
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
OMS-NetZero/FAIR-pro | 239097191 | Title: Basic Implementation of CH4 and N2O
Question:
username_0: Seems to make sense to add both of these at the same time as they are dependent on one another. By "basic", I mean fixed lifetimes for both, all equations and data will be taken from IPCC, mainly from AR5 8.SM. My plan is to do them in as similar a manner as to how Carbon is currently implemented to make the whole code as clear as possible. I'll work in the branch FAIR-pro/FAIR-basic-development/Additional_GHG_Implementation, and will comment fairly exhaustively as I code.
- [ ] Add in all additional parameters to the definition required: M_emissions, N_emissions, M_concs, N_concs, M_life, N_life, M_0, N_0. There may be some unit conversions needed (such as ppm_gtc, but I'll add these as necessary).
- [ ] Add in checks for CH4 and N2O being emissions or concentrations driven (I'm a little wary as this will likely lengthen the program by quite a bit, however, I'll try and be as concise as possible). _I think I'll start by requiring the program is either entirely concentrations driven or entirely emissions driven otherwise it will end up very long. I'll raise an error if concentrations are supplied for some gases and emissions for others._
- [ ] Add in a check that all the emissions or concentrations timeseries are the same length, raise error if not.
- [ ] Create np.zeros in which CH4 and N2O concentrations will be stored, I'll call these M and N for simplicity.
- [ ] Add lines to compute the first timestep concentrations, based on emissions or concentrations, in a manner very similar to CO2.
- [ ] Add in two extra definitions that just contain the equations for RF due to CH4 and N2O- I feel this should make the code clearer than just adding them to the RF line since they are both pretty long.
- [ ] Add the relevant terms to the RF (in both first ts and rest of run).
FAIR should now calculate the temperature including the other gases- no alterations need to be made to the temperature calculations I think.
- [ ] Add M and N concentrations as outputs.
Answers:
username_1: Looks great. The only suggestion I'd make is that to maintain some semblance of backwards compatibility you only return M and N if M and N emissions/concentrations were supplied as inputs?
username_0: Yes, that's a good point, I'll make sure that happens when I get there.
Status: Issue closed
|
google/exposure-notifications-verification-server | 701354303 | Title: User pagination
Question:
username_0: Users of the verification server may have hundreds to thousands of users which may eventually make our /users page unsuable. Consider including pagination / filtering to manager a larger user set.
Context:
https://github.com/google/exposure-notifications-verification-server/issues/517
/kind enhancement
Answers:
username_0: /assign |
zhiyb/MinecraftScripts | 253621767 | Title: 日志中添加日期时间
Question:
username_0: 日志中诸如:
`Fetching manifest...
Latest snapshot: 1.12.1 (2017-08-03T12:40:39+00:00)
File server/1.12.1.jar already exists
Fetching manifest...
Latest snapshot: 1.12.1 (2017-08-03T12:40:39+00:00)
File server/1.12.1.jar already exists
Fetching manifest...
Latest snapshot: 1.12.1 (2017-08-03T12:40:39+00:00)
File server/1.12.1.jar already exists
Fetching manifest...
Latest snapshot: 1.12.1 (2017-08-03T12:40:39+00:00)
File server/1.12.1.jar already exists
./server_update.sh: 第 30 行:echo: 写错误: 设备上没有空间
Fetching manifest...
Latest snapshot: 1.12.1 (2017-08-03T12:40:39+00:00)
File server/1.12.1.jar already exists
./server_update.sh: 第 30 行:echo: 写错误: 设备上没有空间`
出现错误的时间没有记录,希望可以在其中输出日期时间
Status: Issue closed
Answers:
username_1: Please test 56a18a1
username_0: Thanks , its very nice |
coredns/coredns | 525611599 | Title: can not
Question:
username_0: https://coredns.io/2017/07/25/compile-time-enabling-or-disabling-plugins/
https://coredns.io/explugins/pdsql/
Answers:
username_1: External plugins are independently maintained.
Please raise the issue in the external plugin's repository.
Status: Issue closed
|
PhyloStar/CogDetect | 231408917 | Title: Scores None in align_pairs
Question:
username_0: The scores array that is passed as an argument in update_pmi_dict code at line no. 271 in dataio.py code is set to scores.
If the scores is None, then the Online algorithm does not weigh a character pair by the similarity score of the word pair. A weighted version yields stable results than an unweighted version. |
caolan/async | 328855783 | Title: async queue example should show how to handle errors
Question:
username_0: Looking at the docs for async.queue
https://caolan.github.io/async/docs.html#queue
```
// create a queue object with concurrency 2
var q = async.queue(function(task, callback) {
console.log('hello ' + task.name);
callback();
}, 2);
// assign a callback
q.drain = function() {
console.log('all items have been processed');
};
```
is there an
```js
q.onError = function(err){
}
```
handler that we can use?
I don't think q.drain is an error-first callback, and I don't want to pass a callbac for each q.push or q.unshift call, I just want to use one error-first callback.
This should exist and be in the docs, right?
Status: Issue closed
Answers:
username_1: https://caolan.github.io/async/docs.html#QueueObject
`q.error` exists, and there is an optional callback you can pass to `q.push()`.
username_0: @username_1 it needs to be documented in the example, that is the bug. How can I add it to the example? How do I make a PR for the docs?
username_1: The example is in the JSDoc comment in the `queue` source.
username_0: https://github.com/caolan/async/pull/1540
sounds good |
CovertLab/arrow | 393571052 | Title: Suspend alternative propensity calculation 'form's
Question:
username_0: Playing with Numba - I don't think it likes passing around function handles. I get performance hits when trying to wrap `propensity` and `choose` with `@numba.jit`, but if I pull out the `form` option, I get roughly a four-fold speed-up. There's probably a way around this but I think it's going to be easier to step back before moving forward - we also don't have any non-default test cases for the `form` feature. @username_1 thoughts?
(Numba [FAQs](https://numba.pydata.org/numba-doc/dev/user/faq.html) suggest that this is an active area for improvement.)
Answers:
username_1: Yeah I'm happy to walk back the `form` feature if it is holding us back, feel free! It was for a feature Heejo needed, but it turns out she doesn't need it anymore
Status: Issue closed
username_0: Addressed via #28. |
nmwsharp/geometry-central | 792911274 | Title: Any interest in feature preserving mesh smoothing algorithms for triangular meshes?
Question:
username_0: Would there be any interest in an implementation of this algorithm within geometry central?
http://mesh.brown.edu/dgp/pdfs/Jones-sg03.pdf
I have a naive implemetation that I would be happy to try to clean up and submit as a PR.
But, maybe a better question is this: Is there a plan already in the works for a suite of smoothing algorithms within the library? If so, what would that look like? Or is it already there somewhere and I've just missed it? |
TGNThump/AbandonedRuins | 700848592 | Title: Script raised revive events triggered by other mods
Question:
username_0: ### Overview
script_raised_revive events are being triggered by other mods, including the base game mod for pasting blueprints and bot construction, causing assembly machine recipie locking and weaponry force changing.
Thread: https://mods.factorio.com/mod/abandoned_ruins/discussion/5f5da16ed8561730a72f9c73
### Enviroment
- Factorio 1.0
- Abandoned Ruins 1.2.0<issue_closed>
Status: Issue closed |
solo-io/gloo | 428917122 | Title: Need better error checking in glooctl for malformed manifests
Question:
username_0: ```yaml
apiVersion: gloo.solo.io/v1
kind: Upstream
metadata:
labels:
name: my-service-name
upstreamSpec:
kube:
serviceName: my-service-name
serviceNamespace: namespace-name
servicePort: 1234
```
missing `spec:` before `upstreamSpec:` causes
```
[~/charts]$ glooctl get upstream
panic: runtime error: invalid memory address or nil pointer dereference
[signal SIGSEGV: segmentation violation code=0x1 addr=0x0 pc=0x24d8af0]
goroutine 1 [running]:
github.com/solo-io/gloo/projects/gloo/cli/pkg/printers.upstreamType(0xc0007efc00, 0x0, 0x0)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/projects/gloo/cli/pkg/printers/upstream.go:43 +0x20
github.com/solo-io/gloo/projects/gloo/cli/pkg/printers.UpstreamTable(0xc000894000, 0x66, 0x70, 0x3481920, 0xc000010010)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/projects/gloo/cli/pkg/printers/upstream.go:22 +0x220
github.com/solo-io/gloo/projects/gloo/cli/pkg/helpers.PrintUpstreams.func1(0x2fe90a0, 0xc0003c7980, 0x3481920, 0xc000010010, 0x0, 0x0)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/projects/gloo/cli/pkg/helpers/print.go:16 +0x93
github.com/solo-io/gloo/vendor/github.com/solo-io/solo-kit/pkg/utils/cliutils.PrintList(0x0, 0x0, 0x0, 0x0, 0x2fe90a0, 0xc0003c7980, 0x31cb8a8, 0x3481920, 0xc000010010, 0x0, ...)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/vendor/github.com/solo-io/solo-kit/pkg/utils/cliutils/printer.go:81 +0x282
github.com/solo-io/gloo/projects/gloo/cli/pkg/helpers.PrintUpstreams(0xc000894000, 0x66, 0x70, 0x0, 0x0)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/projects/gloo/cli/pkg/helpers/print.go:14 +0xb0
github.com/solo-io/gloo/projects/gloo/cli/pkg/cmd/get.Upstream.func1(0xc000112500, 0x4a6ef60, 0x0, 0x0, 0x0, 0x0)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/projects/gloo/cli/pkg/cmd/get/upstream.go:23 +0x1dc
github.com/solo-io/gloo/vendor/github.com/spf13/cobra.(*Command).execute(0xc000112500, 0x4a6ef60, 0x0, 0x0, 0x0, 0x0)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/vendor/github.com/spf13/cobra/command.go:762 +0xb21
github.com/solo-io/gloo/vendor/github.com/spf13/cobra.(*Command).ExecuteC(0xc000566500, 0xc000112500, 0x0, 0x0)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/vendor/github.com/spf13/cobra/command.go:852 +0x677
github.com/solo-io/gloo/vendor/github.com/spf13/cobra.(*Command).Execute(0xc000566500, 0x0, 0x0)
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/vendor/github.com/spf13/cobra/command.go:800 +0x3b
main.main()
/private/tmp/glooctl-20190329-19689-1njlz4k/src/github.com/solo-io/gloo/projects/gloo/cli/cmd/main.go:18 +0xde
``` |
typescript-eslint/typescript-eslint | 1184007827 | Title: Docs: Website sponsor data includes low-donation spam
Question:
username_0: ### Suggested Changes
See discussion in #4750: there are some bad actors we've reported to OpenCollective who donate <=$5 just to get on our ad space. Not nice.
If we filter our sponsors to just those who have donated, say, either $10/month or a total of $50, we'd get rid of these bad actors. We also have past sponsors such as Sentry who gave larger one-time donations that could be put on there.
### Affected URL(s)
https://typescript-eslint.io |
ArctosDB/arctos | 404926280 | Title: report needed: taxa used in IDs by a collection which do not have a preferred classification
Question:
username_0: for #1419
sql:
```
select
taxon_name.scientific_name
from
identification_taxonomy,
identification,
cataloged_item,
collection,
taxon_name
where
identification_taxonomy.identification_id=identification.identification_id and
identification.collection_object_id=cataloged_item.collection_object_id and
cataloged_item.collection_id=collection.collection_id and
identification_taxonomy.taxon_name_id=taxon_name.taxon_name_id and
collection.guid_prefix='{guid_prefix}' and
taxon_name.taxon_name_id not in
(select taxon_name_id from taxon_term where
taxon_term.taxon_name_id = taxon_name.taxon_name_id and
taxon_term.source=collection.PREFERRED_TAXONOMY_SOURCE
)
;
Answers:
username_1: Can you give me another way to search for these four taxa without a preferred classification for DMNS: Inv?

The SQL doesn't bring up anything - at least the way I ran it.

username_0: It should work there without the trailing semicolon, and you'll need to put in your actual GUID_Prefix.
```
select
taxon_name.scientific_name
from
identification_taxonomy,
identification,
cataloged_item,
collection,
taxon_name
where
identification_taxonomy.identification_id=identification.identification_id and
identification.collection_object_id=cataloged_item.collection_object_id and
cataloged_item.collection_id=collection.collection_id and
identification_taxonomy.taxon_name_id=taxon_name.taxon_name_id and
collection.guid_prefix='DMNS:Inv' and
taxon_name.taxon_name_id not in
(select taxon_name_id from taxon_term where
taxon_term.taxon_name_id = taxon_name.taxon_name_id and
taxon_term.source=collection.PREFERRED_TAXONOMY_SOURCE
)
;
SCIENTIFIC_NAME
------------------------------------------------------------------------------------------------------------------------
Nitidella gausapata
Cerithium septemstriatum
Gemmula gilchristie
Helicostyla stabilis
```
Status: Issue closed
username_1: Thanks. It worked.
username_2: Still getting the same invalid character error when I try Dusty's code. It would be nice to click on the preferred taxonomy error and be sent directly to a table of the specimens with the errors. Any idea what I'm doing wrong?

username_3: for #1419
sql:
```
select
taxon_name.scientific_name
from
identification_taxonomy,
identification,
cataloged_item,
collection,
taxon_name
where
identification_taxonomy.identification_id=identification.identification_id and
identification.collection_object_id=cataloged_item.collection_object_id and
cataloged_item.collection_id=collection.collection_id and
identification_taxonomy.taxon_name_id=taxon_name.taxon_name_id and
collection.guid_prefix='{guid_prefix}' and
taxon_name.taxon_name_id not in
(select taxon_name_id from taxon_term where
taxon_term.taxon_name_id = taxon_name.taxon_name_id and
taxon_term.source=collection.PREFERRED_TAXONOMY_SOURCE
)
;
username_3: @username_0 is the above possible?
username_0: The error is from the semicolon and the next line. Here's the code by itself
```
select
taxon_name.scientific_name
from
identification_taxonomy,
identification,
cataloged_item,
collection,
taxon_name
where
identification_taxonomy.identification_id=identification.identification_id and
identification.collection_object_id=cataloged_item.collection_object_id and
cataloged_item.collection_id=collection.collection_id and
identification_taxonomy.taxon_name_id=taxon_name.taxon_name_id and
collection.guid_prefix='UCSC:Herp' and
taxon_name.taxon_name_id not in
(select taxon_name_id from taxon_term where
taxon_term.taxon_name_id = taxon_name.taxon_name_id and
taxon_term.source=collection.PREFERRED_TAXONOMY_SOURCE
)
```
It finds nothing as of now.
Yes the purpose of this issue is to define and prioritize a report.
username_3: Just turn that code into a tool in Low Quality Data?
username_1: This report could use a modification or additional report.
It is showing as low quality data 779 taxa without a preferred classification. Actually, these are the 780 taxa that are not in WoRMS (via Arctos) so they default to our second source Arctos. Most of them are fossils or terrestrials that WoRMS does not include. This is helpful to know how many taxa are using Arctos classifications.
For the low quality data report, can we modify this to look for classifications from all listed sources before reporting that there is no preferred classification?
username_0: From https://github.com/ArctosDB/arctos/issues/3541
Suggest we change this to "missing from FLAT" which
1. Is easy, and
2. Finds "doesn't have useful data" which seems much more informative.
username_1: Sorry, but what does "missing from FLAT" mean?
Will the report show a list of taxa used in IDs that have no (preferred) classification?
username_0: A classification might include a remark and nothing else; that would not be detected in a "taxon has classification" test.
Etc., etc., etc. - "something there" is what I could potentially detect, that's it, and we know that plenty of classifications do in fact have problems.
"Something in flat" is essentially "has a classification, and it does something useful."
```
select scientific_name from flat where guid_prefix='DMNS:Inv' and phylum is null group by scientific_name order by scientific_name;
```
finds nothing - all of your IDs found something to use for phylum, yay you!
```
arctosprod@arctos>> select scientific_name from flat where guid_prefix='DMNS:Inv' and family is null group by scientific_name order by scientific_name;
scientific_name
-------------------
Ammonitida
Bryozoa
Caridea
Decapoda
Demospongiae
Foraminifera
Gordius
Heterobranchia
Patellogastropoda
Porifera
(10 rows)
```
For those, the scripts have gone through your preferred sources and couldn't find a family value. If any of those are families or below, there's something wrong with all of your preferred sources. If they're not (I think not?) then your preferred classifications supply something useful for all of your records.
username_1: That helps. I always just search the collections periodically for records where the Kingdom (or phylum etc.) is NULL since SQL isn't my first language. It sounds like that's the best way for me for continue to look for problem records.
Yes, the ones with a NULL family are known to be that way. We can't ID them to any lower level at this time.
username_0: That's the same data as what I'm thinking, just from a more taxa-centric viewpoint.
Yes the Dashboard-->Bare Names thing needs rewritten; it's still working under the idea that a collection will prefer exactly one Source.
Some of those are probably a legacy of that, and some may be names used in nonaccepted IDs. The classifications attached to those don't really DO anything so I don't think that's a problem; if it is, maybe it's at least a rare (or strange) enough problem that it can be dealt with via SQL on a case-by-case basis.
username_1: @username_0 I think we can close this assuming that you have a rewrite of the Dashboard "Bare Names" (and same for the cheat sheet) on your To Do list. I'll leave closing it up to you.
username_3: @username_0 the link for taxa without a classification in the something random thingee

goes to this issue, but I think it should now go here - https://github.com/ArctosDB/documentation-wiki/blob/gh-pages/_sql_cheats/taxa_without_classification.markdown
username_0: I can rewrite the query (I think!), but it would be very expensive and I don't think it can be made to run in the UI. Suggest checking computed terms in flat - https://github.com/ArctosDB/arctos/issues/1894#issuecomment-816080112
username_3: Well, how does Arctos know there are two names with no classification? And if it knows that, why can't it tell me what they are? If we can't make it easy for people to fix "low quality data" we might as well not tell them there is any.
username_0: Slowly. FLAT exists so the expensive computations don't have to happen at runtime.
"Has a classification" and "has a useful classification" are wildly different things. Flat gets at "useful" (eg, has expected ranks), along with performing reasonably well. I don't understand the complaint - this is a more informative approach, yay everybody?! https://github.com/ArctosDB/arctos/issues/1894#issuecomment-816080112
username_3: But the query above only looks for "phylum"? Nobody has time to check all the potential levels of every possible classification?
username_3: Keep a list as it goes? Is that asking too much?
username_0: Hu?
username_3: Then why mention family?
```
select scientific_name from flat where guid_prefix='DMNS:Inv' and family is null group by scientific_name order by scientific_name;
scientific_name
```
username_0: Family is just one term/rank that some collections/disciplines seem to care about.
I'd just replace family with other flat-terms and run multiple queries, but I'm not sure I understand what you're asking for here so that may not be useful. What precisely are the goals?
This will get at (or very near) "no classification data" if that's the question.
```
select scientific_name from flat where guid_prefix='DMNS:Inv' and
phylclass is null and
kingdom is null and
phylum is null and
phylorder is null and
family is null and
genus is null and
species is null and
subspecies is null and
author_text is null and
nomenclatural_code is null and
infraspecific_rank is null and
subfamily is null and
tribe is null and
subtribe is null
```
username_3: That works for this and I think would be good for most cases. I'll play with it an see if anything needs added. Thanks!
username_0: Aha! That's where we should be starting - that report is almost certainly not working correctly (https://github.com/ArctosDB/arctos/issues/1894#issuecomment-816236745) - so 2 questions
1. What (if anything) should be be checking, and
2. Then what?
username_3: Just what it says - "bare names" a name used as an identification that has no classification in any of the collection's preferred sources.
username_0: There's a new report in next release
<img width="291" alt="Screen Shot 2021-10-01 at 8 18 46 AM" src="https://user-images.githubusercontent.com/5720791/135645380-ca5a9b9e-a5b5-48b5-bb6f-050ba2bc0a5d.png">
and the dashboard-creator-thing is no longer looking for taxonomy problems because I can't find a way to do so which doesn't return lots of false positives. It should be easy enough to reintroduce that if someone eventually identifies a specific need.
Status: Issue closed
|
juj/fbcp-ili9341 | 712061773 | Title: Screen doesn't fit display
Question:
username_0: I'm relatively sure I'm having the same problem as issue #112, however, I didn't quite understand the fix.
``bcm_host_get_peripheral_address: 0xfe000000, bcm_host_get_peripheral_size: 25165824, bcm_host_get_sdram_address: 0xc0000000
BCM core speed: current: 333333333hz, max turbo: 500000000hz. SPI CDIV: 30, SPI max frequency: 16666667hz
Allocated DMA channel 7
Allocated DMA channel 1
Enabling DMA channels Tx:7 and Rx:1
DMA hardware register file is at ptr: 0xb532d000, using DMA TX channel: 7 and DMA RX channel: 1
DMA hardware TX channel register file is at ptr: 0xb532d700, DMA RX channel register file is at ptr: 0xb532d100
Resetting DMA channels for use
DMA all set up
Initializing display
Resetting display at reset GPIO pin 24
Creating SPI task thread
InitSPI done
DISPLAY_FLIP_ORIENTATION_IN_SOFTWARE: Swapping width/height to update display in portrait mode to minimize tearing.
Relevant source display area size with overscan cropped away: 768x1360.
Source GPU display is 768x1360. Output SPI display is 240x240 with a drawable area of 240x240. Applying scaling factor horiz=0.18x & vert=0.18x, xOffset: 52, yOffset: 0, scaledWidth: 136, scaledHeight: 240
Creating dispmanX resource of size 136x240 (aspect ratio=0.566667).
GPU grab rectangle is offset x=0,y=0, size w=136xh=240, aspect ratio=0.566667
All initialized, now running main loop...``
How do I get the display to correctly fit the screen?
<issue_closed>
Status: Issue closed |
vim/vim | 194862264 | Title: jobs: close_cb and exit_cb are called during processing of out_cb
Question:
username_0: ```vim
call ch_logfile('/tmp/job.log')
let g:lines = []
function Out_cb(channel, data)
echom "CALLBACK" string(a:channel) string(a:data)
sleep 200m
echom "\n"
let g:lines += [a:data]
endfunction
function Close_cb(channel)
let g:lines += ['closed']
echom "CLOSE" string(a:channel)
echom "\n"
endfunction
let job = job_start(['sh', '-c', 'sleep 0.1; echo 1'], {
\ 'out_cb': 'Out_cb',
\ 'close_cb': 'Close_cb',
\ })
sleep 200m
echom "lines" string(g:lines)
```
`vim -u t-job-exit-before-stdout.vim`:
```
CALLBACK channel 0 open '1'
CLOSE process 27123 dead
^@
^@
lines ['closed', '1']
```
I think this is rather unexpected, and that the exit/close callbacks should only be invoked after the stdout/stderr (output) handlers are finished.
Answers:
username_1: Well, why do you invoke :sleep in the callback? Perhaps you ran into
this with some other command?
We should probably change this, but it should not be a big problem.
--
hundred-and-one symptoms of being an internet addict:
109. You actually read -- and enjoy -- lists like this.
/// <NAME> -- <EMAIL> -- http://www.Moolenaar.net \\\
/// sponsor Vim, vote for features -- http://www.Vim.org/sponsor/ \\\
\\\ an exciting new programming language -- http://www.Zimbu.org ///
\\\ help me help AIDS victims -- http://ICCF-Holland.org ///
username_0: I have noticed this with Neomake's tests, where the call to the debug logging seems to trigger this, and in particular the `redraw` therein (https://github.com/neomake/neomake/blob/c65e4fd8c9d412887e2cf83a20f94eb184799856/autoload/neomake/utils.vim#L52).
But using `redraw` instead of `sleep` in the test case here does not trigger it.
(As for Neomake's test: see https://github.com/neomake/neomake/commit/dc16de05686ee5f8b63cc6eb91bca34631bbc7c7#diff-1ceaba5126b0cf477e72f87cb2767af0L775 for the workaround, and https://github.com/neomake/neomake/blob/c65e4fd8c9d412887e2cf83a20f94eb184799856/autoload/neomake/utils.vim#L22 for the core of the debug message function.)
username_0: Came across this again - it is still an issue with Vim 8.0.586.
username_2: I'm having this when I tried to porting my plugin from neovim to vim. I am not using any sleep or redraw, only calling curl with jobstart and then in cb_out the channel is already closed.
username_3: came across with same issue
I think it's because `out_cb` was doing some heavy code that takes a long time, which exceeds vim's timeout? so simply `redraw` may not trigger the issue, but `sleep` would
my current solution is, `sleep` after your original job command, for example, change `curl balabla` to `curl balabala && sleep 1`, but that's tedious and not well-designed |
trentm/node-bunyan | 176041520 | Title: Mute logging when testing
Question:
username_0: It would be great to have possibility to turn off logging when testing application
for example in node.js:
```js
const bunyan = require('bunyan');
if(process.env.NODE_ENV === 'test') {
const log = bunyan.createLogger({
mute: true
name: <string> // Required
});
}
```
Answers:
username_1: You can choose the log level you want to actually log in the logger's streams
```javascript
if (process.env.NODE_ENV === 'test') {
log = bunyan.createLogger({
name: 'Some app',
streams: [{
stream: process.stdout,
level: 'fatal' // Only logs when the level is fatal or higher
}]
});
}
```
I guess it should be enough for your use cases.
If you want to "mute" a chunk of code, you could do something like
```javascript
var oldLog = [];
function muteOn () {
oldLog.push(log);
log = bunyan.createLogger({
name: 'Some app',
streams: [{
stream: process.stdout,
level: 'fatal'
}]
});
}
function muteOff () {
if (oldLog.length) {
log = oldLog[0];
oldLog = [];
}
}
...
muteOn();
...
muteOff();
```
username_2: Thanks for the answer, @username_1.
@username_0 See also this note about a potential future "off" level above fatal that would be more explicit: https://github.com/username_2/node-bunyan/pull/148#issuecomment-53232979
For now, however, using some number higher than `bunyan.FATAL` should work.
Status: Issue closed
|
top-think/think | 441603163 | Title: 请不要再composer.json 中 "topthink/framework": "5.1.*",请每个版本改成对应的版本
Question:
username_0: 新更新的5.1.36 会对我的代码造成影响,
于是我把我的composer.json 锁定为 "topthink/think": "5.1.35"
但是你这个think 项目里用的 "topthink/framework": "5.1.*"
搞得我这个版本锁定一点用都没用!!!!!!!!!!!!!!!
始终只能用最新的topthink/framework!!!!!!!!!!!!!!!!!!!
你们这样搞直接阉割了composer 的功能啊!!!!
还有,你们在5.1.36 里干了什么!!!我的$model->count()全废了,这个我再去提一个issue
Answers:
username_0: 请不要使用 5.1.* 这种版本号,请使用准确的版本号,每次打tag就更新一次,保证 think 项目和 framework 项目的版本完全准确统一,不然我这种项目和你们版本更新不兼容的真的很痛苦啊。真的不敢随便跟着你们升啊,都是锁定版本的。
我每次发版都要手动composer require "topthink/framework": "5.1.35",很难受啊
username_1: 奇怪的是你干嘛要升级think包呢
Status: Issue closed
username_2: 请在版本库中维护 `composer.lock` |
jbcool17/MyHandyScripts | 153239772 | Title: Watch folder and upload to drive
Question:
username_0: I've got some experience with the drive api and google's 2-step authentication api.
I know how to watch folders with node scripts (NOOOODEEE) or gulp?
What do you think?
PS: you and me <- (not in a while) are the only one doing stuff on github from our class!
Answers:
username_1: Nice the dish!! Have a crack.
Yea haven't messed around with that one in a while. what i'm trying to do is create a work flow for when I export a mix(audio file) from Reason. I want it to convert to mp3 then upload to my google drive so i can listen to it later, all in one step.
The problem that I ran into is that the script executes as soon as the audio file is starting to be created, so the file ends up being corrupt. I gotta figure out how to run the script once the file finishes exporting from reason.
Always gotta keep up with the git, Hub style. NoooOOOOooOde! Also gotta get back into the WebGL soon. been too long. |
jlippold/tweakCompatible | 418241270 | Title: `GlowBadge` working on iOS 12.1.1
Question:
username_0: ```
{
"packageId": "com.sassoty.glowbadge",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "com.sassoty.glowbadge",
"deviceId": "iPhone10,3",
"url": "http://cydia.saurik.com/package/com.sassoty.glowbadge/",
"iOSVersion": "12.1.1",
"packageVersionIndexed": true,
"packageName": "GlowBadge",
"category": "Tweaks",
"repository": "BigBoss",
"name": "GlowBadge",
"installed": "1.3-6",
"packageIndexed": true,
"packageStatusExplaination": "A matching version of this tweak for this iOS version could not be found. Please submit a review if you choose to install.",
"id": "com.sassoty.glowbadge",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.1.3",
"shortDescription": "Replace app badges with icon glow!",
"latest": "1.3-6",
"author": "Sassoty",
"packageStatus": "Unknown"
},
"base64": "<KEY>
"chosenStatus": "working",
"notes": ""
}
```<issue_closed>
Status: Issue closed |
mapbox/mapbox-navigation-android | 239803133 | Title: Engine consider end of first leg as arrival (multi-legs navigation doesn't work)
Question:
username_0: **Platform:** Android 7.1.2
**SDK version:** Latest SNAPSHOT
### Steps to trigger behavior
1. Set a route with more than 1 leg
2. Navigation stops at the end of the first leg
This is closely related to the PR I sent about waypoint support, as multi-legs routes are often routes with waypoints (but I believe there is other scenarios where a route can have multiple legs).
I will soon land a PR for this.
### Expected behavior
Navigation should not end until the last leg.
### Actual behavior
Navigation stops at leg index 0.
Answers:
username_1: Duplicate of #27.
Status: Issue closed
|
axotion/laravel-dotpay | 298556333 | Title: [Question] Kiedy i jak wyłapać callback?
Question:
username_0: Cześć, dzięki za paczkę, bardzo przydatna. :)
Mam szybkie pytania o callback, jeśli możesz podpowiedzieć.
1. Czy dotpay w trybie testowym wykonuje callbacki?
2. Jaki routing pod to przygotować? Post, czy get?
3. W którym momencie płatności wykonywany jest taki callback? Czy mogę w etapie końcowym płatności poczekać aż dotpay wykona curla?
Answers:
username_1: 1. Tak, wykonuje. Musisz zarejestrować swoje testowe konto
https://ssl.dotpay.pl/test_seller/test/registration/
2. Pod wysyłkę POST, callback odpowie postem na CURL, a przekieruje użytkownika po URL
3. Gdy użytkownik zapłaci/nie zapłaci wtedy zostaje wykonany callback na CURL
Status: Issue closed
|
webmin/webmin | 98381649 | Title: Squid - missing edit config files manually
Question:
username_0: There is no option to edit config files manually like in other modules?
I think it's worth adding it, right!
Answers:
username_1: Good idea - I've added a page for that.
Status: Issue closed
username_0: Thanks, Jamie but either I'm missing something and simply can't see it but it's not there after I updated squid module?
username_1: Oops, I forgot to check in one file. |
microsoft/BotFramework-Composer | 564827439 | Title: Question: How to access a JSON inner value?
Question:
username_0: The weather tutorial gets the following JSON response from the weather service:
```json
{
"id": 500,
"main": "Rain",
"description": "light rain",
"icon": "http://openweathermap.org/img/wn/[email protected]",
"weather": "Rain",
"temp": 31,
"high": 33,
"low": 30,
"rain": true,
"city": "Schenectady"
}
```
It then stores the content in `dialog.weather` and gets the weather and temperature using `The weather is @{dialog.weather.weather} and the temp is @{dialog.weather.temp}°`
I'm trying to use [OpenWeather](https://openweathermap.org/) service which returns the following JSON:
``` json
{
"coord": {
"lon": -9.13,
"lat": 38.72
},
"weather": [
{
"id": 300,
"main": "Drizzle",
"description": "light intensity drizzle",
"icon": "09d"
}
],
"base": "stations",
"main": {
"temp": 288.12,
"feels_like": 287.16,
"temp_min": 287.15,
"temp_max": 288.71,
"pressure": 1026,
"humidity": 93
},
"visibility": 10000,
"wind": {
"speed": 3.1,
"deg": 210
},
"clouds": {
"all": 75
},
"dt": 1581595588,
"sys": {
"type": 1,
"id": 6901,
"country": "PT",
"sunrise": 1581579052,
"sunset": 1581617449
},
"timezone": 0,
"id": 2267057,
"name": "Lisbon",
"cod": 200
}
```
I also store the content in `dialog.weather` and then try to get the same info using `The weather is @{dialog.weather.weather.main} and the temp is @{dialog.weather.main.temp}°`. I get the following error: `common.lg:Error occurs when evaluating expression bfdactivity-738194(): Error occurs when evaluating expression ‘dialog.weather.weather.main’: dialog.weather.weather.main is evaluated to null`
If I use this instead: `The weather is @{dialog.weather.weather} and the temp is @{dialog.weather.main}°`. I don't get an error but the following: `The weather is [ { “id”: 802, “main”: “Clouds”, “description”: “scattered clouds”, “icon”: “03d” } ] and the temp is { “temp”: 16.05, “feels_like”: 16.23, “temp_min”: 15, “temp_max”: 16.67, “pressure”: 1025, “humidity”: 87 }°`.
Answers:
username_1: @username_0 , could you try this: The weather is @{dialog.weather.weather[0].main} and the temp is @{dialog.weather.main.temp}. weather property is an array, so you need to query the item by index.
username_0: @username_1 Thank you so much for the help!
Just for reference, using this card:
```
[ThumbnailCard
title = Weather for @{dialog.weather.name}
text = The weather is @{dialog.weather.weather[0].main} and @{dialog.weather.main.temp}° (feels like @{dialog.weather.main.feels_like}°)
image = http://openweathermap.org/img/wn/@{dialog.weather.weather[0].icon}@2x.png
]
```
I now get the following:
<img width="493" alt="Screen Shot 2020-02-17 at 10 01 54" src="https://user-images.githubusercontent.com/534533/74643447-a1238980-516c-11ea-9b3a-709c089fec7a.png">
Status: Issue closed
|
nanomsg/nng | 321028426 | Title: want to nni_aio_stop without blocking
Question:
username_0: In general, we often do not need to block when we are stopping things down. We would like to shut down all activity on a pipe, ensuring that nothing can be restarted on it, without necessarily needing to wait for callbacks to complete.
To this end, nni_aio_stop() could be modified to take a boolean, indicating whether to wait or not.
Of course, nni_aio_fini() must wait, and anything that is going to ensure that it is safe to free underlying resources must also wait.
Answers:
username_0: This would be useful with reapers -- we can "stop" without waiting, everything before we submit things for the reaper. This ensures that an orderly cleanup is begun, and then only the reaper needs to worry about blocking for it.
username_0: We have instead taken the route of a new call, nni_aio_close(). This function is much like a non-blocking nni_aio_stop(), but it causes nni_aio_begin() to return NNG_ECLOSED in addition to immediately scheduling a completion callback (avoiding the case of a potentially orphaned callback).
Evidence is that this addresses a potential race condition responsible for sometimes crashing programs in the pipedesc_arm callback.
Status: Issue closed
|
fesoliveira014/yanve | 554709614 | Title: Forward+ Rendering
Question:
username_0: Forward+ is an advanced rendering technique that combines the advantages of deferred rendering and forward rendering, allowing for thousands of lights while enabling the use of different materials and translucent objects.
Resources:
- [Forward+: Bringing Deferred Lighting to the Next Level](https://takahiroharada.files.wordpress.com/2015/04/forward_plus.pdf)
- [Forward+ Renderer](https://github.com/bcrusco/Forward-Plus-Renderer/blob/master/Forward-Plus/Forward-Plus/) |
electron-userland/electron-installer-windows | 431012927 | Title: "TypeError: expected author to be a string" in my app & electron-installer-windows/example
Question:
username_0: Creating package (this may take a while)
electron-installer-windows Reading package metadata from dist/poopie-win32-ia32/resources/app/package.json +0ms
electron-installer-windows Error creating package: expected author to be a string +3ms
TypeError: expected author to be a string
at module.exports (/usr/local/lib/node_modules/electron-installer-windows/node_modules/parse-author/index.js:14:11)
at common.readMetadata.then.pkg (/usr/local/lib/node_modules/electron-installer-windows/src/installer.js:121:26)
at <anonymous> 'TypeError: expected author to be a string\n at module.exports (/usr/local/lib/node_modules/electron-installer-windows/node_modules/parse-author/index.js:14:11)\n at common.readMetadata.then.pkg (/usr/local/lib/node_modules/electron-installer-windows/src/installer.js:121:26)\n at <anonymous>'
npm ERR! Linux 4.15.0-36-generic
npm ERR! argv "/usr/bin/node" "/usr/bin/npm" "run" "set32"
npm ERR! node v8.10.0
npm ERR! npm v3.5.2
npm ERR! code ELIFECYCLE
npm ERR! [email protected] set32: `electron-installer-windows --src dist/poopie-win32-ia32/ --dest dist/installers/ia32/ --config config.json`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] set32 script 'electron-installer-windows --src dist/poopie-win32-ia32/ --dest dist/installers/ia32/ --config config.json'.
npm ERR! Make sure you have the latest version of node.js and npm installed.
npm ERR! If you do, this is most likely a problem with the poopie package,
npm ERR! not with npm itself.
npm ERR! Tell the author that this fails on your system:
npm ERR! electron-installer-windows --src dist/poopie-win32-ia32/ --dest dist/installers/ia32/ --config config.json
npm ERR! You can get information on how to open an issue for this project with:
npm ERR! npm bugs poopie
npm ERR! Or if that isn't available, you can get their info via:
npm ERR! npm owner ls poopie
npm ERR! There is likely additional logging output above.
npm ERR! Please include the following file with any support request:
npm ERR! /home/dewartestserver/dev/electron-installer-windows/example/npm-debug.log
npm ERR! Linux 4.15.0-36-generic
npm ERR! argv "/usr/bin/node" "/usr/bin/npm" "run" "build"
npm ERR! node v8.10.0
npm ERR! npm v3.5.2
npm ERR! code ELIFECYCLE
npm ERR! [email protected] build: `npm run clean && npm run exe32 && npm run set32 && npm run exe64 && npm run set64`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] build script 'npm run clean && npm run exe32 && npm run set32 && npm run exe64 && npm run set64'.
[omitted some final boilerplate]
**What did you do? Please include the configuration you are using for `electron-installer-windows`.**
in project folder: npm install --save-dev electron-installer-windows
package.json:
{
"name": "safety-valve-cache-testing",
"productName": "Safety valve app-srv",
"version": "0.1.2",
"main": "main.js",
"devDependencies": {
"electron": "^4.1.1",
"electron-cli": "^0.2.8",
"electron-installer-windows": "^1.1.1",
"electron-packager": "^13.1.1"
},
"scripts": {
"package-mac": "electron-packager . --overwrite --platform=darwin --arch=x64 --icon=assets/icons/mac/icon.icns --prune=true --ignore=assets --out=release-builds",
"package-win": "electron-packager . safety-valve-training-tool --overwrite --asar=true --platform=win32 --arch=all --icon=assets/icons/win/icon.ico --prune=true --ignore=assets --out=release-builds --version-string.CompanyName=Dewar --version-string.FileDescription=Dewar --version-string.ProductName=\"Safety Valve Cache Testing\"",
[Truncated]
"setup-win32": "electron-installer-windows --src release-builds/safety-valve-training-tool-win32-ia32 --dest release-builds/installers/win32",
"setup-win64": "electron-installer-windows --src release-builds/safety-valve-training-tool-win32-ia64 --dest release-builds/installers/win64"
},
"author": {
"name": "Dewarcommunications",
"email": "[removed]",
"url": "[removed]"
}
}
----------
^^^ Note "author": "name": is one string.
npm run setup-win32
**What did you expect to happen?**
Compile a windows installer exe into [project]/release-builds/installers/win32/
**What actually happened?**
Similar "TypeError: expected author to be a string [...]" as above output of electron-installer-windows/example (!) and mentioned in prior issue(s) -- as previously reported, changing the name to a string (no spaces) does not fix the issue.
Edit: OK, I misunderstood the "string" thing (package.json "author" stuff should be on one line without brackets per "https://docs.npmjs.com/files/package.json#people-fields-author-contributors".
After fixing that, I'm now getting a mono "Error creating package with NuGet"
Status: Issue closed
Answers:
username_0: Built a package after sifting through a lot of errors and fixing them. |
dresden-elektronik/deconz-rest-plugin | 656556585 | Title: IKEA Blind Stopped Working - Now Firmware Update Killed ConBeeII
Question:
username_0: <!--
- Use this issue template to report a bug in the deCONZ REST-API.
- If you want to report a bug for the Phoscon App, please head over to: https://github.com/dresden-elektronik/phoscon-app-beta
- If you're unsure if the bug fits into this issue tracker, please ask for advise in our Discord chat: https://discord.gg/QFhTxqN
- Please make sure sure you're running the latest version of deCONZ: https://github.com/dresden-elektronik/deconz-rest-plugin/releases
-->
## Describe the bug
<!--
Describe the issue you are experiencing here to communicate to the
maintainers. Tell us what you were trying to do and what happened.
Help us understand the issue by providing valuable context.
-->
In the last couple of days, by IKEA blind has stopped responding.
I have factory reset the blind, re-paired it to Deconz, and recharged the battery. Nothing has worked. I then tried updating Deconz to the latest but that hasn't helped either.
I can see the device in VNC and on the web app. but if I try to adjust it from the web app or from home assistant nothing happens. On Home Assistant I get a "Failed to call service cover/close_cover. /lights/2 resource, /lights/2, not available" and on Node-Red I get an API error.
I'm running my system in Docker. It has been working fine for a while.
If I manually call the "cover" service in HA, I see this error in the logs:

I also see this in the logs constantly.

Also, in VNC, the device is sitting with a green flashing indicator. All other devices flash blue.

How can I troubleshoot please? The logs for the add-on don't really show much..
I have tried to update the firmware on the ConbeeII but now Deconz won't connect to it.
## Steps to reproduce the behaviour
<!--
If the problem is reproducible, list the steps here:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. Observed error
If the problem can't be reproduced and is sporadic, please provide some details
on how often and when the issue happens.
-->
Adjust brightness of IKEA blind in Phoscon App - nothing happens
## Expected behavior
<!--
If applicable, describe what you expected to happen.
-->
Blind should open or close.
[Truncated]
12:54:07:650 COM: --dev: /dev/ttyACM0 (ConBee II)
12:54:08:229 device state timeout ignored in state 2
12:54:09:279 device state timeout ignored in state 2
12:54:10:331 device state timeout ignored in state 2
12:54:10:454 try to reconnect to network try=8
12:54:11:954 device state timeout ignored in state 2
12:54:12:954 device state timeout ignored in state 2
12:54:13:954 device state timeout (handled)
12:54:13:994 device disconnected reason: 1, index: 0
12:54:14:454 wait reconnect 15 seconds
12:54:14:454 void zmMaster::handleStateIdle(zmMaster::MasterEvent) not connected goto OFF state
12:54:14:454 device state timeout ignored in state 1
12:54:15:453 failed to reconnect to network try=9
12:54:15:453 wait reconnect 14 seconds`
## Additional context
<!--
If relevant, add any other context about the problem here, like network size, number of routers and end-devices
and what kind of devices/brands are in the network.
-->
Answers:
username_0: Seems like the issue I am having now is the same as this one https://github.com/dresden-elektronik/deconz-rest-plugin/issues/2702
username_0: The firmware update wouldn't work on Hassio, so I created a Ubuntu VM on my PC and flashed it there. Downgrading the firmware doesn't resolve the issue but does complete successfully. Here are the logs.
`chris@chris-VirtualBox:/usr/share/applications$ deCONZ --dbg-info=2 --dbg-zdp=1 --dbg-zcl=1 --db-aps=1 --dbg-http=1
libpng warning: iCCP: known incorrect sRGB profile
14:01:34:989 HTTP Server listen on address 0.0.0.0, port: 8080, root: /usr/share/deCONZ/webapp/
14:01:34:991 CTRL. 3.22.014:01:35:013 COM: /dev/ttyACM0 : ConBee II (0x1CF1/0x0030)
14:01:35:013 ZCLDB init file /home/chris/.local/share/dresden-elektronik/deCONZ/zcldb.txt
14:01:35:052 parent process bash
14:01:35:052 gw run mode: normal
14:01:35:052 GW sd-card image version file does not exist: /home/chris/.local/share/dresden-elektronik/deCONZ/gw-version
14:01:35:052 DB sqlite version 3.22.0
14:01:35:052 DB PRAGMA page_count: 30
14:01:35:052 DB PRAGMA page_size: 4096
14:01:35:052 DB PRAGMA freelist_count: 0
14:01:35:052 DB file size 122880 bytes, free pages 0
14:01:35:052 DB PRAGMA user_version: 6
14:01:35:052 DB cleanup
14:01:35:052 DB create temporary views
14:01:35:052 DB view [0] created
14:01:35:052 DB view [1] created
14:01:35:052 DB view [2] created
14:01:35:052 DB view [3] created
14:01:35:052 sql exec SELECT apikey,devicetype,createdate,lastusedate,useragent FROM auth
14:01:35:052 sql exec SELECT key FROM config2
14:01:35:052 sql exec SELECT key,value FROM config2
14:01:35:052 Load config UTC: 2020-07-14T11:07:46 from db.
14:01:35:052 Load config announceinterval: 10 from db.
14:01:35:053 Load config announceurl: http://dresden-light.appspot.com/discover from db.
14:01:35:053 Load config apiversion: 2.05.77 from db.
14:01:35:053 Load config bridgeid: 00212EFFFF04F8BA from db.
14:01:35:053 Load config datastoreversion: 60 from db.
14:01:35:053 Load config dhcp: true from db.
14:01:35:053 Load config discovery: true from db.
14:01:35:053 Load config factorynew: false from db.
14:01:35:053 Load config fwneedupdate: false from db.
14:01:35:053 Load config fwupdatestate: idle from db.
14:01:35:053 Load config fwversion: 0x264a0700 from db.
14:01:35:053 Load config gateway: 127.0.0.1 from db.
14:01:35:053 Load config group0: 65520 from db.
14:01:35:053 Load config groupdelay: 50 from db.
14:01:35:053 Load config gwpassword: <PASSWORD> from db.
14:01:35:053 Load config gwusername: delight from db.
14:01:35:053 Load config homebridge: not-managed from db.
14:01:35:053 Load config homebridge-pin: from db.
14:01:35:053 Load config homebridgeupdate: false from db.
14:01:35:053 Load config homebridgeupdateversion: from db.
14:01:35:053 Load config homebridgeversion: from db.
14:01:35:053 Load config ipaddress: 10.0.2.15 from db.
14:01:35:053 Load config linkbutton: false from db.
14:01:35:053 Load config localtime: 2020-07-14T12:07:46 from db.
14:01:35:053 Load config mac: 38:60:77:7c:53:18 from db.
14:01:35:053 Load config modelid: deCONZ from db.
14:01:35:053 Load config name: Phoscon-GW from db.
14:01:35:053 Load config netmask: 255.0.0.0 from db.
14:01:35:053 Load config networkopenduration: 60 from db.
14:01:35:053 Load config otauactive: false from db.
14:01:35:053 Load config otaustate: off from db.
14:01:35:053 Load config panid: 0 from db.
14:01:35:053 Load config permitjoin: 0 from db.
14:01:35:053 Load config permitjoinfull: 0 from db.
[Truncated]
14:02:02:788 wait reconnect 3 seconds
14:02:03:789 wait reconnect 2 seconds
14:02:04:791 Daylight now: solarNoon, status: 170, daylight: 1, dark: 0
14:02:04:791 wait reconnect 1 seconds
14:02:04:798 COM: /dev/ttyACM0 : ConBee II (0x1CF1/0x0030)
14:02:04:798 auto connect com /dev/ttyACM0
14:02:04:825 Serial com connected
14:02:05:302 device state timeout ignored in state 2
14:02:05:789 try to reconnect to network try=2
14:02:07:288 device state timeout ignored in state 2
14:02:08:289 device state timeout ignored in state 2
14:02:09:296 device state timeout ignored in state 2
14:02:09:813 COM: /dev/ttyACM0 : ConBee II (0x1CF1/0x0030)
14:02:10:346 device state timeout ignored in state 2
14:02:10:793 try to reconnect to network try=3
14:02:12:290 device state timeout (handled)
14:02:12:290 MASTER kill cmd 0x08 (ERROR)
14:02:12:290 MASTER kill cmd 0x08 (ERROR)
14:02:12:343 Serial com disconnected, reason: 1
14:02:12:343 device disconnected reason: 1, index: 0`
username_1: Have you used version .78? I see .77 in the log...
username_0: I downloaded it this morning and that was the latest... There's no update for the hassio addon.
username_2: @username_0 What version is your HA addon :)?
username_0: 5.3.6. It was 5.3.5 (I think) but as part of my troubleshooting for the IKEA blind I upgraded. Which has only made things worse.
username_2: Okay.
Can you please provide me:
- The output of : https://www.home-assistant.io/integrations/deconz/#debugging-integration that logging
- A screenshot of your configuration page of the HA addon.
username_0: At the moment I have uninstalled the deconz addon for Hassio as part of the troubleshooting I have been trying.
I have Deconz installed on a Windows PC and a Ubuntu VM, I used the Ubunutu VM as the firmware upgrade wouldn't complete on hassio. Neither the UB VM or Windows PC can connect to the ConBeeII since upgrading the firmware.
username_2: https://github.com/dresden-elektronik/deconz-rest-plugin/wiki/Update-deCONZ-manually
Did you follow that guide and read trough it properly?
username_0: Yes, the update does complete successfully, so it says, but the Deconz application will no longer connect.
username_2: The page says:
**Warning: It is strongly advised to use a native installation of one of the update methods. Virtual Machines _may_ work but are not supported, using a VM while trying to update firmware is on your own risk.**
I suggest you to use the deCONZ windows version to update.
username_0: OK so I have the Hassio addon installed, I can VNC to Deconz and I can see the devices. Great :)

However, when I got to the Phoscon webapp I'm missing all the lights (understandable) and when I go to Gateway it's blank...

username_3: Have you tried with another browser ? or with deleting cache ?
On my side I have this bug when I use the wrong ip (the deconz on windows without conbee, instead of using the Pi ip)
username_0: I was just trying that when you replied :) Seems HA cached the page. I'm back in now so I can restore my backup.
username_4: Looks like the REST API resources haven't been created (the nodes still show the NWK address instead of the resource name). Also note the descriptors for the two end devices in the middle haven't been read. Looks like you lost the deCONZ database. Best restore that from backup. Alternatively, you'll need to re-pair each device. Best search for devices in Phoscon and read the _Basic_ cluster attributes in the GUI. When the name of the node changes, the resource has been created and Phoson should show the device. Make sure to wake the end devices when reading the _Basic_ cluster and read the _Simple Descriptor(s)_ from the left drop-down menu to see the clusters.
username_0: Thanks. I only understood some of that, but restoring the backup is exactly what I was just doing. I can see all the names in GUI now and I can see switches and sensors in Phoscon, but not lights... it's empty.


username_0: 

The greyed out devices are expected, they died a while ago and I haven't got round to fixing them.
username_3: I think it can solve your "inivisible" light in phoscon.
For grayed Xiaomi device, I think you can re-include them ^^, for them I think it s dead.
username_0: The lights came back, I didn't change anything :)

username_3: joke application ^^
username_0: OK so things aren't stable. When I try to re-pair a switch (that's greyed out) Deconz crashes. The VNC server closes and I can't control any devices.
Log file from docker.
[Copy of addon_core_deconz.xlsx](https://github.com/dresden-elektronik/deconz-rest-plugin/files/4920199/Copy.of.addon_core_deconz.xlsx)
username_2: Could you provide this in a txt file? This reads really bad.
I've asked you before: Can you show me a screenshot of your configuration page of the addon?
username_2: Edited my last comment a bit.
username_0: I could, but I'll have to convert the file. That's how it was outputted from Docker.
The documents say I can use dev/tty*

Here's the config page.

username_0: Bare in mine my system was working perfectly fine, until the blind stopped working a couple of days ago.
I used to use the full string but it would display my device as a RaspBee not ConBeeII.
username_0: OK changing it to the full device string seems to have fixed the crashing. Weird.
username_2: This also is a HA Addon issue.
username_0: That's fine, It was the addon people that sent me here without fully understanding my issue.
Everything seems to working now. Even the blind has started working, even though nothing had changed to stop it from working in the first place.
username_2: @username_0 Where did they send you here?
Can you provide me a url/name?
username_0: I posted in their github first and they closed it and pointed me here.
Tbh I don't know what the root cause was. In troubleshooting the blind not working I made things worse so additional steps where needed to recover. It's all working now :) thank you.
username_2: Can you provide me the URL of that issue :)?
username_0: I opened two :)
https://github.com/home-assistant/hassio-addons/issues/1460#event-3543256625
https://github.com/home-assistant/hassio-addons/issues/1461#issuecomment-658134820
username_2: Found it already:)
Closed #3044
Status: Issue closed
username_0: Yes.

username_2: This is a Synology VM...
You couldve just renamed to .txt.
username_0: It's a Docker VM on Synology.
I could have, that's what I said about converting it. It wasn't needed anyway. |
gang1998/SEBC | 226934367 | Title: Welcome to SEBC
Question:
username_0: It appears your repository files have not yet been published, and the labels and milestones are not yet configured.
Please ask me or @godiswc for assistance if you need it.
Answers:
username_1: I have created the milestones and update the labels, but I can't use git push to update my reposity. I also created a branch sebc-shanghai-2017. When run the command, I got the error blow:
$ git push –u origin sebc-shanghai-2017
error: src refspec origin does not match any.
error: src refspec sebc-shanghai-2017 does not match any.
error: failed to push some refs to '–u'
Is anything I missed? Thanks
username_1: I resolved the issues by reinitialized the reposity.
Status: Issue closed
|
korlibs/korge | 1094864941 | Title: java.lang.IllegalStateException: Can't find resource '/com/soywiz/korge/intellij/generator/gradlew'
Question:
username_0: Upon creating a new Korge project, I receive the following message. I am running IntelliJ Ultimate Edition 2021.3.1 on openSUSE Tumbleweed and Java 17. The korge plugin version is 2.1.1.6.
`java.lang.IllegalStateException: Can't find resource '/com/soywiz/korge/intellij/generator/gradlew'
at com.soywiz.korge.intellij.KorgeResources.getBytes(KorgeResources.kt:6)
at com.soywiz.korge.intellij.module.KorgeModuleConfig.generate$lambda-3$getFileFromGenerator(KorgeModuleConfig.kt:33)
at com.soywiz.korge.intellij.module.KorgeModuleConfig.generate(KorgeModuleConfig.kt:37)
at com.soywiz.korge.intellij.module.KorgeModuleBuilder$setupRootModel$1$1.invokeSuspend(KorgeModuleBuilder.kt:47)
at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith(ContinuationImpl.kt:33)
at kotlinx.coroutines.DispatchedTask.run(DispatchedTask.kt:106)
at kotlinx.coroutines.EventLoopImplBase.processNextEvent(EventLoop.common.kt:274)
at kotlinx.coroutines.BlockingCoroutine.joinBlocking(Builders.kt:85)
at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking(Builders.kt:59)
at kotlinx.coroutines.BuildersKt.runBlocking(Unknown Source)
at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking$default(Builders.kt:38)
at kotlinx.coroutines.BuildersKt.runBlocking$default(Unknown Source)
at com.soywiz.korge.intellij.module.KorgeModuleBuilder$setupRootModel$1.invoke(KorgeModuleBuilder.kt:46)
at com.soywiz.korge.intellij.module.KorgeModuleBuilder$setupRootModel$1.invoke(KorgeModuleBuilder.kt:43)
at com.soywiz.korge.intellij.util.UtilsKt$backgroundTask$1.run(Utils.kt:103)
at com.intellij.openapi.progress.impl.CoreProgressManager.startTask(CoreProgressManager.java:436)
at com.intellij.openapi.progress.impl.ProgressManagerImpl.startTask(ProgressManagerImpl.java:120)
at com.intellij.openapi.progress.impl.CoreProgressManager.lambda$runProcessWithProgressAsync$5(CoreProgressManager.java:496)
at com.intellij.openapi.progress.impl.ProgressRunner.lambda$submit$3(ProgressRunner.java:244)
at com.intellij.openapi.progress.impl.CoreProgressManager.lambda$runProcess$2(CoreProgressManager.java:188)
at com.intellij.openapi.progress.impl.CoreProgressManager.lambda$executeProcessUnderProgress$12(CoreProgressManager.java:624)
at com.intellij.openapi.progress.impl.CoreProgressManager.registerIndicatorAndRun(CoreProgressManager.java:698)
at com.intellij.openapi.progress.impl.CoreProgressManager.computeUnderProgress(CoreProgressManager.java:646)
at com.intellij.openapi.progress.impl.CoreProgressManager.executeProcessUnderProgress(CoreProgressManager.java:623)
at com.intellij.openapi.progress.impl.ProgressManagerImpl.executeProcessUnderProgress(ProgressManagerImpl.java:66)
at com.intellij.openapi.progress.impl.CoreProgressManager.runProcess(CoreProgressManager.java:175)
at com.intellij.openapi.progress.impl.ProgressRunner.lambda$submit$4(ProgressRunner.java:244)
at java.base/java.util.concurrent.CompletableFuture$AsyncSupply.run(CompletableFuture.java:1700)
at java.base/java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1128)
at java.base/java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:628)
at java.base/java.util.concurrent.Executors$PrivilegedThreadFactory$1$1.run(Executors.java:668)
at java.base/java.util.concurrent.Executors$PrivilegedThreadFactory$1$1.run(Executors.java:665)
at java.base/java.security.AccessController.doPrivileged(Native Method)
at java.base/java.util.concurrent.Executors$PrivilegedThreadFactory$1.run(Executors.java:665)
at java.base/java.lang.Thread.run(Thread.java:829)` |
ScottishCovidResponse/SCRCIssueTracking | 645758427 | Title: Clearly separate inference and prediction configuration
Question:
username_0: Every run of the EERA model uses a common `parameters.ini` file to supply its configuration. This file contains parameters used both in prediction mode and inference mode. This is confusing, as it is not clear which parameters are required for any particular run.
The inference and prediction configuration should be clearly separated, either by separating them into different sections of the file, or alternatively by having them in separate files.
In addition, the I/O functionality in the code should separately read in the inference or prediction configuration, as otherwise there will be parameters in the input data structures which are not initialised, in a non-obvious way.
Related to, but more specific than #437<issue_closed>
Status: Issue closed |
lazychaser/laravel-nestedset | 142301799 | Title: New features for v3 for Laravel 5.1 LTS
Question:
username_0: Hi,
I am wondering if the new (and future) features implemented for v4 will be implemented in v3 as well? Due to LTS and project requirements, I am unable to upgrade to 5.2.
Multi-tenancy will be extremely welcome in my current project.
Answers:
username_1: Sorry, no new features will be implemented in v3. Only bug fixes if any occur.
Status: Issue closed
|
BlackArch/blackarch-config-awesome | 342523000 | Title: Errors in /etc/xdg/awesome/rc.lua
Question:
username_0: It seems to be that some of the code in the configuration file is no longer valid.
When I type mod4 + r:
I get the following error that popups in a red box on the top right corner of my screen:
/etc/xdg/awesome/rc.lua 6466: attempt to index a nil value (field '?')`
Would you have any idea on what could be the cause of this error ?
Here are some information regarding my install:
awesome -version:
awesome v4.2 (Human after all)
• Compiled against Lua 5.3.4 (running with Lua 5.3)
• D-Bus support: ✔
• execinfo support: ✔
• xcb-randr version: 1.5
• LGI version: 0.9.2 |
automatiko-io/automatiko-engine | 921061973 | Title: Create service repositories to be equipped with useful service task implementations to enable simple reuse
Question:
username_0: Many times users require access to certain service types out of the box that can be easily used within the workflows.
Automatiko should build up a service repository that can easily grow with useful operations to be declared in the workflow and simply used instead of require them to be implemented every time.
To start with
- email sending based on template and attachments
- creating zip archives with selected variables
- upload variables into cloud storage like google drive, s3<issue_closed>
Status: Issue closed |
scambra/devise_invitable | 28363208 | Title: mysterious generate_token method
Question:
username_0: `generate_token` is invoked here: https://github.com/username_2/devise_invitable/blob/master/lib/devise_invitable/model.rb#L291
However I can't find any definition of such a method in the devise_invitable, devise, or rails codebases.
I also searched for various things to see if it's generated at runtime and didn't find anything.
I also poked around in Pry and it seems to be undefined.
```
app(dev)> cd User
app(dev)> show-method generate_token
Error: Couldn't locate a definition for generate_token!
app(dev)> show-method invitation_token
From: /Users/john/medstro/devise_invitable/lib/devise_invitable/model.rb @ line 290:
Owner: Devise::Models::Invitable::ClassMethods
Visibility: public
Number of lines: 3
def invitation_token
generate_token(:invitation_token)
end
app(dev)> generate_token(:invitation_token)
NoMethodError: undefined method `generate_token' for User(no database connection):Class
from /Users/john/.rbenv/versions/2.1.1/lib/ruby/gems/2.1.0/gems/activerecord-4.0.3/lib/active_record/dynamic_matchers.rb:22:in `method_missing'
```
Answers:
username_1: I'm using devise_invitable 1.1.8 and here the generate_token method is called but an exception is raised since it can't be found anywhere. This totally breaks the gem and I can't invite any user. I'm running Devise 3.5.10 which is as high as I can go considering other dependencies. Can I upgrade devise_invitable or should I downgrade it? Any recommendations?
username_2: You should upgrade devise_invitable to latest |
dotnet/aspnetcore | 592213881 | Title: .NET Core Debug Blazor Web Assembly in Chrome leads to forever spinning chrome page with about:blank in address bar
Question:
username_0: ### Describe the bug
In VS Code after starting ".NET Core Launch (Blazor Standalone)" then starting
".NET Core Debug Blazor Web Assembly in Chrome" leads to forever loading chrome page with about:blank in the address bar.
### To Reproduce
I followed the tutorial to get started with the template Microsoft.AspNetCore.Components.WebAssembly.Templates::3.2.0-preview3.20168.3
https://docs.microsoft.com/en-us/aspnet/core/blazor/get-started?view=aspnetcore-3.1&tabs=visual-studio-code
Then moved on to debugging instruction
https://docs.microsoft.com/en-us/aspnet/core/blazor/debug?view=aspnetcore-3.1
The project is the one created by
```dotnet new blazorwasm -o WebApplication1```
Without a single change
In VS Code after starting ".NET Core Launch (Blazor Standalone)" standalone then ".NET Core Debug Blazor Web Assembly in Chrome", it opens a chrome page with about:blank which spins forever and never lead to the website.
Putting a breakpoint in the razor pages (for instance, FetchData.razor on currentCount++;) shows "Unbound breakpoint".
At this point if i press F12 in chrome, the page loads, but still debugging does not work.
Breakpoint start to show the message "No symbols have been loaded for this document"
### Further technical details
- dotnet --info
```.NET Core SDK (reflecting any global.json):
Version: 3.1.201
Commit: <PASSWORD>b4ae7
Runtime Environment:
OS Name: Windows
OS Version: 10.0.18362
OS Platform: Windows
RID: win10-x64
Base Path: C:\Program Files\dotnet\sdk\3.1.201\
Host (useful for support):
Version: 3.1.3
Commit: <PASSWORD>
.NET Core SDKs installed:
3.1.201 [C:\Program Files\dotnet\sdk]
.NET Core runtimes installed:
Microsoft.AspNetCore.App 3.1.3 [C:\Program Files\dotnet\shared\Microsoft.AspNetCore.App]
Microsoft.NETCore.App 3.1.1 [C:\Program Files\dotnet\shared\Microsoft.NETCore.App]
Microsoft.NETCore.App 3.1.3 [C:\Program Files\dotnet\shared\Microsoft.NETCore.App]
Microsoft.WindowsDesktop.App 3.1.1 [C:\Program Files\dotnet\shared\Microsoft.WindowsDesktop.App]
Microsoft.WindowsDesktop.App 3.1.3 [C:\Program Files\dotnet\shared\Microsoft.WindowsDesktop.App]
To install additional .NET Core runtimes or SDKs:
https://aka.ms/dotnet-download
```
- IDE VS Code 1.43.2
- Chrome Version 80.0.3987.162 (Official Build) (64-bit)
Answers:
username_1: @username_0 thanks for contacting us.
We'll look into your issue and get back to you.
username_2: @username_4 can you please have a look at this? Thanks!
username_3: Same here.
Stuck on "about:blank" spinning. If i look at VS Code's call stack window, i can see ".NET Core Debug Blazor Web Assembly in Chrome" with "blank" under it.
After a while (i'm guessing debug timeout), the page does load but the call stack in vs code still says "blank" and breakpoint are obviously not being hit.
I also tried with an hosted app created using this : dotnet new blazorwasm --hosted -o TestApp
Same result.
Maybe interesting: if i open up the Dev tools in chrome (f12), the page does load. I'm guessing that it requeries the page and thus doesn't wait after the debugger to attach ?
But yeah, debugging is unusable with VS Code for now and i'd rather not install a preview version of Visual Studio, i've had too many issues with Preview version "sticking" around and creating issues, in the past. So i'm kinda stuck, debugging wise.
username_4: @username_0 / @username_3 how are you running the VSCode bits? Aka, which launch configurations are you invoking and in what order?
@username_7 the debugging instructions on the get started page for Blazor WASM VSCode aren't great. Could we get those updated?
username_4: @username_5 do you have any idea why opening chrome dev tools would then allow the Debug Enabled chrome instance to load? Is there something @username_0 can do to capture more log information to diagnose further?
username_5: Yep: setting `trace: true` in the launch.json will cause the extension to capture verbose logs. The file location will be printed to the debug console, sharing that should shed some light.
username_3: I'm following the instructions found at https://devblogs.microsoft.com/aspnet/blazor-webassembly-3-2-0-preview-3-release-now-available/
So i'm starting .NET Core Launch (Blazor Standalone) first, then once that's running, i'm starting .NET Core Debug Blazor Web Assembly in Chrome
Here's the verbose log i grabbed by adding "trace": true, hopefully it is what you need.
[verbose log.txt](https://github.com/dotnet/aspnetcore/files/4459686/verbose.log.txt)
username_5: The normal process is that we get a target for about:blank, attach to it, and issue a Page.navigate, and then when it loads we're ready to go. We try to do this in the log that nlz sent, but notice that there's never a response to the Page.navigate CDP call. The request/response pair should look like:

Looking at the logs, I wonder if something isn't quite connecting right inside the Blazor proxy. I also noticed that none of the requests (like Runtime.enable, Debugger.enable, which should have an empty successful replies) issued to the page's target after Page.navigate have responses. The requests/responses that nlz has appear to be equivalent to the ones I have up until Page.navigate.
Is there a way to retrieve telemetry/trace logs from the proxy @username_4?
username_0: I went back to the exact same project and after deleting obj and bin it works. I can now debug blazor webassembly from visual studio code. This is weird...
username_4: Sadly I'm not familiar with the proxy side of things. @username_8 could you assist?
username_3: For the record, i tried deleting the obj/bin folders as suggested by @username_0 and this did NOT fix it for me.
I'll be happy to help with whatever is needed (logs, troubleshooting, etc).
username_6: Same issue here but with Visual Studio Preview Version shown below

With the following launchSettings Profile

With this Exceptions after 30 s wait
```
Request starting HTTP/1.1 GET http://localhost:56261/_framework/debug/ws-proxy?browser=ws%3A%2F%2Flocalhost%3A27931%2Fdevtools%2Fbrowser%2F4a007c8e-3691-43b1-885e-ccdb38c71e2d
WsProxy Starting on ws://localhost:27931/devtools/browser/4a007c8e-3691-43b1-885e-ccdb38c71e2d
WsProxy: IDE waiting for connection on ws://localhost:27931/devtools/browser/4a007c8e-3691-43b1-885e-ccdb38c71e2d
WsProxy: Client connected on ws://localhost:27931/devtools/browser/4a007c8e-3691-43b1-885e-ccdb38c71e2d
WsProxy::Run: Exception System.AggregateException: One or more errors occurred. (The remote party closed the WebSocket connection without completing the close handshake.)
---> System.Net.WebSockets.WebSocketException (0x80004005): The remote party closed the WebSocket connection without completing the close handshake.
---> Microsoft.AspNetCore.Connections.ConnectionResetException: An existing connection was forcibly closed by the remote host.
---> System.Net.Sockets.SocketException (10054): An existing connection was forcibly closed by the remote host.
at Microsoft.AspNetCore.Server.Kestrel.Transport.Sockets.Internal.SocketAwaitableEventArgs.<GetResult>g__ThrowSocketException|7_0(SocketError e)
at Microsoft.AspNetCore.Server.Kestrel.Transport.Sockets.Internal.SocketAwaitableEventArgs.GetResult()
at Microsoft.AspNetCore.Server.Kestrel.Transport.Sockets.Internal.SocketConnection.ProcessReceives()
at Microsoft.AspNetCore.Server.Kestrel.Transport.Sockets.Internal.SocketConnection.DoReceive()
--- End of inner exception stack trace ---
at System.IO.Pipelines.PipeCompletion.ThrowLatchedException()
at System.IO.Pipelines.Pipe.GetReadResult(ReadResult& result)
at System.IO.Pipelines.Pipe.GetReadAsyncResult()
at System.IO.Pipelines.Pipe.DefaultPipeReader.GetResult(Int16 token)
at Microsoft.AspNetCore.Server.Kestrel.Core.Internal.Http.HttpRequestStream.ReadAsyncInternal(Memory`1 buffer, CancellationToken cancellationToken)
at System.Net.WebSockets.ManagedWebSocket.EnsureBufferContainsAsync(Int32 minimumRequiredBytes, CancellationToken cancellationToken, Boolean throwOnPrematureClosure)
at System.Net.WebSockets.ManagedWebSocket.ReceiveAsyncPrivate[TWebSocketReceiveResultGetter,TWebSocketReceiveResult](Memory`1 payloadBuffer, CancellationToken cancellationToken, TWebSocketReceiveResultGetter resultGetter)
at System.Net.WebSockets.ManagedWebSocket.ReceiveAsyncPrivate[TWebSocketReceiveResultGetter,TWebSocketReceiveResult](Memory`1 payloadBuffer, CancellationToken cancellationToken, TWebSocketReceiveResultGetter resultGetter)
at WsProxy.WsProxy.ReadOne(WebSocket socket, CancellationToken token)
--- End of inner exception stack trace ---
at System.Threading.Tasks.Task.ThrowIfExceptional(Boolean includeTaskCanceledExceptions)
at System.Threading.Tasks.Task`1.GetResultCore(Boolean waitCompletionNotification)
at WsProxy.WsProxy.Run(Uri browserUri, WebSocket ideSocket)
info: Microsoft.AspNetCore.Hosting.Diagnostics[2]
Request finished in 31351.1739ms 101
```
With this popup
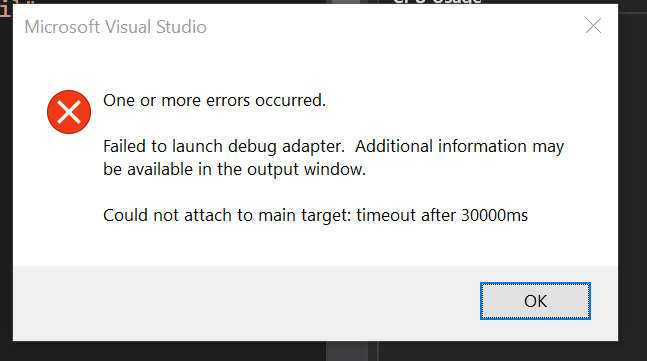
Output of 'dotnet --info'

username_7: @username_6 It looks like the debugging proxy may be crashing. Is this by any chance a PWA?
username_6: No please it's not a PWA
username_8: @username_6 Could you try following the steps for "[debug in the browser](https://docs.microsoft.com/en-us/aspnet/core/blazor/debug?view=aspnetcore-3.1#debug-in-the-browser)" and let us know whether that works in your environment? If not, is there any error message? This might help us pinpoint whether the problem is to do with VS connecting, or whether it's to do with launching the debug proxy.
username_8: @username_3 Could you also try my suggestion above and let us know the result?
username_3: @username_8 following the debug in the browser steps, i'm able to debug from the browser. That works, i see my assembly and i can break (from chrome) into it. Debugging from VS Code still says the symbols aren't loaded. No error messages.
Debugging from Chrome is better than nothing, but it's obviously less... nice ... than from VS / VS Code.
username_6: Hello there I think I figured out why this was occuring It seems I was using the wrong libraries ie `Microsoft.AspNetCore.Blazor` instead of the newer libraries `Microsoft.AspNetCore.Components.WebAssembly`
@username_3 could you check to see if your Nuget Pacakges in your the Client Project and Shared Project Use the Correct Packages
After the Switch Debugging started working fine for me
username_7: @username_6 Awesome! I'm glad you were able to get it working!
username_2: Closing as it seems all the concerns brought up in this thread has been resolved.
Status: Issue closed
|
thonny/thonny | 523933859 | Title: No file dialogue when opening or saving files.
Question:
username_0: I'm running Thonny 3.2.3 on an Arch Linux box and am getting no file dialogue when opening or saving a file. I've tried installing from a release tar.gz and from 'pip install' and still have the same problem.
I would like to give you more information, but I see no errors or really anything in the log files. I've tried setting "debug_mode = True" in the configuration.ini to try and get more information, but I still see nothing when I try to open or save a file.
Any help you could give me with trying to track this down would be appreciated.
Thanks,
Answers:
username_1: Which Thonny version and which Arch version are you using?
Do you have `zenity` installed? Which version? (enter `zenity --version` in Terminal)
username_0: Thanks for the reply. Mentioning `zenity` pushed me in the right direction.
It was just a peculiarity of my environment. I'm running KDE and am using a `zenity` replacment called [qarma](https://github.com/luebking/qarma). It hadn't been updated in a while. Getting the latest version with [AUR and git](https://aur.archlinux.org/packages/qarma-git) was able get it working.
Status: Issue closed
|
ToranSharma/Duo-Strength | 556743367 | Title: skills that need strengthening: practice or next lesson
Question:
username_0: Hi
When i do "skill strengthening" from the duome.eu website it goes to practise i.e. https://www.duolingo.com/skill/es/Pronouns/practice
If i do skill strengthening in your extension it goes to the next lesson in the skill (unless it is L5) i.e. https://www.duolingo.com/skill/es/Pronouns
This may or may not be desired function. i.e. if you wish to keep your language tree (skill) at a particular level.
It was suggested on the forum tha practice exercises at L4 are more difficult that at L5. Don't remember if it was about individual skill practice or global (whole tree)
Answers:
username_1: Hi @username_0,
I was not aware that duome always points to the practice url for the skill. The behaviour of the links in the needs strengthening list etc. are to match with the url that duolingo takes you to if you were to click on the skill manually and click the start/practice button.
I think I am happy with the current functionality, as if all the links were changed to practice, then no crowns progress would be made using Duo Strength. I think this would cause most users confusion, not be what they would want.
However, I can fairly easily add a option to change this behaviour, say at L4, or whenever the user chooses. This it probably the best solution as it will allow normal crown progress, which most users will expect, but also allow users that do not want to get their skills to L5 the option to still strengthen them at this harder level.
What do you think to this solution?
Do note however, that I think in a forum comment, someone from duolingo more or less said that the L5 content being easier than L4 is not intended behaviour on duolingo's part, so this may change in the future.
Toran
username_0: Toran
On duome you have both options: to practice & to proceed to next lesson.
Functionality to practice individual skills ( at levels less than 5 ) is only available on duome.
It sounds great if i can toggle between practice & progress modes! I like your solution.
For me practice (without progress) make sense since i study multiple languages ( and in reverse order) and want to keep Trees at a particular Level before i proceed to the next.
It would be interesting to know profile of typical Duo student: how many languages and if reverse tree is attempted. Method of progress: leveling skill by skill, or opening whole tree and then leveling skills and\or some combination of the two.
Yes, i understand from the forum posts that space repetition is broken and L5 / L4 practice is not as desired. As well as general negative feedback to reduced number of lessons required to progress to L5.
Alex
username_0: suggestion: add **practice option** (link) to your **strength bar **
so if user clicks on the bar it goes to practice if user clicks on the skill icon it goes to normal lesson
username_1: Hi again Alex,
I have added the new option to select the lesson/practice behaviour in be74444. You can choose from "Lessons (Earn Crowns)", "Practice (Strengthen Only)" and "Lessons up to threshold" with a sub-option to change that threshold. This is how it looks in the options menu:
I'll have a think about ways to implement a practice button for each skill. I suppose I could add it underneath the START button which can be relabelled to make it more clear that it starts a lesson. Something like this:

What do you think?
Toran
username_0: i like it. You are the best !
username_1: The PRACTISE button has been added in b4e2208.
I think that is all for this issue, so I'll close it and merge the issue35 branch into the develop branch for inclusion in the next release.
Status: Issue closed
|
uBlockOrigin/uBlock-issues | 390605779 | Title: Heads up: Chrome extension manifest v3 proposal
Question:
username_0: ### Description
This issue is a heads-up on the proposed Chrome extension manifest version 3, which will have a significant impact on ad-blockers.
There is a tracking bug at: https://bugs.chromium.org/p/chromium/issues/detail?id=896897&desc=2
In-progress design doc: https://docs.google.com/document/d/1nPu6Wy4LWR66EFLeYInl3NzzhHzc-qnk4w4PX-0XMw8/edit#
Might be worth a review.
Answers:
username_1: Yes this was announced back in October - https://blog.chromium.org/2018/10/trustworthy-chrome-extensions-by-default.html
Not much for uBO to do though..
username_2: I'm not sure how are they planning on changing the background process and origin access, it might cause some issues. Beside that, I don't see anything else that can cause problem. As for remotely-hosted code, it really should be forbidden since the beginning.
username_1: Bug tracker - https://crbug.com/896897
username_3: Basic ABP-like syntax, 30000 filters MAX...
username_3: I don't see limits to the number of the rules in declarative**Web**Request. declarative**Net**Request have better syntax, but number of rules is limited.
username_1: https://docs.google.com/document/d/1nPu6Wy4LWR66EFLeYInl3NzzhHzc-qnk4w4PX-0XMw8/edit#heading=h.ypclvihky0p6
Read the paragraph that's titled DeclarativeNetRequest
username_1: 30000 is mentioned in https://developer.chrome.com/extensions/declarativeNetRequest#property-MAX_NUMBER_OF_RULES, not sure what to make of this, can you shed some light there ? I don't think it related to 30K ABP styled filters.
username_5: This new API is even worse than being restricted to 30k ABP-style rules -- the rules must also be in a single, bundled json file. Thus any rule changes means a full extension update.
Thinking big picture, I can't same I'm that surprised. Last year Google [started to bundle a lightweight ad blocker in Chrome](https://www.wired.com/story/google-chrome-ad-blocker-change-web/), so I recall thinking that something like this would happen. On the bright side, perhaps this could be a boon to Mozilla, assuming they don't foolishly neuter their API in the same way.
username_6: It is still a draft but is really a big downgrade if it stays this way. Looks to me like Google is doing this to reduce the amount of damage malicious extensions could do using this API by severely limiting the existing one and calling it a privacy and efficiency win....while of course giving more control to Google over what ads/trackers/requests can be blocked. This affects trusted and more advanced extensions like uBO the most.
Hopefully Mozilla and other browser makers don't follow suit on this..
username_2: `declarativeNetRequest` in its current state is really underpowered and isn't going to be enough. Assuming that they will implement a way to modify the rules and the 30k limit will be raised or removed, it looks like the only thing missing is RegExp rules.
Since we will be able to dynamically modify content scripts, we can still implement scriptlets and cosmetic filtering properly.
username_1: It's still not set in stone, so lets see where it goes.
username_4: The fact that they are planning to remove a proper blocking webRequest API with no word of an equivalent replacement is a sign of _intent_, that is, reducing the level of user agency in their user agent (aka Google Chrome).
How to do this? Use privacy/performance as Trojan arguments to rationalize reducing user agency over what all bloated web sites throw at people's user agents. That new declarativeNetRequest API seriously reduces what blockers can do, to the point they will become distinguishable only by their UI, not their capabilities. As a user, I personally won't accept browsing the world wild web without the advanced features in uBO, I find this unthinkable.
There are no issue of privacy/performance with uBO, rather the opposite by giving back to users the power of clamping down on what web sites throw at them, so that argument is just plain fallacious as far as uBO is concerned.
Chromium got its webRequest API at a time it was trying to gain [market share against Firefox](https://en.wikipedia.org/wiki/File:Usage_Share_of_browsers_(updated_August_2018).png) (Sep 2011), where Adblock Plus, Ghostery, Disconnect, NoScript, and other such extensions were the most or among the most popular extensions on Firefox.
I don't expect Firefox to follow suit and also deprecate its own webRequest API.<sup>[1]</sup> I am confident uBO will still exist on Firefox.<sup>[2]</sup>
---
[1] Actually Firefox's own webRequest API is better designed as it's possible to return a Promise, which makes it possible to defer returning an answer to some point in the future.
[2] Which is already better equipped than Chromium's version of uBO -- [example](https://github.com/username_4/uBlock/wiki/Static-filter-syntax#html-filters), [example](https://github.com/username_4/uBlock/wiki/Dashboard:-Settings#important-note) -- (and also better equipped than the Firefox legacy version).
username_4: My comments are made with what is being said now with regard to manifest v3.
username_7: Why would Google want to be compatible with adblocking? After all, their business is advertising.
Not saying that is would be right, but it's not unexpected
username_1: At this juncture, assuming it will get implemented, can you do something about it like not updating to v3 ? or should Chromium users be ready to abandon ship for good ?
username_4: Currently uBO uses blocking listeners on both `webRequest.onBeforeRequest` (to implement static-, rule-, switch-based network filtering) and `webRequest.onHeadersReceived` (to implement disabling or restricting JS execution, static filters' `csp=` options, large media filtering, and other filtering capabilities).
With this information on hands, everybody is free to decide for themselves.
username_7: Hey, I haven't used Chrome in years. I use waterfox
username_6: I think the best thing people can really do for now is to get the word out to extension developers and browser developers (especially Google) that the proposed APIs and manifest should not be restricted to such an extent and that users should retain enough freedom and capabilities to easily control what to do with extensions and requests within their browser. Once the v3 proposal is set in stone and implemented it will be too late of a surprise for the majority of unaware extension users who will notice a shifting of how and what ads/trackers/requests get blocked and it will be near impossible to rollback the changes as the browser market leader has a low incentive to do so. I don't want to sound too dramatic but the implementation of the v3 proposal as it is right now could be the beginning of something that will have wider implications on the web and users' ability to decide how they can browse it. Due to Google's position of power on the web and influence on websites it will almost certainly affect more than just Chromium/Chrome users.
username_1: Post here and let them know -- https://bugs.chromium.org/p/chromium/issues/detail?id=896897
username_8: Neither Otter nor Falkon are based on Chromium so they might be options. Right now neither supports user added extensions, but maybe one or both will eventually. Even new Firefox is questionable. Unfortunately, you can't follow the crowd; best alternatives are the ones that don't have measurable market share.
username_1: comment section there is locked now, so the new place is here - https://groups.google.com/a/chromium.org/forum/#!topic/chromium-extensions/veJy9uAwS00
username_9: can't we star it?
username_1: Starring is always possible, however if you want to add your voice/concern, you will have to do it in the google group link from now onwards.
username_9: I would like to star "Manifest V3: Web Request Changes" but I can't see an option to do so,
only replies I guess
username_10: you can click the arrow on the right of "10 posts by 9 authors" and click "email updates"
username_9: I can't see that option: https://imgur.com/ZAg3csh
username_10: sure, do you have a google account ? use it to log in
username_9: ok, I logged in, I joined group and suddenly it started raining emails...
too much for a draft change, I left the group again...
in other words too much panic so soon I guess..
let's wait and see
username_11: Hi @username_4 ,
I use Nano but since both Nano and UBO extension are almost the same I was asking to @username_2 if forking Chromium to integrate natively UBO and Nano to bypass the weakned API would be possible.
So today when browsing reddit I've seen that Brave browser is already doing it:
A developer on the Brave team was explaining it on Reddit:
_Bat-chriscat
BAT TEAM[M] 34 points 1 day ago* RemindMe!
It's worth noting that our **Brave Shields (ad blocker) is not an extension; it is natively implemented. So extension API changes leave our shields unaffected.**
Edit: We can always remove any code or update we don't like from the Chromium base we use. So even if this didn't just affect extensions but something deeper, we could just exclude it._
**Source**: https://old.reddit.com/r/brave_browser/comments/aijqm4/chrome_may_soon_change_how_3rd_party_ad_blockers/eeopqpb/
I wanted to share this possible solution with you and to know what do you think about it ? 🤔
Having a browser based on Chromium fork to integrate both UBO and Nano since you share 98% of the same code seem to be something that would benefit everybody.
Original discussion with @username_2 : https://github.com/NanoAdblocker/NanoCore/issues/238#issuecomment-456905809
Regards :octocat:
username_5: Incorrect. They're both based on Chromium, using the Qt WebEngine framework that is a wrapper for Chromium.
The reality is there are only 3 [browser engine](https://en.wikipedia.org/wiki/Browser_engine) developers left: Google, Apple, and Mozilla. All of the hobby FOSS browsers are based on one of these. There are no other practical options.
I realize this is an emotionally-charged thread given the severity of what Google may do to its API. But let's try not to spread misinformation here.
And I'm glad I raised awareness of this issue here 2 weeks ago. After reading the V3 draft I was quite surprised nobody had posted in detail here. It's good the word has gotten out, and hopefully that will dissuade Google from neutering webRequest. (But there are big money interests at play here, so it certainly won't be just a technical decision.)
username_5: @username_11 - you seem to be unclear about what you're proposing.
If Google goes ahead with its draft changes and neuters webRequest, it will effectively end uBO for Chromium, as username_4 has described above. (Keep in mind they already have `declarativeNetRequest` implemented in Chrome beta. These are not just words on a document.)
At that point, what to do if we end-users want to retain powerful content filtering capability?
There's still Firefox, though its future isn't exactly rosy. Its market share continues to decline and web compatiblity problems may creep in, which would be a serious problem for its viability.
Another option would be a new FOSS fork of Chromium that leverages the Brave filter engine. (To their credit, Brave shares it as MPL, so others can use it.) Brave itself has their own Basic Attention Token ad vision, so I personally wouldn't use it; I'm too accustomed to having lots of control via uBO.
But a browser fork is a _massive effort_. Much bigger than uBO or any other extension. For those who don't know, web browsers are huge programs with millions of lines of code. Most of it is very technical stuff that paid developers from the 3 companies I already mentioned take care of: rendering, JavaScript engine, the many libraries needed for image and video decoding, and all the other things a browser does.
I think it'd be great if such a project arises, and I have some C++ experience so I would be willing to help out in some capacity. But it's a very serious effort to keep up with Chromium and maintain patches like a modified version of Brave's built-in filtering engine.
username_4: So from this I get that the content of EasyList was used to design the declarativeNetRequest API<sup>[1]</sup> and the commenter report that a total of 30,355 rules were gathered from EasyList<sup>[2]</sup>. This is interesting given that the maximum number of rules allowed by the declarativeNetRequest API has been set at 30,000. Coincidence?
That only EasyList itself was considered explains the limitations of the design with regard to uBO ([and AdGuard](https://bugs.chromium.org/p/chromium/issues/detail?id=896897&desc=2#c32)), given that EasyList maintainers restrict themselves to only work with what Adblock Plus supports.
So far I haven't seen any comments coming from Adblock Plus/AdBlock people. Given that EasyList alone can barely be supported by the new API in one single extension, this does not even leave place for all the exception rules from ABP's "Acceptable Ads". I don't know how many exception filters are in there<sup>[3]</sup>, but I can count over 14,000 lines in the file, `https://easylist-downloads.adblockplus.org/exceptionrules.txt`).
---
[1] Even the option `genericblock`, which is barely used out there (2 instances in EasyList) has been implemented, though it's not exposed to the outside world. I declined supporting that option as I saw it as a anti-user approach to countering anti-blockers.
[2] EasyList probably contains more filters by now.
[3] uBO does not support `document` option in exception filters, [because](https://github.com/username_4/uBlock/blob/master/MANIFESTO.md).
username_10: https://groups.google.com/a/chromium.org/forum/#!topic/chromium-extensions/qNqURIh4Nss
username_12: @username_4 Not sure if it would be helpful if you need to make a case demonstrating examples of what uBlock Origin empowers the user to do _besides_ adblocking, but my list of [CSS Style Modifying Filters](https://github.com/username_12/webannoyances/blob/master/filters/css_style_filters.txt)[1] that is a sublist of the [Web Annoyances Ultralist](https://github.com/username_12/webannoyances) may be a useful point of reference if you want to provide examples of what the downstream impact of the change would potentially mean for users of your extension.
[1] The primary purpose of the CSS Style Modifying Filters list is **not** blocking ads, it is used to enhance the user experience on the web through CSS modifications to distracting elements.
username_13: @username_5 Sorry, could you explain what a "FOSS" fork is?
username_4: FOSS = [Free and open-source software](https://en.wikipedia.org/wiki/Free_and_open-source_software)
username_14: https://groups.google.com/a/chromium.org/d/msg/chromium-extensions/veJy9uAwS00/vIkW_hLCGgAJ
username_7: They can also do away with "inefficient" rules
How about ensuring their own ads can't be blocked? It's feasible with Chrome handling everything, and they are an ad driven company.
I've myself already completely switched to Firefox. Slower, but more privacy and user choices friendly
username_1: https://docs.google.com/document/d/1E5bV3nYlj6UvNblk_mG2DYbwFVK-qnl5KnEYHqKpgAM/edit?usp=sharing
username_15: use waterfox its same speed as chrome and not bloat like original firefox
username_16: and even *less* compatible with the modern Web
username_7: @username_15 That's what I use on desktop. No android version, unfortunately
_Sent from my TETRA using [FastHub](https://play.google.com/store/apps/details?id=com.fastaccess.github)_
username_15: anyway adding to this matter its looks like users will have 2 choices either
1. abandon chrome and its forks for good
2. finding a way to implement ublock internally like brave adblocker
username_15: theres waterfox in play store lol
username_7: @username_16 I've had no issues with Firefox, outside an occasional _google_ site. Probably because they only optimized for Chrome
_Sent from my TETRA using [FastHub](https://play.google.com/store/apps/details?id=com.fastaccess.github)_
username_4: I am supposed to comment in the Google Groups thread how uBO is affected specifically, so I _should_ spent some time to gather all the details about how the ABP-like matching engine does not cut it for uBO.
But as [observed by @username_5 above](https://github.com/uBlockOrigin/uBlock-issues/issues/338#issuecomment-452902474), the biggest setback is that the [API is declarative](https://developers.chrome.com/extensions/declarativeNetRequest#manifest), all the rules are to be shipped in a JSON file in the extension.
How do you create custom filters? How do you point-and-click to create a rule which override one from a 3rd-party list? Etc.
The declarativeNetRequest API is actually really a replacement for [declarativeWebContent](https://developer.chrome.com/extensions/declarativeWebRequest) (which has been lingering in beta for years). You can't replace a non-declarative API, webRequest, with a declarative one -- this makes no sense. The fact that declarativeNetRequest is presented as a replacement for webRequest tells me I would be just wasting time at this point.
I will keep watching the design doc to see if there is any meaningful change of interest to uBO.
username_7: @username_15 Waterfox isn't compatible with my device. It's 64 bit only; I'm on armeabi-v7a
_Sent from my TETRA using [FastHub](https://play.google.com/store/apps/details?id=com.fastaccess.github)_
username_4: So maybe there is hope, ideally of course would be to keep the webRequest API as is.
username_4: Example which came to mind is the new `csp=` option. We couldn't predict that the need for such an option would come up, it's the result of trying to find solutions to what web sites throws at users through their browser.
username_10: <NAME> (ABP / eyeo)
https://groups.google.com/a/chromium.org/d/msg/chromium-extensions/veJy9uAwS00/CxEIxy_OGgAJ
username_14: Adblock/Plus can't be happy with the proposed changes, the 30,000 filters limit would cripple all ad/content-blockers and I really don't understand how nobody responsible for the draft proposal saw that beforehand, even Apple has a 50,000 limit which is bad enough.
username_14: By the way, Mozilla has also announced that they will also transition to manifest v3 in 2019.
https://blog.mozilla.org/addons/2018/10/26/firefox-chrome-and-the-future-of-trustworthy-extensions
username_3: ... but starts preparing the ground
https://old.reddit.com/r/firefox/comments/aithmh/raymond_hill_creator_of_ublock_origin_ubo_and/eerce78/
username_4: Pervasive bloated web sites is where the performance issue is. Content blockers are the solution for this. Anybody can see for themselves by loading a web page from most of almost any top site, and see the result with uBO enabled, and the result without uBO enabled. And somehow we are being misled to believe content blockers need fixing, while they were the solution to the rampant bloat (leaving aside the privacy nightmare of those bloated sites and ubiquitousness of the `facebook.com`, `twitter.com`, `google.com`, etc. as 3rd parties)
username_3: Their performance is also continuously evolving thanks to the innovations and hard work of developers, browser improvements, technologies like WebAssembly, etc. and we do not see how this will cause an issue in the future.[...]
username_1: That sounds like modifying the responsem, no ? HTML Filtering ?
username_4: No, just _some_ response headers, they will pick which ones can be modified.
Still no word on the nature of the matching algorithm -- Easylist-like matching algorithm does not work for uBO's dynamic filtering and uMatrix as a whole.
Strict blocking needs to generate a page on the fly according to what happened filter-wise, this can't happen with a declarative API.
Solution is incredibly simple, just keep the _blocking_ ability of the webRequest API. Nothing of what was said in the post still properly justify removing this ability -- it's really, _really_ hard to not suspect the real reasons are not technical neither altruistic.
The "push-only" nature of filter lists is a sound argument, but that is not a browser issue, this is an issue to be tackled by filter list maintainers and content blocker developers.
And as I already argued, one can use uBO without any filter lists in default-deny mode, but that would go away with an Easylist-like matching algorithm, so such worries can't be genuine when they remove the ability for a content blocker to not rely on _any_ filter list.
With the declarativeNetRequest API, not only the browser gets to decide the limit on how matching algorithm work, but will also be in a position to collect what exact filter triggered a block. Content blockers using a still-working webRequest API would get in the way of this because the browser can only know that something was blocked, not what exactly caused the blocking.
Users are free to install whatever content blocker they wish, and they will be free to install the declarativeNetRequest-based ones if they are convinced by the arguments out there of why it's best for them. The only reason I can see for removing the blocking ability of the webRequest API is that it might interfere with the spread of content blockers relying on the declarativeNetRequest API because the webRequest ones will still give users greater agency.
username_4: As I am looking at what I should work on, I found a typical example of how manifest v3 will be crippling for new content blocking ideas. Consider [this feature request](https://github.com/uBlockOrigin/uBlock-issues/issues/44). Possible with a proper blocking webRequest API with which no specific matching algorithm is enforced. Not possible with declarativeNetRequest API, where the only matching algorithm available is meant to enforce only EasyList-like syntax.
username_1: You should let them know about this.
username_4: I already said this would break uBO's dynamic filtering and uMatrix as a whole, and nothing of what was said a few days ago addressed this -- it's as if I never mentioned this. The reality is that content blockers on Chromium will have to open issues on Chromium issue tracker and wait (possibly forever) when they want something more than what the declarativeNetRequest API allows. The issue I am giving is just an _example_ of a new feature that might be wanted which is entirely possible with a blocking webRequest API, but not possible with limited declarativeNetRequest.
My view is that I don't think there is a genuine exchange going on with their requests for feedback, the decision of Google-paid developers is made regarding the removal of the blocking ability of the webRequest API. I rather not waste my time being part of a pretend discussion, there declarativeNetRequest API was created to enforce EasyList-like filtering[1], nothing more.
[1] I will do my best to not use "ABP-like" as I used to do because people have read more into this expression than they should have, despite that EasyList is completely dedicated to enforce only ABP's filtering syntax.
username_4: I remember there was a Chromium script blocker extension a long while ago (I don't know if it still exists) which I can't remember the name, and it had a feature which I found interesting, and thought it might be worth borrowing the idea.
The script blocker would block all 3rd-party, except those which domain name was close enough to that of the first party site. I don't think it was literally the case but let's say it was using Levenstein distance to determine whether a 3rd-party script should be blocked or not.
The idea was interesting because this was helping in reducing the amount of breakage as a result of blocking 3rd-party scripts. For example, `arstechnica.net` is close enough to `arstechnica.com`, and thus the site wouldn't break with that script blocker.
Whether one agree this is a good idea or not is irrelevant, the point is that its blocking heuristic was original and of course it could be implemented because of the webRequest API. Forget such new ideas with a declarativeNetRequest API.
username_4: [Feedback from the ad blocking community on the proposed changes to the webRequest and declarativeNetRequest APIs](https://docs.google.com/document/d/1sKZFojq_fUusrebKsyNHfRk_9kpbIALFPS1Nvpddfs8/edit)
username_15: a sight of hope
https://www.zdnet.com/article/google-backtracks-on-chrome-modifications-that-would-have-crippled-ad-blockers/
username_17: and this is the same disingenuous rhetoric that Google has been using the entire time. People's concern is with the removal of _specific functions_ in the webRequest category, and Google has consistently been trying to dodge that by saying, "Don't worry, everyone. There will still be a category of functions that happens to be named 'webRequest.'" They blatantly have no intention of backing down from this no matter how many people object to it, and no matter how many times they're caught lying about it.
username_18: I feel like the changes are already happening. Since chrome 72 I feel like uBlock became less effective.
A tiny extension that I wrote also broke. Turn's out, you're no longer allowed to drop the Referrer, you can only replace it. Stupid.
Also somehow connections to gvt1.com have increased and google is able to make it through even though its blocked on local dns. Version 72.0.3626.119 (Official Build) (64-bit)
Eventually we need to leave chrome behind. Hopefully Microsoft will make us proud this time.
Other chromium based browsers are full of social connectors which keep pinging fb and others constantly (Opera, Vivaldi). Firefox is not great either but that might be the next best option.
username_19: I’ve never heard that claim regarding Vivaldi, and I’ve been researching the browser extensively as of late. Do you have a source for that claim?
username_10: Vivaldi is open on privacy:
https://www.ghacks.net/2018/01/30/vivaldi-browser-privacy/
username_4: Why is this? uBO works best in Firefox.
username_19: I think @username_18 is making a commentary on browser policy (“Opera and Vivaldi do some shady things and Firefox isn’t that far behind on its practices”), not on browser technology.
username_18: @username_19 I'm only seeking alternatives and asking where the community is headed.
username_1: Community is not headed anywhere specifically and is waiting for the final draft to see how it all ends up.
username_20: Will Declarative Net Request API be able to modify request and response headers to bypass CORS and access remote content that extension has permission to access ?
We have developed and used various automation tools that heavily rely on modifying request and response headers to send automated web requests to web servers.
Therefore I am hoping that Declarative Net Request API will support
- modifying request and response headers.
- adding new request or response headers.
- removing request or response headers.
There are countless web automation tools deployed on the web that rely on modifying request and response headers.
Apart from automation tools, there are many other legitimate use cases for modifying request or response headers, for example: chrome extension to change user agent.
At the moment there are millions of users that make use of web automation tools.
If Declarative Net Request API fails to add support for modifying headers and webRequest API is phased out then many web automation tools will stop working.
username_4: @username_20 I have nothing to do with Chromium development, this is not the place to ask questions about manifest v3. Follow the links in the opening comment for where to provide feedback to Chromium development.
username_20: @username_4 , yes the comment is off-topic.
But understand the severity of this issue.
U-block will also not be able to modify sensitive headers such as origin or cookies which means it is going to affect U-block and thousand other chrome extension that rely on correctness of origin header to make automation tools.
For example, some extension might have functionality to not let malicious sites access sensitive headers such as cookies, this functionality will cease to exist.
I'm just trying to create enough buzz to let everyone know what is coming!
username_1: That's already done when the thread was created what you 're creting is notifications to the all the people who replied here which in turn causes annoyances as there's no new development regrding this only your speculations along with others.
username_1: Update from <NAME> - https://groups.google.com/a/chromium.org/forum/?utm_medium=email&utm_source=footer#!topic/chromium-extensions/veJy9uAwS00%5B101-125%5D
<details>
Hey extensions developers,
I'd like to respond to some of the feedback we’ve gotten on the proposed changes in Manifest V3. A number of issues raised by the community were captured in the Privacy Badger team's April 19th post in this thread. Rather than address specific points line by line as I often do on the group, I'll be responding to the broader issues they and others have raised.
I'd like to extend my thanks to the EFF and others for taking the time to share their feedback with the community. Writeups like these are truly invaluable as they help us understand not only your concerns, but also the context in which those concerns are rooted. Our goal is to create the best extensions platform we can for our mutual users.
**Manifest V3 Design Doc and Development**
Like most other Chromium design docs, the Manifest V3 doc is the starting point from which implementation work begins. These docs capture the context, motivations, and high-level technical notes on what the feature team plans to implement. They're generally targeted at other Chromium contributors and meant to help clarify what the team will be working on.
Chromium design documents are not a final specification of what will be implemented, nor an API contract that downstream developers can rely on. Additionally, Chromium design documents are not typically updated as designs are polished, features are implemented, and details change.
I mention this because I want to emphasize that the Manifest V3 design document is not exhaustive or immutable. The extensions team is pursuing the goals outlined in this design document and iterating on design and implementation details. The best way for developers to really understand the changes is to experiment with the Manifest V3 platform.
To enable this, the extensions team is currently working on a Developer Preview of Manifest V3. Our goal with this preview is to give developers a way to start experimenting with some of the most significant changes to the platform in order to provide targeted feedback. We're hoping to land this in Canary in the next few months. We'll share more details about the preview in the Chromium Extensions Google Group once we get closer to launch.
**Permissions**
The Privacy Badger team touched on a number of permissions-related issues. Before we get into those issues, I want to address a slight misunderstanding. Chrome is not deprecating <all_urls> in Manifest V3, but we are changing how it works. Our primary motivation here is to give end-users more control over where extensions can inject themselves. The current extension installation flow allows developers to declare that they require access to a given set of hosts and the user must choose whether to grant all required permissions or cancel the installation. We are planning to modify the install flow so the user will be able to choose whether or not they want to grant the extension the ambient host permissions it requested. We're still iterating on the updated UI and will share additional details once this lands in Canary.
Our view, informed by data from the field, is that host permissions are powerful enough that we should work to ensure that users clearly understand when they are making that specific grant. While there are legitimate reasons for extensions to use this power well, we know that other extensions have abused the same power. It is our goal to reduce the risk of abuse while still enabling users to make use of good powerful extensions. We believe Manifest v3 and the permission-granting UX strike a better balance.
We recognize that this kind of functionality is core to some extensions, so we provide the tools necessary to programmatically request host permissions if the user does not opt in at install time. Developers can retrieve the extension's current permissions grants using chrome.permissions.getAll() and can request host permissions or optional permissions declared in the extension's manifest using chrome.permissions.request().
We should all want users to think hard about granting broad permissions that can compromise user security and to be able to retake control for any reason. If the user doesn't want to grant an extension a given capability, it's the extension developer's responsibility to explain why those capabilities are critical and to earn the user’s trust.
**Observation**
Chrome is deprecating the blocking capabilities of the webRequest API in Manifest V3, not the entire webRequest API (though blocking will still be available to enterprise deployments). Extensions with appropriate permissions can still observe network requests using the webRequest API. The webRequest API's ability to observe requests is foundational for extensions that modify their behavior based on the patterns they observe at runtime.
**Improvements to the declarativeNetRequest API**
Since the community started sharing feedback on the Manifest V3 design document, the extensions team has listened to developer concerns and made improvements to the declarativeNetRequest (DNR) API. We're still actively gathering feedback, designing, and expanding the DNR API. Please continue to share your concerns and use cases in order to help us make DNR the best it can be.
**General Improvements**
The first and IMO largest change is that Chrome now has support for dynamic modification of DNR rules via the getDynamicRules(), addDynamicRules(), and removeDynamicRules() methods. DNR has two groups of rules: static rules declared in JSON files and dynamic rules set at runtime. Each of these groups has their own distinct maximum number of allowed rules. These current placeholder max values are specified in the DNR properties documentation. We are planning to raise these values but we won't have updated numbers until we can run performance tests to find a good upper bound that will work across all supported devices.
Developers have clearly shown that they need metrics on rule matching in order to effectively maintain their rulesets. In order to facilitate this use case, the extensions team is also planning to add reporting to the DNR API. We're still working on the design of this feature and hope to share more in the coming months.
**Header Modification**
The extensions team recently added support for a new DNR action called removeHeaders which can remove allowlisted headers from requests. This allowlist currently includes Referer, Cookie, and Set-Cookie headers. We welcome feedback from developers on other headers that should be removable. Removing headers from a request should neither reduce the security of sites (e.g. CSP) nor expose user data.
The extensions team is also planning to add support for static header additions and replacements. Additions would add new headers or extend existing headers. For example, an extension could add additional restrictions to CSP rules or add a new Set-Cookie header. Replacements would behave similar to the removeHeaders action, but rather than removing matching header(s) it would replace the header(s) with the header(s) specified in the rule's action. Again, we welcome developer feedback on this plan.
As for setting Do Not Track headers, Chrome already allows users to set DNT values via their preferences. Rather than modify the DNT header directly, the team is currently leaning towards exposing an extension function to modify this user preference. This approach allows Chrome to avoid situations where multiple extensions replace the request's current DNT header with DNT: 1.
**URL Parameter Modification**
While we don't currently have actions for removing or replacing query parameters, the extensions team is planning to add support for both of these.
I'm a little confused by the suggestion that "declarativeNetRequest should allow the modification and deletion of POST parameters as well as GET parameters." It's not clear to me whether the Privacy Badger team is asking to modify the body of POST requests or the query parameters of POST requests. Query parameters of POST requests should be modifiable like any other request type. Body modification is not currently supported by webRequest and as such the team does not currently plan to implement it for DNR. If this is something you'd like to see supported, please share more information about your use cases. The extensions team is also interested in hearing more about request parameter transformation use cases.
**Contextual redirects**
We are currently examining our options for redirect URL transformations. If/when transformation lands, it should be possible to convert https://www.google.com/url?q=https://example.com into https://example.com by matching the q parameter in the original request and using that as the new URL value. Yegor's example in the Google Group post is trickier because it requires additional processing to generate a usable value. Situations like this are currently out of scope. That said, we'd love to hear more about use cases and what support might look like.
Thank you all for working with us on the Manifest V3 effort. We're looking forward to continuing to collaborate with the community to build a safer, more secure extensions platform.
</details>
username_4: In order for Google Chrome to reach its current user base, it had to support content blockers -- these are the top most popular extensions for any browser. Google strategy has been to find the optimal point between the two goals of growing the user base of Google Chrome and preventing content blockers from harming its business.
The blocking ability of the webRequest API caused Google to yield control of content blocking to content blockers. Now that Google Chrome is the dominant browser, it is in a better position to shift the optimal point between the two goals which benefits Google's primary business.
The deprecation of the blocking ability of the webRequest API is to gain back this control, and to further now instrument and report how web pages are filtered since now the exact filters which are applied to web page is information which will be collectable by Google Chrome.
**Side note:**
eyeo GmbH (owner of Adblock Plus) is a business partner of Google (through its "Acceptable Ads" business plan), and its business share some the same key characteristics as the Google's ones above:
- It gets revenues from the displaying of ads with those with which it has a contract (Google, Taboola, etc.)
- It expressly names uBlock Origin as a risk factor to its business<sup>[1]</sup>
The "Acceptable Ads" plan, aside being the main revenues stream of eyeo GmbH, is also a good way for Google to mitigate against the expressed concerns in its 10K filing regarding content blockers.
***
[1] In its 2016 annual report filed on <https://www.unternehmensregister.de/ureg/>.
username_4: Regarding my comment re. "Promise": Given that each extension runs in its own process, the use of Promises does not look like something that would make a difference. But this would open the door to load the filters in stages, for example a blocker could load the most likely to be hit filters at launch, and load chunks of filters least likely to be hit in an on-demand manner. The way I see it, increasing abilities of content blockers help with efficiency in the big picture. An example of this is that in order to deal with Instart Logic, an extra extension is required with Chromium, while it can be dealt with no extra extension with Firefox. Still, I just don't buy the performance argument to justify deprecating the blocking ability of the webRequest API.
username_21: Great news for Firefox :)
username_22: Promise based blocking APIs are more powerful and potentially but not necessarily faster because they allow the concurrent processing of multiple requests while shoving the into workers, thus not blocking the JS event loop, or retrieving additional information from other contexts via messaging.
username_23: I've got a question: Do we know if this will be a part of the Chromium version of Edge or just Chrome? This is being done to Chromium but has Microsoft said whether they're going to include it in Edge?
username_9: I don't think that Microsoft has anything to do with it,
edge is chromium based so it has no choice but to follow chromium code,
so, whatever changes in chromium it is applied to edge too,
there is no other way around
username_24: @username_9 If Microsoft has the motivation (and it does, because it doesn't share Google's revenue stream but wants to provide a better experience for its users) then it could easily just maintain downstream patches that enable ad-blocking technology.
username_9: yeah, right, that's why the dumped their own browser in the first place?
username_25: Not really. Mozilla has taken over a billion dollars in donations from Google. If Google can pay Mozilla to make them the default search engine, they can pay them to stop supporting ad blockers. Let's not make the same mistake twice.
username_26: I dont think Mozilla will accept any amount of money to undermine their core business strategy.
username_27: My understanding is that the [enterprise chrome bundle](https://cloud.google.com/chrome-enterprise/browser/download/) is just the the normal chrome offline installer wrapped in an msi, bundled with group policy templates.
Which suggests there will be a [policy](https://www.chromium.org/administrators/policy-list-3) that enables webRequest blocking. Although they do have an ability to limit policies to domain joined machines (on windows).
username_28: So Google wants to gimp/remove (ad)-blockers instead of clearing up the quality/quantity of the ads being served through their own service? Cool, I guess we know how this will end.
username_29: This is exactly why I didn't want Microsoft to use Chromium as the base for new Edge. They should've just released a version of Edge that is not dependent on Windows 10 to be updated. That way the Edge team would've had more leeway to work on that browser.
Or just use servo or gecko as the new Edge.
username_30: Is the implication here that no updates will be provided for Chrome and its new API? Just curious, as that could have some _very_ interesting consequences (whether a browser supports uBO is probably more important than the browser's other merits for many users).
username_31: 2) Google could completely re-do how they distribute enterprise, or perhaps they could add functionality that requires you to be signed into Chrome with a G Suite Account with an enterprise license associated.
3) Let's say none of the above happens, Google is putting a lot of effort to remove this functionality from Chrome, you really think they will let extensions install a policy without manual complex user actions?
4) Things only get worse from here, next thing you know all adblockers are required by the Chrome Web Store Terms to use the new adblocking api, next adblockers aren't allowed to block Google ads, and they'll make it harder and harder to install extensions from outside the Chrome Webstore.
I'm not sure how uBlockOrigin core developers feel about picking sides in disputes like this, then again they've been hurt by Google so maybe this is an exception, perhaps prompt users with a notice on the next update and let them know Google is breaking uBlock Origin and they will need to "install a better browser" (For example Brave or Firefox) to continue using uBlock Origin normally.
username_32: I'm all for you developers not moving time try to support manifest v3. Its ridiculous and obviously an effort to prevent us using adblockers, instead of them improving their profit model or even the ads
Maybe its time for Chrome to lose a little market share and get scared. I, for one, no longer even have it on my android phone, I only use Firefox. Especially with Firefox 67, its nearly as fast as Chrome.
And maybe its time uBlock stopped working with a browser developed by an advertising company.
username_33: Could ublock origin chrome version be forked away from the real ublock origin codebase, deprecated, and modified to direct users to other browsers? both apple and microsoft have significant incentive to support ad blocking, so it might be worth talking at their teams. I'll bet they're listening even if they don't answer.
username_18: As mentioned above, they will offer an option on Group Policy to allow ad-blocking on chrome. I already use GPO for chrome for ex. to set whitelist of homemade extension id's. However some important policies require user/device to be part of an AD (active directory, windows server domain... ) for no good reason. I am sure the adblock policy will require AD too.
So maybe we can figure out a workaround to spoof chrome into thinking this is an AD machine?
Just like you can set an exe to check if it's running under a VM instance. (which can also be spoofed)
Food for thought I guess.
username_10: Google Just Gave 2 Billion Chrome Users A Reason To Switch To Firefox
https://www.forbes.com/sites/kateoflahertyuk/2019/05/30/google-just-gave-2-billion-chrome-users-a-reason-to-switch-to-firefox/
username_34: Microsoft makes billions of dollars from Bing ads.
username_35: @username_34 But it is by far not their main source of revenue.
username_36: [$7.5B/year](https://www.bloomberg.com/opinion/articles/2019-05-30/microsoft-s-bing-is-not-the-laughingstock-of-technology-anymore) vs. $120B/yr for Google.
username_37: I'm creating username_37 (not related to w3c) as a scheduled fork of Chromium of the last stable build before Manifest V3 changes. Anyone familiar with Chromium codebase should open up an issue here:
https://github.com/username_37/username_37/issues/new
Why? Because I feel Chromium up till this point has been good. The way forward for the web is an independent fork with maintains parity with original Chromium sans the expected Manifest version 3 changes. Once its big enough with adaption, it will diverge from the original Chromium into its own, completely independent engine.
username_31: @username_37 How do you expect to support new web standards, fix bugs, and backport security patches? Do you have the necessary technical knowledge?
username_37: @username_31 I am somewhat familiar with the extension area of Chromium. Don't know much about the network layer area, still trying to figure out the mammoth.
I plan to fund using Patreon and/or Github sponsorship (launched a few days ago). I did not want donations but after multiple looks at it, Chromium is like an operating system, hence it requires dedicated man hours to keep-up. As for backporting changes, I'm developing a system to conduct smart diff analysis that can see which code interacts with the extension and networking area vs others. Changes which do not affect the relevant areas (blocking web request API initially) will be automatically merged without review after official Chromium publishes.
After build passes the modified tests, it'll be published as stable.
Changes will be kept to a minimum until the project is big enough to ensure security/other features backport easily.
username_38: @username_37 If you have development skills, I'd rather you put your efforts towards Firefox -- they need all the help they can get, and they also happen to be a pretty good browser.
username_37: @username_38
I fear gecko/whatever engine it uses will be gone/abandoned in coming months to year and then Mozilla will have to fork chromium with their necessary changes. If I were Mozilla, I'd fork Chromium and then make desired changes and diverge from it with time. Chromium's codebase is much better IMO.
Chromium has many more features then Firefox, and most website test with Chromium.
It's an uphill battle that cannot be won in current state of the Internet with too many casual consumers. Mozilla was winning last decade because the internet was maturing. Now that it is almost matured, not many websites are tested against Firefox.
I appreciate Mozilla and whatever it has done for the internet, but I've thought about it and the safest bet is Chromium because it will continue to update until Google makes it closed source from which point there will be a large community around it.
A lot more people are familiar with Chromium's codebase then say, gecko.
username_39: It's pretty well known that Mozilla has put a lot of effort and time into rewriting their engine in Rust and they've been progressively applying this change to the core Firefox browser through the Quantum, Electrolysis and WebRender projects, all of which meant very big rewrites of core code and functionality. There's no way they will be throwing it all away.
username_40: I find it a bit dubious that Microsoft Edge starts using Chromium code not too long ago, and now Google wants to prevent ad blocking. Looks like I may be switching back to Firefox, although I like Chromium (Iridium) better.
username_41: As obviated by the responses to your comments here, I don't think the community - and I don't mean the world (only the people who have seen this issue [maybe 5 people? {that's a joke}]) *{- heck for all any of us know maybe this project takes off - if we could reliably predict that I don't think many of us would be in this field :) -}* but I suspect unless you have a more specific gameplan with very specific goals and objectives ***and a roadmap*** no one is going to look at this seriously.
That roadmap is going to need to be pretty stellar.
username_42: Will the ad blockers stop working on other chromium based browsers too? like Brave, Opera, Vivaldi etc. ?
username_31: @username_41 Why would you downvote me in the first place? @username_37 is making the absurd claims here not me.
username_41: @username_31 OMG I'm sorry. I may have had a few drinks. Yes, directed specifically at @username_37
username_41: Don't drink and github, folks
username_31: Haha @username_41 don’t worry about it was just very confessed 😂
username_43: I have to use Chrome at work, but at home I refuse to make google chrome my browser. I use Firefox with uBlock Origin, Privacy Badger.
username_10: Web Request and Declarative Net Request: Explaining the impact on Extensions in Manifest V3
https://blog.chromium.org/2019/06/web-request-and-declarative-net-request.html
username_3: https://groups.google.com/a/chromium.org/d/msg/chromium-extensions/qFNF3KqNd2E/OnidEBO9BgAJ
username_3: [Mozilla’s Manifest v3 FAQ](https://blog.mozilla.org/addons/2019/09/03/mozillas-manifest-v3-faq/)
username_1: So they're keeping the door open? That's concerning.
username_3: [[meta] Manifest v3](https://bugzilla.mozilla.org/show_bug.cgi?id=1578284) on bugzilla.
username_4: Being compatible with manifest v3 does not mean going Google Chrome's way. It makes sense to want to keep Firefox's extensions framework compatible with Google Chrome ones.
For instance, deprecating cross-origin requests from content scripts make a lot of sense. The other item, allow extensions to specify CSP for content script also make sense if cross-origin requests from content scripts is deprecated -- this means extensions will have to explicitly ask permissions to make cross-site requests from their content scripts if they really need such a thing. uBO does not need this, the filter lists are pulled for import/update purpose from the background page.
The other item is replacing background page with service workers -- this could break uBO but I provided feedback about this -- and there is an opened issue for this: <https://bugzilla.mozilla.org/show_bug.cgi?id=1580254>.
username_14: https://developer.chrome.com/extensions/migrating_to_manifest_v3
username_3: ChrEdge will switch to v3 https://blogs.windows.com/msedgedev/2020/10/14/extension-manifest-chromium-edge/
username_4: It's merely store policy, you do not need to wait for manifest v3 for this policy to be enforce. It's has been Firefox's AMO policy since ever WebExtensions came out 3 years ago -- this has nothing to do with manifest v3.
username_3: Adblocker Dev Summit 2020
- Some history of ad blocking and limitations of declarative filtering approach on Apple platforms: https://www.youtube.com/watch?v=_dduavvDj6s
- Status of Manifest v3 in Firefox: https://www.youtube.com/watch?v=tpDFS-GUytg
username_4: I don't really see a divergence issue with keeping a blocking webRequest in Firefox since Google has said it would still be available to Google Chrome Enterprise, the only "divergence" would be who has access to it.
username_10: Manifest V3 Dynamic Content Scripts
https://docs.google.com/document/d/1nRJ6iW-W1MVSpJnQzNrRQFLMsr0RycwsNym06TD5i18/edit#heading=h.itw7kc7egimi
username_4: I might give a go at trying to find out all the features which can be fitted into MV3, if only to make the un-portable features stand out more. But this is quite an amount of work and working on current uBO will always be a higher priority.
username_1: Could this cause performance issue/s ?
username_4: Why? This is how declarative content scripts are currently injected. Firefox already support dynamically registered content scripts, this is even used in uMatrix.
username_1: Because browser vendors acitvely discourage running anything synchronously.
username_10: No include_globs and exclude_globs.
===================================
These are parts of the existing extension API, and in some cases only globs can provide a solution. If you still want to remove them then please use histograms/metrics to confirm the usage is below the removal threshold.
Missing RequestContentScript's features.
===================================
a) The ability to specify `priority` to reorder the scripts without re-registering the entire list. RequestContentScript used the system of filtered events so that was an inherent feature.
b) The much more flexible URL matching, particularly the simplified RE2 regular expression syntax. The absence of both RE2 syntax and globs in the new API, while simplifying the implementation of the API for Chromium developers, will force some of the extension authors to make their scripts run on more pages than necessary and use JS checks for `location.href` inside. This is somewhat wasteful.
c) RCS runs content scripts **before** document_start when DOM doesn't even contain documentElement. For user experience, this is often much better than document_start because the page is still being downloaded in background by Chrome, no DOM work is being done. Whereas when content scripts run at document_start they compete with the page scripts for DOM rendering time, which delays the early stages of page load. It's not that rare for several extensions to delay the initial render by 100ms or even more. If they could run before document_start (say, at document_create) they could initialize their state while the page is still being downloaded.
These features aren't crucial, admittedly, but they worked for almost the entire lifetime of Chrome and solved real problems. RequestContentScript, for example, would be a real hit and is under-used only because it's marked as experimental in documentation due to a couple of edge case problems.
username_10: **Firefox**:
from https://bugzilla.mozilla.org/show_bug.cgi?id=1684703 (Performance issues by having any ad-blocker installed)
_<NAME>_ [:emk] |
(In reply to <NAME> [:kershaw] from comment #2)
Do you have an idea about what we can do here?
**Migrating to Manifest v3? (deprecate blocking webRequest and implement declarativeNetRequest)**
username_4: I looked more into this [priority property](https://developer.chrome.com/docs/extensions/reference/declarativeNetRequest/#type-Rule). It does now allow to support the `important` option<sup>1</sup>, and does allow dynamic block/allow rules to have precedence over static filters, and to also to properly implement precedence between rules themselves (though an actual prototype would tell whether I overlook something).
**However**, it's still not possible to implement noop rules, which purpose is to ignore inherited block/allow rules and fall back strictly on static filters, and which is a key concept to dynamic filtering.
Summary, latest version of declarativeNetRequest, as per documentation, still breaks dynamic filtering in uBO, due to the inability to implement the noop concept. Suggestions welcome if somebody can think of a way to implement noop rules which I am not seeing.
There is also the issue of [`denyallow` filter option](https://github.com/username_4/uBlock/wiki/Static-filter-syntax#denyallow), not supported by the declarativeNetRequest API. It might be possible to implement using negative lookahead complex regexes (which was what `denyallow` was meant to prevent in the first place), but given that the number of regex-based filters are [further limited](https://developer.chrome.com/docs/extensions/reference/declarativeNetRequest/#property-MAX_NUMBER_OF_REGEX_RULES), this is another pain point of the declarativeNetRequest API.
Also, still no way to implement blocking according to response header content, so preventing the no-large-media-elements per-site switch, or the new experimental [`header=` filter option](https://github.com/username_4/uBlock/wiki/Static-filter-syntax#header). Also, no match for [`strict1p`](https://github.com/username_4/uBlock/wiki/Static-filter-syntax#strict1p), [`strict3p`](https://github.com/username_4/uBlock/wiki/Static-filter-syntax#strict3p), and so on as I looked more into the latest documentation.
---
[1] confirmed with a mini extension locally -- a higher priority block could take precedence over a lower priority allow filter
username_1: https://developer.chrome.com/docs/extensions/mv3/mv2-sunset/
username_4: It might be possible to maybe implement _noop_ rules through complicated negative lookahead regex-based filters. For example:
* * 3p-frame block
* * 3p-script block
github.com amazonaws.com * noop
github.com githubapp.com * noop
github.com githubassets.com * noop
github.com render.githubusercontent.com * noop
Maybe could be achieved with:
*$third-party,script,subdocument,domain=~github.com
/^[\w-]+:\/\/(?!(\S+\.)?amazonaws\.com\/|(\S+\.)?githubapp\.com\/|(\S+\.)?githubassets\.com\/|(\S+\.)?render\.githubusercontent\.com\/)/$third-party,script,subdocument,domain=github.com
This is only for medium mode with configuration for one single site. I wonder how this would look like for my current ruleset of 391 rules.
Again, as per declarativeNetRequest documentation, regex-based filters are limited to 1000 (and also [as per declarativeNetRequest](https://developer.chrome.com/docs/extensions/reference/declarativeNetRequest/#type-UnsupportedRegexReason), a regex-based filter can be rejected).
And each time one would click to create/remove a temporary rule as is typically often done when working in medium or hard mode, uBO would have to recompile, [remove and reinstall all the dynamic rules](https://developer.chrome.com/docs/extensions/reference/declarativeNetRequest/#method-updateDynamicRules).
On the other hand, uMatrix does not require the concept of _noop_, and the [priority property](https://developer.chrome.com/docs/extensions/reference/declarativeNetRequest/#type-Rule) should allow the implementation of its matching algorithm.
In the end, only an actual prototype will be require to sort out for sure what is possible or not.
username_4: Given how the deprecation of a blocking webRequest API put a lid on innovations (and regressions in capabilities in the case of uBO) regarding content blocking, it does seem the move could be the ["Not-Owned-But-Operated" strategy](https://twitter.com/fasterthanlime/status/1452053941504684036) applied to content blocking -- the declarativeNetRequest API means the capabilities of (not-owned) content blockers are ultimately operated by Google through the limitations of the API.
username_3: Google plan is to completely block MV3 extensions in **2023** https://developer.chrome.com/docs/extensions/mv3/mv2-sunset/
username_4: An example that the declarativeNetRequest ("DNR") API is an obstacle to innovation in content blockers.
In discussion with filter list maintainers, last year I implemented a new feature, the ability to use "entity" in `domain=` option.[1] The DNR API does support `domain=` option, but it does not support "entity", which is the ability to use a wildcard in place of the effective TLD, to avoid to list all domains belonging to an entity.[2]
I can count over 420 filters currently in the default filterset which uses this feature, clearly a benefit to filter list maintainers. These filters would cease to exist in a DNR-based blocker.
The core issue is the lid on innovation, which is key for content blocker to stay reliable. If the DNR API had been designed in 2014 according to the requirements of the time, content blockers would be awfully equipped to deal properly with the current landscape. The DNR API as designed now not only set back content blockers, but condemn content blockers to stagnate innovation-wise.
---
[1] https://github.com/username_4/uBlock/wiki/Static-filter-syntax#domain
[2] https://github.com/uBlockOrigin/uBlock-issues/issues/1008#issuecomment-624194528 |
unosmium/sciolyff | 533287537 | Title: Refactor validator
Question:
username_0: Should remove Minitest dependency and make validation more heirarchical, which will also make it easier to add unit tests.
Answers:
username_0: Pattern matching! https://speakerdeck.com/k_tsj/pattern-matching-new-feature-in-ruby-2-dot-7
Fits our use case here almost perfectly.
Status: Issue closed
username_0: Nevermind pattern matching. Refactor done in v0.9! |
Oefenweb/ansible-hostname | 436340556 | Title: Update the hostname fails without dbus
Question:
username_0: We use the `Oefenweb.hostname` role to set up the hostname on our template VMs. These template VMs are minimal Debian/stretch installations (made via [debootstrap](https://manpages.debian.org/stretch/debootstrap/debootstrap.8.en.html) / [grml-debootstrap](https://github.com/grml/grml-debootstrap)) to allow full flexibility. We bootstrap the template VMs mainly with [robertdebock.bootstrap](https://github.com/robertdebock/ansible-role-bootstrap) and your `Oefenweb.hostname` roles. (Have a look [here](https://github.com/username_0/ansible-site-template/blob/master/bootstrap-template.yml) if you like).
But when applying the `hostname` role, the playbook fails:
```
TASK [Oefenweb.hostname : update the hostname - hostname module]
fatal: [template-debian-stretch.in.example.com]: FAILED! => {"changed": false, "msg": "Command failed rc=1, out=, err=Failed to create bus connection: No such file or directory\n"}
to retry, use: --limit @/home/username_0/projects/ansible/bootstrap-template.retry
```
After manually installing `dbus` the role works just fine. I think `Oefenweb.hostname` should make sure that `dbus` is installed.
Answers:
username_1: Can you make a PR and verify that it works for all supported operating systems? See the `Vagrantfile`. Thanks in advance.
username_2: I habe dbus installed, i still get this error.
username_0: I just compared the package list of the Vagrant `bento/debian-10` box with my (basic grml-debootstrap) installation and noticed that it contains 99 more packages, including `dbus`:
```
% wc -l dpkg.vagrant.list
399 dpkg.vagrant.list
% wc -l dpkg.bootstrap.list
300 dpkg.bootstrap.list
% grep dbus dpkg.vagrant.list
ii dbus 1.12.20-0+deb10u1 amd64 simple interprocess messaging system (daemon and utilities)
ii libdbus-1-3:amd64 1.12.20-0+deb10u1 amd64 simple interprocess messaging system (library)
% grep dbus dpkg.bootstrap.list
```
As @username_2 also encountered the problem `dbus` is most probably not the only package needed. @username_2 could you please try to compare the package list of you installation with the corresponding Vagrant box. We then might find the other missing package(s). For now I am pretty sure, `dbus` is mandatory for this role and should be added.
I will try to prepare a PR and verify it for all supported operating systems.
Status: Issue closed
|
SmartlyDressedGames/Unturned-3.x-Community | 750936052 | Title: Blizzard button in legacy editor doesn't work
Question:
username_0: I have Can Snow check, I press Blizzard and nothing happens. No settings related to ambience volume in map config. When I spawn blizzard with /weather blizzard it works.
Storm button works, however.
Answers:
username_1: To test this I loaded up the Yukon map, clicked the Blizzard button, and it previewed a blizzard as expected
username_0: I was testing it on custom created maps, not existing ones. It works on Yukon, yes. But not on other maps for some reason. I tried editing Russia, PEI and not only, and nothing happened.
username_1: Were you within the snow height range?
username_0: Guess snow level was at zero after update on all maps by default, because early snow was working. Sorry for bothering.
Status: Issue closed
|
Hongscar/hongscar.github.io | 567420200 | Title: Spring Cloud笔记(六) | Hong's Blog
Question:
username_0: https://hongscar.cn/Spring-Cloud%E7%AC%94%E8%AE%B0-%E5%85%AD.html
一. 前言 上一部分添加了网关Zuul,这时候微服务架构已经基本成型,后续要增加其他功能就添加其他服务组件。但是随着微服务的数量越来越多,配置文件就越需要管理。尽管目前项目只有5-6个配置文件,都已经感觉到有点乱了。所以这部分讲述的是Spring Cloud Config,以及最后docker 简要的部署。 |
imliam/php-unique-gmail-address | 700297932 | Title: Add support for Gsuite domains
Question:
username_0: Gsuite offers the same kind of features to users with email addresses on custom domains. For example, `<EMAIL>` and `<EMAIL>+<EMAIL>` both go to the same inbox.
PHP provides a handful of functions like `getmxrr()` that could be used to check if a domain has MX records pointing to Google, denoting that it's using Gsuite.
https://www.php.net/manual/en/function.getmxrr.php
```
getmxrr('liamhammett.com', $hosts);
$hosts === [
'alt1.aspmx.l.google.com',
'alt2.aspmx.l.google.com',
'alt3.aspmx.l.google.com',
'alt4.aspmx.l.google.com',
'aspmx.l.google.com',
];
```
Answers:
username_1: It would be nice to make rules atomic
- `unlimited-dots`
- `plus-sign-tagging`
- `minus-sign-tagging` (many system do this: `<EMAIL>`)
then start constructor with domains + ->rules `new UniqueEmailAddress(['gmail.com', 'googlemail.com'])->enableunlimitedDots()->enablePlusSignTagging();`
username_1: A new rule could be `mixed-case`
- <EMAIL>
- <EMAIL>
username_1: And `no-subdomains`
- <EMAIL>
- <EMAIL>
Many domain has a wilcard in DNS: `* IN MX mail.exmaple.com`
username_1: And `idn-domain`
- <EMAIL>
- <EMAIL>
username_0: I'd be absolutely on board with such a change. I heard something about hey.com introducing similar rules on its emails, so this kind of rule-based change would make supporting additional services like that much easier.
It'd practically be a rewrite of the package though. I guess each rule could have its own class that accepts the email address with a `normalize` and `regex` method that can be used to perform the actions needed for each rule.
username_1: @username_0 I think `UniqueEmailAddress` should have these features.
- be extendable (with example in the README)
- 100% flexible configuration
- tell whether a **valid** email address belongs to the configured domains
- normalize an address
- compare two add addresses
- _maybe_ return `[ $userPart, $domainPart ]`
- and Nothing else
What are you use cases?
username_0: @username_1 my own case is pretty much handled by the package in its current state; normalising against dots, tags and domain does what I need it to.
I've taken a quick first stab at splitting up the rules in #4 if you want to take a look and go from there?
username_1: I cannot see value in regex-es, only hardship.
username_0: The reason I decided to go with regular expressions is because it's flexible enough to use in various different environments and points in an application; eg. giving the regex to the frontend to match against, giving it to an SQL query to assert against the database, etc.
I don't really see any better solution than regex - in my case I don't want to store the normalised versions of email addresses in a database, I want the original one the user entered - so it's not as simple as doing a direct equality comparison.
username_1: I see. |
kubernetes/org | 1106014495 | Title: REQUEST: New membership for DiptoChakrabarty
Question:
username_0: ### GitHub Username
username_0
### Organization you are requesting membership in
kubernetes
### Requirements
- [X] I have reviewed the [community membership guidelines](https://git.k8s.io/community/community-membership.md)
- [X] I have [enabled 2FA on my GitHub account](https://github.com/settings/security)
- [X] I have subscribed to the [kubernetes-dev e-mail list](https://groups.google.com/forum/#!forum/kubernetes-dev)
- [X] I am actively contributing to 1 or more Kubernetes subprojects
- [X] I have two sponsors that meet the sponsor requirements listed in the community membership guidelines
- [X] I have spoken to my sponsors ahead of this application, and they have agreed to sponsor my application
- [X] **OPTIONAL:** I have taken the [Inclusive Open Source Community Orientation course](https://training.linuxfoundation.org/training/inclusive-open-source-community-orientation-lfc102/)
### Sponsor 1
@username_1
### Sponsor 2
@JamesLaverack
### List of contributions to the Kubernetes project
Member of Bug Triage Shadow team for kubernetes release 1.24
Answers:
username_1: +1 Welcome to the team
username_2: +1 from me as well. Welcome to the team!
username_2: @username_0 -- I've created PR #3200 to add you to the requested org(s). Once that gets merged, you will receive membership invites.
Welcome!
/assign |
kayecandy/surveyform | 457762485 | Title: Created Date
Question:
username_0: The created date should not be editable. *Default* should be `today()` or `now()`. It can be `disabled` even `hidden`. *Was only used on the current site, to balance the number of elements.*
<img width="410" alt="Screen Shot 2019-06-19 at 10 19 12" src="https://user-images.githubusercontent.com/11417007/59730055-ec9f3400-927b-11e9-8679-7dda889bbf2e.png">
Answers:
username_1: Right now, I set it to `disabled` that defaults to `now()`.

This is how it looks like hidden.
Let me know which you prefer
Status: Issue closed
|
srayner/platinum | 6453999 | Title: Add readme
Question:
username_0: Add read me file containing basic installation instructions. ie clone repo, run php composer.phar install, create database, modify local.php.dist, create virtualhost on apache, create dns entry, restart apache, navigate to dns name in browser.
Answers:
username_0: README.md file added, but needs to include installation details.
username_0: Installation details added but needs a little more work.
Status: Issue closed
username_0: Readme file has been updated. Left out the DNS and apache instructions as users may be using another type of webserver. |
connordelacruz/connordelacruz.github.io | 124672604 | Title: Compressed banner images look poor on high resolution mobile device
Question:
username_0: **Description:** On QHD phone screens, compression on banner images is noticeable
**Possible fix:** Use higher quality jpeg (currently medium compression in Photoshop). Also consider looking into progressive compression option (loads multiple times at different quality levels).<issue_closed>
Status: Issue closed |
Unleash/unleash | 274827801 | Title: Docs on how to upgrade
Question:
username_0: Being a user which isn't a contributor to the project I would really appreciate some docs on what to expect when upgrading. I assume it works without issues, but it would be cool with just a note on "upgrading" in relation to the upcoming v3 release.
Answers:
username_1: Agreed, and the plan was to work that out as part of the v3 release.
The `unleash-server` should always support clients one lower major version. So the v3 server needs to provide a format for consumable for v2 clients. This will make it easy for users of unleash to migrate gradually.
Status: Issue closed
|
wekan/wekan | 866698675 | Title: Cards not opening on mobile devices in landscape mode
Question:
username_0: Hi there,
OS: Ubuntu 20.04
Wekan 5.23.0 snap installation
Using wekan on my Galaxy S2 9.7 Tablet in landscape mode it is not possible to open a card.
In portrait mode I can open cards.
Doesn't matter if I use Chrome, Edge or PWA.
If I use my Oneplus 5T in landscape mode and I switch to desktop view in Chrome I can open cards but only if I tap to the card more times fast.
Would be great if wekan is usable on mobile devices.
Answers:
username_1: @username_0
Do you have desktop drag handles enabled? It is designed for touch screen usage.
Click right top your username / Change Settings / Show Desktop Drag Handles.
At mobile, this code should detect device width and enable mobile web UI. Maybe it does not automatically enable desktop drag handles yet?
https://github.com/wekan/wekan/blob/master/client/lib/utils.js#L204
Unfortunately I don't have new enough tablet where I could debug this. Can some Wekan contributors try Wekan in tablet and try debugging this, possibly sending pull request to fix?
username_0: @username_1
Thx for your feedback!
I activated desktop drag handles and now I've got no problems to open the cards, work's fine now.
Desktop drag handles was not enabled, looks like it was not detected automatically.
I'm not a developer so I can't help you with debugging.
Btw: I'm using wekan since 8 weeks and I love it!!!
Helps me to organise my stressful days.
Great tool, great team!
username_1: [Enabling All Touch Screen Support](https://github.com/wekan/wekan/wiki/Touch-Screen-support) |
protocolbuffers/protobuf | 616895243 | Title: Please remove test files from the Pypi distribution (at least from the wheels)
Question:
username_0: Currently the average size of the Python3 Wheel file in pypi is 1.3MBs, and installed 5.3MBs.
This is wasteful, as those tests are not useful (used) after installation via `pip install protobuf`, and when dealing with small python code that uses protobufs, this is a huge size multiplier.
By just excluding the test files, we're able to reduce the installed size to about 3.4MB (~35% smaller)
**What language does this apply to?**
Python
**Describe the problem you are trying to solve.**
Wheel files are too large
**Describe the solution you'd like**
Remove test files from binary (and other) pypi distributions.
**Describe alternatives you've considered**
Delete the files post install.
**Additional context**
https://pypi.org/project/protobuf/#files
Answers:
username_1: Would you be able to submit a PR for this?
username_0: @username_1 , I can and I will :)
username_2: And, please, upload source code to PyPI
https://pypi.org/project/protobuf/#files
Status: Issue closed
|
pytest-dev/pytest | 318676599 | Title: pytest.parametrize fails on test function with non-signature-preserving decorator on Python 3
Question:
username_0: In the [pywbem](https://github.com/pywbem/pywbem) project, we are using `pytest.parametrize` on top of our own decorator [`pytest_extension.test_function`](https://github.com/pywbem/pywbem/blob/master/testsuite/pytest_extensions.py#L14) that handles expected exceptions, expected warnings, and some more things, in an attempt to simplify the test function that is coded. That decorator is signature-preserving. An example of such a test function is [here](https://github.com/pywbem/pywbem/blob/master/testsuite/test_cim_obj.py#L1528). This runs fine on Python 2 and Python 3 since a while now. There is no issue with that, and I'm just mentioning this as a basis.
Now we have made an attempt to further simplify the test function that is coded, with a new variant [`pytest_extension.test_function_new`](https://github.com/pywbem/pywbem/blob/andy/%231201-improved-testfunc-decorator/testsuite/pytest_extensions.py#L141) of our decorator, which eliminates the explicit unpacking of kwargs passed to the test function, and avoids having unused arguments. That new decorator is signature-changing. Its wrapper function provides exactly the signature that is needed by the `pytest.parametrize` decorator. The accordingly modified example test function is [here](https://github.com/pywbem/pywbem/blob/andy/%231201-improved-testfunc-decorator/testsuite/test_cim_obj.py#L1528). This runs fine on Python 2 **but not on Python 3**.
On Python 3.6, it fails while collecting testcases (see [this](https://travis-ci.org/pywbem/pywbem/jobs/372545790) Travis job):
```
bash -c "set -o pipefail; PYTHONWARNINGS=default py.test --cov pywbem --cov pywbem_mock --cov-config coveragerc --ignore=attic --ignore=releases -s 2>&1 |tee test_36.tmp.log"
============================= test session starts ==============================
platform linux -- Python 3.6.3, pytest-3.5.1, py-1.5.2, pluggy-0.6.0
rootdir: /home/travis/build/pywbem/pywbem, inifile:
plugins: cov-2.5.1
Debug: CHECK_0_12_0 = True, __version__ = 0.12.1.dev20
collected 4647 items / 4 errors
==================================== ERRORS ====================================
__________________ ERROR collecting testsuite/test_cim_obj.py __________________
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/pluggy/__init__.py:617: in __call__
return self._hookexec(self, self._nonwrappers + self._wrappers, kwargs)
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/pluggy/__init__.py:222: in _hookexec
return self._inner_hookexec(hook, methods, kwargs)
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/pluggy/__init__.py:216: in <lambda>
firstresult=hook.spec_opts.get('firstresult'),
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/_pytest/python.py:201: in pytest_pycollect_makeitem
res = list(collector._genfunctions(name, obj))
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/_pytest/python.py:379: in _genfunctions
self.ihook.pytest_generate_tests(metafunc=metafunc)
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/pluggy/__init__.py:617: in __call__
return self._hookexec(self, self._nonwrappers + self._wrappers, kwargs)
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/pluggy/__init__.py:222: in _hookexec
return self._inner_hookexec(hook, methods, kwargs)
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/pluggy/__init__.py:216: in <lambda>
firstresult=hook.spec_opts.get('firstresult'),
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/_pytest/python.py:126: in pytest_generate_tests
metafunc.parametrize(*marker.args, **marker.kwargs)
../../../virtualenv/python3.6.3/lib/python3.6/site-packages/_pytest/python.py:811: in parametrize
self.function, name, arg))
E ValueError: <function test_CIMInstanceName_hash at 0x2ac23c8f9d90> uses no argument 'desc'
. . .
```
In that Travis job, the packages in the venv were:
```
Package Version Location
------------------------ ------------ --------------------------------
alabaster 0.7.10
attrs 17.4.0
Babel 2.5.3
backcall 0.1.0
bleach 2.1.3
certifi 2018.4.16
chardet 3.0.4
coverage 4.5.1
decorator 4.3.0
distro 1.2.0
docutils 0.14
entrypoints 0.2.3
flake8 3.5.0
gitdb2 2.0.3
GitPython 2.1.9
[Truncated]
unittest2 1.1.0
urllib3 1.22
wcwidth 0.1.7
webencodings 0.5.1
wheel 0.31.0
widgetsnbextension 3.2.1
yamlordereddictloader 0.4.0
```
It also fails on Python 3.4 with older package versions, see [this](https://travis-ci.org/pywbem/pywbem/jobs/372545789) Travis job. The job log shows the `pip list`.
From the error that is raised, my conclusion was that pytest looks at the signature of the original test function when checking the signature of the function to be called by parametrize, instead of looking at the signature of its wrapper function. At least on Python 3.
I have debugged into pytest and was found that conclusion to be confirmed, but when trying to find the root cause, I gave up at some point.
In case you want to reproduce the issue, create a Python 3 venv, clone the pywbem repo, and issue `make all` in its work directory.
Some interesting questions may be:
-> Why does it succeed on Python 2 but fail on Python 3?
-> Is the use of a signature-changing decorator ok in combination with `pytest.parametrize`?
Answers:
username_1: as far as i can tell the decorator library is completely wrong at preserving python signatures adhering to the `__signature__` protocols - on older pytest it may simply work because we don't adhere to the protocols
for sanity/safety pytest unpacks wrappers unless they declare a valid signature
username_1: @username_0 functools.update_wrapper is broken on python2
username_0: ok, so can you tell me whether we can fix this, and if so, how?
username_1: @username_0 attaching a __signature__ to the function you return should fix it
username_0: Ok, great. We will try that.
username_0: then pytest does not trust the (correct) result of `inspect.signature()` for `follow_wrapped=False`, but thinks setting the (incorrect) `follow_wrapped=True` is a better default if the wrapper does not have a `__signature__` attribute, but if it has one it trusts that one? Just to understand it, not to criticize it ...
username_0: @username_1 Hi Ronny, I first did not want to believe your recommendation because it basically said that exactly in all environments where it worked, some function would be flawed. However, it turned out you were exactly right. So thanks a lot!!
I now have it running on all Python versions we support (2.6+, 3.4+) for both our minimum package levels and the latest package levels. I had to inrease the minimum package levels of pytest to 3.3.2, and of "py" to 1.5.1.
The key parts of our signature-changing `test_function_new` decorator look like this. I cannot use `signature()` with the `follow_wrapped=False` argument because that argument was introduced only in Python 3.5. This would have been more elegant and I verified that it works (On Python 3.5+).
Setting the signature for Python 2 was not necessary to make it work, but I am setting it nevertheless, in case the flawed behavior on Python 2 gets fixed one day.
Let me know if you have further comments.
Andy
```
if six.PY3:
from inspect import Signature, Parameter
else:
from funcsigs import Signature, Parameter
TESTFUNC_SIGNATURE = Signature(
parameters=[
Parameter('desc', Parameter.POSITIONAL_OR_KEYWORD),
Parameter('kwargs', Parameter.POSITIONAL_OR_KEYWORD),
Parameter('exp_exc_types', Parameter.POSITIONAL_OR_KEYWORD),
Parameter('exp_warn_types', Parameter.POSITIONAL_OR_KEYWORD),
Parameter('condition', Parameter.POSITIONAL_OR_KEYWORD),
]
)
def test_function_new(test_func):
def wrapper_func(desc, kwargs, exp_exc_types, exp_warn_types, condition):
. . .
wrapper_func.__signature__ = TESTFUNC_SIGNATURE
return functools.update_wrapper(wrapper_func, test_func)
```
username_1: @username_0 the main problem is that on python2 the `update_wrapper` function does incorrectly not set `__wrapped__` - thus the code works since its not discoverable
that issue has been fixed on python3, which in turn makes things fall apart as they should
username_0: Thanks for the info.
username_1: thanks for your follow-up, i created a tracking issue
Status: Issue closed
|
nicolasbettag/LastFM-Played-for-Wordpress | 140631864 | Title: Feature request: Display the latest track without a widget
Question:
username_0: Hi,
as I actually love my hand-crafted sidebar, I wonder if you plan to provide a way to display the latest Last.fm track directly inside a theme. That would additionally make styling much easier.
Thank you!
Answers:
username_1: Hi there, so you wanna design the widget by yourself? That would be possible. Any specific stuff?
username_0: Depends how much work you'd want to invest to fulfill my wishes. ;-)
Right now I'd like to have something like:
[for 1 to [number of latest tracks]]
<a href="[Last played track: Artist: Last.fm URL]">[Artist]</a> - <a href="[Last played track: Title: Last.fm URL]">[Title]</a>
[/for]
(Given that I, personally, only want to display the very latest track, so *for me* the number would always be 1.)
username_1: I'll implement this, in the next few days. |
jlippold/tweakCompatible | 429963080 | Title: `CarBridge` working on iOS 12.1.1
Question:
username_0: ```
{
"packageId": "com.leftyfl1p.carplay",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "com.leftyfl1p.carplay",
"deviceId": "iPhone8,2",
"url": "http://cydia.saurik.com/package/com.leftyfl1p.carplay/",
"iOSVersion": "12.1.1",
"packageVersionIndexed": true,
"packageName": "CarBridge",
"category": "Tweaks",
"repository": "Chariz",
"name": "CarBridge",
"installed": "1.0.5",
"packageIndexed": true,
"packageStatusExplaination": "This package version has been marked as Working based on feedback from users in the community. The current positive rating is 100% with 2 working reports.",
"id": "com.leftyfl1p.carplay",
"commercial": true,
"packageInstalled": true,
"tweakCompatVersion": "0.1.5",
"shortDescription": "Open any app in CarPlay!",
"latest": "1.0.5",
"author": "leftyfl1p",
"packageStatus": "Working"
},
"base64": "<KEY>
"chosenStatus": "working",
"notes": ""
}
```<issue_closed>
Status: Issue closed |
jlippold/tweakCompatible | 439032889 | Title: `PreferenceLoader` not working on iOS 12.0.1
Question:
username_0: ```
{
"packageId": "preferenceloader",
"action": "notworking",
"userInfo": {
"arch32": false,
"packageId": "preferenceloader",
"deviceId": "iPhone7,1",
"url": "http://cydia.saurik.com/package/preferenceloader/",
"iOSVersion": "12.0.1",
"packageVersionIndexed": true,
"packageName": "PreferenceLoader",
"category": "System",
"repository": "rpetrich repo",
"name": "PreferenceLoader",
"installed": "2.2.3-3",
"packageIndexed": true,
"packageStatusExplaination": "A matching version of this tweak for this iOS version could not be found. Please submit a review if you choose to install.",
"id": "preferenceloader",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.1.5",
"shortDescription": "load preferences in style",
"latest": "2.2.4~beta1",
"author": "<NAME>",
"packageStatus": "Unknown"
},
"base64": "<KEY>
"chosenStatus": "not working",
"notes": "bootloop 6 plus"
}
```<issue_closed>
Status: Issue closed |
antlr/grammars-v4 | 587746785 | Title: ECMASript grammar for CSharpSHarwell is in fact just CSharp
Question:
username_0: ECMASript grammar for CSharpSHarwell contains functions like LA, LT, that are not recognised with Sam Harwells antlr, thus they must be La and Lt. Grammar will biuld fine if we refactor function names.
Answers:
username_1: Have you tried [JavaScript](https://github.com/antlr/grammars-v4/tree/master/javascript/javascript) grammar instead?
username_0: @username_1
Yeah. I also replaced all the methods in ecma file so Harwell's antlr understands it. The thing was to turn the upper case methods into the ones with the first capital letter only. |
FezVrasta/react-resize-aware | 1125321915 | Title: React is not defined: auto jsx runtime
Question:
username_0: Hi, I depend on this package as a dependency of another npm package and I believe this issue: https://github.com/username_1/react-resize-aware/issues/57 is seeing the same problem I see.
When I build with Vite with the auto jsx runtime available in React 17 I cannot use this package due to its microbundle distribution. and I get the error `React is not defined`.
I found that if I updated microbundle to latest and made an adjusted build for the jsx runtime, that I could use patch-package and still use this dependency.
The modified build command would be something like `microbundle --name useResizeAware --jsx jsx --jsxImportSource react --globals react/jsx-runtime=jsx` This was based on a suggestion here: https://github.com/developit/microbundle/issues/763#issuecomment-778848944
I was just wondering if you would consider releasing a package with support for the auto jsx runtime? At least for my situation turning off the auto JSX runtime is not an option I have right now. I would be happy to submit a PR with the build changes, but my only concern would be testing it for other environments.
Thanks! ✌🏻
Answers:
username_1: Thanks, could you please test it with `[email protected]`?
username_0: I will thanks!
username_0: @username_1 That doesn't work for me, I get `jsx` is undefined. But you're still using a very old version of microbundle, maybe thats the issue? In my version I updated microbundle to latest.
username_1: Could you please try `3.1.1-issue-58.1`?
username_1: @username_0 ?
username_1: @username_0 may you please provide some feedback? |
ariftairi/Agile-Software-Development | 548457682 | Title: About Us ( Front-End )
Answers:
username_1: 
Status: Issue closed
username_1: The screen About Us has text and an audio , where is explained the goal of the App and why is important Blood Donation . |
googleapis/gax-dotnet | 471771733 | Title: Work out the best location format to use
Question:
username_0: The metadata JSON in Cloud Run includes a location of "us-central1-1", whereas the logs look for "us-central1". We should work out whether there's a preferred way of handling/detecting this. (Marking as a feature request as logs would still work, they'll just be harder to find.)<issue_closed>
Status: Issue closed |
dom111/webdav-js | 377132350 | Title: index.standalone.html without Google Analytics or CDN
Question:
username_0: For privacy reasons some users would like not to use Google Analytics.
And for security reasons some servers are not connected to the internet disabling the use of a CDN.
Answers:
username_0: 54c26332e210cf67732d336dab2c961809daadf8 merge into `master`?
Status: Issue closed
username_1: @username_0 Should be all set! |
BabylonJS/Documentation | 557929361 | Title: HTML code not consistent on First Steps
Question:
username_0: At https://doc.babylonjs.com/babylon101/first there is sample code (above) that matches the playground and below there is an HTML template with a couple differences. Specifically,
```
var camera = new BABYLON.ArcRotateCamera("Camera", Math.PI / 2, Math.PI / 2, 2, BABYLON.Vector3.Zero(), scene);
var camera = new BABYLON.ArcRotateCamera("Camera", Math.PI / 2, Math.PI / 2, 2, new BABYLON.Vector3(0,0,5), scene);
```
and
```
var sphere = BABYLON.MeshBuilder.CreateSphere("sphere", {}, scene);
var sphere = BABYLON.MeshBuilder.CreateSphere("sphere", {diameter:2}, scene);
```
The top code seems better.
Answers:
username_1: for sphere I prefer the 2nd line as it show the diameter
username_2: I will make this change and also look for any other inconsistencies on this page.
username_3: done
Status: Issue closed
|
jgallagher/rusqlite | 155339602 | Title: Rows cannot implement Drop
Question:
username_0: ```rust
let row = s.query(&[]).unwrap().next().unwrap().unwrap();
// Rows has already been dropped, statement has been reset, no data can be retrieved...
row.get(0)
```
Answers:
username_0: See https://github.com/username_0/rusqlite/commit/d8d220e2dd97ea10ce0c46c675e4991f58c34be4
username_1: Ick. Great catch. I would like for that to not compile, but AFAICT an `Iterator` impl can't return references to itself from `next`, which is what I believe we'd need.
Options:
* Leave it as is and document it. This is related to the already-documented issue that if you call `next` twice, you'll get errors trying to access the first row which is now stale.
* Don't reset when `Rows` is dropped, and go back to `reset_if_needed`. We can keep the `reset` on error / `SQLITE_DONE` to still reset ASAP when possible.
Thoughts? Other options?
username_1: Another option is to deprecate/remove `query`. We already recommend people use `query_map` and/or `query_and_then` instead, neither of which expose this problem.
username_0: Could you please confirm that the problem is related to [streaming iterators](https://www.reddit.com/r/rust/comments/467j1p/iterator_with_item_living_for_one_iteration) ?
username_1: Yes, that's the exact problem.
username_1: I think #153 is a decent compromise. Keep `Rows` but change `next()` to return a `Row<'a, 'stmt>` where `'a` is tied to the vending `Rows` handle. This means `Rows` no longer implements `Iterator`, but it's at least still usable, and this change doesn't affect anyone using `query_map`/`query_and_then`.
username_0: This change breaks the current API (when users iterate on Rows), no ?
username_1: It does, yeah.
We're still in `0.x` versioning, so breaking changes are allowed between minor versions. I was okay with runtime checks to let `Rows` implement `Iterator` when the only thing that could go wrong was if you used a row after calling `next()` again, but adding more runtime checks (or disabling resetting the statement when a `Rows` is dropped) seems bad.
username_0: Ok.
username_1: Closed with #153.
Status: Issue closed
|
conan-io/conan | 1178780096 | Title: [bug] MSBuildToolchain doesn't work as intended when using vs_layout
Question:
username_0: <!--
Please don't forget to update the issue title.
Include all applicable information to help us reproduce your problem.
To help us debug your issue please explain:
-->
When I use `vs_layout`, all deps props are generated in x64/$(BuildConfig)/generators folder which works well. However, `conantoolchain.props` is also placed there instead of somewhere agnostic to the current $(BuildConfig). As a result, when I add the individual Debug/Release conantoolchain.props files, if the VS IDE opens defaulting to a $(BuildConfig) that is not the one that was used for `conan install`, the project fails to load.
Correct me if I'm wrong, but isn't the purpose of `conantoolchain.props` to "switch" the current $(BuildConfig) to the one that conan installed with so that the project loads correctly? If so, it seems like `vs_layout` is incompatible with `MSBuildToolchain`
### Environment Details (include every applicable attribute)
* Operating System+version: Windows 10 21H2
* Compiler+version: N/A
* Conan version: 1.45.0
* Python version: N/A
### Steps to reproduce (Include if Applicable)
1. use the default `vs_layout` in the `layout` method of conanfile.py
2. generate both debug/release deps
3. add `x64/Debug/generators/conantoolchain.props` to the Debug config of the project
3. add `x64/Release/generators/conantoolchain.props` to the Release config of the project
4. `git clean -Xdf`
5. `conan install . user/channel`
6. `conandeps.props`, `conantoolchain.props`, and `conantoolchain_release_x64.props` are created in the `x64/Release/generators` folder
7. open VS IDE
8. because VS defaults to `Debug` build config, it fails to load the project due to `x64/Debug/generators/conantoolchain_debug_x64.props` not being found
Answers:
username_1: Could you please try using my source branch in https://github.com/conan-io/conan/pull/10760? That PR should fix it, as commented in https://github.com/conan-io/conan/issues/9330#issuecomment-1076097283.
It will be released soon in 1.47
username_0: I wasn't able to clone and test with the PR that you referenced yet, but I overrode the settings to match the changes you made to vs_layout:
```
def layout(self):
vs_layout(self)
# temp workaround until Conan 1.47 is released
if self.settings.arch != "x86":
arch = msbuild_arch(self.settings.arch)
base = os.path.join(arch, str(self.settings.build_type))
else:
base = str(self.settings.build_type)
self.folders.build = "."
self.folders.generators = "conan"
self.folders.outdir = base
```
This resolves the issue now that the generated `conantoolchain.props` & `conandeps.props` are generated to the same folder regardless of build_type.
However, is it possible to expose the `base` variable of `vs_layout` as something like `self.folders.outdir` as seen above so when importing or packaging, it uses the correct build_type dependent folders? Otherwise imported dlls are in the wrong folder and packaging sometimes packages debug versions of my built artifacts when creating a release package or vice versa.
Something like this:
```
def imports(self):
self.copy("*.dll", dst=self.folders.outdir, src="bin")
def package(self):
# pick up only artifacts for specific build_type
self.copy("*.lib", src=self.folders.outdir, dst="lib", keep_path=False)
self.copy("*.dll", src=self.folders.outdir, dst="bin", keep_path=False)
```
username_1: Wouldn't it make sense to use the ``self.cpp.build.bindirs`` directories? (it is a list, you can use the ``[0]`` first element).
Also a couple of quick hints towards future:
- ``self.copy`` is being replaced by ``from conan.tools.files import copy`` (available in 1.X)
- ``imports()`` will dissapear in Conan 2.0. Import operations will be explicit ``copy()`` in the ``generate()`` methods.
username_0: yes makes sense; Is it guaranteed to always be the first element?
will progressively look into transitioning to 2.0 stuff thanks
Status: Issue closed
|
alex-robinson/ncio | 312013723 | Title: add lambert conformal and gnomonic grids (GEOS5)
Question:
username_0: I would like to see more map projections added to NCIO. Specifically lambert conformal conic and gnomonic grids
Answers:
username_1: It's always possible to write the projection information to a file by hand (define an integer variable with the name of the grid, and then use `nc_write_attr` to store the projection attributes).
But it should also be easy to add these choices to the subroutine `nc_write_map` as well, and I would be happy to expand its capabilities. I am not familiar with the gnomonic projection - what parameter values and names should be saved in the nc file to define the projection? |
KristofferC/PGFPlotsX.jl | 434875056 | Title: load a tikz library
Question:
username_0: Is there a simple way to load a tikz library?
In LaTeX this would involve adding the line `\usetikzlibrary{library_name}` before the plot.
There are many nice features, such as [patterns](https://tex.stackexchange.com/questions/24964/how-to-combine-fill-and-pattern-in-a-pgfplot-bar-plot/25032#25032).
Answers:
username_1: You should be able to just push that as a string to `CUSTOM_PREAMBLE`, see https://kristofferc.github.io/PGFPlotsX.jl/stable/man/save/#PGFPlotsX.CUSTOM_PREAMBLE.
username_2: Also https://kristofferc.github.io/PGFPlotsX.jl/stable/man/save/#customizing_the_preamble-1
Status: Issue closed
username_0: Thank you both, worked like a charm! For future reference, to load `\usetikzlibrary{patterns}` just add the line:
`push!(PGFPlotsX.CUSTOM_PREAMBLE,"\\usetikzlibrary{patterns}")` |
earwig/mwparserfromhell | 376484387 | Title: AttributeError: module 'mwparserfromhell' has no attribute 'parse'
Question:
username_0: Using example from readme i get this error message
```
Traceback (most recent call last):
File "wikiparser.py", line 16, in <module>
main("M1_Abrams")
File "wikiparser.py", line 13, in main
return mwparserfromhell.parse(text)
AttributeError: module 'mwparserfromhell' has no attribute 'parse'
```
here is code snipet
```
import json
from urllib.parse import urlencode
from urllib.request import urlopen
import mwparserfromhell
API_URL = "https://en.wikipedia.org/w/api.php"
def main(title):
data = {"action": "query", "prop": "revisions", "rvlimit": 1,
"rvprop": "content", "format": "json", "titles": title}
raw = urlopen(API_URL, urlencode(data).encode()).read()
res = json.loads(raw)
text = list(res["query"]["pages"].values())[0]["revisions"][0]["*"]
return mwparserfromhell.parse(text)
if __name__ == '__main__':
main("M1_Abrams")
```
Answers:
username_1: You haven't installed the parser correctly. Is it possible you downloaded the git repo to your current directory? It seems Python might be trying and failing to import it from there directly.
You'll either need to install it with pip (`pip install mwparserfromhell`, possibly with `--user`), or run `python setup.py install` inside the project (again, possibly with `--user`) to install directly from source.
Status: Issue closed
username_0: Thanks
the problem was that the library was installed with```python setup.py install``` but run with python3 command |
itchio/itch.io | 41568920 | Title: Opt-out of Google Analytics
Question:
username_0: Even if I don't provide a Google Analytics key, my profile and games pages have itch.io's GA code injected in them.
I would like to be able to disable this entirely and let people look at my pages without feeding Google's surveillance machine.
Answers:
username_0: Giving up.
Status: Issue closed
username_1: @username_0
Could you leave it open for those of us who don't mind waiting? It seems a little inconsiderate to just close it like that when it costs you nothing to leave it open.
username_0: It costs me time every time I look at my open issues list. It's also inconsiderate to project maintainers for the original reporter to be unresponsive in an issue report.
So no, I won't leave it open. If you're volunteering to deal with it, you can file the bug.
username_1: Huh. I hadn't noticed that GitHub had a mechanism for retrieving an "all open issues" list for a single user.
(Force of habit. I assumed that the user-specific stuff in the black portion of the header was restricted to the grouping on the right end and I didn't see anything like an issues list in the account drop-down or the pages linked from it.) |
firebase/snippets-web | 971211388 | Title: Unused function parameter in distributed counter example
Question:
username_0: https://github.com/firebase/snippets-web/blob/c5bfca32e881d7a40002285384a784749f973c35/firestore/test.solution-counters.js#L25-L32
The parameter `db` is unused in this code example. For [the same example in other languages](https://firebase.google.com/docs/firestore/solutions/counters#java_2), they do not have this parameter, so it is unneeded here. |
dart-lang/dart_style | 100180850 | Title: Prevent reformatting with older dartfmt version
Question:
username_0: If a file has been formatted with dartfmt version x, a reformat with dartfmt version y < x should fail (or at least warn).
For this, dartfmt could insert a comment line into the file, specifying the dartfmt version used, which could be read by subsequent dartfmt runs.
Answers:
username_1: Sorry, but I don't think users want dartfmt leaving its signature in every one other their source files. :-/
Status: Issue closed
|
SamCooper/COMMON_SPEC_RIDS | 192770537 | Title: Configuration service : ServiceProviderKey
Question:
username_0: The comment attached to the domain field of the ServiceProviderKey says that "The domain field supports the wildcard value of "*" only in the last part of the domain whereas :
- Requirements 3.4.8.2 c) & 3.4.9.2 b) say : "if the domain contains a wild card in any of its part ..."
Please clarify aand harmonize.
Answers:
username_1: I have removed the type and moved the wildcard requirements into the relevant operations.
Status: Issue closed
|
tsolucio/corebos | 158185063 | Title: Reports Configuration Step 7 style error
Question:
username_0: Using Chrome.
In step 7 of creating/editing a report the standard conditions are hidden but the height of the hidden rows is respected as a big blank space. The div inside the rows are hidden but the rows aren't so, for some reason the height the div will have is reserved.


In Firefox this looks correct:

**The code is in:**
Smarty/templates/ReportFilters.tpl
Answers:
username_1: For some (unknown) reason Chrome sets height of rows, either hidden or visible. I've setted in each tr a height of 1px.
Tested on Chrome and Firefox.
Status: Issue closed
username_0: Looks great!
Thanks! |
scala-js/scala-js | 706551136 | Title: Matcher region not mutating the matcher
Question:
username_0: Matcher.region() is returning an instance of a new matcher with the given start and end position:
https://github.com/scala-js/scala-js/blob/92737aa24280fddb3e914937e9b02f50d2d01c8f/javalib/src/main/scala/java/util/regex/Matcher.scala#L228-L229
The behavior on the JVM is that the region is updated in-place: https://docs.oracle.com/javase/7/docs/api/java/util/regex/Matcher.html#region(int,%20int)
Answers:
username_1: Thanks for the report :)
username_0: As a workaround, I changed my instance to `var` so I can re-assign the returned value to the same variable (rather than mutating). I then noticed at least one more inconsistency with the JVM object that triggered IllegalStateException. I'll file a separate bug later.
Status: Issue closed
|
mozilla/addons-server | 328157074 | Title: Pano type images (larger in size and wider) have display issues after upload in dev hub
Question:
username_0: STR:
1. Load AMO stage and for a submitted add-on upload as screenshots some images but make sure they are above 3MB in size and wide (as in the attachment)
2.Click the Save Changes and observe the screen
Expected result:
Images are uploaded and displayed.
Actual result:
Images are displayed in continuous loading state for a while and then blank.
Notes:
This issue is intermittent but most of the times reproducible on AMO dev and AMO stage with FF60(Win10).
It is not reproducible on the new frontend in the Screenshot section.
Refreshing page will display the content.

These are the samples I used
[cele 2 mai wide.zip](https://github.com/mozilla/addons-server/files/2058546/cele.2.mai.wide.zip)
Status: Issue closed
Answers:
username_1: Duplicate of #8977 |
vmware/declarative-cluster-management | 1147425501 | Title: Use indexes for correlated sub-queries
Question:
username_0: ### Describe the bug
Correlated subqueries currently don't use indexes.
### Reproduction steps
```bash
Any constraint query with correlated subqueries.
```
### Expected behavior
.
### Additional context
_No response_ |
dotnet/diagnostics | 451101838 | Title: [dotnet-counters] [ERROR] System.Exception: Read past end of stream.
Question:
username_0: This error appears sometimes when using dotnet counters monitor
```
Press p to pause, r to resume, q to quit.
Requests Per Second / 1 sec : 0
Total Requests : 68849
Current Requests : 0[ERROR] System.Exception: Read past end of stream.
at FastSerialization.IOStreamStreamReader.Fill(Int32 minimum)
at FastSerialization.MemoryStreamReader.ReadByte()
at FastSerialization.Deserializer.ReadObject()
at Microsoft.Diagnostics.Tracing.EventPipeEventSource.Process()
at Microsoft.Diagnostics.Tools.Counters.CounterMonitor.<>c__DisplayClass12_0.<StartMonitor>b__0() in C:\dev\git\diagnostics\src\Tools\dotnet-counters\CounterMonitor.cs:line 195
```
Answers:
username_1: Should be fixed with #300
Status: Issue closed
|
facebook/react-native | 305044535 | Title: Fatal Exception: java.lang.NullPointerException
Question:
username_0: ```
Fatal Exception: java.lang.NullPointerException: Attempt to invoke virtual method 'int android.view.View.getId()' on a null object reference
at com.facebook.react.uimanager.NativeViewHierarchyManager.getAnimationRegistry(Unknown Source:67)
at com.facebook.react.uimanager.NativeViewHierarchyManager.getAnimationRegistry(Unknown Source:420)
at com.facebook.react.uimanager.UIViewOperationQueue$ManageChildrenOperation.execute(Unknown Source:14)
at com.facebook.react.uimanager.UIViewOperationQueue$1.run(Unknown Source:87)
at com.facebook.react.uimanager.UIViewOperationQueue.setViewHierarchyUpdateDebugListener(Unknown Source:56)
at com.facebook.react.uimanager.UIViewOperationQueue.access$2100(Unknown Source)
at com.facebook.react.uimanager.UIViewOperationQueue$DispatchUIFrameCallback.doFrameGuarded(Unknown Source:31)
at com.facebook.react.uimanager.GuardedFrameCallback.doFrame(Unknown Source)
at com.facebook.react.modules.core.ReactChoreographer$ReactChoreographerDispatcher.doFrame(Unknown Source:49)
at com.facebook.react.modules.core.ChoreographerCompat$FrameCallback$1.doFrame(Unknown Source:2)
at android.view.Choreographer$CallbackRecord.run(Choreographer.java:964)
at android.view.Choreographer.doCallbacks(Choreographer.java:778)
at android.view.Choreographer.doFrame(Choreographer.java:710)
at android.view.Choreographer$FrameDisplayEventReceiver.run(Choreographer.java:952)
at android.os.Handler.handleCallback(Handler.java:789)
at android.os.Handler.dispatchMessage(Handler.java:98)
at android.os.Looper.loop(Looper.java:164)
at android.app.ActivityThread.main(ActivityThread.java:6809)
at java.lang.reflect.Method.invoke(Method.java)
at com.android.internal.os.Zygote$MethodAndArgsCaller.run(Zygote.java:240)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:767)
```
* RN version: 0.51.0
* OS: 8.0.0
* Device: ONEPLUS A5010
* Not able to reproduce at my end
Answers:
username_1: I have The same crash stack
username_2: I am facing this issue too
username_3: I have the same crash stack. it only happens android 8
username_0: @hramos , this is all information we are getting from stacktrace , not able to reproduce at end.
Seems like its not only me who is facing.
@username_1 @username_2 @username_3 if you people have more information regarding this exception, would be very helpful.
username_4: @hramos this also happens on our end on android 8 only from firebase crash reports... we're trying to see if we can effectively reproduce this, will provide an update soon.
username_5: We have same crash at android 8.0.0
java.lang.NullPointerException: Attempt to invoke virtual method 'int android.view.View.getId()' on a null object reference
at com.facebook.react.uimanager.NativeViewHierarchyManager.dropView(NativeViewHierarchyManager.java:537)
at com.facebook.react.uimanager.NativeViewHierarchyManager.manageChildren(NativeViewHierarchyManager.java:431)
at com.facebook.react.uimanager.UIViewOperationQueue$ManageChildrenOperation.execute(UIViewOperationQueue.java:180)
at com.facebook.react.uimanager.UIViewOperationQueue$1.run(UIViewOperationQueue.java:819)
at com.facebook.react.uimanager.UIViewOperationQueue.flushPendingBatches(UIViewOperationQueue.java:926)
at com.facebook.react.uimanager.UIViewOperationQueue.access$2100(UIViewOperationQueue.java:47)
at com.facebook.react.uimanager.UIViewOperationQueue$DispatchUIFrameCallback.doFrameGuarded(UIViewOperationQueue.java:986)
at com.facebook.react.uimanager.GuardedFrameCallback.doFrame(GuardedFrameCallback.java:31)
at com.facebook.react.modules.core.ReactChoreographer$ReactChoreographerDispatcher.doFrame(ReactChoreographer.java:136)
at com.facebook.react.modules.core.ChoreographerCompat$FrameCallback$1.doFrame(ChoreographerCompat.java:107)
at android.view.Choreographer$CallbackRecord.run(Choreographer.java:979)
at android.view.Choreographer.doCallbacks(Choreographer.java:790)
at android.view.Choreographer.doFrame(Choreographer.java:718)
at android.view.Choreographer$FrameDisplayEventReceiver.run(Choreographer.java:967)
at android.os.Handler.handleCallback(Handler.java:808)
at android.os.Handler.dispatchMessage(Handler.java:101)
at android.os.Looper.loop(Looper.java:166)
at android.app.ActivityThread.main(ActivityThread.java:7425)
at java.lang.reflect.Method.invoke(Native Method)
at com.android.internal.os.Zygote$MethodAndArgsCaller.run(Zygote.java:245)
at com.android.internal.os.ZygoteInit.main(ZygoteInit.java:921)
Environment
react-native: 0.53.3
react: 16.2.0
os: android 8.0 |
zombodb/zombodb | 170245945 | Title: zdb_highlight and proximity search
Question:
username_0: zdb: 2.6.16
When proximity criteria is passed to zdb_highlight and it contains 'OR'ed criteria, the following error is returned.
--SQL
SELECT * FROM zdb_highlight('schema.table_or_view'::REGCLASS, '( ( pk_id:16953417 AND data_fulltext:(("matte" w/3 ("mark" OR "willie"))) ) )'::TEXT, 'pk_id IN (''16953417'')'::TEXT, '{"data_fulltext"}'::TEXT[]) ORDER BY "primaryKey", "fieldName", "arrayIndex", "position";
--ERROR
ERROR: rc=500; {"error":"RuntimeException[Don't know how to match node type: ASTOr]","status":500}
CONTEXT: SQL statement "SELECT zdb_internal_highlight(49453476, E'"( ( pk_doid:16953417 AND data_fulltext:((\\"matte\\" w/3 (\\"mark\\" OR \\"willie\\"))) ) )"', json_agg(row_to_json)) FROM (SELECT row_to_json(the_table) FROM (SELECT data_fulltext,pk_id FROM table_or_view WHERE pk_id IN ('16953417')) the_table) x"
PL/pgSQL function zdb_highlight(regclass,text,text,text[]) line 19 at EXECUTE statement
Answers:
username_1: A fix for this will be in v3.1. Thanks for the report, Mark!
Status: Issue closed
username_1: released in v3.1.0 |
awslabs/goformation | 787360430 | Title: Intrinsic Processor Options not working
Question:
username_0: The intrinsic functions are resolved too quickly in the output.
Answers:
username_1: Light on information here @username_0, I'v also open an issue with more detail with an issue with the intric helper functions specifically Select is this the same thing you are experiencing?
https://github.com/awslabs/goformation/issues/362 |
JSXRED/Codiad-Query-Designer | 56488238 | Title: Move connections
Question:
username_0: Please move connections.php to "<codiad root>/data/config" directory of Codiad during the first startup and rename it to your plugin, sth like querydesigner.php.
https://github.com/JSXRED/Codiad-Query-Designer/blob/master/dbengine/connectionmanager.php#L24 |
cerebral/overmind | 724381208 | Title: How to persist state in browser?
Question:
username_0: Hi guys! Thanks for this amazing project!
I would like to know if is possible to persist state in LocalStorage or (better) IndexedDB between user sessions to speed up data visualization using something like Apollo `networkPolicy: cache-and-network`.
Yes or no?
Answers:
username_1: Hi @username_0!
As I touched on in #456 you'd use `addMutationListener` to keep track of changes to the state. You can then either persist the whole state to LocalStorage, or certain parts.
When doing a full page load, fetch the state from LocalStorage and assign it to state inside OnInitialize :-)
username_0: Ok. I'm new to this. Is there an example?
username_1: @username_0 Seems like `reactions` is the way to go actually. Have not used those, but seems pretty straight-forward. See a fully working sample at https://codesandbox.io/s/overmind-todomvc-typescript-vlulp?file=/src/app/onInitialize.ts. It's running an older version of Overmind, but the relenant bits should still be valid. The docs also mention this: https://overmindjs.org/api-1/reaction
Status: Issue closed
username_2: Closing this for now, but please reopen if you are stuck @username_0 or join us on discord 😄 (Link on website) |
IonicaBizau/git-stats | 256191095 | Title: git-stats --authors truncates top not bottom
Question:
username_0: When using `git-stats --authors` in a repository with a lot of contributing authors (>35), the topmost authors are cut off. I think it'd make more sense to show the "leading" contributors and cut off at the bottom, maybe even with "..." or similar, to show the list has been truncated.
Answers:
username_1: @IonicaBizau Hello, has the bug been resolved now ? Really need it ... Thanks!
username_2: No it's still an issue.
username_3: I just hit this using the pie chart and using a --since of 2010 (our projects has 100s of contributors). It would be great if, either:
1) There was a switch for this to be top 35 instead of bottom 35 (or that top was default).
2) There was an option to center the graph beside a full list of contributors. |
jncc/jncc-website | 456261756 | Title: Ensure archive.jncc.gov.uk is not discoverable by search engines
Question:
username_0: not sure how best to do this
but no index no follow in all headers is one thought
a robots txt file change also
also wondering if the archive site should be a copy of the current live site, which will allow us to do all these changes prior to live
Answers:
username_0: set up http headers in IIS
and put robots page
NOTE - this task can only be done on or just before the site goes live
username_1: Added X-Robots-Tag - noindex, nofollow header to every request coming out from IIS for the old alterian site, the robots.txt file has been returned to normal as google requires access and adding Dissallow / to the file means that the archive site shows up in the main google index anyway.
Status: Issue closed
|
steelbrain/linter | 144303781 | Title: Linter not triggering/updating when the same file is open in two panes
Question:
username_0: If I open the same file in two panes and I modify one of them the linter only triggers in one, not in the other. Its not clear to me exactly whats the logic behind which one triggers, at least for my test with some js and sass files sometimes is the right one and sometimes the left one.
Its specially annoying when you have a ton of fields open and you forget that you already have the file, you open it and you get no errors at all (maybe #1002 is related?) It's seems quite similar to #811 but in this case is not the latest saved one, so it may be some kind of regression?
I can reproduce it consistently and I'm using Atom 1.6.0 on OSX 10.11.4.
Answers:
username_1: Can you please retry this in the master branch? It's very likely that this issue has already been fixed
username_0: Well I just tried and it is actually fixed in master. Thanks and good work!
Status: Issue closed
username_1: I am glad it works, :+1: thanks for the feedback |
Fody/Fody | 314406769 | Title: issues for class inheriting in different assemblies
Question:
username_0: version: 2.5.3.0
make two assemblies with two projects:
1) ClassLibrary1.dll
namespace ClassLibrary1
{
public class Person : INotifyPropertyChanged
{
public event PropertyChangedEventHandler PropertyChanged;
public string GivenNames { get; set; }
public string FamilyName { get; set; }
public string FullName => $"{GivenNames} {FamilyName}";
}
}
2)Model.exe
namespace A4
{
public class Manager: ClassLibrary1.Person
{
public string Territory { get; set; }
}
}
compile error:
1> Fody: Fody (version 3.0.3.0) Executing
1>MSBUILD : error : Fody: An unhandled exception occurred:
1>MSBUILD : error : Exception:
1>MSBUILD : error : Failed to execute weaver C:\Users\Vince\source\repos\WindowsFormsApp1\packages\PropertyChanged.Fody.2.5.3\netclassicweaver\PropertyChanged.Fody.dll
1>MSBUILD : error : Type:
1>MSBUILD : error : System.Exception
1>MSBUILD : error : StackTrace:
1>MSBUILD : error : 在 InnerWeaver.ExecuteWeavers() 位置 C:\projects\fody\FodyIsolated\InnerWeaver.cs:行号 208
1>MSBUILD : error : 在 InnerWeaver.Execute() 位置 C:\projects\fody\FodyIsolated\InnerWeaver.cs:行号 103
1>MSBUILD : error : Source:
1>MSBUILD : error : FodyIsolated
1>MSBUILD : error : TargetSite:
1>MSBUILD : error : Void ExecuteWeavers()
1>MSBUILD : error : Could not inject EventInvoker method on type 'A4.Manager'. It is possible you are inheriting from a base class and have not correctly set 'EventInvokerNames' or you are using a explicit PropertyChanged event and the event field is not visible to this instance. Either correct 'EventInvokerNames' or implement your own EventInvoker on this class. If you want to suppress this place a [DoNotNotifyAttribute] on A4.Manager.
1>MSBUILD : error : Type:
1>MSBUILD : error : Fody.WeavingException
1>MSBUILD : error : StackTrace:
1>MSBUILD : error : 在 ModuleWeaver.InjectMethod(TypeDefinition targetType, InvokerTypes& invokerType) 位置 C:\projects\propertychanged\PropertyChanged.Fody\MethodInjector.cs:行号 81
1>MSBUILD : error : 在 ModuleWeaver.AddOnPropertyChangedMethod(TypeDefinition targetType) 位置 C:\projects\propertychanged\PropertyChanged.Fody\MethodInjector.cs:行号 29
1>MSBUILD : error : 在 ModuleWeaver.FindMethodsForNodes() 位置 C:\projects\propertychanged\PropertyChanged.Fody\MethodFinder.cs:行号 199
1>MSBUILD : error : 在 ModuleWeaver.Execute() 位置 C:\projects\propertychanged\PropertyChanged.Fody\ModuleWeaver.cs:行号 18
1>MSBUILD : error : 在 InnerWeaver.ExecuteWeavers() 位置 C:\projects\fody\FodyIsolated\InnerWeaver.cs:行号 204
1>MSBUILD : error : Source:
1>MSBUILD : error : PropertyChanged.Fody
1>MSBUILD : error : TargetSite:
1>MSBUILD : error : Mono.Cecil.MethodDefinition InjectMethod(Mono.Cecil.TypeDefinition, InvokerTypes ByRef)
1>MSBUILD : error :
1> Fody: Finished Fody 117ms.
Answers:
username_1: please re-read the instructions you are presented with when opening a new issue
Status: Issue closed
username_1: also i think this should be in https://github.com/Fody/PropertyChanged |
MicrosoftDocs/windows-driver-docs-ddi | 1124620327 | Title: maybe a possible bug in the functions RtlStringCchPrintfA and RtlStringCchPrintfW
Question:
username_0: i am sorry if this is not the right support page but the link on the source page has redirect me to this blog
i am trying to use RtlStringCchPrintfA and RtlStringCchPrintfW passing them the 'variable ends parameters'
like the example below ....
i suppose that the RtlStringCchPrintfA and RtlStringCchPrintfW don't support it ... but maybe for a bug
of the function or bad implementation ...
1) could i know if i am in error?
2) could i know, if you don't are the final responsable, some link or email to write to?
thanks awhile
---------------------------------------------------- PROPOSED TO WORK ON USER MODE
va_start(ap, msg);
vsnprintf(buf, sizeof(buf), msg, ap);
va_end(ap);
----------------------------------------------------
---------------------------------------------------- MY TRY IMPLEMENTATION ON KERNEL MODE
va_list args;
va_start(args, params_paf);
status = RtlStringCchPrintfA(A1_Buffer_DST, cchDest, (LPCSTR)P1_Content_Buffer_to_Write_paf, args);
va_end(args);
----------------------------------------------------
[Enter feedback here]
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 412b77ac-d5b9-eebf-8be3-6d0f1c439f93
* Version Independent ID: 054c92fa-e263-50c0-5f25-695af12af92d
* Content: [RtlStringCchPrintfW function (ntstrsafe.h) - Windows drivers](https://docs.microsoft.com/en-us/windows-hardware/drivers/ddi/ntstrsafe/nf-ntstrsafe-rtlstringcchprintfw)
* Content Source: [wdk-ddi-src/content/ntstrsafe/nf-ntstrsafe-rtlstringcchprintfw.md](https://github.com/MicrosoftDocs/windows-driver-docs-ddi/blob/staging/wdk-ddi-src/content/ntstrsafe/nf-ntstrsafe-rtlstringcchprintfw.md)
* Product: **windows-hardware**
* Technology: **wdk-api-reference**
* GitHub Login: @tedhudek
* Microsoft Alias: **tedhudek**
Status: Issue closed
Answers:
username_0: sorry i have found next that RtlStringCchVPrintfW and RtlStringCchVPrintfA are needed for the context |
tyejae/msf.gg.public | 432764773 | Title: Black Panther Passive incorrect
Question:
username_0: A bit *too* good right now

Answers:
username_1: Fixed! This algorithm to formulate that text is a pain! Thanks as always Chronolinq!!!
Status: Issue closed
|
thoughtstem/morugamu | 350126941 | Title: Side quest: Machine Learning / Computer Vision
Question:
username_0: **Step 1**
Start with this blog post and get an existing object detection setup working:
https://towardsdatascience.com/real-time-object-detection-api-using-tensorflow-and-opencv-47b505d745c4
**Step 2**
Train your own models that work with this same setup.
Hint, use tutorials linked from here:
https://github.com/tensorflow/models
Answers:
username_1: ### How to Train Tensorflow Models For GPU's
https://towardsdatascience.com/how-to-traine-tensorflow-models-79426dabd304
username_2: https://towardsdatascience.com/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9
username_1: convert '*.jpg[650x]' TacoFishPhoto%02d.jpg |
Iniciativaz/zos-workshop | 618462538 | Title: Lab3 E LAB4
Question:
username_0: Lab3: item 1 - Não estou conseguindo ver qual é o arquivo de output do sort no sdsf, só vem o nome do job via comando "start sd;st". Daí para frente não sei qual comando informar.
Lab 4 - executei todos os jobs requeridos, anotei os números das execuções, mas eles não aparecem quando eu digito "sd; owner (usuário);st". Para onde foram esses jobs?
Status: Issue closed
Answers:
username_0: Lab3: Qual comando uso para ver o arquivo de output spool? Só vejo esta tela:
 |
ClickHouse/ClickHouse | 1074143988 | Title: Hung query from system.part_log
Question:
username_0: **Describe what's wrong**
Select from system.part_log cannot complete within reasonable time.
Here is information from process list:
```
Row 1:
──────
elapsed: 3538.581210936
query_id: 5644dec2-3388-47fb-ba1e-a7692ab72309
query: SELECT 'bytes' AS metric, sum(read_bytes) AS value
FROM system.part_log
WHERE event_type = 'MergeParts' AND database != 'system'
UNION ALL
SELECT 'rows' AS metric, sum(read_rows) AS value
FROM system.part_log
WHERE event_type = 'MergeParts' AND database != 'system'
FORMAT JSON;
is_cancelled: 0
read: 26445750 rows / 555.36 MiB
written: 0 rows / 0.00 B
memory usage: 0.00 B
user: _metrics
client: python-requests/2.20.0
thread_ids: [1049125,1065638,1065628,1049401,1065638,1049458,1065638,1049410,1065639,1049157,1065619,1065621,1049416,1065617,1049204,1065627,1049448,1065635,1065634,1065618,1065630,1049427,1049437,1049447,1065637,1049454,1049433,1065631,1065620,1049427,1065629,1065635,1065633,1049207,1049155,1065623,1065624,1049160,1065622,1049404,1065626,1065632,1065638,1049157,1065621,1049410,1049458,1065619,1065636,1049401,1065639,1065628,1049204,1065617,1049416,1049453,1065618,1065634,1065637,1049448,1049447,1065625,1049427,1065627,1065631,1049437,1065630,1065633,1065629,1065635,1049433,1065620,1049454]
ProfileEvents: {'Query':1,'SelectQuery':1,'FileOpen':259,'Seek':78,'ReadBufferFromFileDescriptorRead':326,'ReadBufferFromFileDescriptorReadBytes':618295,'ReadCompressedBytes':25675548,'CompressedReadBufferBlocks':5402,'CompressedReadBufferBytes':377671120,'IOBufferAllocs':770,'IOBufferAllocBytes':41995656,'ArenaAllocChunks':80,'ArenaAllocBytes':327680,'FunctionExecute':1710,'MarkCacheHits':265,'MarkCacheMisses':5,'CreatedReadBufferOrdinary':49,'DiskReadElapsedMicroseconds':172,'SelectedParts':32,'SelectedRanges':32,'SelectedMarks':3308,'SelectedRows':26445750,'SelectedBytes':582338526,'ContextLock':106,'RWLockAcquiredReadLocks':2,'RealTimeMicroseconds':17220073,'UserTimeMicroseconds':272859,'SystemTimeMicroseconds':194772,'SoftPageFaults':20465,'OSCPUWaitMicroseconds':507,'OSCPUVirtualTimeMicroseconds':467591,'CreatedHTTPConnections':227,'QueryProfilerRuns':145077,'S3ReadMicroseconds':33728452,'S3ReadBytes':74517920,'S3ReadRequestsCount':226}
Settings: {'s3_min_upload_part_size':'33554432','s3_max_single_part_upload_size':'33554432','use_uncompressed_cache':'0','background_pool_size':'32','distributed_directory_monitor_batch_inserts':'1','log_queries':'0','log_queries_cut_to_length':'10000000','max_concurrent_queries_for_user':'10','insert_distributed_sync':'1','max_execution_time':'29','timeout_before_checking_execution_speed':'300','readonly':'2','join_algorithm':'auto','partial_merge_join_optimizations':'0','max_memory_usage':'10000000000','max_memory_usage_for_user':'0','allow_drop_detached':'1'}
```
The query is executing 3538 seconds. Usually it's completed within seconds. Furthermore, there is a limit on max execution time in 29 seconds.
Stacktrace:
https://gist.githubusercontent.com/username_0/fe79a880343b9cb523396cbf43399edb/raw/34f9abb9445b4d34bb3b2de9a581371e427e2393/stack_trace-20211208.txt
**Does it reproduce on recent release?**
Yes. ClickHouse version: 21.11.4
[The list of releases](https://github.com/ClickHouse/ClickHouse/blob/master/utils/list-versions/version_date.tsv)
Answers:
username_1: ```
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::Epoll::getManyReady(int, epoll_event*, bool) const
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::PollingQueue::wait(std::__1::unique_lock<std::__1::mutex>&)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::PipelineExecutor::executeImpl(unsigned long)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::PipelineExecutor::execute(unsigned long)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::CompletedPipelineExecutor::execute()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::executeQuery(DB::ReadBuffer&, DB::WriteBuffer&, bool, std::__1::shared_ptr<DB::Context>, std::__1::function<void (std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&, std::__1::basic_string<char, std::__1::char_traits<char>, std::__1::allocator<char> > const&)>, std::__1::optional<DB::FormatSettings> const&)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::HTTPHandler::processQuery(DB::HTTPServerRequest&, DB::HTMLForm&, DB::HTTPServerResponse&, DB::HTTPHandler::Output&, std::__1::optional<DB::CurrentThread::QueryScope>&)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::HTTPHandler::handleRequest(DB::HTTPServerRequest&, DB::HTTPServerResponse&)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::HTTPServerConnection::run()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::TCPServerConnection::start()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::TCPServerDispatcher::run()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::PooledThread::run()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::ThreadImpl::runnableEntry(void*)
```
Looks related to #29618
username_2: It is related to DiskS3 feature that is not production ready.
Status: Issue closed
username_2: ```
/lib/x86_64-linux-gnu/libc-2.27.so: __poll
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::SocketImpl::pollImpl(Poco::Timespan&, int)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::SocketImpl::poll(Poco::Timespan const&, int)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::SocketImpl::receiveBytes(void*, int, int)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::HTTPSession::refill()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::HTTPHeaderStreamBuf::readFromDevice(char*, long)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::BasicBufferedStreamBuf<char, std::__1::char_traits<char>, Poco::Net::HTTPBufferAllocator>::underflow()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: std::__1::basic_streambuf<char, std::__1::char_traits<char> >::uflow()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: std::__1::basic_istream<char, std::__1::char_traits<char> >::get()
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::HTTPResponse::read(std::__1::basic_istream<char, std::__1::char_traits<char> >&)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Poco::Net::HTTPClientSession::receiveResponse(Poco::Net::HTTPResponse&)
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::S3::PocoHTTPClient::makeRequestInternal(Aws::Http::HttpRequest&, std::__1::shared_ptr<DB::S3::PocoHTTPResponse>&, Aws::Utils::RateLimits::RateLimiterInterface*, Aws::Utils::RateLimits::RateLimiterInterface*) const
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: DB::S3::PocoHTTPClient::MakeRequest(std::__1::shared_ptr<Aws::Http::HttpRequest> const&, Aws::Utils::RateLimits::RateLimiterInterface*, Aws::Utils::RateLimits::RateLimiterInterface*) const
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Aws::Client::AWSClient::AttemptOneRequest(std::__1::shared_ptr<Aws::Http::HttpRequest> const&, Aws::AmazonWebServiceRequest const&, char const*, char const*, char const*) const
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Aws::Client::AWSClient::AttemptExhaustively(Aws::Http::URI const&, Aws::AmazonWebServiceRequest const&, Aws::Http::HttpMethod, char const*, char const*, char const*) const
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Aws::Client::AWSClient::MakeRequestWithUnparsedResponse(Aws::Http::URI const&, Aws::AmazonWebServiceRequest const&, Aws::Http::HttpMethod, char const*, char const*, char const*) const
/usr/lib/debug/.build-id/83/32e80f7acf6de1033e1a6d9f16415c6e03dbf0.debug: Aws::S3::S3Client::GetObject(Aws::S3::Model::GetObjectRequest const&) const
``` |
dart-lang/sdk | 708619809 | Title: No error if library exports declaration 'main' which is not a function
Question:
username_0: But in fact there are no errors nor in analyzer nor in CFE in all of the cases below
```dart
void getVoid() {}
void main = getVoid();
```
```dart
int get main => 42;
```
```dart
class main {}
```
```dart
typedef void main(List<String> args);
```
```dart
class C {
}
mixin main on C {}
```
`Dart SDK version: 2.10.0-110.0.dev (dev) (Wed Sep 9 17:51:43 2020 -0700) on "windows_x64"`
Answers:
username_1: Created #43556/#43557 specific to CFE/analyzer, moved CFE epic link to #43556.
username_2: Any work left? Can we close this now?
username_1: No more work here, it's covered by sub-issues and they're closed.
Status: Issue closed
|
ionic-team/ionic-cli | 287509749 | Title: ionic cordova run browser --livereload not working with cordova plugin
Question:
username_0: **Description:**
When i run command "ionic cordova run browser" then all works fine, but i have not livereload;
When i run command "ionic cordova run browser --livereload" then app starts, but livereload not work and i have many cordova_not_available errors;
**Steps to Reproduce:**
run command "ionic cordova run browser --livereload"
**Output:**
19:38:26] console.log: Angular is running in the development mode. Call enableProdMode() to enable the production mode.
[19:38:26] console.warn: Native: tried calling StatusBar.styleDefault, but Cordova is not available. Make sure to include cordova.js or run in a device/simulator
[19:38:26] console.warn: Native: tried calling SplashScreen.hide, but Cordova is not available. Make sure to include cordova.js or run in a device/simulator
[19:38:26] console.warn: Native: tried calling QRScanner.prepare, but Cordova is not available. Make sure to include cordova.js or run in a device/simulator
[19:38:26] console.log: Error is cordova_not_available
[19:38:26] console.warn: Native: tried calling QRScanner.prepare, but Cordova is not available. Make sure to include cordova.js or run in a device/simulator
[19:38:26] console.log: Error is cordova_not_available
**My `ionic info`:**
cli packages:
ionic/cli-utils : 1.19.0
ionic (Ionic CLI) : 3.19.0
global packages:
cordova (Cordova CLI) : 7.1.0
local packages:
ionic/app-scripts : 3.1.2
Cordova Platforms : android 6.3.0 browser 5.0.1
Ionic Framework : ionic-angular 3.9.2
System:
Android SDK Tools : 26.1.1
Node : v8.9.1
npm : 5.6.0
OS : Windows 10
Answers:
username_1: Hi @username_0, thanks for posting the issue. Please see this issue -> https://github.com/ionic-team/ionic-cli/issues/2312
We don't have support for the `browser` Cordova platform.
Status: Issue closed
username_2: Any plans of adding that support? |
cds-astro/ipyaladin | 465715453 | Title: JupyterLab 1.0 support
Question:
username_0: JupyterLab 1.0 is released, and ipywidgets 7.5. For ipyaladin to work with those new versions you would need to make the following change in the `package.json` file:
`"@jupyter-widgets/base": "^1.1",` becomes `"@jupyter-widgets/base": "^1.1 || ^2.0",`
Answers:
username_1: As you do this, could you please publish a version of the Jupyterlab widget to npm? It would be convenient to be able to install it with `jupyter labextension install` rather than having to check out the git repository and then do an install from the directory.
username_1: I've built a PR for it:
https://github.com/cds-astro/ipyaladin/pull/18
username_1: Except that it fails to build with `jupyter lab build`. I'll investigate. |
flutter/flutter | 362111452 | Title: Need to animate the old page during transition
Question:
username_0: Currently, the transition (PageRoute) is an overlay, only provide a child widget which is the new page.
It should be involved with the old page. If I want to fade out or do other animations to the old page, I cannot do it with the current method.
For my project, each page has an overlay which is semi-transparent. You will notice the overlay is overlapped by the new page during the transition but suddenly changed to one layer since the old page is hidden when the transition is finished.
I need to animate the old page to move and fade out with the new one coming in to give the user a smooth visual effect.
I also asked on SO ([link](https://stackoverflow.com/questions/52419056/how-to-animate-old-page-during-transition-in-flutter)) and discord, but people from discord suggesting me to ask here.
For comparison, the iOS native transition is able to animate both old and new page, so that you can make very great switching effects.
Answers:
username_1: Did the SO answer help?
username_0: I think the SO answer is not very helpful. I need a solution, not an answer to why it's not working.
But I did write a custom widget to achieve what I want.
I might provide the full solution for this if someone's interested, it's still an experiment, maybe with a lot of problems.
I'm still expecting an official way to do it. It is a must for an iOS native app, especially if you want to make a smooth experience app.
username_2: @username_0 Do you mind sharing your solution? I am looking to do something similar in my app.
username_0: Sorry for the late reply. I'll post the implementation when possible. |
rap2hpoutre/fast-excel | 341878463 | Title: Name sheets in export
Question:
username_0: According to [this comment](https://github.com/username_0/fast-excel/pull/24#issuecomment-397243843), it would be great to be able to name sheets. As suggested by @Harty, it could be done in `SheetCollection` constructor:
```php
$sheets = new SheetCollection(
[User::all(), Project::all()],
['users sheet', 'project sheet']
);
```
So it means a new property (`names`) could be added to `SheetCollection` then it could be passed as a second argument in the `SheetCollection` constructor.
The main advantage to add it in the constructor is that (in a second step), it could be used in import process too: the sheet names would be loaded from the `importSheets` function that returns the `SheetCollection`. So that's cool.
One disadvantage of creating the name of the sheets via `SheetCollection` constructor is that there is no way to name a sheet when exporting only a `Collection` (e.g only one sheet) but I'm not sure it's an actual issue: the main goal is to **name sheets in multiple sheets export**.
Answers:
username_1: How about
```$sheets = new SheetCollection([
'users sheet' => User::all(),
'project sheet' => Project::all()
]);``` and still supporting `$sheets = new SheetCollection([User::all(), Project::all()]);` if you don't want to change sheet names?
When exporting a single collection, you would use `$sheets = new SheetCollection(['users' => User::all()]);`
username_0: @username_1 ... 👍 👍
You are totally right. Your suggestion is really good, thank you so much! I will develop it following your advice. So:
```
$sheets = new SheetCollection(['users' => User::all()]);
(new FastExcel($sheets))->export('file.xlsx');
```
Status: Issue closed
username_0: Fixed via https://github.com/username_0/fast-excel/commit/059442e4e124fab5999fd4d64a19c0a6626a33f0 available in v0.9.0 |
giongto35/cloud-game | 499318760 | Title: Audio support
Question:
username_0: It seems there is no audio when you run games on the cloudretro.io or locally.
Maybe I missed that point in the docs, but does it support audio decode/playback right now?
Tried the latests versions:
W10 / Chrome (Stable, Dev, Canary),
Ubuntu 18 / Chrome (Stable),
Android 8 / Chrome (Stable).
Answers:
username_1: Hi username_0,
The audio is not worked properly right now after my attempt to integrate with LibRetro. And because of autoplay policy, https://developers.google.com/web/updates/2017/09/autoplay-policy-changes, I decided to mute the audio.
https://github.com/username_1/cloud-game/blob/master/web/game.html#L36
The attribute is `mute`.
I'm welcoming for any change that can help improve the audio encoding pipeline.
username_0: Oh, that was easier than I thought. (: Thanks for the info.
P.S. I wish I could help you with this project but, sadly, I'm too don't have that much spare time for hobby projects and mostly lacking in exp with C/GO programming. I've just started to write my own frontend from a scratch based on your work (and nano/no arches) in order to understand libretro. Now, that you've mentioned some audio problems, maybe I'll look into that when I get to that part.
Thanks for your great work, it helps a lot to beginners like me.
Status: Issue closed
|
vimeo/psalm | 607029838 | Title: Have to run psalm twice to fix all the issues
Question:
username_0: Hi, thanks for the nice tool! Something I came across, which I thought I should share. I have to run psalm twice to get all the fixes. It would be really cool if all the fixes can be made in one go.
Here is the code I started with:
```php
public static function foo($s) {
return $s++;
}
foo(10);
```
When I run psalm once with the following command:
`./vendor/bin/psalm --issues=all --alter Class.php`
I get the following fixes:
```php
public function foo(int $s) {
return $s++;
}
foo(10);
```
and then I have to run it again to add the missing return type. When I run the command again:
`./vendor/bin/psalm --issues=all --alter Class.php`
I get the missing return type fixed:
```php
public function foo(int $s): int {
return $s++;
}
foo(10);
```
I was hoping all the fixes would be done in a single pass. Am I missing something? Thanks!
Answers:
username_0: Hey @psalm-github-bot Yes, I was able to do that when using the interactive editor on the article https://psalm.dev/articles/php-or-type-safety-pick-any-two
username_1: As it stands now it may require multiple runs to get all issues fixed. Consider this:
```php
<?php
function a() {
return b();
}
function b() {
return c();
}
function c() {
return d();
}
function d() {
return 1;
}
```
First run adds int return type to `d()`, second adds it to `c()` and so on.
username_0: Thanks @username_1 for the quick response. I will keep this in mind, and would definitely be awesome to be able to have all fixes in the first pass. Thanks again.
username_2: I think I prefer that Psalm only does one sweep at a time, because it means things stay performant, but if anyone wants to look into this Psalter could repurpose Psalm's ability to detect changes in files. |
deeplearning4j/deeplearning4j | 130485409 | Title: Word2Vec : odd formats can lead to misleading results
Question:
username_0: As a newbie, I tried to use the sample file [text8](http://mattmahoney.net/dc/text8.zip) also used in Spark ML examples.
I ran into trouble because the file is a 1 line file of 100Mo words. This took more that 15 hours to process on a decent machine.
It would be good to have a warning for this kind of odd input, thus avoiding misleading results.
Answers:
username_1: Indeed, spark does not cope well with one-liners like that. Here, we modified cleanup perl script to output one line per paragraph of the original text of this corpus.
username_2: As temporary solution warning on misaligned input was added.
General solution to be decided.
Status: Issue closed
|
Azure/webapps-deploy | 596654855 | Title: Deployment Failed with Error: Error: Publish profile does not contain kudu URL
Question:
username_0: 
Any possible reason for this?
Answers:
username_1: Do you have `publishUrl` attribute in your publishprofile file?
username_2: Having the same issue, our credentials were set up automatically via our App Center's Deployment center, after that didn't work we tried going manually via the error link (https://aka.ms/create-secrets-for-GitHub-workflows).
Is there any examples of what the secret value (publish profile) should look like?
username_0: Actually I fixed it, There was issue in publish url. It didn't have scm in the url.
username_0: Actually when you open the publish profile in any text editor, you need to add entire content of that file name as secret. I think to be precise, rhat should contain the publish setting of type web deploy with the publish url as https://<example>.scm.azurewebsites.net
username_2: @username_0
This is the Publish Profile I get from Azure (sensitive data removed)
```xml
<publishData>
<publishProfile profileName="[app-name] - Web Deploy" publishMethod="MSDeploy" publishUrl="waws-prod.publish.azurewebsites.windows.net:443" msdeploySite="[app-name]" userName="$[app-name]" userPWD="***" destinationAppUrl="http://[app-name].azurewebsites.net" SQLServerDBConnectionString="" mySQLDBConnectionString="" hostingProviderForumLink="" controlPanelLink="http://windows.azure.com" webSystem="WebSites">
<databases />
</publishProfile>
<publishProfile profileName="[app-name] - FTP" publishMethod="FTP" publishUrl="ftp://waws-prod.ftp.azurewebsites.windows.net/site/wwwroot" ftpPassiveMode="True" userName="[app-name]\$[app-name]" userPWD="***" destinationAppUrl="http://[app-name].azurewebsites.net" SQLServerDBConnectionString="" mySQLDBConnectionString="" hostingProviderForumLink="" controlPanelLink="http://windows.azure.com" webSystem="WebSites">
<databases />
</publishProfile>
<publishProfile profileName="[app-name] - ReadOnly - FTP" publishMethod="FTP" publishUrl="ftp://waws-prod.ftp.azurewebsites.windows.net/site/wwwroot" ftpPassiveMode="True" userName="[app-name]\$[app-name]" userPWD="***" destinationAppUrl="http://[app-name].azurewebsites.net" SQLServerDBConnectionString="" mySQLDBConnectionString="" hostingProviderForumLink="" controlPanelLink="http://windows.azure.com" webSystem="WebSites">
<databases />
</publishProfile>
</publishData>
```
Do I include everything, the <publishData> tags as well as all 3 publish profiles?
So I need to change the publishURL that they provide? Will get back to you with how that works.
username_0: @username_2
```
<publishData>
<publishProfile profileName="[app-name] - Web Deploy" publishMethod="MSDeploy" publishUrl="waws-prod.publish.azurewebsites.windows.net:443" msdeploySite="[app-name]" userName="$[app-name]" userPWD="***" destinationAppUrl="http://[app-name].azurewebsites.net" SQLServerDBConnectionString="" mySQLDBConnectionString="" hostingProviderForumLink="" controlPanelLink="http://windows.azure.com" webSystem="WebSites">
<databases />
</publishProfile>
```
I had the same issue in this publishurl, use
[app-name].scm.azurewebsites.net instead of
waws-prod.publish.azurewebsites.windows.net
username_2: @username_0 Ok I'll try that, should I include the 2 FTP publish profiles or remove them, or does it not matter?
username_0: @username_2 I think it won't be any issues removing them. However, I didn't removed it. You can try it. But I can assure that ot wouldn't affect removing those 2 ftp. You need msdeploy though.
Status: Issue closed
username_2: Yes that got it to work, thank you very much, was a life saver.
On a side note, we setup the publishing profile for another app service right after spending hours on this one, and it actually created the publishURL correctly, so we didn't have to change anything, which is kind of... funny?
username_0: @username_2 glad it worked. It took me a working day to figure this out. There might be some issues while fetching the publish profile. I didn't find any setting to generate scm url in publish profile.! Good day!
username_3: I'm going to add to this just to verify that I had the same issue. I created a node app and had Azure create the pipeline for me on github. It did this successfully. Then I created a .Net core API and tried to publish using the EXACT same method. It failed.
To fix:
Downloaded the publish profile from azure, edited the file, looked for publishUrl="waws-prod-bay-143.publish.azurewebsites.windows.net:443" and replaced it with publishUrl="[my-app-name].scm.azurewebsites.net:443" then copied the entire contents of the file and updated the secret stored in my github repository. Everything started working.
Also verified that in the publish config file for my Node app that the publishUrl was indeed pointing to scm.azurewebsites.net.
It's obvious this is a bug with the Github deployment in Azure, and specific to .Net Core (and probably other) apps.
username_4: Can confirm had the same issue, still on 14/10/2020. Replacing the URL fixed it👍
username_5: A solution is described [here](https://stackoverflow.com/questions/64376240/github-action-for-azure-python-webapp-failed-to-fetch-credentials-from-publish/64376536#64376536).
username_6: Getting this bug with python 3.8 first deploy and successive deploys
username_6: Also the fix works but you have to put your app name in for the [app-name] bit. Maybe this is obvious but I wasn't sure.
username_7: I can confirm that this URL issue still exists. Also be careful to check the app name to match the app service name that you created in Azure.
username_8: Why is this issue closed? This is still a problem, can this be re-opened?
username_9: It is solved, but the answer is kinda scattered around on this thread. [I made a StackOverflow post about it](https://stackoverflow.com/questions/64518967/azure-github-app-deployment-error-publish-profile-does-not-contain-kudu-url/64518968#64518968) to help people figure it out.
username_10: Please consider re-open the issue @username_0 . The workaround is good but many users will hit the same problem and waste their time. Please fix update either Azure portal or update the Github Actions to ensure the default publish profile work out-of-the-box.
username_3: My understanding of this issue is that it is not an issue of webapps-deploy, and thus not relevant here. It seems to be an Azure portal bug, which is incorrectly generating the script that calls webapps-deploy for certain app types, specifically .Net Core apps. I do not believe webapps-deploy has anything to do with generation of the script within Azure.
username_6: Its not just .Net core, like I stated above. And if it isn't an issue with webapps-deploy, even if this occurs during app deployment, shouldn't there be a new issue opened and a link to it here maybe?
username_8: For those who it might interest, I've opened an issue on [docs.microsoft.com](https://docs.microsoft.com/en-us/answers/questions/137869/publish-profile-publishurl-needs-to-be-adjusted-af.html) as well.
username_8: Here is a temporary solution:
1. Go to your function app and to configuration:

2. Press "New applications setting":

3. Then add the following:

4. Redownload "Publish Profile", then the `publishUrl` will be correct set to scm.
username_11: @username_8 can confirm that this works and in my opinion, is the best / most consistent workaround. Thanks a lot for putting effort into this 🙏 |
quintel/etlocal | 322757643 | Title: Key in the front-end is to long
Question:
username_0: 
Some keys in the front-end are quite lengthy. My preference would be that they can be shortened (@username_1 or @marliekeverweij).
Answers:
username_1: Fixed that, can you enable html for group headers?
 |
aws/aws-iot-device-sdk-java | 464792716 | Title: Best way to have lambda triggered by IOT rule in Java?
Question:
username_0: I'm essentially trying to do this: https://docs.aws.amazon.com/iot/latest/developerguide/iot-lambda-rule.html but in java. I haven't found any good tutorials on the subject and am having trouble setting up the handler. Anything I should know or are there any good tutorials / examples out there?
Thanks!
Answers:
username_0: Never mind, was overestimating the difficulty of the problem quite greatly. I have it working now.
Status: Issue closed
username_0: Feel free to delete this issue |
sequelize/sequelize | 473224268 | Title: Query 10000000 data JavaScript heap out of memory
Question:
username_0: **Is your feature request related to a problem? Please describe.**
Query 10000000 data JavaScript heap out of memory
**Describe the solution you'd like**
Query 10000000 data JavaScript heap out of memory
**Usage example**
await this.ctx.model.GridDynamicFeature.findAll();
Status: Issue closed
Answers:
username_1: Yes that is possible if you have records with large data. It can happen without Sequelize. If you have something concrete which can be tested properly, you can add that to issue description.
------------------------------
Sequelize requires you to file new issues with a specific [issue template](https://github.com/sequelize/sequelize/blob/master/.github/ISSUE_TEMPLATE.md). Please don't ignore our [contribution guidelines](https://github.com/sequelize/sequelize/blob/master/CONTRIBUTING.md#issues) and template structure. They help us quickly triage issues.
Note that this issue will be closed for not following the issue template. You may open a new issue or update this one with correct template. You can add any additional information to your issue.
----------------------------
Please use Github Issue Tracker only for reporting bugs, requesting new features or discussions. Ask questions on [Stackoverflow sequelize.js tag](https://stackoverflow.com/questions/tagged/sequelize.js) or [Slack](sequelize.slack.com). |
google/data-transfer-project | 417493720 | Title: NPE in GooglePhotosExporter for non-album photos
Question:
username_0: Steps:
- Upload photos to Google Photos
- Don't create albums (or remove existing)
- Start transfer to another service
Result:
Photos will not be imported because of exception:
```
java.lang.NullPointerException
at org.datatransferproject.datatransfer.google.photos.GooglePhotosExporter.exportAlbums(GooglePhotosExporter.java:153)
at org.datatransferproject.datatransfer.google.photos.GooglePhotosExporter.export(GooglePhotosExporter.java:89)
at org.datatransferproject.datatransfer.google.photos.GooglePhotosExporter.export(GooglePhotosExporter.java:56)
at org.datatransferproject.transfer.CallableExporter.call(CallableExporter.java:50)
```<issue_closed>
Status: Issue closed |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.