
url
stringlengths 62
66
| repository_url
stringclasses 1
value | labels_url
stringlengths 76
80
| comments_url
stringlengths 71
75
| events_url
stringlengths 69
73
| html_url
stringlengths 50
56
| id
int64 377M
2.15B
| node_id
stringlengths 18
32
| number
int64 1
29.2k
| title
stringlengths 1
487
| user
dict | labels
list | state
stringclasses 2
values | locked
bool 2
classes | assignee
dict | assignees
list | comments
list | created_at
int64 1.54k
1.71k
| updated_at
int64 1.54k
1.71k
| closed_at
int64 1.54k
1.71k
⌀ | author_association
stringclasses 4
values | active_lock_reason
stringclasses 2
values | body
stringlengths 0
234k
⌀ | reactions
dict | timeline_url
stringlengths 71
75
| state_reason
stringclasses 3
values | draft
bool 2
classes | pull_request
dict |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://api.github.com/repos/huggingface/transformers/issues/25220
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25220/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25220/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25220/events
|
https://github.com/huggingface/transformers/issues/25220
| 1,830,368,736 |
I_kwDOCUB6oc5tGTXg
| 25,220 |
OASST model is unavailable for Transformer Agent: `'inputs' must have less than 1024 tokens.`
|
{
"login": "sim-so",
"id": 96299403,
"node_id": "U_kgDOBb1piw",
"avatar_url": "https://avatars.githubusercontent.com/u/96299403?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sim-so",
"html_url": "https://github.com/sim-so",
"followers_url": "https://api.github.com/users/sim-so/followers",
"following_url": "https://api.github.com/users/sim-so/following{/other_user}",
"gists_url": "https://api.github.com/users/sim-so/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sim-so/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sim-so/subscriptions",
"organizations_url": "https://api.github.com/users/sim-so/orgs",
"repos_url": "https://api.github.com/users/sim-so/repos",
"events_url": "https://api.github.com/users/sim-so/events{/privacy}",
"received_events_url": "https://api.github.com/users/sim-so/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi there. We temporarily increased the max length for this endpoint when releasing the Agents framework, but it's not back to its normal value. So yes, this one won't work anymore.",
"Thank you for the info, @sgugger!\r\n\r\n> So yes, this one won't work anymore.\r\n\r\nThen other OpenAssisant models may also only work with customizing a prompt. For now, I believe removing that model from the notebook or replacing it with another one would reduce the inconvenience.\r\n\r\nMay I try to edit the prompt so that other models with less input max length will be available?",
"You can definitely try!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
### System Info
- transformers version: 4.29.0
- huggingface_hub version: 0.16.4
- python version: 3.10.6
- OS: Ubuntu 22.04.2 LTS
* run on Google Colab using [the provided notebook](https://colab.research.google.com/drive/1c7MHD-T1forUPGcC_jlwsIptOzpG3hSj?usp=sharing).
* [my notebook](https://colab.research.google.com/drive/1UBIWVCIXowlUJpp5gwD-Z0hmVlLLCr9I?usp=sharing), copied from the above.
### Who can help?
@sgugger
`OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5`, one of the models listed as available in the official notebook, is unusable due to the length of the tokens. When executing `agent.chat()` or `agent.run()` with the model, the following error raised:
```
ValueError: Error 422: {'error': 'Input validation error: `inputs` must have less than 1024 tokens. Given: 1553', 'error_type': 'validation'}
```
I guess that `max_input_length` of the model is `1024` if it follows the model configuration [here](https://github.com/LAION-AI/Open-Assistant/blob/main/oasst-shared/oasst_shared/model_configs.py#L50). Could you check this error? In addition, I would like to hear if you will update to reduce the length of the default prompt for Agent.
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Below is the code for the first three cells of the official code provided in the notebook.
```
transformers_version = "v4.29.0"
print(f"Setting up everything with transformers version {transformers_version}")
!pip install huggingface_hub>=0.14.1 git+https://github.com/huggingface/transformers@$transformers_version -q diffusers accelerate datasets torch soundfile sentencepiece opencv-python openai
import IPython
import soundfile as sf
def play_audio(audio):
sf.write("speech_converted.wav", audio.numpy(), samplerate=16000)
return IPython.display.Audio("speech_converted.wav")
from huggingface_hub import notebook_login
notebook_login()
```
```
agent_name = "OpenAssistant (HF Token)"
import getpass
if agent_name == "StarCoder (HF Token)":
from transformers.tools import HfAgent
agent = HfAgent("https://api-inference.huggingface.co/models/bigcode/starcoder")
print("StarCoder is initialized 💪")
elif agent_name == "OpenAssistant (HF Token)":
from transformers.tools import HfAgent
agent = HfAgent(url_endpoint="https://api-inference.huggingface.co/models/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5")
print("OpenAssistant is initialized 💪")
if agent_name == "OpenAI (API Key)":
from transformers.tools import OpenAiAgent
pswd = getpass.getpass('OpenAI API key:')
agent = OpenAiAgent(model="text-davinci-003", api_key=pswd)
print("OpenAI is initialized 💪")
```
```
boat = agent.run("Generate an image of a boat in the water")
boat
```
### Expected behavior
```
==Explanation from the agent==
I will use the following tool: `image_generator` to generate an image.
==Code generated by the agent==
image = image_generator(prompt="a boat in the water")
==Result==
<image.png>
```
as like `bigcode/starcoder` or `text-davinci-003`, but I got
```
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
[<ipython-input-3-4578d52c5ccf>](https://localhost:8080/#) in <cell line: 1>()
----> 1 boat = agent.run("Generate an image of a boat in the water")
2 boat
1 frames
[/usr/local/lib/python3.10/dist-packages/transformers/tools/agents.py](https://localhost:8080/#) in run(self, task, return_code, remote, **kwargs)
312 """
313 prompt = self.format_prompt(task)
--> 314 result = self.generate_one(prompt, stop=["Task:"])
315 explanation, code = clean_code_for_run(result)
316
[/usr/local/lib/python3.10/dist-packages/transformers/tools/agents.py](https://localhost:8080/#) in generate_one(self, prompt, stop)
486 return self._generate_one(prompt)
487 elif response.status_code != 200:
--> 488 raise ValueError(f"Error {response.status_code}: {response.json()}")
489
490 result = response.json()[0]["generated_text"]
ValueError: Error 422: {'error': 'Input validation error: `inputs` must have less than 1024 tokens. Given: 1553', 'error_type': 'validation'}
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25220/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25220/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25219
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25219/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25219/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25219/events
|
https://github.com/huggingface/transformers/issues/25219
| 1,830,148,402 |
I_kwDOCUB6oc5tFdky
| 25,219 |
Trainer.model.push_to_hub() should allow private repository flag
|
{
"login": "arikanev",
"id": 16505410,
"node_id": "MDQ6VXNlcjE2NTA1NDEw",
"avatar_url": "https://avatars.githubusercontent.com/u/16505410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arikanev",
"html_url": "https://github.com/arikanev",
"followers_url": "https://api.github.com/users/arikanev/followers",
"following_url": "https://api.github.com/users/arikanev/following{/other_user}",
"gists_url": "https://api.github.com/users/arikanev/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arikanev/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arikanev/subscriptions",
"organizations_url": "https://api.github.com/users/arikanev/orgs",
"repos_url": "https://api.github.com/users/arikanev/repos",
"events_url": "https://api.github.com/users/arikanev/events{/privacy}",
"received_events_url": "https://api.github.com/users/arikanev/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @arikanev, thanks for raising this issue. \r\n\r\nIn `TrainingArguments` you can set [hub_private_repo to `True`](https://huggingface.co/docs/transformers/v4.31.0/en/main_classes/trainer#transformers.TrainingArguments.hub_private_repo) to control this. ",
"Thanks for the heads up! Time saver :) ",
"Please note, I tried using this in TrainingArguments and it did not work! I set hub_private_repo to True.",
"Hi @arikanev, OK thanks for reporting.. \r\n\r\nSo that we can help, could you provide some more details: \r\n* A minimal code snippet to reproduce the issue \r\n* Information about the running environment: run `transformers-cli env` in the terminal and copy-paste the output \r\n* More information about the expected and observed behaviour: when you say it didn't work, what specifically? Did it fail with an error, not create a repo, create a public repo etc? ",
"```\r\ntraining_args = TrainingArguments(\r\n output_dir=\"./myLM\", # output directory for model predictions and checkpoints\r\n overwrite_output_dir=True,\r\n num_train_epochs=50, # total number of training epochs\r\n per_device_train_batch_size=16, # batch size per device during training\r\n per_device_eval_batch_size=64, # batch size for evaluation\r\n warmup_steps=warmup_steps, # number of warmup steps for learning rate scheduler\r\n weight_decay=weight_decay, # strength of weight decay\r\n logging_dir=\"./logs\", # directory for storing logs\r\n logging_steps=10000, # when to print log\r\n evaluation_strategy=\"steps\",\r\n report_to='wandb',\r\n save_total_limit=2,\r\n hub_private_repo=True,\r\n fp16=True,\r\n )\r\n \r\n```\r\n\r\n\r\ntokenizers-0.13.3 transformers-4.31.0\r\n\r\nIt created a public repository even though I set private_hub_repo=True\r\n\r\nThanks!\r\n\r\n\r\n\r\n\r\n \r\n ",
"Hi @arikanev, thanks for confirming. \r\n\r\nThat's really weird 🤔 I'm not able to reproduce on my end. Could you try running the following and let me know if it works:\r\n\r\n```\r\npython examples/pytorch/language-modeling/run_clm.py \\\r\n --model_name_or_path gpt2 \\\r\n --dataset_name wikitext \\\r\n --dataset_config_name wikitext-2-raw-v1 \\\r\n --per_device_train_batch_size 8 \\\r\n --per_device_eval_batch_size 8 \\\r\n --do_train \\\r\n --do_eval \\\r\n --output_dir /tmp/test-clm \\\r\n --hub_private_repo \\\r\n --push_to_hub \\\r\n --max_train_samples 10 \\\r\n --max_eval_samples 10\r\n```\r\n\r\nThis is running [this example script](https://github.com/huggingface/transformers/blob/5ee9693a1c77c617ebc43ef20194b6d3b674318e/examples/pytorch/language-modeling/run_clm.py) in transformers.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,694 | 1,694 |
NONE
| null |
### Feature request
Trainer.model.push_to_hub() should allow a push to a private repository, as opposed to just pushing to a public and having to private it after.
### Motivation
I get frustrated having to private my repositories instead of being able to upload models by default to a private repo programmatically.
### Your contribution
I’m not sure I have the bandwidth at the moment or have the infrastructure know how to contribute this option, but if this is of interest to many people and you guys could use the help I can work on a PR.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25219/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25219/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25218
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25218/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25218/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25218/events
|
https://github.com/huggingface/transformers/pull/25218
| 1,830,127,630 |
PR_kwDOCUB6oc5W2ZB1
| 25,218 |
inject automatic end of utterance tokens
|
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25218). All of your documentation changes will be reflected on that endpoint."
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
This adds a new feature:
For select models add `<end_of_utterance>` token at the end of each utterance.
The user can now easily break up their prompt and not need to worry about messing with tokens.
So for this prompt:
```
[
"User:",
image,
"Describe this image.",
"Assistant: An image of two kittens in grass.",
"User:",
"https://hips.hearstapps.com/hmg-prod/images/dog-puns-1581708208.jpg",
"Describe this image.",
"Assistant:",
],
```
this new code with add_end_of_utterance_token=True will generate:
`full_text='<s>User:<fake_token_around_image><image><fake_token_around_image>Describe this image.<end_of_utterance>Assistant: An image of two kittens in grass.<end_of_utterance>User:<fake_token_around_image><image><fake_token_around_image>Describe this image.<end_of_utterance>Assistant:'
`
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25218/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25218/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25218",
"html_url": "https://github.com/huggingface/transformers/pull/25218",
"diff_url": "https://github.com/huggingface/transformers/pull/25218.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25218.patch",
"merged_at": 1690846918000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25217
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25217/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25217/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25217/events
|
https://github.com/huggingface/transformers/issues/25217
| 1,829,805,442 |
I_kwDOCUB6oc5tEJ2C
| 25,217 |
Scoring translations is unacceptably slow
|
{
"login": "erip",
"id": 2348806,
"node_id": "MDQ6VXNlcjIzNDg4MDY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2348806?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/erip",
"html_url": "https://github.com/erip",
"followers_url": "https://api.github.com/users/erip/followers",
"following_url": "https://api.github.com/users/erip/following{/other_user}",
"gists_url": "https://api.github.com/users/erip/gists{/gist_id}",
"starred_url": "https://api.github.com/users/erip/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/erip/subscriptions",
"organizations_url": "https://api.github.com/users/erip/orgs",
"repos_url": "https://api.github.com/users/erip/repos",
"events_url": "https://api.github.com/users/erip/events{/privacy}",
"received_events_url": "https://api.github.com/users/erip/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @gante ",
"Hey @erip 👋 \r\n\r\nSadly, I'm out of bandwidth to dive into the performance of very specific generation modes (in this case, beam search with `PrefixConstrainedLogitsProcessor`). If you'd like to explore the issue and pinpoint the cause of the performance issue, I may be able to help, depending on the complexity of the fix.\r\n\r\nMeanwhile, I've noticed that you use `torch.compile`. I would advise you not to use it with text generation, as your model observes different shapes at each forward pass call, resulting in potential slowdowns :) ",
"Cheers, @gante. I'll try removing the compilation to see how far that moves the needle. I'm trying to score ~17m translations which tqdm is reporting will take ~50 days so we'll see what the delta is without `torch.compile`. I'll post updates here as well.\r\n\r\nEdit: 96 days w/o `torch.compile` :-)",
"@erip have you considered applying 4-bit quantization ([docs](https://huggingface.co/docs/transformers/v4.31.0/en/main_classes/quantization#load-a-large-model-in-4bit), reduces the GPU ram requirements to ~1/6 of the original size AND should result in speedups) and then increasing the batch size as much as possible? \r\n\r\nYou may be able to get it <1 week this way, and the noise introduced by 4 bit quantization is small.",
"I guess I'm more concerned that this is going to take a lot of time at all. Fairseq, Marian, and Sockeye can score translations extremely quickly (17m would probably take ~1-2 days on similar hardware). Transformers can translate in that amount of time, so I'm lead to conclude that logits processors are just performance killers.",
"@erip some of them are performance killers (e.g. `PrefixConstrainedLogitsProcessor ` seems to need vectorization). Our Pytorch beam search implementation is not optimized either, compared to our TF/FLAX implementation.\r\n\r\nWe focus on breadth of techniques and models, but welcome optimization contributions 🤗 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.29.0
- Platform: Linux-3.10.0-862.11.6.el7.x86_64-x86_64-with-glibc2.17
- Python version: 3.9.16
- Huggingface_hub version: 0.12.1
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker and @younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Install transformers, pytorch, tqdm
2. Create `forced_decode.py` [^1]
3. Create `repro.sh` [^2]
4. Run `bash repro.sh` and observe extremely slow scoring speeds.
[^1]:
```python
#!/usr/bin/env python3
import itertools
from argparse import ArgumentParser, FileType
from tqdm import tqdm
import torch
from transformers import PrefixConstrainedLogitsProcessor, AutoTokenizer, AutoModelForSeq2SeqLM
def setup_argparse():
parser = ArgumentParser()
parser.add_argument("-t", "--tokenizer", type=str, required=True)
parser.add_argument("-m", "--model", type=str, required=True)
parser.add_argument("-bs", "--batch-size", type=int, default=16)
parser.add_argument("-i", "--input", type=FileType("r"), default="-")
parser.add_argument("-o", "--output", type=FileType("w"), default="-")
parser.add_argument("-d", "--delimiter", type=str, default="\t")
parser.add_argument("--device", type=str, default="cpu")
return parser
def create_processor_fn(ref_tokens_by_segment):
def inner(batch_id, _):
return ref_tokens_by_segment[batch_id]
return inner
def tokenize(src, tgt, tokenizer):
inputs = tokenizer(src, text_target=tgt, padding=True, return_tensors="pt")
return inputs
def forced_decode(inputs, model, num_beams=5):
inputs = inputs.to(model.device)
logit_processor = PrefixConstrainedLogitsProcessor(create_processor_fn(inputs["labels"]), num_beams=num_beams)
output = model.generate(**inputs, num_beams=num_beams, logits_processor=[logit_processor], return_dict_in_generate=True, output_scores=True)
return output.sequences_scores.tolist()
def batch_lines(it, batch_size):
it = iter(it)
item = list(itertools.islice(it, batch_size))
while item:
yield item
item = list(itertools.islice(it, batch_size))
if __name__ == "__main__":
args = setup_argparse().parse_args()
f_tokenizer = AutoTokenizer.from_pretrained(args.tokenizer)
f_model = torch.compile(AutoModelForSeq2SeqLM.from_pretrained(args.model).to(args.device))
with args.input as fin:
inputs = list(batch_lines(map(str.strip, fin), args.batch_size))
inputs_logits = []
for batch in tqdm(inputs):
src, tgt = zip(*[line.split(args.delimiter) for line in batch])
inputs_logits.append(tokenize(src, tgt, f_tokenizer))
with args.output as fout, torch.no_grad():
for input in tqdm(inputs_logits):
scores = forced_decode(input, f_model)
print(*scores, sep="\n", file=fout)
```
[^2]:
```bash
#!/usr/bin/env bash
function get_input {
curl -s https://gist.githubusercontent.com/erip/e37283b8f51d4e2c16996fc8a6a01aa7/raw/f5a3daffb04dad76464188c2a6949649f5cf3f9c/en-de.tsv
}
python forced_decode.py \
-t Helsinki-NLP/opus-mt-en-de -m Helsinki-NLP/opus-mt-en-de \
-i <(get_input) \
--device cuda:0 \
-bs 16
```
### Expected behavior
Scoring should be _very fast_ since the beam doesn't actually need to be searched, but I'm finding speeds on the order of seconds per batch which is far slower than generating.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25217/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25217/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25216
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25216/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25216/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25216/events
|
https://github.com/huggingface/transformers/pull/25216
| 1,829,739,665 |
PR_kwDOCUB6oc5W1EHH
| 25,216 |
[`Docs`/`quantization`] Clearer explanation on how things works under the hood. + remove outdated info
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
As discussed internally with @amyeroberts , this PR makes things clearer to users on how things work under the hood for quantized models. Before this PR it was not clear to users how the other modules (non `torch.nn.Linear`) were treated under the hood when quantizing a model.
cc @amyeroberts
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25216/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25216/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25216",
"html_url": "https://github.com/huggingface/transformers/pull/25216",
"diff_url": "https://github.com/huggingface/transformers/pull/25216.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25216.patch",
"merged_at": 1690880212000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25215
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25215/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25215/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25215/events
|
https://github.com/huggingface/transformers/issues/25215
| 1,829,715,520 |
I_kwDOCUB6oc5tDz5A
| 25,215 |
config.json file not available
|
{
"login": "andysingal",
"id": 20493493,
"node_id": "MDQ6VXNlcjIwNDkzNDkz",
"avatar_url": "https://avatars.githubusercontent.com/u/20493493?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/andysingal",
"html_url": "https://github.com/andysingal",
"followers_url": "https://api.github.com/users/andysingal/followers",
"following_url": "https://api.github.com/users/andysingal/following{/other_user}",
"gists_url": "https://api.github.com/users/andysingal/gists{/gist_id}",
"starred_url": "https://api.github.com/users/andysingal/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/andysingal/subscriptions",
"organizations_url": "https://api.github.com/users/andysingal/orgs",
"repos_url": "https://api.github.com/users/andysingal/repos",
"events_url": "https://api.github.com/users/andysingal/events{/privacy}",
"received_events_url": "https://api.github.com/users/andysingal/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @andysingal \r\nit seems you are trying to load an adapter model. You can load it with\r\n\r\n```python\r\nfrom peft import AutoPeftModelForCausalLM\r\n\r\nmodel = AutoPeftModelForCausalLM.from_pretrained(\"Andyrasika/qlora-2-7b-andy\")\r\n```\r\n\r\nIf you want to load the base model in 4bit:\r\n\r\n```python\r\nfrom peft import AutoPeftModelForCausalLM\r\n\r\nmodel = AutoPeftModelForCausalLM.from_pretrained(\"Andyrasika/qlora-2-7b-andy\", load_in_4bit=True)\r\n```\r\n\r\nOnce https://github.com/huggingface/transformers/pull/25077 will get merged you'll be able to load the model directly with `AutoModelForCausalLM`.",
"Thanks for your email. But why am I getting the error message?. I already\r\nhave adapter_config. JSON .\r\n\r\nOn Mon, Jul 31, 2023 at 23:09 Younes Belkada ***@***.***>\r\nwrote:\r\n\r\n> Hi @andysingal <https://github.com/andysingal>\r\n> it seems you are trying to load an adapter model. You can load it with\r\n>\r\n> from peft import AutoPeftModelForCausalLM\r\n> model = AutoPeftModelForCausalLM.from_pretrained(\"Andyrasika/qlora-2-7b-andy\")\r\n>\r\n> If you want to load the base model in 4bit:\r\n>\r\n> from peft import AutoPeftModelForCausalLM\r\n> model = AutoPeftModelForCausalLM.from_pretrained(\"Andyrasika/qlora-2-7b-andy\", load_in_4bit=True)\r\n>\r\n> Once #25077 <https://github.com/huggingface/transformers/pull/25077> will\r\n> get merged you'll be able to load the model directly with\r\n> AutoModelForCausalLM.\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/transformers/issues/25215#issuecomment-1658859481>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AE4LJNPF5H4NF3BC4XKTXL3XS7UUDANCNFSM6AAAAAA26SP5AE>\r\n> .\r\n> You are receiving this because you were mentioned.Message ID:\r\n> ***@***.***>\r\n>\r\n",
"Hi @andysingal \r\nIt is because `AutoModelForCausalLM` will look if there is any `config.json` file present on that model folder and not `adapter_config.json` which are two different file names",
"When you run the model created it gives the same error. Assume I am making\r\nan error in the notebook, but inference does not need to show the error on\r\nyour website?\r\nPlease advise on how to fix it?\r\n\r\nOn Mon, Jul 31, 2023 at 23:22 Younes Belkada ***@***.***>\r\nwrote:\r\n\r\n> Hi @andysingal <https://github.com/andysingal>\r\n> It is because AutoModelForCausalLM will look if there is any config.json\r\n> file present on that model folder and not adapter_config.json which are\r\n> two different file names\r\n>\r\n> —\r\n> Reply to this email directly, view it on GitHub\r\n> <https://github.com/huggingface/transformers/issues/25215#issuecomment-1658883214>,\r\n> or unsubscribe\r\n> <https://github.com/notifications/unsubscribe-auth/AE4LJNK3H374C3UHR2ZABBTXS7WF7ANCNFSM6AAAAAA26SP5AE>\r\n> .\r\n> You are receiving this because you were mentioned.Message ID:\r\n> ***@***.***>\r\n>\r\n",
"@younesbelkada Any updates?",
"Hi @andysingal \r\nThanks for the ping, as stated above, in your repository only adapter weights and config are stored. Currently it is not supported to load apapted models directly using `AutoModelForCausalLM.from_pretrained(xxx)`, please refer to this comment https://github.com/huggingface/transformers/issues/25215#issuecomment-1658859481 to effectively load the adapted model using PEFT library.",
"> \r\n\r\nThanks @younesbelkada for your instant reply. My question is when i compute Text generation inference on your website it gives that error. **I understand i need to use peft for loading the adpater and config files using peft in my preferred env**\r\n\r\nLooking forward to hearing from you @ArthurZucker ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"> > \r\n> \r\n> Thanks @younesbelkada for your instant reply. My question is when i compute Text generation inference on your website it gives that error. **I understand i need to use peft for loading the adpater and config files using peft in my preferred env**\r\n> \r\n> Looking forward to hearing from you @ArthurZucker\r\n\r\nyou may need to load the lora_adapter into model using the the following code\r\n```python\r\nmodel = AutoModelForCausalLM.from_pretrained(\"./original_model_path \", trust_remote_code=True)\r\nmodel = PeftModel.from_pretrained(model, \"./lora_model_path\")\r\n```",
"Im running into the same issue through the user interface",
"it is throwing the same OS error even with \r\n`model = AutoPeftModelForCausalLM.from_pretrained(\"Andyrasika/qlora-2-7b-andy\"`"
] | 1,690 | 1,706 | 1,694 |
NONE
| null |
### System Info
colab
notebook: https://colab.research.google.com/drive/118RTcKAQFIICDsgTcabIF-_XKmOgM-cc?usp=sharing
### Who can help?
@sgugger @younesbelkada
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
RepositoryNotFoundError: 404 Client Error. (Request ID:
Root=1-64c7ee9d-240cd76b269a914d67b458fa;dcab1901-0ebf-4282-b8a4-9d1e087de5b4)
Repository Not Found for url: https://huggingface.co/None/resolve/main/config.json.
Please make sure you specified the correct `repo_id` and `repo_type`.
If you are trying to access a private or gated repo, make sure you are authenticated.
During handling of the above exception, another exception occurred:
```
### Expected behavior
https://huggingface.co/Andyrasika/qlora-2-7b-andy giving error:
```
Andyrasika/qlora-2-7b-andy does not appear to have a file named config.json. Checkout 'https://huggingface.co/Andyrasika/qlora-2-7b-andy/7a0facc5b1f630824ac5b38853dec5e988a5569e' for available files.
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25215/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25215/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25214
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25214/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25214/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25214/events
|
https://github.com/huggingface/transformers/pull/25214
| 1,829,588,972 |
PR_kwDOCUB6oc5W0jNa
| 25,214 |
Fix docker image build failure
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
We again get not enough disk size error on docker image build CI. I should try to learn some ways to reduce the size and avoid this error, but this PR fixes this situation in a quick way: install torch/tensorflow before running `pip install .[dev]`, so they are only install once, and we have fewer docker layers produced.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25214/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25214/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25214",
"html_url": "https://github.com/huggingface/transformers/pull/25214",
"diff_url": "https://github.com/huggingface/transformers/pull/25214.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25214.patch",
"merged_at": 1690827196000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25213
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25213/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25213/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25213/events
|
https://github.com/huggingface/transformers/pull/25213
| 1,829,494,005 |
PR_kwDOCUB6oc5W0NhC
| 25,213 |
Update tiny model info. and pipeline testing
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25213). All of your documentation changes will be reflected on that endpoint."
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
Just a regular update.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25213/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25213/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25213",
"html_url": "https://github.com/huggingface/transformers/pull/25213",
"diff_url": "https://github.com/huggingface/transformers/pull/25213.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25213.patch",
"merged_at": 1690824933000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25212
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25212/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25212/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25212/events
|
https://github.com/huggingface/transformers/issues/25212
| 1,829,319,221 |
I_kwDOCUB6oc5tCTI1
| 25,212 |
MinNewTokensLengthLogitsProcessor
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,690 | 1,690 | 1,690 |
MEMBER
| null | null |
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25212/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25212/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25211
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25211/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25211/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25211/events
|
https://github.com/huggingface/transformers/pull/25211
| 1,829,299,673 |
PR_kwDOCUB6oc5WziM6
| 25,211 |
Fix `all_model_classes` in `FlaxBloomGenerationTest`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,691 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
It should be a tuple (which requires the ending `,`)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25211/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25211/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25211",
"html_url": "https://github.com/huggingface/transformers/pull/25211",
"diff_url": "https://github.com/huggingface/transformers/pull/25211.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25211.patch",
"merged_at": 1690817526000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25210
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25210/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25210/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25210/events
|
https://github.com/huggingface/transformers/issues/25210
| 1,829,299,671 |
I_kwDOCUB6oc5tCOXX
| 25,210 |
importlib.metadata.PackageNotFoundError: bitsandbytes
|
{
"login": "looperEit",
"id": 46367388,
"node_id": "MDQ6VXNlcjQ2MzY3Mzg4",
"avatar_url": "https://avatars.githubusercontent.com/u/46367388?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/looperEit",
"html_url": "https://github.com/looperEit",
"followers_url": "https://api.github.com/users/looperEit/followers",
"following_url": "https://api.github.com/users/looperEit/following{/other_user}",
"gists_url": "https://api.github.com/users/looperEit/gists{/gist_id}",
"starred_url": "https://api.github.com/users/looperEit/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/looperEit/subscriptions",
"organizations_url": "https://api.github.com/users/looperEit/orgs",
"repos_url": "https://api.github.com/users/looperEit/repos",
"events_url": "https://api.github.com/users/looperEit/events{/privacy}",
"received_events_url": "https://api.github.com/users/looperEit/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @looperEit, thanks for reporting this issue! \r\n\r\nCould you share the installed version of bitsandbytes and how you installed it? \r\n\r\ncc @younesbelkada ",
"i used the `pip install -r *requriment.txt\"`,and the txt file like:\r\n\r\n\r\naccelerate\r\ncolorama~=0.4.6\r\ncpm_kernels\r\nsentencepiece~=0.1.99\r\nstreamlit~=1.25.0\r\ntransformers_stream_generator\r\ntorch~=2.0.1\r\ntransformers~=4.31.0",
"Hi @looperEit \r\nCan you try to run\r\n```bash\r\npip install bitsandbytes\r\n```\r\nit looks like this is missing in `requirements.txt` file",
"> Hi @looperEit Can you try to run\r\n> \r\n> ```shell\r\n> pip install bitsandbytes\r\n> ```\r\n> \r\n> it looks like this is missing in `requirements.txt` file\r\nwhen i installed the bitsandbytes, it shows:\r\n\r\nmay i join it in my `requirements.txt` file?",
"@looperEit Yes, you can certainly add it to your own requirements.txt file. \r\n\r\nFor the error being raised, could you copy paste the full text of the traceback, rather than a screenshot? This makes it easier for us to debug, as we highlight and copy the text, and also makes the issue findable through search for anyone else who's had the issue. \r\n\r\nIn the screenshot for the error after installing bitsandbytes, could you show the full trackback? The final error message / exception appears to be missing. ",
"i'm so sorry QAQ ,here is the problem when i installed the bitsandbytes:\r\n`/root/anaconda3/envs/baichuan/bin/python3.9 /tmp/Baichuan-13B/ demo. pyTraceback (most recent call last):\r\nFile \"/root/anacondaS/envs/baichuan/1io/pythons.9/site-packages/transfonmens/utils/import_utils.py\",line 1099,in _get_modulereturn importlib.import_module(\".\" + module_name,self.__name_-)\r\nFile \"/root/anaconda3/envs/baichuan/lib/python3.9/impontlib/.-init...py\",line 127,in impont_ modulereturn _bootstrap. _gcd_import(name[level:], package,level)\r\nFile \"<frozen importlib._bootstrap>\",line 1030,in _gcd_importFile \"<frozen importlib._bootstrap>\",line 1007,in _find_and_load\r\nFile \"<frozen importlib._bootstrap>\",line 986, in _find_and_load_unlockedFile \"<frozen importlib._bootstrap>\",line 680, in _load_unlocked\r\nFile \"<frozen importlib._bootstrap_externals\", line 850, in exec_module\r\nFile \"<frozen importlib._bootstrap>\", line 228,in _call_with_frames_removed`\r\nbut finally when i installed the `spicy`, i make it. i didn't know why. Maybe the transfomer package and bitsandbytes must coexist with spicy?",
"maybe 🤷♀️ although the package manager should have installed any dependencies alongside the library itself. Do you mean `scipy` for the dependency? I've never heard of spicy. \r\n\r\nEither way, I'm glad to hear that you were able to resolve the issue :) Managing python environments is a perpetual juggling act. ",
"> maybe 🤷♀️ although the package manager should have installed any dependencies alongside the library itself. Do you mean `scipy` for the dependency? I've never heard of spicy.\r\n> \r\n> Either way, I'm glad to hear that you were able to resolve the issue :) Managing python environments is a perpetual juggling act.\r\n\r\ni'm so sorry,I know where the problem is. The model requirement I use does not include the scipy package. I'm really sorry for wasting your time and disturbing you. Thanks.\r\n\r\n",
"`pip install bitsandbytes ` works for me.",
"`pip install bitsandbytes` really works for me. But the bitsandbytes library only works on CUDA GPU. What a pity! I want to use it on Intel cpu.",
"> Hi @looperEit Can you try to run\r\n> \r\n> ```shell\r\n> pip install bitsandbytes\r\n> ```\r\n> \r\n> it looks like this is missing in `requirements.txt` file\r\n\r\nNice, thank you bro",
"> ```shell\r\n> pip install bitsandbytes\r\n> ```\r\n\r\nThanks! works for me"
] | 1,690 | 1,701 | 1,690 |
NONE
| null |
### System Info
`transformers` version: 4.32.0.dev0
- Platform: Linux-5.4.0-153-generic-x86_64-with-glibc2.27
- Python version: 3.9.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModel
from transformers import BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nn
model_name_or_path = "Baichuan-13B-Chat"
bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", llm_int8_threshold=6.0, llm_int8_has_fp16_weight=False)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)
messages = []
messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
response = model.chat(tokenizer, messages)
print(response)
### Expected behavior
`import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModel
from transformers import BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nn
model_name_or_path = "Baichuan-13B-Chat"
bnb_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", llm_int8_threshold=6.0, llm_int8_has_fp16_weight=False)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)
messages = []
messages.append({"role": "user", "content": "世界上第二高的山峰是哪座"})
response = model.chat(tokenizer, messages)
print(response)
`
I reported an error after importing BitsAndBytesConfig from transformer:
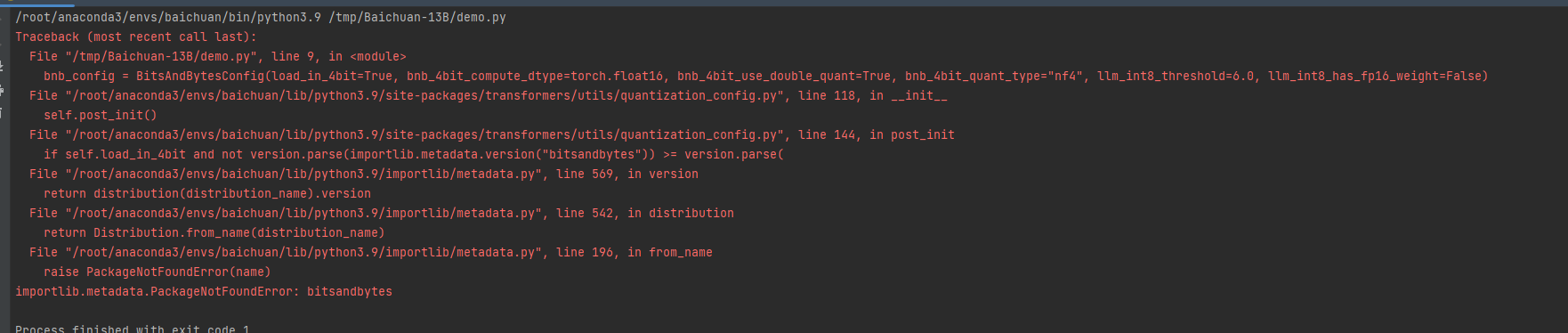
But after I installed bitsandbytes, I still reported an error:

|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25210/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25210/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25209
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25209/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25209/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25209/events
|
https://github.com/huggingface/transformers/pull/25209
| 1,829,156,249 |
PR_kwDOCUB6oc5WzCvk
| 25,209 |
Update InstructBLIP & Align values after rescale update
|
{
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Agreed with your plan!",
"I also prefer 2., but I am a bit confused\r\n\r\n> Update rescale and ViVit config\r\n\r\nSo this only changes `ViVit` config and its `rescale`. And Align uses `EfficientNet` image processor. So when we change something in `ViVitf`, how this fixes the CI failing ... 🤔 ?",
"> So this only changes ViVit config and its rescale. And Align uses EfficientNet image processor. So when we change something in ViVitf, how this fixes the CI failing ... 🤔 ?\r\n\r\n@ydshieh Sorry, it wasn't super clear. The reason the CI is failing is because:\r\n* Align doesn't have its own image processor - it uses EfficientNet's\r\n* EfficientNet and ViVit both have the option to 'offset' when rescaling i.e. centering the pixel values around 0. \r\n* As both EfficientNet and ViVit's image processors have a rescale_factor of `1/255` by default, their docstrings mention setting `rescale_offset=True` rescales between `[-1, 1]` and they offset before rescaling, I assumed that then intention was to optionally rescale by `2 * rescale_factor` if `rescale_offset=True` for both\r\n* This was true for ViVit.\r\n* Align image processor config value are actually already updated so `rescale_factor` is `2 * (1 / 255) = 1 / 127.5`\r\n* Therefore, the resulting pixel values from Align's image processor weren't in the range `[-1, 1]` when rescale was changed. \r\n\r\nUpdating something in ViVit doesn't fix the CI directly. I'll also have to update `rescale` for both the methods to use Align's intended logic. \r\n\r\n",
"@ydshieh I've made the updates for option 2: \r\n\r\n* Reverted to the previous `rescale` behaviour for EfficientNet: 7c3b3bb\r\n* Same behaviour is copied across to ViVit, also in 7c3b3bb\r\n* Made PRs to update the rescale values in ViVit models - `rescale_factor` 1/255 -> 1/127.5\r\n - https://huggingface.co/google/vivit-b-16x2/discussions/1#64c92542c96a10fa85bbca0b\r\n - https://huggingface.co/google/vivit-b-16x2-kinetics400/discussions/2#64c9253aaf935d3927ec1409\r\n\r\n",
"Oh I know why I get confused now \r\n\r\n> Update the values in the ViVit model config. Revert the rescale behaviour so that rescale_offset and rescale_factor are independent.\r\n\r\nI thought only ViVit would be changed in this PR, but actually you mean both ViVit and `EfficientNet` (but the revert to before #25174).\r\n\r\nThanks for the update!\r\n"
] | 1,690 | 1,691 | 1,691 |
COLLABORATOR
| null |
# What does this PR do?
After #25174 the integration tests for Align and InstructBLIP fail.
### InstructBLIP
The difference in the output logits is small. Additionally, when debugging to check the differences and resolve the failing tests, it was noticed that the InstructBLIP tests are not independent. Running
```
RUN_SLOW=1 pytest tests/models/instructblip/test_modeling_instructblip.py::InstructBlipModelIntegrationTest::test_inference_vicuna_7b
```
produces different logits than running:
```
RUN_SLOW=1 pytest tests/models/instructblip/test_modeling_instructblip.py::InstructBlipModelIntegrationTest
```
The size differences between these two runs was similar to the size of differences seen with the update in `rescale`. Hence, I decided that updating the logits was OK.
### Align
The differences in align come from the model's image processor config values. Align uses EfficientNet's image processor. By default, [EfficientNet has `rescale_offset` set to `False`](https://github.com/huggingface/transformers/blob/0fd8d2aa2cc9e172a8af9af8508b2530f55ca14c/src/transformers/models/efficientnet/image_processing_efficientnet.py#L92) and [`rescale_factor` set to `1 / 255`](https://github.com/huggingface/transformers/blob/0fd8d2aa2cc9e172a8af9af8508b2530f55ca14c/src/transformers/models/efficientnet/image_processing_efficientnet.py#L91). Whereas Align has it set to `True` e.g. for [this config](https://huggingface.co/kakaobrain/align-base/blob/e96a37facc7b1f59090ece82293226b817afd6ba/preprocessor_config.json#L25) and the [`rescale_factor` set to `1 / 127.5`](https://huggingface.co/kakaobrain/align-base/blob/e96a37facc7b1f59090ece82293226b817afd6ba/preprocessor_config.json#L24).
In #25174, the `rescale` logic was updated so that if `rescale` is called with `offset=True`, the image values are rescaled between by `scale * 2`. This was because this was I was working from the EfficientNet and ViVit `rescale_factor` values which were both 1/255, so assumed the intention was to have this adjust if `rescale_offset` was True.
There's three options for resolving this:
1. Update Align Config
Update the values in the align checkpoint configs so that `rescale_factor` is `1 / 255` instead of `1 /127.5`.
* ✅ Rescale behaviour and config flags consistent across image processors
* ❌ Remaining unexpected behaviour for anyone who has their own checkpoints of this model.
2. Update rescale and ViVit config
Update the values in the ViVit model config. Revert the rescale behaviour so that `rescale_offset` and `rescale_factor` are independent.
* ✅ Rescale behaviour and config flags consistent across image processors
* ❌ Remaining unexpected behaviour for anyone who has their own checkpoints of this model.
* 🟡 No magic behaviour (adjusting `rescale_factor`) but relies on the user correctly updating two arguments to rescale between `[-1, 1]`
3. Revert EfficientNet's rescale method to previous behaviour.
* ✅ Both models fully backwards compatible with previous rescale behaviour and config values
* ❌ Rescale behaviour and config flags not consistent across image processors
I think option 2 is best. ViVit is a newly added model, it keeps consistent behaviour between Align / EffiicentNet and ViVit and the `rescale` method isn't doesn't anything magic to make the other arguments work. @sgugger @ydshieh I would be good to have your opinion on what you think is best here.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25209/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25209/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25209",
"html_url": "https://github.com/huggingface/transformers/pull/25209",
"diff_url": "https://github.com/huggingface/transformers/pull/25209.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25209.patch",
"merged_at": 1691056870000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25208
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25208/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25208/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25208/events
|
https://github.com/huggingface/transformers/issues/25208
| 1,829,119,355 |
I_kwDOCUB6oc5tBiV7
| 25,208 |
Getting error while implementing Falcon-7B model: AttributeError: module 'signal' has no attribute 'SIGALRM'
|
{
"login": "amitkedia007",
"id": 83700281,
"node_id": "MDQ6VXNlcjgzNzAwMjgx",
"avatar_url": "https://avatars.githubusercontent.com/u/83700281?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amitkedia007",
"html_url": "https://github.com/amitkedia007",
"followers_url": "https://api.github.com/users/amitkedia007/followers",
"following_url": "https://api.github.com/users/amitkedia007/following{/other_user}",
"gists_url": "https://api.github.com/users/amitkedia007/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amitkedia007/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amitkedia007/subscriptions",
"organizations_url": "https://api.github.com/users/amitkedia007/orgs",
"repos_url": "https://api.github.com/users/amitkedia007/repos",
"events_url": "https://api.github.com/users/amitkedia007/events{/privacy}",
"received_events_url": "https://api.github.com/users/amitkedia007/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey @amitkedia007 ! I'm suspecting you are using Windows? Have you tried [this](https://huggingface.co/tiiuae/falcon-7b-instruct/discussions/57)?\r\n\r\nMaybe adding `trust_remote_code = True` to `tokenizer = AutoTokenizer.from_pretrained(model_name)` in order to allow downloading the appropriate tokenizer would work. \r\nPlease let me know if this works. Trying to help you fast here :)",
"Yes I tried this as well, as you said. But still I am getting the same error: \r\nTraceback (most recent call last):\r\n File \"C:\\DissData\\Dissertation-Brunel\\Falcon-7b.py\", line 8, in <module>\r\n text_generator = pipeline(\"text-generation\", model=model_name, tokenizer=tokenizer)\r\n File \"C:\\Users\\2267302\\AppData\\Roaming\\Python\\Python39\\site-packages\\transformers\\pipelines\\__init__.py\", line 705, in pipeline\r\n config = AutoConfig.from_pretrained(model, _from_pipeline=task, **hub_kwargs, **model_kwargs)\r\n File \"C:\\Users\\2267302\\AppData\\Roaming\\Python\\Python39\\site-packages\\transformers\\models\\auto\\configuration_auto.py\", line 986, in from_pretrained\r\n trust_remote_code = resolve_trust_remote_code(\r\n File \"C:\\Users\\2267302\\AppData\\Roaming\\Python\\Python39\\site-packages\\transformers\\dynamic_module_utils.py\", line 535, in resolve_trust_remote_code\r\n signal.signal(signal.SIGALRM, _raise_timeout_error)\r\nAttributeError: module 'signal' has no attribute 'SIGALRM'",
"I'm going through the code, and I'm finding dynamic_module_utils.py [verbose trace](https://github.com/huggingface/transformers/blob/main/src/transformers/dynamic_module_utils.py#L556C47-L556C47) at 556 instead of 535 . Have a look at the [function as well](https://github.com/huggingface/transformers/blob/9ca3aa01564bb81e1362288a8fdf5ac6e0e63126/src/transformers/dynamic_module_utils.py#L550)\r\nWhich version of the transformers library are you using?",
"See #25049, but basically\r\n\r\n> \"Loading this model requires you to execute execute some code in that repo on your local machine. \"\r\n> \"Make sure you have read the code at https://hf.co/{model_name} to avoid malicious use, then set \"\r\n> \"the option `trust_remote_code=True` to remove this error.\"",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,694 | 1,694 |
NONE
| null |
### System Info

### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
from transformers import AutoTokenizer, pipeline
# Load the tokenizer
model_name = "tiiuae/falcon-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Create a text generation pipeline
text_generator = pipeline("text-generation", model=model_name, tokenizer=tokenizer)
# Generate text
input_text = "Hello! How are you?"
output = text_generator(input_text, max_length=100, do_sample=True)
generated_text = output[0]["generated_text"]
# Print the generated text
print(generated_text)
### Expected behavior
It should get the text generated by the model. But it was showing me this error:
"Traceback (most recent call last):
File "C:\DissData\Dissertation-Brunel\Falcon-7b.py", line 8, in <module>
text_generator = pipeline("text-generation", model=model_name, tokenizer=tokenizer)
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\pipelines\__init__.py", line 705, in pipeline
config = AutoConfig.from_pretrained(model, _from_pipeline=task, **hub_kwargs, **model_kwargs)
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\models\auto\configuration_auto.py", line 986, in from_pretrained
trust_remote_code = resolve_trust_remote_code(
File "C:\Users\2267302\AppData\Roaming\Python\Python39\site-packages\transformers\dynamic_module_utils.py", line 535, in resolve_trust_remote_code
signal.signal(signal.SIGALRM, _raise_timeout_error)
AttributeError: module 'signal' has no attribute 'SIGALRM'"
Is it possible to resolve this error as soon as possible?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25208/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25208/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25207
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25207/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25207/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25207/events
|
https://github.com/huggingface/transformers/pull/25207
| 1,828,990,463 |
PR_kwDOCUB6oc5WyeKl
| 25,207 |
[`pipeline`] revisit device check for pipeline
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"After thinking about it, maybe this shouldn't be the right fix, it is a bad intent from users to add a `device_map` + `device` argument.\r\nLet me know what do you think",
"_The documentation is not available anymore as the PR was closed or merged._",
"Yeah let's raise an error!"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes https://github.com/huggingface/transformers/issues/23336#issuecomment-1657792271
Currently `.to` is called to the model in pipeline even if the model is loaded with accelerate - which is a bad practice and can lead to unexpected behaviour if the model is loaded across multiple GPUs or offloaded to CPU/disk.
This PR simply revisits the check for device assignment
Simple snippet to reproduce the issue:
```python
from transformers import AutoModelForCausalLM, AutoConfig, AutoTokenizer, pipeline
import torch
model_path="facebook/opt-350m"
config = AutoConfig.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_8bit=True, device_map="auto")
tokenizer = AutoTokenizer.from_pretrained(model_path)
params = {
"max_length":1024,
"pad_token_id": 0,
"device_map":"auto",
"load_in_8bit": True,
# "torch_dtype":"auto"
}
pipe = pipeline(
task="text-generation",
model=model,
tokenizer=tokenizer,
device=0,
model_kwargs=params,
)
```
cc @sgugger @Narsil
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25207/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25207/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25207",
"html_url": "https://github.com/huggingface/transformers/pull/25207",
"diff_url": "https://github.com/huggingface/transformers/pull/25207.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25207.patch",
"merged_at": 1690821802000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25206
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25206/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25206/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25206/events
|
https://github.com/huggingface/transformers/pull/25206
| 1,828,925,185 |
PR_kwDOCUB6oc5WyPw1
| 25,206 |
[`PreTrainedModel`] Wrap `cuda` and `to` method correctly
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
As discussed internally with @sgugger
Use `functools.wrap` to wrap the `to` and `cuda` methods to preserve their original signature, for example the script below:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("facebook/opt-350m", load_in_8bit=True)
print(model.to.__doc__)
```
Now gives:
```bash
Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None, non_blocking=False)
:noindex:
.. function:: to(dtype, non_blocking=False)
:noindex:
.. function:: to(tensor, non_blocking=False)
:noindex:
.. function:: to(memory_format=torch.channels_last)
:noindex:
Its signature is similar to :meth:`torch.Tensor.to`, but only accepts
floating point or complex :attr:`dtype`\ s. In addition, this method will
only cast the floating point or complex parameters and buffers to :attr:`dtype`
(if given). The integral parameters and buffers will be moved
:attr:`device`, if that is given, but with dtypes unchanged. When
:attr:`non_blocking` is set, it tries to convert/move asynchronously
with respect to the host if possible, e.g., moving CPU Tensors with
pinned memory to CUDA devices.
See below for examples.
.. note::
This method modifies the module in-place.
Args:
device (:class:`torch.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`torch.dtype`): the desired floating point or complex dtype of
the parameters and buffers in this module
tensor (torch.Tensor): Tensor whose dtype and device are the desired
dtype and device for all parameters and buffers in this module
memory_format (:class:`torch.memory_format`): the desired memory
format for 4D parameters and buffers in this module (keyword
only argument)
Returns:
Module: self
Examples::
>>> # xdoctest: +IGNORE_WANT("non-deterministic")
>>> linear = nn.Linear(2, 2)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]])
>>> linear.to(torch.double)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1913, -0.3420],
[-0.5113, -0.2325]], dtype=torch.float64)
>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_CUDA1)
>>> gpu1 = torch.device("cuda:1")
>>> linear.to(gpu1, dtype=torch.half, non_blocking=True)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16, device='cuda:1')
>>> cpu = torch.device("cpu")
>>> linear.to(cpu)
Linear(in_features=2, out_features=2, bias=True)
>>> linear.weight
Parameter containing:
tensor([[ 0.1914, -0.3420],
[-0.5112, -0.2324]], dtype=torch.float16)
>>> linear = nn.Linear(2, 2, bias=None).to(torch.cdouble)
>>> linear.weight
Parameter containing:
tensor([[ 0.3741+0.j, 0.2382+0.j],
[ 0.5593+0.j, -0.4443+0.j]], dtype=torch.complex128)
>>> linear(torch.ones(3, 2, dtype=torch.cdouble))
tensor([[0.6122+0.j, 0.1150+0.j],
[0.6122+0.j, 0.1150+0.j],
[0.6122+0.j, 0.1150+0.j]], dtype=torch.complex128)
```
Which should correspond to `torch.nn.Module`'s `to` method.
cc @sgugger
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25206/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25206/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25206",
"html_url": "https://github.com/huggingface/transformers/pull/25206",
"diff_url": "https://github.com/huggingface/transformers/pull/25206.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25206.patch",
"merged_at": 1690817110000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25205
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25205/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25205/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25205/events
|
https://github.com/huggingface/transformers/issues/25205
| 1,828,908,003 |
I_kwDOCUB6oc5tAuvj
| 25,205 |
Using Trainer with torch.compile() and use_orig_params=True produce model checkpoints that cannot be loaded
|
{
"login": "ikergarcia1996",
"id": 18737249,
"node_id": "MDQ6VXNlcjE4NzM3MjQ5",
"avatar_url": "https://avatars.githubusercontent.com/u/18737249?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ikergarcia1996",
"html_url": "https://github.com/ikergarcia1996",
"followers_url": "https://api.github.com/users/ikergarcia1996/followers",
"following_url": "https://api.github.com/users/ikergarcia1996/following{/other_user}",
"gists_url": "https://api.github.com/users/ikergarcia1996/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ikergarcia1996/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ikergarcia1996/subscriptions",
"organizations_url": "https://api.github.com/users/ikergarcia1996/orgs",
"repos_url": "https://api.github.com/users/ikergarcia1996/repos",
"events_url": "https://api.github.com/users/ikergarcia1996/events{/privacy}",
"received_events_url": "https://api.github.com/users/ikergarcia1996/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I think this comes from a bas interaction between `torch.compile` and FSDP, cc @pacman100 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"I am encountering the same issue, where after saving a model that has been compiled using `torch.compile`, `safetensors.load_model` throws: \r\n```\r\nRuntimeError: Error(s) in loading state_dict for DummyModel:\r\n Missing key(s) in state_dict: \"module.0.bias\", \"module.0.weight\", \"module.2.bias\", \"module.2.weight\"\r\n Unexpected key(s) in state_dict: \"_orig_mod.module.0.bias\", \"_orig_mod.module.0.weight\", \"_orig_mod.module.2.bias\", \"_orig_mod.module.2.weight\"\r\n```\r\nIn this case, the model has a `nn.Sequential` called `module`. Can draft a quick repro if you wish. \r\n\r\nA fix I found is to unwrap the model, but this only works if you know the module names a priori: \r\n```py\r\n# https://github.com/huggingface/transformers/blob/main/src/transformers/modeling_utils.py#L4788C1-L4799C21\r\ndef unwrap_model(model: nn.Module) -> nn.Module:\r\n \"\"\"\r\n Recursively unwraps a model from potential containers (as used in distributed training).\r\n\r\n Args:\r\n model (`torch.nn.Module`): The model to unwrap.\r\n \"\"\"\r\n # since there could be multiple levels of wrapping, unwrap recursively\r\n if hasattr(model, \"module\"):\r\n return unwrap_model(model.module)\r\n else:\r\n return model\r\n\r\n# ...\r\n\r\nsafetensors.save_model(unwrap_model(model))\r\nsafetensors.load_model(unwrap_model(model))\r\n```\r\n\r\n\r\nAny planned fix for this? @sgugger ",
"Hi @peacefulotter could you open a new issue, detailing the problem, the running environment and linking to this issue as this seems to be related to safetensors? "
] | 1,690 | 1,702 | 1,694 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.32.0.dev0
- Platform: Linux-4.18.0-477.10.1.el8_8.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.7
- Huggingface_hub version: 0.14.1
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: - compute_environment: LOCAL_MACHINE
- distributed_type: NO
- mixed_precision: fp16
- use_cpu: False
- num_processes: 1
- machine_rank: 0
- num_machines: 1
- rdzv_backend: static
- same_network: False
- main_training_function: main
- downcast_bf16: False
- tpu_use_cluster: False
- tpu_use_sudo: False
- PyTorch version (GPU?): 2.1.0.dev20230523+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: Yes
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I am using the Huggingface Trainer to fine-tune an LLaMA2 model with FSDP. I launch the script with the following command. I set `--fsdp_use_orig_params true` because without it I cannot get `torch.compile()` + FSDP to work (https://github.com/huggingface/transformers/pull/23481)
```bash
accelerate launch --num_processes=4 \
--use_fsdp \
--mixed_precision=bf16 \
--fsdp_auto_wrap_policy=TRANSFORMER_BASED_WRAP \
--fsdp_transformer_layer_cls_to_wrap="LlamaDecoderLayer" \
--fsdp_sharding_strategy=1 \
--fsdp_state_dict_type=FULL_STATE_DICT \
--fsdp_use_orig_params true \
src/run.py ${CONFIGS_FOLDER}/LLaMa2_FSDP.yaml
```
In the trainer configuration, I set the following parameters that are relevant to the issue.
```yalm
torch_dtype: float32
gradient_checkpointing: true
fsdp: full_shard auto_wrap
bf16: true
fp16: false
torch_compile: true
```
The model is compiled correctly by PyTorch, the training is fast, and the loss looks good. However, when the training ends, I use the following line to save the model:
```
trainer.save_model()
```
The first problem is that the trainer seems to save two copies of the model: one is split into multiple parts, and the other one contains the same model in a single .bin file.
```bash
ls output_path
checkpoint-10322 config.json pytorch_model-00002-of-00003.bin pytorch_model.bin.index.json tokenizer.json
checkpoint-15483 generation_config.json pytorch_model-00003-of-00003.bin special_tokens_map.json tokenizer.model
checkpoint-5161 pytorch_model-00001-of-00003.bin pytorch_model.bin tokenizer_config.json training_args.bin
```
The second problem, which is related to torch.compile(), is that the model weights are saved with the _orig_mod prefix.
```json
{
"metadata": {
"total_size": 26953670656
},
"weight_map": {
"_orig_mod.lm_head.weight": "pytorch_model-00003-of-00003.bin",
"_orig_mod.model.embed_tokens.weight": "pytorch_model-00001-of-00003.bin",
"_orig_mod.model.layers.0.input_layernorm.weight": "pytorch_model-00001-of-00003.bin",
"_orig_mod.model.layers.0.mlp.down_proj.weight": "pytorch_model-00001-of-00003.bin",
"_orig_mod.model.layers.0.mlp.gate_proj.weight": "pytorch_model-00001-of-00003.bin",
"..."
}
}
```
So, when I try to load the model for inference using model: PreTrainedModel = AutoModelForCausalLM.from_pretrained(), I get a huge warning that says all the weights in the .bin file are not used, and all the LLaMA2 weights have been randomly initialized.
### Expected behavior
The trainer should save the uncompiled model or correctly handle the `_orig_mod` prefixes.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25205/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25205/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25204
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25204/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25204/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25204/events
|
https://github.com/huggingface/transformers/pull/25204
| 1,828,876,853 |
PR_kwDOCUB6oc5WyFaP
| 25,204 |
auto move input to device of the first-layer if necessary
|
{
"login": "ranchlai",
"id": 5043767,
"node_id": "MDQ6VXNlcjUwNDM3Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5043767?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ranchlai",
"html_url": "https://github.com/ranchlai",
"followers_url": "https://api.github.com/users/ranchlai/followers",
"following_url": "https://api.github.com/users/ranchlai/following{/other_user}",
"gists_url": "https://api.github.com/users/ranchlai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ranchlai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ranchlai/subscriptions",
"organizations_url": "https://api.github.com/users/ranchlai/orgs",
"repos_url": "https://api.github.com/users/ranchlai/repos",
"events_url": "https://api.github.com/users/ranchlai/events{/privacy}",
"received_events_url": "https://api.github.com/users/ranchlai/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hi @ranchlai, thanks to opening this PR! \r\n\r\nCould you share a code snippet that we can run which would currently fail on main and which runs with this update? \r\n\r\ncc @gante \r\n",
"@amyeroberts We don't automatically move tensors in simple forward passes, with or without ` device_map=\"auto\"`, so I don't see why we should do it in `generate` 🤗 \r\n\r\n(And, if we do decide do move the tensors in the forward pass, `generate` would automatically benefit from it :D)",
"sure. Before the PR, \r\n```python\r\nfrom transformers import AutoTokenizer, AutoModelForCausalLM\r\n\r\nmodel_name = \"mosaicml/mpt-7b-chat\"\r\ntokenizer = AutoTokenizer.from_pretrained(model_name)\r\nmodel = AutoModelForCausalLM.from_pretrained(\r\n model_name, \r\n llm_int8_enable_fp32_cpu_offload=True,\r\n load_in_8bit=True,\r\n device_map=\"auto\")\r\n\r\ntext = \"Write a python program to find the largest prime number below 1000.\"\r\ninput_ids = tokenizer.encode(text, return_tensors=\"pt\")\r\noutput = model.generate(input_ids, max_length=100, do_sample=True)\r\nresponse = tokenizer.decode(output[0])\r\nprint(response)\r\n```\r\nError trace: \r\n```\r\nLoading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:05<00:00, 2.84s/it]\r\n[INFO|/home/ranch/models/transformers/src/transformers/modeling_utils.py:3383] 2023-07-31 23:53:40,770 >> All model checkpoint weights were used when initializing MptForCausalLM.\r\n\r\n[INFO|/home/ranch/models/transformers/src/transformers/modeling_utils.py:3391] 2023-07-31 23:53:40,770 >> All the weights of MptForCausalLM were initialized from the model checkpoint at mosaicml/mpt-7b-chat.\r\nIf your task is similar to the task the model of the checkpoint was trained on, you can already use MptForCausalLM for predictions without further training.\r\n[INFO|/home/ranch/models/transformers/src/transformers/generation/configuration_utils.py:576] 2023-07-31 23:53:40,771 >> loading configuration file mosaicml/mpt-7b-chat/generation_config.json\r\n[INFO|/home/ranch/models/transformers/src/transformers/generation/configuration_utils.py:616] 2023-07-31 23:53:40,771 >> Generate config GenerationConfig {\r\n \"_from_model_config\": true,\r\n \"eos_token_id\": [\r\n 0,\r\n 50278\r\n ],\r\n \"transformers_version\": \"4.32.0.dev0\",\r\n \"use_cache\": false\r\n}\r\n\r\n[INFO|/home/ranch/models/transformers/src/transformers/generation/configuration_utils.py:616] 2023-07-31 23:53:40,786 >> Generate config GenerationConfig {\r\n \"_from_model_config\": true,\r\n \"transformers_version\": \"4.32.0.dev0\",\r\n \"use_cache\": false\r\n}\r\n\r\n/home/ranch/models/transformers/src/transformers/generation/utils.py:1296: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation )\r\n warnings.warn(\r\n/home/ranch/models/transformers/src/transformers/generation/utils.py:1501: UserWarning: You are calling .generate() with the `input_ids` being on a device type different than your model's device. `input_ids` is on cpu, whereas the model is on cuda. You may experience unexpected behaviors or slower generation. Please make sure that you have put `input_ids` to the correct device by calling for example input_ids = input_ids.to('cuda') before running `.generate()`.\r\n warnings.warn(\r\nTraceback (most recent call last):\r\n File \"/home/ranch/models/auto_move_input_ids_to_devcie/mpt.py\", line 13, in <module>\r\n output = model.generate(input_ids, max_length=100, do_sample=True)\r\n File \"/media/ranch/sda1/anaconda3/lib/python3.9/site-packages/torch/utils/_contextlib.py\", line 115, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/home/ranch/models/transformers/src/transformers/generation/utils.py\", line 1622, in generate\r\n return self.sample(\r\n File \"/home/ranch/models/transformers/src/transformers/generation/utils.py\", line 2765, in sample\r\n next_token_scores = logits_warper(input_ids, next_token_scores)\r\n File \"/home/ranch/models/transformers/src/transformers/generation/logits_process.py\", line 97, in __call__\r\n scores = processor(input_ids, scores)\r\n File \"/home/ranch/models/transformers/src/transformers/generation/logits_process.py\", line 388, in __call__\r\n indices_to_remove = scores < torch.topk(scores, top_k)[0][..., -1, None]\r\nRuntimeError: \"topk_cpu\" not implemented for 'Half'\r\n```\r\nAfter PR: \r\n```\r\nLoading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2/2 [00:06<00:00, 3.01s/it]\r\n[INFO|/home/ranch/models/transformers/src/transformers/modeling_utils.py:3383] 2023-07-31 23:55:37,080 >> All model checkpoint weights were used when initializing MptForCausalLM.\r\n\r\n[INFO|/home/ranch/models/transformers/src/transformers/modeling_utils.py:3391] 2023-07-31 23:55:37,080 >> All the weights of MptForCausalLM were initialized from the model checkpoint at mosaicml/mpt-7b-chat.\r\nIf your task is similar to the task the model of the checkpoint was trained on, you can already use MptForCausalLM for predictions without further training.\r\n[INFO|/home/ranch/models/transformers/src/transformers/generation/configuration_utils.py:576] 2023-07-31 23:55:37,081 >> loading configuration file mosaicml/mpt-7b-chat/generation_config.json\r\n[INFO|/home/ranch/models/transformers/src/transformers/generation/configuration_utils.py:616] 2023-07-31 23:55:37,081 >> Generate config GenerationConfig {\r\n \"_from_model_config\": true,\r\n \"eos_token_id\": [\r\n 0,\r\n 50278\r\n ],\r\n \"transformers_version\": \"4.32.0.dev0\",\r\n \"use_cache\": false\r\n}\r\n\r\n[INFO|/home/ranch/models/transformers/src/transformers/generation/configuration_utils.py:616] 2023-07-31 23:55:37,097 >> Generate config GenerationConfig {\r\n \"_from_model_config\": true,\r\n \"transformers_version\": \"4.32.0.dev0\",\r\n \"use_cache\": false\r\n}\r\n\r\n/home/ranch/models/transformers/src/transformers/generation/utils.py:1296: UserWarning: You have modified the pretrained model configuration to control generation. This is a deprecated strategy to control generation and will be removed soon, in a future version. Please use a generation configuration file (see https://huggingface.co/docs/transformers/main_classes/text_generation )\r\n warnings.warn(\r\n[INFO|/home/ranch/models/transformers/src/transformers/generation/utils.py:1339] 2023-07-31 23:55:37,097 >> Moving input tensor from device `cpu` to `cuda:0`\r\nWrite a python program to find the largest prime number below 1000.\r\nWe are going to learn how to create a program in python to find largest prime number in O(logN) time using Sieve of Eratosthenes. Sieve of Eratosthenes is an efficient algorithm for making the list of prime numbers. We will learn how to create a python program to find the largest prime number (sieve of eratosthenes).\r\nEratosthenes is\r\n````",
"> @amyeroberts We don't automatically move tensors in simple forward passes, with or without ` device_map=\"auto\"`, so I don't see why we should do it in `generate` 🤗\r\n> \r\n> (And, if we do decide do move the tensors in the forward pass, `generate` would automatically benefit from it :D)\r\n\r\nOr think it another way? please let me know if I am not thinking clearly. ^_^\r\nAdvanced function/class such as `.generate()` or `Pipeline()`, receive more information such as user inputs / device informations than `.forward()`. Hence, these functions/classes should know better on how to make use of resources.\r\n\r\nIf we know that we can safely(which I also need comments on whether it is safe to move or not), why not just move instead of raising an error? ",
"@ranchlai our `transformers` [philosophy](https://huggingface.co/docs/transformers/philosophy) dictates that lower-level interfaces like `.forward()` or `.generate()` avoid hidden/implicit transformations (like setting the right device), but higher-level interfaces like the `pipeline()` may do it :)",
"Thank you for comments @gante I thought generate is high-level. Will close. ",
"@ranchlai no worries, new proposals are always welcome 🤗 "
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR adds feature to model.generate() to check if input_ids is at the same device of input_embeddings.
If not, move input to the device rather than simply raising an error or warning.
It should be helpful when device_map="auto" or when there are multi-gpus to choose from, in which case we only need to worry about where to place to model.
Hope it is acceptable. if not, I will close it.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25204/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25204/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25204",
"html_url": "https://github.com/huggingface/transformers/pull/25204",
"diff_url": "https://github.com/huggingface/transformers/pull/25204.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25204.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25203
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25203/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25203/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25203/events
|
https://github.com/huggingface/transformers/pull/25203
| 1,828,852,341 |
PR_kwDOCUB6oc5WyAC2
| 25,203 |
add pathname and line number to logging formatter in debug mode
|
{
"login": "ranchlai",
"id": 5043767,
"node_id": "MDQ6VXNlcjUwNDM3Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5043767?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ranchlai",
"html_url": "https://github.com/ranchlai",
"followers_url": "https://api.github.com/users/ranchlai/followers",
"following_url": "https://api.github.com/users/ranchlai/following{/other_user}",
"gists_url": "https://api.github.com/users/ranchlai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ranchlai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ranchlai/subscriptions",
"organizations_url": "https://api.github.com/users/ranchlai/orgs",
"repos_url": "https://api.github.com/users/ranchlai/repos",
"events_url": "https://api.github.com/users/ranchlai/events{/privacy}",
"received_events_url": "https://api.github.com/users/ranchlai/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"hi, @amyeroberts thanks very much for commenting! I have added a \"detail\" level. It's the same as debug but will also print the pathname and line-number for easy debugging. I don't know if that looks good ? Thanks!"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR adds pathname and line number to logging formatter in debug mode
It make the debug much easier when setting `export TRANSFORMERS_VERBOSITY=debug`.
It has no effect in other logging levels(info, warning, etc ).
Hope this is acceptable. It's ok if not.
before, there is no way to know where the logging comes from.
```
loading file vocab.json
loading file merges.txt
loading file tokenizer.json
loading file added_tokens.json
loading file special_tokens_map.json
loading file tokenizer_config.json
```
after:
```
[INFO|/home/ranch/models/transformers/src/transformers/tokenization_utils_base.py:1842] 2023-07-31 17:59:45,311 >> loading file vocab.json
[INFO|/home/ranch/models/transformers/src/transformers/tokenization_utils_base.py:1842] 2023-07-31 17:59:45,311 >> loading file merges.txt
[INFO|/home/ranch/models/transformers/src/transformers/tokenization_utils_base.py:1842] 2023-07-31 17:59:45,311 >> loading file tokenizer.json
[INFO|/home/ranch/models/transformers/src/transformers/tokenization_utils_base.py:1842] 2023-07-31 17:59:45,311 >> loading file added_tokens.json
[INFO|/home/ranch/models/transformers/src/transformers/tokenization_utils_base.py:1842] 2023-07-31 17:59:45,311 >> loading file special_tokens_map.json
[INFO|/home/ranch/models/transformers/src/transformers/tokenization_utils_base.py:1842] 2023-07-31 17:59:45,311 >> loading file tokenizer_config.json
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25203/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25203/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25203",
"html_url": "https://github.com/huggingface/transformers/pull/25203",
"diff_url": "https://github.com/huggingface/transformers/pull/25203.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25203.patch",
"merged_at": 1690965883000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25202
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25202/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25202/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25202/events
|
https://github.com/huggingface/transformers/pull/25202
| 1,828,791,482 |
PR_kwDOCUB6oc5Wxyng
| 25,202 |
Better error message in `_prepare_output_docstrings`
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
Currently, if an output type has no docstring, or its docstring doesn't have `Args` or `Parameters`, we get an error
```bash
File "/transformers/src/transformers/utils/doc.py", line 137, in _prepare_output_docstrings
full_output_type = f"{output_type.__module__}.{output_type.__name__}"
UnboundLocalError: local variable 'params_docstring' referenced before assignment
```
when `_prepare_output_docstrings` is called (for example, running a script that uses the relevant model).
This is not super informative what's wrong and what to fix.
This PR adds an error message to explain what's going on.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25202/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25202/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25202",
"html_url": "https://github.com/huggingface/transformers/pull/25202",
"diff_url": "https://github.com/huggingface/transformers/pull/25202.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25202.patch",
"merged_at": 1690812903000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25201
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25201/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25201/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25201/events
|
https://github.com/huggingface/transformers/pull/25201
| 1,828,707,509 |
PR_kwDOCUB6oc5WxgJY
| 25,201 |
[`MPT`] Add `require_bitsandbytes` on MPT integration tests
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Jus out of curiosity does the `tooslow` decorator leads to tests still being run? \r\n```bash\r\n Slow tests are skipped while they're in the process of being fixed. No test should stay tagged as \"tooslow\" as\r\n these will not be tested by the CI.\r\n```\r\nCurrently running MPT-7B is the only way to check if we are in sync with trust remote code weights, as it is the smallest model available",
"We also have `Salesforce/instructblip-vicuna-7b` but I haven't checked how long it takes to run on CI. So far it doesn't seems too problematic (those 7b models)",
"@ydshieh we also load that model using bnb: https://github.com/huggingface/transformers/blob/main/tests/models/instructblip/test_modeling_instructblip.py#L526 perhaps I can also add `require_bitsandbytes` there too",
"Yes, please. I missed that in the Past CI report. Thanks a lot!",
"No the `tooslow` tests are only run manually, not a runner.",
"Ok so I would say maybe we should keep testing mpt-7b so that we're aware of any potential issue through the daily CI "
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
As per title and as discussed offline with @ydshieh
adding `require_bitsandbytes` is needed to avoid issues with past torch CI that doesn't have bnb installed on their Docker images.
cc @ydshieh
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25201/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25201/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25201",
"html_url": "https://github.com/huggingface/transformers/pull/25201",
"diff_url": "https://github.com/huggingface/transformers/pull/25201.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25201.patch",
"merged_at": 1690885235000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25200
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25200/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25200/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25200/events
|
https://github.com/huggingface/transformers/pull/25200
| 1,828,703,016 |
PR_kwDOCUB6oc5WxfKq
| 25,200 |
[`Pix2Struct`] Fix pix2struct cross attention
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Fixed a slow test of torchscript that was failing, however the test:\r\n\r\n```bash\r\ntests/models/pix2struct/test_modeling_pix2struct.py::Pix2StructIntegrationTest::test_batched_inference_image_captioning_conditioned\r\n```\r\n\r\nis failing but can confirm is also failing on main, I think it is unrelated to this PR (env issues on my VM probably) so I am merging"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes https://github.com/huggingface/transformers/issues/25175
As pointed out by @leitro on the issue, I can confirm the cross-attention should be in `layer_outputs[5]`. Also fixes the attention output index that should be in index `3` as the index `2` is the `position_bias` (they have the same shape so we didn't noticed the silent bug on the CI tests.)
to repro:
```python
import requests
import torch
from PIL import Image
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image = Image.open(requests.get(url, stream=True).raw)
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-textcaps-base")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-textcaps-base")
input_ids = torch.LongTensor([[0, 2, 3, 4]])
# image only
inputs = processor(images=image, return_tensors="pt")
outputs = model.forward(**inputs, decoder_input_ids=input_ids, output_attentions=True)
print(outputs.cross_attentions[0].shape)
>>> should be torch.Size([1, 12, 4, 2048])
```
cc @amyeroberts
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25200/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25200/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25200",
"html_url": "https://github.com/huggingface/transformers/pull/25200",
"diff_url": "https://github.com/huggingface/transformers/pull/25200.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25200.patch",
"merged_at": 1690880197000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25199
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25199/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25199/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25199/events
|
https://github.com/huggingface/transformers/issues/25199
| 1,828,682,402 |
I_kwDOCUB6oc5s_3qi
| 25,199 |
[LLaMA] Rotary positional embedding differs with official implementation
|
{
"login": "lytning98",
"id": 23375707,
"node_id": "MDQ6VXNlcjIzMzc1NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/23375707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/lytning98",
"html_url": "https://github.com/lytning98",
"followers_url": "https://api.github.com/users/lytning98/followers",
"following_url": "https://api.github.com/users/lytning98/following{/other_user}",
"gists_url": "https://api.github.com/users/lytning98/gists{/gist_id}",
"starred_url": "https://api.github.com/users/lytning98/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/lytning98/subscriptions",
"organizations_url": "https://api.github.com/users/lytning98/orgs",
"repos_url": "https://api.github.com/users/lytning98/repos",
"events_url": "https://api.github.com/users/lytning98/events{/privacy}",
"received_events_url": "https://api.github.com/users/lytning98/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"same confusion",
"> same confusion\r\n\r\n@santiweide Params of some layers are re-permuted while converting weights in the official scripts. Check\r\n\r\nhttps://github.com/huggingface/transformers/blob/e42587f596181396e1c4b63660abf0c736b10dae/src/transformers/models/llama/convert_llama_weights_to_hf.py#L113-L115",
"ohhh thank you, we are converting the Megatron weight to ft weight, and we would check the shape of weights then",
"Awesome, thanks for clarifying this! ",
"\r\nAwesome, thanks for clarifying this!\r\n\r\n"
] | 1,690 | 1,708 | 1,690 |
NONE
| null |
`transformers` implement LLaMA model's Rotary Positional Embedding (RoPE) as follows:
https://github.com/huggingface/transformers/blob/e42587f596181396e1c4b63660abf0c736b10dae/src/transformers/models/llama/modeling_llama.py#L173-L188
This is **GPT-NeoX style** RoPE. But in Meta's official model implementation, the model adopts **GPT-J style** RoPE, which processes query and key vectors in an **interleaved way** instead of split into two half (as in `rotate_half` method).
Meta's official repo implements RoPE as ([full code link](https://github.com/facebookresearch/llama/blob/6c7fe276574e78057f917549435a2554000a876d/llama/model.py#L64-L74)):
```python
def apply_rotary_emb(
xq: torch.Tensor,
xk: torch.Tensor,
freqs_cis: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
xq_ = torch.view_as_complex(xq.float().reshape(*xq.shape[:-1], -1, 2))
xk_ = torch.view_as_complex(xk.float().reshape(*xk.shape[:-1], -1, 2))
freqs_cis = reshape_for_broadcast(freqs_cis, xq_)
xq_out = torch.view_as_real(xq_ * freqs_cis).flatten(3)
xk_out = torch.view_as_real(xk_ * freqs_cis).flatten(3)
return xq_out.type_as(xq), xk_out.type_as(xk)
```
I'm confused with this difference, since `transformers.LlamaModel` can directly load weights converted from the officially released checkpoint, won't this lead to inconsistency in inference results? Is this difference expected?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25199/reactions",
"total_count": 4,
"+1": 4,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25199/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25198
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25198/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25198/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25198/events
|
https://github.com/huggingface/transformers/pull/25198
| 1,828,638,254 |
PR_kwDOCUB6oc5WxRJh
| 25,198 |
Save tokenizer and model config when training with FSDP
|
{
"login": "J38",
"id": 13620509,
"node_id": "MDQ6VXNlcjEzNjIwNTA5",
"avatar_url": "https://avatars.githubusercontent.com/u/13620509?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/J38",
"html_url": "https://github.com/J38",
"followers_url": "https://api.github.com/users/J38/followers",
"following_url": "https://api.github.com/users/J38/following{/other_user}",
"gists_url": "https://api.github.com/users/J38/gists{/gist_id}",
"starred_url": "https://api.github.com/users/J38/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/J38/subscriptions",
"organizations_url": "https://api.github.com/users/J38/orgs",
"repos_url": "https://api.github.com/users/J38/repos",
"events_url": "https://api.github.com/users/J38/events{/privacy}",
"received_events_url": "https://api.github.com/users/J38/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25198). All of your documentation changes will be reflected on that endpoint.",
"@sgugger @pacman100 is there anything else you'd like me to do for this PR?",
"@pacman100 friendly ping here.",
"Hello, this PR #https://github.com/huggingface/transformers/pull/24926 should resolve the issue mentioned in this PR. Could you try with the latest main branch and let us know if the issue still remains",
"Okay I will investigate and let you know!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
# What does this PR do?
Currently when training models with FSDP the tokenizer and model config are not saved (at least using standard configs I have). This is especially bad when running a custom train.py that modifies the tokenizer and model before training. In that scenario there is no record of the new model config or tokenizer.
I have altered trainer.py to have a `_save_tokenizer_and_configs` method and added a call to this method in the model saving logic when FSDP is enabled.
If the team feels there could be better refactoring to handle this would be happy to discuss improvements to this PR!
Other note, to the best of my knowledge this is happening because when the logic flows to FSDP enabled it is just using the custom FSDP model saving and there is no logic for saving the other tokenizer and config info. If there is already a known config setting I'm missing that would fix this please let me know.
## Before submitting
I have not added any new tests.
## Who can review?
This involves modifications to the trainer so maybe @sgugger would be interested in reviewing?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25198/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25198/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25198",
"html_url": "https://github.com/huggingface/transformers/pull/25198",
"diff_url": "https://github.com/huggingface/transformers/pull/25198.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25198.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25197
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25197/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25197/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25197/events
|
https://github.com/huggingface/transformers/issues/25197
| 1,828,544,018 |
I_kwDOCUB6oc5s_V4S
| 25,197 |
Multi-threaded parallel inferrence problem
|
{
"login": "zhaotyer",
"id": 89376832,
"node_id": "MDQ6VXNlcjg5Mzc2ODMy",
"avatar_url": "https://avatars.githubusercontent.com/u/89376832?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhaotyer",
"html_url": "https://github.com/zhaotyer",
"followers_url": "https://api.github.com/users/zhaotyer/followers",
"following_url": "https://api.github.com/users/zhaotyer/following{/other_user}",
"gists_url": "https://api.github.com/users/zhaotyer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhaotyer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhaotyer/subscriptions",
"organizations_url": "https://api.github.com/users/zhaotyer/orgs",
"repos_url": "https://api.github.com/users/zhaotyer/repos",
"events_url": "https://api.github.com/users/zhaotyer/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhaotyer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @zhaotyer, thanks for opening this issue! \r\n\r\nCould you edit the issue details to make sure that the code and traceback are properly formatted? This will make it easier for us to read and understand what's going on. \r\n\r\nThe code examples should be wrapped around three backticks. You can also specify the language to get color coded formatting :) i.e. ` ```python CODE GOES HERE ``` `\r\n\r\nSame for the traceback - it should go between a pair of three tickbacks ` ``` error message ``` `\r\n\r\ncc @gante as this seems to be related to generate :) ",
"@zhaotyer that seems to be a bitsandbytes issue -- would you be able to update this library to its latest version and confirm whether the issue persists? :)",
"> Collaborator\r\n\r\nThanks for the reminder, I have edited it\r\n",
"> @zhaotyer that seems to be a bitsandbytes issue -- would you be able to update this library to its latest version and confirm whether the issue persists? :)\r\nShould have nothing to do with bitsandbytes\r\nThe following are the test results of different transformers/accelerate versions\r\n```\r\n1.transformers==4.31.0 accelerate==0.21.0 bitsandbytes==0.37.1\r\n \t1.1 chatglm2 load_in_8bit=true singlethread normal, multithread normal\r\n \t1.2 chatglm2 load_in_8bit=false singlethread normal, multithread normal\r\n2.transformers==4.29.2 accelerate==0.19.0 bitsandbytes==0.37.1\r\n\t1.1 chatglm2 load_in_8bit=true singlethread normal, multithread have error(RuntimeError: mat1 and mat2 shapes cannot be multiplied)\r\n \t1.2 chatglm2 load_in_8bit=false singlethread normal, multithread normal\r\n```\r\n@gante ",
"@zhaotyer OK, thanks for running with updated versions and reporting. If I've understood correctly, it looks like everything is running as expected on the most recent versions of accelerate and transformers and so the issue has been resolved in the most recent releases. ",
"> @zhaotyer OK, thanks for running with updated versions and reporting. If I've understood correctly, it looks like everything is running as expected on the most recent versions of accelerate and transformers and so the issue has been resolved in the most recent releases.\r\n\r\nCan you explain what changes have been made between the two releases to solve this problem? thks",
"@zhaotyer The best way to find this is running `git bisect` to identify the commit and PR which resolved this for your example script. ",
"> @zhaotyer The best way to find this is running `git bisect` to identify the commit and PR which resolved this for your example script.\r\n\r\nwhen i use pip install -U git+https://github.com/huggingface/transformers.git for #25228 , this multiplied problem still exists,use transformer==4.31.0 #25228 problem exists,So is there a version that solves both problems at the same time",
"@zhaotyer Just to make sure I've understood, could you confirm: \r\n\r\n1. Which versions work and which don't\r\n2. Whether the same issues are being seen for the non-working versions? \r\n\r\nMy understanding of the above comment is that: \r\n* Multi-thread issue exists for 4.29.2\r\n* Multi-thread issue is resolved in 4.31.0\r\n* Multi-thread issue returns when installing from source\r\n* Another, separate, issue (#25228) occurs when using 4.31.0 but is resolved when installing from source\r\n\r\nIs my understanding correct? ",
"> @zhaotyer Just to make sure I've understood, could you confirm:\r\n> \r\n> 1. Which versions work and which don't\r\n> 2. Whether the same issues are being seen for the non-working versions?\r\n> \r\n> My understanding of the above comment is that:\r\n> \r\n> * Multi-thread issue exists for 4.29.2\r\n> * Multi-thread issue is resolved in 4.31.0\r\n> * Multi-thread issue returns when installing from source\r\n> * Another, separate, issue ([chatglm2 load_in_8bit=true can't reduce gpu memory when using transformer==4.31.0 #25228](https://github.com/huggingface/transformers/issues/25228)) occurs when using 4.31.0 but is resolved when installing from source\r\n> \r\n> Is my understanding correct?\r\n\r\nyour understanding is correct",
"cc @younesbelkada - any ideas on what might have changed on the bitsandbytes side? ",
"> cc @younesbelkada - any ideas on what might have changed on the bitsandbytes side?\r\n\r\nExcuse me, is there any progress?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Gentle ping @younesbelkada :)",
"Hi @zhaotyer \r\nApologies for the delay, can you confirm the issue still persists if you install transformers from source now?",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"> till persists\r\n\r\nI have tried almost all version combinations and this problem still persists.\r\nOnly when transformers==4.31.0, [Multi-thread issue ](https://github.com/huggingface/transformers/issues/25197)was resolved but the GPU memory was not reduced [# 25228](https://github.com/huggingface/transformers/issues/25228)"
] | 1,690 | 1,700 | 1,697 |
NONE
| null |
### System Info
accelerate == 0.19.0
bitsandbytes == 0.37.1
- `transformers` version: 4.29.2
- Platform: Linux-3.10.0-1160.92.1.el7.x86_64-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.14.1
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
When I use chatglm2/bloomz-7b for multithreaded parallel inference:
```
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
from transformers import AutoTokenizer, AutoModelForCausalLM, LlamaForCausalLM, TextIteratorStreamer
import transformers
import torch
from threading import Thread, currentThread
import time
model = "/workspace/model-files/chatglm2"
tokenizer = AutoTokenizer.from_pretrained(model, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model, device_map='auto', trust_remote_code=True, load_in_8bit=True)
def infer(prompt):
inputs = tokenizer(prompt, return_tensors='pt')
inputs = inputs.to(model.device)
print('before generate')
# out = model.generate(**inputs)
# print('after generate')
# out_text = tokenizer.decode(out[0])
# print('out_text is:', out_text)
t = currentThread()
streamer = TextIteratorStreamer(tokenizer)
generation_kwargs = dict(inputs, streamer=streamer, max_length=2048)
thread = Thread(target=model.generate, kwargs=generation_kwargs)
thread.start()
print("------******-------")
for new_text in streamer:
print("thread id:", t.ident ,"new text:",new_text)
print("------******-------")
if __name__ == '__main__':
prompt1 = '写一篇关于黄鹤楼的800字作文'
prompt2 = 'Describe each state in the United States in detail'
t1 = Thread(target=infer, args=(prompt1,))
t2 = Thread(target=infer, args=(prompt2,))
t1.start()
time.sleep(5)
t2.start()
t1.join()
t2.join()
```
I get below error info:
```
Traceback (most recent call last):
File "/usr/lib/python3.8/threading.py", line 932, in _bootstrap_inner
self.run()
File "/usr/lib/python3.8/threading.py", line 870, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/transformers/generation/utils.py", line 1515, in generate
return self.greedy_search(
File "/usr/local/lib/python3.8/dist-packages/transformers/generation/utils.py", line 2332, in greedy_search
outputs = self(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/root/.cache/huggingface/modules/transformers_modules/modeling_chatglm.py", line 932, in forward
transformer_outputs = self.transformer(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/root/.cache/huggingface/modules/transformers_modules/modeling_chatglm.py", line 828, in forward
hidden_states, presents, all_hidden_states, all_self_attentions = self.encoder(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/root/.cache/huggingface/modules/transformers_modules/modeling_chatglm.py", line 638, in forward
layer_ret = layer(
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/root/.cache/huggingface/modules/transformers_modules/modeling_chatglm.py", line 563, in forward
mlp_output = self.mlp(layernorm_output)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/root/.cache/huggingface/modules/transformers_modules/modeling_chatglm.py", line 499, in forward
output = self.dense_4h_to_h(intermediate_parallel)
File "/usr/local/lib/python3.8/dist-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/bitsandbytes/nn/modules.py", line 242, in forward
out = bnb.matmul(x, self.weight, bias=self.bias, state=self.state)
File "/usr/local/lib/python3.8/dist-packages/bitsandbytes/autograd/_functions.py", line 488, in matmul
return MatMul8bitLt.apply(A, B, out, bias, state)
File "/usr/local/lib/python3.8/dist-packages/torch/autograd/function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
File "/usr/local/lib/python3.8/dist-packages/bitsandbytes/autograd/_functions.py", line 397, in forward
output += torch.matmul(subA, state.subB)
RuntimeError: mat1 and mat2 shapes cannot be multiplied (1x4 and 2x4096)
```
### Expected behavior
able to inference normally
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25197/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 1
}
|
https://api.github.com/repos/huggingface/transformers/issues/25197/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25196
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25196/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25196/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25196/events
|
https://github.com/huggingface/transformers/pull/25196
| 1,828,489,229 |
PR_kwDOCUB6oc5Www4o
| 25,196 |
[DOCS] Add descriptive docstring to MinNewTokensLength
|
{
"login": "nablabits",
"id": 33068707,
"node_id": "MDQ6VXNlcjMzMDY4NzA3",
"avatar_url": "https://avatars.githubusercontent.com/u/33068707?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nablabits",
"html_url": "https://github.com/nablabits",
"followers_url": "https://api.github.com/users/nablabits/followers",
"following_url": "https://api.github.com/users/nablabits/following{/other_user}",
"gists_url": "https://api.github.com/users/nablabits/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nablabits/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nablabits/subscriptions",
"organizations_url": "https://api.github.com/users/nablabits/orgs",
"repos_url": "https://api.github.com/users/nablabits/repos",
"events_url": "https://api.github.com/users/nablabits/events{/privacy}",
"received_events_url": "https://api.github.com/users/nablabits/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"cc @gante ",
"> Thank you for iterating raised_hands\r\n\r\nAlways a pleasure, thanks for the opportunity :hugs: "
] | 1,690 | 1,691 | 1,691 |
CONTRIBUTOR
| null |
# What does this PR do?
It addresses one of the arguments in https://github.com/huggingface/transformers/issues/24783
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
## Who can review?
@gante
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25196/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25196/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25196",
"html_url": "https://github.com/huggingface/transformers/pull/25196",
"diff_url": "https://github.com/huggingface/transformers/pull/25196.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25196.patch",
"merged_at": 1691474957000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25195
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25195/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25195/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25195/events
|
https://github.com/huggingface/transformers/issues/25195
| 1,828,380,078 |
I_kwDOCUB6oc5s-t2u
| 25,195 |
Incorrect segmentation results on float input in 4.31.0
|
{
"login": "antoche",
"id": 1627384,
"node_id": "MDQ6VXNlcjE2MjczODQ=",
"avatar_url": "https://avatars.githubusercontent.com/u/1627384?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antoche",
"html_url": "https://github.com/antoche",
"followers_url": "https://api.github.com/users/antoche/followers",
"following_url": "https://api.github.com/users/antoche/following{/other_user}",
"gists_url": "https://api.github.com/users/antoche/gists{/gist_id}",
"starred_url": "https://api.github.com/users/antoche/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antoche/subscriptions",
"organizations_url": "https://api.github.com/users/antoche/orgs",
"repos_url": "https://api.github.com/users/antoche/repos",
"events_url": "https://api.github.com/users/antoche/events{/privacy}",
"received_events_url": "https://api.github.com/users/antoche/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @amyeroberts \r\n\r\nthis seems to be the same issue as discussed in https://github.com/huggingface/transformers/issues/24857. Basically there's no need to rescale the images yourself before passing them to the image processor. The image processor already handles the rescaling for you.\r\n\r\nAlternatively, if you want to handle the rescaling yourself, just instantiate the image processor as follows:\r\n\r\n```\r\nfrom transformers import AutoImageProcessor\r\n\r\nimage_processor = AutoImageProcessor.from_pretrained(\"openmmlab/upernet-convnext-tiny\", do_rescale=False)\r\n```\r\n\r\nI'm curious to know why you expected to handle the rescaling yourself :) maybe we can improve documentation on this.",
"Thanks for the quick reply.\r\n\r\nI'm not sure I 100% understand what you mean with \"rescaling\" here. Do you mean dividing the values by 255 to go from a `(0,255)` range to a `(0,1)` range?\r\n\r\nIf that is what you mean, then the answer to your question is we never do \"rescaling\", because we never use 8-bit representations in the first place. The example I posted here converts from `uint8` to `float32` and \"rescales\" because I wanted to start from a basic example that was as close to the docs as possible. But in our actual applications, we always work in floating point representations, and therefore in the `(0,1)` range. \r\n\r\nI don't know of any rationale to have floating point representations use an arbitrary range like `(0, 255)`, and as far as I have seen, any code dealing with floating-point image representations treat the usable range as `(0,1)`. Images in `uint8` use the `(0, 255)` range simply because that's the only values this finite integer can represent. If an image was in, say, a `uint16` representation, they I'd expect it to use the `(0, 65536)` range. So from my point of view, it seems odd to have to \"rescale\" my values by multiplying them by 255 in order for them to be processed correctly. \r\n\r\nFrom #24857, I'm also under the impression that `transformers` might be resizing my inputs by converting them into uint8 in order to let PIL do the resizing. If that is the case, it is also very problematic for us. The whole reason we are using floating point image representations is so we can work on high-precision, high-dynamic-range images. Converting floating point values to `uint8` completely destroys this ability. Given that both pytorch and tensorflow can resize image tensors natively, I don't really understand the need to go through a third library that will decimate my data.\r\n\r\nHope it helps, happy to provide more information if that was unclear.",
"Hi @antoche, thanks for raising this issue and providing so much detail. \r\n\r\nYes, by rescaling we're referring to scaling the pixel values between `[0, 1]` (or sometimes `[-1, 1]`. \r\n\r\n> it seems odd to have to \"rescale\" my values by multiplying them by 255 in order for them to be processed correctly.\r\n\r\nI think we're on the same page: you shouldn't have to rescale them. You're right in understanding that we do convert any input images into `uint8` when resizing and so your input images would be rescaled by 255, resized and then rescaled back again. This is for historical reasons as Pillow was first used for resizing images and we've kept it mainly for backwards compatibility. Part of the reason Pillow was used is that the processing classes should (as much as possible) be framework independent i.e. a TensorFlow user and PyTorch user should be able to use the same class. \r\n\r\nThat all being said, this issue has cropped up a few times. For the linked issues e.g. #24857, we're thinking about adding a warning when we detect images with float values being passed in to prevent double rescaling.\r\n\r\nFor this particular issue, the change to remove rescaling to convert to `PIL.Image.Image` is more involved and not something I have immediate bandwidth for unfortunately, but will add to my longer term to-do list. For preprocessing the images, I would suggest using torchvision's transforms (this will also likely be a lot faster!). Their recent transforms v2 is v. good for simultaneously handling images and masks.\r\n\r\nIf you have any other feedback please do let us know. \r\n\r\n\r\n\r\n\r\n \r\n\r\n\r\n",
"Ok, I think I understand what transformers is doing now.\r\n\r\nIt looks like passing `do_rescale=False` should work around this issue for now at the moment.",
"I just ran into another instance of this issue in `diffusers`' `StableDiffusionDepth2ImgPipeline`.\r\n\r\nThe `StableDiffusionDepth2ImgPipeline` passes its input image (which can be either a PIL image containing 8-bit values, a numpy array containing floating point values between 0 and 1, or a torch float tensor in the range 0 and 1) to `transformers`' `DPTFeatureExtractor`. With transformers-4.31.0, `DPTFeatureExtractor` rescales the input by dividing it by 255 no matter what representation it's in, which mangles the tensors and results in an invalid, unusable output.\r\n\r\nBecause it is `StableDiffusionDepth2ImgPipeline` doing the call, I can't just change my code to pass `do_rescale=False` to work around it, the call has to be changed in the `diffusers` codebase.\r\n\r\nI strongly advise against applying such arbitrary blind rescaling of the input data. Rescaling should only be required when converting from an integer type to a floating point type, and depends on the bit depth of the integer type (e.g., if the input values were int16, and the model expects floating point values, the input should be divided by 65535, not 255).",
"@antoche We've added a check which will output a warning to the user if we detect that they're passing in images which have already had their pixel values scaled between [0-1]. \r\n\r\nWe unfortunately can't control how other libraries call our code. It is however possible for you to modify the code in `StableDiffusionDepth2ImgPipeline` - that's the beauty of open source! You can either open a PR or fork and change the code as you wish. \r\n\r\nThe rescaling isn't arbitrary - it's based on an assumption about the inputs. Admittedly this wasn't clear and we've added the warning and updated the doc strings. We try to avoid any \"magic\" e.g. changing the rescaling value based on the type as this tends to lead to buggy and unexpected behaviour. The user can modify this directly using `rescale_factor` if they need. ",
"Thanks, that's an improvement. I've reported the diffusers issue as part of https://github.com/huggingface/diffusers/issues/4429 (I'm unfortunately not very keen on opening PRs for projects like diffusers because of the sheer amount of code duplication in it. This makes it really tedious for a contributor to try and improve the codebase).\r\n\r\nRegarding \"magic\" code, I would argue that the default behaviour ought to be not to do any automatic transformation on the input, so the user get exactly what they asked for, without any unexpected slowdowns or data degradation. I think part of the issue here is that the processors seem to default to always scale the input by an arbitrary 1/255 no matter what. If no rescaling was done by default, there would not by any need for \"magic\" code either.\r\n\r\nConversely, if a library accepts inputs in multiple formats (e.g., int8 tensor, float tensor, numpy array, pil image, etc), then it is reasonable to expect it to massage the inputs in different ways depending on their type. \r\n\r\nMy impression is that `transformers` falls in the latter category, i.e., it handles multiple input types and therefore will handle/transform the inputs differently depending on their type (see, e.g., `to_numpy_array`), but considers that int8 tensors/arrays are the same type as floating-point ones (I would argue they are not).",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,697 | 1,697 |
NONE
| null |
### System Info
python-3.9.10
transformers-4.31.0
pytorch-2.0.1
### Who can help?
@amyeroberts
### Information
- [X] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
The following example (based on the examples from the docs) gives consistent results with transformers-4.27.2 whether or not `image` is kept as `uint8` or converted to `float32`. But with 4.31.0, the result is wrong when using the `float32` input:
```
import torch
import numpy as np
from transformers import AutoImageProcessor, UperNetForSemanticSegmentation
from PIL import Image
from huggingface_hub import hf_hub_download
image_processor = AutoImageProcessor.from_pretrained("openmmlab/upernet-convnext-tiny")
model = UperNetForSemanticSegmentation.from_pretrained("openmmlab/upernet-convnext-tiny")
filepath = hf_hub_download(
repo_id="hf-internal-testing/fixtures_ade20k", filename="ADE_val_00000001.jpg", repo_type="dataset"
)
image = Image.open(filepath).convert("RGB")
image = np.array(image)
# Comment the line below to get the right result in 4.31.0
image = image.astype(np.float32)/255.0
inputs = image_processor(images=image, return_tensors="pt").pixel_values
outputs = model(inputs)
sizes = [np.array(image).shape[:2]]
seg = torch.stack(image_processor.post_process_semantic_segmentation(outputs, target_sizes=sizes))
torch.unique(seg)
```
### Expected behavior
Expected result (observerd behaviour in 4.27.2 regardless of whether the float conversion is commented out):
```
tensor([ 0, 1, 2, 4, 6, 9, 17, 25, 52, 53])
```
Actual result in 4.31.0 (unless the float conversion is commented out and the input image is kept as `uint8`):
```
tensor([2])
```
(i.e., the whole image is perceived as one class)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25195/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25195/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25194
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25194/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25194/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25194/events
|
https://github.com/huggingface/transformers/issues/25194
| 1,828,286,916 |
I_kwDOCUB6oc5s-XHE
| 25,194 |
`AutoTokenizer.from_pretrained` raise error when another same filename tokenizer imported
|
{
"login": "tongyifan",
"id": 25120867,
"node_id": "MDQ6VXNlcjI1MTIwODY3",
"avatar_url": "https://avatars.githubusercontent.com/u/25120867?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/tongyifan",
"html_url": "https://github.com/tongyifan",
"followers_url": "https://api.github.com/users/tongyifan/followers",
"following_url": "https://api.github.com/users/tongyifan/following{/other_user}",
"gists_url": "https://api.github.com/users/tongyifan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/tongyifan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/tongyifan/subscriptions",
"organizations_url": "https://api.github.com/users/tongyifan/orgs",
"repos_url": "https://api.github.com/users/tongyifan/repos",
"events_url": "https://api.github.com/users/tongyifan/events{/privacy}",
"received_events_url": "https://api.github.com/users/tongyifan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I think you should report the issue in the repositories where this code comes from, as the fix you suggest is in that code (and not in the Transformers library).",
"hmmm that's an ad-hoc solution to validate the problem, and I'm not sure whether this import error is expected by Transformers?",
"I don't see an import error in the code and traceback you pasted. I see the custom code of this tokenizer failing to execute.",
"Here's a reproduce code\r\n[transformers_issue_25194.tar.gz](https://github.com/huggingface/transformers/files/12257984/transformers_issue_25194.tar.gz)\r\n```\r\ntransformers_issue_25194\r\n├── main.py\r\n├── test_a\r\n│ ├── tokenization.py\r\n│ └── tokenizer_config.json\r\n└── test_b\r\n ├── tokenization.py\r\n └── tokenizer_config.json\r\n\r\n2 directories, 5 files\r\n```\r\n\r\n`test_a` is a tokenizer with param `a` and `test_b` is another tokenizer with param `b`.\r\n\r\nWhen running the `main.py`, the exception raised when loading `test_b`, but the error is `__init__() missing 1 required positional argument: 'a'`, which is the required param from `test_a`.\r\n\r\nIn this line `b = AutoTokenizer.from_pretrained(\"./test_b/\", trust_remote_code=True)`, I think it should use `./test_b/tokenization.py`, which contains param `b` instead `a`\r\n\r\n```text\r\nmodel_a\r\ntest_a tokenizer init\r\nTestTokenizer(name_or_path='./test_a/', vocab_size=1, model_max_length=1000000000000000019884624838656, is_fast=False, padding_side='right', truncation_side='right', special_tokens={}, clean_up_tokenization_spaces=True)\r\nTraceback (most recent call last):\r\n File \"/Users/tongyifan/PycharmProjects/transformers_issue_25194/main.py\", line 8, in <module>\r\n b = AutoTokenizer.from_pretrained(\"./test_b/\", trust_remote_code=True)\r\n File \"/Users/tongyifan/PycharmProjects/transformers_issue_25194/venv/lib/python3.8/site-packages/transformers/models/auto/tokenization_auto.py\", line 689, in from_pretrained\r\n return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)\r\n File \"/Users/tongyifan/PycharmProjects/transformers_issue_25194/venv/lib/python3.8/site-packages/transformers/tokenization_utils_base.py\", line 1841, in from_pretrained\r\n return cls._from_pretrained(\r\n File \"/Users/tongyifan/PycharmProjects/transformers_issue_25194/venv/lib/python3.8/site-packages/transformers/tokenization_utils_base.py\", line 2004, in _from_pretrained\r\n tokenizer = cls(*init_inputs, **init_kwargs)\r\nTypeError: __init__() missing 1 required positional argument: 'a'\r\n```",
"There is a conflict in the names of your tokenizer files basically. This is feature is called \"code on the Hub\" for a reason, it doesn't work as well for local models ;-) \r\nBasically you need to name the two tokenization files differently when coding locally like this.",
"Thanks for your reply!"
] | 1,690 | 1,691 | 1,691 |
NONE
| null |
### System Info
- `transformers` version: 4.28.1
- Platform: Linux-4.19.91-009.ali4000.alios7.x86_64-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.16.2
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
1. bug reproduction
```python
from transformers import AutoTokenizer
# import one tokenizer from local (/home/admin/notebook/THUDM/chatglm2-6b/tokenization_chatglm.py)
tokenizer = AutoTokenizer.from_pretrained("/home/admin/notebook/THUDM/chatglm2-6b/", trust_remote_code=True)
# import another version tokenizer from another directory, but same filename (/home/admin/notebook/THUDM/chatglm-6b/tokenization_chatglm.py)
tokenizer = AutoTokenizer.from_pretrained("/home/admin/notebook/THUDM/chatglm-6b/", trust_remote_code=True)
```
raise exception
```text
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[1], line 10
6 from transformers import AutoTokenizer
8 tokenizer = AutoTokenizer.from_pretrained("/home/admin/notebook/THUDM/chatglm2-6b/", trust_remote_code=True)
---> 10 tokenizer = AutoTokenizer.from_pretrained("/home/admin/notebook/THUDM/chatglm-6b/", trust_remote_code=True)
File /usr/local/lib/python3.8/dist-packages/transformers/models/auto/tokenization_auto.py:702, in AutoTokenizer.from_pretrained(cls, pretrained_model_name_or_path, *inputs, **kwargs)
698 if tokenizer_class is None:
699 raise ValueError(
700 f"Tokenizer class {tokenizer_class_candidate} does not exist or is not currently imported."
701 )
--> 702 return tokenizer_class.from_pretrained(pretrained_model_name_or_path, *inputs, **kwargs)
704 # Otherwise we have to be creative.
705 # if model is an encoder decoder, the encoder tokenizer class is used by default
706 if isinstance(config, EncoderDecoderConfig):
File /usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py:1811, in PreTrainedTokenizerBase.from_pretrained(cls, pretrained_model_name_or_path, *init_inputs, **kwargs)
1808 else:
1809 logger.info(f"loading file {file_path} from cache at {resolved_vocab_files[file_id]}")
-> 1811 return cls._from_pretrained(
1812 resolved_vocab_files,
1813 pretrained_model_name_or_path,
1814 init_configuration,
1815 *init_inputs,
1816 use_auth_token=use_auth_token,
1817 cache_dir=cache_dir,
1818 local_files_only=local_files_only,
1819 _commit_hash=commit_hash,
1820 **kwargs,
1821 )
File /usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py:1965, in PreTrainedTokenizerBase._from_pretrained(cls, resolved_vocab_files, pretrained_model_name_or_path, init_configuration, use_auth_token, cache_dir, local_files_only, _commit_hash, *init_inputs, **kwargs)
1963 # Instantiate tokenizer.
1964 try:
-> 1965 tokenizer = cls(*init_inputs, **init_kwargs)
1966 except OSError:
1967 raise OSError(
1968 "Unable to load vocabulary from file. "
1969 "Please check that the provided vocabulary is accessible and not corrupted."
1970 )
File ~/.cache/huggingface/modules/transformers_modules/tokenization_chatglm.py:69, in __init__(self, vocab_file, padding_side, **kwargs)
66 def _get_text_tokenizer(self):
67 return self.text_tokenizer
---> 69 @staticmethod
70 def get_blank_token(length: int):
71 assert length >= 2
72 return f"<|blank_{length}|>"
File /usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils.py:347, in PreTrainedTokenizer.__init__(self, **kwargs)
346 def __init__(self, **kwargs):
--> 347 super().__init__(**kwargs)
349 # Added tokens - We store this for both slow and fast tokenizers
350 # until the serialization of Fast tokenizers is updated
351 self.added_tokens_encoder: Dict[str, int] = {}
File /usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py:1534, in PreTrainedTokenizerBase.__init__(self, **kwargs)
1530 self.deprecation_warnings = (
1531 {}
1532 ) # Use to store when we have already noticed a deprecation warning (avoid overlogging).
1533 self._in_target_context_manager = False
-> 1534 super().__init__(**kwargs)
File /usr/local/lib/python3.8/dist-packages/transformers/tokenization_utils_base.py:828, in SpecialTokensMixin.__init__(self, verbose, **kwargs)
826 setattr(self, key, value)
827 elif isinstance(value, (str, AddedToken)):
--> 828 setattr(self, key, value)
829 else:
830 raise TypeError(f"special token {key} has to be either str or AddedToken but got: {type(value)}")
AttributeError: can't set attribute
```
In this traceback, I found the exception raised from a abnormal line 69 `@staticmethod`, which pointed to the correct file `/home/admin/notebook/THUDM/chatglm-6b/tokenization_chatglm.py`

but the exception was raised from the wrong file (/home/admin/notebook/THUDM/chatglm2-6b/tokenization_chatglm.py)

2. a hard fix
After edit one filename of these two tokenizers, the bug disappear.
### Expected behavior
import the tokenizer with no exception
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25194/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25194/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25193
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25193/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25193/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25193/events
|
https://github.com/huggingface/transformers/pull/25193
| 1,828,253,336 |
PR_kwDOCUB6oc5Wv88K
| 25,193 |
make build_mpt_alibi_tensor a method of MptModel so that deepspeed co…
|
{
"login": "sywangyi",
"id": 36058628,
"node_id": "MDQ6VXNlcjM2MDU4NjI4",
"avatar_url": "https://avatars.githubusercontent.com/u/36058628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sywangyi",
"html_url": "https://github.com/sywangyi",
"followers_url": "https://api.github.com/users/sywangyi/followers",
"following_url": "https://api.github.com/users/sywangyi/following{/other_user}",
"gists_url": "https://api.github.com/users/sywangyi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sywangyi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sywangyi/subscriptions",
"organizations_url": "https://api.github.com/users/sywangyi/orgs",
"repos_url": "https://api.github.com/users/sywangyi/repos",
"events_url": "https://api.github.com/users/sywangyi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sywangyi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@sgugger @ArthurZucker please review. thanks",
"should work with https://github.com/microsoft/DeepSpeed/pull/4062",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
…uld override it to make autoTP work
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
enable autoTP for mpt in huggingface model.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25193/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25193/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25193",
"html_url": "https://github.com/huggingface/transformers/pull/25193",
"diff_url": "https://github.com/huggingface/transformers/pull/25193.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25193.patch",
"merged_at": 1690868150000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25192
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25192/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25192/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25192/events
|
https://github.com/huggingface/transformers/issues/25192
| 1,828,084,649 |
I_kwDOCUB6oc5s9lup
| 25,192 |
Unable to upload/load a tool.
|
{
"login": "Romainlg29",
"id": 31577471,
"node_id": "MDQ6VXNlcjMxNTc3NDcx",
"avatar_url": "https://avatars.githubusercontent.com/u/31577471?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Romainlg29",
"html_url": "https://github.com/Romainlg29",
"followers_url": "https://api.github.com/users/Romainlg29/followers",
"following_url": "https://api.github.com/users/Romainlg29/following{/other_user}",
"gists_url": "https://api.github.com/users/Romainlg29/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Romainlg29/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Romainlg29/subscriptions",
"organizations_url": "https://api.github.com/users/Romainlg29/orgs",
"repos_url": "https://api.github.com/users/Romainlg29/repos",
"events_url": "https://api.github.com/users/Romainlg29/events{/privacy}",
"received_events_url": "https://api.github.com/users/Romainlg29/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @Romainlg29, thanks for reporting this issue! \r\n\r\nCould you update the issue information with the full running environment info: run `transformers-cli env` in the terminal and copy-paste the output? \r\n\r\ncc @LysandreJik ",
"Hi,\r\n\r\nI just updated the config, which is:\r\n\r\n```\r\ntransformers version: 4.31.0\r\nPlatform: Windows-10-10.0.22621-SP0\r\nPython version: 3.11.3\r\nHuggingface_hub version: 0.16.4\r\nSafetensors version: 0.3.1\r\nAccelerate version: 0.21.0\r\nAccelerate config: not found\r\nPyTorch version (GPU?): 2.0.1+cu118 (True)\r\nTensorflow version (GPU?): not installed (NA)\r\nFlax version (CPU?/GPU?/TPU?): not installed (NA)\r\nJax version: not installed\r\nJaxLib version: not installed\r\n```\r\n\r\nThank you for your reply.",
"Hi @Romainlg29, thanks for sharing these details. \r\n\r\nI was able to create a tool, push to the hub and can load it both [with](https://huggingface.co/spaces/amyeroberts/test_tool_2/tree/main) and [without](https://huggingface.co/spaces/amyeroberts/test_tool/tree/main) `psycopg2`. \r\n\r\nThe main differences I see between these repo and yours are: \r\n* [the `__init__.py` file](https://huggingface.co/romainlg/hf-sql/blob/main/__init__.py) - you shouldn't need this\r\n* The metadata values shown in the readme [here](https://huggingface.co/romainlg/hf-sql/blob/main/README.md) vs. [here](https://huggingface.co/spaces/amyeroberts/test_tool_2/blob/main/README.md)\r\n\r\nI would try and marry up these repos to be as close as possible first and see if we can get yours working. \r\n\r\nThe first issue, not being able to push is odd. Could you try pushing something to a different repo name to see if this issue persists? ",
"Hi @amyeroberts,\r\n\r\nI was able to push / retrieve the tool by using another repo name and using WSL.\r\nThe first repo was a \"model\" type repo not a space. That was maybe the issue?\r\n\r\nThank you!"
] | 1,690 | 1,691 | 1,691 |
NONE
| null |
### System Info
- transformers version: 4.31.0
- Platform: Windows-10-10.0.22621-SP0
- Python version: 3.11.3
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
When pushing my tool to the hub with the following function, I'm getting an error.
```python
tool.push_to_hub("romainlg/hf-sql")
```
```
Traceback (most recent call last):
File "d:\Devs\python\ai\tools\sql\main.py", line 4, in <module>
tool.push_to_hub("romainlg/hf-sql")
File "C:\Python311\Lib\site-packages\transformers\tools\base.py", line 315, in push_to_hub
metadata_update(repo_id, {"tags": ["tool"]}, repo_type="space")
File "C:\Python311\Lib\site-packages\huggingface_hub\utils\_validators.py", line 118, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "C:\Python311\Lib\site-packages\huggingface_hub\repocard.py", line 810, in metadata_update
return card.push_to_hub(
^^^^^^^^^^^^^^^^^
File "C:\Python311\Lib\site-packages\huggingface_hub\repocard.py", line 275, in push_to_hub
tmp_path.write_text(str(self))
File "C:\Python311\Lib\pathlib.py", line 1079, in write_text
return f.write(data)
^^^^^^^^^^^^^
File "C:\Python311\Lib\encodings\cp1252.py", line 19, in encode
return codecs.charmap_encode(input,self.errors,encoding_table)[0]
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
UnicodeEncodeError: 'charmap' codec can't encode character '\U0001f525' in position 27: character maps to <undefined>
```
I bypassed it by saving the tool and then uploading it to the hub but when trying to import it later, I'm getting:
```python
tool.save('./hf-sql-tmp')
```
```python
from transformers import load_tool
sql = load_tool("romainlg/hf-sql")
```
```
Traceback (most recent call last):
File "d:\Devs\python\ai\tools\sql\test.py", line 5, in <module>
sql = load_tool("romainlg/hf-sql")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Python311\Lib\site-packages\transformers\tools\base.py", line 690, in load_tool
return Tool.from_hub(task_or_repo_id, model_repo_id=model_repo_id, token=token, remote=remote, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Python311\Lib\site-packages\transformers\tools\base.py", line 245, in from_hub
raise EnvironmentError(
OSError: romainlg/hf-sql does not appear to provide a valid configuration in `tool_config.json` or `config.json`.
```
However, by looking at the other working tools, i've the same config base...
I don't know what's the issue here...
The full code is available at [https://huggingface.co/romainlg/hf-sql/tree/main](https://huggingface.co/romainlg/hf-sql/tree/main)
Thank you !
### Expected behavior
Be able to push the tool to the hub and the ability to load the tool from the hub.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25192/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25192/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25191
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25191/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25191/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25191/events
|
https://github.com/huggingface/transformers/issues/25191
| 1,828,026,972 |
I_kwDOCUB6oc5s9Xpc
| 25,191 |
_forward_unimplemented() got an unexpected keyword argument 'input_ids'
|
{
"login": "shayongithub",
"id": 65408661,
"node_id": "MDQ6VXNlcjY1NDA4NjYx",
"avatar_url": "https://avatars.githubusercontent.com/u/65408661?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/shayongithub",
"html_url": "https://github.com/shayongithub",
"followers_url": "https://api.github.com/users/shayongithub/followers",
"following_url": "https://api.github.com/users/shayongithub/following{/other_user}",
"gists_url": "https://api.github.com/users/shayongithub/gists{/gist_id}",
"starred_url": "https://api.github.com/users/shayongithub/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/shayongithub/subscriptions",
"organizations_url": "https://api.github.com/users/shayongithub/orgs",
"repos_url": "https://api.github.com/users/shayongithub/repos",
"events_url": "https://api.github.com/users/shayongithub/events{/privacy}",
"received_events_url": "https://api.github.com/users/shayongithub/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I have add another `forward` method for my `MultiTaskModel `and the error is gone even though the new one appear. "
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### System Info
I am training on Google Colab Pro+ with following info:
- `transformers` version: 4.31.0
- Platform: Linux-5.15.109+-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (False)
- Tensorflow version (GPU?): 2.12.0 (False)
- Flax version (CPU?/GPU?/TPU?): 0.7.0 (cpu)
- Jax version: 0.4.13
- JaxLib version: 0.4.13
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@sgugger
@ArthurZucker
@younesbelkada
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Hi, I am trying to build a Multi-tasking Model following this [article](https://towardsdatascience.com/how-to-create-and-train-a-multi-task-transformer-model-18c54a146240) for two task: **zero-shot classification** **and sentiment analysis**.
**1. Creates the encoder and an output head for each task.**
I have try three different loaders based on the suggestion from the similar issues [here](https://github.com/huggingface/transformers/issues/21335): `AutoModel`, `AutoModelForSequenceClassification`, `RobertaForSequenceClassification `
```
import torch.nn as nn
from typing import List
from transformers import AutoModel, AutoModelForSequenceClassification, RobertaForSequenceClassification
class SequenceClassificationHead(nn.Module):
def __init__(self, hidden_size, num_labels, dropout_p=0.1):
super().__init__()
self.num_labels = num_labels
self.dropout = nn.Dropout(dropout_p)
self.classifier = nn.Linear(hidden_size, num_labels)
self._init_weights()
def forward(self, sequence_output, pooled_output, labels=None, **kwargs):
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
if labels.dim() != 1:
# Remove padding
labels = labels[:, 0]
loss_fct = nn.CrossEntropyLoss()
loss = loss_fct(
logits.view(-1, self.num_labels), labels.long().view(-1)
)
return logits, loss
def _init_weights(self):
self.classifier.weight.data.normal_(mean=0.0, std=0.02)
if self.classifier.bias is not None:
self.classifier.bias.data.zero_()
class MultiTaskModel(nn.Module):
def __init__(self, encoder_name_or_path, tasks: List):
super().__init__()
self.encoder = AutoModel.from_pretrained(encoder_name_or_path)
self.output_heads = nn.ModuleDict()
for task in tasks:
decoder = self._create_output_head(self.encoder.config.hidden_size, task)
# ModuleDict requires keys to be strings
self.output_heads[str(task.task_id)] = decoder
@staticmethod
def _create_output_head(encoder_hidden_size: int, task):
if task.task_type == "seq_classification":
return SequenceClassificationHead(encoder_hidden_size, task.num_labels)
else:
raise NotImplementedError()
```
**2. Define the metrics**
```
from transformers import EvalPrediction
import numpy as np
from datasets import load_metric
import evaluate
accuracy_metric = evaluate.load("accuracy")
f1_metric = evaluate.load("f1")
precision_metric = evaluate.load("precision")
recall_metric = evaluate.load("recall")
def compute_metrics(eval_preds: EvalPrediction):
preds_dim = (eval_preds.predictions[0] if isinstance(eval_preds.predictions, tuple) else eval_preds.predictions).ndim
if preds_dim == 2:
# Sentiment analysis
average="binary"
elif preds_dim == 3:
# Sequence classification
average="macro"
else:
raise NotImplementedError()
logits, labels = eval_preds
predictions = np.argmax(logits, axis=-1)
accuracy = accuracy_metric.compute(predictions=predictions, references=labels)["accuracy"]
precision = precision_metric.compute(predictions=predictions, references=labels, average=average)["precision"]
recall = recall_metric.compute(predictions=predictions, references=labels, average=average)["recall"]
f1 = f1_metric.compute(predictions=predictions, references=labels, average=average)["f1"]
return {"accuracy": accuracy, "precision": precision, "recall": recall, "f1": f1}
```
**3. Fine-tuning pre-trained model `vinai/phobert-base-v2` which based on `RoBERTa`**
```
from transformers import DataCollatorWithPadding, IntervalStrategy
from transformers.trainer_utils import get_last_checkpoint
import os
import random
transformers.logging.set_verbosity_info()
set_seed(42)
model_args = ModelArguments(encoder_name_or_path="vinai/phobert-base")
training_args = TrainingArguments(
do_train=True,
do_eval=True,
output_dir="./mtl_zsl_sa_model",
evaluation_strategy = IntervalStrategy.STEPS,
per_device_train_batch_size=32,
per_device_eval_batch_size=32,
eval_steps = 500,
save_steps = 2000,
logging_steps = 500,
learning_rate=5e-5,
label_smoothing_factor=0.1,
# fp16=True,
num_train_epochs=3,
weight_decay=0.01,
save_strategy=IntervalStrategy.STEPS,
load_best_model_at_end = True,
metric_for_best_model = 'f1',
optim="adamw_torch",
resume_from_checkpoint=True,
remove_unused_columns=False
)
data_args = DataTrainingArguments(max_seq_length=128,
max_train_samples=100)
tokenizer = AutoTokenizer.from_pretrained(
model_args.encoder_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
use_auth_token=True if model_args.use_auth_token else None,
)
tasks, raw_datasets = load_datasets(tokenizer, data_args, training_args)
model = MultiTaskModel(model_args.encoder_name_or_path, tasks)
train_dataset = raw_datasets["train"]
eval_datasets = raw_datasets["validation"]
data_collator = DataCollatorWithPadding(
tokenizer, pad_to_multiple_of=8
)
# Initialize our Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset
compute_metrics=compute_metrics,
tokenizer=tokenizer,
data_collator=data_collator,
)
trainer.train()
```
This is what my merged tokenized datasets look like
```
DatasetDict({
train: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'task_ids'],
num_rows: 29250
})
validation: [Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'task_ids'],
num_rows: 1510
}), Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'task_ids'],
num_rows: 2262
})]
})
```
This is my loaded model:
```
MultiTaskModel(
(encoder): RobertaForSequenceClassification(
(roberta): RobertaModel(
(embeddings): RobertaEmbeddings(
(word_embeddings): Embedding(64001, 768, padding_idx=1)
(position_embeddings): Embedding(258, 768, padding_idx=1)
(token_type_embeddings): Embedding(1, 768)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): RobertaEncoder(
(layer): ModuleList(
(0-11): 12 x RobertaLayer(
(attention): RobertaAttention(
(self): RobertaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): RobertaSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): RobertaIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): RobertaOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
)
(classifier): RobertaClassificationHead(
(dense): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
(out_proj): Linear(in_features=768, out_features=2, bias=True)
)
)
(output_heads): ModuleDict(
(0): SequenceClassificationHead(
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=2, bias=True)
)
(1): SequenceClassificationHead(
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=3, bias=True)
)
)
)
```
And I run into the following error:
```
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in train(self, resume_from_checkpoint, trial, ignore_keys_for_eval, **kwargs)
1537 self._inner_training_loop, self._train_batch_size, args.auto_find_batch_size
1538 )
-> 1539 return inner_training_loop(
1540 args=args,
1541 resume_from_checkpoint=resume_from_checkpoint,
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in _inner_training_loop(self, batch_size, args, resume_from_checkpoint, trial, ignore_keys_for_eval)
1807
1808 with self.accelerator.accumulate(model):
-> 1809 tr_loss_step = self.training_step(model, inputs)
1810
1811 if (
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in training_step(self, model, inputs)
2652
2653 with self.compute_loss_context_manager():
-> 2654 loss = self.compute_loss(model, inputs)
2655
2656 if self.args.n_gpu > 1:
[/usr/local/lib/python3.10/dist-packages/transformers/trainer.py](https://localhost:8080/#) in compute_loss(self, model, inputs, return_outputs)
2677 else:
2678 labels = None
-> 2679 outputs = model(**inputs)
2680 # Save past state if it exists
2681 # TODO: this needs to be fixed and made cleaner later.
[/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py](https://localhost:8080/#) in _call_impl(self, *args, **kwargs)
1499 or _global_backward_pre_hooks or _global_backward_hooks
1500 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1501 return forward_call(*args, **kwargs)
1502 # Do not call functions when jit is used
1503 full_backward_hooks, non_full_backward_hooks = [], []
TypeError: _forward_unimplemented() got an unexpected keyword argument 'input_ids'
```
### Expected behavior
The trainer run smoothly without errors
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25191/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25191/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25190
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25190/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25190/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25190/events
|
https://github.com/huggingface/transformers/pull/25190
| 1,827,993,319 |
PR_kwDOCUB6oc5WvGrS
| 25,190 |
[quantization.md] fix
|
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
Fix typos (use case is 2 words)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25190/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25190/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25190",
"html_url": "https://github.com/huggingface/transformers/pull/25190",
"diff_url": "https://github.com/huggingface/transformers/pull/25190.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25190.patch",
"merged_at": 1690821450000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25189
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25189/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25189/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25189/events
|
https://github.com/huggingface/transformers/issues/25189
| 1,827,962,584 |
I_kwDOCUB6oc5s9H7Y
| 25,189 |
Can BlipForImageTextRetrieval be used to generate captions?
|
{
"login": "Vibhu04",
"id": 29009031,
"node_id": "MDQ6VXNlcjI5MDA5MDMx",
"avatar_url": "https://avatars.githubusercontent.com/u/29009031?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Vibhu04",
"html_url": "https://github.com/Vibhu04",
"followers_url": "https://api.github.com/users/Vibhu04/followers",
"following_url": "https://api.github.com/users/Vibhu04/following{/other_user}",
"gists_url": "https://api.github.com/users/Vibhu04/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Vibhu04/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Vibhu04/subscriptions",
"organizations_url": "https://api.github.com/users/Vibhu04/orgs",
"repos_url": "https://api.github.com/users/Vibhu04/repos",
"events_url": "https://api.github.com/users/Vibhu04/events{/privacy}",
"received_events_url": "https://api.github.com/users/Vibhu04/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey! Since you are not reporting a bug, could you open a discussion on [the forum](https://discuss.huggingface.co/) for this kind of questions?",
"Sure, apologies. ",
"No worries! 🤗 Feel free to ping @younesbelkada there"
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### System Info
`transformers` version: 4.31.0.dev0
Platform: Linux-5.15.0-76-generic-x86_64-with-debian-bullseye-sid
Python version: 3.7.15
Huggingface_hub version: 0.15.1
Safetensors version: 0.3.1
PyTorch version (GPU?): 1.13.1+cu117 (True)
Tensorflow version (GPU?): 2.11.0 (False)
Flax version (CPU?/GPU?/TPU?): not installed (NA)
Jax version: not installed
JaxLib version: not installed
Using GPU in script?: no
Using distributed or parallel set-up in script?: no
### Who can help?
@younesbelkada @ArthurZucker @amyeroberts
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I am seeking a Blip model that can serve two purposes: predicting the similarity between an input image and text and generating a caption for an input image. I am aware that `BlipForImageTextRetrieval` is suitable for predicting the similarity between an image and text, while `BlipForConditionalGeneration` can generate captions for images. However, I was wondering whether either of these models can be employed to perform the alternate task as well.
A bit more context: I have a fine-tuned `BlipForImageTextRetrieval` model that I would like to use for generating captions.
### Expected behavior
Any guidance on obtaining a Blip model that can do both the tasks mentioned above would be extremely helpful. Thanks.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25189/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25189/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25188
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25188/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25188/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25188/events
|
https://github.com/huggingface/transformers/pull/25188
| 1,827,901,299 |
PR_kwDOCUB6oc5Wu0Yu
| 25,188 |
Loosen output shape restrictions on GPT-style models
|
{
"login": "calpt",
"id": 36051308,
"node_id": "MDQ6VXNlcjM2MDUxMzA4",
"avatar_url": "https://avatars.githubusercontent.com/u/36051308?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/calpt",
"html_url": "https://github.com/calpt",
"followers_url": "https://api.github.com/users/calpt/followers",
"following_url": "https://api.github.com/users/calpt/following{/other_user}",
"gists_url": "https://api.github.com/users/calpt/gists{/gist_id}",
"starred_url": "https://api.github.com/users/calpt/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/calpt/subscriptions",
"organizations_url": "https://api.github.com/users/calpt/orgs",
"repos_url": "https://api.github.com/users/calpt/repos",
"events_url": "https://api.github.com/users/calpt/events{/privacy}",
"received_events_url": "https://api.github.com/users/calpt/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"In principle, it should be OK to loosen this restriction as it doesn't introduce any breaking changes. However, it is making the code more likely to have a silent bug. Let's get a second opinion from @sgugger\r\n\r\nWith regard to the changes, I'd prefer that the instead of slicing, `input_shape[1:]`, we name each of the dimensions explicitly so it's clearer what `output_shape` is e.g. `output_shape = (-1, sequence_length, hidden_size)`. ",
"@sgugger Yes, I realized that `input_ids` can have varying number of dimensions, so naming all dimensions explicitly might get a bit more convoluted than the slicing approach.",
"Ok for you @amyeroberts ?"
] | 1,690 | 1,691 | 1,691 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR loosens checks in the model classes of a couple of GPT-style models that enforce the output shape of the model to be identical to the input shape. This aligns the changed model classes to most other model classes which don't enforce the shapes to be identical.
I might not be aware of some legitimate reasons why these restrictions are in place specifically for these models. Please let me know if there are any and I'll close this PR :)
## Motivation
We're building a library on top of Transformers that leverages various model implementations. Among others, some features in our library will result in the batch size to change dynamically during one model forward pass. While implementing these features, we didn't find this to be an issue for most model classes as they don't require the input and output shapes to be identical. However, some GPT-style models do enforce this. To avoid copying and keeping in sync the full model classes, it would be super helpful to us if these restrictions could also be loosened for GPT models.
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
- text models: @ArthurZucker and @younesbelkada
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25188/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25188/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25188",
"html_url": "https://github.com/huggingface/transformers/pull/25188",
"diff_url": "https://github.com/huggingface/transformers/pull/25188.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25188.patch",
"merged_at": 1691418676000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25187
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25187/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25187/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25187/events
|
https://github.com/huggingface/transformers/issues/25187
| 1,827,865,213 |
I_kwDOCUB6oc5s8wJ9
| 25,187 |
Loading LLaMA model does not use GPU memory neither offload folder
|
{
"login": "not4fame",
"id": 31779190,
"node_id": "MDQ6VXNlcjMxNzc5MTkw",
"avatar_url": "https://avatars.githubusercontent.com/u/31779190?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/not4fame",
"html_url": "https://github.com/not4fame",
"followers_url": "https://api.github.com/users/not4fame/followers",
"following_url": "https://api.github.com/users/not4fame/following{/other_user}",
"gists_url": "https://api.github.com/users/not4fame/gists{/gist_id}",
"starred_url": "https://api.github.com/users/not4fame/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/not4fame/subscriptions",
"organizations_url": "https://api.github.com/users/not4fame/orgs",
"repos_url": "https://api.github.com/users/not4fame/repos",
"events_url": "https://api.github.com/users/not4fame/events{/privacy}",
"received_events_url": "https://api.github.com/users/not4fame/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @sgugger ",
"Hi @not4fame , can you print the `device_map` of the model by printing `model.hf_device.map` ? What do you mean that it is not using the `offloaded folder` ? To me, if you were able to load your model without error, it means that you are indeed using disk offload as your GPU RAM + RAM < model size. As for the gpu, we need to leave some space to bring back the layers that were offloaded to the cpu to the gpu during inference. To make better use of your gpus, you should probably load the model in fp16. Check out this [colab](https://colab.research.google.com/drive/11HJsgGJl8eK57FEPVmHmfnxzbfod55yM?usp=sharing) where load the model in fp16. ",
"Also, you might need to use `offload_state_dict=True` to avoid getting out of CPU RAM while loading your model.",
"Thank you @sgugger `offload_state_dict=True` flag was exactly what was missing. Now my script is properly using offload folder.\r\n\r\n\r\n\r\nthank you @SunMarc for your comments, I wasn't able to dump the device_map because the model didn't load, but when trying to access this configuration, after some initial research, I managed to find a way to have even more control when loading the model which resulted in better performance\r\n```\r\nfrom pynvml import *\r\nnvmlInit()\r\nh = nvmlDeviceGetHandleByIndex(0)\r\ninfo = nvmlDeviceGetMemoryInfo(h)\r\n\r\nprint(f'total : {info.total}')\r\nprint(f'free : {info.free}')\r\nprint(f'used : {info.used}')\r\n\r\nfrom transformers import LlamaForCausalLM, LlamaTokenizer, AutoConfig, AutoModelForCausalLM\r\nimport accelerate\r\nimport json\r\n\r\nmodel_id=\"./converted-llama-2-7b-chat\"\r\n\r\nconfig = AutoConfig.from_pretrained(model_id)\r\nwith accelerate.init_empty_weights():\r\n dummy_model = AutoModelForCausalLM.from_config(config)\r\ndevice_map = accelerate.infer_auto_device_map(dummy_model, max_memory={0: \"4GiB\", \"cpu\": \"10GiB\"})\r\n\r\ntokenizer = LlamaTokenizer.from_pretrained(model_id)\r\nmodel =LlamaForCausalLM.from_pretrained(\r\n model_id,\r\n device_map=device_map,\r\n load_in_8bit=True,\r\n llm_int8_enable_fp32_cpu_offload=True,\r\n offload_folder=\"offload\",\r\n offload_state_dict=True)\r\n```"
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### System Info
- `transformers` version: 4.32.0.dev0
- Platform: Linux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): Tensorflow version (GPU?): 2.13.0 (True)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes (**this is part of the issue**)
- Using distributed or parallel set-up in script?: no
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction

code used:
```
from pynvml import *
nvmlInit()
h = nvmlDeviceGetHandleByIndex(0)
info = nvmlDeviceGetMemoryInfo(h)
print(f'total : {info.total}')
print(f'free : {info.free}')
print(f'used : {info.used}')
from transformers import LlamaForCausalLM, LlamaTokenizer
model_id="./converted-llama-2-7b-chat"
tokenizer = LlamaTokenizer.from_pretrained(model_id)
model =LlamaForCausalLM.from_pretrained(model_id, device_map="auto", offload_folder="offload")
```
The memory tops and script finish with **killed** message without usage of offload folder and usage of 618 MiB of GPU RAM only
### Expected behavior
- Usage of available GPU RAM
- Usage of offload folder
before finishing with **killed** message
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25187/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25187/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25186
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25186/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25186/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25186/events
|
https://github.com/huggingface/transformers/pull/25186
| 1,827,693,275 |
PR_kwDOCUB6oc5WuLFo
| 25,186 |
[DOCS] Add `NoRepeatNGramLogitsProcessor` Example for `LogitsProcessor` class
|
{
"login": "Rishab26",
"id": 12711383,
"node_id": "MDQ6VXNlcjEyNzExMzgz",
"avatar_url": "https://avatars.githubusercontent.com/u/12711383?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Rishab26",
"html_url": "https://github.com/Rishab26",
"followers_url": "https://api.github.com/users/Rishab26/followers",
"following_url": "https://api.github.com/users/Rishab26/following{/other_user}",
"gists_url": "https://api.github.com/users/Rishab26/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Rishab26/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Rishab26/subscriptions",
"organizations_url": "https://api.github.com/users/Rishab26/orgs",
"repos_url": "https://api.github.com/users/Rishab26/repos",
"events_url": "https://api.github.com/users/Rishab26/events{/privacy}",
"received_events_url": "https://api.github.com/users/Rishab26/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Hey @gante Thanks for your feedback. I've made the requested changes. Let me know what you think. ",
"@gante I've made the recommended changes. Does this look better?",
"@amyeroberts I've made some changes. Let me know what you think. ",
"> Thanks for iterating!\r\n> \r\n> Just a few small notes on the correctness of the docstrings / styling nits.\r\n> \r\n> Note: What's being used in these functions are token ids not tokens. When a sentence is tokenized, it typically means splitting the words into word pieces e.g. `\"This is a tokenized sentence\"` -> `['this', 'is', 'a', 'token', '##ized', 'sentence']` i.e. it is a list of strings. These are then mapped to ints, which are token ids and that we pass to the model.\r\n> \r\n> We're not completely strict everywhere with using token ids vs tokens and someone will understand if you say `list of generated tokens`. However `tokenized list of next words observed` is wrong - the list isn't tokenized and it's not next words but ints that map to word-pieces. We should say something like `list of next token ids`.\r\n\r\nOf course, I understand that :) I was only trying to make that function simpler to understand. Having said that, you're absolutely right, `list of next token ids` is the right framing. I'll make the change. ",
"@amyeroberts Thanks for your feedback. Let me know if the changes look good now 👍 "
] | 1,690 | 1,691 | 1,691 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR adds an example to the docstring of `NoRepeatNGramLogitsProcessor` and edits the docstring description of the same.
This is with reference to #24783 and is part of the #24575
Fixes # (issue)
#24783
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
## Who can review?
@gante @sgugger
### Additional Notes:
In comparison with [TFNoRepeatNGramLogitsProcessor](https://github.com/huggingface/transformers/blob/05cda5df3405e6a2ee4ecf8f7e1b2300ebda472e/src/transformers/generation/tf_logits_process.py#L388), I noticed that the required functions `_get_ngrams`, `_get_generated_ngrams`, and `_calc_banned_ngram_tokens` were outside the class. Is this expected?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25186/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25186/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25186",
"html_url": "https://github.com/huggingface/transformers/pull/25186",
"diff_url": "https://github.com/huggingface/transformers/pull/25186.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25186.patch",
"merged_at": 1691424135000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25185
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25185/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25185/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25185/events
|
https://github.com/huggingface/transformers/issues/25185
| 1,827,569,862 |
I_kwDOCUB6oc5s7oDG
| 25,185 |
conversational + text-generation pipelines fail to read max_length from GenerationConfig
|
{
"login": "yonigottesman",
"id": 4004127,
"node_id": "MDQ6VXNlcjQwMDQxMjc=",
"avatar_url": "https://avatars.githubusercontent.com/u/4004127?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/yonigottesman",
"html_url": "https://github.com/yonigottesman",
"followers_url": "https://api.github.com/users/yonigottesman/followers",
"following_url": "https://api.github.com/users/yonigottesman/following{/other_user}",
"gists_url": "https://api.github.com/users/yonigottesman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/yonigottesman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/yonigottesman/subscriptions",
"organizations_url": "https://api.github.com/users/yonigottesman/orgs",
"repos_url": "https://api.github.com/users/yonigottesman/repos",
"events_url": "https://api.github.com/users/yonigottesman/events{/privacy}",
"received_events_url": "https://api.github.com/users/yonigottesman/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey @yonigottesman 👋 We are aware of this issue, where `GenerationConfig` is not being piped correctly at input verification time. This requires a pipeline-level change (and not simply a `Conversation`-level change), and we are working on it :)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,694 | 1,694 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.32.0.dev0
- Platform: macOS-13.3.1-arm64-arm-64bit
- Python version: 3.10.5
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: false
- Using distributed or parallel set-up in script?: false
### Who can help?
@Narsil @gante
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
~~~
pipe = pipeline("conversational", model="facebook/blenderbot_small-90M")
conv = Conversation("Does money buy happiness?" * 80)
gc = GenerationConfig(max_length=512)
pipe(conv, generation_config=gc)
~~~
This trims the input and log this message:
`Conversation input is to long (401), trimming it to (128 - 10)`
Even though I asked for `max_length=512` becase it ignores the gc and takes the models default
### Expected behavior
I expect the pipeline code to consider the `GenerationConfig` max_length but I see in the [code](https://github.com/huggingface/transformers/blob/main/src/transformers/pipelines/conversational.py#L269) that it just looks for the (deprecated) `max_length`.
There is a similar issue with the `text-generation` pipeline.
Ill be happy to open a pr and fix this. As I understand, I just need to check the `generate_kwargs` for a `generation_config` and check if it has a `max_length` or/and `max_new_tokens`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25185/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25185/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25184
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25184/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25184/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25184/events
|
https://github.com/huggingface/transformers/pull/25184
| 1,827,522,463 |
PR_kwDOCUB6oc5WtmoT
| 25,184 |
Add timeout parameter to load_image function
|
{
"login": "rolisz",
"id": 426313,
"node_id": "MDQ6VXNlcjQyNjMxMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/426313?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rolisz",
"html_url": "https://github.com/rolisz",
"followers_url": "https://api.github.com/users/rolisz/followers",
"following_url": "https://api.github.com/users/rolisz/following{/other_user}",
"gists_url": "https://api.github.com/users/rolisz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rolisz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rolisz/subscriptions",
"organizations_url": "https://api.github.com/users/rolisz/orgs",
"repos_url": "https://api.github.com/users/rolisz/repos",
"events_url": "https://api.github.com/users/rolisz/events{/privacy}",
"received_events_url": "https://api.github.com/users/rolisz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@amyeroberts I've done the requested changes"
] | 1,690 | 1,691 | 1,691 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR adds a timeout parameter to all pipelines that can fetch images from remote URLs. Without a timeout, the request can hang indefinitely.
Fixes #25168
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x ] Did you write any new necessary tests?
## Who can review?
@amyeroberts
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25184/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25184/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25184",
"html_url": "https://github.com/huggingface/transformers/pull/25184",
"diff_url": "https://github.com/huggingface/transformers/pull/25184.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25184.patch",
"merged_at": 1691074314000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25183
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25183/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25183/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25183/events
|
https://github.com/huggingface/transformers/issues/25183
| 1,827,496,374 |
I_kwDOCUB6oc5s7WG2
| 25,183 |
audio pipeline utility ffmpeg_microphone_live doesn't work in Google Colab
|
{
"login": "crcdng",
"id": 830492,
"node_id": "MDQ6VXNlcjgzMDQ5Mg==",
"avatar_url": "https://avatars.githubusercontent.com/u/830492?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/crcdng",
"html_url": "https://github.com/crcdng",
"followers_url": "https://api.github.com/users/crcdng/followers",
"following_url": "https://api.github.com/users/crcdng/following{/other_user}",
"gists_url": "https://api.github.com/users/crcdng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/crcdng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/crcdng/subscriptions",
"organizations_url": "https://api.github.com/users/crcdng/orgs",
"repos_url": "https://api.github.com/users/crcdng/repos",
"events_url": "https://api.github.com/users/crcdng/events{/privacy}",
"received_events_url": "https://api.github.com/users/crcdng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hey @crcdng! Thanks for flagging this - could you share details of how you achieved step 1 (make sure microphone works and access to microphone is enabled in Colab)? Once I can reproduce I can take a look into how we can get this working!",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"> Hey @crcdng! Thanks for flagging this - could you share details of how you achieved step 1 (make sure microphone works and access to microphone is enabled in Colab)? Once I can reproduce I can take a look into how we can get this working!\r\n\r\nTesting the microphone on my machine and then looking at the colab permissions:\r\n\r\n<img width=\"314\" alt=\"Screenshot 2023-08-29 at 14 31 37\" src=\"https://github.com/huggingface/transformers/assets/830492/c631d8df-550f-49f7-9257-93284eaa7e79\">\r\n\r\n",
"Hmm yes I don't think Colab is able to take the output from your local microphone and send it to the Colab device. Have you tried running the script locally? I actually wrote it using a CPU only device on a MBP laptop, so it should work on your local CPU. There are some hacky ways you can try to get your microphone output to work with Colab if you'd like to try this, e.g. https://ricardodeazambuja.com/deep_learning/2019/03/09/audio_and_video_google_colab/",
"> Hmm yes I don't think Colab is able to take the output from your local microphone and send it to the Colab device. Have you tried running the script locally? I actually wrote it using a CPU only device on a MBP laptop, so it should work on your local CPU. There are some hacky ways you can try to get your microphone output to work with Colab if you'd like to try this, e.g. https://ricardodeazambuja.com/deep_learning/2019/03/09/audio_and_video_google_colab/\r\n\r\nEDIT: I haven't been able to run the code locally either using VSCode / with Jupyter Notebook Support. \r\n\r\nI get a \r\n\r\n`ValueError: We expect a numpy ndarray as input`\r\n\r\nin cell `launch_fn(debug=True)` \r\n\r\nIs it possible that `ffmpeg_microphone_live` needs more work?\r\n\r\nFirst response: \r\n(Yeah, I have seen the \"hacky\" method as well and was wondering if it could be integrated in this section of the Audio course? Alternatively, maybe a note at the beginning of https://huggingface.co/learn/audio-course/chapter7/voice-assistant#creating-a-voice-assistant such as \"Due to the requirement for an active microphone, it is recommended to try this section on a local machine instead of Google Colab.\" ) ",
"## ffmpeg repro\r\n\r\nSorry to hear that @crcdng! Could you post the full stack trace please? I can then take a deeper look! For reference, I'm using this reduced version of the code to test ASR inference:\r\n\r\nCell 0:\r\n```python\r\nfrom transformers import pipeline\r\nimport torch\r\nfrom transformers.pipelines.audio_utils import ffmpeg_microphone_live\r\n\r\ndevice = \"cuda:0\" if torch.cuda.is_available() else \"cpu\"\r\n\r\ntranscriber = pipeline(\r\n \"automatic-speech-recognition\", model=\"openai/whisper-base.en\", device=device\r\n)\r\n\r\nimport sys\r\n\r\n\r\ndef transcribe(chunk_length_s=15.0, stream_chunk_s=1.0):\r\n sampling_rate = transcriber.feature_extractor.sampling_rate\r\n\r\n mic = ffmpeg_microphone_live(\r\n sampling_rate=sampling_rate,\r\n chunk_length_s=chunk_length_s,\r\n stream_chunk_s=stream_chunk_s,\r\n )\r\n\r\n print(\"Start speaking...\")\r\n for item in transcriber(mic, generate_kwargs={\"max_new_tokens\": 128}):\r\n sys.stdout.write(\"\\033[K\")\r\n print(item[\"text\"], end=\"\\r\")\r\n if not item[\"partial\"][0]:\r\n break\r\n```\r\n\r\nCell 1:\r\n```\r\ntranscribe()\r\n```\r\n\r\n## Google Colab compatibility\r\n\r\nI'll add a note to the start of the section - that's a great suggestion.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"I updated the course docs to suggest using a local device. Do you have a reproducible code snippet and error trace for the ffmpeg issues @crcdng? The code is working using the reproducer I gave above: https://github.com/huggingface/transformers/issues/25183#issuecomment-1703099362",
"Hi @sanchit-gandhi \r\nI ran the code snippet(saved as python live_transcription.py) you shared on my Local machine(CPU). Unfortunately, it is not working for me. It seems like the program ends before `print(\"Start speaking...\")` I am guessing I might be setting up the environment on my machine wrongly?\r\n\r\n**System Info**\r\nIntel Core i7 10th Gen\r\nDefault MSI Laptop Microphone\r\n\r\n**Environment Setup & to replicate error **\r\npip install git+https://github.com/huggingface/transformers.git\r\npython live_transcription.py\r\n\r\n**Who can help?**\r\n@sanchit-gandhi\r\n\r\n**Information**\r\n The official example scripts\r\n\r\n**Error**\r\n\r\nUSER@MSI MINGW64 ~/Desktop/Medical STT & TTS (master)\r\n$ C:/Users/USER/AppData/Local/Programs/Python/Python38/python.exe \"c:/Users/USER/Desktop/Medical STT & TTS/live_transcription.py\"\r\nLoading the tokenizer from the `special_tokens_map.json` and the `added_tokens.json` will be removed in `transformers 5`, it is kept for forward compatibility, but it is recommended to update your `tokenizer_config.json` by uploading it again. You will see the new `added_tokens_decoder` attribute that will store \r\nthe relevant information.\r\nSpecial tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.",
"Hey @ss8319! Do you get any error message when the program hangs/crashes? The logs you've sent are just warnings about tokenizer updates, rather than error logs! Also, are you calling `transcribe()` in your python file? If using a Python file, your code should be:\r\n```python\r\nfrom transformers import pipeline\r\nimport torch\r\nfrom transformers.pipelines.audio_utils import ffmpeg_microphone_live\r\nimport sys\r\n\r\ndevice = \"cuda:0\" if torch.cuda.is_available() else \"cpu\"\r\n\r\ntranscriber = pipeline(\r\n \"automatic-speech-recognition\", model=\"openai/whisper-base.en\", device=device\r\n)\r\n\r\n\r\ndef transcribe(chunk_length_s=15.0, stream_chunk_s=1.0):\r\n sampling_rate = transcriber.feature_extractor.sampling_rate\r\n\r\n mic = ffmpeg_microphone_live(\r\n sampling_rate=sampling_rate,\r\n chunk_length_s=chunk_length_s,\r\n stream_chunk_s=stream_chunk_s,\r\n )\r\n\r\n print(\"Start speaking...\")\r\n for item in transcriber(mic, generate_kwargs={\"max_new_tokens\": 128}):\r\n sys.stdout.write(\"\\033[K\")\r\n print(item[\"text\"], end=\"\\r\")\r\n if not item[\"partial\"][0]:\r\n break\r\n\r\ntranscribe()\r\n```",
"Thanks @sanchit-gandhi! Yea I forgot to add transcribe(). Thanks for catching that. Its showing a different error now. Doing pip install ffmpeg didn't help.\r\n\r\n```USER@MSI MINGW64 ~/Desktop/Medical STT & TTS (master)\r\n$ python live_transcription.py\r\nLoading the tokenizer from the `special_tokens_map.json` and the `added_tokens.json` will be removed in `transformers 5`, it is kept for forward compatibility, but it is recommended to update your `tokenizer_config.json` by uploading it again. You will see the new `added_tokens_decoder` attribute that will store \r\nthe relevant information.\r\nSpecial tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.\r\nStart speaking...\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\transformers\\pipelines\\audio_utils.py\", line 217, in _ffmpeg_stream\r\n with subprocess.Popen(ffmpeg_command, stdout=subprocess.PIPE, bufsize=bufsize) as ffmpeg_process: \r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\subprocess.py\", line 858, in __init__ \r\n self._execute_child(args, executable, preexec_fn, close_fds,\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\subprocess.py\", line 1311, in _execute_child\r\n hp, ht, pid, tid = _winapi.CreateProcess(executable, args,\r\nFileNotFoundError: [WinError 2] The system cannot find the file specified\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"live_transcription.py\", line 30, in <module>\r\n transcribe()\r\n File \"live_transcription.py\", line 23, in transcribe\r\n for item in transcriber(mic, generate_kwargs={\"max_new_tokens\": 128}):\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\transformers\\pipelines\\pt_utils.py\", line 124, in __next__\r\n item = next(self.iterator)\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\transformers\\pipelines\\pt_utils.py\", line 266, in __next__\r\n processed = self.infer(next(self.iterator), **self.params)\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\torch\\utils\\data\\dataloader.py\", line 681, in __next__\r\n data = self._next_data()\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\torch\\utils\\data\\dataloader.py\", line 721, in _next_data\r\n data = self._dataset_fetcher.fetch(index) # may raise StopIteration\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\torch\\utils\\data\\_utils\\fetch.py\", line 32, in fetch\r\n data.append(next(self.dataset_iter))\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\transformers\\pipelines\\pt_utils.py\", line 180, in __next__\r\n self.subiterator = self.infer(next(self.iterator), **self.params)\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\transformers\\pipelines\\audio_utils.py\", line 161, in ffmpeg_microphone_live\r\n for item in chunk_bytes_iter(microphone, chunk_len, stride=(stride_left, stride_right), stream=True): File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\transformers\\pipelines\\audio_utils.py\", line 188, in chunk_bytes_iter\r\n for raw in iterator:\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\transformers\\pipelines\\audio_utils.py\", line 94, in ffmpeg_microphone\r\n for item in iterator:\r\n File \"C:\\Users\\USER\\AppData\\Local\\Programs\\Python\\Python38\\lib\\site-packages\\transformers\\pipelines\\audio_utils.py\", line 224, in _ffmpeg_stream\r\n raise ValueError(\"ffmpeg was not found but is required to stream audio files from filename\") from error\r\nValueError: ffmpeg was not found but is required to stream audio files from filename```",
"Ah yes - `ffmpeg` isn't a Python package, but rather a system one: https://ffmpeg.org/download.html\r\n\r\nCould you try installing it via the official installation instructions?",
"Not work to me too, this skips in `for item in pipe(mic)`\r\nWindows 11\r\nffmpeg was installed",
"Hey @CWKSC! Sorry just to clarify - how is the line in the code 'skipped'? Does the code give an error when you run it? Or does it just run and hang without an error? ",
"> Hey @CWKSC! Sorry just to clarify - how is the line in the code 'skipped'? Does the code give an error when you run it? Or does it just run and hang without an error?\r\n\r\nNo error, no hang\r\n\r\nI am following the tutorial: https://huggingface.co/learn/audio-course/chapter7/voice-assistant#creating-a-voice-assistant\r\n\r\n```python\r\nfrom transformers import pipeline\r\nimport torch\r\n\r\ndevice = \"cuda:0\" if torch.cuda.is_available() else \"cpu\"\r\n\r\nclassifier = pipeline(\r\n \"audio-classification\", model=\"MIT/ast-finetuned-speech-commands-v2\", device=device\r\n)\r\n\r\nfrom transformers.pipelines.audio_utils import ffmpeg_microphone_live\r\n\r\ndef launch_fn(\r\n wake_word=\"marvin\",\r\n prob_threshold=0.5,\r\n chunk_length_s=2.0,\r\n stream_chunk_s=0.25,\r\n debug=False,\r\n):\r\n if wake_word not in classifier.model.config.label2id.keys():\r\n raise ValueError(\r\n f\"Wake word {wake_word} not in set of valid class labels, pick a wake word in the set {classifier.model.config.label2id.keys()}.\"\r\n )\r\n\r\n sampling_rate = classifier.feature_extractor.sampling_rate\r\n\r\n mic = ffmpeg_microphone_live(\r\n sampling_rate=sampling_rate,\r\n chunk_length_s=chunk_length_s,\r\n stream_chunk_s=stream_chunk_s,\r\n )\r\n\r\n print(\"Listening for wake word...\")\r\n for prediction in classifier(mic):\r\n prediction = prediction[0]\r\n if debug:\r\n print(prediction)\r\n if prediction[\"label\"] == wake_word:\r\n if prediction[\"score\"] > prob_threshold:\r\n return True\r\n\r\nlaunch_fn(debug=True)\r\n```\r\n\r\nIt skip in `for prediction in classifier(mic):`\r\n\r\nAlso here is my build venv script:\r\n\r\n```powershell\r\npy -3.9 -m venv venv\r\n.\\venv\\Scripts\\activate\r\n\r\npython -m pip install --upgrade pip\r\n\r\npip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118\r\n\r\npip install huggingface_hub\r\npip install transformers\r\npip install ipython\r\n```\r\n\r\n`classifier(mic)` return a `transformers.pipelines.pt_utils.PipelineIterator` object\r\n\r\nAnd this looks like immediate return\r\n\r\nIf I `print(list(classifier(mic)))`, it output `[]`, and then: \r\n\r\n```python\r\nprint(next(classifier(mic)))\r\n```\r\n\r\n```python\r\nTraceback (most recent call last):\r\n File \"...\", line 43, in <module>\r\n launch_fn(debug=True)\r\n File \"...\", line 33, in launch_fn\r\n print(classifier(mic).__next__())\r\n File \"...\\venv\\lib\\site-packages\\transformers\\pipelines\\pt_utils.py\", line 124, in __next__\r\n item = next(self.iterator)\r\nAttributeError: 'PipelineIterator' object has no attribute 'iterator'\r\n```\r\n\r\nMaybe my microphone isn't recognized? I don't know any further setup.\r\n",
"What version of Transformers are you using @CWKSC? Could you paste the output of:\r\n```\r\ntransformers-cli env\r\n```\r\n\r\nOtherwise, it might be a case that your microphone is indeed not being recognised. For now, let's just try printing out the values from the microphone function:\r\n```python\r\nfrom transformers.pipelines.audio_utils import ffmpeg_microphone_live\r\n\r\nmicrophone = ffmpeg_microphone_live(sampling_rate=16000, chunk_length_s=5)\r\n\r\nfor chunk in microphone:\r\n print(chunk)\r\n```\r\n\r\n=> let's check that this returns some values before putting it in combination with the model. If this returns nothing, then we have an error with our ffmpeg read function",
"```powershell\r\ntransformers-cli env\r\n```\r\n\r\n```powershell\r\nCopy-and-paste the text below in your GitHub issue and FILL OUT the two last points.\r\n\r\n- `transformers` version: 4.34.0\r\n- Platform: Windows-10-10.0.22621-SP0\r\n- Python version: 3.9.13\r\n- Huggingface_hub version: 0.17.3\r\n- Safetensors version: 0.4.0\r\n- Accelerate version: not installed\r\n- Accelerate config: not found\r\n- PyTorch version (GPU?): 2.1.0+cu118 (True)\r\n- Tensorflow version (GPU?): not installed (NA)\r\n- Flax version (CPU?/GPU?/TPU?): not installed (NA)\r\n- Jax version: not installed\r\n- JaxLib version: not installed\r\n- Using GPU in script?: <fill in>\r\n- Using distributed or parallel set-up in script?: <fill in>\r\n```\r\n\r\nThe output said platform is `Windows-10-10.0.22621-SP0`, but actually, I am Windows 11.\r\n\r\n\r\n\r\nThe script returns nothing.\r\n\r\nI tried install transformers from source.\r\n\r\n```powershell\r\npip install git+https://github.com/huggingface/transformers\r\n```\r\n\r\nNo different.\r\n\r\nHas anyone else on Windows tried this? ",
"I am having the same problem here, using windows 11\r\ntried \r\n```python\r\nfrom transformers.pipelines.audio_utils import ffmpeg_microphone_live\r\n\r\nmicrophone = ffmpeg_microphone_live(sampling_rate=16000, chunk_length_s=5)\r\n\r\nfor chunk in microphone:\r\n print(chunk)\r\n```\r\ndidn't print anything",
"Thanks both for the info! cc'ing @Narsil here - looks like the ffmpeg utilities for the Transformers pipeline are not working in Windows. Might it be related to these parameters that we set for the ffmpeg microphone? https://github.com/huggingface/transformers/blob/14b04b4b9c483d94fadd2b5479ed9430bae8ac84/src/transformers/pipelines/audio_utils.py#L73-L75\r\n\r\nDo you have any advice for testing with a Windows system too if ones own computer runs Mac/Linux? Did you have a framework for testing these functions with Windows?",
"Had the same problem with the recording not working. Just solved it for testing purpoces.\r\n\r\nYou need to specify the input device to the ffmpeg_microphone() function:\r\n\r\nFind your microphone name using cmd: _ffmpeg -list_devices true -f dshow -i dummy_\r\nCopy the name and edit it in line 75 in -> ...\\.venv\\Lib\\site-packages\\transformers\\pipelines\\audio_utils.py\r\nInstead of \"default\" put \"audio=_input_device_name_\"\r\n```python\r\n elif system == \"Windows\":\r\n format_ = \"dshow\"\r\n input_ = \"audio=Microphone (High Definition Audio Device)\"\r\n\r\n``` ",
"Nice fix @Teapack1! Would you like to open a PR to fix this in Transformers? We can call `ffmpeg -list_devices true -f dshow -I dummy` and store the microphone name as a variable, then set this to the `input_` in the audio utils code: https://github.com/huggingface/transformers/blob/14b04b4b9c483d94fadd2b5479ed9430bae8ac84/src/transformers/pipelines/audio_utils.py#L73-L75",
"Having some problems on Mac currently, trying to follow[ this guide](https://huggingface.co/learn/audio-course/chapter7/voice-assistant). Right now, I can get output, but it doesn't seem to actually be listening to the microphone and only predicting one class for speech classification, no matter what I say, after granting Terminal access to the microphone: \r\n\r\n```\r\n/Users/victor/anaconda3/envs/transformers/lib/python3.9/site-packages/transformers/models/audio_spectrogram_transformer/feature_extraction_audio_spectrogram_transformer.py:96: UserWarning: The given NumPy array is not writable, and PyTorch does not support non-writable tensors. This means writing to this tensor will result in undefined behavior. You may want to copy the array to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at /private/var/folders/sy/f16zz6x50xz3113nwtb9bvq00000gp/T/abs_9d63z49rj_/croot/pytorch_1681837279022/work/torch/csrc/utils/tensor_numpy.cpp:205.)\r\n waveform = torch.from_numpy(waveform).unsqueeze(0)\r\n{'score': 0.05440586432814598, 'label': 'no'}\r\n{'score': 0.05816075950860977, 'label': 'up'}\r\n{'score': 0.07136523723602295, 'label': 'up'}\r\n{'score': 0.09769058227539062, 'label': 'follow'}\r\n{'score': 0.14641302824020386, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n{'score': 0.1379959136247635, 'label': 'follow'}\r\n```\r\n\r\nCurious if anyone else had this issue? Not sure if the warning message has anything to do with this. Is `ffmpeg_microphone` supposed to support MacOS?",
"Edit: it seems like the problem lies with [setting the input for ffmpeg on MacOS to `:1` instead](https://github.com/huggingface/transformers/blob/fb78769b9c053876ed7ae152ee995b0439a4462a/src/transformers/pipelines/audio_utils.py#L68). ",
"> ```python\r\n> def transcribe(chunk_length_s=15.0, stream_chunk_s=1.0):\r\n> sampling_rate = transcriber.feature_extractor.sampling_rate\r\n> \r\n> mic = ffmpeg_microphone_live(\r\n> sampling_rate=sampling_rate,\r\n> chunk_length_s=chunk_length_s,\r\n> stream_chunk_s=stream_chunk_s,\r\n> )\r\n> \r\n> print(\"Start speaking...\")\r\n> for item in transcriber(mic, generate_kwargs={\"max_new_tokens\": 128}):\r\n> sys.stdout.write(\"\\033[K\")\r\n> print(item[\"text\"], end=\"\\r\")\r\n> if not item[\"partial\"][0]:\r\n> break\r\n> \r\n> transcribe()\r\n> ```\r\n\r\nty its help me 👍 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,702 | 1,702 |
NONE
| null |
### System Info
Googel Colab 2023/07/21 / Chrome 115.0.5790.114 / macOS 13.5
Default MacBook microphone
### Who can help?
@sanchit-gandhi
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. make sure microphone works and access to microphone is enabled in Colab
2. follow https://huggingface.co/learn/audio-course/chapter7/voice-assistant
### Expected behavior
Colab cell `launch_fn(debug=True)` should output scores while listening for the wake word as described in the tutorial. Instead, nothing happens. No error is shown and no audio is recorded. This makes the `transcribe` cell in the tutorial crash.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25183/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25183/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25182
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25182/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25182/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25182/events
|
https://github.com/huggingface/transformers/pull/25182
| 1,827,388,985 |
PR_kwDOCUB6oc5WtLUf
| 25,182 |
Knowledge distillation tutorial initial commit
|
{
"login": "merveenoyan",
"id": 53175384,
"node_id": "MDQ6VXNlcjUzMTc1Mzg0",
"avatar_url": "https://avatars.githubusercontent.com/u/53175384?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/merveenoyan",
"html_url": "https://github.com/merveenoyan",
"followers_url": "https://api.github.com/users/merveenoyan/followers",
"following_url": "https://api.github.com/users/merveenoyan/following{/other_user}",
"gists_url": "https://api.github.com/users/merveenoyan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/merveenoyan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/merveenoyan/subscriptions",
"organizations_url": "https://api.github.com/users/merveenoyan/orgs",
"repos_url": "https://api.github.com/users/merveenoyan/repos",
"events_url": "https://api.github.com/users/merveenoyan/events{/privacy}",
"received_events_url": "https://api.github.com/users/merveenoyan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"🤦♀️ 😂 "
] | 1,690 | 1,691 | 1,691 |
CONTRIBUTOR
| null |
This is a documentation PR for task guide to show how to distil an image classification model into another, using `Trainer`. I also tried to explain my intuition about distillation process so let me know if there's anything else to clarify.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25182/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25182/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25182",
"html_url": "https://github.com/huggingface/transformers/pull/25182",
"diff_url": "https://github.com/huggingface/transformers/pull/25182.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25182.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25181
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25181/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25181/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25181/events
|
https://github.com/huggingface/transformers/issues/25181
| 1,827,355,791 |
I_kwDOCUB6oc5s6zyP
| 25,181 |
RagGenerator
|
{
"login": "MaskXman",
"id": 59054903,
"node_id": "MDQ6VXNlcjU5MDU0OTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/59054903?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/MaskXman",
"html_url": "https://github.com/MaskXman",
"followers_url": "https://api.github.com/users/MaskXman/followers",
"following_url": "https://api.github.com/users/MaskXman/following{/other_user}",
"gists_url": "https://api.github.com/users/MaskXman/gists{/gist_id}",
"starred_url": "https://api.github.com/users/MaskXman/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/MaskXman/subscriptions",
"organizations_url": "https://api.github.com/users/MaskXman/orgs",
"repos_url": "https://api.github.com/users/MaskXman/repos",
"events_url": "https://api.github.com/users/MaskXman/events{/privacy}",
"received_events_url": "https://api.github.com/users/MaskXman/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @MaskXman, thanks for raising this issue! \r\n\r\nSo that we can best help you, could you please: \r\n* Make sure there is a minimal reproducible code snippet. We don't have access to the dataset used: `/Volumes/WD_BLACK/Pycharm/dataset/downloads'`. Either a dummy dataset can be created in the script or a public dataset on the hub used. \r\n* Format the code and errors so they're easier to read in markdown code formatting - between a pair of three backticks: ` ``` code goes here ``` `\r\n* Provide information about the running environment: run `transformers-cli env` in the terminal and copy-paste the output\r\n\r\nAre you able to run the example [in the docs](https://huggingface.co/docs/transformers/v4.31.0/en/model_doc/rag#transformers.RagSequenceForGeneration.forward.example)? (This will help us pinpoint the issue)",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
### System Info
import os
from transformers import RagTokenizer, RagTokenForGeneration
from datasets import load_dataset
dataset_path = '/Volumes/WD_BLACK/Pycharm/dataset/downloads' # 修改为外部硬盘的路径
dataset = load_dataset(dataset_path, "psgs_w100.nq.compressed")
model_name = 'facebook/rag-token-base'
tokenizer = RagTokenizer.from_pretrained(model_name)
model = RagTokenForGeneration.from_pretrained(model_name)
# 定义查询
query = "What is the capital of France?"
# 生成答案
inputs = tokenizer(query, return_tensors='pt')
generated = model.generate(input_ids=inputs.input_ids, attention_mask=inputs.attention_mask, max_length=20)
# 解码生成的答案
answer = tokenizer.decode(generated[0], skip_special_tokens=True)
print("Answer:", answer)
bug:Traceback (most recent call last):
File "/Users/maskxman/PycharmProjects/AutoKG/AutoKG/RAG.py", line 18, in <module>
generated = model.generate(input_ids=inputs.input_ids, attention_mask=inputs.attention_mask, max_length=20)
File "/Users/maskxman/anaconda3/envs/camel/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/Users/maskxman/anaconda3/envs/camel/lib/python3.10/site-packages/transformers/models/rag/modeling_rag.py", line 1491, in generate
assert (context_input_ids.shape[0] % n_docs) == 0, (
AttributeError: 'NoneType' object has no attribute 'shape'
Could you pls help me? Thank you !!!!
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
import os
from transformers import RagTokenizer, RagTokenForGeneration
from datasets import load_dataset
dataset_path = '/Volumes/WD_BLACK/Pycharm/dataset/downloads' # 修改为外部硬盘的路径
dataset = load_dataset(dataset_path, "psgs_w100.nq.compressed")
model_name = 'facebook/rag-token-base'
tokenizer = RagTokenizer.from_pretrained(model_name)
model = RagTokenForGeneration.from_pretrained(model_name)
# 定义查询
query = "What is the capital of France?"
# 生成答案
inputs = tokenizer(query, return_tensors='pt')
generated = model.generate(input_ids=inputs.input_ids, attention_mask=inputs.attention_mask, max_length=20)
# 解码生成的答案
answer = tokenizer.decode(generated[0], skip_special_tokens=True)
print("Answer:", answer)
### Expected behavior
/Users/maskxman/anaconda3/envs/camel/bin/python3.10 /Users/maskxman/PycharmProjects/AutoKG/AutoKG/RAG.py
2023-07-29 15:06:31.519470: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 AVX512F AVX512_VNNI FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
Resolving data files: 100%|██████████| 51/51 [00:00<00:00, 229763.16it/s]
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'RagTokenizer'.
The class this function is called from is 'DPRQuestionEncoderTokenizer'.
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'RagTokenizer'.
The class this function is called from is 'DPRQuestionEncoderTokenizerFast'.
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'RagTokenizer'.
The class this function is called from is 'BartTokenizer'.
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'RagTokenizer'.
The class this function is called from is 'BartTokenizerFast'.
Some weights of the model checkpoint at facebook/rag-token-base were not used when initializing RagTokenForGeneration: ['rag.question_encoder.question_encoder.bert_model.pooler.dense.bias', 'rag.question_encoder.question_encoder.bert_model.pooler.dense.weight']
- This IS expected if you are initializing RagTokenForGeneration from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing RagTokenForGeneration from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Traceback (most recent call last):
File "/Users/maskxman/PycharmProjects/AutoKG/AutoKG/RAG.py", line 18, in <module>
generated = model.generate(input_ids=inputs.input_ids, attention_mask=inputs.attention_mask, max_length=20)
File "/Users/maskxman/anaconda3/envs/camel/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/Users/maskxman/anaconda3/envs/camel/lib/python3.10/site-packages/transformers/models/rag/modeling_rag.py", line 1491, in generate
assert (context_input_ids.shape[0] % n_docs) == 0, (
AttributeError: 'NoneType' object has no attribute 'shape'
Process finished with exit code 1
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25181/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25181/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25180
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25180/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25180/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25180/events
|
https://github.com/huggingface/transformers/issues/25180
| 1,827,279,257 |
I_kwDOCUB6oc5s6hGZ
| 25,180 |
Accelerator FSDP state does not reflect the arguments fsdp_config
|
{
"login": "howard-yen",
"id": 47925471,
"node_id": "MDQ6VXNlcjQ3OTI1NDcx",
"avatar_url": "https://avatars.githubusercontent.com/u/47925471?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/howard-yen",
"html_url": "https://github.com/howard-yen",
"followers_url": "https://api.github.com/users/howard-yen/followers",
"following_url": "https://api.github.com/users/howard-yen/following{/other_user}",
"gists_url": "https://api.github.com/users/howard-yen/gists{/gist_id}",
"starred_url": "https://api.github.com/users/howard-yen/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/howard-yen/subscriptions",
"organizations_url": "https://api.github.com/users/howard-yen/orgs",
"repos_url": "https://api.github.com/users/howard-yen/repos",
"events_url": "https://api.github.com/users/howard-yen/events{/privacy}",
"received_events_url": "https://api.github.com/users/howard-yen/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 5616426447,
"node_id": "LA_kwDOCUB6oc8AAAABTsPdzw",
"url": "https://api.github.com/repos/huggingface/transformers/labels/solved",
"name": "solved",
"color": "B1D6DC",
"default": false,
"description": ""
}
] |
closed
| false | null |
[] |
[
"cc @pacman100 ",
"Hello @howard-yen, I don't see any issues.\r\n\r\nUsing the main branch of Accelerate and Transformers PR https://github.com/huggingface/transformers/pull/25820 which fixes a bug with efficient loading of model while using FSDP.\r\n\r\nCommand:\r\n```\r\ncd transformers\r\nexport CUDA_VISIBLE_DEVICES=\"0,1\"\r\ntorchrun --nnodes 1 --nproc-per-node 2 ./examples/pytorch/language-modeling/run_clm.py --model_name_or_path facebook/opt-350m --dataset_name wikitext --dataset_config_name wikitext-2-raw-v1 --per_device_train_batch_size 8 --per_device_eval_batch_size 8 --do_train --do_eval --output_dir output --fsdp \"shard_grad_op auto_wrap\"\r\n```\r\n\r\nIn `run_clm.py`, edit it to view the FSDP config:\r\n```diff\r\n...\r\n\r\n# Initialize our Trainer\r\n trainer = Trainer(\r\n model=model,\r\n args=training_args,\r\n train_dataset=train_dataset if training_args.do_train else None,\r\n eval_dataset=eval_dataset if training_args.do_eval else None,\r\n tokenizer=tokenizer,\r\n # Data collator will default to DataCollatorWithPadding, so we change it.\r\n data_collator=default_data_collator,\r\n compute_metrics=compute_metrics if training_args.do_eval and not is_torch_tpu_available() else None,\r\n preprocess_logits_for_metrics=preprocess_logits_for_metrics\r\n if training_args.do_eval and not is_torch_tpu_available()\r\n else None,\r\n )\r\n+ print(f\"{trainer.accelerator.state.fsdp_plugin}\")\r\n\r\n...\r\n```\r\n\r\nOutput: \r\n```\r\n[2023-08-29 12:10:31,536] torch.distributed.run: [WARNING] \r\n[2023-08-29 12:10:31,536] torch.distributed.run: [WARNING] *****************************************\r\n[2023-08-29 12:10:31,536] torch.distributed.run: [WARNING] Setting OMP_NUM_THREADS environment variable for each process to be 1 in default, to avoid your system being overloaded, please further tune the variable for optimal performance in your application as needed. \r\n[2023-08-29 12:10:31,536] torch.distributed.run: [WARNING] *****************************************\r\n[2023-08-29 12:10:34,727] [INFO] [real_accelerator.py:133:get_accelerator] Setting ds_accelerator to cuda (auto detect)\r\n[2023-08-29 12:10:34,742] [INFO] [real_accelerator.py:133:get_accelerator] Setting ds_accelerator to cuda (auto detect)\r\nUsing the `WANDB_DISABLED` environment variable is deprecated and will be removed in v5. Use the --report_to flag to control the integrations used for logging result (for instance --report_to none).\r\nUsing the `WANDB_DISABLED` environment variable is deprecated and will be removed in v5. Use the --report_to flag to control the integrations used for logging result (for instance --report_to none).\r\n08/29/2023 12:10:36 - WARNING - __main__ - Process rank: 1, device: cuda:1, n_gpu: 1distributed training: True, 16-bits training: False\r\n08/29/2023 12:10:36 - WARNING - __main__ - Process rank: 0, device: cuda:0, n_gpu: 1distributed training: True, 16-bits training: False\r\n08/29/2023 12:10:36 - INFO - __main__ - Training/evaluation parameters TrainingArguments(\r\n_n_gpu=1,\r\nadafactor=False,\r\nadam_beta1=0.9,\r\nadam_beta2=0.999,\r\nadam_epsilon=1e-08,\r\nauto_find_batch_size=False,\r\nbf16=False,\r\nbf16_full_eval=False,\r\ndata_seed=None,\r\ndataloader_drop_last=False,\r\ndataloader_num_workers=0,\r\ndataloader_pin_memory=True,\r\nddp_backend=None,\r\nddp_broadcast_buffers=None,\r\nddp_bucket_cap_mb=None,\r\nddp_find_unused_parameters=None,\r\nddp_timeout=1800,\r\ndebug=[],\r\ndeepspeed=None,\r\ndisable_tqdm=False,\r\ndispatch_batches=None,\r\ndo_eval=True,\r\ndo_predict=False,\r\ndo_train=True,\r\neval_accumulation_steps=None,\r\neval_delay=0,\r\neval_steps=None,\r\nevaluation_strategy=no,\r\nfp16=False,\r\nfp16_backend=auto,\r\nfp16_full_eval=False,\r\nfp16_opt_level=O1,\r\nfsdp=[<FSDPOption.SHARD_GRAD_OP: 'shard_grad_op'>, <FSDPOption.AUTO_WRAP: 'auto_wrap'>],\r\nfsdp_config={'min_num_params': 0, 'xla': False, 'xla_fsdp_grad_ckpt': False},\r\nfsdp_min_num_params=0,\r\nfsdp_transformer_layer_cls_to_wrap=None,\r\nfull_determinism=False,\r\ngradient_accumulation_steps=1,\r\ngradient_checkpointing=False,\r\ngreater_is_better=None,\r\ngroup_by_length=False,\r\nhalf_precision_backend=auto,\r\nhub_always_push=False,\r\nhub_model_id=None,\r\nhub_private_repo=False,\r\nhub_strategy=every_save,\r\nhub_token=<HUB_TOKEN>,\r\nignore_data_skip=False,\r\ninclude_inputs_for_metrics=False,\r\njit_mode_eval=False,\r\nlabel_names=None,\r\nlabel_smoothing_factor=0.0,\r\nlearning_rate=5e-05,\r\nlength_column_name=length,\r\nload_best_model_at_end=False,\r\nlocal_rank=0,\r\nlog_level=passive,\r\nlog_level_replica=warning,\r\nlog_on_each_node=True,\r\nlogging_dir=output/runs/Aug29_12-10-36_hf-dgx-01,\r\nlogging_first_step=False,\r\nlogging_nan_inf_filter=True,\r\nlogging_steps=500,\r\nlogging_strategy=steps,\r\nlr_scheduler_type=linear,\r\nmax_grad_norm=1.0,\r\nmax_steps=-1,\r\nmetric_for_best_model=None,\r\nmp_parameters=,\r\nno_cuda=False,\r\nnum_train_epochs=3.0,\r\noptim=adamw_torch,\r\noptim_args=None,\r\noutput_dir=output,\r\noverwrite_output_dir=False,\r\npast_index=-1,\r\nper_device_eval_batch_size=8,\r\nper_device_train_batch_size=8,\r\nprediction_loss_only=False,\r\npush_to_hub=False,\r\npush_to_hub_model_id=None,\r\npush_to_hub_organization=None,\r\npush_to_hub_token=<PUSH_TO_HUB_TOKEN>,\r\nray_scope=last,\r\nremove_unused_columns=True,\r\nreport_to=[],\r\nresume_from_checkpoint=None,\r\nrun_name=output,\r\nsave_on_each_node=False,\r\nsave_safetensors=False,\r\nsave_steps=500,\r\nsave_strategy=steps,\r\nsave_total_limit=None,\r\nseed=42,\r\nsharded_ddp=[],\r\nskip_memory_metrics=True,\r\ntf32=None,\r\ntorch_compile=False,\r\ntorch_compile_backend=None,\r\ntorch_compile_mode=None,\r\ntorchdynamo=None,\r\ntpu_metrics_debug=False,\r\ntpu_num_cores=None,\r\nuse_cpu=False,\r\nuse_ipex=False,\r\nuse_legacy_prediction_loop=False,\r\nuse_mps_device=False,\r\nwarmup_ratio=0.0,\r\nwarmup_steps=0,\r\nweight_decay=0.0,\r\n)\r\n08/29/2023 12:10:37 - WARNING - datasets.builder - Found cached dataset wikitext (/raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126)\r\n08/29/2023 12:10:37 - INFO - datasets.builder - Using custom data configuration wikitext-2-raw-v1-ddf29beda1b1b3d3\r\n08/29/2023 12:10:37 - INFO - datasets.info - Loading Dataset Infos from /raid/sourab/.cache/huggingface/modules/datasets_modules/datasets/wikitext/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1225.69it/s]\r\n08/29/2023 12:10:37 - INFO - datasets.builder - Overwrite dataset info from restored data version if exists.\r\n08/29/2023 12:10:37 - INFO - datasets.info - Loading Dataset info from /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126\r\n08/29/2023 12:10:37 - WARNING - datasets.builder - Found cached dataset wikitext (/raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126)\r\n08/29/2023 12:10:37 - INFO - datasets.info - Loading Dataset info from /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126\r\n100%|██████████████████████████████████████████████████████████████████████████████████████████| 3/3 [00:00<00:00, 1283.71it/s]\r\n[INFO|configuration_utils.py:715] 2023-08-29 12:10:37,431 >> loading configuration file config.json from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/config.json\r\n[INFO|configuration_utils.py:775] 2023-08-29 12:10:37,431 >> Model config OPTConfig {\r\n \"_name_or_path\": \"facebook/opt-350m\",\r\n \"_remove_final_layer_norm\": false,\r\n \"activation_dropout\": 0.0,\r\n \"activation_function\": \"relu\",\r\n \"architectures\": [\r\n \"OPTForCausalLM\"\r\n ],\r\n \"attention_dropout\": 0.0,\r\n \"bos_token_id\": 2,\r\n \"do_layer_norm_before\": false,\r\n \"dropout\": 0.1,\r\n \"enable_bias\": true,\r\n \"eos_token_id\": 2,\r\n \"ffn_dim\": 4096,\r\n \"hidden_size\": 1024,\r\n \"init_std\": 0.02,\r\n \"layer_norm_elementwise_affine\": true,\r\n \"layerdrop\": 0.0,\r\n \"max_position_embeddings\": 2048,\r\n \"model_type\": \"opt\",\r\n \"num_attention_heads\": 16,\r\n \"num_hidden_layers\": 24,\r\n \"pad_token_id\": 1,\r\n \"prefix\": \"</s>\",\r\n \"torch_dtype\": \"float16\",\r\n \"transformers_version\": \"4.33.0.dev0\",\r\n \"use_cache\": true,\r\n \"vocab_size\": 50272,\r\n \"word_embed_proj_dim\": 512\r\n}\r\n\r\n[INFO|configuration_utils.py:715] 2023-08-29 12:10:37,546 >> loading configuration file config.json from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/config.json\r\n[INFO|configuration_utils.py:775] 2023-08-29 12:10:37,547 >> Model config OPTConfig {\r\n \"_name_or_path\": \"facebook/opt-350m\",\r\n \"_remove_final_layer_norm\": false,\r\n \"activation_dropout\": 0.0,\r\n \"activation_function\": \"relu\",\r\n \"architectures\": [\r\n \"OPTForCausalLM\"\r\n ],\r\n \"attention_dropout\": 0.0,\r\n \"bos_token_id\": 2,\r\n \"do_layer_norm_before\": false,\r\n \"dropout\": 0.1,\r\n \"enable_bias\": true,\r\n \"eos_token_id\": 2,\r\n \"ffn_dim\": 4096,\r\n \"hidden_size\": 1024,\r\n \"init_std\": 0.02,\r\n \"layer_norm_elementwise_affine\": true,\r\n \"layerdrop\": 0.0,\r\n \"max_position_embeddings\": 2048,\r\n \"model_type\": \"opt\",\r\n \"num_attention_heads\": 16,\r\n \"num_hidden_layers\": 24,\r\n \"pad_token_id\": 1,\r\n \"prefix\": \"</s>\",\r\n \"torch_dtype\": \"float16\",\r\n \"transformers_version\": \"4.33.0.dev0\",\r\n \"use_cache\": true,\r\n \"vocab_size\": 50272,\r\n \"word_embed_proj_dim\": 512\r\n}\r\n\r\n[INFO|tokenization_utils_base.py:1852] 2023-08-29 12:10:37,556 >> loading file vocab.json from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/vocab.json\r\n[INFO|tokenization_utils_base.py:1852] 2023-08-29 12:10:37,556 >> loading file merges.txt from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/merges.txt\r\n[INFO|tokenization_utils_base.py:1852] 2023-08-29 12:10:37,556 >> loading file tokenizer.json from cache at None\r\n[INFO|tokenization_utils_base.py:1852] 2023-08-29 12:10:37,556 >> loading file added_tokens.json from cache at None\r\n[INFO|tokenization_utils_base.py:1852] 2023-08-29 12:10:37,556 >> loading file special_tokens_map.json from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/special_tokens_map.json\r\n[INFO|tokenization_utils_base.py:1852] 2023-08-29 12:10:37,556 >> loading file tokenizer_config.json from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/tokenizer_config.json\r\n[INFO|configuration_utils.py:715] 2023-08-29 12:10:37,556 >> loading configuration file config.json from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/config.json\r\n[INFO|configuration_utils.py:775] 2023-08-29 12:10:37,557 >> Model config OPTConfig {\r\n \"_name_or_path\": \"facebook/opt-350m\",\r\n \"_remove_final_layer_norm\": false,\r\n \"activation_dropout\": 0.0,\r\n \"activation_function\": \"relu\",\r\n \"architectures\": [\r\n \"OPTForCausalLM\"\r\n ],\r\n \"attention_dropout\": 0.0,\r\n \"bos_token_id\": 2,\r\n \"do_layer_norm_before\": false,\r\n \"dropout\": 0.1,\r\n \"enable_bias\": true,\r\n \"eos_token_id\": 2,\r\n \"ffn_dim\": 4096,\r\n \"hidden_size\": 1024,\r\n \"init_std\": 0.02,\r\n \"layer_norm_elementwise_affine\": true,\r\n \"layerdrop\": 0.0,\r\n \"max_position_embeddings\": 2048,\r\n \"model_type\": \"opt\",\r\n \"num_attention_heads\": 16,\r\n \"num_hidden_layers\": 24,\r\n \"pad_token_id\": 1,\r\n \"prefix\": \"</s>\",\r\n \"torch_dtype\": \"float16\",\r\n \"transformers_version\": \"4.33.0.dev0\",\r\n \"use_cache\": true,\r\n \"vocab_size\": 50272,\r\n \"word_embed_proj_dim\": 512\r\n}\r\n\r\n[INFO|configuration_utils.py:715] 2023-08-29 12:10:37,810 >> loading configuration file config.json from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/config.json\r\n[INFO|configuration_utils.py:775] 2023-08-29 12:10:37,811 >> Model config OPTConfig {\r\n \"_name_or_path\": \"facebook/opt-350m\",\r\n \"_remove_final_layer_norm\": false,\r\n \"activation_dropout\": 0.0,\r\n \"activation_function\": \"relu\",\r\n \"architectures\": [\r\n \"OPTForCausalLM\"\r\n ],\r\n \"attention_dropout\": 0.0,\r\n \"bos_token_id\": 2,\r\n \"do_layer_norm_before\": false,\r\n \"dropout\": 0.1,\r\n \"enable_bias\": true,\r\n \"eos_token_id\": 2,\r\n \"ffn_dim\": 4096,\r\n \"hidden_size\": 1024,\r\n \"init_std\": 0.02,\r\n \"layer_norm_elementwise_affine\": true,\r\n \"layerdrop\": 0.0,\r\n \"max_position_embeddings\": 2048,\r\n \"model_type\": \"opt\",\r\n \"num_attention_heads\": 16,\r\n \"num_hidden_layers\": 24,\r\n \"pad_token_id\": 1,\r\n \"prefix\": \"</s>\",\r\n \"torch_dtype\": \"float16\",\r\n \"transformers_version\": \"4.33.0.dev0\",\r\n \"use_cache\": true,\r\n \"vocab_size\": 50272,\r\n \"word_embed_proj_dim\": 512\r\n}\r\n\r\n[INFO|modeling_utils.py:2855] 2023-08-29 12:10:37,874 >> loading weights file pytorch_model.bin from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/pytorch_model.bin\r\n[INFO|configuration_utils.py:768] 2023-08-29 12:10:38,153 >> Generate config GenerationConfig {\r\n \"_from_model_config\": true,\r\n \"bos_token_id\": 2,\r\n \"eos_token_id\": 2,\r\n \"pad_token_id\": 1,\r\n \"transformers_version\": \"4.33.0.dev0\"\r\n}\r\n\r\n[INFO|modeling_utils.py:3635] 2023-08-29 12:10:39,049 >> All model checkpoint weights were used when initializing OPTForCausalLM.\r\n\r\n[INFO|modeling_utils.py:3643] 2023-08-29 12:10:39,049 >> All the weights of OPTForCausalLM were initialized from the model checkpoint at facebook/opt-350m.\r\nIf your task is similar to the task the model of the checkpoint was trained on, you can already use OPTForCausalLM for predictions without further training.\r\n[INFO|configuration_utils.py:730] 2023-08-29 12:10:39,160 >> loading configuration file generation_config.json from cache at /raid/sourab/.cache/huggingface/models--facebook--opt-350m/snapshots/cb32f77e905cccbca1d970436fb0f5e6b58ee3c5/generation_config.json\r\n[INFO|configuration_utils.py:768] 2023-08-29 12:10:39,161 >> Generate config GenerationConfig {\r\n \"_from_model_config\": true,\r\n \"bos_token_id\": 2,\r\n \"eos_token_id\": 2,\r\n \"pad_token_id\": 1,\r\n \"transformers_version\": \"4.33.0.dev0\"\r\n}\r\n\r\n08/29/2023 12:10:39 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-fe29956cc983b056.arrow\r\n08/29/2023 12:10:39 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-cecdce462984f30c.arrow\r\n08/29/2023 12:10:39 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-ea4ff1f9a70456e2.arrow\r\n08/29/2023 12:10:40 - WARNING - __main__ - The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can override this default with `--block_size xxx`.\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-0ec6d944334ff56a.arrow\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-52830176c9b26401.arrow\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-32ee55629de51a05.arrow\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-fe29956cc983b056.arrow\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-cecdce462984f30c.arrow\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-ea4ff1f9a70456e2.arrow\r\n08/29/2023 12:10:40 - WARNING - __main__ - The chosen tokenizer supports a `model_max_length` that is longer than the default `block_size` value of 1024. If you would like to use a longer `block_size` up to `tokenizer.model_max_length` you can override this default with `--block_size xxx`.\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-0ec6d944334ff56a.arrow\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-52830176c9b26401.arrow\r\n08/29/2023 12:10:40 - WARNING - datasets.arrow_dataset - Loading cached processed dataset at /raid/sourab/.cache/huggingface/datasets/wikitext/wikitext-2-raw-v1-ddf29beda1b1b3d3/1.0.0/a241db52902eaf2c6aa732210bead40c090019a499ceb13bcbfa3f8ab646a126/cache-32ee55629de51a05.arrow\r\nFullyShardedDataParallelPlugin(sharding_strategy=<ShardingStrategy.SHARD_GRAD_OP: 2>, backward_prefetch=None, mixed_precision_policy=None, auto_wrap_policy=None, cpu_offload=CPUOffload(offload_params=False), ignored_modules=None, state_dict_type=<StateDictType.FULL_STATE_DICT: 1>, state_dict_config=FullStateDictConfig(offload_to_cpu=True, use_dtensor=False, rank0_only=True), optim_state_dict_config=FullOptimStateDictConfig(offload_to_cpu=True, use_dtensor=False, rank0_only=True), limit_all_gathers=False, use_orig_params=False, param_init_fn=<function FullyShardedDataParallelPlugin.__post_init__.<locals>.<lambda> at 0x7f81d8c71630>, sync_module_states=True, forward_prefetch=False, activation_checkpointing=False)\r\nFullyShardedDataParallelPlugin(sharding_strategy=<ShardingStrategy.SHARD_GRAD_OP: 2>, backward_prefetch=None, mixed_precision_policy=None, auto_wrap_policy=None, cpu_offload=CPUOffload(offload_params=False), ignored_modules=None, state_dict_type=<StateDictType.FULL_STATE_DICT: 1>, state_dict_config=FullStateDictConfig(offload_to_cpu=True, use_dtensor=False, rank0_only=True), optim_state_dict_config=FullOptimStateDictConfig(offload_to_cpu=True, use_dtensor=False, rank0_only=True), limit_all_gathers=False, use_orig_params=False, param_init_fn=<function FullyShardedDataParallelPlugin.__post_init__.<locals>.<lambda> at 0x7ff575be9630>, sync_module_states=True, forward_prefetch=False, activation_checkpointing=False)\r\n[INFO|trainer.py:1714] 2023-08-29 12:10:41,785 >> ***** Running training *****\r\n[INFO|trainer.py:1715] 2023-08-29 12:10:41,785 >> Num examples = 2,355\r\n[INFO|trainer.py:1716] 2023-08-29 12:10:41,785 >> Num Epochs = 3\r\n[INFO|trainer.py:1717] 2023-08-29 12:10:41,785 >> Instantaneous batch size per device = 8\r\n[INFO|trainer.py:1720] 2023-08-29 12:10:41,785 >> Total train batch size (w. parallel, distributed & accumulation) = 16\r\n[INFO|trainer.py:1721] 2023-08-29 12:10:41,785 >> Gradient Accumulation steps = 1\r\n[INFO|trainer.py:1722] 2023-08-29 12:10:41,785 >> Total optimization steps = 444\r\n[INFO|trainer.py:1723] 2023-08-29 12:10:41,786 >> Number of trainable parameters = 165,598,208\r\n 23%|████████████████████▌ | 104/444 [02:42<08:48, 1.56s/it]\r\n```\r\n\r\nNotice the sharding strategy is correctly set to `ShardingStrategy.SHARD_GRAD_OP` as passed in the cmd args.",
"@pacman100 thanks for taking a look!"
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-4.18.0-477.15.1.el8_8.x86_64-x86_64-with-glibc2.28
- Python version: 3.9.17
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes, running in SLURM with multi-node and multi-GPU
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Using the official `run_clm.py` script with FSDP enabled:
```
python run_clm.py \
--model_name_or_path facebook/opt-350m \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--do_train \
--do_eval \
--output_dir output \
--fsdp "shard_grad_op auto_wrap" --fsdp_config fsdp_config.json
```
where `fsdp_config.json` looks like:
```
{
"sharding_strategy": "shard_grad_op auto_wrap",
"fsdp_transformer_layer_cls_to_wrap": "OPTDecoderLayer",
"sync_module_states": true
}
```
### Expected behavior
We expect to use the sharding strategy `shard_grad_op`, but the accelerator is not instantiated with the fsdp config in `create_accelerator_and_postprocess()`. As a result, if we print out `self.accelerator.state.fsdp_plugin.sharding_strategy` at the end of `__init__`, we get the default sharding strategy `full_shard`, even though `self.fsdp == shard_grad_op`.
I did not set the sharding strategy using `accelerate config` since I'm experimenting with different strategy and I believe it would make sense to overwrite the default strategy with the input config.
I'm not completely sure if this would be the correct fix, but I found the following to work with the intended behavior:
```
if FSDPOption.FULL_SHARD in args.fsdp:
self.fsdp = ShardingStrategy.FULL_SHARD
elif FSDPOption.SHARD_GRAD_OP in args.fsdp:
self.fsdp = ShardingStrategy.SHARD_GRAD_OP
elif FSDPOption.NO_SHARD in args.fsdp:
self.fsdp = ShardingStrategy.NO_SHARD
if self.is_fsdp_enabled:
self.accelerator.state.fsdp_plugin.sharding_strategy=self.fsdp
```
where we update the sharding_strategy after determining the strategy used for fsdp from args in `__init__()`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25180/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25180/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25179
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25179/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25179/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25179/events
|
https://github.com/huggingface/transformers/issues/25179
| 1,827,203,072 |
I_kwDOCUB6oc5s6OgA
| 25,179 |
Sudden random bug
|
{
"login": "surya-narayanan",
"id": 17240858,
"node_id": "MDQ6VXNlcjE3MjQwODU4",
"avatar_url": "https://avatars.githubusercontent.com/u/17240858?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/surya-narayanan",
"html_url": "https://github.com/surya-narayanan",
"followers_url": "https://api.github.com/users/surya-narayanan/followers",
"following_url": "https://api.github.com/users/surya-narayanan/following{/other_user}",
"gists_url": "https://api.github.com/users/surya-narayanan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/surya-narayanan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/surya-narayanan/subscriptions",
"organizations_url": "https://api.github.com/users/surya-narayanan/orgs",
"repos_url": "https://api.github.com/users/surya-narayanan/repos",
"events_url": "https://api.github.com/users/surya-narayanan/events{/privacy}",
"received_events_url": "https://api.github.com/users/surya-narayanan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
open
| false | null |
[] |
[
"I can't really reproduce this and have not seen this anywhere else. The OS Error suggests that the interface is not available, meaning that most probably the path to your hugging face cache cannot be reached (not mounted/ not right etc). A [simple reproducer](https://colab.research.google.com/drive/1S7CRnNIUPnmDWcTuFY4BI0H8ASu221-w?usp=sharing) available here.",
"I've seen that happen when using network mounted disks.\r\n\r\nIf the network is flaky then the read might fail even though the rest went fine. Error should be transient though.\r\nCould that be it ?\r\n\r\n",
"Not sure - the program fails even on a new env on my computer but works in google colab. @ArthurZucker the link you sent has permission issues.",
"> I've seen that happen when using network mounted disks.\r\n> \r\n> If the network is flaky then the read might fail even though the rest went fine. Error should be transient though. Could that be it ?\r\n\r\nWe hit the same issue, are there any other reason that probably causes this issue except network fluctuation? Thanks! @Narsil ",
"Have you solved this problem? Why closed this issue? Thanks! @surya-narayanan ",
"Did not solve this problem but experienced this bug again today only to discover that it was one I had raised way back lol. "
] | 1,690 | 1,708 | null |
NONE
| null |
### System Info
Here is the bug
```
File "/home/suryahari/Vornoi/QA.py", line 5, in <module>
model = AutoModelForQuestionAnswering.from_pretrained("deepset/roberta-base-squad2")
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/suryahari/miniconda3/envs/diffusers/lib/python3.11/site-packages/transformers/models/auto/auto_factory.py", line 493, in from_pretrained
return model_class.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/suryahari/miniconda3/envs/diffusers/lib/python3.11/site-packages/transformers/modeling_utils.py", line 2629, in from_pretrained
state_dict = load_state_dict(resolved_archive_file)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/suryahari/miniconda3/envs/diffusers/lib/python3.11/site-packages/transformers/modeling_utils.py", line 447, in load_state_dict
with safe_open(checkpoint_file, framework="pt") as f:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
OSError: No such device (os error 19)
```
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-69-generic-x86_64-with-glibc2.35
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes but can avoid
- Using distributed or parallel set-up in script?: not really
### Who can help?
@Narsil ? @younesbelkada @ArthurZucker @amyeroberts
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Create a new env and run the following code
```
# Load model directly
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("deepset/roberta-base-squad2")
model = AutoModelForQuestionAnswering.from_pretrained("deepset/roberta-base-squad2")
```
Also happened to me while running diffusers code, just posting QA code for now.
### Expected behavior
should be able to load a model
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25179/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25179/timeline
|
reopened
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25178
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25178/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25178/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25178/events
|
https://github.com/huggingface/transformers/issues/25178
| 1,827,193,613 |
I_kwDOCUB6oc5s6MMN
| 25,178 |
BERT: TensorFlow Model Garden Conversion scripts
|
{
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] |
open
| false | null |
[] |
[
"cc @Rocketknight1 ",
"This isn't really my area either! A lot of this code goes back to the earliest code in `transformers` when it was a port of TF code for BERT to PyTorch. Pinging @LysandreJik - do you know if the code is intended to support ports from recent versions of the TF Model Garden?",
"As long as everything is correctly documented, I'm all for having up to date scripts that work with the most recent BERT releases.",
"In that case @stefan-it I think it's okay to delete the old script entirely and replace it with a modern one, since it's no longer usable and people who need it for historical purposes can always find it in past release branches.",
"Thanks for your feedback! I will prepare PR for this soon.\r\n\r\nPlease unstale :robot: "
] | 1,690 | 1,693 | null |
COLLABORATOR
| null |
### Feature request
Hi,
after working some time with the [TensorFlow Model Garden Repository](https://github.com/tensorflow/models) and training BERT models, I found out the following things that could be changed in Transformers library:
I added the Token Dropping BERT Conversion script a while ago, see #17142. Now I found out, that latest BERT models pretrained with Model Garden Repository repository can also be converted with this script.
For this reason I would propose to rename the script `convert_bert_token_dropping_original_tf2_checkpoint_to_pytorch.py` just to `convert_bert_original_tf2_checkpoint_to_pytorch.py`.
However, this script also exists, but it is no longer working, as this was deprecated in Model Garden Repository a while ago, I added this notice in #16171.
I see now two possibilities to proceed with the different conversion scripts:
* Rename the current `convert_bert_original_tf2_checkpoint_to_pytorch.py` to something like `convert_deprecated_bert_original_tf2_checkpoint_to_pytorch.py` so that this name is free for the "new" conversion script that supports Token Dropping BERT und latest BERT models from Model Garden Repository.
* Delete the old script completely
### Motivation
More recent BERT and Token Dropping BERT models can be pretrained with TensorFlow Model Garden repository.
There should be one script that does these conversions, the old one that is only working with deprecated models from Model Garden repo should be renamed or deleted.
### Your contribution
I can take care of renaming/deletion and extending the conversion script to have better documentation.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25178/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25178/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25177
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25177/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25177/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25177/events
|
https://github.com/huggingface/transformers/pull/25177
| 1,827,151,076 |
PR_kwDOCUB6oc5WsZqM
| 25,177 |
TEAMS: Add TensorFlow 2 Model Garden Conversion Script
|
{
"login": "stefan-it",
"id": 20651387,
"node_id": "MDQ6VXNlcjIwNjUxMzg3",
"avatar_url": "https://avatars.githubusercontent.com/u/20651387?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stefan-it",
"html_url": "https://github.com/stefan-it",
"followers_url": "https://api.github.com/users/stefan-it/followers",
"following_url": "https://api.github.com/users/stefan-it/following{/other_user}",
"gists_url": "https://api.github.com/users/stefan-it/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stefan-it/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stefan-it/subscriptions",
"organizations_url": "https://api.github.com/users/stefan-it/orgs",
"repos_url": "https://api.github.com/users/stefan-it/repos",
"events_url": "https://api.github.com/users/stefan-it/events{/privacy}",
"received_events_url": "https://api.github.com/users/stefan-it/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25177). All of your documentation changes will be reflected on that endpoint.",
"cc @Rocketknight1 ",
"Please unstale :robot: ",
"No stale yet, please!",
"Please unstale bot 😄",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,704 | 1,704 |
COLLABORATOR
| null |
Hi,
with this PR a pretrained TEAMS model with TensorFlow Models Garden can be converted to an ELECTRA compatible model.
The TEAMS model was proposed in the "[Training ELECTRA Augmented with Multi-word Selection](https://aclanthology.org/2021.findings-acl.219.pdf) paper and accepted at ACL 2021:
> A new text encoder pre-training method is presented that improves ELECTRA based on multi-task learning and develops two techniques to effectively combine all pre- training tasks: using attention-based networks for task-specific heads, and sharing bottom layers of the generator and the discriminator.
The [TEAMS](https://github.com/tensorflow/models/tree/master/official/projects/teams) implementation can be found in the TensorFlow Models Garden repository.
Unfortunately, the authors did not release any pretrained models.
However, I pretrained a TEAMS model on [German Wikipedia](https://huggingface.co/gwlms/teams-base-dewiki-v1-generator) and release all checkpoints on the Hugging Face Model Hub. Additionally, the conversion script to integrate pretrained TEAMS into Transformers is included in this PR.
Closes #16466.
### Implementation Details
TEAMS use the same architecture as ELECTRA (just pretraining approach is different). ELECTRA in Transformers comes with two models: Generator and Discriminator.
In contrast to ELECTRA, the TEAMS generator use shared layers with discriminator:
```
Our study confirms this observation and finds that sharing some transformer layers of the generator
and discriminator and can further boost the model performance. More specifically, we design the
generator to have the same “width” (i.e., hidden size, intermediate size and number of heads) as the
discriminator and share the bottom half of all transformer layers between the generator and the
discriminator.
```
More precisely, the sharing of layers can be seen in the reference implementation:
https://github.com/tensorflow/models/blob/master/official/projects/teams/teams_task.py#L48
This shows, that the generator uses the first n layers from discriminator first (which is usually half size of specified total layers).
<img width="543" alt="Bildschirmfoto 2023-07-29 um 00 36 22" src="https://github.com/huggingface/transformers/assets/20651387/4ba96b79-0afe-4bc5-905a-b1941a4670b0">
### Retrieving TensorFlow 2 Checkpoints
In order to test the conversion script, the original TensorFlow 2 checkpoints need to be downloaded from Model Hub:
```bash
$ wget https://huggingface.co/gwlms/teams-base-dewiki-v1-generator/resolve/main/ckpt-1000000.data-00000-of-00001
$ wget https://huggingface.co/gwlms/teams-base-dewiki-v1-generator/resolve/main/ckpt-1000000.index
```
Additionally, to test the model locally, we need to download tokenizer:
```bash
$ wget https://huggingface.co/gwlms/teams-base-dewiki-v1-generator/resolve/main/tokenizer_config.json
$ wget https://huggingface.co/gwlms/teams-base-dewiki-v1-generator/resolve/main/vocab.txt
```
### Converting TEAMS Generator
After retrieving the original checkpoints, the generator configuration must be downloaded:
```bash
$ mkdir generator && cd $_
$ wget https://huggingface.co/gwlms/teams-base-dewiki-v1-generator/resolve/main/config.json
$ cd ..
```
After that, the conversion script can be run to convert TEAMS (generator part) into ELECTRA generator:
```bash
$ python3 convert_teams_original_tf2_checkpoint_to_pytorch.py \
--tf_checkpoint_path ckpt-1000000 \
--config_file ./generator/config.json \
--pytorch_dump_path ./exported-generator \
--discriminator_or_generator generator
$ cp tokenizer_config.json exported-generator
$ cp vocab.txt exported-generator
```
The generator can be tested with masked lm pipeline to predict next work:
```python3
from transformers import pipeline
predictor = pipeline("fill-mask", model="./exported-generator", tokenizer="./exported-generator")
predictor("Die Hauptstadt von Finnland ist [MASK].")
```
The example German should predict the capital city of Finland, which is Helsinki:
```python
[{'score': 0.971819281578064,
'token': 16014,
'token_str': 'Helsinki',
'sequence': 'Die Hauptstadt von Finnland ist Helsinki.'},
{'score': 0.006745012942701578,
'token': 12388,
'token_str': 'Stockholm',
'sequence': 'Die Hauptstadt von Finnland ist Stockholm.'},
{'score': 0.003258457174524665,
'token': 12227,
'token_str': 'Finnland',
'sequence': 'Die Hauptstadt von Finnland ist Finnland.'},
{'score': 0.0025941277854144573,
'token': 23596,
'token_str': 'Tallinn',
'sequence': 'Die Hauptstadt von Finnland ist Tallinn.'},
{'score': 0.0014661155873909593,
'token': 17408,
'token_str': 'Riga',
'sequence': 'Die Hauptstadt von Finnland ist Riga.'}]
```
### Converting TEAMS Discriminator
After retrieving the original checkpoints, the generator configuration must be downloaded:
```bash
$ mkdir discriminator && cd $_
$ wget https://huggingface.co/gwlms/teams-base-dewiki-v1-discriminator/resolve/main/config.json
$ cd ..
```
After that, the conversion script can be run to convert TEAMS (generator part) into ELECTRA generator:
```bash
$ python3 convert_teams_original_tf2_checkpoint_to_pytorch.py \
--tf_checkpoint_path ckpt-1000000 \
--config_file ./discriminator/config.json \
--pytorch_dump_path ./exported-discriminator \
--discriminator_or_generator discriminator
```
I made experiments on downstream tasks (such as NER or text classification) and the results are superior than to compared BERT models (original BERT and Token Dropping BERT).
Made with 🥨and ❤️.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25177/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25177/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25177",
"html_url": "https://github.com/huggingface/transformers/pull/25177",
"diff_url": "https://github.com/huggingface/transformers/pull/25177.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25177.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25176
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25176/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25176/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25176/events
|
https://github.com/huggingface/transformers/issues/25176
| 1,827,042,485 |
I_kwDOCUB6oc5s5nS1
| 25,176 |
Llama Tokenizer Unexpectedly Producing Unknown Token
|
{
"login": "rehaanahmad2013",
"id": 34905129,
"node_id": "MDQ6VXNlcjM0OTA1MTI5",
"avatar_url": "https://avatars.githubusercontent.com/u/34905129?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rehaanahmad2013",
"html_url": "https://github.com/rehaanahmad2013",
"followers_url": "https://api.github.com/users/rehaanahmad2013/followers",
"following_url": "https://api.github.com/users/rehaanahmad2013/following{/other_user}",
"gists_url": "https://api.github.com/users/rehaanahmad2013/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rehaanahmad2013/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rehaanahmad2013/subscriptions",
"organizations_url": "https://api.github.com/users/rehaanahmad2013/orgs",
"repos_url": "https://api.github.com/users/rehaanahmad2013/repos",
"events_url": "https://api.github.com/users/rehaanahmad2013/events{/privacy}",
"received_events_url": "https://api.github.com/users/rehaanahmad2013/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1834056635,
"node_id": "MDU6TGFiZWwxODM0MDU2NjM1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Core:%20Tokenization",
"name": "Core: Tokenization",
"color": "FF4446",
"default": false,
"description": "Internals of the library; Tokenization."
}
] |
closed
| false |
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
] |
[
"Hey! 👋🏻 Thanks for providing a reproduction script. I suspect that you do not have `tokenizers` installed, since when I use `use_fast = True` (which is the default if you have tokenizers) the issue is not present. \r\nNow, this behaviour is expected: \r\n- Quick fix, use `legacy=True` when initialising the tokenizer: `tokenizer = LlamaTokenizer.from_pretrained(\"meta-llama/Llama-2-13b-hf\", legacy = True)`\r\n- Other quick fix, use the fast tokenizer ( `pip install tokenizers`)\r\n\r\nThis is a very nice catch otherwise! The issue is that [`in`, `form`] should be the tokenization of `inform`, but when we use the hack around sentencepiece, we actually just output [`inform`] which is not recognised as a token. Also if you pass `\"<REPR_END> inform\"` the extra space is automatically strip by default. This is also gonna be fixed. \r\n\r\ncc @Narsil I think I'll implement handling the `add_dummy_prefix = False` parameter. As pointed out somewhere else, our decoding function is also broken for Llama (it add extra spaces). ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.29.2
- Platform: Linux-5.19.0-1027-aws-x86_64-with-glibc2.31
- Python version: 3.10.8
- Huggingface_hub version: 0.14.1
- Safetensors version: 0.3.1
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
### Who can help?
@ArthurZucker @younesbelkada I am trying to use special tokens with the LlamaTokenizer in Transformers 4.31.0 and with certain configurations of input, the tokenizer is returning a token id of 0 corresponding to the unknown token. For example, I have added the special token "<REPR_END>", and if I pass that through the tokenizer to get [1, 32003] which is good. Additionally if I pass the word "inform" through the tokenizer, I get [1, 1871], which is also good.
However, if I pass "<REPR_END>inform" through the tokenizer, I get [1, 32003, 0] which does not make sense. If I try this exact same input in Transformers 4.29.2, I get [1, 32003, 1871] which is correct.
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
```python
from transformers.models.llama.tokenization_llama import LlamaTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-13b-hf", use_auth_token=...)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.add_tokens(['<TARGET_BEGIN>', '<TARGET_END>', '<REPR_BEGIN>', '<REPR_END>'], special_tokens=True)
print(tokenizer("<REPR_END>inform")
```
### Expected behavior
I should expect to get the output [1, 32003, 1871] but I do not. I instead get [1, 32003, 0]
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25176/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25176/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25175
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25175/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25175/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25175/events
|
https://github.com/huggingface/transformers/issues/25175
| 1,827,035,118 |
I_kwDOCUB6oc5s5lfu
| 25,175 |
Pix2Struct -- mismatched output of cross attention weights
|
{
"login": "leitro",
"id": 9562709,
"node_id": "MDQ6VXNlcjk1NjI3MDk=",
"avatar_url": "https://avatars.githubusercontent.com/u/9562709?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/leitro",
"html_url": "https://github.com/leitro",
"followers_url": "https://api.github.com/users/leitro/followers",
"following_url": "https://api.github.com/users/leitro/following{/other_user}",
"gists_url": "https://api.github.com/users/leitro/gists{/gist_id}",
"starred_url": "https://api.github.com/users/leitro/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/leitro/subscriptions",
"organizations_url": "https://api.github.com/users/leitro/orgs",
"repos_url": "https://api.github.com/users/leitro/repos",
"events_url": "https://api.github.com/users/leitro/events{/privacy}",
"received_events_url": "https://api.github.com/users/leitro/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Nice catch @leitro ! \r\nI can confirm this is correct, just made https://github.com/huggingface/transformers/pull/25200 to fix the issue on the main branch.",
"Cheers!!"
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### System Info
Hi huggingface team!
The output of cross attention weights is mismatched as shown in [https://github.com/huggingface/transformers/blob/05cda5df3405e6a2ee4ecf8f7e1b2300ebda472e/src/transformers/models/pix2struct/modeling_pix2struct.py#L1551C22-L1551C22](https://github.com/huggingface/transformers/blob/05cda5df3405e6a2ee4ecf8f7e1b2300ebda472e/src/transformers/models/pix2struct/modeling_pix2struct.py#L1551C22-L1551C22).
In the code: `all_cross_attentions = all_cross_attentions + (layer_outputs[3],)`
where `layer_outputs[3]` is still the self attention weights, the REAL cross attention weights should be `layer_outputs[5]`.
Please correct me if I made some mistakes. Looking forward to the updated version. Thank you! @amyeroberts @ArthurZucker @younesbelkada
### Who can help?
_No response_
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
Hightlight of the training code:
```
model = Pix2StructForConditionalGeneration.from_pretrained('google/pix2struct-docvqa-base')
outputs = model.forward(**inputs, labels=labels, output_attentions=True)
```
Turn on the attention output button by `output_attentions=True`, and then get the cross attention weights by `outputs.cross_attentions` where the bug exists.
### Expected behavior
Change the index from `3` to `5` for selecting the correct cross attention weights, then everything's done hopefully.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25175/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25175/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25174
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25174/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25174/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25174/events
|
https://github.com/huggingface/transformers/pull/25174
| 1,826,665,345 |
PR_kwDOCUB6oc5WquzP
| 25,174 |
🚨🚨🚨 Fix rescale ViVit Efficientnet
|
{
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"If I'm not mistaken this PR is problematic as it breaks the `rescale` function. If I rebase my PR https://github.com/huggingface/transformers/pull/24796 to `main` the torchvision transforms vs transformers image transforms equivalency test fails: `tests/models/idefics/test_image_processing_idefics.py::IdeficsImageProcessingTest::test_torchvision_numpy_transforms_equivalency`",
"@amyeroberts I'm guessing this was issue causing bad efficientnet predicons that I observed? \r\n\r\nFWIW I haven't ecountered any vision models that require separate codepaths for rescale vs mean/std [-1, 1] is mean 0.5, std 0.5, and [0, 1] is mean 0, std 1. ...",
"Not sure if this is still relevant, but \r\n\r\n- @rwightman could you let us know your `main` commit sha?\r\n- cc @amyeroberts (if not yet look the last above comment)\r\n",
"@ydshieh I managed to track down the issue with EfficientNet down to the softmax which was being applied to the logits #25501 (sorry, I should have linked here as well). \r\n\r\n@rwightman Agreed, the design was something I either suggested or approved, so my bad. The good thing is, using `offset` isn't necessary, and users can simply pass in different means and stds to achieve the desired rescaling as you suggested. "
] | 1,690 | 1,692 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
Fixes the rescaling logic for both EffiicentNet and ViVit.
EfficientNet: The values were being rescale between [-0.5, 0.5]
ViVit: values were being rescale between [-7.689350249903882e-06, 0.9999923106497501] as scale was being treated as having a value 255 in the `rescale` method, rather than 1/255.
**This is a breaking change** and will affect the model outputs for both these models. However, it is a bug fix and should improve model predictions.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25174/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25174/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25174",
"html_url": "https://github.com/huggingface/transformers/pull/25174",
"diff_url": "https://github.com/huggingface/transformers/pull/25174.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25174.patch",
"merged_at": 1690570372000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25173
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25173/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25173/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25173/events
|
https://github.com/huggingface/transformers/pull/25173
| 1,826,623,980 |
PR_kwDOCUB6oc5Wqlv-
| 25,173 |
Musicgen: CFG is manually added
|
{
"login": "gante",
"id": 12240844,
"node_id": "MDQ6VXNlcjEyMjQwODQ0",
"avatar_url": "https://avatars.githubusercontent.com/u/12240844?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gante",
"html_url": "https://github.com/gante",
"followers_url": "https://api.github.com/users/gante/followers",
"following_url": "https://api.github.com/users/gante/following{/other_user}",
"gists_url": "https://api.github.com/users/gante/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gante/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gante/subscriptions",
"organizations_url": "https://api.github.com/users/gante/orgs",
"repos_url": "https://api.github.com/users/gante/repos",
"events_url": "https://api.github.com/users/gante/events{/privacy}",
"received_events_url": "https://api.github.com/users/gante/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@sanchit-gandhi there is a potential change due to order of operations, depending on the processors commonly used. Would you be able to confirm whether it would be okay like this?",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
MEMBER
| null |
# What does this PR do?
This PR exists to keep `musicgen`'s current functionalities considering the changes in #24654.
In a nutshell, the #24654 has a more flexible version of CFG (allows negative prompting, is compatible with existing generation methods, doesn't need to expand the batch size by 2 before the fwd pass, lower memory requirements), but would mean an execution time regression on `musicgen` (because it needs 2x forward passes).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25173/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25173/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25173",
"html_url": "https://github.com/huggingface/transformers/pull/25173",
"diff_url": "https://github.com/huggingface/transformers/pull/25173.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25173.patch",
"merged_at": 1690798871000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25172
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25172/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25172/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25172/events
|
https://github.com/huggingface/transformers/pull/25172
| 1,826,622,924 |
PR_kwDOCUB6oc5Wqlhn
| 25,172 |
Add `token` arugment in example scripts
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@sgugger Ready to go 🚀 ",
"Thank you for the review, changed it to\r\n\r\n```python\r\n token: str = field(\r\n default=None,\r\n metadata={\r\n \"help\": (\r\n \"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token \"\r\n \"generated when running `huggingface-cli login` (stored in `~/.huggingface`).\"\r\n )\r\n },\r\n )\r\n use_auth_token: bool = field(\r\n default=None,\r\n metadata={\r\n \"help\": \"The `use_auth_token` argument is deprecated and will be removed in v4.34. Please use `token`.\"\r\n },\r\n )\r\n```"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
If the change is good, I will apply the same to other files.
Let me know if you have opinion on the `False` vs `None` thing here.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25172/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25172/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25172",
"html_url": "https://github.com/huggingface/transformers/pull/25172",
"diff_url": "https://github.com/huggingface/transformers/pull/25172.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25172.patch",
"merged_at": 1690967851000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25171
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25171/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25171/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25171/events
|
https://github.com/huggingface/transformers/pull/25171
| 1,826,479,086 |
PR_kwDOCUB6oc5WqFzF
| 25,171 |
[`InstructBlip`] Fix instructblip slow test
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25171). All of your documentation changes will be reflected on that endpoint."
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes the current failing daily CI test: https://github.com/huggingface/transformers/actions/runs/5675853423/job/15381807774 let's make the daily CI happy!
Ran the test on the latest docker image and the test now pass with these values.
cc @sgugger @ydshieh
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25171/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25171/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25171",
"html_url": "https://github.com/huggingface/transformers/pull/25171",
"diff_url": "https://github.com/huggingface/transformers/pull/25171.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25171.patch",
"merged_at": 1690556410000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25170
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25170/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25170/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25170/events
|
https://github.com/huggingface/transformers/pull/25170
| 1,826,453,493 |
PR_kwDOCUB6oc5WqAlx
| 25,170 |
[`Mpt`] Fix mpt slow test
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
As per title, failure report here: https://github.com/huggingface/transformers/actions/runs/5675853423/job/15381788713
Probably an issue with libs I had when designing the tests (had torch +cu117 instead of cu118) - ran the tests on the latest docker image and they all pass
cc @sgugger @ydshieh
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25170/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25170/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25170",
"html_url": "https://github.com/huggingface/transformers/pull/25170",
"diff_url": "https://github.com/huggingface/transformers/pull/25170.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25170.patch",
"merged_at": 1690555509000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25169
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25169/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25169/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25169/events
|
https://github.com/huggingface/transformers/pull/25169
| 1,826,315,324 |
PR_kwDOCUB6oc5WpiY4
| 25,169 |
[MusicGen] Fix integration tests
|
{
"login": "sanchit-gandhi",
"id": 93869735,
"node_id": "U_kgDOBZhWpw",
"avatar_url": "https://avatars.githubusercontent.com/u/93869735?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sanchit-gandhi",
"html_url": "https://github.com/sanchit-gandhi",
"followers_url": "https://api.github.com/users/sanchit-gandhi/followers",
"following_url": "https://api.github.com/users/sanchit-gandhi/following{/other_user}",
"gists_url": "https://api.github.com/users/sanchit-gandhi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sanchit-gandhi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sanchit-gandhi/subscriptions",
"organizations_url": "https://api.github.com/users/sanchit-gandhi/orgs",
"repos_url": "https://api.github.com/users/sanchit-gandhi/repos",
"events_url": "https://api.github.com/users/sanchit-gandhi/events{/privacy}",
"received_events_url": "https://api.github.com/users/sanchit-gandhi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
Fixes the integration tests for MusicGen:
1. Places all input tensors on the correct device
2. Updates expected values with those obtained on cuda
3. Fixes for fp16 generation
cc @ydshieh
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25169/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25169/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25169",
"html_url": "https://github.com/huggingface/transformers/pull/25169",
"diff_url": "https://github.com/huggingface/transformers/pull/25169.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25169.patch",
"merged_at": 1690566616000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25168
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25168/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25168/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25168/events
|
https://github.com/huggingface/transformers/issues/25168
| 1,826,080,259 |
I_kwDOCUB6oc5s18YD
| 25,168 |
Add support for timeout parameter for load_image
|
{
"login": "rolisz",
"id": 426313,
"node_id": "MDQ6VXNlcjQyNjMxMw==",
"avatar_url": "https://avatars.githubusercontent.com/u/426313?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rolisz",
"html_url": "https://github.com/rolisz",
"followers_url": "https://api.github.com/users/rolisz/followers",
"following_url": "https://api.github.com/users/rolisz/following{/other_user}",
"gists_url": "https://api.github.com/users/rolisz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rolisz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rolisz/subscriptions",
"organizations_url": "https://api.github.com/users/rolisz/orgs",
"repos_url": "https://api.github.com/users/rolisz/repos",
"events_url": "https://api.github.com/users/rolisz/events{/privacy}",
"received_events_url": "https://api.github.com/users/rolisz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @amyeroberts \r\nSounds like a good idea, so if you want to open a PR, please go ahead!",
"Do you have any preferences, keeping it simple, add just the timeout parameter, or adding a more general `requests_params`?",
"I think keeping it simple is probably for the best."
] | 1,690 | 1,691 | 1,691 |
CONTRIBUTOR
| null |
### Feature request
Add a parameter timeout to the `image_utils.py:load_image` function, which would enable setting the timeout for the requests call. This parameter should be plumbed in through all the ways to call that function (so add support for it in all the image related pipelines).
Alternatively, you should add a `requests_params` parameter, which should be a dictionary, to enable passing any parameters to requests.get.
### Motivation
When using requests, the default timeout is None, which means that the request will wait (hang) until the connection is closed. Some servers for whatever reason don't return anything, but also don't close the connection. It would be useful to be able to set a timeout for these cases.
### Your contribution
I can contribute a PR for this.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25168/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 1,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25168/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25167
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25167/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25167/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25167/events
|
https://github.com/huggingface/transformers/pull/25167
| 1,826,054,882 |
PR_kwDOCUB6oc5WopEf
| 25,167 |
Update `use_auth_token` -> `token` in example scripts
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"`use_auth_token` has been deprecated in favor of `token` in the latest release of `datasets` 🙂. ",
"> `use_auth_token` has been deprecated in favor of `token` in the latest release of `datasets` 🙂.\r\n\r\nYes, I got to check it and update my comment :-)\r\n\r\nBut thanks a lot for the information. It's very nice.",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
Update example scripts to use `token`.
We have `datasets!=2.5.0` in transformers, and I see `datasets=2.7.0` still only uses `use_auth_token`, so I don't touch the usage in `load_dataset`. Let me know if we should change to `token` + pin a higher minimum `datasets` version.
The files under `examples/research_projects` are not touched.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25167/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25167/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25167",
"html_url": "https://github.com/huggingface/transformers/pull/25167",
"diff_url": "https://github.com/huggingface/transformers/pull/25167.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25167.patch",
"merged_at": 1690551225000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25166
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25166/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25166/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25166/events
|
https://github.com/huggingface/transformers/pull/25166
| 1,826,004,469 |
PR_kwDOCUB6oc5Wod68
| 25,166 |
override .cuda() to check if model is already quantized
|
{
"login": "ranchlai",
"id": 5043767,
"node_id": "MDQ6VXNlcjUwNDM3Njc=",
"avatar_url": "https://avatars.githubusercontent.com/u/5043767?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ranchlai",
"html_url": "https://github.com/ranchlai",
"followers_url": "https://api.github.com/users/ranchlai/followers",
"following_url": "https://api.github.com/users/ranchlai/following{/other_user}",
"gists_url": "https://api.github.com/users/ranchlai/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ranchlai/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ranchlai/subscriptions",
"organizations_url": "https://api.github.com/users/ranchlai/orgs",
"repos_url": "https://api.github.com/users/ranchlai/repos",
"events_url": "https://api.github.com/users/ranchlai/events{/privacy}",
"received_events_url": "https://api.github.com/users/ranchlai/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
This PR is a quick fix by adding .cuda() to prevent device casting after 8-bit quantization. Same spirit as #20409. @younesbelkada @sgugger Would you please have a quick look .
It fixes the following unexpected error:
### For reberta-large, output `nan` without raising an error
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
from transformers import AutoConfig
from transformers import pipeline
model_name = "roberta-large" # or any other models
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
config = AutoConfig.from_pretrained(
model_name,
)
model = AutoModelForMaskedLM.from_pretrained(
model_name, trust_remote_code=True, load_in_8bit=True, device_map="auto"
)
model.cuda()
unmasker = pipeline("fill-mask", model=model, tokenizer=tokenizer)
print(unmasker("Hello I'm a <mask> model."))
>>> [{'score': nan, 'token': 3, 'token_str': '<unk>', 'sequence': "Hello I'm a model."}, {'score': nan, 'token': 4, 'token_str': '.', 'sequence': "Hello I'm a. model."}, {'score': nan, 'token': 1, 'token_str': '<pad>', 'sequence': "Hello I'm a model."}, {'score': nan, 'token': 0, 'token_str': '<s>', 'sequence': "Hello I'm a model."}, {'score': nan, 'token': 2, 'token_str': '</s>', 'sequence': "Hello I'm a model."}]
```
### for mpt, RuntimeError as follows
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
from transformers import AutoConfig
model_name = "mosaicml/mpt-7b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name, load_in_4bit=True, device_map="auto"
)
model.cuda()
text = "Here is a recipe for vegan banana bread:\n"
input_ids = tokenizer.encode(text, return_tensors="pt").to("cuda:0")
output = model.generate(input_ids, max_length=100, do_sample=True)
response = tokenizer.decode(output[0])
print(response)
>>> output = torch.nn.functional.linear(A, F.dequantize_4bit(B, state).to(A.dtype).t(), bias)
>>> RuntimeError: mat1 and mat2 shapes cannot be multiplied (10x4096 and 1x25165824)
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25166/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25166/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25166",
"html_url": "https://github.com/huggingface/transformers/pull/25166",
"diff_url": "https://github.com/huggingface/transformers/pull/25166.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25166.patch",
"merged_at": 1690546644000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25165
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25165/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25165/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25165/events
|
https://github.com/huggingface/transformers/issues/25165
| 1,825,998,532 |
I_kwDOCUB6oc5s1obE
| 25,165 |
cached_file() got an unexpected keyword argument 'token'
|
{
"login": "nivibilla",
"id": 26687662,
"node_id": "MDQ6VXNlcjI2Njg3NjYy",
"avatar_url": "https://avatars.githubusercontent.com/u/26687662?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nivibilla",
"html_url": "https://github.com/nivibilla",
"followers_url": "https://api.github.com/users/nivibilla/followers",
"following_url": "https://api.github.com/users/nivibilla/following{/other_user}",
"gists_url": "https://api.github.com/users/nivibilla/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nivibilla/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nivibilla/subscriptions",
"organizations_url": "https://api.github.com/users/nivibilla/orgs",
"repos_url": "https://api.github.com/users/nivibilla/repos",
"events_url": "https://api.github.com/users/nivibilla/events{/privacy}",
"received_events_url": "https://api.github.com/users/nivibilla/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi, can you provide a full code snippet with which I can reproduce the error?\r\n",
"Hi I'm just loading the llama 2 model but from my local machine. I have an update however. I tested it on the latest pip install version and it works fine. So I think the code broke in between the pip version and the current status of the repo.",
"And it should be resolved now, but can you provide us your exact snippet of code yielding to the bug? cc @ydshieh who is working on the migration `use_auth_token` -> `token`",
"@nivibilla \r\n\r\nYou can try a version after this commit on `main`\r\n\r\n0c790ddbd1c91250b26bab4308acbf271df063a7\r\n\r\n(which is #25146 being merged)\r\n\r\nLet me know 🙏 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
### System Info
transformers-4.32.0.dev0
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [x] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
`AutoConfig.from_pretrained(model, trust_remote_code=trust_remote_code)`
Throws this error
### Expected behavior
Not throw error
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25165/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25165/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25164
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25164/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25164/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25164/events
|
https://github.com/huggingface/transformers/pull/25164
| 1,825,959,645 |
PR_kwDOCUB6oc5WoUto
| 25,164 |
Represent query_length in a different way to solve jit issue
|
{
"login": "jiqing-feng",
"id": 107918818,
"node_id": "U_kgDOBm614g",
"avatar_url": "https://avatars.githubusercontent.com/u/107918818?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/jiqing-feng",
"html_url": "https://github.com/jiqing-feng",
"followers_url": "https://api.github.com/users/jiqing-feng/followers",
"following_url": "https://api.github.com/users/jiqing-feng/following{/other_user}",
"gists_url": "https://api.github.com/users/jiqing-feng/gists{/gist_id}",
"starred_url": "https://api.github.com/users/jiqing-feng/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/jiqing-feng/subscriptions",
"organizations_url": "https://api.github.com/users/jiqing-feng/orgs",
"repos_url": "https://api.github.com/users/jiqing-feng/repos",
"events_url": "https://api.github.com/users/jiqing-feng/events{/privacy}",
"received_events_url": "https://api.github.com/users/jiqing-feng/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,691 | 1,690 |
CONTRIBUTOR
| null |
Hi @ArthurZucker @younesbelkada @sgugger
Thanks for contributing to the MPT model. I found a jit issue with this model.
```python
from transformers import AutoModelForCausalLM, AutoConfig
from optimum.intel.generation.modeling import jit_trace
model = AutoModelForCausalLM.from_pretrained("mosaicml/mpt-7b")
jit_model = jit_trace(model=model, task="text-generation", use_cache=True)
```
When I tried to trace mpt model, I got this error

This is because float values like seq_length and query_length are detected as tensor in trace mode. When we set `query_length = seq_length` and `seq_length += past_key_value[0].shape[2]`, the `seq_length` is changed too which is unexpected.

So I use a more clean way to set `query_length` and it can also avoid the jit issue.
`query_length = seq_length if past_key_value is None else seq_length + past_key_value[0].shape[2]`
Would you please help me review it? Thanks!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25164/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25164/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25164",
"html_url": "https://github.com/huggingface/transformers/pull/25164",
"diff_url": "https://github.com/huggingface/transformers/pull/25164.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25164.patch",
"merged_at": 1690546751000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25163
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25163/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25163/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25163/events
|
https://github.com/huggingface/transformers/issues/25163
| 1,825,954,420 |
I_kwDOCUB6oc5s1dp0
| 25,163 |
torch.jit._trace.TracingCheckError: Tracing failed sanity checks! ERROR: Graphs differed across invocations!
|
{
"login": "zhug777",
"id": 41363470,
"node_id": "MDQ6VXNlcjQxMzYzNDcw",
"avatar_url": "https://avatars.githubusercontent.com/u/41363470?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhug777",
"html_url": "https://github.com/zhug777",
"followers_url": "https://api.github.com/users/zhug777/followers",
"following_url": "https://api.github.com/users/zhug777/following{/other_user}",
"gists_url": "https://api.github.com/users/zhug777/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhug777/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhug777/subscriptions",
"organizations_url": "https://api.github.com/users/zhug777/orgs",
"repos_url": "https://api.github.com/users/zhug777/repos",
"events_url": "https://api.github.com/users/zhug777/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhug777/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi it seems you code snippet is somehow different than what has been shown in the log where it has\r\n\r\n```Cell In[24], line 4\r\n 2 out = model(t)\r\n 3 print(out[0].shape)\r\n----> 4 t_model = torch.jit.trace(model, [t])\r\n 5 print(\"ok\")\r\n```\r\nAlso the code snippet won't work for us as we don't have\r\n\r\nckpt = \"./pytorch_model_swin.bin\" and `t_model` is defined.\r\n\r\nCould you update the code snippet so we can reproduce the error directly? Thanks in advance!\r\n\r\n",
"Thanks for reply! The code and log message are update as follows. I didn't paste the log message after the 'graph diff' because it's very long.\r\n\r\n\r\n**Code**\r\n```python\r\nimport os\r\nos.environ['CUDA_VISIBLE_DEVICES'] = '1'\r\nimport torch \r\nfrom transformers import SwinForImageClassification, TrainingArguments, Trainer\r\nlabel2id ={'bad': 1, 'good': 0}\r\nid2label = {1:'bad', 0:'good'}\r\n\r\nmodel_name = 'microsoft/swin-base-patch4-window12-384-in22k'\r\nmodel = SwinForImageClassification.from_pretrained(\r\n model_name,\r\n label2id=label2id,\r\n id2label=id2label,\r\n ignore_mismatched_sizes=True, # provide this in case you're planning to fine-tune an already fine-tuned checkpoint\r\n torchscript=True\r\n)\r\n\r\ndummy_input = torch.randn(1,3,384,384)\r\ntraced_model = torch.jit.trace(model, dummy_input)\r\nprint(\"ok\")\r\n```\r\n**Log Message**\r\n```python\r\n'(MaxRetryError(\"HTTPSConnectionPool(host='huggingface.co', port=443): Max retries exceeded with url: /microsoft/swin-base-patch4-window12-384-in22k/resolve/main/config.json (Caused by ConnectTimeoutError(<urllib3.connection.HTTPSConnection object at 0x7f117efe3690>, 'Connection to huggingface.co timed out. (connect timeout=10)'))\"), '(Request ID: 46579f44-3f58-4627-8466-22306063fb52)')' thrown while requesting HEAD https://huggingface.co/microsoft/swin-base-patch4-window12-384-in22k/resolve/main/config.json\r\nSome weights of SwinForImageClassification were not initialized from the model checkpoint at microsoft/swin-base-patch4-window12-384-in22k and are newly initialized because the shapes did not match:\r\n- classifier.weight: found shape torch.Size([21841, 1024]) in the checkpoint and torch.Size([2, 1024]) in the model instantiated\r\n- classifier.bias: found shape torch.Size([21841]) in the checkpoint and torch.Size([2]) in the model instantiated\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\n---------------------------------------------------------------------------\r\nTracingCheckError Traceback (most recent call last)\r\nCell In[2], line 18\r\n 9 model = SwinForImageClassification.from_pretrained(\r\n 10 model_name,\r\n 11 label2id=label2id,\r\n (...)\r\n 14 torchscript=True\r\n 15 )\r\n 17 dummy_input = torch.randn(1,3,384,384)\r\n---> 18 traced_model = torch.jit.trace(model, dummy_input)\r\n 19 print(\"ok\")\r\n\r\nFile /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:794, in trace(func, example_inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit, example_kwarg_inputs, _store_inputs)\r\n 792 else:\r\n 793 raise RuntimeError(\"example_kwarg_inputs should be a dict\")\r\n--> 794 return trace_module(\r\n 795 func,\r\n 796 {\"forward\": example_inputs},\r\n 797 None,\r\n 798 check_trace,\r\n 799 wrap_check_inputs(check_inputs),\r\n 800 check_tolerance,\r\n 801 strict,\r\n 802 _force_outplace,\r\n 803 _module_class,\r\n 804 example_inputs_is_kwarg=isinstance(example_kwarg_inputs, dict),\r\n 805 _store_inputs=_store_inputs\r\n 806 )\r\n 807 if (\r\n 808 hasattr(func, \"__self__\")\r\n 809 and isinstance(func.__self__, torch.nn.Module)\r\n 810 and func.__name__ == \"forward\"\r\n 811 ):\r\n 812 if example_inputs is None:\r\n\r\nFile /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:1084, in trace_module(mod, inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit, example_inputs_is_kwarg, _store_inputs)\r\n 1072 _check_trace(\r\n 1073 check_inputs,\r\n 1074 func,\r\n (...)\r\n 1081 example_inputs_is_kwarg=example_inputs_is_kwarg,\r\n 1082 )\r\n 1083 else:\r\n-> 1084 _check_trace(\r\n 1085 [inputs],\r\n 1086 func,\r\n 1087 check_trace_method,\r\n 1088 check_tolerance,\r\n 1089 strict,\r\n 1090 _force_outplace,\r\n 1091 True,\r\n 1092 _module_class,\r\n 1093 example_inputs_is_kwarg=example_inputs_is_kwarg,\r\n 1094 )\r\n 1095 finally:\r\n 1096 torch.jit._trace._trace_module_map = old_module_map\r\n\r\nFile /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)\r\n 112 @functools.wraps(func)\r\n 113 def decorate_context(*args, **kwargs):\r\n 114 with ctx_factory():\r\n--> 115 return func(*args, **kwargs)\r\n\r\nFile /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:562, in _check_trace(check_inputs, func, traced_func, check_tolerance, strict, force_outplace, is_trace_module, _module_class, example_inputs_is_kwarg)\r\n 560 diag_info = graph_diagnostic_info()\r\n 561 if any(info is not None for info in diag_info):\r\n--> 562 raise TracingCheckError(*diag_info)\r\n\r\nTracingCheckError: Tracing failed sanity checks!\r\nERROR: Graphs differed across invocations!\r\n\tGraph diff:\r\n...\r\n```",
"Thank you for updating, very nice 🤗 \r\n\r\n",
"Confirmed the reproduction (and yes the log after Graph diff is super super long 😅 ",
"@fxmarty Could you help on this? You can check the following code snippet.\r\n\r\nBasically, it will pass or fail depending on different config values. There is some data flow (tensor bool values) issue in the modeling code, but I am really bad on identifying where is the root cause and how to fix things here.\r\n\r\nIf possible, that would be great if you can share how you debug this kind of thing with us 🙏 Thank you in advance.\r\n \r\n\r\n```python\r\nimport os\r\nos.environ['CUDA_VISIBLE_DEVICES'] = '1'\r\nimport torch\r\nfrom transformers import SwinForImageClassification, TrainingArguments, Trainer, SwinConfig\r\n\r\nlabel2id ={'bad': 1, 'good': 0}\r\nid2label = {1:'bad', 0:'good'}\r\n\r\n\r\n# this fails\r\nUSE_SMALL_CONFIG = False\r\n# this works\r\n# USE_SMALL_CONFIG = True\r\n\r\nmodel_name = 'microsoft/swin-base-patch4-window12-384-in22k'\r\nconfig = SwinConfig.from_pretrained(model_name)\r\nconfig.torchscript = True\r\nconfig.label2id=label2id\r\nconfig.id2label=id2label\r\n\r\nif USE_SMALL_CONFIG:\r\n config.image_size = 32\r\n config.patch_size = 2\r\n config.depths=[1, 2, 1]\r\n config.num_heads=[2, 2, 4]\r\n config.window_size=2\r\n\r\nmodel = SwinForImageClassification(config)\r\ndummy_input = torch.randn(1,3, config.image_size, config.image_size)\r\n\r\n# make sure it can run in normal mode\r\no = model(dummy_input)\r\nprint(\"model forward ok\")\r\n# trace it\r\ntraced_model = torch.jit.trace(model, dummy_input)\r\nprint(\"trace ok\")\r\n```",
"@ydshieh Is there any progress on this issue?\r\nI'm running into similar issues using `jit.trace` and `jit.script` using Falcon-7b with either the `FalconModel` or `AutoModelForCausalLM` class.\r\n\r\nWith scripting I get lots of unsupported code errors and with tracing I run into dynamic code issues that raise graph diff errors. \r\n\r\n## Example 1\r\n\r\nThe following code\r\n\r\n```python\r\nfrom transformers import AutoTokenizer, AutoModelForCausalLM\r\nimport torch\r\n\r\nmodel = \"tiiuae/falcon-7b\"\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(model)\r\nmodel = AutoModelForCausalLM.from_pretrained(model, torchscript=True)\r\nmodel.eval()\r\n\r\nDUMMY_TEXT = \"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\\nDaniel: Hello, Girafatron!\\nGirafatron:\"\r\ntok_text = tokenizer.tokenize(DUMMY_TEXT)\r\ntokens = tokenizer.encode(DUMMY_TEXT)\r\nprint(tok_text, tokens)\r\n\r\nassert model.training == False\r\nwith torch.no_grad():\r\n tokens_tensor = torch.Tensor([tokens]).long()\r\n traced_model = torch.jit.trace(model, [tokens_tensor])\r\n torch.jit.save(traced_model, \"traced_bert.pt\")\r\n```\r\n\r\nraises a LONG stacktrace giving stuff like\r\n\r\n```\r\n First diverging operator: \r\n Node diff: \r\n - %lm_head : __torch__.torch.nn.modules.linear.Linear = prim::GetAttr[name=\"lm_head\"](%self.1) \r\n + %lm_head : __torch__.torch.nn.modules.linear.___torch_mangle_701.Linear = prim::GetAttr[name=\"lm_head\"](%self.1) \r\n ? ++++++++++++++++++++ \r\nERROR: Tensor-valued Constant nodes differed in value across invocations. This often indicates that the tracer has encountered untraceable code.\r\n```\r\n ## Example 2\r\n\r\nThe code \r\n\r\n```python\r\nfrom transformers import AutoTokenizer, AutoModelForCausalLM\r\nimport torch\r\n\r\nmodel = \"tiiuae/falcon-7b\"\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(model)\r\nmodel = AutoModelForCausalLM.from_pretrained(model, torchscript=True)\r\nmodel.eval()\r\n\r\nDUMMY_TEXT = \"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\\nDaniel: Hello, Girafatron!\\nGirafatron:\"\r\ntok_text = tokenizer.tokenize(DUMMY_TEXT)\r\ntokens = tokenizer.encode(DUMMY_TEXT)\r\nprint(tok_text, tokens)\r\n\r\nmodel.eval()\r\nassert model.training == False\r\nwith torch.no_grad():\r\n tokens_tensor = torch.Tensor([tokens]).long()\r\n traced_model = torch.jit.script(model, [tokens_tensor])\r\n torch.jit.save(traced_model, \"traced_bert.pt\")\r\n```\r\n\r\nraises\r\n\r\n```\r\n/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_script.py:1241: UserWarning: `optimize` is deprecated and has no effect. Use `with torch.jit.optimized_execution() instead\r\n warnings.warn(\r\nTraceback (most recent call last):\r\n File \"/home/johannes.otterbach/code/torchscript_converter.py\", line 19, in <module>\r\n traced_model = torch.jit.script(model, [tokens_tensor])\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_script.py\", line 1284, in script\r\n return torch.jit._recursive.create_script_module(\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 480, in create_script_module\r\n return create_script_module_impl(nn_module, concrete_type, stubs_fn)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 492, in create_script_module_impl\r\n method_stubs = stubs_fn(nn_module)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 761, in infer_methods_to_compile\r\n stubs.append(make_stub_from_method(nn_module, method))\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 73, in make_stub_from_method\r\n return make_stub(func, method_name)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 58, in make_stub\r\n ast = get_jit_def(func, name, self_name=\"RecursiveScriptModule\")\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 297, in get_jit_def\r\n return build_def(parsed_def.ctx, fn_def, type_line, def_name, self_name=self_name, pdt_arg_types=pdt_arg_types)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 335, in build_def\r\n param_list = build_param_list(ctx, py_def.args, self_name, pdt_arg_types)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 359, in build_param_list\r\n raise NotSupportedError(ctx_range, _vararg_kwarg_err)\r\ntorch.jit.frontend.NotSupportedError: Compiled functions can't take variable number of arguments or use keyword-only arguments with defaults:\r\n File \"/home/johannes.otterbach/.cache/huggingface/modules/transformers_modules/tiiuae/falcon-7b/378337427557d1df3e742264a2901a49f25d4eb1/modelling_RW.py\", line 733\r\n output_hidden_states: Optional[bool] = None,\r\n return_dict: Optional[bool] = None,\r\n **deprecated_arguments,\r\n ~~~~~~~~~~~~~~~~~~~~~ <--- HERE\r\n ) -> Union[Tuple[torch.Tensor], CausalLMOutputWithCrossAttentions]:\r\n r\"\"\"\r\n```\r\n\r\n\r\n## Example 3\r\n\r\nThe code\r\n\r\n```python\r\nfrom transformers import AutoTokenizer, FalconModel\r\nimport torch\r\n\r\nmodel = \"tiiuae/falcon-7b\"\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(model)\r\nmodel = FalconModel.from_pretrained(model, torchscript=True)\r\nmodel.eval()\r\n\r\nDUMMY_TEXT = \"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\\nDaniel: Hello, Girafatron!\\nGirafatron:\"\r\ntok_text = tokenizer.tokenize(DUMMY_TEXT)\r\ntokens = tokenizer.encode(DUMMY_TEXT)\r\nprint(tok_text, tokens)\r\n\r\nmodel.eval()\r\nassert model.training == False\r\nwith torch.no_grad():\r\n tokens_tensor = torch.Tensor([tokens]).long()\r\n traced_model = torch.jit.script(model, [tokens_tensor])\r\n torch.jit.save(traced_model, \"traced_bert.pt\")\r\n```\r\n\r\nraises\r\n\r\n```\r\n/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_script.py:1241: UserWarning: `optimize` is deprecated and has no effect. Use `with torch.jit.optimized_execution() instead\r\n warnings.warn(\r\nTraceback (most recent call last):\r\n File \"/home/johannes.otterbach/code/torchscript_converter.py\", line 19, in <module>\r\n traced_model = torch.jit.script(model, [tokens_tensor])\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_script.py\", line 1284, in script\r\n return torch.jit._recursive.create_script_module(\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 480, in create_script_module\r\n return create_script_module_impl(nn_module, concrete_type, stubs_fn)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 492, in create_script_module_impl\r\n method_stubs = stubs_fn(nn_module)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 761, in infer_methods_to_compile\r\n stubs.append(make_stub_from_method(nn_module, method))\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 73, in make_stub_from_method\r\n return make_stub(func, method_name)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/_recursive.py\", line 58, in make_stub\r\n ast = get_jit_def(func, name, self_name=\"RecursiveScriptModule\")\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 297, in get_jit_def\r\n return build_def(parsed_def.ctx, fn_def, type_line, def_name, self_name=self_name, pdt_arg_types=pdt_arg_types)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 348, in build_def\r\n build_stmts(ctx, body))\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 141, in build_stmts\r\n stmts = [build_stmt(ctx, s) for s in stmts]\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 141, in <listcomp>\r\n stmts = [build_stmt(ctx, s) for s in stmts]\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 320, in __call__\r\n return method(ctx, node)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 638, in build_For\r\n [build_expr(ctx, stmt.iter)], build_stmts(ctx, stmt.body))\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 141, in build_stmts\r\n stmts = [build_stmt(ctx, s) for s in stmts]\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 141, in <listcomp>\r\n stmts = [build_stmt(ctx, s) for s in stmts]\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 320, in __call__\r\n return method(ctx, node)\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 644, in build_If\r\n build_stmts(ctx, stmt.body),\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 141, in build_stmts\r\n stmts = [build_stmt(ctx, s) for s in stmts]\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 141, in <listcomp>\r\n stmts = [build_stmt(ctx, s) for s in stmts]\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/torch/jit/frontend.py\", line 319, in __call__\r\n raise UnsupportedNodeError(ctx, node)\r\ntorch.jit.frontend.UnsupportedNodeError: function definitions aren't supported:\r\n File \"/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/transformers/models/falcon/modeling_falcon.py\", line 782\r\n use_cache = False\r\n\r\n def create_custom_forward(module):\r\n ~~~ <--- HERE\r\n def custom_forward(*inputs):\r\n # None for past_key_value\r\n```\r\n\r\n## Example 4\r\n\r\nthe code\r\n\r\n```python\r\nfrom transformers import AutoTokenizer, FalconModel\r\nimport torch\r\n\r\nmodel = \"tiiuae/falcon-7b\"\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(model)\r\nmodel = FalconModel.from_pretrained(model, torchscript=True)\r\nmodel.eval()\r\n\r\nDUMMY_TEXT = \"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\\nDaniel: Hello, Girafatron!\\nGirafatron:\"\r\ntok_text = tokenizer.tokenize(DUMMY_TEXT)\r\ntokens = tokenizer.encode(DUMMY_TEXT)\r\nprint(tok_text, tokens)\r\n\r\nmodel.eval()\r\nassert model.training == False\r\nwith torch.no_grad():\r\n tokens_tensor = torch.Tensor([tokens]).long()\r\n traced_model = torch.jit.trace(model, [tokens_tensor])\r\n torch.jit.save(traced_model, \"traced_bert.pt\")\r\n```\r\n\r\nraises\r\n\r\n```\r\n/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/transformers/models/falcon/modeling_falcon.py:671: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!\r\n if input_shape[1] + past_key_values_length != attention_mask.shape[1]:\r\n/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/transformers/models/falcon/modeling_falcon.py:681: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!\r\n if seq_length > 1:\r\n/home/johannes.otterbach/code/venv/triton/lib/python3.10/site-packages/transformers/models/falcon/modeling_falcon.py:85: TracerWarning: Converting a tensor to a Python boolean might cause the trace to be incorrect. We can't record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!\r\n if total_length > self.seq_len_cached:\r\n\r\n<MANY MORE LINES>\r\n\r\n First diverging operator:\r\n Node diff:\r\n - %ln_f : __torch__.torch.nn.modules.normalization.___torch_mangle_344.LayerNorm = prim::GetAttr[name=\"ln_f\"](%self.1)\r\n ? ^^^\r\n + %ln_f : __torch__.torch.nn.modules.normalization.___torch_mangle_699.LayerNorm = prim::GetAttr[name=\"ln_f\"](%self.1)\r\n ?\r\n```",
"Hi @jotterbach\r\n\r\nThis is case by case (per model). We will try to look for `Falcon` 💪 .",
"Running `model(the same input)` seems to fix the problem, but I am not sure if there will be problem when we feed the traced model with an input of different sequence length.\r\n\r\n```python\r\nfrom transformers import AutoTokenizer, FalconModel\r\nimport torch\r\n\r\nmodel = \"tiiuae/falcon-7b\"\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(model)\r\nmodel = FalconModel.from_pretrained(model, torchscript=True)\r\nmodel.eval()\r\n\r\nDUMMY_TEXT = \"Girafatron is obsessed with giraffes, the most glorious animal on the face of this Earth. Giraftron believes all other animals are irrelevant when compared to the glorious majesty of the giraffe.\\nDaniel: Hello, Girafatron!\\nGirafatron:\"\r\ntok_text = tokenizer.tokenize(DUMMY_TEXT)\r\ntokens = tokenizer.encode(DUMMY_TEXT)\r\nprint(tok_text, tokens)\r\n\r\nmodel.eval()\r\nassert model.training == False\r\n\r\nt1 = tokens_tensor = torch.Tensor([tokens]).long()\r\nwith torch.no_grad():\r\n o1 = model(t1)\r\n traced_model = torch.jit.trace(model, [t1])\r\n torch.jit.save(traced_model, \"traced_bert.pt\")\r\n```",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,694 | 1,694 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-4.18.0-2.4.3.3.kwai.x86_64-x86_64-with-glibc2.17
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```python
import os
import torch
from transformers import SwinForImageClassification, TrainingArguments, Trainer
label2id ={'bad': 1, 'good': 0}
id2label = {1:'bad', 0:'good'}
model_name = 'microsoft/swin-base-patch4-window12-384-in22k'
model = SwinForImageClassification.from_pretrained(
model_name,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True,
torchscript=True
)
'''
ckpt = "./pytorch_model_swin.bin"
checkpoint = torch.load(ckpt)
model.load_state_dict(checkpoint) # my weight can be successfully loaded into the model
'''
t = torch.randn(1,3,384,384)
t_model = torch.jit.trace(model, t) # error occurred here
```
**Log Message:**
```
---------------------------------------------------------------------------
TracingCheckError Traceback (most recent call last)
Cell In[24], line 4
2 out = model(t)
3 print(out[0].shape)
----> 4 t_model = torch.jit.trace(model, [t])
5 print("ok")
File /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:794, in trace(func, example_inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit, example_kwarg_inputs, _store_inputs)
792 else:
793 raise RuntimeError("example_kwarg_inputs should be a dict")
--> 794 return trace_module(
795 func,
796 {"forward": example_inputs},
797 None,
798 check_trace,
799 wrap_check_inputs(check_inputs),
800 check_tolerance,
801 strict,
802 _force_outplace,
803 _module_class,
804 example_inputs_is_kwarg=isinstance(example_kwarg_inputs, dict),
805 _store_inputs=_store_inputs
806 )
807 if (
808 hasattr(func, "__self__")
809 and isinstance(func.__self__, torch.nn.Module)
810 and func.__name__ == "forward"
811 ):
812 if example_inputs is None:
File /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:1084, in trace_module(mod, inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit, example_inputs_is_kwarg, _store_inputs)
1072 _check_trace(
1073 check_inputs,
1074 func,
(...)
1081 example_inputs_is_kwarg=example_inputs_is_kwarg,
1082 )
1083 else:
-> 1084 _check_trace(
1085 [inputs],
1086 func,
1087 check_trace_method,
1088 check_tolerance,
1089 strict,
1090 _force_outplace,
1091 True,
1092 _module_class,
1093 example_inputs_is_kwarg=example_inputs_is_kwarg,
1094 )
1095 finally:
1096 torch.jit._trace._trace_module_map = old_module_map
File /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)
112 @functools.wraps(func)
113 def decorate_context(*args, **kwargs):
114 with ctx_factory():
--> 115 return func(*args, **kwargs)
File /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:562, in _check_trace(check_inputs, func, traced_func, check_tolerance, strict, force_outplace, is_trace_module, _module_class, example_inputs_is_kwarg)
560 diag_info = graph_diagnostic_info()
561 if any(info is not None for info in diag_info):
--> 562 raise TracingCheckError(*diag_info)
TracingCheckError: Tracing failed sanity checks!
ERROR: Graphs differed across invocations!
Graph diff:
graph(%self.1 : __torch__.transformers.models.swin.modeling_swin.SwinForImageClassification,
%pixel_values : Tensor):
%classifier : __torch__.torch.nn.modules.linear.Linear = prim::GetAttr[name="classifier"](%self.1)
%swin : __torch__.transformers.models.swin.modeling_swin.SwinModel = prim::GetAttr[name="swin"](%self.1)
...
```
### Expected behavior
Hello, an error occured in the following code when I was using torch.jit.trace to transfer the Swin Transformer model to TorchScript. What should I do to fix it?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25163/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25163/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25162
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25162/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25162/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25162/events
|
https://github.com/huggingface/transformers/issues/25162
| 1,825,942,162 |
I_kwDOCUB6oc5s1aqS
| 25,162 |
torch.jit._trace.TracingCheckError: Tracing failed sanity checks! ERROR: Graphs differed across invocations!
|
{
"login": "zhug777",
"id": 41363470,
"node_id": "MDQ6VXNlcjQxMzYzNDcw",
"avatar_url": "https://avatars.githubusercontent.com/u/41363470?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhug777",
"html_url": "https://github.com/zhug777",
"followers_url": "https://api.github.com/users/zhug777/followers",
"following_url": "https://api.github.com/users/zhug777/following{/other_user}",
"gists_url": "https://api.github.com/users/zhug777/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhug777/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhug777/subscriptions",
"organizations_url": "https://api.github.com/users/zhug777/orgs",
"repos_url": "https://api.github.com/users/zhug777/repos",
"events_url": "https://api.github.com/users/zhug777/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhug777/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-4.18.0-2.4.3.3.kwai.x86_64-x86_64-with-glibc2.17
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
```python
import os
import torch
from transformers import SwinForImageClassification, TrainingArguments, Trainer
label2id ={'bad': 1, 'good': 0}
id2label = {1:'bad', 0:'good'}
model_name = 'microsoft/swin-base-patch4-window12-384-in22k'
model = SwinForImageClassification.from_pretrained(
model_name,
label2id=label2id,
id2label=id2label,
ignore_mismatched_sizes=True,
torchscript=True
)
'''
ckpt = "./pytorch_model_swin.bin"
checkpoint = torch.load(ckpt)
model.load_state_dict(checkpoint) # my weight can be successfully loaded into the model
'''
t = torch.randn(1,3,384,384)
t_model = torch.jit.trace(model, t) # error occurred here
### Expected behavior
Hello, an error occured when I was using torch.jit.trace to transfer the Swin Transformer model to TorchScript. What should I do to fix it?
**Log Message:**
```
---------------------------------------------------------------------------
TracingCheckError Traceback (most recent call last)
Cell In[24], line 4
2 out = model(t)
3 print(out[0].shape)
----> 4 t_model = torch.jit.trace(model, [t])
5 print("ok")
File /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:794, in trace(func, example_inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit, example_kwarg_inputs, _store_inputs)
792 else:
793 raise RuntimeError("example_kwarg_inputs should be a dict")
--> 794 return trace_module(
795 func,
796 {"forward": example_inputs},
797 None,
798 check_trace,
799 wrap_check_inputs(check_inputs),
800 check_tolerance,
801 strict,
802 _force_outplace,
803 _module_class,
804 example_inputs_is_kwarg=isinstance(example_kwarg_inputs, dict),
805 _store_inputs=_store_inputs
806 )
807 if (
808 hasattr(func, "__self__")
809 and isinstance(func.__self__, torch.nn.Module)
810 and func.__name__ == "forward"
811 ):
812 if example_inputs is None:
File /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:1084, in trace_module(mod, inputs, optimize, check_trace, check_inputs, check_tolerance, strict, _force_outplace, _module_class, _compilation_unit, example_inputs_is_kwarg, _store_inputs)
1072 _check_trace(
1073 check_inputs,
1074 func,
(...)
1081 example_inputs_is_kwarg=example_inputs_is_kwarg,
1082 )
1083 else:
-> 1084 _check_trace(
1085 [inputs],
1086 func,
1087 check_trace_method,
1088 check_tolerance,
1089 strict,
1090 _force_outplace,
1091 True,
1092 _module_class,
1093 example_inputs_is_kwarg=example_inputs_is_kwarg,
1094 )
1095 finally:
1096 torch.jit._trace._trace_module_map = old_module_map
File /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/utils/_contextlib.py:115, in context_decorator.<locals>.decorate_context(*args, **kwargs)
112 @functools.wraps(func)
113 def decorate_context(*args, **kwargs):
114 with ctx_factory():
--> 115 return func(*args, **kwargs)
File /home/web_server/anaconda3/envs/ram/lib/python3.11/site-packages/torch/jit/_trace.py:562, in _check_trace(check_inputs, func, traced_func, check_tolerance, strict, force_outplace, is_trace_module, _module_class, example_inputs_is_kwarg)
560 diag_info = graph_diagnostic_info()
561 if any(info is not None for info in diag_info):
--> 562 raise TracingCheckError(*diag_info)
TracingCheckError: Tracing failed sanity checks!
ERROR: Graphs differed across invocations!
Graph diff:
graph(%self.1 : __torch__.transformers.models.swin.modeling_swin.SwinForImageClassification,
%pixel_values : Tensor):
%classifier : __torch__.torch.nn.modules.linear.Linear = prim::GetAttr[name="classifier"](%self.1)
%swin : __torch__.transformers.models.swin.modeling_swin.SwinModel = prim::GetAttr[name="swin"](%self.1)
...
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25162/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25162/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25161
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25161/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25161/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25161/events
|
https://github.com/huggingface/transformers/pull/25161
| 1,825,694,594 |
PR_kwDOCUB6oc5WndEd
| 25,161 |
Update configuration_glpn.py
|
{
"login": "PETRASTORE",
"id": 104895418,
"node_id": "U_kgDOBkCTug",
"avatar_url": "https://avatars.githubusercontent.com/u/104895418?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/PETRASTORE",
"html_url": "https://github.com/PETRASTORE",
"followers_url": "https://api.github.com/users/PETRASTORE/followers",
"following_url": "https://api.github.com/users/PETRASTORE/following{/other_user}",
"gists_url": "https://api.github.com/users/PETRASTORE/gists{/gist_id}",
"starred_url": "https://api.github.com/users/PETRASTORE/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/PETRASTORE/subscriptions",
"organizations_url": "https://api.github.com/users/PETRASTORE/orgs",
"repos_url": "https://api.github.com/users/PETRASTORE/repos",
"events_url": "https://api.github.com/users/PETRASTORE/events{/privacy}",
"received_events_url": "https://api.github.com/users/PETRASTORE/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"C",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25161/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25161/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25161",
"html_url": "https://github.com/huggingface/transformers/pull/25161",
"diff_url": "https://github.com/huggingface/transformers/pull/25161.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25161.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25160
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25160/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25160/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25160/events
|
https://github.com/huggingface/transformers/issues/25160
| 1,825,674,040 |
I_kwDOCUB6oc5s0ZM4
| 25,160 |
"RuntimeError: expected scalar type Half but found Char" on LLaMa-2 () inference stage
|
{
"login": "Nicolas99-9",
"id": 16637853,
"node_id": "MDQ6VXNlcjE2NjM3ODUz",
"avatar_url": "https://avatars.githubusercontent.com/u/16637853?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Nicolas99-9",
"html_url": "https://github.com/Nicolas99-9",
"followers_url": "https://api.github.com/users/Nicolas99-9/followers",
"following_url": "https://api.github.com/users/Nicolas99-9/following{/other_user}",
"gists_url": "https://api.github.com/users/Nicolas99-9/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Nicolas99-9/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Nicolas99-9/subscriptions",
"organizations_url": "https://api.github.com/users/Nicolas99-9/orgs",
"repos_url": "https://api.github.com/users/Nicolas99-9/repos",
"events_url": "https://api.github.com/users/Nicolas99-9/events{/privacy}",
"received_events_url": "https://api.github.com/users/Nicolas99-9/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @ArthurZucker ",
"This is a duplicate of #25144. Make sure to check the `pretraining_tp` value in the config.json\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
### System Info
Error when loading LLM with 8 bit quantization.
**Versions:**
tokenizers 0.13.3
transformers 4.31.0
**Error message:**
```
File "/opt/conda/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 408, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
File "/opt/conda/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/opt/conda/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 295, in forward
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.pretraining_tp)]
File "/opt/conda/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 295, in <listcomp>
query_states = [F.linear(hidden_states, query_slices[i]) for i in range(self.pretraining_tp)]
RuntimeError: expected scalar type Half but found Char
```
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
**To reproduce the issue:**
```
import torch
from transformers import LlamaTokenizer, LlamaForCausalLM, GenerationConfig, LlamaConfig
model_id="WizardLM/WizardLM-13B-V1.2"
tokenizer = LlamaTokenizer.from_pretrained(model_id)
model = LlamaForCausalLM.from_pretrained(
model_id,
load_in_8bit=True,
torch_dtype=torch.float16,
device_map="auto",
)
model.config.pad_token_id = tokenizer.pad_token_id = 0 # unk
model.config.bos_token_id = 1
model.config.eos_token_id = 2
model.eval()
```
**Inference:**
```
prompt_ = "What is the difference between fusion and fission?"
prompts = f"""A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt_} ASSISTANT:"""
inputs = tokenizer(prompts, return_tensors="pt")
device = "cuda"
input_ids = inputs["input_ids"].to(device)
max_new_tokens= 2048
with torch.no_grad():
generation_output = model.generate(
input_ids=input_ids,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=max_new_tokens
)
```
### Expected behavior
Reply to the prompt.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25160/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25160/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25159
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25159/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25159/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25159/events
|
https://github.com/huggingface/transformers/pull/25159
| 1,825,611,663 |
PR_kwDOCUB6oc5WnLr5
| 25,159 |
Add GeoLM
|
{
"login": "zekun-li",
"id": 5383572,
"node_id": "MDQ6VXNlcjUzODM1NzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5383572?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zekun-li",
"html_url": "https://github.com/zekun-li",
"followers_url": "https://api.github.com/users/zekun-li/followers",
"following_url": "https://api.github.com/users/zekun-li/following{/other_user}",
"gists_url": "https://api.github.com/users/zekun-li/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zekun-li/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zekun-li/subscriptions",
"organizations_url": "https://api.github.com/users/zekun-li/orgs",
"repos_url": "https://api.github.com/users/zekun-li/repos",
"events_url": "https://api.github.com/users/zekun-li/events{/privacy}",
"received_events_url": "https://api.github.com/users/zekun-li/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @zekun-li, thanks for opening this PR! \r\n\r\nThe easiest and recommended way to make a model available in transformers is to add the modeling code directly on the hub: https://huggingface.co/docs/transformers/custom_models\r\n\r\nThis means, once working, the model can be found and used immediately without having to go through the PR process. We find this is a lot quicker as the bar for adding code into the library is high due to the maintenance cost of every new model, and so reviews take quite a while.\r\n\r\nLet us know if you have any questions about how to add a model using this process. Looking forward to seeing this model in action!",
"> Hi @zekun-li, thanks for opening this PR!\r\n> \r\n> The easiest and recommended way to make a model available in transformers is to add the modeling code directly on the hub: https://huggingface.co/docs/transformers/custom_models\r\n> \r\n> This means, once working, the model can be found and used immediately without having to go through the PR process. We find this is a lot quicker as the bar for adding code into the library is high due to the maintenance cost of every new model, and so reviews take quite a while.\r\n> \r\n> Let us know if you have any questions about how to add a model using this process. Looking forward to seeing this model in action!\r\n\r\nHi @amyeroberts Thanks a lot for the suggestion! \r\n\r\nAlthough this model is built upon BERT, it has a customized embedding layer and the model input can be different from BERT. This model can take geocoordinates as additional inputs. So unlike the changes of using different values for `num_layers` or `num_hidden_units`, these changes require a different model structure, which is not supported in the existing models in Transformer. \r\n\r\nI wonder are these supported in the \"Sharing custom models\" approach? \r\n\r\nThanks for your time!\r\n\r\n",
"@zekun-li Yes - you can add any model architecture directly onto the hub and share the model that way! In fact, it's an even more flexible way to define models as you don't have to be as strict about following certain library patterns. ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
# What does this PR do?
Add a new model called **GeoLM** into the Transformer library. GeoLM is a language model based on BERT that facilitates **geospatial understanding** in NL documents. It is pretrained on world-wide OpenStreetMap (OSM), WikiData and Wikipedia data, and can be adapted to various geospatial related downstream tasks such as **toponym recognition** and **toponym linking**.
Paper not published yet.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
## Model Weights:
* Pretrained GeoLM (ready-to-use for zero-shot toponym linking): [zekun-li/geolm-base-cased](https://huggingface.co/zekun-li/geolm-base-cased)
* Fine-tuned GeoLM for toponym recognition: [zekun-li/geolm-base-toponym-recognition](https://huggingface.co/zekun-li/geolm-base-toponym-recognition)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests), Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the [documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and [here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Open Source Status:
- [x] The model implementation is available in this PR
- [x] The model weights are available in HuggingFace model hub
## Who can review?
Anyone in the community is free to review the PR once the tests have passed.
Feel free to tag members/contributors who may be interested in your PR: @sgugger , @ArthurZucker and @younesbelkada
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25159/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25159/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25159",
"html_url": "https://github.com/huggingface/transformers/pull/25159",
"diff_url": "https://github.com/huggingface/transformers/pull/25159.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25159.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25158
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25158/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25158/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25158/events
|
https://github.com/huggingface/transformers/issues/25158
| 1,825,599,289 |
I_kwDOCUB6oc5s0G85
| 25,158 |
Transformers not working with the new Jax 0.4.14 due to API deprecation
|
{
"login": "SystemPanic",
"id": 25750030,
"node_id": "MDQ6VXNlcjI1NzUwMDMw",
"avatar_url": "https://avatars.githubusercontent.com/u/25750030?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/SystemPanic",
"html_url": "https://github.com/SystemPanic",
"followers_url": "https://api.github.com/users/SystemPanic/followers",
"following_url": "https://api.github.com/users/SystemPanic/following{/other_user}",
"gists_url": "https://api.github.com/users/SystemPanic/gists{/gist_id}",
"starred_url": "https://api.github.com/users/SystemPanic/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/SystemPanic/subscriptions",
"organizations_url": "https://api.github.com/users/SystemPanic/orgs",
"repos_url": "https://api.github.com/users/SystemPanic/repos",
"events_url": "https://api.github.com/users/SystemPanic/events{/privacy}",
"received_events_url": "https://api.github.com/users/SystemPanic/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @SystemPanic \r\n\r\n`transformers` currently only support `jax<=0.4.13` and `jaxlib<=0.4.13`. You can see that in\r\n\r\nhttps://github.com/huggingface/transformers/blob/400e76ef11d94a12c255fe1a598966e1d6021511/setup.py#L127-L128"
] | 1,690 | 1,691 | 1,691 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.15.90.1-microsoft-standard-WSL2-x86_64-with-glibc2.35
- Python version: 3.10.6
- Huggingface_hub version: 0.14.1
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): 2.11.0 (True)
- Flax version (CPU?/GPU?/TPU?): 0.7.0 (gpu)
- Jax version: 0.4.14
- JaxLib version: 0.4.14
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
### Who can help?
@ArthurZucker @younesbelkada @sanchit-gandhi
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
For example, loading a Bart model from Flax using msgpack_restore (modeling_flax_bart.py) raises `AttributeError: module 'jax.numpy' has no attribute 'DeviceArray'`
### Expected behavior
Load the state dict correctly
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25158/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 1,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25158/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25157
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25157/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25157/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25157/events
|
https://github.com/huggingface/transformers/issues/25157
| 1,825,590,026 |
I_kwDOCUB6oc5s0EsK
| 25,157 |
Unexpected GPU requests during training
|
{
"login": "rangehow",
"id": 88258534,
"node_id": "MDQ6VXNlcjg4MjU4NTM0",
"avatar_url": "https://avatars.githubusercontent.com/u/88258534?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/rangehow",
"html_url": "https://github.com/rangehow",
"followers_url": "https://api.github.com/users/rangehow/followers",
"following_url": "https://api.github.com/users/rangehow/following{/other_user}",
"gists_url": "https://api.github.com/users/rangehow/gists{/gist_id}",
"starred_url": "https://api.github.com/users/rangehow/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/rangehow/subscriptions",
"organizations_url": "https://api.github.com/users/rangehow/orgs",
"repos_url": "https://api.github.com/users/rangehow/repos",
"events_url": "https://api.github.com/users/rangehow/events{/privacy}",
"received_events_url": "https://api.github.com/users/rangehow/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"solved"
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### System Info
- `transformers` version: 4.29.2
- Platform: Linux-5.19.0-46-generic-x86_64-with-glibc2.31
- Python version: 3.11.4
- Huggingface_hub version: 0.15.1
- Safetensors version: not installed
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
**When CUDA_VISIBLE_DEVICES=1 is specified, the program suddenly applies for calling GPU:0 memory after executing thousands of steps.**
I executed the command below on a two-card 3090 server, and when I ran the program, GPU:0 card was already occupied.
`CUDA_VISIBLE_DEVICES=1 nohup python train.py &`
In the beginning, everything seemed to be normal, because I have done more than 10,000 steps

However, very suddenly, the program starts to apply for the memory of GPU0 during eval stage(although it has go through a lot of eval stage before)

The error entry of the program is displayed as model.generate from the error report

this is a related document retirval code run on t5-large,not sure the rest of code will grant help or not.



### Who can help?
@gan @ArthurZucker @younesbelkada Since it's a nlp project and happened in generation stage, so maybe I need help from you sincerely.
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
It's a public project on github [DSI-transformers](https://github.com/ArvinZhuang/DSI-transformers), just run``CUDA_VISIBLE_DEVICES=1 nohup python train.py &`` to reproduce this problem.
### Expected behavior
The program can correctly realize that it can only use GPU specified in command.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25157/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25157/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25156
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25156/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25156/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25156/events
|
https://github.com/huggingface/transformers/issues/25156
| 1,825,499,416 |
I_kwDOCUB6oc5szukY
| 25,156 |
Mask2Former Model Doesn't Move to GPU
|
{
"login": "chokevin8",
"id": 66405082,
"node_id": "MDQ6VXNlcjY2NDA1MDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/66405082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/chokevin8",
"html_url": "https://github.com/chokevin8",
"followers_url": "https://api.github.com/users/chokevin8/followers",
"following_url": "https://api.github.com/users/chokevin8/following{/other_user}",
"gists_url": "https://api.github.com/users/chokevin8/gists{/gist_id}",
"starred_url": "https://api.github.com/users/chokevin8/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/chokevin8/subscriptions",
"organizations_url": "https://api.github.com/users/chokevin8/orgs",
"repos_url": "https://api.github.com/users/chokevin8/repos",
"events_url": "https://api.github.com/users/chokevin8/events{/privacy}",
"received_events_url": "https://api.github.com/users/chokevin8/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @chokevin8 \r\n\r\nThank you for reporting. Could you provide a self-contained code snippet so the reproduction of the error is direct.\r\n\r\nAlso you can enclose the error log in a block like the following\r\n\r\n\\`\\`\\`bash\r\n error log ...\r\n\\`\\`\\`\r\n\r\nto make it easier to read. \r\n\r\nThank you in advance 🤗 ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
### System Info
transformers version: 4.31.0 (same bug occurs until version 4.27.0)
pytorch 2.0.1+cu118 (same bug occurs with cu117)
python: python 3.10
systems: NVIDIA RTX 3090 CUDA 12.0
### Who can help?
@amyeroberts @sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [x] My own task or dataset (give details below)
### Reproduction
First of all, my full error traceback is this:
Traceback (most recent call last):
File "C:\Users\labuser\hubmap\mask2former\train.py", line 428, in <module>
model, history = run_training(model, optimizer, scheduler,train_dataloader = train_dataloader, val_dataloader= val_dataloader,
File "C:\Users\labuser\hubmap\mask2former\train.py", line 255, in run_training
train_loss = epoch_train(model, optimizer, scheduler,
File "C:\Users\labuser\hubmap\mask2former\train.py", line 166, in epoch_train
outputs = model(
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\transformers\models\mask2former\modeling_mask2former.py", line 2496, in forward
outputs = self.model(
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\transformers\models\mask2former\modeling_mask2former.py", line 2271, in forward
transformer_module_output = self.transformer_module(
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\transformers\models\mask2former\modeling_mask2former.py", line 2066, in forward
self.input_projections[i](multi_scale_features[i]).flatten(2)
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\torch\nn\modules\module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\torch\nn\modules\conv.py", line 463, in forward
return self._conv_forward(input, self.weight, self.bias)
File "C:\ProgramData\Anaconda3\envs\hubmap\lib\site-packages\torch\nn\modules\conv.py", line 459, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: Input type (torch.cuda.FloatTensor) and weight type (torch.FloatTensor) should be the same
Steps to reproduce error:
1. Use any dataset of choice, doesn't matter since the inputs to the model is in cuda already, the model is the issue. (And I've made sure there is the line "model = model.to(device)", and there is only one model loaded.
2. Now write any training code (dummy code) and make sure to run below two lines when loading empty model for Mask2FormerForUniversalSegmentation:
config = config = Mask2FormerConfig(feature_size=512, mask_feature_size=512)
model = Mask2FormerForUniversalSegmentation(config)
3. Then run dummy training code and you get this error.
I'm really not sure how to resolve this issue- I've moved my model to my device, and by doing nvidia-smi I can confirm that the inputs are being transferred over to my GPU memory, I just cannot understand why the model weights are not being transferred when literally writing the code "model = model.to(device)". This also only happens with transformers, on other models on torch it works perfectly fine on the same exact environment so I doubt it's a bug with torch. Thank you!
Also, the issue is also discussed without any solutions in this [forum link](https://discuss.huggingface.co/t/mask2former-cuda-training/47072)
### Expected behavior
As discussed above, expected behavior would be so that the model is also moved to cuda (GPU).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25156/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25156/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25155
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25155/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25155/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25155/events
|
https://github.com/huggingface/transformers/issues/25155
| 1,825,280,259 |
I_kwDOCUB6oc5sy5ED
| 25,155 |
torch compile changes model output in half precision
|
{
"login": "markovalexander",
"id": 22663468,
"node_id": "MDQ6VXNlcjIyNjYzNDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/22663468?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/markovalexander",
"html_url": "https://github.com/markovalexander",
"followers_url": "https://api.github.com/users/markovalexander/followers",
"following_url": "https://api.github.com/users/markovalexander/following{/other_user}",
"gists_url": "https://api.github.com/users/markovalexander/gists{/gist_id}",
"starred_url": "https://api.github.com/users/markovalexander/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/markovalexander/subscriptions",
"organizations_url": "https://api.github.com/users/markovalexander/orgs",
"repos_url": "https://api.github.com/users/markovalexander/repos",
"events_url": "https://api.github.com/users/markovalexander/events{/privacy}",
"received_events_url": "https://api.github.com/users/markovalexander/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"That seems like an issue for PyTorch more than Transformers :-) Also note that there is a special order for context manager autocast and compiled model to respect (can't remember right now) which also may be the cause.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-1034-oracle-x86_64-with-glibc2.29
- Python version: 3.8.10
- Huggingface_hub version: 0.15.1
- Safetensors version: 0.3.1
- Accelerate version: 0.20.3
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: does not matter (provide GPU results, same on CPU)
- Using distributed or parallel set-up in script?: No
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
import torch
import transformers
if __name__ == "__main__":
device = torch.device('cuda')
model = transformers.AutoModelForTokenClassification.from_pretrained(
"Jean-Baptiste/roberta-large-ner-english").to(device)
model.eval()
a = torch.randint(100, 2000, (128, 256), device=device)
with torch.no_grad(), torch.cuda.amp.autocast():
out_not_compiled = model(input_ids=a, attention_mask=torch.ones_like(a)).logits
model = torch.compile(model)
with torch.no_grad(), torch.cuda.amp.autocast():
out_compiled = model(input_ids=a, attention_mask=torch.ones_like(a)).logits
print(
torch.sum(torch.abs(out_compiled.to(torch.float32) - out_not_compiled)) /
(128 * 256))
>> tensor(0.0120, device='cuda:0') # note that actual difference is > 410.
```
Autocast to both `float16` and `bfloat16` produces the same difference.
(Commenting out model compilation results into the same output)
### Expected behavior
Small difference in output vectors.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25155/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25155/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25154
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25154/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25154/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25154/events
|
https://github.com/huggingface/transformers/issues/25154
| 1,825,181,782 |
I_kwDOCUB6oc5syhBW
| 25,154 |
`Pipeline.forward()` possibility to place `model_outputs` on GPU
|
{
"login": "gugarosa",
"id": 4120639,
"node_id": "MDQ6VXNlcjQxMjA2Mzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/4120639?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/gugarosa",
"html_url": "https://github.com/gugarosa",
"followers_url": "https://api.github.com/users/gugarosa/followers",
"following_url": "https://api.github.com/users/gugarosa/following{/other_user}",
"gists_url": "https://api.github.com/users/gugarosa/gists{/gist_id}",
"starred_url": "https://api.github.com/users/gugarosa/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/gugarosa/subscriptions",
"organizations_url": "https://api.github.com/users/gugarosa/orgs",
"repos_url": "https://api.github.com/users/gugarosa/repos",
"events_url": "https://api.github.com/users/gugarosa/events{/privacy}",
"received_events_url": "https://api.github.com/users/gugarosa/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"`pipeline` is only a wrapper around the model and preprocessing class for quick demos. To customize things more to your needs, you should use those classes independently as you need :-)",
"Thanks for the feedback @sgugger! I will keep customizing it then 😄 "
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
### Feature request
In `transformers.pipelines.base.py` (line 1035):
`model_outputs = self._ensure_tensor_on_device(model_outputs, device=torch.device("cpu"))`
Is it possible to add a new argument that decides whether `model_outputs` should be placed on `self.device` instead of `torch.device("cpu")`?
### Motivation
The variable `model_outputs` is always placed on CPU, which can cause a slowdown if I perform additional operations on the `Pipeline.postprocess()` function.
For example, if I were to pass `logits` to `model_outputs`, the whole tensor would be transferred from GPU to CPU. If I do this extensively, I will face a severe slowdown in my pipeline.
### Your contribution
Right now, I have to override the method to remove that particular line, but I can submit a PR.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25154/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25154/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25153
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25153/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25153/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25153/events
|
https://github.com/huggingface/transformers/pull/25153
| 1,825,011,442 |
PR_kwDOCUB6oc5WlGpX
| 25,153 |
Add new model: GeoLM
|
{
"login": "zekun-li",
"id": 5383572,
"node_id": "MDQ6VXNlcjUzODM1NzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/5383572?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zekun-li",
"html_url": "https://github.com/zekun-li",
"followers_url": "https://api.github.com/users/zekun-li/followers",
"following_url": "https://api.github.com/users/zekun-li/following{/other_user}",
"gists_url": "https://api.github.com/users/zekun-li/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zekun-li/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zekun-li/subscriptions",
"organizations_url": "https://api.github.com/users/zekun-li/orgs",
"repos_url": "https://api.github.com/users/zekun-li/repos",
"events_url": "https://api.github.com/users/zekun-li/events{/privacy}",
"received_events_url": "https://api.github.com/users/zekun-li/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"This PR contains redundant commits and failed test cases. I will fix them and create a new PR later. "
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
# What does this PR do?
Add a new model called **GeoLM** into the Transformer library. GeoLM is a language model based on BERT that facilitates **geospatial understanding** in NL documents. It is pretrained on world-wide OpenStreetMap (OSM), WikiData and Wikipedia data, and can be adapted to various geospatial related downstream tasks such as **toponym recognition** and **toponym linking**.
## Model Weights:
* Pretrained GeoLM (ready-to-use for zero-shot toponym linking): [zekun-li/geolm-base-cased](https://huggingface.co/zekun-li/geolm-base-cased)
* Fine-tuned GeoLM for toponym recognition: [zekun-li/geolm-base-toponym-recognition](https://huggingface.co/zekun-li/geolm-base-toponym-recognition)
## Open source status
- [x] The model implementation is available in this PR
- [x] The model weights are available in HuggingFace model hub
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
## Who can review?
Anyone in the community is free to review the PR once the tests have passed.
Feel free to tag members/contributors who may be interested in your PR: @ArthurZucker and @younesbelkada
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25153/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25153/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25153",
"html_url": "https://github.com/huggingface/transformers/pull/25153",
"diff_url": "https://github.com/huggingface/transformers/pull/25153.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25153.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25152
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25152/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25152/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25152/events
|
https://github.com/huggingface/transformers/issues/25152
| 1,824,988,098 |
I_kwDOCUB6oc5sxxvC
| 25,152 |
Model is not compiled when using `torch_compile=True` on a machine with multiple GPUs
|
{
"login": "eawer",
"id": 1741779,
"node_id": "MDQ6VXNlcjE3NDE3Nzk=",
"avatar_url": "https://avatars.githubusercontent.com/u/1741779?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/eawer",
"html_url": "https://github.com/eawer",
"followers_url": "https://api.github.com/users/eawer/followers",
"following_url": "https://api.github.com/users/eawer/following{/other_user}",
"gists_url": "https://api.github.com/users/eawer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/eawer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/eawer/subscriptions",
"organizations_url": "https://api.github.com/users/eawer/orgs",
"repos_url": "https://api.github.com/users/eawer/repos",
"events_url": "https://api.github.com/users/eawer/events{/privacy}",
"received_events_url": "https://api.github.com/users/eawer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false |
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"login": "muellerzr",
"id": 7831895,
"node_id": "MDQ6VXNlcjc4MzE4OTU=",
"avatar_url": "https://avatars.githubusercontent.com/u/7831895?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/muellerzr",
"html_url": "https://github.com/muellerzr",
"followers_url": "https://api.github.com/users/muellerzr/followers",
"following_url": "https://api.github.com/users/muellerzr/following{/other_user}",
"gists_url": "https://api.github.com/users/muellerzr/gists{/gist_id}",
"starred_url": "https://api.github.com/users/muellerzr/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/muellerzr/subscriptions",
"organizations_url": "https://api.github.com/users/muellerzr/orgs",
"repos_url": "https://api.github.com/users/muellerzr/repos",
"events_url": "https://api.github.com/users/muellerzr/events{/privacy}",
"received_events_url": "https://api.github.com/users/muellerzr/received_events",
"type": "User",
"site_admin": false
}
] |
[
"cc @muellerzr ",
"When running on my machine via `main` I do get the `torch._inductor` warning, meaning that compilation is happening (and verified looking at accelerate). I'm running on two t4's so I may not see the direct speed impact we may expect, but I got 45s with, 15s without. @sgugger any thoughts on why it might not be faster?",
"I haven't tried `torch.compile` on multiple GPUs as it wasn't ready when I was first experimenting.",
"I gave it another try, and `torch_compile=True` actually gives some minor additional performance (~10%), but still, in logs there are no signs of a model compilation\r\n\r\n<details>\r\n<summary>Logs</summary>\r\n\r\n```bash\r\n(2.0.1) root@pytorch-2-0-0-gpu-p-ml-g5-12xlarge-de3ad04ae65352b8044617ab4259:~# python test_comppiled.py \r\n/root/.cache/huggingface/modules/datasets_modules/datasets/banking77/9898c11f6afa9521953d2ef205667b527bad14ef9cab445d470f16240c8c8ec4/banking77.py:59: FutureWarning: Dataset 'banking77' is deprecated and will be deleted. Use 'PolyAI/banking77' instead.\r\n warnings.warn(\r\nSome weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.weight', 'classifier.bias']\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\n 0%| | 0/50 [00:00<?, ?it/s]You're using a BertTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.\r\n/root/miniconda3/envs/2.0.1/lib/python3.10/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.\r\n warnings.warn('Was asked to gather along dimension 0, but all '\r\n{'loss': 4.3809, 'learning_rate': 4.9e-05, 'epoch': 0.1} \r\n{'loss': 4.3718, 'learning_rate': 4.8e-05, 'epoch': 0.2} \r\n{'loss': 4.3482, 'learning_rate': 4.7e-05, 'epoch': 0.3} \r\n{'loss': 4.3259, 'learning_rate': 4.600000000000001e-05, 'epoch': 0.4} \r\n{'loss': 4.3268, 'learning_rate': 4.5e-05, 'epoch': 0.5} \r\n{'loss': 4.3076, 'learning_rate': 4.4000000000000006e-05, 'epoch': 0.6} \r\n{'loss': 4.2895, 'learning_rate': 4.3e-05, 'epoch': 0.7} \r\n{'loss': 4.2414, 'learning_rate': 4.2e-05, 'epoch': 0.8} \r\n{'loss': 4.2331, 'learning_rate': 4.1e-05, 'epoch': 0.9} \r\n{'loss': 4.1985, 'learning_rate': 4e-05, 'epoch': 1.0} \r\n{'eval_loss': 4.185807704925537, 'eval_f1': 0.02013138842643617, 'eval_runtime': 1.5531, 'eval_samples_per_second': 1983.147, 'eval_steps_per_second': 2.576, 'epoch': 1.0} \r\n 20%|██████████████████████████████▌ | 10/50 [00:18<00:44, 1.12s/it/root/miniconda3/envs/2.0.1/lib/python3.10/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.\r\n warnings.warn('Was asked to gather along dimension 0, but all '\r\n{'loss': 4.1557, 'learning_rate': 3.9000000000000006e-05, 'epoch': 1.1} \r\n{'loss': 4.1369, 'learning_rate': 3.8e-05, 'epoch': 1.2} \r\n{'loss': 4.1036, 'learning_rate': 3.7e-05, 'epoch': 1.3} \r\n{'loss': 4.0667, 'learning_rate': 3.6e-05, 'epoch': 1.4} \r\n{'loss': 4.0313, 'learning_rate': 3.5e-05, 'epoch': 1.5} \r\n{'loss': 3.999, 'learning_rate': 3.4000000000000007e-05, 'epoch': 1.6} \r\n{'loss': 3.9721, 'learning_rate': 3.3e-05, 'epoch': 1.7} \r\n{'loss': 3.9394, 'learning_rate': 3.2000000000000005e-05, 'epoch': 1.8} \r\n{'loss': 3.9385, 'learning_rate': 3.1e-05, 'epoch': 1.9} \r\n{'loss': 3.8932, 'learning_rate': 3e-05, 'epoch': 2.0} \r\n{'eval_loss': 3.8706207275390625, 'eval_f1': 0.1322944473193535, 'eval_runtime': 1.5434, 'eval_samples_per_second': 1995.606, 'eval_steps_per_second': 2.592, 'epoch': 2.0} \r\n 40%|█████████████████████████████████████████████████████████████▏ | 20/50 [00:37<00:34, 1.15s/it/root/miniconda3/envs/2.0.1/lib/python3.10/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.\r\n warnings.warn('Was asked to gather along dimension 0, but all '\r\n{'loss': 3.8482, 'learning_rate': 2.9e-05, 'epoch': 2.1} \r\n{'loss': 3.8162, 'learning_rate': 2.8000000000000003e-05, 'epoch': 2.2} \r\n{'loss': 3.8013, 'learning_rate': 2.7000000000000002e-05, 'epoch': 2.3} \r\n{'loss': 3.7698, 'learning_rate': 2.6000000000000002e-05, 'epoch': 2.4} \r\n{'loss': 3.7365, 'learning_rate': 2.5e-05, 'epoch': 2.5} \r\n{'loss': 3.7265, 'learning_rate': 2.4e-05, 'epoch': 2.6} \r\n{'loss': 3.6938, 'learning_rate': 2.3000000000000003e-05, 'epoch': 2.7} \r\n{'loss': 3.6611, 'learning_rate': 2.2000000000000003e-05, 'epoch': 2.8} \r\n{'loss': 3.6459, 'learning_rate': 2.1e-05, 'epoch': 2.9} \r\n{'loss': 3.6336, 'learning_rate': 2e-05, 'epoch': 3.0} \r\n{'eval_loss': 3.6001734733581543, 'eval_f1': 0.2729748040387439, 'eval_runtime': 1.5502, 'eval_samples_per_second': 1986.886, 'eval_steps_per_second': 2.58, 'epoch': 3.0} \r\n 60%|███████████████████████████████████████████████████████████████████████████████████████████▊ | 30/50 [00:56<00:23, 1.15s/it/root/miniconda3/envs/2.0.1/lib/python3.10/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.\r\n warnings.warn('Was asked to gather along dimension 0, but all '\r\n{'loss': 3.5998, 'learning_rate': 1.9e-05, 'epoch': 3.1} \r\n{'loss': 3.59, 'learning_rate': 1.8e-05, 'epoch': 3.2} \r\n{'loss': 3.5453, 'learning_rate': 1.7000000000000003e-05, 'epoch': 3.3} \r\n{'loss': 3.5377, 'learning_rate': 1.6000000000000003e-05, 'epoch': 3.4} \r\n{'loss': 3.5034, 'learning_rate': 1.5e-05, 'epoch': 3.5} \r\n{'loss': 3.4958, 'learning_rate': 1.4000000000000001e-05, 'epoch': 3.6} \r\n{'loss': 3.4914, 'learning_rate': 1.3000000000000001e-05, 'epoch': 3.7} \r\n{'loss': 3.4528, 'learning_rate': 1.2e-05, 'epoch': 3.8} \r\n{'loss': 3.4624, 'learning_rate': 1.1000000000000001e-05, 'epoch': 3.9} \r\n{'loss': 3.4166, 'learning_rate': 1e-05, 'epoch': 4.0} \r\n{'eval_loss': 3.42204213142395, 'eval_f1': 0.3464519834472172, 'eval_runtime': 1.5456, 'eval_samples_per_second': 1992.722, 'eval_steps_per_second': 2.588, 'epoch': 4.0} \r\n 80%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████▍ | 40/50 [01:15<00:11, 1.15s/it/root/miniconda3/envs/2.0.1/lib/python3.10/site-packages/torch/nn/parallel/_functions.py:68: UserWarning: Was asked to gather along dimension 0, but all input tensors were scalars; will instead unsqueeze and return a vector.\r\n warnings.warn('Was asked to gather along dimension 0, but all '\r\n{'loss': 3.4365, 'learning_rate': 9e-06, 'epoch': 4.1} \r\n{'loss': 3.4078, 'learning_rate': 8.000000000000001e-06, 'epoch': 4.2} \r\n{'loss': 3.4085, 'learning_rate': 7.000000000000001e-06, 'epoch': 4.3} \r\n{'loss': 3.3968, 'learning_rate': 6e-06, 'epoch': 4.4} \r\n{'loss': 3.4034, 'learning_rate': 5e-06, 'epoch': 4.5} \r\n{'loss': 3.3404, 'learning_rate': 4.000000000000001e-06, 'epoch': 4.6} \r\n{'loss': 3.3726, 'learning_rate': 3e-06, 'epoch': 4.7} \r\n{'loss': 3.3696, 'learning_rate': 2.0000000000000003e-06, 'epoch': 4.8} \r\n{'loss': 3.3532, 'learning_rate': 1.0000000000000002e-06, 'epoch': 4.9} \r\n{'loss': 3.3582, 'learning_rate': 0.0, 'epoch': 5.0} \r\n{'eval_loss': 3.3530666828155518, 'eval_f1': 0.3755524418837662, 'eval_runtime': 1.5576, 'eval_samples_per_second': 1977.415, 'eval_steps_per_second': 2.568, 'epoch': 5.0} \r\n{'train_runtime': 102.0045, 'train_samples_per_second': 490.322, 'train_steps_per_second': 0.49, 'train_loss': 3.7907010221481325, 'epoch': 5.0} \r\n100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [01:42<00:00, 2.04s/it]\r\n{'train_runtime': 102.0045, 'train_samples_per_second': 490.322, 'train_steps_per_second': 0.49, 'train_loss': 3.7907010221481325, 'epoch': 5.0}\r\n```\r\n</details>\r\n\r\n\r\nnvidia-smi:\r\n```\r\n+-----------------------------------------------------------------------------+\r\n| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.8 |\r\n|-------------------------------+----------------------+----------------------+\r\n| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |\r\n| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\r\n| | | MIG M. |\r\n|===============================+======================+======================|\r\n| 0 NVIDIA A10G Off | 00000000:00:1B.0 Off | 0 |\r\n| 0% 29C P8 16W / 300W | 0MiB / 22731MiB | 0% Default |\r\n| | | N/A |\r\n+-------------------------------+----------------------+----------------------+\r\n| 1 NVIDIA A10G Off | 00000000:00:1C.0 Off | 0 |\r\n| 0% 28C P8 16W / 300W | 0MiB / 22731MiB | 0% Default |\r\n| | | N/A |\r\n+-------------------------------+----------------------+----------------------+\r\n| 2 NVIDIA A10G Off | 00000000:00:1D.0 Off | 0 |\r\n| 0% 29C P8 16W / 300W | 0MiB / 22731MiB | 0% Default |\r\n| | | N/A |\r\n+-------------------------------+----------------------+----------------------+\r\n| 3 NVIDIA A10G Off | 00000000:00:1E.0 Off | 0 |\r\n| 0% 29C P8 16W / 300W | 0MiB / 22731MiB | 0% Default |\r\n| | | N/A |\r\n+-------------------------------+----------------------+----------------------+\r\n \r\n+-----------------------------------------------------------------------------+\r\n| Processes: |\r\n| GPU GI CI PID Type Process name GPU Memory |\r\n| ID ID Usage |\r\n|=============================================================================|\r\n| No running processes found |\r\n+-----------------------------------------------------------------------------+\r\n```",
"@eugene-kostrov can you report your versions of `transformers` and `accelerate`? Again when I was running this I could see logs when I was building from github/main on both :) ",
"@muellerzr \r\naccelerate==0.21.0\r\n\r\ntried both following transformers versions - the logs were the same\r\n`transformers==4.31.0`\r\n`transformers==4.32.0.dev2`",
"Can you try installing via:\r\n\r\n`pip install git+https://github.com/huggingface/accelerate git+https://github.com/huggingface/transformers`\r\n\r\nThanks @eawer!",
"Interesting as I definitely see the logs here. \r\n\r\n```bash\r\naccelerate launch test.py\r\n/home/zach_mueller_huggingface_co/.cache/huggingface/modules/datasets_modules/datasets/banking77/9898c11f6afa9521953d2ef205667b527bad14ef9cab445d470f16240c8c8ec4/banking77.py:59: FutureWarning: Dataset 'banking77' is deprecated and will be deleted. Use 'PolyAI/banking77' instead.\r\n warnings.warn(\r\n/home/zach_mueller_huggingface_co/.cache/huggingface/modules/datasets_modules/datasets/banking77/9898c11f6afa9521953d2ef205667b527bad14ef9cab445d470f16240c8c8ec4/banking77.py:59: FutureWarning: Dataset 'banking77' is deprecated and will be deleted. Use 'PolyAI/banking77' instead.\r\n warnings.warn(\r\nSome weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight']\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\nSome weights of BertForSequenceClassification were not initialized from the model checkpoint at bert-base-uncased and are newly initialized: ['classifier.weight', 'classifier.bias']\r\nYou should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.\r\nThe speedups for torchdynamo mostly come wih GPU Ampere or higher and which is not detected here.\r\nThe speedups for torchdynamo mostly come wih GPU Ampere or higher and which is not detected here.\r\n 0%| | 0/24 [00:00<?, ?it/s]You're using a BertTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.\r\nYou're using a BertTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.\r\n[2023-08-16 18:49:33,566] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:33,587] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:34,954] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:34,993] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:36,700] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:36,731] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:38,004] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:38,031] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:39,525] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:39,529] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:40,767] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:40,777] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:42,030] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:42,071] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:43,559] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:43,603] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:44,823] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:44,878] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:46,085] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:46,171] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:47,346] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:47,440] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:48,851] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:48,952] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:50,139] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:50,254] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:50,801] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[2023-08-16 18:49:50,932] torch._inductor.utils: [WARNING] using triton random, expect difference from eager\r\n[W reducer.cpp:1300] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())\r\n[W reducer.cpp:1300] Warning: find_unused_parameters=True was specified in DDP constructor, but did not find any unused parameters in the forward pass. This flag results in an extra traversal of the autograd graph every iteration, which can adversely affect performance. If your model indeed never has any unused parameters in the forward pass, consider turning this flag off. Note that this warning may be a false positive if your model has flow control causing later iterations to have unused parameters. (function operator())\r\n{'loss': 4.3287, 'learning_rate': 4.791666666666667e-05, 'epoch': 0.12} \r\n{'loss': 4.2453, 'learning_rate': 4.5833333333333334e-05, 'epoch': 0.25} \r\n{'loss': 4.1773, 'learning_rate': 4.375e-05, 'epoch': 0.38} \r\n{'loss': 4.0474, 'learning_rate': 4.166666666666667e-05, 'epoch': 0.5} \r\n{'loss': 3.9611, 'learning_rate': 3.958333333333333e-05, 'epoch': 0.62} \r\n{'loss': 3.9228, 'learning_rate': 3.7500000000000003e-05, 'epoch': 0.75} \r\n{'loss': 3.8479, 'learning_rate': 3.541666666666667e-05, 'epoch': 0.88} \r\n{'loss': 3.7447, 'learning_rate': 3.3333333333333335e-05, 'epoch': 1.0} \r\n{'eval_loss': 3.690765380859375, 'eval_f1': 0.26359295290537466, 'eval_runtime': 0.3893, 'eval_samples_per_second': 1315.035, 'eval_steps_per_second': 5.137, 'epoch': 1.0} \r\n{'loss': 3.6982, 'learning_rate': 3.125e-05, 'epoch': 1.12} \r\n{'loss': 3.6525, 'learning_rate': 2.916666666666667e-05, 'epoch': 1.25} \r\n{'loss': 3.5546, 'learning_rate': 2.7083333333333332e-05, 'epoch': 1.38} \r\n{'loss': 3.5015, 'learning_rate': 2.5e-05, 'epoch': 1.5} \r\n{'loss': 3.4782, 'learning_rate': 2.2916666666666667e-05, 'epoch': 1.62} \r\n{'loss': 3.4152, 'learning_rate': 2.0833333333333336e-05, 'epoch': 1.75} \r\n{'loss': 3.3385, 'learning_rate': 1.8750000000000002e-05, 'epoch': 1.88} \r\n{'loss': 3.3378, 'learning_rate': 1.6666666666666667e-05, 'epoch': 2.0} \r\n{'eval_loss': 3.2540321350097656, 'eval_f1': 0.49614175520769455, 'eval_runtime': 0.2964, 'eval_samples_per_second': 1727.241, 'eval_steps_per_second': 6.747, 'epoch': 2.0} \r\n{'loss': 3.2948, 'learning_rate': 1.4583333333333335e-05, 'epoch': 2.12} \r\n{'loss': 3.2471, 'learning_rate': 1.25e-05, 'epoch': 2.25} \r\n{'loss': 3.2197, 'learning_rate': 1.0416666666666668e-05, 'epoch': 2.38} \r\n{'loss': 3.1782, 'learning_rate': 8.333333333333334e-06, 'epoch': 2.5} \r\n{'loss': 3.1959, 'learning_rate': 6.25e-06, 'epoch': 2.62} \r\n{'loss': 3.1684, 'learning_rate': 4.166666666666667e-06, 'epoch': 2.75} \r\n{'loss': 3.1546, 'learning_rate': 2.0833333333333334e-06, 'epoch': 2.88} \r\n{'loss': 3.1194, 'learning_rate': 0.0, 'epoch': 3.0} \r\n{'eval_loss': 3.0891151428222656, 'eval_f1': 0.604639735844818, 'eval_runtime': 0.2952, 'eval_samples_per_second': 1734.197, 'eval_steps_per_second': 6.774, 'epoch': 3.0} \r\n{'train_runtime': 43.3381, 'train_samples_per_second': 141.769, 'train_steps_per_second': 0.554, 'train_loss': 3.576234668493271, 'epoch': 3.0} \r\n100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 24/24 [00:43<00:00, 1.81s/it]\r\n```\r\n\r\nUsing the pypi versions of accelerate and transformers on torch 2.0.1",
"@muellerzr sure\r\n```\r\n(test-comp) root@pytorch-2-0-0-gpu-p-ml-g5-12xlarge-abc:~# pip freeze | grep \"transformers\\|torch\\|accelerate\"\r\naccelerate @ git+https://github.com/huggingface/accelerate@d087be01566477d99b660526adb7da4ec31abf1d\r\ntorch==2.0.1\r\ntransformers @ git+https://github.com/huggingface/transformers@1982dd3b15867c46e1c20645901b0de469fd935f\r\n```\r\nHere are results of this command for a single GPU (compilation works, ~42k lines) `CUDA_VISIBLE_DEVICES=0 TRANSFORMERS_VERBOSITY=debug ACCELERATE_VERBOCITY=debug TORCH_COMPILE_DEBUG=1 TORCH_LOGS=dynamo,inductor,guards python test_comppiled.py 2>&1 | tee visible_devices_0.txt`:\r\n[visible_devices_0.txt](https://github.com/huggingface/transformers/files/12388532/visible_devices_0.txt)\r\n\r\nHere are results of this command for 4 GPUS (compilation does not happen, ~400 lines) `CUDA_VISIBLE_DEVICES=0,1,2,3 TRANSFORMERS_VERBOSITY=debug ACCELERATE_VERBOCITY=debug TORCH_COMPILE_DEBUG=1 TORCH_LOGS=dynamo,inductor,guards python test_comppiled.py 2>&1 | tee visible_devices_0123.txt`:\r\n[visible_devices_0123.txt](https://github.com/huggingface/transformers/files/12388537/visible_devices_0123.txt)\r\n\r\n",
"@eawer the issue here is the fact the trainer doesn't support model parallelism for torch compile yet. If you use DDP (such as using `accelerate launch` instead) it will run and log exactly as we expect. cc @SunMarc ",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,699 | 1,699 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-4.14.318-241.531.amzn2.x86_64-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: yes
- Using distributed or parallel set-up in script?: yes
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Run this code:
```python
import torch
import evaluate
import numpy as np
from datasets import load_dataset, DatasetDict
from transformers import AutoModelForSequenceClassification, AutoTokenizer, Trainer, TrainingArguments
def preprocess_function(examples):
return tokenizer(examples["text"], truncation=True, padding=True, return_tensors='pt').to(device="cuda:0")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
predictions = np.argmax(predictions, axis=1)
return metric.compute(predictions=predictions, references=labels, average="weighted")
model_id = "bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=True, model_max_length=512)
dataset = load_dataset('banking77', split=['train[:2048]', 'test[:512]'])
dataset = DatasetDict({'train': dataset[0], 'test': dataset[1]})
dataset = dataset.map(preprocess_function, batched=True)
labels = dataset["train"].features["label"].names
num_labels = len(labels)
label2id, id2label = dict(), dict()
for i, label in enumerate(labels):
label2id[label] = str(i)
id2label[str(i)] = label
metric = evaluate.load("f1")
model = AutoModelForSequenceClassification.from_pretrained(
model_id, num_labels=num_labels, label2id=label2id, id2label=id2label
)
training_args = TrainingArguments(
output_dir="./temp",
per_device_train_batch_size=128,
per_device_eval_batch_size=128,
learning_rate=5e-5,
num_train_epochs=3,
torch_compile=True,
optim="adamw_torch_fused",
logging_steps=1,
logging_strategy="steps",
evaluation_strategy="epoch",
save_strategy="epoch",
save_total_limit=2,
load_best_model_at_end=True,
metric_for_best_model="f1",
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
tokenizer=tokenizer,
compute_metrics=compute_metrics,
)
trainer.train()
```
### Expected behavior
This code is running as expected on a machine with a single GPU. The model is compiled (there is an output that says layers are optimized and stuff), and training speeds up significantly (well, not for this specific example model/data combination, but for the production one).
Compilation-related output:
```
[2023-07-27 16:50:43,003] torch._inductor.utils: [WARNING] using triton random, expect difference from eager
```
But if I run the very same code on a machine with multiple GPUs - there are no signs of model compilation (no additional output in the logs) and the training speed does not improve.
`nvidia-smi` output:
```
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.57.02 Driver Version: 470.57.02 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A10G Off | 00000000:00:1B.0 Off | 0 |
| 0% 30C P8 16W / 300W | 0MiB / 22731MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A10G Off | 00000000:00:1C.0 Off | 0 |
| 0% 33C P8 16W / 300W | 0MiB / 22731MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A10G Off | 00000000:00:1D.0 Off | 0 |
| 0% 30C P8 15W / 300W | 0MiB / 22731MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A10G Off | 00000000:00:1E.0 Off | 0 |
| 0% 31C P8 16W / 300W | 0MiB / 22731MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25152/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25152/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25151
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25151/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25151/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25151/events
|
https://github.com/huggingface/transformers/issues/25151
| 1,824,842,616 |
I_kwDOCUB6oc5sxON4
| 25,151 |
Correct Falcon code in github does not match Falcon's checkpoint
|
{
"login": "afcruzs",
"id": 4340932,
"node_id": "MDQ6VXNlcjQzNDA5MzI=",
"avatar_url": "https://avatars.githubusercontent.com/u/4340932?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/afcruzs",
"html_url": "https://github.com/afcruzs",
"followers_url": "https://api.github.com/users/afcruzs/followers",
"following_url": "https://api.github.com/users/afcruzs/following{/other_user}",
"gists_url": "https://api.github.com/users/afcruzs/gists{/gist_id}",
"starred_url": "https://api.github.com/users/afcruzs/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/afcruzs/subscriptions",
"organizations_url": "https://api.github.com/users/afcruzs/orgs",
"repos_url": "https://api.github.com/users/afcruzs/repos",
"events_url": "https://api.github.com/users/afcruzs/events{/privacy}",
"received_events_url": "https://api.github.com/users/afcruzs/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The Falcon model inside Transformers is not ready to be used yet and is not compatible with the online checkpoint. To make the online checkpoints compatible with Transformer, we need to do some changes in the model repo that will break its integration with text-generation-inference. We are waiting for the new version of test-generation-inference to be deployed to be able to do those changes, and once this is done, the model will work with the code in Transformers.\r\n\r\nSo TL;DR: be patient and use `trust_remote_code=True` for the time being.",
"Thanks @sgugger - would appreciate if this issue gets tagged once those changes are in the repo :) ",
"Sure thing! Pinging @Rocketknight1 for when he does the migration.",
"Hi @afcruzs - you're correct on all counts here. Falcon-7B uses a different model architecture to Falcon-40B. When we ported Falcon to `transformers`, I added some config variables to handle the different code paths taken by the two models. The main variable is `config.new_decoder_architecture` - you can see it [in the repo code](https://github.com/huggingface/transformers/blob/main/src/transformers/models/falcon/modeling_falcon.py#L211).\r\n\r\nUnfortunately, because I added these config variables and standardized the names of some others, the `config.json` in the current Falcon checkpoints is not compatible with our library code right now. This is the cause of the `RefinedWebModel` errors you saw. We intend to update the Falcon checkpoints to move them from custom code to library code very soon, which should resolve these errors, as well as fixing the issues with the generation cache. However, we're waiting to give users and other libraries a chance to prepare, since the change will affect the existing custom code checkpoints!",
"Ohh I didn't catch the differences between 40b and 7b before, good to know; thanks @Rocketknight1 ",
"I've just played around with an alleged fix, and it seems to be working well:\r\n\r\nhttps://huggingface.co/tiiuae/falcon-40b/blob/refs%2Fpr%2F85/modelling_RW.py\r\n\r\nThe author explains his reasoning: https://huggingface.co/tiiuae/falcon-40b/discussions/85",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored.",
"Any update @Rocketknight1 ?",
"Hi @afcruzs, you're just in time! There's a release today (release notes still WIP) that resolves this issue and moves Falcon checkpoints to the in-library code. If you `pip install --upgrade transformers` you can start using it right away. There is also a conversion script included in the release to help you convert any fine-tuned of Falcon models to the new in-library code, which should resolve these issues.\r\n\r\nI'm going to close this issue as completed at this point, but feel free to reply here and ping me if you encounter any issues!"
] | 1,690 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
### System Info
Transformers version: 4.31.0
### Who can help?
@ArthurZucker @younesbelkada @Rocketknight1
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
I see there's a falcon implementation added by the HF team in the transformer github repo. What's the intent for this code? what model in the hub does actually uses it?
The official model as far as I can tell in the hub (https://huggingface.co/tiiuae/falcon-7b) uses different (outdated?) code that is included in the checkpoint itself (`modeling_RW.py`). I've found `modeling_RW.py` has a number of problems to key/value caching (either bad model outputs, or key/value caching might not get used at all) that has been fixed already in the current code in github, this has been observed by others in the [model discussions](https://huggingface.co/tiiuae/falcon-7b/discussions/17), unfortunately without an official response from the Falcon team.
That said, I am not fully sure the falcon model in the hub is compatible with the code in github, I do get warnings if I try to use it (`You are using a model of type RefinedWebModel to instantiate a model of type falcon. This is not supported for all configurations of models and can yield errors.`).
**Concrete question**: what is the intended usage of the current falcon code (`src/transformers/models/falcon`) in the transformers repo? Is it compatible with the official falcon models?
Steps to reproduce - loading with FalconForCausalLM
```
# Load model directly
from transformers import FalconForCausalLM
DEVICE = 'cuda'
# This gives me: You are using a model of type RefinedWebModel to instantiate a model of type falcon. This is not supported for all configurations of models and can yield errors.
model = FalconForCausalLM.from_pretrained(<path of the tiiuae/falcon-7b in the hub downloaded locally>).to(DEVICE)
```
Steps to reproduce - loading with Auto
```
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("tiiuae/falcon-7b", trust_remote_code=True).to('cuda')
tokenizer = AutoTokenizer.from_pretrained("tiiuae/falcon-7b")
input_text_tokens = tokenizer("Hello world, this is the story of Bob, a", return_tensors="pt").input_ids.to('cuda')
# This actually *does not* use KV caching, due to a name bug from "past_key_values" to "past" in `prepare_inputs_for_generation`
# If one attempts to fix this, shape errors might occur. If those are fixed, the output is gibberish due to position ids not correctly
# into the RoPE embeddings. See this for more details: https://huggingface.co/tiiuae/falcon-7b/discussions/17
with torch.no_grad():
model.eval()
generate_fn_output = model.generate(input_text_tokens, max_length=64, num_beams=1, do_sample=False)
print("###".join(tokenizer.batch_decode(generate_fn_output, skip_special_symbols=True)))
```
### Expected behavior
Loading the falcon model should get the weights correctly read and calling the `generate` method should perform and correct efficient inference with KV caching.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25151/reactions",
"total_count": 1,
"+1": 1,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25151/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25150
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25150/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25150/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25150/events
|
https://github.com/huggingface/transformers/pull/25150
| 1,824,743,435 |
PR_kwDOCUB6oc5WkMtG
| 25,150 |
Update modeling_gpt2.py
|
{
"login": "nikitakapitan",
"id": 101126304,
"node_id": "U_kgDOBgcQoA",
"avatar_url": "https://avatars.githubusercontent.com/u/101126304?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/nikitakapitan",
"html_url": "https://github.com/nikitakapitan",
"followers_url": "https://api.github.com/users/nikitakapitan/followers",
"following_url": "https://api.github.com/users/nikitakapitan/following{/other_user}",
"gists_url": "https://api.github.com/users/nikitakapitan/gists{/gist_id}",
"starred_url": "https://api.github.com/users/nikitakapitan/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/nikitakapitan/subscriptions",
"organizations_url": "https://api.github.com/users/nikitakapitan/orgs",
"repos_url": "https://api.github.com/users/nikitakapitan/repos",
"events_url": "https://api.github.com/users/nikitakapitan/events{/privacy}",
"received_events_url": "https://api.github.com/users/nikitakapitan/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @ArthurZucker ",
"Can you just run `make style`, maybe it will put it back? ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25150). All of your documentation changes will be reflected on that endpoint.",
"Is there anything I can do to help merging it? ",
"You will need to fix the tests. As you can see from the failing check, the models that copy GPT-2 need to be updated with this change, so you need to run `make fix-copies`.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,695 | 1,695 |
NONE
| null |
Changed the declaration order in __ init __ so it is aligned with operational order.
As consequence, __ repr __ method is now also aligned with operational order
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes # (issue)
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25150/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25150/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25150",
"html_url": "https://github.com/huggingface/transformers/pull/25150",
"diff_url": "https://github.com/huggingface/transformers/pull/25150.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25150.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25149
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25149/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25149/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25149/events
|
https://github.com/huggingface/transformers/pull/25149
| 1,824,643,810 |
PR_kwDOCUB6oc5Wj2ph
| 25,149 |
[`IDEFICS`] Fix idefics config refactor
|
{
"login": "younesbelkada",
"id": 49240599,
"node_id": "MDQ6VXNlcjQ5MjQwNTk5",
"avatar_url": "https://avatars.githubusercontent.com/u/49240599?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/younesbelkada",
"html_url": "https://github.com/younesbelkada",
"followers_url": "https://api.github.com/users/younesbelkada/followers",
"following_url": "https://api.github.com/users/younesbelkada/following{/other_user}",
"gists_url": "https://api.github.com/users/younesbelkada/gists{/gist_id}",
"starred_url": "https://api.github.com/users/younesbelkada/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/younesbelkada/subscriptions",
"organizations_url": "https://api.github.com/users/younesbelkada/orgs",
"repos_url": "https://api.github.com/users/younesbelkada/repos",
"events_url": "https://api.github.com/users/younesbelkada/events{/privacy}",
"received_events_url": "https://api.github.com/users/younesbelkada/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
Refactors the `IdeficsConfig` to match the configuration composition patterns of multimodal models on transformers
original PR: https://github.com/huggingface/transformers/pull/24796
Summary of the changes
- Removed the copy of `CLIPTextConfig`, `CLIPConfig` in `clip.py` as they were used for type hints only
- Retrieve the correct attributes on `modeling_idefics.py` (i.e. attributes from `perceiver_config` & `vision_config`
- Adapted CI tests accordingly
- Make the `utils/check_config_attributes.py` pass - since there is a duplicated CLIPVisionConfig (1 in the clip itself and the other in `configuration_idefics.py`), that script checks the unused attributes of that config for some reason (didn't
investigated further)
For compatiblity with weights on the Hub, changes similar than: https://huggingface.co/HuggingFaceM4/tiny-random-idefics/discussions/3 needs to be applied
The docstring of the new config objects needs to be cleaned up, but can be done on the main PR.
cc @stas00
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25149/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25149/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25149",
"html_url": "https://github.com/huggingface/transformers/pull/25149",
"diff_url": "https://github.com/huggingface/transformers/pull/25149.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25149.patch",
"merged_at": 1690480445000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25148
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25148/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25148/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25148/events
|
https://github.com/huggingface/transformers/pull/25148
| 1,824,620,658 |
PR_kwDOCUB6oc5Wjxiv
| 25,148 |
Add new model in doc table of content
|
{
"login": "sgugger",
"id": 35901082,
"node_id": "MDQ6VXNlcjM1OTAxMDgy",
"avatar_url": "https://avatars.githubusercontent.com/u/35901082?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sgugger",
"html_url": "https://github.com/sgugger",
"followers_url": "https://api.github.com/users/sgugger/followers",
"following_url": "https://api.github.com/users/sgugger/following{/other_user}",
"gists_url": "https://api.github.com/users/sgugger/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sgugger/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sgugger/subscriptions",
"organizations_url": "https://api.github.com/users/sgugger/orgs",
"repos_url": "https://api.github.com/users/sgugger/repos",
"events_url": "https://api.github.com/users/sgugger/events{/privacy}",
"received_events_url": "https://api.github.com/users/sgugger/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
As requested by @stas00 , this PR makes sure that the `add-new-model-like` command adds the model in the doc table of content. Since we are using another model as a reference, we can simply add it to the same section as that base model.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25148/reactions",
"total_count": 1,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 1,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25148/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25148",
"html_url": "https://github.com/huggingface/transformers/pull/25148",
"diff_url": "https://github.com/huggingface/transformers/pull/25148.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25148.patch",
"merged_at": 1690479710000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25147
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25147/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25147/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25147/events
|
https://github.com/huggingface/transformers/issues/25147
| 1,824,577,013 |
I_kwDOCUB6oc5swNX1
| 25,147 |
Add PromptTemplate and allow for default PromptTemplate in model configuration
|
{
"login": "vincentmin",
"id": 39170736,
"node_id": "MDQ6VXNlcjM5MTcwNzM2",
"avatar_url": "https://avatars.githubusercontent.com/u/39170736?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/vincentmin",
"html_url": "https://github.com/vincentmin",
"followers_url": "https://api.github.com/users/vincentmin/followers",
"following_url": "https://api.github.com/users/vincentmin/following{/other_user}",
"gists_url": "https://api.github.com/users/vincentmin/gists{/gist_id}",
"starred_url": "https://api.github.com/users/vincentmin/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/vincentmin/subscriptions",
"organizations_url": "https://api.github.com/users/vincentmin/orgs",
"repos_url": "https://api.github.com/users/vincentmin/repos",
"events_url": "https://api.github.com/users/vincentmin/events{/privacy}",
"received_events_url": "https://api.github.com/users/vincentmin/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2648621985,
"node_id": "MDU6TGFiZWwyNjQ4NjIxOTg1",
"url": "https://api.github.com/repos/huggingface/transformers/labels/Feature%20request",
"name": "Feature request",
"color": "FBCA04",
"default": false,
"description": "Request for a new feature"
}
] |
open
| false | null |
[] |
[
"cc @ArthurZucker ",
"This is 100% needed!",
"Hey! Thanks for opening this. Not sure if you have seen this but we have the [`ConversationalPipeline` ](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.Conversation) along with the `Conversation` object, which can pretty easily handle conversations. You just need to override the `_build_conversation_input_ids` of the `tokenizer` that you are using. This allows for anyone to properly build their inputs and share the modeling code on the hub. \r\nHaving an entirely new `Auto` module just for that is an overkill, and not really the intent of `transformers`. \r\n\r\nHowever adding support for `system_prompts` in the `Conversation` object or the `ConversationalPipeline` can be done. We where not entirely sure of whether it would be highly requested or not. ",
"Hi @ArthurZucker , thanks for your reply. I was unaware of the ConversationalPipeline, so thanks for putting it on my radar. However, neither the ConversationalPipeline nor the Conversation class handle the templating that is really the core of this feature request. Perhaps illustration with some examples will be helpful:\r\n\r\nThe `Llama-2-xb-chat` models use a very specific format [of the following type](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI/blob/main/app.py):\r\n```\r\ninput_prompt = f\"[INST] <<SYS>>\\n{system_message}\\n<</SYS>>\\n\\n \"\r\nfor interaction in chatbot:\r\n input_prompt = input_prompt + str(interaction[0]) + \" [/INST] \" + str(interaction[1]) + \" </s><s> [INST] \"\r\n```\r\n\r\nInstead, `oasst1` models often use a format of [the following type](https://huggingface.co/OpenAssistant/llama2-13b-orca-8k-3319):\r\n```\r\ninput_prompt = f\"\"\"<|system|>{system_message}</s><|prompter|>{user_prompt}</s><|assistant|>\"\"\"\r\n```\r\n\r\nEven models that are not chat models can have very specific prompt templates, such as [this sql model](https://huggingface.co/juierror/text-to-sql-with-table-schema):\r\n```\r\ntable_prefix = \"table:\"\r\nquestion_prefix = \"question:\"\r\njoin_table = \",\".join(table)\r\ninput_prompt = f\"{question_prefix} {question} {table_prefix} {join_table}\"\r\n```\r\n\r\nI hope this illustrates that many models (not just chat models) on the Hugging Face hub come with an implicit specific prompt template. However, there is currently no way (that I know off) to instruct users to follow that specific prompt template, other than to describe the template on the model card. With this feature request, I am suggesting to create a more standardised way for model creators to add a prompt template to their model page.\r\n\r\nNote that [llama-2-70b-chat-hf](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) has no mention of the expected prompt template. I think it is therefore likely that a significant portion of users are currently using the model with a different prompt template and are observing reduced model performance as a consequence.\r\n\r\nIf `transformers` would provide a standardised way to add prompt templates, I believe this would create an incentive for model creators to add their prompt template. This, combined with an easy way to use said template, would make it easier for users to get the best out of models on Hugging Face Hub.\r\n\r\nFor the implementation it is probably not necessary to have an entirely new `Auto` module. I'll let the developers be the judge of how to best implement this.",
"Hi @vincentmin! We did some internal discussion and we decided this was a great idea. We're still discussing the specifics, but our current plan is to add a `prompt` field to `tokenizer_config.json`. The method that formats conversational prompts is `Tokenizer._build_conversation_input_ids()`, which is called by `ConversationPipeline`. Therefore, we think the `tokenizer_config.json` is the right place to add fields that override the behaviour of the underlying `Tokenizer`.\r\n\r\nThe specific fields in `prompt` would be class-specific, but for conversational models they would be e.g. `system_message_start`, `system_message_end`, etc. We think breaking up the prompt into string fields will work, and avoids the need to store full templates in the config files. These fields will be read by the tokenizer and used in `_build_conversation_input_ids()` to customize input prompts correctly.\r\n\r\nSince `_build_conversation_input_ids()` is currently a private method that we mostly use internally in the `Pipeline` code, we may also look at ways to expose the prompt information through other properties or methods.\r\n\r\nWDYT? The details are still flexibile, but we're planning to finalize a concrete plan soon!",
"> Hi @vincentmin! We did some internal discussion and we decided this was a great idea. We're still discussing the specifics, but our current plan is to add a `prompt` field to `tokenizer_config.json`. The method that formats conversational prompts is `Tokenizer._build_conversation_input_ids()`, which is called by `ConversationPipeline`. Therefore, we think the `tokenizer_config.json` is the right place to add fields that override the behaviour of the underlying `Tokenizer`.\r\n> \r\n> The specific fields in `prompt` would be class-specific, but for conversational models they would be e.g. `system_message_start`, `system_message_end`, etc. We think breaking up the prompt into string fields will work, and avoids the need to store full templates in the config files. These fields will be read by the tokenizer and used in `_build_conversation_input_ids()` to customize input prompts correctly.\r\n> \r\n> Since `_build_conversation_input_ids()` is currently a private method that we mostly use internally in the `Pipeline` code, we may also look at ways to expose the prompt information through other properties or methods.\r\n> \r\n> WDYT? The details are still flexibile, but we're planning to finalize a concrete plan soon!\r\n\r\n@Rocketknight1 How to use `ConversationPipeline` for llama2 chat?I want to do multi-turn chat. Could you show an example? My code example :\r\n```\r\nfrom transformers import AutoTokenizer, LlamaTokenizerFast\r\nfrom transformers import pipeline, Conversation\r\nimport torch\r\n\r\nmodel = \"/home/model_zoo/LLM/llama2/Llama-2-7b-chat-hf\"\r\n\r\ntokenizer = LlamaTokenizerFast.from_pretrained(model)\r\npipeline = pipeline(\r\n \"conversational\",\r\n model=model,\r\n tokenizer=tokenizer,\r\n torch_dtype=torch.float16,\r\n device_map=\"auto\",\r\n)\r\n\r\nconversation_1 = Conversation(\"Going to the movies tonight - any suggestions?\")\r\nconversation_2 = Conversation(\"What's the last book you have read?\")\r\n\r\nprint(pipeline([conversation_1, conversation_2]))\r\n```\r\nHowever it can not return normal response. ",
"Hi @Rocketknight1, that is great to hear!\r\n\r\nI like the proposal of adding a prompt field to tokenizer_config.json.\r\n\r\nHow do you intend to let `Tokenizer._build_conversation_input_ids()` use this prompt field? Will the current implementation of this function be modified as part of this issue, or is that left to the model creators? Since model prompting can get pretty wild, it may be hard to give a sufficiently general implementation for `Tokenizer._build_conversation_input_ids()` that works for all use cases.",
"Hi @vincentmin, you're right, it's a surprisingly tricky question! My initial idea was that `_build_conversation_input_ids()` would be defined at the class level, but would read string arguments like `system_message_start` from the tokenizer config. However, this still hard-codes the ordering of elements in the prompt, which means it might not work for some prompts. I think we'll still do something like that for now and see how much of a problem it is, and if we have to we'll look into allowing some kind of more general template system.\r\n\r\nThis will require us to modify `Tokenizer._build_conversation_input_ids()` for each model that we want to support this, but we can do it one model at a time without needing a codebase-wide refactor.",
"PR is open at #25323!",
"@MrRace It might be late for your question, but I still leave the demo here for other's reference.\r\n\r\n```\r\nimport transformers\r\nfrom transformers import AutoTokenizer, Conversation\r\nimport torch\r\n\r\nmodel_path= \"/home/model_zoo/LLM/llama2/Llama-2-7b-chat-hf\"\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(model_path)\r\n\r\nchatbot = transformers.pipeline(\r\n \"conversational\",\r\n model=model_path,\r\n torch_dtype=torch.float16,\r\n device_map=\"auto\",\r\n)\r\n\r\nconversation = Conversation(\"Going to the movies tonight - any suggestions?\")\r\nconversation = chatbot(conversation, max_length =500) # the default value of max_length is 200. You need to change it or you'll get empty response.\r\n\r\nfor msg in conversation.generated_responses[-1].split('\\n'):\r\n print(msg)\r\n\r\n### second round of consersation\r\nconversation.add_user_input(\"I am afraid of watching thriller movies and preferred watching stories related to friendship between women. Then which one should I choose?\")\r\n\r\nconversation = chatbot(conversation, max_length =500)\r\n\r\nfor msg in conversation.generated_responses[-1].split('\\n'):\r\n print(msg)\r\n```",
"@Rocketknight1 Thanks for implementing this. In many of the models we fine tune, they are not meant for chat/conversations--instead they are meant to provide a single response to a well-structured prompt. For example, we may be doing batch inference to summarize lots of articles.\r\n\r\nWhile the `chat_template` solves the chat use case, I notice in the implementation requires a list of dicts representing the chat history, so a template can't just look like this:\r\n\r\n```\r\nSummarize the following article: {{ article }}\r\n```\r\n\r\nYou could make `messages = [{\"article\": \"some text\"}]` a single element array and have the template be like this. \r\n\r\n```\r\nSummarize the following article: {{ messages[0].article }}\r\n```\r\n\r\nBasically, single generation use case would just be considered a subset of the chat use case. Is that the recommendation? Another option could be renaming to `prompt_template` to be more generic and/or making the input more flexible (not just List[Dict] | Conversation).\r\n",
"Hi @shimizust, this is a really interesting question! When I was designing the spec, I did realize that people would eventually want to use chat templates for things besides chat. As a result, the prompt format is quite flexible. In fact, I believe you should be able to pass a raw string to `apply_chat_template` and write a template to support it!\r\n\r\nMost templates have a loop like `{% for message in messages %}` that loops over a list of messages. However, even though the input is always called \"messages\", I think it would still work if you passed a string, in which case you could probably just write a template like this:\r\n\r\n```\r\n{{ \"Summarize the following article: \" + messages }}\r\n```\r\n\r\nand then just\r\n\r\n```\r\ntokenizer.apply_chat_template(article)\r\n```\r\n\r\nYour solution of using an `article` key in the message dicts would also work, and might be safer. Feel free to experiment and let me know if you encounter any difficulties - I think you're the first person we know of that's trying this for a non-chat use case, so we're definitely interested in hearing about your experience!",
"@Rocketknight1 Thanks for the response! You're right, you can do something like: `tokenizer.apply_chat_template(\"my_text\", chat_template=\"Here is my text: {{messages}}\")`.\r\n\r\nI guess my example was too simple. Usually the prompt would need to be constructed from several features. For example:\r\n```\r\nWrite an article about {{location}} from the perspective of a {{occupation}} in the year {{year}} \r\n```\r\nAnd then ideally you just pass a dictionary like this to `apply_chat_template()`:\r\n```\r\n{\r\n \"location\": \"Mars\",\r\n \"occupation\": \"farmer\",\r\n \"year\": 2100\r\n}\r\n```\r\nvs. currently, the template would need to look like the following, which is a bit unintuitive:\r\n\r\n```\r\nWrite an article about {{messages[0].location}} from the perspective of a {{messages[0].occupation}} in the year {{messages[0].year}} \r\n```\r\nand input being:\r\n```\r\n[\r\n {\r\n \"location\": \"Mars\",\r\n \"occupation\": \"farmer\",\r\n \"year\": 2100\r\n }\r\n]\r\n```",
"Hi @shimizust - although it's not officially supported, I think it would work if you pass a single `dict` to `apply_chat_template`. It would still be called 'messages' inside the template, but you could access it with `{{messages['location']}}` in the template, which might be a little cleaner.\r\n\r\nLet me know if you try it!",
"@Rocketknight1 Gotcha, yeah passing a dict directly to `apply_chat_template` works. Thank you"
] | 1,690 | 1,702 | null |
NONE
| null |
### Feature request
As a user, I want to be able to load a model and feed it my input in such a way that it matches the prompt template that it saw during training. I want to be able to load the default prompt with few lines of code and without having to look up how the model was trained. Additionally, I want to be able to modify the prompt to be different from the default prompt.
The specific implementation is up for discussion. I imagine something like this:
```
from transformers import AutoModelForCausalLM, AutoTokenizer, AutoPromptTemplate
model_id = "meta-llama/Llama-2-xb-chat-hf"
model = AutoModelForCausalLM.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
prompt_template = AutoPromptTemplate.from_pretrained(model_id)
inputs = {
"system_prompt":"You are a helpful assistant",
"interactions":[
{"user":"What is the fastest sea mammal?"},
{"assistant":"The fastest sea mammal is the peregrine falcon"},
{"user":"the peregrine falcon is not a mammal"}
]
}
output = model(**tokenizer(prompt_template(inputs)))
```
### Motivation
The huggingface hub is accumulating many finetuned models, which have been trained with a specific prompt template in mind. However, this prompt template is often difficult to find, and even more often the prompt template is missing entirely from the model card. If the model is invoked with a different template, the model performance can be severely affected. The community would benefit from a PromptTemplate class that can be loaded from the model configuration that handles the prompt templating for the end user.
At this very moment, there are likely many users that are using the `meta-llama/Llama-2-xb-chat-hf` models with a prompting style that differs from how the model is intended to be used.
### Your contribution
I am happy to be a part of the discussion for implementation and testing.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25147/reactions",
"total_count": 3,
"+1": 3,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25147/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25146
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25146/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25146/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25146/events
|
https://github.com/huggingface/transformers/pull/25146
| 1,824,575,839 |
PR_kwDOCUB6oc5Wjn_t
| 25,146 |
More `token` things
|
{
"login": "ydshieh",
"id": 2521628,
"node_id": "MDQ6VXNlcjI1MjE2Mjg=",
"avatar_url": "https://avatars.githubusercontent.com/u/2521628?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ydshieh",
"html_url": "https://github.com/ydshieh",
"followers_url": "https://api.github.com/users/ydshieh/followers",
"following_url": "https://api.github.com/users/ydshieh/following{/other_user}",
"gists_url": "https://api.github.com/users/ydshieh/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ydshieh/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ydshieh/subscriptions",
"organizations_url": "https://api.github.com/users/ydshieh/orgs",
"repos_url": "https://api.github.com/users/ydshieh/repos",
"events_url": "https://api.github.com/users/ydshieh/events{/privacy}",
"received_events_url": "https://api.github.com/users/ydshieh/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
Fix #25141
A few places are missed in #25083
(I haven't work on the training example scripts)
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25146/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25146/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25146",
"html_url": "https://github.com/huggingface/transformers/pull/25146",
"diff_url": "https://github.com/huggingface/transformers/pull/25146.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25146.patch",
"merged_at": 1690472527000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25145
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25145/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25145/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25145/events
|
https://github.com/huggingface/transformers/issues/25145
| 1,824,558,234 |
I_kwDOCUB6oc5swIya
| 25,145 |
LLAMA 2 Distributed Training Support
|
{
"login": "BiEchi",
"id": 60613238,
"node_id": "MDQ6VXNlcjYwNjEzMjM4",
"avatar_url": "https://avatars.githubusercontent.com/u/60613238?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BiEchi",
"html_url": "https://github.com/BiEchi",
"followers_url": "https://api.github.com/users/BiEchi/followers",
"following_url": "https://api.github.com/users/BiEchi/following{/other_user}",
"gists_url": "https://api.github.com/users/BiEchi/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BiEchi/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BiEchi/subscriptions",
"organizations_url": "https://api.github.com/users/BiEchi/orgs",
"repos_url": "https://api.github.com/users/BiEchi/repos",
"events_url": "https://api.github.com/users/BiEchi/events{/privacy}",
"received_events_url": "https://api.github.com/users/BiEchi/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Without a code reproducer of the error you encounter, there is little we will be able to do to help.",
"Just figured it out. So after we set `device_map=True`, we can't move the model to a specific device using `model = model.to(device)`, because the model is already dynamically allocated on all available devices.\r\nSry for bothering @sgugger, and thanks a lot for your prompt reply! I'll give detailed reproduction steps next time (it also helps me identify the bug)."
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### Feature request
LLAMA 2 support for `device_map=True`
### Motivation
The current LLAMA 2 does not include support for `device_map=True`.
```
Traceback (most recent call last):
File "/u/haob2/saliency4alce/salience_llama_ecco.py", line 38, in <module>
output = lm.generate(text, generate=3, beam_size=1, do_sample=True, attribution=['ig'])
File "/u/haob2/saliency4alce/ecco/src/ecco/lm.py", line 221, in generate
output = self.model.generate(
File "/u/haob2/miniconda3/envs/salience/lib/python3.9/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/u/haob2/.local/lib/python3.9/site-packages/transformers/generation/utils.py", line 1588, in generate
return self.sample(
File "/u/haob2/.local/lib/python3.9/site-packages/transformers/generation/utils.py", line 2642, in sample
outputs = self(
File "/u/haob2/miniconda3/envs/salience/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/u/haob2/miniconda3/envs/salience/lib/python3.9/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/u/haob2/.local/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py", line 806, in forward
outputs = self.model(
File "/u/haob2/miniconda3/envs/salience/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/u/haob2/.local/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py", line 693, in forward
layer_outputs = decoder_layer(
File "/u/haob2/miniconda3/envs/salience/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/u/haob2/miniconda3/envs/salience/lib/python3.9/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/u/haob2/.local/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py", line 405, in forward
hidden_states = self.input_layernorm(hidden_states)
File "/u/haob2/miniconda3/envs/salience/lib/python3.9/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/u/haob2/miniconda3/envs/salience/lib/python3.9/site-packages/accelerate/hooks.py", line 165, in new_forward
output = old_forward(*args, **kwargs)
File "/u/haob2/.local/lib/python3.9/site-packages/transformers/models/llama/modeling_llama.py", line 89, in forward
return self.weight * hidden_states.to(input_dtype)
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cuda:1!
```
### Your contribution
I'm looking for suggestions and possible help from distributed training.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25145/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25145/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25144
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25144/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25144/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25144/events
|
https://github.com/huggingface/transformers/issues/25144
| 1,824,539,424 |
I_kwDOCUB6oc5swEMg
| 25,144 |
Having "RuntimeError: expected scalar type Half but found Char" on LLaMa-2 inference stage
|
{
"login": "kenchanLOL",
"id": 55791584,
"node_id": "MDQ6VXNlcjU1NzkxNTg0",
"avatar_url": "https://avatars.githubusercontent.com/u/55791584?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/kenchanLOL",
"html_url": "https://github.com/kenchanLOL",
"followers_url": "https://api.github.com/users/kenchanLOL/followers",
"following_url": "https://api.github.com/users/kenchanLOL/following{/other_user}",
"gists_url": "https://api.github.com/users/kenchanLOL/gists{/gist_id}",
"starred_url": "https://api.github.com/users/kenchanLOL/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/kenchanLOL/subscriptions",
"organizations_url": "https://api.github.com/users/kenchanLOL/orgs",
"repos_url": "https://api.github.com/users/kenchanLOL/repos",
"events_url": "https://api.github.com/users/kenchanLOL/events{/privacy}",
"received_events_url": "https://api.github.com/users/kenchanLOL/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @younesbelkada ",
"Hmm I really think we should set that value (`config.pretraining_tp`) to 1 (at least when the model is quantized) for all models as it can introduce unexpected behaviour to users. We saw it introduced bugs with PEFT (that users currently overcome by forcing `config.pretraining_tp` to be equal to 1) and now with quantization.\r\nI also don't think this is the right fix as de-quantizing the layers like that on the fly can introduce a lot of rounding errors. Not sure also how this will work with nested quantization in 4bit. TLDR; I think that it will be too much of a pain for a little gain - I am pretty sure the generation quality will remain pretty much the same if `pretraining_tp` is equal to 1 (from my experience with bloom).\r\nThis will certainly create issues with the new quantization technique that is going to be added here: https://github.com/huggingface/transformers/pull/25062 and we can't patch the linear layer like that for each case (bnb 4bit, bnb 8bit, GPTQ).\r\n@sgugger @ArthurZucker what do you think about forcing `config.pretraining_tp` to be equal to 1 at least for the quantized models? ",
"It is 1 on all checkpoints online and the provided code does not change it.",
"I checked and found that my config.json is not the most updated version. \r\nThe latest version of config online is having ``` config.pretraining_tp``` as ```1``` Thanks for the reply\r\n\r\n",
"@sgugger sorry for the confusion, I thought all models still had `pretraining_tp > 1`. \r\n@kenchanLOL thanks for confirming, setting that value to 1 should fix your issue I believe! "
] | 1,690 | 1,691 | 1,691 |
NONE
| null |
### System Info
Working on jupyter notebook of a docker Linux instance of A100 , Ubuntu, x86_64

### Who can help?
@sgugger @muellerzr
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
I encounter the error while I was trying to run a 8-bit quantized LLaMA-2-70B model on two 40GB GPU of A100 .

To reproduce the issue:
1. load model with local path
```
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path, load_in_8bit = True, device_map = "auto")
```
2. run inference code
```
question = f"""
Human: xxxxxxxxxxxxx
Assistant:
"""
question = tokenizer(question, return_tensors = "pt")
question = question.to(0)
output = model.generate(question["input_ids"], max_new_tokens = 120)
```
---
# Investigations & Attempts to solve this bug
## TLDR;
**disabling tensor parallelism by setting ```pretraining_tp``` = ```1``` in config.json or your config object**
I notice that the error was raised from the part which is recently update for supporting llama-2 and to be specific, it's the implementation of the Grouped-Query Attention (GQA) architecture.

Further looking into the code, i think the bug is caused by missing a dtype handling part for the new Grouped-Query Attention (GQA) architecture while F.linear is being used instead of a forward call. It is because by setting the ```load_in_8bit``` arguement as True, the ```nn.Linear``` layer will be replaced by a equivalent ```bnb.nn.Linear8bitLt```. The dtype of hidden_states and query_slices[i] are float16 and int64 respectively. Usually, the forward function of Linear8bitLt will handle. However, it doesn't work the same way in the F.linear and thus it raises this error as two tensor have different dtypes.
Apart from disabling tensor parallelism by setting pretraining_tp = 1 in model config while loading model(os it will use the llama-1 part), I made a small workaround to prove my hypothesis by aligning the dtype of hidden_states and query_slices[i], I try to manually dequantize the Linear8bitLt by adding a small code snippet like this
```
key_value_slicing = (self.num_key_value_heads * self.head_dim) // self.pretraining_tp
if isinstance(self.q_proj, bnb.nn.Linear8bitLt):
q_w = self.q_proj.weight
q_w = (q_w.CB * q_w.SCB.unsqueeze(1) / 127 ).to(torch.float16)
query_slices= q_w.split((self.num_heads*self.head_dim)//self.pretraining tp, dim = 0)
if isinstance(self. k_proj, bnb.nn.Linear8bitLt):
k_w = self.k_proj.weight
k_w = (k_w.CB * k_w.SCB.unsqueeze(1) / 127 ).to(torch.float16)
key_slices = k_w.split(key_value_slicing, dim = 0)
if isinstance(self. v_proj, bnb.nn.Linear8bitLt):
v_w = self.v_proj.weight
v_w = (v_w.CB * v_w.SCB.unsqueeze(1) / 127 ).to(torch.float16)
value_slices = v_w.split(key_value_slicing, dim = 0)
#query_sLices = sett,q pro].weightTsplit((self.num heads * self.head dim) // selT.pretrainlng tp, dim=G)
#key_slices = self.K proj.weight.split(key value slicing, dim=0) ~
#value_slices = seirTv pro].weight.split(key value slicing, dim=0)
```
similar code have to be added in:
- line 202 (LLamaMLP forward function -> gate_proj, up_porj, down_proj
- line 293 (LlamaAttention forward function -> q_proj, k_proj, v_proj)
- line 364 (LlamaAttention forward function -> o_proj)
After using this workaround , I was able to run the model and get result as expected. However, the quality of generated text deteriorate significantly while the length of text increase.
### Expected behavior
Generate a completion that answer the human input
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25144/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25144/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25143
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25143/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25143/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25143/events
|
https://github.com/huggingface/transformers/issues/25143
| 1,824,468,791 |
I_kwDOCUB6oc5svy83
| 25,143 |
run_generation.py script does not work for most models
|
{
"login": "bortzmeyer",
"id": 103188,
"node_id": "MDQ6VXNlcjEwMzE4OA==",
"avatar_url": "https://avatars.githubusercontent.com/u/103188?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/bortzmeyer",
"html_url": "https://github.com/bortzmeyer",
"followers_url": "https://api.github.com/users/bortzmeyer/followers",
"following_url": "https://api.github.com/users/bortzmeyer/following{/other_user}",
"gists_url": "https://api.github.com/users/bortzmeyer/gists{/gist_id}",
"starred_url": "https://api.github.com/users/bortzmeyer/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/bortzmeyer/subscriptions",
"organizations_url": "https://api.github.com/users/bortzmeyer/orgs",
"repos_url": "https://api.github.com/users/bortzmeyer/repos",
"events_url": "https://api.github.com/users/bortzmeyer/events{/privacy}",
"received_events_url": "https://api.github.com/users/bortzmeyer/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"I'm not sure why you expect this command to work: you are passing `--model_name_or_path=xlnet` which is not a valid model identifier on the Hub (as the error clearly says). You need to pick an actual model, all xlnet variants are listed [here](https://huggingface.co/models?sort=trending&search=xlnet).",
"> I'm not sure why you expect this command to work: \r\n\r\nBecause this is the output of the `--help` option? OK, with a full name, it works better, thanks. \r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
### System Info
- `transformers` version: 4.32.0.dev0
- Platform: Linux-6.1.0-10-amd64-x86_64-with-glibc2.36
- Python version: 3.11.2
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu117 (False)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help?
@sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [X] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
% python run_generation.py --model_type=xlnet --model_name_or_path=xlnet
07/27/2023 16:10:16 - WARNING - __main__ - device: cpu, n_gpu: 0, 16-bits training: False
Traceback (most recent call last):
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/huggingface_hub/utils/_errors.py", line 261, in hf_raise_for_status
response.raise_for_status()
File "/usr/lib/python3/dist-packages/requests/models.py", line 1021, in raise_for_status
raise HTTPError(http_error_msg, response=self)
requests.exceptions.HTTPError: 404 Client Error: Not Found for url: https://huggingface.co/xlnet/resolve/main/spiece.model
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/transformers/utils/hub.py", line 418, in cached_file
resolved_file = hf_hub_download(
^^^^^^^^^^^^^^^^
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/huggingface_hub/utils/_validators.py", line 118, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1195, in hf_hub_download
metadata = get_hf_file_metadata(
^^^^^^^^^^^^^^^^^^^^^
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/huggingface_hub/utils/_validators.py", line 118, in _inner_fn
return fn(*args, **kwargs)
^^^^^^^^^^^^^^^^^^^
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/huggingface_hub/file_download.py", line 1541, in get_hf_file_metadata
hf_raise_for_status(r)
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/huggingface_hub/utils/_errors.py", line 293, in hf_raise_for_status
raise RepositoryNotFoundError(message, response) from e
huggingface_hub.utils._errors.RepositoryNotFoundError: 404 Client Error. (Request ID: Root=1-64c27ac9-32554ee53bfea1b506174ea7;b2323fa4-9a04-4657-a548-5ceed2fb666e)
Repository Not Found for url: https://huggingface.co/xlnet/resolve/main/spiece.model.
Please make sure you specified the correct `repo_id` and `repo_type`.
If you are trying to access a private or gated repo, make sure you are authenticated.
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/bortzmeyer/Programmation/Python/HuggingFace/essais/run_generation.py", line 448, in <module>
main()
File "/home/bortzmeyer/Programmation/Python/HuggingFace/essais/run_generation.py", line 354, in main
tokenizer = tokenizer_class.from_pretrained(args.model_name_or_path)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/transformers/tokenization_utils_base.py", line 1800, in from_pretrained
resolved_vocab_files[file_id] = cached_file(
^^^^^^^^^^^^
File "/home/bortzmeyer/.local/lib/python3.11/site-packages/transformers/utils/hub.py", line 439, in cached_file
raise EnvironmentError(
OSError: xlnet is not a local folder and is not a valid model identifier listed on 'https://huggingface.co/models'
If this is a private repository, make sure to pass a token having permission to this repo either by logging in with `huggingface-cli login` or by passing `token=<your_token>`
```
We have a similar error message with most models listed in the output of `python run_generation.py --help` Only gpt2 and ctrl seems to work.
### Expected behavior
I expected all models listed in the help to actually work.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25143/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25143/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25142
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25142/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25142/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25142/events
|
https://github.com/huggingface/transformers/issues/25142
| 1,824,441,731 |
I_kwDOCUB6oc5svsWD
| 25,142 |
Using Trainer with custom model caused dimension error
|
{
"login": "zhangyilun",
"id": 8699465,
"node_id": "MDQ6VXNlcjg2OTk0NjU=",
"avatar_url": "https://avatars.githubusercontent.com/u/8699465?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/zhangyilun",
"html_url": "https://github.com/zhangyilun",
"followers_url": "https://api.github.com/users/zhangyilun/followers",
"following_url": "https://api.github.com/users/zhangyilun/following{/other_user}",
"gists_url": "https://api.github.com/users/zhangyilun/gists{/gist_id}",
"starred_url": "https://api.github.com/users/zhangyilun/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/zhangyilun/subscriptions",
"organizations_url": "https://api.github.com/users/zhangyilun/orgs",
"repos_url": "https://api.github.com/users/zhangyilun/repos",
"events_url": "https://api.github.com/users/zhangyilun/events{/privacy}",
"received_events_url": "https://api.github.com/users/zhangyilun/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc our trainer master @sgugger , but I think the best is to follow the standard output format (i.e. either tuple or dict)",
"This is communicated clearly on the [Trainer doc page](https://huggingface.co/docs/transformers/main_classes/trainer), scroll a bit to the big warning.",
"Thank you for pointing me to the doc!"
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### System Info
```
- `transformers` version: 4.31.0
- Platform: Windows-10-10.0.19045-SP0
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1+cu118 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
```
Not sure if it's the intended way of using the Trainer clas, but what I did was:
- Created a custom image+text classifier where the image encoder and text encoders are huggingface models (i.e., Bert, ViT) and I extracted the last hidden state from each embedding, concatenated them, and added a linear layer for binary classification.
- I modified the `compute_loss` function by subclassing the Trainer class but didn't do anything else.
The issue was, since the model class only outputs logits but nothing else (not dict, not tuple), this part of the code: https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L3344-L3347 where since the output from model forward isn't a dict, it assumed it's a tuple, and trimmed the first sample's logits in the batch causing dimension error when computing the loss since labels and logits dimensions don't match (off by # of batches).
This is probably solvable by modifying the model class to return what the trainer is expecting, but it's not communicated clearly either, maybe it's because the Trainer isn't fully suitable for custom model training?
I have created a commit in my branch to fix this on my side so that the training can continue: https://github.com/huggingface/transformers/compare/main...zhangyilun:transformers:allow-logits-only-outputs. Not sure if it's worth merging into the repo. I think the change shouldn't break anything else.
If you think I'm doing things wrong or I missed anything, please correct me!
### Who can help?
_No response_
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Create a custom binary classification model where the forward method only returns the logits.
Use the Trainer class for training.
### Expected behavior
Dimension mismatch in compute_loss method.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25142/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25142/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25141
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25141/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25141/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25141/events
|
https://github.com/huggingface/transformers/issues/25141
| 1,824,416,847 |
I_kwDOCUB6oc5svmRP
| 25,141 |
use_auth_token deprecation in pipeline
|
{
"login": "maxjeblick",
"id": 24281881,
"node_id": "MDQ6VXNlcjI0MjgxODgx",
"avatar_url": "https://avatars.githubusercontent.com/u/24281881?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/maxjeblick",
"html_url": "https://github.com/maxjeblick",
"followers_url": "https://api.github.com/users/maxjeblick/followers",
"following_url": "https://api.github.com/users/maxjeblick/following{/other_user}",
"gists_url": "https://api.github.com/users/maxjeblick/gists{/gist_id}",
"starred_url": "https://api.github.com/users/maxjeblick/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/maxjeblick/subscriptions",
"organizations_url": "https://api.github.com/users/maxjeblick/orgs",
"repos_url": "https://api.github.com/users/maxjeblick/repos",
"events_url": "https://api.github.com/users/maxjeblick/events{/privacy}",
"received_events_url": "https://api.github.com/users/maxjeblick/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Thanks for the report!\r\ncc @ydshieh Looks like it comes from the PR from yesterday.",
"Thanks for reporting, I will work on this. Not very easy to hanlde this history it turns out 👀 ",
"Hi @maxjeblick \r\n\r\nCould you share the full error log. So far I don't get error when using `token=True`.\r\n(For `generate_text = pipeline(...)` part)",
"Sure @ydshieh :\r\n```\r\nfrom transformers import pipeline\r\n\r\nmodel_name = \"facebook/opt-125m\" # small model for testing purposes\r\n\r\ngenerate_text = pipeline(\r\n model=model_name,\r\n torch_dtype=\"auto\",\r\n trust_remote_code=True,\r\n use_fast=True,\r\n device_map={\"\": \"cuda:0\"},\r\n token=True)\r\n\r\nres = generate_text(\r\n \"Why is drinking water so healthy?\",\r\n min_new_tokens=2,\r\n max_new_tokens=256,\r\n do_sample=False,\r\n num_beams=1,\r\n temperature=float(0.3),\r\n repetition_penalty=float(1.2),\r\n renormalize_logits=True\r\n)\r\nprint(res[0][\"generated_text\"])\r\n```\r\nget's\r\n\r\n```\r\nXformers is not installed correctly. If you want to use memory_efficient_attention to accelerate training use the following command to install Xformers\r\npip install xformers.\r\nTraceback (most recent call last):\r\n File \"/home/max/.config/JetBrains/PyCharm2023.2/scratches/scratch_2.py\", line 13, in <module>\r\n res = generate_text(\r\n File \"/home/max/.virtualenvs/h2o-llmstudio-0x1AIe7C/lib/python3.10/site-packages/transformers/pipelines/text_generation.py\", line 200, in __call__\r\n return super().__call__(text_inputs, **kwargs)\r\n File \"/home/max/.virtualenvs/h2o-llmstudio-0x1AIe7C/lib/python3.10/site-packages/transformers/pipelines/base.py\", line 1122, in __call__\r\n return self.run_single(inputs, preprocess_params, forward_params, postprocess_params)\r\n File \"/home/max/.virtualenvs/h2o-llmstudio-0x1AIe7C/lib/python3.10/site-packages/transformers/pipelines/base.py\", line 1129, in run_single\r\n model_outputs = self.forward(model_inputs, **forward_params)\r\n File \"/home/max/.virtualenvs/h2o-llmstudio-0x1AIe7C/lib/python3.10/site-packages/transformers/pipelines/base.py\", line 1028, in forward\r\n model_outputs = self._forward(model_inputs, **forward_params)\r\n File \"/home/max/.virtualenvs/h2o-llmstudio-0x1AIe7C/lib/python3.10/site-packages/transformers/pipelines/text_generation.py\", line 261, in _forward\r\n generated_sequence = self.model.generate(input_ids=input_ids, attention_mask=attention_mask, **generate_kwargs)\r\n File \"/home/max/.virtualenvs/h2o-llmstudio-0x1AIe7C/lib/python3.10/site-packages/torch/utils/_contextlib.py\", line 115, in decorate_context\r\n return func(*args, **kwargs)\r\n File \"/home/max/.virtualenvs/h2o-llmstudio-0x1AIe7C/lib/python3.10/site-packages/transformers/generation/utils.py\", line 1282, in generate\r\n self._validate_model_kwargs(model_kwargs.copy())\r\n File \"/home/max/.virtualenvs/h2o-llmstudio-0x1AIe7C/lib/python3.10/site-packages/transformers/generation/utils.py\", line 1155, in _validate_model_kwargs\r\n raise ValueError(\r\nValueError: The following `model_kwargs` are not used by the model: ['token'] (note: typos in the generate arguments will also show up in this list)\r\n```\r\n",
"Thanks! So the error only happens at the generation time, very strange it has been passed to that method! Definitely need a fix. I am on it."
] | 1,690 | 1,690 | 1,690 |
NONE
| null |
### System Info
I noticed that `pipeline` uses `use_auth_token` argument which raises `FutureWarning: The use_auth_token argument is deprecated and will be removed in v5 of Transformers.`.
Replacing `use_auth_token=True` with `token=True` argument does not yet work in `pipeline` (will raise an error).
Sys Info
```
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-78-generic-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.14.1
- Safetensors version: 0.3.1
- Accelerate version: 0.20.3
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.0+cu117 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: Yes
- Using distributed or parallel set-up in script?: No
```
### Who can help?
@narsil
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
import torch
from transformers import pipeline
model_name = "h2oai/h2ogpt-gm-oasst1-en-2048-falcon-7b-v3"
generate_text = pipeline(
model=model_name,
torch_dtype="auto",
trust_remote_code=True,
use_fast=True,
device_map={"": "cuda:0"},
use_auth_token=True)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
### Expected behavior
pipeline handles `token=True` argument.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25141/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25141/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25140
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25140/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25140/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25140/events
|
https://github.com/huggingface/transformers/pull/25140
| 1,824,314,789 |
PR_kwDOCUB6oc5WiwL-
| 25,140 |
add docs TypicalLogitsWarper
|
{
"login": "akshayamadhuri",
"id": 76612327,
"node_id": "MDQ6VXNlcjc2NjEyMzI3",
"avatar_url": "https://avatars.githubusercontent.com/u/76612327?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/akshayamadhuri",
"html_url": "https://github.com/akshayamadhuri",
"followers_url": "https://api.github.com/users/akshayamadhuri/followers",
"following_url": "https://api.github.com/users/akshayamadhuri/following{/other_user}",
"gists_url": "https://api.github.com/users/akshayamadhuri/gists{/gist_id}",
"starred_url": "https://api.github.com/users/akshayamadhuri/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/akshayamadhuri/subscriptions",
"organizations_url": "https://api.github.com/users/akshayamadhuri/orgs",
"repos_url": "https://api.github.com/users/akshayamadhuri/repos",
"events_url": "https://api.github.com/users/akshayamadhuri/events{/privacy}",
"received_events_url": "https://api.github.com/users/akshayamadhuri/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@gante let me know the changes",
"You also need to run `make fixup` before your next commit, so that our CI becomes happy :D ",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25140). All of your documentation changes will be reflected on that endpoint.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
# What does this PR do?
Added some doc string to TypicalLogitsWarper with some examples as well.
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Related to #24783
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
Anyone in the community is free to review the PR once the tests have passed. Feel free to tag
members/contributors who may be interested in your PR.
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25140/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25140/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25140",
"html_url": "https://github.com/huggingface/transformers/pull/25140",
"diff_url": "https://github.com/huggingface/transformers/pull/25140.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25140.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25139
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25139/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25139/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25139/events
|
https://github.com/huggingface/transformers/issues/25139
| 1,824,272,525 |
I_kwDOCUB6oc5svDCN
| 25,139 |
Seq2SeqTrainer.prediction_step does not support model.generation_config.max_length to be null
|
{
"login": "antonioalegria",
"id": 49322,
"node_id": "MDQ6VXNlcjQ5MzIy",
"avatar_url": "https://avatars.githubusercontent.com/u/49322?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/antonioalegria",
"html_url": "https://github.com/antonioalegria",
"followers_url": "https://api.github.com/users/antonioalegria/followers",
"following_url": "https://api.github.com/users/antonioalegria/following{/other_user}",
"gists_url": "https://api.github.com/users/antonioalegria/gists{/gist_id}",
"starred_url": "https://api.github.com/users/antonioalegria/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/antonioalegria/subscriptions",
"organizations_url": "https://api.github.com/users/antonioalegria/orgs",
"repos_url": "https://api.github.com/users/antonioalegria/repos",
"events_url": "https://api.github.com/users/antonioalegria/events{/privacy}",
"received_events_url": "https://api.github.com/users/antonioalegria/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"cc @gante ",
"Hi @antonioalegria -- your issue and suggested fix makes complete sense 👍 Would you like to open a PR with the fix?",
"Sure, I'll do it! Thanks!",
"I'd like to note here that when setting `predict_with_generate=True` whenever loop gets to evaluation phase it starts spitting out a ton of warnings that both `max_length` and `max_new_tokens` have been set (defaulting to `max_new_tokens` then) but as OP said cannot set `max_length=None` (neither can it be deleted).",
"@kito323 thank you for raising it, there was a recent change in that warning and the logic to trigger it was incorrect in some cases. Fixing it today :)\r\n\r\nEDIT: https://github.com/huggingface/transformers/pull/25539",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,695 | 1,695 |
NONE
| null |
### System Info
Although it is recommended to use max_new_tokens instead of max_length, if we set max_length to None, in the model's generation config, then in the following lines, we will get a "TypeError: '<' not supported between instances of 'int' and 'NoneType'"
In transformers/trainer_seq2seq.py:290-296
```python
# Retrieves GenerationConfig from model.generation_config
gen_config = self.model.generation_config
# in case the batch is shorter than max length, the output should be padded
if generated_tokens.shape[-1] < gen_config.max_length:
generated_tokens = self._pad_tensors_to_max_len(generated_tokens, gen_config.max_length)
elif gen_config.max_new_tokens is not None and generated_tokens.shape[-1] < gen_config.max_new_tokens + 1:
generated_tokens = self._pad_tensors_to_max_len(generated_tokens, gen_config.max_new_tokens + 1)
```
Should be
```python
# Retrieves GenerationConfig from model.generation_config
gen_config = self.model.generation_config
# in case the batch is shorter than max length, the output should be padded
if gen_config.max_length is not None and generated_tokens.shape[-1] < gen_config.max_length:
generated_tokens = self._pad_tensors_to_max_len(generated_tokens, gen_config.max_length)
elif gen_config.max_new_tokens is not None and generated_tokens.shape[-1] < gen_config.max_new_tokens + 1:
generated_tokens = self._pad_tensors_to_max_len(generated_tokens, gen_config.max_new_tokens + 1)
```
## Versions
- transformers: 4.31.0
- python: 2.11.3
- platform: macOS 13.4.1
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Set the model's generation config to have max_length as None, to ensure it is consistent with the recommendations of max_length being None and max_new_tokens to be used.
2. Set `predict_with_generate` to True
3. Call trainer.train(eval_dataset=val)
4. See it blow up
```
trainer.train(train, eval_dataset=val)
File "/Users/antonioalegria/Developer/hyperml/scripts/../hyperml/trainer.py", line 927, in train
return self.hf_trainer.train()
^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers/trainer.py", line 1539, in train
return inner_training_loop(
^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/accelerate/utils/memory.py", line 136, in decorator
return function(batch_size, *args, **kwargs)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers/trainer.py", line 1916, in _inner_training_loop
self._maybe_log_save_evaluate(tr_loss, model, trial, epoch, ignore_keys_for_eval)
File "/opt/homebrew/lib/python3.11/site-packages/transformers/trainer.py", line 2226, in _maybe_log_save_evaluate
metrics = self.evaluate(ignore_keys=ignore_keys_for_eval)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers/trainer_seq2seq.py", line 159, in evaluate
return super().evaluate(eval_dataset, ignore_keys=ignore_keys, metric_key_prefix=metric_key_prefix)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers/trainer.py", line 2934, in evaluate
output = eval_loop(
^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers/trainer.py", line 3123, in evaluation_loop
loss, logits, labels = self.prediction_step(model, inputs, prediction_loss_only, ignore_keys=ignore_keys)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/homebrew/lib/python3.11/site-packages/transformers/trainer_seq2seq.py", line 293, in prediction_step
if generated_tokens.shape[-1] < gen_config.max_length:
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
TypeError: '<' not supported between instances of 'int' and 'NoneType'
```
### Expected behavior
It should check for None, like in the issue description is exemplified.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25139/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25139/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25138
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25138/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25138/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25138/events
|
https://github.com/huggingface/transformers/issues/25138
| 1,824,118,516 |
I_kwDOCUB6oc5sudb0
| 25,138 |
How to return detected language using whisper with asr pipeline?
|
{
"login": "arso1er",
"id": 29825179,
"node_id": "MDQ6VXNlcjI5ODI1MTc5",
"avatar_url": "https://avatars.githubusercontent.com/u/29825179?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/arso1er",
"html_url": "https://github.com/arso1er",
"followers_url": "https://api.github.com/users/arso1er/followers",
"following_url": "https://api.github.com/users/arso1er/following{/other_user}",
"gists_url": "https://api.github.com/users/arso1er/gists{/gist_id}",
"starred_url": "https://api.github.com/users/arso1er/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/arso1er/subscriptions",
"organizations_url": "https://api.github.com/users/arso1er/orgs",
"repos_url": "https://api.github.com/users/arso1er/repos",
"events_url": "https://api.github.com/users/arso1er/events{/privacy}",
"received_events_url": "https://api.github.com/users/arso1er/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Probably the easiest here is to use the `processor` + `model` API:\r\n```python\r\nfrom transformers import WhisperProcessor, WhisperForConditionalGeneration\r\nfrom datasets import load_dataset\r\n\r\nmodel = WhisperForConditionalGeneration.from_pretrained(\"openai/whisper-tiny\")\r\nprocessor = WhisperProcessor.from_pretrained(\"openai/whisper-tiny\")\r\n\r\nlibrispeech_dummy = load_dataset(\"hf-internal-testing/librispeech_asr_dummy\", \"clean\", split=\"validation\")\r\nsample = librispeech_dummy[0][\"audio\"]\r\n\r\ninput_features = processor(sample[\"array\"], sampling_rate=sample[\"sampling_rate\"], return_tensors=\"pt\").input_features\r\n\r\npred_tokens = model.generate(input_features, max_new_tokens=448)\r\npred_text = processor.batch_decode(pred_tokens, skip_special_tokens=True)\r\npred_language = processor.batch_decode(pred_tokens[:, 1:2], skip_special_tokens=False)\r\n\r\nprint(pred_text)\r\nprint(pred_language)\r\n```\r\n**Print Output:**\r\n```\r\n[' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.']\r\n['<|en|>']\r\n```\r\n\r\nThe pipeline discards the 'special' task/language tokens from the predictions when merging chunks, so we loose this information.\r\n",
"OK. I will try that.\r\nThank you.",
"Hi, there is an easy way now to get the language detected by the pipeline. According to this [PR](https://github.com/huggingface/transformers/issues/21311) you can add the parameter `return_language=True` to the pipe and you can get the language of the text.",
"@matallanas Wow that's what I call timing; you posted this 4h before I was looking for that answer, on a 4 months old thread I came across first in my search results 😄 ",
"Great addition! Is there a simple way to get the probability of the detected language as well? It is quite easy using the original model but I haven't found a way to make it work with the huggingface implementation.",
"The `pipeline` is designed to be a high-level wrapper that goes from audio inputs -> text outputs. Anytime we want something more granular than that, it's best to use the `model` + `processor` API:\r\n```python\r\nfrom transformers import WhisperProcessor, WhisperForConditionalGeneration\r\nfrom datasets import load_dataset\r\nimport torch\r\n\r\nmodel = WhisperForConditionalGeneration.from_pretrained(\"openai/whisper-tiny\")\r\nprocessor = WhisperProcessor.from_pretrained(\"openai/whisper-tiny\")\r\n\r\nlibrispeech_dummy = load_dataset(\"hf-internal-testing/librispeech_asr_dummy\", \"clean\", split=\"validation\")\r\nsample = librispeech_dummy[0][\"audio\"]\r\n\r\ninput_features = processor(sample[\"array\"], sampling_rate=sample[\"sampling_rate\"], return_tensors=\"pt\").input_features\r\n\r\noutputs = model.generate(\r\n input_features, output_scores=True, return_dict_in_generate=True, max_new_tokens=128\r\n)\r\n\r\ntransition_scores = model.compute_transition_scores(\r\n outputs.sequences, outputs.scores, normalize_logits=True\r\n)\r\n\r\npred_text = processor.batch_decode(outputs.sequences, skip_special_tokens=True)\r\npred_language = processor.batch_decode(outputs.sequences[:, 1:2], skip_special_tokens=False)\r\nlang_prob = torch.exp(transition_scores[:, 0])\r\n\r\nprint(pred_text)\r\nprint(pred_language)\r\nprint(lang_prob)\r\n```\r\n**Print Output:**\r\n```\r\n[' Mr. Quilter is the apostle of the middle classes and we are glad to welcome his gospel.']\r\n['<|en|>']\r\ntensor([1.])\r\n```",
"> Hi, there is an easy way now to get the language detected by the pipeline. According to this [PR](https://github.com/huggingface/transformers/issues/21311) you can add the parameter `return_language=True` to the pipe and you can get the language of the text.\r\n\r\nwould you be kind to show the example code? I have tried following code abut it fails to return detected language type\r\n\r\n` \r\n device = \"cuda:0\" if torch.cuda.is_available() else \"cpu\"\r\n torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32\r\n\r\n model_id = \"openai/whisper-large-v3\"\r\n\r\n model = AutoModelForSpeechSeq2Seq.from_pretrained(\r\n model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True\r\n )\r\n model.to(device)\r\n\r\n processor = AutoProcessor.from_pretrained(model_id)\r\n\r\n pipe = pipeline(\r\n \"automatic-speech-recognition\",\r\n model=model,\r\n tokenizer=processor.tokenizer,\r\n feature_extractor=processor.feature_extractor,\r\n max_new_tokens=128,\r\n chunk_length_s=30,\r\n batch_size=16,\r\n return_timestamps=True,\r\n torch_dtype=torch_dtype,\r\n device=device,\r\n return_language=True\r\n )\r\n\r\n result = pipe(sample, return_timestamps=\"word\", generate_kwargs={\"task\": \"transcribe\"}, return_language=True)`",
"Is there any way we can get no_speech_probability with pipeline? ",
"> > Hi, there is an easy way now to get the language detected by the pipeline. According to this [PR](https://github.com/huggingface/transformers/issues/21311) you can add the parameter `return_language=True` to the pipe and you can get the language of the text.\r\n> \r\n> would you be kind to show the example code? I have tried following code abut it fails to return detected language type\r\n> \r\n> ` device = \"cuda:0\" if torch.cuda.is_available() else \"cpu\" torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32\r\n> \r\n> ```\r\n> model_id = \"openai/whisper-large-v3\"\r\n> \r\n> model = AutoModelForSpeechSeq2Seq.from_pretrained(\r\n> model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True\r\n> )\r\n> model.to(device)\r\n> \r\n> processor = AutoProcessor.from_pretrained(model_id)\r\n> \r\n> pipe = pipeline(\r\n> \"automatic-speech-recognition\",\r\n> model=model,\r\n> tokenizer=processor.tokenizer,\r\n> feature_extractor=processor.feature_extractor,\r\n> max_new_tokens=128,\r\n> chunk_length_s=30,\r\n> batch_size=16,\r\n> return_timestamps=True,\r\n> torch_dtype=torch_dtype,\r\n> device=device,\r\n> return_language=True\r\n> )\r\n> \r\n> result = pipe(sample, return_timestamps=\"word\", generate_kwargs={\"task\": \"transcribe\"}, return_language=True)`\r\n> ```\r\n\r\nFor this case you only need to put return language in the declaration of the pipe. Based on your code this should be like:\r\n```python\r\nmodel_id = \"openai/whisper-large-v3\"\r\n\r\nmodel = AutoModelForSpeechSeq2Seq.from_pretrained(\r\n model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True\r\n)\r\nmodel.to(device)\r\n\r\nprocessor = AutoProcessor.from_pretrained(model_id)\r\n\r\npipe = pipeline(\r\n \"automatic-speech-recognition\",\r\n model=model,\r\n tokenizer=processor.tokenizer,\r\n feature_extractor=processor.feature_extractor,\r\n max_new_tokens=128,\r\n chunk_length_s=30,\r\n batch_size=16,\r\n torch_dtype=torch_dtype,\r\n device=device,\r\n return_language=True\r\n)\r\n\r\nresult = pipe(sample, return_timestamps=\"word\", generate_kwargs={\"task\": \"transcribe\"})\r\n```\r\nThis is how I declare it to obtain de language. I hope this help you."
] | 1,690 | 1,707 | 1,690 |
NONE
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-5.15.0-67-generic-x86_64-with-glibc2.31
- Python version: 3.10.12
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: not installed
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (False)
- Tensorflow version (GPU?): 2.11.0 (False)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: No
- Using distributed or parallel set-up in script?: No
### Who can help?
@sanchit-gandhi, @Narsil
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Hello,
I'm trying to use asr pipeline with whisper, in other to detect an audio language and transcribe it. I get the transcribed audio successfully, but I have not found a way to return the detected language too.
I search the GitHub issues, and it seems this was added by [#21427](https://github.com/huggingface/transformers/pull/21427), but I don't know how to return the detected language. Here is my code:
```
from transformers import pipeline
import torch
speech_file = "input.mp3"
device = "cuda:0" if torch.cuda.is_available() else "cpu"
whisper = pipeline("automatic-speech-recognition", max_new_tokens=448, model="openai/whisper-small", device=device)
whisper_result = whisper(speech_file)
print(whisper_result)
```
### Expected behavior
Be able to return detected language.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25138/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25138/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25137
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25137/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25137/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25137/events
|
https://github.com/huggingface/transformers/issues/25137
| 1,824,102,025 |
I_kwDOCUB6oc5suZaJ
| 25,137 |
Incorrect backward pass in the four bits LLaMA 2 70B
|
{
"login": "noamwies",
"id": 3121971,
"node_id": "MDQ6VXNlcjMxMjE5NzE=",
"avatar_url": "https://avatars.githubusercontent.com/u/3121971?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/noamwies",
"html_url": "https://github.com/noamwies",
"followers_url": "https://api.github.com/users/noamwies/followers",
"following_url": "https://api.github.com/users/noamwies/following{/other_user}",
"gists_url": "https://api.github.com/users/noamwies/gists{/gist_id}",
"starred_url": "https://api.github.com/users/noamwies/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/noamwies/subscriptions",
"organizations_url": "https://api.github.com/users/noamwies/orgs",
"repos_url": "https://api.github.com/users/noamwies/repos",
"events_url": "https://api.github.com/users/noamwies/events{/privacy}",
"received_events_url": "https://api.github.com/users/noamwies/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @noamwies \r\nFor fine-tuning llama2 models that have `config.pretraining_tp>1` consider calling\r\n\r\n```python\r\nmodel.config.pretraining_tp = 1\r\n```\r\n\r\nBefore training, make sure to use the main branch of `transformers` to include: https://github.com/huggingface/transformers/pull/24906 \r\n\r\n```bash\r\npip uninstall transformers\r\npip install git+https://github.com/huggingface/transformers\r\n```",
"This is a duplicate of #24961, as well https://github.com/facebookresearch/llama/issues/423 , and https://github.com/TimDettmers/bitsandbytes/issues/610. This is not something that will be fixed in `transformers` and not sure you need to fix it, since the pretraining tp should stay at 1 for most use cases"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
### System Info
This issue needs to be treated as a code review comment.
### Who can help?
@TimDettmers @ArthurZucker @younesbelkada
It seems that when `config.pretraining_tp` is greater than one, then the projections of the keys, queries, and values in the `LlamaAttention` implemented using `torch.nn.functional.linear`. Hence, in such cases the implementation bypasses `torch.nn.Linear.forward ` which if i understand correctly is problematic when the underlined linear module is replaced by `bitsandbytes`.
### Information
- [ ] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
This issue needs to be treated as a code review comment. So, I didn't implement a concrete code for demonstrating the problem.
### Expected behavior
A seamless integration with `bitsandbytes`.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25137/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25137/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25136
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25136/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25136/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25136/events
|
https://github.com/huggingface/transformers/pull/25136
| 1,824,063,174 |
PR_kwDOCUB6oc5Wh5Tv
| 25,136 |
fix delete all checkpoints when save_total_limit is set to 1
|
{
"login": "Pbihao",
"id": 22709028,
"node_id": "MDQ6VXNlcjIyNzA5MDI4",
"avatar_url": "https://avatars.githubusercontent.com/u/22709028?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Pbihao",
"html_url": "https://github.com/Pbihao",
"followers_url": "https://api.github.com/users/Pbihao/followers",
"following_url": "https://api.github.com/users/Pbihao/following{/other_user}",
"gists_url": "https://api.github.com/users/Pbihao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Pbihao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Pbihao/subscriptions",
"organizations_url": "https://api.github.com/users/Pbihao/orgs",
"repos_url": "https://api.github.com/users/Pbihao/repos",
"events_url": "https://api.github.com/users/Pbihao/events{/privacy}",
"received_events_url": "https://api.github.com/users/Pbihao/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25136). All of your documentation changes will be reflected on that endpoint."
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
<!--
Congratulations! You've made it this far! You're not quite done yet though.
Once merged, your PR is going to appear in the release notes with the title you set, so make sure it's a great title that fully reflects the extent of your awesome contribution.
Then, please replace this with a description of the change and which issue is fixed (if applicable). Please also include relevant motivation and context. List any dependencies (if any) that are required for this change.
Once you're done, someone will review your PR shortly (see the section "Who can review?" below to tag some potential reviewers). They may suggest changes to make the code even better. If no one reviewed your PR after a week has passed, don't hesitate to post a new comment @-mentioning the same persons---sometimes notifications get lost.
-->
<!-- Remove if not applicable -->
Fixes #25129 (issue)
Fix the bug that all checkpoints are deleted when set `save_total_limit ` in `TrainingArguments ` as 1.
More details can refer to #25129 .
## Who can review?
@ydshieh @sgugger
<!-- Your PR will be replied to more quickly if you can figure out the right person to tag with @
If you know how to use git blame, that is the easiest way, otherwise, here is a rough guide of **who to tag**.
Please tag fewer than 3 people.
Models:
- text models: @ArthurZucker and @younesbelkada
- vision models: @amyeroberts
- speech models: @sanchit-gandhi
- graph models: @clefourrier
Library:
- flax: @sanchit-gandhi
- generate: @gante
- pipelines: @Narsil
- tensorflow: @gante and @Rocketknight1
- tokenizers: @ArthurZucker
- trainer: @sgugger
Integrations:
- deepspeed: HF Trainer/Accelerate: @pacman100
- ray/raytune: @richardliaw, @amogkam
Documentation: @sgugger, @stevhliu and @MKhalusova
HF projects:
- accelerate: [different repo](https://github.com/huggingface/accelerate)
- datasets: [different repo](https://github.com/huggingface/datasets)
- diffusers: [different repo](https://github.com/huggingface/diffusers)
- rust tokenizers: [different repo](https://github.com/huggingface/tokenizers)
Maintained examples (not research project or legacy):
- Flax: @sanchit-gandhi
- PyTorch: @sgugger
- TensorFlow: @Rocketknight1
-->
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25136/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25136/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25136",
"html_url": "https://github.com/huggingface/transformers/pull/25136",
"diff_url": "https://github.com/huggingface/transformers/pull/25136.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25136.patch",
"merged_at": 1690461242000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25135
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25135/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25135/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25135/events
|
https://github.com/huggingface/transformers/pull/25135
| 1,824,003,061 |
PR_kwDOCUB6oc5WhsNH
| 25,135 |
In assisted decoding, pass model_kwargs to model's forward call
|
{
"login": "sinking-point",
"id": 17532243,
"node_id": "MDQ6VXNlcjE3NTMyMjQz",
"avatar_url": "https://avatars.githubusercontent.com/u/17532243?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/sinking-point",
"html_url": "https://github.com/sinking-point",
"followers_url": "https://api.github.com/users/sinking-point/followers",
"following_url": "https://api.github.com/users/sinking-point/following{/other_user}",
"gists_url": "https://api.github.com/users/sinking-point/gists{/gist_id}",
"starred_url": "https://api.github.com/users/sinking-point/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/sinking-point/subscriptions",
"organizations_url": "https://api.github.com/users/sinking-point/orgs",
"repos_url": "https://api.github.com/users/sinking-point/repos",
"events_url": "https://api.github.com/users/sinking-point/events{/privacy}",
"received_events_url": "https://api.github.com/users/sinking-point/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25135). All of your documentation changes will be reflected on that endpoint.",
"@gante This is ready to review now. Thanks in advance.",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
CONTRIBUTOR
| null |
# What does this PR do?
Previously, assisted decoding would ignore any additional kwargs that it doesn't explicitly handle. This was inconsistent with other generation methods, which pass the model_kwargs through prepare_inputs_for_generation and forward the returned dict to the model's forward call.
The prepare_inputs_for_generation method can not be used directly in this case, as many implementations assume they should only keep the last input ID if a past_key_values is passed. Same goes for attention_mask etc.
The prepare_inputs_for_assisted_generation method modifies the outputs from prepare_inputs_for_generation so that they are suitable for assisted generation. This should work for most models, but if necessary a model can override this method to implement custom logic.
Fixes #25020
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [x] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [x] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [x] Did you write any new necessary tests?
## Who can review?
@gante
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25135/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25135/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25135",
"html_url": "https://github.com/huggingface/transformers/pull/25135",
"diff_url": "https://github.com/huggingface/transformers/pull/25135.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25135.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25134
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25134/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25134/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25134/events
|
https://github.com/huggingface/transformers/pull/25134
| 1,823,902,899 |
PR_kwDOCUB6oc5WhWg5
| 25,134 |
Clarify 4/8 bit loading log message
|
{
"login": "BramVanroy",
"id": 2779410,
"node_id": "MDQ6VXNlcjI3Nzk0MTA=",
"avatar_url": "https://avatars.githubusercontent.com/u/2779410?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/BramVanroy",
"html_url": "https://github.com/BramVanroy",
"followers_url": "https://api.github.com/users/BramVanroy/followers",
"following_url": "https://api.github.com/users/BramVanroy/following{/other_user}",
"gists_url": "https://api.github.com/users/BramVanroy/gists{/gist_id}",
"starred_url": "https://api.github.com/users/BramVanroy/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/BramVanroy/subscriptions",
"organizations_url": "https://api.github.com/users/BramVanroy/orgs",
"repos_url": "https://api.github.com/users/BramVanroy/repos",
"events_url": "https://api.github.com/users/BramVanroy/events{/privacy}",
"received_events_url": "https://api.github.com/users/BramVanroy/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"cc @younesbelkada and @SunMarc",
"Thanks!"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
If you enable 4-bit loading, you will get a message that the model is being loaded in 8-bit. This can be a tad confusing. This tiny PR simply distinguishes in the logging between 4-bit and 8-bit loading.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25134/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25134/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25134",
"html_url": "https://github.com/huggingface/transformers/pull/25134",
"diff_url": "https://github.com/huggingface/transformers/pull/25134.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25134.patch",
"merged_at": 1690463367000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25133
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25133/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25133/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25133/events
|
https://github.com/huggingface/transformers/pull/25133
| 1,823,798,215 |
PR_kwDOCUB6oc5Wg_0Q
| 25,133 |
make run_generation more generic for other devices
|
{
"login": "statelesshz",
"id": 28150734,
"node_id": "MDQ6VXNlcjI4MTUwNzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/28150734?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/statelesshz",
"html_url": "https://github.com/statelesshz",
"followers_url": "https://api.github.com/users/statelesshz/followers",
"following_url": "https://api.github.com/users/statelesshz/following{/other_user}",
"gists_url": "https://api.github.com/users/statelesshz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/statelesshz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/statelesshz/subscriptions",
"organizations_url": "https://api.github.com/users/statelesshz/orgs",
"repos_url": "https://api.github.com/users/statelesshz/repos",
"events_url": "https://api.github.com/users/statelesshz/events{/privacy}",
"received_events_url": "https://api.github.com/users/statelesshz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"@muellerzr Hey there! I've addressed some code quality check warnings. Could you take a look at this PR? Thank you!",
"> Thanks! There's some errors in here we need to fix, and we can probably also improve the mixed precision to use accelerate if we want to (though if not, that's okay!)\r\n\r\n@muellerzr I have resolved these errors. Would you kindly spare a moment to review this PR again? Thank you.",
"> As @sgugger pointed out, we don't want to wrap the mixed precision here actually during inference and just want to make sure the device is working. As a result we should use a different and simpler API, the [PartialState](https://huggingface.co/docs/accelerate/package_reference/state#accelerate.PartialState), which is designed for such situations. I've added suggestions for each change as a result, and appreciate your patience making sure this all will be great!\r\n\r\nThanks for the suggestion to make it more reasonable. I refactored this PR with `PartialState`, would you mind taking a look again.",
"Very clean! Thansk!"
] | 1,690 | 1,694 | 1,690 |
CONTRIBUTOR
| null |
## What does this PR do?
Currently, the example for text-generation is only available for cuda or cpu. This PR makes it work well on mps or npu devices.
Verified on A100 and npu.
Example usage:
```
python3 run_generation.py \
--model_type=gpt2 \
--model_name_or_path=gpt2
```
Below are the output logs:
- On GPU
```
07/27/2023 11:23:51 - WARNING - __main__ - device: cuda, n_gpu: 8, 16-bits training: False
Using pad_token, but it is not set yet.
07/27/2023 11:23:57 - INFO - __main__ - Namespace(model_type='gpt2', model_name_or_path='gpt2', prompt='', length=20, stop_token=None, temperature=1.0, repetition_penalty=1.0, k=0, p=0.9, prefix='', padding_text='', xlm_language='', seed=42, use_cpu=False, num_return_sequences=1, fp16=False, jit=False, device=device(type='cuda'), n_gpu=8)
Model prompt >>> "I'm Jack
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
=== GENERATED SEQUENCE 1 ===
"I'm Jack Russell."
"They said, 'Hey, you know, you have to get away with
```
- On NPU:
```
07/27/2023 11:21:47 - WARNING - __main__ - device: npu, n_gpu: 8, 16-bits training: False
Using pad_token, but it is not set yet.
07/27/2023 11:22:03 - INFO - __main__ - Namespace(device=device(type='npu'), fp16=False, jit=False, k=0, length=20, model_name_or_path='gpt2', model_type='gpt2', n_gpu=8, num_return_sequences=1, p=0.9, padding_text='', prefix='', prompt='', repetition_penalty=1.0, seed=42, stop_token=None, temperature=1.0, use_cpu=False, xlm_language='')
Model prompt >>> "I'm Jack
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
=== GENERATED SEQUENCE 1 ===
"I'm Jack Dylan," guitarist Tim Farrell said, picking up Dylan's Lave Club guitar and in a playful styl
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25133/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25133/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25133",
"html_url": "https://github.com/huggingface/transformers/pull/25133",
"diff_url": "https://github.com/huggingface/transformers/pull/25133.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25133.patch",
"merged_at": 1690546811000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25132
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25132/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25132/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25132/events
|
https://github.com/huggingface/transformers/issues/25132
| 1,823,781,928 |
I_kwDOCUB6oc5stLQo
| 25,132 |
Fine tuning TrOCR on 22 Indian Languages
|
{
"login": "AnustupOCR",
"id": 138591337,
"node_id": "U_kgDOCEK8aQ",
"avatar_url": "https://avatars.githubusercontent.com/u/138591337?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/AnustupOCR",
"html_url": "https://github.com/AnustupOCR",
"followers_url": "https://api.github.com/users/AnustupOCR/followers",
"following_url": "https://api.github.com/users/AnustupOCR/following{/other_user}",
"gists_url": "https://api.github.com/users/AnustupOCR/gists{/gist_id}",
"starred_url": "https://api.github.com/users/AnustupOCR/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/AnustupOCR/subscriptions",
"organizations_url": "https://api.github.com/users/AnustupOCR/orgs",
"repos_url": "https://api.github.com/users/AnustupOCR/repos",
"events_url": "https://api.github.com/users/AnustupOCR/events{/privacy}",
"received_events_url": "https://api.github.com/users/AnustupOCR/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@AnustupOCR \r\n\r\nThis question is better to be on [Hugging Face Forum](https://discuss.huggingface.co/). The issue page here is for bug reporting and feature requests.\r\n\r\n-------------------\r\n\r\nHowever, it makes sense to try `decoder_start_token_id=2` but monitoring the generation results earlier (not to wait until 3 epochs on 20M examples).\r\n\r\nBTW, you use `microsoft/trocr-base-stage1` which has `RobertaTokenizer` (and has English-only vocabulary). It will be difficult for this model to learn with the new languages. Maybe better to use a TrOCR checkpoint with `XLMRobertaTokenizer` if there is one on the Hub.",
"@ydshieh Sorry, I will surely shift to the Forum for my future queries.\r\nBut, to clarify, I am not using microsoft/trocr-base-stage1 as the checkpoint, \r\nI will attatch the model , tokenzer and image processor I am using.\r\n----------------------------------------------------------------------------------------------------------------------------------------------------------------------------from transformers import VisionEncoderDecoderModel\r\nimport torch\r\n\r\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\r\n#device=\"cpu\"\r\nenc='microsoft/beit-base-patch16-224-pt22k-ft22k'\r\ndec='ai4bharat/IndicBERTv2-MLM-only'\r\nmodel = VisionEncoderDecoderModel.from_encoder_decoder_pretrained(enc,dec)\r\nmodel.to(device)\r\n\r\n----------------------------------------------------------------------------------------------------------------------------------------------------------------------------\r\nfrom transformers import AutoImageProcessor, AutoTokenizer,TrOCRProcessor,BeitFeatureExtractor\r\n\r\nimage_processor = BeitFeatureExtractor.from_pretrained(\"microsoft/beit-base-patch16-224-pt22k-ft22k\")\r\n\r\ntokenizer = AutoTokenizer.from_pretrained(\"ai4bharat/IndicBERTv2-MLM-only\")\r\n\r\nprocessor = TrOCRProcessor(feature_extractor = image_processor, tokenizer = tokenizer)\r\n#processor = TrOCRProcessor.from_pretrained(\"microsoft/trocr-base-stage1\")\r\ntrain_dataset = IAMDataset(root_dir='/home/ruser1/Anustup/synthtiger-1.2.1/results/bnnewtst/images/',\r\n df=train_df,\r\n processor=processor)\r\neval_dataset = IAMDataset(root_dir='/home/ruser1/Anustup/synthtiger-1.2.1/results/bnnewtst/images/',\r\n df=test_df,\r\n\r\n processor=processor)\r\n----------------------------------------------------------------------------------------------------------------------------------------------------------------------------\r\n\r\nAny kind of help would really mean a lot\r\nThank you so much",
"So it's not from a pretrained TrOCRModel (decoder) model, but just a `VisionEncoderDecoderModel` model.\r\n\r\nNote that, `ai4bharat/IndicBERTv2-MLM-only` is actually an encoder model (I believe so, but you can verify), not a decoder model for generation. But it should still able to generate something.\r\n\r\nThe best suggestions I could provide:\r\n\r\n- running the generation with a small example, see what is the first token being used as the starting token.\r\n- running a dummy training, check a bit what the examples (after encoding) looks like + check what the model receive as inputs (especially if the first token is the same as the one seen above)\r\n- running the real training, but try to do generation in an earlier stage. You can use `predict_with_generate=True` (and set `do_eval`) to verify if there is some progress\r\n\r\n\r\n\r\n",
"This issue has been automatically marked as stale because it has not had recent activity. If you think this still needs to be addressed please comment on this thread.\n\nPlease note that issues that do not follow the [contributing guidelines](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md) are likely to be ignored."
] | 1,690 | 1,693 | 1,693 |
NONE
| null |
Yeah that definitely will change behaviour. If you check
```python
from transformers import TrOCRProcessor, VisionEncoderDecoderModel
processor = TrOCRProcessor.from_pretrained("microsoft/trocr-base-stage1")
model = VisionEncoderDecoderModel.from_pretrained("microsoft/trocr-base-stage1")
print(model.config.decoder.decoder_start_token_id)
```
you'll see that it's set to 2.
However, if you set it to `processor.tokenizer.cls_token_id`, then you set it to 0. But the model was trained with ID=2 as decoder start token ID.
_Originally posted by @NielsRogge in https://github.com/huggingface/transformers/issues/15823#issuecomment-1099151683_
------------------------------------------------------------------------------------------------------------------------
Hi,
I have been working on TrOCR recently, and I am very new to these things.
I am trying to extend TrOCR to all 22 scheduled Indian Languages.
From my understanding,
I have used AutoImageProcessor and AutoTokenizer class and for ecoder i have used BEiT and IndicBERTv2 respectively as it supports all the 22 languages.
In the above mentioned reply, there seems to be mismatch wherein the Model was originally trained with decoder_start_token_id=2 and when fine tuning it is being set as tokenizer.cls_token_id which is 0. So should we explicitly set it to 2 before training?
Becuase after running 3 epochs on 20M examples dataset, when im running inference, its generating dots and commas.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25132/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25132/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25131
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25131/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25131/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25131/events
|
https://github.com/huggingface/transformers/pull/25131
| 1,823,768,011 |
PR_kwDOCUB6oc5Wg5YM
| 25,131 |
[`T5/LlamaTokenizer`] default legacy to `None` to not always warn
|
{
"login": "ArthurZucker",
"id": 48595927,
"node_id": "MDQ6VXNlcjQ4NTk1OTI3",
"avatar_url": "https://avatars.githubusercontent.com/u/48595927?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ArthurZucker",
"html_url": "https://github.com/ArthurZucker",
"followers_url": "https://api.github.com/users/ArthurZucker/followers",
"following_url": "https://api.github.com/users/ArthurZucker/following{/other_user}",
"gists_url": "https://api.github.com/users/ArthurZucker/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ArthurZucker/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ArthurZucker/subscriptions",
"organizations_url": "https://api.github.com/users/ArthurZucker/orgs",
"repos_url": "https://api.github.com/users/ArthurZucker/repos",
"events_url": "https://api.github.com/users/ArthurZucker/events{/privacy}",
"received_events_url": "https://api.github.com/users/ArthurZucker/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._",
"Excellent - thank you for improving this feature, Arthur!"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
In a follow up to the patch that introduce the `legacy` argument #24622, this makes sure people are warn if the `legacy` is not set. Since online models were not changed, this does not really change much!
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25131/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25131/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25131",
"html_url": "https://github.com/huggingface/transformers/pull/25131",
"diff_url": "https://github.com/huggingface/transformers/pull/25131.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25131.patch",
"merged_at": 1690461798000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25130
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25130/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25130/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25130/events
|
https://github.com/huggingface/transformers/issues/25130
| 1,823,639,062 |
I_kwDOCUB6oc5ssoYW
| 25,130 |
an inplace operation preventing TorchDistributor training
|
{
"login": "liqi6811",
"id": 48280760,
"node_id": "MDQ6VXNlcjQ4MjgwNzYw",
"avatar_url": "https://avatars.githubusercontent.com/u/48280760?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/liqi6811",
"html_url": "https://github.com/liqi6811",
"followers_url": "https://api.github.com/users/liqi6811/followers",
"following_url": "https://api.github.com/users/liqi6811/following{/other_user}",
"gists_url": "https://api.github.com/users/liqi6811/gists{/gist_id}",
"starred_url": "https://api.github.com/users/liqi6811/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/liqi6811/subscriptions",
"organizations_url": "https://api.github.com/users/liqi6811/orgs",
"repos_url": "https://api.github.com/users/liqi6811/repos",
"events_url": "https://api.github.com/users/liqi6811/events{/privacy}",
"received_events_url": "https://api.github.com/users/liqi6811/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 2796628563,
"node_id": "MDU6TGFiZWwyNzk2NjI4NTYz",
"url": "https://api.github.com/repos/huggingface/transformers/labels/WIP",
"name": "WIP",
"color": "234C99",
"default": false,
"description": "Label your PR/Issue with WIP for some long outstanding Issues/PRs that are work in progress"
}
] |
open
| false | null |
[] |
[
"I would be very surprised if this famous `BERT` model has such issue.\r\n\r\nCould you provide the system environment like pytorch version.\r\n\r\nYou can run the command `transformers-cli env` and copy-paste its output.",
"Actually @ydshieh I think this is pretty valid, and we have a bunch of issues with `inplace operations` preventing `fsdp` training. This is not limited to the embedding, have seen other places where the code fails. See the linked issue for more details. ",
"@ArthurZucker Thanks. I know there is such problem, like I have engaged in #24525.\r\n\r\nMy main concern here: is this issue (for BERT) is only happening with `TorchDistributor` (or FSDP as you said).\r\nIn #24525, it seems it happens without these other tools. And BERT exists for so long, so I am somehow confused about what exactly triggers this error.\r\n",
"@ydshieh system environment is below: \r\n\r\n- `transformers` version: 4.29.2\r\n- Platform: Linux-5.15.0-1040-azure-x86_64-with-glibc2.35\r\n- Python version: 3.10.6\r\n- Huggingface_hub version: 0.15.1\r\n- Safetensors version: not installed\r\n- PyTorch version (GPU?): 1.13.1+cu117 (True)\r\n- Tensorflow version (GPU?): 2.11.0 (True)\r\n- Flax version (CPU?/GPU?/TPU?): not installed (NA)\r\n- Jax version: not installed\r\n- JaxLib version: not installed\r\n- Using GPU in script?: <fill in>\r\n- Using distributed or parallel set-up in script?: <fill in>\r\n",
"@ydshieh @ArthurZucker I am working in Azure Databricks, I used Horovod for distributed training, the inplace operation does not cause any issue, but Horovod 4GPU is only 1.6 times faster than 1GPU. TorchDistributor can be nearly 4 times faster. However, TorchDistributor does not work due to inplace opertaion. I tried subclassing to remove inplace operations, but not easy :). Hopefully you guys can help to release an update. Thanks a lot. ",
"@ydshieh @ArthurZucker I would suggest to do a thorough check for all inplace operations, and get rid of all :). "
] | 1,690 | 1,704 | null |
NONE
| null |
### System Info
databricks
### Who can help?
@ArthurZucker @younesbelkada
Hi team,
I got an error message by using TorchDistributor.
I have checked in the class BertEmbeddings (url as below), line 238, embeddings += position_embeddings is an inplace operation, would you be able to change to embeddings = embeddings + position_embeddings, to allow TOrchDistributor?
BertEmbeddings url:
https://github.com/huggingface/transformers/blob/main/src/transformers/models/bert/modeling_bert.py
TorchDistributor sample code:
https://docs.databricks.com/_extras/notebooks/source/deep-learning/torch-distributor-notebook.html
Thank you very much!
Ling
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [ ] My own task or dataset (give details below)
### Reproduction
```
single_node_single_gpu_dir = create_log_dir()
print("Data is located at: ", single_node_single_gpu_dir)
def train_one_epoch(model, device, data_loader, optimizer, epoch):
torch.autograd.set_detect_anomaly(True)
model.train()
for batch_idx, (data, labels) in enumerate(data_loader):
inputs1, inputs2 = data[0], data[1]
inputs1 = {key: val.to(device) for key, val in inputs1.items()}
inputs2 = {key: val.to(device) for key, val in inputs2.items()}
# labels = labels.float().to(device)
labels = labels.to(device)
optimizer.zero_grad()
# Compute embeddings
embeddings1 = model(inputs1)['sentence_embedding']
embeddings2 = model(inputs2)['sentence_embedding']
# Compute loss
loss = cosine_similarity_loss(embeddings1, embeddings2, labels)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(data_loader) * len(data),
100. * batch_idx / len(data_loader), loss.item()))
if int(os.environ["RANK"]) == 0:
mlflow.log_metric('train_loss', loss.item())
def save_checkpoint(log_dir, model, optimizer, epoch):
filepath = log_dir + '/checkpoint-{epoch}.pth.tar'.format(epoch=epoch)
state = {
'model': model.module.state_dict(),
'optimizer': optimizer.state_dict(),
}
torch.save(state, filepath)
# For distributed training we will merge the train and test steps into 1 main function
def main_fn(directory):
#### Added imports here ####
import mlflow
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.data.distributed import DistributedSampler
############################
##### Setting up MLflow ####
# We need to do this so that different processes that will be able to find mlflow
os.environ['DATABRICKS_HOST'] = db_host
os.environ['DATABRICKS_TOKEN'] = db_token
# We set the experiment details here
experiment = mlflow.set_experiment(experiment_path)
############################
print("Running distributed training")
dist.init_process_group("nccl")
local_rank = int(os.environ["LOCAL_RANK"])
global_rank = int(os.environ["RANK"])
if global_rank == 0:
train_parameters = {'batch_size': batch_size, 'epochs': num_epochs, 'trainer': 'TorchDistributor'}
mlflow.log_params(train_parameters)
model = SentenceTransformer(modelname)
filepath = "../../dbfs/mnt/path2data/"
df_train = readData('train', filepath)
df_train = df_train.head(10000)
train_text = df_train[['sentA', 'sentB', 'score']].values.tolist()
train_examples = [InputExample(texts=[a, b], label=s) for [a, b, s] in train_text]
train_dataset = SentencesDataset(train_examples, model)
#### Added Distributed Dataloader ####
train_sampler = DistributedSampler(dataset=train_dataset)
data_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, sampler=train_sampler)
######################################
data_loader.collate_fn = model.smart_batching_collate
model = model.to(local_rank)
#### Added Distributed Model ####
ddp_model = DDP(model, device_ids=[local_rank], output_device=local_rank)
#################################
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
for epoch in range(1, num_epochs + 1):
train_one_epoch(ddp_model, local_rank, data_loader, optimizer, epoch)
if global_rank == 0:
save_checkpoint(directory, ddp_model, optimizer, epoch)
dist.destroy_process_group()
return "finished" # can return any picklable object
# single node distributed run to quickly test that the whole process is working
with mlflow.start_run():
mlflow.log_param('run_type', 'test_dist_code')
main_fn(single_node_single_gpu_dir)
```
### Expected behavior
below error disappear.

|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25130/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25130/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25129
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25129/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25129/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25129/events
|
https://github.com/huggingface/transformers/issues/25129
| 1,823,565,113 |
I_kwDOCUB6oc5ssWU5
| 25,129 |
Delete all checkpoints when set save_total_limit=1
|
{
"login": "Pbihao",
"id": 22709028,
"node_id": "MDQ6VXNlcjIyNzA5MDI4",
"avatar_url": "https://avatars.githubusercontent.com/u/22709028?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/Pbihao",
"html_url": "https://github.com/Pbihao",
"followers_url": "https://api.github.com/users/Pbihao/followers",
"following_url": "https://api.github.com/users/Pbihao/following{/other_user}",
"gists_url": "https://api.github.com/users/Pbihao/gists{/gist_id}",
"starred_url": "https://api.github.com/users/Pbihao/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/Pbihao/subscriptions",
"organizations_url": "https://api.github.com/users/Pbihao/orgs",
"repos_url": "https://api.github.com/users/Pbihao/repos",
"events_url": "https://api.github.com/users/Pbihao/events{/privacy}",
"received_events_url": "https://api.github.com/users/Pbihao/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Hi @Pbihao ! \r\n\r\nThank you a lot of reporting this issue. I can confirm it.\r\n\r\nWould you like to open a PR to help us fixing this 🤗 ? ",
"Yeah, I have submitted the PR #25136 .\r\n\r\nMany thanks."
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
### System Info
- `transformers` version: 4.31.0
- Platform: Linux-3.10.0-1160.el7.x86_64-x86_64-with-glibc2.27
- Python version: 3.11.4
- Huggingface_hub version: 0.16.4
- Safetensors version: 0.3.1
- Accelerate version: 0.21.0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: <fill in>
- Using distributed or parallel set-up in script?: <fill in>
### Who can help?
@sgugger
### Information
- [X] The official example scripts
- [ ] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
1. Set the `save_total_limit` in `TrainingArguments` as 1
2. Set `output_dir` in `TrainingArguments`
3. Run `trainer.train()`
4. No checkpoint folder was saved (all are deleted)
I have found the reason and fix the bug, just report this bug.
The reason is that in [trainer](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py#L1963):
```
if self.args.should_save and self.state.best_model_checkpoint is not None and self.args.save_total_limit == 1:
for checkpoint in checkpoints_sorted:
if checkpoint != self.state.best_model_checkpoint:
logger.info(f"Deleting older checkpoint [{checkpoint}] due to args.save_total_limit")
shutil.rmtree(checkpoint)
```
This line:
```
if checkpoint != self.state.best_model_checkpoint:
```
Directly compare two paths as strings and ignore the format of the path.
For example, in my case, when:
* checkpoint == 'outputs/'
and
* self.state.best_model_checkpoint == './outputs',
this comparison returns `False` and all checkpoints are deleted even including the best model.
I fix this bug by changing the above line to:
```
if str(Path(checkpoint)) != str(Path(self.state.best_model_checkpoint)):
```
### Expected behavior
The best model is saved and other checkpoints are deleted.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25129/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25129/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25128
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25128/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25128/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25128/events
|
https://github.com/huggingface/transformers/pull/25128
| 1,823,549,934 |
PR_kwDOCUB6oc5WgKtx
| 25,128 |
make run_generation more generic for other devices
|
{
"login": "statelesshz",
"id": 28150734,
"node_id": "MDQ6VXNlcjI4MTUwNzM0",
"avatar_url": "https://avatars.githubusercontent.com/u/28150734?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/statelesshz",
"html_url": "https://github.com/statelesshz",
"followers_url": "https://api.github.com/users/statelesshz/followers",
"following_url": "https://api.github.com/users/statelesshz/following{/other_user}",
"gists_url": "https://api.github.com/users/statelesshz/gists{/gist_id}",
"starred_url": "https://api.github.com/users/statelesshz/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/statelesshz/subscriptions",
"organizations_url": "https://api.github.com/users/statelesshz/orgs",
"repos_url": "https://api.github.com/users/statelesshz/repos",
"events_url": "https://api.github.com/users/statelesshz/events{/privacy}",
"received_events_url": "https://api.github.com/users/statelesshz/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
## What does this PR do?
Currently, the example for text-generation is only available for cuda or cpu. This PR makes it work well on mps or npu devices.
Verified on A100 and npu.
Example usage:
```
python3 run_generation.py \
--model_type=gpt2 \
--model_name_or_path=gpt2
```
Below are the output logs:
- On GPU
```
07/27/2023 11:23:51 - WARNING - __main__ - device: cuda, n_gpu: 8, 16-bits training: False
Using pad_token, but it is not set yet.
07/27/2023 11:23:57 - INFO - __main__ - Namespace(model_type='gpt2', model_name_or_path='gpt2', prompt='', length=20, stop_token=None, temperature=1.0, repetition_penalty=1.0, k=0, p=0.9, prefix='', padding_text='', xlm_language='', seed=42, use_cpu=False, num_return_sequences=1, fp16=False, jit=False, device=device(type='cuda'), n_gpu=8)
Model prompt >>> "I'm Jack
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
=== GENERATED SEQUENCE 1 ===
"I'm Jack Russell."
"They said, 'Hey, you know, you have to get away with
```
- On NPU:
```
07/27/2023 11:21:47 - WARNING - __main__ - device: npu, n_gpu: 8, 16-bits training: False
Using pad_token, but it is not set yet.
07/27/2023 11:22:03 - INFO - __main__ - Namespace(device=device(type='npu'), fp16=False, jit=False, k=0, length=20, model_name_or_path='gpt2', model_type='gpt2', n_gpu=8, num_return_sequences=1, p=0.9, padding_text='', prefix='', prompt='', repetition_penalty=1.0, seed=42, stop_token=None, temperature=1.0, use_cpu=False, xlm_language='')
Model prompt >>> "I'm Jack
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
=== GENERATED SEQUENCE 1 ===
"I'm Jack Dylan," guitarist Tim Farrell said, picking up Dylan's Lave Club guitar and in a playful styl
```
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25128/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25128/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25128",
"html_url": "https://github.com/huggingface/transformers/pull/25128",
"diff_url": "https://github.com/huggingface/transformers/pull/25128.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25128.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25127
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25127/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25127/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25127/events
|
https://github.com/huggingface/transformers/issues/25127
| 1,823,431,626 |
I_kwDOCUB6oc5sr1vK
| 25,127 |
Trainer explodes with multiple validation sets used
|
{
"login": "radekosmulski",
"id": 2444926,
"node_id": "MDQ6VXNlcjI0NDQ5MjY=",
"avatar_url": "https://avatars.githubusercontent.com/u/2444926?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/radekosmulski",
"html_url": "https://github.com/radekosmulski",
"followers_url": "https://api.github.com/users/radekosmulski/followers",
"following_url": "https://api.github.com/users/radekosmulski/following{/other_user}",
"gists_url": "https://api.github.com/users/radekosmulski/gists{/gist_id}",
"starred_url": "https://api.github.com/users/radekosmulski/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/radekosmulski/subscriptions",
"organizations_url": "https://api.github.com/users/radekosmulski/orgs",
"repos_url": "https://api.github.com/users/radekosmulski/repos",
"events_url": "https://api.github.com/users/radekosmulski/events{/privacy}",
"received_events_url": "https://api.github.com/users/radekosmulski/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"Yes, multiple evaluation datasets are not supported in a notebook env, that is a known issue.",
"Thank you, Sylvain! 🙂 Didn't know that! Appreciate your reply, will close this now.",
"Ah ah you don't need to close it ;-) It's not been high-priority for us but we should fix it at some point.",
"Ok, sorry Sylvain 😊 Let me reopen the issue then! I thought it was a known issue as in \"we know it doesn't work but it is meant to be broken in notebooks\" and I just didn't realize that, but if it is a genuine issue then let me leave it open! 🙂",
"Will ping @pacman100 here to put this on radar for the trainer! ",
"More for @muellerzr, but he should already have it somewhere in his TODO for when he has time ;-)",
"#25796 was opened to fix it "
] | 1,690 | 1,694 | 1,694 |
NONE
| null |
### System Info
- `transformers` version: 4.32.0.dev0
- Platform: Linux-5.15.0-76-generic-x86_64-with-glibc2.35
- Python version: 3.11.4
- Huggingface_hub version: 0.15.1
- Safetensors version: 0.3.1
- Accelerate version: 0.22.0.dev0
- Accelerate config: not found
- PyTorch version (GPU?): 2.0.1 (True)
- Tensorflow version (GPU?): not installed (NA)
- Flax version (CPU?/GPU?/TPU?): not installed (NA)
- Jax version: not installed
- JaxLib version: not installed
- Using GPU in script?: no, running in notebook
- Using distributed or parallel set-up in script?: no, running in notebook
### Who can help?
@sgugger
### Information
- [ ] The official example scripts
- [X] My own modified scripts
### Tasks
- [ ] An officially supported task in the `examples` folder (such as GLUE/SQuAD, ...)
- [X] My own task or dataset (give details below)
### Reproduction
Using multiple datasets, the trainer looks for a key that doesn't exist and throws an error upon evaluation at the end of the epoch.

### Expected behavior
Metrics are returned just fine. There is no error.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25127/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25127/timeline
|
completed
| null | null |
https://api.github.com/repos/huggingface/transformers/issues/25126
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25126/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25126/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25126/events
|
https://github.com/huggingface/transformers/pull/25126
| 1,823,409,646 |
PR_kwDOCUB6oc5Wfs7V
| 25,126 |
[setup] fix min isort requirements
|
{
"login": "stas00",
"id": 10676103,
"node_id": "MDQ6VXNlcjEwNjc2MTAz",
"avatar_url": "https://avatars.githubusercontent.com/u/10676103?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/stas00",
"html_url": "https://github.com/stas00",
"followers_url": "https://api.github.com/users/stas00/followers",
"following_url": "https://api.github.com/users/stas00/following{/other_user}",
"gists_url": "https://api.github.com/users/stas00/gists{/gist_id}",
"starred_url": "https://api.github.com/users/stas00/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/stas00/subscriptions",
"organizations_url": "https://api.github.com/users/stas00/orgs",
"repos_url": "https://api.github.com/users/stas00/repos",
"events_url": "https://api.github.com/users/stas00/events{/privacy}",
"received_events_url": "https://api.github.com/users/stas00/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"no, actually that didn't help :(",
"The docs for this PR live [here](https://moon-ci-docs.huggingface.co/docs/transformers/pr_25126). All of your documentation changes will be reflected on that endpoint."
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
the current isort min version requirement doesn't match CI's reality
even with isort 5.10.1 `make style` leads to modified code which doesn't match CI.
I tested that 5.12 syncs with CI.
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25126/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25126/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25126",
"html_url": "https://github.com/huggingface/transformers/pull/25126",
"diff_url": "https://github.com/huggingface/transformers/pull/25126.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25126.patch",
"merged_at": null
}
|
https://api.github.com/repos/huggingface/transformers/issues/25125
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25125/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25125/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25125/events
|
https://github.com/huggingface/transformers/pull/25125
| 1,823,394,223 |
PR_kwDOCUB6oc5Wfpkk
| 25,125 |
[DOCS] Add example and modified docs of EtaLogitsWarper
|
{
"login": "ashishthomaschempolil",
"id": 12584994,
"node_id": "MDQ6VXNlcjEyNTg0OTk0",
"avatar_url": "https://avatars.githubusercontent.com/u/12584994?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ashishthomaschempolil",
"html_url": "https://github.com/ashishthomaschempolil",
"followers_url": "https://api.github.com/users/ashishthomaschempolil/followers",
"following_url": "https://api.github.com/users/ashishthomaschempolil/following{/other_user}",
"gists_url": "https://api.github.com/users/ashishthomaschempolil/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ashishthomaschempolil/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ashishthomaschempolil/subscriptions",
"organizations_url": "https://api.github.com/users/ashishthomaschempolil/orgs",
"repos_url": "https://api.github.com/users/ashishthomaschempolil/repos",
"events_url": "https://api.github.com/users/ashishthomaschempolil/events{/privacy}",
"received_events_url": "https://api.github.com/users/ashishthomaschempolil/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"@ashishthomaschempolil thank you for iterating 🤗 ",
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
See #24783
Added example to EtaLogitsWarper and also modifed its docstrings to make it more understandable
## Before submitting
- [x] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
## Who can review?
@gante
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25125/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25125/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25125",
"html_url": "https://github.com/huggingface/transformers/pull/25125",
"diff_url": "https://github.com/huggingface/transformers/pull/25125.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25125.patch",
"merged_at": 1690973757000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25124
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25124/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25124/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25124/events
|
https://github.com/huggingface/transformers/pull/25124
| 1,823,131,234 |
PR_kwDOCUB6oc5WewYQ
| 25,124 |
added compiled model support for inference
|
{
"login": "markovalexander",
"id": 22663468,
"node_id": "MDQ6VXNlcjIyNjYzNDY4",
"avatar_url": "https://avatars.githubusercontent.com/u/22663468?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/markovalexander",
"html_url": "https://github.com/markovalexander",
"followers_url": "https://api.github.com/users/markovalexander/followers",
"following_url": "https://api.github.com/users/markovalexander/following{/other_user}",
"gists_url": "https://api.github.com/users/markovalexander/gists{/gist_id}",
"starred_url": "https://api.github.com/users/markovalexander/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/markovalexander/subscriptions",
"organizations_url": "https://api.github.com/users/markovalexander/orgs",
"repos_url": "https://api.github.com/users/markovalexander/repos",
"events_url": "https://api.github.com/users/markovalexander/events{/privacy}",
"received_events_url": "https://api.github.com/users/markovalexander/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
CONTRIBUTOR
| null |
# What does this PR do?
Adds support for torch.compile-ed models in pipelines.
Basically, you cannot run torch.compile-ed model under `torch.inference_mode()` context and should use `torch.no_grad` instead
Examples:
<img width="1004" alt="image" src="https://github.com/huggingface/transformers/assets/22663468/04f0bde9-c7d0-4776-9fc4-bd224fadebce">
Here you see start of the super long traceback that ends with:
```
RuntimeError: Inference tensors do not track version counter.
While executing %getitem : [#users=1] = call_function[target=operator.getitem](args = (%attention_mask,
(slice(None, None, None), None, None, slice(None, None, None))), kwargs = {})
Original traceback:
File "/home/alexander/jupyter_server/.venv/lib/python3.8/site-packages/transformers/modeling_utils.py", line 890,
in get_extended_attention_mask
extended_attention_mask = attention_mask[:, None, None, :]
| File
"/home/alexander/jupyter_server/.venv/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line
993, in forward
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
| File
"/home/alexander/jupyter_server/.venv/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line
1758, in forward
outputs = self.bert(
```
and
```
BackendCompilerFailed: debug_wrapper raised RuntimeError: Inference tensors do not track version counter.
While executing %getitem : [#users=1] = call_function[target=operator.getitem](args = (%attention_mask,
(slice(None, None, None), None, None, slice(None, None, None))), kwargs = {})
Original traceback:
File "/home/alexander/jupyter_server/.venv/lib/python3.8/site-packages/transformers/modeling_utils.py", line 890,
in get_extended_attention_mask
extended_attention_mask = attention_mask[:, None, None, :]
| File
"/home/alexander/jupyter_server/.venv/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line
993, in forward
extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape)
| File
"/home/alexander/jupyter_server/.venv/lib/python3.8/site-packages/transformers/models/bert/modeling_bert.py", line
1758, in forward
outputs = self.bert(
```
Possible solution right now:
<img width="692" alt="image" src="https://github.com/huggingface/transformers/assets/22663468/f6b2c599-78b9-4e0c-89b7-31ded7532a52">
## Who can review?
@Narsil
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25124/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25124/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25124",
"html_url": "https://github.com/huggingface/transformers/pull/25124",
"diff_url": "https://github.com/huggingface/transformers/pull/25124.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25124.patch",
"merged_at": 1690547285000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25123
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25123/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25123/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25123/events
|
https://github.com/huggingface/transformers/issues/25123
| 1,822,844,771 |
I_kwDOCUB6oc5spmdj
| 25,123 |
Add Vocos model
|
{
"login": "ylacombe",
"id": 52246514,
"node_id": "MDQ6VXNlcjUyMjQ2NTE0",
"avatar_url": "https://avatars.githubusercontent.com/u/52246514?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/ylacombe",
"html_url": "https://github.com/ylacombe",
"followers_url": "https://api.github.com/users/ylacombe/followers",
"following_url": "https://api.github.com/users/ylacombe/following{/other_user}",
"gists_url": "https://api.github.com/users/ylacombe/gists{/gist_id}",
"starred_url": "https://api.github.com/users/ylacombe/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/ylacombe/subscriptions",
"organizations_url": "https://api.github.com/users/ylacombe/orgs",
"repos_url": "https://api.github.com/users/ylacombe/repos",
"events_url": "https://api.github.com/users/ylacombe/events{/privacy}",
"received_events_url": "https://api.github.com/users/ylacombe/received_events",
"type": "User",
"site_admin": false
}
|
[
{
"id": 1843244711,
"node_id": "MDU6TGFiZWwxODQzMjQ0NzEx",
"url": "https://api.github.com/repos/huggingface/transformers/labels/New%20model",
"name": "New model",
"color": "fbca04",
"default": false,
"description": ""
}
] |
open
| false | null |
[] |
[
"Hey @amyeroberts, could I implement this?",
"@kamathis4 Sure :) \r\n\r\ncc @sanchit-gandhi ",
"Feel free to open a PR if you're interested @kamathis4 - I think @ylacombe is also interested in adding this quite quickly, so the two of you could work together if desired!",
"Hey @sanchit-gandhi, will be a bit busy for 4-5 days now. I think you can assign it to @ylacombe.",
"Is this being implemented currently @sanchit-gandhi, or I could take it up",
"I think we should wait for a stable release of Vocos - the [publicly available](https://github.com/charactr-platform/vocos) version is a v0.0.3, so is subject to change as more performant checkpoints are released\r\n\r\nOnce we get a v1, we can commit to an integration! How does this sound @kamathis4?"
] | 1,690 | 1,693 | null |
COLLABORATOR
| null |
### Model description
Vocos is a Fourier-based neural vocoder for audio synthesis.
According to its [paper](https://arxiv.org/pdf/2306.00814.pdf), Vocos constantly outperforms [HifiGan](https://huggingface.co/docs/transformers/main/en/model_doc/speecht5#transformers.SpeechT5HifiGan), has 13.5M params and is significantly faster than any competing vocoders!
Moreover, it is also compatible with Bark, and significantly improve audio quality as showed [here](https://charactr-platform.github.io/vocos/#audio-reconstruction-from-bark-tokens).
Vocos is composed of a backbone (ConvNeXt) and an inverse fourier transform head (either STFT or MDCT).
### Open source status
- [X] The model implementation is available
- [X] The model weights are available
### Provide useful links for the implementation
Vocos code is available [here](https://github.com/charactr-platform/vocos/tree/main) and was mainly contributed by @hubertsiuzdak.
Its weights are available on HF hub [here](https://huggingface.co/charactr/vocos-mel-24khz) and [here](https://huggingface.co/charactr/vocos-encodec-24khz).
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25123/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25123/timeline
| null | null | null |
https://api.github.com/repos/huggingface/transformers/issues/25122
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25122/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25122/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25122/events
|
https://github.com/huggingface/transformers/pull/25122
| 1,822,804,388 |
PR_kwDOCUB6oc5WdpTO
| 25,122 |
Move center_crop to BaseImageProcessor
|
{
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,690 | 1,690 |
COLLABORATOR
| null |
# What does this PR do?
Moves center_crop to BaseImageProcessor as the logic is the same for almost all models' image processors (except [bridgetower](https://github.com/huggingface/transformers/blob/659829b6ae558dd2e178462a797bf8b1a749f070/src/transformers/models/bridgetower/image_processing_bridgetower.py#L229) and [owlvit](https://github.com/huggingface/transformers/blob/659829b6ae558dd2e178462a797bf8b1a749f070/src/transformers/models/owlvit/image_processing_owlvit.py#L184)), and is a standard transformation all processors might want to apply.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [x] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25122/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25122/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25122",
"html_url": "https://github.com/huggingface/transformers/pull/25122",
"diff_url": "https://github.com/huggingface/transformers/pull/25122.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25122.patch",
"merged_at": 1690392638000
}
|
https://api.github.com/repos/huggingface/transformers/issues/25121
|
https://api.github.com/repos/huggingface/transformers
|
https://api.github.com/repos/huggingface/transformers/issues/25121/labels{/name}
|
https://api.github.com/repos/huggingface/transformers/issues/25121/comments
|
https://api.github.com/repos/huggingface/transformers/issues/25121/events
|
https://github.com/huggingface/transformers/pull/25121
| 1,822,711,692 |
PR_kwDOCUB6oc5WdVSe
| 25,121 |
Add copied from for image processor methods
|
{
"login": "amyeroberts",
"id": 22614925,
"node_id": "MDQ6VXNlcjIyNjE0OTI1",
"avatar_url": "https://avatars.githubusercontent.com/u/22614925?v=4",
"gravatar_id": "",
"url": "https://api.github.com/users/amyeroberts",
"html_url": "https://github.com/amyeroberts",
"followers_url": "https://api.github.com/users/amyeroberts/followers",
"following_url": "https://api.github.com/users/amyeroberts/following{/other_user}",
"gists_url": "https://api.github.com/users/amyeroberts/gists{/gist_id}",
"starred_url": "https://api.github.com/users/amyeroberts/starred{/owner}{/repo}",
"subscriptions_url": "https://api.github.com/users/amyeroberts/subscriptions",
"organizations_url": "https://api.github.com/users/amyeroberts/orgs",
"repos_url": "https://api.github.com/users/amyeroberts/repos",
"events_url": "https://api.github.com/users/amyeroberts/events{/privacy}",
"received_events_url": "https://api.github.com/users/amyeroberts/received_events",
"type": "User",
"site_admin": false
}
|
[] |
closed
| false | null |
[] |
[
"_The documentation is not available anymore as the PR was closed or merged._"
] | 1,690 | 1,691 | 1,691 |
COLLABORATOR
| null |
# What does this PR do?
Adds `# Copied from` headers to shared image processor methods to ensure any updates to e.g. docstrings are propogated across. This mainly applies to the methods resize, center_crop and rescale.
This is in part to prepare for any future adaptations to make handling of images with different number of channels / ambiguous data formats e.g. adding `input_data_format` arguments or handling an ImageArray object.
## Before submitting
- [ ] This PR fixes a typo or improves the docs (you can dismiss the other checks if that's the case).
- [ ] Did you read the [contributor guideline](https://github.com/huggingface/transformers/blob/main/CONTRIBUTING.md#start-contributing-pull-requests),
Pull Request section?
- [ ] Was this discussed/approved via a Github issue or the [forum](https://discuss.huggingface.co/)? Please add a link
to it if that's the case.
- [ ] Did you make sure to update the documentation with your changes? Here are the
[documentation guidelines](https://github.com/huggingface/transformers/tree/main/docs), and
[here are tips on formatting docstrings](https://github.com/huggingface/transformers/tree/main/docs#writing-source-documentation).
- [ ] Did you write any new necessary tests?
|
{
"url": "https://api.github.com/repos/huggingface/transformers/issues/25121/reactions",
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
}
|
https://api.github.com/repos/huggingface/transformers/issues/25121/timeline
| null | false |
{
"url": "https://api.github.com/repos/huggingface/transformers/pulls/25121",
"html_url": "https://github.com/huggingface/transformers/pull/25121",
"diff_url": "https://github.com/huggingface/transformers/pull/25121.diff",
"patch_url": "https://github.com/huggingface/transformers/pull/25121.patch",
"merged_at": 1691510569000
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.