirmation that its redundant.
- funnel, gpt and squeeze bert all have 2 checkpoint models for different tasks, so I left those alone.
Fixes #10193
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10440/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10440/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10440",
"html_url": "https://github.com/huggingface/transformers/pull/10440",
"diff_url": "https://github.com/huggingface/transformers/pull/10440.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10440.patch",
"merged_at": null
} |
https://api.github.com/repos/huggingface/transformers/issues/10439 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10439/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10439/comments | https://api.github.com/repos/huggingface/transformers/issues/10439/events | https://github.com/huggingface/transformers/issues/10439 | 818,056,928 | MDU6SXNzdWU4MTgwNTY5Mjg= | 10,439 | Option to output "test_preds_seq2seq.txt" text file with each checkpoint generated in "run_seq2seq.py" | {
"login": "kingpalethe",
"id": 11775831,
"node_id": "MDQ6VXNlcjExNzc1ODMx",
"avatar_url": "https://avatars.githubusercontent.com/u/11775831?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kingpalethe",
"html_url": "https://github.com/kingpalethe",
"followers_url": "https://api.github.com/users/kingpalethe/followers",
"following_url": "https://api.github.com/users/kingpalethe/following{/other_user}",
"gists_url": "https://api.github.com/users/kingpalethe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kingpalethe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kingpalethe/subscriptions",
"organizations_url": "https://api.github.com/users/kingpalethe/orgs",
"repos_url": "https://api.github.com/users/kingpalethe/repos",
"events_url": "https://api.github.com/users/kingpalethe/events{/privacy}",
"received_events_url": "https://api.github.com/users/kingpalethe/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | I had previously raised an issue in a mistaken belief that this functionality _used_ to exist in Transformers.
Current behavior: The "test_preds_seq2seq.txt" file is created once, at the end of the last epoch.
For many Seq2Seq tasks, at least for mine, it would be very useful to get these predictions at each checkpoint, to see how the model changes over time as it is trained.
thanks | {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10439/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10439/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10438 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10438/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10438/comments | https://api.github.com/repos/huggingface/transformers/issues/10438/events | https://github.com/huggingface/transformers/issues/10438 | 818,044,874 | MDU6SXNzdWU4MTgwNDQ4NzQ= | 10,438 | Setting max_length for model training produces error | {
"login": "neel04",
"id": 11617870,
"node_id": "MDQ6VXNlcjExNjE3ODcw",
"avatar_url": "https://avatars.githubusercontent.com/u/11617870?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/neel04",
"html_url": "https://github.com/neel04",
"followers_url": "https://api.github.com/users/neel04/followers",
"following_url": "https://api.github.com/users/neel04/following{/other_user}",
"gists_url": "https://api.github.com/users/neel04/gists{/gist_id}",
"starred_url": "https://api.github.com/users/neel04/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/neel04/subscriptions",
"organizations_url": "https://api.github.com/users/neel04/orgs",
"repos_url": "https://api.github.com/users/neel04/repos",
"events_url": "https://api.github.com/users/neel04/events{/privacy}",
"received_events_url": "https://api.github.com/users/neel04/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"The RoBERTa model takes maximum lengths of 512 tokens, and you are giving it inputs padded (or truncated) to a length of 4072. This is why you get this error.",
"Hmm... well, I was able to train and infer with `roberta-base` without any errors (though the output was very bad).\r\nIt seems that the only way to proceed is to use longformers. \r\nD'you reckon its easy to swap out roberta and use longformer, or is there some extra step?\r\n\r\nlastly, I would have preferred that this query be answered in the forum rather than coming to Github for help :("
] | 1,614 | 1,614 | 1,614 | NONE | null | ## Environment info
- `transformers` version: 4.3.3
- Platform: Linux-4.19.112+-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.10
- PyTorch version (GPU?): 1.7.1+cu101 (False)
- Tensorflow version (GPU?): 2.4.1 (False)
- Using GPU in script?: True/False
- Using distributed or parallel set-up in script?: False
### Who can help
Models:
- tensorflow: @jplu
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
## Information
Model I am using (Bert, XLNet ...): RoBERTa (Large)
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [x] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [x] my own task or dataset: (give details below)
## To reproduce
**Error on GPU:-**
```py
Some weights of the model checkpoint at roberta-large were not used when initializing RobertaForSequenceClassification: ['lm_head.bias', 'lm_head.dense.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
- This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at roberta-large and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-25-bb6a14612ca7> in <module>()
46 )
47
---> 48 train_results = trainer.train()
17 frames
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, **kwargs)
938 tr_loss += self.training_step(model, inputs)
939 else:
--> 940 tr_loss += self.training_step(model, inputs)
941 self._total_flos += self.floating_point_ops(inputs)
942
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in training_step(self, model, inputs)
1300 if self.use_amp:
1301 with autocast():
-> 1302 loss = self.compute_loss(model, inputs)
1303 else:
1304 loss = self.compute_loss(model, inputs)
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in compute_loss(self, model, inputs, return_outputs)
1332 else:
1333 labels = None
-> 1334 outputs = model(**inputs)
1335 # Save past state if it exists
1336 # TODO: this needs to be fixed and made cleaner later.
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, labels, output_attentions, output_hidden_states, return_dict)
1153 output_attentions=output_attentions,
1154 output_hidden_states=output_hidden_states,
-> 1155 return_dict=return_dict,
1156 )
1157 sequence_output = outputs[0]
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
815 output_attentions=output_attentions,
816 output_hidden_states=output_hidden_states,
--> 817 return_dict=return_dict,
818 )
819 sequence_output = encoder_outputs[0]
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
512 encoder_attention_mask,
513 past_key_value,
--> 514 output_attentions,
515 )
516
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_value, output_attentions)
397 head_mask,
398 output_attentions=output_attentions,
--> 399 past_key_value=self_attn_past_key_value,
400 )
401 attention_output = self_attention_outputs[0]
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_value, output_attentions)
327 encoder_attention_mask,
328 past_key_value,
--> 329 output_attentions,
330 )
331 attention_output = self.output(self_outputs[0], hidden_states)
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_value, output_attentions)
184 output_attentions=False,
185 ):
--> 186 mixed_query_layer = self.query(hidden_states)
187
188 # If this is instantiated as a cross-attention module, the keys
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/linear.py in forward(self, input)
91
92 def forward(self, input: Tensor) -> Tensor:
---> 93 return F.linear(input, self.weight, self.bias)
94
95 def extra_repr(self) -> str:
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py in linear(input, weight, bias)
1690 ret = torch.addmm(bias, input, weight.t())
1691 else:
-> 1692 output = input.matmul(weight.t())
1693 if bias is not None:
1694 output += bias
RuntimeError: CUDA error: CUBLAS_STATUS_ALLOC_FAILED when calling `cublasCreate(handle)`
```
**Error on CPU:-**
```py
Downloading: 100%
482/482 [00:00<00:00, 846B/s]
Downloading: 100%
1.43G/1.43G [00:51<00:00, 27.7MB/s]
Some weights of the model checkpoint at roberta-large were not used when initializing RobertaForSequenceClassification: ['lm_head.bias', 'lm_head.dense.weight', 'lm_head.dense.bias', 'lm_head.layer_norm.weight', 'lm_head.layer_norm.bias', 'lm_head.decoder.weight', 'roberta.pooler.dense.weight', 'roberta.pooler.dense.bias']
- This IS expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RobertaForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of RobertaForSequenceClassification were not initialized from the model checkpoint at roberta-large and are newly initialized: ['classifier.dense.weight', 'classifier.dense.bias', 'classifier.out_proj.weight', 'classifier.out_proj.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-26-6888fbac6ba6> in <module>()
46 )
47
---> 48 train_results = trainer.train()
11 frames
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in train(self, resume_from_checkpoint, trial, **kwargs)
938 tr_loss += self.training_step(model, inputs)
939 else:
--> 940 tr_loss += self.training_step(model, inputs)
941 self._total_flos += self.floating_point_ops(inputs)
942
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in training_step(self, model, inputs)
1302 loss = self.compute_loss(model, inputs)
1303 else:
-> 1304 loss = self.compute_loss(model, inputs)
1305
1306 if self.args.n_gpu > 1:
/usr/local/lib/python3.7/dist-packages/transformers/trainer.py in compute_loss(self, model, inputs, return_outputs)
1332 else:
1333 labels = None
-> 1334 outputs = model(**inputs)
1335 # Save past state if it exists
1336 # TODO: this needs to be fixed and made cleaner later.
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, labels, output_attentions, output_hidden_states, return_dict)
1153 output_attentions=output_attentions,
1154 output_hidden_states=output_hidden_states,
-> 1155 return_dict=return_dict,
1156 )
1157 sequence_output = outputs[0]
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
803 token_type_ids=token_type_ids,
804 inputs_embeds=inputs_embeds,
--> 805 past_key_values_length=past_key_values_length,
806 )
807 encoder_outputs = self.encoder(
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/transformers/models/roberta/modeling_roberta.py in forward(self, input_ids, token_type_ids, position_ids, inputs_embeds, past_key_values_length)
119 embeddings = inputs_embeds + token_type_embeddings
120 if self.position_embedding_type == "absolute":
--> 121 position_embeddings = self.position_embeddings(position_ids)
122 embeddings += position_embeddings
123 embeddings = self.LayerNorm(embeddings)
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
725 result = self._slow_forward(*input, **kwargs)
726 else:
--> 727 result = self.forward(*input, **kwargs)
728 for hook in itertools.chain(
729 _global_forward_hooks.values(),
/usr/local/lib/python3.7/dist-packages/torch/nn/modules/sparse.py in forward(self, input)
124 return F.embedding(
125 input, self.weight, self.padding_idx, self.max_norm,
--> 126 self.norm_type, self.scale_grad_by_freq, self.sparse)
127
128 def extra_repr(self) -> str:
/usr/local/lib/python3.7/dist-packages/torch/nn/functional.py in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
1850 # remove once script supports set_grad_enabled
1851 _no_grad_embedding_renorm_(weight, input, max_norm, norm_type)
-> 1852 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
1853
1854
IndexError: index out of range in self
```
This was working fine actually until I added the `max_length` argument:-
```py
train_encodings = tokenizer(train_text, truncation=True, padding=True, max_length=4072)
val_encodings = tokenizer(val_text, truncation=True, padding=True, max_length=4072)
```
The reason for adding was in the inference stage it was producing an error about the sequence being too long. Figuring I would be inferencing on sequences larger in the test data (I have confirmed it) I tried this but doesn't work.
Any Idea how to solve this?
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10438/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10438/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10437 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10437/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10437/comments | https://api.github.com/repos/huggingface/transformers/issues/10437/events | https://github.com/huggingface/transformers/issues/10437 | 817,975,503 | MDU6SXNzdWU4MTc5NzU1MDM= | 10,437 | [Trainer] add --max_train_samples --max_val_samples --max_test_samples | {
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
} | [
{
"id": 2155169140,
"node_id": "MDU6TGFiZWwyMTU1MTY5MTQw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/trainer",
"name": "trainer",
"color": "2ef289",
"default": false,
"description": ""
}
] | closed | false | {
"login": "bhadreshpsavani",
"id": 26653468,
"node_id": "MDQ6VXNlcjI2NjUzNDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhadreshpsavani",
"html_url": "https://github.com/bhadreshpsavani",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}",
"gists_url": "https://api.github.com/users/bhadreshpsavani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhadreshpsavani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhadreshpsavani/subscriptions",
"organizations_url": "https://api.github.com/users/bhadreshpsavani/orgs",
"repos_url": "https://api.github.com/users/bhadreshpsavani/repos",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhadreshpsavani/received_events",
"type": "User",
"site_admin": false
} | [
{
"login": "bhadreshpsavani",
"id": 26653468,
"node_id": "MDQ6VXNlcjI2NjUzNDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhadreshpsavani",
"html_url": "https://github.com/bhadreshpsavani",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}",
"gists_url": "https://api.github.com/users/bhadreshpsavani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhadreshpsavani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhadreshpsavani/subscriptions",
"organizations_url": "https://api.github.com/users/bhadreshpsavani/orgs",
"repos_url": "https://api.github.com/users/bhadreshpsavani/repos",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhadreshpsavani/received_events",
"type": "User",
"site_admin": false
}
] | [
"Yes, that would be a nice refactor in `Trainer`! I believe this can be done when we create the dataloaders, to keep the original datasets untouched.",
"@bhadreshpsavani, would you like to try this slightly more complex task? \r\n\r\nStep 1 is to take `run_seq2seq.py` and move the functionality that handles `--max_train_samples --max_val_samples --max_test_samples` (args and logic) to `training_args.py` and `trainer.py` correspondingly. And to ensure it works the same way. Please see @sgugger's note above to where to move the logic to.\r\n\r\nStep 2 - no step, every other script should just work with these now-Trainer-level cl args.\r\n\r\nand then later it'd be great to have the metrics updated with the actual number of samples run, like it's done manually right now in `run_seq2seq.py` - I added the full details to the OP. \r\n",
"Ya @stas00,\nI can do that",
"Awesome! Please don't hesitate to ask question if you run into any uncertainties.\r\n\r\nThank you!",
"I agree with the proposed solution here. But we pre-process the datasets in scripts before passing them to the `Trainer`. Now if I just want to use say a 100 validation examples, the script would unnecessary process the whole dataset and then `Trainer` will drop the extra examples.",
"Hi @patil-suraj,\r\nYou are right about that\r\nI was thinking to add the below code [here](https://github.com/huggingface/transformers/blob/master/src/transformers/trainer.py#L544)\r\n```python\r\nif data_args.max_train_samples is not None:\r\n train_dataset = train_dataset.select(range(data_args.max_train_samples))\r\n```\r\nBut ya, it will select sample from processed dataset only",
"Ah, in that case we sadly can't really add this in the `Trainer` as it would be inefficient. I was also thinking more and having the functionality in Trainer will require us to support all kinds of datasets (even iterable datasets) and it's going to be very painful, so I think we should just copy the code in all the scripts.",
"Hi @sgugger,\r\nShall we add this arguments `--max_train_samples --max_val_samples --max_test_samples` and code accordingly in all the scripts like implemented in `run_seq2seq.py`?",
"Yes, I think it's the best solution.",
"Hi @stas00,\r\nI was going through the code of `run_seq2seq` and trying to make changes in other scripts\r\nI came across [`result={}`](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_seq2seq.py#L597). We are not storing anything inside this dictionary and we are returning it at the end as an empty dictionary. Is it necessary?\r\n\r\nIn other scripts like `run_qa.py` we are using results instead of metrics in [eval ](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_qa.py#L495) and test section. Should we unify this behaviour in the scripts? I mean either use metrics like in `run_seq2seq` or use results like other scripts\r\n\r\nI also want to ask that in many scripts we are only doing train and eval things, Not test/predict things. Should we also create a separate issue for that? we might not be adding `--max_test_samples` since we are not doing testing in the script?",
"The test thing should definitely have its separate issue (and `--max_test_samples` can be added when the test/predict is added for those scripts).",
"Good analysis, @bhadreshpsavani!\r\n\r\n> I was going through the code of `run_seq2seq` and trying to make changes in other scripts\r\n> I came across [`result={}`](https://github.com/huggingface/transformers/blob/master/examples/seq2seq/run_seq2seq.py#L597). We are not storing anything inside this dictionary and we are returning it at the end as an empty dictionary. Is it necessary?\r\n\r\nThat was invalid porting of the original. As you can see the original aggregated all the metrics and returned them:\r\n\r\n https://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/examples/legacy/seq2seq/finetune_trainer.py#L299\r\n\r\n> In other scripts like `run_qa.py` we are using results instead of metrics in [eval ](https://github.com/huggingface/transformers/blob/master/examples/question-answering/run_qa.py#L495) and test section. Should we unify this behaviour in the scripts? I mean either use metrics like in `run_seq2seq` or use results like other scripts\r\n\r\nI think all these return metrics from `main` were mainly used for testing. But since we save all the metrics to the disc, this isn't necessarily needed as the data is already accessible - changing this may impact some tests which would need to be adjusted to use the metric dumps.\r\n\r\nAlternatively, we could have the trainer also store all the metrics not only on the disc but internally, and so the last command of `main` in all scripts could be:\r\n```\r\nreturn trainer.metrics()\r\n```\r\n\r\n@sgugger, what do you think - should we just not return anything from `main` in all example scripts or always return all metrics and then tweak the trainer to store all the metrics internally and have an method to return them?\r\n\r\n> I also want to ask that in many scripts we are only doing train and eval things, Not test/predict things. Should we also create a separate issue for that? we might not be adding `--max_test_samples` since we are not doing testing in the script?\r\n\r\nAnother good catch. Probably for now just skip `--max_test_samples` in those scripts, but meanwhile I raised your question here: https://github.com/huggingface/transformers/issues/10482",
"> The test thing should definitely have its separate issue (and `--max_test_samples` can be added when the test/predict is added for those scripts).\r\n\r\nFiled: https://github.com/huggingface/transformers/issues/10482\r\n\r\nIt might be easier to sort out test/predict first then, as it'd make the copy-n-paste of all 3 cl arg flags easier. But either way works.\r\n",
"The metrics returned are mainly for the tests AFAIK, so we can remove that behavior if the tests are all adapted to load the file where the metrics are stored.",
"OK, let's sync everything then to remove the inconsistent return metrics. Just please be aware that the example tests ` examples/test_examples.py` will need to be adapted, e.g. currently they rely on the return value from `main`:\r\n\r\nhttps://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/examples/test_examples.py#L100-L102\r\n\r\nSo instead should write a wrapper to load the metrics from the filesystem and test that.",
"Just to make sure my mentioning of a wrapper wasn't ambiguous:\r\n\r\nFor models and examples we are trying to be as explicit as possible to help the users understand what is going on in the code - so avoiding refactoring and duplicating code where it is needed. Unless we can make something a functional method in Trainer and then all the noise can be abstracted away, especially for code that's really just formatting.\r\n\r\nFor tests it's the software engineering as normal, refactoring is important as it helps minimize hard to maintain code and avoid errors. So there let's not duplicate any code like reading the json file from the filesystem.",
"Hi @stas00,\r\nI could not figure out the code or implementation for a wrapper for loading all metrics for testing in `test_exmaples.py`. We are storing in the file system based on an argument `output_dir` which is accessible for trainer object. I don't how to access the trainer object for individual script in `test_exmaples.py`. \r\n\r\nIn trainer, we can write code for loading the metrics but to access the trainer in `test_examples.py` that I couldn't figure out. \r\n\r\nAnother thing if we use `all_metrics={}` to store all the metrics of train, test, and validation, we can save it once as `all_results.json` like [legacy ](https://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/examples/legacy/seq2seq/finetune_trainer.py#L356) code, right?\r\n\r\nSorry keep asking multiple questions, Once these things are clear then implementation and testing will not take much time",
"> Hi @stas00,\r\n> I could not figure out the code or implementation for a wrapper for loading all metrics for testing in `test_examples.py`. We are storing in the file system based on an argument `output_dir` which is accessible for trainer object. I don't how to access the trainer object for individual script in `test_exmaples.py`.\r\n\r\nYou have the `output_dir` `tmp_dir` here:\r\nhttps://github.com/huggingface/transformers/blob/805c5200dc41aa7ca8dbb851688223df8627b411/examples/test_examples.py#L78\r\n\r\nso you just load the `f\"{tmp_dir}/all_results.json\"` file right after this line:\r\nhttps://github.com/huggingface/transformers/blob/805c5200dc41aa7ca8dbb851688223df8627b411/examples/test_examples.py#L101\r\n\r\nThat's it - You have the metrics to test on the following line ;)\r\n\r\n> Another thing if we use `all_metrics={}` to store all the metrics of train, test, and validation, we can save it once as `all_results.json` like [legacy ](https://github.com/huggingface/transformers/blob/b013842244df7be96b8cc841491bd1e35e475e36/examples/legacy/seq2seq/finetune_trainer.py#L356) code, right?\r\n\r\nI already changed the code to save `all_results.json` auto-magically in `trainer.save_metrics` - make sure you rebased your branch\r\n\r\nhttps://github.com/huggingface/transformers/blob/805c5200dc41aa7ca8dbb851688223df8627b411/src/transformers/trainer_pt_utils.py#L651-L661\r\n\r\n> Sorry keep asking multiple questions, Once these things are clear then implementation and testing will not take much time\r\n\r\nOn the contrary, please don't hesitate to ask any questions. It takes quite some time to find one's way in this complex massive code base.\r\n",
"Hi @stas00, \r\n\r\nBelow two lines in [run_ner.py](https://github.com/huggingface/transformers/blob/master/examples/token-classification/run_ner.py#L421) don't seem much meaningful since `metrics` does not represent any details from test/prediction.\r\n\r\n```python\r\ntrainer.log_metrics(\"test\", metrics)\r\ntrainer.save_metrics(\"test\", metrics)\r\n```",
"Why do you suggest it's not meaningful? \r\n\r\n`metrics` gets set here:\r\n\r\nhttps://github.com/huggingface/transformers/blob/6290169eb3391d72d9a08cab5c54a54b73a87463/examples/token-classification/run_ner.py#L412\r\n",
"oooh, I didn't notice it!\r\nI thought it is taking earlier `metrics`\r\nThanks\r\n",
"Hello @stas00 and @sgugger,\r\n\r\nI have made changes for adding three arguments in PyTorch-based scripts. It's working as expected. I also modified `test_examples.py` accordingly. \r\n\r\nFor TensorFlow-based scripts, I am facing issues while running the script even in colab directly from the master branch without any changes. I create an [issue](https://github.com/huggingface/transformers/issues/10541) for the same.\r\n\r\nWe have four run_tf_*.py files :\r\n1. run_tf_multiple_choice.py (Reported Issue)\r\n2. run_tf_squad.py (Reported Issue)\r\n3. run_tf_glue.py (Got AttributeError: 'TFTrainer' object has no attribute 'log_metrics')\r\n4. run_tf_text_classification.py\r\n\r\nBased on the error in the third file, `trainer.py` only for PyTorch based model, and `trainer_tf.py` is for tf based model. In that case do we need to write `save_metrics()` and `log_metrics()` for `trainer_tf.py`, right? In the last pull request, I could not test the changes for TF Script but I will fix that mistake in this PR. \r\n\r\nDo we need to add test_script for this TensorFlow files, currently, we only have PyTorch-based scripts in the `test_examples.py`?\r\n",
"Please don't touch the TF examples as they have not been cleaned up and will change in the near future. And yes, none of the TF examples are currently tested."
] | 1,614 | 1,615 | 1,615 | CONTRIBUTOR | null | As we were planning to add `--max_train_samples --max_val_samples --max_test_samples` to all examples https://github.com/huggingface/transformers/issues/10423, I thought is there any reason why we don't expand the Trainer to handle that?
It surely would be useful to be able to truncate the dataset at the point of Trainer to enable quick testing.
Another plus is that the metrics can then automatically include the actual number of samples run, rather than how it is done at the moment in examples.
That way this functionality would be built-in and examples will get it for free.
TODO:
1. [ ] port `--max_train_samples --max_val_samples --max_test_samples` to Trainer and remove the then unneeded code in `run_seq2seq.py`
2. [ ] extend metrics to report the number of samples as it's done now in:
https://github.com/huggingface/transformers/blob/aca6288ff42cebded5421020f0ff088adeb446dd/examples/seq2seq/run_seq2seq.py#L590
so that all scripts automatically get this metric reported. Most likely it should be done here:
https://github.com/huggingface/transformers/blob/aca6288ff42cebded5421020f0ff088adeb446dd/src/transformers/trainer_utils.py#L224
@sgugger
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10437/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10437/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10436 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10436/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10436/comments | https://api.github.com/repos/huggingface/transformers/issues/10436/events | https://github.com/huggingface/transformers/pull/10436 | 817,968,027 | MDExOlB1bGxSZXF1ZXN0NTgxMzY1NDQw | 10,436 | updated logging and saving metrics | {
"login": "bhadreshpsavani",
"id": 26653468,
"node_id": "MDQ6VXNlcjI2NjUzNDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/26653468?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bhadreshpsavani",
"html_url": "https://github.com/bhadreshpsavani",
"followers_url": "https://api.github.com/users/bhadreshpsavani/followers",
"following_url": "https://api.github.com/users/bhadreshpsavani/following{/other_user}",
"gists_url": "https://api.github.com/users/bhadreshpsavani/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bhadreshpsavani/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bhadreshpsavani/subscriptions",
"organizations_url": "https://api.github.com/users/bhadreshpsavani/orgs",
"repos_url": "https://api.github.com/users/bhadreshpsavani/repos",
"events_url": "https://api.github.com/users/bhadreshpsavani/events{/privacy}",
"received_events_url": "https://api.github.com/users/bhadreshpsavani/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Please run `make style` and commit to appease to `check_code_quality` CI job"
] | 1,614 | 1,614 | 1,614 | CONTRIBUTOR | null | # What does this PR do?
I have updated redundant code for saving and logging metrics in the example scripts
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #10337
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/master/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/master/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@stas00 @sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10436/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10436/timeline | null | false | {
"url": "https://api.github.com/repos/huggingface/transformers/pulls/10436",
"html_url": "https://github.com/huggingface/transformers/pull/10436",
"diff_url": "https://github.com/huggingface/transformers/pull/10436.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/10436.patch",
"merged_at": 1614448424000
} |
https://api.github.com/repos/huggingface/transformers/issues/10435 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10435/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10435/comments | https://api.github.com/repos/huggingface/transformers/issues/10435/events | https://github.com/huggingface/transformers/issues/10435 | 817,919,300 | MDU6SXNzdWU4MTc5MTkzMDA= | 10,435 | Confused about the time of forword | {
"login": "dy1998",
"id": 27282615,
"node_id": "MDQ6VXNlcjI3MjgyNjE1",
"avatar_url": "https://avatars.githubusercontent.com/u/27282615?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/dy1998",
"html_url": "https://github.com/dy1998",
"followers_url": "https://api.github.com/users/dy1998/followers",
"following_url": "https://api.github.com/users/dy1998/following{/other_user}",
"gists_url": "https://api.github.com/users/dy1998/gists{/gist_id}",
"starred_url": "https://api.github.com/users/dy1998/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/dy1998/subscriptions",
"organizations_url": "https://api.github.com/users/dy1998/orgs",
"repos_url": "https://api.github.com/users/dy1998/repos",
"events_url": "https://api.github.com/users/dy1998/events{/privacy}",
"received_events_url": "https://api.github.com/users/dy1998/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"I assume that that's how Python works, if you run the same thing again, the result will be cached. If you had provided different inputs, then the time would be the same. ",
"> I assume that that's how Python works, if you run the same thing again, the result will be cached. If you had provided different inputs, then the time would be the same.\r\n\r\nThanks for reply,but when i have tried differnt input(same length sentense), the inference time of first forword is longer than second forword(even 100x), i guess the model init produce the time cost",
"The same length sentences can have a different number of tokens after tokenizing. You could rather randomly create `input_ids` of the same shape to test this reliabley.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/master/CONTRIBUTING.md) are likely to be ignored."
] | 1,614 | 1,619 | 1,619 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version:3.0.0
- Platform: ubuntu 1604
- Python version: 3.7
- PyTorch version (GPU?):1.2.0 gpu
- Tensorflow version (GPU?): none
- Using GPU in script?: none
- Using distributed or parallel set-up in script?:No
### Who can help
@LysandreJik
## Information
Model I am using Bert, spceifically roberta_chinese_clue_tiny
The problem arises when using:
BertModel.from_pretrained
The tasks I am working on is:
just forward
Question:
Why the time of same forword is different? How to make it same?
## To reproduce
Steps to reproduce the behavior:
```
from transformers import BertTokenizer, BertModel
import time
tokenizer = BertTokenizer.from_pretrained("clue/roberta_chinese_clue_tiny")
model = BertModel.from_pretrained("clue/roberta_chinese_clue_tiny")
inputs = tokenizer("testtest", return_tensors="pt")
time_start=time.time()
outputs = model(**inputs)
time_end=time.time()
time_start2=time.time()
outputs = model(**inputs)
time_end2=time.time()
print('totally cost',time_end-time_start)
print('totally cost2',time_end2-time_start2)
```
## Expected behavior
```
totally cost 0.2720155715942383
totally cost2 0.007731199264526367
```
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10435/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10435/timeline | completed | null | null |
https://api.github.com/repos/huggingface/transformers/issues/10434 | https://api.github.com/repos/huggingface/transformers | https://api.github.com/repos/huggingface/transformers/issues/10434/labels{/name} | https://api.github.com/repos/huggingface/transformers/issues/10434/comments | https://api.github.com/repos/huggingface/transformers/issues/10434/events | https://github.com/huggingface/transformers/issues/10434 | 817,886,685 | MDU6SXNzdWU4MTc4ODY2ODU= | 10,434 | TF Dataset Pipeline throws `RuntimeError: Already borrowed` when tokenizing | {
"login": "DarshanDeshpande",
"id": 39432636,
"node_id": "MDQ6VXNlcjM5NDMyNjM2",
"avatar_url": "https://avatars.githubusercontent.com/u/39432636?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/DarshanDeshpande",
"html_url": "https://github.com/DarshanDeshpande",
"followers_url": "https://api.github.com/users/DarshanDeshpande/followers",
"following_url": "https://api.github.com/users/DarshanDeshpande/following{/other_user}",
"gists_url": "https://api.github.com/users/DarshanDeshpande/gists{/gist_id}",
"starred_url": "https://api.github.com/users/DarshanDeshpande/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/DarshanDeshpande/subscriptions",
"organizations_url": "https://api.github.com/users/DarshanDeshpande/orgs",
"repos_url": "https://api.github.com/users/DarshanDeshpande/repos",
"events_url": "https://api.github.com/users/DarshanDeshpande/events{/privacy}",
"received_events_url": "https://api.github.com/users/DarshanDeshpande/received_events",
"type": "User",
"site_admin": false
} | [] | closed | false | null | [] | [
"Hello!\r\n\r\nI do not suggest to convert your sentence on the fly but you should do it beforehand. Here the issue you get is because of `sentence = sentence.numpy().decode('utf-8')`, your sentences should not be loaded in a tf datasets before to be processed.\r\n\r\nI recommend you to read your file normally, convert your examples with the tokenizer, and then create a tf.Dataset with the output of the tokenizer. The best solution would be to create a TFRecord file and then stream this file into your pipeline.",
"Hey @jplu\r\nI understand this completely. Infact I did end up creating TFRecords for better training speed but I created this issue just to ask if something was wrong with the tokenizer in the transformers library. As I said before, if I use the tokenizer from the tokenizers library, it works perfectly fine and I can load the data on-the-fly. \r\n\r\nAlso, as a side question, does TF masked language model require some custom script to mask tokens randomly as is done by DataCollatorForLanguageModelling for torch?",
"You have to create your own function to randomly mask the tokens. There is no such function implemented in TF side for now.",
"@jplu Okay thanks. Will you be accepting PRs which implement these functions? Or is someone already working on this?",
"Here a function I'm using for doing this, you can adapt it for your needs:\r\n```python\r\ndef encode(examples, block_size=512):\r\n # `examples` is a list of textual content, the output of a dataset from the datasets lib\r\n # `block_size` represents the max position size of a model.\r\n input_ids = []\r\n texts = []\r\n labels = []\r\n for example in examples[\"text\"]:\r\n tokenized_text = tokenizer.convert_tokens_to_ids(tokenizer.tokenize(example))\r\n\r\n for i in range(0, len(tokenized_text), block_size - 2):\r\n tmp_ids = np.asarray(tokenizer.prepare_for_model(tokenized_text[i : i + block_size - 2], padding=\"max_length\", return_attention_mask=False, return_token_type_ids=False)[\"input_ids\"])\r\n text = \" \".join(tokenizer.convert_ids_to_tokens(tmp_ids, skip_special_tokens=True))\r\n tmp_labels = np.copy(tmp_ids)\r\n probability_matrix = np.full(tmp_labels.shape, 0.15)\r\n special_tokens_mask = tokenizer.get_special_tokens_mask(tmp_labels, already_has_special_tokens=True)\r\n probability_matrix = np.ma.array(probability_matrix, mask=special_tokens_mask, fill_value=0.0).filled()\r\n\r\n if tokenizer._pad_token is not None:\r\n padding_mask = np.equal(tmp_labels, tokenizer.pad_token_id)\r\n probability_matrix = np.ma.array(probability_matrix, mask=padding_mask, fill_value=0.0).filled()\r\n\r\n masked_indices = np.random.default_rng().binomial(1, probability_matrix) != 0\r\n tmp_labels[~masked_indices] = -100\r\n indices_replaced = (np.random.default_rng().binomial(1, np.full(tmp_labels.shape, 0.8)) != 0) & masked_indices\r\n tmp_ids[indices_replaced] = tokenizer.convert_tokens_to_ids(tokenizer.mask_token)\r\n indices_random = (np.random.default_rng().binomial(1, np.full(tmp_labels.shape, 0.5)) != 0) & masked_indices & ~indices_replaced\r\n random_words = np.random.randint(len(tokenizer), size=tmp_labels.shape)\r\n tmp_ids[indices_random] = random_words[indices_random]\r\n\r\n assert tmp_ids.size == tmp_labels.size == 512, 'size input_ids: %r -- size labels: %r' % (tmp_ids.size, tmp_labels.size)\r\n\r\n input_ids.append(tmp_ids.tolist())\r\n labels.append(tmp_labels.tolist())\r\n texts.append(text)\r\n\r\n return {\"text\": texts, \"input_ids\": input_ids, \"labels\": labels}\r\n```",
"Thats nice! Thanks for sharing this.\r\nClosing this issue since there does exist an alternative approach to the original question"
] | 1,614 | 1,614 | 1,614 | NONE | null | ## Environment info
<!-- You can run the command `transformers-cli env` and copy-and-paste its output below.
Don't forget to fill out the missing fields in that output! -->
- `transformers` version: master (4.4.0dev0)
- Platform: Google colab
- Python version: 3.7
- PyTorch version (GPU?): None
- Tensorflow version (GPU?): 2.4
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help
@jplu
<!-- Your issue will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- albert, bert, xlm: @LysandreJik
- blenderbot, bart, marian, pegasus, encoderdecoder, t5: @patrickvonplaten, @patil-suraj
- longformer, reformer, transfoxl, xlnet: @patrickvonplaten
- fsmt: @stas00
- funnel: @sgugger
- gpt2: @patrickvonplaten, @LysandreJik
- rag: @patrickvonplaten, @lhoestq
- tensorflow: @jplu
Library:
- benchmarks: @patrickvonplaten
- deepspeed: @stas00
- ray/raytune: @richardliaw, @amogkam
- text generation: @patrickvonplaten
- tokenizers: @n1t0, @LysandreJik
- trainer: @sgugger
- pipelines: @LysandreJik
Documentation: @sgugger
HF projects:
- nlp datasets: [different repo](https://github.com/huggingface/nlp)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Examples:
- maintained examples (not research project or legacy): @sgugger, @patil-suraj
- research_projects/bert-loses-patience: @JetRunner
- research_projects/distillation: @VictorSanh
-->
## Information
Model I am using (Bert, XLNet ...): None
The problem arises when using:
* [ ] the official example scripts: (give details below)
* [X] my own modified scripts: (give details below)
The tasks I am working on is:
* [ ] an official GLUE/SQUaD task: (give the name)
* [X] my own task or dataset: (give details below)
## To reproduce
Steps to reproduce the behavior:
This might be somewhat of a duplicate of #9629 but in a different use case
```
dataset = tf.data.TextLineDataset("/content/train.txt")
tokenizer = transformers.DistilBertTokenizerFast.from_pretrained("/content/Tokenizer", do_lower_case=False)
def tokenize(sentence):
sentence = sentence.numpy().decode('utf-8')
a = tokenizer.encode_plus(sentence, padding="max_length", max_length=256, truncation=True, return_tensors="tf")
return tf.constant(a.input_ids), tf.constant(a.attention_mask), tf.constant(a.input_ids)
def get_tokenized(sentence):
a = tf.py_function(tokenize, inp=[sentence], Tout=[tf.int32, tf.int32, tf.int32])
return {"input_ids": a[0], "attention_mask": a[1]}, a[2]
dataset = dataset.map(get_tokenized, num_parallel_calls=tf.data.AUTOTUNE)
# dataset = dataset.apply(tf.data.experimental.assert_cardinality(8000))
print(next(iter(dataset)))
```
Error
```
UnknownError: RuntimeError: Already borrowed
Traceback (most recent call last):
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/script_ops.py", line 247, in __call__
return func(device, token, args)
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/ops/script_ops.py", line 135, in __call__
ret = self._func(*args)
File "/usr/local/lib/python3.7/dist-packages/tensorflow/python/autograph/impl/api.py", line 620, in wrapper
return func(*args, **kwargs)
File "<ipython-input-34-2e27f300f71b>", line 9, in tokenize
a = tokenizer.encode_plus(sentence, padding="max_length", max_length=256, truncation=True, return_tensors="tf")
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_base.py", line 2438, in encode_plus
**kwargs,
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_fast.py", line 472, in _encode_plus
**kwargs,
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_fast.py", line 379, in _batch_encode_plus
pad_to_multiple_of=pad_to_multiple_of,
File "/usr/local/lib/python3.7/dist-packages/transformers/tokenization_utils_fast.py", line 330, in set_truncation_and_padding
self._tokenizer.enable_truncation(max_length, stride=stride, strategy=truncation_strategy.value)
RuntimeError: Already borrowed
[[{{node EagerPyFunc}}]]
```
The important thing that I should probably mention here is that if I change my code to load the same using the tokenizers library, the code executes without any issues. I have also tried using the slow implementation and the error still persists. Any help regarding this would be great!
<!-- If you have code snippets, error messages, stack traces please provide them here as well.
Important! Use code tags to correctly format your code. See https://help.github.com/en/github/writing-on-github/creating-and-highlighting-code-blocks#syntax-highlighting
Do not use screenshots, as they are hard to read and (more importantly) don't allow others to copy-and-paste your code.-->
## Expected behavior
Tokenization should happen on the fly without errors as it does with the Tokenizer from the tokenizers library.
<!-- A clear and concise description of what you would expect to happen. -->
| {
"url": "https://api.github.com/repos/huggingface/transformers/issues/10434/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} | https://api.github.com/repos/huggingface/transformers/issues/10434/timeline | completed | null | null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.