Datasets:

metadata
license: apache-2.0
task_categories:
- text-classification
language:
- ko
dataset_info:
features:
- name: comment
dtype: string
- name: preference
dtype: int64
- name: profanity
dtype: int64
- name: gender
dtype: int64
- name: politics
dtype: int64
- name: nation
dtype: int64
- name: race
dtype: int64
- name: region
dtype: int64
- name: generation
dtype: int64
- name: social_hierarchy
dtype: int64
- name: appearance
dtype: int64
- name: others
dtype: int64
splits:
- name: train
num_bytes: 7458552
num_examples: 38361
- name: test
num_bytes: 412144
num_examples: 2000
download_size: 2947880
dataset_size: 7870696
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: test
path: data/test-*
size_categories:
- 1M<n<10M
KoMultiText: Korean Multi-task Dataset for Classifying Biased Speech
Dataset Summary
KoMultiText is a comprehensive Korean multi-task text dataset designed for classifying biased and harmful speech in online platforms. The dataset focuses on tasks such as Preference Detection, Profanity Identification, and Bias Classification across multiple domains, enabling state-of-the-art language models to perform multi-task learning for socially responsible AI applications.
Key Features
- Large-Scale Dataset: Contains 150,000 comments, including labeled and unlabeled data.
- Multi-task Annotations: Covers Preference, Profanity, and nine distinct types of Bias.
- Human-Labeled: All labeled data is annotated by five human experts to ensure high-quality and unbiased annotations.
- Real-world Relevance: Collected from "Real-time Best Gallery" of DC Inside, a popular online community in South Korea.
Labels
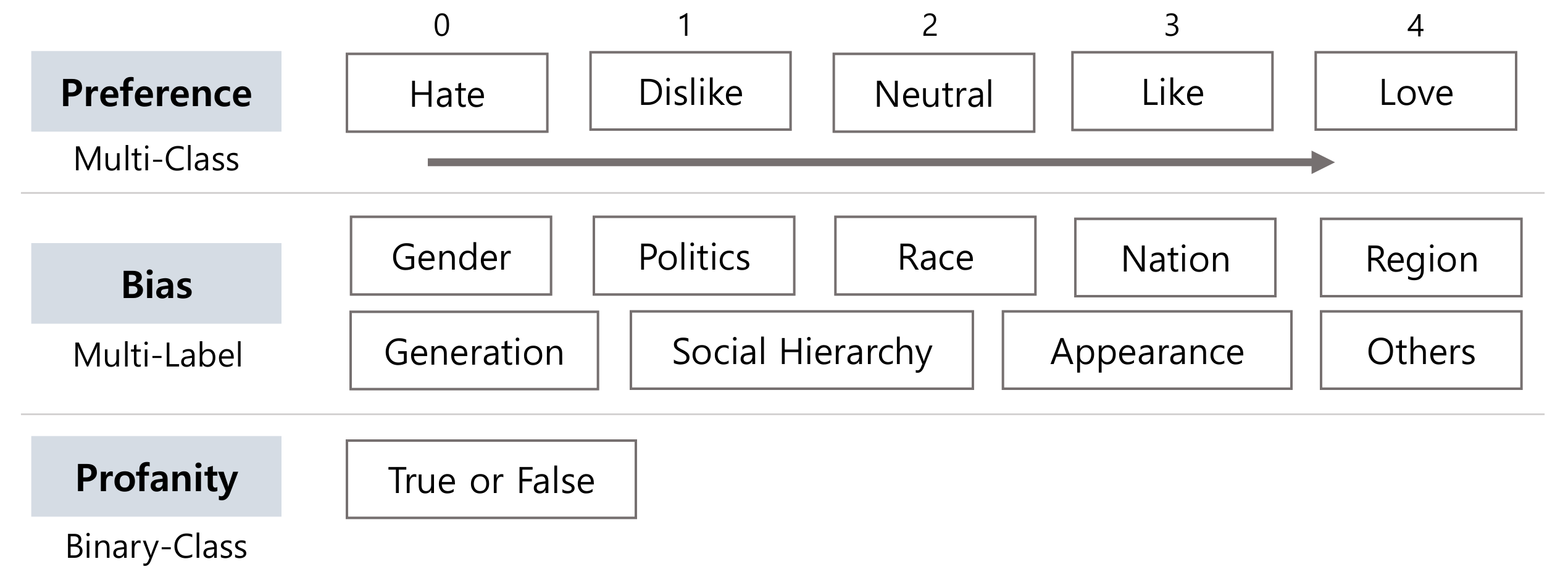
Dataset Creation
Source Data
- Origin: Comments collected from "Real-time Best Gallery" on DC Inside.
- Annotation Process:
- Human Annotation: Five human annotators independently labeled all comments in the dataset to ensure accuracy and minimize bias.
- Labeling Process: Annotators followed strict guidelines to classify comments into Preference, Profanity, and nine types of Bias. Discrepancies were resolved through majority voting and discussion.
- Dataset Composition:
- Labeled Data: 40,361 comments (train/test split).
- Unlabeled Data: 110,000 comments for potential pretraining or unsupervised learning. Veiw Dataset
How to Load the Dataset
from datasets import load_dataset
# Load the dataset
dataset = load_dataset("Dasool/KoMultiText")
# Access train and test splits
train_dataset = dataset["train"]
test_dataset = dataset["test"]
Code
- Korean BERT-based fine-tuning code. Github
Citation
@misc{choi2023largescale,
title={Large-Scale Korean Text Dataset for Classifying Biased Speech in Real-World Online Services},
author={Dasol Choi and Jooyoung Song and Eunsun Lee and Jinwoo Seo and Heejune Park and Dongbin Na},
year={2023},
eprint={2310.04313},
archivePrefix={arXiv},
primaryClass={cs.CL}
}