
repo_name
stringlengths 4
136
| issue_id
stringlengths 5
10
| text
stringlengths 37
4.84M
|
|---|---|---|
pytorch/pytorch | 544843137 | Title: A strange issue about detection of tensor in-place modification
Question:
username_0: I was implementing CTC in pure python PyTorch for fun (and possible modifications). I do alpha computation by modifying a tensor inplace. If torch.logsumexp is used in logadd, everything works fine but slower (especially on CPU). If custom logadd lines are used, I receive:
```
File "ctc.py", line 76, in <module>
custom_ctc_grad, = torch.autograd.grad(custom_ctc.sum(), logits, retain_graph = True)
File "/miniconda/lib/python3.7/site-packages/torch/autograd/__init__.py", line 157, in grad
inputs, allow_unused)
RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.cuda.FloatTensor [4, 10]], which is output 0 of SliceBackward, is at version 17; expected version 16 instead. Hint: enable anomaly detection to find the operation that failed to compute its gradient, with torch.autograd.set_detect_anomaly(True).
```
It is strange because neither logadd version does inplace, so it's not clear why version tracking is much different.
Another issues is absence of fast logsumexp (for two/three arguments) on CPU (related https://github.com/pytorch/pytorch/issues/27522). A custom version is considerably faster on CPU, not sure why. It would be nice if we have all reduction functions supporting lists of tensors to do without temporary torch.stack and not roll custom implementations.
```python
import torch
import torch.nn.functional as F
def logadd(x0, x1, x2):
# everything works if the next line is uncommented
# return torch.logsumexp(torch.stack([x0, x1, x2]), dim = 0)
# keeping the following 4 lines uncommented causes an exception
m = torch.max(torch.max(x0, x1), x2)
m = m.masked_fill(m == float('-inf'), 0)
res = (x0 - m).exp() + (x1 - m).exp() + (x2 - m).exp()
return res.log().add(m)
def ctc_alignment_targets(log_probs, targets, input_lengths, target_lengths, logits, blank = 0):
ctc_loss = F.ctc_loss(log_probs, targets, input_lengths, target_lengths, blank = blank, reduction = 'sum')
ctc_grad, = torch.autograd.grad(ctc_loss, (logits,), retain_graph = True)
temporal_mask = (torch.arange(len(log_probs), device = input_lengths.device, dtype = input_lengths.dtype).unsqueeze(1) < input_lengths.unsqueeze(0)).unsqueeze(-1)
return (log_probs.exp() * temporal_mask - ctc_grad).detach()
def ctc_loss(log_probs, targets, input_lengths, target_lengths, blank : int = 0, reduction : str = 'none', alignment : bool = False):
# https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/LossCTC.cpp#L37
# https://github.com/skaae/Lasagne-CTC/blob/master/ctc_cost.py#L162
B = torch.arange(len(targets), device = input_lengths.device)
targets_ = torch.cat([targets, targets[:, :1]], dim = -1)
targets_ = torch.stack([torch.full_like(targets_, blank), targets_], dim = -1).flatten(start_dim = -2)
diff_labels = torch.cat([torch.as_tensor([[False, False]], device = targets.device).expand(len(B), -1), targets_[:, 2:] != targets_[:, :-2]], dim = 1)
zero, zero_padding = torch.tensor(float('-inf'), device = log_probs.device, dtype = log_probs.dtype), 2
log_probs_ = log_probs.gather(-1, targets_.expand(len(log_probs), -1, -1))
log_alpha = torch.full((len(log_probs), len(B), zero_padding + targets_.shape[-1]), zero, device = log_probs.device, dtype = log_probs.dtype)
log_alpha[0, :, zero_padding + 0] = log_probs[0, :, blank]
log_alpha[0, :, zero_padding + 1] = log_probs[0, B, targets_[:, 1]]
for t in range(1, len(log_probs)):
log_alpha[t, :, 2:] = log_probs_[t] + logadd(log_alpha[t - 1, :, 2:], log_alpha[t - 1, :, 1:-1], torch.where(diff_labels, log_alpha[t - 1, :, :-2], zero))
l1l2 = log_alpha[input_lengths - 1, B].gather(-1, torch.stack([zero_padding + target_lengths * 2 - 1, zero_padding + target_lengths * 2], dim = -1))
loss = -torch.logsumexp(l1l2, dim = -1)
if not alignment:
return loss
path = torch.zeros(len(log_alpha), len(B), device = log_alpha.device, dtype = torch.int64)
path[input_lengths - 1, B] = zero_padding + 2 * target_lengths - 1 + l1l2.max(dim = -1).indices
for t in range(len(path) - 1, 1, -1):
indices = path[t]
indices_ = torch.stack([(indices - 2) * diff_labels[B, (indices - zero_padding).clamp(min = 0)], (indices - 1).clamp(min = 0), indices], dim = -1)
path[t - 1] += (indices - 2 + log_alpha[t - 1, B].gather(-1, indices_).max(dim = -1).indices).clamp(min = 0)
return torch.zeros_like(log_alpha).scatter_(-1, path.unsqueeze(-1), 1.0)[..., 3::2]
[Truncated]
builtin_ctc = F.ctc_loss(log_probs, targets, input_lengths, target_lengths, blank = 0, reduction = 'none')
print('Built-in CTC loss seconds:', tictoc() - tic)
ce_ctc = (-ctc_alignment_targets(log_probs, targets, input_lengths, target_lengths, blank = 0, logits = logits) * log_probs)
tic = tictoc()
custom_ctc = ctc_loss(log_probs, targets, input_lengths, target_lengths, blank = 0, reduction = 'none')
print('Custom CTC loss seconds:', tictoc() - tic)
builtin_ctc_grad, = torch.autograd.grad(builtin_ctc.sum(), logits, retain_graph = True)
custom_ctc_grad, = torch.autograd.grad(custom_ctc.sum(), logits, retain_graph = True)
ce_ctc_grad, = torch.autograd.grad(ce_ctc.sum(), logits, retain_graph = True)
print('Device:', device)
print('Log-probs shape:', 'x'.join(map(str, log_probs.shape)))
print('Custom loss matches:', torch.allclose(builtin_ctc, custom_ctc, rtol = rtol))
print('Grad matches:', torch.allclose(builtin_ctc_grad, custom_ctc_grad, rtol = rtol))
print('CE grad matches:', torch.allclose(builtin_ctc_grad, ce_ctc_grad, rtol = rtol))
print(builtin_ctc_grad[:, 0, :], custom_ctc_grad[:, 0, :])
```
Answers:
username_1: Hi,
This happens because in this for-loop:
```python
```
username_0: In other words, logsumexp does allocate new memory (akin to clone()) inside?
Would you have an advise how to rewrite this code to avoid this problem within framework of computing a full `log_alpha` matrix (I have a workaround that does not preserve the full matrix explicitly, but I think the full matrix iterative computation case is also an important one) without cloning and keeping PyTorch version tracking happy? E.g. would prior `torch.unbind()` and later inplace modification work?
username_1: Given that you never actually use `log_alpha` as a full Tensor, I would keep the first dimension in a list. That way, no need to do inplace on Tensor, just change the entry in the list.
username_0: Yeah, the unbind idea was also to this end! I just wanted to make sure that the tensor is allocated as a chunk (if possible) and might even be reused. When dealing with big sequences, these quadratic matrices can be huge, so allocator quirks can bite. That's why I thought of allocating one big storage (within a tensor) and then unbinding. I guess an explicit storage offset computation tricks would allow to use unbind without relying on buggy version tracking of unbind?
username_1: If you do the same allocations repeatedly on CUDA, the allocation is basically for-free (using our caching allocator). So you should not worry too much about this.
username_0: Oh, you are right! :)
Btw the buggy unbind maybe should stay that way, the semantics of untying version tracking is sometimes important and maybe worth exposing to the user (I think I have filed a similar issue but in another context)
Status: Issue closed
username_1: The only issue is that it will silently compute wrong gradients if you modify both the base and an output :'(
We are looking into ways to extend the version check to handle these non-overlapping cases. But that adds a lot of complexity and is quite hard.
Let's continue the discussion in the other issue for version counter improvement.
username_0: Sure @username_1! Thanks for looking into this case!
username_0: @username_1 I remembered also why I wanted to do it inplace: I'm filling only the part of the tensor, the rest must be padded by some padded value. But it should be possible to achieve the same without a giant pre-filled tensor. |
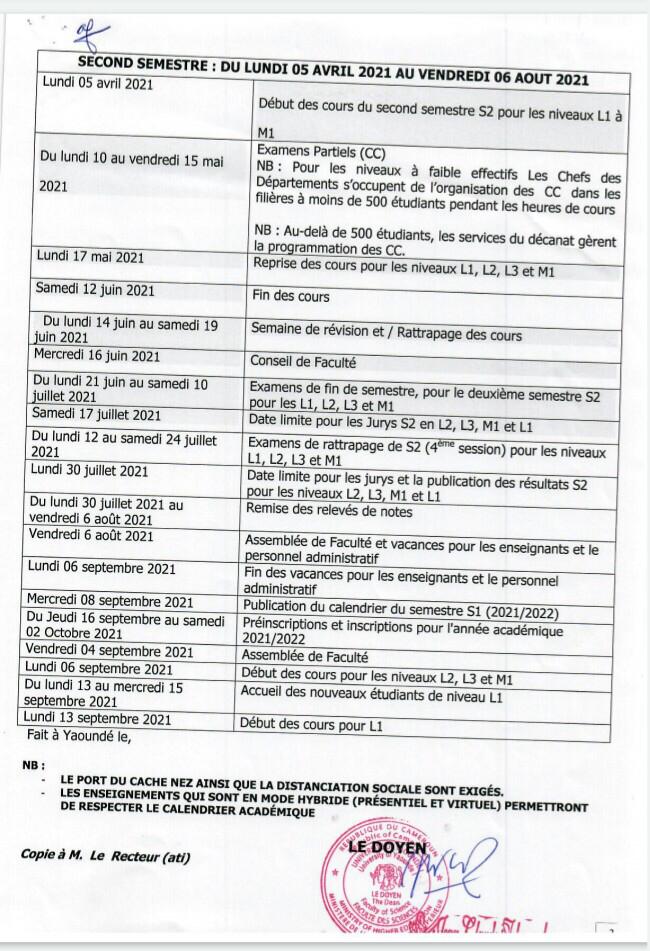
metacurrency/holoSkel | 304433584 | Title: Holo Coherence Call starts March 12 2018 at 04:00PM
Question:
username_0: Title: Holo Coherence Call<br>
<br>
Description: Given the current fluid nature of our organization, and in lieu of our weekly sprint this meeting is intended for: - Celebration - Information sharing - Weekly Intention There will be no Daily Standup on Holo Coherence Call days.<br>
<br>
Location: ceptr.org/salon<br>
<br>
Starts: March 12, 2018 at 04:00PM<br>
<br>
Ends: March 12, 2018 at 05:00PM<br>
<br>
@username_1<issue_closed>
Status: Issue closed |
Lothrazar/Cyclic | 947053397 | Title: Server thread error on PlayerEvent.SaveToFile
Question:
username_0: Minecraft Version: 1.16.5
Forge Version: 36.1.32
Mod Version: 1.3.2
Single Player or Server: Server
Describe problem (what you were doing; what happened; what should have happened):
Constant log entries on every `save-all` command: `[Server thread/ERROR] [com.lothrazar.cyclic.ModCyclic/]: Cyclic PlayerEvent.SaveToFile{inv:{Size:36,Items:[]},spectatorTicks:0,flyTicks:0,storage:0b,tasks:[]}`
Log file link:
[latest.log](https://github.com/username_2/Cyclic/files/6836481/latest.log)
Video/images/gifs (direct upload or link):
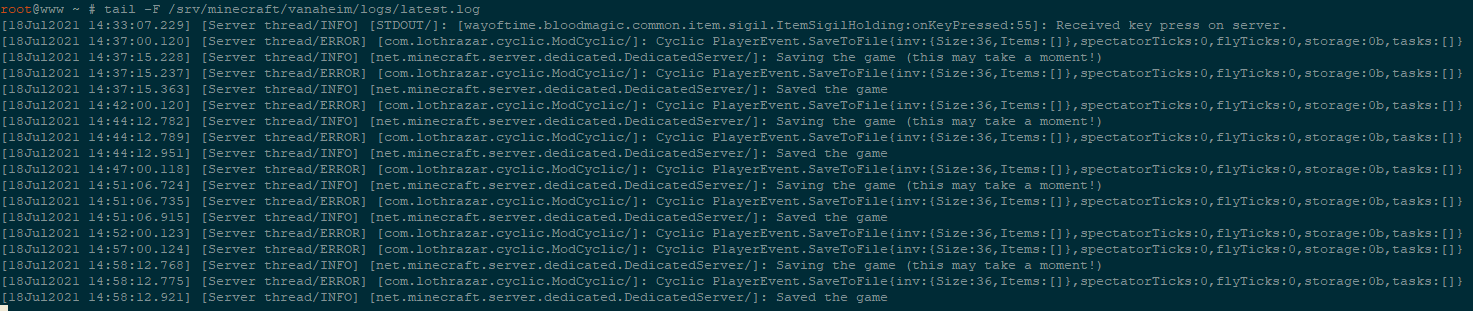
Answers:
username_1: Having this error in ATM6 1.7.1 modpack (Cyclic-1.16.5-1.3.2)
The error did not occur in ATM6 1.6.14 (Cyclic-1.16.5-1.2.11))
username_0: The offending line of code. Stuff like this ought to be a debug level log entry, not an error.
https://github.com/username_2/Cyclic/blob/d7e9e73618c1edb75a61c288ed121dc66f18aa6d/src/main/java/com/lothrazar/cyclic/event/PlayerDataEvents.java#L45
Status: Issue closed
|
KhronosGroup/MoltenVK | 527735948 | Title: Request support VK_EXT_inline_uniform_block
Question:
username_0: From the [spec](https://www.khronos.org/registry/vulkan/specs/1.1-extensions/html/vkspec.html#VK_EXT_inline_uniform_block), looks like it would be very handy for small descriptors (personally looking at using a storage buffer for dynamic lighting, and would like to use this for the light count). Suspect this should be fairly straightforward to implement via `set[Vertex/Fragment/Compute]Bytes`, which I know is used elsewhere in MoltenVK for various quantities.
Answers:
username_0: To head anyone off who might start this, think I might have this implemented. Just a few gaps to fill and to test.
Status: Issue closed
|
pouchdb/pouchdb | 468404447 | Title: allDocs with startkey
Question:
username_0: ```
const db = new new PouchDB('test')
const doc = {_id: 'user_111', username: 'someone'}
await db.put(doc)
await db.allDocs({startkey: 'user1_'})
// this will get the `doc` above, which should not
```
tested in FireFox 70, chrome 75, same performance.
Answers:
username_1: Just wanna add a little bit more info,
you can play around with this here http://jsbin.com/lotaroqila/edit?html,js,output
The behavior is the same in all pouchdb versions back to 3.6.0 (could not test earlier right now)
Seems unexpected for sure!
username_0: @username_1 Why use such robot rules? |
jlippold/tweakCompatible | 339175826 | Title: `BatteryLife` working on iOS 11.3.1
Question:
username_0: ```
{
"packageId": "com.rbt.batterylife",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "com.rbt.batterylife",
"deviceId": "iPhone7,2",
"url": "http://cydia.saurik.com/package/com.rbt.batterylife/",
"iOSVersion": "11.3.1",
"packageVersionIndexed": true,
"packageName": "BatteryLife",
"category": "Utilities",
"repository": "BigBoss",
"name": "BatteryLife",
"packageIndexed": true,
"packageStatusExplaination": "This package version has been marked as Working based on feedback from users in the community. The current positive rating is 100% with 8 working reports.",
"id": "com.rbt.batterylife",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.0.7",
"shortDescription": "Displays useful information about battery health",
"latest": "1.7.0",
"author": "rbt",
"packageStatus": "Working"
},
"base64": "<KEY>
"chosenStatus": "working",
"notes": ""
}
``` |
ajkerr0/kappa | 178454509 | Title: Missing analytical Hessian calculation
Question:
username_0: Just an idea for a feature that _could_ be added. Very low priority. Since the analytical gradients are calculated, right now the Hessian is found via finite differences.
Analytical Hessian may give only slight enhancements to speed and accuracy.
Answers:
username_0: Refer to http://onlinelibrary.wiley.com/doi/10.1002/(SICI)1096-987X(19960715)17:9%3C1132::AID-JCC5%3E3.0.CO;2-T/abstract for the dihedral contribution
Status: Issue closed
|
Shopify/js-buy-sdk | 166646920 | Title: Fetching products by hanles
Question:
username_0: But, 'product-287' is not a valid product Id and I can only get the actual productId from shopify's dashboard. It could have been great If I could fetch 'product-287' instead.
Answers:
username_1: hey @username_0, your situation is not exactly clear.
however, if it is that you are trying to fetch a product using an identification other than the ID, you may want to consider maintaining a local mapping of this identification to the ID locally on your end.
You also have the option of fetching a product using it's `handle`. The handle is "a human-friendly unique string for the Product automatically generated from its title." e.g A product with title `6 Panel - Lumberjack` can be retrieved using `client.fetchQueryProducts({ handle: '6-panel-lumberjack' })`
username_2: Closing as http://shopify.github.io/js-buy-sdk/api/classes/ShopClient.html#method-fetchQueryProducts exists.
Status: Issue closed
|
nielstron/quantulum3 | 353082290 | Title: Automatically generate SI-prefixed versions of units
Question:
username_0: Generally the tool yet lacks the ability to automatically infer SI-prefixed (kilo, mega, etc) versions of all units.
As not all units ate prefixable (i.e. there are no kiloinches, there are megabytes but no millibytes), prefixes should not be able to be parsed anywhere.
all applicable SI-prefixes for a unit could be defined by a separate list inside units.json. Special or additional entities can either be assigned inside that list or by creating a separate unit.
The value "all" , "positive" (kilo and upwards) and "negative" (milli and downwards) or something similar should be available to reduce redundancy.<issue_closed>
Status: Issue closed |
FWAJL/FieldWorkManager | 96367436 | Title: Create a FT webform for the "Collect Data" button.
Question:
username_0: If there are no field forms, create a webform from the Field Data parameters.
The FT will fill in the form and the data shall be uploaded to the database.
If data has been collected, show the data on the form.
Refresh the page every time the FT clicks "OK" so they can verify their data was collected.
If possible, show fields that were retrieved from the database in red as a way of verifying that data was saved.
Maybe do not use the arrays for this?
Related to Issue #1098. See screenshot.
Answers:
username_1: I don't think so. We would query the data each time.
Please let me know your feedback.
username_2: @username_0
A few other suggestions:
- what about preventing the FT to go to the next location until the current one done?
- show the locations done with a marker like a "checked" green marker icon to clearly show the FT it is done.
username_0: We are already doing this. The PM sees a different color marker at `/activetask/map`. Currently, the condition of having a location being "complete" is tied to forms, so we will need to add having a value entered for each of the field parameters as part of that condition, but this is outside the scope of this Issue. Once I have this working like I want for the PM map, I think we could add it to the FT map.
username_0: I
username_1: So as long as locations not completed are clearly in red as not done, then a FT can move to another location if he can save the data at the particular moment for a given location? Maybe then, ask him, like you said, to write down on paper the values?
username_0: So as long as locations not completed are clearly in red as not done, then a FT can move to another location if he can save the data at the particular moment for a given location? Maybe then, ask him, like you said, to write down on paper the values?
a) the FT can move wherever they need to and the website won't be able to stop them. They may complete the form, partially complete the form, or open the form but enter no values. We have to accommodate all three instances.
b) No. The FT would only be notified if the data (which might be a partially completed form) was not successfully saved.
username_1: Ok, so the most important matter is that the data that the FT inputs and saves is really saved. If he does not complete the job, it is his problem, right?
username_0: If he does not complete the job, it is his problem, right?
That is a good question. The best answer I have is that this needs to be addressed with the Build Measure Learn model. I need to first start recording data in the field and learn from that experience to know what to do when real life conditions arise.
username_0: @username_1
I was thinking about this and I realize that what I want is a very common behavior for web sites, so don't overthink it. For example, suppose I am trying to buy something on the web and I am filling out the "new customer" form. Often times, the login name I pick is already chosen, so the page refreshes and it asks me for a now login name. However, all the other fields that I already filled out, like my address and phone number, are pre-poplutated. Otherwise, I have to fill in all the fields again (very annoying). Same idea here. The FT can partially complete the form at any time then come back and finish.
username_1: @username_0
Ok. Now I think we have all the requirements with your last comment. So, what needs to be done is:
1. FT enters the data in the input(s) of each parameter.
2. FT clicks "OK" or "Save" which initiate a request to the server.
3. On the server, the data is saved to the DB.
4. We handle the response after saving the data to the DB. a. If the data is saved, we can highlight the data saved in red, grey or any way you want using CSS. If the data is not saved, we notify the FT.
5. Every time a FT opens the form to collect data for a or several parameter(s), we load the data saved if any.
That concludes the specification discussion.
Can you validate it (repost the points above modified if necessary) and assign it, please?
Thank you.
username_3: @username_1 @username_0
I've understood the requirement, thank you for explaining it point wise and elaborately. I just have one point to confirm. So the web form in question would have rows with the field analyte name and the text box for entering the parameter. Something like the following?
FA1 [ text box for parameter ]
FA2 [ text box for parameter ]
.....................
.....................
[ Save button ] [ Exit button ]
Please confirm and I'm ready to start with this issue.
Thank you.
username_0: @username_3
Yes.
username_3: @username_0 @username_1
I've coded the new Web form. The old code for showing the PDF is present but commented out. I've coded it exactly like the requirement was listed. So that may serve as steps to test. Code is pushed to `feature_devsupport`.
Please review and let me know. Thank you.
username_0: @username_3
Perfect!
Status: Issue closed
|
MDE4CPP/MDE4CPP | 283498230 | Title: evaluate upper / lower bound
Question:
username_0: add .toLowerFirst() for namespace definition.
Problem: uml-Reflection model(s ecore.uml / uml.uml use) UpperFirst Namespace to differ ecor.ecore/uml.ecore
Answers:
username_0: add .toLowerFirst() for namespace definition.
Problem: uml-Reflection model(s ecore.uml / uml.uml use) UpperFirst Namespace to differ ecor.ecore/uml.ecore
username_1: 1. What has an lower and upper bound (of Property multiplicites) to do with upper / lower case of namespaces?
2. Why is a new solution necessary? Is the already existing solution not acceptable?
username_0: uodates handling of multiplicity
Status: Issue closed
|
vdvm/nginx-watermark | 179476196 | Title: how to use it?
Question:
username_0: I build 1.9.15 with this module
yes with --with-http_image_filter_module
sadly I can't make it run
invalid parameter "watermark" in
my config file has a line like this
image_filter watermark "/var/www/logo2.png" "bottom-right";
also I've tried without quotation marks
Answers:
username_1: This is patch for existing http_image_filter_module
```
cd ..../nginx-$NGINX_VERSION && patch -p0 < ...../nginx-watermark/nginx-watermark.patch
```
(last tested with version 1.10.2)
username_0: Works as you stated. Another question is how you would do a variable?
image_filter watermark /etc/nginx/html/$watermarkUrl center; doesn't work
any combination with variable has problems :(
username_1: Try branch "vars" https://github.com/username_2/nginx-watermark/tree/vars
username_0: Works like a charm. Thank you!
Status: Issue closed
|
Azure/azure-storage-azcopy | 469444798 | Title: Azcopy10 - Is it possilbe to copy files within a ADLS gen2 storage account from one folder to another folder
Question:
username_0: ### Which version of the AzCopy was used?
Azcopy 10.2.1
##### Note: The version is visible when running AzCopy without any argument
### Which platform are you using? (ex: Windows, Mac, Linux)
Windows
### What command did you run?
Azcopy cp Storage_account_A Storage_account_A --recursive true
##### Note: Please remove the SAS to avoid exposing your credentials. If you cannot remember the exact command, please retrieve it from the beginning of the log file.
### What problem was encountered?
failed to parse user input due to error: the inferred source/destination combination is currently not supported. Please post an issue on Github if support for this scenario is desired
### How can we reproduce the problem in the simplest way?
### Have you found a mitigation/solution?
Answers:
username_1: AzCopy can't figure out the type of the source or destination, based on the URLs that you've used for the source and destination. There's a known bug where that happens with HTTP. You can add this to the command line to tell it exactly what you mean:
--from-to BlobBlob
Also try putting double quotes around the two URLs, to make sure they parse correctly.
BTW, you said storage_account_a for both source and dest. Is that right?
username_0: Hello, I am trying to copy files with Azure Data Lake Storage Gen2
Here is how the command would looks like from PS command promopt
PS C:\Program Files (x86)\AzCopy>>> .\azcopy cp "" "https://mkdssdedldev212.dfs.core.windows.net/msdsd-dssds-fssdsdys-edfffl-dev-001/refidfdfned/Asdsds/dbo/DisdsdsdResdsdsursdsde_Adff.txt “https://mkdssdedldev212.dfs.core.windows.net/msdsd-dssds-fssdsdys-edfffl-dev-001/refidfdfned/Asdsds/dbo/DisdsdsdResdsdsursdsde_Adff.txt/.replacedfiles/"
I am getting the following error…. Please help ASAP!
failed to parse user input due to error: the inferred source/destination combination is currently not supported. Please post an issue on Github if support for this scenario is desired
Thanks,
<NAME>
username_0: Just updating the command to make it more clear
PS C:\Program Files (x86)\AzCopy>>> .\azcopy cp "https://mkdssdedldev212.dfs.core.windows.net/msdsd-dssds-fssdsdys-edfffl-dev-001/refidfdfned/Asdsds/dbo/DisdsdsdResdsdsursdsde_Adff.txt" “https://mkdssdedldev212.dfs.core.windows.net/msdsd-dssds-fssdsdys-edfffl-dev-001/refidfdfned/Asdsds/dbo/DisdsdsdResdsdsursdsde_Adff.txt/.replacedfiles/"
I am getting the following error…. Please help ASAP!
failed to parse user input due to error: the inferred source/destination combination is currently not supported. Please post an issue on Github if support for this scenario is desired
Thanks,
<NAME>
Markel - IT
Data Services
4501 Highwoods Parkway, Glen Allen, VA 23060
Direct: (804) 525-7041
www.markelcorp.com<http://www.markelcorp.com/>
From: <NAME>
Sent: Thursday, July 18, 2019 8:58 AM
To: 'Azure/azure-storage-azcopy' <<EMAIL>>; Azure/azure-storage-azcopy <<EMAIL>>
Cc: Author <<EMAIL>>
Subject: RE: [Azure/azure-storage-azcopy] Azcopy10 - Is it possilbe to copy files within a ADLS gen2 storage account from one folder to another folder (#507)
Hello, I am trying to copy files with Azure Data Lake Storage Gen2
Here is how the command would looks like from PS command promopt
PS C:\Program Files (x86)\AzCopy>>> .\azcopy cp "" "https://mkdssdedldev212.dfs.core.windows.net/msdsd-dssds-fssdsdys-edfffl-dev-001/refidfdfned/Asdsds/dbo/DisdsdsdResdsdsursdsde_Adff.txt “https://mkdssdedldev212.dfs.core.windows.net/msdsd-dssds-fssdsdys-edfffl-dev-001/refidfdfned/Asdsds/dbo/DisdsdsdResdsdsursdsde_Adff.txt/.replacedfiles/<https://mkdssdedldev212.dfs.core.windows.net/msdsd-dssds-fssdsdys-edfffl-dev-001/refidfdfned/Asdsds/dbo/DisdsdsdResdsdsursdsde_Adff.txt%20“https:/mkdssdedldev212.dfs.core.windows.net/msdsd-dssds-fssdsdys-edfffl-dev-001/refidfdfned/Asdsds/dbo/DisdsdsdResdsdsursdsde_Adff.txt/.replacedfiles/>"
I am getting the following error…. Please help ASAP!
failed to parse user input due to error: the inferred source/destination combination is currently not supported. Please post an issue on Github if support for this scenario is desired
Thanks,
<NAME>
Status: Issue closed
username_1: Ah, I see. Sorry, I did not realise you were copying between dfs endpoints. Unfortunately, that is not currently supported. For account to account copies, we only support blob endpoints (non-hierarchical).
The reason for the limited support is that interoperability, between blob and dfs, is coming in the Storaeg Service, so that you'll be able to use the existing blob to blob copy feature even on hierarchical accounts. That's why we have not written dfs-to-dfs copy (since soon it won't be needed). In fact, interop just went into preview in some regions a few days ago. Here is the link: https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-multi-protocol-access
To copy account to account right now (without interop) you'll need to either download the data to disk then upload it to the target (only works for small-to-moderate data volumes, due to disk space requirements) or use something like Azure Data Factory (I think it as Gen2-to-Gen2 copy). Sorry about the limited support right now, and doubly sorry that I didn't previously see "gen2" right there in the subject line of this issue!!!! Yesterday I just followed the link in from the notification email, and didn't read the title!
username_2: Hello there !
2 days ago, interop general availability has been announced:
https://azure.microsoft.com/fr-fr/blog/multi-protocol-access-on-data-lake-storage-now-generally-available/
However I tried an azcopy between two gen2 storage account but it failed woith same error:
"the inferred source/destination combination is not currently supported."
Do you know when it will be fix ?
username_1: Did you use blob endpoint urls for source and destination?
username_2: Hey John ! Thanks for your answer. Indeed I was only using the DFS ones ! Thanks for pointing that !
With blob, it goes further:
```
~/azcopy_windows_amd64_10.3.2
$ export AZCOPY_SPA_CLIENT_SECRET=XXXXXX
$ ./azcopy.exe login --service-principal --application-id XXXXXXX --tenant-id= XXXXXXX
INFO: SPN Auth via secret succeeded.
$ ./azcopy.exe copy 'https://mystorageaccount.blob.dfs.core.windows.net/fs1/test ' 'https://otherstorageaccount.blob.dfs.core.windows.net/fs2/test' --recursive
INFO: Scanning...
INFO: Using OAuth token for authentication.
failed to perform copy command due to error: a SAS token (or S3 access key) is required as a part of the source in S2S transfers, unless the source is a public resource
```
Unfortunately, my company doesn't allow public resources for security reasons.
I will have to figure out how to generate a SAS Token for 2 storages Account. I know how to do it for one, it's easy on the portal. But for 2 storage Account, I need to find... Or maybe you know John ?
Best regards
username_1: OAuth is fine for the destination. You only need a sas for the source account. The easiest place to generate them is in Storage Explorer. Hopefully it will let you generate a blob style one for your adls gen 2 container. If that doesn't work, Powershell might. Remember you need a blob sas url, not an adls gen 2 sas url.
Let us know if your can't get it working
Btw a future version of AzCopy will remove the need for a sas on the source. (by using OAuth for both source and dest) Choose "watch" on our releases page to be notified when it comes out.
username_3: i am trying to Run Azcopy in ADF V2 custom activity command ,but it's not working .
**ADF Command : Azcopy.exe copy @pipeline().parameters.Source @pipeline().parameters.Dest**
May i know how to pass dynamic source and destination path though the ADF pipeline parameters or Varaibles in AZcopy?
username_0: Thank you, coping files from one folder to another folder with ADLS gen2 storage account.
I have couple of more questions:
1) Is it possible to move the files from one folder to another folder thru AzCopy? my requirement is not keep the files in source folder once they have been moved from source folder to destination.
username_1: We don't currently support "move" (i.e. we don't have support for deleting the source). That's an open feature request here: See https://github.com/Azure/azure-storage-azcopy/issues/45
username_2: Error: unknown flag: --log-level
I have added --log-level DEBUG at the end of my command, but I don't more than before, only:
"
INFO: Scanning...
INFO: Using OAuth token for authentication.
"
How Can I debug more the calls ?
I would to know exactly why it hangs, which calls it is making...
username_1: I think both problems are caused by the same thing. The URLs you're using, as you posted above, contain: "accountname.blob.dfs.core.windows.net". They should have blob OR dfs. Remove the dfs section of the URL, and I think both your test scenarios will work.
username_2: Ohh ! Thank you so much John :-) !
I just had a last struggle by understanding a 403 Error.
In fact, it was the IP Range. I had put 0.0.0.0-255.255.255.255 and it didn't worked, I had 403. I then left the field "IP Range" empty and generated the SAS Token and now it work like a charm !
I successfully copied 1 file from 1 Adlsgen2 storage Account to another Adlsgen2 storage Account ! Perfect !
That's awesome :-) Thanks much again John !
Note: To understand 403, there is several things to check (Blob Data Owner Role, Time of SAS Token, IP Range ...), so if there were explanation on the 403, it would be perfect.
username_0: Hello John, Do we still need to use Blob SAS key to move files from one folder to another folder within Gen2 Storage account? Or AzCopy latest version does not require that?
username_1: It will be version 10.4 that gives the feature you're asking for. You can track the pull request here: https://github.com/Azure/azure-storage-azcopy/pull/689 Note that 10.4 includes three big features, of which this is the smallest (and this SAS issue has been held up behind the other two features a little, but the plan is for all three to be in 10.4).
username_0: Thank you. Do you know when 10.4 will be released?
username_1: We don't pre-announce dates, sorry.
username_2: Thanks for the news, what are the 2 others bigs features for azcopy 10.4 please ?
username_1: Preserving properties (including ACLS) when transferring to and from Azure Files; and preserving folder properties (including ACLS) and existence (including empty folders) when transferring between folder-aware sources. (File systems and Azure Files are folder-aware. Blob storage is not because folders there are just virtual).
ACL preservation is highly-demanded, and folder preservation is necessary to make ACL preservation logically consistent.
username_0: Thank you. Do you know when 10.4 will be released?
From: <NAME>
Sent: Tuesday, January 21, 2020 4:23 PM
To: 'Azure/azure-storage-azcopy' <<EMAIL>>
Subject: RE: [Azure/azure-storage-azcopy] Azcopy10 - Is it possilbe to copy files within a ADLS gen2 storage account from one folder to another folder (#507)
Thank you. Do you know when 10.4 will be released?
username_1: We don't announce release dates in advance, sorry. There's still quite a lot of work to do on 10.4.
username_0: Hello John, I am using 10.4 version, but the flowing function is still not working… Copying files from between Gen2 storage accounts, it is still asking for SAS key. Can you please help?
failed to perform copy command due to error: a SAS token (or S3 access key) is required as a part of the source in S2S transfers, unless the source is a public resource
From: <NAME>
Sent: Thursday, January 23, 2020 11:44 AM
To: 'Azure/azure-storage-azcopy' <<EMAIL>>
Subject: RE: [Azure/azure-storage-azcopy] Azcopy10 - Is it possilbe to copy files within a ADLS gen2 storage account from one folder to another folder (#507)
Thank you. Do you know when 10.4 will be released?
From: <NAME>
Sent: Tuesday, January 21, 2020 4:23 PM
To: 'Azure/azure-storage-azcopy' <<EMAIL><mailto:<EMAIL>>>
Subject: RE: [Azure/azure-storage-azcopy] Azcopy10 - Is it possilbe to copy files within a ADLS gen2 storage account from one folder to another folder (#507)
Thank you. Do you know when 10.4 will be released?
username_4: Hi
I want to copy a bunch of ORC files (about 700 of them) from ADLS Gen 2 to Azure Blob.
Is it not possible? Is it too complex?
thanks.
username_1: @username_4 This looks like a new question. I'd suggest you post it as a new issue.
username_5: @username_1 - like other users in this thread we are trying to do s2s copy (from ADLS Gen2 to ADLS Gen2) and can only do so with a SAS token on the source. Allowing users to create SAS tokens forces us to give these users access permissions (far?) beyond "read", which is a concern for our security folks. What is the best practice to do what we need to do? What are the minimal additional access permissions so that users can get SAS tokens? How are your other customers working with what looks to us like a pretty serious limitation?
You also refer to a solution to the issue in version 10.4 - did that solution end up not making it into the release? Has the referenced PR (https://github.com/Azure/azure-storage-azcopy/pull/689) been abandoned?
username_1: @username_5 I'm on a different project now, and no longer involved in AzCopy. (I only saw this because GitHub notified me when you @-mentioned me.)
@username_6 or @amishra-dev should be able to answer your question.
username_5: @username_6 or @amishra-dev - would you be able to help with the questions above?
username_6: Hi @username_5, it seems that there are some confusions here. In general, your customers should not be in the business of creating SAS tokens, as only the account owner (the one with the storage account key) should do it. If you have users who need a SAS token, you should perhaps have your service hand them the tokens ready.
Please create a new issue if you have any further questions. Thanks!
username_5: @username_6: before I create a new issue, please help me with 2 questions:
(1) What is PR https://github.com/Azure/azure-storage-azcopy/pull/689 about? I thought it would support seamless copy based on OAuth authentication only. Am I mistaken?
(2) Are you suggesting that we build a service that provides users with SAS tokens whenever they need one?
username_6: 1) Yes, the PR needs to be reworked but basically the user can authentication with OAuth, and we'd generate an identity SAS for them. They have to have the right permissions on the account.
2) I'm not aware of your application so I cannot say. I made the comment because typically your users shouldn't be the ones generating SAS using account keys. In some applications, the service hands a token to an end user (ex: a mobile app user) who can use it upload/download blobs. You can also use [RBAC with Storage](https://docs.microsoft.com/en-us/azure/storage/common/storage-auth-aad-rbac-portal). |
matrix-org/synapse | 358016305 | Title: VOIP crashes under Python 3
Question:
username_0: ```
2018-09-07 12:33:00,847 - synapse.http.server - 101 - ERROR - b'GET'-83- Failed handle request via <function JsonResource._async_render at 0x7f3dc8904158>: <XForwardedForRequest at 0x7f3dc633c198 method=b'GET' uri=b'/_matrix/client/r0/voi
p/turnServer?' clientproto=b'HTTP/1.1' site=8008>: Traceback (most recent call last):
File "/home/krombel/synapse/venv35/lib/python3.5/site-packages/Twisted-18.7.0-py3.5-linux-x86_64.egg/twisted/internet/defer.py", line 1418, in _inlineCallbacks
result = g.send(result)
File "/home/krombel/synapse/synapse/http/server.py", line 295, in _async_render
callback_return = yield callback(request, **kwargs)
File "/home/krombel/synapse/venv35/lib/python3.5/site-packages/Twisted-18.7.0-py3.5-linux-x86_64.egg/twisted/internet/defer.py", line 1613, in unwindGenerator
return _cancellableInlineCallbacks(gen)
File "/home/krombel/synapse/venv35/lib/python3.5/site-packages/Twisted-18.7.0-py3.5-linux-x86_64.egg/twisted/internet/defer.py", line 1529, in _cancellableInlineCallbacks
_inlineCallbacks(None, g, status)
--- <exception caught here> ---
File "/home/krombel/synapse/synapse/http/server.py", line 81, in wrapped_request_handler
yield h(self, request)
File "/home/krombel/synapse/synapse/http/server.py", line 295, in _async_render
callback_return = yield callback(request, **kwargs)
File "/home/krombel/synapse/venv35/lib/python3.5/site-packages/Twisted-18.7.0-py3.5-linux-x86_64.egg/twisted/internet/defer.py", line 1418, in _inlineCallbacks result = g.send(result)
File "/home/krombel/synapse/synapse/rest/client/v1/voip.py", line 45, in on_GET
mac = hmac.new(turnSecret, msg=username, digestmod=hashlib.sha1)
File "/home/krombel/synapse/venv35/lib/python3.5/hmac.py", line 144, in new return HMAC(key, msg, digestmod)
File "/home/krombel/synapse/venv35/lib/python3.5/hmac.py", line 42, in __init__
raise TypeError("key: expected bytes or bytearray, but got %r" % type(key).__name__)
builtins.TypeError: key: expected bytes or bytearray, but got 'str'
```
Status: Issue closed
Answers:
username_0: Fixed. Thanks @krombel |
GoogleCloudPlatform/container-engine-accelerators | 411068991 | Title: Pod Unschedulable
Question:
username_0: I am getting two errors after deploying my object detection model for prediction using GPUs:
1.PodUnschedulable Cannot schedule pods: Insufficient nvidia
2.PodUnschedulable Cannot schedule pods: com/gpu.
I have followed this post for deploying of my prediction model:
https://github.com/kubeflow/examples/blob/master/object_detection/tf_serving_gpu.md
and [this](https://cloud.google.com/kubernetes-engine/docs/how-to/gpus#installing_drivers) one for installing nvidia drives to my nodes.
I haven't used nvidia-docker.
This is the output of the `kubectl describe pods` command:
```
ame: xyz-v1-5c5b57cf9c-ltw9m
Namespace: default
Node: <none>
Labels: app=xyz
pod-template-hash=1716137957
version=v1
Annotations: <none>
Status: Pending
IP:
Controlled By: ReplicaSet/xyz-v1-5c5b57cf9c
Containers:
xyz:
Image: tensorflow/serving:1.11.1-gpu
Port: 9000/TCP
Host Port: 0/TCP
Command:
/usr/bin/tensorflow_model_server
Args:
--port=9000
--model_name=xyz
--model_base_path=gs://xyz_kuber_app-xyz-identification/export/
Limits:
cpu: 4
memory: 4Gi
nvidia.com/gpu: 1
Requests:
cpu: 1
memory: 1Gi
nvidia.com/gpu: 1
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-b6dpn (ro)
xyz-http-proxy:
Image: gcr.io/kubeflow-images-public/tf-model-server-http-proxy:v20180606-9dfda4f2
Port: 8000/TCP
Host Port: 0/TCP
Command:
python
/usr/src/app/server.py
--port=8000
--rpc_port=9000
--rpc_timeout=10.0
Limits:
cpu: 1
memory: 1Gi
Requests:
cpu: 500m
memory: 500Mi
Environment: <none>
[Truncated]
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulMountVolume 9m51s kubelet, gke-kuberflow-xyz-gpu-pool-a25f1a36-pvf7 MountVolume.SetUp succeeded for volume "boot"
Normal SuccessfulMountVolume 9m51s kubelet, gke-kuberflow-xyz-gpu-pool-a25f1a36-pvf7 MountVolume.SetUp succeeded for volume "root-mount"
Normal SuccessfulMountVolume 9m51s kubelet, gke-kuberflow-xyz-gpu-pool-a25f1a36-pvf7 MountVolume.SetUp succeeded for volume "dev"
Normal SuccessfulMountVolume 9m51s kubelet, gke-kuberflow-xyz-gpu-pool-a25f1a36-pvf7 MountVolume.SetUp succeeded for volume "default-token-n5t8z"
Normal Pulled 7m1s (x4 over 9m50s) kubelet, gke-kuberflow-xyz-gpu-pool-a25f1a36-pvf7 Container image "gke-nvidia-installer:fixed" already present on machine
Normal Created 7m1s (x4 over 9m50s) kubelet, gke-kuberflow-xyz-gpu-pool-a25f1a36-pvf7 Created container
Normal Started 7m1s (x4 over 9m50s) kubelet, gke-kuberflow-xyz-gpu-pool-a25f1a36-pvf7 Started container
Warning BackOff 4m44s (x12 over 8m30s) kubelet, gke-kuberflow-xyz-gpu-pool-a25f1a36-pvf7 Back-off restarting failed container
```
Error log from the pod `kubectl logs nvidia-driver-installer-p8qqj -n=kube-system` :
`Error from server (BadRequest): container "pause" in pod "nvidia-driver-installer-zxn2m" is waiting to start: PodInitializing`
How can I fix this?
Answers:
username_0: It got fixed after I deleted all of the nvidia pods and deleted the node and recreated it and installed the nvidia drivers and plugin again.
Status: Issue closed
|
TechReborn/TechReborn | 545338947 | Title: Easier way to get Chrome
Question:
username_0: Industrial machine frames and casings call for a LOT of chrome. More than what would be collectible without serious grinding.
Example for blast furnace with industrial machine casings:
- 34 industrial machine casing
- 34*6 chrome plates + 34 * 4 chrome plates (industrial machine frame) => 340 Chrome plates
- 9 ruby dust for 1 Chrome dust in Electrolyzer => 3060 Ruby dust
- 2,5 Rubies per Ruby Ore in Industrial Grinder => 7650 Ruby ore
That's... a lot of ruby ore.
Though there are other means of getting ruby dust (for example 3 for 32 redstone dust, Uvarovite dust, or UU-Matter) it still would take days of playing just for a few casings.<issue_closed>
Status: Issue closed |
JanDitzen/xtdcce2 | 531307996 | Title: ARDL with pooled coefficients and id vector with missing
Question:
username_0: Problem xtdcce_m_lrcalc assigns varnames for variables as varname_1...rows(beta vector); need to add id variable argument to lr program.
Answers:
username_0: Fixed error. program now loops through all id names to create output name lists
Status: Issue closed
|
airn/Rentr | 64430153 | Title: Tests: assertNotEqual for get_invalid_rentable?
Question:
username_0: WTF IS THIS BULLSHIT
Answers:
username_1: I don't know why that is there.
username_1: So i changed the assertion but it fails now. I don't understand why, the store invalid test case is is passing and is the exact same code... The only thing I could see is since the rentables aren't getting deleted after every test there is one for the pk we are passing it since it is returning a 200. I did try and make the pk 900000000000 and i still got a 200.
Status: Issue closed
|
summernote/summernote | 160328384 | Title: onPaste -- pulling out images
Question:
username_0: I have an onImageUpload event that works perfectly for images dropped in (it uploads to a server and changes the url as it should). How do I replicate this for pasted images within data from word or other outside programs (onenote, etc) from the clipboard?
#### steps to reproduce
1. Add image and some text to word document
2. Copy images and text
3. Paste in Summernote
#### browser version and os version
What is your browser and OS? Chrome/Firefox, W10
Answers:
username_1: This is something I'd like to implement into summernote-cleaner. It's something I've been playing with, with the plugin. The ability to convert as much of the formatting to HTML (including getting the images). I think this would be a good option to help client's with editing, and save them time, instead of just stripping all the formatting.
username_2: This is one of the feature that I am looking for as well. Any ideas on what is possible and what can be done?
Ideally when you copy paste text and image, the text formatting should be retained and image could be inlined or uploaded, inserting the link for uploaded image.
Thanks
username_3: I have the text and image working separately but I am also working on combining with JS getdata. I am also looking forward to this feature in summernote as it would be time saving not to have to copy all text then copy images separately to paste.
username_1: @username_3 please keep us updated on this, as this is something I've also been trying to work on for client's, and so far without success. If you wish to integrate it into summernote-cleaner, that would be awesome too.
So far I've been able to stop the img tags from being removed, but the image data is gone, so that's a small step I suppose. If I copy from a website text that has referenced images (referenced from a file on a server), that works as expected, but getting inlined or embedded images to remain in the data is another matter.
Anywho, work progresses.
username_3: So far I have been able to use the text/html to retain the html formatting. Since OneNote or possibly word stores the copied and pasted image into a local appdata temp file, need to work on extracting the image and utilizing summernote's pasteHTML or insertImage to workaround Chrome's Not allowed to load local resource message
Warm regards.
username_4: I've added this to my todo list as you can see above. I'll close this now, as it's been open for a while now.
Status: Issue closed
username_5: any update to this, it is really getting messi as the users are pasting images that goes to the Dbs, so far I limited the amount of characters that can be added, but I would like to just filter out images from clipboard on paste, or better to be able to replace images on clipboard with corresponding links. TY
username_6: Hi,
Is this abandoned? There is some progress?
username_4: Not abandoned as such, just been busy with other things.
username_7: @username_4 you have the steps or logic to do the Pulling out of images on paste?
If have, can you share to be implemented by someone?
I am looking for this segregation too but not found a way to identify when images go to OnImageUpload to ignore OnPaste action.
Thank you :-)
username_4: Not yet, sorry, been very busy with other things to be able to sit down and look at this.
username_8: Hello! I'm not understanding what you are saying
username_8: Please the message above was only trying .I want also to integrate summernote in my web site using that method |
facebookresearch/ParlAI | 228986483 | Title: Add Dockerfile
Question:
username_0: Add Dockerfile and a docker image which might make trying out ParlAI easier.
Answers:
username_1: @username_0 Sure, we are working on that.
CC/ @username_2
username_2: Low priority for the moment, but will add when we get the chance.
Status: Issue closed
username_2: closing for now without dockerfile support |
jendiamond/vue2 | 312757972 | Title: Showing the Player Controls Conditionally
Question:
username_0: Show the sections based on whether the game has started or not.
```html
<section class='row controls' v-if ='!gameOn'>
<div class='small-12 columns'>
<button id='start-game'>START NEW GAME</button>
</div>
</section>
<section class='row controls' v-else ='gameOn'>
<div class='small-12 columns'>
<button id='attack'>ATTACK</button>
<button id='special-attack'>SPECIAL ATTACK</button>
<button id='heal'>HEAL</button>
<button id='give-up'>GIVE UP</button>
</div>
</section>
```
```js
new Vue({
el: '#monsterslayer',
data: {
gameOn: false,
playerHealth: 100,
monsterHealth: 100,
},
});
```
Status: Issue closed
Answers:
username_0: Show the sections based on whether the game has started or not.
```html
<section class='row controls' v-if ='!gameOn'>
<div class='small-12 columns'>
<button id='start-game'>START NEW GAME</button>
</div>
</section>
<section class='row controls' v-else ='gameOn'>
<div class='small-12 columns'>
<button id='attack'>ATTACK</button>
<button id='special-attack'>SPECIAL ATTACK</button>
<button id='heal'>HEAL</button>
<button id='give-up'>GIVE UP</button>
</div>
</section>
```
```js
new Vue({
el: '#monsterslayer',
data: {
gameOn: false,
playerHealth: 100,
monsterHealth: 100,
},
});
```
Status: Issue closed
|
haskell-nix/hnix | 1039726911 | Title: `Prelude` module clashes with `base`
Question:
username_0: v0.15.0 exposes a new `Prelude` module that makes it difficult to use `hnix`, e.g.:
```
src/Dhall/Nix.hs:87:8: error:
Ambiguous module name ‘Prelude’:
it was found in multiple packages: base-4.14.3.0 hnix-0.15.0
|
87 | module Dhall.Nix (
| ^^^^^^^^^
```
Could this `Prelude` be made internal or alternatively be exposed under a different name, say, `Nix.Prelude`?
Answers:
username_1: Woops.
Oh, yes.
Was thinking about it while making it.
Would fix it in nearest time.
Probably making it internal would just work.
Actually I was more surprised/impressed that what I had in mind - I made it work. The setup combines the mixing loaded `relude`s `Prelude` & project local `Utils` into 1 `Prelude` module.
Yep. Serious structural thing.
username_1: Ye....
Cabal works only this way & does not allow to not export the `Prelude` :man_shrugging: ...
Probably would need to go `NoImplicitPrelude` route & import it as `Nix.Prelude` everywhere ...
Today is late, would do it tomorrow.
I made a minor release beforehand, so if some stuff like this happens - there is a backup option.
username_0: Sounds like a `Cabal` bug to me. Might be worth reporting.
In any case this isn't an urgent issue for me. `dhall-nix*` can simply continue using v0.14 for now.
username_1: But as an active HNix maintainer - it is one for me. It is a disservice to make Cabal promote a broken release.
The proper thing in these cases - is to demote that version right away.
I going to make a new release & then open a Cabal report ... ("So many houses, so little time")
username_1: Deprecated the `0.15.0`.
username_2: The `0.15.0` version is still being chosen by `cabal` for build plans, so this is forcing all packages using `hnix` to add an upper-bound constraint of `< 0.13`. Is there a timeframe for a fix (and what is the fix.. rolling back to `Prelude`?)?
username_0: Can you give an example?
It might be helpful to add an impossible constraint like `base < 0` to `v0.15.0`.
username_1: Well. Nix 2.3.15 released with a breakage without documentation & then Nix 2.4 was released with regressions in "stable" features & without increasing the `languageVersion` shipped undocumented changes in the handling of the language. That is not just problem for me, but central Nixpkgs maintainers started & gather signings in the declaration: https://discourse.nixos.org/t/nix-2-4-and-what-s-next/16257 to stop these sudden undocumented top-down breakages
& HNix has & required to follow Nix bug2bug if that is needed & so uses Nix for golden tests. From the tests enabled there is currently breakage in 1 escaping mechanism moment that Nix changed. Because it is not documented, I hunted through the Nix git logs & found no explicit place where escaping was changed, & read through a bunch of C++ at the best of my possibilities, tried to bisect the issue, but you get the picture. The is a need for someone who knows C++ better than me.
I tried to adjust the HNix behavior in https://github.com/haskell-nix/hnix/pull/1009 but failed. & then I decided that if nobody really cares for this - I better do some work in HLS then, which I do currently.
Seems like HNix does the representation of this by running the `iterNValue` directly. I'd loved to see the C++ code - to know in what part of the process the escaping changes.
username_1: & I'd personally put those tests as broken for a time & worked on other things. Because there is a number of new tests to take from Nix that do work & other ones are easier to do for me.
username_1: Set a suggested impossible bound on the `0.15`.
username_2: The main project is not public, but here's a simple reproduction. First, the basic setup of a method to test this:
```
$ mkdir hnix-test
$ cd hnix-test
$ cabal --version
cabal-install version 3.6.0.0
compiled using version 3.6.1.0 of the Cabal library
$ ghc --version
The Glorious Glasgow Haskell Compilation System, version 8.10.7
$ cabal init
...
$ cabal run
...
Hello, Haskell!
```
Then I add hnix as a dependency. With no constraints, cabal selects 0.14.0.5, but alas, this does not build:
```
$ sed -i -e '/build-depends:/s/build-depends: .*/build-depends: base, hnix/' hnix-test.cabal
$ cabal run
Build profile: -w ghc-8.10.7 -O1
...
- hnix-0.14.0.5 (lib) (requires download & build)
- megaparsec-9.1.0 (lib)
...
Starting hnix-0.14.0.5 (lib)
Building hnix-0.14.0.5 (lib)
Failed to build hnix-0.14.0.5
...
[32 of 50] Compiling Paths_hnix ( dist/build/autogen/Paths_hnix.hs, dist/build/Paths_hnix.o, dist/build/Paths_hnix.dyn_o )
dist/build/autogen/Paths_hnix.hs:66:22: error:
* 'last' works with 'NonEmpty', not ordinary lists.
...
66| | isPathSeparator (last dir) = dir ++ fname
```
It works fine for hnix 0.12.0.1:
```
$ cabal run --constraint 'hnix < 0.13'
...
- hnix-0.12.0.1 (lib) (requires download & build)
- megaparsec-9.0.1 (lib)
...
Hello, Haskell!
```
Trying 0.13.1 fails:
```
$ cabal run --constraint 'hnix < 0.14'
...
- hnix-0.13.1 (lib) (requires download & build)
- megaparsec-9.0.1 (lib)
...
[same error as 0.14: 'last' works with 'NonEmpty', not ordinary lists. at line 66 of Paths_hnix.hs]
```
[Truncated]
```
$ sed -i -e '/build-depends:/s/build-depends: .*/build-depends: base, hnix, megaparsec, servant/' hnix-test.cabal
$ cabal run --constraint 'hnix >= 0.11'
...
- servant-0.18.3 (lib) (requires build)
- hnix-0.15.0 (lib) (requires build)
...
Building library for hnix-0.15.0..
[ 1 of 52] Compiling Nix.Utils ( src/Nix/Utils.hs, dist/build/Nix/Utils.o, dist/build/Nix/Utils.o, dist/build/Nix/Utils.dyn_o )
[ 2 of 52] Compiling Prelude ( src/Prelude.hs, dist/build/Prelude.o, dist/build/Prelude.dyn_o )
[ 3 of 52] Compiling Paths_hnix ( dist/build/autogen/Paths_hnix.hs, dist/build/Paths_hnix.o, dist/build/Paths_hnix.dyn_o )
dist/build/autogen/Paths_hnix.hs:66:22: error:
* 'last' works with 'NonEmpty', not ordinary lists
...
```
Based on the above, it appears that:
* all of the releases after 0.12.0.1 are failing (due the switch to `relude` ?) and
* there are some package combinations that will select hnix 0.15.0 without explicit upper-bounds preventing this
username_1: `0.15` supported `megaparsec` `0.9.2`.
That may be the thing that makes it choose it.
What the hell is `Path_hnix` error, if that module is autogenerated.
I would look into it when I have time & would try to make a release soon, but it is probably no earlier then I'm a week.
But since I currenly do not know that is the cause of the syndrome - do not know if new release would fix the autogeneration of the module.
username_0: @username_2 If you `cabal update`, do you still get build plans with `hnix-0.15`? You shouldn't.
Regarding the weird build failures in `Paths_hnix.hs`, I think you're running into a `cabal` bug. See https://github.com/haskell/cabal/blob/master/release-notes/cabal-install-3.6.2.0.md#significant-changes.
If you update your `cabal` installation, it should be gone.
username_2: Running a new `cabal update` seems to resolve the selection of 0.15:
```
$ cabal update 'hackage.haskell.org,2021-12-03T15:52:06Z'
$ cabal run --constraint 'hnix >= 0.11'
...
- hnix-0.15.0
...
$ cabal update 'hackage.haskell.org,2021-12-04T14:47:15Z'
$ cabal run --constraint 'hnix >= 0.11'
...
- hnix-0.14.0.5
...
```
Also, upgrading cabal from 3.6.0.0 to 3.6.2.0 does fix the `Paths_hnix` compile problem and I can successfully build the 0.14.0.5 version.
Interestingly, without the lower bound constraint and when an unconstrained `megaparsec` is part of the build dependencies, cabal still chooses the very old `hnix-0.2.1` (and version 9.2.0 of `megaparsec`). Removing `megaparsec` changes the build plan back to 0.14.0.5. Shrug.
Thank you both, @username_0 and @username_1 for your help on this issue (and your work on hnix). I now have a better plan for using a much more recent version of hnix than 0.12.
username_1: @username_2 Thank you for contributing information & reporting the situation.
Thank you Simon for help here, he is closer to the center of the Haskell stack & knows the specifics. Do not know your current situation hope you would get a living out of it.
Marking these messages as resolved.
This topic overall is still open, as somebody (I) still needs to unbork the bork.
username_1: Currently resolved in `master`.
username_1: Released `0.16.0`, which uses `NoImplicitPrelude` & prelude is in `Nix.Prelude`. |
redisson/redisson | 1042029916 | Title: Redisson client should be created even without all connections being initialized
Question:
username_0: The problem we are facing now with Redisson is that we create the Redisson client at the application start-up and quite often we get an error like the following:
```
Unable to init enough connections amount! Only 49 of 50 were initialized.
```
or for a different use case:
```
Unable to init enough connections amount! Only 1 of 2 were initialized.
```
This leads to the client not being created.
We don't want to retry synchronously because it would slow down the application start-up which in turn would slow down the AutoScalingGroup outscaling.
We would like to get an instance of the Redisson client even if none of the connections are initialized. There should be some async retry mechanism for re-establishing the connections.
We currently use a Dummy client as a fallback (when the Redis is not critical)) or manage the client creation async retry by ourselves, but we need to replicate this retry mechanism for each Redisson client (we have different use cases with different Redis clusters).
Would be very useful to have such a functionality built-in. We used to have Aerospike before Redis and Aerospike had such a functionality (you were able to set [this](https://github.com/aerospike/aerospike-client-java/blob/master/client/src/com/aerospike/client/policy/ClientPolicy.java#L206) property to false) |
laravel/lumen-framework | 430188385 | Title: 127.0.0.1 is not reachable when init server with localhost
Question:
username_0: - Lumen Version: 5.8.4
- PHP Version: 7.1.23
### Description:
127.0.0.1:8000 doesn’t work when I init the server with `php -S localhost:8000 -t public`. Only localhost:8000 works.
If I init it with `php -S 127.0.0.1:8000 -t public`, both 127.0.0.1:8000 and localhost:8000 works.
I found this while playing with a nuxt app making calls with axios. Though I’m not sure if issue is from Lumen making the 127.0.0.1 inaccessible. Or axios converting localhost to 127.0.0.1 which make it impossible to access the API server.
Both Lumen and nuxt is freshly install
Answers:
username_1: Both work for me when I try them out. I believe this might be related to something on your machine specifically. Can you first please try one of the following support channels? If you can actually identify this as a bug, feel free to report back and I'll gladly help you out.
- [Laracasts Forums](https://laracasts.com/discuss)
- [Laravel.io Forums](https://laravel.io/forum)
- [StackOverflow](https://stackoverflow.com/questions/tagged/laravel)
- [Discord](https://discordapp.com/invite/KxwQuKb)
- [Larachat](https://larachat.co)
- [IRC](https://webchat.freenode.net/?nick=laravelnewbie&channels=%23laravel&prompt=1)
Thanks!
Status: Issue closed
|
voila-dashboards/voila | 552439674 | Title: voila dashboard on mybinder 500 error
Question:
username_0: My voila dashbaord example that runs on MyBinder stopped working: https://github.com/ismms-himc/codex_dashboard
It used to display the interactive widget correctly, but not it now shows a 500 internal server error. I'm not sure it it is an issue with MyBinder or Voila. I have myself pinned to voila 0.1.9 (https://github.com/ismms-himc/codex_dashboard/blob/master/requirements.txt) so I think it might be a mybinder problem.
The same Codex dashboard is still working on the voila gallery (https://github.com/voila-gallery/voila-gallery.github.io/blob/master/_data/gallery.yaml#L43, https://voila-gallery.org/)
Answers:
username_1: Could it be another package that got upgraded?
Maybe it is not related, but I tried executing your Notebook from the classic Jupyter Notebook on binder and it seems to hang at this cell:
```python
net.load_df(df['tile-neighbor'])
net.normalize(axis='row', norm_type='zscore')
net.clip(-5,5)
net.widget()
net.widget_instance.observe(on_value_change, names='value')
```
username_1: Sorry, actually it works. But it took more than 20 seconds to execute.
I wonder if that would be possible to start Voila from a terminal on binder, so you can see the actual error message in the terminal.
username_2: The one in the gallery uses this commit: https://github.com/ismms-himc/codex_dashboard/commit/b8c8fb820c918d4fc343cf6d8a25bd81cad837c9
While the one in the repo is built from `master`, so as of today this commit: https://github.com/ismms-himc/codex_dashboard/commit/aa7f8fdd5fb3cac5321a064f33097cf725bee5e1
So it's possible the two Binders were built at different times, and something changed in between.
Have you tried to reproduce the issue locally using [repo2docker](https://repo2docker.readthedocs.io/en/latest/)? mybinder.org is usually using the latest version of it: https://github.com/jupyterhub/mybinder.org-deploy/blob/c1440f66c4c05ca421b53c49a045771e963d4d4d/mybinder/values.yaml#L72
username_2: @username_0 have you tried changing the dashboard, for example by updating voila to 0.1.20?
This would trigger a new build on mybinder.org the next time the binder link is used, and might give some more information on whether something was wrong with the previous build.
username_0: Hi @username_2 I updated the version of voila (https://github.com/ismms-himc/codex_dashboard/blob/master/requirements.txt#L3) but now it is getting stuck on cell 9. I'll try to run it locally and let you all know what happens.
username_2: What does cell 9 do?
username_0: It defines a function see: https://github.com/ismms-himc/codex_dashboard/blob/master/index.ipynb
It runs on my computer, but I want to try the repo2docker suggestion you made above.
username_0: The notebook was getting stuck at cell 10, which does the hierarchical clustering and generate the widget.
I tried running the notebook (index.ipynb) using mybinder (https://mybinder.org/v2/gh/ismms-himc/codex_dashboard/master) and the notebook ran correctly. However clicking the voila button in the classic notebook did not render the Voila dashboard correctly (it got stuck at cell 9 again).
Suspecting the mybinder instance ran out of memory, I lowered the number of matrix columns that were being clustered from 5,000 to 3,000 and then the voila button worked correctly. I updated the current notebook to reduce the size of the matrix and now it is rendering correctly using the launch binder button.
So I suspect that the mybinder instance is running out memory.
Status: Issue closed
username_2: Thanks @username_0 for the update.
Memory on mybinder.org Instances is indeed [limited to 1GB](https://mybinder.readthedocs.io/en/latest/faq.html#how-much-memory-am-i-given-when-using-binder).
Ideally there should be some indication when the kernel is not available anymore (https://github.com/voila-dashboards/voila/issues/67). |
elishacloud/Silent-Hill-2-Enhancements | 421953718 | Title: Invisible wall in Room 312
Question:
username_0: I hope this isn't annoying but..
In the well-known room 312 there is an invisible wall in pass between a bed and a case. Pass rather wide that James could come into it. I do not know for what reason developers did not give such chance. It's a shame at such important point of a game a little. Whether it is possible to correct it? Yes, I do not understand modding of games, so I apologize if my question seems too naive.
Sorry for my bad English.
Answers:
username_1: Hi @username_0 ,
No worries, you're not annoying anyone. :)
As far as I know, I don't believe any one on the team knows how to make new collision boundaries for certain objects.

username_0: Thanks for fast reply:)
username_2: It's possible to find addresses that control collisions of a location by extensive memory scanning (and changing values on the found addresses) and using a hidden minimap as an indicator of change since it draws collisions.
username_2: It's possible to find addresses that control collisions of a location by extensive memory scanning (and changing values on the found addresses) and using a hidden minimap as an indicator of change since it draws collisions. Nekorun says he knows how to activate minimap on PC version.
username_2: Collision data is stored in .cld files. Room 312 data is in `rr91.cld` file.
From what I understand collision data file contains infromation on point pairs that get connected by a line automatically.
This would be a portion (all float values apart from the first several single bytes) that describes one point pair, it has X and Z coordinates for each point and that is needed to move points around:
`01 01 00 00 04 00 00 00 05 00 00 00 00 00 00 00 00 9E 63 47 00 80 F7 C3 00 74 9F 46 00 00 80 3F 00 25 64 47 00 80 F7 C3 00 74 9F 46 00 00 80 3F 00 25 64 47 00 80 F7 C3 00 0C 9E 46 00 00 80 3F 00 9E 63 47 00 80 F7 C3 00 0C 9E 46 00 00 80 3F`
I don't know how to add new data to a .cld file (to create new collision points) that has all the data already stacked together, I can only change existing points position.
Since hidden minimap draws collisions it can be used to track changes made in the file.
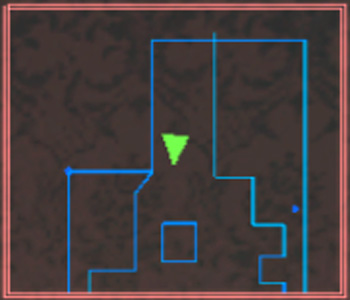
I guess some of the room's outer borders or other lines inside the room could be used to create new portion of the area in question.
username_2: https://youtu.be/4LJg80Bs-ww
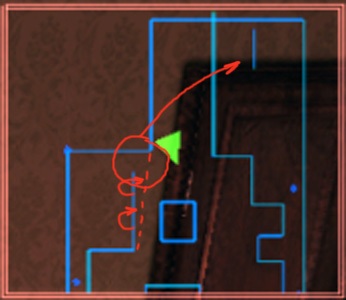
I used three outer borders that a player doesn't connect with during regular gameplay and one piece of single point geometry that is also unreachable and therefore safe to use without breaking existing room design.
If you like it, I will make a new `rr91.cld` file.
username_1: You put a lot of work into this and the results look great. We should definitely include it then!
username_2: [rr91.zip](https://github.com/username_3/Silent-Hill-2-Enhancements/files/3000501/rr91.zip)
I would advice on using original .cld file for any visual effects research in this room since it's unknown if any effects are tied to the room's collisions (if any of those unreachable borders / single point collisions are needed for something else).
username_1: Thanks for your work here, username_2.
We'll add this to the next update release coming soon. If I turns out we need to revert collision data for other visual effects in this room, we can add the original `rr91.cld` file to a future update to replace the file.
@username_0 you can download username_2's edited file above and place it in `KONAMI\Silent Hill 2\sh2e\bg\rr\`
username_0: Wow, username_2, it is really impressive, thank you👍
Status: Issue closed
|
ppy/osu | 329187686 | Title: In the playlist menu box, dragging down or up on a point in the song lags the game and distorts the audio
Question:
username_0: On the song select box in the top right, obviously the current part of the song can be dragged ahead or behind, but when you drag this yellow bar down, it lags terribly, distorting the audio as well
https://youtu.be/4_OLOe1XrAY
Answers:
username_1: I assume the dragging down causes rapid seeking at nearly the same point.
username_0: That sounds right, it just taxes my hardware when I do it so much that the game lags and the audio also freaks out
username_2: Has since been fixed.
Status: Issue closed
|
angular/material | 58688708 | Title: forms: validation. don't show errors until the user has had a chance to do something
Question:
username_0: When a user opens a page that has a bunch of required fields, all they see is a bunch of red. Not very inviting. I would much rather that validation is hidden until `$touched === true`. I would also like to have the ability to control when validation is shown. I appreciate how helpful angular-material is, but I really like that bootstrap allows me to specify when to show validation errors by requiring me to add the `has-error` class myself. This gives me a lot of flexibility. I haven't looked at the implementation for angular-material, but perhaps I could specify a function which would determine whether validation should be visible for a specific field? However it's done, I just don't want to invite users to my page with a bunch of invalid fields. Let them touch the fields first, then we'll tell them it's invalid if it still is after they've had a chance to do something with it.
Answers:
username_0: Sorry, just realized that it doesn't greet the user with a bunch of red. However, it goes red as soon as focus comes into the input. I would rather wait until `$touched` is set to true which means the user has blurred the input.
username_1: There is a way to specify when to show an error: By using the [`md-is-error` attribute][1].
However there are some issues/bugs with properly detecting the `$touched` state (there are several issues about this, I believe).
[1]: https://material.angularjs.org/#/api/material.components.input/directive/mdInputContainer
username_0: I hadn't ever heard of issues with the `$touched` state. I switched my demo to bootstrap and everything is working really well: http://jsbin.com/zuguxi/edit
username_0: Sorry, just realized I never gave the original example here: http://jsbin.com/cadeko/edit
username_1: This turned out to be longer than anticipated, so long story short:
Due to some bugs in the current implementation:
1. Any input inside an `mdInputContainer` gets set to `touched` upon focus.
2. This state change is not properly propagated (because of improper digest lifecycle handling).
---
This is a bug with setting the touched state of the input. It can be found in [input.js#L183-192][1]:
```js
element
.on('focus', function(ev) {
containerCtrl.setFocused(true);
// Error text should not appear before user interaction with the field.
// So we need to check on focus also
ngModelCtrl.$setTouched();
if ( isErrorGetter() ) containerCtrl.setInvalid(true);
})
```
Here is what is going on:
1. There is the `mdIsError` attribute which can be used to determine when the error should be "applied"/shown.
2. If it is present it is `$parse`d and (incorrectly) used for determining if the error should be applied using the `isErrorGetter()` function.
3. If it is not present, a default function is created that returns `ngModelCtrl.$invalid && ngModelCtrl.$touched`. <-- (this is the case in your example)
4. The `isErrorGetter()` is `$watched` and `setInvalid()` is called on the `mdInputContainer`'s controller according to its return value.
5. For reasons that are not clear to me, upon focusing the input, the following happens:
`ngModelCtrl.$setTouched();`
`if ( isErrorGetter() ) containerCtrl.setInvalid(true);`
As a result of (5):
* The element's state is set to `touched` (although this is not consistent with the semantics of default `$touched`).
* `isErrorGetter()` (which checks the controller's internal state) evaluates to `true`, which results in calling `setInvalid(true)` on the `mdInputContainer`'s controller.
* `mdInputContainer` receives the `md-input-invalid` class, thus stying the containing input with the `warn-500` color (by default `red`).
* Since the event happens outside of Angular's `$digest` cycle and there is not explicit `$apply`, the new state is not properly propagated, thus:
- The input does not receive the `ng-touched` class.
- The `ngShow` on the messages' div is not re-evaluated (it would evaluate to `true` and show the errors, if a digest cycle was properly triggered).
Both of the above can be "fixed" by triggering a digest "manually" from the console (for illustration pusposes only).
[1]: https://github.com/angular/material/blob/efbd414a4d5af7b5144f1d08522e46cc043b627d/src/components/input/input.js#L183-192
username_1: (Needless to say, that the Bootstrap version (which does not rely on `mdInputContainer`) works as expected as it avoids the aforementioned bugs.)
username_0: Thanks for the explanation @username_1. Totally makes sense where this came from. Obviously triggering the digest manually is not an option. In `angular-formly` we have logic like this:
```javascript
// scope.fc = the ngModelController
// scope.options = something that the directive user can manipulate
scope.$watch(function() {
if (typeof scope.options.validation.show === 'boolean') {
return scope.fc.$invalid && scope.options.validation.show;
} else {
return scope.fc.$invalid && scope.fc.$touched;
}
}, function(show) {
options.validation.errorExistsAndShouldBeVisible = show;
scope.showError = show; // <-- just a shortcut for the longer version for use in templates
});
```
This is really handy because in templates, people can do something like this (contrived bootstrap example):
```html
<div class="form-group" ng-class="{'has-error': showError}"> <!-- <-- notice that -->
<label for="my-input" class="control-label">My Label</label>
<input ng-model="my.model" name="myForm" class="form-control" id="my-input" />
<div ng-messages="fc.$error" ng-if="showError"> <!-- <-- and that -->
<!-- messages here -->
</div>
</div>
```
I think the `md-is-error` works great because it gives the same kind of control that `options.validation.show` gives, where you can show errors even if the user hasn't touched an input which is useful sometimes. But the more common case is after the user has interacted with the field.
If it were me, I would do what we're doing in `angular-formly`. Don't explicitly set the `ngModelController` to invalid and `$touched` on focus, but instead only show error state if it's `$invalid && ($touched || isErrorGetter())`.
username_2: @username_1 regarding issue 5, I'm guessing the reason its thrown into an error state on focus is because, in the docs for example, all the fields have required directive. So you focus the input, it checks to see if its required, but you havent started typing so no value is present yet, throwing into immediate error state.
username_1: @username_2: The inputs are invalid from the beginning (because they are required and empty). The problem is when they show their invalidity (which in the intended default case should happen after the first blur, but happens on focus).
username_3: Fixed with SHA 747eb9c
Status: Issue closed
username_0: Thanks @username_3 :D
username_4: Hi, maybe I did something really wrong but it does not work with 0.8.3
this is my mini example: http://codepen.io/username_4/pen/JoewqY?editors=101
The myForm.myValue.$touched seems to work correctly at the ng-messages block,
but still if I simply focus the input it turns red
username_5: Yes, looks like it doesn't work in 0.8.3.
username_6: Not working in 0.8.3 |
gatsbyjs/gatsby | 737210710 | Title: Netlifycms Gatsby - Field "image" must not have a selection since type "String" has no subfields.
Question:
username_0: ### Environment
command not found: gatsby
Would not work as its through netlfy
Answers:
username_1: Hi @username_0 !
Is there a way to run and reproduce this locally? If not, we'll need a [minimal reproduction][reproduction]. This is a simplified example of the issue that makes it clear and obvious what the issue is and how we can begin to debug it.
If you're up for it, we'd very much appreciate if you could [provide a minimal reproduction][reproduction] and we'll be able to take another look.
Thanks for using Gatsby! 💜
[reproduction]: https://gatsby.dev/reproduction
username_0: Is there something that I am missing when adding new images??
thanks for your help.
username_0: Here is my repo if you want to have a look at that
https://github.com/username_0/apollon-gatsby
username_2: I have the same problem. I read and try every solution on Internet with the keywords `Field "image" must not have a selection since type "String" has no subfields.` and nothing helped...
username_0: @username_2 I found that in your index.md file if you put quotes around index-page it all works for hot reload.
I didn't have quotes around mine when i downloaded it, after days and days of looking, I had a look at another index.md and realised it had quotes.
Let me know if this works for you.
`---
templateKey: 'index-page'
path: '/'`
username_2: Hi @username_0 . Thanks !
But it doesn't change a thing... :(
Every time i change something on `http://localhost:8000/admin/#/collections/pages/entries/index` then publish i have this error message.
username_3: Hi,
I'm having the same error as well, but I think mine is environment related. I'm running Netlify CMS with Gatsby and I haven't modified my gatsby-config.js or anything past html/text and my gatsby builds have begun to fail. Even if I run previously successful builds on netlify, they fail.
Ignore the orange background, it's a blue-light filter. As you can see, my past successful builds fail on netlify, and the same happens on local deploy.
[You can see my repository here.](https://github.com/username_3/oscarswebservices-portfolio)
The error is too generic and there are too many solutions not working.
username_4: I got stuck on the same problem. Any updates on the issue?
username_5: Hello 👋 This error usually happens when Gatsby fails to detect the type of an image file referenced in the markdown, thus inferring its type as a string.
That in turns fails the `image` query.
Possible solutions are:
1. Defining a custom schema. See [here](https://www.gatsbyjs.com/docs/reference/graphql-data-layer/schema-customization/) for more information.
2. Use relative media folders in the CMS configuration to put media files in the same directory as the markdown file. That makes it easier for Gatsby to find the file. See [here](https://www.netlifycms.org/docs/gatsby/#configuration) for an example configuration.
username_5: Closing this per my comment. Please comment on the issue if still relevant and using the suggested solutions doesn't work.
Status: Issue closed
|
PillowPillow/ng2-webstorage | 168275650 | Title: error TS2305: Module '".../node_modules/ng2-webstorage/index"' has no exported member 'localStorage'
Question:
username_0: I am getting above error while importing `localStorage `. `LocalStorageService` is imported correctly.
Help is appreciated. Thanks.
Answers:
username_0: That was because , i copied it from the doc. It was suppose to be `LocalStorage` . Please correct the doc. In `clear` example.
Status: Issue closed
username_1: fixed, thanks for the issue |
mikefarah/yq | 935145697 | Title: No way to match a pattern that contains * or ?
Question:
username_0: **Describe the bug**
If a user wants to find all strings which exactly match a pattern, however the pattern contains a * or ?, it will match unwanted entries.
Version of yq: 4.9.3
Operating system: mac
Installed via: homebrew
**Input Yaml**
data1.yml:
```yaml
- cat*
- cat*
- cat
```
**Command**
The command you ran:
```
yq eval '.[] | (. == "cat*")' data1.yml # results shown below
yq eval '.[] | (. == "cat\*")' data1.yml # escaping doesn't help
yq eval '.[] | (. == "cat.*")' data1.yml # regex isn't supported
yq eval '.[] | (. === "cat.*")' data1.yml # strict equality operator isn't supported
```
**Actual behavior**
```yaml
true
true
true
```
**Wanted behavior**
```yaml
true
true
false
```
**Additional context**
Either supporting regex matching or adding a `===` operator that does exact matching could fix this.
Answers:
username_1: Yeah good point - I think regex would work well
username_1: 4.10.0 has new regex operators that can be used for this:
```
yq e '.[] | test("cat\*")' examples/data1.yaml
```
Status: Issue closed
|
jaxxstorm/puppet-teleport | 145777766 | Title: Fix install path
Question:
username_0: Currently, we use the archive module to download files to `/opt/teleport`
This unfortunately will break any chance of doing upgrades, because archive won't know to download new software!
We need to change the path to something like `/opt/teleport-${version}`
Answers:
username_0: Closed by #17
username_0: Closed by #17
Status: Issue closed
|
nodes-php/core | 150796257 | Title: Browsecap is slowing down the api
Question:
username_0: $browscap->update() is costing 11sec on my local
Status: Issue closed
Answers:
username_1: We've changed Browscap package in the latest release, so I'll be closing this issue for now.
If the new package is still very slow, then please re-open this issue again :) |
joltup/rn-fetch-blob | 482217434 | Title: Open downloaded file of any type.
Question:
username_0: Hi, I downloaded the file successfully and I want to open the downloaded file which may be of any filetype(pdf/jpg/doc). In iOS open document opens all type of file's but in android how to open the file which has been downloaded???
Answers:
username_1: [https://stackoverflow.com/a/50860387](url)
use this.
or use "application/*", but not recommend. |
ziglang/zig | 609437985 | Title: Proposal: Explicit Shift Operations
Question:
username_0: -- https://en.wikipedia.org/wiki/Arithmetic_shift#Non-equivalence_of_arithmetic_right_shift_and_division
So, for historic one's complement machines, having `n << p` and `n >> p` be synonymous with `n * 2^p` and `n / 2^p` was sensible. Other languages have tried to hold onto this historical nugget, but its time is past. We will not return to one's complement anytime soon.
By defining separate operators for shifts, in terms of zero vs sticky, we sidestep the arithmetic context altogether and treat them exactly as they are: bitwise operators. Any arithmetic context is a convenient side-effect.
# Prior art
[prior-art]: #prior-art
- [The C Standard](http://www.open-std.org/jtc1/sc22/wg14/www/docs/n1256.pdf)
- Every other C inspired programming language
# Unresolved questions
[unresolved-questions]: #unresolved-questions
Does defining shifts in terms of "Flood-zero's" and "Sticky" make users expect a "Flood-one's" operator? Does the lack of one make programming less convenient?
# Future possibilities
[future-possibilities]: #future-possibilities
Shifts have always been in a strange situation, not quite a bitwise operation, not quite an arithmetic one, and weighed down by historic waffling in computing hardware. We are in a position to clarify the purpose of these fundamental tools, decreasing the number of dumb bugs people deal with every day, and increasing their Zen of Zig, one power of two at a time.
Answers:
username_1: RISC-V has logical left shift, logical right shift, and arithmetic right shift. I don't think having one of our operators suddenly not map to a machine instruction is necessarily a good idea. Maybe we could distinguish between logical and arithmetic right shift, but I don't agree with the rest of this proposal.
username_2: I don't think we should make decisions based on the presence or absence of hardware instructions.
username_3: The two variants of left shift are mathematically equivalent, since the sign bit doesn't shift into anything. That's why RISC-V only has one instruction for them. Both map to the same machine instruction.
username_3: Oh wait, I didn't read carefully enough. The proposal is suggesting filling with the _least_ significant bit. Is filling with the lsb actually a useful operation? Most ISAs don't support anything like that, so unless there's a compelling argument that it's a useful primitive for the language to define I don't think it should be included.
username_4: All `std.math.sh*` functions can be adapted for this proposal.
username_0: @username_3 @username_1 I actually have no particularly strong technical opinion on whether the `<<<` aspect of this proposal is implemented or not, but the symmetry of the suggestion feels hard to pass up.
The primary use case I imagine is programmatically creating a right-aligned mask of width `n` of a bitbuffer of size `m`. The operation would likely map to `1 << (m-1) >>> n >> (m-1) - n)`, which has the convenience of creating an unsigned value of `(2^n)-1`.
The strength of its argument is more a matter of its convenience, rather than technical necessity.
username_0: @username_3 @username_1 I actually have no particularly strong technical opinion on whether the `<<<` aspect of this proposal is implemented or not, but the symmetry of the suggestion feels hard to pass up.
The primary use case I imagine is programmatically creating a right-aligned mask of width `n` of a bitbuffer of size `m`. The operation would likely map to `1 << (m-1) >>> n >> (m-1) - n)`, which has the convenience of creating an unsigned value of `(2^(n+1))-1`.
The strength of its argument is more a matter of its convenience, rather than technical necessity.
username_3: Normally, a right-aligned mask of `n` 1s is constructed with `(1 << n) - 1`. This formulation cannot produce the mask of all 1s (because the shift value would overflow), but it can produce the mask of all zeroes when n is zero. The proposed `<<<` flips that edge case by effectively subtracting 1 from n. Where defined, `(1 << n) - 1 == 1 <<< (n-1)`. But with the new formulation, the zero mask is impossible (n-1 would overflow), and the all ones mask can be created (n = max(Log2Int(lhs))). But you still have to remember to subtract 1 when making the mask, so it doesn't necessarily simplify anything IMO. Additionally, having to allow this edge case makes this a pretty expensive operation to implement when generating assembly. Since bit tricks are usually used in the pursuit of performance, I think we should keep the set of available operations relatively close to what hardware supports.
There may be some value in separating logical and arithmetic shift into separate operators. But we have slightly different concerns from Java. Java requires a separate operator because it doesn't have unsigned integer types (for the most part). And it's "default" right shift is sign extending. So we need to consider how it would fit into Zig.
Personally, I feel that shifting zeroes into the top bits of a negative signed integer is extremely unexpected behavor. Then again, shifting a signed integer left also totally clobbers the sign bit, so it's also unexpected. Most hardware has a way to do these things, so we should have some support for them, but maybe it shouldn't be front and center.
It seems like we're kind of in a "damned if you do, damned if you don't" scenario. As you pointed out, using the type to determine what kind of shift to do is a bit of a footgun, especially with Zig's inferred types on everything. But if we break convention from C and Rust and make the `>>` operator always perform an unsigned shift, a lot of C and Rust programmers will shoot themselves in the foot trying to get an arithmetic shift. So here's my counter-proposal:
- disallow both `>>` and `<<` on signed integer types. `<<` clobbers the sign bit, so it doesn't make sense on a signed type. `>>` preserves the sign bit, but may cause unexpected behavior if modeling division or if it's expected to reverse `<<`, so it doesn't really make sense either. By making these compile errors, we remove all chance of confusion with shifts unexpectedly doing the wrong thing.
- add builtins for `@shrSigned`, `@shrSignedExact`, and `@shrSignedWithOverflow`. Hardware supports these operations and we should too, but they don't need to happen implicitly based on the operand type. These builtins accept a signed (or unsigned?) integer as the first argument, and perform a shift that preserves and extends the sign bit.
With these changes, it's difficult to do the wrong thing accidentally. When shifting unsigned integers, sign extending makes no sense so it's obviously shifting zeroes in. When shifting signed integers, they either have to be cast to unsigned or use the explicit `@shrSigned` builtins.
I don't think we should support `@shlSigned` builtins, because it's not obvious what these do. Naively I would expect them to shift left all bits except the sign bit, which gets preserved. But other languages implement shift left on signed as a logical shift left. So we should avoid that ambiguity by not having these builtins at all, and forcing a cast to unsigned if you want to shift left.
username_1: Left-shifting into the sign bit is actually the most sensible option -- it represents the multiplication truncated to the range of the type, and it's easy to check for overflow by watching for a sign change.
username_5: I support this proposal, it's often confusing and error-prone to have arithmetic and logic shift glued to the type. Shifts are not arithmetics and should that should be respected. If i want to divide, i can write `/2`, which most optimizing compilers will transform to a shift anyways |
DLibatique/CLAS199 | 393712102 | Title: Issues Tutorial
Question:
username_0: Hello @username_1! I've assigned you an issue for you to look at. You can take a look directly in the issues tab or go over to the projects tab and see it as a card. If you understand the layout of this issue (such as the fact that you can comment below), you can either close this or comment below.
Status: Issue closed
Answers:
username_1: Awesome! I think I understand. Thanks, @username_0! |
formio/formio.js | 339748727 | Title: Translations disapear after modifying form
Question:
username_0: Hey i found out that there is some problem with i18n that appears in version 3.0.0 rc.20
https://codepen.io/anon/pen/JBjRKP - when u drag and drop or remove or update the form the translations disapear
in version 3.0.0rc.2 it was fine
https://codepen.io/anon/pen/oMNLRv
Status: Issue closed
Answers:
username_1: Closing issue.
This should be resolved on the latest 4x renderer. If the issue persists, please open a new issue |
hellofresh/eks-rolling-update | 1125443073 | Title: [Feature Request] Detach from ASG or Load Balancer / Target Group
Question:
username_0: Hi,
This is probably asking for too much, but there might be other people interested:
*Request:*
When draining a node from ASG: detach it from the load balancer and/or target group if there's any associated with the ASG.
*Alternative*:
When starting draining a node: could the node be detached from the ASG ? (it sounds simpler, but it probably goes against all the logic of this rolling-update tool)
*Why:*
Our setup has 1 NLB with 1 Target Group, and our nodes run istio ingress gateway as a Daemon Set. Because a Daemon Set is not drained from a node, our ingress gw stays up until the node gets killed, terminating quite abruptly any connection (actually, it's not that brutal, since the ASG itself does the detaching when terminating the node - but that does not give enough time).
Thank you |
rails/rails | 52533922 | Title: Rails v4.2.0.rc3 CSRF
Question:
username_0: I have an application. I submit data via Ajax. In Rails v4.1.7, it would work. In Rails v4.2.0.rc3, I am given a CSRF error. Is this a known issue? If not, what information can I provide to help debug it?
Answers:
username_1: @username_0 that doesn't seem to fix the problem. There is still a mismatch, and false is returned. I had the same solution for 4.1 which worked fine. |
tomprogrammer/rust-ascii | 541334223 | Title: All files in crate are executables
Question:
username_0: Hello,
While packaging the latest crate for my distribution, I noticed that all files in the published crate have executable bits. This cause issue with one of our packaging script and seems to be an error. Could you remedy this?
Thank you,
Status: Issue closed
Answers:
username_1: I guess this was the result of uploading the crate from WSL. This shouldn't happen for the next releases. |
react-bootstrap/react-overlays | 164640925 | Title: Babel 6?
Question:
username_0: Any plan to upgrade to babel 6 for this repo? I can help with that if that is a valid plan. Thanks!
Answers:
username_1: go for it!
username_2: Biggest issue might be the prop tables. See e.g. https://github.com/react-bootstrap/react-bootstrap/pull/1802.
username_1: react-metadata _Should_ be working with babel 6, i have react-formal updated to it
Status: Issue closed
|
pypa/virtualenv | 611419887 | Title: python-config is not installed since version 20
Question:
username_0: **Issue**
Prior to virtualenv version 20, eg 16.7.10, virtualenv installs python-config in the virtualenv's bin directory. Since version 20 this no longer happens.
```console
$ pip3 install --user virtualenv\<20
$ ~/.local/bin/virtualenv --version
16.7.10
$ ~/.local/bin/virtualenv venv-16
$ ls venv-16/bin/
activate activate.fish activate_this.py easy_install pip pip3.8 python3 python-config
activate.csh activate.ps1 activate.xsh easy_install-3.8 pip3 python python3.8 wheel
$ pip3 install --user --upgrade virtualenv
[...]
Installing collected packages: virtualenv
Attempting uninstall: virtualenv
Found existing installation: virtualenv 16.7.10
Uninstalling virtualenv-16.7.10:
Successfully uninstalled virtualenv-16.7.10
Successfully installed virtualenv-20.0.18
$ ~/.local/bin/virtualenv --version
virtualenv 20.0.18 from /home/iguana/.local/lib/python3.8/site-packages/virtualenv/__init__.py
$ ~/.local/bin/virtualenv venv-20
$ ls venv-20/bin/
activate activate.fish activate_this.py easy_install easy_install-3.8 pip3 pip3.8 python3 wheel wheel-3.8
activate.csh activate.ps1 activate.xsh easy_install3 pip pip-3.8 python python3.8 wheel3
```
**Environment**
- OS: Debian sid
- ``pip list`` of the host python where ``virtualenv`` is installed:
```console
$ pip3 list
Package Version
---------------------------- --------------
appdirs 1.4.3
apsw 3.30.1.post1
asn1crypto 0.24.0
astropy 4.0
atomicwrites 1.3.0
attrs 19.3.0
Automat 0.8.0
backcall 0.1.0
bcrypt 3.1.7
beautifulsoup4 4.9.0
black 19.10b0
blinker 1.4
boto 2.49.0
Brlapi 0.7.0
certifi 2019.11.28
cffi 1.14.0
chardet 3.0.4
Click 7.0
colorama 0.4.3
configobj 5.0.6
constantly 15.1.0
cryptography 2.8
css-parser 1.0.4
[Truncated]
2073 changing mode of /home/iguana/venv-20/bin/pip to 755 [INFO util:566]
2073 changing mode of /home/iguana/venv-20/bin/pip3.8 to 755 [INFO util:566]
2074 generated console scripts pip pip3.8 pip-3.8 pip3 [DEBUG base:53]
2074 Attempting to release lock 140040557034272 on /home/iguana/.local/share/virtualenv/seed-app-data/v1.0.1/3.8/wheels.lock [DEBUG filelock:315]
2074 Lock 140040557034272 released on /home/iguana/.local/share/virtualenv/seed-app-data/v1.0.1/3.8/wheels.lock [INFO filelock:318]
2074 add activators for Bash, CShell, Fish, PowerShell, Python, Xonsh [INFO session:64]
2075 write /home/iguana/venv-20/pyvenv.cfg [DEBUG pyenv_cfg:34]
2075 home = /usr [DEBUG pyenv_cfg:38]
2075 implementation = CPython [DEBUG pyenv_cfg:38]
2075 version_info = 3.8.3.candidate.1 [DEBUG pyenv_cfg:38]
2075 virtualenv = 20.0.19 [DEBUG pyenv_cfg:38]
2075 include-system-site-packages = false [DEBUG pyenv_cfg:38]
2075 base-prefix = /usr [DEBUG pyenv_cfg:38]
2075 base-exec-prefix = /usr [DEBUG pyenv_cfg:38]
2075 base-executable = /usr/bin/python3 [DEBUG pyenv_cfg:38]
2075 created virtual environment CPython3.8.3.candidate.1-64 in 2033ms
creator CPython3Posix(dest=/home/iguana/venv-20, clear=False, global=False)
seeder FromAppData(download=True, pip=latest, setuptools=latest, wheel=latest, via=copy, app_data_dir=/home/iguana/.local/share/virtualenv/seed-app-data/v1.0.1)
activators BashActivator,CShellActivator,FishActivator,PowerShellActivator,PythonActivator,XonshActivator [WARNING __main__:21]
```
Answers:
username_1: Can you explain why is python-config needed? For comparison venv also does not create these files, so there's precedence for this not being present.
username_0: /bin/sh: 1: python-config: not found
gyp: Call to 'if [ -z "$PY_INCLUDE" ]; then echo $(python-config --includes); else echo $PY_INCLUDE; fi' returned exit status 0 while in binding.gyp. while trying to load binding.gyp
[...]
```
username_1: How does it work with a venv, given that doesn't have it?
username_0: It was working with a venv (using virtualenv <20) because while the system has python3-config installed but not python-config (presumably because I have python3-dev installed from apt and not python2-dev). virtualenv <20 was creating python-config in the venv's bin/ that correctly looked for the Python 3 sysconfig values.
While Debian might switch over to Python 3 for its python-config at some point, it would still be useful to have the virtualenv support, to point python-config at the correct point release of Python 3 (for instance, I have 3.7 and 3.8 and might want different venvs for different Python versions).
username_1: virtualenv before version 20 was not using venv (what's available under ``python3.8 -m venv``); at all. So my question is why do you think virtualenv should offer a feature not part of the venv. The fact that venv does not contain it (see https://www.python.org/dev/peps/pep-0405/), makes me believe there's a better solution than using python-config. I did not understand fully what you were getting at. Felt like you were conflating venv with virtualenv.
username_0: Apologies if my use of terminology was confusing - I meant 'virtualenv' in all cases I used 'venv' above (I was used to abbreviating virtualenv dirs to this before python's built-in venv appeared.)
To directly answer your question "why do you think virtualenv should offer a feature not part of the venv", my answer would be because it used to prior to version 20. However if this feature was dropped to bring virtualenv in-line with Python's built-in venv, I'm happy to be told this, and I'll find a workaround for it.
username_1: This is the case. If you think this should be changed please first raise an issue under http://bugs.python.org/ for venv, and if it is deemed still needed we can add it.
Status: Issue closed
|
angular-ui/ui-grid | 111608076 | Title: Erroneous row.entity
Question:
username_0: Hi I in my grid I want to make a link reference (for each row) to other page,
the link is build of row.entity data of the grid (so it's different and unique for each row),
the problem is when I have scroll implemented (by default) for some rows (when scrolling down) then row.entity is not the same as the row it supposed to be,
but when I display the hall data (by invoking function that gets the data.length and auto-resize ui-grid)
each row.entity is the same as it must be in the grid.
Is it a bug or I need to change something in the gridOptions?
Thanks.
Answers:
username_1: I see this as well. If you have 35 rows in your table and only 20 are shown in the viewport, when you scroll, row.entity for the newly scrolled into view rows matches earlier rows and you get the wrong data. |
dart-lang/sdk | 114966060 | Title: Please merge revision 12e94fc1d92995da5ebedbd345cc888727d39e47 into dev channel
Question:
username_0: @username_1 @mit-mit @kasperl
<Describe the problem this merge is fixing - include issue numbers if applicable>
Make function type checks for types returned by typed JS interop pass in dartium checked mode.
<What revision(s) needs to be merged - please annotate revisions with reason if more than one>
12e94fc1d92995da5ebedbd345cc888727d39e47
7f546e9e0c6bb23afef071a1082cd8acf310ebbd
<-- Fixes a test expectation file for dart2js checked mode (previous cl that should have been merged to dev)
e0f8e96dae2c82005dc13499b674d43c059b7a29
<-- Fixes a test expectation file for dart2js checked mode
This merged cleanly
Status: Issue closed
Answers:
username_1: This was merged in 1.13.0-dev.7.8 |
TheUnit-Grafton/GitTutorialWebSite | 639307521 | Title: Change Logo
Question:
username_0: The logo used in this repo is for TheLab.
Logo needs to be changed for The Unit logo once design has been finalised.
Status: Issue closed
Answers:
username_0: Logos updated to include Square and Rectangular logos for TheUnit.
Logo for TheLab has been removed. |
mehoba/Munchkin | 866800088 | Title: Weglaufen
Question:
username_0: wenn Monster nicht besiegt wird, soll es die Möglichkeit geben wegzulaufen
Hierfür wird gewürfelt (mittels Sensoren - Handy schütteln - umsetzen)
wenn 5 gewürfelt wird ist es gelungen
ansonsten passieren schlimme Dinge
Answers:
username_0: Verwandte Issues bezüglich des Würfelns: #16 #26 |
NervJS/taro-ui | 751519701 | Title: AtInput 在AtModal中 微信小程序,在开发者工具中正常,在ios系统中输入框一直存在。
Question:
username_0: 开发微信小程序,这是代码
这是微信开发者工具中(正常)
这是在ios手机中的样子(不正常,会显示输入框placehoder内容,且点击可调起键盘输入)

Answers:
username_1: 遇到了同样的问题。。你解决了么
username_0: 用v-if控制输入框和弹窗同步显示隐藏
username_2: 我看了下代码 官方用的是 `visibility: hidden/visible`来控制AtModal的显示隐藏,在iOS中input的placeholder一直存在,把`visibility`换成`display`就好了
```
.at-modal{
display: none;
.at-modal--active{
display: block;
} |
julianlam/nodebb-plugin-archiver | 56157868 | Title: Compatibility Issue with v0.6.0
Question:
username_0: ```
1/2 10:20 [17676] - error: Error: Cannot find module './redis'
at Function.Module._resolveFilename (module.js:338:15)
at Function.Module._load (module.js:280:25)
at Module.require (module.js:364:17)
at Object.<anonymous> (/srv/nodebb/node_modules/nodebb-plugin-archiver/index.js:7:22)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Module.require (module.js:364:17)
at require (module.js:380:17)
Error: Cannot find module './redis'
at Function.Module._resolveFilename (module.js:338:15)
at Function.Module._load (module.js:280:25)
at Module.require (module.js:364:17)
at Object.<anonymous> (/srv/nodebb/node_modules/nodebb-plugin-archiver/index.js:7:22)
at Module._compile (module.js:456:26)
at Object.Module._extensions..js (module.js:474:10)
at Module.load (module.js:356:32)
at Function.Module._load (module.js:312:12)
at Module.require (module.js:364:17)
at require (module.js:380:17)
1/2 10:20 [17676] - info: [app] Shutdown (SIGTERM/SIGINT) Initialised.
1/2 10:20 [17676] - info: [app] Database connection closed.
net.js:1236
throw new Error('Not running');
^
Error: Not running
at Server.close (net.js:1236:11)
at shutdown (/srv/nodebb/app.js:374:36)
at process.<anonymous> (/srv/nodebb/app.js:211:7)
at process.emit (events.js:95:17)
at process._fatalException (node.js:272:26)
15 restarts in 10 seconds, most likely an error on startup. Halting.
```
Status: Issue closed
Answers:
username_1: Resolved, please try v1.0.0
username_0: Yeah, it works now :+1:
But I had to install it over NPM, the control panel didn't offer the update. |
justinetroyke/world_citizen | 341679164 | Title: Item Registration
Question:
username_0: When you you click "Item Registration"
- [ ] Should direct to item#new
- [ ] Enter the following:
Selling business name:
Item that gives back:
% or amount donated:
Charity or Non-profit it benefits
Click Submit
- [ ] Direct to items#show
- [ ] Should have an edit button
Answers:
username_0: Switched to item registration rather than business for first iteration. Since anyone can register the item at this point. So O changed this to item new and show, check with Josh if this jives. |
abjur/appAdocao | 835163326 | Title: Criar botão de "ok"
Question:
username_0: Na interface: criar um botão.
No servidor:
a) Criar um reactive que contém os tempos simulados. A simulação só atualiza quando se clica no botão acima.
b) Atualizar o reactive "tempo" no servidor usando os tempos simulados em (a).<issue_closed>
Status: Issue closed |
hapijs/bell | 190704519 | Title: Authorization with Facebook stopped working
Question:
username_0: This is what handler receives in `request.auth`:
```json
{
"isAuthenticated": false,
"strategy": "facebook",
"mode": "try",
"error": {
"data": {
"type": "Buffer",
"data": ["(...lots of bytes here...)"]
},
"isBoom": true,
"isServer": true,
"output": {
"statusCode": 500,
"payload": {
"statusCode": 500,
"error": "Internal Server Error",
"message": "An internal server error occurred"
},
"headers": {}
}
}
}
```
I'm unable to find source of the issue. I'm pretty sure it worked in the first days of August.
Tried with bell version 8.2.1 and 8.3.0. Also, tried to use different applications' credentials and different users. The same result in all cases.
Am I missing something? Or did Facebook change something?
Bell registration:
```js
Server.register(bell, (err) => {
Server.auth.strategy('facebook', 'bell', {
provider: 'facebook',
password: <PASSWORD>,
clientId: Config.auth.facebook.id,
clientSecret: Config.auth.facebook.secret,
isSecure: !DevMode,
location: Config.ownURL,
})
Server.route({
method: ['GET', 'POST'],
path: '/auth/facebook',
config: {
auth: {
strategy: 'facebook',
mode: 'try'
},
handler: app.facebook
}
})
// ...
```
Answers:
username_1: There must be some problem with your code? Or with the very latest version of Hapi...
https://bell.now.sh/ seems to work. I built it just for these issues :)
https://bell.now.sh/_src if you want to see the source code.
Looks like I last deployed it 57 days ago, so whatever version of Hapi was the most recent then is what it's working on.
username_0: "This app is still in development mode ..."
username_0: OK, I found the root on this issue. It appears that Facebook changed requirements for applications. Now you're required to provide a set of valid OAuth redirect URLs for your application.
Status: Issue closed
|
abseil/abseil-cpp | 743267807 | Title: Tautological compare in absl/time/internal/cctz/src/time_zone_libc.cc (on 20200923.2 release)
Question:
username_0: **Describe the bug**
Building abseil 20200923.2 with Clang12.0 and GCC10.2 library in C++20 mode produces this warning:
source_subfolder/absl/time/internal/cctz/src/time_zone_libc.cc:193:9: warning: result of comparison 'const std::int_fast64_t' (aka 'const long') < -9223372036854775808 is always false [-Wtautological-type-limit-compare]
if (s < std::numeric_limits<std::time_t>::min()) {
~ ^ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
source_subfolder/absl/time/internal/cctz/src/time_zone_libc.cc:197:9: warning: result of comparison 'const std::int_fast64_t' (aka 'const long') > 9223372036854775807 is always false [-Wtautological-type-limit-compare]
if (s > std::numeric_limits<std::time_t>::max()) {
~ ^ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
**Steps to reproduce the bug**
Building abseil 20200923.2 with Clang12.0 and GCC10.2 library in C++20 mode.
**What version of Abseil are you using?**
20200923.2
**What operating system and version are you using**
Ubuntu 18.04
**What compiler and version are you using?**
clang version 12.0.0 (https://github.com/llvm/llvm-project.git 96d5d7ef9833d7f88292c694126dd2aa597cec73)
Target: x86_64-unknown-linux-gnu
**What build system are you using?**
cmake 3.18.3
**Additional context**
Add any other context about the problem here.
Answers:
username_1: I think this has already been fixed in the latest version. Please re-open if it is not.
Status: Issue closed
username_0: It might have been fixed on HEAD, but it was not backported to the [lts_2020_09_23](/abseil/abseil-cpp/tree/lts_2020_09_23) branch; the problem is present in tag [20200923.2](/abseil/abseil-cpp/releases/tag/20200923.2).
username_0: @username_1 - I'm not a collaborator in this project and you closed this issue so I can't reopen it.
username_1: Fixes for compile warnings don't get backported. Just turn off the warning with `-Wno-tautological-type-limit-compare`. |
jlippold/tweakCompatible | 310536842 | Title: `Luminous` not working on iOS 11.1.2
Question:
username_0: ```
{
"packageId": "com.chloeeisoaky.luminous",
"action": "notworking",
"userInfo": {
"arch32": false,
"packageId": "com.chloeeisoaky.luminous",
"deviceId": "iPhone10,3",
"url": "http://cydia.saurik.com/package/com.chloeeisoaky.luminous/",
"iOSVersion": "11.1.2",
"packageVersionIndexed": false,
"packageName": "Luminous",
"category": "Tweaks",
"repository": "apt.thebigboss.org",
"name": "Luminous",
"packageIndexed": true,
"packageStatusExplaination": "A matching version of this tweak for this iOS version could not be found. Please submit a review if you choose to install.",
"id": "com.chloeeisoaky.luminous",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.0.6",
"shortDescription": "TrueDarkmode For Snapchat New UI",
"latest": "1.1",
"author": "chloeeisokay",
"packageStatus": "Unknown"
},
"base64": "<KEY>
"chosenStatus": "not working",
"notes": ""
}
```<issue_closed>
Status: Issue closed |
sbt/sbt | 426153999 | Title: sbt 1.3 debug output is missing some log messages
Question:
username_0: Start sbt 1.2.8 on any Scala project, run `;clean;debug;compile`, the last few logs should look like:
```scala
[debug] [zinc] Running cached compiler 5927b044 for Scala compiler version 2.12.8
[debug] [zinc] The Scala compiler is invoked with:
[debug] -bootclasspath
[debug] /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/resources.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/rt.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/sunrsasign.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jsse.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jce.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/charsets.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jfr.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/classes:/home/username_0/.ivy2/cache/org.scala-lang/scala-library/jars/scala-library-2.12.8.jar
[debug] -classpath
[debug] /home/username_0/opt/sbt-hello/target/scala-2.12/classes
[debug] Scala compilation took 3.389653169 s
[info] Done compiling.
[success] Total time: 4 s, completed 27 mars 2019 20:49:48
```
Do the same with sbt 1.3.0-M2 and instead you get:
```scala
[debug] [zinc] Running cached compiler 2c20390 for Scala compiler version 2.12.8
[debug] /usr/lib/jvm/java-8-openjdk-amd64/jre/lib/resources.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/rt.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/sunrsasign.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jsse.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jce.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/charsets.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/jfr.jar:/usr/lib/jvm/java-8-openjdk-amd64/jre/classes:/home/username_0/.sbt/boot/scala-2.12.8/lib/scala-library.jar
[debug] -classpath
[debug] Scala compilation took 0.459572992 s
[debug] Done compiling.
```
It looks some log messages were eaten somewhere, and there's a random newline in the middle.<issue_closed>
Status: Issue closed |
cloudfoundry-incubator/bosh-alicloud-cpi-release | 500929986 | Title: Redact credentials in create_vm response message
Question:
username_0: When the cpi method `create_vm` fails, the cpi returns an error which wraps the full context including certificates and passwords. The cpi should not reveal any credentials.
Answers:
username_1: HI @username_0 The latest release v29.0.0 has removed the credentials from error message. Please check it.
username_2: The Issue can be closed from our side. We validated that no secrets are leaked anymore. We provoked an error by referencing an invalid vm_type with the old and the new version.
Thanks for following up so quickly!
Best regards,
@FlorianNachtigall , @beckermax
Status: Issue closed
|
Mohist-Community/Mohist | 866862452 | Title: Treasure Map Player Marker Disappears When Switching Worlds
Question:
username_0: <!-- Thank you for reporting ! Please note that issues can take a lot of time to be fixed and there is no eta.-->
<!-- If you don't know where to upload your logs and crash reports, you can use these websites : -->
<!-- https://paste.ubuntu.com/ (recommended) -->
<!-- https://mclo.gs -->
<!-- https://haste.mohistmc.com -->
<!-- https://pastebin.com -->
<!-- TO FILL THIS TEMPLATE, YOU NEED TO REPLACE THE {} BY WHAT YOU WANT -->
**Minecraft Version :** {1.16.5}
**Mohist Version :** {1.16.5-517}
**Logs :** {No crashes or errors in console}
**Mod list :** {No mods)
**Plugin list :** {Luckperms
FastChunkPregenerator
Clearlag
Chairs
Vault
UltimateCatcher
UltimateRepairing
Shopkeepers
Worldmania
betterrtp
ultimate_economy
worldedit
essentials
essentialschat
essentialsspawn
betterjails
jobs reborn
griefdefender
coreprotect)
**Description of issue :** {Has been going on for many Mohist versions so its not a recent issue. Used to have multiverse and serversystem, now have essentials (fixed version in plugins-mods discord channel) and worldmania, problem still persists so I'm suspecting mohist. When players use a held map such as a buried treasure map, the white player marker shows correctly by default. If they leave the world the map is based in and then come back, such as through teleportation, the marker is gone. This can only be fixed by having the player log out and back into the server. Does not give any errors in console.}
Answers:
username_0: I can give more information if needed, I just don't know what else there is to offer or where to get it from.
username_0: Alright so I just learned how to make a test server, bear with me:
I tested with no plugins except WorldMania, as I needed it to get from one world to another and back to properly test the bug. I am confident WorldMania isn't causing the bug since this bug happened before I got WorldMania. I used version 528 of mohist, the most recent one.
1: found treasure map, noted location of white player marker
2: teleported to another world. Teleported back to the world the map is in
3: pulled out map. Marker is gone, not located anywhere on the map or at any of the edges.
I then tested this same thing with WorldMania and Paper for 1.16.5. Replicated the same steps as above. When I pulled out the map after teleporting, the marker was there as it is supposed to be. So I can confirm this is a mohist problem. |
holman/ama | 453768783 | Title: What is your favorite domain name registrar?
Question:
username_0: What is your favorite domain name registrar?
Status: Issue closed
Answers:
username_1: On Hover these days, but I think all registrars are kinda crap.
username_2: whois.com is pretty good.
username_1: I’ve since switched most domains to CloudFlare and been pretty happy with it. 🎊
username_2: @username_1 you can't purchase new domain names in cloudflare. only transfering. |
JustArchiNET/ASF-ui | 405794761 | Title: Add Execute button in Commands window
Question:
username_0: For e.g. the one can by lying on back of its sofa, so the monitor and keyboard are like 2 meters away, but wireless mouse is at hands.
In that situation Execute button will be really helpful, if a command will be pasted with a mouse.
My current suggestion looks like this, but it doesn't look good, maybe somebody will come up with a better idea.
Status: Issue closed
Answers:
username_0: For e.g. the one can by lying on back of its sofa, so the monitor and keyboard are like 2 meters away, but wireless mouse is at hands.
In that situation Execute button will be really helpful, if a command will be pasted with a mouse.
My current suggestion looks like this, but it doesn't look good, maybe somebody will come up with a better idea.

Status: Issue closed
|
spcl/dace | 475390878 | Title: Demo for running double buffering in Python.
Question:
username_0: Ask for a demo or usage for running double buffering in Python.
Answers:
username_1: @username_0 We added an example of using the `DoubleBuffering` transformation.
If you go to [double_buffering_test.py](https://github.com/spcl/dace/blob/master/tests/double_buffering_test.py), you will see an example dace program that can be transformed. Here is the SDFG below and exactly what matches (the map and internal transient arrays):
Upon transformation, the map will become a loop, a dimension will be added to the transients (creating the double buffers), and the data will be loaded in an alternating fashion.
Here is the end result:
Hope this helps! Let us know if you have any further questions.
Status: Issue closed
|
kata-containers/kata-containers | 742457560 | Title: Bump CRI-O version in order to enable `k8s-oom.bats` tests
Question:
username_0: Once https://github.com/cri-o/cri-o/pull/4356 gets merged, we should bump CRI-O version to include it, so we can finally enable `k8s-oom.bats` tests, reaching them tests comparity between containerd and CRI-O (at least when thinking about the bats tests).<issue_closed>
Status: Issue closed |
NYCPlanning/labs-zap-search | 486023920 | Title: Milestone and action deduping problem
Question:
username_0: The current deduping logic for milestones and actions is incorrectly dropping records
- Milestones are being deduped based on dcp_milestone and date. Milestones that are missing dates are getting dropped when they shouldn't be.
- Actions are being deduped based on dcp_action and ULURP number. Actions that are missing ULURP numbers are getting dropped when they shouldn't be.
We need to find a way to dedupe based on two columns, without dropping records that have NULL values.
Project to use for reference: P2016Q0306
Answers:
username_0: No longer an issue with the SQL API
Status: Issue closed
|
SEAHood/litbikes-dotnet | 335719206 | Title: Add smack talk to crash messages
Question:
username_0: <a href="https://github.com/username_0"><img src="https://avatars2.githubusercontent.com/u/2376959?v=4" align="left" width="96" height="96" hspace="10"></img></a> **Issue by [username_0](https://github.com/username_0)**
_Tuesday Nov 14, 2017 at 00:34 GMT_
_Originally opened as https://github.com/username_0/litbikes/issues/12_
---- |
ray-project/ray | 232683587 | Title: Integration of etcd for monitoring and configuration.
Question:
username_0: We should consider using a tool like etcd for monitoring the cluster, determining which nodes/processes are alive, and things like that. There are a lot of open questions here about how this should work.
Note, we should also consider using Consul instead of etcd.
cc @atumanov
Status: Issue closed
Answers:
username_0: Closing for now. |
cpuguy83/go-md2man | 1187111938 | Title: `go install` not working as expected
Question:
username_0: It is not possible to use `go install` to have latest go-md2man installed :(
Using `go install` from Go 1.18 to install go-md2man, I see some strange results.
1. By default, `@latest` installs v1.0.10, not v2.0.1.
```console
[kir@kir-rhat ~]$ go install -v -x github.com/cpuguy83/go-md2man@latest
# get https://proxy.golang.org/github.com/@v/list
# get https://proxy.golang.org/github.com/cpuguy83/go-md2man/@v/list
# get https://proxy.golang.org/github.com/cpuguy83/@v/list
# get https://proxy.golang.org/github.com/cpuguy83/@v/list: 410 Gone (0.110s)
# get https://proxy.golang.org/github.com/cpuguy83/go-md2man/@v/list: 200 OK (0.116s)
# get https://proxy.golang.org/github.com/@v/list: 410 Gone (0.117s)
# get https://proxy.golang.org/github.com/cpuguy83/go-md2man/@v/v1.0.10.info
# get https://proxy.golang.org/github.com/cpuguy83/go-md2man/@v/v1.0.10.info: 200 OK (0.014s)
# get https://proxy.golang.org/github.com/cpuguy83/go-md2man/@v/v1.0.10.mod
# get https://proxy.golang.org/github.com/cpuguy83/go-md2man/@v/v1.0.10.mod: 200 OK (0.017s)
# get https://proxy.golang.org/sumdb/sum.golang.org/supported
# get https://proxy.golang.org/sumdb/sum.golang.org/supported: 410 Gone (0.015s)
# get https://sum.golang.org/tile/8/0/x038/464.p/109
# get https://sum.golang.org/tile/8/2/000.p/150
# get https://sum.golang.org/tile/8/1/150.p/64
# get https://sum.golang.org/tile/8/1/150.p/64: 200 OK (0.126s)
# get https://sum.golang.org/tile/8/0/x038/464.p/109: 200 OK (0.128s)
# get https://sum.golang.org/tile/8/2/000.p/150: 200 OK (0.135s)
# get https://sum.golang.org/lookup/github.com/cpuguy83/[email protected]
# get https://sum.golang.org/lookup/github.com/cpuguy83/[email protected]: 200 OK (0.014s)
# get https://sum.golang.org/tile/8/0/013
# get https://sum.golang.org/tile/8/1/000
# get https://sum.golang.org/tile/8/0/013: 200 OK (0.014s)
# get https://sum.golang.org/tile/8/1/000: 200 OK (0.016s)
go: downloading github.com/cpuguy83/go-md2man v1.0.10
# get https://proxy.golang.org/github.com/cpuguy83/go-md2man/@v/v1.0.10.zip
# get https://proxy.golang.org/github.com/cpuguy83/go-md2man/@v/v1.0.10.zip: 200 OK (0.019s)
# get https://proxy.golang.org/github.com/russross/blackfriday/@v/v1.5.2.mod
# get https://proxy.golang.org/github.com/russross/blackfriday/@v/v1.5.2.mod: 200 OK (0.017s)
# get https://sum.golang.org/lookup/github.com/russross/[email protected]
# get https://sum.golang.org/lookup/github.com/russross/[email protected]: 200 OK (0.018s)
# get https://sum.golang.org/tile/8/0/001
# get https://sum.golang.org/tile/8/0/001: 200 OK (0.017s)
go: downloading github.com/russross/blackfriday v1.5.2
# get https://proxy.golang.org/github.com/russross/blackfriday/@v/v1.5.2.zip
# get https://proxy.golang.org/github.com/russross/blackfriday/@v/v1.5.2.zip: 200 OK (0.014s)
# get https://proxy.golang.org/github.com/russross/blackfriday/@v/v1.5.2.info
# get https://proxy.golang.org/github.com/russross/blackfriday/@v/v1.5.2.info: 200 OK (0.019s)
WORK=/tmp/go-build3425548627
github.com/russross/blackfriday
mkdir -p $WORK/b045/
cat >$WORK/b045/importcfg << 'EOF' # internal
# import config
packagefile bytes=/home/kir/sdk/go1.18/pkg/linux_amd64/bytes.a
packagefile fmt=/home/kir/sdk/go1.18/pkg/linux_amd64/fmt.a
packagefile regexp=/home/kir/sdk/go1.18/pkg/linux_amd64/regexp.a
packagefile strconv=/home/kir/sdk/go1.18/pkg/linux_amd64/strconv.a
packagefile strings=/home/kir/sdk/go1.18/pkg/linux_amd64/strings.a
packagefile unicode=/home/kir/sdk/go1.18/pkg/linux_amd64/unicode.a
packagefile unicode/utf8=/home/kir/sdk/go1.18/pkg/linux_amd64/unicode/utf8.a
EOF
cd /home/kir
./sdk/go1.18/pkg/tool/linux_amd64/compile -o $WORK/b045/_pkg_.a -trimpath "$WORK/b045=>" -p github.com/russross/blackfriday -lang=go1.16 -complete -buildid 0vcZLU3osy8Ia58Ojzmy/0vcZLU3osy8Ia58Ojzmy -goversion go1.18 -c=4 -nolocalimports -importcfg $WORK/b045/importcfg -pack ./go/pkg/mod/github.com/russross/[email protected]/block.go ./go/pkg/mod/github.com/russross/[email protected]/doc.go ./go/pkg/mod/github.com/russross/[email protected]/html.go ./go/pkg/mod/github.com/russross/[email protected]/inline.go ./go/pkg/mod/github.com/russross/[email protected]/latex.go ./go/pkg/mod/github.com/russross/[email protected]/markdown.go ./go/pkg/mod/github.com/russross/[email protected]/smartypants.go
[Truncated]
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git fetch -f --depth=1 origin refs/tags/v2.0.0:refs/tags/v2.0.0
0.706s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git fetch -f --depth=1 origin refs/tags/v2.0.0:refs/tags/v2.0.0
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git -c log.showsignature=false log -n1 '--format=format:%H %ct %D' refs/tags/v2.0.0 --
0.005s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git -c log.showsignature=false log -n1 '--format=format:%H %ct %D' refs/tags/v2.0.0 --
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git -c log.showsignature=false log -n1 '--format=format:%H %ct %D' 7762f7e404f8416dfa1d9bb6a8c192aa9acb4d19 --
0.004s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git -c log.showsignature=false log -n1 '--format=format:%H %ct %D' 7762f7e404f8416dfa1d9bb6a8c192aa9acb4d19 --
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git fetch -f --depth=1 origin refs/tags/v1.0.10:refs/tags/v1.0.10
0.773s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git fetch -f --depth=1 origin refs/tags/v1.0.10:refs/tags/v1.0.10
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git -c log.showsignature=false log -n1 '--format=format:%H %ct %D' refs/tags/v1.0.10 --
0.005s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git -c log.showsignature=false log -n1 '--format=format:%H %ct %D' refs/tags/v1.0.10 --
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git cat-file blob 7762f7e404f8416dfa1d9bb6a8c192aa9acb4d19:go.mod
0.004s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git cat-file blob 7762f7e404f8416dfa1d9bb6a8c192aa9acb4d19:go.mod
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git cat-file blob 7762f7e404f8416dfa1d9bb6a8c192aa9acb4d19:go.mod
0.005s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git cat-file blob 7762f7e404f8416dfa1d9bb6a8c192aa9acb4d19:go.mod
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git cat-file blob f79a8a8ca69da163eee19ab442bedad7a35bba5a:go.mod
0.004s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git cat-file blob f79a8a8ca69da163eee19ab442bedad7a35bba5a:go.mod
cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git cat-file blob f79a8a8ca69da163eee19ab442bedad7a35bba5a:go.mod
0.003s # cd /home/kir/go/pkg/mod/cache/vcs/af686cb350700dd71341e2df4d234a7ecf75459b3ee587660c6d179152b68ea0; git cat-file blob f79a8a8ca69da163eee19ab442bedad7a35bba5a:go.mod
go: github.com/cpuguy83/[email protected]: github.com/cpuguy83/[email protected]: invalid version: go.mod has post-v2 module path "github.com/cpuguy83/go-md2man/v2" at revision v2.0.0
```
Answers:
username_0: At the moment I can't figure out why this happens :-\ thus filing this, maybe someone (@cpuguy83 @username_1) has ideas?
I was thinking that maybe `go 1.11` line in go.mod is responsible, but no, changing it to go 1.16 is not helping.
username_1: @username_0 that's because you're telling it to install the latest `v0` or `v1` version;
`github.com/cpuguy83/go-md2man` is dead, long live `github.com/cpuguy83/go-md2man/v2` !!!! It has a new name (quite originally, `v2`), and a new major version `v2.0.1`.
So, to install the latest version of the new `github.com/cpuguy83/go-md2man/v2`, use:
```console
go install -v -x github.com/cpuguy83/go-md2man/v2@latest
```
And to install a specific version, for example, `v2.0.1`:
```console
go install -v -x github.com/cpuguy83/go-md2man/[email protected]
```
The new name is needed to allow multiple versions (v0, v1 and v2) of the same ~binary~ to be ~used at the same time~ overwrite each-other 😉 .
"edit": ah, well, yes, for `go install` there is no reason 🤦
"edit": maybe SemVer doesn't make sense for binaries? 🤔
Yes... it's all completely bonkers..
Also: make sure you don't have a trailing `/` for the name; go1.16 and go1.17 (with `go get @version` allowed `github.com/cpuguy83/go-md2man/v2/@v2.0.1`, but `go install` does not; https://github.com/docker/containerd-packaging/pull/274#issuecomment-1076762053 |
ireapps/census | 430094512 | Title: Segment 12 appears to have an extra data value
Question:
username_0: Segment 12 in the each of the distributed 52 ZIP files appears to have an error.
The SF1 specification states that there should be 255 columns in each of these files. However, there are 256. It appears that the insert column is somewhere before field #129 that defines variable P037A001. This number should be a percentage, but it is clearly a population count in all of the files. The error also causes P038A001 to be reported as a numeric (that is, with a decennial point), even though it is an integer (it is a count), because of the extra value that is inserted.
Has anyone else encountered this? |
nginxinc/docker-nginx-unprivileged | 631592387 | Title: 1.19.0?
Question:
username_0: I'm curious to see if there is any plan to have the version 1.19.0 for https://hub.docker.com/r/nginxinc/nginx-unprivileged/tags?
References:
- http://nginx.org/en/CHANGES
- https://hub.docker.com/_/nginx?tab=tags&page=1&name=1.19
Answers:
username_1: 1.19.0 is already there (stable images got pushed later so they show up first), but I would off on using them until the issues on #37 and #39 are fixed.
username_0: Oh yeah, looks like I missed them by sorting by "Newest" and not properly filtering with the 1.19.0 tag: https://hub.docker.com/r/nginxinc/nginx-unprivileged/tags?page=1&ordering=last_updated&name=1.19.0. Good to know for the knows issues, but there are not just related to 1.19, they were already existing with 1.18, right?
username_1: Some of the changes were applied to 1.18 too, yeah. I would use 1.17.10 for now.
username_0: Got it, thanks @username_1, closing this issue. Thanks!
username_0: Hi @username_1, just curious here, is there any `1.19.0` we could use now which has the issue fixed? https://hub.docker.com/r/nginxinc/nginx-unprivileged/tags?page=1&name=1.19.0&ordering=last_updated. For example `1.19.0-s390x` or `1.19.0-ppc64le`?
username_1: Pulling the latest version of 1.19 should do the trick 😄
username_0: Which one is it in Docker Hub? `1.19.0-s390x` (49.18 MB) or `1.19.0-ppc64le` (56.02 MB)?
username_1: `docker pull nginxinc/nginx-unprivileged:latest` or `docker pull nginxinc/nginx-unprivileged:1.19.0` should do the trick. The images that specify an architecture are specific to that architecture. If you don't specify an architecture Docker will automatically download the right image.
username_0: Ok got it @username_1, thanks. But FYI when I deploy this on Kubernetes I got:
```
/docker-entrypoint.sh: /docker-entrypoint.d/ is not empty, will attempt to perform configuration
/docker-entrypoint.sh: Looking for shell scripts in /docker-entrypoint.d/
/docker-entrypoint.sh: Launching /docker-entrypoint.d/10-listen-on-ipv6-by-default.sh
10-listen-on-ipv6-by-default.sh: Can not modify /etc/nginx/conf.d/default.conf (read-only file system?), exiting
/docker-entrypoint.sh: Launching /docker-entrypoint.d/20-envsubst-on-templates.sh
/docker-entrypoint.sh: Launching /docker-entrypoint.d/30-configure-nginx-unprivileged.sh
sed: can't create temp file '/etc/nginx/conf.d/default.confXXXXXX': Read-only file system
```
username_1: Make sure you remove any pre existing images in your system and pull again. That should do the trick!
username_0: Thanks @username_1, you were right the old/bad version of that tag was cached, after uncached it, I was able to build my image with the new tag and then successfully deploy it on Kubernetes. Thanks! |
Activiti/Activiti | 342620296 | Title: Found Activiti 5 process definition, but no compatibility handler on the classpath
Question:
username_0: How to fix this problem?
Answers:
username_0: @Test
public void getTask() {
List<Task> list = taskService.createTaskQuery().list();
for (Task task:list) {
//it's work
ProcessInstance processInstance = runtimeService.createProcessInstanceQuery().processInstanceId(task.getProcessInstanceId()).singleResult();
BpmnModel bpmnModel = repositoryService.getBpmnModel(processInstance.getProcessDefinitionId());
List<Process> processes = bpmnModel.getProcesses();
for (Process process: processes
) {
System.out.println(process.getFlowElements().size());
}
//it does't work.throw "Found Activiti 5 process definition, but no compatibility handler on the classpath" exception
BpmnModel tempModel = ProcessDefinitionUtil.getBpmnModel(processInstance.getProcessDefinitionId());
}
}
username_0: @ryandawsonuk thank you for your replay.
but i don't need to compatibility activiti 5.0
i want to just use the activiti 6.0.?
username_1: @username_0
seems that [ProcessDefinitionUtil.getBpmnModel](https://github.com/Activiti/Activiti/blob/6.x/modules/activiti-engine/src/main/java/org/activiti/engine/impl/util/ProcessDefinitionUtil.java#L55) requires an active context when called. You should not call it directly instead call repositoryService.getBpmnModel
username_0: @username_1 thanks
How to call an active context first?
username_1: @username_0 use [managementService execute command](https://www.activiti.org/javadocs/org/activiti/engine/managementservice#executeCommand-org.activiti.engine.impl.interceptor.Command-)
Why do you want to call it directly repositoryService.getBpmnModel does the same thing.
username_0: @username_1
Thank you for you reply. U R right. repositoryService.getBpmnModel does the same thing with the ProcessDefinitionUtil.
username_1: @username_0 I'll close this issue then.
Status: Issue closed
|
Activisme-be/Armoede-inventaris | 498122019 | Title: Implematie detacheer van een category.
Question:
username_0: Voor nu is er een method aangemaakt in de applicatie waar we de Items onder een categorie kunnen bekijken. Maar onder het kruis icoontje zou nog een methode moeten komen om de category los te koppen van het item in de inventaris |
spgennard/vscode_cobol | 332447708 | Title: TIME in ws is being picked up and it should not be.
Question:
username_0: TIME in the line below should not be highlighted
```code
78 DSORG-IS VALUE 'IS '.
05 ()-EXPDT PIC 9(08).
05 ()-CREATE-DATE PIC 9(08).
05 ()-TIME-CREATED PIC 9(08).
05 ()-CHG-DATE PIC 9(08).
```
Status: Issue closed
Answers:
username_0: fixed in 2.1.1 |
logstash-plugins/logstash-output-mongodb | 630892563 | Title: Logstash not able to load mongodb output plugin
Question:
username_0: I am getting following error with logstash 6.2.3 (also on logstash 7.7.1) while using mongodb output plugin. I am running logstash inside a container. The plugin is installed without any problem and I can also list it, but it fails to load. Is there any known reason/fix available for this issue?
[2020-06-04T14:45:12,791][ERROR][logstash.plugins.registry] Tried to load a plugin's code, but failed. {:exception=>#<LoadError: load error: mongo/server/connection -- java.lang.NoSuchMethodError: java.nio.ByteBuffer.flip()Ljava/nio/ByteBuffer;>, :path=>"logstash/outputs/mongodb", :type=>"output", :name=>"mongodb"}
[2020-06-04T14:45:12,815][ERROR][logstash.agent ] Failed to execute action {:action=>LogStash::PipelineAction::Create/pipeline_id:bundlestats, :exception=>"Java::JavaLang::IllegalStateException", :message=>"Unable to configure plugins: (PluginLoadingError)
Couldn't find any output plugin named 'mongodb'. Are you sure this is correct? Trying to load the mongodb output plugin resulted in this error: load error: mongo/server/connection -- java.lang.NoSuchMethodError: java.nio.ByteBuffer.flip()Ljava/nio/ByteBuffer;", :backtrace=>["org.logstash.config.ir.CompiledPipeline.<init>(CompiledPipeline.java:119)", "org.logstash.execution.JavaBasePipelineExt.initialize(JavaBasePipelineExt.java:80)", "org.logstash.execution.JavaBasePipelineExt$INVOKER$i$1$0$initialize.call(JavaBasePipelineExt$INVOKER$i$1$0$initialize.gen)", "org.jruby.internal.runtime.methods.JavaMethod$JavaMethodN.call(JavaMethod.java:837)", "org.jruby.ir.runtime.IRRuntimeHelpers.instanceSuper(IRRuntimeHelpers.java:1169)", "org.jruby.ir.runtime.IRRuntimeHelpers.instanceSuperSplatArgs(IRRuntimeHelpers.java:1156)", "org.jruby.ir.targets.InstanceSuperInvokeSite.invoke(InstanceSuperInvokeSite.java:39)", "usr.share.logstash.logstash_minus_core.lib.logstash.java_pipeline.RUBY$method$initialize$0(/usr/share/logstash/logstash-core/lib/logstash/java_pipeline.rb:43)", "org.jruby.internal.runtime.methods.CompiledIRMethod.call(CompiledIRMethod.java:82)", "org.jruby.internal.runtime.methods.MixedModeIRMethod.call(MixedModeIRMethod.java:70)", "org.jruby.runtime.callsite.CachingCallSite.cacheAndCall(CachingCallSite.java:332)", "org.jruby.runtime.callsite.CachingCallSite.call(CachingCallSite.java:86)", "org.jruby.RubyClass.newInstance(RubyClass.java:939)", "org.jruby.RubyClass$INVOKER$i$newInstance.call(RubyClass$INVOKER$i$newInstance.gen)", "org.jruby.runtime.callsite.CachingCallSite.cacheAndCall(CachingCallSite.java:332)", "org.jruby.runtime.callsite.CachingCallSite.call(CachingCallSite.java:86)", "org.jruby.ir.instructions.CallBase.interpret(CallBase.java:552)", "org.jruby.ir.interpreter.InterpreterEngine.processCall(InterpreterEngine.java:361)", "org.jruby.ir.interpreter.StartupInterpreterEngine.interpret(StartupInterpreterEngine.java:72)", "org.jruby.internal.runtime.methods.MixedModeIRMethod.INTERPRET_METHOD(MixedModeIRMethod.java:86)", "org.jruby.internal.runtime.methods.MixedModeIRMethod.call(MixedModeIRMethod.java:73)", "org.jruby.ir.targets.InvokeSite.invoke(InvokeSite.java:207)", "usr.share.logstash.logstash_minus_core.lib.logstash.agent.RUBY$block$converge_state$2(/usr/share/logstash/logstash-core/lib/logstash/agent.rb:342)", "org.jruby.runtime.CompiledIRBlockBody.callDirect(CompiledIRBlockBody.java:138)", "org.jruby.runtime.IRBlockBody.call(IRBlockBody.java:58)", "org.jruby.runtime.IRBlockBody.call(IRBlockBody.java:52)", "org.jruby.runtime.Block.call(Block.java:139)", "org.jruby.RubyProc.call(RubyProc.java:318)", "org.jruby.internal.runtime.RubyRunnable.run(RubyRunnable.java:105)", "java.lang.Thread.run(Thread.java:748)"]}
Answers:
username_1: Do you have the MongoDB jdbc drivers in the same classpath? |
PowerShell/PSReadLine | 444731244 | Title: System.ArgumentOutOfRangeException throw when press quotation mark
Question:
username_0: <!--
Before submitting your bug report, please check for duplicates, and +1 the duplicate if you find one, adding additional details if you have any to add.
There are a few common issues that are commonly reported.
If there is an exception copying to/from the clipboard, it's probably the same as https://github.com/PowerShell/PSReadLine/issues/265
If there is an exception shortly after resizing the console, it's probably the same as https://github.com/PowerShell/PSReadLine/issues/292
-->
There are some possible duplicates with same exception, but no one has the same reproduce steps with mine.
Environment data
----------------
<!-- provide the output of the following:
```powershell
& {
"PS version: $($PSVersionTable.PSVersion)"
$v = (Get-Module PSReadline).Version
$m = Get-Content "$(Split-Path -Parent (Get-Module PSReadLine).Path)\PSReadLine.psd1" | Select-String "Prerelease = '(.*)'"
if ($m) {
$v = "$v-" + $m.Matches[0].Groups[1].Value
}
"PSReadline version: $v"
if ($IsLinux -or $IsMacOS) {
"os: $(uname -a)"
} else {
"os: $((dir $env:SystemRoot\System32\cmd.exe).VersionInfo.FileVersion)"
}
"PS file version: $((dir $pshome\p*[hl].exe).VersionInfo.FileVersion)"
}
```
-->
PS version: 5.1.17763.316
PSReadline version: 2.0.0-beta2
os: 10.0.17763.1 (WinBuild.160101.0800)
PS file version: 10.0.17763.1 (WinBuild.160101.0800)
Steps to reproduce or exception report
--------------------------------------
1. `cd` into a deep, long-named folder, e.g, `~\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup`
2. resize the console so that the prompt occupies exactly one whole line (the cursor is at the second line), as the screenshot shows.
3. press <kbd>'</kbd>
Exception throw:
````
PS C:\Users\Simon> cd "C:\Users\Simon\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup"
PS C:\Users\Simon\AppData\Roaming\Microsoft\Windows\Start Menu\Programs\Startup>
Oops, something went wrong. Please report this bug with the details below.
Report on GitHub: https://github.com/lzybkr/PSReadLine/issues/new
-----------------------------------------------------------------------
Last 83 Keys:
c d Space " C : \ U s e r s \ S i m o n \ A p p D a t a \ R o a m i n g \ M i c r o s o f t \ W i n d o w s \ S t a r t Space M e n u \ P r o g r a m s \ S t a r t u p " Enter
'
Exception:
System.ArgumentOutOfRangeException: The value must be greater than or equal to zero and less than the console's buffer size in that dimension.
Parameter name: left
Actual value was -2.
at System.Console.SetCursorPosition(Int32 left, Int32 top)
at Microsoft.PowerShell.Internal.VirtualTerminal.set_CursorLeft(Int32 value)
at Microsoft.PowerShell.PSConsoleReadLine.ReallyRender(RenderData renderData, String defaultColor)
at Microsoft.PowerShell.PSConsoleReadLine.ForceRender()
at Microsoft.PowerShell.PSConsoleReadLine.Insert(Char c)
at Microsoft.PowerShell.PSConsoleReadLine.SelfInsert(Nullable`1 key, Object arg)
at Microsoft.PowerShell.PSConsoleReadLine.ProcessOneKey(ConsoleKeyInfo key, Dictionary`2 dispatchTable, Boolean ignoreIfNoAction, Object arg)
at Microsoft.PowerShell.PSConsoleReadLine.InputLoop()
at Microsoft.PowerShell.PSConsoleReadLine.ReadLine(Runspace runspace, EngineIntrinsics engineIntrinsics)
-----------------------------------------------------------------------
````<issue_closed>
Status: Issue closed |
Laravel-Backpack/LangFileManager | 502428892 | Title: Problem upgrading 3.6 to 4.0
Question:
username_0: Hi all,
Got a problem while upgrading from 3.6 to 4.0:
composer update
Loading composer repositories with package information
Updating dependencies (including require-dev)
Your requirements could not be resolved to an installable set of packages.
Problem 1
Installation request for laravel/framework ^6.0 -> satisfiable by laravel/framework[6.x-dev, v6.0.0, v6.0.1, v6.0.2, v6.0.3, v6.0.4].
Installation request for backpack/langfilemanager ^1.0 -> satisfiable by backpack/langfilemanager[1.0.0, 1.0.1, 1.0.10, 1.0.11, 1.0.12, 1.0.13, 1.0.14, 1.0.15, 1.0.16, 1.0.17, 1.0.18, 1.0.19, 1.0.2, 1.0.20, 1.0.21, 1.0.22, 1.0.23, 1.0.24, 1.0.25, 1.0.26, 1.0.3, 1.0.4, 1.0.5, 1.0.6, 1.0.7, 1.0.8, 1.0.9, 1.0.x-dev].
Can only install one of: backpack/crud[4.0.0, 3.6.x-dev].
Can only install one of: backpack/crud[4.0.1, 3.6.x-dev].
Can only install one of: backpack/crud[4.0.2, 3.6.x-dev].
Can only install one of: backpack/crud[4.0.3, 3.6.x-dev].
Can only install one of: backpack/crud[4.0.5, 3.6.x-dev].
Can only install one of: backpack/crud[4.0.x-dev, 3.6.x-dev].
Can only install one of: backpack/crud[v4.x-dev, 3.6.x-dev].
Conclusion: install backpack/crud 3.6.x-dev
Installation request for backpack/crud ^4.0.0 -> satisfiable by backpack/crud[4.0.0, 4.0.1, 4.0.2, 4.0.3, 4.0.5, 4.0.x-dev, v4.x-dev].
Any help?
Regards
Status: Issue closed
Status: Issue closed
Answers:
username_1: Just pushed v4 support for this repo. Make sure you require version ```2.*```. Thanks for raising this issue @username_0 , and getting involved @SamSebastien . |
e-lab/torch7-demos | 49033947 | Title: What does the number of threads mean?
Question:
username_0: Hi,
I was looking through your code. I noticed a similar thing in the original code from ```nn```:
What does the number of threads mean? why have you chosen 8 for your face dataset architecture?
Regards,
Siavash<issue_closed>
Status: Issue closed |
OSGeo/gdal | 528461779 | Title: configure: error: HDF5 support requested with arg..., but no hdf5 lib found
Question:
username_0: Hi All
The configure process doesn't pick up the existing hdf5 library I passed through the following command line
"""
$ ./configure --prefix=$APP_PATH --with-gnu-ld --with-python=$PYTHON3_ROOT/bin/python3 --with-java=$JAVA_ROOT--with-hdf4=$HDF4_ROOT --with-hdf5=$HDF5_ROOT --with-netcdf=$NETCDF_ROOT --with-geos=yes --with-cfitsio=$CFITSIO_ROOT/lib --with-xerces=$XERCES_ROOT --with-xerces-inc=$XERCES_ROOT/include --with-xerces-lib="-L/apps/xerces-c/3.2.2/lib -lxerces-c-3.2" --with-proj=$PROJ_ROOT --with-gif=/usr/lib64 --with-png=/usr/lib64 --with-jasper=/user/lib64 --with-libtiff=/usr/lib64 --with-jpeg=/usr/lib64 --with-geotiff=internal
"""
The error message says
"""
.....
checking for H5Fopen in -lhdf5... no
configure: error: HDF5 support requested with arg /apps/hdf5/1.10.5, but no hdf5 lib found
"""
But I got
"""
$ ls -ltrah $HDF5_ROOT/lib/libhdf5.so
lrwxrwxrwx 1 apps z30 18 Nov 4 17:25 /apps/hdf5/1.10.5/lib/libhdf5.so -> libhdf5.so.103.1.0
"""
and
"""
$ nm $HDF5_ROOT/lib/libhdf5.so | grep H5Fopen
00000000000f8555 T H5Fopen
"""
I also added the line
"""
echo $LIBS
"""
into the file ./configure after this section
"""
if test -d $with_hdf5/lib ; then
HDF5_LIB_DIR=$with_hdf5/lib
else
HDF5_LIB_DIR=$with_hdf5
fi
ORIG_LIBS="$LIBS"
LIBS="-L$HDF5_LIB_DIR $LIBS -lhdf5"
"""
and before it checks for the function H5Fopen. The variable LIBS is printed as
"""
-L/apps/hdf5/1.10.5/lib -L/usr/lib64 -L/usr/lib64/lib -lgif -L/usr/lib64 -L/usr/lib64/lib -ljpeg -L/usr/lib64/lib -ltiff -L/usr/lib64 -L/usr/lib64/lib -lpng -L/apps/cfitsio/3.47/lib -L/apps/cfitsio/3.47/lib/lib -lcfitsio -lpq -L/apps/proj/6.2.1/lib -lproj -lz -lpthread -lm -lrt -ldl -lhdf5
"""
Why it doesn't pickup the hdf5 library pre-installed in my system? I actually browsed through the configure file and don't understand why ${ac_cv_lib_hdf5_H5Fopen+:} false is true and where actually the variable is set.
I have to say the following `if-elif-else-fi` statement is not very reader friendly.
"""
if test "$with_hdf5" = "no" ; then
HAVE_HDF5=no
echo "hdf5 support disabled."
elif test "$with_hdf5" = "yes" -o "$with_hdf5" = "" ; then
HDF5_CFLAGS=""
HDF5_LIBS=""
...
else
if test -d $with_hdf5/lib ; then
HDF5_LIB_DIR=$with_hdf5/lib
[Truncated]
"""
It tooks me hours to figure out the structure but I got even more confused about where the variable ac_cv_lib_hdf5_H5Fopen is defined.
## Steps to reproduce the problem.
wget https://github.com/OSGeo/gdal/releases/download/v3.0.2/gdal-3.0.2.tar.gz
tar -xzf gdal-3.0.2.tar.gz
cd gdal-3.0.2
# I set the system specific variables like APP_PATH, PYTHON3_ROOT, and HDF5_ROOT here.
./configure --prefix=$APP_PATH --with-gnu-ld --with-python=$PYTHON3_ROOT/bin/python3 --with-java=$JAVA_ROOT--with-hdf4=$HDF4_ROOT --with-hdf5=$HDF5_ROOT --with-netcdf=$NETCDF_ROOT --with-geos=yes --with-cfitsio=$CFITSIO_ROOT/lib --with-xerces=$XERCES_ROOT --with-xerces-inc=$XERCES_ROOT/include --with-xerces-lib="-L/apps/xerces-c/3.2.2/lib -lxerces-c-3.2" --with-proj=$PROJ_ROOT --with-gif=/usr/lib64 --with-png=/usr/lib64 --with-jasper=/user/lib64 --with-libtiff=/usr/lib64 --with-jpeg=/usr/lib64 --with-geotiff=internal
## Operating system
$ lsb_release -a
LSB Version: :core-4.1-amd64:core-4.1-noarch
Distributor ID: CentOS
Description: CentOS Linux release 8.0.1905 (Core)
Release: 8.0.1905
Codename: Core
## GDAL version and provenance
3.0.2
Answers:
username_1: Here are a couple of random hacking suggestions. I just built gdal 3.0.1 on Mac yesterday with HDF5, and no problem. Try configure with `--with-hdf5=$HDF5_ROOT` and nothing else. If that works, then try adding `--prefix` and `--with-gnu-ld`, one at a time.
I hesitate to suggest backing down from 3.0.2 to 3.0.1, because 3.0.2 is billed as a relatively simple bug fix release. That should not matter.
This message: `checking for H5Fopen in -lhdf5... no` is probably based on the result of a trivial test program that is run internally by the configure script. Check config.log and see if it actually displays the test program source code and the command used to run it. If so, then try running this as a stand-alone program outside of configure. I have very rarely used this to gain insights into linking problems. This gets you away from the delightful intricacies of the configure script.
username_1: It looks to me like either `--with-xerces-inc` should include "-I", or else `--with-xerces-lib` should NOT include "-L". What is going on with that?
username_1: Never mind about that last remark. `configure --help` indicates your usage of `--with-xerces_*` is supported.
username_2: Encountered the same issue on CenOS7.
This is not the only library with the same problem. I can't normally configure also:
- `sqlite3 `- it just not found in provided path
- `curl` - `curl-config` not found (**also when building PROJ**)
GDAL can not find hdf5 libraries from vcpkg in headers (for me they are build to `${vc_packages}/include` path).
It's likely a collision between configured libraries?
I have installed static hdf5 and expat libraries.
`export PKG_CONFIG_PATH="${vc_packages}/lib/pkgconfig"`
I've tried `HDF5_CFLAGS` and` HDF5_LIBS` but they are ignored by configure.
Resolved with `yum install hdf5-devel` and configuring against `/usr/lib64`.
```shell
--with-hdf4 \
--with-hdf5="/usr/lib64" \
--with-expat=${vc_packages}
```
Truncated configure output:
```
checking for Expat XML Parser... yes
checking if Expat XML Parser version is >= 1.95.0... yes
....
checking for H5Fopen in -lhdf5... yes
```
username_3: Same issue (gdal 3.2.3, hdf5-1.10 on centos7)
I noticed the failed tests was:
```$LOCROOT/usr/local/bin/gcc -o conftest -DHAVE_AVX_AT_COMPILE_TIME -DHAVE_SSSE3_AT_COMPILE_TIME -DHAVE_SSE_AT_COMPILE_TIME -g -O2 -fPIC -fvisibility=hidden conftest.c -lhdf5 -lhdf5 -L$LOCROOT/usr/local/lib -L$LOCROOT/usr/local -L$LOCROOT/usr/local/lib -lpng -L$LOCROOT/usr/local/lib -lpq -L$LOCROOT/usr/local/lib -lsqlite3 -lproj -L$LOCROOT/usr/local/lib -lsqlite3 -lz -L$LOCROOT/usr/local -L$LOCROOT/usr/local/lib -lpthread -lm -lrt -ldl -L$LOCROOT/usr/local/lib -lspatialite -lhdf5```
My problem was, my problem was that I didn't have libpng installed in this folder... I don't know if this will help you, but for me it works. |
IlanCosman/tide | 996414536 | Title: pwd item does not work correctly on second line
Question:
username_0: #### Describe the bug
Not sure if this is something feasible, but I would like to have the current path on the second line (and then develop a custom prompt structure suited for me). Unfortunately whenever I put the `pwd` item on the second line, it just stops being correctly interpolated (I guess? I didn't dive deeply in the source), and `@PWD@` is shown.
#### Steps to reproduce
1. Use `set --global tide_left_prompt_items os git pwd newline character`
2. Path is shown correctly on first line, prompt looks correct
3. Use `set --global tide_left_prompt_items os git newline pwd character`
4. Path is not shown, instead `@PWD@` is visible
#### Screenshots
Correct behaviour on first line:

Incorrect behaviour, when working directory is on second line
#### Environment
Output of `tide bug-report`:
```
fish version: 3.3.1
tide version: 5.0.1
term: xterm-256color
os: Manjaro
terminal emulator: gnome-terminal
```
#### Additional context
Nothing to mention
Answers:
username_1: Yes, currently Tide is only set up to work with a PWD in the first line.
One of the major reasons that a two-line prompt is nice, is that every command starts in the same spot. With a one-line prompt, you get a "bumpy" scrollback history.
So I don't really understand why you'd want PWD in the second line. What would go in the first? If you are recreating another prompt, could you provide images of it?
username_0: Yes, you are right, I didn't think about the prompt being bumpy when scrolling.
There is no prompt being recreated, I'm just experimenting with different prompt structures. One thing I wanted to try out is a prompt which has two lines when the user is in a git repository and one line otherwise.
```
<git info><maybe other info, like node, rust, etc.><optional new line, if this line was filled>
/my/path >
```
Now, thinking about it, maybe I will implement a custom pwd item, which only shows the last directory if on the second line, and shows the old pwd item, if it's on the first line.
Thanks for the insight.
Status: Issue closed
username_1: Closing this for now, as there isn't significant justification for changing the current behavior. I'm happy to reconsider if new reasons/examples of good prompts are presented 👍 |
bmewburn/vscode-intelephense | 545681784 | Title: Salesforce and privacy
Question:
username_0: I see that source code size increased a bit.
What purpose have Salesforce in last version (1.3.7) of this extension?
And on that topic what data are collected with license activation?
Answers:
username_1: Salesforce? I don't understand what you mean.
https://github.com/request/request was added to simplify licence activation via proxy which is probably where the bulk of the increase came from as it was the only new package added.
The only data collected is a sha256 hash of some machine data and the IP of the request.
username_0: In source code of language server there is whole bunch of salesforce libs. I can't find them in previous version.
username_1: Can you list an example library?
username_0: I'm unable to identify them by minimized form, only comment is present (6 times).
```
/*!
* Copyright (c) 2015, Salesforce.com, Inc.
* All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions are met:
*
* 1. Redistributions of source code must retain the above copyright notice,
* this list of conditions and the following disclaimer.
*
* 2. Redistributions in binary form must reproduce the above copyright notice,
* this list of conditions and the following disclaimer in the documentation
* and/or other materials provided with the distribution.
*
* 3. Neither the name of Salesforce.com nor the names of its contributors may
* be used to endorse or promote products derived from this software without
* specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
* AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE
* LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR
* CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF
* SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS
* INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN
* CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE)
* ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE
* POSSIBILITY OF SUCH DAMAGE.
*/
```
username_1: https://github.com/salesforce/tough-cookie is a dependency of https://github.com/request/request which is where this is probably coming from.
username_0: That's probably it, thanks for clarification @username_1
Status: Issue closed
|
Nceba2/BuckFizz | 204219674 | Title: write test
Question:
username_0: since i have jasmine and Karma installed.
- i can write tests for the app as i add code
- run the test to see if the code works fine
- make sure it works before i push on to git
Answers:
username_0: test wrote in QUnit and Karma replacing jasmine.
all 3 tests passed. code is working effectively....
Status: Issue closed
|
google/ExoPlayer | 543039689 | Title: Exoplayer HLS returning 403 forbidden
Question:
username_0: Hi guys, I have a android radio App and i'm trying to play an online radio without success. Recently this radio station changed his url and i can't play with exoplayer.
the Url is: https://e.mm.uol.com.br/band/radiobandeirantes_poa/playlist.m3u8
sending this request using chrome postman, this return with successful but when I play on exoplayer Return 403
```
I/System.out: (HTTPLog)-Static: isSBSettingEnabled false
(HTTPLog)-Static: isSBSettingEnabled false
I/System.out: (HTTPLog)-Static: isSBSettingEnabled false
I/System.out: (HTTPLog)-Static: isSBSettingEnabled false
E/ExoPlayerImplInternal: Source error.
com.google.android.exoplayer2.upstream.HttpDataSource$InvalidResponseCodeException: Response code: 403
at com.google.android.exoplayer2.upstream.DefaultHttpDataSource.open(DefaultHttpDataSource.java:300)
at com.google.android.exoplayer2.upstream.DefaultDataSource.open(DefaultDataSource.java:250)
at com.google.android.exoplayer2.upstream.StatsDataSource.open(StatsDataSource.java:83)
at com.google.android.exoplayer2.upstream.DataSourceInputStream.checkOpened(DataSourceInputStream.java:102)
at com.google.android.exoplayer2.upstream.DataSourceInputStream.open(DataSourceInputStream.java:65)
at com.google.android.exoplayer2.upstream.ParsingLoadable.load(ParsingLoadable.java:156)
at com.google.android.exoplayer2.upstream.Loader$LoadTask.run(Loader.java:381)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1167)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:641)
at java.lang.Thread.run(Thread.java:919)
```
I'm using explayer 2.9.1.
I tried lot of solutions founded here and other sites but without success..
code:
```
private void preparePlayerBand() throws IOException {
bandwidthMeter = new DefaultBandwidthMeter();
extractorsFactory = new DefaultExtractorsFactory();
String userAgent = Util.getUserAgent(this, "RS <NAME>");
DefaultHttpDataSourceFactory httpDataSourceFactory = new DefaultHttpDataSourceFactory(
userAgent,
null /* listener */,
DefaultHttpDataSource.DEFAULT_CONNECT_TIMEOUT_MILLIS,
DefaultHttpDataSource.DEFAULT_READ_TIMEOUT_MILLIS,
true /* allowCrossProtocolRedirects */
);
trackSelectionFactory = new AdaptiveTrackSelection.Factory(bandwidthMeter);
trackSelector = new DefaultTrackSelector(trackSelectionFactory);
defaultBandwidthMeter = new DefaultBandwidthMeter();
dataSourceFactory = new DefaultDataSourceFactory(
this,
null /* listener */,
httpDataSourceFactory
);
final MediaSource mediaSource = buildMediaSource(Uri.parse("https://e.mm.uol.com.br/band/radiobandeirantes_poa/playlist.m3u8"),
Uri.parse("https://e.mm.uol.com.br/band/radiobandeirantes_poa/playlist.m3u8").getPath().substring(Uri.parse("https://e.mm.uol.com.br/band/radiobandeirantes_poa/playlist.m3u8").getPath().lastIndexOf(".") + 1),
dataSourceFactory);
//mediaSourceBand = new HlsMediaSource.Factory(dataSourceFactory).setExtractorFactory(defaultHlsExtractorFactory).createMediaSource(Uri.parse(urlBand));
[Truncated]
}
```
I tried to add a cookies on OnCreate:
```
static
{
DEFAULT_COOKIE_MANAGER = new CookieManager();
DEFAULT_COOKIE_MANAGER.setCookiePolicy(CookiePolicy.ACCEPT_ALL);
}
if (CookieHandler.getDefault() != DEFAULT_COOKIE_MANAGER)
{
CookieHandler.setDefault(DEFAULT_COOKIE_MANAGER);
}
```
But keep not working... any idea ? thanks
Answers:
username_1: < HTTP/1.1 403 Forbidden
< Server: nginx
< Date: Mon, 30 Dec 2019 11:58:58 GMT
< Content-Type: text/html
< Content-Length: 162
< Connection: keep-alive
```
When faking the user agent it works:
```
curl --verbose -A "Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1" https://e.mm.uol.com.br/band/radiobandeirantes_poa/playlist.m3u8
```
username_0: Hi @username_1,
thanks for your answer!
They changed recently his URL, so I don't have any other to use.
I tried to simulate with your fake UserAgent and worked.. haha
Stupid workaround.. but.. =)
Thanks
Status: Issue closed
|
RVSchools/buildouts | 65493175 | Title: feb 10-2
Question:
username_0: The other thing that keeps happening is when staff add an item (news, image,page etc) they get a "page can not be found" error showing on a page that displays like the user is not logged in (the members bar is not showing), however when you refresh the page, the item that you added appears, and it goes back to showing the members bar properly. This happened to us repeatedly on Thursday when I was doing some training at Bert Church. It happens on other school sites as well on a regular basis. Not sure if the errors show up here or not.
http://bertchurch.rockyview.ab.ca/prefs_error_log_form
Answers:
username_0: Carlos I'm emailing you a screenshot from Angela re this issue as of today.
username_1: You can attach the image to the ticket.
<NAME>
username_0: 
username_0: pretty sure it's a cache thing. |
uport-project/uport-connect | 250010777 | Title: Issue with the uport app upon rejecting transaction while on the same phone as the dapp run
Question:
username_0: Hi, I have posted this issue on the gitter channel but since I did not get an answer and cannot find a better place to post issue for the uport mobile app, I am posting here :
I have been testing the uport app by interacting with a dapp running on the browser of that **same** phone and that's really cool. I just noticed something a bit annoying: when denying a transaction, the user is brought back to the camera view as opposed to the browser where the dapp run. When accepting the transaction the correct behavior happen : the user is brought back to the web browser where the dapp is running.
Answers:
username_1: @username_0 i believe this issue was fixed in a recent release - could you confirm if it's been resolved or if you're still seeing it?
Status: Issue closed
|
Cudiph/monotonebot | 829814936 | Title: Changing the system to Lavalink
Question:
username_0: Have you considered changing to Lavalink?
Answers:
username_1: Yeah I want it too but that's probably a lot of work to do and I don't have much free time left because of school. Also discordjs team is creating new voice system (discordjs/voice) that looks promising and one of the major PR was merged, so I think I'll wait for the next discord.js major version while I'm working on my school project :)
Status: Issue closed
|
repobee/repobee | 480500326 | Title: Add extension command to inspect the JSON database
Question:
username_0: It should be possible to make rudimentary queries to the database, with pretty-printed results. E.g.:
`repobee db-lookup -s username_0 -mn task-1 task-2 --hook junit4`
should bring up the results for the junit4 hook from task-1 and task-2 for username_0.<issue_closed>
Status: Issue closed |
jlippold/tweakCompatible | 418906353 | Title: `FloatyDock` working on iOS 12.0.1
Question:
username_0: ```
{
"packageId": "com.synnyg.floatydock",
"action": "working",
"userInfo": {
"arch32": false,
"packageId": "com.synnyg.floatydock",
"deviceId": "iPhone9,3",
"url": "http://cydia.saurik.com/package/com.synnyg.floatydock/",
"iOSVersion": "12.0.1",
"packageVersionIndexed": true,
"packageName": "FloatyDock",
"category": "Tweaks",
"repository": "BigBoss",
"name": "FloatyDock",
"installed": "1.4",
"packageIndexed": true,
"packageStatusExplaination": "A matching version of this tweak for this iOS version could not be found. Please submit a review if you choose to install.",
"id": "com.synnyg.floatydock",
"commercial": false,
"packageInstalled": true,
"tweakCompatVersion": "0.1.4",
"shortDescription": "iPad dock power, for all !",
"latest": "1.4",
"author": "SynnyG",
"packageStatus": "Unknown"
},
"base64": "<KEY>
"chosenStatus": "working",
"notes": ""
}
```<issue_closed>
Status: Issue closed |
greenmail-mail-test/greenmail | 314497873 | Title: Web IF in standalone docker
Question:
username_0: Hi there and thanks for a great software!
Is it possible to get a web interface from the docker standalone container just like the JBoss JMX interface?
Or any other management interface besides SSH or setting up a full mailclient?
thanks!
Answers:
username_1: Hi @username_0!
I recommend to use eq squirrelmail or rainloop (eg via docker compose).
GreenMail uses some [web ui docker images](../tree/master/greenmail-docker/clients) for testing.
Adding a mail web UI to GreenMail would be reinventing the wheel, and is out of scope.
You can use any IMAP client and connect to GreenMail.
There is a plan to add an admin mgmt API (#108), though.
Status: Issue closed
|
lizloera/webhotel | 261936824 | Title: Mal uso de spans en enlaces
Question:
username_0: Un enlace por default ya es contenedor de texto.
Usar span dentro de un a seria porque se esta teniendo dos tipos de contenido en el enlace y se quiere dar un diseño diferente.
https://github.com/lizloera/webhotel/commit/1aa4f462ef4e7956cfceae8ba4c3475b40cdf2f8#commitcomment-24686984 |
primefaces/primefaces | 413005794 | Title: TabView: effect attribute on on demand Loading not working on first click
Question:
username_0: ## 1) Environment
- PrimeFaces version: Primefaces Showcase
- Application server + version: no need
- Affected browsers: no need
## 2) Expected behavior
The behavior should be consistent every time.
...
## 3) Actual behavior
On First Click fold effect is not working
..
## 4) Steps to reproduce
Not needed
..
## 5) Sample XHTML
not needed
..
## 6) Sample bean
..
Answers:
username_1: If its reproduceable in the Showcase we need at least a url and steps to reproduce
username_0: Steps to reproduce the issues.
1. URL: https://www.primefaces.org/showcase/ui/panel/tabView.xhtml
2. go to on-demand loading block
3. click on godfather II tab.
4. we cannot observing fold effect.
5. if you click on godfather II tab again you can observe fold effect.
Status: Issue closed
|
gruntjs/grunt | 137337175 | Title: Update copyright notices
Question:
username_0: Although Grunt joined the Dojo Foundation a while back, the copyright notices were never updated from Ben's name. Before I submit a PR I wanted to see whether you really want so many notices here. Just a LICENSE file would be sufficient. Would it be okay to [remove all of these](https://github.com/gruntjs/grunt/search?utf8=%E2%9C%93&q=Copyright), rename LICENSE-MIT to LICENSE, and update the owner? Or does it make sense to keep some of them? That might be the case, for example, if files were distributed independently, but I am not sure if that applies for any of these.
Answers:
username_1: :+1: SGTM. Less to update each year too :)
username_2: YES PLEASE <3
Status: Issue closed
|
google/flutter-desktop-embedding | 590560643 | Title: Implement canLaunch for url_launcher on Linux
Question:
username_0: Originally this wasn't implemented since there's no API to check if launching will succeed, but since the docs say "xdg-open supports file, ftp, http and https URLs" we could just implement it to return true for those and false for everything else. That's not perfect (a give `file:` URL may not actually be openable), but will cover the common cases, and will avoid the problem that the doc-recommended practice ("We recommend checking which URL schemes are supported using the canLaunch method prior to calling launch.") won't always fail.<issue_closed>
Status: Issue closed |
lovell/sharp | 508986765 | Title: tile() with background color
Question:
username_0: [libvips dszave](https://libvips.github.io/libvips/API/current/VipsForeignSave.html#vips-dzsave) provides a `background` option to set the default background color of the tiles, but this option does not seem to work in sharp. Am I doing this incorrectly or is this option not implemented?
Example:
sharp('file.png')
.tile({
size: 512,
overlap: 0,
layout: 'google',
background: '#000'
})
.toFile(tilesDirectory, (error, info) => {
done();
});
Answers:
username_1: Hi, as you've seen, the `background` option of libvips' `dzsave` operation is not currently exposed in sharp.
https://sharp.pixelplumbing.com/en/stable/api-output/#tile
Happy to accept a PR to add this if you're able.
username_0: OK thanks @username_1. I've had a go but C++ isn't my strong suit. See PR #1924.
Status: Issue closed
username_1: v0.23.2 now available, thanks for the PR!
username_2: hello paul i m with problems with star atlas
username_2: https://staratlas.com/
 belt of venus and earth shadow
the star atlas want the new atmosphere i want a new
username_2: Precomputed Atmospheric Scattering Figure 7: Validation. The sky luminance relatively to the zenith luminance for several sun zenith and view zenith angles (and null azimuth between view and sun directions). Comparison between our model (with α¯ = 0.1, β
s
M = 2.210−5 m−1
, β
s
M/β
e
M = 0.9, g = 0.73 and HM = 1.2 km)
and the CIE sky model 12 (based on actual measurements). We note an overestimation near the horizon (view angles near 90 and -90), which
is also visible in Figure 6. As shown in [ZWP07] the Preetham model [PSS99] also suffers from this problem, which probably comes from the
physical models currently used in CG.
Figure 8: Results. (a), from top to bottom: [SFE07], single scattering, multiple scattering and photo. With [SFE07] the shadow does not
appear due to the missing ν parameter. It is too dark with single sattering only. (b) sunset viewed from space. (c) the view used for our
performance measurements.
c 2008 The Author(s)
Journal compilation
c 2008 The Eurographics Association and Blackwell Publishing Ltd.
<NAME> & <NAME> / Precomputed Atmospheric Scattering
Figure 9: Results. Our results (no frames) compared with real photographs found on the Web (red frames). The tone mapping may explain
the sky hue differences on some images compared with the uncalibrated photographs.
Views from space for various altitudes and sun positions.
Views from the ground showing, from left to right, the Earth shadow, the aerial perspective after sunset, sunset, and light shafts at sunrise.
Aerial perspective during the day, and mountain shadows for various view and sun angles |
batocera-linux/batocera-emulationstation | 1151798533 | Title: Theming: add new themeable global variable for retroachievements
Question:
username_0: Hi @fabricecaruso , I know that there is a variable for compatible systems with retroachievemens ("ifCheevos="true"), but a global themeable variable for retroachievements is missing, something like ifCheevosGlobal¿? would be great for theming.
Thanks a lot for the work |
gorilla/sessions | 688479113 | Title: [question] What are the consequences of setting empty "encryption key"?
Question:
username_0: What exactly happen on empty encryption key? The cookie won't be encrypted at all, so the end users might be able to read the data? Or is the encryption key auto-generated somehow?
This is both a question and a request for better documentation :)
Answers:
username_1: If you omit the encryption key, cookies are only _authenticated_ - that is, they cannot be tampered with by the client.
Cookie values are otherwise sent in plaintext, and I would generally advise using TLS (HTTPS) to protect cookies in transit, as a stolen cookie is a real risk. Storing sensitive values in the cookie itself is not recommended in general.
Noted on the docs :)
username_0: If the server uses TLS, authetication doesn't _really_ matter that much anyway though, right. Since TLS is doing the auth already, so we don't really need _second_ auth.
username_1: Not true - you still want to authenticate the cookie so that the client
themselves can’t forge or otherwise edit the cookie in an attempt to
masquerade as an admin or another user.
If you store the user ID in the cookie, for example - a common approach -
you do not want the user to be able to modify it.
That they can see the value in plaintext isn’t an issue.
username_2: I think Karelbilek has a point in the case of using any other than the cookie store implementations. As long as your cookie is big and random the attacker will not be able to guess the cookie of another user. The whole idea of a persistent storage is to use this random value as a lookup key. Since the session manager is the only one with access to the store no one else is able to magically create a session. The chance of an attacker being able to guess an active session are as big as the odds of an attacker being able to generate a correct signature without knowing the private key.
username_1: It's not clear what the ask is here? Remove cookie authentication? Not going to happen.
- Many users of this package may put state in the cookie that would be at risk of being manipulated
- Detecting tampering is useful
- Not all applications or users of this package use TLS - unfortunate, but true.
- a layer of protection against store implementations with predictable IDs
Since the HMAC validation _extremely minimal_ w.r.t CPU load, the risk vs. benefit here is unclear.
Status: Issue closed
username_0: I only asked for better explanation in documentation. Because the drawbacks
are not immediately clear.
Not sure why it was closed. :) but the question was answered here so ok |
bumasoft/instagram_stories_clone | 792752163 | Title: Docs
Question:
username_0: Hey there,
Could you add more details, screenshot and enrich the documentation of the project please!
Answers:
username_1: Hi,
Thanks for your comment. I will try, but I am too busy this period of time, sorry. Maybe in a couple of months, but if you have trouble installing and testing it, I'm happy to answer your questions.
Good luck! |
nodejs/help | 212238962 | Title: Lost/missing data on Unix Domain Socket
Question:
username_0: * **Node.js Version**: 4.4.3
* **OS**: Raspbian 8 (jessie)
* **Scope**: code
I've created a unix domain socket server (via node.js) so I can pass data from several bash scripts to my node.js program. The problem I'm having is that I occasionally miss entire messages on the node.js side. This seems to be a timing issue as if I add delays between messages, each arrives as expected. The problem seems to be with data arriving quickly (I think).
Below is code for the server side implementation which is actually called from other code. For debugging purposes, I'm only calling this code and allowing the server.on("data") to call a function shown here (i.e. UnixSocketData). This function does no processing; it just logs the data it receives. Occasionally, this function doesn't log the data sent to it.
What am I missing or doing wrong?
See bottom snippet for sample bash code that sends data to the unix domain socket.
```js
//======================================================
// require other modules
var fs = require('fs'),
net = require('net');
//======================================================
// Global Variables
var gUnixServer = null; // Unix domain socket server
var gClients = new Array(); // Currently connected clients
var gNextClientID = 0; // ID to be assigned to the next client
var gGotDataCB = null; // Function called when data received via unix port
var gServerReadyCB = null; // Function called when server is running/ready
//======================================================
exports.start = function(receivedDataCallBack, serverReadyCallBack)
{
// Register callback functions
gGotDataCB=receivedDataCallBack;
gServerReadyCB=serverReadyCallBack
openUnixSocket(); // Start listening for connections
}
exports.stop = function()
{
gUnixServer.close(); // Stop the unix port server
// Reinitialize for possible server restart
gClients = new Array();
gNextClientID = 0;
gUnixServer = null;
gGotDataCB = null;
}
/*
* Start a UNIX socket server to allow OS/bash messages to be passed
* to main program
*/
function openUnixSocket()
{
gUnixServer = net.createServer(newUnixConnection);
gUnixServer.listen('/var/run/customPortServer');
console.log('Listening on /var/run/customPortServer');
gServerReadyCB(cVersion);
}
/*
* Received a connection request on the UNIX socket
* Parameters:
* client - the client socket requesting connections
[Truncated]
```
bash script
```bash
#!/bin/bash
mkfifo /tmp/socketServer.fifo
# open connection to node.js socket server (prevents constant opening & closing of socket for every message)
tail -f /tmp/socketServer.fifo | nc -U /var/run/customPortServer &
netcat_pid=$!
# EOL used to parse data (allows partial frames)
echo "{ \"msgCode\": \"log\", \"data\": \"some data here\"}EOL" > /tmp/socketServer.fifo
echo "{ \"msgCode\": \"log\", \"data\": \"some more data here\"}EOL" > /tmp/socketServer.fifo
# You get the idea, do some action, send more messages to the socket/port
kill $netcat_pid
rm /tmp/socketServer.fifo
```
Answers:
username_1: Hey did you ever fix this?
username_0: No. Increasing the delay seems to help reduce the chance of lost data but I still lose data. Unfortunately, I haven't had time to come back to this to figure out a workaround or fix.
username_1: well do you want to pursue this issue? Or are you ok?
username_0: If there's a fix or workaround, that would be great! I haven't been actively working on it because my deadline is next week and I have a lot of work still to do on my program.
If you have suggestions, I can set aside some time to try them out. Any input is greatly appreciated.
username_1: Look I don't have much experience with this tech, but i have just spent time on google searching for answers. And of the top, it looks like delaying the sockets is your best bet. Because they are extremely fast.
And i don't see anything minus this post about unix sockets on Raspbian 8. The only thing i think we can do is scale down the problem. I'm on the net docs & if you want to continue top optimize your current code. We can try something from there. If you wish to give it a go. Let me know.
username_0: I don't think the problem is on the unix socket OS implementation side because I haven't seen any lost data if I just dump data to the port and output it to the terminal or file via a bash listener script. I believe the issue is on the Node.js side. I would have expected the data to be buffered and processed as there were available cycles. If I take node out of the equation, it seems to buffer okay (even if there's a momentary delay because of a busy CPU).
I'd like to find a solution other than just adding delays (if possible) but I realize that it might not be possible.
I'm not sure I follow your second paragraph. How would you recommend optimizing my code?
username_1: Optimize, fix the issue so you don't have to have work arounds in your code.
username_0: Sounds good to me. I'm willing to spend some time to try to figure out what I'm doing wrong or how to do it better.
username_1: Cool, so can you create another file & comment out the problematic one. I want you to scale down the problem.
username_1: http://unix.stackexchange.com/questions/26715/how-can-i-communicate-with-a-unix-domain-socket-via-the-shell-on-debian-squeeze
Have you seen this post?
username_0: I've seen that link and similar methods which was why I thought I might be able to do the same with node.js. In my case, my bash script pipes the output of a fifo to netcat (nc) to send data on the unix socket. I've done it that way because it keeps the connection to the open. If I send commands they rhey do it in the link youbprovided,
Status: Issue closed
username_0: * **Node.js Version**: 4.4.3
* **OS**: Raspbian 8 (jessie)
* **Scope**: code
I've created a unix domain socket server (via node.js) so I can pass data from several bash scripts to my node.js program. The problem I'm having is that I occasionally miss entire messages on the node.js side. This seems to be a timing issue as if I add delays between messages, each arrives as expected. The problem seems to be with data arriving quickly (I think).
Below is code for the server side implementation which is actually called from other code. For debugging purposes, I'm only calling this code and allowing the server.on("data") to call a function shown here (i.e. UnixSocketData). This function does no processing; it just logs the data it receives. Occasionally, this function doesn't log the data sent to it.
What am I missing or doing wrong?
See bottom snippet for sample bash code that sends data to the unix domain socket.
```js
//======================================================
// require other modules
var fs = require('fs'),
net = require('net');
//======================================================
// Global Variables
var gUnixServer = null; // Unix domain socket server
var gClients = new Array(); // Currently connected clients
var gNextClientID = 0; // ID to be assigned to the next client
var gGotDataCB = null; // Function called when data received via unix port
var gServerReadyCB = null; // Function called when server is running/ready
//======================================================
exports.start = function(receivedDataCallBack, serverReadyCallBack)
{
// Register callback functions
gGotDataCB=receivedDataCallBack;
gServerReadyCB=serverReadyCallBack
openUnixSocket(); // Start listening for connections
}
exports.stop = function()
{
gUnixServer.close(); // Stop the unix port server
// Reinitialize for possible server restart
gClients = new Array();
gNextClientID = 0;
gUnixServer = null;
gGotDataCB = null;
}
/*
* Start a UNIX socket server to allow OS/bash messages to be passed
* to main program
*/
function openUnixSocket()
{
gUnixServer = net.createServer(newUnixConnection);
gUnixServer.listen('/var/run/customPortServer');
console.log('Listening on /var/run/customPortServer');
gServerReadyCB(cVersion);
}
/*
* Received a connection request on the UNIX socket
* Parameters:
* client - the client socket requesting connections
[Truncated]
```
bash script
```bash
#!/bin/bash
mkfifo /tmp/socketServer.fifo
# open connection to node.js socket server (prevents constant opening & closing of socket for every message)
tail -f /tmp/socketServer.fifo | nc -U /var/run/customPortServer &
netcat_pid=$!
# EOL used to parse data (allows partial frames)
echo "{ \"msgCode\": \"log\", \"data\": \"some data here\"}EOL" > /tmp/socketServer.fifo
echo "{ \"msgCode\": \"log\", \"data\": \"some more data here\"}EOL" > /tmp/socketServer.fifo
# You get the idea, do some action, send more messages to the socket/port
kill $netcat_pid
rm /tmp/socketServer.fifo
```
username_0: Damn typing on a phone! Lol.
Anyways, If I send commands like they are doing in the link you provided, it repeatedly opens and closes the unix socket connection to the server. This results in unecessary avtivity on the node.js side where it's constantly opening and closing the connection.
username_1: or you on your laptop or pc right now?
username_0: I'm typing from my phone. I had a popup message and went to click it and accidentally clicked the close button that closed the thread.
Any code changes I make will have to happen tomorrow while I'm at work as I only have access to the hardware during business hours. Having said that, I can strategize about what to try.
I have stripped back the code quite a bit previously but didn't get very far. I will look over my notes tomorrow and see if I was getting all the data via the unixSocketData callback function or if it was lost when passed to the other main process.
I just noticed that I missed the code sample you provided. So based on what you show, that would actually be the bash script side and not written in node.js. Essentially, I have several bash scripts that are initiated via node and need to report their progress to the node app. So, I create a unix socket server with node.js, launch the bash script(s), they create a fifo that pipes data to netcat (to keep the server connection alive) which is connected/talking to the node.js unix socket server. The data the server receives then updates the GUI so the user knows whats2 currently happening with the bash scripts.
I hope this makes sense.
username_1: Nope, it makes no sense at all. lol But tomorrow is a good idea, just cc me when your at work. we will keep going like energizer bunny until we fix this though. So tomorrow it is. Bye for now.
username_0: Thanks for the help. Cheers.
username_0: I'm at work right now and have scaled back my program to essentially what was provided above. I basically have three components:
1) unixSocketServer.js - handles opening and closing of server and passing received data (see sample node.js code in original post)
2) mainPgm.js - basic program (represents my main program) that just calls unixSocketServer.start() & .stop() along with passing callbacks.
3) sendMsg.sh - basically the original bash script in my first post (with some minor modifications). This currently loops 100 times and outputs a message with the corresponding step of the loop (i.e. it counts from 1 to 100). This script creates a fifo, connects that fifo (via netcat) to the unix socket created by unixSocketServer.js
If I have the data written directly to the console using unixSocketServer.js (i.e. NOT pass it to mainPgm.js), it seems to get all the data (I cannot 100% guarantee that because data loss has been intermittent). If, however, I use the callback provided by mainPgm to log the data, I more reliably get data loss. If I add a delay when first setting up my connection between the bash fifo and unix domain socket, at this point, I seem to get all of my data.
I'm going to run a bunch of load tests to see if I'm truly getting everything and then scale back up with my actual main program to see what happens.
username_0: If I add processes to increase the CPU workload, I get lost data again. I believe the node.js event loop might just be missing the data. I had thought that it would be buffered but this doesn't seem to be the case. I might be stuck with what I have without a total overhaul of this method. I will keep investigating but I may have just run into a limitation with the way I'm doing it.
username_2: I'm not clear, do you have an up-to-date reproduction? Is it in this thread somewhere?
username_1: Hey where is `cVersion` coming from?

username_0: It was an oversight in my original post. It should have been in the unixSocketServer.js file.
FYI, I'm leaving work in less than an hour but I think I've made progress. I will update you shortly.
username_1: that's what i'm talking about #progress baby 👍
username_0: Okay, so I've attached my test version of the files I'm using. I do the following to test the setup:
1. Start the unix socket server and output the console messages to a file by running:
`node mainPgm.js > output &`
1. Send 200 messages to the server and keep a log of the messages sent:
`./sendMsg.sh`
The bash script now creates a temporary file rather than a FIFO and pipes the output of the file to the unix domain socket. I noticed that if I connected several listeners to the FIFO and cranked up the CPU usage, I would get packets going to some listeners but not all. One scenario simply had two processes using tail and piping it to two separate files. In this case, I had some data going to one file and the rest going to the other. I'm not sure how valid a test that was but it made me re-evaluate the FIFO to begin with.
I believe node.js may not be reading the socket quickly enough which is causing the FIFO to pause or throw a SIGPIPE error. By changing to writing to a temporary file rather than a FIFO, I can change how the data is being buffered. At this point, I'm able to start four processes compressing random data (to busy up the CPU) and use the attached test files without losing any data. I believe this may be the fix but I need to do further testing. I will keep you guys posted and I appreciate the input. Also, if you have a better explanation of why one wasn't working and the other was, I'm open to it. My summary is based on my limited knowledge of the OS inter-processes.
[mainPgm.zip](https://github.com/nodejs/help/files/886647/mainPgm.zip)
username_0: I've done several tests including running my test programs while using 'stress' to busy up the CPU and the I/O and haven't seen one missing message. I believe I've found a fix/workaround (see my last post).
I'm a little surprised and disappointed that I couldn't just use a FIFO but this seems to work fine and has minimal impact on my program (i.e. I only had to make a change to one line of code).
Thanks to @username_2 and, especially, @username_1 for your interest and input; collaboration makes things easier and I hope this thread will help others.
Status: Issue closed
username_3: Hey all,
I'm having the same issue here. @username_0, just to confirm, your solution didn't actually _solve_ the problem, it just got around it, right? I'm in a situation where I need to make call to a service that returns a meaningful response (i.e., I can't just use a tmp file). Here's what I've done:
* I verified that the calls work as expected if you space them out with a `setInterval`.
* I then registered listeners that console log on EVERY POSSIBLE EVENT on the client socket connection.
* Then I added a "write buffer full handler," i.e., I pause writing if I get `false` back after `socket.write` and resume when I receive a "drain" event (though this mechanism is never triggered).
What ends up happening is that all of the calls are written (5 in this case), but only two of them ever make it to the server. No error events are ever fired, and nothing else out of the ordinary seems to be happening. The data is just simply lost.
This seems like a HUGE bug in node. I don't think this issue should be closed....
username_0: @username_3, it's been a while since I have worked on this issue but I can tell you, in general terms, what I found.
In my case, it appeared to me that the problem was with passing messages via multiple callbacks. I had created a library which created a Unix Domain Socket server which was instantiated via a main process. If the library directly processed the data, things seemed to work okay. However, if I had the library pass the data via a callback to the main process, I would occasionally lose data.
I ideally wanted to have my bash script directly send data to the main process via the unix domain socket but I couldn't get it to happen reliably. I added a temporary file to allow a quasi-buffer as I believed that Node.js wasn't queuing the messages/events properly. As I couldn't guarantee 100% that my suspicions were correct, I didn't feel it was fair to leave the ticket opened as I seemed to be the only one with the problem and I had a workaround.
Based on my experience, it seemed to me that if the Node.js event loop got too busy, it would sometimes result in messages being combined (either multiple messages or message fragments). I ended up adding custom start and end of message markers so I could make sure my callback could properly identify complete messages and buffer any others where they were either multiple messages and/or message fragments. Using this method (along with the intermediate file), I was able to 100% reliability.
I'm wondering if you implement your own SOF and EOF to your messages, you can use them to make sure you aren't getting multiple messages per event on your server. Given that you're only sending 5 messages and missing 3 of them, it sounds like there might be another issue. In my case, I was rapidly firing 20 - 30 large messages within a few seconds and missing, maybe, 2 or 3.
username_3: Thanks for the info! After much more debugging, it actually looks like I haven't fully identified the problem. My original setup used a PHP server listening on the socket and a node client connecting to it. That was the setup in which I got the above described behavior. To try to narrow the problem area, I created a simple test node server and used the same client on it. With that setup, the messages seemed to arrive correctly, but the response were chunked significantly differently than with the PHP server.
Anyway, more debugging to do.... I'll try to update this thread if I discover anything else.
username_2: Node only supports stream sockets in the Unix domain, so this is indeed what should happen. You can't rely on a single write of a packet at the sender be received as a single packet (this is the same as TCP). You can use datagram sockets in the unix domain, but you'll need an external module to do that (https://github.com/bnoordhuis/node-unix-dgram, the unix domain equivalent of UDP). Or you can add packet structure to your messages, probably a better approach.
username_4: I might have the same issue, where we have a Go script and a Node.js script.
It seems that messages I'm trying to send from Node.js over the socket, not always make it to the Go application. It all worked fine untill I started sending some more messages at the same time.
Not exactly sure what caused it, but we figured out that Go never received the messages I tried to send from Node.js
I switched from unix sockets to TCP connections, and we didn't have the problem anymore.
The Node.js part:
```javascript
// Create connection
client = net.createConnection(process.env.SOCKET_ADDR);
// Write to client
// Payload is normal javascript object
client.write(JSON.stringify(payload) + '\n');
```
It's hard to debug if Node.js didn't send the message to the socket, or Go never received it, and which "fault" it actually is.
username_2: @username_4 Use strace, you can see the network calls made by the process, should allow you to find where its dropped. https://gist.github.com/jhass/5896418 might help as well.
username_0: Something that I originally overlooked that @username_2 pointed out a few years ago was that Node didn't support Unix domain sockets as I had expected (see the quote above). If I were doing it again from scratch, I might change to a datagram socket as suggested but I've already written my own framing and buffer library around the Unix socket so I will continue using it that way. It's worked well but I suspect the datagram library probably would have saved me some time and headaches.
If you're using Unix Domain sockets like I did, you're probably running into the same thing where data isn't necessarily being dropped but requires some buffering (as you may be getting message fragments or messages mashed together).
Good luck!
username_4: Thanks for your reply @username_0
I currently swapped to TCP connection rather than unix sockets.
Is there any way why I should go with unix sockets instead?
My use-case is running Node.js and Go in different Docker containers on a Raspberry Pi, where Go handles (amongst others) the GPIO
username_0: @username_4 probably not. On a modern system (both hardware and GNU/Linux), TCP via loopback address will be extremely fast. However, if you need faster throughput and/or lower CPU usage, you want to use Unix Domain sockets as it has much less overhead (even when piping through something like netcat). The entire purpose of Unix domain sockets is inter-process communications (IPC) so are probably the fastest method of communications between two processes. They're also easy to implement; in one of my applications, I have a bash script outputting to a unix socket on which Node is listening. Debugging can be done simply by attaching a netcat connection.
Having said all of this, the company that I work at is changing most IPC to TCP or websockets because of ease of maintenance. This allows IPC or external communication between modules/applications. |
ueokande/vim-vixen | 274389126 | Title: missing some feathers comparing with old plugin "vimfx"
Question:
username_0: ### I'm opening this issue because:
- I'll propose some new features
### Description
- copy text in copy mode with a cursor which can move with 'h,j,k,l' and select text we want to copy. In "VimFX", press "c" to show the text area with highlights, choose the near area and move the cursor to the beginning position of the text we want and press "v" to start selection, and then press "y" to copy the selecting text to clipboard.
- copy the location of a link. In "VimFX", press "yf" to show the link with highlights, the location url can be copied to clipboard after we choose its link, press "yy" to copy current url.
- open a link in current tab exactly. In "VimFX", when we choose a link with pressed "f", the link is always opened in current tab, and opened in new tab with pressed "F".
- can vixen work in new tab? I've installed vixen -v0.5 and it doesn't work in new tab.
#### System configuration
- Operating system: Archlinux x86_64 lastest
- Firefox version: 57
- Vim-Vixen version: 0.5
Answers:
username_1: I'm running same OS, firefox version and Vim Vixen version but I have this functionality.
username_2: It is possible to override about:newtab (https://developer.mozilla.org/en-US/Add-ons/WebExtensions/manifest.json/chrome_url_overrides#Syntax) and then run a content script on it, so that you don't lose control.
username_3: #​5 (`gi`) is covered by #98.
username_0: yeah, I have noticed the shortcuts keys 'F' and 'f', pressing 'f' is just equal to clicking the link, not forcing to open this link in current tab. There is a website we can test: "https://www.baidu.com"
username_4: I think you mean "v". VimFx never had a "c" shortcut.
username_0: Yes, pressing "v" in VimFX can enter "cursor" mode, the shortcut "c" works in vimperator which means the mode "caret".
username_5: First and foremost thanks for this awesome extension & great piece of code! Thanks to all Vim-vixen devs!
Secondly, I'd really really second the "copy text mode" feature from VimFX (as @username_0 pointed out).
* **How hard is it to get this in vim-vixen?** (I'm not a firefox add-on dev but happy to give it a shot!)
username_5: p.s.: @username_0 I cannot reproduce your issue as it seems likeL pressing F will trigger the next open link to open in a new tab, whereas f opens it in the current tab = all the expected behavior. (Firefox quantum + last Vim-Vixen version). |
e3nn/e3nn | 792761750 | Title: ❓ [QUESTION] Input point cloud data with 1024 points to the example Network then report an error: out of memory
Question:
username_0: Hi! @username_1
Thanks for your great work! I have done some simple experiments with e3nn recently, which is very effective on point cloud data.
However, it seems that consumed too much memory in CUDA when I used it on point cloud data. I just replaced the input in [e3nn/examples/point/tetris_parity.py](https://github.com/e3nn/e3nn/blob/master/examples/point/tetris_parity.py) with 1024 points, the network was as follows:
````
class Network(torch.nn.Module):
def __init__(self, num_classes):
super().__init__()
R = partial(CosineBasisModel, max_radius=3.0, number_of_basis=3, h=100, L=3, act=relu)
K = partial(Kernel, RadialModel=R)
mul = 7
layers = []
Rs = [(1, 0, +1)]
for i in range(3):
scalars = [(mul, l, p) for mul, l, p in [(mul, 0, +1), (mul, 0, -1)] if haspath(Rs, l, p)]
act_scalars = [(mul, relu if p == 1 else tanh) for mul, l, p in scalars]
nonscalars = [(mul, l, p) for mul, l, p in [(mul, 1, +1), (mul, 1, -1)] if haspath(Rs, l, p)]
gates = [(sum(mul for mul, l, p in nonscalars), 0, +1)]
act_gates = [(-1, sigmoid)]
print("layer {}: from {} to {}".format(i, rs.format_Rs(Rs), rs.format_Rs(scalars + nonscalars)))
act = GatedBlockParity(scalars, act_scalars, gates, act_gates, nonscalars)
conv = Convolution(K(Rs, act.Rs_in))
block = torch.nn.ModuleList([conv, act])
layers.append(block)
Rs = act.Rs_out
act = GatedBlockParity([(mul, 0, +1), (mul, 0, -1)], [(mul, relu), (mul, tanh)], [], [], [])
conv = Convolution(K(Rs, act.Rs_in))
block = torch.nn.ModuleList([conv, act])
layers.append(block)
self.firstlayers = torch.nn.ModuleList(layers)
# the last layer is not equivariant, it is allowed to mix even and odds scalars
self.lastlayers = torch.nn.Sequential(AvgSpacial(), torch.nn.Linear(mul + mul, num_classes))
I also tried input 512 points, but it still consumes about 10G memory, is there any problem?
Could you please give me some help? Thanks very much!
Best wishes!
Answers:
username_1: Hi @username_0,
This specific network uses all possible pairwise distances between points -- I'm guessing this is why it's blowing up when you try 512+ points. I'd recommend trying out this code example instead which uses a radial cutoff for defining nearest neighbors:
https://github.com/e3nn/e3nn/blob/master/examples/point/tetris_torch_geo.py
Please feel free to reopen this issue if using the `torch_geometric` version of this task (above) does not solve the problem.
Status: Issue closed
username_0: Thanks for your reply!
I tried the code in `tetris_torch_geo.py` and modified some parameters , then there was no the OOM error even when I input 10k points, and it brought me excellent results beyond expectations!
But at this time [the step](https://github.com/e3nn/e3nn/blob/447ccb253061a50b29f3a05c6eeffba34cca2c14/examples/point/tetris_torch_geo.py#L47)(line 47) as follows takes too much time for about 2 minutes:
`batch = Batch.from_data_list([DataNeighbors(x, shape, r_max, self_interaction=False) for shape in shapes])`
Is there any better way to make it faster?
username_1: Hi @username_0,
This has more to do with torch and torch_geometric than e3nn. To speed up
the data pre-process I’d recommend implementing your own class to replace
DataNeighbors. if you look into the code, you’ll see it’s a fairly simple
class that inherits from torch_geometric.data.Data. You can likely use
torch_geometric.nn.radius_graph and read the torch_geometric and torch
documentation for best practices for loading and storing theses objects.
Hope that helps! |
jsbroks/coco-annotator | 413847857 | Title: Scale keypoints on zoom
Question:
username_0: Would you please fix the issue when i zoom in for the keypoint ?
Thank you
<img width="1233" alt="screen shot 2019-02-24 at 12 43 44 pm" src="https://user-images.githubusercontent.com/40445787/53302970-c23feb80-3832-11e9-873a-faae4532b6a1.png"><issue_closed>
Status: Issue closed |
fossasia/open-event-frontend | 474290564 | Title: Unable to create paid ticket with price less than 1 (money unit)
Question:
username_0: **Describe the bug**
Unable to create paid ticket like 0.3USD, 0.5 EUR. The minimum amount is 1USD(..)
**Screenshots**
<img src="https://i.ibb.co/x85CrRw/Capture.png" alt="Capture" border="0">
Answers:
username_1: @username_0 Are decimal prices of tickets been observed on any other platform ?
username_2: @username_0 I agree to @username_1
I don't think we need this
username_3: @username_0 I'll fix this but I believe this is a server side related fix.
Status: Issue closed
|
OpenGeoscience/geojs | 123003536 | Title: Implement a tile fetch queue
Question:
username_0: Currently tile ajax requests are occurring on demand. The browser allows only a small number of requests to occur simultaneously and internally keeps a queue of outstanding requests. When a large number of tiles are requested during user interaction, tiles that are no longer relevant for the current view bounds block newer requests from being processed. We should implement a custom queue that checks if the tile is still in bounds before issuing a request. If it is not, it can be safely ignored. Further optimization could possibly adjust the order of the queue so that more important tiles are prioritized.
Answers:
username_1: Charles and I discussed this and I believe he has some code. I request him to bring this code to geojs but I believe he has been busy or forgot about it. @username_2 and I will look at this issue.
username_2: I have an implementation of this that I will submit shortly. I still need to add some tests and check some of the code.
username_1: great @username_2 did you borrow code from slide atlas or this is a new implementation?
username_2: It is a new implementation that uses javascript promises (à la jquery).
username_1: I see. Is there a reason, we should not look into what SlideAtlas has?
username_2: I did look. I decided it would be faster to write code in the same style as what else we have in geojs than it would be to adapt the code in SlideAtlas. Specifically, we use promises to handle a tile when the image is requested. This allows individual components to not need to know about how things are being processed. For instance, the imageTile object doesn't need to know anything about the fetch queue. This will be a good thing when we handle vector tiles, as that class won't need to care about the queue either.
I've written a generic Deferred object fetch queue, so it could be reused for non-tiles if appropriate, too.
username_1: Sure, faster is better :+1: but we should keep looking into slide-atlas code to bring it in geojs if possible and reasonable. Thanks for the update.
Status: Issue closed
username_2: Added in PR #486. |
joomla/showcase.joomla.org | 782061693 | Title: download and launch button are not aligned properly
Question:
username_0: in the phone, they are not aligned properly check this.
Answers:
username_1: Hi @username_0 ,
This issue is part of the common template used by joomla.org websites, same on https://community.joomla.org/
@conconnl do you know please how to process in this case?
Thanks.
username_2: I want to work on this issue
username_3: Hello, please can i work on this issue
Status: Issue closed
username_1: New version of the common template used by joomla.org websites is coming. Closing this issue. |
clld/glottolog3 | 367144586 | Title: any clues why the newick format from pyglottolog doesn't read well into R?
Question:
username_0: Does anyone have any ideas as to why I'm getting two different results when reading in these two Glottolog newick files into R:
1. [tree_glottolog_newick.txt ](https://cdstar.shh.mpg.de/bitstreams/EAEA0-E7DE-FA06-8817-0/tree_glottolog_newick.txt)-file
2. a file I created by saving the output from running` glottolog newick ural1272`
The first one reads in just fine with [ape::read.tree()](https://www.rdocumentation.org/packages/ape/versions/5.2/topics/read.tree), but the second reads in as entirely empty. No error messages though, it's just that the variable is NULL.
I'm trying to teach myself to use pyglottolog, with help from @chrzyki . I thought I'd just render a newick file and see how it goes, just as a simple practice example. I can't really understand why this isn't working. Are there different dialects of newick/new hampshire tree formatting employed? Am I doing something else wrong?
I know that you're not responsible for the ape package in R, naturally. But, if anyone has any clues to what would be different about these two files I'd be very grateful.
Answers:
username_1: Does the latter tree end with semicolon?
username_2: I think it's [this problem](https://github.com/D-PLACE/dplace-data/issues/81)
username_2: Actually, no, it's just the semi-colon :)
username_1: So, all good? If not, that should have been an issue in clld/glottolog
anyway 😉
username_0: Aha, it does not! Added one, and now it reads in just fine. Thanks @username_1
What's the reason it wasn't there before?
Status: Issue closed
username_0: Should I expect to have to add one in each time, or will something else change?
username_2: every time.
username_0: Right, okay. I'll just do a pipe where I read it in as a text file, add a semi-colon and then read it in as a tree with ape. Or just read in [this file](url
https://cdstar.shh.mpg.de/bitstreams/EAEA0-E7DE-FA06-8817-0/tree_glottolog_newick.txt) or [the d-place versions](https://github.com/D-PLACE/dplace-data/tree/master/phylogenies). I guess that since the parentheses must balance, the semi-colon is technically superfluous. But, it's still the expected format.
The pyglottolog tools (besides newick), I think, are meant for a user group that isn't me. Now that I understand this one, I think that's it for me when it comes to pyglottolog.
username_0: The trees in newick format that are downloadable from the website still lack a semicolon at the end.
Example: [https://glottolog.org/resource/languoid/id/mixt1422.newick.txt](https://glottolog.org/resource/languoid/id/mixt1422.newick.txt)
username_0: If this is the set-up continusly, maybe it can be described somewhere? Others are having the same issue.
username_1: fixed now
username_0: Thanks |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.