
file_name
stringlengths 3
137
| prefix
stringlengths 0
918k
| suffix
stringlengths 0
962k
| middle
stringlengths 0
812k
|
|---|---|---|---|
smoke.rs
|
use futures::join;
use lazy_static::lazy_static;
use native_tls::{Certificate, Identity};
use std::{fs, io::Error, path::PathBuf, process::Command};
use tokio::{
io::{AsyncReadExt, AsyncWrite, AsyncWriteExt},
net::{TcpListener, TcpStream},
};
use tokio_native_tls::{TlsAcceptor, TlsConnector};
lazy_static! {
static ref CERT_DIR: PathBuf = {
if cfg!(unix) {
let dir = tempfile::TempDir::new().unwrap();
let path = dir.path().to_str().unwrap();
Command::new("sh")
.arg("-c")
.arg(format!("./scripts/generate-certificate.sh {}", path))
.output()
.expect("failed to execute process");
dir.into_path()
} else {
PathBuf::from("tests")
}
};
}
#[tokio::test]
async fn client_to_server() {
let srv = TcpListener::bind("127.0.0.1:0").await.unwrap();
let addr = srv.local_addr().unwrap();
let (server_tls, client_tls) = context();
// Create a future to accept one socket, connect the ssl stream, and then
// read all the data from it.
let server = async move {
let (socket, _) = srv.accept().await.unwrap();
let mut socket = server_tls.accept(socket).await.unwrap();
// Verify access to all of the nested inner streams (e.g. so that peer
// certificates can be accessed). This is just a compile check.
let native_tls_stream: &native_tls::TlsStream<_> = socket.get_ref();
let _peer_cert = native_tls_stream.peer_certificate().unwrap();
let allow_std_stream: &tokio_native_tls::AllowStd<_> = native_tls_stream.get_ref();
let _tokio_tcp_stream: &tokio::net::TcpStream = allow_std_stream.get_ref();
let mut data = Vec::new();
socket.read_to_end(&mut data).await.unwrap();
data
};
// Create a future to connect to our server, connect the ssl stream, and
// then write a bunch of data to it.
let client = async move {
let socket = TcpStream::connect(&addr).await.unwrap();
let socket = client_tls.connect("foobar.com", socket).await.unwrap();
copy_data(socket).await
};
// Finally, run everything!
let (data, _) = join!(server, client);
// assert_eq!(amt, AMT);
assert!(data == vec![9; AMT]);
}
#[tokio::test]
async fn server_to_client() {
// Create a server listening on a port, then figure out what that port is
let srv = TcpListener::bind("127.0.0.1:0").await.unwrap();
let addr = srv.local_addr().unwrap();
let (server_tls, client_tls) = context();
let server = async move {
let (socket, _) = srv.accept().await.unwrap();
let socket = server_tls.accept(socket).await.unwrap();
copy_data(socket).await
};
let client = async move {
let socket = TcpStream::connect(&addr).await.unwrap();
let mut socket = client_tls.connect("foobar.com", socket).await.unwrap();
let mut data = Vec::new();
socket.read_to_end(&mut data).await.unwrap();
data
};
// Finally, run everything!
let (_, data) = join!(server, client);
assert!(data == vec![9; AMT]);
}
#[tokio::test]
async fn
|
() {
const AMT: usize = 1024;
let srv = TcpListener::bind("127.0.0.1:0").await.unwrap();
let addr = srv.local_addr().unwrap();
let (server_tls, client_tls) = context();
let server = async move {
let (socket, _) = srv.accept().await.unwrap();
let mut socket = server_tls.accept(socket).await.unwrap();
let mut amt = 0;
for b in std::iter::repeat(9).take(AMT) {
let data = [b as u8];
socket.write_all(&data).await.unwrap();
amt += 1;
}
amt
};
let client = async move {
let socket = TcpStream::connect(&addr).await.unwrap();
let mut socket = client_tls.connect("foobar.com", socket).await.unwrap();
let mut data = Vec::new();
loop {
let mut buf = [0; 1];
match socket.read_exact(&mut buf).await {
Ok(_) => data.extend_from_slice(&buf),
Err(ref err) if err.kind() == std::io::ErrorKind::UnexpectedEof => break,
Err(err) => panic!(err),
}
}
data
};
let (amt, data) = join!(server, client);
assert_eq!(amt, AMT);
assert!(data == vec![9; AMT as usize]);
}
fn context() -> (TlsAcceptor, TlsConnector) {
let pkcs12 = fs::read(CERT_DIR.join("identity.p12")).unwrap();
let der = fs::read(CERT_DIR.join("root-ca.der")).unwrap();
let identity = Identity::from_pkcs12(&pkcs12, "mypass").unwrap();
let acceptor = native_tls::TlsAcceptor::builder(identity).build().unwrap();
let cert = Certificate::from_der(&der).unwrap();
let connector = native_tls::TlsConnector::builder()
.add_root_certificate(cert)
.build()
.unwrap();
(acceptor.into(), connector.into())
}
const AMT: usize = 128 * 1024;
async fn copy_data<W: AsyncWrite + Unpin>(mut w: W) -> Result<usize, Error> {
let mut data = vec![9; AMT as usize];
let mut amt = 0;
while !data.is_empty() {
let written = w.write(&data).await?;
if written <= data.len() {
amt += written;
data.resize(data.len() - written, 0);
} else {
w.write_all(&data).await?;
amt += data.len();
break;
}
println!("remaining: {}", data.len());
}
Ok(amt)
}
|
one_byte_at_a_time
|
scene_setting.py
|
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
@author: DIYer22@github
@mail: [email protected]
Created on Thu Jan 16 18:17:20 2020
"""
from boxx import *
from boxx import deg2rad, np, pi
import bpy
import random
def set_cam_pose(cam_radius=1, cam_deg=45, cam_x_deg=None, cam=None):
cam_rad = deg2rad(cam_deg)
if cam_x_deg is None:
cam_x_deg = random.uniform(0, 360)
cam_x_rad = deg2rad(cam_x_deg)
z = cam_radius * np.sin(cam_rad)
xy = (cam_radius ** 2 - z ** 2) ** 0.5
x = xy * np.cos(cam_x_rad)
y = xy * np.sin(cam_x_rad)
cam = cam or bpy.data.objects["Camera"]
cam.location = x, y, z
cam.rotation_euler = pi / 2 - cam_rad, 0.1, pi / 2 + cam_x_rad
cam.scale = (0.1,) * 3
return cam
def set_cam_intrinsic(cam, intrinsic_K, hw=None):
"""
K = [[f_x, 0, c_x],
[0, f_y, c_y],
[0, 0, 1]]
Refrence: https://www.rojtberg.net/1601/from-blender-to-opencv-camera-and-back/
"""
if hw is None:
scene = bpy.context.scene
hw = scene.render.resolution_y, scene.render.resolution_x
near = lambda x, y=0, eps=1e-5: abs(x - y) < eps
assert near(intrinsic_K[0][1], 0)
assert near(intrinsic_K[1][0], 0)
h, w = hw
f_x = intrinsic_K[0][0]
f_y = intrinsic_K[1][1]
c_x = intrinsic_K[0][2]
c_y = intrinsic_K[1][2]
cam = cam.data
cam.shift_x = -(c_x / w - 0.5)
cam.shift_y = (c_y - 0.5 * h) / w
cam.lens = f_x / w * cam.sensor_width
pixel_aspect = f_y / f_x
scene.render.pixel_aspect_x = 1.0
scene.render.pixel_aspect_y = pixel_aspect
def remove_useless_data():
"""
remove all data and release RAM
"""
for block in bpy.data.meshes:
if block.users == 0:
bpy.data.meshes.remove(block)
for block in bpy.data.materials:
if block.users == 0:
bpy.data.materials.remove(block)
for block in bpy.data.textures:
if block.users == 0:
bpy.data.textures.remove(block)
for block in bpy.data.images:
if block.users == 0:
bpy.data.images.remove(block)
def clear_all():
[
bpy.data.objects.remove(obj)
for obj in bpy.data.objects
if obj.type in ("MESH", "LIGHT", "CURVE")
]
remove_useless_data()
def
|
(mode="SOLID", screens=[]):
"""
Performs an action analogous to clicking on the display/shade button of
the 3D view. Mode is one of "RENDERED", "MATERIAL", "SOLID", "WIREFRAME".
The change is applied to the given collection of bpy.data.screens.
If none is given, the function is applied to bpy.context.screen (the
active screen) only. E.g. set all screens to rendered mode:
set_shading_mode("RENDERED", bpy.data.screens)
"""
screens = screens if screens else [bpy.context.screen]
for s in screens:
for spc in s.areas:
if spc.type == "VIEW_3D":
spc.spaces[0].shading.type = mode
break # we expect at most 1 VIEW_3D space
def add_stage(size=2, transparency=False):
"""
add PASSIVE rigidbody cube for physic stage or depth background
Parameters
----------
size : float, optional
size of stage. The default is 2.
transparency : bool, optional
transparency for rgb but set limit for depth. The default is False.
"""
import bpycv
bpy.ops.mesh.primitive_cube_add(size=size, location=(0, 0, -size / 2))
stage = bpy.context.active_object
stage.name = "stage"
with bpycv.activate_obj(stage):
bpy.ops.rigidbody.object_add()
stage.rigid_body.type = "PASSIVE"
if transparency:
stage.rigid_body.use_margin = True
stage.rigid_body.collision_margin = 0.04
stage.location.z -= stage.rigid_body.collision_margin
material = bpy.data.materials.new("transparency_stage_bpycv")
material.use_nodes = True
material.node_tree.nodes.clear()
with bpycv.activate_node_tree(material.node_tree):
bpycv.Node("ShaderNodeOutputMaterial").Surface = bpycv.Node(
"ShaderNodeBsdfPrincipled", Alpha=0
).BSDF
stage.data.materials.append(material)
return stage
if __name__ == "__main__":
pass
|
set_shading_mode
|
build.rs
|
use std::env;
use std::path::PathBuf;
#[cfg(feature = "libsodium-bundled")]
use std::process::Command;
#[cfg(all(feature = "libsodium-bundled", not(target_os = "windows")))]
const LIBSODIUM_NAME: &'static str = "libsodium-1.0.18";
#[cfg(all(feature = "libsodium-bundled", not(target_os = "windows")))]
const LIBSODIUM_URL: &'static str =
"https://download.libsodium.org/libsodium/releases/libsodium-1.0.18.tar.gz";
// skip the build script when building doc on docs.rs
#[cfg(feature = "docs-rs")]
fn main() {}
#[cfg(not(feature = "docs-rs"))]
fn main() {
#[cfg(feature = "libsodium-bundled")]
download_and_install_libsodium();
#[cfg(not(feature = "libsodium-bundled"))]
{
println!("cargo:rerun-if-env-changed=SODIUM_LIB_DIR");
println!("cargo:rerun-if-env-changed=SODIUM_STATIC");
}
// add libsodium link options
if let Ok(lib_dir) = env::var("SODIUM_LIB_DIR") {
println!("cargo:rustc-link-search=native={}", lib_dir);
let mode = match env::var_os("SODIUM_STATIC") {
Some(_) => "static",
None => "dylib",
};
if cfg!(target_os = "windows") {
println!("cargo:rustc-link-lib={0}=libsodium", mode);
} else {
println!("cargo:rustc-link-lib={0}=sodium", mode);
}
} else {
// the static linking doesn't work if libsodium is installed
// under '/usr' dir, in that case use the environment variables
// mentioned above
pkg_config::Config::new()
.atleast_version("1.0.18")
.statik(true)
.probe("libsodium")
.unwrap();
}
// add liblz4 link options
if let Ok(lib_dir) = env::var("LZ4_LIB_DIR") {
println!("cargo:rustc-link-search=native={}", lib_dir);
if cfg!(target_os = "windows") {
println!("cargo:rustc-link-lib=static=liblz4");
} else {
println!("cargo:rustc-link-lib=static=lz4");
}
} else {
// build lz4 static library
let out_dir = PathBuf::from(env::var("OUT_DIR").unwrap());
if !out_dir.join("liblz4.a").exists() {
let mut compiler = cc::Build::new();
|
.file("vendor/lz4/lz4frame.c")
.file("vendor/lz4/lz4hc.c")
.file("vendor/lz4/xxhash.c")
.define("XXH_NAMESPACE", "LZ4_")
.opt_level(3)
.debug(false)
.pic(true)
.shared_flag(false);
if !cfg!(windows) {
compiler.static_flag(true);
}
compiler.compile("liblz4.a");
}
}
}
// This downloads function and builds the libsodium from source for linux and
// unix targets.
// The steps are taken from the libsodium installation instructions:
// https://libsodium.gitbook.io/doc/installation
// effectively:
// $ ./configure
// $ make && make check
// $ sudo make install
#[cfg(all(feature = "libsodium-bundled", not(target_os = "windows")))]
fn download_and_install_libsodium() {
let out_dir = PathBuf::from(env::var("OUT_DIR").unwrap());
let source_dir = out_dir.join(LIBSODIUM_NAME);
let prefix_dir = out_dir.join("libsodium");
let sodium_lib_dir = prefix_dir.join("lib");
let src_file_name = format!("{}.tar.gz", LIBSODIUM_NAME);
// check if command tools exist
Command::new("curl")
.arg("--version")
.output()
.expect("curl not found");
Command::new("tar")
.arg("--version")
.output()
.expect("tar not found");
Command::new("gpg")
.arg("--version")
.output()
.expect("gpg not found");
Command::new("make")
.arg("--version")
.output()
.expect("make not found");
if !source_dir.exists() {
// download source code file
let output = Command::new("curl")
.current_dir(&out_dir)
.args(&[LIBSODIUM_URL, "-sSfL", "-o", &src_file_name])
.output()
.expect("failed to download libsodium");
assert!(output.status.success());
// download signature file
let sig_file_name = format!("{}.sig", src_file_name);
let sig_url = format!("{}.sig", LIBSODIUM_URL);
let output = Command::new("curl")
.current_dir(&out_dir)
.args(&[&sig_url, "-sSfL", "-o", &sig_file_name])
.output()
.expect("failed to download libsodium signature file");
assert!(output.status.success());
// import libsodium author's public key
let output = Command::new("gpg")
.arg("--import")
.arg("libsodium.gpg.key")
.output()
.expect("failed to import libsodium author's gpg key");
assert!(output.status.success());
// verify signature
let output = Command::new("gpg")
.current_dir(&out_dir)
.arg("--verify")
.arg(&sig_file_name)
.output()
.expect("failed to verify libsodium file");
assert!(output.status.success());
// unpack source code files
let output = Command::new("tar")
.current_dir(&out_dir)
.args(&["zxf", &src_file_name])
.output()
.expect("failed to unpack libsodium");
assert!(output.status.success());
}
if !sodium_lib_dir.exists() {
let configure = source_dir.join("./configure");
let output = Command::new(&configure)
.current_dir(&source_dir)
.args(&[std::path::Path::new("--prefix"), &prefix_dir])
.output()
.expect("failed to execute configure");
assert!(output.status.success());
let output = Command::new("make")
.current_dir(&source_dir)
.output()
.expect("failed to execute make");
assert!(output.status.success());
let output = Command::new("make")
.current_dir(&source_dir)
.arg("install")
.output()
.expect("failed to execute make install");
assert!(output.status.success());
}
assert!(
&sodium_lib_dir.exists(),
"libsodium lib directory was not created."
);
env::set_var("SODIUM_LIB_DIR", &sodium_lib_dir);
env::set_var("SODIUM_STATIC", "true");
}
// This downloads function and builds the libsodium from source for windows msvc target.
// The binaries are pre-compiled, so we simply download and link.
// The binary is compressed in zip format.
#[cfg(all(
feature = "libsodium-bundled",
target_os = "windows",
target_env = "msvc"
))]
fn download_and_install_libsodium() {
use std::fs;
use std::fs::OpenOptions;
use std::io;
use std::path::PathBuf;
#[cfg(target_env = "msvc")]
static LIBSODIUM_ZIP: &'static str = "https://download.libsodium.org/libsodium/releases/libsodium-1.0.18-msvc.zip";
#[cfg(target_env = "mingw")]
static LIBSODIUM_ZIP: &'static str = "https://download.libsodium.org/libsodium/releases/libsodium-1.0.18-mingw.tar.gz";
let out_dir = PathBuf::from(env::var("OUT_DIR").unwrap());
let sodium_lib_dir = out_dir.join("libsodium");
if !sodium_lib_dir.exists() {
fs::create_dir(&sodium_lib_dir).unwrap();
}
let sodium_lib_file_path = sodium_lib_dir.join("libsodium.lib");
if !sodium_lib_file_path.exists() {
let mut tmpfile = tempfile::tempfile().unwrap();
reqwest::get(LIBSODIUM_ZIP)
.unwrap()
.copy_to(&mut tmpfile)
.unwrap();
let mut zip = zip::ZipArchive::new(tmpfile).unwrap();
#[cfg(target_arch = "x86_64")]
let mut lib = zip
.by_name("x64/Release/v142/static/libsodium.lib")
.unwrap();
#[cfg(target_arch = "x86")]
let mut lib = zip
.by_name("Win32/Release/v142/static/libsodium.lib")
.unwrap();
#[cfg(not(any(target_arch = "x86_64", target_arch = "x86")))]
compile_error!("Bundled libsodium is only supported on x86 or x86_64 target architecture.");
let mut libsodium_file = OpenOptions::new()
.create(true)
.write(true)
.open(&sodium_lib_file_path)
.unwrap();
io::copy(&mut lib, &mut libsodium_file).unwrap();
}
assert!(
&sodium_lib_dir.exists(),
"libsodium lib directory was not created."
);
env::set_var("SODIUM_LIB_DIR", &sodium_lib_dir);
env::set_var("SODIUM_STATIC", "true");
}
// This downloads function and builds the libsodium from source for windows mingw target.
// The binaries are pre-compiled, so we simply download and link.
// The binary is compressed in tar.gz format.
#[cfg(all(
feature = "libsodium-bundled",
target_os = "windows",
target_env = "gnu"
))]
fn download_and_install_libsodium() {
use libflate::non_blocking::gzip::Decoder;
use std::fs;
use std::fs::OpenOptions;
use std::io;
use std::path::PathBuf;
use tar::Archive;
static LIBSODIUM_ZIP: &'static str = "https://download.libsodium.org/libsodium/releases/libsodium-1.0.18-mingw.tar.gz";
let out_dir = PathBuf::from(env::var("OUT_DIR").unwrap());
let sodium_lib_dir = out_dir.join("libsodium");
if !sodium_lib_dir.exists() {
fs::create_dir(&sodium_lib_dir).unwrap();
}
let sodium_lib_file_path = sodium_lib_dir.join("libsodium.lib");
if !sodium_lib_file_path.exists() {
let response = reqwest::get(LIBSODIUM_ZIP).unwrap();
let decoder = Decoder::new(response);
let mut ar = Archive::new(decoder);
#[cfg(target_arch = "x86_64")]
let filename = PathBuf::from("libsodium-win64/lib/libsodium.a");
#[cfg(target_arch = "x86")]
let filename = PathBuf::from("libsodium-win32/lib/libsodium.a");
#[cfg(not(any(target_arch = "x86_64", target_arch = "x86")))]
compile_error!("Bundled libsodium is only supported on x86 or x86_64 target architecture.");
for file in ar.entries().unwrap() {
let mut f = file.unwrap();
if f.path().unwrap() == *filename {
let mut libsodium_file = OpenOptions::new()
.create(true)
.write(true)
.open(&sodium_lib_file_path)
.unwrap();
io::copy(&mut f, &mut libsodium_file).unwrap();
break;
}
}
}
assert!(
&sodium_lib_dir.exists(),
"libsodium lib directory was not created."
);
env::set_var("SODIUM_LIB_DIR", &sodium_lib_dir);
env::set_var("SODIUM_STATIC", "true");
}
|
compiler
.file("vendor/lz4/lz4.c")
|
proxy.go
|
// Package proxy is a cli proxy
package proxy
import (
"os"
"strings"
"time"
"github.com/go-acme/lego/v3/providers/dns/cloudflare"
"github.com/micro/cli/v2"
"github.com/micro/go-micro/v2"
"github.com/micro/go-micro/v2/api/server/acme"
"github.com/micro/go-micro/v2/api/server/acme/autocert"
"github.com/micro/go-micro/v2/api/server/acme/certmagic"
"github.com/micro/go-micro/v2/auth"
bmem "github.com/micro/go-micro/v2/broker/memory"
"github.com/micro/go-micro/v2/client"
mucli "github.com/micro/go-micro/v2/client"
"github.com/micro/go-micro/v2/config/cmd"
log "github.com/micro/go-micro/v2/logger"
"github.com/micro/go-micro/v2/proxy"
"github.com/micro/go-micro/v2/proxy/grpc"
"github.com/micro/go-micro/v2/proxy/http"
"github.com/micro/go-micro/v2/proxy/mucp"
"github.com/micro/go-micro/v2/registry"
rmem "github.com/micro/go-micro/v2/registry/memory"
"github.com/micro/go-micro/v2/router"
rs "github.com/micro/go-micro/v2/router/service"
"github.com/micro/go-micro/v2/server"
sgrpc "github.com/micro/go-micro/v2/server/grpc"
cfstore "github.com/micro/go-micro/v2/store/cloudflare"
"github.com/micro/go-micro/v2/sync/lock/memory"
"github.com/micro/go-micro/v2/util/mux"
"github.com/micro/go-micro/v2/util/wrapper"
"github.com/micro/micro/v2/internal/helper"
)
var (
// Name of the proxy
Name = "go.micro.proxy"
// The address of the proxy
Address = ":8081"
// the proxy protocol
Protocol = "grpc"
// The endpoint host to route to
Endpoint string
// ACME (Cert management)
ACMEProvider = "autocert"
ACMEChallengeProvider = "cloudflare"
ACMECA = acme.LetsEncryptProductionCA
)
func run(ctx *cli.Context, srvOpts ...micro.Option)
|
func Commands(options ...micro.Option) []*cli.Command {
command := &cli.Command{
Name: "proxy",
Usage: "Run the service proxy",
Flags: []cli.Flag{
&cli.StringFlag{
Name: "router",
Usage: "Set the router to use e.g default, go.micro.router",
EnvVars: []string{"MICRO_ROUTER"},
},
&cli.StringFlag{
Name: "router_address",
Usage: "Set the router address",
EnvVars: []string{"MICRO_ROUTER_ADDRESS"},
},
&cli.StringFlag{
Name: "address",
Usage: "Set the proxy http address e.g 0.0.0.0:8081",
EnvVars: []string{"MICRO_PROXY_ADDRESS"},
},
&cli.StringFlag{
Name: "protocol",
Usage: "Set the protocol used for proxying e.g mucp, grpc, http",
EnvVars: []string{"MICRO_PROXY_PROTOCOL"},
},
&cli.StringFlag{
Name: "endpoint",
Usage: "Set the endpoint to route to e.g greeter or localhost:9090",
EnvVars: []string{"MICRO_PROXY_ENDPOINT"},
},
&cli.StringFlag{
Name: "auth",
Usage: "Set the proxy auth e.g jwt",
EnvVars: []string{"MICRO_PROXY_AUTH"},
},
},
Action: func(ctx *cli.Context) error {
run(ctx, options...)
return nil
},
}
for _, p := range Plugins() {
if cmds := p.Commands(); len(cmds) > 0 {
command.Subcommands = append(command.Subcommands, cmds...)
}
if flags := p.Flags(); len(flags) > 0 {
command.Flags = append(command.Flags, flags...)
}
}
return []*cli.Command{command}
}
|
{
log.Init(log.WithFields(map[string]interface{}{"service": "proxy"}))
// because MICRO_PROXY_ADDRESS is used internally by the go-micro/client
// we need to unset it so we don't end up calling ourselves infinitely
os.Unsetenv("MICRO_PROXY_ADDRESS")
if len(ctx.String("server_name")) > 0 {
Name = ctx.String("server_name")
}
if len(ctx.String("address")) > 0 {
Address = ctx.String("address")
}
if len(ctx.String("endpoint")) > 0 {
Endpoint = ctx.String("endpoint")
}
if len(ctx.String("protocol")) > 0 {
Protocol = ctx.String("protocol")
}
if len(ctx.String("acme_provider")) > 0 {
ACMEProvider = ctx.String("acme_provider")
}
// Init plugins
for _, p := range Plugins() {
p.Init(ctx)
}
// service opts
srvOpts = append(srvOpts, micro.Name(Name))
if i := time.Duration(ctx.Int("register_ttl")); i > 0 {
srvOpts = append(srvOpts, micro.RegisterTTL(i*time.Second))
}
if i := time.Duration(ctx.Int("register_interval")); i > 0 {
srvOpts = append(srvOpts, micro.RegisterInterval(i*time.Second))
}
// set the context
var popts []proxy.Option
// create new router
var r router.Router
routerName := ctx.String("router")
routerAddr := ctx.String("router_address")
ropts := []router.Option{
router.Id(server.DefaultId),
router.Client(client.DefaultClient),
router.Address(routerAddr),
router.Registry(registry.DefaultRegistry),
}
// check if we need to use the router service
switch {
case routerName == "go.micro.router":
r = rs.NewRouter(ropts...)
case routerName == "service":
r = rs.NewRouter(ropts...)
case len(routerAddr) > 0:
r = rs.NewRouter(ropts...)
default:
r = router.NewRouter(ropts...)
}
// start the router
if err := r.Start(); err != nil {
log.Errorf("Proxy error starting router: %s", err)
os.Exit(1)
}
popts = append(popts, proxy.WithRouter(r))
// new proxy
var p proxy.Proxy
var srv server.Server
// set endpoint
if len(Endpoint) > 0 {
switch {
case strings.HasPrefix(Endpoint, "grpc://"):
ep := strings.TrimPrefix(Endpoint, "grpc://")
popts = append(popts, proxy.WithEndpoint(ep))
p = grpc.NewProxy(popts...)
case strings.HasPrefix(Endpoint, "http://"):
// TODO: strip prefix?
popts = append(popts, proxy.WithEndpoint(Endpoint))
p = http.NewProxy(popts...)
default:
// TODO: strip prefix?
popts = append(popts, proxy.WithEndpoint(Endpoint))
p = mucp.NewProxy(popts...)
}
}
serverOpts := []server.Option{
server.Address(Address),
server.Registry(rmem.NewRegistry()),
server.Broker(bmem.NewBroker()),
}
// enable acme will create a net.Listener which
if ctx.Bool("enable_acme") {
var ap acme.Provider
switch ACMEProvider {
case "autocert":
ap = autocert.NewProvider()
case "certmagic":
if ACMEChallengeProvider != "cloudflare" {
log.Fatal("The only implemented DNS challenge provider is cloudflare")
}
apiToken, accountID := os.Getenv("CF_API_TOKEN"), os.Getenv("CF_ACCOUNT_ID")
kvID := os.Getenv("KV_NAMESPACE_ID")
if len(apiToken) == 0 || len(accountID) == 0 {
log.Fatal("env variables CF_API_TOKEN and CF_ACCOUNT_ID must be set")
}
if len(kvID) == 0 {
log.Fatal("env var KV_NAMESPACE_ID must be set to your cloudflare workers KV namespace ID")
}
cloudflareStore := cfstore.NewStore(
cfstore.Token(apiToken),
cfstore.Account(accountID),
cfstore.Namespace(kvID),
cfstore.CacheTTL(time.Minute),
)
storage := certmagic.NewStorage(
memory.NewLock(),
cloudflareStore,
)
config := cloudflare.NewDefaultConfig()
config.AuthToken = apiToken
config.ZoneToken = apiToken
challengeProvider, err := cloudflare.NewDNSProviderConfig(config)
if err != nil {
log.Fatal(err.Error())
}
// define the provider
ap = certmagic.NewProvider(
acme.AcceptToS(true),
acme.CA(ACMECA),
acme.Cache(storage),
acme.ChallengeProvider(challengeProvider),
acme.OnDemand(false),
)
default:
log.Fatalf("Unsupported acme provider: %s\n", ACMEProvider)
}
// generate the tls config
config, err := ap.TLSConfig(helper.ACMEHosts(ctx)...)
if err != nil {
log.Fatalf("Failed to generate acme tls config: %v", err)
}
// set the tls config
serverOpts = append(serverOpts, server.TLSConfig(config))
// enable tls will leverage tls certs and generate a tls.Config
} else if ctx.Bool("enable_tls") {
// get certificates from the context
config, err := helper.TLSConfig(ctx)
if err != nil {
log.Fatal(err)
return
}
serverOpts = append(serverOpts, server.TLSConfig(config))
}
// add auth wrapper to server
if ctx.IsSet("auth") {
a, ok := cmd.DefaultAuths[ctx.String("auth")]
if !ok {
log.Fatalf("%v is not a valid auth", ctx.String("auth"))
return
}
var authOpts []auth.Option
if ctx.IsSet("auth_exclude") {
authOpts = append(authOpts, auth.Exclude(ctx.StringSlice("auth_exclude")...))
}
if ctx.IsSet("auth_public_key") {
authOpts = append(authOpts, auth.PublicKey(ctx.String("auth_public_key")))
}
if ctx.IsSet("auth_private_key") {
authOpts = append(authOpts, auth.PublicKey(ctx.String("auth_private_key")))
}
authFn := func() auth.Auth { return a(authOpts...) }
authOpt := server.WrapHandler(wrapper.AuthHandler(authFn))
serverOpts = append(serverOpts, authOpt)
}
// set proxy
if p == nil && len(Protocol) > 0 {
switch Protocol {
case "http":
p = http.NewProxy(popts...)
// TODO: http server
case "mucp":
popts = append(popts, proxy.WithClient(mucli.NewClient()))
p = mucp.NewProxy(popts...)
serverOpts = append(serverOpts, server.WithRouter(p))
srv = server.NewServer(serverOpts...)
default:
p = mucp.NewProxy(popts...)
serverOpts = append(serverOpts, server.WithRouter(p))
srv = sgrpc.NewServer(serverOpts...)
}
}
if len(Endpoint) > 0 {
log.Infof("Proxy [%s] serving endpoint: %s", p.String(), Endpoint)
} else {
log.Infof("Proxy [%s] serving protocol: %s", p.String(), Protocol)
}
// new service
service := micro.NewService(srvOpts...)
// create a new proxy muxer which includes the debug handler
muxer := mux.New(Name, p)
// set the router
service.Server().Init(
server.WithRouter(muxer),
)
// Start the proxy server
if err := srv.Start(); err != nil {
log.Fatal(err)
}
// Run internal service
if err := service.Run(); err != nil {
log.Fatal(err)
}
// Stop the server
if err := srv.Stop(); err != nil {
log.Fatal(err)
}
}
|
s3.go
|
// Copyright 2020 PingCAP, Inc.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// See the License for the specific language governing permissions and
// limitations under the License.
package cdclog
import (
"context"
"net/url"
"strings"
"time"
"github.com/pingcap/errors"
backup "github.com/pingcap/kvproto/pkg/brpb"
"github.com/pingcap/log"
"github.com/pingcap/ticdc/cdc/model"
"github.com/pingcap/ticdc/cdc/sink/codec"
cerror "github.com/pingcap/ticdc/pkg/errors"
"github.com/pingcap/ticdc/pkg/quotes"
"github.com/pingcap/tidb/br/pkg/storage"
parsemodel "github.com/pingcap/tidb/parser/model"
"github.com/uber-go/atomic"
"go.uber.org/zap"
)
const (
maxPartFlushSize = 5 << 20 // The minimal multipart upload size is 5Mb.
maxCompletePartSize = 100 << 20 // rotate row changed event file if one complete file larger than 100Mb
maxDDLFlushSize = 10 << 20 // rotate ddl event file if one complete file larger than 10Mb
defaultBufferChanSize = 20480
defaultFlushRowChangedEventDuration = 5 * time.Second // TODO make it as a config
)
type tableBuffer struct {
// for log
tableID int64
dataCh chan *model.RowChangedEvent
sendSize *atomic.Int64
sendEvents *atomic.Int64
encoder codec.EventBatchEncoder
uploadParts struct {
writer storage.ExternalFileWriter
uploadNum int
byteSize int64
}
}
func (tb *tableBuffer) dataChan() chan *model.RowChangedEvent {
return tb.dataCh
}
func (tb *tableBuffer) TableID() int64 {
return tb.tableID
}
func (tb *tableBuffer) Events() *atomic.Int64 {
return tb.sendEvents
}
func (tb *tableBuffer) Size() *atomic.Int64 {
return tb.sendSize
}
func (tb *tableBuffer) isEmpty() bool {
return tb.sendEvents.Load() == 0 && tb.uploadParts.uploadNum == 0
}
func (tb *tableBuffer) shouldFlush() bool {
// if sendSize > 5 MB or data chennal is full, flush it
return tb.sendSize.Load() > maxPartFlushSize || tb.sendEvents.Load() == defaultBufferChanSize
}
func (tb *tableBuffer) flush(ctx context.Context, sink *logSink) error {
hashPart := tb.uploadParts
sendEvents := tb.sendEvents.Load()
if sendEvents == 0 && hashPart.uploadNum == 0 {
log.Info("nothing to flush", zap.Int64("tableID", tb.tableID))
return nil
}
firstCreated := false
if tb.encoder == nil {
// create encoder for each file
tb.encoder = sink.encoder()
firstCreated = true
}
var newFileName string
flushedSize := int64(0)
for event := int64(0); event < sendEvents; event++ {
row := <-tb.dataCh
flushedSize += row.ApproximateSize
if event == sendEvents-1 {
// if last event, we record ts as new rotate file name
newFileName = makeTableFileObject(row.Table.TableID, row.CommitTs)
}
_, err := tb.encoder.AppendRowChangedEvent(row)
if err != nil {
return err
}
}
rowDatas := tb.encoder.MixedBuild(firstCreated)
// reset encoder buf for next round append
defer func() {
if tb.encoder != nil {
tb.encoder.Reset()
}
}()
log.Debug("[FlushRowChangedEvents[Debug]] flush table buffer",
zap.Int64("table", tb.tableID),
zap.Int64("event size", sendEvents),
zap.Int("row data size", len(rowDatas)),
zap.Int("upload num", hashPart.uploadNum),
zap.Int64("upload byte size", hashPart.byteSize),
// zap.ByteString("rowDatas", rowDatas),
)
if len(rowDatas) > maxPartFlushSize || hashPart.uploadNum > 0 {
// S3 multi-upload need every chunk(except the last one) is greater than 5Mb
// so, if this batch data size is greater than 5Mb or it has uploadPart already
// we will use multi-upload this batch data
if len(rowDatas) > 0 {
if hashPart.writer == nil {
fileWriter, err := sink.storage().Create(ctx, newFileName)
if err != nil {
return cerror.WrapError(cerror.ErrS3SinkStorageAPI, err)
}
hashPart.writer = fileWriter
}
_, err := hashPart.writer.Write(ctx, rowDatas)
if err != nil {
return cerror.WrapError(cerror.ErrS3SinkStorageAPI, err)
}
hashPart.byteSize += int64(len(rowDatas))
hashPart.uploadNum++
}
if hashPart.byteSize > maxCompletePartSize || len(rowDatas) <= maxPartFlushSize {
// we need do complete when total upload size is greater than 100Mb
// or this part data is less than 5Mb to avoid meet EntityTooSmall error
log.Info("[FlushRowChangedEvents] complete file", zap.Int64("tableID", tb.tableID))
err := hashPart.writer.Close(ctx)
if err != nil {
return cerror.WrapError(cerror.ErrS3SinkStorageAPI, err)
}
hashPart.byteSize = 0
hashPart.uploadNum = 0
hashPart.writer = nil
tb.encoder = nil
}
} else {
// generate normal file because S3 multi-upload need every part at least 5Mb.
log.Info("[FlushRowChangedEvents] normal upload file", zap.Int64("tableID", tb.tableID))
err := sink.storage().WriteFile(ctx, newFileName, rowDatas)
if err != nil {
return cerror.WrapError(cerror.ErrS3SinkStorageAPI, err)
}
tb.encoder = nil
}
tb.sendEvents.Sub(sendEvents)
tb.sendSize.Sub(flushedSize)
tb.uploadParts = hashPart
return nil
}
func newTableBuffer(tableID int64) logUnit
|
type s3Sink struct {
*logSink
prefix string
storage storage.ExternalStorage
logMeta *logMeta
// hold encoder for ddl event log
ddlEncoder codec.EventBatchEncoder
}
func (s *s3Sink) EmitRowChangedEvents(ctx context.Context, rows ...*model.RowChangedEvent) error {
return s.emitRowChangedEvents(ctx, newTableBuffer, rows...)
}
func (s *s3Sink) flushLogMeta(ctx context.Context) error {
data, err := s.logMeta.Marshal()
if err != nil {
return cerror.WrapError(cerror.ErrMarshalFailed, err)
}
return cerror.WrapError(cerror.ErrS3SinkWriteStorage, s.storage.WriteFile(ctx, logMetaFile, data))
}
func (s *s3Sink) FlushRowChangedEvents(ctx context.Context, resolvedTs uint64) (uint64, error) {
// we should flush all events before resolvedTs, there are two kind of flush policy
// 1. flush row events to a s3 chunk: if the event size is not enough,
// TODO: when cdc crashed, we should repair these chunks to a complete file
// 2. flush row events to a complete s3 file: if the event size is enough
return s.flushRowChangedEvents(ctx, resolvedTs)
}
// EmitCheckpointTs update the global resolved ts in log meta
// sleep 5 seconds to avoid update too frequently
func (s *s3Sink) EmitCheckpointTs(ctx context.Context, ts uint64) error {
s.logMeta.GlobalResolvedTS = ts
return s.flushLogMeta(ctx)
}
// EmitDDLEvent write ddl event to S3 directory, all events split by '\n'
// Because S3 doesn't support append-like write.
// we choose a hack way to read origin file then write in place.
func (s *s3Sink) EmitDDLEvent(ctx context.Context, ddl *model.DDLEvent) error {
switch ddl.Type {
case parsemodel.ActionCreateTable:
s.logMeta.Names[ddl.TableInfo.TableID] = quotes.QuoteSchema(ddl.TableInfo.Schema, ddl.TableInfo.Table)
err := s.flushLogMeta(ctx)
if err != nil {
return err
}
case parsemodel.ActionRenameTable:
delete(s.logMeta.Names, ddl.PreTableInfo.TableID)
s.logMeta.Names[ddl.TableInfo.TableID] = quotes.QuoteSchema(ddl.TableInfo.Schema, ddl.TableInfo.Table)
err := s.flushLogMeta(ctx)
if err != nil {
return err
}
}
firstCreated := false
if s.ddlEncoder == nil {
s.ddlEncoder = s.encoder()
firstCreated = true
}
// reset encoder buf for next round append
defer s.ddlEncoder.Reset()
var (
name string
size int64
fileData []byte
)
opt := &storage.WalkOption{
SubDir: ddlEventsDir,
ListCount: 1,
}
err := s.storage.WalkDir(ctx, opt, func(key string, fileSize int64) error {
log.Debug("[EmitDDLEvent] list content from s3",
zap.String("key", key),
zap.Int64("size", size),
zap.Any("ddl", ddl))
name = strings.ReplaceAll(key, s.prefix, "")
size = fileSize
return nil
})
if err != nil {
return cerror.WrapError(cerror.ErrS3SinkStorageAPI, err)
}
// only reboot and (size = 0 or size >= maxRowFileSize) should we add version to s3
withVersion := firstCreated && (size == 0 || size >= maxDDLFlushSize)
// clean ddlEncoder version part
// if we reboot cdc and size between (0, maxDDLFlushSize), we should skip version part in
// JSONEventBatchEncoder.keyBuf, JSONEventBatchEncoder consturctor func has
// alreay filled with version part, see NewJSONEventBatchEncoder and
// JSONEventBatchEncoder.MixedBuild
if firstCreated && size > 0 && size < maxDDLFlushSize {
s.ddlEncoder.Reset()
}
_, er := s.ddlEncoder.EncodeDDLEvent(ddl)
if er != nil {
return er
}
data := s.ddlEncoder.MixedBuild(withVersion)
if size == 0 || size >= maxDDLFlushSize {
// no ddl file exists or
// exists file is oversized. we should generate a new file
fileData = data
name = makeDDLFileObject(ddl.CommitTs)
log.Debug("[EmitDDLEvent] create first or rotate ddl log",
zap.String("name", name), zap.Any("ddl", ddl))
if size > maxDDLFlushSize {
// reset ddl encoder for new file
s.ddlEncoder = nil
}
} else {
// hack way: append data to old file
log.Debug("[EmitDDLEvent] append ddl to origin log",
zap.String("name", name), zap.Any("ddl", ddl))
fileData, err = s.storage.ReadFile(ctx, name)
if err != nil {
return cerror.WrapError(cerror.ErrS3SinkStorageAPI, err)
}
fileData = append(fileData, data...)
}
return s.storage.WriteFile(ctx, name, fileData)
}
func (s *s3Sink) Initialize(ctx context.Context, tableInfo []*model.SimpleTableInfo) error {
if tableInfo != nil {
// update log meta to record the relationship about tableName and tableID
s.logMeta = makeLogMetaContent(tableInfo)
data, err := s.logMeta.Marshal()
if err != nil {
return cerror.WrapError(cerror.ErrMarshalFailed, err)
}
return s.storage.WriteFile(ctx, logMetaFile, data)
}
return nil
}
func (s *s3Sink) Close(ctx context.Context) error {
return nil
}
func (s *s3Sink) Barrier(ctx context.Context) error {
// Barrier does nothing because FlushRowChangedEvents in s3 sink has flushed
// all buffered events forcedlly.
return nil
}
// NewS3Sink creates new sink support log data to s3 directly
func NewS3Sink(ctx context.Context, sinkURI *url.URL, errCh chan error) (*s3Sink, error) {
if len(sinkURI.Host) == 0 {
return nil, errors.Errorf("please specify the bucket for s3 in %s", sinkURI)
}
prefix := strings.Trim(sinkURI.Path, "/")
s3 := &backup.S3{Bucket: sinkURI.Host, Prefix: prefix}
options := &storage.BackendOptions{}
storage.ExtractQueryParameters(sinkURI, &options.S3)
if err := options.S3.Apply(s3); err != nil {
return nil, cerror.WrapError(cerror.ErrS3SinkInitialize, err)
}
// we should set this to true, since br set it by default in parseBackend
s3.ForcePathStyle = true
backend := &backup.StorageBackend{
Backend: &backup.StorageBackend_S3{S3: s3},
}
s3storage, err := storage.New(ctx, backend, &storage.ExternalStorageOptions{
SendCredentials: false,
SkipCheckPath: true,
HTTPClient: nil,
})
if err != nil {
return nil, cerror.WrapError(cerror.ErrS3SinkInitialize, err)
}
s := &s3Sink{
prefix: prefix,
storage: s3storage,
logMeta: newLogMeta(),
logSink: newLogSink("", s3storage),
}
// important! we should flush asynchronously in another goroutine
go func() {
if err := s.startFlush(ctx); err != nil && errors.Cause(err) != context.Canceled {
select {
case <-ctx.Done():
return
case errCh <- err:
default:
log.Error("error channel is full", zap.Error(err))
}
}
}()
return s, nil
}
|
{
return &tableBuffer{
tableID: tableID,
dataCh: make(chan *model.RowChangedEvent, defaultBufferChanSize),
sendSize: atomic.NewInt64(0),
sendEvents: atomic.NewInt64(0),
uploadParts: struct {
writer storage.ExternalFileWriter
uploadNum int
byteSize int64
}{
writer: nil,
uploadNum: 0,
byteSize: 0,
},
}
}
|
main.go
|
// Copyright 2015 Keybase, Inc. All rights reserved. Use of
// this source code is governed by the included BSD license.
package main
import (
"errors"
"fmt"
"io/ioutil"
"os"
"os/signal"
"runtime"
"runtime/debug"
"runtime/pprof"
"syscall"
"time"
"github.com/keybase/client/go/client"
"github.com/keybase/client/go/externals"
"github.com/keybase/client/go/install"
"github.com/keybase/client/go/libcmdline"
"github.com/keybase/client/go/libkb"
"github.com/keybase/client/go/logger"
keybase1 "github.com/keybase/client/go/protocol/keybase1"
"github.com/keybase/client/go/service"
"github.com/keybase/client/go/uidmap"
"github.com/keybase/go-framed-msgpack-rpc/rpc"
"golang.org/x/net/context"
)
var cmd libcmdline.Command
var errParseArgs = errors.New("failed to parse command line arguments")
func handleQuickVersion() bool {
if len(os.Args) == 3 && os.Args[1] == "version" && os.Args[2] == "-S" {
fmt.Printf("%s\n", libkb.VersionString())
return true
}
return false
}
func keybaseExit(exitCode int) {
logger.Shutdown()
logger.RestoreConsoleMode()
os.Exit(exitCode)
}
func main() {
// Preserve non-critical errors that happen very early during
// startup, where logging is not set up yet, to be printed later
// when logging is functioning.
var startupErrors []error
if err := libkb.SaferDLLLoading(); err != nil {
// Don't abort here. This should not happen on any known
// version of Windows, but new MS platforms may create
// regressions.
startupErrors = append(startupErrors,
fmt.Errorf("SaferDLLLoading error: %v", err.Error()))
}
// handle a Quick version query
if handleQuickVersion() {
return
}
g := externals.NewGlobalContextInit()
go HandleSignals(g)
err := mainInner(g, startupErrors)
if g.Env.GetDebug() {
// hack to wait a little bit to receive all the log messages from the
// service before shutting down in debug mode.
time.Sleep(100 * time.Millisecond)
}
mctx := libkb.NewMetaContextTODO(g)
e2 := g.Shutdown(mctx)
if err == nil {
err = e2
}
if err != nil {
// if errParseArgs, the error was already output (along with usage)
if err != errParseArgs {
g.Log.Errorf("%s", stripFieldsFromAppStatusError(err).Error())
}
if g.ExitCode == keybase1.ExitCode_OK {
g.ExitCode = keybase1.ExitCode_NOTOK
}
}
if g.ExitCode != keybase1.ExitCode_OK {
keybaseExit(int(g.ExitCode))
}
}
func tryToDisableProcessTracing(log logger.Logger, e *libkb.Env) {
if e.GetRunMode() != libkb.ProductionRunMode || e.AllowPTrace() {
return
}
if !e.GetFeatureFlags().Admin(e.GetUID()) {
// Admin only for now
return
}
// We do our best but if it's not possible on some systems or
// configurations, it's not a fatal error. Also see documentation
// in ptrace_*.go files.
if err := libkb.DisableProcessTracing(); err != nil {
log.Debug("Unable to disable process tracing: %v", err.Error())
} else {
log.Debug("DisableProcessTracing call succeeded")
}
}
func logStartupIssues(errors []error, log logger.Logger) {
for _, err := range errors {
log.Warning(err.Error())
}
}
func warnNonProd(log logger.Logger, e *libkb.Env) {
mode := e.GetRunMode()
if mode != libkb.ProductionRunMode {
log.Warning("Running in %s mode", mode)
}
}
func checkSystemUser(log logger.Logger) {
if isAdminUser, match, _ := libkb.IsSystemAdminUser(); isAdminUser {
log.Errorf("Oops, you are trying to run as an admin user (%s). This isn't supported.", match)
keybaseExit(int(keybase1.ExitCode_NOTOK))
}
}
func osPreconfigure(g *libkb.GlobalContext) {
switch libkb.RuntimeGroup() {
case keybase1.RuntimeGroup_LINUXLIKE:
// On Linux, we used to put the mountdir in a different location, and
// then we changed it, and also added a default mountdir config var so
// we'll know if the user has changed it.
// Update the mountdir to the new location, but only if they're still
// using the old mountpoint *and* they haven't changed it since we
// added a default. This functionality was originally in the
// run_keybase script.
configReader := g.Env.GetConfig()
if configReader == nil {
// some commands don't configure config.
return
}
userMountdir := configReader.GetMountDir()
userMountdirDefault := configReader.GetMountDirDefault()
oldMountdirDefault := g.Env.GetOldMountDirDefault()
mountdirDefault := g.Env.GetMountDirDefault()
// User has not set a mountdir yet; e.g., on initial install.
nonexistentMountdir := userMountdir == ""
// User does not have a mountdirdefault; e.g., if last used Keybase
// before the change mentioned above.
nonexistentMountdirDefault := userMountdirDefault == ""
usingOldMountdirByDefault := userMountdir == oldMountdirDefault && (userMountdirDefault == oldMountdirDefault || nonexistentMountdirDefault)
shouldResetMountdir := nonexistentMountdir || usingOldMountdirByDefault
if nonexistentMountdirDefault || shouldResetMountdir {
configWriter := g.Env.GetConfigWriter()
if configWriter == nil {
// some commands don't configure config.
return
}
// Set the user's mountdirdefault to the current one if it's
// currently empty.
_ = configWriter.SetStringAtPath("mountdirdefault", mountdirDefault)
if shouldResetMountdir {
_ = configWriter.SetStringAtPath("mountdir", mountdirDefault)
}
}
default:
}
}
func mainInner(g *libkb.GlobalContext, startupErrors []error) error {
cl := libcmdline.NewCommandLine(true, client.GetExtraFlags())
cl.AddCommands(client.GetCommands(cl, g))
cl.AddCommands(service.GetCommands(cl, g))
cl.AddHelpTopics(client.GetHelpTopics())
var err error
cmd, err = cl.Parse(os.Args)
if err != nil {
g.Log.Errorf("Error parsing command line arguments: %s\n\n", err)
if _, isHelp := cmd.(*libcmdline.CmdSpecificHelp); isHelp {
// Parse returned the help command for this command, so run it:
_ = cmd.Run()
}
return errParseArgs
}
if cmd == nil {
return nil
}
if !cmd.GetUsage().AllowRoot && !g.Env.GetAllowRoot() {
checkSystemUser(g.Log)
}
if cl.IsService() {
startProfile(g)
}
if !cl.IsService() {
if logger.SaveConsoleMode() == nil {
defer logger.RestoreConsoleMode()
}
client.InitUI(g)
}
if err = g.ConfigureCommand(cl, cmd); err != nil {
return err
}
g.StartupMessage()
warnNonProd(g.Log, g.Env)
logStartupIssues(startupErrors, g.Log)
tryToDisableProcessTracing(g.Log, g.Env)
// Don't configure mountdir on a nofork command like nix configure redirector.
if cl.GetForkCmd() != libcmdline.NoFork {
osPreconfigure(g)
}
if err := configOtherLibraries(g); err != nil {
return err
}
if err = configureProcesses(g, cl, &cmd); err != nil {
return err
}
err = cmd.Run()
if !cl.IsService() && !cl.SkipOutOfDateCheck() {
// Errors that come up in printing this warning are logged but ignored.
client.PrintOutOfDateWarnings(g)
}
// Warn the user if there is an account reset in progress
if !cl.IsService() && !cl.SkipAccountResetCheck() {
// Errors that come up in printing this warning are logged but ignored.
client.PrintAccountResetWarning(g)
}
return err
}
func configOtherLibraries(g *libkb.GlobalContext) error {
// Set our UID -> Username mapping service
g.SetUIDMapper(uidmap.NewUIDMap(g.Env.GetUIDMapFullNameCacheSize()))
return nil
}
// AutoFork? Standalone? ClientServer? Brew service? This function deals with the
// various run configurations that we can run in.
func configureProcesses(g *libkb.GlobalContext, cl *libcmdline.CommandLine, cmd *libcmdline.Command) (err error) {
g.Log.Debug("+ configureProcesses")
defer func() {
g.Log.Debug("- configureProcesses -> %v", err)
}()
// On Linux, the service configures its own autostart file. Otherwise, no
// need to configure if we're a service.
if cl.IsService() {
g.Log.Debug("| in configureProcesses, is service")
if runtime.GOOS == "linux" {
g.Log.Debug("| calling AutoInstall for Linux")
_, err := install.AutoInstall(g, "", false, 10*time.Second, g.Log)
if err != nil {
return err
}
}
return nil
}
// Start the server on the other end, possibly.
// There are two cases in which we do this: (1) we want
// a local loopback server in standalone mode; (2) we
// need to "autofork" it. Do at most one of these
// operations.
if g.Env.GetStandalone() {
if cl.IsNoStandalone() {
err = client.CantRunInStandaloneError{}
return err
}
svc := service.NewService(g, false /* isDaemon */)
err = svc.SetupCriticalSubServices()
if err != nil {
return err
}
err = svc.StartLoopbackServer()
if err != nil {
return err
}
// StandaloneChatConnector is an interface with only one
// method: StartStandaloneChat. This way we can pass Service
// object while not exposing anything but that one function.
g.StandaloneChatConnector = svc
g.Standalone = true
if pflerr, ok := err.(libkb.PIDFileLockError); ok {
err = fmt.Errorf("Can't run in standalone mode with a service running (see %q)",
pflerr.Filename)
return err
}
return err
}
// After this point, we need to provide a remote logging story if necessary
// If this command specifically asks not to be forked, then we are done in this
// function. This sort of thing is true for the `ctl` commands and also the `version`
// command.
fc := cl.GetForkCmd()
if fc == libcmdline.NoFork {
return configureLogging(g, cl)
}
var newProc bool
if libkb.IsBrewBuild {
// If we're running in Brew mode, we might need to install ourselves as a persistent
// service for future invocations of the command.
newProc, err = install.AutoInstall(g, "", false, 10*time.Second, g.Log)
if err != nil {
return err
}
} else if fc == libcmdline.ForceFork || g.Env.GetAutoFork() {
// If this command warrants an autofork, do it now.
newProc, err = client.AutoForkServer(g, cl)
if err != nil {
return err
}
}
// Restart the service if we see that it's out of date. It's important to do this
// before we make any RPCs to the service --- for instance, before the logging
// calls below. See the v1.0.8 update fiasco for more details. Also, only need
// to do this if we didn't just start a new process.
if !newProc {
if err = client.FixVersionClash(g, cl); err != nil {
return err
}
}
// Ignore error
if err = client.WarnOutdatedKBFS(g, cl); err != nil {
g.Log.Debug("| Could not do kbfs versioncheck: %s", err)
}
g.Log.Debug("| After forks; newProc=%v", newProc)
if err = configureLogging(g, cl); err != nil {
return err
}
// This sends the client's PATH to the service so the service can update
// its PATH if necessary. This is called after FixVersionClash(), which
// happens above in configureProcesses().
if err = configurePath(g, cl); err != nil {
// Further note -- don't die here. It could be we're calling this method
// against an earlier version of the service that doesn't support it.
// It's not critical that it succeed, so continue on.
g.Log.Debug("Configure path failed: %v", err)
}
return nil
}
func configureLogging(g *libkb.GlobalContext, cl *libcmdline.CommandLine) error {
g.Log.Debug("+ configureLogging")
defer func() {
g.Log.Debug("- configureLogging")
}()
// Whether or not we autoforked, we're now running in client-server
// mode (as opposed to standalone). Register a global LogUI so that
// calls to G.Log() in the daemon can be copied to us. This is
// something of a hack on the daemon side.
if !g.Env.GetDoLogForward() || cl.GetLogForward() == libcmdline.LogForwardNone {
g.Log.Debug("Disabling log forwarding")
return nil
}
protocols := []rpc.Protocol{client.NewLogUIProtocol(g)}
if err := client.RegisterProtocolsWithContext(protocols, g); err != nil {
return err
}
logLevel := keybase1.LogLevel_INFO
if g.Env.GetDebug() {
logLevel = keybase1.LogLevel_DEBUG
}
logClient, err := client.GetLogClient(g)
if err != nil {
return err
}
arg := keybase1.RegisterLoggerArg{
Name: "CLI client",
Level: logLevel,
}
if err := logClient.RegisterLogger(context.TODO(), arg); err != nil {
g.Log.Warning("Failed to register as a logger: %s", err)
}
return nil
}
// configurePath sends the client's PATH to the service.
func configurePath(g *libkb.GlobalContext, cl *libcmdline.CommandLine) error {
if cl.IsService() {
// this only runs on the client
return nil
}
return client.SendPath(g)
}
func HandleSignals(g *libkb.GlobalContext) {
c := make(chan os.Signal, 1)
// Note: os.Kill can't be trapped.
signal.Notify(c, os.Interrupt, syscall.SIGTERM)
mctx := libkb.NewMetaContextTODO(g)
for {
s := <-c
if s != nil {
mctx.Debug("trapped signal %v", s)
// if the current command has a Stop function, then call it.
// It will do its own stopping of the process and calling
// shutdown
if stop, ok := cmd.(client.Stopper); ok {
mctx.Debug("Stopping command cleanly via stopper")
stop.Stop(keybase1.ExitCode_OK)
return
}
// if the current command has a Cancel function, then call it:
if canc, ok := cmd.(client.Canceler); ok {
mctx.Debug("canceling running command")
if err := canc.Cancel(); err != nil {
mctx.Warning("error canceling command: %s", err)
}
}
mctx.Debug("calling shutdown")
_ = g.Shutdown(mctx)
mctx.Error("interrupted")
keybaseExit(3)
}
}
}
// stripFieldsFromAppStatusError is an error prettifier. By default, AppStatusErrors print optional
// fields that were problematic. But they make for pretty ugly error messages spit back to the user.
// So strip that out, but still leave in an error-code integer, since those are quite helpful.
func stripFieldsFromAppStatusError(e error) error
|
func startProfile(g *libkb.GlobalContext) {
if os.Getenv("KEYBASE_PERIODIC_MEMPROFILE") == "" {
return
}
interval, err := time.ParseDuration(os.Getenv("KEYBASE_PERIODIC_MEMPROFILE"))
if err != nil {
g.Log.Debug("error parsing KEYBASE_PERIODIC_MEMPROFILE interval duration: %s", err)
return
}
go func() {
g.Log.Debug("periodic memory profile enabled, will dump memory profiles every %s", interval)
for {
time.Sleep(interval)
g.Log.Debug("dumping periodic memory profile")
f, err := ioutil.TempFile("", "keybase_memprofile")
if err != nil {
g.Log.Debug("could not create memory profile: ", err)
continue
}
debug.FreeOSMemory()
runtime.GC() // get up-to-date statistics
if err := pprof.WriteHeapProfile(f); err != nil {
g.Log.Debug("could not write memory profile: ", err)
continue
}
f.Close()
g.Log.Debug("wrote periodic memory profile to %s", f.Name())
var mems runtime.MemStats
runtime.ReadMemStats(&mems)
g.Log.Debug("runtime mem alloc: %v", mems.Alloc)
g.Log.Debug("runtime total alloc: %v", mems.TotalAlloc)
g.Log.Debug("runtime heap alloc: %v", mems.HeapAlloc)
g.Log.Debug("runtime heap sys: %v", mems.HeapSys)
}
}()
}
|
{
if e == nil {
return e
}
if ase, ok := e.(libkb.AppStatusError); ok {
return fmt.Errorf("%s (code %d)", ase.Desc, ase.Code)
}
return e
}
|
traits1.rs
|
// traits1.rs
// Time to implement some traits!
//
// Your task is to implement the trait
// `AppendBar' for the type `String'.
//
// The trait AppendBar has only one function,
// which appends "Bar" to any object
// implementing this trait.
trait AppendBar {
fn append_bar(self) -> Self;
}
impl AppendBar for String {
//Add your code here
fn append_bar(self) -> Self {
self + &String::from("Bar")
}
}
fn main() {
let s = String::from("Foo");
let s = s.append_bar();
println!("s: {}", s);
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn
|
() {
assert_eq!(String::from("Foo").append_bar(), String::from("FooBar"));
}
#[test]
fn is_BarBar() {
assert_eq!(
String::from("").append_bar().append_bar(),
String::from("BarBar")
);
}
}
|
is_FooBar
|
api.ts
|
import axios from 'axios'
import moment from 'moment'
import {
Article,
ArticleMeta,
BlockNode,
BlockValue,
Collection,
PageChunk,
RecordValue,
UnsignedUrl,
} from '../api/types'
async function post<T>(url: string, data: any): Promise<T> {
return axios.post(`https://www.notion.so/api/v3${url}`, data)
.then(res => res.data)
}
const propertiesMap = {
name: 'R>;m',
tags: 'X<$7',
publish: '{JfZ',
date: ',n,"',
}
const getFullBlockId = (blockId: string): string => {
if (blockId.match('^[a-zA-Z0-9]+$')) {
return [
blockId.substr(0, 8),
blockId.substr(8, 4),
blockId.substr(12, 4),
blockId.substr(16, 4),
blockId.substr(20, 32),
].join('-')
}
return blockId
}
const loadPageChunk = (
pageId: string,
count: number,
cursor = { stack: [] },
): Promise<PageChunk> => {
const data = {
chunkNumber: 0,
cursor,
limit: count,
pageId: getFullBlockId(pageId),
verticalColumns: false,
}
return post('/loadPageChunk', data)
}
const queryCollection = (
collectionId: string,
collectionViewId: string,
query: any,
): Promise<Collection> => {
const data = {
collectionId: getFullBlockId(collectionId),
collectionViewId: getFullBlockId(collectionViewId),
loader: {
type: 'table',
},
query: undefined,
}
if (query !== null) {
data.query = query
}
return post('/queryCollection', data)
}
const getPageRecords = async (pageId: string): Promise<RecordValue[]> => {
const limit = 50
const result = []
let cursor = { stack: [] }
do {
const pageChunk = await Promise.resolve(loadPageChunk(pageId, limit, cursor))
for (const id of Object.keys(pageChunk.recordMap.block)) {
if (pageChunk.recordMap.block.hasOwnProperty(id)) {
const item = pageChunk.recordMap.block[id]
if (item.value.alive) {
result.push(item)
}
}
}
cursor = pageChunk.cursor
} while (cursor.stack.length > 0)
return result
}
const loadTablePageBlocks = async (collectionId: string, collectionViewId: string) => {
const pageChunkValues = await loadPageChunk(collectionId, 100)
const recordMap = pageChunkValues.recordMap
const tableView = recordMap.collection_view[getFullBlockId(collectionViewId)]
const collection = recordMap.collection[Object.keys(recordMap.collection)[0]]
return queryCollection(collection.value.id, collectionViewId, tableView.value.query)
}
// tslint:disable-next-line:no-unused
const printTreeLevel = (
root: {
value: { id: string }
children: []
},
level: number,
): void => {
let indent = ''
for (let i = 0; i < level; i++) {
indent += ' '
}
console.log(indent + root.value.id)
for (const c of root.children) {
printTreeLevel(c, level + 1)
}
}
const countTreeNode = (root: BlockNode) => {
let count = 1
for (const c of root.children) {
count += countTreeNode(c)
}
return count
|
}
const recordValueListToBlockNodes = (list: RecordValue[]) => {
type DicNode = {
children: Map<string, DicNode>
record: RecordValue
}
const recordListToDic = (recordList: RecordValue[]): Map<string, DicNode> => {
const findNode = (dic: Map<string, DicNode>, id: string): DicNode | null => {
if (dic.has(id)) {
const result = dic.get(id)
return result ? result : null
}
for (const [, entryValue] of dic) {
const find = findNode(entryValue.children, id)
if (find !== null) {
return find
}
}
return null
}
const dic = new Map()
recordList.forEach((item, idx) => {
const itemId = item.value.id
const itemParentId = item.value.parent_id
console.log(`${idx}: id: ${itemId} parent: ${itemParentId}`)
const node = {
record: item,
children: new Map(),
}
dic.forEach((entryValue, key) => {
if (entryValue.record.value.parent_id === itemId) {
node.children.set(key, entryValue)
dic.delete(key)
}
})
const parent = findNode(dic, itemParentId)
if (parent !== null) {
parent.children.set(itemId, node)
} else {
dic.set(itemId, node)
}
})
return dic
}
const convertDicNodeToBlockNode = (dicNode: DicNode): BlockNode => {
const result: BlockNode[] = []
dicNode.children.forEach(v => {
result.push(convertDicNodeToBlockNode(v))
})
return {
value: dicNode.record.value,
children: result,
}
}
const dicTree = recordListToDic(list)
const result: BlockNode[] = []
dicTree.forEach(v => {
result.push(convertDicNodeToBlockNode(v))
})
console.log(result.map(it => countTreeNode(it)))
return result
}
const getNameFromBlockValue = (value: BlockValue): string => {
const properties = value.properties
if (properties !== undefined) {
const nameValue = properties[propertiesMap.name]
if (nameValue !== undefined && nameValue.length > 0) {
return nameValue[0][0]
}
}
return ''
}
const getDateFromBlockValue = (value: BlockValue): number => {
let mom = moment(value.created_time)
const properties = value.properties
if (properties !== undefined) {
const dateValue = properties[propertiesMap.date]
if (dateValue !== undefined) {
const dateString = dateValue[0][1][0][1].start_date
mom = moment(dateString, 'YYYY-MM-DD')
}
}
return mom.unix()
}
const getTagsFromBlockValue = (value: BlockValue): string[] => {
let result = []
const properties = value.properties
if (properties !== undefined) {
const tagValue = properties[propertiesMap.tags]
if (tagValue !== undefined && tagValue.length > 0) {
result = tagValue[0][0].split(',')
}
}
return result
}
const blockValueToArticleMeta = (block: BlockValue): ArticleMeta => {
return {
name: getNameFromBlockValue(block),
tags: getTagsFromBlockValue(block),
date: getDateFromBlockValue(block),
id: block.id,
title: block.properties ? block.properties.title[0] : undefined,
createdDate: moment(block.created_time).unix(),
lastModifiedDate: moment(block.last_edited_time).unix(),
cover: block.format,
}
}
const getArticle = async (pageId: string): Promise<Article> => {
const chunk = await getPageRecords(pageId)
const tree = recordValueListToBlockNodes(chunk)
const meta = blockValueToArticleMeta(tree[0].value)
return {
meta,
blocks: tree[0].children,
}
}
const getArticleMetaList = async (tableId: string, viewId: string) => {
const result = await loadTablePageBlocks(tableId, viewId)
const blockIds = result.result.blockIds
const recordMap = result.recordMap
return blockIds
.map((it: string) => recordMap.block[it].value)
.map((it: BlockValue) => blockValueToArticleMeta(it))
}
const getSignedFileUrls = async (data: UnsignedUrl) => {
return post('/getSignedFileUrls', data)
}
export default { getArticle, getArticleMetaList, getSignedFileUrls }
| |
vtbl.rs
|
use inline_object::{DrawingContext, InlineObjectContainer};
use std::mem;
use std::panic::catch_unwind;
use std::sync::Arc;
use winapi::Interface;
use winapi::ctypes::c_void;
use winapi::shared::guiddef::{IsEqualIID, REFIID};
use winapi::shared::minwindef::{BOOL, FLOAT, ULONG};
use winapi::shared::winerror::{E_FAIL, E_NOTIMPL, HRESULT, SUCCEEDED, S_OK};
use winapi::um::dwrite::{IDWriteInlineObject, IDWriteInlineObjectVtbl, IDWriteTextRenderer,
DWRITE_BREAK_CONDITION, DWRITE_INLINE_OBJECT_METRICS,
DWRITE_OVERHANG_METRICS};
use winapi::um::unknwnbase::{IUnknown, IUnknownVtbl};
use wio::com::ComPtr;
pub static INLINE_OBJECT_VTBL: IDWriteInlineObjectVtbl = IDWriteInlineObjectVtbl {
parent: IUnknownVtbl {
QueryInterface: query_interface,
AddRef: add_ref,
Release: release,
},
Draw: draw,
GetMetrics: get_metrics,
GetOverhangMetrics: get_overhang_metrics,
GetBreakConditions: get_break_conditions,
};
pub unsafe extern "system" fn
|
(
this: *mut IUnknown,
iid: REFIID,
ppv: *mut *mut c_void,
) -> HRESULT {
if IsEqualIID(&*iid, &IUnknown::uuidof()) {
add_ref(this);
*ppv = this as *mut _;
return S_OK;
}
if IsEqualIID(&*iid, &IDWriteInlineObject::uuidof()) {
add_ref(this);
*ppv = this as *mut _;
return S_OK;
}
return E_NOTIMPL;
}
unsafe extern "system" fn add_ref(this: *mut IUnknown) -> ULONG {
let ptr = this as *const InlineObjectContainer;
let arc = Arc::from_raw(ptr);
mem::forget(arc.clone());
let count = Arc::strong_count(&arc);
mem::forget(arc);
count as ULONG
}
unsafe extern "system" fn release(this: *mut IUnknown) -> ULONG {
let ptr = this as *const InlineObjectContainer;
let arc = Arc::from_raw(ptr);
let count = Arc::strong_count(&arc);
mem::drop(arc);
count as ULONG - 1
}
unsafe extern "system" fn draw(
this: *mut IDWriteInlineObject,
ctx: *mut c_void,
renderer: *mut IDWriteTextRenderer,
origin_x: FLOAT,
origin_y: FLOAT,
is_sideways: BOOL,
is_rtl: BOOL,
effect: *mut IUnknown,
) -> HRESULT {
match catch_unwind(move || {
let obj = &*(this as *const InlineObjectContainer);
// Take a reference to the object for working with later
assert!(!renderer.is_null());
(*renderer).AddRef();
let renderer = ComPtr::from_raw(renderer);
// If there's a client effect, wrap it
let client_effect = if !effect.is_null() {
(*effect).AddRef();
Some(ComPtr::from_raw(effect))
} else {
None
};
let context = DrawingContext {
client_context: ctx,
renderer,
origin_x,
origin_y,
is_sideways: is_sideways != 0,
is_right_to_left: is_rtl != 0,
client_effect,
};
match obj.obj.draw(&context) {
Ok(()) => S_OK,
Err(err) if !SUCCEEDED(err.0) => err.0,
Err(_) => E_FAIL,
}
}) {
Ok(result) => result,
Err(_) => E_FAIL,
}
}
unsafe extern "system" fn get_metrics(
this: *mut IDWriteInlineObject,
metrics: *mut DWRITE_INLINE_OBJECT_METRICS,
) -> HRESULT {
match catch_unwind(move || {
let obj = &*(this as *const InlineObjectContainer);
let m = match obj.obj.get_metrics() {
Ok(metrics) => metrics,
Err(err) if !SUCCEEDED(err.0) => return err.0,
Err(_) => return E_FAIL,
};
let metrics = &mut *metrics;
metrics.width = m.width;
metrics.height = m.height;
metrics.baseline = m.baseline;
metrics.supportsSideways = m.supports_sideways as BOOL;
S_OK
}) {
Ok(result) => result,
Err(_) => E_FAIL,
}
}
unsafe extern "system" fn get_overhang_metrics(
this: *mut IDWriteInlineObject,
metrics: *mut DWRITE_OVERHANG_METRICS,
) -> HRESULT {
match catch_unwind(move || {
let obj = &*(this as *const InlineObjectContainer);
let m = match obj.obj.get_overhang_metrics() {
Ok(metrics) => metrics,
Err(err) if !SUCCEEDED(err.0) => return err.0,
Err(_) => return E_FAIL,
};
let metrics = &mut *metrics;
metrics.left = m.left;
metrics.top = m.top;
metrics.right = m.right;
metrics.bottom = m.bottom;
S_OK
}) {
Ok(result) => result,
Err(_) => E_FAIL,
}
}
unsafe extern "system" fn get_break_conditions(
this: *mut IDWriteInlineObject,
before: *mut DWRITE_BREAK_CONDITION,
after: *mut DWRITE_BREAK_CONDITION,
) -> HRESULT {
match catch_unwind(move || {
let obj = &*(this as *const InlineObjectContainer);
let (b, a) = match obj.obj.get_break_conditions() {
Ok(result) => result,
Err(err) if !SUCCEEDED(err.0) => return err.0,
Err(_) => return E_FAIL,
};
*before = b as u32;
*after = a as u32;
S_OK
}) {
Ok(result) => result,
Err(_) => E_FAIL,
}
}
|
query_interface
|
main.rs
|
use bytemuck::{Pod, Zeroable};
use std::{borrow::Cow, mem};
use wgpu::util::DeviceExt;
#[path = "../framework.rs"]
mod framework;
const MAX_BUNNIES: usize = 1 << 20;
const BUNNY_SIZE: f32 = 0.15 * 256.0;
const GRAVITY: f32 = -9.8 * 100.0;
const MAX_VELOCITY: f32 = 750.0;
#[repr(C)]
#[derive(Clone, Copy, Pod, Zeroable)]
struct Globals {
mvp: [[f32; 4]; 4],
size: [f32; 2],
pad: [f32; 2],
}
#[repr(C, align(256))]
#[derive(Clone, Copy, Zeroable)]
struct Locals {
position: [f32; 2],
velocity: [f32; 2],
color: u32,
_pad: u32,
}
/// Example struct holds references to wgpu resources and frame persistent data
struct Example {
global_group: wgpu::BindGroup,
local_group: wgpu::BindGroup,
pipeline: wgpu::RenderPipeline,
bunnies: Vec<Locals>,
local_buffer: wgpu::Buffer,
extent: [u32; 2],
}
impl framework::Example for Example {
fn init(
config: &wgpu::SurfaceConfiguration,
_adapter: &wgpu::Adapter,
device: &wgpu::Device,
queue: &wgpu::Queue,
) -> Self {
let shader = device.create_shader_module(&wgpu::ShaderModuleDescriptor {
label: None,
source: wgpu::ShaderSource::Wgsl(Cow::Borrowed(include_str!(
"../../../wgpu-hal/examples/halmark/shader.wgsl"
))),
});
let global_bind_group_layout =
device.create_bind_group_layout(&wgpu::BindGroupLayoutDescriptor {
entries: &[
wgpu::BindGroupLayoutEntry {
binding: 0,
visibility: wgpu::ShaderStages::VERTEX,
ty: wgpu::BindingType::Buffer {
ty: wgpu::BufferBindingType::Uniform,
has_dynamic_offset: false,
min_binding_size: wgpu::BufferSize::new(mem::size_of::<Globals>() as _),
},
count: None,
},
wgpu::BindGroupLayoutEntry {
binding: 1,
visibility: wgpu::ShaderStages::FRAGMENT,
ty: wgpu::BindingType::Texture {
sample_type: wgpu::TextureSampleType::Float { filterable: true },
view_dimension: wgpu::TextureViewDimension::D2,
multisampled: false,
},
count: None,
},
wgpu::BindGroupLayoutEntry {
binding: 2,
visibility: wgpu::ShaderStages::FRAGMENT,
ty: wgpu::BindingType::Sampler(wgpu::SamplerBindingType::Filtering),
count: None,
},
],
label: None,
});
let local_bind_group_layout =
device.create_bind_group_layout(&wgpu::BindGroupLayoutDescriptor {
entries: &[wgpu::BindGroupLayoutEntry {
binding: 0,
visibility: wgpu::ShaderStages::VERTEX,
ty: wgpu::BindingType::Buffer {
ty: wgpu::BufferBindingType::Uniform,
has_dynamic_offset: true,
min_binding_size: wgpu::BufferSize::new(mem::size_of::<Locals>() as _),
},
count: None,
}],
label: None,
});
let pipeline_layout = device.create_pipeline_layout(&wgpu::PipelineLayoutDescriptor {
label: None,
bind_group_layouts: &[&global_bind_group_layout, &local_bind_group_layout],
push_constant_ranges: &[],
});
let pipeline = device.create_render_pipeline(&wgpu::RenderPipelineDescriptor {
label: None,
layout: Some(&pipeline_layout),
vertex: wgpu::VertexState {
module: &shader,
entry_point: "vs_main",
buffers: &[],
},
fragment: Some(wgpu::FragmentState {
module: &shader,
entry_point: "fs_main",
targets: &[wgpu::ColorTargetState {
format: config.format,
blend: Some(wgpu::BlendState::ALPHA_BLENDING),
write_mask: wgpu::ColorWrites::default(),
}],
}),
primitive: wgpu::PrimitiveState {
topology: wgpu::PrimitiveTopology::TriangleStrip,
strip_index_format: Some(wgpu::IndexFormat::Uint16),
..wgpu::PrimitiveState::default()
},
depth_stencil: None,
multisample: wgpu::MultisampleState::default(),
multiview: None,
});
let texture = {
let img_data = include_bytes!("../../../logo.png");
let decoder = png::Decoder::new(std::io::Cursor::new(img_data));
let (info, mut reader) = decoder.read_info().unwrap();
let mut buf = vec![0; info.buffer_size()];
reader.next_frame(&mut buf).unwrap();
let size = wgpu::Extent3d {
width: info.width,
height: info.height,
depth_or_array_layers: 1,
};
let texture = device.create_texture(&wgpu::TextureDescriptor {
label: None,
size,
mip_level_count: 1,
sample_count: 1,
dimension: wgpu::TextureDimension::D2,
format: wgpu::TextureFormat::Rgba8UnormSrgb,
usage: wgpu::TextureUsages::COPY_DST | wgpu::TextureUsages::TEXTURE_BINDING,
});
queue.write_texture(
texture.as_image_copy(),
&buf,
wgpu::ImageDataLayout {
offset: 0,
bytes_per_row: std::num::NonZeroU32::new(info.width * 4),
rows_per_image: None,
},
size,
);
texture
};
let sampler = device.create_sampler(&wgpu::SamplerDescriptor {
label: None,
address_mode_u: wgpu::AddressMode::ClampToEdge,
address_mode_v: wgpu::AddressMode::ClampToEdge,
address_mode_w: wgpu::AddressMode::ClampToEdge,
mag_filter: wgpu::FilterMode::Linear,
min_filter: wgpu::FilterMode::Nearest,
mipmap_filter: wgpu::FilterMode::Nearest,
..Default::default()
});
let globals = Globals {
mvp: cgmath::ortho(
0.0,
config.width as f32,
0.0,
config.height as f32,
-1.0,
1.0,
)
.into(),
size: [BUNNY_SIZE; 2],
pad: [0.0; 2],
};
let global_buffer = device.create_buffer_init(&wgpu::util::BufferInitDescriptor {
label: Some("global"),
contents: bytemuck::bytes_of(&globals),
usage: wgpu::BufferUsages::COPY_DST | wgpu::BufferUsages::UNIFORM,
});
let uniform_alignment =
device.limits().min_uniform_buffer_offset_alignment as wgpu::BufferAddress;
let local_buffer = device.create_buffer(&wgpu::BufferDescriptor {
label: Some("local"),
size: (MAX_BUNNIES as wgpu::BufferAddress) * uniform_alignment,
usage: wgpu::BufferUsages::COPY_DST | wgpu::BufferUsages::UNIFORM,
mapped_at_creation: false,
});
let view = texture.create_view(&wgpu::TextureViewDescriptor::default());
let global_group = device.create_bind_group(&wgpu::BindGroupDescriptor {
layout: &global_bind_group_layout,
entries: &[
wgpu::BindGroupEntry {
binding: 0,
resource: global_buffer.as_entire_binding(),
},
wgpu::BindGroupEntry {
binding: 1,
resource: wgpu::BindingResource::TextureView(&view),
},
wgpu::BindGroupEntry {
binding: 2,
resource: wgpu::BindingResource::Sampler(&sampler),
},
],
label: None,
});
let local_group = device.create_bind_group(&wgpu::BindGroupDescriptor {
layout: &local_bind_group_layout,
entries: &[wgpu::BindGroupEntry {
binding: 0,
resource: wgpu::BindingResource::Buffer(wgpu::BufferBinding {
buffer: &local_buffer,
offset: 0,
size: wgpu::BufferSize::new(mem::size_of::<Locals>() as _),
}),
}],
label: None,
});
Example {
pipeline,
global_group,
local_group,
bunnies: Vec::new(),
local_buffer,
extent: [config.width, config.height],
}
}
fn update(&mut self, event: winit::event::WindowEvent) {
if let winit::event::WindowEvent::KeyboardInput {
input:
winit::event::KeyboardInput {
virtual_keycode: Some(winit::event::VirtualKeyCode::Space),
state: winit::event::ElementState::Pressed,
..
},
..
} = event
{
let spawn_count = 64 + self.bunnies.len() / 2;
let color = rand::random::<u32>();
println!(
"Spawning {} bunnies, total at {}",
spawn_count,
self.bunnies.len() + spawn_count
);
for _ in 0..spawn_count {
let speed = rand::random::<f32>() * MAX_VELOCITY - (MAX_VELOCITY * 0.5);
self.bunnies.push(Locals {
position: [0.0, 0.5 * (self.extent[1] as f32)],
velocity: [speed, 0.0],
color,
_pad: 0,
});
}
}
}
fn resize(
&mut self,
_sc_desc: &wgpu::SurfaceConfiguration,
_device: &wgpu::Device,
_queue: &wgpu::Queue,
) {
//empty
}
fn
|
(
&mut self,
view: &wgpu::TextureView,
device: &wgpu::Device,
queue: &wgpu::Queue,
_spawner: &framework::Spawner,
) {
let delta = 0.01;
for bunny in self.bunnies.iter_mut() {
bunny.position[0] += bunny.velocity[0] * delta;
bunny.position[1] += bunny.velocity[1] * delta;
bunny.velocity[1] += GRAVITY * delta;
if (bunny.velocity[0] > 0.0
&& bunny.position[0] + 0.5 * BUNNY_SIZE > self.extent[0] as f32)
|| (bunny.velocity[0] < 0.0 && bunny.position[0] - 0.5 * BUNNY_SIZE < 0.0)
{
bunny.velocity[0] *= -1.0;
}
if bunny.velocity[1] < 0.0 && bunny.position[1] < 0.5 * BUNNY_SIZE {
bunny.velocity[1] *= -1.0;
}
}
let uniform_alignment = device.limits().min_uniform_buffer_offset_alignment;
queue.write_buffer(&self.local_buffer, 0, unsafe {
std::slice::from_raw_parts(
self.bunnies.as_ptr() as *const u8,
self.bunnies.len() * uniform_alignment as usize,
)
});
let mut encoder = device.create_command_encoder(&wgpu::CommandEncoderDescriptor::default());
{
let clear_color = wgpu::Color {
r: 0.1,
g: 0.2,
b: 0.3,
a: 1.0,
};
let mut rpass = encoder.begin_render_pass(&wgpu::RenderPassDescriptor {
label: None,
color_attachments: &[wgpu::RenderPassColorAttachment {
view,
resolve_target: None,
ops: wgpu::Operations {
load: wgpu::LoadOp::Clear(clear_color),
store: true,
},
}],
depth_stencil_attachment: None,
});
rpass.set_pipeline(&self.pipeline);
rpass.set_bind_group(0, &self.global_group, &[]);
for i in 0..self.bunnies.len() {
let offset =
(i as wgpu::DynamicOffset) * (uniform_alignment as wgpu::DynamicOffset);
rpass.set_bind_group(1, &self.local_group, &[offset]);
rpass.draw(0..4, 0..1);
}
}
queue.submit(Some(encoder.finish()));
}
}
fn main() {
framework::run::<Example>("bunnymark");
}
#[test]
fn bunnymark() {
framework::test::<Example>(framework::FrameworkRefTest {
image_path: "/examples/bunnymark/screenshot.png",
width: 1024,
height: 768,
optional_features: wgpu::Features::default(),
base_test_parameters: framework::test_common::TestParameters::default(),
tolerance: 1,
max_outliers: 50,
});
}
|
render
|
informers_map.go
|
/*
Copyright 2018 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package internal
import (
"fmt"
"math/rand"
"sync"
"time"
"k8s.io/apimachinery/pkg/api/meta"
metav1 "k8s.io/apimachinery/pkg/apis/meta/v1"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/schema"
"k8s.io/apimachinery/pkg/runtime/serializer"
"k8s.io/apimachinery/pkg/watch"
"k8s.io/client-go/dynamic"
"k8s.io/client-go/rest"
"k8s.io/client-go/tools/cache"
"sigs.k8s.io/controller-runtime/pkg/client/apiutil"
)
// clientListWatcherFunc knows how to create a ListWatcher
type createListWatcherFunc func(gvk schema.GroupVersionKind, ip *specificInformersMap) (*cache.ListWatch, error)
// newSpecificInformersMap returns a new specificInformersMap (like
// the generical InformersMap, except that it doesn't implement WaitForCacheSync).
func newSpecificInformersMap(config *rest.Config,
scheme *runtime.Scheme,
mapper meta.RESTMapper,
resync time.Duration,
namespace string,
createListWatcher createListWatcherFunc) *specificInformersMap {
ip := &specificInformersMap{
config: config,
Scheme: scheme,
mapper: mapper,
informersByGVK: make(map[schema.GroupVersionKind]*MapEntry),
codecs: serializer.NewCodecFactory(scheme),
paramCodec: runtime.NewParameterCodec(scheme),
resync: resync,
createListWatcher: createListWatcher,
namespace: namespace,
}
return ip
}
// MapEntry contains the cached data for an Informer
type MapEntry struct {
// Informer is the cached informer
Informer cache.SharedIndexInformer
// CacheReader wraps Informer and implements the CacheReader interface for a single type
Reader CacheReader
}
// specificInformersMap create and caches Informers for (runtime.Object, schema.GroupVersionKind) pairs.
// It uses a standard parameter codec constructed based on the given generated Scheme.
type specificInformersMap struct {
// Scheme maps runtime.Objects to GroupVersionKinds
Scheme *runtime.Scheme
// config is used to talk to the apiserver
config *rest.Config
// mapper maps GroupVersionKinds to Resources
mapper meta.RESTMapper
// informersByGVK is the cache of informers keyed by groupVersionKind
informersByGVK map[schema.GroupVersionKind]*MapEntry
// codecs is used to create a new REST client
codecs serializer.CodecFactory
// paramCodec is used by list and watch
paramCodec runtime.ParameterCodec
// stop is the stop channel to stop informers
stop <-chan struct{}
// resync is the base frequency the informers are resynced
// a 10 percent jitter will be added to the resync period between informers
// so that all informers will not send list requests simultaneously.
resync time.Duration
// mu guards access to the map
mu sync.RWMutex
// start is true if the informers have been started
started bool
// createClient knows how to create a client and a list object,
// and allows for abstracting over the particulars of structured vs
// unstructured objects.
createListWatcher createListWatcherFunc
// namespace is the namespace that all ListWatches are restricted to
// default or empty string means all namespaces
namespace string
}
// Start calls Run on each of the informers and sets started to true. Blocks on the stop channel.
// It doesn't return start because it can't return an error, and it's not a runnable directly.
func (ip *specificInformersMap) Start(stop <-chan struct{}) {
func() {
ip.mu.Lock()
defer ip.mu.Unlock()
// Set the stop channel so it can be passed to informers that are added later
ip.stop = stop
// Start each informer
for _, informer := range ip.informersByGVK {
go informer.Informer.Run(stop)
}
// Set started to true so we immediately start any informers added later.
ip.started = true
}()
<-stop
}
// HasSyncedFuncs returns all the HasSynced functions for the informers in this map.
func (ip *specificInformersMap) HasSyncedFuncs() []cache.InformerSynced {
ip.mu.RLock()
defer ip.mu.RUnlock()
syncedFuncs := make([]cache.InformerSynced, 0, len(ip.informersByGVK))
for _, informer := range ip.informersByGVK {
syncedFuncs = append(syncedFuncs, informer.Informer.HasSynced)
}
return syncedFuncs
}
// Get will create a new Informer and add it to the map of specificInformersMap if none exists. Returns
// the Informer from the map.
func (ip *specificInformersMap) Get(gvk schema.GroupVersionKind, obj runtime.Object) (bool, *MapEntry, error) {
// Return the informer if it is found
i, started, ok := func() (*MapEntry, bool, bool) {
ip.mu.RLock()
defer ip.mu.RUnlock()
i, ok := ip.informersByGVK[gvk]
return i, ip.started, ok
}()
if !ok {
var err error
if i, started, err = ip.addInformerToMap(gvk, obj); err != nil {
return started, nil, err
}
}
if started && !i.Informer.HasSynced() {
// Wait for it to sync before returning the Informer so that folks don't read from a stale cache.
if !cache.WaitForCacheSync(ip.stop, i.Informer.HasSynced) {
return started, nil, fmt.Errorf("failed waiting for %T Informer to sync", obj)
}
}
return started, i, nil
}
func (ip *specificInformersMap) addInformerToMap(gvk schema.GroupVersionKind, obj runtime.Object) (*MapEntry, bool, error) {
ip.mu.Lock()
defer ip.mu.Unlock()
// Check the cache to see if we already have an Informer. If we do, return the Informer.
// This is for the case where 2 routines tried to get the informer when it wasn't in the map
// so neither returned early, but the first one created it.
if i, ok := ip.informersByGVK[gvk]; ok {
return i, ip.started, nil
}
// Create a NewSharedIndexInformer and add it to the map.
var lw *cache.ListWatch
lw, err := ip.createListWatcher(gvk, ip)
if err != nil {
return nil, false, err
}
ni := cache.NewSharedIndexInformer(lw, obj, resyncPeriod(ip.resync)(), cache.Indexers{
cache.NamespaceIndex: cache.MetaNamespaceIndexFunc,
})
i := &MapEntry{
Informer: ni,
Reader: CacheReader{indexer: ni.GetIndexer(), groupVersionKind: gvk},
}
ip.informersByGVK[gvk] = i
// Start the Informer if need by
// TODO(seans): write thorough tests and document what happens here - can you add indexers?
// can you add eventhandlers?
if ip.started {
go i.Informer.Run(ip.stop)
}
return i, ip.started, nil
}
// newListWatch returns a new ListWatch object that can be used to create a SharedIndexInformer.
func createStructuredListWatch(gvk schema.GroupVersionKind, ip *specificInformersMap) (*cache.ListWatch, error) {
// Kubernetes APIs work against Resources, not GroupVersionKinds. Map the
// groupVersionKind to the Resource API we will use.
mapping, err := ip.mapper.RESTMapping(gvk.GroupKind(), gvk.Version)
if err != nil {
return nil, err
}
client, err := apiutil.RESTClientForGVK(gvk, ip.config, ip.codecs)
if err != nil
|
listGVK := gvk.GroupVersion().WithKind(gvk.Kind + "List")
listObj, err := ip.Scheme.New(listGVK)
if err != nil {
return nil, err
}
// Create a new ListWatch for the obj
return &cache.ListWatch{
ListFunc: func(opts metav1.ListOptions) (runtime.Object, error) {
res := listObj.DeepCopyObject()
isNamespaceScoped := ip.namespace != "" && mapping.Scope.Name() != meta.RESTScopeNameRoot
err := client.Get().NamespaceIfScoped(ip.namespace, isNamespaceScoped).Resource(mapping.Resource.Resource).VersionedParams(&opts, ip.paramCodec).Do().Into(res)
return res, err
},
// Setup the watch function
WatchFunc: func(opts metav1.ListOptions) (watch.Interface, error) {
// Watch needs to be set to true separately
opts.Watch = true
isNamespaceScoped := ip.namespace != "" && mapping.Scope.Name() != meta.RESTScopeNameRoot
return client.Get().NamespaceIfScoped(ip.namespace, isNamespaceScoped).Resource(mapping.Resource.Resource).VersionedParams(&opts, ip.paramCodec).Watch()
},
}, nil
}
func createUnstructuredListWatch(gvk schema.GroupVersionKind, ip *specificInformersMap) (*cache.ListWatch, error) {
// Kubernetes APIs work against Resources, not GroupVersionKinds. Map the
// groupVersionKind to the Resource API we will use.
mapping, err := ip.mapper.RESTMapping(gvk.GroupKind(), gvk.Version)
if err != nil {
return nil, err
}
dynamicClient, err := dynamic.NewForConfig(ip.config)
if err != nil {
return nil, err
}
// Create a new ListWatch for the obj
return &cache.ListWatch{
ListFunc: func(opts metav1.ListOptions) (runtime.Object, error) {
if ip.namespace != "" && mapping.Scope.Name() != meta.RESTScopeNameRoot {
return dynamicClient.Resource(mapping.Resource).Namespace(ip.namespace).List(opts)
}
return dynamicClient.Resource(mapping.Resource).List(opts)
},
// Setup the watch function
WatchFunc: func(opts metav1.ListOptions) (watch.Interface, error) {
// Watch needs to be set to true separately
opts.Watch = true
if ip.namespace != "" && mapping.Scope.Name() != meta.RESTScopeNameRoot {
return dynamicClient.Resource(mapping.Resource).Namespace(ip.namespace).Watch(opts)
}
return dynamicClient.Resource(mapping.Resource).Watch(opts)
},
}, nil
}
// resyncPeriod returns a function which generates a duration each time it is
// invoked; this is so that multiple controllers don't get into lock-step and all
// hammer the apiserver with list requests simultaneously.
func resyncPeriod(resync time.Duration) func() time.Duration {
return func() time.Duration {
// the factor will fall into [0.9, 1.1)
factor := rand.Float64()/5.0 + 0.9
return time.Duration(float64(resync.Nanoseconds()) * factor)
}
}
|
{
return nil, err
}
|
test_mnist_cnn.py
|
import unittest
import os
import shutil
import random
import pickle
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.multiprocessing as mp
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel
from torch.utils.data.distributed import DistributedSampler
from aitoolbox import TrainLoop, TTModel
from tests_gpu.test_multi_gpu.ddp_prediction_saver import DDPPredictionSave
THIS_DIR = os.path.dirname(os.path.abspath(__file__))
class CNNNet(TTModel):
def __init__(self):
super(CNNNet, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout2d(0.25)
self.dropout2 = nn.Dropout2d(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def get_loss(self, batch_data, criterion, device):
data, target = batch_data
data, target = data.to(device), target.to(device)
output = self(data)
loss = criterion(output, target)
return loss
def get_predictions(self, batch_data, device):
data, y_test = batch_data
data = data.to(device)
output = self(data)
y_pred = output.argmax(dim=1, keepdim=False)
return y_pred.cpu(), y_test, {}
class TestMNISTCNN(unittest.TestCase):
def test_trainloop_core_pytorch_compare(self):
os.mkdir(f'{THIS_DIR}/ddp_cnn_save')
val_loss_tl, y_pred_tl, y_true_tl = self.train_eval_trainloop(num_epochs=5, use_real_train_data=True)
val_loss_pt, y_pred_pt, y_true_pt = self.train_eval_core_pytorch(num_epochs=5, use_real_train_data=True)
self.assertAlmostEqual(val_loss_tl, val_loss_pt, places=8)
self.assertEqual(y_pred_tl, y_pred_pt)
self.assertEqual(y_true_tl, y_true_pt)
project_path = os.path.join(THIS_DIR, 'ddp_cnn_save')
if os.path.exists(project_path):
shutil.rmtree(project_path)
project_path = os.path.join(THIS_DIR, 'data')
if os.path.exists(project_path):
shutil.rmtree(project_path)
def train_eval_trainloop(self, num_epochs, use_real_train_data=False):
self.set_seeds()
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(os.path.join(THIS_DIR, 'data'), train=use_real_train_data, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=100, shuffle=True)
val_loader = torch.utils.data.DataLoader(
datasets.MNIST(os.path.join(THIS_DIR, 'data'), train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=100)
model = CNNNet()
optimizer = optim.Adam(model.parameters(), lr=0.001, betas=(0.9, 0.999))
criterion = nn.NLLLoss()
print('Starting train loop')
tl = TrainLoop(
model,
train_loader, val_loader, None,
optimizer, criterion,
gpu_mode='ddp'
)
self.assertEqual(tl.device.type, "cuda")
tl.fit(num_epochs=num_epochs,
callbacks=[DDPPredictionSave(dir_path=f'{THIS_DIR}/ddp_cnn_save',
file_name='tl_ddp_predictions.p')])
with open(f'{THIS_DIR}/ddp_cnn_save/tl_ddp_predictions.p', 'rb') as f:
val_loss, y_pred, y_true = pickle.load(f)
return val_loss, y_pred, y_true
def train_eval_core_pytorch(self, num_epochs, use_real_train_data=False):
self.set_seeds()
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(os.path.join(THIS_DIR, 'data'), train=use_real_train_data, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=100)
val_loader = torch.utils.data.DataLoader(
datasets.MNIST(os.path.join(THIS_DIR, 'data'), train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=100)
model_pt = CNNNet()
optimizer_pt = optim.Adam(model_pt.parameters(), lr=0.001, betas=(0.9, 0.999))
criterion_pt = nn.NLLLoss()
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '8888'
print('Starting the manual DDP training')
mp.spawn(
self.manual_ddp_training,
args=(num_epochs, model_pt, optimizer_pt, criterion_pt, train_loader, val_loader),
nprocs=torch.cuda.device_count()
)
val_loss, y_pred, y_true = [], [], []
for idx in range(torch.cuda.device_count()):
with open(f'{THIS_DIR}/ddp_cnn_save/pt_ddp_predictions_{idx}.p', 'rb') as f:
val_loss_f, y_pred_f, y_true_f = pickle.load(f)
val_loss += val_loss_f
y_pred += y_pred_f
y_true += y_true_f
val_loss = np.mean(val_loss)
return val_loss, y_pred, y_true
@staticmethod
def
|
(gpu, num_epochs, model_pt, optimizer_pt, criterion_pt, train_loader, val_loader):
rank = gpu
dist.init_process_group(backend='nccl', init_method='env://', world_size=torch.cuda.device_count(), rank=rank)
torch.manual_seed(0)
torch.cuda.set_device(gpu)
device = torch.device(f"cuda:{gpu}")
train_sampler = DistributedSampler(dataset=train_loader.dataset, shuffle=True,
num_replicas=torch.cuda.device_count(), rank=rank)
val_sampler = DistributedSampler(dataset=val_loader.dataset, shuffle=False,
num_replicas=torch.cuda.device_count(), rank=rank)
train_loader_ddp = DataLoader(train_loader.dataset, batch_size=100, sampler=train_sampler)
val_loader_ddp = DataLoader(val_loader.dataset, batch_size=100, sampler=val_sampler)
model_pt = model_pt.to(device)
criterion_pt = criterion_pt.to(device)
model_pt = DistributedDataParallel(model_pt, device_ids=[gpu])
model_pt.train()
for epoch in range(num_epochs):
print(f'Epoch: {epoch}')
train_sampler.set_epoch(epoch)
for i, (input_data, target) in enumerate(train_loader_ddp):
input_data = input_data.to(device)
target = target.to(device)
predicted = model_pt(input_data)
loss = criterion_pt(predicted, target)
loss.backward()
optimizer_pt.step()
optimizer_pt.zero_grad()
# Imitate what happens in auto_execute_end_of_epoch() in TrainLoop
for _ in train_loader:
pass
for _ in val_loader:
pass
print('Evaluating')
val_loss, val_pred, val_true = [], [], []
model_pt.eval()
with torch.no_grad():
for input_data, target in val_loader_ddp:
input_data = input_data.to(device)
target = target.to(device)
predicted = model_pt(input_data)
loss_batch = criterion_pt(predicted, target).cpu().item()
val_pred += predicted.argmax(dim=1, keepdim=False).cpu().tolist()
val_true += target.cpu().tolist()
val_loss.append(loss_batch)
with open(f'{THIS_DIR}/ddp_cnn_save/pt_ddp_predictions_{gpu}.p', 'wb') as f:
pickle.dump([val_loss, val_pred, val_true], f)
@staticmethod
def set_seeds():
manual_seed = 0
torch.backends.cudnn.enabled = False
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
np.random.seed(manual_seed)
random.seed(manual_seed)
torch.manual_seed(manual_seed)
# if you are suing GPU
torch.cuda.manual_seed(manual_seed)
torch.cuda.manual_seed_all(manual_seed)
|
manual_ddp_training
|
semimonomial_transformation_group.py
|
r"""
Semimonomial transformation group
The semimonomial transformation group of degree `n` over a ring `R` is
the semidirect product of the monomial transformation group of degree `n`
(also known as the complete monomial group over the group of units
`R^{\times}` of `R`) and the group of ring automorphisms.
The multiplication of two elements `(\phi, \pi, \alpha)(\psi, \sigma, \beta)`
with
- `\phi, \psi \in {R^{\times}}^n`
- `\pi, \sigma \in S_n` (with the multiplication `\pi\sigma`
done from left to right (like in GAP) --
that is, `(\pi\sigma)(i) = \sigma(\pi(i))` for all `i`.)
- `\alpha, \beta \in Aut(R)`
is defined by
.. MATH::
(\phi, \pi, \alpha)(\psi, \sigma, \beta) =
(\phi \cdot \psi^{\pi, \alpha}, \pi\sigma, \alpha \circ \beta)
where
`\psi^{\pi, \alpha} = (\alpha(\psi_{\pi(1)-1}), \ldots, \alpha(\psi_{\pi(n)-1}))`
and the multiplication of vectors is defined elementwisely. (The indexing
of vectors is `0`-based here, so `\psi = (\psi_0, \psi_1, \ldots, \psi_{n-1})`.)
.. TODO::
Up to now, this group is only implemented for finite fields because of
the limited support of automorphisms for arbitrary rings.
AUTHORS:
- Thomas Feulner (2012-11-15): initial version
EXAMPLES::
sage: S = SemimonomialTransformationGroup(GF(4, 'a'), 4)
sage: G = S.gens()
sage: G[0]*G[1]
((a, 1, 1, 1); (1,2,3,4), Ring endomorphism of Finite Field in a of size 2^2
Defn: a |--> a)
TESTS::
sage: TestSuite(S).run()
sage: TestSuite(S.an_element()).run()
"""
from sage.rings.integer import Integer
from sage.groups.group import FiniteGroup
from sage.structure.unique_representation import UniqueRepresentation
from sage.categories.action import Action
from sage.combinat.permutation import Permutation
from sage.groups.semimonomial_transformations.semimonomial_transformation import SemimonomialTransformation
class SemimonomialTransformationGroup(FiniteGroup, UniqueRepresentation):
r"""
A semimonomial transformation group over a ring.
The semimonomial transformation group of degree `n` over a ring `R` is
the semidirect product of the monomial transformation group of degree `n`
(also known as the complete monomial group over the group of units
`R^{\times}` of `R`) and the group of ring automorphisms.
The multiplication of two elements `(\phi, \pi, \alpha)(\psi, \sigma, \beta)`
with
- `\phi, \psi \in {R^{\times}}^n`
- `\pi, \sigma \in S_n` (with the multiplication `\pi\sigma`
done from left to right (like in GAP) --
that is, `(\pi\sigma)(i) = \sigma(\pi(i))` for all `i`.)
- `\alpha, \beta \in Aut(R)`
is defined by
.. MATH::
(\phi, \pi, \alpha)(\psi, \sigma, \beta) =
(\phi \cdot \psi^{\pi, \alpha}, \pi\sigma, \alpha \circ \beta)
where
`\psi^{\pi, \alpha} = (\alpha(\psi_{\pi(1)-1}), \ldots, \alpha(\psi_{\pi(n)-1}))`
and the multiplication of vectors is defined elementwisely. (The indexing
of vectors is `0`-based here, so `\psi = (\psi_0, \psi_1, \ldots, \psi_{n-1})`.)
.. TODO::
Up to now, this group is only implemented for finite fields because of
the limited support of automorphisms for arbitrary rings.
EXAMPLES::
sage: F.<a> = GF(9)
sage: S = SemimonomialTransformationGroup(F, 4)
sage: g = S(v = [2, a, 1, 2])
sage: h = S(perm = Permutation('(1,2,3,4)'), autom=F.hom([a**3]))
sage: g*h
((2, a, 1, 2); (1,2,3,4), Ring endomorphism of Finite Field in a of size 3^2 Defn: a |--> 2*a + 1)
sage: h*g
((2*a + 1, 1, 2, 2); (1,2,3,4), Ring endomorphism of Finite Field in a of size 3^2 Defn: a |--> 2*a + 1)
sage: S(g)
((2, a, 1, 2); (), Ring endomorphism of Finite Field in a of size 3^2 Defn: a |--> a)
sage: S(1)
((1, 1, 1, 1); (), Ring endomorphism of Finite Field in a of size 3^2 Defn: a |--> a)
"""
Element = SemimonomialTransformation
def __init__(self, R, len):
r"""
Initialization.
INPUT:
- ``R`` -- a ring
- ``len`` -- the degree of the monomial group
OUTPUT:
- the complete semimonomial group
EXAMPLES::
sage: F.<a> = GF(9)
sage: S = SemimonomialTransformationGroup(F, 4)
"""
if not R.is_field():
raise NotImplementedError('the ring must be a field')
self._R = R
self._len = len
from sage.categories.finite_groups import FiniteGroups
super(SemimonomialTransformationGroup, self).__init__(category=FiniteGroups())
def _element_constructor_(self, arg1, v=None, perm=None, autom=None, check=True):
r"""
Coerce ``arg1`` into this permutation group, if ``arg1`` is 0,
then we will try to coerce ``(v, perm, autom)``.
INPUT:
- ``arg1`` (optional) -- either the integers 0, 1 or an element of ``self``
- ``v`` (optional) -- a vector of length ``self.degree()``
- ``perm`` (optional) -- a permutation of degree ``self.degree()``
- ``autom`` (optional) -- an automorphism of the ring
EXAMPLES::
sage: F.<a> = GF(9)
sage: S = SemimonomialTransformationGroup(F, 4)
sage: S(1)
((1, 1, 1, 1); (), Ring endomorphism of Finite Field in a of size 3^2 Defn: a |--> a)
sage: g = S(v=[1,1,1,a])
sage: S(g)
((1, 1, 1, a); (), Ring endomorphism of Finite Field in a of size 3^2 Defn: a |--> a)
sage: S(perm=Permutation('(1,2)(3,4)'))
((1, 1, 1, 1); (1,2)(3,4), Ring endomorphism of Finite Field in a of size 3^2 Defn: a |--> a)
sage: S(autom=F.hom([a**3]))
((1, 1, 1, 1); (), Ring endomorphism of Finite Field in a of size 3^2 Defn: a |--> 2*a + 1)
"""
from sage.categories.homset import End
R = self.base_ring()
if arg1 == 0:
if v is None:
v = [R.one()] * self.degree()
if perm is None:
perm = Permutation(range(1, self.degree() + 1))
if autom is None:
autom = R.hom(R.gens())
if check:
try:
v = [R(x) for x in v]
except TypeError:
raise TypeError('the vector attribute %s ' % v +
'should be iterable')
if len(v) != self.degree():
raise ValueError('the length of the vector is %s,' % len(v) +
' should be %s' % self.degree())
if not all(x.parent() is R and x.is_unit() for x in v):
raise ValueError('there is at least one element in the ' +
'list %s not lying in %s ' % (v, R) +
'or which is not invertible')
try:
perm = Permutation(perm)
except TypeError:
raise TypeError('the permutation attribute %s ' % perm +
'could not be converted to a permutation')
if len(perm) != self.degree():
txt = 'the permutation length is {}, should be {}'
raise ValueError(txt.format(len(perm), self.degree()))
try:
if autom.parent() != End(R):
autom = End(R)(autom)
except TypeError:
raise TypeError('%s of type %s' % (autom, type(autom)) +
' is not coerceable to an automorphism')
return self.Element(self, v, perm, autom)
else:
try:
if arg1.parent() is self:
return arg1
except AttributeError:
pass
try:
from sage.rings.integer import Integer
if Integer(arg1) == 1:
return self()
except TypeError:
pass
raise TypeError('the first argument must be an integer' +
' or an element of this group')
def base_ring(self):
r"""
Return the underlying ring of ``self``.
EXAMPLES::
sage: F.<a> = GF(4)
sage: SemimonomialTransformationGroup(F, 3).base_ring() is F
True
"""
return self._R
def degree(self) -> Integer:
r"""
Return the degree of ``self``.
EXAMPLES::
sage: F.<a> = GF(4)
sage: SemimonomialTransformationGroup(F, 3).degree()
3
"""
return self._len
def _an_element_(self):
r"""
Return an element of ``self``.
EXAMPLES::
sage: F.<a> = GF(4)
sage: SemimonomialTransformationGroup(F, 3).an_element() # indirect doctest
((a, 1, 1); (1,3,2), Ring endomorphism of Finite Field in a of size 2^2 Defn: a |--> a + 1)
"""
R = self.base_ring()
v = [R.primitive_element()] + [R.one()] * (self.degree() - 1)
p = Permutation([self.degree()] + [i for i in range(1, self.degree())])
if not R.is_prime_field():
f = R.hom([R.gen()**R.characteristic()])
else:
f = R.Hom(R).identity()
return self(0, v, p, f)
def __contains__(self, item) -> bool:
r"""
EXAMPLES::
sage: F.<a> = GF(4)
sage: S = SemimonomialTransformationGroup(F, 3)
sage: 1 in S # indirect doctest
True
sage: a in S # indirect doctest
False
"""
try:
self(item, check=True)
except TypeError:
return False
return True
def gens(self):
r"""
Return a tuple of generators of ``self``.
EXAMPLES::
sage: F.<a> = GF(4)
sage: SemimonomialTransformationGroup(F, 3).gens()
[((a, 1, 1); (), Ring endomorphism of Finite Field in a of size 2^2
Defn: a |--> a), ((1, 1, 1); (1,2,3), Ring endomorphism of Finite Field in a of size 2^2
Defn: a |--> a), ((1, 1, 1); (1,2), Ring endomorphism of Finite Field in a of size 2^2
Defn: a |--> a), ((1, 1, 1); (), Ring endomorphism of Finite Field in a of size 2^2
Defn: a |--> a + 1)]
"""
from sage.groups.perm_gps.permgroup_named import SymmetricGroup
R = self.base_ring()
l = [self(v=([R.primitive_element()] + [R.one()] * (self.degree() - 1)))]
for g in SymmetricGroup(self.degree()).gens():
l.append(self(perm=Permutation(g)))
if R.is_field() and not R.is_prime_field():
l.append(self(autom=R.hom([R.primitive_element()**R.characteristic()])))
return l
def order(self) -> Integer:
r"""
Return the number of elements of ``self``.
EXAMPLES::
sage: F.<a> = GF(4)
sage: SemimonomialTransformationGroup(F, 5).order() == (4-1)**5 * factorial(5) * 2
True
"""
from sage.functions.other import factorial
from sage.categories.homset import End
n = self.degree()
R = self.base_ring()
if R.is_field():
multgroup_size = len(R) - 1
autgroup_size = R.degree()
else:
multgroup_size = R.unit_group_order()
autgroup_size = len([x for x in End(R) if x.is_injective()])
|
return multgroup_size**n * factorial(n) * autgroup_size
def _get_action_(self, X, op, self_on_left):
r"""
If ``self`` is the semimonomial group of degree `n` over `R`, then
there is the natural action on `R^n` and on matrices `R^{m \times n}`
for arbitrary integers `m` from the left.
See also:
:class:`~sage.groups.semimonomial_transformations.semimonomial_transformation_group.SemimonomialActionVec` and
:class:`~sage.groups.semimonomial_transformations.semimonomial_transformation_group.SemimonomialActionMat`
EXAMPLES::
sage: F.<a> = GF(4)
sage: s = SemimonomialTransformationGroup(F, 3).an_element()
sage: v = (F**3).0
sage: s*v # indirect doctest
(0, 1, 0)
sage: M = MatrixSpace(F, 3).one()
sage: s*M # indirect doctest
[ 0 1 0]
[ 0 0 1]
[a + 1 0 0]
"""
if self_on_left:
try:
A = SemimonomialActionVec(self, X)
return A
except ValueError:
pass
try:
A = SemimonomialActionMat(self, X)
return A
except ValueError:
pass
return None
def _repr_(self) -> str:
r"""
Return a string describing ``self``.
EXAMPLES::
sage: F.<a> = GF(4)
sage: SemimonomialTransformationGroup(F, 3) # indirect doctest
Semimonomial transformation group over Finite Field in a of size 2^2 of degree 3
"""
return ('Semimonomial transformation group over %s' % self.base_ring() +
' of degree %s' % self.degree())
def _latex_(self) -> str:
r"""
Method for describing ``self`` in LaTeX.
EXAMPLES::
sage: F.<a> = GF(4)
sage: latex(SemimonomialTransformationGroup(F, 3)) # indirect doctest
\left(\Bold{F}_{2^{2}}^3\wr\langle (1,2,3), (1,2) \rangle \right) \rtimes \operatorname{Aut}(\Bold{F}_{2^{2}})
"""
from sage.groups.perm_gps.permgroup_named import SymmetricGroup
ring_latex = self.base_ring()._latex_()
return ('\\left(' + ring_latex + '^' + str(self.degree()) + '\\wr' +
SymmetricGroup(self.degree())._latex_() +
' \\right) \\rtimes \\operatorname{Aut}(' + ring_latex + ')')
class SemimonomialActionVec(Action):
r"""
The natural left action of the semimonomial group on vectors.
The action is defined by:
`(\phi, \pi, \alpha)*(v_0, \ldots, v_{n-1}) :=
(\alpha(v_{\pi(1)-1}) \cdot \phi_0^{-1}, \ldots, \alpha(v_{\pi(n)-1}) \cdot \phi_{n-1}^{-1})`.
(The indexing of vectors is `0`-based here, so
`\psi = (\psi_0, \psi_1, \ldots, \psi_{n-1})`.)
"""
def __init__(self, G, V, check=True):
r"""
Initialization.
EXAMPLES::
sage: F.<a> = GF(4)
sage: s = SemimonomialTransformationGroup(F, 3).an_element()
sage: v = (F**3).1
sage: s*v # indirect doctest
(0, 0, 1)
"""
if check:
from sage.modules.free_module import FreeModule_generic
if not isinstance(G, SemimonomialTransformationGroup):
raise ValueError('%s is not a semimonomial group' % G)
if not isinstance(V, FreeModule_generic):
raise ValueError('%s is not a free module' % V)
if V.ambient_module() != V:
raise ValueError('%s is not equal to its ambient module' % V)
if V.dimension() != G.degree():
raise ValueError('%s has a dimension different to the degree of %s' % (V, G))
if V.base_ring() != G.base_ring():
raise ValueError('%s and %s have different base rings' % (V, G))
Action.__init__(self, G, V.dense_module())
def _act_(self, a, b):
r"""
Apply the semimonomial group element `a` to the vector `b`.
EXAMPLES::
sage: F.<a> = GF(4)
sage: s = SemimonomialTransformationGroup(F, 3).an_element()
sage: v = (F**3).1
sage: s*v # indirect doctest
(0, 0, 1)
"""
b = b.apply_map(a.get_autom())
b = self.codomain()(a.get_perm().action(b))
return b.pairwise_product(self.codomain()(a.get_v_inverse()))
class SemimonomialActionMat(Action):
r"""
The left action of
:class:`~sage.groups.semimonomial_transformations.semimonomial_transformation_group.SemimonomialTransformationGroup`
on matrices over the same ring whose number of columns is equal to the degree.
See :class:`~sage.groups.semimonomial_transformations.semimonomial_transformation_group.SemimonomialActionVec`
for the definition of the action on the row vectors of such a matrix.
"""
def __init__(self, G, M, check=True):
r"""
Initialization.
EXAMPLES::
sage: F.<a> = GF(4)
sage: s = SemimonomialTransformationGroup(F, 3).an_element()
sage: M = MatrixSpace(F, 3).one()
sage: s*M # indirect doctest
[ 0 1 0]
[ 0 0 1]
[a + 1 0 0]
"""
if check:
from sage.matrix.matrix_space import MatrixSpace
if not isinstance(G, SemimonomialTransformationGroup):
raise ValueError('%s is not a semimonomial group' % G)
if not isinstance(M, MatrixSpace):
raise ValueError('%s is not a matrix space' % M)
if M.ncols() != G.degree():
raise ValueError('the number of columns of %s' % M +
' and the degree of %s are different' % G)
if M.base_ring() != G.base_ring():
raise ValueError('%s and %s have different base rings' % (M, G))
Action.__init__(self, G, M)
def _act_(self, a, b):
r"""
Apply the semimonomial group element `a` to the matrix `b`.
EXAMPLES::
sage: F.<a> = GF(4)
sage: s = SemimonomialTransformationGroup(F, 3).an_element()
sage: M = MatrixSpace(F, 3).one()
sage: s*M # indirect doctest
[ 0 1 0]
[ 0 0 1]
[a + 1 0 0]
"""
return self.codomain()([a * x for x in b.rows()])
| |
messages.rs
|
use serde_json;
use serde_repr::{Serialize_repr, Deserialize_repr};
use zmq::Message;
use crate::db::{Delta, Stype, DeltaKey};
use hex::ToHex;
use failure::Error;
// These attributes enable the status to be casted as an i8 object as well
#[derive(Serialize_repr, Deserialize_repr, Clone, Debug)]
#[repr(i8)]
pub enum Status {
Failed = -1,
Passed = 0,
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct IpcMessageRequest {
pub id: String,
#[serde(flatten)]
pub request: IpcRequest
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct IpcMessageResponse {
pub id: String,
#[serde(flatten)]
pub response: IpcResponse
}
#[derive(Serialize, Deserialize, Debug, Clone)]
#[serde(tag = "type")]
pub enum IpcResponse {
GetRegistrationParams { #[serde(flatten)] result: IpcResults },
GetTip { result: IpcDelta },
GetTips { result: IpcResults },
GetAllTips { result: IpcResults },
GetAllAddrs { result: IpcResults },
GetDelta { result: IpcResults },
GetDeltas { result: IpcResults },
GetContract { #[serde(flatten)] result: IpcResults },
UpdateNewContract { address: String, result: IpcResults },
UpdateNewContractOnDeployment { address: String, result: IpcResults },
RemoveContract { address: String, result: IpcResults },
UpdateDeltas { #[serde(flatten)] result: IpcResults },
RemoveDeltas { #[serde(flatten)] result: IpcResults},
NewTaskEncryptionKey { #[serde(flatten)] result: IpcResults },
DeploySecretContract { #[serde(flatten)] result: IpcResults},
ComputeTask { #[serde(flatten)] result: IpcResults },
FailedTask { #[serde(flatten)] result: IpcResults },
GetPTTRequest { #[serde(flatten)] result: IpcResults },
PTTResponse { result: IpcResults },
Error { msg: String },
}
impl IpcResponse {
pub fn display_without_bytecode(&self) -> String {
match self {
IpcResponse::DeploySecretContract {result: e} => {
match e {
IpcResults::DeployResult { used_gas,
delta,
ethereum_address,
ethereum_payload,
signature, .. } =>
format!("IpcResponse {{ used_gas: {}, delta: {:?}, ethereum_address: {}, ethereum_payload: {}, signature: {} }}",
used_gas, delta, ethereum_address, ethereum_payload, signature),
_ => "".to_string(),
}
},
_ => "".to_string(),
}
}
pub fn display_bytecode(&self) -> String {
match self {
IpcResponse::DeploySecretContract {result: e} => {
match e {
IpcResults::DeployResult { output,.. } =>
format!("{}", output),
_ => "".to_string(),
}
},
_ => "".to_string(),
}
}
}
#[derive(Serialize, Deserialize, Debug, Clone)]
#[serde(rename_all = "camelCase", rename = "result")]
pub enum IpcResults {
Errors(Vec<IpcStatusResult>),
|
#[serde(rename = "result")]
Request { request: String, #[serde(rename = "workerSig")] sig: String },
Addresses(Vec<String>),
Delta(String),
Deltas(Vec<IpcDelta>),
#[serde(rename = "result")]
GetContract {
address: String,
bytecode: Vec<u8>,
},
Status(Status),
Tips(Vec<IpcDelta>),
#[serde(rename = "result")]
DeltasResult { status: Status, errors: Vec<IpcStatusResult> },
#[serde(rename = "result")]
DHKey { #[serde(rename = "workerEncryptionKey")] dh_key: String, #[serde(rename = "workerSig")] sig: String },
#[serde(rename = "result")]
RegistrationParams { #[serde(rename = "signingKey")] signing_key: String, report: String, signature: String },
#[serde(rename = "result")]
ComputeResult {
#[serde(rename = "usedGas")]
used_gas: u64,
output: String,
delta: IpcDelta,
#[serde(rename = "ethereumAddress")]
ethereum_address: String,
#[serde(rename = "ethereumPayload")]
ethereum_payload: String,
signature: String,
},
#[serde(rename = "result")]
DeployResult {
#[serde(rename = "preCodeHash")]
pre_code_hash: String,
#[serde(rename = "usedGas")]
used_gas: u64,
output: String,
delta: IpcDelta,
#[serde(rename = "ethereumAddress")]
ethereum_address: String,
#[serde(rename = "ethereumPayload")]
ethereum_payload: String,
signature: String,
},
#[serde(rename = "result")]
FailedTask {
output: String,
#[serde(rename = "usedGas")]
used_gas: u64,
signature: String,
},
}
#[derive(Serialize, Deserialize, Debug, Clone)]
#[serde(tag = "type")]
pub enum IpcRequest {
GetRegistrationParams,
GetTip { input: String },
GetTips { input: Vec<String> },
GetAllTips,
GetAllAddrs,
GetDelta { input: IpcDelta },
GetDeltas { input: Vec<IpcDeltasRange> },
GetContract { input: String },
UpdateNewContract { address: String, bytecode: Vec<u8> },
UpdateNewContractOnDeployment {address: String, bytecode: String, delta: IpcDelta},
RemoveContract { address: String },
UpdateDeltas { deltas: Vec<IpcDelta> },
RemoveDeltas { input: Vec<IpcDeltasRange> },
NewTaskEncryptionKey { #[serde(rename = "userPubKey")] user_pubkey: String },
DeploySecretContract { input: IpcTask},
ComputeTask { input: IpcTask },
GetPTTRequest,
PTTResponse { input: PrincipalResponse },
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct IpcTask {
#[serde(rename = "preCode")]
#[serde(skip_serializing_if = "Option::is_none")]
pub pre_code: Option<Vec<u8>>,
#[serde(rename = "encryptedArgs")]
pub encrypted_args: String,
#[serde(rename = "encryptedFn")]
pub encrypted_fn: String,
#[serde(rename = "userDHKey")]
pub user_dhkey: String,
#[serde(rename = "gasLimit")]
pub gas_limit: u64,
#[serde(rename = "contractAddress")]
pub address: String,
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct IpcStatusResult {
pub address: String,
#[serde(skip_serializing_if = "Option::is_none")]
pub key: Option<i64>,
pub status: Status,
}
#[derive(Serialize, Deserialize, Debug, Clone, Default)]
pub struct IpcDelta {
#[serde(skip_serializing_if = "Option::is_none")]
#[serde(rename = "address")]
pub contract_address: Option<String>,
pub key: u32,
#[serde(skip_serializing_if = "Option::is_none")]
pub data: Option<Vec<u8>>,
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct IpcDeltasRange {
pub address: String,
pub from: u32,
pub to: u32,
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct PrincipalResponse {
pub response: String,
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct Addresses {
pub addresses: Vec<String>,
}
impl std::ops::Deref for Addresses {
type Target = Vec<String>;
fn deref(&self) -> &Vec<String> {
&self.addresses
}
}
impl IpcMessageResponse {
pub fn from_response(response: IpcResponse, id: String) -> Self {
Self { id, response }
}
}
impl IpcMessageRequest {
pub fn from_request(request: IpcRequest, id: String) -> Self {
Self { id, request }
}
}
impl IpcDelta {
pub fn from_delta_key(k: DeltaKey, v: &[u8]) -> Result<Self, Error> {
if let Stype::Delta(indx) = k.key_type {
Ok( IpcDelta { contract_address: Some(k.contract_address.to_hex()), key: indx, data: Some(v.to_vec()) } )
} else {
bail!("This isn't a delta")
}
}
}
impl From<Delta> for IpcDelta {
fn from(delta: Delta) -> Self {
let data = if delta.value.len() == 0 { None } else { Some ( delta.value ) };
let key = delta.key.key_type.unwrap_delta();
IpcDelta { contract_address: None, key, data }
}
}
impl From<Message> for IpcMessageRequest {
fn from(msg: Message) -> Self {
let msg_str = msg.as_str().unwrap();
let req: Self = serde_json::from_str(msg_str).expect(msg_str);
req
}
}
impl Into<Message> for IpcMessageResponse {
fn into(self) -> Message {
let msg = serde_json::to_vec(&self).unwrap();
Message::from(&msg)
}
}
pub(crate) trait UnwrapError<T> {
fn unwrap_or_error(self) -> T;
}
impl<E: std::fmt::Display> UnwrapError<IpcResponse> for Result<IpcResponse, E> {
fn unwrap_or_error(self) -> IpcResponse {
match self {
Ok(m) => m,
Err(e) => {
error!("Unwrapped p2p Message failed: {}", e);
IpcResponse::Error {msg: format!("{}", e)}
}
}
}
}
| |
x.py
|
# -*- coding: utf-8 -*-
# Copyright 2017, IBM.
#
# This source code is licensed under the Apache License, Version 2.0 found in
# the LICENSE.txt file in the root directory of this source tree.
# pylint: disable=invalid-name
"""
Pauli X (bit-flip) gate.
"""
from qiskit.circuit import CompositeGate
from qiskit.circuit import Gate
from qiskit.circuit import QuantumCircuit
from qiskit.circuit import QuantumRegister
from qiskit.circuit.decorators import _op_expand
from qiskit.qasm import pi
from qiskit.extensions.standard.u3 import U3Gate
class XGate(Gate):
"""Pauli X (bit-flip) gate."""
def __init__(self):
"""Create new X gate."""
super().__init__("x", 1, [])
def _define(self):
"""
gate x a {
u3(pi,0,pi) a;
}
"""
definition = []
q = QuantumRegister(1, "q")
rule = [
(U3Gate(pi, 0, pi), [q[0]], [])
]
for inst in rule:
definition.append(inst)
self.definition = definition
|
@_op_expand(1)
def x(self, q):
"""Apply X to q."""
return self.append(XGate(), [q], [])
QuantumCircuit.x = x
CompositeGate.x = x
|
def inverse(self):
"""Invert this gate."""
return XGate() # self-inverse
|
index.js
|
/*
* Copyright 2015, Yahoo Inc.
* Copyrights licensed under the New BSD License.
* See the accompanying LICENSE file for terms.
*/
/* global describe, it */
'use strict';
var expect = require('expect.js');
var extractData = require('../../');
describe('exports', function () {
it('should have a single default export function', function () {
expect(extractData).to.be.a('function');
expect(Object.keys(extractData)).to.eql([]);
});
});
describe('Data shape', function () {
var data = extractData({
pluralRules : true,
relativeFields: true,
});
it('should be keyed by locale', function () {
expect(data).to.have.keys('en', 'zh');
});
it('should have object values for each locale key', function () {
expect(data.en).to.be.an('object');
expect(data.zh).to.be.an('object');
});
describe('locale data object', function () {
it('should have a `locale` property equal to the locale', function () {
var locale = Object.keys(data)[0];
var localeData = data[locale];
expect(localeData).to.have.key('locale');
expect(localeData.locale).to.be.a('string');
expect(localeData.locale).to.equal(locale);
});
it('should have `parentLocale` property when it is not a root locale', function () {
expect(data.en).to.not.have.key('parentLocale');
expect(data['en-US']).to.have.key('parentLocale');
expect(data['en-US'].parentLocale).to.equal('en');
});
it('should have a `pluralRuleFunction`', function () {
expect(data.en).to.have.key('pluralRuleFunction');
expect(data.en.pluralRuleFunction).to.be.a('function');
});
it('should have a `fields` object property', function () {
expect(data.en).to.have.key('fields');
expect(data.en.fields).to.be.an('object');
});
describe('`fields` objects', function () {
var field = data.en.fields[Object.keys(data.en.fields)[0]];
it('should have a `displayName` string property', function () {
expect(field).to.have.key('displayName');
expect(field.displayName).to.be.a('string');
});
it('should have a `relative` object property', function () {
expect(field).to.have.key('relative');
expect(field.relative).to.be.an('object');
});
it('should have a `relativeTime` object property', function () {
expect(field).to.have.key('relativeTime');
expect(field.relativeTime).to.be.an('object');
});
describe('`relative` object', function () {
var keys = Object.keys(field.relative);
it('should have numeric keys', function () {
keys.forEach(function (key) {
key = parseInt(key, 10);
expect(key).to.be.a('number');
expect(isNaN(key)).to.be(false);
});
});
it('should have string values', function () {
keys.forEach(function (key) {
expect(field.relative[key]).to.be.a('string');
});
});
});
describe('`relativeTime` object', function () {
it('should have `future` and `past` object properties', function () {
expect(field.relativeTime).to.have.keys('future', 'past');
expect(field.relativeTime.future).to.be.an('object');
expect(field.relativeTime.past).to.be.an('object');
});
describe('`future` object', function () {
var future = field.relativeTime.future;
var keys = Object.keys(future);
it('should have an `other` key', function () {
expect(future).to.have.key('other');
});
it('should have string values', function () {
keys.forEach(function (key) {
expect(future[key]).to.be.a('string');
});
});
});
describe('`past` object', function () {
var past = field.relativeTime.past;
var keys = Object.keys(past);
it('should have an `other` key', function () {
expect(past).to.have.key('other');
});
it('should have string values', function () {
keys.forEach(function (key) {
expect(past[key]).to.be.a('string');
});
});
});
});
});
});
});
describe('extractData()', function () {
it('should always return an object', function () {
expect(extractData).withArgs().to.not.throwException();
expect(extractData()).to.be.an('object');
});
describe('Options', function () {
describe('locales', function () {
it('should default to all available locales', function () {
var data = extractData({pluralRules: true});
expect(Object.keys(data).length).to.be.greaterThan(0);
});
it('should only accept an array of strings', function () {
expect(extractData).withArgs({locales: []}).to.not.throwException();
expect(extractData).withArgs({locales: ['en']}).to.not.throwException();
expect(extractData).withArgs({locales: [true]}).to.throwException();
expect(extractData).withArgs({locales: true}).to.throwException();
expect(extractData).withArgs({locales: 'en'}).to.throwException();
});
it.skip('should throw when no data exists for a locale', function () {
expect(extractData).withArgs({locales: ['foo-bar']}).to.throwException();
});
it('should always contribute an entry for all specified `locales`', function () {
var data = extractData({
locales : ['en-US', 'zh-Hans-SG'],
pluralRules : true,
relativeFields: true,
});
expect(data).to.have.keys('en-US', 'zh-Hans-SG');
});
it('should recursively expand `locales` to their roots', function () {
var data = extractData({
locales : ['en-US', 'zh-Hans-SG'],
pluralRules : true,
relativeFields: true,
});
expect(data).to.have.keys('en', 'zh', 'zh-Hans');
});
it('should accept `locales` of any case and normalize them', function () {
expect(extractData({
locales : ['en-us', 'ZH-HANT-HK'],
pluralRules : true,
})).to.have.keys('en-US', 'zh-Hant-HK');
});
});
describe('pluralRules', function () {
it('should contribute a `pluralRuleFunction` function property', function () {
var data = extractData({
locales : ['en'],
pluralRules: true,
});
expect(data.en).to.have.key('pluralRuleFunction');
expect(data.en.pluralRuleFunction).to.be.a('function');
});
});
describe('relativeFields', function () {
it('should contribute a `fields` object property', function () {
var data = extractData({
locales : ['en'],
relativeFields: true,
});
expect(data.en).to.have.key('fields');
expect(data.en.fields).to.be.an('object');
});
});
describe('numberFields', function () {
it('should contribute a `numbers` object property', function () {
var data = extractData({
locales : ['en'],
numberFields: true,
});
expect(data.en).to.have.key('numbers');
var numbers = data.en.numbers;
expect(numbers).to.be.an('object');
expect(numbers).to.have.key('decimal');
// [
// [1000, {one: ["0K", 1], other: ["0K", 1]}],
// [10000, %{one: ["00K", 2], other: ["00K", 2]}]
// ]
expect(numbers.decimal).to.have.key('long');
expect(numbers.decimal).to.have.key('short');
expect(numbers.decimal.long.length).to.be.greaterThan(1);
expect(numbers.decimal.short.length).to.be.greaterThan(1);
expect(numbers.decimal.short[0].length).to.be.equal(2);
expect(numbers.decimal.short[0][0]).to.be.equal(1000);
expect(numbers.decimal.short[0][1]).to.have.key('one');
expect(numbers.decimal.short[0][1]).to.have.key('other');
});
});
});
describe('Locale hierarchy', function () {
it('should determine the correct parent locale', function () {
var data = extractData({
locales: [
'en',
'pt-MZ',
'zh-Hant-HK',
|
expect(data['en']).to.not.have.key('parentLocale');
expect(data['pt-MZ']).to.have.key('parentLocale');
expect(data['pt-MZ'].parentLocale).to.equal('pt-PT');
expect(data['zh-Hant-HK']).to.have.key('parentLocale');
expect(data['zh-Hant-HK'].parentLocale).to.equal('zh-Hant');
expect(data['zh-Hant']).to.not.have.key('parentLocale');
});
it('should de-duplicate data with suitable ancestors', function () {
var locales = [
'es-AR',
'es-MX',
'es-VE',
];
var data = extractData({
locales : locales,
pluralRules : true,
relativeFields: true,
numberFields: true,
});
expect(data['es-AR']).to.have.keys('parentLocale');
expect(data['es-AR']).to.not.have.keys('pluralRuleFunction', 'fields');
expect(data['es-MX']).to.have.keys('parentLocale', 'fields');
expect(data['es-MX']).to.not.have.keys('pluralRuleFunction');
expect(data['es-VE']).to.have.keys('parentLocale');
expect(data['es-VE']).to.not.have.keys('pluralRuleFunction', 'fields');
locales.forEach(function (locale) {
var pluralRuleFunction;
var fields;
// Traverse locale hierarchy for `locale` looking for the first
// occurrence of `pluralRuleFunction` and `fields`;
while (locale) {
if (!pluralRuleFunction) {
pluralRuleFunction = data[locale].pluralRuleFunction;
}
if (!fields) {
fields = data[locale].fields;
}
locale = data[locale].parentLocale;
}
expect(pluralRuleFunction).to.be.a('function');
expect(fields).to.be.a('object');
});
});
});
});
|
]
});
|
pollution_A_data_maker.py
|
# This script creates the competition intensity values for the weighted total trade networks
# Importing required modules
import numpy as np
import pandas as pd
# Reading in the data
main_data = pd.read_csv('C:/Users/User/Documents/Data/Pollution/pollution_data.csv')
# Creating a list of all nations
nations = sorted(main_data.Country.unique().tolist())
# Initializing some dataframes
CO2_df = pd.DataFrame()
CH4_df = pd.DataFrame()
NOX_df = pd.DataFrame()
GHG_df = pd.DataFrame()
# Defining two helper functions for subsetting nations to only those with viable data
# This fucntion restricts nations to those with trade network data
def emissions_lists(xxx_nations, ccc_nations, nations):
|
# This function further restricts nations to those with intensity data
def extant_intensity(ydat, listy, emission):
listy2 = [l for l in listy]
for n in listy2:
if (ydat[emission][ydat.Country.tolist().index(n)] > 0) == False:
listy.remove(n)
return listy
# A list of years to iterate through
yrs = [i for i in range(1970,2015)]
# The main loop
for y in yrs:
# Cute message
print('Creating data for year ' + str(y) + '.......')
# Refresh lists of nations to pare down
comp_nations = sorted(main_data.Country.unique().tolist())
co2_nations = sorted(main_data.Country.unique().tolist())
ch4_nations = sorted(main_data.Country.unique().tolist())
nox_nations = sorted(main_data.Country.unique().tolist())
ghg_nations = sorted(main_data.Country.unique().tolist())
# Load W matrix for year y
A_co2 = pd.read_csv('C:/Users/User/Documents/Data/Pollution/Networks/A_' + str(y) + '.csv')
A_ch4 = pd.read_csv('C:/Users/User/Documents/Data/Pollution/Networks/A_' + str(y) + '.csv')
A_nox = pd.read_csv('C:/Users/User/Documents/Data/Pollution/Networks/A_' + str(y) + '.csv')
A_ghg = pd.read_csv('C:/Users/User/Documents/Data/Pollution/Networks/A_' + str(y) + '.csv')
# Determining which countries have all data for current year
# Subset to current year
ydata = main_data[main_data['Year'] == y].reset_index().drop('index', axis = 1)
# Check that each country engaged in competitive behavior
for n in nations:
if (n in A_co2.columns.tolist()) == False:
comp_nations.remove(n)
elif sum(A_co2[n]) == 0:
comp_nations.remove(n)
# Creating a beginning for emissions lists
co2_nations = emissions_lists(co2_nations, comp_nations, nations)
ch4_nations = emissions_lists(ch4_nations, comp_nations, nations)
nox_nations = emissions_lists(nox_nations, comp_nations, nations)
ghg_nations = emissions_lists(ghg_nations, comp_nations, nations)
# Further paring down emissions lists based on the existence of intensities data
co2_nations = extant_intensity(ydata, co2_nations, 'co2_intensity')
ch4_nations = extant_intensity(ydata, ch4_nations, 'ch4_intensity')
nox_nations = extant_intensity(ydata, nox_nations, 'nox_intensity')
ghg_nations = extant_intensity(ydata, ghg_nations, 'ghg_intensity')
# Remove extra rows and columns from TC - for each intensity
co2_indices = A_co2.columns.tolist()
ch4_indices = A_ch4.columns.tolist()
nox_indices = A_nox.columns.tolist()
ghg_indices = A_ghg.columns.tolist()
co2_indices.reverse()
ch4_indices.reverse()
nox_indices.reverse()
ghg_indices.reverse()
for col in co2_indices:
if col not in co2_nations:
A_co2 = A_co2.drop(A_co2.columns.tolist().index(col), axis = 0)
A_co2 = A_co2.drop(col, axis = 1)
for col in ch4_indices:
if col not in ch4_nations:
A_ch4 = A_ch4.drop(A_ch4.columns.tolist().index(col), axis = 0)
A_ch4 = A_ch4.drop(col, axis = 1)
for col in nox_indices:
if col not in nox_nations:
A_nox = A_nox.drop(A_nox.columns.tolist().index(col), axis = 0)
A_nox = A_nox.drop(col, axis = 1)
for col in ghg_indices:
if col not in ghg_nations:
A_ghg = A_ghg.drop(A_ghg.columns.tolist().index(col), axis = 0)
A_ghg = A_ghg.drop(col, axis = 1)
# Normalize TC - for each intensity
# This creates a row normalized matrix -- normalized exports!
co2_sums = [sum(A_co2.iloc[row]) for row in range(len(A_co2))]
ch4_sums = [sum(A_ch4.iloc[row]) for row in range(len(A_ch4))]
nox_sums = [sum(A_nox.iloc[row]) for row in range(len(A_nox))]
ghg_sums = [sum(A_ghg.iloc[row]) for row in range(len(A_ghg))]
M_co2 = np.matrix(A_co2)
M_ch4 = np.matrix(A_ch4)
M_nox = np.matrix(A_nox)
M_ghg = np.matrix(A_ghg)
for row in range(len(co2_sums)):
M_co2[row,:] = M_co2[row,:] / co2_sums[row]
for row in range(len(ch4_sums)):
M_ch4[row,:] = M_ch4[row,:] / ch4_sums[row]
for row in range(len(nox_sums)):
M_nox[row,:] = M_nox[row,:] / nox_sums[row]
for row in range(len(ghg_sums)):
M_ghg[row,:] = M_ghg[row,:] / ghg_sums[row]
# Create vector of actual emissions intensities
co2_ints = np.matrix([ydata.co2_intensity[ydata.Country.tolist().index(n)] for n in co2_nations]).T
ch4_ints = np.matrix([ydata.ch4_intensity[ydata.Country.tolist().index(n)] for n in ch4_nations]).T
nox_ints = np.matrix([ydata.nox_intensity[ydata.Country.tolist().index(n)] for n in nox_nations]).T
ghg_ints = np.matrix([ydata.ghg_intensity[ydata.Country.tolist().index(n)] for n in ghg_nations]).T
# Multpliy matrix X vector - for each intensity
co2_data = np.matmul(M_co2,co2_ints)
ch4_data = np.matmul(M_ch4,ch4_ints)
nox_data = np.matmul(M_nox,nox_ints)
ghg_data = np.matmul(M_ghg,ghg_ints)
# Append to DataFrame
current_year = [y for c in co2_nations]
next_year = [y+1 for c in co2_nations]
co2_d = [x[0] for x in co2_data.tolist()]
temp_co2 = pd.DataFrame({'Current Year':current_year, 'Next Year':next_year,
'Nation':co2_nations, 'CO2 Data':co2_d})
CO2_df = pd.concat([CO2_df, temp_co2], axis = 0)
current_year = [y for c in ch4_nations]
next_year = [y+1 for c in ch4_nations]
ch4_d = [x[0] for x in ch4_data.tolist()]
temp_ch4 = pd.DataFrame({'Current Year':current_year, 'Next Year':next_year,
'Nation':ch4_nations, 'CH4 Data':ch4_d})
CH4_df = pd.concat([CH4_df, temp_ch4], axis = 0)
current_year = [y for c in nox_nations]
next_year = [y+1 for c in nox_nations]
nox_d = [x[0] for x in nox_data.tolist()]
temp_nox = pd.DataFrame({'Current Year':current_year, 'Next Year':next_year,
'Nation':nox_nations, 'NOX Data':nox_d})
NOX_df = pd.concat([NOX_df, temp_nox], axis = 0)
current_year = [y for c in ghg_nations]
next_year = [y+1 for c in ghg_nations]
ghg_d = [x[0] for x in ghg_data.tolist()]
temp_ghg = pd.DataFrame({'Current Year':current_year, 'Next Year':next_year,
'Nation':ghg_nations, 'GHG Data':ghg_d})
GHG_df = pd.concat([GHG_df, temp_ghg], axis = 0)
# Write dataframe to file
CO2_df.to_csv('C:/Users/User/Documents/Data/Pollution/A_DATA_CO2.csv', index = False)
CH4_df.to_csv('C:/Users/User/Documents/Data/Pollution/A_DATA_CH4.csv', index = False)
NOX_df.to_csv('C:/Users/User/Documents/Data/Pollution/A_DATA_NOX.csv', index = False)
GHG_df.to_csv('C:/Users/User/Documents/Data/Pollution/A_DATA_GHG.csv', index = False)
|
for c in nations:
if c not in ccc_nations: # this will be comp_nations in our case
xxx_nations.remove(c)
return xxx_nations
|
alert_actions_helper.py
|
#
# Copyright 2021 Splunk Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
import os.path as op
import sys
from os import makedirs, remove
from splunk_add_on_ucc_framework import conf_parser
from .alert_actions_merge import merge_conf_file
def write_file(file_name, file_path, content, logger, merge="stanza_overwrite"):
logger.debug('operation="write", object="%s" object_type="file"', file_path)
do_merge = False
if file_name.endswith(".conf") or file_name.endswith("conf.spec"):
do_merge = True
else:
logger.info(
'event="Will not merge file="%s", '
+ 'reason="Only support conf file merge"',
file_path,
)
if file_path:
new_file = None
if op.exists(file_path) and do_merge:
|
if new_file:
try:
with open(new_file, "w+") as fhandler:
fhandler.write(content)
merge_conf_file(new_file, file_path, merge)
finally:
if op.exists(new_file):
remove(new_file)
else:
if not op.exists(op.dirname(file_path)):
makedirs(op.dirname(file_path))
with open(file_path, "w+") as fhandler:
fhandler.write(content)
if do_merge:
# need to process the file with conf parser
parser = conf_parser.TABConfigParser()
parser.read(file_path)
with open(file_path, "w") as df:
parser.write(df)
else:
sys.stdout.write(f"\n##################File {file_name}##################\n")
sys.stdout.write(content)
GLOBAL_SETTING_TYPE_MAP = {"text": "text", "checkbox": "bool", "password": "password"}
GLOBAL_SETTING_VALUE_NAME_MAP = {
"text": "content",
"bool": "bool",
"password": "password",
}
def convert_custom_setting(parameters):
"""
convert
[{
"default_value": "message",
"name": "notification_type",
"required": true,
"help_string": "Choose style of HipChat notification.",
"possible_values": {
"Application Card": "card",
"Message": "message"
},
"label": "Notification Style",
"format_type": "dropdownlist",
"value": "xxxx"
}]
to
[{
"title": "customized key",
"name": "customized name",
"type": "text",
"description": "description of customized key"
}]
"""
formated = []
if not parameters:
return formated
for param in parameters:
if param.get("format_type") not in list(GLOBAL_SETTING_TYPE_MAP.keys()):
msg = 'format_type="{}" is not support for global setting'.format(
param.get("format_type")
)
raise Exception(msg)
one_param = {
"title": param.get("label"),
"name": param.get("name"),
"type": GLOBAL_SETTING_TYPE_MAP[param.get("format_type")],
"description": param.get("help_string"),
}
formated.append(one_param)
return formated
def convert_global_setting(global_settings):
"""
convert
{
"customized_settings": {
"string_label": {
"type": "text",
"content": "string"
},
"password": {
"type": "password",
"password": "123"
},
"checkbox": {
"type": "bool",
"bool": true
}
},
"proxy_settings": {
"proxy_password": "sef",
"proxy_type": "http",
"proxy_url": "1.2.3.4",
},
"global_settings": {
"log_level": "INFO"
}
to
{
"title": "Proxy",
"name": "proxy",
"type": "default_proxy",
"description": "proxy settings"
},
{
"title": "Account Key Title",
"name": "username",
"type": "default_account",
"description": "The username of the user account"
},
{
"title": "Account Secret Title",
"name": "password",
"type": "default_account",
"description": "The password of the user account"
},
{
"title": "customized key",
"name": "customized name",
"type": "text",
"description": "description of customized key"
"""
converted = []
if not global_settings:
return converted
for type, settings in list(global_settings.items()):
if type == "proxy_settings":
proxy = {
"title": "Proxy",
"name": "proxy",
"type": "default_proxy",
"description": "proxy settings",
}
converted.append(proxy)
elif type == "log_settings":
logging = {
"title": "Logging",
"name": "logging",
"type": "default_logging",
"description": "logging setting",
}
converted.append(logging)
elif type == "credential_settings":
username = {
"title": "Account Key Title",
"name": "tab_default_account_username",
"type": "default_account",
"description": "The username of the user account",
}
password = {
"title": "Account Secret Title",
"name": "tab_default_account_password",
"type": "default_account",
"description": "The password of the user account",
}
converted.append(username)
converted.append(password)
elif type == "customized_settings":
custom_settings = convert_custom_setting(settings)
converted += custom_settings
return converted
def convert_global_setting_previous(global_settings):
"""
convert global_settings=[
{
"type": "proxy"
},
{
"type": "logging"
},
{
"type": "account"
},
{
"type": "custom",
"parameters": []
}
]
to [
{
"title": "Proxy",
"name": "proxy",
"type": "default_proxy",
"description": "proxy settings"
},
{
"title": "Account Key Title",
"name": "username",
"type": "default_account",
"description": "The username of the user account"
},
{
"title": "Account Secret Title",
"name": "password",
"type": "default_account",
"description": "The password of the user account"
},
{
"title": "customized key",
"name": "customized name",
"type": "text",
"description": "description of customized key"
}
]
"""
converted = []
if not global_settings:
return converted
for setting in global_settings:
if setting.get("type") == "proxy":
proxy = {
"title": "Proxy",
"name": "proxy",
"type": "default_proxy",
"description": "proxy settings",
}
converted.append(proxy)
elif setting.get("type") == "logging":
logging = {
"title": "Logging",
"name": "logging",
"type": "default_logging",
"description": "logging setting",
}
converted.append(logging)
elif setting.get("type") == "account":
username = {
"title": "Account Key Title",
"name": "username",
"type": "default_account",
"description": "The username of the user account",
}
password = {
"title": "Account Secret Title",
"name": "password",
"type": "default_account",
"description": "The password of the user account",
}
converted.append(username)
converted.append(password)
elif setting.get("type") == "custom":
custom_settings = convert_custom_setting(setting.get("parameters"))
converted += custom_settings
return converted
def get_test_parameter_type(param):
if not param:
return None
if param.get("format_type") in list(GLOBAL_SETTING_TYPE_MAP.keys()):
return GLOBAL_SETTING_TYPE_MAP.get(param.get("format_type"))
return None
def get_parameter_type(param, parameters_meta, logger):
if not parameters_meta:
logger.info('parameters_meta="None"')
return None
if not param:
logger.info('param="None"')
return None
for param_meta in parameters_meta:
if param == param_meta["name"]:
return GLOBAL_SETTING_TYPE_MAP.get(param_meta["format_type"])
return None
def convert_test_global_settings(test_global_settings, logger):
"""
convert to:
{
"customized_settings": {
"string_label": {
"type": "text",
"content": "string"
},
"password": {
"type": "password",
"password": "123"
},
"checkbox": {
"type": "bool",
"bool": true
}
},
"proxy_settings": {
"proxy_password": "sef",
"proxy_type": "http",
"proxy_url": "1.2.3.4",
"proxy_rdns": "0",
"proxy_username": "sdf",
"proxy_port": "34",
"proxy_enabled": "1"
},
"global_settings": {
"log_level": "INFO"
}
}
"""
if not test_global_settings:
logger.info('test_global_settings="%s"', test_global_settings)
return {}
converted = {}
for type, settings in list(test_global_settings.items()):
if type == "customized_settings":
converted["customized_settings"] = {}
for setting in settings:
type = get_test_parameter_type(setting)
if not type:
msg = f"No type for {setting} in customized_settings"
raise NotImplementedError(msg)
converted["customized_settings"][setting["name"]] = {
"type": type,
GLOBAL_SETTING_VALUE_NAME_MAP[type]: setting.get("value"),
}
elif type == "log_settings":
converted["global_settings"] = settings
else:
converted[type] = settings
return converted
def split_path(path):
"""
split a path into a list
"""
if not path:
return None
paths = []
(head, tail) = op.split(path)
while tail:
paths.insert(0, tail)
(head, tail) = op.split(head)
(drive, rest) = op.splitdrive(head)
if drive:
paths.insert(0, drive)
else:
paths.insert(0, head)
return paths
|
new_file = op.join(op.dirname(file_path), "new_" + file_name)
|
non_compliant.py
|
# tests for things that are not implemented, or have non-compliant behaviour
try:
import array
import struct
except ImportError:
print("SKIP")
raise SystemExit
# when super can't find self
try:
exec("def f(): super()")
except SyntaxError:
print("SyntaxError")
# store to exception attribute is not allowed
try:
ValueError().x = 0
except AttributeError:
print("AttributeError")
# array deletion not implemented
try:
a = array.array("b", (1, 2, 3))
del a[1]
except TypeError:
print("TypeError")
# slice with step!=1 not implemented
try:
a = array.array("b", (1, 2, 3))
print(a[3:2:2])
except NotImplementedError:
print("NotImplementedError")
# containment, looking for integer not implemented
try:
print(1 in array.array("B", b"12"))
except NotImplementedError:
print("NotImplementedError")
# uPy raises TypeError, shold be ValueError
try:
"%c" % b"\x01\x02"
except (TypeError, ValueError):
print("TypeError, ValueError")
# attributes/subscr not implemented
try:
print("{a[0]}".format(a=[1, 2]))
except NotImplementedError:
print("NotImplementedError")
# str(...) with keywords not implemented
try:
str(b"abc", encoding="utf8")
except NotImplementedError:
print("NotImplementedError")
# str.rsplit(None, n) not implemented
try:
"a a a".rsplit(None, 1)
except NotImplementedError:
print("NotImplementedError")
# str.endswith(s, start) not implemented
try:
"abc".endswith("c", 1)
except NotImplementedError:
print("NotImplementedError")
# str subscr with step!=1 not implemented
try:
print("abc"[1:2:3])
except NotImplementedError:
print("NotImplementedError")
# bytes(...) with keywords not implemented
try:
bytes("abc", encoding="utf8")
except NotImplementedError:
print("NotImplementedError")
# bytes subscr with step!=1 not implemented
try:
b"123"[0:3:2]
except NotImplementedError:
print("NotImplementedError")
# tuple load with step!=1 not implemented
try:
()[2:3:4]
except NotImplementedError:
print("NotImplementedError")
# list store with step!=1 not implemented
try:
[][2:3:4] = []
except NotImplementedError:
|
# list delete with step!=1 not implemented
try:
del [][2:3:4]
except NotImplementedError:
print("NotImplementedError")
# array slice assignment with unsupported RHS
try:
bytearray(4)[0:1] = [1, 2]
except NotImplementedError:
print("NotImplementedError")
# can't assign attributes to a function
def f():
pass
try:
f.x = 1
except AttributeError:
print("AttributeError")
# can't call a function type (ie make new instances of a function)
try:
type(f)()
except TypeError:
print("TypeError")
# test when object explicitly listed at not-last position in parent tuple
# this is not compliant with CPython because of illegal MRO
class A:
def foo(self):
print("A.foo")
class B(object, A):
pass
B().foo()
# can't assign property (or other special accessors) to already-subclassed class
class A:
pass
class B(A):
pass
try:
A.bar = property()
except AttributeError:
print("AttributeError")
|
print("NotImplementedError")
|
chi.go
|
package router
import (
"net/http"
"github.com/go-chi/chi"
)
// ChiRouter is an adapter for chi router that implements the Router interface
type ChiRouter struct {
mux chi.Router
}
// NewChiRouterWithOptions creates a new instance of ChiRouter
// with the provided options
func NewChiRouterWithOptions(options Options) *ChiRouter {
router := chi.NewRouter()
router.NotFound(options.NotFoundHandler)
return &ChiRouter{
mux: router,
}
}
// NewChiRouter creates a new instance of ChiRouter
func NewChiRouter() *ChiRouter {
return NewChiRouterWithOptions(DefaultOptions)
}
// ServeHTTP server the HTTP requests
func (r *ChiRouter) ServeHTTP(w http.ResponseWriter, req *http.Request) {
r.mux.ServeHTTP(w, req)
}
// Any register a path to all HTTP methods
func (r *ChiRouter) Any(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Handle(path, handler)
}
// Handle registers a path, method and handlers to the router
func (r *ChiRouter) Handle(method string, path string, handler http.HandlerFunc, handlers ...Constructor) {
switch method {
case http.MethodGet:
r.GET(path, handler, handlers...)
case http.MethodPost:
r.POST(path, handler, handlers...)
case http.MethodPut:
r.PUT(path, handler, handlers...)
case http.MethodPatch:
r.PATCH(path, handler, handlers...)
case http.MethodDelete:
r.DELETE(path, handler, handlers...)
case http.MethodHead:
r.HEAD(path, handler, handlers...)
case http.MethodOptions:
r.OPTIONS(path, handler, handlers...)
}
}
// GET registers a HTTP GET path
func (r *ChiRouter) GET(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Get(path, handler)
}
// POST registers a HTTP POST path
func (r *ChiRouter) POST(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Post(path, handler)
}
// PUT registers a HTTP PUT path
func (r *ChiRouter) PUT(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Put(path, handler)
}
|
}
// PATCH registers a HTTP PATCH path
func (r *ChiRouter) PATCH(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Patch(path, handler)
}
// HEAD registers a HTTP HEAD path
func (r *ChiRouter) HEAD(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Head(path, handler)
}
// OPTIONS registers a HTTP OPTIONS path
func (r *ChiRouter) OPTIONS(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Options(path, handler)
}
// TRACE registers a HTTP TRACE path
func (r *ChiRouter) TRACE(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Trace(path, handler)
}
// CONNECT registers a HTTP CONNECT path
func (r *ChiRouter) CONNECT(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Connect(path, handler)
}
// Group creates a child router for a specific path
func (r *ChiRouter) Group(path string) Router {
return &ChiRouter{r.mux.Route(path, nil)}
}
// Use attaches a middleware to the router
func (r *ChiRouter) Use(handlers ...Constructor) Router {
r.mux.Use(r.wrapConstructor(handlers)...)
return r
}
// RoutesCount returns number of routes registered
func (r *ChiRouter) RoutesCount() int {
return r.routesCount(r.mux)
}
func (r *ChiRouter) routesCount(routes chi.Routes) int {
count := len(routes.Routes())
for _, route := range routes.Routes() {
if nil != route.SubRoutes {
count += r.routesCount(route.SubRoutes)
}
}
return count
}
func (r *ChiRouter) with(handlers ...Constructor) chi.Router {
return r.mux.With(r.wrapConstructor(handlers)...)
}
func (r *ChiRouter) wrapConstructor(handlers []Constructor) []func(http.Handler) http.Handler {
var cons = make([]func(http.Handler) http.Handler, 0)
for _, m := range handlers {
cons = append(cons, (func(http.Handler) http.Handler)(m))
}
return cons
}
|
// DELETE registers a HTTP DELETE path
func (r *ChiRouter) DELETE(path string, handler http.HandlerFunc, handlers ...Constructor) {
r.with(handlers...).Delete(path, handler)
|
BrowserPreview.tsx
|
import * as React from 'react';
import {truncate} from 'underscore.string';
import {TooltipPlacement} from '../../utils';
import {Svg} from '../svg';
import {Tooltip} from '../tooltip';
export interface BrowserPreviewProps {
headerDescription?: string;
title?: string;
}
export const BrowserPreview: React.FunctionComponent<BrowserPreviewProps> = ({children, headerDescription, title}) => (
<div className="browser-preview flex flex-column">
<BrowserPreviewHeader tooltipTitle={headerDescription ?? DefaultHeaderDescription} title={title ?? ''} />
<div className="browser-preview__content flex flex-column flex-auto px4 py3">{children}</div>
</div>
);
const BrowserPreviewHeader: React.FunctionComponent<{tooltipTitle: string; title?: string}> = ({
title,
tooltipTitle,
}) => (
<div className="browser-preview__header flex space-between px2 py1">
<div>
<span className="bolder">Preview</span>
<Tooltip title={tooltipTitle} placement={TooltipPlacement.Right}>
<Svg svgName="info" svgClass="icon mod-14 ml1" />
</Tooltip>
</div>
<div>
<span className="bolder">{truncate(title, TitleMaxLength)}</span>
|
<div>
<span className="white-dot" />
<span className="white-dot" />
<span className="white-dot" />
</div>
</div>
);
const DefaultHeaderDescription =
'The final look in your search page may differ due to the customization you made in your page.';
const TitleMaxLength = 20;
|
</div>
|
indexer.go
|
package kubernetes
import (
"context"
"errors"
"fmt"
"strings"
corev1 "k8s.io/api/core/v1"
kerrors "k8s.io/apimachinery/pkg/api/errors"
"k8s.io/apimachinery/pkg/runtime"
"k8s.io/apimachinery/pkg/runtime/schema"
"sigs.k8s.io/controller-runtime/pkg/client"
)
const (
indexFieldPublicKey = "wireguard-public-key"
)
var ErrGotMultipleNodesWithPublicKey = errors.New("got more than 1 node with the public key. This must not happen")
func publicKeyIndexFunc(o runtime.Object) []string {
node, ok := o.(*corev1.Node)
if !ok {
return nil
}
if key := node.Annotations[AnnotationKeyPublicKey]; key != "" {
return []string{key}
}
return nil
}
func RegisterPublicKeyIndexer(ctx context.Context, indexer client.FieldIndexer) error {
return indexer.IndexField(ctx, &corev1.Node{}, indexFieldPublicKey, publicKeyIndexFunc)
}
func GetNodeByPublicKey(ctx context.Context, c client.Reader, publicKey string) (*corev1.Node, error) {
nodeList := &corev1.NodeList{}
if err := c.List(ctx, nodeList, client.MatchingFields{indexFieldPublicKey: publicKey}); err != nil {
return nil, fmt.Errorf("unable to list nodes: %w", err)
}
if len(nodeList.Items) == 0 {
// Return a NotFound error so we can check that later
return nil, kerrors.NewNotFound(
schema.GroupResource{
Group: "",
Resource: "Node",
},
publicKey,
)
}
if len(nodeList.Items) > 1 {
return nil, fmt.Errorf("%w: PublicKey='%s' Nodes:%s", ErrGotMultipleNodesWithPublicKey, publicKey, strings.Join(getNodeNames(nodeList), ","))
}
return &nodeList.Items[0], nil
}
func
|
(nodeList *corev1.NodeList) []string {
names := make([]string, len(nodeList.Items))
for i := range nodeList.Items {
names[i] = nodeList.Items[i].Name
}
return names
}
|
getNodeNames
|
attributes.rs
|
//! Basic font attributes: stretch, weight and style.
use super::internal::{head::Os2, RawFont};
use super::{tag_from_bytes, FontRef, Tag, Setting};
use core::fmt;
use core::hash::{Hash, Hasher};
// Variations that apply to attributes.
const WDTH: Tag = tag_from_bytes(b"wdth");
const WGHT: Tag = tag_from_bytes(b"wght");
const SLNT: Tag = tag_from_bytes(b"slnt");
const ITAL: Tag = tag_from_bytes(b"ital");
/// Primary attributes for font classification: stretch, weight and style.
///
/// This struct is created by the [`attributes`](FontRef::attributes) method on [`FontRef`].
#[derive(Copy, Clone)]
pub struct Attributes(pub u32);
impl Attributes {
/// Creates new font attributes from the specified stretch, weight and
/// style.
pub const fn new(stretch: Stretch, weight: Weight, style: Style) -> Self {
let stretch = stretch.0 as u32 & 0x1FF;
let weight = weight.0 as u32 & 0x3FF;
let style = style.pack();
Self(style | weight << 9 | stretch << 19)
}
/// Extracts the attributes from the specified font.
pub fn from_font<'a>(font: &FontRef<'a>) -> Self {
let mut attrs = Self::from_os2(font.os2().as_ref());
let mut var_bits = 0;
for var in font.variations() {
match var.tag() {
WDTH => var_bits |= 1,
WGHT => var_bits |= 2,
SLNT => var_bits |= 4,
ITAL => var_bits |= 8,
_ => {}
}
}
attrs.0 |= var_bits << 28;
attrs
}
pub(crate) fn from_os2(os2: Option<&Os2>) -> Self {
if let Some(os2) = os2 {
let flags = os2.selection_flags();
let style = if flags.italic() {
Style::Italic
} else if flags.oblique() {
Style::Oblique(ObliqueAngle::default())
} else {
Style::Normal
};
let weight = Weight(os2.weight_class() as u16);
let stretch = Stretch::from_raw(os2.width_class() as u16);
Self::new(stretch, weight, style)
} else {
Self::default()
}
}
/// Returns the stretch attribute.
pub fn stretch(&self) -> Stretch {
Stretch((self.0 >> 19 & 0x1FF) as u16)
}
/// Returns the weight attribute.
pub fn weight(&self) -> Weight {
Weight((self.0 >> 9 & 0x3FF) as u16)
}
/// Returns the style attribute.
pub fn style(&self) -> Style {
Style::unpack(self.0 & 0x1FF)
}
/// Returns a tuple containing all attributes.
pub fn parts(&self) -> (Stretch, Weight, Style) {
(self.stretch(), self.weight(), self.style())
}
/// Returns true if the font has variations corresponding to primary
/// attributes.
pub fn has_variations(&self) -> bool {
(self.0 >> 28) != 0
}
/// Returns true if the font has a variation for the stretch attribute.
pub fn has_stretch_variation(&self) -> bool {
let var_bits = self.0 >> 28;
var_bits & 1 != 0
}
/// Returns true if the font has a variation for the weight attribute.
pub fn has_weight_variation(&self) -> bool {
let var_bits = self.0 >> 28;
var_bits & 2 != 0
}
/// Returns true if the font has a variation for the oblique style
/// attribute.
pub fn has_oblique_variation(&self) -> bool {
let var_bits = self.0 >> 28;
var_bits & 4 != 0
}
/// Returns true if the font has a variation for the italic style
/// attribute.
pub fn has_italic_variation(&self) -> bool {
let var_bits = self.0 >> 28;
var_bits & 8 != 0
}
/// Returns a synthesis analysis based on the requested attributes with
/// respect to this set of attributes.
pub fn synthesize(&self, requested: Attributes) -> Synthesis {
let mut synth = Synthesis::default();
if self.0 << 4 == requested.0 << 4 {
return synth;
}
let mut len = 0usize;
if self.has_stretch_variation() {
let stretch = self.stretch();
let req_stretch = requested.stretch();
if stretch != requested.stretch() {
synth.vars[len] = Setting { tag: WDTH, value: req_stretch.to_percentage() };
len += 1;
}
}
let (weight, req_weight) = (self.weight(), requested.weight());
if weight != req_weight {
if self.has_weight_variation() {
synth.vars[len] = Setting { tag: WGHT, value: req_weight.0 as f32 };
len += 1;
} else if req_weight > weight {
synth.embolden = true;
}
}
let (style, req_style) = (self.style(), requested.style());
if style != req_style {
match req_style {
Style::Normal => {}
Style::Italic => {
match style {
Style::Normal => {
if self.has_italic_variation() {
synth.vars[len] = Setting { tag: ITAL, value: 1. };
len += 1;
} else if self.has_oblique_variation() {
synth.vars[len] = Setting { tag: SLNT, value: 14. };
len += 1;
} else {
synth.skew = 14;
}
}
_ => {}
}
}
Style::Oblique(angle) => {
match style {
Style::Normal => {
let degrees = angle.to_degrees();
if self.has_oblique_variation() {
synth.vars[len] = Setting { tag: SLNT, value: degrees };
len += 1;
} else if self.has_italic_variation() && degrees > 0. {
synth.vars[len] = Setting { tag: ITAL, value: 1. };
len += 1;
} else {
synth.skew = degrees as i8;
}
}
_ => {}
}
}
}
}
synth.len = len as u8;
synth
}
}
impl Default for Attributes {
fn default() -> Self {
Self::new(Stretch::NORMAL, Weight::NORMAL, Style::Normal)
}
}
impl PartialEq for Attributes {
fn eq(&self, other: &Self) -> bool {
self.0 << 4 == other.0 << 4
}
}
impl Eq for Attributes {}
impl Hash for Attributes {
fn hash<H: Hasher>(&self, state: &mut H) {
(self.0 << 4).hash(state);
}
}
impl fmt::Display for Attributes {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
let mut space = "";
let (stretch, weight, style) = self.parts();
if style == Style::Normal && weight == Weight::NORMAL && stretch == Stretch::NORMAL {
return write!(f, "regular");
}
if stretch != Stretch::NORMAL {
write!(f, "{}", stretch)?;
space = " ";
}
if style != Style::Normal {
write!(f, "{}{}", space, style)?;
space = " ";
}
if weight != Weight::NORMAL {
write!(f, "{}{}", space, weight)?;
}
|
Ok(())
}
}
impl fmt::Debug for Attributes {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "{:?}", self.parts())?;
if self.has_stretch_variation() {
write!(f, "+wdth")?;
}
if self.has_weight_variation() {
write!(f, "+wght")?;
}
if self.has_italic_variation() {
write!(f, "+ital")?;
}
if self.has_oblique_variation() {
write!(f, "+slnt")?;
}
Ok(())
}
}
impl From<Stretch> for Attributes {
fn from(s: Stretch) -> Self {
Self::new(s, Weight::default(), Style::default())
}
}
impl From<Weight> for Attributes {
fn from(w: Weight) -> Self {
Self::new(Stretch::default(), w, Style::default())
}
}
impl From<Style> for Attributes {
fn from(s: Style) -> Self {
Self::new(Stretch::default(), Weight::default(), s)
}
}
impl From<()> for Attributes {
fn from(_: ()) -> Self {
Self::default()
}
}
impl From<(Stretch, Weight, Style)> for Attributes {
fn from(parts: (Stretch, Weight, Style)) -> Self {
Self::new(parts.0, parts.1, parts.2)
}
}
/// Angle of an oblique style in degrees from -90 to 90.
#[derive(Copy, Clone, PartialEq, Eq, Debug)]
pub struct ObliqueAngle(pub(crate) u8);
impl ObliqueAngle {
/// Creates a new oblique angle from degrees.
pub fn from_degrees(degrees: f32) -> Self {
let a = degrees.min(90.).max(-90.) + 90.;
Self(a as u8)
}
/// Creates a new oblique angle from radians.
pub fn from_radians(radians: f32) -> Self {
let degrees = radians * 180. / core::f32::consts::PI;
Self::from_degrees(degrees)
}
/// Creates a new oblique angle from gradians.
pub fn from_gradians(gradians: f32) -> Self {
Self::from_degrees(gradians / 400. * 360.)
}
/// Creates a new oblique angle from turns.
pub fn from_turns(turns: f32) -> Self {
Self::from_degrees(turns * 360.)
}
/// Returns the oblique angle in degrees.
pub fn to_degrees(self) -> f32 {
self.0 as f32 - 90.
}
}
impl Default for ObliqueAngle {
fn default() -> Self {
Self::from_degrees(14.)
}
}
/// Visual style or 'slope' of a font.
#[derive(Copy, Clone, PartialEq, Eq, Debug)]
pub enum Style {
Normal,
Italic,
Oblique(ObliqueAngle),
}
impl Style {
/// Parses a style from a CSS style value.
pub fn parse(mut s: &str) -> Option<Self> {
s = s.trim();
Some(match s {
"normal" => Self::Normal,
"italic" => Self::Italic,
"oblique" => Self::Oblique(ObliqueAngle::from_degrees(14.)),
_ => {
if s.starts_with("oblique ") {
s = s.get(8..)?;
if s.ends_with("deg") {
s = s.get(..s.len() - 3)?;
if let Ok(a) = s.trim().parse::<f32>() {
return Some(Self::Oblique(ObliqueAngle::from_degrees(a)));
}
} else if s.ends_with("grad") {
s = s.get(..s.len() - 4)?;
if let Ok(a) = s.trim().parse::<f32>() {
return Some(Self::Oblique(ObliqueAngle::from_gradians(a)));
}
} else if s.ends_with("rad") {
s = s.get(..s.len() - 3)?;
if let Ok(a) = s.trim().parse::<f32>() {
return Some(Self::Oblique(ObliqueAngle::from_radians(a)));
}
} else if s.ends_with("turn") {
s = s.get(..s.len() - 4)?;
if let Ok(a) = s.trim().parse::<f32>() {
return Some(Self::Oblique(ObliqueAngle::from_turns(a)));
}
}
return Some(Self::Oblique(ObliqueAngle::default()));
}
return None;
}
})
}
/// Creates a new oblique style with the specified angle
/// in degrees.
pub fn from_degrees(degrees: f32) -> Self {
Self::Oblique(ObliqueAngle::from_degrees(degrees))
}
/// Returns the angle of the style in degrees.
pub fn to_degrees(&self) -> f32 {
match self {
Self::Italic => 14.,
Self::Oblique(angle) => angle.to_degrees(),
_ => 0.,
}
}
fn unpack(bits: u32) -> Self {
if bits & 1 != 0 {
Self::Oblique(ObliqueAngle((bits >> 1) as u8))
} else if bits == 0b110 {
Self::Italic
} else {
Self::Normal
}
}
const fn pack(&self) -> u32 {
match self {
Self::Normal => 0b10,
Self::Italic => 0b110,
Self::Oblique(angle) => 1 | (angle.0 as u32) << 1,
}
}
}
impl fmt::Display for Style {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(
f,
"{}",
match self {
Self::Normal => "normal",
Self::Italic => "italic",
Self::Oblique(angle) => {
let degrees = angle.to_degrees();
if degrees == 14. {
"oblique"
} else {
return write!(f, "oblique({}deg)", degrees);
}
}
}
)
}
}
impl Default for Style {
fn default() -> Self {
Self::Normal
}
}
/// Visual weight class of a font on a scale from 1 to 1000.
#[derive(Copy, Clone, PartialOrd, Ord, PartialEq, Eq, Hash, Debug)]
pub struct Weight(pub u16);
impl Weight {
pub const THIN: Weight = Weight(100);
pub const EXTRA_LIGHT: Weight = Weight(200);
pub const LIGHT: Weight = Weight(300);
pub const NORMAL: Weight = Weight(400);
pub const MEDIUM: Weight = Weight(500);
pub const SEMI_BOLD: Weight = Weight(600);
pub const BOLD: Weight = Weight(700);
pub const EXTRA_BOLD: Weight = Weight(800);
pub const BLACK: Weight = Weight(900);
/// Parses a CSS style font weight attribute.
pub fn parse(s: &str) -> Option<Self> {
let s = s.trim();
Some(match s {
"normal" => Self::NORMAL,
"bold" => Self::BOLD,
_ => Self(s.parse::<u32>().ok()?.min(1000).max(1) as u16),
})
}
}
impl fmt::Display for Weight {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
let s = match *self {
Self::THIN => "thin",
Self::EXTRA_LIGHT => "extra-light",
Self::LIGHT => "light",
Self::NORMAL => "normal",
Self::MEDIUM => "medium",
Self::SEMI_BOLD => "semi-bold",
Self::BOLD => "bold",
Self::EXTRA_BOLD => "extra-bold",
Self::BLACK => "black",
_ => "",
};
if s.is_empty() {
write!(f, "{}", self.0)
} else {
write!(f, "{}", s)
}
}
}
impl Default for Weight {
fn default() -> Self {
Self::NORMAL
}
}
/// Visual width of a font-- a relative change from the normal aspect
/// ratio.
#[derive(Copy, Clone, PartialOrd, Ord, PartialEq, Eq, Hash)]
pub struct Stretch(pub(crate) u16);
impl Stretch {
pub const ULTRA_CONDENSED: Self = Self(0);
pub const EXTRA_CONDENSED: Self = Self(25);
pub const CONDENSED: Self = Self(50);
pub const SEMI_CONDENSED: Self = Self(75);
pub const NORMAL: Self = Self(100);
pub const SEMI_EXPANDED: Self = Self(125);
pub const EXPANDED: Self = Self(150);
pub const EXTRA_EXPANDED: Self = Self(200);
pub const ULTRA_EXPANDED: Self = Self(300);
/// Creates a stretch attribute from a percentage. The value will be
/// clamped at half percentage increments between 50% and 200%,
/// inclusive.
pub fn from_percentage(percentage: f32) -> Self {
let value = ((percentage.min(200.).max(50.) - 50.) * 2.) as u16;
Self(value)
}
/// Converts the stretch value to a percentage.
pub fn to_percentage(self) -> f32 {
(self.0 as f32) * 0.5 + 50.
}
/// Returns true if the stretch is normal.
pub fn is_normal(self) -> bool {
self == Self::NORMAL
}
/// Returns true if the stretch is condensed (less than normal).
pub fn is_condensed(self) -> bool {
self < Self::NORMAL
}
/// Returns true if the stretch is expanded (greater than normal).
pub fn is_expanded(self) -> bool {
self > Self::NORMAL
}
/// Parses the stretch from a CSS style keyword or a percentage value.
pub fn parse(s: &str) -> Option<Self> {
let s = s.trim();
Some(match s {
"ultra-condensed" => Self::ULTRA_CONDENSED,
"extra-condensed" => Self::EXTRA_CONDENSED,
"condensed" => Self::CONDENSED,
"semi-condensed" => Self::SEMI_CONDENSED,
"normal" => Self::NORMAL,
"semi-expanded" => Self::SEMI_EXPANDED,
"extra-expanded" => Self::EXTRA_EXPANDED,
"ultra-expanded" => Self::ULTRA_EXPANDED,
_ => {
if s.ends_with("%") {
let p = s.get(..s.len() - 1)?.parse::<f32>().ok()?;
return Some(Self::from_percentage(p));
}
return None;
}
})
}
/// Returns the raw value of the stretch attribute.
pub fn raw(self) -> u16 {
self.0
}
pub(crate) fn from_raw(raw: u16) -> Self {
match raw {
1 => Self::ULTRA_CONDENSED,
2 => Self::EXTRA_CONDENSED,
3 => Self::CONDENSED,
4 => Self::SEMI_CONDENSED,
5 => Self::NORMAL,
6 => Self::SEMI_EXPANDED,
7 => Self::EXPANDED,
8 => Self::EXTRA_EXPANDED,
9 => Self::ULTRA_EXPANDED,
_ => Self::NORMAL,
}
}
}
impl fmt::Display for Stretch {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(
f,
"{}",
match *self {
Self::ULTRA_CONDENSED => "ultra-condensed",
Self::EXTRA_CONDENSED => "extra-condensed",
Self::CONDENSED => "condensed",
Self::SEMI_CONDENSED => "semi-condensed",
Self::NORMAL => "normal",
Self::SEMI_EXPANDED => "semi-expanded",
Self::EXPANDED => "expanded",
Self::EXTRA_EXPANDED => "extra-expanded",
Self::ULTRA_EXPANDED => "ultra-expanded",
_ => {
return write!(f, "{}%", self.to_percentage());
}
}
)
}
}
impl fmt::Debug for Stretch {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "Stretch({})", self.to_percentage())
}
}
impl Default for Stretch {
fn default() -> Self {
Self::NORMAL
}
}
/// Synthesis suggestions for mistmatched font attributes.
///
/// This is generated by the [`synthesize`](Attributes::synthesize) method on
/// [`Attributes`].
#[derive(Copy, Clone, Default)]
pub struct Synthesis {
vars: [Setting<f32>; 3],
len: u8,
embolden: bool,
skew: i8,
}
impl Synthesis {
/// Returns true if any synthesis suggestions are available.
pub fn any(&self) -> bool {
self.len != 0 || self.embolden || self.skew != 0
}
/// Returns the variations that should be applied to match the requested
/// attributes.
pub fn variations(&self) -> &[Setting<f32>] {
&self.vars[..self.len as usize]
}
/// Returns true if the scaler should apply a faux bold.
pub fn embolden(&self) -> bool {
self.embolden
}
/// Returns a skew angle for faux italic/oblique, if requested.
pub fn skew(&self) -> Option<f32> {
if self.skew != 0 {
Some(self.skew as f32)
} else {
None
}
}
}
impl PartialEq for Synthesis {
fn eq(&self, other: &Self) -> bool {
if self.len != other.len {
return false;
}
if self.len != 0 && self.variations() != other.variations() {
return false;
}
self.embolden == other.embolden && self.skew == other.skew
}
}
| |
0007_auto_20210124_0442.py
|
# Generated by Django 3.1.4 on 2021-01-24 04:42
from django.db import migrations, models
class
|
(migrations.Migration):
dependencies = [
('exam', '0006_exam_duration'),
]
operations = [
migrations.AlterField(
model_name='exam',
name='duration',
field=models.CharField(default=0, max_length=4, verbose_name='Durasi Ujian'),
),
]
|
Migration
|
parse_mtrace.py
|
"""
Parsing a mtrace log file and append to timeline-footprint format
"""
from numpy import *
import numpy as np
import glob
import os
import linecache
import csv
# 1038 bytes is the size of a heap log file with no heap activity (only heap info)
def ValidHeapFile(fpath):
header_lines=1
with open(fpath) as f:
lines = len(list(f))
return True if os.path.isfile(fpath) and lines > header_lines else False
print ("INFO: --------------------- \nINFO: Parsing mtrace logs \nINFO: ---------------------")
mtrace_files = glob.glob("/tmp/mtrace*.txt")
mtraces=len(mtrace_files)
print ("INFO: Total mtrace logs found:", mtraces)
colours=['b','g','r','c','m','y','k']
elapsed_time=208000
#with plt.xkcd():
total_bytes_allocated=0
index=0
fout = open("/tmp/mtrace.out",'w')
lines_parsed=0
event_time=0
#Heaps log parsing
for cur_mtrace in sorted(mtrace_files):
if ValidHeapFile(cur_mtrace):
fin = open(cur_mtrace,'r')
total_lines = len(fin.readlines())
tic=elapsed_time/(total_lines-3)
print ("total_lines = ", total_lines, "tic = ", tic)
fin.close()
fin = open(cur_mtrace,'r')
for line in fin:
line = line.rstrip().split(' ')
#print ("length(line) = ", len(line), "index=", index)
if lines_parsed>=2 and lines_parsed<total_lines-1:
sign = line[2]
if sign == '+':
cur_bytes = line[4]
cur_bytes_dec = int(cur_bytes, 16)
total_bytes_allocated = total_bytes_allocated + cur_bytes_dec
#print ("INFO: Adding ", cur_bytes_dec, "bytes", "total_bytes_allocated=", total_bytes_allocated)
elif sign == '-':
total_bytes_allocated = total_bytes_allocated - cur_bytes_dec
#print ("INFO: Subtracting ", cur_bytes_dec, "bytes", "total_bytes_allocated=", total_bytes_allocated)
else:
|
event_time=event_time+tic
fout.write(str(index)+" "+str(event_time)+" "+str(total_bytes_allocated)+"\n")
index=index+1
else:
print ("WARNING: Ignoring this line", line)
lines_parsed=lines_parsed+1
else:
print ("INFO: Current mtrace path :", cur_mtrace, "-> Skipping empty file")
fin.close()
fout.close()
|
print ("ERROR: Unknown sign", sign, "Aborting...")
__exit__
|
runtimeConfig.ts
|
import { name, version } from "./package.json";
import { defaultProvider as credentialDefaultProvider } from "@aws-sdk/credential-provider-node";
import { Hash } from "@aws-sdk/hash-node";
import { NodeHttpHandler, streamCollector } from "@aws-sdk/node-http-handler";
import { defaultProvider as regionDefaultProvider } from "@aws-sdk/region-provider";
import { maxAttemptsProvider as maxAttemptsDefaultProvider } from "@aws-sdk/retry-config-provider";
import { parseUrl } from "@aws-sdk/url-parser-node";
import { fromBase64, toBase64 } from "@aws-sdk/util-base64-node";
import { calculateBodyLength } from "@aws-sdk/util-body-length-node";
import { defaultUserAgent } from "@aws-sdk/util-user-agent-node";
import { fromUtf8, toUtf8 } from "@aws-sdk/util-utf8-node";
import { ClientDefaults } from "./PinpointClient";
|
export const ClientDefaultValues: Required<ClientDefaults> = {
...ClientSharedValues,
runtime: "node",
base64Decoder: fromBase64,
base64Encoder: toBase64,
bodyLengthChecker: calculateBodyLength,
credentialDefaultProvider,
defaultUserAgent: defaultUserAgent(name, version),
maxAttemptsDefaultProvider,
regionDefaultProvider,
requestHandler: new NodeHttpHandler(),
sha256: Hash.bind(null, "sha256"),
streamCollector,
urlParser: parseUrl,
utf8Decoder: fromUtf8,
utf8Encoder: toUtf8,
};
|
import { ClientSharedValues } from "./runtimeConfig.shared";
|
opcode_intercept.py
|
from collections.abc import MutableMapping, Set
import dis
from types import CodeType
from types import FrameType
from sys import version_info
from crosshair.core import CrossHairValue
from crosshair.core import register_opcode_patch
from crosshair.libimpl.builtinslib import SymbolicInt
from crosshair.libimpl.builtinslib import AnySymbolicStr
from crosshair.libimpl.builtinslib import LazyIntSymbolicStr
from crosshair.simplestructs import LinearSet
from crosshair.simplestructs import ShellMutableSequence
from crosshair.simplestructs import ShellMutableSet
from crosshair.simplestructs import SimpleDict
from crosshair.simplestructs import SliceView
from crosshair.tracers import COMPOSITE_TRACER
from crosshair.tracers import TracingModule
|
BINARY_SUBSCR = dis.opmap["BINARY_SUBSCR"]
BUILD_STRING = dis.opmap["BUILD_STRING"]
COMPARE_OP = dis.opmap["COMPARE_OP"]
CONTAINS_OP = dis.opmap.get("CONTAINS_OP", 118)
FORMAT_VALUE = dis.opmap["FORMAT_VALUE"]
MAP_ADD = dis.opmap["MAP_ADD"]
SET_ADD = dis.opmap["SET_ADD"]
def frame_op_arg(frame):
return frame.f_code.co_code[frame.f_lasti + 1]
class SymbolicSubscriptInterceptor(TracingModule):
opcodes_wanted = frozenset([BINARY_SUBSCR])
def trace_op(self, frame, codeobj, codenum):
# Note that because this is called from inside a Python trace handler, tracing
# is automatically disabled, so there's no need for a `with NoTracing():` guard.
key = frame_stack_read(frame, -1)
if isinstance(key, (int, float, str)):
return
# If we got this far, the index is likely symbolic (or perhaps a slice object)
container = frame_stack_read(frame, -2)
container_type = type(container)
if container_type is dict:
# SimpleDict won't hash the keys it's given!
wrapped_dict = SimpleDict(list(container.items()))
frame_stack_write(frame, -2, wrapped_dict)
elif container_type is list:
if isinstance(key, slice):
if key.step not in (1, None):
return
start, stop = key.start, key.stop
if isinstance(start, SymbolicInt) or isinstance(stop, SymbolicInt):
view_wrapper = SliceView(container, 0, len(container))
frame_stack_write(frame, -2, ShellMutableSequence(view_wrapper))
else:
pass
# Nothing useful to do with concrete list and symbolic numeric index.
_CONTAINMENT_OP_TYPES = tuple(
i for (i, name) in enumerate(dis.cmp_op) if name in ("in", "not in")
)
assert len(_CONTAINMENT_OP_TYPES) in (0, 2)
class ContainmentInterceptor(TracingModule):
opcodes_wanted = frozenset(
[
COMPARE_OP,
CONTAINS_OP,
]
)
def trace_op(self, frame, codeobj, codenum):
if codenum == COMPARE_OP:
compare_type = frame_op_arg(frame)
if compare_type not in _CONTAINMENT_OP_TYPES:
return
item = frame_stack_read(frame, -2)
if not isinstance(item, CrossHairValue):
return
container = frame_stack_read(frame, -1)
containertype = type(container)
new_container = None
if containertype is str:
new_container = LazyIntSymbolicStr([ord(c) for c in container])
elif containertype is set:
new_container = ShellMutableSet(LinearSet(container))
if new_container is not None:
frame_stack_write(frame, -1, new_container)
class BuildStringInterceptor(TracingModule):
"""
Adds symbolic handling for the BUILD_STRING opcode (used by f-strings).
BUILD_STRING concatenates strings from the stack is a fast, but unforgiving way:
it requires all the substrings to be real Python strings.
We work around this by replacing the substrings with empty strings, computing the
concatenation ourselves, and swaping our result in after the opcode completes.
"""
opcodes_wanted = frozenset([BUILD_STRING])
def trace_op(self, frame, codeobj, codenum):
count = frame_op_arg(frame)
real_result = ""
for offset in range(-(count), 0):
substr = frame_stack_read(frame, offset)
if not isinstance(substr, (str, AnySymbolicStr)):
raise CrosshairInternal
# Because we know these are all symbolic or concrete strings, it's ok to
# not have tracing on when we do the concatenation here:
real_result += substr
frame_stack_write(frame, offset, "")
def post_op():
frame_stack_write(frame, -1, real_result)
COMPOSITE_TRACER.set_postop_callback(codeobj, post_op)
class FormatValueInterceptor(TracingModule):
"""Avoid realization during FORMAT_VALUE (used by f-strings)."""
opcodes_wanted = frozenset([FORMAT_VALUE])
def trace_op(self, frame, codeobj, codenum):
flags = frame_op_arg(frame)
if flags not in (0x00, 0x01):
return # formatting spec is present
orig_obj = frame_stack_read(frame, -1)
if not isinstance(orig_obj, AnySymbolicStr):
return
# Format a dummy empty string, and swap the original back in:
frame_stack_write(frame, -1, "")
def post_op():
frame_stack_write(frame, -1, orig_obj)
COMPOSITE_TRACER.set_postop_callback(codeobj, post_op)
class MapAddInterceptor(TracingModule):
"""De-optimize MAP_ADD over symbolics (used in dict comprehensions)."""
opcodes_wanted = frozenset([MAP_ADD])
def trace_op(self, frame: FrameType, codeobj: CodeType, codenum: int) -> None:
dict_offset = -(frame_op_arg(frame) + 2)
dict_obj = frame_stack_read(frame, dict_offset)
if not isinstance(dict_obj, (dict, MutableMapping)):
raise CrosshairInternal
top, second = frame_stack_read(frame, -1), frame_stack_read(frame, -2)
# Key and value were swapped in Python 3.8
key, value = (second, top) if version_info >= (3, 8) else (top, second)
if isinstance(dict_obj, dict):
if isinstance(key, CrossHairValue):
dict_obj = SimpleDict(list(dict_obj.items()))
else:
# Key and dict are concrete; continue as normal.
return
# Have the interpreter do a fake assinment, namely `{}[1] = 1`
frame_stack_write(frame, dict_offset, {})
frame_stack_write(frame, -1, 1)
frame_stack_write(frame, -2, 1)
# And do our own assignment separately:
dict_obj[key] = value
# Later, overwrite the interpreter's result with ours:
def post_op():
frame_stack_write(frame, dict_offset + 2, dict_obj)
COMPOSITE_TRACER.set_postop_callback(codeobj, post_op)
class SetAddInterceptor(TracingModule):
"""De-optimize SET_ADD over symbolics (used in set comprehensions)."""
opcodes_wanted = frozenset([SET_ADD])
def trace_op(self, frame: FrameType, codeobj: CodeType, codenum: int) -> None:
set_offset = -(frame_op_arg(frame) + 1)
set_obj = frame_stack_read(frame, set_offset)
if not isinstance(set_obj, Set):
raise CrosshairInternal(type(set_obj))
item = frame_stack_read(frame, -1)
if isinstance(set_obj, set):
if isinstance(item, CrossHairValue):
set_obj = ShellMutableSet(set_obj)
else:
# Set and value are concrete; continue as normal.
return
# Have the interpreter do a fake addition, namely `set().add(1)`
frame_stack_write(frame, set_offset, set())
frame_stack_write(frame, -1, 1)
# And do our own addition separately:
set_obj.add(item)
# Later, overwrite the interpreter's result with ours:
def post_op():
frame_stack_write(frame, set_offset + 1, set_obj)
COMPOSITE_TRACER.set_postop_callback(codeobj, post_op)
def make_registrations():
register_opcode_patch(SymbolicSubscriptInterceptor())
register_opcode_patch(ContainmentInterceptor())
register_opcode_patch(BuildStringInterceptor())
register_opcode_patch(FormatValueInterceptor())
register_opcode_patch(MapAddInterceptor())
register_opcode_patch(SetAddInterceptor())
|
from crosshair.tracers import frame_stack_read
from crosshair.tracers import frame_stack_write
from crosshair.util import CrosshairInternal
|
0002_initial.py
|
# Generated by Django 3.2.7 on 2021-12-02 21:01
from django.conf import settings
from django.db import migrations, models
class
|
(migrations.Migration):
initial = True
dependencies = [
('Author', '0001_initial'),
('Posts', '0001_initial'),
]
operations = [
migrations.AddField(
model_name='inbox',
name='iPosts',
field=models.ManyToManyField(blank=True, default=list, to='Posts.Post'),
),
migrations.AddField(
model_name='followers',
name='items',
field=models.ManyToManyField(blank=True, default=list, related_name='items', to=settings.AUTH_USER_MODEL),
),
]
|
Migration
|
engine.py
|
class Engine:
PANDAS = "pandas"
POSTGRES = "postgres"
PRESTO = "Presto"
SPARK = "Spark"
SQL_SERVER = "SqlServer"
|
known_engines = {PANDAS, POSTGRES, PRESTO, SPARK, SQL_SERVER}
| |
new.rs
|
use crate::commands::calendar::DOC_SEPARATOR;
use anyhow::Result;
use bartholomew::content::{Content, Head};
use chrono::Utc;
use std::{collections::HashMap, path::PathBuf};
use structopt::StructOpt;
use tokio::{fs::File, io::AsyncWriteExt};
/// Create a new page or website from a template.
#[derive(StructOpt, Debug)]
pub enum
|
{
Post(NewPostCommand),
}
impl NewCommand {
pub async fn run(self) -> Result<()> {
match self {
NewCommand::Post(cmd) => cmd.run().await,
}
}
}
/// Create a new post.
#[derive(StructOpt, Debug)]
pub struct NewPostCommand {
/// Path to the directory where to create the new post.
pub dir: PathBuf,
/// Name of the file.
#[structopt(default_value = "untitled.md")]
pub file: String,
/// Title for the post.
#[structopt(long = "title", default_value = "Untitled")]
pub title: String,
/// Description for the post.
#[structopt(long = "description")]
pub description: Option<String>,
/// Template for the post.
#[structopt(long = "template", default_value = "blog")]
pub template: String,
/// Type of the post.
#[structopt(long = "type", default_value = "post")]
pub post_type: String,
/// Author of the post.
#[structopt(long = "author", default_value = "John Doe")]
pub author: String,
}
impl NewPostCommand {
pub async fn run(self) -> Result<()> {
let template = Some(self.template);
let title = self.title;
let date = Some(Utc::now());
let mut extra = HashMap::new();
extra.insert("author".to_string(), self.author);
extra.insert("type".to_string(), self.post_type);
let description = self.description;
// Published means...
// - If 'Some(true)', always mark it published
// - If 'Some(false)', never mark it published
// - If 'None', use the regular publishing rules (e.g. date)
let published = None;
let extra = Some(extra);
let head = Head {
title,
date,
description,
template,
extra,
published,
..Default::default()
};
let body = r#"
Begin with intro paragraph
<!-- Ideally, for SEO there should be an image after the first paragraph or two -->
## Headers Should Be Second-level, Not First
"#
.to_string();
let content = Content {
head,
body,
published: true,
};
let content = serialize_content(&content)?;
let path = self.dir.join(&self.file);
let mut file = File::create(&path).await?;
file.write_all(content.as_bytes()).await?;
println!("Wrote new post in file {}", path.display());
Ok(())
}
}
fn serialize_content(content: &Content) -> Result<String> {
let mut res = toml::to_string(&content.head)?;
res.push_str(DOC_SEPARATOR);
res.push_str(&content.body);
Ok(res)
}
|
NewCommand
|
index.js
|
let state = {
count: 0
};
function
|
(state, action) {
switch (action.type) {
case 'increment':
return {count: state.count + 1};
case 'decrement':
return {count: state.count - 1};
default:
throw new Error();
}
}
export {state, reducer};
|
reducer
|
package.py
|
##############################################################################
# Copyright (c) 2013-2018, Lawrence Livermore National Security, LLC.
# Produced at the Lawrence Livermore National Laboratory.
#
# This file is part of Spack.
# Created by Todd Gamblin, [email protected], All rights reserved.
# LLNL-CODE-647188
#
# For details, see https://github.com/spack/spack
# Please also see the NOTICE and LICENSE files for our notice and the LGPL.
#
# This program is free software; you can redistribute it and/or modify
# it under the terms of the GNU Lesser General Public License (as
# published by the Free Software Foundation) version 2.1, February 1999.
#
# This program is distributed in the hope that it will be useful, but
# WITHOUT ANY WARRANTY; without even the IMPLIED WARRANTY OF
# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the terms and
# conditions of the GNU Lesser General Public License for more details.
#
# You should have received a copy of the GNU Lesser General Public
# License along with this program; if not, write to the Free Software
# Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
##############################################################################
from spack import *
class PyQuantities(PythonPackage):
|
"""Support for physical quantities with units, based on numpy"""
homepage = "http://python-quantities.readthedocs.org"
url = "https://pypi.io/packages/source/q/quantities/quantities-0.12.1.tar.gz"
version('0.12.1', '9c9ecda15e905cccfc420e5341199512')
version('0.11.1', 'f4c6287bfd2e93322b25a7c1311a0243',
url="https://pypi.io/packages/source/q/quantities/quantities-0.11.1.zip")
conflicts('[email protected]:', when='@:0.11.99')
depends_on('[email protected]:')
depends_on('[email protected]:', type=('build', 'run'))
|
|
TaobaoJushitaJmsTopicsGet.go
|
package jms
|
"github.com/bububa/opentaobao/core"
"github.com/bububa/opentaobao/model/jms"
)
/*
根据用户nick获取开通的消息列表
taobao.jushita.jms.topics.get
根据用户nick获取开通的消息列表
*/
func TaobaoJushitaJmsTopicsGet(clt *core.SDKClient, req *jms.TaobaoJushitaJmsTopicsGetRequest, session string) (*jms.TaobaoJushitaJmsTopicsGetAPIResponse, error) {
var resp jms.TaobaoJushitaJmsTopicsGetAPIResponse
err := clt.Post(req, &resp, session)
if err != nil {
return nil, err
}
return &resp, nil
}
|
import (
|
deployer_defaults_test.go
|
/*
Copyright 2019 the original author or authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package v1alpha1
import (
"testing"
"github.com/google/go-cmp/cmp"
corev1 "k8s.io/api/core/v1"
)
func TestDeployerDefault(t *testing.T) {
tests := []struct {
name string
in *Deployer
want *Deployer
}{{
name: "empty",
in: &Deployer{},
want: &Deployer{
Spec: DeployerSpec{
Template: &corev1.PodSpec{
Containers: []corev1.Container{
{},
},
},
IngressPolicy: IngressPolicyExternal,
},
},
}}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got := test.in
got.Default()
if diff := cmp.Diff(test.want, got); diff != "" {
t.Errorf("Default (-want, +got) = %v", diff)
}
})
}
}
func
|
(t *testing.T) {
tests := []struct {
name string
in *DeployerSpec
want *DeployerSpec
}{{
name: "ensure at least one container",
in: &DeployerSpec{},
want: &DeployerSpec{
Template: &corev1.PodSpec{
Containers: []corev1.Container{
{},
},
},
IngressPolicy: IngressPolicyExternal,
},
}}
for _, test := range tests {
t.Run(test.name, func(t *testing.T) {
got := test.in
got.Default()
if diff := cmp.Diff(test.want, got); diff != "" {
t.Errorf("Default (-want, +got) = %v", diff)
}
})
}
}
|
TestDeployerSpecDefault
|
button.rs
|
use crate::*;
/// Clickable button with text.
///
/// See also [`Ui::button`].
///
/// ```
/// # let ui = &mut egui::Ui::__test();
/// # fn do_stuff() {}
///
/// if ui.add(egui::Button::new("Click me")).clicked() {
/// do_stuff();
/// }
///
/// // A greyed-out and non-interactive button:
/// if ui.add_enabled(false, egui::Button::new("Can't click this")).clicked() {
/// unreachable!();
/// }
/// ```
#[must_use = "You should put this widget in an ui with `ui.add(widget);`"]
pub struct Button {
text: WidgetText,
wrap: Option<bool>,
/// None means default for interact
fill: Option<Color32>,
stroke: Option<Stroke>,
sense: Sense,
small: bool,
frame: Option<bool>,
min_size: Vec2,
}
impl Button {
pub fn new(text: impl Into<WidgetText>) -> Self {
Self {
text: text.into(),
wrap: None,
fill: None,
stroke: None,
sense: Sense::click(),
small: false,
frame: None,
min_size: Vec2::ZERO,
}
}
/// If `true`, the text will wrap to stay within the max width of the `Ui`.
///
/// By default [`Self::wrap`] will be true in vertical layouts
/// and horizontal layouts with wrapping,
/// and false on non-wrapping horizontal layouts.
///
/// Note that any `\n` in the text will always produce a new line.
#[inline]
pub fn wrap(mut self, wrap: bool) -> Self {
self.wrap = Some(wrap);
self
}
#[deprecated = "Replaced by: Button::new(RichText::new(text).color(…))"]
pub fn te
|
ut self, text_color: Color32) -> Self {
self.text = self.text.color(text_color);
self
}
#[deprecated = "Replaced by: Button::new(RichText::new(text).text_style(…))"]
pub fn text_style(mut self, text_style: TextStyle) -> Self {
self.text = self.text.text_style(text_style);
self
}
/// Override background fill color. Note that this will override any on-hover effects.
/// Calling this will also turn on the frame.
pub fn fill(mut self, fill: impl Into<Color32>) -> Self {
self.fill = Some(fill.into());
self.frame = Some(true);
self
}
/// Override button stroke. Note that this will override any on-hover effects.
/// Calling this will also turn on the frame.
pub fn stroke(mut self, stroke: impl Into<Stroke>) -> Self {
self.stroke = Some(stroke.into());
self.frame = Some(true);
self
}
/// Make this a small button, suitable for embedding into text.
pub fn small(mut self) -> Self {
self.text = self.text.text_style(TextStyle::Body);
self.small = true;
self
}
/// Turn off the frame
pub fn frame(mut self, frame: bool) -> Self {
self.frame = Some(frame);
self
}
/// By default, buttons senses clicks.
/// Change this to a drag-button with `Sense::drag()`.
pub fn sense(mut self, sense: Sense) -> Self {
self.sense = sense;
self
}
pub(crate) fn min_size(mut self, min_size: Vec2) -> Self {
self.min_size = min_size;
self
}
}
impl Widget for Button {
fn ui(self, ui: &mut Ui) -> Response {
let Button {
text,
wrap,
fill,
stroke,
sense,
small,
frame,
min_size,
} = self;
let frame = frame.unwrap_or_else(|| ui.visuals().button_frame);
let mut button_padding = ui.spacing().button_padding;
if small {
button_padding.y = 0.0;
}
let total_extra = button_padding + button_padding;
let wrap_width = ui.available_width() - total_extra.x;
let text = text.into_galley(ui, wrap, wrap_width, TextStyle::Button);
let mut desired_size = text.size() + 2.0 * button_padding;
if !small {
desired_size.y = desired_size.y.at_least(ui.spacing().interact_size.y);
}
desired_size = desired_size.at_least(min_size);
let (rect, response) = ui.allocate_at_least(desired_size, sense);
response.widget_info(|| WidgetInfo::labeled(WidgetType::Button, text.text()));
if ui.is_rect_visible(rect) {
let visuals = ui.style().interact(&response);
let text_pos = ui
.layout()
.align_size_within_rect(text.size(), rect.shrink2(button_padding))
.min;
if frame {
let fill = fill.unwrap_or(visuals.bg_fill);
let stroke = stroke.unwrap_or(visuals.bg_stroke);
ui.painter().rect(
rect.expand(visuals.expansion),
visuals.corner_radius,
fill,
stroke,
);
}
text.paint_with_visuals(ui.painter(), text_pos, visuals);
}
response
}
}
// ----------------------------------------------------------------------------
// TODO: allow checkbox without a text label
/// Boolean on/off control with text label.
///
/// Usually you'd use [`Ui::checkbox`] instead.
///
/// ```
/// # let ui = &mut egui::Ui::__test();
/// # let mut my_bool = true;
/// // These are equivalent:
/// ui.checkbox(&mut my_bool, "Checked");
/// ui.add(egui::Checkbox::new(&mut my_bool, "Checked"));
/// ```
#[must_use = "You should put this widget in an ui with `ui.add(widget);`"]
pub struct Checkbox<'a> {
checked: &'a mut bool,
text: WidgetText,
}
impl<'a> Checkbox<'a> {
pub fn new(checked: &'a mut bool, text: impl Into<WidgetText>) -> Self {
Checkbox {
checked,
text: text.into(),
}
}
#[deprecated = "Replaced by: Checkbox::new(RichText::new(text).color(…))"]
pub fn text_color(mut self, text_color: Color32) -> Self {
self.text = self.text.color(text_color);
self
}
#[deprecated = "Replaced by: Checkbox::new(RichText::new(text).text_style(…))"]
pub fn text_style(mut self, text_style: TextStyle) -> Self {
self.text = self.text.text_style(text_style);
self
}
}
impl<'a> Widget for Checkbox<'a> {
fn ui(self, ui: &mut Ui) -> Response {
let Checkbox { checked, text } = self;
let spacing = &ui.spacing();
let icon_width = spacing.icon_width;
let icon_spacing = ui.spacing().icon_spacing;
let button_padding = spacing.button_padding;
let total_extra = button_padding + vec2(icon_width + icon_spacing, 0.0) + button_padding;
let wrap_width = ui.available_width() - total_extra.x;
let text = text.into_galley(ui, None, wrap_width, TextStyle::Button);
let mut desired_size = total_extra + text.size();
desired_size = desired_size.at_least(spacing.interact_size);
desired_size.y = desired_size.y.max(icon_width);
let (rect, mut response) = ui.allocate_exact_size(desired_size, Sense::click());
if response.clicked() {
*checked = !*checked;
response.mark_changed();
}
response.widget_info(|| WidgetInfo::selected(WidgetType::Checkbox, *checked, text.text()));
if ui.is_rect_visible(rect) {
// let visuals = ui.style().interact_selectable(&response, *checked); // too colorful
let visuals = ui.style().interact(&response);
let text_pos = pos2(
rect.min.x + button_padding.x + icon_width + icon_spacing,
rect.center().y - 0.5 * text.size().y,
);
let (small_icon_rect, big_icon_rect) = ui.spacing().icon_rectangles(rect);
ui.painter().add(epaint::RectShape {
rect: big_icon_rect.expand(visuals.expansion),
corner_radius: visuals.corner_radius,
fill: visuals.bg_fill,
stroke: visuals.bg_stroke,
});
if *checked {
// Check mark:
ui.painter().add(Shape::line(
vec![
pos2(small_icon_rect.left(), small_icon_rect.center().y),
pos2(small_icon_rect.center().x, small_icon_rect.bottom()),
pos2(small_icon_rect.right(), small_icon_rect.top()),
],
visuals.fg_stroke,
));
}
text.paint_with_visuals(ui.painter(), text_pos, visuals);
}
response
}
}
// ----------------------------------------------------------------------------
/// One out of several alternatives, either selected or not.
///
/// Usually you'd use [`Ui::radio_value`] or [`Ui::radio`] instead.
///
/// ```
/// # let ui = &mut egui::Ui::__test();
/// #[derive(PartialEq)]
/// enum Enum { First, Second, Third }
/// let mut my_enum = Enum::First;
///
/// ui.radio_value(&mut my_enum, Enum::First, "First");
///
/// // is equivalent to:
///
/// if ui.add(egui::RadioButton::new(my_enum == Enum::First, "First")).clicked() {
/// my_enum = Enum::First
/// }
/// ```
#[must_use = "You should put this widget in an ui with `ui.add(widget);`"]
pub struct RadioButton {
checked: bool,
text: WidgetText,
}
impl RadioButton {
pub fn new(checked: bool, text: impl Into<WidgetText>) -> Self {
Self {
checked,
text: text.into(),
}
}
#[deprecated = "Replaced by: RadioButton::new(RichText::new(text).color(…))"]
pub fn text_color(mut self, text_color: Color32) -> Self {
self.text = self.text.color(text_color);
self
}
#[deprecated = "Replaced by: RadioButton::new(RichText::new(text).text_style(…))"]
pub fn text_style(mut self, text_style: TextStyle) -> Self {
self.text = self.text.text_style(text_style);
self
}
}
impl Widget for RadioButton {
fn ui(self, ui: &mut Ui) -> Response {
let RadioButton { checked, text } = self;
let icon_width = ui.spacing().icon_width;
let icon_spacing = ui.spacing().icon_spacing;
let button_padding = ui.spacing().button_padding;
let total_extra = button_padding + vec2(icon_width + icon_spacing, 0.0) + button_padding;
let wrap_width = ui.available_width() - total_extra.x;
let text = text.into_galley(ui, None, wrap_width, TextStyle::Button);
let mut desired_size = total_extra + text.size();
desired_size = desired_size.at_least(ui.spacing().interact_size);
desired_size.y = desired_size.y.max(icon_width);
let (rect, response) = ui.allocate_exact_size(desired_size, Sense::click());
response
.widget_info(|| WidgetInfo::selected(WidgetType::RadioButton, checked, text.text()));
if ui.is_rect_visible(rect) {
let text_pos = pos2(
rect.min.x + button_padding.x + icon_width + icon_spacing,
rect.center().y - 0.5 * text.size().y,
);
// let visuals = ui.style().interact_selectable(&response, checked); // too colorful
let visuals = ui.style().interact(&response);
let (small_icon_rect, big_icon_rect) = ui.spacing().icon_rectangles(rect);
let painter = ui.painter();
painter.add(epaint::CircleShape {
center: big_icon_rect.center(),
radius: big_icon_rect.width() / 2.0 + visuals.expansion,
fill: visuals.bg_fill,
stroke: visuals.bg_stroke,
});
if checked {
painter.add(epaint::CircleShape {
center: small_icon_rect.center(),
radius: small_icon_rect.width() / 3.0,
fill: visuals.fg_stroke.color, // Intentional to use stroke and not fill
// fill: ui.visuals().selection.stroke.color, // too much color
stroke: Default::default(),
});
}
text.paint_with_visuals(ui.painter(), text_pos, visuals);
}
response
}
}
// ----------------------------------------------------------------------------
/// A clickable image within a frame.
#[must_use = "You should put this widget in an ui with `ui.add(widget);`"]
#[derive(Clone, Debug)]
pub struct ImageButton {
image: widgets::Image,
sense: Sense,
frame: bool,
selected: bool,
}
impl ImageButton {
pub fn new(texture_id: TextureId, size: impl Into<Vec2>) -> Self {
Self {
image: widgets::Image::new(texture_id, size),
sense: Sense::click(),
frame: true,
selected: false,
}
}
/// Select UV range. Default is (0,0) in top-left, (1,1) bottom right.
pub fn uv(mut self, uv: impl Into<Rect>) -> Self {
self.image = self.image.uv(uv);
self
}
/// Multiply image color with this. Default is WHITE (no tint).
pub fn tint(mut self, tint: impl Into<Color32>) -> Self {
self.image = self.image.tint(tint);
self
}
/// If `true`, mark this button as "selected".
pub fn selected(mut self, selected: bool) -> Self {
self.selected = selected;
self
}
/// Turn off the frame
pub fn frame(mut self, frame: bool) -> Self {
self.frame = frame;
self
}
/// By default, buttons senses clicks.
/// Change this to a drag-button with `Sense::drag()`.
pub fn sense(mut self, sense: Sense) -> Self {
self.sense = sense;
self
}
}
impl Widget for ImageButton {
fn ui(self, ui: &mut Ui) -> Response {
let Self {
image,
sense,
frame,
selected,
} = self;
let padding = if frame {
// so we can see that it is a button:
Vec2::splat(ui.spacing().button_padding.x)
} else {
Vec2::ZERO
};
let padded_size = image.size() + 2.0 * padding;
let (rect, response) = ui.allocate_exact_size(padded_size, sense);
response.widget_info(|| WidgetInfo::new(WidgetType::ImageButton));
if ui.is_rect_visible(rect) {
let (expansion, corner_radius, fill, stroke) = if selected {
let selection = ui.visuals().selection;
(-padding, 0.0, selection.bg_fill, selection.stroke)
} else if frame {
let visuals = ui.style().interact(&response);
let expansion = if response.hovered {
Vec2::splat(visuals.expansion) - padding
} else {
Vec2::splat(visuals.expansion)
};
(
expansion,
visuals.corner_radius,
visuals.bg_fill,
visuals.bg_stroke,
)
} else {
Default::default()
};
// Draw frame background (for transparent images):
ui.painter()
.rect_filled(rect.expand2(expansion), corner_radius, fill);
let image_rect = ui
.layout()
.align_size_within_rect(image.size(), rect.shrink2(padding));
// let image_rect = image_rect.expand2(expansion); // can make it blurry, so let's not
image.paint_at(ui, image_rect);
// Draw frame outline:
ui.painter()
.rect_stroke(rect.expand2(expansion), corner_radius, stroke);
}
response
}
}
|
xt_color(m
|
serial.rs
|
#![no_std]
#![no_main]
extern crate cortex_m;
extern crate cortex_m_semihosting;
extern crate samd11_bare as hal;
#[cfg(not(feature = "use_semihosting"))]
extern crate panic_halt;
#[cfg(feature = "use_semihosting")]
extern crate panic_semihosting;
#[macro_use(block)]
extern crate nb;
use hal::clock::GenericClockController;
use hal::delay::Delay;
use hal::entry;
use hal::pac::{CorePeripherals, Peripherals};
use hal::prelude::*;
use hal::pac::gclk::clkctrl::GEN_A;
use hal::pac::gclk::genctrl::SRC_A;
use hal::sercom::{PadPin, Sercom0Pad0, Sercom0Pad1, UART0};
#[entry]
fn
|
() -> ! {
let mut peripherals = Peripherals::take().unwrap();
let core = CorePeripherals::take().unwrap();
let mut clocks = GenericClockController::with_internal_32kosc(
peripherals.GCLK,
&mut peripherals.PM,
&mut peripherals.SYSCTRL,
&mut peripherals.NVMCTRL,
);
clocks.configure_gclk_divider_and_source(GEN_A::GCLK2, 1, SRC_A::DFLL48M, false);
let gclk2 = clocks
.get_gclk(GEN_A::GCLK2)
.expect("Could not get clock 2");
let mut pins = hal::Pins::new(peripherals.PORT);
let mut delay = Delay::new(core.SYST, &mut clocks);
let rx: Sercom0Pad1<_> = pins
.d1
.into_pull_down_input(&mut pins.port)
.into_pad(&mut pins.port);
let tx: Sercom0Pad0<_> = pins
.d14
.into_pull_down_input(&mut pins.port)
.into_pad(&mut pins.port);
let uart_clk = clocks
.sercom0_core(&gclk2)
.expect("Could not configure sercom0 clock");
let mut uart = UART0::new(
&uart_clk,
9600.hz(),
peripherals.SERCOM0,
&mut peripherals.PM,
(rx, tx),
);
loop {
for byte in b"Hello, world!" {
// NOTE `block!` blocks until `uart.write()` completes and returns
// `Result<(), Error>`
block!(uart.write(*byte)).unwrap();
}
delay.delay_ms(1000u16);
}
}
|
main
|
gen_pbentity_template.go
|
package gen
|
// ==========================================================================
// Code generated by GoFrame CLI tool. DO NOT EDIT.
// ==========================================================================
syntax = "proto3";
package {PackageName};
import "github.com/gogo/protobuf/gogoproto/gogo.proto";
{OptionContent}
{EntityMessage}
`
|
const templatePbEntityMessageContent = `
|
edit_region_mask.py
|
from pathlib import Path
import os
import numpy as np
import netCDF4
import matplotlib.pyplot as plt
from aps.util.nc_index_by_coordinate import tunnel_fast
# Creates the mask over the small regions of 20x20 km size
def create_small_regions_mask():
p = Path(os.path.dirname(os.path.abspath(__file__))).parent
nc_file = p / 'data' / 'terrain_parameters' / 'VarslingsOmr_2017.nc'
nc = netCDF4.Dataset(nc_file, "a")
# removes inconsistencies wrt fill_value in VarslingsOmr_2017
vr = nc.variables["VarslingsOmr_2017"]
regions = vr[:]
regions[regions == 0] = 65536
regions[regions == 65535] = 65536
vr[:] = regions
# create mask based on dictionary with small regions to monitor
regions_small = regions
regions_small[regions > 3000] = 65536
# extend in each direction from center in km
ext_x, ext_y = 10, 10
# dict over smaller region with Id and coordinates of center-point
# VarslingsOmr have Id in range 3000-3999 - LokalOmr in 4000-4999
s_reg = {"Hemsedal": {"Id": 4001, "Lat": 60.95, "Lon": 8.28},
"Tyin": {"Id": 4002, "Lat": 61.255, "Lon": 8.2},
"Kattfjordeidet": {"Id": 4003, "Lat": 69.65, "Lon": 18.5},
"Lavangsdalen": {"Id": 4004, "Lat": 69.46, "Lon": 19.24}}
for key in s_reg:
y, x = get_xgeo_indicies(s_reg[key]['Lat'], s_reg[key]['Lon'])
regions_small[y - ext_y : y + ext_y + 1, x - ext_x : x + ext_x + 1] = s_reg[key]['Id']
# set up new netCDF variable and attributes
lr = nc.createVariable('LokalOmr_2018', np.int32, ('y', 'x'))
lr.units = vr.units
lr.long_name = 'Mindre test omraader'
lr.missing_value = vr.missing_value
lr.coordinates = vr.coordinates
lr.grid_mapping = vr.grid_mapping
lr.esri_pe_string = vr.esri_pe_string
lr[:] = regions_small
nc.close()
print('Dataset is closed!')
def add_lat_lon():
p = Path(os.path.dirname(os.path.abspath(__file__))).parent
nc_file = p / 'data' / 'terrain_parameters' / 'VarslingsOmr_2017.nc'
nc = netCDF4.Dataset(nc_file, "a")
nc_ref = netCDF4.Dataset(r"\\hdata\grid\metdata\prognosis\meps\det\archive\2018\meps_det_pp_1km_20180127T00Z.nc", "r")
lat_ref = nc_ref.variables['lat']
|
lat = nc.createVariable('lat', np.float64, ('y', 'x'))
lat.units = lat_ref.units
lat.standard_name = lat_ref.standard_name
lat.long_name = lat_ref.long_name
lon = nc.createVariable('lon', np.float64, ('y', 'x'))
lon.units = lon_ref.units
lon.standard_name = lon_ref.standard_name
lon.long_name = lon_ref.long_name
nc.close()
nc_ref.close()
def get_xgeo_indicies(lat, lon):
# region mask is flipped up-down with regard to MET-data in netCDF files
y_max = 1550
nc = netCDF4.Dataset(r"\\hdata\grid\metdata\prognosis\meps\det\archive\2018\meps_det_pp_1km_20180127T00Z.nc", "r")
y, x = tunnel_fast(nc.variables['lat'], nc.variables['lon'], lat, lon)
return y_max-y, x
if __name__ == "__main__":
print("BLING BLING")
#y, x = get_xgeo_indicies(60.95, 8.28); print(y, x)
#create_small_regions_mask()
add_lat_lon()
|
lon_ref = nc_ref.variables['lon']
|
main.go
|
package main
import (
log "github.com/kdpujie/log4go"
)
// SetLog set logger
func SetLog() {
w := log.NewConsoleWriterWithLevel(log.DEBUG)
w.SetColor(true)
log.Register(w)
log.SetLayout("2006-01-02 15:04:05")
}
func
|
() {
SetLog()
defer log.Close()
var name = "skoo"
log.Debug("log4go by %s", name)
log.Info("log4go by %s", name)
log.Warn("log4go by %s", name)
log.Error("log4go by %s", name)
log.Fatal("log4go by %s", name)
}
|
main
|
cal_coefficients.py
|
# -*- coding: utf-8 -*-
"""
The main user-facing module of ``edges-cal``.
This module contains wrappers around lower-level functions in other modules, providing
a one-stop interface for everything related to calibration.
"""
from __future__ import annotations
import attr
import h5py
import numpy as np
import tempfile
import warnings
import yaml
from abc import ABCMeta, abstractmethod
from astropy.convolution import Gaussian1DKernel, convolve
from copy import copy
from edges_io import io
from edges_io.logging import logger
from functools import lru_cache
from hashlib import md5
from matplotlib import pyplot as plt
from pathlib import Path
from scipy.interpolate import InterpolatedUnivariateSpline as Spline
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
from . import DATA_PATH
from . import modelling as mdl
from . import receiver_calibration_func as rcf
from . import reflection_coefficient as rc
from . import s11_correction as s11
from . import tools
from . import types as tp
from . import xrfi
from .cached_property import cached_property
from .tools import EdgesFrequencyRange, FrequencyRange
class S1P:
def __init__(
self,
s1p: tp.PathLike | io.S1P,
f_low: float | None = None,
f_high: float | None = None,
switchval: int | None = None,
):
"""
An object representing the measurements of a VNA.
The measurements are read in via a .s1p file
Parameters
----------
s1p : str, Path or :class:`io.S1P`
The path to a valid .s1p file containing VNA measurements, or an S1P
object of such a type.
f_low, f_high : float
The minimum/maximum frequency to keep.
switchval : int
The standard value of the switch for the component.
"""
try:
s1p = Path(s1p)
self.s1p = io.S1P(s1p)
except TypeError:
if isinstance(s1p, io.S1P):
self.s1p = s1p
else:
raise TypeError(
"s1p must be a path to an s1p file, or an io.S1P object"
)
self.load_name = self.s1p.kind
self.repeat_num = self.s1p.repeat_num
spec = self.s1p.s11
f = self.s1p.freq
self.freq = FrequencyRange(f, f_low, f_high)
self.s11 = spec[self.freq.mask]
self._switchval = switchval
@cached_property
def switchval(self):
"""The standard value of the switch for the component."""
if self._switchval is not None:
return self._switchval * np.ones_like(self.freq.freq)
else:
return None
# For backwards compatibility
VNA = S1P
class _S11Base(metaclass=ABCMeta):
default_nterms = {
"ambient": 37,
"hot_load": 37,
"open": 105,
"short": 105,
"AntSim2": 55,
"AntSim3": 55,
"AntSim4": 55,
"lna": 37,
}
def __init__(
self,
*,
load_s11: Union[io._S11SubDir, io.ReceiverReading],
f_low: Optional[float] = None,
f_high: Optional[float] = None,
n_terms: Optional[int] = None,
model_type: tp.Modelable = "fourier",
):
"""
A class representing relevant switch corrections for a load.
Parameters
----------
load_s11 : :class:`io._S11SubDir`
An instance of the basic ``io`` S11 folder.
f_low : float
Minimum frequency to use. Default is all frequencies.
f_high : float
Maximum frequency to use. Default is all frequencies.
resistance : float
The resistance of the switch (in Ohms).
n_terms : int
The number of terms to use in fitting a model to the S11 (used to both
smooth and interpolate the data). Must be odd.
"""
self.load_s11 = load_s11
self.base_path = self.load_s11.path
try:
self.load_name = getattr(self.load_s11, "load_name")
except AttributeError:
self.load_name = None
self.run_num = self.load_s11.run_num
switchvals = {"open": 1, "short": -1, "match": 0}
for name in self.load_s11.STANDARD_NAMES:
setattr(
self,
name.lower(),
S1P(
s1p=self.load_s11.children[name.lower()],
f_low=f_low,
f_high=f_high,
switchval=switchvals.get(name.lower()),
),
)
# Expose one of the frequency objects
self.freq = self.open.freq
self._nterms = int(n_terms) if n_terms is not None else None
self.model_type = model_type
@cached_property
def n_terms(self):
"""Number of terms to use (by default) in modelling the S11.
Raises
------
ValueError
If n_terms is even.
"""
res = self._nterms or self.default_nterms.get(self.load_name, None)
if not (isinstance(res, int) and res % 2):
raise ValueError(
f"n_terms must be odd for S11 models. For {self.load_name} got "
f"n_terms={res}."
)
return res
@classmethod
@abstractmethod
def from_path(cls, **kwargs):
pass # pragma: no cover
@cached_property
@abstractmethod
def measured_load_s11_raw(self):
pass # pragma: no cover
@cached_property
def corrected_load_s11(self) -> np.ndarray:
"""The measured S11 of the load, corrected for internal switch."""
return self.measured_load_s11_raw
@lru_cache()
def get_corrected_s11_model(
self,
n_terms: int | None = None,
model_type: tp.Modelable | None = None,
):
"""Generate a callable model for the S11 correction.
This should closely match :method:`s11_correction`.
Parameters
----------
n_terms : int
Number of terms used in the fourier-based model. Not necessary if
`load_name` is specified in the class.
Returns
-------
callable :
A function of one argument, f, which should be a frequency in the same units
as `self.freq.freq`.
Raises
------
ValueError
If n_terms is not an integer, or not odd.
"""
n_terms = n_terms or self.n_terms
model_type = mdl.get_mdl(model_type or self.model_type)
model = model_type(
n_terms=n_terms,
transform=mdl.UnitTransform(range=[self.freq.min, self.freq.max]),
)
emodel = model.at(x=self.freq.freq)
cmodel = mdl.ComplexMagPhaseModel(mag=emodel, phs=emodel)
s11_correction = self.corrected_load_s11
return cmodel.fit(ydata=s11_correction)
@cached_property
def s11_model(self) -> callable:
"""The S11 model."""
return self.get_corrected_s11_model()
def plot_residuals(
self,
fig=None,
ax=None,
color_abs="C0",
color_diff="g",
label=None,
title=None,
decade_ticks=True,
ylabels=True,
) -> plt.Figure:
"""
Make a plot of the residuals of the S11 model and the correction data.
Residuals obtained via :func:`get_corrected_s11_model`
Returns
-------
fig :
Matplotlib Figure handle.
"""
if fig is None or ax is None or len(ax) != 4:
fig, ax = plt.subplots(
4, 1, sharex=True, gridspec_kw={"hspace": 0.05}, facecolor="w"
)
if decade_ticks:
for axx in ax:
axx.xaxis.set_ticks(
[50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180],
minor=[],
)
axx.grid(True)
ax[-1].set_xlabel("Frequency [MHz]")
corr = self.corrected_load_s11
model = self.s11_model(self.freq.freq)
ax[0].plot(
self.freq.freq, 20 * np.log10(np.abs(model)), color=color_abs, label=label
)
if ylabels:
ax[0].set_ylabel(r"$|S_{11}|$")
ax[1].plot(self.freq.freq, np.abs(model) - np.abs(corr), color_diff)
if ylabels:
ax[1].set_ylabel(r"$\Delta |S_{11}|$")
ax[2].plot(
self.freq.freq, np.unwrap(np.angle(model)) * 180 / np.pi, color=color_abs
)
if ylabels:
ax[2].set_ylabel(r"$\angle S_{11}$")
ax[3].plot(
self.freq.freq,
np.unwrap(np.angle(model)) - np.unwrap(np.angle(corr)),
color_diff,
)
if ylabels:
ax[3].set_ylabel(r"$\Delta \angle S_{11}$")
if title is None:
title = f"{self.load_name} Reflection Coefficient Models"
if title:
fig.suptitle(f"{self.load_name} Reflection Coefficient Models", fontsize=14)
if label:
ax[0].legend()
return fig
class LoadS11(_S11Base):
def __init__(self, *, internal_switch: s11.InternalSwitch, **kwargs):
"""S11 for a lab calibration load.
Parameters
----------
internal_switch : :class:`s11.InternalSwitch`
The internal switch state corresponding to the load.
Other Parameters
----------------
Passed through to :class:`_S11Base`.
"""
assert isinstance(internal_switch, s11.InternalSwitch)
self.internal_switch = internal_switch
super().__init__(**kwargs)
@classmethod
def from_path(
cls,
load_name: str,
path: tp.PathLike,
run_num_load: int = 1,
run_num_switch: int = 1,
repeat_num_load: int = None,
repeat_num_switch: int = None,
resistance: float = 50.166,
model_internal_switch: mdl.Model = attr.NOTHING,
**kwargs,
):
"""
Create a new object from a given path and load name.
Parameters
----------
load_name : str
The name of the load to create.
path : str or Path
The path to the overall calibration observation.
run_num_load : int
The run to use (default is last run available).
run_num_switch : int
The run to use for the switch S11 (default is last run available).
kwargs
All other arguments are passed through to the constructor of
:class:`LoadS11`.
Returns
-------
s11 : :class:`LoadS11`
The S11 of the load.
"""
antsim = load_name.startswith("AntSim")
path = Path(path)
if not antsim:
load_name = io.LOAD_ALIASES[load_name]
s11_load_dir = (io.AntSimS11 if antsim else io.LoadS11)(
path / "S11" / f"{load_name}{run_num_load:02}", repeat_num=repeat_num_load
)
internal_switch = s11.InternalSwitch(
data=io.SwitchingState(
path / "S11" / f"SwitchingState{run_num_switch:02}",
repeat_num=repeat_num_switch,
),
resistance=resistance,
model=model_internal_switch,
)
return cls(load_s11=s11_load_dir, internal_switch=internal_switch, **kwargs)
@cached_property
def measured_load_s11_raw(self):
"""The measured S11 of the load, calculated from raw internal standards."""
return rc.de_embed(
self.open.switchval,
self.short.switchval,
self.match.switchval,
self.open.s11,
self.short.s11,
self.match.s11,
self.external.s11,
)[0]
@cached_property
def corrected_load_s11(self) -> np.ndarray:
"""The measured S11 of the load, corrected for the internal switch."""
return rc.gamma_de_embed(
self.internal_switch.s11_model(self.freq.freq),
self.internal_switch.s12_model(self.freq.freq),
self.internal_switch.s22_model(self.freq.freq),
self.measured_load_s11_raw,
)
class LNA(_S11Base):
def __init__(
self, load_s11: io.ReceiverReading, resistance: float = 50.009, **kwargs
):
"""A special case of :class:`SwitchCorrection` for the LNA.
Parameters
----------
load_s11 : :class:`io.ReceiverReading`
The Receiver Reading S11 measurements.
resistance : float
The resistance of the receiver.
kwargs :
All other arguments passed to :class:`SwitchCorrection`.
"""
super().__init__(load_s11=load_s11, **kwargs)
self.resistance = resistance
self.load_name = "lna"
self.repeat_num = self.load_s11.repeat_num
@classmethod
def from_path(
cls,
path: Union[str, Path],
repeat_num: Optional[int] = None,
run_num: int = 1,
**kwargs,
):
"""
Create an instance from a given path.
Parameters
----------
path : str or Path
Path to overall Calibration Observation.
run_num_load : int
The run to use for the LNA (default latest available).
run_num_switch : int
The run to use for the switching state (default lastest available).
kwargs
All other arguments passed through to :class:`SwitchCorrection`.
Returns
-------
lna : :class:`LNA`
The LNA object.
"""
path = Path(path)
load_s11 = io.ReceiverReading(
path=path / "S11" / f"ReceiverReading{run_num:02}",
repeat_num=repeat_num,
fix=False,
)
return cls(load_s11=load_s11, **kwargs)
@cached_property
def external(self):
"""VNA S11 measurements for the load."""
return S1P(
self.load_s11.children["receiverreading"],
f_low=self.freq.freq.min(),
f_high=self.freq.freq.max(),
)
@cached_property
def measured_load_s11_raw(self):
"""Measured S11 of of the LNA."""
# Models of standards
oa, sa, la = rc.agilent_85033E(
self.freq.freq, self.resistance, match_delay=True
)
# Correction at switch
return rc.de_embed(
oa, sa, la, self.open.s11, self.short.s11, self.match.s11, self.external.s11
)[0]
class LoadSpectrum:
def __init__(
self,
spec_obj: List[io.Spectrum],
resistance_obj: io.Resistance,
switch_correction: Optional[LoadS11] = None,
f_low: float = 40.0,
f_high: Optional[float] = None,
ignore_times_percent: float = 5.0,
rfi_removal: str = "1D2D",
rfi_kernel_width_time: int = 16,
rfi_kernel_width_freq: int = 16,
rfi_threshold: float = 6,
cache_dir: Optional[Union[str, Path]] = None,
t_load: float = 300.0,
t_load_ns: float = 400.0,
):
"""A class representing a measured spectrum from some Load.
Parameters
----------
spec_obj : :class:`io.Spectrum`
The base Spectrum object defining the on-disk spectra.
resistance_obj : :class:`io.Resistance`
The base Resistance object defining the on-disk resistance measurements.
switch_correction : :class:`SwitchCorrection`
A `SwitchCorrection` for this particular load. If not given, will be
constructed automatically.
f_low : float
Minimum frequency to keep.
f_high : float
Maximum frequency to keep.
ignore_times_percent : float
Must be between 0 and 100. Number of time-samples in a file to reject
from the start of the file.
rfi_removal : str
Either '1D', '2D' or '1D2D'. If given, will perform median and mean-filtered
xRFI over either the
2D waterfall, or integrated 1D spectrum. The latter is usually reasonable
for calibration sources, while the former is good for field data. "1D2D"
is a hybrid approach in which the variance per-frequency is determined
from the 2D data, but filtering occurs only over frequency.
rfi_kernel_width_time : int
The kernel width for the detrending of data for
RFI removal in the time dimension (only used if `rfi_removal` is "2D").
rfi_kernel_width_freq : int
The kernel width for the detrending of data for
RFI removal in the frequency dimension.
rfi_threshold : float
The threshold (in equivalent standard deviation units) above which to
flag data as RFI.
cache_dir : str or Path
An alternative directory in which to load/save cached reduced files. By
default, the same as the path to the .mat files. If you don't have
write permission there, it may be useful to use an alternative path.
t_load
Fiducial guess for the temperature of the internal load.
t_load_ns
Fiducial guess for the temperature of the internal load + noise source.
"""
self.spec_obj = spec_obj
self.resistance_obj = resistance_obj
self.load_name = self.spec_obj[0].load_name
assert (
self.load_name == self.resistance_obj.load_name
), "spec and resistance load_name must be the same"
self.spec_files = (spec_obj.path for spec_obj in self.spec_obj)
self.resistance_file = self.resistance_obj.path
self.run_num = self.spec_obj[0].run_num
self.cache_dir = Path(cache_dir or ".")
self.rfi_kernel_width_time = rfi_kernel_width_time
self.rfi_kernel_width_freq = rfi_kernel_width_freq
self.rfi_threshold = rfi_threshold
assert rfi_removal in [
"1D",
"2D",
"1D2D",
False,
None,
], "rfi_removal must be either '1D', '2D', '1D2D, or False/None"
self.rfi_removal = rfi_removal
self.switch_correction = switch_correction
self.ignore_times_percent = ignore_times_percent
self.freq = EdgesFrequencyRange(f_low=f_low, f_high=f_high)
self.t_load = t_load
self.t_load_ns = t_load_ns
@classmethod
def from_load_name(
cls,
load_name: str,
direc: Union[str, Path],
run_num: Optional[int] = None,
filetype: Optional[str] = None,
**kwargs,
):
"""Instantiate the class from a given load name and directory.
Parameters
----------
load_name : str
The load name (one of 'ambient', 'hot_load', 'open' or 'short').
direc : str or Path
The top-level calibration observation directory.
run_num : int
The run number to use for the spectra.
filetype : str
The filetype to look for (acq or h5).
kwargs :
All other arguments to :class:`LoadSpectrum`.
Returns
-------
:class:`LoadSpectrum`.
"""
direc = Path(direc)
spec = io.Spectrum.from_load(
load=load_name, direc=direc / "Spectra", run_num=run_num, filetype=filetype
)
res = io.Resistance.from_load(
load=load_name,
direc=direc / "Resistance",
run_num=run_num,
filetype=filetype,
)
return cls(spec_obj=spec, resistance_obj=res, **kwargs)
@cached_property
def averaged_Q(self) -> np.ndarray:
"""Ratio of powers averaged over time.
Notes
-----
The formula is
.. math:: Q = (P_source - P_load)/(P_noise - P_load)
"""
# TODO: should also get weights!
spec = self._ave_and_var_spec[0]["Q"]
if self.rfi_removal == "1D":
flags, _ = xrfi.xrfi_medfilt(
spec, threshold=self.rfi_threshold, kf=self.rfi_kernel_width_freq
)
spec[flags] = np.nan
return spec
@property
def variance_Q(self) -> np.ndarray:
"""Variance of Q across time (see averaged_Q)."""
return self._ave_and_var_spec[1]["Q"]
@property
def averaged_spectrum(self) -> np.ndarray:
"""T* = T_noise * Q + T_load."""
return self.averaged_Q * self.t_load_ns + self.t_load
@property
def variance_spectrum(self) -> np.ndarray:
"""Variance of uncalibrated spectrum across time (see averaged_spectrum)."""
return self.variance_Q * self.t_load_ns ** 2
@property
def ancillary(self) -> dict:
"""Ancillary measurement data."""
return [d.data["meta"] for d in self.spec_obj]
@property
def averaged_p0(self) -> np.ndarray:
"""Power of the load, averaged over time."""
return self._ave_and_var_spec[0]["p0"]
@property
def averaged_p1(self) -> np.ndarray:
"""Power of the noise-source, averaged over time."""
return self._ave_and_var_spec[0]["p1"]
@property
def averaged_p2(self) -> np.ndarray:
"""Power of the load plus noise-source, averaged over time."""
return self._ave_and_var_spec[0]["p2"]
@property
def variance_p0(self) -> np.ndarray:
"""Variance of the load, averaged over time."""
return self._ave_and_var_spec[1]["p0"]
@property
def variance_p1(self) -> np.ndarray:
"""Variance of the noise-source, averaged over time."""
return self._ave_and_var_spec[1]["p1"]
@property
def variance_p2(self) -> np.ndarray:
"""Variance of the load plus noise-source, averaged over time."""
return self._ave_and_var_spec[1]["p2"]
@property
def n_integrations(self) -> int:
"""The number of integrations recorded for the spectrum (after ignoring)."""
return self._ave_and_var_spec[2]
def _get_integrated_filename(self):
"""Determine a unique filename for the reduced data of this instance."""
params = (
self.rfi_threshold,
self.rfi_kernel_width_time,
self.rfi_kernel_width_freq,
self.rfi_removal,
self.ignore_times_percent,
self.freq.min,
self.freq.max,
self.t_load,
self.t_load_ns,
tuple(path.name for path in self.spec_files),
)
hsh = md5(str(params).encode()).hexdigest()
return self.cache_dir / f"{self.load_name}_{hsh}.h5"
@cached_property
def _ave_and_var_spec(self) -> Tuple[Dict, Dict, int]:
"""Get the mean and variance of the spectra."""
fname = self._get_integrated_filename()
kinds = ["p0", "p1", "p2", "Q"]
if fname.exists():
logger.info(
f"Reading in previously-created integrated {self.load_name} spectra..."
)
means = {}
variances = {}
with h5py.File(fname, "r") as fl:
for kind in kinds:
means[kind] = fl[kind + "_mean"][...]
variances[kind] = fl[kind + "_var"][...]
n_integrations = fl.attrs.get("n_integrations", 0)
return means, variances, n_integrations
logger.info(f"Reducing {self.load_name} spectra...")
spectra = self.get_spectra()
means = {}
variances = {}
for key, spec in spectra.items():
# Weird thing where there are zeros in the spectra.
spec[spec == 0] = np.nan
mean = np.nanmean(spec, axis=1)
var = np.nanvar(spec, axis=1)
n_intg = spec.shape[1]
if self.rfi_removal == "1D2D":
nsample = np.sum(~np.isnan(spec), axis=1)
varfilt = xrfi.flagged_filter(
var, size=2 * self.rfi_kernel_width_freq + 1
)
resid = mean - xrfi.flagged_filter(
mean, size=2 * self.rfi_kernel_width_freq + 1
)
flags = np.logical_or(
resid > self.rfi_threshold * np.sqrt(varfilt / nsample),
var - varfilt
> self.rfi_threshold * np.sqrt(2 * varfilt ** 2 / (nsample - 1)),
)
mean[flags] = np.nan
var[flags] = np.nan
means[key] = mean
variances[key] = var
if not self.cache_dir.exists():
self.cache_dir.mkdir()
with h5py.File(fname, "w") as fl:
logger.info(f"Saving reduced spectra to cache at {fname}")
for kind in kinds:
fl[kind + "_mean"] = means[kind]
fl[kind + "_var"] = variances[kind]
fl.attrs["n_integrations"] = n_intg
return means, variances, n_intg
def get_spectra(self) -> dict:
"""Read all spectra and remove RFI.
Returns
-------
dict :
A dictionary with keys being different powers (p1, p2, p3, Q), and values
being ndarrays.
"""
spec = self._read_spectrum()
if self.rfi_removal == "2D":
for key, val in spec.items():
# Need to set nans and zeros to inf so that median/mean detrending
# can work.
val[np.isnan(val)] = np.inf
if key != "Q":
val[val == 0] = np.inf
flags, _ = xrfi.xrfi_medfilt(
val,
threshold=self.rfi_threshold,
kt=self.rfi_kernel_width_time,
kf=self.rfi_kernel_width_freq,
)
val[flags] = np.nan
spec[key] = val
return spec
def _read_spectrum(self) -> dict:
"""
Read the contents of the spectrum files into memory.
Removes a starting percentage of times, and masks out certain frequencies.
Returns
-------
dict :
A dictionary of the contents of the file. Usually p0, p1, p2 (un-normalised
powers of source, load, and load+noise respectively), and ant_temp (the
uncalibrated, but normalised antenna temperature).
"""
data = [spec_obj.data for spec_obj in self.spec_obj]
n_times = sum(len(d["time_ancillary"]["times"]) for d in data)
out = {
"p0": np.empty((len(self.freq.freq), n_times)),
"p1": np.empty((len(self.freq.freq), n_times)),
"p2": np.empty((len(self.freq.freq), n_times)),
"Q": np.empty((len(self.freq.freq), n_times)),
}
index_start_spectra = int((self.ignore_times_percent / 100) * n_times)
for key, val in out.items():
nn = 0
for d in data:
n = len(d["time_ancillary"]["times"])
val[:, nn : (nn + n)] = d["spectra"][key][self.freq.mask]
nn += n
out[key] = val[:, index_start_spectra:]
return out
@cached_property
def thermistor(self) -> np.ndarray:
"""The thermistor readings."""
ary = self.resistance_obj.read()[0]
return ary[int((self.ignore_times_percent / 100) * len(ary)) :]
@cached_property
def thermistor_temp(self):
"""The associated thermistor temperature in K."""
return rcf.temperature_thermistor(self.thermistor["load_resistance"])
@cached_property
def temp_ave(self):
"""Average thermistor temperature (over time and frequency)."""
return np.nanmean(self.thermistor_temp)
def write(self, path=None):
"""
Write a HDF5 file containing the contents of the LoadSpectrum.
Parameters
----------
path : str
Directory into which to save the file, or full path to file.
If a directory, filename will be <load_name>_averaged_spectrum.h5.
Default is current directory.
"""
path = Path(path or ".")
# Allow to pass in a directory name *or* full path.
if path.is_dir():
path /= f"{self.load_name}_averaged_spectrum.h5"
with h5py.File(path, "w") as fl:
fl.attrs["load_name"] = self.load_name
fl["freq"] = self.freq.freq
fl["averaged_raw_spectrum"] = self.averaged_spectrum
fl["temperature"] = self.thermistor_temp
def plot(
self, thermistor=False, fig=None, ax=None, xlabel=True, ylabel=True, **kwargs
):
"""
Make a plot of the averaged uncalibrated spectrum associated with this load.
Parameters
----------
thermistor : bool
Whether to plot the thermistor temperature on the same axis.
fig : Figure
Optionally, pass a matplotlib figure handle which will be used to plot.
ax : Axis
Optional, pass a matplotlib Axis handle which will be added to.
xlabel : bool
Whether to make an x-axis label.
ylabel : bool
Whether to plot the y-axis label
kwargs :
All other arguments are passed to `plt.subplots()`.
"""
if fig is None:
fig, ax = plt.subplots(
1, 1, facecolor=kwargs.pop("facecolor", "white"), **kwargs
)
if thermistor:
ax.plot(self.freq.freq, self.thermistor_temp)
if ylabel:
ax.set_ylabel("Temperature [K]")
else:
ax.plot(self.freq.freq, self.averaged_spectrum)
if ylabel:
ax.set_ylabel("$T^*$ [K]")
ax.grid(True)
if xlabel:
ax.set_xlabel("Frequency [MHz]")
class HotLoadCorrection:
_kinds = {"s11": 0, "s12": 1, "s22": 2}
def __init__(
self,
path: Union[str, Path] = ":semi_rigid_s_parameters_WITH_HEADER.txt",
f_low: Optional[float] = None,
f_high: Optional[float] = None,
n_terms: int = 21,
):
"""
Corrections for the hot load.
Measurements required to define the HotLoad temperature, from Monsalve et al.
(2017), Eq. 8+9.
Parameters
----------
path : str or Path, optional
Path to a file containing measurements of the semi-rigid cable reflection
parameters. A preceding colon (:) indicates to prefix with DATA_PATH.
The default file was measured in 2015, but there is also a file included
that can be used from 2017: ":semi_rigid_s_parameters_2017.txt".
f_low, f_high : float
Lowest/highest frequency to retain from measurements.
"""
# Get the path to the S11 file.
if not isinstance(path, Path):
path = DATA_PATH / path[1:] if path[0] == ":" else Path(path)
self.path = path
data = np.genfromtxt(self.path)
f = data[:, 0]
self.freq = FrequencyRange(f, f_low, f_high)
if data.shape[1] == 7: # Original file from 2015
self.data = data[self.freq.mask, 1::2] + 1j * data[self.freq.mask, 2::2]
elif data.shape[1] == 6: # File from 2017
self.data = np.array(
[
data[self.freq.mask, 1] + 1j * data[self.freq.mask, 2],
data[self.freq.mask, 3],
data[self.freq.mask, 4] + 1j * data[self.freq.mask, 5],
]
).T
else:
raise IOError("Semi-Rigid Cable file has wrong data format.")
self.n_terms = int(n_terms)
def _get_model_kind(self, kind):
model = mdl.Polynomial(
n_terms=self.n_terms,
transform=mdl.UnitTransform(range=(self.freq.min, self.freq.max)),
)
model = mdl.ComplexMagPhaseModel(mag=model, phs=model)
return model.fit(xdata=self.freq.freq, ydata=self.data[:, self._kinds[kind]])
@cached_property
def s11_model(self):
"""The reflection coefficient."""
return self._get_model_kind("s11")
@cached_property
def s12_model(self):
"""The transmission coefficient."""
return self._get_model_kind("s12")
@cached_property
def s22_model(self):
"""The reflection coefficient from the other side."""
return self._get_model_kind("s22")
def power_gain(self, freq: np.ndarray, hot_load_s11: LoadS11) -> np.ndarray:
"""
Calculate the power gain.
Parameters
----------
freq : np.ndarray
The frequencies.
hot_load_s11 : :class:`LoadS11`
The S11 of the hot load.
Returns
-------
gain : np.ndarray
The power gain as a function of frequency.
"""
assert isinstance(
hot_load_s11, LoadS11
), "hot_load_s11 must be a switch correction"
assert (
hot_load_s11.load_name == "hot_load"
), "hot_load_s11 must be a hot_load s11"
return self.get_power_gain(
{
"s11": self.s11_model(freq),
"s12s21": self.s12_model(freq),
"s22": self.s22_model(freq),
},
hot_load_s11.s11_model(freq),
)
@staticmethod
def get_power_gain(
semi_rigid_sparams: dict, hot_load_s11: np.ndarray
) -> np.ndarray:
"""Define Eq. 9 from M17.
Parameters
----------
semi_rigid_sparams : dict
A dictionary of reflection coefficient measurements as a function of
frequency for the semi-rigid cable.
hot_load_s11 : array-like
The S11 measurement of the hot_load.
Returns
-------
gain : np.ndarray
The power gain.
"""
rht = rc.gamma_de_embed(
semi_rigid_sparams["s11"],
semi_rigid_sparams["s12s21"],
semi_rigid_sparams["s22"],
hot_load_s11,
)
return (
np.abs(semi_rigid_sparams["s12s21"])
* (1 - np.abs(rht) ** 2)
/ (
(np.abs(1 - semi_rigid_sparams["s11"] * rht)) ** 2
* (1 - np.abs(hot_load_s11) ** 2)
)
)
class Load:
def __init__(
self,
spectrum: LoadSpectrum,
reflections: LoadS11,
hot_load_correction: Optional[HotLoadCorrection] = None,
ambient: Optional[LoadSpectrum] = None,
):
"""Wrapper class containing all relevant information for a given load.
Parameters
----------
spectrum : :class:`LoadSpectrum`
The spectrum for this particular load.
reflections : :class:`SwitchCorrection`
The S11 measurements for this particular load.
hot_load_correction : :class:`HotLoadCorrection`
If this is a hot load, provide a hot load correction.
ambient : :class:`LoadSpectrum`
If this is a hot load, need to provide an ambient spectrum to correct it.
"""
assert isinstance(spectrum, LoadSpectrum), "spectrum must be a LoadSpectrum"
assert isinstance(reflections, LoadS11), "spectrum must be a SwitchCorrection"
assert spectrum.load_name == reflections.load_name
self.spectrum = spectrum
self.reflections = reflections
self.load_name = spectrum.load_name
self.t_load = self.spectrum.t_load
self.t_load_ns = self.spectrum.t_load_ns
if self.load_name == "hot_load":
self._correction = hot_load_correction
self._ambient = ambient
@classmethod
def from_path(
cls,
path: Union[str, Path],
load_name: str,
f_low: Optional[float] = None,
f_high: Optional[float] = None,
reflection_kwargs: Optional[dict] = None,
spec_kwargs: Optional[dict] = None,
):
"""
Define a full :class:`Load` from a path and name.
Parameters
----------
path : str or Path
Path to the top-level calibration observation.
load_name : str
Name of a load to define.
f_low, f_high : float
Min/max frequencies to keep in measurements.
reflection_kwargs : dict
Extra arguments to pass through to :class:`SwitchCorrection`.
spec_kwargs : dict
Extra arguments to pass through to :class:`LoadSpectrum`.
Returns
-------
load : :class:`Load`
The load object, containing all info about spectra and S11's for that load.
"""
if not spec_kwargs:
spec_kwargs = {}
if not reflection_kwargs:
reflection_kwargs = {}
spec = LoadSpectrum.from_load_name(
load_name,
path,
f_low=f_low,
f_high=f_high,
**spec_kwargs,
)
refl = LoadS11.from_path(
load_name,
path,
f_low=f_low,
f_high=f_high,
**reflection_kwargs,
)
return cls(spec, refl)
@property
def s11_model(self):
"""The S11 model."""
return self.reflections.s11_model
@cached_property
def temp_ave(self):
"""The average temperature of the thermistor (over frequency and time)."""
if self.load_name != "hot_load":
return self.spectrum.temp_ave
gain = self._correction.power_gain(self.freq.freq, self.reflections)
# temperature
return gain * self.spectrum.temp_ave + (1 - gain) * self._ambient.temp_ave
@property
def averaged_Q(self):
"""Averaged power ratio."""
return self.spectrum.averaged_Q
@property
def averaged_spectrum(self):
"""Averaged uncalibrated temperature."""
return self.spectrum.averaged_spectrum
@property
def freq(self):
"""A :class:`FrequencyRange` object corresponding to this measurement."""
return self.spectrum.freq
class CalibrationObservation:
_sources = ("ambient", "hot_load", "open", "short")
def __init__(
self,
path: Union[str, Path],
semi_rigid_path: Union[str, Path] = ":semi_rigid_s_parameters_WITH_HEADER.txt",
f_low: Optional[float] = 40,
f_high: Optional[float] = None,
run_num: Union[None, int, dict] = None,
repeat_num: Union[None, int, dict] = None,
resistance_f: Optional[float] = None,
cterms: int = 5,
wterms: int = 7,
load_kwargs: Optional[dict] = None,
s11_kwargs: Optional[dict] = None,
load_spectra: Optional[dict] = None,
load_s11s: Optional[dict] = None,
compile_from_def: bool = True,
include_previous: bool = False,
internal_switch_kwargs: Optional[Dict[str, Any]] = None,
):
"""
A composite object representing a full Calibration Observation.
This includes spectra of all calibrators, and methods to find the calibration
parameters. It strictly follows Monsalve et al. (2017) in its formalism.
While by default the class uses the calibrator sources ("ambient", "hot_load",
"open", "short"), it can be modified to take other sources by setting
``CalibrationObservation._sources`` to a new tuple of strings.
Parameters
----------
path : str or Path
Path to the directory containing all relevant measurements. It is assumed
that in this directory is an `S11`, `Resistance` and `Spectra` directory.
semi_rigid_path : str or Path, optional
Path to a file containing S11 measurements for the semi rigid cable. Used to
correct the hot load S11. Found automatically if not given.
ambient_temp : int
Ambient temperature (C) at which measurements were taken.
f_low : float
Minimum frequency to keep for all loads (and their S11's). If for some
reason different frequency bounds are desired per-load, one can pass in
full load objects through ``load_spectra``.
f_high : float
Maximum frequency to keep for all loads (and their S11's). If for some
reason different frequency bounds are desired per-load, one can pass in
full load objects through ``load_spectra``.
run_num : int or dict
Which run number to use for the calibrators. Default is to use the last run
for each. Passing an int will attempt to use that run for each source. Pass
a dict mapping sources to numbers to use different combinations.
repeat_num : int or dict
Which repeat number to use for the calibrators. Default is to use the last
repeat for each. Passing an int will attempt to use that repeat for each
source. Pass a dict mapping sources to numbers to use different
combinations.
resistance_f : float
Female resistance (Ohms). Used for the LNA S11.
cterms : int
The number of terms to use for the polynomial fits to the calibration
functions.
wterms : int
The number of terms to use for the polynomial fits to the noise-wave
calibration functions.
load_kwargs : dict
Keyword arguments used to instantiate the calibrator :class:`LoadSpectrum`
objects. See its documentation for relevant parameters. Parameters specified
here are used for _all_ calibrator sources.
s11_kwargs : dict
Keyword arguments used to instantiate the calibrator :class:`LoadS11`
objects. See its documentation for relevant parameters. Parameters specified
here are used for _all_ calibrator sources.
load_spectra : dict
A dictionary mapping load names of calibration sources (eg. ambient, short)
to either :class:`LoadSpectrum` instances or dictionaries of keywords to
instantiate those objects. Useful for individually specifying
properties of each load separately. Values in these dictionaries (if
supplied) over-ride those given in ``load_kwargs`` (but values in
``load_kwargs`` are still used if not over-ridden).
load_s11s : dict
A dictionary mapping load names of calibration sources (eg. ambient, short)
to :class:`LoadS11` instances or dictionaries of keywords to instantiate
those objects. Useful for individually specifying properties of each load
separately. Values in these dictionaries (if supplied) over-ride those
given in ``s11_kwargs`` (but values in ``s11_kwargs`` are still used if not
over-ridden).
compile_from_def : bool
Whether to attempt compiling a virtual observation from a
``definition.yaml`` inside the observation directory. This is the default
behaviour, but can be turned off to enforce that the current directory
should be used directly.
include_previous : bool
Whether to include the previous observation by default to supplement this
one if required files are missing.
Examples
--------
This will setup an observation with all default options applied:
>>> path = '/CalibrationObservations/Receiver01_25C_2019_11_26_040_to_200MHz'
>>> calobs = CalibrationObservation(path)
To specify some options for constructing the various calibrator load spectra:
>>> calobs = CalibrationObservation(
>>> path,
>>> load_kwargs={"cache_dir":".", "ignore_times_percent": 50}
>>> )
But if we typically wanted 50% of times ignored, but in one special case we'd
like 80%:
>>> calobs = CalibrationObservation(
>>> path,
>>> load_kwargs={"cache_dir":".", "ignore_times_percent": 50},
>>> load_spectra={"short": {"ignore_times_percent": 80}}
>>> )
"""
load_spectra = load_spectra or {}
load_s11s = load_s11s or {}
load_kwargs = load_kwargs or {}
s11_kwargs = s11_kwargs or {}
internal_switch_kwargs = internal_switch_kwargs or {}
assert all(name in self._sources for name in load_spectra)
assert all(name in self._sources + ("lna",) for name in load_s11s)
self.io = io.CalibrationObservation(
path,
run_num=run_num,
repeat_num=repeat_num,
fix=False,
compile_from_def=compile_from_def,
include_previous=include_previous,
)
self.compiled_from_def = compile_from_def
self.previous_included = include_previous
self.path = Path(self.io.path)
hot_load_correction = HotLoadCorrection(semi_rigid_path, f_low, f_high)
self.internal_switch = s11.InternalSwitch(
data=self.io.s11.switching_state,
resistance=self.io.definition["measurements"]["resistance_m"][
self.io.s11.switching_state.run_num
],
**internal_switch_kwargs,
)
self._loads = {}
for source in self._sources:
load = load_spectra.get(source, {})
if isinstance(load, dict):
load = LoadSpectrum(
spec_obj=getattr(self.io.spectra, source),
resistance_obj=getattr(self.io.resistance, source),
f_low=f_low,
f_high=f_high,
**{**load_kwargs, **load},
)
# Ensure that we finally have a LoadSpectrum
if not isinstance(load, LoadSpectrum):
raise TypeError("load_spectra must be a dict of LoadSpectrum or dicts.")
refl = load_s11s.get(source, {})
if isinstance(refl, dict):
refl = LoadS11(
load_s11=getattr(self.io.s11, source),
internal_switch=self.internal_switch,
f_low=f_low,
f_high=f_high,
**{**s11_kwargs, **refl},
)
if source == "hot_load":
self._loads[source] = Load(
load,
refl,
hot_load_correction=hot_load_correction,
ambient=self._loads["ambient"].spectrum,
)
else:
self._loads[source] = Load(load, refl)
for name, load in self._loads.items():
setattr(self, name, load)
refl = load_s11s.get("lna", {})
self.lna = LNA(
load_s11=self.io.s11.receiver_reading,
f_low=f_low,
f_high=f_high,
resistance=resistance_f
or self.io.definition["measurements"]["resistance_f"][
self.io.s11.receiver_reading.run_num
],
**{**s11_kwargs, **refl},
)
# We must use the most restricted frequency range available from all available
# sources as well as the LNA.
fmin = max(
sum(
(
[load.spectrum.freq.min, load.reflections.freq.min]
for load in self._loads.values()
),
[],
)
+ [self.lna.freq.min]
)
fmax = min(
sum(
(
[load.spectrum.freq.max, load.reflections.freq.max]
for load in self._loads.values()
),
[],
)
+ [self.lna.freq.max]
)
if fmax <= fmin:
raise ValueError(
"The inputs loads and S11s have non-overlapping frequency ranges!"
)
self.freq = EdgesFrequencyRange(f_low=fmin, f_high=fmax)
# Now make everything actually consistent in its frequency range.
for load in self._loads.values():
load.spectrum.freq = self.freq
self.cterms = cterms
self.wterms = wterms
self.t_load = self.ambient.t_load
self.t_load_ns = self.ambient.t_load_ns
@property
def load_names(self) -> Tuple[str]:
"""Names of the loads."""
return tuple(self._loads.keys())
def new_load(
self,
load_name: str,
run_num: int = 1,
reflection_kwargs: Optional[dict] = None,
spec_kwargs: Optional[dict] = None,
):
"""Create a new load with the given load name.
Uses files inside the current observation.
Parameters
----------
load_name : str
The name of the load ('ambient', 'hot_load', 'open', 'short').
run_num_spec : dict or int
Run number to use for the spectrum.
run_num_load : dict or int
Run number to use for the load's S11.
reflection_kwargs : dict
Keyword arguments to construct the :class:`SwitchCorrection`.
spec_kwargs : dict
Keyword arguments to construct the :class:`LoadSpectrum`.
"""
reflection_kwargs = reflection_kwargs or {}
spec_kwargs = spec_kwargs or {}
# Fill up kwargs with keywords from this instance
if "resistance" not in reflection_kwargs:
reflection_kwargs[
"resistance"
] = self.open.reflections.internal_switch.resistance
for key in [
"ignore_times_percent",
"rfi_removal",
"rfi_kernel_width_freq",
"rfi_kernel_width_time",
"rfi_threshold",
"cache_dir",
"t_load",
"t_load_ns",
]:
if key not in spec_kwargs:
spec_kwargs[key] = getattr(self.open.spectrum, key)
reflection_kwargs["run_num_load"] = run_num
reflection_kwargs["repeat_num_switch"] = self.io.s11.switching_state.repeat_num
reflection_kwargs["run_num_switch"] = self.io.s11.switching_state.run_num
spec_kwargs["run_num"] = run_num
return Load.from_path(
path=self.io.path,
load_name=load_name,
f_low=self.freq.min,
f_high=self.freq.max,
reflection_kwargs=reflection_kwargs,
spec_kwargs=spec_kwargs,
)
def plot_raw_spectra(self, fig=None, ax=None) -> plt.Figure:
"""
Plot raw uncalibrated spectra for all calibrator sources.
Parameters
----------
fig : :class:`plt.Figure`
A matplotlib figure on which to make the plot. By default creates a new one.
ax : :class:`plt.Axes`
A matplotlib Axes on which to make the plot. By default creates a new one.
Returns
-------
fig : :class:`plt.Figure`
The figure on which the plot was made.
"""
if fig is None and ax is None:
fig, ax = plt.subplots(
len(self._sources), 1, sharex=True, gridspec_kw={"hspace": 0.05}
)
for i, (name, load) in enumerate(self._loads.items()):
load.spectrum.plot(
fig=fig, ax=ax[i], xlabel=(i == (len(self._sources) - 1))
)
ax[i].set_title(name)
return fig
def plot_s11_models(self, **kwargs):
"""
Plot residuals of S11 models for all sources.
Returns
-------
dict:
Each entry has a key of the source name, and the value is a matplotlib fig.
"""
out = {
name: source.reflections.plot_residuals(**kwargs)
for name, source in self._loads.items()
}
out.update({"lna": self.lna.plot_residuals(**kwargs)})
return out
@cached_property
def s11_correction_models(self):
"""Dictionary of S11 correction models, one for each source."""
try:
return dict(self._injected_source_s11s)
except (TypeError, AttributeError):
return {
name: source.s11_model(self.freq.freq)
for name, source in self._loads.items()
}
@cached_property
def source_thermistor_temps(self) -> Dict[str, Union[float, np.ndarray]]:
"""Dictionary of input source thermistor temperatures."""
if (
hasattr(self, "_injected_source_temps")
and self._injected_source_temps is not None
):
return self._injected_source_temps
return {k: source.temp_ave for k, source in self._loads.items()}
@cached_property
def _calibration_coefficients(self):
"""The calibration polynomials, evaluated at `freq.freq`."""
if (
hasattr(self, "_injected_averaged_spectra")
and self._injected_averaged_spectra is not None
):
ave_spec = self._injected_averaged_spectra
else:
ave_spec = {
k: source.averaged_spectrum for k, source in self._loads.items()
}
scale, off, Tu, TC, TS = rcf.get_calibration_quantities_iterative(
self.freq.freq_recentred,
temp_raw=ave_spec,
gamma_rec=self.lna_s11,
gamma_ant=self.s11_correction_models,
temp_ant=self.source_thermistor_temps,
cterms=self.cterms,
wterms=self.wterms,
temp_amb_internal=self.t_load,
)
return scale, off, Tu, TC, TS
@cached_property
def C1_poly(self): # noqa: N802
"""`np.poly1d` object describing the Scaling calibration coefficient C1.
The polynomial is defined to act on normalized frequencies such that `freq.min`
and `freq.max` map to -1 and 1 respectively. Use :func:`~C1` as a direct
function on frequency.
"""
return self._calibration_coefficients[0]
@cached_property
def C2_poly(self): # noqa: N802
"""`np.poly1d` object describing the offset calibration coefficient C2.
The polynomial is defined to act on normalized frequencies such that `freq.min`
and `freq.max` map to -1 and 1 respectively. Use :func:`~C2` as a direct
function on frequency.
"""
return self._calibration_coefficients[1]
@cached_property
def Tunc_poly(self): # noqa: N802
"""`np.poly1d` object describing the uncorrelated noise-wave parameter, Tunc.
The polynomial is defined to act on normalized frequencies such that `freq.min`
and `freq.max` map to -1 and 1 respectively. Use :func:`~Tunc` as a direct
function on frequency.
"""
return self._calibration_coefficients[2]
@cached_property
def Tcos_poly(self): # noqa: N802
"""`np.poly1d` object describing the cosine noise-wave parameter, Tcos.
The polynomial is defined to act on normalized frequencies such that `freq.min`
and `freq.max` map to -1 and 1 respectively. Use :func:`~Tcos` as a direct
function on frequency.
"""
return self._calibration_coefficients[3]
@cached_property
def Tsin_poly(self): # noqa: N802
"""`np.poly1d` object describing the sine noise-wave parameter, Tsin.
The polynomial is defined to act on normalized frequencies such that `freq.min`
and `freq.max` map to -1 and 1 respectively. Use :func:`~Tsin` as a direct
function on frequency.
"""
return self._calibration_coefficients[4]
def C1(self, f: Optional[Union[float, np.ndarray]] = None): # noqa: N802
"""
Scaling calibration parameter.
Parameters
----------
f : array-like
The frequencies at which to evaluate C1. By default, the frequencies of this
instance.
"""
if hasattr(self, "_injected_c1") and self._injected_c1 is not None:
return np.array(self._injected_c1)
fnorm = self.freq.freq_recentred if f is None else self.freq.normalize(f)
return self.C1_poly(fnorm)
def C2(self, f: Optional[Union[float, np.ndarray]] = None): # noqa: N802
"""
Offset calibration parameter.
Parameters
----------
f : array-like
The frequencies at which to evaluate C2. By default, the frequencies of this
instance.
"""
if hasattr(self, "_injected_c2") and self._injected_c2 is not None:
return np.array(self._injected_c2)
fnorm = self.freq.freq_recentred if f is None else self.freq.normalize(f)
return self.C2_poly(fnorm)
def Tunc(self, f: Optional[Union[float, np.ndarray]] = None): # noqa: N802
"""
Uncorrelated noise-wave parameter.
Parameters
----------
f : array-like
The frequencies at which to evaluate Tunc. By default, the frequencies of
thisinstance.
"""
if hasattr(self, "_injected_t_unc") and self._injected_t_unc is not None:
return np.array(self._injected_t_unc)
fnorm = self.freq.freq_recentred if f is None else self.freq.normalize(f)
return self.Tunc_poly(fnorm)
def Tcos(self, f: Optional[Union[float, np.ndarray]] = None): # noqa: N802
"""
Cosine noise-wave parameter.
Parameters
----------
f : array-like
The frequencies at which to evaluate Tcos. By default, the frequencies of
this instance.
"""
if hasattr(self, "_injected_t_cos") and self._injected_t_cos is not None:
return np.array(self._injected_t_cos)
fnorm = self.freq.freq_recentred if f is None else self.freq.normalize(f)
return self.Tcos_poly(fnorm)
def Tsin(self, f: Optional[Union[float, np.ndarray]] = None): # noqa: N802
"""
Sine noise-wave parameter.
Parameters
----------
f : array-like
The frequencies at which to evaluate Tsin. By default, the frequencies of
this instance.
"""
if hasattr(self, "_injected_t_sin") and self._injected_t_sin is not None:
return np.array(self._injected_t_sin)
fnorm = self.freq.freq_recentred if f is None else self.freq.normalize(f)
return self.Tsin_poly(fnorm)
@cached_property
def lna_s11(self):
"""The corrected S11 of the LNA evaluated at the data frequencies."""
if hasattr(self, "_injected_lna_s11") and self._injected_lna_s11 is not None:
return self._injected_lna_s11
else:
return self.lna.s11_model(self.freq.freq)
def get_linear_coefficients(self, load: Union[Load, str]):
"""
Calibration coefficients a,b such that T = aT* + b (derived from Eq. 7).
Parameters
----------
load : str or :class:`Load`
The load for which to get the linear coefficients.
"""
if isinstance(load, str):
load_s11 = self.s11_correction_models[load]
elif load.load_name in self.s11_correction_models:
load_s11 = self.s11_correction_models[load.load_name]
else:
load_s11 = load.s11_model(self.freq.freq)
return rcf.get_linear_coefficients(
load_s11,
self.lna_s11,
self.C1(self.freq.freq),
self.C2(self.freq.freq),
self.Tunc(self.freq.freq),
self.Tcos(self.freq.freq),
self.Tsin(self.freq.freq),
t_load=self.t_load,
)
def calibrate(self, load: Union[Load, str], q=None, temp=None):
"""
Calibrate the temperature of a given load.
Parameters
----------
load : :class:`Load` or str
The load to calibrate.
Returns
-------
array : calibrated antenna temperature in K, len(f).
"""
load = self._load_str_to_load(load)
a, b = self.get_linear_coefficients(load)
if q is not None:
temp = self.t_load_ns * q + self.t_load
elif temp is None:
temp = load.averaged_spectrum
return a * temp + b
def _load_str_to_load(self, load: Union[Load, str]):
if isinstance(load, str):
try:
load = self._loads[load]
except AttributeError:
raise AttributeError(
"load must be a Load object or a string (one of "
"{ambient,hot_load,open,short})"
)
else:
assert isinstance(
load, Load
), "load must be a Load instance, got the {} {}".format(load, type(Load))
return load
def decalibrate(
self, temp: np.ndarray, load: Union[Load, str], freq: np.ndarray = None
):
"""
Decalibrate a temperature spectrum, yielding uncalibrated T*.
Parameters
----------
temp : array_like
A temperature spectrum, with the same length as `freq.freq`.
load : str or :class:`Load`
The load to calibrate.
freq : array-like
The frequencies at which to decalibrate. By default, the frequencies of the
instance.
Returns
-------
array_like : T*, the normalised uncalibrated temperature.
"""
if freq is None:
freq = self.freq.freq
if freq.min() < self.freq.freq.min():
warnings.warn(
"The minimum frequency is outside the calibrated range "
f"({self.freq.freq.min()} - {self.freq.freq.max()} MHz)"
)
if freq.min() > self.freq.freq.max():
warnings.warn("The maximum frequency is outside the calibrated range ")
a, b = self.get_linear_coefficients(load)
return (temp - b) / a
def get_K(
self, freq: np.ndarray | None = None
) -> Dict[str, Tuple[np.ndarray, np.ndarray, np.ndarray, np.ndarray]]:
"""Get the source-S11-dependent factors of Monsalve (2017) Eq. 7."""
if freq is None:
freq = self.freq.freq
gamma_ants = self.s11_correction_models
else:
gamma_ants = {
name: source.s11_model(freq) for name, source in self._loads.items()
}
lna_s11 = self.lna.s11_model(freq)
return {
name: rcf.get_K(gamma_rec=lna_s11, gamma_ant=gamma_ant)
for name, gamma_ant in gamma_ants.items()
}
def plot_calibrated_temp(
self,
load: Union[Load, str],
bins: int = 2,
fig=None,
ax=None,
xlabel=True,
ylabel=True,
):
"""
Make a plot of calibrated temperature for a given source.
Parameters
----------
load : :class:`~LoadSpectrum` instance
Source to plot.
bins : int
Number of bins to smooth over (std of Gaussian kernel)
fig : Figure
Optionally provide a matplotlib figure to add to.
ax : Axis
Optionally provide a matplotlib Axis to add to.
xlabel : bool
Whether to write the x-axis label
ylabel : bool
Whether to write the y-axis label
Returns
-------
|
load = self._load_str_to_load(load)
if fig is None and ax is None:
fig, ax = plt.subplots(1, 1, facecolor="w")
# binning
temp_calibrated = self.calibrate(load)
if bins > 0:
freq_ave_cal = convolve(
temp_calibrated, Gaussian1DKernel(stddev=bins), boundary="extend"
)
else:
freq_ave_cal = temp_calibrated
freq_ave_cal[np.isinf(freq_ave_cal)] = np.nan
rms = np.sqrt(np.mean((freq_ave_cal - np.mean(freq_ave_cal)) ** 2))
ax.plot(
self.freq.freq,
freq_ave_cal,
label=f"Calibrated {load.spectrum.load_name} [RMS = {rms:.3f}]",
)
temp_ave = self.source_thermistor_temps.get(load.load_name, load.temp_ave)
if not hasattr(temp_ave, "__len__"):
ax.axhline(temp_ave, color="C2", label="Average thermistor temp")
else:
ax.plot(
self.freq.freq,
temp_ave,
color="C2",
label="Average thermistor temp",
)
ax.set_ylim([np.nanmin(freq_ave_cal), np.nanmax(freq_ave_cal)])
if xlabel:
ax.set_xlabel("Frequency [MHz]")
if ylabel:
ax.set_ylabel("Temperature [K]")
plt.ticklabel_format(useOffset=False)
ax.grid()
ax.legend()
return plt.gcf()
def get_load_residuals(self):
"""Get residuals of the calibrated temperature for a each load."""
out = {}
for source in self._sources:
load = self._load_str_to_load(source)
cal = self.calibrate(load)
true = self.source_thermistor_temps[source]
out[source] = cal - true
return out
def get_rms(self, smooth: int = 4):
"""Return a dict of RMS values for each source.
Parameters
----------
smooth : int
The number of bins over which to smooth residuals before taking the RMS.
"""
resids = self.get_load_residuals()
out = {}
for name, res in resids.items():
if smooth > 1:
res = convolve(res, Gaussian1DKernel(stddev=smooth), boundary="extend")
out[name] = np.sqrt(np.nanmean(res ** 2))
return out
def plot_calibrated_temps(self, bins=64, fig=None, ax=None):
"""
Plot all calibrated temperatures in a single figure.
Parameters
----------
bins : int
Number of bins in the smoothed spectrum
Returns
-------
fig :
Matplotlib figure that was created.
"""
if fig is None or ax is None or len(ax) != len(self._sources):
fig, ax = plt.subplots(
len(self._sources),
1,
sharex=True,
gridspec_kw={"hspace": 0.05},
figsize=(10, 12),
)
for i, source in enumerate(self._sources):
self.plot_calibrated_temp(
source,
bins=bins,
fig=fig,
ax=ax[i],
xlabel=i == (len(self._sources) - 1),
)
fig.suptitle("Calibrated Temperatures for Calibration Sources", fontsize=15)
return fig
def write_coefficients(self, path: Optional[str] = None):
"""
Save a text file with the derived calibration co-efficients.
Parameters
----------
path : str
Directory in which to write the file. The filename starts with
`All_cal-params` and includes parameters of the class in the filename.
By default, current directory.
"""
path = Path(path or ".")
if path.is_dir():
path /= (
f"calibration_parameters_fmin{self.freq.freq.min()}_"
f"fmax{self.freq.freq.max()}_C{self.cterms}_W{self.wterms}.txt"
)
np.savetxt(
path,
[
self.freq.freq,
self.C1(),
self.C2(),
self.Tunc(),
self.Tcos(),
self.Tsin(),
],
)
def plot_coefficients(self, fig=None, ax=None):
"""
Make a plot of the calibration models, C1, C2, Tunc, Tcos and Tsin.
Parameters
----------
fig : Figure
Optionally pass a matplotlib figure to add to.
ax : Axis
Optionally pass a matplotlib axis to pass to. Must have 5 axes.
"""
if fig is None or ax is None:
fig, ax = plt.subplots(
5, 1, facecolor="w", gridspec_kw={"hspace": 0.05}, figsize=(10, 9)
)
labels = [
"Scale ($C_1$)",
"Offset ($C_2$) [K]",
r"$T_{\rm unc}$ [K]",
r"$T_{\rm cos}$ [K]",
r"$T_{\rm sin}$ [K]",
]
for i, (kind, label) in enumerate(
zip(["C1", "C2", "Tunc", "Tcos", "Tsin"], labels)
):
ax[i].plot(self.freq.freq, getattr(self, kind)())
ax[i].set_ylabel(label, fontsize=13)
ax[i].grid()
plt.ticklabel_format(useOffset=False)
if i == 4:
ax[i].set_xlabel("Frequency [MHz]", fontsize=13)
fig.suptitle("Calibration Parameters", fontsize=15)
return fig
def invalidate_cache(self):
"""Invalidate all cached attributes so they must be recalculated."""
if not hasattr(self, "_cached_"):
return
for cache in self._cached_:
del self.__dict__[cache]
def update(self, **kwargs):
"""Update the class in-place, invalidating the cache as well.
Parameters
----------
kwargs :
All parameters to be updated.
"""
self.invalidate_cache()
for k, v in kwargs.items():
setattr(self, k, v)
def write(self, filename: Union[str, Path]):
"""
Write all information required to calibrate a new spectrum to file.
Parameters
----------
filename : path
The filename to write to.
"""
with h5py.File(filename, "w") as fl:
# Write attributes
fl.attrs["path"] = str(self.io.original_path)
fl.attrs["cterms"] = self.cterms
fl.attrs["wterms"] = self.wterms
fl.attrs["switch_path"] = str(self.internal_switch.data.path)
fl.attrs["switch_repeat_num"] = self.internal_switch.data.repeat_num
fl.attrs["switch_resistance"] = self.internal_switch.resistance
fl.attrs["switch_nterms"] = self.internal_switch.n_terms[0]
fl.attrs["switch_model"] = str(self.internal_switch.model)
fl.attrs["t_load"] = self.open.spectrum.t_load
fl.attrs["t_load_ns"] = self.open.spectrum.t_load_ns
fl["C1"] = self.C1_poly.coefficients
fl["C2"] = self.C2_poly.coefficients
fl["Tunc"] = self.Tunc_poly.coefficients
fl["Tcos"] = self.Tcos_poly.coefficients
fl["Tsin"] = self.Tsin_poly.coefficients
fl["frequencies"] = self.freq.freq
fl["lna_s11_real"] = self.lna.s11_model(self.freq.freq).real
fl["lna_s11_imag"] = self.lna.s11_model(self.freq.freq).imag
fl["internal_switch_s11_real"] = np.real(
self.internal_switch.s11_model(self.freq.freq)
)
fl["internal_switch_s11_imag"] = np.imag(
self.internal_switch.s11_model(self.freq.freq)
)
fl["internal_switch_s12_real"] = np.real(
self.internal_switch.s12_model(self.freq.freq)
)
fl["internal_switch_s12_imag"] = np.imag(
self.internal_switch.s12_model(self.freq.freq)
)
fl["internal_switch_s22_real"] = np.real(
self.internal_switch.s22_model(self.freq.freq)
)
fl["internal_switch_s22_imag"] = np.imag(
self.internal_switch.s22_model(self.freq.freq)
)
load_grp = fl.create_group("loads")
for name, load in self._loads.items():
grp = load_grp.create_group(name)
grp.attrs["s11_model"] = yaml.dump(load.s11_model)
grp["averaged_Q"] = load.spectrum.averaged_Q
grp["variance_Q"] = load.spectrum.variance_Q
grp["temp_ave"] = load.temp_ave
grp.attrs["n_integrations"] = load.spectrum.n_integrations
def to_calfile(self):
"""Directly create a :class:`Calibration` object without writing to file."""
return Calibration.from_calobs(self)
def inject(
self,
lna_s11: np.ndarray = None,
source_s11s: Dict[str, np.ndarray] = None,
c1: np.ndarray = None,
c2: np.ndarray = None,
t_unc: np.ndarray = None,
t_cos: np.ndarray = None,
t_sin: np.ndarray = None,
averaged_spectra: Dict[str, np.ndarray] = None,
thermistor_temp_ave: Dict[str, np.ndarray] = None,
) -> CalibrationObservation:
"""Make a new :class:`CalibrationObservation` based on this, with injections.
Parameters
----------
lna_s11
The LNA S11 as a function of frequency to inject.
source_s11s
Dictionary of ``{source: S11}`` for each source to inject.
c1
Scaling parameter as a function of frequency to inject.
c2 : [type], optional
Offset parameter to inject as a function of frequency.
t_unc
Uncorrelated temperature to inject (as function of frequency)
t_cos
Correlated temperature to inject (as function of frequency)
t_sin
Correlated temperature to inject (as function of frequency)
averaged_spectra
Dictionary of ``{source: spectrum}`` for each source to inject.
Returns
-------
:class:`CalibrationObservation`
A new observation object with the injected models.
"""
new = copy(self)
new.invalidate_cache()
new._injected_lna_s11 = lna_s11
new._injected_source_s11s = source_s11s
new._injected_c1 = c1
new._injected_c2 = c2
new._injected_t_unc = t_unc
new._injected_t_cos = t_cos
new._injected_t_sin = t_sin
new._injected_averaged_spectra = averaged_spectra
new._injected_source_temps = thermistor_temp_ave
return new
@attr.s
class _LittleS11:
s11_model: Callable = attr.ib()
@attr.s
class _LittleSpectrum:
averaged_Q: np.ndarray = attr.ib()
variance_Q: np.ndarray = attr.ib()
n_integrations: int = attr.ib()
@attr.s
class _LittleLoad:
reflections: _LittleS11 = attr.ib()
spectrum: _LittleSpectrum = attr.ib()
temp_ave: np.ndarray = attr.ib()
class Calibration:
def __init__(self, filename: Union[str, Path]):
"""
A class defining an interface to a HDF5 file containing calibration information.
Parameters
----------
filename : str or Path
The path to the calibration file.
"""
self.calfile = Path(filename)
with h5py.File(filename, "r") as fl:
self.calobs_path = fl.attrs["path"]
self.cterms = int(fl.attrs["cterms"])
self.wterms = int(fl.attrs["wterms"])
self.t_load = fl.attrs.get("t_load", 300)
self.t_load_ns = fl.attrs.get("t_load_ns", 400)
self.C1_poly = np.poly1d(fl["C1"][...])
self.C2_poly = np.poly1d(fl["C2"][...])
self.Tcos_poly = np.poly1d(fl["Tcos"][...])
self.Tsin_poly = np.poly1d(fl["Tsin"][...])
self.Tunc_poly = np.poly1d(fl["Tunc"][...])
self.freq = FrequencyRange(fl["frequencies"][...])
self._loads = {}
if "loads" in fl:
lg = fl["loads"]
self.load_names = list(lg.keys())
for name, grp in lg.items():
self._loads[name] = _LittleLoad(
reflections=_LittleS11(
s11_model=yaml.load(
grp.attrs["s11_model"], Loader=yaml.FullLoader
).at(x=self.freq.freq)
),
spectrum=_LittleSpectrum(
averaged_Q=grp["averaged_Q"][...],
variance_Q=grp["variance_Q"][...],
n_integrations=grp.attrs["n_integrations"],
),
temp_ave=grp["temp_ave"][...],
)
self._lna_s11_rl = Spline(self.freq.freq, fl["lna_s11_real"][...])
self._lna_s11_im = Spline(self.freq.freq, fl["lna_s11_imag"][...])
self._intsw_s11_rl = Spline(
self.freq.freq, fl["internal_switch_s11_real"][...]
)
self._intsw_s11_im = Spline(
self.freq.freq, fl["internal_switch_s11_imag"][...]
)
self._intsw_s12_rl = Spline(
self.freq.freq, fl["internal_switch_s12_real"][...]
)
self._intsw_s12_im = Spline(
self.freq.freq, fl["internal_switch_s12_imag"][...]
)
self._intsw_s22_rl = Spline(
self.freq.freq, fl["internal_switch_s22_real"][...]
)
self._intsw_s22_im = Spline(
self.freq.freq, fl["internal_switch_s22_imag"][...]
)
@classmethod
def from_calobs(cls, calobs: CalibrationObservation) -> Calibration:
"""Generate a :class:`Calibration` from an in-memory observation."""
tmp = tempfile.mktemp()
calobs.write(tmp)
return cls(tmp)
def lna_s11(self, freq=None):
"""Get the LNA S11 at given frequencies."""
if freq is None:
freq = self.freq.freq
return self._lna_s11_rl(freq) + 1j * self._lna_s11_im(freq)
def internal_switch_s11(self, freq=None):
"""Get the S11 of the internal switch at given frequencies."""
if freq is None:
freq = self.freq.freq
return self._intsw_s11_rl(freq) + 1j * self._intsw_s11_im(freq)
def internal_switch_s12(self, freq=None):
"""Get the S12 of the internal switch at given frequencies."""
if freq is None:
freq = self.freq.freq
return self._intsw_s12_rl(freq) + 1j * self._intsw_s12_im(freq)
def internal_switch_s22(self, freq=None):
"""Get the S22 of the internal switch at given frequencies."""
if freq is None:
freq = self.freq.freq
return self._intsw_s22_rl(freq) + 1j * self._intsw_s22_im(freq)
def C1(self, freq=None):
"""Evaluate the Scale polynomial at given frequencies."""
if freq is None:
freq = self.freq.freq
return self.C1_poly(self.freq.normalize(freq))
def C2(self, freq=None):
"""Evaluate the Offset polynomial at given frequencies."""
if freq is None:
freq = self.freq.freq
return self.C2_poly(self.freq.normalize(freq))
def Tcos(self, freq=None):
"""Evaluate the cos temperature polynomial at given frequencies."""
if freq is None:
freq = self.freq.freq
return self.Tcos_poly(self.freq.normalize(freq))
def Tsin(self, freq=None):
"""Evaluate the sin temperature polynomial at given frequencies."""
if freq is None:
freq = self.freq.freq
return self.Tsin_poly(self.freq.normalize(freq))
def Tunc(self, freq=None):
"""Evaluate the uncorrelated temperature polynomial at given frequencies."""
if freq is None:
freq = self.freq.freq
return self.Tunc_poly(self.freq.normalize(freq))
def _linear_coefficients(self, freq, ant_s11):
return rcf.get_linear_coefficients(
ant_s11,
self.lna_s11(freq),
self.C1(freq),
self.C2(freq),
self.Tunc(freq),
self.Tcos(freq),
self.Tsin(freq),
self.t_load,
)
def calibrate_temp(self, freq: np.ndarray, temp: np.ndarray, ant_s11: np.ndarray):
"""
Calibrate given uncalibrated spectrum.
Parameters
----------
freq : np.ndarray
The frequencies at which to calibrate
temp : np.ndarray
The temperatures to calibrate (in K).
ant_s11 : np.ndarray
The antenna S11 for the load.
Returns
-------
temp : np.ndarray
The calibrated temperature.
"""
a, b = self._linear_coefficients(freq, ant_s11)
return temp * a + b
def decalibrate_temp(self, freq, temp, ant_s11):
"""
De-calibrate given calibrated spectrum.
Parameters
----------
freq : np.ndarray
The frequencies at which to calibrate
temp : np.ndarray
The temperatures to calibrate (in K).
ant_s11 : np.ndarray
The antenna S11 for the load.
Returns
-------
temp : np.ndarray
The calibrated temperature.
Notes
-----
Using this and then :method:`calibrate_temp` immediately should be an identity
operation.
"""
a, b = self._linear_coefficients(freq, ant_s11)
return (temp - b) / a
def calibrate_Q(
self, freq: np.ndarray, q: np.ndarray, ant_s11: np.ndarray
) -> np.ndarray:
"""
Calibrate given power ratio spectrum.
Parameters
----------
freq : np.ndarray
The frequencies at which to calibrate
q : np.ndarray
The power ratio to calibrate.
ant_s11 : np.ndarray
The antenna S11 for the load.
Returns
-------
temp : np.ndarray
The calibrated temperature.
"""
uncal_temp = self.t_load_ns * q + self.t_load
return self.calibrate_temp(freq, uncal_temp, ant_s11)
def perform_term_sweep(
calobs: CalibrationObservation,
delta_rms_thresh: float = 0,
max_cterms: int = 15,
max_wterms: int = 15,
explore_run_nums: bool = False,
explore_repeat_nums: bool = False,
direc=".",
verbose=False,
) -> CalibrationObservation:
"""For a given calibration definition, perform a sweep over number of terms.
There are options to save _every_ calibration solution, or just the "best" one.
Parameters
----------
calobs: :class:`CalibrationObservation` instance
The definition calibration class. The `cterms` and `wterms` in this instance
should define the *lowest* values of the parameters to sweep over.
delta_rms_thresh : float
The threshold in change in RMS between one set of parameters and the next that
will define where to cut off. If zero, will run all sets of parameters up to
the maximum terms specified.
max_cterms : int
The maximum number of cterms to trial.
max_wterms : int
The maximum number of wterms to trial.
explore_run_nums : bool
Whether to iterate over S11 run numbers to find the best residuals.
explore_repeat_nums : bool
Whether to iterate over S11 repeat numbers to find the best residuals.
direc : str
Directory to write resultant :class:`Calibration` file to.
verbose : bool
Whether to write out the RMS values derived throughout the sweep.
Notes
-----
When exploring run/repeat nums, run nums are kept constant within a load (i.e. the
match/short/open etc. all have either run_num=1 or run_num=2 for the same load.
This is physically motivated.
"""
cterms = range(calobs.cterms, max_cterms)
wterms = range(calobs.wterms, max_wterms)
winner = np.zeros(len(cterms), dtype=int)
s11_keys = ["switching_state", "receiver_reading"] + list(io.LOAD_ALIASES.keys())
if explore_repeat_nums:
# Note that we don't explore run_nums for spectra/resistance, because it's rare
# to have those, and they'll only exist if one got completely botched (and that
# should be set by the user).
rep_num = {
k: range(1, getattr(calobs.io.s11, k).max_repeat_num + 1) for k in s11_keys
}
else:
rep_num = {k: [getattr(calobs.io.s11, k).repeat_num] for k in s11_keys}
rep_num = tools.dct_of_list_to_list_of_dct(rep_num)
if explore_run_nums:
run_num = {
"switching_state": range(
1, calobs.io.s11.get_highest_run_num("SwitchingState") + 1
),
"receiver_reading": range(
1, calobs.io.s11.get_highest_run_num("ReceiverReading") + 1
),
}
else:
run_num = {
"switching_state": [calobs.io.s11.switching_state.run_num],
"receiver_reading": [calobs.io.s11.receiver_reading.run_num],
}
run_num = tools.dct_of_list_to_list_of_dct(run_num)
best_rms = np.inf
for this_rep_num in rep_num:
for this_run_num in run_num:
tmp_run_num = copy(calobs.io.run_num)
tmp_run_num.update(this_run_num)
# Change the base io.CalObs because it will change with rep/run.
calobs.io = io.CalibrationObservation(
path=calobs.io.path,
run_num=tmp_run_num,
repeat_num=this_rep_num,
fix=False,
compile_from_def=calobs.compiled_from_def,
include_previous=calobs.previous_included,
)
calobs.lna = LNA(
calobs.io.s11.receiver_reading,
f_low=calobs.freq.min,
f_high=calobs.freq.max,
resistance=calobs.lna.resistance,
)
# If we're changing anything else, we need to change each load.
for name, load in calobs._loads.items():
load.reflections = LoadS11.from_path(
load_name=name,
path=calobs.io.path,
repeat_num_load=this_rep_num[name],
run_num_switch=this_run_num["switching_state"],
repeat_num_switch=this_rep_num["switching_state"],
)
if verbose:
print(
f"SWEEPING SwSt={calobs.io.s11.switching_state.repeat_num}, "
f"RcvRd={calobs.io.s11.receiver_reading.repeat_num} "
f"[Sw={calobs.io.s11.switching_state.run_num}, "
f"RR={calobs.io.s11.receiver_reading.run_num}, "
f"open={calobs.io.s11.open.run_num}, "
f"short={calobs.io.s11.short.run_num}, "
f"ambient={calobs.io.s11.ambient.run_num}, "
f"hot={calobs.io.s11.hot_load.run_num}]"
)
print("-" * 30)
rms = np.zeros((len(cterms), len(wterms)))
for i, c in enumerate(cterms):
for j, w in enumerate(wterms):
calobs.update(cterms=c, wterms=w)
res = calobs.get_load_residuals()
dof = sum(len(r) for r in res.values()) - c - w
rms[i, j] = np.sqrt(
sum(np.nansum(np.square(x)) for x in res.values()) / dof
)
if verbose:
print(f"Nc = {c:02}, Nw = {w:02}; RMS/dof = {rms[i, j]:1.3e}")
# If we've decreased by more than the threshold, this wterms becomes
# the new winner (for this number of cterms)
if j > 0 and rms[i, j] >= rms[i, j - 1] - delta_rms_thresh:
winner[i] = j - 1
break
if (
i > 0
and rms[i, winner[i]]
>= rms[i - 1, winner[i - 1]] - delta_rms_thresh
):
break
if verbose:
print(
f"Best parameters found for Nc={cterms[i-1]}, "
f"Nw={wterms[winner[i-1]]}, "
f"with RMS = {rms[i-1, winner[i-1]]}."
)
print()
if rms[i - 1, winner[i - 1]] < best_rms:
best_run_combo = (
calobs.io.run_num,
calobs.io.s11.receiver_reading.repeat_num,
calobs.io.s11.switching_state.repeat_num,
)
best_cterms = cterms[i - 1]
best_wterms = wterms[winner[i - 1]]
if verbose and (explore_repeat_nums or explore_run_nums):
print("The very best parameters were found were for:")
print(f"\tSwitchingState Repeat = {best_run_combo[2]}")
print(f"\tReceiverReading Repeat = {best_run_combo[1]}")
print(f"\tRun Numbers = {best_run_combo[0]}")
print(f"\t# C-terms = {best_cterms}")
print(f"\t# W-terms = {best_wterms}")
calobs.update(cterms=best_cterms, wterms=best_wterms)
calobs.io = io.CalibrationObservation(
path=calobs.io.path,
run_num=best_run_combo[0],
repeat_num={
"switching_state": best_run_combo[2],
"receiver_reading": best_run_combo[1],
},
fix=False,
compile_from_def=calobs.compiled_from_def,
include_previous=calobs.previous_included,
)
calobs.lna = LNA(
calobs.io.s11.receiver_reading,
f_low=calobs.freq.min,
f_high=calobs.freq.max,
resistance=calobs.lna.resistance,
)
if direc is not None:
direc = Path(direc)
if not direc.exists():
direc.mkdir(parents=True)
pth = Path(calobs.path).parent.name
pth = str(pth) + f"_c{calobs.cterms}_w{calobs.wterms}.h5"
calobs.write(direc / pth)
return calobs
|
fig :
The matplotlib figure that was created.
"""
|
IoTDBRpcDataSet.py
|
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing,
# software distributed under the License is distributed on an
# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
# KIND, either express or implied. See the License for the
# specific language governing permissions and limitations
# under the License.
#
# for package
import logging
from thrift.transport import TTransport
from iotdb.thrift.rpc.TSIService import TSFetchResultsReq, TSCloseOperationReq
from iotdb.utils.IoTDBConstants import TSDataType
logger = logging.getLogger("IoTDB")
class IoTDBRpcDataSet(object):
TIMESTAMP_STR = "Time"
# VALUE_IS_NULL = "The value got by %s (column name) is NULL."
START_INDEX = 2
FLAG = 0x80
def __init__(
self,
sql,
column_name_list,
column_type_list,
column_name_index,
ignore_timestamp,
query_id,
client,
session_id,
query_data_set,
fetch_size,
):
self.__session_id = session_id
self.__ignore_timestamp = ignore_timestamp
self.__sql = sql
self.__query_id = query_id
self.__client = client
self.__fetch_size = fetch_size
self.__column_size = len(column_name_list)
self.__default_time_out = 1000
self.__column_name_list = []
self.__column_type_list = []
self.__column_ordinal_dict = {}
if not ignore_timestamp:
self.__column_name_list.append(IoTDBRpcDataSet.TIMESTAMP_STR)
self.__column_type_list.append(TSDataType.INT64)
self.__column_ordinal_dict[IoTDBRpcDataSet.TIMESTAMP_STR] = 1
if column_name_index is not None:
self.__column_type_deduplicated_list = [
None for _ in range(len(column_name_index))
]
for i in range(len(column_name_list)):
name = column_name_list[i]
self.__column_name_list.append(name)
self.__column_type_list.append(TSDataType[column_type_list[i]])
if name not in self.__column_ordinal_dict:
index = column_name_index[name]
self.__column_ordinal_dict[name] = (
index + IoTDBRpcDataSet.START_INDEX
)
self.__column_type_deduplicated_list[index] = TSDataType[
column_type_list[i]
]
else:
index = IoTDBRpcDataSet.START_INDEX
self.__column_type_deduplicated_list = []
for i in range(len(column_name_list)):
name = column_name_list[i]
self.__column_name_list.append(name)
self.__column_type_list.append(TSDataType[column_type_list[i]])
if name not in self.__column_ordinal_dict:
self.__column_ordinal_dict[name] = index
index += 1
self.__column_type_deduplicated_list.append(
TSDataType[column_type_list[i]]
)
self.__time_bytes = bytes(0)
self.__current_bitmap = [
bytes(0) for _ in range(len(self.__column_type_deduplicated_list))
]
self.__value = [None for _ in range(len(self.__column_type_deduplicated_list))]
self.__query_data_set = query_data_set
self.__is_closed = False
self.__empty_resultSet = False
self.__has_cached_record = False
self.__rows_index = 0
def close(self):
if self.__is_closed:
return
if self.__client is not None:
try:
status = self.__client.closeOperation(
TSCloseOperationReq(self.__session_id, self.__query_id)
)
logger.debug(
"close session {}, message: {}".format(
self.__session_id, status.message
)
)
except TTransport.TException as e:
raise RuntimeError(
"close session {} failed because: ".format(self.__session_id), e
)
self.__is_closed = True
self.__client = None
def next(self):
if self.has_cached_result():
self.construct_one_row()
return True
if self.__empty_resultSet:
return False
if self.fetch_results():
self.construct_one_row()
return True
return False
def has_cached_result(self):
return (self.__query_data_set is not None) and (
len(self.__query_data_set.time) != 0
)
def construct_one_row(self):
# simulating buffer, read 8 bytes from data set and discard first 8 bytes which have been read.
self.__time_bytes = self.__query_data_set.time[:8]
self.__query_data_set.time = self.__query_data_set.time[8:]
for i in range(len(self.__query_data_set.bitmapList)):
bitmap_buffer = self.__query_data_set.bitmapList[i]
# another 8 new rows, should move the bitmap buffer position to next byte
if self.__rows_index % 8 == 0:
self.__current_bitmap[i] = bitmap_buffer[0]
self.__query_data_set.bitmapList[i] = bitmap_buffer[1:]
if not self.is_null(i, self.__rows_index):
value_buffer = self.__query_data_set.valueList[i]
data_type = self.__column_type_deduplicated_list[i]
# simulating buffer
if data_type == TSDataType.BOOLEAN:
self.__value[i] = value_buffer[:1]
self.__query_data_set.valueList[i] = value_buffer[1:]
elif data_type == TSDataType.INT32:
self.__value[i] = value_buffer[:4]
self.__query_data_set.valueList[i] = value_buffer[4:]
elif data_type == TSDataType.INT64:
self.__value[i] = value_buffer[:8]
self.__query_data_set.valueList[i] = value_buffer[8:]
elif data_type == TSDataType.FLOAT:
self.__value[i] = value_buffer[:4]
self.__query_data_set.valueList[i] = value_buffer[4:]
elif data_type == TSDataType.DOUBLE:
self.__value[i] = value_buffer[:8]
self.__query_data_set.valueList[i] = value_buffer[8:]
elif data_type == TSDataType.TEXT:
length = int.from_bytes(
value_buffer[:4], byteorder="big", signed=False
)
self.__value[i] = value_buffer[4 : 4 + length]
self.__query_data_set.valueList[i] = value_buffer[4 + length :]
else:
raise RuntimeError("unsupported data type {}.".format(data_type))
self.__rows_index += 1
self.__has_cached_record = True
def fetch_results(self):
self.__rows_index = 0
request = TSFetchResultsReq(
self.__session_id,
self.__sql,
self.__fetch_size,
self.__query_id,
True,
self.__default_time_out,
)
try:
resp = self.__client.fetchResults(request)
if not resp.hasResultSet:
self.__empty_resultSet = True
else:
self.__query_data_set = resp.queryDataSet
return resp.hasResultSet
except TTransport.TException as e:
raise RuntimeError(
"Cannot fetch result from server, because of network connection: ", e
)
def is_null(self, index, row_num):
bitmap = self.__current_bitmap[index]
shift = row_num % 8
return ((IoTDBRpcDataSet.FLAG >> shift) & (bitmap & 0xFF)) == 0
def is_null_by_index(self, column_index):
index = (
self.__column_ordinal_dict[self.find_column_name_by_index(column_index)]
- IoTDBRpcDataSet.START_INDEX
)
# time column will never be None
if index < 0:
return True
return self.is_null(index, self.__rows_index - 1)
def is_null_by_name(self, column_name):
index = self.__column_ordinal_dict[column_name] - IoTDBRpcDataSet.START_INDEX
# time column will never be None
if index < 0:
return True
return self.is_null(index, self.__rows_index - 1)
def find_column_name_by_index(self, column_index):
if column_index <= 0:
raise Exception("Column index should start from 1")
if column_index > len(self.__column_name_list):
raise Exception(
"column index {} out of range {}".format(
column_index, self.__column_size
)
)
return self.__column_name_list[column_index - 1]
def get_fetch_size(self):
return self.__fetch_size
def set_fetch_size(self, fetch_size):
self.__fetch_size = fetch_size
def get_column_names(self):
return self.__column_name_list
def get_column_types(self):
return self.__column_type_list
def get_column_size(self):
return self.__column_size
def get_ignore_timestamp(self):
return self.__ignore_timestamp
def get_column_ordinal_dict(self):
return self.__column_ordinal_dict
def
|
(self):
return self.__column_type_deduplicated_list
def get_values(self):
return self.__value
def get_time_bytes(self):
return self.__time_bytes
def get_has_cached_record(self):
return self.__has_cached_record
|
get_column_type_deduplicated_list
|
Index.go
|
package soaClient
import (
"../logger"
"net/http"
"net"
"time"
"fmt"
"io"
"io/ioutil"
"../../exceptions"
"encoding/json"
"net/url"
"strings"
"os"
)
var (
maxIdleConn,
maxIdleConnPerHost,
idleConnTimeout int
)
func init() {
maxIdleConn = 100
maxIdleConnPerHost = 100
idleConnTimeout = 90
}
func JsonToObject(chunk string) (map[string]interface{}, error){
rep := make(map[string]interface{})
err := json.Unmarshal([]byte(chunk), &rep)
if nil != err {
return nil, err
}
return rep, nil
}
func Encode(params map[string]interface{}) string {
context := url.Values{}
for key, value := range params {
context.Add(key, value.(string))
}
return context.Encode()
}
func Invoke(remote *http.Request, module string, callback func(response *http.Response) (map[string]interface{}, error)) (map[string]interface{}, error) {
response, err := GeneratorClient().Do(remote)
if err != nil && response == nil {
logger.Error(module, fmt.Sprintf("forward %+v", err))
return nil, err
} else {
defer response.Body.Close()
logger.Logger(module, fmt.Sprintf("%3d | %-7s | %s", response.StatusCode, remote.Method,
remote.URL))
if nil == callback {
return defaultFunc(response)
} else {
return callback(response)
}
}
}
func defaultFunc(response *http.Response) (map[string]interface{}, error) {
reply, err := ioutil.ReadAll(response.Body)
if nil != err {
return nil, err
}
return JsonToObject(string(reply))
}
func Call(method, serviceName, url string, body io.Reader, header map[string]string) (map[string]interface{}, error) {
reqUrl := fmt.Sprintf("http://%s%s", serviceName, url)
remote, err := http.NewRequest(method, reqUrl, body)
for key, value := range header {
remote.Header.Add(key, value)
}
if nil != err {
return nil, err
}
return Invoke(remote, "soa-client", defaultFunc)
}
func GeneratorClient() *http.Client {
client := &http.Client{
Transport: &http.Transport{
Proxy: http.ProxyFromEnvironment,
DialContext: (&net.Dialer{ Timeout: 30 * time.Second,}).DialContext,
MaxIdleConns: maxIdleConn,
MaxIdleConnsPerHost: maxIdleConnPerHost,
IdleConnTimeout: time.Duration(idleConnTimeout)* time.Second,
},
Timeout: 30 * time.Second,
}
return client
}
func GeneratorBody(vol interface{}) io.Reader {
buf, err := json.Marshal(vol)
if nil != err {
return nil
}
return strings.NewReader(string(buf))
}
func DownloadFile(url,savePath string) (map[string]interface{}, error)
|
{
remote, err := http.NewRequest("GET", url, nil)
if nil != err {
return nil, err
}
return Invoke(remote, "soa-client", func(response *http.Response) (map[string]interface{}, error) {
if 200 != response.StatusCode {
return nil, &exceptions.Error{Msg: "download failed.", Code: 500}
}
_, e := os.Stat(savePath)
if nil != e {
os.Mkdir(savePath, os.ModePerm)
}
head := response.Header.Get("Content-Disposition")
filename := strings.Split(head, "attachment;filename=")[1]
desFile, _ := os.Create(savePath + "/" + filename)
io.Copy(desFile, response.Body)
defer desFile.Close()
defer response.Body.Close()
return map[string]interface{} {
"savePath": savePath,
"fileName": filename,
}, nil
})
}
|
|
job-apply.js
|
import React, {Component} from 'react';
import axios from 'axios';
import Spinner from './spinner';
class
|
extends Component {
state = {
name: '',
email: '',
phone: '',
dateOfBirth: '',
experience: 0,
education: '',
message: '',
loading: false,
responseMessage: ''
};
onChangeName(e) {
this.setState({name: e.target.value});
}
onChangeEmail(e) {
this.setState({email: e.target.value});
}
onChangePhone(e) {
this.setState({phone: e.target.value});
}
onChangeMessage(e) {
this.setState({message: e.target.value});
}
onChangeEducation(e) {
this.setState({education: e.target.value});
}
onChangeExperience(e) {
this.setState({experience: e.target.value});
}
onChangeDateOfBirth(e) {
this.setState({dateOfBirth: e.target.value});
}
async onSubmit(e) {
e.preventDefault();
this.setState({loading: true});
const formData = new FormData();
formData.append('name', this.state.name);
formData.append('email', this.state.email);
formData.append('dateOfBirth', this.state.dateOfBirth);
formData.append('phone', this.state.phone);
formData.append('workExperience', this.state.experience);
formData.append('education', this.state.education);
formData.append('message', this.state.message);
formData.append('type', this.props.formType);
const endpoint =
'https://getform.io/f/9cc051c4-96c9-45f6-acb2-23d52c39c866';
try {
const result = await axios.post(endpoint, formData);
if (result.status === 200) {
this.setState({
loading: false,
responseMessage: 'Your application has been submitted.'
});
} else {
this.setState({
loading: false,
responseMessage: 'Something went wrong. Please try later.'
});
}
} catch (err) {
this.setState({
loading: false,
responseMessage: 'Something went wrong. Please try later.'
});
}
}
renderForm() {
return (
<form className="form" onSubmit={this.onSubmit.bind(this)}>
<div className="form-field">
<label htmlFor="name" className="form-label">
Name* (required)
</label>
<input
type="text"
className="form-input"
name="name"
id="name"
value={this.state.name}
onChange={this.onChangeName.bind(this)}
placeholder="Enter your name"
required
/>
</div>
<div className="form-field">
<label htmlFor="email" className="form-label">
Email
</label>
<input
type="email"
className="form-input"
id="email"
name="email"
value={this.state.email}
onChange={this.onChangeEmail.bind(this)}
placeholder="Enter your email"
/>
</div>
<div className="form-field">
<label htmlFor="phone" className="form-label">
Phone* (required)
</label>
<input
type="text"
className="form-input"
id="phone"
name="phone"
value={this.state.phone}
onChange={this.onChangePhone.bind(this)}
placeholder="Enter your phone number"
required
/>
</div>
<div className="form-field">
<label htmlFor="education" className="form-label">
Education* (required)
</label>
<input
type="text"
className="form-input"
id="education"
name="education"
value={this.state.education}
onChange={this.onChangeEducation.bind(this)}
placeholder="Enter your highest educational qualification"
required
/>
</div>
<div className="form-field">
<label htmlFor="experience" className="form-label">
Work Experience (in years)
</label>
<input
type="number"
className="form-input"
id="experience"
name="experience"
value={this.state.experience}
onChange={this.onChangeExperience.bind(this)}
placeholder="Number of years of work experience"
required
/>
</div>
<div className="form-field">
<label htmlFor="dob" className="form-label">
Date of Birth
</label>
<input
type="date"
className="form-input"
id="dob"
name="date-of-birth"
value={this.state.dateOfBirth}
onChange={this.onChangeDateOfBirth.bind(this)}
/>
</div>
<div className="form-field">
<label htmlFor="message" className="form-label">
Explain why you want to join WISHALL and what role you'd like to
play* (required)
</label>
<textarea
className="form-input"
id="message"
name="message"
placeholder="Enter your message"
value={this.state.message}
onChange={this.onChangeMessage.bind(this)}
rows="5"
required
/>
</div>
<div className="right-text">
<button
type="button"
className="btn btn-secondary"
onClick={this.props.onCancel}>
Cancel
</button>
<button type="submit" className="btn btn-primary">
Submit
</button>
</div>
</form>
);
}
render() {
let content = <Spinner />;
if (this.state.loading) {
content = <Spinner />;
} else if (this.state.responseMessage !== '') {
content = (
<div className="center-text">
<h2 style={{marginBottom: '1rem'}}>{this.state.responseMessage}</h2>
<button onClick={this.props.onCancel} className="btn btn-secondary">
Close
</button>
</div>
);
} else {
content = this.renderForm();
}
return (
<div className="job-form">
<h2 className="form-title">Apply to join the WISHALL team</h2>
{content}
</div>
);
}
}
export default JobApply;
|
JobApply
|
lib.rs
|
//! Definitions for the ACPI table
//!
//! RSDT is the Root System Descriptor Table, whereas
//! XSDT is the Extended System Descriptor Table.
//! They are identical except that the XSDT uses 64-bit physical addresses
//! to point to other ACPI SDTs, while the RSDT uses 32-bit physical addresses.
#![no_std]
extern crate alloc;
#[macro_use] extern crate log;
extern crate memory;
extern crate sdt;
extern crate zerocopy;
use core::ops::DerefMut;
use alloc::collections::BTreeMap;
use memory::{MappedPages, allocate_pages, PageTable, EntryFlags, PhysicalAddress, Frame, FrameRange, get_frame_allocator_ref, PhysicalMemoryArea};
use sdt::Sdt;
use core::ops::Add;
use zerocopy::FromBytes;
/// All ACPI tables are identified by a 4-byte signature,
/// typically an ASCII string like "APIC" or "RSDT".
pub type AcpiSignature = [u8; 4];
/// A record that tracks where an ACPI Table exists in memory,
/// given in terms of offsets into the `AcpiTables`'s `MappedPages`.
#[derive(Debug)]
pub struct TableLocation {
/// The offset of the statically-sized part of the table,
/// which is the entire table if there is no dynamically-sized component.
pub offset: usize,
/// The offset and length of the dynamically-sized part of the table, if it exists.
/// If the entire table is statically-sized, this is `None`.
pub slice_offset_and_length: Option<(usize, usize)>,
}
/// The struct holding all ACPI tables and records of where they exist in memory.
/// All ACPI tables are covered by a single large MappedPages object,
/// which is necessary because they may span multiple pages/frames,
/// and generally should not be multiply aliased/accessed due to potential race conditions.
/// As more ACPI tables are discovered, the single MappedPages object is
pub struct AcpiTables {
/// The range of pages that cover all of the discovered ACPI tables.
mapped_pages: MappedPages,
/// The physical memory frames that hold the ACPI tables,
/// and are thus covered by the `mapped_pages`.
frames: FrameRange,
/// The location of all ACPI tables in memory.
/// This is a mapping from ACPI table signature to the location in the `mapped_pages` object
/// where the corresponding table is located.
tables: BTreeMap<AcpiSignature, TableLocation>,
}
impl AcpiTables {
/// Map the ACPI table that exists at the given PhysicalAddress, where an `SDT` header must exist.
/// Ensures that the entire ACPI table is mapped, including extra length that may be specified within the SDT.
///
/// Returns a tuple describing the SDT discovered at the given `sdt_phys_addr`:
/// the `AcpiSignature` and the total length of the table.
pub fn map_new_table(&mut self, sdt_phys_addr: PhysicalAddress, page_table: &mut PageTable) -> Result<(AcpiSignature, usize), &'static str> {
let allocator = get_frame_allocator_ref().ok_or("couldn't get Frame Allocator")?;
let mut mapping_changed = false;
// First, we map the SDT header so we can obtain its `length` field,
// which determines whether we need to map additional pages.
// Then, later, we'll obtain its `signature` field so we can invoke its specific handler
// that will add that table to the list of tables.
let first_frame = Frame::containing_address(sdt_phys_addr);
// If the Frame containing the given `sdt_phys_addr` wasn't already mapped, then we need to map it.
if !self.frames.contains(&first_frame) {
let new_frames = self.frames.to_extended(first_frame);
let new_pages = allocate_pages(new_frames.size_in_frames()).ok_or("couldn't allocate_pages")?;
let new_mapped_pages = page_table.map_allocated_pages_to(
new_pages,
new_frames.clone(),
EntryFlags::PRESENT | EntryFlags::WRITABLE | EntryFlags::NO_EXECUTE,
allocator.lock().deref_mut(),
)?;
self.adjust_mapping_offsets(new_frames, new_mapped_pages);
mapping_changed = true;
}
let sdt_offset = self.frames.offset_from_start(sdt_phys_addr)
.ok_or("BUG: AcpiTables::map_new_table(): SDT physical address wasn't in expected frame iter")?;
// Here we check if the header of the ACPI table fits at the offset.
// If not, we add the next frame as well.
if sdt_offset + core::mem::size_of::<Sdt>() > self.mapped_pages.size_in_bytes() {
let new_frames = self.frames.to_extended(first_frame.add(1));
let new_pages = allocate_pages(new_frames.size_in_frames()).ok_or("couldn't allocate_pages")?;
let new_mapped_pages = page_table.map_allocated_pages_to(
new_pages,
new_frames.clone(),
EntryFlags::PRESENT | EntryFlags::WRITABLE | EntryFlags::NO_EXECUTE,
allocator.lock().deref_mut(),
)?;
self.adjust_mapping_offsets(new_frames, new_mapped_pages);
mapping_changed = true;
}
// Here, if the current mapped_pages is insufficient to cover the table's full length,
// then we need to create a new mapping to cover it and the length of all of its entries.
let (sdt_signature, sdt_length) = {
let sdt: &Sdt = self.mapped_pages.as_type(sdt_offset)?;
(sdt.signature, sdt.length as usize)
};
let last_frame_of_table = Frame::containing_address(sdt_phys_addr + sdt_length);
if !self.frames.contains(&last_frame_of_table) {
trace!("AcpiTables::map_new_table(): SDT's length requires mapping frames {:#X} to {:#X}", self.frames.end().start_address(), last_frame_of_table.start_address());
let new_frames = self.frames.to_extended(last_frame_of_table);
let new_pages = allocate_pages(new_frames.size_in_frames()).ok_or("couldn't allocate_pages")?;
let new_mapped_pages = page_table.map_allocated_pages_to(
new_pages,
new_frames.clone(),
EntryFlags::PRESENT | EntryFlags::WRITABLE | EntryFlags::NO_EXECUTE,
allocator.lock().deref_mut(),
)?;
// No real need to adjust mapping offsets here, since we've only appended frames (not prepended);
// we call this just to set the new frames and new mapped pages
self.adjust_mapping_offsets(new_frames, new_mapped_pages);
mapping_changed = true;
}
// Inform the frame allocator that the physical frame(s) where the RSDT/XSDT exists are now in use.
if mapping_changed
|
// Here, the entire table is mapped into memory, and ready to be used elsewhere.
Ok((sdt_signature, sdt_length))
}
/// Adjusts the offsets for all tables based on the new `MappedPages` and the new `FrameRange`.
/// This object's (self) `frames` and `mappped_pages` will be replaced with the given items.
fn adjust_mapping_offsets(&mut self, new_frames: FrameRange, new_mapped_pages: MappedPages) {
// The basic idea here is that if we mapped new frames to the beginning of the mapped pages,
// then all of the table offsets will be wrong and need to be adjusted.
// To fix them, we simply add the number of bytes in the new frames that were prepended to the memory region.
// For example, if two frames were added, then we need to add (2 * frame size) = 8192 to each offset.
if new_frames.start() < self.frames.start() {
let diff = self.frames.start_address().value() - new_frames.start_address().value();
trace!("ACPI table: adjusting mapping offsets +{}", diff);
for mut loc in self.tables.values_mut() {
loc.offset += diff;
if let Some((ref mut slice_offset, _)) = loc.slice_offset_and_length {
*slice_offset += diff;
}
}
}
self.frames = new_frames;
self.mapped_pages = new_mapped_pages;
}
/// Add the location and size details of a discovered ACPI table,
/// which allows others to query for and access the table in the future.
///
/// # Arguments
/// * `signature`: the signature of the ACPI table that is being added, e.g., `b"RSDT"`.
/// * `phys_addr`: the `PhysicalAddress` of the table in memory, which is used to calculate its offset.
/// * `slice_phys_addr_and_length`: a tuple of the `PhysicalAddress` where the dynamic part of this table begins,
/// and the number of elements in that dynamic table part.
/// If this table does not have a dynamic part, this is `None`.
pub fn add_table_location(
&mut self,
signature: AcpiSignature,
phys_addr: PhysicalAddress,
slice_phys_addr_and_length: Option<(PhysicalAddress, usize)>
) -> Result<(), &'static str> {
if self.table_location(&signature).is_some() {
error!("AcpiTables::add_table_location(): signature {:?} already existed.", core::str::from_utf8(&signature));
return Err("ACPI signature already existed");
}
let offset = self.frames.offset_from_start(phys_addr).ok_or("ACPI table's physical address is beyond the ACPI table bounds.")?;
let slice_offset_and_length = if let Some((slice_paddr, slice_len)) = slice_phys_addr_and_length {
Some((
self.frames.offset_from_start(slice_paddr).ok_or("ACPI table's slice physical address is beyond the ACPI table bounds.")?,
slice_len,
))
} else {
None
};
self.tables.insert(signature, TableLocation { offset, slice_offset_and_length });
Ok(())
}
/// Returns the location of the ACPI table based on the given table `signature`.
pub fn table_location(&self, signature: &AcpiSignature) -> Option<&TableLocation> {
self.tables.get(signature)
}
/// Returns a reference to the table that matches the specified ACPI `signature`.
pub fn table<T: FromBytes>(&self, signature: &AcpiSignature) -> Result<&T, &'static str> {
let loc = self.tables.get(signature).ok_or("couldn't find ACPI table with matching signature")?;
self.mapped_pages.as_type(loc.offset)
}
/// Returns a mutable reference to the table that matches the specified ACPI `signature`.
pub fn table_mut<T: FromBytes>(&mut self, signature: &AcpiSignature) -> Result<&mut T, &'static str> {
let loc = self.tables.get(signature).ok_or("couldn't find ACPI table with matching signature")?;
self.mapped_pages.as_type_mut(loc.offset)
}
/// Returns a reference to the dynamically-sized part at the end of the table that matches the specified ACPI `signature`,
/// if it exists.
/// For example, this returns the array of SDT physical addresses at the end of the [`RSDT`](../) table.
pub fn table_slice<S: FromBytes>(&self, signature: &AcpiSignature) -> Result<&[S], &'static str> {
let loc = self.tables.get(signature).ok_or("couldn't find ACPI table with matching signature")?;
let (offset, len) = loc.slice_offset_and_length.ok_or("specified ACPI table has no dynamically-sized part")?;
self.mapped_pages.as_slice(offset, len)
}
/// Returns a mutable reference to the dynamically-sized part at the end of the table that matches the specified ACPI `signature`,
/// if it exists.
/// For example, this returns the array of SDT physical addresses at the end of the [`RSDT`](../) table.
pub fn table_slice_mut<S: FromBytes>(&mut self, signature: &AcpiSignature) -> Result<&mut [S], &'static str> {
let loc = self.tables.get(signature).ok_or("couldn't find ACPI table with matching signature")?;
let (offset, len) = loc.slice_offset_and_length.ok_or("specified ACPI table has no dynamically-sized part")?;
self.mapped_pages.as_slice_mut(offset, len)
}
/// Returns an immutable reference to the underlying `MappedPages` that covers the ACPI tables.
/// To access the ACPI tables, use the table's `get()` function, e.g., `Fadt::get(...)` instead of this function.
pub fn mapping(&self) -> &MappedPages {
&self.mapped_pages
}
}
impl Default for AcpiTables {
fn default() -> AcpiTables {
AcpiTables {
mapped_pages: MappedPages::empty(),
frames: FrameRange::empty(),
tables: BTreeMap::new(),
}
}
}
|
{
let sdt_area = PhysicalMemoryArea::new(sdt_phys_addr, sdt_length, 1, 3);
allocator.lock().add_area(sdt_area, false)?;
}
|
tree.es5.js
|
/**
* @license
* Copyright Google LLC All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
import { SelectionModel, isDataSource } from '@angular/cdk/collections';
import { __extends } from 'tslib';
import { Observable, BehaviorSubject, of, Subject } from 'rxjs';
import { take, filter, takeUntil } from 'rxjs/operators';
import { Directive, TemplateRef, ViewContainerRef, ChangeDetectionStrategy, ChangeDetectorRef, Component, ContentChildren, ElementRef, Input, IterableDiffers, ViewChild, ViewEncapsulation, Optional, Renderer2, NgModule } from '@angular/core';
import { Directionality } from '@angular/cdk/bidi';
import { coerceNumberProperty, coerceBooleanProperty } from '@angular/cdk/coercion';
import { FocusMonitor } from '@angular/cdk/a11y';
import { CommonModule } from '@angular/common';
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Base tree control. It has basic toggle/expand/collapse operations on a single data node.
* @abstract
* @template T
*/
var /**
* Base tree control. It has basic toggle/expand/collapse operations on a single data node.
* @abstract
* @template T
*/
BaseTreeControl = /** @class */ (function () {
function BaseTreeControl() {
/**
* A selection model with multi-selection to track expansion status.
*/
this.expansionModel = new SelectionModel(true);
}
/** Toggles one single data node's expanded/collapsed state. */
/**
* Toggles one single data node's expanded/collapsed state.
* @param {?} dataNode
* @return {?}
*/
BaseTreeControl.prototype.toggle = /**
* Toggles one single data node's expanded/collapsed state.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
this.expansionModel.toggle(dataNode);
};
/** Expands one single data node. */
/**
* Expands one single data node.
* @param {?} dataNode
* @return {?}
*/
BaseTreeControl.prototype.expand = /**
* Expands one single data node.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
this.expansionModel.select(dataNode);
};
/** Collapses one single data node. */
/**
* Collapses one single data node.
* @param {?} dataNode
* @return {?}
*/
BaseTreeControl.prototype.collapse = /**
* Collapses one single data node.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
this.expansionModel.deselect(dataNode);
};
/** Whether a given data node is expanded or not. Returns true if the data node is expanded. */
/**
* Whether a given data node is expanded or not. Returns true if the data node is expanded.
* @param {?} dataNode
* @return {?}
*/
BaseTreeControl.prototype.isExpanded = /**
* Whether a given data node is expanded or not. Returns true if the data node is expanded.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
return this.expansionModel.isSelected(dataNode);
};
/** Toggles a subtree rooted at `node` recursively. */
/**
* Toggles a subtree rooted at `node` recursively.
* @param {?} dataNode
* @return {?}
*/
BaseTreeControl.prototype.toggleDescendants = /**
* Toggles a subtree rooted at `node` recursively.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
this.expansionModel.isSelected(dataNode)
? this.collapseDescendants(dataNode)
: this.expandDescendants(dataNode);
};
/** Collapse all dataNodes in the tree. */
/**
* Collapse all dataNodes in the tree.
* @return {?}
*/
BaseTreeControl.prototype.collapseAll = /**
* Collapse all dataNodes in the tree.
* @return {?}
*/
function () {
this.expansionModel.clear();
};
/** Expands a subtree rooted at given data node recursively. */
/**
* Expands a subtree rooted at given data node recursively.
* @param {?} dataNode
* @return {?}
*/
BaseTreeControl.prototype.expandDescendants = /**
* Expands a subtree rooted at given data node recursively.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
var _a;
/** @type {?} */
var toBeProcessed = [dataNode];
toBeProcessed.push.apply(toBeProcessed, this.getDescendants(dataNode));
(_a = this.expansionModel).select.apply(_a, toBeProcessed);
|
/** Collapses a subtree rooted at given data node recursively. */
/**
* Collapses a subtree rooted at given data node recursively.
* @param {?} dataNode
* @return {?}
*/
BaseTreeControl.prototype.collapseDescendants = /**
* Collapses a subtree rooted at given data node recursively.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
var _a;
/** @type {?} */
var toBeProcessed = [dataNode];
toBeProcessed.push.apply(toBeProcessed, this.getDescendants(dataNode));
(_a = this.expansionModel).deselect.apply(_a, toBeProcessed);
};
return BaseTreeControl;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Flat tree control. Able to expand/collapse a subtree recursively for flattened tree.
* @template T
*/
var /**
* Flat tree control. Able to expand/collapse a subtree recursively for flattened tree.
* @template T
*/
FlatTreeControl = /** @class */ (function (_super) {
__extends(FlatTreeControl, _super);
/** Construct with flat tree data node functions getLevel and isExpandable. */
function FlatTreeControl(getLevel, isExpandable) {
var _this = _super.call(this) || this;
_this.getLevel = getLevel;
_this.isExpandable = isExpandable;
return _this;
}
/**
* Gets a list of the data node's subtree of descendent data nodes.
*
* To make this working, the `dataNodes` of the TreeControl must be flattened tree nodes
* with correct levels.
*/
/**
* Gets a list of the data node's subtree of descendent data nodes.
*
* To make this working, the `dataNodes` of the TreeControl must be flattened tree nodes
* with correct levels.
* @param {?} dataNode
* @return {?}
*/
FlatTreeControl.prototype.getDescendants = /**
* Gets a list of the data node's subtree of descendent data nodes.
*
* To make this working, the `dataNodes` of the TreeControl must be flattened tree nodes
* with correct levels.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
/** @type {?} */
var startIndex = this.dataNodes.indexOf(dataNode);
/** @type {?} */
var results = [];
// Goes through flattened tree nodes in the `dataNodes` array, and get all descendants.
// The level of descendants of a tree node must be greater than the level of the given
// tree node.
// If we reach a node whose level is equal to the level of the tree node, we hit a sibling.
// If we reach a node whose level is greater than the level of the tree node, we hit a
// sibling of an ancestor.
for (var i = startIndex + 1; i < this.dataNodes.length && this.getLevel(dataNode) < this.getLevel(this.dataNodes[i]); i++) {
results.push(this.dataNodes[i]);
}
return results;
};
/**
* Expands all data nodes in the tree.
*
* To make this working, the `dataNodes` variable of the TreeControl must be set to all flattened
* data nodes of the tree.
*/
/**
* Expands all data nodes in the tree.
*
* To make this working, the `dataNodes` variable of the TreeControl must be set to all flattened
* data nodes of the tree.
* @return {?}
*/
FlatTreeControl.prototype.expandAll = /**
* Expands all data nodes in the tree.
*
* To make this working, the `dataNodes` variable of the TreeControl must be set to all flattened
* data nodes of the tree.
* @return {?}
*/
function () {
var _a;
(_a = this.expansionModel).select.apply(_a, this.dataNodes);
};
return FlatTreeControl;
}(BaseTreeControl));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Nested tree control. Able to expand/collapse a subtree recursively for NestedNode type.
* @template T
*/
var /**
* Nested tree control. Able to expand/collapse a subtree recursively for NestedNode type.
* @template T
*/
NestedTreeControl = /** @class */ (function (_super) {
__extends(NestedTreeControl, _super);
/** Construct with nested tree function getChildren. */
function NestedTreeControl(getChildren) {
var _this = _super.call(this) || this;
_this.getChildren = getChildren;
return _this;
}
/**
* Expands all dataNodes in the tree.
*
* To make this working, the `dataNodes` variable of the TreeControl must be set to all root level
* data nodes of the tree.
*/
/**
* Expands all dataNodes in the tree.
*
* To make this working, the `dataNodes` variable of the TreeControl must be set to all root level
* data nodes of the tree.
* @return {?}
*/
NestedTreeControl.prototype.expandAll = /**
* Expands all dataNodes in the tree.
*
* To make this working, the `dataNodes` variable of the TreeControl must be set to all root level
* data nodes of the tree.
* @return {?}
*/
function () {
var _this = this;
var _a;
this.expansionModel.clear();
/** @type {?} */
var allNodes = this.dataNodes.reduce(function (accumulator, dataNode) {
return accumulator.concat(_this.getDescendants(dataNode), [dataNode]);
}, []);
(_a = this.expansionModel).select.apply(_a, allNodes);
};
/** Gets a list of descendant dataNodes of a subtree rooted at given data node recursively. */
/**
* Gets a list of descendant dataNodes of a subtree rooted at given data node recursively.
* @param {?} dataNode
* @return {?}
*/
NestedTreeControl.prototype.getDescendants = /**
* Gets a list of descendant dataNodes of a subtree rooted at given data node recursively.
* @param {?} dataNode
* @return {?}
*/
function (dataNode) {
/** @type {?} */
var descendants = [];
this._getDescendants(descendants, dataNode);
// Remove the node itself
return descendants.splice(1);
};
/** A helper function to get descendants recursively. */
/**
* A helper function to get descendants recursively.
* @protected
* @param {?} descendants
* @param {?} dataNode
* @return {?}
*/
NestedTreeControl.prototype._getDescendants = /**
* A helper function to get descendants recursively.
* @protected
* @param {?} descendants
* @param {?} dataNode
* @return {?}
*/
function (descendants, dataNode) {
var _this = this;
descendants.push(dataNode);
/** @type {?} */
var childrenNodes = this.getChildren(dataNode);
if (Array.isArray(childrenNodes)) {
childrenNodes.forEach(function (child) { return _this._getDescendants(descendants, child); });
}
else if (childrenNodes instanceof Observable) {
childrenNodes.pipe(take(1), filter(Boolean)).subscribe(function (children) {
children.forEach(function (child) { return _this._getDescendants(descendants, child); });
});
}
};
return NestedTreeControl;
}(BaseTreeControl));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Context provided to the tree node component.
* @template T
*/
var /**
* Context provided to the tree node component.
* @template T
*/
CdkTreeNodeOutletContext = /** @class */ (function () {
function CdkTreeNodeOutletContext(data) {
this.$implicit = data;
}
return CdkTreeNodeOutletContext;
}());
/**
* Data node definition for the CdkTree.
* Captures the node's template and a when predicate that describes when this node should be used.
* @template T
*/
var CdkTreeNodeDef = /** @class */ (function () {
/** @docs-private */
function CdkTreeNodeDef(template) {
this.template = template;
}
CdkTreeNodeDef.decorators = [
{ type: Directive, args: [{
selector: '[cdkTreeNodeDef]',
inputs: [
'when: cdkTreeNodeDefWhen'
],
},] },
];
/** @nocollapse */
CdkTreeNodeDef.ctorParameters = function () { return [
{ type: TemplateRef }
]; };
return CdkTreeNodeDef;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Outlet for nested CdkNode. Put `[cdkTreeNodeOutlet]` on a tag to place children dataNodes
* inside the outlet.
*/
var CdkTreeNodeOutlet = /** @class */ (function () {
function CdkTreeNodeOutlet(viewContainer) {
this.viewContainer = viewContainer;
}
CdkTreeNodeOutlet.decorators = [
{ type: Directive, args: [{
selector: '[cdkTreeNodeOutlet]'
},] },
];
/** @nocollapse */
CdkTreeNodeOutlet.ctorParameters = function () { return [
{ type: ViewContainerRef }
]; };
return CdkTreeNodeOutlet;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Returns an error to be thrown when there is no usable data.
* \@docs-private
* @return {?}
*/
function getTreeNoValidDataSourceError() {
return Error("A valid data source must be provided.");
}
/**
* Returns an error to be thrown when there are multiple nodes that are missing a when function.
* \@docs-private
* @return {?}
*/
function getTreeMultipleDefaultNodeDefsError() {
return Error("There can only be one default row without a when predicate function.");
}
/**
* Returns an error to be thrown when there are no matching node defs for a particular set of data.
* \@docs-private
* @return {?}
*/
function getTreeMissingMatchingNodeDefError() {
return Error("Could not find a matching node definition for the provided node data.");
}
/**
* Returns an error to be thrown when there are tree control.
* \@docs-private
* @return {?}
*/
function getTreeControlMissingError() {
return Error("Could not find a tree control for the tree.");
}
/**
* Returns an error to be thrown when tree control did not implement functions for flat/nested node.
* \@docs-private
* @return {?}
*/
function getTreeControlFunctionsMissingError() {
return Error("Could not find functions for nested/flat tree in tree control.");
}
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* CDK tree component that connects with a data source to retrieve data of type `T` and renders
* dataNodes with hierarchy. Updates the dataNodes when new data is provided by the data source.
* @template T
*/
var CdkTree = /** @class */ (function () {
function CdkTree(_differs, _changeDetectorRef) {
this._differs = _differs;
this._changeDetectorRef = _changeDetectorRef;
/**
* Subject that emits when the component has been destroyed.
*/
this._onDestroy = new Subject();
/**
* Level of nodes
*/
this._levels = new Map();
// TODO(tinayuangao): Setup a listener for scrolling, emit the calculated view to viewChange.
// Remove the MAX_VALUE in viewChange
/**
* Stream containing the latest information on what rows are being displayed on screen.
* Can be used by the data source to as a heuristic of what data should be provided.
*/
this.viewChange = new BehaviorSubject({ start: 0, end: Number.MAX_VALUE });
}
Object.defineProperty(CdkTree.prototype, "dataSource", {
/**
* Provides a stream containing the latest data array to render. Influenced by the tree's
* stream of view window (what dataNodes are currently on screen).
* Data source can be an observable of data array, or a data array to render.
*/
get: /**
* Provides a stream containing the latest data array to render. Influenced by the tree's
* stream of view window (what dataNodes are currently on screen).
* Data source can be an observable of data array, or a data array to render.
* @return {?}
*/
function () { return this._dataSource; },
set: /**
* @param {?} dataSource
* @return {?}
*/
function (dataSource) {
if (this._dataSource !== dataSource) {
this._switchDataSource(dataSource);
}
},
enumerable: true,
configurable: true
});
/**
* @return {?}
*/
CdkTree.prototype.ngOnInit = /**
* @return {?}
*/
function () {
this._dataDiffer = this._differs.find([]).create(this.trackBy);
if (!this.treeControl) {
throw getTreeControlMissingError();
}
};
/**
* @return {?}
*/
CdkTree.prototype.ngOnDestroy = /**
* @return {?}
*/
function () {
this._nodeOutlet.viewContainer.clear();
this._onDestroy.next();
this._onDestroy.complete();
if (this._dataSource && typeof ((/** @type {?} */ (this._dataSource))).disconnect === 'function') {
((/** @type {?} */ (this.dataSource))).disconnect(this);
}
if (this._dataSubscription) {
this._dataSubscription.unsubscribe();
this._dataSubscription = null;
}
};
/**
* @return {?}
*/
CdkTree.prototype.ngAfterContentChecked = /**
* @return {?}
*/
function () {
/** @type {?} */
var defaultNodeDefs = this._nodeDefs.filter(function (def) { return !def.when; });
if (defaultNodeDefs.length > 1) {
throw getTreeMultipleDefaultNodeDefsError();
}
this._defaultNodeDef = defaultNodeDefs[0];
if (this.dataSource && this._nodeDefs && !this._dataSubscription) {
this._observeRenderChanges();
}
};
// TODO(tinayuangao): Work on keyboard traversal and actions, make sure it's working for RTL
// and nested trees.
/**
* Switch to the provided data source by resetting the data and unsubscribing from the current
* render change subscription if one exists. If the data source is null, interpret this by
* clearing the node outlet. Otherwise start listening for new data.
*/
// TODO(tinayuangao): Work on keyboard traversal and actions, make sure it's working for RTL
// and nested trees.
/**
* Switch to the provided data source by resetting the data and unsubscribing from the current
* render change subscription if one exists. If the data source is null, interpret this by
* clearing the node outlet. Otherwise start listening for new data.
* @private
* @param {?} dataSource
* @return {?}
*/
CdkTree.prototype._switchDataSource =
// TODO(tinayuangao): Work on keyboard traversal and actions, make sure it's working for RTL
// and nested trees.
/**
* Switch to the provided data source by resetting the data and unsubscribing from the current
* render change subscription if one exists. If the data source is null, interpret this by
* clearing the node outlet. Otherwise start listening for new data.
* @private
* @param {?} dataSource
* @return {?}
*/
function (dataSource) {
if (this._dataSource && typeof ((/** @type {?} */ (this._dataSource))).disconnect === 'function') {
((/** @type {?} */ (this.dataSource))).disconnect(this);
}
if (this._dataSubscription) {
this._dataSubscription.unsubscribe();
this._dataSubscription = null;
}
// Remove the all dataNodes if there is now no data source
if (!dataSource) {
this._nodeOutlet.viewContainer.clear();
}
this._dataSource = dataSource;
if (this._nodeDefs) {
this._observeRenderChanges();
}
};
/** Set up a subscription for the data provided by the data source. */
/**
* Set up a subscription for the data provided by the data source.
* @private
* @return {?}
*/
CdkTree.prototype._observeRenderChanges = /**
* Set up a subscription for the data provided by the data source.
* @private
* @return {?}
*/
function () {
var _this = this;
/** @type {?} */
var dataStream;
if (isDataSource(this._dataSource)) {
dataStream = this._dataSource.connect(this);
}
else if (this._dataSource instanceof Observable) {
dataStream = this._dataSource;
}
else if (Array.isArray(this._dataSource)) {
dataStream = of(this._dataSource);
}
if (dataStream) {
this._dataSubscription = dataStream.pipe(takeUntil(this._onDestroy))
.subscribe(function (data) { return _this.renderNodeChanges(data); });
}
else {
throw getTreeNoValidDataSourceError();
}
};
/** Check for changes made in the data and render each change (node added/removed/moved). */
/**
* Check for changes made in the data and render each change (node added/removed/moved).
* @param {?} data
* @param {?=} dataDiffer
* @param {?=} viewContainer
* @param {?=} parentData
* @return {?}
*/
CdkTree.prototype.renderNodeChanges = /**
* Check for changes made in the data and render each change (node added/removed/moved).
* @param {?} data
* @param {?=} dataDiffer
* @param {?=} viewContainer
* @param {?=} parentData
* @return {?}
*/
function (data, dataDiffer, viewContainer, parentData) {
var _this = this;
if (dataDiffer === void 0) { dataDiffer = this._dataDiffer; }
if (viewContainer === void 0) { viewContainer = this._nodeOutlet.viewContainer; }
/** @type {?} */
var changes = dataDiffer.diff(data);
if (!changes) {
return;
}
changes.forEachOperation(function (item, adjustedPreviousIndex, currentIndex) {
if (item.previousIndex == null) {
_this.insertNode(data[(/** @type {?} */ (currentIndex))], (/** @type {?} */ (currentIndex)), viewContainer, parentData);
}
else if (currentIndex == null) {
viewContainer.remove((/** @type {?} */ (adjustedPreviousIndex)));
_this._levels.delete(item.item);
}
else {
/** @type {?} */
var view = viewContainer.get((/** @type {?} */ (adjustedPreviousIndex)));
viewContainer.move((/** @type {?} */ (view)), currentIndex);
}
});
this._changeDetectorRef.detectChanges();
};
/**
* Finds the matching node definition that should be used for this node data. If there is only
* one node definition, it is returned. Otherwise, find the node definition that has a when
* predicate that returns true with the data. If none return true, return the default node
* definition.
*/
/**
* Finds the matching node definition that should be used for this node data. If there is only
* one node definition, it is returned. Otherwise, find the node definition that has a when
* predicate that returns true with the data. If none return true, return the default node
* definition.
* @param {?} data
* @param {?} i
* @return {?}
*/
CdkTree.prototype._getNodeDef = /**
* Finds the matching node definition that should be used for this node data. If there is only
* one node definition, it is returned. Otherwise, find the node definition that has a when
* predicate that returns true with the data. If none return true, return the default node
* definition.
* @param {?} data
* @param {?} i
* @return {?}
*/
function (data, i) {
if (this._nodeDefs.length === 1) {
return this._nodeDefs.first;
}
/** @type {?} */
var nodeDef = this._nodeDefs.find(function (def) { return def.when && def.when(i, data); }) || this._defaultNodeDef;
if (!nodeDef) {
throw getTreeMissingMatchingNodeDefError();
}
return nodeDef;
};
/**
* Create the embedded view for the data node template and place it in the correct index location
* within the data node view container.
*/
/**
* Create the embedded view for the data node template and place it in the correct index location
* within the data node view container.
* @param {?} nodeData
* @param {?} index
* @param {?=} viewContainer
* @param {?=} parentData
* @return {?}
*/
CdkTree.prototype.insertNode = /**
* Create the embedded view for the data node template and place it in the correct index location
* within the data node view container.
* @param {?} nodeData
* @param {?} index
* @param {?=} viewContainer
* @param {?=} parentData
* @return {?}
*/
function (nodeData, index, viewContainer, parentData) {
/** @type {?} */
var node = this._getNodeDef(nodeData, index);
// Node context that will be provided to created embedded view
/** @type {?} */
var context = new CdkTreeNodeOutletContext(nodeData);
// If the tree is flat tree, then use the `getLevel` function in flat tree control
// Otherwise, use the level of parent node.
if (this.treeControl.getLevel) {
context.level = this.treeControl.getLevel(nodeData);
}
else if (typeof parentData !== 'undefined' && this._levels.has(parentData)) {
context.level = (/** @type {?} */ (this._levels.get(parentData))) + 1;
}
else {
context.level = 0;
}
this._levels.set(nodeData, context.level);
// Use default tree nodeOutlet, or nested node's nodeOutlet
/** @type {?} */
var container = viewContainer ? viewContainer : this._nodeOutlet.viewContainer;
container.createEmbeddedView(node.template, context, index);
// Set the data to just created `CdkTreeNode`.
// The `CdkTreeNode` created from `createEmbeddedView` will be saved in static variable
// `mostRecentTreeNode`. We get it from static variable and pass the node data to it.
if (CdkTreeNode.mostRecentTreeNode) {
CdkTreeNode.mostRecentTreeNode.data = nodeData;
}
};
CdkTree.decorators = [
{ type: Component, args: [{selector: 'cdk-tree',
exportAs: 'cdkTree',
template: "<ng-container cdkTreeNodeOutlet></ng-container>",
host: {
'class': 'cdk-tree',
'role': 'tree',
},
encapsulation: ViewEncapsulation.None,
changeDetection: ChangeDetectionStrategy.OnPush
},] },
];
/** @nocollapse */
CdkTree.ctorParameters = function () { return [
{ type: IterableDiffers },
{ type: ChangeDetectorRef }
]; };
CdkTree.propDecorators = {
dataSource: [{ type: Input }],
treeControl: [{ type: Input }],
trackBy: [{ type: Input }],
_nodeOutlet: [{ type: ViewChild, args: [CdkTreeNodeOutlet,] }],
_nodeDefs: [{ type: ContentChildren, args: [CdkTreeNodeDef,] }]
};
return CdkTree;
}());
/**
* Tree node for CdkTree. It contains the data in the tree node.
* @template T
*/
var CdkTreeNode = /** @class */ (function () {
function CdkTreeNode(_elementRef, _tree) {
this._elementRef = _elementRef;
this._tree = _tree;
/**
* Subject that emits when the component has been destroyed.
*/
this._destroyed = new Subject();
/**
* The role of the node should be 'group' if it's an internal node,
* and 'treeitem' if it's a leaf node.
*/
this.role = 'treeitem';
CdkTreeNode.mostRecentTreeNode = (/** @type {?} */ (this));
}
Object.defineProperty(CdkTreeNode.prototype, "data", {
/** The tree node's data. */
get: /**
* The tree node's data.
* @return {?}
*/
function () { return this._data; },
set: /**
* @param {?} value
* @return {?}
*/
function (value) {
this._data = value;
this._setRoleFromData();
},
enumerable: true,
configurable: true
});
Object.defineProperty(CdkTreeNode.prototype, "isExpanded", {
get: /**
* @return {?}
*/
function () {
return this._tree.treeControl.isExpanded(this._data);
},
enumerable: true,
configurable: true
});
Object.defineProperty(CdkTreeNode.prototype, "level", {
get: /**
* @return {?}
*/
function () {
return this._tree.treeControl.getLevel ? this._tree.treeControl.getLevel(this._data) : 0;
},
enumerable: true,
configurable: true
});
/**
* @return {?}
*/
CdkTreeNode.prototype.ngOnDestroy = /**
* @return {?}
*/
function () {
// If this is the last tree node being destroyed,
// clear out the reference to avoid leaking memory.
if (CdkTreeNode.mostRecentTreeNode === this) {
CdkTreeNode.mostRecentTreeNode = null;
}
this._destroyed.next();
this._destroyed.complete();
};
/** Focuses the menu item. Implements for FocusableOption. */
/**
* Focuses the menu item. Implements for FocusableOption.
* @return {?}
*/
CdkTreeNode.prototype.focus = /**
* Focuses the menu item. Implements for FocusableOption.
* @return {?}
*/
function () {
this._elementRef.nativeElement.focus();
};
/**
* @protected
* @return {?}
*/
CdkTreeNode.prototype._setRoleFromData = /**
* @protected
* @return {?}
*/
function () {
var _this = this;
if (this._tree.treeControl.isExpandable) {
this.role = this._tree.treeControl.isExpandable(this._data) ? 'group' : 'treeitem';
}
else {
if (!this._tree.treeControl.getChildren) {
throw getTreeControlFunctionsMissingError();
}
/** @type {?} */
var childrenNodes = this._tree.treeControl.getChildren(this._data);
if (Array.isArray(childrenNodes)) {
this._setRoleFromChildren((/** @type {?} */ (childrenNodes)));
}
else if (childrenNodes instanceof Observable) {
childrenNodes.pipe(takeUntil(this._destroyed))
.subscribe(function (children) { return _this._setRoleFromChildren(children); });
}
}
};
/**
* @protected
* @param {?} children
* @return {?}
*/
CdkTreeNode.prototype._setRoleFromChildren = /**
* @protected
* @param {?} children
* @return {?}
*/
function (children) {
this.role = children && children.length ? 'group' : 'treeitem';
};
/**
* The most recently created `CdkTreeNode`. We save it in static variable so we can retrieve it
* in `CdkTree` and set the data to it.
*/
CdkTreeNode.mostRecentTreeNode = null;
CdkTreeNode.decorators = [
{ type: Directive, args: [{
selector: 'cdk-tree-node',
exportAs: 'cdkTreeNode',
host: {
'[attr.aria-expanded]': 'isExpanded',
'[attr.aria-level]': 'role === "treeitem" ? level : null',
'[attr.role]': 'role',
'class': 'cdk-tree-node',
},
},] },
];
/** @nocollapse */
CdkTreeNode.ctorParameters = function () { return [
{ type: ElementRef },
{ type: CdkTree }
]; };
CdkTreeNode.propDecorators = {
role: [{ type: Input }]
};
return CdkTreeNode;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Nested node is a child of `<cdk-tree>`. It works with nested tree.
* By using `cdk-nested-tree-node` component in tree node template, children of the parent node will
* be added in the `cdkTreeNodeOutlet` in tree node template.
* For example:
* ```html
* <cdk-nested-tree-node>
* {{node.name}}
* <ng-template cdkTreeNodeOutlet></ng-template>
* </cdk-nested-tree-node>
* ```
* The children of node will be automatically added to `cdkTreeNodeOutlet`, the result dom will be
* like this:
* ```html
* <cdk-nested-tree-node>
* {{node.name}}
* <cdk-nested-tree-node>{{child1.name}}</cdk-nested-tree-node>
* <cdk-nested-tree-node>{{child2.name}}</cdk-nested-tree-node>
* </cdk-nested-tree-node>
* ```
* @template T
*/
var CdkNestedTreeNode = /** @class */ (function (_super) {
__extends(CdkNestedTreeNode, _super);
function CdkNestedTreeNode(_elementRef, _tree, _differs) {
var _this = _super.call(this, _elementRef, _tree) || this;
_this._elementRef = _elementRef;
_this._tree = _tree;
_this._differs = _differs;
return _this;
}
/**
* @return {?}
*/
CdkNestedTreeNode.prototype.ngAfterContentInit = /**
* @return {?}
*/
function () {
var _this = this;
this._dataDiffer = this._differs.find([]).create(this._tree.trackBy);
if (!this._tree.treeControl.getChildren) {
throw getTreeControlFunctionsMissingError();
}
/** @type {?} */
var childrenNodes = this._tree.treeControl.getChildren(this.data);
if (Array.isArray(childrenNodes)) {
this.updateChildrenNodes((/** @type {?} */ (childrenNodes)));
}
else if (childrenNodes instanceof Observable) {
childrenNodes.pipe(takeUntil(this._destroyed))
.subscribe(function (result) { return _this.updateChildrenNodes(result); });
}
this.nodeOutlet.changes.pipe(takeUntil(this._destroyed))
.subscribe(function () { return _this.updateChildrenNodes(); });
};
/**
* @return {?}
*/
CdkNestedTreeNode.prototype.ngOnDestroy = /**
* @return {?}
*/
function () {
this._clear();
_super.prototype.ngOnDestroy.call(this);
};
/** Add children dataNodes to the NodeOutlet */
/**
* Add children dataNodes to the NodeOutlet
* @protected
* @param {?=} children
* @return {?}
*/
CdkNestedTreeNode.prototype.updateChildrenNodes = /**
* Add children dataNodes to the NodeOutlet
* @protected
* @param {?=} children
* @return {?}
*/
function (children) {
if (children) {
this._children = children;
}
if (this.nodeOutlet.length && this._children) {
/** @type {?} */
var viewContainer = this.nodeOutlet.first.viewContainer;
this._tree.renderNodeChanges(this._children, this._dataDiffer, viewContainer, this._data);
}
else {
// Reset the data differ if there's no children nodes displayed
this._dataDiffer.diff([]);
}
};
/** Clear the children dataNodes. */
/**
* Clear the children dataNodes.
* @protected
* @return {?}
*/
CdkNestedTreeNode.prototype._clear = /**
* Clear the children dataNodes.
* @protected
* @return {?}
*/
function () {
if (this.nodeOutlet && this.nodeOutlet.first) {
this.nodeOutlet.first.viewContainer.clear();
this._dataDiffer.diff([]);
}
};
CdkNestedTreeNode.decorators = [
{ type: Directive, args: [{
selector: 'cdk-nested-tree-node',
exportAs: 'cdkNestedTreeNode',
host: {
'[attr.aria-expanded]': 'isExpanded',
'[attr.role]': 'role',
'class': 'cdk-tree-node cdk-nested-tree-node',
},
providers: [{ provide: CdkTreeNode, useExisting: CdkNestedTreeNode }]
},] },
];
/** @nocollapse */
CdkNestedTreeNode.ctorParameters = function () { return [
{ type: ElementRef },
{ type: CdkTree },
{ type: IterableDiffers }
]; };
CdkNestedTreeNode.propDecorators = {
nodeOutlet: [{ type: ContentChildren, args: [CdkTreeNodeOutlet,] }]
};
return CdkNestedTreeNode;
}(CdkTreeNode));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Regex used to split a string on its CSS units.
* @type {?}
*/
var cssUnitPattern = /([A-Za-z%]+)$/;
/**
* Indent for the children tree dataNodes.
* This directive will add left-padding to the node to show hierarchy.
* @template T
*/
var CdkTreeNodePadding = /** @class */ (function () {
function CdkTreeNodePadding(_treeNode, _tree, _renderer, _element, _dir) {
var _this = this;
this._treeNode = _treeNode;
this._tree = _tree;
this._renderer = _renderer;
this._element = _element;
this._dir = _dir;
/**
* Subject that emits when the component has been destroyed.
*/
this._destroyed = new Subject();
/**
* CSS units used for the indentation value.
*/
this.indentUnits = 'px';
this._indent = 40;
this._setPadding();
if (_dir) {
_dir.change.pipe(takeUntil(this._destroyed)).subscribe(function () { return _this._setPadding(); });
}
}
Object.defineProperty(CdkTreeNodePadding.prototype, "level", {
/** The level of depth of the tree node. The padding will be `level * indent` pixels. */
get: /**
* The level of depth of the tree node. The padding will be `level * indent` pixels.
* @return {?}
*/
function () { return this._level; },
set: /**
* @param {?} value
* @return {?}
*/
function (value) {
this._level = coerceNumberProperty(value);
this._setPadding();
},
enumerable: true,
configurable: true
});
Object.defineProperty(CdkTreeNodePadding.prototype, "indent", {
/**
* The indent for each level. Can be a number or a CSS string.
* Default number 40px from material design menu sub-menu spec.
*/
get: /**
* The indent for each level. Can be a number or a CSS string.
* Default number 40px from material design menu sub-menu spec.
* @return {?}
*/
function () { return this._indent; },
set: /**
* @param {?} indent
* @return {?}
*/
function (indent) {
/** @type {?} */
var value = indent;
/** @type {?} */
var units = 'px';
if (typeof indent === 'string') {
/** @type {?} */
var parts = indent.split(cssUnitPattern);
value = parts[0];
units = parts[1] || units;
}
this.indentUnits = units;
this._indent = coerceNumberProperty(value);
this._setPadding();
},
enumerable: true,
configurable: true
});
/**
* @return {?}
*/
CdkTreeNodePadding.prototype.ngOnDestroy = /**
* @return {?}
*/
function () {
this._destroyed.next();
this._destroyed.complete();
};
/** The padding indent value for the tree node. Returns a string with px numbers if not null. */
/**
* The padding indent value for the tree node. Returns a string with px numbers if not null.
* @return {?}
*/
CdkTreeNodePadding.prototype._paddingIndent = /**
* The padding indent value for the tree node. Returns a string with px numbers if not null.
* @return {?}
*/
function () {
/** @type {?} */
var nodeLevel = (this._treeNode.data && this._tree.treeControl.getLevel)
? this._tree.treeControl.getLevel(this._treeNode.data)
: null;
/** @type {?} */
var level = this._level || nodeLevel;
return level ? "" + level * this._indent + this.indentUnits : null;
};
/**
* @return {?}
*/
CdkTreeNodePadding.prototype._setPadding = /**
* @return {?}
*/
function () {
/** @type {?} */
var element = this._element.nativeElement;
/** @type {?} */
var padding = this._paddingIndent();
/** @type {?} */
var paddingProp = this._dir && this._dir.value === 'rtl' ? 'paddingRight' : 'paddingLeft';
/** @type {?} */
var resetProp = paddingProp === 'paddingLeft' ? 'paddingRight' : 'paddingLeft';
this._renderer.setStyle(element, paddingProp, padding);
this._renderer.setStyle(element, resetProp, '');
};
CdkTreeNodePadding.decorators = [
{ type: Directive, args: [{
selector: '[cdkTreeNodePadding]',
},] },
];
/** @nocollapse */
CdkTreeNodePadding.ctorParameters = function () { return [
{ type: CdkTreeNode },
{ type: CdkTree },
{ type: Renderer2 },
{ type: ElementRef },
{ type: Directionality, decorators: [{ type: Optional }] }
]; };
CdkTreeNodePadding.propDecorators = {
level: [{ type: Input, args: ['cdkTreeNodePadding',] }],
indent: [{ type: Input, args: ['cdkTreeNodePaddingIndent',] }]
};
return CdkTreeNodePadding;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* Node toggle to expand/collapse the node.
* @template T
*/
var CdkTreeNodeToggle = /** @class */ (function () {
function CdkTreeNodeToggle(_tree, _treeNode) {
this._tree = _tree;
this._treeNode = _treeNode;
this._recursive = false;
}
Object.defineProperty(CdkTreeNodeToggle.prototype, "recursive", {
/** Whether expand/collapse the node recursively. */
get: /**
* Whether expand/collapse the node recursively.
* @return {?}
*/
function () { return this._recursive; },
set: /**
* @param {?} value
* @return {?}
*/
function (value) { this._recursive = coerceBooleanProperty(value); },
enumerable: true,
configurable: true
});
/**
* @param {?} event
* @return {?}
*/
CdkTreeNodeToggle.prototype._toggle = /**
* @param {?} event
* @return {?}
*/
function (event) {
this.recursive
? this._tree.treeControl.toggleDescendants(this._treeNode.data)
: this._tree.treeControl.toggle(this._treeNode.data);
event.stopPropagation();
};
CdkTreeNodeToggle.decorators = [
{ type: Directive, args: [{
selector: '[cdkTreeNodeToggle]',
host: {
'(click)': '_toggle($event)',
}
},] },
];
/** @nocollapse */
CdkTreeNodeToggle.ctorParameters = function () { return [
{ type: CdkTree },
{ type: CdkTreeNode }
]; };
CdkTreeNodeToggle.propDecorators = {
recursive: [{ type: Input, args: ['cdkTreeNodeToggleRecursive',] }]
};
return CdkTreeNodeToggle;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/** @type {?} */
var EXPORTED_DECLARATIONS = [
CdkNestedTreeNode,
CdkTreeNodeDef,
CdkTreeNodePadding,
CdkTreeNodeToggle,
CdkTree,
CdkTreeNode,
CdkTreeNodeOutlet,
];
var CdkTreeModule = /** @class */ (function () {
function CdkTreeModule() {
}
CdkTreeModule.decorators = [
{ type: NgModule, args: [{
imports: [CommonModule],
exports: EXPORTED_DECLARATIONS,
declarations: EXPORTED_DECLARATIONS,
providers: [FocusMonitor, CdkTreeNodeDef]
},] },
];
return CdkTreeModule;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
/**
* @fileoverview added by tsickle
* @suppress {checkTypes,extraRequire,missingReturn,unusedPrivateMembers,uselessCode} checked by tsc
*/
export { BaseTreeControl, FlatTreeControl, NestedTreeControl, CdkNestedTreeNode, CdkTreeNodeOutletContext, CdkTreeNodeDef, CdkTreeNodePadding, CdkTreeNodeOutlet, CdkTree, CdkTreeNode, getTreeNoValidDataSourceError, getTreeMultipleDefaultNodeDefsError, getTreeMissingMatchingNodeDefError, getTreeControlMissingError, getTreeControlFunctionsMissingError, CdkTreeModule, CdkTreeNodeToggle };
//# sourceMappingURL=tree.es5.js.map
|
};
|
user_create.go
|
// Code generated by entc, DO NOT EDIT.
package ent
import (
"context"
"errors"
"fmt"
"entgo.io/ent/dialect/sql/sqlgraph"
"entgo.io/ent/schema/field"
"github.com/trinhdaiphuc/togo/database/ent/task"
"github.com/trinhdaiphuc/togo/database/ent/user"
)
// UserCreate is the builder for creating a User entity.
type UserCreate struct {
config
mutation *UserMutation
hooks []Hook
}
// SetUsername sets the "username" field.
func (uc *UserCreate) SetUsername(s string) *UserCreate {
uc.mutation.SetUsername(s)
return uc
}
// SetPassword sets the "password" field.
func (uc *UserCreate) SetPassword(s string) *UserCreate {
uc.mutation.SetPassword(s)
return uc
}
// SetTaskLimit sets the "task_limit" field.
func (uc *UserCreate) SetTaskLimit(i int) *UserCreate {
uc.mutation.SetTaskLimit(i)
return uc
}
// SetNillableTaskLimit sets the "task_limit" field if the given value is not nil.
func (uc *UserCreate) SetNillableTaskLimit(i *int) *UserCreate {
if i != nil {
uc.SetTaskLimit(*i)
}
return uc
}
// AddUserTaskIDs adds the "user_task" edge to the Task entity by IDs.
func (uc *UserCreate) AddUserTaskIDs(ids ...int) *UserCreate {
uc.mutation.AddUserTaskIDs(ids...)
return uc
}
// AddUserTask adds the "user_task" edges to the Task entity.
func (uc *UserCreate) AddUserTask(t ...*Task) *UserCreate {
ids := make([]int, len(t))
for i := range t {
ids[i] = t[i].ID
}
return uc.AddUserTaskIDs(ids...)
}
// Mutation returns the UserMutation object of the builder.
func (uc *UserCreate) Mutation() *UserMutation {
return uc.mutation
}
// Save creates the User in the database.
func (uc *UserCreate) Save(ctx context.Context) (*User, error) {
var (
err error
node *User
)
uc.defaults()
if len(uc.hooks) == 0 {
if err = uc.check(); err != nil {
return nil, err
}
node, err = uc.sqlSave(ctx)
} else {
var mut Mutator = MutateFunc(func(ctx context.Context, m Mutation) (Value, error) {
mutation, ok := m.(*UserMutation)
if !ok {
return nil, fmt.Errorf("unexpected mutation type %T", m)
}
if err = uc.check(); err != nil {
return nil, err
}
uc.mutation = mutation
if node, err = uc.sqlSave(ctx); err != nil {
return nil, err
}
mutation.id = &node.ID
mutation.done = true
return node, err
})
for i := len(uc.hooks) - 1; i >= 0; i-- {
if uc.hooks[i] == nil {
return nil, fmt.Errorf("ent: uninitialized hook (forgotten import ent/runtime?)")
}
mut = uc.hooks[i](mut)
}
if _, err := mut.Mutate(ctx, uc.mutation); err != nil {
return nil, err
}
}
return node, err
}
// SaveX calls Save and panics if Save returns an error.
func (uc *UserCreate) SaveX(ctx context.Context) *User {
v, err := uc.Save(ctx)
if err != nil {
panic(err)
}
return v
}
// Exec executes the query.
func (uc *UserCreate) Exec(ctx context.Context) error {
_, err := uc.Save(ctx)
return err
}
// ExecX is like Exec, but panics if an error occurs.
func (uc *UserCreate) ExecX(ctx context.Context) {
if err := uc.Exec(ctx); err != nil {
panic(err)
}
}
// defaults sets the default values of the builder before save.
func (uc *UserCreate) defaults() {
if _, ok := uc.mutation.TaskLimit(); !ok {
v := user.DefaultTaskLimit
uc.mutation.SetTaskLimit(v)
}
}
// check runs all checks and user-defined validators on the builder.
func (uc *UserCreate) check() error {
if _, ok := uc.mutation.Username(); !ok {
return &ValidationError{Name: "username", err: errors.New(`ent: missing required field "User.username"`)}
}
if _, ok := uc.mutation.Password(); !ok {
return &ValidationError{Name: "password", err: errors.New(`ent: missing required field "User.password"`)}
}
if _, ok := uc.mutation.TaskLimit(); !ok {
return &ValidationError{Name: "task_limit", err: errors.New(`ent: missing required field "User.task_limit"`)}
}
if v, ok := uc.mutation.TaskLimit(); ok {
if err := user.TaskLimitValidator(v); err != nil {
return &ValidationError{Name: "task_limit", err: fmt.Errorf(`ent: validator failed for field "User.task_limit": %w`, err)}
}
}
return nil
}
func (uc *UserCreate) sqlSave(ctx context.Context) (*User, error) {
_node, _spec := uc.createSpec()
if err := sqlgraph.CreateNode(ctx, uc.driver, _spec); err != nil
|
id := _spec.ID.Value.(int64)
_node.ID = int(id)
return _node, nil
}
func (uc *UserCreate) createSpec() (*User, *sqlgraph.CreateSpec) {
var (
_node = &User{config: uc.config}
_spec = &sqlgraph.CreateSpec{
Table: user.Table,
ID: &sqlgraph.FieldSpec{
Type: field.TypeInt,
Column: user.FieldID,
},
}
)
if value, ok := uc.mutation.Username(); ok {
_spec.Fields = append(_spec.Fields, &sqlgraph.FieldSpec{
Type: field.TypeString,
Value: value,
Column: user.FieldUsername,
})
_node.Username = value
}
if value, ok := uc.mutation.Password(); ok {
_spec.Fields = append(_spec.Fields, &sqlgraph.FieldSpec{
Type: field.TypeString,
Value: value,
Column: user.FieldPassword,
})
_node.Password = value
}
if value, ok := uc.mutation.TaskLimit(); ok {
_spec.Fields = append(_spec.Fields, &sqlgraph.FieldSpec{
Type: field.TypeInt,
Value: value,
Column: user.FieldTaskLimit,
})
_node.TaskLimit = value
}
if nodes := uc.mutation.UserTaskIDs(); len(nodes) > 0 {
edge := &sqlgraph.EdgeSpec{
Rel: sqlgraph.O2M,
Inverse: false,
Table: user.UserTaskTable,
Columns: []string{user.UserTaskColumn},
Bidi: false,
Target: &sqlgraph.EdgeTarget{
IDSpec: &sqlgraph.FieldSpec{
Type: field.TypeInt,
Column: task.FieldID,
},
},
}
for _, k := range nodes {
edge.Target.Nodes = append(edge.Target.Nodes, k)
}
_spec.Edges = append(_spec.Edges, edge)
}
return _node, _spec
}
// UserCreateBulk is the builder for creating many User entities in bulk.
type UserCreateBulk struct {
config
builders []*UserCreate
}
// Save creates the User entities in the database.
func (ucb *UserCreateBulk) Save(ctx context.Context) ([]*User, error) {
specs := make([]*sqlgraph.CreateSpec, len(ucb.builders))
nodes := make([]*User, len(ucb.builders))
mutators := make([]Mutator, len(ucb.builders))
for i := range ucb.builders {
func(i int, root context.Context) {
builder := ucb.builders[i]
builder.defaults()
var mut Mutator = MutateFunc(func(ctx context.Context, m Mutation) (Value, error) {
mutation, ok := m.(*UserMutation)
if !ok {
return nil, fmt.Errorf("unexpected mutation type %T", m)
}
if err := builder.check(); err != nil {
return nil, err
}
builder.mutation = mutation
nodes[i], specs[i] = builder.createSpec()
var err error
if i < len(mutators)-1 {
_, err = mutators[i+1].Mutate(root, ucb.builders[i+1].mutation)
} else {
spec := &sqlgraph.BatchCreateSpec{Nodes: specs}
// Invoke the actual operation on the latest mutation in the chain.
if err = sqlgraph.BatchCreate(ctx, ucb.driver, spec); err != nil {
if sqlgraph.IsConstraintError(err) {
err = &ConstraintError{err.Error(), err}
}
}
}
if err != nil {
return nil, err
}
mutation.id = &nodes[i].ID
mutation.done = true
if specs[i].ID.Value != nil {
id := specs[i].ID.Value.(int64)
nodes[i].ID = int(id)
}
return nodes[i], nil
})
for i := len(builder.hooks) - 1; i >= 0; i-- {
mut = builder.hooks[i](mut)
}
mutators[i] = mut
}(i, ctx)
}
if len(mutators) > 0 {
if _, err := mutators[0].Mutate(ctx, ucb.builders[0].mutation); err != nil {
return nil, err
}
}
return nodes, nil
}
// SaveX is like Save, but panics if an error occurs.
func (ucb *UserCreateBulk) SaveX(ctx context.Context) []*User {
v, err := ucb.Save(ctx)
if err != nil {
panic(err)
}
return v
}
// Exec executes the query.
func (ucb *UserCreateBulk) Exec(ctx context.Context) error {
_, err := ucb.Save(ctx)
return err
}
// ExecX is like Exec, but panics if an error occurs.
func (ucb *UserCreateBulk) ExecX(ctx context.Context) {
if err := ucb.Exec(ctx); err != nil {
panic(err)
}
}
|
{
if sqlgraph.IsConstraintError(err) {
err = &ConstraintError{err.Error(), err}
}
return nil, err
}
|
mod.rs
|
//! Function expression parsing.
//!
//! More information:
//! - [MDN documentation][mdn]
//! - [ECMAScript specification][spec]
//!
//! [mdn]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/function
//! [spec]: https://tc39.es/ecma262/#prod-FunctionExpression
#[cfg(test)]
mod tests;
|
use crate::{
syntax::{
ast::{node::FunctionExpr, Keyword, Punctuator},
lexer::{Error as LexError, Position, TokenKind},
parser::{
function::{FormalParameters, FunctionBody},
statement::BindingIdentifier,
Cursor, ParseError, TokenParser,
},
},
BoaProfiler,
};
use std::io::Read;
/// Function expression parsing.
///
/// More information:
/// - [MDN documentation][mdn]
/// - [ECMAScript specification][spec]
///
/// [mdn]: https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Operators/function
/// [spec]: https://tc39.es/ecma262/#prod-FunctionExpression
#[derive(Debug, Clone, Copy)]
pub(super) struct FunctionExpression;
impl<R> TokenParser<R> for FunctionExpression
where
R: Read,
{
type Output = FunctionExpr;
fn parse(self, cursor: &mut Cursor<R>) -> Result<Self::Output, ParseError> {
let _timer = BoaProfiler::global().start_event("FunctionExpression", "Parsing");
let name = if let Some(token) = cursor.peek(0)? {
match token.kind() {
TokenKind::Identifier(_)
| TokenKind::Keyword(Keyword::Yield)
| TokenKind::Keyword(Keyword::Await) => {
Some(BindingIdentifier::new(false, false).parse(cursor)?)
}
_ => None,
}
} else {
None
};
// Early Error: If BindingIdentifier is present and the source code matching BindingIdentifier is strict mode code,
// it is a Syntax Error if the StringValue of BindingIdentifier is "eval" or "arguments".
if let Some(name) = &name {
if cursor.strict_mode() && ["eval", "arguments"].contains(&name.as_ref()) {
return Err(ParseError::lex(LexError::Syntax(
"Unexpected eval or arguments in strict mode".into(),
match cursor.peek(0)? {
Some(token) => token.span().end(),
None => Position::new(1, 1),
},
)));
}
}
let params_start_position = cursor
.expect(Punctuator::OpenParen, "function expression")?
.span()
.end();
let params = FormalParameters::new(false, false).parse(cursor)?;
cursor.expect(Punctuator::CloseParen, "function expression")?;
cursor.expect(Punctuator::OpenBlock, "function expression")?;
let body = FunctionBody::new(false, false).parse(cursor)?;
cursor.expect(Punctuator::CloseBlock, "function expression")?;
// Early Error: If the source code matching FormalParameters is strict mode code,
// the Early Error rules for UniqueFormalParameters : FormalParameters are applied.
if (cursor.strict_mode() || body.strict()) && params.has_duplicates {
return Err(ParseError::lex(LexError::Syntax(
"Duplicate parameter name not allowed in this context".into(),
params_start_position,
)));
}
// Early Error: It is a Syntax Error if FunctionBodyContainsUseStrict of GeneratorBody is true
// and IsSimpleParameterList of FormalParameters is false.
if body.strict() && !params.is_simple {
return Err(ParseError::lex(LexError::Syntax(
"Illegal 'use strict' directive in function with non-simple parameter list".into(),
params_start_position,
)));
}
// It is a Syntax Error if any element of the BoundNames of FormalParameters
// also occurs in the LexicallyDeclaredNames of FunctionBody.
// https://tc39.es/ecma262/#sec-function-definitions-static-semantics-early-errors
{
let lexically_declared_names = body.lexically_declared_names();
for param in params.parameters.as_ref() {
for param_name in param.names() {
if lexically_declared_names.contains(param_name) {
return Err(ParseError::lex(LexError::Syntax(
format!("Redeclaration of formal parameter `{}`", param_name).into(),
match cursor.peek(0)? {
Some(token) => token.span().end(),
None => Position::new(1, 1),
},
)));
}
}
}
}
Ok(FunctionExpr::new(name, params.parameters, body))
}
}
| |
dcim_inventory_item_roles_create_responses.go
|
// Code generated by go-swagger; DO NOT EDIT.
// Copyright 2020 The go-netbox Authors.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
//
package dcim
// This file was generated by the swagger tool.
// Editing this file might prove futile when you re-run the swagger generate command
import (
"fmt"
"io"
"github.com/go-openapi/runtime"
"github.com/go-openapi/strfmt"
"github.com/tomasherout/go-netbox/netbox/models"
)
// DcimInventoryItemRolesCreateReader is a Reader for the DcimInventoryItemRolesCreate structure.
type DcimInventoryItemRolesCreateReader struct {
formats strfmt.Registry
}
// ReadResponse reads a server response into the received o.
func (o *DcimInventoryItemRolesCreateReader) ReadResponse(response runtime.ClientResponse, consumer runtime.Consumer) (interface{}, error) {
switch response.Code() {
case 201:
result := NewDcimInventoryItemRolesCreateCreated()
if err := result.readResponse(response, consumer, o.formats); err != nil {
return nil, err
}
return result, nil
default:
return nil, runtime.NewAPIError("response status code does not match any response statuses defined for this endpoint in the swagger spec", response, response.Code())
}
}
// NewDcimInventoryItemRolesCreateCreated creates a DcimInventoryItemRolesCreateCreated with default headers values
func NewDcimInventoryItemRolesCreateCreated() *DcimInventoryItemRolesCreateCreated
|
/* DcimInventoryItemRolesCreateCreated describes a response with status code 201, with default header values.
DcimInventoryItemRolesCreateCreated dcim inventory item roles create created
*/
type DcimInventoryItemRolesCreateCreated struct {
Payload *models.InventoryItemRole
}
func (o *DcimInventoryItemRolesCreateCreated) Error() string {
return fmt.Sprintf("[POST /dcim/inventory-item-roles/][%d] dcimInventoryItemRolesCreateCreated %+v", 201, o.Payload)
}
func (o *DcimInventoryItemRolesCreateCreated) GetPayload() *models.InventoryItemRole {
return o.Payload
}
func (o *DcimInventoryItemRolesCreateCreated) readResponse(response runtime.ClientResponse, consumer runtime.Consumer, formats strfmt.Registry) error {
o.Payload = new(models.InventoryItemRole)
// response payload
if err := consumer.Consume(response.Body(), o.Payload); err != nil && err != io.EOF {
return err
}
return nil
}
|
{
return &DcimInventoryItemRolesCreateCreated{}
}
|
date.py
|
import time
def
|
(format = '%Y-%m-%d %H:%M:%S'):
datetime = time.localtime()
formatted = time.strftime(format, datetime)
return formatted
|
dateFormatted
|
index.js
|
import { createStore, compose, applyMiddleware } from 'redux';
// import { fromJS } from 'immutable';
import createSagaMiddleware from 'redux-saga';
import devTools from 'remote-redux-devtools';
import createReducer from './reducers';
import sagas from '../sagas';
import Settings from '../settings';
import { autoRehydrate } from 'redux-persist'
const settings = Settings.load();
const sagaMiddleware = createSagaMiddleware();
function
|
(initialState = {}) {
const enhancers = [
applyMiddleware(sagaMiddleware),
autoRehydrate()
];
if (__DEV__) {
enhancers.push(devTools());
}
const store = createStore(createReducer(), initialState, compose(...enhancers));
sagas.forEach(saga => sagaMiddleware.run(saga));
return store;
}
module.exports = configureStore;
|
configureStore
|
path_token_role_test.go
|
// Copyright 2021 Splunk Inc.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
package gitlabtoken
import (
"context"
"fmt"
"testing"
"github.com/hashicorp/vault/sdk/logical"
"github.com/stretchr/testify/assert"
"github.com/stretchr/testify/require"
"github.com/xanzy/go-gitlab"
)
func TestAccRoleToken(t *testing.T)
|
// create the token given role name
func testIssueRoleToken(t *testing.T, b logical.Backend, req *logical.Request, roleName string, data map[string]interface{}) (*logical.Response, error) {
req.Operation = logical.CreateOperation
req.Path = fmt.Sprintf("%s/%s", pathPatternToken, roleName)
req.Data = data
resp, err := b.HandleRequest(context.Background(), req)
return resp, err
}
|
{
if testing.Short() {
t.Skip("skipping integration test (short)")
}
req, backend := newGitlabAccEnv(t)
ID := envAsInt("GITLAB_PROJECT_ID", 1)
t.Run("successfully create", func(t *testing.T) {
data := map[string]interface{}{
"id": ID,
"name": "vault-role-test",
"scopes": []string{"read_api"},
}
roleName := "successful"
mustRoleCreate(t, backend, req.Storage, roleName, data)
resp, err := testIssueRoleToken(t, backend, req, roleName, nil)
require.NoError(t, err)
require.False(t, resp.IsError())
assert.NotEmpty(t, resp.Data["token"], "no token returned")
assert.NotEmpty(t, resp.Data["id"], "no id returned")
assert.NotEmpty(t, resp.Data["access_level"], "no access_level returned")
assert.NotEmpty(t, resp.Data["expires_at"], "default is 1d for expires_at")
// check for default value
assert.Equal(t, gitlab.AccessLevelValue(40), resp.Data["access_level"])
})
t.Run("successfully create token for role with access level", func(t *testing.T) {
data := map[string]interface{}{
"id": ID,
"name": "vault-role-test-access-level",
"access_level": 30,
"scopes": []string{"read_api"},
}
roleName := "successful-access-level"
mustRoleCreate(t, backend, req.Storage, roleName, data)
resp, err := testIssueRoleToken(t, backend, req, roleName, nil)
require.NoError(t, err)
require.False(t, resp.IsError())
assert.NotEmpty(t, resp.Data["token"], "no token returned")
assert.NotEmpty(t, resp.Data["id"], "no id returned")
assert.NotEmpty(t, resp.Data["access_level"], "no access_level returned")
assert.NotEmpty(t, resp.Data["expires_at"], "default is 1d for expires_at")
assert.Equal(t, gitlab.AccessLevelValue(30), resp.Data["access_level"])
})
t.Run("non-existing role", func(t *testing.T) {
resp, err := testIssueRoleToken(t, backend, req, "non-existing", nil)
require.NoError(t, err)
require.True(t, resp.IsError())
})
}
|
image_loader.rs
|
use super::{Map, TileType};
use rltk::rex::XpFile;
/// Loads a RexPaint file, and converts it into our map format
pub fn load_rex_map(new_depth: i32, xp_file: &XpFile) -> Map {
let mut map: Map = Map::new(new_depth);
for layer in &xp_file.layers {
for y in 0..layer.height {
for x in 0..layer.width {
let cell = layer.get(x, y).unwrap();
if x < map.width as usize && y < map.height as usize {
let idx = map.xy_idx(x as i32, y as i32);
match cell.ch {
32 => map.tiles[idx] = TileType::Floor, // #
35 => map.tiles[idx] = TileType::Wall, // #
_ => {}
}
}
|
map
}
|
}
}
}
|
__init__.py
|
import dateutil.parser
import datetime
import time
import re
import requests
from bs4 import BeautifulSoup
from comment import Comment
from difflib import SequenceMatcher
from handlers.AbstractBaseHandler import AbstractBaseHandler, HandlerError
from newspaper import Article
from nltk.util import ngrams
import codecs
class STHandler(AbstractBaseHandler):
soup = None
url = None
title = None
MAX_DAYS_OFFSET = 2
MAX_CURLS_ALLOWED = 5
MIN_PASSING_SCORE = 0.5
SLEEP_BETWEEN_CURLS = 1
ST_PUBLISH_CUTOFF_HOUR = 5
MODERATED_MAX = 0.8 # we don't want perfect scores overwhelming
@classmethod
def handle(cls, url):
cls.url = url
cls.soup = cls.makeSoup()
return cls.handlePremium() if cls.isPremiumArticle() else cls.handleNonPremium()
@classmethod
def makeSoup(cls):
html = requests.get(cls.url).text
soup = BeautifulSoup(html, "html.parser")
cls.soup = soup
return soup
@classmethod
def isPremiumArticle(cls):
html = requests.get(cls.url).text
elem = cls.soup.find(name="div", class_="paid-premium st-flag-1")
return elem is not None
@classmethod
def handleNonPremium(cls):
article = Article(cls.url)
article.download()
article.parse()
title = article.title
body = article.text
return Comment(title, body)
@classmethod
def handlePremium(cls):
cls.title = cls.soup.find(name="meta", property="og:title")['content']
print(f"article title: {cls.title}")
# An article may run for multiple days or be published a day or two later
for days_offset in range(0, cls.MAX_DAYS_OFFSET):
# Trying to find a scraped article with the closest title/body to the submission
possibleMatchingArticles = cls.generateTodaysArticles(days_offset)
closestArticle = cls.getMatchingArticle(possibleMatchingArticles)
if closestArticle is not None:
return closestArticle
print(f"unable to find a suitable article that matches {cls.title}, skipping submission")
return None
@classmethod
def generateTodaysArticles(cls, days_offset):
articlesList = BeautifulSoup(cls.getArticlesIndex(days_offset), "html.parser")
articles = articlesList.findAll(name="a")
scoredArticles = [( article, cls.similar(article.text, cls.title)) for article in articles]
# sorted such that scoredArticles[0] has the best chance of being the article we want
scoredArticles = sorted(scoredArticles, key=lambda x: x[1], reverse=True)
return scoredArticles
@classmethod
def getMatchingArticle(cls, scoredArticles):
# every article in scoredArticles has a chance of being the article we want
# with scoredArticles[0] being the most likely and the last element being the least
# due to rate limits we cannot check all of the articles
articlesCheckedSoFar = 0
while articlesCheckedSoFar < cls.MAX_CURLS_ALLOWED and len(scoredArticles) > 0:
currArticle = scoredArticles.pop(0)
currComment = cls.makeComment(currArticle[0]['href'])
previewComment = cls.handleNonPremium()
if cls.articleBodiesMatch(previewComment.body, currComment.body):
return currComment
articlesCheckedSoFar = articlesCheckedSoFar + 1
time.sleep(cls.SLEEP_BETWEEN_CURLS)
@classmethod
def articleBodiesMatch(cls, previewBody, articleBody):
# the higher the score, the better confidence that previewBody is a subset of articleBody
score = 0
for sentence in cls.split_into_sentences(previewBody):
|
@classmethod
def makeComment(cls, bestCandidate):
url = f"https://www.pressreader.com{bestCandidate}"
article = Article(url, browser_user_agent = "Googlebot-News", keep_article_html=True)
article.download()
try:
article.parse()
except:
return Comment('','')
title = article.title.replace("\xad", "") # clean the text
body = article.text.replace("\xad", "") # clean the text
print(f"checking the article in this url: {url} with title {title}")
return Comment(title, body)
@classmethod
def getArticlesIndex(cls, days_offset):
publishedDate = cls.getDate(days_offset)
userAgent = "Googlebot-News"
url = f"https://www.pressreader.com/singapore/the-straits-times/{publishedDate}"
headers = { "User-Agent": userAgent }
articlesList = requests.get(url, headers=headers).text
articlesList = articlesList.replace("­", "") # clean the text
return articlesList
@classmethod
def getDate(cls, days_offset):
elem = cls.soup.find(name="meta", property="article:published_time")
rawDateTime = elem['content']
dateTime = dateutil.parser.parse(rawDateTime) + datetime.timedelta(days=days_offset)
# articles published after the cutoff hour will only appear in the next days index
if dateTime.hour > cls.ST_PUBLISH_CUTOFF_HOUR:
dateTime = dateTime + datetime.timedelta(days=1)
return dateTime.strftime('%Y%m%d')
# is candidate title "similar" to title?
# some fuzzy matching is used
# returns 0 <= score <= 1
# higher score is more similar
@classmethod
def similar(cls, candidate, title):
title = title.lower()
candidate = candidate.lower()
articles = ["a", "an", "the"]
pronouns = ["all", "another", "any", "anybody", "anyone", "anything", "as", "aught", "both", "each", "each", "other", "either", "enough", "everybody", "everyone", "everything", "few", "he", "her", "hers", "herself", "him", "himself", "his", "idem", "it", "its", "itself", "many", "me", "mine", "most", "my", "myself", "naught", "neither", "no", "one", "nobody", "none", "nothing", "nought", "one", "one", "another", "other", "others", "ought", "our", "ours", "ourself", "ourselves", "several", "she", "some", "somebody", "someone", "something", "somewhat", "such", "suchlike", "that", "thee", "their", "theirs", "theirself", "theirselves", "them", "themself", "themselves", "there", "these", "they", "thine", "this", "those", "thou", "thy", "thyself", "us", "we", "what", "whatever", "whatnot", "whatsoever", "whence", "where", "whereby", "wherefrom", "wherein", "whereinto", "whereof", "whereon", "wherever", "wheresoever", "whereto", "whereunto", "wherewith", "wherewithal", "whether", "which", "whichever", "whichsoever", "who", "whoever", "whom", "whomever", "whomso", "whomsoever", "whose", "whosever", "whosesoever", "whoso", "whosoever", "ye", "yon", "yonder", "you", "your", "yours", "yourself", "yourselves"]
prepositions = ["of", "with", "at", "from", "into", "during", "including", "until", "against", "among", "throughout", "despite", "towards", "upon", "concerning", "to", "in", "for", "on", "by", "about", "like", "through", "over", "before", "between", "after", "since", "without", "under", "within", "along", "following", "across", "behind", "beyond", "plus", "except", "but", "up", "out", "around", "down", "off", "above", "near"]
conjunctions = ["for", "and", "nor", "but", "or", "yet", "so", "after", "although", "as", "as", "if", "as", "long", "as", "as", "much", "as", "as", "soon", "as", "as", "though", "because", "before", "by", "the", "time", "even", "if", "even", "though", "if", "in", "order", "that", "in", "case", "lest", "once", "only", "if", "provided", "that", "since", "so", "that", "than", "that", "though", "till", "unless", "until", "when", "whenever", "where", "wherever", "while", "both", "and", "either", "or", "neither", "nor", "not", "only", "but", "also", "whether", "or"]
redherrings = ["singapore", "singaporeans", "s'pore", "says", "is", "has", "are", "am", "were", "been", "have", "had", "having"]
blacklist = set(articles + pronouns + prepositions + conjunctions + redherrings)
score = 0
wordsScored = 0
for word in re.compile("[ '.:\;,.!&\"]").split(candidate):
if word in blacklist:
continue
currScore = cls.isNeedleInHay(needle=word, hay=title)
currScore = (currScore - 0.5) * 2 # ranges 0.5-1, so normalise to 0-1
if currScore < 0.5:
continue
wordsScored = wordsScored + 1
score = score + currScore
if wordsScored > 0:
finalScore = (score / wordsScored)
else:
finalScore = 0
return cls.MODERATED_MAX if finalScore == 1 else finalScore
#https://stackoverflow.com/a/31433394
# fuzzily searches for a needle in a haystack and returns the confidence that needle was found
@classmethod
def isNeedleInHay(cls, needle, hay):
needle_length = len(needle.split())
max_sim_val = 0
max_sim_string = u""
for ngram in ngrams(hay.split(), needle_length + int(.2*needle_length)):
hay_ngram = u" ".join(ngram)
similarity = SequenceMatcher(None, hay_ngram, needle).ratio()
if similarity > max_sim_val:
max_sim_val = similarity
max_sim_string = hay_ngram
return max_sim_val # how confident are we that needle was found in hay
#https://stackoverflow.com/a/31505798
# given a string paragraph, return a list of sentences
@classmethod
def split_into_sentences(cls, text):
alphabets= "([A-Za-z])"
prefixes = "(Mr|St|Mrs|Ms|Dr)[.]"
suffixes = "(Inc|Ltd|Jr|Sr|Co)"
starters = "(Mr|Mrs|Ms|Dr|He\s|She\s|It\s|They\s|Their\s|Our\s|We\s|But\s|However\s|That\s|This\s|Wherever)"
acronyms = "([A-Z][.][A-Z][.](?:[A-Z][.])?)"
websites = "[.](com|net|org|io|gov)"
text = " " + text + " "
text = text.replace("\n"," ")
text = re.sub(prefixes,"\\1<prd>",text)
text = re.sub(websites,"<prd>\\1",text)
if "Ph.D" in text: text = text.replace("Ph.D.","Ph<prd>D<prd>")
text = re.sub("\s" + alphabets + "[.] "," \\1<prd> ",text)
text = re.sub(acronyms+" "+starters,"\\1<stop> \\2",text)
text = re.sub(alphabets + "[.]" + alphabets + "[.]" + alphabets + "[.]","\\1<prd>\\2<prd>\\3<prd>",text)
text = re.sub(alphabets + "[.]" + alphabets + "[.]","\\1<prd>\\2<prd>",text)
text = re.sub(" "+suffixes+"[.] "+starters," \\1<stop> \\2",text)
text = re.sub(" "+suffixes+"[.]"," \\1<prd>",text)
text = re.sub(" " + alphabets + "[.]"," \\1<prd>",text)
if "”" in text: text = text.replace(".”","”.")
if "\"" in text: text = text.replace(".\"","\".")
if "!" in text: text = text.replace("!\"","\"!")
if "?" in text: text = text.replace("?\"","\"?")
text = text.replace(".",".<stop>")
text = text.replace("?","?<stop>")
text = text.replace("!","!<stop>")
text = text.replace("<prd>",".")
sentences = text.split("<stop>")
sentences = sentences[:-1]
sentences = [s.strip() for s in sentences]
return sentences
|
weight = len(sentence) / float(len(previewBody)) #longer sentences carry more weight
score = score + cls.isNeedleInHay(needle=sentence, hay=articleBody) * weight
return score > cls.MIN_PASSING_SCORE
|
tab1_mapview.py
|
from dash import Input, Output, callback, html, dcc, State
import dash_bootstrap_components as dbc
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.io as pio
import plotly.graph_objects as go
from urllib.request import urlopen
import json
df_all = pd.read_csv(
"data/Primary-energy-consumption-from-fossilfuels-nuclear-renewables.csv"
)
df_notna_wide = df_all[df_all["Code"].notna()]
df_notna = df_notna_wide.melt(
id_vars=["Entity", "Code", "Year"],
value_vars=["Fossil", "Renewables", "Nuclear"],
var_name="energy_type",
value_name="percentage",
).merge(df_notna_wide, on=["Year", "Code", "Entity"])
df_countries = df_notna[df_notna["Code"] != "OWID_WRL"]
df_world = df_notna[df_notna["Code"] == "OWID_WRL"]
df_continents = df_all[df_all["Code"].isna()]
list_of_continents = df_continents["Entity"].unique()
list_of_countries = df_countries["Entity"].unique()
list_yrs = df_all["Year"].unique()
proj_param = {
"World": [0, 0, 1],
"North America": [40, -120, 2],
"Europe": [50, 20, 4],
"Africa": [0, 20, 2],
}
# ==============================================================================
# Layout for map and barchart
# ==============================================================================
tab1_plots = dbc.Col(
[
dbc.Row(
[
html.H4("World Consumption by Country", style={"width": "fit-content"}),
dbc.Col(
[
dbc.Button(
id="map_tooltip",
color="secondary",
children="?",
size="sm",
outline=True,
),
dbc.Tooltip(
"Drag and select the number of year to view the change of engergy consumption distribution using the slide bar. You can hover or zoom to get the details of a specific region.",
target="map_tooltip",
placement="bottom",
),
]
),
],
style={"padding": "3vh 0"},
),
dcc.Graph(id="tab1-map"),
html.Div(
dcc.Slider(
id="tab1-year-slider",
min=list_yrs.min(),
max=list_yrs.max(),
step=1,
value=list_yrs.max(),
marks={
int(i): str(i) for i in np.append(list_yrs[::5], [list_yrs.max()])
},
tooltip={"placement": "top", "always_visible": True},
updatemode="drag",
),
style={"padding": "0vh 10vw"},
),
html.Br(),
dbc.Row(
[
html.H4(
"Top/Bottom energy consumer nations", style={"width": "fit-content"}
),
dbc.Col(
[
dbc.Button(
id="bar_tooltip",
color="secondary",
children="?",
size="sm",
outline=True,
),
dbc.Tooltip(
"Select the number of countries to view in the bar plot using the input tab,"
"then select whether to view to the top or bottom consumers."
"Hover the bar for details.",
target="bar_tooltip",
placement="bottom",
),
],
style={"padding": "0 0"},
),
]
),
html.Br(),
dbc.Row(
[
dbc.Col(
[
dbc.Row(
[
html.H4(
"Number of countries",
style={"font-size": "20px", "width": "fit-content"},
),
dbc.Col(
[
dbc.Button(
id="topN_tooltip",
color="secondary",
children="?",
size="sm",
outline=True,
),
dbc.Tooltip(
"Controls the number of countries to view in the barchart. Select upto 15 countries",
target="topN_tooltip",
placement="bottom",
),
],
style={"padding": "0 0"},
),
]
),
html.Br(),
dbc.Input(
id="tab1-input-topN",
value=10,
type="number",
debounce=True,
required=True,
minlength=1,
max=15,
min=0,
),
]
),
dbc.Col(
[
dbc.Row(
[
html.H4(
"Ranking type",
style={"font-size": "20px", "width": "fit-content"},
),
dbc.Col(
[
dbc.Button(
id="top_bot_tooltip",
color="secondary",
children="?",
size="sm",
outline=True,
),
dbc.Tooltip(
"Select whether you want to view the top or bottom consumers",
target="top_bot_tooltip",
placement="bottom",
),
],
style={"padding": "0 0"},
),
]
),
html.Br(),
dcc.RadioItems(
["Top", "Bottom"],
value="Top",
id="tab1_top_bot",
inline=True,
labelStyle={
"margin-right": "10px",
"margin-top": "1px",
"display": "inline-block",
"horizontal-align": "",
},
),
],
style={
"padding": "0 0",
},
),
]
),
html.Br(),
dcc.Graph(id="tab1-barchart"),
]
)
# ==============================================================================
# World Map
# ==============================================================================
@callback(
Output("tab1-map", "figure"),
Input("tab1-energy-type-dropdown", "value"),
Input("tab1-year-slider", "value"),
Input("tab1-map-focus", "value"),
)
def display_map(energy_type, year, scope):
"""
Docs
"""
# scope = "Africa"
df = df_notna.query("Year==@year & energy_type==@energy_type")
fig = px.choropleth(
df,
locations="Code",
color="percentage",
hover_name="Entity",
hover_data={
"Year": True,
"Fossil": True,
"Nuclear": True,
"Renewables": True,
"percentage": False,
"Code": False,
},
color_continuous_scale=px.colors.sequential.YlGn,
range_color=[0, 100],
)
fig.update_layout(
dragmode="zoom",
margin={"r": 0, "t": 0, "l": 0, "b": 0},
title={
"text": "Global "
+ str(energy_type)
+ " Energy Consumption in "
+ str(year),
"x": 0.5,
"xanchor": "center",
},
)
fig.update_geos(
showcountries=True,
center={"lat": proj_param[scope][0], "lon": proj_param[scope][1]},
projection={"scale": proj_param[scope][2]},
)
return fig
# ==============================================================================
# Top N countries barchart
# ==============================================================================
@callback(
Output("tab1-barchart", "figure"),
Input("tab1-energy-type-dropdown", "value"),
Input("tab1-year-slider", "value"),
Input("tab1-input-topN", "value"),
Input("tab1_top_bot", "value"),
)
def
|
(energy_type, year, topN, top_bot):
"""
Docs
"""
if top_bot == "Top":
df_sorted = df_countries.query(
"Year==@year & energy_type==@energy_type"
).sort_values(["percentage"], ascending=False)[:topN]
elif top_bot == "Bottom":
df_sorted = df_countries.query(
"Year==@year & energy_type==@energy_type"
).sort_values(["percentage"], ascending=False)[-topN:]
fig_bar = px.bar(
df_sorted,
x="percentage",
y="Entity",
color="percentage",
# title="Bar Graph",
hover_name="Entity",
hover_data={
"Year": True,
"Fossil": True,
"Nuclear": True,
"Renewables": True,
"percentage": False,
"Entity": False,
},
range_color=[0, 100],
color_continuous_scale=px.colors.sequential.YlGn,
range_x=[0, 105],
text_auto=True,
)
fig_bar.update_layout(
xaxis_title="Percentage %",
yaxis_title="Country",
legend_title="%",
)
fig_bar.update_coloraxes(showscale=False)
fig_bar.update_traces(textposition="outside")
if top_bot == "Top":
fig_bar.update_layout(
yaxis={"categoryorder": "total ascending"},
title={
"text": "Top "
+ str(topN)
+ " "
+ str(energy_type)
+ " Energy Consumers in "
+ str(year),
"x": 0.5,
"xanchor": "center",
},
)
elif top_bot == "Bottom":
fig_bar.update_layout(
# yaxis={"categoryorder": "total descending"},
title={
"text": "Bottom "
+ str(topN)
+ " "
+ str(energy_type)
+ " Energy Consumers in "
+ str(year),
"x": 0.5,
"xanchor": "center",
},
)
return fig_bar
|
display_barchart
|
restage.py
|
# Copyright 2013-2020 Lawrence Livermore National Security, LLC and other
# Spack Project Developers. See the top-level COPYRIGHT file for details.
#
# SPDX-License-Identifier: (Apache-2.0 OR MIT)
import argparse
import llnl.util.tty as tty
import spack.cmd
import spack.repo
description = "revert checked out package source code"
section = "build"
level = "long"
def setup_parser(subparser):
subparser.add_argument('packages', nargs=argparse.REMAINDER,
help="specs of packages to restage")
|
def restage(parser, args):
if not args.packages:
tty.die("spack restage requires at least one package spec.")
specs = spack.cmd.parse_specs(args.packages, concretize=True)
for spec in specs:
package = spack.repo.get(spec)
package.do_restage()
| |
svt.py
|
# coding: utf-8
from __future__ import unicode_literals
import re
from .common import InfoExtractor
from ..compat import (
compat_parse_qs,
compat_urllib_parse_urlparse,
)
from ..utils import (
determine_ext,
dict_get,
int_or_none,
try_get,
urljoin,
compat_str,
)
class SVTBaseIE(InfoExtractor):
_GEO_COUNTRIES = ['SE']
def _extract_video(self, video_info, video_id):
is_live = dict_get(video_info, ('live', 'simulcast'), default=False)
m3u8_protocol = 'm3u8' if is_live else 'm3u8_native'
formats = []
for vr in video_info['videoReferences']:
player_type = vr.get('playerType') or vr.get('format')
vurl = vr['url']
ext = determine_ext(vurl)
if ext == 'm3u8':
formats.extend(self._extract_m3u8_formats(
vurl, video_id,
ext='mp4', entry_protocol=m3u8_protocol,
m3u8_id=player_type, fatal=False))
elif ext == 'f4m':
formats.extend(self._extract_f4m_formats(
vurl + '?hdcore=3.3.0', video_id,
f4m_id=player_type, fatal=False))
elif ext == 'mpd':
if player_type == 'dashhbbtv':
formats.extend(self._extract_mpd_formats(
vurl, video_id, mpd_id=player_type, fatal=False))
else:
formats.append({
'format_id': player_type,
'url': vurl,
})
if not formats and video_info.get('rights', {}).get('geoBlockedSweden'):
self.raise_geo_restricted(
'This video is only available in Sweden',
countries=self._GEO_COUNTRIES)
self._sort_formats(formats)
subtitles = {}
subtitle_references = dict_get(video_info, ('subtitles', 'subtitleReferences'))
if isinstance(subtitle_references, list):
for sr in subtitle_references:
subtitle_url = sr.get('url')
subtitle_lang = sr.get('language', 'sv')
if subtitle_url:
if determine_ext(subtitle_url) == 'm3u8':
# TODO(yan12125): handle WebVTT in m3u8 manifests
continue
subtitles.setdefault(subtitle_lang, []).append({'url': subtitle_url})
title = video_info.get('title')
series = video_info.get('programTitle')
season_number = int_or_none(video_info.get('season'))
episode = video_info.get('episodeTitle')
episode_number = int_or_none(video_info.get('episodeNumber'))
duration = int_or_none(dict_get(video_info, ('materialLength', 'contentDuration')))
age_limit = None
adult = dict_get(
video_info, ('inappropriateForChildren', 'blockedForChildren'),
skip_false_values=False)
if adult is not None:
age_limit = 18 if adult else 0
return {
'id': video_id,
'title': title,
'formats': formats,
'subtitles': subtitles,
'duration': duration,
'age_limit': age_limit,
'series': series,
'season_number': season_number,
'episode': episode,
'episode_number': episode_number,
'is_live': is_live,
}
class SVTIE(SVTBaseIE):
_VALID_URL = r'https?://(?:www\.)?svt\.se/wd\?(?:.*?&)?widgetId=(?P<widget_id>\d+)&.*?\barticleId=(?P<id>\d+)'
_TEST = {
'url': 'http://www.svt.se/wd?widgetId=23991§ionId=541&articleId=2900353&type=embed&contextSectionId=123&autostart=false',
'md5': '33e9a5d8f646523ce0868ecfb0eed77d',
'info_dict': {
'id': '2900353',
'ext': 'mp4',
'title': 'Stjärnorna skojar till det - under SVT-intervjun',
'duration': 27,
'age_limit': 0,
},
}
@staticmethod
def _extract_url(webpage):
mobj = re.search(
r'(?:<iframe src|href)="(?P<url>%s[^"]*)"' % SVTIE._VALID_URL, webpage)
if mobj:
return mobj.group('url')
def _real_extract(self, url):
mobj = re.match(self._VALID_URL, url)
widget_id = mobj.group('widget_id')
article_id = mobj.group('id')
info = self._download_json(
'http://www.svt.se/wd?widgetId=%s&articleId=%s&format=json&type=embed&output=json' % (widget_id, article_id),
article_id)
info_dict = self._extract_video(info['video'], article_id)
info_dict['title'] = info['context']['title']
return info_dict
class SVTPlayBaseIE(SVTBaseIE):
_SVTPLAY_RE = r'root\s*\[\s*(["\'])_*svtplay\1\s*\]\s*=\s*(?P<json>{.+?})\s*;\s*\n'
class S
|
SVTPlayBaseIE):
IE_DESC = 'SVT Play and Öppet arkiv'
_VALID_URL = r'https?://(?:www\.)?(?:svtplay|oppetarkiv)\.se/(?:video|klipp|kanaler)/(?P<id>[^/?#&]+)'
_TESTS = [{
'url': 'http://www.svtplay.se/video/5996901/flygplan-till-haile-selassie/flygplan-till-haile-selassie-2',
'md5': '2b6704fe4a28801e1a098bbf3c5ac611',
'info_dict': {
'id': '5996901',
'ext': 'mp4',
'title': 'Flygplan till Haile Selassie',
'duration': 3527,
'thumbnail': r're:^https?://.*[\.-]jpg$',
'age_limit': 0,
'subtitles': {
'sv': [{
'ext': 'wsrt',
}]
},
},
}, {
# geo restricted to Sweden
'url': 'http://www.oppetarkiv.se/video/5219710/trollflojten',
'only_matching': True,
}, {
'url': 'http://www.svtplay.se/klipp/9023742/stopptid-om-bjorn-borg',
'only_matching': True,
}, {
'url': 'https://www.svtplay.se/kanaler/svt1',
'only_matching': True,
}]
def _real_extract(self, url):
video_id = self._match_id(url)
webpage = self._download_webpage(url, video_id)
data = self._parse_json(
self._search_regex(
self._SVTPLAY_RE, webpage, 'embedded data', default='{}',
group='json'),
video_id, fatal=False)
thumbnail = self._og_search_thumbnail(webpage)
def adjust_title(info):
if info['is_live']:
info['title'] = self._live_title(info['title'])
if data:
video_info = try_get(
data, lambda x: x['context']['dispatcher']['stores']['VideoTitlePageStore']['data']['video'],
dict)
if video_info:
info_dict = self._extract_video(video_info, video_id)
info_dict.update({
'title': data['context']['dispatcher']['stores']['MetaStore']['title'],
'thumbnail': thumbnail,
})
adjust_title(info_dict)
return info_dict
video_id = self._search_regex(
r'<video[^>]+data-video-id=["\']([\da-zA-Z-]+)',
webpage, 'video id', default=None)
if video_id:
data = self._download_json(
'https://api.svt.se/videoplayer-api/video/%s' % video_id,
video_id, headers=self.geo_verification_headers())
info_dict = self._extract_video(data, video_id)
if not info_dict.get('title'):
info_dict['title'] = re.sub(
r'\s*\|\s*.+?$', '',
info_dict.get('episode') or self._og_search_title(webpage))
adjust_title(info_dict)
return info_dict
class SVTSeriesIE(SVTPlayBaseIE):
_VALID_URL = r'https?://(?:www\.)?svtplay\.se/(?P<id>[^/?&#]+)'
_TESTS = [{
'url': 'https://www.svtplay.se/rederiet',
'info_dict': {
'id': 'rederiet',
'title': 'Rederiet',
'description': 'md5:505d491a58f4fcf6eb418ecab947e69e',
},
'playlist_mincount': 318,
}, {
'url': 'https://www.svtplay.se/rederiet?tab=sasong2',
'info_dict': {
'id': 'rederiet-sasong2',
'title': 'Rederiet - Säsong 2',
'description': 'md5:505d491a58f4fcf6eb418ecab947e69e',
},
'playlist_count': 12,
}]
@classmethod
def suitable(cls, url):
return False if SVTIE.suitable(url) or SVTPlayIE.suitable(url) else super(SVTSeriesIE, cls).suitable(url)
def _real_extract(self, url):
series_id = self._match_id(url)
qs = compat_parse_qs(compat_urllib_parse_urlparse(url).query)
season_slug = qs.get('tab', [None])[0]
if season_slug:
series_id += '-%s' % season_slug
webpage = self._download_webpage(
url, series_id, 'Downloading series page')
root = self._parse_json(
self._search_regex(
self._SVTPLAY_RE, webpage, 'content', group='json'),
series_id)
season_name = None
entries = []
for season in root['relatedVideoContent']['relatedVideosAccordion']:
if not isinstance(season, dict):
continue
if season_slug:
if season.get('slug') != season_slug:
continue
season_name = season.get('name')
videos = season.get('videos')
if not isinstance(videos, list):
continue
for video in videos:
content_url = video.get('contentUrl')
if not content_url or not isinstance(content_url, compat_str):
continue
entries.append(
self.url_result(
urljoin(url, content_url),
ie=SVTPlayIE.ie_key(),
video_title=video.get('title')
))
metadata = root.get('metaData')
if not isinstance(metadata, dict):
metadata = {}
title = metadata.get('title')
season_name = season_name or season_slug
if title and season_name:
title = '%s - %s' % (title, season_name)
elif season_slug:
title = season_slug
return self.playlist_result(
entries, series_id, title, metadata.get('description'))
|
VTPlayIE(
|
Layout.js
|
import { useRouter } from 'next/router';
import { Helmet } from 'react-helmet';
import styles from './Layout.module.scss';
import useSite from 'hooks/use-site';
import { helmetSettingsFromMetadata } from 'lib/site';
import Nav from 'components/Nav';
import Main from 'components/Main';
import Footer from 'components/Footer';
import Image from 'next/image';
import hero from 'public/AD-hero.jpg';
const Layout = ({ children }) => {
const router = useRouter();
const { asPath } = router;
|
}
metadata.og.url = `${homepage}${asPath}`;
const helmetSettings = {
defaultTitle: metadata.title,
titleTemplate: process.env.WORDPRESS_PLUGIN_SEO === true ? '%s' : `%s - ${metadata.title}`,
...helmetSettingsFromMetadata(metadata, {
setTitle: false,
link: [
{
rel: 'alternate',
type: 'application/rss+xml',
href: '/feed.xml',
},
// Favicon sizes and manifest generated via https://favicon.io/
{
rel: 'apple-touch-icon',
sizes: '180x180',
href: '/apple-touch-icon.png',
},
{
rel: 'icon',
type: 'image/png',
sizes: '16x16',
href: '/favicon-16x16.png',
},
{
rel: 'icon',
type: 'image/png',
sizes: '32x32',
href: '/favicon-32x32.png',
},
{
rel: 'manifest',
href: '/site.webmanifest',
},
],
}),
};
return (
<>
<div className={styles.layoutContainer}>
<Image src={hero} layout="fill" objectFit="cover" />
<Helmet {...helmetSettings} />
<Nav />
<Main>{children}</Main>
</div>
<div>
<Footer />
</div>
</>
);
};
export default Layout;
|
const { homepage, metadata = {} } = useSite();
if (!metadata.og) {
metadata.og = {};
|
setup.rs
|
use crate::{
cli::{CliArgs, Command},
consts::{
FEATURES, SYSTEM_DEFAULT_CONFIG_DIR, SYSTEM_DEFAULT_DATA_DIR_PREFIX, VERSION,
ZELLIJ_PROJ_DIR,
},
input::{
config::{Config, ConfigError},
layout::{LayoutFromYaml, LayoutFromYamlIntermediate},
options::Options,
},
};
use clap::{Args, IntoApp};
use clap_complete::Shell;
use directories_next::BaseDirs;
use serde::{Deserialize, Serialize};
use std::{
convert::TryFrom, fmt::Write as FmtWrite, io::Write, path::Path, path::PathBuf, process,
};
const CONFIG_LOCATION: &str = ".config/zellij";
const CONFIG_NAME: &str = "config.yaml";
static ARROW_SEPARATOR: &str = "";
#[cfg(not(test))]
/// Goes through a predefined list and checks for an already
/// existing config directory, returns the first match
pub fn find_default_config_dir() -> Option<PathBuf> {
default_config_dirs()
.into_iter()
.filter(|p| p.is_some())
.find(|p| p.clone().unwrap().exists())
.flatten()
}
#[cfg(test)]
pub fn find_default_config_dir() -> Option<PathBuf> {
None
}
/// Order in which config directories are checked
fn default_config_dirs() -> Vec<Option<PathBuf>> {
vec![
home_config_dir(),
Some(xdg_config_dir()),
Some(Path::new(SYSTEM_DEFAULT_CONFIG_DIR).to_path_buf()),
]
}
/// Looks for an existing dir, uses that, else returns a
/// dir matching the config spec.
pub fn get_default_data_dir() -> PathBuf {
[
xdg_data_dir(),
Path::new(SYSTEM_DEFAULT_DATA_DIR_PREFIX).join("share/zellij"),
]
.into_iter()
.find(|p| p.exists())
.unwrap_or_else(xdg_data_dir)
}
pub fn xdg_config_dir() -> PathBuf {
ZELLIJ_PROJ_DIR.config_dir().to_owned()
}
pub fn xdg_data_dir() -> PathBuf {
ZELLIJ_PROJ_DIR.data_dir().to_owned()
}
pub fn home_config_dir() -> Option<PathBuf> {
if let Some(user_dirs) = BaseDirs::new() {
let config_dir = user_dirs.home_dir().join(CONFIG_LOCATION);
Some(config_dir)
} else {
None
}
}
pub fn get_layout_dir(config_dir: Option<PathBuf>) -> Option<PathBuf> {
config_dir.map(|dir| dir.join("layouts"))
}
pub fn dump_asset(asset: &[u8]) -> std::io::Result<()> {
std::io::stdout().write_all(asset)?;
Ok(())
}
pub const DEFAULT_CONFIG: &[u8] = include_bytes!(concat!(
env!("CARGO_MANIFEST_DIR"),
"/",
"assets/config/default.yaml"
));
pub const DEFAULT_LAYOUT: &[u8] = include_bytes!(concat!(
env!("CARGO_MANIFEST_DIR"),
"/",
"assets/layouts/default.yaml"
));
pub const STRIDER_LAYOUT: &[u8] = include_bytes!(concat!(
env!("CARGO_MANIFEST_DIR"),
"/",
"assets/layouts/strider.yaml"
));
pub const NO_STATUS_LAYOUT: &[u8] = include_bytes!(concat!(
env!("CARGO_MANIFEST_DIR"),
"/",
"assets/layouts/disable-status-bar.yaml"
));
pub const FISH_EXTRA_COMPLETION: &[u8] = include_bytes!(concat!(
env!("CARGO_MANIFEST_DIR"),
"/",
"assets/completions/comp.fish"
));
pub const BASH_AUTO_START_SCRIPT: &[u8] = include_bytes!(concat!(
env!("CARGO_MANIFEST_DIR"),
"/",
"assets/shell/auto-start.bash"
));
pub const FISH_AUTO_START_SCRIPT: &[u8] = include_bytes!(concat!(
env!("CARGO_MANIFEST_DIR"),
"/",
"assets/shell/auto-start.fish"
));
pub const ZSH_AUTO_START_SCRIPT: &[u8] = include_bytes!(concat!(
env!("CARGO_MANIFEST_DIR"),
"/",
"assets/shell/auto-start.zsh"
));
pub fn dump_default_config() -> std::io::Result<()> {
dump_asset(DEFAULT_CONFIG)
}
pub fn dump_specified_layout(layout: &str) -> std::io::Result<()> {
match layout {
"strider" => dump_asset(STRIDER_LAYOUT),
"default" => dump_asset(DEFAULT_LAYOUT),
"disable-status" => dump_asset(NO_STATUS_LAYOUT),
not_found => Err(std::io::Error::new(
std::io::ErrorKind::Other,
format!("Layout: {} not found", not_found),
)),
}
}
#[derive(Debug, Default, Clone, Args, Serialize, Deserialize)]
pub struct Setup {
/// Dump the default configuration file to stdout
#[clap(long)]
pub dump_config: bool,
/// Disables loading of configuration file at default location,
/// loads the defaults that zellij ships with
#[clap(long)]
pub clean: bool,
/// Checks the configuration of zellij and displays
/// currently used directories
#[clap(long)]
pub check: bool,
/// Dump the specified layout file to stdout
#[clap(long)]
pub dump_layout: Option<String>,
/// Generates completion for the specified shell
#[clap(long, value_name = "SHELL")]
pub generate_completion: Option<String>,
/// Generates auto-start script for the specified shell
#[clap(long, value_name = "SHELL")]
pub generate_auto_start: Option<String>,
}
impl Setup {
/// Entrypoint from main
/// Merges options from the config file and the command line options
/// into `[Options]`, the command line options superceeding the layout
/// file options, superceeding the config file options:
/// 1. command line options (`zellij options`)
/// 2. layout options
/// (`layout.yaml` / `zellij --layout` / `zellij --layout-path`)
/// 3. config options (`config.yaml`)
pub fn from_options(
opts: &CliArgs,
) -> Result<(Config, Option<LayoutFromYaml>, Options), ConfigError> {
let clean = match &opts.command {
Some(Command::Setup(ref setup)) => setup.clean,
_ => false,
};
// setup functions that don't require deserialisation of the config
if let Some(Command::Setup(ref setup)) = &opts.command {
setup.from_cli().map_or_else(
|e| {
eprintln!("{:?}", e);
process::exit(1);
},
|_| {},
);
};
let config = if !clean {
match Config::try_from(opts) {
Ok(config) => config,
Err(e) => {
return Err(e);
}
}
} else {
Config::default()
};
let config_options = Options::from_cli(&config.options, opts.command.clone());
let layout_dir = config_options
.layout_dir
.clone()
.or_else(|| get_layout_dir(opts.config_dir.clone().or_else(find_default_config_dir)));
let layout_result = LayoutFromYamlIntermediate::from_path_or_default(
opts.layout.as_ref(),
opts.layout_path.as_ref(),
layout_dir,
);
let layout = match layout_result {
None => None,
Some(Ok(layout)) => Some(layout),
Some(Err(e)) => {
return Err(e);
}
};
if let Some(Command::Setup(ref setup)) = &opts.command {
setup
.from_cli_with_options(opts, &config_options)
.map_or_else(
|e| {
|
|_| {},
);
};
Setup::merge_config_with_layout(config, layout, config_options)
}
/// General setup helpers
pub fn from_cli(&self) -> std::io::Result<()> {
if self.clean {
return Ok(());
}
if self.dump_config {
dump_default_config()?;
std::process::exit(0);
}
if let Some(shell) = &self.generate_completion {
Self::generate_completion(shell);
std::process::exit(0);
}
if let Some(shell) = &self.generate_auto_start {
Self::generate_auto_start(shell);
std::process::exit(0);
}
if let Some(layout) = &self.dump_layout {
dump_specified_layout(layout)?;
std::process::exit(0);
}
Ok(())
}
/// Checks the merged configuration
pub fn from_cli_with_options(
&self,
opts: &CliArgs,
config_options: &Options,
) -> std::io::Result<()> {
if self.check {
Setup::check_defaults_config(opts, config_options)?;
std::process::exit(0);
}
Ok(())
}
fn merge_config_with_layout(
config: Config,
layout: Option<LayoutFromYamlIntermediate>,
config_options: Options,
) -> Result<(Config, Option<LayoutFromYaml>, Options), ConfigError> {
let (layout, layout_config) = match layout.map(|l| l.to_layout_and_config()) {
None => (None, None),
Some((layout, layout_config)) => (Some(layout), layout_config),
};
let (config, config_options) = if let Some(layout_config) = layout_config {
let config_options = if let Some(options) = layout_config.options.clone() {
config_options.merge(options)
} else {
config_options
};
let config = config.merge(layout_config.try_into()?);
(config, config_options)
} else {
(config, config_options)
};
Ok((config, layout, config_options))
}
pub fn check_defaults_config(opts: &CliArgs, config_options: &Options) -> std::io::Result<()> {
let data_dir = opts.data_dir.clone().unwrap_or_else(get_default_data_dir);
let config_dir = opts.config_dir.clone().or_else(find_default_config_dir);
let plugin_dir = data_dir.join("plugins");
let layout_dir = config_options
.layout_dir
.clone()
.or_else(|| get_layout_dir(config_dir.clone()));
let system_data_dir = PathBuf::from(SYSTEM_DEFAULT_DATA_DIR_PREFIX).join("share/zellij");
let config_file = opts
.config
.clone()
.or_else(|| config_dir.clone().map(|p| p.join(CONFIG_NAME)));
// according to
// https://gist.github.com/egmontkob/eb114294efbcd5adb1944c9f3cb5feda
let hyperlink_start = "\u{1b}]8;;";
let hyperlink_mid = "\u{1b}\\";
let hyperlink_end = "\u{1b}]8;;\u{1b}\\";
let mut message = String::new();
writeln!(&mut message, "[Version]: {:?}", VERSION).unwrap();
if let Some(config_dir) = config_dir {
writeln!(&mut message, "[CONFIG DIR]: {:?}", config_dir).unwrap();
} else {
message.push_str("[CONFIG DIR]: Not Found\n");
let mut default_config_dirs = default_config_dirs()
.iter()
.filter_map(|p| p.clone())
.collect::<Vec<PathBuf>>();
default_config_dirs.dedup();
message.push_str(
" On your system zellij looks in the following config directories by default:\n",
);
for dir in default_config_dirs {
writeln!(&mut message, " {:?}", dir).unwrap();
}
}
if let Some(config_file) = config_file {
writeln!(&mut message, "[CONFIG FILE]: {:?}", config_file).unwrap();
match Config::new(&config_file) {
Ok(_) => message.push_str("[CONFIG FILE]: Well defined.\n"),
Err(e) => writeln!(&mut message, "[CONFIG ERROR]: {}", e).unwrap(),
}
} else {
message.push_str("[CONFIG FILE]: Not Found\n");
writeln!(
&mut message,
" By default zellij looks for a file called [{}] in the configuration directory",
CONFIG_NAME
)
.unwrap();
}
writeln!(&mut message, "[DATA DIR]: {:?}", data_dir).unwrap();
message.push_str(&format!("[PLUGIN DIR]: {:?}\n", plugin_dir));
if let Some(layout_dir) = layout_dir {
writeln!(&mut message, "[LAYOUT DIR]: {:?}", layout_dir).unwrap();
} else {
message.push_str("[LAYOUT DIR]: Not Found\n");
}
writeln!(&mut message, "[SYSTEM DATA DIR]: {:?}", system_data_dir).unwrap();
writeln!(&mut message, "[ARROW SEPARATOR]: {}", ARROW_SEPARATOR).unwrap();
message.push_str(" Is the [ARROW_SEPARATOR] displayed correctly?\n");
message.push_str(" If not you may want to either start zellij with a compatible mode: 'zellij options --simplified-ui true'\n");
let mut hyperlink_compat = String::new();
hyperlink_compat.push_str(hyperlink_start);
hyperlink_compat.push_str("https://zellij.dev/documentation/compatibility.html#the-status-bar-fonts-dont-render-correctly");
hyperlink_compat.push_str(hyperlink_mid);
hyperlink_compat.push_str("https://zellij.dev/documentation/compatibility.html#the-status-bar-fonts-dont-render-correctly");
hyperlink_compat.push_str(hyperlink_end);
write!(
&mut message,
" Or check the font that is in use:\n {}\n",
hyperlink_compat
)
.unwrap();
message.push_str("[MOUSE INTERACTION]: \n");
message.push_str(" Can be temporarily disabled through pressing the [SHIFT] key.\n");
message.push_str(" If that doesn't fix any issues consider to disable the mouse handling of zellij: 'zellij options --disable-mouse-mode'\n");
writeln!(&mut message, "[FEATURES]: {:?}", FEATURES).unwrap();
let mut hyperlink = String::new();
hyperlink.push_str(hyperlink_start);
hyperlink.push_str("https://www.zellij.dev/documentation/");
hyperlink.push_str(hyperlink_mid);
hyperlink.push_str("zellij.dev/documentation");
hyperlink.push_str(hyperlink_end);
writeln!(&mut message, "[DOCUMENTATION]: {}", hyperlink).unwrap();
//printf '\e]8;;http://example.com\e\\This is a link\e]8;;\e\\\n'
std::io::stdout().write_all(message.as_bytes())?;
Ok(())
}
fn generate_completion(shell: &str) {
let shell: Shell = match shell.to_lowercase().parse() {
Ok(shell) => shell,
_ => {
eprintln!("Unsupported shell: {}", shell);
std::process::exit(1);
}
};
let mut out = std::io::stdout();
clap_complete::generate(shell, &mut CliArgs::command(), "zellij", &mut out);
// add shell dependent extra completion
match shell {
Shell::Bash => {}
Shell::Elvish => {}
Shell::Fish => {
let _ = out.write_all(FISH_EXTRA_COMPLETION);
}
Shell::PowerShell => {}
Shell::Zsh => {}
_ => {}
};
}
fn generate_auto_start(shell: &str) {
let shell: Shell = match shell.to_lowercase().parse() {
Ok(shell) => shell,
_ => {
eprintln!("Unsupported shell: {}", shell);
std::process::exit(1);
}
};
let mut out = std::io::stdout();
match shell {
Shell::Bash => {
let _ = out.write_all(BASH_AUTO_START_SCRIPT);
}
Shell::Fish => {
let _ = out.write_all(FISH_AUTO_START_SCRIPT);
}
Shell::Zsh => {
let _ = out.write_all(ZSH_AUTO_START_SCRIPT);
}
_ => {}
}
}
}
#[cfg(test)]
mod setup_test {
use super::Setup;
use crate::input::{
config::{Config, ConfigError},
layout::LayoutFromYamlIntermediate,
options::Options,
};
fn deserialise_config_and_layout(
config: &str,
layout: &str,
) -> Result<(Config, LayoutFromYamlIntermediate), ConfigError> {
let config = Config::from_yaml(config)?;
let layout = LayoutFromYamlIntermediate::from_yaml(layout)?;
Ok((config, layout))
}
#[test]
fn empty_config_empty_layout() {
let goal = Config::default();
let config = r"";
let layout = r"";
let config_layout_result = deserialise_config_and_layout(config, layout);
let (config, layout) = config_layout_result.unwrap();
let config_options = Options::default();
let (config, _layout, _config_options) =
Setup::merge_config_with_layout(config, Some(layout), config_options).unwrap();
assert_eq!(config, goal);
}
#[test]
fn config_empty_layout() {
let mut goal = Config::default();
goal.options.default_shell = Some(std::path::PathBuf::from("fish"));
let config = r"---
default_shell: fish";
let layout = r"";
let config_layout_result = deserialise_config_and_layout(config, layout);
let (config, layout) = config_layout_result.unwrap();
let config_options = Options::default();
let (config, _layout, _config_options) =
Setup::merge_config_with_layout(config, Some(layout), config_options).unwrap();
assert_eq!(config, goal);
}
#[test]
fn layout_overwrites_config() {
let mut goal = Config::default();
goal.options.default_shell = Some(std::path::PathBuf::from("bash"));
let config = r"---
default_shell: fish";
let layout = r"---
default_shell: bash";
let config_layout_result = deserialise_config_and_layout(config, layout);
let (config, layout) = config_layout_result.unwrap();
let config_options = Options::default();
let (config, _layout, _config_options) =
Setup::merge_config_with_layout(config, Some(layout), config_options).unwrap();
assert_eq!(config, goal);
}
#[test]
fn empty_config_nonempty_layout() {
let mut goal = Config::default();
goal.options.default_shell = Some(std::path::PathBuf::from("bash"));
let config = r"";
let layout = r"---
default_shell: bash";
let config_layout_result = deserialise_config_and_layout(config, layout);
let (config, layout) = config_layout_result.unwrap();
let config_options = Options::default();
let (config, _layout, _config_options) =
Setup::merge_config_with_layout(config, Some(layout), config_options).unwrap();
assert_eq!(config, goal);
}
#[test]
fn nonempty_config_nonempty_layout() {
let mut goal = Config::default();
goal.options.default_shell = Some(std::path::PathBuf::from("bash"));
goal.options.default_mode = Some(zellij_tile::prelude::InputMode::Locked);
let config = r"---
default_mode: locked";
let layout = r"---
default_shell: bash";
let config_layout_result = deserialise_config_and_layout(config, layout);
let (config, layout) = config_layout_result.unwrap();
let config_options = Options::default();
let (config, _layout, _config_options) =
Setup::merge_config_with_layout(config, Some(layout), config_options).unwrap();
assert_eq!(config, goal);
}
}
|
eprintln!("{:?}", e);
process::exit(1);
},
|
value_utils.py
|
# Lint as: python3
# Copyright 2018, The TensorFlow Federated Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Utilities file for functions with TFF `Value`s as inputs and outputs."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from six.moves import range
from tensorflow_federated.python.common_libs import anonymous_tuple
from tensorflow_federated.python.common_libs import py_typecheck
from tensorflow_federated.python.core.api import computation_types
from tensorflow_federated.python.core.api import placements
from tensorflow_federated.python.core.api import value_base
from tensorflow_federated.python.core.impl import computation_building_blocks
from tensorflow_federated.python.core.impl import intrinsic_defs
from tensorflow_federated.python.core.impl import type_utils
from tensorflow_federated.python.core.impl import value_impl
def zip_two_tuple(input_val, context_stack):
"""Helper function to perform 2-tuple at a time zipping.
Takes 2-tuple of federated values and returns federated 2-tuple of values.
Args:
input_val: 2-tuple TFF `Value` of `NamedTuple` type, whose elements must be
`FederatedTypes` with the same placement.
context_stack: The context stack to use, as in `impl.value_impl.to_value`.
Returns:
TFF `Value` of `FederatedType` with member of 2-tuple `NamedTuple` type.
"""
py_typecheck.check_type(input_val, value_base.Value)
py_typecheck.check_type(input_val.type_signature,
computation_types.NamedTupleType)
py_typecheck.check_type(input_val[0].type_signature,
computation_types.FederatedType)
zip_uris = {
placements.CLIENTS: intrinsic_defs.FEDERATED_ZIP_AT_CLIENTS.uri,
placements.SERVER: intrinsic_defs.FEDERATED_ZIP_AT_SERVER.uri,
}
zip_all_equal = {
placements.CLIENTS: False,
placements.SERVER: True,
}
output_placement = input_val[0].type_signature.placement
if output_placement not in zip_uris:
raise TypeError('The argument must have components placed at SERVER or '
'CLIENTS')
output_all_equal_bit = zip_all_equal[output_placement]
for elem in input_val:
type_utils.check_federated_value_placement(elem, output_placement)
num_elements = len(anonymous_tuple.to_elements(input_val.type_signature))
if num_elements != 2:
raise ValueError('The argument of zip_two_tuple must be a 2-tuple, '
'not an {}-tuple'.format(num_elements))
result_type = computation_types.FederatedType(
[(name, e.member)
for name, e in anonymous_tuple.to_elements(input_val.type_signature)],
output_placement, output_all_equal_bit)
def
|
(x):
return computation_types.FederatedType(x.member, x.placement,
output_all_equal_bit)
adjusted_input_type = computation_types.NamedTupleType([
(k, _adjust_all_equal_bit(v)) if k else _adjust_all_equal_bit(v)
for k, v in anonymous_tuple.to_elements(input_val.type_signature)
])
intrinsic = value_impl.ValueImpl(
computation_building_blocks.Intrinsic(
zip_uris[output_placement],
computation_types.FunctionType(adjusted_input_type, result_type)),
context_stack)
return intrinsic(input_val)
def flatten_first_index(apply_fn, type_to_add, context_stack):
"""Returns a value `(arg -> APPEND(apply_fn(arg[0]), arg[1]))`.
In the above, `APPEND(a,b)` refers to appending element b to tuple a.
Constructs a Value of a TFF functional type that:
1. Takes as argument a 2-element tuple `(x, y)` of TFF type
`[apply_fn.type_signature.parameter, type_to_add]`.
2. Transforms the 1st element `x` of this 2-tuple by applying `apply_fn`,
producing a result `z` that must be a TFF tuple (e.g, as a result of
flattening `x`).
3. Leaves the 2nd element `y` of the argument 2-tuple unchanged.
4. Returns the result of appending the unchanged `y` at the end of the
tuple `z` returned by `apply_fn`.
Args:
apply_fn: TFF `Value` of type_signature `FunctionType`, a function taking
TFF `Value`s to `Value`s of type `NamedTupleType`.
type_to_add: 2-tuple specifying name and TFF type of arg[1]. Name can be
`None` or `string`.
context_stack: The context stack to use, as in `impl.value_impl.to_value`.
Returns:
TFF `Value` of `FunctionType`, taking 2-tuples to N-tuples, which calls
`apply_fn` on the first index of its argument, appends the second
index to the resulting (N-1)-tuple, then returns the N-tuple thus created.
"""
py_typecheck.check_type(apply_fn, value_base.Value)
py_typecheck.check_type(apply_fn.type_signature,
computation_types.FunctionType)
py_typecheck.check_type(apply_fn.type_signature.result,
computation_types.NamedTupleType)
py_typecheck.check_type(type_to_add, tuple)
if len(type_to_add) != 2:
raise ValueError('Please pass a 2-tuple as type_to_add to '
'flatten_first_index, with first index name or None '
'and second index instance of `computation_types.Type` '
'or something convertible to one by '
'`computationtypes.to_type`.')
prev_param_type = apply_fn.type_signature.parameter
inputs = value_impl.to_value(
computation_building_blocks.Reference(
'inputs',
computation_types.NamedTupleType([prev_param_type, type_to_add])),
None, context_stack)
intermediate = apply_fn(inputs[0])
full_type_spec = anonymous_tuple.to_elements(
apply_fn.type_signature.result) + [type_to_add]
named_values = [
(full_type_spec[k][0], intermediate[k]) for k in range(len(intermediate))
] + [(full_type_spec[-1][0], inputs[1])]
new_elements = value_impl.to_value(
anonymous_tuple.AnonymousTuple(named_values),
type_spec=full_type_spec,
context_stack=context_stack)
return value_impl.to_value(
computation_building_blocks.Lambda(
'inputs', inputs.type_signature,
value_impl.ValueImpl.get_comp(new_elements)), None, context_stack)
def get_curried(fn):
"""Returns a curried version of function `fn` that takes a parameter tuple.
For functions `fn` of types <T1,T2,....,Tn> -> U, the result is a function
of the form T1 -> (T2 -> (T3 -> .... (Tn -> U) ... )).
NOTE: No attempt is made at avoiding naming conflicts in cases where `fn`
contains references. The arguments of the curriend function are named `argN`
with `N` starting at 0.
Args:
fn: A value of a functional TFF type.
Returns:
A value that represents the curried form of `fn`.
"""
py_typecheck.check_type(fn, value_base.Value)
py_typecheck.check_type(fn.type_signature, computation_types.FunctionType)
py_typecheck.check_type(fn.type_signature.parameter,
computation_types.NamedTupleType)
param_elements = anonymous_tuple.to_elements(fn.type_signature.parameter)
references = []
for idx, (_, elem_type) in enumerate(param_elements):
references.append(
computation_building_blocks.Reference('arg{}'.format(idx), elem_type))
result = computation_building_blocks.Call(
value_impl.ValueImpl.get_comp(fn),
computation_building_blocks.Tuple(references))
for ref in references[::-1]:
result = computation_building_blocks.Lambda(ref.name, ref.type_signature,
result)
return value_impl.ValueImpl(result,
value_impl.ValueImpl.get_context_stack(fn))
|
_adjust_all_equal_bit
|
processActionProcessors.ts
|
import loop from './utils/loop';
import processActionProcessor from './processActionProcessor';
export default function
|
<T>
( actionsConf:AR_Conf.Actions
, state:T
, processors:AR_Build.ActionProcessors
, actions:AR_Build.Actions
, parentIdentifier:AR_Conf.CapitalizedString
, parentType:AR_Conf.SnakeCasedString
, path:string[]
)
{
loop(actionsConf,(conf,id)=>
processActionProcessor(state,processors,actions,parentIdentifier,parentType,conf,id,path)
)
}
|
processActionProcessors
|
node.js
|
import { isBlock, isVoid, hasVoid, isMeaningfulWhenBlank, hasMeaningfulWhenBlank } from './utilities'
export default function Node (node, options) {
node.isBlock = isBlock(node)
node.isCode = node.nodeName === 'CODE' || node.parentNode.isCode
node.isBlank = isBlank(node)
node.flankingWhitespace = flankingWhitespace(node, options)
return node
}
function isBlank (node) {
return (
!isVoid(node) &&
!isMeaningfulWhenBlank(node) &&
/^\s*$/i.test(node.textContent) &&
!node.textContent.startsWith('\u2003') && // added by wizweishijun, for markdown safe space char
!hasVoid(node) &&
!hasMeaningfulWhenBlank(node)
)
}
function flankingWhitespace (node, options) {
if (node.isBlock || (options.preformattedCode && node.isCode)) {
return { leading: '', trailing: '' }
}
var edges = edgeWhitespace(node.textContent)
// abandon leading ASCII WS if left-flanked by ASCII WS
if (edges.leadingAscii && isFlankedByWhitespace('left', node, options)) {
edges.leading = edges.leadingNonAscii
}
// abandon trailing ASCII WS if right-flanked by ASCII WS
if (edges.trailingAscii && isFlankedByWhitespace('right', node, options)) {
edges.trailing = edges.trailingNonAscii
}
return { leading: edges.leading, trailing: edges.trailing }
}
function edgeWhitespace (string) {
|
var m = string.match(/^(([ \t\r\n]*)(\s*))[\s\S]*?((\s*?)([ \t\r\n]*))$/)
return {
leading: m[1], // whole string for whitespace-only strings
leadingAscii: m[2],
leadingNonAscii: m[3],
trailing: m[4], // empty for whitespace-only strings
trailingNonAscii: m[5],
trailingAscii: m[6]
}
}
function isFlankedByWhitespace (side, node, options) {
var sibling
var regExp
var isFlanked
if (side === 'left') {
sibling = node.previousSibling
regExp = / $/
} else {
sibling = node.nextSibling
regExp = /^ /
}
if (sibling) {
if (sibling.nodeType === 3) {
isFlanked = regExp.test(sibling.nodeValue)
} else if (options.preformattedCode && sibling.nodeName === 'CODE') {
isFlanked = false
} else if (sibling.nodeType === 1 && !isBlock(sibling)) {
isFlanked = regExp.test(sibling.textContent)
}
}
return isFlanked
}
| |
section_0217.rs
|
//! @ Conversely, when \TeX\ is finished on the current level, the former
//! state is restored by calling |pop_nest|. This routine will never be
//! called at the lowest semantic level, nor will it be called unless |head|
//! is a node that should be returned to free memory.
//
// @p procedure pop_nest; {leave a semantic level, re-enter the old}
/// leave a semantic level, re-enter the old
#[allow(unused_variables)]
pub(crate) fn pop_nest(globals: &mut TeXGlobals) {
// begin free_avail(head); decr(nest_ptr); cur_list:=nest[nest_ptr];
free_avail!(globals, head!(globals));
decr!(globals.nest_ptr);
globals.cur_list = globals.nest[globals.nest_ptr];
// end;
}
use crate::section_0004::TeXGlobals;
|
use crate::section_0016::decr;
use crate::section_0121::free_avail;
use crate::section_0213::head;
|
|
extractor.go
|
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package openwhisk
import (
"fmt"
"io/ioutil"
"os"
"strconv"
)
// higherDir will find the highest numeric name a sub directory has
// 0 if no numeric dir names found
func
|
(dir string) int {
files, err := ioutil.ReadDir(dir)
if err != nil {
return 0
}
max := 0
for _, file := range files {
n, err := strconv.Atoi(file.Name())
if err == nil {
if n > max {
max = n
}
}
}
return max
}
// ExtractAction accept a byte array and write it to a file
// it handles zip files extracting the content
// it stores in a new directory under ./action/XXX/suffix where x is incremented every time
// it returns the file if a file or the directory if it was a zip file
func (ap *ActionProxy) ExtractAction(buf *[]byte, suffix string) (string, error) {
if buf == nil || len(*buf) == 0 {
return "", fmt.Errorf("no file")
}
ap.currentDir++
newDir := fmt.Sprintf("%s/%d/%s", ap.baseDir, ap.currentDir, suffix)
os.MkdirAll(newDir, 0755)
file := newDir + "/exec"
if IsZip(*buf) {
Debug("Extract Action, assuming a zip")
return file, Unzip(*buf, newDir)
}
return file, ioutil.WriteFile(file, *buf, 0755)
}
|
highestDir
|
addresses.py
|
import os
from typing import Optional
from fastapi import APIRouter
from fastapi import HTTPException
from fastapi import Request
from management.models.addresses import Addresses
from management.utils import user_is_admin
from management.utils import user_logged
from pydantic import BaseModel
router = APIRouter()
class Address(BaseModel):
hotel_id: Optional[int] = 1
number: str
street: str
town: str
postal_code: int
@router.get("/addresses/all/", tags=["addresses"])
async def get_all_addresses():
|
"""Get all addresses"""
addresses = Addresses().get_all_addresses()
return {"addresses": addresses}
@router.get("/addresses/{address_id}", tags=["addresses"])
async def get_address_by_id(address_id: int = 1):
"""Get detail about an address"""
addresses = Addresses()
address = addresses.get_address_by_id(address_id)
if not address:
raise HTTPException(status_code=404, detail="Address not found")
return {"address": address}
@router.get("/addresses/{hotel_id}", tags=["addresses"])
async def get_address_by_hotel_id(hotel_id: int = 1):
"""Get address by its hotel."""
address = Addresses().get_address_by_hotel_id(hotel_id)
if not address:
raise HTTPException(status_code=404, detail="Address not found")
return {"address": address}
@router.get("/addresses/last/", tags=["addresses"])
async def get_last_address():
"""Get detail about an address"""
addresses = Addresses().get_all_addresses()
address = addresses[-1]
return {"address": address}
@router.post("/addresses/", tags=["addresses"])
async def create_address(request: Request, address: Address):
"""Post detail about an address"""
if "PYTEST_CURRENT_TEST" not in os.environ:
user = user_logged(request.headers.get("authorization"))
user_is_admin(user)
address = Addresses().create_address(address, address.hotel_id)
return {"address": address}
@router.put("/addresses/{address_id}", tags=["addresses"])
async def update_address(
request: Request,
address: Address,
address_id: int = 1,
):
"""Update address by its id."""
if "PYTEST_CURRENT_TEST" not in os.environ:
user = user_logged(request.headers.get("authorization"))
user_is_admin(user)
if not Addresses().get_address_by_id(address_id):
raise HTTPException(status_code=404, detail="Address not found")
address = Addresses().update_address(address, address_id)
return {"address": address}
@router.delete("/addresses/{address_id}", tags=["addresses"])
async def delete_address(request: Request, address_id: int = 0):
"""Delete address by its id."""
if "PYTEST_CURRENT_TEST" not in os.environ:
user = user_logged(request.headers.get("authorization"))
user_is_admin(user)
if address_id > 0:
address = Addresses().delete_address(address_id)
if not address:
raise HTTPException(status_code=404, detail="Address not found")
return {}
# curl -X POST -d '{"key1":"value1", "key2":"value2"}' \
# 127.0.0.1:5555/addresses/test/
# @router.post("/addresses/test/", tags=["addresses"])
# async def test(request: Request):
# return await request.json()
| |
app.controller.ts
|
import { Controller, Get, UseGuards } from '@nestjs/common';
import { AppService } from './app.service';
import { JwtAuthGuard } from './modules/auth/jwt-auth.guard';
@Controller()
export class
|
{
constructor(private readonly appService: AppService) {}
@Get()
getHello(): string {
return this.appService.getHello();
}
@UseGuards(JwtAuthGuard)
@Get('/health')
getHealth() {
return {
message: 'Fine',
};
}
}
|
AppController
|
lib.rs
|
//! https://github.com/Enet4/bra-rs/issues/1
//!
//! bra-rs 安全漏洞:读取未初始化内存导致 UB
//!
//! `GreedyAccessReader::fill_buf`方法创建了一个未初始化的缓冲区,
//! 并将其传递给用户提供的Read实现(`self.inner.read(buf)`)。
//! 这是不合理的,因为它允许`Safe Rust`代码表现出未定义的行为(从未初始化的内存读取)。
//!
//! 在标准库`Read` trait 的 `read` 方法文档中所示:
//!
//! > 您有责任在调用`read`之前确保`buf`已初始化。
//! > 用未初始化的`buf`(通过`MaybeUninit <T>`获得的那种)调用`read`是不安全的,并且可能导致未定义的行为。
//! https://doc.rust-lang.org/std/io/trait.Read.html#tymethod.read
//!
//! 解决方法:
//! 在`read`之前将新分配的`u8`缓冲区初始化为零是安全的,以防止用户提供的`Read`读取新分配的堆内存的旧内容。
// 以下是有安全风险的代码示例:
impl<R> BufRead for GreedyAccessReader<R>
where
R: Read,
{
fn fill_buf(&mut self) -> IoResult<&[u8]> {
if self.buf.capacity() == self.consumed {
self.reserve_up_to(self.buf.capacity() + 16);
}
let b = self.buf.len();
let buf = unsafe {
// safe because it's within the buffer's limits
// and we won't be reading uninitialized memory
// 这里虽然没有读取未初始化内存,但是会导致用户读取
std::slice::from_raw_parts_mut(
self.buf.as_mut_ptr().offset(b as isize),
self.buf.capacity() - b)
};
match self.inner.read(buf) {
Ok(o) => {
unsafe {
// reset the size to include the written portion,
// safe because the extra data is initialized
self.buf.set_len(b + o);
}
Ok(&self.buf[self.consumed..])
}
Err(e) => Err(e),
}
}
fn consume(&mut self, amt: usize) {
self.consumed += amt;
}
}
// 修正以后的代码示例,去掉了未初始化的buf:
impl<R> BufRead for GreedyAccessReader<R>
where
R: Read,
{
fn fill_buf(&mut self) -> IoResult<&[u8]> {
if self.buf.capacity() == self.consumed {
self.reserve_up_to(self.buf.capacity() + 16);
}
let b = self.buf.len();
self.buf.resize(self.buf.capacity(), 0);
let buf = &mut self.buf[b..];
let o = self.inner.read(buf)?;
// truncate to exclude non-written portion
self.buf.truncate(b + o);
Ok(&self.buf[self.consumed..])
}
fn consume(&mut self, amt: usize) {
self.consumed += amt;
}
}
| ||
ILanguage.ts
|
title: string,
}
|
export interface ILanguage {
or: string,
text: string,
|
|
coherence-impls-sized.rs
|
// Copyright 2015 The Rust Project Developers. See the COPYRIGHT
// file at the top-level directory of this distribution and at
// http://rust-lang.org/COPYRIGHT.
//
// Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or
// http://www.apache.org/licenses/LICENSE-2.0> or the MIT license
// <LICENSE-MIT or http://opensource.org/licenses/MIT>, at your
// option. This file may not be copied, modified, or distributed
// except according to those terms.
#![feature(optin_builtin_traits)]
use std::marker::Copy;
enum TestE {
A
}
struct
|
;
struct NotSync;
impl !Sync for NotSync {}
impl Sized for TestE {} //~ ERROR E0322
//~^ impl of 'Sized' not allowed
impl Sized for MyType {} //~ ERROR E0322
//~^ impl of 'Sized' not allowed
impl Sized for (MyType, MyType) {} //~ ERROR E0117
impl Sized for &'static NotSync {} //~ ERROR E0322
//~^ impl of 'Sized' not allowed
impl Sized for [MyType] {} //~ ERROR E0117
impl Sized for &'static [NotSync] {} //~ ERROR E0117
fn main() {
}
|
MyType
|
Banner.tsx
|
import React, { ReactElement } from "react";
import "./styles/banner.scss";
const Banner = (): ReactElement => {
return (
<section className="container banner__container">
<h2 id="about" className="banner__title">
VIANCH
|
<div className="banner__avatar-container">
<img
className="banner__avatar"
src="/images/avatar.png"
alt="avatar"
/>
</div>
<p className="banner__description">
Full stack application Developer and photographer based in Bogotá
Colombia. Developer at{" "}
<a
className="banner__link"
href="https://www.todaytix.com/"
target="_blank"
>
TodayTix Group
</a>{" "}
in New York and{" "}
<a className="banner__link" href="https://zaga.dev/" target="_blank">
Zaga{" "}
</a>
Colombia.
</p>
</div>
</section>
);
};
export default Banner;
|
</h2>
<div className="banner__info">
|
root.go
|
package keys
import (
"github.com/gorilla/mux"
"github.com/spf13/cobra"
"github.com/cosmos/cosmos-sdk/client"
)
// Commands registers a sub-tree of commands to interact with
// local private key storage.
func Commands() *cobra.Command
|
// resgister REST routes
func RegisterRoutes(r *mux.Router, indent bool) {
r.HandleFunc("/keys", QueryKeysRequestHandler(indent)).Methods("GET")
r.HandleFunc("/keys", AddNewKeyRequestHandler(indent)).Methods("POST")
r.HandleFunc("/keys/seed", SeedRequestHandler).Methods("GET")
r.HandleFunc("/keys/{name}/recover", RecoverRequestHandler(indent)).Methods("POST")
r.HandleFunc("/keys/{name}", GetKeyRequestHandler(indent)).Methods("GET")
r.HandleFunc("/keys/{name}", UpdateKeyRequestHandler).Methods("PUT")
r.HandleFunc("/keys/{name}", DeleteKeyRequestHandler).Methods("DELETE")
}
|
{
cmd := &cobra.Command{
Use: "keys",
Short: "Add or view local private keys",
Long: `Keys allows you to manage your local keystore for tendermint.
These keys may be in any format supported by go-crypto and can be
used by light-clients, full nodes, or any other application that
needs to sign with a private key.`,
}
cmd.AddCommand(
mnemonicKeyCommand(),
addKeyCommand(),
listKeysCmd,
showKeysCmd(),
client.LineBreak,
deleteKeyCommand(),
updateKeyCommand(),
)
return cmd
}
|
lib.rs
|
//! <https://www.codewars.com/kata/56dbe0e313c2f63be4000b25/train/rust>
pub fn hor_mirror(s: String) -> String {
let mut rev_lines = s.rsplit('\n');
let first = if let Some(first) = rev_lines.next() {
first
} else {
return s;
};
let mut res = String::with_capacity(s.len());
res.push_str(first);
for line in rev_lines {
res.push('\n');
res.push_str(line);
}
res
}
pub fn vert_mirror(s: String) -> String
|
pub fn oper(f: fn(String) -> String, s: String) -> String {
f(s)
}
|
{
let mut lines = s.split('\n');
let first = if let Some(first) = lines.next() {
first
} else {
return s;
};
let mut res = String::with_capacity(s.len());
res.extend(first.chars().rev());
for line in lines {
res.push('\n');
res.extend(line.chars().rev());
}
res
}
|
gene.rs
|
use std::io::BufRead;
use std::str::FromStr;
use quick_xml::events::BytesStart;
use quick_xml::Reader;
use crate::error::Error;
use crate::error::InvalidValue;
use crate::parser::utils::attributes_to_hashmap;
use crate::parser::utils::decode_attribute;
use crate::parser::utils::get_evidences;
use crate::parser::FromXml;
#[derive(Debug, Clone, Default)]
/// Describes a gene.
pub struct Gene {
pub names: Vec<Name>,
}
impl FromXml for Gene {
fn from_xml<B: BufRead>(
event: &BytesStart,
reader: &mut Reader<B>,
buffer: &mut Vec<u8>,
) -> Result<Self, Error> {
debug_assert_eq!(event.local_name(), b"gene");
let mut gene = Gene::default();
parse_inner! {event, reader, buffer,
e @ b"name" => {
gene.names.push(FromXml::from_xml(&e, reader, buffer)?);
}
}
Ok(gene)
}
}
// ---------------------------------------------------------------------------
#[derive(Debug, Clone)]
/// Describes different types of gene designations.
pub struct Name {
pub value: String,
pub ty: NameType,
pub evidence: Vec<usize>,
}
impl Name {
pub fn new(value: String, ty: NameType) -> Self {
Self::new_with_evidence(value, ty, Vec::new())
}
pub fn new_with_evidence(value: String, ty: NameType, evidence: Vec<usize>) -> Self {
Self {
value,
ty,
evidence,
}
}
}
// ---------------------------------------------------------------------------
impl FromXml for Name {
fn from_xml<B: BufRead>(
event: &BytesStart,
reader: &mut Reader<B>,
buffer: &mut Vec<u8>,
) -> Result<Self, Error> {
debug_assert_eq!(event.local_name(), b"name");
let attr = attributes_to_hashmap(event)?;
let name = reader.read_text(event.local_name(), buffer)?;
let evidence = get_evidences(reader, &attr)?;
let ty = decode_attribute(event, reader, "type", "name")?;
Ok(Self::new_with_evidence(name, ty, evidence))
}
}
// ---------------------------------------------------------------------------
#[derive(Debug, Clone)]
pub enum NameType {
Primary,
Synonym,
OrderedLocus,
Orf,
}
impl FromStr for NameType {
type Err = InvalidValue;
|
fn from_str(s: &str) -> Result<Self, Self::Err> {
match s {
"primary" => Ok(NameType::Primary),
"synonym" => Ok(NameType::Synonym),
"ordered locus" => Ok(NameType::OrderedLocus),
"ORF" => Ok(NameType::Orf),
other => Err(InvalidValue::from(other)),
}
}
}
| |
F19.py
|
#!/usr/bin/env python
# ------------------------------------------------------------------------------------------------------%
# Created by "Thieu Nguyen" at 19:26, 20/04/2020 %
# %
# Email: [email protected] %
# Homepage: https://www.researchgate.net/profile/Thieu_Nguyen6 %
# Github: https://github.com/thieunguyen5991 %
#-------------------------------------------------------------------------------------------------------%
from opfunu.cec.cec2005.root import Root
from numpy import sum, dot, sqrt, array, cos, pi, exp, e, ones, max
class
|
(Root):
def __init__(self, f_name="Rotated Hybrid Composition Function 2 with narrow basin global optimum",
f_shift_data_file="data_hybrid_func2",
f_ext='.txt', f_bias=10, f_matrix=None):
Root.__init__(self, f_name, f_shift_data_file, f_ext, f_bias)
self.f_matrix = f_matrix
def __f12__(self, solution=None):
return -20 * exp(-0.2 * sqrt(sum(solution ** 2) / len(solution))) - exp(sum(cos(2 * pi * solution)) / len(solution)) + 20 + e
def __f34__(self, solution=None):
return sum(solution ** 2 - 10 * cos(2 * pi * solution) + 10)
def __f56__(self, solution=None):
return sum(solution ** 2)
def __f78__(self, solution=None, a=0.5, b=3, k_max=20):
result = 0.0
for i in range(len(solution)):
result += sum([a ** k * cos(2 * pi * b ** k * (solution + 0.5)) for k in range(0, k_max)])
return result - len(solution) * sum([a ** k * cos(2 * pi * b ** k * 0.5) for k in range(0, k_max)])
def __f910__(self, solution=None):
result = sum(solution ** 2) / 4000
temp = 1.0
for i in range(len(solution)):
temp *= cos(solution[i] / sqrt(i + 1))
return result - temp + 1
def __fi__(self, solution=None, idx=None):
if idx == 0 or idx == 1:
return self.__f12__(solution)
elif idx == 2 or idx == 3:
return self.__f34__(solution)
elif idx == 4 or idx == 5:
return self.__f56__(solution)
elif idx == 6 or idx == 7:
return self.__f78__(solution)
else:
return self.__f910__(solution)
def _main__(self, solution=None):
problem_size = len(solution)
if problem_size > 100:
print("CEC 2005 not support for problem size > 100")
return 1
if problem_size == 10 or problem_size == 30 or problem_size == 50:
self.f_matrix = "hybrid_func2_M_D" + str(problem_size)
else:
print("CEC 2005 F19 function only support problem size 10, 30, 50")
return 1
num_funcs = 10
C = 2000
xichma = array([0.1, 2, 1.5, 1.5, 1, 1, 1.5, 1.5, 2, 2])
lamda = array([0.1 * 5 / 32, 5.0 / 32, 2 * 1, 1, 2 * 5.0 / 100, 5.0 / 100, 2.0 * 10, 10, 2 * 5.0 / 60, 5.0 / 60])
bias = array([0, 100, 200, 300, 400, 500, 600, 700, 800, 900])
y = 5 * ones(problem_size)
shift_data = self.load_matrix_data(self.f_shift_data_file)
shift_data = shift_data[:, :problem_size]
matrix = self.load_matrix_data(self.f_matrix)
weights = ones(num_funcs)
fits = ones(num_funcs)
for i in range(0, num_funcs):
w_i = exp(-sum((solution - shift_data[i]) ** 2) / (2 * problem_size * xichma[i] ** 2))
z = dot((solution - shift_data[i]) / lamda[i], matrix[i * problem_size:(i + 1) * problem_size, :])
fit_i = self.__fi__(z, i)
f_maxi = self.__fi__(dot((y / lamda[i]), matrix[i * problem_size:(i + 1) * problem_size, :]), i)
fit_i = C * fit_i / f_maxi
weights[i] = w_i
fits[i] = fit_i
sw = sum(weights)
maxw = max(weights)
for i in range(0, num_funcs):
if weights[i] != maxw:
weights[i] = weights[i] * (1 - maxw ** 10)
weights[i] = weights[i] / sw
fx = sum(dot(weights, (fits + bias)))
return fx + self.f_bias
|
Model
|
platform-browser.js
|
/**
* @license Angular v5.1.2
* (c) 2010-2017 Google, Inc. https://angular.io/
* License: MIT
*/
import { CommonModule, DOCUMENT, PlatformLocation, ɵPLATFORM_BROWSER_ID, ɵparseCookieValue } from '@angular/common';
import { APP_ID, APP_INITIALIZER, ApplicationInitStatus, ApplicationModule, ApplicationRef, ErrorHandler, Inject, Injectable, InjectionToken, Injector, NgModule, NgProbeToken, NgZone, Optional, PLATFORM_ID, PLATFORM_INITIALIZER, RendererFactory2, RendererStyleFlags2, Sanitizer, SecurityContext, SkipSelf, Testability, Version, ViewEncapsulation, createPlatformFactory, getDebugNode, isDevMode, platformCore, setTestabilityGetter, ɵglobal } from '@angular/core';
import { __assign, __extends } from 'tslib';
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var _DOM = /** @type {?} */ ((null));
/**
* @return {?}
*/
function getDOM() {
return _DOM;
}
/**
* @param {?} adapter
* @return {?}
*/
/**
* @param {?} adapter
* @return {?}
*/
function setRootDomAdapter(adapter) {
if (!_DOM) {
_DOM = adapter;
}
}
/**
* Provides DOM operations in an environment-agnostic way.
*
* \@security Tread carefully! Interacting with the DOM directly is dangerous and
* can introduce XSS risks.
* @abstract
*/
var DomAdapter = /** @class */ (function () {
function DomAdapter() {
this.resourceLoaderType = /** @type {?} */ ((null));
}
Object.defineProperty(DomAdapter.prototype, "attrToPropMap", {
/**
* Maps attribute names to their corresponding property names for cases
* where attribute name doesn't match property name.
*/
get: /**
* Maps attribute names to their corresponding property names for cases
* where attribute name doesn't match property name.
* @return {?}
*/
function () { return this._attrToPropMap; },
set: /**
* @param {?} value
* @return {?}
*/
function (value) { this._attrToPropMap = value; },
enumerable: true,
configurable: true
});
return DomAdapter;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* Provides DOM operations in any browser environment.
*
* \@security Tread carefully! Interacting with the DOM directly is dangerous and
* can introduce XSS risks.
* @abstract
*/
var GenericBrowserDomAdapter = /** @class */ (function (_super) {
__extends(GenericBrowserDomAdapter, _super);
function GenericBrowserDomAdapter() {
var _this = _super.call(this) || this;
_this._animationPrefix = null;
_this._transitionEnd = null;
try {
var /** @type {?} */ element_1 = _this.createElement('div', document);
if (_this.getStyle(element_1, 'animationName') != null) {
_this._animationPrefix = '';
}
else {
var /** @type {?} */ domPrefixes = ['Webkit', 'Moz', 'O', 'ms'];
for (var /** @type {?} */ i = 0; i < domPrefixes.length; i++) {
if (_this.getStyle(element_1, domPrefixes[i] + 'AnimationName') != null) {
_this._animationPrefix = '-' + domPrefixes[i].toLowerCase() + '-';
break;
}
}
}
var /** @type {?} */ transEndEventNames_1 = {
WebkitTransition: 'webkitTransitionEnd',
MozTransition: 'transitionend',
OTransition: 'oTransitionEnd otransitionend',
transition: 'transitionend'
};
Object.keys(transEndEventNames_1).forEach(function (key) {
if (_this.getStyle(element_1, key) != null) {
_this._transitionEnd = transEndEventNames_1[key];
}
});
}
catch (/** @type {?} */ e) {
_this._animationPrefix = null;
_this._transitionEnd = null;
}
return _this;
}
/**
* @param {?} el
* @return {?}
*/
GenericBrowserDomAdapter.prototype.getDistributedNodes = /**
* @param {?} el
* @return {?}
*/
function (el) { return (/** @type {?} */ (el)).getDistributedNodes(); };
/**
* @param {?} el
* @param {?} baseUrl
* @param {?} href
* @return {?}
*/
GenericBrowserDomAdapter.prototype.resolveAndSetHref = /**
* @param {?} el
* @param {?} baseUrl
* @param {?} href
* @return {?}
*/
function (el, baseUrl, href) {
el.href = href == null ? baseUrl : baseUrl + '/../' + href;
};
/**
* @return {?}
*/
GenericBrowserDomAdapter.prototype.supportsDOMEvents = /**
* @return {?}
*/
function () { return true; };
/**
* @return {?}
*/
GenericBrowserDomAdapter.prototype.supportsNativeShadowDOM = /**
* @return {?}
*/
function () {
return typeof (/** @type {?} */ (document.body)).createShadowRoot === 'function';
};
/**
* @return {?}
*/
GenericBrowserDomAdapter.prototype.getAnimationPrefix = /**
* @return {?}
*/
function () { return this._animationPrefix ? this._animationPrefix : ''; };
/**
* @return {?}
*/
GenericBrowserDomAdapter.prototype.getTransitionEnd = /**
* @return {?}
*/
function () { return this._transitionEnd ? this._transitionEnd : ''; };
/**
* @return {?}
*/
GenericBrowserDomAdapter.prototype.supportsAnimation = /**
* @return {?}
*/
function () {
return this._animationPrefix != null && this._transitionEnd != null;
};
return GenericBrowserDomAdapter;
}(DomAdapter));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var _attrToPropMap = {
'class': 'className',
'innerHtml': 'innerHTML',
'readonly': 'readOnly',
'tabindex': 'tabIndex',
};
var DOM_KEY_LOCATION_NUMPAD = 3;
// Map to convert some key or keyIdentifier values to what will be returned by getEventKey
var _keyMap = {
// The following values are here for cross-browser compatibility and to match the W3C standard
// cf http://www.w3.org/TR/DOM-Level-3-Events-key/
'\b': 'Backspace',
'\t': 'Tab',
'\x7F': 'Delete',
'\x1B': 'Escape',
'Del': 'Delete',
'Esc': 'Escape',
'Left': 'ArrowLeft',
'Right': 'ArrowRight',
'Up': 'ArrowUp',
'Down': 'ArrowDown',
'Menu': 'ContextMenu',
'Scroll': 'ScrollLock',
'Win': 'OS'
};
// There is a bug in Chrome for numeric keypad keys:
// https://code.google.com/p/chromium/issues/detail?id=155654
// 1, 2, 3 ... are reported as A, B, C ...
var _chromeNumKeyPadMap = {
'A': '1',
'B': '2',
'C': '3',
'D': '4',
'E': '5',
'F': '6',
'G': '7',
'H': '8',
'I': '9',
'J': '*',
'K': '+',
'M': '-',
'N': '.',
'O': '/',
'\x60': '0',
'\x90': 'NumLock'
};
var nodeContains;
if (ɵglobal['Node']) {
nodeContains = ɵglobal['Node'].prototype.contains || function (node) {
return !!(this.compareDocumentPosition(node) & 16);
};
}
/**
* A `DomAdapter` powered by full browser DOM APIs.
*
* \@security Tread carefully! Interacting with the DOM directly is dangerous and
* can introduce XSS risks.
*/
var BrowserDomAdapter = /** @class */ (function (_super) {
__extends(BrowserDomAdapter, _super);
function BrowserDomAdapter() {
return _super !== null && _super.apply(this, arguments) || this;
}
/**
* @param {?} templateHtml
* @return {?}
*/
BrowserDomAdapter.prototype.parse = /**
* @param {?} templateHtml
* @return {?}
*/
function (templateHtml) { throw new Error('parse not implemented'); };
/**
* @return {?}
*/
BrowserDomAdapter.makeCurrent = /**
* @return {?}
*/
function () { setRootDomAdapter(new BrowserDomAdapter()); };
/**
* @param {?} element
* @param {?} name
* @return {?}
*/
BrowserDomAdapter.prototype.hasProperty = /**
* @param {?} element
* @param {?} name
* @return {?}
*/
function (element, name) { return name in element; };
/**
* @param {?} el
* @param {?} name
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setProperty = /**
* @param {?} el
* @param {?} name
* @param {?} value
* @return {?}
*/
function (el, name, value) { (/** @type {?} */ (el))[name] = value; };
/**
* @param {?} el
* @param {?} name
* @return {?}
*/
BrowserDomAdapter.prototype.getProperty = /**
* @param {?} el
* @param {?} name
* @return {?}
*/
function (el, name) { return (/** @type {?} */ (el))[name]; };
/**
* @param {?} el
* @param {?} methodName
* @param {?} args
* @return {?}
*/
BrowserDomAdapter.prototype.invoke = /**
* @param {?} el
* @param {?} methodName
* @param {?} args
* @return {?}
*/
function (el, methodName, args) {
(_a = (/** @type {?} */ (el)))[methodName].apply(_a, args);
var _a;
};
// TODO(tbosch): move this into a separate environment class once we have it
/**
* @param {?} error
* @return {?}
*/
BrowserDomAdapter.prototype.logError = /**
* @param {?} error
* @return {?}
*/
function (error) {
if (window.console) {
if (console.error) {
console.error(error);
}
else {
console.log(error);
}
}
};
/**
* @param {?} error
* @return {?}
*/
BrowserDomAdapter.prototype.log = /**
* @param {?} error
* @return {?}
*/
function (error) {
if (window.console) {
window.console.log && window.console.log(error);
}
};
/**
* @param {?} error
* @return {?}
*/
BrowserDomAdapter.prototype.logGroup = /**
* @param {?} error
* @return {?}
*/
function (error) {
if (window.console) {
window.console.group && window.console.group(error);
}
};
/**
* @return {?}
*/
BrowserDomAdapter.prototype.logGroupEnd = /**
* @return {?}
*/
function () {
if (window.console) {
window.console.groupEnd && window.console.groupEnd();
}
};
Object.defineProperty(BrowserDomAdapter.prototype, "attrToPropMap", {
get: /**
* @return {?}
*/
function () { return _attrToPropMap; },
enumerable: true,
configurable: true
});
/**
* @param {?} nodeA
* @param {?} nodeB
* @return {?}
*/
BrowserDomAdapter.prototype.contains = /**
* @param {?} nodeA
* @param {?} nodeB
* @return {?}
*/
function (nodeA, nodeB) { return nodeContains.call(nodeA, nodeB); };
/**
* @param {?} el
* @param {?} selector
* @return {?}
*/
BrowserDomAdapter.prototype.querySelector = /**
* @param {?} el
* @param {?} selector
* @return {?}
*/
function (el, selector) { return el.querySelector(selector); };
/**
* @param {?} el
* @param {?} selector
* @return {?}
*/
BrowserDomAdapter.prototype.querySelectorAll = /**
* @param {?} el
* @param {?} selector
* @return {?}
*/
function (el, selector) { return el.querySelectorAll(selector); };
/**
* @param {?} el
* @param {?} evt
* @param {?} listener
* @return {?}
*/
BrowserDomAdapter.prototype.on = /**
* @param {?} el
* @param {?} evt
* @param {?} listener
* @return {?}
*/
function (el, evt, listener) { el.addEventListener(evt, listener, false); };
/**
* @param {?} el
* @param {?} evt
* @param {?} listener
* @return {?}
*/
BrowserDomAdapter.prototype.onAndCancel = /**
* @param {?} el
* @param {?} evt
* @param {?} listener
* @return {?}
*/
function (el, evt, listener) {
el.addEventListener(evt, listener, false);
// Needed to follow Dart's subscription semantic, until fix of
// https://code.google.com/p/dart/issues/detail?id=17406
return function () { el.removeEventListener(evt, listener, false); };
};
/**
* @param {?} el
* @param {?} evt
* @return {?}
*/
BrowserDomAdapter.prototype.dispatchEvent = /**
* @param {?} el
* @param {?} evt
* @return {?}
*/
function (el, evt) { el.dispatchEvent(evt); };
/**
* @param {?} eventType
* @return {?}
*/
BrowserDomAdapter.prototype.createMouseEvent = /**
* @param {?} eventType
* @return {?}
*/
function (eventType) {
var /** @type {?} */ evt = this.getDefaultDocument().createEvent('MouseEvent');
evt.initEvent(eventType, true, true);
return evt;
};
/**
* @param {?} eventType
* @return {?}
*/
BrowserDomAdapter.prototype.createEvent = /**
* @param {?} eventType
* @return {?}
*/
function (eventType) {
var /** @type {?} */ evt = this.getDefaultDocument().createEvent('Event');
evt.initEvent(eventType, true, true);
return evt;
};
/**
* @param {?} evt
* @return {?}
*/
BrowserDomAdapter.prototype.preventDefault = /**
* @param {?} evt
* @return {?}
*/
function (evt) {
evt.preventDefault();
evt.returnValue = false;
};
/**
* @param {?} evt
* @return {?}
*/
BrowserDomAdapter.prototype.isPrevented = /**
* @param {?} evt
* @return {?}
*/
function (evt) {
return evt.defaultPrevented || evt.returnValue != null && !evt.returnValue;
};
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getInnerHTML = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.innerHTML; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getTemplateContent = /**
* @param {?} el
* @return {?}
*/
function (el) {
return 'content' in el && this.isTemplateElement(el) ? (/** @type {?} */ (el)).content : null;
};
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getOuterHTML = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.outerHTML; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.nodeName = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.nodeName; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.nodeValue = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.nodeValue; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.type = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.type; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.content = /**
* @param {?} node
* @return {?}
*/
function (node) {
if (this.hasProperty(node, 'content')) {
return (/** @type {?} */ (node)).content;
}
else {
return node;
}
};
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.firstChild = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.firstChild; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.nextSibling = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.nextSibling; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.parentElement = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.parentNode; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.childNodes = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.childNodes; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.childNodesAsList = /**
* @param {?} el
* @return {?}
*/
function (el) {
var /** @type {?} */ childNodes = el.childNodes;
var /** @type {?} */ res = new Array(childNodes.length);
for (var /** @type {?} */ i = 0; i < childNodes.length; i++) {
res[i] = childNodes[i];
}
return res;
};
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.clearNodes = /**
* @param {?} el
* @return {?}
*/
function (el) {
while (el.firstChild) {
el.removeChild(el.firstChild);
}
};
/**
* @param {?} el
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.appendChild = /**
* @param {?} el
* @param {?} node
* @return {?}
*/
function (el, node) { el.appendChild(node); };
/**
* @param {?} el
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.removeChild = /**
* @param {?} el
* @param {?} node
* @return {?}
*/
function (el, node) { el.removeChild(node); };
/**
* @param {?} el
* @param {?} newChild
* @param {?} oldChild
* @return {?}
*/
BrowserDomAdapter.prototype.replaceChild = /**
* @param {?} el
* @param {?} newChild
* @param {?} oldChild
* @return {?}
*/
function (el, newChild, oldChild) { el.replaceChild(newChild, oldChild); };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.remove = /**
* @param {?} node
* @return {?}
*/
function (node) {
if (node.parentNode) {
node.parentNode.removeChild(node);
}
return node;
};
/**
* @param {?} parent
* @param {?} ref
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.insertBefore = /**
* @param {?} parent
* @param {?} ref
* @param {?} node
* @return {?}
*/
function (parent, ref, node) { parent.insertBefore(node, ref); };
/**
* @param {?} parent
* @param {?} ref
* @param {?} nodes
* @return {?}
*/
BrowserDomAdapter.prototype.insertAllBefore = /**
* @param {?} parent
* @param {?} ref
* @param {?} nodes
* @return {?}
*/
function (parent, ref, nodes) {
nodes.forEach(function (n) { return parent.insertBefore(n, ref); });
};
/**
* @param {?} parent
* @param {?} ref
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.insertAfter = /**
* @param {?} parent
* @param {?} ref
* @param {?} node
* @return {?}
*/
function (parent, ref, node) { parent.insertBefore(node, ref.nextSibling); };
/**
* @param {?} el
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setInnerHTML = /**
* @param {?} el
* @param {?} value
* @return {?}
*/
function (el, value) { el.innerHTML = value; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getText = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.textContent; };
/**
* @param {?} el
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setText = /**
* @param {?} el
* @param {?} value
* @return {?}
*/
function (el, value) { el.textContent = value; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getValue = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.value; };
/**
* @param {?} el
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setValue = /**
* @param {?} el
* @param {?} value
* @return {?}
*/
function (el, value) { el.value = value; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getChecked = /**
* @param {?} el
* @return {?}
*/
function (el) { return el.checked; };
/**
* @param {?} el
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setChecked = /**
* @param {?} el
* @param {?} value
* @return {?}
*/
function (el, value) { el.checked = value; };
/**
* @param {?} text
* @return {?}
*/
BrowserDomAdapter.prototype.createComment = /**
* @param {?} text
* @return {?}
*/
function (text) { return this.getDefaultDocument().createComment(text); };
/**
* @param {?} html
* @return {?}
*/
BrowserDomAdapter.prototype.createTemplate = /**
* @param {?} html
* @return {?}
*/
function (html) {
var /** @type {?} */ t = this.getDefaultDocument().createElement('template');
t.innerHTML = html;
return t;
};
/**
* @param {?} tagName
* @param {?=} doc
* @return {?}
*/
BrowserDomAdapter.prototype.createElement = /**
* @param {?} tagName
* @param {?=} doc
* @return {?}
*/
function (tagName, doc) {
doc = doc || this.getDefaultDocument();
return doc.createElement(tagName);
};
/**
* @param {?} ns
* @param {?} tagName
* @param {?=} doc
* @return {?}
*/
BrowserDomAdapter.prototype.createElementNS = /**
* @param {?} ns
* @param {?} tagName
* @param {?=} doc
* @return {?}
*/
function (ns, tagName, doc) {
doc = doc || this.getDefaultDocument();
return doc.createElementNS(ns, tagName);
};
/**
* @param {?} text
* @param {?=} doc
* @return {?}
*/
BrowserDomAdapter.prototype.createTextNode = /**
* @param {?} text
* @param {?=} doc
* @return {?}
*/
function (text, doc) {
doc = doc || this.getDefaultDocument();
return doc.createTextNode(text);
};
/**
* @param {?} attrName
* @param {?} attrValue
* @param {?=} doc
* @return {?}
*/
BrowserDomAdapter.prototype.createScriptTag = /**
* @param {?} attrName
* @param {?} attrValue
* @param {?=} doc
* @return {?}
*/
function (attrName, attrValue, doc) {
doc = doc || this.getDefaultDocument();
var /** @type {?} */ el = /** @type {?} */ (doc.createElement('SCRIPT'));
el.setAttribute(attrName, attrValue);
return el;
};
/**
* @param {?} css
* @param {?=} doc
* @return {?}
*/
BrowserDomAdapter.prototype.createStyleElement = /**
* @param {?} css
* @param {?=} doc
* @return {?}
*/
function (css, doc) {
doc = doc || this.getDefaultDocument();
var /** @type {?} */ style = /** @type {?} */ (doc.createElement('style'));
this.appendChild(style, this.createTextNode(css, doc));
return style;
};
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.createShadowRoot = /**
* @param {?} el
* @return {?}
*/
function (el) { return (/** @type {?} */ (el)).createShadowRoot(); };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getShadowRoot = /**
* @param {?} el
* @return {?}
*/
function (el) { return (/** @type {?} */ (el)).shadowRoot; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getHost = /**
* @param {?} el
* @return {?}
*/
function (el) { return (/** @type {?} */ (el)).host; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.clone = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.cloneNode(true); };
/**
* @param {?} element
* @param {?} name
* @return {?}
*/
BrowserDomAdapter.prototype.getElementsByClassName = /**
* @param {?} element
* @param {?} name
* @return {?}
*/
function (element, name) {
return element.getElementsByClassName(name);
};
/**
* @param {?} element
* @param {?} name
* @return {?}
*/
BrowserDomAdapter.prototype.getElementsByTagName = /**
* @param {?} element
* @param {?} name
* @return {?}
*/
function (element, name) {
return element.getElementsByTagName(name);
};
/**
* @param {?} element
* @return {?}
*/
BrowserDomAdapter.prototype.classList = /**
* @param {?} element
* @return {?}
*/
function (element) { return Array.prototype.slice.call(element.classList, 0); };
/**
* @param {?} element
* @param {?} className
* @return {?}
*/
BrowserDomAdapter.prototype.addClass = /**
* @param {?} element
* @param {?} className
* @return {?}
*/
function (element, className) { element.classList.add(className); };
/**
* @param {?} element
* @param {?} className
* @return {?}
*/
BrowserDomAdapter.prototype.removeClass = /**
* @param {?} element
* @param {?} className
* @return {?}
*/
function (element, className) { element.classList.remove(className); };
/**
* @param {?} element
* @param {?} className
* @return {?}
*/
BrowserDomAdapter.prototype.hasClass = /**
* @param {?} element
* @param {?} className
* @return {?}
*/
function (element, className) {
return element.classList.contains(className);
};
/**
* @param {?} element
* @param {?} styleName
* @param {?} styleValue
* @return {?}
*/
BrowserDomAdapter.prototype.setStyle = /**
* @param {?} element
* @param {?} styleName
* @param {?} styleValue
* @return {?}
*/
function (element, styleName, styleValue) {
element.style[styleName] = styleValue;
};
/**
* @param {?} element
* @param {?} stylename
* @return {?}
*/
BrowserDomAdapter.prototype.removeStyle = /**
* @param {?} element
* @param {?} stylename
* @return {?}
*/
function (element, stylename) {
// IE requires '' instead of null
// see https://github.com/angular/angular/issues/7916
element.style[stylename] = '';
};
/**
* @param {?} element
* @param {?} stylename
* @return {?}
*/
BrowserDomAdapter.prototype.getStyle = /**
* @param {?} element
* @param {?} stylename
* @return {?}
*/
function (element, stylename) { return element.style[stylename]; };
/**
* @param {?} element
* @param {?} styleName
* @param {?=} styleValue
* @return {?}
*/
BrowserDomAdapter.prototype.hasStyle = /**
* @param {?} element
* @param {?} styleName
* @param {?=} styleValue
* @return {?}
*/
function (element, styleName, styleValue) {
var /** @type {?} */ value = this.getStyle(element, styleName) || '';
return styleValue ? value == styleValue : value.length > 0;
};
/**
* @param {?} element
* @return {?}
*/
BrowserDomAdapter.prototype.tagName = /**
* @param {?} element
* @return {?}
*/
function (element) { return element.tagName; };
/**
* @param {?} element
* @return {?}
*/
BrowserDomAdapter.prototype.attributeMap = /**
* @param {?} element
* @return {?}
*/
function (element) {
var /** @type {?} */ res = new Map();
var /** @type {?} */ elAttrs = element.attributes;
for (var /** @type {?} */ i = 0; i < elAttrs.length; i++) {
var /** @type {?} */ attrib = elAttrs.item(i);
res.set(attrib.name, attrib.value);
}
return res;
};
/**
* @param {?} element
* @param {?} attribute
* @return {?}
*/
BrowserDomAdapter.prototype.hasAttribute = /**
* @param {?} element
* @param {?} attribute
* @return {?}
*/
function (element, attribute) {
return element.hasAttribute(attribute);
};
/**
* @param {?} element
* @param {?} ns
* @param {?} attribute
* @return {?}
*/
BrowserDomAdapter.prototype.hasAttributeNS = /**
* @param {?} element
* @param {?} ns
* @param {?} attribute
* @return {?}
*/
function (element, ns, attribute) {
return element.hasAttributeNS(ns, attribute);
};
/**
* @param {?} element
* @param {?} attribute
* @return {?}
*/
BrowserDomAdapter.prototype.getAttribute = /**
* @param {?} element
* @param {?} attribute
* @return {?}
*/
function (element, attribute) {
return element.getAttribute(attribute);
};
/**
* @param {?} element
* @param {?} ns
* @param {?} name
* @return {?}
*/
BrowserDomAdapter.prototype.getAttributeNS = /**
* @param {?} element
* @param {?} ns
* @param {?} name
* @return {?}
*/
function (element, ns, name) {
return element.getAttributeNS(ns, name);
};
/**
* @param {?} element
* @param {?} name
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setAttribute = /**
* @param {?} element
* @param {?} name
* @param {?} value
* @return {?}
*/
function (element, name, value) { element.setAttribute(name, value); };
/**
* @param {?} element
* @param {?} ns
* @param {?} name
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setAttributeNS = /**
* @param {?} element
* @param {?} ns
* @param {?} name
* @param {?} value
* @return {?}
*/
function (element, ns, name, value) {
element.setAttributeNS(ns, name, value);
};
/**
* @param {?} element
* @param {?} attribute
* @return {?}
*/
BrowserDomAdapter.prototype.removeAttribute = /**
* @param {?} element
* @param {?} attribute
* @return {?}
*/
function (element, attribute) { element.removeAttribute(attribute); };
/**
* @param {?} element
* @param {?} ns
* @param {?} name
* @return {?}
*/
BrowserDomAdapter.prototype.removeAttributeNS = /**
* @param {?} element
* @param {?} ns
* @param {?} name
* @return {?}
*/
function (element, ns, name) {
element.removeAttributeNS(ns, name);
};
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.templateAwareRoot = /**
* @param {?} el
* @return {?}
*/
function (el) { return this.isTemplateElement(el) ? this.content(el) : el; };
/**
* @return {?}
*/
BrowserDomAdapter.prototype.createHtmlDocument = /**
* @return {?}
*/
function () {
return document.implementation.createHTMLDocument('fakeTitle');
};
/**
* @return {?}
*/
BrowserDomAdapter.prototype.getDefaultDocument = /**
* @return {?}
*/
function () { return document; };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getBoundingClientRect = /**
* @param {?} el
* @return {?}
*/
function (el) {
try {
return el.getBoundingClientRect();
}
catch (/** @type {?} */ e) {
return { top: 0, bottom: 0, left: 0, right: 0, width: 0, height: 0 };
}
};
/**
* @param {?} doc
* @return {?}
*/
BrowserDomAdapter.prototype.getTitle = /**
* @param {?} doc
* @return {?}
*/
function (doc) { return doc.title; };
/**
* @param {?} doc
* @param {?} newTitle
* @return {?}
*/
BrowserDomAdapter.prototype.setTitle = /**
* @param {?} doc
* @param {?} newTitle
* @return {?}
*/
function (doc, newTitle) { doc.title = newTitle || ''; };
/**
* @param {?} n
* @param {?} selector
* @return {?}
*/
BrowserDomAdapter.prototype.elementMatches = /**
* @param {?} n
* @param {?} selector
* @return {?}
*/
function (n, selector) {
if (this.isElementNode(n)) {
return n.matches && n.matches(selector) ||
n.msMatchesSelector && n.msMatchesSelector(selector) ||
n.webkitMatchesSelector && n.webkitMatchesSelector(selector);
}
return false;
};
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.isTemplateElement = /**
* @param {?} el
* @return {?}
*/
function (el) {
return this.isElementNode(el) && el.nodeName === 'TEMPLATE';
};
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.isTextNode = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.nodeType === Node.TEXT_NODE; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.isCommentNode = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.nodeType === Node.COMMENT_NODE; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.isElementNode = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.nodeType === Node.ELEMENT_NODE; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.hasShadowRoot = /**
* @param {?} node
* @return {?}
*/
function (node) {
return node.shadowRoot != null && node instanceof HTMLElement;
};
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.isShadowRoot = /**
* @param {?} node
* @return {?}
*/
function (node) { return node instanceof DocumentFragment; };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.importIntoDoc = /**
* @param {?} node
* @return {?}
*/
function (node) { return document.importNode(this.templateAwareRoot(node), true); };
/**
* @param {?} node
* @return {?}
*/
BrowserDomAdapter.prototype.adoptNode = /**
* @param {?} node
* @return {?}
*/
function (node) { return document.adoptNode(node); };
/**
* @param {?} el
* @return {?}
*/
BrowserDomAdapter.prototype.getHref = /**
* @param {?} el
* @return {?}
*/
function (el) { return /** @type {?} */ ((el.getAttribute('href'))); };
/**
* @param {?} event
* @return {?}
*/
BrowserDomAdapter.prototype.getEventKey = /**
* @param {?} event
* @return {?}
*/
function (event) {
var /** @type {?} */ key = event.key;
if (key == null) {
key = event.keyIdentifier;
// keyIdentifier is defined in the old draft of DOM Level 3 Events implemented by Chrome and
// Safari cf
// http://www.w3.org/TR/2007/WD-DOM-Level-3-Events-20071221/events.html#Events-KeyboardEvents-Interfaces
if (key == null) {
return 'Unidentified';
}
if (key.startsWith('U+')) {
key = String.fromCharCode(parseInt(key.substring(2), 16));
if (event.location === DOM_KEY_LOCATION_NUMPAD && _chromeNumKeyPadMap.hasOwnProperty(key)) {
// There is a bug in Chrome for numeric keypad keys:
// https://code.google.com/p/chromium/issues/detail?id=155654
// 1, 2, 3 ... are reported as A, B, C ...
key = (/** @type {?} */ (_chromeNumKeyPadMap))[key];
}
}
}
return _keyMap[key] || key;
};
/**
* @param {?} doc
* @param {?} target
* @return {?}
*/
BrowserDomAdapter.prototype.getGlobalEventTarget = /**
* @param {?} doc
* @param {?} target
* @return {?}
*/
function (doc, target) {
if (target === 'window') {
return window;
}
if (target === 'document') {
return doc;
}
if (target === 'body') {
return doc.body;
}
return null;
};
/**
* @return {?}
*/
BrowserDomAdapter.prototype.getHistory = /**
* @return {?}
*/
function () { return window.history; };
/**
* @return {?}
*/
BrowserDomAdapter.prototype.getLocation = /**
* @return {?}
*/
function () { return window.location; };
/**
* @param {?} doc
* @return {?}
*/
BrowserDomAdapter.prototype.getBaseHref = /**
* @param {?} doc
* @return {?}
*/
function (doc) {
var /** @type {?} */ href = getBaseElementHref();
return href == null ? null : relativePath(href);
};
/**
* @return {?}
*/
BrowserDomAdapter.prototype.resetBaseElement = /**
* @return {?}
*/
function () { baseElement = null; };
/**
* @return {?}
*/
BrowserDomAdapter.prototype.getUserAgent = /**
* @return {?}
*/
function () { return window.navigator.userAgent; };
/**
* @param {?} element
* @param {?} name
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setData = /**
* @param {?} element
* @param {?} name
* @param {?} value
* @return {?}
*/
function (element, name, value) {
this.setAttribute(element, 'data-' + name, value);
};
/**
* @param {?} element
* @param {?} name
* @return {?}
*/
BrowserDomAdapter.prototype.getData = /**
* @param {?} element
* @param {?} name
* @return {?}
*/
function (element, name) {
return this.getAttribute(element, 'data-' + name);
};
/**
* @param {?} element
* @return {?}
*/
BrowserDomAdapter.prototype.getComputedStyle = /**
* @param {?} element
* @return {?}
*/
function (element) { return getComputedStyle(element); };
// TODO(tbosch): move this into a separate environment class once we have it
/**
* @return {?}
*/
BrowserDomAdapter.prototype.supportsWebAnimation = /**
* @return {?}
*/
function () {
return typeof (/** @type {?} */ (Element)).prototype['animate'] === 'function';
};
/**
* @return {?}
*/
BrowserDomAdapter.prototype.performanceNow = /**
* @return {?}
*/
function () {
// performance.now() is not available in all browsers, see
// http://caniuse.com/#search=performance.now
return window.performance && window.performance.now ? window.performance.now() :
new Date().getTime();
};
/**
* @return {?}
*/
BrowserDomAdapter.prototype.supportsCookies = /**
* @return {?}
*/
function () { return true; };
/**
* @param {?} name
* @return {?}
*/
BrowserDomAdapter.prototype.getCookie = /**
* @param {?} name
* @return {?}
*/
function (name) { return ɵparseCookieValue(document.cookie, name); };
/**
* @param {?} name
* @param {?} value
* @return {?}
*/
BrowserDomAdapter.prototype.setCookie = /**
* @param {?} name
* @param {?} value
* @return {?}
*/
function (name, value) {
// document.cookie is magical, assigning into it assigns/overrides one cookie value, but does
// not clear other cookies.
document.cookie = encodeURIComponent(name) + '=' + encodeURIComponent(value);
};
return BrowserDomAdapter;
}(GenericBrowserDomAdapter));
var baseElement = null;
/**
* @return {?}
*/
function getBaseElementHref() {
if (!baseElement) {
baseElement = /** @type {?} */ ((document.querySelector('base')));
if (!baseElement) {
return null;
}
}
return baseElement.getAttribute('href');
}
// based on urlUtils.js in AngularJS 1
var urlParsingNode;
/**
* @param {?} url
* @return {?}
*/
function relativePath(url) {
if (!urlParsingNode) {
urlParsingNode = document.createElement('a');
}
urlParsingNode.setAttribute('href', url);
return (urlParsingNode.pathname.charAt(0) === '/') ? urlParsingNode.pathname :
'/' + urlParsingNode.pathname;
}
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* A DI Token representing the main rendering context. In a browser this is the DOM Document.
*
* Note: Document might not be available in the Application Context when Application and Rendering
* Contexts are not the same (e.g. when running the application into a Web Worker).
*
* @deprecated import from `\@angular/common` instead.
*/
var DOCUMENT$1 = DOCUMENT;
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* @return {?}
*/
function supportsState() {
return !!window.history.pushState;
}
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* `PlatformLocation` encapsulates all of the direct calls to platform APIs.
* This class should not be used directly by an application developer. Instead, use
* {\@link Location}.
*/
var BrowserPlatformLocation = /** @class */ (function (_super) {
__extends(BrowserPlatformLocation, _super);
function BrowserPlatformLocation(_doc) {
var _this = _super.call(this) || this;
_this._doc = _doc;
_this._init();
return _this;
}
// This is moved to its own method so that `MockPlatformLocationStrategy` can overwrite it
/** @internal */
/**
* \@internal
* @return {?}
*/
BrowserPlatformLocation.prototype._init = /**
* \@internal
* @return {?}
*/
function () {
(/** @type {?} */ (this)).location = getDOM().getLocation();
this._history = getDOM().getHistory();
};
/**
* @return {?}
*/
BrowserPlatformLocation.prototype.getBaseHrefFromDOM = /**
* @return {?}
*/
function () { return /** @type {?} */ ((getDOM().getBaseHref(this._doc))); };
/**
* @param {?} fn
* @return {?}
*/
BrowserPlatformLocation.prototype.onPopState = /**
* @param {?} fn
* @return {?}
*/
function (fn) {
getDOM().getGlobalEventTarget(this._doc, 'window').addEventListener('popstate', fn, false);
};
/**
* @param {?} fn
* @return {?}
*/
BrowserPlatformLocation.prototype.onHashChange = /**
* @param {?} fn
* @return {?}
*/
function (fn) {
getDOM().getGlobalEventTarget(this._doc, 'window').addEventListener('hashchange', fn, false);
};
Object.defineProperty(BrowserPlatformLocation.prototype, "pathname", {
get: /**
* @return {?}
*/
function () { return this.location.pathname; },
set: /**
* @param {?} newPath
* @return {?}
*/
function (newPath) { this.location.pathname = newPath; },
enumerable: true,
configurable: true
});
Object.defineProperty(BrowserPlatformLocation.prototype, "search", {
get: /**
* @return {?}
*/
function () { return this.location.search; },
enumerable: true,
configurable: true
});
Object.defineProperty(BrowserPlatformLocation.prototype, "hash", {
get: /**
* @return {?}
*/
function () { return this.location.hash; },
enumerable: true,
configurable: true
});
/**
* @param {?} state
* @param {?} title
* @param {?} url
* @return {?}
*/
BrowserPlatformLocation.prototype.pushState = /**
* @param {?} state
* @param {?} title
* @param {?} url
* @return {?}
*/
function (state, title, url) {
if (supportsState()) {
this._history.pushState(state, title, url);
}
else {
this.location.hash = url;
}
};
/**
* @param {?} state
* @param {?} title
* @param {?} url
* @return {?}
*/
BrowserPlatformLocation.prototype.replaceState = /**
* @param {?} state
* @param {?} title
* @param {?} url
* @return {?}
*/
function (state, title, url) {
if (supportsState()) {
this._history.replaceState(state, title, url);
}
else {
this.location.hash = url;
}
};
/**
* @return {?}
*/
BrowserPlatformLocation.prototype.forward = /**
* @return {?}
*/
function () { this._history.forward(); };
/**
* @return {?}
*/
BrowserPlatformLocation.prototype.back = /**
* @return {?}
*/
function () { this._history.back(); };
BrowserPlatformLocation.decorators = [
{ type: Injectable },
];
/** @nocollapse */
BrowserPlatformLocation.ctorParameters = function () { return [
{ type: undefined, decorators: [{ type: Inject, args: [DOCUMENT$1,] },] },
]; };
return BrowserPlatformLocation;
}(PlatformLocation));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* A service that can be used to get and add meta tags.
*
* \@experimental
*/
var Meta = /** @class */ (function () {
function Meta(_doc) {
this._doc = _doc;
this._dom = getDOM();
}
/**
* @param {?} tag
* @param {?=} forceCreation
* @return {?}
*/
Meta.prototype.addTag = /**
* @param {?} tag
* @param {?=} forceCreation
* @return {?}
*/
function (tag, forceCreation) {
if (forceCreation === void 0) { forceCreation = false; }
if (!tag)
return null;
return this._getOrCreateElement(tag, forceCreation);
};
/**
* @param {?} tags
* @param {?=} forceCreation
* @return {?}
*/
Meta.prototype.addTags = /**
* @param {?} tags
* @param {?=} forceCreation
* @return {?}
*/
function (tags, forceCreation) {
var _this = this;
if (forceCreation === void 0) { forceCreation = false; }
if (!tags)
return [];
return tags.reduce(function (result, tag) {
if (tag) {
result.push(_this._getOrCreateElement(tag, forceCreation));
}
return result;
}, []);
};
/**
* @param {?} attrSelector
* @return {?}
*/
Meta.prototype.getTag = /**
* @param {?} attrSelector
* @return {?}
*/
function (attrSelector) {
if (!attrSelector)
return null;
return this._dom.querySelector(this._doc, "meta[" + attrSelector + "]") || null;
};
/**
* @param {?} attrSelector
* @return {?}
*/
Meta.prototype.getTags = /**
* @param {?} attrSelector
* @return {?}
*/
function (attrSelector) {
if (!attrSelector)
return [];
var /** @type {?} */ list = this._dom.querySelectorAll(this._doc, "meta[" + attrSelector + "]");
return list ? [].slice.call(list) : [];
};
/**
* @param {?} tag
* @param {?=} selector
* @return {?}
*/
Meta.prototype.updateTag = /**
* @param {?} tag
* @param {?=} selector
* @return {?}
*/
function (tag, selector) {
if (!tag)
return null;
selector = selector || this._parseSelector(tag);
var /** @type {?} */ meta = /** @type {?} */ ((this.getTag(selector)));
if (meta) {
return this._setMetaElementAttributes(tag, meta);
}
return this._getOrCreateElement(tag, true);
};
/**
* @param {?} attrSelector
* @return {?}
*/
Meta.prototype.removeTag = /**
* @param {?} attrSelector
* @return {?}
*/
function (attrSelector) { this.removeTagElement(/** @type {?} */ ((this.getTag(attrSelector)))); };
/**
* @param {?} meta
* @return {?}
*/
Meta.prototype.removeTagElement = /**
* @param {?} meta
* @return {?}
*/
function (meta) {
if (meta) {
this._dom.remove(meta);
}
};
/**
* @param {?} meta
* @param {?=} forceCreation
* @return {?}
*/
Meta.prototype._getOrCreateElement = /**
* @param {?} meta
* @param {?=} forceCreation
* @return {?}
*/
function (meta, forceCreation) {
if (forceCreation === void 0) { forceCreation = false; }
if (!forceCreation) {
var /** @type {?} */ selector = this._parseSelector(meta);
var /** @type {?} */ elem = /** @type {?} */ ((this.getTag(selector)));
// It's allowed to have multiple elements with the same name so it's not enough to
// just check that element with the same name already present on the page. We also need to
// check if element has tag attributes
if (elem && this._containsAttributes(meta, elem))
return elem;
}
var /** @type {?} */ element = /** @type {?} */ (this._dom.createElement('meta'));
this._setMetaElementAttributes(meta, element);
var /** @type {?} */ head = this._dom.getElementsByTagName(this._doc, 'head')[0];
this._dom.appendChild(head, element);
return element;
};
/**
* @param {?} tag
* @param {?} el
* @return {?}
*/
Meta.prototype._setMetaElementAttributes = /**
* @param {?} tag
* @param {?} el
* @return {?}
*/
function (tag, el) {
var _this = this;
Object.keys(tag).forEach(function (prop) { return _this._dom.setAttribute(el, prop, tag[prop]); });
return el;
};
/**
* @param {?} tag
* @return {?}
*/
Meta.prototype._parseSelector = /**
* @param {?} tag
* @return {?}
*/
function (tag) {
var /** @type {?} */ attr = tag.name ? 'name' : 'property';
return attr + "=\"" + tag[attr] + "\"";
};
/**
* @param {?} tag
* @param {?} elem
* @return {?}
*/
Meta.prototype._containsAttributes = /**
* @param {?} tag
* @param {?} elem
* @return {?}
*/
function (tag, elem) {
var _this = this;
return Object.keys(tag).every(function (key) { return _this._dom.getAttribute(elem, key) === tag[key]; });
};
Meta.decorators = [
{ type: Injectable },
];
/** @nocollapse */
Meta.ctorParameters = function () { return [
{ type: undefined, decorators: [{ type: Inject, args: [DOCUMENT$1,] },] },
]; };
return Meta;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* An id that identifies a particular application being bootstrapped, that should
* match across the client/server boundary.
*/
var TRANSITION_ID = new InjectionToken('TRANSITION_ID');
/**
* @param {?} transitionId
* @param {?} document
* @param {?} injector
* @return {?}
*/
function appInitializerFactory(transitionId, document, injector) {
return function () {
// Wait for all application initializers to be completed before removing the styles set by
// the server.
injector.get(ApplicationInitStatus).donePromise.then(function () {
var /** @type {?} */ dom = getDOM();
var /** @type {?} */ styles = Array.prototype.slice.apply(dom.querySelectorAll(document, "style[ng-transition]"));
styles.filter(function (el) { return dom.getAttribute(el, 'ng-transition') === transitionId; })
.forEach(function (el) { return dom.remove(el); });
});
};
}
var SERVER_TRANSITION_PROVIDERS = [
{
provide: APP_INITIALIZER,
useFactory: appInitializerFactory,
deps: [TRANSITION_ID, DOCUMENT$1, Injector],
multi: true
},
];
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var BrowserGetTestability = /** @class */ (function () {
function BrowserGetTestability() {
}
/**
* @return {?}
*/
BrowserGetTestability.init = /**
* @return {?}
*/
function () { setTestabilityGetter(new BrowserGetTestability()); };
/**
* @param {?} registry
* @return {?}
*/
BrowserGetTestability.prototype.addToWindow = /**
* @param {?} registry
* @return {?}
*/
function (registry) {
ɵglobal['getAngularTestability'] = function (elem, findInAncestors) {
if (findInAncestors === void 0) { findInAncestors = true; }
var /** @type {?} */ testability = registry.findTestabilityInTree(elem, findInAncestors);
if (testability == null) {
throw new Error('Could not find testability for element.');
}
return testability;
};
ɵglobal['getAllAngularTestabilities'] = function () { return registry.getAllTestabilities(); };
ɵglobal['getAllAngularRootElements'] = function () { return registry.getAllRootElements(); };
var /** @type {?} */ whenAllStable = function (callback /** TODO #9100 */) {
var /** @type {?} */ testabilities = ɵglobal['getAllAngularTestabilities']();
var /** @type {?} */ count = testabilities.length;
var /** @type {?} */ didWork = false;
var /** @type {?} */ decrement = function (didWork_ /** TODO #9100 */) {
didWork = didWork || didWork_;
count--;
if (count == 0) {
callback(didWork);
}
};
testabilities.forEach(function (testability /** TODO #9100 */) {
testability.whenStable(decrement);
});
};
if (!ɵglobal['frameworkStabilizers']) {
ɵglobal['frameworkStabilizers'] = [];
}
ɵglobal['frameworkStabilizers'].push(whenAllStable);
};
/**
* @param {?} registry
* @param {?} elem
* @param {?} findInAncestors
* @return {?}
*/
BrowserGetTestability.prototype.findTestabilityInTree = /**
* @param {?} registry
* @param {?} elem
* @param {?} findInAncestors
* @return {?}
*/
function (registry, elem, findInAncestors) {
if (elem == null) {
return null;
}
var /** @type {?} */ t = registry.getTestability(elem);
if (t != null) {
return t;
}
else if (!findInAncestors) {
return null;
}
if (getDOM().isShadowRoot(elem)) {
return this.findTestabilityInTree(registry, getDOM().getHost(elem), true);
}
return this.findTestabilityInTree(registry, getDOM().parentElement(elem), true);
};
return BrowserGetTestability;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* A service that can be used to get and set the title of a current HTML document.
*
* Since an Angular application can't be bootstrapped on the entire HTML document (`<html>` tag)
* it is not possible to bind to the `text` property of the `HTMLTitleElement` elements
* (representing the `<title>` tag). Instead, this service can be used to set and get the current
* title value.
*
* \@experimental
*/
var Title = /** @class */ (function () {
function Title(_doc) {
this._doc = _doc;
}
/**
* Get the title of the current HTML document.
*/
/**
* Get the title of the current HTML document.
* @return {?}
*/
Title.prototype.getTitle = /**
* Get the title of the current HTML document.
* @return {?}
*/
function () { return getDOM().getTitle(this._doc); };
/**
* Set the title of the current HTML document.
* @param newTitle
*/
/**
* Set the title of the current HTML document.
* @param {?} newTitle
* @return {?}
*/
Title.prototype.setTitle = /**
* Set the title of the current HTML document.
* @param {?} newTitle
* @return {?}
*/
function (newTitle) { getDOM().setTitle(this._doc, newTitle); };
Title.decorators = [
{ type: Injectable },
];
/** @nocollapse */
Title.ctorParameters = function () { return [
{ type: undefined, decorators: [{ type: Inject, args: [DOCUMENT$1,] },] },
]; };
return Title;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* @param {?} input
* @return {?}
*/
/**
* @param {?} input
* @return {?}
*/
/**
* Exports the value under a given `name` in the global property `ng`. For example `ng.probe` if
* `name` is `'probe'`.
* @param {?} name Name under which it will be exported. Keep in mind this will be a property of the
* global `ng` object.
* @param {?} value The value to export.
* @return {?}
*/
function exportNgVar(name, value) {
if (typeof COMPILED === 'undefined' || !COMPILED) {
// Note: we can't export `ng` when using closure enhanced optimization as:
// - closure declares globals itself for minified names, which sometimes clobber our `ng` global
// - we can't declare a closure extern as the namespace `ng` is already used within Google
// for typings for angularJS (via `goog.provide('ng....')`).
var /** @type {?} */ ng = ɵglobal['ng'] = (/** @type {?} */ (ɵglobal['ng'])) || {};
ng[name] = value;
}
}
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var CORE_TOKENS = {
'ApplicationRef': ApplicationRef,
'NgZone': NgZone,
};
var INSPECT_GLOBAL_NAME = 'probe';
var CORE_TOKENS_GLOBAL_NAME = 'coreTokens';
/**
* Returns a {\@link DebugElement} for the given native DOM element, or
* null if the given native element does not have an Angular view associated
* with it.
* @param {?} element
* @return {?}
*/
function inspectNativeElement(element) {
return getDebugNode(element);
}
/**
* @param {?} coreTokens
* @return {?}
*/
function _createNgProbe(coreTokens) {
exportNgVar(INSPECT_GLOBAL_NAME, inspectNativeElement);
exportNgVar(CORE_TOKENS_GLOBAL_NAME, __assign({}, CORE_TOKENS, _ngProbeTokensToMap(coreTokens || [])));
return function () { return inspectNativeElement; };
}
/**
* @param {?} tokens
* @return {?}
*/
function _ngProbeTokensToMap(tokens) {
return tokens.reduce(function (prev, t) { return (prev[t.name] = t.token, prev); }, {});
}
/**
* Providers which support debugging Angular applications (e.g. via `ng.probe`).
*/
var ELEMENT_PROBE_PROVIDERS = [
{
provide: APP_INITIALIZER,
useFactory: _createNgProbe,
deps: [
[NgProbeToken, new Optional()],
],
multi: true,
},
];
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* \@stable
*/
var EVENT_MANAGER_PLUGINS = new InjectionToken('EventManagerPlugins');
/**
* \@stable
*/
var EventManager = /** @class */ (function () {
function EventManager(plugins, _zone) {
var _this = this;
this._zone = _zone;
this._eventNameToPlugin = new Map();
plugins.forEach(function (p) { return p.manager = _this; });
this._plugins = plugins.slice().reverse();
}
/**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
EventManager.prototype.addEventListener = /**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
function (element, eventName, handler) {
var /** @type {?} */ plugin = this._findPluginFor(eventName);
return plugin.addEventListener(element, eventName, handler);
};
/**
* @param {?} target
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
EventManager.prototype.addGlobalEventListener = /**
* @param {?} target
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
function (target, eventName, handler) {
var /** @type {?} */ plugin = this._findPluginFor(eventName);
return plugin.addGlobalEventListener(target, eventName, handler);
};
/**
* @return {?}
*/
EventManager.prototype.getZone = /**
* @return {?}
*/
function () { return this._zone; };
/** @internal */
/**
* \@internal
* @param {?} eventName
* @return {?}
*/
EventManager.prototype._findPluginFor = /**
* \@internal
* @param {?} eventName
* @return {?}
*/
function (eventName) {
var /** @type {?} */ plugin = this._eventNameToPlugin.get(eventName);
if (plugin) {
return plugin;
}
var /** @type {?} */ plugins = this._plugins;
for (var /** @type {?} */ i = 0; i < plugins.length; i++) {
var /** @type {?} */ plugin_1 = plugins[i];
if (plugin_1.supports(eventName)) {
this._eventNameToPlugin.set(eventName, plugin_1);
return plugin_1;
}
}
throw new Error("No event manager plugin found for event " + eventName);
};
EventManager.decorators = [
{ type: Injectable },
];
/** @nocollapse */
EventManager.ctorParameters = function () { return [
{ type: Array, decorators: [{ type: Inject, args: [EVENT_MANAGER_PLUGINS,] },] },
{ type: NgZone, },
]; };
return EventManager;
}());
/**
* @abstract
*/
var EventManagerPlugin = /** @class */ (function () {
function EventManagerPlugin(_doc) {
this._doc = _doc;
}
/**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
EventManagerPlugin.prototype.addGlobalEventListener = /**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
function (element, eventName, handler) {
var /** @type {?} */ target = getDOM().getGlobalEventTarget(this._doc, element);
if (!target) {
throw new Error("Unsupported event target " + target + " for event " + eventName);
}
return this.addEventListener(target, eventName, handler);
};
return EventManagerPlugin;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var SharedStylesHost = /** @class */ (function () {
function SharedStylesHost() {
/**
* \@internal
*/
this._stylesSet = new Set();
}
/**
* @param {?} styles
* @return {?}
*/
SharedStylesHost.prototype.addStyles = /**
* @param {?} styles
* @return {?}
*/
function (styles) {
var _this = this;
var /** @type {?} */ additions = new Set();
styles.forEach(function (style) {
if (!_this._stylesSet.has(style)) {
_this._stylesSet.add(style);
additions.add(style);
}
});
this.onStylesAdded(additions);
};
/**
* @param {?} additions
* @return {?}
*/
SharedStylesHost.prototype.onStylesAdded = /**
* @param {?} additions
* @return {?}
*/
function (additions) { };
/**
* @return {?}
*/
SharedStylesHost.prototype.getAllStyles = /**
* @return {?}
*/
function () { return Array.from(this._stylesSet); };
SharedStylesHost.decorators = [
{ type: Injectable },
];
/** @nocollapse */
SharedStylesHost.ctorParameters = function () { return []; };
return SharedStylesHost;
}());
var DomSharedStylesHost = /** @class */ (function (_super) {
__extends(DomSharedStylesHost, _super);
function DomSharedStylesHost(_doc) {
var _this = _super.call(this) || this;
_this._doc = _doc;
_this._hostNodes = new Set();
_this._styleNodes = new Set();
_this._hostNodes.add(_doc.head);
return _this;
}
/**
* @param {?} styles
* @param {?} host
* @return {?}
*/
DomSharedStylesHost.prototype._addStylesToHost = /**
* @param {?} styles
* @param {?} host
* @return {?}
*/
function (styles, host) {
var _this = this;
styles.forEach(function (style) {
var /** @type {?} */ styleEl = _this._doc.createElement('style');
styleEl.textContent = style;
_this._styleNodes.add(host.appendChild(styleEl));
});
};
/**
* @param {?} hostNode
* @return {?}
*/
DomSharedStylesHost.prototype.addHost = /**
* @param {?} hostNode
* @return {?}
*/
function (hostNode) {
this._addStylesToHost(this._stylesSet, hostNode);
this._hostNodes.add(hostNode);
};
/**
* @param {?} hostNode
* @return {?}
*/
DomSharedStylesHost.prototype.removeHost = /**
* @param {?} hostNode
* @return {?}
*/
function (hostNode) { this._hostNodes.delete(hostNode); };
/**
* @param {?} additions
* @return {?}
*/
DomSharedStylesHost.prototype.onStylesAdded = /**
* @param {?} additions
* @return {?}
*/
function (additions) {
var _this = this;
this._hostNodes.forEach(function (hostNode) { return _this._addStylesToHost(additions, hostNode); });
};
/**
* @return {?}
*/
DomSharedStylesHost.prototype.ngOnDestroy = /**
* @return {?}
*/
function () { this._styleNodes.forEach(function (styleNode) { return getDOM().remove(styleNode); }); };
DomSharedStylesHost.decorators = [
{ type: Injectable },
];
/** @nocollapse */
DomSharedStylesHost.ctorParameters = function () { return [
{ type: undefined, decorators: [{ type: Inject, args: [DOCUMENT$1,] },] },
]; };
return DomSharedStylesHost;
}(SharedStylesHost));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var NAMESPACE_URIS = {
'svg': 'http://www.w3.org/2000/svg',
'xhtml': 'http://www.w3.org/1999/xhtml',
'xlink': 'http://www.w3.org/1999/xlink',
'xml': 'http://www.w3.org/XML/1998/namespace',
'xmlns': 'http://www.w3.org/2000/xmlns/',
};
var COMPONENT_REGEX = /%COMP%/g;
var COMPONENT_VARIABLE = '%COMP%';
var HOST_ATTR = "_nghost-" + COMPONENT_VARIABLE;
var CONTENT_ATTR = "_ngcontent-" + COMPONENT_VARIABLE;
/**
* @param {?} componentShortId
* @return {?}
*/
function shimContentAttribute(componentShortId) {
return CONTENT_ATTR.replace(COMPONENT_REGEX, componentShortId);
}
/**
* @param {?} componentShortId
* @return {?}
*/
function shimHostAttribute(componentShortId) {
return HOST_ATTR.replace(COMPONENT_REGEX, componentShortId);
}
/**
* @param {?} compId
* @param {?} styles
* @param {?} target
* @return {?}
*/
function flattenStyles(compId, styles, target) {
for (var /** @type {?} */ i = 0; i < styles.length; i++) {
var /** @type {?} */ style = styles[i];
if (Array.isArray(style)) {
flattenStyles(compId, style, target);
}
else {
style = style.replace(COMPONENT_REGEX, compId);
target.push(style);
}
}
return target;
}
/**
* @param {?} eventHandler
* @return {?}
*/
function decoratePreventDefault(eventHandler) {
return function (event) {
var /** @type {?} */ allowDefaultBehavior = eventHandler(event);
if (allowDefaultBehavior === false) {
// TODO(tbosch): move preventDefault into event plugins...
event.preventDefault();
event.returnValue = false;
}
};
}
var DomRendererFactory2 = /** @class */ (function () {
function DomRendererFactory2(eventManager, sharedStylesHost) {
this.eventManager = eventManager;
this.sharedStylesHost = sharedStylesHost;
this.rendererByCompId = new Map();
this.defaultRenderer = new DefaultDomRenderer2(eventManager);
}
/**
* @param {?} element
* @param {?} type
* @return {?}
*/
DomRendererFactory2.prototype.createRenderer = /**
* @param {?} element
* @param {?} type
* @return {?}
*/
function (element, type) {
if (!element || !type) {
return this.defaultRenderer;
}
switch (type.encapsulation) {
case ViewEncapsulation.Emulated: {
var /** @type {?} */ renderer = this.rendererByCompId.get(type.id);
if (!renderer) {
renderer =
new EmulatedEncapsulationDomRenderer2(this.eventManager, this.sharedStylesHost, type);
this.rendererByCompId.set(type.id, renderer);
}
(/** @type {?} */ (renderer)).applyToHost(element);
return renderer;
}
case ViewEncapsulation.Native:
return new ShadowDomRenderer(this.eventManager, this.sharedStylesHost, element, type);
default: {
if (!this.rendererByCompId.has(type.id)) {
var /** @type {?} */ styles = flattenStyles(type.id, type.styles, []);
this.sharedStylesHost.addStyles(styles);
this.rendererByCompId.set(type.id, this.defaultRenderer);
}
return this.defaultRenderer;
}
}
};
/**
* @return {?}
*/
DomRendererFactory2.prototype.begin = /**
* @return {?}
*/
function () { };
/**
* @return {?}
*/
DomRendererFactory2.prototype.end = /**
* @return {?}
*/
function () { };
DomRendererFactory2.decorators = [
{ type: Injectable },
];
/** @nocollapse */
DomRendererFactory2.ctorParameters = function () { return [
{ type: EventManager, },
{ type: DomSharedStylesHost, },
]; };
return DomRendererFactory2;
}());
var DefaultDomRenderer2 = /** @class */ (function () {
function DefaultDomRenderer2(eventManager) {
this.eventManager = eventManager;
this.data = Object.create(null);
}
/**
* @return {?}
*/
DefaultDomRenderer2.prototype.destroy = /**
* @return {?}
*/
function () { };
/**
* @param {?} name
* @param {?=} namespace
* @return {?}
*/
DefaultDomRenderer2.prototype.createElement = /**
* @param {?} name
* @param {?=} namespace
* @return {?}
*/
function (name, namespace) {
if (namespace) {
return document.createElementNS(NAMESPACE_URIS[namespace], name);
}
return document.createElement(name);
};
/**
* @param {?} value
* @return {?}
*/
DefaultDomRenderer2.prototype.createComment = /**
* @param {?} value
* @return {?}
*/
function (value) { return document.createComment(value); };
/**
* @param {?} value
* @return {?}
*/
DefaultDomRenderer2.prototype.createText = /**
* @param {?} value
* @return {?}
*/
function (value) { return document.createTextNode(value); };
/**
* @param {?} parent
* @param {?} newChild
* @return {?}
*/
DefaultDomRenderer2.prototype.appendChild = /**
* @param {?} parent
* @param {?} newChild
* @return {?}
*/
function (parent, newChild) { parent.appendChild(newChild); };
/**
* @param {?} parent
* @param {?} newChild
* @param {?} refChild
* @return {?}
*/
DefaultDomRenderer2.prototype.insertBefore = /**
* @param {?} parent
* @param {?} newChild
* @param {?} refChild
* @return {?}
*/
function (parent, newChild, refChild) {
if (parent) {
parent.insertBefore(newChild, refChild);
}
};
/**
* @param {?} parent
* @param {?} oldChild
* @return {?}
*/
DefaultDomRenderer2.prototype.removeChild = /**
* @param {?} parent
* @param {?} oldChild
* @return {?}
*/
function (parent, oldChild) {
if (parent) {
parent.removeChild(oldChild);
}
};
/**
* @param {?} selectorOrNode
* @return {?}
*/
DefaultDomRenderer2.prototype.selectRootElement = /**
* @param {?} selectorOrNode
* @return {?}
*/
function (selectorOrNode) {
var /** @type {?} */ el = typeof selectorOrNode === 'string' ? document.querySelector(selectorOrNode) :
selectorOrNode;
if (!el) {
throw new Error("The selector \"" + selectorOrNode + "\" did not match any elements");
}
el.textContent = '';
return el;
};
/**
* @param {?} node
* @return {?}
*/
DefaultDomRenderer2.prototype.parentNode = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.parentNode; };
/**
* @param {?} node
* @return {?}
*/
DefaultDomRenderer2.prototype.nextSibling = /**
* @param {?} node
* @return {?}
*/
function (node) { return node.nextSibling; };
/**
* @param {?} el
* @param {?} name
* @param {?} value
* @param {?=} namespace
* @return {?}
*/
DefaultDomRenderer2.prototype.setAttribute = /**
* @param {?} el
* @param {?} name
* @param {?} value
* @param {?=} namespace
* @return {?}
*/
function (el, name, value, namespace) {
if (namespace) {
name = namespace + ":" + name;
var /** @type {?} */ namespaceUri = NAMESPACE_URIS[namespace];
if (namespaceUri) {
el.setAttributeNS(namespaceUri, name, value);
}
else {
el.setAttribute(name, value);
}
}
else {
el.setAttribute(name, value);
}
};
/**
* @param {?} el
* @param {?} name
* @param {?=} namespace
* @return {?}
*/
DefaultDomRenderer2.prototype.removeAttribute = /**
* @param {?} el
* @param {?} name
* @param {?=} namespace
* @return {?}
*/
function (el, name, namespace) {
if (namespace) {
var /** @type {?} */ namespaceUri = NAMESPACE_URIS[namespace];
if (namespaceUri) {
el.removeAttributeNS(namespaceUri, name);
}
else {
el.removeAttribute(namespace + ":" + name);
}
}
else {
el.removeAttribute(name);
}
};
/**
* @param {?} el
* @param {?} name
* @return {?}
*/
DefaultDomRenderer2.prototype.addClass = /**
* @param {?} el
* @param {?} name
* @return {?}
*/
function (el, name) { el.classList.add(name); };
/**
* @param {?} el
* @param {?} name
* @return {?}
*/
DefaultDomRenderer2.prototype.removeClass = /**
* @param {?} el
* @param {?} name
* @return {?}
*/
function (el, name) { el.classList.remove(name); };
/**
* @param {?} el
* @param {?} style
* @param {?} value
* @param {?} flags
* @return {?}
*/
DefaultDomRenderer2.prototype.setStyle = /**
* @param {?} el
* @param {?} style
* @param {?} value
* @param {?} flags
* @return {?}
*/
function (el, style, value, flags) {
if (flags & RendererStyleFlags2.DashCase) {
el.style.setProperty(style, value, !!(flags & RendererStyleFlags2.Important) ? 'important' : '');
}
else {
el.style[style] = value;
}
};
/**
* @param {?} el
* @param {?} style
* @param {?} flags
* @return {?}
*/
DefaultDomRenderer2.prototype.removeStyle = /**
* @param {?} el
* @param {?} style
* @param {?} flags
* @return {?}
*/
function (el, style, flags) {
if (flags & RendererStyleFlags2.DashCase) {
el.style.removeProperty(style);
}
else {
// IE requires '' instead of null
// see https://github.com/angular/angular/issues/7916
el.style[style] = '';
}
};
/**
* @param {?} el
* @param {?} name
* @param {?} value
* @return {?}
*/
DefaultDomRenderer2.prototype.setProperty = /**
* @param {?} el
* @param {?} name
* @param {?} value
* @return {?}
*/
function (el, name, value) {
checkNoSyntheticProp(name, 'property');
el[name] = value;
};
/**
* @param {?} node
* @param {?} value
* @return {?}
*/
DefaultDomRenderer2.prototype.setValue = /**
* @param {?} node
* @param {?} value
* @return {?}
*/
function (node, value) { node.nodeValue = value; };
/**
* @param {?} target
* @param {?} event
* @param {?} callback
* @return {?}
*/
DefaultDomRenderer2.prototype.listen = /**
* @param {?} target
* @param {?} event
* @param {?} callback
* @return {?}
*/
function (target, event, callback) {
checkNoSyntheticProp(event, 'listener');
if (typeof target === 'string') {
return /** @type {?} */ (this.eventManager.addGlobalEventListener(target, event, decoratePreventDefault(callback)));
}
return /** @type {?} */ ((this.eventManager.addEventListener(target, event, decoratePreventDefault(callback))));
};
return DefaultDomRenderer2;
}());
var AT_CHARCODE = '@'.charCodeAt(0);
/**
* @param {?} name
* @param {?} nameKind
* @return {?}
*/
function checkNoSyntheticProp(name, nameKind) {
if (name.charCodeAt(0) === AT_CHARCODE) {
throw new Error("Found the synthetic " + nameKind + " " + name + ". Please include either \"BrowserAnimationsModule\" or \"NoopAnimationsModule\" in your application.");
}
}
var EmulatedEncapsulationDomRenderer2 = /** @class */ (function (_super) {
__extends(EmulatedEncapsulationDomRenderer2, _super);
function EmulatedEncapsulationDomRenderer2(eventManager, sharedStylesHost, component) {
var _this = _super.call(this, eventManager) || this;
_this.component = component;
var /** @type {?} */ styles = flattenStyles(component.id, component.styles, []);
sharedStylesHost.addStyles(styles);
_this.contentAttr = shimContentAttribute(component.id);
_this.hostAttr = shimHostAttribute(component.id);
return _this;
}
/**
* @param {?} element
* @return {?}
*/
EmulatedEncapsulationDomRenderer2.prototype.applyToHost = /**
* @param {?} element
* @return {?}
*/
function (element) { _super.prototype.setAttribute.call(this, element, this.hostAttr, ''); };
/**
* @param {?} parent
* @param {?} name
* @return {?}
*/
EmulatedEncapsulationDomRenderer2.prototype.createElement = /**
* @param {?} parent
* @param {?} name
* @return {?}
*/
function (parent, name) {
var /** @type {?} */ el = _super.prototype.createElement.call(this, parent, name);
_super.prototype.setAttribute.call(this, el, this.contentAttr, '');
return el;
};
return EmulatedEncapsulationDomRenderer2;
}(DefaultDomRenderer2));
var ShadowDomRenderer = /** @class */ (function (_super) {
__extends(ShadowDomRenderer, _super);
function ShadowDomRenderer(eventManager, sharedStylesHost, hostEl, component) {
var _this = _super.call(this, eventManager) || this;
_this.sharedStylesHost = sharedStylesHost;
_this.hostEl = hostEl;
_this.component = component;
_this.shadowRoot = (/** @type {?} */ (hostEl)).createShadowRoot();
_this.sharedStylesHost.addHost(_this.shadowRoot);
var /** @type {?} */ styles = flattenStyles(component.id, component.styles, []);
for (var /** @type {?} */ i = 0; i < styles.length; i++) {
var /** @type {?} */ styleEl = document.createElement('style');
styleEl.textContent = styles[i];
_this.shadowRoot.appendChild(styleEl);
}
return _this;
}
/**
* @param {?} node
* @return {?}
*/
ShadowDomRenderer.prototype.nodeOrShadowRoot = /**
* @param {?} node
* @return {?}
*/
function (node) { return node === this.hostEl ? this.shadowRoot : node; };
/**
* @return {?}
*/
ShadowDomRenderer.prototype.destroy = /**
* @return {?}
*/
function () { this.sharedStylesHost.removeHost(this.shadowRoot); };
/**
* @param {?} parent
* @param {?} newChild
* @return {?}
*/
ShadowDomRenderer.prototype.appendChild = /**
* @param {?} parent
* @param {?} newChild
* @return {?}
*/
function (parent, newChild) {
return _super.prototype.appendChild.call(this, this.nodeOrShadowRoot(parent), newChild);
};
/**
* @param {?} parent
* @param {?} newChild
* @param {?} refChild
* @return {?}
*/
ShadowDomRenderer.prototype.insertBefore = /**
* @param {?} parent
* @param {?} newChild
* @param {?} refChild
* @return {?}
*/
function (parent, newChild, refChild) {
return _super.prototype.insertBefore.call(this, this.nodeOrShadowRoot(parent), newChild, refChild);
};
/**
* @param {?} parent
* @param {?} oldChild
* @return {?}
*/
ShadowDomRenderer.prototype.removeChild = /**
* @param {?} parent
* @param {?} oldChild
* @return {?}
*/
function (parent, oldChild) {
return _super.prototype.removeChild.call(this, this.nodeOrShadowRoot(parent), oldChild);
};
/**
* @param {?} node
* @return {?}
*/
ShadowDomRenderer.prototype.parentNode = /**
* @param {?} node
* @return {?}
*/
function (node) {
return this.nodeOrShadowRoot(_super.prototype.parentNode.call(this, this.nodeOrShadowRoot(node)));
};
return ShadowDomRenderer;
}(DefaultDomRenderer2));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var ɵ0 = function (v) {
return '__zone_symbol__' + v;
};
/**
* Detect if Zone is present. If it is then use simple zone aware 'addEventListener'
* since Angular can do much more
* efficient bookkeeping than Zone can, because we have additional information. This speeds up
* addEventListener by 3x.
*/
var __symbol__ = (typeof Zone !== 'undefined') && (/** @type {?} */ (Zone))['__symbol__'] || ɵ0;
var ADD_EVENT_LISTENER = __symbol__('addEventListener');
var REMOVE_EVENT_LISTENER = __symbol__('removeEventListener');
var symbolNames = {};
var FALSE = 'FALSE';
var ANGULAR = 'ANGULAR';
var NATIVE_ADD_LISTENER = 'addEventListener';
var NATIVE_REMOVE_LISTENER = 'removeEventListener';
// use the same symbol string which is used in zone.js
var stopSymbol = '__zone_symbol__propagationStopped';
var stopMethodSymbol = '__zone_symbol__stopImmediatePropagation';
var blackListedEvents = (typeof Zone !== 'undefined') && (/** @type {?} */ (Zone))[__symbol__('BLACK_LISTED_EVENTS')];
var blackListedMap;
if (blackListedEvents) {
blackListedMap = {};
blackListedEvents.forEach(function (eventName) { blackListedMap[eventName] = eventName; });
}
var isBlackListedEvent = function (eventName) {
if (!blackListedMap) {
return false;
}
return blackListedMap.hasOwnProperty(eventName);
};
// a global listener to handle all dom event,
// so we do not need to create a closure everytime
var globalListener = function (event) {
var /** @type {?} */ symbolName = symbolNames[event.type];
if (!symbolName) {
return;
}
var /** @type {?} */ taskDatas = this[symbolName];
if (!taskDatas) {
return;
}
var /** @type {?} */ args = [event];
if (taskDatas.length === 1) {
// if taskDatas only have one element, just invoke it
var /** @type {?} */ taskData = taskDatas[0];
if (taskData.zone !== Zone.current) {
// only use Zone.run when Zone.current not equals to stored zone
return taskData.zone.run(taskData.handler, this, args);
}
else {
return taskData.handler.apply(this, args);
}
}
else {
// copy tasks as a snapshot to avoid event handlers remove
// itself or others
var /** @type {?} */ copiedTasks = taskDatas.slice();
for (var /** @type {?} */ i = 0; i < copiedTasks.length; i++) {
// if other listener call event.stopImmediatePropagation
// just break
if ((/** @type {?} */ (event))[stopSymbol] === true) {
break;
}
var /** @type {?} */ taskData = copiedTasks[i];
if (taskData.zone !== Zone.current) {
// only use Zone.run when Zone.current not equals to stored zone
taskData.zone.run(taskData.handler, this, args);
}
else {
taskData.handler.apply(this, args);
}
}
}
};
var DomEventsPlugin = /** @class */ (function (_super) {
__extends(DomEventsPlugin, _super);
function DomEventsPlugin(doc, ngZone) {
var _this = _super.call(this, doc) || this;
_this.ngZone = ngZone;
_this.patchEvent();
return _this;
}
/**
* @return {?}
*/
DomEventsPlugin.prototype.patchEvent = /**
* @return {?}
*/
function () {
if (!Event || !Event.prototype) {
return;
}
if ((/** @type {?} */ (Event.prototype))[stopMethodSymbol]) {
// already patched by zone.js
return;
}
var /** @type {?} */ delegate = (/** @type {?} */ (Event.prototype))[stopMethodSymbol] =
Event.prototype.stopImmediatePropagation;
Event.prototype.stopImmediatePropagation = function () {
if (this) {
this[stopSymbol] = true;
}
// should call native delegate in case
// in some enviroment part of the application
// will not use the patched Event
delegate && delegate.apply(this, arguments);
};
};
// This plugin should come last in the list of plugins, because it accepts all
// events.
/**
* @param {?} eventName
* @return {?}
*/
DomEventsPlugin.prototype.supports = /**
* @param {?} eventName
* @return {?}
*/
function (eventName) { return true; };
/**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
DomEventsPlugin.prototype.addEventListener = /**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
function (element, eventName, handler) {
var _this = this;
/**
* This code is about to add a listener to the DOM. If Zone.js is present, than
* `addEventListener` has been patched. The patched code adds overhead in both
* memory and speed (3x slower) than native. For this reason if we detect that
* Zone.js is present we use a simple version of zone aware addEventListener instead.
* The result is faster registration and the zone will be restored.
* But ZoneSpec.onScheduleTask, ZoneSpec.onInvokeTask, ZoneSpec.onCancelTask
* will not be invoked
* We also do manual zone restoration in element.ts renderEventHandlerClosure method.
*
* NOTE: it is possible that the element is from different iframe, and so we
* have to check before we execute the method.
*/
var /** @type {?} */ self = this;
var /** @type {?} */ zoneJsLoaded = element[ADD_EVENT_LISTENER];
var /** @type {?} */ callback = /** @type {?} */ (handler);
// if zonejs is loaded and current zone is not ngZone
// we keep Zone.current on target for later restoration.
if (zoneJsLoaded && (!NgZone.isInAngularZone() || isBlackListedEvent(eventName))) {
var /** @type {?} */ symbolName = symbolNames[eventName];
if (!symbolName) {
symbolName = symbolNames[eventName] = __symbol__(ANGULAR + eventName + FALSE);
}
var /** @type {?} */ taskDatas = (/** @type {?} */ (element))[symbolName];
var /** @type {?} */ globalListenerRegistered = taskDatas && taskDatas.length > 0;
if (!taskDatas) {
taskDatas = (/** @type {?} */ (element))[symbolName] = [];
}
var /** @type {?} */ zone = isBlackListedEvent(eventName) ? Zone.root : Zone.current;
if (taskDatas.length === 0) {
taskDatas.push({ zone: zone, handler: callback });
}
else {
var /** @type {?} */ callbackRegistered = false;
for (var /** @type {?} */ i = 0; i < taskDatas.length; i++) {
if (taskDatas[i].handler === callback) {
callbackRegistered = true;
break;
}
}
if (!callbackRegistered) {
taskDatas.push({ zone: zone, handler: callback });
}
}
if (!globalListenerRegistered) {
element[ADD_EVENT_LISTENER](eventName, globalListener, false);
}
}
else {
element[NATIVE_ADD_LISTENER](eventName, callback, false);
}
return function () { return _this.removeEventListener(element, eventName, callback); };
};
/**
* @param {?} target
* @param {?} eventName
* @param {?} callback
* @return {?}
*/
DomEventsPlugin.prototype.removeEventListener = /**
* @param {?} target
* @param {?} eventName
* @param {?} callback
* @return {?}
*/
function (target, eventName, callback) {
var /** @type {?} */ underlyingRemove = target[REMOVE_EVENT_LISTENER];
// zone.js not loaded, use native removeEventListener
if (!underlyingRemove) {
return target[NATIVE_REMOVE_LISTENER].apply(target, [eventName, callback, false]);
}
var /** @type {?} */ symbolName = symbolNames[eventName];
var /** @type {?} */ taskDatas = symbolName && target[symbolName];
if (!taskDatas) {
// addEventListener not using patched version
// just call native removeEventListener
return target[NATIVE_REMOVE_LISTENER].apply(target, [eventName, callback, false]);
}
// fix issue 20532, should be able to remove
// listener which was added inside of ngZone
var /** @type {?} */ found = false;
for (var /** @type {?} */ i = 0; i < taskDatas.length; i++) {
// remove listener from taskDatas if the callback equals
if (taskDatas[i].handler === callback) {
found = true;
taskDatas.splice(i, 1);
break;
}
}
if (found) {
if (taskDatas.length === 0) {
// all listeners are removed, we can remove the globalListener from target
underlyingRemove.apply(target, [eventName, globalListener, false]);
}
}
else {
// not found in taskDatas, the callback may be added inside of ngZone
// use native remove listener to remove the calback
target[NATIVE_REMOVE_LISTENER].apply(target, [eventName, callback, false]);
}
};
DomEventsPlugin.decorators = [
{ type: Injectable },
];
/** @nocollapse */
DomEventsPlugin.ctorParameters = function () { return [
{ type: undefined, decorators: [{ type: Inject, args: [DOCUMENT$1,] },] },
{ type: NgZone, },
]; };
return DomEventsPlugin;
}(EventManagerPlugin));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var EVENT_NAMES = {
// pan
'pan': true,
'panstart': true,
'panmove': true,
'panend': true,
'pancancel': true,
'panleft': true,
'panright': true,
'panup': true,
'pandown': true,
// pinch
'pinch': true,
'pinchstart': true,
'pinchmove': true,
'pinchend': true,
'pinchcancel': true,
'pinchin': true,
'pinchout': true,
// press
'press': true,
'pressup': true,
// rotate
'rotate': true,
'rotatestart': true,
'rotatemove': true,
'rotateend': true,
'rotatecancel': true,
// swipe
'swipe': true,
'swipeleft': true,
'swiperight': true,
'swipeup': true,
'swipedown': true,
// tap
'tap': true,
};
/**
* A DI token that you can use to provide{\@link HammerGestureConfig} to Angular. Use it to configure
* Hammer gestures.
*
* \@experimental
*/
var HAMMER_GESTURE_CONFIG = new InjectionToken('HammerGestureConfig');
/**
* @record
*/
/**
* \@experimental
*/
var HammerGestureConfig = /** @class */ (function () {
function HammerGestureConfig() {
this.events = [];
this.overrides = {};
}
/**
* @param {?} element
* @return {?}
*/
HammerGestureConfig.prototype.buildHammer = /**
* @param {?} element
* @return {?}
*/
function (element) {
var /** @type {?} */ mc = new Hammer(element);
mc.get('pinch').set({ enable: true });
mc.get('rotate').set({ enable: true });
for (var /** @type {?} */ eventName in this.overrides) {
mc.get(eventName).set(this.overrides[eventName]);
}
return mc;
};
HammerGestureConfig.decorators = [
{ type: Injectable },
];
/** @nocollapse */
HammerGestureConfig.ctorParameters = function () { return []; };
return HammerGestureConfig;
}());
var HammerGesturesPlugin = /** @class */ (function (_super) {
__extends(HammerGesturesPlugin, _super);
function HammerGesturesPlugin(doc, _config) {
var _this = _super.call(this, doc) || this;
_this._config = _config;
return _this;
}
/**
* @param {?} eventName
* @return {?}
*/
HammerGesturesPlugin.prototype.supports = /**
* @param {?} eventName
* @return {?}
*/
function (eventName) {
if (!EVENT_NAMES.hasOwnProperty(eventName.toLowerCase()) && !this.isCustomEvent(eventName)) {
return false;
}
if (!(/** @type {?} */ (window)).Hammer) {
throw new Error("Hammer.js is not loaded, can not bind " + eventName + " event");
}
return true;
};
/**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
HammerGesturesPlugin.prototype.addEventListener = /**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
function (element, eventName, handler) {
var _this = this;
var /** @type {?} */ zone = this.manager.getZone();
eventName = eventName.toLowerCase();
return zone.runOutsideAngular(function () {
// Creating the manager bind events, must be done outside of angular
var /** @type {?} */ mc = _this._config.buildHammer(element);
var /** @type {?} */ callback = function (eventObj) {
zone.runGuarded(function () { handler(eventObj); });
};
mc.on(eventName, callback);
return function () { return mc.off(eventName, callback); };
});
};
/**
* @param {?} eventName
* @return {?}
*/
HammerGesturesPlugin.prototype.isCustomEvent = /**
* @param {?} eventName
* @return {?}
*/
function (eventName) { return this._config.events.indexOf(eventName) > -1; };
HammerGesturesPlugin.decorators = [
{ type: Injectable },
];
/** @nocollapse */
HammerGesturesPlugin.ctorParameters = function () { return [
{ type: undefined, decorators: [{ type: Inject, args: [DOCUMENT$1,] },] },
{ type: HammerGestureConfig, decorators: [{ type: Inject, args: [HAMMER_GESTURE_CONFIG,] },] },
]; };
return HammerGesturesPlugin;
}(EventManagerPlugin));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var MODIFIER_KEYS = ['alt', 'control', 'meta', 'shift'];
var ɵ0$1 = function (event) { return event.altKey; };
var ɵ1$1 = function (event) { return event.ctrlKey; };
var ɵ2$1 = function (event) { return event.metaKey; };
var ɵ3 = function (event) { return event.shiftKey; };
var MODIFIER_KEY_GETTERS = {
'alt': ɵ0$1,
'control': ɵ1$1,
'meta': ɵ2$1,
'shift': ɵ3
};
/**
* \@experimental
*/
var KeyEventsPlugin = /** @class */ (function (_super) {
__extends(KeyEventsPlugin, _super);
function KeyEventsPlugin(doc) {
return _super.call(this, doc) || this;
}
/**
* @param {?} eventName
* @return {?}
*/
KeyEventsPlugin.prototype.supports = /**
* @param {?} eventName
* @return {?}
*/
function (eventName) { return KeyEventsPlugin.parseEventName(eventName) != null; };
/**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
KeyEventsPlugin.prototype.addEventListener = /**
* @param {?} element
* @param {?} eventName
* @param {?} handler
* @return {?}
*/
function (element, eventName, handler) {
var /** @type {?} */ parsedEvent = /** @type {?} */ ((KeyEventsPlugin.parseEventName(eventName)));
var /** @type {?} */ outsideHandler = KeyEventsPlugin.eventCallback(parsedEvent['fullKey'], handler, this.manager.getZone());
return this.manager.getZone().runOutsideAngular(function () {
return getDOM().onAndCancel(element, parsedEvent['domEventName'], outsideHandler);
});
};
/**
* @param {?} eventName
* @return {?}
*/
KeyEventsPlugin.parseEventName = /**
* @param {?} eventName
* @return {?}
*/
function (eventName) {
var /** @type {?} */ parts = eventName.toLowerCase().split('.');
var /** @type {?} */ domEventName = parts.shift();
if ((parts.length === 0) || !(domEventName === 'keydown' || domEventName === 'keyup')) {
return null;
}
var /** @type {?} */ key = KeyEventsPlugin._normalizeKey(/** @type {?} */ ((parts.pop())));
var /** @type {?} */ fullKey = '';
MODIFIER_KEYS.forEach(function (modifierName) {
var /** @type {?} */ index = parts.indexOf(modifierName);
if (index > -1) {
parts.splice(index, 1);
fullKey += modifierName + '.';
}
});
fullKey += key;
if (parts.length != 0 || key.length === 0) {
// returning null instead of throwing to let another plugin process the event
return null;
}
var /** @type {?} */ result = {};
result['domEventName'] = domEventName;
result['fullKey'] = fullKey;
return result;
};
/**
* @param {?} event
* @return {?}
*/
KeyEventsPlugin.getEventFullKey = /**
* @param {?} event
* @return {?}
*/
function (event) {
var /** @type {?} */ fullKey = '';
var /** @type {?} */ key = getDOM().getEventKey(event);
key = key.toLowerCase();
if (key === ' ') {
key = 'space'; // for readability
}
else if (key === '.') {
key = 'dot'; // because '.' is used as a separator in event names
}
MODIFIER_KEYS.forEach(function (modifierName) {
if (modifierName != key) {
var /** @type {?} */ modifierGetter = MODIFIER_KEY_GETTERS[modifierName];
if (modifierGetter(event)) {
fullKey += modifierName + '.';
}
}
});
fullKey += key;
return fullKey;
};
/**
* @param {?} fullKey
* @param {?} handler
* @param {?} zone
* @return {?}
*/
KeyEventsPlugin.eventCallback = /**
* @param {?} fullKey
* @param {?} handler
* @param {?} zone
* @return {?}
*/
function (fullKey, handler, zone) {
return function (event /** TODO #9100 */) {
if (KeyEventsPlugin.getEventFullKey(event) === fullKey) {
zone.runGuarded(function () { return handler(event); });
}
};
};
/** @internal */
/**
* \@internal
* @param {?} keyName
* @return {?}
*/
KeyEventsPlugin._normalizeKey = /**
* \@internal
* @param {?} keyName
* @return {?}
*/
function (keyName) {
// TODO: switch to a Map if the mapping grows too much
switch (keyName) {
case 'esc':
return 'escape';
default:
return keyName;
}
};
KeyEventsPlugin.decorators = [
{ type: Injectable },
];
/** @nocollapse */
KeyEventsPlugin.ctorParameters = function () { return [
{ type: undefined, decorators: [{ type: Inject, args: [DOCUMENT$1,] },] },
]; };
return KeyEventsPlugin;
}(EventManagerPlugin));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* A pattern that recognizes a commonly useful subset of URLs that are safe.
*
* This regular expression matches a subset of URLs that will not cause script
* execution if used in URL context within a HTML document. Specifically, this
* regular expression matches if (comment from here on and regex copied from
* Soy's EscapingConventions):
* (1) Either a protocol in a whitelist (http, https, mailto or ftp).
* (2) or no protocol. A protocol must be followed by a colon. The below
* allows that by allowing colons only after one of the characters [/?#].
* A colon after a hash (#) must be in the fragment.
* Otherwise, a colon after a (?) must be in a query.
* Otherwise, a colon after a single solidus (/) must be in a path.
* Otherwise, a colon after a double solidus (//) must be in the authority
* (before port).
*
* The pattern disallows &, used in HTML entity declarations before
* one of the characters in [/?#]. This disallows HTML entities used in the
* protocol name, which should never happen, e.g. "http" for "http".
* It also disallows HTML entities in the first path part of a relative path,
* e.g. "foo<bar/baz". Our existing escaping functions should not produce
* that. More importantly, it disallows masking of a colon,
* e.g. "javascript:...".
*
* This regular expression was taken from the Closure sanitization library.
*/
var SAFE_URL_PATTERN = /^(?:(?:https?|mailto|ftp|tel|file):|[^&:/?#]*(?:[/?#]|$))/gi;
/**
* A pattern that matches safe data URLs. Only matches image, video and audio types.
*/
var DATA_URL_PATTERN = /^data:(?:image\/(?:bmp|gif|jpeg|jpg|png|tiff|webp)|video\/(?:mpeg|mp4|ogg|webm)|audio\/(?:mp3|oga|ogg|opus));base64,[a-z0-9+\/]+=*$/i;
/**
* @param {?} url
* @return {?}
*/
function sanitizeUrl(url) {
url = String(url);
if (url.match(SAFE_URL_PATTERN) || url.match(DATA_URL_PATTERN))
return url;
if (isDevMode()) {
getDOM().log("WARNING: sanitizing unsafe URL value " + url + " (see http://g.co/ng/security#xss)");
}
return 'unsafe:' + url;
}
/**
* @param {?} srcset
* @return {?}
*/
function sanitizeSrcset(srcset) {
srcset = String(srcset);
return srcset.split(',').map(function (srcset) { return sanitizeUrl(srcset.trim()); }).join(', ');
}
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* A <body> element that can be safely used to parse untrusted HTML. Lazily initialized below.
*/
var inertElement = null;
/**
* Lazily initialized to make sure the DOM adapter gets set before use.
*/
var DOM = /** @type {?} */ ((null));
/**
* Returns an HTML element that is guaranteed to not execute code when creating elements in it.
* @return {?}
*/
function getInertElement() {
if (inertElement)
return inertElement;
DOM = getDOM();
// Prefer using <template> element if supported.
var /** @type {?} */ templateEl = DOM.createElement('template');
if ('content' in templateEl)
return templateEl;
var /** @type {?} */ doc = DOM.createHtmlDocument();
inertElement = DOM.querySelector(doc, 'body');
if (inertElement == null) {
// usually there should be only one body element in the document, but IE doesn't have any, so we
// need to create one.
var /** @type {?} */ html = DOM.createElement('html', doc);
inertElement = DOM.createElement('body', doc);
DOM.appendChild(html, inertElement);
DOM.appendChild(doc, html);
}
return inertElement;
}
/**
* @param {?} tags
* @return {?}
*/
function tagSet(tags) {
var /** @type {?} */ res = {};
for (var _i = 0, _a = tags.split(','); _i < _a.length; _i++) {
var t = _a[_i];
res[t] = true;
}
return res;
}
/**
* @param {...?} sets
* @return {?}
*/
function merge() {
var sets = [];
for (var _i = 0; _i < arguments.length; _i++) {
sets[_i] = arguments[_i];
}
var /** @type {?} */ res = {};
for (var _a = 0, sets_1 = sets; _a < sets_1.length; _a++) {
var s = sets_1[_a];
for (var /** @type {?} */ v in s) {
if (s.hasOwnProperty(v))
res[v] = true;
}
}
return res;
}
// Good source of info about elements and attributes
// http://dev.w3.org/html5/spec/Overview.html#semantics
// http://simon.html5.org/html-elements
// Safe Void Elements - HTML5
// http://dev.w3.org/html5/spec/Overview.html#void-elements
var VOID_ELEMENTS = tagSet('area,br,col,hr,img,wbr');
// Elements that you can, intentionally, leave open (and which close themselves)
// http://dev.w3.org/html5/spec/Overview.html#optional-tags
var OPTIONAL_END_TAG_BLOCK_ELEMENTS = tagSet('colgroup,dd,dt,li,p,tbody,td,tfoot,th,thead,tr');
var OPTIONAL_END_TAG_INLINE_ELEMENTS = tagSet('rp,rt');
var OPTIONAL_END_TAG_ELEMENTS = merge(OPTIONAL_END_TAG_INLINE_ELEMENTS, OPTIONAL_END_TAG_BLOCK_ELEMENTS);
// Safe Block Elements - HTML5
var BLOCK_ELEMENTS = merge(OPTIONAL_END_TAG_BLOCK_ELEMENTS, tagSet('address,article,' +
'aside,blockquote,caption,center,del,details,dialog,dir,div,dl,figure,figcaption,footer,h1,h2,h3,h4,h5,' +
'h6,header,hgroup,hr,ins,main,map,menu,nav,ol,pre,section,summary,table,ul'));
// Inline Elements - HTML5
var INLINE_ELEMENTS = merge(OPTIONAL_END_TAG_INLINE_ELEMENTS, tagSet('a,abbr,acronym,audio,b,' +
'bdi,bdo,big,br,cite,code,del,dfn,em,font,i,img,ins,kbd,label,map,mark,picture,q,ruby,rp,rt,s,' +
'samp,small,source,span,strike,strong,sub,sup,time,track,tt,u,var,video'));
var VALID_ELEMENTS = merge(VOID_ELEMENTS, BLOCK_ELEMENTS, INLINE_ELEMENTS, OPTIONAL_END_TAG_ELEMENTS);
// Attributes that have href and hence need to be sanitized
var URI_ATTRS = tagSet('background,cite,href,itemtype,longdesc,poster,src,xlink:href');
// Attributes that have special href set hence need to be sanitized
var SRCSET_ATTRS = tagSet('srcset');
var HTML_ATTRS = tagSet('abbr,accesskey,align,alt,autoplay,axis,bgcolor,border,cellpadding,cellspacing,class,clear,color,cols,colspan,' +
'compact,controls,coords,datetime,default,dir,download,face,headers,height,hidden,hreflang,hspace,' +
'ismap,itemscope,itemprop,kind,label,lang,language,loop,media,muted,nohref,nowrap,open,preload,rel,rev,role,rows,rowspan,rules,' +
'scope,scrolling,shape,size,sizes,span,srclang,start,summary,tabindex,target,title,translate,type,usemap,' +
'valign,value,vspace,width');
// NB: This currently consciously doesn't support SVG. SVG sanitization has had several security
// issues in the past, so it seems safer to leave it out if possible. If support for binding SVG via
// innerHTML is required, SVG attributes should be added here.
// NB: Sanitization does not allow <form> elements or other active elements (<button> etc). Those
// can be sanitized, but they increase security surface area without a legitimate use case, so they
// are left out here.
var VALID_ATTRS = merge(URI_ATTRS, SRCSET_ATTRS, HTML_ATTRS);
/**
* SanitizingHtmlSerializer serializes a DOM fragment, stripping out any unsafe elements and unsafe
* attributes.
*/
var SanitizingHtmlSerializer = /** @class */ (function () {
function SanitizingHtmlSerializer() {
this.sanitizedSomething = false;
this.buf = [];
}
/**
* @param {?} el
* @return {?}
*/
SanitizingHtmlSerializer.prototype.sanitizeChildren = /**
* @param {?} el
* @return {?}
*/
function (el) {
// This cannot use a TreeWalker, as it has to run on Angular's various DOM adapters.
// However this code never accesses properties off of `document` before deleting its contents
// again, so it shouldn't be vulnerable to DOM clobbering.
var /** @type {?} */ current = /** @type {?} */ ((el.firstChild));
while (current) {
if (DOM.isElementNode(current)) {
this.startElement(/** @type {?} */ (current));
}
else if (DOM.isTextNode(current)) {
this.chars(/** @type {?} */ ((DOM.nodeValue(current))));
}
else {
// Strip non-element, non-text nodes.
this.sanitizedSomething = true;
}
if (DOM.firstChild(current)) {
current = /** @type {?} */ ((DOM.firstChild(current)));
continue;
}
while (current) {
// Leaving the element. Walk up and to the right, closing tags as we go.
if (DOM.isElementNode(current)) {
this.endElement(/** @type {?} */ (current));
}
var /** @type {?} */ next = checkClobberedElement(current, /** @type {?} */ ((DOM.nextSibling(current))));
if (next) {
current = next;
break;
}
current = checkClobberedElement(current, /** @type {?} */ ((DOM.parentElement(current))));
}
}
return this.buf.join('');
};
/**
* @param {?} element
* @return {?}
*/
SanitizingHtmlSerializer.prototype.startElement = /**
* @param {?} element
* @return {?}
*/
function (element) {
var _this = this;
var /** @type {?} */ tagName = DOM.nodeName(element).toLowerCase();
if (!VALID_ELEMENTS.hasOwnProperty(tagName)) {
this.sanitizedSomething = true;
return;
}
this.buf.push('<');
this.buf.push(tagName);
DOM.attributeMap(element).forEach(function (value, attrName) {
var /** @type {?} */ lower = attrName.toLowerCase();
if (!VALID_ATTRS.hasOwnProperty(lower)) {
_this.sanitizedSomething = true;
return;
}
// TODO(martinprobst): Special case image URIs for data:image/...
if (URI_ATTRS[lower])
value = sanitizeUrl(value);
if (SRCSET_ATTRS[lower])
value = sanitizeSrcset(value);
_this.buf.push(' ');
_this.buf.push(attrName);
_this.buf.push('="');
_this.buf.push(encodeEntities(value));
_this.buf.push('"');
});
this.buf.push('>');
};
/**
* @param {?} current
* @return {?}
*/
SanitizingHtmlSerializer.prototype.endElement = /**
* @param {?} current
* @return {?}
*/
function (current) {
var /** @type {?} */ tagName = DOM.nodeName(current).toLowerCase();
if (VALID_ELEMENTS.hasOwnProperty(tagName) && !VOID_ELEMENTS.hasOwnProperty(tagName)) {
this.buf.push('</');
this.buf.push(tagName);
this.buf.push('>');
}
};
/**
* @param {?} chars
* @return {?}
*/
SanitizingHtmlSerializer.prototype.chars = /**
* @param {?} chars
* @return {?}
*/
function (chars) { this.buf.push(encodeEntities(chars)); };
return SanitizingHtmlSerializer;
}());
/**
* @param {?} node
* @param {?} nextNode
* @return {?}
*/
function checkClobberedElement(node, nextNode) {
if (nextNode && DOM.contains(node, nextNode)) {
throw new Error("Failed to sanitize html because the element is clobbered: " + DOM.getOuterHTML(node));
}
return nextNode;
}
// Regular Expressions for parsing tags and attributes
var SURROGATE_PAIR_REGEXP = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g;
// ! to ~ is the ASCII range.
var NON_ALPHANUMERIC_REGEXP = /([^\#-~ |!])/g;
/**
* Escapes all potentially dangerous characters, so that the
* resulting string can be safely inserted into attribute or
* element text.
* @param {?} value
* @return {?}
*/
function encodeEntities(value) {
return value.replace(/&/g, '&')
.replace(SURROGATE_PAIR_REGEXP, function (match) {
var /** @type {?} */ hi = match.charCodeAt(0);
var /** @type {?} */ low = match.charCodeAt(1);
return '&#' + (((hi - 0xD800) * 0x400) + (low - 0xDC00) + 0x10000) + ';';
})
.replace(NON_ALPHANUMERIC_REGEXP, function (match) { return '&#' + match.charCodeAt(0) + ';'; })
.replace(/</g, '<')
.replace(/>/g, '>');
}
/**
* When IE9-11 comes across an unknown namespaced attribute e.g. 'xlink:foo' it adds 'xmlns:ns1'
* attribute to declare ns1 namespace and prefixes the attribute with 'ns1' (e.g. 'ns1:xlink:foo').
*
* This is undesirable since we don't want to allow any of these custom attributes. This method
* strips them all.
* @param {?} el
* @return {?}
*/
function stripCustomNsAttrs(el) {
DOM.attributeMap(el).forEach(function (_, attrName) {
if (attrName === 'xmlns:ns1' || attrName.indexOf('ns1:') === 0) {
DOM.removeAttribute(el, attrName);
}
});
for (var _i = 0, _a = DOM.childNodesAsList(el); _i < _a.length; _i++) {
var n = _a[_i];
if (DOM.isElementNode(n))
stripCustomNsAttrs(/** @type {?} */ (n));
}
}
/**
* Sanitizes the given unsafe, untrusted HTML fragment, and returns HTML text that is safe to add to
* the DOM in a browser environment.
* @param {?} defaultDoc
* @param {?} unsafeHtmlInput
* @return {?}
*/
function sanitizeHtml(defaultDoc, unsafeHtmlInput) {
try {
var /** @type {?} */ containerEl = getInertElement();
// Make sure unsafeHtml is actually a string (TypeScript types are not enforced at runtime).
var /** @type {?} */ unsafeHtml = unsafeHtmlInput ? String(unsafeHtmlInput) : '';
// mXSS protection. Repeatedly parse the document to make sure it stabilizes, so that a browser
// trying to auto-correct incorrect HTML cannot cause formerly inert HTML to become dangerous.
var /** @type {?} */ mXSSAttempts = 5;
var /** @type {?} */ parsedHtml = unsafeHtml;
do {
if (mXSSAttempts === 0) {
throw new Error('Failed to sanitize html because the input is unstable');
}
mXSSAttempts--;
unsafeHtml = parsedHtml;
DOM.setInnerHTML(containerEl, unsafeHtml);
if (defaultDoc.documentMode) {
// strip custom-namespaced attributes on IE<=11
stripCustomNsAttrs(containerEl);
}
parsedHtml = DOM.getInnerHTML(containerEl);
} while (unsafeHtml !== parsedHtml);
var /** @type {?} */ sanitizer = new SanitizingHtmlSerializer();
var /** @type {?} */ safeHtml = sanitizer.sanitizeChildren(DOM.getTemplateContent(containerEl) || containerEl);
// Clear out the body element.
var /** @type {?} */ parent_1 = DOM.getTemplateContent(containerEl) || containerEl;
for (var _i = 0, _a = DOM.childNodesAsList(parent_1); _i < _a.length; _i++) {
var child = _a[_i];
DOM.removeChild(parent_1, child);
}
if (isDevMode() && sanitizer.sanitizedSomething) {
DOM.log('WARNING: sanitizing HTML stripped some content (see http://g.co/ng/security#xss).');
}
return safeHtml;
}
catch (/** @type {?} */ e) {
// In case anything goes wrong, clear out inertElement to reset the entire DOM structure.
inertElement = null;
throw e;
}
}
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* Regular expression for safe style values.
*
* Quotes (" and ') are allowed, but a check must be done elsewhere to ensure they're balanced.
*
* ',' allows multiple values to be assigned to the same property (e.g. background-attachment or
* font-family) and hence could allow multiple values to get injected, but that should pose no risk
* of XSS.
*
* The function expression checks only for XSS safety, not for CSS validity.
*
* This regular expression was taken from the Closure sanitization library, and augmented for
* transformation values.
*/
var VALUES = '[-,."\'%_!# a-zA-Z0-9]+';
var TRANSFORMATION_FNS = '(?:matrix|translate|scale|rotate|skew|perspective)(?:X|Y|3d)?';
var COLOR_FNS = '(?:rgb|hsl)a?';
var GRADIENTS = '(?:repeating-)?(?:linear|radial)-gradient';
var CSS3_FNS = '(?:calc|attr)';
var FN_ARGS = '\\([-0-9.%, #a-zA-Z]+\\)';
var SAFE_STYLE_VALUE = new RegExp("^(" + VALUES + "|" +
("(?:" + TRANSFORMATION_FNS + "|" + COLOR_FNS + "|" + GRADIENTS + "|" + CSS3_FNS + ")") +
(FN_ARGS + ")$"), 'g');
/**
* Matches a `url(...)` value with an arbitrary argument as long as it does
* not contain parentheses.
*
|
*
* `url(...)` values are a very common use case, e.g. for `background-image`. With carefully crafted
* CSS style rules, it is possible to construct an information leak with `url` values in CSS, e.g.
* by observing whether scroll bars are displayed, or character ranges used by a font face
* definition.
*
* Angular only allows binding CSS values (as opposed to entire CSS rules), so it is unlikely that
* binding a URL value without further cooperation from the page will cause an information leak, and
* if so, it is just a leak, not a full blown XSS vulnerability.
*
* Given the common use case, low likelihood of attack vector, and low impact of an attack, this
* code is permissive and allows URLs that sanitize otherwise.
*/
var URL_RE = /^url\(([^)]+)\)$/;
/**
* Checks that quotes (" and ') are properly balanced inside a string. Assumes
* that neither escape (\) nor any other character that could result in
* breaking out of a string parsing context are allowed;
* see http://www.w3.org/TR/css3-syntax/#string-token-diagram.
*
* This code was taken from the Closure sanitization library.
* @param {?} value
* @return {?}
*/
function hasBalancedQuotes(value) {
var /** @type {?} */ outsideSingle = true;
var /** @type {?} */ outsideDouble = true;
for (var /** @type {?} */ i = 0; i < value.length; i++) {
var /** @type {?} */ c = value.charAt(i);
if (c === '\'' && outsideDouble) {
outsideSingle = !outsideSingle;
}
else if (c === '"' && outsideSingle) {
outsideDouble = !outsideDouble;
}
}
return outsideSingle && outsideDouble;
}
/**
* Sanitizes the given untrusted CSS style property value (i.e. not an entire object, just a single
* value) and returns a value that is safe to use in a browser environment.
* @param {?} value
* @return {?}
*/
function sanitizeStyle(value) {
value = String(value).trim(); // Make sure it's actually a string.
if (!value)
return '';
// Single url(...) values are supported, but only for URLs that sanitize cleanly. See above for
// reasoning behind this.
var /** @type {?} */ urlMatch = value.match(URL_RE);
if ((urlMatch && sanitizeUrl(urlMatch[1]) === urlMatch[1]) ||
value.match(SAFE_STYLE_VALUE) && hasBalancedQuotes(value)) {
return value; // Safe style values.
}
if (isDevMode()) {
getDOM().log("WARNING: sanitizing unsafe style value " + value + " (see http://g.co/ng/security#xss).");
}
return 'unsafe';
}
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* Marker interface for a value that's safe to use in a particular context.
*
* \@stable
* @record
*/
/**
* Marker interface for a value that's safe to use as HTML.
*
* \@stable
* @record
*/
/**
* Marker interface for a value that's safe to use as style (CSS).
*
* \@stable
* @record
*/
/**
* Marker interface for a value that's safe to use as JavaScript.
*
* \@stable
* @record
*/
/**
* Marker interface for a value that's safe to use as a URL linking to a document.
*
* \@stable
* @record
*/
/**
* Marker interface for a value that's safe to use as a URL to load executable code from.
*
* \@stable
* @record
*/
/**
* DomSanitizer helps preventing Cross Site Scripting Security bugs (XSS) by sanitizing
* values to be safe to use in the different DOM contexts.
*
* For example, when binding a URL in an `<a [href]="someValue">` hyperlink, `someValue` will be
* sanitized so that an attacker cannot inject e.g. a `javascript:` URL that would execute code on
* the website.
*
* In specific situations, it might be necessary to disable sanitization, for example if the
* application genuinely needs to produce a `javascript:` style link with a dynamic value in it.
* Users can bypass security by constructing a value with one of the `bypassSecurityTrust...`
* methods, and then binding to that value from the template.
*
* These situations should be very rare, and extraordinary care must be taken to avoid creating a
* Cross Site Scripting (XSS) security bug!
*
* When using `bypassSecurityTrust...`, make sure to call the method as early as possible and as
* close as possible to the source of the value, to make it easy to verify no security bug is
* created by its use.
*
* It is not required (and not recommended) to bypass security if the value is safe, e.g. a URL that
* does not start with a suspicious protocol, or an HTML snippet that does not contain dangerous
* code. The sanitizer leaves safe values intact.
*
* \@security Calling any of the `bypassSecurityTrust...` APIs disables Angular's built-in
* sanitization for the value passed in. Carefully check and audit all values and code paths going
* into this call. Make sure any user data is appropriately escaped for this security context.
* For more detail, see the [Security Guide](http://g.co/ng/security).
*
* \@stable
* @abstract
*/
var DomSanitizer = /** @class */ (function () {
function DomSanitizer() {
}
return DomSanitizer;
}());
var DomSanitizerImpl = /** @class */ (function (_super) {
__extends(DomSanitizerImpl, _super);
function DomSanitizerImpl(_doc) {
var _this = _super.call(this) || this;
_this._doc = _doc;
return _this;
}
/**
* @param {?} ctx
* @param {?} value
* @return {?}
*/
DomSanitizerImpl.prototype.sanitize = /**
* @param {?} ctx
* @param {?} value
* @return {?}
*/
function (ctx, value) {
if (value == null)
return null;
switch (ctx) {
case SecurityContext.NONE:
return /** @type {?} */ (value);
case SecurityContext.HTML:
if (value instanceof SafeHtmlImpl)
return value.changingThisBreaksApplicationSecurity;
this.checkNotSafeValue(value, 'HTML');
return sanitizeHtml(this._doc, String(value));
case SecurityContext.STYLE:
if (value instanceof SafeStyleImpl)
return value.changingThisBreaksApplicationSecurity;
this.checkNotSafeValue(value, 'Style');
return sanitizeStyle(/** @type {?} */ (value));
case SecurityContext.SCRIPT:
if (value instanceof SafeScriptImpl)
return value.changingThisBreaksApplicationSecurity;
this.checkNotSafeValue(value, 'Script');
throw new Error('unsafe value used in a script context');
case SecurityContext.URL:
if (value instanceof SafeResourceUrlImpl || value instanceof SafeUrlImpl) {
// Allow resource URLs in URL contexts, they are strictly more trusted.
return value.changingThisBreaksApplicationSecurity;
}
this.checkNotSafeValue(value, 'URL');
return sanitizeUrl(String(value));
case SecurityContext.RESOURCE_URL:
if (value instanceof SafeResourceUrlImpl) {
return value.changingThisBreaksApplicationSecurity;
}
this.checkNotSafeValue(value, 'ResourceURL');
throw new Error('unsafe value used in a resource URL context (see http://g.co/ng/security#xss)');
default:
throw new Error("Unexpected SecurityContext " + ctx + " (see http://g.co/ng/security#xss)");
}
};
/**
* @param {?} value
* @param {?} expectedType
* @return {?}
*/
DomSanitizerImpl.prototype.checkNotSafeValue = /**
* @param {?} value
* @param {?} expectedType
* @return {?}
*/
function (value, expectedType) {
if (value instanceof SafeValueImpl) {
throw new Error("Required a safe " + expectedType + ", got a " + value.getTypeName() + " " +
"(see http://g.co/ng/security#xss)");
}
};
/**
* @param {?} value
* @return {?}
*/
DomSanitizerImpl.prototype.bypassSecurityTrustHtml = /**
* @param {?} value
* @return {?}
*/
function (value) { return new SafeHtmlImpl(value); };
/**
* @param {?} value
* @return {?}
*/
DomSanitizerImpl.prototype.bypassSecurityTrustStyle = /**
* @param {?} value
* @return {?}
*/
function (value) { return new SafeStyleImpl(value); };
/**
* @param {?} value
* @return {?}
*/
DomSanitizerImpl.prototype.bypassSecurityTrustScript = /**
* @param {?} value
* @return {?}
*/
function (value) { return new SafeScriptImpl(value); };
/**
* @param {?} value
* @return {?}
*/
DomSanitizerImpl.prototype.bypassSecurityTrustUrl = /**
* @param {?} value
* @return {?}
*/
function (value) { return new SafeUrlImpl(value); };
/**
* @param {?} value
* @return {?}
*/
DomSanitizerImpl.prototype.bypassSecurityTrustResourceUrl = /**
* @param {?} value
* @return {?}
*/
function (value) {
return new SafeResourceUrlImpl(value);
};
DomSanitizerImpl.decorators = [
{ type: Injectable },
];
/** @nocollapse */
DomSanitizerImpl.ctorParameters = function () { return [
{ type: undefined, decorators: [{ type: Inject, args: [DOCUMENT$1,] },] },
]; };
return DomSanitizerImpl;
}(DomSanitizer));
/**
* @abstract
*/
var SafeValueImpl = /** @class */ (function () {
function SafeValueImpl(changingThisBreaksApplicationSecurity) {
// empty
this.changingThisBreaksApplicationSecurity = changingThisBreaksApplicationSecurity;
}
/**
* @return {?}
*/
SafeValueImpl.prototype.toString = /**
* @return {?}
*/
function () {
return "SafeValue must use [property]=binding: " + this.changingThisBreaksApplicationSecurity +
" (see http://g.co/ng/security#xss)";
};
return SafeValueImpl;
}());
var SafeHtmlImpl = /** @class */ (function (_super) {
__extends(SafeHtmlImpl, _super);
function SafeHtmlImpl() {
return _super !== null && _super.apply(this, arguments) || this;
}
/**
* @return {?}
*/
SafeHtmlImpl.prototype.getTypeName = /**
* @return {?}
*/
function () { return 'HTML'; };
return SafeHtmlImpl;
}(SafeValueImpl));
var SafeStyleImpl = /** @class */ (function (_super) {
__extends(SafeStyleImpl, _super);
function SafeStyleImpl() {
return _super !== null && _super.apply(this, arguments) || this;
}
/**
* @return {?}
*/
SafeStyleImpl.prototype.getTypeName = /**
* @return {?}
*/
function () { return 'Style'; };
return SafeStyleImpl;
}(SafeValueImpl));
var SafeScriptImpl = /** @class */ (function (_super) {
__extends(SafeScriptImpl, _super);
function SafeScriptImpl() {
return _super !== null && _super.apply(this, arguments) || this;
}
/**
* @return {?}
*/
SafeScriptImpl.prototype.getTypeName = /**
* @return {?}
*/
function () { return 'Script'; };
return SafeScriptImpl;
}(SafeValueImpl));
var SafeUrlImpl = /** @class */ (function (_super) {
__extends(SafeUrlImpl, _super);
function SafeUrlImpl() {
return _super !== null && _super.apply(this, arguments) || this;
}
/**
* @return {?}
*/
SafeUrlImpl.prototype.getTypeName = /**
* @return {?}
*/
function () { return 'URL'; };
return SafeUrlImpl;
}(SafeValueImpl));
var SafeResourceUrlImpl = /** @class */ (function (_super) {
__extends(SafeResourceUrlImpl, _super);
function SafeResourceUrlImpl() {
return _super !== null && _super.apply(this, arguments) || this;
}
/**
* @return {?}
*/
SafeResourceUrlImpl.prototype.getTypeName = /**
* @return {?}
*/
function () { return 'ResourceURL'; };
return SafeResourceUrlImpl;
}(SafeValueImpl));
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var INTERNAL_BROWSER_PLATFORM_PROVIDERS = [
{ provide: PLATFORM_ID, useValue: ɵPLATFORM_BROWSER_ID },
{ provide: PLATFORM_INITIALIZER, useValue: initDomAdapter, multi: true },
{ provide: PlatformLocation, useClass: BrowserPlatformLocation, deps: [DOCUMENT$1] },
{ provide: DOCUMENT$1, useFactory: _document, deps: [] },
];
/**
* \@security Replacing built-in sanitization providers exposes the application to XSS risks.
* Attacker-controlled data introduced by an unsanitized provider could expose your
* application to XSS risks. For more detail, see the [Security Guide](http://g.co/ng/security).
* \@experimental
*/
var BROWSER_SANITIZATION_PROVIDERS = [
{ provide: Sanitizer, useExisting: DomSanitizer },
{ provide: DomSanitizer, useClass: DomSanitizerImpl, deps: [DOCUMENT$1] },
];
/**
* \@stable
*/
var platformBrowser = createPlatformFactory(platformCore, 'browser', INTERNAL_BROWSER_PLATFORM_PROVIDERS);
/**
* @return {?}
*/
function initDomAdapter() {
BrowserDomAdapter.makeCurrent();
BrowserGetTestability.init();
}
/**
* @return {?}
*/
function errorHandler() {
return new ErrorHandler();
}
/**
* @return {?}
*/
function _document() {
return document;
}
/**
* The ng module for the browser.
*
* \@stable
*/
var BrowserModule = /** @class */ (function () {
function BrowserModule(parentModule) {
if (parentModule) {
throw new Error("BrowserModule has already been loaded. If you need access to common directives such as NgIf and NgFor from a lazy loaded module, import CommonModule instead.");
}
}
/**
* Configures a browser-based application to transition from a server-rendered app, if
* one is present on the page. The specified parameters must include an application id,
* which must match between the client and server applications.
*
* @experimental
*/
/**
* Configures a browser-based application to transition from a server-rendered app, if
* one is present on the page. The specified parameters must include an application id,
* which must match between the client and server applications.
*
* \@experimental
* @param {?} params
* @return {?}
*/
BrowserModule.withServerTransition = /**
* Configures a browser-based application to transition from a server-rendered app, if
* one is present on the page. The specified parameters must include an application id,
* which must match between the client and server applications.
*
* \@experimental
* @param {?} params
* @return {?}
*/
function (params) {
return {
ngModule: BrowserModule,
providers: [
{ provide: APP_ID, useValue: params.appId },
{ provide: TRANSITION_ID, useExisting: APP_ID },
SERVER_TRANSITION_PROVIDERS,
],
};
};
BrowserModule.decorators = [
{ type: NgModule, args: [{
providers: [
BROWSER_SANITIZATION_PROVIDERS,
{ provide: ErrorHandler, useFactory: errorHandler, deps: [] },
{ provide: EVENT_MANAGER_PLUGINS, useClass: DomEventsPlugin, multi: true },
{ provide: EVENT_MANAGER_PLUGINS, useClass: KeyEventsPlugin, multi: true },
{ provide: EVENT_MANAGER_PLUGINS, useClass: HammerGesturesPlugin, multi: true },
{ provide: HAMMER_GESTURE_CONFIG, useClass: HammerGestureConfig },
DomRendererFactory2,
{ provide: RendererFactory2, useExisting: DomRendererFactory2 },
{ provide: SharedStylesHost, useExisting: DomSharedStylesHost },
DomSharedStylesHost,
Testability,
EventManager,
ELEMENT_PROBE_PROVIDERS,
Meta,
Title,
],
exports: [CommonModule, ApplicationModule]
},] },
];
/** @nocollapse */
BrowserModule.ctorParameters = function () { return [
{ type: BrowserModule, decorators: [{ type: Optional }, { type: SkipSelf },] },
]; };
return BrowserModule;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var win = typeof window !== 'undefined' && window || /** @type {?} */ ({});
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var ChangeDetectionPerfRecord = /** @class */ (function () {
function ChangeDetectionPerfRecord(msPerTick, numTicks) {
this.msPerTick = msPerTick;
this.numTicks = numTicks;
}
return ChangeDetectionPerfRecord;
}());
/**
* Entry point for all Angular profiling-related debug tools. This object
* corresponds to the `ng.profiler` in the dev console.
*/
var AngularProfiler = /** @class */ (function () {
function AngularProfiler(ref) {
this.appRef = ref.injector.get(ApplicationRef);
}
// tslint:disable:no-console
/**
* Exercises change detection in a loop and then prints the average amount of
* time in milliseconds how long a single round of change detection takes for
* the current state of the UI. It runs a minimum of 5 rounds for a minimum
* of 500 milliseconds.
*
* Optionally, a user may pass a `config` parameter containing a map of
* options. Supported options are:
*
* `record` (boolean) - causes the profiler to record a CPU profile while
* it exercises the change detector. Example:
*
* ```
* ng.profiler.timeChangeDetection({record: true})
* ```
*/
/**
* Exercises change detection in a loop and then prints the average amount of
* time in milliseconds how long a single round of change detection takes for
* the current state of the UI. It runs a minimum of 5 rounds for a minimum
* of 500 milliseconds.
*
* Optionally, a user may pass a `config` parameter containing a map of
* options. Supported options are:
*
* `record` (boolean) - causes the profiler to record a CPU profile while
* it exercises the change detector. Example:
*
* ```
* ng.profiler.timeChangeDetection({record: true})
* ```
* @param {?} config
* @return {?}
*/
AngularProfiler.prototype.timeChangeDetection = /**
* Exercises change detection in a loop and then prints the average amount of
* time in milliseconds how long a single round of change detection takes for
* the current state of the UI. It runs a minimum of 5 rounds for a minimum
* of 500 milliseconds.
*
* Optionally, a user may pass a `config` parameter containing a map of
* options. Supported options are:
*
* `record` (boolean) - causes the profiler to record a CPU profile while
* it exercises the change detector. Example:
*
* ```
* ng.profiler.timeChangeDetection({record: true})
* ```
* @param {?} config
* @return {?}
*/
function (config) {
var /** @type {?} */ record = config && config['record'];
var /** @type {?} */ profileName = 'Change Detection';
// Profiler is not available in Android browsers, nor in IE 9 without dev tools opened
var /** @type {?} */ isProfilerAvailable = win.console.profile != null;
if (record && isProfilerAvailable) {
win.console.profile(profileName);
}
var /** @type {?} */ start = getDOM().performanceNow();
var /** @type {?} */ numTicks = 0;
while (numTicks < 5 || (getDOM().performanceNow() - start) < 500) {
this.appRef.tick();
numTicks++;
}
var /** @type {?} */ end = getDOM().performanceNow();
if (record && isProfilerAvailable) {
// need to cast to <any> because type checker thinks there's no argument
// while in fact there is:
//
// https://developer.mozilla.org/en-US/docs/Web/API/Console/profileEnd
(/** @type {?} */ (win.console.profileEnd))(profileName);
}
var /** @type {?} */ msPerTick = (end - start) / numTicks;
win.console.log("ran " + numTicks + " change detection cycles");
win.console.log(msPerTick.toFixed(2) + " ms per check");
return new ChangeDetectionPerfRecord(msPerTick, numTicks);
};
return AngularProfiler;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
var PROFILER_GLOBAL_NAME = 'profiler';
/**
* Enabled Angular debug tools that are accessible via your browser's
* developer console.
*
* Usage:
*
* 1. Open developer console (e.g. in Chrome Ctrl + Shift + j)
* 1. Type `ng.` (usually the console will show auto-complete suggestion)
* 1. Try the change detection profiler `ng.profiler.timeChangeDetection()`
* then hit Enter.
*
* \@experimental All debugging apis are currently experimental.
* @template T
* @param {?} ref
* @return {?}
*/
function enableDebugTools(ref) {
exportNgVar(PROFILER_GLOBAL_NAME, new AngularProfiler(ref));
return ref;
}
/**
* Disables Angular tools.
*
* \@experimental All debugging apis are currently experimental.
* @return {?}
*/
function disableDebugTools() {
exportNgVar(PROFILER_GLOBAL_NAME, null);
}
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* @param {?} text
* @return {?}
*/
function escapeHtml(text) {
var /** @type {?} */ escapedText = {
'&': '&a;',
'"': '&q;',
'\'': '&s;',
'<': '&l;',
'>': '&g;',
};
return text.replace(/[&"'<>]/g, function (s) { return escapedText[s]; });
}
/**
* @param {?} text
* @return {?}
*/
function unescapeHtml(text) {
var /** @type {?} */ unescapedText = {
'&a;': '&',
'&q;': '"',
'&s;': '\'',
'&l;': '<',
'&g;': '>',
};
return text.replace(/&[^;]+;/g, function (s) { return unescapedText[s]; });
}
/**
* Create a `StateKey<T>` that can be used to store value of type T with `TransferState`.
*
* Example:
*
* ```
* const COUNTER_KEY = makeStateKey<number>('counter');
* let value = 10;
*
* transferState.set(COUNTER_KEY, value);
* ```
*
* \@experimental
* @template T
* @param {?} key
* @return {?}
*/
function makeStateKey(key) {
return /** @type {?} */ (key);
}
/**
* A key value store that is transferred from the application on the server side to the application
* on the client side.
*
* `TransferState` will be available as an injectable token. To use it import
* `ServerTransferStateModule` on the server and `BrowserTransferStateModule` on the client.
*
* The values in the store are serialized/deserialized using JSON.stringify/JSON.parse. So only
* boolean, number, string, null and non-class objects will be serialized and deserialzied in a
* non-lossy manner.
*
* \@experimental
*/
var TransferState = /** @class */ (function () {
function TransferState() {
this.store = {};
this.onSerializeCallbacks = {};
}
/** @internal */
/**
* \@internal
* @param {?} initState
* @return {?}
*/
TransferState.init = /**
* \@internal
* @param {?} initState
* @return {?}
*/
function (initState) {
var /** @type {?} */ transferState = new TransferState();
transferState.store = initState;
return transferState;
};
/**
* Get the value corresponding to a key. Return `defaultValue` if key is not found.
*/
/**
* Get the value corresponding to a key. Return `defaultValue` if key is not found.
* @template T
* @param {?} key
* @param {?} defaultValue
* @return {?}
*/
TransferState.prototype.get = /**
* Get the value corresponding to a key. Return `defaultValue` if key is not found.
* @template T
* @param {?} key
* @param {?} defaultValue
* @return {?}
*/
function (key, defaultValue) { return /** @type {?} */ (this.store[key]) || defaultValue; };
/**
* Set the value corresponding to a key.
*/
/**
* Set the value corresponding to a key.
* @template T
* @param {?} key
* @param {?} value
* @return {?}
*/
TransferState.prototype.set = /**
* Set the value corresponding to a key.
* @template T
* @param {?} key
* @param {?} value
* @return {?}
*/
function (key, value) { this.store[key] = value; };
/**
* Remove a key from the store.
*/
/**
* Remove a key from the store.
* @template T
* @param {?} key
* @return {?}
*/
TransferState.prototype.remove = /**
* Remove a key from the store.
* @template T
* @param {?} key
* @return {?}
*/
function (key) { delete this.store[key]; };
/**
* Test whether a key exists in the store.
*/
/**
* Test whether a key exists in the store.
* @template T
* @param {?} key
* @return {?}
*/
TransferState.prototype.hasKey = /**
* Test whether a key exists in the store.
* @template T
* @param {?} key
* @return {?}
*/
function (key) { return this.store.hasOwnProperty(key); };
/**
* Register a callback to provide the value for a key when `toJson` is called.
*/
/**
* Register a callback to provide the value for a key when `toJson` is called.
* @template T
* @param {?} key
* @param {?} callback
* @return {?}
*/
TransferState.prototype.onSerialize = /**
* Register a callback to provide the value for a key when `toJson` is called.
* @template T
* @param {?} key
* @param {?} callback
* @return {?}
*/
function (key, callback) {
this.onSerializeCallbacks[key] = callback;
};
/**
* Serialize the current state of the store to JSON.
*/
/**
* Serialize the current state of the store to JSON.
* @return {?}
*/
TransferState.prototype.toJson = /**
* Serialize the current state of the store to JSON.
* @return {?}
*/
function () {
// Call the onSerialize callbacks and put those values into the store.
for (var /** @type {?} */ key in this.onSerializeCallbacks) {
if (this.onSerializeCallbacks.hasOwnProperty(key)) {
try {
this.store[key] = this.onSerializeCallbacks[key]();
}
catch (/** @type {?} */ e) {
console.warn('Exception in onSerialize callback: ', e);
}
}
}
return JSON.stringify(this.store);
};
TransferState.decorators = [
{ type: Injectable },
];
/** @nocollapse */
TransferState.ctorParameters = function () { return []; };
return TransferState;
}());
/**
* @param {?} doc
* @param {?} appId
* @return {?}
*/
function initTransferState(doc, appId) {
// Locate the script tag with the JSON data transferred from the server.
// The id of the script tag is set to the Angular appId + 'state'.
var /** @type {?} */ script = doc.getElementById(appId + '-state');
var /** @type {?} */ initialState = {};
if (script && script.textContent) {
try {
initialState = JSON.parse(unescapeHtml(script.textContent));
}
catch (/** @type {?} */ e) {
console.warn('Exception while restoring TransferState for app ' + appId, e);
}
}
return TransferState.init(initialState);
}
/**
* NgModule to install on the client side while using the `TransferState` to transfer state from
* server to client.
*
* \@experimental
*/
var BrowserTransferStateModule = /** @class */ (function () {
function BrowserTransferStateModule() {
}
BrowserTransferStateModule.decorators = [
{ type: NgModule, args: [{
providers: [{ provide: TransferState, useFactory: initTransferState, deps: [DOCUMENT$1, APP_ID] }],
},] },
];
/** @nocollapse */
BrowserTransferStateModule.ctorParameters = function () { return []; };
return BrowserTransferStateModule;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* Predicates for use with {\@link DebugElement}'s query functions.
*
* \@experimental All debugging apis are currently experimental.
*/
var By = /** @class */ (function () {
function By() {
}
/**
* Match all elements.
*
* ## Example
*
* {@example platform-browser/dom/debug/ts/by/by.ts region='by_all'}
*/
/**
* Match all elements.
*
* ## Example
*
* {\@example platform-browser/dom/debug/ts/by/by.ts region='by_all'}
* @return {?}
*/
By.all = /**
* Match all elements.
*
* ## Example
*
* {\@example platform-browser/dom/debug/ts/by/by.ts region='by_all'}
* @return {?}
*/
function () { return function (debugElement) { return true; }; };
/**
* Match elements by the given CSS selector.
*
* ## Example
*
* {@example platform-browser/dom/debug/ts/by/by.ts region='by_css'}
*/
/**
* Match elements by the given CSS selector.
*
* ## Example
*
* {\@example platform-browser/dom/debug/ts/by/by.ts region='by_css'}
* @param {?} selector
* @return {?}
*/
By.css = /**
* Match elements by the given CSS selector.
*
* ## Example
*
* {\@example platform-browser/dom/debug/ts/by/by.ts region='by_css'}
* @param {?} selector
* @return {?}
*/
function (selector) {
return function (debugElement) {
return debugElement.nativeElement != null ?
getDOM().elementMatches(debugElement.nativeElement, selector) :
false;
};
};
/**
* Match elements that have the given directive present.
*
* ## Example
*
* {@example platform-browser/dom/debug/ts/by/by.ts region='by_directive'}
*/
/**
* Match elements that have the given directive present.
*
* ## Example
*
* {\@example platform-browser/dom/debug/ts/by/by.ts region='by_directive'}
* @param {?} type
* @return {?}
*/
By.directive = /**
* Match elements that have the given directive present.
*
* ## Example
*
* {\@example platform-browser/dom/debug/ts/by/by.ts region='by_directive'}
* @param {?} type
* @return {?}
*/
function (type) {
return function (debugElement) { return ((debugElement.providerTokens)).indexOf(type) !== -1; };
};
return By;
}());
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* @module
* @description
* Entry point for all public APIs of the common package.
*/
/**
* \@stable
*/
var VERSION = new Version('5.1.2');
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* @license
* Copyright Google Inc. All Rights Reserved.
*
* Use of this source code is governed by an MIT-style license that can be
* found in the LICENSE file at https://angular.io/license
*/
/**
* @module
* @description
* Entry point for all public APIs of this package.
*/
// This file only reexports content of the `src` folder. Keep it that way.
/**
* @fileoverview added by tsickle
* @suppress {checkTypes} checked by tsc
*/
/**
* Generated bundle index. Do not edit.
*/
export { BrowserModule, platformBrowser, Meta, Title, disableDebugTools, enableDebugTools, BrowserTransferStateModule, TransferState, makeStateKey, By, DOCUMENT$1 as DOCUMENT, EVENT_MANAGER_PLUGINS, EventManager, HAMMER_GESTURE_CONFIG, HammerGestureConfig, DomSanitizer, VERSION, BROWSER_SANITIZATION_PROVIDERS as ɵBROWSER_SANITIZATION_PROVIDERS, INTERNAL_BROWSER_PLATFORM_PROVIDERS as ɵINTERNAL_BROWSER_PLATFORM_PROVIDERS, initDomAdapter as ɵinitDomAdapter, BrowserDomAdapter as ɵBrowserDomAdapter, BrowserPlatformLocation as ɵBrowserPlatformLocation, TRANSITION_ID as ɵTRANSITION_ID, BrowserGetTestability as ɵBrowserGetTestability, escapeHtml as ɵescapeHtml, ELEMENT_PROBE_PROVIDERS as ɵELEMENT_PROBE_PROVIDERS, DomAdapter as ɵDomAdapter, getDOM as ɵgetDOM, setRootDomAdapter as ɵsetRootDomAdapter, DomRendererFactory2 as ɵDomRendererFactory2, NAMESPACE_URIS as ɵNAMESPACE_URIS, flattenStyles as ɵflattenStyles, shimContentAttribute as ɵshimContentAttribute, shimHostAttribute as ɵshimHostAttribute, DomEventsPlugin as ɵDomEventsPlugin, HammerGesturesPlugin as ɵHammerGesturesPlugin, KeyEventsPlugin as ɵKeyEventsPlugin, DomSharedStylesHost as ɵDomSharedStylesHost, SharedStylesHost as ɵSharedStylesHost, _document as ɵb, errorHandler as ɵa, GenericBrowserDomAdapter as ɵi, SERVER_TRANSITION_PROVIDERS as ɵg, appInitializerFactory as ɵf, initTransferState as ɵc, _createNgProbe as ɵh, EventManagerPlugin as ɵd, DomSanitizerImpl as ɵe };
//# sourceMappingURL=platform-browser.js.map
|
* The URL value still needs to be sanitized separately.
|
iter.rs
|
// Copyright 2014 The Rust Project Developers. See the COPYRIGHT
// file at the top-level directory of this distribution and at
// http://rust-lang.org/COPYRIGHT.
//
// Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or
// http://www.apache.org/licenses/LICENSE-2.0> or the MIT license
// <LICENSE-MIT or http://opensource.org/licenses/MIT>, at your
// option. This file may not be copied, modified, or distributed
// except according to those terms.
use core::iter::*;
use core::iter::order::*;
use core::iter::MinMaxResult::*;
use core::num::SignedInt;
use core::uint;
use core::cmp;
use core::ops::Slice;
use test::Bencher;
#[test]
fn test_lt() {
let empty: [int; 0] = [];
let xs = [1i,2,3];
let ys = [1i,2,0];
assert!(!lt(xs.iter(), ys.iter()));
assert!(!le(xs.iter(), ys.iter()));
assert!( gt(xs.iter(), ys.iter()));
assert!( ge(xs.iter(), ys.iter()));
assert!( lt(ys.iter(), xs.iter()));
assert!( le(ys.iter(), xs.iter()));
assert!(!gt(ys.iter(), xs.iter()));
assert!(!ge(ys.iter(), xs.iter()));
assert!( lt(empty.iter(), xs.iter()));
assert!( le(empty.iter(), xs.iter()));
assert!(!gt(empty.iter(), xs.iter()));
assert!(!ge(empty.iter(), xs.iter()));
// Sequence with NaN
let u = [1.0f64, 2.0];
let v = [0.0f64/0.0, 3.0];
assert!(!lt(u.iter(), v.iter()));
assert!(!le(u.iter(), v.iter()));
assert!(!gt(u.iter(), v.iter()));
assert!(!ge(u.iter(), v.iter()));
let a = [0.0f64/0.0];
let b = [1.0f64];
let c = [2.0f64];
assert!(lt(a.iter(), b.iter()) == (a[0] < b[0]));
assert!(le(a.iter(), b.iter()) == (a[0] <= b[0]));
assert!(gt(a.iter(), b.iter()) == (a[0] > b[0]));
assert!(ge(a.iter(), b.iter()) == (a[0] >= b[0]));
assert!(lt(c.iter(), b.iter()) == (c[0] < b[0]));
assert!(le(c.iter(), b.iter()) == (c[0] <= b[0]));
assert!(gt(c.iter(), b.iter()) == (c[0] > b[0]));
assert!(ge(c.iter(), b.iter()) == (c[0] >= b[0]));
}
#[test]
fn test_multi_iter() {
let xs = [1i,2,3,4];
let ys = [4i,3,2,1];
assert!(eq(xs.iter(), ys.iter().rev()));
assert!(lt(xs.iter(), xs.iter().skip(2)));
}
#[test]
fn test_counter_from_iter() {
let it = count(0i, 5).take(10);
let xs: Vec<int> = FromIterator::from_iter(it);
assert!(xs == vec![0, 5, 10, 15, 20, 25, 30, 35, 40, 45]);
}
#[test]
fn test_iterator_chain() {
let xs = [0u, 1, 2, 3, 4, 5];
let ys = [30u, 40, 50, 60];
let expected = [0, 1, 2, 3, 4, 5, 30, 40, 50, 60];
let mut it = xs.iter().chain(ys.iter());
let mut i = 0;
for &x in it {
assert_eq!(x, expected[i]);
i += 1;
}
assert_eq!(i, expected.len());
let ys = count(30u, 10).take(4);
let mut it = xs.iter().map(|&x| x).chain(ys);
let mut i = 0;
for x in it {
assert_eq!(x, expected[i]);
i += 1;
}
assert_eq!(i, expected.len());
}
#[test]
fn test_filter_map() {
let mut it = count(0u, 1u).take(10)
.filter_map(|x| if x % 2 == 0 { Some(x*x) } else { None });
assert!(it.collect::<Vec<uint>>() == vec![0*0, 2*2, 4*4, 6*6, 8*8]);
}
#[test]
fn test_iterator_enumerate() {
let xs = [0u, 1, 2, 3, 4, 5];
let mut it = xs.iter().enumerate();
for (i, &x) in it {
assert_eq!(i, x);
}
}
#[test]
fn test_iterator_peekable() {
let xs = vec![0u, 1, 2, 3, 4, 5];
let mut it = xs.iter().map(|&x|x).peekable();
assert_eq!(it.peek().unwrap(), &0);
assert_eq!(it.next().unwrap(), 0);
assert_eq!(it.next().unwrap(), 1);
assert_eq!(it.next().unwrap(), 2);
assert_eq!(it.peek().unwrap(), &3);
assert_eq!(it.peek().unwrap(), &3);
assert_eq!(it.next().unwrap(), 3);
assert_eq!(it.next().unwrap(), 4);
assert_eq!(it.peek().unwrap(), &5);
assert_eq!(it.next().unwrap(), 5);
assert!(it.peek().is_none());
assert!(it.next().is_none());
}
#[test]
fn test_iterator_take_while() {
let xs = [0u, 1, 2, 3, 5, 13, 15, 16, 17, 19];
let ys = [0u, 1, 2, 3, 5, 13];
let mut it = xs.iter().take_while(|&x| *x < 15u);
let mut i = 0;
for x in it {
assert_eq!(*x, ys[i]);
i += 1;
}
assert_eq!(i, ys.len());
}
#[test]
fn test_iterator_skip_while() {
let xs = [0u, 1, 2, 3, 5, 13, 15, 16, 17, 19];
let ys = [15, 16, 17, 19];
let mut it = xs.iter().skip_while(|&x| *x < 15u);
let mut i = 0;
for x in it {
assert_eq!(*x, ys[i]);
i += 1;
}
assert_eq!(i, ys.len());
}
#[test]
fn test_iterator_skip() {
let xs = [0u, 1, 2, 3, 5, 13, 15, 16, 17, 19, 20, 30];
let ys = [13, 15, 16, 17, 19, 20, 30];
let mut it = xs.iter().skip(5);
let mut i = 0;
for &x in it {
assert_eq!(x, ys[i]);
i += 1;
}
assert_eq!(i, ys.len());
}
#[test]
fn test_iterator_take() {
let xs = [0u, 1, 2, 3, 5, 13, 15, 16, 17, 19];
let ys = [0u, 1, 2, 3, 5];
let mut it = xs.iter().take(5);
let mut i = 0;
for &x in it {
assert_eq!(x, ys[i]);
i += 1;
}
assert_eq!(i, ys.len());
}
#[test]
fn test_iterator_scan() {
// test the type inference
fn add(old: &mut int, new: &uint) -> Option<f64> {
*old += *new as int;
Some(*old as f64)
}
let xs = [0u, 1, 2, 3, 4];
let ys = [0f64, 1.0, 3.0, 6.0, 10.0];
let mut it = xs.iter().scan(0, add);
let mut i = 0;
for x in it {
assert_eq!(x, ys[i]);
i += 1;
}
assert_eq!(i, ys.len());
}
#[test]
fn test_iterator_flat_map() {
let xs = [0u, 3, 6];
let ys = [0u, 1, 2, 3, 4, 5, 6, 7, 8];
let mut it = xs.iter().flat_map(|&x| count(x, 1).take(3));
let mut i = 0;
for x in it {
assert_eq!(x, ys[i]);
i += 1;
}
assert_eq!(i, ys.len());
}
#[test]
fn test_inspect() {
let xs = [1u, 2, 3, 4];
let mut n = 0u;
let ys = xs.iter()
.map(|&x| x)
.inspect(|_| n += 1)
.collect::<Vec<uint>>();
assert_eq!(n, xs.len());
assert_eq!(xs[], ys[]);
}
#[test]
fn test_unfoldr() {
fn count(st: &mut uint) -> Option<uint> {
if *st < 10 {
let ret = Some(*st);
*st += 1;
ret
} else {
None
}
}
let mut it = Unfold::new(0, count);
let mut i = 0;
for counted in it {
assert_eq!(counted, i);
i += 1;
}
assert_eq!(i, 10);
}
#[test]
fn test_cycle() {
let cycle_len = 3;
let it = count(0u, 1).take(cycle_len).cycle();
assert_eq!(it.size_hint(), (uint::MAX, None));
for (i, x) in it.take(100).enumerate() {
assert_eq!(i % cycle_len, x);
}
let mut it = count(0u, 1).take(0).cycle();
assert_eq!(it.size_hint(), (0, Some(0)));
assert_eq!(it.next(), None);
}
#[test]
fn test_iterator_nth() {
let v: &[_] = &[0i, 1, 2, 3, 4];
for i in range(0u, v.len()) {
assert_eq!(v.iter().nth(i).unwrap(), &v[i]);
}
assert_eq!(v.iter().nth(v.len()), None);
}
#[test]
fn test_iterator_last() {
let v: &[_] = &[0i, 1, 2, 3, 4];
assert_eq!(v.iter().last().unwrap(), &4);
assert_eq!(v[0..1].iter().last().unwrap(), &0);
}
#[test]
fn test_iterator_len() {
let v: &[_] = &[0i, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
assert_eq!(v[0..4].iter().count(), 4);
assert_eq!(v[0..10].iter().count(), 10);
assert_eq!(v[0..0].iter().count(), 0);
}
#[test]
fn test_iterator_sum() {
let v: &[_] = &[0i, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
assert_eq!(v[0..4].iter().map(|&x| x).sum(), 6);
assert_eq!(v.iter().map(|&x| x).sum(), 55);
assert_eq!(v[0..0].iter().map(|&x| x).sum(), 0);
}
#[test]
fn test_iterator_product() {
let v: &[_] = &[0i, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
assert_eq!(v[0..4].iter().map(|&x| x).product(), 0);
assert_eq!(v[1..5].iter().map(|&x| x).product(), 24);
assert_eq!(v[0..0].iter().map(|&x| x).product(), 1);
}
#[test]
fn test_iterator_max() {
let v: &[_] = &[0i, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
assert_eq!(v[0..4].iter().map(|&x| x).max(), Some(3));
assert_eq!(v.iter().map(|&x| x).max(), Some(10));
assert_eq!(v[0..0].iter().map(|&x| x).max(), None);
}
#[test]
fn test_iterator_min() {
let v: &[_] = &[0i, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
assert_eq!(v[0..4].iter().map(|&x| x).min(), Some(0));
assert_eq!(v.iter().map(|&x| x).min(), Some(0));
assert_eq!(v[0..0].iter().map(|&x| x).min(), None);
}
#[test]
fn test_iterator_size_hint() {
let c = count(0i, 1);
let v: &[_] = &[0i, 1, 2, 3, 4, 5, 6, 7, 8, 9];
let v2 = &[10i, 11, 12];
let vi = v.iter();
assert_eq!(c.size_hint(), (uint::MAX, None));
assert_eq!(vi.size_hint(), (10, Some(10)));
assert_eq!(c.take(5).size_hint(), (5, Some(5)));
assert_eq!(c.skip(5).size_hint().1, None);
assert_eq!(c.take_while(|_| false).size_hint(), (0, None));
assert_eq!(c.skip_while(|_| false).size_hint(), (0, None));
assert_eq!(c.enumerate().size_hint(), (uint::MAX, None));
assert_eq!(c.chain(vi.map(|&i| i)).size_hint(), (uint::MAX, None));
assert_eq!(c.zip(vi).size_hint(), (10, Some(10)));
assert_eq!(c.scan(0i, |_,_| Some(0i)).size_hint(), (0, None));
assert_eq!(c.filter(|_| false).size_hint(), (0, None));
assert_eq!(c.map(|_| 0i).size_hint(), (uint::MAX, None));
assert_eq!(c.filter_map(|_| Some(0i)).size_hint(), (0, None));
assert_eq!(vi.take(5).size_hint(), (5, Some(5)));
assert_eq!(vi.take(12).size_hint(), (10, Some(10)));
assert_eq!(vi.skip(3).size_hint(), (7, Some(7)));
assert_eq!(vi.skip(12).size_hint(), (0, Some(0)));
assert_eq!(vi.take_while(|_| false).size_hint(), (0, Some(10)));
assert_eq!(vi.skip_while(|_| false).size_hint(), (0, Some(10)));
assert_eq!(vi.enumerate().size_hint(), (10, Some(10)));
assert_eq!(vi.chain(v2.iter()).size_hint(), (13, Some(13)));
assert_eq!(vi.zip(v2.iter()).size_hint(), (3, Some(3)));
assert_eq!(vi.scan(0i, |_,_| Some(0i)).size_hint(), (0, Some(10)));
assert_eq!(vi.filter(|_| false).size_hint(), (0, Some(10)));
assert_eq!(vi.map(|&i| i+1).size_hint(), (10, Some(10)));
assert_eq!(vi.filter_map(|_| Some(0i)).size_hint(), (0, Some(10)));
}
#[test]
fn test_collect() {
let a = vec![1i, 2, 3, 4, 5];
let b: Vec<int> = a.iter().map(|&x| x).collect();
assert!(a == b);
}
#[test]
fn test_all() {
let v: Box<[int]> = box [1i, 2, 3, 4, 5];
assert!(v.iter().all(|&x| x < 10));
assert!(!v.iter().all(|&x| x % 2 == 0));
assert!(!v.iter().all(|&x| x > 100));
assert!(v.slice_or_fail(&0, &0).iter().all(|_| panic!()));
}
#[test]
fn test_any() {
let v: Box<[int]> = box [1i, 2, 3, 4, 5];
assert!(v.iter().any(|&x| x < 10));
assert!(v.iter().any(|&x| x % 2 == 0));
assert!(!v.iter().any(|&x| x > 100));
assert!(!v.slice_or_fail(&0, &0).iter().any(|_| panic!()));
}
#[test]
fn test_find() {
let v: &[int] = &[1i, 3, 9, 27, 103, 14, 11];
assert_eq!(*v.iter().find(|&&x| x & 1 == 0).unwrap(), 14);
assert_eq!(*v.iter().find(|&&x| x % 3 == 0).unwrap(), 3);
assert!(v.iter().find(|&&x| x % 12 == 0).is_none());
}
#[test]
fn test_position() {
let v = &[1i, 3, 9, 27, 103, 14, 11];
assert_eq!(v.iter().position(|x| *x & 1 == 0).unwrap(), 5);
assert_eq!(v.iter().position(|x| *x % 3 == 0).unwrap(), 1);
assert!(v.iter().position(|x| *x % 12 == 0).is_none());
}
#[test]
fn test_count() {
let xs = &[1i, 2, 2, 1, 5, 9, 0, 2];
assert_eq!(xs.iter().filter(|x| **x == 2).count(), 3);
assert_eq!(xs.iter().filter(|x| **x == 5).count(), 1);
assert_eq!(xs.iter().filter(|x| **x == 95).count(), 0);
}
#[test]
fn test_max_by() {
let xs: &[int] = &[-3i, 0, 1, 5, -10];
assert_eq!(*xs.iter().max_by(|x| x.abs()).unwrap(), -10);
}
#[test]
fn test_min_by() {
let xs: &[int] = &[-3i, 0, 1, 5, -10];
assert_eq!(*xs.iter().min_by(|x| x.abs()).unwrap(), 0);
}
#[test]
fn test_by_ref() {
let mut xs = range(0i, 10);
// sum the first five values
let partial_sum = xs.by_ref().take(5).fold(0, |a, b| a + b);
assert_eq!(partial_sum, 10);
assert_eq!(xs.next(), Some(5));
}
#[test]
fn test_rev() {
let xs = [2i, 4, 6, 8, 10, 12, 14, 16];
let mut it = xs.iter();
it.next();
it.next();
assert!(it.rev().map(|&x| x).collect::<Vec<int>>() ==
vec![16, 14, 12, 10, 8, 6]);
}
#[test]
fn test_cloned() {
let xs = [2u8, 4, 6, 8];
let mut it = xs.iter().cloned();
assert_eq!(it.len(), 4);
assert_eq!(it.next(), Some(2));
assert_eq!(it.len(), 3);
assert_eq!(it.next(), Some(4));
assert_eq!(it.len(), 2);
assert_eq!(it.next_back(), Some(8));
assert_eq!(it.len(), 1);
assert_eq!(it.next_back(), Some(6));
assert_eq!(it.len(), 0);
assert_eq!(it.next_back(), None);
}
#[test]
fn test_double_ended_map() {
let xs = [1i, 2, 3, 4, 5, 6];
let mut it = xs.iter().map(|&x| x * -1);
assert_eq!(it.next(), Some(-1));
assert_eq!(it.next(), Some(-2));
assert_eq!(it.next_back(), Some(-6));
assert_eq!(it.next_back(), Some(-5));
assert_eq!(it.next(), Some(-3));
assert_eq!(it.next_back(), Some(-4));
assert_eq!(it.next(), None);
}
#[test]
fn test_double_ended_enumerate() {
let xs = [1i, 2, 3, 4, 5, 6];
let mut it = xs.iter().map(|&x| x).enumerate();
assert_eq!(it.next(), Some((0, 1)));
assert_eq!(it.next(), Some((1, 2)));
assert_eq!(it.next_back(), Some((5, 6)));
assert_eq!(it.next_back(), Some((4, 5)));
assert_eq!(it.next_back(), Some((3, 4)));
assert_eq!(it.next_back(), Some((2, 3)));
assert_eq!(it.next(), None);
}
#[test]
fn test_double_ended_zip() {
let xs = [1i, 2, 3, 4, 5, 6];
let ys = [1i, 2, 3, 7];
let a = xs.iter().map(|&x| x);
let b = ys.iter().map(|&x| x);
let mut it = a.zip(b);
assert_eq!(it.next(), Some((1, 1)));
assert_eq!(it.next(), Some((2, 2)));
assert_eq!(it.next_back(), Some((4, 7)));
assert_eq!(it.next_back(), Some((3, 3)));
assert_eq!(it.next(), None);
}
#[test]
fn test_double_ended_filter() {
let xs = [1i, 2, 3, 4, 5, 6];
let mut it = xs.iter().filter(|&x| *x & 1 == 0);
assert_eq!(it.next_back().unwrap(), &6);
assert_eq!(it.next_back().unwrap(), &4);
assert_eq!(it.next().unwrap(), &2);
assert_eq!(it.next_back(), None);
}
#[test]
fn test_double_ended_filter_map() {
let xs = [1i, 2, 3, 4, 5, 6];
let mut it = xs.iter().filter_map(|&x| if x & 1 == 0 { Some(x * 2) } else { None });
assert_eq!(it.next_back().unwrap(), 12);
assert_eq!(it.next_back().unwrap(), 8);
assert_eq!(it.next().unwrap(), 4);
assert_eq!(it.next_back(), None);
}
#[test]
fn test_double_ended_chain() {
let xs = [1i, 2, 3, 4, 5];
let ys = [7i, 9, 11];
let mut it = xs.iter().chain(ys.iter()).rev();
assert_eq!(it.next().unwrap(), &11);
assert_eq!(it.next().unwrap(), &9);
assert_eq!(it.next_back().unwrap(), &1);
assert_eq!(it.next_back().unwrap(), &2);
assert_eq!(it.next_back().unwrap(), &3);
assert_eq!(it.next_back().unwrap(), &4);
assert_eq!(it.next_back().unwrap(), &5);
assert_eq!(it.next_back().unwrap(), &7);
assert_eq!(it.next_back(), None);
}
#[test]
fn test_rposition() {
fn f(xy: &(int, char)) -> bool { let (_x, y) = *xy; y == 'b' }
fn g(xy: &(int, char)) -> bool { let (_x, y) = *xy; y == 'd' }
let v = [(0i, 'a'), (1, 'b'), (2, 'c'), (3, 'b')];
assert_eq!(v.iter().rposition(f), Some(3u));
assert!(v.iter().rposition(g).is_none());
}
#[test]
#[should_fail]
fn test_rposition_panic() {
let v = [(box 0i, box 0i), (box 0i, box 0i),
(box 0i, box 0i), (box 0i, box 0i)];
let mut i = 0i;
v.iter().rposition(|_elt| {
if i == 2 {
panic!()
}
i += 1;
false
});
}
#[cfg(test)]
fn check_randacc_iter<A: PartialEq, T: Clone + RandomAccessIterator<A>>(a: T, len: uint)
{
let mut b = a.clone();
assert_eq!(len, b.indexable());
let mut n = 0u;
for (i, elt) in a.enumerate() {
assert!(Some(elt) == b.idx(i));
n += 1;
}
assert_eq!(n, len);
assert!(None == b.idx(n));
// call recursively to check after picking off an element
if len > 0 {
b.next();
check_randacc_iter(b, len-1);
}
}
#[test]
fn test_double_ended_flat_map() {
let u = [0u,1];
let v = [5u,6,7,8];
let mut it = u.iter().flat_map(|x| v[*x..v.len()].iter());
assert_eq!(it.next_back().unwrap(), &8);
assert_eq!(it.next().unwrap(), &5);
assert_eq!(it.next_back().unwrap(), &7);
assert_eq!(it.next_back().unwrap(), &6);
assert_eq!(it.next_back().unwrap(), &8);
assert_eq!(it.next().unwrap(), &6);
assert_eq!(it.next_back().unwrap(), &7);
assert_eq!(it.next_back(), None);
assert_eq!(it.next(), None);
assert_eq!(it.next_back(), None);
}
#[test]
fn test_random_access_chain() {
let xs = [1i, 2, 3, 4, 5];
let ys = [7i, 9, 11];
let mut it = xs.iter().chain(ys.iter());
assert_eq!(it.idx(0).unwrap(), &1);
assert_eq!(it.idx(5).unwrap(), &7);
assert_eq!(it.idx(7).unwrap(), &11);
assert!(it.idx(8).is_none());
it.next();
it.next();
it.next_back();
assert_eq!(it.idx(0).unwrap(), &3);
assert_eq!(it.idx(4).unwrap(), &9);
assert!(it.idx(6).is_none());
check_randacc_iter(it, xs.len() + ys.len() - 3);
}
#[test]
fn test_random_access_enumerate() {
let xs = [1i, 2, 3, 4, 5];
check_randacc_iter(xs.iter().enumerate(), xs.len());
}
#[test]
fn test_random_access_rev() {
let xs = [1i, 2, 3, 4, 5];
check_randacc_iter(xs.iter().rev(), xs.len());
let mut it = xs.iter().rev();
it.next();
it.next_back();
it.next();
check_randacc_iter(it, xs.len() - 3);
}
#[test]
fn test_random_access_zip() {
let xs = [1i, 2, 3, 4, 5];
let ys = [7i, 9, 11];
check_randacc_iter(xs.iter().zip(ys.iter()), cmp::min(xs.len(), ys.len()));
}
#[test]
fn test_random_access_take() {
let xs = [1i, 2, 3, 4, 5];
let empty: &[int] = &[];
check_randacc_iter(xs.iter().take(3), 3);
check_randacc_iter(xs.iter().take(20), xs.len());
check_randacc_iter(xs.iter().take(0), 0);
check_randacc_iter(empty.iter().take(2), 0);
}
#[test]
fn test_random_access_skip() {
let xs = [1i, 2, 3, 4, 5];
let empty: &[int] = &[];
check_randacc_iter(xs.iter().skip(2), xs.len() - 2);
check_randacc_iter(empty.iter().skip(2), 0);
}
#[test]
fn test_random_access_inspect() {
let xs = [1i, 2, 3, 4, 5];
// test .map and .inspect that don't implement Clone
let mut it = xs.iter().inspect(|_| {});
assert_eq!(xs.len(), it.indexable());
for (i, elt) in xs.iter().enumerate() {
assert_eq!(Some(elt), it.idx(i));
}
}
#[test]
fn test_random_access_map() {
let xs = [1i, 2, 3, 4, 5];
let mut it = xs.iter().map(|x| *x);
|
for (i, elt) in xs.iter().enumerate() {
assert_eq!(Some(*elt), it.idx(i));
}
}
#[test]
fn test_random_access_cycle() {
let xs = [1i, 2, 3, 4, 5];
let empty: &[int] = &[];
check_randacc_iter(xs.iter().cycle().take(27), 27);
check_randacc_iter(empty.iter().cycle(), 0);
}
#[test]
fn test_double_ended_range() {
assert!(range(11i, 14).rev().collect::<Vec<int>>() == vec![13i, 12, 11]);
for _ in range(10i, 0).rev() {
panic!("unreachable");
}
assert!(range(11u, 14).rev().collect::<Vec<uint>>() == vec![13u, 12, 11]);
for _ in range(10u, 0).rev() {
panic!("unreachable");
}
}
#[test]
fn test_range() {
assert!(range(0i, 5).collect::<Vec<int>>() == vec![0i, 1, 2, 3, 4]);
assert!(range(-10i, -1).collect::<Vec<int>>() ==
vec![-10, -9, -8, -7, -6, -5, -4, -3, -2]);
assert!(range(0i, 5).rev().collect::<Vec<int>>() == vec![4, 3, 2, 1, 0]);
assert_eq!(range(200i, -5).count(), 0);
assert_eq!(range(200i, -5).rev().count(), 0);
assert_eq!(range(200i, 200).count(), 0);
assert_eq!(range(200i, 200).rev().count(), 0);
assert_eq!(range(0i, 100).size_hint(), (100, Some(100)));
// this test is only meaningful when sizeof uint < sizeof u64
assert_eq!(range(uint::MAX - 1, uint::MAX).size_hint(), (1, Some(1)));
assert_eq!(range(-10i, -1).size_hint(), (9, Some(9)));
}
#[test]
fn test_range_inclusive() {
assert!(range_inclusive(0i, 5).collect::<Vec<int>>() ==
vec![0i, 1, 2, 3, 4, 5]);
assert!(range_inclusive(0i, 5).rev().collect::<Vec<int>>() ==
vec![5i, 4, 3, 2, 1, 0]);
assert_eq!(range_inclusive(200i, -5).count(), 0);
assert_eq!(range_inclusive(200i, -5).rev().count(), 0);
assert!(range_inclusive(200i, 200).collect::<Vec<int>>() == vec![200]);
assert!(range_inclusive(200i, 200).rev().collect::<Vec<int>>() == vec![200]);
}
#[test]
fn test_range_step() {
assert!(range_step(0i, 20, 5).collect::<Vec<int>>() ==
vec![0, 5, 10, 15]);
assert!(range_step(20i, 0, -5).collect::<Vec<int>>() ==
vec![20, 15, 10, 5]);
assert!(range_step(20i, 0, -6).collect::<Vec<int>>() ==
vec![20, 14, 8, 2]);
assert!(range_step(200u8, 255, 50).collect::<Vec<u8>>() ==
vec![200u8, 250]);
assert!(range_step(200i, -5, 1).collect::<Vec<int>>() == vec![]);
assert!(range_step(200i, 200, 1).collect::<Vec<int>>() == vec![]);
}
#[test]
fn test_range_step_inclusive() {
assert!(range_step_inclusive(0i, 20, 5).collect::<Vec<int>>() ==
vec![0, 5, 10, 15, 20]);
assert!(range_step_inclusive(20i, 0, -5).collect::<Vec<int>>() ==
vec![20, 15, 10, 5, 0]);
assert!(range_step_inclusive(20i, 0, -6).collect::<Vec<int>>() ==
vec![20, 14, 8, 2]);
assert!(range_step_inclusive(200u8, 255, 50).collect::<Vec<u8>>() ==
vec![200u8, 250]);
assert!(range_step_inclusive(200i, -5, 1).collect::<Vec<int>>() ==
vec![]);
assert!(range_step_inclusive(200i, 200, 1).collect::<Vec<int>>() ==
vec![200]);
}
#[test]
fn test_reverse() {
let mut ys = [1i, 2, 3, 4, 5];
ys.iter_mut().reverse_();
assert!(ys == [5, 4, 3, 2, 1]);
}
#[test]
fn test_peekable_is_empty() {
let a = [1i];
let mut it = a.iter().peekable();
assert!( !it.is_empty() );
it.next();
assert!( it.is_empty() );
}
#[test]
fn test_min_max() {
let v: [int; 0] = [];
assert_eq!(v.iter().min_max(), NoElements);
let v = [1i];
assert!(v.iter().min_max() == OneElement(&1));
let v = [1i, 2, 3, 4, 5];
assert!(v.iter().min_max() == MinMax(&1, &5));
let v = [1i, 2, 3, 4, 5, 6];
assert!(v.iter().min_max() == MinMax(&1, &6));
let v = [1i, 1, 1, 1];
assert!(v.iter().min_max() == MinMax(&1, &1));
}
#[test]
fn test_min_max_result() {
let r: MinMaxResult<int> = NoElements;
assert_eq!(r.into_option(), None);
let r = OneElement(1i);
assert_eq!(r.into_option(), Some((1,1)));
let r = MinMax(1i,2);
assert_eq!(r.into_option(), Some((1,2)));
}
#[test]
fn test_iterate() {
let mut it = iterate(1u, |x| x * 2);
assert_eq!(it.next(), Some(1u));
assert_eq!(it.next(), Some(2u));
assert_eq!(it.next(), Some(4u));
assert_eq!(it.next(), Some(8u));
}
#[test]
fn test_repeat() {
let mut it = repeat(42u);
assert_eq!(it.next(), Some(42u));
assert_eq!(it.next(), Some(42u));
assert_eq!(it.next(), Some(42u));
}
#[bench]
fn bench_rposition(b: &mut Bencher) {
let it: Vec<uint> = range(0u, 300).collect();
b.iter(|| {
it.iter().rposition(|&x| x <= 150);
});
}
#[bench]
fn bench_skip_while(b: &mut Bencher) {
b.iter(|| {
let it = range(0u, 100);
let mut sum = 0;
it.skip_while(|&x| { sum += x; sum < 4000 }).all(|_| true);
});
}
#[bench]
fn bench_multiple_take(b: &mut Bencher) {
let mut it = range(0u, 42).cycle();
b.iter(|| {
let n = it.next().unwrap();
for _ in range(0u, n) {
it.take(it.next().unwrap()).all(|_| true);
}
});
}
|
assert_eq!(xs.len(), it.indexable());
|
g2_multiexp.go
|
// Copyright 2020 ConsenSys Software Inc.
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
// Code generated by gurvy DO NOT EDIT
package bn256
import (
"math"
"runtime"
"sync"
"github.com/consensys/gurvy/bn256/fr"
)
// MultiExp implements section 4 of https://eprint.iacr.org/2012/549.pdf
// optionally, takes as parameter a CPUSemaphore struct
// enabling to set max number of cpus to use
func (p *G2Jac) MultiExp(points []G2Affine, scalars []fr.Element, opts ...*CPUSemaphore) *G2Jac {
// note:
// each of the msmCX method is the same, except for the c constant it declares
// duplicating (through template generation) these methods allows to declare the buckets on the stack
// the choice of c needs to be improved:
// there is a theoritical value that gives optimal asymptotics
// but in practice, other factors come into play, including:
// * if c doesn't divide 64, the word size, then we're bound to select bits over 2 words of our scalars, instead of 1
// * number of CPUs
// * cache friendliness (which depends on the host, G1 or G2... )
// --> for example, on BN256, a G1 point fits into one cache line of 64bytes, but a G2 point don't.
// for each msmCX
// step 1
// we compute, for each scalars over c-bit wide windows, nbChunk digits
// if the digit is larger than 2^{c-1}, then, we borrow 2^c from the next window and substract
// 2^{c} to the current digit, making it negative.
// negative digits will be processed in the next step as adding -G into the bucket instead of G
// (computing -G is cheap, and this saves us half of the buckets)
// step 2
// buckets are declared on the stack
// notice that we have 2^{c-1} buckets instead of 2^{c} (see step1)
// we use jacobian extended formulas here as they are faster than mixed addition
// msmProcessChunk places points into buckets base on their selector and return the weighted bucket sum in given channel
// step 3
// reduce the buckets weigthed sums into our result (msmReduceChunk)
var opt *CPUSemaphore
if len(opts) > 0 {
opt = opts[0]
} else {
opt = NewCPUSemaphore(runtime.NumCPU())
}
var C uint64
nbPoints := len(points)
// implemented msmC methods (the c we use must be in this slice)
implementedCs := []uint64{4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 20, 21, 22}
// approximate cost (in group operations)
// cost = bits/c * (nbPoints + 2^{c})
// this needs to be verified empirically.
// for example, on a MBP 2016, for G2 MultiExp > 8M points, hand picking c gives better results
min := math.MaxFloat64
for _, c := range implementedCs {
cc := fr.Limbs * 64 * (nbPoints + (1 << (c)))
cost := float64(cc) / float64(c)
if cost < min {
min = cost
C = c
}
}
// empirical, needs to be tuned.
// if C > 16 && nbPoints < 1 << 23 {
// C = 16
// }
// take all the cpus to ourselves
opt.lock.Lock()
// partition the scalars
// note: we do that before the actual chunk processing, as for each c-bit window (starting from LSW)
// if it's larger than 2^{c-1}, we have a carry we need to propagate up to the higher window
scalars = partitionScalars(scalars, C)
switch C {
case 4:
return p.msmC4(points, scalars, opt)
case 5:
return p.msmC5(points, scalars, opt)
case 6:
return p.msmC6(points, scalars, opt)
case 7:
return p.msmC7(points, scalars, opt)
case 8:
return p.msmC8(points, scalars, opt)
case 9:
return p.msmC9(points, scalars, opt)
case 10:
return p.msmC10(points, scalars, opt)
case 11:
return p.msmC11(points, scalars, opt)
case 12:
return p.msmC12(points, scalars, opt)
case 13:
return p.msmC13(points, scalars, opt)
case 14:
return p.msmC14(points, scalars, opt)
case 15:
return p.msmC15(points, scalars, opt)
case 16:
return p.msmC16(points, scalars, opt)
case 20:
return p.msmC20(points, scalars, opt)
case 21:
return p.msmC21(points, scalars, opt)
case 22:
return p.msmC22(points, scalars, opt)
default:
panic("unimplemented")
}
}
// msmReduceChunkG2 reduces the weighted sum of the buckets into the result of the multiExp
func msmReduceChunkG2(p *G2Jac, c int, chChunks []chan G2Jac) *G2Jac {
totalj := <-chChunks[len(chChunks)-1]
p.Set(&totalj)
for j := len(chChunks) - 2; j >= 0; j-- {
for l := 0; l < c; l++ {
p.DoubleAssign()
}
totalj := <-chChunks[j]
p.AddAssign(&totalj)
}
return p
}
func msmProcessChunkG2(chunk uint64,
chRes chan<- G2Jac,
buckets []g2JacExtended,
c uint64,
points []G2Affine,
scalars []fr.Element) {
mask := uint64((1 << c) - 1) // low c bits are 1
msbWindow := uint64(1 << (c - 1))
for i := 0; i < len(buckets); i++ {
buckets[i].setInfinity()
}
jc := uint64(chunk * c)
s := selector{}
s.index = jc / 64
s.shift = jc - (s.index * 64)
s.mask = mask << s.shift
s.multiWordSelect = (64%c) != 0 && s.shift > (64-c) && s.index < (fr.Limbs-1)
if s.multiWordSelect {
nbBitsHigh := s.shift - uint64(64-c)
s.maskHigh = (1 << nbBitsHigh) - 1
s.shiftHigh = (c - nbBitsHigh)
}
// for each scalars, get the digit corresponding to the chunk we're processing.
for i := 0; i < len(scalars); i++ {
bits := (scalars[i][s.index] & s.mask) >> s.shift
if s.multiWordSelect {
bits += (scalars[i][s.index+1] & s.maskHigh) << s.shiftHigh
}
if bits == 0 {
continue
}
// if msbWindow bit is set, we need to substract
if bits&msbWindow == 0 {
// add
buckets[bits-1].add(&points[i])
} else {
// sub
buckets[bits & ^msbWindow].sub(&points[i])
}
}
// reduce buckets into total
// total = bucket[0] + 2*bucket[1] + 3*bucket[2] ... + n*bucket[n-1]
var runningSum, tj, total G2Jac
runningSum.Set(&g2Infinity)
total.Set(&g2Infinity)
for k := len(buckets) - 1; k >= 0; k-- {
if !buckets[k].ZZ.IsZero() {
runningSum.AddAssign(tj.unsafeFromJacExtended(&buckets[k]))
}
total.AddAssign(&runningSum)
}
chRes <- total
close(chRes)
}
func (p *G2Jac) msmC4(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 4 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
for chunk := nbChunks - 1; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC5(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 5 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC6(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 6 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC7(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 7 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC8(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 8 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
for chunk := nbChunks - 1; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC9(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 9 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC10(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 10 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC11(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 11 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC12(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 12 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC13(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 13 // scalars partitioned into c-bit radixes
|
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC14(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 14 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC15(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 15 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC16(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 16 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
for chunk := nbChunks - 1; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC20(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 20 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC21(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 21 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
func (p *G2Jac) msmC22(points []G2Affine, scalars []fr.Element, opt *CPUSemaphore) *G2Jac {
const c = 22 // scalars partitioned into c-bit radixes
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
// wait group to wait for all the go routines to start
var wg sync.WaitGroup
// c doesn't divide 256, last window is smaller we can allocate less buckets
const lastC = (fr.Limbs * 64) - (c * (fr.Limbs * 64 / c))
chChunks[nbChunks-1] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (lastC - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(nbChunks-1), chChunks[nbChunks-1], points, scalars)
for chunk := nbChunks - 2; chunk >= 0; chunk-- {
chChunks[chunk] = make(chan G2Jac, 1)
<-opt.chCpus // wait to have a cpu before scheduling
wg.Add(1)
go func(j uint64, chRes chan G2Jac, points []G2Affine, scalars []fr.Element) {
wg.Done()
var buckets [1 << (c - 1)]g2JacExtended
msmProcessChunkG2(j, chRes, buckets[:], c, points, scalars)
opt.chCpus <- struct{}{} // release token in the semaphore
}(uint64(chunk), chChunks[chunk], points, scalars)
}
// wait for all goRoutines to actually start
wg.Wait()
// all my tasks are scheduled, I can let other func use avaiable tokens in the semaphore
opt.lock.Unlock()
return msmReduceChunkG2(p, c, chChunks[:])
}
// g2JacExtended parameterized jacobian coordinates (x=X/ZZ, y=Y/ZZZ, ZZ**3=ZZZ**2)
type g2JacExtended struct {
X, Y, ZZ, ZZZ e2
}
// setInfinity sets p to O
func (p *g2JacExtended) setInfinity() *g2JacExtended {
p.X.SetOne()
p.Y.SetOne()
p.ZZ = e2{}
p.ZZZ = e2{}
return p
}
// fromJacExtended sets Q in affine coords
func (p *G2Affine) fromJacExtended(Q *g2JacExtended) *G2Affine {
if Q.ZZ.IsZero() {
p.X = e2{}
p.Y = e2{}
return p
}
p.X.Inverse(&Q.ZZ).Mul(&p.X, &Q.X)
p.Y.Inverse(&Q.ZZZ).Mul(&p.Y, &Q.Y)
return p
}
// fromJacExtended sets Q in Jacobian coords
func (p *G2Jac) fromJacExtended(Q *g2JacExtended) *G2Jac {
if Q.ZZ.IsZero() {
p.Set(&g2Infinity)
return p
}
p.X.Mul(&Q.ZZ, &Q.X).Mul(&p.X, &Q.ZZ)
p.Y.Mul(&Q.ZZZ, &Q.Y).Mul(&p.Y, &Q.ZZZ)
p.Z.Set(&Q.ZZZ)
return p
}
// unsafeFromJacExtended sets p in jacobian coords, but don't check for infinity
func (p *G2Jac) unsafeFromJacExtended(Q *g2JacExtended) *G2Jac {
p.X.Square(&Q.ZZ).Mul(&p.X, &Q.X)
p.Y.Square(&Q.ZZZ).Mul(&p.Y, &Q.Y)
p.Z = Q.ZZZ
return p
}
// sub same as add, but will negate a.Y
// http://www.hyperelliptic.org/EFD/ g2p/auto-shortw-xyzz.html#addition-madd-2008-s
func (p *g2JacExtended) sub(a *G2Affine) *g2JacExtended {
//if a is infinity return p
if a.X.IsZero() && a.Y.IsZero() {
return p
}
// p is infinity, return a
if p.ZZ.IsZero() {
p.X = a.X
p.Y = a.Y
p.Y.Neg(&p.Y)
p.ZZ.SetOne()
p.ZZZ.SetOne()
return p
}
var P, R e2
// p2: a, p1: p
P.Mul(&a.X, &p.ZZ)
P.Sub(&P, &p.X)
R.Mul(&a.Y, &p.ZZZ)
R.Neg(&R)
R.Sub(&R, &p.Y)
if P.IsZero() {
if R.IsZero() {
return p.doubleNeg(a)
}
p.ZZ = e2{}
p.ZZZ = e2{}
return p
}
var PP, PPP, Q, Q2, RR, X3, Y3 e2
PP.Square(&P)
PPP.Mul(&P, &PP)
Q.Mul(&p.X, &PP)
RR.Square(&R)
X3.Sub(&RR, &PPP)
Q2.Double(&Q)
p.X.Sub(&X3, &Q2)
Y3.Sub(&Q, &p.X).Mul(&Y3, &R)
R.Mul(&p.Y, &PPP)
p.Y.Sub(&Y3, &R)
p.ZZ.Mul(&p.ZZ, &PP)
p.ZZZ.Mul(&p.ZZZ, &PPP)
return p
}
// add
// http://www.hyperelliptic.org/EFD/ g2p/auto-shortw-xyzz.html#addition-madd-2008-s
func (p *g2JacExtended) add(a *G2Affine) *g2JacExtended {
//if a is infinity return p
if a.X.IsZero() && a.Y.IsZero() {
return p
}
// p is infinity, return a
if p.ZZ.IsZero() {
p.X = a.X
p.Y = a.Y
p.ZZ.SetOne()
p.ZZZ.SetOne()
return p
}
var P, R e2
// p2: a, p1: p
P.Mul(&a.X, &p.ZZ)
P.Sub(&P, &p.X)
R.Mul(&a.Y, &p.ZZZ)
R.Sub(&R, &p.Y)
if P.IsZero() {
if R.IsZero() {
return p.double(a)
}
p.ZZ = e2{}
p.ZZZ = e2{}
return p
}
var PP, PPP, Q, Q2, RR, X3, Y3 e2
PP.Square(&P)
PPP.Mul(&P, &PP)
Q.Mul(&p.X, &PP)
RR.Square(&R)
X3.Sub(&RR, &PPP)
Q2.Double(&Q)
p.X.Sub(&X3, &Q2)
Y3.Sub(&Q, &p.X).Mul(&Y3, &R)
R.Mul(&p.Y, &PPP)
p.Y.Sub(&Y3, &R)
p.ZZ.Mul(&p.ZZ, &PP)
p.ZZZ.Mul(&p.ZZZ, &PPP)
return p
}
// doubleNeg same as double, but will negate q.Y
func (p *g2JacExtended) doubleNeg(q *G2Affine) *g2JacExtended {
var U, S, M, _M, Y3 e2
U.Double(&q.Y)
U.Neg(&U)
p.ZZ.Square(&U)
p.ZZZ.Mul(&U, &p.ZZ)
S.Mul(&q.X, &p.ZZ)
_M.Square(&q.X)
M.Double(&_M).
Add(&M, &_M) // -> + a, but a=0 here
p.X.Square(&M).
Sub(&p.X, &S).
Sub(&p.X, &S)
Y3.Sub(&S, &p.X).Mul(&Y3, &M)
U.Mul(&p.ZZZ, &q.Y)
p.Y.Add(&Y3, &U)
return p
}
// double point in ZZ coords
// http://www.hyperelliptic.org/EFD/ g2p/auto-shortw-xyzz.html#doubling-dbl-2008-s-1
func (p *g2JacExtended) double(q *G2Affine) *g2JacExtended {
var U, S, M, _M, Y3 e2
U.Double(&q.Y)
p.ZZ.Square(&U)
p.ZZZ.Mul(&U, &p.ZZ)
S.Mul(&q.X, &p.ZZ)
_M.Square(&q.X)
M.Double(&_M).
Add(&M, &_M) // -> + a, but a=0 here
p.X.Square(&M).
Sub(&p.X, &S).
Sub(&p.X, &S)
Y3.Sub(&S, &p.X).Mul(&Y3, &M)
U.Mul(&p.ZZZ, &q.Y)
p.Y.Sub(&Y3, &U)
return p
}
|
const nbChunks = (fr.Limbs * 64 / c) + 1 // number of c-bit radixes in a scalar
// for each chunk, spawn a go routine that'll loop through all the scalars
var chChunks [nbChunks]chan G2Jac
|
get_all.go
|
package cmd
import (
"context"
log "github.com/sirupsen/logrus"
"google.golang.org/grpc"
"time"
"github.com/joostvdg/cat/pkg/api/v1"
)
func
|
() {
log.SetFormatter(&log.JSONFormatter{})
log.SetReportCaller(true)
log.SetLevel(log.InfoLevel)
}
func GetAll(address string) {
// Set up a connection to the server.
conn, err := grpc.Dial(address, grpc.WithInsecure())
if err != nil {
log.Fatalf("did not connect: %v", err)
}
defer conn.Close()
c := v1.NewApplicationServiceClient(conn)
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// Read
req := v1.ReadAllRequest{
Api: apiVersion,
}
res, err := c.ReadAll(ctx, &req)
if err != nil {
log.Fatalf("Read failed: %v", err)
}
log.Printf("Read result: count=%v, <%+v>\n", len(res.Applications), res.Applications)
}
|
init
|
mod.rs
|
use std::sync::Arc;
use crate::{
bitmap::Bitmap,
datatypes::{DataType, Field},
};
use super::{debug_fmt, new_empty_array, new_null_array, Array};
mod ffi;
mod iterator;
pub use iterator::*;
mod mutable;
pub use mutable::*;
/// The Arrow's equivalent to an immutable `Vec<Option<[T; size]>>` where `T` is an Arrow type.
/// Cloning and slicing this struct is `O(1)`.
#[derive(Clone)]
pub struct FixedSizeListArray {
size: usize, // this is redundant with `data_type`, but useful to not have to deconstruct the data_type.
data_type: DataType,
values: Arc<dyn Array>,
validity: Option<Bitmap>,
}
impl FixedSizeListArray {
/// Returns a new empty [`FixedSizeListArray`].
pub fn new_empty(data_type: DataType) -> Self {
let values =
new_empty_array(Self::get_child_and_size(&data_type).0.data_type().clone()).into();
Self::from_data(data_type, values, None)
}
/// Returns a new null [`FixedSizeListArray`].
pub fn new_null(data_type: DataType, length: usize) -> Self {
let values = new_null_array(
Self::get_child_and_size(&data_type).0.data_type().clone(),
length,
)
.into();
Self::from_data(data_type, values, Some(Bitmap::new_zeroed(length)))
}
/// Returns a [`FixedSizeListArray`].
pub fn from_data(
data_type: DataType,
values: Arc<dyn Array>,
validity: Option<Bitmap>,
) -> Self {
let (_, size) = Self::get_child_and_size(&data_type);
assert_eq!(values.len() % size, 0);
if let Some(ref validity) = validity {
assert_eq!(values.len() / size, validity.len());
}
Self {
size,
data_type,
values,
validity,
}
}
/// Returns a slice of this [`FixedSizeListArray`].
/// # Implementation
/// This operation is `O(1)`.
/// # Panics
/// panics iff `offset + length > self.len()`
pub fn slice(&self, offset: usize, length: usize) -> Self {
assert!(
offset + length <= self.len(),
"the offset of the new Buffer cannot exceed the existing length"
);
unsafe { self.slice_unchecked(offset, length) }
}
/// Returns a slice of this [`FixedSizeListArray`].
/// # Implementation
/// This operation is `O(1)`.
/// # Safety
/// The caller must ensure that `offset + length <= self.len()`.
|
pub unsafe fn slice_unchecked(&self, offset: usize, length: usize) -> Self {
let validity = self
.validity
.clone()
.map(|x| x.slice_unchecked(offset, length));
let values = self
.values
.clone()
.slice_unchecked(offset * self.size as usize, length * self.size as usize)
.into();
Self {
data_type: self.data_type.clone(),
size: self.size,
values,
validity,
}
}
/// Sets the validity bitmap on this [`FixedSizeListArray`].
/// # Panic
/// This function panics iff `validity.len() != self.len()`.
pub fn with_validity(&self, validity: Option<Bitmap>) -> Self {
if matches!(&validity, Some(bitmap) if bitmap.len() != self.len()) {
panic!("validity should be as least as large as the array")
}
let mut arr = self.clone();
arr.validity = validity;
arr
}
}
// accessors
impl FixedSizeListArray {
/// Returns the length of this array
#[inline]
pub fn len(&self) -> usize {
self.values.len() / self.size as usize
}
/// The optional validity.
#[inline]
pub fn validity(&self) -> Option<&Bitmap> {
self.validity.as_ref()
}
/// Returns the inner array.
pub fn values(&self) -> &Arc<dyn Array> {
&self.values
}
/// Returns the `Vec<T>` at position `i`.
/// # Panic:
/// panics iff `i >= self.len()`
#[inline]
pub fn value(&self, i: usize) -> Box<dyn Array> {
self.values
.slice(i * self.size as usize, self.size as usize)
}
/// Returns the `Vec<T>` at position `i`.
/// # Safety
/// Caller must ensure that `i < self.len()`
#[inline]
pub unsafe fn value_unchecked(&self, i: usize) -> Box<dyn Array> {
self.values
.slice_unchecked(i * self.size as usize, self.size as usize)
}
}
impl FixedSizeListArray {
pub(crate) fn get_child_and_size(data_type: &DataType) -> (&Field, usize) {
match data_type.to_logical_type() {
DataType::FixedSizeList(child, size) => (child.as_ref(), *size as usize),
_ => panic!("FixedSizeListArray expects DataType::FixedSizeList"),
}
}
/// Returns a [`DataType`] consistent with [`FixedSizeListArray`].
pub fn default_datatype(data_type: DataType, size: usize) -> DataType {
let field = Box::new(Field::new("item", data_type, true));
DataType::FixedSizeList(field, size)
}
}
impl Array for FixedSizeListArray {
#[inline]
fn as_any(&self) -> &dyn std::any::Any {
self
}
#[inline]
fn len(&self) -> usize {
self.len()
}
#[inline]
fn data_type(&self) -> &DataType {
&self.data_type
}
fn validity(&self) -> Option<&Bitmap> {
self.validity.as_ref()
}
fn slice(&self, offset: usize, length: usize) -> Box<dyn Array> {
Box::new(self.slice(offset, length))
}
unsafe fn slice_unchecked(&self, offset: usize, length: usize) -> Box<dyn Array> {
Box::new(self.slice_unchecked(offset, length))
}
fn with_validity(&self, validity: Option<Bitmap>) -> Box<dyn Array> {
Box::new(self.with_validity(validity))
}
}
impl std::fmt::Debug for FixedSizeListArray {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
debug_fmt(self.iter(), "FixedSizeListArray", f, true)
}
}
| |
error_reporting.rs
|
use super::{
ConstEvalFailure,
EvaluationResult,
FulfillmentError,
FulfillmentErrorCode,
MismatchedProjectionTypes,
ObjectSafetyViolation,
Obligation,
ObligationCause,
ObligationCauseCode,
OnUnimplementedDirective,
OnUnimplementedNote,
OutputTypeParameterMismatch,
Overflow,
PredicateObligation,
SelectionContext,
SelectionError,
TraitNotObjectSafe,
};
use crate::hir;
use crate::hir::Node;
use crate::hir::def_id::DefId;
use crate::infer::{self, InferCtxt};
use crate::infer::type_variable::{TypeVariableOrigin, TypeVariableOriginKind};
use crate::session::DiagnosticMessageId;
use crate::ty::{self, AdtKind, DefIdTree, ToPredicate, ToPolyTraitRef, Ty, TyCtxt, TypeFoldable};
use crate::ty::GenericParamDefKind;
use crate::ty::error::ExpectedFound;
use crate::ty::fast_reject;
use crate::ty::fold::TypeFolder;
use crate::ty::subst::Subst;
use crate::ty::SubtypePredicate;
use crate::util::nodemap::{FxHashMap, FxHashSet};
use errors::{Applicability, DiagnosticBuilder, pluralize};
use std::fmt;
use syntax::ast;
use syntax::symbol::{sym, kw};
use syntax_pos::{DUMMY_SP, Span, ExpnKind, MultiSpan};
impl<'a, 'tcx> InferCtxt<'a, 'tcx> {
pub fn report_fulfillment_errors(
&self,
errors: &[FulfillmentError<'tcx>],
body_id: Option<hir::BodyId>,
fallback_has_occurred: bool,
) {
#[derive(Debug)]
struct ErrorDescriptor<'tcx> {
predicate: ty::Predicate<'tcx>,
index: Option<usize>, // None if this is an old error
}
let mut error_map: FxHashMap<_, Vec<_>> =
self.reported_trait_errors.borrow().iter().map(|(&span, predicates)| {
(span, predicates.iter().map(|predicate| ErrorDescriptor {
predicate: predicate.clone(),
index: None
}).collect())
}).collect();
for (index, error) in errors.iter().enumerate() {
// We want to ignore desugarings here: spans are equivalent even
// if one is the result of a desugaring and the other is not.
let mut span = error.obligation.cause.span;
let expn_data = span.ctxt().outer_expn_data();
if let ExpnKind::Desugaring(_) = expn_data.kind {
span = expn_data.call_site;
}
error_map.entry(span).or_default().push(
ErrorDescriptor {
predicate: error.obligation.predicate.clone(),
index: Some(index)
}
);
self.reported_trait_errors.borrow_mut()
.entry(span).or_default()
.push(error.obligation.predicate.clone());
}
// We do this in 2 passes because we want to display errors in order, though
// maybe it *is* better to sort errors by span or something.
let mut is_suppressed = vec![false; errors.len()];
for (_, error_set) in error_map.iter() {
// We want to suppress "duplicate" errors with the same span.
for error in error_set {
if let Some(index) = error.index {
// Suppress errors that are either:
// 1) strictly implied by another error.
// 2) implied by an error with a smaller index.
for error2 in error_set {
if error2.index.map_or(false, |index2| is_suppressed[index2]) {
// Avoid errors being suppressed by already-suppressed
// errors, to prevent all errors from being suppressed
// at once.
continue
}
if self.error_implies(&error2.predicate, &error.predicate) &&
!(error2.index >= error.index &&
self.error_implies(&error.predicate, &error2.predicate))
{
info!("skipping {:?} (implied by {:?})", error, error2);
is_suppressed[index] = true;
break
}
}
}
}
}
for (error, suppressed) in errors.iter().zip(is_suppressed) {
if !suppressed {
self.report_fulfillment_error(error, body_id, fallback_has_occurred);
}
}
}
// returns if `cond` not occurring implies that `error` does not occur - i.e., that
// `error` occurring implies that `cond` occurs.
fn error_implies(
&self,
cond: &ty::Predicate<'tcx>,
error: &ty::Predicate<'tcx>,
) -> bool {
if cond == error {
return true
}
let (cond, error) = match (cond, error) {
(&ty::Predicate::Trait(..), &ty::Predicate::Trait(ref error))
=> (cond, error),
_ => {
// FIXME: make this work in other cases too.
return false
}
};
for implication in super::elaborate_predicates(self.tcx, vec![cond.clone()]) {
if let ty::Predicate::Trait(implication) = implication {
let error = error.to_poly_trait_ref();
let implication = implication.to_poly_trait_ref();
// FIXME: I'm just not taking associated types at all here.
// Eventually I'll need to implement param-env-aware
// `Γ₁ ⊦ φ₁ => Γ₂ ⊦ φ₂` logic.
let param_env = ty::ParamEnv::empty();
if self.can_sub(param_env, error, implication).is_ok() {
debug!("error_implies: {:?} -> {:?} -> {:?}", cond, error, implication);
return true
}
}
}
false
}
fn report_fulfillment_error(
&self,
error: &FulfillmentError<'tcx>,
body_id: Option<hir::BodyId>,
fallback_has_occurred: bool,
) {
debug!("report_fulfillment_errors({:?})", error);
match error.code {
FulfillmentErrorCode::CodeSelectionError(ref selection_error) => {
self.report_selection_error(
&error.obligation,
selection_error,
fallback_has_occurred,
error.points_at_arg_span,
);
}
FulfillmentErrorCode::CodeProjectionError(ref e) => {
self.report_projection_error(&error.obligation, e);
}
FulfillmentErrorCode::CodeAmbiguity => {
self.maybe_report_ambiguity(&error.obligation, body_id);
}
FulfillmentErrorCode::CodeSubtypeError(ref expected_found, ref err) => {
self.report_mismatched_types(
&error.obligation.cause,
expected_found.expected,
expected_found.found,
err.clone(),
).emit();
}
}
}
fn report_projection_error(
&self,
obligation: &PredicateObligation<'tcx>,
error: &MismatchedProjectionTypes<'tcx>,
) {
let predicate = self.resolve_vars_if_possible(&obligation.predicate);
if predicate.references_error() {
return
}
self.probe(|_| {
let err_buf;
let mut err = &error.err;
let mut values = None;
// try to find the mismatched types to report the error with.
//
// this can fail if the problem was higher-ranked, in which
// cause I have no idea for a good error message.
if let ty::Predicate::Projection(ref data) = predicate {
let mut selcx = SelectionContext::new(self);
let (data, _) = self.replace_bound_vars_with_fresh_vars(
obligation.cause.span,
infer::LateBoundRegionConversionTime::HigherRankedType,
data
);
let mut obligations = vec![];
let normalized_ty = super::normalize_projection_type(
&mut selcx,
obligation.param_env,
data.projection_ty,
obligation.cause.clone(),
0,
&mut obligations
);
debug!("report_projection_error obligation.cause={:?} obligation.param_env={:?}",
obligation.cause, obligation.param_env);
debug!("report_projection_error normalized_ty={:?} data.ty={:?}",
normalized_ty, data.ty);
let is_normalized_ty_expected = match &obligation.cause.code {
ObligationCauseCode::ItemObligation(_) |
ObligationCauseCode::BindingObligation(_, _) |
ObligationCauseCode::ObjectCastObligation(_) => false,
_ => true,
};
if let Err(error) = self.at(&obligation.cause, obligation.param_env)
.eq_exp(is_normalized_ty_expected, normalized_ty, data.ty)
{
values = Some(infer::ValuePairs::Types(
ExpectedFound::new(is_normalized_ty_expected, normalized_ty, data.ty)));
err_buf = error;
err = &err_buf;
}
}
let msg = format!("type mismatch resolving `{}`", predicate);
let error_id = (
DiagnosticMessageId::ErrorId(271),
Some(obligation.cause.span),
msg,
);
let fresh = self.tcx.sess.one_time_diagnostics.borrow_mut().insert(error_id);
if fresh {
let mut diag = struct_span_err!(
self.tcx.sess,
obligation.cause.span,
E0271,
"type mismatch resolving `{}`",
predicate
);
self.note_type_err(&mut diag, &obligation.cause, None, values, err);
self.note_obligation_cause(&mut diag, obligation);
diag.emit();
}
});
}
fn fuzzy_match_tys(&self, a: Ty<'tcx>, b: Ty<'tcx>) -> bool {
/// returns the fuzzy category of a given type, or None
/// if the type can be equated to any type.
fn type_category(t: Ty<'_>) -> Option<u32> {
match t.kind {
ty::Bool => Some(0),
ty::Char => Some(1),
ty::Str => Some(2),
ty::Int(..) | ty::Uint(..) | ty::Infer(ty::IntVar(..)) => Some(3),
ty::Float(..) | ty::Infer(ty::FloatVar(..)) => Some(4),
ty::Ref(..) | ty::RawPtr(..) => Some(5),
ty::Array(..) | ty::Slice(..) => Some(6),
ty::FnDef(..) | ty::FnPtr(..) => Some(7),
ty::Dynamic(..) => Some(8),
ty::Closure(..) => Some(9),
ty::Tuple(..) => Some(10),
ty::Projection(..) => Some(11),
ty::Param(..) => Some(12),
ty::Opaque(..) => Some(13),
ty::Never => Some(14),
ty::Adt(adt, ..) => match adt.adt_kind() {
AdtKind::Struct => Some(15),
AdtKind::Union => Some(16),
AdtKind::Enum => Some(17),
},
ty::Generator(..) => Some(18),
ty::Foreign(..) => Some(19),
ty::GeneratorWitness(..) => Some(20),
ty::Placeholder(..) | ty::Bound(..) | ty::Infer(..) | ty::Error => None,
ty::UnnormalizedProjection(..) => bug!("only used with chalk-engine"),
}
}
match (type_category(a), type_category(b)) {
(Some(cat_a), Some(cat_b)) => match (&a.kind, &b.kind) {
(&ty::Adt(def_a, _), &ty::Adt(def_b, _)) => def_a == def_b,
_ => cat_a == cat_b
},
// infer and error can be equated to all types
_ => true
}
}
fn impl_similar_to(&self,
trait_ref: ty::PolyTraitRef<'tcx>,
obligation: &PredicateObligation<'tcx>)
-> Option<DefId>
{
let tcx = self.tcx;
let param_env = obligation.param_env;
let trait_ref = tcx.erase_late_bound_regions(&trait_ref);
let trait_self_ty = trait_ref.self_ty();
let mut self_match_impls = vec![];
let mut fuzzy_match_impls = vec![];
self.tcx.for_each_relevant_impl(
trait_ref.def_id, trait_self_ty, |def_id| {
let impl_substs = self.fresh_substs_for_item(obligation.cause.span, def_id);
let impl_trait_ref = tcx
.impl_trait_ref(def_id)
.unwrap()
.subst(tcx, impl_substs);
let impl_self_ty = impl_trait_ref.self_ty();
if let Ok(..) = self.can_eq(param_env, trait_self_ty, impl_self_ty) {
self_match_impls.push(def_id);
if trait_ref.substs.types().skip(1)
.zip(impl_trait_ref.substs.types().skip(1))
.all(|(u,v)| self.fuzzy_match_tys(u, v))
{
fuzzy_match_impls.push(def_id);
}
}
});
let impl_def_id = if self_match_impls.len() == 1 {
self_match_impls[0]
} else if fuzzy_match_impls.len() == 1 {
fuzzy_match_impls[0]
} else {
return None
};
if tcx.has_attr(impl_def_id, sym::rustc_on_unimplemented) {
Some(impl_def_id)
} else {
None
}
}
fn describe_generator(&self, body_id: hir::BodyId) -> Option<&'static str> {
self.tcx.hir().body(body_id).generator_kind.map(|gen_kind| {
match gen_kind {
hir::GeneratorKind::Gen => "a generator",
hir::GeneratorKind::Async(hir::AsyncGeneratorKind::Block) => "an async block",
hir::GeneratorKind::Async(hir::AsyncGeneratorKind::Fn) => "an async function",
hir::GeneratorKind::Async(hir::AsyncGeneratorKind::Closure) => "an async closure",
}
})
}
/// Used to set on_unimplemented's `ItemContext`
/// to be the enclosing (async) block/function/closure
fn describe_enclosure(&self, hir_id: hir::HirId) -> Option<&'static str> {
let hir = &self.tcx.hir();
let node = hir.find(hir_id)?;
if let hir::Node::Item(
hir::Item{kind: hir::ItemKind::Fn(sig, _, body_id), .. }) = &node {
self.describe_generator(*body_id).or_else(||
Some(if let hir::FnHeader{ asyncness: hir::IsAsync::Async, .. } = sig.header {
"an async function"
} else {
"a function"
})
)
} else if let hir::Node::Expr(hir::Expr {
kind: hir::ExprKind::Closure(_is_move, _, body_id, _, gen_movability), .. }) = &node {
self.describe_generator(*body_id).or_else(||
Some(if gen_movability.is_some() {
"an async closure"
} else {
"a closure"
})
)
} else if let hir::Node::Expr(hir::Expr { .. }) = &node {
let parent_hid = hir.get_parent_node(hir_id);
if parent_hid != hir_id {
return self.describe_enclosure(parent_hid);
} else {
None
}
} else {
None
}
}
fn on_unimplemented_note(
&self,
trait_ref: ty::PolyTraitRef<'tcx>,
obligation: &PredicateObligation<'tcx>,
) -> OnUnimplementedNote {
let def_id = self.impl_similar_to(trait_ref, obligation)
.unwrap_or_else(|| trait_ref.def_id());
let trait_ref = *trait_ref.skip_binder();
let mut flags = vec![];
flags.push((sym::item_context,
self.describe_enclosure(obligation.cause.body_id).map(|s|s.to_owned())));
match obligation.cause.code {
ObligationCauseCode::BuiltinDerivedObligation(..) |
ObligationCauseCode::ImplDerivedObligation(..) => {}
_ => {
// this is a "direct", user-specified, rather than derived,
// obligation.
flags.push((sym::direct, None));
}
}
if let ObligationCauseCode::ItemObligation(item) = obligation.cause.code {
// FIXME: maybe also have some way of handling methods
// from other traits? That would require name resolution,
// which we might want to be some sort of hygienic.
//
// Currently I'm leaving it for what I need for `try`.
if self.tcx.trait_of_item(item) == Some(trait_ref.def_id) {
let method = self.tcx.item_name(item);
flags.push((sym::from_method, None));
flags.push((sym::from_method, Some(method.to_string())));
}
}
if let Some(t) = self.get_parent_trait_ref(&obligation.cause.code) {
flags.push((sym::parent_trait, Some(t)));
}
if let Some(k) = obligation.cause.span.desugaring_kind() {
flags.push((sym::from_desugaring, None));
flags.push((sym::from_desugaring, Some(format!("{:?}", k))));
}
let generics = self.tcx.generics_of(def_id);
let self_ty = trait_ref.self_ty();
// This is also included through the generics list as `Self`,
// but the parser won't allow you to use it
flags.push((sym::_Self, Some(self_ty.to_string())));
if let Some(def) = self_ty.ty_adt_def() {
// We also want to be able to select self's original
// signature with no type arguments resolved
flags.push((sym::_Self, Some(self.tcx.type_of(def.did).to_string())));
}
for param in generics.params.iter() {
let value = match param.kind {
GenericParamDefKind::Type { .. } |
GenericParamDefKind::Const => {
trait_ref.substs[param.index as usize].to_string()
},
GenericParamDefKind::Lifetime => continue,
};
let name = param.name;
flags.push((name, Some(value)));
}
if let Some(true) = self_ty.ty_adt_def().map(|def| def.did.is_local()) {
flags.push((sym::crate_local, None));
}
// Allow targeting all integers using `{integral}`, even if the exact type was resolved
if self_ty.is_integral() {
flags.push((sym::_Self, Some("{integral}".to_owned())));
}
if let ty::Array(aty, len) = self_ty.kind {
flags.push((sym::_Self, Some("[]".to_owned())));
flags.push((sym::_Self, Some(format!("[{}]", aty))));
if let Some(def) = aty.ty_adt_def() {
// We also want to be able to select the array's type's original
// signature with no type arguments resolved
flags.push((
sym::_Self,
Some(format!("[{}]", self.tcx.type_of(def.did).to_string())),
));
let tcx = self.tcx;
if let Some(len) = len.try_eval_usize(tcx, ty::ParamEnv::empty()) {
flags.push((
sym::_Self,
Some(format!("[{}; {}]", self.tcx.type_of(def.did).to_string(), len)),
));
} else {
flags.push((
sym::_Self,
Some(format!("[{}; _]", self.tcx.type_of(def.did).to_string())),
));
}
}
}
if let Ok(Some(command)) = OnUnimplementedDirective::of_item(
self.tcx, trait_ref.def_id, def_id
) {
command.evaluate(self.tcx, trait_ref, &flags[..])
} else {
OnUnimplementedNote::empty()
}
}
fn find_similar_impl_candidates(
&self,
trait_ref: ty::PolyTraitRef<'tcx>,
) -> Vec<ty::TraitRef<'tcx>> {
let simp = fast_reject::simplify_type(self.tcx, trait_ref.skip_binder().self_ty(), true);
let all_impls = self.tcx.all_impls(trait_ref.def_id());
match simp {
Some(simp) => all_impls.iter().filter_map(|&def_id| {
let imp = self.tcx.impl_trait_ref(def_id).unwrap();
let imp_simp = fast_reject::simplify_type(self.tcx, imp.self_ty(), true);
if let Some(imp_simp) = imp_simp {
if simp != imp_simp {
return None
}
}
Some(imp)
}).collect(),
None => all_impls.iter().map(|&def_id|
self.tcx.impl_trait_ref(def_id).unwrap()
).collect()
}
}
fn report_similar_impl_candidates(
&self,
impl_candidates: Vec<ty::TraitRef<'tcx>>,
err: &mut DiagnosticBuilder<'_>,
) {
if impl_candidates.is_empty() {
return;
}
let len = impl_candidates.len();
let end = if impl_candidates.len() <= 5 {
impl_candidates.len()
} else {
4
};
let normalize = |candidate| self.tcx.infer_ctxt().enter(|ref infcx| {
let normalized = infcx
.at(&ObligationCause::dummy(), ty::ParamEnv::empty())
.normalize(candidate)
.ok();
match normalized {
Some(normalized) => format!("\n {:?}", normalized.value),
None => format!("\n {:?}", candidate),
}
});
// Sort impl candidates so that ordering is consistent for UI tests.
let mut normalized_impl_candidates = impl_candidates
.iter()
.map(normalize)
.collect::<Vec<String>>();
// Sort before taking the `..end` range,
// because the ordering of `impl_candidates` may not be deterministic:
// https://github.com/rust-lang/rust/pull/57475#issuecomment-455519507
normalized_impl_candidates.sort();
err.help(&format!("the following implementations were found:{}{}",
normalized_impl_candidates[..end].join(""),
if len > 5 {
format!("\nand {} others", len - 4)
} else {
String::new()
}
));
}
/// Reports that an overflow has occurred and halts compilation. We
/// halt compilation unconditionally because it is important that
/// overflows never be masked -- they basically represent computations
/// whose result could not be truly determined and thus we can't say
/// if the program type checks or not -- and they are unusual
/// occurrences in any case.
pub fn report_overflow_error<T>(
&self,
obligation: &Obligation<'tcx, T>,
suggest_increasing_limit: bool,
) -> !
where T: fmt::Display + TypeFoldable<'tcx>
{
let predicate =
self.resolve_vars_if_possible(&obligation.predicate);
let mut err = struct_span_err!(
self.tcx.sess,
obligation.cause.span,
E0275,
"overflow evaluating the requirement `{}`",
predicate
);
if suggest_increasing_limit {
self.suggest_new_overflow_limit(&mut err);
}
self.note_obligation_cause_code(
&mut err,
&obligation.predicate,
&obligation.cause.code,
&mut vec![],
);
err.emit();
self.tcx.sess.abort_if_errors();
bug!();
}
/// Reports that a cycle was detected which led to overflow and halts
/// compilation. This is equivalent to `report_overflow_error` except
/// that we can give a more helpful error message (and, in particular,
/// we do not suggest increasing the overflow limit, which is not
/// going to help).
pub fn report_overflow_error_cycle(&self, cycle: &[PredicateObligation<'tcx>]) -> ! {
let cycle = self.resolve_vars_if_possible(&cycle.to_owned());
assert!(cycle.len() > 0);
debug!("report_overflow_error_cycle: cycle={:?}", cycle);
self.report_overflow_error(&cycle[0], false);
}
pub fn report_extra_impl_obligation(&self,
error_span: Span,
item_name: ast::Name,
_impl_item_def_id: DefId,
trait_item_def_id: DefId,
requirement: &dyn fmt::Display)
-> DiagnosticBuilder<'tcx>
{
let msg = "impl has stricter requirements than trait";
let sp = self.tcx.sess.source_map().def_span(error_span);
let mut err = struct_span_err!(self.tcx.sess, sp, E0276, "{}", msg);
if let Some(trait_item_span) = self.tcx.hir().span_if_local(trait_item_def_id) {
let span = self.tcx.sess.source_map().def_span(trait_item_span);
err.span_label(span, format!("definition of `{}` from trait", item_name));
}
err.span_label(sp, format!("impl has extra requirement {}", requirement));
err
}
/// Gets the parent trait chain start
fn get_parent_trait_ref(&self, code: &ObligationCauseCode<'tcx>) -> Option<String> {
match code {
&ObligationCauseCode::BuiltinDerivedObligation(ref data) => {
let parent_trait_ref = self.resolve_vars_if_possible(
&data.parent_trait_ref);
match self.get_parent_trait_ref(&data.parent_code) {
Some(t) => Some(t),
None => Some(parent_trait_ref.skip_binder().self_ty().to_string()),
}
}
_ => None,
}
}
pub fn report_selection_error(
&self,
obligation: &PredicateObligation<'tcx>,
error: &SelectionError<'tcx>,
fallback_has_occurred: bool,
points_at_arg: bool,
) {
let span = obligation.cause.span;
let mut err = match *error {
SelectionError::Unimplemented => {
if let ObligationCauseCode::CompareImplMethodObligation {
item_name, impl_item_def_id, trait_item_def_id,
} = obligation.cause.code {
self.report_extra_impl_obligation(
span,
item_name,
impl_item_def_id,
trait_item_def_id,
&format!("`{}`", obligation.predicate))
.emit();
return;
}
match obligation.predicate {
ty::Predicate::Trait(ref trait_predicate) => {
let trait_predicate =
self.resolve_vars_if_possible(trait_predicate);
if self.tcx.sess.has_errors() && trait_predicate.references_error() {
return;
}
let trait_ref = trait_predicate.to_poly_trait_ref();
let (post_message, pre_message) =
self.get_parent_trait_ref(&obligation.cause.code)
.map(|t| (format!(" in `{}`", t), format!("within `{}`, ", t)))
.unwrap_or_default();
let OnUnimplementedNote { message, label, note }
= self.on_unimplemented_note(trait_ref, obligation);
let have_alt_message = message.is_some() || label.is_some();
let is_try = self.tcx.sess.source_map().span_to_snippet(span)
.map(|s| &s == "?")
.unwrap_or(false);
let is_from = format!("{}", trait_ref).starts_with("std::convert::From<");
let (message, note) = if is_try && is_from {
(Some(format!(
"`?` couldn't convert the error to `{}`",
trait_ref.self_ty(),
)), Some(
"the question mark operation (`?`) implicitly performs a \
conversion on the error value using the `From` trait".to_owned()
))
} else {
(message, note)
};
let mut err = struct_span_err!(
self.tcx.sess,
span,
E0277,
"{}",
message.unwrap_or_else(|| format!(
"the trait bound `{}` is not satisfied{}",
trait_ref.to_predicate(),
post_message,
)));
let explanation =
if obligation.cause.code == ObligationCauseCode::MainFunctionType {
"consider using `()`, or a `Result`".to_owned()
} else {
format!(
"{}the trait `{}` is not implemented for `{}`",
pre_message,
trait_ref,
trait_ref.self_ty(),
)
};
if let Some(ref s) = label {
// If it has a custom `#[rustc_on_unimplemented]`
// error message, let's display it as the label!
err.span_label(span, s.as_str());
err.help(&explanation);
} else {
err.span_label(span, explanation);
}
if let Some(ref s) = note {
// If it has a custom `#[rustc_on_unimplemented]` note, let's display it
err.note(s.as_str());
}
self.suggest_borrow_on_unsized_slice(&obligation.cause.code, &mut err);
self.suggest_fn_call(&obligation, &mut err, &trait_ref, points_at_arg);
self.suggest_remove_reference(&obligation, &mut err, &trait_ref);
self.suggest_semicolon_removal(&obligation, &mut err, span, &trait_ref);
// Try to report a help message
if !trait_ref.has_infer_types() &&
self.predicate_can_apply(obligation.param_env, trait_ref) {
// If a where-clause may be useful, remind the
// user that they can add it.
//
// don't display an on-unimplemented note, as
// these notes will often be of the form
// "the type `T` can't be frobnicated"
// which is somewhat confusing.
self.suggest_restricting_param_bound(
&mut err,
&trait_ref,
obligation.cause.body_id,
);
} else {
if !have_alt_message {
// Can't show anything else useful, try to find similar impls.
let impl_candidates = self.find_similar_impl_candidates(trait_ref);
self.report_similar_impl_candidates(impl_candidates, &mut err);
}
self.suggest_change_mut(
&obligation,
&mut err,
&trait_ref,
points_at_arg,
);
}
// If this error is due to `!: Trait` not implemented but `(): Trait` is
// implemented, and fallback has occurred, then it could be due to a
// variable that used to fallback to `()` now falling back to `!`. Issue a
// note informing about the change in behaviour.
if trait_predicate.skip_binder().self_ty().is_never()
&& fallback_has_occurred
{
let predicate = trait_predicate.map_bound(|mut trait_pred| {
trait_pred.trait_ref.substs = self.tcx.mk_substs_trait(
self.tcx.mk_unit(),
&trait_pred.trait_ref.substs[1..],
);
trait_pred
});
let unit_obligation = Obligation {
predicate: ty::Predicate::Trait(predicate),
.. obligation.clone()
};
if self.predicate_may_hold(&unit_obligation) {
err.note("the trait is implemented for `()`. \
Possibly this error has been caused by changes to \
Rust's type-inference algorithm \
(see: https://github.com/rust-lang/rust/issues/48950 \
for more info). Consider whether you meant to use the \
type `()` here instead.");
}
}
err
}
ty::Predicate::Subtype(ref predicate) => {
// Errors for Subtype predicates show up as
// `FulfillmentErrorCode::CodeSubtypeError`,
// not selection error.
span_bug!(span, "subtype requirement gave wrong error: `{:?}`", predicate)
}
ty::Predicate::RegionOutlives(ref predicate) => {
|
ty::Predicate::Projection(..) | ty::Predicate::TypeOutlives(..) => {
let predicate =
self.resolve_vars_if_possible(&obligation.predicate);
struct_span_err!(self.tcx.sess, span, E0280,
"the requirement `{}` is not satisfied",
predicate)
}
ty::Predicate::ObjectSafe(trait_def_id) => {
let violations = self.tcx.object_safety_violations(trait_def_id);
self.tcx.report_object_safety_error(
span,
trait_def_id,
violations,
)
}
ty::Predicate::ClosureKind(closure_def_id, closure_substs, kind) => {
let found_kind = self.closure_kind(closure_def_id, closure_substs).unwrap();
let closure_span = self.tcx.sess.source_map()
.def_span(self.tcx.hir().span_if_local(closure_def_id).unwrap());
let hir_id = self.tcx.hir().as_local_hir_id(closure_def_id).unwrap();
let mut err = struct_span_err!(
self.tcx.sess, closure_span, E0525,
"expected a closure that implements the `{}` trait, \
but this closure only implements `{}`",
kind,
found_kind);
err.span_label(
closure_span,
format!("this closure implements `{}`, not `{}`", found_kind, kind));
err.span_label(
obligation.cause.span,
format!("the requirement to implement `{}` derives from here", kind));
// Additional context information explaining why the closure only implements
// a particular trait.
if let Some(tables) = self.in_progress_tables {
let tables = tables.borrow();
match (found_kind, tables.closure_kind_origins().get(hir_id)) {
(ty::ClosureKind::FnOnce, Some((span, name))) => {
err.span_label(*span, format!(
"closure is `FnOnce` because it moves the \
variable `{}` out of its environment", name));
},
(ty::ClosureKind::FnMut, Some((span, name))) => {
err.span_label(*span, format!(
"closure is `FnMut` because it mutates the \
variable `{}` here", name));
},
_ => {}
}
}
err.emit();
return;
}
ty::Predicate::WellFormed(ty) => {
if !self.tcx.sess.opts.debugging_opts.chalk {
// WF predicates cannot themselves make
// errors. They can only block due to
// ambiguity; otherwise, they always
// degenerate into other obligations
// (which may fail).
span_bug!(span, "WF predicate not satisfied for {:?}", ty);
} else {
// FIXME: we'll need a better message which takes into account
// which bounds actually failed to hold.
self.tcx.sess.struct_span_err(
span,
&format!("the type `{}` is not well-formed (chalk)", ty)
)
}
}
ty::Predicate::ConstEvaluatable(..) => {
// Errors for `ConstEvaluatable` predicates show up as
// `SelectionError::ConstEvalFailure`,
// not `Unimplemented`.
span_bug!(span,
"const-evaluatable requirement gave wrong error: `{:?}`", obligation)
}
}
}
OutputTypeParameterMismatch(ref found_trait_ref, ref expected_trait_ref, _) => {
let found_trait_ref = self.resolve_vars_if_possible(&*found_trait_ref);
let expected_trait_ref = self.resolve_vars_if_possible(&*expected_trait_ref);
if expected_trait_ref.self_ty().references_error() {
return;
}
let found_trait_ty = found_trait_ref.self_ty();
let found_did = match found_trait_ty.kind {
ty::Closure(did, _) | ty::Foreign(did) | ty::FnDef(did, _) => Some(did),
ty::Adt(def, _) => Some(def.did),
_ => None,
};
let found_span = found_did.and_then(|did|
self.tcx.hir().span_if_local(did)
).map(|sp| self.tcx.sess.source_map().def_span(sp)); // the sp could be an fn def
if self.reported_closure_mismatch.borrow().contains(&(span, found_span)) {
// We check closures twice, with obligations flowing in different directions,
// but we want to complain about them only once.
return;
}
self.reported_closure_mismatch.borrow_mut().insert((span, found_span));
let found = match found_trait_ref.skip_binder().substs.type_at(1).kind {
ty::Tuple(ref tys) => vec![ArgKind::empty(); tys.len()],
_ => vec![ArgKind::empty()],
};
let expected_ty = expected_trait_ref.skip_binder().substs.type_at(1);
let expected = match expected_ty.kind {
ty::Tuple(ref tys) => tys.iter()
.map(|t| ArgKind::from_expected_ty(t.expect_ty(), Some(span))).collect(),
_ => vec![ArgKind::Arg("_".to_owned(), expected_ty.to_string())],
};
if found.len() == expected.len() {
self.report_closure_arg_mismatch(span,
found_span,
found_trait_ref,
expected_trait_ref)
} else {
let (closure_span, found) = found_did
.and_then(|did| self.tcx.hir().get_if_local(did))
.map(|node| {
let (found_span, found) = self.get_fn_like_arguments(node);
(Some(found_span), found)
}).unwrap_or((found_span, found));
self.report_arg_count_mismatch(span,
closure_span,
expected,
found,
found_trait_ty.is_closure())
}
}
TraitNotObjectSafe(did) => {
let violations = self.tcx.object_safety_violations(did);
self.tcx.report_object_safety_error(span, did, violations)
}
// already reported in the query
ConstEvalFailure(err) => {
self.tcx.sess.delay_span_bug(
span,
&format!("constant in type had an ignored error: {:?}", err),
);
return;
}
Overflow => {
bug!("overflow should be handled before the `report_selection_error` path");
}
};
self.note_obligation_cause(&mut err, obligation);
err.emit();
}
fn suggest_restricting_param_bound(
&self,
err: &mut DiagnosticBuilder<'_>,
trait_ref: &ty::PolyTraitRef<'_>,
body_id: hir::HirId,
) {
let self_ty = trait_ref.self_ty();
let (param_ty, projection) = match &self_ty.kind {
ty::Param(_) => (true, None),
ty::Projection(projection) => (false, Some(projection)),
_ => return,
};
let mut suggest_restriction = |generics: &hir::Generics, msg| {
let span = generics.where_clause.span_for_predicates_or_empty_place();
if !span.from_expansion() && span.desugaring_kind().is_none() {
err.span_suggestion(
generics.where_clause.span_for_predicates_or_empty_place().shrink_to_hi(),
&format!("consider further restricting {}", msg),
format!(
"{} {} ",
if !generics.where_clause.predicates.is_empty() {
","
} else {
" where"
},
trait_ref.to_predicate(),
),
Applicability::MachineApplicable,
);
}
};
// FIXME: Add check for trait bound that is already present, particularly `?Sized` so we
// don't suggest `T: Sized + ?Sized`.
let mut hir_id = body_id;
while let Some(node) = self.tcx.hir().find(hir_id) {
match node {
hir::Node::TraitItem(hir::TraitItem {
generics,
kind: hir::TraitItemKind::Method(..), ..
}) if param_ty && self_ty == self.tcx.types.self_param => {
// Restricting `Self` for a single method.
suggest_restriction(&generics, "`Self`");
return;
}
hir::Node::Item(hir::Item {
kind: hir::ItemKind::Fn(_, generics, _), ..
}) |
hir::Node::TraitItem(hir::TraitItem {
generics,
kind: hir::TraitItemKind::Method(..), ..
}) |
hir::Node::ImplItem(hir::ImplItem {
generics,
kind: hir::ImplItemKind::Method(..), ..
}) |
hir::Node::Item(hir::Item {
kind: hir::ItemKind::Trait(_, _, generics, _, _), ..
}) |
hir::Node::Item(hir::Item {
kind: hir::ItemKind::Impl(_, _, _, generics, ..), ..
}) if projection.is_some() => {
// Missing associated type bound.
suggest_restriction(&generics, "the associated type");
return;
}
hir::Node::Item(hir::Item { kind: hir::ItemKind::Struct(_, generics), span, .. }) |
hir::Node::Item(hir::Item { kind: hir::ItemKind::Enum(_, generics), span, .. }) |
hir::Node::Item(hir::Item { kind: hir::ItemKind::Union(_, generics), span, .. }) |
hir::Node::Item(hir::Item {
kind: hir::ItemKind::Trait(_, _, generics, ..), span, ..
}) |
hir::Node::Item(hir::Item {
kind: hir::ItemKind::Impl(_, _, _, generics, ..), span, ..
}) |
hir::Node::Item(hir::Item {
kind: hir::ItemKind::Fn(_, generics, _), span, ..
}) |
hir::Node::Item(hir::Item {
kind: hir::ItemKind::TyAlias(_, generics), span, ..
}) |
hir::Node::Item(hir::Item {
kind: hir::ItemKind::TraitAlias(generics, _), span, ..
}) |
hir::Node::Item(hir::Item {
kind: hir::ItemKind::OpaqueTy(hir::OpaqueTy { generics, .. }), span, ..
}) |
hir::Node::TraitItem(hir::TraitItem { generics, span, .. }) |
hir::Node::ImplItem(hir::ImplItem { generics, span, .. })
if param_ty => {
// Missing generic type parameter bound.
let restrict_msg = "consider further restricting this bound";
let param_name = self_ty.to_string();
for param in generics.params.iter().filter(|p| {
p.name.ident().as_str() == param_name
}) {
if param_name.starts_with("impl ") {
// `impl Trait` in argument:
// `fn foo(x: impl Trait) {}` → `fn foo(t: impl Trait + Trait2) {}`
err.span_suggestion(
param.span,
restrict_msg,
// `impl CurrentTrait + MissingTrait`
format!("{} + {}", param.name.ident(), trait_ref),
Applicability::MachineApplicable,
);
} else if generics.where_clause.predicates.is_empty() &&
param.bounds.is_empty()
{
// If there are no bounds whatsoever, suggest adding a constraint
// to the type parameter:
// `fn foo<T>(t: T) {}` → `fn foo<T: Trait>(t: T) {}`
err.span_suggestion(
param.span,
"consider restricting this bound",
format!("{}", trait_ref.to_predicate()),
Applicability::MachineApplicable,
);
} else if !generics.where_clause.predicates.is_empty() {
// There is a `where` clause, so suggest expanding it:
// `fn foo<T>(t: T) where T: Debug {}` →
// `fn foo<T>(t: T) where T: Debug, T: Trait {}`
err.span_suggestion(
generics.where_clause.span().unwrap().shrink_to_hi(),
&format!(
"consider further restricting type parameter `{}`",
param_name,
),
format!(", {}", trait_ref.to_predicate()),
Applicability::MachineApplicable,
);
} else {
// If there is no `where` clause lean towards constraining to the
// type parameter:
// `fn foo<X: Bar, T>(t: T, x: X) {}` → `fn foo<T: Trait>(t: T) {}`
// `fn foo<T: Bar>(t: T) {}` → `fn foo<T: Bar + Trait>(t: T) {}`
let sp = param.span.with_hi(span.hi());
let span = self.tcx.sess.source_map()
.span_through_char(sp, ':');
if sp != param.span && sp != span {
// Only suggest if we have high certainty that the span
// covers the colon in `foo<T: Trait>`.
err.span_suggestion(span, restrict_msg, format!(
"{} + ",
trait_ref.to_predicate(),
), Applicability::MachineApplicable);
} else {
err.span_label(param.span, &format!(
"consider adding a `where {}` bound",
trait_ref.to_predicate(),
));
}
}
return;
}
}
hir::Node::Crate => return,
_ => {}
}
hir_id = self.tcx.hir().get_parent_item(hir_id);
}
}
/// When encountering an assignment of an unsized trait, like `let x = ""[..];`, provide a
/// suggestion to borrow the initializer in order to use have a slice instead.
fn suggest_borrow_on_unsized_slice(
&self,
code: &ObligationCauseCode<'tcx>,
err: &mut DiagnosticBuilder<'tcx>,
) {
if let &ObligationCauseCode::VariableType(hir_id) = code {
let parent_node = self.tcx.hir().get_parent_node(hir_id);
if let Some(Node::Local(ref local)) = self.tcx.hir().find(parent_node) {
if let Some(ref expr) = local.init {
if let hir::ExprKind::Index(_, _) = expr.kind {
if let Ok(snippet) = self.tcx.sess.source_map().span_to_snippet(expr.span) {
err.span_suggestion(
expr.span,
"consider borrowing here",
format!("&{}", snippet),
Applicability::MachineApplicable
);
}
}
}
}
}
}
fn suggest_fn_call(
&self,
obligation: &PredicateObligation<'tcx>,
err: &mut DiagnosticBuilder<'_>,
trait_ref: &ty::Binder<ty::TraitRef<'tcx>>,
points_at_arg: bool,
) {
let self_ty = trait_ref.self_ty();
match self_ty.kind {
ty::FnDef(def_id, _) => {
// We tried to apply the bound to an `fn`. Check whether calling it would evaluate
// to a type that *would* satisfy the trait binding. If it would, suggest calling
// it: `bar(foo)` -> `bar(foo)`. This case is *very* likely to be hit if `foo` is
// `async`.
let output_ty = self_ty.fn_sig(self.tcx).output();
let new_trait_ref = ty::TraitRef {
def_id: trait_ref.def_id(),
substs: self.tcx.mk_substs_trait(output_ty.skip_binder(), &[]),
};
let obligation = Obligation::new(
obligation.cause.clone(),
obligation.param_env,
new_trait_ref.to_predicate(),
);
match self.evaluate_obligation(&obligation) {
Ok(EvaluationResult::EvaluatedToOk) |
Ok(EvaluationResult::EvaluatedToOkModuloRegions) |
Ok(EvaluationResult::EvaluatedToAmbig) => {
if let Some(hir::Node::Item(hir::Item {
ident,
kind: hir::ItemKind::Fn(.., body_id),
..
})) = self.tcx.hir().get_if_local(def_id) {
let body = self.tcx.hir().body(*body_id);
let msg = "use parentheses to call the function";
let snippet = format!(
"{}({})",
ident,
body.params.iter()
.map(|arg| match &arg.pat.kind {
hir::PatKind::Binding(_, _, ident, None)
if ident.name != kw::SelfLower => ident.to_string(),
_ => "_".to_string(),
}).collect::<Vec<_>>().join(", "),
);
// When the obligation error has been ensured to have been caused by
// an argument, the `obligation.cause.span` points at the expression
// of the argument, so we can provide a suggestion. This is signaled
// by `points_at_arg`. Otherwise, we give a more general note.
if points_at_arg {
err.span_suggestion(
obligation.cause.span,
msg,
snippet,
Applicability::HasPlaceholders,
);
} else {
err.help(&format!("{}: `{}`", msg, snippet));
}
}
}
_ => {}
}
}
_ => {}
}
}
/// Whenever references are used by mistake, like `for (i, e) in &vec.iter().enumerate()`,
/// suggest removing these references until we reach a type that implements the trait.
fn suggest_remove_reference(
&self,
obligation: &PredicateObligation<'tcx>,
err: &mut DiagnosticBuilder<'tcx>,
trait_ref: &ty::Binder<ty::TraitRef<'tcx>>,
) {
let trait_ref = trait_ref.skip_binder();
let span = obligation.cause.span;
if let Ok(snippet) = self.tcx.sess.source_map().span_to_snippet(span) {
let refs_number = snippet.chars()
.filter(|c| !c.is_whitespace())
.take_while(|c| *c == '&')
.count();
if let Some('\'') = snippet.chars()
.filter(|c| !c.is_whitespace())
.skip(refs_number)
.next()
{ // Do not suggest removal of borrow from type arguments.
return;
}
let mut trait_type = trait_ref.self_ty();
for refs_remaining in 0..refs_number {
if let ty::Ref(_, t_type, _) = trait_type.kind {
trait_type = t_type;
let substs = self.tcx.mk_substs_trait(trait_type, &[]);
let new_trait_ref = ty::TraitRef::new(trait_ref.def_id, substs);
let new_obligation = Obligation::new(
ObligationCause::dummy(),
obligation.param_env,
new_trait_ref.to_predicate(),
);
if self.predicate_may_hold(&new_obligation) {
let sp = self.tcx.sess.source_map()
.span_take_while(span, |c| c.is_whitespace() || *c == '&');
let remove_refs = refs_remaining + 1;
let format_str = format!("consider removing {} leading `&`-references",
remove_refs);
err.span_suggestion_short(
sp, &format_str, String::new(), Applicability::MachineApplicable
);
break;
}
} else {
break;
}
}
}
}
/// Check if the trait bound is implemented for a different mutability and note it in the
/// final error.
fn suggest_change_mut(
&self,
obligation: &PredicateObligation<'tcx>,
err: &mut DiagnosticBuilder<'tcx>,
trait_ref: &ty::Binder<ty::TraitRef<'tcx>>,
points_at_arg: bool,
) {
let span = obligation.cause.span;
if let Ok(snippet) = self.tcx.sess.source_map().span_to_snippet(span) {
let refs_number = snippet.chars()
.filter(|c| !c.is_whitespace())
.take_while(|c| *c == '&')
.count();
if let Some('\'') = snippet.chars()
.filter(|c| !c.is_whitespace())
.skip(refs_number)
.next()
{ // Do not suggest removal of borrow from type arguments.
return;
}
let trait_ref = self.resolve_vars_if_possible(trait_ref);
if trait_ref.has_infer_types() {
// Do not ICE while trying to find if a reborrow would succeed on a trait with
// unresolved bindings.
return;
}
if let ty::Ref(region, t_type, mutability) = trait_ref.skip_binder().self_ty().kind {
let trait_type = match mutability {
hir::Mutability::Mutable => self.tcx.mk_imm_ref(region, t_type),
hir::Mutability::Immutable => self.tcx.mk_mut_ref(region, t_type),
};
let substs = self.tcx.mk_substs_trait(&trait_type, &[]);
let new_trait_ref = ty::TraitRef::new(trait_ref.skip_binder().def_id, substs);
let new_obligation = Obligation::new(
ObligationCause::dummy(),
obligation.param_env,
new_trait_ref.to_predicate(),
);
if self.evaluate_obligation_no_overflow(
&new_obligation,
).must_apply_modulo_regions() {
let sp = self.tcx.sess.source_map()
.span_take_while(span, |c| c.is_whitespace() || *c == '&');
if points_at_arg &&
mutability == hir::Mutability::Immutable &&
refs_number > 0
{
err.span_suggestion(
sp,
"consider changing this borrow's mutability",
"&mut ".to_string(),
Applicability::MachineApplicable,
);
} else {
err.note(&format!(
"`{}` is implemented for `{:?}`, but not for `{:?}`",
trait_ref,
trait_type,
trait_ref.skip_binder().self_ty(),
));
}
}
}
}
}
fn suggest_semicolon_removal(
&self,
obligation: &PredicateObligation<'tcx>,
err: &mut DiagnosticBuilder<'tcx>,
span: Span,
trait_ref: &ty::Binder<ty::TraitRef<'tcx>>,
) {
let hir = self.tcx.hir();
let parent_node = hir.get_parent_node(obligation.cause.body_id);
let node = hir.find(parent_node);
if let Some(hir::Node::Item(hir::Item {
kind: hir::ItemKind::Fn(sig, _, body_id),
..
})) = node {
let body = hir.body(*body_id);
if let hir::ExprKind::Block(blk, _) = &body.value.kind {
if sig.decl.output.span().overlaps(span) && blk.expr.is_none() &&
"()" == &trait_ref.self_ty().to_string()
{
// FIXME(estebank): When encountering a method with a trait
// bound not satisfied in the return type with a body that has
// no return, suggest removal of semicolon on last statement.
// Once that is added, close #54771.
if let Some(ref stmt) = blk.stmts.last() {
let sp = self.tcx.sess.source_map().end_point(stmt.span);
err.span_label(sp, "consider removing this semicolon");
}
}
}
}
}
/// Given some node representing a fn-like thing in the HIR map,
/// returns a span and `ArgKind` information that describes the
/// arguments it expects. This can be supplied to
/// `report_arg_count_mismatch`.
pub fn get_fn_like_arguments(&self, node: Node<'_>) -> (Span, Vec<ArgKind>) {
match node {
Node::Expr(&hir::Expr {
kind: hir::ExprKind::Closure(_, ref _decl, id, span, _),
..
}) => {
(self.tcx.sess.source_map().def_span(span),
self.tcx.hir().body(id).params.iter()
.map(|arg| {
if let hir::Pat {
kind: hir::PatKind::Tuple(ref args, _),
span,
..
} = *arg.pat {
ArgKind::Tuple(
Some(span),
args.iter().map(|pat| {
let snippet = self.tcx.sess.source_map()
.span_to_snippet(pat.span).unwrap();
(snippet, "_".to_owned())
}).collect::<Vec<_>>(),
)
} else {
let name = self.tcx.sess.source_map()
.span_to_snippet(arg.pat.span).unwrap();
ArgKind::Arg(name, "_".to_owned())
}
})
.collect::<Vec<ArgKind>>())
}
Node::Item(&hir::Item {
span,
kind: hir::ItemKind::Fn(ref sig, ..),
..
}) |
Node::ImplItem(&hir::ImplItem {
span,
kind: hir::ImplItemKind::Method(ref sig, _),
..
}) |
Node::TraitItem(&hir::TraitItem {
span,
kind: hir::TraitItemKind::Method(ref sig, _),
..
}) => {
(self.tcx.sess.source_map().def_span(span), sig.decl.inputs.iter()
.map(|arg| match arg.clone().kind {
hir::TyKind::Tup(ref tys) => ArgKind::Tuple(
Some(arg.span),
vec![("_".to_owned(), "_".to_owned()); tys.len()]
),
_ => ArgKind::empty()
}).collect::<Vec<ArgKind>>())
}
Node::Ctor(ref variant_data) => {
let span = variant_data.ctor_hir_id()
.map(|hir_id| self.tcx.hir().span(hir_id))
.unwrap_or(DUMMY_SP);
let span = self.tcx.sess.source_map().def_span(span);
(span, vec![ArgKind::empty(); variant_data.fields().len()])
}
_ => panic!("non-FnLike node found: {:?}", node),
}
}
/// Reports an error when the number of arguments needed by a
/// trait match doesn't match the number that the expression
/// provides.
pub fn report_arg_count_mismatch(
&self,
span: Span,
found_span: Option<Span>,
expected_args: Vec<ArgKind>,
found_args: Vec<ArgKind>,
is_closure: bool,
) -> DiagnosticBuilder<'tcx> {
let kind = if is_closure { "closure" } else { "function" };
let args_str = |arguments: &[ArgKind], other: &[ArgKind]| {
let arg_length = arguments.len();
let distinct = match &other[..] {
&[ArgKind::Tuple(..)] => true,
_ => false,
};
match (arg_length, arguments.get(0)) {
(1, Some(&ArgKind::Tuple(_, ref fields))) => {
format!("a single {}-tuple as argument", fields.len())
}
_ => format!("{} {}argument{}",
arg_length,
if distinct && arg_length > 1 { "distinct " } else { "" },
pluralize!(arg_length))
}
};
let expected_str = args_str(&expected_args, &found_args);
let found_str = args_str(&found_args, &expected_args);
let mut err = struct_span_err!(
self.tcx.sess,
span,
E0593,
"{} is expected to take {}, but it takes {}",
kind,
expected_str,
found_str,
);
err.span_label(span, format!("expected {} that takes {}", kind, expected_str));
if let Some(found_span) = found_span {
err.span_label(found_span, format!("takes {}", found_str));
// move |_| { ... }
// ^^^^^^^^-- def_span
//
// move |_| { ... }
// ^^^^^-- prefix
let prefix_span = self.tcx.sess.source_map().span_until_non_whitespace(found_span);
// move |_| { ... }
// ^^^-- pipe_span
let pipe_span = if let Some(span) = found_span.trim_start(prefix_span) {
span
} else {
found_span
};
// Suggest to take and ignore the arguments with expected_args_length `_`s if
// found arguments is empty (assume the user just wants to ignore args in this case).
// For example, if `expected_args_length` is 2, suggest `|_, _|`.
if found_args.is_empty() && is_closure {
let underscores = vec!["_"; expected_args.len()].join(", ");
err.span_suggestion(
pipe_span,
&format!(
"consider changing the closure to take and ignore the expected argument{}",
if expected_args.len() < 2 {
""
} else {
"s"
}
),
format!("|{}|", underscores),
Applicability::MachineApplicable,
);
}
if let &[ArgKind::Tuple(_, ref fields)] = &found_args[..] {
if fields.len() == expected_args.len() {
let sugg = fields.iter()
.map(|(name, _)| name.to_owned())
.collect::<Vec<String>>()
.join(", ");
err.span_suggestion(
found_span,
"change the closure to take multiple arguments instead of a single tuple",
format!("|{}|", sugg),
Applicability::MachineApplicable,
);
}
}
if let &[ArgKind::Tuple(_, ref fields)] = &expected_args[..] {
if fields.len() == found_args.len() && is_closure {
let sugg = format!(
"|({}){}|",
found_args.iter()
.map(|arg| match arg {
ArgKind::Arg(name, _) => name.to_owned(),
_ => "_".to_owned(),
})
.collect::<Vec<String>>()
.join(", "),
// add type annotations if available
if found_args.iter().any(|arg| match arg {
ArgKind::Arg(_, ty) => ty != "_",
_ => false,
}) {
format!(": ({})",
fields.iter()
.map(|(_, ty)| ty.to_owned())
.collect::<Vec<String>>()
.join(", "))
} else {
String::new()
},
);
err.span_suggestion(
found_span,
"change the closure to accept a tuple instead of individual arguments",
sugg,
Applicability::MachineApplicable,
);
}
}
}
err
}
fn report_closure_arg_mismatch(
&self,
span: Span,
found_span: Option<Span>,
expected_ref: ty::PolyTraitRef<'tcx>,
found: ty::PolyTraitRef<'tcx>,
) -> DiagnosticBuilder<'tcx> {
fn build_fn_sig_string<'tcx>(tcx: TyCtxt<'tcx>, trait_ref: &ty::TraitRef<'tcx>) -> String {
let inputs = trait_ref.substs.type_at(1);
let sig = if let ty::Tuple(inputs) = inputs.kind {
tcx.mk_fn_sig(
inputs.iter().map(|k| k.expect_ty()),
tcx.mk_ty_infer(ty::TyVar(ty::TyVid { index: 0 })),
false,
hir::Unsafety::Normal,
::rustc_target::spec::abi::Abi::Rust
)
} else {
tcx.mk_fn_sig(
::std::iter::once(inputs),
tcx.mk_ty_infer(ty::TyVar(ty::TyVid { index: 0 })),
false,
hir::Unsafety::Normal,
::rustc_target::spec::abi::Abi::Rust
)
};
ty::Binder::bind(sig).to_string()
}
let argument_is_closure = expected_ref.skip_binder().substs.type_at(0).is_closure();
let mut err = struct_span_err!(self.tcx.sess, span, E0631,
"type mismatch in {} arguments",
if argument_is_closure { "closure" } else { "function" });
let found_str = format!(
"expected signature of `{}`",
build_fn_sig_string(self.tcx, found.skip_binder())
);
err.span_label(span, found_str);
let found_span = found_span.unwrap_or(span);
let expected_str = format!(
"found signature of `{}`",
build_fn_sig_string(self.tcx, expected_ref.skip_binder())
);
err.span_label(found_span, expected_str);
err
}
}
impl<'tcx> TyCtxt<'tcx> {
pub fn recursive_type_with_infinite_size_error(self,
type_def_id: DefId)
-> DiagnosticBuilder<'tcx>
{
assert!(type_def_id.is_local());
let span = self.hir().span_if_local(type_def_id).unwrap();
let span = self.sess.source_map().def_span(span);
let mut err = struct_span_err!(self.sess, span, E0072,
"recursive type `{}` has infinite size",
self.def_path_str(type_def_id));
err.span_label(span, "recursive type has infinite size");
err.help(&format!("insert indirection (e.g., a `Box`, `Rc`, or `&`) \
at some point to make `{}` representable",
self.def_path_str(type_def_id)));
err
}
pub fn report_object_safety_error(
self,
span: Span,
trait_def_id: DefId,
violations: Vec<ObjectSafetyViolation>,
) -> DiagnosticBuilder<'tcx> {
let trait_str = self.def_path_str(trait_def_id);
let span = self.sess.source_map().def_span(span);
let mut err = struct_span_err!(
self.sess, span, E0038,
"the trait `{}` cannot be made into an object",
trait_str);
err.span_label(span, format!("the trait `{}` cannot be made into an object", trait_str));
let mut reported_violations = FxHashSet::default();
for violation in violations {
if reported_violations.insert(violation.clone()) {
match violation.span() {
Some(span) => err.span_label(span, violation.error_msg()),
None => err.note(&violation.error_msg()),
};
}
}
if self.sess.trait_methods_not_found.borrow().contains(&span) {
// Avoid emitting error caused by non-existing method (#58734)
err.cancel();
}
err
}
}
impl<'a, 'tcx> InferCtxt<'a, 'tcx> {
fn maybe_report_ambiguity(
&self,
obligation: &PredicateObligation<'tcx>,
body_id: Option<hir::BodyId>,
) {
// Unable to successfully determine, probably means
// insufficient type information, but could mean
// ambiguous impls. The latter *ought* to be a
// coherence violation, so we don't report it here.
let predicate = self.resolve_vars_if_possible(&obligation.predicate);
let span = obligation.cause.span;
debug!(
"maybe_report_ambiguity(predicate={:?}, obligation={:?} body_id={:?}, code={:?})",
predicate,
obligation,
body_id,
obligation.cause.code,
);
// Ambiguity errors are often caused as fallout from earlier
// errors. So just ignore them if this infcx is tainted.
if self.is_tainted_by_errors() {
return;
}
match predicate {
ty::Predicate::Trait(ref data) => {
let trait_ref = data.to_poly_trait_ref();
let self_ty = trait_ref.self_ty();
debug!("self_ty {:?} {:?} trait_ref {:?}", self_ty, self_ty.kind, trait_ref);
if predicate.references_error() {
return;
}
// Typically, this ambiguity should only happen if
// there are unresolved type inference variables
// (otherwise it would suggest a coherence
// failure). But given #21974 that is not necessarily
// the case -- we can have multiple where clauses that
// are only distinguished by a region, which results
// in an ambiguity even when all types are fully
// known, since we don't dispatch based on region
// relationships.
// This is kind of a hack: it frequently happens that some earlier
// error prevents types from being fully inferred, and then we get
// a bunch of uninteresting errors saying something like "<generic
// #0> doesn't implement Sized". It may even be true that we
// could just skip over all checks where the self-ty is an
// inference variable, but I was afraid that there might be an
// inference variable created, registered as an obligation, and
// then never forced by writeback, and hence by skipping here we'd
// be ignoring the fact that we don't KNOW the type works
// out. Though even that would probably be harmless, given that
// we're only talking about builtin traits, which are known to be
// inhabited. We used to check for `self.tcx.sess.has_errors()` to
// avoid inundating the user with unnecessary errors, but we now
// check upstream for type errors and dont add the obligations to
// begin with in those cases.
if
self.tcx.lang_items().sized_trait()
.map_or(false, |sized_id| sized_id == trait_ref.def_id())
{
self.need_type_info_err(body_id, span, self_ty).emit();
} else {
let mut err = struct_span_err!(
self.tcx.sess,
span,
E0283,
"type annotations needed: cannot resolve `{}`",
predicate,
);
self.note_obligation_cause(&mut err, obligation);
err.emit();
}
}
ty::Predicate::WellFormed(ty) => {
// Same hacky approach as above to avoid deluging user
// with error messages.
if !ty.references_error() && !self.tcx.sess.has_errors() {
self.need_type_info_err(body_id, span, ty).emit();
}
}
ty::Predicate::Subtype(ref data) => {
if data.references_error() || self.tcx.sess.has_errors() {
// no need to overload user in such cases
} else {
let &SubtypePredicate { a_is_expected: _, a, b } = data.skip_binder();
// both must be type variables, or the other would've been instantiated
assert!(a.is_ty_var() && b.is_ty_var());
self.need_type_info_err(body_id,
obligation.cause.span,
a).emit();
}
}
_ => {
if !self.tcx.sess.has_errors() {
let mut err = struct_span_err!(
self.tcx.sess,
obligation.cause.span,
E0284,
"type annotations needed: cannot resolve `{}`",
predicate,
);
self.note_obligation_cause(&mut err, obligation);
err.emit();
}
}
}
}
/// Returns `true` if the trait predicate may apply for *some* assignment
/// to the type parameters.
fn predicate_can_apply(
&self,
param_env: ty::ParamEnv<'tcx>,
pred: ty::PolyTraitRef<'tcx>,
) -> bool {
struct ParamToVarFolder<'a, 'tcx> {
infcx: &'a InferCtxt<'a, 'tcx>,
var_map: FxHashMap<Ty<'tcx>, Ty<'tcx>>,
}
impl<'a, 'tcx> TypeFolder<'tcx> for ParamToVarFolder<'a, 'tcx> {
fn tcx<'b>(&'b self) -> TyCtxt<'tcx> { self.infcx.tcx }
fn fold_ty(&mut self, ty: Ty<'tcx>) -> Ty<'tcx> {
if let ty::Param(ty::ParamTy {name, .. }) = ty.kind {
let infcx = self.infcx;
self.var_map.entry(ty).or_insert_with(||
infcx.next_ty_var(
TypeVariableOrigin {
kind: TypeVariableOriginKind::TypeParameterDefinition(name),
span: DUMMY_SP,
}
)
)
} else {
ty.super_fold_with(self)
}
}
}
self.probe(|_| {
let mut selcx = SelectionContext::new(self);
let cleaned_pred = pred.fold_with(&mut ParamToVarFolder {
infcx: self,
var_map: Default::default()
});
let cleaned_pred = super::project::normalize(
&mut selcx,
param_env,
ObligationCause::dummy(),
&cleaned_pred
).value;
let obligation = Obligation::new(
ObligationCause::dummy(),
param_env,
cleaned_pred.to_predicate()
);
self.predicate_may_hold(&obligation)
})
}
fn note_obligation_cause(
&self,
err: &mut DiagnosticBuilder<'_>,
obligation: &PredicateObligation<'tcx>,
) {
// First, attempt to add note to this error with an async-await-specific
// message, and fall back to regular note otherwise.
if !self.note_obligation_cause_for_async_await(err, obligation) {
self.note_obligation_cause_code(err, &obligation.predicate, &obligation.cause.code,
&mut vec![]);
}
}
/// Adds an async-await specific note to the diagnostic:
///
/// ```ignore (diagnostic)
/// note: future does not implement `std::marker::Send` because this value is used across an
/// await
/// --> $DIR/issue-64130-non-send-future-diags.rs:15:5
/// |
/// LL | let g = x.lock().unwrap();
/// | - has type `std::sync::MutexGuard<'_, u32>`
/// LL | baz().await;
/// | ^^^^^^^^^^^ await occurs here, with `g` maybe used later
/// LL | }
/// | - `g` is later dropped here
/// ```
///
/// Returns `true` if an async-await specific note was added to the diagnostic.
fn note_obligation_cause_for_async_await(
&self,
err: &mut DiagnosticBuilder<'_>,
obligation: &PredicateObligation<'tcx>,
) -> bool {
debug!("note_obligation_cause_for_async_await: obligation.predicate={:?} \
obligation.cause.span={:?}", obligation.predicate, obligation.cause.span);
let source_map = self.tcx.sess.source_map();
// Look into the obligation predicate to determine the type in the generator which meant
// that the predicate was not satisifed.
let (trait_ref, target_ty) = match obligation.predicate {
ty::Predicate::Trait(trait_predicate) =>
(trait_predicate.skip_binder().trait_ref, trait_predicate.skip_binder().self_ty()),
_ => return false,
};
debug!("note_obligation_cause_for_async_await: target_ty={:?}", target_ty);
// Attempt to detect an async-await error by looking at the obligation causes, looking
// for only generators, generator witnesses, opaque types or `std::future::GenFuture` to
// be present.
//
// When a future does not implement a trait because of a captured type in one of the
// generators somewhere in the call stack, then the result is a chain of obligations.
// Given a `async fn` A that calls a `async fn` B which captures a non-send type and that
// future is passed as an argument to a function C which requires a `Send` type, then the
// chain looks something like this:
//
// - `BuiltinDerivedObligation` with a generator witness (B)
// - `BuiltinDerivedObligation` with a generator (B)
// - `BuiltinDerivedObligation` with `std::future::GenFuture` (B)
// - `BuiltinDerivedObligation` with `impl std::future::Future` (B)
// - `BuiltinDerivedObligation` with `impl std::future::Future` (B)
// - `BuiltinDerivedObligation` with a generator witness (A)
// - `BuiltinDerivedObligation` with a generator (A)
// - `BuiltinDerivedObligation` with `std::future::GenFuture` (A)
// - `BuiltinDerivedObligation` with `impl std::future::Future` (A)
// - `BuiltinDerivedObligation` with `impl std::future::Future` (A)
// - `BindingObligation` with `impl_send (Send requirement)
//
// The first obligations in the chain can be used to get the details of the type that is
// captured but the entire chain must be inspected to detect this case.
let mut generator = None;
let mut next_code = Some(&obligation.cause.code);
while let Some(code) = next_code {
debug!("note_obligation_cause_for_async_await: code={:?}", code);
match code {
ObligationCauseCode::BuiltinDerivedObligation(derived_obligation) |
ObligationCauseCode::ImplDerivedObligation(derived_obligation) => {
debug!("note_obligation_cause_for_async_await: self_ty.kind={:?}",
derived_obligation.parent_trait_ref.self_ty().kind);
match derived_obligation.parent_trait_ref.self_ty().kind {
ty::Adt(ty::AdtDef { did, .. }, ..) if
self.tcx.is_diagnostic_item(sym::gen_future, *did) => {},
ty::Generator(did, ..) => generator = generator.or(Some(did)),
ty::GeneratorWitness(_) | ty::Opaque(..) => {},
_ => return false,
}
next_code = Some(derived_obligation.parent_code.as_ref());
},
ObligationCauseCode::ItemObligation(_) | ObligationCauseCode::BindingObligation(..)
if generator.is_some() => break,
_ => return false,
}
}
let generator_did = generator.expect("can only reach this if there was a generator");
// Only continue to add a note if the generator is from an `async` function.
let parent_node = self.tcx.parent(generator_did)
.and_then(|parent_did| self.tcx.hir().get_if_local(parent_did));
debug!("note_obligation_cause_for_async_await: parent_node={:?}", parent_node);
if let Some(hir::Node::Item(hir::Item {
kind: hir::ItemKind::Fn(sig, _, _),
..
})) = parent_node {
debug!("note_obligation_cause_for_async_await: header={:?}", sig.header);
if sig.header.asyncness != hir::IsAsync::Async {
return false;
}
}
let span = self.tcx.def_span(generator_did);
let tables = self.tcx.typeck_tables_of(generator_did);
debug!("note_obligation_cause_for_async_await: generator_did={:?} span={:?} ",
generator_did, span);
// Look for a type inside the generator interior that matches the target type to get
// a span.
let target_span = tables.generator_interior_types.iter()
.find(|ty::GeneratorInteriorTypeCause { ty, .. }| ty::TyS::same_type(*ty, target_ty))
.map(|ty::GeneratorInteriorTypeCause { span, scope_span, .. }|
(span, source_map.span_to_snippet(*span), scope_span));
if let Some((target_span, Ok(snippet), scope_span)) = target_span {
// Look at the last interior type to get a span for the `.await`.
let await_span = tables.generator_interior_types.iter().map(|i| i.span).last().unwrap();
let mut span = MultiSpan::from_span(await_span);
span.push_span_label(
await_span, format!("await occurs here, with `{}` maybe used later", snippet));
span.push_span_label(*target_span, format!("has type `{}`", target_ty));
// If available, use the scope span to annotate the drop location.
if let Some(scope_span) = scope_span {
span.push_span_label(
source_map.end_point(*scope_span),
format!("`{}` is later dropped here", snippet),
);
}
err.span_note(span, &format!(
"future does not implement `{}` as this value is used across an await",
trait_ref,
));
// Add a note for the item obligation that remains - normally a note pointing to the
// bound that introduced the obligation (e.g. `T: Send`).
debug!("note_obligation_cause_for_async_await: next_code={:?}", next_code);
self.note_obligation_cause_code(
err,
&obligation.predicate,
next_code.unwrap(),
&mut Vec::new(),
);
true
} else {
false
}
}
fn note_obligation_cause_code<T>(&self,
err: &mut DiagnosticBuilder<'_>,
predicate: &T,
cause_code: &ObligationCauseCode<'tcx>,
obligated_types: &mut Vec<&ty::TyS<'tcx>>)
where T: fmt::Display
{
let tcx = self.tcx;
match *cause_code {
ObligationCauseCode::ExprAssignable |
ObligationCauseCode::MatchExpressionArm { .. } |
ObligationCauseCode::MatchExpressionArmPattern { .. } |
ObligationCauseCode::IfExpression { .. } |
ObligationCauseCode::IfExpressionWithNoElse |
ObligationCauseCode::MainFunctionType |
ObligationCauseCode::StartFunctionType |
ObligationCauseCode::IntrinsicType |
ObligationCauseCode::MethodReceiver |
ObligationCauseCode::ReturnNoExpression |
ObligationCauseCode::MiscObligation => {}
ObligationCauseCode::SliceOrArrayElem => {
err.note("slice and array elements must have `Sized` type");
}
ObligationCauseCode::TupleElem => {
err.note("only the last element of a tuple may have a dynamically sized type");
}
ObligationCauseCode::ProjectionWf(data) => {
err.note(&format!(
"required so that the projection `{}` is well-formed",
data,
));
}
ObligationCauseCode::ReferenceOutlivesReferent(ref_ty) => {
err.note(&format!(
"required so that reference `{}` does not outlive its referent",
ref_ty,
));
}
ObligationCauseCode::ObjectTypeBound(object_ty, region) => {
err.note(&format!(
"required so that the lifetime bound of `{}` for `{}` is satisfied",
region,
object_ty,
));
}
ObligationCauseCode::ItemObligation(item_def_id) => {
let item_name = tcx.def_path_str(item_def_id);
let msg = format!("required by `{}`", item_name);
if let Some(sp) = tcx.hir().span_if_local(item_def_id) {
let sp = tcx.sess.source_map().def_span(sp);
err.span_label(sp, &msg);
} else {
err.note(&msg);
}
}
ObligationCauseCode::BindingObligation(item_def_id, span) => {
let item_name = tcx.def_path_str(item_def_id);
let msg = format!("required by this bound in `{}`", item_name);
if let Some(ident) = tcx.opt_item_name(item_def_id) {
err.span_label(ident.span, "");
}
if span != DUMMY_SP {
err.span_label(span, &msg);
} else {
err.note(&msg);
}
}
ObligationCauseCode::ObjectCastObligation(object_ty) => {
err.note(&format!("required for the cast to the object type `{}`",
self.ty_to_string(object_ty)));
}
ObligationCauseCode::Coercion { source: _, target } => {
err.note(&format!("required by cast to type `{}`",
self.ty_to_string(target)));
}
ObligationCauseCode::RepeatVec(suggest_const_in_array_repeat_expression) => {
err.note("the `Copy` trait is required because the \
repeated element will be copied");
if suggest_const_in_array_repeat_expression {
err.note("this array initializer can be evaluated at compile-time, for more \
information, see issue \
https://github.com/rust-lang/rust/issues/49147");
if tcx.sess.opts.unstable_features.is_nightly_build() {
err.help("add `#![feature(const_in_array_repeat_expression)]` to the \
crate attributes to enable");
}
}
}
ObligationCauseCode::VariableType(_) => {
err.note("all local variables must have a statically known size");
if !self.tcx.features().unsized_locals {
err.help("unsized locals are gated as an unstable feature");
}
}
ObligationCauseCode::SizedArgumentType => {
err.note("all function arguments must have a statically known size");
if !self.tcx.features().unsized_locals {
err.help("unsized locals are gated as an unstable feature");
}
}
ObligationCauseCode::SizedReturnType => {
err.note("the return type of a function must have a \
statically known size");
}
ObligationCauseCode::SizedYieldType => {
err.note("the yield type of a generator must have a \
statically known size");
}
ObligationCauseCode::AssignmentLhsSized => {
err.note("the left-hand-side of an assignment must have a statically known size");
}
ObligationCauseCode::TupleInitializerSized => {
err.note("tuples must have a statically known size to be initialized");
}
ObligationCauseCode::StructInitializerSized => {
err.note("structs must have a statically known size to be initialized");
}
ObligationCauseCode::FieldSized { adt_kind: ref item, last } => {
match *item {
AdtKind::Struct => {
if last {
err.note("the last field of a packed struct may only have a \
dynamically sized type if it does not need drop to be run");
} else {
err.note("only the last field of a struct may have a dynamically \
sized type");
}
}
AdtKind::Union => {
err.note("no field of a union may have a dynamically sized type");
}
AdtKind::Enum => {
err.note("no field of an enum variant may have a dynamically sized type");
}
}
}
ObligationCauseCode::ConstSized => {
err.note("constant expressions must have a statically known size");
}
ObligationCauseCode::ConstPatternStructural => {
err.note("constants used for pattern-matching must derive `PartialEq` and `Eq`");
}
ObligationCauseCode::SharedStatic => {
err.note("shared static variables must have a type that implements `Sync`");
}
ObligationCauseCode::BuiltinDerivedObligation(ref data) => {
let parent_trait_ref = self.resolve_vars_if_possible(&data.parent_trait_ref);
let ty = parent_trait_ref.skip_binder().self_ty();
err.note(&format!("required because it appears within the type `{}`", ty));
obligated_types.push(ty);
let parent_predicate = parent_trait_ref.to_predicate();
if !self.is_recursive_obligation(obligated_types, &data.parent_code) {
self.note_obligation_cause_code(err,
&parent_predicate,
&data.parent_code,
obligated_types);
}
}
ObligationCauseCode::ImplDerivedObligation(ref data) => {
let parent_trait_ref = self.resolve_vars_if_possible(&data.parent_trait_ref);
err.note(
&format!("required because of the requirements on the impl of `{}` for `{}`",
parent_trait_ref,
parent_trait_ref.skip_binder().self_ty()));
let parent_predicate = parent_trait_ref.to_predicate();
self.note_obligation_cause_code(err,
&parent_predicate,
&data.parent_code,
obligated_types);
}
ObligationCauseCode::CompareImplMethodObligation { .. } => {
err.note(
&format!("the requirement `{}` appears on the impl method \
but not on the corresponding trait method",
predicate));
}
ObligationCauseCode::ReturnType |
ObligationCauseCode::ReturnValue(_) |
ObligationCauseCode::BlockTailExpression(_) => (),
ObligationCauseCode::TrivialBound => {
err.help("see issue #48214");
if tcx.sess.opts.unstable_features.is_nightly_build() {
err.help("add `#![feature(trivial_bounds)]` to the \
crate attributes to enable",
);
}
}
ObligationCauseCode::AssocTypeBound(ref data) => {
err.span_label(data.original, "associated type defined here");
if let Some(sp) = data.impl_span {
err.span_label(sp, "in this `impl` item");
}
for sp in &data.bounds {
err.span_label(*sp, "restricted in this bound");
}
}
}
}
fn suggest_new_overflow_limit(&self, err: &mut DiagnosticBuilder<'_>) {
let current_limit = self.tcx.sess.recursion_limit.get();
let suggested_limit = current_limit * 2;
err.help(&format!("consider adding a `#![recursion_limit=\"{}\"]` attribute to your crate",
suggested_limit));
}
fn is_recursive_obligation(&self,
obligated_types: &mut Vec<&ty::TyS<'tcx>>,
cause_code: &ObligationCauseCode<'tcx>) -> bool {
if let ObligationCauseCode::BuiltinDerivedObligation(ref data) = cause_code {
let parent_trait_ref = self.resolve_vars_if_possible(&data.parent_trait_ref);
if obligated_types.iter().any(|ot| ot == &parent_trait_ref.skip_binder().self_ty()) {
return true;
}
}
false
}
}
/// Summarizes information
#[derive(Clone)]
pub enum ArgKind {
/// An argument of non-tuple type. Parameters are (name, ty)
Arg(String, String),
/// An argument of tuple type. For a "found" argument, the span is
/// the locationo in the source of the pattern. For a "expected"
/// argument, it will be None. The vector is a list of (name, ty)
/// strings for the components of the tuple.
Tuple(Option<Span>, Vec<(String, String)>),
}
impl ArgKind {
fn empty() -> ArgKind {
ArgKind::Arg("_".to_owned(), "_".to_owned())
}
/// Creates an `ArgKind` from the expected type of an
/// argument. It has no name (`_`) and an optional source span.
pub fn from_expected_ty(t: Ty<'_>, span: Option<Span>) -> ArgKind {
match t.kind {
ty::Tuple(ref tys) => ArgKind::Tuple(
span,
tys.iter()
.map(|ty| ("_".to_owned(), ty.to_string()))
.collect::<Vec<_>>()
),
_ => ArgKind::Arg("_".to_owned(), t.to_string()),
}
}
}
|
let predicate = self.resolve_vars_if_possible(predicate);
let err = self.region_outlives_predicate(&obligation.cause,
&predicate).err().unwrap();
struct_span_err!(
self.tcx.sess, span, E0279,
"the requirement `{}` is not satisfied (`{}`)",
predicate, err,
)
}
|
lib.rs
|
/*!
# `wasm_bindgen_webidl`
Converts WebIDL into wasm-bindgen's internal AST form, so that bindings can be
emitted for the types and methods described in the WebIDL.
*/
#![deny(missing_docs)]
#![deny(missing_debug_implementations)]
#![doc(html_root_url = "https://docs.rs/wasm-bindgen-webidl/0.2")]
#[macro_use]
extern crate failure;
#[macro_use]
extern crate failure_derive;
extern crate heck;
#[macro_use]
extern crate log;
extern crate proc_macro2;
#[macro_use]
extern crate quote;
#[macro_use]
extern crate syn;
extern crate wasm_bindgen_backend as backend;
extern crate weedle;
mod first_pass;
mod idl_type;
mod util;
mod error;
use std::collections::BTreeSet;
use std::fs;
use std::io::{self, Read};
use std::iter::FromIterator;
use std::path::Path;
use backend::ast;
use backend::TryToTokens;
use backend::defined::{ImportedTypeDefinitions, RemoveUndefinedImports};
use backend::defined::ImportedTypeReferences;
use backend::util::{ident_ty, rust_ident, raw_ident, wrap_import_function};
use failure::ResultExt;
use heck::{ShoutySnakeCase, SnakeCase};
use proc_macro2::{Ident, Span};
use weedle::argument::Argument;
use weedle::attribute::{ExtendedAttribute, ExtendedAttributeList};
use weedle::dictionary::DictionaryMember;
use first_pass::{FirstPass, FirstPassRecord, OperationId};
use util::{public, webidl_const_v_to_backend_const_v, TypePosition, camel_case_ident, mdn_doc};
use idl_type::{IdlType, ToIdlType};
pub use error::{Error, ErrorKind, Result};
/// Parse the WebIDL at the given path into a wasm-bindgen AST.
fn parse_file(webidl_path: &Path) -> Result<backend::ast::Program> {
let file = fs::File::open(webidl_path).context(ErrorKind::OpeningWebIDLFile)?;
let mut file = io::BufReader::new(file);
let mut source = String::new();
file.read_to_string(&mut source).context(ErrorKind::ReadingWebIDLFile)?;
parse(&source)
}
/// Parse a string of WebIDL source text into a wasm-bindgen AST.
fn parse(webidl_source: &str) -> Result<backend::ast::Program> {
let definitions = match weedle::parse(webidl_source) {
Ok(def) => def,
Err(e) => {
return Err(match &e {
weedle::Err::Incomplete(needed) => {
format_err!("needed {:?} more bytes", needed)
.context(ErrorKind::ParsingWebIDLSource).into()
}
weedle::Err::Error(cx) |
weedle::Err::Failure(cx) => {
let remaining = match cx {
weedle::Context::Code(remaining, _) => remaining,
};
let pos = webidl_source.len() - remaining.len();
format_err!("failed to parse WebIDL")
.context(ErrorKind::ParsingWebIDLSourcePos(pos)).into()
}
// webidl::ParseError::UnrecognizedToken { token: Some((start, ..)), .. } => {
// ErrorKind::ParsingWebIDLSourcePos(*start)
// }
// webidl::ParseError::ExtraToken { token: (start, ..) } => {
// ErrorKind::ParsingWebIDLSourcePos(*start)
// },
// _ => ErrorKind::ParsingWebIDLSource
});
}
};
let mut first_pass_record = Default::default();
definitions.first_pass(&mut first_pass_record, ())?;
let mut program = Default::default();
definitions.webidl_parse(&mut program, &first_pass_record, ())?;
Ok(program)
}
/// Compile the given WebIDL file into Rust source text containing
/// `wasm-bindgen` bindings to the things described in the WebIDL.
pub fn compile_file(webidl_path: &Path) -> Result<String> {
let ast = parse_file(webidl_path)?;
Ok(compile_ast(ast))
}
/// Compile the given WebIDL source text into Rust source text containing
/// `wasm-bindgen` bindings to the things described in the WebIDL.
pub fn compile(webidl_source: &str) -> Result<String> {
let ast = parse(webidl_source)?;
Ok(compile_ast(ast))
}
/// Run codegen on the AST to generate rust code.
fn compile_ast(mut ast: backend::ast::Program) -> String {
// Iteratively prune all entries from the AST which reference undefined
// fields. Each pass may remove definitions of types and so we need to
// reexecute this pass to see if we need to keep removing types until we
// reach a steady state.
let builtin = BTreeSet::from_iter(
vec![
"str", "char", "bool", "JsValue", "u8", "i8", "u16", "i16", "u32", "i32", "u64", "i64",
"usize", "isize", "f32", "f64", "Result", "String", "Vec", "Option",
"ArrayBuffer", "Object", "Promise",
].into_iter()
.map(|id| proc_macro2::Ident::new(id, proc_macro2::Span::call_site())),
);
loop {
let mut defined = builtin.clone();
ast.imported_type_definitions(&mut |id| {
defined.insert(id.clone());
});
if !ast.remove_undefined_imports(&|id| defined.contains(id)) {
break
}
}
let mut tokens = proc_macro2::TokenStream::new();
if let Err(e) = ast.try_to_tokens(&mut tokens) {
e.panic();
}
tokens.to_string()
}
/// The main trait for parsing WebIDL AST into wasm-bindgen AST.
trait WebidlParse<'src, Ctx> {
/// Parse `self` into wasm-bindgen AST, and insert it into `program`.
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
context: Ctx,
) -> Result<()>;
}
impl<'src> WebidlParse<'src, ()> for [weedle::Definition<'src>] {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
(): (),
) -> Result<()> {
for def in self {
def.webidl_parse(program, first_pass, ())?;
}
Ok(())
}
}
impl<'src> WebidlParse<'src, ()> for weedle::Definition<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
(): (),
) -> Result<()> {
match self {
weedle::Definition::Enum(enumeration) => {
enumeration.webidl_parse(program, first_pass, ())?
}
weedle::Definition::Interface(interface) => {
interface.webidl_parse(program, first_pass, ())?
}
weedle::Definition::PartialInterface(interface) => {
interface.webidl_parse(program, first_pass, ())?
}
| weedle::Definition::Typedef(_)
| weedle::Definition::InterfaceMixin(_)
| weedle::Definition::PartialInterfaceMixin(_)
| weedle::Definition::IncludesStatement(..)
| weedle::Definition::PartialDictionary(..)
| weedle::Definition::PartialNamespace(..)=> {
// handled in the first pass
}
weedle::Definition::Implements(..) => {
// nothing to do for this, ignore it
}
weedle::Definition::Namespace(namespace) => {
namespace.webidl_parse(program, first_pass, ())?
}
weedle::Definition::Dictionary(dict) => {
dict.webidl_parse(program, first_pass, ())?
}
// TODO
weedle::Definition::Callback(..) => {
warn!("Unsupported WebIDL Callback definition: {:?}", self)
}
weedle::Definition::CallbackInterface(..) => {
warn!("Unsupported WebIDL CallbackInterface definition: {:?}", self)
}
}
Ok(())
}
}
impl<'src> WebidlParse<'src, ()> for weedle::InterfaceDefinition<'src> {
fn
|
(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
(): (),
) -> Result<()> {
if util::is_chrome_only(&self.attributes) {
info!("Skipping because of `ChromeOnly` attribute: {:?}", self);
return Ok(());
}
if util::is_no_interface_object(&self.attributes) {
info!("Skipping because of `NoInterfaceObject` attribute: {:?}", self);
return Ok(());
}
let doc_comment = Some(format!(
"The `{}` object\n\n{}",
self.identifier.0,
mdn_doc(self.identifier.0, None),
));
program.imports.push(backend::ast::Import {
module: None,
js_namespace: None,
kind: backend::ast::ImportKind::Type(backend::ast::ImportType {
vis: public(),
rust_name: rust_ident(camel_case_ident(self.identifier.0).as_str()),
js_name: self.identifier.0.to_string(),
attrs: Vec::new(),
doc_comment,
instanceof_shim: format!("__widl_instanceof_{}", self.identifier.0),
extends: first_pass.all_superclasses(self.identifier.0)
.map(|name| Ident::new(&name, Span::call_site()))
.collect(),
}),
});
if let Some(attrs) = &self.attributes {
for attr in &attrs.body.list {
attr.webidl_parse(program, first_pass, self)?;
}
}
fn parse<'src>(
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &str,
mixin_name: &str,
) -> Result<()> {
if let Some(mixin_data) = first_pass.mixins.get(mixin_name) {
for member in &mixin_data.members {
member.webidl_parse(program, first_pass, self_name)?;
}
}
if let Some(mixin_names) = first_pass.includes.get(mixin_name) {
for mixin_name in mixin_names {
parse(program, first_pass, self_name, mixin_name)?;
}
}
Ok(())
}
for member in &self.members.body {
member.webidl_parse(program, first_pass, self.identifier.0)?;
}
parse(program, first_pass, self.identifier.0, self.identifier.0)?;
Ok(())
}
}
impl<'src> WebidlParse<'src, ()> for weedle::PartialInterfaceDefinition<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
(): (),
) -> Result<()> {
if util::is_chrome_only(&self.attributes) {
return Ok(());
}
if first_pass
.interfaces
.get(self.identifier.0)
.map(|interface_data| interface_data.partial)
.unwrap_or(true) {
info!(
"Partial interface {} missing non-partial interface",
self.identifier.0
);
}
for member in &self.members.body {
member.webidl_parse(program, first_pass, self.identifier.0)?;
}
Ok(())
}
}
impl<'src> WebidlParse<'src, &'src weedle::InterfaceDefinition<'src>> for ExtendedAttribute<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
interface: &'src weedle::InterfaceDefinition<'src>,
) -> Result<()> {
let mut add_constructor = |arguments: &[Argument], class: &str| {
let (overloaded, same_argument_names) = first_pass.get_operation_overloading(
arguments,
&::first_pass::OperationId::Constructor,
interface.identifier.0,
false,
);
let self_ty = ident_ty(rust_ident(camel_case_ident(interface.identifier.0).as_str()));
let kind = backend::ast::ImportFunctionKind::Method {
class: class.to_string(),
ty: self_ty.clone(),
kind: backend::ast::MethodKind::Constructor,
};
let structural = false;
// Constructors aren't annotated with `[Throws]` extended attributes
// (how could they be, since they themselves are extended
// attributes?) so we must conservatively assume that they can
// always throw.
//
// From https://heycam.github.io/webidl/#Constructor (emphasis
// mine):
//
// > The prose definition of a constructor must either return an IDL
// > value of a type corresponding to the interface the
// > `[Constructor]` extended attribute appears on, **or throw an
// > exception**.
let throws = true;
for import_function in first_pass.create_function(
"new",
overloaded,
same_argument_names,
&match first_pass.convert_arguments(arguments) {
Some(arguments) => arguments,
None => return,
},
IdlType::Interface(interface.identifier.0),
kind,
structural,
throws,
None,
) {
program.imports.push(wrap_import_function(import_function));
}
};
match self {
ExtendedAttribute::ArgList(list)
if list.identifier.0 == "Constructor" =>
{
add_constructor(&list.args.body.list, interface.identifier.0)
}
ExtendedAttribute::NoArgs(other) if (other.0).0 == "Constructor" => {
add_constructor(&[], interface.identifier.0)
}
ExtendedAttribute::NamedArgList(list)
if list.lhs_identifier.0 == "NamedConstructor" =>
{
add_constructor(&list.args.body.list, list.rhs_identifier.0)
}
// these appear to be mapping to gecko preferences, seems like we
// can safely ignore
ExtendedAttribute::Ident(id) if id.lhs_identifier.0 == "Pref" => {}
// looks to be a gecko-specific attribute to tie WebIDL back to C++
// functions perhaps
ExtendedAttribute::Ident(id) if id.lhs_identifier.0 == "Func" => {}
ExtendedAttribute::Ident(id) if id.lhs_identifier.0 == "JSImplementation" => {}
ExtendedAttribute::Ident(id) if id.lhs_identifier.0 == "HeaderFile" => {}
// Not actually mentioned in the spec and presumably a hint to
// Gecko's JS engine? Unsure, but seems like it doesn't matter to us
ExtendedAttribute::NoArgs(id)
if (id.0).0 == "ProbablyShortLivingWrapper" => {}
// Indicates something about enumerable properties, we're not too
// interested in it
// https://heycam.github.io/webidl/#LegacyUnenumerableNamedProperties
ExtendedAttribute::NoArgs(id)
if (id.0).0 == "LegacyUnenumerableNamedProperties" => {}
// Indicates where objects are defined (web workers and such), we
// may later want to use this for cfgs but for now we ignore it.
// https://heycam.github.io/webidl/#Exposed
ExtendedAttribute::Ident(id) if id.lhs_identifier.0 == "Exposed" => {}
ExtendedAttribute::IdentList(id) if id.identifier.0 == "Exposed" => {}
// We handle this with the "structural" attribute elsewhere
ExtendedAttribute::IdentList(id) if id.identifier.0 == "Global" => {}
// Seems like it's safe to ignore for now, just telling us where a
// binding appears
// https://heycam.github.io/webidl/#SecureContext
ExtendedAttribute::NoArgs(id) if (id.0).0 == "SecureContext" => {}
// We handle this elsewhere
ExtendedAttribute::NoArgs(id) if (id.0).0 == "Unforgeable" => {}
// Looks like this attribute just says that we can't call the
// constructor
// https://html.spec.whatwg.org/multipage/dom.html#htmlconstructor
ExtendedAttribute::NoArgs(id) if (id.0).0 == "HTMLConstructor" => {}
ExtendedAttribute::ArgList(_)
| ExtendedAttribute::Ident(_)
| ExtendedAttribute::IdentList(_)
| ExtendedAttribute::NamedArgList(_)
| ExtendedAttribute::NoArgs(_) => {
warn!("Unsupported WebIDL extended attribute: {:?}", self);
}
}
Ok(())
}
}
impl<'src> WebidlParse<'src, &'src str> for weedle::interface::InterfaceMember<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'src str,
) -> Result<()> {
use weedle::interface::InterfaceMember::*;
match self {
Attribute(attr) => {
attr.webidl_parse(program, first_pass, self_name)
}
Operation(op) => {
op.webidl_parse(program, first_pass, self_name)
}
Const(const_) => {
const_.webidl_parse(program, first_pass, self_name)
}
Iterable(iterable) => {
iterable.webidl_parse(program, first_pass, self_name)
}
// TODO
Maplike(_) => {
warn!("Unsupported WebIDL Maplike interface member: {:?}", self);
Ok(())
}
Stringifier(_) => {
warn!("Unsupported WebIDL Stringifier interface member: {:?}", self);
Ok(())
}
Setlike(_) => {
warn!("Unsupported WebIDL Setlike interface member: {:?}", self);
Ok(())
}
}
}
}
impl<'a, 'src> WebidlParse<'src, &'a str> for weedle::mixin::MixinMember<'src> {
fn webidl_parse(
&self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'a str,
) -> Result<()> {
match self {
weedle::mixin::MixinMember::Attribute(attr) => {
attr.webidl_parse(program, first_pass, self_name)
}
weedle::mixin::MixinMember::Operation(op) => {
op.webidl_parse(program, first_pass, self_name)
}
weedle::mixin::MixinMember::Const(const_) => {
const_.webidl_parse(program, first_pass, self_name)
}
// TODO
weedle::mixin::MixinMember::Stringifier(_) => {
warn!("Unsupported WebIDL stringifier mixin member: {:?}", self);
Ok(())
}
}
}
}
impl<'src> WebidlParse<'src, &'src str> for weedle::interface::AttributeInterfaceMember<'src> {
fn webidl_parse(
&self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'src str,
) -> Result<()> {
member_attribute(
program,
first_pass,
self_name,
&self.attributes,
self.modifier,
self.readonly.is_some(),
&self.type_,
self.identifier.0,
)
}
}
impl<'src> WebidlParse<'src, &'src str> for weedle::mixin::AttributeMixinMember<'src> {
fn webidl_parse(
&self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'src str,
) -> Result<()> {
member_attribute(
program,
first_pass,
self_name,
&self.attributes,
if let Some(s) = self.stringifier {
Some(weedle::interface::StringifierOrInheritOrStatic::Stringifier(s))
} else {
None
},
self.readonly.is_some(),
&self.type_,
self.identifier.0,
)
}
}
fn member_attribute<'src>(
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'src str,
attrs: &'src Option<ExtendedAttributeList>,
modifier: Option<weedle::interface::StringifierOrInheritOrStatic>,
readonly: bool,
type_: &'src weedle::types::AttributedType<'src>,
identifier: &'src str,
) -> Result<()> {
use weedle::interface::StringifierOrInheritOrStatic::*;
if util::is_chrome_only(attrs) {
return Ok(());
}
let is_static = match modifier {
Some(Stringifier(_)) => {
warn!("Unsupported stringifier on type: {:?}", (self_name, identifier));
return Ok(())
}
Some(Inherit(_)) => false,
Some(Static(_)) => true,
None => false,
};
if type_.attributes.is_some() {
warn!("Unsupported attributes on type: {:?}", (self_name, identifier));
return Ok(())
}
let is_structural = util::is_structural(attrs);
let throws = util::throws(attrs);
for import_function in first_pass.create_getter(
identifier,
&type_.type_,
self_name,
is_static,
is_structural,
throws,
) {
program.imports.push(wrap_import_function(import_function));
}
if !readonly {
for import_function in first_pass.create_setter(
identifier,
type_.type_.clone(),
self_name,
is_static,
is_structural,
throws,
) {
program.imports.push(wrap_import_function(import_function));
}
}
Ok(())
}
impl<'src> WebidlParse<'src, &'src str> for weedle::interface::OperationInterfaceMember<'src> {
fn webidl_parse(
&self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'src str,
) -> Result<()> {
member_operation(
program,
first_pass,
self_name,
&self.attributes,
self.modifier,
&self.specials,
&self.return_type,
&self.args.body.list,
&self.identifier,
)
}
}
impl<'src> WebidlParse<'src, &'src str> for weedle::mixin::OperationMixinMember<'src> {
fn webidl_parse(
&self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'src str,
) -> Result<()> {
member_operation(
program,
first_pass,
self_name,
&self.attributes,
None,
&[],
&self.return_type,
&self.args.body.list,
&self.identifier,
)
}
}
fn member_operation<'src>(
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'src str,
attrs: &'src Option<ExtendedAttributeList>,
modifier: Option<weedle::interface::StringifierOrStatic>,
specials: &[weedle::interface::Special],
return_type: &'src weedle::types::ReturnType<'src>,
args: &'src [Argument],
identifier: &Option<weedle::common::Identifier<'src>>,
) -> Result<()> {
use weedle::interface::StringifierOrStatic::*;
use weedle::interface::Special;
if util::is_chrome_only(attrs) {
info!("Skipping `ChromeOnly` operation: {:?}", (self_name, identifier));
return Ok(());
}
let is_static = match modifier {
Some(Stringifier(_)) => {
warn!("Unsupported stringifier on type: {:?}", (self_name, identifier));
return Ok(())
}
Some(Static(_)) => true,
None => false,
};
let mut operation_ids = vec![
OperationId::Operation(identifier.map(|s| s.0)),
];
if specials.len() > 1 {
warn!(
"Unsupported specials: ({:?}) on type {:?}",
specials,
(self_name, identifier),
);
return Ok(())
} else if specials.len() == 1 {
let id = match specials[0] {
Special::Getter(weedle::term::Getter) => OperationId::IndexingGetter,
Special::Setter(weedle::term::Setter) => OperationId::IndexingSetter,
Special::Deleter(weedle::term::Deleter) => OperationId::IndexingDeleter,
Special::LegacyCaller(weedle::term::LegacyCaller) => {
warn!("Unsupported legacy caller: {:?}", (self_name, identifier));
return Ok(());
},
};
operation_ids.push(id);
}
for id in operation_ids {
let methods = first_pass
.create_basic_method(
args,
id,
return_type,
self_name,
is_static,
match id {
OperationId::IndexingGetter |
OperationId::IndexingSetter |
OperationId::IndexingDeleter => true,
_ => {
first_pass
.interfaces
.get(self_name)
.map(|interface_data| interface_data.global)
.unwrap_or(false)
}
},
util::throws(attrs),
);
for method in methods {
program.imports.push(wrap_import_function(method));
}
}
Ok(())
}
impl<'src> WebidlParse<'src, &'src str> for weedle::interface::IterableInterfaceMember<'src> {
fn webidl_parse(
&self,
_program: &mut backend::ast::Program,
_first_pass: &FirstPassRecord<'src>,
_self_name: &'src str,
) -> Result<()> {
// if util::is_chrome_only(&self.attributes) {
// return Ok(());
// }
/* TODO
let throws = util::throws(&self.extended_attributes);
let return_value = weedle::ReturnType::NonVoid(self.value_type.clone());
let args = [];
first_pass
.create_basic_method(
&args,
Some(&"values".to_string()),
&return_value,
self_name,
false,
false, // Should be false
)
.map(wrap_import_function)
.map(|import| program.imports.push(import));
first_pass
.create_basic_method(
&args,
Some(&"keys".to_string()),
&return_value, // Should be a number
self_name,
false,
false, // Should be false
)
.map(wrap_import_function)
.map(|import| program.imports.push(import));
*/
Ok(())
}
}
impl<'src> WebidlParse<'src, ()> for weedle::EnumDefinition<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
_: &FirstPassRecord<'src>,
(): (),
) -> Result<()> {
if util::is_chrome_only(&self.attributes) {
return Ok(());
}
let variants = &self.values.body.list;
program.imports.push(backend::ast::Import {
module: None,
js_namespace: None,
kind: backend::ast::ImportKind::Enum(backend::ast::ImportEnum {
vis: public(),
name: rust_ident(camel_case_ident(self.identifier.0).as_str()),
variants: variants
.iter()
.map(|v| {
if !v.0.is_empty() {
rust_ident(camel_case_ident(&v.0).as_str())
} else {
rust_ident("None")
}
})
.collect(),
variant_values: variants.iter().map(|v| v.0.to_string()).collect(),
rust_attrs: vec![parse_quote!(#[derive(Copy, Clone, PartialEq, Debug)])],
}),
});
Ok(())
}
}
impl<'src> WebidlParse<'src, &'src str> for weedle::interface::ConstMember<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
self_name: &'src str,
) -> Result<()> {
if util::is_chrome_only(&self.attributes) {
return Ok(());
}
let idl_type = match self.const_type.to_idl_type(first_pass) {
None => return Ok(()),
Some(idl_type) => idl_type,
};
let ty = match idl_type.to_syn_type(TypePosition::Return) {
None => {
warn!(
"Cannot convert const type to syn type: {:?} in {:?} on {:?}",
idl_type,
self,
self_name
);
return Ok(());
},
Some(ty) => ty,
};
program.consts.push(backend::ast::Const {
vis: public(),
name: rust_ident(self.identifier.0.to_shouty_snake_case().as_str()),
class: Some(rust_ident(camel_case_ident(&self_name).as_str())),
ty,
value: webidl_const_v_to_backend_const_v(&self.const_value),
});
Ok(())
}
}
impl<'src> WebidlParse<'src, ()> for weedle::NamespaceDefinition<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
(): (),
) -> Result<()> {
if util::is_chrome_only(&self.attributes) {
return Ok(());
}
if let Some(attrs) = &self.attributes {
for attr in &attrs.body.list {
attr.webidl_parse(program, first_pass, self)?;
}
}
let mut module = backend::ast::Module {
vis: public(),
name: rust_ident(self.identifier.0.to_snake_case().as_str()),
imports: Default::default(),
};
if let Some(namespace_data) = first_pass.namespaces.get(&self.identifier.0) {
for member in &namespace_data.members {
member.webidl_parse(program, first_pass, (&self.identifier.0, &mut module))?;
}
}
program.modules.push(module);
Ok(())
}
}
impl<'src> WebidlParse<'src, &'src weedle::NamespaceDefinition<'src>> for ExtendedAttribute<'src> {
fn webidl_parse(
&'src self,
_program: &mut backend::ast::Program,
_first_pass: &FirstPassRecord<'src>,
_namespace: &'src weedle::NamespaceDefinition<'src>,
) -> Result<()> {
warn!("Unsupported WebIDL extended attribute: {:?}", self);
Ok(())
}
}
impl<'src> WebidlParse<'src, (&'src str, &'src mut backend::ast::Module)> for weedle::namespace::NamespaceMember<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
(self_name, module): (&'src str, &mut backend::ast::Module),
) -> Result<()> {
match self {
weedle::namespace::NamespaceMember::Operation(op) => {
op.webidl_parse(program, first_pass, (self_name, module))?;
}
weedle::namespace::NamespaceMember::Attribute(attr) => {
warn!("Unsupported attribute namespace member: {:?}", attr)
}
}
Ok(())
}
}
impl<'src> WebidlParse<'src, (&'src str, &'src mut backend::ast::Module)> for weedle::namespace::OperationNamespaceMember<'src> {
fn webidl_parse(
&'src self,
_program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
(self_name, module): (&'src str, &mut backend::ast::Module),
) -> Result<()> {
if util::is_chrome_only(&self.attributes) {
return Ok(());
}
for import_function in first_pass.create_namespace_operation(
&self.args.body.list,
self.identifier.as_ref().map(|id| id.0),
&self.return_type,
self_name,
util::throws(&self.attributes)
) {
module.imports.push(
backend::ast::Import {
module: None,
js_namespace: Some(raw_ident(self_name)),
kind: backend::ast::ImportKind::Function(import_function),
}
);
};
Ok(())
}
}
// tons more data for what's going on here at
// https://www.w3.org/TR/WebIDL-1/#idl-dictionaries
impl<'src> WebidlParse<'src, ()> for weedle::DictionaryDefinition<'src> {
fn webidl_parse(
&'src self,
program: &mut backend::ast::Program,
first_pass: &FirstPassRecord<'src>,
(): (),
) -> Result<()> {
if util::is_chrome_only(&self.attributes) {
return Ok(());
}
let mut fields = Vec::new();
if !push_members(first_pass, self.identifier.0, &mut fields) {
return Ok(())
}
program.dictionaries.push(ast::Dictionary {
name: rust_ident(&camel_case_ident(self.identifier.0)),
fields,
});
return Ok(());
fn push_members<'src>(
data: &FirstPassRecord<'src>,
dict: &'src str,
dst: &mut Vec<ast::DictionaryField>,
) -> bool {
let dict_data = &data.dictionaries[&dict];
let definition = dict_data.definition.unwrap();
// > The order of the dictionary members on a given dictionary is
// > such that inherited dictionary members are ordered before
// > non-inherited members ...
if let Some(parent) = &definition.inheritance {
if !push_members(data, parent.identifier.0, dst) {
return false
}
}
// > ... and the dictionary members on the one dictionary
// > definition (including any partial dictionary definitions) are
// > ordered lexicographically by the Unicode codepoints that
// > comprise their identifiers.
let start = dst.len();
let members = definition.members.body.iter();
let partials = dict_data.partials.iter().flat_map(|d| &d.members.body);
for member in members.chain(partials) {
match mkfield(data, member) {
Some(f) => dst.push(f),
None => {
warn!(
"unsupported dictionary field {:?}",
(dict, member.identifier.0),
);
// If this is required then we can't support the
// dictionary at all, but if it's not required we can
// avoid generating bindings for the field and keep
// going otherwise.
if member.required.is_some() {
return false
}
}
}
}
// Note that this sort isn't *quite* right in that it is sorting
// based on snake case instead of the original casing which could
// produce inconsistent results, but should work well enough for
// now!
dst[start..].sort_by_key(|f| f.name.clone());
return true
}
fn mkfield<'src>(
data: &FirstPassRecord<'src>,
field: &'src DictionaryMember<'src>,
) -> Option<ast::DictionaryField> {
// use argument position now as we're just binding setters
let ty = field.type_.to_idl_type(data)?.to_syn_type(TypePosition::Argument)?;
// Slice types aren't supported because they don't implement
// `Into<JsValue>`
if let syn::Type::Reference(ty) = &ty {
match &*ty.elem {
syn::Type::Slice(_) => return None,
_ => {}
}
}
// Similarly i64/u64 aren't supported because they don't
// implement `Into<JsValue>`
let mut any_64bit = false;
ty.imported_type_references(&mut |i| {
any_64bit = any_64bit || i == "u64" || i == "i64";
});
if any_64bit {
return None
}
Some(ast::DictionaryField {
required: field.required.is_some(),
name: rust_ident(&field.identifier.0.to_snake_case()),
ty,
})
}
}
}
|
webidl_parse
|
readerbuf_test.go
|
package utils
import (
"bytes"
"crypto/rand"
"io"
"io/ioutil"
"testing"
"testing/iotest"
"github.com/stretchr/testify/require"
)
func
|
(t *testing.T, amount int) []byte {
data := make([]byte, amount)
_, err := rand.Read(data)
require.NoError(t, err)
return data
}
func TestReaderBuf(t *testing.T) {
testReaderBuf(t, 1024*1024, func(r io.Reader) io.Reader { return r })
testReaderBuf(t, 1024*1024, iotest.DataErrReader)
testReaderBuf(t, 1024*1024, iotest.HalfReader)
testReaderBuf(t, 1024*1024, iotest.OneByteReader)
testReaderBuf(t, 64*1024+3, func(r io.Reader) io.Reader { return r })
testReaderBuf(t, 64*1024+3, iotest.DataErrReader)
testReaderBuf(t, 64*1024+3, iotest.HalfReader)
testReaderBuf(t, 64*1024+3, iotest.OneByteReader)
}
func testReaderBuf(t *testing.T, amount int, wrappers func(io.Reader) io.Reader) {
expected := randData(t, amount)
rb := NewReaderBuf(ioutil.NopCloser(wrappers(bytes.NewReader(expected))))
defer rb.Close()
actual, err := ioutil.ReadAll(rb)
require.NoError(t, err)
require.True(t, bytes.Equal(expected, actual))
}
|
randData
|
transport.rs
|
#[cfg(feature = "http")]
use crate::{HttpTransport, HttpTransportBuilder};
use dyn_clone::DynClone;
use std::error::Error;
use std::fmt::{Debug, Display, Formatter};
use std::io::{ErrorKind, Read};
use url::Url;
/// A trait to abstract over the method/protocol by which files are obtained.
///
/// The trait hides the underlying types involved by returning the `Read` object as a
/// `Box<dyn Read + Send>` and by requiring concrete type [`TransportError`] as the error type.
///
/// Inclusion of the `DynClone` trait means that you will need to implement `Clone` when
/// implementing a `Transport`.
pub trait Transport: Debug + DynClone {
/// Opens a `Read` object for the file specified by `url`.
fn fetch(&self, url: Url) -> Result<Box<dyn Read + Send>, TransportError>;
}
// Implements `Clone` for `Transport` trait objects (i.e. on `Box::<dyn Clone>`). To facilitate
// this, `Clone` needs to be implemented for any `Transport`s. The compiler will enforce this.
dyn_clone::clone_trait_object!(Transport);
// =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^=
/// The kind of error that the transport object experienced during `fetch`.
#[derive(Debug, Copy, Clone)]
#[non_exhaustive]
pub enum TransportErrorKind {
/// The [`Transport`] does not handle the URL scheme. e.g. `file://` or `http://`.
UnsupportedUrlScheme,
/// The file cannot be found.
///
/// Some TUF operations could benefit from knowing whether a [`Transport`] failure is a result
/// of a file not existing. In particular:
/// > TUF v1.0.16 5.2.2. Try downloading version N+1 of the root metadata file `[...]` If this
/// > file is not available `[...]` then go to step 5.1.9.
///
/// We want to distinguish cases when a specific file probably doesn't exist from cases where
/// the failure to fetch it is due to some other problem (i.e. some fault in the [`Transport`]
/// or the machine hosting the file).
///
/// For some transports, the distinction is obvious. For example, a local file transport should
/// return `FileNotFound` for `std::error::ErrorKind::NotFound` and nothing else. For other
/// transports it might be less obvious, but the intent of `FileNotFound` is to indicate that
/// the file probably doesn't exist.
FileNotFound,
/// The transport failed for any other reason, e.g. IO error, HTTP broken pipe, etc.
Other,
}
impl Display for TransportErrorKind {
fn
|
(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
write!(
f,
"{}",
match self {
TransportErrorKind::UnsupportedUrlScheme => "unsupported URL scheme",
TransportErrorKind::FileNotFound => "file not found",
TransportErrorKind::Other => "other",
}
)
}
}
/// The error type that [`Transport::fetch`] returns.
#[derive(Debug)]
pub struct TransportError {
/// The kind of error that occurred.
kind: TransportErrorKind,
/// The URL that the transport was trying to fetch.
url: String,
/// The underlying error that occurred (if any).
source: Option<Box<dyn Error + Send + Sync>>,
}
impl TransportError {
/// Creates a new [`TransportError`]. Use this when there is no underlying error to wrap.
pub fn new<S>(kind: TransportErrorKind, url: S) -> Self
where
S: AsRef<str>,
{
Self {
kind,
url: url.as_ref().into(),
source: None,
}
}
/// Creates a new [`TransportError`]. Use this to preserve an underlying error.
pub fn new_with_cause<S, E>(kind: TransportErrorKind, url: S, source: E) -> Self
where
E: Into<Box<dyn Error + Send + Sync>>,
S: AsRef<str>,
{
Self {
kind,
url: url.as_ref().into(),
source: Some(source.into()),
}
}
/// The type of [`Transport`] error that occurred.
pub fn kind(&self) -> TransportErrorKind {
self.kind
}
/// The URL that the [`Transport`] was trying to fetch when the error occurred.
pub fn url(&self) -> &str {
self.url.as_str()
}
}
impl Display for TransportError {
fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
if let Some(e) = self.source.as_ref() {
write!(
f,
"Transport '{}' error fetching '{}': {}",
self.kind, self.url, e
)
} else {
write!(f, "Transport '{}' error fetching '{}'", self.kind, self.url)
}
}
}
impl Error for TransportError {
fn source(&self) -> Option<&(dyn Error + 'static)> {
self.source.as_ref().map(|e| e.as_ref() as &(dyn Error))
}
}
// =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^=
/// Provides a [`Transport`] for local files.
#[derive(Debug, Clone, Copy)]
pub struct FilesystemTransport;
impl Transport for FilesystemTransport {
fn fetch(&self, url: Url) -> Result<Box<dyn Read + Send>, TransportError> {
if url.scheme() != "file" {
return Err(TransportError::new(
TransportErrorKind::UnsupportedUrlScheme,
url,
));
}
let f = std::fs::File::open(url.path()).map_err(|e| {
let kind = match e.kind() {
ErrorKind::NotFound => TransportErrorKind::FileNotFound,
_ => TransportErrorKind::Other,
};
TransportError::new_with_cause(kind, url, e)
})?;
Ok(Box::new(f))
}
}
// =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^= =^..^=
/// A Transport that provides support for both local files and, if the `http` feature is enabled,
/// HTTP-transported files.
#[derive(Debug, Clone, Copy)]
pub struct DefaultTransport {
file: FilesystemTransport,
#[cfg(feature = "http")]
http: HttpTransport,
}
impl Default for DefaultTransport {
fn default() -> Self {
Self {
file: FilesystemTransport,
#[cfg(feature = "http")]
http: HttpTransport::default(),
}
}
}
impl DefaultTransport {
/// Creates a new `DefaultTransport`. Same as `default()`.
pub fn new() -> Self {
Self::default()
}
}
#[cfg(feature = "http")]
impl DefaultTransport {
/// Create a new `DefaultTransport` with potentially customized settings.
pub fn new_with_http_settings(builder: HttpTransportBuilder) -> Self {
Self {
file: FilesystemTransport,
http: builder.build(),
}
}
}
impl Transport for DefaultTransport {
fn fetch(&self, url: Url) -> Result<Box<dyn Read + Send>, TransportError> {
match url.scheme() {
"file" => self.file.fetch(url),
"http" | "https" => self.handle_http(url),
_ => Err(TransportError::new(
TransportErrorKind::UnsupportedUrlScheme,
url,
)),
}
}
}
impl DefaultTransport {
#[cfg(not(feature = "http"))]
#[allow(clippy::trivially_copy_pass_by_ref, clippy::unused_self)]
fn handle_http(&self, url: Url) -> Result<Box<dyn Read + Send>, TransportError> {
Err(TransportError::new_with_cause(
TransportErrorKind::UnsupportedUrlScheme,
url,
"The library was not compiled with the http feature enabled.",
))
}
#[cfg(feature = "http")]
fn handle_http(&self, url: Url) -> Result<Box<dyn Read + Send>, TransportError> {
self.http.fetch(url)
}
}
|
fmt
|
prepares.go
|
/*
Copyright 2021 The KubeSphere Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package certs
import (
"path/filepath"
"github.com/kubesphere/kubekey/pkg/certs/templates"
"github.com/kubesphere/kubekey/pkg/common"
"github.com/kubesphere/kubekey/pkg/core/connector"
)
type AutoRenewCertsEnabled struct {
common.KubePrepare
Not bool
}
func (a *AutoRenewCertsEnabled) PreCheck(runtime connector.Runtime) (bool, error) {
exist, err := runtime.GetRunner().FileExist(filepath.Join("/etc/systemd/system/", templates.K8sCertsRenewService.Name()))
if err != nil {
return false, err
}
if exist
|
return a.Not, nil
}
|
{
return !a.Not, nil
}
|
PikcioChain.py
|
import base64
import json
import os
import requests
import time
from flask import Flask, jsonify, abort, make_response, redirect, request, \
url_for
from flask_oauthlib.client import OAuth
from selenium import webdriver
from config import get_config
from log import Logger
access_token = ''
def init_api_client():
"""
Initialize Flask API Client
This is necessary for the grant code method
"""
log = Logger()
config = get_config()
app_name = config.get('application', 'name')
app = Flask('{0}_api_client'.format(app_name), template_folder='templates')
os.environ['DEBUG'] = 'true'
try:
client_id = config.get('api_client', 'client_id')
client_secret = config.get('api_client', 'client_secret')
public_ip_server = config.get('server', 'public_ip')
public_port_server = config.get('server', 'public_port')
private_ip_server = config.get('server', 'public_ip')
private_port_server = config.get('server', 'public_port')
https = config.get('server', 'tls')
redirect_uri = config.getboolean('server', 'redirect_uri')
except Exception as e:
log.error('init_api_client Exception : {0}'.format(e))
return json.dumps("Invalid config file")
@app.route('/api/authorized')
def grant_code():
try:
global access_token
# get access token with the authorization_code method
# to be able to use the access token easily, we store it in a
# global variable
code = request.args.get('code')
data = {
'grant_type': 'authorization_code',
'client_id': client_id,
'client_secret': client_secret,
'code': code,
'redirect_uri': redirect_uri
}
if https:
p = requests.post(
url='https://' + public_ip_server + ':' +
public_port_server + '/oauth/token',
data=data, verify=False)
else:
p = requests.post(
url='http://' + public_ip_server + ':' +
public_port_server + '/oauth/token',
data=data, verify=False)
access_token = p.json().get('access_token')
if not access_token:
# we try with private ip
if https:
p = requests.post(
|
url='https://' + private_ip_server + ':' +
private_port_server + '/oauth/token',
data=data, verify=False)
else:
p = requests.post(
url='http://' + private_ip_server + ':' +
private_port_server + '/oauth/token',
data=data, verify=False)
access_token = p.json().get('access_token')
return access_token
except Exception as ex:
log.error('init_api_client Exception : {0}'.format(ex))
return json.dumps("Invalid config file")
return app
class ClientAPI:
"""
Class access for python Client API
"""
def __init__(self, username=None, password=None):
config = get_config()
self.api_public_ip = config.get('server', 'public_ip')
self.api_public_port = config.get('server', 'public_port')
self.api_private_ip = config.get('server', 'private_ip')
self.api_private_port = config.get('server', 'private_port')
self.client_id = config.get('api_client', 'client_id')
self.client_secret = config.get('api_client', 'client_secret')
self.scope = config.get('api_client', 'scope')
self.method = config.get('api_client', 'auth_type')
self.https = config.getboolean('server', 'tls')
self.username = username
self.password = password
self.log = Logger(system=self)
self.app_name = config.get('application', 'name')
self.app = Flask('{0}_api_client'.format(self.app_name))
self.oauth = OAuth(self.app)
os.environ['DEBUG'] = 'true'
if self.https:
self.api_base_url = 'https://{0}:{1}/api/'.format(
self.api_public_ip, self.api_public_port)
self.access_token_url = 'https://{0}:{1}/oauth/token'.format(
self.api_public_ip, self.api_public_port)
self.authorize_url = 'https://{0}:{1}/oauth/authorize'.format(
self.api_public_ip, self.api_public_port)
else:
self.api_base_url = 'http://{0}:{1}/api/'.format(
self.api_public_ip, self.api_public_port)
self.access_token_url = 'http://{0}:{1}/oauth/token'.format(
self.api_public_ip, self.api_public_port)
self.authorize_url = 'http://{0}:{1}/oauth/authorize'.format(
self.api_public_ip, self.api_public_port)
self.remote = self.oauth.remote_app(
'remote',
consumer_key=self.client_id,
consumer_secret=self.client_secret,
request_token_params={'scope': self.scope},
base_url=self.api_base_url,
request_token_url=None,
access_token_url=self.access_token_url,
authorize_url=self.authorize_url
)
self.remote_oauth = ''
self.access_token = ''
self.refresh_token = ''
self.retries = 0
self.req_initiator_url = ''
self.web_server = ''
"""
Everything related to API connection
"""
def get_oauth_token(self):
return self.remote_oauth
def refresh_tok(self):
token = self.get_oauth_token()
if token == '' or token[1] == '':
return self.authorize()
data = {
'grant_type': 'refresh_token',
'client_id': self.client_id,
'refresh_token': token[1],
'scope': self.scope,
'client_secret': self.client_secret,
'username': self.username,
'password': self.password
}
auth_code = base64.b64encode(
'{0}:{1}'.format(self.client_id, self.client_secret))
res = requests.post(self.access_token_url, data=data, headers={
'Authorization': 'Basic {0}'.format(auth_code)},
verify=False)
if res.status_code == 401:
self.remote_oauth = ''
return self.authorize()
if res.status_code in (200, 201):
self.remote_oauth = (
res.json().get('access_token'),
res.json().get('refresh_token'))
self.access_token = res.json().get('access_token')
self.refresh_token = res.json().get('refresh_token')
return True
return False
def require_authorize(self, f):
"""
Decorator used to validate client authorization; In case the client
is not authorized, redirect to the Authorize Page, otherwise check
if the access token expired and request new one using the refresh
token.
:return:
"""
def wrap(*args, **kwargs):
token = self.get_oauth_token()
if not token:
self.req_initiator_url = '/api'
return redirect('/authorize')
resp = f(*args, **kwargs)
if not resp.status or resp.status in (401,):
token = self.get_oauth_token()
if token and token[1]:
self.refresh_tok()
else:
return redirect('/authorize')
resp = f(*args, **kwargs)
return make_response(jsonify(resp.data), resp.status)
return wrap
def authorize(self):
if self.remote_oauth != '':
return redirect(url_for('api_index'))
next_url = request.args.get('next') or request.referrer or None
return self.remote.authorize(
callback=url_for('authorized', next=next_url, _external=True)
)
def authorized(self):
resp = self.remote.authorized_response()
# print resp
if not resp:
return jsonify(
error=request.args.get('error'),
message=request.args.get('error_description') or ''
)
elif hasattr(resp, 'data') and resp.data.get('error'):
return jsonify(
error=resp.data['error'],
message=resp.message or ''
)
if not resp.get('access_token') or not resp.get('refresh_token'):
abort(401)
self.refresh_token = resp['refresh_token']
self.access_token = resp['access_token']
if self.req_initiator_url != '':
req_initiator = self.req_initiator_url
return redirect(req_initiator)
return redirect('/api')
def deauthorize(self):
if self.remote_oauth != '':
self.remote_oauth = ''
self.refresh_token = ''
self.access_token = ''
return redirect(url_for('authorize'))
def api_index(self):
resp = self.remote.get('home')
return resp
def generic_request(self, url, method, params=None):
global access_token
try:
# if we used grant_code method, the access token variable of the
# class won't be initialised yet
if self.access_token == '':
# if the access token hasn't been got yet, we wait 5s and call
# the function again until the global variable isn't null
# anymore
if access_token != '':
self.access_token = access_token
else:
self.retries += 1
if self.retries == 3:
self.retries = 0
p = jsonify({
'error': 'Too many failed attempts to retrieve '
'access token, please try the password '
'method.'})
return p
time.sleep(5)
return self.generic_request(url, method, params)
if method.lower() == 'get':
p = requests.get(
url=url + '?access_token=' + self.access_token,
verify=False)
elif method.lower() == 'post':
p = requests.post(
url=url + '?access_token=' + self.access_token,
data=params,
headers={'Content-Type': 'application/json'}, verify=False)
elif method.lower() == 'delete':
p = requests.delete(
url=url + '?access_token=' + self.access_token,
data=params, verify=False)
else:
p = json.dumps('Bad request')
if p.status_code == 401 and self.retries < 1:
if self.refresh_tok():
self.retries += 1
if method.lower() == 'get':
p = requests.get(
url=url + '?access_token=' + self.access_token,
verify=False)
elif method.lower() == 'post':
p = requests.post(
url=url + '?access_token=' + self.access_token,
data=params,
headers={'Content-Type': 'application/json'},
verify=False)
elif method.lower() == 'delete':
p = requests.delete(
url=url + '?access_token=' + self.access_token,
data=params, verify=False)
else:
p = json.dumps('API connexion lost')
elif p.status_code == 500:
self.log.error('Server connexion error : {0}'.format(p))
return json.dumps('Server failure, please report the bug')
else:
self.retries = 0
except Exception as e:
self.log.error('generic_request Exception : {0}'.format(e))
return json.dumps('Bad request')
return p
def get_access_token(self):
try:
if self.method.lower() == 'password_header':
data = {
'grant_type': 'password',
'username': self.username,
'password': self.password,
'scope': self.scope
}
auth_code = base64.b64encode(
bytes(self.client_id + ':' + self.client_secret))
try:
p = requests.post(url=self.access_token_url, data=data,
headers={
'Authorization': 'Basic {0}'.format(
auth_code)}, verify=False,
timeout=10)
except (requests.Timeout, requests.ConnectionError):
# try with private IP
self.log.error('Failed to connect public IP, try to '
'connect private IP')
base_url = 'http{0}://{1}:{2}/'.format(
's' if self.https else '',
self.api_private_ip,
self.api_private_port
)
self.api_base_url = base_url + 'api/'
self.access_token_url = base_url + 'oauth/token'
self.authorize_url = base_url + 'oauth/authorize'
p = requests.post(url=self.access_token_url, data=data,
headers={
'Authorization': 'Basic {0}'.format(
auth_code)}, verify=False,
timeout=10)
if p and p.status_code == 401:
return json.dumps(
{'status': False, 'msg': 'API authentication failed'})
else:
self.access_token = p.json().get('access_token')
self.refresh_token = p.json().get('refresh_token')
self.remote_oauth = (self.access_token, self.refresh_token)
return json.dumps(
{'status': True, 'msg': 'API access granted'})
elif self.method.lower() == 'password_data':
data = {
'grant_type': 'password',
'client_id': self.client_id,
'client_secret': self.client_secret,
'username': self.username,
'password': self.password,
'scope': self.scope
}
try:
p = requests.post(url=self.access_token_url, data=data,
verify=False, timeout=10)
except (requests.Timeout, requests.ConnectionError):
# try with private IP
self.log.error(
'Failed to connect public IP, try to connect private '
'IP')
base_url = 'http{0}://{1}:{2}/'.format(
's' if self.https else '',
self.api_private_ip,
self.api_private_port
)
self.api_base_url = base_url + 'api/'
self.access_token_url = base_url + 'oauth/token'
self.authorize_url = base_url + 'oauth/authorize'
p = requests.post(url=self.access_token_url, data=data,
verify=False, timeout=10)
if p.status_code == 401:
return json.dumps(
{'status': False, 'msg': 'API authentication failed'})
else:
self.access_token = p.json().get('access_token')
self.refresh_token = p.json().get('refresh_token')
self.remote_oauth = (self.access_token, self.refresh_token)
return json.dumps(
{'status': True, 'msg': 'API access granted'})
# todo : to be tested + manage https and private/public IP address
elif self.method.lower() == "grant_code":
url = self.authorize_url + '?client_id=' + self.client_id + \
"&response_type=code"
driver = webdriver.Firefox()
return driver.get(url)
else:
return json.dumps(
{'status': False, 'msg': 'Invalid grant type'})
except Exception as e:
self.log.error('get_access_token Exception : {0}'.format(e))
return json.dumps(
{'status': False, 'msg': 'API authentication failed'})
"""
Everything related to the user
"""
def get_user_profile(self):
try:
p = self.generic_request(url=self.api_base_url + 'user/profile',
method='GET')
except Exception as e:
self.log.error('get_user_profile Exception : {0}'.format(e))
return json.dumps('Get user profile : Bad request')
return p
def update_user_profile(self, data):
try:
p = self.generic_request(url=self.api_base_url + 'user/profile',
method='POST', params=json.dumps(data))
except Exception as e:
self.log.error('update_user_profile Exception : {0}'.format(e))
return json.dumps('Update user profile : Bad request')
return p
def delete_custom_profile_item(self, data):
try:
p = self.generic_request(
url=self.api_base_url + 'user/profile/delete_item',
method='POST', params=json.dumps(data))
except Exception as e:
self.log.error(
'delete_custom_profile_item Exception : {0}'.format(e))
return json.dumps('Delete custom profile item : Bad request')
return p
def get_user_avatar(self):
try:
p = self.generic_request(url=self.api_base_url + 'user/avatar',
method='GET')
except Exception as e:
self.log.error('get_user_avatar Exception : {0}'.format(e))
return json.dumps('Get user avatar : Bad request')
return p
def set_user_avatar(self, data):
try:
p = self.generic_request(url=self.api_base_url + 'user/avatar',
method='POST', params=json.dumps(data))
except Exception as e:
self.log.error('set_user_avatar Exception : {0}'.format(e))
return json.dumps('Update user avatar : Bad request')
return p
def update_password(self, data):
try:
p = self.generic_request(
url=self.api_base_url + 'profile/change_password',
method='POST',
params=json.dumps(data))
except Exception as e:
self.log.error('update_password Exception : {0}'.format(e))
return json.dumps('Update password : Bad request')
return p
"""
Everything related to chat messages
"""
def send_chat_message(self, data):
try:
p = self.generic_request(url=self.api_base_url + 'chat/send',
method="POST", params=json.dumps(data))
except Exception as e:
self.log.error('send_chat_message Exception : {0}'.format(e))
return json.dumps('Send chat message : Bad request')
return p
def delete_chat_message(self, msg_id):
try:
p = self.generic_request(url=self.api_base_url + 'chat/' + msg_id,
method="DELETE")
except Exception as e:
self.log.error('delete_chat_message Exception : {0}'.format(e))
return json.dumps('Delete chat message : Bad request')
return p
def get_chat_conversation(self, data):
try:
p = self.generic_request(url=self.api_base_url + 'chat',
method='POST', params=json.dumps(data))
except Exception as e:
self.log.error('get_chat_conversation Exception : {0}'.format(e))
return json.dumps('Get chat conversation : Bad request')
return p
"""
Everything related to file messages
"""
def get_file_messages(self, data):
try:
p = self.generic_request(url=self.api_base_url + 'file_message',
method='POST', params=json.dumps(data))
except Exception as e:
self.log.error('get_file_messages Exception : {0}'.format(e))
return json.dumps('Get file messages : Bad request')
return p
def send_file_message(self, data):
try:
p = self.generic_request(
url=self.api_base_url + 'file_message/send',
method="POST",
params=json.dumps(data))
except Exception as e:
self.log.error('send_file_message Exception : {0}'.format(e))
return json.dumps('Send file message : Bad request')
return p
def delete_file_message(self, msg_id):
try:
p = self.generic_request(
url=self.api_base_url + 'file_message/' + msg_id,
method='DELETE')
except Exception as e:
self.log.error('delete_file_message Exception : {0}'.format(e))
return json.dumps('Set file message as read : Bad request')
return p
"""
Everything related to contacts
"""
def get_contacts(self):
try:
p = self.generic_request(url=self.api_base_url + 'contacts',
method='GET')
except Exception as e:
self.log.error('get_contacts Exception : {0}'.format(e))
return json.dumps(
'Get contacts list : Bad request : {0}'.format(e))
return p
def find_user(self, query):
try:
p = self.generic_request(
url=self.api_base_url + 'contacts/find_user' + query,
method='GET')
except Exception as e:
self.log.error('find_user Exception : {0}'.format(e))
return json.dumps('Find user : Bad request')
return p
def add_contact(self, data):
try:
p = self.generic_request(url=self.api_base_url + 'contacts/add',
method='POST', params=json.dumps(data))
except Exception as e:
self.log.error('add_contact Exception : {0}'.format(e))
return json.dumps('Add contact : Bad request')
return p
def remove_contact(self, data):
try:
p = self.generic_request(url=self.api_base_url + 'contacts/remove',
method='POST', params=json.dumps(data))
except Exception as e:
self.log.error('remove_contact Exception : {0}'.format(e))
return json.dumps('Remove contact : Bad request')
return p
def accept_contact_request(self, matr_id):
try:
p = self.generic_request(
url=self.api_base_url + 'contacts/accept/' + matr_id,
method='GET')
except Exception as e:
self.log.error('accept_contact_request Exception : {0}'.format(e))
return json.dumps('Accept contact request : Bad request')
return p
def reject_contact_request(self, matr_id):
try:
p = self.generic_request(
url=self.api_base_url + 'contacts/reject/' + matr_id,
method='GET')
except Exception as e:
self.log.error('reject_contact_request Exception : {0}'.format(e))
return json.dumps('Reject contact request : Bad request')
return p
def get_contact_profile(self, matr_id):
try:
p = self.generic_request(
url=self.api_base_url + 'contacts/' + matr_id, method='GET')
except Exception as e:
self.log.error('get_contact_profile Exception : {0}'.format(e))
return json.dumps('Get contact profile : Bad request')
return p
| |
providers.rs
|
use accounting_system::providers::belarus::{FileCriminalCase, RaiseEnterprise, KGB};
use accounting_system::providers::russia::{Miller, StealALotOfMoney, StealSomeMoney};
use accounting_system::providers::{
belarus_factory, russia_factory, Product, ProductCreator, Responsible,
};
fn main()
|
{
let gasprom = russia_factory();
let product = gasprom.create_product();
let price = product.get_price();
let responsible = gasprom.create_responsible("Ivan");
let info = responsible.get_info();
println!("price {}", price);
println!("info from responsible: {}", info);
let mut miller = Miller::default();
miller.add_command(Box::new(StealSomeMoney));
miller.add_command(Box::new(StealALotOfMoney));
miller.execute_all();
let belarus_factory = belarus_factory();
let product = belarus_factory.create_product();
let responsible = belarus_factory.create_responsible("Boris");
let info = responsible.get_info();
let price = product.get_price();
println!("price {}", price);
println!("info from responsible: {}", info);
let mut kgb = KGB::default();
kgb.add_command(Box::new(FileCriminalCase));
kgb.add_command(Box::new(RaiseEnterprise));
kgb.execute_all();
}
|
|
read_entry.rs
|
use bencher::{benchmark_group, benchmark_main};
use std::io::{Cursor, Read, Write};
use bencher::Bencher;
use rand::{RngCore};
use zip::{ZipArchive, ZipWriter};
fn generate_random_archive(size: usize) -> Vec<u8> {
let data = Vec::new();
let mut writer = ZipWriter::new(Cursor::new(data));
let options =
zip::write::FileOptions::default().compression_method(zip::CompressionMethod::Stored);
writer.start_file("random.dat", options).unwrap();
let mut bytes = vec![0u8; size];
rand::thread_rng().fill_bytes(&mut bytes);
writer.write_all(&bytes).unwrap();
writer.finish().unwrap().into_inner()
}
fn read_entry(bench: &mut Bencher) {
let size = 1024 * 1024;
|
bench.iter(|| {
let mut file = archive.by_name("random.dat").unwrap();
let mut buf = [0u8; 1024];
loop {
let n = file.read(&mut buf).unwrap();
if n == 0 {
break;
}
}
});
bench.bytes = size as u64;
}
benchmark_group!(benches, read_entry);
benchmark_main!(benches);
|
let bytes = generate_random_archive(size);
let mut archive = ZipArchive::new(Cursor::new(bytes.as_slice())).unwrap();
|
client.go
|
/*
* Copyright 2018 The CovenantSQL Authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package main
import (
"flag"
"fmt"
"net"
"path/filepath"
"strings"
"syscall"
"time"
"github.com/CovenantSQL/CovenantSQL/conf"
"github.com/CovenantSQL/CovenantSQL/crypto/kms"
"github.com/CovenantSQL/CovenantSQL/proto"
"github.com/CovenantSQL/CovenantSQL/rpc"
"github.com/CovenantSQL/CovenantSQL/utils/log"
"golang.org/x/crypto/ssh/terminal"
)
func runClient(nodeID proto.NodeID) (err error) {
var idx int
for i, n := range conf.GConf.KnownNodes {
if n.ID == nodeID {
idx = i
break
}
}
rootPath := conf.GConf.WorkingRoot
pubKeyStorePath := filepath.Join(rootPath, conf.GConf.PubKeyStoreFile)
privateKeyPath := filepath.Join(rootPath, conf.GConf.PrivateKeyFile)
// read master key
var masterKey []byte
if !conf.GConf.IsTestMode {
fmt.Print("Type in Master key to continue: ")
masterKey, err = terminal.ReadPassword(syscall.Stdin)
if err != nil {
fmt.Printf("Failed to read Master Key: %v", err)
}
fmt.Println("")
}
err = kms.InitLocalKeyPair(privateKeyPath, masterKey)
if err != nil {
log.WithError(err).Error("init local key pair failed")
return
}
conf.GConf.KnownNodes[idx].PublicKey, err = kms.GetLocalPublicKey()
if err != nil {
log.WithError(err).Error("get local public key failed")
return
}
//nodeInfo := asymmetric.GetPubKeyNonce(AllNodes[idx].PublicKey, 20, 500*time.Millisecond, nil)
//log.Debugf("client pubkey:\n%x", AllNodes[idx].PublicKey.Serialize())
//log.Debugf("client nonce:\n%v", nodeInfo)
// init nodes
log.Info("init peers")
_, _, _, err = initNodePeers(nodeID, pubKeyStorePath)
if err != nil {
return
}
// do client request
if err = clientRequest(clientOperation, flag.Arg(0)); err != nil {
return
}
return
}
func
|
(reqType string, sql string) (err error) {
log.SetLevel(log.DebugLevel)
leaderNodeID := kms.BP.NodeID
var conn net.Conn
var client *rpc.Client
if len(reqType) > 0 && strings.Title(reqType[:1]) == "P" {
if conn, err = rpc.DialToNode(leaderNodeID, rpc.GetSessionPoolInstance(), false); err != nil {
return
}
if client, err = rpc.InitClientConn(conn); err != nil {
return
}
reqType = "Ping"
node1 := proto.NewNode()
node1.InitNodeCryptoInfo(100 * time.Millisecond)
reqA := &proto.PingReq{
Node: *node1,
}
respA := new(proto.PingResp)
log.Debugf("req %#v: %#v", reqType, reqA)
err = client.Call("DHT."+reqType, reqA, respA)
if err != nil {
log.Fatal(err)
}
log.Debugf("resp %#v: %#v", reqType, respA)
} else {
for _, bp := range conf.GConf.KnownNodes {
if bp.Role == proto.Leader || bp.Role == proto.Follower {
if conn, err = rpc.DialToNode(bp.ID, rpc.GetSessionPoolInstance(), false); err != nil {
return
}
if client, err = rpc.InitClientConn(conn); err != nil {
return
}
log.WithField("bp", bp.ID).Debug("Calling BP")
reqType = "FindNeighbor"
req := &proto.FindNeighborReq{
ID: proto.NodeID(flag.Arg(0)),
Count: 10,
}
resp := new(proto.FindNeighborResp)
log.Debugf("req %#v: %#v", reqType, req)
err = client.Call("DHT."+reqType, req, resp)
if err != nil {
log.Fatal(err)
}
log.Debugf("resp %#v: %#v", reqType, resp)
}
}
}
return
}
|
clientRequest
|
calib3d.rs
|
#![allow(
unused_parens,
clippy::excessive_precision,
clippy::missing_safety_doc,
clippy::not_unsafe_ptr_arg_deref,
clippy::should_implement_trait,
clippy::too_many_arguments,
clippy::unused_unit,
)]
//! # Camera Calibration and 3D Reconstruction
//!
//! The functions in this section use a so-called pinhole camera model. The view of a scene
//! is obtained by projecting a scene's 3D point  into the image plane using a perspective
//! transformation which forms the corresponding pixel . Both  and  are
//! represented in homogeneous coordinates, i.e. as 3D and 2D homogeneous vector respectively. You will
//! find a brief introduction to projective geometry, homogeneous vectors and homogeneous
//! transformations at the end of this section's introduction. For more succinct notation, we often drop
//! the 'homogeneous' and say vector instead of homogeneous vector.
//!
//! The distortion-free projective transformation given by a pinhole camera model is shown below.
//!
//! 
//!
//! where  is a 3D point expressed with respect to the world coordinate system,
//!  is a 2D pixel in the image plane,  is the camera intrinsic matrix,
//!  and  are the rotation and translation that describe the change of coordinates from
//! world to camera coordinate systems (or camera frame) and  is the projective transformation's
//! arbitrary scaling and not part of the camera model.
//!
//! The camera intrinsic matrix  (notation used as in [Zhang2000](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Zhang2000) and also generally notated
//! as ) projects 3D points given in the camera coordinate system to 2D pixel coordinates, i.e.
//!
//! 
//!
//! The camera intrinsic matrix 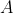 is composed of the focal lengths  and , which are
//! expressed in pixel units, and the principal point , that is usually close to the
//! image center:
//!
//! 
//!
//! and thus
//!
//! 
//!
//! The matrix of intrinsic parameters does not depend on the scene viewed. So, once estimated, it can
//! be re-used as long as the focal length is fixed (in case of a zoom lens). Thus, if an image from the
//! camera is scaled by a factor, all of these parameters need to be scaled (multiplied/divided,
//! respectively) by the same factor.
//!
//! The joint rotation-translation matrix 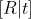 is the matrix product of a projective
//! transformation and a homogeneous transformation. The 3-by-4 projective transformation maps 3D points
//! represented in camera coordinates to 2D points in the image plane and represented in normalized
//! camera coordinates  and :
//!
//! 
//!
//! The homogeneous transformation is encoded by the extrinsic parameters 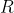 and 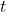 and
//! represents the change of basis from world coordinate system  to the camera coordinate sytem
//! . Thus, given the representation of the point  in world coordinates, , we
//! obtain 's representation in the camera coordinate system, , by
//!
//! 
//!
//! This homogeneous transformation is composed out of , a 3-by-3 rotation matrix, and , a
//! 3-by-1 translation vector:
//!
//! 
//!
//! and therefore
//!
//! 
//!
//! Combining the projective transformation and the homogeneous transformation, we obtain the projective
//! transformation that maps 3D points in world coordinates into 2D points in the image plane and in
//! normalized camera coordinates:
//!
//! 
//!
//! with  and . Putting the equations for instrincs and extrinsics together, we can write out
//!  as
//!
//! 
//!
//! If , the transformation above is equivalent to the following,
//!
//! 
//!
//! with
//!
//! 
//!
//! The following figure illustrates the pinhole camera model.
//!
//! 
//!
//! Real lenses usually have some distortion, mostly radial distortion, and slight tangential distortion.
//! So, the above model is extended as:
//!
//! 
//!
//! where
//!
//! 
//!
//! with
//!
//! 
//!
//! and
//!
//! 
//!
//! if .
//!
//! The distortion parameters are the radial coefficients , , , , , and 
//! , and  are the tangential distortion coefficients, and , , , and ,
//! are the thin prism distortion coefficients. Higher-order coefficients are not considered in OpenCV.
//!
//! The next figures show two common types of radial distortion: barrel distortion
//! ( monotonically decreasing)
//! and pincushion distortion ( monotonically increasing).
//! Radial distortion is always monotonic for real lenses,
//! and if the estimator produces a non-monotonic result,
//! this should be considered a calibration failure.
//! More generally, radial distortion must be monotonic and the distortion function must be bijective.
//! A failed estimation result may look deceptively good near the image center
//! but will work poorly in e.g. AR/SFM applications.
//! The optimization method used in OpenCV camera calibration does not include these constraints as
//! the framework does not support the required integer programming and polynomial inequalities.
//! See [issue #15992](https://github.com/opencv/opencv/issues/15992) for additional information.
//!
//! 
//! 
//!
//! In some cases, the image sensor may be tilted in order to focus an oblique plane in front of the
//! camera (Scheimpflug principle). This can be useful for particle image velocimetry (PIV) or
//! triangulation with a laser fan. The tilt causes a perspective distortion of  and
//! . This distortion can be modeled in the following way, see e.g. [Louhichi07](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Louhichi07).
//!
//! 
//!
//! where
//!
//! 
//!
//! and the matrix  is defined by two rotations with angular parameter
//!  and , respectively,
//!
//! 
//!
//! In the functions below the coefficients are passed or returned as
//!
//! 
//!
//! vector. That is, if the vector contains four elements, it means that  . The distortion
//! coefficients do not depend on the scene viewed. Thus, they also belong to the intrinsic camera
//! parameters. And they remain the same regardless of the captured image resolution. If, for example, a
//! camera has been calibrated on images of 320 x 240 resolution, absolutely the same distortion
//! coefficients can be used for 640 x 480 images from the same camera while , ,
//! , and  need to be scaled appropriately.
//!
//! The functions below use the above model to do the following:
//!
//! * Project 3D points to the image plane given intrinsic and extrinsic parameters.
//! * Compute extrinsic parameters given intrinsic parameters, a few 3D points, and their
//! projections.
//! * Estimate intrinsic and extrinsic camera parameters from several views of a known calibration
//! pattern (every view is described by several 3D-2D point correspondences).
//! * Estimate the relative position and orientation of the stereo camera "heads" and compute the
//! *rectification* transformation that makes the camera optical axes parallel.
//!
//! <B> Homogeneous Coordinates </B><br>
//! Homogeneous Coordinates are a system of coordinates that are used in projective geometry. Their use
//! allows to represent points at infinity by finite coordinates and simplifies formulas when compared
//! to the cartesian counterparts, e.g. they have the advantage that affine transformations can be
//! expressed as linear homogeneous transformation.
//!
//! One obtains the homogeneous vector  by appending a 1 along an n-dimensional cartesian
//! vector  e.g. for a 3D cartesian vector the mapping  is:
//!
//! 
//!
//! For the inverse mapping , one divides all elements of the homogeneous vector
//! by its last element, e.g. for a 3D homogeneous vector one gets its 2D cartesian counterpart by:
//!
//! 
//!
//! if .
//!
//! Due to this mapping, all multiples , for , of a homogeneous point represent
//! the same point . An intuitive understanding of this property is that under a projective
//! transformation, all multiples of  are mapped to the same point. This is the physical
//! observation one does for pinhole cameras, as all points along a ray through the camera's pinhole are
//! projected to the same image point, e.g. all points along the red ray in the image of the pinhole
//! camera model above would be mapped to the same image coordinate. This property is also the source
//! for the scale ambiguity s in the equation of the pinhole camera model.
//!
//! As mentioned, by using homogeneous coordinates we can express any change of basis parameterized by
//!  and  as a linear transformation, e.g. for the change of basis from coordinate system
//! 0 to coordinate system 1 becomes:
//!
//! 
//!
//!
//! Note:
//! * Many functions in this module take a camera intrinsic matrix as an input parameter. Although all
//! functions assume the same structure of this parameter, they may name it differently. The
//! parameter's description, however, will be clear in that a camera intrinsic matrix with the structure
//! shown above is required.
//! * A calibration sample for 3 cameras in a horizontal position can be found at
//! opencv_source_code/samples/cpp/3calibration.cpp
//! * A calibration sample based on a sequence of images can be found at
//! opencv_source_code/samples/cpp/calibration.cpp
//! * A calibration sample in order to do 3D reconstruction can be found at
//! opencv_source_code/samples/cpp/build3dmodel.cpp
//! * A calibration example on stereo calibration can be found at
//! opencv_source_code/samples/cpp/stereo_calib.cpp
//! * A calibration example on stereo matching can be found at
//! opencv_source_code/samples/cpp/stereo_match.cpp
//! * (Python) A camera calibration sample can be found at
//! opencv_source_code/samples/python/calibrate.py
//! # Fisheye camera model
//!
//! Definitions: Let P be a point in 3D of coordinates X in the world reference frame (stored in the
//! matrix X) The coordinate vector of P in the camera reference frame is:
//!
//! 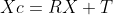
//!
//! where R is the rotation matrix corresponding to the rotation vector om: R = rodrigues(om); call x, y
//! and z the 3 coordinates of Xc:
//!
//! 
//!
//! The pinhole projection coordinates of P is [a; b] where
//!
//! 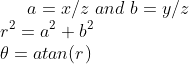
//!
//! Fisheye distortion:
//!
//! 
//!
//! The distorted point coordinates are [x'; y'] where
//!
//! 
//!
//! Finally, conversion into pixel coordinates: The final pixel coordinates vector [u; v] where:
//!
//! 
//!
//! # C API
use crate::{mod_prelude::*, core, sys, types};
pub mod prelude {
pub use { super::LMSolver_CallbackConst, super::LMSolver_Callback, super::LMSolverConst, super::LMSolver, super::StereoMatcherConst, super::StereoMatcher, super::StereoBMConst, super::StereoBM, super::StereoSGBMConst, super::StereoSGBM };
}
pub const CALIB_CB_ACCURACY: i32 = 32;
pub const CALIB_CB_ADAPTIVE_THRESH: i32 = 1;
pub const CALIB_CB_ASYMMETRIC_GRID: i32 = 2;
pub const CALIB_CB_CLUSTERING: i32 = 4;
pub const CALIB_CB_EXHAUSTIVE: i32 = 16;
pub const CALIB_CB_FAST_CHECK: i32 = 8;
pub const CALIB_CB_FILTER_QUADS: i32 = 4;
pub const CALIB_CB_LARGER: i32 = 64;
pub const CALIB_CB_MARKER: i32 = 128;
pub const CALIB_CB_NORMALIZE_IMAGE: i32 = 2;
pub const CALIB_CB_SYMMETRIC_GRID: i32 = 1;
pub const CALIB_FIX_ASPECT_RATIO: i32 = 2;
pub const CALIB_FIX_FOCAL_LENGTH: i32 = 16;
pub const CALIB_FIX_INTRINSIC: i32 = 256;
pub const CALIB_FIX_K1: i32 = 32;
pub const CALIB_FIX_K2: i32 = 64;
pub const CALIB_FIX_K3: i32 = 128;
pub const CALIB_FIX_K4: i32 = 2048;
pub const CALIB_FIX_K5: i32 = 4096;
pub const CALIB_FIX_K6: i32 = 8192;
pub const CALIB_FIX_PRINCIPAL_POINT: i32 = 4;
pub const CALIB_FIX_S1_S2_S3_S4: i32 = 65536;
pub const CALIB_FIX_TANGENT_DIST: i32 = 2097152;
pub const CALIB_FIX_TAUX_TAUY: i32 = 524288;
/// On-line Hand-Eye Calibration [Andreff99](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Andreff99)
pub const CALIB_HAND_EYE_ANDREFF: i32 = 3;
/// Hand-Eye Calibration Using Dual Quaternions [Daniilidis98](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Daniilidis98)
pub const CALIB_HAND_EYE_DANIILIDIS: i32 = 4;
/// Hand-eye Calibration [Horaud95](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Horaud95)
pub const CALIB_HAND_EYE_HORAUD: i32 = 2;
/// Robot Sensor Calibration: Solving AX = XB on the Euclidean Group [Park94](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Park94)
pub const CALIB_HAND_EYE_PARK: i32 = 1;
/// A New Technique for Fully Autonomous and Efficient 3D Robotics Hand/Eye Calibration [Tsai89](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Tsai89)
pub const CALIB_HAND_EYE_TSAI: i32 = 0;
pub const CALIB_NINTRINSIC: i32 = 18;
pub const CALIB_RATIONAL_MODEL: i32 = 16384;
/// Simultaneous robot-world and hand-eye calibration using dual-quaternions and kronecker product [Li2010SimultaneousRA](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Li2010SimultaneousRA)
pub const CALIB_ROBOT_WORLD_HAND_EYE_LI: i32 = 1;
/// Solving the robot-world/hand-eye calibration problem using the kronecker product [Shah2013SolvingTR](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Shah2013SolvingTR)
pub const CALIB_ROBOT_WORLD_HAND_EYE_SHAH: i32 = 0;
pub const CALIB_SAME_FOCAL_LENGTH: i32 = 512;
pub const CALIB_THIN_PRISM_MODEL: i32 = 32768;
pub const CALIB_TILTED_MODEL: i32 = 262144;
/// for stereoCalibrate
pub const CALIB_USE_EXTRINSIC_GUESS: i32 = 4194304;
pub const CALIB_USE_INTRINSIC_GUESS: i32 = 1;
/// use LU instead of SVD decomposition for solving. much faster but potentially less precise
pub const CALIB_USE_LU: i32 = 131072;
/// use QR instead of SVD decomposition for solving. Faster but potentially less precise
pub const CALIB_USE_QR: i32 = 1048576;
pub const CALIB_ZERO_DISPARITY: i32 = 1024;
pub const CALIB_ZERO_TANGENT_DIST: i32 = 8;
/// 7-point algorithm
pub const FM_7POINT: i32 = 1;
/// 8-point algorithm
pub const FM_8POINT: i32 = 2;
/// least-median algorithm. 7-point algorithm is used.
pub const FM_LMEDS: i32 = 4;
/// RANSAC algorithm. It needs at least 15 points. 7-point algorithm is used.
pub const FM_RANSAC: i32 = 8;
pub const Fisheye_CALIB_CHECK_COND: i32 = 4;
pub const Fisheye_CALIB_FIX_FOCAL_LENGTH: i32 = 2048;
pub const Fisheye_CALIB_FIX_INTRINSIC: i32 = 256;
pub const Fisheye_CALIB_FIX_K1: i32 = 16;
pub const Fisheye_CALIB_FIX_K2: i32 = 32;
pub const Fisheye_CALIB_FIX_K3: i32 = 64;
pub const Fisheye_CALIB_FIX_K4: i32 = 128;
pub const Fisheye_CALIB_FIX_PRINCIPAL_POINT: i32 = 512;
pub const Fisheye_CALIB_FIX_SKEW: i32 = 8;
pub const Fisheye_CALIB_RECOMPUTE_EXTRINSIC: i32 = 2;
pub const Fisheye_CALIB_USE_INTRINSIC_GUESS: i32 = 1;
pub const Fisheye_CALIB_ZERO_DISPARITY: i32 = 1024;
/// least-median of squares algorithm
pub const LMEDS: i32 = 4;
pub const LOCAL_OPTIM_GC: i32 = 3;
pub const LOCAL_OPTIM_INNER_AND_ITER_LO: i32 = 2;
pub const LOCAL_OPTIM_INNER_LO: i32 = 1;
pub const LOCAL_OPTIM_NULL: i32 = 0;
pub const LOCAL_OPTIM_SIGMA: i32 = 4;
pub const NEIGH_FLANN_KNN: i32 = 0;
pub const NEIGH_FLANN_RADIUS: i32 = 2;
pub const NEIGH_GRID: i32 = 1;
pub const PROJ_SPHERICAL_EQRECT: i32 = 1;
pub const PROJ_SPHERICAL_ORTHO: i32 = 0;
/// RANSAC algorithm
pub const RANSAC: i32 = 8;
/// RHO algorithm
pub const RHO: i32 = 16;
pub const SAMPLING_NAPSAC: i32 = 2;
pub const SAMPLING_PROGRESSIVE_NAPSAC: i32 = 1;
pub const SAMPLING_PROSAC: i32 = 3;
pub const SAMPLING_UNIFORM: i32 = 0;
pub const SCORE_METHOD_LMEDS: i32 = 3;
pub const SCORE_METHOD_MAGSAC: i32 = 2;
pub const SCORE_METHOD_MSAC: i32 = 1;
pub const SCORE_METHOD_RANSAC: i32 = 0;
/// An Efficient Algebraic Solution to the Perspective-Three-Point Problem [Ke17](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Ke17)
pub const SOLVEPNP_AP3P: i32 = 5;
/// **Broken implementation. Using this flag will fallback to EPnP.**
///
/// A Direct Least-Squares (DLS) Method for PnP [hesch2011direct](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_hesch2011direct)
pub const SOLVEPNP_DLS: i32 = 3;
/// EPnP: Efficient Perspective-n-Point Camera Pose Estimation [lepetit2009epnp](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_lepetit2009epnp)
pub const SOLVEPNP_EPNP: i32 = 1;
/// Infinitesimal Plane-Based Pose Estimation [Collins14](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Collins14)
///
/// Object points must be coplanar.
pub const SOLVEPNP_IPPE: i32 = 6;
/// Infinitesimal Plane-Based Pose Estimation [Collins14](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Collins14)
///
/// This is a special case suitable for marker pose estimation.
///
/// 4 coplanar object points must be defined in the following order:
/// - point 0: [-squareLength / 2, squareLength / 2, 0]
/// - point 1: [ squareLength / 2, squareLength / 2, 0]
/// - point 2: [ squareLength / 2, -squareLength / 2, 0]
/// - point 3: [-squareLength / 2, -squareLength / 2, 0]
pub const SOLVEPNP_IPPE_SQUARE: i32 = 7;
pub const SOLVEPNP_ITERATIVE: i32 = 0;
/// Used for count
pub const SOLVEPNP_MAX_COUNT: i32 = 9;
/// Complete Solution Classification for the Perspective-Three-Point Problem [gao2003complete](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_gao2003complete)
pub const SOLVEPNP_P3P: i32 = 2;
/// SQPnP: A Consistently Fast and Globally OptimalSolution to the Perspective-n-Point Problem [Terzakis20](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Terzakis20)
pub const SOLVEPNP_SQPNP: i32 = 8;
/// **Broken implementation. Using this flag will fallback to EPnP.**
///
/// Exhaustive Linearization for Robust Camera Pose and Focal Length Estimation [penate2013exhaustive](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_penate2013exhaustive)
pub const SOLVEPNP_UPNP: i32 = 4;
pub const StereoBM_PREFILTER_NORMALIZED_RESPONSE: i32 = 0;
pub const StereoBM_PREFILTER_XSOBEL: i32 = 1;
pub const StereoMatcher_DISP_SCALE: i32 = 16;
pub const StereoMatcher_DISP_SHIFT: i32 = 4;
pub const StereoSGBM_MODE_HH: i32 = 1;
pub const StereoSGBM_MODE_HH4: i32 = 3;
pub const StereoSGBM_MODE_SGBM: i32 = 0;
pub const StereoSGBM_MODE_SGBM_3WAY: i32 = 2;
/// USAC, accurate settings
pub const USAC_ACCURATE: i32 = 36;
/// USAC algorithm, default settings
pub const USAC_DEFAULT: i32 = 32;
/// USAC, fast settings
pub const USAC_FAST: i32 = 35;
/// USAC, fundamental matrix 8 points
pub const USAC_FM_8PTS: i32 = 34;
/// USAC, runs MAGSAC++
pub const USAC_MAGSAC: i32 = 38;
/// USAC, parallel version
pub const USAC_PARALLEL: i32 = 33;
/// USAC, sorted points, runs PROSAC
pub const USAC_PROSAC: i32 = 37;
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum CirclesGridFinderParameters_GridType {
SYMMETRIC_GRID = 0,
ASYMMETRIC_GRID = 1,
}
opencv_type_enum! { crate::calib3d::CirclesGridFinderParameters_GridType }
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum HandEyeCalibrationMethod {
/// A New Technique for Fully Autonomous and Efficient 3D Robotics Hand/Eye Calibration [Tsai89](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Tsai89)
CALIB_HAND_EYE_TSAI = 0,
/// Robot Sensor Calibration: Solving AX = XB on the Euclidean Group [Park94](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Park94)
CALIB_HAND_EYE_PARK = 1,
/// Hand-eye Calibration [Horaud95](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Horaud95)
CALIB_HAND_EYE_HORAUD = 2,
/// On-line Hand-Eye Calibration [Andreff99](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Andreff99)
CALIB_HAND_EYE_ANDREFF = 3,
/// Hand-Eye Calibration Using Dual Quaternions [Daniilidis98](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Daniilidis98)
CALIB_HAND_EYE_DANIILIDIS = 4,
}
opencv_type_enum! { crate::calib3d::HandEyeCalibrationMethod }
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum LocalOptimMethod {
LOCAL_OPTIM_NULL = 0,
LOCAL_OPTIM_INNER_LO = 1,
LOCAL_OPTIM_INNER_AND_ITER_LO = 2,
LOCAL_OPTIM_GC = 3,
LOCAL_OPTIM_SIGMA = 4,
}
opencv_type_enum! { crate::calib3d::LocalOptimMethod }
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum
|
{
NEIGH_FLANN_KNN = 0,
NEIGH_GRID = 1,
NEIGH_FLANN_RADIUS = 2,
}
opencv_type_enum! { crate::calib3d::NeighborSearchMethod }
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum RobotWorldHandEyeCalibrationMethod {
/// Solving the robot-world/hand-eye calibration problem using the kronecker product [Shah2013SolvingTR](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Shah2013SolvingTR)
CALIB_ROBOT_WORLD_HAND_EYE_SHAH = 0,
/// Simultaneous robot-world and hand-eye calibration using dual-quaternions and kronecker product [Li2010SimultaneousRA](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Li2010SimultaneousRA)
CALIB_ROBOT_WORLD_HAND_EYE_LI = 1,
}
opencv_type_enum! { crate::calib3d::RobotWorldHandEyeCalibrationMethod }
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum SamplingMethod {
SAMPLING_UNIFORM = 0,
SAMPLING_PROGRESSIVE_NAPSAC = 1,
SAMPLING_NAPSAC = 2,
SAMPLING_PROSAC = 3,
}
opencv_type_enum! { crate::calib3d::SamplingMethod }
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum ScoreMethod {
SCORE_METHOD_RANSAC = 0,
SCORE_METHOD_MSAC = 1,
SCORE_METHOD_MAGSAC = 2,
SCORE_METHOD_LMEDS = 3,
}
opencv_type_enum! { crate::calib3d::ScoreMethod }
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum SolvePnPMethod {
SOLVEPNP_ITERATIVE = 0,
/// EPnP: Efficient Perspective-n-Point Camera Pose Estimation [lepetit2009epnp](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_lepetit2009epnp)
SOLVEPNP_EPNP = 1,
/// Complete Solution Classification for the Perspective-Three-Point Problem [gao2003complete](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_gao2003complete)
SOLVEPNP_P3P = 2,
/// **Broken implementation. Using this flag will fallback to EPnP.**
///
/// A Direct Least-Squares (DLS) Method for PnP [hesch2011direct](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_hesch2011direct)
SOLVEPNP_DLS = 3,
/// **Broken implementation. Using this flag will fallback to EPnP.**
///
/// Exhaustive Linearization for Robust Camera Pose and Focal Length Estimation [penate2013exhaustive](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_penate2013exhaustive)
SOLVEPNP_UPNP = 4,
/// An Efficient Algebraic Solution to the Perspective-Three-Point Problem [Ke17](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Ke17)
SOLVEPNP_AP3P = 5,
/// Infinitesimal Plane-Based Pose Estimation [Collins14](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Collins14)
///
/// Object points must be coplanar.
SOLVEPNP_IPPE = 6,
/// Infinitesimal Plane-Based Pose Estimation [Collins14](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Collins14)
///
/// This is a special case suitable for marker pose estimation.
///
/// 4 coplanar object points must be defined in the following order:
/// - point 0: [-squareLength / 2, squareLength / 2, 0]
/// - point 1: [ squareLength / 2, squareLength / 2, 0]
/// - point 2: [ squareLength / 2, -squareLength / 2, 0]
/// - point 3: [-squareLength / 2, -squareLength / 2, 0]
SOLVEPNP_IPPE_SQUARE = 7,
/// SQPnP: A Consistently Fast and Globally OptimalSolution to the Perspective-n-Point Problem [Terzakis20](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Terzakis20)
SOLVEPNP_SQPNP = 8,
/// Used for count
SOLVEPNP_MAX_COUNT = 9,
}
opencv_type_enum! { crate::calib3d::SolvePnPMethod }
/// cv::undistort mode
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub enum UndistortTypes {
PROJ_SPHERICAL_ORTHO = 0,
PROJ_SPHERICAL_EQRECT = 1,
}
opencv_type_enum! { crate::calib3d::UndistortTypes }
pub type CirclesGridFinderParameters2 = crate::calib3d::CirclesGridFinderParameters;
/// Computes an RQ decomposition of 3x3 matrices.
///
/// ## Parameters
/// * src: 3x3 input matrix.
/// * mtxR: Output 3x3 upper-triangular matrix.
/// * mtxQ: Output 3x3 orthogonal matrix.
/// * Qx: Optional output 3x3 rotation matrix around x-axis.
/// * Qy: Optional output 3x3 rotation matrix around y-axis.
/// * Qz: Optional output 3x3 rotation matrix around z-axis.
///
/// The function computes a RQ decomposition using the given rotations. This function is used in
/// #decomposeProjectionMatrix to decompose the left 3x3 submatrix of a projection matrix into a camera
/// and a rotation matrix.
///
/// It optionally returns three rotation matrices, one for each axis, and the three Euler angles in
/// degrees (as the return value) that could be used in OpenGL. Note, there is always more than one
/// sequence of rotations about the three principal axes that results in the same orientation of an
/// object, e.g. see [Slabaugh](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Slabaugh) . Returned tree rotation matrices and corresponding three Euler angles
/// are only one of the possible solutions.
///
/// ## C++ default parameters
/// * qx: noArray()
/// * qy: noArray()
/// * qz: noArray()
pub fn rq_decomp3x3(src: &dyn core::ToInputArray, mtx_r: &mut dyn core::ToOutputArray, mtx_q: &mut dyn core::ToOutputArray, qx: &mut dyn core::ToOutputArray, qy: &mut dyn core::ToOutputArray, qz: &mut dyn core::ToOutputArray) -> Result<core::Vec3d> {
input_array_arg!(src);
output_array_arg!(mtx_r);
output_array_arg!(mtx_q);
output_array_arg!(qx);
output_array_arg!(qy);
output_array_arg!(qz);
unsafe { sys::cv_RQDecomp3x3_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR(src.as_raw__InputArray(), mtx_r.as_raw__OutputArray(), mtx_q.as_raw__OutputArray(), qx.as_raw__OutputArray(), qy.as_raw__OutputArray(), qz.as_raw__OutputArray()) }.into_result()
}
/// Converts a rotation matrix to a rotation vector or vice versa.
///
/// ## Parameters
/// * src: Input rotation vector (3x1 or 1x3) or rotation matrix (3x3).
/// * dst: Output rotation matrix (3x3) or rotation vector (3x1 or 1x3), respectively.
/// * jacobian: Optional output Jacobian matrix, 3x9 or 9x3, which is a matrix of partial
/// derivatives of the output array components with respect to the input array components.
///
/// 
///
/// Inverse transformation can be also done easily, since
///
/// 
///
/// A rotation vector is a convenient and most compact representation of a rotation matrix (since any
/// rotation matrix has just 3 degrees of freedom). The representation is used in the global 3D geometry
/// optimization procedures like @ref calibrateCamera, @ref stereoCalibrate, or @ref solvePnP .
///
///
/// Note: More information about the computation of the derivative of a 3D rotation matrix with respect to its exponential coordinate
/// can be found in:
/// - A Compact Formula for the Derivative of a 3-D Rotation in Exponential Coordinates, Guillermo Gallego, Anthony J. Yezzi [Gallego2014ACF](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Gallego2014ACF)
///
///
/// Note: Useful information on SE(3) and Lie Groups can be found in:
/// - A tutorial on SE(3) transformation parameterizations and on-manifold optimization, Jose-Luis Blanco [blanco2010tutorial](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_blanco2010tutorial)
/// - Lie Groups for 2D and 3D Transformation, Ethan Eade [Eade17](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Eade17)
/// - A micro Lie theory for state estimation in robotics, Joan Solà, Jérémie Deray, Dinesh Atchuthan [Sol2018AML](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Sol2018AML)
///
/// ## C++ default parameters
/// * jacobian: noArray()
pub fn rodrigues(src: &dyn core::ToInputArray, dst: &mut dyn core::ToOutputArray, jacobian: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(src);
output_array_arg!(dst);
output_array_arg!(jacobian);
unsafe { sys::cv_Rodrigues_const__InputArrayR_const__OutputArrayR_const__OutputArrayR(src.as_raw__InputArray(), dst.as_raw__OutputArray(), jacobian.as_raw__OutputArray()) }.into_result()
}
/// Finds the camera intrinsic and extrinsic parameters from several views of a calibration pattern.
///
/// This function is an extension of #calibrateCamera with the method of releasing object which was
/// proposed in [strobl2011iccv](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_strobl2011iccv). In many common cases with inaccurate, unmeasured, roughly planar
/// targets (calibration plates), this method can dramatically improve the precision of the estimated
/// camera parameters. Both the object-releasing method and standard method are supported by this
/// function. Use the parameter **iFixedPoint** for method selection. In the internal implementation,
/// #calibrateCamera is a wrapper for this function.
///
/// ## Parameters
/// * objectPoints: Vector of vectors of calibration pattern points in the calibration pattern
/// coordinate space. See #calibrateCamera for details. If the method of releasing object to be used,
/// the identical calibration board must be used in each view and it must be fully visible, and all
/// objectPoints[i] must be the same and all points should be roughly close to a plane. **The calibration
/// target has to be rigid, or at least static if the camera (rather than the calibration target) is
/// shifted for grabbing images.**
/// * imagePoints: Vector of vectors of the projections of calibration pattern points. See
/// #calibrateCamera for details.
/// * imageSize: Size of the image used only to initialize the intrinsic camera matrix.
/// * iFixedPoint: The index of the 3D object point in objectPoints[0] to be fixed. It also acts as
/// a switch for calibration method selection. If object-releasing method to be used, pass in the
/// parameter in the range of [1, objectPoints[0].size()-2], otherwise a value out of this range will
/// make standard calibration method selected. Usually the top-right corner point of the calibration
/// board grid is recommended to be fixed when object-releasing method being utilized. According to
/// \cite strobl2011iccv, two other points are also fixed. In this implementation, objectPoints[0].front
/// and objectPoints[0].back.z are used. With object-releasing method, accurate rvecs, tvecs and
/// newObjPoints are only possible if coordinates of these three fixed points are accurate enough.
/// * cameraMatrix: Output 3x3 floating-point camera matrix. See #calibrateCamera for details.
/// * distCoeffs: Output vector of distortion coefficients. See #calibrateCamera for details.
/// * rvecs: Output vector of rotation vectors estimated for each pattern view. See #calibrateCamera
/// for details.
/// * tvecs: Output vector of translation vectors estimated for each pattern view.
/// * newObjPoints: The updated output vector of calibration pattern points. The coordinates might
/// be scaled based on three fixed points. The returned coordinates are accurate only if the above
/// mentioned three fixed points are accurate. If not needed, noArray() can be passed in. This parameter
/// is ignored with standard calibration method.
/// * stdDeviationsIntrinsics: Output vector of standard deviations estimated for intrinsic parameters.
/// See #calibrateCamera for details.
/// * stdDeviationsExtrinsics: Output vector of standard deviations estimated for extrinsic parameters.
/// See #calibrateCamera for details.
/// * stdDeviationsObjPoints: Output vector of standard deviations estimated for refined coordinates
/// of calibration pattern points. It has the same size and order as objectPoints[0] vector. This
/// parameter is ignored with standard calibration method.
/// * perViewErrors: Output vector of the RMS re-projection error estimated for each pattern view.
/// * flags: Different flags that may be zero or a combination of some predefined values. See
/// #calibrateCamera for details. If the method of releasing object is used, the calibration time may
/// be much longer. CALIB_USE_QR or CALIB_USE_LU could be used for faster calibration with potentially
/// less precise and less stable in some rare cases.
/// * criteria: Termination criteria for the iterative optimization algorithm.
///
/// ## Returns
/// the overall RMS re-projection error.
///
/// The function estimates the intrinsic camera parameters and extrinsic parameters for each of the
/// views. The algorithm is based on [Zhang2000](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Zhang2000), [BouguetMCT](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_BouguetMCT) and [strobl2011iccv](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_strobl2011iccv). See
/// #calibrateCamera for other detailed explanations.
/// ## See also
/// calibrateCamera, findChessboardCorners, solvePnP, initCameraMatrix2D, stereoCalibrate, undistort
///
/// ## C++ default parameters
/// * flags: 0
/// * criteria: TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,30,DBL_EPSILON)
pub fn calibrate_camera_ro_extended(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, image_size: core::Size, i_fixed_point: i32, camera_matrix: &mut dyn core::ToInputOutputArray, dist_coeffs: &mut dyn core::ToInputOutputArray, rvecs: &mut dyn core::ToOutputArray, tvecs: &mut dyn core::ToOutputArray, new_obj_points: &mut dyn core::ToOutputArray, std_deviations_intrinsics: &mut dyn core::ToOutputArray, std_deviations_extrinsics: &mut dyn core::ToOutputArray, std_deviations_obj_points: &mut dyn core::ToOutputArray, per_view_errors: &mut dyn core::ToOutputArray, flags: i32, criteria: core::TermCriteria) -> Result<f64> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_output_array_arg!(camera_matrix);
input_output_array_arg!(dist_coeffs);
output_array_arg!(rvecs);
output_array_arg!(tvecs);
output_array_arg!(new_obj_points);
output_array_arg!(std_deviations_intrinsics);
output_array_arg!(std_deviations_extrinsics);
output_array_arg!(std_deviations_obj_points);
output_array_arg!(per_view_errors);
unsafe { sys::cv_calibrateCameraRO_const__InputArrayR_const__InputArrayR_Size_int_const__InputOutputArrayR_const__InputOutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_int_TermCriteria(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), image_size.opencv_as_extern(), i_fixed_point, camera_matrix.as_raw__InputOutputArray(), dist_coeffs.as_raw__InputOutputArray(), rvecs.as_raw__OutputArray(), tvecs.as_raw__OutputArray(), new_obj_points.as_raw__OutputArray(), std_deviations_intrinsics.as_raw__OutputArray(), std_deviations_extrinsics.as_raw__OutputArray(), std_deviations_obj_points.as_raw__OutputArray(), per_view_errors.as_raw__OutputArray(), flags, criteria.opencv_as_extern()) }.into_result()
}
/// Finds the camera intrinsic and extrinsic parameters from several views of a calibration pattern.
///
/// This function is an extension of #calibrateCamera with the method of releasing object which was
/// proposed in [strobl2011iccv](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_strobl2011iccv). In many common cases with inaccurate, unmeasured, roughly planar
/// targets (calibration plates), this method can dramatically improve the precision of the estimated
/// camera parameters. Both the object-releasing method and standard method are supported by this
/// function. Use the parameter **iFixedPoint** for method selection. In the internal implementation,
/// #calibrateCamera is a wrapper for this function.
///
/// ## Parameters
/// * objectPoints: Vector of vectors of calibration pattern points in the calibration pattern
/// coordinate space. See #calibrateCamera for details. If the method of releasing object to be used,
/// the identical calibration board must be used in each view and it must be fully visible, and all
/// objectPoints[i] must be the same and all points should be roughly close to a plane. **The calibration
/// target has to be rigid, or at least static if the camera (rather than the calibration target) is
/// shifted for grabbing images.**
/// * imagePoints: Vector of vectors of the projections of calibration pattern points. See
/// #calibrateCamera for details.
/// * imageSize: Size of the image used only to initialize the intrinsic camera matrix.
/// * iFixedPoint: The index of the 3D object point in objectPoints[0] to be fixed. It also acts as
/// a switch for calibration method selection. If object-releasing method to be used, pass in the
/// parameter in the range of [1, objectPoints[0].size()-2], otherwise a value out of this range will
/// make standard calibration method selected. Usually the top-right corner point of the calibration
/// board grid is recommended to be fixed when object-releasing method being utilized. According to
/// \cite strobl2011iccv, two other points are also fixed. In this implementation, objectPoints[0].front
/// and objectPoints[0].back.z are used. With object-releasing method, accurate rvecs, tvecs and
/// newObjPoints are only possible if coordinates of these three fixed points are accurate enough.
/// * cameraMatrix: Output 3x3 floating-point camera matrix. See #calibrateCamera for details.
/// * distCoeffs: Output vector of distortion coefficients. See #calibrateCamera for details.
/// * rvecs: Output vector of rotation vectors estimated for each pattern view. See #calibrateCamera
/// for details.
/// * tvecs: Output vector of translation vectors estimated for each pattern view.
/// * newObjPoints: The updated output vector of calibration pattern points. The coordinates might
/// be scaled based on three fixed points. The returned coordinates are accurate only if the above
/// mentioned three fixed points are accurate. If not needed, noArray() can be passed in. This parameter
/// is ignored with standard calibration method.
/// * stdDeviationsIntrinsics: Output vector of standard deviations estimated for intrinsic parameters.
/// See #calibrateCamera for details.
/// * stdDeviationsExtrinsics: Output vector of standard deviations estimated for extrinsic parameters.
/// See #calibrateCamera for details.
/// * stdDeviationsObjPoints: Output vector of standard deviations estimated for refined coordinates
/// of calibration pattern points. It has the same size and order as objectPoints[0] vector. This
/// parameter is ignored with standard calibration method.
/// * perViewErrors: Output vector of the RMS re-projection error estimated for each pattern view.
/// * flags: Different flags that may be zero or a combination of some predefined values. See
/// #calibrateCamera for details. If the method of releasing object is used, the calibration time may
/// be much longer. CALIB_USE_QR or CALIB_USE_LU could be used for faster calibration with potentially
/// less precise and less stable in some rare cases.
/// * criteria: Termination criteria for the iterative optimization algorithm.
///
/// ## Returns
/// the overall RMS re-projection error.
///
/// The function estimates the intrinsic camera parameters and extrinsic parameters for each of the
/// views. The algorithm is based on [Zhang2000](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Zhang2000), [BouguetMCT](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_BouguetMCT) and [strobl2011iccv](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_strobl2011iccv). See
/// #calibrateCamera for other detailed explanations.
/// ## See also
/// calibrateCamera, findChessboardCorners, solvePnP, initCameraMatrix2D, stereoCalibrate, undistort
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * flags: 0
/// * criteria: TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,30,DBL_EPSILON)
pub fn calibrate_camera_ro(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, image_size: core::Size, i_fixed_point: i32, camera_matrix: &mut dyn core::ToInputOutputArray, dist_coeffs: &mut dyn core::ToInputOutputArray, rvecs: &mut dyn core::ToOutputArray, tvecs: &mut dyn core::ToOutputArray, new_obj_points: &mut dyn core::ToOutputArray, flags: i32, criteria: core::TermCriteria) -> Result<f64> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_output_array_arg!(camera_matrix);
input_output_array_arg!(dist_coeffs);
output_array_arg!(rvecs);
output_array_arg!(tvecs);
output_array_arg!(new_obj_points);
unsafe { sys::cv_calibrateCameraRO_const__InputArrayR_const__InputArrayR_Size_int_const__InputOutputArrayR_const__InputOutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_int_TermCriteria(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), image_size.opencv_as_extern(), i_fixed_point, camera_matrix.as_raw__InputOutputArray(), dist_coeffs.as_raw__InputOutputArray(), rvecs.as_raw__OutputArray(), tvecs.as_raw__OutputArray(), new_obj_points.as_raw__OutputArray(), flags, criteria.opencv_as_extern()) }.into_result()
}
/// Finds the camera intrinsic and extrinsic parameters from several views of a calibration
/// pattern.
///
/// ## Parameters
/// * objectPoints: In the new interface it is a vector of vectors of calibration pattern points in
/// the calibration pattern coordinate space (e.g. std::vector<std::vector<cv::Vec3f>>). The outer
/// vector contains as many elements as the number of pattern views. If the same calibration pattern
/// is shown in each view and it is fully visible, all the vectors will be the same. Although, it is
/// possible to use partially occluded patterns or even different patterns in different views. Then,
/// the vectors will be different. Although the points are 3D, they all lie in the calibration pattern's
/// XY coordinate plane (thus 0 in the Z-coordinate), if the used calibration pattern is a planar rig.
/// In the old interface all the vectors of object points from different views are concatenated
/// together.
/// * imagePoints: In the new interface it is a vector of vectors of the projections of calibration
/// pattern points (e.g. std::vector<std::vector<cv::Vec2f>>). imagePoints.size() and
/// objectPoints.size(), and imagePoints[i].size() and objectPoints[i].size() for each i, must be equal,
/// respectively. In the old interface all the vectors of object points from different views are
/// concatenated together.
/// * imageSize: Size of the image used only to initialize the camera intrinsic matrix.
/// * cameraMatrix: Input/output 3x3 floating-point camera intrinsic matrix
///  . If @ref CALIB_USE_INTRINSIC_GUESS
/// and/or @ref CALIB_FIX_ASPECT_RATIO, @ref CALIB_FIX_PRINCIPAL_POINT or @ref CALIB_FIX_FOCAL_LENGTH
/// are specified, some or all of fx, fy, cx, cy must be initialized before calling the function.
/// * distCoeffs: Input/output vector of distortion coefficients
/// .
/// * rvecs: Output vector of rotation vectors (@ref Rodrigues ) estimated for each pattern view
/// (e.g. std::vector<cv::Mat>>). That is, each i-th rotation vector together with the corresponding
/// i-th translation vector (see the next output parameter description) brings the calibration pattern
/// from the object coordinate space (in which object points are specified) to the camera coordinate
/// space. In more technical terms, the tuple of the i-th rotation and translation vector performs
/// a change of basis from object coordinate space to camera coordinate space. Due to its duality, this
/// tuple is equivalent to the position of the calibration pattern with respect to the camera coordinate
/// space.
/// * tvecs: Output vector of translation vectors estimated for each pattern view, see parameter
/// describtion above.
/// * stdDeviationsIntrinsics: Output vector of standard deviations estimated for intrinsic
/// parameters. Order of deviations values:
///  If one of parameters is not estimated, it's deviation is equals to zero.
/// * stdDeviationsExtrinsics: Output vector of standard deviations estimated for extrinsic
/// parameters. Order of deviations values:  where M is
/// the number of pattern views. 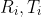 are concatenated 1x3 vectors.
/// * perViewErrors: Output vector of the RMS re-projection error estimated for each pattern view.
/// * flags: Different flags that may be zero or a combination of the following values:
/// * @ref CALIB_USE_INTRINSIC_GUESS cameraMatrix contains valid initial values of
/// fx, fy, cx, cy that are optimized further. Otherwise, (cx, cy) is initially set to the image
/// center ( imageSize is used), and focal distances are computed in a least-squares fashion.
/// Note, that if intrinsic parameters are known, there is no need to use this function just to
/// estimate extrinsic parameters. Use @ref solvePnP instead.
/// * @ref CALIB_FIX_PRINCIPAL_POINT The principal point is not changed during the global
/// optimization. It stays at the center or at a different location specified when
/// @ref CALIB_USE_INTRINSIC_GUESS is set too.
/// * @ref CALIB_FIX_ASPECT_RATIO The functions consider only fy as a free parameter. The
/// ratio fx/fy stays the same as in the input cameraMatrix . When
/// @ref CALIB_USE_INTRINSIC_GUESS is not set, the actual input values of fx and fy are
/// ignored, only their ratio is computed and used further.
/// * @ref CALIB_ZERO_TANGENT_DIST Tangential distortion coefficients  are set
/// to zeros and stay zero.
/// * @ref CALIB_FIX_FOCAL_LENGTH The focal length is not changed during the global optimization if
/// @ref CALIB_USE_INTRINSIC_GUESS is set.
/// * @ref CALIB_FIX_K1,..., @ref CALIB_FIX_K6 The corresponding radial distortion
/// coefficient is not changed during the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is
/// set, the coefficient from the supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * @ref CALIB_RATIONAL_MODEL Coefficients k4, k5, and k6 are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the rational model and return 8 coefficients or more.
/// * @ref CALIB_THIN_PRISM_MODEL Coefficients s1, s2, s3 and s4 are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the thin prism model and return 12 coefficients or more.
/// * @ref CALIB_FIX_S1_S2_S3_S4 The thin prism distortion coefficients are not changed during
/// the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set, the coefficient from the
/// supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * @ref CALIB_TILTED_MODEL Coefficients tauX and tauY are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the tilted sensor model and return 14 coefficients.
/// * @ref CALIB_FIX_TAUX_TAUY The coefficients of the tilted sensor model are not changed during
/// the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set, the coefficient from the
/// supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * criteria: Termination criteria for the iterative optimization algorithm.
///
/// ## Returns
/// the overall RMS re-projection error.
///
/// The function estimates the intrinsic camera parameters and extrinsic parameters for each of the
/// views. The algorithm is based on [Zhang2000](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Zhang2000) and [BouguetMCT](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_BouguetMCT) . The coordinates of 3D object
/// points and their corresponding 2D projections in each view must be specified. That may be achieved
/// by using an object with known geometry and easily detectable feature points. Such an object is
/// called a calibration rig or calibration pattern, and OpenCV has built-in support for a chessboard as
/// a calibration rig (see @ref findChessboardCorners). Currently, initialization of intrinsic
/// parameters (when @ref CALIB_USE_INTRINSIC_GUESS is not set) is only implemented for planar calibration
/// patterns (where Z-coordinates of the object points must be all zeros). 3D calibration rigs can also
/// be used as long as initial cameraMatrix is provided.
///
/// The algorithm performs the following steps:
///
/// * Compute the initial intrinsic parameters (the option only available for planar calibration
/// patterns) or read them from the input parameters. The distortion coefficients are all set to
/// zeros initially unless some of CALIB_FIX_K? are specified.
///
/// * Estimate the initial camera pose as if the intrinsic parameters have been already known. This is
/// done using @ref solvePnP .
///
/// * Run the global Levenberg-Marquardt optimization algorithm to minimize the reprojection error,
/// that is, the total sum of squared distances between the observed feature points imagePoints and
/// the projected (using the current estimates for camera parameters and the poses) object points
/// objectPoints. See @ref projectPoints for details.
///
///
/// Note:
/// If you use a non-square (i.e. non-N-by-N) grid and @ref findChessboardCorners for calibration,
/// and @ref calibrateCamera returns bad values (zero distortion coefficients,  and
///  very far from the image center, and/or large differences between  and
///  (ratios of 10:1 or more)), then you are probably using patternSize=cvSize(rows,cols)
/// instead of using patternSize=cvSize(cols,rows) in @ref findChessboardCorners.
/// ## See also
/// calibrateCameraRO, findChessboardCorners, solvePnP, initCameraMatrix2D, stereoCalibrate,
/// undistort
///
/// ## C++ default parameters
/// * flags: 0
/// * criteria: TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,30,DBL_EPSILON)
pub fn calibrate_camera_extended(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, image_size: core::Size, camera_matrix: &mut dyn core::ToInputOutputArray, dist_coeffs: &mut dyn core::ToInputOutputArray, rvecs: &mut dyn core::ToOutputArray, tvecs: &mut dyn core::ToOutputArray, std_deviations_intrinsics: &mut dyn core::ToOutputArray, std_deviations_extrinsics: &mut dyn core::ToOutputArray, per_view_errors: &mut dyn core::ToOutputArray, flags: i32, criteria: core::TermCriteria) -> Result<f64> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_output_array_arg!(camera_matrix);
input_output_array_arg!(dist_coeffs);
output_array_arg!(rvecs);
output_array_arg!(tvecs);
output_array_arg!(std_deviations_intrinsics);
output_array_arg!(std_deviations_extrinsics);
output_array_arg!(per_view_errors);
unsafe { sys::cv_calibrateCamera_const__InputArrayR_const__InputArrayR_Size_const__InputOutputArrayR_const__InputOutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_int_TermCriteria(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), image_size.opencv_as_extern(), camera_matrix.as_raw__InputOutputArray(), dist_coeffs.as_raw__InputOutputArray(), rvecs.as_raw__OutputArray(), tvecs.as_raw__OutputArray(), std_deviations_intrinsics.as_raw__OutputArray(), std_deviations_extrinsics.as_raw__OutputArray(), per_view_errors.as_raw__OutputArray(), flags, criteria.opencv_as_extern()) }.into_result()
}
/// Finds the camera intrinsic and extrinsic parameters from several views of a calibration
/// pattern.
///
/// ## Parameters
/// * objectPoints: In the new interface it is a vector of vectors of calibration pattern points in
/// the calibration pattern coordinate space (e.g. std::vector<std::vector<cv::Vec3f>>). The outer
/// vector contains as many elements as the number of pattern views. If the same calibration pattern
/// is shown in each view and it is fully visible, all the vectors will be the same. Although, it is
/// possible to use partially occluded patterns or even different patterns in different views. Then,
/// the vectors will be different. Although the points are 3D, they all lie in the calibration pattern's
/// XY coordinate plane (thus 0 in the Z-coordinate), if the used calibration pattern is a planar rig.
/// In the old interface all the vectors of object points from different views are concatenated
/// together.
/// * imagePoints: In the new interface it is a vector of vectors of the projections of calibration
/// pattern points (e.g. std::vector<std::vector<cv::Vec2f>>). imagePoints.size() and
/// objectPoints.size(), and imagePoints[i].size() and objectPoints[i].size() for each i, must be equal,
/// respectively. In the old interface all the vectors of object points from different views are
/// concatenated together.
/// * imageSize: Size of the image used only to initialize the camera intrinsic matrix.
/// * cameraMatrix: Input/output 3x3 floating-point camera intrinsic matrix
///  . If @ref CALIB_USE_INTRINSIC_GUESS
/// and/or @ref CALIB_FIX_ASPECT_RATIO, @ref CALIB_FIX_PRINCIPAL_POINT or @ref CALIB_FIX_FOCAL_LENGTH
/// are specified, some or all of fx, fy, cx, cy must be initialized before calling the function.
/// * distCoeffs: Input/output vector of distortion coefficients
/// .
/// * rvecs: Output vector of rotation vectors (@ref Rodrigues ) estimated for each pattern view
/// (e.g. std::vector<cv::Mat>>). That is, each i-th rotation vector together with the corresponding
/// i-th translation vector (see the next output parameter description) brings the calibration pattern
/// from the object coordinate space (in which object points are specified) to the camera coordinate
/// space. In more technical terms, the tuple of the i-th rotation and translation vector performs
/// a change of basis from object coordinate space to camera coordinate space. Due to its duality, this
/// tuple is equivalent to the position of the calibration pattern with respect to the camera coordinate
/// space.
/// * tvecs: Output vector of translation vectors estimated for each pattern view, see parameter
/// describtion above.
/// * stdDeviationsIntrinsics: Output vector of standard deviations estimated for intrinsic
/// parameters. Order of deviations values:
///  If one of parameters is not estimated, it's deviation is equals to zero.
/// * stdDeviationsExtrinsics: Output vector of standard deviations estimated for extrinsic
/// parameters. Order of deviations values:  where M is
/// the number of pattern views.  are concatenated 1x3 vectors.
/// * perViewErrors: Output vector of the RMS re-projection error estimated for each pattern view.
/// * flags: Different flags that may be zero or a combination of the following values:
/// * @ref CALIB_USE_INTRINSIC_GUESS cameraMatrix contains valid initial values of
/// fx, fy, cx, cy that are optimized further. Otherwise, (cx, cy) is initially set to the image
/// center ( imageSize is used), and focal distances are computed in a least-squares fashion.
/// Note, that if intrinsic parameters are known, there is no need to use this function just to
/// estimate extrinsic parameters. Use @ref solvePnP instead.
/// * @ref CALIB_FIX_PRINCIPAL_POINT The principal point is not changed during the global
/// optimization. It stays at the center or at a different location specified when
/// @ref CALIB_USE_INTRINSIC_GUESS is set too.
/// * @ref CALIB_FIX_ASPECT_RATIO The functions consider only fy as a free parameter. The
/// ratio fx/fy stays the same as in the input cameraMatrix . When
/// @ref CALIB_USE_INTRINSIC_GUESS is not set, the actual input values of fx and fy are
/// ignored, only their ratio is computed and used further.
/// * @ref CALIB_ZERO_TANGENT_DIST Tangential distortion coefficients  are set
/// to zeros and stay zero.
/// * @ref CALIB_FIX_FOCAL_LENGTH The focal length is not changed during the global optimization if
/// @ref CALIB_USE_INTRINSIC_GUESS is set.
/// * @ref CALIB_FIX_K1,..., @ref CALIB_FIX_K6 The corresponding radial distortion
/// coefficient is not changed during the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is
/// set, the coefficient from the supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * @ref CALIB_RATIONAL_MODEL Coefficients k4, k5, and k6 are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the rational model and return 8 coefficients or more.
/// * @ref CALIB_THIN_PRISM_MODEL Coefficients s1, s2, s3 and s4 are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the thin prism model and return 12 coefficients or more.
/// * @ref CALIB_FIX_S1_S2_S3_S4 The thin prism distortion coefficients are not changed during
/// the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set, the coefficient from the
/// supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * @ref CALIB_TILTED_MODEL Coefficients tauX and tauY are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the tilted sensor model and return 14 coefficients.
/// * @ref CALIB_FIX_TAUX_TAUY The coefficients of the tilted sensor model are not changed during
/// the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set, the coefficient from the
/// supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * criteria: Termination criteria for the iterative optimization algorithm.
///
/// ## Returns
/// the overall RMS re-projection error.
///
/// The function estimates the intrinsic camera parameters and extrinsic parameters for each of the
/// views. The algorithm is based on [Zhang2000](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Zhang2000) and [BouguetMCT](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_BouguetMCT) . The coordinates of 3D object
/// points and their corresponding 2D projections in each view must be specified. That may be achieved
/// by using an object with known geometry and easily detectable feature points. Such an object is
/// called a calibration rig or calibration pattern, and OpenCV has built-in support for a chessboard as
/// a calibration rig (see @ref findChessboardCorners). Currently, initialization of intrinsic
/// parameters (when @ref CALIB_USE_INTRINSIC_GUESS is not set) is only implemented for planar calibration
/// patterns (where Z-coordinates of the object points must be all zeros). 3D calibration rigs can also
/// be used as long as initial cameraMatrix is provided.
///
/// The algorithm performs the following steps:
///
/// * Compute the initial intrinsic parameters (the option only available for planar calibration
/// patterns) or read them from the input parameters. The distortion coefficients are all set to
/// zeros initially unless some of CALIB_FIX_K? are specified.
///
/// * Estimate the initial camera pose as if the intrinsic parameters have been already known. This is
/// done using @ref solvePnP .
///
/// * Run the global Levenberg-Marquardt optimization algorithm to minimize the reprojection error,
/// that is, the total sum of squared distances between the observed feature points imagePoints and
/// the projected (using the current estimates for camera parameters and the poses) object points
/// objectPoints. See @ref projectPoints for details.
///
///
/// Note:
/// If you use a non-square (i.e. non-N-by-N) grid and @ref findChessboardCorners for calibration,
/// and @ref calibrateCamera returns bad values (zero distortion coefficients,  and
///  very far from the image center, and/or large differences between  and
///  (ratios of 10:1 or more)), then you are probably using patternSize=cvSize(rows,cols)
/// instead of using patternSize=cvSize(cols,rows) in @ref findChessboardCorners.
/// ## See also
/// calibrateCameraRO, findChessboardCorners, solvePnP, initCameraMatrix2D, stereoCalibrate,
/// undistort
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * flags: 0
/// * criteria: TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,30,DBL_EPSILON)
pub fn calibrate_camera(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, image_size: core::Size, camera_matrix: &mut dyn core::ToInputOutputArray, dist_coeffs: &mut dyn core::ToInputOutputArray, rvecs: &mut dyn core::ToOutputArray, tvecs: &mut dyn core::ToOutputArray, flags: i32, criteria: core::TermCriteria) -> Result<f64> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_output_array_arg!(camera_matrix);
input_output_array_arg!(dist_coeffs);
output_array_arg!(rvecs);
output_array_arg!(tvecs);
unsafe { sys::cv_calibrateCamera_const__InputArrayR_const__InputArrayR_Size_const__InputOutputArrayR_const__InputOutputArrayR_const__OutputArrayR_const__OutputArrayR_int_TermCriteria(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), image_size.opencv_as_extern(), camera_matrix.as_raw__InputOutputArray(), dist_coeffs.as_raw__InputOutputArray(), rvecs.as_raw__OutputArray(), tvecs.as_raw__OutputArray(), flags, criteria.opencv_as_extern()) }.into_result()
}
/// Computes Hand-Eye calibration: 
///
/// ## Parameters
/// * R_gripper2base: Rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the gripper frame to the robot base frame ().
/// This is a vector (`vector<Mat>`) that contains the rotation, `(3x3)` rotation matrices or `(3x1)` rotation vectors,
/// for all the transformations from gripper frame to robot base frame.
/// * t_gripper2base: Translation part extracted from the homogeneous matrix that transforms a point
/// expressed in the gripper frame to the robot base frame ().
/// This is a vector (`vector<Mat>`) that contains the `(3x1)` translation vectors for all the transformations
/// from gripper frame to robot base frame.
/// * R_target2cam: Rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the target frame to the camera frame ().
/// This is a vector (`vector<Mat>`) that contains the rotation, `(3x3)` rotation matrices or `(3x1)` rotation vectors,
/// for all the transformations from calibration target frame to camera frame.
/// * t_target2cam: Rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the target frame to the camera frame ().
/// This is a vector (`vector<Mat>`) that contains the `(3x1)` translation vectors for all the transformations
/// from calibration target frame to camera frame.
/// * R_cam2gripper:[out] Estimated `(3x3)` rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the camera frame to the gripper frame ().
/// * t_cam2gripper:[out] Estimated `(3x1)` translation part extracted from the homogeneous matrix that transforms a point
/// expressed in the camera frame to the gripper frame ().
/// * method: One of the implemented Hand-Eye calibration method, see cv::HandEyeCalibrationMethod
///
/// The function performs the Hand-Eye calibration using various methods. One approach consists in estimating the
/// rotation then the translation (separable solutions) and the following methods are implemented:
/// - R. Tsai, R. Lenz A New Technique for Fully Autonomous and Efficient 3D Robotics Hand/EyeCalibration \cite Tsai89
/// - F. Park, B. Martin Robot Sensor Calibration: Solving AX = XB on the Euclidean Group \cite Park94
/// - R. Horaud, F. Dornaika Hand-Eye Calibration \cite Horaud95
///
/// Another approach consists in estimating simultaneously the rotation and the translation (simultaneous solutions),
/// with the following implemented methods:
/// - N. Andreff, R. Horaud, B. Espiau On-line Hand-Eye Calibration \cite Andreff99
/// - K. Daniilidis Hand-Eye Calibration Using Dual Quaternions \cite Daniilidis98
///
/// The following picture describes the Hand-Eye calibration problem where the transformation between a camera ("eye")
/// mounted on a robot gripper ("hand") has to be estimated. This configuration is called eye-in-hand.
///
/// The eye-to-hand configuration consists in a static camera observing a calibration pattern mounted on the robot
/// end-effector. The transformation from the camera to the robot base frame can then be estimated by inputting
/// the suitable transformations to the function, see below.
///
/// 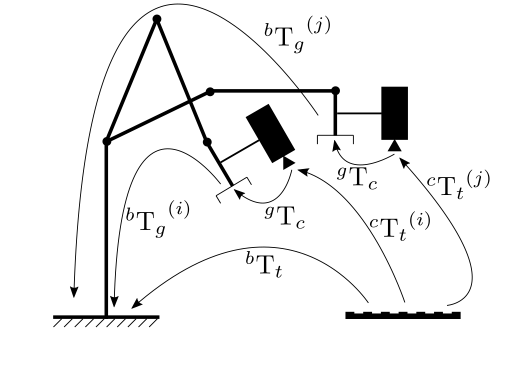
///
/// The calibration procedure is the following:
/// - a static calibration pattern is used to estimate the transformation between the target frame
/// and the camera frame
/// - the robot gripper is moved in order to acquire several poses
/// - for each pose, the homogeneous transformation between the gripper frame and the robot base frame is recorded using for
/// instance the robot kinematics
/// 
/// - for each pose, the homogeneous transformation between the calibration target frame and the camera frame is recorded using
/// for instance a pose estimation method (PnP) from 2D-3D point correspondences
/// 
///
/// The Hand-Eye calibration procedure returns the following homogeneous transformation
/// 
///
/// This problem is also known as solving the 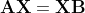 equation:
/// - for an eye-in-hand configuration
/// 
///
/// - for an eye-to-hand configuration
/// 
///
/// \note
/// Additional information can be found on this [website](http://campar.in.tum.de/Chair/HandEyeCalibration).
/// \note
/// A minimum of 2 motions with non parallel rotation axes are necessary to determine the hand-eye transformation.
/// So at least 3 different poses are required, but it is strongly recommended to use many more poses.
///
/// ## C++ default parameters
/// * method: CALIB_HAND_EYE_TSAI
pub fn calibrate_hand_eye(r_gripper2base: &dyn core::ToInputArray, t_gripper2base: &dyn core::ToInputArray, r_target2cam: &dyn core::ToInputArray, t_target2cam: &dyn core::ToInputArray, r_cam2gripper: &mut dyn core::ToOutputArray, t_cam2gripper: &mut dyn core::ToOutputArray, method: crate::calib3d::HandEyeCalibrationMethod) -> Result<()> {
input_array_arg!(r_gripper2base);
input_array_arg!(t_gripper2base);
input_array_arg!(r_target2cam);
input_array_arg!(t_target2cam);
output_array_arg!(r_cam2gripper);
output_array_arg!(t_cam2gripper);
unsafe { sys::cv_calibrateHandEye_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_HandEyeCalibrationMethod(r_gripper2base.as_raw__InputArray(), t_gripper2base.as_raw__InputArray(), r_target2cam.as_raw__InputArray(), t_target2cam.as_raw__InputArray(), r_cam2gripper.as_raw__OutputArray(), t_cam2gripper.as_raw__OutputArray(), method) }.into_result()
}
/// Computes Robot-World/Hand-Eye calibration:  and 
///
/// ## Parameters
/// * R_world2cam: Rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the world frame to the camera frame ().
/// This is a vector (`vector<Mat>`) that contains the rotation, `(3x3)` rotation matrices or `(3x1)` rotation vectors,
/// for all the transformations from world frame to the camera frame.
/// * t_world2cam: Translation part extracted from the homogeneous matrix that transforms a point
/// expressed in the world frame to the camera frame ().
/// This is a vector (`vector<Mat>`) that contains the `(3x1)` translation vectors for all the transformations
/// from world frame to the camera frame.
/// * R_base2gripper: Rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the robot base frame to the gripper frame ().
/// This is a vector (`vector<Mat>`) that contains the rotation, `(3x3)` rotation matrices or `(3x1)` rotation vectors,
/// for all the transformations from robot base frame to the gripper frame.
/// * t_base2gripper: Rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the robot base frame to the gripper frame ().
/// This is a vector (`vector<Mat>`) that contains the `(3x1)` translation vectors for all the transformations
/// from robot base frame to the gripper frame.
/// * R_base2world:[out] Estimated `(3x3)` rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the robot base frame to the world frame ().
/// * t_base2world:[out] Estimated `(3x1)` translation part extracted from the homogeneous matrix that transforms a point
/// expressed in the robot base frame to the world frame ().
/// * R_gripper2cam:[out] Estimated `(3x3)` rotation part extracted from the homogeneous matrix that transforms a point
/// expressed in the gripper frame to the camera frame ().
/// * t_gripper2cam:[out] Estimated `(3x1)` translation part extracted from the homogeneous matrix that transforms a point
/// expressed in the gripper frame to the camera frame ().
/// * method: One of the implemented Robot-World/Hand-Eye calibration method, see cv::RobotWorldHandEyeCalibrationMethod
///
/// The function performs the Robot-World/Hand-Eye calibration using various methods. One approach consists in estimating the
/// rotation then the translation (separable solutions):
/// - M. Shah, Solving the robot-world/hand-eye calibration problem using the kronecker product \cite Shah2013SolvingTR
///
/// Another approach consists in estimating simultaneously the rotation and the translation (simultaneous solutions),
/// with the following implemented method:
/// - A. Li, L. Wang, and D. Wu, Simultaneous robot-world and hand-eye calibration using dual-quaternions and kronecker product \cite Li2010SimultaneousRA
///
/// The following picture describes the Robot-World/Hand-Eye calibration problem where the transformations between a robot and a world frame
/// and between a robot gripper ("hand") and a camera ("eye") mounted at the robot end-effector have to be estimated.
///
/// 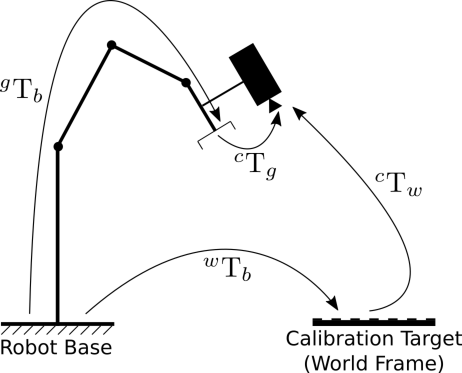
///
/// The calibration procedure is the following:
/// - a static calibration pattern is used to estimate the transformation between the target frame
/// and the camera frame
/// - the robot gripper is moved in order to acquire several poses
/// - for each pose, the homogeneous transformation between the gripper frame and the robot base frame is recorded using for
/// instance the robot kinematics
/// 
/// - for each pose, the homogeneous transformation between the calibration target frame (the world frame) and the camera frame is recorded using
/// for instance a pose estimation method (PnP) from 2D-3D point correspondences
/// 
///
/// The Robot-World/Hand-Eye calibration procedure returns the following homogeneous transformations
/// 
/// 
///
/// This problem is also known as solving the  equation, with:
/// - 
/// - 
/// - 
/// - 
///
/// \note
/// At least 3 measurements are required (input vectors size must be greater or equal to 3).
///
/// ## C++ default parameters
/// * method: CALIB_ROBOT_WORLD_HAND_EYE_SHAH
pub fn calibrate_robot_world_hand_eye(r_world2cam: &dyn core::ToInputArray, t_world2cam: &dyn core::ToInputArray, r_base2gripper: &dyn core::ToInputArray, t_base2gripper: &dyn core::ToInputArray, r_base2world: &mut dyn core::ToOutputArray, t_base2world: &mut dyn core::ToOutputArray, r_gripper2cam: &mut dyn core::ToOutputArray, t_gripper2cam: &mut dyn core::ToOutputArray, method: crate::calib3d::RobotWorldHandEyeCalibrationMethod) -> Result<()> {
input_array_arg!(r_world2cam);
input_array_arg!(t_world2cam);
input_array_arg!(r_base2gripper);
input_array_arg!(t_base2gripper);
output_array_arg!(r_base2world);
output_array_arg!(t_base2world);
output_array_arg!(r_gripper2cam);
output_array_arg!(t_gripper2cam);
unsafe { sys::cv_calibrateRobotWorldHandEye_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_RobotWorldHandEyeCalibrationMethod(r_world2cam.as_raw__InputArray(), t_world2cam.as_raw__InputArray(), r_base2gripper.as_raw__InputArray(), t_base2gripper.as_raw__InputArray(), r_base2world.as_raw__OutputArray(), t_base2world.as_raw__OutputArray(), r_gripper2cam.as_raw__OutputArray(), t_gripper2cam.as_raw__OutputArray(), method) }.into_result()
}
/// Computes useful camera characteristics from the camera intrinsic matrix.
///
/// ## Parameters
/// * cameraMatrix: Input camera intrinsic matrix that can be estimated by #calibrateCamera or
/// #stereoCalibrate .
/// * imageSize: Input image size in pixels.
/// * apertureWidth: Physical width in mm of the sensor.
/// * apertureHeight: Physical height in mm of the sensor.
/// * fovx: Output field of view in degrees along the horizontal sensor axis.
/// * fovy: Output field of view in degrees along the vertical sensor axis.
/// * focalLength: Focal length of the lens in mm.
/// * principalPoint: Principal point in mm.
/// * aspectRatio: 
///
/// The function computes various useful camera characteristics from the previously estimated camera
/// matrix.
///
///
/// Note:
/// Do keep in mind that the unity measure 'mm' stands for whatever unit of measure one chooses for
/// the chessboard pitch (it can thus be any value).
pub fn calibration_matrix_values(camera_matrix: &dyn core::ToInputArray, image_size: core::Size, aperture_width: f64, aperture_height: f64, fovx: &mut f64, fovy: &mut f64, focal_length: &mut f64, principal_point: &mut core::Point2d, aspect_ratio: &mut f64) -> Result<()> {
input_array_arg!(camera_matrix);
unsafe { sys::cv_calibrationMatrixValues_const__InputArrayR_Size_double_double_doubleR_doubleR_doubleR_Point2dR_doubleR(camera_matrix.as_raw__InputArray(), image_size.opencv_as_extern(), aperture_width, aperture_height, fovx, fovy, focal_length, principal_point, aspect_ratio) }.into_result()
}
pub fn check_chessboard(img: &dyn core::ToInputArray, size: core::Size) -> Result<bool> {
input_array_arg!(img);
unsafe { sys::cv_checkChessboard_const__InputArrayR_Size(img.as_raw__InputArray(), size.opencv_as_extern()) }.into_result()
}
/// Combines two rotation-and-shift transformations.
///
/// ## Parameters
/// * rvec1: First rotation vector.
/// * tvec1: First translation vector.
/// * rvec2: Second rotation vector.
/// * tvec2: Second translation vector.
/// * rvec3: Output rotation vector of the superposition.
/// * tvec3: Output translation vector of the superposition.
/// * dr3dr1: Optional output derivative of rvec3 with regard to rvec1
/// * dr3dt1: Optional output derivative of rvec3 with regard to tvec1
/// * dr3dr2: Optional output derivative of rvec3 with regard to rvec2
/// * dr3dt2: Optional output derivative of rvec3 with regard to tvec2
/// * dt3dr1: Optional output derivative of tvec3 with regard to rvec1
/// * dt3dt1: Optional output derivative of tvec3 with regard to tvec1
/// * dt3dr2: Optional output derivative of tvec3 with regard to rvec2
/// * dt3dt2: Optional output derivative of tvec3 with regard to tvec2
///
/// The functions compute:
///
/// 
///
/// where  denotes a rotation vector to a rotation matrix transformation, and
///  denotes the inverse transformation. See Rodrigues for details.
///
/// Also, the functions can compute the derivatives of the output vectors with regards to the input
/// vectors (see matMulDeriv ). The functions are used inside #stereoCalibrate but can also be used in
/// your own code where Levenberg-Marquardt or another gradient-based solver is used to optimize a
/// function that contains a matrix multiplication.
///
/// ## C++ default parameters
/// * dr3dr1: noArray()
/// * dr3dt1: noArray()
/// * dr3dr2: noArray()
/// * dr3dt2: noArray()
/// * dt3dr1: noArray()
/// * dt3dt1: noArray()
/// * dt3dr2: noArray()
/// * dt3dt2: noArray()
pub fn compose_rt(rvec1: &dyn core::ToInputArray, tvec1: &dyn core::ToInputArray, rvec2: &dyn core::ToInputArray, tvec2: &dyn core::ToInputArray, rvec3: &mut dyn core::ToOutputArray, tvec3: &mut dyn core::ToOutputArray, dr3dr1: &mut dyn core::ToOutputArray, dr3dt1: &mut dyn core::ToOutputArray, dr3dr2: &mut dyn core::ToOutputArray, dr3dt2: &mut dyn core::ToOutputArray, dt3dr1: &mut dyn core::ToOutputArray, dt3dt1: &mut dyn core::ToOutputArray, dt3dr2: &mut dyn core::ToOutputArray, dt3dt2: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(rvec1);
input_array_arg!(tvec1);
input_array_arg!(rvec2);
input_array_arg!(tvec2);
output_array_arg!(rvec3);
output_array_arg!(tvec3);
output_array_arg!(dr3dr1);
output_array_arg!(dr3dt1);
output_array_arg!(dr3dr2);
output_array_arg!(dr3dt2);
output_array_arg!(dt3dr1);
output_array_arg!(dt3dt1);
output_array_arg!(dt3dr2);
output_array_arg!(dt3dt2);
unsafe { sys::cv_composeRT_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR(rvec1.as_raw__InputArray(), tvec1.as_raw__InputArray(), rvec2.as_raw__InputArray(), tvec2.as_raw__InputArray(), rvec3.as_raw__OutputArray(), tvec3.as_raw__OutputArray(), dr3dr1.as_raw__OutputArray(), dr3dt1.as_raw__OutputArray(), dr3dr2.as_raw__OutputArray(), dr3dt2.as_raw__OutputArray(), dt3dr1.as_raw__OutputArray(), dt3dt1.as_raw__OutputArray(), dt3dr2.as_raw__OutputArray(), dt3dt2.as_raw__OutputArray()) }.into_result()
}
/// For points in an image of a stereo pair, computes the corresponding epilines in the other image.
///
/// ## Parameters
/// * points: Input points.  or  matrix of type CV_32FC2 or
/// vector\<Point2f\> .
/// * whichImage: Index of the image (1 or 2) that contains the points .
/// * F: Fundamental matrix that can be estimated using #findFundamentalMat or #stereoRectify .
/// * lines: Output vector of the epipolar lines corresponding to the points in the other image.
/// Each line  is encoded by 3 numbers  .
///
/// For every point in one of the two images of a stereo pair, the function finds the equation of the
/// corresponding epipolar line in the other image.
///
/// From the fundamental matrix definition (see #findFundamentalMat ), line  in the second
/// image for the point  in the first image (when whichImage=1 ) is computed as:
///
/// 
///
/// And vice versa, when whichImage=2,  is computed from  as:
///
/// 
///
/// Line coefficients are defined up to a scale. They are normalized so that  .
pub fn compute_correspond_epilines(points: &dyn core::ToInputArray, which_image: i32, f: &dyn core::ToInputArray, lines: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(points);
input_array_arg!(f);
output_array_arg!(lines);
unsafe { sys::cv_computeCorrespondEpilines_const__InputArrayR_int_const__InputArrayR_const__OutputArrayR(points.as_raw__InputArray(), which_image, f.as_raw__InputArray(), lines.as_raw__OutputArray()) }.into_result()
}
/// Converts points from homogeneous to Euclidean space.
///
/// ## Parameters
/// * src: Input vector of N-dimensional points.
/// * dst: Output vector of N-1-dimensional points.
///
/// The function converts points homogeneous to Euclidean space using perspective projection. That is,
/// each point (x1, x2, ... x(n-1), xn) is converted to (x1/xn, x2/xn, ..., x(n-1)/xn). When xn=0, the
/// output point coordinates will be (0,0,0,...).
pub fn convert_points_from_homogeneous(src: &dyn core::ToInputArray, dst: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(src);
output_array_arg!(dst);
unsafe { sys::cv_convertPointsFromHomogeneous_const__InputArrayR_const__OutputArrayR(src.as_raw__InputArray(), dst.as_raw__OutputArray()) }.into_result()
}
/// Converts points to/from homogeneous coordinates.
///
/// ## Parameters
/// * src: Input array or vector of 2D, 3D, or 4D points.
/// * dst: Output vector of 2D, 3D, or 4D points.
///
/// The function converts 2D or 3D points from/to homogeneous coordinates by calling either
/// #convertPointsToHomogeneous or #convertPointsFromHomogeneous.
///
///
/// Note: The function is obsolete. Use one of the previous two functions instead.
pub fn convert_points_homogeneous(src: &dyn core::ToInputArray, dst: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(src);
output_array_arg!(dst);
unsafe { sys::cv_convertPointsHomogeneous_const__InputArrayR_const__OutputArrayR(src.as_raw__InputArray(), dst.as_raw__OutputArray()) }.into_result()
}
/// Converts points from Euclidean to homogeneous space.
///
/// ## Parameters
/// * src: Input vector of N-dimensional points.
/// * dst: Output vector of N+1-dimensional points.
///
/// The function converts points from Euclidean to homogeneous space by appending 1's to the tuple of
/// point coordinates. That is, each point (x1, x2, ..., xn) is converted to (x1, x2, ..., xn, 1).
pub fn convert_points_to_homogeneous(src: &dyn core::ToInputArray, dst: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(src);
output_array_arg!(dst);
unsafe { sys::cv_convertPointsToHomogeneous_const__InputArrayR_const__OutputArrayR(src.as_raw__InputArray(), dst.as_raw__OutputArray()) }.into_result()
}
/// Refines coordinates of corresponding points.
///
/// ## Parameters
/// * F: 3x3 fundamental matrix.
/// * points1: 1xN array containing the first set of points.
/// * points2: 1xN array containing the second set of points.
/// * newPoints1: The optimized points1.
/// * newPoints2: The optimized points2.
///
/// The function implements the Optimal Triangulation Method (see Multiple View Geometry for details).
/// For each given point correspondence points1[i] \<-\> points2[i], and a fundamental matrix F, it
/// computes the corrected correspondences newPoints1[i] \<-\> newPoints2[i] that minimize the geometric
/// error  (where  is the
/// geometric distance between points  and  ) subject to the epipolar constraint
///  .
pub fn correct_matches(f: &dyn core::ToInputArray, points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, new_points1: &mut dyn core::ToOutputArray, new_points2: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(f);
input_array_arg!(points1);
input_array_arg!(points2);
output_array_arg!(new_points1);
output_array_arg!(new_points2);
unsafe { sys::cv_correctMatches_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR(f.as_raw__InputArray(), points1.as_raw__InputArray(), points2.as_raw__InputArray(), new_points1.as_raw__OutputArray(), new_points2.as_raw__OutputArray()) }.into_result()
}
/// Decompose an essential matrix to possible rotations and translation.
///
/// ## Parameters
/// * E: The input essential matrix.
/// * R1: One possible rotation matrix.
/// * R2: Another possible rotation matrix.
/// * t: One possible translation.
///
/// This function decomposes the essential matrix E using svd decomposition [HartleyZ00](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_HartleyZ00). In
/// general, four possible poses exist for the decomposition of E. They are ,
/// , , .
///
/// If E gives the epipolar constraint  between the image
/// points  in the first image and  in second image, then any of the tuples
/// , , ,  is a change of basis from the first
/// camera's coordinate system to the second camera's coordinate system. However, by decomposing E, one
/// can only get the direction of the translation. For this reason, the translation t is returned with
/// unit length.
pub fn decompose_essential_mat(e: &dyn core::ToInputArray, r1: &mut dyn core::ToOutputArray, r2: &mut dyn core::ToOutputArray, t: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(e);
output_array_arg!(r1);
output_array_arg!(r2);
output_array_arg!(t);
unsafe { sys::cv_decomposeEssentialMat_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR(e.as_raw__InputArray(), r1.as_raw__OutputArray(), r2.as_raw__OutputArray(), t.as_raw__OutputArray()) }.into_result()
}
/// Decompose a homography matrix to rotation(s), translation(s) and plane normal(s).
///
/// ## Parameters
/// * H: The input homography matrix between two images.
/// * K: The input camera intrinsic matrix.
/// * rotations: Array of rotation matrices.
/// * translations: Array of translation matrices.
/// * normals: Array of plane normal matrices.
///
/// This function extracts relative camera motion between two views of a planar object and returns up to
/// four mathematical solution tuples of rotation, translation, and plane normal. The decomposition of
/// the homography matrix H is described in detail in [Malis](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Malis).
///
/// If the homography H, induced by the plane, gives the constraint
///  on the source image points
///  and the destination image points , then the tuple of rotations[k] and
/// translations[k] is a change of basis from the source camera's coordinate system to the destination
/// camera's coordinate system. However, by decomposing H, one can only get the translation normalized
/// by the (typically unknown) depth of the scene, i.e. its direction but with normalized length.
///
/// If point correspondences are available, at least two solutions may further be invalidated, by
/// applying positive depth constraint, i.e. all points must be in front of the camera.
pub fn decompose_homography_mat(h: &dyn core::ToInputArray, k: &dyn core::ToInputArray, rotations: &mut dyn core::ToOutputArray, translations: &mut dyn core::ToOutputArray, normals: &mut dyn core::ToOutputArray) -> Result<i32> {
input_array_arg!(h);
input_array_arg!(k);
output_array_arg!(rotations);
output_array_arg!(translations);
output_array_arg!(normals);
unsafe { sys::cv_decomposeHomographyMat_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR(h.as_raw__InputArray(), k.as_raw__InputArray(), rotations.as_raw__OutputArray(), translations.as_raw__OutputArray(), normals.as_raw__OutputArray()) }.into_result()
}
/// Decomposes a projection matrix into a rotation matrix and a camera intrinsic matrix.
///
/// ## Parameters
/// * projMatrix: 3x4 input projection matrix P.
/// * cameraMatrix: Output 3x3 camera intrinsic matrix .
/// * rotMatrix: Output 3x3 external rotation matrix R.
/// * transVect: Output 4x1 translation vector T.
/// * rotMatrixX: Optional 3x3 rotation matrix around x-axis.
/// * rotMatrixY: Optional 3x3 rotation matrix around y-axis.
/// * rotMatrixZ: Optional 3x3 rotation matrix around z-axis.
/// * eulerAngles: Optional three-element vector containing three Euler angles of rotation in
/// degrees.
///
/// The function computes a decomposition of a projection matrix into a calibration and a rotation
/// matrix and the position of a camera.
///
/// It optionally returns three rotation matrices, one for each axis, and three Euler angles that could
/// be used in OpenGL. Note, there is always more than one sequence of rotations about the three
/// principal axes that results in the same orientation of an object, e.g. see [Slabaugh](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Slabaugh) . Returned
/// tree rotation matrices and corresponding three Euler angles are only one of the possible solutions.
///
/// The function is based on RQDecomp3x3 .
///
/// ## C++ default parameters
/// * rot_matrix_x: noArray()
/// * rot_matrix_y: noArray()
/// * rot_matrix_z: noArray()
/// * euler_angles: noArray()
pub fn decompose_projection_matrix(proj_matrix: &dyn core::ToInputArray, camera_matrix: &mut dyn core::ToOutputArray, rot_matrix: &mut dyn core::ToOutputArray, trans_vect: &mut dyn core::ToOutputArray, rot_matrix_x: &mut dyn core::ToOutputArray, rot_matrix_y: &mut dyn core::ToOutputArray, rot_matrix_z: &mut dyn core::ToOutputArray, euler_angles: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(proj_matrix);
output_array_arg!(camera_matrix);
output_array_arg!(rot_matrix);
output_array_arg!(trans_vect);
output_array_arg!(rot_matrix_x);
output_array_arg!(rot_matrix_y);
output_array_arg!(rot_matrix_z);
output_array_arg!(euler_angles);
unsafe { sys::cv_decomposeProjectionMatrix_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR(proj_matrix.as_raw__InputArray(), camera_matrix.as_raw__OutputArray(), rot_matrix.as_raw__OutputArray(), trans_vect.as_raw__OutputArray(), rot_matrix_x.as_raw__OutputArray(), rot_matrix_y.as_raw__OutputArray(), rot_matrix_z.as_raw__OutputArray(), euler_angles.as_raw__OutputArray()) }.into_result()
}
/// Renders the detected chessboard corners.
///
/// ## Parameters
/// * image: Destination image. It must be an 8-bit color image.
/// * patternSize: Number of inner corners per a chessboard row and column
/// (patternSize = cv::Size(points_per_row,points_per_column)).
/// * corners: Array of detected corners, the output of #findChessboardCorners.
/// * patternWasFound: Parameter indicating whether the complete board was found or not. The
/// return value of #findChessboardCorners should be passed here.
///
/// The function draws individual chessboard corners detected either as red circles if the board was not
/// found, or as colored corners connected with lines if the board was found.
pub fn draw_chessboard_corners(image: &mut dyn core::ToInputOutputArray, pattern_size: core::Size, corners: &dyn core::ToInputArray, pattern_was_found: bool) -> Result<()> {
input_output_array_arg!(image);
input_array_arg!(corners);
unsafe { sys::cv_drawChessboardCorners_const__InputOutputArrayR_Size_const__InputArrayR_bool(image.as_raw__InputOutputArray(), pattern_size.opencv_as_extern(), corners.as_raw__InputArray(), pattern_was_found) }.into_result()
}
/// Draw axes of the world/object coordinate system from pose estimation. see also: solvePnP
///
/// ## Parameters
/// * image: Input/output image. It must have 1 or 3 channels. The number of channels is not altered.
/// * cameraMatrix: Input 3x3 floating-point matrix of camera intrinsic parameters.
/// 
/// * distCoeffs: Input vector of distortion coefficients
/// . If the vector is empty, the zero distortion coefficients are assumed.
/// * rvec: Rotation vector (see @ref Rodrigues ) that, together with tvec, brings points from
/// the model coordinate system to the camera coordinate system.
/// * tvec: Translation vector.
/// * length: Length of the painted axes in the same unit than tvec (usually in meters).
/// * thickness: Line thickness of the painted axes.
///
/// This function draws the axes of the world/object coordinate system w.r.t. to the camera frame.
/// OX is drawn in red, OY in green and OZ in blue.
///
/// ## C++ default parameters
/// * thickness: 3
pub fn draw_frame_axes(image: &mut dyn core::ToInputOutputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, rvec: &dyn core::ToInputArray, tvec: &dyn core::ToInputArray, length: f32, thickness: i32) -> Result<()> {
input_output_array_arg!(image);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
input_array_arg!(rvec);
input_array_arg!(tvec);
unsafe { sys::cv_drawFrameAxes_const__InputOutputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_float_int(image.as_raw__InputOutputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), rvec.as_raw__InputArray(), tvec.as_raw__InputArray(), length, thickness) }.into_result()
}
pub fn estimate_affine_2d_1(pts1: &dyn core::ToInputArray, pts2: &dyn core::ToInputArray, inliers: &mut dyn core::ToOutputArray, params: crate::calib3d::UsacParams) -> Result<core::Mat> {
input_array_arg!(pts1);
input_array_arg!(pts2);
output_array_arg!(inliers);
unsafe { sys::cv_estimateAffine2D_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const_UsacParamsR(pts1.as_raw__InputArray(), pts2.as_raw__InputArray(), inliers.as_raw__OutputArray(), ¶ms) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Computes an optimal affine transformation between two 2D point sets.
///
/// It computes
/// 
///
/// ## Parameters
/// * from: First input 2D point set containing .
/// * to: Second input 2D point set containing .
/// * inliers: Output vector indicating which points are inliers (1-inlier, 0-outlier).
/// * method: Robust method used to compute transformation. The following methods are possible:
/// * @ref RANSAC - RANSAC-based robust method
/// * @ref LMEDS - Least-Median robust method
/// RANSAC is the default method.
/// * ransacReprojThreshold: Maximum reprojection error in the RANSAC algorithm to consider
/// a point as an inlier. Applies only to RANSAC.
/// * maxIters: The maximum number of robust method iterations.
/// * confidence: Confidence level, between 0 and 1, for the estimated transformation. Anything
/// between 0.95 and 0.99 is usually good enough. Values too close to 1 can slow down the estimation
/// significantly. Values lower than 0.8-0.9 can result in an incorrectly estimated transformation.
/// * refineIters: Maximum number of iterations of refining algorithm (Levenberg-Marquardt).
/// Passing 0 will disable refining, so the output matrix will be output of robust method.
///
/// ## Returns
/// Output 2D affine transformation matrix  or empty matrix if transformation
/// could not be estimated. The returned matrix has the following form:
/// 
///
/// The function estimates an optimal 2D affine transformation between two 2D point sets using the
/// selected robust algorithm.
///
/// The computed transformation is then refined further (using only inliers) with the
/// Levenberg-Marquardt method to reduce the re-projection error even more.
///
///
/// Note:
/// The RANSAC method can handle practically any ratio of outliers but needs a threshold to
/// distinguish inliers from outliers. The method LMeDS does not need any threshold but it works
/// correctly only when there are more than 50% of inliers.
/// ## See also
/// estimateAffinePartial2D, getAffineTransform
///
/// ## C++ default parameters
/// * inliers: noArray()
/// * method: RANSAC
/// * ransac_reproj_threshold: 3
/// * max_iters: 2000
/// * confidence: 0.99
/// * refine_iters: 10
pub fn estimate_affine_2d(from: &dyn core::ToInputArray, to: &dyn core::ToInputArray, inliers: &mut dyn core::ToOutputArray, method: i32, ransac_reproj_threshold: f64, max_iters: size_t, confidence: f64, refine_iters: size_t) -> Result<core::Mat> {
input_array_arg!(from);
input_array_arg!(to);
output_array_arg!(inliers);
unsafe { sys::cv_estimateAffine2D_const__InputArrayR_const__InputArrayR_const__OutputArrayR_int_double_size_t_double_size_t(from.as_raw__InputArray(), to.as_raw__InputArray(), inliers.as_raw__OutputArray(), method, ransac_reproj_threshold, max_iters, confidence, refine_iters) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Computes an optimal affine transformation between two 3D point sets.
///
/// It computes
/// 
///
/// ## Parameters
/// * src: First input 3D point set containing .
/// * dst: Second input 3D point set containing .
/// * out: Output 3D affine transformation matrix  of the form
/// 
/// * inliers: Output vector indicating which points are inliers (1-inlier, 0-outlier).
/// * ransacThreshold: Maximum reprojection error in the RANSAC algorithm to consider a point as
/// an inlier.
/// * confidence: Confidence level, between 0 and 1, for the estimated transformation. Anything
/// between 0.95 and 0.99 is usually good enough. Values too close to 1 can slow down the estimation
/// significantly. Values lower than 0.8-0.9 can result in an incorrectly estimated transformation.
///
/// The function estimates an optimal 3D affine transformation between two 3D point sets using the
/// RANSAC algorithm.
///
/// ## C++ default parameters
/// * ransac_threshold: 3
/// * confidence: 0.99
pub fn estimate_affine_3d(src: &dyn core::ToInputArray, dst: &dyn core::ToInputArray, out: &mut dyn core::ToOutputArray, inliers: &mut dyn core::ToOutputArray, ransac_threshold: f64, confidence: f64) -> Result<i32> {
input_array_arg!(src);
input_array_arg!(dst);
output_array_arg!(out);
output_array_arg!(inliers);
unsafe { sys::cv_estimateAffine3D_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_double_double(src.as_raw__InputArray(), dst.as_raw__InputArray(), out.as_raw__OutputArray(), inliers.as_raw__OutputArray(), ransac_threshold, confidence) }.into_result()
}
/// Computes an optimal affine transformation between two 3D point sets.
///
/// It computes  minimizing 
/// where  is a 3x3 rotation matrix,  is a 3x1 translation vector and  is a
/// scalar size value. This is an implementation of the algorithm by Umeyama \cite umeyama1991least .
/// The estimated affine transform has a homogeneous scale which is a subclass of affine
/// transformations with 7 degrees of freedom. The paired point sets need to comprise at least 3
/// points each.
///
/// ## Parameters
/// * src: First input 3D point set.
/// * dst: Second input 3D point set.
/// * scale: If null is passed, the scale parameter c will be assumed to be 1.0.
/// Else the pointed-to variable will be set to the optimal scale.
/// * force_rotation: If true, the returned rotation will never be a reflection.
/// This might be unwanted, e.g. when optimizing a transform between a right- and a
/// left-handed coordinate system.
/// ## Returns
/// 3D affine transformation matrix  of the form
/// 
///
/// ## C++ default parameters
/// * scale: nullptr
/// * force_rotation: true
pub fn estimate_affine_3d_1(src: &dyn core::ToInputArray, dst: &dyn core::ToInputArray, scale: &mut f64, force_rotation: bool) -> Result<core::Mat> {
input_array_arg!(src);
input_array_arg!(dst);
unsafe { sys::cv_estimateAffine3D_const__InputArrayR_const__InputArrayR_doubleX_bool(src.as_raw__InputArray(), dst.as_raw__InputArray(), scale, force_rotation) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Computes an optimal limited affine transformation with 4 degrees of freedom between
/// two 2D point sets.
///
/// ## Parameters
/// * from: First input 2D point set.
/// * to: Second input 2D point set.
/// * inliers: Output vector indicating which points are inliers.
/// * method: Robust method used to compute transformation. The following methods are possible:
/// * @ref RANSAC - RANSAC-based robust method
/// * @ref LMEDS - Least-Median robust method
/// RANSAC is the default method.
/// * ransacReprojThreshold: Maximum reprojection error in the RANSAC algorithm to consider
/// a point as an inlier. Applies only to RANSAC.
/// * maxIters: The maximum number of robust method iterations.
/// * confidence: Confidence level, between 0 and 1, for the estimated transformation. Anything
/// between 0.95 and 0.99 is usually good enough. Values too close to 1 can slow down the estimation
/// significantly. Values lower than 0.8-0.9 can result in an incorrectly estimated transformation.
/// * refineIters: Maximum number of iterations of refining algorithm (Levenberg-Marquardt).
/// Passing 0 will disable refining, so the output matrix will be output of robust method.
///
/// ## Returns
/// Output 2D affine transformation (4 degrees of freedom) matrix  or
/// empty matrix if transformation could not be estimated.
///
/// The function estimates an optimal 2D affine transformation with 4 degrees of freedom limited to
/// combinations of translation, rotation, and uniform scaling. Uses the selected algorithm for robust
/// estimation.
///
/// The computed transformation is then refined further (using only inliers) with the
/// Levenberg-Marquardt method to reduce the re-projection error even more.
///
/// Estimated transformation matrix is:
/// 
/// Where  is the rotation angle,  the scaling factor and  are
/// translations in  axes respectively.
///
///
/// Note:
/// The RANSAC method can handle practically any ratio of outliers but need a threshold to
/// distinguish inliers from outliers. The method LMeDS does not need any threshold but it works
/// correctly only when there are more than 50% of inliers.
/// ## See also
/// estimateAffine2D, getAffineTransform
///
/// ## C++ default parameters
/// * inliers: noArray()
/// * method: RANSAC
/// * ransac_reproj_threshold: 3
/// * max_iters: 2000
/// * confidence: 0.99
/// * refine_iters: 10
pub fn estimate_affine_partial_2d(from: &dyn core::ToInputArray, to: &dyn core::ToInputArray, inliers: &mut dyn core::ToOutputArray, method: i32, ransac_reproj_threshold: f64, max_iters: size_t, confidence: f64, refine_iters: size_t) -> Result<core::Mat> {
input_array_arg!(from);
input_array_arg!(to);
output_array_arg!(inliers);
unsafe { sys::cv_estimateAffinePartial2D_const__InputArrayR_const__InputArrayR_const__OutputArrayR_int_double_size_t_double_size_t(from.as_raw__InputArray(), to.as_raw__InputArray(), inliers.as_raw__OutputArray(), method, ransac_reproj_threshold, max_iters, confidence, refine_iters) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Estimates the sharpness of a detected chessboard.
///
/// Image sharpness, as well as brightness, are a critical parameter for accuracte
/// camera calibration. For accessing these parameters for filtering out
/// problematic calibraiton images, this method calculates edge profiles by traveling from
/// black to white chessboard cell centers. Based on this, the number of pixels is
/// calculated required to transit from black to white. This width of the
/// transition area is a good indication of how sharp the chessboard is imaged
/// and should be below ~3.0 pixels.
///
/// ## Parameters
/// * image: Gray image used to find chessboard corners
/// * patternSize: Size of a found chessboard pattern
/// * corners: Corners found by #findChessboardCornersSB
/// * rise_distance: Rise distance 0.8 means 10% ... 90% of the final signal strength
/// * vertical: By default edge responses for horizontal lines are calculated
/// * sharpness: Optional output array with a sharpness value for calculated edge responses (see description)
///
/// The optional sharpness array is of type CV_32FC1 and has for each calculated
/// profile one row with the following five entries:
/// * 0 = x coordinate of the underlying edge in the image
/// * 1 = y coordinate of the underlying edge in the image
/// * 2 = width of the transition area (sharpness)
/// * 3 = signal strength in the black cell (min brightness)
/// * 4 = signal strength in the white cell (max brightness)
///
/// ## Returns
/// Scalar(average sharpness, average min brightness, average max brightness,0)
///
/// ## C++ default parameters
/// * rise_distance: 0.8F
/// * vertical: false
/// * sharpness: noArray()
pub fn estimate_chessboard_sharpness(image: &dyn core::ToInputArray, pattern_size: core::Size, corners: &dyn core::ToInputArray, rise_distance: f32, vertical: bool, sharpness: &mut dyn core::ToOutputArray) -> Result<core::Scalar> {
input_array_arg!(image);
input_array_arg!(corners);
output_array_arg!(sharpness);
unsafe { sys::cv_estimateChessboardSharpness_const__InputArrayR_Size_const__InputArrayR_float_bool_const__OutputArrayR(image.as_raw__InputArray(), pattern_size.opencv_as_extern(), corners.as_raw__InputArray(), rise_distance, vertical, sharpness.as_raw__OutputArray()) }.into_result()
}
/// Computes an optimal translation between two 3D point sets.
///
/// It computes
/// 
///
/// ## Parameters
/// * src: First input 3D point set containing 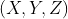.
/// * dst: Second input 3D point set containing .
/// * out: Output 3D translation vector  of the form
/// 
/// * inliers: Output vector indicating which points are inliers (1-inlier, 0-outlier).
/// * ransacThreshold: Maximum reprojection error in the RANSAC algorithm to consider a point as
/// an inlier.
/// * confidence: Confidence level, between 0 and 1, for the estimated transformation. Anything
/// between 0.95 and 0.99 is usually good enough. Values too close to 1 can slow down the estimation
/// significantly. Values lower than 0.8-0.9 can result in an incorrectly estimated transformation.
///
/// The function estimates an optimal 3D translation between two 3D point sets using the
/// RANSAC algorithm.
///
/// ## C++ default parameters
/// * ransac_threshold: 3
/// * confidence: 0.99
pub fn estimate_translation_3d(src: &dyn core::ToInputArray, dst: &dyn core::ToInputArray, out: &mut dyn core::ToOutputArray, inliers: &mut dyn core::ToOutputArray, ransac_threshold: f64, confidence: f64) -> Result<i32> {
input_array_arg!(src);
input_array_arg!(dst);
output_array_arg!(out);
output_array_arg!(inliers);
unsafe { sys::cv_estimateTranslation3D_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_double_double(src.as_raw__InputArray(), dst.as_raw__InputArray(), out.as_raw__OutputArray(), inliers.as_raw__OutputArray(), ransac_threshold, confidence) }.into_result()
}
/// Filters homography decompositions based on additional information.
///
/// ## Parameters
/// * rotations: Vector of rotation matrices.
/// * normals: Vector of plane normal matrices.
/// * beforePoints: Vector of (rectified) visible reference points before the homography is applied
/// * afterPoints: Vector of (rectified) visible reference points after the homography is applied
/// * possibleSolutions: Vector of int indices representing the viable solution set after filtering
/// * pointsMask: optional Mat/Vector of 8u type representing the mask for the inliers as given by the #findHomography function
///
/// This function is intended to filter the output of the #decomposeHomographyMat based on additional
/// information as described in [Malis](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Malis) . The summary of the method: the #decomposeHomographyMat function
/// returns 2 unique solutions and their "opposites" for a total of 4 solutions. If we have access to the
/// sets of points visible in the camera frame before and after the homography transformation is applied,
/// we can determine which are the true potential solutions and which are the opposites by verifying which
/// homographies are consistent with all visible reference points being in front of the camera. The inputs
/// are left unchanged; the filtered solution set is returned as indices into the existing one.
///
/// ## C++ default parameters
/// * points_mask: noArray()
pub fn filter_homography_decomp_by_visible_refpoints(rotations: &dyn core::ToInputArray, normals: &dyn core::ToInputArray, before_points: &dyn core::ToInputArray, after_points: &dyn core::ToInputArray, possible_solutions: &mut dyn core::ToOutputArray, points_mask: &dyn core::ToInputArray) -> Result<()> {
input_array_arg!(rotations);
input_array_arg!(normals);
input_array_arg!(before_points);
input_array_arg!(after_points);
output_array_arg!(possible_solutions);
input_array_arg!(points_mask);
unsafe { sys::cv_filterHomographyDecompByVisibleRefpoints_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__InputArrayR(rotations.as_raw__InputArray(), normals.as_raw__InputArray(), before_points.as_raw__InputArray(), after_points.as_raw__InputArray(), possible_solutions.as_raw__OutputArray(), points_mask.as_raw__InputArray()) }.into_result()
}
/// Filters off small noise blobs (speckles) in the disparity map
///
/// ## Parameters
/// * img: The input 16-bit signed disparity image
/// * newVal: The disparity value used to paint-off the speckles
/// * maxSpeckleSize: The maximum speckle size to consider it a speckle. Larger blobs are not
/// affected by the algorithm
/// * maxDiff: Maximum difference between neighbor disparity pixels to put them into the same
/// blob. Note that since StereoBM, StereoSGBM and may be other algorithms return a fixed-point
/// disparity map, where disparity values are multiplied by 16, this scale factor should be taken into
/// account when specifying this parameter value.
/// * buf: The optional temporary buffer to avoid memory allocation within the function.
///
/// ## C++ default parameters
/// * buf: noArray()
pub fn filter_speckles(img: &mut dyn core::ToInputOutputArray, new_val: f64, max_speckle_size: i32, max_diff: f64, buf: &mut dyn core::ToInputOutputArray) -> Result<()> {
input_output_array_arg!(img);
input_output_array_arg!(buf);
unsafe { sys::cv_filterSpeckles_const__InputOutputArrayR_double_int_double_const__InputOutputArrayR(img.as_raw__InputOutputArray(), new_val, max_speckle_size, max_diff, buf.as_raw__InputOutputArray()) }.into_result()
}
/// finds subpixel-accurate positions of the chessboard corners
pub fn find4_quad_corner_subpix(img: &dyn core::ToInputArray, corners: &mut dyn core::ToInputOutputArray, region_size: core::Size) -> Result<bool> {
input_array_arg!(img);
input_output_array_arg!(corners);
unsafe { sys::cv_find4QuadCornerSubpix_const__InputArrayR_const__InputOutputArrayR_Size(img.as_raw__InputArray(), corners.as_raw__InputOutputArray(), region_size.opencv_as_extern()) }.into_result()
}
/// Finds the positions of internal corners of the chessboard using a sector based approach.
///
/// ## Parameters
/// * image: Source chessboard view. It must be an 8-bit grayscale or color image.
/// * patternSize: Number of inner corners per a chessboard row and column
/// ( patternSize = cv::Size(points_per_row,points_per_colum) = cv::Size(columns,rows) ).
/// * corners: Output array of detected corners.
/// * flags: Various operation flags that can be zero or a combination of the following values:
/// * @ref CALIB_CB_NORMALIZE_IMAGE Normalize the image gamma with equalizeHist before detection.
/// * @ref CALIB_CB_EXHAUSTIVE Run an exhaustive search to improve detection rate.
/// * @ref CALIB_CB_ACCURACY Up sample input image to improve sub-pixel accuracy due to aliasing effects.
/// * @ref CALIB_CB_LARGER The detected pattern is allowed to be larger than patternSize (see description).
/// * @ref CALIB_CB_MARKER The detected pattern must have a marker (see description).
/// This should be used if an accurate camera calibration is required.
/// * meta: Optional output arrray of detected corners (CV_8UC1 and size = cv::Size(columns,rows)).
/// Each entry stands for one corner of the pattern and can have one of the following values:
/// * 0 = no meta data attached
/// * 1 = left-top corner of a black cell
/// * 2 = left-top corner of a white cell
/// * 3 = left-top corner of a black cell with a white marker dot
/// * 4 = left-top corner of a white cell with a black marker dot (pattern origin in case of markers otherwise first corner)
///
/// The function is analog to #findChessboardCorners but uses a localized radon
/// transformation approximated by box filters being more robust to all sort of
/// noise, faster on larger images and is able to directly return the sub-pixel
/// position of the internal chessboard corners. The Method is based on the paper
/// [duda2018](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_duda2018) "Accurate Detection and Localization of Checkerboard Corners for
/// Calibration" demonstrating that the returned sub-pixel positions are more
/// accurate than the one returned by cornerSubPix allowing a precise camera
/// calibration for demanding applications.
///
/// In the case, the flags @ref CALIB_CB_LARGER or @ref CALIB_CB_MARKER are given,
/// the result can be recovered from the optional meta array. Both flags are
/// helpful to use calibration patterns exceeding the field of view of the camera.
/// These oversized patterns allow more accurate calibrations as corners can be
/// utilized, which are as close as possible to the image borders. For a
/// consistent coordinate system across all images, the optional marker (see image
/// below) can be used to move the origin of the board to the location where the
/// black circle is located.
///
///
/// Note: The function requires a white boarder with roughly the same width as one
/// of the checkerboard fields around the whole board to improve the detection in
/// various environments. In addition, because of the localized radon
/// transformation it is beneficial to use round corners for the field corners
/// which are located on the outside of the board. The following figure illustrates
/// a sample checkerboard optimized for the detection. However, any other checkerboard
/// can be used as well.
/// 
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * flags: 0
pub fn find_chessboard_corners_sb(image: &dyn core::ToInputArray, pattern_size: core::Size, corners: &mut dyn core::ToOutputArray, flags: i32) -> Result<bool> {
input_array_arg!(image);
output_array_arg!(corners);
unsafe { sys::cv_findChessboardCornersSB_const__InputArrayR_Size_const__OutputArrayR_int(image.as_raw__InputArray(), pattern_size.opencv_as_extern(), corners.as_raw__OutputArray(), flags) }.into_result()
}
/// Finds the positions of internal corners of the chessboard using a sector based approach.
///
/// ## Parameters
/// * image: Source chessboard view. It must be an 8-bit grayscale or color image.
/// * patternSize: Number of inner corners per a chessboard row and column
/// ( patternSize = cv::Size(points_per_row,points_per_colum) = cv::Size(columns,rows) ).
/// * corners: Output array of detected corners.
/// * flags: Various operation flags that can be zero or a combination of the following values:
/// * @ref CALIB_CB_NORMALIZE_IMAGE Normalize the image gamma with equalizeHist before detection.
/// * @ref CALIB_CB_EXHAUSTIVE Run an exhaustive search to improve detection rate.
/// * @ref CALIB_CB_ACCURACY Up sample input image to improve sub-pixel accuracy due to aliasing effects.
/// * @ref CALIB_CB_LARGER The detected pattern is allowed to be larger than patternSize (see description).
/// * @ref CALIB_CB_MARKER The detected pattern must have a marker (see description).
/// This should be used if an accurate camera calibration is required.
/// * meta: Optional output arrray of detected corners (CV_8UC1 and size = cv::Size(columns,rows)).
/// Each entry stands for one corner of the pattern and can have one of the following values:
/// * 0 = no meta data attached
/// * 1 = left-top corner of a black cell
/// * 2 = left-top corner of a white cell
/// * 3 = left-top corner of a black cell with a white marker dot
/// * 4 = left-top corner of a white cell with a black marker dot (pattern origin in case of markers otherwise first corner)
///
/// The function is analog to #findChessboardCorners but uses a localized radon
/// transformation approximated by box filters being more robust to all sort of
/// noise, faster on larger images and is able to directly return the sub-pixel
/// position of the internal chessboard corners. The Method is based on the paper
/// [duda2018](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_duda2018) "Accurate Detection and Localization of Checkerboard Corners for
/// Calibration" demonstrating that the returned sub-pixel positions are more
/// accurate than the one returned by cornerSubPix allowing a precise camera
/// calibration for demanding applications.
///
/// In the case, the flags @ref CALIB_CB_LARGER or @ref CALIB_CB_MARKER are given,
/// the result can be recovered from the optional meta array. Both flags are
/// helpful to use calibration patterns exceeding the field of view of the camera.
/// These oversized patterns allow more accurate calibrations as corners can be
/// utilized, which are as close as possible to the image borders. For a
/// consistent coordinate system across all images, the optional marker (see image
/// below) can be used to move the origin of the board to the location where the
/// black circle is located.
///
///
/// Note: The function requires a white boarder with roughly the same width as one
/// of the checkerboard fields around the whole board to improve the detection in
/// various environments. In addition, because of the localized radon
/// transformation it is beneficial to use round corners for the field corners
/// which are located on the outside of the board. The following figure illustrates
/// a sample checkerboard optimized for the detection. However, any other checkerboard
/// can be used as well.
/// 
pub fn find_chessboard_corners_sb_with_meta(image: &dyn core::ToInputArray, pattern_size: core::Size, corners: &mut dyn core::ToOutputArray, flags: i32, meta: &mut dyn core::ToOutputArray) -> Result<bool> {
input_array_arg!(image);
output_array_arg!(corners);
output_array_arg!(meta);
unsafe { sys::cv_findChessboardCornersSB_const__InputArrayR_Size_const__OutputArrayR_int_const__OutputArrayR(image.as_raw__InputArray(), pattern_size.opencv_as_extern(), corners.as_raw__OutputArray(), flags, meta.as_raw__OutputArray()) }.into_result()
}
/// Finds the positions of internal corners of the chessboard.
///
/// ## Parameters
/// * image: Source chessboard view. It must be an 8-bit grayscale or color image.
/// * patternSize: Number of inner corners per a chessboard row and column
/// ( patternSize = cv::Size(points_per_row,points_per_colum) = cv::Size(columns,rows) ).
/// * corners: Output array of detected corners.
/// * flags: Various operation flags that can be zero or a combination of the following values:
/// * @ref CALIB_CB_ADAPTIVE_THRESH Use adaptive thresholding to convert the image to black
/// and white, rather than a fixed threshold level (computed from the average image brightness).
/// * @ref CALIB_CB_NORMALIZE_IMAGE Normalize the image gamma with equalizeHist before
/// applying fixed or adaptive thresholding.
/// * @ref CALIB_CB_FILTER_QUADS Use additional criteria (like contour area, perimeter,
/// square-like shape) to filter out false quads extracted at the contour retrieval stage.
/// * @ref CALIB_CB_FAST_CHECK Run a fast check on the image that looks for chessboard corners,
/// and shortcut the call if none is found. This can drastically speed up the call in the
/// degenerate condition when no chessboard is observed.
///
/// The function attempts to determine whether the input image is a view of the chessboard pattern and
/// locate the internal chessboard corners. The function returns a non-zero value if all of the corners
/// are found and they are placed in a certain order (row by row, left to right in every row).
/// Otherwise, if the function fails to find all the corners or reorder them, it returns 0. For example,
/// a regular chessboard has 8 x 8 squares and 7 x 7 internal corners, that is, points where the black
/// squares touch each other. The detected coordinates are approximate, and to determine their positions
/// more accurately, the function calls cornerSubPix. You also may use the function cornerSubPix with
/// different parameters if returned coordinates are not accurate enough.
///
/// Sample usage of detecting and drawing chessboard corners: :
/// ```ignore
/// Size patternsize(8,6); //interior number of corners
/// Mat gray = ....; //source image
/// vector<Point2f> corners; //this will be filled by the detected corners
///
/// //CALIB_CB_FAST_CHECK saves a lot of time on images
/// //that do not contain any chessboard corners
/// bool patternfound = findChessboardCorners(gray, patternsize, corners,
/// CALIB_CB_ADAPTIVE_THRESH + CALIB_CB_NORMALIZE_IMAGE
/// + CALIB_CB_FAST_CHECK);
///
/// if(patternfound)
/// cornerSubPix(gray, corners, Size(11, 11), Size(-1, -1),
/// TermCriteria(CV_TERMCRIT_EPS + CV_TERMCRIT_ITER, 30, 0.1));
///
/// drawChessboardCorners(img, patternsize, Mat(corners), patternfound);
/// ```
///
///
/// Note: The function requires white space (like a square-thick border, the wider the better) around
/// the board to make the detection more robust in various environments. Otherwise, if there is no
/// border and the background is dark, the outer black squares cannot be segmented properly and so the
/// square grouping and ordering algorithm fails.
///
/// ## C++ default parameters
/// * flags: CALIB_CB_ADAPTIVE_THRESH+CALIB_CB_NORMALIZE_IMAGE
pub fn find_chessboard_corners(image: &dyn core::ToInputArray, pattern_size: core::Size, corners: &mut dyn core::ToOutputArray, flags: i32) -> Result<bool> {
input_array_arg!(image);
output_array_arg!(corners);
unsafe { sys::cv_findChessboardCorners_const__InputArrayR_Size_const__OutputArrayR_int(image.as_raw__InputArray(), pattern_size.opencv_as_extern(), corners.as_raw__OutputArray(), flags) }.into_result()
}
/// Finds centers in the grid of circles.
///
/// ## Parameters
/// * image: grid view of input circles; it must be an 8-bit grayscale or color image.
/// * patternSize: number of circles per row and column
/// ( patternSize = Size(points_per_row, points_per_colum) ).
/// * centers: output array of detected centers.
/// * flags: various operation flags that can be one of the following values:
/// * @ref CALIB_CB_SYMMETRIC_GRID uses symmetric pattern of circles.
/// * @ref CALIB_CB_ASYMMETRIC_GRID uses asymmetric pattern of circles.
/// * @ref CALIB_CB_CLUSTERING uses a special algorithm for grid detection. It is more robust to
/// perspective distortions but much more sensitive to background clutter.
/// * blobDetector: feature detector that finds blobs like dark circles on light background.
/// If `blobDetector` is NULL then `image` represents Point2f array of candidates.
/// * parameters: struct for finding circles in a grid pattern.
///
/// The function attempts to determine whether the input image contains a grid of circles. If it is, the
/// function locates centers of the circles. The function returns a non-zero value if all of the centers
/// have been found and they have been placed in a certain order (row by row, left to right in every
/// row). Otherwise, if the function fails to find all the corners or reorder them, it returns 0.
///
/// Sample usage of detecting and drawing the centers of circles: :
/// ```ignore
/// Size patternsize(7,7); //number of centers
/// Mat gray = ...; //source image
/// vector<Point2f> centers; //this will be filled by the detected centers
///
/// bool patternfound = findCirclesGrid(gray, patternsize, centers);
///
/// drawChessboardCorners(img, patternsize, Mat(centers), patternfound);
/// ```
///
///
/// Note: The function requires white space (like a square-thick border, the wider the better) around
/// the board to make the detection more robust in various environments.
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * flags: CALIB_CB_SYMMETRIC_GRID
/// * blob_detector: SimpleBlobDetector::create()
pub fn find_circles_grid_1(image: &dyn core::ToInputArray, pattern_size: core::Size, centers: &mut dyn core::ToOutputArray, flags: i32, blob_detector: &core::Ptr<crate::features2d::Feature2D>) -> Result<bool> {
input_array_arg!(image);
output_array_arg!(centers);
unsafe { sys::cv_findCirclesGrid_const__InputArrayR_Size_const__OutputArrayR_int_const_Ptr_Feature2D_R(image.as_raw__InputArray(), pattern_size.opencv_as_extern(), centers.as_raw__OutputArray(), flags, blob_detector.as_raw_PtrOfFeature2D()) }.into_result()
}
/// Finds centers in the grid of circles.
///
/// ## Parameters
/// * image: grid view of input circles; it must be an 8-bit grayscale or color image.
/// * patternSize: number of circles per row and column
/// ( patternSize = Size(points_per_row, points_per_colum) ).
/// * centers: output array of detected centers.
/// * flags: various operation flags that can be one of the following values:
/// * @ref CALIB_CB_SYMMETRIC_GRID uses symmetric pattern of circles.
/// * @ref CALIB_CB_ASYMMETRIC_GRID uses asymmetric pattern of circles.
/// * @ref CALIB_CB_CLUSTERING uses a special algorithm for grid detection. It is more robust to
/// perspective distortions but much more sensitive to background clutter.
/// * blobDetector: feature detector that finds blobs like dark circles on light background.
/// If `blobDetector` is NULL then `image` represents Point2f array of candidates.
/// * parameters: struct for finding circles in a grid pattern.
///
/// The function attempts to determine whether the input image contains a grid of circles. If it is, the
/// function locates centers of the circles. The function returns a non-zero value if all of the centers
/// have been found and they have been placed in a certain order (row by row, left to right in every
/// row). Otherwise, if the function fails to find all the corners or reorder them, it returns 0.
///
/// Sample usage of detecting and drawing the centers of circles: :
/// ```ignore
/// Size patternsize(7,7); //number of centers
/// Mat gray = ...; //source image
/// vector<Point2f> centers; //this will be filled by the detected centers
///
/// bool patternfound = findCirclesGrid(gray, patternsize, centers);
///
/// drawChessboardCorners(img, patternsize, Mat(centers), patternfound);
/// ```
///
///
/// Note: The function requires white space (like a square-thick border, the wider the better) around
/// the board to make the detection more robust in various environments.
pub fn find_circles_grid(image: &dyn core::ToInputArray, pattern_size: core::Size, centers: &mut dyn core::ToOutputArray, flags: i32, blob_detector: &core::Ptr<crate::features2d::Feature2D>, parameters: crate::calib3d::CirclesGridFinderParameters) -> Result<bool> {
input_array_arg!(image);
output_array_arg!(centers);
unsafe { sys::cv_findCirclesGrid_const__InputArrayR_Size_const__OutputArrayR_int_const_Ptr_Feature2D_R_const_CirclesGridFinderParametersR(image.as_raw__InputArray(), pattern_size.opencv_as_extern(), centers.as_raw__OutputArray(), flags, blob_detector.as_raw_PtrOfFeature2D(), ¶meters) }.into_result()
}
pub fn find_essential_mat_4(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, camera_matrix1: &dyn core::ToInputArray, camera_matrix2: &dyn core::ToInputArray, dist_coeff1: &dyn core::ToInputArray, dist_coeff2: &dyn core::ToInputArray, mask: &mut dyn core::ToOutputArray, params: crate::calib3d::UsacParams) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
input_array_arg!(camera_matrix1);
input_array_arg!(camera_matrix2);
input_array_arg!(dist_coeff1);
input_array_arg!(dist_coeff2);
output_array_arg!(mask);
unsafe { sys::cv_findEssentialMat_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const_UsacParamsR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), camera_matrix1.as_raw__InputArray(), camera_matrix2.as_raw__InputArray(), dist_coeff1.as_raw__InputArray(), dist_coeff2.as_raw__InputArray(), mask.as_raw__OutputArray(), ¶ms) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Calculates an essential matrix from the corresponding points in two images from potentially two different cameras.
///
/// ## Parameters
/// * points1: Array of N (N \>= 5) 2D points from the first image. The point coordinates should
/// be floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * cameraMatrix1: Camera matrix 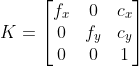 .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * cameraMatrix2: Camera matrix 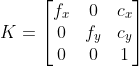 .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * distCoeffs1: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * distCoeffs2: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * method: Method for computing an essential matrix.
/// * @ref RANSAC for the RANSAC algorithm.
/// * @ref LMEDS for the LMedS algorithm.
/// * prob: Parameter used for the RANSAC or LMedS methods only. It specifies a desirable level of
/// confidence (probability) that the estimated matrix is correct.
/// * threshold: Parameter used for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * mask: Output array of N elements, every element of which is set to 0 for outliers and to 1
/// for the other points. The array is computed only in the RANSAC and LMedS methods.
///
/// This function estimates essential matrix based on the five-point algorithm solver in [Nister03](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Nister03) .
/// [SteweniusCFS](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_SteweniusCFS) is also a related. The epipolar geometry is described by the following equation:
///
/// 
///
/// where  is an essential matrix,  and  are corresponding points in the first and the
/// second images, respectively. The result of this function may be passed further to
/// #decomposeEssentialMat or #recoverPose to recover the relative pose between cameras.
///
/// ## C++ default parameters
/// * method: RANSAC
/// * prob: 0.999
/// * threshold: 1.0
/// * mask: noArray()
pub fn find_essential_mat_3(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, camera_matrix1: &dyn core::ToInputArray, dist_coeffs1: &dyn core::ToInputArray, camera_matrix2: &dyn core::ToInputArray, dist_coeffs2: &dyn core::ToInputArray, method: i32, prob: f64, threshold: f64, mask: &mut dyn core::ToOutputArray) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
input_array_arg!(camera_matrix1);
input_array_arg!(dist_coeffs1);
input_array_arg!(camera_matrix2);
input_array_arg!(dist_coeffs2);
output_array_arg!(mask);
unsafe { sys::cv_findEssentialMat_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_int_double_double_const__OutputArrayR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), camera_matrix1.as_raw__InputArray(), dist_coeffs1.as_raw__InputArray(), camera_matrix2.as_raw__InputArray(), dist_coeffs2.as_raw__InputArray(), method, prob, threshold, mask.as_raw__OutputArray()) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Calculates an essential matrix from the corresponding points in two images from potentially two different cameras.
///
/// ## Parameters
/// * points1: Array of N (N \>= 5) 2D points from the first image. The point coordinates should
/// be floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * cameraMatrix1: Camera matrix 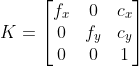 .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * cameraMatrix2: Camera matrix 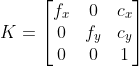 .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * distCoeffs1: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * distCoeffs2: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * method: Method for computing an essential matrix.
/// * @ref RANSAC for the RANSAC algorithm.
/// * @ref LMEDS for the LMedS algorithm.
/// * prob: Parameter used for the RANSAC or LMedS methods only. It specifies a desirable level of
/// confidence (probability) that the estimated matrix is correct.
/// * threshold: Parameter used for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * mask: Output array of N elements, every element of which is set to 0 for outliers and to 1
/// for the other points. The array is computed only in the RANSAC and LMedS methods.
///
/// This function estimates essential matrix based on the five-point algorithm solver in [Nister03](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Nister03) .
/// [SteweniusCFS](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_SteweniusCFS) is also a related. The epipolar geometry is described by the following equation:
///
/// 
///
/// where 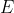 is an essential matrix,  and  are corresponding points in the first and the
/// second images, respectively. The result of this function may be passed further to
/// #decomposeEssentialMat or #recoverPose to recover the relative pose between cameras.
///
/// ## Overloaded parameters
pub fn find_essential_mat_matrix(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, method: i32, prob: f64, threshold: f64, mask: &mut dyn core::ToOutputArray) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
input_array_arg!(camera_matrix);
output_array_arg!(mask);
unsafe { sys::cv_findEssentialMat_const__InputArrayR_const__InputArrayR_const__InputArrayR_int_double_double_const__OutputArrayR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), method, prob, threshold, mask.as_raw__OutputArray()) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Calculates an essential matrix from the corresponding points in two images.
///
/// ## Parameters
/// * points1: Array of N (N \>= 5) 2D points from the first image. The point coordinates should
/// be floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * cameraMatrix: Camera intrinsic matrix  .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera intrinsic matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera intrinsic matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * method: Method for computing an essential matrix.
/// * @ref RANSAC for the RANSAC algorithm.
/// * @ref LMEDS for the LMedS algorithm.
/// * prob: Parameter used for the RANSAC or LMedS methods only. It specifies a desirable level of
/// confidence (probability) that the estimated matrix is correct.
/// * threshold: Parameter used for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * mask: Output array of N elements, every element of which is set to 0 for outliers and to 1
/// for the other points. The array is computed only in the RANSAC and LMedS methods.
/// * maxIters: The maximum number of robust method iterations.
///
/// This function estimates essential matrix based on the five-point algorithm solver in [Nister03](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Nister03) .
/// [SteweniusCFS](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_SteweniusCFS) is also a related. The epipolar geometry is described by the following equation:
///
/// 
///
/// where 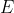 is an essential matrix,  and  are corresponding points in the first and the
/// second images, respectively. The result of this function may be passed further to
/// #decomposeEssentialMat or #recoverPose to recover the relative pose between cameras.
///
/// ## C++ default parameters
/// * method: RANSAC
/// * prob: 0.999
/// * threshold: 1.0
/// * max_iters: 1000
/// * mask: noArray()
pub fn find_essential_mat(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, method: i32, prob: f64, threshold: f64, max_iters: i32, mask: &mut dyn core::ToOutputArray) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
input_array_arg!(camera_matrix);
output_array_arg!(mask);
unsafe { sys::cv_findEssentialMat_const__InputArrayR_const__InputArrayR_const__InputArrayR_int_double_double_int_const__OutputArrayR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), method, prob, threshold, max_iters, mask.as_raw__OutputArray()) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Calculates an essential matrix from the corresponding points in two images from potentially two different cameras.
///
/// ## Parameters
/// * points1: Array of N (N \>= 5) 2D points from the first image. The point coordinates should
/// be floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * cameraMatrix1: Camera matrix 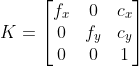 .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * cameraMatrix2: Camera matrix  .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * distCoeffs1: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * distCoeffs2: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * method: Method for computing an essential matrix.
/// * @ref RANSAC for the RANSAC algorithm.
/// * @ref LMEDS for the LMedS algorithm.
/// * prob: Parameter used for the RANSAC or LMedS methods only. It specifies a desirable level of
/// confidence (probability) that the estimated matrix is correct.
/// * threshold: Parameter used for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * mask: Output array of N elements, every element of which is set to 0 for outliers and to 1
/// for the other points. The array is computed only in the RANSAC and LMedS methods.
///
/// This function estimates essential matrix based on the five-point algorithm solver in [Nister03](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Nister03) .
/// [SteweniusCFS](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_SteweniusCFS) is also a related. The epipolar geometry is described by the following equation:
///
/// 
///
/// where 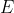 is an essential matrix,  and  are corresponding points in the first and the
/// second images, respectively. The result of this function may be passed further to
/// #decomposeEssentialMat or #recoverPose to recover the relative pose between cameras.
///
/// ## Overloaded parameters
pub fn find_essential_mat_2(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, focal: f64, pp: core::Point2d, method: i32, prob: f64, threshold: f64, mask: &mut dyn core::ToOutputArray) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
output_array_arg!(mask);
unsafe { sys::cv_findEssentialMat_const__InputArrayR_const__InputArrayR_double_Point2d_int_double_double_const__OutputArrayR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), focal, pp.opencv_as_extern(), method, prob, threshold, mask.as_raw__OutputArray()) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Calculates an essential matrix from the corresponding points in two images from potentially two different cameras.
///
/// ## Parameters
/// * points1: Array of N (N \>= 5) 2D points from the first image. The point coordinates should
/// be floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * cameraMatrix1: Camera matrix 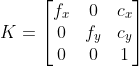 .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * cameraMatrix2: Camera matrix 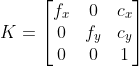 .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera matrix. If this assumption does not hold for your use case, use
/// #undistortPoints with `P = cv::NoArray()` for both cameras to transform image points
/// to normalized image coordinates, which are valid for the identity camera matrix. When
/// passing these coordinates, pass the identity matrix for this parameter.
/// * distCoeffs1: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * distCoeffs2: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * method: Method for computing an essential matrix.
/// * @ref RANSAC for the RANSAC algorithm.
/// * @ref LMEDS for the LMedS algorithm.
/// * prob: Parameter used for the RANSAC or LMedS methods only. It specifies a desirable level of
/// confidence (probability) that the estimated matrix is correct.
/// * threshold: Parameter used for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * mask: Output array of N elements, every element of which is set to 0 for outliers and to 1
/// for the other points. The array is computed only in the RANSAC and LMedS methods.
///
/// This function estimates essential matrix based on the five-point algorithm solver in [Nister03](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Nister03) .
/// [SteweniusCFS](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_SteweniusCFS) is also a related. The epipolar geometry is described by the following equation:
///
/// 
///
/// where  is an essential matrix,  and  are corresponding points in the first and the
/// second images, respectively. The result of this function may be passed further to
/// #decomposeEssentialMat or #recoverPose to recover the relative pose between cameras.
///
/// ## Overloaded parameters
///
/// * points1: Array of N (N \>= 5) 2D points from the first image. The point coordinates should
/// be floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * focal: focal length of the camera. Note that this function assumes that points1 and points2
/// are feature points from cameras with same focal length and principal point.
/// * pp: principal point of the camera.
/// * method: Method for computing a fundamental matrix.
/// * @ref RANSAC for the RANSAC algorithm.
/// * @ref LMEDS for the LMedS algorithm.
/// * threshold: Parameter used for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * prob: Parameter used for the RANSAC or LMedS methods only. It specifies a desirable level of
/// confidence (probability) that the estimated matrix is correct.
/// * mask: Output array of N elements, every element of which is set to 0 for outliers and to 1
/// for the other points. The array is computed only in the RANSAC and LMedS methods.
/// * maxIters: The maximum number of robust method iterations.
///
/// This function differs from the one above that it computes camera intrinsic matrix from focal length and
/// principal point:
///
/// 
///
/// ## C++ default parameters
/// * focal: 1.0
/// * pp: Point2d(0,0)
/// * method: RANSAC
/// * prob: 0.999
/// * threshold: 1.0
/// * max_iters: 1000
/// * mask: noArray()
pub fn find_essential_mat_1(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, focal: f64, pp: core::Point2d, method: i32, prob: f64, threshold: f64, max_iters: i32, mask: &mut dyn core::ToOutputArray) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
output_array_arg!(mask);
unsafe { sys::cv_findEssentialMat_const__InputArrayR_const__InputArrayR_double_Point2d_int_double_double_int_const__OutputArrayR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), focal, pp.opencv_as_extern(), method, prob, threshold, max_iters, mask.as_raw__OutputArray()) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
pub fn find_fundamental_mat_2(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, mask: &mut dyn core::ToOutputArray, params: crate::calib3d::UsacParams) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
output_array_arg!(mask);
unsafe { sys::cv_findFundamentalMat_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const_UsacParamsR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), mask.as_raw__OutputArray(), ¶ms) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Calculates a fundamental matrix from the corresponding points in two images.
///
/// ## Parameters
/// * points1: Array of N points from the first image. The point coordinates should be
/// floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * method: Method for computing a fundamental matrix.
/// * @ref FM_7POINT for a 7-point algorithm. 
/// * @ref FM_8POINT for an 8-point algorithm. 
/// * @ref FM_RANSAC for the RANSAC algorithm. 
/// * @ref FM_LMEDS for the LMedS algorithm. 
/// * ransacReprojThreshold: Parameter used only for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * confidence: Parameter used for the RANSAC and LMedS methods only. It specifies a desirable level
/// of confidence (probability) that the estimated matrix is correct.
/// * mask:[out] optional output mask
/// * maxIters: The maximum number of robust method iterations.
///
/// The epipolar geometry is described by the following equation:
///
/// 
///
/// where  is a fundamental matrix,  and  are corresponding points in the first and the
/// second images, respectively.
///
/// The function calculates the fundamental matrix using one of four methods listed above and returns
/// the found fundamental matrix. Normally just one matrix is found. But in case of the 7-point
/// algorithm, the function may return up to 3 solutions (  matrix that stores all 3
/// matrices sequentially).
///
/// The calculated fundamental matrix may be passed further to computeCorrespondEpilines that finds the
/// epipolar lines corresponding to the specified points. It can also be passed to
/// #stereoRectifyUncalibrated to compute the rectification transformation. :
/// ```ignore
/// // Example. Estimation of fundamental matrix using the RANSAC algorithm
/// int point_count = 100;
/// vector<Point2f> points1(point_count);
/// vector<Point2f> points2(point_count);
///
/// // initialize the points here ...
/// for( int i = 0; i < point_count; i++ )
/// {
/// points1[i] = ...;
/// points2[i] = ...;
/// }
///
/// Mat fundamental_matrix =
/// findFundamentalMat(points1, points2, FM_RANSAC, 3, 0.99);
/// ```
///
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * method: FM_RANSAC
/// * ransac_reproj_threshold: 3.
/// * confidence: 0.99
pub fn find_fundamental_mat_mask(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, mask: &mut dyn core::ToOutputArray, method: i32, ransac_reproj_threshold: f64, confidence: f64) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
output_array_arg!(mask);
unsafe { sys::cv_findFundamentalMat_const__InputArrayR_const__InputArrayR_const__OutputArrayR_int_double_double(points1.as_raw__InputArray(), points2.as_raw__InputArray(), mask.as_raw__OutputArray(), method, ransac_reproj_threshold, confidence) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Calculates a fundamental matrix from the corresponding points in two images.
///
/// ## Parameters
/// * points1: Array of N points from the first image. The point coordinates should be
/// floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * method: Method for computing a fundamental matrix.
/// * @ref FM_7POINT for a 7-point algorithm. 
/// * @ref FM_8POINT for an 8-point algorithm. 
/// * @ref FM_RANSAC for the RANSAC algorithm. 
/// * @ref FM_LMEDS for the LMedS algorithm. 
/// * ransacReprojThreshold: Parameter used only for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * confidence: Parameter used for the RANSAC and LMedS methods only. It specifies a desirable level
/// of confidence (probability) that the estimated matrix is correct.
/// * mask:[out] optional output mask
/// * maxIters: The maximum number of robust method iterations.
///
/// The epipolar geometry is described by the following equation:
///
/// 
///
/// where  is a fundamental matrix,  and  are corresponding points in the first and the
/// second images, respectively.
///
/// The function calculates the fundamental matrix using one of four methods listed above and returns
/// the found fundamental matrix. Normally just one matrix is found. But in case of the 7-point
/// algorithm, the function may return up to 3 solutions (  matrix that stores all 3
/// matrices sequentially).
///
/// The calculated fundamental matrix may be passed further to computeCorrespondEpilines that finds the
/// epipolar lines corresponding to the specified points. It can also be passed to
/// #stereoRectifyUncalibrated to compute the rectification transformation. :
/// ```ignore
/// // Example. Estimation of fundamental matrix using the RANSAC algorithm
/// int point_count = 100;
/// vector<Point2f> points1(point_count);
/// vector<Point2f> points2(point_count);
///
/// // initialize the points here ...
/// for( int i = 0; i < point_count; i++ )
/// {
/// points1[i] = ...;
/// points2[i] = ...;
/// }
///
/// Mat fundamental_matrix =
/// findFundamentalMat(points1, points2, FM_RANSAC, 3, 0.99);
/// ```
///
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * method: FM_RANSAC
/// * ransac_reproj_threshold: 3.
/// * confidence: 0.99
/// * mask: noArray()
pub fn find_fundamental_mat_1(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, method: i32, ransac_reproj_threshold: f64, confidence: f64, mask: &mut dyn core::ToOutputArray) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
output_array_arg!(mask);
unsafe { sys::cv_findFundamentalMat_const__InputArrayR_const__InputArrayR_int_double_double_const__OutputArrayR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), method, ransac_reproj_threshold, confidence, mask.as_raw__OutputArray()) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Calculates a fundamental matrix from the corresponding points in two images.
///
/// ## Parameters
/// * points1: Array of N points from the first image. The point coordinates should be
/// floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * method: Method for computing a fundamental matrix.
/// * @ref FM_7POINT for a 7-point algorithm. 
/// * @ref FM_8POINT for an 8-point algorithm. 
/// * @ref FM_RANSAC for the RANSAC algorithm. 
/// * @ref FM_LMEDS for the LMedS algorithm. 
/// * ransacReprojThreshold: Parameter used only for RANSAC. It is the maximum distance from a point to an epipolar
/// line in pixels, beyond which the point is considered an outlier and is not used for computing the
/// final fundamental matrix. It can be set to something like 1-3, depending on the accuracy of the
/// point localization, image resolution, and the image noise.
/// * confidence: Parameter used for the RANSAC and LMedS methods only. It specifies a desirable level
/// of confidence (probability) that the estimated matrix is correct.
/// * mask:[out] optional output mask
/// * maxIters: The maximum number of robust method iterations.
///
/// The epipolar geometry is described by the following equation:
///
/// 
///
/// where  is a fundamental matrix,  and  are corresponding points in the first and the
/// second images, respectively.
///
/// The function calculates the fundamental matrix using one of four methods listed above and returns
/// the found fundamental matrix. Normally just one matrix is found. But in case of the 7-point
/// algorithm, the function may return up to 3 solutions (  matrix that stores all 3
/// matrices sequentially).
///
/// The calculated fundamental matrix may be passed further to computeCorrespondEpilines that finds the
/// epipolar lines corresponding to the specified points. It can also be passed to
/// #stereoRectifyUncalibrated to compute the rectification transformation. :
/// ```ignore
/// // Example. Estimation of fundamental matrix using the RANSAC algorithm
/// int point_count = 100;
/// vector<Point2f> points1(point_count);
/// vector<Point2f> points2(point_count);
///
/// // initialize the points here ...
/// for( int i = 0; i < point_count; i++ )
/// {
/// points1[i] = ...;
/// points2[i] = ...;
/// }
///
/// Mat fundamental_matrix =
/// findFundamentalMat(points1, points2, FM_RANSAC, 3, 0.99);
/// ```
///
///
/// ## C++ default parameters
/// * mask: noArray()
pub fn find_fundamental_mat(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, method: i32, ransac_reproj_threshold: f64, confidence: f64, max_iters: i32, mask: &mut dyn core::ToOutputArray) -> Result<core::Mat> {
input_array_arg!(points1);
input_array_arg!(points2);
output_array_arg!(mask);
unsafe { sys::cv_findFundamentalMat_const__InputArrayR_const__InputArrayR_int_double_double_int_const__OutputArrayR(points1.as_raw__InputArray(), points2.as_raw__InputArray(), method, ransac_reproj_threshold, confidence, max_iters, mask.as_raw__OutputArray()) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
pub fn find_homography_1(src_points: &dyn core::ToInputArray, dst_points: &dyn core::ToInputArray, mask: &mut dyn core::ToOutputArray, params: crate::calib3d::UsacParams) -> Result<core::Mat> {
input_array_arg!(src_points);
input_array_arg!(dst_points);
output_array_arg!(mask);
unsafe { sys::cv_findHomography_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const_UsacParamsR(src_points.as_raw__InputArray(), dst_points.as_raw__InputArray(), mask.as_raw__OutputArray(), ¶ms) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Finds a perspective transformation between two planes.
///
/// ## Parameters
/// * srcPoints: Coordinates of the points in the original plane, a matrix of the type CV_32FC2
/// or vector\<Point2f\> .
/// * dstPoints: Coordinates of the points in the target plane, a matrix of the type CV_32FC2 or
/// a vector\<Point2f\> .
/// * method: Method used to compute a homography matrix. The following methods are possible:
/// * **0** - a regular method using all the points, i.e., the least squares method
/// * @ref RANSAC - RANSAC-based robust method
/// * @ref LMEDS - Least-Median robust method
/// * @ref RHO - PROSAC-based robust method
/// * ransacReprojThreshold: Maximum allowed reprojection error to treat a point pair as an inlier
/// (used in the RANSAC and RHO methods only). That is, if
/// 
/// then the point  is considered as an outlier. If srcPoints and dstPoints are measured in pixels,
/// it usually makes sense to set this parameter somewhere in the range of 1 to 10.
/// * mask: Optional output mask set by a robust method ( RANSAC or LMeDS ). Note that the input
/// mask values are ignored.
/// * maxIters: The maximum number of RANSAC iterations.
/// * confidence: Confidence level, between 0 and 1.
///
/// The function finds and returns the perspective transformation  between the source and the
/// destination planes:
///
/// 
///
/// so that the back-projection error
///
/// 
///
/// is minimized. If the parameter method is set to the default value 0, the function uses all the point
/// pairs to compute an initial homography estimate with a simple least-squares scheme.
///
/// However, if not all of the point pairs ( ,  ) fit the rigid perspective
/// transformation (that is, there are some outliers), this initial estimate will be poor. In this case,
/// you can use one of the three robust methods. The methods RANSAC, LMeDS and RHO try many different
/// random subsets of the corresponding point pairs (of four pairs each, collinear pairs are discarded), estimate the homography matrix
/// using this subset and a simple least-squares algorithm, and then compute the quality/goodness of the
/// computed homography (which is the number of inliers for RANSAC or the least median re-projection error for
/// LMeDS). The best subset is then used to produce the initial estimate of the homography matrix and
/// the mask of inliers/outliers.
///
/// Regardless of the method, robust or not, the computed homography matrix is refined further (using
/// inliers only in case of a robust method) with the Levenberg-Marquardt method to reduce the
/// re-projection error even more.
///
/// The methods RANSAC and RHO can handle practically any ratio of outliers but need a threshold to
/// distinguish inliers from outliers. The method LMeDS does not need any threshold but it works
/// correctly only when there are more than 50% of inliers. Finally, if there are no outliers and the
/// noise is rather small, use the default method (method=0).
///
/// The function is used to find initial intrinsic and extrinsic matrices. Homography matrix is
/// determined up to a scale. Thus, it is normalized so that . Note that whenever an  matrix
/// cannot be estimated, an empty one will be returned.
/// ## See also
/// getAffineTransform, estimateAffine2D, estimateAffinePartial2D, getPerspectiveTransform, warpPerspective,
/// perspectiveTransform
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * method: 0
/// * ransac_reproj_threshold: 3
pub fn find_homography(src_points: &dyn core::ToInputArray, dst_points: &dyn core::ToInputArray, mask: &mut dyn core::ToOutputArray, method: i32, ransac_reproj_threshold: f64) -> Result<core::Mat> {
input_array_arg!(src_points);
input_array_arg!(dst_points);
output_array_arg!(mask);
unsafe { sys::cv_findHomography_const__InputArrayR_const__InputArrayR_const__OutputArrayR_int_double(src_points.as_raw__InputArray(), dst_points.as_raw__InputArray(), mask.as_raw__OutputArray(), method, ransac_reproj_threshold) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Finds a perspective transformation between two planes.
///
/// ## Parameters
/// * srcPoints: Coordinates of the points in the original plane, a matrix of the type CV_32FC2
/// or vector\<Point2f\> .
/// * dstPoints: Coordinates of the points in the target plane, a matrix of the type CV_32FC2 or
/// a vector\<Point2f\> .
/// * method: Method used to compute a homography matrix. The following methods are possible:
/// * **0** - a regular method using all the points, i.e., the least squares method
/// * @ref RANSAC - RANSAC-based robust method
/// * @ref LMEDS - Least-Median robust method
/// * @ref RHO - PROSAC-based robust method
/// * ransacReprojThreshold: Maximum allowed reprojection error to treat a point pair as an inlier
/// (used in the RANSAC and RHO methods only). That is, if
/// 
/// then the point  is considered as an outlier. If srcPoints and dstPoints are measured in pixels,
/// it usually makes sense to set this parameter somewhere in the range of 1 to 10.
/// * mask: Optional output mask set by a robust method ( RANSAC or LMeDS ). Note that the input
/// mask values are ignored.
/// * maxIters: The maximum number of RANSAC iterations.
/// * confidence: Confidence level, between 0 and 1.
///
/// The function finds and returns the perspective transformation  between the source and the
/// destination planes:
///
/// 
///
/// so that the back-projection error
///
/// 
///
/// is minimized. If the parameter method is set to the default value 0, the function uses all the point
/// pairs to compute an initial homography estimate with a simple least-squares scheme.
///
/// However, if not all of the point pairs ( ,  ) fit the rigid perspective
/// transformation (that is, there are some outliers), this initial estimate will be poor. In this case,
/// you can use one of the three robust methods. The methods RANSAC, LMeDS and RHO try many different
/// random subsets of the corresponding point pairs (of four pairs each, collinear pairs are discarded), estimate the homography matrix
/// using this subset and a simple least-squares algorithm, and then compute the quality/goodness of the
/// computed homography (which is the number of inliers for RANSAC or the least median re-projection error for
/// LMeDS). The best subset is then used to produce the initial estimate of the homography matrix and
/// the mask of inliers/outliers.
///
/// Regardless of the method, robust or not, the computed homography matrix is refined further (using
/// inliers only in case of a robust method) with the Levenberg-Marquardt method to reduce the
/// re-projection error even more.
///
/// The methods RANSAC and RHO can handle practically any ratio of outliers but need a threshold to
/// distinguish inliers from outliers. The method LMeDS does not need any threshold but it works
/// correctly only when there are more than 50% of inliers. Finally, if there are no outliers and the
/// noise is rather small, use the default method (method=0).
///
/// The function is used to find initial intrinsic and extrinsic matrices. Homography matrix is
/// determined up to a scale. Thus, it is normalized so that . Note that whenever an  matrix
/// cannot be estimated, an empty one will be returned.
/// ## See also
/// getAffineTransform, estimateAffine2D, estimateAffinePartial2D, getPerspectiveTransform, warpPerspective,
/// perspectiveTransform
///
/// ## C++ default parameters
/// * method: 0
/// * ransac_reproj_threshold: 3
/// * mask: noArray()
/// * max_iters: 2000
/// * confidence: 0.995
pub fn find_homography_ext(src_points: &dyn core::ToInputArray, dst_points: &dyn core::ToInputArray, method: i32, ransac_reproj_threshold: f64, mask: &mut dyn core::ToOutputArray, max_iters: i32, confidence: f64) -> Result<core::Mat> {
input_array_arg!(src_points);
input_array_arg!(dst_points);
output_array_arg!(mask);
unsafe { sys::cv_findHomography_const__InputArrayR_const__InputArrayR_int_double_const__OutputArrayR_const_int_const_double(src_points.as_raw__InputArray(), dst_points.as_raw__InputArray(), method, ransac_reproj_threshold, mask.as_raw__OutputArray(), max_iters, confidence) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Performs camera calibaration
///
/// ## Parameters
/// * objectPoints: vector of vectors of calibration pattern points in the calibration pattern
/// coordinate space.
/// * imagePoints: vector of vectors of the projections of calibration pattern points.
/// imagePoints.size() and objectPoints.size() and imagePoints[i].size() must be equal to
/// objectPoints[i].size() for each i.
/// * image_size: Size of the image used only to initialize the camera intrinsic matrix.
/// * K: Output 3x3 floating-point camera intrinsic matrix
///  . If
/// @ref fisheye::CALIB_USE_INTRINSIC_GUESS is specified, some or all of fx, fy, cx, cy must be
/// initialized before calling the function.
/// * D: Output vector of distortion coefficients .
/// * rvecs: Output vector of rotation vectors (see Rodrigues ) estimated for each pattern view.
/// That is, each k-th rotation vector together with the corresponding k-th translation vector (see
/// the next output parameter description) brings the calibration pattern from the model coordinate
/// space (in which object points are specified) to the world coordinate space, that is, a real
/// position of the calibration pattern in the k-th pattern view (k=0.. *M* -1).
/// * tvecs: Output vector of translation vectors estimated for each pattern view.
/// * flags: Different flags that may be zero or a combination of the following values:
/// * @ref fisheye::CALIB_USE_INTRINSIC_GUESS cameraMatrix contains valid initial values of
/// fx, fy, cx, cy that are optimized further. Otherwise, (cx, cy) is initially set to the image
/// center ( imageSize is used), and focal distances are computed in a least-squares fashion.
/// * @ref fisheye::CALIB_RECOMPUTE_EXTRINSIC Extrinsic will be recomputed after each iteration
/// of intrinsic optimization.
/// * @ref fisheye::CALIB_CHECK_COND The functions will check validity of condition number.
/// * @ref fisheye::CALIB_FIX_SKEW Skew coefficient (alpha) is set to zero and stay zero.
/// * @ref fisheye::CALIB_FIX_K1,..., @ref fisheye::CALIB_FIX_K4 Selected distortion coefficients
/// are set to zeros and stay zero.
/// * @ref fisheye::CALIB_FIX_PRINCIPAL_POINT The principal point is not changed during the global
/// optimization. It stays at the center or at a different location specified when @ref fisheye::CALIB_USE_INTRINSIC_GUESS is set too.
/// * @ref fisheye::CALIB_FIX_FOCAL_LENGTH The focal length is not changed during the global
/// optimization. It is the  or the provided ,  when @ref fisheye::CALIB_USE_INTRINSIC_GUESS is set too.
/// * criteria: Termination criteria for the iterative optimization algorithm.
///
/// ## C++ default parameters
/// * flags: 0
/// * criteria: TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,100,DBL_EPSILON)
pub fn calibrate(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, image_size: core::Size, k: &mut dyn core::ToInputOutputArray, d: &mut dyn core::ToInputOutputArray, rvecs: &mut dyn core::ToOutputArray, tvecs: &mut dyn core::ToOutputArray, flags: i32, criteria: core::TermCriteria) -> Result<f64> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_output_array_arg!(k);
input_output_array_arg!(d);
output_array_arg!(rvecs);
output_array_arg!(tvecs);
unsafe { sys::cv_fisheye_calibrate_const__InputArrayR_const__InputArrayR_const_SizeR_const__InputOutputArrayR_const__InputOutputArrayR_const__OutputArrayR_const__OutputArrayR_int_TermCriteria(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), &image_size, k.as_raw__InputOutputArray(), d.as_raw__InputOutputArray(), rvecs.as_raw__OutputArray(), tvecs.as_raw__OutputArray(), flags, criteria.opencv_as_extern()) }.into_result()
}
/// Distorts 2D points using fisheye model.
///
/// ## Parameters
/// * undistorted: Array of object points, 1xN/Nx1 2-channel (or vector\<Point2f\> ), where N is
/// the number of points in the view.
/// * K: Camera intrinsic matrix .
/// * D: Input vector of distortion coefficients .
/// * alpha: The skew coefficient.
/// * distorted: Output array of image points, 1xN/Nx1 2-channel, or vector\<Point2f\> .
///
/// Note that the function assumes the camera intrinsic matrix of the undistorted points to be identity.
/// This means if you want to transform back points undistorted with #fisheye::undistortPoints you have to
/// multiply them with .
///
/// ## C++ default parameters
/// * alpha: 0
pub fn distort_points(undistorted: &dyn core::ToInputArray, distorted: &mut dyn core::ToOutputArray, k: &dyn core::ToInputArray, d: &dyn core::ToInputArray, alpha: f64) -> Result<()> {
input_array_arg!(undistorted);
output_array_arg!(distorted);
input_array_arg!(k);
input_array_arg!(d);
unsafe { sys::cv_fisheye_distortPoints_const__InputArrayR_const__OutputArrayR_const__InputArrayR_const__InputArrayR_double(undistorted.as_raw__InputArray(), distorted.as_raw__OutputArray(), k.as_raw__InputArray(), d.as_raw__InputArray(), alpha) }.into_result()
}
/// Estimates new camera intrinsic matrix for undistortion or rectification.
///
/// ## Parameters
/// * K: Camera intrinsic matrix .
/// * image_size: Size of the image
/// * D: Input vector of distortion coefficients .
/// * R: Rectification transformation in the object space: 3x3 1-channel, or vector: 3x1/1x3
/// 1-channel or 1x1 3-channel
/// * P: New camera intrinsic matrix (3x3) or new projection matrix (3x4)
/// * balance: Sets the new focal length in range between the min focal length and the max focal
/// length. Balance is in range of [0, 1].
/// * new_size: the new size
/// * fov_scale: Divisor for new focal length.
///
/// ## C++ default parameters
/// * balance: 0.0
/// * new_size: Size()
/// * fov_scale: 1.0
pub fn estimate_new_camera_matrix_for_undistort_rectify(k: &dyn core::ToInputArray, d: &dyn core::ToInputArray, image_size: core::Size, r: &dyn core::ToInputArray, p: &mut dyn core::ToOutputArray, balance: f64, new_size: core::Size, fov_scale: f64) -> Result<()> {
input_array_arg!(k);
input_array_arg!(d);
input_array_arg!(r);
output_array_arg!(p);
unsafe { sys::cv_fisheye_estimateNewCameraMatrixForUndistortRectify_const__InputArrayR_const__InputArrayR_const_SizeR_const__InputArrayR_const__OutputArrayR_double_const_SizeR_double(k.as_raw__InputArray(), d.as_raw__InputArray(), &image_size, r.as_raw__InputArray(), p.as_raw__OutputArray(), balance, &new_size, fov_scale) }.into_result()
}
/// Computes undistortion and rectification maps for image transform by #remap. If D is empty zero
/// distortion is used, if R or P is empty identity matrixes are used.
///
/// ## Parameters
/// * K: Camera intrinsic matrix .
/// * D: Input vector of distortion coefficients .
/// * R: Rectification transformation in the object space: 3x3 1-channel, or vector: 3x1/1x3
/// 1-channel or 1x1 3-channel
/// * P: New camera intrinsic matrix (3x3) or new projection matrix (3x4)
/// * size: Undistorted image size.
/// * m1type: Type of the first output map that can be CV_32FC1 or CV_16SC2 . See #convertMaps
/// for details.
/// * map1: The first output map.
/// * map2: The second output map.
pub fn fisheye_init_undistort_rectify_map(k: &dyn core::ToInputArray, d: &dyn core::ToInputArray, r: &dyn core::ToInputArray, p: &dyn core::ToInputArray, size: core::Size, m1type: i32, map1: &mut dyn core::ToOutputArray, map2: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(k);
input_array_arg!(d);
input_array_arg!(r);
input_array_arg!(p);
output_array_arg!(map1);
output_array_arg!(map2);
unsafe { sys::cv_fisheye_initUndistortRectifyMap_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const_SizeR_int_const__OutputArrayR_const__OutputArrayR(k.as_raw__InputArray(), d.as_raw__InputArray(), r.as_raw__InputArray(), p.as_raw__InputArray(), &size, m1type, map1.as_raw__OutputArray(), map2.as_raw__OutputArray()) }.into_result()
}
/// Projects points using fisheye model
///
/// ## Parameters
/// * objectPoints: Array of object points, 1xN/Nx1 3-channel (or vector\<Point3f\> ), where N is
/// the number of points in the view.
/// * imagePoints: Output array of image points, 2xN/Nx2 1-channel or 1xN/Nx1 2-channel, or
/// vector\<Point2f\>.
/// * affine:
/// * K: Camera intrinsic matrix .
/// * D: Input vector of distortion coefficients .
/// * alpha: The skew coefficient.
/// * jacobian: Optional output 2Nx15 jacobian matrix of derivatives of image points with respect
/// to components of the focal lengths, coordinates of the principal point, distortion coefficients,
/// rotation vector, translation vector, and the skew. In the old interface different components of
/// the jacobian are returned via different output parameters.
///
/// The function computes projections of 3D points to the image plane given intrinsic and extrinsic
/// camera parameters. Optionally, the function computes Jacobians - matrices of partial derivatives of
/// image points coordinates (as functions of all the input parameters) with respect to the particular
/// parameters, intrinsic and/or extrinsic.
///
/// ## C++ default parameters
/// * alpha: 0
/// * jacobian: noArray()
pub fn fisheye_project_points(object_points: &dyn core::ToInputArray, image_points: &mut dyn core::ToOutputArray, affine: core::Affine3d, k: &dyn core::ToInputArray, d: &dyn core::ToInputArray, alpha: f64, jacobian: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(object_points);
output_array_arg!(image_points);
input_array_arg!(k);
input_array_arg!(d);
output_array_arg!(jacobian);
unsafe { sys::cv_fisheye_projectPoints_const__InputArrayR_const__OutputArrayR_const_Affine3dR_const__InputArrayR_const__InputArrayR_double_const__OutputArrayR(object_points.as_raw__InputArray(), image_points.as_raw__OutputArray(), &affine, k.as_raw__InputArray(), d.as_raw__InputArray(), alpha, jacobian.as_raw__OutputArray()) }.into_result()
}
/// Projects points using fisheye model
///
/// ## Parameters
/// * objectPoints: Array of object points, 1xN/Nx1 3-channel (or vector\<Point3f\> ), where N is
/// the number of points in the view.
/// * imagePoints: Output array of image points, 2xN/Nx2 1-channel or 1xN/Nx1 2-channel, or
/// vector\<Point2f\>.
/// * affine:
/// * K: Camera intrinsic matrix .
/// * D: Input vector of distortion coefficients .
/// * alpha: The skew coefficient.
/// * jacobian: Optional output 2Nx15 jacobian matrix of derivatives of image points with respect
/// to components of the focal lengths, coordinates of the principal point, distortion coefficients,
/// rotation vector, translation vector, and the skew. In the old interface different components of
/// the jacobian are returned via different output parameters.
///
/// The function computes projections of 3D points to the image plane given intrinsic and extrinsic
/// camera parameters. Optionally, the function computes Jacobians - matrices of partial derivatives of
/// image points coordinates (as functions of all the input parameters) with respect to the particular
/// parameters, intrinsic and/or extrinsic.
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * alpha: 0
/// * jacobian: noArray()
pub fn fisheye_project_points_vec(object_points: &dyn core::ToInputArray, image_points: &mut dyn core::ToOutputArray, rvec: &dyn core::ToInputArray, tvec: &dyn core::ToInputArray, k: &dyn core::ToInputArray, d: &dyn core::ToInputArray, alpha: f64, jacobian: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(object_points);
output_array_arg!(image_points);
input_array_arg!(rvec);
input_array_arg!(tvec);
input_array_arg!(k);
input_array_arg!(d);
output_array_arg!(jacobian);
unsafe { sys::cv_fisheye_projectPoints_const__InputArrayR_const__OutputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_double_const__OutputArrayR(object_points.as_raw__InputArray(), image_points.as_raw__OutputArray(), rvec.as_raw__InputArray(), tvec.as_raw__InputArray(), k.as_raw__InputArray(), d.as_raw__InputArray(), alpha, jacobian.as_raw__OutputArray()) }.into_result()
}
/// Performs stereo calibration
///
/// ## Parameters
/// * objectPoints: Vector of vectors of the calibration pattern points.
/// * imagePoints1: Vector of vectors of the projections of the calibration pattern points,
/// observed by the first camera.
/// * imagePoints2: Vector of vectors of the projections of the calibration pattern points,
/// observed by the second camera.
/// * K1: Input/output first camera intrinsic matrix:
///  ,  . If
/// any of @ref fisheye::CALIB_USE_INTRINSIC_GUESS , @ref fisheye::CALIB_FIX_INTRINSIC are specified,
/// some or all of the matrix components must be initialized.
/// * D1: Input/output vector of distortion coefficients  of 4 elements.
/// * K2: Input/output second camera intrinsic matrix. The parameter is similar to K1 .
/// * D2: Input/output lens distortion coefficients for the second camera. The parameter is
/// similar to D1 .
/// * imageSize: Size of the image used only to initialize camera intrinsic matrix.
/// * R: Output rotation matrix between the 1st and the 2nd camera coordinate systems.
/// * T: Output translation vector between the coordinate systems of the cameras.
/// * flags: Different flags that may be zero or a combination of the following values:
/// * @ref fisheye::CALIB_FIX_INTRINSIC Fix K1, K2? and D1, D2? so that only R, T matrices
/// are estimated.
/// * @ref fisheye::CALIB_USE_INTRINSIC_GUESS K1, K2 contains valid initial values of
/// fx, fy, cx, cy that are optimized further. Otherwise, (cx, cy) is initially set to the image
/// center (imageSize is used), and focal distances are computed in a least-squares fashion.
/// * @ref fisheye::CALIB_RECOMPUTE_EXTRINSIC Extrinsic will be recomputed after each iteration
/// of intrinsic optimization.
/// * @ref fisheye::CALIB_CHECK_COND The functions will check validity of condition number.
/// * @ref fisheye::CALIB_FIX_SKEW Skew coefficient (alpha) is set to zero and stay zero.
/// * @ref fisheye::CALIB_FIX_K1,..., @ref fisheye::CALIB_FIX_K4 Selected distortion coefficients are set to zeros and stay
/// zero.
/// * criteria: Termination criteria for the iterative optimization algorithm.
///
/// ## C++ default parameters
/// * flags: fisheye::CALIB_FIX_INTRINSIC
/// * criteria: TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,100,DBL_EPSILON)
pub fn fisheye_stereo_calibrate(object_points: &dyn core::ToInputArray, image_points1: &dyn core::ToInputArray, image_points2: &dyn core::ToInputArray, k1: &mut dyn core::ToInputOutputArray, d1: &mut dyn core::ToInputOutputArray, k2: &mut dyn core::ToInputOutputArray, d2: &mut dyn core::ToInputOutputArray, image_size: core::Size, r: &mut dyn core::ToOutputArray, t: &mut dyn core::ToOutputArray, flags: i32, criteria: core::TermCriteria) -> Result<f64> {
input_array_arg!(object_points);
input_array_arg!(image_points1);
input_array_arg!(image_points2);
input_output_array_arg!(k1);
input_output_array_arg!(d1);
input_output_array_arg!(k2);
input_output_array_arg!(d2);
output_array_arg!(r);
output_array_arg!(t);
unsafe { sys::cv_fisheye_stereoCalibrate_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_Size_const__OutputArrayR_const__OutputArrayR_int_TermCriteria(object_points.as_raw__InputArray(), image_points1.as_raw__InputArray(), image_points2.as_raw__InputArray(), k1.as_raw__InputOutputArray(), d1.as_raw__InputOutputArray(), k2.as_raw__InputOutputArray(), d2.as_raw__InputOutputArray(), image_size.opencv_as_extern(), r.as_raw__OutputArray(), t.as_raw__OutputArray(), flags, criteria.opencv_as_extern()) }.into_result()
}
/// Stereo rectification for fisheye camera model
///
/// ## Parameters
/// * K1: First camera intrinsic matrix.
/// * D1: First camera distortion parameters.
/// * K2: Second camera intrinsic matrix.
/// * D2: Second camera distortion parameters.
/// * imageSize: Size of the image used for stereo calibration.
/// * R: Rotation matrix between the coordinate systems of the first and the second
/// cameras.
/// * tvec: Translation vector between coordinate systems of the cameras.
/// * R1: Output 3x3 rectification transform (rotation matrix) for the first camera.
/// * R2: Output 3x3 rectification transform (rotation matrix) for the second camera.
/// * P1: Output 3x4 projection matrix in the new (rectified) coordinate systems for the first
/// camera.
/// * P2: Output 3x4 projection matrix in the new (rectified) coordinate systems for the second
/// camera.
/// * Q: Output  disparity-to-depth mapping matrix (see reprojectImageTo3D ).
/// * flags: Operation flags that may be zero or @ref fisheye::CALIB_ZERO_DISPARITY . If the flag is set,
/// the function makes the principal points of each camera have the same pixel coordinates in the
/// rectified views. And if the flag is not set, the function may still shift the images in the
/// horizontal or vertical direction (depending on the orientation of epipolar lines) to maximize the
/// useful image area.
/// * newImageSize: New image resolution after rectification. The same size should be passed to
/// #initUndistortRectifyMap (see the stereo_calib.cpp sample in OpenCV samples directory). When (0,0)
/// is passed (default), it is set to the original imageSize . Setting it to larger value can help you
/// preserve details in the original image, especially when there is a big radial distortion.
/// * balance: Sets the new focal length in range between the min focal length and the max focal
/// length. Balance is in range of [0, 1].
/// * fov_scale: Divisor for new focal length.
///
/// ## C++ default parameters
/// * new_image_size: Size()
/// * balance: 0.0
/// * fov_scale: 1.0
pub fn fisheye_stereo_rectify(k1: &dyn core::ToInputArray, d1: &dyn core::ToInputArray, k2: &dyn core::ToInputArray, d2: &dyn core::ToInputArray, image_size: core::Size, r: &dyn core::ToInputArray, tvec: &dyn core::ToInputArray, r1: &mut dyn core::ToOutputArray, r2: &mut dyn core::ToOutputArray, p1: &mut dyn core::ToOutputArray, p2: &mut dyn core::ToOutputArray, q: &mut dyn core::ToOutputArray, flags: i32, new_image_size: core::Size, balance: f64, fov_scale: f64) -> Result<()> {
input_array_arg!(k1);
input_array_arg!(d1);
input_array_arg!(k2);
input_array_arg!(d2);
input_array_arg!(r);
input_array_arg!(tvec);
output_array_arg!(r1);
output_array_arg!(r2);
output_array_arg!(p1);
output_array_arg!(p2);
output_array_arg!(q);
unsafe { sys::cv_fisheye_stereoRectify_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const_SizeR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_int_const_SizeR_double_double(k1.as_raw__InputArray(), d1.as_raw__InputArray(), k2.as_raw__InputArray(), d2.as_raw__InputArray(), &image_size, r.as_raw__InputArray(), tvec.as_raw__InputArray(), r1.as_raw__OutputArray(), r2.as_raw__OutputArray(), p1.as_raw__OutputArray(), p2.as_raw__OutputArray(), q.as_raw__OutputArray(), flags, &new_image_size, balance, fov_scale) }.into_result()
}
/// Transforms an image to compensate for fisheye lens distortion.
///
/// ## Parameters
/// * distorted: image with fisheye lens distortion.
/// * undistorted: Output image with compensated fisheye lens distortion.
/// * K: Camera intrinsic matrix .
/// * D: Input vector of distortion coefficients .
/// * Knew: Camera intrinsic matrix of the distorted image. By default, it is the identity matrix but you
/// may additionally scale and shift the result by using a different matrix.
/// * new_size: the new size
///
/// The function transforms an image to compensate radial and tangential lens distortion.
///
/// The function is simply a combination of #fisheye::initUndistortRectifyMap (with unity R ) and #remap
/// (with bilinear interpolation). See the former function for details of the transformation being
/// performed.
///
/// See below the results of undistortImage.
/// * a\) result of undistort of perspective camera model (all possible coefficients (k_1, k_2, k_3,
/// k_4, k_5, k_6) of distortion were optimized under calibration)
/// * b\) result of #fisheye::undistortImage of fisheye camera model (all possible coefficients (k_1, k_2,
/// k_3, k_4) of fisheye distortion were optimized under calibration)
/// * c\) original image was captured with fisheye lens
///
/// Pictures a) and b) almost the same. But if we consider points of image located far from the center
/// of image, we can notice that on image a) these points are distorted.
///
/// 
///
/// ## C++ default parameters
/// * knew: cv::noArray()
/// * new_size: Size()
pub fn fisheye_undistort_image(distorted: &dyn core::ToInputArray, undistorted: &mut dyn core::ToOutputArray, k: &dyn core::ToInputArray, d: &dyn core::ToInputArray, knew: &dyn core::ToInputArray, new_size: core::Size) -> Result<()> {
input_array_arg!(distorted);
output_array_arg!(undistorted);
input_array_arg!(k);
input_array_arg!(d);
input_array_arg!(knew);
unsafe { sys::cv_fisheye_undistortImage_const__InputArrayR_const__OutputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const_SizeR(distorted.as_raw__InputArray(), undistorted.as_raw__OutputArray(), k.as_raw__InputArray(), d.as_raw__InputArray(), knew.as_raw__InputArray(), &new_size) }.into_result()
}
/// Undistorts 2D points using fisheye model
///
/// ## Parameters
/// * distorted: Array of object points, 1xN/Nx1 2-channel (or vector\<Point2f\> ), where N is the
/// number of points in the view.
/// * K: Camera intrinsic matrix .
/// * D: Input vector of distortion coefficients .
/// * R: Rectification transformation in the object space: 3x3 1-channel, or vector: 3x1/1x3
/// 1-channel or 1x1 3-channel
/// * P: New camera intrinsic matrix (3x3) or new projection matrix (3x4)
/// * undistorted: Output array of image points, 1xN/Nx1 2-channel, or vector\<Point2f\> .
///
/// ## C++ default parameters
/// * r: noArray()
/// * p: noArray()
pub fn fisheye_undistort_points(distorted: &dyn core::ToInputArray, undistorted: &mut dyn core::ToOutputArray, k: &dyn core::ToInputArray, d: &dyn core::ToInputArray, r: &dyn core::ToInputArray, p: &dyn core::ToInputArray) -> Result<()> {
input_array_arg!(distorted);
output_array_arg!(undistorted);
input_array_arg!(k);
input_array_arg!(d);
input_array_arg!(r);
input_array_arg!(p);
unsafe { sys::cv_fisheye_undistortPoints_const__InputArrayR_const__OutputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR(distorted.as_raw__InputArray(), undistorted.as_raw__OutputArray(), k.as_raw__InputArray(), d.as_raw__InputArray(), r.as_raw__InputArray(), p.as_raw__InputArray()) }.into_result()
}
/// Returns the default new camera matrix.
///
/// The function returns the camera matrix that is either an exact copy of the input cameraMatrix (when
/// centerPrinicipalPoint=false ), or the modified one (when centerPrincipalPoint=true).
///
/// In the latter case, the new camera matrix will be:
///
/// 
///
/// where  and  are  and  elements of cameraMatrix, respectively.
///
/// By default, the undistortion functions in OpenCV (see #initUndistortRectifyMap, #undistort) do not
/// move the principal point. However, when you work with stereo, it is important to move the principal
/// points in both views to the same y-coordinate (which is required by most of stereo correspondence
/// algorithms), and may be to the same x-coordinate too. So, you can form the new camera matrix for
/// each view where the principal points are located at the center.
///
/// ## Parameters
/// * cameraMatrix: Input camera matrix.
/// * imgsize: Camera view image size in pixels.
/// * centerPrincipalPoint: Location of the principal point in the new camera matrix. The
/// parameter indicates whether this location should be at the image center or not.
///
/// ## C++ default parameters
/// * imgsize: Size()
/// * center_principal_point: false
pub fn get_default_new_camera_matrix(camera_matrix: &dyn core::ToInputArray, imgsize: core::Size, center_principal_point: bool) -> Result<core::Mat> {
input_array_arg!(camera_matrix);
unsafe { sys::cv_getDefaultNewCameraMatrix_const__InputArrayR_Size_bool(camera_matrix.as_raw__InputArray(), imgsize.opencv_as_extern(), center_principal_point) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Returns the new camera intrinsic matrix based on the free scaling parameter.
///
/// ## Parameters
/// * cameraMatrix: Input camera intrinsic matrix.
/// * distCoeffs: Input vector of distortion coefficients
/// . If the vector is NULL/empty, the zero distortion coefficients are
/// assumed.
/// * imageSize: Original image size.
/// * alpha: Free scaling parameter between 0 (when all the pixels in the undistorted image are
/// valid) and 1 (when all the source image pixels are retained in the undistorted image). See
/// #stereoRectify for details.
/// * newImgSize: Image size after rectification. By default, it is set to imageSize .
/// * validPixROI: Optional output rectangle that outlines all-good-pixels region in the
/// undistorted image. See roi1, roi2 description in #stereoRectify .
/// * centerPrincipalPoint: Optional flag that indicates whether in the new camera intrinsic matrix the
/// principal point should be at the image center or not. By default, the principal point is chosen to
/// best fit a subset of the source image (determined by alpha) to the corrected image.
/// ## Returns
/// new_camera_matrix Output new camera intrinsic matrix.
///
/// The function computes and returns the optimal new camera intrinsic matrix based on the free scaling parameter.
/// By varying this parameter, you may retrieve only sensible pixels alpha=0 , keep all the original
/// image pixels if there is valuable information in the corners alpha=1 , or get something in between.
/// When alpha\>0 , the undistorted result is likely to have some black pixels corresponding to
/// "virtual" pixels outside of the captured distorted image. The original camera intrinsic matrix, distortion
/// coefficients, the computed new camera intrinsic matrix, and newImageSize should be passed to
/// #initUndistortRectifyMap to produce the maps for #remap .
///
/// ## C++ default parameters
/// * new_img_size: Size()
/// * valid_pix_roi: 0
/// * center_principal_point: false
pub fn get_optimal_new_camera_matrix(camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, image_size: core::Size, alpha: f64, new_img_size: core::Size, valid_pix_roi: &mut core::Rect, center_principal_point: bool) -> Result<core::Mat> {
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
unsafe { sys::cv_getOptimalNewCameraMatrix_const__InputArrayR_const__InputArrayR_Size_double_Size_RectX_bool(camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), image_size.opencv_as_extern(), alpha, new_img_size.opencv_as_extern(), valid_pix_roi, center_principal_point) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// computes valid disparity ROI from the valid ROIs of the rectified images (that are returned by #stereoRectify)
pub fn get_valid_disparity_roi(roi1: core::Rect, roi2: core::Rect, min_disparity: i32, number_of_disparities: i32, block_size: i32) -> Result<core::Rect> {
unsafe { sys::cv_getValidDisparityROI_Rect_Rect_int_int_int(roi1.opencv_as_extern(), roi2.opencv_as_extern(), min_disparity, number_of_disparities, block_size) }.into_result()
}
/// Finds an initial camera intrinsic matrix from 3D-2D point correspondences.
///
/// ## Parameters
/// * objectPoints: Vector of vectors of the calibration pattern points in the calibration pattern
/// coordinate space. In the old interface all the per-view vectors are concatenated. See
/// #calibrateCamera for details.
/// * imagePoints: Vector of vectors of the projections of the calibration pattern points. In the
/// old interface all the per-view vectors are concatenated.
/// * imageSize: Image size in pixels used to initialize the principal point.
/// * aspectRatio: If it is zero or negative, both  and  are estimated independently.
/// Otherwise,  .
///
/// The function estimates and returns an initial camera intrinsic matrix for the camera calibration process.
/// Currently, the function only supports planar calibration patterns, which are patterns where each
/// object point has z-coordinate =0.
///
/// ## C++ default parameters
/// * aspect_ratio: 1.0
pub fn init_camera_matrix_2d(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, image_size: core::Size, aspect_ratio: f64) -> Result<core::Mat> {
input_array_arg!(object_points);
input_array_arg!(image_points);
unsafe { sys::cv_initCameraMatrix2D_const__InputArrayR_const__InputArrayR_Size_double(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), image_size.opencv_as_extern(), aspect_ratio) }.into_result().map(|r| unsafe { core::Mat::opencv_from_extern(r) } )
}
/// Computes the projection and inverse-rectification transformation map. In essense, this is the inverse of
/// #initUndistortRectifyMap to accomodate stereo-rectification of projectors ('inverse-cameras') in projector-camera pairs.
///
/// The function computes the joint projection and inverse rectification transformation and represents the
/// result in the form of maps for #remap. The projected image looks like a distorted version of the original which,
/// once projected by a projector, should visually match the original. In case of a monocular camera, newCameraMatrix
/// is usually equal to cameraMatrix, or it can be computed by
/// #getOptimalNewCameraMatrix for a better control over scaling. In case of a projector-camera pair,
/// newCameraMatrix is normally set to P1 or P2 computed by #stereoRectify .
///
/// The projector is oriented differently in the coordinate space, according to R. In case of projector-camera pairs,
/// this helps align the projector (in the same manner as #initUndistortRectifyMap for the camera) to create a stereo-rectified pair. This
/// allows epipolar lines on both images to become horizontal and have the same y-coordinate (in case of a horizontally aligned projector-camera pair).
///
/// The function builds the maps for the inverse mapping algorithm that is used by #remap. That
/// is, for each pixel  in the destination (projected and inverse-rectified) image, the function
/// computes the corresponding coordinates in the source image (that is, in the original digital image). The following process is applied:
///
/// 
/// where 
/// are the distortion coefficients vector distCoeffs.
///
/// In case of a stereo-rectified projector-camera pair, this function is called for the projector while #initUndistortRectifyMap is called for the camera head.
/// This is done after #stereoRectify, which in turn is called after #stereoCalibrate. If the projector-camera pair
/// is not calibrated, it is still possible to compute the rectification transformations directly from
/// the fundamental matrix using #stereoRectifyUncalibrated. For the projector and camera, the function computes
/// homography H as the rectification transformation in a pixel domain, not a rotation matrix R in 3D
/// space. R can be computed from H as
/// 
/// where cameraMatrix can be chosen arbitrarily.
///
/// ## Parameters
/// * cameraMatrix: Input camera matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * R: Optional rectification transformation in the object space (3x3 matrix). R1 or R2,
/// computed by #stereoRectify can be passed here. If the matrix is empty, the identity transformation
/// is assumed.
/// * newCameraMatrix: New camera matrix .
/// * size: Distorted image size.
/// * m1type: Type of the first output map. Can be CV_32FC1, CV_32FC2 or CV_16SC2, see #convertMaps
/// * map1: The first output map for #remap.
/// * map2: The second output map for #remap.
pub fn init_inverse_rectification_map(camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, r: &dyn core::ToInputArray, new_camera_matrix: &dyn core::ToInputArray, size: core::Size, m1type: i32, map1: &mut dyn core::ToOutputArray, map2: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
input_array_arg!(r);
input_array_arg!(new_camera_matrix);
output_array_arg!(map1);
output_array_arg!(map2);
unsafe { sys::cv_initInverseRectificationMap_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const_SizeR_int_const__OutputArrayR_const__OutputArrayR(camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), r.as_raw__InputArray(), new_camera_matrix.as_raw__InputArray(), &size, m1type, map1.as_raw__OutputArray(), map2.as_raw__OutputArray()) }.into_result()
}
/// Computes the undistortion and rectification transformation map.
///
/// The function computes the joint undistortion and rectification transformation and represents the
/// result in the form of maps for #remap. The undistorted image looks like original, as if it is
/// captured with a camera using the camera matrix =newCameraMatrix and zero distortion. In case of a
/// monocular camera, newCameraMatrix is usually equal to cameraMatrix, or it can be computed by
/// #getOptimalNewCameraMatrix for a better control over scaling. In case of a stereo camera,
/// newCameraMatrix is normally set to P1 or P2 computed by #stereoRectify .
///
/// Also, this new camera is oriented differently in the coordinate space, according to R. That, for
/// example, helps to align two heads of a stereo camera so that the epipolar lines on both images
/// become horizontal and have the same y- coordinate (in case of a horizontally aligned stereo camera).
///
/// The function actually builds the maps for the inverse mapping algorithm that is used by #remap. That
/// is, for each pixel  in the destination (corrected and rectified) image, the function
/// computes the corresponding coordinates in the source image (that is, in the original image from
/// camera). The following process is applied:
/// 
/// where 
/// are the distortion coefficients.
///
/// In case of a stereo camera, this function is called twice: once for each camera head, after
/// #stereoRectify, which in its turn is called after #stereoCalibrate. But if the stereo camera
/// was not calibrated, it is still possible to compute the rectification transformations directly from
/// the fundamental matrix using #stereoRectifyUncalibrated. For each camera, the function computes
/// homography H as the rectification transformation in a pixel domain, not a rotation matrix R in 3D
/// space. R can be computed from H as
/// 
/// where cameraMatrix can be chosen arbitrarily.
///
/// ## Parameters
/// * cameraMatrix: Input camera matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * R: Optional rectification transformation in the object space (3x3 matrix). R1 or R2 ,
/// computed by #stereoRectify can be passed here. If the matrix is empty, the identity transformation
/// is assumed. In cvInitUndistortMap R assumed to be an identity matrix.
/// * newCameraMatrix: New camera matrix .
/// * size: Undistorted image size.
/// * m1type: Type of the first output map that can be CV_32FC1, CV_32FC2 or CV_16SC2, see #convertMaps
/// * map1: The first output map.
/// * map2: The second output map.
pub fn init_undistort_rectify_map(camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, r: &dyn core::ToInputArray, new_camera_matrix: &dyn core::ToInputArray, size: core::Size, m1type: i32, map1: &mut dyn core::ToOutputArray, map2: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
input_array_arg!(r);
input_array_arg!(new_camera_matrix);
output_array_arg!(map1);
output_array_arg!(map2);
unsafe { sys::cv_initUndistortRectifyMap_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_Size_int_const__OutputArrayR_const__OutputArrayR(camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), r.as_raw__InputArray(), new_camera_matrix.as_raw__InputArray(), size.opencv_as_extern(), m1type, map1.as_raw__OutputArray(), map2.as_raw__OutputArray()) }.into_result()
}
/// initializes maps for #remap for wide-angle
///
/// ## C++ default parameters
/// * proj_type: PROJ_SPHERICAL_EQRECT
/// * alpha: 0
pub fn init_wide_angle_proj_map(camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, image_size: core::Size, dest_image_width: i32, m1type: i32, map1: &mut dyn core::ToOutputArray, map2: &mut dyn core::ToOutputArray, proj_type: crate::calib3d::UndistortTypes, alpha: f64) -> Result<f32> {
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
output_array_arg!(map1);
output_array_arg!(map2);
unsafe { sys::cv_initWideAngleProjMap_const__InputArrayR_const__InputArrayR_Size_int_int_const__OutputArrayR_const__OutputArrayR_UndistortTypes_double(camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), image_size.opencv_as_extern(), dest_image_width, m1type, map1.as_raw__OutputArray(), map2.as_raw__OutputArray(), proj_type, alpha) }.into_result()
}
/// Computes partial derivatives of the matrix product for each multiplied matrix.
///
/// ## Parameters
/// * A: First multiplied matrix.
/// * B: Second multiplied matrix.
/// * dABdA: First output derivative matrix d(A\*B)/dA of size
///  .
/// * dABdB: Second output derivative matrix d(A\*B)/dB of size
///  .
///
/// The function computes partial derivatives of the elements of the matrix product  with regard to
/// the elements of each of the two input matrices. The function is used to compute the Jacobian
/// matrices in #stereoCalibrate but can also be used in any other similar optimization function.
pub fn mat_mul_deriv(a: &dyn core::ToInputArray, b: &dyn core::ToInputArray, d_a_bd_a: &mut dyn core::ToOutputArray, d_a_bd_b: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(a);
input_array_arg!(b);
output_array_arg!(d_a_bd_a);
output_array_arg!(d_a_bd_b);
unsafe { sys::cv_matMulDeriv_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR(a.as_raw__InputArray(), b.as_raw__InputArray(), d_a_bd_a.as_raw__OutputArray(), d_a_bd_b.as_raw__OutputArray()) }.into_result()
}
/// Projects 3D points to an image plane.
///
/// ## Parameters
/// * objectPoints: Array of object points expressed wrt. the world coordinate frame. A 3xN/Nx3
/// 1-channel or 1xN/Nx1 3-channel (or vector\<Point3f\> ), where N is the number of points in the view.
/// * rvec: The rotation vector (@ref Rodrigues) that, together with tvec, performs a change of
/// basis from world to camera coordinate system, see @ref calibrateCamera for details.
/// * tvec: The translation vector, see parameter description above.
/// * cameraMatrix: Camera intrinsic matrix  .
/// * distCoeffs: Input vector of distortion coefficients
///  . If the vector is empty, the zero distortion coefficients are assumed.
/// * imagePoints: Output array of image points, 1xN/Nx1 2-channel, or
/// vector\<Point2f\> .
/// * jacobian: Optional output 2Nx(10+\<numDistCoeffs\>) jacobian matrix of derivatives of image
/// points with respect to components of the rotation vector, translation vector, focal lengths,
/// coordinates of the principal point and the distortion coefficients. In the old interface different
/// components of the jacobian are returned via different output parameters.
/// * aspectRatio: Optional "fixed aspect ratio" parameter. If the parameter is not 0, the
/// function assumes that the aspect ratio () is fixed and correspondingly adjusts the
/// jacobian matrix.
///
/// The function computes the 2D projections of 3D points to the image plane, given intrinsic and
/// extrinsic camera parameters. Optionally, the function computes Jacobians -matrices of partial
/// derivatives of image points coordinates (as functions of all the input parameters) with respect to
/// the particular parameters, intrinsic and/or extrinsic. The Jacobians are used during the global
/// optimization in @ref calibrateCamera, @ref solvePnP, and @ref stereoCalibrate. The function itself
/// can also be used to compute a re-projection error, given the current intrinsic and extrinsic
/// parameters.
///
///
/// Note: By setting rvec = tvec = , or by setting cameraMatrix to a 3x3 identity matrix,
/// or by passing zero distortion coefficients, one can get various useful partial cases of the
/// function. This means, one can compute the distorted coordinates for a sparse set of points or apply
/// a perspective transformation (and also compute the derivatives) in the ideal zero-distortion setup.
///
/// ## C++ default parameters
/// * jacobian: noArray()
/// * aspect_ratio: 0
pub fn project_points(object_points: &dyn core::ToInputArray, rvec: &dyn core::ToInputArray, tvec: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, image_points: &mut dyn core::ToOutputArray, jacobian: &mut dyn core::ToOutputArray, aspect_ratio: f64) -> Result<()> {
input_array_arg!(object_points);
input_array_arg!(rvec);
input_array_arg!(tvec);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
output_array_arg!(image_points);
output_array_arg!(jacobian);
unsafe { sys::cv_projectPoints_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_double(object_points.as_raw__InputArray(), rvec.as_raw__InputArray(), tvec.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), image_points.as_raw__OutputArray(), jacobian.as_raw__OutputArray(), aspect_ratio) }.into_result()
}
/// Recovers the relative camera rotation and the translation from an estimated essential
/// matrix and the corresponding points in two images, using cheirality check. Returns the number of
/// inliers that pass the check.
///
/// ## Parameters
/// * E: The input essential matrix.
/// * points1: Array of N 2D points from the first image. The point coordinates should be
/// floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * cameraMatrix: Camera intrinsic matrix  .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera intrinsic matrix.
/// * R: Output rotation matrix. Together with the translation vector, this matrix makes up a tuple
/// that performs a change of basis from the first camera's coordinate system to the second camera's
/// coordinate system. Note that, in general, t can not be used for this tuple, see the parameter
/// described below.
/// * t: Output translation vector. This vector is obtained by @ref decomposeEssentialMat and
/// therefore is only known up to scale, i.e. t is the direction of the translation vector and has unit
/// length.
/// * mask: Input/output mask for inliers in points1 and points2. If it is not empty, then it marks
/// inliers in points1 and points2 for then given essential matrix E. Only these inliers will be used to
/// recover pose. In the output mask only inliers which pass the cheirality check.
///
/// This function decomposes an essential matrix using @ref decomposeEssentialMat and then verifies
/// possible pose hypotheses by doing cheirality check. The cheirality check means that the
/// triangulated 3D points should have positive depth. Some details can be found in [Nister03](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Nister03).
///
/// This function can be used to process the output E and mask from @ref findEssentialMat. In this
/// scenario, points1 and points2 are the same input for #findEssentialMat :
/// ```ignore
/// // Example. Estimation of fundamental matrix using the RANSAC algorithm
/// int point_count = 100;
/// vector<Point2f> points1(point_count);
/// vector<Point2f> points2(point_count);
///
/// // initialize the points here ...
/// for( int i = 0; i < point_count; i++ )
/// {
/// points1[i] = ...;
/// points2[i] = ...;
/// }
///
/// // cametra matrix with both focal lengths = 1, and principal point = (0, 0)
/// Mat cameraMatrix = Mat::eye(3, 3, CV_64F);
///
/// Mat E, R, t, mask;
///
/// E = findEssentialMat(points1, points2, cameraMatrix, RANSAC, 0.999, 1.0, mask);
/// recoverPose(E, points1, points2, cameraMatrix, R, t, mask);
/// ```
///
///
/// ## C++ default parameters
/// * mask: noArray()
pub fn recover_pose_camera(e: &dyn core::ToInputArray, points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, r: &mut dyn core::ToOutputArray, t: &mut dyn core::ToOutputArray, mask: &mut dyn core::ToInputOutputArray) -> Result<i32> {
input_array_arg!(e);
input_array_arg!(points1);
input_array_arg!(points2);
input_array_arg!(camera_matrix);
output_array_arg!(r);
output_array_arg!(t);
input_output_array_arg!(mask);
unsafe { sys::cv_recoverPose_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__InputOutputArrayR(e.as_raw__InputArray(), points1.as_raw__InputArray(), points2.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), r.as_raw__OutputArray(), t.as_raw__OutputArray(), mask.as_raw__InputOutputArray()) }.into_result()
}
/// Recovers the relative camera rotation and the translation from an estimated essential
/// matrix and the corresponding points in two images, using cheirality check. Returns the number of
/// inliers that pass the check.
///
/// ## Parameters
/// * E: The input essential matrix.
/// * points1: Array of N 2D points from the first image. The point coordinates should be
/// floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * cameraMatrix: Camera intrinsic matrix  .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera intrinsic matrix.
/// * R: Output rotation matrix. Together with the translation vector, this matrix makes up a tuple
/// that performs a change of basis from the first camera's coordinate system to the second camera's
/// coordinate system. Note that, in general, t can not be used for this tuple, see the parameter
/// described below.
/// * t: Output translation vector. This vector is obtained by @ref decomposeEssentialMat and
/// therefore is only known up to scale, i.e. t is the direction of the translation vector and has unit
/// length.
/// * mask: Input/output mask for inliers in points1 and points2. If it is not empty, then it marks
/// inliers in points1 and points2 for then given essential matrix E. Only these inliers will be used to
/// recover pose. In the output mask only inliers which pass the cheirality check.
///
/// This function decomposes an essential matrix using @ref decomposeEssentialMat and then verifies
/// possible pose hypotheses by doing cheirality check. The cheirality check means that the
/// triangulated 3D points should have positive depth. Some details can be found in [Nister03](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Nister03).
///
/// This function can be used to process the output E and mask from @ref findEssentialMat. In this
/// scenario, points1 and points2 are the same input for #findEssentialMat :
/// ```ignore
/// // Example. Estimation of fundamental matrix using the RANSAC algorithm
/// int point_count = 100;
/// vector<Point2f> points1(point_count);
/// vector<Point2f> points2(point_count);
///
/// // initialize the points here ...
/// for( int i = 0; i < point_count; i++ )
/// {
/// points1[i] = ...;
/// points2[i] = ...;
/// }
///
/// // cametra matrix with both focal lengths = 1, and principal point = (0, 0)
/// Mat cameraMatrix = Mat::eye(3, 3, CV_64F);
///
/// Mat E, R, t, mask;
///
/// E = findEssentialMat(points1, points2, cameraMatrix, RANSAC, 0.999, 1.0, mask);
/// recoverPose(E, points1, points2, cameraMatrix, R, t, mask);
/// ```
///
///
/// ## Overloaded parameters
///
/// * E: The input essential matrix.
/// * points1: Array of N 2D points from the first image. The point coordinates should be
/// floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1.
/// * cameraMatrix: Camera intrinsic matrix  .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera intrinsic matrix.
/// * R: Output rotation matrix. Together with the translation vector, this matrix makes up a tuple
/// that performs a change of basis from the first camera's coordinate system to the second camera's
/// coordinate system. Note that, in general, t can not be used for this tuple, see the parameter
/// description below.
/// * t: Output translation vector. This vector is obtained by @ref decomposeEssentialMat and
/// therefore is only known up to scale, i.e. t is the direction of the translation vector and has unit
/// length.
/// * distanceThresh: threshold distance which is used to filter out far away points (i.e. infinite
/// points).
/// * mask: Input/output mask for inliers in points1 and points2. If it is not empty, then it marks
/// inliers in points1 and points2 for then given essential matrix E. Only these inliers will be used to
/// recover pose. In the output mask only inliers which pass the cheirality check.
/// * triangulatedPoints: 3D points which were reconstructed by triangulation.
///
/// This function differs from the one above that it outputs the triangulated 3D point that are used for
/// the cheirality check.
///
/// ## C++ default parameters
/// * mask: noArray()
/// * triangulated_points: noArray()
pub fn recover_pose_camera_with_points(e: &dyn core::ToInputArray, points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, r: &mut dyn core::ToOutputArray, t: &mut dyn core::ToOutputArray, distance_thresh: f64, mask: &mut dyn core::ToInputOutputArray, triangulated_points: &mut dyn core::ToOutputArray) -> Result<i32> {
input_array_arg!(e);
input_array_arg!(points1);
input_array_arg!(points2);
input_array_arg!(camera_matrix);
output_array_arg!(r);
output_array_arg!(t);
input_output_array_arg!(mask);
output_array_arg!(triangulated_points);
unsafe { sys::cv_recoverPose_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_double_const__InputOutputArrayR_const__OutputArrayR(e.as_raw__InputArray(), points1.as_raw__InputArray(), points2.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), r.as_raw__OutputArray(), t.as_raw__OutputArray(), distance_thresh, mask.as_raw__InputOutputArray(), triangulated_points.as_raw__OutputArray()) }.into_result()
}
/// Recovers the relative camera rotation and the translation from an estimated essential
/// matrix and the corresponding points in two images, using cheirality check. Returns the number of
/// inliers that pass the check.
///
/// ## Parameters
/// * E: The input essential matrix.
/// * points1: Array of N 2D points from the first image. The point coordinates should be
/// floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * cameraMatrix: Camera intrinsic matrix  .
/// Note that this function assumes that points1 and points2 are feature points from cameras with the
/// same camera intrinsic matrix.
/// * R: Output rotation matrix. Together with the translation vector, this matrix makes up a tuple
/// that performs a change of basis from the first camera's coordinate system to the second camera's
/// coordinate system. Note that, in general, t can not be used for this tuple, see the parameter
/// described below.
/// * t: Output translation vector. This vector is obtained by @ref decomposeEssentialMat and
/// therefore is only known up to scale, i.e. t is the direction of the translation vector and has unit
/// length.
/// * mask: Input/output mask for inliers in points1 and points2. If it is not empty, then it marks
/// inliers in points1 and points2 for then given essential matrix E. Only these inliers will be used to
/// recover pose. In the output mask only inliers which pass the cheirality check.
///
/// This function decomposes an essential matrix using @ref decomposeEssentialMat and then verifies
/// possible pose hypotheses by doing cheirality check. The cheirality check means that the
/// triangulated 3D points should have positive depth. Some details can be found in [Nister03](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Nister03).
///
/// This function can be used to process the output E and mask from @ref findEssentialMat. In this
/// scenario, points1 and points2 are the same input for #findEssentialMat :
/// ```ignore
/// // Example. Estimation of fundamental matrix using the RANSAC algorithm
/// int point_count = 100;
/// vector<Point2f> points1(point_count);
/// vector<Point2f> points2(point_count);
///
/// // initialize the points here ...
/// for( int i = 0; i < point_count; i++ )
/// {
/// points1[i] = ...;
/// points2[i] = ...;
/// }
///
/// // cametra matrix with both focal lengths = 1, and principal point = (0, 0)
/// Mat cameraMatrix = Mat::eye(3, 3, CV_64F);
///
/// Mat E, R, t, mask;
///
/// E = findEssentialMat(points1, points2, cameraMatrix, RANSAC, 0.999, 1.0, mask);
/// recoverPose(E, points1, points2, cameraMatrix, R, t, mask);
/// ```
///
///
/// ## Overloaded parameters
///
/// * E: The input essential matrix.
/// * points1: Array of N 2D points from the first image. The point coordinates should be
/// floating-point (single or double precision).
/// * points2: Array of the second image points of the same size and format as points1 .
/// * R: Output rotation matrix. Together with the translation vector, this matrix makes up a tuple
/// that performs a change of basis from the first camera's coordinate system to the second camera's
/// coordinate system. Note that, in general, t can not be used for this tuple, see the parameter
/// description below.
/// * t: Output translation vector. This vector is obtained by @ref decomposeEssentialMat and
/// therefore is only known up to scale, i.e. t is the direction of the translation vector and has unit
/// length.
/// * focal: Focal length of the camera. Note that this function assumes that points1 and points2
/// are feature points from cameras with same focal length and principal point.
/// * pp: principal point of the camera.
/// * mask: Input/output mask for inliers in points1 and points2. If it is not empty, then it marks
/// inliers in points1 and points2 for then given essential matrix E. Only these inliers will be used to
/// recover pose. In the output mask only inliers which pass the cheirality check.
///
/// This function differs from the one above that it computes camera intrinsic matrix from focal length and
/// principal point:
///
/// 
///
/// ## C++ default parameters
/// * focal: 1.0
/// * pp: Point2d(0,0)
/// * mask: noArray()
pub fn recover_pose(e: &dyn core::ToInputArray, points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, r: &mut dyn core::ToOutputArray, t: &mut dyn core::ToOutputArray, focal: f64, pp: core::Point2d, mask: &mut dyn core::ToInputOutputArray) -> Result<i32> {
input_array_arg!(e);
input_array_arg!(points1);
input_array_arg!(points2);
output_array_arg!(r);
output_array_arg!(t);
input_output_array_arg!(mask);
unsafe { sys::cv_recoverPose_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_double_Point2d_const__InputOutputArrayR(e.as_raw__InputArray(), points1.as_raw__InputArray(), points2.as_raw__InputArray(), r.as_raw__OutputArray(), t.as_raw__OutputArray(), focal, pp.opencv_as_extern(), mask.as_raw__InputOutputArray()) }.into_result()
}
/// computes the rectification transformations for 3-head camera, where all the heads are on the same line.
pub fn rectify3_collinear(camera_matrix1: &dyn core::ToInputArray, dist_coeffs1: &dyn core::ToInputArray, camera_matrix2: &dyn core::ToInputArray, dist_coeffs2: &dyn core::ToInputArray, camera_matrix3: &dyn core::ToInputArray, dist_coeffs3: &dyn core::ToInputArray, imgpt1: &dyn core::ToInputArray, imgpt3: &dyn core::ToInputArray, image_size: core::Size, r12: &dyn core::ToInputArray, t12: &dyn core::ToInputArray, r13: &dyn core::ToInputArray, t13: &dyn core::ToInputArray, r1: &mut dyn core::ToOutputArray, r2: &mut dyn core::ToOutputArray, r3: &mut dyn core::ToOutputArray, p1: &mut dyn core::ToOutputArray, p2: &mut dyn core::ToOutputArray, p3: &mut dyn core::ToOutputArray, q: &mut dyn core::ToOutputArray, alpha: f64, new_img_size: core::Size, roi1: &mut core::Rect, roi2: &mut core::Rect, flags: i32) -> Result<f32> {
input_array_arg!(camera_matrix1);
input_array_arg!(dist_coeffs1);
input_array_arg!(camera_matrix2);
input_array_arg!(dist_coeffs2);
input_array_arg!(camera_matrix3);
input_array_arg!(dist_coeffs3);
input_array_arg!(imgpt1);
input_array_arg!(imgpt3);
input_array_arg!(r12);
input_array_arg!(t12);
input_array_arg!(r13);
input_array_arg!(t13);
output_array_arg!(r1);
output_array_arg!(r2);
output_array_arg!(r3);
output_array_arg!(p1);
output_array_arg!(p2);
output_array_arg!(p3);
output_array_arg!(q);
unsafe { sys::cv_rectify3Collinear_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_Size_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_double_Size_RectX_RectX_int(camera_matrix1.as_raw__InputArray(), dist_coeffs1.as_raw__InputArray(), camera_matrix2.as_raw__InputArray(), dist_coeffs2.as_raw__InputArray(), camera_matrix3.as_raw__InputArray(), dist_coeffs3.as_raw__InputArray(), imgpt1.as_raw__InputArray(), imgpt3.as_raw__InputArray(), image_size.opencv_as_extern(), r12.as_raw__InputArray(), t12.as_raw__InputArray(), r13.as_raw__InputArray(), t13.as_raw__InputArray(), r1.as_raw__OutputArray(), r2.as_raw__OutputArray(), r3.as_raw__OutputArray(), p1.as_raw__OutputArray(), p2.as_raw__OutputArray(), p3.as_raw__OutputArray(), q.as_raw__OutputArray(), alpha, new_img_size.opencv_as_extern(), roi1, roi2, flags) }.into_result()
}
/// Reprojects a disparity image to 3D space.
///
/// ## Parameters
/// * disparity: Input single-channel 8-bit unsigned, 16-bit signed, 32-bit signed or 32-bit
/// floating-point disparity image. The values of 8-bit / 16-bit signed formats are assumed to have no
/// fractional bits. If the disparity is 16-bit signed format, as computed by @ref StereoBM or
/// @ref StereoSGBM and maybe other algorithms, it should be divided by 16 (and scaled to float) before
/// being used here.
/// * _3dImage: Output 3-channel floating-point image of the same size as disparity. Each element of
/// _3dImage(x,y) contains 3D coordinates of the point (x,y) computed from the disparity map. If one
/// uses Q obtained by @ref stereoRectify, then the returned points are represented in the first
/// camera's rectified coordinate system.
/// * Q:  perspective transformation matrix that can be obtained with
/// @ref stereoRectify.
/// * handleMissingValues: Indicates, whether the function should handle missing values (i.e.
/// points where the disparity was not computed). If handleMissingValues=true, then pixels with the
/// minimal disparity that corresponds to the outliers (see StereoMatcher::compute ) are transformed
/// to 3D points with a very large Z value (currently set to 10000).
/// * ddepth: The optional output array depth. If it is -1, the output image will have CV_32F
/// depth. ddepth can also be set to CV_16S, CV_32S or CV_32F.
///
/// The function transforms a single-channel disparity map to a 3-channel image representing a 3D
/// surface. That is, for each pixel (x,y) and the corresponding disparity d=disparity(x,y) , it
/// computes:
///
/// 
/// ## See also
/// To reproject a sparse set of points {(x,y,d),...} to 3D space, use perspectiveTransform.
///
/// ## C++ default parameters
/// * handle_missing_values: false
/// * ddepth: -1
pub fn reproject_image_to_3d(disparity: &dyn core::ToInputArray, _3d_image: &mut dyn core::ToOutputArray, q: &dyn core::ToInputArray, handle_missing_values: bool, ddepth: i32) -> Result<()> {
input_array_arg!(disparity);
output_array_arg!(_3d_image);
input_array_arg!(q);
unsafe { sys::cv_reprojectImageTo3D_const__InputArrayR_const__OutputArrayR_const__InputArrayR_bool_int(disparity.as_raw__InputArray(), _3d_image.as_raw__OutputArray(), q.as_raw__InputArray(), handle_missing_values, ddepth) }.into_result()
}
/// Calculates the Sampson Distance between two points.
///
/// The function cv::sampsonDistance calculates and returns the first order approximation of the geometric error as:
/// 
/// The fundamental matrix may be calculated using the #findFundamentalMat function. See [HartleyZ00](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_HartleyZ00) 11.4.3 for details.
/// ## Parameters
/// * pt1: first homogeneous 2d point
/// * pt2: second homogeneous 2d point
/// * F: fundamental matrix
/// ## Returns
/// The computed Sampson distance.
pub fn sampson_distance(pt1: &dyn core::ToInputArray, pt2: &dyn core::ToInputArray, f: &dyn core::ToInputArray) -> Result<f64> {
input_array_arg!(pt1);
input_array_arg!(pt2);
input_array_arg!(f);
unsafe { sys::cv_sampsonDistance_const__InputArrayR_const__InputArrayR_const__InputArrayR(pt1.as_raw__InputArray(), pt2.as_raw__InputArray(), f.as_raw__InputArray()) }.into_result()
}
/// Finds an object pose from 3 3D-2D point correspondences.
///
/// ## Parameters
/// * objectPoints: Array of object points in the object coordinate space, 3x3 1-channel or
/// 1x3/3x1 3-channel. vector\<Point3f\> can be also passed here.
/// * imagePoints: Array of corresponding image points, 3x2 1-channel or 1x3/3x1 2-channel.
/// vector\<Point2f\> can be also passed here.
/// * cameraMatrix: Input camera intrinsic matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// . If the vector is NULL/empty, the zero distortion coefficients are
/// assumed.
/// * rvecs: Output rotation vectors (see @ref Rodrigues ) that, together with tvecs, brings points from
/// the model coordinate system to the camera coordinate system. A P3P problem has up to 4 solutions.
/// * tvecs: Output translation vectors.
/// * flags: Method for solving a P3P problem:
/// * @ref SOLVEPNP_P3P Method is based on the paper of X.S. Gao, X.-R. Hou, J. Tang, H.-F. Chang
/// "Complete Solution Classification for the Perspective-Three-Point Problem" ([gao2003complete](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_gao2003complete)).
/// * @ref SOLVEPNP_AP3P Method is based on the paper of T. Ke and S. Roumeliotis.
/// "An Efficient Algebraic Solution to the Perspective-Three-Point Problem" ([Ke17](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Ke17)).
///
/// The function estimates the object pose given 3 object points, their corresponding image
/// projections, as well as the camera intrinsic matrix and the distortion coefficients.
///
///
/// Note:
/// The solutions are sorted by reprojection errors (lowest to highest).
pub fn solve_p3p(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, rvecs: &mut dyn core::ToOutputArray, tvecs: &mut dyn core::ToOutputArray, flags: i32) -> Result<i32> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
output_array_arg!(rvecs);
output_array_arg!(tvecs);
unsafe { sys::cv_solveP3P_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_int(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), rvecs.as_raw__OutputArray(), tvecs.as_raw__OutputArray(), flags) }.into_result()
}
/// Finds an object pose from 3D-2D point correspondences.
/// This function returns a list of all the possible solutions (a solution is a <rotation vector, translation vector>
/// couple), depending on the number of input points and the chosen method:
/// - P3P methods (@ref SOLVEPNP_P3P, @ref SOLVEPNP_AP3P): 3 or 4 input points. Number of returned solutions can be between 0 and 4 with 3 input points.
/// - @ref SOLVEPNP_IPPE Input points must be >= 4 and object points must be coplanar. Returns 2 solutions.
/// - @ref SOLVEPNP_IPPE_SQUARE Special case suitable for marker pose estimation.
/// Number of input points must be 4 and 2 solutions are returned. Object points must be defined in the following order:
/// - point 0: [-squareLength / 2, squareLength / 2, 0]
/// - point 1: [ squareLength / 2, squareLength / 2, 0]
/// - point 2: [ squareLength / 2, -squareLength / 2, 0]
/// - point 3: [-squareLength / 2, -squareLength / 2, 0]
/// - for all the other flags, number of input points must be >= 4 and object points can be in any configuration.
/// Only 1 solution is returned.
///
/// ## Parameters
/// * objectPoints: Array of object points in the object coordinate space, Nx3 1-channel or
/// 1xN/Nx1 3-channel, where N is the number of points. vector\<Point3d\> can be also passed here.
/// * imagePoints: Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel,
/// where N is the number of points. vector\<Point2d\> can be also passed here.
/// * cameraMatrix: Input camera intrinsic matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// . If the vector is NULL/empty, the zero distortion coefficients are
/// assumed.
/// * rvecs: Vector of output rotation vectors (see @ref Rodrigues ) that, together with tvecs, brings points from
/// the model coordinate system to the camera coordinate system.
/// * tvecs: Vector of output translation vectors.
/// * useExtrinsicGuess: Parameter used for #SOLVEPNP_ITERATIVE. If true (1), the function uses
/// the provided rvec and tvec values as initial approximations of the rotation and translation
/// vectors, respectively, and further optimizes them.
/// * flags: Method for solving a PnP problem:
/// * @ref SOLVEPNP_ITERATIVE Iterative method is based on a Levenberg-Marquardt optimization. In
/// this case the function finds such a pose that minimizes reprojection error, that is the sum
/// of squared distances between the observed projections imagePoints and the projected (using
/// #projectPoints ) objectPoints .
/// * @ref SOLVEPNP_P3P Method is based on the paper of X.S. Gao, X.-R. Hou, J. Tang, H.-F. Chang
/// "Complete Solution Classification for the Perspective-Three-Point Problem" ([gao2003complete](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_gao2003complete)).
/// In this case the function requires exactly four object and image points.
/// * @ref SOLVEPNP_AP3P Method is based on the paper of T. Ke, S. Roumeliotis
/// "An Efficient Algebraic Solution to the Perspective-Three-Point Problem" ([Ke17](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Ke17)).
/// In this case the function requires exactly four object and image points.
/// * @ref SOLVEPNP_EPNP Method has been introduced by F.Moreno-Noguer, V.Lepetit and P.Fua in the
/// paper "EPnP: Efficient Perspective-n-Point Camera Pose Estimation" ([lepetit2009epnp](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_lepetit2009epnp)).
/// * @ref SOLVEPNP_DLS **Broken implementation. Using this flag will fallback to EPnP.**
///
/// Method is based on the paper of Joel A. Hesch and Stergios I. Roumeliotis.
/// "A Direct Least-Squares (DLS) Method for PnP" ([hesch2011direct](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_hesch2011direct)).
/// * @ref SOLVEPNP_UPNP **Broken implementation. Using this flag will fallback to EPnP.**
///
/// Method is based on the paper of A.Penate-Sanchez, J.Andrade-Cetto,
/// F.Moreno-Noguer. "Exhaustive Linearization for Robust Camera Pose and Focal Length
/// Estimation" ([penate2013exhaustive](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_penate2013exhaustive)). In this case the function also estimates the parameters  and 
/// assuming that both have the same value. Then the cameraMatrix is updated with the estimated
/// focal length.
/// * @ref SOLVEPNP_IPPE Method is based on the paper of T. Collins and A. Bartoli.
/// "Infinitesimal Plane-Based Pose Estimation" ([Collins14](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Collins14)). This method requires coplanar object points.
/// * @ref SOLVEPNP_IPPE_SQUARE Method is based on the paper of Toby Collins and Adrien Bartoli.
/// "Infinitesimal Plane-Based Pose Estimation" ([Collins14](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Collins14)). This method is suitable for marker pose estimation.
/// It requires 4 coplanar object points defined in the following order:
/// - point 0: [-squareLength / 2, squareLength / 2, 0]
/// - point 1: [ squareLength / 2, squareLength / 2, 0]
/// - point 2: [ squareLength / 2, -squareLength / 2, 0]
/// - point 3: [-squareLength / 2, -squareLength / 2, 0]
/// * rvec: Rotation vector used to initialize an iterative PnP refinement algorithm, when flag is @ref SOLVEPNP_ITERATIVE
/// and useExtrinsicGuess is set to true.
/// * tvec: Translation vector used to initialize an iterative PnP refinement algorithm, when flag is @ref SOLVEPNP_ITERATIVE
/// and useExtrinsicGuess is set to true.
/// * reprojectionError: Optional vector of reprojection error, that is the RMS error
/// () between the input image points
/// and the 3D object points projected with the estimated pose.
///
/// The function estimates the object pose given a set of object points, their corresponding image
/// projections, as well as the camera intrinsic matrix and the distortion coefficients, see the figure below
/// (more precisely, the X-axis of the camera frame is pointing to the right, the Y-axis downward
/// and the Z-axis forward).
///
/// 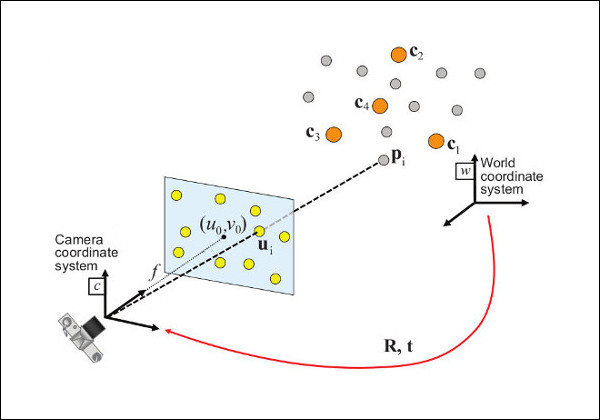
///
/// Points expressed in the world frame  are projected into the image plane 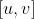
/// using the perspective projection model  and the camera intrinsic parameters matrix :
///
/// 
///
/// The estimated pose is thus the rotation (`rvec`) and the translation (`tvec`) vectors that allow transforming
/// a 3D point expressed in the world frame into the camera frame:
///
/// 
///
///
/// Note:
/// * An example of how to use solvePnP for planar augmented reality can be found at
/// opencv_source_code/samples/python/plane_ar.py
/// * If you are using Python:
/// - Numpy array slices won't work as input because solvePnP requires contiguous
/// arrays (enforced by the assertion using cv::Mat::checkVector() around line 55 of
/// modules/calib3d/src/solvepnp.cpp version 2.4.9)
/// - The P3P algorithm requires image points to be in an array of shape (N,1,2) due
/// to its calling of #undistortPoints (around line 75 of modules/calib3d/src/solvepnp.cpp version 2.4.9)
/// which requires 2-channel information.
/// - Thus, given some data D = np.array(...) where D.shape = (N,M), in order to use a subset of
/// it as, e.g., imagePoints, one must effectively copy it into a new array: imagePoints =
/// np.ascontiguousarray(D[:,:2]).reshape((N,1,2))
/// * The methods @ref SOLVEPNP_DLS and @ref SOLVEPNP_UPNP cannot be used as the current implementations are
/// unstable and sometimes give completely wrong results. If you pass one of these two
/// flags, @ref SOLVEPNP_EPNP method will be used instead.
/// * The minimum number of points is 4 in the general case. In the case of @ref SOLVEPNP_P3P and @ref SOLVEPNP_AP3P
/// methods, it is required to use exactly 4 points (the first 3 points are used to estimate all the solutions
/// of the P3P problem, the last one is used to retain the best solution that minimizes the reprojection error).
/// * With @ref SOLVEPNP_ITERATIVE method and `useExtrinsicGuess=true`, the minimum number of points is 3 (3 points
/// are sufficient to compute a pose but there are up to 4 solutions). The initial solution should be close to the
/// global solution to converge.
/// * With @ref SOLVEPNP_IPPE input points must be >= 4 and object points must be coplanar.
/// * With @ref SOLVEPNP_IPPE_SQUARE this is a special case suitable for marker pose estimation.
/// Number of input points must be 4. Object points must be defined in the following order:
/// - point 0: [-squareLength / 2, squareLength / 2, 0]
/// - point 1: [ squareLength / 2, squareLength / 2, 0]
/// - point 2: [ squareLength / 2, -squareLength / 2, 0]
/// - point 3: [-squareLength / 2, -squareLength / 2, 0]
///
/// ## C++ default parameters
/// * use_extrinsic_guess: false
/// * flags: SOLVEPNP_ITERATIVE
/// * rvec: noArray()
/// * tvec: noArray()
/// * reprojection_error: noArray()
pub fn solve_pnp_generic(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, rvecs: &mut dyn core::ToOutputArray, tvecs: &mut dyn core::ToOutputArray, use_extrinsic_guess: bool, flags: crate::calib3d::SolvePnPMethod, rvec: &dyn core::ToInputArray, tvec: &dyn core::ToInputArray, reprojection_error: &mut dyn core::ToOutputArray) -> Result<i32> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
output_array_arg!(rvecs);
output_array_arg!(tvecs);
input_array_arg!(rvec);
input_array_arg!(tvec);
output_array_arg!(reprojection_error);
unsafe { sys::cv_solvePnPGeneric_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_bool_SolvePnPMethod_const__InputArrayR_const__InputArrayR_const__OutputArrayR(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), rvecs.as_raw__OutputArray(), tvecs.as_raw__OutputArray(), use_extrinsic_guess, flags, rvec.as_raw__InputArray(), tvec.as_raw__InputArray(), reprojection_error.as_raw__OutputArray()) }.into_result()
}
/// Finds an object pose from 3D-2D point correspondences using the RANSAC scheme.
///
/// ## Parameters
/// * objectPoints: Array of object points in the object coordinate space, Nx3 1-channel or
/// 1xN/Nx1 3-channel, where N is the number of points. vector\<Point3d\> can be also passed here.
/// * imagePoints: Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel,
/// where N is the number of points. vector\<Point2d\> can be also passed here.
/// * cameraMatrix: Input camera intrinsic matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// . If the vector is NULL/empty, the zero distortion coefficients are
/// assumed.
/// * rvec: Output rotation vector (see @ref Rodrigues ) that, together with tvec, brings points from
/// the model coordinate system to the camera coordinate system.
/// * tvec: Output translation vector.
/// * useExtrinsicGuess: Parameter used for @ref SOLVEPNP_ITERATIVE. If true (1), the function uses
/// the provided rvec and tvec values as initial approximations of the rotation and translation
/// vectors, respectively, and further optimizes them.
/// * iterationsCount: Number of iterations.
/// * reprojectionError: Inlier threshold value used by the RANSAC procedure. The parameter value
/// is the maximum allowed distance between the observed and computed point projections to consider it
/// an inlier.
/// * confidence: The probability that the algorithm produces a useful result.
/// * inliers: Output vector that contains indices of inliers in objectPoints and imagePoints .
/// * flags: Method for solving a PnP problem (see @ref solvePnP ).
///
/// The function estimates an object pose given a set of object points, their corresponding image
/// projections, as well as the camera intrinsic matrix and the distortion coefficients. This function finds such
/// a pose that minimizes reprojection error, that is, the sum of squared distances between the observed
/// projections imagePoints and the projected (using @ref projectPoints ) objectPoints. The use of RANSAC
/// makes the function resistant to outliers.
///
///
/// Note:
/// * An example of how to use solvePNPRansac for object detection can be found at
/// opencv_source_code/samples/cpp/tutorial_code/calib3d/real_time_pose_estimation/
/// * The default method used to estimate the camera pose for the Minimal Sample Sets step
/// is #SOLVEPNP_EPNP. Exceptions are:
/// - if you choose #SOLVEPNP_P3P or #SOLVEPNP_AP3P, these methods will be used.
/// - if the number of input points is equal to 4, #SOLVEPNP_P3P is used.
/// * The method used to estimate the camera pose using all the inliers is defined by the
/// flags parameters unless it is equal to #SOLVEPNP_P3P or #SOLVEPNP_AP3P. In this case,
/// the method #SOLVEPNP_EPNP will be used instead.
///
/// ## C++ default parameters
/// * use_extrinsic_guess: false
/// * iterations_count: 100
/// * reprojection_error: 8.0
/// * confidence: 0.99
/// * inliers: noArray()
/// * flags: SOLVEPNP_ITERATIVE
pub fn solve_pnp_ransac(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, rvec: &mut dyn core::ToOutputArray, tvec: &mut dyn core::ToOutputArray, use_extrinsic_guess: bool, iterations_count: i32, reprojection_error: f32, confidence: f64, inliers: &mut dyn core::ToOutputArray, flags: i32) -> Result<bool> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
output_array_arg!(rvec);
output_array_arg!(tvec);
output_array_arg!(inliers);
unsafe { sys::cv_solvePnPRansac_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_bool_int_float_double_const__OutputArrayR_int(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), rvec.as_raw__OutputArray(), tvec.as_raw__OutputArray(), use_extrinsic_guess, iterations_count, reprojection_error, confidence, inliers.as_raw__OutputArray(), flags) }.into_result()
}
/// ## C++ default parameters
/// * params: UsacParams()
pub fn solve_pnp_ransac_1(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, camera_matrix: &mut dyn core::ToInputOutputArray, dist_coeffs: &dyn core::ToInputArray, rvec: &mut dyn core::ToOutputArray, tvec: &mut dyn core::ToOutputArray, inliers: &mut dyn core::ToOutputArray, params: crate::calib3d::UsacParams) -> Result<bool> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_output_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
output_array_arg!(rvec);
output_array_arg!(tvec);
output_array_arg!(inliers);
unsafe { sys::cv_solvePnPRansac_const__InputArrayR_const__InputArrayR_const__InputOutputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const_UsacParamsR(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), camera_matrix.as_raw__InputOutputArray(), dist_coeffs.as_raw__InputArray(), rvec.as_raw__OutputArray(), tvec.as_raw__OutputArray(), inliers.as_raw__OutputArray(), ¶ms) }.into_result()
}
/// Refine a pose (the translation and the rotation that transform a 3D point expressed in the object coordinate frame
/// to the camera coordinate frame) from a 3D-2D point correspondences and starting from an initial solution.
///
/// ## Parameters
/// * objectPoints: Array of object points in the object coordinate space, Nx3 1-channel or 1xN/Nx1 3-channel,
/// where N is the number of points. vector\<Point3d\> can also be passed here.
/// * imagePoints: Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel,
/// where N is the number of points. vector\<Point2d\> can also be passed here.
/// * cameraMatrix: Input camera intrinsic matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// . If the vector is NULL/empty, the zero distortion coefficients are
/// assumed.
/// * rvec: Input/Output rotation vector (see @ref Rodrigues ) that, together with tvec, brings points from
/// the model coordinate system to the camera coordinate system. Input values are used as an initial solution.
/// * tvec: Input/Output translation vector. Input values are used as an initial solution.
/// * criteria: Criteria when to stop the Levenberg-Marquard iterative algorithm.
///
/// The function refines the object pose given at least 3 object points, their corresponding image
/// projections, an initial solution for the rotation and translation vector,
/// as well as the camera intrinsic matrix and the distortion coefficients.
/// The function minimizes the projection error with respect to the rotation and the translation vectors, according
/// to a Levenberg-Marquardt iterative minimization [Madsen04](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Madsen04) [Eade13](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Eade13) process.
///
/// ## C++ default parameters
/// * criteria: TermCriteria(TermCriteria::EPS+TermCriteria::COUNT,20,FLT_EPSILON)
pub fn solve_pnp_refine_lm(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, rvec: &mut dyn core::ToInputOutputArray, tvec: &mut dyn core::ToInputOutputArray, criteria: core::TermCriteria) -> Result<()> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
input_output_array_arg!(rvec);
input_output_array_arg!(tvec);
unsafe { sys::cv_solvePnPRefineLM_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_TermCriteria(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), rvec.as_raw__InputOutputArray(), tvec.as_raw__InputOutputArray(), criteria.opencv_as_extern()) }.into_result()
}
/// Refine a pose (the translation and the rotation that transform a 3D point expressed in the object coordinate frame
/// to the camera coordinate frame) from a 3D-2D point correspondences and starting from an initial solution.
///
/// ## Parameters
/// * objectPoints: Array of object points in the object coordinate space, Nx3 1-channel or 1xN/Nx1 3-channel,
/// where N is the number of points. vector\<Point3d\> can also be passed here.
/// * imagePoints: Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel,
/// where N is the number of points. vector\<Point2d\> can also be passed here.
/// * cameraMatrix: Input camera intrinsic matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// . If the vector is NULL/empty, the zero distortion coefficients are
/// assumed.
/// * rvec: Input/Output rotation vector (see @ref Rodrigues ) that, together with tvec, brings points from
/// the model coordinate system to the camera coordinate system. Input values are used as an initial solution.
/// * tvec: Input/Output translation vector. Input values are used as an initial solution.
/// * criteria: Criteria when to stop the Levenberg-Marquard iterative algorithm.
/// * VVSlambda: Gain for the virtual visual servoing control law, equivalent to the 
/// gain in the Damped Gauss-Newton formulation.
///
/// The function refines the object pose given at least 3 object points, their corresponding image
/// projections, an initial solution for the rotation and translation vector,
/// as well as the camera intrinsic matrix and the distortion coefficients.
/// The function minimizes the projection error with respect to the rotation and the translation vectors, using a
/// virtual visual servoing (VVS) [Chaumette06](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Chaumette06) [Marchand16](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Marchand16) scheme.
///
/// ## C++ default parameters
/// * criteria: TermCriteria(TermCriteria::EPS+TermCriteria::COUNT,20,FLT_EPSILON)
/// * vv_slambda: 1
pub fn solve_pnp_refine_vvs(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, rvec: &mut dyn core::ToInputOutputArray, tvec: &mut dyn core::ToInputOutputArray, criteria: core::TermCriteria, vv_slambda: f64) -> Result<()> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
input_output_array_arg!(rvec);
input_output_array_arg!(tvec);
unsafe { sys::cv_solvePnPRefineVVS_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_TermCriteria_double(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), rvec.as_raw__InputOutputArray(), tvec.as_raw__InputOutputArray(), criteria.opencv_as_extern(), vv_slambda) }.into_result()
}
/// Finds an object pose from 3D-2D point correspondences.
/// This function returns the rotation and the translation vectors that transform a 3D point expressed in the object
/// coordinate frame to the camera coordinate frame, using different methods:
/// - P3P methods (@ref SOLVEPNP_P3P, @ref SOLVEPNP_AP3P): need 4 input points to return a unique solution.
/// - @ref SOLVEPNP_IPPE Input points must be >= 4 and object points must be coplanar.
/// - @ref SOLVEPNP_IPPE_SQUARE Special case suitable for marker pose estimation.
/// Number of input points must be 4. Object points must be defined in the following order:
/// - point 0: [-squareLength / 2, squareLength / 2, 0]
/// - point 1: [ squareLength / 2, squareLength / 2, 0]
/// - point 2: [ squareLength / 2, -squareLength / 2, 0]
/// - point 3: [-squareLength / 2, -squareLength / 2, 0]
/// - for all the other flags, number of input points must be >= 4 and object points can be in any configuration.
///
/// ## Parameters
/// * objectPoints: Array of object points in the object coordinate space, Nx3 1-channel or
/// 1xN/Nx1 3-channel, where N is the number of points. vector\<Point3d\> can be also passed here.
/// * imagePoints: Array of corresponding image points, Nx2 1-channel or 1xN/Nx1 2-channel,
/// where N is the number of points. vector\<Point2d\> can be also passed here.
/// * cameraMatrix: Input camera intrinsic matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// . If the vector is NULL/empty, the zero distortion coefficients are
/// assumed.
/// * rvec: Output rotation vector (see @ref Rodrigues ) that, together with tvec, brings points from
/// the model coordinate system to the camera coordinate system.
/// * tvec: Output translation vector.
/// * useExtrinsicGuess: Parameter used for #SOLVEPNP_ITERATIVE. If true (1), the function uses
/// the provided rvec and tvec values as initial approximations of the rotation and translation
/// vectors, respectively, and further optimizes them.
/// * flags: Method for solving a PnP problem:
/// * @ref SOLVEPNP_ITERATIVE Iterative method is based on a Levenberg-Marquardt optimization. In
/// this case the function finds such a pose that minimizes reprojection error, that is the sum
/// of squared distances between the observed projections imagePoints and the projected (using
/// @ref projectPoints ) objectPoints .
/// * @ref SOLVEPNP_P3P Method is based on the paper of X.S. Gao, X.-R. Hou, J. Tang, H.-F. Chang
/// "Complete Solution Classification for the Perspective-Three-Point Problem" ([gao2003complete](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_gao2003complete)).
/// In this case the function requires exactly four object and image points.
/// * @ref SOLVEPNP_AP3P Method is based on the paper of T. Ke, S. Roumeliotis
/// "An Efficient Algebraic Solution to the Perspective-Three-Point Problem" ([Ke17](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Ke17)).
/// In this case the function requires exactly four object and image points.
/// * @ref SOLVEPNP_EPNP Method has been introduced by F. Moreno-Noguer, V. Lepetit and P. Fua in the
/// paper "EPnP: Efficient Perspective-n-Point Camera Pose Estimation" ([lepetit2009epnp](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_lepetit2009epnp)).
/// * @ref SOLVEPNP_DLS **Broken implementation. Using this flag will fallback to EPnP.**
///
/// Method is based on the paper of J. Hesch and S. Roumeliotis.
/// "A Direct Least-Squares (DLS) Method for PnP" ([hesch2011direct](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_hesch2011direct)).
/// * @ref SOLVEPNP_UPNP **Broken implementation. Using this flag will fallback to EPnP.**
///
/// Method is based on the paper of A. Penate-Sanchez, J. Andrade-Cetto,
/// F. Moreno-Noguer. "Exhaustive Linearization for Robust Camera Pose and Focal Length
/// Estimation" ([penate2013exhaustive](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_penate2013exhaustive)). In this case the function also estimates the parameters  and 
/// assuming that both have the same value. Then the cameraMatrix is updated with the estimated
/// focal length.
/// * @ref SOLVEPNP_IPPE Method is based on the paper of T. Collins and A. Bartoli.
/// "Infinitesimal Plane-Based Pose Estimation" ([Collins14](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Collins14)). This method requires coplanar object points.
/// * @ref SOLVEPNP_IPPE_SQUARE Method is based on the paper of Toby Collins and Adrien Bartoli.
/// "Infinitesimal Plane-Based Pose Estimation" ([Collins14](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Collins14)). This method is suitable for marker pose estimation.
/// It requires 4 coplanar object points defined in the following order:
/// - point 0: [-squareLength / 2, squareLength / 2, 0]
/// - point 1: [ squareLength / 2, squareLength / 2, 0]
/// - point 2: [ squareLength / 2, -squareLength / 2, 0]
/// - point 3: [-squareLength / 2, -squareLength / 2, 0]
/// * @ref SOLVEPNP_SQPNP Method is based on the paper "A Consistently Fast and Globally Optimal Solution to the
/// Perspective-n-Point Problem" by G. Terzakis and M.Lourakis ([Terzakis20](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Terzakis20)). It requires 3 or more points.
///
///
/// The function estimates the object pose given a set of object points, their corresponding image
/// projections, as well as the camera intrinsic matrix and the distortion coefficients, see the figure below
/// (more precisely, the X-axis of the camera frame is pointing to the right, the Y-axis downward
/// and the Z-axis forward).
///
/// 
///
/// Points expressed in the world frame  are projected into the image plane 
/// using the perspective projection model  and the camera intrinsic parameters matrix :
///
/// 
///
/// The estimated pose is thus the rotation (`rvec`) and the translation (`tvec`) vectors that allow transforming
/// a 3D point expressed in the world frame into the camera frame:
///
/// 
///
///
/// Note:
/// * An example of how to use solvePnP for planar augmented reality can be found at
/// opencv_source_code/samples/python/plane_ar.py
/// * If you are using Python:
/// - Numpy array slices won't work as input because solvePnP requires contiguous
/// arrays (enforced by the assertion using cv::Mat::checkVector() around line 55 of
/// modules/calib3d/src/solvepnp.cpp version 2.4.9)
/// - The P3P algorithm requires image points to be in an array of shape (N,1,2) due
/// to its calling of #undistortPoints (around line 75 of modules/calib3d/src/solvepnp.cpp version 2.4.9)
/// which requires 2-channel information.
/// - Thus, given some data D = np.array(...) where D.shape = (N,M), in order to use a subset of
/// it as, e.g., imagePoints, one must effectively copy it into a new array: imagePoints =
/// np.ascontiguousarray(D[:,:2]).reshape((N,1,2))
/// * The methods @ref SOLVEPNP_DLS and @ref SOLVEPNP_UPNP cannot be used as the current implementations are
/// unstable and sometimes give completely wrong results. If you pass one of these two
/// flags, @ref SOLVEPNP_EPNP method will be used instead.
/// * The minimum number of points is 4 in the general case. In the case of @ref SOLVEPNP_P3P and @ref SOLVEPNP_AP3P
/// methods, it is required to use exactly 4 points (the first 3 points are used to estimate all the solutions
/// of the P3P problem, the last one is used to retain the best solution that minimizes the reprojection error).
/// * With @ref SOLVEPNP_ITERATIVE method and `useExtrinsicGuess=true`, the minimum number of points is 3 (3 points
/// are sufficient to compute a pose but there are up to 4 solutions). The initial solution should be close to the
/// global solution to converge.
/// * With @ref SOLVEPNP_IPPE input points must be >= 4 and object points must be coplanar.
/// * With @ref SOLVEPNP_IPPE_SQUARE this is a special case suitable for marker pose estimation.
/// Number of input points must be 4. Object points must be defined in the following order:
/// - point 0: [-squareLength / 2, squareLength / 2, 0]
/// - point 1: [ squareLength / 2, squareLength / 2, 0]
/// - point 2: [ squareLength / 2, -squareLength / 2, 0]
/// - point 3: [-squareLength / 2, -squareLength / 2, 0]
/// * With @ref SOLVEPNP_SQPNP input points must be >= 3
///
/// ## C++ default parameters
/// * use_extrinsic_guess: false
/// * flags: SOLVEPNP_ITERATIVE
pub fn solve_pnp(object_points: &dyn core::ToInputArray, image_points: &dyn core::ToInputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, rvec: &mut dyn core::ToOutputArray, tvec: &mut dyn core::ToOutputArray, use_extrinsic_guess: bool, flags: i32) -> Result<bool> {
input_array_arg!(object_points);
input_array_arg!(image_points);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
output_array_arg!(rvec);
output_array_arg!(tvec);
unsafe { sys::cv_solvePnP_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_bool_int(object_points.as_raw__InputArray(), image_points.as_raw__InputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), rvec.as_raw__OutputArray(), tvec.as_raw__OutputArray(), use_extrinsic_guess, flags) }.into_result()
}
/// Calibrates a stereo camera set up. This function finds the intrinsic parameters
/// for each of the two cameras and the extrinsic parameters between the two cameras.
///
/// ## Parameters
/// * objectPoints: Vector of vectors of the calibration pattern points. The same structure as
/// in @ref calibrateCamera. For each pattern view, both cameras need to see the same object
/// points. Therefore, objectPoints.size(), imagePoints1.size(), and imagePoints2.size() need to be
/// equal as well as objectPoints[i].size(), imagePoints1[i].size(), and imagePoints2[i].size() need to
/// be equal for each i.
/// * imagePoints1: Vector of vectors of the projections of the calibration pattern points,
/// observed by the first camera. The same structure as in @ref calibrateCamera.
/// * imagePoints2: Vector of vectors of the projections of the calibration pattern points,
/// observed by the second camera. The same structure as in @ref calibrateCamera.
/// * cameraMatrix1: Input/output camera intrinsic matrix for the first camera, the same as in
/// @ref calibrateCamera. Furthermore, for the stereo case, additional flags may be used, see below.
/// * distCoeffs1: Input/output vector of distortion coefficients, the same as in
/// @ref calibrateCamera.
/// * cameraMatrix2: Input/output second camera intrinsic matrix for the second camera. See description for
/// cameraMatrix1.
/// * distCoeffs2: Input/output lens distortion coefficients for the second camera. See
/// description for distCoeffs1.
/// * imageSize: Size of the image used only to initialize the camera intrinsic matrices.
/// * R: Output rotation matrix. Together with the translation vector T, this matrix brings
/// points given in the first camera's coordinate system to points in the second camera's
/// coordinate system. In more technical terms, the tuple of R and T performs a change of basis
/// from the first camera's coordinate system to the second camera's coordinate system. Due to its
/// duality, this tuple is equivalent to the position of the first camera with respect to the
/// second camera coordinate system.
/// * T: Output translation vector, see description above.
/// * E: Output essential matrix.
/// * F: Output fundamental matrix.
/// * perViewErrors: Output vector of the RMS re-projection error estimated for each pattern view.
/// * flags: Different flags that may be zero or a combination of the following values:
/// * @ref CALIB_FIX_INTRINSIC Fix cameraMatrix? and distCoeffs? so that only R, T, E, and F
/// matrices are estimated.
/// * @ref CALIB_USE_INTRINSIC_GUESS Optimize some or all of the intrinsic parameters
/// according to the specified flags. Initial values are provided by the user.
/// * @ref CALIB_USE_EXTRINSIC_GUESS R and T contain valid initial values that are optimized further.
/// Otherwise R and T are initialized to the median value of the pattern views (each dimension separately).
/// * @ref CALIB_FIX_PRINCIPAL_POINT Fix the principal points during the optimization.
/// * @ref CALIB_FIX_FOCAL_LENGTH Fix  and  .
/// * @ref CALIB_FIX_ASPECT_RATIO Optimize  . Fix the ratio 
/// .
/// * @ref CALIB_SAME_FOCAL_LENGTH Enforce  and  .
/// * @ref CALIB_ZERO_TANGENT_DIST Set tangential distortion coefficients for each camera to
/// zeros and fix there.
/// * @ref CALIB_FIX_K1,..., @ref CALIB_FIX_K6 Do not change the corresponding radial
/// distortion coefficient during the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set,
/// the coefficient from the supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * @ref CALIB_RATIONAL_MODEL Enable coefficients k4, k5, and k6. To provide the backward
/// compatibility, this extra flag should be explicitly specified to make the calibration
/// function use the rational model and return 8 coefficients. If the flag is not set, the
/// function computes and returns only 5 distortion coefficients.
/// * @ref CALIB_THIN_PRISM_MODEL Coefficients s1, s2, s3 and s4 are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the thin prism model and return 12 coefficients. If the flag is not
/// set, the function computes and returns only 5 distortion coefficients.
/// * @ref CALIB_FIX_S1_S2_S3_S4 The thin prism distortion coefficients are not changed during
/// the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set, the coefficient from the
/// supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * @ref CALIB_TILTED_MODEL Coefficients tauX and tauY are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the tilted sensor model and return 14 coefficients. If the flag is not
/// set, the function computes and returns only 5 distortion coefficients.
/// * @ref CALIB_FIX_TAUX_TAUY The coefficients of the tilted sensor model are not changed during
/// the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set, the coefficient from the
/// supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * criteria: Termination criteria for the iterative optimization algorithm.
///
/// The function estimates the transformation between two cameras making a stereo pair. If one computes
/// the poses of an object relative to the first camera and to the second camera,
/// ( , ) and (,), respectively, for a stereo camera where the
/// relative position and orientation between the two cameras are fixed, then those poses definitely
/// relate to each other. This means, if the relative position and orientation (,) of the
/// two cameras is known, it is possible to compute (,) when (,) is
/// given. This is what the described function does. It computes (,) such that:
///
/// 
/// 
///
/// Therefore, one can compute the coordinate representation of a 3D point for the second camera's
/// coordinate system when given the point's coordinate representation in the first camera's coordinate
/// system:
///
/// 
///
///
/// Optionally, it computes the essential matrix E:
///
/// 
///
/// where  are components of the translation vector  :  .
/// And the function can also compute the fundamental matrix F:
///
/// 
///
/// Besides the stereo-related information, the function can also perform a full calibration of each of
/// the two cameras. However, due to the high dimensionality of the parameter space and noise in the
/// input data, the function can diverge from the correct solution. If the intrinsic parameters can be
/// estimated with high accuracy for each of the cameras individually (for example, using
/// #calibrateCamera ), you are recommended to do so and then pass @ref CALIB_FIX_INTRINSIC flag to the
/// function along with the computed intrinsic parameters. Otherwise, if all the parameters are
/// estimated at once, it makes sense to restrict some parameters, for example, pass
/// @ref CALIB_SAME_FOCAL_LENGTH and @ref CALIB_ZERO_TANGENT_DIST flags, which is usually a
/// reasonable assumption.
///
/// Similarly to #calibrateCamera, the function minimizes the total re-projection error for all the
/// points in all the available views from both cameras. The function returns the final value of the
/// re-projection error.
///
/// ## C++ default parameters
/// * flags: CALIB_FIX_INTRINSIC
/// * criteria: TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,30,1e-6)
pub fn stereo_calibrate_extended(object_points: &dyn core::ToInputArray, image_points1: &dyn core::ToInputArray, image_points2: &dyn core::ToInputArray, camera_matrix1: &mut dyn core::ToInputOutputArray, dist_coeffs1: &mut dyn core::ToInputOutputArray, camera_matrix2: &mut dyn core::ToInputOutputArray, dist_coeffs2: &mut dyn core::ToInputOutputArray, image_size: core::Size, r: &mut dyn core::ToInputOutputArray, t: &mut dyn core::ToInputOutputArray, e: &mut dyn core::ToOutputArray, f: &mut dyn core::ToOutputArray, per_view_errors: &mut dyn core::ToOutputArray, flags: i32, criteria: core::TermCriteria) -> Result<f64> {
input_array_arg!(object_points);
input_array_arg!(image_points1);
input_array_arg!(image_points2);
input_output_array_arg!(camera_matrix1);
input_output_array_arg!(dist_coeffs1);
input_output_array_arg!(camera_matrix2);
input_output_array_arg!(dist_coeffs2);
input_output_array_arg!(r);
input_output_array_arg!(t);
output_array_arg!(e);
output_array_arg!(f);
output_array_arg!(per_view_errors);
unsafe { sys::cv_stereoCalibrate_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_Size_const__InputOutputArrayR_const__InputOutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_int_TermCriteria(object_points.as_raw__InputArray(), image_points1.as_raw__InputArray(), image_points2.as_raw__InputArray(), camera_matrix1.as_raw__InputOutputArray(), dist_coeffs1.as_raw__InputOutputArray(), camera_matrix2.as_raw__InputOutputArray(), dist_coeffs2.as_raw__InputOutputArray(), image_size.opencv_as_extern(), r.as_raw__InputOutputArray(), t.as_raw__InputOutputArray(), e.as_raw__OutputArray(), f.as_raw__OutputArray(), per_view_errors.as_raw__OutputArray(), flags, criteria.opencv_as_extern()) }.into_result()
}
/// Calibrates a stereo camera set up. This function finds the intrinsic parameters
/// for each of the two cameras and the extrinsic parameters between the two cameras.
///
/// ## Parameters
/// * objectPoints: Vector of vectors of the calibration pattern points. The same structure as
/// in @ref calibrateCamera. For each pattern view, both cameras need to see the same object
/// points. Therefore, objectPoints.size(), imagePoints1.size(), and imagePoints2.size() need to be
/// equal as well as objectPoints[i].size(), imagePoints1[i].size(), and imagePoints2[i].size() need to
/// be equal for each i.
/// * imagePoints1: Vector of vectors of the projections of the calibration pattern points,
/// observed by the first camera. The same structure as in @ref calibrateCamera.
/// * imagePoints2: Vector of vectors of the projections of the calibration pattern points,
/// observed by the second camera. The same structure as in @ref calibrateCamera.
/// * cameraMatrix1: Input/output camera intrinsic matrix for the first camera, the same as in
/// @ref calibrateCamera. Furthermore, for the stereo case, additional flags may be used, see below.
/// * distCoeffs1: Input/output vector of distortion coefficients, the same as in
/// @ref calibrateCamera.
/// * cameraMatrix2: Input/output second camera intrinsic matrix for the second camera. See description for
/// cameraMatrix1.
/// * distCoeffs2: Input/output lens distortion coefficients for the second camera. See
/// description for distCoeffs1.
/// * imageSize: Size of the image used only to initialize the camera intrinsic matrices.
/// * R: Output rotation matrix. Together with the translation vector T, this matrix brings
/// points given in the first camera's coordinate system to points in the second camera's
/// coordinate system. In more technical terms, the tuple of R and T performs a change of basis
/// from the first camera's coordinate system to the second camera's coordinate system. Due to its
/// duality, this tuple is equivalent to the position of the first camera with respect to the
/// second camera coordinate system.
/// * T: Output translation vector, see description above.
/// * E: Output essential matrix.
/// * F: Output fundamental matrix.
/// * perViewErrors: Output vector of the RMS re-projection error estimated for each pattern view.
/// * flags: Different flags that may be zero or a combination of the following values:
/// * @ref CALIB_FIX_INTRINSIC Fix cameraMatrix? and distCoeffs? so that only R, T, E, and F
/// matrices are estimated.
/// * @ref CALIB_USE_INTRINSIC_GUESS Optimize some or all of the intrinsic parameters
/// according to the specified flags. Initial values are provided by the user.
/// * @ref CALIB_USE_EXTRINSIC_GUESS R and T contain valid initial values that are optimized further.
/// Otherwise R and T are initialized to the median value of the pattern views (each dimension separately).
/// * @ref CALIB_FIX_PRINCIPAL_POINT Fix the principal points during the optimization.
/// * @ref CALIB_FIX_FOCAL_LENGTH Fix  and  .
/// * @ref CALIB_FIX_ASPECT_RATIO Optimize  . Fix the ratio 
/// .
/// * @ref CALIB_SAME_FOCAL_LENGTH Enforce  and  .
/// * @ref CALIB_ZERO_TANGENT_DIST Set tangential distortion coefficients for each camera to
/// zeros and fix there.
/// * @ref CALIB_FIX_K1,..., @ref CALIB_FIX_K6 Do not change the corresponding radial
/// distortion coefficient during the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set,
/// the coefficient from the supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * @ref CALIB_RATIONAL_MODEL Enable coefficients k4, k5, and k6. To provide the backward
/// compatibility, this extra flag should be explicitly specified to make the calibration
/// function use the rational model and return 8 coefficients. If the flag is not set, the
/// function computes and returns only 5 distortion coefficients.
/// * @ref CALIB_THIN_PRISM_MODEL Coefficients s1, s2, s3 and s4 are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the thin prism model and return 12 coefficients. If the flag is not
/// set, the function computes and returns only 5 distortion coefficients.
/// * @ref CALIB_FIX_S1_S2_S3_S4 The thin prism distortion coefficients are not changed during
/// the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set, the coefficient from the
/// supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * @ref CALIB_TILTED_MODEL Coefficients tauX and tauY are enabled. To provide the
/// backward compatibility, this extra flag should be explicitly specified to make the
/// calibration function use the tilted sensor model and return 14 coefficients. If the flag is not
/// set, the function computes and returns only 5 distortion coefficients.
/// * @ref CALIB_FIX_TAUX_TAUY The coefficients of the tilted sensor model are not changed during
/// the optimization. If @ref CALIB_USE_INTRINSIC_GUESS is set, the coefficient from the
/// supplied distCoeffs matrix is used. Otherwise, it is set to 0.
/// * criteria: Termination criteria for the iterative optimization algorithm.
///
/// The function estimates the transformation between two cameras making a stereo pair. If one computes
/// the poses of an object relative to the first camera and to the second camera,
/// ( , ) and (,), respectively, for a stereo camera where the
/// relative position and orientation between the two cameras are fixed, then those poses definitely
/// relate to each other. This means, if the relative position and orientation (,) of the
/// two cameras is known, it is possible to compute (,) when (,) is
/// given. This is what the described function does. It computes (,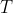) such that:
///
/// 
/// 
///
/// Therefore, one can compute the coordinate representation of a 3D point for the second camera's
/// coordinate system when given the point's coordinate representation in the first camera's coordinate
/// system:
///
/// 
///
///
/// Optionally, it computes the essential matrix E:
///
/// 
///
/// where  are components of the translation vector 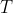 :  .
/// And the function can also compute the fundamental matrix F:
///
/// 
///
/// Besides the stereo-related information, the function can also perform a full calibration of each of
/// the two cameras. However, due to the high dimensionality of the parameter space and noise in the
/// input data, the function can diverge from the correct solution. If the intrinsic parameters can be
/// estimated with high accuracy for each of the cameras individually (for example, using
/// #calibrateCamera ), you are recommended to do so and then pass @ref CALIB_FIX_INTRINSIC flag to the
/// function along with the computed intrinsic parameters. Otherwise, if all the parameters are
/// estimated at once, it makes sense to restrict some parameters, for example, pass
/// @ref CALIB_SAME_FOCAL_LENGTH and @ref CALIB_ZERO_TANGENT_DIST flags, which is usually a
/// reasonable assumption.
///
/// Similarly to #calibrateCamera, the function minimizes the total re-projection error for all the
/// points in all the available views from both cameras. The function returns the final value of the
/// re-projection error.
///
/// ## Overloaded parameters
///
/// ## C++ default parameters
/// * flags: CALIB_FIX_INTRINSIC
/// * criteria: TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,30,1e-6)
pub fn stereo_calibrate(object_points: &dyn core::ToInputArray, image_points1: &dyn core::ToInputArray, image_points2: &dyn core::ToInputArray, camera_matrix1: &mut dyn core::ToInputOutputArray, dist_coeffs1: &mut dyn core::ToInputOutputArray, camera_matrix2: &mut dyn core::ToInputOutputArray, dist_coeffs2: &mut dyn core::ToInputOutputArray, image_size: core::Size, r: &mut dyn core::ToOutputArray, t: &mut dyn core::ToOutputArray, e: &mut dyn core::ToOutputArray, f: &mut dyn core::ToOutputArray, flags: i32, criteria: core::TermCriteria) -> Result<f64> {
input_array_arg!(object_points);
input_array_arg!(image_points1);
input_array_arg!(image_points2);
input_output_array_arg!(camera_matrix1);
input_output_array_arg!(dist_coeffs1);
input_output_array_arg!(camera_matrix2);
input_output_array_arg!(dist_coeffs2);
output_array_arg!(r);
output_array_arg!(t);
output_array_arg!(e);
output_array_arg!(f);
unsafe { sys::cv_stereoCalibrate_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_const__InputOutputArrayR_Size_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_int_TermCriteria(object_points.as_raw__InputArray(), image_points1.as_raw__InputArray(), image_points2.as_raw__InputArray(), camera_matrix1.as_raw__InputOutputArray(), dist_coeffs1.as_raw__InputOutputArray(), camera_matrix2.as_raw__InputOutputArray(), dist_coeffs2.as_raw__InputOutputArray(), image_size.opencv_as_extern(), r.as_raw__OutputArray(), t.as_raw__OutputArray(), e.as_raw__OutputArray(), f.as_raw__OutputArray(), flags, criteria.opencv_as_extern()) }.into_result()
}
/// Computes a rectification transform for an uncalibrated stereo camera.
///
/// ## Parameters
/// * points1: Array of feature points in the first image.
/// * points2: The corresponding points in the second image. The same formats as in
/// #findFundamentalMat are supported.
/// * F: Input fundamental matrix. It can be computed from the same set of point pairs using
/// #findFundamentalMat .
/// * imgSize: Size of the image.
/// * H1: Output rectification homography matrix for the first image.
/// * H2: Output rectification homography matrix for the second image.
/// * threshold: Optional threshold used to filter out the outliers. If the parameter is greater
/// than zero, all the point pairs that do not comply with the epipolar geometry (that is, the points
/// for which 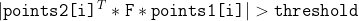 ) are
/// rejected prior to computing the homographies. Otherwise, all the points are considered inliers.
///
/// The function computes the rectification transformations without knowing intrinsic parameters of the
/// cameras and their relative position in the space, which explains the suffix "uncalibrated". Another
/// related difference from #stereoRectify is that the function outputs not the rectification
/// transformations in the object (3D) space, but the planar perspective transformations encoded by the
/// homography matrices H1 and H2 . The function implements the algorithm [Hartley99](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_Hartley99) .
///
///
/// Note:
/// While the algorithm does not need to know the intrinsic parameters of the cameras, it heavily
/// depends on the epipolar geometry. Therefore, if the camera lenses have a significant distortion,
/// it would be better to correct it before computing the fundamental matrix and calling this
/// function. For example, distortion coefficients can be estimated for each head of stereo camera
/// separately by using #calibrateCamera . Then, the images can be corrected using #undistort , or
/// just the point coordinates can be corrected with #undistortPoints .
///
/// ## C++ default parameters
/// * threshold: 5
pub fn stereo_rectify_uncalibrated(points1: &dyn core::ToInputArray, points2: &dyn core::ToInputArray, f: &dyn core::ToInputArray, img_size: core::Size, h1: &mut dyn core::ToOutputArray, h2: &mut dyn core::ToOutputArray, threshold: f64) -> Result<bool> {
input_array_arg!(points1);
input_array_arg!(points2);
input_array_arg!(f);
output_array_arg!(h1);
output_array_arg!(h2);
unsafe { sys::cv_stereoRectifyUncalibrated_const__InputArrayR_const__InputArrayR_const__InputArrayR_Size_const__OutputArrayR_const__OutputArrayR_double(points1.as_raw__InputArray(), points2.as_raw__InputArray(), f.as_raw__InputArray(), img_size.opencv_as_extern(), h1.as_raw__OutputArray(), h2.as_raw__OutputArray(), threshold) }.into_result()
}
/// Computes rectification transforms for each head of a calibrated stereo camera.
///
/// ## Parameters
/// * cameraMatrix1: First camera intrinsic matrix.
/// * distCoeffs1: First camera distortion parameters.
/// * cameraMatrix2: Second camera intrinsic matrix.
/// * distCoeffs2: Second camera distortion parameters.
/// * imageSize: Size of the image used for stereo calibration.
/// * R: Rotation matrix from the coordinate system of the first camera to the second camera,
/// see @ref stereoCalibrate.
/// * T: Translation vector from the coordinate system of the first camera to the second camera,
/// see @ref stereoCalibrate.
/// * R1: Output 3x3 rectification transform (rotation matrix) for the first camera. This matrix
/// brings points given in the unrectified first camera's coordinate system to points in the rectified
/// first camera's coordinate system. In more technical terms, it performs a change of basis from the
/// unrectified first camera's coordinate system to the rectified first camera's coordinate system.
/// * R2: Output 3x3 rectification transform (rotation matrix) for the second camera. This matrix
/// brings points given in the unrectified second camera's coordinate system to points in the rectified
/// second camera's coordinate system. In more technical terms, it performs a change of basis from the
/// unrectified second camera's coordinate system to the rectified second camera's coordinate system.
/// * P1: Output 3x4 projection matrix in the new (rectified) coordinate systems for the first
/// camera, i.e. it projects points given in the rectified first camera coordinate system into the
/// rectified first camera's image.
/// * P2: Output 3x4 projection matrix in the new (rectified) coordinate systems for the second
/// camera, i.e. it projects points given in the rectified first camera coordinate system into the
/// rectified second camera's image.
/// * Q: Output  disparity-to-depth mapping matrix (see @ref reprojectImageTo3D).
/// * flags: Operation flags that may be zero or @ref CALIB_ZERO_DISPARITY . If the flag is set,
/// the function makes the principal points of each camera have the same pixel coordinates in the
/// rectified views. And if the flag is not set, the function may still shift the images in the
/// horizontal or vertical direction (depending on the orientation of epipolar lines) to maximize the
/// useful image area.
/// * alpha: Free scaling parameter. If it is -1 or absent, the function performs the default
/// scaling. Otherwise, the parameter should be between 0 and 1. alpha=0 means that the rectified
/// images are zoomed and shifted so that only valid pixels are visible (no black areas after
/// rectification). alpha=1 means that the rectified image is decimated and shifted so that all the
/// pixels from the original images from the cameras are retained in the rectified images (no source
/// image pixels are lost). Any intermediate value yields an intermediate result between
/// those two extreme cases.
/// * newImageSize: New image resolution after rectification. The same size should be passed to
/// #initUndistortRectifyMap (see the stereo_calib.cpp sample in OpenCV samples directory). When (0,0)
/// is passed (default), it is set to the original imageSize . Setting it to a larger value can help you
/// preserve details in the original image, especially when there is a big radial distortion.
/// * validPixROI1: Optional output rectangles inside the rectified images where all the pixels
/// are valid. If alpha=0 , the ROIs cover the whole images. Otherwise, they are likely to be smaller
/// (see the picture below).
/// * validPixROI2: Optional output rectangles inside the rectified images where all the pixels
/// are valid. If alpha=0 , the ROIs cover the whole images. Otherwise, they are likely to be smaller
/// (see the picture below).
///
/// The function computes the rotation matrices for each camera that (virtually) make both camera image
/// planes the same plane. Consequently, this makes all the epipolar lines parallel and thus simplifies
/// the dense stereo correspondence problem. The function takes the matrices computed by #stereoCalibrate
/// as input. As output, it provides two rotation matrices and also two projection matrices in the new
/// coordinates. The function distinguishes the following two cases:
///
/// * **Horizontal stereo**: the first and the second camera views are shifted relative to each other
/// mainly along the x-axis (with possible small vertical shift). In the rectified images, the
/// corresponding epipolar lines in the left and right cameras are horizontal and have the same
/// y-coordinate. P1 and P2 look like:
///
/// 
///
/// 
///
/// where  is a horizontal shift between the cameras and  if
/// @ref CALIB_ZERO_DISPARITY is set.
///
/// * **Vertical stereo**: the first and the second camera views are shifted relative to each other
/// mainly in the vertical direction (and probably a bit in the horizontal direction too). The epipolar
/// lines in the rectified images are vertical and have the same x-coordinate. P1 and P2 look like:
///
/// 
///
/// 
///
/// where  is a vertical shift between the cameras and  if
/// @ref CALIB_ZERO_DISPARITY is set.
///
/// As you can see, the first three columns of P1 and P2 will effectively be the new "rectified" camera
/// matrices. The matrices, together with R1 and R2 , can then be passed to #initUndistortRectifyMap to
/// initialize the rectification map for each camera.
///
/// See below the screenshot from the stereo_calib.cpp sample. Some red horizontal lines pass through
/// the corresponding image regions. This means that the images are well rectified, which is what most
/// stereo correspondence algorithms rely on. The green rectangles are roi1 and roi2 . You see that
/// their interiors are all valid pixels.
///
/// 
///
/// ## C++ default parameters
/// * flags: CALIB_ZERO_DISPARITY
/// * alpha: -1
/// * new_image_size: Size()
/// * valid_pix_roi1: 0
/// * valid_pix_roi2: 0
pub fn stereo_rectify(camera_matrix1: &dyn core::ToInputArray, dist_coeffs1: &dyn core::ToInputArray, camera_matrix2: &dyn core::ToInputArray, dist_coeffs2: &dyn core::ToInputArray, image_size: core::Size, r: &dyn core::ToInputArray, t: &dyn core::ToInputArray, r1: &mut dyn core::ToOutputArray, r2: &mut dyn core::ToOutputArray, p1: &mut dyn core::ToOutputArray, p2: &mut dyn core::ToOutputArray, q: &mut dyn core::ToOutputArray, flags: i32, alpha: f64, new_image_size: core::Size, valid_pix_roi1: &mut core::Rect, valid_pix_roi2: &mut core::Rect) -> Result<()> {
input_array_arg!(camera_matrix1);
input_array_arg!(dist_coeffs1);
input_array_arg!(camera_matrix2);
input_array_arg!(dist_coeffs2);
input_array_arg!(r);
input_array_arg!(t);
output_array_arg!(r1);
output_array_arg!(r2);
output_array_arg!(p1);
output_array_arg!(p2);
output_array_arg!(q);
unsafe { sys::cv_stereoRectify_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_Size_const__InputArrayR_const__InputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_const__OutputArrayR_int_double_Size_RectX_RectX(camera_matrix1.as_raw__InputArray(), dist_coeffs1.as_raw__InputArray(), camera_matrix2.as_raw__InputArray(), dist_coeffs2.as_raw__InputArray(), image_size.opencv_as_extern(), r.as_raw__InputArray(), t.as_raw__InputArray(), r1.as_raw__OutputArray(), r2.as_raw__OutputArray(), p1.as_raw__OutputArray(), p2.as_raw__OutputArray(), q.as_raw__OutputArray(), flags, alpha, new_image_size.opencv_as_extern(), valid_pix_roi1, valid_pix_roi2) }.into_result()
}
/// This function reconstructs 3-dimensional points (in homogeneous coordinates) by using
/// their observations with a stereo camera.
///
/// ## Parameters
/// * projMatr1: 3x4 projection matrix of the first camera, i.e. this matrix projects 3D points
/// given in the world's coordinate system into the first image.
/// * projMatr2: 3x4 projection matrix of the second camera, i.e. this matrix projects 3D points
/// given in the world's coordinate system into the second image.
/// * projPoints1: 2xN array of feature points in the first image. In the case of the c++ version,
/// it can be also a vector of feature points or two-channel matrix of size 1xN or Nx1.
/// * projPoints2: 2xN array of corresponding points in the second image. In the case of the c++
/// version, it can be also a vector of feature points or two-channel matrix of size 1xN or Nx1.
/// * points4D: 4xN array of reconstructed points in homogeneous coordinates. These points are
/// returned in the world's coordinate system.
///
///
/// Note:
/// Keep in mind that all input data should be of float type in order for this function to work.
///
///
/// Note:
/// If the projection matrices from @ref stereoRectify are used, then the returned points are
/// represented in the first camera's rectified coordinate system.
/// ## See also
/// reprojectImageTo3D
pub fn triangulate_points(proj_matr1: &dyn core::ToInputArray, proj_matr2: &dyn core::ToInputArray, proj_points1: &dyn core::ToInputArray, proj_points2: &dyn core::ToInputArray, points4_d: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(proj_matr1);
input_array_arg!(proj_matr2);
input_array_arg!(proj_points1);
input_array_arg!(proj_points2);
output_array_arg!(points4_d);
unsafe { sys::cv_triangulatePoints_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__OutputArrayR(proj_matr1.as_raw__InputArray(), proj_matr2.as_raw__InputArray(), proj_points1.as_raw__InputArray(), proj_points2.as_raw__InputArray(), points4_d.as_raw__OutputArray()) }.into_result()
}
/// Computes the ideal point coordinates from the observed point coordinates.
///
/// The function is similar to #undistort and #initUndistortRectifyMap but it operates on a
/// sparse set of points instead of a raster image. Also the function performs a reverse transformation
/// to #projectPoints. In case of a 3D object, it does not reconstruct its 3D coordinates, but for a
/// planar object, it does, up to a translation vector, if the proper R is specified.
///
/// For each observed point coordinate 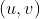 the function computes:
/// 
///
/// where *undistort* is an approximate iterative algorithm that estimates the normalized original
/// point coordinates out of the normalized distorted point coordinates ("normalized" means that the
/// coordinates do not depend on the camera matrix).
///
/// The function can be used for both a stereo camera head or a monocular camera (when R is empty).
/// ## Parameters
/// * src: Observed point coordinates, 2xN/Nx2 1-channel or 1xN/Nx1 2-channel (CV_32FC2 or CV_64FC2) (or
/// vector\<Point2f\> ).
/// * dst: Output ideal point coordinates (1xN/Nx1 2-channel or vector\<Point2f\> ) after undistortion and reverse perspective
/// transformation. If matrix P is identity or omitted, dst will contain normalized point coordinates.
/// * cameraMatrix: Camera matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * R: Rectification transformation in the object space (3x3 matrix). R1 or R2 computed by
/// #stereoRectify can be passed here. If the matrix is empty, the identity transformation is used.
/// * P: New camera matrix (3x3) or new projection matrix (3x4) . P1 or P2 computed by
/// #stereoRectify can be passed here. If the matrix is empty, the identity new camera matrix is used.
///
/// ## C++ default parameters
/// * r: noArray()
/// * p: noArray()
pub fn undistort_points(src: &dyn core::ToInputArray, dst: &mut dyn core::ToOutputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, r: &dyn core::ToInputArray, p: &dyn core::ToInputArray) -> Result<()> {
input_array_arg!(src);
output_array_arg!(dst);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
input_array_arg!(r);
input_array_arg!(p);
unsafe { sys::cv_undistortPoints_const__InputArrayR_const__OutputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR(src.as_raw__InputArray(), dst.as_raw__OutputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), r.as_raw__InputArray(), p.as_raw__InputArray()) }.into_result()
}
/// Computes the ideal point coordinates from the observed point coordinates.
///
/// The function is similar to #undistort and #initUndistortRectifyMap but it operates on a
/// sparse set of points instead of a raster image. Also the function performs a reverse transformation
/// to #projectPoints. In case of a 3D object, it does not reconstruct its 3D coordinates, but for a
/// planar object, it does, up to a translation vector, if the proper R is specified.
///
/// For each observed point coordinate 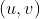 the function computes:
/// 
///
/// where *undistort* is an approximate iterative algorithm that estimates the normalized original
/// point coordinates out of the normalized distorted point coordinates ("normalized" means that the
/// coordinates do not depend on the camera matrix).
///
/// The function can be used for both a stereo camera head or a monocular camera (when R is empty).
/// ## Parameters
/// * src: Observed point coordinates, 2xN/Nx2 1-channel or 1xN/Nx1 2-channel (CV_32FC2 or CV_64FC2) (or
/// vector\<Point2f\> ).
/// * dst: Output ideal point coordinates (1xN/Nx1 2-channel or vector\<Point2f\> ) after undistortion and reverse perspective
/// transformation. If matrix P is identity or omitted, dst will contain normalized point coordinates.
/// * cameraMatrix: Camera matrix  .
/// * distCoeffs: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * R: Rectification transformation in the object space (3x3 matrix). R1 or R2 computed by
/// #stereoRectify can be passed here. If the matrix is empty, the identity transformation is used.
/// * P: New camera matrix (3x3) or new projection matrix (3x4) . P1 or P2 computed by
/// #stereoRectify can be passed here. If the matrix is empty, the identity new camera matrix is used.
///
/// ## Overloaded parameters
///
///
/// Note: Default version of #undistortPoints does 5 iterations to compute undistorted points.
pub fn undistort_points_iter(src: &dyn core::ToInputArray, dst: &mut dyn core::ToOutputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, r: &dyn core::ToInputArray, p: &dyn core::ToInputArray, criteria: core::TermCriteria) -> Result<()> {
input_array_arg!(src);
output_array_arg!(dst);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
input_array_arg!(r);
input_array_arg!(p);
unsafe { sys::cv_undistortPoints_const__InputArrayR_const__OutputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR_TermCriteria(src.as_raw__InputArray(), dst.as_raw__OutputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), r.as_raw__InputArray(), p.as_raw__InputArray(), criteria.opencv_as_extern()) }.into_result()
}
/// Transforms an image to compensate for lens distortion.
///
/// The function transforms an image to compensate radial and tangential lens distortion.
///
/// The function is simply a combination of #initUndistortRectifyMap (with unity R ) and #remap
/// (with bilinear interpolation). See the former function for details of the transformation being
/// performed.
///
/// Those pixels in the destination image, for which there is no correspondent pixels in the source
/// image, are filled with zeros (black color).
///
/// A particular subset of the source image that will be visible in the corrected image can be regulated
/// by newCameraMatrix. You can use #getOptimalNewCameraMatrix to compute the appropriate
/// newCameraMatrix depending on your requirements.
///
/// The camera matrix and the distortion parameters can be determined using #calibrateCamera. If
/// the resolution of images is different from the resolution used at the calibration stage,  and  need to be scaled accordingly, while the distortion coefficients remain
/// the same.
///
/// ## Parameters
/// * src: Input (distorted) image.
/// * dst: Output (corrected) image that has the same size and type as src .
/// * cameraMatrix: Input camera matrix 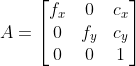 .
/// * distCoeffs: Input vector of distortion coefficients
/// 
/// of 4, 5, 8, 12 or 14 elements. If the vector is NULL/empty, the zero distortion coefficients are assumed.
/// * newCameraMatrix: Camera matrix of the distorted image. By default, it is the same as
/// cameraMatrix but you may additionally scale and shift the result by using a different matrix.
///
/// ## C++ default parameters
/// * new_camera_matrix: noArray()
pub fn undistort(src: &dyn core::ToInputArray, dst: &mut dyn core::ToOutputArray, camera_matrix: &dyn core::ToInputArray, dist_coeffs: &dyn core::ToInputArray, new_camera_matrix: &dyn core::ToInputArray) -> Result<()> {
input_array_arg!(src);
output_array_arg!(dst);
input_array_arg!(camera_matrix);
input_array_arg!(dist_coeffs);
input_array_arg!(new_camera_matrix);
unsafe { sys::cv_undistort_const__InputArrayR_const__OutputArrayR_const__InputArrayR_const__InputArrayR_const__InputArrayR(src.as_raw__InputArray(), dst.as_raw__OutputArray(), camera_matrix.as_raw__InputArray(), dist_coeffs.as_raw__InputArray(), new_camera_matrix.as_raw__InputArray()) }.into_result()
}
/// validates disparity using the left-right check. The matrix "cost" should be computed by the stereo correspondence algorithm
///
/// ## C++ default parameters
/// * disp12_max_disp: 1
pub fn validate_disparity(disparity: &mut dyn core::ToInputOutputArray, cost: &dyn core::ToInputArray, min_disparity: i32, number_of_disparities: i32, disp12_max_disp: i32) -> Result<()> {
input_output_array_arg!(disparity);
input_array_arg!(cost);
unsafe { sys::cv_validateDisparity_const__InputOutputArrayR_const__InputArrayR_int_int_int(disparity.as_raw__InputOutputArray(), cost.as_raw__InputArray(), min_disparity, number_of_disparities, disp12_max_disp) }.into_result()
}
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub struct CirclesGridFinderParameters {
pub density_neighborhood_size: core::Size2f,
pub min_density: f32,
pub kmeans_attempts: i32,
pub min_distance_to_add_keypoint: i32,
pub keypoint_scale: i32,
pub min_graph_confidence: f32,
pub vertex_gain: f32,
pub vertex_penalty: f32,
pub existing_vertex_gain: f32,
pub edge_gain: f32,
pub edge_penalty: f32,
pub convex_hull_factor: f32,
pub min_rng_edge_switch_dist: f32,
pub grid_type: crate::calib3d::CirclesGridFinderParameters_GridType,
/// Distance between two adjacent points. Used by CALIB_CB_CLUSTERING.
pub square_size: f32,
/// Max deviation from prediction. Used by CALIB_CB_CLUSTERING.
pub max_rectified_distance: f32,
}
opencv_type_simple! { crate::calib3d::CirclesGridFinderParameters }
impl CirclesGridFinderParameters {
pub fn default() -> Result<crate::calib3d::CirclesGridFinderParameters> {
unsafe { sys::cv_CirclesGridFinderParameters_CirclesGridFinderParameters() }.into_result()
}
}
/// Levenberg-Marquardt solver. Starting with the specified vector of parameters it
/// optimizes the target vector criteria "err"
/// (finds local minima of each target vector component absolute value).
///
/// When needed, it calls user-provided callback.
pub trait LMSolverConst: core::AlgorithmTraitConst {
fn as_raw_LMSolver(&self) -> *const c_void;
/// Runs Levenberg-Marquardt algorithm using the passed vector of parameters as the start point.
/// The final vector of parameters (whether the algorithm converged or not) is stored at the same
/// vector. The method returns the number of iterations used. If it's equal to the previously specified
/// maxIters, there is a big chance the algorithm did not converge.
///
/// ## Parameters
/// * param: initial/final vector of parameters.
///
/// Note that the dimensionality of parameter space is defined by the size of param vector,
/// and the dimensionality of optimized criteria is defined by the size of err vector
/// computed by the callback.
fn run(&self, param: &mut dyn core::ToInputOutputArray) -> Result<i32> {
input_output_array_arg!(param);
unsafe { sys::cv_LMSolver_run_const_const__InputOutputArrayR(self.as_raw_LMSolver(), param.as_raw__InputOutputArray()) }.into_result()
}
/// Retrieves the current maximum number of iterations
fn get_max_iters(&self) -> Result<i32> {
unsafe { sys::cv_LMSolver_getMaxIters_const(self.as_raw_LMSolver()) }.into_result()
}
}
pub trait LMSolver: core::AlgorithmTrait + crate::calib3d::LMSolverConst {
fn as_raw_mut_LMSolver(&mut self) -> *mut c_void;
/// Sets the maximum number of iterations
/// ## Parameters
/// * maxIters: the number of iterations
fn set_max_iters(&mut self, max_iters: i32) -> Result<()> {
unsafe { sys::cv_LMSolver_setMaxIters_int(self.as_raw_mut_LMSolver(), max_iters) }.into_result()
}
}
impl dyn LMSolver + '_ {
/// Creates Levenberg-Marquard solver
///
/// ## Parameters
/// * cb: callback
/// * maxIters: maximum number of iterations that can be further
/// modified using setMaxIters() method.
pub fn create(cb: &core::Ptr<dyn crate::calib3d::LMSolver_Callback>, max_iters: i32) -> Result<core::Ptr<dyn crate::calib3d::LMSolver>> {
unsafe { sys::cv_LMSolver_create_const_Ptr_Callback_R_int(cb.as_raw_PtrOfLMSolver_Callback(), max_iters) }.into_result().map(|r| unsafe { core::Ptr::<dyn crate::calib3d::LMSolver>::opencv_from_extern(r) } )
}
pub fn create_ext(cb: &core::Ptr<dyn crate::calib3d::LMSolver_Callback>, max_iters: i32, eps: f64) -> Result<core::Ptr<dyn crate::calib3d::LMSolver>> {
unsafe { sys::cv_LMSolver_create_const_Ptr_Callback_R_int_double(cb.as_raw_PtrOfLMSolver_Callback(), max_iters, eps) }.into_result().map(|r| unsafe { core::Ptr::<dyn crate::calib3d::LMSolver>::opencv_from_extern(r) } )
}
}
pub trait LMSolver_CallbackConst {
fn as_raw_LMSolver_Callback(&self) -> *const c_void;
/// computes error and Jacobian for the specified vector of parameters
///
/// ## Parameters
/// * param: the current vector of parameters
/// * err: output vector of errors: err_i = actual_f_i - ideal_f_i
/// * J: output Jacobian: J_ij = d(err_i)/d(param_j)
///
/// when J=noArray(), it means that it does not need to be computed.
/// Dimensionality of error vector and param vector can be different.
/// The callback should explicitly allocate (with "create" method) each output array
/// (unless it's noArray()).
fn compute(&self, param: &dyn core::ToInputArray, err: &mut dyn core::ToOutputArray, j: &mut dyn core::ToOutputArray) -> Result<bool> {
input_array_arg!(param);
output_array_arg!(err);
output_array_arg!(j);
unsafe { sys::cv_LMSolver_Callback_compute_const_const__InputArrayR_const__OutputArrayR_const__OutputArrayR(self.as_raw_LMSolver_Callback(), param.as_raw__InputArray(), err.as_raw__OutputArray(), j.as_raw__OutputArray()) }.into_result()
}
}
pub trait LMSolver_Callback: crate::calib3d::LMSolver_CallbackConst {
fn as_raw_mut_LMSolver_Callback(&mut self) -> *mut c_void;
}
/// Class for computing stereo correspondence using the block matching algorithm, introduced and
/// contributed to OpenCV by K. Konolige.
pub trait StereoBMConst: crate::calib3d::StereoMatcherConst {
fn as_raw_StereoBM(&self) -> *const c_void;
fn get_pre_filter_type(&self) -> Result<i32> {
unsafe { sys::cv_StereoBM_getPreFilterType_const(self.as_raw_StereoBM()) }.into_result()
}
fn get_pre_filter_size(&self) -> Result<i32> {
unsafe { sys::cv_StereoBM_getPreFilterSize_const(self.as_raw_StereoBM()) }.into_result()
}
fn get_pre_filter_cap(&self) -> Result<i32> {
unsafe { sys::cv_StereoBM_getPreFilterCap_const(self.as_raw_StereoBM()) }.into_result()
}
fn get_texture_threshold(&self) -> Result<i32> {
unsafe { sys::cv_StereoBM_getTextureThreshold_const(self.as_raw_StereoBM()) }.into_result()
}
fn get_uniqueness_ratio(&self) -> Result<i32> {
unsafe { sys::cv_StereoBM_getUniquenessRatio_const(self.as_raw_StereoBM()) }.into_result()
}
fn get_smaller_block_size(&self) -> Result<i32> {
unsafe { sys::cv_StereoBM_getSmallerBlockSize_const(self.as_raw_StereoBM()) }.into_result()
}
fn get_roi1(&self) -> Result<core::Rect> {
unsafe { sys::cv_StereoBM_getROI1_const(self.as_raw_StereoBM()) }.into_result()
}
fn get_roi2(&self) -> Result<core::Rect> {
unsafe { sys::cv_StereoBM_getROI2_const(self.as_raw_StereoBM()) }.into_result()
}
}
pub trait StereoBM: crate::calib3d::StereoBMConst + crate::calib3d::StereoMatcher {
fn as_raw_mut_StereoBM(&mut self) -> *mut c_void;
fn set_pre_filter_type(&mut self, pre_filter_type: i32) -> Result<()> {
unsafe { sys::cv_StereoBM_setPreFilterType_int(self.as_raw_mut_StereoBM(), pre_filter_type) }.into_result()
}
fn set_pre_filter_size(&mut self, pre_filter_size: i32) -> Result<()> {
unsafe { sys::cv_StereoBM_setPreFilterSize_int(self.as_raw_mut_StereoBM(), pre_filter_size) }.into_result()
}
fn set_pre_filter_cap(&mut self, pre_filter_cap: i32) -> Result<()> {
unsafe { sys::cv_StereoBM_setPreFilterCap_int(self.as_raw_mut_StereoBM(), pre_filter_cap) }.into_result()
}
fn set_texture_threshold(&mut self, texture_threshold: i32) -> Result<()> {
unsafe { sys::cv_StereoBM_setTextureThreshold_int(self.as_raw_mut_StereoBM(), texture_threshold) }.into_result()
}
fn set_uniqueness_ratio(&mut self, uniqueness_ratio: i32) -> Result<()> {
unsafe { sys::cv_StereoBM_setUniquenessRatio_int(self.as_raw_mut_StereoBM(), uniqueness_ratio) }.into_result()
}
fn set_smaller_block_size(&mut self, block_size: i32) -> Result<()> {
unsafe { sys::cv_StereoBM_setSmallerBlockSize_int(self.as_raw_mut_StereoBM(), block_size) }.into_result()
}
fn set_roi1(&mut self, roi1: core::Rect) -> Result<()> {
unsafe { sys::cv_StereoBM_setROI1_Rect(self.as_raw_mut_StereoBM(), roi1.opencv_as_extern()) }.into_result()
}
fn set_roi2(&mut self, roi2: core::Rect) -> Result<()> {
unsafe { sys::cv_StereoBM_setROI2_Rect(self.as_raw_mut_StereoBM(), roi2.opencv_as_extern()) }.into_result()
}
}
impl dyn StereoBM + '_ {
/// Creates StereoBM object
///
/// ## Parameters
/// * numDisparities: the disparity search range. For each pixel algorithm will find the best
/// disparity from 0 (default minimum disparity) to numDisparities. The search range can then be
/// shifted by changing the minimum disparity.
/// * blockSize: the linear size of the blocks compared by the algorithm. The size should be odd
/// (as the block is centered at the current pixel). Larger block size implies smoother, though less
/// accurate disparity map. Smaller block size gives more detailed disparity map, but there is higher
/// chance for algorithm to find a wrong correspondence.
///
/// The function create StereoBM object. You can then call StereoBM::compute() to compute disparity for
/// a specific stereo pair.
///
/// ## C++ default parameters
/// * num_disparities: 0
/// * block_size: 21
pub fn create(num_disparities: i32, block_size: i32) -> Result<core::Ptr<dyn crate::calib3d::StereoBM>> {
unsafe { sys::cv_StereoBM_create_int_int(num_disparities, block_size) }.into_result().map(|r| unsafe { core::Ptr::<dyn crate::calib3d::StereoBM>::opencv_from_extern(r) } )
}
}
/// The base class for stereo correspondence algorithms.
pub trait StereoMatcherConst: core::AlgorithmTraitConst {
fn as_raw_StereoMatcher(&self) -> *const c_void;
fn get_min_disparity(&self) -> Result<i32> {
unsafe { sys::cv_StereoMatcher_getMinDisparity_const(self.as_raw_StereoMatcher()) }.into_result()
}
fn get_num_disparities(&self) -> Result<i32> {
unsafe { sys::cv_StereoMatcher_getNumDisparities_const(self.as_raw_StereoMatcher()) }.into_result()
}
fn get_block_size(&self) -> Result<i32> {
unsafe { sys::cv_StereoMatcher_getBlockSize_const(self.as_raw_StereoMatcher()) }.into_result()
}
fn get_speckle_window_size(&self) -> Result<i32> {
unsafe { sys::cv_StereoMatcher_getSpeckleWindowSize_const(self.as_raw_StereoMatcher()) }.into_result()
}
fn get_speckle_range(&self) -> Result<i32> {
unsafe { sys::cv_StereoMatcher_getSpeckleRange_const(self.as_raw_StereoMatcher()) }.into_result()
}
fn get_disp12_max_diff(&self) -> Result<i32> {
unsafe { sys::cv_StereoMatcher_getDisp12MaxDiff_const(self.as_raw_StereoMatcher()) }.into_result()
}
}
pub trait StereoMatcher: core::AlgorithmTrait + crate::calib3d::StereoMatcherConst {
fn as_raw_mut_StereoMatcher(&mut self) -> *mut c_void;
/// Computes disparity map for the specified stereo pair
///
/// ## Parameters
/// * left: Left 8-bit single-channel image.
/// * right: Right image of the same size and the same type as the left one.
/// * disparity: Output disparity map. It has the same size as the input images. Some algorithms,
/// like StereoBM or StereoSGBM compute 16-bit fixed-point disparity map (where each disparity value
/// has 4 fractional bits), whereas other algorithms output 32-bit floating-point disparity map.
fn compute(&mut self, left: &dyn core::ToInputArray, right: &dyn core::ToInputArray, disparity: &mut dyn core::ToOutputArray) -> Result<()> {
input_array_arg!(left);
input_array_arg!(right);
output_array_arg!(disparity);
unsafe { sys::cv_StereoMatcher_compute_const__InputArrayR_const__InputArrayR_const__OutputArrayR(self.as_raw_mut_StereoMatcher(), left.as_raw__InputArray(), right.as_raw__InputArray(), disparity.as_raw__OutputArray()) }.into_result()
}
fn set_min_disparity(&mut self, min_disparity: i32) -> Result<()> {
unsafe { sys::cv_StereoMatcher_setMinDisparity_int(self.as_raw_mut_StereoMatcher(), min_disparity) }.into_result()
}
fn set_num_disparities(&mut self, num_disparities: i32) -> Result<()> {
unsafe { sys::cv_StereoMatcher_setNumDisparities_int(self.as_raw_mut_StereoMatcher(), num_disparities) }.into_result()
}
fn set_block_size(&mut self, block_size: i32) -> Result<()> {
unsafe { sys::cv_StereoMatcher_setBlockSize_int(self.as_raw_mut_StereoMatcher(), block_size) }.into_result()
}
fn set_speckle_window_size(&mut self, speckle_window_size: i32) -> Result<()> {
unsafe { sys::cv_StereoMatcher_setSpeckleWindowSize_int(self.as_raw_mut_StereoMatcher(), speckle_window_size) }.into_result()
}
fn set_speckle_range(&mut self, speckle_range: i32) -> Result<()> {
unsafe { sys::cv_StereoMatcher_setSpeckleRange_int(self.as_raw_mut_StereoMatcher(), speckle_range) }.into_result()
}
fn set_disp12_max_diff(&mut self, disp12_max_diff: i32) -> Result<()> {
unsafe { sys::cv_StereoMatcher_setDisp12MaxDiff_int(self.as_raw_mut_StereoMatcher(), disp12_max_diff) }.into_result()
}
}
/// The class implements the modified H. Hirschmuller algorithm [HH08](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_HH08) that differs from the original
/// one as follows:
///
/// * By default, the algorithm is single-pass, which means that you consider only 5 directions
/// instead of 8. Set mode=StereoSGBM::MODE_HH in createStereoSGBM to run the full variant of the
/// algorithm but beware that it may consume a lot of memory.
/// * The algorithm matches blocks, not individual pixels. Though, setting blockSize=1 reduces the
/// blocks to single pixels.
/// * Mutual information cost function is not implemented. Instead, a simpler Birchfield-Tomasi
/// sub-pixel metric from [BT98](https://docs.opencv.org/4.5.3/d0/de3/citelist.html#CITEREF_BT98) is used. Though, the color images are supported as well.
/// * Some pre- and post- processing steps from K. Konolige algorithm StereoBM are included, for
/// example: pre-filtering (StereoBM::PREFILTER_XSOBEL type) and post-filtering (uniqueness
/// check, quadratic interpolation and speckle filtering).
///
///
/// Note:
/// * (Python) An example illustrating the use of the StereoSGBM matching algorithm can be found
/// at opencv_source_code/samples/python/stereo_match.py
pub trait StereoSGBMConst: crate::calib3d::StereoMatcherConst {
fn as_raw_StereoSGBM(&self) -> *const c_void;
fn get_pre_filter_cap(&self) -> Result<i32> {
unsafe { sys::cv_StereoSGBM_getPreFilterCap_const(self.as_raw_StereoSGBM()) }.into_result()
}
fn get_uniqueness_ratio(&self) -> Result<i32> {
unsafe { sys::cv_StereoSGBM_getUniquenessRatio_const(self.as_raw_StereoSGBM()) }.into_result()
}
fn get_p1(&self) -> Result<i32> {
unsafe { sys::cv_StereoSGBM_getP1_const(self.as_raw_StereoSGBM()) }.into_result()
}
fn get_p2(&self) -> Result<i32> {
unsafe { sys::cv_StereoSGBM_getP2_const(self.as_raw_StereoSGBM()) }.into_result()
}
fn get_mode(&self) -> Result<i32> {
unsafe { sys::cv_StereoSGBM_getMode_const(self.as_raw_StereoSGBM()) }.into_result()
}
}
pub trait StereoSGBM: crate::calib3d::StereoMatcher + crate::calib3d::StereoSGBMConst {
fn as_raw_mut_StereoSGBM(&mut self) -> *mut c_void;
fn set_pre_filter_cap(&mut self, pre_filter_cap: i32) -> Result<()> {
unsafe { sys::cv_StereoSGBM_setPreFilterCap_int(self.as_raw_mut_StereoSGBM(), pre_filter_cap) }.into_result()
}
fn set_uniqueness_ratio(&mut self, uniqueness_ratio: i32) -> Result<()> {
unsafe { sys::cv_StereoSGBM_setUniquenessRatio_int(self.as_raw_mut_StereoSGBM(), uniqueness_ratio) }.into_result()
}
fn set_p1(&mut self, p1: i32) -> Result<()> {
unsafe { sys::cv_StereoSGBM_setP1_int(self.as_raw_mut_StereoSGBM(), p1) }.into_result()
}
fn set_p2(&mut self, p2: i32) -> Result<()> {
unsafe { sys::cv_StereoSGBM_setP2_int(self.as_raw_mut_StereoSGBM(), p2) }.into_result()
}
fn set_mode(&mut self, mode: i32) -> Result<()> {
unsafe { sys::cv_StereoSGBM_setMode_int(self.as_raw_mut_StereoSGBM(), mode) }.into_result()
}
}
impl dyn StereoSGBM + '_ {
/// Creates StereoSGBM object
///
/// ## Parameters
/// * minDisparity: Minimum possible disparity value. Normally, it is zero but sometimes
/// rectification algorithms can shift images, so this parameter needs to be adjusted accordingly.
/// * numDisparities: Maximum disparity minus minimum disparity. The value is always greater than
/// zero. In the current implementation, this parameter must be divisible by 16.
/// * blockSize: Matched block size. It must be an odd number \>=1 . Normally, it should be
/// somewhere in the 3..11 range.
/// * P1: The first parameter controlling the disparity smoothness. See below.
/// * P2: The second parameter controlling the disparity smoothness. The larger the values are,
/// the smoother the disparity is. P1 is the penalty on the disparity change by plus or minus 1
/// between neighbor pixels. P2 is the penalty on the disparity change by more than 1 between neighbor
/// pixels. The algorithm requires P2 \> P1 . See stereo_match.cpp sample where some reasonably good
/// P1 and P2 values are shown (like 8\*number_of_image_channels\*blockSize\*blockSize and
/// 32\*number_of_image_channels\*blockSize\*blockSize , respectively).
/// * disp12MaxDiff: Maximum allowed difference (in integer pixel units) in the left-right
/// disparity check. Set it to a non-positive value to disable the check.
/// * preFilterCap: Truncation value for the prefiltered image pixels. The algorithm first
/// computes x-derivative at each pixel and clips its value by [-preFilterCap, preFilterCap] interval.
/// The result values are passed to the Birchfield-Tomasi pixel cost function.
/// * uniquenessRatio: Margin in percentage by which the best (minimum) computed cost function
/// value should "win" the second best value to consider the found match correct. Normally, a value
/// within the 5-15 range is good enough.
/// * speckleWindowSize: Maximum size of smooth disparity regions to consider their noise speckles
/// and invalidate. Set it to 0 to disable speckle filtering. Otherwise, set it somewhere in the
/// 50-200 range.
/// * speckleRange: Maximum disparity variation within each connected component. If you do speckle
/// filtering, set the parameter to a positive value, it will be implicitly multiplied by 16.
/// Normally, 1 or 2 is good enough.
/// * mode: Set it to StereoSGBM::MODE_HH to run the full-scale two-pass dynamic programming
/// algorithm. It will consume O(W\*H\*numDisparities) bytes, which is large for 640x480 stereo and
/// huge for HD-size pictures. By default, it is set to false .
///
/// The first constructor initializes StereoSGBM with all the default parameters. So, you only have to
/// set StereoSGBM::numDisparities at minimum. The second constructor enables you to set each parameter
/// to a custom value.
///
/// ## C++ default parameters
/// * min_disparity: 0
/// * num_disparities: 16
/// * block_size: 3
/// * p1: 0
/// * p2: 0
/// * disp12_max_diff: 0
/// * pre_filter_cap: 0
/// * uniqueness_ratio: 0
/// * speckle_window_size: 0
/// * speckle_range: 0
/// * mode: StereoSGBM::MODE_SGBM
pub fn create(min_disparity: i32, num_disparities: i32, block_size: i32, p1: i32, p2: i32, disp12_max_diff: i32, pre_filter_cap: i32, uniqueness_ratio: i32, speckle_window_size: i32, speckle_range: i32, mode: i32) -> Result<core::Ptr<dyn crate::calib3d::StereoSGBM>> {
unsafe { sys::cv_StereoSGBM_create_int_int_int_int_int_int_int_int_int_int_int(min_disparity, num_disparities, block_size, p1, p2, disp12_max_diff, pre_filter_cap, uniqueness_ratio, speckle_window_size, speckle_range, mode) }.into_result().map(|r| unsafe { core::Ptr::<dyn crate::calib3d::StereoSGBM>::opencv_from_extern(r) } )
}
}
#[repr(C)]
#[derive(Copy, Clone, Debug, PartialEq)]
pub struct UsacParams {
pub confidence: f64,
pub is_parallel: bool,
pub lo_iterations: i32,
pub lo_method: crate::calib3d::LocalOptimMethod,
pub lo_sample_size: i32,
pub max_iterations: i32,
pub neighbors_search: crate::calib3d::NeighborSearchMethod,
pub random_generator_state: i32,
pub sampler: crate::calib3d::SamplingMethod,
pub score: crate::calib3d::ScoreMethod,
pub threshold: f64,
}
opencv_type_simple! { crate::calib3d::UsacParams }
impl UsacParams {
pub fn default() -> Result<crate::calib3d::UsacParams> {
unsafe { sys::cv_UsacParams_UsacParams() }.into_result()
}
}
|
NeighborSearchMethod
|
log-to-nsq.go
|
/*
log_to_nsq is an example program that demonstrates the use of apexovernsq. When invoked with the IP adress and port of one or more running nsqd and a topic name, it will pu
sh two structured log messages to that nsq daemon (or deamons) and then exit.
To see this working the following three things should be invoked.
1. Start the nsqdaemon:
nsqd
... take note of the port number for TCP that it informs you of.
2. Start nsq_tail:
nsq_tail -topic log --nsqd-tcp-address <IPADDRESS:PORT>
Not that <IPADDRESS:PORT> should be replaced with the IP address of the machine where nsqd is running and the port number you took note of in step one.
3. invoke this program:
./example -nsqd-address <IPADDRESS:PORT> -topic log
This program should exit almost immediately, but if you check the nsq_tail process you should see some output that looks like this:
{"fields":{"flavour":"pistachio","scoops":"two"},"level":"info","timestamp":"2017-08-04T15:48:22.044783085+02:00","message":"It's ice cream time!"}
{"fields":{"error":"ouch, brainfreeze"},"level":"error","timestamp":"2017-08-04T15:48:22.047870426+02:00","message":"Problem consuming ice cream"}
*/
package main
import (
"flag"
"fmt"
"log"
"strings"
"code.avct.io/apexovernsq"
"code.avct.io/apexovernsq/protobuf"
alog "github.com/apex/log"
nsq "github.com/nsqio/go-nsq"
)
type stringFlags []string
func (n *stringFlags) Set(value string) error {
*n = append(*n, value)
return nil
}
func (n *stringFlags) String() string {
return strings.Join(*n, ",")
}
var (
topic = flag.String("topic", "", "NSQ topic to publish to [Required]")
nsqdAddresses = stringFlags{}
)
func init() {
flag.Var(&nsqdAddresses, "nsqd-address", "The IP Address of a nsqd you with to publish to. Give this option once for every nsqd [1 or more required].")
}
func
|
() {
flag.PrintDefaults()
}
func makeProducers(addresses stringFlags, cfg *nsq.Config) []*nsq.Producer {
var producer *nsq.Producer
var err error
producerCount := len(addresses)
producers := make([]*nsq.Producer, producerCount, producerCount)
for i, address := range addresses {
producer, err = nsq.NewProducer(address, cfg)
if err != nil {
log.Fatalf("Error creating nsq.Producer: %s", err)
}
producers[i] = producer
}
return producers
}
func makePublisher(producers []*nsq.Producer) apexovernsq.PublishFunc {
return func(topic string, body []byte) (err error) {
for _, producer := range producers {
err = producer.Publish(topic, body)
if err != nil {
return err
}
}
return nil
}
}
func main() {
flag.Parse()
if len(*topic) == 0 || len(nsqdAddresses) == 0 {
usage()
log.Fatal("Required parameters missing.")
}
cfg := nsq.NewConfig()
producers := makeProducers(nsqdAddresses, cfg)
publisher := makePublisher(producers)
handler := apexovernsq.NewApexLogNSQHandler(protobuf.Marshal, publisher, "log")
alog.SetHandler(handler)
ctx := apexovernsq.NewApexLogServiceContext()
ctx.WithFields(alog.Fields{
"flavour": "pistachio",
"scoops": "two",
}).Info("It's ice cream time!")
ctx.WithError(fmt.Errorf("ouch, brainfreeze")).Error("Problem consuming ice cream")
}
|
usage
|
attr-main.rs
|
// Copyright 2012-2014 The Rust Project Developers. See the COPYRIGHT
// file at the top-level directory of this distribution and at
// http://rust-lang.org/COPYRIGHT.
//
// Licensed under the Apache License, Version 2.0 <LICENSE-APACHE or
// http://www.apache.org/licenses/LICENSE-2.0> or the MIT license
// <LICENSE-MIT or http://opensource.org/licenses/MIT>, at your
// option. This file may not be copied, modified, or distributed
// except according to those terms.
// ignore-fast
#[main]
fn
|
() {
}
|
foo
|
accountimport_test.go
|
// Copyright (c) 2019 IoTeX Foundation
// This is an alpha (internal) release and is not suitable for production. This source code is provided 'as is' and no
// warranties are given as to title or non-infringement, merchantability or fitness for purpose and, to the extent
// permitted by law, all liability for your use of the code is disclaimed. This source code is governed by Apache
// License 2.0 that can be found in the LICENSE file.
package account
import (
"github.com/iotexproject/iotex-core/testutil"
"os"
"path/filepath"
"strings"
"testing"
"github.com/golang/mock/gomock"
"github.com/stretchr/testify/require"
"github.com/iotexproject/iotex-core/ioctl/config"
"github.com/iotexproject/iotex-core/ioctl/util"
"github.com/iotexproject/iotex-core/test/mock/mock_ioctlclient"
)
func TestNewAccountImportCmd(t *testing.T) {
require := require.New(t)
ctrl := gomock.NewController(t)
defer ctrl.Finish()
client := mock_ioctlclient.NewMockClient(ctrl)
client.EXPECT().SelectTranslation(gomock.Any()).Return("", config.English).AnyTimes()
client.EXPECT().Config().Return(config.Config{}).AnyTimes()
cmd := NewAccountImportCmd(client)
result, err := util.ExecuteCmd(cmd, "hh")
require.NotNil(result)
require.Error(err)
}
func TestNewAccountImportKeyCmd(t *testing.T) {
require := require.New(t)
ctrl := gomock.NewController(t)
defer ctrl.Finish()
client := mock_ioctlclient.NewMockClient(ctrl)
client.EXPECT().SelectTranslation(gomock.Any()).Return("", config.English).AnyTimes()
client.EXPECT().Config().Return(config.Config{}).AnyTimes()
cmd := NewAccountImportKeyCmd(client)
result, err := util.ExecuteCmd(cmd, "hh")
require.NotNil(result)
require.Error(err)
}
func TestNewAccountImportKeyStoreCmd(t *testing.T) {
require := require.New(t)
ctrl := gomock.NewController(t)
defer ctrl.Finish()
client := mock_ioctlclient.NewMockClient(ctrl)
client.EXPECT().SelectTranslation(gomock.Any()).Return("", config.English).AnyTimes()
client.EXPECT().Config().Return(config.Config{}).AnyTimes()
testAccountFolder := filepath.Join(os.TempDir(), "testAccountImportKeyStore")
require.NoError(os.MkdirAll(testAccountFolder, os.ModePerm))
defer func() {
require.NoError(os.RemoveAll(testAccountFolder))
}()
cmd := NewAccountImportKeyStoreCmd(client)
result, err := util.ExecuteCmd(cmd, []string{"hh", "./testAccountImportKeyStoreCmd"}...)
require.NotNil(result)
require.Error(err)
}
func TestNewAccountImportPemCmd(t *testing.T) {
require := require.New(t)
ctrl := gomock.NewController(t)
defer ctrl.Finish()
client := mock_ioctlclient.NewMockClient(ctrl)
client.EXPECT().SelectTranslation(gomock.Any()).Return("", config.English).AnyTimes()
client.EXPECT().Config().Return(config.Config{}).AnyTimes()
cmd := NewAccountImportPemCmd(client)
result, err := util.ExecuteCmd(cmd, []string{"hh", "./testAccountImportPemCmd"}...)
require.NotNil(result)
require.Error(err)
}
func TestValidateAlias(t *testing.T) {
require := require.New(t)
testFilePath := filepath.Join(os.TempDir(), testPath)
defer testutil.CleanupPath(testFilePath)
alias := "aaa"
config.ReadConfig.Aliases = map[string]string{}
err := validateAlias(alias)
require.NoError(err)
config.ReadConfig.Aliases[alias] = "a"
err = validateAlias(alias)
require.Error(err)
alias = strings.Repeat("a", 50)
err = validateAlias(alias)
require.Error(err)
}
func TestWriteToFile(t *testing.T) {
require := require.New(t)
testFilePath := filepath.Join(os.TempDir(), testPath)
defer testutil.CleanupPath(testFilePath)
alias := "aaa"
addr := "bbb"
err := writeToFile(alias, addr)
require.NoError(err)
}
func TestReadPasswordFromStdin(t *testing.T)
|
{
require := require.New(t)
_, err := readPasswordFromStdin()
require.Error(err)
}
|
|
walletunlock.py
|
pwd = raw_input("Enter wallet passphrase: ")
access.walletpassphrase(pwd, 60)
|
from jsonrpc import ServiceProxy
access = ServiceProxy("http://127.0.0.1:4354")
|
|
user.ts
|
export default interface User {
|
_id: string;
email: string;
password: string;
}
|
|
get_group.py
|
# coding=utf-8
# *** WARNING: this file was generated by the Pulumi SDK Generator. ***
# *** Do not edit by hand unless you're certain you know what you are doing! ***
import warnings
import pulumi
import pulumi.runtime
from typing import Any, Mapping, Optional, Sequence, Union, overload
from .. import _utilities
from . import outputs
from ._enums import *
__all__ = [
'GetGroupResult',
'AwaitableGetGroupResult',
'get_group',
'get_group_output',
]
@pulumi.output_type
class GetGroupResult:
def __init__(__self__, arn=None, configuration=None, description=None, resource_query=None, resources=None, tags=None):
if arn and not isinstance(arn, str):
raise TypeError("Expected argument 'arn' to be a str")
pulumi.set(__self__, "arn", arn)
if configuration and not isinstance(configuration, list):
raise TypeError("Expected argument 'configuration' to be a list")
pulumi.set(__self__, "configuration", configuration)
if description and not isinstance(description, str):
raise TypeError("Expected argument 'description' to be a str")
pulumi.set(__self__, "description", description)
if resource_query and not isinstance(resource_query, dict):
raise TypeError("Expected argument 'resource_query' to be a dict")
pulumi.set(__self__, "resource_query", resource_query)
if resources and not isinstance(resources, list):
raise TypeError("Expected argument 'resources' to be a list")
pulumi.set(__self__, "resources", resources)
if tags and not isinstance(tags, list):
raise TypeError("Expected argument 'tags' to be a list")
pulumi.set(__self__, "tags", tags)
@property
@pulumi.getter
def arn(self) -> Optional[str]:
"""
The Resource Group ARN.
"""
return pulumi.get(self, "arn")
@property
@pulumi.getter
def configuration(self) -> Optional[Sequence['outputs.GroupConfigurationItem']]:
return pulumi.get(self, "configuration")
@property
@pulumi.getter
def description(self) -> Optional[str]:
"""
The description of the resource group
"""
return pulumi.get(self, "description")
@property
@pulumi.getter(name="resourceQuery")
def resource_query(self) -> Optional['outputs.GroupResourceQuery']:
return pulumi.get(self, "resource_query")
@property
@pulumi.getter
def
|
(self) -> Optional[Sequence[str]]:
return pulumi.get(self, "resources")
@property
@pulumi.getter
def tags(self) -> Optional[Sequence['outputs.GroupTag']]:
return pulumi.get(self, "tags")
class AwaitableGetGroupResult(GetGroupResult):
# pylint: disable=using-constant-test
def __await__(self):
if False:
yield self
return GetGroupResult(
arn=self.arn,
configuration=self.configuration,
description=self.description,
resource_query=self.resource_query,
resources=self.resources,
tags=self.tags)
def get_group(name: Optional[str] = None,
opts: Optional[pulumi.InvokeOptions] = None) -> AwaitableGetGroupResult:
"""
Schema for ResourceGroups::Group
:param str name: The name of the resource group
"""
__args__ = dict()
__args__['name'] = name
if opts is None:
opts = pulumi.InvokeOptions()
if opts.version is None:
opts.version = _utilities.get_version()
__ret__ = pulumi.runtime.invoke('aws-native:resourcegroups:getGroup', __args__, opts=opts, typ=GetGroupResult).value
return AwaitableGetGroupResult(
arn=__ret__.arn,
configuration=__ret__.configuration,
description=__ret__.description,
resource_query=__ret__.resource_query,
resources=__ret__.resources,
tags=__ret__.tags)
@_utilities.lift_output_func(get_group)
def get_group_output(name: Optional[pulumi.Input[str]] = None,
opts: Optional[pulumi.InvokeOptions] = None) -> pulumi.Output[GetGroupResult]:
"""
Schema for ResourceGroups::Group
:param str name: The name of the resource group
"""
...
|
resources
|
token.rs
|
#[derive(Debug)]
|
pub value: String
}
|
pub struct Token {
pub id: String,
|
config_test.go
|
// Copyright (c) 2018 Intel Corporation
// Copyright (c) 2018 HyperHQ Inc.
//
// SPDX-License-Identifier: Apache-2.0
//
package katautils
import (
"bytes"
"fmt"
"io/ioutil"
"os"
"path"
"path/filepath"
"reflect"
goruntime "runtime"
"strings"
"syscall"
"testing"
ktu "github.com/kata-containers/kata-containers/src/runtime/pkg/katatestutils"
vc "github.com/kata-containers/kata-containers/src/runtime/virtcontainers"
"github.com/kata-containers/kata-containers/src/runtime/virtcontainers/pkg/oci"
"github.com/kata-containers/kata-containers/src/runtime/virtcontainers/utils"
"github.com/stretchr/testify/assert"
)
var (
hypervisorDebug = false
proxyDebug = false
runtimeDebug = false
runtimeTrace = false
netmonDebug = false
agentDebug = false
agentTrace = false
)
type testRuntimeConfig struct {
RuntimeConfig oci.RuntimeConfig
RuntimeConfigFile string
ConfigPath string
ConfigPathLink string
LogDir string
LogPath string
}
func createConfig(configPath string, fileData string) error {
err := ioutil.WriteFile(configPath, []byte(fileData), testFileMode)
if err != nil {
fmt.Fprintf(os.Stderr, "Unable to create config file %s %v\n", configPath, err)
return err
}
return nil
}
// createAllRuntimeConfigFiles creates all files necessary to call
// loadConfiguration().
func createAllRuntimeConfigFiles(dir, hypervisor string) (config testRuntimeConfig, err error) {
if dir == "" {
return config, fmt.Errorf("BUG: need directory")
}
if hypervisor == "" {
return config, fmt.Errorf("BUG: need hypervisor")
}
hypervisorPath := path.Join(dir, "hypervisor")
kernelPath := path.Join(dir, "kernel")
kernelParams := "foo=bar xyz"
imagePath := path.Join(dir, "image")
proxyPath := path.Join(dir, "proxy")
netmonPath := path.Join(dir, "netmon")
logDir := path.Join(dir, "logs")
logPath := path.Join(logDir, "runtime.log")
machineType := "machineType"
disableBlockDevice := true
blockDeviceDriver := "virtio-scsi"
enableIOThreads := true
hotplugVFIOOnRootBus := true
pcieRootPort := uint32(2)
disableNewNetNs := false
sharedFS := "virtio-9p"
virtioFSdaemon := path.Join(dir, "virtiofsd")
configFileOptions := ktu.RuntimeConfigOptions{
Hypervisor: "qemu",
HypervisorPath: hypervisorPath,
KernelPath: kernelPath,
ImagePath: imagePath,
KernelParams: kernelParams,
MachineType: machineType,
ProxyPath: proxyPath,
NetmonPath: netmonPath,
LogPath: logPath,
DefaultGuestHookPath: defaultGuestHookPath,
DisableBlock: disableBlockDevice,
BlockDeviceDriver: blockDeviceDriver,
EnableIOThreads: enableIOThreads,
HotplugVFIOOnRootBus: hotplugVFIOOnRootBus,
PCIeRootPort: pcieRootPort,
DisableNewNetNs: disableNewNetNs,
DefaultVCPUCount: defaultVCPUCount,
DefaultMaxVCPUCount: defaultMaxVCPUCount,
DefaultMemSize: defaultMemSize,
DefaultMsize9p: defaultMsize9p,
HypervisorDebug: hypervisorDebug,
RuntimeDebug: runtimeDebug,
RuntimeTrace: runtimeTrace,
ProxyDebug: proxyDebug,
NetmonDebug: netmonDebug,
AgentDebug: agentDebug,
AgentTrace: agentTrace,
SharedFS: sharedFS,
VirtioFSDaemon: virtioFSdaemon,
}
runtimeConfigFileData := ktu.MakeRuntimeConfigFileData(configFileOptions)
configPath := path.Join(dir, "runtime.toml")
err = createConfig(configPath, runtimeConfigFileData)
if err != nil {
return config, err
}
configPathLink := path.Join(filepath.Dir(configPath), "link-to-configuration.toml")
// create a link to the config file
err = syscall.Symlink(configPath, configPathLink)
if err != nil {
return config, err
}
files := []string{hypervisorPath, kernelPath, imagePath, proxyPath}
for _, file := range files {
// create the resource (which must be >0 bytes)
err := WriteFile(file, "foo", testFileMode)
if err != nil {
return config, err
}
}
hypervisorConfig := vc.HypervisorConfig{
HypervisorPath: hypervisorPath,
KernelPath: kernelPath,
ImagePath: imagePath,
KernelParams: vc.DeserializeParams(strings.Fields(kernelParams)),
HypervisorMachineType: machineType,
NumVCPUs: defaultVCPUCount,
DefaultMaxVCPUs: uint32(goruntime.NumCPU()),
MemorySize: defaultMemSize,
DisableBlockDeviceUse: disableBlockDevice,
BlockDeviceDriver: defaultBlockDeviceDriver,
DefaultBridges: defaultBridgesCount,
Mlock: !defaultEnableSwap,
EnableIOThreads: enableIOThreads,
HotplugVFIOOnRootBus: hotplugVFIOOnRootBus,
PCIeRootPort: pcieRootPort,
Msize9p: defaultMsize9p,
MemSlots: defaultMemSlots,
EntropySource: defaultEntropySource,
GuestHookPath: defaultGuestHookPath,
VhostUserStorePath: defaultVhostUserStorePath,
SharedFS: sharedFS,
VirtioFSDaemon: virtioFSdaemon,
VirtioFSCache: defaultVirtioFSCacheMode,
}
agentConfig := vc.KataAgentConfig{}
proxyConfig := vc.ProxyConfig{
Path: proxyPath,
}
netmonConfig := vc.NetmonConfig{
Path: netmonPath,
Debug: false,
Enable: false,
}
factoryConfig := oci.FactoryConfig{
TemplatePath: defaultTemplatePath,
VMCacheEndpoint: defaultVMCacheEndpoint,
}
runtimeConfig := oci.RuntimeConfig{
HypervisorType: defaultHypervisor,
HypervisorConfig: hypervisorConfig,
AgentConfig: agentConfig,
ProxyType: defaultProxy,
ProxyConfig: proxyConfig,
NetmonConfig: netmonConfig,
DisableNewNetNs: disableNewNetNs,
FactoryConfig: factoryConfig,
}
err = SetKernelParams(&runtimeConfig)
if err != nil {
return config, err
}
config = testRuntimeConfig{
RuntimeConfig: runtimeConfig,
RuntimeConfigFile: configPath,
ConfigPath: configPath,
ConfigPathLink: configPathLink,
LogDir: logDir,
LogPath: logPath,
}
return config, nil
}
// testLoadConfiguration accepts an optional function that can be used
// to modify the test: if a function is specified, it indicates if the
// subsequent call to loadConfiguration() is expected to fail by
// returning a bool. If the function itself fails, that is considered an
// error.
func testLoadConfiguration(t *testing.T, dir string,
fn func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error)) {
subDir := path.Join(dir, "test")
for _, hypervisor := range []string{"qemu"} {
Loop:
for _, ignoreLogging := range []bool{true, false} {
err := os.RemoveAll(subDir)
assert.NoError(t, err)
err = os.MkdirAll(subDir, testDirMode)
assert.NoError(t, err)
testConfig, err := createAllRuntimeConfigFiles(subDir, hypervisor)
assert.NoError(t, err)
configFiles := []string{testConfig.ConfigPath, testConfig.ConfigPathLink, ""}
// override
defaultRuntimeConfiguration = testConfig.ConfigPath
defaultSysConfRuntimeConfiguration = ""
for _, file := range configFiles {
var err error
expectFail := false
if fn != nil {
expectFail, err = fn(testConfig, file, ignoreLogging)
assert.NoError(t, err)
}
resolvedConfigPath, config, err := LoadConfiguration(file, ignoreLogging, false)
if expectFail {
assert.Error(t, err)
// no point proceeding in the error scenario.
break Loop
} else {
assert.NoError(t, err)
}
if file == "" {
assert.Equal(t, defaultRuntimeConfiguration, resolvedConfigPath)
} else {
assert.Equal(t, testConfig.ConfigPath, resolvedConfigPath)
}
assert.Equal(t, defaultRuntimeConfiguration, resolvedConfigPath)
result := reflect.DeepEqual(config, testConfig.RuntimeConfig)
if !result {
t.Fatalf("Expected\n%+v\nGot\n%+v", config, testConfig.RuntimeConfig)
}
assert.True(t, result)
err = os.RemoveAll(testConfig.LogDir)
assert.NoError(t, err)
}
}
}
}
func TestConfigLoadConfiguration(t *testing.T) {
tmpdir, err := ioutil.TempDir(testDir, "load-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir, nil)
}
func TestConfigLoadConfigurationFailBrokenSymLink(t *testing.T) {
tmpdir, err := ioutil.TempDir(testDir, "runtime-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir,
func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error) {
expectFail := false
if configFile == config.ConfigPathLink {
// break the symbolic link
err = os.Remove(config.ConfigPathLink)
if err != nil {
return expectFail, err
}
expectFail = true
}
return expectFail, nil
})
}
func TestConfigLoadConfigurationFailSymLinkLoop(t *testing.T) {
tmpdir, err := ioutil.TempDir(testDir, "runtime-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir,
func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error) {
expectFail := false
if configFile == config.ConfigPathLink {
// remove the config file
err = os.Remove(config.ConfigPath)
if err != nil {
return expectFail, err
}
// now, create a sym-link loop
err := os.Symlink(config.ConfigPathLink, config.ConfigPath)
if err != nil {
return expectFail, err
}
expectFail = true
}
return expectFail, nil
})
}
func TestConfigLoadConfigurationFailMissingHypervisor(t *testing.T) {
tmpdir, err := ioutil.TempDir(testDir, "runtime-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir,
func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error) {
expectFail := true
err = os.Remove(config.RuntimeConfig.HypervisorConfig.HypervisorPath)
if err != nil {
return expectFail, err
}
return expectFail, nil
})
}
func TestConfigLoadConfigurationFailMissingImage(t *testing.T) {
tmpdir, err := ioutil.TempDir(testDir, "runtime-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir,
func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error) {
expectFail := true
err = os.Remove(config.RuntimeConfig.HypervisorConfig.ImagePath)
if err != nil {
return expectFail, err
}
return expectFail, nil
})
}
func TestConfigLoadConfigurationFailMissingKernel(t *testing.T) {
tmpdir, err := ioutil.TempDir(testDir, "runtime-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir,
func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error) {
expectFail := true
err = os.Remove(config.RuntimeConfig.HypervisorConfig.KernelPath)
if err != nil {
return expectFail, err
}
return expectFail, nil
})
}
func TestConfigLoadConfigurationFailUnreadableConfig(t *testing.T) {
if tc.NotValid(ktu.NeedNonRoot()) {
t.Skip(ktu.TestDisabledNeedNonRoot)
}
tmpdir, err := ioutil.TempDir(testDir, "runtime-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir,
func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error) {
expectFail := true
// make file unreadable by non-root user
err = os.Chmod(config.ConfigPath, 0000)
if err != nil {
return expectFail, err
}
return expectFail, nil
})
}
func TestConfigLoadConfigurationFailTOMLConfigFileInvalidContents(t *testing.T) {
if tc.NotValid(ktu.NeedNonRoot()) {
t.Skip(ktu.TestDisabledNeedNonRoot)
}
tmpdir, err := ioutil.TempDir(testDir, "runtime-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir,
func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error) {
expectFail := true
err := createFile(config.ConfigPath,
`<?xml version="1.0"?>
<foo>I am not TOML! ;-)</foo>
<bar>I am invalid XML!`)
if err != nil {
return expectFail, err
}
return expectFail, nil
})
}
func TestConfigLoadConfigurationFailTOMLConfigFileDuplicatedData(t *testing.T) {
if tc.NotValid(ktu.NeedNonRoot()) {
t.Skip(ktu.TestDisabledNeedNonRoot)
}
tmpdir, err := ioutil.TempDir(testDir, "runtime-config-")
assert.NoError(t, err)
defer os.RemoveAll(tmpdir)
testLoadConfiguration(t, tmpdir,
func(config testRuntimeConfig, configFile string, ignoreLogging bool) (bool, error) {
expectFail := true
text, err := GetFileContents(config.ConfigPath)
if err != nil {
return expectFail, err
}
// create a config file containing two sets of
// data.
err = createFile(config.ConfigPath, fmt.Sprintf("%s\n%s\n", text, text))
if err != nil {
return expectFail, err
}
return expectFail, nil
})
}
func TestMinimalRuntimeConfig(t *testing.T) {
dir, err := ioutil.TempDir(testDir, "minimal-runtime-config-")
if err != nil {
t.Fatal(err)
}
defer os.RemoveAll(dir)
proxyPath := path.Join(dir, "proxy")
hypervisorPath := path.Join(dir, "hypervisor")
defaultHypervisorPath = hypervisorPath
jailerPath := path.Join(dir, "jailer")
defaultJailerPath = jailerPath
netmonPath := path.Join(dir, "netmon")
imagePath := path.Join(dir, "image.img")
initrdPath := path.Join(dir, "initrd.img")
kernelPath := path.Join(dir, "kernel")
savedDefaultImagePath := defaultImagePath
savedDefaultInitrdPath := defaultInitrdPath
savedDefaultHypervisorPath := defaultHypervisorPath
savedDefaultJailerPath := defaultJailerPath
savedDefaultKernelPath := defaultKernelPath
defer func() {
defaultImagePath = savedDefaultImagePath
defaultInitrdPath = savedDefaultInitrdPath
defaultHypervisorPath = savedDefaultHypervisorPath
defaultJailerPath = savedDefaultJailerPath
defaultKernelPath = savedDefaultKernelPath
}()
// Temporarily change the defaults to avoid this test using the real
// resource files that might be installed on the system!
defaultImagePath = imagePath
defaultInitrdPath = initrdPath
defaultHypervisorPath = hypervisorPath
defaultJailerPath = jailerPath
defaultKernelPath = kernelPath
for _, file := range []string{defaultImagePath, defaultInitrdPath, defaultHypervisorPath, defaultJailerPath, defaultKernelPath} {
err = WriteFile(file, "foo", testFileMode)
if err != nil {
t.Fatal(err)
}
}
runtimeMinimalConfig := `
# Runtime configuration file
[proxy.kata]
path = "` + proxyPath + `"
[agent.kata]
[netmon]
path = "` + netmonPath + `"
`
configPath := path.Join(dir, "runtime.toml")
err = createConfig(configPath, runtimeMinimalConfig)
if err != nil {
t.Fatal(err)
}
err = createEmptyFile(proxyPath)
if err != nil {
t.Error(err)
}
err = createEmptyFile(hypervisorPath)
if err != nil {
t.Error(err)
}
err = createEmptyFile(jailerPath)
if err != nil {
t.Error(err)
}
err = createEmptyFile(netmonPath)
if err != nil {
t.Error(err)
}
_, config, err := LoadConfiguration(configPath, false, false)
if err != nil {
t.Fatal(err)
}
expectedHypervisorConfig := vc.HypervisorConfig{
HypervisorPath: defaultHypervisorPath,
JailerPath: defaultJailerPath,
KernelPath: defaultKernelPath,
ImagePath: defaultImagePath,
InitrdPath: defaultInitrdPath,
HypervisorMachineType: defaultMachineType,
NumVCPUs: defaultVCPUCount,
DefaultMaxVCPUs: defaultMaxVCPUCount,
MemorySize: defaultMemSize,
DisableBlockDeviceUse: defaultDisableBlockDeviceUse,
DefaultBridges: defaultBridgesCount,
Mlock: !defaultEnableSwap,
BlockDeviceDriver: defaultBlockDeviceDriver,
Msize9p: defaultMsize9p,
GuestHookPath: defaultGuestHookPath,
VhostUserStorePath: defaultVhostUserStorePath,
VirtioFSCache: defaultVirtioFSCacheMode,
}
expectedAgentConfig := vc.KataAgentConfig{}
expectedProxyConfig := vc.ProxyConfig{
Path: proxyPath,
}
expectedNetmonConfig := vc.NetmonConfig{
Path: netmonPath,
Debug: false,
Enable: false,
}
expectedFactoryConfig := oci.FactoryConfig{
TemplatePath: defaultTemplatePath,
VMCacheEndpoint: defaultVMCacheEndpoint,
}
expectedConfig := oci.RuntimeConfig{
HypervisorType: defaultHypervisor,
HypervisorConfig: expectedHypervisorConfig,
AgentConfig: expectedAgentConfig,
ProxyType: defaultProxy,
ProxyConfig: expectedProxyConfig,
NetmonConfig: expectedNetmonConfig,
FactoryConfig: expectedFactoryConfig,
}
err = SetKernelParams(&expectedConfig)
if err != nil {
t.Fatal(err)
}
if reflect.DeepEqual(config, expectedConfig) == false {
t.Fatalf("Got %+v\n expecting %+v", config, expectedConfig)
}
}
func TestMinimalRuntimeConfigWithVsock(t *testing.T) {
dir, err := ioutil.TempDir(testDir, "minimal-runtime-config-")
if err != nil {
t.Fatal(err)
}
defer os.RemoveAll(dir)
imagePath := path.Join(dir, "image.img")
initrdPath := path.Join(dir, "initrd.img")
proxyPath := path.Join(dir, "proxy")
hypervisorPath := path.Join(dir, "hypervisor")
kernelPath := path.Join(dir, "kernel")
savedDefaultImagePath := defaultImagePath
savedDefaultInitrdPath := defaultInitrdPath
savedDefaultHypervisorPath := defaultHypervisorPath
savedDefaultKernelPath := defaultKernelPath
defer func() {
defaultImagePath = savedDefaultImagePath
defaultInitrdPath = savedDefaultInitrdPath
defaultHypervisorPath = savedDefaultHypervisorPath
defaultKernelPath = savedDefaultKernelPath
}()
// Temporarily change the defaults to avoid this test using the real
// resource files that might be installed on the system!
defaultImagePath = imagePath
defaultInitrdPath = initrdPath
defaultHypervisorPath = hypervisorPath
defaultKernelPath = kernelPath
for _, file := range []string{proxyPath, hypervisorPath, kernelPath, imagePath} {
err = WriteFile(file, "foo", testFileMode)
if err != nil {
t.Fatal(err)
}
}
// minimal config with vsock enabled
runtimeMinimalConfig := `
# Runtime configuration file
[hypervisor.qemu]
use_vsock = true
image = "` + imagePath + `"
[proxy.kata]
path = "` + proxyPath + `"
[agent.kata]
`
orgVHostVSockDevicePath := utils.VHostVSockDevicePath
defer func() {
utils.VHostVSockDevicePath = orgVHostVSockDevicePath
}()
utils.VHostVSockDevicePath = "/dev/null"
configPath := path.Join(dir, "runtime.toml")
err = createConfig(configPath, runtimeMinimalConfig)
if err != nil {
t.Fatal(err)
}
_, config, err := LoadConfiguration(configPath, false, false)
if err != nil {
t.Fatal(err)
}
if config.ProxyType != vc.NoProxyType {
t.Fatalf("Proxy type must be NoProxy, got %+v", config.ProxyType)
}
if !reflect.DeepEqual(config.ProxyConfig, vc.ProxyConfig{}) {
t.Fatalf("Got %+v\n expecting %+v", config.ProxyConfig, vc.ProxyConfig{})
}
if config.HypervisorConfig.UseVSock != true {
t.Fatalf("use_vsock must be true, got %v", config.HypervisorConfig.UseVSock)
}
}
func TestNewQemuHypervisorConfig(t *testing.T) {
dir, err := ioutil.TempDir(testDir, "hypervisor-config-")
if err != nil {
t.Fatal(err)
}
defer os.RemoveAll(dir)
hypervisorPath := path.Join(dir, "hypervisor")
kernelPath := path.Join(dir, "kernel")
imagePath := path.Join(dir, "image")
machineType := "machineType"
disableBlock := true
enableIOThreads := true
hotplugVFIOOnRootBus := true
pcieRootPort := uint32(2)
orgVHostVSockDevicePath := utils.VHostVSockDevicePath
defer func() {
utils.VHostVSockDevicePath = orgVHostVSockDevicePath
}()
utils.VHostVSockDevicePath = "/dev/abc/xyz"
// 10Mbits/sec
rxRateLimiterMaxRate := uint64(10000000)
txRateLimiterMaxRate := uint64(10000000)
hypervisor := hypervisor{
Path: hypervisorPath,
Kernel: kernelPath,
Image: imagePath,
MachineType: machineType,
DisableBlockDeviceUse: disableBlock,
EnableIOThreads: enableIOThreads,
HotplugVFIOOnRootBus: hotplugVFIOOnRootBus,
PCIeRootPort: pcieRootPort,
UseVSock: true,
RxRateLimiterMaxRate: rxRateLimiterMaxRate,
TxRateLimiterMaxRate: txRateLimiterMaxRate,
}
files := []string{hypervisorPath, kernelPath, imagePath}
filesLen := len(files)
for i, file := range files {
_, err := newQemuHypervisorConfig(hypervisor)
if err == nil {
t.Fatalf("Expected newQemuHypervisorConfig to fail as not all paths exist (not created %v)",
strings.Join(files[i:filesLen], ","))
}
// create the resource
err = createEmptyFile(file)
if err != nil {
t.Error(err)
}
}
// falling back to legacy serial port
|
if err != nil {
t.Fatal(err)
}
utils.VHostVSockDevicePath = "/dev/null"
// all paths exist now
config, err = newQemuHypervisorConfig(hypervisor)
if err != nil {
t.Fatal(err)
}
if config.HypervisorPath != hypervisor.Path {
t.Errorf("Expected hypervisor path %v, got %v", hypervisor.Path, config.HypervisorPath)
}
if config.KernelPath != hypervisor.Kernel {
t.Errorf("Expected kernel path %v, got %v", hypervisor.Kernel, config.KernelPath)
}
if config.ImagePath != hypervisor.Image {
t.Errorf("Expected image path %v, got %v", hypervisor.Image, config.ImagePath)
}
if config.DisableBlockDeviceUse != disableBlock {
t.Errorf("Expected value for disable block usage %v, got %v", disableBlock, config.DisableBlockDeviceUse)
}
if config.EnableIOThreads != enableIOThreads {
t.Errorf("Expected value for enable IOThreads %v, got %v", enableIOThreads, config.EnableIOThreads)
}
if config.HotplugVFIOOnRootBus != hotplugVFIOOnRootBus {
t.Errorf("Expected value for HotplugVFIOOnRootBus %v, got %v", hotplugVFIOOnRootBus, config.HotplugVFIOOnRootBus)
}
if config.PCIeRootPort != pcieRootPort {
t.Errorf("Expected value for PCIeRootPort %v, got %v", pcieRootPort, config.PCIeRootPort)
}
if config.RxRateLimiterMaxRate != rxRateLimiterMaxRate {
t.Errorf("Expected value for rx rate limiter %v, got %v", rxRateLimiterMaxRate, config.RxRateLimiterMaxRate)
}
if config.TxRateLimiterMaxRate != txRateLimiterMaxRate {
t.Errorf("Expected value for tx rate limiter %v, got %v", txRateLimiterMaxRate, config.TxRateLimiterMaxRate)
}
}
func TestNewFirecrackerHypervisorConfig(t *testing.T) {
dir, err := ioutil.TempDir(testDir, "hypervisor-config-")
if err != nil {
t.Fatal(err)
}
defer os.RemoveAll(dir)
hypervisorPath := path.Join(dir, "hypervisor")
kernelPath := path.Join(dir, "kernel")
imagePath := path.Join(dir, "image")
jailerPath := path.Join(dir, "jailer")
disableBlockDeviceUse := false
disableVhostNet := true
useVSock := true
blockDeviceDriver := "virtio-mmio"
// !0Mbits/sec
rxRateLimiterMaxRate := uint64(10000000)
txRateLimiterMaxRate := uint64(10000000)
orgVHostVSockDevicePath := utils.VHostVSockDevicePath
defer func() {
utils.VHostVSockDevicePath = orgVHostVSockDevicePath
}()
utils.VHostVSockDevicePath = "/dev/null"
hypervisor := hypervisor{
Path: hypervisorPath,
Kernel: kernelPath,
Image: imagePath,
JailerPath: jailerPath,
DisableBlockDeviceUse: disableBlockDeviceUse,
BlockDeviceDriver: blockDeviceDriver,
RxRateLimiterMaxRate: rxRateLimiterMaxRate,
TxRateLimiterMaxRate: txRateLimiterMaxRate,
}
files := []string{hypervisorPath, kernelPath, imagePath, jailerPath}
filesLen := len(files)
for i, file := range files {
_, err := newFirecrackerHypervisorConfig(hypervisor)
if err == nil {
t.Fatalf("Expected newFirecrackerHypervisorConfig to fail as not all paths exist (not created %v)",
strings.Join(files[i:filesLen], ","))
}
// create the resource
err = createEmptyFile(file)
if err != nil {
t.Error(err)
}
}
config, err := newFirecrackerHypervisorConfig(hypervisor)
if err != nil {
t.Fatal(err)
}
if config.HypervisorPath != hypervisor.Path {
t.Errorf("Expected hypervisor path %v, got %v", hypervisor.Path, config.HypervisorPath)
}
if config.KernelPath != hypervisor.Kernel {
t.Errorf("Expected kernel path %v, got %v", hypervisor.Kernel, config.KernelPath)
}
if config.ImagePath != hypervisor.Image {
t.Errorf("Expected image path %v, got %v", hypervisor.Image, config.ImagePath)
}
if config.JailerPath != hypervisor.JailerPath {
t.Errorf("Expected jailer path %v, got %v", hypervisor.JailerPath, config.JailerPath)
}
if config.DisableBlockDeviceUse != disableBlockDeviceUse {
t.Errorf("Expected value for disable block usage %v, got %v", disableBlockDeviceUse, config.DisableBlockDeviceUse)
}
if config.BlockDeviceDriver != blockDeviceDriver {
t.Errorf("Expected value for block device driver %v, got %v", blockDeviceDriver, config.BlockDeviceDriver)
}
if config.DisableVhostNet != disableVhostNet {
t.Errorf("Expected value for disable vhost net usage %v, got %v", disableVhostNet, config.DisableVhostNet)
}
if config.UseVSock != useVSock {
t.Errorf("Expected value for vsock usage %v, got %v", useVSock, config.UseVSock)
}
if config.RxRateLimiterMaxRate != rxRateLimiterMaxRate {
t.Errorf("Expected value for rx rate limiter %v, got %v", rxRateLimiterMaxRate, config.RxRateLimiterMaxRate)
}
if config.TxRateLimiterMaxRate != txRateLimiterMaxRate {
t.Errorf("Expected value for tx rate limiter %v, got %v", txRateLimiterMaxRate, config.TxRateLimiterMaxRate)
}
}
func TestNewQemuHypervisorConfigImageAndInitrd(t *testing.T) {
assert := assert.New(t)
tmpdir, err := ioutil.TempDir(testDir, "")
assert.NoError(err)
defer os.RemoveAll(tmpdir)
imagePath := filepath.Join(tmpdir, "image")
initrdPath := filepath.Join(tmpdir, "initrd")
hypervisorPath := path.Join(tmpdir, "hypervisor")
kernelPath := path.Join(tmpdir, "kernel")
for _, file := range []string{imagePath, initrdPath, hypervisorPath, kernelPath} {
err = createEmptyFile(file)
assert.NoError(err)
}
machineType := "machineType"
disableBlock := true
enableIOThreads := true
hotplugVFIOOnRootBus := true
pcieRootPort := uint32(2)
hypervisor := hypervisor{
Path: hypervisorPath,
Kernel: kernelPath,
Image: imagePath,
Initrd: initrdPath,
MachineType: machineType,
DisableBlockDeviceUse: disableBlock,
EnableIOThreads: enableIOThreads,
HotplugVFIOOnRootBus: hotplugVFIOOnRootBus,
PCIeRootPort: pcieRootPort,
}
_, err = newQemuHypervisorConfig(hypervisor)
// specifying both an image+initrd is invalid
assert.Error(err)
}
func TestNewClhHypervisorConfig(t *testing.T) {
assert := assert.New(t)
tmpdir, err := ioutil.TempDir(testDir, "")
assert.NoError(err)
defer os.RemoveAll(tmpdir)
hypervisorPath := path.Join(tmpdir, "hypervisor")
kernelPath := path.Join(tmpdir, "kernel")
imagePath := path.Join(tmpdir, "image")
virtioFsDaemon := path.Join(tmpdir, "virtiofsd")
for _, file := range []string{imagePath, hypervisorPath, kernelPath, virtioFsDaemon} {
err = createEmptyFile(file)
assert.NoError(err)
}
hypervisor := hypervisor{
Path: hypervisorPath,
Kernel: kernelPath,
Image: imagePath,
VirtioFSDaemon: virtioFsDaemon,
VirtioFSCache: "always",
}
config, err := newClhHypervisorConfig(hypervisor)
if err != nil {
t.Fatal(err)
}
if config.HypervisorPath != hypervisor.Path {
t.Errorf("Expected hypervisor path %v, got %v", hypervisor.Path, config.HypervisorPath)
}
if config.KernelPath != hypervisor.Kernel {
t.Errorf("Expected kernel path %v, got %v", hypervisor.Kernel, config.KernelPath)
}
if config.ImagePath != hypervisor.Image {
t.Errorf("Expected image path %v, got %v", hypervisor.Image, config.ImagePath)
}
if config.ImagePath != hypervisor.Image {
t.Errorf("Expected image path %v, got %v", hypervisor.Image, config.ImagePath)
}
if config.UseVSock != true {
t.Errorf("Expected UseVSock %v, got %v", true, config.UseVSock)
}
if config.DisableVhostNet != true {
t.Errorf("Expected DisableVhostNet %v, got %v", true, config.DisableVhostNet)
}
if config.VirtioFSCache != "always" {
t.Errorf("Expected VirtioFSCache %v, got %v", true, config.VirtioFSCache)
}
}
func TestHypervisorDefaults(t *testing.T) {
assert := assert.New(t)
numCPUs := goruntime.NumCPU()
h := hypervisor{}
assert.Equal(h.machineType(), defaultMachineType, "default hypervisor machine type wrong")
assert.Equal(h.defaultVCPUs(), defaultVCPUCount, "default vCPU number is wrong")
assert.Equal(h.defaultMaxVCPUs(), uint32(numCPUs), "default max vCPU number is wrong")
assert.Equal(h.defaultMemSz(), defaultMemSize, "default memory size is wrong")
machineType := "foo"
h.MachineType = machineType
assert.Equal(h.machineType(), machineType, "custom hypervisor machine type wrong")
// auto inferring
h.NumVCPUs = -1
assert.Equal(h.defaultVCPUs(), uint32(numCPUs), "default vCPU number is wrong")
h.NumVCPUs = 2
assert.Equal(h.defaultVCPUs(), uint32(2), "default vCPU number is wrong")
h.NumVCPUs = int32(numCPUs) + 1
assert.Equal(h.defaultVCPUs(), uint32(numCPUs), "default vCPU number is wrong")
h.DefaultMaxVCPUs = 2
assert.Equal(h.defaultMaxVCPUs(), uint32(2), "default max vCPU number is wrong")
h.DefaultMaxVCPUs = uint32(numCPUs) + 1
assert.Equal(h.defaultMaxVCPUs(), uint32(numCPUs), "default max vCPU number is wrong")
maxvcpus := vc.MaxQemuVCPUs()
h.DefaultMaxVCPUs = maxvcpus + 1
assert.Equal(h.defaultMaxVCPUs(), uint32(numCPUs), "default max vCPU number is wrong")
h.MemorySize = 1024
assert.Equal(h.defaultMemSz(), uint32(1024), "default memory size is wrong")
}
func TestHypervisorDefaultsHypervisor(t *testing.T) {
assert := assert.New(t)
tmpdir, err := ioutil.TempDir(testDir, "")
assert.NoError(err)
defer os.RemoveAll(tmpdir)
testHypervisorPath := filepath.Join(tmpdir, "hypervisor")
testHypervisorLinkPath := filepath.Join(tmpdir, "hypervisor-link")
err = createEmptyFile(testHypervisorPath)
assert.NoError(err)
err = syscall.Symlink(testHypervisorPath, testHypervisorLinkPath)
assert.NoError(err)
savedHypervisorPath := defaultHypervisorPath
defer func() {
defaultHypervisorPath = savedHypervisorPath
}()
defaultHypervisorPath = testHypervisorPath
h := hypervisor{}
p, err := h.path()
assert.NoError(err)
assert.Equal(p, defaultHypervisorPath, "default hypervisor path wrong")
// test path resolution
defaultHypervisorPath = testHypervisorLinkPath
h = hypervisor{}
p, err = h.path()
assert.NoError(err)
assert.Equal(p, testHypervisorPath)
}
func TestHypervisorDefaultsKernel(t *testing.T) {
assert := assert.New(t)
tmpdir, err := ioutil.TempDir(testDir, "")
assert.NoError(err)
defer os.RemoveAll(tmpdir)
testKernelPath := filepath.Join(tmpdir, "kernel")
testKernelLinkPath := filepath.Join(tmpdir, "kernel-link")
err = createEmptyFile(testKernelPath)
assert.NoError(err)
err = syscall.Symlink(testKernelPath, testKernelLinkPath)
assert.NoError(err)
savedKernelPath := defaultKernelPath
defer func() {
defaultKernelPath = savedKernelPath
}()
defaultKernelPath = testKernelPath
h := hypervisor{}
p, err := h.kernel()
assert.NoError(err)
assert.Equal(p, defaultKernelPath, "default Kernel path wrong")
// test path resolution
defaultKernelPath = testKernelLinkPath
h = hypervisor{}
p, err = h.kernel()
assert.NoError(err)
assert.Equal(p, testKernelPath)
assert.Equal(h.kernelParams(), defaultKernelParams, "default hypervisor image wrong")
kernelParams := "foo=bar xyz"
h.KernelParams = kernelParams
assert.Equal(h.kernelParams(), kernelParams, "custom hypervisor kernel parameterms wrong")
}
// The default initrd path is not returned by h.initrd()
func TestHypervisorDefaultsInitrd(t *testing.T) {
assert := assert.New(t)
tmpdir, err := ioutil.TempDir(testDir, "")
assert.NoError(err)
defer os.RemoveAll(tmpdir)
testInitrdPath := filepath.Join(tmpdir, "initrd")
testInitrdLinkPath := filepath.Join(tmpdir, "initrd-link")
err = createEmptyFile(testInitrdPath)
assert.NoError(err)
err = syscall.Symlink(testInitrdPath, testInitrdLinkPath)
assert.NoError(err)
savedInitrdPath := defaultInitrdPath
defer func() {
defaultInitrdPath = savedInitrdPath
}()
defaultInitrdPath = testInitrdPath
h := hypervisor{}
p, err := h.initrd()
assert.Error(err)
assert.Equal(p, "", "default Image path wrong")
// test path resolution
defaultInitrdPath = testInitrdLinkPath
h = hypervisor{}
p, err = h.initrd()
assert.Error(err)
assert.Equal(p, "")
}
// The default image path is not returned by h.image()
func TestHypervisorDefaultsImage(t *testing.T) {
assert := assert.New(t)
tmpdir, err := ioutil.TempDir(testDir, "")
assert.NoError(err)
defer os.RemoveAll(tmpdir)
testImagePath := filepath.Join(tmpdir, "image")
testImageLinkPath := filepath.Join(tmpdir, "image-link")
err = createEmptyFile(testImagePath)
assert.NoError(err)
err = syscall.Symlink(testImagePath, testImageLinkPath)
assert.NoError(err)
savedImagePath := defaultImagePath
defer func() {
defaultImagePath = savedImagePath
}()
defaultImagePath = testImagePath
h := hypervisor{}
p, err := h.image()
assert.Error(err)
assert.Equal(p, "", "default Image path wrong")
// test path resolution
defaultImagePath = testImageLinkPath
h = hypervisor{}
p, err = h.image()
assert.Error(err)
assert.Equal(p, "")
}
func TestHypervisorDefaultsGuestHookPath(t *testing.T) {
assert := assert.New(t)
h := hypervisor{}
guestHookPath := h.guestHookPath()
assert.Equal(guestHookPath, defaultGuestHookPath, "default guest hook path wrong")
testGuestHookPath := "/test/guest/hook/path"
h = hypervisor{
GuestHookPath: testGuestHookPath,
}
guestHookPath = h.guestHookPath()
assert.Equal(guestHookPath, testGuestHookPath, "custom guest hook path wrong")
}
func TestHypervisorDefaultsVhostUserStorePath(t *testing.T) {
assert := assert.New(t)
h := hypervisor{}
vhostUserStorePath := h.vhostUserStorePath()
assert.Equal(vhostUserStorePath, defaultVhostUserStorePath, "default vhost-user store path wrong")
testVhostUserStorePath := "/test/vhost/user/store/path"
h = hypervisor{
VhostUserStorePath: testVhostUserStorePath,
}
vhostUserStorePath = h.vhostUserStorePath()
assert.Equal(vhostUserStorePath, testVhostUserStorePath, "custom vhost-user store path wrong")
}
func TestProxyDefaults(t *testing.T) {
assert := assert.New(t)
tmpdir, err := ioutil.TempDir(testDir, "")
assert.NoError(err)
defer os.RemoveAll(tmpdir)
testProxyPath := filepath.Join(tmpdir, "proxy")
testProxyLinkPath := filepath.Join(tmpdir, "proxy-link")
err = createEmptyFile(testProxyPath)
assert.NoError(err)
err = syscall.Symlink(testProxyPath, testProxyLinkPath)
assert.NoError(err)
savedProxyPath := defaultProxyPath
defer func() {
defaultProxyPath = savedProxyPath
}()
defaultProxyPath = testProxyPath
p := proxy{}
path, err := p.path()
assert.NoError(err)
assert.Equal(path, defaultProxyPath, "default proxy path wrong")
// test path resolution
defaultProxyPath = testProxyLinkPath
p = proxy{}
path, err = p.path()
assert.NoError(err)
assert.Equal(path, testProxyPath)
assert.False(p.debug())
p.Debug = true
assert.True(p.debug())
}
func TestAgentDefaults(t *testing.T) {
assert := assert.New(t)
a := agent{}
assert.Equal(a.debug(), a.Debug)
a.Debug = true
assert.Equal(a.debug(), a.Debug)
assert.Equal(a.trace(), a.Tracing)
a.Tracing = true
assert.Equal(a.trace(), a.Tracing)
assert.Equal(a.traceMode(), a.TraceMode)
assert.Equal(a.traceType(), a.TraceType)
}
func TestGetDefaultConfigFilePaths(t *testing.T) {
assert := assert.New(t)
results := GetDefaultConfigFilePaths()
// There should be atleast two config file locations
assert.True(len(results) >= 2)
for _, f := range results {
// Paths cannot be empty
assert.NotNil(f)
}
}
func TestGetDefaultConfigFile(t *testing.T) {
assert := assert.New(t)
tmpdir, err := ioutil.TempDir(testDir, "")
assert.NoError(err)
defer os.RemoveAll(tmpdir)
hypervisor := "qemu"
confDir := filepath.Join(tmpdir, "conf")
sysConfDir := filepath.Join(tmpdir, "sysconf")
for _, dir := range []string{confDir, sysConfDir} {
err = os.MkdirAll(dir, testDirMode)
assert.NoError(err)
}
confDirConfig, err := createAllRuntimeConfigFiles(confDir, hypervisor)
assert.NoError(err)
sysConfDirConfig, err := createAllRuntimeConfigFiles(sysConfDir, hypervisor)
assert.NoError(err)
savedConf := defaultRuntimeConfiguration
savedSysConf := defaultSysConfRuntimeConfiguration
defaultRuntimeConfiguration = confDirConfig.ConfigPath
defaultSysConfRuntimeConfiguration = sysConfDirConfig.ConfigPath
defer func() {
defaultRuntimeConfiguration = savedConf
defaultSysConfRuntimeConfiguration = savedSysConf
}()
got, err := getDefaultConfigFile()
assert.NoError(err)
// defaultSysConfRuntimeConfiguration has priority over defaultRuntimeConfiguration
assert.Equal(got, defaultSysConfRuntimeConfiguration)
// force defaultRuntimeConfiguration to be returned
os.Remove(defaultSysConfRuntimeConfiguration)
got, err = getDefaultConfigFile()
assert.NoError(err)
assert.Equal(got, defaultRuntimeConfiguration)
// force error
os.Remove(defaultRuntimeConfiguration)
_, err = getDefaultConfigFile()
assert.Error(err)
}
func TestDefaultBridges(t *testing.T) {
assert := assert.New(t)
h := hypervisor{DefaultBridges: 0}
bridges := h.defaultBridges()
assert.Equal(defaultBridgesCount, bridges)
h.DefaultBridges = maxPCIBridges + 1
bridges = h.defaultBridges()
assert.Equal(maxPCIBridges, bridges)
h.DefaultBridges = maxPCIBridges
bridges = h.defaultBridges()
assert.Equal(maxPCIBridges, bridges)
}
func TestDefaultVirtioFSCache(t *testing.T) {
assert := assert.New(t)
h := hypervisor{VirtioFSCache: ""}
cache := h.defaultVirtioFSCache()
assert.Equal(defaultVirtioFSCacheMode, cache)
h.VirtioFSCache = "always"
cache = h.defaultVirtioFSCache()
assert.Equal("always", cache)
h.VirtioFSCache = "none"
cache = h.defaultVirtioFSCache()
assert.Equal("none", cache)
}
func TestDefaultFirmware(t *testing.T) {
assert := assert.New(t)
// save default firmware path
oldDefaultFirmwarePath := defaultFirmwarePath
f, err := ioutil.TempFile(os.TempDir(), "qboot.bin")
assert.NoError(err)
assert.NoError(f.Close())
defer os.RemoveAll(f.Name())
h := hypervisor{}
defaultFirmwarePath = ""
p, err := h.firmware()
assert.NoError(err)
assert.Empty(p)
defaultFirmwarePath = f.Name()
p, err = h.firmware()
assert.NoError(err)
assert.NotEmpty(p)
// restore default firmware path
defaultFirmwarePath = oldDefaultFirmwarePath
}
func TestDefaultMachineAccelerators(t *testing.T) {
assert := assert.New(t)
machineAccelerators := "abc,123,rgb"
h := hypervisor{MachineAccelerators: machineAccelerators}
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = ""
h.MachineAccelerators = machineAccelerators
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc"
h.MachineAccelerators = machineAccelerators
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc,123"
h.MachineAccelerators = "abc,,123"
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc,123"
h.MachineAccelerators = ",,abc,,123,,,"
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc,123"
h.MachineAccelerators = "abc,,123,,,"
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc"
h.MachineAccelerators = ",,abc,"
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc"
h.MachineAccelerators = ", , abc , ,"
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc"
h.MachineAccelerators = " abc "
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc,123"
h.MachineAccelerators = ", abc , 123 ,"
assert.Equal(machineAccelerators, h.machineAccelerators())
machineAccelerators = "abc,123"
h.MachineAccelerators = ",, abc ,,, 123 ,,"
assert.Equal(machineAccelerators, h.machineAccelerators())
}
func TestDefaultCPUFeatures(t *testing.T) {
assert := assert.New(t)
cpuFeatures := "abc,123,rgb"
h := hypervisor{CPUFeatures: cpuFeatures}
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = ""
h.CPUFeatures = cpuFeatures
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc"
h.CPUFeatures = cpuFeatures
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc,123"
h.CPUFeatures = "abc,,123"
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc,123"
h.CPUFeatures = ",,abc,,123,,,"
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc,123"
h.CPUFeatures = "abc,,123,,,"
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc"
h.CPUFeatures = ",,abc,"
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc"
h.CPUFeatures = ", , abc , ,"
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc"
h.CPUFeatures = " abc "
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc,123"
h.CPUFeatures = ", abc , 123 ,"
assert.Equal(cpuFeatures, h.cpuFeatures())
cpuFeatures = "abc,123"
h.CPUFeatures = ",, abc ,,, 123 ,,"
assert.Equal(cpuFeatures, h.cpuFeatures())
}
func TestUpdateRuntimeConfigurationVMConfig(t *testing.T) {
assert := assert.New(t)
vcpus := uint(2)
mem := uint32(2048)
config := oci.RuntimeConfig{}
expectedVMConfig := mem
tomlConf := tomlConfig{
Hypervisor: map[string]hypervisor{
qemuHypervisorTableType: {
NumVCPUs: int32(vcpus),
MemorySize: mem,
Path: "/",
Kernel: "/",
Image: "/",
Firmware: "/",
},
},
}
err := updateRuntimeConfig("", tomlConf, &config, false)
assert.NoError(err)
assert.Equal(expectedVMConfig, config.HypervisorConfig.MemorySize)
}
func TestUpdateRuntimeConfigurationFactoryConfig(t *testing.T) {
assert := assert.New(t)
config := oci.RuntimeConfig{}
expectedFactoryConfig := oci.FactoryConfig{
Template: true,
TemplatePath: defaultTemplatePath,
VMCacheEndpoint: defaultVMCacheEndpoint,
}
tomlConf := tomlConfig{Factory: factory{Template: true}}
err := updateRuntimeConfig("", tomlConf, &config, false)
assert.NoError(err)
assert.Equal(expectedFactoryConfig, config.FactoryConfig)
}
func TestUpdateRuntimeConfigurationInvalidKernelParams(t *testing.T) {
assert := assert.New(t)
config := oci.RuntimeConfig{}
tomlConf := tomlConfig{}
savedFunc := GetKernelParamsFunc
defer func() {
GetKernelParamsFunc = savedFunc
}()
GetKernelParamsFunc = func(needSystemd, trace bool) []vc.Param {
return []vc.Param{
{
Key: "",
Value: "",
},
}
}
err := updateRuntimeConfig("", tomlConf, &config, false)
assert.EqualError(err, "Empty kernel parameter")
}
func TestCheckHypervisorConfig(t *testing.T) {
assert := assert.New(t)
dir, err := ioutil.TempDir(testDir, "")
if err != nil {
t.Fatal(err)
}
defer os.RemoveAll(dir)
// Not created on purpose
imageENOENT := filepath.Join(dir, "image-ENOENT.img")
initrdENOENT := filepath.Join(dir, "initrd-ENOENT.img")
imageEmpty := filepath.Join(dir, "image-empty.img")
initrdEmpty := filepath.Join(dir, "initrd-empty.img")
for _, file := range []string{imageEmpty, initrdEmpty} {
err = createEmptyFile(file)
assert.NoError(err)
}
image := filepath.Join(dir, "image.img")
initrd := filepath.Join(dir, "initrd.img")
mb := uint32(1024 * 1024)
fileSizeMB := uint32(3)
fileSizeBytes := fileSizeMB * mb
fileData := strings.Repeat("X", int(fileSizeBytes))
for _, file := range []string{image, initrd} {
err = WriteFile(file, fileData, testFileMode)
assert.NoError(err)
}
type testData struct {
imagePath string
initrdPath string
memBytes uint32
expectError bool
expectLogWarning bool
}
// Note that checkHypervisorConfig() does not check to ensure an image
// or an initrd has been specified - that's handled by a separate
// function, hence no test for it here.
data := []testData{
{"", "", 0, true, false},
{imageENOENT, "", 2, true, false},
{"", initrdENOENT, 2, true, false},
{imageEmpty, "", 2, true, false},
{"", initrdEmpty, 2, true, false},
{image, "", fileSizeMB + 2, false, false},
{image, "", fileSizeMB + 1, false, false},
{image, "", fileSizeMB + 0, false, true},
{image, "", fileSizeMB - 1, false, true},
{image, "", fileSizeMB - 2, false, true},
{"", initrd, fileSizeMB + 2, false, false},
{"", initrd, fileSizeMB + 1, false, false},
{"", initrd, fileSizeMB + 0, true, false},
{"", initrd, fileSizeMB - 1, true, false},
{"", initrd, fileSizeMB - 2, true, false},
}
for i, d := range data {
savedOut := kataUtilsLogger.Logger.Out
// create buffer to save logger output
logBuf := &bytes.Buffer{}
// capture output to buffer
kataUtilsLogger.Logger.Out = logBuf
config := vc.HypervisorConfig{
ImagePath: d.imagePath,
InitrdPath: d.initrdPath,
MemorySize: d.memBytes,
}
err := checkHypervisorConfig(config)
if d.expectError {
assert.Error(err, "test %d (%+v)", i, d)
} else {
assert.NoError(err, "test %d (%+v)", i, d)
}
if d.expectLogWarning {
assert.True(strings.Contains(logBuf.String(), "warning"))
} else {
assert.Empty(logBuf.String())
}
// reset logger
kataUtilsLogger.Logger.Out = savedOut
}
}
func TestCheckNetNsConfig(t *testing.T) {
assert := assert.New(t)
config := oci.RuntimeConfig{
DisableNewNetNs: true,
NetmonConfig: vc.NetmonConfig{
Enable: true,
},
}
err := checkNetNsConfig(config)
assert.Error(err)
config = oci.RuntimeConfig{
DisableNewNetNs: true,
InterNetworkModel: vc.NetXConnectDefaultModel,
}
err = checkNetNsConfig(config)
assert.Error(err)
}
func TestCheckFactoryConfig(t *testing.T) {
assert := assert.New(t)
type testData struct {
factoryEnabled bool
expectError bool
imagePath string
initrdPath string
}
data := []testData{
{false, false, "", ""},
{false, false, "image", ""},
{false, false, "", "initrd"},
{true, false, "", "initrd"},
{true, true, "image", ""},
}
for i, d := range data {
config := oci.RuntimeConfig{
HypervisorConfig: vc.HypervisorConfig{
ImagePath: d.imagePath,
InitrdPath: d.initrdPath,
},
FactoryConfig: oci.FactoryConfig{
Template: d.factoryEnabled,
},
}
err := checkFactoryConfig(config)
if d.expectError {
assert.Error(err, "test %d (%+v)", i, d)
} else {
assert.NoError(err, "test %d (%+v)", i, d)
}
}
}
|
config, err := newQemuHypervisorConfig(hypervisor)
|
Dropdown.react.js
|
import {isNil, pluck, omit, type} from 'ramda';
import React, {Component} from 'react';
import ReactDropdown from 'react-virtualized-select';
import createFilterOptions from 'react-select-fast-filter-options';
import '../components/css/[email protected]';
import '../components/css/[email protected]';
import {propTypes, defaultProps} from '../components/Dropdown.react';
// Custom tokenizer, see https://github.com/bvaughn/js-search/issues/43
// Split on spaces
const REGEX = /\s+/;
const TOKENIZER = {
tokenize(text) {
return text.split(REGEX).filter(
// Filter empty tokens
text => text
);
},
};
const DELIMETER = ',';
export default class Dropdown extends Component {
constructor(props) {
super(props);
this.state = {
filterOptions: createFilterOptions({
options: props.options,
tokenizer: TOKENIZER,
}),
};
}
componentWillReceiveProps(newProps) {
if (newProps.options !== this.props.options) {
this.setState({
filterOptions: createFilterOptions({
options: newProps.options,
tokenizer: TOKENIZER,
}),
});
}
}
render() {
const {
id,
clearable,
multi,
options,
setProps,
style,
loading_state,
value,
} = this.props;
const {filterOptions} = this.state;
let selectedValue;
if (type(value) === 'array') {
selectedValue = value.join(DELIMETER);
} else {
selectedValue = value;
}
return (
<div
id={id}
style={style}
data-dash-is-loading={
(loading_state && loading_state.is_loading) || undefined
}
>
<ReactDropdown
filterOptions={filterOptions}
options={options}
value={selectedValue}
onChange={selectedOption => {
if (multi) {
let value;
if (isNil(selectedOption)) {
value = [];
} else {
value = pluck('value', selectedOption);
|
if (isNil(selectedOption)) {
value = null;
} else {
value = selectedOption.value;
}
setProps({value});
}
}}
onInputChange={search_value => setProps({search_value})}
backspaceRemoves={clearable}
deleteRemoves={clearable}
{...omit(['setProps', 'value'], this.props)}
/>
</div>
);
}
}
Dropdown.propTypes = propTypes;
Dropdown.defaultProps = defaultProps;
|
}
setProps({value});
} else {
let value;
|
oauth_test.go
|
/*
Copyright 2015 All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package main
import (
"crypto/x509"
"encoding/json"
"encoding/pem"
"fmt"
"math/rand"
"net/http"
"net/http/httptest"
"net/url"
"strings"
"testing"
"time"
"github.com/andreashille/go-oidc/jose"
"github.com/andreashille/go-oidc/oauth2"
"github.com/pressly/chi"
"github.com/pressly/chi/middleware"
"github.com/stretchr/testify/assert"
)
type fakeAuthServer struct {
location *url.URL
key jose.JWK
signer jose.Signer
server *httptest.Server
expiration time.Duration
}
const fakePrivateKey = `
-----BEGIN RSA PRIVATE KEY-----
MIIEpQIBAAKCAQEAxMLIwi//YG6GPdYUPaV0PCXBEXjg2Xhf8/+NMB/1nt+wip4Z
rrAQf14PTCTlN4sbc2QGgRGtYikJBHQyfg/lCthrnasfdgL8c6SErr7Db524SqiD
m+/yKGI680LmBUIPkA0ikCJgb4cYVCiJ3HuYnFZUTsUAeK14SoXgcJdWulj0h6aP
iUIg5VrehuqAG+1RlK+GURgr9DbOmXJ/SYVKX/QArdBzjZ3BiQ1nxWWwBCLHfwv4
8bWxPJIbDDnUNl6LolpSJkxg4qlp+0I/xgEveK1n1CMEA0mHuXFHeekKO72GDKAk
h89C9qVF2GmpDfo8G0D3lFm2m3jFNyMQTWkSkwIDAQABAoIBADwhOrD9chHKNQQY
tD7SnV70OrhYNH7BJrGuWztlyO4wdgcmobqc263Q1OP0Mohy3oS5ALPY7x+cYsEV
sYiM2vYhhWG9tfOenf/JOzMb4SXvES7fqLiy71IgEtvcieb5dUAUg4eAue/bXTf6
24ahztWYHFOmKKq4eJZtq1U9KqfvlW1T4bg3mXV70huvfoMhYKwYryTOsQ5yiYCf
Yo4UGUBLfg3capIB5gxQdcqdDk+UTe9be7GQBj+3oziALb1nIhW7cpy0nw/r22A5
pv1FbRqND2VYKjZCQyUbxnjty5eDIW7fKBIh0Ez9yZHqz4KHb1u/KlFm31NGZpMU
Xs/WN+ECgYEA+kcAi7fTUjagqov5a4Y595ptu2gmU4Cxr+EBhMWadJ0g7enCXjTI
HAFEsVi2awbSRswjxdIG533SiKg8NIXThMntfbTm+Kw3LSb0/++Zyr7OuKJczKvQ
KfjAHvqsV8yJqy1gApYqVOeU4/jMLDs2sMY59/IQNkUVHNncZO09aa8CgYEAyUKG
BUyvxSim++YPk3OznBFZhqJqR75GYtWSu91BgZk/YmgYM4ht2u5q96AIRbJ664Ks
v93varNfqyKN1BN3JPLw8Ph8uX/7k9lMmECXoNp2Tm3A54zlsHyNOGOSvU7axvUg
PfIhpvRZKA0QQK3c1CZDghs94siJeBSIpuzCsl0CgYEA8Z28LCZiT3tHbn5FY4Wo
zp36k7L/VRvn7niVg71U2IGc+bHzoAjqqwaab2/KY9apCAop+t9BJRi2OJHZ1Ybg
5dAfg30ygh2YAvIaEj8YxL+iSGMOndS82Ng5eW7dFMH0ohnjF3wrD96mQdO+IHFl
4hDsg67f8dSNhlXYzGKwKCcCgYEAlAsrKprOcOkGbCU/L+fcJuFcSX0PUNbWT71q
wmZu2TYxOeH4a2/f3zuh06UUcLBpWvQ0vq4yfvqTVP+F9IqdCcDrG1at6IYMOSWP
AjABWYFZpTd2vt0V2EzGVMRqHHb014VYwjhqKLV1H9D8M5ew6R18ayg+zaNV+86e
9qsSTMECgYEA322XUN8yUBTTWBkXY7ipzTHSWkxMuj1Pa0gtBd6Qqqu3v7qI+jMZ
hlWS2akhJ+3e7f3+KCslG8YMItld4VvAK0eHKQbQM/onav/+/iiR6C2oRBm3OwqO
Ka0WPQGKjQJhZRtqDAT3sfnrEEUa34+MkXQeKFCu6Yi0dRFic4iqOYU=
-----END RSA PRIVATE KEY-----
`
type fakeDiscoveryResponse struct {
AuthorizationEndpoint string `json:"authorization_endpoint"`
EndSessionEndpoint string `json:"end_session_endpoint"`
GrantTypesSupported []string `json:"grant_types_supported"`
IDTokenSigningAlgValuesSupported []string `json:"id_token_signing_alg_values_supported"`
Issuer string `json:"issuer"`
JwksURI string `json:"jwks_uri"`
RegistrationEndpoint string `json:"registration_endpoint"`
ResponseModesSupported []string `json:"response_modes_supported"`
ResponseTypesSupported []string `json:"response_types_supported"`
SubjectTypesSupported []string `json:"subject_types_supported"`
TokenEndpoint string `json:"token_endpoint"`
TokenIntrospectionEndpoint string `json:"token_introspection_endpoint"`
UserinfoEndpoint string `json:"userinfo_endpoint"`
}
var letterRunes = []rune("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ")
// newFakeAuthServer simulates a oauth service
func newFakeAuthServer() *fakeAuthServer {
// step: load the private key
block, _ := pem.Decode([]byte(fakePrivateKey))
privateKey, err := x509.ParsePKCS1PrivateKey(block.Bytes)
if err != nil {
panic("failed to parse the private key, error: " + err.Error())
}
service := &fakeAuthServer{
key: jose.JWK{
ID: "test-kid",
Type: "RSA",
Alg: "RS256",
Use: "sig",
Exponent: privateKey.PublicKey.E,
Modulus: privateKey.PublicKey.N,
Secret: block.Bytes,
},
signer: jose.NewSignerRSA("test-kid", *privateKey),
}
r := chi.NewRouter()
r.Use(middleware.Recoverer)
r.Get("/auth/realms/hod-test/.well-known/openid-configuration", service.discoveryHandler)
r.Get("/auth/realms/hod-test/protocol/openid-connect/certs", service.keysHandler)
r.Get("/auth/realms/hod-test/protocol/openid-connect/token", service.tokenHandler)
r.Get("/auth/realms/hod-test/protocol/openid-connect/auth", service.authHandler)
r.Get("/auth/realms/hod-test/protocol/openid-connect/userinfo", service.userInfoHandler)
r.Post("/auth/realms/hod-test/protocol/openid-connect/logout", service.logoutHandler)
r.Post("/auth/realms/hod-test/protocol/openid-connect/token", service.tokenHandler)
service.server = httptest.NewServer(r)
location, err := url.Parse(service.server.URL)
if err != nil {
panic("unable to create fake oauth service, error: " + err.Error())
}
service.location = location
service.expiration = time.Duration(1) * time.Hour
return service
}
func (r *fakeAuthServer) Close() {
r.server.Close()
}
func (r *fakeAuthServer) getLocation() string {
return fmt.Sprintf("%s://%s/auth/realms/hod-test", r.location.Scheme, r.location.Host)
}
func (r *fakeAuthServer) getRevocationURL() string {
return fmt.Sprintf("%s://%s/auth/realms/hod-test/protocol/openid-connect/logout", r.location.Scheme, r.location.Host)
}
func (r *fakeAuthServer) signToken(claims jose.Claims) (*jose.JWT, error) {
return jose.NewSignedJWT(claims, r.signer)
}
func (r *fakeAuthServer) setTokenExpiration(tm time.Duration) *fakeAuthServer {
r.expiration = tm
return r
}
func (r *fakeAuthServer) discoveryHandler(w http.ResponseWriter, req *http.Request) {
renderJSON(http.StatusOK, w, req, fakeDiscoveryResponse{
AuthorizationEndpoint: fmt.Sprintf("http://%s/auth/realms/hod-test/protocol/openid-connect/auth", r.location.Host),
EndSessionEndpoint: fmt.Sprintf("http://%s/auth/realms/hod-test/protocol/openid-connect/logout", r.location.Host),
Issuer: fmt.Sprintf("http://%s/auth/realms/hod-test", r.location.Host),
JwksURI: fmt.Sprintf("http://%s/auth/realms/hod-test/protocol/openid-connect/certs", r.location.Host),
RegistrationEndpoint: fmt.Sprintf("http://%s/auth/realms/hod-test/clients-registrations/openid-connect", r.location.Host),
TokenEndpoint: fmt.Sprintf("http://%s/auth/realms/hod-test/protocol/openid-connect/token", r.location.Host),
TokenIntrospectionEndpoint: fmt.Sprintf("http://%s/auth/realms/hod-test/protocol/openid-connect/token/introspect", r.location.Host),
UserinfoEndpoint: fmt.Sprintf("http://%s/auth/realms/hod-test/protocol/openid-connect/userinfo", r.location.Host),
GrantTypesSupported: []string{"authorization_code", "implicit", "refresh_token", "password", "client_credentials"},
IDTokenSigningAlgValuesSupported: []string{"RS256"},
ResponseModesSupported: []string{"query", "fragment", "form_post"},
ResponseTypesSupported: []string{"code", "none", "id_token", "token", "id_token token", "code id_token", "code token", "code id_token token"},
SubjectTypesSupported: []string{"public"},
})
}
func (r *fakeAuthServer) keysHandler(w http.ResponseWriter, req *http.Request) {
renderJSON(http.StatusOK, w, req, jose.JWKSet{Keys: []jose.JWK{r.key}})
}
func (r *fakeAuthServer) authHandler(w http.ResponseWriter, req *http.Request) {
state := req.URL.Query().Get("state")
redirect := req.URL.Query().Get("redirect_uri")
if redirect == "" {
w.WriteHeader(http.StatusInternalServerError)
return
}
if state == "" {
state = "/"
}
redirectionURL := fmt.Sprintf("%s?state=%s&code=%s", redirect, state, getRandomString(32))
http.Redirect(w, req, redirectionURL, http.StatusTemporaryRedirect)
}
func (r *fakeAuthServer) logoutHandler(w http.ResponseWriter, req *http.Request) {
if refreshToken := req.FormValue("refresh_token"); refreshToken == "" {
w.WriteHeader(http.StatusBadRequest)
return
}
w.WriteHeader(http.StatusNoContent)
}
func (r *fakeAuthServer) userInfoHandler(w http.ResponseWriter, req *http.Request) {
items := strings.Split(req.Header.Get("Authorization"), " ")
if len(items) != 2 {
w.WriteHeader(http.StatusUnauthorized)
return
}
decoded, err := jose.ParseJWT(items[1])
if err != nil {
w.WriteHeader(http.StatusUnauthorized)
return
}
claims, err := decoded.Claims()
if err != nil {
w.WriteHeader(http.StatusUnauthorized)
return
}
renderJSON(http.StatusOK, w, req, map[string]interface{}{
"sub": claims["sub"],
"name": claims["name"],
"given_name": claims["given_name"],
"family_name": claims["familty_name"],
"preferred_username": claims["preferred_username"],
"email": claims["email"],
"picture": claims["picture"],
})
}
func (r *fakeAuthServer) tokenHandler(w http.ResponseWriter, req *http.Request) {
expires := time.Now().Add(r.expiration)
unsigned := newTestToken(r.getLocation())
unsigned.setExpiration(expires)
// sign the token with the private key
token, err := jose.NewSignedJWT(unsigned.claims, r.signer)
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
return
}
switch req.FormValue("grant_type") {
case oauth2.GrantTypeUserCreds:
username := req.FormValue("username")
password := req.FormValue("password")
if username == "" || password == "" {
w.WriteHeader(http.StatusBadRequest)
return
}
if username == validUsername && password == validPassword {
renderJSON(http.StatusOK, w, req, tokenResponse{
IDToken: token.Encode(),
AccessToken: token.Encode(),
RefreshToken: token.Encode(),
ExpiresIn: expires.UTC().Second(),
})
return
}
renderJSON(http.StatusUnauthorized, w, req, map[string]string{
"error": "invalid_grant",
"error_description": "Invalid user credentials",
})
case oauth2.GrantTypeRefreshToken:
fallthrough
case oauth2.GrantTypeAuthCode:
renderJSON(http.StatusOK, w, req, tokenResponse{
IDToken: token.Encode(),
AccessToken: token.Encode(),
RefreshToken: token.Encode(),
ExpiresIn: expires.Second(),
})
default:
w.WriteHeader(http.StatusBadRequest)
}
}
func TestGetUserinfo(t *testing.T) {
px, idp, _ := newTestProxyService(nil)
token := newTestToken(idp.getLocation()).getToken()
client, _ := px.client.OAuthClient()
claims, err := getUserinfo(client, px.idp.UserInfoEndpoint.String(), token.Encode())
assert.NoError(t, err)
assert.NotEmpty(t, claims)
}
func TestTokenExpired(t *testing.T)
|
func getRandomString(n int) string {
b := make([]rune, n)
for i := range b {
b[i] = letterRunes[rand.Intn(len(letterRunes))]
}
return string(b)
}
func renderJSON(code int, w http.ResponseWriter, req *http.Request, data interface{}) {
w.Header().Set("Content-Type", "application/json")
w.WriteHeader(code)
if err := json.NewEncoder(w).Encode(data); err != nil {
w.WriteHeader(http.StatusInternalServerError)
return
}
}
|
{
px, idp, _ := newTestProxyService(nil)
token := newTestToken(idp.getLocation())
cs := []struct {
Expire time.Duration
OK bool
}{
{
Expire: time.Duration(1 * time.Hour),
OK: true,
},
{
Expire: time.Duration(-5 * time.Hour),
},
}
for i, x := range cs {
token.setExpiration(time.Now().Add(x.Expire))
signed, err := idp.signToken(token.claims)
if err != nil {
t.Errorf("case %d unable to sign the token, error: %s", i, err)
continue
}
err = verifyToken(px.client, *signed)
if x.OK && err != nil {
t.Errorf("case %d, expected: %t got error: %s", i, x.OK, err)
}
if !x.OK && err == nil {
t.Errorf("case %d, expected: %t got no error", i, x.OK)
}
}
}
|
flag.f.Lookup.go
|
/************************************************************************************
**Author: Axe Tang; Email: [email protected]
**Package: flag
**Element: flag.Lookup
**Type: func
------------------------------------------------------------------------------------
**Definition:
func Lookup(name string) *Flag
------------------------------------------------------------------------------------
**Description:
Lookup returns the Flag structure of the named command-line flag, returning
nil if none exists.
------------------------------------------------------------------------------------
**要点总结:
1. Lookup函数返回参数name string指定的命令行参数的指针即*Flag结构体信息;
2. 如果不存在该参数,则函数返回nil。
*************************************************************************************/
package main
func main() {
}
| ||
_LandingActionGoal.py
|
# This Python file uses the following encoding: utf-8
"""autogenerated by genpy from hector_uav_msgs/LandingActionGoal.msg. Do not edit."""
import sys
python3 = True if sys.hexversion > 0x03000000 else False
import genpy
import struct
import geometry_msgs.msg
import hector_uav_msgs.msg
import genpy
import actionlib_msgs.msg
import std_msgs.msg
class LandingActionGoal(genpy.Message):
_md5sum = "f5e95feb07d8f5f21d989eb34d7c3243"
_type = "hector_uav_msgs/LandingActionGoal"
_has_header = True #flag to mark the presence of a Header object
_full_text = """# ====== DO NOT MODIFY! AUTOGENERATED FROM AN ACTION DEFINITION ======
Header header
actionlib_msgs/GoalID goal_id
LandingGoal goal
================================================================================
MSG: std_msgs/Header
# Standard metadata for higher-level stamped data types.
# This is generally used to communicate timestamped data
# in a particular coordinate frame.
#
# sequence ID: consecutively increasing ID
uint32 seq
#Two-integer timestamp that is expressed as:
# * stamp.sec: seconds (stamp_secs) since epoch (in Python the variable is called 'secs')
# * stamp.nsec: nanoseconds since stamp_secs (in Python the variable is called 'nsecs')
# time-handling sugar is provided by the client library
time stamp
#Frame this data is associated with
# 0: no frame
# 1: global frame
string frame_id
================================================================================
MSG: actionlib_msgs/GoalID
# The stamp should store the time at which this goal was requested.
# It is used by an action server when it tries to preempt all
# goals that were requested before a certain time
time stamp
# The id provides a way to associate feedback and
# result message with specific goal requests. The id
# specified must be unique.
string id
================================================================================
MSG: hector_uav_msgs/LandingGoal
# ====== DO NOT MODIFY! AUTOGENERATED FROM AN ACTION DEFINITION ======
# Landing pose, pose.z is ignored.
# If no stamp is provided, landing_zone is assumed to be empty and
# robot will land directly below
geometry_msgs/PoseStamped landing_zone
================================================================================
MSG: geometry_msgs/PoseStamped
# A Pose with reference coordinate frame and timestamp
Header header
Pose pose
================================================================================
MSG: geometry_msgs/Pose
# A representation of pose in free space, composed of position and orientation.
Point position
Quaternion orientation
================================================================================
MSG: geometry_msgs/Point
# This contains the position of a point in free space
float64 x
float64 y
float64 z
================================================================================
MSG: geometry_msgs/Quaternion
# This represents an orientation in free space in quaternion form.
float64 x
float64 y
float64 z
float64 w
"""
__slots__ = ['header','goal_id','goal']
_slot_types = ['std_msgs/Header','actionlib_msgs/GoalID','hector_uav_msgs/LandingGoal']
def __init__(self, *args, **kwds):
"""
Constructor. Any message fields that are implicitly/explicitly
set to None will be assigned a default value. The recommend
use is keyword arguments as this is more robust to future message
changes. You cannot mix in-order arguments and keyword arguments.
The available fields are:
header,goal_id,goal
:param args: complete set of field values, in .msg order
:param kwds: use keyword arguments corresponding to message field names
to set specific fields.
"""
if args or kwds:
super(LandingActionGoal, self).__init__(*args, **kwds)
#message fields cannot be None, assign default values for those that are
if self.header is None:
self.header = std_msgs.msg.Header()
if self.goal_id is None:
self.goal_id = actionlib_msgs.msg.GoalID()
if self.goal is None:
self.goal = hector_uav_msgs.msg.LandingGoal()
else:
self.header = std_msgs.msg.Header()
self.goal_id = actionlib_msgs.msg.GoalID()
self.goal = hector_uav_msgs.msg.LandingGoal()
def _get_types(self):
"""
internal API method
"""
return self._slot_types
def serialize(self, buff):
"""
serialize message into buffer
:param buff: buffer, ``StringIO``
"""
try:
_x = self
buff.write(_get_struct_3I().pack(_x.header.seq, _x.header.stamp.secs, _x.header.stamp.nsecs))
_x = self.header.frame_id
length = len(_x)
if python3 or type(_x) == unicode:
_x = _x.encode('utf-8')
length = len(_x)
buff.write(struct.pack('<I%ss'%length, length, _x))
_x = self
buff.write(_get_struct_2I().pack(_x.goal_id.stamp.secs, _x.goal_id.stamp.nsecs))
_x = self.goal_id.id
length = len(_x)
if python3 or type(_x) == unicode:
_x = _x.encode('utf-8')
length = len(_x)
buff.write(struct.pack('<I%ss'%length, length, _x))
_x = self
buff.write(_get_struct_3I().pack(_x.goal.landing_zone.header.seq, _x.goal.landing_zone.header.stamp.secs, _x.goal.landing_zone.header.stamp.nsecs))
_x = self.goal.landing_zone.header.frame_id
length = len(_x)
if python3 or type(_x) == unicode:
_x = _x.encode('utf-8')
length = len(_x)
buff.write(struct.pack('<I%ss'%length, length, _x))
_x = self
buff.write(_get_struct_7d().pack(_x.goal.landing_zone.pose.position.x, _x.goal.landing_zone.pose.position.y, _x.goal.landing_zone.pose.position.z, _x.goal.landing_zone.pose.orientation.x, _x.goal.landing_zone.pose.orientation.y, _x.goal.landing_zone.pose.orientation.z, _x.goal.landing_zone.pose.orientation.w))
except struct.error as se: self._check_types(struct.error("%s: '%s' when writing '%s'" % (type(se), str(se), str(locals().get('_x', self)))))
except TypeError as te: self._check_types(ValueError("%s: '%s' when writing '%s'" % (type(te), str(te), str(locals().get('_x', self)))))
def deserialize(self, str):
"""
unpack serialized message in str into this message instance
:param str: byte array of serialized message, ``str``
"""
try:
if self.header is None:
self.header = std_msgs.msg.Header()
if self.goal_id is None:
self.goal_id = actionlib_msgs.msg.GoalID()
if self.goal is None:
self.goal = hector_uav_msgs.msg.LandingGoal()
end = 0
_x = self
start = end
end += 12
(_x.header.seq, _x.header.stamp.secs, _x.header.stamp.nsecs,) = _get_struct_3I().unpack(str[start:end])
start = end
end += 4
(length,) = _struct_I.unpack(str[start:end])
start = end
end += length
if python3:
self.header.frame_id = str[start:end].decode('utf-8')
else:
self.header.frame_id = str[start:end]
_x = self
start = end
end += 8
(_x.goal_id.stamp.secs, _x.goal_id.stamp.nsecs,) = _get_struct_2I().unpack(str[start:end])
start = end
end += 4
(length,) = _struct_I.unpack(str[start:end])
start = end
end += length
if python3:
self.goal_id.id = str[start:end].decode('utf-8')
else:
self.goal_id.id = str[start:end]
_x = self
start = end
end += 12
(_x.goal.landing_zone.header.seq, _x.goal.landing_zone.header.stamp.secs, _x.goal.landing_zone.header.stamp.nsecs,) = _get_struct_3I().unpack(str[start:end])
start = end
end += 4
(length,) = _struct_I.unpack(str[start:end])
start = end
end += length
if python3:
self.goal.landing_zone.header.frame_id = str[start:end].decode('utf-8')
else:
self.goal.landing_zone.header.frame_id = str[start:end]
_x = self
start = end
end += 56
(_x.goal.landing_zone.pose.position.x, _x.goal.landing_zone.pose.position.y, _x.goal.landing_zone.pose.position.z, _x.goal.landing_zone.pose.orientation.x, _x.goal.landing_zone.pose.orientation.y, _x.goal.landing_zone.pose.orientation.z, _x.goal.landing_zone.pose.orientation.w,) = _get_struct_7d().unpack(str[start:end])
return self
except struct.error as e:
raise genpy.DeserializationError(e) #most likely buffer underfill
def serialize_numpy(self, buff, numpy):
"""
serialize message with numpy array types into buffer
:param buff: buffer, ``StringIO``
:param numpy: numpy python module
"""
try:
_x = self
buff.write(_get_struct_3I().pack(_x.header.seq, _x.header.stamp.secs, _x.header.stamp.nsecs))
_x = self.header.frame_id
length = len(_x)
if python3 or type(_x) == unicode:
_x = _x.encode('utf-8')
length = len(_x)
buff.write(struct.pack('<I%ss'%length, length, _x))
_x = self
buff.write(_get_struct_2I().pack(_x.goal_id.stamp.secs, _x.goal_id.stamp.nsecs))
_x = self.goal_id.id
length = len(_x)
if python3 or type(_x) == unicode:
_x = _x.encode('utf-8')
length = len(_x)
buff.write(struct.pack('<I%ss'%length, length, _x))
_x = self
buff.write(_get_struct_3I().pack(_x.goal.landing_zone.header.seq, _x.goal.landing_zone.header.stamp.secs, _x.goal.landing_zone.header.stamp.nsecs))
_x = self.goal.landing_zone.header.frame_id
length = len(_x)
if python3 or type(_x) == unicode:
_x = _x.encode('utf-8')
length = len(_x)
buff.write(struct.pack('<I%ss'%length, length, _x))
_x = self
buff.write(_get_struct_7d().pack(_x.goal.landing_zone.pose.position.x, _x.goal.landing_zone.pose.position.y, _x.goal.landing_zone.pose.position.z, _x.goal.landing_zone.pose.orientation.x, _x.goal.landing_zone.pose.orientation.y, _x.goal.landing_zone.pose.orientation.z, _x.goal.landing_zone.pose.orientation.w))
except struct.error as se: self._check_types(struct.error("%s: '%s' when writing '%s'" % (type(se), str(se), str(locals().get('_x', self)))))
except TypeError as te: self._check_types(ValueError("%s: '%s' when writing '%s'" % (type(te), str(te), str(locals().get('_x', self)))))
def deserialize_numpy(self, str, numpy):
"""
unpack serialized message in str into this message instance using numpy for array types
:param str: byte array of serialized message, ``str``
:param numpy: numpy python module
"""
try:
if self.header is None:
self.header = std_msgs.msg.Header()
if self.goal_id is None:
self.goal_id = actionlib_msgs.msg.GoalID()
if self.goal is None:
self.goal = hector_uav_msgs.msg.LandingGoal()
end = 0
_x = self
start = end
end += 12
(_x.header.seq, _x.header.stamp.secs, _x.header.stamp.nsecs,) = _get_struct_3I().unpack(str[start:end])
start = end
end += 4
(length,) = _struct_I.unpack(str[start:end])
start = end
end += length
if python3:
self.header.frame_id = str[start:end].decode('utf-8')
else:
self.header.frame_id = str[start:end]
_x = self
start = end
end += 8
(_x.goal_id.stamp.secs, _x.goal_id.stamp.nsecs,) = _get_struct_2I().unpack(str[start:end])
start = end
end += 4
(length,) = _struct_I.unpack(str[start:end])
start = end
end += length
if python3:
self.goal_id.id = str[start:end].decode('utf-8')
else:
self.goal_id.id = str[start:end]
_x = self
start = end
end += 12
(_x.goal.landing_zone.header.seq, _x.goal.landing_zone.header.stamp.secs, _x.goal.landing_zone.header.stamp.nsecs,) = _get_struct_3I().unpack(str[start:end])
start = end
end += 4
(length,) = _struct_I.unpack(str[start:end])
start = end
end += length
if python3:
self.goal.landing_zone.header.frame_id = str[start:end].decode('utf-8')
else:
self.goal.landing_zone.header.frame_id = str[start:end]
_x = self
start = end
end += 56
(_x.goal.landing_zone.pose.position.x, _x.goal.landing_zone.pose.position.y, _x.goal.landing_zone.pose.position.z, _x.goal.landing_zone.pose.orientation.x, _x.goal.landing_zone.pose.orientation.y, _x.goal.landing_zone.pose.orientation.z, _x.goal.landing_zone.pose.orientation.w,) = _get_struct_7d().unpack(str[start:end])
return self
except struct.error as e:
raise genpy.DeserializationError(e) #most likely buffer underfill
_struct_I = genpy.struct_I
def
|
():
global _struct_I
return _struct_I
_struct_3I = None
def _get_struct_3I():
global _struct_3I
if _struct_3I is None:
_struct_3I = struct.Struct("<3I")
return _struct_3I
_struct_7d = None
def _get_struct_7d():
global _struct_7d
if _struct_7d is None:
_struct_7d = struct.Struct("<7d")
return _struct_7d
_struct_2I = None
def _get_struct_2I():
global _struct_2I
if _struct_2I is None:
_struct_2I = struct.Struct("<2I")
return _struct_2I
|
_get_struct_I
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.