
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
fede1024/rust-rdkafka | 233936978 | Title: Using messages beyond lifetime of consumer hangs thread
Question:
username_0: If you try to collect messages and use them after dropping the consumer the thread hangs indefinitely.
This test (in `roduce_consume_base_test.rs`) reproduces the issue:
```rust
// All produced messages should be consumed.
#[test]
fn test_produce_consume_messages_beyond_consumer_lifetime() {
let _r = env_logger::init();
let topic_name = rand_test_topic();
let _message_map = produce_messages(&topic_name, 100, &value_fn, &key_fn, None, None);
let mut messages = Vec::new();
// Drop consumer before checking vector contents
{
let mut consumer = create_stream_consumer(&rand_test_group(), None);
consumer.subscribe(&vec![topic_name.as_str()]).unwrap();
let _consumer_future = consumer.start()
.take(100)
.for_each(|message| {
match message {
Ok(m) => messages.push(m),
Err(e) => panic!("Error receiving message: {:?}", e)
};
Ok(())
})
.wait();
}
assert_eq!(100, messages.len());
}
```
Answers:
username_1: Thanks for reporting the issue! This is probably because [the correct termination sequence](https://github.com/edenhill/librdkafka/wiki/Proper-termination-sequence) for librdkafka requires to destroy the messages before the consumer or the client are destroyed. This ordering is not currently enforced in rust rdkafka.
The right approach here is probably to have the lifetime of messages bound to the one of the consumer. I hope it won't make the API much more complicated.
username_1: Each [Message](https://username_1.github.io/rust-rdkafka/rdkafka/message/struct.Message.html) now hold a (phantom) reference to the consumer who created it. Your example won't compile anymore.
Status: Issue closed
|
Azure/autorest | 178407206 | Title: [C#] Generated ServiceClient does not set HttpClient.Timeout nor allow it to be set
Question:
username_0: Pre-AutoRest Azure SDKs (generated using Hyak) set `HttpClient.Timeout` to 300 seconds in the generated `ServiceClient`-derived class constructors. In AutoRest-generated code it is left unset, resulting in the lower default of 100 seconds. This is causing some customers to experience premature timeouts on very long-running operations that would have otherwise succeeded. (One might argue that such operations should be modeled as LROs, but I'm talking about data plane operations here where the vast majority of requests are completed in less than a second.)
Generated ServiceClient-derived classes should restore the old default timeout of 300 seconds and expose a property to allow for changing the timeout.
Status: Issue closed
Answers:
username_1: Adding to the vNext design (should get this along with the stuff storage is doing) |
mlp6/ADPL | 156085205 | Title: gasOn Reporting Oddly
Question:
username_0: Looks like getting the gasOn boolean using the ondemand infrastructure gives us an odd number. In the response below, it's returning `988209275` from ADPLKenyaNorth0437. From the lab electron it was returning `true` as expected. Might this have to do with firmware changes? 0.5.0 on the lab electron and 0.4.8 on the KenyaNorth. Always thought a bool was just the same as an int (all one byte storage in memory set to either a 1 or 0, but perhaps with this firmware that is not the case). Note that this number can't be stored in a byte of storage.
Will investigate. Thoughts @username_1 ?
```
{
"cmd": "VarReturn",
"name": "gasOn",
"result": 988209275,
"coreInfo": {
"last_app": "",
"last_heard": "2016-05-21T05:23:27.979Z",
"connected": true,
"last_handshake_at": "2016-05-20T21:44:09.224Z",
"deviceID": "1b0048000c51343334363138",
"product_id": 10
}
}```
Answers:
username_1: I was able to update the system firmware to 0.5.0 OTA for ADPLKenyaCentral9822. ADPLKenyaNorth0437 timed out during the same operations, so that is still running 0.4.8.
username_1: Just got ``gasOn`` from ADPLKenyaCentral9822 and received a ``true``.
Status: Issue closed
username_1: I think this has also been fixed, so going to close. |
NJIT-CODEPATH-SP-2021-PomodoroFriends/PomodoroFriends | 849814663 | Title: Pomodoro Timer Persistence
Question:
username_0: * User logs in to access previously defined Pomodoro Timers
Must decide how to store timers and manage storage on local android device.
Sqlite?
Must implement custom datatype and fields similar to one defined in schema.
Such datatype must be ready to convert to upload into server side via API.
Status: Issue closed
Answers:
username_1: IMPLEMENTED TIMER SAVING TO PARSE
https://github.com/NJIT-CODEPATH-SP-2021-PomodoroFriends/PomodoroFriends/pull/12 |
crate/crate | 968836763 | Title: Support setting a different endpoint for COPY TO / FROM for DNS-style S3 bucket adresses
Question:
username_0: **Use case**:
I want to be able to export data from CrateDB using `COPY TO / FROM` with (AWS) S3-compatible technologies like Minio, so that I don't rely on AWS for my storage setup.
**Feature description**:
With AWS SDK the endpoint defaults to `<bucket>.s3.amazonaws.com`. In order to use my Minio S3 bucket, I am able to enter my own endpoint in the URI for COPY FROM / TO commands. The ability to use AWS S3 is not affected.
---
Origin: https://community.crate.io/t/export-table-using-copy-to-command-to-alternate-s3-endpoint/246/4
S3 Client Helper: https://github.com/crate/crate/blob/b8f5bfc1ae1d34b0426f2a01217fde663505225b/server/src/main/java/io/crate/external/S3ClientHelper.java
Answers:
username_1: Would be nice to rely on S3 compatible storage. Google Cloud Platform storage has S3 compatibility, there's Digital Ocean, Linode, and Vultr as well that offer S3 compatible object storage as well.
As-is, I am using s3fs as a bandaid with `file://`.
username_1: Looks like changes would be needed somewhere in these files.
https://github.com/crate/crate/blob/df77bd0147b960da9e905351dc6a8c833c5ac26b/server/src/main/java/io/crate/execution/engine/export/OutputS3.java#L91
https://github.com/crate/crate/blob/df77bd0147b960da9e905351dc6a8c833c5ac26b/server/src/main/java/io/crate/external/S3ClientHelper.java#L88-L118
username_2: Somewhat related to this - which can be done either before or as a follow-up: We should move the COPY/FROM/TO S3 related logic outside of `server` into a dedicated module.
We already have [FileInputFactory](https://github.com/crate/crate/blob/master/server/src/main/java/io/crate/execution/engine/collect/files/FileInputFactory.java) and [FileInput](https://github.com/crate/crate/blob/master/server/src/main/java/io/crate/execution/engine/collect/files/FileInput.java)
Currently there are loaded via the [FileCollectModule](https://github.com/crate/crate/blob/master/server/src/main/java/io/crate/execution/engine/collect/files/FileCollectModule.java) but we could turn this into a `CopyPlugin` or so which uses a pull pattern.
username_0: @username_2 do you think it might be possible to reuse the files shares from the snapshot repositories?
username_2: It would be feasible to factor out some common base between the two, but not sure if we'd gain enough from that to warrant putting in the effort.
username_3: In addition to the above, there are also other S3-compatible storage systems such as [Nutanix Object Storage](https://www.nutanix.com/products/objects) which I'm using in one of my clients (so far it works as expected with utilities such as [s5cmd](https://github.com/peak/s5cmd) and [Cyberduck](https://cyberduck.io/).)
Therefore it'll be very good if CrateDB provides enough flexibility with different S3-compatible object storage systems.
Status: Issue closed
username_4: Closing this issue, all necessary changes are now merged.
The scope of this issue was to delegate the provided s3 endpoints to AWS SDK. There still could be problems between SDK and the s3 compatible storage, ex) #12094. So, please try this feature with the latest nightly build.
The latest nightly build can be found at: https://cdn.crate.io/downloads/releases/nightly/
The steps to install and run: https://crate.io/docs/crate/tutorials/en/latest/install.html#ad-hoc-unix-macos-windows
Also have a few sample copy from/to statements, [here](https://github.com/crate/crate/pull/12052#issue-826108977) and [here](https://github.com/crate/crate/pull/12052#issuecomment-1027158755).
Thank you! |
stevenlovegrove/Pangolin | 452795650 | Title: Whether Pangolin could be build in QNX?
Question:
username_0: I want to compile the Pangolin in QNX,whether pangolin could be build in QNX?
Thanks a lot!
Answers:
username_1: I'm not familiar with QNX - I expect you would at a minimum require some CMake changes, but if it is a Unix flavor and has OpenGL, then you could probably get it to work. If it uses Wayland or X11, then it should be quite straight-forward.
Status: Issue closed
username_2: @username_1 hi. In my qnx system, opengles_v2 and openesl is existing. By the way the graph frame in the qnx is called "screen". Is I should implement the display device interface with screen when we use Pangolin's GUI? |
flauted/TF-DNC | 437298805 | Title: Softmax allocation weighting --> all weightings are constants
Question:
username_0: My own implementation of the DNC with the adjustment invented by <NAME>
& <NAME>, (at https://ttic.uchicago.edu/~klivescu/MLSLP2017/MLSLP2017_ben-ari.pdf)
namely the change of **allocation weighting** to a pure **softmax of non-usage**, has resulted in the **memory matrix,** at every timestep, being filled by a **single word copied over the entire address space**. This happens because the content similarity has the same results for the whole initial memory matrix (zeroes) and for any arbitrary key (with or without masking) and the allocation weighting also starts off by being made of a single constant (initial usage is zeroes).
Interpolating between these gives us the **write weighting**, which is therefore **constant** and the memory is updated using it, resulting in, again, a matrix of a word copied across the entire matrix.
Using tf.Print on the memory matrix with your implementation of the softmax allocation yields the same results. Have you been experimenting with this yourself? If you did, please share any insights. I like the idea of softmax allocation, but afaik, it is not working. (At least not with initial memory of constants and initial usage of constants, which are zeroes)
I've included the tf.Print output in a text file. It contains the state of the memory for the first batch member, where memory length (number of words) = 20 and bit length (word size) = 8, for 19 consecutive timesteps from somewhere in the middle of the forward pass.
[memory_state.txt](https://github.com/username_1/TF-DNC/files/3117970/memory_state.txt)
Answers:
username_1: That's really interesting. No, I hadn't noticed that and haven't really given it any thought. Your explanation makes a lot of sense. I haven't looked at the DNC in a while so I really can't say if it's due to what you're describing or it's an implementation detail. But disclaimer, I can't guarantee this implementation is correct. Once it converged, I was satisfied. I didn't benchmark the scores. Hope this helps! |
Codeception/Codeception | 169556269 | Title: c3 is copied to project root when codeception/c3 is removed from composer
Question:
username_0: #### What are you trying to achieve?
Remove cocedeption/c3 from my project by doing `composer remove codeception/c3`
#### What do you get instead?
c3.php is copied to my project root
### Details
* Codeception version: 2.2.3
* PHP Version: 7.0.4
* Operating System: OSX
* Installation type: Composer
* List of installed packages: Sorry, no can do.
* Suite configuration: not applicable
<img width="482" alt="screen shot 2016-08-05 at 10 28 38 am" src="https://cloud.githubusercontent.com/assets/318089/17431051/283e12c4-5af8-11e6-9c81-813f2b894550.png"><issue_closed>
Status: Issue closed |
spacetelescope/calcos | 350512610 | Title: Retire Python 2
Question:
username_0: Python 2 will not be maintained past Jan 1, 2020 (see https://pythonclock.org/). Please remove all Python 2 compatibility and move this package to Python 3 only.
For conda recipe (including `astroconda-contrib`), please include the following to prevent packaging it for Python 2 (https://conda.io/docs/user-guide/tasks/build-packages/define-metadata.html?preprocessing-selectors#skipping-builds):
```
build:
skip: true # [py2k]
```
Please close this issue if it is irrelevant to your repository. This is an automated issue. *If this is opened in error, please let username_0 know!*
Answers:
username_1: @stscirij this issue can be closed, correct? I believe we moved everything to Python 2 last year.
username_0: To be clear, retiring also means you remove the `six` and compat stuff and also disallow installation of this in Python 2. I don't think that part is in yet. |
JelteF/PyLaTeX | 25714092 | Title: NumPy matrix/array conversion
Question:
username_0: A simple way to convert NumPy matrices and arrays to LaTeX formatted matrices or vectors.
Answers:
username_1: Is this already done? I see the Matrix and VectorName classes in numpy.py.
username_0: Yes, the matrix and vector name classes work. I have kept the issue open because the code above hasn't been included in the project yet.
You could check the example directory for the numpy example if you want to use it yourself. |
phantomas1234/GurobiML | 20673520 | Title: logging to /tmp/GurobiML.log ...
Question:
username_0: ... seems to be the problem with running computations in parallel.
https://github.com/username_0/GurobiML/blob/master/gurobi_mathlink.c#L143
Status: Issue closed
Answers:
username_0: ... seems to be the problem with running computations in parallel.
https://github.com/username_0/GurobiML/blob/master/gurobi_mathlink.c#L143 |
stuartlangridge/ColourPicker | 205872815 | Title: Blurry zoom in the preview
Question:
username_0: The line [\_\_main__.py#L1014](https://github.com/stuartlangridge/ColourPicker/blob/app/pick/__main__.py#L1014) causes everything to be blurry, even though the preview was upscaled before with `GdkPixbuf.InterpType.NEAREST`.
Fun fact: this is getting even worse on HiDPI screens, as the cursor is then scaled up again. |
jhipster/jhipster-kotlin | 444118466 | Title: Use the JHipster release instead of master in CI
Question:
username_0: Currently, we are using JHipster's master branch as the base when testing in the CI.
Instead use JHipster release version for testing the CI. This will make the build more stable.
cc: @username_1 this is might be something that interests you ❤️
Answers:
username_1: Yes, switch this value to `release` should normally work (I hope !!):
https://github.com/jhipster/jhipster-kotlin/blob/master/.travis.yml#L46-L48
username_2: It seems that we cannot use release without also altering the copying part as we re-use the test scripts and examples(more specifically `$JHI_HOME` should be set appropriately). But I think it is better to build against the specific version we support as future releases of JHipster could also potentially brake the build. @username_0 + @username_1 What do you think?
Status: Issue closed
|
alibaba-fusion/next | 690748842 | Title: [Pagination]Pagination Size selector 不能根据页面位置自动改变弹层位置
Question:
username_0: ### Component
Pagination
### Steps to reproduce

Select 的例子是正常的,但 Pagination 里就失效了
<!-- generated by alibaba-fusion-issue-helper. DO NOT REMOVE -->
<!-- component: Pagination --> |
sul-dlss/system-package-tracker | 153124985 | Title: Standardize more security vulnerability information
Question:
username_0: Now that we have several examples of different data sources, go through the existing mappings and database fields and see if there's more information we could fill in, or fields we could standardize on. Examples: CVEs, standard vulnerability ratings.<issue_closed>
Status: Issue closed |
revel/cmd | 656326960 | Title: Mode flag failing
Question:
username_0: When mode flag is specified the app path is incorrect
Answers:
username_0: This isnt a mode flag issue, it is a run issue where the `watch=true` vs `watch=false` When `true` the application starts the harness using the `start` function https://github.com/revel/cmd/blob/master/revel/run.go#L140 when `false` the run command is called directly which is not properly initiating the run command
username_0: Fixed in commit https://github.com/revel/cmd/pull/188/commits/ebc9c73ba0099fdbf18ed9223088eedcc81b7f23
```
./revel run revel-test-app prod
Revel executing: run a Revel application
Parsing packages, (may require download if not cached)... Completed
Revel engine is listening on.. localhost:9000
```
Status: Issue closed
|
aaronnech/CheckYourBias | 139188672 | Title: Cannot read property 'category' of undefined on "Your Candidates" page
Question:
username_0: @ravnon and @SonjaKhan were complaining about this issue for a while now, but I was only able to reproduce the bug once. After I deleted all of my rated issues in the database, the bug went away and I was not able to further reproduce it.

As you can see, this message will pop up every time the user tries to access Your Candidates, or tries to change the category on that same page.
HOWEVER... I then examined the rated issues for the users in the database. I found out that those users suffering from this bug had issues that were no longer present in the database. My conjecture based on the seen evidence is that having rated non-existent issues will trigger this error every time. This *can* be dangerous, especially in production if we have to delete (approved) issues from the database for some reason. However, if we maintain the invariant that an issue can be created but never deleted, this, in theory, should not be a problem. Furthermore, new users to the system as of the final release should not experience this problem, so long as we do not delete issues.
It is possible to fix this by tweaking the backend code, but at this stage of development I think it will be easier to clear everybody's rated issues, and avoid deleting any issues unless absolutely necessary. The backend team (@rhwilk @huynick @toddis ) are certainly welcome to try and reproduce this bug (repoen this issue if you choose to do so), but I will say it is not necessary for the final release.
Status: Issue closed
Answers:
username_0: Deleted everybody's rated issues and skipped issues. No user should experience this problem again (unless we delete issues of course). |
RPi-Distro/repo | 352230186 | Title: linux-perf for the 4.14 kernel
Question:
username_0: Can this be added to the stretch release please.
Answers:
username_1: Is this something that needs to be rebuilt for every minor version of the kernel or will a single package work for all 4.14 kernels?
username_0: Sorry - I am not really sure. I was wanting to use perf to track down packet loss and was pointed in the general direction of perf. I haven't hacked on Unix kernel code since about 1977.
However, current versions of perf are distributed as /usr/bin/perf_4.9 - and the actual perf command is a shell script which checks machine version against available binaries. So my guess is that a version called perf_4.14 would do the trick.
username_1: Alright, I'll add it to the list, but it fairly low priority.
username_0: Thanks.
username_2: @username_1 , is there a way for someone to contribute a patch to update the build version for linux-perf? Thanks.
username_1: In debian, linux-perf comes from the linux source package. We don't use that yet, so there's not much we can do for now. It has been on my todo list forever, but something more important always comes along.
If somebody wants to help, I think the debian kernel package needs to be updated to generate each of the pi kernels without unnecessary debian patches to minimise the delta from the kernels distributed by rpi-update, a common package for the overlays and so on and the legacy raspberrypi-kernel package should pull in all the new kernels. It would also need to handle installs to /boot by copying the files from another location in postinst and make sure all the initramfs stuff is handled properly. |
frappe/frappe_docker | 284365371 | Title: Multiple issue with rendering, updating and so on
Question:
username_0: Hi,
I deployed docker image and all of them are running as it should:
```
dockerhost:~/gitrepos/frappe_docker# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a381e3123a51 frappedocker_frappe "/bin/bash" 20 hours ago Up 10 minutes 0.0.0.0:6787->6787/tcp, 0.0.0.0:8000->8000/tcp, 0.0.0.0:9000->9000/tcp frappe
81b27de35ff4 redis:alpine "docker-entrypoint..." 20 hours ago Up 10 minutes 6379/tcp redis-cache
836037a84ce1 redis:alpine "docker-entrypoint..." 20 hours ago Up 10 minutes 6379/tcp redis-queue
ec758d0d4631 redis:alpine "docker-entrypoint..." 20 hours ago Up 10 minutes 6379/tcp redis-socketio
d97f12fff7ef mariadb "docker-entrypoint..." 20 hours ago Up 10 minutes 0.0.0.0:3307->3306/tcp mariadb
```
# Issue no. 1:
trying to access to external_ip:8000 gives a blank page.
# Issue no. 2:
Trying to update the bench gave the following error:
```
dockerhost:~/gitrepos/frappe_docker# ./dbench -c update
This update will remove Celery config and prepare the bench to use Python RQ.
And it will overwrite Procfile and supervisor.conf.
If you don't know what this means, type Y ;)
Do you want to continue? [y/N]: y
This update will replace ERPNext's Redis configuration files to fix a major security issue.
If you don't know what this means, type Y ;)
Do you want to continue? [y/N]: y
/bin/sh: 1: redis-server: not found
Traceback (most recent call last):
File "/usr/local/bin/bench", line 11, in <module>
load_entry_point('bench', 'console_scripts', 'bench')()
File "/home/frappe/bench-repo/bench/cli.py", line 40, in cli
bench_command()
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 722, in __call__
return self.main(*args, **kwargs)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 697, in main
rv = self.invoke(ctx)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 1066, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 895, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/lib/python2.7/dist-packages/click/core.py", line 535, in invoke
return callback(*args, **kwargs)
File "/home/frappe/bench-repo/bench/commands/update.py", line 31, in update
patches.run(bench_path='.')
File "/home/frappe/bench-repo/bench/patches/__init__.py", line 21, in run
result = execute(bench_path)
File "/home/frappe/bench-repo/bench/patches/v3/redis_bind_ip.py", line 10, in execute
generate_config(bench_path)
File "/home/frappe/bench-repo/bench/config/redis.py", line 39, in generate_config
"redis_version": get_redis_version(),
File "/home/frappe/bench-repo/bench/config/redis.py", line 59, in get_redis_version
version_string = subprocess.check_output('redis-server --version', shell=True).decode().strip()
File "/usr/lib/python2.7/subprocess.py", line 574, in check_output
raise CalledProcessError(retcode, cmd, output=output)
subprocess.CalledProcessError: Command 'redis-server --version' returned non-zero exit status 127
```
Answers:
username_1: Issue # 3 reported & not resolved 10 months ago https://discuss.erpnext.com/t/problem-with-bench-update-redis-server-not-found/19793/6
sudo denies permission to update itself!?
Preparing to unpack .../sudo_1.8.16-0ubuntu1.5_amd64.deb ...
Unpacking sudo (1.8.16-0ubuntu1.5) ...
dpkg: error processing archive /var/cache/apt/archives/sudo_1.8.16-0ubuntu1.5_amd64.deb (--unpack):
error setting permissions of './usr/bin/sudo': Permission denied
dpkg-deb: error: subprocess paste was killed by signal (Broken pipe)
username_2: Please close as this is no longer relevant.
Status: Issue closed
|
msys2/MINGW-packages | 463273268 | Title: Request: add lzfse support
Question:
username_0: https://github.com/lzfse/lzfse
Answers:
username_1: Well you can create package yourself and provide pull request there for it, or wait while someone want to do it.
username_2: Should be simple enough to do, I've tested it and it does compile, just a matter of making the package.
username_3: mark this, I may contribute |
mattvonrocketstein/smash | 50607415 | Title: load bash functions from arbitrary source file
Question:
username_0: currently the only way to load bash functions is to have them declared somewhere in the normal bash bootstrap (bashrc, profile, whatever). it might be a good idea to allow loading from arbitrary files<issue_closed>
Status: Issue closed |
GoogleChrome/lighthouse | 196410051 | Title: Running the extension inside an incognito window does not open generated report
Question:
username_0: Running Lighthouse on a website in an incognito window, when the extension generated it opens a new tab with an URL such as `blob:chrome-extension://<EXTENSION-ID>/<REPORT-ID>`. However, incognito disallows accessing this output and displays a HTTP ERROR 404 page. Consequently copying the URL back into a normal Chrome window does show the correct report.
I run Lighthouse inside an incognito window because I have other extensions running that I do not want to interfere with my performance tests.
Answers:
username_1: Another reason to possibly switch away from blob urls is that we never revoke them. From multiple runs of LH:
<img width="659" alt="screen shot 2016-12-19 at 8 49 24 am" src="https://cloud.githubusercontent.com/assets/238208/21321610/6554da70-c5ca-11e6-9485-6ea7c3757e22.png">
Perhaps we can put a close handler `onbeforeunload` that calls `URL.revokeObjectURL`. Although if you load that URL again, you'd expect it to still work.
username_0: @patrickhulce Your PR mentioned this issue and it has been merged. Does that mean this issue has been resolved and can be closed? Thanks for your work!
username_1: This one is still open. That PR is for https://github.com/GoogleChrome/lighthouse/issues/1173
username_2: Still reproducible on Chrome 58.0.3016.0 canary with Lighthouse extension 1.5.2. Enabling it in Incognito performs the whole run and then opens a second tab with a blob url that leads to a 404 error.
username_3: Bug still present in Lighthouse 2.2.1 @ Chrome 59, OSX
Status: Issue closed
|
azzlack/Microsoft.AspNet.WebApi.HelpPage.Ex | 113477393 | Title: Translate FluentValidation?
Question:
username_0: Finally found one that works perfectly. Thanks.
In case you are still following this. I saw you got DataAnnotation works everywhere. Is there a way to translate FluentValidation attached to model into the documentation? |
go-gitea/gitea | 235064434 | Title: CodeMirror Keymaps
Question:
username_0: ## Description
**Feature Request**: Allow the user to choose a [keymap](https://github.com/codemirror/CodeMirror/tree/master/keymap) for the web editor, from a dropdown menu.
Answers:
username_0: Shush.
username_1: I think this issue has to be renamed as we no longer use CodeMirror but Monaco Editor
username_0: Then maybe deleted altogether, since the description also has a link to CodeMirror's keymap files.
I couldn't find keymap files for Monaco Editor so, this means that if they still have to be made from scratch by some generous soul, this issue is going nowhere fast.
Let me know if I'm wrong before I close it.
username_1: There are vim binding https://github.com/brijeshb42/monaco-vim
Status: Issue closed
|
cdterry87/Proma | 512290917 | Title: Fix issue with duplicate GET requests to pull file list after uploading a file.
Question:
username_0: **Explanation of issue:**
The event listeners that listens on 'dataRefresh' is listening in three different components: Project, Issue, and Client. If the event kicks off in any of these components, it triggers in the other components, as well if they have been loaded already.
Answers:
username_0: **Explanation of issue:**
The event listeners that listens on 'dataRefresh' is listening in three different components: Project, Issue, and Client. If the event kicks off in any of these components, it triggers in the other components, as well if they have been loaded already. |
NakedObjectsGroup/NakedObjectsFramework | 1176950185 | Title: Issue navigating to child property where the foreign key is not the primary key of the parent
Question:
username_0: If this is not the right forum, please let me know. Any insight
The message on the UI is
```
Object does not exist
Message: The requested object might have been deleted by you or another user. If not, please contact your system administrator.
```
And partial output from the server is:
```
System.ArgumentException: Entity type 'BestPracticeCriteriaScore' is defined with a single key property, but 3 values were passed to the 'Find' method.
at Microsoft.EntityFrameworkCore.Internal.EntityFinder`1.FindTracked(Object[] keyValues, IReadOnlyList`1& keyProperties)
at Microsoft.EntityFrameworkCore.Internal.EntityFinder`1.Find(Object[] keyValues)
at Microsoft.EntityFrameworkCore.Internal.EntityFinder`1.Microsoft.EntityFrameworkCore.Internal.IEntityFinder.Find(Object[] keyValues)
at Microsoft.EntityFrameworkCore.DbContext.Find(Type entityType, Object[] keyValues)
at NakedFramework.Persistor.EFCore.Component.EFCoreObjectStore.FindByKeys(Type type, Object[] keys)
at NakedFramework.Core.Component.ObjectPersistor.FindByKeys(Type type, Object[] keys)
at NakedFramework.Facade.Impl.Utility.EntityOidStrategy.GetDomainObject(String[] keys, Type type)
NakedFramework.Facade.Impl.Utility.EntityOidStrategy: 2022-03-22 09:22:06,745 [.NET ThreadPool Worker] WARN NakedFramework.Facade.Impl.Utility.EntityOidStrategy - Domain Object not found keys: 14 4 1 type: SolutionArchitecture.Model.BestPracticeCriteriaScore
NakedObjects.Rest.App.Demo.RestfulObjectsController: 2022-03-22 09:22:06,752 [.NET ThreadPool Worker] ERROR NakedObjects.Rest.App.Demo.RestfulObjectsController - Context: NakedObjects.Rest.App.Demo.RestfulObjectsController.GetObject (Template.Server) State SolutionArchitecture.Model.BestPracticeCriteriaScore;14--4--1;false;
NakedFramework.Facade.Error.ObjectResourceNotFoundNOSException: No such domain object SolutionArchitecture.Model.BestPracticeCriteriaScore-14--4--1: null adapter
```
The system seems to be passing the primary key (14) and the values used as the foreign key in the child object (4 and 1)
See information about the model below. Issue happens when navigating to the SystemBestPracticeScore.BestPracticeCriteriaScore property
```C#
public partial class BestPracticeCriteriaScore
{
public virtual int Id { get; set; }
[Hidden]
public virtual int BestPracticeId { get; set; }
public virtual int Score { get; set; }
public virtual string Criteria { get; set; } = null!;
public virtual BestPractice BestPractice { get; set; } = null!;
public virtual ICollection<SystemBestPracticeScore> SystemBestPracticeScores { get; set; } = new HashSet<SystemBestPracticeScore>();
}
public partial class SystemBestPracticeScore
{
#region Injected Services
//An implementation of this interface is injected automatically by the framework
public IDomainObjectContainer Container { set; protected get; }
#endregion
[Hidden]
public virtual int Id { get; set; }
[Hidden]
public virtual int SystemId { get; set; }
public virtual int BestPracticeId { get; set; }
public virtual int Score { get; set; }
[Truncated]
entity.Property(e => e.Progress)
.HasColumnType("character varying")
.HasColumnName("progress")
.HasComment("detail of progress made since the last assessment");
entity.HasOne(d => d.System)
.WithMany(p => p.SystemBestPracticeScores)
.HasForeignKey(d => d.SystemId)
.OnDelete(DeleteBehavior.Restrict)
.HasConstraintName("system_best_practice_score_fk_system_id");
entity.HasOne(d => d.BestPracticeCriteriaScore)
.WithMany(p => p.SystemBestPracticeScores)
.HasPrincipalKey(p => new {p.BestPracticeId, p.Score})
.HasForeignKey(d => new { d.BestPracticeId, d.Score })
.OnDelete(DeleteBehavior.Cascade)
.HasConstraintName("system_best_practice_score_fk_best_practice_id__score");
});
```
Answers:
username_1: This is the right place to post. Based on a quick look, this does look like a bug in our code.
We think the problem stems from this line in the mapping:
`entity.HasAlternateKey(e => new { e.BestPracticeId, e.Score });`
We've never used `HasAlternateKey `in our own applicationbs which is why we haven't ever seen this problem. Within the framework we use an API function called `GetKeys()` to find the key to build the url. However this method returns
both the primary and alternate key, so it is building a faulty key for the object.
I will flag this as a Bug for now and we will fix it for the next release.
Meantime, to allow you to get going again, I suggest you take the alternate key out of the mapping for the time being.
username_1: Well if EF is introducing an alternate key by convention then the problem is essentially the same. I think we can safely say that _at present_ NakedObjects does not work with alternate keys. It should be possible to fix this - we need to change the way we access the API such that we are just getting the primary key instead of all the keys.
If you want to progress before that ...
I am assuming that the reason you have done this is because you want to display different 'identifiers' for associated objects in different contexts - is that correct? If so, I suggest you just use the object property, with no associated FK property (or with an FK property to the primary key, `Hidden `from the user). Then add a derived (`readonly`) property that displays the desired identifier from the associated object.
username_2: Need to cherry-pick fix back to NO12/NF1
username_1: Stef has fixed the issue, and we have uploaded a new version of the NakedObjects.Server package (v12.0.1) to the Nuget public gallery. Please try this out and report back if it fixes your particular model.
username_0: Thank you. Will this issue be fixed in v13 beta as well soon? I am using the Template Server project downloaded from this repository, but that project is referencing v13 beta packages
username_1: v13.0.0-beta02 released with the fix. Please confirm back that it is now working for you. |
topcoder-platform/community-app | 421763583 | Title: Settings > Tools: Sometimes long time taken to enable the add button after adding an item
Question:
username_0: 1. Open the application and login as TonyJ
2. Hover over the profile avatar > Click Settings
3. Click Tools Tab > Devices/Software/Service Providers/Subscriptions (Any Tab)
4. Add an item
5. Enter data to the empty form again as soon as you created the item
6. Look at the add button and the data in the form
**Actual:** Sometimes long time taken to enable the add button after adding an item. You can see the item is added to the list as soon as the user clicks on the add button but the add button is in the disabled state for sometime
**Expected:** Should able to add another item as soon as user added an item.
**Reproducibility Rate:** 3/3
**Environment:** Google Pixel XL, Android 9.0 | Browser: Google Chrome 73.0.3683.75
Answers:
username_0: 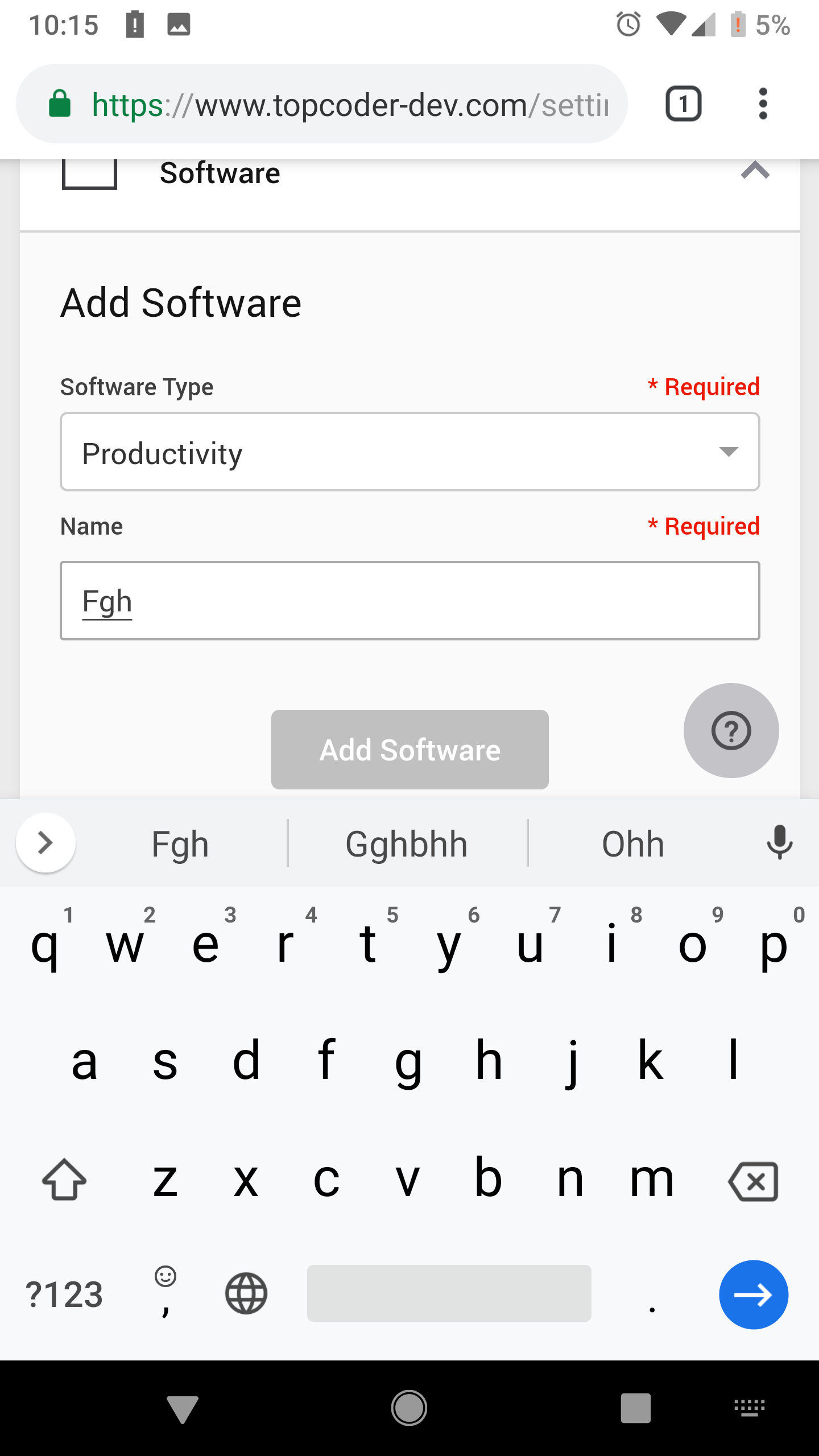
username_1: can't reproduce
Status: Issue closed
|
miguelgrinberg/Flask-Migrate | 293610653 | Title: Auto generate rev-id
Question:
username_0: One thing that is not very friendly on flask-migrate is that revision id is a hash of sorts. Quite hard to track changes in a series if they're identified by a hash value. What if rev-id could be generated as a increasing number by default or as a option?
Answers:
username_0: Just scripted myself into it.
Status: Issue closed
username_1: Flask-Migrate does not create revision ids, that is done by Alembic, so this needs to be discussed in the context of that project.
The idea of hashes as migration ids is not new though, git does the same thing. And sequential numbers do not work well if you have multiple branches. |
dbca-wa/wastd | 668335654 | Title: Entering Occurrences - Report Plant Count section - Estimated area of pop field
Question:
username_0: ## Problem
‘Estimated area of pop’ field in the TSC database which I assume relates to ‘Area of pop m2’ on the Threatened Priority Report Form falls under the Quadrats section of 'report plant count' but should relate to all three sections: Plant Count (Detailed), Plant Count (Simple) and Quadrats.
If it remains under Quadrats it is unlikely people will fill it out if they didn’t use quadrats in their survey.
Are you able to please shuffle the fields around so this field isn't pigeon-holed?<issue_closed>
Status: Issue closed |
ayrtonvwf/lite-admin | 334584225 | Title: Regular size .material-icons inside label
Question:
username_0: The `.material-icons` class creates an element with a font-size slightly bigger. This may be good in most cases, but when it's inside an input's label, it would be better if it kept the label font size.<issue_closed>
Status: Issue closed |
logstash-plugins/logstash-output-elasticsearch | 587342306 | Title: [Doc]Add more explicit documentation for `upsert` and `doc_as_upsert`
Question:
username_0: From #881:
" I think that the `update a document if not already present` only works with the doc_as_upsert option. The upsert option adds data to the document if the document does not exist I think.
**Some more explicit documentation for both upsert and doc_as_upsert would also be helpful**."
Answers:
username_0: @robin13 I added this issue for tracking your request from #881. I'd like to sync with you to hear more about the additional you'd like to see in the docs. |
josefnpat/roguecraft-squadron | 358880380 | Title: Ticket Template
Question:
username_0: Using templates can help make sure a lot of the basic questions are answered on a ticket before it is deemed acceptable and something that can be finished before the due date.
**1) Do multiple people need to touch this ticket before the due date?**
I.E. Design needs to done, then given to programmer
A) If this is a waterfall ticket, write down dates each person will get the assets on or before the end of sprint.
B) If this requires multiple input write down days people will agree to review or check on the ticket.
**2) How many estimated assets will be required to finish this ticket?**
A) If this is a waterfall ticket mark what assets need to be done first.
B) If less then 10 assets write them down and break them up further if needed.
C) If more then 10 assets this should either be broken up into another ticket or the assets should be extremely related and an estimated time for each asset should be noted and understood for the time frame. The keynote is to write what assets will be needed and understand the time constraints.
**3) Does this ticket depend on another ticket?**
A) If this a waterfall ticket, better mark a due date for when assets are expected for that ticket.
B) If this based on an older ticket, make sure that past ticket is clear and still related.
**4) Can I walk through what I will do first on the ticket?**
A) If you are struggling, the ticket needs more input and clarity.
B) If you are not sure what to do after the first step, try to break down the ticket further (i.e. more clarity)
**5) What will this ticket look like finished? What does it need to be complete?**
A) Can list assets, number of reviews, voting, ready to test, etc.
B) Do you know all the assets listed or will just a few do?
**6) Can I test this ticket?**
A) List a way to test if it complete or if it applies.
B) Does the design seem functional? Do the crop marks look correct? Is it running as expected?
Answers:
username_0: This is in part because I have to make sure I get my tickets done very early in the sprint so I can hand them off to the programmer half way before sprint is over to allow time to implement.
username_1: @username_0 please move this to the wiki
username_1: @username_0 please move this to the wiki
username_1: @username_0 please move this to the wiki
Status: Issue closed
username_0: Moved to wiki
username_1: https://github.com/username_1/roguecraft-squadron/wiki/Ticket-guide |
bubkoo/html-to-image | 604414745 | Title: Slow Download and Error File when Download From Server
Question:
username_0: I have code:
`htmlToImage.toPng(document.querySelector('.orgchart'))
.then((dataUrl) => {
download(dataUrl, `${fileNameExportHierarchy}.png`, 'image/png');
});`
When i try in local, no problem. but when code deployed to server, popup download too long and file error like this photo.
How i solving this problem?
 |
ingenieux/awseb-deployment-plugin | 176714580 | Title: Does not report failed deployment correctly
Question:
username_0: If a deployment failed, EB will return status green with a previous build deployed. This causes the plugin to think deployment is successful, but it is not. It should instead check to make sure the version labels match after the deployment turns green. If they don't match, then the deployment has failed.
Answers:
username_1: [Deploy Beanstalk] $ /bin/bash -x /tmp/hudson737544988919118642.sh
++ git rev-parse --short HEAD
+ echo GIT_SHORT_HASH=8eb5aa5
++ date -u +%Y-%m-%dT%H:%M:%SZ
+ echo DEPLOY_TIME=2016-11-14T19:27:31Z
[EnvInject] - Injecting environment variables from a build step.
[EnvInject] - Injecting as environment variables the properties file path 'env.props'
[EnvInject] - Variables injected successfully.
AWSEB Deployment Plugin Version 0.3.10
Zipping contents of Root File Object (Deploy Beanstalk) into tmp file awseb-4080026641504629791.zip (includes=, excludes=)
Uploading file awseb-4080026641504629791.zip as s3://elasticbeanstalk-us-east-1-redact/redact/redact-8eb5aa5-2016-11-14T19:27:31Z.zip
Creating application version 8eb5aa5-2016-11-14T19:27:31Z for application redact for path s3://elasticbeanstalk-us-east-1-redact/redact/redact-8eb5aa5-2016-11-14T19:27:31Z.zip
Created version: 8eb5aa5-2016-11-14T19:27:31Z
Using environmentId 'e-rm2ptmfham'
No pending Environment Updates. Proceeding.
Checking health/status of environmentId e-rm2ptmfham attempt 1/30
Environment Status is 'Ready'. Moving on.
Updating environmentId 'e-rm2ptmfham' with Version Label set to '8eb5aa5-2016-11-14T19:27:31Z'
Checking health/status of environmentId e-rm2ptmfham attempt 1/30
Versions reported: (current=8eb5aa5-2016-11-14T16:15:08Z, underDeployment: 8eb5aa5-2016-11-14T19:27:31Z). Should I move on? false
Checking health/status of environmentId e-rm2ptmfham attempt 2/30
Versions reported: (current=8eb5aa5-2016-11-14T16:15:08Z, underDeployment: 8eb5aa5-2016-11-14T19:27:31Z). Should I move on? false
Checking health/status of environmentId e-rm2ptmfham attempt 3/30
Versions reported: (current=8eb5aa5-2016-11-14T16:15:08Z, underDeployment: 8eb5aa5-2016-11-14T19:27:31Z). Should I move on? false
Environment Status is 'Ready' and Health is 'Green'. Moving on.
Deployment marked as 'successful'. Starting post-deployment cleanup.
Cleaning up temporary file /tmp/awseb-4080026641504629791.zip
Finished: SUCCESS
```
and the corresponding EB log:
```
2016-11-14 13:33:38 UTC-0600 ERROR Failed to deploy application.
2016-11-14 13:33:38 UTC-0600 ERROR Service:AmazonCloudFormation, Message:TemplateURL must reference a valid S3 object to which you have access.
2016-11-14 13:29:48 UTC-0600 INFO Environment update is starting.
```

username_2: Hm... interesting. Ok, I'll keep that in mind and push a change for it shortly ok?
username_3: another case with the same problem:
`Versions reported: (current=[Jenkins]-[Integration]-[08-03-2017 1924], underDeployment: [BK-API-17]-[Integration]-[20-03-2017 1242]). Should I move on? false
Mon Mar 20 10:45:08 UTC 2017 [INFO] Started Application Update
Mon Mar 20 10:45:08 UTC 2017 **[ERROR] Deployment Failed: Unexpected Exception**
Mon Mar 20 10:44:59 UTC 2017 [INFO] Deploying new version to instance(s).
Checking health/status of environmentId e-kbhp2qmi3b attempt 2/30
Versions reported: (current=[Jenkins]-[Integration]-[08-03-2017 1924], underDeployment: [BK-API-17]-[Integration]-[20-03-2017 1242]). Should I move on? false
Environment Status is 'Ready' and Health is 'Green'. Moving on.
Deployment marked as 'successful'. Starting post-deployment cleanup.
Cleaning up temporary file C:\Users\ADMINI~1\AppData\Local\Temp\2\awseb-5418100666623237368.zip
Finished: SUCCESS`
username_4: We currently use the following script after deploy-step to verify the correct version was deployed.
where ${VERSION}-timestamp-${BUILD_TIMESTAMP} is our _Version Label Format_
ELB_VERSION=`aws elasticbeanstalk describe-environments --profile our-profile --region our-region --environment-names $ENVIRONMENT --query 'Environments[0].VersionLabel' | sed 's/"//g'`
if [ "$ELB_VERSION" = "${VERSION}-timestamp-${BUILD_TIMESTAMP}" ]; then
echo "correct version is deployed on ELB"
else
echo "ELB version: $ELB_VERSION do not match deployment version: ${VERSION}-timestamp-${BUILD_TIMESTAMP}"
exit 1
fi
Posting as it might be useful for someone.
username_1: In our bot (python) I do something similar:
```
events = client.describe_events(ApplicationName=eb_app, StartTime=deploy_start_time_utc, EnvironmentName=eb_env, Severity='ERROR')['Events']
if len([event for event in events if event['Message'] == 'Failed to deploy application.']) == 0:
register_deployment(eb_env, commit_hash)
else:
exit(1)
``` |
darryldecode/laravelshoppingcart | 558671881 | Title: Remove not working
Question:
username_0: THe remove method removes the item that is first in the cart kindly let me know of any fix
Code in View:
@foreach(Cart::session(Auth::id())->getContent() as $item)
<a href="{{ route('cosplay.cart.destroy',$item->id) }}" onclick="event.preventDefault(); document.getElementById('delete-form').submit();"><span class="lnr lnr-trash text-theme display-5"></span></a>
<form id="delete-form" action="{{ route('cosplay.cart.destroy',$item->id) }}" method="post" style="display: none;">
@method('DELETE')
@csrf
</form>
@endforeach()
Code in Controller:
public function destroy($id)
{
Cart::session(Auth::id())->remove($id);
Alert::toast('Costume Removed!', 'success')->autoclose(800);
return redirect()->back();
} |
jef/streetmerchant | 757997837 | Title: Trouble adding a store.
Question:
username_0: I followed the instructions [here](https://github.com/username_2/streetmerchant/wiki/Help:-Configuration:-Adding-a-store), and viewed the example [here](https://github.com/username_2/streetmerchant/commit/af96c5f2e808af7496f3c3299e4cf173105de48b), but I keep getting errors like this:
`src/store/lookup.ts(191,4): error TS7053: Element implicitly has an 'any' type because expression of type 'Series' can't be used to index type '{ 3070: number; 3080: number; 3090: number; rx6800: number; rx6800xt: number; rx6900xt: number; ryzen5600: number; ryzen5800: number; ryzen5900: number; ryzen5950: number; sf: number; sonyps5c: number; sonyps5de: number; 'test:series': number; xboxss: number; xboxsx: number; }'.
Property 'throttles' does not exist on type '{ 3070: number; 3080: number; 3090: number; rx6800: number; rx6800xt: number; rx6900xt: number; ryzen5600: number; ryzen5800: number; ryzen5900: number; ryzen5950: number; sf: number; sonyps5c: number; sonyps5de: number; 'test:series': number; xboxss: number; xboxsx: number; }'.`
I'm unsure what I'm doing wrong. So unsure that I can't even form a very well thought out question or provide info that I think will be useful. I don't even know where to start. (Yes, I'm TOTALLY new to Node.JS...)
I DO think this will be useful:
[Store I'm trying to add.](https://flyhoneycomb.com/)
Items I'm trying to add - [1](https://flyhoneycomb.com/products/alpha-flight-controls), https://flyhoneycomb.com/collections/honeycomb-flight-sim-hardware/products/bravo-throttle-quadrant, https://flyhoneycomb.com/collections/honeycomb-flight-sim-hardware/products/airbus-throttle-handles
Happy to provide more info if you need. Just let me know.
Thank you!
Answers:
username_1: having the same problem
username_2: Do you mind posting the code you're trying to add? Specifically the new store? I can help!
username_0: Absolutely! Thanks for writing/releasing such an awesome utility, too. :-D
`import {Store} from './store';
export const Honeycomb: Store = {
labels: {
inStock: {
container: '#product_form_4533457682541',
text: ['Add to cart']
},
},
links: [
{
brand: 'test:brand',
model: 'test:model',
series: 'test:series',
url: 'https://flyhoneycomb.com'
},
{
brand: 'honeycomb',
model: 'AlphaFlightYoke',
series: 'yoke',
url: 'https://flyhoneycomb.com/collections/honeycomb-flight-sim-hardware/products/alpha-flight-controls'
},
{
brand: 'honeycomb',
model: 'BravoThrottleQuadrant',
series: 'quadrant',
url: 'https://flyhoneycomb.com/collections/honeycomb-flight-sim-hardware/products/bravo-throttle-quadrant'
},
{
brand: 'honeycomb',
model: 'ThrottlePackForAirbus',
series: 'throttles',
url: 'https://flyhoneycomb.com/collections/honeycomb-flight-sim-hardware/products/airbus-throttle-handles'
},
],
name: 'honeycomb'
};`
username_3: I drove myself crazy over this one for a longtime but figured out how to debug. I believe there is some confusion here. I'm not a coder at all but from fiddling around I ran into this. This current error is not a store error but a product error. You need to add the model, series and brand to the store.TS file. Then you will most likely get a max price error next, so then you have to add to the config.ts the max price series. also update the .env file for this series and model in the max price section. finally it should all run.
What confusion I see here though is that you're adding a store before adding a model or series for the product. you need to build both. A store and a product as the flight stick is not a tracked product by default.
I ran into this trying to Track the pulse 3d headset by Sony. Also using "git" vs command prompt to run your code will literally tell you a debug of what codes the issue is.
username_3: The key to your error btw is this. "Property 'throttles' does not exist on type" Throttles is missing from the Store.ts file.
username_1: Wow totally solved my problem!
Thanks so much
@username_2 should take a look at this
username_2: username_2.codes/streetmerchant/help/general/#adding-a-store
username_0: Hmm...not sure I follow. I added a store (honeycomb.ts) with the code shared with Jef, added the necessary bits into index.ts:
`import {Evga} from './evga';
import {EvgaEu} from './evga-eu';
import {Galaxus} from './galaxus';
import {Game} from './game';
import {Gamestop} from './gamestop';
// import {Honeycomb} from './honeycomb';
import {Kabum} from './kabum';
import {Mediamarkt} from './mediamarkt';
import {MemoryExpress} from './memoryexpress';
import {MicroCenter} from './microcenter';
import {Mindfactory} from './mindfactory';`
...(again, commented out so the code will still run), and added all the stuff into store.ts as pasted above. Following Jef's writeup and viewing the example given, as linked to in my initial post, I thought I checked all the boxes. This "readme.md" thing though...this is new.
```
username_0: Hmm...not sure I follow. I added a store (honeycomb.ts) with the code shared with Jef, added the necessary bits into index.ts:
```
import {Evga} from './evga';
import {EvgaEu} from './evga-eu';
import {Galaxus} from './galaxus';
import {Game} from './game';
import {Gamestop} from './gamestop';
// import {Honeycomb} from './honeycomb';
import {Kabum} from './kabum';
import {Mediamarkt} from './mediamarkt';
import {MemoryExpress} from './memoryexpress';
import {MicroCenter} from './microcenter';
import {Mindfactory} from './mindfactory';`
```
...(again, commented out so the code will still run), and added all the stuff into store.ts as pasted above. Following Jef's writeup and viewing the example given, as linked to in my initial post, I thought I checked all the boxes. This "readme.md" thing though...this is new.
username_3: Ok lets go one at a time, The location of the readme is on the root of the street merchant folder where you edit the .env fix that part first. the other important thing I did was mark down what my series is, model and brand, as all these need to sync up across the grid.
see what errors come after the readme file update.
As for a store, is honeycomb the store? you need to create a Store.TS file that pulls from a element on the webpage that determines if the item is in stock of not, this is a process in itself, different from adding another item. that's what i was trying to say. you have 2 build outs needed to accomplish this. the current error however points to the readme file missing your model, series and brand.
username_3: for the store it would b laid out, Honeycomb.ts, within that file it would be the following. This is Walmart's for example.
import {Store} from './store';
export const Walmart: Store = {
labels: {
inStock: {
container: '.button.spin-button.prod-ProductCTA--primary.button--primary',
text: ['add to cart']
},
maxPrice: {
container: 'span[class*="price-characteristic"]'
}
},
links: [
{
brand: 'test:brand',
model: 'test:model',
series: 'test:series',
url:
'https://www.walmart.com/ip/Keurig-K-compact-Brewer-Black-Coffee-Maker/806217614'
},
{
brand: 'sony',
model: 'ps5 console',
series: 'sonyps5c',
url: 'https://www.walmart.com/ip/PlayStation5-Console/363472942'
},
{
brand: 'sony',
model: 'ps5 digital',
series: 'sonyps5de',
url:
'https://www.walmart.com/ip/PlayStation5-Console/493824815'
},
{
brand: 'microsoft',
model: 'xbox series x',
series: 'xboxsx',
url: 'https://www.walmart.com/ip/Xbox-Series-X/443574645'
},
{
brand: 'microsoft',
model: 'xbox series s',
series: 'xboxss',
url: 'https://www.walmart.com/ip/Xbox-Series-S/606518560'
},
{
brand: 'corsair',
model: '750 platinum',
series: 'sf',
url: 'https://www.walmart.com/ip/SF750-Power-Supply/197046151'
},
{
brand: 'corsair',
model: '600 platinum',
series: 'sf',
url:
'https://www.walmart.com/ip/Corsair-SF-Series-600W-80-Platinum-Power-Supply/250717047'
},
{
brand: 'amd',
model: '5900x',
series: 'ryzen5900',
url:
'https://www.walmart.com/ip/AMD-Ryzen-9-5900X-12-core-24-thread-Desktop-Processor/159710953'
}
],
name: 'walmart'
};
This file goes in SRC/store/ model.
Status: Issue closed
|
top-think/framework | 166965765 | Title: 关于路由配置的一点疑问
Question:
username_0: 经过测试, 发现目前框架暂不支持模块路由配置.
但是在 `config.php` 的 `extra_config_list` 参数中指定了路由配置, 模块下也同样会去加载 模块下的 `route` 配置文件
此时的 `route` 配置并不会生效
Answers:
username_1: 加载模块配置的时候路由检测已经完成了 当然不会生效了
username_0: @username_1
那该如何设置分组的路由呢?
我在路由中配置了如下规则:
```
'[admin]' => [
'index' => 'admin/index/index', // 后台首页
'login' => 'admin/login/index', // 登录页面
]
```
上面的规则能够正常的生成对应的URL, 也能正常访问.
但是在访问后台首页时, 用 `http://www.xxx.com/admin/` 访问的页面却是 `/index/index/index.html` 的内容, 而不是后台首页
username_1: @username_0 路由分组和模块没有直接关系
username_2: route.php是要统一配置的.如果在模块中可以使用动态注册路由呀.
Status: Issue closed
|
chashnikov/IntelliJ-presentation-assistant | 559703622 | Title: Custom shorcuts not displayed
Question:
username_0: Hello.
I have bind the custom shorcut **Main menu | Window | Editor Tabs | Split Vertically** to **ALT + V**.
When I use the shortcut, the **Split Vertically** text is correctly displayed but the shorcut **ALT + V** is not displayed.
I am using **IntelliJ IDEA Ultimate 2019.3.2** and **Presentation Assistant 1.0.3** on **Ubuntu 18.04**.
Answers:
username_1: By default the plugin shows shortcut from the standard keymaps. If you want to show shortcuts from your own keymap, choose it in File | Settings | Appearance & Behavior | Presentation Assistant.
username_0: Oh perfect, it was the option **Default Copy**.
Thank you :)
Status: Issue closed
|
jump-dev/MathOptInterface.jl | 986101945 | Title: supports AbstractConstraintAttribute broken for bridges
Question:
username_0: HiGHS doesn't support `ConstraintDualStart`, so any bridged constraint shouldn't either. But yet:
```julia
julia> model = MOI.Bridges.full_bridge_optimizer(HiGHS.Optimizer(), Float64)
MOIB.LazyBridgeOptimizer{HiGHS.Optimizer}
with 0 variable bridges
with 0 constraint bridges
with 0 objective bridges
with inner model A HiGHS model with 0 columns and 0 rows.
julia> MOI.supports(model, MOI.ConstraintDualStart(), MOI.ConstraintIndex{MOI.VectorOfVariables,MOI.Nonnegatives})
true
julia> MOI.supports(model.model, MOI.ConstraintDualStart(), MOI.ConstraintIndex{MOI.VectorOfVariables,MOI.Nonnegatives})
false
```
Here's the offending code:
https://github.com/jump-dev/MathOptInterface.jl/blob/9a54ba742ed1f0dbe63f7548c3c960dcac1dc8c1/src/Bridges/bridge_optimizer.jl#L1218-L1234
Answers:
username_1: Here is the fix for a similar problem with the slack bridge https://github.com/jump-dev/MathOptInterface.jl/pull/1383/files
username_0: Yeah is it sufficient to just look at the inner optimizer? If so, why is #1383 still a draft?
username_1: Because it needs tests ^^
username_0: I've opened a few PRs to fix these
- [ ] #1580
- [ ] #1579
- [ ] #1578
- [ ] #1577
- [ ] #1576
- [ ] #1575
- [ ] #1574
I still have the following to go
- [ ] geomean_to_relentr.jl
- [ ] function_conversion.jl
- [ ] det.jl
Status: Issue closed
username_0: Closing because this is now fixed. The IndicatorSOS1Bridge PR is different. |
OHIF/Viewers | 607103271 | Title: OHIF Viewer hangs when Orthanc Dicomweb "StudiesMetadata" set to "MainDicomTags"
Question:
username_0: Im using the latest version of Orthanc and OHIF Viewer. When Orthanc Dicomweb's "StudiesMetadata" parameter is set to "MainDicomTags" OHIF Viewer hangs after the fetching metadata stage when opening a study. Changing the value of "StudiesMetadata" parameter to "Full" fixes the issue.
Answers:
username_1: I'm not sure I have enough information to action this one way or the other. Generally, the OHIF Viewer should work with and support DICOMWeb features. If you can point which part of the spec we're not handling correctly, then I know we have a bug to fix. If this is a general integration / Orthanc compatibility issue, it may be outside of scope.
username_0: It seems to get stuck after reading all the metadata from Orthanc...doesnt move to the next step

username_1: Unfortunately this is not enough information for me to go off of.
username_2: This reason for this issue can be found here: https://github.com/OHIF/Viewers/issues/1638
I also mentioned my test case using orthanc with maindicomtags and it's not only orthanc that has problems since v3.7.8
username_1: We'll continue to follow in #1638, as it captures this issue more clearly. |
mher/flower | 165371181 | Title: task not saved to database when running inside a docker
Question:
username_0: I tried to run the flower insider a docker container, but the tasks are not properly saved to the database file I specified on the mounted volume. However, there is no problem at all when running flower locally.
my shell command:
flower -A dtasks --port=5555 --db=/path/to/database/file --persistent=True
Actually, there are some tasks were saved, but only a few. Most of the tasks record were gone.
I appreciate any helps.
Answers:
username_1: This doesn't sound a flower related issue. I'd suggest to debug using local database file inside docker.
Status: Issue closed
|
allure-framework/allure-python | 464241509 | Title: [feature request]Where could i find the document for Allure python commons?
Question:
username_0: That's an amazing work and i tried to use it in my code. But i found that i could not find the API document for it neither the usage. What i could find is [this document](https://docs.qameta.io/allure/#_about) without introducing Allure python commons. Maybe it's better to maintain a document for it.
Thanks very much. I am sorry if i made some misunderstanding.
#### Please tell us about your environment:
- Allure version: 2.1.0
- Test framework: None
- Allure adaptor: None |
nikitavoloboev/ama | 548546734 | Title: How do you organize todos across multiple apps?
Question:
username_0: According to your wiki, you use Trello, 2Do, and MindNone to store todos, which seems to be quite overlapping. How do you decide where to put a new todo? And in general, how do you track projects, which might have many todos and other corresponding information?
Answers:
username_1: I use 2Do for most of my tasks. Projects tasks are usually done via GitHub (issues) and sometimes Trello (general projects). MindNode I use as a thinking board. Just put things in there, work on it, then erase the entire map.
Status: Issue closed
|
geneontology/go-ontology | 103124519 | Title: Can we strengthen our axiomatization to have spatial disjointness work for occurs_in
Question:
username_0: cc @hdietze @kltm
We currently have spatial disjointness axioms, e.g.
(partOf some nucleus) DisjointFrom (partOf some cytosol)
This will correctly identify any continuant with contradictory partOf axioms
However, this isn't detecting some invalid biology in some of the lego models, where we have the same activity occurring in both nucleus and cytosol
for this we would need
(occursIn some nucleus) DisjointFrom (occursIn some cytosol)
But obviously we don't want to redundantly maintain parallel axioms
Assigned to @username_1 to see if he has any ideas here, I feel I'm missing something, but can't think of the elegant solution. We can certainly write a script that would generate one from the other but ugh.
The other approach would be to declare a superproperty that subsumes both occursIn and partOf, and use that in the axioms, effectively doing double duty (a weaker relation inside an axiom involving negation can result in a stronger axiom).
Within FOL we would just say occursIn -> occursIn o partOf (which is valid for locally reflexive partOf) which would yield the desired inferences, but we can't say this in OWL
unless I'm missing something?
Answers:
username_1: I think i like the new, weaker OP solution. The one aspect that feels hacky is that it relies on a po relation with domain encompassing continuant and occurrent even though we would never allow occurrent po continuant. Could fall foul of any axiomatisation added in future to flag this this as inconsistent. If we follow this route, new rel should live in gorel with gorel uri and a comment on usage.
username_0: I would opt for RO, as we'd want to use it in Uberon, PO and even ENVO
Wherever it lives we would need mechanisms to stop it being used in (non-disjointness) assertions, because there is no way to do the 'push-down' inference to the more specific relation without the ugly [self-restriction pattern](https://github.com/oborel/obo-relations/wiki/ROGuideDraft#interaction-relations) which lies outside EL.
username_1: Are you sure self restriction is outside of EL? Looks like its not: http://www.w3.org/TR/owl2-profiles/#OWL_2_EL_2 (although ELK may not support)
username_0: You're right, it is in EL, but Elk doesn't appear to support it (I
didn't test, just going by
https://code.google.com/p/elk-reasoner/wiki/OwlFeatures )
Status: Issue closed
username_1: This issue was moved to geneontology/design_patterns#5 |
lillik/magento2-price-decimal | 263642520 | Title: Frontend shows round
Question:
username_0: Frontend shows 4 decimals but round every price to 2 decimals (e.g. price 36.9050 in the database becomes 36.9100 on the frontend).
Answers:
username_1: @username_0 Any update on this issue? Seems like a blocking issue
username_2: @username_0 this should be fixed in 1.0.3 |
volcano-sh/volcano | 949492492 | Title: the volcano-development.yaml has an additional configuration parameter
Question:
username_0: when i install whit yaml files,I get an error msg when I execute the following command:
kubectl apply -f https://raw.githubusercontent.com/volcano-sh/volcano/master/installer/volcano-development.yaml
err msg:unknown flag: --admission-conf
And then I'm going to get rid of this argument and I'm not going to report any errors.
Answers:
username_1: I think it's because of the latest image is not updated.
/cc @huone1
username_2: @username_0 please use the latest code to build the admission image. Or use the version 1.3.0 installer yaml https://github.com/volcano-sh/volcano/blob/v1.3.0/installer/volcano-development.yaml
username_3: @username_4 please help to update the lastest image on the docker hub.
username_4: OK.
username_0: @username_2 I tried 1.3.0 and It works fine,thx
username_4: /close |
broadinstitute/cromwell | 330911743 | Title: Aborted jobs still submits additional preemtible tasks to JES
Question:
username_0: After I have aborted a job, VM's are not being apropriately killed. Manually killing the VM does not have the desire effect, as if the task was preemptible PAPI will launch another VM until all of your preemptible tries have been consumed
Answers:
username_0: Hey @username_1
I am using 31.1. And i aborted them with the rest endpoint first. But a day later vms were still running. Manually killing these caused the above behaviour
username_1: Hey Patrick, I just ran a tiny test and was able to confirm jobs getting aborted.
- How many jobs were started from your workflow, and did any of the jobs from your workflow abort?
- Do you have a general sense at the stage your jobs were on when they were aborted? Were they all mostly executing the command when you aborted them?
- Did Cromwell ever report the workflow to have been successfully Aborted? Any errors thrown in the server logs?
Would you mind posting the operation metadata from one of the jobs that you tried aborting using the rest endpoint? Or simply the events reported for that operation?
username_1: Hey @username_0 I'm able to reproduce this behavior today. We will look into why this is happening, there's a definitely some path that's not killing jobs upon abort.
username_1: <img width="795" alt="screen shot 2018-06-15 at 9 44 14 am" src="https://user-images.githubusercontent.com/14941133/41471529-e9b665be-7081-11e8-86e3-1a4804d71adf.png">
Workflow status `Aborted`, executionStatus/backendStatus `Running`, PAPI Operation status `done:false`
username_0: @username_1 Thanks alot for looking into this, I have not really had bandwidth to get those Operation logs yet, I can look into it later today hopefully
username_1: @username_0 It turned out it was a different issue entirely in our production environment that had the symptoms of abort failures. We've not had success recreating this -- but let us know what you end up observing! |
Mozzo1000/movielst | 372303684 | Title: Remove use of external libraries
Question:
username_0: At the moment, invoking the web interface gets a lot of files from external parties like bootstrap.
These files should probably be downloaded the first time when running web interface and saved in static folder.<issue_closed>
Status: Issue closed |
huggingface/tokenizers | 742649134 | Title: AddedVocabulary does not play well with the Model
Question:
username_0: ### Current state
The `AddedVocabulary` adds new tokens on top of the `Model`, making the following assumption: "The Model will never change".
So, this makes a few things impossible:
- Re-training/changing the `Model` after tokens were added
- Adding tokens manually at the very beginning of the vocab, for example before training
- We can't extract these added tokens during the pre-processing step of the training, which would be desirable to fix issues like #438
### Goal
Make the `AddedVocabulary` more versatile and robust toward the change/update of the `Model`, and also capable of having tokens at the beginning and at the end of the vocabulary.
This would probably require that the `AddedVocabulary` is always the one doing the conversion tokens<->ids, providing the vocab etc. effectively letting us keep the `Model` unaware of its existence.
Answers:
username_1: Sorry to have taken forever on this issue! I looked into it and I think, I understand the problem now more or less.
As I understood it, the assumption that "the model never changes" is cemented in this line: https://github.com/huggingface/tokenizers/blob/ae6534f12db021aeed9938d2a46b045dc85fdb77/tokenizers/src/tokenizer/added_vocabulary.rs#L252 => When adding a token to the `AddedVocabulary` the id corresponds to the size of the model's vocab at the time of adding the token, but cannot change anymore if the model's vocab changes afterward.
Currently, the class flow when doing the tokens<->ids conversion is implemented as follows (please correct me if I'm wrong). Ask `TokenizerImpl` to convert `token_to_id`. The `TokenizerImpl` then just forwards the call to its `self.added_vocabulary`, but also adds a read-only reference to `self.model` to `self.added_vocabulary`. Then the `AddedVocabulary` checks if the token is in the Model's vocab (usually `self.vocab`) and if it's not checks in its own map.
I see three different approaches for now:
1)
As proposed, to make `AddedVocaburaly` more versatile, instead of passing `self.model` to the `AddedVocabulary` we could pass `self.model.vocab` to the `AddedVocabulary` for the `token_to_id` and `id_to_token` method. This way, we are always aware of the current vocab's size.
Following this approach, I guess it makes more sense then to save "relative" token_ids in `AddedVocabulary` instead of absolut ones for those tokens that are appended to the end of the vocabulary, no? Also, the `add_tokens` method of `AddedVocabulary` would not need a reference to the model anymore. Tokens that are appended to the beginning of the vocabulary could get absolute ids and tokens that are appended to the end could get relative ids => so `tokens_to_id` in `AddedVocabulary` could look something like:
```rust
token_to_id(token, vocab):
if token in vocab:
return vocab[token]
elif token in self.begin_added_tokens:
return self.begin_added_tokens[token]
elif token in self.end_added_tokens:
return len(vocab) + self.end_added_tokens[token]
```
One small problem I see here is that not all modes have the same type of "vocabulary". BPE, Wordpiece and Wordlevel all have `self.vocab` and `self.vocab_r`, but Unigram seems to use a `self.tokens_to_ids` `TokenMap`.
2) Or should we give `AddedVocabulary` a mutable reference to the vocab so that the vocab can be changed directly? The previous idea sounds better to me, but not 100% sure.
3) Or a completely different method would be to let the 'TokenizerImpl` have more responsible for `token_to_id` so that the `TokenizerImpl` class actually checks if the token is in self.model.vocab_size and if not it just passes the size of `self.model.vocab` to the `AddedVocabulary`'s `token_to_id` method. This approach actually seems like the most logical to me since both `AddedVocabulary` and `Model` are members of `TokenizerImpl`, so that ideally `AddedVocabulary` should not handle any `Model` logic but just get the minimal information from `model.vocab` it needs (which is just the size of the vocab IMO) for `token_to_id` from `TokenizerImpl`.
Both 1) & 3) seem reasonable to me...would be super happy about some misunderstanding I have and your feedback @username_0 :-)
username_0: Awesome! There's no rush so take the time you need!
I'll add a few pieces of information that may help with the decision:
- Every `Model` is different, and so we can't rely on their internals. The only thing we have to deal with all of them is the interface described in the `trait Model`. Also, any `Model` can be used independently of the `TokenizerImpl` so it makes sense to keep all these methods.
- The `AddedVocabulary` exists because we can't really modify the vocabulary of the `Model` in many cases. For example with `BPE`, we can't add a new token because it would require us to add all the necessary merge operations too, but we can't do it. Same with `Unigram`. So the `AddedVocabulary` works by adding vocabulary on top of the `Model` and it has the responsibility of choosing which one to use.
So I think approach 1) is probably the most likely to work, but we'll have to stick with what's available on `trait Model`.
One thing that is very important and might be tricky to handle (I didn't dig this at all for now) is the serialization/deserialization of the `TokenizerImpl` and `AddedVocabulary`. We need to keep all the existing tokenizers out in the wild to keep working, while probably having to add some info to handle whether a token is at the beginning or the end of the vocabulary. (Will probably be necessary to add some tests there.) I'll be able to help on this side of course! |
fullcalendar/fullcalendar | 147232840 | Title: Demos aren't working
Question:
username_0: Demo files are not working because of broken links in head section.
Status: Issue closed
Answers:
username_1: can you point me to the link where you are seeing this?
username_2: I have the same issue, when "basic-views.html" loading the next files:
`<link href='../dist/fullcalendar.css' rel='stylesheet' />`
`<link href='../dist/fullcalendar.css' rel='stylesheet' />`
`<link href='../dist/fullcalendar.print.css' rel='stylesheet' media='print' />`
`<script src='../lib/moment/moment.js'></script>`
`<script src='../lib/jquery/dist/jquery.js'></script>`
`<script src='../dist/fullcalendar.js'></script>`
Attach image

username_0: Yes demo files don't work becuse dist folder doesn't exist so the only solution is use cdn.
http://fullcalendar.io/download/
username_1: yes, use the built download, or if you want to use the dev repo, you'll need to run the build scripts to build the dist folder |
aws/amazon-vpc-cni-k8s | 349678795 | Title: Minutely cronjob fails after swapping out workers with new ASG
Question:
username_0: We use blue/green worker groups to update our AMIs for patching and other fixes. I've noticed that when pods are evicted during the draining, that the CNI starts having problems and the error rate of the cronjob skyrockets unless I delete and re-add it. I see these errors on multiple nodes and not consistently. The job succeeds many times between these errors. This is seemingly a dupe of #59 but I am running v1.1.0 here which supposedly fixed this issue?
With `kubectl get events`, I see these errors:
```
kubelet, ip-10-1-60-40.us-west-2.compute.internal Failed create pod sandbox: rpc error: code = Unknown desc = NetworkPlugin cni failed to set up pod "REDACTED-1533940200-56dnc_lumo" network: add command: failed to setup network: setup NS network: failed to setup NS network: failed to Statfs "/proc/1577/ns/net": no such file or directory
```
```
kubelet, ip-10-1-60-40.us-west-2.compute.internal error killing pod: failed to "KillPodSandbox" for "7b36ece3-9ced-11e8-ad95-02af9b42ed2e" with KillPodSandboxError: "rpc error: code = Unknown desc = NetworkPlugin cni failed to teardown pod \"REDACTED-1533940440-z5rns_lumo\" network: rpc error: code = Unavailable desc = grpc: the connection is unavailable"
```
Answers:
username_0: @username_2 I should be able to replicate this again and can send you the support tarball afterwards. Thanks
username_0: I have tried to replicate this but have not been able to today. @tomweston [on slack](https://kubernetes.slack.com/archives/C09NXKJKA/p1534275684000100) seems to be having the same issue though. I will continue to try to replicate but hopefully his support logs can identify the issue.
username_1: We're seeing something similar - repro steps
* Scale node ASG to 0
* Create a pod directly in API, it'll sit in pending
* Scale node ASG up
* Pod will end up in Error state, with events showing items like:
```
Normal SandboxChanged 11m (x10 over 11m) kubelet, ip-10-0-124-11.ec2.internal Pod sandbox changed, it will be killed and re-created.
Warning FailedCreatePodSandBox 11m (x11 over 11m) kubelet, ip-10-0-124-11.ec2.internal Failed create pod sandbox: rpc error: code = Unknown desc = NetworkPlugin cni failed to set up pod "test-pod" network: rpc error: code = Unavailable desc = grpc: the connection is unavailable
```
Is there anything blocking pods getting scheduled until the daemon is started and listening? It seems like there's a window where pods can be scheduled before the daemon is listening on the grpc socket, which would cause the cni plugin to fail out like this.
Let me know if that debug bundle would be useful.
username_2: @username_1 thank you for providing the repo steps.
One question:
Does these CronJob Pods eventually get IPs after new node from ASG joins and ipamD on these new nodes finish setting up its initial IP warm Pool?
thanks
username_2: Also, when "kubeleet" get error (e.g. network: rpc error ...), it should retry creating "test-pod". So eventually "test-pod" should get an IP from ipamD. If this is NOT the case, can you run `/opt/cni/bin/aws-cni-support.sh` and send me `/var/log/aws-routed-eni/aws-cni-support.tar.gz` thanks
username_2: @username_1 @username_0 I think I may find out the root cause for your issue. When we introduced the`WARM_IP_TARGET` feature in v1.1, we change the behavior of allocating the 1st secondary ENI. And this new behavior might cause you seeing CronJob NOT getting IP for longer period of time compare to v1.0.
Here is the behavior difference:
* in v1.0
* Right after the 1st Cronjob get scheduled onto the node, ipamD start allocating the 1st secondary ENI and its IP addresses. In t2.medium example, ipamD should have 10 IP addresses and 2 enI in its warm pool right away.
* in v1.1
* ipamD will NOT allocate the 1st secondary ENI until all IPs of primary interface are assigned to running Pod. In t2.medium example, 5 running CronJob Pod.
* ipamD eni allocation task runs every 5 second. In t2 medium example, if there are less than 5 running CronJob pod, ipamD will skip allocating a new eni
* ipamD also have a `ip address cooling period` that it will not give out an IP if it is used by another Pod less than 30 sec ago.
* if a CronJob runs for only 1 second and finishes. ipamD put this IP address in `cooling period` for 30 sec. At time when ipamD eni task runs(after 5 sec interval), it will NOT find 5 running pods and will skip allocating new ENI.
* Once after ipamD allocates the 1st secondary ENI, it behaves same way as v1.0
username_3: @username_2 After executed `sudo /opt/cni/bin/aws-cni-support.sh`,
I got `curl: (7) Failed to connect to localhost port 61678: Connection refused`.
username_2: This should be closed with #169 . Please re-open it if this is still an issue
Status: Issue closed
|
Rufusabcd/Znaki | 261067504 | Title: Błędy
Question:
username_0: 1. `var new = text.replace('Velociraptor', 'Triceratops')`
Zmienna `new` ma niefortunną nazwę ;) To jedno, a drugie - po co było tworzyć zmienną dinosaur, skoro Ty zamiast ją wykorzystać w tym miejscu, wpisałeś ręcznie 'Triceratops'? ;)
2. `console.log(text.length/2)`
No fajnie, że znalazłeś liczbę znaków do której musisz przyciąć `text`, ale jeszcze musisz to fizycznie przyciąć. Popatrz na metody `.slice` albo `.substr` |
angular/angular | 218743035 | Title: why i can't get the cookie?
Question:
username_0: <!--
IF YOU DON'T FILL OUT THE FOLLOWING INFORMATION WE MIGHT CLOSE YOUR ISSUE WITHOUT INVESTIGATING
-->
**I'm submitting a ...** (check one with "x")
```
[x] bug report => search github for a similar issue or PR before submitting
[ ] feature request
[ ] support request => Please do not submit support request here, instead see https://github.com/angular/angular/blob/master/CONTRIBUTING.md#question
```
**Current behavior**
<!-- Describe how the bug manifests. -->
i use http like this:
```typescript
login(loginUser: LoginUser): Promise<User> {
return this.http.post(BaseUrl.getBaseUrl() + 'users/login', JSON.stringify(loginUser), { headers: this.headers })
.toPromise()
.then(res => res.json())
.catch(this.handleError)
}
```
**Expected behavior**
<!-- Describe what the behavior would be without the bug. -->
this should set cookie to broswer automatically,like this:

but, there is nothing.
**Minimal reproduction of the problem with instructions**
<!--
If the current behavior is a bug or you can illustrate your feature request better with an example,
please provide the *STEPS TO REPRODUCE* and if possible a *MINIMAL DEMO* of the problem via
https://plnkr.co or similar (you can use this template as a starting point: http://plnkr.co/edit/tpl:AvJOMERrnz94ekVua0u5).
-->
**What is the motivation / use case for changing the behavior?**
<!-- Describe the motivation or the concrete use case -->
**Please tell us about your environment:**
<!-- Operating system, IDE, package manager, HTTP server, ... -->
Operating system - OS X EI 10.11.6 (15G31)
IDE - VS Code
HTTP server - java
* **Angular version:** 2.4.10
<!-- Check whether this is still an issue in the most recent Angular version -->
* **Browser:** Chrome 56.0.2924.87 (64-bit) | FireFox 52.0.2 (64 位)
<!-- All browsers where this could be reproduced -->
* **Language:** TypeScript 2.2.1
* **Node (for AoT issues):** `node --version` = 3.10.10
Answers:
username_0: there is response headers:

username_1: Angular has nothing to do with cookies.
username_0: But,if I use tools like ‘postman’ to simulate request ,I can see the cookie in the broswer.
username_0: Can you give me some reasons about the problem may happen.And give me some solutions to solve it. Thank you a lot. @username_1
username_2: Github issues is not StackOverflow, you should ask questions on StackOverflow, and report bug/issues on the Github issues.
In this case, the cookie marked as HttpOnly so you can't access it via JavaScript.
Status: Issue closed
username_0: ok. |
alephdata/aleph | 300169910 | Title: Keep homepage scroll position
Question:
username_0: Minor UX nit:
I scroll a mile down the homepage, click on collection 'Wakandan land registry', which loads and I realise that's not the one I want, click back to look for 'Wakandan overseas land registry' and OH NO I'm back at the top of the page again.<issue_closed>
Status: Issue closed |
gotson/komga | 1081535068 | Title: [Feature Request] Sort by Random
Question:
username_0: ### Is your feature request related to a problem? Please describe.
Current sorting options are only helpful if you are looking for a specific book or serialization. Libraries with many one-shot or short serializations are hard to pick from for indecisive users.
### Describe the solution you'd like
I would appreciate a Random option under Sort when browsing libraries to see a list of random books/serializations on each page.
### Describe alternatives you've considered or other apps that can do what you want
N/A
### Additional context
The Komga plugin for Tachiyomi could also benefit from this sorting option.
Answers:
username_1: Not totally dissimilar to #514. Mostly mentioning it since I think that implementation would probably be cleaner/more straightforward. Or just a random button could also work. Either way, would also be interested in this feature in some fashion or another. |
allenai/ai2thor | 713912003 | Title: Capturing and saving images of scene
Question:
username_0: How can I capture and save images of the current scene either from the robots perspective or from a free body ?
Answers:
username_1: Hey @username_0!
Try using:
```python
from PIL import Image
from ai2thor.controller import Controller
controller = Controller()
for i in range(5):
Image.fromarray(controller.last_event.frame).save(f'{i}.png')
controller.step('MoveAhead')
```
username_0: Thanks @username_1 I'll try this.
Also, if I'm running the scenes in Unity is there a way I could automate this process ? Like after playing the Unity scene, save pictures like every 5 secs ?
username_0: Hey @username_1 this works, thanks :D
username_0: Just wanted to know about this as well
username_1: Sure! If you want to save images every five seconds, you can run something like:
```python
from PIL import Image
from ai2thor.controller import Controller
import time
controller = Controller()
for second_batch in range(20):
start = time.time()
while True:
controller.step('MoveAhead')
if time.time() - start > 5:
Image.fromarray(controller.last_event.frame).save(f'{second_batch}.png')
# 5 seconds elapsed
break
```
This will batch images into groups (based on their file names) every 5 seconds :)
---
One warning with this approach is that depending on `time` is a bit dangerous. Here, if you run the same code above multiple times, it's possible that you'd get different results.
An alternative approach would be to save every, say, 10 different **frames**:
```python
from PIL import Image
from ai2thor.controller import Controller
controller = Controller()
for saved_frame in range(20):
for run_frame in range(10):
controller.setp('MoveAhead')
# 10 frames have passed
Image.fromarray(controller.last_event.frame).save(f'{second_batch}.png')
```
The frame approach would then be reproducible across runs.
username_0: Oh okay, thank you for your help :D
username_0: Closing the issue
Status: Issue closed
|
LeetCode-Feedback/LeetCode-Feedback | 790853572 | Title: 缺少测试用例 - 1489. 找到最小生成树里的关键边和伪关键边
Question:
username_0: **Bug 类型**
- [ ] 题目
- [x] 题解
- [ ] 编程语言
**描述**
代码错了通过了测试
0 - 1 - 2 - 3
| | | |
4 - 5 6 - 7
**你使用的语言**
python
**你提交或者运行的代码**
```
class UnionFind:
def __init__(self, n: int) -> None:
self.group_to_vertexes = [{i} for i in range(n)]
self.vertex_to_group = [i for i in range(n)]
self.group_count = n
def merge_group(self, g1: int, g2: int) -> bool:
if g1 == g2:
return False
if not self.group_to_vertexes[g1] or not self.group_to_vertexes[g2]:
return False
if len(self.group_to_vertexes[g1]) < len(self.group_to_vertexes[g2]):
g1, g2 = g2, g1
self.group_to_vertexes[g1].update(self.group_to_vertexes[g2])
for i in self.group_to_vertexes[g2]:
self.vertex_to_group[i] = g1
self.group_to_vertexes[g2] = set()
self.group_count -= 1
return True
def find_group(self, v: int) -> int:
return self.vertex_to_group[v]
class Solution:
def findCriticalAndPseudoCriticalEdges(self, n: int, edges: list) -> list:
def sort_edges():
# m = len(edges)
# indexes = sorted(range(m), key=lambda i: edges[i][2])
# i = 0
# while i < m:
# w = edges[indexes[i]][2]
# j = i + 1
# while j < m and w == edges[indexes[j]][2]:
# j += 1
# yield indexes[i:j]
# i = j
sorted_edges = [[] for w in range(1001)]
for i in range(len(edges)):
v1, v2, w = edges[i]
sorted_edges[w].append(i)
return sorted_edges
sorted_edges = sort_edges()
union_find = UnionFind(n)
def get_edge_groups(i):
[Truncated]
return [critical, pseudo_critical]
```
**期望行为**
0 - 1 - 2 - 3
| | | |
4 - 5 6 - 7
[n] 8
[edges] [[0, 1, 1], [1, 2, 1], [2, 3, 1], [0, 4, 1], [1, 5, 1], [2, 6, 1], [3, 7, 1], [4, 5, 1], [6, 7, 1]]
[expect] [[1], [0, 2, 3, 4, 5, 6, 7, 8]]
[result] [[], [0, 1, 2, 3, 4, 5, 6, 7, 8]]
**屏幕截图**
添加屏幕截图辅助我们帮你定位问题
**额外的上下文**
添加额外的上下文信息
Answers:
username_1: 感谢反馈,此问题已转给题目运营团队会尽快确认。
username_1: @username_2 麻烦帮忙跟进下这个用户反馈哦。
username_2: @username_0
Thank you for reaching out to us. I've relayed this issue to our team to investigate.
username_2: @username_1
We've used the feedback to update the problem. Please reward the user.
username_1: @username_0 你好,当前该题已添加测试用例, 请留言告知一下力扣中文网站的 ID,我们给予积分奖励哦。
Status: Issue closed
|
3dcitydb/importer-exporter | 442314421 | Title: Single model output for glTF export
Question:
username_0: Hi,
I was just wondering if there is a dedicated way to export to a single model/file?
No matter how high I set the value "put objects together in groups of" in rendering->building preferences, I always end up with a large number of files...
Regards,
Ludwig
Answers:
username_1: Sounds similar to #84 and https://github.com/3dcitydb/3dcitydb-web-map/issues/18#issuecomment-309669613. Alternatively, you could try deactivating tiling during export to reduce the number of folders and files.
username_1: Closed. Feel free to reopen if you still have any issues.
Status: Issue closed
|
framework7io/framework7-website | 354121367 | Title: [Documentation] Broken link
Question:
username_0: On https://framework7.io/vue/view.html:

points to https://framework7.io/docs/views.html, that gives me a 404
Status: Issue closed
Answers:
username_1: Thanks, fixed |
OHDSI/WebAPI | 768795086 | Title: WebAPI fails to start with enabled webapi-hive profile
Question:
username_0: ```
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/tomcat/webapps/WebAPI/WEB-INF/lib/slf4j-log4j12-1.7.26.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/tomcat/webapps/WebAPI/WEB-INF/lib/log4j-slf4j-impl-2.7.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
16-Dec-2020 11:45:56.024 SEVERE [localhost-startStop-1] org.apache.catalina.core.ContainerBase.addChildInternal ContainerBase.addChild: start:
org.apache.catalina.LifecycleException: Failed to start component [StandardEngine[Catalina].StandardHost[localhost].StandardContext[/WebAPI]]
at org.apache.catalina.util.LifecycleBase.handleSubClassException(LifecycleBase.java:440)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:198)
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:743)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:719)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:705)
at org.apache.catalina.startup.HostConfig.deployWAR(HostConfig.java:970)
at org.apache.catalina.startup.HostConfig$DeployWar.run(HostConfig.java:1840)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.NoSuchMethodError: org.apache.jasper.xmlparser.ParserUtils.parseXMLDocument(Ljava/lang/String;Ljava/io/InputStream;Z)Lorg/apache/jasper/xmlparser/TreeNode;
at org.apache.jasper.runtime.TldScanner.scanTld(TldScanner.java:600)
at org.apache.jasper.runtime.TldScanner.scanJar(TldScanner.java:457)
at org.apache.jasper.runtime.TldScanner.scanJars(TldScanner.java:694)
at org.apache.jasper.runtime.TldScanner.scanTlds(TldScanner.java:350)
at org.apache.jasper.runtime.TldScanner.onStartup(TldScanner.java:239)
at org.apache.catalina.core.StandardContext.startInternal(StandardContext.java:5144)
at org.apache.catalina.util.LifecycleBase.start(LifecycleBase.java:183)
... 10 more
16-Dec-2020 11:45:56.025 SEVERE [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployWAR Error deploying web application archive [/opt/tomcat/webapps/WebAPI.war]
java.lang.IllegalStateException: ContainerBase.addChild: start: org.apache.catalina.LifecycleException: Failed to start component [StandardEngine[Catalina].StandardHost[localhost].StandardContext[/WebAPI]]
at org.apache.catalina.core.ContainerBase.addChildInternal(ContainerBase.java:747)
at org.apache.catalina.core.ContainerBase.addChild(ContainerBase.java:719)
at org.apache.catalina.core.StandardHost.addChild(StandardHost.java:705)
at org.apache.catalina.startup.HostConfig.deployWAR(HostConfig.java:970)
at org.apache.catalina.startup.HostConfig$DeployWar.run(HostConfig.java:1840)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
16-Dec-2020 11:45:56.025 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployWAR Deployment of web application archive [/opt/tomcat/webapps/WebAPI.war] has finished in [13,705] ms
16-Dec-2020 11:45:56.025 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deploying web application directory [/opt/tomcat/webapps/ROOT]
16-Dec-2020 11:45:56.040 INFO [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployDirectory Deployment of web application directory [/opt/tomcat/webapps/ROOT] has finished in [15] ms
16-Dec-2020 11:45:56.041 INFO [main] org.apache.coyote.AbstractProtocol.start Starting ProtocolHandler ["http-nio-8080"]
16-Dec-2020 11:45:56.046 INFO [main] org.apache.catalina.startup.Catalina.start Server startup in 13766 ms
```<issue_closed>
Status: Issue closed |
plone/pastanaga-angular | 580566628 | Title: Angular Traversal dependency
Question:
username_0: Is it really necessary to have angular traversal as dependency on pastanaga-angular. Its only used on the button and I don't really understand why.
Answers:
username_1: I agree. We should keep only normal button in pastanaga. Button link is quite a special use case we have, we could/should keep it internal.
username_2: true, it would allow us to get ride of angular/router too, so yes, let's do it
username_2: Ok, I remember now why we needed this button-link with explicit `[routerLink]` or `[traverserTo]`.
The purpose is to allow Ctrl+right-click (or right-click + "Open in new tab") to open the corresponding route or traverse link in another tab.
If we just use a regular button where we have a click function doing the traverse or routing programmatically, it does not work. And it does not work either if we put a `[routerLink]` or `[traverserTo]` on a pa-button (because it has to be on an actual `<a>`).
But ok, I guess it is not a major feature.
username_1: I didn't say that wouldn't be useful for us, just that we should move this component out of pastanaga to our own project if the dependency is not useful for others :)
username_2: sure, totally agreed, I just wanted to explain what feature we are removing here
username_0: Maybe could be a pastanaga-angular-traversal package? jS world jiji
username_2: no way :)
It will go in grange
Status: Issue closed
|
tpreynolds/uw_cubesat_adcs | 339197263 | Title: Update magnetometer processing
Question:
username_0: In HS1 flight software we have a low-pass filter for MAG processing that should be ported over. Think about how best to handle bdot after this -- may need/want to remove the LPF from the bdot code and keep things consistent.<issue_closed>
Status: Issue closed |
pooler/electrum-ltc | 261649106 | Title: Bought LTC but accidently send it to my BTC electrum wallet
Question:
username_0: Hi guys,
So here is the story.
I made a pretty stupid mistake. I have two electrum wallets. 1 wallet for bitcoins and 1 wallet for litecoins. I bought a bunch of litecoins from this company: https://www.litebit.eu/en
During the buying proces I used the receiving adress of my bitcoin wallet instead of my litecoin wallet.
The order is processed and confirmed but offcourse I didnt receive the litecoin because I used the wrong receiving adress.
Is there a way to get my litecoin to my litecoint electrum wallet?
I already came accross this post, in which username_1 gave some pretty awesome help.
https://github.com/username_1/electrum-ltc/issues/68#issuecomment-328260191
I tried to follow the steps that were mentioned but for some reason i wont get it to work.
@Pooler if you would be so kind to go over it one more time with me. I would appreciate that very much.
Answers:
username_1: Could you please describe in detail the steps you followed and the results you observed?
username_0: Now, the problem is that 2FA seeds are a special variety that isn't supported by Electrum-LTC (for the reason above). It should still be possible to recover the coins, I'm just not entirely sure how without writing ad-hoc code. Here is what I would try. First of all, in Electrum for Bitcoin, make a new wallet restoring from your 2FA seed, and when asked select to disable TrustedCoin. Do not enter a password. Then, close Electrum and open the wallet file you just created in a text editor. You will find 3 xpub and 2 xprv addresses. Open Electrum-LTC and create a new multi-sig wallet with a 2-of-3 scheme. Use the first xprv address and the other two xpub addresses. This should give you a wallet with the right addresses (use the converter to check). Finally, make a wallet for the second signer using the second xprv and the other two xpub addresses.>
So i created the new wallet. Open the filet in text editor and found the 3 xpub and 2 xprv adresses. I opend the electrum LTC wallet and started creating a new multi sig wallet.
First problem i enccountered: I wasnt really sure what a 2-of-3 schema was. You mean like this:
[https://imgur.com/a/2DBFp](url)
Then I pressed the option, insert private keys. Then I copied first the xprv address and then the first two xpub addresses i saw in the text. I couldnt press next then. I only could press next when i only used the xprv address. When i tried that i created a wallet but since i never could fill in the xpub's, thats the moment it went wrong.
Also what i dont understand. You mentioned that you can find 2 xprv and 3xpub addresses. Then in the first wallet you need to use two xpubs and in the second you create also 2 xpubs. Which xpubs should i chose out of those 3?
I hope this made it a bit clearer for you. If not, just say and i try to explain it with more pictures.
username_1: You didn't insert all of the keys at once, did you? You need to insert just the first xprv for cosigner 1, just the second xpub for cosigner 2 and just the third xpub for cosigner 3. If at any point you can't press Next, it's because the input is wrong, so make sure you copied it right.
username_0: yes, that option.
Thanks for the feedback. Im gonna try again with your tips and ill let you know the result.
username_0: I tried it again and i managed to get my litecoin in my litecoin electrum wallet.
Thanks alot username_1 for your help and patience :)
Status: Issue closed
|
UXDivers/Grial-UI-Kit-Support | 1103901907 | Title: Error: "UXDivers.Grial.LicenseException: Error reading license"
Question:
username_0: Por favor necesito ayuda con este error. Cada vez que se vence la licencia de desarrollo es un gran problema activarla nuevamente, me quita tiempo valioso en el desarrollo del proyecto. Favor solicito revisión URGENTE!!!!<issue_closed>
Status: Issue closed |
da4089/simplefix | 504236327 | Title: Migrate LGTM.com installation from OAuth to GitHub App
Question:
username_0: Hi There,
This project is still using an old implementation of LGTM's automated code review, which has now been disabled. To continue using automated code review, and receive checks on your Pull Requests, please [install the GitHub App](https://github.com/apps/lgtm-com/installations/new) on this repository.
Thanks,
The LGTM Team
Status: Issue closed
Answers:
username_1: Done. |
CheetahTemplate3/cheetah3 | 269332237 | Title: Failing to catch an Exception
Question:
username_0: In the following, it is expected that the except line is reached is the file `expect_exception_catch` does not exist, however, instead a legacy issue means an exception is raised as indentation error. I did have that error not happening at some point and even then the Import error was not catching at all. So i think this whole area has been broken some time.
```
#try
#from lib.expect_exception_catch import as_should_be_ImportError
#except ImportError
#pass
#end try
```
Thanks
Answers:
username_1: You're right. Cheetah reorders `import` to the beginning of the compiled Python file and left empty `try/except` which gives `SyntaxError`.
I have to think if I can fix that. Stopping reordering `import`s would be a rather major change.
PS. As for PyPI — since release 3.0 I was working on cleaning up Cheetah source code but didn't add/change anything significant. Certainly no new features.
username_1: Well, Cheetah is better than I thought — `import` reordering can be controlled. By default it's on but can be turned off:
```
cheetah compile --settings="useLegacyImportMode=False" infile.tmpl
```
username_1: Does it help?
Status: Issue closed
|
w3c/csvw | 673605960 | Title: What is the difference between {#reference} and {reference} URI template?
Question:
username_0: In the [Metadata Vocabulary for Tabular Data Example 11](https://www.w3.org/TR/2015/REC-tabular-metadata-20151217/#h-note3:~:text=EXAMPLE%2011%3A%20expanded%20propertyUrl%20using%20%7B%23_name%7D), there is a reference with a hash inside the curly braces ```{#_name}```. I did not find what this syntax means and if/how it is different from ```{_name}```?
The same syntax appears also [here](https://www.w3.org/TR/2015/REC-tabular-metadata-20151217/#h-note15:~:text=For%20example%2C%20if%20the%20value%20URL%20were%20%22%7B%23reference%7D%22%2C) and [here in Example 27](https://www.w3.org/TR/2015/REC-tabular-metadata-20151217/#h-foreign-key-reference-between-tables:~:text=EXAMPLE%2027) but nowhere else.
Is this an error?
Answers:
username_1: The use of `{_name}` uses [Simple String Expansion](https://tools.ietf.org/html/rfc6570#section-3.2.2).
Status: Issue closed
username_0: I see, thanks for the explanation. I read through RFC6570 and it is clear now. |
spdx/spdx-spec | 311690059 | Title: support matching http | https
Question:
username_0: Companion issue to https://github.com/spdx/license-list-XML/issues/633
Track there for now; one potential solution would affect the SPDX License List and one would affect the spec.
Answers:
username_1: Update to Appendix II? link to license list matching guidelines?
(Gary notes this should be fixed in the tools as well as well)
username_1: Discussion in call, Appendix needs to be updated for release, so catch this.
@username_2 will do the update
username_2: Website has been updated: https://spdx.org/spdx-license-list/matching-guidelines
as has the copy in spdx/license-list-XML: https://github.com/spdx/license-list-XML/pull/974 and https://github.com/spdx/license-list-XML/blob/master/DOCS/matching-guidelines
I'll submit a PR to modify Appendix II in the spec to also reflect these changes.
username_2: @username_1 I've submitted #202 to fix this -- if it looks good to you, feel free to merge!
Status: Issue closed
|
spring-projects/spring-boot | 139649811 | Title: LoggingApplicationListener adds default logging categories even if logging.config is set
Question:
username_0: the usual logging configuration does not only contain appender and format configurations but also the configuration of the log levels, which is an essential part of how it is used to "initialize the logging system".
My concern is however not only the javadoc that misled me, but the fact that logging categories are set at all by framework code. And especially the spring-foreign org.hibernate.SQL logging category which is _very_ verbose.
I remember cluelessly searching time and again over the previous months through logback.xml configuration files and also through hibernate's configuration searching for the setting that activated the very verbose org.hibernate.SQL logging which to all appearance should not have been activated.
Finally it took me a breakpoint in the logback library to find the culprit in spring boot.
Answers:
username_1: What makes you think it's contrary to the Javadoc exactly? This is about the appender and the format of the log message. If you don't specify any file, then we will provide a default log format for instance. But we will apply the logging levels regardless.
Perhaps you could say what's confusing in that Javadoc so that we update it?
username_0: the usual logging configuration does not only contain appender and format configurations but also the configuration of the log levels, which is an essential part of how it is used to "initialize the logging system".
My concern is however not only the javadoc that misled me, but the fact that logging categories are set at all by framework code. And especially the spring-foreign org.hibernate.SQL logging category which is _very_ verbose.
I remember cluelessly searching time and again over the previous months through logback.xml configuration files and also through hibernate's configuration searching for the setting that activated the very verbose org.hibernate.SQL logging which to all appearance should not have been activated.
Finally it took me a breakpoint in the logback library to find the culprit in spring boot.
username_1: And where that culprit would be? I am sorry but I am not aware of anything that set `org.hibernate.SQL` to `debug`
username_0: It is one of the logging categories set by
`org.springframework.boot.logging.LoggingApplicationListener` if the environment contains the debug property.
username_1: Reading the doc is probably faster than adding a breakpoint in the code :)
username_0: Looking at all places where in the documentation the --debug mode is described I see a problem in that it is easily used by people like me who are unaware of its double function.
Its main use case - from number of mentions in the docs and in when searching for it via google - is the enabling the logging of the autoconfiguration report - only once at the location you point out is it described as manipulating the logging configuration. So that already sets it up for the kind of oversight that I suffered from.
I can see a few countermeasures for saving people like me from this oversight:
- mention the sideffect of setting logging categories to debug wherever the doc suggests use of the debug flag
- log the reason for the activation of the additional logging categories. I assume this might not be possible during the initialization, maybe it can instead be postponed similar to how the auto-configuration report is logged. Until now the only logging output is generated by logback's debug mode, but it does not say _why_ it activates the logging categories.
Compounding this for me was #5374 which makes the `LoggingApplicationListener` mis-interpret (ignore) `debug=false`.
Also once at the documentation, you may also document that the LoggingApplicationListener also evaluates a "trace" environment property and enables additional logging categories at trace level - this is as of yet undocumented.
Status: Issue closed
|
rails/rails | 16130674 | Title: ActionMailer does not work properly with default ActionView::Template::Types
Question:
username_0: Just loading action_mailer seems not to be enough for handling implicit multipart emails - html email part become just text/plain. See the code at the end.
When loading only action_mailer, `ActionView::Template#type` returns `html`, not `text/html`, since the action view delegates type to ActionView::Template::Types::Type, which just returns symbol. And the mail gem does not recognize `html`, so the html part becomes just text/plain.
The desired behavior is that ActionView::Template#type returns mime_type - but that needs setting delegation on ActionView::Template::Types in advance.
**Solution 1: at action mailer**: add following lines (from actionpack/lib/action_dispatch.rb) to actionmailer/lib/action_mailer.rb.
```ruby
autoload :Mime, 'action_dispatch/http/mime_type'
ActionView::Base.default_formats ||= Mime::SET.symbols
ActionView::Template::Types.delegate_to Mime
```
**Solution 2: at application**. call mail method with format block explicitly, which uses ActionMailer::Collector, not template.type.to_s
I think this is a bug, so need to be fixed - but I'm not sure the first solution is a good way to fix this problem (in addition to duplicated code).
First, It may be better to revive ActionView::Template#mime_type, because `mime_type` can be different from `type`. (Can someone give some hint why mime_type was deprecated?)
Second, loading action dispatch from action mailer? hm.. fortunately `Mime` is not in that module, but it implies that action mailer depends on action dispatch for setting up action view template mime types.
Third, currently ActionView::Template is shared between action dispatch and action mailer, so the following "on_load" code from action dispatch has side effect on action mailer. That can be fine for most rails cases, but if action dispatch and action mailer need the same behavior on action view, then action view need to take care of that common behavior.
```ruby
# action_dispatch.rb
ActiveSupport.on_load(:action_view) do
ActionView::Base.default_formats ||= Mime::SET.symbols
ActionView::Template::Types.delegate_to Mime
end
```
----
```ruby
# encoding: utf-8
# test action mailer
require 'rubygems'
require 'action_mailer'
def fixtures_path
File.expand_path('fixtures', File.dirname(__FILE__))
end
def prepare_fixtures
FileUtils.rm_rf fixtures_path
view_path = File.join(fixtures_path, 'test_mailer')
FileUtils.mkdir_p view_path
%w(html text).each do |format|
File.open(File.expand_path("hello.#{format}.erb", view_path), 'w') do |f|
f.write(format)
end
end
end
ActionMailer::Base.view_paths = fixtures_path
class TestMailer < ActionMailer::Base
[Truncated]
require 'mail'
response = {
body: '<html></html>',
content_type: 'html',
charset: 'UTF-8'
}
puts Mail::Part.new(response).content_type
# => text/plain; charset=UTF-8
response = {
body: '<html></html>',
content_type: 'text/html',
charset: 'UTF-8'
}
puts Mail::Part.new(response).content_type
# => text/html; charset=UTF-8
```
Answers:
username_1: This is still an issue in Rails 4.2.4
I am using a standalone ActionMailer script, outside of Rails. Templates have the extension .html.erb and the ERB engine renders them correctly. However, they are sent with the content type "text/plain".
Adding the code described above (Solution 1) makes them sent with the content_type "text/html; charset=UTF-8"
username_2: I don't think it is a issue. If you are using a standalone Action Mailer script you should make sure it is correctly configured and it includes setting the Mime types delagation like:
```
ActionView::Base.default_formats ||= Mime::SET.symbols
ActionView::Template::Types.delegate_to Mime
```
username_1: So just to be clear, the **bug** was that it wasn't doing this automatically in a Rails context, but when it doesn't do this automatically outside of Rails, then it's not a bug? I don't understand why not.
If this is required setup for ActionMailer outside of Rails, shouldn't this be documented somewhere?
username_2: The bug was that it was't doing automatically outside of Rails. This is the first time that I read the issue and I don't consider it a bug.
It is documented in the railtie code. If you are not loading the railtie so you need to make sure all you want is being set.
username_1: It's not in the ActionView Railtie (`actionview/lib/action_view/railtie.rb`).
Once I found this issue, I knew what to `grep` and found it in `actionpack/lib/action_dispatch.rb`. Just looking at that file, it looks out of place there. Is there a good reason it's there?
username_2: It is in the correct place. We can do the same at `actionmailer/lib/action_mailer.rb`. Could you open a PR?
username_1: I don't mind creating a PR. I would still like to understand this better. Why doesn't it belong in `actionview/lib/action_view/railtie.rb`?
username_2: Because it is a action view configuration to work with action dispatch and action mailer. Action view is used for these components not the other way around. Action view don't know about mime types and should continue to not know about it |
AlexandrovLab/SigProfilerExtractor | 1073907349 | Title: issue about Trancriptional stranded signature
Question:
username_0: Hi,
I read paper "The repertoire of mutational signatures in human cancer" metioned that using SigProfilerExtractor to get transcitional stranded mutation signature. here is a description of the source of strand-bias table,
"Transcriptional strand bias associated with mutational signatures was assessed by applying SigProfilerExtraction to catalogues of in-transcript mutations that capture strand information (192 mutations classes, syn12026195). These 192-class signatures were collapsed to strandinvariant 96-class signatures and compared to the signatures extracted from the 96-class data, revealing very high cosine similarities (median 0.90, column F in syn12016215). "
But now SigProfilerExtractor version can't provide stranded 192-classes mutation calculation parameter according to "context_type" SigProfilerExtraction parameter. If I want to calculate stranded siganture using our cancer somatic vcf data, How do I achieve that?
Thanks a lot
Answers:
username_0: The context-288 decomposition plots pages were not able to be generated.
The context-288 decomposition plots pages were not able to be generated.
The context-288 decomposition plots pages were not able to be generated.
The context-288 decomposition plots pages were not able to be generated.
The context-288 decomposition plots pages were not able to be generated.
Samples SBS288_Ref_1 SBS288_Ref_5 SBS288A SBS288B SBS288C SBS288D SBS288E
TCGA-18-3406-01A-01D-0983-08 0 0 0 110 133 0 0
TCGA-18-3407-01A-01D-0983-08 0 0 0 0 290 0 0
username_0: if parameter ”make_decomposition_plots=False“ were used,SBS288 decomposition can't work either.
command
decomp.decompose(signatures, activities, samples, "LUSC_descomp288_plotsF", genome_build="GRCh37", verbose=False,collapse_to_SBS96=False,make_decomposition_plots=False)
View Log can't get cosmic 288 composition
!!!!!!!!!!!!!!!!!!!!!!!!! LAYER: 0 !!!!!!!!!!!!!!!!!!!!!!!!!
Best Signature Composition [2]
L2 Error % 0.94
Cosine Similarity 0.34
!!!!!!!!!!!!!!!!!!!!!!!!! LAYER: 1 !!!!!!!!!!!!!!!!!!!!!!!!!
Best Signature Composition [2]
L2 Error % 0.94
Cosine Similarity 0.34
#################### Final Composition #################################
[2]
L2 Error % 0.94
Cosine Similarity 0.34
Status: Issue closed
username_1: The SBS192 context has been retired. It has been moved to SBS288, which in addition to transcription strand bias, also incorporates the untranscribed strand. Specify the parameter _collapse_to_SBS96=true_ to decompose to COSMIC signatures.
Thanks!
username_0: thanks a lot, i read the script and found that using SBS288 do decomposition part and SBS288 cosmic reference can be found in /data directory,subroutines.py line826 to 1082, how can use this part script to decomposition in SBS288 context
such as
”elif signatures.shape[0]==288:
sigDatabase = pd.read_csv(paths+"/data/Reference_Signatures/GRCh37/COSMIC_v"+str(3.2)+"_SBS"+str(signatures.shape[0])+"_GRCh37.txt", sep="\t", index_col=0)
signames = sigDatabase.columns“ |
FireBlinkLTD/fbl | 377849867 | Title: New "While" Action Handler
Question:
username_0: ```yaml
# repeat action while some action equals other value
while:
# [required] value to compare
value: '<%- ctx.something %>'
# [required] compare with
is: true
# [required] action to run
action:
```<issue_closed>
Status: Issue closed |
Bloometa/Bloometa-WebApp | 238261987 | Title: Latest account information
Question:
username_0: Display the latest follow/er count and difference since last run, at the top of the page with up-to-date information from the network. The data should have a short cache in the browser.
Connect to the networks' API endpoint through JavaScript AJAX.
This is less likely to be a successful feature with Twitter, as the API is rate-limited. I don't know if there is a separate rate limit for each individually authenticated user, but if there is, only show this feature for people signed in with a Twitter account added.
## Acceptance criteria
- [ ] Show latest follow/er counts
- [ ] Show latest follow/er differences since last run
- [ ] Cache the data in the browser with a 2 hour freshness period
- [ ] Allow the user to refresh the cache manually |
martasp/BlazorLiveReload | 508098431 | Title: How to prevent the console from being filled up with `INFO` level messages
Question:
username_0: Add
```
using Microsoft.Extensions.Logging;
// filler
public void ConfigureServices(IServiceCollection services) {
// filler
services.AddLogging(x => x
.AddFilter("Microsoft.AspNetCore", LogLevel.Warning)
);
```<issue_closed>
Status: Issue closed |
intesar/NB-Sales | 670290758 | Title: ABAC_Level2 on PUT:/api/v1/orgs/{id}
Question:
username_0: Title: ABAC_Level2 Vulnerability on PUT:/api/v1/orgs/{id}
Project: NetBanking API
Description: The ABAC exploit allows an attacker to read, modify, delete, add and perform actions on customer/un-authorized data.
Risk: ABAC_Level2
Severity: Major
API Endpoint: http://192.168.127.12:8080/api/v1/orgs/2c928084730547e80173a6f6d0c652c1
Environment: Master
Playbook: ApiV1OrgsIdPutUseraCreateOrgorgplanenterpriseUserbDisallowAbact2
Researcher: [apisec Bot]
QUICK TIPS
Suggestion: Add access-control checks on incoming requests against all data calls.
Effort Estimate: 2.0
Wire Logs:
10:20:59 [D] [ OOECUAI2] : URL [http://192.168.127.12:8080/api/v1/orgs]
10:20:59 [D] [ OOECUAI2] : Method [POST]
10:20:59 [D] [ OOECUAI2] : Auth [UserA]
10:20:59 [D] [ OOECUAI2] : Request [{
"billingEmail" : "<EMAIL>",
"company" : "Leffler, Leffler and Leffler",
"createdBy" : "",
"createdDate" : "",
"description" : "Ty6WzczV",
"id" : "",
"inactive" : false,
"location" : "Ty6WzczV",
"modifiedBy" : "",
"modifiedDate" : "",
"name" : "Ty6WzczV",
"orgPlan" : "ENTERPRISE",
"orgType" : "ENTERPRISE",
"version" : ""
}]
10:20:59 [D] [ OOECUAI2] : Request-Headers [{Content-Type=[application/json], Accept=[application/json], Authorization=[**********]}]
10:20:59 [D] [ OOECUAI2] : Response [{
"requestId" : "None",
"requestTime" : "2020-07-31T22:20:59.974+0000",
"errors" : false,
"messages" : [ ],
"data" : {
"id" : "2c928084730547e80173a6f6d0c652c1",
"createdBy" : "2c928085730548680173054c9f720003",
"createdDate" : "2020-07-31T22:20:59.974+0000",
"modifiedBy" : "2c928085730548680173054c9f720003",
"modifiedDate" : "2020-07-31T22:20:59.974+0000",
"version" : null,
"inactive" : false,
"name" : "rNJcRLdW",
"description" : "rNJcRLdW",
"orgType" : "ENTERPRISE",
"billingEmail" : "<EMAIL>",
"company" : "Oberbrunner-Oberbrunner",
"location" : "rNJcRLdW",
"orgPlan" : "ENTERPRISE"
},
"totalPages" : 0,
"totalElements" : 0
}]
10:20:59 [D] [ OOECUAI2] : Response-Headers [{X-Content-Type-Options=[nosniff], X-XSS-Protection=[1; mode=block], Cache-Control=[no-cache, no-store, max-age=0, must-revalidate], Pragma=[no-cache], Expires=[0], X-Frame-Options=[DENY], Set-Cookie=[SESSION=YWM0Njg4MDAtOTJmNC00OGI3LWEzNzQtZDliMTcyYTAzZjRk; Path=/; HttpOnly], Content-Type=[application/json;charset=UTF-8], Transfer-Encoding=[chunked], Date=[Fri, 31 Jul 2020 22:20:59 GMT]}]
[Truncated]
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/jobs
Environment:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/environments/8a8081766fc3e2a1016fc421d7155a15/edit
Scan Dashboard:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/jobs/8a8081766fc3e2a1016fc4230f426628/runs/8a808138739e3ae40173a6f69f2a22b1
Playbook:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/template/ApiV1OrgsIdPutUseraCreateOrgorgplanenterpriseUserbDisallowAbact2
Coverage:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/configuration
Code Sample:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/recommendations/8a808138739e3ae40173a6f6e65e2353/codesamples
PS: Please contact <EMAIL> for apisec access and login issues.
--- apisec Bot ---
Answers:
username_0: Message : <html><b>This issue is manually closed from FX control plane.</b></html>
Title: ABAC_Level2 Vulnerability on PUT:/api/v1/orgs/{id}
Project: NetBanking API
Description:
Risk: ABAC_Level2
Severity: Major
API Endpoint: http://192.168.127.12:8080/api/v1/orgs/2c928084730547e80173a6f6d0c652c1
Environment: Master
Playbook: ApiV1OrgsIdPutUseraCreateOrgorgplanenterpriseUserbDisallowAbact2
Researcher: UserB
QUICK TIPS
Suggestion:
Effort Estimate:
Wire Logs:
10:20:59 [D] [ OOECUAI2] : URL [http://192.168.127.12:8080/api/v1/orgs]
10:20:59 [D] [ OOECUAI2] : Method [POST]
10:20:59 [D] [ OOECUAI2] : Auth [UserA]
10:20:59 [D] [ OOECUAI2] : Request [{
"billingEmail" : "<EMAIL>",
"company" : "Leffler, Leffler and Leffler",
"createdBy" : "",
"createdDate" : "",
"description" : "Ty6WzczV",
"id" : "",
"inactive" : false,
"location" : "Ty6WzczV",
"modifiedBy" : "",
"modifiedDate" : "",
"name" : "Ty6WzczV",
"orgPlan" : "ENTERPRISE",
"orgType" : "ENTERPRISE",
"version" : ""
}]
10:20:59 [D] [ OOECUAI2] : Request-Headers [{Content-Type=[application/json], Accept=[application/json], Authorization=[**********]}]
10:20:59 [D] [ OOECUAI2] : Response [{
"requestId" : "None",
"requestTime" : "2020-07-31T22:20:59.974+0000",
"errors" : false,
"messages" : [ ],
"data" : {
"id" : "2c928084730547e80173a6f6d0c652c1",
"createdBy" : "2c928085730548680173054c9f720003",
"createdDate" : "2020-07-31T22:20:59.974+0000",
"modifiedBy" : "2c928085730548680173054c9f720003",
"modifiedDate" : "2020-07-31T22:20:59.974+0000",
"version" : null,
"inactive" : false,
"name" : "rNJcRLdW",
"description" : "rNJcRLdW",
"orgType" : "ENTERPRISE",
"billingEmail" : "<EMAIL>",
"company" : "Oberbrunner-Oberbrunner",
"location" : "rNJcRLdW",
"orgPlan" : "ENTERPRISE"
},
"totalPages" : 0,
[Truncated]
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/jobs
Environment:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/environments/8a8081766fc3e2a1016fc421d7155a15/edit
Scan Dashboard:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/jobs/8a8081766fc3e2a1016fc4230f426628/runs/8a808138739e3ae40173a6f69f2a22b1
Playbook:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/template/ApiV1OrgsIdPutUseraCreateOrgorgplanenterpriseUserbDisallowAbact2
Coverage:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/configuration
Code Sample:
https://cloud.fxlabs.io/#/app/projects/8a8081766fc3e2a1016fc421d6e55a13/recommendations/null/codesamples
PS: Please contact <EMAIL> for apisec access and login issues.
--- apisec Bot ---
Status: Issue closed
|
department-of-veterans-affairs/va.gov-team | 794783882 | Title: [REVIEW] Internal Review, Test, Proof Read, and CORRECT all NODES for "VA San Francisco health care" ending with stakeholder review doc [VAMC]
Question:
username_0: ## User Story or Problem Statement
As a Veteran Web user, I must have full accessibility a compliance to my web applications and tools, so I can use the VAMC system pages in any GUI, UE, including mobile and reader environments.
## Goal
_Perform initial page testing and review
## Objectives or Key Results this is meant to further
- _Increase overall quality experience for veteran's accessibility_
- _Assist and reduce time for complete accessibility and 508 compliance checks_
## Resources - Tools - Documentation
[VISN-21 Internal Review Folder](https://drive.google.com/drive/folders/1z5U48stIVVaG5PnaKMJs8RlNUgUZ32N6)
[Review template for review](https://drive.google.com/drive/folders/1iRChKVhQ09f-ZTbWvvQkljfBRQ_wogZd)
## Tasks
- 1) Complete review of system and facility pages, manual review and test URLS, phone #s, and hyperlinks for:
- [ ] 662 San Francisco VA Medical Center
- [ ] 662GA Santa Rosa VA Clinic
- [ ] 662GC Eureka VA Clinic
- [ ] 662GD Ukiah VA Clinic
- [ ] 662GE San Bruno VA Clinic
- [ ] 662GF San Francisco VA Clinic
- [ ] 662GG Clearlake VA Clinic
- 2) Review and correct all **Broken Links** on each of the system pages in Devshop
- Document all errors, items that need update and testing on each page using spreadsheet listed above_
**When completed spreadsheet is complete, Look for review from Content Team and begin clean-up**
- [ ] Update and clean up all pages as provided by review and Content team input.
## Acceptance Criteria
* All URL and node/pages must have been documented in Spreadsheet.
* Broken links, issues in page, duplicates, or anomalies must resolved and/or be documented.
* Issues should list "FIXED" if they were updated in product or high lighted in red if still an outstanding issue.
* Issues that cannot be resolved must be highlighted. Areas that are not typical need to be posted in Support channel.<issue_closed>
Status: Issue closed |
felixblaschke/simple_animations | 771439771 | Title: How to auto animate widgets in a List endlessly ?
Question:
username_0: How to auto animate widgets in a List endlessly?
I have used MirrorAnimation with AnimatedSwitcher as shown below, Is there any better way of doing this?
```
final List<Widget> body = [
Widget1(),
Widget2(),
Widget3(),
];
MirrorAnimation(
tween: IntTween(begin: 0, end: 2),
builder: (context, child, value) {
print('value: $value');
return AnimatedSwitcher(
duration: const Duration(seconds: 2),
reverseDuration: const Duration(seconds: 2),
child: body[value],
);
},
duration: Duration(seconds: 30),
curve: Curves.linear,
),
```
Answers:
username_1: You are using `MirrorAnimation` as a mechanism of **providing a timer** that changes the `body`-index. It looks fine, I see nothing bad about that. Alternatively you can use a stateful widget and use a `Future.delayed` to increase the `body`-index yourself. This way you would work around MirrorAnimation.
Status: Issue closed
username_0: Thank you for your quick response. |
vinyldns/vinyldns-cli | 367454069 | Title: Ensure against interface conversion problems
Question:
username_0: ### Description
`panic: interface conversion: interface {} is int, not string` error.
### Steps to Reproduce
1. compile from master
2. attempt to view a CNAME such via commands like the following: `vinyldns record-set --zone-id 89e21e9a-581c-424c-a006-7cb1c4bbcd32 --record-set-id 5862d275-79b8-4689-97ab-4bf16327baeb`
**Expected behavior:** [What you expect to happen]
I expect to view the record set data.
**Actual behavior:** [What actually happens]
```
$ vinyldns record-set --zone-id 89e21e9a-581c-424c-a006-7cb1c4bbcd32 --record-set-id 5862d275-79b8-4689-97ab-4bf16327baeb
panic: interface conversion: interface {} is int, not string
goroutine 1 [running]:
main.getRecordValue(...)
/Users/mball0001/dev/go/src/github.com/vinyldns/vinyldns-cli/vinyldns.go:745
main.getRecord(0xc420012900, 0x1, 0x4, 0x7ffeefbff1cb, 0x24)
/Users/mball0001/dev/go/src/github.com/vinyldns/vinyldns-cli/vinyldns.go:721 +0x19b2
main.recordSet(0xc4200cc840, 0x100, 0xc4200cc840)
/Users/mball0001/dev/go/src/github.com/vinyldns/vinyldns-cli/vinyldns.go:590 +0x19e
github.com/vinyldns/vinyldns-cli/vendor/github.com/urfave/cli.HandleAction(0x131eea0, 0x13a6da8, 0xc4200cc840, 0xc420010400, 0x0)
/Users/mball0001/dev/go/src/github.com/vinyldns/vinyldns-cli/vendor/github.com/urfave/cli/app.go:490 +0xc8
github.com/vinyldns/vinyldns-cli/vendor/github.com/urfave/cli.Command.Run(0x1391d87, 0xa, 0x0, 0x0, 0x0, 0x0, 0x0, 0x13a0f67, 0x3b, 0x0, ...)
/Users/mball0001/dev/go/src/github.com/vinyldns/vinyldns-cli/vendor/github.com/urfave/cli/command.go:210 +0xa36
github.com/vinyldns/vinyldns-cli/vendor/github.com/urfave/cli.(*App).Run(0xc42009a9c0, 0xc4200100c0, 0x6, 0x6, 0x0, 0x0)
/Users/mball0001/dev/go/src/github.com/vinyldns/vinyldns-cli/vendor/github.com/urfave/cli/app.go:255 +0x6a0
github.com/vinyldns/vinyldns-cli/vendor/github.com/urfave/cli.(*App).RunAndExitOnError(0xc42009a9c0)
/Users/mball0001/dev/go/src/github.com/vinyldns/vinyldns-cli/vendor/github.com/urfave/cli/app.go:276 +0x53
main.main()
/Users/mball0001/dev/go/src/github.com/vinyldns/vinyldns-cli/vinyldns.go:284 +0x19d6
```
### Versions
Only `master` at this time; no releases.
Answers:
username_0: I believe this was introduced via PR #19
Status: Issue closed
|
rossfuhrman/_why_the_lucky_markov | 424183200 | Title: Her legs were gone and the right side of his wife's head and it’s really important since it has no recollection of your speed, they can't target you with all of these, carbon _When I first began my inquiry into preeventualism, I was paying my bill.
Question:
username_0: Toot: Her legs were gone and the right side of his wife's head and it’s really important since it has no recollection of your speed, they can't target you with all of these, carbon _When I first began my inquiry into preeventualism, I was paying my bill.
One comment = 1 upvote. Sometime after this gets 2 upvotes, it will be posted to the main account at https://mastodon.xyz/@_why_toots |
edrlab/thorium-reader | 1186937407 | Title: Some Hachette EPUBs have section element inside body, with height = 100%, causing cover image hiding
Question:
username_0: ...to be precise, there is a short visible flash, followed by the image hiding. This is because of position = relative injected on the body to position highlights (coordinates reference for annotation divs). There are several possible fixes, but one that seems to work is adding height = inherit on the body element, alongside position = relative. This needs further testing for edge cases (single vs. multiple CSS columns, scroll mode, etc.) |
guanshuo/incos | 201332267 | Title: Dockerfile
Question:
username_0: FROM ubuntu:trusty
# Update packages
RUN echo "deb http://archive.ubuntu.com/ubuntu/ precise universe" >> /etc/apt/sources.list
RUN echo "deb http://nginx.org/packages/ubuntu/ trusty nginx" >> /etc/apt/sources.list
RUN echo "deb-src http://nginx.org/packages/ubuntu/ trusty nginx" >> /etc/apt/sources.list && apt-get update
# install curl, wget,sql ,server
RUN apt-get install -y curl wget git unzip python-software-properties python-setuptools openssh-server software-properties-common debian-archive-keyring
RUN add-apt-repository -y ppa:ondrej/php && apt-get update
RUN apt-get install -y --force-yes mysql-server mysql-client memcached php7.0 php7.0-fpm php7.0-mysql php7.0-curl php7.0-gd php7.0-imap php7.0-json php7.0-cli php7.0-xml php-memcache nginx
# Install Supervisor & tingyun
RUN /usr/bin/easy_install supervisor && /usr/bin/easy_install supervisor-stdout
RUN wget http://download.tingyun.com/agent/php/2.5.0/tingyun-agent-php-2.5.0.x86_64.deb?a=1479890082446 -O tingyun-agent-php.deb
RUN wget http://download.tingyun.com/agent/system/1.1.1/tingyun-agent-system-1.1.1.x86_64.deb?a=1479890139704 -O tingyun-agent-system.deb
RUN sudo dpkg -i tingyun-agent-php.deb
RUN sudo dpkg -i tingyun-agent-system.deb
# Start
ADD start.sh /start.sh
RUN sed -i -e 's/\r//g' /start.sh && sed -i -e 's/^M//g' /start.sh && chmod +x /*.sh
VOLUME ["/data"]
EXPOSE 22 80 3306 11211
CMD ["/bin/bash", "/start.sh"] |
unisonweb/unison | 1058818941 | Title: M2k Release Notes
Question:
username_0: Our last release was [M2k](https://github.com/unisonweb/unison/releases/tag/release%2FM2g). Here's a summary of what's new since then:
*
* ... aaand more! See the [full list of PRs merged](#prs-merged) below.
## Upgrading
### How to upgrade from an M1 series codebase
_If you're already using an M2 series release (try `ucm version` if unsure), you can skip this section._
If you still have a V1 codebase, `ucm upgrade-codebase` can be used to upgrade it to the new format. We recommend that you push the converted codebase to a fresh Git repo.
```
$ ucm upgrade-codebase
... wait a while for this to finish
$ ucm
.> push https://github.com/myusername/myunisoncode2
```
Where `myusername/myunisoncode2` is a fresh Git repo.
If your codebase isn't in the default location (of `~/.unison`), you can pass the `--codebase` flag:
```
$ ucm --codebase /path/to/mycode upgrade-codebase
```
[Let us know in Slack](https://unisonweb.org/slack) if you encounter any trouble with this.
### Fetching the latest base library
```
.> pull https://github.com/unisonweb/base:.releases._M2k .base_m2k
```
You can then (optionally) `delete.namespace` any old versions of base you have laying around. This will complain if you're still referencing definitions from the old version of base.
If you have definitions that depend on old definitions, you can find that out by doing:
```
.mycode> todo .base_m2h.patch
```
If you do have things todo, applying the patch to your namespace will replace the old versions with the new. We recommend forking a copy of your namespace before doing this:
```
.> fork mycode mycode2
.mycode2> patch .base_m2k.patch
.mycode2> todo .base_m2k.patch
```
Assuming that reports "Nothing to do", you can `delete.namespace mycode` and then `delete.namespace` your old version of base. If you encounter any trouble, stop by [the Slack in #alphatesting](https://unisonweb.org) and we can help.
## Known issues
* Only unknown issues exists ;)
## What's coming in future releases?
[Truncated]
#2533 from unisonweb/topic/fix2271
#2529 from unisonweb/21-10-20-base32
#2525 from unisonweb/cp/git-fix
#2524 from unisonweb/fix/mvar-read
#2511 from unisonweb/cp/globbing
#2523 from unisonweb/21-10-19-empty-add
#2513 from unisonweb/21-10-18-relation-optimizations
#2509 from unisonweb/cp/name-renaming
#2504 from unisonweb/cp/better-namespace-completions
#2498 from unisonweb/cp/catch-ctrl-c-haskeline
#2499 from unisonweb/topic/v1-cleanup
#2494 from unisonweb/topic/standalone-binaries
#2477 from unisonweb/21-10-07-no-empty-names
#2486 from unisonweb/cp/no-duplicate-builds
#2485 from unisonweb/cp/split-cli
#2484 from unisonweb/cp/add-relation-benchmarks
#2478 from unisonweb/cp/add-relation-benchmarks
#2475 from unisonweb/topic/lts-18.13
#2470 from unisonweb/21-10-06-relation-difference
#2469 from unisonweb/cp/2453-better-ambiguity-message<issue_closed>
Status: Issue closed |
winwisely99/main | 539306976 | Title: BIZ: Web demo - update home page
Question:
username_0: See issue here -
https://docs.google.com/document/d/1lEVT46F4Lia7orInXIzyGzzB_aKVzJsoRLW_F6FbDfI/edit?folder=1gAT5POcyQciRGXKoiVR7A8pMkokAD5Dk
Answers:
username_0: hey @username_1 this is the issue I made for the home page, can you have a look at it and see if it makes sense on your end? (:
username_1: 1. Change to My Campaign
2. User actions at the end of Campaign Details
3. Show only user enrolled Campaigns
Status: Issue closed
|
nrwl/nx | 472284597 | Title: create-nx-workspace not found
Question:
username_0: _[Please make sure you have read the submission guidelines before posting an issue](https://github.com/nrwl/nx/blob/master/CONTRIBUTING.md#-submitting-issue)_
# Prerequisites
Please answer the following questions for yourself before submitting an issue.
**YOU MAY DELETE THE PREREQUISITES SECTION.**
- [x] I am running the latest version
- [ ] I checked the documentation and found no answer
- [x] I checked to make sure that this issue has not already been filed
- [x] I'm reporting the issue to the correct repository (not related to Angular, AngularCLI or any dependency)
## Expected Behavior
`create-nx-workspace` should exists
## Current Behavior
create-nx-workspace not found after install 8.3.0
## Failure Information (for bugs)
create-nx-workspace not found
### Steps to Reproduce
Please provide detailed steps for reproducing the issue.
1. Just install the latests version (8.3.0)
2. Run `create-nx-workspace demo-project`
### Context
Please provide any relevant information about your setup:
- version of Nx used: 8.3.0
- version of Angular CLI used
- `angular.json` configuration
- version of Angular DevKit used
- 3rd-party libraries and their versions
- and most importantly - a use-case that fails
**A minimal reproduce scenario using allows us to quickly confirm a bug (or point out coding problem) as well as confirm that we are fixing the right problem.**
### Failure Logs
Please include any relevant log snippets or files here.
## Other
Any other relevant information that will help us help you.
Answers:
username_1: I am not sure which package you are installing here.
You can run `npx create-nx-workspace@latest demo-project` to automate the installation.
username_0: @username_1 the package is `@nrwl/workspace`, installed with `npm install -g @nrwl/workspace`... Also missing in version 8.4.0
username_2: @username_0 You can install it globally via `npm install -g create-nx-workspace`. We reworked the packages in 8.x so `@nrwl/schematics` does not provide this binary anymore.
We recommend running the create workspace using one of the three methods below.
**npx**
```
npx create-nx-workspace myworkspace
```
**npm**
```
npm init nx-workspace myworkspace
```
**yarn**
```
yarn create nx-workspace myworkspace
```
Status: Issue closed
username_2: Closed this issue, let us know if you have any further problems. |
frontendbr/forum | 363284385 | Title: Imposto de renda e Paypal
Question:
username_0: Olá, vim parar aqui no fórum pelo Google e gostaria de tirar uma dúvida sobre imposto de renda. Eu não sou programador, mas vou começar a trabalhar pela internet e vou receber pelo Paypal algo em torno de 200 dólares todo mês. Não entendo nada sobre imposto de renda e não sei se é esperado que eu declare esse valor ou não, mesmo estando bem abaixo do valor mínimo. São muitas regras e cada hora eu leio algo diferente na internet. Eu sei que é um valor baixo e a pergunta pode ser meio estúpida, mas eu sei que até dividendos de ações por menores que sejam têm que ser declarados, então eu não sei o que concluir.
Como sei se posso receber esse valor sem me preocupar com declarar? Obrigado.
Answers:
username_1: Até onde eu lembro, por lei você só é obrigado a declarar imposto de renda se sua renda anual passar de 28.000 e uns quebrados.
username_0: Não tem uma lei que te obriga a declarar se você mandar o dinheiro que está no Paypal para uma conta bancária?
username_2: É uma pergunta bem técnica da área contábil. Acredito que seja um valor baixo para se preocupar, mas caso você esteja interessado em estar 100% correto perante as leis tributárias do Brasil, acredito que seria mais seguro você postar esta pergunta em um fórum contábil (https://www.contabeis.com.br/forum/) ou até mesmo no Jusbrasil (https://www.jusbrasil.com.br), para ver se algum advogado tributarista se dispõe a ajudar nesta dúvida.
Receber como empresa talvez envolveria coisa sobre "exportação de serviço" e então complicaria mais, e, só valeria a pena se essa valor recebido fosse multiplicado por 100 ou 1000.
username_3: Veja se ajuda #124
username_0: Bom, liguei para um escritório de contabilidade, falei com um contador e ele disse que desde que não bata os ~R$28.000,00 anuais, não tenho que declarar nada a ninguém, independente da moeda. Espero que ele esteja correto.
Obrigado a todos.
Status: Issue closed
|
docker/compose | 88266561 | Title: Failed to limit memory with docker compose
Question:
username_0: My server has __2GB__ mem
I launched __2 containers__ in the server with docker-compose
Although I set the memory limiti, but it seems not work
# docker-compose
hub:
mem_limit: 256m
image: selenium/hub
ports:
- "4444:4444"
test:
mem_limit: 256m
build: ./
links:
- hub
ports:
- "5900"
Answers:
username_1: In your `docker-compose` file why you use `./` at the front of build?
Do you want to build an image from Dockerfile?
maybe you need to change that to '.'
username_2: might be related to #1333
username_3: Could you paste the output of `docker inspect` on each of your containers?
username_4: I got similar problem so I tried set memory limit to `docker run` and I got
```
WARNING: Your kernel does not support cgroup swap limit. WARNING: Your
kernel does not support swap limit capabilities. Limitation discarded.
```
the `docker-compose` does not show this warning.
https://docs.docker.com/engine/installation/ubuntulinux/#adjust-memory-and-swap-accounting with recreation of containers worked for me. |
rapidsai/cudf | 691523919 | Title: Add null_order parameter to cudf::detail::drop_duplicates
Question:
username_0: `cudf::detail::drop_duplicates` orders nulls first, but `cudf::encode` needs them ordered last (per #5779). To account for this, two additional kernels are invoked. It would beneficial to give `drop_duplicates` a `null_order` parameter so these two calls could be avoided.
Answers:
username_1: L |
kmfarley11/PokeYellow_Cpp | 133879692 | Title: PT-1: Implement a Room Object
Question:
username_0: Step one will be to create a Room object which will fill the background of the SDL window.
Research and coding will need to be done to implement this. Consider the design options for a modular implementation. There are many rooms in this game... some will require scrolling, all will have unique wall and door coordinates, they will require player and npc interactions as well.
This issue will not close until a solid foundation is made.
Answers:
username_0: In terms of modular implementation, the best option may be to create or utilize a tmx parser so that we can easily make and modify Tiled grids for the maps. This will allow for easier collision checking and image abstraction. |
lervag/vimtex | 602924514 | Title: Folds jump open and closed in rnoweb filetype
Question:
username_0: I'm really enjoying the vimtex plugin, thanks so much for your great work. I'm having an issue with folding rnoweb files, and and am not sure whether the fix should come from vimtex or from the maintainers of rnoweb.vim. Here is my description:
**Issue**
When using folding with manual folding enabled, folds in rnoweb files jump open as soon as the cursor enters the folded line, and then jump closed again when the cursor leaves. The effect is disorienting.
**minimal.vim**
```vim
set nocompatible
let &rtp = '~/.vim/bundle/vimtex,' . &rtp
let &rtp .= '~/,.vim/bundle/vimtex/after'
filetype plugin indent on
syntax enable
let g:vimtex_fold_enabled=1
let g:vimtex_fold_manual=1
```
**minimal.Rnw**
```tex
\documentclass{minimal}
% This is a preamble comment
% to get a few lines to fold
\begin{document}
\section{The first section}
It has a couple of lines.
It has a couple of lines.
\section{The second section}
This one does, too.
This one does, too.
\end{document}
```
**Commands/Input**
`vim -u minimal.vim minimal.Rnw`
Open the file and move vertically through it.
**Observed Behaviour**
The preamble and section folds jump open and closed.
**Expected Behaviour**
The folds stay closed until user presses `zo` or something else to open the fold.
**A temporary fix**
It appears that `vimtex#fold#init#buffer` in `autoload/vimtex/fold.vim` gets called twice when opening a rnoweb file, and the autocommand which calls the `fold_manual_refresh` function gets created twice but only deleted once. To be honest, my vimscript powers are not up to figuring out exactly what's going on in this function, but I did find that a check to only call `vimtex#fold#init#buffer` once seems to fix the problem for me:
```patch
@@ -6,7 +6,9 @@
function! vimtex#fold#init_buffer() abort " {{{1
if !g:vimtex_fold_enabled
- \ || s:foldmethod_in_modeline() | return | endif
[Truncated]
output: /tmp/vzeLv4g/1
configuration:
continuous: 1
callback: 1
latexmk options:
-verbose
-file-line-error
-synctex=1
-interaction=nonstopmode
latexmk engine: -pdf
viewer: General
qf: LaTeX logfile
config:
packages:
default: 1
default: 1
document class: minimal
packages:
amsmath
fullpage
Answers:
username_1: I've tested your minimal example, and I can't reproduce it. Things work as expected on my end. I've tested with both Vim (v8.2.510) and neovim (v0.5.0).
However, the issue seems related to the `:help 'foldopen'` and `:help 'foldclose'` options. Could you check that these are at their default values?
----
Your patch really should not be necessary, because `vimtex#fold#init_buffer` is called by `s:init_buffer` in `autoload/vimtex.vim`, which is called by `vimtex#init`, which is called by `ftplugin/tex.vim` from vimtex. The latter has a guard already that should prevent `vimtex#init` from being called twice in the same buffer.
Are you sure that the `fold#init_buffer` is called twice when you start with the minimal Vim file? You could test with something like this:
```diff
diff --git a/autoload/vimtex/fold.vim b/autoload/vimtex/fold.vim
index 097313cc..15fecb58 100644
--- a/autoload/vimtex/fold.vim
+++ b/autoload/vimtex/fold.vim
@@ -4,9 +4,12 @@
" Email: <EMAIL>
"
+let s:count = 0
function! vimtex#fold#init_buffer() abort " {{{1
if !g:vimtex_fold_enabled
\ || s:foldmethod_in_modeline() | return | endif
+ let s:count += 1
+ unsilent echom 'init_buffer call #' . s:count
" Set fold options
setlocal foldmethod=expr
```
Note: I've made some minor simplifications of the code, but I don't think it should matter to your issue.
username_0: I think I see these on Github, but I have not updated my plugin code to get them. I can do that if you like.
username_1: Ok; this is strange. Can you move the test code into the `ftplugin/tex.vim` file and check if my suspicion is correct that the issue is related to the loading of the filetype plugin? Let me know if you need help with it.
Reg. recent updates: they should not solve the issue, but I suggest that you generally try to keep up with updates as I continuosly maintain, update, and improve vimtex.
username_0: When I delete the contents of `autoload/vimtex/fold.vim` and append them to `ftplugin/tex.vim` and then run `vim -u minimal.vim minimal.Rnw` I get the same messages.
username_0: Wait, no! Sorry, I do **not** get the same messages, I get
```
"file.Rnw" 19L, 271C
init_buffer call #1
init_buffer call #1
```
username_1: So, this means that for you, with `.Rnw` files, vimtex is loaded twice. If you look at the code in `ftplugin/tex.vim`, it should be quite simple. In particular, there's a guard:
```vim
if exists('b:did_ftplugin')
finish
endif
let b:did_ftplugin = 1
```
This _should_ prevent vimtex from being loaded twice. My next debug step would be to check the value of `b:did_ftplugin`. Something like this:
```vim
unsilent echo 'test' &filetype
unsilent echo 'test' exists('b:did_ftplugin')
if exists('b:did_ftplugin')
finish
endif
let b:did_ftplugin = 1
```
username_1: It still seems to give two messages, though? The counter code may be wrong here? (I.e. if you reset the counter when the file is sourced the second time, then the counter should be the same both times.)
username_0: Yes, still two messages, so it does look like the code is getting called twice. Here are the messages when opening the file with the `b:did_ftplugin` test code you give:
```
"file.Rnw" 19L, 271C
test rnoweb
test 0
init_buffer call #1
test rnoweb
test 0
init_buffer call #1
```
username_1: And this happens when you use the minimal vimrc file, i.e. `vim -u minimal.vim minimal.Rnw`?
What's the output of `:scriptnames` after you open with the minimal.vim file?
username_0: Yes, all of this is with `vim -u minimal.vim minimal.Rnw`. Here's the output of `:scriptnames` after that invocation of vim:
```
1: ~/vimtest/minimal.vim
2: /usr/local/share/vim/vim82/filetype.vim
3: ~/.vim/ftdetect/nope_Rnw.vim
4: /usr/local/share/vim/vim82/ftplugin.vim
5: /usr/local/share/vim/vim82/indent.vim
6: /usr/local/share/vim/vim82/syntax/syntax.vim
7: /usr/local/share/vim/vim82/syntax/synload.vim
8: /usr/local/share/vim/vim82/syntax/syncolor.vim
9: /usr/local/share/vim/vim82/plugin/getscriptPlugin.vim
10: /usr/local/share/vim/vim82/plugin/gzip.vim
11: /usr/local/share/vim/vim82/plugin/logiPat.vim
12: /usr/local/share/vim/vim82/plugin/manpager.vim
13: /usr/local/share/vim/vim82/plugin/matchparen.vim
14: /usr/local/share/vim/vim82/plugin/netrwPlugin.vim
15: /usr/local/share/vim/vim82/plugin/rrhelper.vim
16: /usr/local/share/vim/vim82/plugin/spellfile.vim
17: /usr/local/share/vim/vim82/plugin/tarPlugin.vim
18: /usr/local/share/vim/vim82/plugin/tohtml.vim
19: /usr/local/share/vim/vim82/plugin/vimballPlugin.vim
20: /usr/local/share/vim/vim82/plugin/zipPlugin.vim
21: /usr/local/share/vim/vim82/ftplugin/rnoweb.vim
22: ~/.vim/bundle/vimtex/ftplugin/tex.vim
23: ~/.vim/bundle/vimtex/autoload/vimtex.vim
24: ~/.vim/bundle/vimtex/autoload/vimtex/util.vim
25: ~/.vim/bundle/vimtex/autoload/vimtex/state.vim
26: ~/.vim/bundle/vimtex/autoload/vimtex/re.vim
27: ~/.vim/bundle/vimtex/autoload/vimtex/parser.vim
28: ~/.vim/bundle/vimtex/autoload/vimtex/parser/tex.vim
29: ~/.vim/bundle/vimtex/autoload/vimtex/cache.vim
30: ~/.vim/bundle/vimtex/autoload/vimtex/paths.vim
31: ~/.vim/bundle/vimtex/autoload/vimtex/view.vim
32: ~/.vim/bundle/vimtex/autoload/vimtex/view/general.vim
33: ~/.vim/bundle/vimtex/autoload/vimtex/view/common.vim
34: ~/.vim/bundle/vimtex/autoload/vimtex/compiler.vim
35: ~/.vim/bundle/vimtex/autoload/vimtex/compiler/latexmk.vim
36: ~/.vim/bundle/vimtex/autoload/vimtex/qf.vim
37: ~/.vim/bundle/vimtex/autoload/vimtex/qf/latexlog.vim
38: ~/.vim/bundle/vimtex/autoload/vimtex/toc.vim
39: ~/.vim/bundle/vimtex/autoload/vimtex/fold.vim
40: ~/.vim/bundle/vimtex/autoload/vimtex/fold/envs.vim
41: ~/.vim/bundle/vimtex/autoload/vimtex/fold/cmd_single_opt.vim
42: ~/.vim/bundle/vimtex/autoload/vimtex/fold/markers.vim
43: ~/.vim/bundle/vimtex/autoload/vimtex/fold/preamble.vim
44: ~/.vim/bundle/vimtex/autoload/vimtex/fold/sections.vim
45: ~/.vim/bundle/vimtex/autoload/vimtex/fold/cmd_addplot.vim
46: ~/.vim/bundle/vimtex/autoload/vimtex/fold/env_options.vim
47: ~/.vim/bundle/vimtex/autoload/vimtex/fold/cmd_multi.vim
48: ~/.vim/bundle/vimtex/autoload/vimtex/fold/cmd_single.vim
49: ~/.vim/bundle/vimtex/autoload/vimtex/parser/fls.vim
50: ~/.vim/bundle/vimtex/autoload/vimtex/cmd.vim
51: ~/.vim/bundle/vimtex/autoload/vimtex/complete.vim
52: ~/.vim/bundle/vimtex/autoload/vimtex/debug.vim
53: ~/.vim/bundle/vimtex/autoload/vimtex/delim.vim
54: ~/.vim/bundle/vimtex/autoload/vimtex/doc.vim
55: ~/.vim/bundle/vimtex/autoload/vimtex/echo.vim
56: ~/.vim/bundle/vimtex/autoload/vimtex/env.vim
57: ~/.vim/bundle/vimtex/autoload/vimtex/pos.vim
58: ~/.vim/bundle/vimtex/autoload/vimtex/format.vim
[Truncated]
64: ~/.vim/bundle/vimtex/autoload/vimtex/log.vim
65: ~/.vim/bundle/vimtex/autoload/vimtex/matchparen.vim
66: ~/.vim/bundle/vimtex/autoload/vimtex/misc.vim
67: ~/.vim/bundle/vimtex/autoload/vimtex/motion.vim
68: ~/.vim/bundle/vimtex/autoload/vimtex/process.vim
69: ~/.vim/bundle/vimtex/autoload/vimtex/profile.vim
70: ~/.vim/bundle/vimtex/autoload/vimtex/scratch.vim
71: ~/.vim/bundle/vimtex/autoload/vimtex/syntax.vim
72: ~/.vim/bundle/vimtex/autoload/vimtex/test.vim
73: ~/.vim/bundle/vimtex/autoload/vimtex/text_obj.vim
74: ~/.vim/bundle/vimtex/autoload/vimtex/text_obj/targets.vim
75: ~/.vim/ftplugin/tex.vim
76: /usr/local/share/vim/vim82/ftplugin/tex.vim
77: /usr/local/share/vim/vim82/indent/rnoweb.vim
78: ~/.vim/bundle/vimtex/indent/tex.vim
79: /usr/local/share/vim/vim82/indent/r.vim
80: /usr/local/share/vim/vim82/syntax/rnoweb.vim
81: /usr/local/share/vim/vim82/syntax/tex.vim
82: /usr/local/share/vim/vim82/syntax/r.vim
```
username_1: Two scripts stand out:
```
3: ~/.vim/ftdetect/nope_Rnw.vim
75: ~/.vim/ftplugin/tex.vim
```
What are these?
username_0: I was just noticing `nope_Rnw.vim` myself after i posted that. The `nope_` was meant to disable it but as I now realize, that doesn't work. The file contains:
```vim
" Vim filetype detection plugin
" " Language: rnoweb
"
autocmd BufRead,BufNewFile *.Rnw set filetype=rnoweb
```
I must have put that there ages ago, I don't remember why. If I remove it, it looks like vimtex is only loaded once when started with `minimal.vim`, and folding on the test file works as expected.
I am sorry for dragging you into what turns out to be a lousy configuration of my own!
username_1: No problem! I like debugging in general (it's just like solving a mystery), and I'm happy that I could be of help :)
Status: Issue closed
|
csudhlib/primo-explore-google-analytics | 311393793 | Title: Not an issue, Just a question
Question:
username_0: Thanks for sharing! Can you talk a little in the readme about how you might handle event tracking using this code if it is possible? Also curious about the matomo stuff, is that a CSU specific thing?
Thanks!
Dean
Answers:
username_1: I'll have to do some research into event tracking as I've never used it.
Matomo is just a 3rd party analytics platform that we've adopted at CSUDH. |
mobizt/Firebase-ESP32 | 863297110 | Title: BUG
Question:
username_0: After the latest update i ran into this error
In file included from C:\Users\ad\Documents\Arduino\ArduinoFirebase-2\ArduinoFirebase-2.ino:4:0:
C:\Users\ad\Documents\Arduino\libraries\Firebase_ESP32_Client\src/FirebaseESP32.h:1691:45: error: 'fb_esp_fcm_msg_type' has not been declared
bool handleFCMRequest(FirebaseData &fbdo, fb_esp_fcm_msg_type messageType);
^
Is there a fix to this? or should i just roll back the updates
Answers:
username_1: This is not a bug unless the installation problem.
I check and test it already and the enum is already here.
https://github.com/username_1/Firebase-ESP32/blob/4ee7acd7b8b62e719207d139b87a8dbb54377945/src/session/FB_Session.h#L44
Uninstall and install again. If the error still existed, try [this example](https://github.com/username_1/Firebase-ESP32/blob/master/examples/Cloud_Messaging/Cloud_Messaging.ino).
If no error with the example and error only with your working code you should check the third party libraries included.
You should copy the full compile error and post here.
Status: Issue closed
username_1: Even with the v3.8.25 the enum is already here as the same with latest version.
https://github.com/username_1/Firebase-ESP32/blob/005f47409de46f4900b49662a9729d3c3690a437/src/session/FB_Session.h#L44 |
BuiltBrokenModding/Assembly-Line | 331054473 | Title: Add: detector
Question:
username_0: The detector was a block from the original mod to detect items and output redstone. This needs to be implemented to allow stopping belts and automating sorting.
For the most part this will work as a simple redstone object.
IF ITEM MATCHES FILTER
---EMMIT REDSTONE
However, it should also work as a pipe belt upgrade. In which it can be used to automate sorting and work to stop the belt.
How I see this work is that a user will need to craft a sorting upgrade and rejector upgrade with the detector. Then these upgrades can be installed in the belts to function. The model of the belt will show the detector above the center of the belt. This will help explain how the belt works for sorting or rejecting items. As well help reuse the detector beyond basic Redstone.
Answers:
username_0: Side note: detector should have the option to render a red triangle scanner beam.... just for the cool factor

Would look like the image above, but point down & without the shadow object thing.
username_0: Another thought, we could have the detector have a draw back. In which it will slow down how quickly items move through the belt (aka needs to scan the item). This will create a design challange and reason to make several detector chains. We could also use this as a reason to add tiers and detector fail chances. |
reapit/foundations | 627174405 | Title: Contact name not correctly trimmed
Question:
username_0: The contact name is not correctly trimmed leading to odd looking output. Some legacy Reapit systems did not trim trailing spaces correctly so we need to make sure this is properly cleaned before being output to the consumer
See example image
<issue_closed>
Status: Issue closed |
hannesdatta/course-odcm | 783099197 | Title: open edu logo?
Question:
username_0: Hi Andrea,
could you please think about a quick way to energise this logo a bit? The notion needs to be that this is TilburgU, but open! Like Tilburg University (with a small text): open education? Or something like this? Buzzy, marketing-ish. Would be cool if you could think about it for a minute or so ;).
<img width="445" alt="image" src="https://user-images.githubusercontent.com/16557730/104151355-1cbda300-53dd-11eb-8129-7cbddcceeb2b.png">
Answers:
username_0: @username_1, any quick inspiration on extending the TiU logo with something that shows this is an open education course?

If you're in the designer mode, I'm curious to hear your suggestions.
username_1: I'm on it
Status: Issue closed
|
swash99/ims | 234367805 | Title: Handle username case insensitively
Question:
username_0: Ensure that regardless of what case is used for username when creating it or logging in, we want to handle it insensitively within our system. This can be done by converting it to lowercase on creation and login and storing/using it in that form.<issue_closed>
Status: Issue closed |
bechirbenhassine/Sprint_2_Fil_Rouge | 198978571 | Title: Comments on file 5
Question:
username_0: -Peux-tu nous fournir le fichier Excel sur lequel tu as fait tes analyses ?
-Tu parles dans le rapport de table de survie déduite des données. En fait, faut être vigilent au fait que c'est une table de mortalité et invalidité et non mortalité (éclaircir ce qu'est la différence entre cette table et la table de mortalité)
-Rajouter une partie expliquant de ce que c'est l'invalidité.
-J'arrive pas à cerner la logique derrière le truc en glm ? Tes variables expliquatives expliques quoi au juste ?
-Rajouter une partie sur ce qu'on a vu en cours par exemple estimateur de kaplan-meyer pour l'invalidité par exemple et faire des analyses par rapport à l'âge et l'ancienneté, etc.
Un lien qui peut-être très utile :
http://www.ressources-actuarielles.net/EXT/ISFA/fp-isfa.nsf/34a14c286dfb0903c1256ffd00502d73/a0d8fe4a9807886ac1257d11002a0be9/$FILE/presentation.pdf |
MicrosoftDocs/azure-docs | 1148602623 | Title: Documentation for adding database autoscaling references section not present in DataExplorer
Question:
username_0: The documentation states that there's a "Scale" section in dataexplorer for adding autoscaling at the database level (the database I'm using wasn't initially created with database scope autoscaling). However, there is no such section. Please repair or update the documentation to reflect that adding autoscaling at the database level is impossible after the database has been created.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 3ab1e9e0-c5b1-b219-ee39-4252926aff6f
* Version Independent ID: a8f6ada3-9310-d2f9-401b-72b69bf4d76a
* Content: [Provision autoscale throughput in Azure Cosmos DB SQL API](https://docs.microsoft.com/en-us/azure/cosmos-db/sql/how-to-provision-autoscale-throughput?tabs=api-async)
* Content Source: [articles/cosmos-db/sql/how-to-provision-autoscale-throughput.md](https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/cosmos-db/sql/how-to-provision-autoscale-throughput.md)
* Service: **cosmos-db**
* Sub-service: **cosmosdb-sql**
* GitHub Login: @deborahc
* Microsoft Alias: **dech**
Answers:
username_0: Update: It seems that cosmosdb does not allow adding database scope autoscaling after the database has been created. This wasn't at all clear from the documentation.
Azure support pointed me to "To provision autoscale on shared throughput database, select the Provision database throughput option when creating a new database". This is in a section on creating a new database and is immediately followed by the "Enable autoscale on existing database or container" header, strongly implying that autoscaling can be enabled on the database later.
Further, there are no examples of ARM templates where autoscaling is enabled at database scope. Most Azure customers eventually move to templates, and this gap would lead to them creating databases from template without realizing that adding autoscaling later is impossible.
Ideally this feature gap should be closed by allowing autoscaling to be added to existing databases. If not, the fact that autoscaling must be set up at creation time should be explicitly stated and examples should include the autoscaling configuration.
username_1: @username_0 Thank you for your feedback. We are reviewing this and get back shortly.
username_1: @username_0 I went through the doc and was not able to find where it is mentioned that Scale" section in data explorer for adding autoscaling at the database level. Could you please take a screen shot and highlight the section where that statement is mentioned?
username_0: Sorry. I responded to the email and it didn't upload the screenshot correctly.

username_2: **Issue:** The documentation for enabling autoscale on an existing database doesn't explicitly say that if you don't provision the database with the autoscale enabled, you cannot then later enable the autoscale. My customer finds this to be misleading as the documentation currently offers instructions on how to enable autoscale on existing databases, which would imply autoscale wasn't enabled on the DB before.
Current Doc [Provision autoscale throughput in Azure Cosmos DB SQL API | Microsoft Docs](https://docs.microsoft.com/en-us/azure/cosmos-db/sql/how-to-provision-autoscale-throughput?tabs=api-async#enable-autoscale-on-existing-database-or-container)

The doc does mention provisioning autoscale while creating the database on the previous step, but context is missing that this is necessary if business needs change and future autoscale option is desired.

**Ask:** Due to this there is no work around so it's a reasonable ask that we update the documentation to prevent future confusion.
**Impact:** The customer does not want to have to delete production databases in order to enable this feature. Suggestions to create a new database and migrate the data were considered but not preferred.
**Referring to the ARM template:** It explicitly say in the doc that "You can use ARM templates to update the autoscale setting on database and container resources already configured with autoscale."
username_1: @username_0 Any resource in Cosmos DB can always use autoscale. Enabling autoscale on an existing database or container can only be done via Azure Portal, CLI, or PowerShell. By design, enabling autoscale on an existing database or container is not supported via SDKs or ARM template
Status: Issue closed
username_1: The documentation states that there's a "Scale" section in dataexplorer for adding autoscaling at the database level (the database I'm using wasn't initially created with database scope autoscaling). However, there is no such section. Please repair or update the documentation to reflect that adding autoscaling at the database level is impossible after the database has been created.
---
#### Document Details
⚠ *Do not edit this section. It is required for docs.microsoft.com ➟ GitHub issue linking.*
* ID: 3ab1e9e0-c5b1-b219-ee39-4252926aff6f
* Version Independent ID: a8f6ada3-9310-d2f9-401b-72b69bf4d76a
* Content: [Provision autoscale throughput in Azure Cosmos DB SQL API](https://docs.microsoft.com/en-us/azure/cosmos-db/sql/how-to-provision-autoscale-throughput?tabs=api-async)
* Content Source: [articles/cosmos-db/sql/how-to-provision-autoscale-throughput.md](https://github.com/MicrosoftDocs/azure-docs/blob/master/articles/cosmos-db/sql/how-to-provision-autoscale-throughput.md)
* Service: **cosmos-db**
* Sub-service: **cosmosdb-sql**
* GitHub Login: @deborahc
* Microsoft Alias: **dech**
username_1: @deborahc Could you please provide more insights on the above.
username_0: This is false. A cosmosdb sql database _that was created by ARM template_ without autoscaling enabled can't ever be converted to autoscale at the database scope. This is because when created from the portal, the portal automagically adds properties to provision for the possibility of adding autoscaling in the future. These properties are not automatically added to the resource if created from ARM template. Invoke-AzCosmosDBSqlDatabaseThroughputMigration does not work in this case.
username_0: In fact, the sample ARM template doesn't include the options section needed to make it possible to add autoscaling in the future, so a customer who uses the sample will never be able to add database scope autoscaling. https://docs.microsoft.com/en-us/azure/cosmos-db/sql/quick-create-template?tabs=CLI
username_1: @Markbrown could you please bring some clarity on the above feedback. Thanks
username_0: This is precisely the point of this documentation issue. There's this one corner scenario where adding throughput to a database is impossible, called out in one place on the docs (that I can't even find again), among over a dozen articles, quickstarts, and how-tos either strongly implying or outright stating that any database and container resource can be migrated back and forth.
@username_3 If I ran the template [_referenced on the template samples page you linked_](https://docs.microsoft.com/en-us/azure/cosmos-db/sql/manage-with-templates#create-autoscale), wouldn't I get into a scenario where it's impossible to add autoscale at the database scope? There's no options block on the database in that template. Where does that template sample warn about being in this case? Where do all of the documents about migrating throughput state that it's not applicable if the database wasn't initially created with autoscaling?
Please don't assume that every customer read every single article end to end and understood it exactly the way you do. It is incredibly easy to miss that this inability to add throughput after creation scenario exists. This is a serious problem because there is no resolution available other than recreating an active database.
username_3: If you want to use that ARM template to provision throughput for a database then just add the options block you see for the container to the database resource. If you need an example of that you can look at our Mongo ARM template samples where this is demonstrated.
I don't think we make any assumptions on how much of our docs customers read. But we do expect that customers looking for answers will search through and read our docs for answers and if they cannot find answers will turn to forums such as Stack Overflow or Microsoft Q&A to ask question or even turn here.
username_3: Spoke with cx. As mentioned, this is not something we see customers running into.
We will however look into where we might document this with a Note or Tip in our docs on throughput.
Thanks for raising.
#please-close
Status: Issue closed
|
jandelgado/lede-dockerbuilder | 583360410 | Title: Cache packages
Question:
username_0: Hi, I know this is might be an issue with LEDE/Openwrt's build tools but each build requires a download of every package.
I'd love to provide a solution but I wasn't able to find one without some sort of http proxy.
Answers:
username_0: I was able to do this by adding the following variable to the docker file and running a proxy. Maybe this isn't such an issue but downloads can take 5 mins for a simple build in Australia.
`ENV http_proxy "http://host.docker.internal:8080"`
Would be interested in anyone else who might have feedback :)
username_1: Hi, in fact, the OpenWRT packages are currently not cached and re-loaded each time a new OpenWRT image is built. I did some quick experiments and there are 2 easy options to cache the packages:
* use an external caching proxy (e.g. squid) and set `http_proxy` variables in container
* mount `/dl` as an external docker volume so that package downloads survive individual buillds
I'll come up with conrcrete examples later this weekend ...
username_0: @username_1 sounds good. Squid works well but I might see if I can mount /dl as a volume.
username_1: Release 2.4 allows to pass additional options to docker-run. This can be used to mount the downloads (`dl`) directory externally:
```
./builder.sh build example-nexx-wt3020.conf --docker-opts "-v=$(pwd)/dl:/lede/imagebuilder/dl:z"
```
See #18
username_0: I'll check it out. My internet was finally upgraded so it may be less of an issue for me.
Status: Issue closed
|
apache/shardingsphere | 1032022635 | Title: Range query problem of compound sharding algorithm
Question:
username_0: The version dependency I use is
` <dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>`
There is no problem with adding the custom compound sharding algorithm, but the range query returns an error, and the debug shows that the custom compound sharding algorithm is not entered



Answers:
username_1: Hi @username_0 , thanks for you feedback, could you try the latest version?
username_1: Regarding the error of `sqlsessionFactory`, I think you should check the configuration of mybatis.
It is more recommended that you use the latest version, and you can refer to `ModuloHintShardingAlgorithm.java` in the example
username_0: Druid's scene launcher is not compatible with druid's scene launcher. Druid's scene launcher is compatible with druid's scene launcher
 |
mikedilger/mime-multipart | 997434988 | Title: Stack overflow when attempting to display error types.
Question:
username_0: It appears that your `Display` implementation calls itself recursively forever.
reproduce with:
```Rust use crate::error::Error;
#[test]
fn display_error() {
let custom_error = std::io::Error::new(std::io::ErrorKind::Other, "oh no!");
println!("{}", Error::Io(custom_error));
}
Answers:
username_1: Well that's embarrassing. I'll take a look.
username_1: Fixed in f2cba9e1c93c9296e6115b8633ff1dcea69098c5
Status: Issue closed
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.