
prompt
large_stringlengths 70
991k
| completion
large_stringlengths 0
1.02k
|
|---|---|
<|file_name|>monitor_test.go<|end_file_name|><|fim▁begin|>package command
import (
"strings"
"testing"
"time"
"github.com/hashicorp/nomad/api"
"github.com/hashicorp/nomad/nomad/structs"
"github.com/mitchellh/cli"
)
func TestMonitor_Update_Eval(t *testing.T) {
t.Parallel()<|fim▁hole|> mon := newMonitor(ui, nil, fullId)
// Evals triggered by jobs log
state := &evalState{
status: structs.EvalStatusPending,
job: "job1",
}
mon.update(state)
out := ui.OutputWriter.String()
if !strings.Contains(out, "job1") {
t.Fatalf("missing job\n\n%s", out)
}
ui.OutputWriter.Reset()
// Evals trigerred by nodes log
state = &evalState{
status: structs.EvalStatusPending,
node: "12345678-abcd-efab-cdef-123456789abc",
}
mon.update(state)
out = ui.OutputWriter.String()
if !strings.Contains(out, "12345678-abcd-efab-cdef-123456789abc") {
t.Fatalf("missing node\n\n%s", out)
}
// Transition to pending should not be logged
if strings.Contains(out, structs.EvalStatusPending) {
t.Fatalf("should skip status\n\n%s", out)
}
ui.OutputWriter.Reset()
// No logs sent if no update
mon.update(state)
if out := ui.OutputWriter.String(); out != "" {
t.Fatalf("expected no output\n\n%s", out)
}
// Status change sends more logs
state = &evalState{
status: structs.EvalStatusComplete,
node: "12345678-abcd-efab-cdef-123456789abc",
}
mon.update(state)
out = ui.OutputWriter.String()
if !strings.Contains(out, structs.EvalStatusComplete) {
t.Fatalf("missing status\n\n%s", out)
}
}
func TestMonitor_Update_Allocs(t *testing.T) {
t.Parallel()
ui := new(cli.MockUi)
mon := newMonitor(ui, nil, fullId)
// New allocations write new logs
state := &evalState{
allocs: map[string]*allocState{
"alloc1": &allocState{
id: "87654321-abcd-efab-cdef-123456789abc",
group: "group1",
node: "12345678-abcd-efab-cdef-123456789abc",
desired: structs.AllocDesiredStatusRun,
client: structs.AllocClientStatusPending,
index: 1,
},
},
}
mon.update(state)
// Logs were output
out := ui.OutputWriter.String()
if !strings.Contains(out, "87654321-abcd-efab-cdef-123456789abc") {
t.Fatalf("missing alloc\n\n%s", out)
}
if !strings.Contains(out, "group1") {
t.Fatalf("missing group\n\n%s", out)
}
if !strings.Contains(out, "12345678-abcd-efab-cdef-123456789abc") {
t.Fatalf("missing node\n\n%s", out)
}
if !strings.Contains(out, "created") {
t.Fatalf("missing created\n\n%s", out)
}
ui.OutputWriter.Reset()
// No change yields no logs
mon.update(state)
if out := ui.OutputWriter.String(); out != "" {
t.Fatalf("expected no output\n\n%s", out)
}
ui.OutputWriter.Reset()
// Alloc updates cause more log lines
state = &evalState{
allocs: map[string]*allocState{
"alloc1": &allocState{
id: "87654321-abcd-efab-cdef-123456789abc",
group: "group1",
node: "12345678-abcd-efab-cdef-123456789abc",
desired: structs.AllocDesiredStatusRun,
client: structs.AllocClientStatusRunning,
index: 2,
},
},
}
mon.update(state)
// Updates were logged
out = ui.OutputWriter.String()
if !strings.Contains(out, "87654321-abcd-efab-cdef-123456789abc") {
t.Fatalf("missing alloc\n\n%s", out)
}
if !strings.Contains(out, "pending") {
t.Fatalf("missing old status\n\n%s", out)
}
if !strings.Contains(out, "running") {
t.Fatalf("missing new status\n\n%s", out)
}
}
func TestMonitor_Update_AllocModification(t *testing.T) {
t.Parallel()
ui := new(cli.MockUi)
mon := newMonitor(ui, nil, fullId)
// New allocs with a create index lower than the
// eval create index are logged as modifications
state := &evalState{
index: 2,
allocs: map[string]*allocState{
"alloc3": &allocState{
id: "87654321-abcd-bafe-cdef-123456789abc",
node: "12345678-abcd-efab-cdef-123456789abc",
group: "group2",
index: 1,
},
},
}
mon.update(state)
// Modification was logged
out := ui.OutputWriter.String()
if !strings.Contains(out, "87654321-abcd-bafe-cdef-123456789abc") {
t.Fatalf("missing alloc\n\n%s", out)
}
if !strings.Contains(out, "group2") {
t.Fatalf("missing group\n\n%s", out)
}
if !strings.Contains(out, "12345678-abcd-efab-cdef-123456789abc") {
t.Fatalf("missing node\n\n%s", out)
}
if !strings.Contains(out, "modified") {
t.Fatalf("missing modification\n\n%s", out)
}
}
func TestMonitor_Monitor(t *testing.T) {
t.Parallel()
srv, client, _ := testServer(t, false, nil)
defer srv.Shutdown()
// Create the monitor
ui := new(cli.MockUi)
mon := newMonitor(ui, client, fullId)
// Submit a job - this creates a new evaluation we can monitor
job := testJob("job1")
resp, _, err := client.Jobs().Register(job, nil)
if err != nil {
t.Fatalf("err: %s", err)
}
// Start monitoring the eval
var code int
doneCh := make(chan struct{})
go func() {
defer close(doneCh)
code = mon.monitor(resp.EvalID, false)
}()
// Wait for completion
select {
case <-doneCh:
case <-time.After(5 * time.Second):
t.Fatalf("eval monitor took too long")
}
// Check the return code. We should get exit code 2 as there
// would be a scheduling problem on the test server (no clients).
if code != 2 {
t.Fatalf("expect exit 2, got: %d", code)
}
// Check the output
out := ui.OutputWriter.String()
if !strings.Contains(out, resp.EvalID) {
t.Fatalf("missing eval\n\n%s", out)
}
if !strings.Contains(out, "finished with status") {
t.Fatalf("missing final status\n\n%s", out)
}
}
func TestMonitor_MonitorWithPrefix(t *testing.T) {
t.Parallel()
srv, client, _ := testServer(t, false, nil)
defer srv.Shutdown()
// Create the monitor
ui := new(cli.MockUi)
mon := newMonitor(ui, client, shortId)
// Submit a job - this creates a new evaluation we can monitor
job := testJob("job1")
resp, _, err := client.Jobs().Register(job, nil)
if err != nil {
t.Fatalf("err: %s", err)
}
// Start monitoring the eval
var code int
doneCh := make(chan struct{})
go func() {
defer close(doneCh)
code = mon.monitor(resp.EvalID[:8], true)
}()
// Wait for completion
select {
case <-doneCh:
case <-time.After(5 * time.Second):
t.Fatalf("eval monitor took too long")
}
// Check the return code. We should get exit code 2 as there
// would be a scheduling problem on the test server (no clients).
if code != 2 {
t.Fatalf("expect exit 2, got: %d", code)
}
// Check the output
out := ui.OutputWriter.String()
if !strings.Contains(out, resp.EvalID[:8]) {
t.Fatalf("missing eval\n\n%s", out)
}
if strings.Contains(out, resp.EvalID) {
t.Fatalf("expected truncated eval id, got: %s", out)
}
if !strings.Contains(out, "finished with status") {
t.Fatalf("missing final status\n\n%s", out)
}
// Fail on identifier with too few characters
code = mon.monitor(resp.EvalID[:1], true)
if code != 1 {
t.Fatalf("expect exit 1, got: %d", code)
}
if out := ui.ErrorWriter.String(); !strings.Contains(out, "must contain at least two characters.") {
t.Fatalf("expected too few characters error, got: %s", out)
}
ui.ErrorWriter.Reset()
code = mon.monitor(resp.EvalID[:3], true)
if code != 2 {
t.Fatalf("expect exit 2, got: %d", code)
}
if out := ui.OutputWriter.String(); !strings.Contains(out, "Monitoring evaluation") {
t.Fatalf("expected evaluation monitoring output, got: %s", out)
}
}
func TestMonitor_DumpAllocStatus(t *testing.T) {
t.Parallel()
ui := new(cli.MockUi)
// Create an allocation and dump its status to the UI
alloc := &api.Allocation{
ID: "87654321-abcd-efab-cdef-123456789abc",
TaskGroup: "group1",
ClientStatus: structs.AllocClientStatusRunning,
Metrics: &api.AllocationMetric{
NodesEvaluated: 10,
NodesFiltered: 5,
NodesExhausted: 1,
DimensionExhausted: map[string]int{
"cpu": 1,
},
ConstraintFiltered: map[string]int{
"$attr.kernel.name = linux": 1,
},
ClassExhausted: map[string]int{
"web-large": 1,
},
},
}
dumpAllocStatus(ui, alloc, fullId)
// Check the output
out := ui.OutputWriter.String()
if !strings.Contains(out, "87654321-abcd-efab-cdef-123456789abc") {
t.Fatalf("missing alloc\n\n%s", out)
}
if !strings.Contains(out, structs.AllocClientStatusRunning) {
t.Fatalf("missing status\n\n%s", out)
}
if !strings.Contains(out, "5/10") {
t.Fatalf("missing filter stats\n\n%s", out)
}
if !strings.Contains(
out, `Constraint "$attr.kernel.name = linux" filtered 1 nodes`) {
t.Fatalf("missing constraint\n\n%s", out)
}
if !strings.Contains(out, "Resources exhausted on 1 nodes") {
t.Fatalf("missing resource exhaustion\n\n%s", out)
}
if !strings.Contains(out, `Class "web-large" exhausted on 1 nodes`) {
t.Fatalf("missing class exhaustion\n\n%s", out)
}
if !strings.Contains(out, `Dimension "cpu" exhausted on 1 nodes`) {
t.Fatalf("missing dimension exhaustion\n\n%s", out)
}
ui.OutputWriter.Reset()
// Dumping alloc status with no eligible nodes adds a warning
alloc.Metrics.NodesEvaluated = 0
dumpAllocStatus(ui, alloc, shortId)
// Check the output
out = ui.OutputWriter.String()
if !strings.Contains(out, "No nodes were eligible") {
t.Fatalf("missing eligibility warning\n\n%s", out)
}
if strings.Contains(out, "87654321-abcd-efab-cdef-123456789abc") {
t.Fatalf("expected truncated id, got %s", out)
}
if !strings.Contains(out, "87654321") {
t.Fatalf("expected alloc id, got %s", out)
}
}<|fim▁end|> | ui := new(cli.MockUi) |
<|file_name|>csr.ts<|end_file_name|><|fim▁begin|>import { Pkcs10CertificateRequest } from "@peculiar/x509";
import * as graphene from "graphene-pk11";
import { Convert } from "pvtsutils";
import * as core from "webcrypto-core";
import { CryptoKey } from "../key";
import { Pkcs11Object } from "../p11_object";
import { CryptoCertificate, Pkcs11ImportAlgorithms } from "./cert";
export class X509CertificateRequest extends CryptoCertificate implements core.CryptoX509CertificateRequest {
public get subjectName() {
return this.getData()?.subject;
}
public type: "request" = "request";
public p11Object?: graphene.Data;
public csr?: Pkcs10CertificateRequest;
public get value(): ArrayBuffer {
Pkcs11Object.assertStorage(this.p11Object);
return new Uint8Array(this.p11Object.value).buffer as ArrayBuffer;
}
/**
* Creates new CertificateRequest in PKCS11 session
* @param data
* @param algorithm
* @param keyUsages
*/
public async importCert(data: Buffer, algorithm: Pkcs11ImportAlgorithms, keyUsages: KeyUsage[]) {
const array = new Uint8Array(data).buffer as ArrayBuffer;
this.parse(array);
const { token, label, sensitive, ...keyAlg } = algorithm; // remove custom attrs for key
this.publicKey = await this.getData().publicKey.export(keyAlg, keyUsages, this.crypto as globalThis.Crypto) as CryptoKey;
const hashSPKI = this.publicKey.p11Object.id;
const template = this.crypto.templateBuilder.build({
action: "import",<|fim▁hole|> type: "request",
attributes: {
id: hashSPKI,
label: algorithm.label || "X509 Request",
token: !!(algorithm.token),
},
})
// set data attributes
template.value = Buffer.from(data);
this.p11Object = this.crypto.session.create(template).toType<graphene.Data>();
}
public async exportCert() {
return this.value;
}
public toJSON() {
return {
publicKey: this.publicKey.toJSON(),
subjectName: this.subjectName,
type: this.type,
value: Convert.ToBase64Url(this.value),
};
}
public async exportKey(): Promise<CryptoKey>;
public async exportKey(algorithm: Algorithm, usages: KeyUsage[]): Promise<CryptoKey>;
public async exportKey(algorithm?: Algorithm, usages?: KeyUsage[]) {
if (!this.publicKey) {
const publicKeyID = this.id.replace(/\w+-\w+-/i, "");
const keyIndexes = await this.crypto.keyStorage.keys();
for (const keyIndex of keyIndexes) {
const parts = keyIndex.split("-");
if (parts[0] === "public" && parts[2] === publicKeyID) {
if (algorithm && usages) {
this.publicKey = await this.crypto.keyStorage.getItem(keyIndex, algorithm, true, usages);
} else {
this.publicKey = await this.crypto.keyStorage.getItem(keyIndex);
}
break;
}
}
if (!this.publicKey) {
if (algorithm && usages) {
this.publicKey = await this.getData().publicKey.export(algorithm, usages, this.crypto as globalThis.Crypto) as CryptoKey;
} else {
this.publicKey = await this.getData().publicKey.export(this.crypto as globalThis.Crypto) as CryptoKey;
}
}
}
return this.publicKey;
}
protected parse(data: ArrayBuffer) {
this.csr = new Pkcs10CertificateRequest(data);
}
/**
* returns parsed ASN1 value
*/
protected getData() {
if (!this.csr) {
this.parse(this.value);
}
return this.csr!;
}
}<|fim▁end|> | |
<|file_name|>solution.py<|end_file_name|><|fim▁begin|>#!/bin/python3
<|fim▁hole|>
n = int(input().strip())
fct = fact(n)
print(fct)<|fim▁end|> | import sys
fact = lambda n: 1 if n <= 1 else n * fact(n - 1) |
<|file_name|>FTSRequest.py<|end_file_name|><|fim▁begin|>#############################################################################
# $HeadURL$
#############################################################################
""" ..mod: FTSRequest
=================
Helper class to perform FTS job submission and monitoring.
"""
# # imports
import sys
import re
import time
# # from DIRAC
from DIRAC import gLogger, S_OK, S_ERROR
from DIRAC.Core.Utilities.File import checkGuid
from DIRAC.Core.Utilities.Adler import compareAdler, intAdlerToHex, hexAdlerToInt
from DIRAC.Core.Utilities.SiteSEMapping import getSitesForSE
from DIRAC.Core.Utilities.Time import dateTime
from DIRAC.Resources.Storage.StorageElement import StorageElement
from DIRAC.Resources.Catalog.FileCatalog import FileCatalog
from DIRAC.Core.Utilities.ReturnValues import returnSingleResult
from DIRAC.AccountingSystem.Client.Types.DataOperation import DataOperation
from DIRAC.ConfigurationSystem.Client.Helpers.Resources import Resources
from DIRAC.Core.Security.ProxyInfo import getProxyInfo
from DIRAC.ConfigurationSystem.Client.Helpers.Operations import Operations
from DIRAC.DataManagementSystem.Client.FTSJob import FTSJob
from DIRAC.DataManagementSystem.Client.FTSFile import FTSFile
# # RCSID
__RCSID__ = "$Id$"
class FTSRequest( object ):
"""
.. class:: FTSRequest
Helper class for FTS job submission and monitoring.
"""
# # default checksum type
__defaultCksmType = "ADLER32"
# # flag to disablr/enable checksum test, default: disabled
__cksmTest = False
def __init__( self ):
"""c'tor
:param self: self reference
"""
self.log = gLogger.getSubLogger( self.__class__.__name__, True )
# # final states tuple
self.finalStates = ( 'Canceled', 'Failed', 'Hold',
'Finished', 'FinishedDirty' )
# # failed states tuple
self.failedStates = ( 'Canceled', 'Failed',
'Hold', 'FinishedDirty' )
# # successful states tuple
self.successfulStates = ( 'Finished', 'Done' )
# # all file states tuple
self.fileStates = ( 'Done', 'Active', 'Pending', 'Ready', 'Canceled', 'Failed',
'Finishing', 'Finished', 'Submitted', 'Hold', 'Waiting' )
self.statusSummary = {}
# # request status
self.requestStatus = 'Unknown'
# # dict for FTS job files
self.fileDict = {}
# # dict for replicas information
self.catalogReplicas = {}
# # dict for metadata information
self.catalogMetadata = {}
# # dict for files that failed to register
self.failedRegistrations = {}
# # placehoder for FileCatalog reference
self.oCatalog = None
# # submit timestamp
self.submitTime = ''
# # placeholder FTS job GUID
self.ftsGUID = ''
# # placeholder for FTS server URL
self.ftsServer = ''
# # flag marking FTS job completness
self.isTerminal = False
# # completness percentage
self.percentageComplete = 0.0
# # source SE name
self.sourceSE = ''
# # flag marking source SE validity
self.sourceValid = False
# # source space token
self.sourceToken = ''
# # target SE name
self.targetSE = ''
# # flag marking target SE validity
self.targetValid = False
# # target space token
self.targetToken = ''
# # placeholder for target StorageElement
self.oTargetSE = None
# # placeholder for source StorageElement
self.oSourceSE = None
# # checksum type, set it to default
self.__cksmType = self.__defaultCksmType
# # disable checksum test by default
self.__cksmTest = False
# # statuses that prevent submitting to FTS
self.noSubmitStatus = ( 'Failed', 'Done', 'Staging' )
# # were sources resolved?
self.sourceResolved = False
# # Number of file transfers actually submitted
self.submittedFiles = 0
self.transferTime = 0
self.submitCommand = Operations().getValue( 'DataManagement/FTSPlacement/FTS2/SubmitCommand', 'glite-transfer-submit' )
self.monitorCommand = Operations().getValue( 'DataManagement/FTSPlacement/FTS2/MonitorCommand', 'glite-transfer-status' )
self.ftsJob = None
self.ftsFiles = []
####################################################################
#
# Methods for setting/getting/checking the SEs
#
def setSourceSE( self, se ):
""" set SE for source
:param self: self reference
:param str se: source SE name
"""
if se == self.targetSE:
return S_ERROR( "SourceSE is TargetSE" )
self.sourceSE = se
self.oSourceSE = StorageElement( self.sourceSE )
return self.__checkSourceSE()
def __checkSourceSE( self ):
""" check source SE availability
:param self: self reference
"""
if not self.sourceSE:
return S_ERROR( "SourceSE not set" )
res = self.oSourceSE.isValid( 'Read' )
if not res['OK']:
return S_ERROR( "SourceSE not available for reading" )
res = self.__getSESpaceToken( self.oSourceSE )
if not res['OK']:
self.log.error( "FTSRequest failed to get SRM Space Token for SourceSE", res['Message'] )
return S_ERROR( "SourceSE does not support FTS transfers" )
if self.__cksmTest:
res = self.oSourceSE.getChecksumType()
if not res["OK"]:
self.log.error( "Unable to get checksum type for SourceSE",
"%s: %s" % ( self.sourceSE, res["Message"] ) )
cksmType = res["Value"]
if cksmType in ( "NONE", "NULL" ):
self.log.warn( "Checksum type set to %s at SourceSE %s, disabling checksum test" % ( cksmType,
self.sourceSE ) )
self.__cksmTest = False
elif cksmType != self.__cksmType:
self.log.warn( "Checksum type mismatch, disabling checksum test" )
self.__cksmTest = False
self.sourceToken = res['Value']
self.sourceValid = True
return S_OK()
def setTargetSE( self, se ):
""" set target SE
:param self: self reference
:param str se: target SE name
"""
if se == self.sourceSE:
return S_ERROR( "TargetSE is SourceSE" )
self.targetSE = se
self.oTargetSE = StorageElement( self.targetSE )
return self.__checkTargetSE()
def setTargetToken( self, token ):
""" target space token setter
:param self: self reference
:param str token: target space token
"""
self.targetToken = token
return S_OK()
def __checkTargetSE( self ):
""" check target SE availability
:param self: self reference
"""
if not self.targetSE:
return S_ERROR( "TargetSE not set" )
res = self.oTargetSE.isValid( 'Write' )
if not res['OK']:
return S_ERROR( "TargetSE not available for writing" )
res = self.__getSESpaceToken( self.oTargetSE )
if not res['OK']:
self.log.error( "FTSRequest failed to get SRM Space Token for TargetSE", res['Message'] )
return S_ERROR( "TargetSE does not support FTS transfers" )
# # check checksum types
if self.__cksmTest:
res = self.oTargetSE.getChecksumType()
if not res["OK"]:
self.log.error( "Unable to get checksum type for TargetSE",
"%s: %s" % ( self.targetSE, res["Message"] ) )
cksmType = res["Value"]
if cksmType in ( "NONE", "NULL" ):
self.log.warn( "Checksum type set to %s at TargetSE %s, disabling checksum test" % ( cksmType,
self.targetSE ) )
self.__cksmTest = False
elif cksmType != self.__cksmType:
self.log.warn( "Checksum type mismatch, disabling checksum test" )
self.__cksmTest = False
self.targetToken = res['Value']
self.targetValid = True
return S_OK()
@staticmethod
def __getSESpaceToken( oSE ):
""" get space token from StorageElement instance
:param self: self reference
:param StorageElement oSE: StorageElement instance
"""
res = oSE.getStorageParameters( "SRM2" )
if not res['OK']:
return res
return S_OK( res['Value'].get( 'SpaceToken' ) )
####################################################################
#
# Methods for setting/getting FTS request parameters
#
def setFTSGUID( self, guid ):
""" FTS job GUID setter
:param self: self reference
:param str guid: string containg GUID
"""
if not checkGuid( guid ):
return S_ERROR( "Incorrect GUID format" )
self.ftsGUID = guid
return S_OK()
def setFTSServer( self, server ):
""" FTS server setter
:param self: self reference
:param str server: FTS server URL
"""
self.ftsServer = server
return S_OK()
def isRequestTerminal( self ):
""" check if FTS job has terminated
:param self: self reference
"""
if self.requestStatus in self.finalStates:
self.isTerminal = True
return S_OK( self.isTerminal )
def setCksmTest( self, cksmTest = False ):
""" set cksm test
:param self: self reference
:param bool cksmTest: flag to enable/disable checksum test
"""
self.__cksmTest = bool( cksmTest )
return S_OK( self.__cksmTest )
####################################################################
#
# Methods for setting/getting/checking files and their metadata
#
def setLFN( self, lfn ):
""" add LFN :lfn: to :fileDict:
:param self: self reference
:param str lfn: LFN to add to
"""
self.fileDict.setdefault( lfn, {'Status':'Waiting'} )
return S_OK()
def setSourceSURL( self, lfn, surl ):
""" source SURL setter
:param self: self reference
:param str lfn: LFN
:param str surl: source SURL
"""
target = self.fileDict[lfn].get( 'Target' )
if target == surl:
return S_ERROR( "Source and target the same" )
return self.__setFileParameter( lfn, 'Source', surl )
def getSourceSURL( self, lfn ):
""" get source SURL for LFN :lfn:
:param self: self reference
:param str lfn: LFN
"""
return self.__getFileParameter( lfn, 'Source' )
def setTargetSURL( self, lfn, surl ):
""" set target SURL for LFN :lfn:
:param self: self reference
:param str lfn: LFN
:param str surl: target SURL
"""
source = self.fileDict[lfn].get( 'Source' )
if source == surl:
return S_ERROR( "Source and target the same" )
return self.__setFileParameter( lfn, 'Target', surl )
def getFailReason( self, lfn ):
""" get fail reason for file :lfn:
:param self: self reference
:param str lfn: LFN
"""
return self.__getFileParameter( lfn, 'Reason' )
def getRetries( self, lfn ):
""" get number of attepmts made to transfer file :lfn:
:param self: self reference
:param str lfn: LFN
"""
return self.__getFileParameter( lfn, 'Retries' )
def getTransferTime( self, lfn ):
""" get duration of transfer for file :lfn:
:param self: self reference
:param str lfn: LFN
"""
return self.__getFileParameter( lfn, 'Duration' )
def getFailed( self ):
""" get list of wrongly transferred LFNs
:param self: self reference
"""
return S_OK( [ lfn for lfn in self.fileDict
if self.fileDict[lfn].get( 'Status', '' ) in self.failedStates ] )
def getStaging( self ):
""" get files set for prestaging """
return S_OK( [lfn for lfn in self.fileDict
if self.fileDict[lfn].get( 'Status', '' ) == 'Staging'] )
def getDone( self ):
""" get list of succesfully transferred LFNs
:param self: self reference
"""
return S_OK( [ lfn for lfn in self.fileDict
if self.fileDict[lfn].get( 'Status', '' ) in self.successfulStates ] )
def __setFileParameter( self, lfn, paramName, paramValue ):
""" set :paramName: to :paramValue: for :lfn: file
:param self: self reference
:param str lfn: LFN
:param str paramName: parameter name
:param mixed paramValue: a new parameter value
"""
self.setLFN( lfn )
self.fileDict[lfn][paramName] = paramValue
return S_OK()
def __getFileParameter( self, lfn, paramName ):
""" get value of :paramName: for file :lfn:
:param self: self reference
:param str lfn: LFN
:param str paramName: parameter name
"""
if lfn not in self.fileDict:
return S_ERROR( "Supplied file not set" )
if paramName not in self.fileDict[lfn]:
return S_ERROR( "%s not set for file" % paramName )
return S_OK( self.fileDict[lfn][paramName] )
####################################################################
#
# Methods for submission
#
def submit( self, monitor = False, printOutput = True ):
""" submit FTS job
:param self: self reference
:param bool monitor: flag to monitor progress of FTS job
:param bool printOutput: flag to print output of execution to stdout
"""
res = self.__prepareForSubmission()
if not res['OK']:
return res
res = self.__submitFTSTransfer()
if not res['OK']:
return res
resDict = { 'ftsGUID' : self.ftsGUID, 'ftsServer' : self.ftsServer, 'submittedFiles' : self.submittedFiles }
if monitor or printOutput:
gLogger.always( "Submitted %s@%s" % ( self.ftsGUID, self.ftsServer ) )
if monitor:
self.monitor( untilTerminal = True, printOutput = printOutput, full = False )
return S_OK( resDict )
def __prepareForSubmission( self ):
""" check validity of job before submission
:param self: self reference
"""
if not self.fileDict:
return S_ERROR( "No files set" )
if not self.sourceValid:
return S_ERROR( "SourceSE not valid" )
if not self.targetValid:
return S_ERROR( "TargetSE not valid" )
if not self.ftsServer:
res = self.__resolveFTSServer()
if not res['OK']:
return S_ERROR( "FTSServer not valid" )
self.resolveSource()
self.resolveTarget()
res = self.__filesToSubmit()
if not res['OK']:
return S_ERROR( "No files to submit" )
return S_OK()
def __getCatalogObject( self ):
""" CatalogInterface instance facade
:param self: self reference
"""
try:
if not self.oCatalog:
self.oCatalog = FileCatalog()
return S_OK()
except:
return S_ERROR()
def __updateReplicaCache( self, lfns = None, overwrite = False ):
""" update replica cache for list of :lfns:
:param self: self reference
:param mixed lfns: list of LFNs
:param bool overwrite: flag to trigger cache clearing and updating
"""
if not lfns:
lfns = self.fileDict.keys()
toUpdate = [ lfn for lfn in lfns if ( lfn not in self.catalogReplicas ) or overwrite ]
if not toUpdate:
return S_OK()
res = self.__getCatalogObject()
if not res['OK']:
return res
res = self.oCatalog.getReplicas( toUpdate )
if not res['OK']:
return S_ERROR( "Failed to update replica cache: %s" % res['Message'] )
for lfn, error in res['Value']['Failed'].items():
self.__setFileParameter( lfn, 'Reason', error )
self.__setFileParameter( lfn, 'Status', 'Failed' )
for lfn, replicas in res['Value']['Successful'].items():
self.catalogReplicas[lfn] = replicas
return S_OK()
def __updateMetadataCache( self, lfns = None ):
""" update metadata cache for list of LFNs
:param self: self reference
:param list lnfs: list of LFNs
"""
if not lfns:
lfns = self.fileDict.keys()
toUpdate = [ lfn for lfn in lfns if lfn not in self.catalogMetadata ]
if not toUpdate:
return S_OK()
res = self.__getCatalogObject()
if not res['OK']:
return res
res = self.oCatalog.getFileMetadata( toUpdate )
if not res['OK']:
return S_ERROR( "Failed to get source catalog metadata: %s" % res['Message'] )
for lfn, error in res['Value']['Failed'].items():
self.__setFileParameter( lfn, 'Reason', error )
self.__setFileParameter( lfn, 'Status', 'Failed' )
for lfn, metadata in res['Value']['Successful'].items():
self.catalogMetadata[lfn] = metadata
return S_OK()
def resolveSource( self ):
""" resolve source SE eligible for submission
:param self: self reference
"""
# Avoid resolving sources twice
if self.sourceResolved:
return S_OK()
# Only resolve files that need a transfer
toResolve = [ lfn for lfn in self.fileDict if self.fileDict[lfn].get( "Status", "" ) != "Failed" ]
if not toResolve:
return S_OK()
res = self.__updateMetadataCache( toResolve )
if not res['OK']:
return res
res = self.__updateReplicaCache( toResolve )
if not res['OK']:
return res
# Define the source URLs
for lfn in toResolve:
replicas = self.catalogReplicas.get( lfn, {} )
if self.sourceSE not in replicas:
gLogger.warn( "resolveSource: skipping %s - not replicas at SourceSE %s" % ( lfn, self.sourceSE ) )
self.__setFileParameter( lfn, 'Reason', "No replica at SourceSE" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
continue
res = returnSingleResult( self.oSourceSE.getURL( lfn, protocol = 'srm' ) )
if not res['OK']:
gLogger.warn( "resolveSource: skipping %s - %s" % ( lfn, res["Message"] ) )
self.__setFileParameter( lfn, 'Reason', res['Message'] )
self.__setFileParameter( lfn, 'Status', 'Failed' )
continue
res = self.setSourceSURL( lfn, res['Value'] )
if not res['OK']:
gLogger.warn( "resolveSource: skipping %s - %s" % ( lfn, res["Message"] ) )
self.__setFileParameter( lfn, 'Reason', res['Message'] )
self.__setFileParameter( lfn, 'Status', 'Failed' )
continue
toResolve = []
for lfn in self.fileDict:
if "Source" in self.fileDict[lfn]:
toResolve.append( lfn )
if not toResolve:
return S_ERROR( "No eligible Source files" )
# Get metadata of the sources, to check for existance, availability and caching
res = self.oSourceSE.getFileMetadata( toResolve )
if not res['OK']:
return S_ERROR( "Failed to check source file metadata" )
for lfn, error in res['Value']['Failed'].items():
if re.search( 'File does not exist', error ):
gLogger.warn( "resolveSource: skipping %s - source file does not exists" % lfn )
self.__setFileParameter( lfn, 'Reason', "Source file does not exist" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
else:
gLogger.warn( "resolveSource: skipping %s - failed to get source metadata" % lfn )
self.__setFileParameter( lfn, 'Reason', "Failed to get Source metadata" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
toStage = []
nbStagedFiles = 0
for lfn, metadata in res['Value']['Successful'].items():
lfnStatus = self.fileDict.get( lfn, {} ).get( 'Status' )
if metadata['Unavailable']:
gLogger.warn( "resolveSource: skipping %s - source file unavailable" % lfn )
self.__setFileParameter( lfn, 'Reason', "Source file Unavailable" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
elif metadata['Lost']:
gLogger.warn( "resolveSource: skipping %s - source file lost" % lfn )
self.__setFileParameter( lfn, 'Reason', "Source file Lost" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
elif not metadata['Cached']:
if lfnStatus != 'Staging':
toStage.append( lfn )
elif metadata['Size'] != self.catalogMetadata[lfn]['Size']:
gLogger.warn( "resolveSource: skipping %s - source file size mismatch" % lfn )
self.__setFileParameter( lfn, 'Reason', "Source size mismatch" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
elif self.catalogMetadata[lfn]['Checksum'] and metadata['Checksum'] and \
not compareAdler( metadata['Checksum'], self.catalogMetadata[lfn]['Checksum'] ):
gLogger.warn( "resolveSource: skipping %s - source file checksum mismatch" % lfn )
self.__setFileParameter( lfn, 'Reason', "Source checksum mismatch" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
elif lfnStatus == 'Staging':
# file that was staging is now cached
self.__setFileParameter( lfn, 'Status', 'Waiting' )
nbStagedFiles += 1
# Some files were being staged
if nbStagedFiles:
self.log.info( 'resolveSource: %d files have been staged' % nbStagedFiles )
# Launching staging of files not in cache
if toStage:
gLogger.warn( "resolveSource: %s source files not cached, prestaging..." % len( toStage ) )
stage = self.oSourceSE.prestageFile( toStage )
if not stage["OK"]:
gLogger.error( "resolveSource: error is prestaging", stage["Message"] )
for lfn in toStage:
self.__setFileParameter( lfn, 'Reason', stage["Message"] )
self.__setFileParameter( lfn, 'Status', 'Failed' )
else:
for lfn in toStage:
if lfn in stage['Value']['Successful']:
self.__setFileParameter( lfn, 'Status', 'Staging' )
elif lfn in stage['Value']['Failed']:
self.__setFileParameter( lfn, 'Reason', stage['Value']['Failed'][lfn] )
self.__setFileParameter( lfn, 'Status', 'Failed' )
self.sourceResolved = True
return S_OK()
def resolveTarget( self ):
""" find target SE eligible for submission
:param self: self reference
"""
toResolve = [ lfn for lfn in self.fileDict
if self.fileDict[lfn].get( 'Status' ) not in self.noSubmitStatus ]
if not toResolve:
return S_OK()
res = self.__updateReplicaCache( toResolve )
if not res['OK']:
return res
for lfn in toResolve:
res = returnSingleResult( self.oTargetSE.getURL( lfn, protocol = 'srm' ) )
if not res['OK']:
reason = res.get( 'Message', res['Message'] )
gLogger.warn( "resolveTarget: skipping %s - %s" % ( lfn, reason ) )
self.__setFileParameter( lfn, 'Reason', reason )
self.__setFileParameter( lfn, 'Status', 'Failed' )
continue
res = self.setTargetSURL( lfn, res['Value'] )
if not res['OK']:
gLogger.warn( "resolveTarget: skipping %s - %s" % ( lfn, res["Message"] ) )
self.__setFileParameter( lfn, 'Reason', res['Message'] )
self.__setFileParameter( lfn, 'Status', 'Failed' )
continue
toResolve = []
for lfn in self.fileDict:
if "Target" in self.fileDict[lfn]:
toResolve.append( lfn )
if not toResolve:
return S_ERROR( "No eligible Target files" )
res = self.oTargetSE.exists( toResolve )
if not res['OK']:
return S_ERROR( "Failed to check target existence" )
for lfn, error in res['Value']['Failed'].items():
self.__setFileParameter( lfn, 'Reason', error )
self.__setFileParameter( lfn, 'Status', 'Failed' )
toRemove = []
for lfn, exists in res['Value']['Successful'].items():
if exists:
res = self.getSourceSURL( lfn )
if not res['OK']:
gLogger.warn( "resolveTarget: skipping %s - target exists" % lfn )
self.__setFileParameter( lfn, 'Reason', "Target exists" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
elif res['Value'] == self.fileDict[lfn]['Target']:
gLogger.warn( "resolveTarget: skipping %s - source and target pfns are the same" % lfn )
self.__setFileParameter( lfn, 'Reason', "Source and Target the same" )
self.__setFileParameter( lfn, 'Status', 'Failed' )
else:
toRemove.append( lfn )
if toRemove:
self.oTargetSE.removeFile( toRemove )
return S_OK()<|fim▁hole|> """
check if there is at least one file to submit
:return: S_OK if at least one file is present, S_ERROR otherwise
"""
for lfn in self.fileDict:
lfnStatus = self.fileDict[lfn].get( 'Status' )
source = self.fileDict[lfn].get( 'Source' )
target = self.fileDict[lfn].get( 'Target' )
if lfnStatus not in self.noSubmitStatus and source and target:
return S_OK()
return S_ERROR()
def __createFTSFiles( self ):
""" create LFNs file for glite-transfer-submit command
This file consists one line for each fiel to be transferred:
sourceSURL targetSURL [CHECKSUMTYPE:CHECKSUM]
:param self: self reference
"""
self.__updateMetadataCache()
for lfn in self.fileDict:
lfnStatus = self.fileDict[lfn].get( 'Status' )
if lfnStatus not in self.noSubmitStatus:
cksmStr = ""
# # add chsmType:cksm only if cksmType is specified, else let FTS decide by itself
if self.__cksmTest and self.__cksmType:
checkSum = self.catalogMetadata.get( lfn, {} ).get( 'Checksum' )
if checkSum:
cksmStr = " %s:%s" % ( self.__cksmType, intAdlerToHex( hexAdlerToInt( checkSum ) ) )
ftsFile = FTSFile()
ftsFile.LFN = lfn
ftsFile.SourceSURL = self.fileDict[lfn].get( 'Source' )
ftsFile.TargetSURL = self.fileDict[lfn].get( 'Target' )
ftsFile.SourceSE = self.sourceSE
ftsFile.TargetSE = self.targetSE
ftsFile.Status = self.fileDict[lfn].get( 'Status' )
ftsFile.Checksum = cksmStr
ftsFile.Size = self.catalogMetadata.get( lfn, {} ).get( 'Size' )
self.ftsFiles.append( ftsFile )
self.submittedFiles += 1
return S_OK()
def __createFTSJob( self, guid = None ):
self.__createFTSFiles()
ftsJob = FTSJob()
ftsJob.RequestID = 0
ftsJob.OperationID = 0
ftsJob.SourceSE = self.sourceSE
ftsJob.TargetSE = self.targetSE
ftsJob.SourceToken = self.sourceToken
ftsJob.TargetToken = self.targetToken
ftsJob.FTSServer = self.ftsServer
if guid:
ftsJob.FTSGUID = guid
for ftsFile in self.ftsFiles:
ftsFile.Attempt += 1
ftsFile.Error = ""
ftsJob.addFile( ftsFile )
self.ftsJob = ftsJob
def __submitFTSTransfer( self ):
""" create and execute glite-transfer-submit CLI command
:param self: self reference
"""
log = gLogger.getSubLogger( 'Submit' )
self.__createFTSJob()
submit = self.ftsJob.submitFTS2( command = self.submitCommand )
if not submit["OK"]:
log.error( "unable to submit FTSJob: %s" % submit["Message"] )
return submit
log.info( "FTSJob '%s'@'%s' has been submitted" % ( self.ftsJob.FTSGUID, self.ftsJob.FTSServer ) )
# # update statuses for job files
for ftsFile in self.ftsJob:
ftsFile.FTSGUID = self.ftsJob.FTSGUID
ftsFile.Status = "Submitted"
ftsFile.Attempt += 1
log.info( "FTSJob '%s'@'%s' has been submitted" % ( self.ftsJob.FTSGUID, self.ftsJob.FTSServer ) )
self.ftsGUID = self.ftsJob.FTSGUID
return S_OK()
def __resolveFTSServer( self ):
"""
resolve FTS server to use, it should be the closest one from target SE
:param self: self reference
"""
from DIRAC.ConfigurationSystem.Client.Helpers.Resources import getFTSServersForSites
if not self.targetSE:
return S_ERROR( "Target SE not set" )
res = getSitesForSE( self.targetSE )
if not res['OK'] or not res['Value']:
return S_ERROR( "Could not determine target site" )
targetSites = res['Value']
targetSite = ''
for targetSite in targetSites:
targetFTS = getFTSServersForSites( [targetSite] )
if targetFTS['OK']:
ftsTarget = targetFTS['Value'][targetSite]
if ftsTarget:
self.ftsServer = ftsTarget
return S_OK( self.ftsServer )
else:
return targetFTS
return S_ERROR( 'No FTS server found for %s' % targetSite )
####################################################################
#
# Methods for monitoring
#
def summary( self, untilTerminal = False, printOutput = False ):
""" summary of FTS job
:param self: self reference
:param bool untilTerminal: flag to monitor FTS job to its final state
:param bool printOutput: flag to print out monitoring information to the stdout
"""
res = self.__isSummaryValid()
if not res['OK']:
return res
while not self.isTerminal:
res = self.__parseOutput( full = True )
if not res['OK']:
return res
if untilTerminal:
self.__print()
self.isRequestTerminal()
if res['Value'] or ( not untilTerminal ):
break
time.sleep( 1 )
if untilTerminal:
print ""
if printOutput and ( not untilTerminal ):
return self.dumpSummary( printOutput = printOutput )
return S_OK()
def monitor( self, untilTerminal = False, printOutput = False, full = True ):
""" monitor FTS job
:param self: self reference
:param bool untilTerminal: flag to monitor FTS job to its final state
:param bool printOutput: flag to print out monitoring information to the stdout
"""
if not self.ftsJob:
self.resolveSource()
self.__createFTSJob( self.ftsGUID )
res = self.__isSummaryValid()
if not res['OK']:
return res
if untilTerminal:
res = self.summary( untilTerminal = untilTerminal, printOutput = printOutput )
if not res['OK']:
return res
res = self.__parseOutput( full = full )
if not res['OK']:
return res
if untilTerminal:
self.finalize()
if printOutput:
self.dump()
return res
def dumpSummary( self, printOutput = False ):
""" get FTS job summary as str
:param self: self reference
:param bool printOutput: print summary to stdout
"""
outStr = ''
for status in sorted( self.statusSummary ):
if self.statusSummary[status]:
outStr = '%s\t%-10s : %-10s\n' % ( outStr, status, str( self.statusSummary[status] ) )
outStr = outStr.rstrip( '\n' )
if printOutput:
print outStr
return S_OK( outStr )
def __print( self ):
""" print progress bar of FTS job completeness to stdout
:param self: self reference
"""
width = 100
bits = int( ( width * self.percentageComplete ) / 100 )
outStr = "|%s>%s| %.1f%s %s %s" % ( "="*bits, " "*( width - bits ),
self.percentageComplete, "%",
self.requestStatus, " "*10 )
sys.stdout.write( "%s\r" % ( outStr ) )
sys.stdout.flush()
def dump( self ):
""" print FTS job parameters and files to stdout
:param self: self reference
"""
print "%-10s : %-10s" % ( "Status", self.requestStatus )
print "%-10s : %-10s" % ( "Source", self.sourceSE )
print "%-10s : %-10s" % ( "Target", self.targetSE )
print "%-10s : %-128s" % ( "Server", self.ftsServer )
print "%-10s : %-128s" % ( "GUID", self.ftsGUID )
for lfn in sorted( self.fileDict ):
print "\n %-15s : %-128s" % ( 'LFN', lfn )
for key in ['Source', 'Target', 'Status', 'Reason', 'Duration']:
print " %-15s : %-128s" % ( key, str( self.fileDict[lfn].get( key ) ) )
return S_OK()
def __isSummaryValid( self ):
""" check validity of FTS job summary report
:param self: self reference
"""
if not self.ftsServer:
return S_ERROR( "FTSServer not set" )
if not self.ftsGUID:
return S_ERROR( "FTSGUID not set" )
return S_OK()
def __parseOutput( self, full = False ):
""" execute glite-transfer-status command and parse its output
:param self: self reference
:param bool full: glite-transfer-status verbosity level, when set, collect information of files as well
"""
monitor = self.ftsJob.monitorFTS2( command = self.monitorCommand, full = full )
if not monitor['OK']:
return monitor
self.percentageComplete = self.ftsJob.Completeness
self.requestStatus = self.ftsJob.Status
self.submitTime = self.ftsJob.SubmitTime
statusSummary = monitor['Value']
if statusSummary:
for state in statusSummary:
self.statusSummary[state] = statusSummary[state]
self.transferTime = 0
for ftsFile in self.ftsJob:
lfn = ftsFile.LFN
self.__setFileParameter( lfn, 'Status', ftsFile.Status )
self.__setFileParameter( lfn, 'Reason', ftsFile.Error )
self.__setFileParameter( lfn, 'Duration', ftsFile._duration )
targetURL = self.__getFileParameter( lfn, 'Target' )
if not targetURL['OK']:
self.__setFileParameter( lfn, 'Target', ftsFile.TargetSURL )
self.transferTime += int( ftsFile._duration )
return S_OK()
####################################################################
#
# Methods for finalization
#
def finalize( self ):
""" finalize FTS job
:param self: self reference
"""
self.__updateMetadataCache()
transEndTime = dateTime()
regStartTime = time.time()
res = self.getTransferStatistics()
transDict = res['Value']
res = self.__registerSuccessful( transDict['transLFNs'] )
regSuc, regTotal = res['Value']
regTime = time.time() - regStartTime
if self.sourceSE and self.targetSE:
self.__sendAccounting( regSuc, regTotal, regTime, transEndTime, transDict )
return S_OK()
def getTransferStatistics( self ):
""" collect information of Transfers that can be used by Accounting
:param self: self reference
"""
transDict = { 'transTotal': len( self.fileDict ),
'transLFNs': [],
'transOK': 0,
'transSize': 0 }
for lfn in self.fileDict:
if self.fileDict[lfn].get( 'Status' ) in self.successfulStates:
if self.fileDict[lfn].get( 'Duration', 0 ):
transDict['transLFNs'].append( lfn )
transDict['transOK'] += 1
if lfn in self.catalogMetadata:
transDict['transSize'] += self.catalogMetadata[lfn].get( 'Size', 0 )
return S_OK( transDict )
def getFailedRegistrations( self ):
""" get failed registrations dict
:param self: self reference
"""
return S_OK( self.failedRegistrations )
def __registerSuccessful( self, transLFNs ):
""" register successfully transferred files to the catalogs,
fill failedRegistrations dict for files that failed to register
:param self: self reference
:param list transLFNs: LFNs in FTS job
"""
self.failedRegistrations = {}
toRegister = {}
for lfn in transLFNs:
res = returnSingleResult( self.oTargetSE.getURL( self.fileDict[lfn].get( 'Target' ), protocol = 'srm' ) )
if not res['OK']:
self.__setFileParameter( lfn, 'Reason', res['Message'] )
self.__setFileParameter( lfn, 'Status', 'Failed' )
else:
toRegister[lfn] = { 'PFN' : res['Value'], 'SE' : self.targetSE }
if not toRegister:
return S_OK( ( 0, 0 ) )
res = self.__getCatalogObject()
if not res['OK']:
for lfn in toRegister:
self.failedRegistrations = toRegister
self.log.error( 'Failed to get Catalog Object', res['Message'] )
return S_OK( ( 0, len( toRegister ) ) )
res = self.oCatalog.addReplica( toRegister )
if not res['OK']:
self.failedRegistrations = toRegister
self.log.error( 'Failed to get Catalog Object', res['Message'] )
return S_OK( ( 0, len( toRegister ) ) )
for lfn, error in res['Value']['Failed'].items():
self.failedRegistrations[lfn] = toRegister[lfn]
self.log.error( 'Registration of Replica failed', '%s : %s' % ( lfn, str( error ) ) )
return S_OK( ( len( res['Value']['Successful'] ), len( toRegister ) ) )
def __sendAccounting( self, regSuc, regTotal, regTime, transEndTime, transDict ):
""" send accounting record
:param self: self reference
:param regSuc: number of files successfully registered
:param regTotal: number of files attepted to register
:param regTime: time stamp at the end of registration
:param transEndTime: time stamp at the end of FTS job
:param dict transDict: dict holding couters for files being transerred, their sizes and successfull transfers
"""
oAccounting = DataOperation()
oAccounting.setEndTime( transEndTime )
oAccounting.setStartTime( self.submitTime )
accountingDict = {}
accountingDict['OperationType'] = 'replicateAndRegister'
result = getProxyInfo()
if not result['OK']:
userName = 'system'
else:
userName = result['Value'].get( 'username', 'unknown' )
accountingDict['User'] = userName
accountingDict['Protocol'] = 'FTS' if 'fts3' not in self.ftsServer else 'FTS3'
accountingDict['RegistrationTime'] = regTime
accountingDict['RegistrationOK'] = regSuc
accountingDict['RegistrationTotal'] = regTotal
accountingDict['TransferOK'] = transDict['transOK']
accountingDict['TransferTotal'] = transDict['transTotal']
accountingDict['TransferSize'] = transDict['transSize']
accountingDict['FinalStatus'] = self.requestStatus
accountingDict['Source'] = self.sourceSE
accountingDict['Destination'] = self.targetSE
accountingDict['TransferTime'] = self.transferTime
oAccounting.setValuesFromDict( accountingDict )
self.log.verbose( "Attempting to commit accounting message..." )
oAccounting.commit()
self.log.verbose( "...committed." )
return S_OK()<|fim▁end|> |
def __filesToSubmit( self ): |
<|file_name|>manage.py<|end_file_name|><|fim▁begin|>#!/usr/bin/env python3
import os
import sys
if __name__ == "__main__":
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "arsoft.web.crashupload.settings")
from django.core.management import execute_from_command_line<|fim▁hole|><|fim▁end|> |
execute_from_command_line(sys.argv) |
<|file_name|>notify_messages.py<|end_file_name|><|fim▁begin|># vim: tabstop=4 shiftwidth=4 softtabstop=4
# =================================================================
# =================================================================
# NOTE: notify message MUST follow these rules:
#
# - Messages must be wrappered with _() for translation
#
# - Replacement variables must be wrappered with brackets
#
# - Replacement variables must be from the following list:'
# {instance_id}
# {instance_name}
# {host_name}
# {source_host_name}
# {target_host_name}
# {error}
from paxes_nova import _
PAUSE_SUCCESS = (_("Pause of virtual machine {instance_name} on host "
"{host_name} was successful."))
PAUSE_ERROR = (_("Pause of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
SUSPEND_SUCCESS = (_("Suspend of virtual machine {instance_name} on host "
"{host_name} was successful."))
SUSPEND_ERROR = (_("Suspend of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
RESUME_SUCCESS = (_("Resume of virtual machine {instance_name} on host "
"{host_name} was successful."))
RESUME_ERROR = (_("Resume of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
DEPLOY_SUCCESS = (_("Deploy of virtual machine {instance_name} on host "
"{host_name} was successful."))
DEPLOY_ERROR = (_("Deploy of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
START_SUCCESS = (_("Start of virtual machine {instance_name} on host "
"{host_name} was successful."))
START_ERROR = (_("Start of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
STOP_SUCCESS = (_("Stop of virtual machine {instance_name} on host "
"{host_name} was successful."))
STOP_ERROR = (_("Stop of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
RESTART_SUCCESS = (_("Restart of virtual machine {instance_name} on host "
"{host_name} was successful."))<|fim▁hole|>RESTART_ERROR = (_("Restart of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
LPM_SUCCESS = (_("Migration of virtual machine {instance_name} from host "
"{source_host_name} to host {target_host_name} was "
"successful."))
LPM_ERROR = (_("Migration of virtual machine {instance_name} to host "
"{target_host_name} failed with exception: {error}"))
LPM_ERROR_DEST = (_("Migration of virtual machine {instance_name} to host "
"{host_name} failed with exception: {error}"))
DELETE_ERROR = (_("Delete of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
DELETE_SUCCESS = (_("Delete of virtual machine {instance_name} on host "
"{host_name} was successful. "))
RESIZE_ERROR = (_("Resize of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
RESIZE_SUCCESS = (_("Resize of virtual machine {instance_name} on host "
"{host_name} was successful."))
CAPTURE_SUCCESS = (_("Capture of virtual machine {instance_name} on host "
"{host_name} was successful"))
CAPTURE_ERROR = (_("Capture of virtual machine {instance_name} on host "
"{host_name} failed with exception: {error}"))
ATTACH_SUCCESS = (_("Volume {volume_id} was successfully attached to "
"virtual machine {instance_name}."))
ATTACH_ERROR = (_("Volume {volume_id} could not be attached to "
"virtual machine {instance_name}. Error message: {error}"))
DETACH_SUCCESS = (_("Volume {volume_id} was successfully detached from "
"virtual machine {instance_name}."))
DETACH_ERROR = (_("Volume {volume_id} could not be detached from "
"virtual machine {instance_name}. Error message: {error}"))<|fim▁end|> | |
<|file_name|>index.ts<|end_file_name|><|fim▁begin|>// Copyright (c) Jupyter Development Team.
// Distributed under the terms of the Modified BSD License.
import {
Application
} from 'phosphor/lib/ui/application';
import {
ApplicationShell
} from './shell';
/**
* The type for all JupyterLab plugins.
*/
export
type JupyterLabPlugin<T> = Application.IPlugin<JupyterLab, T>;
/**
* JupyterLab is the main application class. It is instantiated once and shared.
*/
export
class JupyterLab extends Application<ApplicationShell> {
/**
* Create the application shell for the JupyterLab application.
*/
protected createShell(): ApplicationShell {
return new ApplicationShell();
}<|fim▁hole|><|fim▁end|> | } |
<|file_name|>netconfig.py<|end_file_name|><|fim▁begin|>"""
Network Config
==============
Manage the configuration on a network device given a specific static config or template.
:codeauthor: Mircea Ulinic <[email protected]> & Jerome Fleury <[email protected]>
:maturity: new
:depends: napalm
:platform: unix
Dependencies
------------
- :mod:`NAPALM proxy minion <salt.proxy.napalm>`
- :mod:`Network-related basic features execution module <salt.modules.napalm_network>`
.. versionadded:: 2017.7.0
"""
import logging
import salt.utils.napalm
log = logging.getLogger(__name__)
# ----------------------------------------------------------------------------------------------------------------------
# state properties
# ----------------------------------------------------------------------------------------------------------------------
__virtualname__ = "netconfig"
# ----------------------------------------------------------------------------------------------------------------------
# global variables
# ----------------------------------------------------------------------------------------------------------------------
# ----------------------------------------------------------------------------------------------------------------------
# property functions
# ----------------------------------------------------------------------------------------------------------------------
def __virtual__():
"""
NAPALM library must be installed for this module to work and run in a (proxy) minion.
"""
return salt.utils.napalm.virtual(__opts__, __virtualname__, __file__)
# ----------------------------------------------------------------------------------------------------------------------
# helper functions -- will not be exported
# ----------------------------------------------------------------------------------------------------------------------
def _update_config(
template_name,
template_source=None,
template_hash=None,
template_hash_name=None,
template_user="root",
template_group="root",
template_mode="755",
template_attrs="--------------e----",
saltenv=None,
template_engine="jinja",
skip_verify=False,
defaults=None,
test=False,
commit=True,
debug=False,
replace=False,
**template_vars
):
"""
Call the necessary functions in order to execute the state.
For the moment this only calls the ``net.load_template`` function from the
:mod:`Network-related basic features execution module <salt.modules.napalm_network>`, but this may change in time.
"""
return __salt__["net.load_template"](
template_name,
template_source=template_source,
template_hash=template_hash,
template_hash_name=template_hash_name,
template_user=template_user,
template_group=template_group,
template_mode=template_mode,
template_attrs=template_attrs,
saltenv=saltenv,
template_engine=template_engine,
skip_verify=skip_verify,
defaults=defaults,
test=test,
commit=commit,
debug=debug,
replace=replace,
**template_vars
)
# ----------------------------------------------------------------------------------------------------------------------
# callable functions
# ----------------------------------------------------------------------------------------------------------------------
def replace_pattern(
name,
pattern,
repl,
count=0,
flags=8,
bufsize=1,
append_if_not_found=False,
prepend_if_not_found=False,
not_found_content=None,
search_only=False,
show_changes=True,
backslash_literal=False,
source="running",
path=None,
test=False,
replace=True,
debug=False,
commit=True,
):
"""
.. versionadded:: 2019.2.0
Replace occurrences of a pattern in the configuration source. If
``show_changes`` is ``True``, then a diff of what changed will be returned,
otherwise a ``True`` will be returned when changes are made, and ``False``
when no changes are made.
This is a pure Python implementation that wraps Python's :py:func:`~re.sub`.
pattern
A regular expression, to be matched using Python's
:py:func:`~re.search`.
repl
The replacement text.
count: ``0``
Maximum number of pattern occurrences to be replaced. If count is a
positive integer ``n``, only ``n`` occurrences will be replaced,
otherwise all occurrences will be replaced.
flags (list or int): ``8``
A list of flags defined in the ``re`` module documentation from the
Python standard library. Each list item should be a string that will
correlate to the human-friendly flag name. E.g., ``['IGNORECASE',
'MULTILINE']``. Optionally, ``flags`` may be an int, with a value
corresponding to the XOR (``|``) of all the desired flags. Defaults to
8 (which supports 'MULTILINE').
bufsize (int or str): ``1``
How much of the configuration to buffer into memory at once. The
default value ``1`` processes one line at a time. The special value
``file`` may be specified which will read the entire file into memory
before processing.
append_if_not_found: ``False``
If set to ``True``, and pattern is not found, then the content will be
appended to the file.
prepend_if_not_found: ``False``
If set to ``True`` and pattern is not found, then the content will be
prepended to the file.
not_found_content
Content to use for append/prepend if not found. If None (default), uses
``repl``. Useful when ``repl`` uses references to group in pattern.
search_only: ``False``
If set to true, this no changes will be performed on the file, and this
function will simply return ``True`` if the pattern was matched, and
``False`` if not.
show_changes: ``True``
If ``True``, return a diff of changes made. Otherwise, return ``True``
if changes were made, and ``False`` if not.
backslash_literal: ``False``
Interpret backslashes as literal backslashes for the repl and not
escape characters. This will help when using append/prepend so that
the backslashes are not interpreted for the repl on the second run of
the state.
source: ``running``
The configuration source. Choose from: ``running``, ``candidate``, or
``startup``. Default: ``running``.
path
Save the temporary configuration to a specific path, then read from
there.
test: ``False``
Dry run? If set as ``True``, will apply the config, discard and return
the changes. Default: ``False`` and will commit the changes on the
device.
commit: ``True``
Commit the configuration changes? Default: ``True``.
debug: ``False``
Debug mode. Will insert a new key in the output dictionary, as
``loaded_config`` containing the raw configuration loaded on the device.
replace: ``True``
Load and replace the configuration. Default: ``True``.
If an equal sign (``=``) appears in an argument to a Salt command it is
interpreted as a keyword argument in the format ``key=val``. That
processing can be bypassed in order to pass an equal sign through to the
remote shell command by manually specifying the kwarg:
State SLS Example:
.. code-block:: yaml
update_policy_name:
netconfig.replace_pattern:
- pattern: OLD-POLICY-NAME
- repl: new-policy-name
- debug: true
"""
ret = salt.utils.napalm.default_ret(name)
# the user can override the flags the equivalent CLI args
# which have higher precedence
test = test or __opts__["test"]
debug = __salt__["config.merge"]("debug", debug)
commit = __salt__["config.merge"]("commit", commit)
replace = __salt__["config.merge"]("replace", replace) # this might be a bit risky
replace_ret = __salt__["net.replace_pattern"](
pattern,
repl,
count=count,
flags=flags,
bufsize=bufsize,
append_if_not_found=append_if_not_found,
prepend_if_not_found=prepend_if_not_found,
not_found_content=not_found_content,
search_only=search_only,
show_changes=show_changes,
backslash_literal=backslash_literal,
source=source,
path=path,
test=test,
replace=replace,
debug=debug,
commit=commit,
)
return salt.utils.napalm.loaded_ret(ret, replace_ret, test, debug)
def saved(
name,
source="running",
user=None,
group=None,
mode=None,
attrs=None,
makedirs=False,
dir_mode=None,
replace=True,
backup="",
show_changes=True,
create=True,
tmp_dir="",
tmp_ext="",
encoding=None,
encoding_errors="strict",
allow_empty=False,
follow_symlinks=True,
check_cmd=None,
win_owner=None,
win_perms=None,
win_deny_perms=None,
win_inheritance=True,
win_perms_reset=False,
**kwargs
):
"""
.. versionadded:: 2019.2.0
Save the configuration to a file on the local file system.
name
Absolute path to file where to save the configuration.
To push the files to the Master, use
:mod:`cp.push <salt.modules.cp.push>` Execution function.
source: ``running``
The configuration source. Choose from: ``running``, ``candidate``,
``startup``. Default: ``running``.
user
The user to own the file, this defaults to the user salt is running as
on the minion
group
The group ownership set for the file, this defaults to the group salt
is running as on the minion. On Windows, this is ignored
mode
The permissions to set on this file, e.g. ``644``, ``0775``, or
``4664``.
The default mode for new files and directories corresponds to the
umask of the salt process. The mode of existing files and directories
will only be changed if ``mode`` is specified.<|fim▁hole|> The attributes to have on this file, e.g. ``a``, ``i``. The attributes
can be any or a combination of the following characters:
``aAcCdDeijPsStTu``.
.. note::
This option is **not** supported on Windows.
makedirs: ``False``
If set to ``True``, then the parent directories will be created to
facilitate the creation of the named file. If ``False``, and the parent
directory of the destination file doesn't exist, the state will fail.
dir_mode
If directories are to be created, passing this option specifies the
permissions for those directories. If this is not set, directories
will be assigned permissions by adding the execute bit to the mode of
the files.
The default mode for new files and directories corresponds umask of salt
process. For existing files and directories it's not enforced.
replace: ``True``
If set to ``False`` and the file already exists, the file will not be
modified even if changes would otherwise be made. Permissions and
ownership will still be enforced, however.
backup
Overrides the default backup mode for this specific file. See
:ref:`backup_mode documentation <file-state-backups>` for more details.
show_changes: ``True``
Output a unified diff of the old file and the new file. If ``False``
return a boolean if any changes were made.
create: ``True``
If set to ``False``, then the file will only be managed if the file
already exists on the system.
encoding
If specified, then the specified encoding will be used. Otherwise, the
file will be encoded using the system locale (usually UTF-8). See
https://docs.python.org/3/library/codecs.html#standard-encodings for
the list of available encodings.
encoding_errors: ``'strict'``
Error encoding scheme. Default is ```'strict'```.
See https://docs.python.org/2/library/codecs.html#codec-base-classes
for the list of available schemes.
allow_empty: ``True``
If set to ``False``, then the state will fail if the contents specified
by ``contents_pillar`` or ``contents_grains`` are empty.
follow_symlinks: ``True``
If the desired path is a symlink follow it and make changes to the
file to which the symlink points.
check_cmd
The specified command will be run with an appended argument of a
*temporary* file containing the new managed contents. If the command
exits with a zero status the new managed contents will be written to
the managed destination. If the command exits with a nonzero exit
code, the state will fail and no changes will be made to the file.
tmp_dir
Directory for temp file created by ``check_cmd``. Useful for checkers
dependent on config file location (e.g. daemons restricted to their
own config directories by an apparmor profile).
tmp_ext
Suffix for temp file created by ``check_cmd``. Useful for checkers
dependent on config file extension (e.g. the init-checkconf upstart
config checker).
win_owner: ``None``
The owner of the directory. If this is not passed, user will be used. If
user is not passed, the account under which Salt is running will be
used.
win_perms: ``None``
A dictionary containing permissions to grant and their propagation. For
example: ``{'Administrators': {'perms': 'full_control'}}`` Can be a
single basic perm or a list of advanced perms. ``perms`` must be
specified. ``applies_to`` does not apply to file objects.
win_deny_perms: ``None``
A dictionary containing permissions to deny and their propagation. For
example: ``{'Administrators': {'perms': 'full_control'}}`` Can be a
single basic perm or a list of advanced perms. ``perms`` must be
specified. ``applies_to`` does not apply to file objects.
win_inheritance: ``True``
True to inherit permissions from the parent directory, False not to
inherit permission.
win_perms_reset: ``False``
If ``True`` the existing DACL will be cleared and replaced with the
settings defined in this function. If ``False``, new entries will be
appended to the existing DACL. Default is ``False``.
State SLS Example:
.. code-block:: yaml
/var/backups/{{ opts.id }}/{{ salt.status.time('%s') }}.cfg:
netconfig.saved:
- source: running
- makedirs: true
The state SLS above would create a backup config grouping the files by the
Minion ID, in chronological files. For example, if the state is executed at
on the 3rd of August 2018, at 5:15PM, on the Minion ``core1.lon01``, the
configuration would saved in the file:
``/var/backups/core01.lon01/1533316558.cfg``
"""
ret = __salt__["net.config"](source=source)
if not ret["result"]:
return {"name": name, "changes": {}, "result": False, "comment": ret["comment"]}
return __states__["file.managed"](
name,
user=user,
group=group,
mode=mode,
attrs=attrs,
makedirs=makedirs,
dir_mode=dir_mode,
replace=replace,
backup=backup,
show_changes=show_changes,
create=create,
contents=ret["out"][source],
tmp_dir=tmp_dir,
tmp_ext=tmp_ext,
encoding=encoding,
encoding_errors=encoding_errors,
allow_empty=allow_empty,
follow_symlinks=follow_symlinks,
check_cmd=check_cmd,
win_owner=win_owner,
win_perms=win_perms,
win_deny_perms=win_deny_perms,
win_inheritance=win_inheritance,
win_perms_reset=win_perms_reset,
**kwargs
)
def managed(
name,
template_name=None,
template_source=None,
template_hash=None,
template_hash_name=None,
saltenv="base",
template_engine="jinja",
skip_verify=False,
context=None,
defaults=None,
test=False,
commit=True,
debug=False,
replace=False,
commit_in=None,
commit_at=None,
revert_in=None,
revert_at=None,
**template_vars
):
"""
Manages the configuration on network devices.
By default this state will commit the changes on the device. If there are no changes required, it does not commit
and the field ``already_configured`` from the output dictionary will be set as ``True`` to notify that.
To avoid committing the configuration, set the argument ``test`` to ``True`` (or via the CLI argument ``test=True``)
and will discard (dry run).
To preserve the changes, set ``commit`` to ``False`` (either as CLI argument, either as state parameter).
However, this is recommended to be used only in exceptional cases when there are applied few consecutive states
and/or configuration changes. Otherwise the user might forget that the config DB is locked and the candidate config
buffer is not cleared/merged in the running config.
To replace the config, set ``replace`` to ``True``. This option is recommended to be used with caution!
template_name
Identifies path to the template source. The template can be either stored on the local machine,
either remotely.
The recommended location is under the ``file_roots`` as specified in the master config file.
For example, let's suppose the ``file_roots`` is configured as:
.. code-block:: yaml
file_roots:
base:
- /etc/salt/states
Placing the template under ``/etc/salt/states/templates/example.jinja``, it can be used as
``salt://templates/example.jinja``.
Alternatively, for local files, the user can specify the absolute path.
If remotely, the source can be retrieved via ``http``, ``https`` or ``ftp``.
Examples:
- ``salt://my_template.jinja``
- ``/absolute/path/to/my_template.jinja``
- ``http://example.com/template.cheetah``
- ``https:/example.com/template.mako``
- ``ftp://example.com/template.py``
.. versionchanged:: 2019.2.0
This argument can now support a list of templates to be rendered.
The resulting configuration text is loaded at once, as a single
configuration chunk.
template_source: None
Inline config template to be rendered and loaded on the device.
template_hash: None
Hash of the template file. Format: ``{hash_type: 'md5', 'hsum': <md5sum>}``
template_hash_name: None
When ``template_hash`` refers to a remote file, this specifies the filename to look for in that file.
saltenv: base
Specifies the template environment. This will influence the relative imports inside the templates.
template_engine: jinja
The following templates engines are supported:
- :mod:`cheetah<salt.renderers.cheetah>`
- :mod:`genshi<salt.renderers.genshi>`
- :mod:`jinja<salt.renderers.jinja>`
- :mod:`mako<salt.renderers.mako>`
- :mod:`py<salt.renderers.py>`
- :mod:`wempy<salt.renderers.wempy>`
skip_verify: False
If ``True``, hash verification of remote file sources (``http://``, ``https://``, ``ftp://``) will be skipped,
and the ``source_hash`` argument will be ignored.
.. versionchanged:: 2017.7.1
test: False
Dry run? If set to ``True``, will apply the config, discard and return the changes. Default: ``False``
(will commit the changes on the device).
commit: True
Commit? Default: ``True``.
debug: False
Debug mode. Will insert a new key under the output dictionary, as ``loaded_config`` containing the raw
result after the template was rendered.
.. note::
This argument cannot be used directly on the command line. Instead,
it can be passed through the ``pillar`` variable when executing
either of the :py:func:`state.sls <salt.modules.state.sls>` or
:py:func:`state.apply <salt.modules.state.apply>` (see below for an
example).
commit_in: ``None``
Commit the changes in a specific number of minutes / hours. Example of
accepted formats: ``5`` (commit in 5 minutes), ``2m`` (commit in 2
minutes), ``1h`` (commit the changes in 1 hour)`, ``5h30m`` (commit
the changes in 5 hours and 30 minutes).
.. note::
This feature works on any platforms, as it does not rely on the
native features of the network operating system.
.. note::
After the command is executed and the ``diff`` is not satisfactory,
or for any other reasons you have to discard the commit, you are
able to do so using the
:py:func:`net.cancel_commit <salt.modules.napalm_network.cancel_commit>`
execution function, using the commit ID returned by this function.
.. warning::
Using this feature, Salt will load the exact configuration you
expect, however the diff may change in time (i.e., if an user
applies a manual configuration change, or a different process or
command changes the configuration in the meanwhile).
.. versionadded:: 2019.2.0
commit_at: ``None``
Commit the changes at a specific time. Example of accepted formats:
``1am`` (will commit the changes at the next 1AM), ``13:20`` (will
commit at 13:20), ``1:20am``, etc.
.. note::
This feature works on any platforms, as it does not rely on the
native features of the network operating system.
.. note::
After the command is executed and the ``diff`` is not satisfactory,
or for any other reasons you have to discard the commit, you are
able to do so using the
:py:func:`net.cancel_commit <salt.modules.napalm_network.cancel_commit>`
execution function, using the commit ID returned by this function.
.. warning::
Using this feature, Salt will load the exact configuration you
expect, however the diff may change in time (i.e., if an user
applies a manual configuration change, or a different process or
command changes the configuration in the meanwhile).
.. versionadded:: 2019.2.0
revert_in: ``None``
Commit and revert the changes in a specific number of minutes / hours.
Example of accepted formats: ``5`` (revert in 5 minutes), ``2m`` (revert
in 2 minutes), ``1h`` (revert the changes in 1 hour)`, ``5h30m`` (revert
the changes in 5 hours and 30 minutes).
.. note::
To confirm the commit, and prevent reverting the changes, you will
have to execute the
:mod:`net.confirm_commit <salt.modules.napalm_network.confirm_commit>`
function, using the commit ID returned by this function.
.. warning::
This works on any platform, regardless if they have or don't have
native capabilities to confirming a commit. However, please be
*very* cautious when using this feature: on Junos (as it is the only
NAPALM core platform supporting this natively) it executes a commit
confirmed as you would do from the command line.
All the other platforms don't have this capability natively,
therefore the revert is done via Salt. That means, your device needs
to be reachable at the moment when Salt will attempt to revert your
changes. Be cautious when pushing configuration changes that would
prevent you reach the device.
Similarly, if an user or a different process apply other
configuration changes in the meanwhile (between the moment you
commit and till the changes are reverted), these changes would be
equally reverted, as Salt cannot be aware of them.
.. versionadded:: 2019.2.0
revert_at: ``None``
Commit and revert the changes at a specific time. Example of accepted
formats: ``1am`` (will commit and revert the changes at the next 1AM),
``13:20`` (will commit and revert at 13:20), ``1:20am``, etc.
.. note::
To confirm the commit, and prevent reverting the changes, you will
have to execute the
:mod:`net.confirm_commit <salt.modules.napalm_network.confirm_commit>`
function, using the commit ID returned by this function.
.. warning::
This works on any platform, regardless if they have or don't have
native capabilities to confirming a commit. However, please be
*very* cautious when using this feature: on Junos (as it is the only
NAPALM core platform supporting this natively) it executes a commit
confirmed as you would do from the command line.
All the other platforms don't have this capability natively,
therefore the revert is done via Salt. That means, your device needs
to be reachable at the moment when Salt will attempt to revert your
changes. Be cautious when pushing configuration changes that would
prevent you reach the device.
Similarly, if an user or a different process apply other
configuration changes in the meanwhile (between the moment you
commit and till the changes are reverted), these changes would be
equally reverted, as Salt cannot be aware of them.
.. versionadded:: 2019.2.0
replace: False
Load and replace the configuration. Default: ``False`` (will apply load merge).
context: None
Overrides default context variables passed to the template.
.. versionadded:: 2019.2.0
defaults: None
Default variables/context passed to the template.
template_vars
Dictionary with the arguments/context to be used when the template is rendered. Do not explicitly specify this
argument. This represents any other variable that will be sent to the template rendering system. Please
see an example below! In both ``ntp_peers_example_using_pillar`` and ``ntp_peers_example``, ``peers`` is sent as
template variable.
.. note::
It is more recommended to use the ``context`` argument instead, to
avoid any conflicts with other arguments.
SLS Example (e.g.: under salt://router/config.sls) :
.. code-block:: yaml
whole_config_example:
netconfig.managed:
- template_name: salt://path/to/complete_config.jinja
- debug: True
- replace: True
bgp_config_example:
netconfig.managed:
- template_name: /absolute/path/to/bgp_neighbors.mako
- template_engine: mako
prefix_lists_example:
netconfig.managed:
- template_name: prefix_lists.cheetah
- debug: True
- template_engine: cheetah
ntp_peers_example:
netconfig.managed:
- template_name: http://bit.ly/2gKOj20
- skip_verify: False
- debug: True
- peers:
- 192.168.0.1
- 192.168.0.1
ntp_peers_example_using_pillar:
netconfig.managed:
- template_name: http://bit.ly/2gKOj20
- peers: {{ pillar.get('ntp.peers', []) }}
Multi template example:
.. code-block:: yaml
hostname_and_ntp:
netconfig.managed:
- template_name:
- https://bit.ly/2OhSgqP
- https://bit.ly/2M6C4Lx
- https://bit.ly/2OIWVTs
- debug: true
- context:
hostname: {{ opts.id }}
servers:
- 172.17.17.1
- 172.17.17.2
peers:
- 192.168.0.1
- 192.168.0.2
Usage examples:
.. code-block:: bash
$ sudo salt 'juniper.device' state.sls router.config test=True
$ sudo salt -N all-routers state.sls router.config pillar="{'debug': True}"
``router.config`` depends on the location of the SLS file (see above). Running this command, will be executed all
five steps from above. These examples above are not meant to be used in a production environment, their sole purpose
is to provide usage examples.
Output example:
.. code-block:: bash
$ sudo salt 'juniper.device' state.sls router.config test=True
juniper.device:
----------
ID: ntp_peers_example_using_pillar
Function: netconfig.managed
Result: None
Comment: Testing mode: Configuration discarded.
Started: 12:01:40.744535
Duration: 8755.788 ms
Changes:
----------
diff:
[edit system ntp]
peer 192.168.0.1 { ... }
+ peer 172.17.17.1;
+ peer 172.17.17.3;
Summary for juniper.device
------------
Succeeded: 1 (unchanged=1, changed=1)
Failed: 0
------------
Total states run: 1
Total run time: 8.756 s
Raw output example (useful when the output is reused in other states/execution modules):
.. code-block:: bash
$ sudo salt --out=pprint 'juniper.device' state.sls router.config test=True debug=True
.. code-block:: python
{
'juniper.device': {
'netconfig_|-ntp_peers_example_using_pillar_|-ntp_peers_example_using_pillar_|-managed': {
'__id__': 'ntp_peers_example_using_pillar',
'__run_num__': 0,
'already_configured': False,
'changes': {
'diff': '[edit system ntp] peer 192.168.0.1 { ... }+ peer 172.17.17.1;+ peer 172.17.17.3;'
},
'comment': 'Testing mode: Configuration discarded.',
'duration': 7400.759,
'loaded_config': 'system { ntp { peer 172.17.17.1; peer 172.17.17.3; } }',
'name': 'ntp_peers_example_using_pillar',
'result': None,
'start_time': '12:09:09.811445'
}
}
}
"""
ret = salt.utils.napalm.default_ret(name)
# the user can override the flags the equivalent CLI args
# which have higher precedence
test = test or __opts__["test"]
debug = __salt__["config.merge"]("debug", debug)
commit = __salt__["config.merge"]("commit", commit)
replace = __salt__["config.merge"]("replace", replace) # this might be a bit risky
skip_verify = __salt__["config.merge"]("skip_verify", skip_verify)
commit_in = __salt__["config.merge"]("commit_in", commit_in)
commit_at = __salt__["config.merge"]("commit_at", commit_at)
revert_in = __salt__["config.merge"]("revert_in", revert_in)
revert_at = __salt__["config.merge"]("revert_at", revert_at)
config_update_ret = _update_config(
template_name=template_name,
template_source=template_source,
template_hash=template_hash,
template_hash_name=template_hash_name,
saltenv=saltenv,
template_engine=template_engine,
skip_verify=skip_verify,
context=context,
defaults=defaults,
test=test,
commit=commit,
commit_in=commit_in,
commit_at=commit_at,
revert_in=revert_in,
revert_at=revert_at,
debug=debug,
replace=replace,
**template_vars
)
return salt.utils.napalm.loaded_ret(ret, config_update_ret, test, debug)
def commit_cancelled(name):
"""
.. versionadded:: 2019.2.0
Cancel a commit scheduled to be executed via the ``commit_in`` and
``commit_at`` arguments from the
:py:func:`net.load_template <salt.modules.napalm_network.load_template>` or
:py:func:`net.load_config <salt.modules.napalm_network.load_config>`
execution functions. The commit ID is displayed when the commit is scheduled
via the functions named above.
State SLS Example:
.. code-block:: yaml
'20180726083540640360':
netconfig.commit_cancelled
"""
cancelled = {"name": name, "result": None, "changes": {}, "comment": ""}
if __opts__["test"]:
cancelled["comment"] = "It would cancel commit #{}".format(name)
return cancelled
ret = __salt__["net.cancel_commit"](name)
cancelled.update(ret)
return cancelled
def commit_confirmed(name):
"""
.. versionadded:: 2019.2.0
Confirm a commit scheduled to be reverted via the ``revert_in`` and
``revert_at`` arguments from the
:mod:`net.load_template <salt.modules.napalm_network.load_template>` or
:mod:`net.load_config <salt.modules.napalm_network.load_config>`
execution functions. The commit ID is displayed when the commit confirmed
is scheduled via the functions named above.
State SLS Example:
.. code-block:: yaml
'20180726083540640360':
netconfig.commit_confirmed
"""
confirmed = {"name": name, "result": None, "changes": {}, "comment": ""}
if __opts__["test"]:
confirmed["comment"] = "It would confirm commit #{}".format(name)
return confirmed
ret = __salt__["net.confirm_commit"](name)
confirmed.update(ret)
return confirmed<|fim▁end|> |
.. note::
This option is **not** supported on Windows.
attrs |
<|file_name|>bitcoin_es.ts<|end_file_name|><|fim▁begin|><?xml version="1.0" ?><!DOCTYPE TS><TS language="es" version="2.0">
<defaultcodec>UTF-8</defaultcodec>
<context>
<name>AboutDialog</name>
<message>
<location filename="../forms/aboutdialog.ui" line="+14"/>
<source>About Klondikecoin</source>
<translation>Acerca de Klondikecoin</translation>
</message>
<message>
<location line="+39"/>
<source><b>Klondikecoin</b> version</source>
<translation>Versión de <b>Klondikecoin</b></translation>
</message>
<message>
<location line="+57"/>
<source>
This is experimental software.
Distributed under the MIT/X11 software license, see the accompanying file COPYING or http://www.opensource.org/licenses/mit-license.php.
This product includes software developed by the OpenSSL Project for use in the OpenSSL Toolkit (http://www.openssl.org/) and cryptographic software written by Eric Young ([email protected]) and UPnP software written by Thomas Bernard.</source>
<translation>
Este es un software experimental.
Distribuido bajo la licencia MIT/X11, vea el archivo adjunto
COPYING o http://www.opensource.org/licenses/mit-license.php.
Este producto incluye software desarrollado por OpenSSL Project para su uso en
el OpenSSL Toolkit (http://www.openssl.org/) y software criptográfico escrito por
Eric Young ([email protected]) y el software UPnP escrito por Thomas Bernard.</translation>
</message>
<message>
<location filename="../aboutdialog.cpp" line="+14"/>
<source>Copyright</source>
<translation>Copyright</translation>
</message>
<message>
<location line="+0"/>
<source>The Klondikecoin developers</source>
<translation>Los programadores Klondikecoin</translation>
</message>
</context>
<context>
<name>AddressBookPage</name>
<message>
<location filename="../forms/addressbookpage.ui" line="+14"/>
<source>Address Book</source>
<translation>Libreta de direcciones</translation>
</message>
<message>
<location line="+19"/>
<source>Double-click to edit address or label</source>
<translation>Haga doble clic para editar una dirección o etiqueta</translation>
</message>
<message>
<location line="+27"/>
<source>Create a new address</source>
<translation>Crear una nueva dirección</translation>
</message>
<message>
<location line="+14"/>
<source>Copy the currently selected address to the system clipboard</source>
<translation>Copiar la dirección seleccionada al portapapeles del sistema</translation>
</message>
<message>
<location line="-11"/>
<source>&New Address</source>
<translation>&Añadir dirección</translation>
</message>
<message>
<location filename="../addressbookpage.cpp" line="+63"/>
<source>These are your Klondikecoin addresses for receiving payments. You may want to give a different one to each sender so you can keep track of who is paying you.</source>
<translation>Estas son sus direcciones Klondikecoin para recibir pagos. Puede utilizar una diferente por cada persona emisora para saber quién le está pagando.</translation>
</message>
<message>
<location filename="../forms/addressbookpage.ui" line="+14"/>
<source>&Copy Address</source>
<translation>&Copiar dirección</translation>
</message>
<message>
<location line="+11"/>
<source>Show &QR Code</source>
<translation>Mostrar código &QR </translation>
</message>
<message>
<location line="+11"/>
<source>Sign a message to prove you own a Klondikecoin address</source>
<translation>Firmar un mensaje para demostrar que se posee una dirección Klondikecoin</translation>
</message>
<message>
<location line="+3"/>
<source>Sign &Message</source>
<translation>&Firmar mensaje</translation>
</message>
<message>
<location line="+25"/>
<source>Delete the currently selected address from the list</source>
<translation>Borrar de la lista la dirección seleccionada</translation>
</message>
<message>
<location line="+27"/>
<source>Export the data in the current tab to a file</source>
<translation>Exportar a un archivo los datos de esta pestaña</translation>
</message>
<message>
<location line="+3"/>
<source>&Export</source>
<translation>&Exportar</translation>
</message>
<message>
<location line="-44"/>
<source>Verify a message to ensure it was signed with a specified Klondikecoin address</source>
<translation>Verificar un mensaje para comprobar que fue firmado con la dirección Klondikecoin indicada</translation>
</message>
<message>
<location line="+3"/>
<source>&Verify Message</source>
<translation>&Verificar mensaje</translation>
</message>
<message>
<location line="+14"/>
<source>&Delete</source>
<translation>&Eliminar</translation>
</message>
<message>
<location filename="../addressbookpage.cpp" line="-5"/>
<source>These are your Klondikecoin addresses for sending payments. Always check the amount and the receiving address before sending coins.</source>
<translation>Estas son sus direcciones Klondikecoin para enviar pagos. Compruebe siempre la cantidad y la dirección receptora antes de transferir monedas.</translation>
</message>
<message>
<location line="+13"/>
<source>Copy &Label</source>
<translation>Copiar &etiqueta</translation>
</message>
<message>
<location line="+1"/>
<source>&Edit</source>
<translation>&Editar</translation>
</message>
<message>
<location line="+1"/>
<source>Send &Coins</source>
<translation>Enviar &monedas</translation>
</message>
<message>
<location line="+260"/>
<source>Export Address Book Data</source>
<translation>Exportar datos de la libreta de direcciones</translation>
</message>
<message>
<location line="+1"/>
<source>Comma separated file (*.csv)</source>
<translation>Archivos de columnas separadas por coma (*.csv)</translation>
</message>
<message>
<location line="+13"/>
<source>Error exporting</source>
<translation>Error al exportar</translation>
</message>
<message>
<location line="+0"/>
<source>Could not write to file %1.</source>
<translation>No se pudo escribir en el archivo %1.</translation>
</message>
</context>
<context>
<name>AddressTableModel</name>
<message>
<location filename="../addresstablemodel.cpp" line="+144"/>
<source>Label</source>
<translation>Etiqueta</translation>
</message>
<message>
<location line="+0"/>
<source>Address</source>
<translation>Dirección</translation>
</message>
<message>
<location line="+36"/>
<source>(no label)</source>
<translation>(sin etiqueta)</translation>
</message>
</context>
<context>
<name>AskPassphraseDialog</name>
<message>
<location filename="../forms/askpassphrasedialog.ui" line="+26"/>
<source>Passphrase Dialog</source>
<translation>Diálogo de contraseña</translation>
</message>
<message>
<location line="+21"/>
<source>Enter passphrase</source>
<translation>Introducir contraseña</translation>
</message>
<message>
<location line="+14"/>
<source>New passphrase</source>
<translation>Nueva contraseña</translation>
</message>
<message>
<location line="+14"/>
<source>Repeat new passphrase</source>
<translation>Repita la nueva contraseña</translation>
</message>
<message>
<location filename="../askpassphrasedialog.cpp" line="+33"/>
<source>Enter the new passphrase to the wallet.<br/>Please use a passphrase of <b>10 or more random characters</b>, or <b>eight or more words</b>.</source>
<translation>Introduzca la nueva contraseña del monedero.<br/>Por favor elija una con <b>10 o más caracteres aleatorios</b> u <b>ocho o más palabras</b>.</translation>
</message>
<message>
<location line="+1"/>
<source>Encrypt wallet</source>
<translation>Cifrar el monedero</translation>
</message>
<message>
<location line="+3"/>
<source>This operation needs your wallet passphrase to unlock the wallet.</source>
<translation>Esta operación requiere su contraseña para desbloquear el monedero.</translation>
</message>
<message>
<location line="+5"/>
<source>Unlock wallet</source>
<translation>Desbloquear monedero</translation>
</message>
<message>
<location line="+3"/>
<source>This operation needs your wallet passphrase to decrypt the wallet.</source>
<translation>Esta operación requiere su contraseña para descifrar el monedero.</translation>
</message>
<message>
<location line="+5"/>
<source>Decrypt wallet</source>
<translation>Descifrar el monedero</translation>
</message>
<message>
<location line="+3"/>
<source>Change passphrase</source>
<translation>Cambiar contraseña</translation>
</message>
<message>
<location line="+1"/>
<source>Enter the old and new passphrase to the wallet.</source>
<translation>Introduzca la contraseña anterior del monedero y la nueva. </translation>
</message>
<message>
<location line="+46"/>
<source>Confirm wallet encryption</source>
<translation>Confirmar cifrado del monedero</translation>
</message>
<message>
<location line="+1"/>
<source>Warning: If you encrypt your wallet and lose your passphrase, you will <b>LOSE ALL OF YOUR LITECOINS</b>!</source>
<translation>Atencion: ¡Si cifra su monedero y pierde la contraseña perderá <b>TODOS SUS LITECOINS</b>!"</translation>
</message>
<message>
<location line="+0"/>
<source>Are you sure you wish to encrypt your wallet?</source>
<translation>¿Seguro que desea cifrar su monedero?</translation>
</message>
<message>
<location line="+15"/>
<source>IMPORTANT: Any previous backups you have made of your wallet file should be replaced with the newly generated, encrypted wallet file. For security reasons, previous backups of the unencrypted wallet file will become useless as soon as you start using the new, encrypted wallet.</source>
<translation>IMPORTANTE: Cualquier copia de seguridad que haya realizado previamente de su archivo de monedero debe reemplazarse con el nuevo archivo de monedero cifrado. Por razones de seguridad, las copias de seguridad previas del archivo de monedero no cifradas serán inservibles en cuanto comience a usar el nuevo monedero cifrado.</translation>
</message>
<message>
<location line="+100"/>
<location line="+24"/>
<source>Warning: The Caps Lock key is on!</source>
<translation>Aviso: ¡La tecla de bloqueo de mayúsculas está activada!</translation>
</message>
<message>
<location line="-130"/>
<location line="+58"/>
<source>Wallet encrypted</source>
<translation>Monedero cifrado</translation>
</message>
<message>
<location line="-56"/>
<source>Klondikecoin will close now to finish the encryption process. Remember that encrypting your wallet cannot fully protect your klondikecoins from being stolen by malware infecting your computer.</source>
<translation>Klondikecoin se cerrará para finalizar el proceso de cifrado. Recuerde que el cifrado de su monedero no puede proteger totalmente sus klondikecoins de robo por malware que infecte su sistema.</translation>
</message>
<message>
<location line="+13"/>
<location line="+7"/>
<location line="+42"/>
<location line="+6"/>
<source>Wallet encryption failed</source>
<translation>Ha fallado el cifrado del monedero</translation>
</message>
<message>
<location line="-54"/>
<source>Wallet encryption failed due to an internal error. Your wallet was not encrypted.</source>
<translation>Ha fallado el cifrado del monedero debido a un error interno. El monedero no ha sido cifrado.</translation>
</message>
<message>
<location line="+7"/>
<location line="+48"/>
<source>The supplied passphrases do not match.</source>
<translation>Las contraseñas no coinciden.</translation>
</message>
<message>
<location line="-37"/>
<source>Wallet unlock failed</source>
<translation>Ha fallado el desbloqueo del monedero</translation>
</message>
<message>
<location line="+1"/>
<location line="+11"/>
<location line="+19"/>
<source>The passphrase entered for the wallet decryption was incorrect.</source>
<translation>La contraseña introducida para descifrar el monedero es incorrecta.</translation>
</message>
<message>
<location line="-20"/>
<source>Wallet decryption failed</source>
<translation>Ha fallado el descifrado del monedero</translation>
</message>
<message>
<location line="+14"/>
<source>Wallet passphrase was successfully changed.</source>
<translation>Se ha cambiado correctamente la contraseña del monedero.</translation>
</message>
</context>
<context>
<name>BitcoinGUI</name>
<message>
<location filename="../bitcoingui.cpp" line="+233"/>
<source>Sign &message...</source>
<translation>Firmar &mensaje...</translation>
</message>
<message>
<location line="+280"/>
<source>Synchronizing with network...</source>
<translation>Sincronizando con la red…</translation>
</message>
<message>
<location line="-349"/>
<source>&Overview</source>
<translation>&Vista general</translation>
</message>
<message>
<location line="+1"/>
<source>Show general overview of wallet</source>
<translation>Mostrar vista general del monedero</translation>
</message>
<message>
<location line="+20"/>
<source>&Transactions</source>
<translation>&Transacciones</translation>
</message>
<message>
<location line="+1"/>
<source>Browse transaction history</source>
<translation>Examinar el historial de transacciones</translation>
</message>
<message>
<location line="+7"/>
<source>Edit the list of stored addresses and labels</source>
<translation>Editar la lista de las direcciones y etiquetas almacenadas</translation>
</message>
<message>
<location line="-14"/>
<source>Show the list of addresses for receiving payments</source>
<translation>Mostrar la lista de direcciones utilizadas para recibir pagos</translation>
</message>
<message>
<location line="+31"/>
<source>E&xit</source>
<translation>&Salir</translation>
</message>
<message>
<location line="+1"/>
<source>Quit application</source>
<translation>Salir de la aplicación</translation>
</message>
<message>
<location line="+4"/>
<source>Show information about Klondikecoin</source>
<translation>Mostrar información acerca de Klondikecoin</translation>
</message>
<message>
<location line="+2"/>
<source>About &Qt</source>
<translation>Acerca de &Qt</translation>
</message>
<message>
<location line="+1"/>
<source>Show information about Qt</source>
<translation>Mostrar información acerca de Qt</translation>
</message>
<message>
<location line="+2"/>
<source>&Options...</source>
<translation>&Opciones...</translation>
</message>
<message>
<location line="+6"/>
<source>&Encrypt Wallet...</source>
<translation>&Cifrar monedero…</translation>
</message>
<message>
<location line="+3"/>
<source>&Backup Wallet...</source>
<translation>Copia de &respaldo del monedero...</translation>
</message>
<message>
<location line="+2"/>
<source>&Change Passphrase...</source>
<translation>&Cambiar la contraseña…</translation>
</message>
<message>
<location line="+285"/>
<source>Importing blocks from disk...</source>
<translation>Importando bloques de disco...</translation>
</message>
<message>
<location line="+3"/>
<source>Reindexing blocks on disk...</source>
<translation>Reindexando bloques en disco...</translation>
</message>
<message>
<location line="-347"/>
<source>Send coins to a Klondikecoin address</source>
<translation>Enviar monedas a una dirección Klondikecoin</translation>
</message>
<message>
<location line="+49"/>
<source>Modify configuration options for Klondikecoin</source>
<translation>Modificar las opciones de configuración de Klondikecoin</translation>
</message>
<message>
<location line="+9"/>
<source>Backup wallet to another location</source>
<translation>Copia de seguridad del monedero en otra ubicación</translation>
</message>
<message>
<location line="+2"/>
<source>Change the passphrase used for wallet encryption</source>
<translation>Cambiar la contraseña utilizada para el cifrado del monedero</translation>
</message>
<message>
<location line="+6"/>
<source>&Debug window</source>
<translation>Ventana de &depuración</translation>
</message>
<message>
<location line="+1"/>
<source>Open debugging and diagnostic console</source>
<translation>Abrir la consola de depuración y diagnóstico</translation>
</message>
<message>
<location line="-4"/>
<source>&Verify message...</source>
<translation>&Verificar mensaje...</translation>
</message>
<message>
<location line="-165"/>
<location line="+530"/>
<source>Klondikecoin</source>
<translation>Klondikecoin</translation>
</message>
<message>
<location line="-530"/>
<source>Wallet</source>
<translation>Monedero</translation>
</message>
<message>
<location line="+101"/>
<source>&Send</source>
<translation>&Enviar</translation>
</message>
<message>
<location line="+7"/>
<source>&Receive</source>
<translation>&Recibir</translation>
</message>
<message>
<location line="+14"/>
<source>&Addresses</source>
<translation>&Direcciones</translation>
</message>
<message>
<location line="+22"/>
<source>&About Klondikecoin</source>
<translation>&Acerca de Klondikecoin</translation>
</message>
<message>
<location line="+9"/>
<source>&Show / Hide</source>
<translation>Mo&strar/ocultar</translation>
</message>
<message>
<location line="+1"/>
<source>Show or hide the main Window</source>
<translation>Mostrar u ocultar la ventana principal</translation>
</message>
<message>
<location line="+3"/>
<source>Encrypt the private keys that belong to your wallet</source>
<translation>Cifrar las claves privadas de su monedero</translation>
</message>
<message>
<location line="+7"/>
<source>Sign messages with your Klondikecoin addresses to prove you own them</source>
<translation>Firmar mensajes con sus direcciones Klondikecoin para demostrar la propiedad</translation>
</message>
<message>
<location line="+2"/>
<source>Verify messages to ensure they were signed with specified Klondikecoin addresses</source>
<translation>Verificar mensajes comprobando que están firmados con direcciones Klondikecoin concretas</translation>
</message>
<message>
<location line="+28"/>
<source>&File</source>
<translation>&Archivo</translation>
</message>
<message>
<location line="+7"/>
<source>&Settings</source>
<translation>&Configuración</translation>
</message>
<message>
<location line="+6"/>
<source>&Help</source>
<translation>A&yuda</translation>
</message>
<message>
<location line="+9"/>
<source>Tabs toolbar</source>
<translation>Barra de pestañas</translation>
</message>
<message>
<location line="+17"/>
<location line="+10"/>
<source>[testnet]</source>
<translation>[testnet]</translation>
</message>
<message>
<location line="+47"/>
<source>Klondikecoin client</source>
<translation>Cliente Klondikecoin</translation>
</message>
<message numerus="yes">
<location line="+141"/>
<source>%n active connection(s) to Klondikecoin network</source>
<translation><numerusform>%n conexión activa hacia la red Klondikecoin</numerusform><numerusform>%n conexiones activas hacia la red Klondikecoin</numerusform></translation>
</message>
<message>
<location line="+22"/>
<source>No block source available...</source>
<translation>Ninguna fuente de bloques disponible ...</translation>
</message>
<message>
<location line="+12"/>
<source>Processed %1 of %2 (estimated) blocks of transaction history.</source>
<translation>Se han procesado %1 de %2 bloques (estimados) del historial de transacciones.</translation>
</message>
<message>
<location line="+4"/>
<source>Processed %1 blocks of transaction history.</source>
<translation>Procesados %1 bloques del historial de transacciones.</translation>
</message>
<message numerus="yes">
<location line="+20"/>
<source>%n hour(s)</source>
<translation><numerusform>%n hora</numerusform><numerusform>%n horas</numerusform></translation>
</message>
<message numerus="yes">
<location line="+4"/>
<source>%n day(s)</source>
<translation><numerusform>%n día</numerusform><numerusform>%n días</numerusform></translation>
</message>
<message numerus="yes">
<location line="+4"/>
<source>%n week(s)</source>
<translation><numerusform>%n semana</numerusform><numerusform>%n semanas</numerusform></translation>
</message>
<message>
<location line="+4"/>
<source>%1 behind</source>
<translation>%1 atrás</translation>
</message>
<message>
<location line="+14"/>
<source>Last received block was generated %1 ago.</source>
<translation>El último bloque recibido fue generado hace %1.</translation>
</message>
<message>
<location line="+2"/>
<source>Transactions after this will not yet be visible.</source>
<translation>Las transacciones posteriores a esta aún no están visibles.</translation>
</message>
<message>
<location line="+22"/>
<source>Error</source>
<translation>Error</translation>
</message>
<message>
<location line="+3"/>
<source>Warning</source>
<translation>Aviso</translation>
</message>
<message>
<location line="+3"/>
<source>Information</source>
<translation>Información</translation>
</message>
<message>
<location line="+70"/>
<source>This transaction is over the size limit. You can still send it for a fee of %1, which goes to the nodes that process your transaction and helps to support the network. Do you want to pay the fee?</source>
<translation>Esta transacción supera el límite de tamaño. Puede enviarla con una comisión de %1, destinada a los nodos que procesen su transacción para contribuir al mantenimiento de la red. ¿Desea pagar esta comisión?</translation>
</message>
<message>
<location line="-140"/>
<source>Up to date</source>
<translation>Actualizado</translation>
</message>
<message>
<location line="+31"/><|fim▁hole|> <message>
<location line="+113"/>
<source>Confirm transaction fee</source>
<translation>Confirme la tarifa de la transacción</translation>
</message>
<message>
<location line="+8"/>
<source>Sent transaction</source>
<translation>Transacción enviada</translation>
</message>
<message>
<location line="+0"/>
<source>Incoming transaction</source>
<translation>Transacción entrante</translation>
</message>
<message>
<location line="+1"/>
<source>Date: %1
Amount: %2
Type: %3
Address: %4
</source>
<translation>Fecha: %1
Cantidad: %2
Tipo: %3
Dirección: %4
</translation>
</message>
<message>
<location line="+33"/>
<location line="+23"/>
<source>URI handling</source>
<translation>Gestión de URI</translation>
</message>
<message>
<location line="-23"/>
<location line="+23"/>
<source>URI can not be parsed! This can be caused by an invalid Klondikecoin address or malformed URI parameters.</source>
<translation>¡No se puede interpretar la URI! Esto puede deberse a una dirección Klondikecoin inválida o a parámetros de URI mal formados.</translation>
</message>
<message>
<location line="+17"/>
<source>Wallet is <b>encrypted</b> and currently <b>unlocked</b></source>
<translation>El monedero está <b>cifrado</b> y actualmente <b>desbloqueado</b></translation>
</message>
<message>
<location line="+8"/>
<source>Wallet is <b>encrypted</b> and currently <b>locked</b></source>
<translation>El monedero está <b>cifrado</b> y actualmente <b>bloqueado</b></translation>
</message>
<message>
<location filename="../bitcoin.cpp" line="+111"/>
<source>A fatal error occurred. Klondikecoin can no longer continue safely and will quit.</source>
<translation>Ha ocurrido un error crítico. Klondikecoin ya no puede continuar con seguridad y se cerrará.</translation>
</message>
</context>
<context>
<name>ClientModel</name>
<message>
<location filename="../clientmodel.cpp" line="+104"/>
<source>Network Alert</source>
<translation>Alerta de red</translation>
</message>
</context>
<context>
<name>EditAddressDialog</name>
<message>
<location filename="../forms/editaddressdialog.ui" line="+14"/>
<source>Edit Address</source>
<translation>Editar Dirección</translation>
</message>
<message>
<location line="+11"/>
<source>&Label</source>
<translation>&Etiqueta</translation>
</message>
<message>
<location line="+10"/>
<source>The label associated with this address book entry</source>
<translation>La etiqueta asociada con esta entrada en la libreta</translation>
</message>
<message>
<location line="+7"/>
<source>&Address</source>
<translation>&Dirección</translation>
</message>
<message>
<location line="+10"/>
<source>The address associated with this address book entry. This can only be modified for sending addresses.</source>
<translation>La dirección asociada con esta entrada en la guía. Solo puede ser modificada para direcciones de envío.</translation>
</message>
<message>
<location filename="../editaddressdialog.cpp" line="+21"/>
<source>New receiving address</source>
<translation>Nueva dirección para recibir</translation>
</message>
<message>
<location line="+4"/>
<source>New sending address</source>
<translation>Nueva dirección para enviar</translation>
</message>
<message>
<location line="+3"/>
<source>Edit receiving address</source>
<translation>Editar dirección de recepción</translation>
</message>
<message>
<location line="+4"/>
<source>Edit sending address</source>
<translation>Editar dirección de envío</translation>
</message>
<message>
<location line="+76"/>
<source>The entered address "%1" is already in the address book.</source>
<translation>La dirección introducida "%1" ya está presente en la libreta de direcciones.</translation>
</message>
<message>
<location line="-5"/>
<source>The entered address "%1" is not a valid Klondikecoin address.</source>
<translation>La dirección introducida "%1" no es una dirección Klondikecoin válida.</translation>
</message>
<message>
<location line="+10"/>
<source>Could not unlock wallet.</source>
<translation>No se pudo desbloquear el monedero.</translation>
</message>
<message>
<location line="+5"/>
<source>New key generation failed.</source>
<translation>Ha fallado la generación de la nueva clave.</translation>
</message>
</context>
<context>
<name>GUIUtil::HelpMessageBox</name>
<message>
<location filename="../guiutil.cpp" line="+424"/>
<location line="+12"/>
<source>Klondikecoin-Qt</source>
<translation>Klondikecoin-Qt</translation>
</message>
<message>
<location line="-12"/>
<source>version</source>
<translation>versión</translation>
</message>
<message>
<location line="+2"/>
<source>Usage:</source>
<translation>Uso:</translation>
</message>
<message>
<location line="+1"/>
<source>command-line options</source>
<translation>opciones de la línea de órdenes</translation>
</message>
<message>
<location line="+4"/>
<source>UI options</source>
<translation>Opciones GUI</translation>
</message>
<message>
<location line="+1"/>
<source>Set language, for example "de_DE" (default: system locale)</source>
<translation>Establecer el idioma, por ejemplo, "es_ES" (predeterminado: configuración regional del sistema)</translation>
</message>
<message>
<location line="+1"/>
<source>Start minimized</source>
<translation>Arrancar minimizado</translation>
</message>
<message>
<location line="+1"/>
<source>Show splash screen on startup (default: 1)</source>
<translation>Mostrar pantalla de bienvenida en el inicio (predeterminado: 1)</translation>
</message>
</context>
<context>
<name>OptionsDialog</name>
<message>
<location filename="../forms/optionsdialog.ui" line="+14"/>
<source>Options</source>
<translation>Opciones</translation>
</message>
<message>
<location line="+16"/>
<source>&Main</source>
<translation>&Principal</translation>
</message>
<message>
<location line="+6"/>
<source>Optional transaction fee per kB that helps make sure your transactions are processed quickly. Most transactions are 1 kB.</source>
<translation>Tarifa de transacción opcional por kB que ayuda a asegurar que sus transacciones sean procesadas rápidamente. La mayoría de transacciones son de 1kB.</translation>
</message>
<message>
<location line="+15"/>
<source>Pay transaction &fee</source>
<translation>Comisión de &transacciones</translation>
</message>
<message>
<location line="+31"/>
<source>Automatically start Klondikecoin after logging in to the system.</source>
<translation>Iniciar Klondikecoin automáticamente al encender el sistema.</translation>
</message>
<message>
<location line="+3"/>
<source>&Start Klondikecoin on system login</source>
<translation>&Iniciar Klondikecoin al iniciar el sistema</translation>
</message>
<message>
<location line="+35"/>
<source>Reset all client options to default.</source>
<translation>Restablecer todas las opciones del cliente a las predeterminadas.</translation>
</message>
<message>
<location line="+3"/>
<source>&Reset Options</source>
<translation>&Restablecer opciones</translation>
</message>
<message>
<location line="+13"/>
<source>&Network</source>
<translation>&Red</translation>
</message>
<message>
<location line="+6"/>
<source>Automatically open the Klondikecoin client port on the router. This only works when your router supports UPnP and it is enabled.</source>
<translation>Abrir automáticamente el puerto del cliente Klondikecoin en el router. Esta opción solo funciona si el router admite UPnP y está activado.</translation>
</message>
<message>
<location line="+3"/>
<source>Map port using &UPnP</source>
<translation>Mapear el puerto usando &UPnP</translation>
</message>
<message>
<location line="+7"/>
<source>Connect to the Klondikecoin network through a SOCKS proxy (e.g. when connecting through Tor).</source>
<translation>Conectar a la red Klondikecoin a través de un proxy SOCKS (ej. para conectar con la red Tor)</translation>
</message>
<message>
<location line="+3"/>
<source>&Connect through SOCKS proxy:</source>
<translation>&Conectar a través de un proxy SOCKS:</translation>
</message>
<message>
<location line="+9"/>
<source>Proxy &IP:</source>
<translation>Dirección &IP del proxy:</translation>
</message>
<message>
<location line="+19"/>
<source>IP address of the proxy (e.g. 127.0.0.1)</source>
<translation>Dirección IP del proxy (ej. 127.0.0.1)</translation>
</message>
<message>
<location line="+7"/>
<source>&Port:</source>
<translation>&Puerto:</translation>
</message>
<message>
<location line="+19"/>
<source>Port of the proxy (e.g. 9050)</source>
<translation>Puerto del servidor proxy (ej. 9050)</translation>
</message>
<message>
<location line="+7"/>
<source>SOCKS &Version:</source>
<translation>&Versión SOCKS:</translation>
</message>
<message>
<location line="+13"/>
<source>SOCKS version of the proxy (e.g. 5)</source>
<translation>Versión del proxy SOCKS (ej. 5)</translation>
</message>
<message>
<location line="+36"/>
<source>&Window</source>
<translation>&Ventana</translation>
</message>
<message>
<location line="+6"/>
<source>Show only a tray icon after minimizing the window.</source>
<translation>Minimizar la ventana a la bandeja de iconos del sistema.</translation>
</message>
<message>
<location line="+3"/>
<source>&Minimize to the tray instead of the taskbar</source>
<translation>&Minimizar a la bandeja en vez de a la barra de tareas</translation>
</message>
<message>
<location line="+7"/>
<source>Minimize instead of exit the application when the window is closed. When this option is enabled, the application will be closed only after selecting Quit in the menu.</source>
<translation>Minimizar en lugar de salir de la aplicación al cerrar la ventana.Cuando esta opción está activa, la aplicación solo se puede cerrar seleccionando Salir desde el menú.</translation>
</message>
<message>
<location line="+3"/>
<source>M&inimize on close</source>
<translation>M&inimizar al cerrar</translation>
</message>
<message>
<location line="+21"/>
<source>&Display</source>
<translation>&Interfaz</translation>
</message>
<message>
<location line="+8"/>
<source>User Interface &language:</source>
<translation>I&dioma de la interfaz de usuario</translation>
</message>
<message>
<location line="+13"/>
<source>The user interface language can be set here. This setting will take effect after restarting Klondikecoin.</source>
<translation>El idioma de la interfaz de usuario puede establecerse aquí. Este ajuste se aplicará cuando se reinicie Klondikecoin.</translation>
</message>
<message>
<location line="+11"/>
<source>&Unit to show amounts in:</source>
<translation>Mostrar las cantidades en la &unidad:</translation>
</message>
<message>
<location line="+13"/>
<source>Choose the default subdivision unit to show in the interface and when sending coins.</source>
<translation>Elegir la subdivisión predeterminada para mostrar cantidades en la interfaz y cuando se envían monedas.</translation>
</message>
<message>
<location line="+9"/>
<source>Whether to show Klondikecoin addresses in the transaction list or not.</source>
<translation>Mostrar o no las direcciones Klondikecoin en la lista de transacciones.</translation>
</message>
<message>
<location line="+3"/>
<source>&Display addresses in transaction list</source>
<translation>&Mostrar las direcciones en la lista de transacciones</translation>
</message>
<message>
<location line="+71"/>
<source>&OK</source>
<translation>&Aceptar</translation>
</message>
<message>
<location line="+7"/>
<source>&Cancel</source>
<translation>&Cancelar</translation>
</message>
<message>
<location line="+10"/>
<source>&Apply</source>
<translation>&Aplicar</translation>
</message>
<message>
<location filename="../optionsdialog.cpp" line="+53"/>
<source>default</source>
<translation>predeterminado</translation>
</message>
<message>
<location line="+130"/>
<source>Confirm options reset</source>
<translation>Confirme el restablecimiento de las opciones</translation>
</message>
<message>
<location line="+1"/>
<source>Some settings may require a client restart to take effect.</source>
<translation>Algunas configuraciones pueden requerir un reinicio del cliente para que sean efectivas.</translation>
</message>
<message>
<location line="+0"/>
<source>Do you want to proceed?</source>
<translation>¿Quiere proceder?</translation>
</message>
<message>
<location line="+42"/>
<location line="+9"/>
<source>Warning</source>
<translation>Aviso</translation>
</message>
<message>
<location line="-9"/>
<location line="+9"/>
<source>This setting will take effect after restarting Klondikecoin.</source>
<translation>Esta configuración tendrá efecto tras reiniciar Klondikecoin.</translation>
</message>
<message>
<location line="+29"/>
<source>The supplied proxy address is invalid.</source>
<translation>La dirección proxy indicada es inválida.</translation>
</message>
</context>
<context>
<name>OverviewPage</name>
<message>
<location filename="../forms/overviewpage.ui" line="+14"/>
<source>Form</source>
<translation>Desde</translation>
</message>
<message>
<location line="+50"/>
<location line="+166"/>
<source>The displayed information may be out of date. Your wallet automatically synchronizes with the Klondikecoin network after a connection is established, but this process has not completed yet.</source>
<translation>La información mostrada puede estar desactualizada. Su monedero se sincroniza automáticamente con la red Klondikecoin después de que se haya establecido una conexión , pero este proceso aún no se ha completado.</translation>
</message>
<message>
<location line="-124"/>
<source>Balance:</source>
<translation>Saldo:</translation>
</message>
<message>
<location line="+29"/>
<source>Unconfirmed:</source>
<translation>No confirmado(s):</translation>
</message>
<message>
<location line="-78"/>
<source>Wallet</source>
<translation>Monedero</translation>
</message>
<message>
<location line="+107"/>
<source>Immature:</source>
<translation>No disponible:</translation>
</message>
<message>
<location line="+13"/>
<source>Mined balance that has not yet matured</source>
<translation>Saldo recién minado que aún no está disponible.</translation>
</message>
<message>
<location line="+46"/>
<source><b>Recent transactions</b></source>
<translation><b>Movimientos recientes</b></translation>
</message>
<message>
<location line="-101"/>
<source>Your current balance</source>
<translation>Su saldo actual</translation>
</message>
<message>
<location line="+29"/>
<source>Total of transactions that have yet to be confirmed, and do not yet count toward the current balance</source>
<translation>Total de las transacciones que faltan por confirmar y que no contribuyen al saldo actual</translation>
</message>
<message>
<location filename="../overviewpage.cpp" line="+116"/>
<location line="+1"/>
<source>out of sync</source>
<translation>desincronizado</translation>
</message>
</context>
<context>
<name>PaymentServer</name>
<message>
<location filename="../paymentserver.cpp" line="+107"/>
<source>Cannot start klondikecoin: click-to-pay handler</source>
<translation>No se pudo iniciar klondikecoin: manejador de pago-al-clic</translation>
</message>
</context>
<context>
<name>QRCodeDialog</name>
<message>
<location filename="../forms/qrcodedialog.ui" line="+14"/>
<source>QR Code Dialog</source>
<translation>Diálogo de códigos QR</translation>
</message>
<message>
<location line="+59"/>
<source>Request Payment</source>
<translation>Solicitud de pago</translation>
</message>
<message>
<location line="+56"/>
<source>Amount:</source>
<translation>Cuantía:</translation>
</message>
<message>
<location line="-44"/>
<source>Label:</source>
<translation>Etiqueta:</translation>
</message>
<message>
<location line="+19"/>
<source>Message:</source>
<translation>Mensaje:</translation>
</message>
<message>
<location line="+71"/>
<source>&Save As...</source>
<translation>&Guardar como...</translation>
</message>
<message>
<location filename="../qrcodedialog.cpp" line="+62"/>
<source>Error encoding URI into QR Code.</source>
<translation>Error al codificar la URI en el código QR.</translation>
</message>
<message>
<location line="+40"/>
<source>The entered amount is invalid, please check.</source>
<translation>La cantidad introducida es inválida. Compruébela, por favor.</translation>
</message>
<message>
<location line="+23"/>
<source>Resulting URI too long, try to reduce the text for label / message.</source>
<translation>URI esultante demasiado larga. Intente reducir el texto de la etiqueta / mensaje.</translation>
</message>
<message>
<location line="+25"/>
<source>Save QR Code</source>
<translation>Guardar código QR</translation>
</message>
<message>
<location line="+0"/>
<source>PNG Images (*.png)</source>
<translation>Imágenes PNG (*.png)</translation>
</message>
</context>
<context>
<name>RPCConsole</name>
<message>
<location filename="../forms/rpcconsole.ui" line="+46"/>
<source>Client name</source>
<translation>Nombre del cliente</translation>
</message>
<message>
<location line="+10"/>
<location line="+23"/>
<location line="+26"/>
<location line="+23"/>
<location line="+23"/>
<location line="+36"/>
<location line="+53"/>
<location line="+23"/>
<location line="+23"/>
<location filename="../rpcconsole.cpp" line="+339"/>
<source>N/A</source>
<translation>N/D</translation>
</message>
<message>
<location line="-217"/>
<source>Client version</source>
<translation>Versión del cliente</translation>
</message>
<message>
<location line="-45"/>
<source>&Information</source>
<translation>&Información</translation>
</message>
<message>
<location line="+68"/>
<source>Using OpenSSL version</source>
<translation>Utilizando la versión OpenSSL</translation>
</message>
<message>
<location line="+49"/>
<source>Startup time</source>
<translation>Hora de inicio</translation>
</message>
<message>
<location line="+29"/>
<source>Network</source>
<translation>Red</translation>
</message>
<message>
<location line="+7"/>
<source>Number of connections</source>
<translation>Número de conexiones</translation>
</message>
<message>
<location line="+23"/>
<source>On testnet</source>
<translation>En la red de pruebas</translation>
</message>
<message>
<location line="+23"/>
<source>Block chain</source>
<translation>Cadena de bloques</translation>
</message>
<message>
<location line="+7"/>
<source>Current number of blocks</source>
<translation>Número actual de bloques</translation>
</message>
<message>
<location line="+23"/>
<source>Estimated total blocks</source>
<translation>Bloques totales estimados</translation>
</message>
<message>
<location line="+23"/>
<source>Last block time</source>
<translation>Hora del último bloque</translation>
</message>
<message>
<location line="+52"/>
<source>&Open</source>
<translation>&Abrir</translation>
</message>
<message>
<location line="+16"/>
<source>Command-line options</source>
<translation>Opciones de la línea de órdenes</translation>
</message>
<message>
<location line="+7"/>
<source>Show the Klondikecoin-Qt help message to get a list with possible Klondikecoin command-line options.</source>
<translation>Mostrar el mensaje de ayuda de Klondikecoin-Qt que enumera las opciones disponibles de línea de órdenes para Klondikecoin.</translation>
</message>
<message>
<location line="+3"/>
<source>&Show</source>
<translation>&Mostrar</translation>
</message>
<message>
<location line="+24"/>
<source>&Console</source>
<translation>&Consola</translation>
</message>
<message>
<location line="-260"/>
<source>Build date</source>
<translation>Fecha de compilación</translation>
</message>
<message>
<location line="-104"/>
<source>Klondikecoin - Debug window</source>
<translation>Klondikecoin - Ventana de depuración</translation>
</message>
<message>
<location line="+25"/>
<source>Klondikecoin Core</source>
<translation>Núcleo de Klondikecoin</translation>
</message>
<message>
<location line="+279"/>
<source>Debug log file</source>
<translation>Archivo de registro de depuración</translation>
</message>
<message>
<location line="+7"/>
<source>Open the Klondikecoin debug log file from the current data directory. This can take a few seconds for large log files.</source>
<translation>Abrir el archivo de registro de depuración en el directorio actual de datos. Esto puede llevar varios segundos para archivos de registro grandes.</translation>
</message>
<message>
<location line="+102"/>
<source>Clear console</source>
<translation>Borrar consola</translation>
</message>
<message>
<location filename="../rpcconsole.cpp" line="-30"/>
<source>Welcome to the Klondikecoin RPC console.</source>
<translation>Bienvenido a la consola RPC de Klondikecoin</translation>
</message>
<message>
<location line="+1"/>
<source>Use up and down arrows to navigate history, and <b>Ctrl-L</b> to clear screen.</source>
<translation>Use las flechas arriba y abajo para navegar por el historial y <b>Control+L</b> para limpiar la pantalla.</translation>
</message>
<message>
<location line="+1"/>
<source>Type <b>help</b> for an overview of available commands.</source>
<translation>Escriba <b>help</b> para ver un resumen de los comandos disponibles.</translation>
</message>
</context>
<context>
<name>SendCoinsDialog</name>
<message>
<location filename="../forms/sendcoinsdialog.ui" line="+14"/>
<location filename="../sendcoinsdialog.cpp" line="+124"/>
<location line="+5"/>
<location line="+5"/>
<location line="+5"/>
<location line="+6"/>
<location line="+5"/>
<location line="+5"/>
<source>Send Coins</source>
<translation>Enviar monedas</translation>
</message>
<message>
<location line="+50"/>
<source>Send to multiple recipients at once</source>
<translation>Enviar a multiples destinatarios de una vez</translation>
</message>
<message>
<location line="+3"/>
<source>Add &Recipient</source>
<translation>Añadir &destinatario</translation>
</message>
<message>
<location line="+20"/>
<source>Remove all transaction fields</source>
<translation>Eliminar todos los campos de las transacciones</translation>
</message>
<message>
<location line="+3"/>
<source>Clear &All</source>
<translation>Limpiar &todo</translation>
</message>
<message>
<location line="+22"/>
<source>Balance:</source>
<translation>Saldo:</translation>
</message>
<message>
<location line="+10"/>
<source>123.456 BTC</source>
<translation>123.456 BTC</translation>
</message>
<message>
<location line="+31"/>
<source>Confirm the send action</source>
<translation>Confirmar el envío</translation>
</message>
<message>
<location line="+3"/>
<source>S&end</source>
<translation>&Enviar</translation>
</message>
<message>
<location filename="../sendcoinsdialog.cpp" line="-59"/>
<source><b>%1</b> to %2 (%3)</source>
<translation><b>%1</b> a %2 (%3)</translation>
</message>
<message>
<location line="+5"/>
<source>Confirm send coins</source>
<translation>Confirmar el envío de monedas</translation>
</message>
<message>
<location line="+1"/>
<source>Are you sure you want to send %1?</source>
<translation>¿Está seguro de que desea enviar %1?</translation>
</message>
<message>
<location line="+0"/>
<source> and </source>
<translation>y</translation>
</message>
<message>
<location line="+23"/>
<source>The recipient address is not valid, please recheck.</source>
<translation>La dirección de recepción no es válida, compruébela de nuevo.</translation>
</message>
<message>
<location line="+5"/>
<source>The amount to pay must be larger than 0.</source>
<translation>La cantidad por pagar tiene que ser mayor de 0.</translation>
</message>
<message>
<location line="+5"/>
<source>The amount exceeds your balance.</source>
<translation>La cantidad sobrepasa su saldo.</translation>
</message>
<message>
<location line="+5"/>
<source>The total exceeds your balance when the %1 transaction fee is included.</source>
<translation>El total sobrepasa su saldo cuando se incluye la tasa de envío de %1</translation>
</message>
<message>
<location line="+6"/>
<source>Duplicate address found, can only send to each address once per send operation.</source>
<translation>Se ha encontrado una dirección duplicada. Solo se puede enviar a cada dirección una vez por operación de envío.</translation>
</message>
<message>
<location line="+5"/>
<source>Error: Transaction creation failed!</source>
<translation>Error: ¡Ha fallado la creación de la transacción!</translation>
</message>
<message>
<location line="+5"/>
<source>Error: The transaction was rejected. This might happen if some of the coins in your wallet were already spent, such as if you used a copy of wallet.dat and coins were spent in the copy but not marked as spent here.</source>
<translation>Error: transacción rechazada. Puede haber ocurrido si alguna de las monedas ya estaba gastada o si ha usado una copia de wallet.dat y las monedas se gastaron en la copia pero no se han marcado así aquí.</translation>
</message>
</context>
<context>
<name>SendCoinsEntry</name>
<message>
<location filename="../forms/sendcoinsentry.ui" line="+14"/>
<source>Form</source>
<translation>Envío</translation>
</message>
<message>
<location line="+15"/>
<source>A&mount:</source>
<translation>Ca&ntidad:</translation>
</message>
<message>
<location line="+13"/>
<source>Pay &To:</source>
<translation>&Pagar a:</translation>
</message>
<message>
<location line="+34"/>
<source>The address to send the payment to (e.g. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</source>
<translation>La dirección a la que enviar el pago (p. ej. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</translation>
</message>
<message>
<location line="+60"/>
<location filename="../sendcoinsentry.cpp" line="+26"/>
<source>Enter a label for this address to add it to your address book</source>
<translation>Etiquete esta dirección para añadirla a la libreta</translation>
</message>
<message>
<location line="-78"/>
<source>&Label:</source>
<translation>&Etiqueta:</translation>
</message>
<message>
<location line="+28"/>
<source>Choose address from address book</source>
<translation>Elija una dirección de la libreta de direcciones</translation>
</message>
<message>
<location line="+10"/>
<source>Alt+A</source>
<translation>Alt+A</translation>
</message>
<message>
<location line="+7"/>
<source>Paste address from clipboard</source>
<translation>Pegar dirección desde portapapeles</translation>
</message>
<message>
<location line="+10"/>
<source>Alt+P</source>
<translation>Alt+P</translation>
</message>
<message>
<location line="+7"/>
<source>Remove this recipient</source>
<translation>Eliminar destinatario</translation>
</message>
<message>
<location filename="../sendcoinsentry.cpp" line="+1"/>
<source>Enter a Klondikecoin address (e.g. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</source>
<translation>Introduzca una dirección Klondikecoin (ej. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</translation>
</message>
</context>
<context>
<name>SignVerifyMessageDialog</name>
<message>
<location filename="../forms/signverifymessagedialog.ui" line="+14"/>
<source>Signatures - Sign / Verify a Message</source>
<translation>Firmas - Firmar / verificar un mensaje</translation>
</message>
<message>
<location line="+13"/>
<source>&Sign Message</source>
<translation>&Firmar mensaje</translation>
</message>
<message>
<location line="+6"/>
<source>You can sign messages with your addresses to prove you own them. Be careful not to sign anything vague, as phishing attacks may try to trick you into signing your identity over to them. Only sign fully-detailed statements you agree to.</source>
<translation>Puede firmar mensajes con sus direcciones para demostrar que las posee. Tenga cuidado de no firmar cualquier cosa vaga, ya que los ataques de phishing pueden tratar de engañarle para suplantar su identidad. Firme solo declaraciones totalmente detalladas con las que usted esté de acuerdo.</translation>
</message>
<message>
<location line="+18"/>
<source>The address to sign the message with (e.g. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</source>
<translation>La dirección con la que firmar el mensaje (ej. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</translation>
</message>
<message>
<location line="+10"/>
<location line="+213"/>
<source>Choose an address from the address book</source>
<translation>Elija una dirección de la libreta de direcciones</translation>
</message>
<message>
<location line="-203"/>
<location line="+213"/>
<source>Alt+A</source>
<translation>Alt+A</translation>
</message>
<message>
<location line="-203"/>
<source>Paste address from clipboard</source>
<translation>Pegar dirección desde portapapeles</translation>
</message>
<message>
<location line="+10"/>
<source>Alt+P</source>
<translation>Alt+P</translation>
</message>
<message>
<location line="+12"/>
<source>Enter the message you want to sign here</source>
<translation>Introduzca el mensaje que desea firmar aquí</translation>
</message>
<message>
<location line="+7"/>
<source>Signature</source>
<translation>Firma</translation>
</message>
<message>
<location line="+27"/>
<source>Copy the current signature to the system clipboard</source>
<translation>Copiar la firma actual al portapapeles del sistema</translation>
</message>
<message>
<location line="+21"/>
<source>Sign the message to prove you own this Klondikecoin address</source>
<translation>Firmar el mensaje para demostrar que se posee esta dirección Klondikecoin</translation>
</message>
<message>
<location line="+3"/>
<source>Sign &Message</source>
<translation>Firmar &mensaje</translation>
</message>
<message>
<location line="+14"/>
<source>Reset all sign message fields</source>
<translation>Limpiar todos los campos de la firma de mensaje</translation>
</message>
<message>
<location line="+3"/>
<location line="+146"/>
<source>Clear &All</source>
<translation>Limpiar &todo</translation>
</message>
<message>
<location line="-87"/>
<source>&Verify Message</source>
<translation>&Verificar mensaje</translation>
</message>
<message>
<location line="+6"/>
<source>Enter the signing address, message (ensure you copy line breaks, spaces, tabs, etc. exactly) and signature below to verify the message. Be careful not to read more into the signature than what is in the signed message itself, to avoid being tricked by a man-in-the-middle attack.</source>
<translation>Introduzca la dirección para la firma, el mensaje (asegurándose de copiar tal cual los saltos de línea, espacios, tabulaciones, etc.) y la firma a continuación para verificar el mensaje. Tenga cuidado de no asumir más información de lo que dice el propio mensaje firmado para evitar fraudes basados en ataques de tipo man-in-the-middle.</translation>
</message>
<message>
<location line="+21"/>
<source>The address the message was signed with (e.g. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</source>
<translation>La dirección con la que se firmó el mensaje (ej. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</translation>
</message>
<message>
<location line="+40"/>
<source>Verify the message to ensure it was signed with the specified Klondikecoin address</source>
<translation>Verificar el mensaje para comprobar que fue firmado con la dirección Klondikecoin indicada</translation>
</message>
<message>
<location line="+3"/>
<source>Verify &Message</source>
<translation>Verificar &mensaje</translation>
</message>
<message>
<location line="+14"/>
<source>Reset all verify message fields</source>
<translation>Limpiar todos los campos de la verificación de mensaje</translation>
</message>
<message>
<location filename="../signverifymessagedialog.cpp" line="+27"/>
<location line="+3"/>
<source>Enter a Klondikecoin address (e.g. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</source>
<translation>Introduzca una dirección Klondikecoin (ej. Ler4HNAEfwYhBmGXcFP2Po1NpRUEiK8km2)</translation>
</message>
<message>
<location line="-2"/>
<source>Click "Sign Message" to generate signature</source>
<translation>Haga clic en "Firmar mensaje" para generar la firma</translation>
</message>
<message>
<location line="+3"/>
<source>Enter Klondikecoin signature</source>
<translation>Introduzca una firma Klondikecoin</translation>
</message>
<message>
<location line="+82"/>
<location line="+81"/>
<source>The entered address is invalid.</source>
<translation>La dirección introducida es inválida.</translation>
</message>
<message>
<location line="-81"/>
<location line="+8"/>
<location line="+73"/>
<location line="+8"/>
<source>Please check the address and try again.</source>
<translation>Verifique la dirección e inténtelo de nuevo.</translation>
</message>
<message>
<location line="-81"/>
<location line="+81"/>
<source>The entered address does not refer to a key.</source>
<translation>La dirección introducida no corresponde a una clave.</translation>
</message>
<message>
<location line="-73"/>
<source>Wallet unlock was cancelled.</source>
<translation>Se ha cancelado el desbloqueo del monedero. </translation>
</message>
<message>
<location line="+8"/>
<source>Private key for the entered address is not available.</source>
<translation>No se dispone de la clave privada para la dirección introducida.</translation>
</message>
<message>
<location line="+12"/>
<source>Message signing failed.</source>
<translation>Ha fallado la firma del mensaje.</translation>
</message>
<message>
<location line="+5"/>
<source>Message signed.</source>
<translation>Mensaje firmado.</translation>
</message>
<message>
<location line="+59"/>
<source>The signature could not be decoded.</source>
<translation>No se puede decodificar la firma.</translation>
</message>
<message>
<location line="+0"/>
<location line="+13"/>
<source>Please check the signature and try again.</source>
<translation>Compruebe la firma e inténtelo de nuevo.</translation>
</message>
<message>
<location line="+0"/>
<source>The signature did not match the message digest.</source>
<translation>La firma no coincide con el resumen del mensaje.</translation>
</message>
<message>
<location line="+7"/>
<source>Message verification failed.</source>
<translation>La verificación del mensaje ha fallado.</translation>
</message>
<message>
<location line="+5"/>
<source>Message verified.</source>
<translation>Mensaje verificado.</translation>
</message>
</context>
<context>
<name>SplashScreen</name>
<message>
<location filename="../splashscreen.cpp" line="+22"/>
<source>The Klondikecoin developers</source>
<translation>Los programadores Klondikecoin</translation>
</message>
<message>
<location line="+1"/>
<source>[testnet]</source>
<translation>[testnet]</translation>
</message>
</context>
<context>
<name>TransactionDesc</name>
<message>
<location filename="../transactiondesc.cpp" line="+20"/>
<source>Open until %1</source>
<translation>Abierto hasta %1</translation>
</message>
<message>
<location line="+6"/>
<source>%1/offline</source>
<translation>%1/fuera de línea</translation>
</message>
<message>
<location line="+2"/>
<source>%1/unconfirmed</source>
<translation>%1/no confirmado</translation>
</message>
<message>
<location line="+2"/>
<source>%1 confirmations</source>
<translation>%1 confirmaciones</translation>
</message>
<message>
<location line="+18"/>
<source>Status</source>
<translation>Estado</translation>
</message>
<message numerus="yes">
<location line="+7"/>
<source>, broadcast through %n node(s)</source>
<translation><numerusform>, transmitir a través de %n nodo</numerusform><numerusform>, transmitir a través de %n nodos</numerusform></translation>
</message>
<message>
<location line="+4"/>
<source>Date</source>
<translation>Fecha</translation>
</message>
<message>
<location line="+7"/>
<source>Source</source>
<translation>Fuente</translation>
</message>
<message>
<location line="+0"/>
<source>Generated</source>
<translation>Generado</translation>
</message>
<message>
<location line="+5"/>
<location line="+17"/>
<source>From</source>
<translation>De</translation>
</message>
<message>
<location line="+1"/>
<location line="+22"/>
<location line="+58"/>
<source>To</source>
<translation>Para</translation>
</message>
<message>
<location line="-77"/>
<location line="+2"/>
<source>own address</source>
<translation>dirección propia</translation>
</message>
<message>
<location line="-2"/>
<source>label</source>
<translation>etiqueta</translation>
</message>
<message>
<location line="+37"/>
<location line="+12"/>
<location line="+45"/>
<location line="+17"/>
<location line="+30"/>
<source>Credit</source>
<translation>Crédito</translation>
</message>
<message numerus="yes">
<location line="-102"/>
<source>matures in %n more block(s)</source>
<translation><numerusform>disponible en %n bloque más</numerusform><numerusform>disponible en %n bloques más</numerusform></translation>
</message>
<message>
<location line="+2"/>
<source>not accepted</source>
<translation>no aceptada</translation>
</message>
<message>
<location line="+44"/>
<location line="+8"/>
<location line="+15"/>
<location line="+30"/>
<source>Debit</source>
<translation>Débito</translation>
</message>
<message>
<location line="-39"/>
<source>Transaction fee</source>
<translation>Comisión de transacción</translation>
</message>
<message>
<location line="+16"/>
<source>Net amount</source>
<translation>Cantidad neta</translation>
</message>
<message>
<location line="+6"/>
<source>Message</source>
<translation>Mensaje</translation>
</message>
<message>
<location line="+2"/>
<source>Comment</source>
<translation>Comentario</translation>
</message>
<message>
<location line="+2"/>
<source>Transaction ID</source>
<translation>Identificador de transacción</translation>
</message>
<message>
<location line="+3"/>
<source>Generated coins must mature 120 blocks before they can be spent. When you generated this block, it was broadcast to the network to be added to the block chain. If it fails to get into the chain, its state will change to "not accepted" and it won't be spendable. This may occasionally happen if another node generates a block within a few seconds of yours.</source>
<translation>Las monedas generadas deben esperar 120 bloques antes de que se puedan gastar. Cuando se generó este bloque, se emitió a la red para ser agregado a la cadena de bloques. Si no consigue incorporarse a la cadena, su estado cambiará a "no aceptado" y las monedas no se podrán gastar. Esto puede ocurrir ocasionalmente si otro nodo genera un bloque casi al mismo tiempo que el suyo.</translation>
</message>
<message>
<location line="+7"/>
<source>Debug information</source>
<translation>Información de depuración</translation>
</message>
<message>
<location line="+8"/>
<source>Transaction</source>
<translation>Transacción</translation>
</message>
<message>
<location line="+3"/>
<source>Inputs</source>
<translation>entradas</translation>
</message>
<message>
<location line="+23"/>
<source>Amount</source>
<translation>Cantidad</translation>
</message>
<message>
<location line="+1"/>
<source>true</source>
<translation>verdadero</translation>
</message>
<message>
<location line="+0"/>
<source>false</source>
<translation>falso</translation>
</message>
<message>
<location line="-209"/>
<source>, has not been successfully broadcast yet</source>
<translation>, todavía no se ha sido difundido satisfactoriamente</translation>
</message>
<message numerus="yes">
<location line="-35"/>
<source>Open for %n more block(s)</source>
<translation><numerusform>Abrir para %n bloque más</numerusform><numerusform>Abrir para %n bloques más</numerusform></translation>
</message>
<message>
<location line="+70"/>
<source>unknown</source>
<translation>desconocido</translation>
</message>
</context>
<context>
<name>TransactionDescDialog</name>
<message>
<location filename="../forms/transactiondescdialog.ui" line="+14"/>
<source>Transaction details</source>
<translation>Detalles de transacción</translation>
</message>
<message>
<location line="+6"/>
<source>This pane shows a detailed description of the transaction</source>
<translation>Esta ventana muestra información detallada sobre la transacción</translation>
</message>
</context>
<context>
<name>TransactionTableModel</name>
<message>
<location filename="../transactiontablemodel.cpp" line="+225"/>
<source>Date</source>
<translation>Fecha</translation>
</message>
<message>
<location line="+0"/>
<source>Type</source>
<translation>Tipo</translation>
</message>
<message>
<location line="+0"/>
<source>Address</source>
<translation>Dirección</translation>
</message>
<message>
<location line="+0"/>
<source>Amount</source>
<translation>Cantidad</translation>
</message>
<message numerus="yes">
<location line="+57"/>
<source>Open for %n more block(s)</source>
<translation><numerusform>Abrir para %n bloque más</numerusform><numerusform>Abrir para %n bloques más</numerusform></translation>
</message>
<message>
<location line="+3"/>
<source>Open until %1</source>
<translation>Abierto hasta %1</translation>
</message>
<message>
<location line="+3"/>
<source>Offline (%1 confirmations)</source>
<translation>Fuera de línea (%1 confirmaciones)</translation>
</message>
<message>
<location line="+3"/>
<source>Unconfirmed (%1 of %2 confirmations)</source>
<translation>No confirmado (%1 de %2 confirmaciones)</translation>
</message>
<message>
<location line="+3"/>
<source>Confirmed (%1 confirmations)</source>
<translation>Confirmado (%1 confirmaciones)</translation>
</message>
<message numerus="yes">
<location line="+8"/>
<source>Mined balance will be available when it matures in %n more block(s)</source>
<translation><numerusform>El saldo recién minado estará disponible cuando venza el plazo en %n bloque más</numerusform><numerusform>El saldo recién minado estará disponible cuando venza el plazo en %n bloques más</numerusform></translation>
</message>
<message>
<location line="+5"/>
<source>This block was not received by any other nodes and will probably not be accepted!</source>
<translation>Este bloque no ha sido recibido por otros nodos y probablemente no sea aceptado!</translation>
</message>
<message>
<location line="+3"/>
<source>Generated but not accepted</source>
<translation>Generado pero no aceptado</translation>
</message>
<message>
<location line="+43"/>
<source>Received with</source>
<translation>Recibido con</translation>
</message>
<message>
<location line="+2"/>
<source>Received from</source>
<translation>Recibidos de</translation>
</message>
<message>
<location line="+3"/>
<source>Sent to</source>
<translation>Enviado a</translation>
</message>
<message>
<location line="+2"/>
<source>Payment to yourself</source>
<translation>Pago propio</translation>
</message>
<message>
<location line="+2"/>
<source>Mined</source>
<translation>Minado</translation>
</message>
<message>
<location line="+38"/>
<source>(n/a)</source>
<translation>(nd)</translation>
</message>
<message>
<location line="+199"/>
<source>Transaction status. Hover over this field to show number of confirmations.</source>
<translation>Estado de transacción. Pasa el ratón sobre este campo para ver el número de confirmaciones.</translation>
</message>
<message>
<location line="+2"/>
<source>Date and time that the transaction was received.</source>
<translation>Fecha y hora en que se recibió la transacción.</translation>
</message>
<message>
<location line="+2"/>
<source>Type of transaction.</source>
<translation>Tipo de transacción.</translation>
</message>
<message>
<location line="+2"/>
<source>Destination address of transaction.</source>
<translation>Dirección de destino de la transacción.</translation>
</message>
<message>
<location line="+2"/>
<source>Amount removed from or added to balance.</source>
<translation>Cantidad retirada o añadida al saldo.</translation>
</message>
</context>
<context>
<name>TransactionView</name>
<message>
<location filename="../transactionview.cpp" line="+52"/>
<location line="+16"/>
<source>All</source>
<translation>Todo</translation>
</message>
<message>
<location line="-15"/>
<source>Today</source>
<translation>Hoy</translation>
</message>
<message>
<location line="+1"/>
<source>This week</source>
<translation>Esta semana</translation>
</message>
<message>
<location line="+1"/>
<source>This month</source>
<translation>Este mes</translation>
</message>
<message>
<location line="+1"/>
<source>Last month</source>
<translation>Mes pasado</translation>
</message>
<message>
<location line="+1"/>
<source>This year</source>
<translation>Este año</translation>
</message>
<message>
<location line="+1"/>
<source>Range...</source>
<translation>Rango...</translation>
</message>
<message>
<location line="+11"/>
<source>Received with</source>
<translation>Recibido con</translation>
</message>
<message>
<location line="+2"/>
<source>Sent to</source>
<translation>Enviado a</translation>
</message>
<message>
<location line="+2"/>
<source>To yourself</source>
<translation>A usted mismo</translation>
</message>
<message>
<location line="+1"/>
<source>Mined</source>
<translation>Minado</translation>
</message>
<message>
<location line="+1"/>
<source>Other</source>
<translation>Otra</translation>
</message>
<message>
<location line="+7"/>
<source>Enter address or label to search</source>
<translation>Introduzca una dirección o etiqueta que buscar</translation>
</message>
<message>
<location line="+7"/>
<source>Min amount</source>
<translation>Cantidad mínima</translation>
</message>
<message>
<location line="+34"/>
<source>Copy address</source>
<translation>Copiar dirección</translation>
</message>
<message>
<location line="+1"/>
<source>Copy label</source>
<translation>Copiar etiqueta</translation>
</message>
<message>
<location line="+1"/>
<source>Copy amount</source>
<translation>Copiar cuantía</translation>
</message>
<message>
<location line="+1"/>
<source>Copy transaction ID</source>
<translation>Copiar identificador de transacción</translation>
</message>
<message>
<location line="+1"/>
<source>Edit label</source>
<translation>Editar etiqueta</translation>
</message>
<message>
<location line="+1"/>
<source>Show transaction details</source>
<translation>Mostrar detalles de la transacción</translation>
</message>
<message>
<location line="+139"/>
<source>Export Transaction Data</source>
<translation>Exportar datos de la transacción</translation>
</message>
<message>
<location line="+1"/>
<source>Comma separated file (*.csv)</source>
<translation>Archivos de columnas separadas por coma (*.csv)</translation>
</message>
<message>
<location line="+8"/>
<source>Confirmed</source>
<translation>Confirmado</translation>
</message>
<message>
<location line="+1"/>
<source>Date</source>
<translation>Fecha</translation>
</message>
<message>
<location line="+1"/>
<source>Type</source>
<translation>Tipo</translation>
</message>
<message>
<location line="+1"/>
<source>Label</source>
<translation>Etiqueta</translation>
</message>
<message>
<location line="+1"/>
<source>Address</source>
<translation>Dirección</translation>
</message>
<message>
<location line="+1"/>
<source>Amount</source>
<translation>Cantidad</translation>
</message>
<message>
<location line="+1"/>
<source>ID</source>
<translation>ID</translation>
</message>
<message>
<location line="+4"/>
<source>Error exporting</source>
<translation>Error exportando</translation>
</message>
<message>
<location line="+0"/>
<source>Could not write to file %1.</source>
<translation>No se pudo escribir en el archivo %1.</translation>
</message>
<message>
<location line="+100"/>
<source>Range:</source>
<translation>Rango:</translation>
</message>
<message>
<location line="+8"/>
<source>to</source>
<translation>para</translation>
</message>
</context>
<context>
<name>WalletModel</name>
<message>
<location filename="../walletmodel.cpp" line="+193"/>
<source>Send Coins</source>
<translation>Enviar monedas</translation>
</message>
</context>
<context>
<name>WalletView</name>
<message>
<location filename="../walletview.cpp" line="+42"/>
<source>&Export</source>
<translation>&Exportar</translation>
</message>
<message>
<location line="+1"/>
<source>Export the data in the current tab to a file</source>
<translation>Exportar a un archivo los datos de esta pestaña</translation>
</message>
<message>
<location line="+193"/>
<source>Backup Wallet</source>
<translation>Respaldo de monedero</translation>
</message>
<message>
<location line="+0"/>
<source>Wallet Data (*.dat)</source>
<translation>Datos de monedero (*.dat)</translation>
</message>
<message>
<location line="+3"/>
<source>Backup Failed</source>
<translation>Ha fallado el respaldo</translation>
</message>
<message>
<location line="+0"/>
<source>There was an error trying to save the wallet data to the new location.</source>
<translation>Se ha producido un error al intentar guardar los datos del monedero en la nueva ubicación.</translation>
</message>
<message>
<location line="+4"/>
<source>Backup Successful</source>
<translation>Se ha completado con éxito la copia de respaldo</translation>
</message>
<message>
<location line="+0"/>
<source>The wallet data was successfully saved to the new location.</source>
<translation>Los datos del monedero se han guardado con éxito en la nueva ubicación.</translation>
</message>
</context>
<context>
<name>bitcoin-core</name>
<message>
<location filename="../bitcoinstrings.cpp" line="+94"/>
<source>Klondikecoin version</source>
<translation>Versión de Klondikecoin</translation>
</message>
<message>
<location line="+102"/>
<source>Usage:</source>
<translation>Uso:</translation>
</message>
<message>
<location line="-29"/>
<source>Send command to -server or klondikecoind</source>
<translation>Envíar comando a -server o klondikecoind</translation>
</message>
<message>
<location line="-23"/>
<source>List commands</source>
<translation>Muestra comandos
</translation>
</message>
<message>
<location line="-12"/>
<source>Get help for a command</source>
<translation>Recibir ayuda para un comando
</translation>
</message>
<message>
<location line="+24"/>
<source>Options:</source>
<translation>Opciones:
</translation>
</message>
<message>
<location line="+24"/>
<source>Specify configuration file (default: klondikecoin.conf)</source>
<translation>Especificar archivo de configuración (predeterminado: klondikecoin.conf)
</translation>
</message>
<message>
<location line="+3"/>
<source>Specify pid file (default: klondikecoind.pid)</source>
<translation>Especificar archivo pid (predeterminado: klondikecoin.pid)
</translation>
</message>
<message>
<location line="-1"/>
<source>Specify data directory</source>
<translation>Especificar directorio para los datos</translation>
</message>
<message>
<location line="-9"/>
<source>Set database cache size in megabytes (default: 25)</source>
<translation>Establecer el tamaño de caché de la base de datos en megabytes (predeterminado: 25)</translation>
</message>
<message>
<location line="-28"/>
<source>Listen for connections on <port> (default: 9333 or testnet: 19333)</source>
<translation>Escuchar conexiones en <puerto> (predeterminado: 9333 o testnet: 19333)</translation>
</message>
<message>
<location line="+5"/>
<source>Maintain at most <n> connections to peers (default: 125)</source>
<translation>Mantener como máximo <n> conexiones a pares (predeterminado: 125)</translation>
</message>
<message>
<location line="-48"/>
<source>Connect to a node to retrieve peer addresses, and disconnect</source>
<translation>Conectar a un nodo para obtener direcciones de pares y desconectar</translation>
</message>
<message>
<location line="+82"/>
<source>Specify your own public address</source>
<translation>Especifique su propia dirección pública</translation>
</message>
<message>
<location line="+3"/>
<source>Threshold for disconnecting misbehaving peers (default: 100)</source>
<translation>Umbral para la desconexión de pares con mal comportamiento (predeterminado: 100)</translation>
</message>
<message>
<location line="-134"/>
<source>Number of seconds to keep misbehaving peers from reconnecting (default: 86400)</source>
<translation>Número de segundos en que se evita la reconexión de pares con mal comportamiento (predeterminado: 86400)</translation>
</message>
<message>
<location line="-29"/>
<source>An error occurred while setting up the RPC port %u for listening on IPv4: %s</source>
<translation>Ha ocurrido un error al configurar el puerto RPC %u para escucha en IPv4: %s</translation>
</message>
<message>
<location line="+27"/>
<source>Listen for JSON-RPC connections on <port> (default: 9332 or testnet: 19332)</source>
<translation>Escuchar conexiones JSON-RPC en <puerto> (predeterminado: 9332 o testnet:19332)</translation>
</message>
<message>
<location line="+37"/>
<source>Accept command line and JSON-RPC commands</source>
<translation>Aceptar comandos consola y JSON-RPC
</translation>
</message>
<message>
<location line="+76"/>
<source>Run in the background as a daemon and accept commands</source>
<translation>Correr como demonio y aceptar comandos
</translation>
</message>
<message>
<location line="+37"/>
<source>Use the test network</source>
<translation>Usar la red de pruebas
</translation>
</message>
<message>
<location line="-112"/>
<source>Accept connections from outside (default: 1 if no -proxy or -connect)</source>
<translation>Aceptar conexiones desde el exterior (predeterminado: 1 si no -proxy o -connect)</translation>
</message>
<message>
<location line="-80"/>
<source>%s, you must set a rpcpassword in the configuration file:
%s
It is recommended you use the following random password:
rpcuser=klondikecoinrpc
rpcpassword=%s
(you do not need to remember this password)
The username and password MUST NOT be the same.
If the file does not exist, create it with owner-readable-only file permissions.
It is also recommended to set alertnotify so you are notified of problems;
for example: alertnotify=echo %%s | mail -s "Klondikecoin Alert" [email protected]
</source>
<translation>%s, debe establecer un valor rpcpassword en el archivo de configuración:
%s
Se recomienda utilizar la siguiente contraseña aleatoria:
rpcuser=klondikecoinrpc
rpcpassword=%s
(no es necesario recordar esta contraseña)
El nombre de usuario y la contraseña DEBEN NO ser iguales.
Si el archivo no existe, créelo con permisos de archivo de solo lectura.
Se recomienda también establecer alertnotify para recibir notificaciones de problemas.
Por ejemplo: alertnotify=echo %%s | mail -s "Klondikecoin Alert" [email protected]
</translation>
</message>
<message>
<location line="+17"/>
<source>An error occurred while setting up the RPC port %u for listening on IPv6, falling back to IPv4: %s</source>
<translation>Ha ocurrido un error al configurar el puerto RPC %u para escuchar mediante IPv6. Recurriendo a IPv4: %s</translation>
</message>
<message>
<location line="+3"/>
<source>Bind to given address and always listen on it. Use [host]:port notation for IPv6</source>
<translation>Vincular a la dirección dada y escuchar siempre en ella. Utilice la notación [host]:port para IPv6</translation>
</message>
<message>
<location line="+3"/>
<source>Cannot obtain a lock on data directory %s. Klondikecoin is probably already running.</source>
<translation>No se puede bloquear el directorio de datos %s. Probablemente Klondikecoin ya se está ejecutando.</translation>
</message>
<message>
<location line="+3"/>
<source>Error: The transaction was rejected! This might happen if some of the coins in your wallet were already spent, such as if you used a copy of wallet.dat and coins were spent in the copy but not marked as spent here.</source>
<translation>¡Error: se ha rechazado la transacción! Esto puede ocurrir si ya se han gastado algunas de las monedas del monedero, como ocurriría si hubiera hecho una copia de wallet.dat y se hubieran gastado monedas a partir de la copia, con lo que no se habrían marcado aquí como gastadas.</translation>
</message>
<message>
<location line="+4"/>
<source>Error: This transaction requires a transaction fee of at least %s because of its amount, complexity, or use of recently received funds!</source>
<translation>¡Error: Esta transacción requiere una comisión de al menos %s debido a su monto, complejidad, o al uso de fondos recién recibidos!</translation>
</message>
<message>
<location line="+3"/>
<source>Execute command when a relevant alert is received (%s in cmd is replaced by message)</source>
<translation>Ejecutar orden cuando se reciba un aviso relevante (%s en cmd se reemplazará por el mensaje)</translation>
</message>
<message>
<location line="+3"/>
<source>Execute command when a wallet transaction changes (%s in cmd is replaced by TxID)</source>
<translation>Ejecutar comando cuando una transacción del monedero cambia (%s en cmd se remplazará por TxID)</translation>
</message>
<message>
<location line="+11"/>
<source>Set maximum size of high-priority/low-fee transactions in bytes (default: 27000)</source>
<translation>Establecer el tamaño máximo de las transacciones de alta prioridad/comisión baja en bytes (predeterminado:27000)</translation>
</message>
<message>
<location line="+6"/>
<source>This is a pre-release test build - use at your own risk - do not use for mining or merchant applications</source>
<translation>Esta es una versión de pre-prueba - utilícela bajo su propio riesgo. No la utilice para usos comerciales o de minería.</translation>
</message>
<message>
<location line="+5"/>
<source>Warning: -paytxfee is set very high! This is the transaction fee you will pay if you send a transaction.</source>
<translation>Aviso: ¡-paytxfee tiene un valor muy alto! Esta es la comisión que pagará si envía una transacción.</translation>
</message>
<message>
<location line="+3"/>
<source>Warning: Displayed transactions may not be correct! You may need to upgrade, or other nodes may need to upgrade.</source>
<translation>Aviso: ¡Las transacciones mostradas pueden no ser correctas! Puede necesitar una actualización o bien otros nodos necesitan actualizarse.</translation>
</message>
<message>
<location line="+3"/>
<source>Warning: Please check that your computer's date and time are correct! If your clock is wrong Klondikecoin will not work properly.</source>
<translation>Precaución: Por favor, ¡revise que la fecha y hora de su ordenador son correctas! Si su reloj está mal, Klondikecoin no funcionará correctamente.</translation>
</message>
<message>
<location line="+3"/>
<source>Warning: error reading wallet.dat! All keys read correctly, but transaction data or address book entries might be missing or incorrect.</source>
<translation>Aviso: ¡Error al leer wallet.dat! Todas las claves se han leído correctamente, pero podrían faltar o ser incorrectos los datos de transacciones o las entradas de la libreta de direcciones.</translation>
</message>
<message>
<location line="+3"/>
<source>Warning: wallet.dat corrupt, data salvaged! Original wallet.dat saved as wallet.{timestamp}.bak in %s; if your balance or transactions are incorrect you should restore from a backup.</source>
<translation>Aviso: ¡Recuperados datos de wallet.dat corrupto! El wallet.dat original se ha guardado como wallet.{timestamp}.bak en %s; si hubiera errores en su saldo o transacciones, deberá restaurar una copia de seguridad.</translation>
</message>
<message>
<location line="+14"/>
<source>Attempt to recover private keys from a corrupt wallet.dat</source>
<translation>Intento de recuperar claves privadas de un wallet.dat corrupto</translation>
</message>
<message>
<location line="+2"/>
<source>Block creation options:</source>
<translation>Opciones de creación de bloques:</translation>
</message>
<message>
<location line="+5"/>
<source>Connect only to the specified node(s)</source>
<translation>Conectar sólo a los nodos (o nodo) especificados</translation>
</message>
<message>
<location line="+3"/>
<source>Corrupted block database detected</source>
<translation>Corrupción de base de datos de bloques detectada.</translation>
</message>
<message>
<location line="+1"/>
<source>Discover own IP address (default: 1 when listening and no -externalip)</source>
<translation>Descubrir dirección IP propia (predeterminado: 1 al escuchar sin -externalip)</translation>
</message>
<message>
<location line="+1"/>
<source>Do you want to rebuild the block database now?</source>
<translation>¿Quieres reconstruir la base de datos de bloques ahora?</translation>
</message>
<message>
<location line="+2"/>
<source>Error initializing block database</source>
<translation>Error al inicializar la base de datos de bloques</translation>
</message>
<message>
<location line="+1"/>
<source>Error initializing wallet database environment %s!</source>
<translation>Error al inicializar el entorno de la base de datos del monedero %s</translation>
</message>
<message>
<location line="+1"/>
<source>Error loading block database</source>
<translation>Error cargando base de datos de bloques</translation>
</message>
<message>
<location line="+4"/>
<source>Error opening block database</source>
<translation>Error al abrir base de datos de bloques.</translation>
</message>
<message>
<location line="+2"/>
<source>Error: Disk space is low!</source>
<translation>Error: ¡Espacio en disco bajo!</translation>
</message>
<message>
<location line="+1"/>
<source>Error: Wallet locked, unable to create transaction!</source>
<translation>Error: ¡El monedero está bloqueado; no se puede crear la transacción!</translation>
</message>
<message>
<location line="+1"/>
<source>Error: system error: </source>
<translation>Error: error de sistema: </translation>
</message>
<message>
<location line="+1"/>
<source>Failed to listen on any port. Use -listen=0 if you want this.</source>
<translation>Ha fallado la escucha en todos los puertos. Use -listen=0 si desea esto.</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to read block info</source>
<translation>No se ha podido leer la información de bloque</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to read block</source>
<translation>No se ha podido leer el bloque</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to sync block index</source>
<translation>No se ha podido sincronizar el índice de bloques</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to write block index</source>
<translation>No se ha podido escribir en el índice de bloques</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to write block info</source>
<translation>No se ha podido escribir la información de bloques</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to write block</source>
<translation>No se ha podido escribir el bloque</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to write file info</source>
<translation>No se ha podido escribir la información de archivo</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to write to coin database</source>
<translation>No se ha podido escribir en la base de datos de monedas</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to write transaction index</source>
<translation>No se ha podido escribir en el índice de transacciones</translation>
</message>
<message>
<location line="+1"/>
<source>Failed to write undo data</source>
<translation>No se han podido escribir los datos de deshacer</translation>
</message>
<message>
<location line="+2"/>
<source>Find peers using DNS lookup (default: 1 unless -connect)</source>
<translation>Encontrar pares mediante búsqueda de DNS (predeterminado: 1 salvo con -connect)</translation>
</message>
<message>
<location line="+1"/>
<source>Generate coins (default: 0)</source>
<translation>Generar monedas (por defecto: 0)</translation>
</message>
<message>
<location line="+2"/>
<source>How many blocks to check at startup (default: 288, 0 = all)</source>
<translation>Cuántos bloques comprobar al iniciar (predeterminado: 288, 0 = todos)</translation>
</message>
<message>
<location line="+1"/>
<source>How thorough the block verification is (0-4, default: 3)</source>
<translation>Como es de exhaustiva la verificación de bloques (0-4, por defecto 3)</translation>
</message>
<message>
<location line="+19"/>
<source>Not enough file descriptors available.</source>
<translation>No hay suficientes descriptores de archivo disponibles. </translation>
</message>
<message>
<location line="+8"/>
<source>Rebuild block chain index from current blk000??.dat files</source>
<translation>Reconstruir el índice de la cadena de bloques a partir de los archivos blk000??.dat actuales</translation>
</message>
<message>
<location line="+16"/>
<source>Set the number of threads to service RPC calls (default: 4)</source>
<translation>Establecer el número de hilos para atender las llamadas RPC (predeterminado: 4)</translation>
</message>
<message>
<location line="+26"/>
<source>Verifying blocks...</source>
<translation>Verificando bloques...</translation>
</message>
<message>
<location line="+1"/>
<source>Verifying wallet...</source>
<translation>Verificando monedero...</translation>
</message>
<message>
<location line="-69"/>
<source>Imports blocks from external blk000??.dat file</source>
<translation>Importa los bloques desde un archivo blk000??.dat externo</translation>
</message>
<message>
<location line="-76"/>
<source>Set the number of script verification threads (up to 16, 0 = auto, <0 = leave that many cores free, default: 0)</source>
<translation>Configura el número de hilos para el script de verificación (hasta 16, 0 = auto, <0 = leave that many cores free, por fecto: 0)</translation>
</message>
<message>
<location line="+77"/>
<source>Information</source>
<translation>Información</translation>
</message>
<message>
<location line="+3"/>
<source>Invalid -tor address: '%s'</source>
<translation>Dirección -tor inválida: '%s'</translation>
</message>
<message>
<location line="+1"/>
<source>Invalid amount for -minrelaytxfee=<amount>: '%s'</source>
<translation>Inválido por el monto -minrelaytxfee=<amount>: '%s'</translation>
</message>
<message>
<location line="+1"/>
<source>Invalid amount for -mintxfee=<amount>: '%s'</source>
<translation>Inválido por el monto -mintxfee=<amount>: '%s'</translation>
</message>
<message>
<location line="+8"/>
<source>Maintain a full transaction index (default: 0)</source>
<translation>Mantener índice de transacciones completo (predeterminado: 0)</translation>
</message>
<message>
<location line="+2"/>
<source>Maximum per-connection receive buffer, <n>*1000 bytes (default: 5000)</source>
<translation>Búfer de recepción máximo por conexión, <n>*1000 bytes (predeterminado: 5000)</translation>
</message>
<message>
<location line="+1"/>
<source>Maximum per-connection send buffer, <n>*1000 bytes (default: 1000)</source>
<translation>Búfer de recepción máximo por conexión, , <n>*1000 bytes (predeterminado: 1000)</translation>
</message>
<message>
<location line="+2"/>
<source>Only accept block chain matching built-in checkpoints (default: 1)</source>
<translation>Aceptar solamente cadena de bloques que concuerde con los puntos de control internos (predeterminado: 1)</translation>
</message>
<message>
<location line="+1"/>
<source>Only connect to nodes in network <net> (IPv4, IPv6 or Tor)</source>
<translation>Conectarse solo a nodos de la red <net> (IPv4, IPv6 o Tor)</translation>
</message>
<message>
<location line="+2"/>
<source>Output extra debugging information. Implies all other -debug* options</source>
<translation>Mostrar información de depuración adicional. Implica todos los demás opciones -debug*</translation>
</message>
<message>
<location line="+1"/>
<source>Output extra network debugging information</source>
<translation>Mostrar información de depuración adicional</translation>
</message>
<message>
<location line="+2"/>
<source>Prepend debug output with timestamp</source>
<translation>Anteponer marca temporal a la información de depuración</translation>
</message>
<message>
<location line="+5"/>
<source>SSL options: (see the Klondikecoin Wiki for SSL setup instructions)</source>
<translation>Opciones SSL: (ver la Klondikecoin Wiki para instrucciones de configuración SSL)</translation>
</message>
<message>
<location line="+1"/>
<source>Select the version of socks proxy to use (4-5, default: 5)</source>
<translation>Elija la versión del proxy socks a usar (4-5, predeterminado: 5)</translation>
</message>
<message>
<location line="+3"/>
<source>Send trace/debug info to console instead of debug.log file</source>
<translation>Enviar información de trazas/depuración a la consola en lugar de al archivo debug.log</translation>
</message>
<message>
<location line="+1"/>
<source>Send trace/debug info to debugger</source>
<translation>Enviar información de trazas/depuración al depurador</translation>
</message>
<message>
<location line="+5"/>
<source>Set maximum block size in bytes (default: 250000)</source>
<translation>Establecer tamaño máximo de bloque en bytes (predeterminado: 250000)</translation>
</message>
<message>
<location line="+1"/>
<source>Set minimum block size in bytes (default: 0)</source>
<translation>Establecer tamaño mínimo de bloque en bytes (predeterminado: 0)</translation>
</message>
<message>
<location line="+2"/>
<source>Shrink debug.log file on client startup (default: 1 when no -debug)</source>
<translation>Reducir el archivo debug.log al iniciar el cliente (predeterminado: 1 sin -debug)</translation>
</message>
<message>
<location line="+1"/>
<source>Signing transaction failed</source>
<translation>Transacción falló</translation>
</message>
<message>
<location line="+2"/>
<source>Specify connection timeout in milliseconds (default: 5000)</source>
<translation>Especificar el tiempo máximo de conexión en milisegundos (predeterminado: 5000)</translation>
</message>
<message>
<location line="+4"/>
<source>System error: </source>
<translation>Error de sistema: </translation>
</message>
<message>
<location line="+4"/>
<source>Transaction amount too small</source>
<translation>Monto de la transacción muy pequeño</translation>
</message>
<message>
<location line="+1"/>
<source>Transaction amounts must be positive</source>
<translation>Montos de transacciones deben ser positivos</translation>
</message>
<message>
<location line="+1"/>
<source>Transaction too large</source>
<translation>Transacción demasiado grande</translation>
</message>
<message>
<location line="+7"/>
<source>Use UPnP to map the listening port (default: 0)</source>
<translation>Usar UPnP para asignar el puerto de escucha (predeterminado: 0)</translation>
</message>
<message>
<location line="+1"/>
<source>Use UPnP to map the listening port (default: 1 when listening)</source>
<translation>Usar UPnP para asignar el puerto de escucha (predeterminado: 1 al escuchar)</translation>
</message>
<message>
<location line="+1"/>
<source>Use proxy to reach tor hidden services (default: same as -proxy)</source>
<translation>Utilizar proxy para conectar a Tor servicios ocultos (predeterminado: igual que -proxy)</translation>
</message>
<message>
<location line="+2"/>
<source>Username for JSON-RPC connections</source>
<translation>Nombre de usuario para las conexiones JSON-RPC
</translation>
</message>
<message>
<location line="+4"/>
<source>Warning</source>
<translation>Aviso</translation>
</message>
<message>
<location line="+1"/>
<source>Warning: This version is obsolete, upgrade required!</source>
<translation>Aviso: Esta versión es obsoleta, actualización necesaria!</translation>
</message>
<message>
<location line="+1"/>
<source>You need to rebuild the databases using -reindex to change -txindex</source>
<translation>Necesita reconstruir las bases de datos con la opción -reindex para modificar -txindex</translation>
</message>
<message>
<location line="+1"/>
<source>wallet.dat corrupt, salvage failed</source>
<translation>wallet.dat corrupto. Ha fallado la recuperación.</translation>
</message>
<message>
<location line="-50"/>
<source>Password for JSON-RPC connections</source>
<translation>Contraseña para las conexiones JSON-RPC
</translation>
</message>
<message>
<location line="-67"/>
<source>Allow JSON-RPC connections from specified IP address</source>
<translation>Permitir conexiones JSON-RPC desde la dirección IP especificada
</translation>
</message>
<message>
<location line="+76"/>
<source>Send commands to node running on <ip> (default: 127.0.0.1)</source>
<translation>Enviar comando al nodo situado en <ip> (predeterminado: 127.0.0.1)
</translation>
</message>
<message>
<location line="-120"/>
<source>Execute command when the best block changes (%s in cmd is replaced by block hash)</source>
<translation>Ejecutar un comando cuando cambia el mejor bloque (%s en cmd se sustituye por el hash de bloque)</translation>
</message>
<message>
<location line="+147"/>
<source>Upgrade wallet to latest format</source>
<translation>Actualizar el monedero al último formato</translation>
</message>
<message>
<location line="-21"/>
<source>Set key pool size to <n> (default: 100)</source>
<translation>Ajustar el número de claves en reserva <n> (predeterminado: 100)
</translation>
</message>
<message>
<location line="-12"/>
<source>Rescan the block chain for missing wallet transactions</source>
<translation>Volver a examinar la cadena de bloques en busca de transacciones del monedero perdidas</translation>
</message>
<message>
<location line="+35"/>
<source>Use OpenSSL (https) for JSON-RPC connections</source>
<translation>Usar OpenSSL (https) para las conexiones JSON-RPC
</translation>
</message>
<message>
<location line="-26"/>
<source>Server certificate file (default: server.cert)</source>
<translation>Certificado del servidor (predeterminado: server.cert)
</translation>
</message>
<message>
<location line="+1"/>
<source>Server private key (default: server.pem)</source>
<translation>Clave privada del servidor (predeterminado: server.pem)
</translation>
</message>
<message>
<location line="-151"/>
<source>Acceptable ciphers (default: TLSv1+HIGH:!SSLv2:!aNULL:!eNULL:!AH:!3DES:@STRENGTH)</source>
<translation>Cifrados aceptados (predeterminado: TLSv1+HIGH:!SSLv2:!aNULL:!eNULL:!AH:!3DES:@STRENGTH)
</translation>
</message>
<message>
<location line="+165"/>
<source>This help message</source>
<translation>Este mensaje de ayuda
</translation>
</message>
<message>
<location line="+6"/>
<source>Unable to bind to %s on this computer (bind returned error %d, %s)</source>
<translation>No es posible conectar con %s en este sistema (bind ha dado el error %d, %s)</translation>
</message>
<message>
<location line="-91"/>
<source>Connect through socks proxy</source>
<translation>Conectar mediante proxy socks</translation>
</message>
<message>
<location line="-10"/>
<source>Allow DNS lookups for -addnode, -seednode and -connect</source>
<translation>Permitir búsquedas DNS para -addnode, -seednode y -connect</translation>
</message>
<message>
<location line="+55"/>
<source>Loading addresses...</source>
<translation>Cargando direcciones...</translation>
</message>
<message>
<location line="-35"/>
<source>Error loading wallet.dat: Wallet corrupted</source>
<translation>Error al cargar wallet.dat: el monedero está dañado</translation>
</message>
<message>
<location line="+1"/>
<source>Error loading wallet.dat: Wallet requires newer version of Klondikecoin</source>
<translation>Error al cargar wallet.dat: El monedero requiere una versión más reciente de Klondikecoin</translation>
</message>
<message>
<location line="+93"/>
<source>Wallet needed to be rewritten: restart Klondikecoin to complete</source>
<translation>El monedero ha necesitado ser reescrito. Reinicie Klondikecoin para completar el proceso</translation>
</message>
<message>
<location line="-95"/>
<source>Error loading wallet.dat</source>
<translation>Error al cargar wallet.dat</translation>
</message>
<message>
<location line="+28"/>
<source>Invalid -proxy address: '%s'</source>
<translation>Dirección -proxy inválida: '%s'</translation>
</message>
<message>
<location line="+56"/>
<source>Unknown network specified in -onlynet: '%s'</source>
<translation>La red especificada en -onlynet '%s' es desconocida</translation>
</message>
<message>
<location line="-1"/>
<source>Unknown -socks proxy version requested: %i</source>
<translation>Solicitada versión de proxy -socks desconocida: %i</translation>
</message>
<message>
<location line="-96"/>
<source>Cannot resolve -bind address: '%s'</source>
<translation>No se puede resolver la dirección de -bind: '%s'</translation>
</message>
<message>
<location line="+1"/>
<source>Cannot resolve -externalip address: '%s'</source>
<translation>No se puede resolver la dirección de -externalip: '%s'</translation>
</message>
<message>
<location line="+44"/>
<source>Invalid amount for -paytxfee=<amount>: '%s'</source>
<translation>Cantidad inválida para -paytxfee=<amount>: '%s'</translation>
</message>
<message>
<location line="+1"/>
<source>Invalid amount</source>
<translation>Cuantía no válida</translation>
</message>
<message>
<location line="-6"/>
<source>Insufficient funds</source>
<translation>Fondos insuficientes</translation>
</message>
<message>
<location line="+10"/>
<source>Loading block index...</source>
<translation>Cargando el índice de bloques...</translation>
</message>
<message>
<location line="-57"/>
<source>Add a node to connect to and attempt to keep the connection open</source>
<translation>Añadir un nodo al que conectarse y tratar de mantener la conexión abierta</translation>
</message>
<message>
<location line="-25"/>
<source>Unable to bind to %s on this computer. Klondikecoin is probably already running.</source>
<translation>No es posible conectar con %s en este sistema. Probablemente Klondikecoin ya está ejecutándose.</translation>
</message>
<message>
<location line="+64"/>
<source>Fee per KB to add to transactions you send</source>
<translation>Tarifa por KB que añadir a las transacciones que envíe</translation>
</message>
<message>
<location line="+19"/>
<source>Loading wallet...</source>
<translation>Cargando monedero...</translation>
</message>
<message>
<location line="-52"/>
<source>Cannot downgrade wallet</source>
<translation>No se puede rebajar el monedero</translation>
</message>
<message>
<location line="+3"/>
<source>Cannot write default address</source>
<translation>No se puede escribir la dirección predeterminada</translation>
</message>
<message>
<location line="+64"/>
<source>Rescanning...</source>
<translation>Reexplorando...</translation>
</message>
<message>
<location line="-57"/>
<source>Done loading</source>
<translation>Generado pero no aceptado</translation>
</message>
<message>
<location line="+82"/>
<source>To use the %s option</source>
<translation>Para utilizar la opción %s</translation>
</message>
<message>
<location line="-74"/>
<source>Error</source>
<translation>Error</translation>
</message>
<message>
<location line="-31"/>
<source>You must set rpcpassword=<password> in the configuration file:
%s
If the file does not exist, create it with owner-readable-only file permissions.</source>
<translation>Tiene que establecer rpcpassword=<contraseña> en el fichero de configuración: ⏎
%s ⏎
Si el archivo no existe, créelo con permiso de lectura solamente del propietario.</translation>
</message>
</context>
</TS><|fim▁end|> | <source>Catching up...</source>
<translation>Actualizando...</translation>
</message> |
<|file_name|>webroot.py<|end_file_name|><|fim▁begin|># -*- coding: utf-8 -*-
import json
import os
import re
import cherrypy
import mako
from girder import constants
from girder.models.setting import Setting
from girder.settings import SettingKey
from girder.utility import config
class WebrootBase:
"""
Serves a template file in response to GET requests.
This will typically be the base class of any non-API endpoints.
"""
exposed = True
def __init__(self, templatePath):
self.vars = {}
self.config = config.getConfig()
self._templateDirs = []
self.setTemplatePath(templatePath)
def updateHtmlVars(self, vars):
"""
If any of the variables in the index html need to change, call this
with the updated set of variables to render the template with.
"""
self.vars.update(vars)
def setTemplatePath(self, templatePath):
"""
Set the path to a template file to render instead of the default template.
The default template remains available so that custom templates can
inherit from it. To do so, save the default template filename from
the templateFilename attribute before calling this function, pass
it as a variable to the custom template using updateHtmlVars(), and
reference that variable in an <%inherit> directive like:
<%inherit file="${context.get('defaultTemplateFilename')}"/>
"""
templateDir, templateFilename = os.path.split(templatePath)
self._templateDirs.append(templateDir)
self.templateFilename = templateFilename
# Reset TemplateLookup instance so that it will be instantiated lazily,
# with the latest template directories, on the next GET request
self._templateLookup = None
@staticmethod
def _escapeJavascript(string):
# Per the advice at:
# https://www.owasp.org/index.php/XSS_(Cross_Site_Scripting)_Prevention_Cheat_Sheet#Output_Encoding_Rules_Summary
# replace all non-alphanumeric characters with "\0uXXXX" unicode escaping:
# https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Lexical_grammar#Unicode_escape_sequences
return re.sub(
r'[^a-zA-Z0-9]',
lambda match: '\\u%04X' % ord(match.group()),
string
)
def _renderHTML(self):
if self._templateLookup is None:
self._templateLookup = mako.lookup.TemplateLookup(directories=self._templateDirs)
template = self._templateLookup.get_template(self.templateFilename)
return template.render(js=self._escapeJavascript, json=json.dumps, **self.vars)
def GET(self, **params):
return self._renderHTML()
def DELETE(self, **params):
raise cherrypy.HTTPError(405)
def PATCH(self, **params):
raise cherrypy.HTTPError(405)
def POST(self, **params):
raise cherrypy.HTTPError(405)<|fim▁hole|>
class Webroot(WebrootBase):
"""
The webroot endpoint simply serves the main index HTML file.
"""
def __init__(self, templatePath=None):
if not templatePath:
templatePath = os.path.join(constants.PACKAGE_DIR, 'utility', 'webroot.mako')
super().__init__(templatePath)
self.vars = {}
def _renderHTML(self):
from girder.utility import server
from girder.plugin import loadedPlugins
self.vars['plugins'] = loadedPlugins()
self.vars['pluginCss'] = []
self.vars['pluginJs'] = []
builtDir = os.path.join(constants.STATIC_ROOT_DIR, 'built', 'plugins')
for plugin in self.vars['plugins']:
if os.path.exists(os.path.join(builtDir, plugin, 'plugin.min.css')):
self.vars['pluginCss'].append(plugin)
if os.path.exists(os.path.join(builtDir, plugin, 'plugin.min.js')):
self.vars['pluginJs'].append(plugin)
self.vars['apiRoot'] = server.getApiRoot()
self.vars['staticPublicPath'] = server.getStaticPublicPath()
self.vars['brandName'] = Setting().get(SettingKey.BRAND_NAME)
self.vars['contactEmail'] = Setting().get(SettingKey.CONTACT_EMAIL_ADDRESS)
self.vars['privacyNoticeHref'] = Setting().get(SettingKey.PRIVACY_NOTICE)
self.vars['bannerColor'] = Setting().get(SettingKey.BANNER_COLOR)
self.vars['registrationPolicy'] = Setting().get(SettingKey.REGISTRATION_POLICY)
self.vars['enablePasswordLogin'] = Setting().get(SettingKey.ENABLE_PASSWORD_LOGIN)
return super()._renderHTML()<|fim▁end|> |
def PUT(self, **params):
raise cherrypy.HTTPError(405)
|
<|file_name|>numpy_pi.py<|end_file_name|><|fim▁begin|># file: numpy_pi.py
"""Calculating pi with Monte Carlo Method and NumPy.<|fim▁hole|>"""
from __future__ import print_function
import numpy #1
@profile
def pi_numpy(total): #2
"""Compute pi.
"""
x = numpy.random.rand(total) #3
y = numpy.random.rand(total) #4
dist = numpy.sqrt(x * x + y * y) #5
count_inside = len(dist[dist < 1]) #6
return 4.0 * count_inside / total
if __name__ == '__main__':
def test():
"""Time the execution.
"""
import timeit
start = timeit.default_timer()
pi_numpy(int(1e6))
print('run time', timeit.default_timer() - start)
test()<|fim▁end|> | |
<|file_name|>BaseDemographicForm.py<|end_file_name|><|fim▁begin|>from django import forms
from ..models import BaseDemographic<|fim▁hole|>
class BaseDemographicForm(forms.ModelForm):
class Meta:
model = BaseDemographic
fields = ['first_name','last_name','phone','dob']<|fim▁end|> | |
<|file_name|>OpeningHours.java<|end_file_name|><|fim▁begin|>package com.github.ypid.complexalarm;
import java.io.IOException;
import java.io.InputStream;
import java.util.Scanner;
import android.content.Context;
import android.content.res.AssetManager;
import android.util.Log;
import com.evgenii.jsevaluator.JsEvaluator;
import com.evgenii.jsevaluator.JsFunctionCallFormatter;
import com.evgenii.jsevaluator.interfaces.JsCallback;
/*
* Simple wrapper for the API documented here:
* https://github.com/ypid/opening_hours.js#library-api
*/
public class OpeningHours {
private JsEvaluator mJsEvaluator;
final private String nominatiomTestJSONString = "{\"place_id\":\"44651229\",\"licence\":\"Data \u00a9 OpenStreetMap contributors, ODbL 1.0. http://www.openstreetmap.org/copyright\",\"osm_type\":\"way\",\"osm_id\":\"36248375\",\"lat\":\"49.5400039\",\"lon\":\"9.7937133\",\"display_name\":\"K 2847, Lauda-K\u00f6nigshofen, Main-Tauber-Kreis, Regierungsbezirk Stuttgart, Baden-W\u00fcrttemberg, Germany, European Union\",\"address\":{\"road\":\"K 2847\",\"city\":\"Lauda-K\u00f6nigshofen\",\"county\":\"Main-Tauber-Kreis\",\"state_district\":\"Regierungsbezirk Stuttgart\",\"state\":\"Baden-W\u00fcrttemberg\",\"country\":\"Germany\",\"country_code\":\"de\",\"continent\":\"European Union\"}}";
private Scanner scanner;
private String globalResult;
private String getFileContent(String fileName, Context context)
throws IOException {
final AssetManager am = context.getAssets();
final InputStream inputStream = am.open(fileName);
scanner = new Scanner(inputStream, "UTF-8");
return scanner.useDelimiter("\\A").next();
}
private String loadJs(String fileName, Context context) {
try {
return getFileContent(fileName, context);
} catch (final IOException e) {
e.printStackTrace();
}
return null;
}
protected OpeningHours(Context context) {
Log.d("OpeningHours", "Loading up opening_hours.js");
mJsEvaluator = new JsEvaluator(context);
String librarySrouce = loadJs("javascript-libs/suncalc/suncalc.min.js",
context);
mJsEvaluator.evaluate(librarySrouce);
librarySrouce = loadJs(
"javascript-libs/opening_hours/opening_hours.min.js", context);
mJsEvaluator.evaluate(librarySrouce);
}
protected String evalOpeningHours(String value, String nominatiomJSON,
byte oh_mode) {
String ohConstructorCall = "new opening_hours('" + value
+ "', JSON.parse('" + nominatiomJSON + "'), " + oh_mode + ")";
Log.d("OpeningHours constructor", ohConstructorCall);
final String code = "var oh, warnings, crashed = true;" + "try {"
+ " oh = " + ohConstructorCall + ";"
+ " warnings = oh.getWarnings();" + " crashed = false;"
+ "} catch(err) {" + " crashed = err;" + "}"
+ "oh.getNextChange().toString();" +
// "crashed.toString();" +
"";
mJsEvaluator.evaluate(code, new JsCallback() {
@Override
public void onResult(final String resultValue) {
Log.d("OpeningHours", String.format("Result: %s", resultValue));
}
});
return "test";
}
protected String getDate() {
globalResult = null;
mJsEvaluator.evaluate("new Date().toString()", new JsCallback() {
@Override
public void onResult(final String resultValue) {
Log.d("Date", String.format("Result: %s", resultValue));
// Block until event occurs.
globalResult = resultValue;
Log.d("Date", String.format("globalResult: %s", globalResult));
}
});
for (int i = 0; i < 100; i++) {
Log.d("Date", String.format("%d, %s", i, globalResult));
try {
Log.d("Date", "sleep");
Thread.sleep(100);
} catch (InterruptedException e) {<|fim▁hole|> // TODO Auto-generated catch block
Log.d("Date", "Catch");
e.printStackTrace();
}
if (globalResult != null) {
break;
}
}
return globalResult;
}
protected String returnDate() {
return globalResult;
}
protected String evalOpeningHours(String value, String nominatiomJSON) {
return evalOpeningHours(value, nominatiomJSON, (byte) 0);
}
protected String evalOpeningHours(String value) {
// evalOpeningHours(value, "{}");
return evalOpeningHours(value, nominatiomTestJSONString); // FIXME
// testing
// only
}
}<|fim▁end|> | |
<|file_name|>check_for_currupt_references.py<|end_file_name|><|fim▁begin|>from engine.api import API
from engine.utils.printing_utils import progressBar
from setup.utils.datastore_utils import repair_corrupt_reference, link_references_to_paper
def remove_duplicates_from_cited_by():
print("\nRemove Duplicates")
api = API()
papers = api.get_all_paper()
for i, paper in enumerate(papers):
progressBar(i, len(papers))
paper.cited_by = list(dict.fromkeys(paper.cited_by))
api.client.update_paper(paper)
def check_references():
print("\nCheck References")
api = API()
papers = api.get_all_paper()
for i, paper in enumerate(papers):
progressBar(i, len(papers))
other_papers = [p for p in papers if p.id != paper.id]
for reference in paper.references:
if not reference.get_paper_id():
continue
ref_paper = api.get_paper(reference.get_paper_id())<|fim▁hole|> api.client.update_paper(paper)
repair_corrupt_reference(reference, paper, other_papers, api)
def check_cited_by():
print("\nCheck Cited by")
api = API()
papers = api.get_all_paper()
for i, paper in enumerate(papers):
progressBar(i, len(papers))
for cited_paper_id in paper.cited_by:
if not api.contains_paper(cited_paper_id):
paper.cited_by.remove(cited_paper_id)
api.client.update_paper(paper)
continue
cited_paper = api.get_paper(cited_paper_id)
cited_paper_refs = [ref.get_paper_id() for ref in cited_paper.references if ref.get_paper_id()]
if cited_paper_refs.count(paper.id) == 0:
print()
paper.cited_by.remove(cited_paper_id)
api.client.update_paper(paper)
link_references_to_paper(cited_paper, paper, api)
def perform_checks():
check_cited_by()
remove_duplicates_from_cited_by()
check_references()
if __name__ == "__main__":
perform_checks()
exit(0)<|fim▁end|> | if ref_paper.cited_by.count(paper.id) == 0:
print()
reference.paper_id = [] |
<|file_name|>metricsaccountant_suite_test.go<|end_file_name|><|fim▁begin|>package metricsaccountant_test
import (
. "github.com/onsi/ginkgo"<|fim▁hole|> . "github.com/onsi/gomega"
"testing"
)
func TestMetricsAccountant(t *testing.T) {
RegisterFailHandler(Fail)
RunSpecs(t, "Metricsaccountant Suite")
}<|fim▁end|> | |
<|file_name|>test_light_sensor.py<|end_file_name|><|fim▁begin|>import unittest
import mock
from greenpithumb import light_sensor
class LightSensorTest(unittest.TestCase):
def setUp(self):
self.mock_adc = mock.Mock()
channel = 1
self.light_sensor = light_sensor.LightSensor(self.mock_adc, channel)
<|fim▁hole|>
def test_ambient_light_too_low(self):
"""Light sensor value less than min should raise a ValueError."""
with self.assertRaises(light_sensor.LightSensorLowError):
self.mock_adc.read_adc.return_value = (
light_sensor._LIGHT_SENSOR_MIN_VALUE - 1)
self.light_sensor.light()<|fim▁end|> | def test_light_50_pct(self):
"""Near midpoint light sensor value should return near 50."""
self.mock_adc.read_adc.return_value = 511
self.assertAlmostEqual(self.light_sensor.light(), 50.0, places=1) |
<|file_name|>print_mail.py<|end_file_name|><|fim▁begin|>import os
import sys
import glob
import json
import subprocess
from collections import defaultdict
from utils import UnicodeReader, slugify, count_pages, combine_pdfs, parser
import addresscleaner
from click2mail import Click2MailBatch
parser.add_argument("directory", help="Path to downloaded mail batch")
parser.add_argument("--skip-letters", action='store_true', default=False)
parser.add_argument("--skip-postcards", action='store_true', default=False)
def fix_lines(address):
"""
Click2Mail screws up addresses with 3 lines. If we have only one address
line, put it in "address1". If we have more, put the first in
"organization", and subsequent ones in "addressN".
"""
lines = [a for a in [
address.get('organization', None),
address.get('address1', None),
address.get('address2', None),
address.get('address3', None)] if a]
if len(lines) == 1:
address['organization'] = ''
address['address1'] = lines[0]
address['address2'] = ''
address['address3'] = ''
if len(lines) >= 2:
address['organization'] = lines[0]
address['address1'] = lines[1]
address['address2'] = ''
address['address3'] = ''
if len(lines) >= 3:<|fim▁hole|> if len(lines) >= 4:
address['address3'] = lines[3]
return address
def collate_letters(mailing_dir, letters, page=1):
# Sort by recipient.
recipient_letters = defaultdict(list)
for letter in letters:
recipient_letters[(letter['recipient'], letter['sender'])].append(letter)
# Assemble list of files and jobs.
files = []
jobs = {}
for (recipient, sender), letters in recipient_letters.iteritems():
count = 0
for letter in letters:
filename = os.path.join(mailing_dir, letter["file"])
files.append(filename)
count += count_pages(filename)
end = page + count
jobs[recipient] = {
"startingPage": page,
"endingPage": end - 1,
"recipients": [fix_lines(addresscleaner.parse_address(recipient))],
"sender": addresscleaner.parse_address(sender),
"type": "letter"
}
page = end
vals = jobs.values()
vals.sort(key=lambda j: j['startingPage'])
return files, vals, page
def collate_postcards(postcards, page=1):
# Collate postcards into a list per type and sender.
type_sender_postcards = defaultdict(list)
for letter in postcards:
key = (letter['type'], letter['sender'])
type_sender_postcards[key].append(letter)
files = []
jobs = []
for (postcard_type, sender), letters in type_sender_postcards.iteritems():
files.append(os.path.join(
os.path.dirname(__file__),
"postcards",
"{}.pdf".format(postcard_type)
))
jobs.append({
"startingPage": page + len(files) - 1,
"endingPage": page + len(files) - 1,
"recipients": [
fix_lines(addresscleaner.parse_address(letter['recipient'])) for letter in letters
],
"sender": addresscleaner.parse_address(sender),
"type": "postcard",
})
return files, jobs, page + len(files)
def run_batch(args, files, jobs):
filename = combine_pdfs(files)
print "Building job with", filename
batch = Click2MailBatch(
username=args.username,
password=args.password,
filename=filename,
jobs=jobs,
staging=args.staging)
if batch.run(args.dry_run):
os.remove(filename)
def main():
args = parser.parse_args()
if args.directory.endswith(".zip"):
directory = os.path.abspath(args.directory[0:-len(".zip")])
if not os.path.exists(directory):
subprocess.check_call([
"unzip", args.directory, "-d", os.path.dirname(args.directory)
])
else:
directory = args.directory
with open(os.path.join(directory, "manifest.json")) as fh:
manifest = json.load(fh)
if manifest["letters"] and not args.skip_letters:
lfiles, ljobs, lpage = collate_letters(directory, manifest["letters"], 1)
print "Found", len(ljobs), "letter jobs"
if ljobs:
run_batch(args, lfiles, ljobs)
if manifest["postcards"] and not args.skip_postcards:
pfiles, pjobs, ppage = collate_postcards(manifest["postcards"], 1)
print "Found", len(pjobs), "postcard jobs"
if pjobs:
run_batch(args, pfiles, pjobs)
if __name__ == "__main__":
main()<|fim▁end|> | address['address2'] = lines[2]
address['address3'] = '' |
<|file_name|>HierarchicalModelType.java<|end_file_name|><|fim▁begin|>package dr.app.beauti.types;
/**<|fim▁hole|>public enum HierarchicalModelType {
NORMAL_HPM,
LOGNORMAL_HPM;
public String toString() {
switch (this) {
case NORMAL_HPM:
return "Normal";
case LOGNORMAL_HPM:
return "Lognormal";
default:
return "";
}
}
}<|fim▁end|> | * @author Marc A. Suchard
*/ |
<|file_name|>indicators.src.js<|end_file_name|><|fim▁begin|>/**
* @license Highstock JS v9.0.1 (2021-02-16)
*
* Indicator series type for Highstock
*
* (c) 2010-2021 Pawel Fus, Sebastian Bochan
*
* License: www.highcharts.com/license
*/
'use strict';
(function (factory) {
if (typeof module === 'object' && module.exports) {
factory['default'] = factory;
module.exports = factory;
} else if (typeof define === 'function' && define.amd) {
define('highcharts/indicators/indicators', ['highcharts', 'highcharts/modules/stock'], function (Highcharts) {
factory(Highcharts);
factory.Highcharts = Highcharts;
return factory;
});
} else {
factory(typeof Highcharts !== 'undefined' ? Highcharts : undefined);
}
}(function (Highcharts) {
var _modules = Highcharts ? Highcharts._modules : {};
function _registerModule(obj, path, args, fn) {
if (!obj.hasOwnProperty(path)) {
obj[path] = fn.apply(null, args);
}
}
_registerModule(_modules, 'Mixins/IndicatorRequired.js', [_modules['Core/Utilities.js']], function (U) {
/**
*
* (c) 2010-2021 Daniel Studencki
*
* License: www.highcharts.com/license
*
* !!!!!!! SOURCE GETS TRANSPILED BY TYPESCRIPT. EDIT TS FILE ONLY. !!!!!!!
*
* */
var error = U.error;
/* eslint-disable no-invalid-this, valid-jsdoc */
var requiredIndicatorMixin = {
/**
* Check whether given indicator is loaded,
else throw error.
* @private
* @param {Highcharts.Indicator} indicator
* Indicator constructor function.
* @param {string} requiredIndicator
* Required indicator type.
* @param {string} type
* Type of indicator where function was called (parent).
* @param {Highcharts.IndicatorCallbackFunction} callback
* Callback which is triggered if the given indicator is loaded.
* Takes indicator as an argument.
* @param {string} errMessage
* Error message that will be logged in console.
* @return {boolean}
* Returns false when there is no required indicator loaded.
*/
isParentLoaded: function (indicator,
requiredIndicator,
type,
callback,
errMessage) {
if (indicator) {
return callback ? callback(indicator) : true;
}
error(errMessage || this.generateMessage(type, requiredIndicator));
return false;
},
/**
* @private
* @param {string} indicatorType
* Indicator type
* @param {string} required
* Required indicator
* @return {string}
* Error message
*/
generateMessage: function (indicatorType, required) {
return 'Error: "' + indicatorType +
'" indicator type requires "' + required +
'" indicator loaded before. Please read docs: ' +
'https://api.highcharts.com/highstock/plotOptions.' +
indicatorType;
}
};
return requiredIndicatorMixin;
});
_registerModule(_modules, 'Stock/Indicators/SMA/SMAComposition.js', [_modules['Core/Series/SeriesRegistry.js'], _modules['Core/Utilities.js']], function (SeriesRegistry, U) {
/* *
*
* License: www.highcharts.com/license
*
* !!!!!!! SOURCE GETS TRANSPILED BY TYPESCRIPT. EDIT TS FILE ONLY. !!!!!!!
*
* */
var Series = SeriesRegistry.series,
ohlcProto = SeriesRegistry.seriesTypes.ohlc.prototype;
var addEvent = U.addEvent,
extend = U.extend;
/* *
*
* Composition
*
* */
addEvent(Series, 'init', function (eventOptions) {
// eslint-disable-next-line no-invalid-this
var series = this,
options = eventOptions.options;
if (options.useOhlcData &&
options.id !== 'highcharts-navigator-series') {
extend(series, {
pointValKey: ohlcProto.pointValKey,
keys: ohlcProto.keys,
pointArrayMap: ohlcProto.pointArrayMap,
toYData: ohlcProto.toYData
});
}
});
addEvent(Series, 'afterSetOptions', function (e) {
var options = e.options,
dataGrouping = options.dataGrouping;
if (dataGrouping &&
options.useOhlcData &&
options.id !== 'highcharts-navigator-series') {
dataGrouping.approximation = 'ohlc';
}
});
});
_registerModule(_modules, 'Stock/Indicators/SMA/SMAIndicator.js', [_modules['Mixins/IndicatorRequired.js'], _modules['Core/Series/SeriesRegistry.js'], _modules['Core/Utilities.js']], function (RequiredIndicatorMixin, SeriesRegistry, U) {
/* *
*
* License: www.highcharts.com/license
*
* !!!!!!! SOURCE GETS TRANSPILED BY TYPESCRIPT. EDIT TS FILE ONLY. !!!!!!!
*
* */
var __extends = (this && this.__extends) || (function () {
var extendStatics = function (d,
b) {
extendStatics = Object.setPrototypeOf ||
({ __proto__: [] } instanceof Array && function (d,
b) { d.__proto__ = b; }) ||
function (d,
b) { for (var p in b) if (b.hasOwnProperty(p)) d[p] = b[p]; };
return extendStatics(d, b);
};
return function (d, b) {
extendStatics(d, b);
function __() { this.constructor = d; }
d.prototype = b === null ? Object.create(b) : (__.prototype = b.prototype, new __());
};
})();
var LineSeries = SeriesRegistry.seriesTypes.line;
var addEvent = U.addEvent,
error = U.error,
extend = U.extend,
isArray = U.isArray,
merge = U.merge,
pick = U.pick,
splat = U.splat;
var generateMessage = RequiredIndicatorMixin.generateMessage;
/* *
*
* Class
*
* */
/**
* The SMA series type.
*
* @private
*/
var SMAIndicator = /** @class */ (function (_super) {
__extends(SMAIndicator, _super);
function SMAIndicator() {
/* *
*
* Static Properties
*
* */
var _this = _super !== null && _super.apply(this,
arguments) || this;
/* *
*
* Properties
*
* */
_this.data = void 0;
_this.dataEventsToUnbind = void 0;
_this.linkedParent = void 0;
_this.options = void 0;
_this.points = void 0;
return _this;
/* eslint-enable valid-jsdoc */
}
/* *
*
* Functions
*
* */
/* eslint-disable valid-jsdoc */
/**
* @private
*/
SMAIndicator.prototype.destroy = function () {
this.dataEventsToUnbind.forEach(function (unbinder) {
unbinder();
});
_super.prototype.destroy.apply(this, arguments);
};
/**
* @private
*/
SMAIndicator.prototype.getName = function () {
var name = this.name,
params = [];
if (!name) {
(this.nameComponents || []).forEach(function (component, index) {
params.push(this.options.params[component] +
pick(this.nameSuffixes[index], ''));
}, this);
name = (this.nameBase || this.type.toUpperCase()) +
(this.nameComponents ? ' (' + params.join(', ') + ')' : '');
}
return name;
};
/**
* @private
*/
SMAIndicator.prototype.getValues = function (series, params) {
var period = params.period,
xVal = series.xData,
yVal = series.yData,
yValLen = yVal.length,
range = 0,
sum = 0,
SMA = [],
xData = [],
yData = [],
index = -1,
i,
SMAPoint;
if (xVal.length < period) {<|fim▁hole|> index = params.index ? params.index : 0;
}
// Accumulate first N-points
while (range < period - 1) {
sum += index < 0 ? yVal[range] : yVal[range][index];
range++;
}
// Calculate value one-by-one for each period in visible data
for (i = range; i < yValLen; i++) {
sum += index < 0 ? yVal[i] : yVal[i][index];
SMAPoint = [xVal[i], sum / period];
SMA.push(SMAPoint);
xData.push(SMAPoint[0]);
yData.push(SMAPoint[1]);
sum -= (index < 0 ?
yVal[i - range] :
yVal[i - range][index]);
}
return {
values: SMA,
xData: xData,
yData: yData
};
};
/**
* @private
*/
SMAIndicator.prototype.init = function (chart, options) {
var indicator = this,
requiredIndicators = indicator.requireIndicators();
// Check whether all required indicators are loaded.
if (!requiredIndicators.allLoaded) {
return error(generateMessage(indicator.type, requiredIndicators.needed));
}
_super.prototype.init.call(indicator, chart, options);
// Make sure we find series which is a base for an indicator
chart.linkSeries();
indicator.dataEventsToUnbind = [];
/**
* @private
* @return {void}
*/
function recalculateValues() {
var oldData = indicator.points || [],
oldDataLength = (indicator.xData || []).length,
processedData = (indicator.getValues(indicator.linkedParent,
indicator.options.params) || {
values: [],
xData: [],
yData: []
}),
croppedDataValues = [],
overwriteData = true,
oldFirstPointIndex,
oldLastPointIndex,
croppedData,
min,
max,
i;
// We need to update points to reflect changes in all,
// x and y's, values. However, do it only for non-grouped
// data - grouping does it for us (#8572)
if (oldDataLength &&
!indicator.hasGroupedData &&
indicator.visible &&
indicator.points) {
// When data is cropped update only avaliable points (#9493)
if (indicator.cropped) {
if (indicator.xAxis) {
min = indicator.xAxis.min;
max = indicator.xAxis.max;
}
croppedData = indicator.cropData(processedData.xData, processedData.yData, min, max);
for (i = 0; i < croppedData.xData.length; i++) {
// (#10774)
croppedDataValues.push([
croppedData.xData[i]
].concat(splat(croppedData.yData[i])));
}
oldFirstPointIndex = processedData.xData.indexOf(indicator.xData[0]);
oldLastPointIndex = processedData.xData.indexOf(indicator.xData[indicator.xData.length - 1]);
// Check if indicator points should be shifted (#8572)
if (oldFirstPointIndex === -1 &&
oldLastPointIndex === processedData.xData.length - 2) {
if (croppedDataValues[0][0] === oldData[0].x) {
croppedDataValues.shift();
}
}
indicator.updateData(croppedDataValues);
// Omit addPoint() and removePoint() cases
}
else if (processedData.xData.length !== oldDataLength - 1 &&
processedData.xData.length !== oldDataLength + 1) {
overwriteData = false;
indicator.updateData(processedData.values);
}
}
if (overwriteData) {
indicator.xData = processedData.xData;
indicator.yData = processedData.yData;
indicator.options.data = processedData.values;
}
// Removal of processedXData property is required because on
// first translate processedXData array is empty
if (indicator.bindTo.series === false) {
delete indicator.processedXData;
indicator.isDirty = true;
indicator.redraw();
}
indicator.isDirtyData = false;
}
if (!indicator.linkedParent) {
return error('Series ' +
indicator.options.linkedTo +
' not found! Check `linkedTo`.', false, chart);
}
indicator.dataEventsToUnbind.push(addEvent(indicator.bindTo.series ?
indicator.linkedParent :
indicator.linkedParent.xAxis, indicator.bindTo.eventName, recalculateValues));
if (indicator.calculateOn === 'init') {
recalculateValues();
}
else {
var unbinder = addEvent(indicator.chart,
indicator.calculateOn,
function () {
recalculateValues();
// Call this just once, on init
unbinder();
});
}
// return indicator;
};
/**
* @private
*/
SMAIndicator.prototype.processData = function () {
var series = this,
compareToMain = series.options.compareToMain,
linkedParent = series.linkedParent;
_super.prototype.processData.apply(series, arguments);
if (linkedParent && linkedParent.compareValue && compareToMain) {
series.compareValue = linkedParent.compareValue;
}
return;
};
/**
* @private
*/
SMAIndicator.prototype.requireIndicators = function () {
var obj = {
allLoaded: true
};
// Check whether all required indicators are loaded, else return
// the object with missing indicator's name.
this.requiredIndicators.forEach(function (indicator) {
if (SeriesRegistry.seriesTypes[indicator]) {
SeriesRegistry.seriesTypes[indicator].prototype.requireIndicators();
}
else {
obj.allLoaded = false;
obj.needed = indicator;
}
});
return obj;
};
/**
* The parameter allows setting line series type and use OHLC indicators.
* Data in OHLC format is required.
*
* @sample {highstock} stock/indicators/use-ohlc-data
* Plot line on Y axis
*
* @type {boolean}
* @product highstock
* @apioption plotOptions.line.useOhlcData
*/
/**
* Simple moving average indicator (SMA). This series requires `linkedTo`
* option to be set.
*
* @sample stock/indicators/sma
* Simple moving average indicator
*
* @extends plotOptions.line
* @since 6.0.0
* @excluding allAreas, colorAxis, dragDrop, joinBy, keys,
* navigatorOptions, pointInterval, pointIntervalUnit,
* pointPlacement, pointRange, pointStart, showInNavigator,
* stacking, useOhlcData
* @product highstock
* @requires stock/indicators/indicators
* @optionparent plotOptions.sma
*/
SMAIndicator.defaultOptions = merge(LineSeries.defaultOptions, {
/**
* The name of the series as shown in the legend, tooltip etc. If not
* set, it will be based on a technical indicator type and default
* params.
*
* @type {string}
*/
name: void 0,
tooltip: {
/**
* Number of decimals in indicator series.
*/
valueDecimals: 4
},
/**
* The main series ID that indicator will be based on. Required for this
* indicator.
*
* @type {string}
*/
linkedTo: void 0,
/**
* Whether to compare indicator to the main series values
* or indicator values.
*
* @sample {highstock} stock/plotoptions/series-comparetomain/
* Difference between comparing SMA values to the main series
* and its own values.
*
* @type {boolean}
*/
compareToMain: false,
/**
* Paramters used in calculation of regression series' points.
*/
params: {
/**
* The point index which indicator calculations will base. For
* example using OHLC data, index=2 means the indicator will be
* calculated using Low values.
*/
index: 0,
/**
* The base period for indicator calculations. This is the number of
* data points which are taken into account for the indicator
* calculations.
*/
period: 14
}
});
return SMAIndicator;
}(LineSeries));
extend(SMAIndicator.prototype, {
bindTo: {
series: true,
eventName: 'updatedData'
},
calculateOn: 'init',
hasDerivedData: true,
nameComponents: ['period'],
nameSuffixes: [],
// Defines on which other indicators is this indicator based on.
requiredIndicators: [],
useCommonDataGrouping: true
});
SeriesRegistry.registerSeriesType('sma', SMAIndicator);
/* *
*
* Default Export
*
* */
/* *
*
* API Options
*
* */
/**
* A `SMA` series. If the [type](#series.sma.type) option is not specified, it
* is inherited from [chart.type](#chart.type).
*
* @extends series,plotOptions.sma
* @since 6.0.0
* @product highstock
* @excluding dataParser, dataURL, useOhlcData
* @requires stock/indicators/indicators
* @apioption series.sma
*/
''; // adds doclet above to the transpiled file
return SMAIndicator;
});
_registerModule(_modules, 'masters/indicators/indicators.src.js', [], function () {
});
}));<|fim▁end|> | return;
}
// Switch index for OHLC / Candlestick / Arearange
if (isArray(yVal[0])) { |
<|file_name|>constants.py<|end_file_name|><|fim▁begin|># Copyright (c) 2012 OpenStack Foundation.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
# implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from neutron_lib import constants as p_const
# Special vlan_tci value indicating flat network
FLAT_VLAN_TCI = '0x0000/0x1fff'
# Topic for tunnel notifications between the plugin and agent
TUNNEL = 'tunnel'
# Name prefixes for veth device or patch port pair linking the integration
# bridge with the physical bridge for a physical network
PEER_INTEGRATION_PREFIX = 'int-'
PEER_PHYSICAL_PREFIX = 'phy-'
# Nonexistent peer used to create patch ports without associating them, it
# allows to define flows before association
NONEXISTENT_PEER = 'nonexistent-peer'
# The different types of tunnels
TUNNEL_NETWORK_TYPES = [p_const.TYPE_GRE, p_const.TYPE_VXLAN,
p_const.TYPE_GENEVE]
# --- OpenFlow table IDs
# --- Integration bridge (int_br)
LOCAL_SWITCHING = 0
# The pyhsical network types of support DVR router
DVR_PHYSICAL_NETWORK_TYPES = [p_const.TYPE_VLAN, p_const.TYPE_FLAT]
# Various tables for DVR use of integration bridge flows
DVR_TO_SRC_MAC = 1
DVR_TO_SRC_MAC_PHYSICAL = 2
ARP_DVR_MAC_TO_DST_MAC = 3
ARP_DVR_MAC_TO_DST_MAC_PHYSICAL = 4
CANARY_TABLE = 23
# Table for ARP poison/spoofing prevention rules
ARP_SPOOF_TABLE = 24
# Table for MAC spoof filtering
MAC_SPOOF_TABLE = 25
LOCAL_EGRESS_TABLE = 30
LOCAL_IP_TABLE = 31
# packet rate limit table
PACKET_RATE_LIMIT = 59
# Table to decide whether further filtering is needed
TRANSIENT_TABLE = 60
LOCAL_MAC_DIRECT = 61
TRANSIENT_EGRESS_TABLE = 62
# Table for DHCP
DHCP_IPV4_TABLE = 77
DHCP_IPV6_TABLE = 78
# Tables used for ovs firewall
BASE_EGRESS_TABLE = 71
RULES_EGRESS_TABLE = 72
ACCEPT_OR_INGRESS_TABLE = 73
BASE_INGRESS_TABLE = 81
RULES_INGRESS_TABLE = 82
OVS_FIREWALL_TABLES = (
BASE_EGRESS_TABLE,
RULES_EGRESS_TABLE,
ACCEPT_OR_INGRESS_TABLE,
BASE_INGRESS_TABLE,
RULES_INGRESS_TABLE,
)
# Tables for parties interacting with ovs firewall
ACCEPTED_EGRESS_TRAFFIC_TABLE = 91
ACCEPTED_INGRESS_TRAFFIC_TABLE = 92
DROPPED_TRAFFIC_TABLE = 93
ACCEPTED_EGRESS_TRAFFIC_NORMAL_TABLE = 94
INT_BR_ALL_TABLES = (
LOCAL_SWITCHING,
DVR_TO_SRC_MAC,
DVR_TO_SRC_MAC_PHYSICAL,
CANARY_TABLE,
ARP_SPOOF_TABLE,
MAC_SPOOF_TABLE,
LOCAL_MAC_DIRECT,
LOCAL_EGRESS_TABLE,
LOCAL_IP_TABLE,
PACKET_RATE_LIMIT,
TRANSIENT_TABLE,
TRANSIENT_EGRESS_TABLE,
BASE_EGRESS_TABLE,
RULES_EGRESS_TABLE,
ACCEPT_OR_INGRESS_TABLE,
DHCP_IPV4_TABLE,
DHCP_IPV6_TABLE,
BASE_INGRESS_TABLE,
RULES_INGRESS_TABLE,
ACCEPTED_EGRESS_TRAFFIC_TABLE,
ACCEPTED_INGRESS_TRAFFIC_TABLE,
DROPPED_TRAFFIC_TABLE)
# --- Tunnel bridge (tun_br)
# Various tables for tunneling flows
DVR_PROCESS = 1
PATCH_LV_TO_TUN = 2
GRE_TUN_TO_LV = 3
VXLAN_TUN_TO_LV = 4
GENEVE_TUN_TO_LV = 6
DVR_NOT_LEARN = 9
LEARN_FROM_TUN = 10
UCAST_TO_TUN = 20
ARP_RESPONDER = 21
FLOOD_TO_TUN = 22
# NOTE(vsaienko): transit table used by networking-bagpipe driver to
# mirror traffic to EVPN and standard tunnels to gateway nodes
BAGPIPE_FLOOD_TO_TUN_BROADCAST = 222
TUN_BR_ALL_TABLES = (
LOCAL_SWITCHING,
DVR_PROCESS,
PATCH_LV_TO_TUN,
GRE_TUN_TO_LV,
VXLAN_TUN_TO_LV,
GENEVE_TUN_TO_LV,
DVR_NOT_LEARN,
LEARN_FROM_TUN,
UCAST_TO_TUN,
ARP_RESPONDER,
FLOOD_TO_TUN)
# --- Physical Bridges (phys_brs)
# Various tables for DVR use of physical bridge flows
DVR_PROCESS_PHYSICAL = 1
LOCAL_VLAN_TRANSLATION = 2
DVR_NOT_LEARN_PHYSICAL = 3
PHY_BR_ALL_TABLES = (
LOCAL_SWITCHING,
DVR_PROCESS_PHYSICAL,
LOCAL_VLAN_TRANSLATION,
DVR_NOT_LEARN_PHYSICAL)
# --- end of OpenFlow table IDs
# type for ARP reply in ARP header
ARP_REPLY = '0x2'
# Map tunnel types to tables number
TUN_TABLE = {p_const.TYPE_GRE: GRE_TUN_TO_LV,
p_const.TYPE_VXLAN: VXLAN_TUN_TO_LV,
p_const.TYPE_GENEVE: GENEVE_TUN_TO_LV}
# The default respawn interval for the ovsdb monitor
DEFAULT_OVSDBMON_RESPAWN = 30
# Represent invalid OF Port
OFPORT_INVALID = -1
ARP_RESPONDER_ACTIONS = ('move:NXM_OF_ETH_SRC[]->NXM_OF_ETH_DST[],'
'mod_dl_src:%(mac)s,'
'load:0x2->NXM_OF_ARP_OP[],'
'move:NXM_NX_ARP_SHA[]->NXM_NX_ARP_THA[],'
'move:NXM_OF_ARP_SPA[]->NXM_OF_ARP_TPA[],'
'load:%(mac)#x->NXM_NX_ARP_SHA[],'
'load:%(ip)#x->NXM_OF_ARP_SPA[],'
'in_port')
# Represent ovs status
OVS_RESTARTED = 0
OVS_NORMAL = 1
OVS_DEAD = 2
EXTENSION_DRIVER_TYPE = 'ovs'
# ovs datapath types
OVS_DATAPATH_SYSTEM = 'system'
OVS_DATAPATH_NETDEV = 'netdev'
OVS_DPDK_VHOST_USER = 'dpdkvhostuser'
OVS_DPDK_VHOST_USER_CLIENT = 'dpdkvhostuserclient'
OVS_DPDK_PORT_TYPES = [OVS_DPDK_VHOST_USER, OVS_DPDK_VHOST_USER_CLIENT]
# default ovs vhost-user socket location
VHOST_USER_SOCKET_DIR = '/var/run/openvswitch'
MAX_DEVICE_RETRIES = 5
# OpenFlow version constants
OPENFLOW10 = "OpenFlow10"
OPENFLOW11 = "OpenFlow11"
OPENFLOW12 = "OpenFlow12"
OPENFLOW13 = "OpenFlow13"
OPENFLOW14 = "OpenFlow14"
OPENFLOW15 = "OpenFlow15"
<|fim▁hole|># A placeholder for dead vlans.
DEAD_VLAN_TAG = p_const.MAX_VLAN_TAG + 1
# callback resource for setting 'bridge_name' in the 'binding:vif_details'
OVS_BRIDGE_NAME = 'ovs_bridge_name'
# callback resource for notifying to ovsdb handler
OVSDB_RESOURCE = 'ovsdb'
# Used in ovs port 'external_ids' in order mark it for no cleanup when
# ovs_cleanup script is used.
SKIP_CLEANUP = 'skip_cleanup'<|fim▁end|> | OPENFLOW_MAX_PRIORITY = 65535
|
<|file_name|>dataarray.py<|end_file_name|><|fim▁begin|>import contextlib
import functools
import warnings
import numpy as np
import pandas as pd
from ..plot.plot import _PlotMethods
from . import indexing
from . import groupby
from . import ops
from . import utils
from . import variable
from .alignment import align
from .common import AbstractArray, BaseDataObject
from .coordinates import DataArrayCoordinates, Indexes
from .dataset import Dataset
from .pycompat import iteritems, basestring, OrderedDict, zip
from .utils import FrozenOrderedDict
from .variable import as_variable, _as_compatible_data, Coordinate
from .formatting import format_item
def _infer_coords_and_dims(shape, coords, dims):
"""All the logic for creating a new DataArray"""
if (coords is not None and not utils.is_dict_like(coords)
and len(coords) != len(shape)):
raise ValueError('coords is not dict-like, but it has %s items, '
'which does not match the %s dimensions of the '
'data' % (len(coords), len(shape)))
if isinstance(dims, basestring):
dims = [dims]
if dims is None:
dims = ['dim_%s' % n for n in range(len(shape))]
if coords is not None and len(coords) == len(shape):
# try to infer dimensions from coords
if utils.is_dict_like(coords):
dims = list(coords.keys())
else:
for n, (dim, coord) in enumerate(zip(dims, coords)):
if getattr(coord, 'name', None) is None:
coord = as_variable(coord, key=dim).to_coord()
dims[n] = coord.name
else:
for d in dims:
if not isinstance(d, basestring):
raise TypeError('dimension %s is not a string' % d)
if coords is not None and not utils.is_dict_like(coords):
# ensure coordinates have the right dimensions
coords = [Coordinate(dim, coord, getattr(coord, 'attrs', {}))
for dim, coord in zip(dims, coords)]
if coords is None:
coords = {}
elif not utils.is_dict_like(coords):
coords = OrderedDict(zip(dims, coords))
return coords, dims
class _LocIndexer(object):
def __init__(self, data_array):
self.data_array = data_array
def _remap_key(self, key):
def lookup_positions(dim, labels):
index = self.data_array.indexes[dim]
return indexing.convert_label_indexer(index, labels)
if utils.is_dict_like(key):
return dict((dim, lookup_positions(dim, labels))
for dim, labels in iteritems(key))
else:
# expand the indexer so we can handle Ellipsis
key = indexing.expanded_indexer(key, self.data_array.ndim)
return tuple(lookup_positions(dim, labels) for dim, labels
in zip(self.data_array.dims, key))
def __getitem__(self, key):
return self.data_array[self._remap_key(key)]
def __setitem__(self, key, value):
self.data_array[self._remap_key(key)] = value
class DataArray(AbstractArray, BaseDataObject):
"""N-dimensional array with labeled coordinates and dimensions.
DataArray provides a wrapper around numpy ndarrays that uses labeled
dimensions and coordinates to support metadata aware operations. The API is
similar to that for the pandas Series or DataFrame, but DataArray objects
can have any number of dimensions, and their contents have fixed data
types.
Additional features over raw numpy arrays:
- Apply operations over dimensions by name: ``x.sum('time')``.
- Select or assign values by integer location (like numpy): ``x[:10]``
or by label (like pandas): ``x.loc['2014-01-01']`` or
``x.sel(time='2014-01-01')``.
- Mathematical operations (e.g., ``x - y``) vectorize across multiple
dimensions (known in numpy as "broadcasting") based on dimension names,
regardless of their original order.
- Keep track of arbitrary metadata in the form of a Python dictionary:
``x.attrs``
- Convert to a pandas Series: ``x.to_series()``.
Getting items from or doing mathematical operations with a DataArray
always returns another DataArray.
Attributes
----------
dims : tuple
Dimension names associated with this array.
values : np.ndarray
Access or modify DataArray values as a numpy array.
coords : dict-like
Dictionary of Coordinate objects that label values along each dimension.
name : str or None
Name of this array.
attrs : OrderedDict
Dictionary for holding arbitrary metadata.
"""
groupby_cls = groupby.DataArrayGroupBy
def __init__(self, data, coords=None, dims=None, name=None,
attrs=None, encoding=None):
"""
Parameters
----------
data : array_like
Values for this array. Must be an ``numpy.ndarray``, ndarray like,
or castable to an ``ndarray``. If a self-described xray or pandas
object, attempts are made to use this array's metadata to fill in
other unspecified arguments. A view of the array's data is used
instead of a copy if possible.
coords : sequence or dict of array_like objects, optional
Coordinates (tick labels) to use for indexing along each dimension.
If dict-like, should be a mapping from dimension names to the
corresponding coordinates.
dims : str or sequence of str, optional
Name(s) of the the data dimension(s). Must be either a string (only
for 1D data) or a sequence of strings with length equal to the
number of dimensions. If this argument is omited, dimension names
are taken from ``coords`` (if possible) and otherwise default to
``['dim_0', ... 'dim_n']``.
name : str or None, optional
Name of this array.
attrs : dict_like or None, optional
Attributes to assign to the new variable. By default, an empty
attribute dictionary is initialized.
encoding : dict_like or None, optional
Dictionary specifying how to encode this array's data into a
serialized format like netCDF4. Currently used keys (for netCDF)
include '_FillValue', 'scale_factor', 'add_offset', 'dtype',
'units' and 'calendar' (the later two only for datetime arrays).
Unrecognized keys are ignored.
"""
# try to fill in arguments from data if they weren't supplied
if coords is None:
coords = getattr(data, 'coords', None)
if isinstance(data, pd.Series):
coords = [data.index]
elif isinstance(data, pd.DataFrame):
coords = [data.index, data.columns]
elif isinstance(data, (pd.Index, variable.Coordinate)):
coords = [data]
elif isinstance(data, pd.Panel):
coords = [data.items, data.major_axis, data.minor_axis]
if dims is None:
dims = getattr(data, 'dims', getattr(coords, 'dims', None))
if name is None:
name = getattr(data, 'name', None)
if attrs is None:
attrs = getattr(data, 'attrs', None)
if encoding is None:
encoding = getattr(data, 'encoding', None)
data = _as_compatible_data(data)
coords, dims = _infer_coords_and_dims(data.shape, coords, dims)
dataset = Dataset(coords=coords)
# insert data afterwards in case of redundant coords/data
dataset[name] = (dims, data, attrs, encoding)
for k, v in iteritems(dataset.coords):
if any(d not in dims for d in v.dims):
raise ValueError('coordinate %s has dimensions %s, but these '
'are not a subset of the DataArray '
'dimensions %s' % (k, v.dims, dims))
# these fully describe a DataArray
self._dataset = dataset
self._name = name
@classmethod
def _new_from_dataset(cls, original_dataset, name):
"""Private constructor for the benefit of Dataset.__getitem__ (skips
all validation)
"""
dataset = original_dataset._copy_listed([name], keep_attrs=False)
if name not in dataset:
# handle virtual variables
try:
_, name = name.split('.', 1)
except Exception:
raise KeyError(name)
if name not in dataset._dims:
dataset._coord_names.discard(name)
return cls._new_from_dataset_no_copy(dataset, name)
@classmethod
def _new_from_dataset_no_copy(cls, dataset, name):
obj = object.__new__(cls)
obj._dataset = dataset
obj._name = name
return obj
def _with_replaced_dataset(self, dataset):
return self._new_from_dataset_no_copy(dataset, self.name)
def _to_dataset_split(self, dim):
def subset(dim, label):
array = self.loc[{dim: label}].drop(dim)
array.attrs = {}
return array
variables = OrderedDict([(str(label), subset(dim, label))
for label in self.indexes[dim]])
coords = self.coords.to_dataset()
del coords[dim]
return Dataset(variables, coords, self.attrs)
def _to_dataset_whole(self, name):
if name is None:
return self._dataset.copy()
else:
return self.rename(name)._dataset
def to_dataset(self, dim=None, name=None):
"""Convert a DataArray to a Dataset.
Parameters
----------
dim : str, optional
Name of the dimension on this array along which to split this array
into separate variables. If not provided, this array is converted
into a Dataset of one variable.
name : str, optional
Name to substitute for this array's name. Only valid is ``dim`` is
not provided.
Returns
-------
dataset : Dataset
"""
if dim is not None and dim not in self.dims:
warnings.warn('the order of the arguments on DataArray.to_dataset '
'has changed; you now need to supply ``name`` as '
'a keyword argument',
FutureWarning, stacklevel=2)
name = dim
dim = None
if dim is not None:
if name is not None:
raise TypeError('cannot supply both dim and name arguments')
return self._to_dataset_split(dim)
else:
return self._to_dataset_whole(name)
@property
def name(self):
"""The name of this array.
"""
return self._name
@contextlib.contextmanager
def _set_new_dataset(self):
"""Context manager to use for modifying _dataset, in a manner that
can be safely rolled back if an error is encountered.
"""
ds = self._dataset.copy(deep=False)
yield ds
self._dataset = ds
@name.setter
def name(self, value):
with self._set_new_dataset() as ds:
ds.rename({self.name: value}, inplace=True)
self._name = value
@property
def variable(self):
return self._dataset._variables[self.name]
@property
def dtype(self):
return self.variable.dtype
@property
def shape(self):
return self.variable.shape
@property
def size(self):
return self.variable.size
@property
def nbytes(self):
return self.variable.nbytes
@property
def ndim(self):
return self.variable.ndim
def __len__(self):
return len(self.variable)
@property
def data(self):
"""The array's data as a dask or numpy array"""
return self.variable.data
@property
def values(self):
"""The array's data as a numpy.ndarray"""
return self.variable.values
@values.setter
def values(self, value):
self.variable.values = value
@property
def _in_memory(self):
return self.variable._in_memory
def to_index(self):
"""Convert this variable to a pandas.Index. Only possible for 1D
arrays.
"""
return self.variable.to_index()
@property
def dims(self):
"""Dimension names associated with this array."""
return self.variable.dims
@dims.setter
def dims(self, value):
raise AttributeError('you cannot assign dims on a DataArray. Use '
'.rename() or .swap_dims() instead.')
def _item_key_to_dict(self, key):
if utils.is_dict_like(key):
return key
else:
key = indexing.expanded_indexer(key, self.ndim)
return dict(zip(self.dims, key))
def __getitem__(self, key):
if isinstance(key, basestring):
return self.coords[key]
else:
# orthogonal array indexing
return self.isel(**self._item_key_to_dict(key))
def __setitem__(self, key, value):
if isinstance(key, basestring):
self.coords[key] = value
else:
# orthogonal array indexing
self.variable[key] = value
def __delitem__(self, key):
del self._dataset[key]
@property
def _attr_sources(self):
"""List of places to look-up items for attribute-style access"""
return [self.coords, self.attrs]
def __contains__(self, key):
return key in self._dataset
@property
def loc(self):
"""Attribute for location based indexing like pandas.
"""
return _LocIndexer(self)
@property
def attrs(self):
"""Dictionary storing arbitrary metadata with this array."""
return self.variable.attrs
@attrs.setter
def attrs(self, value):
self.variable.attrs = value
@property
def encoding(self):
"""Dictionary of format-specific settings for how this array should be
serialized."""
return self.variable.encoding
@encoding.setter
def encoding(self, value):
self.variable.encoding = value
@property
def indexes(self):
"""OrderedDict of pandas.Index objects used for label based indexing
"""
return Indexes(self)
@property
def coords(self):
"""Dictionary-like container of coordinate arrays.
"""
return DataArrayCoordinates(self)
def reset_coords(self, names=None, drop=False, inplace=False):
"""Given names of coordinates, reset them to become variables.
Parameters
----------
names : str or list of str, optional
Name(s) of non-index coordinates in this dataset to reset into
variables. By default, all non-index coordinates are reset.
drop : bool, optional
If True, remove coordinates instead of converting them into
variables.
inplace : bool, optional
If True, modify this dataset inplace. Otherwise, create a new
object.
Returns
-------
Dataset, or DataArray if ``drop == True``
"""
if inplace and not drop:
raise ValueError('cannot reset coordinates in-place on a '
'DataArray without ``drop == True``')
if names is None:
names = (self._dataset._coord_names - set(self.dims)
- set([self.name]))
ds = self._dataset.reset_coords(names, drop, inplace)
return ds[self.name] if drop else ds
def load(self):
"""Manually trigger loading of this array's data from disk or a
remote source into memory and return this array.
Normally, it should not be necessary to call this method in user code,
because all xray functions should either work on deferred data or
load data automatically. However, this method can be necessary when
working with many file objects on disk.
"""
self._dataset.load()
return self
def load_data(self): # pragma: no cover
warnings.warn('the DataArray method `load_data` has been deprecated; '
'use `load` instead',
FutureWarning, stacklevel=2)
return self.load()
def copy(self, deep=True):
"""Returns a copy of this array.
If `deep=True`, a deep copy is made of all variables in the underlying
dataset. Otherwise, a shallow copy is made, so each variable in the new
array's dataset is also a variable in this array's dataset.
"""
ds = self._dataset.copy(deep=deep)
return self._with_replaced_dataset(ds)
def __copy__(self):
return self.copy(deep=False)
def __deepcopy__(self, memo=None):
# memo does nothing but is required for compatability with
# copy.deepcopy
return self.copy(deep=True)
# mutable objects should not be hashable
__hash__ = None
@property
def chunks(self):
"""Block dimensions for this array's data or None if it's not a dask
array.
"""
return self.variable.chunks
def chunk(self, chunks=None):
"""Coerce this array's data into a dask arrays with the given chunks.
If this variable is a non-dask array, it will be converted to dask
array. If it's a dask array, it will be rechunked to the given chunk
sizes.
If neither chunks is not provided for one or more dimensions, chunk
sizes along that dimension will not be updated; non-dask arrays will be
converted into dask arrays with a single block.
Parameters
----------
chunks : int, tuple or dict, optional
Chunk sizes along each dimension, e.g., ``5``, ``(5, 5)`` or
``{'x': 5, 'y': 5}``.
Returns
-------
chunked : xray.DataArray
"""
if isinstance(chunks, (list, tuple)):
chunks = dict(zip(self.dims, chunks))
ds = self._dataset.chunk(chunks)
return self._with_replaced_dataset(ds)
def isel(self, **indexers):
"""Return a new DataArray whose dataset is given by integer indexing
along the specified dimension(s).
See Also
--------
Dataset.isel
DataArray.sel
"""
ds = self._dataset.isel(**indexers)
return self._with_replaced_dataset(ds)
def sel(self, method=None, **indexers):
"""Return a new DataArray whose dataset is given by selecting
index labels along the specified dimension(s).
See Also
--------
Dataset.sel
DataArray.isel
"""
return self.isel(**indexing.remap_label_indexers(self, indexers,
method=method))
def isel_points(self, dim='points', **indexers):
"""Return a new DataArray whose dataset is given by pointwise integer
indexing along the specified dimension(s).
See Also
--------
Dataset.isel_points
"""
ds = self._dataset.isel_points(dim=dim, **indexers)
return self._with_replaced_dataset(ds)
def sel_points(self, dim='points', method=None, **indexers):
"""Return a new DataArray whose dataset is given by pointwise selection
of index labels along the specified dimension(s).
See Also
--------
Dataset.sel_points
"""
ds = self._dataset.sel_points(dim=dim, method=method, **indexers)
return self._with_replaced_dataset(ds)
def reindex_like(self, other, method=None, copy=True):
"""Conform this object onto the indexes of another object, filling
in missing values with NaN.
Parameters
----------
other : Dataset or DataArray
Object with an 'indexes' attribute giving a mapping from dimension
names to pandas.Index objects, which provides coordinates upon
which to index the variables in this dataset. The indexes on this
other object need not be the same as the indexes on this
dataset. Any mis-matched index values will be filled in with
NaN, and any mis-matched dimension names will simply be ignored.
method : {None, 'nearest', 'pad'/'ffill', 'backfill'/'bfill'}, optional
Method to use for filling index values from other not found on this
data array:
* None (default): don't fill gaps
* pad / ffill: propgate last valid index value forward
* backfill / bfill: propagate next valid index value backward
* nearest: use nearest valid index value (requires pandas>=0.16)
copy : bool, optional
If `copy=True`, the returned array's dataset contains only copied
variables. If `copy=False` and no reindexing is required then
original variables from this array's dataset are returned.
Returns
-------
reindexed : DataArray
Another dataset array, with this array's data but coordinates from
the other object.
See Also
--------
DataArray.reindex
align
"""
return self.reindex(method=method, copy=copy, **other.indexes)
def reindex(self, method=None, copy=True, **indexers):
"""Conform this object onto a new set of indexes, filling in
missing values with NaN.
Parameters
----------
copy : bool, optional
If `copy=True`, the returned array's dataset contains only copied
variables. If `copy=False` and no reindexing is required then
original variables from this array's dataset are returned.
method : {None, 'nearest', 'pad'/'ffill', 'backfill'/'bfill'}, optional
Method to use for filling index values in ``indexers`` not found on
this data array:
* None (default): don't fill gaps
* pad / ffill: propgate last valid index value forward
* backfill / bfill: propagate next valid index value backward
* nearest: use nearest valid index value (requires pandas>=0.16)
**indexers : dict
Dictionary with keys given by dimension names and values given by
arrays of coordinates tick labels. Any mis-matched coordinate values
will be filled in with NaN, and any mis-matched dimension names will
simply be ignored.
Returns
-------
reindexed : DataArray
Another dataset array, with this array's data but replaced
coordinates.
See Also
--------
DataArray.reindex_like
align
"""
ds = self._dataset.reindex(method=method, copy=copy, **indexers)
return self._with_replaced_dataset(ds)
def rename(self, new_name_or_name_dict):
"""Returns a new DataArray with renamed coordinates and/or a new name.
Parameters
----------
new_name_or_name_dict : str or dict-like
If the argument is dict-like, it it used as a mapping from old
names to new names for coordinates (and/or this array itself).
Otherwise, use the argument as the new name for this array.
Returns
-------
renamed : DataArray
Renamed array or array with renamed coordinates.
See Also
--------
Dataset.rename
DataArray.swap_dims
"""
if utils.is_dict_like(new_name_or_name_dict):
name_dict = new_name_or_name_dict
new_name = name_dict.get(self.name, self.name)
else:
new_name = new_name_or_name_dict
name_dict = {self.name: new_name}
renamed_dataset = self._dataset.rename(name_dict)
return renamed_dataset[new_name]
def swap_dims(self, dims_dict):
"""Returns a new DataArray with swapped dimensions.
Parameters
----------
dims_dict : dict-like
Dictionary whose keys are current dimension names and whose values
are new names. Each value must already be a coordinate on this
array.
inplace : bool, optional
If True, swap dimensions in-place. Otherwise, return a new object.
Returns
-------
renamed : Dataset
DataArray with swapped dimensions.
See Also
--------
DataArray.rename
Dataset.swap_dims
"""
ds = self._dataset.swap_dims(dims_dict)
return self._with_replaced_dataset(ds)
def transpose(self, *dims):
"""Return a new DataArray object with transposed dimensions.
Parameters
----------
*dims : str, optional
By default, reverse the dimensions. Otherwise, reorder the
dimensions to this order.
Returns
-------
transposed : DataArray
The returned DataArray's array is transposed.
Notes
-----
Although this operation returns a view of this array's data, it is
not lazy -- the data will be fully loaded.
See Also
--------
numpy.transpose
Dataset.transpose
"""
ds = self._dataset.copy()
ds[self.name] = self.variable.transpose(*dims)
return self._with_replaced_dataset(ds)
def squeeze(self, dim=None):
"""Return a new DataArray object with squeezed data.
Parameters
----------
dim : None or str or tuple of str, optional
Selects a subset of the length one dimensions. If a dimension is
selected with length greater than one, an error is raised. If
None, all length one dimensions are squeezed.
Returns
-------
squeezed : DataArray
This array, but with with all or a subset of the dimensions of
length 1 removed.
Notes
-----
Although this operation returns a view of this array's data, it is
not lazy -- the data will be fully loaded.
See Also
--------
numpy.squeeze
"""
ds = self._dataset.squeeze(dim)
return self._with_replaced_dataset(ds)
def drop(self, labels, dim=None):
"""Drop coordinates or index labels from this DataArray.
Parameters
----------
labels : str
Names of coordinate variables or index labels to drop.
dim : str, optional
Dimension along which to drop index labels. By default (if
``dim is None``), drops coordinates rather than index labels.
Returns
-------
dropped : DataArray
"""
if utils.is_scalar(labels):
labels = [labels]
if dim is None and self.name in labels:
raise ValueError('cannot drop this DataArray from itself')
ds = self._dataset.drop(labels, dim)
return self._with_replaced_dataset(ds)
def dropna(self, dim, how='any', thresh=None):
"""Returns a new array with dropped labels for missing values along
the provided dimension.
Parameters
----------
dim : str
Dimension along which to drop missing values. Dropping along
multiple dimensions simultaneously is not yet supported.
how : {'any', 'all'}, optional
* any : if any NA values are present, drop that label
* all : if all values are NA, drop that label
thresh : int, default None
If supplied, require this many non-NA values.
Returns
-------
DataArray
"""
ds = self._dataset.dropna(dim, how=how, thresh=thresh)
return self._with_replaced_dataset(ds)
def fillna(self, value):
"""Fill missing values in this object.
This operation follows the normal broadcasting and alignment rules that
xray uses for binary arithmetic, except the result is aligned to this
object (``join='left'``) instead of aligned to the intersection of
index coordinates (``join='inner'``).
Parameters
----------
value : scalar, ndarray or DataArray
Used to fill all matching missing values in this array. If the
argument is a DataArray, it is first aligned with (reindexed to)
this array.
Returns
-------
DataArray
"""
if utils.is_dict_like(value):
raise TypeError('cannot provide fill value as a dictionary with '
'fillna on a DataArray')
return self._fillna(value)
def reduce(self, func, dim=None, axis=None, keep_attrs=False, **kwargs):
"""Reduce this array by applying `func` along some dimension(s).
Parameters
----------
func : function
Function which can be called in the form
`f(x, axis=axis, **kwargs)` to return the result of reducing an
np.ndarray over an integer valued axis.
dim : str or sequence of str, optional
Dimension(s) over which to apply `func`.
axis : int or sequence of int, optional
Axis(es) over which to repeatedly apply `func`. Only one of the
'dim' and 'axis' arguments can be supplied. If neither are
supplied, then the reduction is calculated over the flattened array
(by calling `f(x)` without an axis argument).
keep_attrs : bool, optional
If True, the variable's attributes (`attrs`) will be copied from
the original object to the new one. If False (default), the new
object will be returned without attributes.
**kwargs : dict
Additional keyword arguments passed on to `func`.
Returns
-------
reduced : DataArray
DataArray with this object's array replaced with an array with
summarized data and the indicated dimension(s) removed.
"""
var = self.variable.reduce(func, dim, axis, keep_attrs, **kwargs)
ds = self._dataset.drop(set(self.dims) - set(var.dims))
ds[self.name] = var
return self._with_replaced_dataset(ds)
def to_pandas(self):
"""Convert this array into a pandas object with the same shape.
The type of the returned object depends on the number of DataArray
dimensions:
* 1D -> `pandas.Series`
* 2D -> `pandas.DataFrame`
* 3D -> `pandas.Panel`
Only works for arrays with 3 or fewer dimensions.
The DataArray constructor performs the inverse transformation.
"""
# TODO: consolidate the info about pandas constructors and the
# attributes that correspond to their indexes into a separate module?
constructors = {0: lambda x: x,
1: pd.Series,
2: pd.DataFrame,
3: pd.Panel}
try:
constructor = constructors[self.ndim]
except KeyError:
raise ValueError('cannot convert arrays with %s dimensions into '
'pandas objects' % self.ndim)
return constructor(self.values, *self.indexes.values())
def to_dataframe(self):
"""Convert this array and its coordinates into a tidy pandas.DataFrame.
The DataFrame is indexed by the Cartesian product of index coordinates
(in the form of a :py:class:`pandas.MultiIndex`).
Other coordinates are included as columns in the DataFrame.
"""
# TODO: add a 'name' parameter
dims = OrderedDict(zip(self.dims, self.shape))
return self._dataset._to_dataframe(dims)
def to_series(self):
"""Convert this array into a pandas.Series.
The Series is indexed by the Cartesian product of index coordinates
(in the form of a :py:class:`pandas.MultiIndex`).
"""
index = self.coords.to_index()
return pd.Series(self.values.reshape(-1), index=index, name=self.name)
def to_masked_array(self, copy=True):
"""Convert this array into a numpy.ma.MaskedArray
Parameters
----------
copy : bool
If True (default) make a copy of the array in the result. If False,
a MaskedArray view of DataArray.values is returned.
Returns
-------
result : MaskedArray
Masked where invalid values (nan or inf) occur.
"""
isnull = pd.isnull(self.values)
return np.ma.masked_where(isnull, self.values, copy=copy)
@classmethod
def from_series(cls, series):
"""Convert a pandas.Series into an xray.DataArray.
If the series's index is a MultiIndex, it will be expanded into a
tensor product of one-dimensional coordinates (filling in missing values
with NaN). Thus this operation should be the inverse of the `to_series`
method.
"""
# TODO: add a 'name' parameter
df = pd.DataFrame({series.name: series})
ds = Dataset.from_dataframe(df)
return cls._new_from_dataset_no_copy(ds, series.name)
def to_cdms2(self):
"""Convert this array into a cdms2.Variable
"""
from ..convert import to_cdms2
return to_cdms2(self)
@classmethod
def from_cdms2(cls, variable):
"""Convert a cdms2.Variable into an xray.DataArray
"""
from ..convert import from_cdms2
return from_cdms2(variable)
def _all_compat(self, other, compat_str):
"""Helper function for equals and identical"""
compat = lambda x, y: getattr(x.variable, compat_str)(y.variable)
return (utils.dict_equiv(self.coords, other.coords, compat=compat)
and compat(self, other))
def broadcast_equals(self, other):
"""Two DataArrays are broadcast equal if they are equal after
broadcasting them against each other such that they have the same
dimensions.
See Also
--------<|fim▁hole|> """
try:
return self._all_compat(other, 'broadcast_equals')
except (TypeError, AttributeError):
return False
def equals(self, other):
"""True if two DataArrays have the same dimensions, coordinates and
values; otherwise False.
DataArrays can still be equal (like pandas objects) if they have NaN
values in the same locations.
This method is necessary because `v1 == v2` for ``DataArray``
does element-wise comparisions (like numpy.ndarrays).
See Also
--------
DataArray.broadcast_equals
DataArray.identical
"""
try:
return self._all_compat(other, 'equals')
except (TypeError, AttributeError):
return False
def identical(self, other):
"""Like equals, but also checks the array name and attributes, and
attributes on all coordinates.
See Also
--------
DataArray.broadcast_equals
DataArray.equal
"""
try:
return (self.name == other.name
and self._all_compat(other, 'identical'))
except (TypeError, AttributeError):
return False
__default_name = object()
def _result_name(self, other=None):
if self.name in self.dims:
# these names match dimension, so if we preserve them we will also
# rename indexes
return None
if other is None:
# shortcut
return self.name
other_name = getattr(other, 'name', self.__default_name)
other_dims = getattr(other, 'dims', ())
if other_name in other_dims:
# same trouble as above
return None
# use the same naming heuristics as pandas:
# https://github.com/ContinuumIO/blaze/issues/458#issuecomment-51936356
if other_name is self.__default_name or other_name == self.name:
return self.name
return None
def __array_wrap__(self, obj, context=None):
new_var = self.variable.__array_wrap__(obj, context)
ds = self.coords.to_dataset()
name = self._result_name()
ds[name] = new_var
return self._new_from_dataset_no_copy(ds, name)
@staticmethod
def _unary_op(f):
@functools.wraps(f)
def func(self, *args, **kwargs):
return self.__array_wrap__(f(self.variable.data, *args, **kwargs))
return func
@staticmethod
def _binary_op(f, reflexive=False, join='inner', **ignored_kwargs):
@functools.wraps(f)
def func(self, other):
if isinstance(other, (Dataset, groupby.GroupBy)):
return NotImplemented
if hasattr(other, 'indexes'):
self, other = align(self, other, join=join, copy=False)
empty_indexes = [d for d, s in zip(self.dims, self.shape)
if s == 0]
if empty_indexes:
raise ValueError('no overlapping labels for some '
'dimensions: %s' % empty_indexes)
other_coords = getattr(other, 'coords', None)
other_variable = getattr(other, 'variable', other)
ds = self.coords.merge(other_coords)
name = self._result_name(other)
ds[name] = (f(self.variable, other_variable)
if not reflexive
else f(other_variable, self.variable))
result = self._new_from_dataset_no_copy(ds, name)
return result
return func
@staticmethod
def _inplace_binary_op(f):
@functools.wraps(f)
def func(self, other):
if isinstance(other, groupby.GroupBy):
raise TypeError('in-place operations between a DataArray and '
'a grouped object are not permitted')
other_coords = getattr(other, 'coords', None)
other_variable = getattr(other, 'variable', other)
with self.coords._merge_inplace(other_coords):
f(self.variable, other_variable)
return self
return func
@property
def plot(self):
'''
Access plotting functions
>>> d = DataArray([[1, 2], [3, 4]])
For convenience just call this directly
>>> d.plot()
Or use it as a namespace to use xray.plot functions as
DataArray methods
>>> d.plot.imshow() # equivalent to xray.plot.imshow(d)
'''
return _PlotMethods(self)
def _title_for_slice(self, truncate=50):
'''
If the dataarray has 1 dimensional coordinates or comes from a slice
we can show that info in the title
Parameters
----------
truncate : integer
maximum number of characters for title
Returns
-------
title : string
Can be used for plot titles
'''
one_dims = []
for dim, coord in iteritems(self.coords):
if coord.size == 1:
one_dims.append('{dim} = {v}'.format(dim=dim,
v=format_item(coord.values)))
title = ', '.join(one_dims)
if len(title) > truncate:
title = title[:(truncate - 3)] + '...'
return title
def diff(self, dim, n=1, label='upper'):
"""Calculate the n-th order discrete difference along given axis.
Parameters
----------
dim : str, optional
Dimension over which to calculate the finite difference.
n : int, optional
The number of times values are differenced.
label : str, optional
The new coordinate in dimension ``dim`` will have the
values of either the minuend's or subtrahend's coordinate
for values 'upper' and 'lower', respectively. Other
values are not supported.
Returns
-------
difference : same type as caller
The n-th order finite differnce of this object.
Examples
--------
>>> arr = xray.DataArray([5, 5, 6, 6], [[1, 2, 3, 4]], ['x'])
>>> arr.diff('x')
<xray.DataArray (x: 3)>
array([0, 1, 0])
Coordinates:
* x (x) int64 2 3 4
>>> arr.diff('x', 2)
<xray.DataArray (x: 2)>
array([ 1, -1])
Coordinates:
* x (x) int64 3 4
"""
ds = self._dataset.diff(n=n, dim=dim, label=label)
return self._with_replaced_dataset(ds)
@property
def real(self):
return self._with_replaced_dataset(self._dataset.real)
@property
def imag(self):
return self._with_replaced_dataset(self._dataset.imag)
# priority most be higher than Variable to properly work with binary ufuncs
ops.inject_all_ops_and_reduce_methods(DataArray, priority=60)<|fim▁end|> | DataArray.equals
DataArray.identical |
<|file_name|>nrburst_pickle_preserve.py<|end_file_name|><|fim▁begin|>#!/usr/bin/env python
# -*- coding: utf-8 -*-
# Copyright (C) 2015-2016 James Clark <[email protected]>
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation; either version 2 of the License, or
# (at your option) any later version.
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#<|fim▁hole|># with this program; if not, write to the Free Software Foundation, Inc.,
# 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
"""
nrburst_pickle_preserve.py
Crunch together pickles from nrburst_match.py
"""
import sys
import glob
import cPickle as pickle
import numpy as np
pickle_files = glob.glob(sys.argv[1]+'*pickle')
user_tag = sys.argv[2]
delta_samp=100
sample_pairs=zip(range(0,1000,delta_samp), range(delta_samp-1,1000,delta_samp))
# Get numbers for pre-allocation
sim_instances = [name.split('-')[1] for name in pickle_files]
sim_names = np.unique(sim_instances)
# XXX: assume all sample runs have same number of jobs..
n_sample_runs = sim_instances.count(sim_names[0])
# Load first one to extract data for preallocation
current_matches, current_masses, current_inclinations, config, \
simulations = pickle.load(open(pickle_files[0],'r'))
nSims = len(sim_names)
nsampls = config.nsampls * n_sample_runs
# --- Preallocate
matches = np.zeros(shape=(nSims, nsampls))
masses = np.zeros(shape=(nSims, nsampls))
inclinations = np.zeros(shape=(nSims, nsampls))
# be a bit careful with the simulations object
setattr(simulations, 'simulations', [])
setattr(simulations, 'nsimulations', nSims)
for f, name in enumerate(sim_names):
startidx=0
endidx=len(current_matches[0])
for s in xrange(n_sample_runs):
if n_sample_runs>1:
file = glob.glob('*%s-minsamp_%d-maxsamp_%d*'%(
name, min(sample_pairs[s]), max(sample_pairs[s])))[0]
else:
file = pickle_files[f]
current_matches, current_masses, current_inclinations, config, \
current_simulations = pickle.load(open(file,'r'))
matches[f,startidx:endidx] = current_matches[0]
masses[f,startidx:endidx] = current_masses[0]
inclinations[f,startidx:endidx] = current_inclinations[0]
startidx += len(current_matches[0])
endidx = startidx + len(current_matches[0])
simulations.simulations.append(current_simulations.simulations[0])
filename=user_tag+'_'+config.algorithm+'.pickle'
pickle.dump([matches, masses, inclinations, config, simulations],
open(filename, "wb"))<|fim▁end|> | # You should have received a copy of the GNU General Public License along |
<|file_name|>feed_parse_extractToomtummootstranslationsWordpressCom.py<|end_file_name|><|fim▁begin|>def extractToomtummootstranslationsWordpressCom(item):
'''
Parser for 'toomtummootstranslations.wordpress.com'
'''
vol, chp, frag, postfix = extractVolChapterFragmentPostfix(item['title'])
if not (chp or vol) or "preview" in item['title'].lower():
return None
<|fim▁hole|> tagmap = [
('PRC', 'PRC', 'translated'),
('Loiterous', 'Loiterous', 'oel'),
]
for tagname, name, tl_type in tagmap:
if tagname in item['tags']:
return buildReleaseMessageWithType(item, name, vol, chp, frag=frag, postfix=postfix, tl_type=tl_type)
return False<|fim▁end|> | |
<|file_name|>topPost.service.ts<|end_file_name|><|fim▁begin|>import { Injectable } from '@angular/core';
import { Http, Response } from '@angular/http';
import { TopPostComponent } from './TopPost.component';
import {Observable} from 'rxjs/Rx';
@Injectable()
export class TopPostservice {
constructor(private http: Http) {
}<|fim▁hole|> .catch((error:any) => Observable.throw(error.json().error || 'Server error'));
}
}<|fim▁end|> | getTopPlaces() : Observable<TopPostComponent[]> {
return this.http.get('http://localhost:3000/api/v1/places/top.json')
.map(res => (<Response>res).json().data) |
<|file_name|>implicit.js<|end_file_name|><|fim▁begin|>/*
* Copyright (c) Microsoft Corporation. All rights reserved.
* Licensed under the MIT License. See License.txt in the project root for
* license information.
*
* Code generated by Microsoft (R) AutoRest Code Generator.
* Changes may cause incorrect behavior and will be lost if the code is
* regenerated.
*/
'use strict';
var util = require('util');
var msRest = require('ms-rest');
var WebResource = msRest.WebResource;
/**
* @class
* Implicit
* __NOTE__: An instance of this class is automatically created for an
* instance of the AutoRestRequiredOptionalTestService.
* Initializes a new instance of the Implicit class.
* @constructor
*
* @param {AutoRestRequiredOptionalTestService} client Reference to the service client.
*/
function Implicit(client) {
this.client = client;
}
/**
* Test implicitly required path parameter
*
* @param {string} pathParameter
*
* @param {object} [options] Optional Parameters.
*
* @param {object} [options.customHeaders] Headers that will be added to the
* request
*
* @param {function} callback
*
* @returns {function} callback(err, result, request, response)
*
* {Error} err - The Error object if an error occurred, null otherwise.
*
* {object} [result] - The deserialized result object.
* See {@link ErrorModel} for more information.
*
* {object} [request] - The HTTP Request object if an error did not occur.
*
* {stream} [response] - The HTTP Response stream if an error did not occur.
*/
Implicit.prototype.getRequiredPath = function (pathParameter, options, callback) {
var client = this.client;
if(!callback && typeof options === 'function') {
callback = options;
options = null;
}
if (!callback) {
throw new Error('callback cannot be null.');
}
// Validate
try {
if (pathParameter === null || pathParameter === undefined || typeof pathParameter.valueOf() !== 'string') {
throw new Error('pathParameter cannot be null or undefined and it must be of type string.');
}
} catch (error) {
return callback(error);
}
// Construct URL
var baseUrl = this.client.baseUri;
var requestUrl = baseUrl + (baseUrl.endsWith('/') ? '' : '/') + 'reqopt/implicit/required/path/{pathParameter}';
requestUrl = requestUrl.replace('{pathParameter}', encodeURIComponent(pathParameter));
// Create HTTP transport objects
var httpRequest = new WebResource();
httpRequest.method = 'GET';
httpRequest.headers = {};
httpRequest.url = requestUrl;
// Set Headers
if(options) {
for(var headerName in options['customHeaders']) {
if (options['customHeaders'].hasOwnProperty(headerName)) {
httpRequest.headers[headerName] = options['customHeaders'][headerName];
}
}
}
httpRequest.headers['Content-Type'] = 'application/json; charset=utf-8';
httpRequest.body = null;
// Send Request
return client.pipeline(httpRequest, function (err, response, responseBody) {
if (err) {
return callback(err);
}
var statusCode = response.statusCode;
if (statusCode < 200 || statusCode >= 300) {
var error = new Error(responseBody);
error.statusCode = response.statusCode;
error.request = msRest.stripRequest(httpRequest);
error.response = msRest.stripResponse(response);
if (responseBody === '') responseBody = null;
var parsedErrorResponse;
try {
parsedErrorResponse = JSON.parse(responseBody);
if (parsedErrorResponse) {
if (parsedErrorResponse.error) parsedErrorResponse = parsedErrorResponse.error;
if (parsedErrorResponse.code) error.code = parsedErrorResponse.code;
if (parsedErrorResponse.message) error.message = parsedErrorResponse.message;
}
if (parsedErrorResponse !== null && parsedErrorResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
error.body = client.deserialize(resultMapper, parsedErrorResponse, 'error.body');
}
} catch (defaultError) {
error.message = util.format('Error "%s" occurred in deserializing the responseBody ' +
'- "%s" for the default response.', defaultError.message, responseBody);
return callback(error);
}
return callback(error);
}
// Create Result
var result = null;
if (responseBody === '') responseBody = null;
var parsedResponse = null;
try {
parsedResponse = JSON.parse(responseBody);
result = JSON.parse(responseBody);
if (parsedResponse !== null && parsedResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
result = client.deserialize(resultMapper, parsedResponse, 'result');
}
} catch (error) {
var deserializationError = new Error(util.format('Error "%s" occurred in deserializing the responseBody - "%s"', error, responseBody));
deserializationError.request = msRest.stripRequest(httpRequest);
deserializationError.response = msRest.stripResponse(response);
return callback(deserializationError);
}
return callback(null, result, httpRequest, response);
});
};
/**
* Test implicitly optional query parameter
*
* @param {object} [options] Optional Parameters.
*
* @param {string} [options.queryParameter]
*
* @param {object} [options.customHeaders] Headers that will be added to the
* request
*
* @param {function} callback
*
* @returns {function} callback(err, result, request, response)
*
* {Error} err - The Error object if an error occurred, null otherwise.
*
* {null} [result] - The deserialized result object.
*
* {object} [request] - The HTTP Request object if an error did not occur.
*
* {stream} [response] - The HTTP Response stream if an error did not occur.
*/
Implicit.prototype.putOptionalQuery = function (options, callback) {
var client = this.client;
if(!callback && typeof options === 'function') {
callback = options;
options = null;
}
if (!callback) {
throw new Error('callback cannot be null.');
}
var queryParameter = (options && options.queryParameter !== undefined) ? options.queryParameter : undefined;
// Validate
try {
if (queryParameter !== null && queryParameter !== undefined && typeof queryParameter.valueOf() !== 'string') {
throw new Error('queryParameter must be of type string.');
}
} catch (error) {
return callback(error);
}
// Construct URL
var baseUrl = this.client.baseUri;
var requestUrl = baseUrl + (baseUrl.endsWith('/') ? '' : '/') + 'reqopt/implicit/optional/query';
var queryParameters = [];
if (queryParameter !== null && queryParameter !== undefined) {
queryParameters.push('queryParameter=' + encodeURIComponent(queryParameter));
}
if (queryParameters.length > 0) {
requestUrl += '?' + queryParameters.join('&');
}
// Create HTTP transport objects
var httpRequest = new WebResource();
httpRequest.method = 'PUT';
httpRequest.headers = {};
httpRequest.url = requestUrl;
// Set Headers
if(options) {
for(var headerName in options['customHeaders']) {
if (options['customHeaders'].hasOwnProperty(headerName)) {
httpRequest.headers[headerName] = options['customHeaders'][headerName];
}
}
}
httpRequest.headers['Content-Type'] = 'application/json; charset=utf-8';
httpRequest.body = null;
// Send Request
return client.pipeline(httpRequest, function (err, response, responseBody) {
if (err) {
return callback(err);
}
var statusCode = response.statusCode;
if (statusCode !== 200) {
var error = new Error(responseBody);
error.statusCode = response.statusCode;
error.request = msRest.stripRequest(httpRequest);
error.response = msRest.stripResponse(response);
if (responseBody === '') responseBody = null;
var parsedErrorResponse;
try {
parsedErrorResponse = JSON.parse(responseBody);
if (parsedErrorResponse) {
if (parsedErrorResponse.error) parsedErrorResponse = parsedErrorResponse.error;
if (parsedErrorResponse.code) error.code = parsedErrorResponse.code;
if (parsedErrorResponse.message) error.message = parsedErrorResponse.message;
}
if (parsedErrorResponse !== null && parsedErrorResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
error.body = client.deserialize(resultMapper, parsedErrorResponse, 'error.body');
}
} catch (defaultError) {
error.message = util.format('Error "%s" occurred in deserializing the responseBody ' +
'- "%s" for the default response.', defaultError.message, responseBody);
return callback(error);
}
return callback(error);
}
// Create Result
var result = null;
if (responseBody === '') responseBody = null;
return callback(null, result, httpRequest, response);
});
};
/**
* Test implicitly optional header parameter
*
* @param {object} [options] Optional Parameters.
*
* @param {string} [options.queryParameter]
*
* @param {object} [options.customHeaders] Headers that will be added to the
* request
*
* @param {function} callback
*
* @returns {function} callback(err, result, request, response)
*
* {Error} err - The Error object if an error occurred, null otherwise.
*
* {null} [result] - The deserialized result object.
*
* {object} [request] - The HTTP Request object if an error did not occur.
*
* {stream} [response] - The HTTP Response stream if an error did not occur.
*/
Implicit.prototype.putOptionalHeader = function (options, callback) {
var client = this.client;
if(!callback && typeof options === 'function') {
callback = options;
options = null;
}
if (!callback) {
throw new Error('callback cannot be null.');
}
var queryParameter = (options && options.queryParameter !== undefined) ? options.queryParameter : undefined;
// Validate
try {
if (queryParameter !== null && queryParameter !== undefined && typeof queryParameter.valueOf() !== 'string') {
throw new Error('queryParameter must be of type string.');
}
} catch (error) {
return callback(error);
}
// Construct URL
var baseUrl = this.client.baseUri;
var requestUrl = baseUrl + (baseUrl.endsWith('/') ? '' : '/') + 'reqopt/implicit/optional/header';
// Create HTTP transport objects
var httpRequest = new WebResource();
httpRequest.method = 'PUT';
httpRequest.headers = {};
httpRequest.url = requestUrl;
// Set Headers
if (queryParameter !== undefined && queryParameter !== null) {
httpRequest.headers['queryParameter'] = queryParameter;
}
if(options) {
for(var headerName in options['customHeaders']) {
if (options['customHeaders'].hasOwnProperty(headerName)) {
httpRequest.headers[headerName] = options['customHeaders'][headerName];
}
}
}
httpRequest.headers['Content-Type'] = 'application/json; charset=utf-8';
httpRequest.body = null;
// Send Request
return client.pipeline(httpRequest, function (err, response, responseBody) {
if (err) {
return callback(err);
}
var statusCode = response.statusCode;
if (statusCode !== 200) {
var error = new Error(responseBody);
error.statusCode = response.statusCode;
error.request = msRest.stripRequest(httpRequest);
error.response = msRest.stripResponse(response);
if (responseBody === '') responseBody = null;
var parsedErrorResponse;
try {
parsedErrorResponse = JSON.parse(responseBody);
if (parsedErrorResponse) {
if (parsedErrorResponse.error) parsedErrorResponse = parsedErrorResponse.error;
if (parsedErrorResponse.code) error.code = parsedErrorResponse.code;
if (parsedErrorResponse.message) error.message = parsedErrorResponse.message;
}
if (parsedErrorResponse !== null && parsedErrorResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
error.body = client.deserialize(resultMapper, parsedErrorResponse, 'error.body');
}
} catch (defaultError) {
error.message = util.format('Error "%s" occurred in deserializing the responseBody ' +
'- "%s" for the default response.', defaultError.message, responseBody);
return callback(error);
}
return callback(error);
}
// Create Result
var result = null;
if (responseBody === '') responseBody = null;
return callback(null, result, httpRequest, response);
});
};
/**
* Test implicitly optional body parameter
*
* @param {object} [options] Optional Parameters.
*
* @param {string} [options.bodyParameter]
*
* @param {object} [options.customHeaders] Headers that will be added to the
* request
*
* @param {function} callback
*
* @returns {function} callback(err, result, request, response)
*
* {Error} err - The Error object if an error occurred, null otherwise.
*
* {null} [result] - The deserialized result object.
*
* {object} [request] - The HTTP Request object if an error did not occur.
*
* {stream} [response] - The HTTP Response stream if an error did not occur.
*/
Implicit.prototype.putOptionalBody = function (options, callback) {
var client = this.client;
if(!callback && typeof options === 'function') {
callback = options;
options = null;
}
if (!callback) {
throw new Error('callback cannot be null.');
}
var bodyParameter = (options && options.bodyParameter !== undefined) ? options.bodyParameter : undefined;
// Validate
try {
if (bodyParameter !== null && bodyParameter !== undefined && typeof bodyParameter.valueOf() !== 'string') {
throw new Error('bodyParameter must be of type string.');
}
} catch (error) {
return callback(error);
}
// Construct URL
var baseUrl = this.client.baseUri;
var requestUrl = baseUrl + (baseUrl.endsWith('/') ? '' : '/') + 'reqopt/implicit/optional/body';
// Create HTTP transport objects
var httpRequest = new WebResource();
httpRequest.method = 'PUT';
httpRequest.headers = {};
httpRequest.url = requestUrl;
// Set Headers
if(options) {
for(var headerName in options['customHeaders']) {
if (options['customHeaders'].hasOwnProperty(headerName)) {
httpRequest.headers[headerName] = options['customHeaders'][headerName];
}
}
}
httpRequest.headers['Content-Type'] = 'application/json; charset=utf-8';
// Serialize Request
var requestContent = null;
var requestModel = null;
try {
if (bodyParameter !== null && bodyParameter !== undefined) {
var requestModelMapper = {
required: false,
serializedName: 'bodyParameter',
type: {
name: 'String'
}
};
requestModel = client.serialize(requestModelMapper, bodyParameter, 'bodyParameter');
requestContent = JSON.stringify(requestModel);
}
} catch (error) {
var serializationError = new Error(util.format('Error "%s" occurred in serializing the ' +
'payload - "%s"', error.message, util.inspect(bodyParameter, {depth: null})));
return callback(serializationError);
}
httpRequest.body = requestContent;
// Send Request
return client.pipeline(httpRequest, function (err, response, responseBody) {
if (err) {
return callback(err);
}
var statusCode = response.statusCode;
if (statusCode !== 200) {
var error = new Error(responseBody);
error.statusCode = response.statusCode;
error.request = msRest.stripRequest(httpRequest);
error.response = msRest.stripResponse(response);
if (responseBody === '') responseBody = null;
var parsedErrorResponse;
try {
parsedErrorResponse = JSON.parse(responseBody);
if (parsedErrorResponse) {
if (parsedErrorResponse.error) parsedErrorResponse = parsedErrorResponse.error;
if (parsedErrorResponse.code) error.code = parsedErrorResponse.code;
if (parsedErrorResponse.message) error.message = parsedErrorResponse.message;
}
if (parsedErrorResponse !== null && parsedErrorResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
error.body = client.deserialize(resultMapper, parsedErrorResponse, 'error.body');
}
} catch (defaultError) {
error.message = util.format('Error "%s" occurred in deserializing the responseBody ' +
'- "%s" for the default response.', defaultError.message, responseBody);
return callback(error);
}
return callback(error);
}
// Create Result
var result = null;
if (responseBody === '') responseBody = null;
return callback(null, result, httpRequest, response);
});
};
/**
* Test implicitly required path parameter
*
* @param {object} [options] Optional Parameters.
*
* @param {object} [options.customHeaders] Headers that will be added to the
* request
*
* @param {function} callback
*
* @returns {function} callback(err, result, request, response)
*
* {Error} err - The Error object if an error occurred, null otherwise.
*
* {object} [result] - The deserialized result object.
* See {@link ErrorModel} for more information.
*
* {object} [request] - The HTTP Request object if an error did not occur.
*
* {stream} [response] - The HTTP Response stream if an error did not occur.
*/
Implicit.prototype.getRequiredGlobalPath = function (options, callback) {
var client = this.client;
if(!callback && typeof options === 'function') {
callback = options;
options = null;
}
if (!callback) {
throw new Error('callback cannot be null.');
}
// Validate
try {
if (this.client.requiredGlobalPath === null || this.client.requiredGlobalPath === undefined || typeof this.client.requiredGlobalPath.valueOf() !== 'string') {
throw new Error('this.client.requiredGlobalPath cannot be null or undefined and it must be of type string.');
}
} catch (error) {
return callback(error);
}
// Construct URL
var baseUrl = this.client.baseUri;
var requestUrl = baseUrl + (baseUrl.endsWith('/') ? '' : '/') + 'reqopt/global/required/path/{required-global-path}';
requestUrl = requestUrl.replace('{required-global-path}', encodeURIComponent(this.client.requiredGlobalPath));
// Create HTTP transport objects
var httpRequest = new WebResource();
httpRequest.method = 'GET';
httpRequest.headers = {};
httpRequest.url = requestUrl;
// Set Headers
if(options) {
for(var headerName in options['customHeaders']) {
if (options['customHeaders'].hasOwnProperty(headerName)) {
httpRequest.headers[headerName] = options['customHeaders'][headerName];
}
}
}
httpRequest.headers['Content-Type'] = 'application/json; charset=utf-8';
httpRequest.body = null;
// Send Request
return client.pipeline(httpRequest, function (err, response, responseBody) {
if (err) {
return callback(err);
}
var statusCode = response.statusCode;
if (statusCode < 200 || statusCode >= 300) {
var error = new Error(responseBody);
error.statusCode = response.statusCode;
error.request = msRest.stripRequest(httpRequest);
error.response = msRest.stripResponse(response);
if (responseBody === '') responseBody = null;
var parsedErrorResponse;
try {
parsedErrorResponse = JSON.parse(responseBody);
if (parsedErrorResponse) {
if (parsedErrorResponse.error) parsedErrorResponse = parsedErrorResponse.error;
if (parsedErrorResponse.code) error.code = parsedErrorResponse.code;
if (parsedErrorResponse.message) error.message = parsedErrorResponse.message;
}
if (parsedErrorResponse !== null && parsedErrorResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
error.body = client.deserialize(resultMapper, parsedErrorResponse, 'error.body');
}
} catch (defaultError) {
error.message = util.format('Error "%s" occurred in deserializing the responseBody ' +
'- "%s" for the default response.', defaultError.message, responseBody);
return callback(error);
}
return callback(error);
}
// Create Result
var result = null;
if (responseBody === '') responseBody = null;
var parsedResponse = null;
try {
parsedResponse = JSON.parse(responseBody);
result = JSON.parse(responseBody);
if (parsedResponse !== null && parsedResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
result = client.deserialize(resultMapper, parsedResponse, 'result');
}
} catch (error) {
var deserializationError = new Error(util.format('Error "%s" occurred in deserializing the responseBody - "%s"', error, responseBody));
deserializationError.request = msRest.stripRequest(httpRequest);
deserializationError.response = msRest.stripResponse(response);
return callback(deserializationError);
}
return callback(null, result, httpRequest, response);
});
};
/**
* Test implicitly required query parameter
*
* @param {object} [options] Optional Parameters.
*
* @param {object} [options.customHeaders] Headers that will be added to the
* request
*
* @param {function} callback
*
* @returns {function} callback(err, result, request, response)
*
* {Error} err - The Error object if an error occurred, null otherwise.
*
* {object} [result] - The deserialized result object.
* See {@link ErrorModel} for more information.
*
* {object} [request] - The HTTP Request object if an error did not occur.
*
* {stream} [response] - The HTTP Response stream if an error did not occur.
*/
Implicit.prototype.getRequiredGlobalQuery = function (options, callback) {
var client = this.client;
if(!callback && typeof options === 'function') {
callback = options;
options = null;
}
if (!callback) {
throw new Error('callback cannot be null.');
}
// Validate
try {
if (this.client.requiredGlobalQuery === null || this.client.requiredGlobalQuery === undefined || typeof this.client.requiredGlobalQuery.valueOf() !== 'string') {
throw new Error('this.client.requiredGlobalQuery cannot be null or undefined and it must be of type string.');
}
} catch (error) {
return callback(error);
}
// Construct URL
var baseUrl = this.client.baseUri;
var requestUrl = baseUrl + (baseUrl.endsWith('/') ? '' : '/') + 'reqopt/global/required/query';
var queryParameters = [];
queryParameters.push('required-global-query=' + encodeURIComponent(this.client.requiredGlobalQuery));
if (queryParameters.length > 0) {
requestUrl += '?' + queryParameters.join('&');
}
// Create HTTP transport objects
var httpRequest = new WebResource();
httpRequest.method = 'GET';
httpRequest.headers = {};
httpRequest.url = requestUrl;
// Set Headers
if(options) {
for(var headerName in options['customHeaders']) {
if (options['customHeaders'].hasOwnProperty(headerName)) {
httpRequest.headers[headerName] = options['customHeaders'][headerName];
}
}
}
httpRequest.headers['Content-Type'] = 'application/json; charset=utf-8';
httpRequest.body = null;
// Send Request
return client.pipeline(httpRequest, function (err, response, responseBody) {
if (err) {
return callback(err);
}
var statusCode = response.statusCode;
if (statusCode < 200 || statusCode >= 300) {
var error = new Error(responseBody);
error.statusCode = response.statusCode;
error.request = msRest.stripRequest(httpRequest);
error.response = msRest.stripResponse(response);
if (responseBody === '') responseBody = null;
var parsedErrorResponse;
try {
parsedErrorResponse = JSON.parse(responseBody);
if (parsedErrorResponse) {
if (parsedErrorResponse.error) parsedErrorResponse = parsedErrorResponse.error;
if (parsedErrorResponse.code) error.code = parsedErrorResponse.code;
if (parsedErrorResponse.message) error.message = parsedErrorResponse.message;
}
if (parsedErrorResponse !== null && parsedErrorResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
error.body = client.deserialize(resultMapper, parsedErrorResponse, 'error.body');
}
} catch (defaultError) {
error.message = util.format('Error "%s" occurred in deserializing the responseBody ' +
'- "%s" for the default response.', defaultError.message, responseBody);
return callback(error);
}
return callback(error);
}
// Create Result
var result = null;
if (responseBody === '') responseBody = null;
var parsedResponse = null;
try {
parsedResponse = JSON.parse(responseBody);
result = JSON.parse(responseBody);
if (parsedResponse !== null && parsedResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
result = client.deserialize(resultMapper, parsedResponse, 'result');
}
} catch (error) {
var deserializationError = new Error(util.format('Error "%s" occurred in deserializing the responseBody - "%s"', error, responseBody));
deserializationError.request = msRest.stripRequest(httpRequest);
deserializationError.response = msRest.stripResponse(response);
return callback(deserializationError);
}
return callback(null, result, httpRequest, response);
});
};
/**
* Test implicitly optional query parameter
*
* @param {object} [options] Optional Parameters.
*
* @param {object} [options.customHeaders] Headers that will be added to the
* request
*
* @param {function} callback
*
* @returns {function} callback(err, result, request, response)
*
* {Error} err - The Error object if an error occurred, null otherwise.
*
* {object} [result] - The deserialized result object.
* See {@link ErrorModel} for more information.
*
* {object} [request] - The HTTP Request object if an error did not occur.
*
* {stream} [response] - The HTTP Response stream if an error did not occur.
*/
Implicit.prototype.getOptionalGlobalQuery = function (options, callback) {
var client = this.client;
if(!callback && typeof options === 'function') {
callback = options;
options = null;
}
if (!callback) {
throw new Error('callback cannot be null.');
}
// Validate
try {
if (this.client.optionalGlobalQuery !== null && this.client.optionalGlobalQuery !== undefined && typeof this.client.optionalGlobalQuery !== 'number') {
throw new Error('this.client.optionalGlobalQuery must be of type number.');
}
} catch (error) {
return callback(error);
}
// Construct URL
var baseUrl = this.client.baseUri;
var requestUrl = baseUrl + (baseUrl.endsWith('/') ? '' : '/') + 'reqopt/global/optional/query';
var queryParameters = [];
if (this.client.optionalGlobalQuery !== null && this.client.optionalGlobalQuery !== undefined) {
queryParameters.push('optional-global-query=' + encodeURIComponent(this.client.optionalGlobalQuery.toString()));
}
if (queryParameters.length > 0) {
requestUrl += '?' + queryParameters.join('&');
}
// Create HTTP transport objects
var httpRequest = new WebResource();
httpRequest.method = 'GET';
httpRequest.headers = {};
httpRequest.url = requestUrl;
// Set Headers
if(options) {
for(var headerName in options['customHeaders']) {
if (options['customHeaders'].hasOwnProperty(headerName)) {
httpRequest.headers[headerName] = options['customHeaders'][headerName];
}
}
}
httpRequest.headers['Content-Type'] = 'application/json; charset=utf-8';
httpRequest.body = null;
// Send Request
return client.pipeline(httpRequest, function (err, response, responseBody) {
if (err) {
return callback(err);
}
var statusCode = response.statusCode;
if (statusCode < 200 || statusCode >= 300) {
var error = new Error(responseBody);
error.statusCode = response.statusCode;
error.request = msRest.stripRequest(httpRequest);
error.response = msRest.stripResponse(response);
if (responseBody === '') responseBody = null;
var parsedErrorResponse;
try {
parsedErrorResponse = JSON.parse(responseBody);
if (parsedErrorResponse) {
if (parsedErrorResponse.error) parsedErrorResponse = parsedErrorResponse.error;
if (parsedErrorResponse.code) error.code = parsedErrorResponse.code;
if (parsedErrorResponse.message) error.message = parsedErrorResponse.message;
}
if (parsedErrorResponse !== null && parsedErrorResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
error.body = client.deserialize(resultMapper, parsedErrorResponse, 'error.body');<|fim▁hole|> '- "%s" for the default response.', defaultError.message, responseBody);
return callback(error);
}
return callback(error);
}
// Create Result
var result = null;
if (responseBody === '') responseBody = null;
var parsedResponse = null;
try {
parsedResponse = JSON.parse(responseBody);
result = JSON.parse(responseBody);
if (parsedResponse !== null && parsedResponse !== undefined) {
var resultMapper = new client.models['ErrorModel']().mapper();
result = client.deserialize(resultMapper, parsedResponse, 'result');
}
} catch (error) {
var deserializationError = new Error(util.format('Error "%s" occurred in deserializing the responseBody - "%s"', error, responseBody));
deserializationError.request = msRest.stripRequest(httpRequest);
deserializationError.response = msRest.stripResponse(response);
return callback(deserializationError);
}
return callback(null, result, httpRequest, response);
});
};
module.exports = Implicit;<|fim▁end|> | }
} catch (defaultError) {
error.message = util.format('Error "%s" occurred in deserializing the responseBody ' + |
<|file_name|>NullServlet.java<|end_file_name|><|fim▁begin|>/*
* SPDX-FileCopyrightText: 2006-2009 Dirk Riehle <[email protected]> https://dirkriehle.com
* SPDX-License-Identifier: AGPL-3.0-or-later
*/
package org.wahlzeit.servlets;
import java.io.*;
import javax.servlet.*;
import javax.servlet.http.*;
/**
* A null servlet.
*/
public class NullServlet extends AbstractServlet {
/**
*
*/
private static final long serialVersionUID = 42L; // any one does; class never serialized
/**
*
*/
public void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
displayNullPage(request, response);
}
/**
*
*/
public void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {<|fim▁hole|>}<|fim▁end|> | displayNullPage(request, response);
}
|
<|file_name|>lib.rs<|end_file_name|><|fim▁begin|>//! [tui](https://github.com/fdehau/tui-rs) is a library used to build rich
//! terminal users interfaces and dashboards.
//!
//! 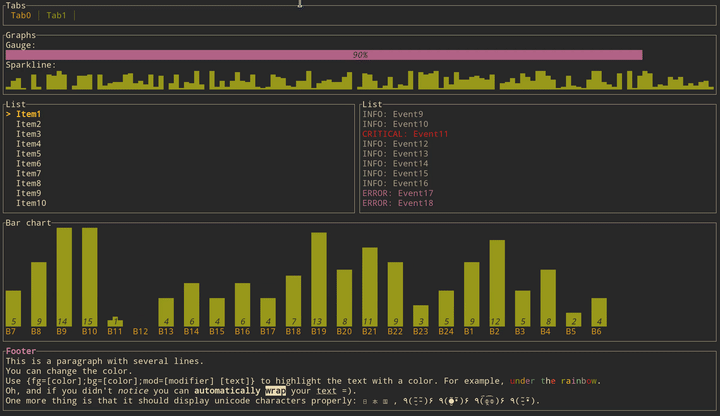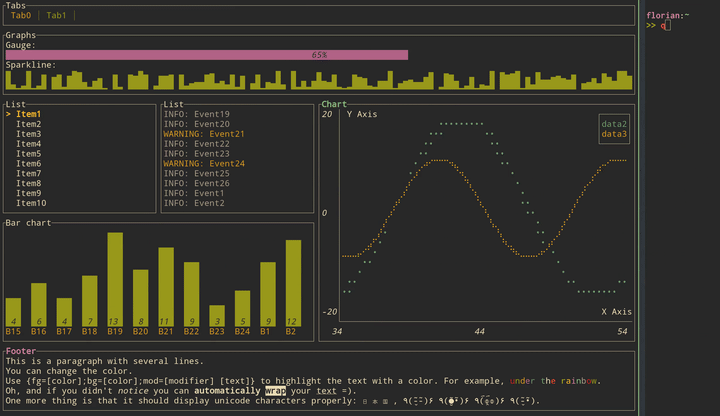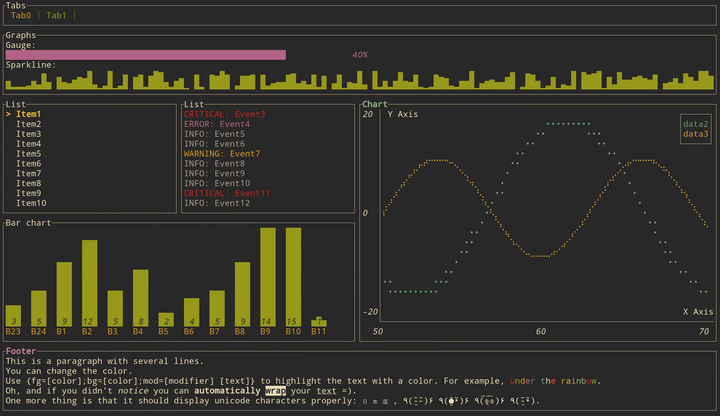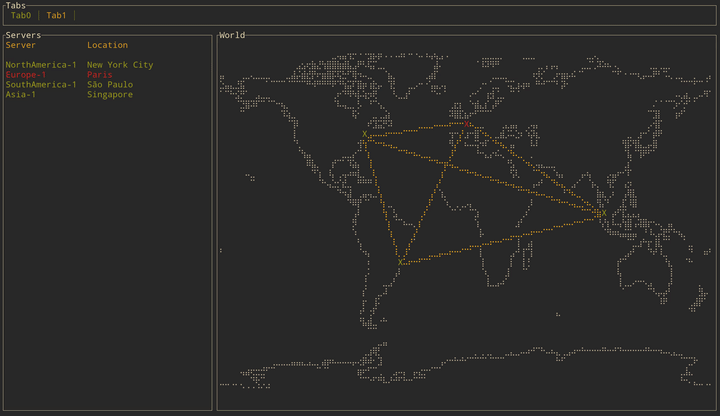
//!
//! # Get started
//!
//! ## Adding `tui` as a dependency
//!
//! ```toml
//! [dependencies]
//! tui = "0.17"<|fim▁hole|>//! The crate is using the `crossterm` backend by default that works on most platforms. But if for
//! example you want to use the `termion` backend instead. This can be done by changing your
//! dependencies specification to the following:
//!
//! ```toml
//! [dependencies]
//! termion = "1.5"
//! tui = { version = "0.17", default-features = false, features = ['termion'] }
//!
//! ```
//!
//! The same logic applies for all other available backends.
//!
//! ## Creating a `Terminal`
//!
//! Every application using `tui` should start by instantiating a `Terminal`. It is a light
//! abstraction over available backends that provides basic functionalities such as clearing the
//! screen, hiding the cursor, etc.
//!
//! ```rust,no_run
//! use std::io;
//! use tui::{backend::CrosstermBackend, Terminal};
//!
//! fn main() -> Result<(), io::Error> {
//! let stdout = io::stdout();
//! let backend = CrosstermBackend::new(stdout);
//! let mut terminal = Terminal::new(backend)?;
//! Ok(())
//! }
//! ```
//!
//! If you had previously chosen `termion` as a backend, the terminal can be created in a similar
//! way:
//!
//! ```rust,ignore
//! use std::io;
//! use tui::{backend::TermionBackend, Terminal};
//! use termion::raw::IntoRawMode;
//!
//! fn main() -> Result<(), io::Error> {
//! let stdout = io::stdout().into_raw_mode()?;
//! let backend = TermionBackend::new(stdout);
//! let mut terminal = Terminal::new(backend)?;
//! Ok(())
//! }
//! ```
//!
//! You may also refer to the examples to find out how to create a `Terminal` for each available
//! backend.
//!
//! ## Building a User Interface (UI)
//!
//! Every component of your interface will be implementing the `Widget` trait. The library comes
//! with a predefined set of widgets that should meet most of your use cases. You are also free to
//! implement your own.
//!
//! Each widget follows a builder pattern API providing a default configuration along with methods
//! to customize them. The widget is then rendered using [`Frame::render_widget`] which takes
//! your widget instance and an area to draw to.
//!
//! The following example renders a block of the size of the terminal:
//!
//! ```rust,no_run
//! use std::{io, thread, time::Duration};
//! use tui::{
//! backend::CrosstermBackend,
//! widgets::{Widget, Block, Borders},
//! layout::{Layout, Constraint, Direction},
//! Terminal
//! };
//! use crossterm::{
//! event::{self, DisableMouseCapture, EnableMouseCapture, Event, KeyCode},
//! execute,
//! terminal::{disable_raw_mode, enable_raw_mode, EnterAlternateScreen, LeaveAlternateScreen},
//! };
//!
//! fn main() -> Result<(), io::Error> {
//! // setup terminal
//! enable_raw_mode()?;
//! let mut stdout = io::stdout();
//! execute!(stdout, EnterAlternateScreen, EnableMouseCapture)?;
//! let backend = CrosstermBackend::new(stdout);
//! let mut terminal = Terminal::new(backend)?;
//!
//! terminal.draw(|f| {
//! let size = f.size();
//! let block = Block::default()
//! .title("Block")
//! .borders(Borders::ALL);
//! f.render_widget(block, size);
//! })?;
//!
//! thread::sleep(Duration::from_millis(5000));
//!
//! // restore terminal
//! disable_raw_mode()?;
//! execute!(
//! terminal.backend_mut(),
//! LeaveAlternateScreen,
//! DisableMouseCapture
//! )?;
//! terminal.show_cursor()?;
//!
//! Ok(())
//! }
//! ```
//!
//! ## Layout
//!
//! The library comes with a basic yet useful layout management object called `Layout`. As you may
//! see below and in the examples, the library makes heavy use of the builder pattern to provide
//! full customization. And `Layout` is no exception:
//!
//! ```rust,no_run
//! use tui::{
//! backend::Backend,
//! layout::{Constraint, Direction, Layout},
//! widgets::{Block, Borders},
//! Frame,
//! };
//! fn ui<B: Backend>(f: &mut Frame<B>) {
//! let chunks = Layout::default()
//! .direction(Direction::Vertical)
//! .margin(1)
//! .constraints(
//! [
//! Constraint::Percentage(10),
//! Constraint::Percentage(80),
//! Constraint::Percentage(10)
//! ].as_ref()
//! )
//! .split(f.size());
//! let block = Block::default()
//! .title("Block")
//! .borders(Borders::ALL);
//! f.render_widget(block, chunks[0]);
//! let block = Block::default()
//! .title("Block 2")
//! .borders(Borders::ALL);
//! f.render_widget(block, chunks[1]);
//! }
//! ```
//!
//! This let you describe responsive terminal UI by nesting layouts. You should note that by
//! default the computed layout tries to fill the available space completely. So if for any reason
//! you might need a blank space somewhere, try to pass an additional constraint and don't use the
//! corresponding area.
pub mod backend;
pub mod buffer;
pub mod layout;
pub mod style;
pub mod symbols;
pub mod terminal;
pub mod text;
pub mod widgets;
pub use self::terminal::{Frame, Terminal, TerminalOptions, Viewport};<|fim▁end|> | //! crossterm = "0.22"
//! ```
//! |
<|file_name|>adsbibtex_cache.py<|end_file_name|><|fim▁begin|>""" simple cache based on shelve
"""
import shelve
import time
def load_cache(cache_file):
cache = shelve.open(cache_file)
return cache
<|fim▁hole|>def read_key(cache, key, ttl):
""" Reads value from cache, if doesnt exist or is older than ttl, raises KeyError
"""
bibtex, timestamp = cache[key]
if (timestamp + ttl) < time.time():
raise KeyError("Cached entry is too old")
else:
return bibtex
def save_key(cache, key, value):
cache[key] = (value, time.time())<|fim▁end|> | |
<|file_name|>E0282.rs<|end_file_name|><|fim▁begin|>fn main() {<|fim▁hole|> let x = "hello".chars().rev().collect(); //~ ERROR E0282
}<|fim▁end|> | |
<|file_name|>shelterpro_dbf.py<|end_file_name|><|fim▁begin|>#!/usr/bin/env python3
import asm, datetime, os
"""
Import script for Shelterpro databases in DBF format
Requires my hack to dbfread to support VFP9 -
copy parseC in FieldParser.py and rename it parseV, then remove
encoding so it's just a binary string that can be ignored.
Requires address.dbf, addrlink.dbf, animal.dbf, incident.dbf, license.dbf, note.dbf, person.dbf, shelter.dbf, vacc.dbf
Will also look in PATH/images/IMAGEKEY.[jpg|JPG] for animal photos if available.
29th December, 2016 - 2nd April 2020
"""
PATH = "/home/robin/tmp/asm3_import_data/shelterpro_bc2243"
START_ID = 100
INCIDENT_IMPORT = False
LICENCE_IMPORT = False
PICTURE_IMPORT = True
VACCINATION_IMPORT = True
NOTE_IMPORT = True
SHELTER_IMPORT = True
SEPARATE_ADDRESS_TABLE = True
IMPORT_ANIMALS_WITH_NO_NAME = True
""" when faced with a field type it doesn't understand, dbfread can produce an error
'Unknown field type xx'. This parser returns anything unrecognised as binary data """
class ExtraFieldParser(dbfread.FieldParser):
def parse(self, field, data):
try:
return dbfread.FieldParser.parse(self, field, data)
except ValueError:
return data
def open_dbf(name):
return asm.read_dbf(name)
def gettype(animaldes):
spmap = {
"DOG": 2,
"CAT": 11
}
species = animaldes.split(" ")[0]
if species in spmap:
return spmap[species]
else:
return 2
def gettypeletter(aid):
tmap = {
2: "D",
10: "A",
11: "U",
12: "S"
}
return tmap[aid]
def getsize(size):
if size == "VERY":
return 0
elif size == "LARGE":
return 1
elif size == "MEDIUM":
return 2
else:
return 3
def getdateage(age, arrivaldate):
""" Returns a date adjusted for age. Age can be one of
ADULT, PUPPY, KITTEN, SENIOR """
d = arrivaldate
if d == None: d = datetime.datetime.today()
if age == "ADULT":
d = d - datetime.timedelta(days = 365 * 2)
if age == "SENIOR":
d = d - datetime.timedelta(days = 365 * 7)
if age == "KITTEN":
d = d - datetime.timedelta(days = 60)
if age == "PUPPY":
d = d - datetime.timedelta(days = 60)
return d
owners = []
ownerlicences = []
logs = []
movements = []
animals = []
animalvaccinations = []
animalcontrol = []
animalcontrolanimals = []
ppa = {}
ppo = {}
ppi = {}
addresses = {}
addrlink = {}
notes = {}
asm.setid("adoption", START_ID)
asm.setid("animal", START_ID)
asm.setid("animalcontrol", START_ID)
asm.setid("log", START_ID)
asm.setid("owner", START_ID)
if VACCINATION_IMPORT: asm.setid("animalvaccination", START_ID)
if LICENCE_IMPORT: asm.setid("ownerlicence", START_ID)
if PICTURE_IMPORT: asm.setid("media", START_ID)
if PICTURE_IMPORT: asm.setid("dbfs", START_ID)
# Remove existing
print("\\set ON_ERROR_STOP\nBEGIN;")
print("DELETE FROM adoption WHERE ID >= %d AND CreatedBy = 'conversion';" % START_ID)
print("DELETE FROM animal WHERE ID >= %d AND CreatedBy = 'conversion';" % START_ID)
print("DELETE FROM owner WHERE ID >= %d AND CreatedBy = 'conversion';" % START_ID)
if INCIDENT_IMPORT: print("DELETE FROM animalcontrol WHERE ID >= %d AND CreatedBy = 'conversion';" % START_ID)
if VACCINATION_IMPORT: print("DELETE FROM animalvaccination WHERE ID >= %d AND CreatedBy = 'conversion';" % START_ID)
if LICENCE_IMPORT: print("DELETE FROM ownerlicence WHERE ID >= %d AND CreatedBy = 'conversion';" % START_ID)
if PICTURE_IMPORT: print("DELETE FROM media WHERE ID >= %d;" % START_ID)
if PICTURE_IMPORT: print("DELETE FROM dbfs WHERE ID >= %d;" % START_ID)
# Create a transfer owner
to = asm.Owner()
owners.append(to)
to.OwnerSurname = "Other Shelter"
to.OwnerName = to.OwnerSurname
# Create an unknown owner
uo = asm.Owner()
owners.append(uo)
uo.OwnerSurname = "Unknown Owner"
uo.OwnerName = uo.OwnerSurname
# Load up data files
if SEPARATE_ADDRESS_TABLE:
caddress = open_dbf("address")
caddrlink = open_dbf("addrlink")
canimal = open_dbf("animal")
if LICENCE_IMPORT: clicense = open_dbf("license")
cperson = open_dbf("person")
if SHELTER_IMPORT: cshelter = open_dbf("shelter")
if VACCINATION_IMPORT: cvacc = open_dbf("vacc")
if INCIDENT_IMPORT: cincident = open_dbf("incident")
if NOTE_IMPORT: cnote = open_dbf("note")
if PICTURE_IMPORT: cimage = open_dbf("image")
# Addresses if we have a separate file
if SEPARATE_ADDRESS_TABLE:
for row in caddress:
addresses[row["ADDRESSKEY"]] = {
"address": asm.strip(row["ADDRESSSTR"]) + " " + asm.strip(row["ADDRESSST2"]) + " " + asm.strip(row["ADDRESSST3"]),
"city": asm.strip(row["ADDRESSCIT"]),
"state": asm.strip(row["ADDRESSSTA"]),
"zip": asm.strip(row["ADDRESSPOS"])
}
# The link between addresses and people
for row in caddrlink:
addrlink[row["EVENTKEY"]] = row["ADDRLINKAD"]
# People
for row in cperson:
o = asm.Owner()
owners.append(o)
personkey = 0
# Sometimes called UNIQUE
if "PERSONKEY" in row: personkey = row["PERSONKEY"]
elif "UNIQUE" in row: personkey = row["UNIQUE"]
ppo[personkey] = o
o.OwnerForeNames = asm.strip(row["FNAME"])
o.OwnerSurname = asm.strip(row["LNAME"])
o.OwnerName = o.OwnerTitle + " " + o.OwnerForeNames + " " + o.OwnerSurname
# Find the address if it's in a separate table
if SEPARATE_ADDRESS_TABLE:
if personkey in addrlink:
addrkey = addrlink[personkey]
if addrkey in addresses:
add = addresses[addrkey]
o.OwnerAddress = add["address"]
o.OwnerTown = add["city"]
o.OwnerCounty = add["state"]
o.OwnerPostcode = add["zip"]
else:
# Otherwise, address fields are in the person table
o.OwnerAddress = row["ADDR1"].encode("ascii", "xmlcharrefreplace") + "\n" + row["ADDR2"].encode("ascii", "xmlcharrefreplace")
o.OwnerTown = row["CITY"]
o.OwnerCounty = row["STATE"]
o.OwnerPostcode = row["POSTAL_ID"]
if asm.strip(row["EMAIL"]) != "(": o.EmailAddress = asm.strip(row["EMAIL"])
if row["HOME_PH"] != 0: o.HomeTelephone = asm.strip(row["HOME_PH"])
if row["WORK_PH"] != 0: o.WorkTelephone = asm.strip(row["WORK_PH"])
if row["THIRD_PH"] != 0: o.MobileTelephone = asm.strip(row["THIRD_PH"])
o.IsACO = asm.cint(row["ACO_IND"])
o.IsStaff = asm.cint(row["STAFF_IND"])
o.IsVolunteer = asm.cint(row["VOL_IND"])
o.IsDonor = asm.cint(row["DONOR_IND"])
o.IsMember = asm.cint(row["MEMBER_IND"])
o.IsBanned = asm.cint(row["NOADOPT"] == "T" and "1" or "0")
if "FOSTERS" in row: o.IsFosterer = asm.cint(row["FOSTERS"])
# o.ExcludeFromBulkEmail = asm.cint(row["MAILINGSAM"]) # Not sure this is correct
# Animals
for row in canimal:
if not IMPORT_ANIMALS_WITH_NO_NAME and row["PETNAME"].strip() == "": continue
a = asm.Animal()
animals.append(a)
ppa[row["ANIMALKEY"]] = a
a.AnimalTypeID = gettype(row["ANIMLDES"])
a.SpeciesID = asm.species_id_for_name(row["ANIMLDES"].split(" ")[0])
a.AnimalName = asm.strip(row["PETNAME"]).title()
if a.AnimalName.strip() == "":
a.AnimalName = "(unknown)"
age = row["AGE"].split(" ")[0]
added = asm.now()
if "ADDEDDATET" in row and row["ADDEDDATET"] is not None: added = row["ADDEDDATET"]
if "DOB" in row: a.DateOfBirth = row["DOB"]
if a.DateOfBirth is None: a.DateOfBirth = getdateage(age, added)
a.DateBroughtIn = added
a.LastChangedDate = a.DateBroughtIn
a.CreatedDate = a.DateBroughtIn
a.EntryReasonID = 4
a.generateCode(gettypeletter(a.AnimalTypeID))
a.ShortCode = row["ANIMALKEY"]
a.Neutered = asm.cint(row["FIX"])
a.Declawed = asm.cint(row["DECLAWED"])
a.IsNotAvailableForAdoption = 0
a.ShelterLocation = 1
a.Sex = asm.getsex_mf(asm.strip(row["GENDER"]))
a.Size = getsize(asm.strip(row["WEIGHT"]))
a.BaseColourID = asm.colour_id_for_names(asm.strip(row["FURCOLR1"]), asm.strip(row["FURCOLR2"]))
a.IdentichipNumber = asm.strip(row["MICROCHIP"])
if a.IdentichipNumber <> "": a.Identichipped = 1
comments = "Original breed: " + asm.strip(row["BREED1"]) + "/" + asm.strip(row["CROSSBREED"]) + ", age: " + age
comments += ",Color: " + asm.strip(row["FURCOLR1"]) + "/" + asm.strip(row["FURCOLR2"])
comments += ", Coat: " + asm.strip(row["COAT"])
comments += ", Collar: " + asm.strip(row["COLLRTYP"])
a.BreedID = asm.breed_id_for_name(asm.strip(row["BREED1"]))
a.Breed2ID = a.BreedID
a.BreedName = asm.breed_name_for_id(a.BreedID)
if row["PUREBRED"] == "0":
a.Breed2ID = asm.breed_id_for_name(asm.strip(row["CROSSBREED"]))
if a.Breed2ID == 1: a.Breed2ID = 442
a.BreedName = "%s / %s" % ( asm.breed_name_for_id(a.BreedID), asm.breed_name_for_id(a.Breed2ID) )
a.HiddenAnimalDetails = comments
# Make everything non-shelter until it's in the shelter file
a.NonShelterAnimal = 1
a.Archived = 1
# If the row has an original owner
if row["PERSOWNR"] in ppo:
o = ppo[row["PERSOWNR"]]
a.OriginalOwnerID = o.ID
# Shelterpro records Deceased as Status == 2 as far as we can tell
if row["STATUS"] == 2:
a.DeceasedDate = a.DateBroughtIn
a.PTSReasonID = 2 # Died
# Vaccinations
if VACCINATION_IMPORT:
for row in cvacc:
if not row["ANIMALKEY"] in ppa: continue
a = ppa[row["ANIMALKEY"]]
# Each row contains a vaccination
av = asm.AnimalVaccination()
animalvaccinations.append(av)
vaccdate = row["VACCEFFECT"]
if vaccdate is None:
vaccdate = a.DateBroughtIn
av.AnimalID = a.ID
av.VaccinationID = 8
if row["VACCTYPE"].find("DHLPP") != -1: av.VaccinationID = 8
if row["VACCTYPE"].find("BORDETELLA") != -1: av.VaccinationID = 6
if row["VACCTYPE"].find("RABIES") != -1: av.VaccinationID = 4
av.DateRequired = vaccdate
av.DateOfVaccination = vaccdate
av.DateExpires = row["VACCEXPIRA"]
av.Manufacturer = row["VACCMANUFA"]
av.BatchNumber = row["VACCSERIAL"]
av.Comments = "Name: %s, Issue: %s" % (row["VACCDRUGNA"], row["VACCISSUED"])
# Run through the shelter file and create any movements/euthanisation info
if SHELTER_IMPORT:
for row in cshelter:
a = None
if row["ANIMALKEY"] in ppa:
a = ppa[row["ANIMALKEY"]]
arivdate = row["ARIVDATE"]
a.ShortCode = asm.strip(row["ANIMALKEY"])
a.ShelterLocationUnit = asm.strip(row["KENNEL"])
a.NonShelterAnimal = 0
if arivdate is not None:
a.DateBroughtIn = arivdate
a.LastChangedDate = a.DateBroughtIn
a.CreatedDate = a.DateBroughtIn
a.generateCode(gettypeletter(a.AnimalTypeID))
a.ShortCode = asm.strip(row["ANIMALKEY"])
else:
# Couldn't find an animal record, bail
continue
o = None
if row["OWNERATDIS"] in ppo:
o = ppo[row["OWNERATDIS"]]
dispmeth = asm.strip(row["DISPMETH"])
dispdate = row["DISPDATE"]
# Apply other fields
if row["ARIVREAS"] == "QUARANTINE":
a.IsQuarantine = 1
elif row["ARIVREAS"] == "STRAY":
if a.AnimalTypeID == 2: a.AnimalTypeID = 10
if a.AnimalTypeID == 11: a.AnimalTypeID = 12
a.EntryReasonID = 7
# Adoptions
if dispmeth == "ADOPTED":
if a is None or o is None: continue
m = asm.Movement()
m.AnimalID = a.ID
m.OwnerID = o.ID
m.MovementType = 1
m.MovementDate = dispdate
a.Archived = 1
a.ActiveMovementID = m.ID
a.ActiveMovementDate = m.MovementDate
a.ActiveMovementType = 1
movements.append(m)
# Reclaims
elif dispmeth == "RETURN TO OWNER":
if a is None or o is None: continue
m = asm.Movement()
m.AnimalID = a.ID
m.OwnerID = o.ID
m.MovementType = 5
m.MovementDate = dispdate
a.Archived = 1
a.ActiveMovementID = m.ID
a.ActiveMovementDate = m.MovementDate
a.ActiveMovementType = 5
movements.append(m)
# Released or Other
elif dispmeth == "RELEASED" or dispmeth == "OTHER":
if a is None or o is None: continue
m = asm.Movement()
m.AnimalID = a.ID
m.OwnerID = 0
m.MovementType = 7
m.MovementDate = dispdate
m.Comments = dispmeth
a.Archived = 1
a.ActiveMovementDate = m.MovementDate
a.ActiveMovementID = m.ID
a.ActiveMovementType = 7
movements.append(m)
# Holding
elif dispmeth == "" and row["ANIMSTAT"] == "HOLDING":
a.IsHold = 1
a.Archived = 0
# Deceased
elif dispmeth == "DECEASED":
a.DeceasedDate = dispdate
a.PTSReasonID = 2 # Died
a.Archived = 1
# Euthanized
elif dispmeth == "EUTHANIZED":
a.DeceasedDate = dispdate
a.PutToSleep = 1
a.PTSReasonID = 4 # Sick/Injured
a.Archived = 1
# If the outcome is blank, it's on the shelter
elif dispmeth == "":
a.Archived = 0
# It's the name of an organisation that received the animal
else:
if a is None: continue
m = asm.Movement()
m.AnimalID = a.ID
m.OwnerID = to.ID
m.MovementType = 3
m.MovementDate = dispdate
m.Comments = dispmeth
a.Archived = 1
a.ActiveMovementID = m.ID
a.ActiveMovementType = 3
movements.append(m)
if LICENCE_IMPORT:
for row in clicense:
a = None
if row["ANIMALKEY"] in ppa:
a = ppa[row["ANIMALKEY"]]
o = None
if row["LICENSEOWN"] in ppo:
o = ppo[row["LICENSEOWN"]]
if a is not None and o is not None:
if row["LICENSEEFF"] is None:
continue
ol = asm.OwnerLicence()
ownerlicences.append(ol)
ol.AnimalID = a.ID
ol.OwnerID = o.ID
ol.IssueDate = row["LICENSEEFF"]
ol.ExpiryDate = row["LICENSEEXP"]
if ol.ExpiryDate is None: ol.ExpiryDate = ol.IssueDate
ol.LicenceNumber = asm.strip(row["LICENSE"])
ol.LicenceTypeID = 2 # Unaltered dog
if a.Neutered == 1:
ol.LicenceTypeID = 1 # Altered dog
if PICTURE_IMPORT:
for row in cimage:
a = None
if not row["ANIMALKEY"] in ppa:
continue
a = ppa[row["ANIMALKEY"]]
imdata = None
if os.path.exists(PATH + "/images/%s.jpg" % row["IMAGEKEY"]):
f = open(PATH + "/images/%s.jpg" % row["IMAGEKEY"], "rb")
imdata = f.read()
f.close()
if imdata is not None:
asm.animal_image(a.ID, imdata)
# Incidents
if INCIDENT_IMPORT:
for row in cincident:
ac = asm.AnimalControl()
animalcontrol.append(ac)
calldate = row["DATETIMEAS"]
if calldate is None: calldate = row["DATETIMEOR"]
if calldate is None: calldate = asm.now()
ac.CallDateTime = calldate
ac.IncidentDateTime = calldate
ac.DispatchDateTime = calldate
ac.CompletedDate = row["DATETIMEOU"]
if ac.CompletedDate is None: ac.CompletedDate = calldate
if row["CITIZENMAK"] in ppo:
ac.CallerID = ppo[row["CITIZENMAK"]].ID
if row["OWNERATORI"] in ppo:
ac.OwnerID = ppo[row["OWNERATORI"]].ID
ac.IncidentCompletedID = 2
if row["FINALOUTCO"] == "ANIMAL PICKED UP":
ac.IncidentCompletedID = 2
elif row["FINALOUTCO"] == "OTHER":
ac.IncidentCompletedID = 6 # Does not exist in default data
ac.IncidentTypeID = 1
incidentkey = 0
if "INCIDENTKE" in row: incidentkey = row["INCIDENTKE"]
elif "KEY" in row: incidentkey = row["KEY"]
comments = "case: %s\n" % incidentkey
comments += "outcome: %s\n" % asm.strip(row["FINALOUTCO"])
comments += "precinct: %s\n" % asm.strip(row["PRECINCT"])
ac.CallNotes = comments
ac.Sex = 2
if "ANIMALKEY" in row:
if row["ANIMALKEY"] in ppa:
a = ppa[row["ANIMALKEY"]]
animalcontrolanimals.append("INSERT INTO animalcontrolanimal (AnimalControlID, AnimalID) VALUES (%s, %s);" % (ac.ID, a.ID))
# Notes as log entries
if NOTE_IMPORT:
for row in cnote:
eventtype = row["EVENTTYPE"]
eventkey = row["EVENTKEY"]
notedate = row["NOTEDATE"]
memo = row["NOTEMEMO"]
if eventtype in [ 1, 3 ]: # animal/intake or case notes
if not eventkey in ppa: continue
linkid = ppa[eventkey].ID
ppa[eventkey].HiddenAnimalDetails += "\n" + memo
l = asm.Log()
logs.append(l)
l.LogTypeID = 3
l.LinkID = linkid
l.LinkType = 0
l.Date = notedate
if l.Date is None:
l.Date = asm.now()
l.Comments = memo
elif eventtype in [ 2, 5, 10 ]: # person, case and incident notes
if not eventkey in ppi: continue
linkid = ppi[eventkey].ID
ppi[eventkey].CallNotes += "\n" + memo
l = asm.Log()
logs.append(l)
l.LogTypeID = 3
l.LinkID = linkid
l.LinkType = 6
l.Date = notedate
if l.Date is None:
l.Date = asm.now()
l.Comments = memo
# Run back through the animals, if we have any that are still<|fim▁hole|># Now that everything else is done, output stored records
for a in animals:
print(a)
for av in animalvaccinations:
print(av)
for o in owners:
print(o)
for l in logs:
print(l)
for m in movements:
print(m)
for ol in ownerlicences:
print(ol)
for ac in animalcontrol:
print(ac)
for aca in animalcontrolanimals:
print(aca)
asm.stderr_summary(animals=animals, animalvaccinations=animalvaccinations, logs=logs, owners=owners, movements=movements, ownerlicences=ownerlicences, animalcontrol=animalcontrol)
print("DELETE FROM configuration WHERE ItemName LIKE 'DBView%';")
print("COMMIT;")<|fim▁end|> | # on shelter after 2 years, add an adoption to an unknown owner
#asm.adopt_older_than(animals, movements, uo.ID, 365*2)
|
<|file_name|>http.py<|end_file_name|><|fim▁begin|># Copyright (c) 2016 RIPE NCC
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# You should have received a copy of the GNU General Public License
# along with this program. If not, see <http://www.gnu.org/licenses/>.
from .base import Result, ParsingDict
class Response(ParsingDict):
def __init__(self, data, **kwargs):
ParsingDict.__init__(self, **kwargs)
self.raw_data = data
self.af = self.ensure("af", int)
self.body_size = self.ensure("bsize", int)
self.head_size = self.ensure("hsize", int)
self.destination_address = self.ensure("dst_addr", str)
self.source_address = self.ensure("src_addr", str)
self.code = self.ensure("res", int)<|fim▁hole|> self.destination_address = self.ensure(
"addr", str, self.destination_address)
if not self.source_address:
self.source_address = self.ensure(
"srcaddr", str, self.source_address)
if not self.code:
self._handle_malformation("No response code available")
error = self.ensure("err", str)
if error:
self._handle_error(error)
class HttpResult(Result):
METHOD_GET = "GET"
METHOD_POST = "POST"
METHOD_PUT = "PUT"
METHOD_DELETE = "DELETE"
METHOD_HEAD = "HEAD"
METHODS = {
METHOD_GET: "GET",
METHOD_POST: "POST",
METHOD_PUT: "PUT",
METHOD_DELETE: "DELETE",
METHOD_HEAD: "HEAD"
}
def __init__(self, data, **kwargs):
Result.__init__(self, data, **kwargs)
self.uri = self.ensure("uri", str)
self.method = None
self.responses = []
if "result" not in self.raw_data:
self._handle_malformation("No result value found")
return
if isinstance(self.raw_data["result"], list):
# All modern results
for response in self.raw_data["result"]:
self.responses.append(Response(response, **kwargs))
if self.responses:
method = self.raw_data["result"][0].get(
"method",
self.raw_data["result"][0].get("mode") # Firmware == 4300
)
if method:
method = method.replace("4", "").replace("6", "")
if method in self.METHODS.keys():
self.method = self.METHODS[method]
else:
# Firmware <= 1
response = self.raw_data["result"].split(" ")
self.method = response[0].replace("4", "").replace("6", "")
self.responses.append(Response({
"dst_addr": response[1],
"rt": float(response[2]) * 1000,
"res": int(response[3]),
"hsize": int(response[4]),
"bsize": int(response[5]),
}))
__all__ = (
"HttpResult"
)<|fim▁end|> | self.response_time = self.ensure("rt", float)
self.version = self.ensure("ver", str)
if not self.destination_address: |
<|file_name|>diagnostics.rs<|end_file_name|><|fim▁begin|><|fim▁hole|>//! Diagnostics related methods for `TyS`.
use crate::ty::TyKind::*;
use crate::ty::{InferTy, TyCtxt, TyS};
use rustc_errors::{Applicability, DiagnosticBuilder};
use rustc_hir as hir;
use rustc_hir::def_id::DefId;
use rustc_hir::{QPath, TyKind, WhereBoundPredicate, WherePredicate};
impl<'tcx> TyS<'tcx> {
/// Similar to `TyS::is_primitive`, but also considers inferred numeric values to be primitive.
pub fn is_primitive_ty(&self) -> bool {
matches!(
self.kind(),
Bool | Char
| Str
| Int(_)
| Uint(_)
| Float(_)
| Infer(
InferTy::IntVar(_)
| InferTy::FloatVar(_)
| InferTy::FreshIntTy(_)
| InferTy::FreshFloatTy(_)
)
)
}
/// Whether the type is succinctly representable as a type instead of just referred to with a
/// description in error messages. This is used in the main error message.
pub fn is_simple_ty(&self) -> bool {
match self.kind() {
Bool
| Char
| Str
| Int(_)
| Uint(_)
| Float(_)
| Infer(
InferTy::IntVar(_)
| InferTy::FloatVar(_)
| InferTy::FreshIntTy(_)
| InferTy::FreshFloatTy(_),
) => true,
Ref(_, x, _) | Array(x, _) | Slice(x) => x.peel_refs().is_simple_ty(),
Tuple(tys) if tys.is_empty() => true,
_ => false,
}
}
/// Whether the type is succinctly representable as a type instead of just referred to with a
/// description in error messages. This is used in the primary span label. Beyond what
/// `is_simple_ty` includes, it also accepts ADTs with no type arguments and references to
/// ADTs with no type arguments.
pub fn is_simple_text(&self) -> bool {
match self.kind() {
Adt(_, substs) => substs.non_erasable_generics().next().is_none(),
Ref(_, ty, _) => ty.is_simple_text(),
_ => self.is_simple_ty(),
}
}
/// Whether the type can be safely suggested during error recovery.
pub fn is_suggestable(&self) -> bool {
!matches!(
self.kind(),
Opaque(..)
| FnDef(..)
| FnPtr(..)
| Dynamic(..)
| Closure(..)
| Infer(..)
| Projection(..)
)
}
}
pub fn suggest_arbitrary_trait_bound(
generics: &hir::Generics<'_>,
err: &mut DiagnosticBuilder<'_>,
param_name: &str,
constraint: &str,
) -> bool {
let param = generics.params.iter().find(|p| p.name.ident().as_str() == param_name);
match (param, param_name) {
(Some(_), "Self") => return false,
_ => {}
}
// Suggest a where clause bound for a non-type paremeter.
let (action, prefix) = if generics.where_clause.predicates.is_empty() {
("introducing a", " where ")
} else {
("extending the", ", ")
};
err.span_suggestion_verbose(
generics.where_clause.tail_span_for_suggestion(),
&format!(
"consider {} `where` bound, but there might be an alternative better way to express \
this requirement",
action,
),
format!("{}{}: {}", prefix, param_name, constraint),
Applicability::MaybeIncorrect,
);
true
}
fn suggest_removing_unsized_bound(
generics: &hir::Generics<'_>,
err: &mut DiagnosticBuilder<'_>,
param_name: &str,
param: &hir::GenericParam<'_>,
def_id: Option<DefId>,
) {
// See if there's a `?Sized` bound that can be removed to suggest that.
// First look at the `where` clause because we can have `where T: ?Sized`,
// then look at params.
for (where_pos, predicate) in generics.where_clause.predicates.iter().enumerate() {
match predicate {
WherePredicate::BoundPredicate(WhereBoundPredicate {
bounded_ty:
hir::Ty {
kind:
hir::TyKind::Path(hir::QPath::Resolved(
None,
hir::Path {
segments: [segment],
res: hir::def::Res::Def(hir::def::DefKind::TyParam, _),
..
},
)),
..
},
bounds,
span,
..
}) if segment.ident.as_str() == param_name => {
for (pos, bound) in bounds.iter().enumerate() {
match bound {
hir::GenericBound::Trait(poly, hir::TraitBoundModifier::Maybe)
if poly.trait_ref.trait_def_id() == def_id => {}
_ => continue,
}
let sp = match (
bounds.len(),
pos,
generics.where_clause.predicates.len(),
where_pos,
) {
// where T: ?Sized
// ^^^^^^^^^^^^^^^
(1, _, 1, _) => generics.where_clause.span,
// where Foo: Bar, T: ?Sized,
// ^^^^^^^^^^^
(1, _, len, pos) if pos == len - 1 => generics.where_clause.predicates
[pos - 1]
.span()
.shrink_to_hi()
.to(*span),
// where T: ?Sized, Foo: Bar,
// ^^^^^^^^^^^
(1, _, _, pos) => {
span.until(generics.where_clause.predicates[pos + 1].span())
}
// where T: ?Sized + Bar, Foo: Bar,
// ^^^^^^^^^
(_, 0, _, _) => bound.span().to(bounds[1].span().shrink_to_lo()),
// where T: Bar + ?Sized, Foo: Bar,
// ^^^^^^^^^
(_, pos, _, _) => bounds[pos - 1].span().shrink_to_hi().to(bound.span()),
};
err.span_suggestion_verbose(
sp,
"consider removing the `?Sized` bound to make the \
type parameter `Sized`",
String::new(),
Applicability::MaybeIncorrect,
);
}
}
_ => {}
}
}
for (pos, bound) in param.bounds.iter().enumerate() {
match bound {
hir::GenericBound::Trait(poly, hir::TraitBoundModifier::Maybe)
if poly.trait_ref.trait_def_id() == def_id =>
{
let sp = match (param.bounds.len(), pos) {
// T: ?Sized,
// ^^^^^^^^
(1, _) => param.span.shrink_to_hi().to(bound.span()),
// T: ?Sized + Bar,
// ^^^^^^^^^
(_, 0) => bound.span().to(param.bounds[1].span().shrink_to_lo()),
// T: Bar + ?Sized,
// ^^^^^^^^^
(_, pos) => param.bounds[pos - 1].span().shrink_to_hi().to(bound.span()),
};
err.span_suggestion_verbose(
sp,
"consider removing the `?Sized` bound to make the type parameter \
`Sized`",
String::new(),
Applicability::MaybeIncorrect,
);
}
_ => {}
}
}
}
/// Suggest restricting a type param with a new bound.
pub fn suggest_constraining_type_param(
tcx: TyCtxt<'_>,
generics: &hir::Generics<'_>,
err: &mut DiagnosticBuilder<'_>,
param_name: &str,
constraint: &str,
def_id: Option<DefId>,
) -> bool {
let param = generics.params.iter().find(|p| p.name.ident().as_str() == param_name);
let Some(param) = param else {
return false;
};
const MSG_RESTRICT_BOUND_FURTHER: &str = "consider further restricting this bound";
let msg_restrict_type = format!("consider restricting type parameter `{}`", param_name);
let msg_restrict_type_further =
format!("consider further restricting type parameter `{}`", param_name);
if def_id == tcx.lang_items().sized_trait() {
// Type parameters are already `Sized` by default.
err.span_label(param.span, &format!("this type parameter needs to be `{}`", constraint));
suggest_removing_unsized_bound(generics, err, param_name, param, def_id);
return true;
}
let mut suggest_restrict = |span| {
err.span_suggestion_verbose(
span,
MSG_RESTRICT_BOUND_FURTHER,
format!(" + {}", constraint),
Applicability::MachineApplicable,
);
};
if param_name.starts_with("impl ") {
// If there's an `impl Trait` used in argument position, suggest
// restricting it:
//
// fn foo(t: impl Foo) { ... }
// --------
// |
// help: consider further restricting this bound with `+ Bar`
//
// Suggestion for tools in this case is:
//
// fn foo(t: impl Foo) { ... }
// --------
// |
// replace with: `impl Foo + Bar`
suggest_restrict(param.span.shrink_to_hi());
return true;
}
if generics.where_clause.predicates.is_empty()
// Given `trait Base<T = String>: Super<T>` where `T: Copy`, suggest restricting in the
// `where` clause instead of `trait Base<T: Copy = String>: Super<T>`.
&& !matches!(param.kind, hir::GenericParamKind::Type { default: Some(_), .. })
{
if let Some(bounds_span) = param.bounds_span() {
// If user has provided some bounds, suggest restricting them:
//
// fn foo<T: Foo>(t: T) { ... }
// ---
// |
// help: consider further restricting this bound with `+ Bar`
//
// Suggestion for tools in this case is:
//
// fn foo<T: Foo>(t: T) { ... }
// --
// |
// replace with: `T: Bar +`
suggest_restrict(bounds_span.shrink_to_hi());
} else {
// If user hasn't provided any bounds, suggest adding a new one:
//
// fn foo<T>(t: T) { ... }
// - help: consider restricting this type parameter with `T: Foo`
err.span_suggestion_verbose(
param.span.shrink_to_hi(),
&msg_restrict_type,
format!(": {}", constraint),
Applicability::MachineApplicable,
);
}
true
} else {
// This part is a bit tricky, because using the `where` clause user can
// provide zero, one or many bounds for the same type parameter, so we
// have following cases to consider:
//
// 1) When the type parameter has been provided zero bounds
//
// Message:
// fn foo<X, Y>(x: X, y: Y) where Y: Foo { ... }
// - help: consider restricting this type parameter with `where X: Bar`
//
// Suggestion:
// fn foo<X, Y>(x: X, y: Y) where Y: Foo { ... }
// - insert: `, X: Bar`
//
//
// 2) When the type parameter has been provided one bound
//
// Message:
// fn foo<T>(t: T) where T: Foo { ... }
// ^^^^^^
// |
// help: consider further restricting this bound with `+ Bar`
//
// Suggestion:
// fn foo<T>(t: T) where T: Foo { ... }
// ^^
// |
// replace with: `T: Bar +`
//
//
// 3) When the type parameter has been provided many bounds
//
// Message:
// fn foo<T>(t: T) where T: Foo, T: Bar {... }
// - help: consider further restricting this type parameter with `where T: Zar`
//
// Suggestion:
// fn foo<T>(t: T) where T: Foo, T: Bar {... }
// - insert: `, T: Zar`
//
// Additionally, there may be no `where` clause whatsoever in the case that this was
// reached because the generic parameter has a default:
//
// Message:
// trait Foo<T=()> {... }
// - help: consider further restricting this type parameter with `where T: Zar`
//
// Suggestion:
// trait Foo<T=()> where T: Zar {... }
// - insert: `where T: Zar`
if matches!(param.kind, hir::GenericParamKind::Type { default: Some(_), .. })
&& generics.where_clause.predicates.len() == 0
{
// Suggest a bound, but there is no existing `where` clause *and* the type param has a
// default (`<T=Foo>`), so we suggest adding `where T: Bar`.
err.span_suggestion_verbose(
generics.where_clause.tail_span_for_suggestion(),
&msg_restrict_type_further,
format!(" where {}: {}", param_name, constraint),
Applicability::MachineApplicable,
);
} else {
let mut param_spans = Vec::new();
for predicate in generics.where_clause.predicates {
if let WherePredicate::BoundPredicate(WhereBoundPredicate {
span,
bounded_ty,
..
}) = predicate
{
if let TyKind::Path(QPath::Resolved(_, path)) = &bounded_ty.kind {
if let Some(segment) = path.segments.first() {
if segment.ident.to_string() == param_name {
param_spans.push(span);
}
}
}
}
}
match param_spans[..] {
[¶m_span] => suggest_restrict(param_span.shrink_to_hi()),
_ => {
err.span_suggestion_verbose(
generics.where_clause.tail_span_for_suggestion(),
&msg_restrict_type_further,
format!(", {}: {}", param_name, constraint),
Applicability::MachineApplicable,
);
}
}
}
true
}
}
/// Collect al types that have an implicit `'static` obligation that we could suggest `'_` for.
pub struct TraitObjectVisitor<'tcx>(pub Vec<&'tcx hir::Ty<'tcx>>, pub crate::hir::map::Map<'tcx>);
impl<'v> hir::intravisit::Visitor<'v> for TraitObjectVisitor<'v> {
type Map = rustc_hir::intravisit::ErasedMap<'v>;
fn nested_visit_map(&mut self) -> hir::intravisit::NestedVisitorMap<Self::Map> {
hir::intravisit::NestedVisitorMap::None
}
fn visit_ty(&mut self, ty: &'v hir::Ty<'v>) {
match ty.kind {
hir::TyKind::TraitObject(
_,
hir::Lifetime {
name:
hir::LifetimeName::ImplicitObjectLifetimeDefault | hir::LifetimeName::Static,
..
},
_,
) => {
self.0.push(ty);
}
hir::TyKind::OpaqueDef(item_id, _) => {
self.0.push(ty);
let item = self.1.item(item_id);
hir::intravisit::walk_item(self, item);
}
_ => {}
}
hir::intravisit::walk_ty(self, ty);
}
}<|fim▁end|> | |
<|file_name|>core.rs<|end_file_name|><|fim▁begin|>//! High level wrapper of LMDB APIs
//!
//! Requires knowledge of LMDB terminology
//!
//! # Environment
//!
//! Environment is actually the center point of LMDB, it's a container
//! of everything else. As some settings couldn't be adjusted after
//! opening, `Environment` is constructed using `EnvBuilder`, which
//! sets up maximum size, maximum count of named databases, maximum
//! readers which could be used from different threads without locking
//! and so on.
//!
//! # Database
//!
//! Actual key-value store. The most crucial aspect is whether a database
//! allows duplicates or not. It is specified on creation and couldn't be
//! changed later. Entries for the same key are called `items`.
//!
//! There are a couple of optmizations to use, like marking
//! keys or data as integer, allowing sorting using reverse key, marking
//! keys/data as fixed size.
//!
//! # Transaction
//!
//! Absolutely every db operation happens in a transaction. It could
//! be a read-only transaction (reader), which is lockless and therefore
//! cheap. Or it could be a read-write transaction, which is unique, i.e.
//! there could be only one writer at a time.
//!
//! While readers are cheap and lockless, they work better being short-lived
//! as in other case they may lock pages from being reused. Readers have
//! a special API for marking as finished and renewing.
//!
//! It is perfectly fine to create nested transactions.
//!
//!
//! # Example
//!
#![allow(non_upper_case_globals)]
use libc::{self, c_int, c_uint, size_t, c_void};
use std;
use std::borrow::ToOwned;
use std::cell::{UnsafeCell};
use std::cmp::{Ordering};
use std::collections::HashMap;
use std::error::Error;
use std::ffi::{CString};
use std::path::Path;
use std::mem;
use std::os::unix::ffi::{OsStrExt};
use std::ptr;
use std::result::Result;
use std::sync::{Arc, Mutex};
use ffi::{self, MDB_val};
pub use MdbError::{NotFound, KeyExists, Other, StateError, Corrupted, Panic};
pub use MdbError::{InvalidPath, TxnFull, CursorFull, PageFull, CacheError};
use traits::{ToMdbValue, FromMdbValue};
use utils::{error_msg};
macro_rules! lift_mdb {
($e:expr) => (lift_mdb!($e, ()));
($e:expr, $r:expr) => (
{
let t = $e;
match t {
ffi::MDB_SUCCESS => Ok($r),
_ => return Err(MdbError::new_with_code(t))
}
})
}
macro_rules! try_mdb {
($e:expr) => (
{
let t = $e;
match t {
ffi::MDB_SUCCESS => (),
_ => return Err(MdbError::new_with_code(t))
}
})
}
macro_rules! assert_state_eq {
($log:ident, $cur:expr, $exp:expr) =>
({
let c = $cur;
let e = $exp;
if c == e {
()
} else {
let msg = format!("{} requires {:?}, is in {:?}", stringify!($log), c, e);
return Err(StateError(msg))
}})
}
macro_rules! assert_state_not {
($log:ident, $cur:expr, $exp:expr) =>
({
let c = $cur;
let e = $exp;
if c != e {
()
} else {
let msg = format!("{} shouldn't be in {:?}", stringify!($log), e);
return Err(StateError(msg))
}})
}
/// MdbError wraps information about LMDB error
#[derive(Debug)]
pub enum MdbError {
NotFound,
KeyExists,
TxnFull,
CursorFull,
PageFull,
Corrupted,
Panic,
InvalidPath,
StateError(String),
CacheError,
Other(c_int, String)
}
impl MdbError {
pub fn new_with_code(code: c_int) -> MdbError {
match code {
ffi::MDB_NOTFOUND => NotFound,
ffi::MDB_KEYEXIST => KeyExists,
ffi::MDB_TXN_FULL => TxnFull,
ffi::MDB_CURSOR_FULL => CursorFull,
ffi::MDB_PAGE_FULL => PageFull,
ffi::MDB_CORRUPTED => Corrupted,
ffi::MDB_PANIC => Panic,
_ => Other(code, error_msg(code))
}
}
}
impl std::fmt::Display for MdbError {
fn fmt(&self, fmt: &mut std::fmt::Formatter) -> std::fmt::Result {
match self {
&NotFound | &KeyExists | &TxnFull |
&CursorFull | &PageFull | &Corrupted |
&Panic | &InvalidPath | &CacheError => write!(fmt, "{}", self.description()),
&StateError(ref msg) => write!(fmt, "{}", msg),
&Other(code, ref msg) => write!(fmt, "{}: {}", code, msg)
}
}
}
impl Error for MdbError {
fn description(&self) -> &'static str {
match self {
&NotFound => "not found",
&KeyExists => "key exists",
&TxnFull => "txn full",
&CursorFull => "cursor full",
&PageFull => "page full",
&Corrupted => "corrupted",
&Panic => "panic",
&InvalidPath => "invalid path for database",
&StateError(_) => "state error",
&CacheError => "db cache error",
&Other(_, _) => "other error",
}
}
}
pub type MdbResult<T> = Result<T, MdbError>;
bitflags! {
#[doc = "A set of environment flags which could be changed after opening"]
flags EnvFlags: c_uint {
#[doc="Don't flush system buffers to disk when committing a
transaction. This optimization means a system crash can
corrupt the database or lose the last transactions if buffers
are not yet flushed to disk. The risk is governed by how
often the system flushes dirty buffers to disk and how often
mdb_env_sync() is called. However, if the filesystem
preserves write order and the MDB_WRITEMAP flag is not used,
transactions exhibit ACI (atomicity, consistency, isolation)
properties and only lose D (durability). I.e. database
integrity is maintained, but a system crash may undo the
final transactions. Note that (MDB_NOSYNC | MDB_WRITEMAP)
leaves the system with no hint for when to write transactions
to disk, unless mdb_env_sync() is called. (MDB_MAPASYNC |
MDB_WRITEMAP) may be preferable. This flag may be changed at
any time using mdb_env_set_flags()."]
const EnvNoSync = ffi::MDB_NOSYNC,
#[doc="Flush system buffers to disk only once per transaction,
omit the metadata flush. Defer that until the system flushes
files to disk, or next non-MDB_RDONLY commit or
mdb_env_sync(). This optimization maintains database
integrity, but a system crash may undo the last committed
transaction. I.e. it preserves the ACI (atomicity,
consistency, isolation) but not D (durability) database
property. This flag may be changed at any time using
mdb_env_set_flags()."]
const EnvNoMetaSync = ffi::MDB_NOMETASYNC,
#[doc="When using MDB_WRITEMAP, use asynchronous flushes to
disk. As with MDB_NOSYNC, a system crash can then corrupt the
database or lose the last transactions. Calling
mdb_env_sync() ensures on-disk database integrity until next
commit. This flag may be changed at any time using
mdb_env_set_flags()."]
const EnvMapAsync = ffi::MDB_MAPASYNC,
#[doc="Don't initialize malloc'd memory before writing to
unused spaces in the data file. By default, memory for pages
written to the data file is obtained using malloc. While
these pages may be reused in subsequent transactions, freshly
malloc'd pages will be initialized to zeroes before use. This
avoids persisting leftover data from other code (that used
the heap and subsequently freed the memory) into the data
file. Note that many other system libraries may allocate and
free memory from the heap for arbitrary uses. E.g., stdio may
use the heap for file I/O buffers. This initialization step
has a modest performance cost so some applications may want
to disable it using this flag. This option can be a problem
for applications which handle sensitive data like passwords,
and it makes memory checkers like Valgrind noisy. This flag
is not needed with MDB_WRITEMAP, which writes directly to the
mmap instead of using malloc for pages. The initialization is
also skipped if MDB_RESERVE is used; the caller is expected
to overwrite all of the memory that was reserved in that
case. This flag may be changed at any time using
mdb_env_set_flags()."]
const EnvNoMemInit = ffi::MDB_NOMEMINIT
}
}
bitflags! {
#[doc = "A set of all environment flags"]
flags EnvCreateFlags: c_uint {
#[doc="Use a fixed address for the mmap region. This flag must be"]
#[doc=" specified when creating the environment, and is stored persistently"]
#[doc=" in the environment. If successful, the memory map will always reside"]
#[doc=" at the same virtual address and pointers used to reference data items"]
#[doc=" in the database will be constant across multiple invocations. This "]
#[doc="option may not always work, depending on how the operating system has"]
#[doc=" allocated memory to shared libraries and other uses. The feature is highly experimental."]
const EnvCreateFixedMap = ffi::MDB_FIXEDMAP,
#[doc="By default, LMDB creates its environment in a directory whose"]
#[doc=" pathname is given in path, and creates its data and lock files"]
#[doc=" under that directory. With this option, path is used as-is"]
#[doc=" for the database main data file. The database lock file is"]
#[doc=" the path with \"-lock\" appended."]
const EnvCreateNoSubDir = ffi::MDB_NOSUBDIR,
#[doc="Don't flush system buffers to disk when committing a"]
#[doc=" transaction. This optimization means a system crash can corrupt"]
#[doc=" the database or lose the last transactions if buffers are not"]
#[doc=" yet flushed to disk. The risk is governed by how often the"]
#[doc=" system flushes dirty buffers to disk and how often"]
#[doc=" mdb_env_sync() is called. However, if the filesystem preserves"]
#[doc=" write order and the MDB_WRITEMAP flag is not used, transactions"]
#[doc=" exhibit ACI (atomicity, consistency, isolation) properties and"]
#[doc=" only lose D (durability). I.e. database integrity is"]
#[doc=" maintained, but a system crash may undo the final"]
#[doc=" transactions. Note that (MDB_NOSYNC | MDB_WRITEMAP) leaves"]
#[doc=" the system with no hint for when to write transactions to"]
#[doc=" disk, unless mdb_env_sync() is called."]
#[doc=" (MDB_MAPASYNC | MDB_WRITEMAP) may be preferable. This flag"]
#[doc=" may be changed at any time using mdb_env_set_flags()."]
const EnvCreateNoSync = ffi::MDB_NOSYNC,
#[doc="Open the environment in read-only mode. No write operations"]
#[doc=" will be allowed. LMDB will still modify the lock file - except"]
#[doc=" on read-only filesystems, where LMDB does not use locks."]
const EnvCreateReadOnly = ffi::MDB_RDONLY,
#[doc="Flush system buffers to disk only once per transaction,"]
#[doc=" omit the metadata flush. Defer that until the system flushes"]
#[doc=" files to disk, or next non-MDB_RDONLY commit or mdb_env_sync()."]
#[doc=" This optimization maintains database integrity, but a system"]
#[doc=" crash may undo the last committed transaction. I.e. it"]
#[doc=" preserves the ACI (atomicity, consistency, isolation) but"]
#[doc=" not D (durability) database property. This flag may be changed"]
#[doc=" at any time using mdb_env_set_flags()."]
const EnvCreateNoMetaSync = ffi::MDB_NOMETASYNC,
#[doc="Use a writeable memory map unless MDB_RDONLY is set. This is"]
#[doc="faster and uses fewer mallocs, but loses protection from"]
#[doc="application bugs like wild pointer writes and other bad updates"]
#[doc="into the database. Incompatible with nested"]
#[doc="transactions. Processes with and without MDB_WRITEMAP on the"]
#[doc="same environment do not cooperate well."]
const EnvCreateWriteMap = ffi::MDB_WRITEMAP,
#[doc="When using MDB_WRITEMAP, use asynchronous flushes to disk. As"]
#[doc="with MDB_NOSYNC, a system crash can then corrupt the database or"]
#[doc="lose the last transactions. Calling mdb_env_sync() ensures"]
#[doc="on-disk database integrity until next commit. This flag may be"]
#[doc="changed at any time using mdb_env_set_flags()."]
const EnvCreataMapAsync = ffi::MDB_MAPASYNC,
#[doc="Don't use Thread-Local Storage. Tie reader locktable slots to"]
#[doc="ffi::MDB_txn objects instead of to threads. I.e. mdb_txn_reset()"]
#[doc="keeps the slot reseved for the ffi::MDB_txn object. A thread may"]
#[doc="use parallel read-only transactions. A read-only transaction may"]
#[doc="span threads if the user synchronizes its use. Applications that"]
#[doc="multiplex many user threads over individual OS threads need this"]
#[doc="option. Such an application must also serialize the write"]
#[doc="transactions in an OS thread, since LMDB's write locking is"]
#[doc="unaware of the user threads."]
const EnvCreateNoTls = ffi::MDB_NOTLS,
#[doc="Don't do any locking. If concurrent access is anticipated, the"]
#[doc="caller must manage all concurrency itself. For proper operation"]
#[doc="the caller must enforce single-writer semantics, and must ensure"]
#[doc="that no readers are using old transactions while a writer is"]
#[doc="active. The simplest approach is to use an exclusive lock so"]
#[doc="that no readers may be active at all when a writer begins. "]
const EnvCreateNoLock = ffi::MDB_NOLOCK,
#[doc="Turn off readahead. Most operating systems perform readahead on"]
#[doc="read requests by default. This option turns it off if the OS"]
#[doc="supports it. Turning it off may help random read performance"]
#[doc="when the DB is larger than RAM and system RAM is full. The"]
#[doc="option is not implemented on Windows."]
const EnvCreateNoReadAhead = ffi::MDB_NORDAHEAD,
#[doc="Don't initialize malloc'd memory before writing to unused spaces"]
#[doc="in the data file. By default, memory for pages written to the"]
#[doc="data file is obtained using malloc. While these pages may be"]
#[doc="reused in subsequent transactions, freshly malloc'd pages will"]
#[doc="be initialized to zeroes before use. This avoids persisting"]
#[doc="leftover data from other code (that used the heap and"]
#[doc="subsequently freed the memory) into the data file. Note that"]
#[doc="many other system libraries may allocate and free memory from"]
#[doc="the heap for arbitrary uses. E.g., stdio may use the heap for"]
#[doc="file I/O buffers. This initialization step has a modest"]
#[doc="performance cost so some applications may want to disable it"]
#[doc="using this flag. This option can be a problem for applications"]
#[doc="which handle sensitive data like passwords, and it makes memory"]
#[doc="checkers like Valgrind noisy. This flag is not needed with"]
#[doc="MDB_WRITEMAP, which writes directly to the mmap instead of using"]
#[doc="malloc for pages. The initialization is also skipped if"]
#[doc="MDB_RESERVE is used; the caller is expected to overwrite all of"]
#[doc="the memory that was reserved in that case. This flag may be"]
#[doc="changed at any time using mdb_env_set_flags()."]
const EnvCreateNoMemInit = ffi::MDB_NOMEMINIT
}
}
bitflags! {
#[doc = "A set of database flags"]
flags DbFlags: c_uint {
#[doc="Keys are strings to be compared in reverse order, from the"]
#[doc=" end of the strings to the beginning. By default, Keys are"]
#[doc=" treated as strings and compared from beginning to end."]
const DbReverseKey = ffi::MDB_REVERSEKEY,
#[doc="Duplicate keys may be used in the database. (Or, from another"]
#[doc="perspective, keys may have multiple data items, stored in sorted"]
#[doc="order.) By default keys must be unique and may have only a"]
#[doc="single data item."]
const DbAllowDups = ffi::MDB_DUPSORT,
#[doc="Keys are binary integers in native byte order. Setting this"]
#[doc="option requires all keys to be the same size, typically"]
#[doc="sizeof(int) or sizeof(size_t)."]
const DbIntKey = ffi::MDB_INTEGERKEY,
#[doc="This flag may only be used in combination with"]
#[doc="ffi::MDB_DUPSORT. This option tells the library that the data"]
#[doc="items for this database are all the same size, which allows"]
#[doc="further optimizations in storage and retrieval. When all data"]
#[doc="items are the same size, the ffi::MDB_GET_MULTIPLE and"]
#[doc="ffi::MDB_NEXT_MULTIPLE cursor operations may be used to retrieve"]
#[doc="multiple items at once."]
const DbDupFixed = ffi::MDB_DUPFIXED,
#[doc="This option specifies that duplicate data items are also"]
#[doc="integers, and should be sorted as such."]
const DbAllowIntDups = ffi::MDB_INTEGERDUP,
#[doc="This option specifies that duplicate data items should be"]
#[doc=" compared as strings in reverse order."]
const DbReversedDups = ffi::MDB_REVERSEDUP,
#[doc="Create the named database if it doesn't exist. This option"]
#[doc=" is not allowed in a read-only transaction or a read-only"]
#[doc=" environment."]
const DbCreate = ffi::MDB_CREATE,
}
}
/// Database
pub struct Database<'a> {
handle: ffi::MDB_dbi,
txn: &'a NativeTransaction<'a>,
}
// FIXME: provide different interfaces for read-only/read-write databases
// FIXME: provide different interfaces for simple KV and storage with duplicates
impl<'a> Database<'a> {
fn new_with_handle(handle: ffi::MDB_dbi, txn: &'a NativeTransaction<'a>) -> Database<'a> {
Database { handle: handle, txn: txn }
}
/// Retrieves current db's statistics.
pub fn stat(&'a self) -> MdbResult<ffi::MDB_stat> {
self.txn.stat(self.handle)
}
/// Retrieves a value by key. In case of DbAllowDups it will be the first value
pub fn get<V: FromMdbValue + 'a>(&'a self, key: &ToMdbValue) -> MdbResult<V> {
self.txn.get(self.handle, key)
}
/// Sets value for key. In case of DbAllowDups it will add a new item
pub fn set(&self, key: &ToMdbValue, value: &ToMdbValue) -> MdbResult<()> {
self.txn.set(self.handle, key, value)
}
/// Appends new key-value pair to database, starting a new page instead of splitting an
/// existing one if necessary. Requires that key be >= all existing keys in the database
/// (or will return KeyExists error).
pub fn append<K: ToMdbValue, V: ToMdbValue>(&self, key: &K, value: &V) -> MdbResult<()> {
self.txn.append(self.handle, key, value)
}
/// Appends new value for the given key (requires DbAllowDups), starting a new page instead
/// of splitting an existing one if necessary. Requires that value be >= all existing values
/// for the given key (or will return KeyExists error).
pub fn append_duplicate<K: ToMdbValue, V: ToMdbValue>(&self, key: &K, value: &V) -> MdbResult<()> {
self.txn.append_duplicate(self.handle, key, value)
}
/// Set value for key. Fails if key already exists, even when duplicates are allowed.
pub fn insert(&self, key: &ToMdbValue, value: &ToMdbValue) -> MdbResult<()> {
self.txn.insert(self.handle, key, value)
}
/// Deletes value for key.
pub fn del(&self, key: &ToMdbValue) -> MdbResult<()> {
self.txn.del(self.handle, key)
}
/// Should be used only with DbAllowDups. Deletes corresponding (key, value)
pub fn del_item(&self, key: &ToMdbValue, data: &ToMdbValue) -> MdbResult<()> {
self.txn.del_item(self.handle, key, data)
}
/// Returns a new cursor
pub fn new_cursor(&'a self) -> MdbResult<Cursor<'a>> {
self.txn.new_cursor(self.handle)
}
/// Deletes current db, also moves it out
pub fn del_db(self) -> MdbResult<()> {
self.txn.del_db(self)
}
/// Removes all key/values from db
pub fn clear(&self) -> MdbResult<()> {
self.txn.clear_db(self.handle)
}
/// Returns an iterator for all values in database
pub fn iter(&'a self) -> MdbResult<CursorIterator<'a, CursorIter>> {
self.txn.new_cursor(self.handle)
.and_then(|c| Ok(CursorIterator::wrap(c, CursorIter)))
}
/// Returns an iterator through keys starting with start_key (>=), start_key is included
pub fn keyrange_from<'c, K: ToMdbValue + 'c>(&'c self, start_key: &'c K) -> MdbResult<CursorIterator<'c, CursorFromKeyIter>> {
let cursor = try!(self.txn.new_cursor(self.handle));
let key_range = CursorFromKeyIter::new(start_key);
let wrap = CursorIterator::wrap(cursor, key_range);
Ok(wrap)
}
/// Returns an iterator through keys less than end_key, end_key is not included
pub fn keyrange_to<'c, K: ToMdbValue + 'c>(&'c self, end_key: &'c K) -> MdbResult<CursorIterator<'c, CursorToKeyIter>> {
let cursor = try!(self.txn.new_cursor(self.handle));
let key_range = CursorToKeyIter::new(end_key);
let wrap = CursorIterator::wrap(cursor, key_range);
Ok(wrap)
}
/// Returns an iterator through keys `start_key <= x < end_key`. This is, start_key is
/// included in the iteration, while end_key is kept excluded.
pub fn keyrange_from_to<'c, K: ToMdbValue + 'c>(&'c self, start_key: &'c K, end_key: &'c K)
-> MdbResult<CursorIterator<'c, CursorKeyRangeIter>>
{
let cursor = try!(self.txn.new_cursor(self.handle));
let key_range = CursorKeyRangeIter::new(start_key, end_key, false);
let wrap = CursorIterator::wrap(cursor, key_range);
Ok(wrap)
}
/// Returns an iterator for values between start_key and end_key (included).
/// Currently it works only for unique keys (i.e. it will skip
/// multiple items when DB created with ffi::MDB_DUPSORT).
/// Iterator is valid while cursor is valid
pub fn keyrange<'c, K: ToMdbValue + 'c>(&'c self, start_key: &'c K, end_key: &'c K)
-> MdbResult<CursorIterator<'c, CursorKeyRangeIter>>
{
let cursor = try!(self.txn.new_cursor(self.handle));
let key_range = CursorKeyRangeIter::new(start_key, end_key, true);
let wrap = CursorIterator::wrap(cursor, key_range);
Ok(wrap)
}
/// Returns an iterator for all items (i.e. values with same key)
pub fn item_iter<'c, 'db: 'c, K: ToMdbValue>(&'db self, key: &'c K) -> MdbResult<CursorIterator<'c, CursorItemIter<'c>>> {
let cursor = try!(self.txn.new_cursor(self.handle));
let inner_iter = CursorItemIter::<'c>::new(key);
Ok(CursorIterator::<'c>::wrap(cursor, inner_iter))
}
/// Sets the key compare function for this database.
///
/// Warning: This function must be called before any data access functions
/// are used, otherwise data corruption may occur. The same comparison
/// function must be used by every program accessing the database, every
/// time the database is used.
///
/// If not called, keys are compared lexically, with shorter keys collating
/// before longer keys.
///
/// Setting lasts for the lifetime of the underlying db handle.
pub fn set_compare(&self, cmp_fn: extern "C" fn(*const MDB_val, *const MDB_val) -> c_int) -> MdbResult<()> {
lift_mdb!(unsafe {
ffi::mdb_set_compare(self.txn.handle, self.handle, cmp_fn)
})
}
/// Sets the value comparison function for values of the same key in this database.
///
/// Warning: This function must be called before any data access functions
/// are used, otherwise data corruption may occur. The same dupsort
/// function must be used by every program accessing the database, every
/// time the database is used.
///
/// If not called, values are compared lexically, with shorter values collating
/// before longer values.
///
/// Only used when DbAllowDups is true.
/// Setting lasts for the lifetime of the underlying db handle.
pub fn set_dupsort(&self, cmp_fn: extern "C" fn(*const MDB_val, *const MDB_val) -> c_int) -> MdbResult<()> {
lift_mdb!(unsafe {
ffi::mdb_set_dupsort(self.txn.handle, self.handle, cmp_fn)
})
}
}
/// Constructs environment with settigs which couldn't be
/// changed after opening. By default it tries to create
/// corresponding dir if it doesn't exist, use `autocreate_dir()`
/// to override that behavior
#[derive(Copy, Clone)]
pub struct EnvBuilder {
flags: EnvCreateFlags,
max_readers: Option<usize>,
max_dbs: Option<usize>,
map_size: Option<u64>,
autocreate_dir: bool,
}
impl EnvBuilder {
pub fn new() -> EnvBuilder {
EnvBuilder {
flags: EnvCreateFlags::empty(),
max_readers: None,
max_dbs: None,
map_size: None,
autocreate_dir: true,
}
}
/// Sets environment flags
pub fn flags(mut self, flags: EnvCreateFlags) -> EnvBuilder {
self.flags = flags;
self
}
/// Sets max concurrent readers operating on environment
pub fn max_readers(mut self, max_readers: usize) -> EnvBuilder {
self.max_readers = Some(max_readers);
self
}
/// Set max number of databases
pub fn max_dbs(mut self, max_dbs: usize) -> EnvBuilder {
self.max_dbs = Some(max_dbs);
self
}
/// Sets max environment size, i.e. size in memory/disk of
/// all data
pub fn map_size(mut self, map_size: u64) -> EnvBuilder {
self.map_size = Some(map_size);
self
}
/// Sets whetever `lmdb-rs` should try to autocreate dir with default
/// permissions on opening (default is true)
pub fn autocreate_dir(mut self, autocreate_dir: bool) -> EnvBuilder {
self.autocreate_dir = autocreate_dir;
self
}
/// Opens environment in specified path
pub fn open(self, path: &Path, perms: u32) -> MdbResult<Environment> {
let changeable_flags: EnvCreateFlags = EnvCreataMapAsync | EnvCreateNoMemInit | EnvCreateNoSync | EnvCreateNoMetaSync;
let env: *mut ffi::MDB_env = ptr::null_mut();
unsafe {
let p_env: *mut *mut ffi::MDB_env = std::mem::transmute(&env);
let _ = try_mdb!(ffi::mdb_env_create(p_env));
}
// Enable only flags which can be changed, otherwise it'll fail
try_mdb!(unsafe { ffi::mdb_env_set_flags(env, self.flags.bits() & changeable_flags.bits(), 1)});
if let Some(map_size) = self.map_size {
try_mdb!(unsafe { ffi::mdb_env_set_mapsize(env, map_size as size_t)});
}
if let Some(max_readers) = self.max_readers {
try_mdb!(unsafe { ffi::mdb_env_set_maxreaders(env, max_readers as u32)});
}
if let Some(max_dbs) = self.max_dbs {
try_mdb!(unsafe { ffi::mdb_env_set_maxdbs(env, max_dbs as u32)});
}
if self.autocreate_dir {
let _ = try!(EnvBuilder::check_path(path, self.flags));
}
let is_readonly = self.flags.contains(EnvCreateReadOnly);
let res = unsafe {
// FIXME: revert back once `convert` is stable
// let c_path = path.as_os_str().to_cstring().unwrap();
let path_str = try!(path.to_str().ok_or(MdbError::InvalidPath));
let c_path = try!(CString::new(path_str).map_err(|_| MdbError::InvalidPath));
ffi::mdb_env_open(mem::transmute(env), c_path.as_ptr(), self.flags.bits(),
perms as libc::mode_t)
};
drop(self);
match res {
ffi::MDB_SUCCESS => {
Ok(Environment::from_raw(env, is_readonly))
},
_ => {
unsafe { ffi::mdb_env_close(mem::transmute(env)); }
Err(MdbError::new_with_code(res))
}
}
}
fn check_path(path: &Path, flags: EnvCreateFlags) -> MdbResult<()> {
use std::{fs, io};
if flags.contains(EnvCreateNoSubDir) {
// FIXME: check parent dir existence/absence
warn!("checking for path in NoSubDir mode isn't implemented yet");
return Ok(());
}
// There should be a directory before open
match fs::metadata(path) {
Ok(meta) => {
if meta.is_dir() {
Ok(())
} else {
Err(MdbError::InvalidPath)
}
},
Err(e) => {
if e.kind() == io::ErrorKind::NotFound {
fs::create_dir_all(path.clone()).map_err(|e| {
error!("failed to auto create dir: {}", e);
MdbError::InvalidPath
})
} else {
Err(MdbError::InvalidPath)
}
}
}
}
}
struct EnvHandle(*mut ffi::MDB_env);
impl Drop for EnvHandle {
fn drop(&mut self) {
unsafe {
if self.0 != ptr::null_mut() {
ffi::mdb_env_close(self.0);
}
}
}
}
/// Represents LMDB Environment. Should be opened using `EnvBuilder`
pub struct Environment {
env: Arc<EnvHandle>,
db_cache: Arc<Mutex<UnsafeCell<HashMap<String, ffi::MDB_dbi>>>>,
is_readonly: bool, // true if opened in 'read-only' mode
}
impl Environment {
pub fn new() -> EnvBuilder {
EnvBuilder::new()
}
fn from_raw(env: *mut ffi::MDB_env, is_readonly: bool) -> Environment {
Environment {
env: Arc::new(EnvHandle(env)),
db_cache: Arc::new(Mutex::new(UnsafeCell::new(HashMap::new()))),
is_readonly: is_readonly,
}
}
/// Check for stale entries in the reader lock table.
///
/// Returns the number of stale slots that were cleared.
pub fn reader_check(&self) -> MdbResult<c_int> {
let mut dead: c_int = 0;
lift_mdb!(unsafe { ffi::mdb_reader_check(self.env.0, &mut dead as *mut c_int)}, dead)
}
/// Retrieve environment statistics
pub fn stat(&self) -> MdbResult<ffi::MDB_stat> {
let mut tmp: ffi::MDB_stat = unsafe { std::mem::zeroed() };
lift_mdb!(unsafe { ffi::mdb_env_stat(self.env.0, &mut tmp)}, tmp)
}
pub fn info(&self) -> MdbResult<ffi::MDB_envinfo> {
let mut tmp: ffi::MDB_envinfo = unsafe { std::mem::zeroed() };
lift_mdb!(unsafe { ffi::mdb_env_info(self.env.0, &mut tmp)}, tmp)
}
/// Sync environment to disk
pub fn sync(&self, force: bool) -> MdbResult<()> {
lift_mdb!(unsafe { ffi::mdb_env_sync(self.env.0, if force {1} else {0})})
}
/// This one sets only flags which are available for change even
/// after opening, see also [get_flags](#method.get_flags) and [get_all_flags](#method.get_all_flags)
pub fn set_flags(&mut self, flags: EnvFlags, turn_on: bool) -> MdbResult<()> {
lift_mdb!(unsafe {
ffi::mdb_env_set_flags(self.env.0, flags.bits(), if turn_on {1} else {0})
})
}
/// Get flags of environment, which could be changed after it was opened
/// use [get_all_flags](#method.get_all_flags) if you need also creation time flags
pub fn get_flags(&self) -> MdbResult<EnvFlags> {
let tmp = try!(self.get_all_flags());
Ok(EnvFlags::from_bits_truncate(tmp.bits()))
}
/// Get all flags of environment, including which were specified on creation
/// See also [get_flags](#method.get_flags) if you're interested only in modifiable flags
pub fn get_all_flags(&self) -> MdbResult<EnvCreateFlags> {
let mut flags: c_uint = 0;
lift_mdb!(unsafe {ffi::mdb_env_get_flags(self.env.0, &mut flags)}, EnvCreateFlags::from_bits_truncate(flags))
}
pub fn get_maxreaders(&self) -> MdbResult<c_uint> {
let mut max_readers: c_uint = 0;
lift_mdb!(unsafe {
ffi::mdb_env_get_maxreaders(self.env.0, &mut max_readers)
}, max_readers)
}
pub fn get_maxkeysize(&self) -> c_int {
unsafe {ffi::mdb_env_get_maxkeysize(self.env.0)}
}
/// Creates a backup copy in specified file descriptor
pub fn copy_to_fd(&self, fd: ffi::mdb_filehandle_t) -> MdbResult<()> {
lift_mdb!(unsafe { ffi::mdb_env_copyfd(self.env.0, fd) })
}
/// Gets file descriptor of this environment
pub fn get_fd(&self) -> MdbResult<ffi::mdb_filehandle_t> {
let mut fd = 0;
lift_mdb!({ unsafe { ffi::mdb_env_get_fd(self.env.0, &mut fd) }}, fd)
}
/// Creates a backup copy in specified path
// FIXME: check who is responsible for creating path: callee or caller
pub fn copy_to_path(&self, path: &Path) -> MdbResult<()> {
// FIXME: revert back once `convert` is stable
// let c_path = path.as_os_str().to_cstring().unwrap();
let path_str = try!(path.to_str().ok_or(MdbError::InvalidPath));
let c_path = try!(CString::new(path_str).map_err(|_| MdbError::InvalidPath));
unsafe {
lift_mdb!(ffi::mdb_env_copy(self.env.0, c_path.as_ptr()))
}
}
fn create_transaction(&self, parent: Option<NativeTransaction>, flags: c_uint) -> MdbResult<NativeTransaction> {
let mut handle: *mut ffi::MDB_txn = ptr::null_mut();
let parent_handle = match parent {
Some(t) => t.handle,
_ => ptr::null_mut()
};
lift_mdb!(unsafe { ffi::mdb_txn_begin(self.env.0, parent_handle, flags, &mut handle) },
NativeTransaction::new_with_handle(handle, flags as usize, self))
}
/// Creates a new read-write transaction
///
/// Use `get_reader` to get much faster lock-free alternative
pub fn new_transaction(&self) -> MdbResult<Transaction> {
if self.is_readonly {
return Err(MdbError::StateError("Error: creating read-write transaction in read-only environment".to_owned()))
}
self.create_transaction(None, 0)
.and_then(|txn| Ok(Transaction::new_with_native(txn)))
}
/// Creates a readonly transaction
pub fn get_reader(&self) -> MdbResult<ReadonlyTransaction> {
self.create_transaction(None, ffi::MDB_RDONLY)
.and_then(|txn| Ok(ReadonlyTransaction::new_with_native(txn)))
}
fn _open_db(&self, db_name: & str, flags: DbFlags, force_creation: bool) -> MdbResult<ffi::MDB_dbi> {
debug!("Opening {} (create={}, read_only={})", db_name, force_creation, self.is_readonly);
// From LMDB docs for mdb_dbi_open:
//
// This function must not be called from multiple concurrent
// transactions. A transaction that uses this function must finish
// (either commit or abort) before any other transaction may use
// this function
match self.db_cache.lock() {
Err(_) => Err(MdbError::CacheError),
Ok(guard) => {
let ref cell = *guard;
let cache = cell.get();
unsafe {
if let Some(db) = (*cache).get(db_name) {
debug!("Cached value for {}: {}", db_name, *db);
return Ok(*db);
}
}
let mut txn = {
let txflags = if self.is_readonly { ffi::MDB_RDONLY } else { 0 };
try!(self.create_transaction(None, txflags))
};
let opt_name = if db_name.len() > 0 {Some(db_name)} else {None};
let flags = if force_creation {flags | DbCreate} else {flags - DbCreate};
let mut db: ffi::MDB_dbi = 0;
let db_res = match opt_name {
None => unsafe { ffi::mdb_dbi_open(txn.handle, ptr::null(), flags.bits(), &mut db) },
Some(db_name) => {
let db_name = CString::new(db_name.as_bytes()).unwrap();
unsafe {
ffi::mdb_dbi_open(txn.handle, db_name.as_ptr(), flags.bits(), &mut db)
}
}
};
try_mdb!(db_res);
try!(txn.commit());
debug!("Caching: {} -> {}", db_name, db);
unsafe {
(*cache).insert(db_name.to_owned(), db);
};
Ok(db)
}
}
}
/// Opens existing DB
pub fn get_db(& self, db_name: &str, flags: DbFlags) -> MdbResult<DbHandle> {
let db = try!(self._open_db(db_name, flags, false));
Ok(DbHandle {handle: db, flags: flags})
}
/// Opens or creates a DB
pub fn create_db(&self, db_name: &str, flags: DbFlags) -> MdbResult<DbHandle> {
let db = try!(self._open_db(db_name, flags, true));
Ok(DbHandle {handle: db, flags: flags})
}
/// Opens default DB with specified flags
pub fn get_default_db(&self, flags: DbFlags) -> MdbResult<DbHandle> {
self.get_db("", flags)
}
fn drop_db_from_cache(&self, handle: ffi::MDB_dbi) {
match self.db_cache.lock() {
Err(_) => (),
Ok(guard) => {
let ref cell = *guard;
unsafe {
let cache = cell.get();
let mut key = None;
for (k, v) in (*cache).iter() {
if *v == handle {
key = Some(k);
break;
}
}
if let Some(key) = key {
(*cache).remove(key);
}
}
}
}
}
}
unsafe impl Sync for Environment {}
unsafe impl Send for Environment {}
impl Clone for Environment {
fn clone(&self) -> Environment {
Environment {
env: self.env.clone(),
db_cache: self.db_cache.clone(),
is_readonly: self.is_readonly,
}
}
}
#[allow(dead_code)]
#[derive(Copy, Clone)]
/// A handle to a database
///
/// It can be cached to avoid opening db on every access
/// In the current state it is unsafe as other thread
/// can ask to drop it.
pub struct DbHandle {
handle: ffi::MDB_dbi,
flags: DbFlags
}
unsafe impl Sync for DbHandle {}
unsafe impl Send for DbHandle {}
#[derive(Copy, PartialEq, Debug, Eq, Clone)]
enum TransactionState {
Normal, // Normal, any operation possible
Released, // Released (reset on readonly), has to be renewed
Invalid, // Invalid, no further operation possible
}
struct NativeTransaction<'a> {
handle: *mut ffi::MDB_txn,
env: &'a Environment,
flags: usize,
state: TransactionState,
}
impl<'a> NativeTransaction<'a> {
fn new_with_handle(h: *mut ffi::MDB_txn, flags: usize, env: &Environment) -> NativeTransaction {
// debug!("new native txn");
NativeTransaction {
handle: h,
flags: flags,
state: TransactionState::Normal,
env: env,
}
}
fn is_readonly(&self) -> bool {
(self.flags as u32 & ffi::MDB_RDONLY) == ffi::MDB_RDONLY
}
fn commit(&mut self) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
debug!("commit txn");
try_mdb!(unsafe { ffi::mdb_txn_commit(self.handle) } );
self.state = if self.is_readonly() {
TransactionState::Released
} else {
TransactionState::Invalid
};
Ok(())
}
fn abort(&mut self) {
if self.state != TransactionState::Normal {
debug!("Can't abort transaction: current state {:?}", self.state)
} else {
debug!("abort txn");
unsafe { ffi::mdb_txn_abort(self.handle); }
self.state = if self.is_readonly() {
TransactionState::Released
} else {
TransactionState::Invalid
};
}
}
/// Resets read only transaction, handle is kept. Must be followed
/// by a call to `renew`
fn reset(&mut self) {
if self.state != TransactionState::Normal {
debug!("Can't reset transaction: current state {:?}", self.state);
} else {
unsafe { ffi::mdb_txn_reset(self.handle); }
self.state = TransactionState::Released;
}
}
/// Acquires a new reader lock after it was released by reset
fn renew(&mut self) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Released);
try_mdb!(unsafe {ffi::mdb_txn_renew(self.handle)});
self.state = TransactionState::Normal;
Ok(())
}
fn new_child(&self, flags: c_uint) -> MdbResult<NativeTransaction> {
let mut out: *mut ffi::MDB_txn = ptr::null_mut();
try_mdb!(unsafe { ffi::mdb_txn_begin(ffi::mdb_txn_env(self.handle), self.handle, flags, &mut out) });
Ok(NativeTransaction::new_with_handle(out, flags as usize, self.env))
}
/// Used in Drop to switch state
fn silent_abort(&mut self) {
if self.state == TransactionState::Normal {
debug!("silent abort");
unsafe {ffi::mdb_txn_abort(self.handle);}
self.state = TransactionState::Invalid;
}
}
fn get_value<V: FromMdbValue + 'a>(&'a self, db: ffi::MDB_dbi, key: &ToMdbValue) -> MdbResult<V> {
let mut key_val = key.to_mdb_value();
unsafe {
let mut data_val: MdbValue = std::mem::zeroed();
try_mdb!(ffi::mdb_get(self.handle, db, &mut key_val.value, &mut data_val.value));
Ok(FromMdbValue::from_mdb_value(&data_val))
}
}
fn get<V: FromMdbValue + 'a>(&'a self, db: ffi::MDB_dbi, key: &ToMdbValue) -> MdbResult<V> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
self.get_value(db, key)
}
fn set_value(&self, db: ffi::MDB_dbi, key: &ToMdbValue, value: &ToMdbValue) -> MdbResult<()> {
self.set_value_with_flags(db, key, value, 0)
}
fn set_value_with_flags(&self, db: ffi::MDB_dbi, key: &ToMdbValue, value: &ToMdbValue, flags: c_uint) -> MdbResult<()> {
unsafe {
let mut key_val = key.to_mdb_value();
let mut data_val = value.to_mdb_value();
lift_mdb!(ffi::mdb_put(self.handle, db, &mut key_val.value, &mut data_val.value, flags))
}
}
/// Sets a new value for key, in case of enabled duplicates
/// it actually appends a new value
// FIXME: think about creating explicit separation of
// all traits for databases with dup keys
fn set(&self, db: ffi::MDB_dbi, key: &ToMdbValue, value: &ToMdbValue) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
self.set_value(db, key, value)
}
fn append(&self, db: ffi::MDB_dbi, key: &ToMdbValue, value: &ToMdbValue) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
self.set_value_with_flags(db, key, value, ffi::MDB_APPEND)
}
fn append_duplicate(&self, db: ffi::MDB_dbi, key: &ToMdbValue, value: &ToMdbValue) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
self.set_value_with_flags(db, key, value, ffi::MDB_APPENDDUP)
}
/// Set the value for key only if the key does not exist in the database,
/// even if the database supports duplicates.
fn insert(&self, db: ffi::MDB_dbi, key: &ToMdbValue, value: &ToMdbValue) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
self.set_value_with_flags(db, key, value, ffi::MDB_NOOVERWRITE)
}
/// Deletes all values by key
fn del_value(&self, db: ffi::MDB_dbi, key: &ToMdbValue) -> MdbResult<()> {
unsafe {
let mut key_val = key.to_mdb_value();
lift_mdb!(ffi::mdb_del(self.handle, db, &mut key_val.value, ptr::null_mut()))
}
}
/// If duplicate keys are allowed deletes value for key which is equal to data
fn del_item(&self, db: ffi::MDB_dbi, key: &ToMdbValue, data: &ToMdbValue) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
unsafe {
let mut key_val = key.to_mdb_value();
let mut data_val = data.to_mdb_value();
lift_mdb!(ffi::mdb_del(self.handle, db, &mut key_val.value, &mut data_val.value))
}
}
/// Deletes all values for key
fn del(&self, db: ffi::MDB_dbi, key: &ToMdbValue) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
self.del_value(db, key)
}
/// Creates a new cursor in current transaction tied to db
fn new_cursor(&'a self, db: ffi::MDB_dbi) -> MdbResult<Cursor<'a>> {
Cursor::new(self, db)
}
/// Deletes provided database completely
fn del_db(&self, db: Database) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
unsafe {
self.env.drop_db_from_cache(db.handle);
lift_mdb!(ffi::mdb_drop(self.handle, db.handle, 1))
}
}
/// Empties provided database
fn clear_db(&self, db: ffi::MDB_dbi) -> MdbResult<()> {
assert_state_eq!(txn, self.state, TransactionState::Normal);
unsafe {
lift_mdb!(ffi::mdb_drop(self.handle, db, 0))
}
}
/// Retrieves provided database's statistics
fn stat(&self, db: ffi::MDB_dbi) -> MdbResult<ffi::MDB_stat> {
let mut tmp: ffi::MDB_stat = unsafe { std::mem::zeroed() };
lift_mdb!(unsafe { ffi::mdb_stat(self.handle, db, &mut tmp)}, tmp)
}
/*
fn get_db(&self, name: &str, flags: DbFlags) -> MdbResult<Database> {
self.env.get_db(name, flags)
.and_then(|db| Ok(Database::new_with_handle(db.handle, self)))
}
*/
/*
fn get_or_create_db(&self, name: &str, flags: DbFlags) -> MdbResult<Database> {
self.get_db(name, flags | DbCreate)
}
*/
}
impl<'a> Drop for NativeTransaction<'a> {
fn drop(&mut self) {
//debug!("Dropping native transaction!");
self.silent_abort();
}
}
pub struct Transaction<'a> {
inner: NativeTransaction<'a>,
}
impl<'a> Transaction<'a> {
fn new_with_native(txn: NativeTransaction<'a>) -> Transaction<'a> {
Transaction {
inner: txn
}
}
pub fn new_child(&self) -> MdbResult<Transaction> {
self.inner.new_child(0)
.and_then(|txn| Ok(Transaction::new_with_native(txn)))
}
pub fn new_ro_child(&self) -> MdbResult<ReadonlyTransaction> {
self.inner.new_child(ffi::MDB_RDONLY)
.and_then(|txn| Ok(ReadonlyTransaction::new_with_native(txn)))
}
/// Commits transaction, moves it out
pub fn commit(self) -> MdbResult<()> {
//self.inner.commit()
let mut t = self;
t.inner.commit()
}
/// Aborts transaction, moves it out
pub fn abort(self) {
let mut t = self;
t.inner.abort();
}
pub fn bind(&self, db_handle: &DbHandle) -> Database {
Database::new_with_handle(db_handle.handle, &self.inner)
}
}
pub struct ReadonlyTransaction<'a> {
inner: NativeTransaction<'a>,
}
impl<'a> ReadonlyTransaction<'a> {
fn new_with_native(txn: NativeTransaction<'a>) -> ReadonlyTransaction<'a> {
ReadonlyTransaction {
inner: txn,
}
}
pub fn new_ro_child(&self) -> MdbResult<ReadonlyTransaction> {
self.inner.new_child(ffi::MDB_RDONLY)
.and_then(|txn| Ok(ReadonlyTransaction::new_with_native(txn)))
}
/// Aborts transaction. But readonly transaction could be
/// reused later by calling `renew`
pub fn abort(&mut self) {
self.inner.abort();
}
/// Resets read only transaction, handle is kept. Must be followed
/// by call to `renew`
pub fn reset(&mut self) {
self.inner.reset();
}
/// Acquires a new reader lock after transaction
/// `abort` or `reset`
pub fn renew(&mut self) -> MdbResult<()> {
self.inner.renew()
}
pub fn bind(&self, db_handle: &DbHandle) -> Database {
Database::new_with_handle(db_handle.handle, &self.inner)
}
}
/// Helper to determine the property of "less than or equal to" where
/// the "equal to" part is to be specified at runtime.
trait IsLess {
fn is_less(&self, or_equal: bool) -> bool;
}
impl IsLess for Ordering {
fn is_less(&self, or_equal: bool) -> bool {
match (*self, or_equal) {
(Ordering::Less, _) => true,
(Ordering::Equal, true) => true,
_ => false,
}
}
}
impl IsLess for MdbResult<Ordering> {
fn is_less(&self, or_equal: bool) -> bool {
match *self {
Ok(ord) => ord.is_less(or_equal),
Err(_) => false,
}
}
}
pub struct Cursor<'txn> {
handle: *mut ffi::MDB_cursor,
data_val: ffi::MDB_val,
key_val: ffi::MDB_val,
txn: &'txn NativeTransaction<'txn>,
db: ffi::MDB_dbi,
valid_key: bool,
}
impl<'txn> Cursor<'txn> {
fn new(txn: &'txn NativeTransaction, db: ffi::MDB_dbi) -> MdbResult<Cursor<'txn>> {
debug!("Opening cursor in {}", db);
let mut tmp: *mut ffi::MDB_cursor = std::ptr::null_mut();
try_mdb!(unsafe { ffi::mdb_cursor_open(txn.handle, db, &mut tmp) });
Ok(Cursor {
handle: tmp,
data_val: unsafe { std::mem::zeroed() },
key_val: unsafe { std::mem::zeroed() },
txn: txn,
db: db,
valid_key: false,
})
}
fn navigate(&mut self, op: ffi::MDB_cursor_op) -> MdbResult<()> {
self.valid_key = false;
let res = unsafe {
ffi::mdb_cursor_get(self.handle, &mut self.key_val, &mut self.data_val, op)
};
match res {
ffi::MDB_SUCCESS => {
// MDB_SET is the only cursor operation which doesn't
// writes back a new value. In this case any access to
// cursor key value should cause a cursor retrieval
// to get back pointer to database owned memory instead
// of value used to set the cursor as it might be
// already destroyed and there is no need to borrow it
self.valid_key = op != ffi::MDB_cursor_op::MDB_SET;
Ok(())
},
e => Err(MdbError::new_with_code(e))
}
}
fn move_to<K, V>(&mut self, key: &K, value: Option<&V>, op: ffi::MDB_cursor_op) -> MdbResult<()>
where K: ToMdbValue, V: ToMdbValue {
self.key_val = key.to_mdb_value().value;
self.data_val = match value {
Some(v) => v.to_mdb_value().value,
_ => unsafe {std::mem::zeroed() }
};
self.navigate(op)
}
/// Moves cursor to first entry
pub fn to_first(&mut self) -> MdbResult<()> {
self.navigate(ffi::MDB_cursor_op::MDB_FIRST)
}
/// Moves cursor to last entry
pub fn to_last(&mut self) -> MdbResult<()> {
self.navigate(ffi::MDB_cursor_op::MDB_LAST)
}
/// Moves cursor to first entry for key if it exists
pub fn to_key<'k, K: ToMdbValue>(&mut self, key: &'k K) -> MdbResult<()> {
self.move_to(key, None::<&MdbValue<'k>>, ffi::MDB_cursor_op::MDB_SET_KEY)
}
/// Moves cursor to first entry for key greater than
/// or equal to ke
pub fn to_gte_key<'k, K: ToMdbValue>(&mut self, key: &'k K) -> MdbResult<()> {
self.move_to(key, None::<&MdbValue<'k>>, ffi::MDB_cursor_op::MDB_SET_RANGE)
}
/// Moves cursor to specific item (for example, if cursor
/// already points to a correct key and you need to delete
/// a specific item through cursor)
pub fn to_item<K, V>(&mut self, key: &K, value: & V) -> MdbResult<()> where K: ToMdbValue, V: ToMdbValue {
self.move_to(key, Some(value), ffi::MDB_cursor_op::MDB_GET_BOTH)
}
/// Moves cursor to next key, i.e. skip items
/// with duplicate keys
pub fn to_next_key(&mut self) -> MdbResult<()> {
self.navigate(ffi::MDB_cursor_op::MDB_NEXT_NODUP)
}
/// Moves cursor to next item with the same key as current
pub fn to_next_item(&mut self) -> MdbResult<()> {
self.navigate(ffi::MDB_cursor_op::MDB_NEXT_DUP)
}
/// Moves cursor to prev entry, i.e. skips items
/// with duplicate keys
pub fn to_prev_key(&mut self) -> MdbResult<()> {
self.navigate(ffi::MDB_cursor_op::MDB_PREV_NODUP)
}
/// Moves cursor to prev item with the same key as current
pub fn to_prev_item(&mut self) -> MdbResult<()> {
self.navigate(ffi::MDB_cursor_op::MDB_PREV_DUP)
}
/// Moves cursor to first item with the same key as current
pub fn to_first_item(&mut self) -> MdbResult<()> {
self.navigate(ffi::MDB_cursor_op::MDB_FIRST_DUP)
}
<|fim▁hole|> pub fn to_last_item(&mut self) -> MdbResult<()> {
self.navigate(ffi::MDB_cursor_op::MDB_LAST_DUP)
}
/// Retrieves current key/value as tuple
pub fn get<'a, T: FromMdbValue + 'a, U: FromMdbValue + 'a>(&'a mut self) -> MdbResult<(T, U)> {
let (k, v) = try!(self.get_plain());
unsafe {
Ok((FromMdbValue::from_mdb_value(mem::transmute(&k)),
FromMdbValue::from_mdb_value(mem::transmute(&v))))
}
}
/// Retrieves current value
pub fn get_value<'a, V: FromMdbValue + 'a>(&'a mut self) -> MdbResult<V> {
let (_, v) = try!(self.get_plain());
unsafe {
Ok(FromMdbValue::from_mdb_value(mem::transmute(&v)))
}
}
/// Retrieves current key
pub fn get_key<'a, K: FromMdbValue + 'a>(&'a mut self) -> MdbResult<K> {
let (k, _) = try!(self.get_plain());
unsafe {
Ok(FromMdbValue::from_mdb_value(mem::transmute(&k)))
}
}
/// Compares the cursor's current key with the specified other one.
#[inline]
fn cmp_key(&mut self, other: &MdbValue) -> MdbResult<Ordering> {
let (k, _) = try!(self.get_plain());
let mut kval = k.value;
let cmp = unsafe {
ffi::mdb_cmp(self.txn.handle, self.db, &mut kval, mem::transmute(other))
};
Ok(match cmp {
n if n < 0 => Ordering::Less,
n if n > 0 => Ordering::Greater,
_ => Ordering::Equal,
})
}
#[inline]
fn ensure_key_valid(&mut self) -> MdbResult<()> {
// If key might be invalid simply perform cursor get to be sure
// it points to database memory instead of user one
if !self.valid_key {
unsafe {
try_mdb!(ffi::mdb_cursor_get(self.handle, &mut self.key_val,
ptr::null_mut(),
ffi::MDB_cursor_op::MDB_GET_CURRENT));
}
self.valid_key = true;
}
Ok(())
}
#[inline]
fn get_plain(&mut self) -> MdbResult<(MdbValue<'txn>, MdbValue<'txn>)> {
try!(self.ensure_key_valid());
let k = MdbValue {value: self.key_val, marker: ::std::marker::PhantomData};
let v = MdbValue {value: self.data_val, marker: ::std::marker::PhantomData};
Ok((k, v))
}
#[allow(dead_code)]
// This one is used for debugging, so it's to OK to leave it for a while
fn dump_value(&self, prefix: &str) {
if self.valid_key {
println!("{}: key {:?}, data {:?}", prefix,
self.key_val,
self.data_val);
}
}
fn set_value<V: ToMdbValue>(&mut self, value: &V, flags: c_uint) -> MdbResult<()> {
try!(self.ensure_key_valid());
self.data_val = value.to_mdb_value().value;
lift_mdb!(unsafe {ffi::mdb_cursor_put(self.handle, &mut self.key_val, &mut self.data_val, flags)})
}
pub fn set<K: ToMdbValue, V: ToMdbValue>(&mut self, key: &K, value: &V, flags: c_uint) -> MdbResult<()> {
self.key_val = key.to_mdb_value().value;
self.valid_key = true;
let res = self.set_value(value, flags);
self.valid_key = false;
res
}
/// Overwrites value for current item
/// Note: overwrites max cur_value.len() bytes
pub fn replace<V: ToMdbValue>(&mut self, value: &V) -> MdbResult<()> {
let res = self.set_value(value, ffi::MDB_CURRENT);
self.valid_key = false;
res
}
/// Adds a new item when created with allowed duplicates
pub fn add_item<V: ToMdbValue>(&mut self, value: &V) -> MdbResult<()> {
let res = self.set_value(value, 0);
self.valid_key = false;
res
}
fn del_value(&mut self, flags: c_uint) -> MdbResult<()> {
lift_mdb!(unsafe { ffi::mdb_cursor_del(self.handle, flags) })
}
/// Deletes current key
pub fn del(&mut self) -> MdbResult<()> {
self.del_all()
}
/// Deletes only current item
///
/// Note that it doesn't check anything so it is caller responsibility
/// to make sure that correct item is deleted if, for example, caller
/// wants to delete only items of current key
pub fn del_item(&mut self) -> MdbResult<()> {
let res = self.del_value(0);
self.valid_key = false;
res
}
/// Deletes all items with same key as current
pub fn del_all(&mut self) -> MdbResult<()> {
self.del_value(ffi::MDB_NODUPDATA)
}
/// Returns count of items with the same key as current
pub fn item_count(&self) -> MdbResult<size_t> {
let mut tmp: size_t = 0;
lift_mdb!(unsafe {ffi::mdb_cursor_count(self.handle, &mut tmp)}, tmp)
}
pub fn get_item<'k, K: ToMdbValue>(self, k: &'k K) -> CursorItemAccessor<'txn, 'k, K> {
CursorItemAccessor {
cursor: self,
key: k
}
}
}
impl<'txn> Drop for Cursor<'txn> {
fn drop(&mut self) {
unsafe { ffi::mdb_cursor_close(self.handle) };
}
}
pub struct CursorItemAccessor<'c, 'k, K: 'k> {
cursor: Cursor<'c>,
key: &'k K,
}
impl<'k, 'c: 'k, K: ToMdbValue> CursorItemAccessor<'c, 'k, K> {
pub fn get<'a, V: FromMdbValue + 'a>(&'a mut self) -> MdbResult<V> {
try!(self.cursor.to_key(self.key));
self.cursor.get_value()
}
pub fn add<V: ToMdbValue>(&mut self, v: &V) -> MdbResult<()> {
self.cursor.set(self.key, v, 0)
}
pub fn del<V: ToMdbValue>(&mut self, v: &V) -> MdbResult<()> {
try!(self.cursor.to_item(self.key, v));
self.cursor.del_item()
}
pub fn del_all(&mut self) -> MdbResult<()> {
try!(self.cursor.to_key(self.key));
self.cursor.del_all()
}
pub fn into_inner(self) -> Cursor<'c> {
let tmp = self;
tmp.cursor
}
}
pub struct CursorValue<'cursor> {
key: MdbValue<'cursor>,
value: MdbValue<'cursor>,
marker: ::std::marker::PhantomData<&'cursor ()>,
}
/// CursorValue performs lazy data extraction from iterator
/// avoiding any data conversions and memory copy. Lifetime
/// is limited to iterator lifetime
impl<'cursor> CursorValue<'cursor> {
pub fn get_key<T: FromMdbValue + 'cursor>(&'cursor self) -> T {
FromMdbValue::from_mdb_value(&self.key)
}
pub fn get_value<T: FromMdbValue + 'cursor>(&'cursor self) -> T {
FromMdbValue::from_mdb_value(&self.value)
}
pub fn get<T: FromMdbValue + 'cursor, U: FromMdbValue + 'cursor>(&'cursor self) -> (T, U) {
(FromMdbValue::from_mdb_value(&self.key),
FromMdbValue::from_mdb_value(&self.value))
}
}
/// This one should once become public and allow to create custom
/// iterators
trait CursorIteratorInner {
/// Returns true if initialization successful, for example that
/// the key exists.
fn init_cursor<'a, 'b: 'a>(&'a self, cursor: &mut Cursor<'b>) -> bool;
/// Returns true if there is still data and iterator is in correct range
fn move_to_next<'iter, 'cursor: 'iter>(&'iter self, cursor: &'cursor mut Cursor<'cursor>) -> bool;
/// Returns size hint considering current state of cursor
fn get_size_hint(&self, _cursor: &Cursor) -> (usize, Option<usize>) {
(0, None)
}
}
pub struct CursorIterator<'c, I> {
inner: I,
has_data: bool,
cursor: Cursor<'c>,
marker: ::std::marker::PhantomData<&'c ()>,
}
impl<'c, I: CursorIteratorInner + 'c> CursorIterator<'c, I> {
fn wrap(cursor: Cursor<'c>, inner: I) -> CursorIterator<'c, I> {
let mut cursor = cursor;
let has_data = inner.init_cursor(&mut cursor);
CursorIterator {
inner: inner,
has_data: has_data,
cursor: cursor,
marker: ::std::marker::PhantomData,
}
}
#[allow(dead_code)]
fn unwrap(self) -> Cursor<'c> {
self.cursor
}
}
impl<'c, I: CursorIteratorInner + 'c> Iterator for CursorIterator<'c, I> {
type Item = CursorValue<'c>;
fn next(&mut self) -> Option<CursorValue<'c>> {
if !self.has_data {
None
} else {
match self.cursor.get_plain() {
Err(_) => None,
Ok((k, v)) => {
self.has_data = unsafe { self.inner.move_to_next(mem::transmute(&mut self.cursor)) };
Some(CursorValue {
key: k,
value: v,
marker: ::std::marker::PhantomData
})
}
}
}
}
fn size_hint(&self) -> (usize, Option<usize>) {
self.inner.get_size_hint(&self.cursor)
}
}
pub struct CursorKeyRangeIter<'a> {
start_key: MdbValue<'a>,
end_key: MdbValue<'a>,
end_inclusive: bool,
marker: ::std::marker::PhantomData<&'a ()>,
}
impl<'a> CursorKeyRangeIter<'a> {
pub fn new<K: ToMdbValue+'a>(start_key: &'a K, end_key: &'a K, end_inclusive: bool) -> CursorKeyRangeIter<'a> {
CursorKeyRangeIter {
start_key: start_key.to_mdb_value(),
end_key: end_key.to_mdb_value(),
end_inclusive: end_inclusive,
marker: ::std::marker::PhantomData,
}
}
}
impl<'iter> CursorIteratorInner for CursorKeyRangeIter<'iter> {
fn init_cursor<'a, 'b: 'a>(&'a self, cursor: & mut Cursor<'b>) -> bool {
let ok = unsafe {
cursor.to_gte_key(mem::transmute::<&'a MdbValue<'a>, &'b MdbValue<'b>>(&self.start_key)).is_ok()
};
ok && cursor.cmp_key(&self.end_key).is_less(self.end_inclusive)
}
fn move_to_next<'i, 'c: 'i>(&'i self, cursor: &'c mut Cursor<'c>) -> bool {
let moved = cursor.to_next_key().is_ok();
if !moved {
false
} else {
cursor.cmp_key(&self.end_key).is_less(self.end_inclusive)
}
}
}
pub struct CursorFromKeyIter<'a> {
start_key: MdbValue<'a>,
marker: ::std::marker::PhantomData<&'a ()>,
}
impl<'a> CursorFromKeyIter<'a> {
pub fn new<K: ToMdbValue+'a>(start_key: &'a K) -> CursorFromKeyIter<'a> {
CursorFromKeyIter {
start_key: start_key.to_mdb_value(),
marker: ::std::marker::PhantomData
}
}
}
impl<'iter> CursorIteratorInner for CursorFromKeyIter<'iter> {
fn init_cursor<'a, 'b: 'a>(&'a self, cursor: & mut Cursor<'b>) -> bool {
unsafe {
cursor.to_gte_key(mem::transmute::<&'a MdbValue<'a>, &'b MdbValue<'b>>(&self.start_key)).is_ok()
}
}
fn move_to_next<'i, 'c: 'i>(&'i self, cursor: &'c mut Cursor<'c>) -> bool {
cursor.to_next_key().is_ok()
}
}
pub struct CursorToKeyIter<'a> {
end_key: MdbValue<'a>,
marker: ::std::marker::PhantomData<&'a ()>,
}
impl<'a> CursorToKeyIter<'a> {
pub fn new<K: ToMdbValue+'a>(end_key: &'a K) -> CursorToKeyIter<'a> {
CursorToKeyIter {
end_key: end_key.to_mdb_value(),
marker: ::std::marker::PhantomData,
}
}
}
impl<'iter> CursorIteratorInner for CursorToKeyIter<'iter> {
fn init_cursor<'a, 'b: 'a>(&'a self, cursor: & mut Cursor<'b>) -> bool {
let ok = cursor.to_first().is_ok();
ok && cursor.cmp_key(&self.end_key).is_less(false)
}
fn move_to_next<'i, 'c: 'i>(&'i self, cursor: &'c mut Cursor<'c>) -> bool {
let moved = cursor.to_next_key().is_ok();
if !moved {
false
} else {
cursor.cmp_key(&self.end_key).is_less(false)
}
}
}
#[allow(missing_copy_implementations)]
pub struct CursorIter;
impl<'iter> CursorIteratorInner for CursorIter {
fn init_cursor<'a, 'b: 'a>(&'a self, cursor: & mut Cursor<'b>) -> bool {
cursor.to_first().is_ok()
}
fn move_to_next<'i, 'c: 'i>(&'i self, cursor: &'c mut Cursor<'c>) -> bool {
cursor.to_next_key().is_ok()
}
}
pub struct CursorItemIter<'a> {
key: MdbValue<'a>,
marker: ::std::marker::PhantomData<&'a ()>,
}
impl<'a> CursorItemIter<'a> {
pub fn new<K: ToMdbValue+'a>(key: &'a K) -> CursorItemIter<'a> {
CursorItemIter {
key: key.to_mdb_value(),
marker: ::std::marker::PhantomData
}
}
}
impl<'iter> CursorIteratorInner for CursorItemIter<'iter> {
fn init_cursor<'a, 'b: 'a>(&'a self, cursor: & mut Cursor<'b>) -> bool {
unsafe {
cursor.to_key(mem::transmute::<&MdbValue, &'b MdbValue<'b>>(&self.key)).is_ok()
}
}
fn move_to_next<'i, 'c: 'i>(&'i self, cursor: &'c mut Cursor<'c>) -> bool {
cursor.to_next_item().is_ok()
}
fn get_size_hint(&self, c: &Cursor) -> (usize, Option<usize>) {
match c.item_count() {
Err(_) => (0, None),
Ok(cnt) => (0, Some(cnt as usize))
}
}
}
#[derive(Copy, Clone)]
pub struct MdbValue<'a> {
value: MDB_val,
marker: ::std::marker::PhantomData<&'a ()>,
}
impl<'a> MdbValue<'a> {
#[inline]
pub unsafe fn new(data: *const c_void, len: usize) -> MdbValue<'a> {
MdbValue {
value: MDB_val {
mv_data: data,
mv_size: len as size_t
},
marker: ::std::marker::PhantomData
}
}
#[inline]
pub unsafe fn from_raw(mdb_val: *const ffi::MDB_val) -> MdbValue<'a> {
MdbValue::new((*mdb_val).mv_data, (*mdb_val).mv_size as usize)
}
#[inline]
pub fn new_from_sized<T>(data: &'a T) -> MdbValue<'a> {
unsafe {
MdbValue::new(mem::transmute(data), mem::size_of::<T>())
}
}
#[inline]
pub unsafe fn get_ref(&'a self) -> *const c_void {
self.value.mv_data
}
#[inline]
pub fn get_size(&self) -> usize {
self.value.mv_size as usize
}
}<|fim▁end|> | /// Moves cursor to last item with the same key as current |
<|file_name|>lib.rs<|end_file_name|><|fim▁begin|>#![feature(test)]
extern crate nalgebra as na;<|fim▁hole|>extern crate nalgebra_lapack as nl;
extern crate rand;
extern crate test;
mod linalg;<|fim▁end|> | |
<|file_name|>setup.py<|end_file_name|><|fim▁begin|>#!/usr/bin/env python
from distutils.core import setup
<|fim▁hole|> packages=['fetcher'])<|fim▁end|> | setup(
name='fetcher',
version='0.4',
install_requires=['pycurl==7.19.0.2'], |
<|file_name|>conf.py<|end_file_name|><|fim▁begin|>import os
import sys
from recommonmark.parser import CommonMarkParser
sys.path.insert(0, os.path.join(os.path.dirname(__file__), '..', 'askomics'))
extensions = ['sphinx.ext.autodoc', 'sphinx.ext.napoleon']
master_doc = 'index'
# The suffix of source filenames.
source_suffix = ['.rst', '.md']
source_parsers = {
'.md': CommonMarkParser,
}
def run_apidoc(_):<|fim▁hole|> sys.path.append(parent_folder)
module = os.path.join(parent_folder, 'askomics')
output_path = os.path.join(cur_dir, 'api')
main(['-e', '-f', '-o', output_path, module])
def setup(app):
app.connect('builder-inited', run_apidoc)<|fim▁end|> | from sphinx.apidoc import main
parent_folder = os.path.join(os.path.dirname(__file__), '..')
cur_dir = os.path.abspath(os.path.dirname(__file__)) |
<|file_name|>focus.rs<|end_file_name|><|fim▁begin|>use dces::prelude::Entity;
use crate::{
prelude::*,
proc_macros::{Event, IntoHandler},
};
<|fim▁hole|>/// Used to request keyboard focus on the window.
#[derive(Event, Clone)]
pub enum FocusEvent {
RequestFocus(Entity),
RemoveFocus(Entity),
}
pub type FocusHandlerFn = dyn Fn(&mut StatesContext, FocusEvent) -> bool + 'static;
/// Structure for the focus handling of an event
#[derive(IntoHandler)]
pub struct FocusEventHandler {
/// A reference counted handler
pub handler: Rc<FocusHandlerFn>,
}
impl EventHandler for FocusEventHandler {
fn handle_event(&self, states: &mut StatesContext, event: &EventBox) -> bool {
if let Ok(event) = event.downcast_ref::<FocusEvent>() {
return (self.handler)(states, event.clone());
}
false
}
fn handles_event(&self, event: &EventBox) -> bool {
event.is_type::<FocusEvent>()
}
}<|fim▁end|> | |
<|file_name|>Juego.java<|end_file_name|><|fim▁begin|>package schoolprojects;
import java.util.Random;
import java.util.Scanner;
/**
* Piedra, papel o tijera es un juego infantil.
* Un juego de manos en el cual existen tres elementos.
* La piedra que vence a la tijera rompiéndola; la tijera que vencen al papel cortándolo;
* y el papel que vence a la piedra envolviéndola. Esto representa un ciclo, el cual
* le da su esencia al juego. Este juego es muy utilizado para decidir quien de dos
* personas hará algo, tal y como a veces se hace usando una moneda, o para dirimir algún asunto.
*
* En esta version del juego habra un Jugador Humano y un jugador artificial ( es decir el ordenador )
*
* @author Velik Georgiev Chelebiev
* @version 0.0.1
*/
public class Juego {
/**
* @param args Argumentos de la linea de comandos
*/
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
Random rand = new Random();
<|fim▁hole|> * Movimientos disponibles en forma de cadena.
*/
String[] movimientos = {"Piedra", "Papel", "Tijera"};
/**
* Moviemiento elegido por el usuario en forma de numero entero.
*/
int entradaUsuario = 0;
/**
* Un numero aleatorio que representara el movimiento del ordenador.
*/
int movimientoAleatorio = 0;
/**
* Los resultados posibles de la partida. 0 EMPATE 1 El jugador gana 2
* El jugador pierde
*/
String[] resultados = {"Empate", "Ganas", "Pierdes"};
/**
* El resultado de la partida respecto el jugador.
*/
int resultadoJugador = -1;
/**
* Aqui es donde epieza el juego.
*
* Pedimos al usuario que elija uno de los movimientos disponibles
* y generamos un movimiento aleatorio, que sera el movimiento del ordenador.
* Despues comptrobamos si el jugador gana al ordenador , si pierde o si hay un empate.
* Mostramos el resultado en la pantalla y el bucle se repite hasta que
* el jugador no introduce -1 como movimiento.
*/
do {
// Mostramos informacion sobre los movimientos validos y
// los numeros que le corresponden.
for (int i = 0; i < movimientos.length; i++) {
System.out.print("(" + (i + 1) + ") " + movimientos[i] + "\n");
}
// Valor predeterminado ( o entrada no valida, por si el usuario no introduce ningun valor )
entradaUsuario = 0;
// Leemos la entrada ( el moviemiento ) del usuario
try {
System.out.print("Movimiento: ");
entradaUsuario = Integer.parseInt(scan.nextLine());
} catch (NumberFormatException ex) {
// Si la entrada no tiene un formato valido, mostraremos un mensaje de error
// y le pediremos al usuario que introduzca un movimiento nuevamente.
entradaUsuario = 0;
}
// Si la opcion elegida por el usuario no es valida imprimimos un
// mensaje de error y le volvemos a pedir que introduzca una opcion
if (entradaUsuario < 1 || entradaUsuario > 3) {
System.out.println("\n*** El movimiento elegido no es valido. ***");
continue;
}
// Restamos 1 a la entrada del usuario.
// Esto lo hacemos para que sea un indice de vector valido.
entradaUsuario -= 1;
// Generamos un movimiento aleatorio
movimientoAleatorio = rand.nextInt(movimientos.length);
// Para separar el "menu" de moviemientos y la entrada del usuario
// con la salida/resultado de la partida marco
System.out.println("\n*******************************\n");
// Imprimimos las jugadas del jugador y del ordenador
System.out.println("Tu: (" + movimientos[entradaUsuario] + ") [VS] PC: (" + movimientos[movimientoAleatorio] + ")");
// Comprobamos si el jugador gana
if ((entradaUsuario == 0 && movimientoAleatorio == 2) ||
(entradaUsuario == 1 && movimientoAleatorio == 0) ||
(entradaUsuario == 2 && movimientoAleatorio == 1)) {
resultadoJugador = 1;
} else if(entradaUsuario == movimientoAleatorio) { // Comprobamos si es un empate
resultadoJugador = 0;
} else { // en el resto de los casos el jugador pierde
resultadoJugador = 2;
}
// Imprimimos el resultado de la partida
System.out.println("Resultado: " + resultados[resultadoJugador]);
// Para separar el "menu" de moviemientos y la entrada del usuario
// con la salida/resultado de la partida marco
System.out.println("\n*******************************\n");
} while (entradaUsuario != -1);
}
}<|fim▁end|> | /** |
<|file_name|>prism.py<|end_file_name|><|fim▁begin|>__author__ = 'jbellino'
import os
import csv<|fim▁hole|>import gdalconst
import zipfile as zf
import numpy as np
import pandas as pd
from unitconversion import *
prismGrid_shp = r'G:\archive\datasets\PRISM\shp\prismGrid_p.shp'
prismGrid_pts = r'G:\archive\datasets\PRISM\shp\prismGrid_p.txt'
prismProj = r'G:\archive\datasets\PRISM\shp\PRISM_ppt_bil.prj'
ncol = 1405
nrow = 621
max_grid_id = ncol * nrow
def getMonthlyPrecipData(year, month, mask=None, conversion=None):
# print 'Getting data for', year, month
bil = r'/vsizip/G:\archive\datasets\PRISM\monthly\ppt\{0}\PRISM_ppt_stable_4kmM2_{0}_all_bil.zip\PRISM_ppt_stable_4kmM2_{0}{1:0>2d}_bil.bil'.format(year, month)
b = BilFile(bil, mask=mask)
data = b.data
if conversion is not None:
data *= conversion
# b.save_to_esri_grid('ppt_{}'.format(year), conversion_factor=mm_to_in)
return data
def getAnnualPrecipData(year, mask=None, conversion=None):
# print 'Getting data for year', year
bil = r'/vsizip/G:\archive\datasets\PRISM\monthly\ppt\{0}\PRISM_ppt_stable_4kmM2_{0}_all_bil.zip\PRISM_ppt_stable_4kmM2_{0}_bil.bil'.format(year)
b = BilFile(bil, mask=mask)
data = b.data
if conversion is not None:
data *= conversion
# b.save_to_esri_grid('ppt_{}'.format(year), conversion_factor=mm_to_in)
return data
def getGridIdFromRowCol(row, col):
"""
Determines the PRISM grid id based on a row, col input.
"""
assert 1 <= row <= nrow, 'Valid row numbers are bewteen 1 and {}.'.format(nrow)
assert 1 <= col <= ncol, 'Valid col numbers are bewteen 1 and {}.'.format(ncol)
grid_id = ((row-1)*ncol)+col
return grid_id
def getRowColFromGridId(grid_id):
"""
Determines the row, col based on a PRISM grid id.
"""
assert 1 <= grid_id <= max_grid_id, 'Valid Grid IDs are bewteen 1 and {}, inclusively.'.format(max_grid_id)
q, r = divmod(grid_id, ncol)
return q+1, r
def writeGridPointsToTxt(prismGrid_shp=prismGrid_shp, out_file=prismGrid_pts):
"""
Writes the PRISM grid id, row, and col for each feature in the PRISM grid shapefile.
"""
import arcpy
data = []
rowends = range(ncol, max_grid_id+1, ncol)
with arcpy.da.SearchCursor(prismGrid_shp, ['grid_code', 'row', 'col']) as cur:
rowdata = []
for rec in cur:
rowdata.append(rec[0])
if rec[2] in rowends:
data.append(rowdata)
rowdata = []
a = np.array(data, dtype=np.int)
np.savetxt(out_file, a)
def getGridPointsFromTxt(prismGrid_pts=prismGrid_pts):
"""
Returns an array of the PRISM grid id, row, and col for each feature in the PRISM grid shapefile.
"""
a = np.genfromtxt(prismGrid_pts, dtype=np.int, usemask=True)
return a
def makeGridMask(grid_pnts, grid_codes=None):
"""
Makes a mask with the same shape as the PRISM grid.
'grid_codes' is a list containing the grid id's of those cells to INCLUDE in your analysis.
"""
mask = np.ones((nrow, ncol), dtype=bool)
for row in range(mask.shape[0]):
mask[row] = np.in1d(grid_pnts[row], grid_codes, invert=True)
return mask
def downloadPrismFtpData(parm, output_dir=os.getcwd(), timestep='monthly', years=None, server='prism.oregonstate.edu'):
"""
Downloads ESRI BIL (.hdr) files from the PRISM FTP site.
'parm' is the parameter of interest: 'ppt', precipitation; 'tmax', temperature, max' 'tmin', temperature, min /
'tmean', temperature, mean
'timestep' is either 'monthly' or 'daily'. This string is used to direct the function to the right set of remote folders.
'years' is a list of the years for which data is desired.
"""
from ftplib import FTP
def handleDownload(block):
file.write(block)
# print ".\n"
# Play some defense
assert parm in ['ppt', 'tmax', 'tmean', 'tmin'], "'parm' must be one of: ['ppt', 'tmax', 'tmean', 'tmin']"
assert timestep in ['daily', 'monthly'], "'timestep' must be one of: ['daily', 'monthly']"
assert years is not None, 'Please enter a year for which data will be fetched.'
if isinstance(years, int):
years = list(years)
ftp = FTP(server)
print 'Logging into', server
ftp.login()
# Wrap everything in a try clause so we close the FTP connection gracefully
try:
for year in years:
dir = 'monthly'
if timestep == 'daily':
dir = timestep
dir_string = '{}/{}/{}'.format(dir, parm, year)
remote_files = []
ftp.dir(dir_string, remote_files.append)
for f_string in remote_files:
f = f_string.rsplit(' ')[-1]
if not '_all_bil' in f:
continue
print 'Downloading', f
if not os.path.isdir(os.path.join(output_dir, str(year))):
os.makedirs(os.path.join(output_dir, str(year)))
local_f = os.path.join(output_dir, str(year), f)
with open(local_f, 'wb') as file:
f_path = '{}/{}'.format(dir_string, f)
ftp.retrbinary('RETR ' + f_path, handleDownload)
except Exception as e:
print e
finally:
print('Closing the connection.')
ftp.close()
return
class BilFile(object):
"""
This class returns a BilFile object using GDAL to read the array data. Data units are in millimeters.
"""
def __init__(self, bil_file, mask=None):
self.bil_file = bil_file
self.hdr_file = bil_file[:-3]+'hdr'
gdal.GetDriverByName('EHdr').Register()
self.get_array(mask=mask)
self.originX = self.geotransform[0]
self.originY = self.geotransform[3]
self.pixelWidth = self.geotransform[1]
self.pixelHeight = self.geotransform[5]
def get_array(self, mask=None):
self.data = None
img = gdal.Open(self.bil_file, gdalconst.GA_ReadOnly)
band = img.GetRasterBand(1)
self.nodatavalue = band.GetNoDataValue()
self.data = band.ReadAsArray()
self.data = np.ma.masked_where(self.data==self.nodatavalue, self.data)
if mask is not None:
self.data = np.ma.masked_where(mask==True, self.data)
self.ncol = img.RasterXSize
self.nrow = img.RasterYSize
self.geotransform = img.GetGeoTransform()
def save_to_esri_grid(self, out_grid, conversion_factor=None, proj=None):
import arcpy
arcpy.env.overwriteOutput = True
arcpy.env.workspace = os.getcwd()
arcpy.CheckOutExtension('Spatial')
arcpy.env.outputCoordinateSystem = prismProj
if proj is not None:
arcpy.env.outputCoordinateSystem = proj
df = np.ma.filled(self.data, self.nodatavalue)
llx = self.originX
lly = self.originY - (self.nrow * -1 * self.pixelHeight)
point = arcpy.Point(llx, lly)
r = arcpy.NumPyArrayToRaster(df, lower_left_corner=point, x_cell_size=self.pixelWidth,
y_cell_size=-1*self.pixelHeight, value_to_nodata=self.nodatavalue)
if conversion_factor is not None:
r *= conversion_factor
r.save(out_grid)
def __extract_bil_from_zip(self, parent_zip):
with zf.ZipFile(parent_zip, 'r') as myzip:
if self.bil_file in myzip.namelist():
myzip.extract(self.bil_file, self.pth)
myzip.extract(self.hdr_file, self.pth)
return
def __clean_up(self):
try:
os.remove(os.path.join(self.pth, self.bil_file))
os.remove(os.path.join(self.pth, self.hdr_file))
except:
pass
if __name__ == '__main__':
grid_id = getGridIdFromRowCol(405, 972)
print grid_id
row, col = getRowColFromGridId(grid_id)
print row, col<|fim▁end|> | import gdal |
<|file_name|>body.js<|end_file_name|><|fim▁begin|>const test = require('tape')
const parse = require('../../parse').element('Body')
test('b(N+1,N+2)', function (t) {
const res = parse('b(N+1,N+2)')
t.equal(typeof res, 'object')
t.ok(res instanceof Array)
t.equal(res.length, 1)
t.end()
})
test('b(N+1,N+2), c(N-1)', function (t) {
const res = parse('b(N+1,N+2), c(N-1)')
t.equal(typeof res, 'object')
t.ok(res instanceof Array)
t.equal(res.length, 2)
<|fim▁hole|>})<|fim▁end|> | t.end() |
<|file_name|>segmentation.rs<|end_file_name|><|fim▁begin|>use core::fmt;
use shared::descriptor;
use shared::PrivilegeLevel;
/// Specifies which element to load into a segment from
/// descriptor tables (i.e., is a index to LDT or GDT table
/// with some additional flags).
///
/// See Intel 3a, Section 3.4.2 "Segment Selectors"
bitflags! {
#[repr(C, packed)]
pub flags SegmentSelector: u16 {
/// Requestor Privilege Level
const RPL_0 = 0b00,
const RPL_1 = 0b01,
const RPL_2 = 0b10,
const RPL_3 = 0b11,
/// Table Indicator (TI) 0 means GDT is used.
const TI_GDT = 0 << 3,
/// Table Indicator (TI) 1 means LDT is used.
const TI_LDT = 1 << 3,
}
}
/// Reload code segment register.
/// Note this is special since we can not directly move
/// to %cs. Instead we push the new segment selector
/// and return value on the stack and use lretq
/// to reload cs and continue at 1:.
pub unsafe fn set_cs(sel: SegmentSelector) {
#[cfg(target_arch="x86")]
#[inline(always)]
unsafe fn inner(sel: SegmentSelector) {
asm!("pushl $0; \
pushl $$1f; \
lretl; \
1:" :: "ri" (sel.bits() as usize) : "rax" "memory");
}
#[cfg(target_arch="x86_64")]
#[inline(always)]
unsafe fn inner(sel: SegmentSelector) {
asm!("pushq $0; \
leaq 1f(%rip), %rax; \
pushq %rax; \
lretq; \
1:" :: "ri" (sel.bits() as usize) : "rax" "memory");
}
inner(sel)
}
impl SegmentSelector {
/// Create a new SegmentSelector
///
/// # Arguments
/// * `index` index in GDT or LDT array.
///
pub const fn new(index: u16, rpl: PrivilegeLevel) -> SegmentSelector {
SegmentSelector { bits: index << 3 | (rpl as u16) }
}
pub const fn from_raw(bits: u16) -> SegmentSelector {
SegmentSelector { bits: bits }
}
}
impl fmt::Display for SegmentSelector {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
let r0 = match self.contains(RPL_0) {
false => "",
true => "Ring 0 segment selector.",
};
let r1 = match self.contains(RPL_1) {
false => "",
true => "Ring 1 segment selector.",
};
let r2 = match self.contains(RPL_2) {
false => "",
true => "Ring 2 segment selector.",
};
let r3 = match self.contains(RPL_3) {
false => "",
true => "Ring 3 segment selector.",
};
let tbl = match self.contains(TI_LDT) {
false => "GDT Table",
true => "LDT Table",
};
write!(f,
"Index {} in {}, {}{}{}{}",
self.bits >> 3,
tbl,
r0,
r1,
r2,
r3)
// write!(f, "Index")
}
}
/// Reload stack segment register.
pub unsafe fn load_ss(sel: SegmentSelector) {
asm!("movw $0, %ss " :: "r" (sel) : "memory");
}
/// Reload data segment register.
pub unsafe fn load_ds(sel: SegmentSelector) {
asm!("movw $0, %ds " :: "r" (sel) : "memory");
}
/// Reload es segment register.
pub unsafe fn load_es(sel: SegmentSelector) {
asm!("movw $0, %es " :: "r" (sel) : "memory");
}
/// Reload fs segment register.
pub unsafe fn load_fs(sel: SegmentSelector) {
asm!("movw $0, %fs " :: "r" (sel) : "memory");
}
/// Reload gs segment register.
pub unsafe fn load_gs(sel: SegmentSelector) {
asm!("movw $0, %gs " :: "r" (sel) : "memory");
}
/// Returns the current value of the code segment register.
pub fn cs() -> SegmentSelector {
let segment: u16;
unsafe { asm!("mov %cs, $0" : "=r" (segment) ) };
SegmentSelector::from_raw(segment)
}
bitflags! {
/// Data segment types. All are readable.
///
/// See Table 3-1, "Code- and Data-Segment Types"
pub flags DataAccess: u8 {
/// Segment is writable
const DATA_WRITE = 1 << 1,
/// Segment grows down, for stack
const DATA_EXPAND_DOWN = 1 << 2,
}
}
bitflags! {
/// Code segment types. All are executable.
///
/// See Table 3-1, "Code- and Data-Segment Types"
pub flags CodeAccess: u8 {
/// Segment is readable
const CODE_READ = 1 << 1,
/// Segment is callable from segment with fewer privileges.
const CODE_CONFORMING = 1 << 2,
}
}
/// Umbrella Segment Type.
///
/// See Table 3-1, "Code- and Data-Segment Types"
#[repr(u8)]
pub enum Type {
Data(DataAccess),
Code(CodeAccess),
}
impl Type {
pub fn pack(self) -> u8 {
match self {
Type::Data(d) => d.bits | 0b0_000,
Type::Code(c) => c.bits | 0b1_000,
}
}
}
/// Entry for GDT or LDT. Provides size and location of a segment.
///
/// See Intel 3a, Section 3.4.5 "Segment Descriptors", and Section 3.5.2
/// "Segment Descriptor Tables in IA-32e Mode", especially Figure 3-8.<|fim▁hole|> limit1: u16,
base1: u16,
base2: u8,
access: descriptor::Flags,
limit2_flags: Flags,
base3: u8,
}
/// This is data-structure is a ugly mess thing so we provide some
/// convenience function to program it.
impl SegmentDescriptor {
pub const NULL: SegmentDescriptor = SegmentDescriptor {
base1: 0,
base2: 0,
base3: 0,
access: descriptor::Flags::BLANK,
limit1: 0,
limit2_flags: Flags::BLANK,
};
pub fn new(base: u32, limit: u32,
ty: Type, accessed: bool, dpl: PrivilegeLevel) -> SegmentDescriptor
{
let fine_grained = limit < 0x100000;
let (limit1, limit2) = if fine_grained {
((limit & 0xFFFF) as u16, ((limit & 0xF0000) >> 16) as u8)
} else {
if ((limit - 0xFFF) & 0xFFF) > 0 {
panic!("bad segment limit for GDT entry");
}
(((limit & 0xFFFF000) >> 12) as u16, ((limit & 0xF0000000) >> 28) as u8)
};
let ty1 = descriptor::Type::SegmentDescriptor {
ty: ty,
accessed: accessed
};
SegmentDescriptor {
base1: base as u16,
base2: ((base as usize & 0xFF0000) >> 16) as u8,
base3: ((base as usize & 0xFF000000) >> 24) as u8,
access: descriptor::Flags::from_type(ty1)
| descriptor::Flags::from_priv(dpl),
limit1: limit1,
limit2_flags: FLAGS_DB
| if fine_grained { FLAGS_G } else { Flags::empty() }
| Flags::from_limit2(limit2),
}
}
}
bitflags! {
pub flags Flags: u8 {
/// Available for use by system software.
const FLAGS_AVL = 1 << 4,
/// 64-bit code segment (IA-32e mode only).
const FLAGS_L = 1 << 5,
/// Default operation size (0 = 16-bit segment, 1 = 32-bit segment).
const FLAGS_DB = 1 << 6,
/// Granularity (0 = limit in bytes, 1 = limt in 4 KiB Pages).
const FLAGS_G = 1 << 7,
}
}
impl Flags {
pub const BLANK: Flags = Flags { bits: 0 };
pub fn from_limit2(limit2: u8) -> Flags {
assert_eq!(limit2 & !0b111, 0);
Flags { bits: limit2 }
}
}<|fim▁end|> | #[derive(Copy, Clone, Debug)]
#[repr(C, packed)]
pub struct SegmentDescriptor { |
<|file_name|>search_tutor.py<|end_file_name|><|fim▁begin|>##############################################################################
#
# OSIS stands for Open Student Information System. It's an application
# designed to manage the core business of higher education institutions,
# such as universities, faculties, institutes and professional schools.
# The core business involves the administration of students, teachers,
# courses, programs and so on.
#
# Copyright (C) 2015-2018 Université catholique de Louvain (http://www.uclouvain.be)
#
# This program is free software: you can redistribute it and/or modify
# it under the terms of the GNU General Public License as published by
# the Free Software Foundation, either version 3 of the License, or
# (at your option) any later version.
#
# This program is distributed in the hope that it will be useful,
# but WITHOUT ANY WARRANTY; without even the implied warranty of
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
# GNU General Public License for more details.
#
# A copy of this license - GNU General Public License - is available
# at the root of the source code of this program. If not,
# see http://www.gnu.org/licenses/.
#
##############################################################################
from django import forms
from django.utils.translation import ugettext_lazy as _
from base.forms.search.search_form import BaseSearchForm
from base.models import tutor
<|fim▁hole|> name = forms.CharField(max_length=40,
label=_("name"))
def search(self):
return tutor.search(**self.cleaned_data).order_by("person__last_name", "person__first_name")<|fim▁end|> | class TutorSearchForm(BaseSearchForm): |
<|file_name|>__main__.py<|end_file_name|><|fim▁begin|>import os
import sys
import textwrap
from collections import OrderedDict
from argparse import ArgumentParser, RawDescriptionHelpFormatter
from faice.tools.run.__main__ import main as run_main
from faice.tools.run.__main__ import DESCRIPTION as RUN_DESCRIPTION
from faice.tools.vagrant.__main__ import main as vagrant_main
from faice.tools.vagrant.__main__ import DESCRIPTION as VAGRANT_DESCRIPTION
VERSION = '1.2'
TOOLS = OrderedDict([
('run', run_main),
('vagrant', vagrant_main)
])
def main():
description = [
'FAICE Copyright (C) 2017 Christoph Jansen',
'',
'This program comes with ABSOLUTELY NO WARRANTY. This is free software, and you are welcome to redistribute it'
'under certain conditions. See the LICENSE file distributed with this software for details.',
]
parser = ArgumentParser(
description=os.linesep.join([textwrap.fill(block) for block in description]),
formatter_class=RawDescriptionHelpFormatter
)
parser.add_argument(
'-v', '--version', action='version', version=VERSION
)
subparsers = parser.add_subparsers(title="tools")
sub_parser = subparsers.add_parser('run', help=RUN_DESCRIPTION, add_help=False)
_ = subparsers.add_parser('vagrant', help=VAGRANT_DESCRIPTION, add_help=False)
if len(sys.argv) < 2:
parser.print_help()
exit()
_ = parser.parse_known_args()
sub_args = sub_parser.parse_known_args()<|fim▁hole|>
tool = TOOLS[sub_args[1][0]]
sys.argv[0] = 'faice {}'.format(sys.argv[1])
del sys.argv[1]
exit(tool())
if __name__ == '__main__':
main()<|fim▁end|> | |
<|file_name|>RhnQueueJob.java<|end_file_name|><|fim▁begin|>/**
* Copyright (c) 2009--2012 Red Hat, Inc.
*
* This software is licensed to you under the GNU General Public License,
* version 2 (GPLv2). There is NO WARRANTY for this software, express or
* implied, including the implied warranties of MERCHANTABILITY or FITNESS
* FOR A PARTICULAR PURPOSE. You should have received a copy of GPLv2
* along with this software; if not, see
* http://www.gnu.org/licenses/old-licenses/gpl-2.0.txt.
*
* Red Hat trademarks are not licensed under GPLv2. No permission is
* granted to use or replicate Red Hat trademarks that are incorporated
* in this software or its documentation.
*/
package com.redhat.rhn.taskomatic.task;
import com.redhat.rhn.common.conf.Config;
import com.redhat.rhn.common.hibernate.HibernateFactory;
import com.redhat.rhn.taskomatic.TaskoRun;
import com.redhat.rhn.taskomatic.task.threaded.TaskQueue;
import com.redhat.rhn.taskomatic.task.threaded.TaskQueueFactory;
import org.apache.log4j.FileAppender;
import org.apache.log4j.Logger;
import org.apache.log4j.PatternLayout;
import org.quartz.JobExecutionContext;
import org.quartz.JobExecutionException;
import java.io.IOException;
/**
* Custom Quartz Job implementation which only allows one thread to
* run at a time. All other threads return without performing any work.
* This policy was chosen instead of blocking so as to reduce threading
* problems inside Quartz itself.
*
* @version $Rev $
*
*/
public abstract class RhnQueueJob implements RhnJob {
private TaskoRun jobRun = null;
protected abstract Logger getLogger();
/**
* {@inheritDoc}
*/
public void appendExceptionToLogError(Exception e) {
getLogger().error(e.getMessage());
getLogger().error(e.getCause());
}
private void logToNewFile() {
PatternLayout pattern =
new PatternLayout(DEFAULT_LOGGING_LAYOUT);<|fim▁hole|> getLogger().removeAllAppenders();
FileAppender appender = new FileAppender(pattern,
jobRun.buildStdOutputLogPath());
getLogger().addAppender(appender);
}
catch (IOException e) {
getLogger().warn("Logging to file disabled");
}
}
/**
* {@inheritDoc}
*/
public void execute(JobExecutionContext ctx, TaskoRun runIn)
throws JobExecutionException {
setJobRun(runIn);
try {
execute(ctx);
}
catch (Exception e) {
if (HibernateFactory.getSession().getTransaction().isActive()) {
HibernateFactory.rollbackTransaction();
HibernateFactory.closeSession();
}
appendExceptionToLogError(e);
jobRun.saveStatus(TaskoRun.STATUS_FAILED);
}
HibernateFactory.commitTransaction();
HibernateFactory.closeSession();
}
/**
* {@inheritDoc}
*/
public void execute(JobExecutionContext ctx)
throws JobExecutionException {
TaskQueueFactory factory = TaskQueueFactory.get();
String queueName = getQueueName();
TaskQueue queue = factory.getQueue(queueName);
if (queue == null) {
try {
queue = factory.createQueue(queueName, getDriverClass(), getLogger());
}
catch (Exception e) {
getLogger().error(e);
return;
}
}
if (queue.changeRun(jobRun)) {
jobRun.start();
HibernateFactory.commitTransaction();
HibernateFactory.closeSession();
logToNewFile();
getLogger().debug("Starting run " + jobRun.getId());
}
else {
// close current run
TaskoRun run = (TaskoRun) HibernateFactory.reload(jobRun);
run.appendToOutputLog("Run with id " + queue.getQueueRun().getId() +
" handles the whole task queue.");
run.skipped();
HibernateFactory.commitTransaction();
HibernateFactory.closeSession();
}
int defaultItems = 3;
if (queueName.equals("channel_repodata")) {
defaultItems = 1;
}
int maxWorkItems = Config.get().getInt("taskomatic." + queueName +
"_max_work_items", defaultItems);
if (queue.getQueueSize() < maxWorkItems) {
queue.run(this);
}
else {
getLogger().debug("Maximum number of workers already put ... skipping.");
}
}
/**
* @return Returns the run.
*/
public TaskoRun getRun() {
return jobRun;
}
/**
* @param runIn The run to set.
*/
public void setJobRun(TaskoRun runIn) {
jobRun = runIn;
}
protected abstract Class getDriverClass();
protected abstract String getQueueName();
}<|fim▁end|> | try { |
<|file_name|>title_test.py<|end_file_name|><|fim▁begin|>from os.path import abspath, dirname, join
from unittest.mock import MagicMock, Mock, call<|fim▁hole|>from netflix.data.genre import NetflixGenre
from netflix.parsers.title import NetflixTitleParser
from netflix.utils import netflix_url
class TestNetflixTitleParser(NetflixTestFixture):
def setUp(self):
self.tv_title_string = self._read("tv_title.html")
self.movie_title_string = self._read("movie_title.html")
def tearDown(self):
pass
def _read(self, filename):
input_path = join(dirname(abspath(__file__)), filename)
with open(input_path) as f:
return f.read()
def test_get_tv_title(self):
parser = NetflixTitleParser()
title = parser.get_title(self.tv_title_string)
self.assertEqual(title.title, "House of Cards")
self.assertEqual(title.title_id, 70178217)
self.assertEqual(title.year, 2013)
self.assertEqual(title.maturity, "Adult")
self.assertEqual(title.duration, "4 Seasons")
self.assertEqual(title.description, "Foo. Bar. Baz.")
self.assertEqual(title.background_url, "https://scdn.nflximg.net/ipl/29399/578030fdb9fc2b6de6f3d47b2f347da96a5da95c.jpg")
def test_get_movie_title(self):
parser = NetflixTitleParser()
title = parser.get_title(self.movie_title_string)
self.assertEqual(title.title, "Mad Max: Fury Road")
self.assertEqual(title.title_id, 80025919)
self.assertEqual(title.year, 2015)
self.assertEqual(title.maturity, "15")
self.assertEqual(title.duration, "120m")
self.assertEqual(title.description, "Foo. Bar. Baz.")
self.assertEqual(title.background_url, "https://scdn.nflximg.net/ipl/20552/de6776c61b5509db1c0a028ae81fc71b15bd6ef5.jpg")<|fim▁end|> |
from tests.common import NetflixTestFixture
|
<|file_name|>storage_data.py<|end_file_name|><|fim▁begin|># coding: utf-8
from __future__ import absolute_import
from .base_model_ import Model
from datetime import date, datetime
from typing import List, Dict
from ..util import deserialize_model
class StorageData(Model):
"""
NOTE: This class is auto generated by the swagger code generator program.
Do not edit the class manually.
"""
def __init__(self, name=None, description=None, comment=None):
"""
StorageData - a model defined in Swagger
:param name: The name of this StorageData.
:type name: str
:param description: The description of this StorageData.
:type description: str
:param comment: The comment of this StorageData.
:type comment: str
"""
self.swagger_types = {
'name': str,
'description': str,
'comment': str
}
self.attribute_map = {
'name': 'name',
'description': 'description',
'comment': 'comment'
}
self._name = name
self._description = description
self._comment = comment
@classmethod
def from_dict(cls, dikt):
"""
Returns the dict as a model
:param dikt: A dict.
:type: dict
:return: The StorageData of this StorageData.
:rtype: StorageData
"""
return deserialize_model(dikt, cls)
@property
def name(self):
"""
Gets the name of this StorageData.
:return: The name of this StorageData.
:rtype: str
"""
return self._name
@name.setter
def name(self, name):
"""
Sets the name of this StorageData.
:param name: The name of this StorageData.
:type name: str
"""
self._name = name
@property
def description(self):
"""
Gets the description of this StorageData.
:return: The description of this StorageData.
:rtype: str
"""
return self._description
@description.setter
def description(self, description):
"""
Sets the description of this StorageData.
:param description: The description of this StorageData.
:type description: str
"""
self._description = description
@property
def comment(self):
"""
Gets the comment of this StorageData.
:return: The comment of this StorageData.
:rtype: str
"""
return self._comment
<|fim▁hole|> Sets the comment of this StorageData.
:param comment: The comment of this StorageData.
:type comment: str
"""
self._comment = comment<|fim▁end|> | @comment.setter
def comment(self, comment):
""" |
<|file_name|>index.js<|end_file_name|><|fim▁begin|>import Image from 'next/image'
import styles from '../styles/Home.module.scss'
import About from '../components/About/About'
import Header from '../components/Header/Header'
import Photo from '../components/Photo/Photo'
import { HomeContextProvider } from '../contexts/HomeContext/HomeContext'
import Events from '../components/Events/Events'
import Social from '../components/Social/Social'
import casualImg from '../public/casual.jpeg'
import scrumImg from '../public/scrum.jpeg'
import presentationImg from '../public/presentation.jpg'
import anniversaryImg from '../public/anniversary_cake.jpg'
import bgImg from '../public/bg.jpg'
export default function Home() {
return (
<HomeContextProvider>
<div className={styles.container}>
<div className={styles.bg}>
<Image
src={bgImg}
placeholder="blur"
layout="fill"
objectFit="cover"
objectPosition="center"<|fim▁hole|> <div className={styles.scrim} />
<Header />
<div className={styles.items}>
<About />
<Photo src={casualImg} />
<Photo src={scrumImg} />
<Photo src={presentationImg} />
<Events />
<Photo src={anniversaryImg} />
</div>
<Social />
</div>
</HomeContextProvider>
)
}<|fim▁end|> | />
</div> |
<|file_name|>Stack2.py<|end_file_name|><|fim▁begin|>"""
By Simon Harms.
Copyright 2015 Simon Harms, MIT LICENSE
Name: Stack2
Summary: Stack Version 2
"""
class Stack:
"""
Python Stack V2 with view and change.
"""
def __init__(self):
"""
Initialize the Stack.
"""
self.__storage = []
def is_empty(self):
"""
Returns if the Stack is empty.
"""
return len(self.__storage) == 0
def push(self, pushed):
"""
Add to the Stack.
"""
self.__storage.append(pushed)
def pop(self):
"""
Delete the top element.
"""
return self.__storage.pop()
def view(self):
"""
Return the Topmost item in the Stack.
"""
return self.__storage[-1]
def change(self, new):
"""
Make edits to the Topmost item in the Stack.
"""
self.__storage[-1] = new
def get_len(self):
"""
Return the length of the stack.<|fim▁hole|> """
Return the stack. (Can't edit it though. It is just a getter.)
"""
return self.__storage
def set_stack(self, new_stack):
"""
Set the stack as the stack pased in. (use the newStacks getStack function.)
"""
self.__storage = new_stack
def get_string(self):
"""
Get a string of the stack.
"""
return "".join(self.__storage)<|fim▁end|> | """
return len(self.__storage)
def get_stack(self): |
<|file_name|>97bbc733896c_create_oauthclient_tables.py<|end_file_name|><|fim▁begin|># -*- coding: utf-8 -*-
#
# This file is part of Invenio.
# Copyright (C) 2016-2018 CERN.
#
# Invenio is free software; you can redistribute it and/or modify it
# under the terms of the MIT License; see LICENSE file for more details.
"""Create oauthclient tables."""
import sqlalchemy as sa
import sqlalchemy_utils
from alembic import op
from sqlalchemy.engine.reflection import Inspector
# revision identifiers, used by Alembic.
revision = '97bbc733896c'<|fim▁hole|>
def upgrade():
"""Upgrade database."""
op.create_table(
'oauthclient_remoteaccount',
sa.Column('id', sa.Integer(), nullable=False),
sa.Column('user_id', sa.Integer(), nullable=False),
sa.Column('client_id', sa.String(length=255), nullable=False),
sa.Column(
'extra_data',
sqlalchemy_utils.JSONType(),
nullable=False),
sa.ForeignKeyConstraint(['user_id'], [u'accounts_user.id'], ),
sa.PrimaryKeyConstraint('id'),
sa.UniqueConstraint('user_id', 'client_id')
)
op.create_table(
'oauthclient_useridentity',
sa.Column('id', sa.String(length=255), nullable=False),
sa.Column('method', sa.String(length=255), nullable=False),
sa.Column('id_user', sa.Integer(), nullable=False),
sa.ForeignKeyConstraint(['id_user'], [u'accounts_user.id'], ),
sa.PrimaryKeyConstraint('id', 'method')
)
op.create_index(
'useridentity_id_user_method', 'oauthclient_useridentity',
['id_user', 'method'], unique=True
)
op.create_table(
'oauthclient_remotetoken',
sa.Column('id_remote_account', sa.Integer(), nullable=False),
sa.Column('token_type', sa.String(length=40), nullable=False),
sa.Column(
'access_token',
sqlalchemy_utils.EncryptedType(),
nullable=False),
sa.Column('secret', sa.Text(), nullable=False),
sa.ForeignKeyConstraint(
['id_remote_account'], [u'oauthclient_remoteaccount.id'],
name='fk_oauthclient_remote_token_remote_account'
),
sa.PrimaryKeyConstraint('id_remote_account', 'token_type')
)
def downgrade():
"""Downgrade database."""
ctx = op.get_context()
insp = Inspector.from_engine(ctx.connection.engine)
op.drop_table('oauthclient_remotetoken')
for fk in insp.get_foreign_keys('oauthclient_useridentity'):
if fk['referred_table'] == 'accounts_user':
op.drop_constraint(
op.f(fk['name']),
'oauthclient_useridentity',
type_='foreignkey'
)
op.drop_index(
'useridentity_id_user_method',
table_name='oauthclient_useridentity')
op.drop_table('oauthclient_useridentity')
op.drop_table('oauthclient_remoteaccount')<|fim▁end|> | down_revision = '44ab9963e8cf'
branch_labels = ()
depends_on = '9848d0149abd' |
<|file_name|>TypeEqual.hh<|end_file_name|><|fim▁begin|>#ifndef LUCE_HEADER_TYPETRAIT_TYPEEQUAL_HH
#define LUCE_HEADER_TYPETRAIT_TYPEEQUAL_HH
#include <Luce/Configuration.hh>
#include <Luce/Utility/NonComparable.hh>
<|fim▁hole|> namespace TypeTrait
{
template<typename Lhs_, typename Rhs_>
struct TypeEqual LUCE_MACRO_FINAL
: private Utility::NonComparable, private Utility::NonCopyable
{
LUCE_MACRO_CANNOT_PARENT(TypeEqual)
public:
static const bool Value = false;
};
template<typename Type_>
struct TypeEqual<Type_, Type_> LUCE_MACRO_FINAL
: private Utility::NonComparable, private Utility::NonCopyable
{
LUCE_MACRO_CANNOT_PARENT(TypeEqual)
public:
static const bool Value = true;
};
}
using Luce::TypeTrait::TypeEqual;
}
#endif<|fim▁end|> | #include <Luce/Utility/NonCopyable.hh>
namespace Luce
{
|
<|file_name|>meeg.py<|end_file_name|><|fim▁begin|>"""
scitran.data.meeg
=================
Data format for M/EEG data using mne-python.
"""
import logging
import tempfile
import zipfile
import warnings
import os
from os import path as op
from datetime import datetime, date
import shutil
from mne.io import read_raw_fif
from .. import data
log = logging.getLogger(__name__) # root logger already configured
# see data.py for expected project properties
project_properties = data.project_properties
# add additional session properties, which should be added as attributes of
# the Reader object
_session_properties = {
'subject': {
'type': 'object',
'properties': {
'firstname': {
'field': 'subj_firstname',
'title': 'First Name',
'type': 'string',
},
'lastname': {
'field': 'subj_lastname',
'title': 'Last Name',
'type': 'string',
},
'dob': {
'field': 'subj_dob',
'title': 'Date of Birth',
'type': 'string',
'format': 'date', # i.e., datetime object
},
'sex': {
'field': 'subj_sex',
'title': 'Sex',
'type': 'string',
'enum': ['male', 'female'],
},
'hand': {
'field': 'subj_hand',
'title': 'Handedness',
'type': 'string',
'enum': ['right', 'left'],
},
},
},
}
session_properties = data.dict_merge(data.session_properties,
_session_properties)
_acquisition_properties = { # add custom acquisition properties
}
acquisition_properties = data.dict_merge(data.acquisition_properties,
_acquisition_properties)
class MEEGError(data.DataError):
pass
class MEEGReader(data.Reader):
"""
Parameters
----------
path : str
Path to input file.
load_data : boolean
Indicate if a reader should attempt to immediately load all data.
Default False.
"""
project_properties = project_properties
session_properties = session_properties
acquisition_properties = acquisition_properties
domain = u'meeg'
filetype = u'meeg'
state = ['orig']
def __init__(self, path, load_data=False, timezone=None):
super(MEEGReader, self).__init__(path, load_data, timezone)
#
# Process the incoming data
#
self._temp_dir = tempfile.mkdtemp()
os.mkdir(op.join(self._temp_dir, 'reap'))
try:
with zipfile.ZipFile(self.filepath, 'r') as zip_file:
zip_fnames = [op.join('reap', op.basename(fname))
for fname in zip_file.namelist()]
fnames = [zip_file.extract(fname, self._temp_dir)
for fname in zip_fnames if fname.endswith('.fif')]
except Exception as e:
raise MEEGError(e)
# load information and optionally data from the files
with warnings.catch_warnings(record=True):
self._raws = [read_raw_fif(fname, allow_maxshield=True,
preload=load_data)
for fname in fnames]
info = self._raws[0].info
subject_info = info['subject_info']
hand_dict = {1: 'right', 2: 'left'}
sex_dict = {1: 'male', 2: 'female'}
#
# Parameters required by NIMS
#
# pick a unique filename
meas_date = datetime.fromtimestamp(info['meas_date'][0])
fname = meas_date.strftime('%Y_%m_%d_%H_%M_%S')
self.filename = fname
self.group_id = info['experimenter'] # XXX always "neuromag", !useful
self.project_name = info['proj_name']
self.session_id = meas_date.strftime('%Y%m%d')
self.acquisition = info['description']
self.session_subject = subject_info['his_id']
#
# Additional session properties
#
self.subj_firstname = subject_info['first_name']
self.subj_lastname = subject_info['last_name']
self.subj_dob = \
datetime.combine(date(*subject_info['birthday']),
datetime.min.time())
self.subj_hand = hand_dict[subject_info['hand']]
self.subj_sex = sex_dict[subject_info['sex']]
# Parsing is complete
self.metadata_status = 'complete'
def __del__(self):
shutil.rmtree(self._temp_dir)
def load_data(self):
super(MEEGReader, self).load_data()
for raw in self._raws:
raw.preload_data()
@property
def nims_group_id(self):
return self.group_id<|fim▁hole|> def nims_project(self):
return self.project_name
@property
def nims_session_id(self):
return self.session_id
@property
def nims_session_label(self):
return self.session_id
@property
def nims_session_subject(self):
return self.session_subject
@property
def nims_acquisition_id(self):
return self.acquisition
@property
def nims_acquisition_label(self):
return self.acquisition
@property
def nims_acquisition_description(self):
return self.acquisition
@property
def nims_file_name(self):
return self.filename
@property
def nims_file_kinds(self):
return ['FIF']
# the following are all handled by the super class Reader
@property
def nims_metadata_status(self):
return super(MEEGReader, self).nims_metadata_status
@property
def nims_file_ext(self):
return super(MEEGReader, self).nims_file_ext
@property
def nims_file_domain(self):
return super(MEEGReader, self).nims_file_domain
@property
def nims_file_type(self):
return super(MEEGReader, self).nims_file_type
@property
def nims_file_state(self):
return super(MEEGReader, self).nims_file_state
@property
def nims_timestamp(self):
return super(MEEGReader, self).nims_timestamp
@property
def nims_timezone(self):
return super(MEEGReader, self).nims_timezone<|fim▁end|> |
@property |
<|file_name|>JsonOutput.java<|end_file_name|><|fim▁begin|>/*******************************************************************************
*
* Pentaho Data Integration
*
* Copyright (C) 2002-2012 by Pentaho : http://www.pentaho.com
*
*******************************************************************************
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*
******************************************************************************/
package org.pentaho.di.trans.steps.jsonoutput;
import java.io.BufferedOutputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import org.apache.commons.vfs.FileObject;
import org.json.simple.JSONArray;
import org.json.simple.JSONObject;
import org.pentaho.di.core.Const;
import org.pentaho.di.core.ResultFile;
import org.pentaho.di.core.exception.KettleException;
import org.pentaho.di.core.exception.KettleStepException;
import org.pentaho.di.core.row.RowDataUtil;
import org.pentaho.di.core.row.ValueMeta;
import org.pentaho.di.core.row.ValueMetaInterface;
import org.pentaho.di.core.vfs.KettleVFS;
import org.pentaho.di.i18n.BaseMessages;
import org.pentaho.di.trans.Trans;
import org.pentaho.di.trans.TransMeta;
import org.pentaho.di.trans.step.BaseStep;
import org.pentaho.di.trans.step.StepDataInterface;
import org.pentaho.di.trans.step.StepInterface;
import org.pentaho.di.trans.step.StepMeta;
import org.pentaho.di.trans.step.StepMetaInterface;
/**
* Converts input rows to one or more XML files.
*
* @author Matt
* @since 14-jan-2006
*/
public class JsonOutput extends BaseStep implements StepInterface
{
private static Class<?> PKG = JsonOutput.class; // for i18n purposes, needed by Translator2!! $NON-NLS-1$
private JsonOutputMeta meta;
private JsonOutputData data;
private interface CompatibilityFactory {
public void execute(Object[] row) throws KettleException;
}
@SuppressWarnings("unchecked")
private class CompatibilityMode implements CompatibilityFactory {
public void execute(Object[] row) throws KettleException {
for (int i=0;i<data.nrFields;i++) {
JsonOutputField outputField = meta.getOutputFields()[i];
ValueMetaInterface v = data.inputRowMeta.getValueMeta(data.fieldIndexes[i]);
// Create a new object with specified fields
JSONObject jo = new JSONObject();
switch (v.getType()) {
case ValueMeta.TYPE_BOOLEAN:
jo.put(outputField.getElementName(), data.inputRowMeta.getBoolean(row, data.fieldIndexes[i]));
break;
case ValueMeta.TYPE_INTEGER:
jo.put(outputField.getElementName(), data.inputRowMeta.getInteger(row, data.fieldIndexes[i]));<|fim▁hole|> break;
case ValueMeta.TYPE_BIGNUMBER:
jo.put(outputField.getElementName(), data.inputRowMeta.getBigNumber(row, data.fieldIndexes[i]));
break;
default:
jo.put(outputField.getElementName(), data.inputRowMeta.getString(row, data.fieldIndexes[i]));
break;
}
data.ja.add(jo);
}
data.nrRow++;
if(data.nrRowsInBloc>0) {
// System.out.println("data.nrRow%data.nrRowsInBloc = "+ data.nrRow%data.nrRowsInBloc);
if(data.nrRow%data.nrRowsInBloc==0) {
// We can now output an object
// System.out.println("outputting the row.");
outPutRow(row);
}
}
}
}
@SuppressWarnings("unchecked")
private class FixedMode implements CompatibilityFactory {
public void execute(Object[] row) throws KettleException {
// Create a new object with specified fields
JSONObject jo = new JSONObject();
for (int i=0;i<data.nrFields;i++) {
JsonOutputField outputField = meta.getOutputFields()[i];
ValueMetaInterface v = data.inputRowMeta.getValueMeta(data.fieldIndexes[i]);
switch (v.getType()) {
case ValueMeta.TYPE_BOOLEAN:
jo.put(outputField.getElementName(), data.inputRowMeta.getBoolean(row, data.fieldIndexes[i]));
break;
case ValueMeta.TYPE_INTEGER:
jo.put(outputField.getElementName(), data.inputRowMeta.getInteger(row, data.fieldIndexes[i]));
break;
case ValueMeta.TYPE_NUMBER:
jo.put(outputField.getElementName(), data.inputRowMeta.getNumber(row, data.fieldIndexes[i]));
break;
case ValueMeta.TYPE_BIGNUMBER:
jo.put(outputField.getElementName(), data.inputRowMeta.getBigNumber(row, data.fieldIndexes[i]));
break;
default:
jo.put(outputField.getElementName(), data.inputRowMeta.getString(row, data.fieldIndexes[i]));
break;
}
}
data.ja.add(jo);
data.nrRow++;
if(data.nrRowsInBloc > 0) {
// System.out.println("data.nrRow%data.nrRowsInBloc = "+ data.nrRow%data.nrRowsInBloc);
if(data.nrRow%data.nrRowsInBloc==0) {
// We can now output an object
// System.out.println("outputting the row.");
outPutRow(row);
}
}
}
}
private CompatibilityFactory compatibilityFactory;
public JsonOutput(StepMeta stepMeta, StepDataInterface stepDataInterface, int copyNr, TransMeta transMeta, Trans trans)
{
super(stepMeta, stepDataInterface, copyNr, transMeta, trans);
// Here we decide whether or not to build the structure in
// compatible mode or fixed mode
JsonOutputMeta jsonOutputMeta = (JsonOutputMeta)(stepMeta.getStepMetaInterface());
if (jsonOutputMeta.isCompatibilityMode()) {
compatibilityFactory = new CompatibilityMode();
}
else {
compatibilityFactory = new FixedMode();
}
}
public boolean processRow(StepMetaInterface smi, StepDataInterface sdi) throws KettleException {
meta=(JsonOutputMeta)smi;
data=(JsonOutputData)sdi;
Object[] r = getRow(); // This also waits for a row to be finished.
if (r==null) {
// no more input to be expected...
if(!data.rowsAreSafe) {
// Let's output the remaining unsafe data
outPutRow(r);
}
setOutputDone();
return false;
}
if (first) {
first=false;
data.inputRowMeta=getInputRowMeta();
data.inputRowMetaSize=data.inputRowMeta.size();
if(data.outputValue) {
data.outputRowMeta = data.inputRowMeta.clone();
meta.getFields(data.outputRowMeta, getStepname(), null, null, this);
}
// Cache the field name indexes
//
data.nrFields=meta.getOutputFields().length;
data.fieldIndexes = new int[data.nrFields];
for (int i=0;i<data.nrFields;i++) {
data.fieldIndexes[i] = data.inputRowMeta.indexOfValue(meta.getOutputFields()[i].getFieldName());
if (data.fieldIndexes[i]<0) {
throw new KettleException(BaseMessages.getString(PKG, "JsonOutput.Exception.FieldNotFound")); //$NON-NLS-1$
}
JsonOutputField field = meta.getOutputFields()[i];
field.setElementName(environmentSubstitute(field.getElementName()));
}
}
data.rowsAreSafe=false;
compatibilityFactory.execute(r);
if(data.writeToFile && !data.outputValue) {
putRow(data.inputRowMeta,r ); // in case we want it go further...
incrementLinesOutput();
}
return true;
}
@SuppressWarnings("unchecked")
private void outPutRow(Object[] rowData) throws KettleStepException {
// We can now output an object
data.jg = new JSONObject();
data.jg.put(data.realBlocName, data.ja);
String value = data.jg.toJSONString();
if(data.outputValue) {
Object[] outputRowData = RowDataUtil.addValueData(rowData, data.inputRowMetaSize, value);
incrementLinesOutput();
putRow(data.outputRowMeta, outputRowData);
}
if(data.writeToFile) {
// Open a file
if (!openNewFile()) {
throw new KettleStepException(BaseMessages.getString(PKG, "JsonOutput.Error.OpenNewFile", buildFilename()));
}
// Write data to file
try {
data.writer.write(value);
}catch(Exception e) {
throw new KettleStepException(BaseMessages.getString(PKG, "JsonOutput.Error.Writing"), e);
}
// Close file
closeFile();
}
// Data are safe
data.rowsAreSafe=true;
data.ja = new JSONArray();
}
public boolean init(StepMetaInterface smi, StepDataInterface sdi)
{
meta=(JsonOutputMeta)smi;
data=(JsonOutputData)sdi;
if(super.init(smi, sdi)) {
data.writeToFile = (meta.getOperationType() != JsonOutputMeta.OPERATION_TYPE_OUTPUT_VALUE);
data.outputValue = (meta.getOperationType() != JsonOutputMeta.OPERATION_TYPE_WRITE_TO_FILE);
if(data.outputValue) {
// We need to have output field name
if(Const.isEmpty(environmentSubstitute(meta.getOutputValue()))) {
logError(BaseMessages.getString(PKG, "JsonOutput.Error.MissingOutputFieldName"));
stopAll();
setErrors(1);
return false;
}
}
if(data.writeToFile) {
// We need to have output field name
if(!meta.isServletOutput() && Const.isEmpty(meta.getFileName())) {
logError(BaseMessages.getString(PKG, "JsonOutput.Error.MissingTargetFilename"));
stopAll();
setErrors(1);
return false;
}
if(!meta.isDoNotOpenNewFileInit()) {
if (!openNewFile()) {
logError(BaseMessages.getString(PKG, "JsonOutput.Error.OpenNewFile", buildFilename()));
stopAll();
setErrors(1);
return false;
}
}
}
data.realBlocName = Const.NVL(environmentSubstitute(meta.getJsonBloc()), "");
data.nrRowsInBloc = Const.toInt(environmentSubstitute(meta.getNrRowsInBloc()), 0);
return true;
}
return false;
}
public void dispose(StepMetaInterface smi, StepDataInterface sdi) {
meta=(JsonOutputMeta)smi;
data=(JsonOutputData)sdi;
if(data.ja!=null) data.ja=null;
if(data.jg!=null) data.jg=null;
closeFile();
super.dispose(smi, sdi);
}
private void createParentFolder(String filename) throws KettleStepException {
if(!meta.isCreateParentFolder()) return;
// Check for parent folder
FileObject parentfolder=null;
try {
// Get parent folder
parentfolder=KettleVFS.getFileObject(filename, getTransMeta()).getParent();
if(!parentfolder.exists()) {
if(log.isDebug()) logDebug(BaseMessages.getString(PKG, "JsonOutput.Error.ParentFolderNotExist", parentfolder.getName()));
parentfolder.createFolder();
if(log.isDebug()) logDebug(BaseMessages.getString(PKG, "JsonOutput.Log.ParentFolderCreated"));
}
}catch (Exception e) {
throw new KettleStepException(BaseMessages.getString(PKG, "JsonOutput.Error.ErrorCreatingParentFolder", parentfolder.getName()));
} finally {
if ( parentfolder != null ){
try {
parentfolder.close();
}catch ( Exception ex ) {};
}
}
}
public boolean openNewFile()
{
if(data.writer!=null) return true;
boolean retval=false;
try {
if (meta.isServletOutput()) {
data.writer = getTrans().getServletPrintWriter();
} else {
String filename = buildFilename();
createParentFolder(filename);
if (meta.AddToResult()) {
// Add this to the result file names...
ResultFile resultFile = new ResultFile(ResultFile.FILE_TYPE_GENERAL, KettleVFS.getFileObject(filename, getTransMeta()), getTransMeta().getName(), getStepname());
resultFile.setComment(BaseMessages.getString(PKG, "JsonOutput.ResultFilenames.Comment"));
addResultFile(resultFile);
}
OutputStream outputStream;
OutputStream fos = KettleVFS.getOutputStream(filename, getTransMeta(), meta.isFileAppended());
outputStream=fos;
if (!Const.isEmpty(meta.getEncoding())) {
data.writer = new OutputStreamWriter(new BufferedOutputStream(outputStream, 5000), environmentSubstitute(meta.getEncoding()));
} else {
data.writer = new OutputStreamWriter(new BufferedOutputStream(outputStream, 5000));
}
if(log.isDetailed()) logDetailed(BaseMessages.getString(PKG, "JsonOutput.FileOpened", filename));
data.splitnr++;
}
retval=true;
} catch(Exception e) {
logError(BaseMessages.getString(PKG, "JsonOutput.Error.OpeningFile", e.toString()));
}
return retval;
}
public String buildFilename() {
return meta.buildFilename(environmentSubstitute(meta.getFileName()), getCopy(), data.splitnr);
}
private boolean closeFile()
{
if(data.writer==null) return true;
boolean retval=false;
try
{
data.writer.close();
data.writer=null;
retval=true;
}
catch(Exception e)
{
logError(BaseMessages.getString(PKG, "JsonOutput.Error.ClosingFile", e.toString()));
setErrors(1);
retval = false;
}
return retval;
}
}<|fim▁end|> | break;
case ValueMeta.TYPE_NUMBER:
jo.put(outputField.getElementName(), data.inputRowMeta.getNumber(row, data.fieldIndexes[i])); |
<|file_name|>element.rs<|end_file_name|><|fim▁begin|>use event;
use text;
use modifier;
/// A stream representing a single element.
#[derive(Debug)]<|fim▁hole|>impl<S> SingleElement<S> {
pub(crate) fn new(stream: S, event: event::Event) -> SingleElement<S> {
SingleElement {
state: modifier::State::new(SingleElementState::Start { event, stream }),
}
}
}
impl<S> event::ElementStream for SingleElement<S> where S: event::Stream {}
impl<S> event::Stream for SingleElement<S> where S: event::Stream {
fn next_event(&mut self) -> event::StreamResult {
self.state.step(|state| match state {
SingleElementState::Start { event, stream } => match event {
event::Event(event::EventKind::OpeningTag { tag, attributes }) => Ok(Some((
event::open(tag.clone(), attributes),
Some(SingleElementState::EmitUntilClose { tag, stream, level: 0 }),
))),
event::Event(event::EventKind::SelfClosedTag { tag, attributes }) =>
Ok(Some((event::self_closed(tag, attributes), None))),
event::Event(event::EventKind::VoidTag { tag, attributes }) =>
Ok(Some((event::void(tag, attributes), None))),
other => Err(event::StreamError::expected_open(Some(other))),
},
SingleElementState::EmitUntilClose { tag, mut stream, level } => {
let event = match stream.next_event()? {
Some(event) => event,
None => return Ok(None),
};
if event.is_opening_tag_for(&tag) {
Ok(Some((event, Some(SingleElementState::EmitUntilClose {
tag,
stream,
level: level + 1,
}))))
} else if event.is_closing_tag_for(&tag) {
if level == 0 {
Ok(Some((event, None)))
} else {
Ok(Some((event, Some(SingleElementState::EmitUntilClose {
tag,
stream,
level: level - 1,
}))))
}
} else {
Ok(Some((event, Some(SingleElementState::EmitUntilClose {
tag, stream, level,
}))))
}
},
})
}
}
#[derive(Debug)]
enum SingleElementState<S> {
Start {
event: event::Event,
stream: S,
},
EmitUntilClose {
tag: text::Identifier,
stream: S,
level: usize,
},
}<|fim▁end|> | pub struct SingleElement<S> {
state: modifier::State<SingleElementState<S>>,
}
|
<|file_name|>day_05.rs<|end_file_name|><|fim▁begin|>pub fn first() {
let filename = "day05-01.txt";
let mut lines: Vec<String> = super::helpers::read_lines(filename)
.into_iter()
.map(|x| x.unwrap())
.collect();
lines.sort();
let mut max = 0;
for line in lines {
let id = get_id(&line);
if id > max {
max = id;
}
}
println!("Day 05 - 1: {}", max);
}
fn get_id(code: &str) -> i32 {
let fb = &code[0..7];
let lr = &code[7..];
let mut idx;
let mut min: i32 = 0;
let mut max: i32 = 127;<|fim▁hole|> for y in fb.chars() {
if y == 'F' {
max = max - gap / 2;
} else if y == 'B' {
min = min + gap / 2;
}
gap = max - min + 1;
println!("{} {} {}", max, min, gap);
}
idx = max * 8;
min = 0;
max = 7;
gap = max - min + 1;
for x in lr.chars() {
if x == 'L' {
max = max - gap / 2;
} else if x == 'R' {
min = min + gap / 2;
}
gap = max - min + 1;
println!("{} {} {}", max, min, gap);
}
idx += max;
println!("{}-{}", max, min);
idx
}
pub fn second() {
let filename = "day05-01.txt";
let lines: Vec<String> = super::helpers::read_lines(filename)
.into_iter()
.map(|x| x.unwrap())
.collect();
let mut ids: Vec<i32> = lines.iter().map(|x| get_id(&x)).collect();
ids.sort();
let first = ids.iter();
let mut second = ids.iter();
second.next();
let zipped = first.zip(second);
for (a, b) in zipped {
// println!("{} {}", a, b);
if b - a == 2 {
println!("Day 05 - 2: {}", b - 1);
break;
}
}
}<|fim▁end|> | let mut gap = max - min + 1;
|
<|file_name|>mod.rs<|end_file_name|><|fim▁begin|>#[cfg(feature = "backend_session")]
use std::cell::RefCell;
use std::os::unix::io::{AsRawFd, RawFd};
use std::path::PathBuf;
use std::sync::{atomic::AtomicBool, Arc};
use std::time::{Instant, SystemTime};
use calloop::{EventSource, Interest, Poll, PostAction, Readiness, Token, TokenFactory};
use drm::control::{connector, crtc, Device as ControlDevice, Event, Mode, ResourceHandles};
use drm::{ClientCapability, Device as BasicDevice, DriverCapability};
use nix::libc::dev_t;
use nix::sys::stat::fstat;
pub(super) mod atomic;
pub(super) mod legacy;
use super::surface::{atomic::AtomicDrmSurface, legacy::LegacyDrmSurface, DrmSurface, DrmSurfaceInternal};
use super::{error::Error, planes, Planes};
use atomic::AtomicDrmDevice;
use legacy::LegacyDrmDevice;
use slog::{error, info, o, trace, warn};
/// An open drm device
#[derive(Debug)]
pub struct DrmDevice<A: AsRawFd + 'static> {
pub(super) dev_id: dev_t,
pub(crate) internal: Arc<DrmDeviceInternal<A>>,
#[cfg(feature = "backend_session")]
pub(super) links: RefCell<Vec<crate::utils::signaling::SignalToken>>,
has_universal_planes: bool,
has_monotonic_timestamps: bool,
resources: ResourceHandles,
pub(super) logger: ::slog::Logger,
token: Token,
}
impl<A: AsRawFd + 'static> AsRawFd for DrmDevice<A> {
fn as_raw_fd(&self) -> RawFd {
match &*self.internal {
DrmDeviceInternal::Atomic(dev) => dev.fd.as_raw_fd(),<|fim▁hole|> }
}
impl<A: AsRawFd + 'static> BasicDevice for DrmDevice<A> {}
impl<A: AsRawFd + 'static> ControlDevice for DrmDevice<A> {}
#[derive(Debug)]
pub struct FdWrapper<A: AsRawFd + 'static> {
fd: A,
pub(super) privileged: bool,
logger: ::slog::Logger,
}
impl<A: AsRawFd + 'static> AsRawFd for FdWrapper<A> {
fn as_raw_fd(&self) -> RawFd {
self.fd.as_raw_fd()
}
}
impl<A: AsRawFd + 'static> BasicDevice for FdWrapper<A> {}
impl<A: AsRawFd + 'static> ControlDevice for FdWrapper<A> {}
impl<A: AsRawFd + 'static> Drop for FdWrapper<A> {
fn drop(&mut self) {
info!(self.logger, "Dropping device: {:?}", self.dev_path());
if self.privileged {
if let Err(err) = self.release_master_lock() {
error!(self.logger, "Failed to drop drm master state. Error: {}", err);
}
}
}
}
#[derive(Debug)]
#[allow(clippy::large_enum_variant)]
pub enum DrmDeviceInternal<A: AsRawFd + 'static> {
Atomic(AtomicDrmDevice<A>),
Legacy(LegacyDrmDevice<A>),
}
impl<A: AsRawFd + 'static> AsRawFd for DrmDeviceInternal<A> {
fn as_raw_fd(&self) -> RawFd {
match self {
DrmDeviceInternal::Atomic(dev) => dev.fd.as_raw_fd(),
DrmDeviceInternal::Legacy(dev) => dev.fd.as_raw_fd(),
}
}
}
impl<A: AsRawFd + 'static> BasicDevice for DrmDeviceInternal<A> {}
impl<A: AsRawFd + 'static> ControlDevice for DrmDeviceInternal<A> {}
impl<A: AsRawFd + 'static> DrmDevice<A> {
/// Create a new [`DrmDevice`] from an open drm node
///
/// # Arguments
///
/// - `fd` - Open drm node
/// - `disable_connectors` - Setting this to true will initialize all connectors \
/// as disabled on device creation. smithay enables connectors, when attached \
/// to a surface, and disables them, when detached. Setting this to `false` \
/// requires usage of `drm-rs` to disable unused connectors to prevent them \
/// showing garbage, but will also prevent flickering of already turned on \
/// connectors (assuming you won't change the resolution).
/// - `logger` - Optional [`slog::Logger`] to be used by this device.
///
/// # Return
///
/// Returns an error if the file is no valid drm node or the device is not accessible.
pub fn new<L>(fd: A, disable_connectors: bool, logger: L) -> Result<Self, Error>
where
A: AsRawFd + 'static,
L: Into<Option<::slog::Logger>>,
{
let log = crate::slog_or_fallback(logger).new(o!("smithay_module" => "backend_drm"));
info!(log, "DrmDevice initializing");
let dev_id = fstat(fd.as_raw_fd()).map_err(Error::UnableToGetDeviceId)?.st_rdev;
let active = Arc::new(AtomicBool::new(true));
let dev = Arc::new({
let mut dev = FdWrapper {
fd,
privileged: false,
logger: log.clone(),
};
// We want to modeset, so we better be the master, if we run via a tty session.
// This is only needed on older kernels. Newer kernels grant this permission,
// if no other process is already the *master*. So we skip over this error.
if dev.acquire_master_lock().is_err() {
warn!(log, "Unable to become drm master, assuming unprivileged mode");
} else {
dev.privileged = true;
}
dev
});
let has_universal_planes = dev
.set_client_capability(ClientCapability::UniversalPlanes, true)
.is_ok();
let has_monotonic_timestamps = dev
.get_driver_capability(DriverCapability::MonotonicTimestamp)
.unwrap_or(0)
== 1;
let resources = dev.resource_handles().map_err(|source| Error::Access {
errmsg: "Error loading resource handles",
dev: dev.dev_path(),
source,
})?;
let internal = Arc::new(DrmDevice::create_internal(
dev,
active,
disable_connectors,
log.clone(),
)?);
Ok(DrmDevice {
dev_id,
internal,
#[cfg(feature = "backend_session")]
links: RefCell::new(Vec::new()),
has_universal_planes,
has_monotonic_timestamps,
resources,
logger: log,
token: Token::invalid(),
})
}
fn create_internal(
dev: Arc<FdWrapper<A>>,
active: Arc<AtomicBool>,
disable_connectors: bool,
log: ::slog::Logger,
) -> Result<DrmDeviceInternal<A>, Error> {
let force_legacy = std::env::var("SMITHAY_USE_LEGACY")
.map(|x| {
x == "1" || x.to_lowercase() == "true" || x.to_lowercase() == "yes" || x.to_lowercase() == "y"
})
.unwrap_or(false);
if force_legacy {
info!(log, "SMITHAY_USE_LEGACY is set. Forcing LegacyDrmDevice.");
};
Ok(
if !force_legacy && dev.set_client_capability(ClientCapability::Atomic, true).is_ok() {
DrmDeviceInternal::Atomic(AtomicDrmDevice::new(dev, active, disable_connectors, log)?)
} else {
info!(log, "Falling back to LegacyDrmDevice");
DrmDeviceInternal::Legacy(LegacyDrmDevice::new(dev, active, disable_connectors, log)?)
},
)
}
/// Returns if the underlying implementation uses atomic-modesetting or not.
pub fn is_atomic(&self) -> bool {
match *self.internal {
DrmDeviceInternal::Atomic(_) => true,
DrmDeviceInternal::Legacy(_) => false,
}
}
/// Returns a list of crtcs for this device
pub fn crtcs(&self) -> &[crtc::Handle] {
self.resources.crtcs()
}
/// Returns a set of available planes for a given crtc
pub fn planes(&self, crtc: &crtc::Handle) -> Result<Planes, Error> {
planes(self, crtc, self.has_universal_planes)
}
/// Creates a new rendering surface.
///
/// # Arguments
///
/// Initialization of surfaces happens through the types provided by
/// [`drm-rs`](drm).
///
/// - [`crtcs`](drm::control::crtc) represent scanout engines of the device pointing to one framebuffer. \
/// Their responsibility is to read the data of the framebuffer and export it into an "Encoder". \
/// The number of crtc's represent the number of independent output devices the hardware may handle.
/// - [`mode`](drm::control::Mode) describes the resolution and rate of images produced by the crtc and \
/// has to be compatible with the provided `connectors`.
/// - [`connectors`](drm::control::connector) - List of connectors driven by the crtc. At least one(!) connector needs to be \
/// attached to a crtc in smithay.
pub fn create_surface(
&self,
crtc: crtc::Handle,
mode: Mode,
connectors: &[connector::Handle],
) -> Result<DrmSurface<A>, Error> {
if connectors.is_empty() {
return Err(Error::SurfaceWithoutConnectors(crtc));
}
let plane = planes(self, &crtc, self.has_universal_planes)?.primary;
let info = self.get_plane(plane).map_err(|source| Error::Access {
errmsg: "Failed to get plane info",
dev: self.dev_path(),
source,
})?;
let filter = info.possible_crtcs();
if !self.resources.filter_crtcs(filter).contains(&crtc) {
return Err(Error::PlaneNotCompatible(crtc, plane));
}
let active = match &*self.internal {
DrmDeviceInternal::Atomic(dev) => dev.active.clone(),
DrmDeviceInternal::Legacy(dev) => dev.active.clone(),
};
let internal = if self.is_atomic() {
let mapping = match &*self.internal {
DrmDeviceInternal::Atomic(dev) => dev.prop_mapping.clone(),
_ => unreachable!(),
};
DrmSurfaceInternal::Atomic(AtomicDrmSurface::new(
self.internal.clone(),
active,
crtc,
plane,
mapping,
mode,
connectors,
self.logger.clone(),
)?)
} else {
DrmSurfaceInternal::Legacy(LegacyDrmSurface::new(
self.internal.clone(),
active,
crtc,
mode,
connectors,
self.logger.clone(),
)?)
};
Ok(DrmSurface {
dev_id: self.dev_id,
crtc,
primary: plane,
internal: Arc::new(internal),
has_universal_planes: self.has_universal_planes,
#[cfg(feature = "backend_session")]
links: RefCell::new(Vec::new()),
})
}
/// Returns the device_id of the underlying drm node
pub fn device_id(&self) -> dev_t {
self.dev_id
}
}
/// Trait representing open devices that *may* return a `Path`
pub trait DevPath {
/// Returns the path of the open device if possible
fn dev_path(&self) -> Option<PathBuf>;
}
impl<A: AsRawFd> DevPath for A {
fn dev_path(&self) -> Option<PathBuf> {
use std::fs;
fs::read_link(format!("/proc/self/fd/{:?}", self.as_raw_fd())).ok()
}
}
/// Events that can be generated by a DrmDevice
#[derive(Debug)]
pub enum DrmEvent {
/// A vblank blank event on the provided crtc has happened
VBlank(crtc::Handle),
/// An error happened while processing events
Error(Error),
}
/// Timing metadata for page-flip events
#[derive(Debug)]
pub struct EventMetadata {
/// The time the frame flip happend
pub time: Time,
/// The sequence number of the frame
pub sequence: u32,
}
/// Either a realtime or monotonic timestamp
#[derive(Debug)]
pub enum Time {
/// Monotonic time stamp
Monotonic(Instant),
/// Realtime time stamp
Realtime(SystemTime),
}
impl<A> EventSource for DrmDevice<A>
where
A: AsRawFd + 'static,
{
type Event = DrmEvent;
type Metadata = Option<EventMetadata>;
type Ret = ();
fn process_events<F>(
&mut self,
_: Readiness,
token: Token,
mut callback: F,
) -> std::io::Result<PostAction>
where
F: FnMut(Self::Event, &mut Self::Metadata) -> Self::Ret,
{
if token != self.token {
return Ok(PostAction::Continue);
}
match self.receive_events() {
Ok(events) => {
for event in events {
if let Event::PageFlip(event) = event {
trace!(self.logger, "Got a page-flip event for crtc ({:?})", event.crtc);
let metadata = EventMetadata {
time: if self.has_monotonic_timestamps {
// There is no way to create an Instant, although the underlying type on unix systems
// is just libc::timespec, which is literally what drm-rs is getting from the kernel and just converting
// into a Duration. So we cheat and initialize a Zero-Instant (because although Instant::ZERO
// exists, its private, so you cannot create abitrary Instants). What we really need is a unix-Ext
// trait for both SystemTime and Instant to convert from a libc::timespec.
//
// But this works for now, although it is quite the hack.
Time::Monotonic(unsafe { std::mem::zeroed::<Instant>() } + event.duration)
} else {
Time::Realtime(SystemTime::UNIX_EPOCH + event.duration)
},
sequence: event.frame,
};
callback(DrmEvent::VBlank(event.crtc), &mut Some(metadata));
} else {
trace!(
self.logger,
"Got a non-page-flip event of device '{:?}'.",
self.dev_path()
);
}
}
}
Err(source) => {
callback(
DrmEvent::Error(Error::Access {
errmsg: "Error processing drm events",
dev: self.dev_path(),
source,
}),
&mut None,
);
}
}
Ok(PostAction::Continue)
}
fn register(&mut self, poll: &mut Poll, factory: &mut TokenFactory) -> std::io::Result<()> {
self.token = factory.token();
poll.register(self.as_raw_fd(), Interest::READ, calloop::Mode::Level, self.token)
}
fn reregister(&mut self, poll: &mut Poll, factory: &mut TokenFactory) -> std::io::Result<()> {
self.token = factory.token();
poll.reregister(self.as_raw_fd(), Interest::READ, calloop::Mode::Level, self.token)
}
fn unregister(&mut self, poll: &mut Poll) -> std::io::Result<()> {
self.token = Token::invalid();
poll.unregister(self.as_raw_fd())
}
}<|fim▁end|> | DrmDeviceInternal::Legacy(dev) => dev.fd.as_raw_fd(),
} |
<|file_name|>BillingEntity.ts<|end_file_name|><|fim▁begin|>module BillForward {
export type EntityReference = string | BillingEntity;
export class BillingEntity {
protected _client:Client;
protected _exemptFromSerialization:Array<string> = ['_client', '_exemptFromSerialization', '_registeredEntities', '_registeredEntityArrays'];
protected _registeredEntities: { [classKey:string]:typeof BillingEntity } = {};
protected _registeredEntityArrays: { [classKey:string]:typeof BillingEntity } = {};
constructor(stateParams:Object = {}, client:Client = null) {
if (!client) {
client = BillingEntity.getSingletonClient();
}
this.setClient(client);
}
getClient():Client {
return this._client;
}
setClient(client:Client):void {
this._client = client;
}
protected static resolveRoute(endpoint:string = ""):string {
var entityClass = this.getDerivedClassStatic();
var controller = entityClass.getResourcePath().getPath();
var fullRoute = Imports.util.format("%s/%s", controller, endpoint);
return fullRoute;
}
protected static makeHttpPromise(verb:string, endpoint:string, queryParams:Object, payload:Object, client:Client = null):Q.Promise<any> {
return <Q.Promise<any>>Imports.Q.Promise((resolve, reject) => {
try {
if (!client) {
client = BillingEntity.getSingletonClient();
}
var myClass = this.getDerivedClassStatic();
var fullRoute = myClass.resolveRoute(endpoint);
return resolve(client.request(verb, fullRoute, queryParams, payload));
} catch(e) {
return reject(e);
}
});<|fim▁hole|> }
protected static makeGetPromise(endpoint:string, queryParams:Object, client:Client = null) {
return <Q.Promise<Array<BillingEntity>>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
return resolve(myClass.makeHttpPromise("GET", endpoint, queryParams, null, client));
} catch(e) {
return reject(e);
}
});
}
protected static makePutPromise(endpoint:string, queryParams:Object, payload:Object, client:Client = null) {
return <Q.Promise<Array<BillingEntity>>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
return resolve(myClass.makeHttpPromise("PUT", endpoint, queryParams, payload, client));
} catch(e) {
return reject(e);
}
});
}
protected static makePostPromise(endpoint:string, queryParams:Object, payload:Object, client:Client = null) {
return <Q.Promise<Array<BillingEntity>>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
return resolve(myClass.makeHttpPromise("POST", endpoint, queryParams, payload, client));
} catch(e) {
return reject(e);
}
});
}
protected static postEntityAndGrabFirst(endpoint:string, queryParams:Object, entity:BillingEntity, client:Client = null, responseEntity:BillingEntity = null) {
return <Q.Promise<BillingEntity>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
var serial = entity.serialize();
return resolve(myClass.postAndGrabFirst(endpoint, queryParams, serial, client, responseEntity));
} catch(e) {
return reject(e);
}
});
}
protected static postEntityAndGrabCollection(endpoint:string, queryParams:Object, entity:BillingEntity, client:Client = null, responseEntity:BillingEntity = null) {
return <Q.Promise<Array<BillingEntity>>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
var serial = entity.serialize();
return resolve(myClass.postAndGrabCollection(endpoint, queryParams, serial, client, responseEntity));
} catch(e) {
return reject(e);
}
});
}
protected static postAndGrabFirst(endpoint:string, queryParams:Object, payload:Object, client:Client = null, responseEntity:BillingEntity = null) {
return <Q.Promise<BillingEntity>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
var responseClass = responseEntity.getDerivedClass();
return resolve(
myClass.makePostPromise(endpoint, queryParams, payload, client)
.then(payload => {
return responseClass.getFirstEntityFromResponse(payload, client);
})
);
} catch(e) {
return reject(e);
}
});
}
protected static postAndGrabCollection(endpoint:string, queryParams:Object, payload:Object, client:Client = null, responseEntity:BillingEntity = null) {
return <Q.Promise<Array<BillingEntity>>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
var responseClass = responseEntity.getDerivedClass();
return resolve(
myClass.makePostPromise(endpoint, queryParams, payload, client)
.then(payload => {
return responseClass.getAllEntitiesFromResponse(payload, client);
})
);
} catch(e) {
return reject(e);
}
});
}
protected static getAndGrabFirst(endpoint:string, queryParams:Object, client:Client = null, responseEntity:BillingEntity = null) {
return <Q.Promise<BillingEntity>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
var responseClass = responseEntity ? responseEntity.getDerivedClass() : myClass;
return resolve(
myClass.makeGetPromise(endpoint, queryParams, client)
.then(payload => {
return responseClass.getFirstEntityFromResponse(payload, client);
})
);
} catch(e) {
return reject(e);
}
});
}
protected static getAndGrabCollection(endpoint:string, queryParams:Object, client:Client = null, responseEntity:BillingEntity = null) {
return <Q.Promise<Array<BillingEntity>>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
var responseClass = responseEntity ? responseEntity.getDerivedClass() : myClass;
return resolve(
myClass.makeGetPromise(endpoint, queryParams, client)
.then(payload => {
return responseClass.getAllEntitiesFromResponse(payload, client);
})
);
} catch(e) {
return reject(e);
}
});
}
static getByID(id:string, queryParams:Object = {}, client:Client = null) {
return <Q.Promise<BillingEntity>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
var endpoint = Imports.util.format("%s", encodeURIComponent(id));
return resolve(myClass.getAndGrabFirst(endpoint, queryParams, client));
} catch(e) {
return reject(e);
}
});
}
static getAll(queryParams:Object = {}, client:Client = null) {
return <Q.Promise<Array<BillingEntity>>>Imports.Q.Promise((resolve, reject) => {
try {
var myClass = this.getDerivedClassStatic();
var endpoint = "";
return resolve(myClass.getAndGrabCollection(endpoint, queryParams, client));
} catch(e) {
return reject(e);
}
});
}
static getResourcePath() {
return this.getDerivedClassStatic()._resourcePath;
}
static getSingletonClient():Client {
return Client.getDefaultClient();;
}
static getDerivedClassStatic():any {
return <any>this;
}
protected registerEntity(key:string, entityClass:typeof BillingEntity) {
this._registeredEntities[key] = entityClass;
}
protected registerEntityArray(key:string, entityClass:typeof BillingEntity) {
this._registeredEntityArrays[key] = entityClass;
}
getDerivedClass():any {
return (<any>this).constructor;
}
static serializeProperty(value:any):any {
// if (!value) return false;
if (value instanceof Array) {
return Imports._.map(value, BillingEntity.serializeProperty);
}
if (value instanceof BillingEntity) {
return value.serialize();
}
return value;
}
serialize():Object {
var pruned = Imports._.omit(this, this._exemptFromSerialization);
var pruned = Imports._.omit(pruned, function(property) {
return property instanceof Function;
});
var serialized = Imports._.mapValues(pruned, BillingEntity.serializeProperty);
return serialized;
}
toString() : string {
return JSON.stringify(this.serialize(), null, "\t");
}
protected unserialize(json:Object) {
for (var key in json) {
var value = json[key];
this.addToEntity(key, value);
}
}
protected addToEntity(key:string, value:any) {
var unserializedValue:any;
if (Imports._.has(this._registeredEntities, key)) {
var entityClass = this._registeredEntities[key];
unserializedValue = this.buildEntity(entityClass, value);
} else if (Imports._.includes(this._registeredEntityArrays, key)) {
var entityClass = this._registeredEntityArrays[key];
unserializedValue = this.buildEntityArray(entityClass, value);
} else {
// JSON or primitive
unserializedValue = value;
}
this[key] = unserializedValue;
}
protected buildEntity(entityClass:typeof BillingEntity, constructArgs:any):BillingEntity {
if (constructArgs instanceof entityClass) {
// the entity has already been constructed!
return constructArgs;
}
var constructArgsType = typeof constructArgs;
if (constructArgsType !== 'object') {
throw new BFInvocationError(Imports.util.format("Expected either a property map or an entity of type '%s'. Instead received: '%s'; %s", entityClass, constructArgsType, constructArgs));
}
var client = this.getClient();
var newEntity:BillingEntity = entityClass.makeEntityFromPayload(constructArgs, client);
return newEntity;
}
protected buildEntityArray(entityClass:typeof BillingEntity, constructArgs:Array<any>):Array<BillingEntity> {
var client = this.getClient();
var entities = Imports._.map(constructArgs, this.buildEntity);
return entities;
}
protected static getFirstEntityFromResponse(payload:any, client:Client):BillingEntity {
if (!payload.results || payload.results.length === undefined || payload.results.length === null)
throw new BFMalformedAPIResponseError("Received malformed response from API.");
if (payload.results.length<1)
throw new BFNoResultsError("No results returned upon API request.");
var entity:BillingEntity;
var results = payload.results;
var assumeFirst = results[0];
var stateParams = assumeFirst;
var entityClass = this.getDerivedClassStatic();
entity = entityClass.makeEntityFromPayload(stateParams, client);
if (!entity)
throw new BFResponseUnserializationFailure("Failed to unserialize API response into entity.");
return entity;
}
protected static getAllEntitiesFromResponse(payload:any, client:Client): Array<BillingEntity> {
if (!payload.results || payload.results.length === undefined || payload.results.length === null)
throw new BFMalformedAPIResponseError("Received malformed response from API.");
if (payload.results.length<1)
throw new BFNoResultsError("No results returned upon API request.");
var entities:Array<BillingEntity>;
var results = payload.results;
entities = Imports._.map(results, (value:Object):any => {
var entityClass = this.getDerivedClassStatic();
var entity = entityClass.makeEntityFromPayload(value, client);
if (!entity)
throw new BFResponseUnserializationFailure("Failed to unserialize API response into entity.");
return entity;
});
if (!entities)
throw new BFResponseUnserializationFailure("Failed to unserialize API response into entity.");
return entities;
}
protected static makeEntityFromPayload(payload:Object, client:Client):BillingEntity {
var entityClass = this.getDerivedClassStatic();
return new entityClass(payload, client);
}
/**
* Fetches (if necessary) entity by ID from API.
* Otherwise returns entity as-is.
* @param mixed ENUM[string id, BillingEntity entity] Reference to the entity. <id>: Fetches entity by ID. <entity>: Returns entity as-is.
* @return Q.Promise<static> The gotten entity.
*/
static fetchIfNecessary(entityReference: EntityReference): Q.Promise<BillingEntity> {
return <Q.Promise<BillingEntity>>Imports.Q.Promise((resolve, reject) => {
try {
var entityClass = this.getDerivedClassStatic();
if (typeof entityReference === "string") {
// fetch entity by ID
return resolve(entityClass.getByID(entityReference));
}
if (<any>entityReference instanceof entityClass) {
// is already a usable entity
return resolve(<any>entityReference);
}
throw new BFInvocationError("Cannot fetch entity; referenced entity is neither an ID, nor an object extending the desired entity class.");
} catch (e) {
return reject(e);
}
});
}
/**
* Get ID of referenced entity.
* @param EntityReference Reference to the entity. <string>: ID of the entity. <BillingEntity>: Entity object, from whom an ID can be extracted.
* @return static The gotten entity.
*/
static getIdentifier(entityReference: EntityReference): string {
if (typeof entityReference === "string") {
// is already an ID; we're done here.
return entityReference;
}
var entityClass = this.getDerivedClassStatic();
if (<any>entityReference instanceof entityClass) {
return (<any>entityReference).id;
}
throw new BFInvocationError("Cannot get identifier of referenced entity; referenced entity is neither an ID, nor an object extending the desired entity class.");
}
static makeBillForwardDate(date:Date) {
var asISO = date.toISOString();
var removeMilli = asISO.slice(0, -5)+"Z";
return removeMilli;
}
static getBillForwardNow() {
var now = new Date();
var entityClass = this.getDerivedClassStatic();
return entityClass.makeBillForwardDate(now);
}
}
}<|fim▁end|> | |
<|file_name|>background.py<|end_file_name|><|fim▁begin|>import tornado.web
from datetime import date
from sqlalchemy.orm.exc import NoResultFound
from pyprint.handler import BaseHandler
from pyprint.models import User, Link, Post
class SignInHandler(BaseHandler):
def get(self):
return self.background_render('login.html')
def post(self):
username = self.get_argument('username', None)
password = self.get_argument('password', None)
if username and password:
try:
user = self.orm.query(User).filter(User.username == username).one()
except NoResultFound:
return self.redirect('/login')
if user.check(password):
self.set_secure_cookie('username', user.username)
self.redirect('/kamisama/posts')
return self.redirect('/login')
class ManagePostHandler(BaseHandler):
@tornado.web.authenticated
def get(self):
posts = self.orm.query(Post.title, Post.id).order_by(Post.id.desc()).all()
self.background_render('posts.html', posts=posts)
@tornado.web.authenticated
def post(self):
action = self.get_argument('action', None)
if action == 'del':
post_id = self.get_argument('id', 0)
if post_id:
post = self.orm.query(Post).filter(Post.id == post_id).one()
self.orm.delete(post)
self.orm.commit()
class AddPostHandler(BaseHandler):
@tornado.web.authenticated
def get(self):
self.background_render('add_post.html', post=None)
@tornado.web.authenticated
def post(self):
title = self.get_argument('title', None)
content = self.get_argument('content', None)<|fim▁hole|> post = self.orm.query(Post.title).filter(Post.title == title).all()
if post:
return self.write('<script>alert("Title has already existed");window.history.go(-1);</script>')
self.orm.add(Post(title=title, content=content, created_time=date.today()))
self.orm.commit()
return self.redirect('/kamisama/posts')
class AddLinkHandler(BaseHandler):
@tornado.web.authenticated
def get(self):
links = self.orm.query(Link).all()
self.background_render('links.html', links=links)
@tornado.web.authenticated
def post(self):
action = self.get_argument('action', None)
if action == 'add':
name = self.get_argument('name', '')
url = self.get_argument('url', '')
if not name or not url:
return self.redirect('/kamisama/links')
self.orm.add(Link(name=name, url=url))
self.orm.commit()
return self.redirect('/kamisama/links')
elif action == 'del':
link_id = self.get_argument('id', 0)
if link_id:
link = self.orm.query(Link).filter(Link.id == link_id).one()
self.orm.delete(link)
self.orm.commit()<|fim▁end|> | tags = self.get_argument('tags', '').strip().split(',')
if not title or not content:
return self.redirect('/kamisama/posts/add')
|
<|file_name|>comment-douyu.py<|end_file_name|><|fim▁begin|>import socket
import time
import random
import threading
import re
import json
import sys
import os
import platform
import notify2
from urllib import request
g_rid= b'265352'
g_username= b'visitor42'
g_ip= b'danmu.douyutv.com'
g_port= 8601
g_gid= b'0'
g_exit= False
sysinfo = platform.system()<|fim▁hole|># notify2.init('douyu')
# notify2.Notification(title, message).show()
else:
t = '-title {!r}'.format(title)
m = '-message {!r}'.format(message)
os.system('terminal-notifier {}'.format(' '.join([m, t])))
def is_exit():
global g_exit
return g_exit
def cast_wetght(g):
g= int(g)
if g>1e6:
return str(round(g/1e6,2))+'t'
elif g>1e3:
return str(round(g/1e3,2))+'kg'
else:
return str(g)+'g'
def sendmsg(s,msg,code=689):
data_length= len(msg)+8
s.send(int.to_bytes(data_length,4,'little'))
s.send(int.to_bytes(data_length,4,'little'))
s.send(int.to_bytes(code,4,'little'))
sent=0
while sent<len(msg):
tn= s.send(msg[sent:])
sent= sent + tn
def recvmsg(s):
bdata_length= s.recv(12)
data_length= int.from_bytes(bdata_length[:4],'little')-8
if data_length<=0:
print('badlength',bdata_length)
return None
total_data=[]
while True:
msg= s.recv(data_length)
if not msg: break
data_length= data_length - len(msg)
total_data.append(msg)
ret= b''.join(total_data)
return ret
def unpackage(data):
ret={}
lines= data.split(b'/')
lines.pop() # pop b''
for line in lines:
kv= line.split(b'@=')
if len(kv)==2:
ret[kv[0]]= kv[1].replace(b'@S',b'/').replace(b'@A',b'@')
else:
ret[len(ret)]= kv[0].replace(b'@S',b'/').replace(b'@A',b'@')
return ret
def unpackage_list(l):
ret=[]
lines= l.split(b'@S')
for line in lines:
line= line.replace(b'@AA',b'')
mp= line.split(b'@AS')
tb={}
for kv in mp:
try:
k,v= kv.split(b'=')
tb[k]=v
except:
pass
ret.append(tb)
return ret
def get_longinres(s_ip=b'117.79.132.20', s_port=8001, rid=b'265352'):
s= socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((s_ip, int(s_port)))
sendmsg(s,b'type@=loginreq/username@=/password@=/roomid@='+rid+b'/\x00')
print('==========longinres')
longinres= unpackage(recvmsg(s))
#print('==========msgrepeaterlist')
msgrepeaterlist= unpackage(recvmsg(s))
lst= unpackage(msgrepeaterlist[b'list'])
tb= unpackage(random.choice(tuple(lst.values())))
#print('==========setmsggroup')
setmsggroup= unpackage(recvmsg(s))
ret= {'rid':rid,
'username': longinres[b'username'],
'ip': tb[b'ip'],
'port': tb[b'port'],
'gid': setmsggroup[b'gid']
}
def keepalive_send():
while not is_exit():
sendmsg(s,b'type@=keeplive/tick@='+str(random.randint(1,99)).encode('ascii')+b'/\x00')
time.sleep(45)
s.close()
threading.Thread(target=keepalive_send).start()
def keepalive_recv():
while not is_exit():
bmsg= recvmsg(s)
print('*** usr alive:',unpackage(bmsg),'***')
s.close()
threading.Thread(target=keepalive_recv).start()
return ret
def get_danmu(rid=b'5275', ip=b'danmu.douyutv.com', port=8001, username=b'visitor42', gid=b'0'):
"args needs bytes not str"
print('==========danmu')
s= socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((ip,int(port)))
sendmsg(s,b'type@=loginreq/username@='+username+b'/password@=1234567890123456/roomid@='+rid+b'/\x00')
loginres= unpackage(recvmsg(s))
sendmsg(s,b'type@=joingroup/rid@='+rid+b'/gid@='+gid+b'/\x00')
def keepalive():
while not is_exit():
sendmsg(s,b'type@=keeplive/tick@='+str(random.randint(1,99)).encode('ascii')+b'/\x00')
time.sleep(45)
s.close()
threading.Thread(target=keepalive).start()
while True:
bmsg= recvmsg(s)
if not bmsg:
print('*** connection break ***')
global g_exit
g_exit= True
break
msg= unpackage(bmsg)
msgtype= msg.get(b'type',b'undefined')
if msgtype==b'chatmessage':
nick= msg[b'snick'].decode('utf8')
content= msg.get(b'content',b'undefined').decode('utf8')
print(nick, ': ', content)
notify(nick, content)
elif msgtype==b'donateres':
sui= unpackage(msg.get(b'sui',b'nick@=undifined//00'))
nick= sui[b'nick'].decode('utf8')
print('***', nick, '送给主播', int(msg[b'ms']),\
'个鱼丸 (', cast_wetght(msg[b'dst_weight']), ') ***')
notify(nick, '送给主播' + str(int(msg[b'ms'])) + '个鱼丸')
elif msgtype==b'keeplive':
print('*** dm alive:',msg,'***')
elif msgtype in (b'userenter'):
pass
else:
print(msg)
###########from common.py
def match1(text, *patterns):
"""Scans through a string for substrings matched some patterns (first-subgroups only).
Args:
text: A string to be scanned.
patterns: Arbitrary number of regex patterns.
Returns:
When only one pattern is given, returns a string (None if no match found).
When more than one pattern are given, returns a list of strings ([] if no match found).
"""
if len(patterns) == 1:
pattern = patterns[0]
match = re.search(pattern, text)
if match:
return match.group(1)
else:
return None
else:
ret = []
for pattern in patterns:
match = re.search(pattern, text)
if match:
ret.append(match.group(1))
return ret
def get_content(url, headers={}, decoded=True, cookies_txt=''):
"""Gets the content of a URL via sending a HTTP GET request.
Args:
url: A URL.
headers: Request headers used by the client.
decoded: Whether decode the response body using UTF-8 or the charset specified in Content-Type.
Returns:
The content as a string.
"""
req = request.Request(url, headers=headers)
if cookies_txt:
cookies_txt.add_cookie_header(req)
req.headers.update(req.unredirected_hdrs)
response = request.urlopen(req)
data = response.read()
# Handle HTTP compression for gzip and deflate (zlib)
content_encoding = response.getheader('Content-Encoding')
if content_encoding == 'gzip':
data = ungzip(data)
elif content_encoding == 'deflate':
data = undeflate(data)
# Decode the response body
if decoded:
charset = match1(response.getheader('Content-Type'), r'charset=([\w-]+)')
if charset is not None:
data = data.decode(charset)
else:
data = data.decode('utf-8')
return data
###########from util/strings.py
try:
# py 3.4
from html import unescape as unescape_html
except ImportError:
import re
from html.entities import entitydefs
def unescape_html(string):
'''HTML entity decode'''
string = re.sub(r'&#[^;]+;', _sharp2uni, string)
string = re.sub(r'&[^;]+;', lambda m: entitydefs[m.group(0)[1:-1]], string)
return string
def _sharp2uni(m):
'''&#...; ==> unicode'''
s = m.group(0)[2:].rstrip(';;')
if s.startswith('x'):
return chr(int('0'+s, 16))
else:
return chr(int(s))
##########
def get_room_info(url):
print('==========room')
html = get_content(url)
room_id_patt = r'"room_id":(\d{1,99}),'
title_patt = r'<div class="headline clearfix">\s*<h1>([^<]{1,9999})</h1>'
title_patt_backup = r'<title>([^<]{1,9999})</title>'
roomid = match1(html,room_id_patt)
title = match1(html,title_patt) or match1(html,title_patt_backup)
title = unescape_html(title)
conf = get_content("http://www.douyutv.com/api/client/room/"+roomid)
metadata = json.loads(conf)
servers= metadata['data']['servers']
dest_server= servers[0]
return {'s_ip': dest_server['ip'],
's_port': dest_server['port'],
'rid': metadata['data']['room_id'].encode()
}
print(metadata)
def main(url='http://www.douyutv.com/xtd'):
login_user_info= get_room_info(url)
print('login_user_info:', login_user_info)
login_room_info= get_longinres(**login_user_info)
print('login_room_info', login_room_info)
get_danmu(**login_room_info)
if __name__=='__main__':
url= sys.argv[1] if len(sys.argv)>1 else 'http://www.douyutv.com/zeek'
main(url)<|fim▁end|> |
def notify(title, message):
if sysinfo == 'Linux':
os.system('notify-send {}'.format(': '.join([title, message]))) |
<|file_name|>app.e2e-spec.ts<|end_file_name|><|fim▁begin|>import { AppPage } from './app.po';<|fim▁hole|> let page: AppPage;
beforeEach(() => {
page = new AppPage();
});
it('should display welcome message', () => {
page.navigateTo();
expect(page.getParagraphText()).toEqual('Welcome to app!');
});
});<|fim▁end|> |
describe('avam-sp App', () => { |
<|file_name|>manipulating_objects.js<|end_file_name|><|fim▁begin|>// Manipulating JavaScript Objects
// I worked on this challenge: [by myself, with: ]
// There is a section below where you will write your code.
// DO NOT ALTER THIS OBJECT BY ADDING ANYTHING WITHIN THE CURLY BRACES!
var terah = {
name: "Terah",
age: 32,
height: 66,
weight: 130,
hairColor: "brown",
eyeColor: "brown"
}
// __________________________________________
// Write your code below.
var adam = {
}
adam.name = "Adam";
terah.spouse = adam;
terah.weight = 125;
delete terah.eyeColor;
adam.spouse = terah;
terah.children = new Object();
var carson = {
name: "Carson",
}
terah.children.carson = carson;
var carter = {
name: "Carter",
}
terah.children.carter = carter;
var colton = {
name: "Colton",
}
terah.children.colton = colton;
adam.children = terah.children;
// __________________________________________
// Reflection: Use the reflection guidelines
/*
What tests did you have trouble passing? What did you do to make
it pass? Why did that work?
There were two tests that I had difficulty with, the first was
assigning terah a spouse. This was mainly because I had misread
the instructions and I was passing terah adam.name and not the
object adam. The second was assigning carson to terah.children,
again this ending up being more a confusion with the instructions
and I failed to initially create carson as a property of
terah.children. Once I realized the mistake, I passed the tests
and moved on.
How difficult was it to add and delete properties outside of the
object itself?
It was easy for the most part and I just needed to spend more
time reading the directions and figuring out what was being asked.
What did you learn about manipulating objects in this challenge?
I started this challenge before finishing 7.2 Eloquent
JavaScript, having only completed the Codecademy JavaScript
track. So I had to do some research on deleting a property. Other
than that, it was mostly things I had already covered.
*/
// __________________________________________
// Driver Code: Do not alter code below this line.
function assert(test, message, test_number) {
if (!test) {
console.log(test_number + "false");
throw "ERROR: " + message;
}
console.log(test_number + "true");
return true;
}
assert(
(adam instanceof Object),
"The value of adam should be an Object.",
"1. "
)
assert(
(adam.name === "Adam"),
"The value of the adam name property should be 'Adam'.",
"2. "
)
assert(
terah.spouse === adam,
"terah should have a spouse property with the value of the object adam.",
"3. "
)
assert(
terah.weight === 125,
"The terah weight property should be 125.",
"4. "
)<|fim▁hole|> terah.eyeColor === undefined || null,
"The terah eyeColor property should be deleted.",
"5. "
)
assert(
terah.spouse.spouse === terah,
"Terah's spouse's spouse property should refer back to the terah object.",
"6. "
)
assert(
(terah.children instanceof Object),
"The value of the terah children property should be defined as an Object.",
"7. "
)
assert(
(terah.children.carson instanceof Object),
"carson should be defined as an object and assigned as a child of Terah",
"8. "
)
assert(
terah.children.carson.name === "Carson",
"Terah's children should include an object called carson which has a name property equal to 'Carson'.",
"9. "
)
assert(
(terah.children.carter instanceof Object),
"carter should be defined as an object and assigned as a child of Terah",
"10. "
)
assert(
terah.children.carter.name === "Carter",
"Terah's children should include an object called carter which has a name property equal to 'Carter'.",
"11. "
)
assert(
(terah.children.colton instanceof Object),
"colton should be defined as an object and assigned as a child of Terah",
"12. "
)
assert(
terah.children.colton.name === "Colton",
"Terah's children should include an object called colton which has a name property equal to 'Colton'.",
"13. "
)
assert(
adam.children === terah.children,
"The value of the adam children property should be equal to the value of the terah children property",
"14. "
)
console.log("\nHere is your final terah object:")
console.log(terah)<|fim▁end|> |
assert( |
<|file_name|>header.ts<|end_file_name|><|fim▁begin|>export class Header {
readonly title: string;
readonly link: string;
active: boolean;
viewing: boolean;
}
export enum HeaderTitles {
HOME = 'Home',
OUR_STORY = 'Our Story',
DETAILS = 'Details',
RSVP = 'RSVP',
MIAMI = 'Miami',
PHOTOS = 'Photos',
REGISTRY = 'Registry',
CONTACT = 'Contact',
}
export enum HeaderLinks {
HOME = '/home',<|fim▁hole|> DETAILS = '/details',
RSVP = '/rsvp',
MIAMI = '/miami',
PHOTOS = '/photos',
REGISTRY = '/registry',
CONTACT = '/contact',
}<|fim▁end|> | OUR_STORY = '/our-story', |
<|file_name|>mod.rs<|end_file_name|><|fim▁begin|>// Copyright 2015 The Rust Project Developers. See the COPYRIGHT
// file at the top-level directory of this distribution and at
// http://rust-lang.org/COPYRIGHT.
//
// Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or
// http://www.apache.org/licenses/LICENSE-2.0> or the MIT license
// <LICENSE-MIT or http://opensource.org/licenses/MIT>, at your
// option. This file may not be copied, modified, or distributed<|fim▁hole|>
#![unstable(feature = "raw_ext", reason = "recently added API")]
pub mod raw;
pub mod fs {
pub use sys::fs::MetadataExt;
}<|fim▁end|> | // except according to those terms.
//! Android-specific definitions |
<|file_name|>byte_vs_string_obj.py<|end_file_name|><|fim▁begin|>a = 'GeeksforGeeks'
# initialising a byte object
c = b'GeeksforGeeks'
# using encode() to encode the String
# encoded version of a is stored in d
# using ASCII mapping
d = a.encode('ASCII')
# checking if a is converted to bytes or not
if (d==c):
print ("Encoding successful")
else : print ("Encoding Unsuccessful")
# initialising a String
a = 'GeeksforGeeks'
# initialising a byte object
c = b'GeeksforGeeks'
# using decode() to decode the Byte object
# decoded version of c is stored in d
# using ASCII mapping
d = c.decode('ASCII')
# checking if c is converted to String or not
if (d==a):<|fim▁hole|>else : print ("Decoding Unsuccessful")<|fim▁end|> | print ("Decoding successful") |
<|file_name|>jut_run_tests.py<|end_file_name|><|fim▁begin|>"""
basic set of `jut run` tests
"""
import json
import unittest
from tests.util import jut
BAD_PROGRAM = 'foo'
BAD_PROGRAM_ERROR = 'Error line 1, column 1 of main: Error: no such sub: foo'
class JutRunTests(unittest.TestCase):
def test_jut_run_syntatically_incorrect_program_reports_error_with_format_json(self):
"""
verify an invalid program reports the failure correctly when using json
output format
"""
process = jut('run', BAD_PROGRAM, '-f', 'json')
process.expect_status(255)
process.expect_error(BAD_PROGRAM_ERROR)
def test_jut_run_syntatically_incorrect_program_reports_error_with_format_text(self):
"""
verify an invalid program reports the failure correctly when using text
output format
"""
process = jut('run', BAD_PROGRAM, '-f', 'text')
process.expect_status(255)
process.expect_error(BAD_PROGRAM_ERROR)
def test_jut_run_syntatically_incorrect_program_reports_error_with_format_csv(self):
"""
verify an invalid program reports the failure correctly when using csv
output format
"""
process = jut('run', BAD_PROGRAM, '-f', 'json')
process.expect_status(255)
process.expect_error(BAD_PROGRAM_ERROR)
def test_jut_run_emit_to_json(self):
"""
use jut to run the juttle program:
emit -from :2014-01-01T00:00:00.000Z: -limit 5
and verify the output is in the expected JSON format
"""
process = jut('run',
'emit -from :2014-01-01T00:00:00.000Z: -limit 5')
process.expect_status(0)<|fim▁hole|>
self.assertEqual(points,
[
{'time': '2014-01-01T00:00:00.000Z'},
{'time': '2014-01-01T00:00:01.000Z'},
{'time': '2014-01-01T00:00:02.000Z'},
{'time': '2014-01-01T00:00:03.000Z'},
{'time': '2014-01-01T00:00:04.000Z'}
])
def test_jut_run_emit_to_text(self):
"""
use jut to run the juttle program:
emit -from :2014-01-01T00:00:00.000Z: -limit 5
and verify the output is in the expected text format
"""
process = jut('run',
'--format', 'text',
'emit -from :2014-01-01T00:00:00.000Z: -limit 5')
process.expect_status(0)
stdout = process.read_output()
process.expect_eof()
self.assertEqual(stdout, '2014-01-01T00:00:00.000Z\n'
'2014-01-01T00:00:01.000Z\n'
'2014-01-01T00:00:02.000Z\n'
'2014-01-01T00:00:03.000Z\n'
'2014-01-01T00:00:04.000Z\n')
def test_jut_run_emit_to_csv(self):
"""
use jut to run the juttle program:
emit -from :2014-01-01T00:00:00.000Z: -limit 5
and verify the output is in the expected csv format
"""
process = jut('run',
'--format', 'csv',
'emit -from :2014-01-01T00:00:00.000Z: -limit 5')
process.expect_status(0)
stdout = process.read_output()
process.expect_eof()
self.assertEqual(stdout, '#time\n'
'2014-01-01T00:00:00.000Z\n'
'2014-01-01T00:00:01.000Z\n'
'2014-01-01T00:00:02.000Z\n'
'2014-01-01T00:00:03.000Z\n'
'2014-01-01T00:00:04.000Z\n')<|fim▁end|> | points = json.loads(process.read_output())
process.expect_eof() |
<|file_name|>Map.Control.js<|end_file_name|><|fim▁begin|>L.Map.include({
addControl: function (control) {
control.addTo(this);
return this;
},
removeControl: function (control) {
control.removeFrom(this);
return this;
},
_initControlPos: function () {<|fim▁hole|> l = 'leaflet-',
container = this._controlContainer =
L.DomUtil.create('div', l + 'control-container', this._container);
function createCorner(vSide, hSide) {
var className = l + vSide + ' ' + l + hSide;
corners[vSide + hSide] =
L.DomUtil.create('div', className, container);
}
createCorner('top', 'left');
createCorner('top', 'right');
createCorner('bottom', 'left');
createCorner('bottom', 'right');
}
});<|fim▁end|> | var corners = this._controlCorners = {}, |
<|file_name|>Paddle.js<|end_file_name|><|fim▁begin|>/*
* This class represent a game paddle
*/
'use strict';
import Vector from 'Vector.js';
export default class {
constructor(x, y, width, height, color = '#FFFFFF', speed = 3) {
this.width = width;
this.height = height;
this.color = color;
<|fim▁hole|> this.position = new Vector(x, y);
this.velocity = new Vector(speed, 0);
this.computer = false;
// Control keys.
this.rightPressed = false;
this.leftPressed = false;
}
// Setting the paddle to a specific position.
setPosition(x, y) {
this.position.setCoordinates(x, y);
}
move(doMove) {
if (this.rightPressed || this.leftPressed) {
if (this.rightPressed) {
this.velocity.x = Math.abs(this.velocity.x);
} else if (this.leftPressed) {
this.velocity.x = -Math.abs(this.velocity.x);
}
if (doMove) {
this.position.add(this.velocity);
}
}
}
// Returns relevant drawing information related to
// the paddle.
getDrawInfo() {
return {
drawType: 'rect',
color: this.color,
params: [
this.position.x,
this.position.y,
this.width,
this.height
]
};
}
}<|fim▁end|> | |
<|file_name|>test_jsonrpc.py<|end_file_name|><|fim▁begin|>#
# This file is part of Gruvi. Gruvi is free software available under the
# terms of the MIT license. See the file "LICENSE" that was provided
# together with this source file for the licensing terms.
#
# Copyright (c) 2012-2017 the Gruvi authors. See the file "AUTHORS" for a
# complete list.
from __future__ import absolute_import, print_function
import os
import json
import unittest
import six
import gruvi
from gruvi import jsonrpc
from gruvi.jsonrpc import JsonRpcError, JsonRpcVersion
from gruvi.jsonrpc import JsonRpcProtocol, JsonRpcClient, JsonRpcServer
from gruvi.jsonrpc_ffi import ffi as _ffi, lib as _lib
from gruvi.transports import TransportError
from support import UnitTest, MockTransport
_keepalive = None
def set_buffer(ctx, buf):
global _keepalive # See note in JsonRpcProtocol
_keepalive = ctx.buf = _ffi.from_buffer(buf)
ctx.buflen = len(buf)
ctx.offset = 0
def split_string(s):
ctx = _ffi.new('struct split_context *')
set_buffer(ctx, s)
_lib.json_split(ctx)
return ctx
JsonRpcProtocol.default_version = '1.0'
class TestJsonSplitter(UnitTest):
def test_simple(self):
r = b'{ "foo": "bar" }'
ctx = split_string(r)
self.assertEqual(ctx.error, 0)
self.assertEqual(ctx.offset, len(r))
def test_leading_whitespace(self):
r = b' { "foo": "bar" }'
ctx = split_string(r)
self.assertEqual(ctx.error, 0)
self.assertEqual(ctx.offset, len(r))
r = b' \t\n{ "foo": "bar" }'
ctx = split_string(r)
self.assertEqual(ctx.error, 0)
self.assertEqual(ctx.offset, len(r))
def test_trailing_whitespace(self):
r = b'{ "foo": "bar" } '
ctx = split_string(r)
self.assertEqual(ctx.error, 0)
self.assertEqual(ctx.offset, len(r)-1)
error = _lib.json_split(ctx)
self.assertEqual(error, ctx.error) == _lib.INCOMPLETE
self.assertEqual(ctx.offset, len(r))
def test_brace_in_string(self):
r = b'{ "foo": "b{r" }'
ctx = split_string(r)
self.assertEqual(ctx.error, 0)
self.assertEqual(ctx.offset, len(r))
r = b'{ "foo": "b}r" }'
ctx = split_string(r)
self.assertEqual(ctx.error, 0)
self.assertEqual(ctx.offset, len(r))
def test_string_escape(self):
r = b'{ "foo": "b\\"}" }'
ctx = split_string(r)
self.assertEqual(ctx.error, 0)
self.assertEqual(ctx.offset, len(r))
def test_error(self):
r = b' x { "foo": "bar" }'
ctx = split_string(r)
self.assertEqual(ctx.error, _lib.ERROR)
self.assertEqual(ctx.offset, 1)
r = b'[ { "foo": "bar" } ]'
ctx = split_string(r)
self.assertEqual(ctx.error, _lib.ERROR)
self.assertEqual(ctx.offset, 0)
def test_multiple(self):
r = b'{ "foo": "bar" } { "baz": "qux" }'
ctx = split_string(r)
self.assertEqual(ctx.error, 0)
self.assertEqual(ctx.offset, 16)
error = _lib.json_split(ctx)
self.assertEqual(error, ctx.error) == 0
self.assertEqual(ctx.offset, len(r))
def test_incremental(self):
r = b'{ "foo": "bar" }'
ctx = _ffi.new('struct split_context *')
for i in range(len(r)-1):
set_buffer(ctx, r[i:i+1])
error = _lib.json_split(ctx)
self.assertEqual(error, ctx.error) == _lib.INCOMPLETE
self.assertEqual(ctx.offset, 1)
set_buffer(ctx, r[-1:])
error = _lib.json_split(ctx)
self.assertEqual(error, ctx.error) == 0
self.assertEqual(ctx.offset, 1)
class TestJsonRpcV1(UnitTest):
def setUp(self):
super(TestJsonRpcV1, self).setUp()
self.version = JsonRpcVersion.create('1.0')
def test_check_request(self):
v = self.version
msg = {'id': 1, 'method': 'foo', 'params': []}
self.assertEqual(v.check_message(msg), jsonrpc.REQUEST)
msg = {'id': None, 'method': 'foo', 'params': []}
self.assertEqual(v.check_message(msg), jsonrpc.REQUEST)
def test_check_request_missing_id(self):
v = self.version
msg = {'method': 'foo', 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_request_missing_method(self):
v = self.version
msg = {'id': 1, 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_request_illegal_method(self):
v = self.version
msg = {'id': 1, 'method': None, 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'method': 1, 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'method': {}, 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'method': [], 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'method': [1], 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_request_missing_params(self):
v = self.version
msg = {'id': 1, 'method': 'foo'}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_request_illegal_params(self):
v = self.version
msg = {'id': 1, 'method': 'foo', 'params': None}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'method': 'foo', 'params': 1}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'method': 'foo', 'params': 'foo'}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'method': 'foo', 'params': {}}
def test_check_request_extraneous_fields(self):
v = self.version
msg = {'id': 1, 'method': 'foo', 'params': [], 'bar': 'baz'}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response(self):
v = self.version
msg = {'id': 1, 'result': 'foo', 'error': None}
self.assertEqual(v.check_message(msg), jsonrpc.RESPONSE)
def test_check_response_null_result(self):
v = self.version
msg = {'id': 1, 'result': None, 'error': None}
self.assertEqual(v.check_message(msg), jsonrpc.RESPONSE)
def test_check_response_error(self):
v = self.version
msg = {'id': 1, 'result': None, 'error': {'code': 1}}
self.assertEqual(v.check_message(msg), jsonrpc.RESPONSE)
def test_check_response_missing_id(self):
v = self.version
msg = {'result': 'foo', 'error': None}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_missing_result(self):
v = self.version
msg = {'id': 1, 'error': None}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_missing_error(self):
v = self.version
msg = {'id': 1, 'result': None}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_illegal_error(self):
v = self.version
msg = {'id': 1, 'result': None, 'error': 1}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'result': None, 'error': 'foo'}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'id': 1, 'result': None, 'error': []}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_result_error_both_set(self):
v = self.version
msg = {'id': 1, 'result': 1, 'error': 0}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_extraneous_fields(self):
v = self.version
msg = {'id': 1, 'result': 1, 'error': None, 'bar': 'baz'}
self.assertRaises(ValueError, v.check_message, msg)
def test_create_request(self):
v = self.version
msg = v.create_request('foo', [])
self.assertIsInstance(msg['id'], six.string_types)
self.assertEqual(msg['method'], 'foo')
self.assertEqual(msg['params'], [])
self.assertEqual(len(msg), 3)
def test_create_request_notification(self):
v = self.version
msg = v.create_request('foo', [], notification=True)
self.assertIsNone(msg['id'])
self.assertEqual(msg['method'], 'foo')
self.assertEqual(msg['params'], [])
self.assertEqual(len(msg), 3)
def test_create_response(self):
v = self.version
req = {'id': 'gruvi.0'}
msg = v.create_response(req, 1)
self.assertEqual(msg['id'], req['id'])
self.assertEqual(msg['result'], 1)
self.assertIsNone(msg['error'])
self.assertEqual(len(msg), 3)
def test_create_response_null_result(self):
v = self.version
req = {'id': 'gruvi.0'}
msg = v.create_response(req, None)
self.assertEqual(msg['id'], req['id'])
self.assertIsNone(msg['result'])
self.assertIsNone(msg['error'])
self.assertEqual(len(msg), 3)
def test_create_response_error(self):
v = self.version
req = {'id': 'gruvi.0'}
msg = v.create_response(req, error={'code': 1})
self.assertEqual(msg['id'], req['id'])
self.assertIsNone(msg['result'])
self.assertEqual(msg['error'], {'code': 1})
self.assertEqual(len(msg), 3)
class TestJsonRpcV2(UnitTest):
def setUp(self):<|fim▁hole|> v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'method': 'foo', 'params': []}
self.assertEqual(v.check_message(msg), jsonrpc.REQUEST)
msg = {'jsonrpc': '2.0', 'id': 1, 'method': 'foo', 'params': {}}
self.assertEqual(v.check_message(msg), jsonrpc.REQUEST)
def test_check_request_notification(self):
v = self.version
msg = {'jsonrpc': '2.0', 'method': 'foo', 'params': []}
self.assertEqual(v.check_message(msg), jsonrpc.REQUEST)
msg = {'jsonrpc': '2.0', 'method': 'foo', 'params': {}}
self.assertEqual(v.check_message(msg), jsonrpc.REQUEST)
def test_check_request_missing_version(self):
v = self.version
msg = {'id': 1, 'method': 'foo', 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_request_missing_method(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_request_illegal_method(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'method': None, 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'method': 1, 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'method': {}, 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'method': [], 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'method': [1], 'params': []}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_request_missing_params(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'method': 'foo'}
self.assertEqual(v.check_message(msg), jsonrpc.REQUEST)
def test_check_request_illegal_params(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'method': 'foo', 'params': None}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'method': 'foo', 'params': 1}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'method': 'foo', 'params': 'foo'}
def test_check_request_extraneous_fields(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'method': 'foo', 'params': [], 'bar': 'baz'}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'result': 'foo'}
self.assertEqual(v.check_message(msg), jsonrpc.RESPONSE)
def test_check_response_null_result(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'result': None}
self.assertEqual(v.check_message(msg), jsonrpc.RESPONSE)
def test_check_response_error(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'error': {'code': 1}}
self.assertEqual(v.check_message(msg), jsonrpc.RESPONSE)
def test_check_response_missing_id(self):
v = self.version
msg = {'jsonrpc': '2.0', 'result': 'foo'}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_null_id(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': None, 'result': 'foo'}
self.assertEqual(v.check_message(msg), jsonrpc.RESPONSE)
def test_check_response_error_missing_id(self):
v = self.version
msg = {'jsonrpc': '2.0', 'error': {'code': 10}}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_error_null_id(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': None, 'error': {'code': 1}}
self.assertEqual(v.check_message(msg), jsonrpc.RESPONSE)
def test_check_response_missing_result_and_error(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_illegal_error(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'error': 1}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'error': 'foo'}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'error': []}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_result_error_both_present(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'result': None, 'error': None}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'result': 1, 'error': None}
self.assertRaises(ValueError, v.check_message, msg)
msg = {'jsonrpc': '2.0', 'id': 1, 'result': None, 'error': {'code': 10}}
self.assertRaises(ValueError, v.check_message, msg)
def test_check_response_extraneous_fields(self):
v = self.version
msg = {'jsonrpc': '2.0', 'id': 1, 'result': 1, 'error': None, 'bar': 'baz'}
self.assertRaises(ValueError, v.check_message, msg)
def test_create_request(self):
v = self.version
msg = v.create_request('foo', [])
self.assertEqual(msg['jsonrpc'], '2.0')
self.assertIsInstance(msg['id'], six.string_types)
self.assertEqual(msg['method'], 'foo')
self.assertEqual(msg['params'], [])
self.assertEqual(len(msg), 4)
def test_create_request_notification(self):
v = self.version
msg = v.create_request('foo', [], notification=True)
self.assertEqual(msg['jsonrpc'], '2.0')
self.assertNotIn('id', msg)
self.assertEqual(msg['method'], 'foo')
self.assertEqual(msg['params'], [])
self.assertEqual(len(msg), 3)
def test_create_response(self):
v = self.version
req = {'id': 'gruvi.0'}
msg = v.create_response(req, 1)
self.assertEqual(msg['jsonrpc'], '2.0')
self.assertEqual(msg['id'], req['id'])
self.assertEqual(msg['result'], 1)
self.assertNotIn('error', msg)
self.assertEqual(len(msg), 3)
def test_create_response_null_result(self):
v = self.version
req = {'id': 'gruvi.0'}
msg = v.create_response(req, None)
self.assertEqual(msg['jsonrpc'], '2.0')
self.assertEqual(msg['id'], req['id'])
self.assertIsNone(msg['result'])
self.assertNotIn('error', msg)
self.assertEqual(len(msg), 3)
def test_create_response_error(self):
v = self.version
req = {'id': 'gruvi.0'}
msg = v.create_response(req, error={'code': 1})
self.assertEqual(msg['jsonrpc'], '2.0')
self.assertEqual(msg['id'], req['id'])
self.assertNotIn('result', msg)
self.assertEqual(msg['error'], {'code': 1})
self.assertEqual(len(msg), 3)
class TestJsonRpcProtocol(UnitTest):
def setUp(self):
super(TestJsonRpcProtocol, self).setUp()
self.transport = MockTransport()
self.protocol = JsonRpcProtocol(self.message_handler)
self.transport.start(self.protocol)
self.messages = []
self.protocols = []
def message_handler(self, message, transport, protocol):
self.messages.append(message)
self.protocols.append(protocol)
def get_messages(self):
# run dispatcher thread so that it calls our message handler
gruvi.sleep(0)
return self.messages
def test_simple(self):
m = b'{ "id": "1", "method": "foo", "params": [] }'
proto = self.protocol
proto.data_received(m)
mm = self.get_messages()
self.assertEqual(len(mm), 1)
self.assertIsInstance(mm[0], dict)
self.assertEqual(mm[0], {'id': '1', 'method': 'foo', 'params': []})
pp = self.protocols
self.assertEqual(len(pp), 1)
self.assertIs(pp[0], proto)
def test_multiple(self):
m = b'{ "id": "1", "method": "foo", "params": [] }' \
b'{ "id": "2", "method": "bar", "params": [] }'
proto = self.protocol
proto.data_received(m)
mm = self.get_messages()
self.assertEqual(len(mm), 2)
self.assertEqual(mm[0], {'id': '1', 'method': 'foo', 'params': []})
self.assertEqual(mm[1], {'id': '2', 'method': 'bar', 'params': []})
pp = self.protocols
self.assertEqual(len(pp), 2)
self.assertIs(pp[0], proto)
self.assertIs(pp[1], proto)
def test_whitespace(self):
m = b' { "id": "1", "method": "foo", "params": [] }' \
b' { "id": "2", "method": "bar", "params": [] }'
proto = self.protocol
proto.data_received(m)
mm = self.get_messages()
self.assertEqual(len(mm), 2)
self.assertEqual(mm[0], {'id': '1', 'method': 'foo', 'params': []})
self.assertEqual(mm[1], {'id': '2', 'method': 'bar', 'params': []})
def test_incremental(self):
m = b'{ "id": "1", "method": "foo", "params": [] }'
proto = self.protocol
for i in range(len(m)-1):
proto.data_received(m[i:i+1])
self.assertEqual(self.get_messages(), [])
proto.data_received(m[-1:])
mm = self.get_messages()
self.assertEqual(len(mm), 1)
self.assertEqual(mm[0], {'id': '1', 'method': 'foo', "params": []})
def test_framing_error(self):
m = b'xxx'
proto = self.protocol
proto.data_received(m)
self.assertEqual(self.get_messages(), [])
self.assertIsInstance(proto._error, JsonRpcError)
def test_encoding_error(self):
m = b'{ xxx\xff }'
proto = self.protocol
proto.data_received(m)
self.assertEqual(self.get_messages(), [])
self.assertIsInstance(proto._error, JsonRpcError)
def test_illegal_json(self):
m = b'{ "xxxx" }'
proto = self.protocol
proto.data_received(m)
self.assertEqual(self.get_messages(), [])
self.assertIsInstance(proto._error, JsonRpcError)
def test_illegal_jsonrpc(self):
m = b'{ "xxxx": "yyyy" }'
proto = self.protocol
proto.data_received(m)
self.assertEqual(self.get_messages(), [])
self.assertIsInstance(proto._error, JsonRpcError)
def test_maximum_message_size_exceeded(self):
proto = self.protocol
proto.max_message_size = 100
message = {'id': 1, 'method': 'foo', 'params': ['x'*100]}
message = json.dumps(message).encode('utf8')
self.assertGreater(len(message), proto.max_message_size)
proto.data_received(message)
self.assertEqual(self.get_messages(), [])
self.assertIsInstance(proto._error, JsonRpcError)
def test_flow_control(self):
# Write more messages than the protocol is willing to pipeline. Flow
# control should kick in and alternate scheduling of the producer and
# the consumer.
proto, trans = self.protocol, self.transport
self.assertTrue(trans._reading)
proto.max_pipeline_size = 10
message = b'{ "id": 1, "method": "foo", "params": [] }'
interrupted = 0
for i in range(1000):
proto.data_received(message)
if not trans._reading:
interrupted += 1
gruvi.sleep(0) # run dispatcher
self.assertTrue(trans._reading)
mm = self.get_messages()
self.assertEqual(len(mm), 1000)
self.assertEqual(interrupted, 100)
message = json.loads(message.decode('utf8'))
for m in mm:
self.assertEqual(m, message)
def echo_app(message, transport, protocol):
if message.get('method') != 'echo':
protocol.send_response(message, error={'code': jsonrpc.METHOD_NOT_FOUND})
else:
protocol.send_response(message, message['params'])
def reflect_app(message, transport, protocol):
if message.get('method') != 'echo':
return
value = protocol.call_method('echo', *message['params'])
protocol.send_response(message, value)
def notification_app():
notifications = []
def application(message, transport, protocol):
if message.get('id') is None:
notifications.append((message['method'], message['params']))
elif message['method'] == 'get_notifications':
protocol.send_response(message, notifications)
return application
class TestJsonRpc(UnitTest):
def test_errno(self):
code = jsonrpc.SERVER_ERROR
self.assertIsInstance(code, int)
name = jsonrpc.errorcode[code]
self.assertIsInstance(name, str)
self.assertEqual(getattr(jsonrpc, name), code)
desc = jsonrpc.strerror(code)
self.assertIsInstance(desc, str)
def test_call_method_tcp(self):
server = JsonRpcServer(echo_app)
server.listen(('localhost', 0))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
result = client.call_method('echo', 'foo')
self.assertEqual(result, ['foo'])
server.close()
client.close()
def test_call_method_pipe(self):
server = JsonRpcServer(echo_app)
server.listen(self.pipename(abstract=True))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
result = client.call_method('echo', 'foo')
self.assertEqual(result, ['foo'])
server.close()
client.close()
def test_call_method_ssl(self):
server = JsonRpcServer(echo_app)
server.listen(('localhost', 0), **self.ssl_s_args)
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr, **self.ssl_c_args)
result = client.call_method('echo', 'foo')
self.assertEqual(result, ['foo'])
server.close()
client.close()
def test_call_method_no_args(self):
server = JsonRpcServer(echo_app)
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
result = client.call_method('echo')
self.assertEqual(result, [])
server.close()
client.close()
def test_call_method_multiple_args(self):
server = JsonRpcServer(echo_app)
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
result = client.call_method('echo', 'foo', 'bar')
self.assertEqual(result, ['foo', 'bar'])
server.close()
client.close()
def test_call_method_error(self):
server = JsonRpcServer(echo_app)
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
exc = self.assertRaises(JsonRpcError, client.call_method, 'echo2')
self.assertIsInstance(exc, JsonRpcError)
self.assertIsInstance(exc.error, dict)
self.assertEqual(exc.error['code'], jsonrpc.METHOD_NOT_FOUND)
server.close()
client.close()
def test_send_notification(self):
server = JsonRpcServer(notification_app())
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
client.send_notification('notify_foo', 'foo')
notifications = client.call_method('get_notifications')
self.assertEqual(notifications, [['notify_foo', ['foo']]])
server.close()
client.close()
def test_call_method_ping_pong(self):
server = JsonRpcServer(reflect_app)
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
client = JsonRpcClient(echo_app)
client.connect(addr)
result = client.call_method('echo', 'foo')
self.assertEqual(result, ['foo'])
server.close()
client.close()
def test_send_evil(self):
server = JsonRpcServer(echo_app)
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
exc = None
try:
chunk = b'{' * 1024
while True:
client.transport.write(chunk)
gruvi.sleep(0)
except Exception as e:
exc = e
self.assertIsInstance(exc, TransportError)
server.close()
client.close()
def test_send_whitespace(self):
server = JsonRpcServer(echo_app)
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
exc = None
try:
chunk = b' ' * 1024
while True:
client.transport.write(chunk)
gruvi.sleep(0)
except Exception as e:
exc = e
self.assertIsInstance(exc, TransportError)
server.close()
client.close()
def test_send_random(self):
server = JsonRpcServer(echo_app)
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
client = JsonRpcClient()
client.connect(addr)
exc = None
try:
while True:
chunk = os.urandom(1024)
client.transport.write(chunk)
gruvi.sleep(0)
except Exception as e:
exc = e
self.assertIsInstance(exc, TransportError)
server.close()
client.close()
def test_connection_limit(self):
server = JsonRpcServer(echo_app)
server.listen(('127.0.0.1', 0))
addr = server.addresses[0]
server.max_connections = 2
clients = []
exc = None
try:
for i in range(3):
client = JsonRpcClient(timeout=2)
client.connect(addr)
client.call_method('echo')
clients.append(client)
except Exception as e:
exc = e
self.assertIsInstance(exc, TransportError)
self.assertEqual(len(server.connections), server.max_connections)
for client in clients:
client.close()
server.close()
if __name__ == '__main__':
unittest.main()<|fim▁end|> | super(TestJsonRpcV2, self).setUp()
self.version = JsonRpcVersion.create('2.0')
def test_check_request(self): |
<|file_name|>GameObject.ts<|end_file_name|><|fim▁begin|>/// <reference path="Transform3D.ts" />
namespace zen {
export class GameObject extends Transform3D {
public name:string = "GameObject";
public tag:string = "";<|fim▁hole|>
private _guid:string = zen.guid.create();
public get guid() {
return this._guid;
}
private _app:Application;
constructor(app:Application) {
super();
this._app = app;
}
private _components:{[key:string]:Component} = {};
public addComponent(component:Component):void {
let system:System = this._app.systemManager.getSystem(component.type);
if(system) {
if(!this._components[component.type]) {
component.gameObject = this;
system.addComponent(this, component);
this._components[component.type] = component;
} else {
console.error("Game Object already has " + component.type + " Component");
}
} else {
console.error("System: " + component.type + " doesn't exist");
}
}
public getComponent<T extends Component>(type:ComponentType | number):T {
return <T>this._components[type];
}
public removeComponent(component:Component):void {
let system:System = this._app.systemManager.getSystem(component.type);
if(system) {
if(this._components[component.type]) {
component.gameObject = null;
system.removeComponent(this);
delete this._components[component.type];
} else {
console.error("Game Object doesn't have " + component.type + " Component");
}
} else {
console.error("System: " + component.type + " doesn't exist");
}
}
}
}<|fim▁end|> |
public layer:string = ""; |
<|file_name|>sensor.py<|end_file_name|><|fim▁begin|>"""Support for RESTful API sensors."""
import json
import logging
from xml.parsers.expat import ExpatError
import httpx
from jsonpath import jsonpath
import voluptuous as vol
import xmltodict
from homeassistant.components.sensor import DEVICE_CLASSES_SCHEMA, PLATFORM_SCHEMA<|fim▁hole|> CONF_FORCE_UPDATE,
CONF_HEADERS,
CONF_METHOD,
CONF_NAME,
CONF_PASSWORD,
CONF_PAYLOAD,
CONF_RESOURCE,
CONF_RESOURCE_TEMPLATE,
CONF_TIMEOUT,
CONF_UNIT_OF_MEASUREMENT,
CONF_USERNAME,
CONF_VALUE_TEMPLATE,
CONF_VERIFY_SSL,
HTTP_BASIC_AUTHENTICATION,
HTTP_DIGEST_AUTHENTICATION,
)
from homeassistant.exceptions import PlatformNotReady
import homeassistant.helpers.config_validation as cv
from homeassistant.helpers.entity import Entity
from homeassistant.helpers.reload import async_setup_reload_service
from . import DOMAIN, PLATFORMS
from .data import DEFAULT_TIMEOUT, RestData
_LOGGER = logging.getLogger(__name__)
DEFAULT_METHOD = "GET"
DEFAULT_NAME = "REST Sensor"
DEFAULT_VERIFY_SSL = True
DEFAULT_FORCE_UPDATE = False
CONF_JSON_ATTRS = "json_attributes"
CONF_JSON_ATTRS_PATH = "json_attributes_path"
METHODS = ["POST", "GET"]
PLATFORM_SCHEMA = PLATFORM_SCHEMA.extend(
{
vol.Exclusive(CONF_RESOURCE, CONF_RESOURCE): cv.url,
vol.Exclusive(CONF_RESOURCE_TEMPLATE, CONF_RESOURCE): cv.template,
vol.Optional(CONF_AUTHENTICATION): vol.In(
[HTTP_BASIC_AUTHENTICATION, HTTP_DIGEST_AUTHENTICATION]
),
vol.Optional(CONF_HEADERS): vol.Schema({cv.string: cv.string}),
vol.Optional(CONF_JSON_ATTRS, default=[]): cv.ensure_list_csv,
vol.Optional(CONF_METHOD, default=DEFAULT_METHOD): vol.In(METHODS),
vol.Optional(CONF_NAME, default=DEFAULT_NAME): cv.string,
vol.Optional(CONF_PASSWORD): cv.string,
vol.Optional(CONF_PAYLOAD): cv.string,
vol.Optional(CONF_UNIT_OF_MEASUREMENT): cv.string,
vol.Optional(CONF_DEVICE_CLASS): DEVICE_CLASSES_SCHEMA,
vol.Optional(CONF_USERNAME): cv.string,
vol.Optional(CONF_JSON_ATTRS_PATH): cv.string,
vol.Optional(CONF_VALUE_TEMPLATE): cv.template,
vol.Optional(CONF_VERIFY_SSL, default=DEFAULT_VERIFY_SSL): cv.boolean,
vol.Optional(CONF_FORCE_UPDATE, default=DEFAULT_FORCE_UPDATE): cv.boolean,
vol.Optional(CONF_TIMEOUT, default=DEFAULT_TIMEOUT): cv.positive_int,
}
)
PLATFORM_SCHEMA = vol.All(
cv.has_at_least_one_key(CONF_RESOURCE, CONF_RESOURCE_TEMPLATE), PLATFORM_SCHEMA
)
async def async_setup_platform(hass, config, async_add_entities, discovery_info=None):
"""Set up the RESTful sensor."""
await async_setup_reload_service(hass, DOMAIN, PLATFORMS)
name = config.get(CONF_NAME)
resource = config.get(CONF_RESOURCE)
resource_template = config.get(CONF_RESOURCE_TEMPLATE)
method = config.get(CONF_METHOD)
payload = config.get(CONF_PAYLOAD)
verify_ssl = config.get(CONF_VERIFY_SSL)
username = config.get(CONF_USERNAME)
password = config.get(CONF_PASSWORD)
headers = config.get(CONF_HEADERS)
unit = config.get(CONF_UNIT_OF_MEASUREMENT)
device_class = config.get(CONF_DEVICE_CLASS)
value_template = config.get(CONF_VALUE_TEMPLATE)
json_attrs = config.get(CONF_JSON_ATTRS)
json_attrs_path = config.get(CONF_JSON_ATTRS_PATH)
force_update = config.get(CONF_FORCE_UPDATE)
timeout = config.get(CONF_TIMEOUT)
if value_template is not None:
value_template.hass = hass
if resource_template is not None:
resource_template.hass = hass
resource = resource_template.render(parse_result=False)
if username and password:
if config.get(CONF_AUTHENTICATION) == HTTP_DIGEST_AUTHENTICATION:
auth = httpx.DigestAuth(username, password)
else:
auth = (username, password)
else:
auth = None
rest = RestData(method, resource, auth, headers, payload, verify_ssl, timeout)
await rest.async_update()
if rest.data is None:
raise PlatformNotReady
# Must update the sensor now (including fetching the rest resource) to
# ensure it's updating its state.
async_add_entities(
[
RestSensor(
hass,
rest,
name,
unit,
device_class,
value_template,
json_attrs,
force_update,
resource_template,
json_attrs_path,
)
],
True,
)
class RestSensor(Entity):
"""Implementation of a REST sensor."""
def __init__(
self,
hass,
rest,
name,
unit_of_measurement,
device_class,
value_template,
json_attrs,
force_update,
resource_template,
json_attrs_path,
):
"""Initialize the REST sensor."""
self._hass = hass
self.rest = rest
self._name = name
self._state = None
self._unit_of_measurement = unit_of_measurement
self._device_class = device_class
self._value_template = value_template
self._json_attrs = json_attrs
self._attributes = None
self._force_update = force_update
self._resource_template = resource_template
self._json_attrs_path = json_attrs_path
@property
def name(self):
"""Return the name of the sensor."""
return self._name
@property
def unit_of_measurement(self):
"""Return the unit the value is expressed in."""
return self._unit_of_measurement
@property
def device_class(self):
"""Return the class of this sensor."""
return self._device_class
@property
def available(self):
"""Return if the sensor data are available."""
return self.rest.data is not None
@property
def state(self):
"""Return the state of the device."""
return self._state
@property
def force_update(self):
"""Force update."""
return self._force_update
async def async_update(self):
"""Get the latest data from REST API and update the state."""
if self._resource_template is not None:
self.rest.set_url(self._resource_template.render(parse_result=False))
await self.rest.async_update()
value = self.rest.data
_LOGGER.debug("Data fetched from resource: %s", value)
if self.rest.headers is not None:
# If the http request failed, headers will be None
content_type = self.rest.headers.get("content-type")
if content_type and (
content_type.startswith("text/xml")
or content_type.startswith("application/xml")
):
try:
value = json.dumps(xmltodict.parse(value))
_LOGGER.debug("JSON converted from XML: %s", value)
except ExpatError:
_LOGGER.warning(
"REST xml result could not be parsed and converted to JSON"
)
_LOGGER.debug("Erroneous XML: %s", value)
if self._json_attrs:
self._attributes = {}
if value:
try:
json_dict = json.loads(value)
if self._json_attrs_path is not None:
json_dict = jsonpath(json_dict, self._json_attrs_path)
# jsonpath will always store the result in json_dict[0]
# so the next line happens to work exactly as needed to
# find the result
if isinstance(json_dict, list):
json_dict = json_dict[0]
if isinstance(json_dict, dict):
attrs = {
k: json_dict[k] for k in self._json_attrs if k in json_dict
}
self._attributes = attrs
else:
_LOGGER.warning(
"JSON result was not a dictionary"
" or list with 0th element a dictionary"
)
except ValueError:
_LOGGER.warning("REST result could not be parsed as JSON")
_LOGGER.debug("Erroneous JSON: %s", value)
else:
_LOGGER.warning("Empty reply found when expecting JSON data")
if value is not None and self._value_template is not None:
value = self._value_template.async_render_with_possible_json_value(
value, None
)
self._state = value
async def async_will_remove_from_hass(self):
"""Shutdown the session."""
await self.rest.async_remove()
@property
def device_state_attributes(self):
"""Return the state attributes."""
return self._attributes<|fim▁end|> | from homeassistant.const import (
CONF_AUTHENTICATION,
CONF_DEVICE_CLASS, |
<|file_name|>menu.rs<|end_file_name|><|fim▁begin|>// Copyright 2013-2014 Jeffery Olson
//
// Licensed under the 3-Clause BSD License, see LICENSE.txt
// at the top-level of this repository.
// This file may not be copied, modified, or distributed
// except according to those terms.
use std::vec::Vec;
use gfx::GameDisplay;
use super::{UiBox, UiFont, draw_text_box, compute_text_box_bounds};
pub struct VertTextMenu<TFont, TBox> {
pub entries: Vec<String>,
pub formatted_entries: Vec<String>,
pub bg_color: (u8, u8, u8),
pub selected_prefix: String,
pub unselected_prefix: String,
pub curr_selected: uint,
pub coords: (int, int),
pub box_size: (uint, uint),
pub text_gap: uint
}
impl<TFont: UiFont, TBox: UiBox>
VertTextMenu<TFont, TBox> {
pub fn new() -> VertTextMenu<TFont, TBox> {
VertTextMenu {
entries: Vec::new(),
formatted_entries: Vec::new(),
bg_color: (0,0,0),
selected_prefix: "".to_string(),
unselected_prefix: "".to_string(),
curr_selected: 0,
coords: (0,0),
box_size: (0,0),
text_gap: 2
}
}
pub fn move_down(&mut self) {
let last_idx = self.entries.len() - 1;
if self.curr_selected < last_idx {
let new_idx = self.curr_selected + 1;
self.update_selected(new_idx);
}
}
pub fn move_up(&mut self) {
if self.curr_selected > 0 {
let new_idx = self.curr_selected - 1;
self.update_selected(new_idx);
}
}
fn update_selected(&mut self, new_idx: uint) {
let old_selected = self.curr_selected;
self.curr_selected = new_idx;
let selected_formatted = self.get_formatted(self.curr_selected);
self.formatted_entries.push(selected_formatted);
self.formatted_entries.swap_remove(self.curr_selected);
let unselected_formatted = self.get_formatted(old_selected);
self.formatted_entries.push(unselected_formatted);
self.formatted_entries.swap_remove(old_selected);
}
fn get_formatted(&self, v: uint) -> String {
let entry = &self.entries[v];
let prefix = if v == self.curr_selected {
&self.selected_prefix
} else {
&self.unselected_prefix
};
format!("{} {}", *prefix, entry)
}
pub fn update_bounds(&mut self, coords: (int, int), ui_font: &TFont, ui_box: &TBox) {
// figure out width, in pixels, of the text (based on longest entry line)
self.formatted_entries = Vec::new();
for v in range(0, self.entries.len()) {
let formatted = self.get_formatted(v);<|fim▁hole|> self.coords = coords;
}
pub fn draw_menu(&self, display: &GameDisplay, ui_font: &TFont, ui_box: &TBox) {
draw_text_box(
display, self.coords, self.box_size, self.bg_color,
self.formatted_entries.slice_from(0), ui_font, ui_box, self.text_gap);
}
}<|fim▁end|> | self.formatted_entries.push(formatted);
}
self.box_size = compute_text_box_bounds(
self.formatted_entries.as_slice(), ui_font, ui_box, self.text_gap); |
<|file_name|>component-info-header.component.ts<|end_file_name|><|fim▁begin|>/*!
* @license MIT
* Copyright (c) 2017 Bernhard Grünewaldt - codeclou.io
* https://github.com/cloukit/legal
*/
import { Component, Input } from '@angular/core';
import * as _ from 'lodash';<|fim▁hole|> template: `
<div class="info-header">
<div class="info-header-buttons">
<span
class="vendor-logo-link"
[ngStyle]="getButtonStyle(getStatusSwitchNameForComponentStatus(componentStatus))"
(mouseover)="hoverStatus(componentStatus)"
(mouseleave)="resetSwitchState()"
><img [src]="getComponentStatusUri()" class="vendor-logo"></span>
<a
href="https://www.npmjs.com/package/@cloukit/{{componentName}}"
target="_blank"
class="vendor-logo-link"
[ngStyle]="getButtonStyle('npm')"
(mouseover)="switchState.npm=true"
(mouseleave)="resetSwitchState()"
><img [src]="getVendorLogo('npm')" class="vendor-logo"></a>
<a
href="https://github.com/cloukit/{{componentName}}/tree/{{componentVersion}}"
target="_blank"
class="vendor-logo-link"
[ngStyle]="getButtonStyle('github')"
(mouseover)="switchState.github=true"
(mouseleave)="resetSwitchState()"
><img [src]="getVendorLogo('github')" class="vendor-logo"></a>
<a
href="https://unpkg.com/@cloukit/{{componentName}}@{{componentVersion}}/"
target="_blank"
class="vendor-logo-link"
[ngStyle]="getButtonStyle('unpkg')"
(mouseover)="switchState.unpkg=true"
(mouseleave)="resetSwitchState()"
><img [src]="getVendorLogo('unpkg')" class="vendor-logo"></a>
<a
href="https://cloukit.github.io/{{componentName}}/{{componentVersion}}/documentation/"
target="_blank"
class="vendor-logo-link"
[ngStyle]="getButtonStyle('compodoc')"
(mouseover)="switchState.compodoc=true"
(mouseleave)="resetSwitchState()"
><img [src]="getVendorLogo('compodoc')" class="vendor-logo"></a>
</div>
<div class="info-header-bar" [ngStyle]="getInfoHeaderStyle()">
<div class="info-header-bar-content">
<div *ngIf="isSwitchStateOn()">
{{switchState.statusExperimental ? 'API might change unexpectedly. Use at own risk. It is alive!' : ''}}
{{switchState.statusStable ? 'API should be stable.' : ''}}
{{switchState.npm ? 'Show package page on npmjs.com' : ''}}
{{switchState.github ? 'Show example project on github.com' : ''}}
{{switchState.unpkg ? 'Show dist contents on unpkg.com' : ''}}
{{switchState.compodoc ? 'Show detailed Component Documentation' : ''}}
</div>
</div>
</div>
</div>`,
styles: [
'.vendor-logo { width:120px; }',
'.info-header-bar { height:40px; width:100%; }',
'.info-header-bar-content { width:100%; padding: 10px; text-align:center; }',
'.info-header-buttons { display: flex; justify-content: space-between; }',
'.vendor-logo-link { display:flex; width: 120px; min-width:120px; max-width: 120px; padding:0; height:65px; }',
],
})
export class ComponentInfoHeaderComponent {
@Input()
componentName: string;
@Input()
componentVersion: string;
@Input()
componentStatus: string;
private initialSwitchState = {
npm: false,
unpkg: false,
github: false,
compodoc: false,
statusStable: false,
statusExperimental: false,
};
private colors = {
npm: {
bg: '#cb3837',
fg: '#fff',
},
unpkg: {
bg: '#000',
fg: '#fff',
},
github: {
bg: '#0366d6',
fg: '#fff',
},
compodoc: {
bg: '#2582d5',
fg: '#fff',
},
statusStable: {
bg: '#4ad57d',
fg: '#fff',
},
statusExperimental: {
bg: '#d55900',
fg: '#fff',
},
};
switchState = Object.assign({}, this.initialSwitchState);
getSwitchState(name: string) {
return this.switchState[name] ? 'on' : 'off';
}
isSwitchStateOn() {
for (let pair of _.toPairs(this.switchState)) {
if (pair[1]) {
return true;
}
}
return false;
}
getOnSwitchName() {
for (let pair of _.toPairs(this.switchState)) {
if (pair[1]) {
return pair[0];
}
}
return null;
}
getVendorLogo(name: string) {
return `/assets/images/vendor-logos/${name}-${this.getSwitchState(name)}.svg`;
}
resetSwitchState() {
this.switchState = Object.assign({}, this.initialSwitchState);
}
getButtonStyle(name: string) {
return this.switchState[name] ? {
border: `3px solid ${this.colors[name]['bg']}`,
transition: 'border-color 200ms linear'
} : {
border: `3px solid transparent`,
transition: 'border-color 200ms linear'
};
}
getInfoHeaderStyle() {
return this.isSwitchStateOn() ? {
backgroundColor: this.colors[this.getOnSwitchName()]['bg'],
color: this.colors[this.getOnSwitchName()]['fg'],
transition: 'background-color 200ms linear'
} : {
backgroundColor: 'transparent',
transition: 'background-color 200ms linear'
};
}
//
// STATUS
//
getStatusSwitchNameForComponentStatus(status: string) {
if (status === 'STABLE') {
return 'statusStable';
}
if (status === 'EXPERIMENTAL') {
return 'statusExperimental';
}
return null;
}
hoverStatus(status: string) {
if (status === 'STABLE') {
this.switchState.statusStable = true;
}
if (status === 'EXPERIMENTAL') {
this.switchState.statusExperimental = true;
}
}
getComponentStatusUri() {
if (this.componentStatus === 'STABLE') {
if (this.switchState.statusStable) {
return '/assets/images/status-icons/status-stable-on.svg';
}
return '/assets/images/status-icons/status-stable-off.svg';
}
if (this.componentStatus === 'EXPERIMENTAL') {
if (this.switchState.statusExperimental) {
return '/assets/images/status-icons/status-experimental-on.svg';
}
return '/assets/images/status-icons/status-experimental-off.svg';
}
}
}<|fim▁end|> |
@Component({
selector: 'app-component-info-header', |
<|file_name|>navController.js<|end_file_name|><|fim▁begin|>/* Copyright 2016 Devon Call, Zeke Hunter-Green, Paige Ormiston, Joe Renner, Jesse Sliter
This file is part of Myrge.
Myrge is free software: you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
Myrge is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
<|fim▁hole|>
app.controller('NavCtrl', [
'$scope',
'$state',
'auth',
function($scope, $state, auth){
$scope.isLoggedIn = auth.isLoggedIn;
$scope.currentUser = auth.currentUser;
$scope.logOut = auth.logOut;
$scope.loggedin = auth.isLoggedIn();
if($scope.loggedin){
auth.validate(auth.getToken()).success(function(data){
if(!data.valid){
auth.logOut();
$state.go("login");
}
});
}
}]);<|fim▁end|> | You should have received a copy of the GNU General Public License
along with Myrge. If not, see <http://www.gnu.org/licenses/>. */ |
<|file_name|>tables.py<|end_file_name|><|fim▁begin|>import logging
from django.utils.html import format_html
import django_tables2 as tables
from django_tables2.rows import BoundPinnedRow, BoundRow
logger = logging.getLogger(__name__)
# A cheat to force BoundPinnedRows to use the same rendering as BoundRows
# otherwise links don't work
# BoundPinnedRow._get_and_render_with = BoundRow._get_and_render_with
class MultiLinkColumn(tables.RelatedLinkColumn):
"""
Like RelatedLinkColumn but allows multiple choices of accessor to be
rendered in a hierarchy, e.g.
accessors = ['foo.bar', 'baz.bof']
text = '{instance.number}: {instance}'
In this case if 'foo.bar' resolves, it will be rendered. Otherwise
'baz.bof' will be tested to resolve, and so on. If nothing renders,
the column will be blank. The text string will resolve using instance.
"""
def __init__(self, accessors, **kwargs):
"""Here we force order by the accessors. By default MultiLinkColumns
have empty_values: () to force calculation every time.
"""
defaults = {
'order_by': accessors,
'empty_values': (),
}
defaults.update(**kwargs)
super().__init__(**defaults)
self.accessors = [tables.A(a) for a in accessors]
def compose_url(self, record, bound_column):
"""Resolve the first accessor which resolves. """
for a in self.accessors:
try:
return a.resolve(record).get_absolute_url()
except (ValueError, AttributeError):
continue
return ""
def text_value(self, record, value):
"""If self.text is set, it will be used as a format string for the
instance returned by the accessor with the keyword `instance`.
"""
for a in self.accessors:
try:
instance = a.resolve(record)
if instance is None:
raise ValueError
except ValueError:
continue
# Use self.text as a format string
if self.text:
return self.text.format(instance=instance, record=record,
value=value)
else:
return str(instance)
# Finally if no accessors were resolved, return value or a blank string
# return super().text_value(record, value)
return value or ""
class XeroLinkColumn(tables.Column):
"""Renders a badge link to the objects record in xero."""
def render(self, value, record=None):
if record.xero_id:
return format_html(
'<span class="badge progress-bar-info">'<|fim▁hole|>
class BaseTable(tables.Table):
class Meta:
attrs = {"class": "table table-bordered table-striped table-hover "
"table-condensed"}
# @classmethod
# def set_header_color(cls, color):
# """
# Sets all column headers to have this background colour.
# """
# for column in cls.base_columns.values():
# try:
# column.attrs['th'].update(
# {'style': f'background-color:{color};'})
# except KeyError:
# column.attrs['th'] = {'style': f'background-color:{color};'}
def set_header_color(self, color):
"""
Sets all column headers to have this background colour.
"""
for column in self.columns.columns.values():
try:
column.column.attrs['th'].update(
{'style': f'background-color:{color};'})
except KeyError:
column.column.attrs['th'] = {
'style': f'background-color:{color};'}
class ModelTable(BaseTable):
class Meta(BaseTable.Meta):
exclude = ('id',)
class CurrencyColumn(tables.Column):
"""Render a table column as GBP."""
def render(self, value):
return f'£{value:,.2f}'
class NumberColumn(tables.Column):
"""Only render decimal places if necessary."""
def render(self, value):
if value is not None:
return f'{value:n}'
class ColorColumn(tables.Column):
"""Render the colour in a box."""
def __init__(self, *args, **kwargs):
"""This will ignore other attrs passed in."""
kwargs.setdefault('attrs', {'td': {'class': "small-width text-center"}})
super().__init__(*args, **kwargs)
def render(self, value):
if value:
return format_html(
'<div class="color-box" style="background:{};"></div>', value)<|fim▁end|> | '<a class="alert-link" role="button" target="_blank" '
'href="{href}">View in Xero</a></span>',
href=record.get_xero_url()
) |
<|file_name|>ProxyStore.js<|end_file_name|><|fim▁begin|>/**
* ProxyStore is a superclass of {@link Ext.data.Store} and {@link Ext.data.BufferedStore}. It's never used directly,
* but offers a set of methods used by both of those subclasses.
*
* We've left it here in the docs for reference purposes, but unless you need to make a whole new type of Store, what
* you're probably looking for is {@link Ext.data.Store}. If you're still interested, here's a brief description of what
* ProxyStore is and is not.
*
* ProxyStore provides the basic configuration for anything that can be considered a Store. It expects to be
* given a {@link Ext.data.Model Model} that represents the type of data in the Store. It also expects to be given a
* {@link Ext.data.proxy.Proxy Proxy} that handles the loading of data into the Store.
*
* ProxyStore provides a few helpful methods such as {@link #method-load} and {@link #sync}, which load and save data
* respectively, passing the requests through the configured {@link #proxy}.
*
* Built-in Store subclasses add extra behavior to each of these functions. Note also that each ProxyStore subclass
* has its own way of storing data - in {@link Ext.data.Store} the data is saved as a flat {@link Ext.util.Collection Collection},
* whereas in {@link Ext.data.BufferedStore BufferedStore} we use a {@link Ext.data.PageMap} to maintain a client side cache of pages of records.
*
* The store provides filtering and sorting support. This sorting/filtering can happen on the client side
* or can be completed on the server. This is controlled by the {@link Ext.data.Store#remoteSort remoteSort} and
* {@link Ext.data.Store#remoteFilter remoteFilter} config options. For more information see the {@link #method-sort} and
* {@link Ext.data.Store#filter filter} methods.
*/
Ext.define('Ext.data.ProxyStore', {
extend: 'Ext.data.AbstractStore',
requires: [
'Ext.data.Model',
'Ext.data.proxy.Proxy',
'Ext.data.proxy.Memory',
'Ext.data.operation.*'
],
config: {
// @cmd-auto-dependency {aliasPrefix: "model.", mvc: true, blame: "all"}
/**
* @cfg {String/Ext.data.Model} model
* Name of the {@link Ext.data.Model Model} associated with this store. See
* {@link Ext.data.Model#entityName}.
*
* May also be the actual Model subclass.
*
* This config is required for the store to be able to read data unless you have defined
* the {@link #fields} config which will create an anonymous `Ext.data.Model`.
*/
model: undefined,
// @cmd-auto-dependency {aliasPrefix: "data.field."}
/**
* @cfg {Object[]} fields
* This may be used in place of specifying a {@link #model} configuration. The fields should be a
* set of {@link Ext.data.Field} configuration objects. The store will automatically create a {@link Ext.data.Model}
* with these fields. In general this configuration option should only be used for simple stores like
* a two-field store of ComboBox. For anything more complicated, such as specifying a particular id property or
* associations, a {@link Ext.data.Model} should be defined and specified for the {@link #model}
* config.
* @since 2.3.0
*/
fields: null,
// @cmd-auto-dependency {aliasPrefix : "proxy."}
/**
* @cfg {String/Ext.data.proxy.Proxy/Object} proxy
* The Proxy to use for this Store. This can be either a string, a config object or a Proxy instance -
* see {@link #setProxy} for details.
* @since 1.1.0
*/
proxy: undefined,
/**
* @cfg {Boolean/Object} autoLoad
* If data is not specified, and if autoLoad is true or an Object, this store's load method is automatically called
* after creation. If the value of autoLoad is an Object, this Object will be passed to the store's load method.
*
* It's important to note that {@link Ext.data.TreeStore Tree Stores} will
* load regardless of autoLoad's value if expand is set to true on the
* {@link Ext.data.TreeStore#root root node}.
*
* @since 2.3.0
*/
autoLoad: undefined,
/**
* @cfg {Boolean} autoSync
* True to automatically sync the Store with its Proxy after every edit to one of its Records. Defaults to false.
*/
autoSync: false,
/**
* @cfg {String} batchUpdateMode
* Sets the updating behavior based on batch synchronization. 'operation' (the default) will update the Store's
* internal representation of the data after each operation of the batch has completed, 'complete' will wait until
* the entire batch has been completed before updating the Store's data. 'complete' is a good choice for local
* storage proxies, 'operation' is better for remote proxies, where there is a comparatively high latency.
*/
batchUpdateMode: 'operation',
/**
* @cfg {Boolean} sortOnLoad
* If true, any sorters attached to this Store will be run after loading data, before the datachanged event is fired.
* Defaults to true, ignored if {@link Ext.data.Store#remoteSort remoteSort} is true
*/
sortOnLoad: true,
/**
* @cfg {Boolean} [trackRemoved=true]
* This config controls whether removed records are remembered by this store for
* later saving to the server.
*/
trackRemoved: true,
/**
* @private.
* The delay time to kick of the initial autoLoad task
*/
autoLoadDelay: 1
},
onClassExtended: function(cls, data, hooks) {
var model = data.model,
onBeforeClassCreated;
if (typeof model === 'string') {
onBeforeClassCreated = hooks.onBeforeCreated;
hooks.onBeforeCreated = function() {
var me = this,
args = arguments;
Ext.require(model, function() {
onBeforeClassCreated.apply(me, args);
});
};
}
},
/**
* @private
* @property {Boolean}
* The class name of the model that this store uses if no explicit {@link #model} is given
*/
implicitModel: 'Ext.data.Model',
blockLoadCounter: 0,
loadsWhileBlocked: 0,
/**
* @property {Object} lastOptions
* Property to hold the last options from a {@link #method-load} method call. This object is used for the {@link #method-reload}
* to reuse the same options. Please see {@link #method-reload} for a simple example on how to use the lastOptions property.
*/
/**
* @property {Number} autoSyncSuspended
* A counter to track suspensions.
* @private
*/
autoSyncSuspended: 0,
//documented above
constructor: function(config) {
var me = this;
// <debug>
var configModel = me.model;
// </debug>
/**
* @event beforeload
* Fires before a request is made for a new data object. If the beforeload handler returns false the load
* action will be canceled.
* @param {Ext.data.Store} store This Store
* @param {Ext.data.operation.Operation} operation The Ext.data.operation.Operation object that will be passed to the Proxy to
* load the Store
* @since 1.1.0
*/
/**
* @event load
* Fires whenever the store reads data from a remote data source.
* @param {Ext.data.Store} this
* @param {Ext.data.Model[]} records An array of records
* @param {Boolean} successful True if the operation was successful.
* @since 1.1.0
*/
/**
* @event write
* Fires whenever a successful write has been made via the configured {@link #proxy Proxy}
* @param {Ext.data.Store} store This Store
* @param {Ext.data.operation.Operation} operation The {@link Ext.data.operation.Operation Operation} object that was used in
* the write
* @since 3.4.0
*/
/**
* @event beforesync
* Fired before a call to {@link #sync} is executed. Return false from any listener to cancel the sync
* @param {Object} options Hash of all records to be synchronized, broken down into create, update and destroy
*/
/**
* @event metachange
* Fires when this store's underlying reader (available via the proxy) provides new metadata.
* Metadata usually consists of new field definitions, but can include any configuration data
* required by an application, and can be processed as needed in the event handler.
* This event is currently only fired for JsonReaders.
* @param {Ext.data.Store} this
* @param {Object} meta The JSON metadata
* @since 1.1.0
*/
/**
* Temporary cache in which removed model instances are kept until successfully
* synchronised with a Proxy, at which point this is cleared.
*
* This cache is maintained unless you set `trackRemoved` to `false`.
*
* @protected
* @property {Ext.data.Model[]} removed
*/
me.removed = [];
me.blockLoad();
me.callParent(arguments);
me.unblockLoad();
// <debug>
if (!me.getModel() && me.useModelWarning !== false && me.getStoreId() !== 'ext-empty-store') {
// There are a number of ways things could have gone wrong, try to give as much information as possible
var logMsg = [
Ext.getClassName(me) || 'Store',
' created with no model.'
];
if (typeof configModel === 'string') {
logMsg.push(" The name '", configModel, "'", ' does not correspond to a valid model.');
}
Ext.log.warn(logMsg.join(''));
}
// </debug>
},
updateAutoLoad: function(autoLoad) {
var me = this,
task;
// Ensure the data collection is set up
me.getData();
if (autoLoad) {
task = me.loadTask || (me.loadTask = new Ext.util.DelayedTask(null, null, null, null, false));
// Defer the load until the store (and probably the view) is fully constructed
task.delay(me.autoLoadDelay, me.attemptLoad, me, Ext.isObject(autoLoad) ? [autoLoad] : undefined);
}
},
/**
* Returns the total number of {@link Ext.data.Model Model} instances that the {@link Ext.data.proxy.Proxy Proxy}
* indicates exist. This will usually differ from {@link #getCount} when using paging - getCount returns the
* number of records loaded into the Store at the moment, getTotalCount returns the number of records that
* could be loaded into the Store if the Store contained all data
* @return {Number} The total number of Model instances available via the Proxy. 0 returned if
* no value has been set via the reader.
*/
getTotalCount: function() {
return this.totalCount || 0;
},
applyFields: function(fields) {
if (fields) {
this.createImplicitModel(fields);
}
},
applyModel: function(model) {
if (model) {
model = Ext.data.schema.Schema.lookupEntity(model);
}
// If no model, ensure that the fields config is converted to a model.
else {
this.getFields();
model = this.getModel() || this.createImplicitModel();
}
return model;
},
applyProxy: function(proxy) {
var model = this.getModel();
if (proxy !== null) {
if (proxy) {
if (proxy.isProxy) {
proxy.setModel(model);
} else {
if (Ext.isString(proxy)) {
proxy = {
type: proxy,
model: model
};
} else if (!proxy.model) {
proxy = Ext.apply({
model: model
}, proxy);
}
proxy = Ext.createByAlias('proxy.' + proxy.type, proxy);
proxy.autoCreated = true;
}
} else if (model) {
proxy = model.getProxy();
}
if (!proxy) {
proxy = Ext.createByAlias('proxy.memory');
proxy.autoCreated = true;
}
}
return proxy;
},
applyState: function (state) {
var me = this,
doLoad = me.getAutoLoad() || me.isLoaded();
me.blockLoad();
me.callParent([state]);
me.unblockLoad(doLoad);
},
updateProxy: function(proxy, oldProxy) {
this.proxyListeners = Ext.destroy(this.proxyListeners);
},
updateTrackRemoved: function (track) {
this.cleanRemoved();
this.removed = track ? [] : null;
},
/**
* @private
*/
onMetaChange: function(proxy, meta) {
this.fireEvent('metachange', this, meta);
},
//saves any phantom records
create: function(data, options) {
var me = this,
Model = me.getModel(),
instance = new Model(data),
operation;
options = Ext.apply({}, options);
if (!options.records) {
options.records = [instance];
}
options.internalScope = me;
options.internalCallback = me.onProxyWrite;
operation = me.createOperation('create', options);
return operation.execute();
},
read: function() {
return this.load.apply(this, arguments);
},
update: function(options) {
var me = this,
operation;
options = Ext.apply({}, options);
if (!options.records) {
options.records = me.getUpdatedRecords();
}
options.internalScope = me;
options.internalCallback = me.onProxyWrite;
operation = me.createOperation('update', options);
return operation.execute();
},
/**
* @private
* Callback for any write Operation over the Proxy. Updates the Store's MixedCollection to reflect
* the updates provided by the Proxy
*/
onProxyWrite: function(operation) {
var me = this,
success = operation.wasSuccessful(),
records = operation.getRecords();
switch (operation.getAction()) {
case 'create':
me.onCreateRecords(records, operation, success);
break;
case 'update':
me.onUpdateRecords(records, operation, success);
break;
case 'destroy':
me.onDestroyRecords(records, operation, success);
break;
}
if (success) {
me.fireEvent('write', me, operation);
me.fireEvent('datachanged', me);
}
},
// may be implemented by store subclasses
onCreateRecords: Ext.emptyFn,
// may be implemented by store subclasses
onUpdateRecords: Ext.emptyFn,
/**
* Removes any records when a write is returned from the server.
* @private
* @param {Ext.data.Model[]} records The array of removed records
* @param {Ext.data.operation.Operation} operation The operation that just completed
* @param {Boolean} success True if the operation was successful
*/
onDestroyRecords: function(records, operation, success) {
if (success) {
this.cleanRemoved();
}
},
// tells the attached proxy to destroy the given records
// @since 3.4.0
erase: function(options) {
var me = this,
operation;
options = Ext.apply({}, options);
if (!options.records) {
options.records = me.getRemovedRecords();
}
options.internalScope = me;
options.internalCallback = me.onProxyWrite;
operation = me.createOperation('destroy', options);
return operation.execute();
},
/**
* @private
* Attached as the 'operationcomplete' event listener to a proxy's Batch object. By default just calls through
* to onProxyWrite.
*/
onBatchOperationComplete: function(batch, operation) {
return this.onProxyWrite(operation);
},
/**
* @private
* Attached as the 'complete' event listener to a proxy's Batch object. Iterates over the batch operations
* and updates the Store's internal data MixedCollection.
*/
onBatchComplete: function(batch, operation) {
var me = this,
operations = batch.operations,
length = operations.length,
i;
if (me.batchUpdateMode !== 'operation') {
me.suspendEvents();
for (i = 0; i < length; i++) {
me.onProxyWrite(operations[i]);
}
me.resumeEvents();
}
me.isSyncing = false;
me.fireEvent('datachanged', me);
},
/**
* @private
*/
onBatchException: function(batch, operation) {
// //decide what to do... could continue with the next operation
// batch.start();
//
// //or retry the last operation
// batch.retry();
},
/**
* @private
* Filter function for new records.
*/
filterNew: function(item) {
// only want phantom records that are valid
return item.phantom === true && item.isValid();
},
/**
* Returns all Model instances that are either currently a phantom (e.g. have no id), or have an ID but have not
* yet been saved on this Store (this happens when adding a non-phantom record from another Store into this one)
* @return {Ext.data.Model[]} The Model instances
*/
getNewRecords: function() {
return [];
},
/**
* Returns all valid, non-phantom Model instances that have been updated in the Store but not yet synchronized with the Proxy.
* @return {Ext.data.Model[]} The updated Model instances
*/
getUpdatedRecords: function() {
return [];
},
/**
* Gets all {@link Ext.data.Model records} added or updated since the last commit. Note that the order of records
* returned is not deterministic and does not indicate the order in which records were modified. Note also that
* removed records are not included (use {@link #getRemovedRecords} for that).
* @return {Ext.data.Model[]} The added and updated Model instances
*/
getModifiedRecords : function(){
return [].concat(this.getNewRecords(), this.getUpdatedRecords());
},
/**
* @private
* Filter function for updated records.
*/
filterUpdated: function(item) {
// only want dirty records, not phantoms that are valid
return item.dirty === true && item.phantom !== true && item.isValid();
},
/**
* Returns any records that have been removed from the store but not yet destroyed on the proxy.
* @return {Ext.data.Model[]} The removed Model instances
*/
getRemovedRecords: function() {
return this.removed;
},
/**
* Synchronizes the store with its {@link #proxy}. This asks the proxy to batch together any new, updated
* and deleted records in the store, updating the store's internal representation of the records
* as each operation completes.
*
* @param {Object} [options] Object containing one or more properties supported by the sync method (these get
* passed along to the underlying proxy's {@link Ext.data.Proxy#batch batch} method):
*
* @param {Ext.data.Batch/Object} [options.batch] A {@link Ext.data.Batch} object (or batch config to apply
* to the created batch). If unspecified a default batch will be auto-created as needed.
*
* @param {Function} [options.callback] The function to be called upon completion of the sync.
* The callback is called regardless of success or failure and is passed the following parameters:
* @param {Ext.data.Batch} options.callback.batch The {@link Ext.data.Batch batch} that was processed,
* containing all operations in their current state after processing
* @param {Object} options.callback.options The options argument that was originally passed into sync
*
* @param {Function} [options.success] The function to be called upon successful completion of the sync. The
* success function is called only if no exceptions were reported in any operations. If one or more exceptions
* occurred then the failure function will be called instead. The success function is called
* with the following parameters:
* @param {Ext.data.Batch} options.success.batch The {@link Ext.data.Batch batch} that was processed,
* containing all operations in their current state after processing
* @param {Object} options.success.options The options argument that was originally passed into sync
*
* @param {Function} [options.failure] The function to be called upon unsuccessful completion of the sync. The
* failure function is called when one or more operations returns an exception during processing (even if some
* operations were also successful). In this case you can check the batch's {@link Ext.data.Batch#exceptions
* exceptions} array to see exactly which operations had exceptions. The failure function is called with the
* following parameters:
* @param {Ext.data.Batch} options.failure.batch The {@link Ext.data.Batch} that was processed, containing all
* operations in their current state after processing
* @param {Object} options.failure.options The options argument that was originally passed into sync
*
* @param {Object} [options.params] Additional params to send during the sync Operation(s).
*
* @param {Object} [options.scope] The scope in which to execute any callbacks (i.e. the `this` object inside
* the callback, success and/or failure functions). Defaults to the store's proxy.
*
* @return {Ext.data.Store} this
*/
sync: function(options) {
var me = this,
operations = {},
toCreate = me.getNewRecords(),
toUpdate = me.getUpdatedRecords(),
toDestroy = me.getRemovedRecords(),
needsSync = false;
//<debug>
if (me.isSyncing) {
Ext.log.warn('Sync called while a sync operation is in progress. Consider configuring autoSync as false.');
}
//</debug>
me.needsSync = false;
if (toCreate.length > 0) {
operations.create = toCreate;
needsSync = true;
}
if (toUpdate.length > 0) {
operations.update = toUpdate;
needsSync = true;
}
if (toDestroy.length > 0) {
operations.destroy = toDestroy;
needsSync = true;
}
if (needsSync && me.fireEvent('beforesync', operations) !== false) {
me.isSyncing = true;
options = options || {};
me.proxy.batch(Ext.apply(options, {
operations: operations,
listeners: me.getBatchListeners()
}));
}
return me;
},
/**
* @private
* Returns an object which is passed in as the listeners argument to proxy.batch inside this.sync.
* This is broken out into a separate function to allow for customisation of the listeners
* @return {Object} The listeners object
*/
getBatchListeners: function() {
var me = this,
listeners = {
scope: me,
exception: me.onBatchException,
complete: me.onBatchComplete
};
if (me.batchUpdateMode === 'operation') {
listeners.operationcomplete = me.onBatchOperationComplete;
}
return listeners;
},
/**
* Saves all pending changes via the configured {@link #proxy}. Use {@link #sync} instead.
* @deprecated 4.0.0 Will be removed in the next major version
*/
save: function() {
return this.sync.apply(this, arguments);
},
/**
* Loads the Store using its configured {@link #proxy}.
* @param {Object} [options] This is passed into the {@link Ext.data.operation.Operation Operation}
* object that is created and then sent to the proxy's {@link Ext.data.proxy.Proxy#read} function
*
* @return {Ext.data.Store} this
* @since 1.1.0
*/
load: function(options) {
// Prevent loads from being triggered while applying initial configs
if (this.isLoadBlocked()) {
return;
}
var me = this,
operation;
me.setLoadOptions(options);
if (me.getRemoteSort() && options.sorters) {
me.fireEvent('beforesort', me, options.sorters);
}
operation = Ext.apply({
internalScope: me,
internalCallback: me.onProxyLoad,
scope: me
}, options);
me.lastOptions = operation;
operation = me.createOperation('read', operation);
if (me.fireEvent('beforeload', me, operation) !== false) {
me.onBeforeLoad(operation);
me.loading = true;
me.clearLoadTask();
operation.execute();
}
return me;
},
/**
* Reloads the store using the last options passed to the {@link #method-load} method. You can use the reload method to reload the
* store using the parameters from the last load() call. For example:
*
* store.load({
* params : {
* userid : 22216
* }
* });
*
* //...
*
* store.reload();
*
* The initial {@link #method-load} execution will pass the `userid` parameter in the request. The {@link #reload} execution
* will also send the same `userid` parameter in its request as it will reuse the `params` object from the last {@link #method-load} call.
*
* You can override a param by passing in the config object with the `params` object:
*
* store.load({
* params : {
* userid : 22216,
* foo : 'bar'
* }
* });
*
* //...
*
* store.reload({
* params : {
* userid : 1234
* }
* });
*
* The initial {@link #method-load} execution sends the `userid` and `foo` parameters but in the {@link #reload} it only sends
* the `userid` paramter because you are overriding the `params` config not just overriding the one param. To only change a single param
* but keep other params, you will have to get the last params from the {@link #lastOptions} property:
*
* var lastOptions = store.lastOptions,
* lastParams = Ext.clone(lastOptions.params); // make a copy of the last params so we don't affect future reload() calls
*
* lastParams.userid = 1234;
*
* store.reload({
* params : lastParams
* });
*
* This will now send the `userid` parameter as `1234` and the `foo` param as `'bar'`.
*
* @param {Object} [options] A config object which contains options which may override the options passed to the previous load call. See the
* {@link #method-load} method for valid configs.
*/
reload: function(options) {
var o = Ext.apply({}, options, this.lastOptions);
return this.load(o);
},
onEndUpdate: function() {
var me = this;
if (me.needsSync && me.autoSync && !me.autoSyncSuspended) {
me.sync();
}
},
/**
* @private
* A model instance should call this method on the Store it has been {@link Ext.data.Model#join joined} to..
* @param {Ext.data.Model} record The model instance that was edited
* @since 3.4.0
*/
afterReject: function(record) {
var me = this;
// Must pass the 5th param (modifiedFieldNames) as null, otherwise the
// event firing machinery appends the listeners "options" object to the arg list
// which may get used as the modified fields array by a handler.
// This array is used for selective grid cell updating by Grid View.
// Null will be treated as though all cells need updating.
if (me.contains(record)) {
me.onUpdate(record, Ext.data.Model.REJECT, null);
me.fireEvent('update', me, record, Ext.data.Model.REJECT, null);
}
},
/**
* @private
* A model instance should call this method on the Store it has been {@link Ext.data.Model#join joined} to.
* @param {Ext.data.Model} record The model instance that was edited
* @since 3.4.0
*/
afterCommit: function(record, modifiedFieldNames) {
var me = this;
if (!modifiedFieldNames) {
modifiedFieldNames = null;
}
if (me.contains(record)) {
me.onUpdate(record, Ext.data.Model.COMMIT, modifiedFieldNames);
me.fireEvent('update', me, record, Ext.data.Model.COMMIT, modifiedFieldNames);
}
},
afterErase: function(record) {
this.onErase(record);
},
onErase: Ext.emptyFn,
onUpdate: Ext.emptyFn,
/**
* @private
*/
onDestroy: function() {
var me = this,
proxy = me.getProxy();
me.blockLoad();
me.clearData();
me.setProxy(null);
if (proxy.autoCreated) {
proxy.destroy();
}
me.setModel(null);
},
/**
* Returns true if the store has a pending load task.
* @return {Boolean} `true` if the store has a pending load task.
* @private
*/
hasPendingLoad: function() {
return !!this.loadTask || this.isLoading();
},
/**
* Returns true if the Store is currently performing a load operation
* @return {Boolean} `true` if the Store is currently loading
*/
isLoading: function() {
return !!this.loading;
},
/**
* Returns `true` if the Store has been loaded.
* @return {Boolean} `true` if the Store has been loaded.
*/
isLoaded: function() {
return this.loadCount > 0;
},
/**
* Suspends automatically syncing the Store with its Proxy. Only applicable if {@link #autoSync} is `true`
*/
suspendAutoSync: function() {
++this.autoSyncSuspended;
},
/**
* Resumes automatically syncing the Store with its Proxy. Only applicable if {@link #autoSync} is `true`
* @param {Boolean} syncNow Pass `true` to synchronize now. Only synchronizes with the Proxy if the suspension
* count has gone to zero (We are not under a higher level of suspension)
*
*/
resumeAutoSync: function(syncNow) {
var me = this;
//<debug>
if (!me.autoSyncSuspended) {
Ext.log.warn('Mismatched call to resumeAutoSync - auto synchronization is currently not suspended.');
}
//</debug>
if (me.autoSyncSuspended && ! --me.autoSyncSuspended) {
if (syncNow) {
me.sync();
}
}
},
/**
* Removes all records from the store. This method does a "fast remove",
* individual remove events are not called. The {@link #clear} event is
* fired upon completion.
* @method
* @since 1.1.0
*/
removeAll: Ext.emptyFn,
// individual store subclasses should implement a "fast" remove
// and fire a clear event afterwards
// to be implemented by subclasses
clearData: Ext.emptyFn,
privates: {
onExtraParamsChanged: function() {
},
attemptLoad: function(options) {
if (this.isLoadBlocked()) {
++this.loadsWhileBlocked;
return;
}
this.load(options);
},
blockLoad: function (value) {
++this.blockLoadCounter;
},
clearLoadTask: function() {
var loadTask = this.loadTask;
if (loadTask) {
loadTask.cancel();
this.loadTask = null;
}
},
cleanRemoved: function() {
var removed = this.removed,
len, i;
if (removed) {<|fim▁hole|> removed[i].unjoin(this);
}
removed.length = 0;
}
},
createOperation: function(type, options) {
var me = this,
proxy = me.getProxy(),
listeners;
if (!me.proxyListeners) {
listeners = {
scope: me,
destroyable: true,
beginprocessresponse: me.beginUpdate,
endprocessresponse: me.endUpdate
};
if (!me.disableMetaChangeEvent) {
listeners.metachange = me.onMetaChange;
}
me.proxyListeners = proxy.on(listeners);
}
return proxy.createOperation(type, options);
},
createImplicitModel: function(fields) {
var me = this,
modelCfg = {
extend: me.implicitModel,
statics: {
defaultProxy: 'memory'
}
},
proxy, model;
if (fields) {
modelCfg.fields = fields;
}
model = Ext.define(null, modelCfg);
me.setModel(model);
proxy = me.getProxy();
if (proxy) {
model.setProxy(proxy);
} else {
me.setProxy(model.getProxy());
}
},
isLoadBlocked: function () {
return !!this.blockLoadCounter;
},
loadsSynchronously: function() {
return this.getProxy().isSynchronous;
},
onBeforeLoad: Ext.privateFn,
removeFromRemoved: function(record) {
var removed = this.removed;
if (removed) {
Ext.Array.remove(removed, record);
record.unjoin(this);
}
},
setLoadOptions: function(options) {
var me = this,
filters, sorters;
if (me.getRemoteFilter()) {
filters = me.getFilters(false);
if (filters && filters.getCount()) {
options.filters = filters.getRange();
}
}
if (me.getRemoteSort()) {
sorters = me.getSorters(false);
if (sorters && sorters.getCount()) {
options.sorters = sorters.getRange();
}
}
},
unblockLoad: function (doLoad) {
var me = this,
loadsWhileBlocked = me.loadsWhileBlocked;
--me.blockLoadCounter;
if (!me.blockLoadCounter) {
me.loadsWhileBlocked = 0;
if (doLoad && loadsWhileBlocked) {
me.load();
}
}
}
}
});<|fim▁end|> | for (i = 0, len = removed.length; i < len; ++i) { |
<|file_name|>radioInterface.cpp<|end_file_name|><|fim▁begin|>/*
* Copyright 2008, 2009 Free Software Foundation, Inc.
*
* This software is distributed under the terms of the GNU Affero Public License.
* See the COPYING file in the main directory for details.
*
* This use of this software may be subject to additional restrictions.
* See the LEGAL file in the main directory for details.
This program is free software: you can redistribute it and/or modify
it under the terms of the GNU Affero General Public License as published by
the Free Software Foundation, either version 3 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU Affero General Public License for more details.
You should have received a copy of the GNU Affero General Public License
along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
#include "radioInterface.h"
#include "Resampler.h"
#include <Logger.h>
extern "C" {
#include "convert.h"
}
#define CHUNK 625
#define NUMCHUNKS 4
RadioInterface::RadioInterface(RadioDevice *wRadio,
size_t sps, size_t chans, size_t diversity,
int wReceiveOffset, GSM::Time wStartTime)
: mRadio(wRadio), mSPSTx(sps), mSPSRx(1), mChans(chans), mMIMO(diversity),
sendCursor(0), recvCursor(0), underrun(false), overrun(false),
receiveOffset(wReceiveOffset), mOn(false)
{
mClock.set(wStartTime);
}
RadioInterface::~RadioInterface(void)
{
close();
}
bool RadioInterface::init(int type)
{
if ((type != RadioDevice::NORMAL) || (mMIMO > 1) || !mChans) {
LOG(ALERT) << "Invalid configuration";
return false;
}
close();
sendBuffer.resize(mChans);
recvBuffer.resize(mChans);
convertSendBuffer.resize(mChans);
convertRecvBuffer.resize(mChans);
mReceiveFIFO.resize(mChans);
powerScaling.resize(mChans);
for (size_t i = 0; i < mChans; i++) {
sendBuffer[i] = new signalVector(CHUNK * mSPSTx);
recvBuffer[i] = new signalVector(NUMCHUNKS * CHUNK * mSPSRx);
convertSendBuffer[i] = new short[sendBuffer[i]->size() * 2];
convertRecvBuffer[i] = new short[recvBuffer[i]->size() * 2];
}
sendCursor = 0;
recvCursor = 0;
return true;
}
void RadioInterface::close()
{
for (size_t i = 0; i < sendBuffer.size(); i++)
delete sendBuffer[i];
for (size_t i = 0; i < recvBuffer.size(); i++)
delete recvBuffer[i];
for (size_t i = 0; i < convertSendBuffer.size(); i++)
delete convertSendBuffer[i];
for (size_t i = 0; i < convertRecvBuffer.size(); i++)
delete convertRecvBuffer[i];
sendBuffer.resize(0);
recvBuffer.resize(0);
convertSendBuffer.resize(0);
convertRecvBuffer.resize(0);
}
double RadioInterface::fullScaleInputValue(void) {
return mRadio->fullScaleInputValue();
}
double RadioInterface::fullScaleOutputValue(void) {
return mRadio->fullScaleOutputValue();
}
int RadioInterface::setPowerAttenuation(int atten, size_t chan)
{
double rfGain, digAtten;
if (chan >= mChans) {
LOG(ALERT) << "Invalid channel requested";
return -1;
}
if (atten < 0.0)
atten = 0.0;
rfGain = mRadio->setTxGain(mRadio->maxTxGain() - (double) atten, chan);
digAtten = (double) atten - mRadio->maxTxGain() + rfGain;
if (digAtten < 1.0)
powerScaling[chan] = 1.0;
else
powerScaling[chan] = 1.0 / sqrt(pow(10, digAtten / 10.0));
return atten;
}
int RadioInterface::radioifyVector(signalVector &wVector,
float *retVector,
bool zero)
{
if (zero) {
memset(retVector, 0, wVector.size() * 2 * sizeof(float));
return wVector.size();
}
memcpy(retVector, wVector.begin(), wVector.size() * 2 * sizeof(float));
return wVector.size();
}
int RadioInterface::unRadioifyVector(float *floatVector,
signalVector& newVector)
{
signalVector::iterator itr = newVector.begin();
if (newVector.size() > recvCursor) {
LOG(ALERT) << "Insufficient number of samples in receive buffer";
return -1;
}
for (size_t i = 0; i < newVector.size(); i++) {
*itr++ = Complex<float>(floatVector[2 * i + 0],
floatVector[2 * i + 1]);
}
return newVector.size();
}
bool RadioInterface::tuneTx(double freq, size_t chan)
{
return mRadio->setTxFreq(freq, chan);
}
bool RadioInterface::tuneRx(double freq, size_t chan)
{
return mRadio->setRxFreq(freq, chan);
}
bool RadioInterface::start()
{
if (mOn)
return true;
LOG(INFO) << "Starting radio device";
#ifdef USRP1
mAlignRadioServiceLoopThread.start((void * (*)(void*))AlignRadioServiceLoopAdapter,
(void*)this);
#endif
if (!mRadio->start())
return false;
recvCursor = 0;
sendCursor = 0;
writeTimestamp = mRadio->initialWriteTimestamp();
readTimestamp = mRadio->initialReadTimestamp();
mRadio->updateAlignment(writeTimestamp-10000);
mRadio->updateAlignment(writeTimestamp-10000);
mOn = true;
LOG(INFO) << "Radio started";
return true;
}
/*
* Stop the radio device
*
* This is a pass-through call to the device interface. Because the underlying
* stop command issuance generally doesn't return confirmation on device status,
* this call will only return false if the device is already stopped.
*/
bool RadioInterface::stop()
{
if (!mOn || !mRadio->stop())
return false;
mOn = false;
return true;
}
#ifdef USRP1
void *AlignRadioServiceLoopAdapter(RadioInterface *radioInterface)
{
while (1) {
radioInterface->alignRadio();
pthread_testcancel();
}
return NULL;
}
void RadioInterface::alignRadio() {
sleep(60);
mRadio->updateAlignment(writeTimestamp+ (TIMESTAMP) 10000);
}
#endif
void RadioInterface::driveTransmitRadio(std::vector<signalVector *> &bursts,
std::vector<bool> &zeros)
{
if (!mOn)
return;
for (size_t i = 0; i < mChans; i++) {
radioifyVector(*bursts[i],
(float *) (sendBuffer[i]->begin() + sendCursor), zeros[i]);
}
sendCursor += bursts[0]->size();
pushBuffer();
}
bool RadioInterface::driveReceiveRadio()
{
radioVector *burst = NULL;
if (!mOn)
return false;
pullBuffer();
GSM::Time rcvClock = mClock.get();
rcvClock.decTN(receiveOffset);
unsigned tN = rcvClock.TN();
int recvSz = recvCursor;
int readSz = 0;
const int symbolsPerSlot = gSlotLen + 8;
int burstSize = (symbolsPerSlot + (tN % 4 == 0)) * mSPSRx;
/*
* Pre-allocate head room for the largest correlation size
* so we can later avoid a re-allocation and copy
* */
size_t head = GSM::gRACHSynchSequence.size();
/*
* Form receive bursts and pass up to transceiver. Use repeating
* pattern of 157-156-156-156 symbols per timeslot
*/
while (recvSz > burstSize) {
for (size_t i = 0; i < mChans; i++) {
burst = new radioVector(rcvClock, burstSize, head, mMIMO);
for (size_t n = 0; n < mMIMO; n++) {
unRadioifyVector((float *)
(recvBuffer[mMIMO * i + n]->begin() + readSz),
*burst->getVector(n));
}
if (mReceiveFIFO[i].size() < 32)
mReceiveFIFO[i].write(burst);
else
delete burst;
}
mClock.incTN();
rcvClock.incTN();
readSz += burstSize;
recvSz -= burstSize;
tN = rcvClock.TN();
burstSize = (symbolsPerSlot + (tN % 4 == 0)) * mSPSRx;
}
if (readSz > 0) {
for (size_t i = 0; i < recvBuffer.size(); i++) {
memmove(recvBuffer[i]->begin(),
recvBuffer[i]->begin() + readSz,
(recvCursor - readSz) * 2 * sizeof(float));
}
recvCursor -= readSz;
}
return true;
}
bool RadioInterface::isUnderrun()
{
bool retVal = underrun;
underrun = false;
return retVal;
}
VectorFIFO* RadioInterface::receiveFIFO(size_t chan)
{
if (chan >= mReceiveFIFO.size())
return NULL;
return &mReceiveFIFO[chan];
}
double RadioInterface::setRxGain(double dB, size_t chan)
{
if (mRadio)
return mRadio->setRxGain(dB, chan);
else
return -1;
}
double RadioInterface::getRxGain(size_t chan)
{
if (mRadio)
return mRadio->getRxGain(chan);
else
return -1;
}
/* Receive a timestamped chunk from the device */
void RadioInterface::pullBuffer()
{
bool local_underrun;
int num_recv;
float *output;
if (recvCursor > recvBuffer[0]->size() - CHUNK)
return;
/* Outer buffer access size is fixed */
num_recv = mRadio->readSamples(convertRecvBuffer,
CHUNK,
&overrun,
readTimestamp,
&local_underrun);
if (num_recv != CHUNK) {
LOG(ALERT) << "Receive error " << num_recv;
return;
}
for (size_t i = 0; i < mChans; i++) {
output = (float *) (recvBuffer[i]->begin() + recvCursor);
convert_short_float(output, convertRecvBuffer[i], 2 * num_recv);
}
underrun |= local_underrun;
readTimestamp += num_recv;
recvCursor += num_recv;
}
/* Send timestamped chunk to the device with arbitrary size */
void RadioInterface::pushBuffer()
{
int num_sent;
if (sendCursor < CHUNK)
return;
if (sendCursor > sendBuffer[0]->size())
LOG(ALERT) << "Send buffer overflow";
for (size_t i = 0; i < mChans; i++) {
convert_float_short(convertSendBuffer[i],
(float *) sendBuffer[i]->begin(),
powerScaling[i], 2 * sendCursor);
}
/* Send the all samples in the send buffer */
num_sent = mRadio->writeSamples(convertSendBuffer,<|fim▁hole|> writeTimestamp);
writeTimestamp += num_sent;
sendCursor = 0;
}<|fim▁end|> | sendCursor,
&underrun, |
<|file_name|>launcher.rs<|end_file_name|><|fim▁begin|>extern crate foo;
use std::io::stdio::stdout;
use std::io::BufferedWriter;<|fim▁hole|>use foo::Template;
#[test]
fn test_execution_of_produce_file() {
foo::Template(&mut BufferedWriter::new(~stdout() as ~Writer), 4);
}
#[test]
fn test_parsing_and_execution() {
}<|fim▁end|> | |
<|file_name|>VectorEncoder.py<|end_file_name|><|fim▁begin|>#encoding=utf-8
#一大类特征
from scipy import sparse
import re
class VectorEncoder(object):
def __init__(self):
self.n_size = 0
self.idmap = {}
def fit(self, X):
for row in X:
units = re.split("\\s+", row)
for unit in units:
if unit == '-1': unit = 'null:0'
ent, value = unit.split(":")
if ent not in self.idmap:
self.idmap[ent] = 1 + len(self.idmap)
def size(self):
return len(self.idmap)
def transform(self, X):
"""
:param X:
:return: sparse matrix.
"""
data = []
indices = []
indptr= [0] # row-i indptr[i]:indptr[i+1]
n_row = 0
n_col = self.size() + 1
for row in X:
n_row += 1
units = re.split("\\s+", row)
buf = []
for unit in units:
if unit == '-1': unit = 'null:0'
ent, value = unit.split(":")
value = float(value)
<|fim▁hole|> if ent in self.idmap:
ind = self.idmap[ent]
buf.append((ind, value))
# a = (1,2)
buf = sorted(buf, key=lambda x : x[0] )
for ind, val in buf:
indices.append(ind)
data.append(val)
indptr.append(len(data))
return sparse.csr_matrix((data, indices, indptr),shape=(n_row,n_col), dtype=float)
if __name__ == '__main__':
data = [
"a:1 b:2",
"a:3 c:4"
]
enc = VectorEncoder()
enc.fit(data)
print(enc.transform(data).toarray())<|fim▁end|> | |
<|file_name|>padding.py<|end_file_name|><|fim▁begin|># This file is dual licensed under the terms of the Apache License, Version
# 2.0, and the BSD License. See the LICENSE file in the root of this repository
# for complete details.
from __future__ import absolute_import, division, print_function
import abc
import os
import six
from cryptography import utils
from cryptography.exceptions import AlreadyFinalized
from cryptography.hazmat.bindings.utils import LazyLibrary, build_ffi
with open(os.path.join(os.path.dirname(__file__), "src/padding.h")) as f:
TYPES = f.read()
with open(os.path.join(os.path.dirname(__file__), "src/padding.c")) as f:
FUNCTIONS = f.read()
_ffi = build_ffi(cdef_source=TYPES, verify_source=FUNCTIONS)
_lib = LazyLibrary(_ffi)
@six.add_metaclass(abc.ABCMeta)
class PaddingContext(object):
@abc.abstractmethod
def update(self, data):
"""
Pads the provided bytes and returns any available data as bytes.
"""
@abc.abstractmethod
def finalize(self):
"""
Finalize the padding, returns bytes.
"""
class PKCS7(object):
def __init__(self, block_size):
if not (0 <= block_size < 256):
raise ValueError("block_size must be in range(0, 256).")
if block_size % 8 != 0:
raise ValueError("block_size must be a multiple of 8.")
self.block_size = block_size
def padder(self):
return _PKCS7PaddingContext(self.block_size)
def unpadder(self):
return _PKCS7UnpaddingContext(self.block_size)
@utils.register_interface(PaddingContext)
class _PKCS7PaddingContext(object):
def __init__(self, block_size):
self.block_size = block_size
# TODO: more copies than necessary, we should use zero-buffer (#193)
self._buffer = b""
def update(self, data):
if self._buffer is None:
raise AlreadyFinalized("Context was already finalized.")
if not isinstance(data, bytes):
raise TypeError("data must be bytes.")
self._buffer += data
finished_blocks = len(self._buffer) // (self.block_size // 8)
result = self._buffer[:finished_blocks * (self.block_size // 8)]
self._buffer = self._buffer[finished_blocks * (self.block_size // 8):]
return result
def finalize(self):
if self._buffer is None:
raise AlreadyFinalized("Context was already finalized.")
pad_size = self.block_size // 8 - len(self._buffer)
result = self._buffer + six.int2byte(pad_size) * pad_size
self._buffer = None
return result
@utils.register_interface(PaddingContext)
class _PKCS7UnpaddingContext(object):
def __init__(self, block_size):
self.block_size = block_size
# TODO: more copies than necessary, we should use zero-buffer (#193)
self._buffer = b""
def update(self, data):
if self._buffer is None:
raise AlreadyFinalized("Context was already finalized.")
if not isinstance(data, bytes):
raise TypeError("data must be bytes.")
self._buffer += data
finished_blocks = max(
len(self._buffer) // (self.block_size // 8) - 1,
0<|fim▁hole|> self._buffer = self._buffer[finished_blocks * (self.block_size // 8):]
return result
def finalize(self):
if self._buffer is None:
raise AlreadyFinalized("Context was already finalized.")
if len(self._buffer) != self.block_size // 8:
raise ValueError("Invalid padding bytes.")
valid = _lib.Cryptography_check_pkcs7_padding(
self._buffer, self.block_size // 8
)
if not valid:
raise ValueError("Invalid padding bytes.")
pad_size = six.indexbytes(self._buffer, -1)
res = self._buffer[:-pad_size]
self._buffer = None
return res<|fim▁end|> | )
result = self._buffer[:finished_blocks * (self.block_size // 8)] |
<|file_name|>react-native-firebase.js<|end_file_name|><|fim▁begin|>export default {
analytics: () => {
return {
logEvent: () => {},
setCurrentScreen: () => {}
};
}<|fim▁hole|><|fim▁end|> | }; |
<|file_name|>tools.py<|end_file_name|><|fim▁begin|>import time
def import_grid(file_to_open):
grid = []
print(file_to_open)
with open(file_to_open) as file:
for i, line in enumerate(file):
if i == 0:
iterations = int(line.split(" ")[0])
delay = float(line.split(" ")[1])
else:
grid.append([])
<|fim▁hole|>
return grid, iterations, delay
def save_grid(file, grid):
with open(file, 'w') as file:
for line in grid:
file.write(line + "\n")
def check_time(prev_time, freq):
if time.time() - prev_time > freq:
return True
else:
return False<|fim▁end|> | line = line.strip()
for item in line:
grid[i-1].append(int(item))
|
<|file_name|>issue22656.rs<|end_file_name|><|fim▁begin|>// Copyright 2013-2015 The Rust Project Developers. See the COPYRIGHT
// file at the top-level directory of this distribution and at
// http://rust-lang.org/COPYRIGHT.
//
// Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or
// http://www.apache.org/licenses/LICENSE-2.0> or the MIT license
// <LICENSE-MIT or http://opensource.org/licenses/MIT>, at your
// option. This file may not be copied, modified, or distributed
// except according to those terms.
// This test makes sure that the LLDB pretty printer does not throw an exception
// when trying to handle a Vec<> or anything else that contains zero-sized
// fields.
<|fim▁hole|>// ignore-gdb
// ignore-tidy-linelength
// compile-flags:-g
// === LLDB TESTS ==================================================================================
// lldb-command:run
// lldb-command:print v
// lldb-check:[...]$0 = vec![1, 2, 3]
// lldb-command:print zs
// lldb-check:[...]$1 = StructWithZeroSizedField { x: ZeroSizedStruct, y: 123, z: ZeroSizedStruct, w: 456 }
// lldb-command:continue
#![allow(unused_variables)]
#![allow(dead_code)]
#![omit_gdb_pretty_printer_section]
struct ZeroSizedStruct;
struct StructWithZeroSizedField {
x: ZeroSizedStruct,
y: u32,
z: ZeroSizedStruct,
w: u64
}
fn main() {
let v = vec![1,2,3];
let zs = StructWithZeroSizedField {
x: ZeroSizedStruct,
y: 123,
z: ZeroSizedStruct,
w: 456
};
zzz(); // #break
}
fn zzz() { () }<|fim▁end|> | // min-lldb-version: 310 |
<|file_name|>configuration.go<|end_file_name|><|fim▁begin|>// Copyright © 2017 The Things Network. Use of this source code is governed by the MIT license that can be found in the LICENSE file.
package pktfwd
import (
"github.com/TheThingsNetwork/go-account-lib/account"
"github.com/TheThingsNetwork/go-utils/log"
"github.com/TheThingsNetwork/packet_forwarder/util"
"github.com/TheThingsNetwork/packet_forwarder/wrapper"
)
// Multitech concentrators require a clksrc of 0, even if the frequency plan indicates a value of 1.
// This value, modified at build to include the platform type, is currently useful as a flag to
// ignore the frequency plan value of `clksrc`.
var platform = ""
func configureBoard(ctx log.Interface, conf util.Config, gpsPath string) error {
if platform == "multitech" {
ctx.Info("Forcing clock source to 0 (Multitech concentrator)")
conf.Concentrator.Clksrc = 0
}
err := wrapper.SetBoardConf(ctx, conf)
if err != nil {
return err
}
err = configureChannels(ctx, conf)
if err != nil {
return err
}
err = enableGPS(ctx, gpsPath)
if err != nil {
return err
}
<|fim▁hole|> // Configuring LoRa standard channel
if lora := conf.Concentrator.LoraSTDChannel; lora != nil {
err := wrapper.SetStandardChannel(ctx, *lora)
if err != nil {
return err
}
ctx.Info("LoRa standard channel configured")
} else {
ctx.Warn("No configuration for LoRa standard channel, ignoring")
}
// Configuring FSK channel
if fsk := conf.Concentrator.FSKChannel; fsk != nil {
err := wrapper.SetFSKChannel(ctx, *fsk)
if err != nil {
return err
}
ctx.Info("FSK channel configured")
} else {
ctx.Warn("No configuration for FSK standard channel, ignoring")
}
return nil
}
func configureChannels(ctx log.Interface, conf util.Config) error {
// Configuring the TX Gain Lut
err := wrapper.SetTXGainConf(ctx, conf.Concentrator)
if err != nil {
return err
}
// Configuring the RF and SF channels
err = wrapper.SetRFChannels(ctx, conf)
if err != nil {
return err
}
wrapper.SetSFChannels(ctx, conf)
// Configuring the individual LoRa standard and FSK channels
err = configureIndividualChannels(ctx, conf)
if err != nil {
return err
}
return nil
}
// FetchConfig reads the configuration from the distant server
func FetchConfig(ctx log.Interface, ttnConfig *TTNConfig) (*util.Config, error) {
a := account.New(ttnConfig.AuthServer)
gw, err := a.FindGateway(ttnConfig.ID)
ctx = ctx.WithFields(log.Fields{"GatewayID": ttnConfig.ID, "AuthServer": ttnConfig.AuthServer})
if err != nil {
ctx.WithError(err).Error("Failed to find gateway specified as gateway ID")
return nil, err
}
ctx.WithField("URL", gw.FrequencyPlanURL).Info("Found gateway parameters, getting frequency plans")
if gw.Attributes.Description != nil {
ttnConfig.GatewayDescription = *gw.Attributes.Description
}
config, err := util.FetchConfigFromURL(ctx, gw.FrequencyPlanURL)
if err != nil {
return nil, err
}
return &config, nil
}<|fim▁end|> | return nil
}
func configureIndividualChannels(ctx log.Interface, conf util.Config) error { |
<|file_name|>genetic_modification.py<|end_file_name|><|fim▁begin|>import pytest
@pytest.fixture
def genetic_modification(testapp, lab, award):
item = {
'award': award['@id'],
'lab': lab['@id'],
'modified_site_by_coordinates': {
'assembly': 'GRCh38',
'chromosome': '11',
'start': 20000,
'end': 21000
},
'purpose': 'repression',
'category': 'deletion',
'method': 'CRISPR',
'zygosity': 'homozygous'
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def genetic_modification_RNAi(testapp, lab, award):
item = {
'award': award['@id'],
'lab': lab['@id'],
'modified_site_by_coordinates': {
'assembly': 'GRCh38',
'chromosome': '11',
'start': 20000,
'end': 21000
},
'purpose': 'repression',
'category': 'deletion',
'method': 'RNAi'
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def genetic_modification_source(testapp, lab, award, source, gene):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'introduced_gene': gene['@id'],
'purpose': 'expression',
'method': 'CRISPR',
'reagents': [
{
'source': source['@id'],
'identifier': 'sigma:ABC123'
}
]
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def crispr_deletion(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'deletion',
'purpose': 'repression',
'method': 'CRISPR'
}
@pytest.fixture
def crispr_deletion_1(testapp, lab, award, target):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'deletion',
'purpose': 'repression',
'method': 'CRISPR',
'modified_site_by_target_id': target['@id'],
'guide_rna_sequences': ['ACCGGAGA']
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def tale_deletion(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'deletion',
'purpose': 'repression',<|fim▁hole|> 'method': 'TALEN',
'zygosity': 'heterozygous'
}
@pytest.fixture
def crispr_tag(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'tagging',
'method': 'CRISPR'
}
@pytest.fixture
def bombardment_tag(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'tagging',
'nucleic_acid_delivery_method': ['bombardment']
}
@pytest.fixture
def recomb_tag(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'tagging',
'method': 'site-specific recombination'
}
@pytest.fixture
def transfection_tag(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'tagging',
'nucleic_acid_delivery_method': ['stable transfection']
}
@pytest.fixture
def crispri(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'interference',
'purpose': 'repression',
'method': 'CRISPR'
}
@pytest.fixture
def rnai(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'interference',
'purpose': 'repression',
'method': 'RNAi'
}
@pytest.fixture
def mutagen(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'mutagenesis',
'purpose': 'repression',
'method': 'mutagen treatment'
}
@pytest.fixture
def tale_replacement(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'replacement',
'purpose': 'characterization',
'method': 'TALEN',
'zygosity': 'heterozygous'
}
@pytest.fixture
def mpra(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'characterization',
'nucleic_acid_delivery_method': ['transduction']
}
@pytest.fixture
def starr_seq(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'episome',
'purpose': 'characterization',
'nucleic_acid_delivery_method': ['transient transfection']
}
@pytest.fixture
def introduced_elements(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'episome',
'purpose': 'characterization',
'nucleic_acid_delivery_method': ['transient transfection'],
'introduced_elements': 'genomic DNA regions'
}
@pytest.fixture
def crispr_tag_1(testapp, lab, award, ctcf):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'tagging',
'method': 'CRISPR',
'modified_site_by_gene_id': ctcf['@id'],
'introduced_tags': [{'name': 'mAID-mClover', 'location': 'C-terminal'}]
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def mpra_1(testapp, lab, award):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'characterization',
'nucleic_acid_delivery_method': ['transduction'],
'introduced_elements': 'synthesized DNA',
'modified_site_nonspecific': 'random'
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def recomb_tag_1(testapp, lab, award, target, treatment_5, document):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'tagging',
'method': 'site-specific recombination',
'modified_site_by_target_id': target['@id'],
'modified_site_nonspecific': 'random',
'category': 'insertion',
'treatments': [treatment_5['@id']],
'documents': [document['@id']],
'introduced_tags': [{'name': 'eGFP', 'location': 'C-terminal'}]
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def rnai_1(testapp, lab, award, source, target):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'interference',
'purpose': 'repression',
'method': 'RNAi',
'reagents': [{'source': source['@id'], 'identifier': 'addgene:12345'}],
'rnai_sequences': ['ATTACG'],
'modified_site_by_target_id': target['@id']
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def genetic_modification_1(lab, award):
return {
'modification_type': 'deletion',
'award': award['uuid'],
'lab': lab['uuid'],
'modifiction_description': 'some description'
}
@pytest.fixture
def genetic_modification_2(lab, award):
return {
'modification_type': 'deletion',
'award': award['uuid'],
'lab': lab['uuid'],
'modification_description': 'some description',
'modification_zygocity': 'homozygous',
'modification_purpose': 'tagging',
'modification_treatments': [],
'modification_genome_coordinates': [{
'chromosome': '11',
'start': 5309435,
'end': 5309451
}]
}
@pytest.fixture
def crispr_gm(lab, award, source):
return {
'lab': lab['uuid'],
'award': award['uuid'],
'source': source['uuid'],
'guide_rna_sequences': [
"ACA",
"GCG"
],
'insert_sequence': 'TCGA',
'aliases': ['encode:crispr_technique1'],
'@type': ['Crispr', 'ModificationTechnique', 'Item'],
'@id': '/crisprs/79c1ec08-c878-4419-8dba-66aa4eca156b/',
'uuid': '79c1ec08-c878-4419-8dba-66aa4eca156b'
}
@pytest.fixture
def genetic_modification_5(lab, award, crispr_gm):
return {
'modification_type': 'deletion',
'award': award['uuid'],
'lab': lab['uuid'],
'description': 'blah blah description blah',
'zygosity': 'homozygous',
'treatments': [],
'source': 'sigma',
'product_id': '12345',
'modification_techniques': [crispr_gm],
'modified_site': [{
'assembly': 'GRCh38',
'chromosome': '11',
'start': 5309435,
'end': 5309451
}]
}
@pytest.fixture
def genetic_modification_6(lab, award, crispr_gm, source):
return {
'purpose': 'validation',
'category': 'deeltion',
'award': award['uuid'],
'lab': lab['uuid'],
'description': 'blah blah description blah',
"method": "CRISPR",
"modified_site_by_target_id": "/targets/FLAG-ZBTB43-human/",
"reagents": [
{
"identifier": "placeholder_id",
"source": source['uuid']
}
]
}
@pytest.fixture
def genetic_modification_7_invalid_reagent(lab, award, crispr_gm):
return {
'purpose': 'characterization',
'category': 'deletion',
'award': award['uuid'],
'lab': lab['uuid'],
'description': 'blah blah description blah',
"method": "CRISPR",
"modified_site_by_target_id": "/targets/FLAG-ZBTB43-human/",
"reagents": [
{
"identifier": "placeholder_id",
"source": "/sources/sigma/"
}
]
}
@pytest.fixture
def genetic_modification_7_valid_reagent(lab, award, crispr_gm):
return {
'purpose': 'characterization',
'category': 'deletion',
'award': award['uuid'],
'lab': lab['uuid'],
'description': 'blah blah description blah',
"method": "CRISPR",
"modified_site_by_target_id": "/targets/FLAG-ZBTB43-human/",
"reagents": [
{
"identifier": "ABC123",
"source": "/sources/sigma/"
}
]
}
@pytest.fixture
def genetic_modification_7_addgene_source(testapp):
item = {
'name': 'addgene',
'title': 'Addgene',
'status': 'released'
}
return testapp.post_json('/source', item).json['@graph'][0]
@pytest.fixture
def genetic_modification_7_multiple_matched_identifiers(lab, award, crispr_gm):
return {
'purpose': 'characterization',
'category': 'deletion',
'award': award['uuid'],
'lab': lab['uuid'],
'description': 'blah blah description blah',
"method": "CRISPR",
"modified_site_by_target_id": "/targets/FLAG-ZBTB43-human/",
"reagents": [
{
"identifier": "12345",
"source": "/sources/addgene/"
}
]
}
@pytest.fixture
def genetic_modification_7_multiple_reagents(lab, award, crispr_gm):
return {
'purpose': 'characterization',
'category': 'deletion',
'award': award['uuid'],
'lab': lab['uuid'],
'description': 'blah blah description blah',
"method": "CRISPR",
"modified_site_by_target_id": "/targets/FLAG-ZBTB43-human/",
"reagents": [
{
"identifier": "12345",
"source": "/sources/addgene/",
"url": "http://www.addgene.org"
},
{
"identifier": "67890",
"source": "/sources/addgene/",
"url": "http://www.addgene.org"
}
]
}
@pytest.fixture
def genetic_modification_8(lab, award):
return {
'purpose': 'analysis',
'category': 'interference',
'award': award['uuid'],
'lab': lab['uuid'],
"method": "CRISPR",
}
@pytest.fixture
def construct_genetic_modification(
testapp,
lab,
award,
document,
target_ATF5_genes,
target_promoter):
item = {
'award': award['@id'],
'documents': [document['@id']],
'lab': lab['@id'],
'category': 'insertion',
'purpose': 'tagging',
'nucleic_acid_delivery_method': ['stable transfection'],
'introduced_tags': [{'name':'eGFP', 'location': 'C-terminal', 'promoter_used': target_promoter['@id']}],
'modified_site_by_target_id': target_ATF5_genes['@id']
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def construct_genetic_modification_N(
testapp,
lab,
award,
document,
target):
item = {
'award': award['@id'],
'documents': [document['@id']],
'lab': lab['@id'],
'category': 'insertion',
'purpose': 'tagging',
'nucleic_acid_delivery_method': ['stable transfection'],
'introduced_tags': [{'name':'eGFP', 'location': 'N-terminal'}],
'modified_site_by_target_id': target['@id']
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def interference_genetic_modification(
testapp,
lab,
award,
document,
target):
item = {
'award': award['@id'],
'documents': [document['@id']],
'lab': lab['@id'],
'category': 'interference',
'purpose': 'repression',
'method': 'RNAi',
'modified_site_by_target_id': target['@id']
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def crispr_knockout(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'knockout',
'purpose': 'characterization',
'method': 'CRISPR'
}
@pytest.fixture
def recombination_knockout(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'knockout',
'purpose': 'repression',
'method': 'site-specific recombination',
'modified_site_by_coordinates': {
"assembly": "GRCh38",
"chromosome": "11",
"start": 60000,
"end": 62000
}
}
@pytest.fixture
def characterization_insertion_transfection(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'characterization',
'nucleic_acid_delivery_method': ['stable transfection'],
'modified_site_nonspecific': 'random',
'introduced_elements': 'synthesized DNA'
}
@pytest.fixture
def characterization_insertion_CRISPR(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'characterization',
'method': 'CRISPR',
'modified_site_nonspecific': 'random',
'introduced_elements': 'synthesized DNA'
}
@pytest.fixture
def disruption_genetic_modification(testapp, lab, award):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'CRISPR cutting',
'purpose': 'characterization',
'method': 'CRISPR'
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def activation_genetic_modification(testapp, lab, award):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'CRISPRa',
'purpose': 'characterization',
'method': 'CRISPR'
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def binding_genetic_modification(testapp, lab, award):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'CRISPR dCas',
'purpose': 'characterization',
'method': 'CRISPR'
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def HR_knockout(lab, award, target):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'knockout',
'purpose': 'repression',
'method': 'homologous recombination',
'modified_site_by_target_id': target['@id']
}
@pytest.fixture
def CRISPR_introduction(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'expression',
'nucleic_acid_delivery_method': ['transient transfection']
}
@pytest.fixture
def genetic_modification_9(lab, award, human_donor_1):
return {
'lab': lab['@id'],
'award': award['@id'],
'donor': human_donor_1['@id'],
'category': 'insertion',
'purpose': 'expression',
'method': 'transient transfection'
}
@pytest.fixture
def transgene_insertion(testapp, lab, award, ctcf):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'in vivo enhancer characterization',
'nucleic_acid_delivery_method': ['mouse pronuclear microinjection'],
'modified_site_by_gene_id': ctcf['@id'],
'introduced_sequence': 'ATCGTA'
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def guides_transduction_GM(testapp, lab, award):
item = {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'expression',
'nucleic_acid_delivery_method': ['transduction'],
'introduced_elements': 'gRNAs and CRISPR machinery',
'MOI': 'high',
'guide_type': 'sgRNA'
}
return testapp.post_json('/genetic_modification', item).json['@graph'][0]
@pytest.fixture
def genetic_modification_10(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'insertion',
'purpose': 'expression',
'nucleic_acid_delivery_method': ['transduction'],
'introduced_elements': 'gRNAs and CRISPR machinery',
}
@pytest.fixture
def genetic_modification_11(lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'disruption',
'purpose': 'characterization',
'method': 'CRISPR'
}
@pytest.fixture
def transgene_insertion_2(testapp, lab, award, ctcf):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'transgene insertion',
'purpose': 'in vivo enhancer characterization',
'nucleic_acid_delivery_method': ['mouse pronuclear microinjection'],
'modified_site_by_gene_id': ctcf['@id'],
'introduced_sequence': 'ATCGTA'
}
@pytest.fixture
def activation_genetic_modification_2(testapp, lab, award):
return{
'lab': lab['@id'],
'award': award['@id'],
'category': 'activation',
'purpose': 'characterization',
'method': 'CRISPR'
}
@pytest.fixture
def binding_genetic_modification_2(testapp, lab, award):
return {
'lab': lab['@id'],
'award': award['@id'],
'category': 'binding',
'purpose': 'characterization',
'method': 'CRISPR'
}<|fim▁end|> | |
<|file_name|>test_sup.rs<|end_file_name|><|fim▁begin|>//! Encapsulate running the `hab-sup` executable for tests.
use std::{collections::HashSet,
env,
net::TcpListener,
path::{Path,
PathBuf},
process::{Child,
Command,
Stdio},
string::ToString,
sync::Mutex,
thread,
time::Duration};
use crate::hcore::url::BLDR_URL_ENVVAR;
use rand::{self,
distributions::{Distribution,
Uniform}};
use super::test_butterfly;
lazy_static! {
/// Keep track of all TCP ports currently being used by TestSup
/// instances. Allows us to run tests in parallel without fear of
/// port conflicts between them.
static ref CLAIMED_PORTS: Mutex<HashSet<u16>> = {
Mutex::new(HashSet::new())
};
}
pub struct TestSup {
pub hab_root: PathBuf,
pub origin_name: String,
pub package_name: String,
pub service_group: String,
pub http_port: u16,
pub butterfly_port: u16,
pub control_port: u16,
pub butterfly_client: test_butterfly::Client,
pub cmd: Command,
pub process: Option<Child>,
}
/// Return a free TCP port number. We test to see that the system has
/// not already bound the port, while also tracking which ports are
/// being used by other test supervisors that may be running alongside
/// this one.
///
/// Once you receive a port number from this function, you can be
/// reasonably sure that you're the only one that will be using
/// it. There could be a race condition if the machine the tests are
/// running on just happens to claim the same port number for
/// something between the time we check and the time the TestSup
/// claims it. If that happens to you, you should probably buy lottery
/// tickets, though.
///
/// This function will recursively call itself with a decremented
/// value for `tries` if it happens to pick a port that's already in
/// use. Once all tries are used up, it panics! Yay!
fn unclaimed_port(tries: u16) -> u16 {
if tries == 0 {
panic!("Couldn't find an unclaimed port for the test Supervisor!")
}
let p = random_port();
match TcpListener::bind(format!("127.0.0.1:{}", p)) {
Ok(_listener) => {
// The system hasn't bound it. Now we make sure none of
// our other tests have bound it.
let mut ports = CLAIMED_PORTS.lock().unwrap();
if ports.contains(&p) {
// Oops, another test is using it, try again
thread::sleep(Duration::from_millis(500));
unclaimed_port(tries - 1)
} else {
// Nobody was using it. Return the port; the TcpListener
// that is currently bound to the port will be dropped,
// thus freeing the port for our use.
ports.insert(p);
p
}
}
Err(_) => {
// port already in use, try again
unclaimed_port(tries - 1)
}
}
}
/// Return a random unprivileged, unregistered TCP port number.
fn random_port() -> u16 {
// IANA port registrations go to 49151
let between = Uniform::new_inclusive(49152, ::std::u16::MAX);
let mut rng = rand::thread_rng();
between.sample(&mut rng)
}
/// Find an executable relative to the current integration testing
/// executable.
///
/// Thus if the current executable is
///
/// /home/me/habitat/target/debug/deps/compilation-ccaf2f45c24e3840
///
/// and we look for `hab-sup`, we'll find it at
///
/// /home/me/habitat/target/debug/hab-sup
fn find_exe<B>(binary_name: B) -> PathBuf
where B: AsRef<Path>
{
let exe_root = env::current_exe()
.unwrap()
.parent() // deps
.unwrap()
.parent() // debug
.unwrap()
.to_path_buf();
let bin = exe_root.join(binary_name.as_ref());
assert!(bin.exists(),
"Expected to find a {:?} executable at {:?}",
binary_name.as_ref(),
bin);
bin
}
/// Return whether or not the tests are being run with the `--nocapture` flag meaning we want to
/// see more output.
fn nocapture_set() -> bool {
if env::args().any(|arg| arg == "--nocapture") {
true
} else {
match env::var("RUST_TEST_NOCAPTURE") {
Ok(val) => &val != "0",
Err(_) => false,
}
}
}
impl TestSup {
/// Create a new `TestSup` that will listen on randomly-selected
/// ports for both gossip and HTTP requests so tests run in
/// parallel don't step on each other.
///
/// See also `new`.
pub fn new_with_random_ports<R>(fs_root: R,
origin: &str,
pkg_name: &str,
service_group: &str)
-> TestSup
where R: AsRef<Path>
{
// We'll give 10 tries to find a free port number
let http_port = unclaimed_port(10);
let butterfly_port = unclaimed_port(10);
let control_port = unclaimed_port(10);
TestSup::new(fs_root,
origin,
pkg_name,
service_group,
http_port,
butterfly_port,
control_port)
}
/// Bundle up a Habitat Supervisor process along with an
/// associated Butterfly client for injecting new configuration
/// values. The Supervisor executable is the one that has been
/// compiled for the current `cargo test` invocation.
///
/// The Supervisor is configured to run a single package for a
/// test. This package is assumed to have already been installed
/// relative to `fs_root` (i.e., the `FS_ROOT` environment
/// variable, which in our tests will be a randomly-named
/// temporary directory that this Supervisor will view as `/`.).
///
/// A Butterfly client is also created for interacting with this
/// Supervisor and package. It is properly configured according to
/// the value provided for `butterfly_port`. To use it, see the
/// `apply_config` function.
///
/// (No HTTP interaction with the Supervisor is currently called
/// for, so we don't have a HTTP client.)
pub fn new<R>(fs_root: R,
origin: &str,
pkg_name: &str,
service_group: &str,
http_port: u16,
butterfly_port: u16,
control_port: u16)
-> TestSup
where R: AsRef<Path>
{
let sup_exe = find_exe("hab-sup");
let launcher_exe = find_exe("hab-launch");
let mut cmd = Command::new(&launcher_exe);
let listen_host = "0.0.0.0";
let origin = origin.to_string();
let pkg_name = pkg_name.to_string();
let service_group = service_group.to_string();
cmd.env(
"FS_ROOT",
fs_root.as_ref().to_string_lossy().as_ref(),
)
.env("HAB_SUP_BINARY", &sup_exe)
.env(BLDR_URL_ENVVAR, "http://hab.sup.test")
.arg("run")
.arg("--listen-gossip")
.arg(format!("{}:{}", listen_host, butterfly_port))
.arg("--listen-http")
.arg(format!("{}:{}", listen_host, http_port))
.arg("--listen-ctl")
.arg(format!("{}:{}", listen_host, control_port))
// Note: we will have already dropped off the spec files
// needed to run our test service, so we don't supply a
// package identifier here
.stdin(Stdio::null());
if !nocapture_set() {
cmd.stdout(Stdio::null());
cmd.stderr(Stdio::null());
}
let bc = test_butterfly::Client::new(&pkg_name, &service_group, butterfly_port);
TestSup { hab_root: fs_root.as_ref().to_path_buf(),
origin_name: origin,
package_name: pkg_name,
service_group,
http_port,
butterfly_port,
control_port,
butterfly_client: bc,
cmd,
process: None }
}
/// Spawn a process actually running the Supervisor.
pub fn start(&mut self) {
let child = self.cmd.spawn().expect("Couldn't start the Supervisor!");
self.process = Some(child);
}
/// Stop the Supervisor.
pub fn stop(&mut self) {
let mut ports = CLAIMED_PORTS.lock().unwrap();
ports.remove(&self.http_port);
ports.remove(&self.butterfly_port);
ports.remove(&self.control_port);
self.process
.take()<|fim▁hole|> .kill()
.expect("Tried to kill Supervisor!");
}
/// The equivalent of performing `hab apply` with the given
/// configuration.
pub fn apply_config(&mut self, toml_config: &str) { self.butterfly_client.apply(toml_config) }
}
// We kill the Supervisor so you don't have to! We also free up the
// ports used by this Supervisor so other tests can use them.
impl Drop for TestSup {
fn drop(&mut self) { self.stop(); }
}<|fim▁end|> | .expect("No process to kill!") |
<|file_name|>averageZeroSignalsWithinPeaks.py<|end_file_name|><|fim▁begin|>import sys
import argparse
from itertools import izip
import math
def parseArgument():
# Parse the input
parser = argparse.ArgumentParser(description = "Make regions with 0 signal the average of their surrounding regions")
parser.add_argument("--signalsFileName", required=True, help='Signals file')
parser.add_argument("--peakIndexesFileName", required=True, help='Peak indexes file')
parser.add_argument("--outputFileName", required=True, help='Output file, where signals that were 0 will be the average of their surrounding signals')
options = parser.parse_args();
return options
def averageZeroSignalsWithinPeaks(options):
signalsFile = open(options.signalsFileName)
peakIndexesFile = open(options.peakIndexesFileName)
outputFile = open(options.outputFileName, 'w+')
lastSignal = None
lastLastSignal = None
lastPeakIndex = None
lastLastPeakIndex = None
for signalsLine, peakIndexesLine in izip(signalsFile, peakIndexesFile):
# Iterate through the signals and set those that are zero to the average of those of the surrounding regions
signal = float(signalsLine.strip())
peakIndex = int(peakIndexesLine.strip())
if lastSignal == 0:
# The previous signal was a zero, so set it to the average of the surrounding signals
if (peakIndex == lastPeakIndex) and (not math.isnan(lastSignal)):
# Include the current region in the average
if (lastPeakIndex == lastLastPeakIndex) and (not math.isnan(lastLastSignal)):
# Include the region before the previous region in the average
if not math.isnan(signal):
# The current signal is not a nan, so include it in the average
lastSignalCorrected = (signal + lastLastSignal)/2.0
outputFile.write(str(lastSignalCorrected) + "\n")
else:
# The current signal is a nan, so use only the previous signal
outputFile.write(str(lastLastSignal) + "\n")
elif not math.isnan(signal):
outputFile.write(str(signal) + "\n")
else:
outputFile.write(str(lastSignal) + "\n")<|fim▁hole|> # Set the output to the region before it
outputFile.write(str(lastLastSignal) + "\n")
else:
outputFile.write(str(lastSignal) + "\n")
if signal != 0:
# The current signal is not 0, so record it
outputFile.write(str(signal) + "\n")
lastLastSignal = lastSignal
lastLastPeakIndex = lastPeakIndex
lastSignal = signal
lastPeakIndex = peakIndex
if lastSignal == 0:
# The final signal was a zero, so set it to the signal before it
if (lastPeakIndex == lastLastPeakIndex) and (not math.isnan(lastLastSignal)):
# Set the output to the region before it
outputFile.write(str(lastLastSignal) + "\n")
else:
outputFile.write(str(lastSignal) + "\n")
signalsFile.close()
peakIndexesFile.close()
outputFile.close()
if __name__=="__main__":
options = parseArgument()
averageZeroSignalsWithinPeaks(options)<|fim▁end|> | elif (lastPeakIndex == lastLastPeakIndex) and (not math.isnan(lastLastSignal)): |
<|file_name|>imagefilter.rs<|end_file_name|><|fim▁begin|>//! MMX image filters
extern crate c_vec;
use std::mem;
use libc::{self,size_t, c_void, c_uint, c_int};
use ::get_error;
use c_vec::CVec;
mod ll {
/* automatically generated by rust-bindgen */
use libc::*;
extern "C" {
pub fn SDL_imageFilterMMXdetect() -> c_int;
pub fn SDL_imageFilterMMXoff();
pub fn SDL_imageFilterMMXon();
pub fn SDL_imageFilterAdd(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) -> c_int;
pub fn SDL_imageFilterMean(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) -> c_int;
pub fn SDL_imageFilterSub(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) -> c_int;
pub fn SDL_imageFilterAbsDiff(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) ->
c_int;
pub fn SDL_imageFilterMult(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) -> c_int;
pub fn SDL_imageFilterMultNor(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) ->
c_int;
pub fn SDL_imageFilterMultDivby2(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) ->
c_int;
pub fn SDL_imageFilterMultDivby4(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) ->
c_int;
pub fn SDL_imageFilterBitAnd(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) -> c_int;
pub fn SDL_imageFilterBitOr(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) -> c_int;
pub fn SDL_imageFilterDiv(Src1: *mut u8, Src2: *mut u8,
Dest: *mut u8, length: c_uint) -> c_int;
pub fn SDL_imageFilterBitNegation(Src1: *mut u8, Dest: *mut u8,
length: c_uint) -> c_int;
pub fn SDL_imageFilterAddByte(Src1: *mut u8, Dest: *mut u8,
length: c_uint, C: u8) -> c_int;
pub fn SDL_imageFilterAddUint(Src1: *mut u8, Dest: *mut u8,
length: c_uint, C: c_uint) -> c_int;
pub fn SDL_imageFilterAddByteToHalf(Src1: *mut u8,
Dest: *mut u8, length: c_uint,
C: u8) -> c_int;
pub fn SDL_imageFilterSubByte(Src1: *mut u8, Dest: *mut u8,
length: c_uint, C: u8) -> c_int;
pub fn SDL_imageFilterSubUint(Src1: *mut u8, Dest: *mut u8,
length: c_uint, C: c_uint) -> c_int;
pub fn SDL_imageFilterShiftRight(Src1: *mut u8, Dest: *mut u8,
length: c_uint, N: u8) -> c_int;
pub fn SDL_imageFilterShiftRightUint(Src1: *mut u8,
Dest: *mut u8, length: c_uint,
N: u8) -> c_int;
pub fn SDL_imageFilterMultByByte(Src1: *mut u8, Dest: *mut u8,
length: c_uint, C: u8) -> c_int;
pub fn SDL_imageFilterShiftRightAndMultByByte(Src1: *mut u8,
Dest: *mut u8,
length: c_uint, N: u8,
C: u8) -> c_int;
pub fn SDL_imageFilterShiftLeftByte(Src1: *mut u8,
Dest: *mut u8, length: c_uint,
N: u8) -> c_int;
pub fn SDL_imageFilterShiftLeftUint(Src1: *mut u8,
Dest: *mut u8, length: c_uint,
N: u8) -> c_int;
pub fn SDL_imageFilterShiftLeft(Src1: *mut u8, Dest: *mut u8,
length: c_uint, N: u8) -> c_int;
pub fn SDL_imageFilterBinarizeUsingThreshold(Src1: *mut u8,
Dest: *mut u8,
length: c_uint, T: u8)
-> c_int;
pub fn SDL_imageFilterClipToRange(Src1: *mut u8, Dest: *mut u8,
length: c_uint, Tmin: u8,
Tmax: u8) -> c_int;
pub fn SDL_imageFilterNormalizeLinear(Src: *mut u8,
Dest: *mut u8, length: c_uint,
Cmin: c_int, Cmax: c_int,
Nmin: c_int, Nmax: c_int) -> c_int;
}
}
/// MMX detection routine (with override flag).
pub fn mmx_detect() -> bool {
unsafe { ll::SDL_imageFilterMMXdetect() == 1 }
}
/// Disable MMX check for filter functions and and force to use non-MMX C based code.
pub fn mmx_off() {
unsafe { ll::SDL_imageFilterMMXoff() }
}
/// Enable MMX check for filter functions and use MMX code if available.
pub fn mmx_on() {
unsafe { ll::SDL_imageFilterMMXon() }
}
#[inline]
fn cvec_with_size(sz: usize) -> CVec<u8> {
unsafe {
let p = libc::malloc(sz as size_t) as *mut u8;
CVec::new_with_dtor(p, sz, move |p| {
libc::free(p as *mut c_void)
})
}
}
/// Filter using Add: D = saturation255(S1 + S2).
pub fn add(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterAdd(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using Mean: D = S1/2 + S2/2.
pub fn mean(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterMean(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using Sub: D = saturation0(S1 - S2).
pub fn sub(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterSub(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using AbsDiff: D = | S1 - S2 |.
pub fn abs_diff(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterAbsDiff(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using Mult: D = saturation255(S1 * S2).
pub fn mult(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterMult(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using MultNor: D = S1 * S2.
pub fn mult_nor(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterMultNor(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using MultDivby2: D = saturation255(S1/2 * S2).
pub fn mult_div_by2(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterMultDivby2(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using MultDivby4: D = saturation255(S1/2 * S2/2).
pub fn mult_div_by4(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterMultDivby4(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using BitAnd: D = S1 & S2.
pub fn bit_and(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterBitAnd(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using BitOr: D = S1 | S2.
pub fn bit_or(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterBitOr(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using Div: D = S1 / S2.
pub fn div(src1: CVec<u8>, src2: CVec<u8>) -> Result<CVec<u8>, String> {
assert_eq!(src1.len(), src2.len());
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterDiv(mem::transmute(src1.get(0)),
mem::transmute(src2.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using BitNegation: D = !S.
pub fn bit_negation(src1: CVec<u8>) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterBitNegation(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using AddByte: D = saturation255(S + C).
pub fn add_byte(src1: CVec<u8>, c: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterAddByte(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, c) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using AddUint: D = saturation255((S[i] + Cs[i % 4]), Cs=Swap32((uint)C).
pub fn add_uint(src1: CVec<u8>, c: u32) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterAddUint(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, c) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using AddByteToHalf: D = saturation255(S/2 + C).
pub fn add_byte_to_half(src1: CVec<u8>, c: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterAddByteToHalf(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, c) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using SubByte: D = saturation0(S - C).
pub fn sub_byte(src1: CVec<u8>, c: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterSubByte(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, c) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using SubUint: D = saturation0(S[i] - Cs[i % 4]), Cs=Swap32((uint)C).
pub fn sub_uint(src1: CVec<u8>, c: u32) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterSubUint(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, c) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using ShiftRight: D = saturation0(S >> N).
pub fn shift_right(src1: CVec<u8>, n: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterShiftRight(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, n) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using ShiftRightUint: D = saturation0((uint)S[i] >> N).
pub fn shift_right_uint(src1: CVec<u8>, n: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterShiftRightUint(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, n) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using MultByByte: D = saturation255(S * C).
pub fn mult_by_byte(src1: CVec<u8>, c: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterMultByByte(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, c) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using ShiftRightAndMultByByte: D = saturation255((S >> N) * C).
pub fn shift_right_and_mult_by_byte(src1: CVec<u8>, n: u8, c: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterShiftRightAndMultByByte(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, n, c) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using ShiftLeftByte: D = (S << N).
pub fn shift_left_byte(src1: CVec<u8>, n: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterShiftLeftByte(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, n) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using ShiftLeftUint: D = ((uint)S << N).
pub fn shift_left_uint(src1: CVec<u8>, n: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterShiftLeftUint(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, n) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter ShiftLeft: D = saturation255(S << N).
pub fn shift_left(src1: CVec<u8>, n: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterShiftLeft(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, n) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using BinarizeUsingThreshold: D = (S >= T) ? 255:0.
pub fn binarize_using_threshold(src1: CVec<u8>, t: u8) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterBinarizeUsingThreshold(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, t) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }<|fim▁hole|> let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterClipToRange(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint, tmin, tmax) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}
/// Filter using NormalizeLinear: D = saturation255((Nmax - Nmin)/(Cmax - Cmin)*(S - Cmin) + Nmin).
pub fn normalize_linear(src1: CVec<u8>, cmin: i32, cmax: i32, nmin: i32, nmax: i32) -> Result<CVec<u8>, String> {
let size = src1.len();
let dest = cvec_with_size(size);
let ret = unsafe { ll::SDL_imageFilterNormalizeLinear(mem::transmute(src1.get(0)),
mem::transmute(dest.get(0)),
size as c_uint,
cmin as c_int, cmax as c_int,
nmin as c_int, nmax as c_int) };
if ret == 0 { Ok(dest) }
else { Err(get_error()) }
}<|fim▁end|> | }
/// Filter using ClipToRange: D = (S >= Tmin) & (S <= Tmax) S:Tmin | Tmax.
pub fn clip_to_range(src1: CVec<u8>, tmin: u8, tmax: u8) -> Result<CVec<u8>, String> { |
<|file_name|>hooks.py<|end_file_name|><|fim▁begin|>import os
def post_add(conf, name):
if "POST_ADD_HOOK" in conf:
if "NEW_PASSWORD_NAME" in os.environ:
del os.environ["NEW_PASSWORD_NAME"]<|fim▁hole|>
passwd_dir = os.path.expanduser(os.path.expandvars(conf["PASSWD_DIR"]))
hook_exec = os.path.expandvars(conf["POST_ADD_HOOK"])
os.chdir(passwd_dir)
os.putenv("NEW_PASSWORD_NAME", name)
os.putenv("PASSWD_FILE", os.path.expandvars(conf["PASSWD_FILE"]))
os.system(hook_exec)<|fim▁end|> | |
<|file_name|>client.rs<|end_file_name|><|fim▁begin|>// Copyright © 2014, Peter Atashian
use std::io::timer::sleep;
use std::io::{TcpStream};
use std::sync::Arc;
use std::sync::atomics::{AtomicUint, SeqCst};
use std::task::TaskBuilder;
use std::time::duration::Duration;
fn main() {
let count = Arc::new(AtomicUint::new(0));
loop {
let clone = count.clone();
TaskBuilder::new().stack_size(32768).spawn(proc() {
let mut tcp = match TcpStream::connect("127.0.0.1", 273) {<|fim▁hole|> };
println!("+{}", clone.fetch_add(1, SeqCst));
loop {
if tcp.read_u8().is_err() {
println!("-{}", clone.fetch_add(-1, SeqCst));
return;
}
}
});
sleep(Duration::seconds(1));
}
}<|fim▁end|> | Ok(tcp) => tcp,
Err(_) => return, |
<|file_name|>files.cpp<|end_file_name|><|fim▁begin|>/*
* A small crossplatform set of file manipulation functions.
* All input/output strings are UTF-8 encoded, even on Windows!
*
* Copyright (c) 2017-2020 Vitaly Novichkov <[email protected]>
*
* Permission is hereby granted, free of charge, to any person obtaining a copy of this
* software and associated documentation files (the "Software"), to deal in the Software
* without restriction, including without limitation the rights to use, copy, modify,
* merge, publish, distribute, sublicense, and/or sell copies of the Software, and to
* permit persons to whom the Software is furnished to do so, subject to the following
* conditions:
*
* The above copyright notice and this permission notice shall be included in all copies
* or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED,
* INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR
* PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE
* FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR
* OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
* DEALINGS IN THE SOFTWARE.
*/
#include "files.h"
#include <stdio.h>
#include <locale>
#ifdef _WIN32
#include <windows.h>
#include <shlwapi.h>
static std::wstring Str2WStr(const std::string &path)
{
std::wstring wpath;
wpath.resize(path.size());
int newlen = MultiByteToWideChar(CP_UTF8, 0, path.c_str(), static_cast<int>(path.length()), &wpath[0], static_cast<int>(path.length()));
wpath.resize(newlen);
return wpath;
}
#else
#include <unistd.h>
#include <fcntl.h> // open
#include <string.h>
#include <sys/stat.h> // fstat
#include <sys/types.h> // fstat
#include <cstdio> // BUFSIZ
#endif
#if defined(__CYGWIN__) || defined(__DJGPP__) || defined(__MINGW32__)
#define IS_PATH_SEPARATOR(c) (((c) == '/') || ((c) == '\\'))
#else
#define IS_PATH_SEPARATOR(c) ((c) == '/')
#endif
static char fi_path_dot[] = ".";
static char fi_path_root[] = "/";
static char *fi_basename(char *s)
{
char *rv;
if(!s || !*s)
return fi_path_dot;
rv = s + strlen(s) - 1;
do
{
if(IS_PATH_SEPARATOR(*rv))
return rv + 1;
--rv;
}
while(rv >= s);
return s;
}
static char *fi_dirname(char *path)
{
char *p;
if(path == NULL || *path == '\0')
return fi_path_dot;
p = path + strlen(path) - 1;
while(IS_PATH_SEPARATOR(*p))
{
if(p == path)
return path;
*p-- = '\0';
}
while(p >= path && !IS_PATH_SEPARATOR(*p))
p--;
if(p < path)
return fi_path_dot;
if(p == path)
return fi_path_root;
*p = '\0';
return path;
}
FILE *Files::utf8_fopen(const char *filePath, const char *modes)
{
#ifndef _WIN32
return ::fopen(filePath, modes);
#else
wchar_t wfile[MAX_PATH + 1];
wchar_t wmode[21];
int wfile_len = (int)strlen(filePath);
int wmode_len = (int)strlen(modes);
wfile_len = MultiByteToWideChar(CP_UTF8, 0, filePath, wfile_len, wfile, MAX_PATH);
wmode_len = MultiByteToWideChar(CP_UTF8, 0, modes, wmode_len, wmode, 20);
wfile[wfile_len] = L'\0';
wmode[wmode_len] = L'\0';
return ::_wfopen(wfile, wmode);
#endif
}
bool Files::fileExists(const std::string &path)
{
#ifdef _WIN32
std::wstring wpath = Str2WStr(path);
return PathFileExistsW(wpath.c_str()) == TRUE;
#else
FILE *ops = fopen(path.c_str(), "rb");
if(ops)
{
fclose(ops);
return true;
}
return false;
#endif
}
bool Files::deleteFile(const std::string &path)
{
#ifdef _WIN32
std::wstring wpath = Str2WStr(path);
return (DeleteFileW(wpath.c_str()) == TRUE);
#else
return ::unlink(path.c_str()) == 0;
#endif
}
bool Files::copyFile(const std::string &to, const std::string &from, bool override)
{
if(!override && fileExists(to))
return false;// Don't override exist target if not requested
bool ret = true;
#ifdef _WIN32
std::wstring wfrom = Str2WStr(from);<|fim▁hole|> std::wstring wto = Str2WStr(to);
ret = (bool)CopyFileW(wfrom.c_str(), wto.c_str(), !override);
#else
char buf[BUFSIZ];
ssize_t size;
ssize_t sizeOut;
int source = open(from.c_str(), O_RDONLY, 0);
if(source == -1)
return false;
int dest = open(to.c_str(), O_WRONLY | O_CREAT | O_TRUNC, 0640);
if(dest == -1)
{
close(source);
return false;
}
while((size = read(source, buf, BUFSIZ)) > 0)
{
sizeOut = write(dest, buf, static_cast<size_t>(size));
if(sizeOut != size)
{
ret = false;
break;
}
}
close(source);
close(dest);
#endif
return ret;
}
bool Files::moveFile(const std::string& to, const std::string& from, bool override)
{
bool ret = copyFile(to, from, override);
if(ret)
ret &= deleteFile(from);
return ret;
}
std::string Files::dirname(std::string path)
{
char *p = strdup(path.c_str());
char *d = ::fi_dirname(p);
path = d;
free(p);
return path;
}
std::string Files::basename(std::string path)
{
char *p = strdup(path.c_str());
char *d = ::fi_basename(p);
path = d;
free(p);
return path;
}
std::string Files::basenameNoSuffix(std::string path)
{
char *p = strdup(path.c_str());
char *d = ::fi_basename(p);
path = d;
free(p);
std::string::size_type dot = path.find_last_of('.');
if(dot != std::string::npos)
path.resize(dot);
return path;
}
std::string Files::changeSuffix(std::string path, const std::string &suffix)
{
size_t pos = path.find_last_of('.');// Find dot
if((path.size() < suffix.size()) || (pos == std::string::npos))
path.append(suffix);
else
path.replace(pos, suffix.size(), suffix);
return path;
}
bool Files::hasSuffix(const std::string &path, const std::string &suffix)
{
if(suffix.size() > path.size())
return false;
std::locale loc;
std::string f = path.substr(path.size() - suffix.size(), suffix.size());
for(char &c : f)
c = std::tolower(c, loc);
return (f.compare(suffix) == 0);
}
bool Files::isAbsolute(const std::string& path)
{
bool firstCharIsSlash = (path.size() > 0) ? path[0] == '/' : false;
#ifdef _WIN32
bool containsWinChars = (path.size() > 2) ? (path[1] == ':') && ((path[2] == '\\') || (path[2] == '/')) : false;
if(firstCharIsSlash || containsWinChars)
{
return true;
}
return false;
#else
return firstCharIsSlash;
#endif
}
void Files::getGifMask(std::string& mask, const std::string& front)
{
mask = front;
//Make mask filename
size_t dotPos = mask.find_last_of('.');
if(dotPos == std::string::npos)
mask.push_back('m');
else
mask.insert(mask.begin() + dotPos, 'm');
}<|fim▁end|> | |
<|file_name|>setup.py<|end_file_name|><|fim▁begin|>from distutils.core import setup
setup(
name='captcha2upload',
packages=['captcha2upload'],
package_dir={'captcha2upload': 'src/captcha2upload'},
version='0.2',
install_requires=['requests'],
description='Upload your image and solve captche using the 2Captcha '
'Service',
author='Alessandro Sbarbati',
author_email='[email protected]',<|fim▁hole|>)<|fim▁end|> | url='https://github.com/Mirio/captcha2upload',
download_url='https://github.com/Mirio/captcha2upload/tarball/0.1',
keywords=['2captcha', 'captcha', 'Image Recognition'],
classifiers=["Topic :: Scientific/Engineering :: Image Recognition"], |
<|file_name|>supplemental.min.js<|end_file_name|><|fim▁begin|>version https://git-lfs.github.com/spec/v1<|fim▁hole|><|fim▁end|> | oid sha256:2624aaed17536733cabbaeeac1e3b7c75455924c253869c12a812940c3e1241f
size 1195 |
<|file_name|>setup-seafile-mysql.py<|end_file_name|><|fim▁begin|>#coding: UTF-8
'''This script would guide the seafile admin to setup seafile with MySQL'''
import sys
import os
import time
import re
import shutil
import glob
import subprocess
import hashlib
import getpass
import uuid
import warnings
import MySQLdb
from ConfigParser import ConfigParser
try:
import readline # pylint: disable=W0611
except ImportError:
pass
SERVER_MANUAL_HTTP = 'https://github.com/haiwen/seafile/wiki'
class Utils(object):
'''Groups all helper functions here'''
@staticmethod
def welcome():
'''Show welcome message'''
welcome_msg = '''\
-----------------------------------------------------------------
This script will guide you to setup your seafile server using MySQL.
Make sure you have read seafile server manual at
%s
Press ENTER to continue
-----------------------------------------------------------------''' % SERVER_MANUAL_HTTP
print welcome_msg
raw_input()
@staticmethod
def highlight(content):
'''Add ANSI color to content to get it highlighted on terminal'''
return '\x1b[33m%s\x1b[m' % content
@staticmethod
def info(msg):
print msg
@staticmethod
def error(msg):
'''Print error and exit'''
print
print 'Error: ' + msg
sys.exit(1)
@staticmethod
def run_argv(argv, cwd=None, env=None, suppress_stdout=False, suppress_stderr=False):
'''Run a program and wait it to finish, and return its exit code. The
standard output of this program is supressed.
'''
with open(os.devnull, 'w') as devnull:
if suppress_stdout:
stdout = devnull
else:
stdout = sys.stdout
if suppress_stderr:
stderr = devnull
else:
stderr = sys.stderr
proc = subprocess.Popen(argv,
cwd=cwd,
stdout=stdout,
stderr=stderr,
env=env)
return proc.wait()
@staticmethod
def run(cmdline, cwd=None, env=None, suppress_stdout=False, suppress_stderr=False):
'''Like run_argv but specify a command line string instead of argv'''
with open(os.devnull, 'w') as devnull:
if suppress_stdout:
stdout = devnull
else:
stdout = sys.stdout
if suppress_stderr:
stderr = devnull
else:
stderr = sys.stderr
proc = subprocess.Popen(cmdline,
cwd=cwd,
stdout=stdout,
stderr=stderr,
env=env,
shell=True)
return proc.wait()
@staticmethod
def prepend_env_value(name, value, env=None, seperator=':'):
'''prepend a new value to a list'''
if env is None:
env = os.environ
try:
current_value = env[name]
except KeyError:
current_value = ''
new_value = value
if current_value:
new_value += seperator + current_value
env[name] = new_value
@staticmethod
def must_mkdir(path):
'''Create a directory, exit on failure'''
try:
os.mkdir(path)
except OSError, e:
Utils.error('failed to create directory %s:%s' % (path, e))
@staticmethod
def must_copy(src, dst):
'''Copy src to dst, exit on failure'''
try:
shutil.copy(src, dst)
except Exception, e:
Utils.error('failed to copy %s to %s: %s' % (src, dst, e))
@staticmethod
def find_in_path(prog):
if 'win32' in sys.platform:
sep = ';'
else:
sep = ':'
dirs = os.environ['PATH'].split(sep)
for d in dirs:
d = d.strip()
if d == '':
continue
path = os.path.join(d, prog)
if os.path.exists(path):
return path
return None
@staticmethod
def get_python_executable():
'''Return the python executable. This should be the PYTHON environment
variable which is set in setup-seafile-mysql.sh
'''
return os.environ['PYTHON']
@staticmethod
def read_config(fn):
'''Return a case sensitive ConfigParser by reading the file "fn"'''
cp = ConfigParser()
cp.optionxform = str
cp.read(fn)
return cp
@staticmethod
def write_config(cp, fn):
'''Return a case sensitive ConfigParser by reading the file "fn"'''
with open(fn, 'w') as fp:
cp.write(fp)
@staticmethod
def ask_question(desc,
key=None,
note=None,
default=None,
validate=None,
yes_or_no=False,
password=False):
'''Ask a question, return the answer.
@desc description, e.g. "What is the port of ccnet?"
@key a name to represent the target of the question, e.g. "port for
ccnet server"
@note additional information for the question, e.g. "Must be a valid
port number"
@default the default value of the question. If the default value is
not None, when the user enter nothing and press [ENTER], the default
value would be returned
@validate a function that takes the user input as the only parameter
and validate it. It should return a validated value, or throws an
"InvalidAnswer" exception if the input is not valid.
@yes_or_no If true, the user must answer "yes" or "no", and a boolean
value would be returned
@password If true, the user input would not be echoed to the
console
'''
assert key or yes_or_no
# Format description
print
if note:
desc += '\n' + note
desc += '\n'
if yes_or_no:
desc += '[ yes or no ]'
else:
if default:
desc += '[ default "%s" ]' % default
else:
desc += '[ %s ]' % key
desc += ' '
while True:
# prompt for user input
if password:
answer = getpass.getpass(desc).strip()
else:
answer = raw_input(desc).strip()
# No user input: use default
if not answer:
if default:
answer = default
else:
continue
# Have user input: validate answer
if yes_or_no:
if answer not in ['yes', 'no']:
print Utils.highlight('\nPlease answer yes or no\n')
continue
else:
return answer == 'yes'
else:
if validate:
try:
return validate(answer)
except InvalidAnswer, e:
print Utils.highlight('\n%s\n' % e)
continue
else:
return answer
@staticmethod
def validate_port(port):
try:
port = int(port)
except ValueError:
raise InvalidAnswer('%s is not a valid port' % Utils.highlight(port))
if port <= 0 or port > 65535:
raise InvalidAnswer('%s is not a valid port' % Utils.highlight(port))
return port
class InvalidAnswer(Exception):
def __init__(self, msg):
Exception.__init__(self)
self.msg = msg
def __str__(self):
return self.msg
### END of Utils
####################
class EnvManager(object):
'''System environment and directory layout'''
def __init__(self):
self.install_path = os.path.dirname(os.path.abspath(__file__))
self.top_dir = os.path.dirname(self.install_path)
self.bin_dir = os.path.join(self.install_path, 'seafile', 'bin')
def check_pre_condiction(self):
def error_if_not_exists(path):
if not os.path.exists(path):
Utils.error('"%s" not found' % path)
paths = [
os.path.join(self.install_path, 'seafile'),
os.path.join(self.install_path, 'seahub'),
os.path.join(self.install_path, 'runtime'),
]
for path in paths:
error_if_not_exists(path)
if os.path.exists(ccnet_config.ccnet_dir):
Utils.error('Ccnet config dir \"%s\" already exists.' % ccnet_config.ccnet_dir)
def get_seahub_env(self):
'''Prepare for seahub syncdb'''
env = dict(os.environ)
env['CCNET_CONF_DIR'] = ccnet_config.ccnet_dir
env['SEAFILE_CONF_DIR'] = seafile_config.seafile_dir
self.setup_python_path(env)
return env
def setup_python_path(self, env):
'''And PYTHONPATH and CCNET_CONF_DIR/SEAFILE_CONF_DIR to env, which is
needed by seahub
'''
install_path = self.install_path
pro_pylibs_dir = os.path.join(install_path, 'pro', 'python')
extra_python_path = [
pro_pylibs_dir,
os.path.join(install_path, 'seahub', 'thirdpart'),
os.path.join(install_path, 'seafile/lib/python2.6/site-packages'),
os.path.join(install_path, 'seafile/lib64/python2.6/site-packages'),
os.path.join(install_path, 'seafile/lib/python2.7/site-packages'),
os.path.join(install_path, 'seafile/lib64/python2.7/site-packages'),
]
for path in extra_python_path:
Utils.prepend_env_value('PYTHONPATH', path, env=env)
def get_binary_env(self):
'''Set LD_LIBRARY_PATH for seafile server executables'''
env = dict(os.environ)
lib_dir = os.path.join(self.install_path, 'seafile', 'lib')
lib64_dir = os.path.join(self.install_path, 'seafile', 'lib64')
Utils.prepend_env_value('LD_LIBRARY_PATH', lib_dir, env=env)
Utils.prepend_env_value('LD_LIBRARY_PATH', lib64_dir, env=env)
return env
class AbstractConfigurator(object):
'''Abstract Base class for ccnet/seafile/seahub/db configurator'''
def __init__(self):
pass
def ask_questions(self):
raise NotImplementedError
def generate(self):
raise NotImplementedError
class AbstractDBConfigurator(AbstractConfigurator):
'''Abstract class for database related configuration'''
def __init__(self):
AbstractConfigurator.__init__(self)
self.mysql_host = 'localhost'
self.mysql_port = 3306
self.use_existing_db = False
self.seafile_mysql_user = ''
self.seafile_mysql_password = ''
self.ccnet_db_name = ''
self.seafile_db_name = ''
self.seahub_db_name = ''
self.seahub_admin_email = ''
self.seahub_admin_password = ''
@staticmethod
def ask_use_existing_db():
def validate(choice):
if choice not in ['1', '2']:
raise InvalidAnswer('Please choose 1 or 2')
return choice == '2'
question = '''\
-------------------------------------------------------
Please choose a way to initialize seafile databases:
-------------------------------------------------------
'''
note = '''\
[1] Create new ccnet/seafile/seahub databases
[2] Use existing ccnet/seafile/seahub databases
'''
return Utils.ask_question(question,
key='1 or 2',
note=note,
validate=validate)
def ask_mysql_host_port(self):
def validate(host):
if not re.match(r'^[a-zA-Z0-9_\-\.]+$', host):
raise InvalidAnswer('%s is not a valid host' % Utils.highlight(host))
if host == 'localhost':
host = '127.0.0.1'
question = 'What is the port of mysql server?'
key = 'mysql server port'
default = '3306'
port = Utils.ask_question(question,
key=key,
default=default,
validate=Utils.validate_port)
# self.check_mysql_server(host, port)
self.mysql_port = port
return host
question = 'What is the host of mysql server?'
key = 'mysql server host'
default = 'localhost'
self.mysql_host = Utils.ask_question(question,
key=key,
default=default,
validate=validate)
def check_mysql_server(self, host, port):
print '\nverifying mysql server running ... ',
try:
dummy = MySQLdb.connect(host=host, port=port)
except Exception:
print
raise InvalidAnswer('Failed to connect to mysql server at "%s:%s"' \
% (host, port))
print 'done'
def check_mysql_user(self, user, password):
print '\nverifying password of user %s ... ' % user,
kwargs = dict(host=self.mysql_host,
port=self.mysql_port,
user=user,
passwd=password)
try:
conn = MySQLdb.connect(**kwargs)
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
raise InvalidAnswer('Failed to connect to mysql server using user "%s" and password "***": %s' \
% (user, e.args[1]))
else:
raise InvalidAnswer('Failed to connect to mysql server using user "%s" and password "***": %s' \
% (user, e))
print 'done'
return conn
def create_seahub_admin(self):
try:
conn = MySQLdb.connect(host=self.mysql_host,
port=self.mysql_port,
user=self.seafile_mysql_user,
passwd=self.seafile_mysql_password,
db=self.ccnet_db_name)
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
Utils.error('Failed to connect to mysql database %s: %s' % (self.ccnet_db_name, e.args[1]))
else:
Utils.error('Failed to connect to mysql database %s: %s' % (self.ccnet_db_name, e))
cursor = conn.cursor()
sql = '''\
CREATE TABLE IF NOT EXISTS EmailUser (id INTEGER NOT NULL PRIMARY KEY AUTO_INCREMENT, email VARCHAR(255), passwd CHAR(64), is_staff BOOL NOT NULL, is_active BOOL NOT NULL, ctime BIGINT, UNIQUE INDEX (email)) ENGINE=INNODB'''
try:
cursor.execute(sql)
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
Utils.error('Failed to create ccnet user table: %s' % e.args[1])
else:
Utils.error('Failed to create ccnet user table: %s' % e)
sql = '''REPLACE INTO EmailUser(email, passwd, is_staff, is_active, ctime) VALUES ('%s', '%s', 1, 1, 0)''' \
% (seahub_config.admin_email, seahub_config.hashed_admin_password())
try:
cursor.execute(sql)
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
Utils.error('Failed to create admin user: %s' % e.args[1])
else:
Utils.error('Failed to create admin user: %s' % e)
conn.commit()
def ask_questions(self):
'''Ask questions and do database operations'''
raise NotImplementedError
class NewDBConfigurator(AbstractDBConfigurator):
'''Handles the case of creating new mysql databases for ccnet/seafile/seahub'''
def __init__(self):
AbstractDBConfigurator.__init__(self)
self.root_password = ''
self.root_conn = ''
def ask_questions(self):
self.ask_mysql_host_port()
self.ask_root_password()
self.ask_seafile_mysql_user_password()
self.ask_db_names()
def generate(self):
if not self.mysql_user_exists(self.seafile_mysql_user):
self.create_user()
self.create_databases()
def ask_root_password(self):
def validate(password):
self.root_conn = self.check_mysql_user('root', password)
return password
question = 'What is the password of the mysql root user?'
key = 'root password'
self.root_password = Utils.ask_question(question,
key=key,
validate=validate,
password=True)
def mysql_user_exists(self, user):
cursor = self.root_conn.cursor()
sql = '''SELECT EXISTS(SELECT 1 FROM mysql.user WHERE user = '%s')''' % user
try:
cursor.execute(sql)
return cursor.fetchall()[0][0]
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
Utils.error('Failed to check mysql user %s: %s' % (user, e.args[1]))
else:
Utils.error('Failed to check mysql user %s: %s' % (user, e))
finally:
cursor.close()
def ask_seafile_mysql_user_password(self):
def validate(user):
if user == 'root':
self.seafile_mysql_password = self.root_password
else:
question = 'Enter the password for mysql user "%s":' % Utils.highlight(user)
key = 'password for %s' % user
password = Utils.ask_question(question, key=key, password=True)
# If the user already exists, check the password here
if self.mysql_user_exists(user):
self.check_mysql_user(user, password)
self.seafile_mysql_password = password
return user
question = 'Enter the name for mysql user of seafile. It would be created if not exists.'
key = 'mysql user for seafile'
default = 'root'
self.seafile_mysql_user = Utils.ask_question(question,
key=key,
default=default,
validate=validate)
def ask_db_name(self, program, default):
question = 'Enter the database name for %s:' % program
key = '%s database' % program
return Utils.ask_question(question,
key=key,
default=default,
validate=self.validate_db_name)
def ask_db_names(self):
self.ccnet_db_name = self.ask_db_name('ccnet-server', 'ccnet-db')
self.seafile_db_name = self.ask_db_name('seafile-server', 'seafile-db')
self.seahub_db_name = self.ask_db_name('seahub', 'seahub-db')
def validate_db_name(self, db_name):
return db_name
def create_user(self):
cursor = self.root_conn.cursor()
sql = '''CREATE USER '%s'@'localhost' IDENTIFIED BY '%s' ''' \
% (self.seafile_mysql_user, self.seafile_mysql_password)
try:
cursor.execute(sql)
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
Utils.error('Failed to create mysql user %s: %s' % (self.seafile_mysql_user, e.args[1]))
else:
Utils.error('Failed to create mysql user %s: %s' % (self.seafile_mysql_user, e))
finally:
cursor.close()
def create_db(self, db_name):
cursor = self.root_conn.cursor()
sql = '''CREATE DATABASE IF NOT EXISTS `%s` CHARACTER SET UTF8''' \
% db_name
try:
cursor.execute(sql)
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
Utils.error('Failed to create database %s: %s' % (db_name, e.args[1]))
else:
Utils.error('Failed to create database %s: %s' % (db_name, e))
finally:
cursor.close()
def grant_db_permission(self, db_name):
cursor = self.root_conn.cursor()
sql = '''GRANT ALL PRIVILEGES ON `%s`.* to `%s` ''' \
% (db_name, self.seafile_mysql_user)
try:
cursor.execute(sql)
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
Utils.error('Failed to grant permission of database %s: %s' % (db_name, e.args[1]))
else:
Utils.error('Failed to grant permission of database %s: %s' % (db_name, e))
finally:
cursor.close()
def create_databases(self):
self.create_db(self.ccnet_db_name)
self.create_db(self.seafile_db_name)
self.create_db(self.seahub_db_name)
if self.seafile_mysql_user != 'root':
self.grant_db_permission(self.ccnet_db_name)
self.grant_db_permission(self.seafile_db_name)
self.grant_db_permission(self.seahub_db_name)
class ExistingDBConfigurator(AbstractDBConfigurator):
'''Handles the case of use existing mysql databases for ccnet/seafile/seahub'''
def __init__(self):
AbstractDBConfigurator.__init__(self)
self.use_existing_db = True
def ask_questions(self):
self.ask_mysql_host_port()
self.ask_existing_mysql_user_password()
self.ccnet_db_name = self.ask_db_name('ccnet')
self.seafile_db_name = self.ask_db_name('seafile')
self.seahub_db_name = self.ask_db_name('seahub')
def generate(self):
pass
def ask_existing_mysql_user_password(self):
def validate(user):
question = 'What is the password for mysql user "%s"?' % Utils.highlight(user)
key = 'password for %s' % user
password = Utils.ask_question(question, key=key, password=True)
self.check_mysql_user(user, password)
self.seafile_mysql_password = password
return user
question = 'Which mysql user to use for seafile?'
key = 'mysql user for seafile'
self.seafile_mysql_user = Utils.ask_question(question,
key=key,
validate=validate)
def ask_db_name(self, program):
def validate(db_name):
if self.seafile_mysql_user != 'root':
self.check_user_db_access(db_name)
return db_name
question = 'Enter the existing database name for %s:' % program
key = '%s database' % program
return Utils.ask_question(question,
key=key,
validate=validate)
def check_user_db_access(self, db_name):
user = self.seafile_mysql_user
password = self.seafile_mysql_password
print '\nverifying user "%s" access to database %s ... ' % (user, db_name),
try:
conn = MySQLdb.connect(host=self.mysql_host,
port=self.mysql_port,
user=user,
passwd=password,
db=db_name)
except Exception, e:
if isinstance(e, MySQLdb.OperationalError):
raise InvalidAnswer('Failed to access database %s using user "%s" and password "***": %s' \
% (db_name, user, e.args[1]))
else:
raise InvalidAnswer('Failed to access database %s using user "%s" and password "***": %s' \
% (db_name, user, e))
print 'done'
return conn
class CcnetConfigurator(AbstractConfigurator):
SERVER_NAME_REGEX = r'^[a-zA-Z0-9_\-]{3,14}$'
SERVER_IP_OR_DOMAIN_REGEX = '^[^.].+\..+[^.]$'
def __init__(self):
'''Initialize default values of ccnet configuration'''
AbstractConfigurator.__init__(self)
self.ccnet_dir = os.path.join(env_mgr.top_dir, 'ccnet')
self.port = 10001
self.server_name = 'my-seafile'
self.ip_or_domain = None
def ask_questions(self):
self.ask_server_name()
self.ask_server_ip_or_domain()
self.ask_port()
def generate(self):
print 'Generating ccnet configuration ...\n'
ccnet_init = os.path.join(env_mgr.bin_dir, 'ccnet-init')
argv = [
ccnet_init,
'--config-dir', self.ccnet_dir,
'--name', self.server_name,
'--host', self.ip_or_domain,
'--port', str(self.port),
]
if Utils.run_argv(argv, env=env_mgr.get_binary_env()) != 0:
Utils.error('Failed to generate ccnet configuration')
time.sleep(1)
self.generate_db_conf()
def generate_db_conf(self):
ccnet_conf = os.path.join(self.ccnet_dir, 'ccnet.conf')
config = Utils.read_config(ccnet_conf)
# [Database]
# ENGINE=
# HOST=
# USER=
# PASSWD=
# DB=
db_section = 'Database'
if not config.has_section(db_section):
config.add_section(db_section)
config.set(db_section, 'ENGINE', 'mysql')
config.set(db_section, 'HOST', db_config.mysql_host)
config.set(db_section, 'PORT', db_config.mysql_port)
config.set(db_section, 'USER', db_config.seafile_mysql_user)
config.set(db_section, 'PASSWD', db_config.seafile_mysql_password)
config.set(db_section, 'DB', db_config.ccnet_db_name)
config.set(db_section, 'CONNECTION_CHARSET', 'utf8')
Utils.write_config(config, ccnet_conf)
def ask_server_name(self):
def validate(name):
if not re.match(self.SERVER_NAME_REGEX, name):
raise InvalidAnswer('%s is not a valid name' % Utils.highlight(name))
return name
question = 'What is the name of the server? It will be displayed on the client.'
key = 'server name'
note = '3 - 15 letters or digits'
self.server_name = Utils.ask_question(question,
key=key,
note=note,
validate=validate)
def ask_server_ip_or_domain(self):
def validate(ip_or_domain):
if not re.match(self.SERVER_IP_OR_DOMAIN_REGEX, ip_or_domain):
raise InvalidAnswer('%s is not a valid ip or domain' % ip_or_domain)
return ip_or_domain
question = 'What is the ip or domain of the server?'
key = 'This server\'s ip or domain'
note = 'For example: www.mycompany.com, 192.168.1.101'
self.ip_or_domain = Utils.ask_question(question,
key=key,
note=note,
validate=validate)
def ask_port(self):<|fim▁hole|> return Utils.validate_port(port)
question = 'Which port do you want to use for the ccnet server?'
key = 'ccnet server port'
default = 10001
self.port = Utils.ask_question(question,
key=key,
default=default,
validate=validate)
class SeafileConfigurator(AbstractConfigurator):
def __init__(self):
AbstractConfigurator.__init__(self)
self.seafile_dir = os.path.join(env_mgr.top_dir, 'seafile-data')
self.port = 12001
self.httpserver_port = 8082
def ask_questions(self):
self.ask_seafile_dir()
self.ask_port()
self.ask_httpserver_port()
def generate(self):
print 'Generating seafile configuration ...\n'
seafserv_init = os.path.join(env_mgr.bin_dir, 'seaf-server-init')
argv = [
seafserv_init,
'--seafile-dir', self.seafile_dir,
'--port', str(self.port),
'--httpserver-port', str(self.httpserver_port),
]
if Utils.run_argv(argv, env=env_mgr.get_binary_env()) != 0:
Utils.error('Failed to generate ccnet configuration')
time.sleep(1)
self.generate_db_conf()
self.write_seafile_ini()
print 'done'
def generate_db_conf(self):
seafile_conf = os.path.join(self.seafile_dir, 'seafile.conf')
config = Utils.read_config(seafile_conf)
# [database]
# type=
# host=
# user=
# password=
# db_name=
# unix_socket=
db_section = 'database'
if not config.has_section(db_section):
config.add_section(db_section)
config.set(db_section, 'type', 'mysql')
config.set(db_section, 'host', db_config.mysql_host)
config.set(db_section, 'port', db_config.mysql_port)
config.set(db_section, 'user', db_config.seafile_mysql_user)
config.set(db_section, 'password', db_config.seafile_mysql_password)
config.set(db_section, 'db_name', db_config.seafile_db_name)
config.set(db_section, 'connection_charset', 'utf8')
Utils.write_config(config, seafile_conf)
def ask_seafile_dir(self):
def validate(path):
if os.path.exists(path):
raise InvalidAnswer('%s already exists' % Utils.highlight(path))
return path
question = 'Where do you want to put your seafile data?'
key = 'seafile-data'
note = 'Please use a volume with enough free space'
default = os.path.join(env_mgr.top_dir, 'seafile-data')
self.seafile_dir = Utils.ask_question(question,
key=key,
note=note,
default=default,
validate=validate)
def ask_port(self):
def validate(port):
port = Utils.validate_port(port)
if port == ccnet_config.port:
raise InvalidAnswer('%s is used by ccnet server, choose another one' \
% Utils.highlight(port))
return port
question = 'Which port do you want to use for the seafile server?'
key = 'seafile server port'
default = 12001
self.port = Utils.ask_question(question,
key=key,
default=default,
validate=validate)
def ask_httpserver_port(self):
def validate(port):
port = Utils.validate_port(port)
if port == ccnet_config.port:
raise InvalidAnswer('%s is used by ccnet server, choose another one' \
% Utils.highlight(port))
if port == seafile_config.port:
raise InvalidAnswer('%s is used by seafile server, choose another one' \
% Utils.highlight(port))
return port
question = 'Which port do you want to use for the seafile httpserver?'
key = 'seafile httpserver port'
default = 8082
self.httpserver_port = Utils.ask_question(question,
key=key,
default=default,
validate=validate)
def write_seafile_ini(self):
seafile_ini = os.path.join(ccnet_config.ccnet_dir, 'seafile.ini')
with open(seafile_ini, 'w') as fp:
fp.write(self.seafile_dir)
class SeahubConfigurator(AbstractConfigurator):
def __init__(self):
AbstractConfigurator.__init__(self)
self.admin_email = ''
self.admin_password = ''
def hashed_admin_password(self):
return hashlib.sha1(self.admin_password).hexdigest() # pylint: disable=E1101
def ask_questions(self):
pass
# self.ask_admin_email()
# self.ask_admin_password()
def generate(self):
'''Generating seahub_settings.py'''
print 'Generating seahub configuration ...\n'
time.sleep(1)
seahub_settings_py = os.path.join(env_mgr.top_dir, 'seahub_settings.py')
with open(seahub_settings_py, 'w') as fp:
self.write_secret_key(fp)
self.write_database_config(fp)
def write_secret_key(self, fp):
text = 'SECRET_KEY = "%s"\n\n' % self.gen_secret_key()
fp.write(text)
def write_database_config(self, fp):
template = '''\
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '%(name)s',
'USER': '%(username)s',
'PASSWORD': '%(password)s',
'HOST': '%(host)s',
'PORT': '%(port)s',
'OPTIONS': {
'init_command': 'SET storage_engine=INNODB',
}
}
}
'''
text = template % dict(name=db_config.seahub_db_name,
username=db_config.seafile_mysql_user,
password=db_config.seafile_mysql_password,
host=db_config.mysql_host,
port=db_config.mysql_port)
fp.write(text)
def gen_secret_key(self):
data = str(uuid.uuid4()) + str(uuid.uuid4())
return data[:40]
def ask_admin_email(self):
print
print '----------------------------------------'
print 'Now let\'s create the admin account'
print '----------------------------------------'
def validate(email):
# whitespace is not allowed
if re.match(r'[\s]', email):
raise InvalidAnswer('%s is not a valid email address' % Utils.highlight(email))
# must be a valid email address
if not re.match(r'^.+@.*\..+$', email):
raise InvalidAnswer('%s is not a valid email address' % Utils.highlight(email))
return email
key = 'admin email'
question = 'What is the ' + Utils.highlight('email') + ' for the admin account?'
self.admin_email = Utils.ask_question(question,
key=key,
validate=validate)
def ask_admin_password(self):
def validate(password):
key = 'admin password again'
question = 'Enter the ' + Utils.highlight('password again:')
password_again = Utils.ask_question(question,
key=key,
password=True)
if password_again != password:
raise InvalidAnswer('password mismatch')
return password
key = 'admin password'
question = 'What is the ' + Utils.highlight('password') + ' for the admin account?'
self.admin_password = Utils.ask_question(question,
key=key,
password=True,
validate=validate)
def do_syncdb(self):
print '----------------------------------------'
print 'Now creating seahub database tables ...\n'
print '----------------------------------------'
env = env_mgr.get_seahub_env()
cwd = os.path.join(env_mgr.install_path, 'seahub')
argv = [
Utils.get_python_executable(),
'manage.py',
'syncdb',
]
if Utils.run_argv(argv, cwd=cwd, env=env) != 0:
Utils.error("Failed to create seahub databases")
def prepare_avatar_dir(self):
# media_dir=${INSTALLPATH}/seahub/media
# orig_avatar_dir=${INSTALLPATH}/seahub/media/avatars
# dest_avatar_dir=${TOPDIR}/seahub-data/avatars
# if [[ ! -d ${dest_avatar_dir} ]]; then
# mkdir -p "${TOPDIR}/seahub-data"
# mv "${orig_avatar_dir}" "${dest_avatar_dir}"
# ln -s ../../../seahub-data/avatars ${media_dir}
# fi
try:
media_dir = os.path.join(env_mgr.install_path, 'seahub', 'media')
orig_avatar_dir = os.path.join(media_dir, 'avatars')
seahub_data_dir = os.path.join(env_mgr.top_dir, 'seahub-data')
dest_avatar_dir = os.path.join(seahub_data_dir, 'avatars')
if os.path.exists(dest_avatar_dir):
return
if not os.path.exists(seahub_data_dir):
os.mkdir(seahub_data_dir)
shutil.move(orig_avatar_dir, dest_avatar_dir)
os.symlink('../../../seahub-data/avatars', orig_avatar_dir)
except Exception, e:
Utils.error('Failed to prepare seahub avatars dir: %s' % e)
class SeafDavConfigurator(AbstractConfigurator):
def __init__(self):
AbstractConfigurator.__init__(self)
self.conf_dir = None
self.seafdav_conf = None
def ask_questions(self):
pass
def generate(self):
self.conf_dir = os.path.join(env_mgr.top_dir, 'conf')
if not os.path.exists('conf'):
Utils.must_mkdir(self.conf_dir)
self.seafdav_conf = os.path.join(self.conf_dir, 'seafdav.conf')
text = '''
[WEBDAV]
enabled = false
port = 8080
fastcgi = false
share_name = /
'''
with open(self.seafdav_conf, 'w') as fp:
fp.write(text)
class UserManualHandler(object):
def __init__(self):
self.src_docs_dir = os.path.join(env_mgr.install_path, 'seafile', 'docs')
self.library_template_dir = None
def copy_user_manuals(self):
self.library_template_dir = os.path.join(seafile_config.seafile_dir, 'library-template')
Utils.must_mkdir(self.library_template_dir)
pattern = os.path.join(self.src_docs_dir, '*.doc')
for doc in glob.glob(pattern):
Utils.must_copy(doc, self.library_template_dir)
def report_config():
print
print '---------------------------------'
print 'This is your configuration'
print '---------------------------------'
print
template = '''\
server name: %(server_name)s
server ip/domain: %(ip_or_domain)s
ccnet port: %(ccnet_port)s
seafile data dir: %(seafile_dir)s
seafile port: %(seafile_port)s
httpserver port: %(httpserver_port)s
database: %(use_existing_db)s
ccnet database: %(ccnet_db_name)s
seafile database: %(seafile_db_name)s
seahub database: %(seahub_db_name)s
database user: %(db_user)s
'''
config = {
'server_name' : ccnet_config.server_name,
'ip_or_domain' : ccnet_config.ip_or_domain,
'ccnet_port' : ccnet_config.port,
'seafile_dir' : seafile_config.seafile_dir,
'seafile_port' : seafile_config.port,
'httpserver_port' : seafile_config.httpserver_port,
'admin_email' : seahub_config.admin_email,
'use_existing_db': 'use exising' if db_config.use_existing_db else 'create new',
'ccnet_db_name': db_config.ccnet_db_name,
'seafile_db_name': db_config.seafile_db_name,
'seahub_db_name': db_config.seahub_db_name,
'db_user': db_config.seafile_mysql_user
}
print template % config
print
print '---------------------------------'
print 'Press ENTER to continue, or Ctrl-C to abort'
print '---------------------------------'
raw_input()
def create_seafile_server_symlink():
print '\ncreating seafile-server-latest symbolic link ... ',
seafile_server_symlink = os.path.join(env_mgr.top_dir, 'seafile-server-latest')
try:
os.symlink(os.path.basename(env_mgr.install_path), seafile_server_symlink)
except Exception, e:
print '\n'
Utils.error('Failed to create symbolic link %s: %s' % (seafile_server_symlink, e))
else:
print 'done\n\n'
env_mgr = EnvManager()
ccnet_config = CcnetConfigurator()
seafile_config = SeafileConfigurator()
seafdav_config = SeafDavConfigurator()
seahub_config = SeahubConfigurator()
user_manuals_handler = UserManualHandler()
# Would be created after AbstractDBConfigurator.ask_use_existing_db()
db_config = None
def main():
global db_config
Utils.welcome()
warnings.filterwarnings('ignore', category=MySQLdb.Warning)
env_mgr.check_pre_condiction()
# Part 1: collect configuration
ccnet_config.ask_questions()
seafile_config.ask_questions()
seahub_config.ask_questions()
if AbstractDBConfigurator.ask_use_existing_db():
db_config = ExistingDBConfigurator()
else:
db_config = NewDBConfigurator()
db_config.ask_questions()
report_config()
# Part 2: generate configuration
db_config.generate()
ccnet_config.generate()
seafile_config.generate()
seafdav_config.generate()
seahub_config.generate()
seahub_config.do_syncdb()
seahub_config.prepare_avatar_dir()
# db_config.create_seahub_admin()
user_manuals_handler.copy_user_manuals()
create_seafile_server_symlink()
report_success()
def report_success():
message = '''\
-----------------------------------------------------------------
Your seafile server configuration has been finished successfully.
-----------------------------------------------------------------
run seafile server: ./seafile.sh { start | stop | restart }
run seahub server: ./seahub.sh { start <port> | stop | restart <port> }
-----------------------------------------------------------------
If you are behind a firewall, remember to allow input/output of these tcp ports:
-----------------------------------------------------------------
port of ccnet server: %(ccnet_port)s
port of seafile server: %(seafile_port)s
port of seafile httpserver: %(httpserver_port)s
port of seahub: 8000
When problems occur, Refer to
%(server_manual_http)s
for information.
'''
print message % dict(ccnet_port=ccnet_config.port,
seafile_port=seafile_config.port,
httpserver_port=seafile_config.httpserver_port,
server_manual_http=SERVER_MANUAL_HTTP)
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
print
print Utils.highlight('The setup process is aborted')
print<|fim▁end|> | def validate(port): |
<|file_name|>authentication.py<|end_file_name|><|fim▁begin|># -*- coding: utf-8 -*-
from oauth2 import Consumer, Client, Token
from httplib2 import ProxyInfo
from httplib2.socks import PROXY_TYPE_HTTP
from django.conf import settings
class Authentication(object):
def __init__(self, consumer_key, consumer_secret, token_key, token_secret):
consumer = Consumer(key=consumer_key, secret=consumer_secret)
token = Token(key=token_key, secret=token_secret)
<|fim▁hole|> if hasattr(settings, 'PROXY_HOST') and \
hasattr(settings, 'PROXY_PORT'):
proxy_info = ProxyInfo(
proxy_type=PROXY_TYPE_HTTP,
proxy_host=settings.PROXY_HOST,
proxy_port=settings.PROXY_PORT)
self.client = Client(
consumer=consumer,
token=token,
proxy_info=proxy_info)
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
pass<|fim▁end|> | proxy_info = None |
<|file_name|>issue-88844.rs<|end_file_name|><|fim▁begin|>// Regression test for #88844.
struct Struct { value: i32 }
//~^ NOTE: similarly named struct `Struct` defined here
impl Stuct {
//~^ ERROR: cannot find type `Stuct` in this scope [E0412]
//~| HELP: a struct with a similar name exists<|fim▁hole|> Self { value: 42 }
}
}
fn main() {}<|fim▁end|> | fn new() -> Self { |
<|file_name|>lunet2.py<|end_file_name|><|fim▁begin|>import DeepFried2 as df
from .. import dfext
def mknet(mkbn=lambda chan: df.BatchNormalization(chan, 0.95)):
kw = dict(mkbn=mkbn)
net = df.Sequential(
# -> 128x48
df.SpatialConvolutionCUDNN(3, 64, (7,7), border='same', bias=None),
dfext.resblock(64, **kw),
df.PoolingCUDNN((2,2)), # -> 64x24
dfext.resblock(64, **kw),
dfext.resblock(64, **kw),
dfext.resblock(64, 96, **kw),
df.PoolingCUDNN((2,2)), # -> 32x12
dfext.resblock(96, **kw),
dfext.resblock(96, **kw),
df.PoolingCUDNN((2,2)), # -> 16x6
dfext.resblock(96, **kw),
dfext.resblock(96, **kw),<|fim▁hole|> dfext.resblock(96, 128, **kw),
df.PoolingCUDNN((2,2)), # -> 8x3
dfext.resblock(128, **kw),
dfext.resblock(128, **kw),
df.PoolingCUDNN((2,3)), # -> 4x1
dfext.resblock(128, **kw),
# Eq. to flatten + linear
df.SpatialConvolutionCUDNN(128, 256, (4,1), bias=None),
mkbn(256), df.ReLU(),
df.StoreOut(df.SpatialConvolutionCUDNN(256, 128, (1,1)))
)
net.emb_mod = net[-1]
net.in_shape = (128, 48)
net.scale_factor = (2*2*2*2*2, 2*2*2*2*3)
print("Net has {:.2f}M params".format(df.utils.count_params(net)/1000/1000), flush=True)
return net
def add_piou(lunet2):
newnet = lunet2[:-1]
newnet.emb_mod = lunet2[-1]
newnet.iou_mod = df.StoreOut(df.Sequential(df.SpatialConvolutionCUDNN(256, 1, (1,1)), df.Sigmoid()))
newnet.add(df.RepeatInput(newnet.emb_mod, newnet.iou_mod))
newnet.embs_from_out = lambda out: out[0]
newnet.ious_from_out = lambda out: out[1][:,0] # Also remove the first size-1 dimension.
newnet.in_shape = lunet2.in_shape
newnet.scale_factor = lunet2.scale_factor
print("Added {:.2f}k params".format(df.utils.count_params(newnet.iou_mod)/1000), flush=True)
return newnet<|fim▁end|> | |
<|file_name|>matrix.hpp<|end_file_name|><|fim▁begin|>/*
* MATRIX COMPUTATION FOR RESERVATION BASED SYSTEMS<|fim▁hole|> *
* Copyright (C) 2013, University of Trento
* Authors: Luigi Palopoli <[email protected]>
*
* This program is free software; you can redistribute it and/or modify
* it under the terms of the GNU General Public License version 2 as
* published by the Free Software Foundation.
*/
#ifndef MATRIX_HPP
#define MATRIX_HPP
double matrix_prob_ts(int i, int j, int q, const cdf &p,
const pmf &u);
double matrix_prob_ts_compressed(int i, int j, int q, const cdf &p,
const pmf &u);
void compute_matrixes(const MatrixXd & mat, int dim, MatrixXd & B, MatrixXd & A0,
MatrixXd & A1, MatrixXd & A2);
#endif<|fim▁end|> | |
<|file_name|>auditTime.ts<|end_file_name|><|fim▁begin|>import {async} from '../scheduler/async';
import {Operator} from '../Operator';
import {Scheduler} from '../Scheduler';
import {Subscriber} from '../Subscriber';
import {Observable} from '../Observable';
import {Subscription} from '../Subscription';
/**
* Ignores source values for `duration` milliseconds, then emits the most recent
* value from the source Observable, then repeats this process.
*
* <span class="informal">When it sees a source values, it ignores that plus
* the next ones for `duration` milliseconds, and then it emits the most recent
* value from the source.</span>
*
* <img src="./img/auditTime.png" width="100%">
*
* `auditTime` is similar to `throttleTime`, but emits the last value from the
* silenced time window, instead of the first value. `auditTime` emits the most
* recent value from the source Observable on the output Observable as soon as
* its internal timer becomes disabled, and ignores source values while the
* timer is enabled. Initially, the timer is disabled. As soon as the first
* source value arrives, the timer is enabled. After `duration` milliseconds (or
* the time unit determined internally by the optional `scheduler`) has passed,
* the timer is disabled, then the most recent source value is emitted on the
* output Observable, and this process repeats for the next source value.
* Optionally takes a {@link Scheduler} for managing timers.
*
* @example <caption>Emit clicks at a rate of at most one click per second</caption>
* var clicks = Rx.Observable.fromEvent(document, 'click');
* var result = clicks.auditTime(1000);
* result.subscribe(x => console.log(x));
*
* @see {@link audit}
* @see {@link debounceTime}
* @see {@link delay}
* @see {@link sampleTime}
* @see {@link throttleTime}
*
* @param {number} duration Time to wait before emitting the most recent source
* value, measured in milliseconds or the time unit determined internally
* by the optional `scheduler`.
* @param {Scheduler} [scheduler=async] The {@link Scheduler} to use for
* managing the timers that handle the rate-limiting behavior.
* @return {Observable<T>} An Observable that performs rate-limiting of
* emissions from the source Observable.
* @method auditTime
* @owner Observable
*/
export function auditTime<T>(duration: number, scheduler: Scheduler = async): Observable<T> {
return this.lift(new AuditTimeOperator(duration, scheduler));
}
export interface AuditTimeSignature<T> {
(duration: number, scheduler?: Scheduler): Observable<T>;
}
class AuditTimeOperator<T> implements Operator<T, T> {
constructor(private duration: number,
private scheduler: Scheduler) {
}
call(subscriber: Subscriber<T>, source: any): any {
return source._subscribe(new AuditTimeSubscriber(subscriber, this.duration, this.scheduler));
}
}
/**
* We need this JSDoc comment for affecting ESDoc.
* @ignore
* @extends {Ignored}
*/
class AuditTimeSubscriber<T> extends Subscriber<T> {
private value: T;
private hasValue: boolean = false;
private throttled: Subscription;
constructor(destination: Subscriber<T>,
private duration: number,
private scheduler: Scheduler) {
super(destination);
}
protected _next(value: T): void {
this.value = value;
this.hasValue = true;
if (!this.throttled) {
this.add(this.throttled = this.scheduler.schedule(dispatchNext, this.duration, this));
}
}
<|fim▁hole|> if (throttled) {
this.remove(throttled);
this.throttled = null;
throttled.unsubscribe();
}
if (hasValue) {
this.value = null;
this.hasValue = false;
this.destination.next(value);
}
}
}
function dispatchNext<T>(subscriber: AuditTimeSubscriber<T>): void {
subscriber.clearThrottle();
}<|fim▁end|> | clearThrottle(): void {
const { value, hasValue, throttled } = this; |
<|file_name|>pki_helpers_test.go<|end_file_name|><|fim▁begin|>/*
Copyright 2016 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package pkiutil
import (
"crypto/rand"
"crypto/rsa"
"crypto/x509"
"io/ioutil"
"net"
"os"
"testing"
certutil "k8s.io/client-go/util/cert"
kubeadmapi "k8s.io/kubernetes/cmd/kubeadm/app/apis/kubeadm"
)
func TestNewCertificateAuthority(t *testing.T) {
cert, key, err := NewCertificateAuthority()
if cert == nil {
t.Errorf(
"failed NewCertificateAuthority, cert == nil",
)
}
if key == nil {
t.Errorf(
"failed NewCertificateAuthority, key == nil",
)
}
if err != nil {
t.Errorf(
"failed NewCertificateAuthority with an error: %v",
err,
)
}
}
func TestNewCertAndKey(t *testing.T) {
var tests = []struct {
caKeySize int
expected bool
}{
{
// RSA key too small
caKeySize: 128,
expected: false,
},
{
// Should succeed
caKeySize: 2048,
expected: true,
},
}
for _, rt := range tests {
caKey, err := rsa.GenerateKey(rand.Reader, rt.caKeySize)
if err != nil {
t.Fatalf("Couldn't create rsa Private Key")
}
caCert := &x509.Certificate{}
config := certutil.Config{
CommonName: "test",
Organization: []string{"test"},
Usages: []x509.ExtKeyUsage{x509.ExtKeyUsageClientAuth},
}
_, _, actual := NewCertAndKey(caCert, caKey, config)
if (actual == nil) != rt.expected {
t.Errorf(
"failed NewCertAndKey:\n\texpected: %t\n\t actual: %t",
rt.expected,
(actual == nil),
)
}
}
}
func TestHasServerAuth(t *testing.T) {
caCert, caKey, _ := NewCertificateAuthority()
var tests = []struct {
config certutil.Config
expected bool
}{
{
config: certutil.Config{
CommonName: "test",
Usages: []x509.ExtKeyUsage{x509.ExtKeyUsageServerAuth},
},
expected: true,
},
{
config: certutil.Config{
CommonName: "test",
Usages: []x509.ExtKeyUsage{x509.ExtKeyUsageClientAuth},
},
expected: false,
},
}
for _, rt := range tests {
cert, _, err := NewCertAndKey(caCert, caKey, rt.config)
if err != nil {
t.Fatalf("Couldn't create cert: %v", err)
}
actual := HasServerAuth(cert)
if actual != rt.expected {
t.Errorf(
"failed HasServerAuth:\n\texpected: %t\n\t actual: %t",
rt.expected,
actual,
)
}
}
}
func TestWriteCertAndKey(t *testing.T) {
tmpdir, err := ioutil.TempDir("", "")
if err != nil {
t.Fatalf("Couldn't create tmpdir")
}
defer os.RemoveAll(tmpdir)
caKey, err := rsa.GenerateKey(rand.Reader, 2048)
if err != nil {
t.Fatalf("Couldn't create rsa Private Key")
}
caCert := &x509.Certificate{}
actual := WriteCertAndKey(tmpdir, "foo", caCert, caKey)
if actual != nil {
t.Errorf(
"failed WriteCertAndKey with an error: %v",
actual,
)
}
}
func TestWriteCert(t *testing.T) {
tmpdir, err := ioutil.TempDir("", "")
if err != nil {
t.Fatalf("Couldn't create tmpdir")
}
defer os.RemoveAll(tmpdir)
caCert := &x509.Certificate{}
actual := WriteCert(tmpdir, "foo", caCert)
if actual != nil {
t.Errorf(
"failed WriteCertAndKey with an error: %v",
actual,
)
}
}
func TestWriteKey(t *testing.T) {
tmpdir, err := ioutil.TempDir("", "")
if err != nil {
t.Fatalf("Couldn't create tmpdir")
}
defer os.RemoveAll(tmpdir)
caKey, err := rsa.GenerateKey(rand.Reader, 2048)
if err != nil {
t.Fatalf("Couldn't create rsa Private Key")
}
actual := WriteKey(tmpdir, "foo", caKey)
if actual != nil {
t.Errorf(
"failed WriteCertAndKey with an error: %v",
actual,
)
}
}
func TestWritePublicKey(t *testing.T) {
tmpdir, err := ioutil.TempDir("", "")
if err != nil {
t.Fatalf("Couldn't create tmpdir")
}
defer os.RemoveAll(tmpdir)
caKey, err := rsa.GenerateKey(rand.Reader, 2048)
if err != nil {
t.Fatalf("Couldn't create rsa Private Key")
}
actual := WritePublicKey(tmpdir, "foo", &caKey.PublicKey)
if actual != nil {
t.Errorf(
"failed WriteCertAndKey with an error: %v",
actual,
)
}
}
func TestCertOrKeyExist(t *testing.T) {
tmpdir, err := ioutil.TempDir("", "")
if err != nil {
t.Fatalf("Couldn't create tmpdir")
}
defer os.RemoveAll(tmpdir)
caKey, err := rsa.GenerateKey(rand.Reader, 2048)
if err != nil {
t.Fatalf("Couldn't create rsa Private Key")
}
caCert := &x509.Certificate{}
actual := WriteCertAndKey(tmpdir, "foo", caCert, caKey)
if actual != nil {
t.Errorf(
"failed WriteCertAndKey with an error: %v",
actual,
)
}
var tests = []struct {
path string
name string
expected bool
}{
{
path: "",
name: "",
expected: false,
},
{
path: tmpdir,
name: "foo",
expected: true,
},
}
for _, rt := range tests {
actual := CertOrKeyExist(rt.path, rt.name)
if actual != rt.expected {
t.Errorf(
"failed CertOrKeyExist:\n\texpected: %t\n\t actual: %t",
rt.expected,
actual,
)
}
}
}
func TestTryLoadCertAndKeyFromDisk(t *testing.T) {
tmpdir, err := ioutil.TempDir("", "")
if err != nil {
t.Fatalf("Couldn't create tmpdir")
}
defer os.RemoveAll(tmpdir)
caCert, caKey, err := NewCertificateAuthority()
if err != nil {
t.Errorf(
"failed to create cert and key with an error: %v",
err,
)
}
err = WriteCertAndKey(tmpdir, "foo", caCert, caKey)
if err != nil {
t.Errorf(
"failed to write cert and key with an error: %v",
err,
)
}
var tests = []struct {
path string
name string
expected bool
}{
{
path: "",
name: "",
expected: false,
},
{
path: tmpdir,
name: "foo",
expected: true,
},
}
for _, rt := range tests {
_, _, actual := TryLoadCertAndKeyFromDisk(rt.path, rt.name)
if (actual == nil) != rt.expected {
t.Errorf(
"failed TryLoadCertAndKeyFromDisk:\n\texpected: %t\n\t actual: %t",
rt.expected,
(actual == nil),
)
}
}
}
func TestTryLoadCertFromDisk(t *testing.T) {
tmpdir, err := ioutil.TempDir("", "")
if err != nil {
t.Fatalf("Couldn't create tmpdir")
}
defer os.RemoveAll(tmpdir)
caCert, _, err := NewCertificateAuthority()
if err != nil {
t.Errorf(
"failed to create cert and key with an error: %v",
err,
)
}
err = WriteCert(tmpdir, "foo", caCert)
if err != nil {
t.Errorf(
"failed to write cert and key with an error: %v",
err,
)
}
var tests = []struct {
path string
name string
expected bool
}{
{
path: "",
name: "",
expected: false,
},
{
path: tmpdir,
name: "foo",
expected: true,
},
}
for _, rt := range tests {
_, actual := TryLoadCertFromDisk(rt.path, rt.name)
if (actual == nil) != rt.expected {
t.Errorf(
"failed TryLoadCertAndKeyFromDisk:\n\texpected: %t\n\t actual: %t",
rt.expected,
(actual == nil),
)
}
}
}
func TestTryLoadKeyFromDisk(t *testing.T) {
tmpdir, err := ioutil.TempDir("", "")
if err != nil {
t.Fatalf("Couldn't create tmpdir")
}
defer os.RemoveAll(tmpdir)
_, caKey, err := NewCertificateAuthority()
if err != nil {
t.Errorf(
"failed to create cert and key with an error: %v",
err,
)
}
err = WriteKey(tmpdir, "foo", caKey)
if err != nil {
t.Errorf(
"failed to write cert and key with an error: %v",
err,
)
}
var tests = []struct {
path string
name string
expected bool
}{
{
path: "",
name: "",
expected: false,
},
{
path: tmpdir,
name: "foo",
expected: true,
},
}
for _, rt := range tests {
_, actual := TryLoadKeyFromDisk(rt.path, rt.name)
if (actual == nil) != rt.expected {
t.Errorf(
"failed TryLoadCertAndKeyFromDisk:\n\texpected: %t\n\t actual: %t",
rt.expected,
(actual == nil),
)
}
}
}
func TestPathsForCertAndKey(t *testing.T) {
crtPath, keyPath := pathsForCertAndKey("/foo", "bar")
if crtPath != "/foo/bar.crt" {
t.Errorf("unexpected certificate path: %s", crtPath)
}
if keyPath != "/foo/bar.key" {
t.Errorf("unexpected key path: %s", keyPath)
}
}
func TestPathForCert(t *testing.T) {
crtPath := pathForCert("/foo", "bar")
if crtPath != "/foo/bar.crt" {
t.Errorf("unexpected certificate path: %s", crtPath)
}
}
func TestPathForKey(t *testing.T) {
keyPath := pathForKey("/foo", "bar")
if keyPath != "/foo/bar.key" {
t.Errorf("unexpected certificate path: %s", keyPath)
}
}
func TestPathForPublicKey(t *testing.T) {
pubPath := pathForPublicKey("/foo", "bar")
if pubPath != "/foo/bar.pub" {
t.Errorf("unexpected certificate path: %s", pubPath)
}
}
func TestGetAPIServerAltNames(t *testing.T) {
var tests = []struct {
name string
cfg *kubeadmapi.MasterConfiguration
expectedDNSNames []string
expectedIPAddresses []string
}{
{
name: "ControlPlaneEndpoint DNS",
cfg: &kubeadmapi.MasterConfiguration{
API: kubeadmapi.API{AdvertiseAddress: "1.2.3.4", ControlPlaneEndpoint: "api.k8s.io:6443"},
Networking: kubeadmapi.Networking{ServiceSubnet: "10.96.0.0/12", DNSDomain: "cluster.local"},
NodeRegistration: kubeadmapi.NodeRegistrationOptions{Name: "valid-hostname"},
APIServerCertSANs: []string{"10.1.245.94", "10.1.245.95", "1.2.3.L", "invalid,commas,in,DNS"},
},
expectedDNSNames: []string{"valid-hostname", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster.local", "api.k8s.io"},<|fim▁hole|> },
{
name: "ControlPlaneEndpoint IP",
cfg: &kubeadmapi.MasterConfiguration{
API: kubeadmapi.API{AdvertiseAddress: "1.2.3.4", ControlPlaneEndpoint: "4.5.6.7:6443"},
Networking: kubeadmapi.Networking{ServiceSubnet: "10.96.0.0/12", DNSDomain: "cluster.local"},
NodeRegistration: kubeadmapi.NodeRegistrationOptions{Name: "valid-hostname"},
APIServerCertSANs: []string{"10.1.245.94", "10.1.245.95", "1.2.3.L", "invalid,commas,in,DNS"},
},
expectedDNSNames: []string{"valid-hostname", "kubernetes", "kubernetes.default", "kubernetes.default.svc", "kubernetes.default.svc.cluster.local"},
expectedIPAddresses: []string{"10.96.0.1", "1.2.3.4", "10.1.245.94", "10.1.245.95", "4.5.6.7"},
},
}
for _, rt := range tests {
altNames, err := GetAPIServerAltNames(rt.cfg)
if err != nil {
t.Fatalf("failed calling GetAPIServerAltNames: %s: %v", rt.name, err)
}
for _, DNSName := range rt.expectedDNSNames {
found := false
for _, val := range altNames.DNSNames {
if val == DNSName {
found = true
break
}
}
if !found {
t.Errorf("%s: altNames does not contain DNSName %s but %v", rt.name, DNSName, altNames.DNSNames)
}
}
for _, IPAddress := range rt.expectedIPAddresses {
found := false
for _, val := range altNames.IPs {
if val.Equal(net.ParseIP(IPAddress)) {
found = true
break
}
}
if !found {
t.Errorf("%s: altNames does not contain IPAddress %s but %v", rt.name, IPAddress, altNames.IPs)
}
}
}
}
func TestGetEtcdAltNames(t *testing.T) {
proxy := "user-etcd-proxy"
proxyIP := "10.10.10.100"
cfg := &kubeadmapi.MasterConfiguration{
Etcd: kubeadmapi.Etcd{
Local: &kubeadmapi.LocalEtcd{
ServerCertSANs: []string{
proxy,
proxyIP,
"1.2.3.L",
"invalid,commas,in,DNS",
},
},
},
}
altNames, err := GetEtcdAltNames(cfg)
if err != nil {
t.Fatalf("failed calling GetEtcdAltNames: %v", err)
}
expectedDNSNames := []string{"localhost", proxy}
for _, DNSName := range expectedDNSNames {
found := false
for _, val := range altNames.DNSNames {
if val == DNSName {
found = true
break
}
}
if !found {
t.Errorf("altNames does not contain DNSName %s", DNSName)
}
}
expectedIPAddresses := []string{"127.0.0.1", proxyIP}
for _, IPAddress := range expectedIPAddresses {
found := false
for _, val := range altNames.IPs {
if val.Equal(net.ParseIP(IPAddress)) {
found = true
break
}
}
if !found {
t.Errorf("altNames does not contain IPAddress %s", IPAddress)
}
}
}
func TestGetEtcdPeerAltNames(t *testing.T) {
hostname := "valid-hostname"
proxy := "user-etcd-proxy"
proxyIP := "10.10.10.100"
advertiseIP := "1.2.3.4"
cfg := &kubeadmapi.MasterConfiguration{
API: kubeadmapi.API{AdvertiseAddress: advertiseIP},
NodeRegistration: kubeadmapi.NodeRegistrationOptions{Name: hostname},
Etcd: kubeadmapi.Etcd{
Local: &kubeadmapi.LocalEtcd{
PeerCertSANs: []string{
proxy,
proxyIP,
"1.2.3.L",
"invalid,commas,in,DNS",
},
},
},
}
altNames, err := GetEtcdPeerAltNames(cfg)
if err != nil {
t.Fatalf("failed calling GetEtcdPeerAltNames: %v", err)
}
expectedDNSNames := []string{hostname, proxy}
for _, DNSName := range expectedDNSNames {
found := false
for _, val := range altNames.DNSNames {
if val == DNSName {
found = true
break
}
}
if !found {
t.Errorf("altNames does not contain DNSName %s", DNSName)
}
}
expectedIPAddresses := []string{advertiseIP, proxyIP}
for _, IPAddress := range expectedIPAddresses {
found := false
for _, val := range altNames.IPs {
if val.Equal(net.ParseIP(IPAddress)) {
found = true
break
}
}
if !found {
t.Errorf("altNames does not contain IPAddress %s", IPAddress)
}
}
}<|fim▁end|> | expectedIPAddresses: []string{"10.96.0.1", "1.2.3.4", "10.1.245.94", "10.1.245.95"}, |
<|file_name|>editeur.js<|end_file_name|><|fim▁begin|>$(document).ready(function () {
// Regex pour avoir les contenus des balises <amb>
// Exemple : L'<amb>avocat</amb> mange des <amb>avocats</amb>.
// Donne : $1 = avocat, puis $1 = avocats
var regAmb = new RegExp('<amb>(.*?)</amb>', 'ig');
// Regex pour avoir les contenus des balises <amb> et leurs id
// Exemple : L'<amb id="1">avocat</amb> mange des <amb id="2">avocats</amb>.
// Donne : $1 = 1 et $3 = avocat, puis $1 = 2 et $3 = avocats
var regAmbId = new RegExp('<amb id="([0-9]+)"( title=".*")?>(.*?)</amb>', 'ig');
// Le formulaire d'édition
var editorForm = $("#phrase-editor-form");
// Div contenant le prototype du formulaire MAP
var $container = $('div#proto_motsAmbigusPhrase');
// La div modifiable
var phraseEditor = $("div.phrase-editor");
// Div des erreurs
var errorForm = $('#form-errors');
// Le mode actif
var modeEditor = $('#nav-editor li.active').data('mode');
// Pour numéroter le mot ambigu
var indexMotAmbigu = 0;
// Tableau des mots ambigus de la phrase
var motsAmbigus = [];
function getPhraseTexte() {
return phraseEditor
.html()
.replace(/ /ig, ' ')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/<br>/g, '')
.replace(/ style=""/g, '')
.replace(/ title="Ce mot est ambigu \(id : [0-9]+\)"/ig, '');
}
// Mise à jour du mode d'éditeur
$('#nav-editor li').on('click', function(){
$('#nav-editor li.active').removeClass('active');
$(this).addClass('active');
var oldModeEditor = modeEditor;
modeEditor = $(this).data('mode');
if (oldModeEditor != modeEditor) {
if (modeEditor === 'wysiwyg') {
// Affiche la phrase en mode HTML
phraseEditor.html(phraseEditor.text());
$.each(phraseEditor.find('amb'), function (i, val) {
$(this).attr('title', 'Ce mot est ambigu (id : ' + $(this).attr('id') + ')');
});
}
else if (modeEditor === 'source') {
// Affiche la phrase en mode texte
phraseEditor.text(getPhraseTexte());
}
}
});
// Ajout d'un mot ambigu
$("#addAmb").on('click', function () {
var sel = window.getSelection();
var selText = sel.toString();
// S'il y a bien un mot séléctionné
if (selText.trim() !== '') {
var regAlpha = /[a-zA-ZáàâäãåçéèêëíìîïñóòôöõúùûüýÿæœÁÀÂÄÃÅÇÉÈÊËÍÌÎÏÑÓÒÔÖÕÚÙÛÜÝŸÆŒ]/;
var parentBase = sel.anchorNode.parentNode;
var parentFocus = sel.focusNode.parentNode;
var numPrevChar = Math.min(sel.focusOffset, sel.anchorOffset) - 1;
var numFirstChar = Math.min(sel.focusOffset, sel.anchorOffset);
var numLastChar = Math.max(sel.focusOffset, sel.anchorOffset) - 1;
var numNextChar = Math.max(sel.focusOffset, sel.anchorOffset);
var prevChar = sel.focusNode.textContent.charAt(numPrevChar);
var firstChar = sel.focusNode.textContent.charAt(numFirstChar);
var lastChar = sel.focusNode.textContent.charAt(numLastChar);
var nextChar = sel.focusNode.textContent.charAt(numNextChar);
errorForm.empty();
var success = true;
if (phraseEditor.html() != parentBase.innerHTML || phraseEditor.html() != parentFocus.innerHTML) {
errorForm.append('Le mot sélectionné est déjà ambigu<br>');
success = false;
}
if (sel.anchorNode != sel.focusNode) {
errorForm.append('Le mot sélectionné contient déjà un mot ambigu<br>');
success = false;
}
if (prevChar.match(regAlpha)) {
errorForm.append('Le premier caractère sélectionné ne doit pas être précédé d\'un caractère alphabétique<br>');
success = false;
}
if (!firstChar.match(regAlpha)) {
errorForm.append('Le premier caractère sélectionné doit être alphabétique<br>');
success = false;
}
if (!lastChar.match(regAlpha)) {
errorForm.append('Le dernier caractère sélectionné doit être alphabétique<br>');
success = false;
}
if (nextChar.match(regAlpha)) {
errorForm.append('Le dernier caractère sélectionné ne doit pas être suivi d\'un caractère alphabétique<br>');
success = false;
}
// S'il y a une erreur on affiche la div des erreurs
if (!success) {
errorForm.show();
return false;
}
// Sinon on cache la div
else {
errorForm.hide();
}
// Transformation du texte sélectionné en mot ambigu selon le mode utilisé
var range = document.getSelection().getRangeAt(0);
var clone = $(range.cloneContents());
range.deleteContents();
range.insertNode($('<amb>').append(clone).get(0));
document.getSelection().setPosition(null);
phraseEditor.trigger('input');
}
});
// A chaque modification de la phrase
phraseEditor.on('input', function (){
var phrase = getPhraseTexte();
// Compte le nombre d'occurence de balise <amb>
var replaced = phrase.search(regAmb) >= 0;
// Si au moins 1
if(replaced) {
// On ajout dans la balise <amb> l'id du mot ambigu
var temp = phrase.replace(regAmb, function ($0, motAmbigu) {
indexMotAmbigu++;
var indexLocal = indexMotAmbigu;
motsAmbigus[indexMotAmbigu] = motAmbigu;
// On ajoute le nom unique et l'id
var template = $container.attr('data-prototype')
.replace(/__name__label__/g, '')
.replace(/__name__/g, indexMotAmbigu)
.replace(/__id__/g, indexMotAmbigu)
.replace(/__MA__/g, motAmbigu);
var $prototype = $(template);
// Trouve la balise qui à la class amb
var amb = $prototype.find('.amb');
// Ajoute la valeur du mot ambigu en supprimant les espaces avant et après le mot, et ajoute l'id
amb.val(motAmbigu);
$prototype.attr('id', 'rep' + indexMotAmbigu);
var $deleteLink = $('<a href="#" class="sup-amb btn btn-danger">Supprimer le mot ambigu</a>');
$prototype.find('.gloseAction').append($deleteLink);
getGloses($prototype.find('select.gloses'), motAmbigu, function () {
// Pour la page d'édition, sélection des gloses automatique
if (typeof reponsesOri != 'undefined') {
reponsesOri.forEach((item, index) => {
if (item.map_ordre == indexLocal) {
$prototype.find('option[value=' + item.glose_id + ']').prop('selected', true)
}
});
}
});
$container.append($prototype);
if (modeEditor == 'wysiwyg') {
return '<amb id="' + indexMotAmbigu + '" title="Ce mot est ambigu (id : ' + indexMotAmbigu + ')">' + motAmbigu + '</amb>';
}
else {
return '<amb id="' + indexMotAmbigu + '">' + motAmbigu + '</amb>';
}
});
if (modeEditor == 'wysiwyg') {
phraseEditor.html(temp);
}
else {
phraseEditor.text(temp);
}
}
var phrase = getPhraseTexte();
phrase.replace(regAmbId, function ($0, $1, $2, $3) {
var motAmbiguForm = $('#phrase_motsAmbigusPhrase_' + $1 + '_valeur');
// Mot ambigu modifié dans la phrase -> passage en rouge du MA dans le formulaire
if (motsAmbigus[$1] != $3) {
motAmbiguForm.val($3).css('color', 'red');
}
// Si le MA modifié reprend sa valeur initiale -> efface la couleur rouge du MA dans le formulaire
else if (motsAmbigus[$1] != motAmbiguForm.val($3)) {
motAmbiguForm.val(motsAmbigus[$1]).css('color', '');
}
});
});
phraseEditor.trigger('input'); // Pour mettre en forme en cas de phrase au chargement (édition ou création échouée)
// Mise à jour des gloses des mots ambigus
phraseEditor.on('focusout', function () {
var phrase = getPhraseTexte();
phrase.replace(regAmbId, function ($0, $1, $2, $3) {<|fim▁hole|> if (motsAmbigus[$1] != $3) {
$('#phrase_motsAmbigusPhrase_' + $1 + '_valeur').trigger('focusout');
motsAmbigus[$1] = $3;
}
});
});
// Désactive la touche entrée dans l'éditeur de phrase
phraseEditor.on('keypress', function(e) {
var keyCode = e.which;
if (keyCode == 13) {
return false;
}
});
// Coller sans le formatage
phraseEditor.on('paste', function(e) {
e.preventDefault();
var text = (e.originalEvent || e).clipboardData.getData('text/plain');
if (modeEditor == 'wysiwyg') {
$(this).html(text);
}
else {
$(this).text(text);
}
phraseEditor.trigger('input'); // Pour mettre en forme après avoir collé
});
// Modification d'un mot ambigu
editorForm.on('input', '.amb', function () {
// On récupère l'id qui est dans l'attribut id (id="rep1"), en supprimant le rep
var id = $(this).closest('.reponseGroupe').attr('id').replace(/rep/, '');
// Mot ambigu modifié -> passage en rouge du MA
if (motsAmbigus[id] != $(this).val()) {
$(this).css('color', 'red');
}
// Si le MA modifié reprend sa valeur initiale -> efface la couleur rouge du MA
else {
$(this).css('color', '');
}
var phrase = getPhraseTexte();
// Regex pour trouver la bonne balise <amb id="">, et en récupérer le contenu
var reg3 = new RegExp('<amb id="' + id + '">(.*?)' + '</amb>', 'g');
// Met à jour le mot ambigu dans la phrase
if (modeEditor == 'wysiwyg') {
phraseEditor.html(phrase.replace(reg3, '<amb id="' + id + '" title="Ce mot est ambigu (id : ' + id + ')">' + $(this).val() + '</amb>'));
}
else {
phraseEditor.text(phrase.replace(reg3, '<amb id="' + id + '">' + $(this).val() + '</amb>'));
}
});
// Mise à jour des gloses d'un mot ambigu
editorForm.on('focusout', '.amb', function (){
// On récupère l'id qui est dans l'attribut id (id="rep1"), en supprimant le rep
var id = $(this).closest('.reponseGroupe').attr('id').replace(/rep/, '');
if (motsAmbigus[id] != $(this).val()) {
$(this).css('color', '');
motsAmbigus[id] = $(this).val();
var phrase = getPhraseTexte();
// Regex pour trouver la bonne balise <amb id="">, et en récupérer le contenu
var reg3 = new RegExp('<amb id="' + id + '">(.*?)' + '</amb>', 'g');
// Met à jour le mot ambigu dans la phrase
if (modeEditor == 'wysiwyg') {
phraseEditor.html(phrase.replace(reg3, '<amb id="' + id + '" title="Ce mot est ambigu (id : ' + id + ')">' + $(this).val() + '</amb>'));
}
else {
phraseEditor.text(phrase.replace(reg3, '<amb id="' + id + '">' + $(this).val() + '</amb>'));
}
getGloses($(this).closest('.colAmb').next().find('select.gloses'), $(this).val());
}
});
// Suppression d'un mot ambigu
editorForm.on('click', '.sup-amb', function(e) {
$(this).closest('.reponseGroupe').trigger('mouseleave');
var phrase = getPhraseTexte();
// On récupère l'id qui est dans l'attribut id (id="rep1"), en supprimant le rep
var id = $(this).closest('.reponseGroupe').attr('id').replace(/rep/, '');
delete motsAmbigus[id];
// Regex pour trouver la bonne balise <amb id="">, et en récupérer le contenu
var reg3 = new RegExp('<amb id="' + id + '">(.*?)</amb>', 'g');
// Modifie le textarea pour supprimé la balise <amb id=""></amb> et remettre le contenu
if (modeEditor == 'wysiwyg') {
phraseEditor.html(phrase.replace(reg3, '$1'));
}
else {
phraseEditor.text(phrase.replace(reg3, '$1'));
}
$(this).closest('.reponseGroupe').remove();
e.preventDefault(); // Évite qu'un # soit ajouté dans l'URL
});
// A la soumission du formulaire
$('.btn-phrase-editor').on('click', function(){
$('#phrase_contenu').val(getPhraseTexte());
});
});<|fim▁end|> | |
<|file_name|>Resources_ja.java<|end_file_name|><|fim▁begin|>/*
* Copyright (c) 2000, 2019, Oracle and/or its affiliates. All rights reserved.
* DO NOT ALTER OR REMOVE COPYRIGHT NOTICES OR THIS FILE HEADER.
*
* This code is free software; you can redistribute it and/or modify it
* under the terms of the GNU General Public License version 2 only, as
* published by the Free Software Foundation. Oracle designates this
* particular file as subject to the "Classpath" exception as provided
* by Oracle in the LICENSE file that accompanied this code.
*
* This code is distributed in the hope that it will be useful, but WITHOUT
* ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or
* FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
* version 2 for more details (a copy is included in the LICENSE file that
* accompanied this code).
*
* You should have received a copy of the GNU General Public License version
* 2 along with this work; if not, write to the Free Software Foundation,
* Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA.
*
* Please contact Oracle, 500 Oracle Parkway, Redwood Shores, CA 94065 USA
* or visit www.oracle.com if you need additional information or have any
* questions.
*/
package sun.security.tools.keytool;
/**
* <p> This class represents the <code>ResourceBundle</code>
* for the keytool.
*
*/
public class Resources_ja extends java.util.ListResourceBundle {
private static final Object[][] contents = {
{"NEWLINE", "\n"},
{"STAR",
"*******************************************"},
{"STARNN",
"*******************************************\n\n"},
// keytool: Help part
{".OPTION.", " [OPTION]..."},
{"Options.", "\u30AA\u30D7\u30B7\u30E7\u30F3:"},
{"option.1.set.twice", "%s\u30AA\u30D7\u30B7\u30E7\u30F3\u304C\u8907\u6570\u56DE\u6307\u5B9A\u3055\u308C\u3066\u3044\u307E\u3059\u3002\u6700\u5F8C\u306E\u3082\u306E\u4EE5\u5916\u306F\u3059\u3079\u3066\u7121\u8996\u3055\u308C\u307E\u3059\u3002"},
{"multiple.commands.1.2", "1\u3064\u306E\u30B3\u30DE\u30F3\u30C9\u306E\u307F\u8A31\u53EF\u3055\u308C\u307E\u3059: %1$s\u3068%2$s\u306E\u4E21\u65B9\u304C\u6307\u5B9A\u3055\u308C\u307E\u3057\u305F\u3002"},
{"Use.keytool.help.for.all.available.commands",
"\u3053\u306E\u30D8\u30EB\u30D7\u30FB\u30E1\u30C3\u30BB\u30FC\u30B8\u3092\u8868\u793A\u3059\u308B\u306B\u306F\"keytool -?\u3001-h\u307E\u305F\u306F--help\"\u3092\u4F7F\u7528\u3057\u307E\u3059"},
{"Key.and.Certificate.Management.Tool",
"\u30AD\u30FC\u304A\u3088\u3073\u8A3C\u660E\u66F8\u7BA1\u7406\u30C4\u30FC\u30EB"},
{"Commands.", "\u30B3\u30DE\u30F3\u30C9:"},
{"Use.keytool.command.name.help.for.usage.of.command.name",
"command_name\u306E\u4F7F\u7528\u65B9\u6CD5\u306B\u3064\u3044\u3066\u306F\u3001\"keytool -command_name --help\"\u3092\u4F7F\u7528\u3057\u307E\u3059\u3002\n\u4E8B\u524D\u69CB\u6210\u6E08\u306E\u30AA\u30D7\u30B7\u30E7\u30F3\u30FB\u30D5\u30A1\u30A4\u30EB\u3092\u6307\u5B9A\u3059\u308B\u306B\u306F\u3001-conf <url>\u30AA\u30D7\u30B7\u30E7\u30F3\u3092\u4F7F\u7528\u3057\u307E\u3059\u3002"},
// keytool: help: commands
{"Generates.a.certificate.request",
"\u8A3C\u660E\u66F8\u30EA\u30AF\u30A8\u30B9\u30C8\u3092\u751F\u6210\u3057\u307E\u3059"}, //-certreq
{"Changes.an.entry.s.alias",
"\u30A8\u30F3\u30C8\u30EA\u306E\u5225\u540D\u3092\u5909\u66F4\u3057\u307E\u3059"}, //-changealias
{"Deletes.an.entry",
"\u30A8\u30F3\u30C8\u30EA\u3092\u524A\u9664\u3057\u307E\u3059"}, //-delete
{"Exports.certificate",
"\u8A3C\u660E\u66F8\u3092\u30A8\u30AF\u30B9\u30DD\u30FC\u30C8\u3057\u307E\u3059"}, //-exportcert
{"Generates.a.key.pair",
"\u30AD\u30FC\u30FB\u30DA\u30A2\u3092\u751F\u6210\u3057\u307E\u3059"}, //-genkeypair
{"Generates.a.secret.key",
"\u79D8\u5BC6\u30AD\u30FC\u3092\u751F\u6210\u3057\u307E\u3059"}, //-genseckey
{"Generates.certificate.from.a.certificate.request",
"\u8A3C\u660E\u66F8\u30EA\u30AF\u30A8\u30B9\u30C8\u304B\u3089\u8A3C\u660E\u66F8\u3092\u751F\u6210\u3057\u307E\u3059"}, //-gencert
{"Generates.CRL", "CRL\u3092\u751F\u6210\u3057\u307E\u3059"}, //-gencrl
{"Generated.keyAlgName.secret.key",
"{0}\u79D8\u5BC6\u30AD\u30FC\u3092\u751F\u6210\u3057\u307E\u3057\u305F"}, //-genseckey
{"Generated.keysize.bit.keyAlgName.secret.key",
"{0}\u30D3\u30C3\u30C8{1}\u79D8\u5BC6\u30AD\u30FC\u3092\u751F\u6210\u3057\u307E\u3057\u305F"}, //-genseckey
{"Imports.entries.from.a.JDK.1.1.x.style.identity.database",
"JDK 1.1.x-style\u30A2\u30A4\u30C7\u30F3\u30C6\u30A3\u30C6\u30A3\u30FB\u30C7\u30FC\u30BF\u30D9\u30FC\u30B9\u304B\u3089\u30A8\u30F3\u30C8\u30EA\u3092\u30A4\u30F3\u30DD\u30FC\u30C8\u3057\u307E\u3059"}, //-identitydb
{"Imports.a.certificate.or.a.certificate.chain",
"\u8A3C\u660E\u66F8\u307E\u305F\u306F\u8A3C\u660E\u66F8\u30C1\u30A7\u30FC\u30F3\u3092\u30A4\u30F3\u30DD\u30FC\u30C8\u3057\u307E\u3059"}, //-importcert
{"Imports.a.password",
"\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u30A4\u30F3\u30DD\u30FC\u30C8\u3057\u307E\u3059"}, //-importpass
{"Imports.one.or.all.entries.from.another.keystore",
"\u5225\u306E\u30AD\u30FC\u30B9\u30C8\u30A2\u304B\u30891\u3064\u307E\u305F\u306F\u3059\u3079\u3066\u306E\u30A8\u30F3\u30C8\u30EA\u3092\u30A4\u30F3\u30DD\u30FC\u30C8\u3057\u307E\u3059"}, //-importkeystore
{"Clones.a.key.entry",
"\u30AD\u30FC\u30FB\u30A8\u30F3\u30C8\u30EA\u306E\u30AF\u30ED\u30FC\u30F3\u3092\u4F5C\u6210\u3057\u307E\u3059"}, //-keyclone
{"Changes.the.key.password.of.an.entry",
"\u30A8\u30F3\u30C8\u30EA\u306E\u30AD\u30FC\u30FB\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5909\u66F4\u3057\u307E\u3059"}, //-keypasswd
{"Lists.entries.in.a.keystore",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u5185\u306E\u30A8\u30F3\u30C8\u30EA\u3092\u30EA\u30B9\u30C8\u3057\u307E\u3059"}, //-list
{"Prints.the.content.of.a.certificate",
"\u8A3C\u660E\u66F8\u306E\u5185\u5BB9\u3092\u51FA\u529B\u3057\u307E\u3059"}, //-printcert
{"Prints.the.content.of.a.certificate.request",
"\u8A3C\u660E\u66F8\u30EA\u30AF\u30A8\u30B9\u30C8\u306E\u5185\u5BB9\u3092\u51FA\u529B\u3057\u307E\u3059"}, //-printcertreq
{"Prints.the.content.of.a.CRL.file",
"CRL\u30D5\u30A1\u30A4\u30EB\u306E\u5185\u5BB9\u3092\u51FA\u529B\u3057\u307E\u3059"}, //-printcrl
{"Generates.a.self.signed.certificate",
"\u81EA\u5DF1\u7F72\u540D\u578B\u8A3C\u660E\u66F8\u3092\u751F\u6210\u3057\u307E\u3059"}, //-selfcert
{"Changes.the.store.password.of.a.keystore",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30B9\u30C8\u30A2\u30FB\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5909\u66F4\u3057\u307E\u3059"}, //-storepasswd
{"showinfo.command.help", "\u30BB\u30AD\u30E5\u30EA\u30C6\u30A3\u95A2\u9023\u60C5\u5831\u3092\u8868\u793A\u3057\u307E\u3059"},
// keytool: help: options
{"alias.name.of.the.entry.to.process",
"\u51E6\u7406\u3059\u308B\u30A8\u30F3\u30C8\u30EA\u306E\u5225\u540D"}, //-alias
{"groupname.option.help",
"\u30B0\u30EB\u30FC\u30D7\u540D\u3002\u305F\u3068\u3048\u3070\u3001\u6955\u5186\u66F2\u7DDA\u540D\u3067\u3059\u3002"}, //-groupname
{"destination.alias",
"\u51FA\u529B\u5148\u306E\u5225\u540D"}, //-destalias
{"destination.key.password",
"\u51FA\u529B\u5148\u30AD\u30FC\u306E\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-destkeypass
{"destination.keystore.name",
"\u51FA\u529B\u5148\u30AD\u30FC\u30B9\u30C8\u30A2\u540D"}, //-destkeystore
{"destination.keystore.password.protected",
"\u51FA\u529B\u5148\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u4FDD\u8B77\u5BFE\u8C61\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-destprotected
{"destination.keystore.provider.name",
"\u51FA\u529B\u5148\u30AD\u30FC\u30B9\u30C8\u30A2\u30FB\u30D7\u30ED\u30D0\u30A4\u30C0\u540D"}, //-destprovidername
{"destination.keystore.password",
"\u51FA\u529B\u5148\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-deststorepass
{"destination.keystore.type",
"\u51FA\u529B\u5148\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30BF\u30A4\u30D7"}, //-deststoretype
{"distinguished.name",
"\u8B58\u5225\u540D"}, //-dname
{"X.509.extension",
"X.509\u62E1\u5F35"}, //-ext
{"output.file.name",
"\u51FA\u529B\u30D5\u30A1\u30A4\u30EB\u540D"}, //-file and -outfile
{"input.file.name",
"\u5165\u529B\u30D5\u30A1\u30A4\u30EB\u540D"}, //-file and -infile
{"key.algorithm.name",
"\u30AD\u30FC\u30FB\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0\u540D"}, //-keyalg
{"key.password",
"\u30AD\u30FC\u306E\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-keypass
{"key.bit.size",
"\u30AD\u30FC\u306E\u30D3\u30C3\u30C8\u30FB\u30B5\u30A4\u30BA"}, //-keysize
{"keystore.name",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u540D"}, //-keystore
{"access.the.cacerts.keystore",
"cacerts\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u30A2\u30AF\u30BB\u30B9\u3059\u308B"}, // -cacerts
{"warning.cacerts.option",
"\u8B66\u544A: cacerts\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u30A2\u30AF\u30BB\u30B9\u3059\u308B\u306B\u306F-cacerts\u30AA\u30D7\u30B7\u30E7\u30F3\u3092\u4F7F\u7528\u3057\u3066\u304F\u3060\u3055\u3044"},
{"new.password",
"\u65B0\u898F\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-new
{"do.not.prompt",
"\u30D7\u30ED\u30F3\u30D7\u30C8\u3092\u8868\u793A\u3057\u306A\u3044"}, //-noprompt
{"password.through.protected.mechanism",
"\u4FDD\u8B77\u30E1\u30AB\u30CB\u30BA\u30E0\u306B\u3088\u308B\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-protected
{"tls.option.help", "TLS\u69CB\u6210\u60C5\u5831\u3092\u8868\u793A\u3057\u307E\u3059"},
// The following 2 values should span 2 lines, the first for the
// option itself, the second for its -providerArg value.
{"addprovider.option",
"\u540D\u524D\u3067\u30BB\u30AD\u30E5\u30EA\u30C6\u30A3\u30FB\u30D7\u30ED\u30D0\u30A4\u30C0\u3092\u8FFD\u52A0\u3059\u308B(SunPKCS11\u306A\u3069)\n-addprovider\u306E\u5F15\u6570\u3092\u69CB\u6210\u3059\u308B"}, //-addprovider
{"provider.class.option",
"\u5B8C\u5168\u4FEE\u98FE\u30AF\u30E9\u30B9\u540D\u3067\u30BB\u30AD\u30E5\u30EA\u30C6\u30A3\u30FB\u30D7\u30ED\u30D0\u30A4\u30C0\u3092\u8FFD\u52A0\u3059\u308B\n-providerclass\u306E\u5F15\u6570\u3092\u69CB\u6210\u3059\u308B"}, //-providerclass
{"provider.name",
"\u30D7\u30ED\u30D0\u30A4\u30C0\u540D"}, //-providername
{"provider.classpath",
"\u30D7\u30ED\u30D0\u30A4\u30C0\u30FB\u30AF\u30E9\u30B9\u30D1\u30B9"}, //-providerpath
{"output.in.RFC.style",
"RFC\u30B9\u30BF\u30A4\u30EB\u306E\u51FA\u529B"}, //-rfc
{"signature.algorithm.name",
"\u7F72\u540D\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0\u540D"}, //-sigalg
{"source.alias",
"\u30BD\u30FC\u30B9\u5225\u540D"}, //-srcalias
{"source.key.password",
"\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u306E\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-srckeypass
{"source.keystore.name",
"\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u540D"}, //-srckeystore
{"source.keystore.password.protected",
"\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u4FDD\u8B77\u5BFE\u8C61\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-srcprotected
{"source.keystore.provider.name",<|fim▁hole|> "\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-srcstorepass
{"source.keystore.type",
"\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30BF\u30A4\u30D7"}, //-srcstoretype
{"SSL.server.host.and.port",
"SSL\u30B5\u30FC\u30D0\u30FC\u306E\u30DB\u30B9\u30C8\u3068\u30DD\u30FC\u30C8"}, //-sslserver
{"signed.jar.file",
"\u7F72\u540D\u4ED8\u304DJAR\u30D5\u30A1\u30A4\u30EB"}, //=jarfile
{"certificate.validity.start.date.time",
"\u8A3C\u660E\u66F8\u306E\u6709\u52B9\u958B\u59CB\u65E5\u6642"}, //-startdate
{"keystore.password",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9"}, //-storepass
{"keystore.type",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30BF\u30A4\u30D7"}, //-storetype
{"trust.certificates.from.cacerts",
"cacerts\u304B\u3089\u306E\u8A3C\u660E\u66F8\u3092\u4FE1\u983C\u3059\u308B"}, //-trustcacerts
{"verbose.output",
"\u8A73\u7D30\u51FA\u529B"}, //-v
{"validity.number.of.days",
"\u59A5\u5F53\u6027\u65E5\u6570"}, //-validity
{"Serial.ID.of.cert.to.revoke",
"\u5931\u52B9\u3059\u308B\u8A3C\u660E\u66F8\u306E\u30B7\u30EA\u30A2\u30EBID"}, //-id
// keytool: Running part
{"keytool.error.", "keytool\u30A8\u30E9\u30FC: "},
{"Illegal.option.", "\u4E0D\u6B63\u306A\u30AA\u30D7\u30B7\u30E7\u30F3: "},
{"Illegal.value.", "\u4E0D\u6B63\u306A\u5024: "},
{"Unknown.password.type.", "\u4E0D\u660E\u306A\u30D1\u30B9\u30EF\u30FC\u30C9\u30FB\u30BF\u30A4\u30D7: "},
{"Cannot.find.environment.variable.",
"\u74B0\u5883\u5909\u6570\u304C\u898B\u3064\u304B\u308A\u307E\u305B\u3093: "},
{"Cannot.find.file.", "\u30D5\u30A1\u30A4\u30EB\u304C\u898B\u3064\u304B\u308A\u307E\u305B\u3093: "},
{"Command.option.flag.needs.an.argument.", "\u30B3\u30DE\u30F3\u30C9\u30FB\u30AA\u30D7\u30B7\u30E7\u30F3{0}\u306B\u306F\u5F15\u6570\u304C\u5FC5\u8981\u3067\u3059\u3002"},
{"Warning.Different.store.and.key.passwords.not.supported.for.PKCS12.KeyStores.Ignoring.user.specified.command.value.",
"\u8B66\u544A: PKCS12\u30AD\u30FC\u30B9\u30C8\u30A2\u3067\u306F\u3001\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u3068\u30AD\u30FC\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u304C\u7570\u306A\u308B\u72B6\u6CC1\u306F\u30B5\u30DD\u30FC\u30C8\u3055\u308C\u307E\u305B\u3093\u3002\u30E6\u30FC\u30B6\u30FC\u304C\u6307\u5B9A\u3057\u305F{0}\u306E\u5024\u306F\u7121\u8996\u3057\u307E\u3059\u3002"},
{"the.keystore.or.storetype.option.cannot.be.used.with.the.cacerts.option",
"-keystore\u307E\u305F\u306F-storetype\u30AA\u30D7\u30B7\u30E7\u30F3\u306F\u3001-cacerts\u30AA\u30D7\u30B7\u30E7\u30F3\u3068\u3068\u3082\u306B\u4F7F\u7528\u3067\u304D\u307E\u305B\u3093"},
{".keystore.must.be.NONE.if.storetype.is.{0}",
"-storetype\u304C{0}\u306E\u5834\u5408\u3001-keystore\u306FNONE\u3067\u3042\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059"},
{"Too.many.retries.program.terminated",
"\u518D\u8A66\u884C\u304C\u591A\u3059\u304E\u307E\u3059\u3002\u30D7\u30ED\u30B0\u30E9\u30E0\u304C\u7D42\u4E86\u3057\u307E\u3057\u305F"},
{".storepasswd.and.keypasswd.commands.not.supported.if.storetype.is.{0}",
"-storetype\u304C{0}\u306E\u5834\u5408\u3001-storepasswd\u30B3\u30DE\u30F3\u30C9\u304A\u3088\u3073-keypasswd\u30B3\u30DE\u30F3\u30C9\u306F\u30B5\u30DD\u30FC\u30C8\u3055\u308C\u307E\u305B\u3093"},
{".keypasswd.commands.not.supported.if.storetype.is.PKCS12",
"-storetype\u304CPKCS12\u306E\u5834\u5408\u3001-keypasswd\u30B3\u30DE\u30F3\u30C9\u306F\u30B5\u30DD\u30FC\u30C8\u3055\u308C\u307E\u305B\u3093"},
{".keypass.and.new.can.not.be.specified.if.storetype.is.{0}",
"-storetype\u304C{0}\u306E\u5834\u5408\u3001-keypass\u3068-new\u306F\u6307\u5B9A\u3067\u304D\u307E\u305B\u3093"},
{"if.protected.is.specified.then.storepass.keypass.and.new.must.not.be.specified",
"-protected\u304C\u6307\u5B9A\u3055\u308C\u3066\u3044\u308B\u5834\u5408\u3001-storepass\u3001-keypass\u304A\u3088\u3073-new\u306F\u6307\u5B9A\u3067\u304D\u307E\u305B\u3093"},
{"if.srcprotected.is.specified.then.srcstorepass.and.srckeypass.must.not.be.specified",
"-srcprotected\u304C\u6307\u5B9A\u3055\u308C\u3066\u3044\u308B\u5834\u5408\u3001-srcstorepass\u304A\u3088\u3073-srckeypass\u306F\u6307\u5B9A\u3067\u304D\u307E\u305B\u3093"},
{"if.keystore.is.not.password.protected.then.storepass.keypass.and.new.must.not.be.specified",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u304C\u30D1\u30B9\u30EF\u30FC\u30C9\u3067\u4FDD\u8B77\u3055\u308C\u3066\u3044\u306A\u3044\u5834\u5408\u3001-storepass\u3001-keypass\u304A\u3088\u3073-new\u306F\u6307\u5B9A\u3067\u304D\u307E\u305B\u3093"},
{"if.source.keystore.is.not.password.protected.then.srcstorepass.and.srckeypass.must.not.be.specified",
"\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u304C\u30D1\u30B9\u30EF\u30FC\u30C9\u3067\u4FDD\u8B77\u3055\u308C\u3066\u3044\u306A\u3044\u5834\u5408\u3001-srcstorepass\u304A\u3088\u3073-srckeypass\u306F\u6307\u5B9A\u3067\u304D\u307E\u305B\u3093"},
{"Illegal.startdate.value", "startdate\u5024\u304C\u7121\u52B9\u3067\u3059"},
{"Validity.must.be.greater.than.zero",
"\u59A5\u5F53\u6027\u306F\u30BC\u30ED\u3088\u308A\u5927\u304D\u3044\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059"},
{"provclass.not.a.provider", "%s\u306F\u30D7\u30ED\u30D0\u30A4\u30C0\u3067\u306F\u3042\u308A\u307E\u305B\u3093"},
{"provider.name.not.found", "\u30D7\u30ED\u30D0\u30A4\u30C0\u540D\"%s\"\u304C\u898B\u3064\u304B\u308A\u307E\u305B\u3093"},
{"provider.class.not.found", "\u30D7\u30ED\u30D0\u30A4\u30C0\"%s\"\u304C\u898B\u3064\u304B\u308A\u307E\u305B\u3093"},
{"Usage.error.no.command.provided", "\u4F7F\u7528\u30A8\u30E9\u30FC: \u30B3\u30DE\u30F3\u30C9\u304C\u6307\u5B9A\u3055\u308C\u3066\u3044\u307E\u305B\u3093"},
{"Source.keystore.file.exists.but.is.empty.", "\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u30FB\u30D5\u30A1\u30A4\u30EB\u306F\u3001\u5B58\u5728\u3057\u307E\u3059\u304C\u7A7A\u3067\u3059: "},
{"Please.specify.srckeystore", "-srckeystore\u3092\u6307\u5B9A\u3057\u3066\u304F\u3060\u3055\u3044"},
{"Must.not.specify.both.v.and.rfc.with.list.command",
"'list'\u30B3\u30DE\u30F3\u30C9\u306B-v\u3068-rfc\u306E\u4E21\u65B9\u3092\u6307\u5B9A\u3059\u308B\u3053\u3068\u306F\u3067\u304D\u307E\u305B\u3093"},
{"Key.password.must.be.at.least.6.characters",
"\u30AD\u30FC\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u306F6\u6587\u5B57\u4EE5\u4E0A\u3067\u3042\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059"},
{"New.password.must.be.at.least.6.characters",
"\u65B0\u898F\u30D1\u30B9\u30EF\u30FC\u30C9\u306F6\u6587\u5B57\u4EE5\u4E0A\u3067\u3042\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059"},
{"Keystore.file.exists.but.is.empty.",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u30FB\u30D5\u30A1\u30A4\u30EB\u306F\u5B58\u5728\u3057\u307E\u3059\u304C\u3001\u7A7A\u3067\u3059: "},
{"Keystore.file.does.not.exist.",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u30FB\u30D5\u30A1\u30A4\u30EB\u306F\u5B58\u5728\u3057\u307E\u305B\u3093: "},
{"Must.specify.destination.alias", "\u51FA\u529B\u5148\u306E\u5225\u540D\u3092\u6307\u5B9A\u3059\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059"},
{"Must.specify.alias", "\u5225\u540D\u3092\u6307\u5B9A\u3059\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059"},
{"Keystore.password.must.be.at.least.6.characters",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u306F6\u6587\u5B57\u4EE5\u4E0A\u3067\u3042\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059"},
{"Enter.the.password.to.be.stored.",
"\u4FDD\u5B58\u3059\u308B\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{"Enter.keystore.password.", "\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{"Enter.source.keystore.password.", "\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{"Enter.destination.keystore.password.", "\u51FA\u529B\u5148\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{"Keystore.password.is.too.short.must.be.at.least.6.characters",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u304C\u77ED\u3059\u304E\u307E\u3059 - 6\u6587\u5B57\u4EE5\u4E0A\u306B\u3057\u3066\u304F\u3060\u3055\u3044"},
{"Unknown.Entry.Type", "\u4E0D\u660E\u306A\u30A8\u30F3\u30C8\u30EA\u30FB\u30BF\u30A4\u30D7"},
{"Entry.for.alias.alias.successfully.imported.",
"\u5225\u540D{0}\u306E\u30A8\u30F3\u30C8\u30EA\u306E\u30A4\u30F3\u30DD\u30FC\u30C8\u306B\u6210\u529F\u3057\u307E\u3057\u305F\u3002"},
{"Entry.for.alias.alias.not.imported.", "\u5225\u540D{0}\u306E\u30A8\u30F3\u30C8\u30EA\u306F\u30A4\u30F3\u30DD\u30FC\u30C8\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F\u3002"},
{"Problem.importing.entry.for.alias.alias.exception.Entry.for.alias.alias.not.imported.",
"\u5225\u540D{0}\u306E\u30A8\u30F3\u30C8\u30EA\u306E\u30A4\u30F3\u30DD\u30FC\u30C8\u4E2D\u306B\u554F\u984C\u304C\u767A\u751F\u3057\u307E\u3057\u305F: {1}\u3002\n\u5225\u540D{0}\u306E\u30A8\u30F3\u30C8\u30EA\u306F\u30A4\u30F3\u30DD\u30FC\u30C8\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F\u3002"},
{"Import.command.completed.ok.entries.successfully.imported.fail.entries.failed.or.cancelled",
"\u30A4\u30F3\u30DD\u30FC\u30C8\u30FB\u30B3\u30DE\u30F3\u30C9\u304C\u5B8C\u4E86\u3057\u307E\u3057\u305F: {0}\u4EF6\u306E\u30A8\u30F3\u30C8\u30EA\u306E\u30A4\u30F3\u30DD\u30FC\u30C8\u304C\u6210\u529F\u3057\u307E\u3057\u305F\u3002{1}\u4EF6\u306E\u30A8\u30F3\u30C8\u30EA\u306E\u30A4\u30F3\u30DD\u30FC\u30C8\u304C\u5931\u6557\u3057\u305F\u304B\u53D6\u308A\u6D88\u3055\u308C\u307E\u3057\u305F"},
{"Warning.Overwriting.existing.alias.alias.in.destination.keystore",
"\u8B66\u544A: \u51FA\u529B\u5148\u30AD\u30FC\u30B9\u30C8\u30A2\u5185\u306E\u65E2\u5B58\u306E\u5225\u540D{0}\u3092\u4E0A\u66F8\u304D\u3057\u3066\u3044\u307E\u3059"},
{"Existing.entry.alias.alias.exists.overwrite.no.",
"\u65E2\u5B58\u306E\u30A8\u30F3\u30C8\u30EA\u306E\u5225\u540D{0}\u304C\u5B58\u5728\u3057\u3066\u3044\u307E\u3059\u3002\u4E0A\u66F8\u304D\u3057\u307E\u3059\u304B\u3002[\u3044\u3044\u3048]: "},
{"Too.many.failures.try.later", "\u969C\u5BB3\u304C\u591A\u3059\u304E\u307E\u3059 - \u5F8C\u3067\u5B9F\u884C\u3057\u3066\u304F\u3060\u3055\u3044"},
{"Certification.request.stored.in.file.filename.",
"\u8A8D\u8A3C\u30EA\u30AF\u30A8\u30B9\u30C8\u304C\u30D5\u30A1\u30A4\u30EB<{0}>\u306B\u4FDD\u5B58\u3055\u308C\u307E\u3057\u305F"},
{"Submit.this.to.your.CA", "\u3053\u308C\u3092CA\u306B\u63D0\u51FA\u3057\u3066\u304F\u3060\u3055\u3044"},
{"if.alias.not.specified.destalias.and.srckeypass.must.not.be.specified",
"\u5225\u540D\u3092\u6307\u5B9A\u3057\u306A\u3044\u5834\u5408\u3001\u51FA\u529B\u5148\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u5225\u540D\u304A\u3088\u3073\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u306F\u6307\u5B9A\u3067\u304D\u307E\u305B\u3093"},
{"The.destination.pkcs12.keystore.has.different.storepass.and.keypass.Please.retry.with.destkeypass.specified.",
"\u51FA\u529B\u5148pkcs12\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u3001\u7570\u306A\u308Bstorepass\u304A\u3088\u3073keypass\u304C\u3042\u308A\u307E\u3059\u3002-destkeypass\u3092\u6307\u5B9A\u3057\u3066\u518D\u8A66\u884C\u3057\u3066\u304F\u3060\u3055\u3044\u3002"},
{"Certificate.stored.in.file.filename.",
"\u8A3C\u660E\u66F8\u304C\u30D5\u30A1\u30A4\u30EB<{0}>\u306B\u4FDD\u5B58\u3055\u308C\u307E\u3057\u305F"},
{"Certificate.reply.was.installed.in.keystore",
"\u8A3C\u660E\u66F8\u5FDC\u7B54\u304C\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u30A4\u30F3\u30B9\u30C8\u30FC\u30EB\u3055\u308C\u307E\u3057\u305F"},
{"Certificate.reply.was.not.installed.in.keystore",
"\u8A3C\u660E\u66F8\u5FDC\u7B54\u304C\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u30A4\u30F3\u30B9\u30C8\u30FC\u30EB\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F"},
{"Certificate.was.added.to.keystore",
"\u8A3C\u660E\u66F8\u304C\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u8FFD\u52A0\u3055\u308C\u307E\u3057\u305F"},
{"Certificate.was.not.added.to.keystore",
"\u8A3C\u660E\u66F8\u304C\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u8FFD\u52A0\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F"},
{".Storing.ksfname.", "[{0}\u3092\u683C\u7D0D\u4E2D]"},
{"alias.has.no.public.key.certificate.",
"{0}\u306B\u306F\u516C\u958B\u30AD\u30FC(\u8A3C\u660E\u66F8)\u304C\u3042\u308A\u307E\u305B\u3093"},
{"Cannot.derive.signature.algorithm",
"\u7F72\u540D\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0\u3092\u53D6\u5F97\u3067\u304D\u307E\u305B\u3093"},
{"Alias.alias.does.not.exist",
"\u5225\u540D<{0}>\u306F\u5B58\u5728\u3057\u307E\u305B\u3093"},
{"Alias.alias.has.no.certificate",
"\u5225\u540D<{0}>\u306B\u306F\u8A3C\u660E\u66F8\u304C\u3042\u308A\u307E\u305B\u3093"},
{"groupname.keysize.coexist",
"-groupname\u3068-keysize\u306E\u4E21\u65B9\u3092\u6307\u5B9A\u3067\u304D\u307E\u305B\u3093"},
{"deprecate.keysize.for.ec",
"-keysize\u306E\u6307\u5B9A\u306B\u3088\u308BEC\u30AD\u30FC\u306E\u751F\u6210\u306F\u975E\u63A8\u5968\u3067\u3059\u3002\u304B\u308F\u308A\u306B\"-groupname %s\"\u3092\u4F7F\u7528\u3057\u3066\u304F\u3060\u3055\u3044\u3002"},
{"Key.pair.not.generated.alias.alias.already.exists",
"\u30AD\u30FC\u30FB\u30DA\u30A2\u306F\u751F\u6210\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F\u3002\u5225\u540D<{0}>\u306F\u3059\u3067\u306B\u5B58\u5728\u3057\u307E\u3059"},
{"Generating.keysize.bit.keyAlgName.key.pair.and.self.signed.certificate.sigAlgName.with.a.validity.of.validality.days.for",
"{3}\u65E5\u9593\u6709\u52B9\u306A{0}\u30D3\u30C3\u30C8\u306E{1}\u306E\u30AD\u30FC\u30FB\u30DA\u30A2\u3068\u81EA\u5DF1\u7F72\u540D\u578B\u8A3C\u660E\u66F8({2})\u3092\u751F\u6210\u3057\u3066\u3044\u307E\u3059\n\t\u30C7\u30A3\u30EC\u30AF\u30C8\u30EA\u540D: {4}"},
{"Enter.key.password.for.alias.", "<{0}>\u306E\u30AD\u30FC\u30FB\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044"},
{".RETURN.if.same.as.keystore.password.",
"\t(\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u3068\u540C\u3058\u5834\u5408\u306FRETURN\u3092\u62BC\u3057\u3066\u304F\u3060\u3055\u3044): "},
{"Key.password.is.too.short.must.be.at.least.6.characters",
"\u30AD\u30FC\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u304C\u77ED\u3059\u304E\u307E\u3059 - 6\u6587\u5B57\u4EE5\u4E0A\u3092\u6307\u5B9A\u3057\u3066\u304F\u3060\u3055\u3044"},
{"Too.many.failures.key.not.added.to.keystore",
"\u969C\u5BB3\u304C\u591A\u3059\u304E\u307E\u3059 - \u30AD\u30FC\u306F\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u8FFD\u52A0\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F"},
{"Destination.alias.dest.already.exists",
"\u51FA\u529B\u5148\u306E\u5225\u540D<{0}>\u306F\u3059\u3067\u306B\u5B58\u5728\u3057\u307E\u3059"},
{"Password.is.too.short.must.be.at.least.6.characters",
"\u30D1\u30B9\u30EF\u30FC\u30C9\u304C\u77ED\u3059\u304E\u307E\u3059 - 6\u6587\u5B57\u4EE5\u4E0A\u3092\u6307\u5B9A\u3057\u3066\u304F\u3060\u3055\u3044"},
{"Too.many.failures.Key.entry.not.cloned",
"\u969C\u5BB3\u304C\u591A\u3059\u304E\u307E\u3059\u3002\u30AD\u30FC\u30FB\u30A8\u30F3\u30C8\u30EA\u306E\u30AF\u30ED\u30FC\u30F3\u306F\u4F5C\u6210\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F"},
{"key.password.for.alias.", "<{0}>\u306E\u30AD\u30FC\u306E\u30D1\u30B9\u30EF\u30FC\u30C9"},
{"No.entries.from.identity.database.added",
"\u30A2\u30A4\u30C7\u30F3\u30C6\u30A3\u30C6\u30A3\u30FB\u30C7\u30FC\u30BF\u30D9\u30FC\u30B9\u304B\u3089\u8FFD\u52A0\u3055\u308C\u305F\u30A8\u30F3\u30C8\u30EA\u306F\u3042\u308A\u307E\u305B\u3093"},
{"Alias.name.alias", "\u5225\u540D: {0}"},
{"Creation.date.keyStore.getCreationDate.alias.",
"\u4F5C\u6210\u65E5: {0,date}"},
{"alias.keyStore.getCreationDate.alias.",
"{0},{1,date}, "},
{"alias.", "{0}, "},
{"Entry.type.type.", "\u30A8\u30F3\u30C8\u30EA\u30FB\u30BF\u30A4\u30D7: {0}"},
{"Certificate.chain.length.", "\u8A3C\u660E\u66F8\u30C1\u30A7\u30FC\u30F3\u306E\u9577\u3055: "},
{"Certificate.i.1.", "\u8A3C\u660E\u66F8[{0,number,integer}]:"},
{"Certificate.fingerprint.SHA.256.", "\u8A3C\u660E\u66F8\u306E\u30D5\u30A3\u30F3\u30AC\u30D7\u30EA\u30F3\u30C8(SHA-256): "},
{"Keystore.type.", "\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30BF\u30A4\u30D7: "},
{"Keystore.provider.", "\u30AD\u30FC\u30B9\u30C8\u30A2\u30FB\u30D7\u30ED\u30D0\u30A4\u30C0: "},
{"Your.keystore.contains.keyStore.size.entry",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u306F{0,number,integer}\u30A8\u30F3\u30C8\u30EA\u304C\u542B\u307E\u308C\u307E\u3059"},
{"Your.keystore.contains.keyStore.size.entries",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u306F{0,number,integer}\u30A8\u30F3\u30C8\u30EA\u304C\u542B\u307E\u308C\u307E\u3059"},
{"Failed.to.parse.input", "\u5165\u529B\u306E\u69CB\u6587\u89E3\u6790\u306B\u5931\u6557\u3057\u307E\u3057\u305F"},
{"Empty.input", "\u5165\u529B\u304C\u3042\u308A\u307E\u305B\u3093"},
{"Not.X.509.certificate", "X.509\u8A3C\u660E\u66F8\u3067\u306F\u3042\u308A\u307E\u305B\u3093"},
{"alias.has.no.public.key", "{0}\u306B\u306F\u516C\u958B\u30AD\u30FC\u304C\u3042\u308A\u307E\u305B\u3093"},
{"alias.has.no.X.509.certificate", "{0}\u306B\u306FX.509\u8A3C\u660E\u66F8\u304C\u3042\u308A\u307E\u305B\u3093"},
{"New.certificate.self.signed.", "\u65B0\u3057\u3044\u8A3C\u660E\u66F8(\u81EA\u5DF1\u7F72\u540D\u578B):"},
{"Reply.has.no.certificates", "\u5FDC\u7B54\u306B\u306F\u8A3C\u660E\u66F8\u304C\u3042\u308A\u307E\u305B\u3093"},
{"Certificate.not.imported.alias.alias.already.exists",
"\u8A3C\u660E\u66F8\u306F\u30A4\u30F3\u30DD\u30FC\u30C8\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F\u3002\u5225\u540D<{0}>\u306F\u3059\u3067\u306B\u5B58\u5728\u3057\u307E\u3059"},
{"Input.not.an.X.509.certificate", "\u5165\u529B\u306FX.509\u8A3C\u660E\u66F8\u3067\u306F\u3042\u308A\u307E\u305B\u3093"},
{"Certificate.already.exists.in.keystore.under.alias.trustalias.",
"\u8A3C\u660E\u66F8\u306F\u3001\u5225\u540D<{0}>\u306E\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u3059\u3067\u306B\u5B58\u5728\u3057\u307E\u3059"},
{"Do.you.still.want.to.add.it.no.",
"\u8FFD\u52A0\u3057\u307E\u3059\u304B\u3002[\u3044\u3044\u3048]: "},
{"Certificate.already.exists.in.system.wide.CA.keystore.under.alias.trustalias.",
"\u8A3C\u660E\u66F8\u306F\u3001\u5225\u540D<{0}>\u306E\u30B7\u30B9\u30C6\u30E0\u898F\u6A21\u306ECA\u30AD\u30FC\u30B9\u30C8\u30A2\u5185\u306B\u3059\u3067\u306B\u5B58\u5728\u3057\u307E\u3059"},
{"Do.you.still.want.to.add.it.to.your.own.keystore.no.",
"\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u8FFD\u52A0\u3057\u307E\u3059\u304B\u3002 [\u3044\u3044\u3048]: "},
{"Trust.this.certificate.no.", "\u3053\u306E\u8A3C\u660E\u66F8\u3092\u4FE1\u983C\u3057\u307E\u3059\u304B\u3002 [\u3044\u3044\u3048]: "},
{"New.prompt.", "\u65B0\u898F{0}: "},
{"Passwords.must.differ", "\u30D1\u30B9\u30EF\u30FC\u30C9\u306F\u7570\u306A\u3063\u3066\u3044\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059"},
{"Re.enter.new.prompt.", "\u65B0\u898F{0}\u3092\u518D\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{"Re.enter.password.", "\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u518D\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{"Re.enter.new.password.", "\u65B0\u898F\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u518D\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{"They.don.t.match.Try.again", "\u4E00\u81F4\u3057\u307E\u305B\u3093\u3002\u3082\u3046\u4E00\u5EA6\u5B9F\u884C\u3057\u3066\u304F\u3060\u3055\u3044"},
{"Enter.prompt.alias.name.", "{0}\u306E\u5225\u540D\u3092\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{"Enter.new.alias.name.RETURN.to.cancel.import.for.this.entry.",
"\u65B0\u3057\u3044\u5225\u540D\u3092\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044\t(\u3053\u306E\u30A8\u30F3\u30C8\u30EA\u306E\u30A4\u30F3\u30DD\u30FC\u30C8\u3092\u53D6\u308A\u6D88\u3059\u5834\u5408\u306FRETURN\u3092\u62BC\u3057\u3066\u304F\u3060\u3055\u3044): "},
{"Enter.alias.name.", "\u5225\u540D\u3092\u5165\u529B\u3057\u3066\u304F\u3060\u3055\u3044: "},
{".RETURN.if.same.as.for.otherAlias.",
"\t(<{0}>\u3068\u540C\u3058\u5834\u5408\u306FRETURN\u3092\u62BC\u3057\u3066\u304F\u3060\u3055\u3044)"},
{"What.is.your.first.and.last.name.",
"\u59D3\u540D\u306F\u4F55\u3067\u3059\u304B\u3002"},
{"What.is.the.name.of.your.organizational.unit.",
"\u7D44\u7E54\u5358\u4F4D\u540D\u306F\u4F55\u3067\u3059\u304B\u3002"},
{"What.is.the.name.of.your.organization.",
"\u7D44\u7E54\u540D\u306F\u4F55\u3067\u3059\u304B\u3002"},
{"What.is.the.name.of.your.City.or.Locality.",
"\u90FD\u5E02\u540D\u307E\u305F\u306F\u5730\u57DF\u540D\u306F\u4F55\u3067\u3059\u304B\u3002"},
{"What.is.the.name.of.your.State.or.Province.",
"\u90FD\u9053\u5E9C\u770C\u540D\u307E\u305F\u306F\u5DDE\u540D\u306F\u4F55\u3067\u3059\u304B\u3002"},
{"What.is.the.two.letter.country.code.for.this.unit.",
"\u3053\u306E\u5358\u4F4D\u306B\u8A72\u5F53\u3059\u308B2\u6587\u5B57\u306E\u56FD\u30B3\u30FC\u30C9\u306F\u4F55\u3067\u3059\u304B\u3002"},
{"Is.name.correct.", "{0}\u3067\u3088\u308D\u3057\u3044\u3067\u3059\u304B\u3002"},
{"no", "\u3044\u3044\u3048"},
{"yes", "\u306F\u3044"},
{"y", "y"},
{".defaultValue.", " [{0}]: "},
{"Alias.alias.has.no.key",
"\u5225\u540D<{0}>\u306B\u306F\u30AD\u30FC\u304C\u3042\u308A\u307E\u305B\u3093"},
{"Alias.alias.references.an.entry.type.that.is.not.a.private.key.entry.The.keyclone.command.only.supports.cloning.of.private.key",
"\u5225\u540D<{0}>\u304C\u53C2\u7167\u3057\u3066\u3044\u308B\u30A8\u30F3\u30C8\u30EA\u30FB\u30BF\u30A4\u30D7\u306F\u79D8\u5BC6\u30AD\u30FC\u30FB\u30A8\u30F3\u30C8\u30EA\u3067\u306F\u3042\u308A\u307E\u305B\u3093\u3002-keyclone\u30B3\u30DE\u30F3\u30C9\u306F\u79D8\u5BC6\u30AD\u30FC\u30FB\u30A8\u30F3\u30C8\u30EA\u306E\u30AF\u30ED\u30FC\u30F3\u4F5C\u6210\u306E\u307F\u3092\u30B5\u30DD\u30FC\u30C8\u3057\u307E\u3059"},
{".WARNING.WARNING.WARNING.",
"***************** WARNING WARNING WARNING *****************"},
{"Signer.d.", "\u7F72\u540D\u8005\u756A\u53F7%d:"},
{"Timestamp.", "\u30BF\u30A4\u30E0\u30B9\u30BF\u30F3\u30D7:"},
{"Signature.", "\u7F72\u540D:"},
{"Certificate.owner.", "\u8A3C\u660E\u66F8\u306E\u6240\u6709\u8005: "},
{"Not.a.signed.jar.file", "\u7F72\u540D\u4ED8\u304DJAR\u30D5\u30A1\u30A4\u30EB\u3067\u306F\u3042\u308A\u307E\u305B\u3093"},
{"No.certificate.from.the.SSL.server",
"SSL\u30B5\u30FC\u30D0\u30FC\u304B\u3089\u306E\u8A3C\u660E\u66F8\u304C\u3042\u308A\u307E\u305B\u3093"},
{".The.integrity.of.the.information.stored.in.your.keystore.",
"*\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u4FDD\u5B58\u3055\u308C\u305F\u60C5\u5831\u306E\u6574\u5408\u6027\u306F*\n*\u691C\u8A3C\u3055\u308C\u3066\u3044\u307E\u305B\u3093\u3002\u6574\u5408\u6027\u3092\u691C\u8A3C\u3059\u308B\u306B\u306F*\n*\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5165\u529B\u3059\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059\u3002*"},
{".The.integrity.of.the.information.stored.in.the.srckeystore.",
"*\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u306B\u4FDD\u5B58\u3055\u308C\u305F\u60C5\u5831\u306E\u6574\u5408\u6027\u306F*\n*\u691C\u8A3C\u3055\u308C\u3066\u3044\u307E\u305B\u3093\u3002\u6574\u5408\u6027\u3092\u691C\u8A3C\u3059\u308B\u306B\u306F*\n*\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u306E\u30D1\u30B9\u30EF\u30FC\u30C9\u3092\u5165\u529B\u3059\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059\u3002*"},
{"Certificate.reply.does.not.contain.public.key.for.alias.",
"\u8A3C\u660E\u66F8\u5FDC\u7B54\u306B\u306F\u3001<{0}>\u306E\u516C\u958B\u30AD\u30FC\u306F\u542B\u307E\u308C\u307E\u305B\u3093"},
{"Incomplete.certificate.chain.in.reply",
"\u5FDC\u7B54\u3057\u305F\u8A3C\u660E\u66F8\u30C1\u30A7\u30FC\u30F3\u306F\u4E0D\u5B8C\u5168\u3067\u3059"},
{"Top.level.certificate.in.reply.",
"\u5FDC\u7B54\u3057\u305F\u30C8\u30C3\u30D7\u30EC\u30D9\u30EB\u306E\u8A3C\u660E\u66F8:\n"},
{".is.not.trusted.", "... \u306F\u4FE1\u983C\u3055\u308C\u3066\u3044\u307E\u305B\u3093\u3002 "},
{"Install.reply.anyway.no.", "\u5FDC\u7B54\u3092\u30A4\u30F3\u30B9\u30C8\u30FC\u30EB\u3057\u307E\u3059\u304B\u3002[\u3044\u3044\u3048]: "},
{"Public.keys.in.reply.and.keystore.don.t.match",
"\u5FDC\u7B54\u3057\u305F\u516C\u958B\u30AD\u30FC\u3068\u30AD\u30FC\u30B9\u30C8\u30A2\u304C\u4E00\u81F4\u3057\u307E\u305B\u3093"},
{"Certificate.reply.and.certificate.in.keystore.are.identical",
"\u8A3C\u660E\u66F8\u5FDC\u7B54\u3068\u30AD\u30FC\u30B9\u30C8\u30A2\u5185\u306E\u8A3C\u660E\u66F8\u304C\u540C\u3058\u3067\u3059"},
{"Failed.to.establish.chain.from.reply",
"\u5FDC\u7B54\u304B\u3089\u9023\u9396\u3092\u78BA\u7ACB\u3067\u304D\u307E\u305B\u3093\u3067\u3057\u305F"},
{"n", "n"},
{"Wrong.answer.try.again", "\u5FDC\u7B54\u304C\u9593\u9055\u3063\u3066\u3044\u307E\u3059\u3002\u3082\u3046\u4E00\u5EA6\u5B9F\u884C\u3057\u3066\u304F\u3060\u3055\u3044"},
{"Secret.key.not.generated.alias.alias.already.exists",
"\u79D8\u5BC6\u30AD\u30FC\u306F\u751F\u6210\u3055\u308C\u307E\u305B\u3093\u3067\u3057\u305F\u3002\u5225\u540D<{0}>\u306F\u3059\u3067\u306B\u5B58\u5728\u3057\u307E\u3059"},
{"Please.provide.keysize.for.secret.key.generation",
"\u79D8\u5BC6\u30AD\u30FC\u306E\u751F\u6210\u6642\u306B\u306F -keysize\u3092\u6307\u5B9A\u3057\u3066\u304F\u3060\u3055\u3044"},
{"warning.not.verified.make.sure.keystore.is.correct",
"\u8B66\u544A: \u691C\u8A3C\u3055\u308C\u3066\u3044\u307E\u305B\u3093\u3002-keystore\u304C\u6B63\u3057\u3044\u3053\u3068\u3092\u78BA\u8A8D\u3057\u3066\u304F\u3060\u3055\u3044\u3002"},
{"Extensions.", "\u62E1\u5F35: "},
{".Empty.value.", "(\u7A7A\u306E\u5024)"},
{"Extension.Request.", "\u62E1\u5F35\u30EA\u30AF\u30A8\u30B9\u30C8:"},
{"Unknown.keyUsage.type.", "\u4E0D\u660E\u306AkeyUsage\u30BF\u30A4\u30D7: "},
{"Unknown.extendedkeyUsage.type.", "\u4E0D\u660E\u306AextendedkeyUsage\u30BF\u30A4\u30D7: "},
{"Unknown.AccessDescription.type.", "\u4E0D\u660E\u306AAccessDescription\u30BF\u30A4\u30D7: "},
{"Unrecognized.GeneralName.type.", "\u8A8D\u8B58\u3055\u308C\u306A\u3044GeneralName\u30BF\u30A4\u30D7: "},
{"This.extension.cannot.be.marked.as.critical.",
"\u3053\u306E\u62E1\u5F35\u306F\u30AF\u30EA\u30C6\u30A3\u30AB\u30EB\u3068\u3057\u3066\u30DE\u30FC\u30AF\u4ED8\u3051\u3067\u304D\u307E\u305B\u3093\u3002 "},
{"Odd.number.of.hex.digits.found.", "\u5947\u6570\u306E16\u9032\u6570\u304C\u898B\u3064\u304B\u308A\u307E\u3057\u305F: "},
{"Unknown.extension.type.", "\u4E0D\u660E\u306A\u62E1\u5F35\u30BF\u30A4\u30D7: "},
{"command.{0}.is.ambiguous.", "\u30B3\u30DE\u30F3\u30C9{0}\u306F\u3042\u3044\u307E\u3044\u3067\u3059:"},
// 8171319: keytool should print out warnings when reading or
// generating cert/cert req using weak algorithms
{"the.certificate.request", "\u8A3C\u660E\u66F8\u30EA\u30AF\u30A8\u30B9\u30C8"},
{"the.issuer", "\u767A\u884C\u8005"},
{"the.generated.certificate", "\u751F\u6210\u3055\u308C\u305F\u8A3C\u660E\u66F8"},
{"the.generated.crl", "\u751F\u6210\u3055\u308C\u305FCRL"},
{"the.generated.certificate.request", "\u751F\u6210\u3055\u308C\u305F\u8A3C\u660E\u66F8\u30EA\u30AF\u30A8\u30B9\u30C8"},
{"the.certificate", "\u8A3C\u660E\u66F8"},
{"the.crl", "CRL"},
{"the.tsa.certificate", "TSA\u8A3C\u660E\u66F8"},
{"the.input", "\u5165\u529B"},
{"reply", "\u5FDC\u7B54"},
{"one.in.many", "%1$s #%2$d / %3$d"},
{"alias.in.cacerts", "cacerts\u5185\u306E\u767A\u884C\u8005<%s>"},
{"alias.in.keystore", "\u767A\u884C\u8005<%s>"},
{"with.weak", "%s (\u5F31)"},
{"key.bit", "%1$d\u30D3\u30C3\u30C8%2$s\u30AD\u30FC"},
{"key.bit.weak", "%1$d\u30D3\u30C3\u30C8%2$s\u30AD\u30FC(\u5F31)"},
{"unknown.size.1", "\u4E0D\u660E\u306A\u30B5\u30A4\u30BA\u306E%s\u30AD\u30FC"},
{".PATTERN.printX509Cert.with.weak",
"\u6240\u6709\u8005: {0}\n\u767A\u884C\u8005: {1}\n\u30B7\u30EA\u30A2\u30EB\u756A\u53F7: {2}\n\u6709\u52B9\u671F\u9593\u306E\u958B\u59CB\u65E5: {3}\u7D42\u4E86\u65E5: {4}\n\u8A3C\u660E\u66F8\u306E\u30D5\u30A3\u30F3\u30AC\u30D7\u30EA\u30F3\u30C8:\n\t SHA1: {5}\n\t SHA256: {6}\n\u7F72\u540D\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0\u540D: {7}\n\u30B5\u30D6\u30B8\u30A7\u30AF\u30C8\u516C\u958B\u30AD\u30FC\u30FB\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0: {8}\n\u30D0\u30FC\u30B8\u30E7\u30F3: {9}"},
{"PKCS.10.with.weak",
"PKCS #10\u8A3C\u660E\u66F8\u30EA\u30AF\u30A8\u30B9\u30C8(\u30D0\u30FC\u30B8\u30E7\u30F31.0)\n\u30B5\u30D6\u30B8\u30A7\u30AF\u30C8: %1$s\n\u30D5\u30A9\u30FC\u30DE\u30C3\u30C8: %2$s\n\u516C\u958B\u30AD\u30FC: %3$s\n\u7F72\u540D\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0: %4$s\n"},
{"verified.by.s.in.s.weak", "%2$s\u5185\u306E%1$s\u306B\u3088\u308A%3$s\u3067\u691C\u8A3C\u3055\u308C\u307E\u3057\u305F"},
{"whose.sigalg.risk", "%1$s\u306F%2$s\u7F72\u540D\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0\u3092\u4F7F\u7528\u3057\u3066\u304A\u308A\u3001\u3053\u308C\u306F\u30BB\u30AD\u30E5\u30EA\u30C6\u30A3\u30FB\u30EA\u30B9\u30AF\u3068\u307F\u306A\u3055\u308C\u307E\u3059\u3002"},
{"whose.key.risk", "%1$s\u306F%2$s\u3092\u4F7F\u7528\u3057\u3066\u304A\u308A\u3001\u3053\u308C\u306F\u30BB\u30AD\u30E5\u30EA\u30C6\u30A3\u30FB\u30EA\u30B9\u30AF\u3068\u307F\u306A\u3055\u308C\u307E\u3059\u3002"},
{"jks.storetype.warning", "%1$s\u30AD\u30FC\u30B9\u30C8\u30A2\u306F\u72EC\u81EA\u306E\u5F62\u5F0F\u3092\u4F7F\u7528\u3057\u3066\u3044\u307E\u3059\u3002\"keytool -importkeystore -srckeystore %2$s -destkeystore %2$s -deststoretype pkcs12\"\u3092\u4F7F\u7528\u3059\u308B\u696D\u754C\u6A19\u6E96\u306E\u5F62\u5F0F\u3067\u3042\u308BPKCS12\u306B\u79FB\u884C\u3059\u308B\u3053\u3068\u3092\u304A\u85A6\u3081\u3057\u307E\u3059\u3002"},
{"migrate.keystore.warning", "\"%1$s\"\u304C%4$s\u306B\u79FB\u884C\u3055\u308C\u307E\u3057\u305F\u3002%2$s\u30AD\u30FC\u30B9\u30C8\u30A2\u306F\"%3$s\"\u3068\u3057\u3066\u30D0\u30C3\u30AF\u30A2\u30C3\u30D7\u3055\u308C\u307E\u3059\u3002"},
{"backup.keystore.warning", "\u5143\u306E\u30AD\u30FC\u30B9\u30C8\u30A2\"%1$s\"\u306F\"%3$s\"\u3068\u3057\u3066\u30D0\u30C3\u30AF\u30A2\u30C3\u30D7\u3055\u308C\u307E\u3059..."},
{"importing.keystore.status", "\u30AD\u30FC\u30B9\u30C8\u30A2%1$s\u3092%2$s\u306B\u30A4\u30F3\u30DD\u30FC\u30C8\u3057\u3066\u3044\u307E\u3059..."},
{"keyalg.option.1.missing.warning", "-keyalg\u30AA\u30D7\u30B7\u30E7\u30F3\u304C\u3042\u308A\u307E\u305B\u3093\u3002\u30C7\u30D5\u30A9\u30EB\u30C8\u306E\u30AD\u30FC\u30FB\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0(%s)\u306F\u3001\u65E7\u5F0F\u306E\u30A2\u30EB\u30B4\u30EA\u30BA\u30E0\u3067\u3001\u73FE\u5728\u306F\u63A8\u5968\u3055\u308C\u307E\u305B\u3093\u3002JDK\u306E\u5F8C\u7D9A\u306E\u30EA\u30EA\u30FC\u30B9\u3067\u306F\u3001\u30C7\u30D5\u30A9\u30EB\u30C8\u306F\u524A\u9664\u3055\u308C\u308B\u4E88\u5B9A\u3067\u3001-keyalg\u30AA\u30D7\u30B7\u30E7\u30F3\u3092\u6307\u5B9A\u3059\u308B\u5FC5\u8981\u304C\u3042\u308A\u307E\u3059\u3002"},
{"showinfo.no.option", "-showinfo\u306E\u30AA\u30D7\u30B7\u30E7\u30F3\u304C\u3042\u308A\u307E\u305B\u3093\u3002\"keytool -showinfo -tls\"\u3092\u8A66\u3057\u3066\u304F\u3060\u3055\u3044\u3002"},
};
/**
* Returns the contents of this <code>ResourceBundle</code>.
*
* <p>
*
* @return the contents of this <code>ResourceBundle</code>.
*/
@Override
public Object[][] getContents() {
return contents;
}
}<|fim▁end|> | "\u30BD\u30FC\u30B9\u30FB\u30AD\u30FC\u30B9\u30C8\u30A2\u30FB\u30D7\u30ED\u30D0\u30A4\u30C0\u540D"}, //-srcprovidername
{"source.keystore.password", |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.