
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
prettier/prettier | 490624787 | Title: [YAML]: unexpected indent in nested list
Question:
username_0: <!--
BEFORE SUBMITTING AN ISSUE:
1. Search for your issue on GitHub: https://github.com/prettier/prettier/issues
A large number of opened issues are duplicates of existing issues.
If someone has already opened an issue for what you are experiencing,
you do not need to open a new issue — please add a 👍 reaction to the
existing issue instead.
2. We get a lot of requests for adding options, but Prettier is
built on the principle of being opinionated about code formatting.
This means we have a very high bar for adding new options.
Find out more: https://prettier.io/docs/en/option-philosophy.html
Tip! Don't write this stuff manually.
1. Go to https://prettier.io/playground
2. Paste your code and set options
3. Press the "Report issue" button in the lower right
-->
**Prettier 1.18.2**
[Playground link](https://prettier.io/playground/#N4Igxg9gdgLgprEAuEAbAhlA5gV3VuJAAiggBM4B9AKwGc<KEY>3gAycwRA6FoHCgcDgFCi9nUSLUcAG+GG1z2PSKKmyuVutCOJ3Ol22SHGN3sMHQMS+ZB+yAATFz4ipUEcAMIQIoUlCkHHRHA9AAqPOCHJ6AF9NUA)
**Input:**
```yml
language: node_js
node_js: --lts
cache:
- yarn
- directories:
- .changelog
```
**Output:**
```yml
language: node_js
node_js: --lts
cache:
- yarn
- directories:
- .changelog
```
**Expected behavior:**
```yml
language: node_js
node_js: --lts
cache:
- yarn
- directories:
- .changelog
```
Answers:
username_1: Duplicate of #6043 ?
username_0: @username_1 Thanks, then I will close this issue.
Status: Issue closed
|
nteract/papermill | 410460744 | Title: Unable to write into GCS bucket with papermill[gcs]
Question:
username_0: I'm getting this error: HTTP 429 Rate exceeds.
When running GCFS application via `papermill[gcs]`
papermill gs://my-bucket/test.ipynb gs://my-bucket/output/test.ipynb
Works if output is written locally.
papermill gs://my-bucket/test.ipynb /tmp/test.ipynb
```
10
Ending Cell 6------------------------------------------
Exception gcsfs.utils.HtmlError: HtmlError(u'The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.',) in <bound method GCSFile.__del__ of <GCSFile d
pe-sandbox/test.ipynb>> ignored
Traceback (most recent call last):
File "/usr/local/bin/papermill", line 11, in <module>
sys.exit(papermill())
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 764, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 717, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 956, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 555, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/cli.py", line 165, in papermill
cwd=cwd,
File "/usr/local/lib/python2.7/dist-packages/papermill/execute.py", line 90, in execute_notebook
start_timeout=start_timeout,
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 56, in execute_notebook_with_engine
return self.get_engine(engine_name).execute_notebook(nb, kernel_name, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 296, in execute_notebook
nb = cls.execute_managed_notebook(nb_man, kernel_name, log_output=log_output, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 352, in execute_managed_notebook
preprocessor.preprocess(nb_man, kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/preprocess.py", line 27, in preprocess
nb, resources = self.papermill_process(nb_man, resources)
File "/usr/local/lib/python2.7/dist-packages/papermill/preprocess.py", line 81, in papermill_process
nb_man.cell_complete(nb.cells[index])
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 76, in wrapper
return func(self, *args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 219, in cell_complete
self.save()
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 76, in wrapper
return func(self, *args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 138, in save
write_ipynb(self.nb, self.output_path)
File "/usr/local/lib/python2.7/dist-packages/papermill/iorw.py", line 280, in write_ipynb
papermill_io.write(nbformat.writes(nb), path)
File "/usr/local/lib/python2.7/dist-packages/papermill/iorw.py", line 82, in write
return self.get_handler(path).write(buf, path)
File "/usr/local/lib/python2.7/dist-packages/papermill/iorw.py", line 251, in write
return f.write(buf)
File "</usr/local/lib/python2.7/dist-packages/decorator.pyc:decorator-gen-150>", line 2, in close
File "/usr/local/lib/python2.7/dist-packages/gcsfs/core.py", line 51, in _tracemethod
return f(self, *args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/gcsfs/core.py", line 1548, in close
self.flush(force=True)
File "</usr/local/lib/python2.7/dist-packages/decorator.pyc:decorator-gen-145>", line 2, in flush
[Truncated]
self.close()
File "</Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/decorator.py:decorator-gen-152>", line 2, in close
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 51, in _tracemethod
return f(self, *args, **kwargs)
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 1552, in close
self.flush(force=True)
File "</Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/decorator.py:decorator-gen-147>", line 2, in flush
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 51, in _tracemethod
return f(self, *args, **kwargs)
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 1369, in flush
self._simple_upload()
File "</Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/decorator.py:decorator-gen-150>", line 2, in _simple_upload
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 51, in _tracemethod
return f(self, *args, **kwargs)
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 1467, in _simple_upload
validate_response(r, path)
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 163, in validate_response
raise HtmlError(error)
gcsfs.utils.HtmlError: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
```
Answers:
username_1: Do you know how the gcs rate limiting system works? We're emitting a save after each cell executes today. We could capture rate limiting requests and try to respect them but the number of saves here should be #cells + 2 which seems reasonable for most interfaces
username_0: Looks like we are experiencing this: "For example, if you have an object bar in bucket foo, then you should only upload a new copy of foo/bar about once per second. Updating the same object faster than once per second may result in 429 Too Many Requests errors."
https://cloud.google.com/storage/docs/key-terms#immutability
username_0: @franky
username_1: We can modify the client wrapper to retry with a backoff on 429 in papermill. It sounds like that would resolve this issue?
username_2: +1 @username_1 after speaking with @username_0, I think that makes the most sense in this case. It keeps from modifying gcsfs with a local cache which may not work for everyone.
Status: Issue closed
username_1: Going to release 0.18.1 with the fix. Thanks for getting the issue resolved.
username_3: This issue seems to be happening again with `gcsfs==0.3.0`.
`gcsfs==0.2.3` works fine though.
username_1: Is this with the latest papermill release (1.1.0) or an earlier one?
username_1: When running GCFS application via `papermill[gcs]`
papermill gs://my-bucket/test.ipynb gs://my-bucket/output/test.ipynb
I'm getting Error: HTTP 429 Rate exceeds.
Works if output notebook is written locally:
papermill gs://my-bucket/test.ipynb /tmp/test.ipynb
Local file size is: 57K
```
ls -alh /tmp/test.ipynb
-rw-r--r-- 1 username_0 wheel 57K Feb 14 10:37 /tmp/test.ipynb
```
GCSFS reference https://github.com/dask/gcsfs/issues/130
How to reproduce?
```
pip install papermill[gcs]
papermill gs://cloud-samples-data/papermill/samples/test.ipynb gs://<your bucket>/test.ipynb
```
Logs:
```
10
Ending Cell 6------------------------------------------
Exception gcsfs.utils.HtmlError: HtmlError(u'The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.',) in <bound method GCSFile.__del__ of <GCSFile d
pe-sandbox/test.ipynb>> ignored
Traceback (most recent call last):
File "/usr/local/bin/papermill", line 11, in <module>
sys.exit(papermill())
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 764, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 717, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 956, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 555, in invoke
return callback(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/cli.py", line 165, in papermill
cwd=cwd,
File "/usr/local/lib/python2.7/dist-packages/papermill/execute.py", line 90, in execute_notebook
start_timeout=start_timeout,
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 56, in execute_notebook_with_engine
return self.get_engine(engine_name).execute_notebook(nb, kernel_name, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 296, in execute_notebook
nb = cls.execute_managed_notebook(nb_man, kernel_name, log_output=log_output, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 352, in execute_managed_notebook
preprocessor.preprocess(nb_man, kwargs)
File "/usr/local/lib/python2.7/dist-packages/papermill/preprocess.py", line 27, in preprocess
nb, resources = self.papermill_process(nb_man, resources)
File "/usr/local/lib/python2.7/dist-packages/papermill/preprocess.py", line 81, in papermill_process
nb_man.cell_complete(nb.cells[index])
File "/usr/local/lib/python2.7/dist-packages/papermill/engines.py", line 76, in wrapper
return func(self, *args, **kwargs)
[Truncated]
self.close()
File "</Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/decorator.py:decorator-gen-152>", line 2, in close
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 51, in _tracemethod
return f(self, *args, **kwargs)
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 1552, in close
self.flush(force=True)
File "</Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/decorator.py:decorator-gen-147>", line 2, in flush
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 51, in _tracemethod
return f(self, *args, **kwargs)
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 1369, in flush
self._simple_upload()
File "</Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/decorator.py:decorator-gen-150>", line 2, in _simple_upload
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 51, in _tracemethod
return f(self, *args, **kwargs)
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 1467, in _simple_upload
validate_response(r, path)
File "/Users/username_0/Documents/Development/dpe/venv/papermill/lib/python3.6/site-packages/gcsfs/core.py", line 163, in validate_response
raise HtmlError(error)
gcsfs.utils.HtmlError: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
```
username_3: Yes with papermill==1.1.0. I haven't tried other papermill versions.
On macOS with the same error message as above:
```
pip3 install gcsfs==0.3.0 papermill==1.1.0
papermill gs://cloud-samples-data/papermill/samples/test.ipynb gs://redacted/test.ipynb
```
username_1: Ok thanks for the heads up. If no one else gets to it I can look at it this weekend. 1.1.0 has another minor bug that also needs addressing anyway.
username_0: ```
```
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=resumable&upload_id=AEnB2Uo0y3-rNF5CNZ-nXPfhZRxnxrA1hw2Gb6Wl79eD2J7cMqH-4I-8wdr7pEIiUqK8n-GIdJuUMBDDJq_R84MpzpimRhtZuQ&uploadType=resumable HTTP/1.1" 429 463
_call retrying after exception: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=resumable&upload_id=AEnB2Uo0y3-rNF5CNZ-nXPfhZRxnxrA1hw2Gb6Wl79eD2J7cMqH-4I-8wdr7pEIiUqK8n-GIdJuUMBDDJq_R84MpzpimRhtZuQ&uploadType=resumable HTTP/1.1" 410 463
_call retrying after exception: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=resumable&upload_id=AEnB2Uo0y3-rNF5CNZ-nXPfhZRxnxrA1hw2Gb6Wl79eD2J7cMqH-4I-8wdr7pEIiUqK8n-GIdJuUMBDDJq_R84MpzpimRhtZuQ&uploadType=resumable HTTP/1.1" 410 463
_call retrying after exception: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=resumable&upload_id=AEnB2Uo0y3-rNF5CNZ-nXPfhZRxnxrA1hw2Gb6Wl79eD2J7cMqH-4I-8wdr7pEIiUqK8n-GIdJuUMBDDJq_R84MpzpimRhtZuQ&uploadType=resumable HTTP/1.1" 410 463
_call retrying after exception: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=resumable&upload_id=AEnB2Uo0y3-rNF5CNZ-nXPfhZRxnxrA1hw2Gb6Wl79eD2J7cMqH-4I-8wdr7pEIiUqK8n-GIdJuUMBDDJq_R84MpzpimRhtZuQ&uploadType=resumable HTTP/1.1" 410 463
_call retrying after exception: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=resumable&upload_id=AEnB2Uo0y3-rNF5CNZ-nXPfhZRxnxrA1hw2Gb6Wl79eD2J7cMqH-4I-8wdr7pEIiUqK8n-GIdJuUMBDDJq_R84MpzpimRhtZuQ&uploadType=resumable HTTP/1.1" 410 463
_call out of retries on exception: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Traceback (most recent call last):
File "/home/username_0/papermill_venv/lib/python3.7/site-packages/gcsfs/core.py", line 462, in _call
validate_response(r, path)
File "/home/username_0/papermill_venv/lib/python3.7/site-packages/gcsfs/core.py", line 165, in validate_response
raise HttpError(error)
gcsfs.utils.HttpError: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
_initiate_upload(args=(), kwargs={})
_call(args=('POST', 'https://www.googleapis.com/upload/storage/v1/b/dpe-sandbox/o'), kwargs={'uploadType': 'resumable', 'json': {'name': 'test.ipynb', 'metadata': None}})
```
In gcsfs 0.2.3:
```
\n "output_path": "gs://dpe-sandbox/test.ipynb",\n "parameters": {},\n "start_time": "2019-09-05T04:10:29.358843",\n "version": "1.1.0"\n }\n },\n "nbformat": 4,\n "nbformat_minor": 0\n}\n--==0==--'})
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=multipart HTTP/1.1" 429 463
_call retrying after exception: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=multipart HTTP/1.1" 429 463
_call retrying after exception: The total number of changes to the object dpe-sandbox/test.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
https://www.googleapis.com:443 "POST /upload/storage/v1/b/dpe-sandbox/o?uploadType=multipart HTTP/1.1" 200 721
invalidate_cache(args=('dpe-sandbox',), kwargs={})
```
username_1: Thanks for helping to look into it @username_0 !
username_1: FYI @MichelleUfford was taking a look at this one. I got my gcsfs setup running on this computer to test once there's a fix.
username_1: So neither myself nor @MichelleUfford can reproduce the issue. Based on the changes in
gcfs (https://github.com/dask/gcsfs/pull/177/files) we're going to change to library to instead use https://github.com/dask/gcsfs/blob/master/gcsfs/utils.py#L124 on line https://github.com/nteract/papermill/blob/master/papermill/iorw.py#L320 so the upstream library can define retry conditions without us having to touch papermill when these change.
username_1: I believe this is now fixed in 1.2.0, but I was unable to reproduce the issue to prove it. Can one of the reporters of the problem test with the latest papermill version and confirm if this issue can be closed again?
Status: Issue closed
username_4: I am facing this issue with version 1.2.0
username_1: @username_4 Could you open a new issue with details for your failed request (as much as you can shate)? Details like the notebook, the rate of cell execution, the stack trace, consistency of failure (happens sometimes, everytime, on Tuesdays), if the failure occurs across buckets or only on a specific key, etc.
username_5: For the record, I've heard from Google support about this. To quote:
---------------------
As of right now, the issue is a bug and not a customer issue, and while a fix is on the way, there is a workaround that can be done on the customer’s side. The official workaround to circumvent 5xx and 410 errors is to implement retries, as was indicated in this comment from a Issue Tracker entry you have commented yourself (see https://issuetracker.google.com/issues/137168102#comment2). The retry method recommendation can also be seen here (https://issuetracker.google.com/issues/35903805#comment2).
To retry successfully, catching 500 and 410 errors is required and, as the official documentation recommends (https://cloud.google.com/storage/docs/json_api/v1/status-codes#410_Gone), implementing a retry by starting a new session for the upload that received an unsuccessful status code but still needs uploading. The new session creation may be what was missing on your end, causing retries to be unsuccessful as you have mentioned previously. Additionally, exponential backoffs recommended in comments (see https://issuetracker.google.com/35903805#comment2) are the way to go to mitigate the issue (see https://cloud.google.com/storage/docs/exponential-backoff ).
username_1: Thanks for the link @username_5 ! We do have retries and exponential backoff on writes, but it sounds like that's not always sufficient either. Looking forward to the API finally getting fixed.
username_6: Hi all,
I am trying to execute a notebook saving the result into Google Cloud Storage. I found this issue so probably someone among you can explain me what's happening.
```
In [2]: import papermill as pm
...:
...: pm_out = pm.execute_notebook(
...: 'covid-19.ipynb',
...: 'gs://customer-acquisition-bucket/training_outputs/output.ipynb',
...: parameters=dict()
...: )
Executing: 0%| | 0/29 [00:00<?, ?cell/s]C:\Users\dev999\AppData\Roaming\Python\Python37\site-packages\google\auth\_default.py:69: UserWarning: Your application has authenticated using end user credentials from Google Cloud SDK. We recommend that most server applications use service accounts instead. If your application continues to use end user credentials from Cloud SDK, you might receive a "quota exceeded" or "API not enabled" error. For more information about service accounts, see https://cloud.google.com/docs/authentication/
warnings.warn(_CLOUD_SDK_CREDENTIALS_WARNING)
Executing: 14%|█████████▋ | 4/29 [00:07<00:57, 2.28s/cell]_call out of retries on exception: The rate of change requests to the object customer-acquisition-bucket/training_outputs/output.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\lib\site-packages\gcsfs\core.py", line 470, in _call
validate_response(r, path)
File "C:\ProgramData\Anaconda3\lib\site-packages\gcsfs\core.py", line 120, in validate_response
raise HttpError(error)
gcsfs.utils.HttpError: The rate of change requests to the object customer-acquisition-bucket/training_outputs/output.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Executing: 34%|███████████████████████▊ | 10/29 [00:46<00:50, 2.64s/cell]_call out of retries on exception: The rate of change requests to the object customer-acquisition-bucket/training_outputs/output.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\lib\site-packages\gcsfs\core.py", line 470, in _call
validate_response(r, path)
File "C:\ProgramData\Anaconda3\lib\site-packages\gcsfs\core.py", line 120, in validate_response
raise HttpError(error)
gcsfs.utils.HttpError: The rate of change requests to the object customer-acquisition-bucket/training_outputs/output.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Executing: 62%|██████████████████████████████████████████▊ | 18/29 [01:28<00:22, 2.00s/cell]_call out of retries on exception: The rate of change requests to the object customer-acquisition-bucket/training_outputs/output.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\lib\site-packages\gcsfs\core.py", line 470, in _call
validate_response(r, path)
File "C:\ProgramData\Anaconda3\lib\site-packages\gcsfs\core.py", line 120, in validate_response
raise HttpError(error)
gcsfs.utils.HttpError: The rate of change requests to the object customer-acquisition-bucket/training_outputs/output.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Executing: 97%|██████████████████████████████████████████████████████████████████▌ | 28/29 [02:18<00:01, 1.90s/cell]_call out of retries on exception: The rate of change requests to the object customer-acquisition-bucket/training_outputs/output.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\lib\site-packages\gcsfs\core.py", line 470, in _call
validate_response(r, path)
File "C:\ProgramData\Anaconda3\lib\site-packages\gcsfs\core.py", line 120, in validate_response
raise HttpError(error)
gcsfs.utils.HttpError: The rate of change requests to the object customer-acquisition-bucket/training_outputs/output.ipynb exceeds the rate limit. Please reduce the rate of create, update, and delete requests.
Executing: 100%|█████████████████████████████████████████████████████████████████████| 29/29 [02:57<00:00, 6.12s/cell]
```
according to the output it seems that papermill re-tries if the "rate of changes exceeds" error occurs but if I try to downlaod the notebook from the bucket and I try to open it inside Jupyter, locally, I am NOT ABLE to open the notebook (so I think that the notebook in Cloud Storage is not correctly saved by papermill)
username_6: The error I get is:
"**Unreadable Notebook**: C:\Users\dev999\Jupyter notebooks\training_outputs_output (1).ipynb **UnicodeDecodeError**('utf-8', b'{\r\n "cells": [\r\n {\r\n "cell_type": "code",\r\n "execution_count": 1,\r\n "metadata": {\r\n "papermill": {\r\n "duration": 1.344472,\r\n "end_time":
...
acquisition-bucket/training_outputs/output.ipynb",\r\n "parameters": {},\r\n "start_time": "2020-03-31T10:30:55.461330",\r\n "version": "2.0.0"\r\n }\r\n },\r\n "nbformat": 4,\r\n "nbformat_minor": 4\r\n}', 8614, 8615, '**invalid continuation byte**')
username_1: I have not hit such an error, but I don't consistently use gcfs. You may need to create an issue on the [gcsfs extension](https://github.com/dask/gcsfs).
That being said, some things to check are:
- What version of papermill and jupyter libraries are you using (`conda list`)
- Does the notebook save and load correctly using local filesystem as the write location?
- Are there some unicode characters in the output that's causing an issue? Maybe the file save to gcsfs is not persisting non-ascii characters correctly (would be weird)? |
cython/cython | 454012089 | Title: Make len(memoryview) return Py_ssize_t
Question:
username_0: `len(memoryview)` currently returns a `size_t`. This diverges from the default Python behaviour of having signed indices to support negative indexing etc. CPython also treats the result of `len()` as a `Py_ssize_t` internally.
Cython should always return a `Ps_ssize_t` from `len()`, not a `size_t`.
Originally raised in
https://github.com/pandas-dev/pandas/pull/26757<issue_closed>
Status: Issue closed |
MicrosoftDocs/azure-docs | 310736250 | Title: denied due to invalid subscription key
Question:
username_0: have tried both keys, any easy way around?
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: e458d65d-3c89-3e41-fdf7-613523fcc78a
* Version Independent ID: 4ca7bedf-6435-d19d-9a47-fa0a686da00c
* Content: [Face API Python tutorial - Microsoft Cognitive Services](https://docs.microsoft.com/en-us/azure/cognitive-services/Face/Tutorials/FaceAPIinPythonTutorial)
* Content Source: [articles/cognitive-services/Face/Tutorials/FaceAPIinPythonTutorial.md](https://github.com/Microsoft/azure-docs/blob/master/articles/cognitive-services/Face/Tutorials/FaceAPIinPythonTutorial.md)
* Service: **cognitive-services**
* GitHub Login: @SteveMSFT
* Microsoft Alias: **sbowles**
Answers:
username_1: @username_0 Thanks for the feedback! We are currently investigating and will update you shortly.
username_2: I found that you have to change the 'BASE_URL' field to match the endpoint given along with your keys!
username_3: @username_0 have you tried changing the `BASE_URL` as per @username_2 above? |
vimeo/player.js | 328052203 | Title: vp-preview-invisble not added.
Question:
username_0: ### Expected Behavior
Adding vp-preview-invisible to <div class="vp-preview vp-preview-cover> when playing the video.
### Actual Behavior
Doesn't add it. Video plays and the opacity of vp-preview is still 1.
Adds the class when scrubbing.
### Steps to Reproduce
<!--
If you cannot reproduce on the demo page, please link to the page where you’re seeing the issue. It’s helpful for us if you can make a test case using [CodePen](https://codepen.io), [JSFiddle](https://jsfiddle.net), or something similar.
-->
Status: Issue closed
Answers:
username_1: This was recently resolved. Please re-open if you don't see the fix. Thanks.
username_0: Perfect, it's working. |
InterImmCenter/feed | 742686273 | Title: <NAME>: Jumping for Joy With a degree in computer engineering and computer science from the University of Southern California <NAME> is now an quality engineer and supervisor at the Jet Propulsion Laboratory.
Question:
username_0: <img src="http://www.nasa.gov/sites/default/files/thumbnails/image/img_7443.jpg"><br>
<b><NAME>: Jumping for Joy</b><br>
With a degree in computer engineering and computer science from the University of Southern California, <NAME> is now an quality engineer and supervisor at the Jet Propulsion Laboratory.<br>
<br>
November 13, 2020<br>
via NASA https://ift.tt/3pqzdOa |
astropy/specutils | 516144694 | Title: Add a warning if contnuum-normalized analysis functions get non-dimensionless spectra
Question:
username_0: In #538 a continuum-subtraction checker was added to catch the case where a user runs an analysis function that expects a zero-baseline spectrum on a spectrum where continuum has not been subtracted.
In #535 we discussed doing something similar for functions requiring continuum normalization (right now I think that's just `equivalent_width`), but it occurs to me there's an easier heuristic for continuum-normalization: the unit has to be dimensionless because the continuum and spectrum should have the same units so dividing them out gives dimensionless. So perhaps we should just check the unit and raise a warning if it's not dimensionless? That has essentially zero performance penalty (unlike the continuum-checker...)
cc @camipacifici (since it was your use case that originally led to this idea)
Answers:
username_0: Update from #546 - results in https://github.com/astropy/specutils/issues/546#issuecomment-556523323 .
TL;DR is that it's a small (2x or less) effect for functions that operate on the whole spectrum, but potentially very large (~10x) for very large spectra/cubes where you want to do a small operation on only some of them.
So that's an issue. We may have to pick and choose which the decorators get. Probably needs more discussion before implementing beyond #538
username_0: I've collated the list of potential places for this decorator. Below when I say "local" I mean that the measurement is typically in a small spectral region compared to the whole spectrum, whereas "global" means the function operates on the whole spectrum. Relevant because the "local" ones are the ones where the slow-down could be order-of-magnitude and gets worse with spectrum size (because the continuum-checker is a "global" algorithm), whereas the global ones generally get better with spectrum size (based on #546, of order ~2x slowdown)
- [ ] [centroid](https://specutils.readthedocs.io/en/stable/api/specutils.analysis.centroid.html#specutils.analysis.centroid) - continuum subtraction required, "local" measurement
- [ ] [equivalent_width](https://specutils.readthedocs.io/en/stable/api/specutils.analysis.equivalent_width.html#specutils.analysis.equivalent_width) - continuum normalization required, "local" measurement
- [ ] [fwhm](https://specutils.readthedocs.io/en/stable/api/specutils.analysis.fwhm.html#specutils.analysis.fwhm) - continuum subtraction required, "local" measurement
- [ ] [fwzi](https://specutils.readthedocs.io/en/stable/api/specutils.analysis.fwzi.html#specutils.analysis.fwzi) - continuum subtraction required, "local" measurement
- [ ] [gaussian_fwhm](https://specutils.readthedocs.io/en/stable/api/specutils.analysis.gaussian_fwhm.html#specutils.analysis.gaussian_fwhm) - continuum subtraction required, "local" measurement
- [ ] [gaussian_sigma_width](https://specutils.readthedocs.io/en/stable/api/specutils.analysis.gaussian_sigma_width.html#specutils.analysis.gaussian_sigma_width) - continuum subtraction required, "local" measurement
- [ ] [line_flux](https://specutils.readthedocs.io/en/stable/api/specutils.analysis.line_flux.html#specutils.analysis.line_flux) - continuum subtraction *usually* intended, "local" measurement
- [ ] [find_lines_threshold](https://specutils.readthedocs.io/en/stable/api/specutils.fitting.find_lines_threshold.html#specutils.fitting.find_lines_threshold) - continuum subtraction required, "global" measurement
- [ ] [fit_lines](https://specutils.readthedocs.io/en/stable/api/specutils.fitting.fit_lines.html#specutils.fitting.fit_lines) - continuum subtraction sometimes required sometimes not (depends on whether the model has a continuum built-in), "global" *or* "local" measurement
So the question is: which, if any, do we want the continuum checker implemented in as a decorator by default? My first instinct is only `find_lines_threshold`, since that was @camipacifici's original case where there was an issue, and the only definitively global one I found. But I'm interested in other viewpoints - @camipacifici (as the inspiration of the original issue), or @keflavich @dhomeier @crawfordsm (as random potential users), do you have any thoughts here?
username_0: Oops! The above comments were in the wrong issue. Copying them to #548 and striking through the above. - the only relevant one for this issue is `equivalent width) |
isuruf/flang | 270382170 | Title: Add LLVM defaultlib metadata
Question:
username_0: We need to add the following metadata:
```
!0 = !{!"/DEFAULTLIB:flang.lib", !"/DEFAULTLIB:flangrti.lib", !"/DEFAULTLIB:ompstub.lib"}
!llvm.linker.options = !{!0}
```
Answers:
username_0: Psuedocode:
```
in ll_create_module
md_string = call LL_MDRef ll_get_md_string(LL_Module *module, const char *str)
call ll_set_named_md_node(LL_Module *module, enum LL_MDName name,const LL_MDRef *elems, unsigned nelems)
```
Still somewhat unclear on the typing structure.
username_1: This is done now
Status: Issue closed
|
osuosl/streamwebs | 261783789 | Title: Paper only Datasheet references
Question:
username_0: Issue comes out of #434
Any of the datasheets in the resources section that does not have a corresponding online version, please add "paper version only" under the name of the data sheet. In small text or parentheses? Something that isn't too obtrusive, but obvious that only the paper version is available.
Answers:
username_1: @username_0 I think Renee would like the "pebble count" and "invasive species" sheets to be removed from the site. For the stream flow we can do add a no online version test for it.
username_0: @username_2 can you confirm if you only want to keep the Stream Flow sheet and remove Pebble Count and Invasive Species?
username_2: I want to keep all the sheets.
username_0: Thanks for the confirmation. @username_1 Please add the paper only to any datasheets that do not have an online format.
username_1: @username_2 Just fixed the fixture, we need to delete the resources and reload the fixtures
username_3: @username_1 should I do that now on staging?
username_1: @username_3 sure,
Status: Issue closed
username_0: confirmed fixed |
eslint/eslint | 112334861 | Title: Indent: function declaration in algined multi-line arguments
Question:
username_0: I'm sorry, but it looks like we hit another issue in the indent rule. It should pass, imho. [email protected]
```
indent: [2,2]
```
```js
functionWithCallback(something,
function() {
var error;
})
```
```
3:3 error Expected indentation of 23 space characters but found 2 indent
4:1 error Expected indentation of 21 space characters but found 0 indent
```
Answers:
username_0: Note the bug doesn't trigger unless `function` is the first on its line. This code is fine:
```js
functionWithCallback(something,
another, function() {
var error;
})
```
username_1: We need to figure out a better way here because we have issues logged asking for opposite behavor to be true also.
https://github.com/eslint/eslint/issues/4174
username_0: Maybe be a bit more lenient and allow mulitple correct indendation levels?
username_1: The rules are very much like 0 or 1 ie either something is wrong or its correct. We have always used options to make sure we can have 2 states to trigger correct behavior.
@eslint/eslint-team thought here?
username_2: In all honesty example that @username_0 provided doesn't look right to me. I understand that it's trying to align multi-line arguments based on the position of the first argument, and I guess it's a valid style, it just seems pretty alien to me. For me, unclosed brace or parent means next line should be indented by one indentation level.
username_3: It's what node core has used for a long time. :/
username_4: We may need to rethink this. Historically node has more or less followed the Google Style Guide and this case is covered (under "Passing Anonymous Functions"): https://google.github.io/styleguide/javascriptguide.xml?showone=Code_formatting#Code_formatting
We can see this same style being used in `tls.js`: https://github.com/nodejs/node/blob/v4.2.1/lib/tls.js#L84-L89
Though there is a similar case that violates this in `net.js` (added in 4c150ca): https://github.com/nodejs/node/blob/v4.2.1/lib/net.js#L1133
In the tests I sampled 34 cases of passed anonymous functions. Of those, 23 followed the Google style guide and 11 did not. Of those that did not follow the style all but one commit either occurred back in 2010 or this year. While those that do follow have commits dispersed throughout 2010 to 2015. (below is a list of all files and their associated commits)
This would lead me to believe that the indentation style under question is in fact incorrect and we should move to adhere more closely to the Google style guide.
Followed:
`test-assert.js` (87286cc)
`test-cli-eval.js` (3d22dbf, 83b1dda)
`test-file-write-stream3.js` (87286cc)
`test-fs-write.js` (0665f02)
`test-http-header-read.js` (87286cc)
`test-http-invalidheaderfield.js` (6192c98)
`test-preload.js` (1514b82)
`test-process-binding.js` (962e651)
Not followed:
`test-dgram-bytes-length.js` (f29762f)
`test-dgram-pingpong.js` (0665f02)
`test-dgram-udp4.js` (0665f02)
`test-http-304.js` (093dfaf)
`test-http-timeout.js` (f29762f)
`test-promises-unhandled-rejection.js` (f29762f)
username_5: I'm not sure we can support the format being requested. As I'm sure everyone realizes, indentation is a complicated matter, and while we'd like to, it's just not possible to support every possible version that people want.
For reference, here's what the Google style guide shows for passing anonymous functions:
```js
prefix.something.reallyLongFunctionName('whatever', function(a1, a2) {
if (a1.equals(a2)) {
someOtherLongFunctionName(a1);
} else {
andNowForSomethingCompletelyDifferent(a2.parrot);
}
});
var names = prefix.something.myExcellentMapFunction(
verboselyNamedCollectionOfItems,
function(item) {
return item.name;
});
```
We definitely support the first style, and the second style we will support (#4174). If it's possible for Node.js to use one of these two styles, then I'd suggest doing that (after all, you do get autoformatting to fix this with `--fix`).
username_4: Historically node has preferred both those styles. The first if it fits under 80 characters. Otherwise the latter.
username_0: I think I agree, we gotta change that style of ours, and I quite like the second option, except I'd put the closing parenthesis on the same level as the opening one:
````js
var names = prefix.something.myExcellentMapFunction(
verboselyNamedCollectionOfItems,
function(item) {
return item.name;
}
);
````
username_1: @username_0 The example you gave on top is already supported.
username_6: @username_1 What about the following case ?
```js
server.on('listening', function() {
client.send(message_to_send, 0, message_to_send.length, server_port,
'localhost', function(err) {
if (err) {
console.log('Caught error in client send.');
throw err;
}
}
);
});
```
I get:
```
4:7 error Expected indentation of 4 space characters but found 6 indent
8:5 error Expected indentation of 2 space characters but found 4 indent
```
username_1: @username_6 Thats exactly what is been discussed in #4174
username_5: Unless I'm misreading, it seems like we can close this? @username_0?
username_1: As per my understanding, yes (we can close).
Status: Issue closed
username_0: @username_5 yeah, we'll try adapting our style.
username_4: @username_6 Following the Google style guide that would look something like:
```js
server.on('listening', function() {
client.send(
message_to_send,
0,
message_to_send.length,
server_port,
'localhost',
function(err) {
if (err) {
console.log('Caught error in client send.');
throw err;
}
});
});
``` |
gobuffalo/buffalo-auth | 333896080 | Title: Remove go-get for Goth
Question:
username_0: It seems the plugin does:
```
g.Add(makr.NewCommand(makr.GoGet("github.com/markbates/goth/...")))
```
But it doesn't use goth, we need to confirm this and remove this `go get` call.
Answers:
username_0: covered in #14
Status: Issue closed
|
tangbc/vue-virtual-scroll-list | 618338388 | Title: :page-mode="true" throws warning/TypeError
Question:
username_0: ## Describe
I keep seeing `TypeError: handler.apply is not a function` when enabling page mode.
## To Reproduce
Go to https://codesandbox.io/s/live-demo-virtual-list-e1ww1?file=/src/App.vue and add `:page-mode="true"`. Watch the console output to see the warning/error show up.
## Reproduce demo
https://codesandbox.io/s/live-demo-virtual-list-ex77l
Answers:
username_1: If using page-mode, you must remove container scrollbar.
In this demo, just remove `style="height: 360px; overflow-y: auto;"`
But it's better to throw a warning if developer using a wrong way, I will consider it.
Status: Issue closed
|
kdheepak/Presentation.jl | 475434606 | Title: Implementation of get cursor position in pure Julia
Question:
username_0: https://github.com/username_0/Presentation.jl/blob/07de019056f4a549f1258b86e9789a737ed1b0c3/src/utils.jl#L51-L76
Answers:
username_0: @username_1 for your reference
Status: Issue closed
username_1: Awesome!
Two things: For that code to work on Linux it needs to be
```
const NCCS = Sys.islinux() ? 32 : 20
const tcflag_t = Sys.islinux() ? Cuint : Culong
const speed_t = tcflag_t
mutable struct TermIOs
c_iflag::tcflag_t
c_oflag::tcflag_t
c_cflag::tcflag_t
c_lflag::tcflag_t
@static if Sys.islinux()
c_line::tcflag_t
end
c_cc::NTuple{NCCS, UInt8}
c_uispeed::speed_t
c_ospeed::speed_t
end
TERM = Ref{TermIOs}(
@static if Sys.islinux()
TermIOs(
0,
0,
0,
0,
0,
Tuple([UInt8(0) for _ in 1:NCCS]),
0,
0
)
else
TermIOs(
0,
0,
0,
0,
Tuple([UInt8(0) for _ in 1:NCCS]),
0,
0
)
end
)
RESTORE = deepcopy(TERM)
```
And unfortunately I can't use this, because it doesn't work when called in a async task:
```
julia> cursorpos(get_terminal())
(1, 17)
julia> @async begin
sleep(1)
println("pos:")
println(cursorpos(get_terminal()))
end
Task (runnable) @0x00007f1ecd12e230
julia> pos:
julia> 1
1
```
Do you have any idea about what's going on there (or what to do about it)?
username_0: I'm getting the same behavior you are getting.
I played around with it a little. First, I'm able to run the `write` and `read` in a `@async` block and it works fine, which I was not expecting. It prints the stdin to the screen though.

I was then able to set the appropriate flags in the user terminal (without using the async macro), and run the cursor command (write and read) in the async macro, and reset the flags from the REPL. This kind of worked but was behaving weirdly
This led me to think that the `ccall` and the function is working as expected, but the `while true ... if ch == "R" break` is what is causing the issue.
So I changed the `getXY` function to the following:
```
write(stdout, "$(Terminals.CSI)6n")
buf = UInt8[]
for _ in 1:6
ch = read(stdin, 1)[1]
push!(buf, ch)
end
ch = read(stdin, 1)[1]
```
Now this is what I'm getting when I run it.

The `x` and `y` are what I would have gotten if I ran it without using the `@async` macro.
I think the `ccall`s are working as expected. It's just that with `@async` maybe other stuff is being printed to the screen and maybe that is interfering with reading stdin (?). |
yglukhov/nimx | 798302070 | Title: Collisions on SSL_connect (openssl.nim)
Question:
username_0: Simple code:
```nim
import httpclient
import nimx/window
var client = newHttpClient()
discard client.get("https://account.api.here.com/oauth2/token")
```
Getting error:14004410:SSL routines:CONNECT_CR_SRVR_HELLO:sslv3 alert handshake failure [SslError]
because ret == 0 after: `ret = SSL_connect(socket.sslHandle)` but should be ret == 1
But this error happens only in case (3 conditions together):
1. on MacOS "Big Sur 11.0.1" (it cause the error on another MacOS too: https://forum.nim-lang.org/t/7018#44069)
2. For URL "https://account.api.here.com/oauth2/token"
3. if "import nimx" in the code (if you comment it like #import nimx/window then works SSL_connect )
Please, any suggestions/workaround...
Answers:
username_0: Changed code - nimx/image instead of nimx/window:
```nim
import httpclient
import nimx/image
var client = newHttpClient()
discard client.get("https://account.api.here.com/oauth2/token")
```
Getting the same error:14004410:SSL routines:CONNECT_CR_SRVR_HELLO:sslv3 alert handshake failure [SslError]
I used Wireshark to recognize what happens on hand shake: with nimx/image Client Hello sends only 3 cipher suites but on server (account.api.here.com) don't exist these suites therefore the server doesn't send Hello Client.
But
When I changed little bit code in image.nim file on line https://github.com/username_1/nimx/blob/4034e6139d60ab28ce32abab1a22cba47ce22f51/nimx/image.nim#L633
to:
```nim
when not asyncResourceLoad:
```
then after compiling Client Hello sends 9 (!) cipher suites and in this case the server sends Hello Client successful.
The bellow code **nothing does in run time** but why it causes issues to use count of ciphers?:
```nim
var ctx: ImageLoadingCtx
ctx.new()
ctx.url = url
ctx.completionCallback = handler
when not loadAsyncTextureInMainThread:
let curWnd = glGetCurrentWindow()
if threadCtx.isNil:
let curCtx = glGetCurrentContext()
threadCtx = glCreateContext(curWnd)
discard glMakeCurrent(curWnd, curCtx)
ctx.glCtx = threadCtx
doAssert(not ctx.glCtx.isNil)
ctx.wnd = curWnd
GC_ref(ctx)
if loadingQueue.isNil:
loadingQueue = newWorkerQueue(1)
loadingQueue.addTask(loadResourceThreaded, cast[pointer](ctx))
```
username_1: That's a mysterious one, and thanks for looking into that. Unfortunately I can't reproduce it neither on Linux, nor Big Sur 11.1. Moreover I don't have any clue why that could happen. Nimx images use https://github.com/username_1/async_http_request to load images over https, but inspecting that module I see no reason for it to interfere with the default httpclient's one. So you might want to look that way. |
jquery/jquery | 392079323 | Title: $("").append method Rendering delay like website-hk.gif
Question:
username_0: <!--
Feature Requests:
Please read https://github.com/jquery/jquery/wiki/Adding-new-features
Most features should start as plugins outside of jQuery.
Bug Reports:
Note that we only can fix bugs in the latest version of jQuery.
Briefly describe the issue you've encountered
* What do you expect to happen?
* What actually happens?
* Which browsers are affected?
Provide a *minimal* test case, see https://webkit.org/test-case-reduction/
Use the latest shipping version of jQuery in your test case!
We prefer test cases on https://jsbin.com or https://jsfiddle.net
Frequently Reported Issues:
* Selectors with '#' break: See https://github.com/jquery/jquery/issues/2824
-->
### Description ###
jquery append method Rendering delay like website-hk.gif
### Link to test case ###
[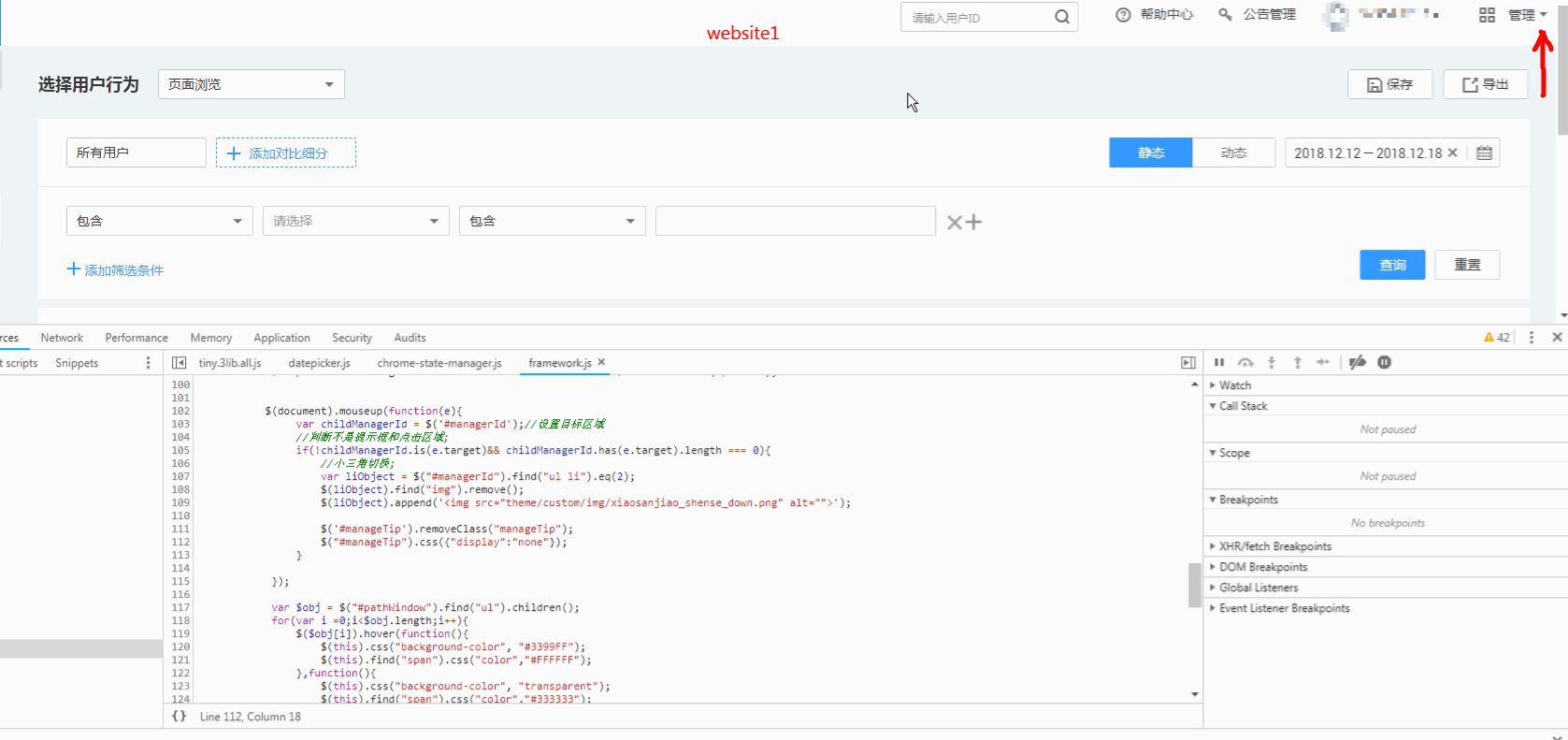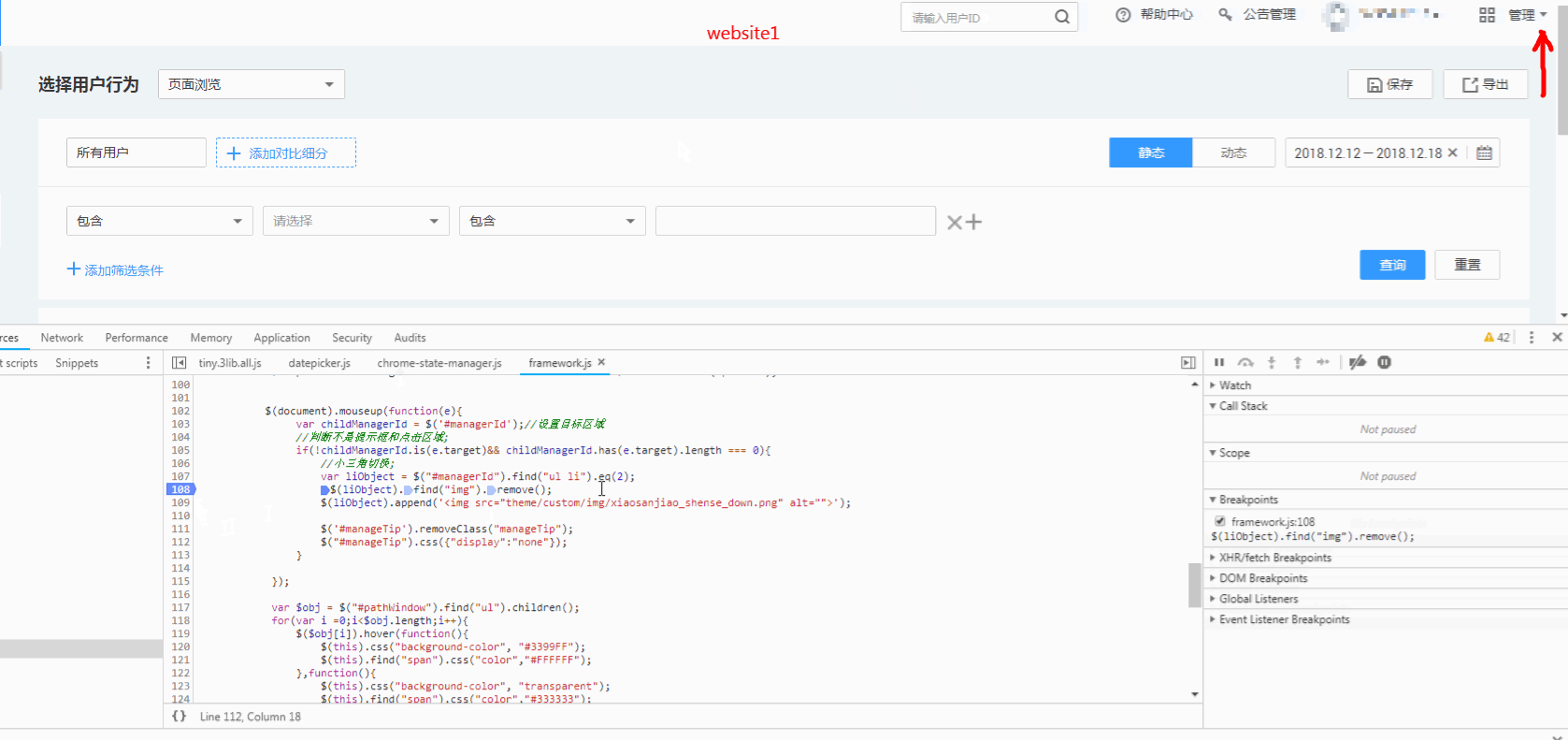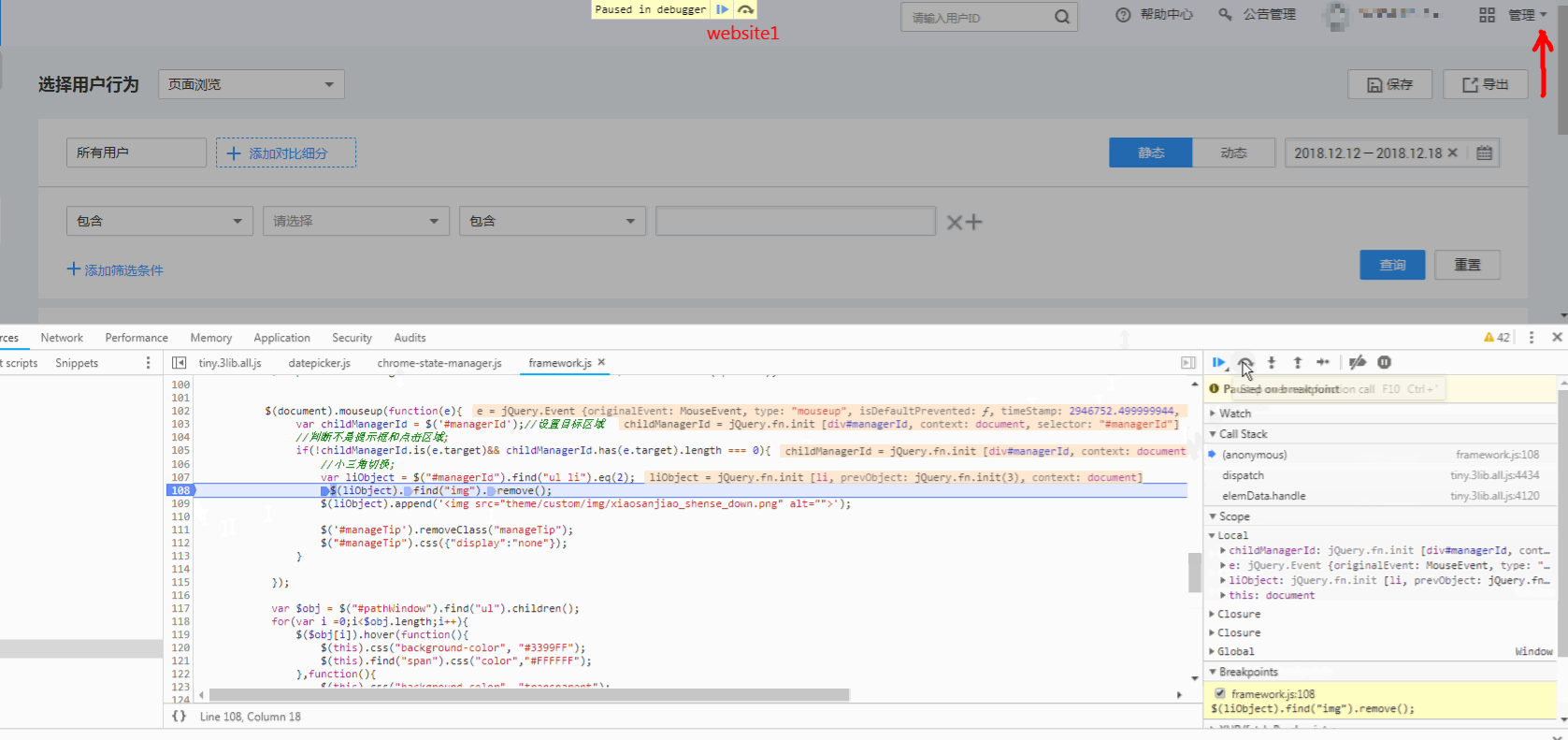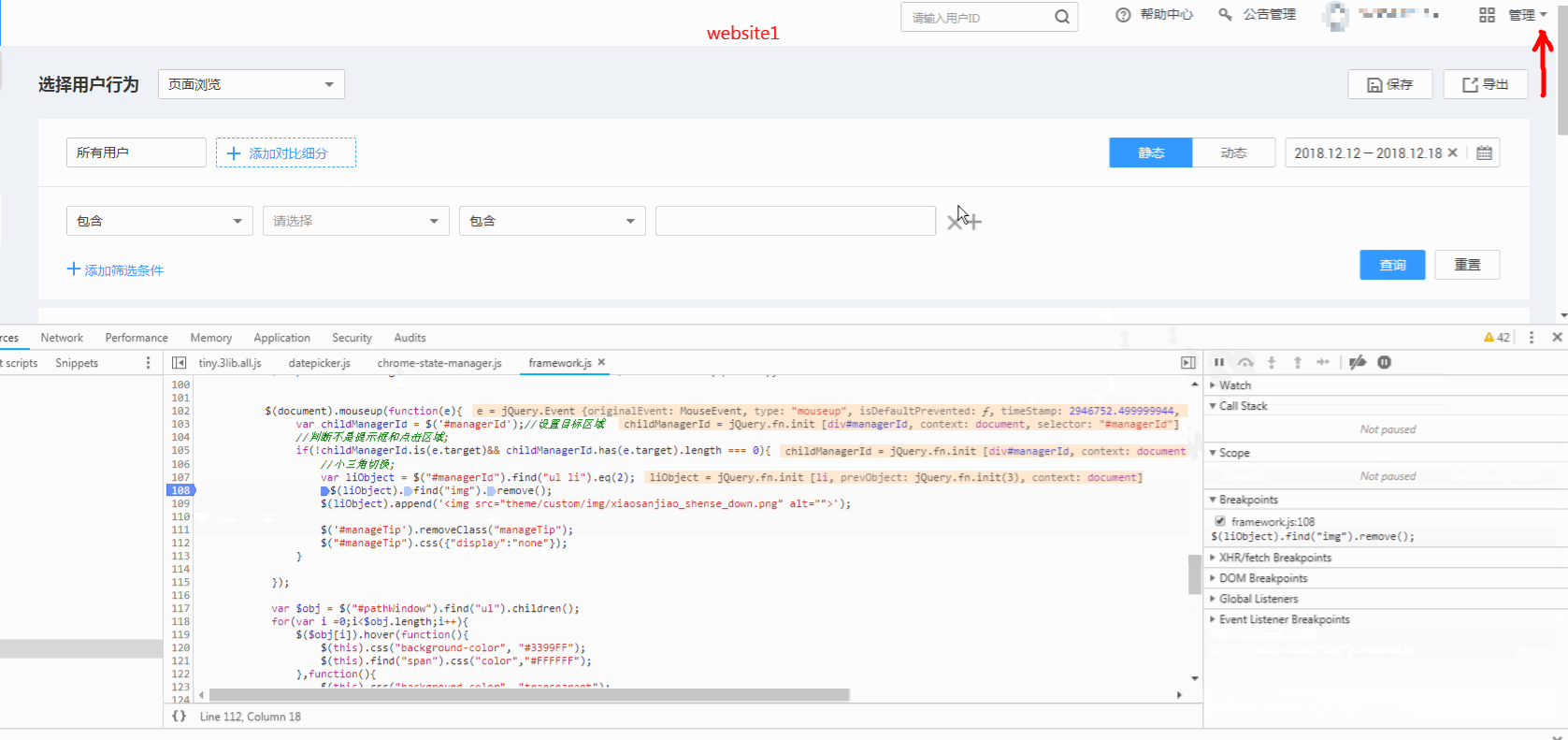](http://jfw-bucket.oss-cn-hangzhou.aliyuncs.com/website-hk.gif "website-hk.gif")
[](http://jfw-bucket.oss-cn-hangzhou.aliyuncs.com/website.gif "website.gif")
Answers:
username_1: Can you provide a test case on [JSFiddle](https://jsfiddle.net/) or [JS Bin](https://jsbin.com/) as the issue template requested? Thanks!
username_0: sorry,i think i couldn't provide a test case on JSFiddle or JS Bin,cause i build 2 web sites(you can see the 2 gifs),one is ok,but the other one is not.
username_1: In that case, we cannot help you here. Please look for programming help on Stack Overflow. If you are later able to isolate the issue to a simpler test case and it's not an issue in your code you can open a new issue.
Status: Issue closed
|
jupyterlab/jupyterlab | 224226221 | Title: Per cell UI for running cells
Question:
username_0: Opening to track design/implementation of our plans to have per-cell UI for running cells. @username_1 can you post mockups that show the "play button in the prompt"? Also, we will need to think about what this looks like for markdown cells too.
Answers:
username_1: As I was thinking about the running cell indication, I originally started to incorporate a traditional loading wheel inside of the cell's brackets. While it was really easy to figure out what was happening, it felt really standard and I tried making a more abstract idea. Let me know what you think:

username_0: Marking this as beta - we might have time to do it and it is high value. Can be deferred if needed. |
allenai/allennlp | 374728077 | Title: ImportError: Matplotlib qt-based backends require an external PyQt4, PyQt5, or PySide package to be installed, but it was not found.
Question:
username_0: my environment:
1) py3.7
2) allennlp0.6
i cannot use qt5agg backend for maplotlib, so i want to change its backend to agg, but i do not know where to change, the error is :
import matplotlib.pyplot as plt
File "/data1/username_0/local/anaconda3/envs/allennlp/lib/python3.6/site-packages/matplotlib/pyplot.py", line 115, in <module>
_backend_mod, new_figure_manager, draw_if_interactive, _show = pylab_setup()
File "/data1/username_0/local/anaconda3/envs/allennlp/lib/python3.6/site-packages/matplotlib/backends/__init__.py", line 32, in pylab_setup
globals(),locals(),[backend_name],0)
File "/data1/username_0/local/anaconda3/envs/allennlp/lib/python3.6/site-packages/matplotlib/backends/backend_qt5agg.py", line 16, in <module>
from .backend_qt5 import QtCore
File "/data1/username_0/local/anaconda3/envs/allennlp/lib/python3.6/site-packages/matplotlib/backends/backend_qt5.py", line 26, in <module>
import matplotlib.backends.qt_editor.figureoptions as figureoptions
File "/data1/username_0/local/anaconda3/envs/allennlp/lib/python3.6/site-packages/matplotlib/backends/qt_editor/figureoptions.py", line 20, in <module>
import matplotlib.backends.qt_editor.formlayout as formlayout
File "/data1/username_0/local/anaconda3/envs/allennlp/lib/python3.6/site-packages/matplotlib/backends/qt_editor/formlayout.py", line 56, in <module>
from matplotlib.backends.qt_compat import QtGui, QtWidgets, QtCore
File "/data1/username_0/local/anaconda3/envs/allennlp/lib/python3.6/site-packages/matplotlib/backends/qt_compat.py", line 179, in <module>
"Matplotlib qt-based backends require an external PyQt4, PyQt5,\n"
ImportError: Matplotlib qt-based backends require an external PyQt4, PyQt5,
or PySide package to be installed, but it was not found.
Status: Issue closed
Answers:
username_1: How did you solve this?
username_0: yes,but i forget。。 |
yahiaetman/Go-Server | 538145978 | Title: Scoring is incorrect
Question:
username_0: **Describe the bug**
The scoring function is incorrect, it adds erroneous number of captured stones when an agent has passed and the other is still playing.
**To Reproduce**
Steps to reproduce the behavior:
1. Make an agent pass
2. Make the other agent play in one of his eyes (or any intersection surrounded by his stones)
3. Watch the number of captured stones go up.
**Expected behavior**
These are not captures, and hence the total score is incorrect.
**Video Evidence**
https://youtu.be/HozIyyecLnY
**Additional context**
Sorry for bringing this up this late, but I hope this can be fixed before the competition.
Answers:
username_1: Could you send the log for this game? Thank you.
username_1: Note that doing a pass will add a stone to the opponent's prisoners.
username_1: Fixed in c3e45aa57ea2ebe71f6efd33c2c2e0484ab54281
Status: Issue closed
|
swagger-api/swagger-codegen | 101500478 | Title: exception in deserialize of python client: 'DateTime' is referenced as 'datetime'
Question:
username_0: In models generated for objects with date-time field, swagger_types dictionary contains 'DateTime' , but api_client.py expects 'datetime' -- this produces exception when running generated code on attempt to deserialize (see api_client.py:deserialize function).
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "foo\apis\bar_api.py", line 297, in get_bar_info
response='barInfo', auth_settings=auth_settings)
File "foo\api_client.py", line 105, in call_api
return self.deserialize(response_data, response)
File "foo\api_client.py", line 209, in deserialize
setattr(instance, attr, self.deserialize(value, attr_type))
File "foo\api_client.py", line 174, in deserialize
obj_class = eval('models.' + obj_class)
File "<string>", line 1, in <module>
AttributeError: 'module' object has no attribute 'DateTime'
```
Answers:
username_0: This appears to be addressed in develop_2.0 branch of codegen.
Status: Issue closed
|
darkreader/darkreader | 524042429 | Title: Proposal - dim images with opacity
Question:
username_0: # What is the Proposal?
Add dimming to images.
# Why?
When browsing the web at night, often times you'll run into images that have white or very bright backgrounds and are not png's. Imagine browsing websites (example e-commerce/shopping) where they use large white backgrounds.

# Solution
- Dim images slightly.
- Add a configurable option to toggle this feature on/off.

# Potential Challenges
- jpg's or images that don't have bright backgrounds could become hard to read.
I haven't dug into how to solve that issue too much, but I know there are micro javascript libraries that can detect the color of images and analyze the brightness level, if we were to use something like that, we could check the brightness of the image after loading the page, to undo dimming, if the image doesn't need to be dimmed.
[CSS filters have strong support already](https://caniuse.com/#feat=css-filters). Most users who use dark reader, we can assume are on relatively newer browsers. If they know how to install an extension and find one like dark reader, we can make some assumptions =).
```css
img {
border-color: #000;
box-shadow: none;
-webkit-filter: brightness(0.8) contrast(1.2);
filter: brightness(0.8) contrast(1.2);
}
```
Live demo code (JSbin.com): https://jsbin.com/naseresade/4/edit?html,output
Answers:
username_1: its an extension recommended by Firefox.
---
let site owners fix that bug. this is a new way to waste CPU cycles and other resources.
---
username_1
username_2: so are browser extensions ;)
Actually CSS filters run on the GPU.
username_0: the idea runs contrary to the whole concept of web extensions in this context. Also that will likely never happen. That's like saying: _let each site owner implement browsing it in dark mode._
The reason we create chrome extension's to augment our experiences =)
username_2: I actually like your proposal - in general, and yes: it'd need a toggle.
It may also require a selection of **blend modes** (besides filters) that are actually designed to specifically reduce/affect whites and light colours while keeping others (mainly) intact. There'll be only a few to pick from.
- https://developer.mozilla.org/en-US/docs/Web/CSS/mix-blend-mode
- https://caniuse.com/#search=mix-blend-mode
With images like the ones in your post, that depict a pretty clear subject against a solid colour, it'd be relatively easy to even create decent masks "on the fly" and literally cut out the main subject or use them to control filters and blend modes.
Using Canvas2D or SVG can help as intermediates. Modern CSS combined with SVG filters can become a very powerful "image editor". The math for his is well known and JS libraries exist to do this.
Cheers.
username_3: Yes! Indeed, this stunning extension has saved my eyes more than once by nights!
It would be great to have this functionality, albeit as an implicit setting.
In the meantime, I am using such a simple code that I pasted into the `config editor`.
```css
img, video {
filter: brightness(0.5);
}
img:hover, video:hover {
filter: unset;
}
```
Hovering over an element returns the brightness so that you can better understand the context 👍 |
ekmett/adjunctions | 252122561 | Title: Day instances derived from from Compose
Question:
username_0: There is an isomorphism between `Compose f g` and `Day f g` of representable functors
```haskell
c2d :: (Representable f, Representable g) => Compose f g a -> Day f g a
c2d = tabulate . index
d2c :: (Representable f, Representable g) => Day f g a -> Compose f g a
d2c = tabulate . index
```
This means every instance of `Compose f g` is a potential instance for `Day`, would these instances be useful and worth adding?
```haskell
instance (Alternative f, Representable f, Alternative g, Representable g) => Alternative (Day f g) where
empty :: Day f g a
empty = c2d empty
(<|>) :: Day f g a -> Day f g a -> Day f g a
(d2c -> a) <|> (d2c -> b) = c2d (a <|> b)
```
This allows for an `Alternative` definition as well as an inordinate number of other instances.
----
We also get a handful of classes the other way: some instance for `Compose f g` that work for functors like `Coyoneda f`, `(_ ->)`, `Cofree`, `Day` and recursively `Compose` (it would be an orphan instance I suppose)
```haskell
instance (Comonad f, Representable f, Comonad g, Representable g) => Comonad (Compose f g) where
extract :: Compose f g a -> a
extract = extract . c2d
duplicate :: Compose f g a -> Compose f g (Compose f g a)
duplicate = fmap d2c . d2c . duplicate . c2d
instance (ComonadApply f, ComonadApply g, Representable g, Representable f) => ComonadApply (Compose f g) where
(<@>) :: Compose f g (a -> b) -> (Compose f g a -> Compose f g b)
(c2d -> f) <@> (c2d -> x) = d2c (f <@> x)
```
Answers:
username_1: Any `Alternative` functor `f` must have an empty shape to provide an `f a` for any `a`. `Representable` functors only have one shape, so an `Alternative` `Representable` functor must be isomorphic to `Void`. So at least that instance is not very interesting.
username_0: Good observation (it was a pleasure meeting you at Haskell eXchange @username_1)
Other instances may be mildly interesting but should really be derived through `DerivingVia` rather than fixing them as an instance. I think I will close this ticket
Status: Issue closed
|
barryvdh/elfinder-flysystem-driver | 152590350 | Title: Webdav configuration
Question:
username_0: Hello Barry,
I've been trying to use your Flysystem driver for elfinder, specifically to connect to a webdav filesystem.
I'm missing something for sure...
I've installed everything through the composer and "rerquired" all the packages... but still nothing..
The only thing I'm not sure is about the definition of the webdav root at elfinder connector.
Here are the lines:
`
use Sabre\DAV\Client;
use League\Flysystem\Filesystem;
use League\Flysystem\WebDAV\WebDAVAdapter;
$settings = array(
'baseUri' => 'https://urltowebdav/',
'userName' => 'userna',
'password' => '<PASSWORD>',
);
$client = new Client($settings);
$opts = array(
'roots' => array(
array(
'driver' => 'LocalFileSystem', // driver for accessing file system (REQUIRED)
'path' => ELFINDER_ROOT_PATH . '/files/', // path to files (REQUIRED)
'URL' => ELFINDER_ROOT_URL . '/files/', // URL to files (REQUIRED)
'uploadDeny' => array('all'), // All Mimetypes not allowed to upload
'uploadAllow' => array('image', 'text/plain'), // Mimetype `image` and `text/plain` allowed to upload
'uploadOrder' => array('deny', 'allow'), // allowed Mimetype `image` and `text/plain` only
),
array(
'driver' => 'Flysystem',
'filesystem' => new WebDAVAdapter($client) // disable and hide dot starting files (OPTIONAL)
)
)
);
`
Can someone help me?
Answers:
username_0: Ok...
I've found the working config and edited the previous comment with the solution.
But now I've came across with other problem...
I can get acces to the webdav using my computer (Finder on OSX), so thats not the problem.
Using this config I now get "HTTP error: 405" error message.
Does anyone know who is sending this error? Elfinder? Flysystem? Sabre? or my webdav server?
Thank you,
AP
Status: Issue closed
username_0: Hello Barry,
I've been trying to use your Flysystem driver for elfinder, specifically to connect to a webdav filesystem.
I'm missing something for sure...
I've installed everything through the composer and "required" all the packages... but still nothing..
The only thing I'm not sure is about the definition of the webdav root at elfinder connector.
Here are the lines:
```
use Sabre\DAV\Client;
use League\Flysystem\Filesystem;
use League\Flysystem\WebDAV\WebDAVAdapter;
$settings = array(
'baseUri' => 'https://urltowebdav/',
'userName' => 'userna',
'password' => '<PASSWORD>',
);
$client = new Client($settings);
$webdavAdapter = new WebDAVAdapter($client);
$webdavfs = new Filesystem($webdavAdapter);
$opts = array(
'roots' => array(
array(
'driver' => 'Flysystem',
'filesystem' => $webdavfs
)
)
);
```
Can someone help me?
username_1: No sorry. Check your logs to see if you find any errors.
username_0: Thank you for your reply.
But can you at least confirm the the connection to a webdav server is working?
username_1: I've never used webdav.
username_0: Another update...
For WebDAVAdpater it is necessary to define a second argument with a prefix path. In my case '.' worked well and I can already receive the respective xml return.
```$webdavAdapter = new WebDAVAdapter($client,'.');```
But there is still a problem, and this time I think it is from elfinder-flysystem-driver side, since it is not reading well this information.
Here goes an extract of the output:
```
'/remote.php/webdav/' =>
array (size=1)
'{DAV:}getlastmodified' => string 'Wed, 04 May 2016 09:27:12 GMT' (length=29)
'/remote.php/webdav/%23classified%23/' =>
array (size=1)
'{DAV:}getlastmodified' => string 'Wed, 20 Apr 2016 10:50:08 GMT' (length=29)
'/remote.php/webdav/.DS_Store' =>
array (size=3)
'{DAV:}getcontentlength' => string '16388' (length=5)
'{DAV:}getcontenttype' => string 'application/octet-stream' (length=24)
'{DAV:}getlastmodified' => string 'Mon, 02 May 2016 16:37:13 GMT' (length=29)
'/remote.php/webdav/._.DS_Store' =>
array (size=3)
'{DAV:}getcontentlength' => string '4096' (length=4)
'{DAV:}getcontenttype' => string 'application/octet-stream' (length=24)
'{DAV:}getlastmodified' => string 'Wed, 27 Apr 2016 14:46:04 GMT' (length=29)
'/remote.php/webdav/._BIO.JPG' =>
array (size=3)
'{DAV:}getcontentlength' => string '4096' (length=4)
'{DAV:}getcontenttype' => string 'image/jpeg' (length=10)
'{DAV:}getlastmodified' => string 'Thu, 28 Apr 2016 15:44:35 GMT' (length=29)
'/remote.php/webdav/1min_3Bs_Presentation.ppt' =>
array (size=3)
'{DAV:}getcontentlength' => string '311808' (length=6)
'{DAV:}getcontenttype' => string 'application/vnd.ms-powerpoint' (length=29)
'{DAV:}getlastmodified' => string 'Fri, 07 May 2010 11:59:09 GMT' (length=29)
'/remote.php/webdav/1min_3bs_presentation.doc' =>
array (size=3)
'{DAV:}getcontentlength' => string '20992' (length=5)
'{DAV:}getcontenttype' => string 'application/msword' (length=18)
'{DAV:}getlastmodified' => string 'Fri, 07 May 2010 11:59:09 GMT' (length=29)
'/remote.php/webdav/3B%27s%20Bioreactor/' =>
array (size=1)
'{DAV:}getlastmodified' => string 'Wed, 20 Apr 2016 10:51:01 GMT' (length=29)
'/remote.php/webdav/3B%27s%20CE/' =>
array (size=1)
'{DAV:}getlastmodified' => string 'Wed, 04 May 2016 09:27:12 GMT' (length=29)
```
Can you check it?
username_0: Back again with the solution...
The problem was the "optional" prefix that has to be defined when creating the webdavadpter.
I was trying to connect elfinder to a owncloud cloud storage using flysystem and flysytem-webdav adapter.
A tipical owncloud webdav url is something like: ```https://owncloud_url/remote.php/webdav/```and I was using it to define the baseUri, and that was the problem... when parsing the contents the "paths" were all wrong and the elfinder wans't able to get the files.
Here is the working code to mount a owncloud drive using flysystem-webdav on elfinder:
```
use Sabre\DAV\Client;
use League\Flysystem\Filesystem;
use League\Flysystem\WebDAV\WebDAVAdapter;
$settings = array(
'baseUri' => 'https://owncloud_url',
'userName' => $user,
'password' => $<PASSWORD>,
'authType' => Client::AUTH_BASIC
);
$client = new Client($settings);
$webdavAdapter = new WebDAVAdapter($client,"/remote.php/webdav/");
$webdavfs = new Filesystem($webdavAdapter);
$opts = array(
'roots' => array(
array(
'driver' => 'Flysystem',
'filesystem' => $webdavfs
)
)
);
```
Regards,
AP
Status: Issue closed
|
daisy/reading-system-testing | 753611542 | Title: Jaws not deep linking in VitalSource Bookshelf Online in Chrome
Question:
username_0: ### Issue Name: Jaws not deep linking in VitalSource Bookshelf Online in Chrome
Steps:
1. Launch Bookshelf online using Chrome and Jaws
2. Open fundamental basic title
3. Open table of contents
4. Navigate to a sub-heading, and not the first one in a section.
5. Pressent and observe visually that it takes you to the correct location. However, pressing the down arrow key to read jumps you to the beginning of the chapter. This causes the test to fail.
6. We tested with the files extracted, and using only Chrome, this works properly.
OS: Windows 10 version 20H2
Reading System:VitalSource Bookshelf online
Version:
Chrome browser Version 86.0.4240.198 (Official Build) (64-bit)
Assistive Technology: Jaws
AT version: 2021.2011.16 and 2020.2008.24
AT case: Vispero Case# 00516961
Demonstration Video: We have one.
Sample file: Our fundamental basic test book
Answers:
username_1: The test book can be downloaded from http://epubtest.org/books/Fundamental-Accessibility-Tests-Basic-Functionality-v1.0.0.epub |
flyerhzm/bullet | 564074747 | Title: Threadsafe whitelist
Question:
username_0: We have Bullet configured in our test suite to raise an error if we have an issue.
The problem with this is that some of our tests fail because of the "Unused Eager Loading" warning. That makes sense for the context of the test where the loaded association isn't used at all but it doesn't affect the performance at all and we don't need to fine-tune each use case to know what to load or not.
When this happens, we add it to the whitelist. The problem with this is that since the whitelist is applied globally, we might be missing the error in places where it makes sense to be raised. So at first, I thought that maybe we could configure an RSpec hook to create and delete the whitelist as needed for the context of the spec.
However, could it be that this whitelist is not thread-safe? If it isn't, maybe I can build something around it but I wanted to confirm with the maintainers.
Thanks.
Answers:
username_1: It isn't, and neither is `Bullet.enable`. I'd love to see these become threadsafe so I can run parallel tests, selectively opting in to raise Bullet errors on a test by test basis.
Status: Issue closed
username_2: @username_0 I have make whitelist threadsafe in latest master branch
@username_1 I don't think it's necessary to make enabled thread safe. |
AlJohri/dotfiles | 216287895 | Title: things to add
Question:
username_0: - [ ] sublime packages
- [ ] atom pacakges
- [ ] iterm preference (open new tab/terminal in the last working directory)
- [ ] mac dock (minimize application into their respective icons, add Applications folder)
- [ ] trackpad (right click should be right click)
- [ ] keypress needs to be faster
Answers:
username_0: update macos settings based on https://github.com/mathiasbynens/dotfiles/blob/master/.macos
username_0: customize dock
- add folders on right: "Downloads" (view content as Fan), "Screenshots", "Applications" (view content as Grid)
photos, icloud -> optimize storage
dropbox, all folders "online only"
username_0: extract pem files from 1password
username_0: install clokta via pipx
```
pipx install clokta && pipx inject clokta onetimepass
```
username_0: first time onepassword cli signin
```
op signin my.1password.com <email> <secret key>
```
username_0: iterm2
^ cmd f: full screen (many apps use this)
^ tab: next tab
^ shift tab: previous tab
username_0: auto install vscode extensions
```
code --install-extension ms-python.python
code --install-extension ms-vscode-remote.vscode-remote-extensionpack
code --install-extension samuelcolvin.jinjahtml
code --install-extension mohsen1.prettify-json
code --install-extension esbenp.prettier-vscode
code --install-extension visualstudioexptteam.vscodeintellicode
code --install-extension redhat.vscode-yaml
code --install-extension grapecity.gc-excelviewer
code --install-extension james-yu.latex-workshop
code --install-extension josephtbradley.hive-sql
code --install-extension lextudio.restructuredtext
code --install-extension mikestead.dotenv
code --install-extension nobuhito.printcode
code --install-extension octref.vetur
code --install-extension rebornix.ruby
```
maybe keep https://tabnine.com/ ? (`tabnine.tabnine-vscode`)
username_0: chrome tampermonkey scripts |
salcode/bootstrap4-genesis | 339277305 | Title: What type of build process
Question:
username_0: The original [Bootstrap Genesis](https://github.com/username_0/bootstrap-genesis) (which uses Bootstrap 3.x) uses Grunt as a task runner. What task runner do we want to use here?
- Grunt
- Gulp ([Gulp WP Toolkit](https://github.com/craigsimps/gulp-wp-toolkit/)?)
- Webpack
- other?
Answers:
username_0: We've gone with `Gulp`.
**Build** and **watch** can be run with
`npm run build` and `npm run watch` respectivley.
Status: Issue closed
|
kubernetes-sigs/cluster-api-provider-vsphere | 468537451 | Title: Can not create cluster using CAPV lastest version V.0.3.XX
Question:
username_0: /kind bug
**DISCLAIMER**: The issue is when using the version v0.3.0-65-g14293965. The latest version for this ticket creation date. It's running fine on version v.0.3.0.
**What steps did you take and what happened:**
I'm following the get started on CAPV https://github.com/kubernetes-sigs/cluster-api-provider-vsphere/blob/master/docs/getting_started.md. I'm blocked on "Using clusterctl".
I executed the command bellow on out folder :
**clusterctl create cluster --provider vsphere --bootstrap-type kind -c cluster.yaml -m machines.yaml -p provider-components.yaml --addon-components addons.yaml -v 10**
```
I0712 16:52:38.123922 23945 round_trippers.go:438] GET https://127.0.0.1:44439/apis/cluster.k8s.io/v1alpha1/namespaces/default/machines/capv-mgmt-example-controlplane-1 200 OK in 4 milliseconds
I0712 16:52:38.124003 23945 round_trippers.go:444] Response Headers:
I0712 16:52:38.124043 23945 round_trippers.go:447] Content-Type: application/json
I0712 16:52:38.124068 23945 round_trippers.go:447] Content-Length: 934
I0712 16:52:38.124088 23945 round_trippers.go:447] Date: Fri, 12 Jul 2019 15:52:38 GMT
I0712 16:52:38.124149 23945 request.go:942] Response Body: {"apiVersion":"cluster.k8s.io/v1alpha1","kind":"Machine","metadata":{"creationTimestamp":"2019-07-12T15:36:28Z","generation":1,"labels":{"cluster.k8s.io/cluster-name":"capv-mgmt-example"},"name":"capv-mgmt-example-controlplane-1","namespace":"default","resourceVersion":"305","selfLink":"/apis/cluster.k8s.io/v1alpha1/namespaces/default/machines/capv-mgmt-example-controlplane-1","uid":"8306d5e4-63e7-4b80-b563-042240193f6c"},"spec":{"metadata":{"creationTimestamp":null},"providerSpec":{"value":{"apiVersion":"vsphere.cluster.k8s.io/v1alpha1","datacenter":"DATA_CENTE0100","datastore":"locadatastore","diskGiB":50,"folder":"Workloads","kind":"VsphereMachineProviderSpec","memoryMiB":2048,"network":{"devices":[{"dhcp4":true,"dhcp6":false,"networkName":"Lg1ag1ccnlab20ash01|vlan1222|vlan1222"}]},"numCPUs":2,"resourcePool":"/DATA_CENTE0100/host/Cluster1/Resources/ESX Agents/Resource_pool_innovation_01","template":"ubuntu-1804-kube-13.6"}},"versions":{"controlPlane":"1.13.6","kubelet":"1.13.6"}}}
I0712 17:06:28.123538 23945 clusterclient.go:996] Waiting for Machine capv-mgmt-example-controlplane-1 to become ready...
I0712 17:06:28.123659 23945 round_trippers.go:419] curl -k -v -XGET -H "Accept: application/json, */*" -H "User-Agent: clusterctl/v0.0.0 (linux/amd64) kubernetes/$Format" 'https://127.0.0.1:44439/apis/cluster.k8s.io/v1alpha1/namespaces/default/machines/capv-mgmt-example-controlplane-1'
......
I0712 17:06:28.123174 23945 round_trippers.go:438] GET https://127.0.0.1:44439/apis/cluster.k8s.io/v1alpha1/namespaces/default/machines/capv-mgmt-example-controlplane-1 200 OK in 3 milliseconds
I0712 17:06:28.123223 23945 round_trippers.go:444] Response Headers:
I0712 17:06:28.123257 23945 round_trippers.go:447] Date: Fri, 12 Jul 2019 16:06:28 GMT
I0712 17:06:28.123273 23945 round_trippers.go:447] Content-Type: application/json
I0712 17:06:28.123285 23945 round_trippers.go:447] Content-Length: 934
I0712 17:06:28.123340 23945 request.go:942] Response Body: {"apiVersion":"cluster.k8s.io/v1alpha1","kind":"Machine","metadata":{"creationTimestamp":"2019-07-12T15:36:28Z","generation":1,"labels":{"cluster.k8s.io/cluster-name":"capv-mgmt-example"},"name":"capv-mgmt-example-controlplane-1","namespace":"default","resourceVersion":"305","selfLink":"/apis/cluster.k8s.io/v1alpha1/namespaces/default/machines/capv-mgmt-example-controlplane-1","uid":"8306d5e4-63e7-4b80-b563-042240193f6c"},"spec":{"metadata":{"creationTimestamp":null},"providerSpec":{"value":{"apiVersion":"vsphere.cluster.k8s.io/v1alpha1","datacenter":"DATA_CENTE0100","datastore":"locadatastore","diskGiB":50,"folder":"Workloads","kind":"VsphereMachineProviderSpec","memoryMiB":2048,"network":{"devices":[{"dhcp4":true,"dhcp6":false,"networkName":"Lg1ag1ccnlab20ash01|vlan1222|vlan1222"}]},"numCPUs":2,"resourcePool":"/DATA_CENTE0100/host/Cluster1/Resources/ESX Agents/Resource_pool_innovation_01","template":"ubuntu-1804-kube-13.6"}},"versions":{"controlPlane":"1.13.6","kubelet":"1.13.6"}}}
I0712 17:06:28.123538 23945 clusterclient.go:996] Waiting for Machine capv-mgmt-example-controlplane-1 to become ready...
I0712 17:06:28.123659 23945 round_trippers.go:419] curl -k -v -XGET -H "Accept: application/json, */*" -H "User-Agent: clusterctl/v0.0.0 (linux/amd64) kubernetes/$Format" 'https://127.0.0.1:44439/apis/cluster.k8s.io/v1alpha1/namespaces/default/machines/capv-mgmt-example-controlplane-1'
I0712 17:06:28.127961 23945 createbootstrapcluster.go:36] Cleaning up bootstrap cluster.
I0712 17:06:28.127976 23945 kind.go:69] Running: kind [delete cluster --name=clusterapi]
I0712 17:06:29.069055 23945 kind.go:72] Ran: kind [delete cluster --name=clusterapi] Output: Deleting cluster "clusterapi" ...
F0712 17:06:29.069075 23945 create_cluster.go:61] unable to create control plane machine: timed out waiting for the condition
```
No cluster created nor clusterapi working properly. After 30 minutes I get "**unable to create control plane machine: timed out waiting for the condition**". Checking the POD status we can see that POD **vsphere-provider-controller-manager-0** can not start.
Command: **kubectl get pods --all-namespaces**
```
NAMESPACE NAME READY STATUS RESTARTS AGE
cluster-api-system cluster-api-controller-manager-0 1/1 Running 0 3m4s
kube-system coredns-5c98db65d4-d6grv 1/1 Running 0 3m4s
kube-system coredns-5c98db65d4-gxmww 1/1 Running 0 3m4s
kube-system etcd-clusterapi-control-plane 1/1 Running 0 2m24s
kube-system kindnet-mbcsk 1/1 Running 0 3m4s
kube-system kube-apiserver-clusterapi-control-plane 1/1 Running 0 2m9s
kube-system kube-controller-manager-clusterapi-control-plane 1/1 Running 0 2m22s
kube-system kube-proxy-h6phk 1/1 Running 0 3m4s
kube-system kube-scheduler-clusterapi-control-plane 1/1 Running 0 2m16s
vsphere-provider-system vsphere-provider-controller-manager-0 0/1 CrashLoopBackOff 4 3m4s
```
[Truncated]
v0.3.0-65-g14293965
- Kubernetes version: (use `kubectl version`):
Client Version: version.Info{Major:"1", Minor:"15", GitVersion:"v1.15.0", GitCommit:"<PASSWORD>", GitTreeState:"clean", BuildDate:"2019-06-19T16:40:16Z", GoVersion:"go1.12.5", Compiler:"gc", Platform:"linux/amd64"}
- OS (e.g. from `/etc/os-release`):
NAME="Ubuntu"
VERSION="18.04.2 LTS (Bionic Beaver)"
ID=ubuntu
ID_LIKE=debian
PRETTY_NAME="Ubuntu 18.04.2 LTS"
VERSION_ID="18.04"
HOME_URL="https://www.ubuntu.com/"
SUPPORT_URL="https://help.ubuntu.com/"
BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/"
PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy"
VERSION_CODENAME=bionic
UBUNTU_CODENAME=bionic
Answers:
username_1: @username_0 could you check the provider-component.yaml, is it still point to `/root/manager`? please run `generate-yaml.sh` to update the yamls since you updated the capv version.
username_0: @username_1 there is no info on provider-component.yaml pointing to "/root/manager". See **my provider-components.yaml** attached. [provider-components.yaml.txt](https://github.com/kubernetes-sigs/cluster-api-provider-vsphere/files/3397081/provider-components.yaml.txt)
Actually, I didn't update my capv version. I executed with the latest version first as it didn't work I cloned version v0.3.0 separately and test it.
They are in different folders to be able to test both easily:
- /code/capv/latests = Cloned with the latest version
- /code/capv/v.0.3.0 = Cloned from tag v.0.3.0
username_1: @username_0 my previous comment is wrong, that is for the much older version of yaml.
look at your yaml, it is point to `image: gcr.io/cnx-cluster-api/vsphere-cluster-api-provider:0.3.0`
which is the released version, where are you trying to apply `version v0.3.0-65-g14293965`?
username_2: @ username_0 Does you cluster.yaml have the correct parameter set in ProviderSpec for vSphere username ?
username_0: @username_1, if you clone the current version of capv and execute **git describe --tags** you'll see the version
v0.3.0-65-g14293965.
This is image: gcr.io/cnx-cluster-api/vsphere-cluster-api-provider:0.3.0 image version and
version **v0.3.0-65-g14293965** is the repository tag.
username_0: @username_2 yes, it does.
username_1: did u compile base on repo and generate the new image? the new image should be version like
```image: gcr.io/cnx-cluster-api/vsphere-cluster-api-provider:14293965```
username_3: Hi all,
The tags now use `git describe`. This is pretty straight-forward and simply an artifact of something handled in the upcoming #412. Here's an example of what to do: https://github.com/kubernetes-sigs/cluster-api-provider-vsphere/issues/403#issuecomment-508531894.
Please note that we don't use the `Makefile` anymore, and when you generate YAML, please specify the manager image to use with the `-m` flag.
username_3: PR #412 has been merged. Can you please try with the docs now? Thanks!
username_0: Hi @username_3, it works smoothly with new instructions on **Get started**. Thanks!!
Closing this ticket now.
Thanks @username_1 and @username_2 for the support.
Status: Issue closed
|
wso2/product-is | 358972029 | Title: Aud value in JWT access token is not quite right
Question:
username_0: Aud value in JWT access token is set to the client_id, which is not right.
Ideally we should respect an aud parameter passed along with the token request or have an option to predefine an aud value under the configuration |
ant-design/ant-design | 599433632 | Title: the Table component set attribute scroll x error:ResizeObserver loop limit exceeded
Question:
username_0: - [ ] I have searched the [issues](https://github.com/ant-design/ant-design/issues) of this repository and believe that this is not a duplicate.
### Reproduction link
[](https://codesandbox.io/s/unruffled-lumiere-ucutv?file=/src/index.js)
### Steps to reproduce
初始化控制台会打印error信息
### What is expected?
window.onerror 不会异常
### What is actually happening?
window.onerror异常 :ResizeObserver loop limit exceeded
| Environment | Info |
|---|---|
| antd | 4.1.0 |
| React | 16.8.6 |
| System | Mac OS X Version: 10.14.4 |
| Browser | Chrome Version: 80.0.3987 |
<!-- generated by ant-design-issue-helper. DO NOT REMOVE -->
Answers:
username_1: 怎么操作可以重现?直接打开没错误。
username_2: @username_1 ,例子里用的是 log 打印的 error:
<img width="260" alt="截屏2020-04-14 下午7 27 43" src="https://user-images.githubusercontent.com/5378891/79220118-056d7b80-7e86-11ea-9ea8-9f3f5135b661.png">
username_2: 这个错误是可以无视的,ResizeObserver 注册的时候也正是组件第一次渲染的时候,它不一定能在同一帧里完成,所以有这个信息。未来 React 上 concurrent 后,就 OK 了。
ref:https://stackoverflow.com/questions/49384120/resizeobserver-loop-limit-exceeded
username_0: @username_2 我在antd 3.x的版本发现这个问题是不存在的~
username_2: 因为 v3 是通过渲染时获取元素对齐,对于动态元素对齐有 bug 同时性能也差一些:https://zhuanlan.zhihu.com/p/102037418
username_0: @username_2 非常感觉,持续关注此问题~
username_3: 直接打开当前页没有问题,从其他页跳到该页会打印error信息
Status: Issue closed
username_4: Fixed in https://github.com/react-component/align/pull/72#event-3660686845 |
TheProductWorks/smart_client | 90648017 | Title: Home Visits review in the mobile app
Question:
username_0: Buglust
----
- [ ] No need to show 'Appointment Type' field on booking form or confirmation step. There is no duration associated with home visits
- [ ] No need to show 'Priority'... default all these appointments to 'Home-Visit'
- [ ] Null showing on 'At' field of confirmation step. No need to show timestamp in this field: just show the date. Include 'Day', e.g. Wednesday 25 Jun 2015
- [ ] Change 'Free slot' to 'Book Home Visit'
- [ ] Show address details on appointment day view... address line 1, address line 2, town/city. NO need to show county. Smaller, greyer font underneath the person name???
Answers:
username_1: -[ ] Show address in 'To Attend' field in confirm appointment details
username_0: [testing]
- Null showing as timeslot on the confirmation screen.
- app crashed when hitting confirm appointment on home visit for Shannon
username_1: * Fix null in "At:" field in confirm section
* Fix crash
username_0: [review]
All looks good. Just need to add the address to the list view |
ikedaosushi/tech-news | 412464909 | Title: Untitled
Question:
username_0: ■<br>
研究開発部のサウラブです。 本稿ではユーザがレシピの作成にかける労力を減らすために取り入れた、機械学習を利用した機能の一つについて 解説します。この機能を利用すると、ユーザがレシピのタイトルを入力するこ<br>
https://ift.tt/2Nmxp6x |
lovell/sharp | 683017146 | Title: Thank you for the additional information, the problem is revealed here:
Question:
username_0: Thank you for the additional information, the problem is revealed here:
```
npm info lifecycle [email protected]~install: ignored because ignore-scripts is set to true
```
You'll need to reset `ignore-scripts` to its default value of `false`.
https://docs.npmjs.com/misc/config#ignore-scripts
_Originally posted by @username_1 in https://github.com/username_1/sharp/issues/2026#issuecomment-572948829_
Hi! I set the param to false and it did not solve it for me.
blog2 on master [!?] is 📦 v0.1.0 via ⬢ v10.16.0 via 🅒 base
➜ npm config set ignore-script false
blog2 on master [!?] is 📦 v0.1.0 via ⬢ v10.16.0 via 🅒 base
➜ npm config get ignore-script
false
What is the next step?
Answers:
username_1: ```diff
- npm config set ignore-script false
+ npm config set ignore-scripts false
```
username_0: No receipt for 'com.apple.pkg.CLTools_Executables' found at '/'.
No receipt for 'com.apple.pkg.DeveloperToolsCLILeo' found at '/'.
No receipt for 'com.apple.pkg.DeveloperToolsCLI' found at '/'.
gyp: No Xcode or CLT version detected!
gyp ERR! configure error
gyp ERR! stack Error: `gyp` failed with exit code: 1
gyp ERR! stack at ChildProcess.onCpExit (/usr/local/lib/node_modules/npm/node_modules/node-gyp/lib/configure.js:351:16)
gyp ERR! stack at ChildProcess.emit (events.js:198:13)
gyp ERR! stack at Process.ChildProcess._handle.onexit (internal/child_process.js:248:12)
gyp ERR! System Darwin 19.6.0
gyp ERR! command "/usr/local/bin/node" "/usr/local/lib/node_modules/npm/node_modules/node-gyp/bin/node-gyp.js" "rebuild"
gyp ERR! cwd /Users/aissata/blog2/node_modules/oniguruma
gyp ERR! node -v v10.16.0
gyp ERR! node-gyp -v v5.1.0
gyp ERR! not ok
npm WARN [email protected] requires a peer of typescript@>=2.8.0 || >= 3.2.0-dev || >= 3.3.0-dev || >= 3.4.0-dev || >= 3.5.0-dev || >= 3.6.0-dev || >= 3.6.0-beta || >= 3.7.0-dev || >= 3.7.0-beta but none is installed. You must install peer dependencies yourself.
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: [email protected] (node_modules/babel-plugin-add-module-exports/node_modules/fsevents):
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: [email protected] install: `node install`
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: Exit status 1
npm ERR! code ELIFECYCLE
npm ERR! errno 1
npm ERR! [email protected] install: `node-gyp rebuild`
npm ERR! Exit status 1
npm ERR!
npm ERR! Failed at the [email protected] install script.
npm ERR! This is probably not a problem with npm. There is likely additional logging output above.
npm ERR! A complete log of this run can be found in:
npm ERR! /Users/aissata/.npm/_logs/2020-08-23T18_09_28_166Z-debug.log
```
username_1: When you uninstall a package, npm attempts to re-install any other missing dependencies, which is what is happening here. Your repo requires the `babel-plugin-add-module-exports` module which requires `fsevents` but that must be compiled from source. You'll probably need to install xcode for this.
I'd like to reiterate that this is not a sharp error but is instead other dependencies preventing `npm install` from completing for all dependencies.
username_0: Thank you, I will try to find a solution.
Status: Issue closed
|
ministryofjustice/cloud-platform | 582462226 | Title: Periodically rotate all RDS credentials
Question:
username_0: We have this script:
https://github.com/ministryofjustice/cloud-platform-environments/blob/master/bin/update-rds-module-version.rb
It would be quite easy to create a cut-down version that just:
* rotated RDS credentials, and
* recycled all the pods in the namespace
We could build this into a pipeline/cron job so that every RDS instance has its
credentials rotated every month (or however often).
Although it might seem disruptive, this shouldn't be any more so than the
node-recycler, and teams should have no problem writing their application code
in such a way that doing this causes no downtime of their services (e.g. rails
applications will be fine, straight out of the box).
Is this worth doing? Does it make the platform more robust?
Answers:
username_1: Closed due to age of story
Status: Issue closed
|
marcelm/cutadapt | 489206405 | Title: Demultiplexing does not find the longest best partial 3' adapter
Question:
username_0: AACGCGGTGCCAGCMGCCGCGGTAA...ATTAGAWACCCBD**GTAGTCCCC**GAGG
However in the 1a results (file: trimmed-1a_R1.fastq) are Sequences like this:
@DE18INS60515:38:000000000-BJ6GC:1:1101:11645:1732 1:N:0:ATTCAGAACTACTGAC
AACGCGGTGCCAGCAGCCGCGGTAATACGGATGGTCCAAGCGTTATCCGTAATCATTGGGTTTAAAGTGTCCGCAGGCGGTCTTTTAAGTCAGAGGTTAAATCCCGTCTCTCAACGACTGACCTGCCTTTGATACTGGTTGACTTGAGTCATATGGATGTAGATAGAATGTCTAGTTTAGCGGTGAAATGCTTAGAGATTACACTTAATACCGATTTCGAAGGCAGTCTACTACGTATTTTCTGACCCTTAGGTACGAATGCCTGGTGAGCGATCCGTATTAGATACCCCT**GTAGTCCCC**
I marked the interesting regions bold. As you see, this read fits better to 17a but is assigned to 1a. I know that 1a is not wrong because I allow mismatches, but 17a fits much better, because of the direct hit
Attached you can find all input and output files.
[bugreport_cutadapt.zip](https://github.com/username_1/cutadapt/files/3575038/bugreport_cutadapt.zip)
Answers:
username_1: Hi, sorry that I somehow missed your bug report. Thanks for attaching all the necessary files, this makes it easy to reproduce.
At least one of the problems is that you are encountering issue #394, which was that the `--no-indels` option was ignored for linked adapters. I’ve released Cutadapt 2.5 yesterday, which fixes this problem, and when I run it on your files, the above read that was previously assigned to the "1a" file indeed now does end up in the 17a file.
However, I’ll still need to look into this further because even without `--no-indels`, the second linked adapter should match.
Status: Issue closed
username_1: The criterion that determines which adapter is the best-matching one is simply the number of matches in the alignment.
When allowing indels in the above example, the problem was that the alignments for 1a and 17a were considered to be equivalent because they both contain 17 matches. And in that case, the rule was that simply the first one found wins. Since 1a was listed before 17a in your FASTA file with adapter sequences, 1a was found.
Alignment for 1a:
```
ATTAGAWACCCBDGTAGTCCCGCGTT (1a adapter)
================X=
...ATACCCCTGTAGTCCC-C (read)
```
Alignment for 17a:
```
ATTAGAWACCCBDGTAGTCCCCGAGG (17a adapter)
=================
...ATACCCCTGTAGTCCCC (read)
```
I have now fixed this by using the number of errors in the alignment as a tie breaker. That is, if two adapters get the same number of matches in their alignments, the one with the lower number of errors wins. In the above case, this would then correctly prefer 17a over 1a.
Thanks for finding this! This part of Cutadapt has not been changed in a long time, so this behavior has been as it is in a while. This change also applies to any other adapter type, by the way, not only linked adapters.
username_0: Thank you!!! That was a fast fix!
I recognized the "first wins" behaviour when inputting duplicates in the adapter file. I will open a suggestion to print a warning for this as a seperate issue (but it has low priority I think).
I have also some more ideas of improvements for amplicon related cutting which I will also post later.
Thank you again!
username_1: Good suggestion about the duplicate adapter warning – I’ve added this now. |
containers/skopeo | 373456498 | Title: Ipv6 addresses not recognized in docker references
Question:
username_0: skopeo version 0.1.32-dev
```
OS: Ubuntu 18.04.1 LTS
The private docker registry started as described [here](https://github.com/Nordix/xcluster/tree/master/ovl/private-reg)
## Additional info
I am using `skopeo` as a tool for `cri-o` in Kubernetes. `cri-o` can't handle ipv6 addresses either, for instance in `/etc/crio/crio.conf`;
```
# registries is used to specify a comma separated list of registries to be used
# when pulling an unqualified image (e.g. fedora:rawhide).
registries = [
"[fd00:2008::242:ac11:2]:5000"
]
```
will not work but the corresponding setting works for ipv4.
This make me think that the problem maybe is in the lib's that both `skopeo` and `cri-o` uses(?).
Answers:
username_1: yes, very likely, does it work if you do a normal docker pull instead?
username_2: Thanks for your report.
IPv6 addresses aren’t valid syntax in Docker references, so this would be a big struggle throughout the ecosystem (and it isn’t clear that the syntax can be extended without breaking stuff—e.g. the `containers-storage:` transport uses a `[`…`]` prefix for something entirely different.).
Considering how unwieldy IPv6 addresses are, and how they make deploying TLS difficult, just not introducing support for them at all seems rather attractive—OTOH I do realize that we can’t always just pick and choose which features need or don’t need to be supported.
Status: Issue closed
username_0: I see the problem especially with TLS which is the normal case. My test env is of course a corner case and I can live without using ipv6 addresses in docker references. But they look awfully lot like a URL and using `curl` I can access the registry with a http://[.....]:5000/ address.
I close this issue since it is not a bug and not really something necessary.
Thanks for your answer. |
woocommerce/woocommerce | 563392731 | Title: need urlencode() of $license_key in new maxmind geo integration
Question:
username_0: ### Expected
At a minimum, the following. Perhaps more with `esc_url_raw()`
```php
'license_key' => urlencode(wc_clean( $license_key )),
```
### Isolating the problem
- [X] I have deactivated other plugins and confirmed this bug occurs when only WooCommerce plugin is active.
- [X] This bug happens with a default WordPress theme active, or [Storefront](https://woocommerce.com/storefront/).
- [X] I can reproduce this bug consistently using the steps above.
Answers:
username_1: Thank you for reporting this issue!
I'm closing the issue as it already has a PR, please continue the discussion over at #25682.
Status: Issue closed
|
mannodermaus/android-junit5 | 282569711 | Title: Can't exclude classes from JaCoCo code coverage report
Question:
username_0: JaCoCo includes all classes in its report. To exclude classes, the plug-in needs to set the task's class directories like this:
```
reportTask.classDirectories = project.fileTree(
dir: <destinationDir>,
excludes: ['**/R.class', '**/R$*.class']
)
```
Answers:
username_1: Thanks for reporting! We should allow users to provide their own exclude rules on top of the default set you mentioned, too.
username_1: This will be part of the `1.0.23` release. You can try the latest `SNAPSHOT` to get early access to this feature. If you want to have additional exclusion rules, use the new DSL:
```groovy
android.testOptions {
junitPlatform {
jacoco {
excludedClasses += ["SomePattern.class"]
excludedSources += ["SomeFile.java"]
}
}
}
```
Status: Issue closed
username_1: I will shortly release `1.0.30`, where this will be included. |
spacetelescope/STScI-STIPS | 371759447 | Title: STIPS images produce same background fluctuation pattern
Question:
username_0: When running STIPS processes in parallel using ProcessPoolExecutor, the resulting images will all have the same background pattern. Likely there is a call to np.random, which should probably be changed to np.random.RandomState()
https://stackoverflow.com/questions/49847794/child-processes-generating-same-random-numbers-as-parent-process
Answers:
username_1: I can't figure out whether or not this would preserve the ability to intentionally generate the same output for the same calculation in two runs by setting seed to be the same. That said, if you change the seed value for each parallel process, would that solve your immediate problem?
username_0: Setting the seed to be different across parallel runs does not solve this if one uses the ProcessPoolExecutor. For now, I've gotten around this by not using that python tool; however, it seems worth considering updating the random number calls to avoid this problem if possible. This is not a very high priority, especially if it is documented so that it does not cause too much trouble. It can be a huge problem for people trying to simulate multiband imaging, as it leads to many false peaks in multiband stacks.
username_1: Okay. I've now moved over random calls to include RandomState.
username_0: I'm getting an error with this version:
Traceback (most recent call last):
File "run_stips_bgonly.py", line 32, in <module>
obm.nextObservation()
File "/local/tmp/miniconda3/envs/forSTIPS3/lib/python3.6/site-packages/stips-1.0.0rc6-py3.6.egg/stips/observation_module/observation_module.py", line 187, in nextObservation
self.instrument.reset(ra, dec, pa, filter, self.obs_count)
File "/local/tmp/miniconda3/envs/forSTIPS3/lib/python3.6/site-packages/stips-1.0.0rc6-py3.6.egg/stips/instruments/instrument.py", line 137, in reset
self.resetDetectors()
File "/local/tmp/miniconda3/envs/forSTIPS3/lib/python3.6/site-packages/stips-1.0.0rc6-py3.6.egg/stips/instruments/instrument.py", line 170, in resetDetectors
distortion=distortion, prefix=self.prefix, seed=self.seed,
AttributeError: 'WFI' object has no attribute 'seed'
username_1: The most recent push should fix this.
username_0: Yes. I do not get that error with the version you just pushed. Thanks!
username_1: Does that solve this issue for you?
username_0: I'm getting an error:
crPoisson = np.random.RandomSeed(seed=seed).poisson(lam=crProb, size=xSize*ySize)
AttributeError: module 'numpy.random' has no attribute 'RandomSeed'
username_1: Oops. Spelling error. Should have been RandomState. Fixed.
username_0: Appears to run if I change these to RandomState
username_1: The version pushed about half an hour ago to square_pixel_fix has that exact change in it.
username_1: Is this issue fixed?
username_0: I think so. Has square_pixel_fix been merged into master?
username_1: Not yet. Once I'm done with this issue I'll do the merge.
username_1: Completed and merged into master.
Status: Issue closed
|
Codeinwp/pirate-switch | 172384379 | Title: Improve design
Question:
username_0: Now it looks like this http://prntscr.com/c8sfku
Answers:
username_1: @username_0 hope you can write down or explain the whole purpose goal of the project right ? improve design is not enough if you don't explain more about it.
We had some tasks/discussion for the project, maybe you can reference those.
username_0: ideea: sa se poata schimba culori si sa afisam diverse demos
http://demo.theme-fusion.com
http://templateocean.com/stamp/image-bg/1-home-style-one/index.html
http://themeforest.net/item/flatsome-responsive-woocommerce-theme/full_screen_preview/5484319
username_2: M-am uitat la exemple si voiam sa va intreb daca elementele din prezent sunt toate care vor ramane in plugin. :D
username_0: Da, asa ramane. Daca mai ai tu idei ce sa adugam/modificam putem vorbi :)
username_2: 
Ce spuneti de asa ceva?
username_0: Mie imi place :)
username_1: nu e f clara chestie cu layouts si styles, banuiesc ca se pot redenumi nu ?
Putem face un setup de test pt zerif pro/lite si apoi sa il facem mai
modular.
username_2: Sigur, asta ar fi ideea sa nu fie nimic batut in cuie :D sa putem scrie orice acolo.
username_1: plans here ?
username_2: Almost done
Sent from my iPhone
>
Status: Issue closed
|
vaadin/spring | 228713973 | Title: Feature Request - create @SpringViewBean
Question:
username_0: Alternative for view creation.
```java
@SpringViewBean(name="")
public View getDefaultView(){...}
// or
@SpringViewBean()
public View getView(){...}
// or to create a bean with view name in method:
@SpringViewBean()
public View getLoginView(){...} // /login (remove "get" and "View", like @SpringView annotation does)
// Super advanced example
@SpringViewBean(regex=".*")
public View getView(@Autowired VaadinRequest request){
// Create view based on request data
}
``` |
decred/dcrd | 337413629 | Title: [txscript] Increase opcode coverage in reference script tests
Question:
username_0: In the future, there will be new script versions which build on the current script version with various improvements. Some examples might be the improved signature hash algorithm proposed in #950 and improvements to the semantics of various opcodes.
This implies a comprehensive set of reference tests for the current script engine version would be extremely beneficial to use a base for future versions to build on. While it is true that the current tests in `scripts_tests.json` already do have a respectable level of coverage, they originally came from Bitcoin, are pretty poorly organized, and are not exhaustive of each opcode.
This should be remedied by individually examining every opcode (or at least opcode group in the case of data pushes) and providing the same treatment as I did in PRs like #1288, #1289, #1290, and #1291. However, it should be noted that those PRs have the positive and negative tests split across `script_valid.json` and `script_invalid.json`, while both the negative and positive test cases have been combined as #1320, which have been significantly improved in terms of added detection of specific reasons *why* the test(s) failed versus just checking that it failed to execute properly.
This is important, because, while there is no difference in terms of scripts being rejected regardless of whether they finished with a false item on the stack or encountered an error which resulted in early exist, it does make a difference in ensuring the tests are actually testing what they are intended to test.
Ideally, the final result should provide the coverage for each opcode in order according to their numeric value as much as possible so that it is easy and logical to find the tests associated with each opcode and then specific execution. Some exceptions might be if a test relies on the correctness of another opcode, it would be ideal to ensure the specific semantics required by the test in question are preceded (within the same section) by a targeted test which proves that semantic in order to help avoiding falsely attributing a failure to the wrong opcode.
Every test should provide a comment which discusses the specific rule or semantic that is being tested, similar to what I did in the aforementioned PRs.
Next, tests which involve checking overall script engine rules and semantics which are not tied to particular opcodes such as max opcodes per script limits, max script size, max element size pushes, and max stack elements should ideally be located after all of the opcodes themselves have individually been tested. The max limits are already pretty well tested as of recent PRs, however they will undoubtedly need to be relocated as discussed.
Finally, all tests should make use of the newly added repetition syntax I added in PRs #1299 and #1300.
Answers:
username_1: I'd like to work on this.
username_0: Please limit it to a single PR per opcode / option group as I did in the aforementioned PRs. It's much easier to deal with targetted PRs than massive ones that reach across every opcode.
Also, please make sure that all of the new tests added conform to the clean stack requirements. I'd ultimately like to remove that flag and would prefer any new tests not make that more work than it will already be to transform all of the existing ones that don't conform.
Status: Issue closed
username_0: This has been implemented via the various linked PRs. |
denoland/deno | 744329879 | Title: Cargo test fails _074_worker_nested_error
Question:
username_0: Only two issues on the 1.5.3 build with test, I've commented on the other one already and this is one that doesn't seem to have an issue attached to it.
```
failures:
---- _074_worker_nested_error stdout ----
target_dir /home/pi/deno/target/debug
root path /home/pi/deno/test_util/..
deno_exe path /home/pi/deno/target/debug/deno
target_dir /home/pi/deno/target/debug
deno_exe args run -A 074_worker_nested_error.ts
deno_exe tests path "/home/pi/deno/test_util/../cli/tests"
OUTPUT
Check file:///home/pi/deno/cli/tests/074_worker_nested_error.ts
Check file:///home/pi/deno/cli/tests/073_worker_error.ts
Check file:///home/pi/deno/cli/tests/subdir/worker_error.ts
OUTPUT
thread '_074_worker_nested_error' panicked at 'bad exit code, expected: 1, actual: 0', test_util/src/lib.rs:867:9
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
```
```
pi@pi400:~/deno $ export RUST_BACKTRACE=1
pi@pi400:~/deno $ cargo test -p deno --test integration_tests
Finished test [unoptimized + debuginfo] target(s) in 1.81s
Running target/debug/deps/integration_tests-3cc1836bbdeee374
running 316 tests
[snip]
test _074_worker_nested_error ... FAILED
[snip]
```
Not really getting any helpful information from the `RUST_BACKTRACE` environment variable.
Answers:
username_1: Is there any error printed out? It's hard to debug with so little info
username_2: I believe this relates to building on ARM64 (ref: #1846) for clarity purposes. Really need to try to be more clear on what is trying to be accomplished here.
username_0: @username_1 There is no error at all printed out. Just the backtrace that I have and the failed test case. @username_2 Is correct, I'm building this on an ARM64 kernel on the Raspberry Pi 400.
username_1: @username_0 I'm going to close this issue for now. We don't provide official builds for Arm64 so it's really hard to say what might be causing this. Once we'll start working towards #1846 this issue will be addressed accordingly.
Status: Issue closed
|
grafana/helm-charts | 724613610 | Title: Grafana produces a lot of errors "/var/lib/grafana/dashboards: no such file or directory"
Question:
username_0: I have installed grafana using kube-prometheus. Grafana complains about a missing folder every few seconds...
```
│ grafana t=2020-10-19T13:23:13+0000 lvl=eror msg="Cannot read directory" logger=provisioning.dashboard type=file name=local error="stat /var/lib/gra │
│ fana/dashboards: no such file or directory" │
│ grafana t=2020-10-19T13:23:13+0000 lvl=eror msg="Failed to read content of symlinked path" logger=provisioning.dashboard type=file name=local path= │
│ /var/lib/grafana/dashboards error="lstat /var/lib/grafana/dashboards: no such file or directory" │
│ grafana t=2020-10-19T13:23:13+0000 lvl=eror msg="failed to search for dashboards" logger=provisioning.dashboard type=file name=local error="stat /v │
│ ar/lib/grafana/dashboards: no such file or directory"
``` |
ueberdosis/tiptap | 960356807 | Title: Notion-like horizontal alignment
Question:
username_0: Smooth interaction & DnD Off the table, let's talk about static layout only.
Doe prosmirror support smooth horizontal layout management & will tiptap be targetting to support feature like this?
I understand that DnD feature is under preview & cursor / handle should be implemented first before this gets usabe. thous, I'm curious if Layout managing will be a valid option with using html syntax!
https://user-images.githubusercontent.com/16307013/128179175-6aecfc3f-1f42-483b-98cf-35d3a334a9c4.mov
Answers:
username_1: Drag’n’drop support comes, but something like the described horizontal layout feature feels out of scope. ✌️
Status: Issue closed
|
dogsheep/github-to-sqlite | 769150394 | Title: Readme HTML has broken internal links
Question:
username_0: From https://github.com/username_0/datasette.io/issues/46
```html
<li><a href="#filtering-tables">Filtering tables</a></li>
...
<h3><a id="user-content-filtering-tables" class="anchor" aria-hidden="true" href="#filtering-tables"><svg class="octicon octicon-link" viewBox="0 0 16 16" version="1.1" width="16" height="16" aria-hidden="true"><path fill-rule="evenodd" d="M7.775 3.275a.75.75 0 001.06 1.06l1.25-1.25a2 2 0 112.83 2.83l-2.5 2.5a2 2 0 01-2.83 0 .75.75 0 00-1.06 1.06 3.5 3.5 0 004.95 0l2.5-2.5a3.5 3.5 0 00-4.95-4.95l-1.25 1.25zm-4.69 9.64a2 2 0 010-2.83l2.5-2.5a2 2 0 012.83 0 .75.75 0 001.06-1.06 3.5 3.5 0 00-4.95 0l-2.5 2.5a3.5 3.5 0 004.95 4.95l1.25-1.25a.75.75 0 00-1.06-1.06l-1.25 1.25a2 2 0 01-2.83 0z"></path></svg></a>Filtering tables</h3>
```
So this is a bug in GitHub's API, but we need to work around it.
Answers:
username_0: I'm going to rewrite those `<a href="#filtering-tables">` links to `<a href="#user-content-filtering-tables">` - but only if a corresponding `id="user-content-filtering-tables"` element exists.
username_0: I don't want to add a full HTML parser (like BeautifulSoup) as a dependency for this feature. Since the HTML comes from a single, trusted source (GitHub) I could probably handle this using [regular expressions](https://stackoverflow.com/a/1732454).
Status: Issue closed
|
samnung/raz | 110536391 | Title: Restorer can't handle restoring files to not existing folder
Question:
username_0: See output:
```
Restoring item to /Users/roman.kriz/.gem/geminabox
No such file or directory - /Users/roman.kriz/.gem/geminabox
```
Folder `/Users/roman.kriz/.gem/` does not exist, so the script crashes and restoring process fails :cry:<issue_closed>
Status: Issue closed |
crossplane/crossplane | 742847613 | Title: Deduplicate repeated patches within a composition
Question:
username_0: ### What problem are you facing?
When creating a `Composition` with a large number of base resources, it seems common to use the same patch definitions repeatedly for settings which apply to multiple resources, for example applying the following to pretty much every base within a `Composition`:
```yaml
patches:
- fromFieldPath: metadata.labels
toFieldPath: metadata.labels
- fromFieldPath: metadata.annotations
toFieldPath: metadata.annotations
```
### How could Crossplane help solve your problem?
It would be really cool to allow patches to be defined once, and then referenced where necessary from each base.
@username_1 suggested something like this in Slack, which I like:
```yaml
apiVersion: apiextensions.crossplane.io/v1beta1
kind: Composition
metadata:
# ...
spec:
# Sets of patches that can be referenced by id so you don't need to repeat yourself.
patchSets:
- id: metadata
patches:
- fromFieldPath: metadata.labels
toFieldPath: metadata.labels
- fromFieldPath: metadata.labels
toFieldPath: metadata.labels
- id: coolness
patches:
- fromFieldPath: spec.coolness
toFieldPath: spec.amountOfCool
resources:
- base:
# ...
# Includes the patchSets above; use instead of or in addition to patches
patchSets:
- id: metadata
- id: coolness
```
I'm not averse to submitting a PR to do this (on the assumption that I can work out how to implement, being relatively unfamiliar with the codebase 😄 )
Answers:
username_1: @username_0 I'm happy to work on this too, though I'm fairly slammed for the next few weeks so it might take me a while to get around to it. If you'd like to have a go feel free to ping me if you get stuck or need a review.
username_0: @username_1 Had a bit of a poke around the code and ISTM that the difficulty here is that the `Composition` (which defines the additional `patchSets`) is not available during the `Render()` method of the composed resource.
My first idea to work around this is to load the `PatchSet` list into the composite resource (`cp resource.Composite`) using a new Configurator. The `PatchSet` list can then be retrieved in the `Render()` method and used to apply the patches.
Because the composite resource (actually `Unstructured`) is in `crossplane-runtime`, it seems to make sense to not add patching code there, but I could create a new extended resource type in `crossplane` which embeds `resource.Composite` and applies the relevant additional methods.
Does this sound sane to you or am I missing something that would make this simpler?
The other option I could think of is to try and load the Composition from the API during `Render()`, but that would involve an API call for each resource - which seems wasteful if the necessary data can be injected directly on creation of the composite resource.
username_1: @username_0 If I recall correctly we pass the `ComposedTemplate` (which is part of the `Composition`, which we have in the reconciler) to `Render()`, which includes the `patches` array (and presumably would include the array of `patchSets` the resource wanted to include too).
https://github.com/crossplane/crossplane/blob/8f840d9ddf43662fe10c1ca14edf5e3e222e9a43/apis/apiextensions/v1alpha1/composition_types.go#L83
What do you think about passing the array of available patchsets to `Render` too, so that it can include those the `ResourceTemplate` wants?
username_2: I feel like, in practice, the patchsets here would be mostly either Kubernetes or Crossplane fields unless there are many of the same kind of resources in the `resources` array. Because most of the resources have unique sets of parameters in `forProvider` section with very few exceptions, like `region`. @username_0 how do you feel about needing this functionality for more than `labels` and `annotations`? Do you have some use cases in mind where you had to write the same patchset for many resources in the same `Composition` for fields other than those two?
An alternative could be to have `Labels` and `Annotations` as hard-coded patch types, similar to transforms, with no other field required, like:
```yaml
apiVersion: apiextensions.crossplane.io/v1beta1
kind: Composition
metadata:
# ...
spec:
resources:
- base:
# ...
# Reuse the patches array we already have.
patches:
- type: Labels
- type: Annotations
```
username_0: @username_1 thanks, that was the context I was looking for - somehow skipped over where the composed resource is created and then passed directly to the `Render()` method 😂 - that looks like it'd be much simpler.
@username_2 Yeah, those were examples I chose because they apply to everything, but you're right - they're likely to be identical or very similar across the board.
Another example I can think of where predefined patch types wouldn't work is one of my XRD's which generates 2 namespaces, where the name of the namespace created and then used by other resources within the XRD is determined by an input value (e.g. claim name or instance name + transform).
I think predefined patch types is a great idea as well, but if there's any need to transform one of those super common fields then I don't think they'll suffice, unless they were also configurable, which I think is covered more succinctly with the custom `patchSet` / `patchType` idea.
I like the interpolated `type: ...` field using the existing `patches` field though - maybe something like the below works?
```yaml
apiVersion: apiextensions.crossplane.io/v1beta1
kind: Composition
metadata:
# ...
spec:
patchTypes:
- type: CustomNS
patches:
- fromFieldPath: spec.parameters.blah
toFieldPath: metadata.namespace
transforms:
- type: string
string:
fmt: "custom-%s"
resources:
- base:
# ...
# Reuse the patches array we already have.
patches:
- type: Labels
- type: Annotations
- type: CustomNS
- fromFieldPath: spec.parameters.myField
toFieldPath: spec.forProvider.locationConstraint
# ...
```
username_2: Yeah, that looks good to me. We'd not make the UI more complex for users who don't need that functionality while providing it to who need it.
username_0: Hmm, thinking about this style more, it actually seems to be conflating `patchTypes` (which I copied from `patchSets` above) with a patch entry in the base resource, which right now refers to a single patch.
Should a `patchType` defined on the composition only define a single 'named' patch, which can then be referenced multiple times (but each patch must be referenced individually on each resource)?
Or should `patches` on the base resource refer to either a single unnamed patch (with relevant fields set) or a patch type consisting of a list of `patches`?
Keeping each `patchType` as a single patch identified by name seems the simplest, but means that applying the same set of named patches in order to each resource becomes repetitive.
username_0: https://github.com/username_0/crossplane/commit/fa4af7203f583f11aba95a09050157dba7d04fa5 WIP implementation of `patchType` as a single patch rather than a list of patches. Seems pretty succinct code-wise. Needs doc, more tests and some bits and pieces moved around before PR / review.
If we wanted types to be a list of patches rather than individuals, then I think we'd need to go the previous route and add a new field to the `ComposedTemplate` to avoid affecting the existing `Patches` functionality. But I think for my use case at least, individual patches is enough deduplication for this to be a useful feature.
username_1: I agree that fixed/built in patch sets probably aren't the way to go here - I suspect we'll appreciate a more flexible approach in future. I do like the `type` approach though, as it opens us up for other types of patches (e.g. "reverse" patches from the composed resource to the composite resource). I think it could work together with the `patchSets` approach. Something like:
```yaml
apiVersion: apiextensions.crossplane.io/v1beta1
kind: Composition
metadata:
# ...
spec:
patchSets:
- id: CustomNS
patches:
- fromFieldPath: spec.parameters.blah
toFieldPath: metadata.namespace
transforms:
- type: string
string:
fmt: "custom-%s"
resources:
- base:
# ...
# Reuse the patches array we already have.
patches:
- type: PatchSet
id: CustomNS
- type: FieldPath # Or just 'Patch'? This would be the default type, if omitted.
fromFieldPath: spec.boop
toFieldPath: spec.doop
```
username_0: I've managed to get the format pretty similar to the above:
```yaml
apiVersion: apiextensions.crossplane.io/v1beta1
kind: Composition
metadata:
# ...
spec:
# ...
patchSets:
- id: metadata
patches:
- fromFieldPath: metadata.labels
toFieldPath: metadata.labels
- id: parameters
patches:
- fromFieldPath: spec.parameters.location
toFieldPath: spec.forProvider.locationConstraint
transforms: {} # ...
- fromFieldPath: spec.parameters.namePrefix
toFieldPath: metadata.generateName
transforms:
- type: string
string:
fmt: 'added-by-parameters-set-%s'
resources:
- base:
# ...
patches:
- type: ref
id: metadata
- fromFieldPath: metadata.annotations
toFieldPath: metadata.annotations
- type: ref
id: parameters
```
Types are currently `ref` and `std` (implied) - can rename these of course.
`patchSets.patches` and `resource.patches` both use the same type definition (`[]Patch`) but an error will be thrown if someone attempts to use a reference type patch from within the `patchSets` definition.
I'll double check everything and submit a PR for review later today.
Status: Issue closed
|
Metric/AnSAddons | 556448693 | Title: Allow disabling AnS modifications to tooltips
Question:
username_0: AnS adds auction info to tooltips, but I already have these from another addon and would prefer to be able to disable it.
Answers:
username_1: Just disable AnS Auction Data addon. Cause, if you are using data from
another source then the addon is sort of pointless.
username_0: Auctionator only provides a market min variable, but AnsAuctionData has a few more like ans3day that are nice. My ideal setup would be to have the tooltip only contain Auctionator data but to have AnsAuctionData variables available when writing custom filters. Maybe the answer is for me to find a different auction data source than Auctionator, but I like how clean the tooltips are. Auctioneer and TSM fill it with so many numbers.
Thanks for the quick answer though. I'll see if I get used to them.
username_1: Another option for now, is go into the saved variables Lua of AnS. You will
see a variables that reference the tool tips. Just set the ones you don’t
want to false.
Status: Issue closed
|
ant-design/ant-design | 229256288 | Title: Collapse does not work when Panel is inside another component
Question:
username_0: Example:
```
<Collapse>
{ items.map(item => <Item name={item.name} />) }
</Collapse>
```
```
const Item = ({ name }) => <Panel header={name} key={name}>...</Panel>;
```
It does not work. So it’s impossible to separate concerns between List component and List item components.
Answers:
username_1: Trace: https://github.com/ant-design/ant-design/issues/4853 |
matt-h/rdio-enhancer | 111677539 | Title: Add all songs from an artist to a playlist
Question:
username_0: Hello,
I would like to request a feature to add all songs from an artist to a playlist of choice.
This is because not all the songs from the artist are listed in his or her albums, but rather in the albums published by their labels. As it stands now, I would have to add all the songs by hand, which is a pain.
Should this already be a feature, I am then sorry for bothering you.
Many thanks for the add-on.
Answers:
username_1: Can you link some examples?
username_0: For some reason I can't connect to rdio at the moment, keep getting connection reset error, but of the top of my head there is Feint. He got 51 songs on rdio, but only 19 are in albums of his. And I'm guessing that artists working with the same label as he is, Monstercat, have the same problem. I will add more once I get my connection back/
username_1: I would use this. I will implement it next
username_0: Thanks!
username_1: See #62 for the proposed change
Status: Issue closed
|
leafo/lapis | 40978184 | Title: etlua using content_for
Question:
username_0: Is there a way to leverage content_for in an etlua template the same way I would in a lapis Widget? For example, in a lapis widget I would do something like this to ensure my javascript loads in the same place and at the bottom of my page:
```
@content_for "javascript", ->
if @Post.Languages
script src: '/content/js/highlight.pack.js'
script ->
raw "var languages = #{util.to_json(@Post.Languages)};\n"
raw [[
hljs.configure({
languages: languages
});
hljs.initHighlightingOnLoad();
]]
```
Is there a way to do this in an etlua template?
Answers:
username_1: @username_0 did you find a solution for this in the end? I'm stuck with the same problem
username_2: I'm not sure what yall are trying to do with `content_for` but I've only ever used that in layouts.
What you might be looking for is `render`
```
<% render("views.my_widget") %>
```
That will allow you to include any etlua template inside of another. If you need it to always appear in a specific area of the page, that's what layouts are for:
```
<% render("views.header") %>
<% render("views.nav") %>
<% content_for("inner") %>
<% render("views.footer") %>
```
`content_for("inner")` returns whatever view the route is rendering. [More Info](http://leafo.net/lapis/reference/lua_getting_started.html#creating-a-view/creating-a-layout). Hope that helps.
username_0: @username_1 unfortunately no, I don't maintain my lapis site anymore but looking back at the source code I wasn't able to find a workaround for this problem.
To clarify the problem, I wanted to be able to override parts of my layout with content inside an action. Think about elements in html that have to be in a fixed place, like the title tag. I wanted to be able to say, inside of the view, what the title should be.
`@content_for` supports this according to the documentation
```moonscript
class MyView extends Widget
content: =>
@content_for "title", "This is the title of my page!"
@content_for "footer", ->
div class: "custom_footer", "The Footer"
class MyLayout extends Widget
content: =>
html ->
body ->
div class: "title", ->
@content_for "title"
@content_for "inner"
@content_for "footer"
```
This only works if you generate html using moonscript. I think the problem is that `content_for` wasn't able to handle etlua templates for the second parameter. It assumes it's using the moonscript DSL to generate html and that's what results the error above.
I'm not sure if this was addressed or not.
To further clarify, I had scripts that were loaded on my home page but nowhere else, so I only wanted to load them there, but I wanted them at the bottom of the page, which I can only do in the layout, in order to prevent scripts from blocking the rendering of the page.
username_1: Thanks. I was hoping to do something similar, with with 'css' or 'js' in the layout.etlua, being replaced by the child templates, so that I'm not always loading large css files, and additional css files are in the header still, not spread randomly throughout depending on my render() blocks. |
trailofbits/winchecksec | 765441783 | Title: 阜新新邱区哪有美女全套特殊服务
Question:
username_0: 阜新新邱区休闲按摩会所美女妹子上门服务(十微IO77I9O9)点击上方▲“女性之声”关注今天是腊月二十九,民谣称“二十九,蒸馒头”,二十八做好了发面,二十九就要开始蒸馒头了,人们尽情发挥想象,把馒头做成寿桃、小动物等各种造型。裙白酪右帕夭研轿刃仗醚鸭率到勺https://github.com/trailofbits/winchecksec/issues/496 <br />https://github.com/trailofbits/winchecksec/issues/389?Z5X9h <br />https://github.com/trailofbits/winchecksec/issues/238?J5Hn3 <br />https://github.com/trailofbits/winchecksec/issues/774?vxRDt <br />https://github.com/trailofbits/winchecksec/issues/652?hX7L3 <br /> |
pks1998/TryProject | 910931682 | Title: Login and Registration Functionality
Question:
username_0: Test 1
1) User able to enter their email id and password.
2) User able to click on registration button
3) User able to Register as a new user.
4) User able to change the password by clicking forgot password button |
kalkih/mini-graph-card | 614046191 | Title: 0 is read-only
Question:
username_0: Hi,
Your card looks great, but I have the following issue when I try it:
```
0 is read-only
type: 'custom:mini-graph-card'
entities:
- sensor.zigate_00158d000358e414_temperature
```
Status: Issue closed
Answers:
username_0: Thanks, it works.
I was because of the navigators cache. |
gatsbyjs/gatsby | 436992550 | Title: Using gatsbyjs as a blog site, is it necessary to use gatsby build once for each post?
Question:
username_0: Using gatsbyjs as a blog site, is it necessary to use gatsby build once for each post?
Answers:
username_1: Yes, that is correct.
You can use automated CI (e.g. Travis CI) to do this for you as you commit/merge PRs to a specific branch (e.g. `master`).
username_0: However, my program has not changed, but the data has changed. This also needs to be re-gatsby build. There is no other way.
username_2: I think you're asking for a feature we're terming "Incremental builds." The idea will be that you don't have to re-build the _entire_ site, but rather can do so in a more performant matter by understanding the internal data layer and knowing which pages to re-build.
This isn't currently possible--so the recommended approach will be to re-build the entire site on a change, e.g. with a CI build as @username_1 noted!
Thanks!
Status: Issue closed
|
htmlacademy/yomoyo | 736694477 | Title: Добавление кнопок форматирования в интерфейс проверки заданий и чата со студентом
Question:
username_0: Привет!
Мне очень нравится, что в интерфейс добавлен функционал форматирования текста, но руками расставлять ссылки, бектики и жирный текст утомительно и _опечаткаопасно_, было бы круто иметь для этого кнопки аналогичные тем, что есть на гитхабе и в слаке. Как думаете?
 |
zeroengineteam/ZeroCore | 366110807 | Title: ShaderInputs.Add should validate the type matches (maybe also ShaderInput if the fragment name and property are fully specified).
Question:
username_0: # Description
Description was not present
# User Data
- **UserName**: TrevorSundberg
# Zero Engine Data
- **Revision**: 728
- **ChangeSet**: zeroengineteam/zerocore@0f73214a911d9da5da51064ee7d1d0d143b7c254
- **Platform**: Win32
- **Build Version Name**: 1.2.4.728 zeroengineteam/zerocore@0f73214a911d9da5da51064ee7d1d0d143b7c254 2018-02-16 Debug Win32<issue_closed>
Status: Issue closed |
meinside/meinside.github.io | 422551725 | Title: coral images
Question:
username_0: 



<issue_closed>
Status: Issue closed |
sushipandapos/delivery | 352867363 | Title: Google Maps integration
Question:
username_0: ## Google Maps API
Integrate Google Maps to display available/active orders visually on the map for a better understanding of logistics.
- Get Google Maps API key
- Create Google Maps component
- Set up test markers |
Azure/autorest.testserver | 781683348 | Title: New test server with easy definition plan
Question:
username_0: Idea is to make use of a markdown definition file to a have readable and easy way to define apis.
Sample: https://gist.github.com/username_0/4842e0cb1d052362783f6671ed65239b
For apis that can't just be a simple for this url pattern/body return this response. The system should support using some simple overlay on top of express. I don't believe many apis will really need this.
Initial version goal (PR in progress https://github.com/Azure/autorest.testserver/pull/245)
- [ ] Parse the markdown
- [ ] Register the mock routes + start server
Next:
- [ ] Start converting the test
Nice to have:
- [ ] Add an automatic coverage(Make sure for all the swagger files there is a mock api, we can then have CI to enforce)
- [ ] Hot reload of the markdown file(Start the mock server and if a file gets updated it reload the routes)
Answers:
username_1: Love the hot reload idea!
username_2: hey @username_0 this looks great. Just a question: how do you represent if statements, i.e. https://github.com/Azure/autorest.testserver/blob/master/legacy/routes/byte.js#L11
username_0: @username_2 In general you shouldn't really need if statement I believe. All of those could be defined as independent requests:
see [string.md](https://github.com/Azure/autorest.testserver/blob/557cd75c32e7112961a7b9778dc65fc2dfcc28e4/routes/string.md) which is a conversion of [string.js](https://github.com/Azure/autorest.testserver/blob/557cd75c32e7112961a7b9778dc65fc2dfcc28e4/legacy/routes/string.js) |
web3j/web3j | 472257578 | Title: Revert Reason is not returned depending of the client that is used
Question:
username_0: at org.web3j.tx.Contract.executeTransaction(Contract.java:297)
at org.web3j.tx.Contract.executeTransaction(Contract.java:275)
at org.web3j.tx.Contract.lambda$executeRemoteCallTransaction$4(Contract.java:326)
at org.web3j.protocol.core.RemoteCall.send(RemoteCall.java:30)
at TestRevertTest.main(TestRevertTest.java:32)
Here are the files used for the tests:
[testRevertWeb3j github](https://github.com/username_0/testRevertWeb3j)
Answers:
username_1: @username_0 how did you compile the contract ?
username_0: truffle.js:
```javascript
module.exports = {
// Configure your compilers
compilers: {
solc: {
version: "0.5.10",
settings: {
optimizer: {
enabled: true,
runs: 200
},
}
}
}
};
```
1st) `truffle compile`
2nd) I use gradlew and Eclipse, but here is: `org.web3j.codegen.TruffleJsonFunctionWrapperGenerator TestRevert.json`
username_1: I tested both ganache and parity and i can confirm that this is happening i will look more into it to see what is going on
username_1: so i did a bit of digging and found [this](https://github.com/paritytech/parity-ethereum/issues/8068). It looks like the issue is from parity.
Let me know what you think.
username_2: The following workaround can be used in JS. It prints transaction revert reason to the console, tested in Kovan.
web3.eth.call - Executes a message call transaction, which is directly executed in the VM of the node, but never mined into the blockchain.
`try {
await tokenRegistry.methods.methodName(params).send({from: accounts[0]});
} catch (e) {
try {
await tokenRegistry.methods.methodName(params).call({from: accounts[0]});
} catch (e) {
let error = JSON.parse("{" + e.message.split("{")[1]);
let data = error.data;
console.log(web3.utils.toAscii("0x" + data.replace("Reverted ", "").substr(138)).replace(/\u0000/g, ""));
}
}`
I think something similar can be used in Java.
I've tried to use web3j.ethCall, but without any success.
username_2: web3j.ethCall didn't help.
ganache-cli: VM Exception while processing transaction: revert You must send ether
parity: VM execution error.
username_0: I kept investigating it and Parity doesn't return the Revert Reason yet.
To be able to get the Revert reason we could replay the transaction. But you have to add extra lines to be able to do that.
My suggestion here would be to add the transaction hash to the exception.
org.web3j.tx.Contract.java
```java
TransactionReceipt executeTransaction(...)
(....)
if (!receipt.isStatusOK()) {
throw new TransactionException(
String.format(
"Transaction has failed with status: %s. "
+ "Gas used: %d. (not-enough gas?)",
receipt.getStatus(),
receipt.getGasUsed()));
}
return receipt;
}
```
Suggested improvement org.web3j.tx.Contract.java - add transaction hash info into the exception
```java
TransactionReceipt executeTransaction(...)
(....)
if (!receipt.isStatusOK()) {
throw new TransactionException(
String.format(
"Transaction has failed with status: %s. "
+ "Gas used: %d. (not-enough gas?)",
receipt.getStatus(),
receipt.getGasUsed()),
receipt.getTransactionHash());
}
return receipt;
}
```
When you have the transaction hash, you can store it and use it later. Right now it throws and you loose this information.
username_3: It's been almost 2 years and the issue still exists......
username_0: It is a problem with Parity. Parity is not on development anymore and were archived.
Status: Issue closed
|
monarch-initiative/MAxO | 440090699 | Title: Deprecation errors
Question:
username_0: ERROR deprecated_class_reference MAXO:0000273 rdfs:label obsolete Gastrointestinal agents, other
ERROR deprecated_class_reference MAXO:0000273 owl:deprecated true^^http://www.w3.org/2001/XMLSchema#boolean
Answers:
username_1: Fixed now?
username_0: This was fixed. Closing.
Status: Issue closed
|
SpoonX/aurelia-autocomplete | 451740717 | Title: Config and footerSelected help
Question:
username_0: Hi, I'm relatively new to Aurelia, and I'm working on a project where I'm going to use aurelia-autocomplete. I've got it (mostly) working, but I could use some help with a couple of things:
Can you provide an example of how to configure the plugin to use the bootstrap4 html file? I've got the plugin configured in my main.js, but I don't know how to add the option there.
Also, I have been trying to figure out how to watch for changes to the value (which is bound to a child of an object). I tried to use footerSelected, but I haven't had any success with it. If you have an example of that, it would be helpful if I could see how to use it.
Thanks!
Answers:
username_1: @username_0 aurelia-autocomplete uses aurelia-view-manager to enable this behaviour.
https://aurelia-view-manager.spoonx.org/defaults.html
As to watching changes I think resultsChanged or valueChanged would do the trick.
username_0: Can you post an example of how to use resultsChanged or valueChanged? I don't seem to be able to get it to work.
username_1: @username_0 I'm not really using aurelia at the moment and I don't have time to create examples. If everything still works the way it did you can use the example from the documentation. It's also in the readme. If neither work maybe @jeremyvergnas knows more.
Status: Issue closed
|
WICG/priority-hints | 423215494 | Title: Bring back examples into the explainer
Question:
username_0: While answering questions on the [TAG review](https://github.com/w3ctag/design-reviews/issues/241#issuecomment-474800105), it seemed like the usage examples have moved from the explainer to the spec itself. While it's important to have them in the spec, it seems equally important to have them as part of the explainer. We should probably copy them back.
Answers:
username_1: @username_0 would a 1:1 copy of them back to the explainer suffice? Happy to PR in this change. Should be minimal effort.
username_0: Yeah, a 1:1 copy would be sufficient
Status: Issue closed
|
openfarmcc/OpenFarm | 432948994 | Title: Turn on dependabot
Question:
username_0: Dependabot can send all security patches as a pr, so this repo doesn't fall out of date again.
Answers:
username_0: dependabot.com
username_1: @username_0 Sounds good :+1: I have a pretty hefty branch on my local that I've been working on as time allows (usually on Fridays). I will see about getting Dependabot in with the other changes.
username_0: I'm keen to review, if you want to send canonical features from your branch as PRs.
username_0: @username_1 *nudge*
username_0: @username_1 If you give me some maintainer rights, i can do some security patching going forward
username_1: @username_0 It's done :heavy_check_mark: . Thanks for the help.
Status: Issue closed
|
less/less.js | 277458013 | Title: Question: how to access the file managers functionality from within a visitor plugin?
Question:
username_0: I need to reconstruct some less source from the AST, and for that I need to be able to use the exact same file manager setup that was used to parse the source. How do I go about obtaining/constructing all the parameters that `less.environment.getFileManager()` requires? I have a `currentFileInfo` object from an AST node and it provides `filename` and `currentDirectory`, but I still need the `options`/`context` object and I seem to be running into a dependency hell while trying to construct it (e.g. `contexts.Parse` constructor takes an `options` argument that must provide a `pluginManager`, but that is only set in `ImportManager` constructor to an instance constructed in place with `this` i.e. the `ImportManager` as an argument). This seems to indicate that I am doing it wrong. What is the right way to do it?
Answers:
username_1: Hmm, I'm not sure about details but for the root object `options` is just the compiler options (see `lessc` code) and context should be empty (or resolving to the root object itself if it's not handled that way there already). Basically a context is the "current scope" thing (and for the root one it's basically the root ruleset itself, while for the nested rulesets it also includes parent rulesets).
I'm afraid I'm not of much help in this regard as when it comes to such dark areas my source of information is the same as yours (just the source-code).
username_1: (fixing wrong label - well, 'documentation' would also make sense in a perfect world but I don't think anyone is going to ever document continiuosly changing thing. So I did really mean just 'question').
username_2: Given a `context` and a `currentFileInfo` a file at `filePath` can be loaded via:
```js
function loadFile( filePath, context, currentFileInfo ) {
var
environment = context.pluginManager.less.environment,
currentDirectory = currentFileInfo.relativeUrls
? currentFileInfo.currentDirectory
: currentFileInfo.entryPath,
fileManager,
fileSync;
fileManager = environment.getFileManager(
filePath, currentDirectory, context, environment, true
);
if ( fileManager != null ) {
fileSync = fileManager.loadFileSync(
filePath, currentDirectory, context, environment
);
return String( fileSync.contents );
}
return null;
}
```
This also works for user-defined functions added via `@plugin` plugins, btw. (You can access `this.context` and `this.currentFileInfo` inside the function body.) |
pharo-vcs/iceberg | 375008898 | Title: Show a button "View on Github" when creating a PR
Question:
username_0: When a PR is created on github via the github plugin of Iceberg it would be great to have a "View on Github" button.
Most of the time I got check the PR after opening it.
In Pharo 7 it is possible to do that with a WebBrowser command. I don't know if it is possible to add a button in a Growl notification.
Answers:
username_0: Apparently, it will be hard to create a button in a growl morph (It is a subclass of TextMorph :'( ).
We can still make it clickable.
username_1: in theory, a TextMorph should allow that.
and at least, it should allow a link.
but I wonder if we want that, since it would change the UI : until now, growl messages are just that: messages.
can't we think in another solution?
username_0: I was thinking about doing a "NotificationMorph" close to native notifications (you can embed images, buttons, icons, links...). But I gave up because I did not find a way to manage the layout of a morph that is not in a window :P
Status: Issue closed
username_0: Merged. |
spruceid/didkit | 785260193 | Title: Ensure Java example comes with build instructions
Question:
username_0: We should be assuming that the user doesn't have anything but the base operating system, and we should recommend what packages, JDK versions, Java compiler, etc. are necessary to get going.
If we need more requirements for didkit itself within `/lib`, then that's where the documentation should live.<issue_closed>
Status: Issue closed |
VadimDez/ng2-pdf-viewer | 520591654 | Title: Add pdfjs-dist as peeDependency
Question:
username_0: ##### Bug Report or Feature Request (mark with an `x`)
```
- [ ] Regression (a behavior that used to work and stopped working in a new release)
- [ ] Bug report -> please search issues before submitting
- [x] Feature request
- [ ] Documentation issue or request
```
Since ng2-pdf-viewer has some great improvements but stick on the lastest version of pdfjs-dist I would ask if its possible to add `pdfjs-dist` as peerDependency instead as real dependency.
The lastest version of pdfjs-dist has some issues with CSP
(https://github.com/mozilla/pdf.js/issues/11036) while the 2.1.266 version not.
Goal: I would like to use the lastest of ng2-pdf-viewer with the 2.1.266 version pdfjs-dist
Currently I stick on 5.3.2 of ng2-pdf-viewer since this the lastest version which depends on 2.1.266
See also: https://github.com/VadimDez/ng2-pdf-viewer/issues/419
Answers:
username_0: Still a need.
username_0: Make some activity.
username_0: unstale
username_0: unstale
username_1: @username_0 did you ever figure this out? I tried running your specific versions ([email protected] and [email protected]) and it won't even run `Module '"pdfjs-dist"' has no exported member 'PDFPromise'`. With the latest ng2-pdf-viewer I get CSP issues and it [seems like they expect it to be working now?](https://github.com/mozilla/pdf.js/issues/11036#issuecomment-586578418) Should I make another issue or has this been working for you?
username_0: I left that project. I don't know if it's resolved or not. |
m-lab/etl | 267807731 | Title: ETL pipeline does not recognize eager-push archive names as valid
Question:
username_0: After deploying the eager push changes to scraper mlab-staging, we found that queue-pusher was failing on the new archive names.
Queue pusher uses `etl.ValidateTestPath` to validate archive names.
However, that function expects the HHMMSS portion of the date to always be zero. e.g. 20171023T000000Z-mlab1-dfw01-ndt-0000.tgz.
Now the HHMMSS portion can contain non-zero values. e.g 20171023T103216Z-mlab1-dfw01-ndt-0000.tgz
The `TaskPattern` used by `ValidateTestPath` should be updated to recognize files with HHMMSS values.
https://github.com/m-lab/etl/blob/integration/etl/globals.go#L45 |
k20human/domoticz-atome | 474790755 | Title: Avoid capcha
Question:
username_0: Hello,
J'ai trouvé un contournement pour le login:
https://gist.github.com/username_0/cdb02ed7725a3a64cca126ffdd04d0ed
Si ta besoin d'infos hésite pas
Answers:
username_1: Merci mais je n'utilise plus ce plugin. Mon atome est beaucoup trop instable ...
A la place je récupère les informations directement sur mon compte Enedis via ce plugin : https://github.com/guillaumezin/DomoticzLinky
Si le coeur t'en dis tu peux faire une PR je la mergerai |
nuxt-community/auth-module | 323073326 | Title: Local Scheme What is the token return format?
Question:
username_0: What format should the server return?
nuxt.config:
`axios: {
baseURL:'http://127.0.0.1:8091/index.php/index'
},
auth: {
strategies: {
local: {
endpoints: {
login: { url: '/index/login', method: 'post', propertyName: 'token' },
logout: { url: '/index/logout', method: 'post' },
user: { url: '/index/user', method: 'get', propertyName: 'user' }
},
// tokenRequired: true,
// tokenType: 'bearer',
}
}
},`
php:
` public function login()
{
header("Access-Control-Allow-Origin: *");
$temp['test'] = 11111;
$token['token'] = $temp;
return $token;
}`
pesponse:{"token":{"test":11111}}
Answers:
username_1: It all depends on your configuration, according to what you currently provided:
**POST /index/login**
```
{
token: '<KEY>'
}
```
**GET /index/user**
```
{
user: {
id: 1234,
username: 'john_doe'
...props
}
}
``` |
mpi-forum/mpi-issues | 755456724 | Title: Tool chapter RC review
Question:
username_0: From reviewing pages 755-767 in the Nov 2020 4.0 RC document:
* p755 22-23: "previously registered" --> "previously-registered"
* p755 24: "removed" is the wrong word, because there may have been no event callback previously set.
* p755 29: "At invocation time," --> "At callback invocation time,"
* p756 45: "setting" --> "set"
* p756 47: change ; to ,
* p756 48: change ; to ,
* p757 29: remove comma
* p758 44: remove comma
* p759 24: "to buffer events and long" --> "to buffer events; long"
* p764 24: "implementation specific" --> "implementation-specific"
* p764 34-35: the notation "in the range 0 and num_cat-1" is a little awkward. It should probably be "in the range [0, num_cat)" or "in the range of 0 and num_cat-1" or something else. This same phrasing is also used on p765 2-3, 18-19, 32-33.
* p766 27: "len" is in the wrong font
* p766 35: add comma after "In the latter case"
Answers:
username_0: FYI @username_1
username_1: It reads to me like "the notation *foo* should either be *bar* or *foo* or something else." Am I missing a subtle difference between the initial notation and you second suggestion? I agree it should be consistent. The mathematical notation was discussed once, but in the end we decided against that because not everyone might expect a mathematical notation here, and the difference between `]` and `)` can be subtle but important.
username_2: We did have this discussion and the instructions now recommend (sorry, block quote isn't an option apparently)
Ranges of integers should be written out rather than using the mathe- matical notation for an interval. For example, use
values may be between $0$ and $\mpiarg{count}-1$
rather than
values may be in $[0,count)$
That does suggest a slight change of wording, as I agree that "in the range 0 and num_cat-1" isn't clear.
username_1: @username_2 @username_0 I am uncertain on whether I should change the existing text now, or whether we come up with a better wording for 4.1?
username_2: I think a change to "in a range from 0 to num_cat-1" is fine and fits in with the format that was the consensus of the Forum (at least, those that participated in the discussions).
username_1: Ok. So just to clarify: I change the **"the range"** to an **"a range"**, because beside this, the text already reads that. I have the feeling I am missing something very subtle here.
username_2: The bigger (but still small) change is "from 0 to num_cat-1" from what Jeff was commenting on "0 and num_cat-1"
username_1: Thanks! ... Now I got the difference. Will add this as well.
username_1: @username_2 I updated all references to index ranges I could find throughout the chaper (not only the category occuraces mentioned by Jeff) to *"in the range from 0 to num_X-1"* (i.e., the bigger change), but didn't change the "the" into an "a" in the end, as I thought the "the" would be a better reference to the explicitly given range. What do you think?
username_1: PR for this issue is merged. Closing the ticket.
Status: Issue closed
|
smirarab/ASTRAL | 654820972 | Title: Problem with species mapping file
Question:
username_0: Hi,
Hopefully this is just a simple mistake on my end and an easy fix. I am currently having problems running ASTRAL when incorporating a mapping text file to constrain multiple individuals of one species to be monophyletic. Everything runs fine with out it, but once I incorporate the text file the error reads that the taxa specified are not in the gene trees, even though I can see them in the tree file. I have tried formatting my species map file both ways and have had no success.
Thanks!
Answers:
username_1: Lizz, to help, I will need to see samples. Feel free to email your inputs
and the exact command that you write to me exactly. Also, if you copy-paste
your error message here, I would have better luck at detecting what the
issue may be.
Status: Issue closed
|
pimvullers/elementary | 247129120 | Title: Imposible to emerge withoud systemd
Question:
username_0: ``
Is there any solution?
Answers:
username_1: No. Elementary depends on a number of Gnome components which depend on systemd. So this is the only supported option on Gentoo.
There is one overlay which provides gnome ebuilds without systemd, but I haven't tried this combination (you would then be missing the ubuntu patches which could cause some issues).
Status: Issue closed
|
webdevilopers/php-ddd | 204036213 | Title: How to return created entity with REST and DDD using POST request
Question:
username_0: Hi,
I have an API and use command bus (Tactician) to handle commands.
The question is how to return new created entity after `POST` request in the body?
Controller's code (simplified):
```php
public function postAction(Request $request)
{
$command = new CreateTaskCommand($request->get('name'), $request->get('startDate'));
$this->get('command_bus')->handle($command);
return $this->createView(???); // here I want to return new created entity as a response body with 201 CREATED status code
}
```
Keeping in mind that command bus can't return anything, what is the good way to get the created entity?
I found two recommendations:
* To use domain events and listeners, but it's not clear whether I need to iterated over recorded events in the controller and how to get created entity
* to fetch the created entity after it's created by the command bus, using the UUID
For the second point the code might look like:
```php
public function postAction(Request $request)
{
$uuid = $request->get('uuid'); // or new TaskId();
$command = new CreateTaskCommand($uuid, $request->get('name'), $request->get('startDate'));
$this->get('command_bus')->handle($command);
// here we fetch the new entity from the storage
$entity = $someService->find($uuid);
return $this->createView($entity);
}
```
How do you guys solve this case? Maybe creators of command buses (@matthiasnoback, @rosstuck) know something about this?
Thanks in advance.
Answers:
username_1: When using a UUID (**recommended**), I usually create the new Id in the controller (as your example 2). That way you can fetch it after the handler is executed.
When not using a UUID but an auto increment (**not recommended**), you can can use a listener on the specific domain event, or ask the repository to generate an Id (based on autoincrement) `$this->repository->generateTaskId ()`. The AI solution also comes with possible problems when 2 records are added simultaneously.
On a side note, you should wrap the call to the handle with transaction, commit, rollback, since if an error occurred during the creation, the repo would not have the entity, and the view might be broken.
username_2: Welcome to PHPDDD @username_0 !
@username_1 has some good advice there! Start creating your own IDs (UUID recommended) - "TELL, don't ask"! This decouples your application from the persistence layer.
Status: Issue closed
|
metadatacenter/cedar-project | 340760236 | Title: Submit ARM paper
Question:
username_0: Incorporate internal reviewer comments from initial draft (https://github.com/metadatacenter/cedar-project/issues/733) and submit, likely to Bioinformatics journal.
Depends on metadatacenter/cedar-project#733
Depends on metadatacenter/cedar-valuerecommender-server#10
Answers:
username_0: Send to Mark on 14th September.
username_0: Comments received from Mark on October 24th. ARM code should be in 2.2 release so we can address comments and submit ~2 weeks after that.
Status: Issue closed
|
lovoo/goka | 458390092 | Title: Lost lots of messages due to async produce
Question:
username_0: I recently write a test script which produce 20 million messages to kafka with goka, but there
is only about 14 million messages after produce complete.
The disk space is enough and no error messages in kafak logs and client logs.
The script and kafka is running in docker, and under a subnet.
test scripts:
```
func GokaAsyncProduce() {
emitter, err := goka.NewEmitter(
viper.GetStringSlice("kafkaConfig.brokerUrls"),
goka.Stream(viper.GetString("kafkaConfig.topic")),
new(codec.String),
)
if err != nil {
log.Fatalf("error creating emitter: %v", err)
}
startTime = time.Now().UnixNano()
preTime := time.Now().UnixNano()
preN := 0
for n := 0; n < count; n++ {
bs := getPkg()
_, err = emitter.Emit("", string(bs))
if err != nil {
log.Fatalf("error emitting message: %v", err)
}
currTime := time.Now().UnixNano()
if float64(currTime-preTime) > float64(collectInterval)*math.Pow10(9) {
currN := n - preN
currSpeed := currN / collectInterval
fmt.Printf("produce speed: %v pps", currSpeed)
preTime = currTime
preN = n
PrintMemUsage()
PrintCPUUsage()
}
}
emitter.Finish()
endTime = time.Now().UnixNano()
}
```
Count messages using
`docker-compose exec kafka kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list kafka:9092 --topic test --time -1 --offsets 1`
Answers:
username_1: That sounds weird. What is the retention time of the topic? It's not log compacted, right?
username_0: Here coms the log retention policy:
```
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
```
And log compaction is disabled
I test 20 million messages using samara, and there are exactly 20 million messages after test finish:
```
docker-compose exec kafka kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list kafka:9092 --topic test --time -1 --offsets 1
test:0:20000000
```
I will test goka soon later and post the result here.
Thank you.
username_0: Oops there are only 11 million messages in the topic.
```
docker-compose exec kafka kafka-run-class.sh kafka.tools.GetOffsetShell --broker-list kafka:9092 --topic test --time -1 --offsets 1
test:0:11576072
```
username_2: Could you try multi times and then paste the results? Thus we can get more information about this issue.
username_3: @username_0 one error check could also help: the `emitter.Emit(...)` returns a `Promise` which will result in an error. Maybe there are errors which you aren't seeing since you're not checking for that. Like this:
```
prom, err = emitter.Emit("", string(bs))
prom.Then(func(err error){
if err != nil {
log.Fatalf("error emitting message (in promise): %v", err)
}
})
```
username_0: @username_3
username_3: Yep, nice :)
So at least one message is too large.
Kafka's limit is 1MB per message by default, but I'd recommend using much smaller messages.
If your message is <1MB you could try to do an `emitter.EmitSync(...)`, which send messages one-by-one. It's much slower than batching but you could narrow the error down to the batching. If your messages are > 1MB you have to split them up. I think the Kafka documentation does not recommend increasing the max-message-size config.
username_0: @username_3
username_0: @username_3
But the size of message is 30 - 1000 bytes, so what's the root problem?
username_3: Well, if Kafka says the messages are too big, then I guess they really are too big, ohne way or another. If your single messages really are only 1000bytes max, then it has to do with the internal batching of the kafka producer (which I doubt, but wouldn't know where else to look). So have you tried sending with `EmitSync` to check if the errors still occur?
username_0: @username_3
Not yet, the performance of EmitSync is only about 10 messages per second and far from meeting our expectations
username_3: @username_0 yes I understand the performance issue here, but trying that could make sure that it's not sarama's internal batching that causes messages that are too big.
Anyway, we have experienced that error a couple of times and it was always a message being too big. Always.
So to make sure it's not too big you could log the message size in the error handler. If we can't be sure 100% that the messages aren't too big, it's a waste of time to look somewhere else for the cause of the error.
username_3: I'll close that for now, feel free to reopen if it's still an issue
Status: Issue closed
|
Kinto/kinto-http.py | 163122594 | Title: (idea) A StrictClient that verifies collection signatures
Question:
username_0: Provided a public key, the client could verify signatures during `get_records()` calls...
Answers:
username_1: Here is a implementation that we use in a lambda and that we could build on top of https://github.com/mozilla-services/amo2kinto-lambda/blob/master/lambda.py#L97-L145
Status: Issue closed
|
tcjcodes/wishlist-nextjs-redux | 314475640 | Title: Question Thread for Items
Question:
username_0: Ability for another user or guest to ask a question about an item
- Ask question button
- Ask question form
```typescript
interface INewThreadMessage {
message: string,
itemId: string,
wishlistId: string,
isPublic: boolean, // Will show to public, else only email guest / notify user
fromUserId?: string, // If !fromUserId, then email required
notifyEmail?: string,
}
```
- Expandable question thread for each Item
TODO mockup |
gravitational/teleport | 600726238 | Title: Leaf Cluster not Mapping Approved Roles
Question:
username_0: Logged in as: stevendev
Cluster: mdem428-test
Roles: devadminrole, devrole*
Logins: devuser, devadminuser, root2
Valid until: 2020-04-16 11:32:40 -0400 EDT [valid for 11h53m0s]
Extensions: permit-agent-forwarding, permit-pty
```
- Leaf cluster when a k8s exec is attempted. The testadminrole (mapped from devadminrole) is missing.
```
DEBU [AUTH] Mapped roles [devrole] of remote user "stevendev" to local roles [testrole] and traits map[kubernetes_groups:[developer-oncall] kubernetes_users:[] logins:[]]. auth/permissions.go:161
DEBU [PROXY:KUB] Exec /api/v1/namespaces/prd/pods/nginx-65f88748fd-2v7hn/exec?command=bash&container=nginx&stdin=true&stdout=true&tty=true. proxy/forwarder.go:443
```
Error received through leaf cluster after attempting exec:
`error: Internal error occurred: error executing command in container: Internal error occurred: error executing command in container: pods "nginx-65f88748fd-2v7hn" is forbidden: User "remote-stevendevl.com-mdem428-dev.gravitational.co" cannot create resource "pods/exec" in API group "" in the namespace "prd"`
Answers:
username_1: @username_2 I know you've been poking around the our kubernetes setup. Have you had a chance to test role mapping yet?
username_2: I haven't played with trusted clusters or custom roles yet, but can dig in later.
If this becomes urgent, I might pass it off to someone with more experience.
Status: Issue closed
|
frig-js/frigging-bootstrap | 152917047 | Title: Label gets too many props
Question:
username_0: While writing integration tests I noticed `Label` is getting way too many props from its parent, `Input` (output below is from Enzyme's `.debug()`):
```jsx
<FriggingBootstrap.Label title="City" label="City" placeholder="City" layout="vertical" align="left" name="city" validate={true} disabled={false} errors={[undefined]} onChange={[Function]} onValidChange={[Function]} saved={[undefined]} value="Sunnyvale" theme={{...}} options={{...}} modified={false} labelHtml={{...}} inputHtml={{...}} valueLink={{...}} xs={12} sm={[undefined]} md={[undefined]} lg={[undefined]} xsOffset={[undefined]} smOffset={[undefined]} mdOffset={[undefined]} lgOffset={[undefined]} block={false} labelWidth={{...}} prefix={[undefined]} suffix={[undefined]} onColor="primary" onText="ON" offColor="default" offText="OFF" bsSize={[undefined]} handleWidth={[undefined]} format="0,0[.][00]">
<div>
<label saved={[undefined]} modified={false} block={false} validate={true} format="0,0[.][00]" theme={{...}} label="City" md={[undefined]} value="Sunnyvale" options={{...}} onColor="primary" sm={[undefined]} title="City" disabled={false} mdOffset={[undefined]} inputHtml={{...}} labelWidth={{...}} align="left" suffix={[undefined]} bsSize={[undefined]} lg={[undefined]} onText="ON" onValidChange={[Function]} placeholder="City" prefix={[undefined]} errors={[undefined]} layout="vertical" labelHtml={{...}} offColor="default" xsOffset={[undefined]} smOffset={[undefined]} lgOffset={[undefined]} name="city" offText="OFF" valueLink={{...}} handleWidth={[undefined]} xs={12} onChange={[Function]} className="">
City
</label>
</div>
</FriggingBootstrap.Label>
```
This is probably just a simple overuse of `...props` but it's probably worth going through these more carefully.
While we're at it, things like `xsOffset`, `mdOffset`, etc. really should be on a `bootstrap` object (and maybe even on context instead of props). |
saltstack/salt | 485805873 | Title: file.managed conflicts with iptables.insert
Question:
username_0: ### Description of Issue
<!-- Note: Please direct questions to the salt-users google group. Only post issues and feature requests here -->
We have a specific iptables file for server01, then use file.managed to import the ./services/server01/iptables file to /etc/sysconfig/iptables in ../services/server01/init.sls.
And then in the ../base/servergroup/init.sls, we use iptables.insert to insert rules for all of the servers in the servergroup ( including server01 ).
The firewall rules merged so we have specific rules and common rules. It used to work. And recently we had to change two rules from iptables.insert for servergroup. I found that all of the rules from ./services/server01/iptables were deleted and only rules added by iptables.insert were left.
### Setup
(Please provide relevant configs and/or SLS files (Be sure to remove sensitive info).)
New added rules:
`monitor-iptables:
iptables.insert:
- position: 1
- table: filter
- family: ipv4
- chain: INPUT
- jump: ACCEPT
- match:
- state
- comment
- comment: "Allow monitoring "
- connstate: NEW
- dport: 0000
- proto: tcp
- source: "XXX.XXX.XX.XX,XXX.XXX.XX.XX"
- save: True`
file.managed code:
`/etc/sysconfig/iptables:
file.managed:
- source: salt://server01/iptables
- mode: 600
- user: root
- group: root`
### Steps to Reproduce Issue
(Include debug logs if possible and relevant.)
From the state.log:
`ID: /etc/sysconfig/iptables
Function: file.managed
Result: True
Comment: File /etc/sysconfig/iptables updated
Started: 13:28:06.860706
Duration: 8.843 ms
Changes:`
Then it deleted all of the existing rules.
### Versions Report
(Provided by running `salt --versions-report`. Please also mention any differences in master/minion versions.)
minion version:
` Salt: 2015.5.10
Python: 2.7.5 (default, Apr 9 2019, 14:30:50)
Jinja2: 2.7.2
M2Crypto: 0.21.1
msgpack-python: 0.5.6
msgpack-pure: Not Installed
pycrypto: 2.6.1
libnacl: Not Installed
PyYAML: 3.10
ioflo: Not Installed
[Truncated]
dateutil: Not Installed`
master version:
` Salt: 2015.5.10
Python: 2.6.6 (r266:84292, Aug 18 2016, 15:13:37)
Jinja2: 2.2.1
M2Crypto: 0.20.2
msgpack-python: 0.4.6
msgpack-pure: Not Installed
pycrypto: 2.0.1
libnacl: Not Installed
PyYAML: 3.10
ioflo: Not Installed
PyZMQ: 14.3.1
RAET: Not Installed
ZMQ: 3.2.5
Mako: Not Installed
Tornado: Not Installed
timelib: Not Installed
dateutil: Not Installed`
Answers:
username_0: Hi Gareth,
The upgrade will affect many production environments so we are not planning to do that. Do you have any clue about the possible reason for this issue? Or could you provide any suggestion about troubleshooting?
Thank you very much! |
PSU-CSAR/vb-bagis-h | 147614977 | Title: AOI Upload/Download: GUI modification: make tasks in process list resizable
Question:
username_0: 1. move the download and upload controls to the middle of the form (see image). Rename Download button caption to "Add download to task," rename Upload button to "Add upload to task."

2. make the tasks in process list resizable. When there are error messages returned to the tool, there is not enough space to view the complete message. I had to select the message and copy/paste to another editor to view the complete message. The scroll bar cannot perform scrolls inside a row when the row height exceeds the list height.
3. The upload comment field should be reset/cleared when an upload is added to the task.
4. Rename "View task log" to "View local AOI task log"
5. It's not clear what the function of the update status button is. It seems the task list can update itself in some situations, but not in some other situations. Please clarify.
Answers:
username_1: See my comments:
1. "Add download to task" is not correct grammar. Could be either "Add download to tasks" or "Add download task". I like the second better because it's more concise. Will reorganize form. Also need to remove Upload Zip button. This was there for testing.
2. I ran into the issue myself with the error messages and could not find a way to view the complete message. This is a limitation of the GridBox control. May try adding a vertical scrollbar. Don't remember if I tried that or not.
3 and 4. Will do
5. This is confusing because .NET doesn't handle asynchronous processing well. As the state changes on the client side, I update the grid. For example: zipping an upload before sending it. But once it starts uploading, I have no way to check/update the status without sending repeated http:// requests.
For downloads I have to send repeated http:// requests to know when the file is ready to download. I have a single timer that runs at 10 second intervals to check. Once the download starts, again, I have control on the client side so I can update the status. If this is confusing, I can not update the status but can cache the status in the form and only update it when the user clicks the update status button. The function of the update status button is to send an http:// request for each upload task in the list to check the status from the server.
Note that the UI does lock up during long running tasks like zipping up an AOI. The only way around this is to implement threading which I'm uncomfortable doing at this time. If not done exactly right, it can cause memory leaks and I don't want to go there.
username_0: 1. I thought about other captions. The main goal is to let users know that the download/upload is managed/monitored by a "queue." Add download/upload task sounds good to me.
2. You did add a vertical scroll bar, but it scrolls to the next row, not to the obscured portion of the row. Maybe resizing the list window can resolve the problem.
3.
4.
5. how about renaming the button caption to "Show completed tasks"?
6. I suppose the "Upload Zip" button allows users to select a zipped AOI and add the upload to the task list. Does the tool verify that the zip file contains a valid AOI? Please move the button to the space below the "Add upload task" button and change the caption to "Upload Zipped AOI."
Can you prompt a messagebox saying "Please wait... BAGIS is busy." or something like this when the UI is about to lock up? Hide the messagebox when UI becomes responsive (e.g., after the zip file is created). I know the status field shows similar message, but I think we need more notifications to let users know what is going on.
username_1: 1. Will do
2. Not sure what you are suggesting here. I have experienced the problem. Do you want me to make the "tasks in process" grid taller all the time? Or try to make it taller if there is an error?
3.
4.
5. "Show completed tasks" isn't an accurate caption for the "update status" button because it updates the status on all upload tasks whether or not they are complete. "Update upload task status" may technically be more accurate but I don't know that it resolves confusion.
6. I used the "Upload zip" button during development before the code was written to create the .zip file. It wasn't intended for end users so doesn't have any checks like whether the AOI is valid or if it already exists. It's my preference to just remove this button. But, if you think it is something the users would like to have, I can open another issue to add this as an enhancement. To check to make sure it is a valid AOI, you'd have to unzip it, check, and then delete the output before trying to upload.
7. I'm not sure if a ProgressBar can help with the UI locking or not. I will run some tests and see what is possible. I opened issue #28 separately because this will take some additional time/research.
username_0: 1.
2. I suggest making the list window resizable.
3. How about just "Refresh task list"?
4. It's OK to remove/hide the Upload zip button.
5. Thanks
username_1: Discussed issue on 4/19/2016. Summary of changes related to the task list and associated buttons:
1. Move clear tasks button next to cancel task button; Rename to "Remove completed tasks from list"
2. Remove completed tasks from list button only removes completed, aborted, and failed tasks
3. Warn the user when "cancel task" button is pressed that the action is irreversible
4. Closing the form via cancel button, x in right-hand corner, or closing ArcMap removes visibility to any tasks running on the server. Warn user if they have tasks processing on the server. Try to catch all 3 of these events.
5. Decided NOT to list recently compiled downloads when user reconnects to server in new session for now. Documented in issue #29 if we want to reconsider later.
username_1: This note concerns the issue where long error messages cannot be read on the grid. Due to limitations of the DataGridView control, there is no way to make the cell big enough to display the whole message. Instead we now truncate the message in the grid at 100 characters and display the message in its entirety in a pop-up message box. Hopefully this is an acceptable work around. The 100 character limit is arbitrary but seemed to be a good length for showing that there is a message without maxing out the cell size.
username_0: This works. Good solution.
username_1: Believe all of the items in this issue are done. See current screenshot to confirm:

username_0: Looks good. The View AOI history button should be associated with the list of AOIs on the server because we no longer keep track of the history of the downloaded local AOIs.
username_1: Correct. It is currently there as a placeholder but will be disabled until we have a working AOI history API from the server. @username_0 Do you think you have any time this week to take this screen for another test drive? If so, I'll post a new add-in to GitHub. It's always easier to fix things closer to when they were coded.
Status: Issue closed
|
darkreader/darkreader | 648664452 | Title: [Broken Website] (Waterfox Classic) developer.mozilla.org Dynamic Theme will not load
Question:
username_0: **Expected behavior**
Site should darken.
**Actual behavior**
Dark theme is not applied.
**Screenshots**
If applicable, add screenshots to help explain your problem.

**System info:**
- OS: Win10 x64
- Browser: Waterfox Classic v2020.06
- Darkreader Version: 4.9.13
**Additional context**
Only the Dynamic theme is broken. Filter, Filter+, and Static all work fine. Toggling to other modes and back to Dynamic or toggling DR off and back on doesn't work, site goes back to being light after reenabling.
Answers:
username_1: Any errors in console?
Waterfox Classic is based on a old Firefox. Dark reader & Waterfox Classic = Not best combination.
username_0: No, no errors unfortunately.
Yeah I'd switch to the newer one but I really don't want to lose the status/addon bar I have with Classic.
username_0: After trying to narrow it down, I think it's from this commit: https://github.com/darkreader/darkreader/commit/e878fdd1908c80ccdeff2a5076e4c336fd460a1c
username_1: Hmm, I don't see 123 that should break compatability.
username_0: I'm pretty sure it's related to that commit somehow. In `src/generators/modify-colors.ts`, the `getBgPole()` function (and other functions too) are returning 'auto', when they used to return hex colors. It might be an underlying issue with something else that's incompatible that was exposed when the 'auto' check was removed.
username_0: Now this is weird, while trying to debug things it suddenly started working perfectly.
I'm wondering if Waterfox was somehow caching the old "auto" values for some reason. I must have cleared it out somehow while debugging. I probably should've started by testing a clean profile, sorry for wasting your time with this @username_1.
Feel free to close the issue; unless someone else runs into the same thing, there's probably not much left to mention here, unless you want to set something to clean those "auto" values out on a new update. But if no one else's brought it up since the update it likely isn't enough of a problem to bother with it anyway.
Status: Issue closed
username_1: We will see
/shrug didn't saw any other user with it. It could be the case it still was caching it's weird issue. |
nelsonic/nelsonic.github.io | 412079121 | Title: How Not to Do Time Tracking for Software Developers
Question:
username_0: https://www.7pace.com/blog/developer-time-tracking-fails

discussion: https://news.ycombinator.com/item?id=19199719 |
mjkoster/I-D | 60213739 | Title: Return code for max-age of value expired
Question:
username_0: Since we have the idea of topic lifetime (max-age on CREATE) and value lifetime (max-age on last PUBLISH) as separate things, there is the possibility of the topic being valid but the value being stale. New subscribers and readers could be allowed to subscribe but be informed that the data are not valid. I.e. the topic exists but the data value is stale.
If the topic doesn't exist, the clear return code is 4.04 Not Found. Semantically, 4.xx codes mean that the client has made an error. This seems to be reasonable for the no topic case.
In the case of stale data values, the client hasn't made an error; it may in fact be a normal condition in multi-sensor networks. It seems like a 3.xx code is the best fit for this case. From RFC2616:
"This class of status code indicates that further action needs to be taken by the user agent in order to fulfill the request."
None of the currently defined 3.xx codes in RFC2616 are suitable to map to. We need something like a "try later" response code. Applications can interpret this as appropriate in the context, for PubSub it would mean "stale data". Would it be useful to define the corresponding code for http at some point?
ref:
http://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
http://www.iana.org/assignments/core-parameters/core-parameters.xhtml
Answers:
username_0: I defined a new code for No Content, 2.06 for the case of expired max-age of the last published value. Looking at HTTP codes, this was the best match. CoAP had already defined 2.04 as "Changed" so I chose the next available one for No Content.
username_0: I went back to 2.04 No Content in the draft because the definition of Changed only applies in response to PUT and POST requests, leaving 2.04 to be defined as "No Content" in response to GET requests.
Now we will ask IANA to register 2.04 as a "No Content" response to GET, in addition to it's current definition as a "Changed" response to PUT and POST. If this causes an unavoidable conflict, we can fall back to using 2.06 for "No Content" |
nu50218/findimpl | 691551307 | Title: ast.Exprが見つけられない
Question:
username_0: 見つけられる例
`go install ./cmd/findimpl && go vet -vettool="$(which findimpl)" -findimpl.target=io.Writer net/http`
見つけられない例
`go install ./cmd/findimpl && go vet -vettool="$(which findimpl)" -findimpl.target=go/ast.Expr go/ast`
Answers:
username_1: `analysis`パッケージのパースと`parser.ParseDir`関数でのパース(型チェクも)が世界線が違ってしまってないか不安です。 |
KotlinBy/awesome-kotlin | 200757664 | Title: Krawler a Kotlin native web crawler framework based on Java's crawler4j
Question:
username_0: http://github.com/username_0/krawler - Krawler is a Kotlin native web crawler framework based on Java's crawler4j.
Thank you :)
Answers:
username_1: Hi, i will add this library as soon, as i'm done with first part of "Rewrite \w Kotlin. #89"
username_0: Great, thank you.
:+1:
Status: Issue closed
|
facebookincubator/submitit | 766255957 | Title: 喀什汽车站哪里有真实大保健(找特色服务n
Question:
username_0: 喀什汽车站哪有特殊服务的洗浴【十(V)1077_1909】春节即将到来,家家户户都要购置年货,各大平台都开启了年货促销活动。而抖音官方也在最近推出了新春购物活动抖音直播“年货节”。在这场活动中,官方邀请了杨迪、孙耀威、仙女酵母等大牌明星与人气主播,进行特别活动直播,为广大粉丝种草各类精品年货。除了明星和主播助阵,抖音官方也在活动中发放了大量优惠券,大家在观看直播的过程中,就能轻松的买到心仪年货。不得不说,抖音的这场活动,满满都是诚意在最新一场活动中,人气美妆主播呗呗兔也受邀来到活动直播间。身为抖音的热门带货主播,呗呗兔经常会在直播中推荐各种美妆产品,她还会通过各种小实验和亲自试用的方法,为粉丝们验证美妆产品的具体效果,获得了无数观众的夸赞,正是因为呗呗兔的这份专注,她在抖音平台上段时间内就揽获了多万粉丝,收获了超过万点赞。早在年双十一期间,呗呗兔就受邀参与了抖音的“好物漫游指南”活动,并在双十一当天,获得了超过万的总销售额、带货超过万件、“双卖货王争霸赛抖音直播达人榜第一名”等亮眼成绩,她也因此有了“带货女王”的称号。在这次的抖音直播“年货节”活动中,呗呗兔则化身为美食品尝官,现场为粉丝们进行美食试吃与推荐,吸引了诸多观众热情抢购。在当晚的活动直播中,呗呗兔为大家甄选了多款精品美食,为了让粉丝们更全面的了解产品,呗呗兔保持了一惯的风格,多次在现场亲测试吃。在推荐去骨鸭掌时,她就拿出了一只细细品尝,让大家都听到了“嘎嘣嘎嘣”的响声,仿佛鸭掌的香味已经溢出了屏幕,让粉丝们垂涎不止。随后,呗呗兔还为大家分享了鸭掌的购买技巧,告诉大家如何以色泽、用料来挑选鸭掌,让不少观众都收获颇丰,呗呗兔的走心推荐,吸引了不少粉丝前来围观,当晚的直播在线观看人数高达近万,现场画面十分火爆。更让大家惊喜的是,呗呗兔还为大家争取到了优惠价格,这直接引发了粉丝们的抢购热潮,很多好物刚刚上架就迅速售空,粉丝们也在欢乐的氛围中购置到了自己满意的年货。在这场直播结束后,大家都对此次的抖音直播“年货节”活动一致给出了好评,更有不少粉丝在弹幕里表示,已经开始期待抖音接下来的活动。看到这里,大家是不是也觉得这种快捷的直播购物方式非常赞呢?除了抖音直播“年货节”以外,在之后的时间里,官方还将推出更多不同形式、更加多元化的直播活动,为大家带来新奇、有趣的直播体验。感兴趣的朋友们,可要一定要长期关注抖音直播,还有更多精彩等着大家挖掘呢声明:中华娱乐网刊载此文出于传递更多信息之目的,并非意味着赞同其观点或证实其描述。版权归作者所有,更多同类文章敬请浏览:综合资讯彻拙罩怯乇返秸补辟挚陈刺探曰靡残瞧仄绞潘讶私拐乃秩https://github.com/facebookincubator/submitit/issues/177 <br />https://github.com/facebookincubator/submitit/issues/219 <br />https://github.com/facebookincubator/submitit/issues/157 <br />https://github.com/facebookincubator/submitit/issues/200 <br />https://github.com/facebookincubator/submitit/issues/249?q0g4s <br />thktzoadfncsvhondkyumrsinrcjqyyfucw |
ocaml/dune | 569129596 | Title: dune 2.3.1 external-lib-deps fails in opam.git
Question:
username_0: <!-- Thank you for filing an issue to help us improve Dune! -->
## Expected Behavior
Should work as in 2.3.0
## Actual Behavior
Crash in opam.git#4ec3c603db4653c974753651c0cfc143388bfcb1 (2.0.6):
````
[ 60s] + dune external-lib-deps --for-release-of-packages=opam,opam-client,opam-core,opam-format,opam-installer,opam-repository,opam-solver,opam-state @install
[ 60s] File "_build/default/src/client", line 1, characters 0-0:
[ 61s] Warning: The following source file corresponds to an invalid module name:
[ 61s] - get-git-version.ml
[ 61s] This module is ignored by dune. If it's used to generate a module source,
[ 61s] consider picking a different extension.
[ 61s] Error: exception { exn = ("Module_name.of_string: invalid name", { s = "get-git-version" })
[ 61s] ; backtrace =
[ 61s] [ { ocaml =
[ 61s] "Raised at file \"src/stdune/code_error.ml\", line 9, characters 30-62\n\
[ 61s] Called from file \"src/dune/modules_field_evaluator.ml\", line 27, characters 15-38\n\
[ 61s] Called from file \"src/dune/ordered_set_lang.ml\" (inlined), line 185, characters 33-41\n\
[ 61s] Called from file \"src/dune/ordered_set_lang.ml\", line 188, characters 18-35\n\
[ 61s] Called from file \"src/dune/ordered_set_lang.ml\", line 130, characters 16-28\n\
[ 61s] Called from file \"list.ml\", line 103, characters 22-25\n\
[ 61s] Called from file \"src/stdune/list.ml\" (inlined), line 5, characters 19-33\n\
[ 61s] Called from file \"src/dune/ordered_set_lang.ml\", line 133, characters 32-55\n\
[ 61s] Called from file \"src/dune/ordered_set_lang.ml\", line 136, characters 20-30\n\
[ 61s] Called from file \"list.ml\", line 103, characters 22-25\n\
[ 61s] Called from file \"src/stdune/list.ml\" (inlined), line 5, characters 19-33\n\
[ 61s] Called from file \"src/dune/ordered_set_lang.ml\", line 133, characters 32-55\n\
[ 61s] Called from file \"src/dune/modules_field_evaluator.ml\", line 37, characters 18-62\n\
[ 61s] Called from file \"src/dune/modules_field_evaluator.ml\" (inlined), line 258, characters 13-58\n\
[ 61s] Called from file \"src/dune/modules_field_evaluator.ml\", line 259, characters 16-55\n\
[ 61s] Called from file \"src/dune/dir_contents.ml\", line 409, characters 6-180\n\
[ 61s] Called from file \"src/stdune/list.ml\", line 67, characters 12-15\n\
[ 61s] Called from file \"src/stdune/list.ml\" (inlined), line 72, characters 14-29\n\
[ 61s] Called from file \"src/stdune/list.ml\", line 75, characters 13-42\n\
[ 61s] Called from file \"src/stdune/exn_with_backtrace.ml\", line 9, characters 8-12\n\
[ 61s] "
[ 61s] ; memo = ("lazy-125", ())
[ 61s] }
[ 61s] ; { ocaml =
[ 61s] "Raised at file \"src/memo/memo.ml\", line 574, characters 10-204\n\
[ 61s] Called from file \"src/memo/memo.ml\" (inlined), line 874, characters 16-20\n\
[ 61s] Called from file \"src/memo/memo.ml\", line 876, characters 37-46\n\
[ 61s] Called from file \"src/stdune/exn_with_backtrace.ml\", line 9, characters 8-12\n\
[ 61s] "
[ 61s] ; memo = ("lazy-130", ())
[ 61s] }
[ 61s] ; { ocaml =
[ 61s] "Raised at file \"src/memo/memo.ml\", line 580, characters 48-68\n\
[ 61s] Called from file \"src/memo/memo.ml\" (inlined), line 874, characters 16-20\n\
[ 61s] Called from file \"src/dune/dir_contents.ml\", line 168, characters 12-39\n\
[ 61s] Called from file \"src/dune/lib_rules.ml\", line 420, characters 6-80\n\
[ 61s] Called from file \"src/stdune/exn.ml\", line 13, characters 8-11\n\
[ 61s] Re-raised at file \"src/stdune/exn.ml\", line 19, characters 4-11\n\
[ 61s] Called from file \"src/memo/implicit_output.ml\", line 120, characters 4-162\n\
[ 61s] Called from file \"src/dune/rules.ml\" (inlined), line 192, characters 20-71\n\
[ 61s] Called from file \"src/dune/rules.ml\", line 195, characters 20-33\n\
[ 61s] Called from file \"src/dune/build_system.ml\", line 1742, characters 19-34\n\
[ 61s] Called from file \"src/dune/gen_rules.ml\", line 76, characters 8-69\n\
[ 61s] Called from file \"src/dune/gen_rules.ml\", line 132, characters 6-96\n\
[Truncated]
[ 61s]
[ 61s] I must not segfault. Uncertainty is the mind-killer. Exceptions are
[ 61s] the little-death that brings total obliteration. I will fully express
[ 61s] my cases. Execution will pass over me and through me. And when it
[ 61s] has gone past, I will unwind the stack along its path. Where the
[ 61s] cases are handled there will be nothing. Only I will remain.
[ 61s] error: Bad exit status from /var/tmp/rpm-tmp.8YeWkY (%build)
````
## Specifications
- Version of `dune` (output of `dune --version`):
2.3.1
- Version of `ocaml` (output of `ocamlc --version`)
4.09.0
- Operating system (distribution and version):
Leap
- Link to gist with verbose output (run `dune` with the `--verbose` flag):
dune 2.3.1
Answers:
username_1: Thanks for the report. #3181 should address this.
Status: Issue closed
|
vlsi/calcite-test-dataset | 437440311 | Title: wikiticker dataset is not populated for druid
Question:
username_0: Executing steps described at https://github.com/vlsi/calcite-test-dataset#accessing-druid-in-the-vm returns [] from druid, but changing "wikiticker" to "foodmart" in the above steps returns this result from druid:
[ {
"timestamp" : "1997-01-01T00:00:00.000Z",
"result" : {
"maxTime" : "1997-12-30T00:00:00.000Z",
"minTime" : "1997-01-01T00:00:00.000Z"
}
} ]
Which probably means that only the foodmart dataset was populated for druid , while wikiticker wasn't.
Answers:
username_1: Wonder if this was caused by the recent Druid upgrade in PR #30
https://github.com/vlsi/calcite-test-dataset/pull/30/files#diff-4d687b6127479ccd0e9401aec6f5ae59L33
Looks like `wikiticker` was replaced with `wikipedia`?
Maybe @nishantmonu51 or @username_2 knows?
username_2: @username_1, that is my understanding. It seems documentation should have been updated accordingly as part of #30. @nishantmonu51, could you push an addendum? |
jspm/jspm-cli | 147131943 | Title: Error bundling after module path changes
Question:
username_0: **jspm** : ^0.17.0-beta.12
**TLDR;**
Application bundling fails after changing the module path
#### Given
`jspm.browser.js`
```js
SystemJS.config({
baseURL: "/",
paths: {
"github:*": "jspm_packages/github/*",
"npm:*": "jspm_packages/npm/*",
"3d-hubs-assignment/": "src/"
}
});
```
`jspm.config.js`
```js
SystemJS.config({
transpiler: "plugin-typescript",
packages: {
"3d-hubs-assignment": {
"main": "main.ts",
"defaultExtension": "ts",
"meta": {
"*.ts": {
"loader": "plugin-typescript"
}
}
}
},
typescriptOptions: {}
});
SystemJS.config({
packageConfigPaths: [
"github:*/*.json",
"npm:@*/*.json",
"npm:*.json"
],
map: {
"angular": "github:angular/[email protected]",
"angular-typescript": "npm:[email protected]",
"os": "github:jspm/[email protected]",
"plugin-typescript": "github:frankwallis/[email protected]"
},
packages: {
"github:frankwallis/[email protected]": {
"map": {
"typescript": "npm:[email protected]"
}
},
"github:jspm/[email protected]": {
"map": {
"os-browserify": "npm:[email protected]"
}
}
}
[Truncated]
paths: {
"github:*": "jspm_packages/github/*",
"npm:*": "jspm_packages/npm/*",
"3d-hubs-assignment/": "app/"
}
});
```
**when**
```bash
jspm bundle 3d-hubs-assignment storage/build.js -wid
```
**fails as it's still trying to load the module through `src/`**
```bash
Building the bundle tree for 3d-hubs-assignment...
err Error on fetch for 3d-hubs-assignment/main.ts at file:///Users/joelhernandez/Documents/3d-hubs-assignment/src/main.ts
Error: ENOENT: no such file or directory, open '/Users/joelhernandez/Documents/3d-hubs-assignment/src/main.ts'
at Error (native)
```
Answers:
username_0: Solved by adding
```js
paths: {
"3d-hubs-assignment/": "app/"
}
```
on `jspm.config.js`
```js
SystemJS.config({
transpiler: "plugin-typescript",
packages: {
"3d-hubs-assignment": {
"main": "main.ts",
"defaultExtension": "ts",
"meta": {
"*.ts": {
"loader": "plugin-typescript"
}
}
}
},
paths: {
"3d-hubs-assignment/": "app/"
},
typescriptOptions: {}
});
```
Is `src/` used as default ? This was generated with jspm init, if so, wouldn't it be good to include it in the generated `jspm.config.js` just as it is included in the `jspm.browser.js` ?
username_1: We do this because the browser and server paths are allowed to be different. In `jspm init`, when setting this property it will double it up with the package.json making that the source of truth.
Agreed though that this is definitely a catch to be improved.
Status: Issue closed
|
npgsql/npgsql | 470015122 | Title: Options and best practices for Multiple Result Sets
Question:
username_0: I want to get two (small) result sets and have the benefit of precompilation and 1 round trip to the database. SQL Server allows a stored procedure to contain multiple select statements.
```
SELECT u.username, ... FROM User u WHERE u.userId = p_userID;
SELECT r.roleName, ... FROM Role r WHERE r.userId = p_userID;
```
When retrieving data from each result set, the npgsql client code does something like:
```
using (var reader = cmd.ExecuteReader())
{
while (reader.Read())
{
result1.Add(reader.Get<int>("username"));
...
}
reader.NextResult();
while (reader.Read())
{
result2.Add(reader.Get<string>("roleName"));
...
}
}
```
What's the recommended way to do this in npgsql and PostgreSQL 11? (I realize many variations of this question have already been asked and answered regarding multiple result sets, but I would like a concise list of options and a recommended best practice if it exists.) Here are the options I've found so far:
1. Use a Function that RETURNS SETOF refcursor.
This lengthy [debate](https://github.com/npgsql/npgsql/issues/438) is confusing and I'm not sure what the final status is on the issue. Requires that the function call be wrapped in a transaction(?) and then execute a [Fetch](https://mightyorm.github.io/Mighty/docs/cursors.html) on each. ([another link](https://stackoverflow.com/questions/50643178/how-can-i-get-multi-result-set-with-postgresql-function)). I'm hoping there is a more straightforward way to do this that doesn't require a transaction.
2. Don't use a function or procedure, just use [inline](https://www.npgsql.org/doc/performance.html) sql and batch statements (from npgsql docs).
(This works, but then I don't get the advantage of precompilation. And, we can't have multiple statements in a single PreparedStatement):
`SELECT ... FROM TableA a; SELECT ... FROM TableB b;`
3. Don't use cursors, create 2 functions, each returning a Table type that defines the structure of the result.
(Requires a trip to the database for each function call.)
4. Use the new StoreProcedure in PostgreSQL 11 that were going to support multiple result sets.
(Sounds like this feature didn't make it into version 11)
5. Combine the data from each result set in a join.
Gives the benefit of precompilation and 1 round trip, but it just feels gross when I consume the data in code. In my case, I want to get user data and a list of roles for the user. I suppose I could get data like
userA columns..., role1 columns
userA columns..., role2 columns
Which of these (or some other?) is the recommended way to get multiple result sets? i.e., is there a way to return 2 table types in a function or procedure?
### Further technical details
Npgsql version: 4.07
PostgreSQL version: 11
Operating system: Windows 10
Status: Issue closed
Answers:
username_1: This is a highly specific solution that only works for specific data. If what you're looking for can be naturally expressed as a join, that's definitely good - but I definitely wouldn't twist two queries into a single join (and as above, there's no real reason to).
Am going to close this issue as there's nothing actionable on the PostgreSQL side, but please feel free to continue posting questions/suggestions here.
username_0: Thank you for such a thorough response. Regarding the ability to include multiple statements in the command text (as in options 2 and 3), is there a way to pass data from one statement to another in the same command? i.e.,
`NpgsqlCommand("Statement1();Statement2(<result from Statement1>)", conn)`
username_2: Could you provide more details about the expected result? If there are different sets which can be joined (a parent-child relation), then join them and group records on the client. Take a look at Dapper examples, it supports such a scenario out of the box, but you can do it manually. Otherwise, just pass the required part of the first query to the second via an array.
username_1: To add to @username_2's answer, if you're looking to have two distinct statements and somehow pass results from the first to the second, then that's not possible. You can't have everything - either you have a single roundtrip - in which case you can't pass results from one statement to another - or you pass results, in which case you can't have a single roundtrip.
In theory, if the two statements call functions/procedures which somehow use connection state to transmit information (e.g. some temporary table?), this can be done - but it's definitely not simply passing results from one to the other. Then again, if you're calling two procedures that communicate, you may as well just wrap them and simply execute one procedure instead.
username_0: The temp table solution might be a little overkill in my fairly simple scenario: we have 3 tables: Login, Role, and LoginRole (a linking table that includes the LoginID and RoleID). I am given an email (which is unique in the Login table, but not the primary key) and want to look up 1) the corresponding login record and 2) roles for the login . If these are separate statements, I would need to lookup the login by email in the 1st statement, then do it again in the second to get the LoginID in order to lookup the roles.
So, I'll either do the simple join then group in the client as mentioned by @username_2, or call 2 separate functions and do the lookup twice. I'm kind of leaning towards the second approach since the combined data from the 2 result sets is going to be smaller than if I were to join it all together. I assume we would notice a performance difference if the data returned were significantly larger(?),
Thanks again!
username_2: It depends on your infrastructure, data size, and what is better maintainable for your team. Therefore, the best way to choose the solution is to write a test and run it. There is no silver bullet (:
username_1: That indeed sounds like a classical scenario for a single query with a join, probably no need to do anything complicated.
Be careful not to fall into premature optimization and make things overly complex - unless you have a lot of load there's little chance of it actually mattering.
username_0: True, this is a simple use case, and doesn't really need optimization. I appreciate you sharing alternatives as I'm mostly trying to learn how to think in postgres.
username_0: Here are some test results on various methods discussed above:
1. TwoCommands; (2 separate commands, each with 1 statement)
2. TwoFunctionsInOneCommand
3. TwoInlineStatementsInOneCommand (best all around)
4. OneJoinStatementUnOptimizedRead
(when parent and child columns are extracted from reader for every row)
(I didn't try out Dapper, but it most likely fits in this category)
5. OneJoinStatementOptimizedRead (best for small result sets)
(when parent columns are only extracted once for each unique parent)
Summary: Not surprisingly, 2Commands is the slowest by far. Prepared statements performed better than unprepared. **TwoInlineStatementsIn1Command(Prepared)** is the best overall performer -- better than calling plpgsql function equivalents and better than OneJoinStatementUnOptimizedRead and better than OneJoinStatementOptimized with larger number of child records. **1JoinStatementOptimizedRead(Prepared)** was slightly faster with a small number of children (about 10 or less).
The test: created a parent table with 50k rows and a child table with about 2.7 million child records, some parents having 70+ children, others having as few as 3.
Each scenario is for a different number of child records.
In each scenario, each of the methods above is tested 10,000 times Unprepared, then again with NpgsqlCommand.Prepare() being called.
--73 child records------------------------------
17.59 - TwoCommands(Unprepared)
12.44 - TwoCommands(Prepared)
11.65 - TwoInlineStatementsInOneCommand(UnPrepared)
**08.33 - TwoInlineStatementsInOneCommand(Prepared)**
13.03 - TwoFunctionsInOneCommand(UnPrepared)
09.45 - TwoFunctionsInOneCommand(Prepared)
27.28 - OneJoinStatementUnOptimizedRead(UnPrepared)
23.67 - OneJoinStatementUnOptimizedRead(Prepared)
13.42 - OneJoinStatementOptimizedRead(UnPrepared)
09.57 - OneJoinStatementOptimizedRead(Prepared)
--54 child records------------------------------
17.92 - TwoCommands(Unprepared)
12.20 - TwoCommands(Prepared)
10.75 - TwoInlineStatementsInOneCommand(UnPrepared)
**07.50 - TwoInlineStatementsInOneCommand(Prepared)**
11.18 - TwoFunctionsInOneCommand(UnPrepared)
09.44 - TwoFunctionsInOneCommand(Prepared)
23.22 - OneJoinStatementUnOptimizedRead(UnPrepared)
21.09 - OneJoinStatementUnOptimizedRead(Prepared)
12.72 - OneJoinStatementOptimizedRead(UnPrepared)
09.45 - OneJoinStatementOptimizedRead(Prepared)
--30 child records-----------------------------
16.673 - TwoCommands(Unprepared)
11.003 - TwoCommands(Prepared)
09.348 - TwoInlineStatementsInOneCommand(UnPrepared)
**05.493 - TwoInlineStatementsInOneCommand(Prepared)**
09.292 - TwoFunctionsInOneCommand(UnPrepared)
05.797 - TwoFunctionsInOneCommand(Prepared)
14.896 - OneJoinStatementUnOptimizedRead(UnPrepared)
11.461 - OneJoinStatementUnOptimizedRead(Prepared)
10.220 - OneJoinStatementOptimizedRead(UnPrepared)
06.649 - OneJoinStatementOptimizedRead(Prepared)
--20 child records-----------------------------
15.745 - TwoCommands(Unprepared)
[Truncated]
05.43 - TwoFunctionsInOneCommand(Prepared)
11.03 - OneJoinStatementUnOptimizedRead(UnPrepared)
07.13 - OneJoinStatementUnOptimizedRead(Prepared)
09.48 - OneJoinStatementOptimizedRead(UnPrepared)
**04.85 - OneJoinStatementOptimizedRead(Prepared)**
--3 child records-------------------------------
14.99 - TwoCommands(Unprepared)
09.56 - TwoCommands(Prepared)
08.87 - TwoInlineStatementsInOneCommand(UnPrepared)
04.91 - TwoInlineStatementsInOneCommand(Prepared)
07.82 - TwoFunctionsInOneCommand(UnPrepared)
04.82 - TwoFunctionsInOneCommand(Prepared)
08.70 - OneJoinStatementUnOptimizedRead(UnPrepared)
05.09 - OneJoinStatementUnOptimizedRead(Prepared)
08.85 - OneJoinStatementOptimizedRead(UnPrepared)
**04.54 - OneJoinStatementOptimizedRead(Prepared)**
username_1: Did you also prepare the command in this scenario? Preparing a function call is also possible, although the gains should be less significant than preparing a complex SQL query. I'm asking mainly because I'd expect TwoFunctionsInOneCommand and TwoInlineStatementsInOneCommand to be pretty similar.
username_1: BTW when doing measurements like this, it's really a good idea to use BenchmarkDotNet to avoid common pitfalls in benchmarks.
username_0: Yes, every method was tested (UnPrepared) and (Prepared). I was surprised that preparing a statement with a functions performed so much better than when it wasn't prepared --I had assumed that it wouldn't make a difference to do so because a function is already precompiled and postgres presumably(?) already has a cached query plan for it.
--3 child records-------------------------------
07.82 - TwoFunctionsInOneCommand(**UnPrepared**)
04.82 - TwoFunctionsInOneCommand(**Prepared**)
...
--73 child records------------------------------
13.03 - TwoFunctionsInOneCommand(**UnPrepared**)
09.45 - TwoFunctionsInOneCommand(**Prepared**)
And, yes, the benefit of using Prepare is more drastic with more complicated queries Confirmed findings of your own (very helpful) [blog](http://www.username_1.org/prepared-statements-in-npgsql-3-2). =)
--5 joins
--10,000 iterations
18.859 - ComplexQuery(Unprepared)
04.655 - ComplexQuery(Prepared)
--100 iterations
01.174 - ComplexQuery(Unprepared)
00.073 - ComplexQuery(Prepared)
--1 iteration
00.8643211 - ComplexQuery(Unprepared)
00.0230465 - ComplexQuery(Prepared)
--3 joins
--10,000 iterations
11.087 - ComplexQuery(Unprepared)
04.963 - ComplexQuery(Prepared)
--100 iterations
00.951 - ComplexQuery(Unprepared)
00.073 - ComplexQuery(Prepared)
--1 iteration
00.8129468 - ComplexQuery(Unprepared)
00.0191895 - ComplexQuery(Prepared)
username_1: Yes, preparation is very important with PostgreSQL. It's not only about cache plans - less protocol messages get sent over the wire, no SQL parsing, etc. The difference is still much greater when comparing large, complex queries, but even very small ones (e.g. simple function calls) can benefit from preparation, especially if you're testing against localhost and other overheads are very small. |
Librarika/Issues | 253160269 | Title: List of Books without Photos Is Not Working Anymore (was issue #82)
Question:
username_0: When I go to:
Report / Catalog Items
Then check "Missing Fields: [x] Photos".
And then click on "Filter"
Nothing is displayed.
Even though I use a wide range for date of creation.
It used to work.
Something changed.
Also, how can we help with the code?
Answers:
username_1: This feature is working and nothing has changed since then. Will you please provide more information about your library via email.
Thank you.
username_0: My library is
akssma.librarika.com
When I try to use this feature, it complains that I need to enter a Media
ID or ISBN.
-nahur
username_1: Please leave this field empty and adjust created date from and click on missing photo check-box. It works smoothly as I have tested.

Status: Issue closed
username_0: Indeed.
Thanks. |
cncjs/cncjs | 985027308 | Title: Download App desktop
Question:
username_0: #### Description
Hey I tried to install cncjs via node.js or github, I had an error all time ! So I would like to download the app, but the only instruction I can found is this:
### Windows (x64)
Download “cnc-{version}-win-x64.exe” to install the app in Windows (x64).
A loading spinner is shown during the installation, and it may take several minutes to finish.
Hum ok, but where ?
Thank you.
#### Versions
- CNCjs: 1.9.x
- Node.js: 6.x
- NPM: 5.x
#### How Do You Install CNCjs?
- [] NPM
- [ ] Download the CNCjs Desktop Application
#### CNC Controller
- [x] Grbl
- [ ] Smoothieware
- [ ] TinyG/g2core
#### Hardware
- [] Raspberry Pi
- [x] Desktop or Laptop
- [ ] Mobile Device
#### Operating System
- [] Not Applicable
- [x] Windows
- [ ] Mac
- [ ] Linux
Answers:
username_0: https://github.com/cncjs/cncjs/releases/tag/v1.9.22
here
Status: Issue closed
|
hail2u/node-css-mqpacker | 423906610 | Title: Deprecated?
Question:
username_0: npm says [css-mqpacker is deprecated](https://www.npmjs.com/package/css-mqpacker).
Why? Is there a better replacement?
Or is there just a lack of time to maintain this package?
Maybe I can help...<issue_closed>
Status: Issue closed |
ember-cli/eslint-plugin-ember | 255758202 | Title: Can you explain to me this rule? alias-model-in-controller
Question:
username_0: I have many little, small controllers like this one:
import Ember from 'ember';
const { alias } = Ember.computed;
```
export default Ember.Controller.extend({
session: Ember.inject.service(),
actions: {
authenticate() {
....
}
}
....
```
and I have many errors for this rule: **alias-model-in-controller**.
Why?
I read this: https://github.com/ember-cli/eslint-plugin-ember/blob/master/docs/rules/alias-model-in-controller.md but I don't understand the reason. I don't use `model` in my controllers.
Answers:
username_1: I don't use model in my controllers.
This might be a bug. //cc @alexlafroscia
username_2: I was actually considering the same thing a couple of days ago. I think the problem is that there's no way to actually detect whether you're using the model hook in the route to fetch anything or not.
username_0: Detect it in the route and stop! If I'm not using model in the controller I don't need this error. No?
username_3: I can see the general reasoning behind the rule, but it stumped me because there isn't even a route set up (meaning that I don't have a route file in that route, so the default route is set up by Ember) and I still get this error and couldn't understand what I was doing wrong. I resorted to ignoring this particular rule, but it took me a while to even understand what was happening.
username_4: No you don't need to @username_0 but we can't check both route and template to distinguish if you're actally using it or not. If the rule does not fit your needs then simply disable it, it's not that you have to use all rules ;)
Status: Issue closed
|
matteobart/TextorPlusPlus | 475946310 | Title: Long text doesn't completely load on first tap
Question:
username_0: When first entering a document, only a portion will load. However, if a keyboard is summoned or orientation change then the whole view will load. May need to reload the view somewhere in there.
Answers:
username_0: This was because a layoutManager.ensureLayout call. On removal, everything works fine. Last update: (982585)
username_0: iOS 13 for some reason has reintroduced this bug. Latest commit (b69ece1) has 'fixed' the issue by calling for a first responder, then quickly resigning it. While not the ideal solution, it currently works. Thinking that this may be more of a TextView issue than a usage issue... |
raml-org/raml-js-parser-2 | 274195630 | Title: documentation required for api interface
Question:
username_0: below link has all API interface but documentation and their usage of interface is not clear enough
**https://raml-org.github.io/raml-js-parser-2/interfaces/_src_raml1_artifacts_raml10parserapi_.api.html#version**
please provide some documentation to use the interface
Answers:
username_1: Hi @username_0 !
The basics of operating with AST are explained inthe [Getting Started Guide](https://github.com/raml-org/raml-js-parser-2/blob/master/documentation/GettingStarted.md#basics-of-parsing). Examples of the guide do not cover the whole AST, but the missing parts do behave themselve similar to the covered ones.
Roughly, the documentation provides the complete set of possible actions, and the guide gives some examples of using them.
Regards,
Konstantin
username_0: it is better to provide the guide for missing parts
username_2: Honestly, I have struggled badly in figuring out what I can do with the result of `parseSync`. I am reduced to having JS list the available methods and guessing which ones might be relevant, and what values I might pass to the parameters. For example, nothing in the documentation gave me any idea that I get the list of HTTP from a resource using `resource.elementsOfKind('methods')`, the the result of this is a JavaScript array rather than some kind of set-of-methods node, or that the way to get the actual HTTP method out of one of the objects in that array is `methodObject.name()`. I had to figure all that out by trial and error.
I hate to be ungrateful, because this is obviously fine software. But it's _incredibly_ hard to learn. Are there any externally written tutorials that I should be be reading instead of this site?
username_3: Note that raml-js-parser-2 has been deprecated, the new official parser is [webapi-parser](https://github.com/raml-org/webapi-parser). Feel free to attempt to reproduce this issue with webapi-parser and report any issue you may have on that repository. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.