
text
stringlengths 7
328k
| id
stringlengths 14
166
| metadata
dict | __index_level_0__
int64 0
459
|
|---|---|---|---|
# coding=utf-8
# Copyright 2022 Facebook AI and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch ViT MAE (masked autoencoder) model."""
import collections.abc
import math
from copy import deepcopy
from dataclasses import dataclass
from typing import Optional, Set, Tuple, Union
import numpy as np
import torch
import torch.utils.checkpoint
from torch import nn
from ...activations import ACT2FN
from ...modeling_outputs import BaseModelOutput
from ...modeling_utils import PreTrainedModel
from ...pytorch_utils import find_pruneable_heads_and_indices, prune_linear_layer
from ...utils import (
ModelOutput,
add_start_docstrings,
add_start_docstrings_to_model_forward,
logging,
replace_return_docstrings,
)
from .configuration_vit_mae import ViTMAEConfig
logger = logging.get_logger(__name__)
_CONFIG_FOR_DOC = "ViTMAEConfig"
_CHECKPOINT_FOR_DOC = "facebook/vit-mae-base"
VIT_MAE_PRETRAINED_MODEL_ARCHIVE_LIST = [
"facebook/vit-mae-base",
# See all ViTMAE models at https://huggingface.co/models?filter=vit_mae
]
@dataclass
class ViTMAEModelOutput(ModelOutput):
"""
Class for ViTMAEModel's outputs, with potential hidden states and attentions.
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
Tensor indicating which patches are masked (1) and which are not (0).
ids_restore (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Tensor containing the original index of the (shuffled) masked patches.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
"""
last_hidden_state: torch.FloatTensor = None
mask: torch.LongTensor = None
ids_restore: torch.LongTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class ViTMAEDecoderOutput(ModelOutput):
"""
Class for ViTMAEDecoder's outputs, with potential hidden states and attentions.
Args:
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, patch_size ** 2 * num_channels)`):
Pixel reconstruction logits.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
"""
logits: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class ViTMAEForPreTrainingOutput(ModelOutput):
"""
Class for ViTMAEForPreTraining's outputs, with potential hidden states and attentions.
Args:
loss (`torch.FloatTensor` of shape `(1,)`):
Pixel reconstruction loss.
logits (`torch.FloatTensor` of shape `(batch_size, sequence_length, patch_size ** 2 * num_channels)`):
Pixel reconstruction logits.
mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
Tensor indicating which patches are masked (1) and which are not (0).
ids_restore (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Tensor containing the original index of the (shuffled) masked patches.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer) of
shape `(batch_size, sequence_length, hidden_size)`. Hidden-states of the model at the output of each layer
plus the initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`. Attentions weights after the attention softmax, used to compute the weighted average in
the self-attention heads.
"""
loss: Optional[torch.FloatTensor] = None
logits: torch.FloatTensor = None
mask: torch.LongTensor = None
ids_restore: torch.LongTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
def get_2d_sincos_pos_embed(embed_dim, grid_size, add_cls_token=False):
"""
Create 2D sin/cos positional embeddings.
Args:
embed_dim (`int`):
Embedding dimension.
grid_size (`int`):
The grid height and width.
add_cls_token (`bool`, *optional*, defaults to `False`):
Whether or not to add a classification (CLS) token.
Returns:
(`torch.FloatTensor` of shape (grid_size*grid_size, embed_dim) or (1+grid_size*grid_size, embed_dim): the
position embeddings (with or without classification token)
"""
grid_h = np.arange(grid_size, dtype=np.float32)
grid_w = np.arange(grid_size, dtype=np.float32)
grid = np.meshgrid(grid_w, grid_h) # here w goes first
grid = np.stack(grid, axis=0)
grid = grid.reshape([2, 1, grid_size, grid_size])
pos_embed = get_2d_sincos_pos_embed_from_grid(embed_dim, grid)
if add_cls_token:
pos_embed = np.concatenate([np.zeros([1, embed_dim]), pos_embed], axis=0)
return pos_embed
def get_2d_sincos_pos_embed_from_grid(embed_dim, grid):
if embed_dim % 2 != 0:
raise ValueError("embed_dim must be even")
# use half of dimensions to encode grid_h
emb_h = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[0]) # (H*W, D/2)
emb_w = get_1d_sincos_pos_embed_from_grid(embed_dim // 2, grid[1]) # (H*W, D/2)
emb = np.concatenate([emb_h, emb_w], axis=1) # (H*W, D)
return emb
def get_1d_sincos_pos_embed_from_grid(embed_dim, pos):
"""
embed_dim: output dimension for each position pos: a list of positions to be encoded: size (M,) out: (M, D)
"""
if embed_dim % 2 != 0:
raise ValueError("embed_dim must be even")
omega = np.arange(embed_dim // 2, dtype=float)
omega /= embed_dim / 2.0
omega = 1.0 / 10000**omega # (D/2,)
pos = pos.reshape(-1) # (M,)
out = np.einsum("m,d->md", pos, omega) # (M, D/2), outer product
emb_sin = np.sin(out) # (M, D/2)
emb_cos = np.cos(out) # (M, D/2)
emb = np.concatenate([emb_sin, emb_cos], axis=1) # (M, D)
return emb
class ViTMAEEmbeddings(nn.Module):
"""
Construct the CLS token, position and patch embeddings.
"""
def __init__(self, config):
super().__init__()
self.cls_token = nn.Parameter(torch.zeros(1, 1, config.hidden_size))
self.patch_embeddings = ViTMAEPatchEmbeddings(config)
self.num_patches = self.patch_embeddings.num_patches
# fixed sin-cos embedding
self.position_embeddings = nn.Parameter(
torch.zeros(1, self.num_patches + 1, config.hidden_size), requires_grad=False
)
self.config = config
self.initialize_weights()
def initialize_weights(self):
# initialize (and freeze) position embeddings by sin-cos embedding
pos_embed = get_2d_sincos_pos_embed(
self.position_embeddings.shape[-1], int(self.patch_embeddings.num_patches**0.5), add_cls_token=True
)
self.position_embeddings.data.copy_(torch.from_numpy(pos_embed).float().unsqueeze(0))
# initialize patch_embeddings like nn.Linear (instead of nn.Conv2d)
w = self.patch_embeddings.projection.weight.data
torch.nn.init.xavier_uniform_(w.view([w.shape[0], -1]))
# timm's trunc_normal_(std=.02) is effectively normal_(std=0.02) as cutoff is too big (2.)
torch.nn.init.normal_(self.cls_token, std=self.config.initializer_range)
def random_masking(self, sequence, noise=None):
"""
Perform per-sample random masking by per-sample shuffling. Per-sample shuffling is done by argsort random
noise.
Args:
sequence (`torch.LongTensor` of shape `(batch_size, sequence_length, dim)`)
noise (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) which is
mainly used for testing purposes to control randomness and maintain the reproducibility
"""
batch_size, seq_length, dim = sequence.shape
len_keep = int(seq_length * (1 - self.config.mask_ratio))
if noise is None:
noise = torch.rand(batch_size, seq_length, device=sequence.device) # noise in [0, 1]
# sort noise for each sample
ids_shuffle = torch.argsort(noise, dim=1) # ascend: small is keep, large is remove
ids_restore = torch.argsort(ids_shuffle, dim=1)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep]
sequence_unmasked = torch.gather(sequence, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, dim))
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([batch_size, seq_length], device=sequence.device)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore)
return sequence_unmasked, mask, ids_restore
def forward(self, pixel_values, noise=None):
batch_size, num_channels, height, width = pixel_values.shape
embeddings = self.patch_embeddings(pixel_values)
# add position embeddings w/o cls token
embeddings = embeddings + self.position_embeddings[:, 1:, :]
# masking: length -> length * config.mask_ratio
embeddings, mask, ids_restore = self.random_masking(embeddings, noise)
# append cls token
cls_token = self.cls_token + self.position_embeddings[:, :1, :]
cls_tokens = cls_token.expand(embeddings.shape[0], -1, -1)
embeddings = torch.cat((cls_tokens, embeddings), dim=1)
return embeddings, mask, ids_restore
class ViTMAEPatchEmbeddings(nn.Module):
"""
This class turns `pixel_values` of shape `(batch_size, num_channels, height, width)` into the initial
`hidden_states` (patch embeddings) of shape `(batch_size, seq_length, hidden_size)` to be consumed by a
Transformer.
"""
def __init__(self, config):
super().__init__()
image_size, patch_size = config.image_size, config.patch_size
num_channels, hidden_size = config.num_channels, config.hidden_size
image_size = image_size if isinstance(image_size, collections.abc.Iterable) else (image_size, image_size)
patch_size = patch_size if isinstance(patch_size, collections.abc.Iterable) else (patch_size, patch_size)
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.num_patches = num_patches
self.projection = nn.Conv2d(num_channels, hidden_size, kernel_size=patch_size, stride=patch_size)
def forward(self, pixel_values):
batch_size, num_channels, height, width = pixel_values.shape
if num_channels != self.num_channels:
raise ValueError(
"Make sure that the channel dimension of the pixel values match with the one set in the configuration."
)
if height != self.image_size[0] or width != self.image_size[1]:
raise ValueError(
f"Input image size ({height}*{width}) doesn't match model ({self.image_size[0]}*{self.image_size[1]})."
)
x = self.projection(pixel_values).flatten(2).transpose(1, 2)
return x
# Copied from transformers.models.vit.modeling_vit.ViTSelfAttention ViT->ViTMAE
class ViTMAESelfAttention(nn.Module):
def __init__(self, config: ViTMAEConfig) -> None:
super().__init__()
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
raise ValueError(
f"The hidden size {config.hidden_size,} is not a multiple of the number of attention "
f"heads {config.num_attention_heads}."
)
self.num_attention_heads = config.num_attention_heads
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
self.all_head_size = self.num_attention_heads * self.attention_head_size
self.query = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.key = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.value = nn.Linear(config.hidden_size, self.all_head_size, bias=config.qkv_bias)
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
def transpose_for_scores(self, x: torch.Tensor) -> torch.Tensor:
new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
x = x.view(new_x_shape)
return x.permute(0, 2, 1, 3)
def forward(
self, hidden_states, head_mask: Optional[torch.Tensor] = None, output_attentions: bool = False
) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
mixed_query_layer = self.query(hidden_states)
key_layer = self.transpose_for_scores(self.key(hidden_states))
value_layer = self.transpose_for_scores(self.value(hidden_states))
query_layer = self.transpose_for_scores(mixed_query_layer)
# Take the dot product between "query" and "key" to get the raw attention scores.
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
# Normalize the attention scores to probabilities.
attention_probs = nn.functional.softmax(attention_scores, dim=-1)
# This is actually dropping out entire tokens to attend to, which might
# seem a bit unusual, but is taken from the original Transformer paper.
attention_probs = self.dropout(attention_probs)
# Mask heads if we want to
if head_mask is not None:
attention_probs = attention_probs * head_mask
context_layer = torch.matmul(attention_probs, value_layer)
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
context_layer = context_layer.view(new_context_layer_shape)
outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
return outputs
# Copied from transformers.models.vit.modeling_vit.ViTSelfOutput with ViT->ViTMAE
class ViTMAESelfOutput(nn.Module):
"""
The residual connection is defined in ViTMAELayer instead of here (as is the case with other models), due to the
layernorm applied before each block.
"""
def __init__(self, config: ViTMAEConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
return hidden_states
# Copied from transformers.models.vit.modeling_vit.ViTAttention with ViT->ViTMAE
class ViTMAEAttention(nn.Module):
def __init__(self, config: ViTMAEConfig) -> None:
super().__init__()
self.attention = ViTMAESelfAttention(config)
self.output = ViTMAESelfOutput(config)
self.pruned_heads = set()
def prune_heads(self, heads: Set[int]) -> None:
if len(heads) == 0:
return
heads, index = find_pruneable_heads_and_indices(
heads, self.attention.num_attention_heads, self.attention.attention_head_size, self.pruned_heads
)
# Prune linear layers
self.attention.query = prune_linear_layer(self.attention.query, index)
self.attention.key = prune_linear_layer(self.attention.key, index)
self.attention.value = prune_linear_layer(self.attention.value, index)
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
# Update hyper params and store pruned heads
self.attention.num_attention_heads = self.attention.num_attention_heads - len(heads)
self.attention.all_head_size = self.attention.attention_head_size * self.attention.num_attention_heads
self.pruned_heads = self.pruned_heads.union(heads)
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
self_outputs = self.attention(hidden_states, head_mask, output_attentions)
attention_output = self.output(self_outputs[0], hidden_states)
outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
return outputs
# Copied from transformers.models.vit.modeling_vit.ViTIntermediate ViT->ViTMAE
class ViTMAEIntermediate(nn.Module):
def __init__(self, config: ViTMAEConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
if isinstance(config.hidden_act, str):
self.intermediate_act_fn = ACT2FN[config.hidden_act]
else:
self.intermediate_act_fn = config.hidden_act
def forward(self, hidden_states: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.intermediate_act_fn(hidden_states)
return hidden_states
# Copied from transformers.models.vit.modeling_vit.ViTOutput ViT->ViTMAE
class ViTMAEOutput(nn.Module):
def __init__(self, config: ViTMAEConfig) -> None:
super().__init__()
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
self.dropout = nn.Dropout(config.hidden_dropout_prob)
def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
hidden_states = self.dense(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = hidden_states + input_tensor
return hidden_states
# Copied from transformers.models.vit.modeling_vit.ViTLayer with ViT->ViTMAE
class ViTMAELayer(nn.Module):
"""This corresponds to the Block class in the timm implementation."""
def __init__(self, config: ViTMAEConfig) -> None:
super().__init__()
self.chunk_size_feed_forward = config.chunk_size_feed_forward
self.seq_len_dim = 1
self.attention = ViTMAEAttention(config)
self.intermediate = ViTMAEIntermediate(config)
self.output = ViTMAEOutput(config)
self.layernorm_before = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.layernorm_after = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Union[Tuple[torch.Tensor, torch.Tensor], Tuple[torch.Tensor]]:
self_attention_outputs = self.attention(
self.layernorm_before(hidden_states), # in ViTMAE, layernorm is applied before self-attention
head_mask,
output_attentions=output_attentions,
)
attention_output = self_attention_outputs[0]
outputs = self_attention_outputs[1:] # add self attentions if we output attention weights
# first residual connection
hidden_states = attention_output + hidden_states
# in ViTMAE, layernorm is also applied after self-attention
layer_output = self.layernorm_after(hidden_states)
layer_output = self.intermediate(layer_output)
# second residual connection is done here
layer_output = self.output(layer_output, hidden_states)
outputs = (layer_output,) + outputs
return outputs
# Copied from transformers.models.vit.modeling_vit.ViTEncoder with ViT->ViTMAE
class ViTMAEEncoder(nn.Module):
def __init__(self, config: ViTMAEConfig) -> None:
super().__init__()
self.config = config
self.layer = nn.ModuleList([ViTMAELayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.Tensor,
head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
output_hidden_states: bool = False,
return_dict: bool = True,
) -> Union[tuple, BaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
for i, layer_module in enumerate(self.layer):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
layer_head_mask = head_mask[i] if head_mask is not None else None
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
layer_head_mask,
output_attentions,
)
else:
layer_outputs = layer_module(hidden_states, layer_head_mask, output_attentions)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
class ViTMAEPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = ViTMAEConfig
base_model_prefix = "vit"
main_input_name = "pixel_values"
supports_gradient_checkpointing = True
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, (nn.Linear, nn.Conv2d)):
# Slightly different from the TF version which uses truncated_normal for initialization
# cf https://github.com/pytorch/pytorch/pull/5617
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
VIT_MAE_START_DOCSTRING = r"""
This model is a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it
as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and
behavior.
Parameters:
config ([`ViTMAEConfig`]): Model configuration class with all the parameters of the model.
Initializing with a config file does not load the weights associated with the model, only the
configuration. Check out the [`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
VIT_MAE_INPUTS_DOCSTRING = r"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values. Pixel values can be obtained using [`AutoImageProcessor`]. See [`ViTImageProcessor.__call__`]
for details.
head_mask (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*):
Mask to nullify selected heads of the self-attention modules. Mask values selected in `[0, 1]`:
- 1 indicates the head is **not masked**,
- 0 indicates the head is **masked**.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The bare ViTMAE Model transformer outputting raw hidden-states without any specific head on top.",
VIT_MAE_START_DOCSTRING,
)
class ViTMAEModel(ViTMAEPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.config = config
self.embeddings = ViTMAEEmbeddings(config)
self.encoder = ViTMAEEncoder(config)
self.layernorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.embeddings.patch_embeddings
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
@add_start_docstrings_to_model_forward(VIT_MAE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=ViTMAEModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values: Optional[torch.FloatTensor] = None,
noise: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, ViTMAEModelOutput]:
r"""
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, ViTMAEModel
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = ViTMAEModel.from_pretrained("facebook/vit-mae-base")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if pixel_values is None:
raise ValueError("You have to specify pixel_values")
# Prepare head mask if needed
# 1.0 in head_mask indicate we keep the head
# attention_probs has shape bsz x n_heads x N x N
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output, mask, ids_restore = self.embeddings(pixel_values, noise=noise)
encoder_outputs = self.encoder(
embedding_output,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = encoder_outputs[0]
sequence_output = self.layernorm(sequence_output)
if not return_dict:
return (sequence_output, mask, ids_restore) + encoder_outputs[1:]
return ViTMAEModelOutput(
last_hidden_state=sequence_output,
mask=mask,
ids_restore=ids_restore,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
class ViTMAEDecoder(nn.Module):
def __init__(self, config, num_patches):
super().__init__()
self.decoder_embed = nn.Linear(config.hidden_size, config.decoder_hidden_size, bias=True)
self.mask_token = nn.Parameter(torch.zeros(1, 1, config.decoder_hidden_size))
self.decoder_pos_embed = nn.Parameter(
torch.zeros(1, num_patches + 1, config.decoder_hidden_size), requires_grad=False
) # fixed sin-cos embedding
decoder_config = deepcopy(config)
decoder_config.hidden_size = config.decoder_hidden_size
decoder_config.num_hidden_layers = config.decoder_num_hidden_layers
decoder_config.num_attention_heads = config.decoder_num_attention_heads
decoder_config.intermediate_size = config.decoder_intermediate_size
self.decoder_layers = nn.ModuleList(
[ViTMAELayer(decoder_config) for _ in range(config.decoder_num_hidden_layers)]
)
self.decoder_norm = nn.LayerNorm(config.decoder_hidden_size, eps=config.layer_norm_eps)
self.decoder_pred = nn.Linear(
config.decoder_hidden_size, config.patch_size**2 * config.num_channels, bias=True
) # encoder to decoder
self.gradient_checkpointing = False
self.config = config
self.initialize_weights(num_patches)
def initialize_weights(self, num_patches):
# initialize (and freeze) position embeddings by sin-cos embedding
decoder_pos_embed = get_2d_sincos_pos_embed(
self.decoder_pos_embed.shape[-1], int(num_patches**0.5), add_cls_token=True
)
self.decoder_pos_embed.data.copy_(torch.from_numpy(decoder_pos_embed).float().unsqueeze(0))
# timm's trunc_normal_(std=.02) is effectively normal_(std=0.02) as cutoff is too big (2.)
torch.nn.init.normal_(self.mask_token, std=self.config.initializer_range)
def forward(
self,
hidden_states,
ids_restore,
output_attentions=False,
output_hidden_states=False,
return_dict=True,
):
# embed tokens
x = self.decoder_embed(hidden_states)
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # no cls token
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle
x = torch.cat([x[:, :1, :], x_], dim=1) # append cls token
# add pos embed
hidden_states = x + self.decoder_pos_embed
# apply Transformer layers (blocks)
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
for i, layer_module in enumerate(self.decoder_layers):
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
layer_module.__call__,
hidden_states,
None,
output_attentions,
)
else:
layer_outputs = layer_module(hidden_states, head_mask=None, output_attentions=output_attentions)
hidden_states = layer_outputs[0]
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
hidden_states = self.decoder_norm(hidden_states)
# predictor projection
logits = self.decoder_pred(hidden_states)
# remove cls token
logits = logits[:, 1:, :]
if not return_dict:
return tuple(v for v in [logits, all_hidden_states, all_self_attentions] if v is not None)
return ViTMAEDecoderOutput(
logits=logits,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
@add_start_docstrings(
"""The ViTMAE Model transformer with the decoder on top for self-supervised pre-training.
<Tip>
Note that we provide a script to pre-train this model on custom data in our [examples
directory](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
</Tip>
""",
VIT_MAE_START_DOCSTRING,
)
class ViTMAEForPreTraining(ViTMAEPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.config = config
self.vit = ViTMAEModel(config)
self.decoder = ViTMAEDecoder(config, num_patches=self.vit.embeddings.num_patches)
# Initialize weights and apply final processing
self.post_init()
def get_input_embeddings(self):
return self.vit.embeddings.patch_embeddings
def _prune_heads(self, heads_to_prune):
"""
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
class PreTrainedModel
"""
for layer, heads in heads_to_prune.items():
self.encoder.layer[layer].attention.prune_heads(heads)
def patchify(self, pixel_values):
"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values.
Returns:
`torch.FloatTensor` of shape `(batch_size, num_patches, patch_size**2 * num_channels)`:
Patchified pixel values.
"""
patch_size, num_channels = self.config.patch_size, self.config.num_channels
# sanity checks
if (pixel_values.shape[2] != pixel_values.shape[3]) or (pixel_values.shape[2] % patch_size != 0):
raise ValueError("Make sure the pixel values have a squared size that is divisible by the patch size")
if pixel_values.shape[1] != num_channels:
raise ValueError(
"Make sure the number of channels of the pixel values is equal to the one set in the configuration"
)
# patchify
batch_size = pixel_values.shape[0]
num_patches_one_direction = pixel_values.shape[2] // patch_size
patchified_pixel_values = pixel_values.reshape(
batch_size, num_channels, num_patches_one_direction, patch_size, num_patches_one_direction, patch_size
)
patchified_pixel_values = torch.einsum("nchpwq->nhwpqc", patchified_pixel_values)
patchified_pixel_values = patchified_pixel_values.reshape(
batch_size, num_patches_one_direction * num_patches_one_direction, patch_size**2 * num_channels
)
return patchified_pixel_values
def unpatchify(self, patchified_pixel_values):
"""
Args:
patchified_pixel_values (`torch.FloatTensor` of shape `(batch_size, num_patches, patch_size**2 * num_channels)`:
Patchified pixel values.
Returns:
`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`:
Pixel values.
"""
patch_size, num_channels = self.config.patch_size, self.config.num_channels
num_patches_one_direction = int(patchified_pixel_values.shape[1] ** 0.5)
# sanity check
if num_patches_one_direction**2 != patchified_pixel_values.shape[1]:
raise ValueError("Make sure that the number of patches can be squared")
# unpatchify
batch_size = patchified_pixel_values.shape[0]
patchified_pixel_values = patchified_pixel_values.reshape(
batch_size,
num_patches_one_direction,
num_patches_one_direction,
patch_size,
patch_size,
num_channels,
)
patchified_pixel_values = torch.einsum("nhwpqc->nchpwq", patchified_pixel_values)
pixel_values = patchified_pixel_values.reshape(
batch_size,
num_channels,
num_patches_one_direction * patch_size,
num_patches_one_direction * patch_size,
)
return pixel_values
def forward_loss(self, pixel_values, pred, mask):
"""
Args:
pixel_values (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)`):
Pixel values.
pred (`torch.FloatTensor` of shape `(batch_size, num_patches, patch_size**2 * num_channels)`:
Predicted pixel values.
mask (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
Tensor indicating which patches are masked (1) and which are not (0).
Returns:
`torch.FloatTensor`: Pixel reconstruction loss.
"""
target = self.patchify(pixel_values)
if self.config.norm_pix_loss:
mean = target.mean(dim=-1, keepdim=True)
var = target.var(dim=-1, keepdim=True)
target = (target - mean) / (var + 1.0e-6) ** 0.5
loss = (pred - target) ** 2
loss = loss.mean(dim=-1) # [N, L], mean loss per patch
loss = (loss * mask).sum() / mask.sum() # mean loss on removed patches
return loss
@add_start_docstrings_to_model_forward(VIT_MAE_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=ViTMAEForPreTrainingOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
pixel_values: Optional[torch.FloatTensor] = None,
noise: Optional[torch.FloatTensor] = None,
head_mask: Optional[torch.FloatTensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, ViTMAEForPreTrainingOutput]:
r"""
Returns:
Examples:
```python
>>> from transformers import AutoImageProcessor, ViTMAEForPreTraining
>>> from PIL import Image
>>> import requests
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image_processor = AutoImageProcessor.from_pretrained("facebook/vit-mae-base")
>>> model = ViTMAEForPreTraining.from_pretrained("facebook/vit-mae-base")
>>> inputs = image_processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> loss = outputs.loss
>>> mask = outputs.mask
>>> ids_restore = outputs.ids_restore
```"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.vit(
pixel_values,
noise=noise,
head_mask=head_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
latent = outputs.last_hidden_state
ids_restore = outputs.ids_restore
mask = outputs.mask
decoder_outputs = self.decoder(latent, ids_restore)
logits = decoder_outputs.logits # shape (batch_size, num_patches, patch_size*patch_size*num_channels)
loss = self.forward_loss(pixel_values, logits, mask)
if not return_dict:
output = (logits, mask, ids_restore) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return ViTMAEForPreTrainingOutput(
loss=loss,
logits=logits,
mask=mask,
ids_restore=ids_restore,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
| transformers/src/transformers/models/vit_mae/modeling_vit_mae.py/0 | {
"file_path": "transformers/src/transformers/models/vit_mae/modeling_vit_mae.py",
"repo_id": "transformers",
"token_count": 17941
} | 338 |
# coding=utf-8
# Copyright 2023 The Kakao Enterprise Authors and the HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" PyTorch VITS model."""
import math
from dataclasses import dataclass
from typing import Any, Optional, Tuple, Union
import numpy as np
import torch
import torch.utils.checkpoint
from torch import nn
from ...activations import ACT2FN
from ...integrations.deepspeed import is_deepspeed_zero3_enabled
from ...modeling_attn_mask_utils import _prepare_4d_attention_mask
from ...modeling_outputs import (
BaseModelOutput,
ModelOutput,
)
from ...modeling_utils import PreTrainedModel
from ...utils import add_start_docstrings, add_start_docstrings_to_model_forward, logging, replace_return_docstrings
from .configuration_vits import VitsConfig
logger = logging.get_logger(__name__)
# General docstring
_CONFIG_FOR_DOC = "VitsConfig"
VITS_PRETRAINED_MODEL_ARCHIVE_LIST = [
"facebook/mms-tts-eng",
# See all VITS models at https://huggingface.co/models?filter=vits
# and all MMS models at https://huggingface.co/models?sort=trending&search=facebook%2Fmms-tts
]
@dataclass
class VitsModelOutput(ModelOutput):
"""
Describes the outputs for the VITS model, with potential hidden states and attentions.
Args:
waveform (`torch.FloatTensor` of shape `(batch_size, sequence_length)`):
The final audio waveform predicted by the model.
sequence_lengths (`torch.FloatTensor` of shape `(batch_size,)`):
The length in samples of each element in the `waveform` batch.
spectrogram (`torch.FloatTensor` of shape `(batch_size, sequence_length, num_bins)`):
The log-mel spectrogram predicted at the output of the flow model. This spectrogram is passed to the Hi-Fi
GAN decoder model to obtain the final audio waveform.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attention weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
waveform: torch.FloatTensor = None
sequence_lengths: torch.FloatTensor = None
spectrogram: Optional[Tuple[torch.FloatTensor]] = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@dataclass
class VitsTextEncoderOutput(ModelOutput):
"""
Describes the outputs for the VITS text encoder model, with potential hidden states and attentions.
Args:
last_hidden_state (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
prior_means (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
The predicted mean values of the prior distribution for the latent text variables.
prior_log_variances (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`):
The predicted log-variance values of the prior distribution for the latent text variables.
hidden_states (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, +
one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
attentions (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`):
Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
Attention weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
last_hidden_state: torch.FloatTensor = None
prior_means: torch.FloatTensor = None
prior_log_variances: torch.FloatTensor = None
hidden_states: Optional[Tuple[torch.FloatTensor]] = None
attentions: Optional[Tuple[torch.FloatTensor]] = None
@torch.jit.script
def fused_add_tanh_sigmoid_multiply(input_a, input_b, num_channels):
in_act = input_a + input_b
t_act = torch.tanh(in_act[:, :num_channels, :])
s_act = torch.sigmoid(in_act[:, num_channels:, :])
acts = t_act * s_act
return acts
def _unconstrained_rational_quadratic_spline(
inputs,
unnormalized_widths,
unnormalized_heights,
unnormalized_derivatives,
reverse=False,
tail_bound=5.0,
min_bin_width=1e-3,
min_bin_height=1e-3,
min_derivative=1e-3,
):
"""
This transformation represents a monotonically increasing piecewise rational quadratic function. Outside of the
`tail_bound`, the transform behaves as an identity function.
Args:
inputs (`torch.FloatTensor` of shape `(batch_size, channels, seq_len)`:
Second half of the hidden-states input to the Vits convolutional flow module.
unnormalized_widths (`torch.FloatTensor` of shape `(batch_size, channels, seq_len, duration_predictor_flow_bins)`):
First `duration_predictor_flow_bins` of the hidden-states from the output of the convolution projection
layer in the convolutional flow module
unnormalized_heights (`torch.FloatTensor` of shape `(batch_size, channels, seq_len, duration_predictor_flow_bins)`):
Second `duration_predictor_flow_bins` of the hidden-states from the output of the convolution projection
layer in the convolutional flow module
unnormalized_derivatives (`torch.FloatTensor` of shape `(batch_size, channels, seq_len, duration_predictor_flow_bins)`):
Third `duration_predictor_flow_bins` of the hidden-states from the output of the convolution projection
layer in the convolutional flow module
reverse (`bool`, *optional*, defaults to `False`):
Whether the model is being run in reverse mode.
tail_bound (`float`, *optional* defaults to 5):
Upper and lower limit bound for the rational quadratic function. Outside of this `tail_bound`, the
transform behaves as an identity function.
min_bin_width (`float`, *optional*, defaults to 1e-3):
Minimum bin value across the width dimension for the piecewise rational quadratic function.
min_bin_height (`float`, *optional*, defaults to 1e-3):
Minimum bin value across the height dimension for the piecewise rational quadratic function.
min_derivative (`float`, *optional*, defaults to 1e-3):
Minimum bin value across the derivatives for the piecewise rational quadratic function.
Returns:
outputs (`torch.FloatTensor` of shape `(batch_size, channels, seq_len)`:
Hidden-states as transformed by the piecewise rational quadratic function with the `tail_bound` limits
applied.
log_abs_det (`torch.FloatTensor` of shape `(batch_size, channels, seq_len)`:
Logarithm of the absolute value of the determinants corresponding to the `outputs` with the `tail_bound`
limits applied.
"""
inside_interval_mask = (inputs >= -tail_bound) & (inputs <= tail_bound)
outside_interval_mask = ~inside_interval_mask
outputs = torch.zeros_like(inputs)
log_abs_det = torch.zeros_like(inputs)
constant = np.log(np.exp(1 - min_derivative) - 1)
unnormalized_derivatives = nn.functional.pad(unnormalized_derivatives, pad=(1, 1))
unnormalized_derivatives[..., 0] = constant
unnormalized_derivatives[..., -1] = constant
outputs[outside_interval_mask] = inputs[outside_interval_mask]
log_abs_det[outside_interval_mask] = 0.0
outputs[inside_interval_mask], log_abs_det[inside_interval_mask] = _rational_quadratic_spline(
inputs=inputs[inside_interval_mask],
unnormalized_widths=unnormalized_widths[inside_interval_mask, :],
unnormalized_heights=unnormalized_heights[inside_interval_mask, :],
unnormalized_derivatives=unnormalized_derivatives[inside_interval_mask, :],
reverse=reverse,
tail_bound=tail_bound,
min_bin_width=min_bin_width,
min_bin_height=min_bin_height,
min_derivative=min_derivative,
)
return outputs, log_abs_det
def _rational_quadratic_spline(
inputs,
unnormalized_widths,
unnormalized_heights,
unnormalized_derivatives,
reverse,
tail_bound,
min_bin_width,
min_bin_height,
min_derivative,
):
"""
This transformation represents a monotonically increasing piecewise rational quadratic function. Unlike the
function `_unconstrained_rational_quadratic_spline`, the function behaves the same across the `tail_bound`.
Args:
inputs (`torch.FloatTensor` of shape `(batch_size, channels, seq_len)`:
Second half of the hidden-states input to the Vits convolutional flow module.
unnormalized_widths (`torch.FloatTensor` of shape `(batch_size, channels, seq_len, duration_predictor_flow_bins)`):
First `duration_predictor_flow_bins` of the hidden-states from the output of the convolution projection
layer in the convolutional flow module
unnormalized_heights (`torch.FloatTensor` of shape `(batch_size, channels, seq_len, duration_predictor_flow_bins)`):
Second `duration_predictor_flow_bins` of the hidden-states from the output of the convolution projection
layer in the convolutional flow module
unnormalized_derivatives (`torch.FloatTensor` of shape `(batch_size, channels, seq_len, duration_predictor_flow_bins)`):
Third `duration_predictor_flow_bins` of the hidden-states from the output of the convolution projection
layer in the convolutional flow module
reverse (`bool`):
Whether the model is being run in reverse mode.
tail_bound (`float`):
Upper and lower limit bound for the rational quadratic function. Outside of this `tail_bound`, the
transform behaves as an identity function.
min_bin_width (`float`):
Minimum bin value across the width dimension for the piecewise rational quadratic function.
min_bin_height (`float`):
Minimum bin value across the height dimension for the piecewise rational quadratic function.
min_derivative (`float`):
Minimum bin value across the derivatives for the piecewise rational quadratic function.
Returns:
outputs (`torch.FloatTensor` of shape `(batch_size, channels, seq_len)`:
Hidden-states as transformed by the piecewise rational quadratic function.
log_abs_det (`torch.FloatTensor` of shape `(batch_size, channels, seq_len)`:
Logarithm of the absolute value of the determinants corresponding to the `outputs`.
"""
upper_bound = tail_bound
lower_bound = -tail_bound
if torch.min(inputs) < lower_bound or torch.max(inputs) > upper_bound:
raise ValueError("Input to a transform is not within its domain")
num_bins = unnormalized_widths.shape[-1]
if min_bin_width * num_bins > 1.0:
raise ValueError(f"Minimal bin width {min_bin_width} too large for the number of bins {num_bins}")
if min_bin_height * num_bins > 1.0:
raise ValueError(f"Minimal bin height {min_bin_height} too large for the number of bins {num_bins}")
widths = nn.functional.softmax(unnormalized_widths, dim=-1)
widths = min_bin_width + (1 - min_bin_width * num_bins) * widths
cumwidths = torch.cumsum(widths, dim=-1)
cumwidths = nn.functional.pad(cumwidths, pad=(1, 0), mode="constant", value=0.0)
cumwidths = (upper_bound - lower_bound) * cumwidths + lower_bound
cumwidths[..., 0] = lower_bound
cumwidths[..., -1] = upper_bound
widths = cumwidths[..., 1:] - cumwidths[..., :-1]
derivatives = min_derivative + nn.functional.softplus(unnormalized_derivatives)
heights = nn.functional.softmax(unnormalized_heights, dim=-1)
heights = min_bin_height + (1 - min_bin_height * num_bins) * heights
cumheights = torch.cumsum(heights, dim=-1)
cumheights = nn.functional.pad(cumheights, pad=(1, 0), mode="constant", value=0.0)
cumheights = (upper_bound - lower_bound) * cumheights + lower_bound
cumheights[..., 0] = lower_bound
cumheights[..., -1] = upper_bound
heights = cumheights[..., 1:] - cumheights[..., :-1]
bin_locations = cumheights if reverse else cumwidths
bin_locations[..., -1] += 1e-6
bin_idx = torch.sum(inputs[..., None] >= bin_locations, dim=-1) - 1
bin_idx = bin_idx[..., None]
input_cumwidths = cumwidths.gather(-1, bin_idx)[..., 0]
input_bin_widths = widths.gather(-1, bin_idx)[..., 0]
input_cumheights = cumheights.gather(-1, bin_idx)[..., 0]
delta = heights / widths
input_delta = delta.gather(-1, bin_idx)[..., 0]
input_derivatives = derivatives.gather(-1, bin_idx)[..., 0]
input_derivatives_plus_one = derivatives[..., 1:].gather(-1, bin_idx)[..., 0]
input_heights = heights.gather(-1, bin_idx)[..., 0]
intermediate1 = input_derivatives + input_derivatives_plus_one - 2 * input_delta
if not reverse:
theta = (inputs - input_cumwidths) / input_bin_widths
theta_one_minus_theta = theta * (1 - theta)
numerator = input_heights * (input_delta * theta.pow(2) + input_derivatives * theta_one_minus_theta)
denominator = input_delta + intermediate1 * theta_one_minus_theta
outputs = input_cumheights + numerator / denominator
derivative_numerator = input_delta.pow(2) * (
input_derivatives_plus_one * theta.pow(2)
+ 2 * input_delta * theta_one_minus_theta
+ input_derivatives * (1 - theta).pow(2)
)
log_abs_det = torch.log(derivative_numerator) - 2 * torch.log(denominator)
return outputs, log_abs_det
else:
# find the roots of a quadratic equation
intermediate2 = inputs - input_cumheights
intermediate3 = intermediate2 * intermediate1
a = input_heights * (input_delta - input_derivatives) + intermediate3
b = input_heights * input_derivatives - intermediate3
c = -input_delta * intermediate2
discriminant = b.pow(2) - 4 * a * c
if not (discriminant >= 0).all():
raise RuntimeError(f"invalid discriminant {discriminant}")
root = (2 * c) / (-b - torch.sqrt(discriminant))
outputs = root * input_bin_widths + input_cumwidths
theta_one_minus_theta = root * (1 - root)
denominator = input_delta + intermediate1 * theta_one_minus_theta
derivative_numerator = input_delta.pow(2) * (
input_derivatives_plus_one * root.pow(2)
+ 2 * input_delta * theta_one_minus_theta
+ input_derivatives * (1 - root).pow(2)
)
log_abs_det = torch.log(derivative_numerator) - 2 * torch.log(denominator)
return outputs, -log_abs_det
class VitsWaveNet(torch.nn.Module):
def __init__(self, config: VitsConfig, num_layers: int):
super().__init__()
self.hidden_size = config.hidden_size
self.num_layers = num_layers
self.in_layers = torch.nn.ModuleList()
self.res_skip_layers = torch.nn.ModuleList()
self.dropout = nn.Dropout(config.wavenet_dropout)
if hasattr(nn.utils.parametrizations, "weight_norm"):
weight_norm = nn.utils.parametrizations.weight_norm
else:
weight_norm = nn.utils.weight_norm
if config.speaker_embedding_size != 0:
cond_layer = torch.nn.Conv1d(config.speaker_embedding_size, 2 * config.hidden_size * num_layers, 1)
self.cond_layer = weight_norm(cond_layer, name="weight")
for i in range(num_layers):
dilation = config.wavenet_dilation_rate**i
padding = (config.wavenet_kernel_size * dilation - dilation) // 2
in_layer = torch.nn.Conv1d(
in_channels=config.hidden_size,
out_channels=2 * config.hidden_size,
kernel_size=config.wavenet_kernel_size,
dilation=dilation,
padding=padding,
)
in_layer = weight_norm(in_layer, name="weight")
self.in_layers.append(in_layer)
# last one is not necessary
if i < num_layers - 1:
res_skip_channels = 2 * config.hidden_size
else:
res_skip_channels = config.hidden_size
res_skip_layer = torch.nn.Conv1d(config.hidden_size, res_skip_channels, 1)
res_skip_layer = weight_norm(res_skip_layer, name="weight")
self.res_skip_layers.append(res_skip_layer)
def forward(self, inputs, padding_mask, global_conditioning=None):
outputs = torch.zeros_like(inputs)
num_channels_tensor = torch.IntTensor([self.hidden_size])
if global_conditioning is not None:
global_conditioning = self.cond_layer(global_conditioning)
for i in range(self.num_layers):
hidden_states = self.in_layers[i](inputs)
if global_conditioning is not None:
cond_offset = i * 2 * self.hidden_size
global_states = global_conditioning[:, cond_offset : cond_offset + 2 * self.hidden_size, :]
else:
global_states = torch.zeros_like(hidden_states)
acts = fused_add_tanh_sigmoid_multiply(hidden_states, global_states, num_channels_tensor[0])
acts = self.dropout(acts)
res_skip_acts = self.res_skip_layers[i](acts)
if i < self.num_layers - 1:
res_acts = res_skip_acts[:, : self.hidden_size, :]
inputs = (inputs + res_acts) * padding_mask
outputs = outputs + res_skip_acts[:, self.hidden_size :, :]
else:
outputs = outputs + res_skip_acts
return outputs * padding_mask
def remove_weight_norm(self):
if self.speaker_embedding_size != 0:
torch.nn.utils.remove_weight_norm(self.cond_layer)
for layer in self.in_layers:
torch.nn.utils.remove_weight_norm(layer)
for layer in self.res_skip_layers:
torch.nn.utils.remove_weight_norm(layer)
class VitsPosteriorEncoder(nn.Module):
def __init__(self, config: VitsConfig):
super().__init__()
self.out_channels = config.flow_size
self.conv_pre = nn.Conv1d(config.spectrogram_bins, config.hidden_size, 1)
self.wavenet = VitsWaveNet(config, num_layers=config.posterior_encoder_num_wavenet_layers)
self.conv_proj = nn.Conv1d(config.hidden_size, self.out_channels * 2, 1)
def forward(self, inputs, padding_mask, global_conditioning=None):
inputs = self.conv_pre(inputs) * padding_mask
inputs = self.wavenet(inputs, padding_mask, global_conditioning)
stats = self.conv_proj(inputs) * padding_mask
mean, log_stddev = torch.split(stats, self.out_channels, dim=1)
sampled = (mean + torch.randn_like(mean) * torch.exp(log_stddev)) * padding_mask
return sampled, mean, log_stddev
# Copied from transformers.models.speecht5.modeling_speecht5.HifiGanResidualBlock
class HifiGanResidualBlock(nn.Module):
def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5), leaky_relu_slope=0.1):
super().__init__()
self.leaky_relu_slope = leaky_relu_slope
self.convs1 = nn.ModuleList(
[
nn.Conv1d(
channels,
channels,
kernel_size,
stride=1,
dilation=dilation[i],
padding=self.get_padding(kernel_size, dilation[i]),
)
for i in range(len(dilation))
]
)
self.convs2 = nn.ModuleList(
[
nn.Conv1d(
channels,
channels,
kernel_size,
stride=1,
dilation=1,
padding=self.get_padding(kernel_size, 1),
)
for _ in range(len(dilation))
]
)
def get_padding(self, kernel_size, dilation=1):
return (kernel_size * dilation - dilation) // 2
def apply_weight_norm(self):
for layer in self.convs1:
nn.utils.weight_norm(layer)
for layer in self.convs2:
nn.utils.weight_norm(layer)
def remove_weight_norm(self):
for layer in self.convs1:
nn.utils.remove_weight_norm(layer)
for layer in self.convs2:
nn.utils.remove_weight_norm(layer)
def forward(self, hidden_states):
for conv1, conv2 in zip(self.convs1, self.convs2):
residual = hidden_states
hidden_states = nn.functional.leaky_relu(hidden_states, self.leaky_relu_slope)
hidden_states = conv1(hidden_states)
hidden_states = nn.functional.leaky_relu(hidden_states, self.leaky_relu_slope)
hidden_states = conv2(hidden_states)
hidden_states = hidden_states + residual
return hidden_states
class VitsHifiGan(nn.Module):
def __init__(self, config: VitsConfig):
super().__init__()
self.config = config
self.num_kernels = len(config.resblock_kernel_sizes)
self.num_upsamples = len(config.upsample_rates)
self.conv_pre = nn.Conv1d(
config.flow_size,
config.upsample_initial_channel,
kernel_size=7,
stride=1,
padding=3,
)
self.upsampler = nn.ModuleList()
for i, (upsample_rate, kernel_size) in enumerate(zip(config.upsample_rates, config.upsample_kernel_sizes)):
self.upsampler.append(
nn.ConvTranspose1d(
config.upsample_initial_channel // (2**i),
config.upsample_initial_channel // (2 ** (i + 1)),
kernel_size=kernel_size,
stride=upsample_rate,
padding=(kernel_size - upsample_rate) // 2,
)
)
self.resblocks = nn.ModuleList()
for i in range(len(self.upsampler)):
channels = config.upsample_initial_channel // (2 ** (i + 1))
for kernel_size, dilation in zip(config.resblock_kernel_sizes, config.resblock_dilation_sizes):
self.resblocks.append(HifiGanResidualBlock(channels, kernel_size, dilation, config.leaky_relu_slope))
self.conv_post = nn.Conv1d(channels, 1, kernel_size=7, stride=1, padding=3, bias=False)
if config.speaker_embedding_size != 0:
self.cond = nn.Conv1d(config.speaker_embedding_size, config.upsample_initial_channel, 1)
def apply_weight_norm(self):
for layer in self.upsampler:
nn.utils.weight_norm(layer)
for layer in self.resblocks:
layer.apply_weight_norm()
def remove_weight_norm(self):
for layer in self.upsampler:
nn.utils.remove_weight_norm(layer)
for layer in self.resblocks:
layer.remove_weight_norm()
def forward(
self, spectrogram: torch.FloatTensor, global_conditioning: Optional[torch.FloatTensor] = None
) -> torch.FloatTensor:
r"""
Converts a spectrogram into a speech waveform.
Args:
spectrogram (`torch.FloatTensor` of shape `(batch_size, config.spectrogram_bins, sequence_length)`):
Tensor containing the spectrograms.
global_conditioning (`torch.FloatTensor` of shape `(batch_size, config.speaker_embedding_size, 1)`, *optional*):
Tensor containing speaker embeddings, for multispeaker models.
Returns:
`torch.FloatTensor`: Tensor of shape shape `(batch_size, 1, num_frames)` containing the speech waveform.
"""
hidden_states = self.conv_pre(spectrogram)
if global_conditioning is not None:
hidden_states = hidden_states + self.cond(global_conditioning)
for i in range(self.num_upsamples):
hidden_states = nn.functional.leaky_relu(hidden_states, self.config.leaky_relu_slope)
hidden_states = self.upsampler[i](hidden_states)
res_state = self.resblocks[i * self.num_kernels](hidden_states)
for j in range(1, self.num_kernels):
res_state += self.resblocks[i * self.num_kernels + j](hidden_states)
hidden_states = res_state / self.num_kernels
hidden_states = nn.functional.leaky_relu(hidden_states)
hidden_states = self.conv_post(hidden_states)
waveform = torch.tanh(hidden_states)
return waveform
class VitsResidualCouplingLayer(nn.Module):
def __init__(self, config: VitsConfig):
super().__init__()
self.half_channels = config.flow_size // 2
self.conv_pre = nn.Conv1d(self.half_channels, config.hidden_size, 1)
self.wavenet = VitsWaveNet(config, num_layers=config.prior_encoder_num_wavenet_layers)
self.conv_post = nn.Conv1d(config.hidden_size, self.half_channels, 1)
def forward(self, inputs, padding_mask, global_conditioning=None, reverse=False):
first_half, second_half = torch.split(inputs, [self.half_channels] * 2, dim=1)
hidden_states = self.conv_pre(first_half) * padding_mask
hidden_states = self.wavenet(hidden_states, padding_mask, global_conditioning)
mean = self.conv_post(hidden_states) * padding_mask
log_stddev = torch.zeros_like(mean)
if not reverse:
second_half = mean + second_half * torch.exp(log_stddev) * padding_mask
outputs = torch.cat([first_half, second_half], dim=1)
log_determinant = torch.sum(log_stddev, [1, 2])
return outputs, log_determinant
else:
second_half = (second_half - mean) * torch.exp(-log_stddev) * padding_mask
outputs = torch.cat([first_half, second_half], dim=1)
return outputs, None
class VitsResidualCouplingBlock(nn.Module):
def __init__(self, config: VitsConfig):
super().__init__()
self.flows = nn.ModuleList()
for _ in range(config.prior_encoder_num_flows):
self.flows.append(VitsResidualCouplingLayer(config))
def forward(self, inputs, padding_mask, global_conditioning=None, reverse=False):
if not reverse:
for flow in self.flows:
inputs, _ = flow(inputs, padding_mask, global_conditioning)
inputs = torch.flip(inputs, [1])
else:
for flow in reversed(self.flows):
inputs = torch.flip(inputs, [1])
inputs, _ = flow(inputs, padding_mask, global_conditioning, reverse=True)
return inputs
class VitsDilatedDepthSeparableConv(nn.Module):
def __init__(self, config: VitsConfig, dropout_rate=0.0):
super().__init__()
kernel_size = config.duration_predictor_kernel_size
channels = config.hidden_size
self.num_layers = config.depth_separable_num_layers
self.dropout = nn.Dropout(dropout_rate)
self.convs_dilated = nn.ModuleList()
self.convs_pointwise = nn.ModuleList()
self.norms_1 = nn.ModuleList()
self.norms_2 = nn.ModuleList()
for i in range(self.num_layers):
dilation = kernel_size**i
padding = (kernel_size * dilation - dilation) // 2
self.convs_dilated.append(
nn.Conv1d(
in_channels=channels,
out_channels=channels,
kernel_size=kernel_size,
groups=channels,
dilation=dilation,
padding=padding,
)
)
self.convs_pointwise.append(nn.Conv1d(channels, channels, 1))
self.norms_1.append(nn.LayerNorm(channels))
self.norms_2.append(nn.LayerNorm(channels))
def forward(self, inputs, padding_mask, global_conditioning=None):
if global_conditioning is not None:
inputs = inputs + global_conditioning
for i in range(self.num_layers):
hidden_states = self.convs_dilated[i](inputs * padding_mask)
hidden_states = self.norms_1[i](hidden_states.transpose(1, -1)).transpose(1, -1)
hidden_states = nn.functional.gelu(hidden_states)
hidden_states = self.convs_pointwise[i](hidden_states)
hidden_states = self.norms_2[i](hidden_states.transpose(1, -1)).transpose(1, -1)
hidden_states = nn.functional.gelu(hidden_states)
hidden_states = self.dropout(hidden_states)
inputs = inputs + hidden_states
return inputs * padding_mask
class VitsConvFlow(nn.Module):
def __init__(self, config: VitsConfig):
super().__init__()
self.filter_channels = config.hidden_size
self.half_channels = config.depth_separable_channels // 2
self.num_bins = config.duration_predictor_flow_bins
self.tail_bound = config.duration_predictor_tail_bound
self.conv_pre = nn.Conv1d(self.half_channels, self.filter_channels, 1)
self.conv_dds = VitsDilatedDepthSeparableConv(config)
self.conv_proj = nn.Conv1d(self.filter_channels, self.half_channels * (self.num_bins * 3 - 1), 1)
def forward(self, inputs, padding_mask, global_conditioning=None, reverse=False):
first_half, second_half = torch.split(inputs, [self.half_channels] * 2, dim=1)
hidden_states = self.conv_pre(first_half)
hidden_states = self.conv_dds(hidden_states, padding_mask, global_conditioning)
hidden_states = self.conv_proj(hidden_states) * padding_mask
batch_size, channels, length = first_half.shape
hidden_states = hidden_states.reshape(batch_size, channels, -1, length).permute(0, 1, 3, 2)
unnormalized_widths = hidden_states[..., : self.num_bins] / math.sqrt(self.filter_channels)
unnormalized_heights = hidden_states[..., self.num_bins : 2 * self.num_bins] / math.sqrt(self.filter_channels)
unnormalized_derivatives = hidden_states[..., 2 * self.num_bins :]
second_half, log_abs_det = _unconstrained_rational_quadratic_spline(
second_half,
unnormalized_widths,
unnormalized_heights,
unnormalized_derivatives,
reverse=reverse,
tail_bound=self.tail_bound,
)
outputs = torch.cat([first_half, second_half], dim=1) * padding_mask
if not reverse:
log_determinant = torch.sum(log_abs_det * padding_mask, [1, 2])
return outputs, log_determinant
else:
return outputs, None
class VitsElementwiseAffine(nn.Module):
def __init__(self, config: VitsConfig):
super().__init__()
self.channels = config.depth_separable_channels
self.translate = nn.Parameter(torch.zeros(self.channels, 1))
self.log_scale = nn.Parameter(torch.zeros(self.channels, 1))
def forward(self, inputs, padding_mask, global_conditioning=None, reverse=False):
if not reverse:
outputs = self.translate + torch.exp(self.log_scale) * inputs
outputs = outputs * padding_mask
log_determinant = torch.sum(self.log_scale * padding_mask, [1, 2])
return outputs, log_determinant
else:
outputs = (inputs - self.translate) * torch.exp(-self.log_scale) * padding_mask
return outputs, None
class VitsStochasticDurationPredictor(nn.Module):
def __init__(self, config):
super().__init__()
embed_dim = config.speaker_embedding_size
filter_channels = config.hidden_size
self.conv_pre = nn.Conv1d(filter_channels, filter_channels, 1)
self.conv_proj = nn.Conv1d(filter_channels, filter_channels, 1)
self.conv_dds = VitsDilatedDepthSeparableConv(
config,
dropout_rate=config.duration_predictor_dropout,
)
if embed_dim != 0:
self.cond = nn.Conv1d(embed_dim, filter_channels, 1)
self.flows = nn.ModuleList()
self.flows.append(VitsElementwiseAffine(config))
for _ in range(config.duration_predictor_num_flows):
self.flows.append(VitsConvFlow(config))
self.post_conv_pre = nn.Conv1d(1, filter_channels, 1)
self.post_conv_proj = nn.Conv1d(filter_channels, filter_channels, 1)
self.post_conv_dds = VitsDilatedDepthSeparableConv(
config,
dropout_rate=config.duration_predictor_dropout,
)
self.post_flows = nn.ModuleList()
self.post_flows.append(VitsElementwiseAffine(config))
for _ in range(config.duration_predictor_num_flows):
self.post_flows.append(VitsConvFlow(config))
def forward(self, inputs, padding_mask, global_conditioning=None, durations=None, reverse=False, noise_scale=1.0):
inputs = torch.detach(inputs)
inputs = self.conv_pre(inputs)
if global_conditioning is not None:
global_conditioning = torch.detach(global_conditioning)
inputs = inputs + self.cond(global_conditioning)
inputs = self.conv_dds(inputs, padding_mask)
inputs = self.conv_proj(inputs) * padding_mask
if not reverse:
hidden_states = self.post_conv_pre(durations)
hidden_states = self.post_conv_dds(hidden_states, padding_mask)
hidden_states = self.post_conv_proj(hidden_states) * padding_mask
random_posterior = (
torch.randn(durations.size(0), 2, durations.size(2)).to(device=inputs.device, dtype=inputs.dtype)
* padding_mask
)
log_determinant_posterior_sum = 0
latents_posterior = random_posterior
for flow in self.post_flows:
latents_posterior, log_determinant = flow(
latents_posterior, padding_mask, global_conditioning=inputs + hidden_states
)
latents_posterior = torch.flip(latents_posterior, [1])
log_determinant_posterior_sum += log_determinant
first_half, second_half = torch.split(latents_posterior, [1, 1], dim=1)
log_determinant_posterior_sum += torch.sum(
(nn.functional.logsigmoid(first_half) + nn.functional.logsigmoid(-first_half)) * padding_mask, [1, 2]
)
logq = (
torch.sum(-0.5 * (math.log(2 * math.pi) + (random_posterior**2)) * padding_mask, [1, 2])
- log_determinant_posterior_sum
)
first_half = (durations - torch.sigmoid(first_half)) * padding_mask
first_half = torch.log(torch.clamp_min(first_half, 1e-5)) * padding_mask
log_determinant_sum = torch.sum(-first_half, [1, 2])
latents = torch.cat([first_half, second_half], dim=1)
for flow in self.flows:
latents, log_determinant = flow(latents, padding_mask, global_conditioning=inputs)
latents = torch.flip(latents, [1])
log_determinant_sum += log_determinant
nll = torch.sum(0.5 * (math.log(2 * math.pi) + (latents**2)) * padding_mask, [1, 2]) - log_determinant_sum
return nll + logq
else:
flows = list(reversed(self.flows))
flows = flows[:-2] + [flows[-1]] # remove a useless vflow
latents = (
torch.randn(inputs.size(0), 2, inputs.size(2)).to(device=inputs.device, dtype=inputs.dtype)
* noise_scale
)
for flow in flows:
latents = torch.flip(latents, [1])
latents, _ = flow(latents, padding_mask, global_conditioning=inputs, reverse=True)
log_duration, _ = torch.split(latents, [1, 1], dim=1)
return log_duration
class VitsDurationPredictor(nn.Module):
def __init__(self, config):
super().__init__()
kernel_size = config.duration_predictor_kernel_size
filter_channels = config.duration_predictor_filter_channels
self.dropout = nn.Dropout(config.duration_predictor_dropout)
self.conv_1 = nn.Conv1d(config.hidden_size, filter_channels, kernel_size, padding=kernel_size // 2)
self.norm_1 = nn.LayerNorm(filter_channels, eps=config.layer_norm_eps)
self.conv_2 = nn.Conv1d(filter_channels, filter_channels, kernel_size, padding=kernel_size // 2)
self.norm_2 = nn.LayerNorm(filter_channels, eps=config.layer_norm_eps)
self.proj = nn.Conv1d(filter_channels, 1, 1)
if config.speaker_embedding_size != 0:
self.cond = nn.Conv1d(config.speaker_embedding_size, config.hidden_size, 1)
def forward(self, inputs, padding_mask, global_conditioning=None):
inputs = torch.detach(inputs)
if global_conditioning is not None:
global_conditioning = torch.detach(global_conditioning)
inputs = inputs + self.cond(global_conditioning)
inputs = self.conv_1(inputs * padding_mask)
inputs = torch.relu(inputs)
inputs = self.norm_1(inputs.transpose(1, -1)).transpose(1, -1)
inputs = self.dropout(inputs)
inputs = self.conv_2(inputs * padding_mask)
inputs = torch.relu(inputs)
inputs = self.norm_2(inputs.transpose(1, -1)).transpose(1, -1)
inputs = self.dropout(inputs)
inputs = self.proj(inputs * padding_mask)
return inputs * padding_mask
class VitsAttention(nn.Module):
"""Multi-headed attention with relative positional representation."""
def __init__(self, config: VitsConfig):
super().__init__()
self.embed_dim = config.hidden_size
self.num_heads = config.num_attention_heads
self.dropout = config.attention_dropout
self.window_size = config.window_size
self.head_dim = self.embed_dim // self.num_heads
self.scaling = self.head_dim**-0.5
if (self.head_dim * self.num_heads) != self.embed_dim:
raise ValueError(
f"hidden_size must be divisible by num_attention_heads (got `hidden_size`: {self.embed_dim}"
f" and `num_attention_heads`: {self.num_heads})."
)
self.k_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.use_bias)
self.v_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.use_bias)
self.q_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.use_bias)
self.out_proj = nn.Linear(self.embed_dim, self.embed_dim, bias=config.use_bias)
if self.window_size:
self.emb_rel_k = nn.Parameter(torch.randn(1, self.window_size * 2 + 1, self.head_dim) * self.scaling)
self.emb_rel_v = nn.Parameter(torch.randn(1, self.window_size * 2 + 1, self.head_dim) * self.scaling)
def _shape(self, tensor: torch.Tensor, seq_len: int, bsz: int):
return tensor.view(bsz, seq_len, self.num_heads, self.head_dim).transpose(1, 2).contiguous()
def forward(
self,
hidden_states: torch.Tensor,
key_value_states: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
layer_head_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
) -> Tuple[torch.Tensor, Optional[torch.Tensor]]:
"""Input shape: Batch x Time x Channel"""
# if key_value_states are provided this layer is used as a cross-attention layer
# for the decoder
bsz, tgt_len, _ = hidden_states.size()
# get query proj
query_states = self.q_proj(hidden_states) * self.scaling
# self_attention
key_states = self._shape(self.k_proj(hidden_states), -1, bsz)
value_states = self._shape(self.v_proj(hidden_states), -1, bsz)
proj_shape = (bsz * self.num_heads, -1, self.head_dim)
query_states = self._shape(query_states, tgt_len, bsz).view(*proj_shape)
key_states = key_states.view(*proj_shape)
value_states = value_states.view(*proj_shape)
src_len = key_states.size(1)
attn_weights = torch.bmm(query_states, key_states.transpose(1, 2))
if attn_weights.size() != (bsz * self.num_heads, tgt_len, src_len):
raise ValueError(
f"Attention weights should be of size {(bsz * self.num_heads, tgt_len, src_len)}, but is"
f" {attn_weights.size()}"
)
if self.window_size is not None:
key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, src_len)
relative_logits = torch.matmul(query_states, key_relative_embeddings.transpose(-2, -1))
rel_pos_bias = self._relative_position_to_absolute_position(relative_logits)
attn_weights += rel_pos_bias
if attention_mask is not None:
if attention_mask.size() != (bsz, 1, tgt_len, src_len):
raise ValueError(
f"Attention mask should be of size {(bsz, 1, tgt_len, src_len)}, but is {attention_mask.size()}"
)
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len) + attention_mask
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
attn_weights = nn.functional.softmax(attn_weights, dim=-1)
if layer_head_mask is not None:
if layer_head_mask.size() != (self.num_heads,):
raise ValueError(
f"Head mask for a single layer should be of size {(self.num_heads,)}, but is"
f" {layer_head_mask.size()}"
)
attn_weights = layer_head_mask.view(1, -1, 1, 1) * attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
if output_attentions:
# this operation is a bit awkward, but it's required to
# make sure that attn_weights keeps its gradient.
# In order to do so, attn_weights have to be reshaped
# twice and have to be reused in the following
attn_weights_reshaped = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
attn_weights = attn_weights_reshaped.view(bsz * self.num_heads, tgt_len, src_len)
else:
attn_weights_reshaped = None
attn_probs = nn.functional.dropout(attn_weights, p=self.dropout, training=self.training)
attn_output = torch.bmm(attn_probs, value_states)
if attn_output.size() != (bsz * self.num_heads, tgt_len, self.head_dim):
raise ValueError(
f"`attn_output` should be of size {(bsz, self.num_heads, tgt_len, self.head_dim)}, but is"
f" {attn_output.size()}"
)
if self.window_size is not None:
value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, src_len)
relative_weights = self._absolute_position_to_relative_position(attn_probs)
rel_pos_bias = torch.matmul(relative_weights, value_relative_embeddings)
attn_output += rel_pos_bias
attn_output = attn_output.view(bsz, self.num_heads, tgt_len, self.head_dim)
attn_output = attn_output.transpose(1, 2)
# Use the `embed_dim` from the config (stored in the class) rather than `hidden_state` because `attn_output` can be
# partitioned aross GPUs when using tensor-parallelism.
attn_output = attn_output.reshape(bsz, tgt_len, self.embed_dim)
attn_output = self.out_proj(attn_output)
return attn_output, attn_weights_reshaped
def _get_relative_embeddings(self, relative_embeddings, length):
pad_length = max(length - (self.window_size + 1), 0)
if pad_length > 0:
relative_embeddings = nn.functional.pad(relative_embeddings, [0, 0, pad_length, pad_length, 0, 0])
slice_start_position = max((self.window_size + 1) - length, 0)
slice_end_position = slice_start_position + 2 * length - 1
return relative_embeddings[:, slice_start_position:slice_end_position]
def _relative_position_to_absolute_position(self, x):
batch_heads, length, _ = x.size()
# Concat columns of pad to shift from relative to absolute indexing.
x = nn.functional.pad(x, [0, 1, 0, 0, 0, 0])
# Concat extra elements so to add up to shape (len+1, 2*len-1).
x_flat = x.view([batch_heads, length * 2 * length])
x_flat = nn.functional.pad(x_flat, [0, length - 1, 0, 0])
# Reshape and slice out the padded elements.
x_final = x_flat.view([batch_heads, length + 1, 2 * length - 1])
x_final = x_final[:, :length, length - 1 :]
return x_final
def _absolute_position_to_relative_position(self, x):
batch_heads, length, _ = x.size()
# Pad along column
x = nn.functional.pad(x, [0, length - 1, 0, 0, 0, 0])
x_flat = x.view([batch_heads, length * (2 * length - 1)])
# Add 0's in the beginning that will skew the elements after reshape
x_flat = nn.functional.pad(x_flat, [length, 0, 0, 0])
x_final = x_flat.view([batch_heads, length, 2 * length])[:, :, 1:]
return x_final
class VitsFeedForward(nn.Module):
def __init__(self, config):
super().__init__()
self.conv_1 = nn.Conv1d(config.hidden_size, config.ffn_dim, config.ffn_kernel_size)
self.conv_2 = nn.Conv1d(config.ffn_dim, config.hidden_size, config.ffn_kernel_size)
self.dropout = nn.Dropout(config.activation_dropout)
if isinstance(config.hidden_act, str):
self.act_fn = ACT2FN[config.hidden_act]
else:
self.act_fn = config.hidden_act
if config.ffn_kernel_size > 1:
pad_left = (config.ffn_kernel_size - 1) // 2
pad_right = config.ffn_kernel_size // 2
self.padding = [pad_left, pad_right, 0, 0, 0, 0]
else:
self.padding = None
def forward(self, hidden_states, padding_mask):
hidden_states = hidden_states.permute(0, 2, 1)
padding_mask = padding_mask.permute(0, 2, 1)
hidden_states = hidden_states * padding_mask
if self.padding is not None:
hidden_states = nn.functional.pad(hidden_states, self.padding)
hidden_states = self.conv_1(hidden_states)
hidden_states = self.act_fn(hidden_states)
hidden_states = self.dropout(hidden_states)
hidden_states = hidden_states * padding_mask
if self.padding is not None:
hidden_states = nn.functional.pad(hidden_states, self.padding)
hidden_states = self.conv_2(hidden_states)
hidden_states = hidden_states * padding_mask
hidden_states = hidden_states.permute(0, 2, 1)
return hidden_states
class VitsEncoderLayer(nn.Module):
def __init__(self, config: VitsConfig):
super().__init__()
self.attention = VitsAttention(config)
self.dropout = nn.Dropout(config.hidden_dropout)
self.layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
self.feed_forward = VitsFeedForward(config)
self.final_layer_norm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
padding_mask: torch.FloatTensor,
attention_mask: Optional[torch.Tensor] = None,
output_attentions: bool = False,
):
residual = hidden_states
hidden_states, attn_weights = self.attention(
hidden_states=hidden_states,
attention_mask=attention_mask,
output_attentions=output_attentions,
)
hidden_states = self.dropout(hidden_states)
hidden_states = self.layer_norm(residual + hidden_states)
residual = hidden_states
hidden_states = self.feed_forward(hidden_states, padding_mask)
hidden_states = self.dropout(hidden_states)
hidden_states = self.final_layer_norm(residual + hidden_states)
outputs = (hidden_states,)
if output_attentions:
outputs += (attn_weights,)
return outputs
class VitsEncoder(nn.Module):
def __init__(self, config: VitsConfig):
super().__init__()
self.config = config
self.layers = nn.ModuleList([VitsEncoderLayer(config) for _ in range(config.num_hidden_layers)])
self.gradient_checkpointing = False
self.layerdrop = config.layerdrop
def forward(
self,
hidden_states: torch.FloatTensor,
padding_mask: torch.FloatTensor,
attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple, BaseModelOutput]:
all_hidden_states = () if output_hidden_states else None
all_self_attentions = () if output_attentions else None
# expand attention_mask
if attention_mask is not None:
# [bsz, seq_len] -> [bsz, 1, tgt_seq_len, src_seq_len]
attention_mask = _prepare_4d_attention_mask(attention_mask, hidden_states.dtype)
hidden_states = hidden_states * padding_mask
deepspeed_zero3_is_enabled = is_deepspeed_zero3_enabled()
for encoder_layer in self.layers:
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
# add LayerDrop (see https://arxiv.org/abs/1909.11556 for description)
dropout_probability = np.random.uniform(0, 1)
skip_the_layer = self.training and (dropout_probability < self.layerdrop)
if not skip_the_layer or deepspeed_zero3_is_enabled:
# under deepspeed zero3 all gpus must run in sync
if self.gradient_checkpointing and self.training:
layer_outputs = self._gradient_checkpointing_func(
encoder_layer.__call__,
hidden_states,
padding_mask,
attention_mask,
output_attentions,
)
else:
layer_outputs = encoder_layer(
hidden_states,
attention_mask=attention_mask,
padding_mask=padding_mask,
output_attentions=output_attentions,
)
hidden_states = layer_outputs[0]
if skip_the_layer:
layer_outputs = (None, None)
if output_attentions:
all_self_attentions = all_self_attentions + (layer_outputs[1],)
hidden_states = hidden_states * padding_mask
if output_hidden_states:
all_hidden_states = all_hidden_states + (hidden_states,)
if not return_dict:
return tuple(v for v in [hidden_states, all_hidden_states, all_self_attentions] if v is not None)
return BaseModelOutput(
last_hidden_state=hidden_states,
hidden_states=all_hidden_states,
attentions=all_self_attentions,
)
class VitsTextEncoder(nn.Module):
"""
Transformer encoder that uses relative positional representation instead of absolute positional encoding.
"""
def __init__(self, config: VitsConfig):
super().__init__()
self.config = config
self.embed_tokens = nn.Embedding(config.vocab_size, config.hidden_size, config.pad_token_id)
self.encoder = VitsEncoder(config)
self.project = nn.Conv1d(config.hidden_size, config.flow_size * 2, kernel_size=1)
def get_input_embeddings(self):
return self.embed_tokens
def set_input_embeddings(self, value):
self.embed_tokens = value
def forward(
self,
input_ids: torch.Tensor,
padding_mask: torch.FloatTensor,
attention_mask: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = True,
) -> Union[Tuple[torch.Tensor], VitsTextEncoderOutput]:
hidden_states = self.embed_tokens(input_ids) * math.sqrt(self.config.hidden_size)
encoder_outputs = self.encoder(
hidden_states=hidden_states,
padding_mask=padding_mask,
attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
last_hidden_state = encoder_outputs[0] if not return_dict else encoder_outputs.last_hidden_state
stats = self.project(last_hidden_state.transpose(1, 2)).transpose(1, 2) * padding_mask
prior_means, prior_log_variances = torch.split(stats, self.config.flow_size, dim=2)
if not return_dict:
outputs = (last_hidden_state, prior_means, prior_log_variances) + encoder_outputs[1:]
return outputs
return VitsTextEncoderOutput(
last_hidden_state=last_hidden_state,
prior_means=prior_means,
prior_log_variances=prior_log_variances,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
)
class VitsPreTrainedModel(PreTrainedModel):
"""
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
models.
"""
config_class = VitsConfig
base_model_prefix = "vits"
main_input_name = "input_ids"
supports_gradient_checkpointing = True
def _init_weights(self, module):
"""Initialize the weights"""
if isinstance(module, nn.Linear):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
elif isinstance(module, nn.Conv1d):
nn.init.kaiming_normal_(module.weight)
if module.bias is not None:
k = math.sqrt(module.groups / (module.in_channels * module.kernel_size[0]))
nn.init.uniform_(module.bias, a=-k, b=k)
elif isinstance(module, nn.Embedding):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if module.padding_idx is not None:
module.weight.data[module.padding_idx].zero_()
VITS_START_DOCSTRING = r"""
This model inherits from [`PreTrainedModel`]. Check the superclass documentation for the generic methods the
library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads
etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass.
Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage
and behavior.
Parameters:
config ([`VitsConfig`]):
Model configuration class with all the parameters of the model. Initializing with a config file does not
load the weights associated with the model, only the configuration. Check out the
[`~PreTrainedModel.from_pretrained`] method to load the model weights.
"""
VITS_INPUTS_DOCSTRING = r"""
Args:
input_ids (`torch.LongTensor` of shape `(batch_size, sequence_length)`):
Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide
it.
Indices can be obtained using [`AutoTokenizer`]. See [`PreTrainedTokenizer.encode`] and
[`PreTrainedTokenizer.__call__`] for details.
[What are input IDs?](../glossary#input-ids)
attention_mask (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*):
Mask to avoid performing convolution and attention on padding token indices. Mask values selected in `[0,
1]`:
- 1 for tokens that are **not masked**,
- 0 for tokens that are **masked**.
[What are attention masks?](../glossary#attention-mask)
speaker_id (`int`, *optional*):
Which speaker embedding to use. Only used for multispeaker models.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned
tensors for more detail.
output_hidden_states (`bool`, *optional*):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for
more detail.
return_dict (`bool`, *optional*):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
"""
@add_start_docstrings(
"The complete VITS model, for text-to-speech synthesis.",
VITS_START_DOCSTRING,
)
class VitsModel(VitsPreTrainedModel):
def __init__(self, config: VitsConfig):
super().__init__(config)
self.config = config
self.text_encoder = VitsTextEncoder(config)
self.flow = VitsResidualCouplingBlock(config)
self.decoder = VitsHifiGan(config)
if config.use_stochastic_duration_prediction:
self.duration_predictor = VitsStochasticDurationPredictor(config)
else:
self.duration_predictor = VitsDurationPredictor(config)
if config.num_speakers > 1:
self.embed_speaker = nn.Embedding(config.num_speakers, config.speaker_embedding_size)
# This is used only for training.
self.posterior_encoder = VitsPosteriorEncoder(config)
# These parameters control the synthesised speech properties
self.speaking_rate = config.speaking_rate
self.noise_scale = config.noise_scale
self.noise_scale_duration = config.noise_scale_duration
# Initialize weights and apply final processing
self.post_init()
def get_encoder(self):
return self.text_encoder
@add_start_docstrings_to_model_forward(VITS_INPUTS_DOCSTRING)
@replace_return_docstrings(output_type=VitsModelOutput, config_class=_CONFIG_FOR_DOC)
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
speaker_id: Optional[int] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
labels: Optional[torch.FloatTensor] = None,
) -> Union[Tuple[Any], VitsModelOutput]:
r"""
labels (`torch.FloatTensor` of shape `(batch_size, config.spectrogram_bins, sequence_length)`, *optional*):
Float values of target spectrogram. Timesteps set to `-100.0` are ignored (masked) for the loss
computation.
Returns:
Example:
```python
>>> from transformers import VitsTokenizer, VitsModel, set_seed
>>> import torch
>>> tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-eng")
>>> model = VitsModel.from_pretrained("facebook/mms-tts-eng")
>>> inputs = tokenizer(text="Hello - my dog is cute", return_tensors="pt")
>>> set_seed(555) # make deterministic
>>> with torch.no_grad():
... outputs = model(inputs["input_ids"])
>>> outputs.waveform.shape
torch.Size([1, 45824])
```
"""
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
if attention_mask is not None:
input_padding_mask = attention_mask.unsqueeze(-1).float()
else:
input_padding_mask = torch.ones_like(input_ids).unsqueeze(-1).float()
if self.config.num_speakers > 1 and speaker_id is not None:
if not 0 <= speaker_id < self.config.num_speakers:
raise ValueError(f"Set `speaker_id` in the range 0-{self.config.num_speakers - 1}.")
if isinstance(speaker_id, int):
speaker_id = torch.full(size=(1,), fill_value=speaker_id, device=self.device)
speaker_embeddings = self.embed_speaker(speaker_id).unsqueeze(-1)
else:
speaker_embeddings = None
if labels is not None:
raise NotImplementedError("Training of VITS is not supported yet.")
text_encoder_output = self.text_encoder(
input_ids=input_ids,
padding_mask=input_padding_mask,
attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = text_encoder_output[0] if not return_dict else text_encoder_output.last_hidden_state
hidden_states = hidden_states.transpose(1, 2)
input_padding_mask = input_padding_mask.transpose(1, 2)
prior_means = text_encoder_output[1] if not return_dict else text_encoder_output.prior_means
prior_log_variances = text_encoder_output[2] if not return_dict else text_encoder_output.prior_log_variances
if self.config.use_stochastic_duration_prediction:
log_duration = self.duration_predictor(
hidden_states,
input_padding_mask,
speaker_embeddings,
reverse=True,
noise_scale=self.noise_scale_duration,
)
else:
log_duration = self.duration_predictor(hidden_states, input_padding_mask, speaker_embeddings)
length_scale = 1.0 / self.speaking_rate
duration = torch.ceil(torch.exp(log_duration) * input_padding_mask * length_scale)
predicted_lengths = torch.clamp_min(torch.sum(duration, [1, 2]), 1).long()
# Create a padding mask for the output lengths of shape (batch, 1, max_output_length)
indices = torch.arange(predicted_lengths.max(), dtype=predicted_lengths.dtype, device=predicted_lengths.device)
output_padding_mask = indices.unsqueeze(0) < predicted_lengths.unsqueeze(1)
output_padding_mask = output_padding_mask.unsqueeze(1).to(input_padding_mask.dtype)
# Reconstruct an attention tensor of shape (batch, 1, out_length, in_length)
attn_mask = torch.unsqueeze(input_padding_mask, 2) * torch.unsqueeze(output_padding_mask, -1)
batch_size, _, output_length, input_length = attn_mask.shape
cum_duration = torch.cumsum(duration, -1).view(batch_size * input_length, 1)
indices = torch.arange(output_length, dtype=duration.dtype, device=duration.device)
valid_indices = indices.unsqueeze(0) < cum_duration
valid_indices = valid_indices.to(attn_mask.dtype).view(batch_size, input_length, output_length)
padded_indices = valid_indices - nn.functional.pad(valid_indices, [0, 0, 1, 0, 0, 0])[:, :-1]
attn = padded_indices.unsqueeze(1).transpose(2, 3) * attn_mask
# Expand prior distribution
prior_means = torch.matmul(attn.squeeze(1), prior_means).transpose(1, 2)
prior_log_variances = torch.matmul(attn.squeeze(1), prior_log_variances).transpose(1, 2)
prior_latents = prior_means + torch.randn_like(prior_means) * torch.exp(prior_log_variances) * self.noise_scale
latents = self.flow(prior_latents, output_padding_mask, speaker_embeddings, reverse=True)
spectrogram = latents * output_padding_mask
waveform = self.decoder(spectrogram, speaker_embeddings)
waveform = waveform.squeeze(1)
sequence_lengths = predicted_lengths * np.prod(self.config.upsample_rates)
if not return_dict:
outputs = (waveform, sequence_lengths, spectrogram) + text_encoder_output[3:]
return outputs
return VitsModelOutput(
waveform=waveform,
sequence_lengths=sequence_lengths,
spectrogram=spectrogram,
hidden_states=text_encoder_output.hidden_states,
attentions=text_encoder_output.attentions,
)
| transformers/src/transformers/models/vits/modeling_vits.py/0 | {
"file_path": "transformers/src/transformers/models/vits/modeling_vits.py",
"repo_id": "transformers",
"token_count": 28934
} | 339 |
# coding=utf-8
# Copyright 2021 The Facebook Inc. and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Tokenization class for Wav2Vec2."""
import json
import os
import sys
import warnings
from dataclasses import dataclass
from itertools import groupby
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
import numpy as np
from ...tokenization_utils import PreTrainedTokenizer
from ...tokenization_utils_base import AddedToken, BatchEncoding
from ...utils import (
ModelOutput,
PaddingStrategy,
TensorType,
add_end_docstrings,
is_flax_available,
is_tf_available,
is_torch_available,
logging,
to_py_obj,
)
logger = logging.get_logger(__name__)
if TYPE_CHECKING:
if is_torch_available():
import torch
if is_tf_available():
import tensorflow as tf
if is_flax_available():
import jax.numpy as jnp # noqa: F401
VOCAB_FILES_NAMES = {
"vocab_file": "vocab.json",
"tokenizer_config_file": "tokenizer_config.json",
}
PRETRAINED_VOCAB_FILES_MAP = {
"vocab_file": {
"facebook/wav2vec2-base-960h": "https://huggingface.co/facebook/wav2vec2-base-960h/resolve/main/vocab.json",
},
"tokenizer_config_file": {
"facebook/wav2vec2-base-960h": (
"https://huggingface.co/facebook/wav2vec2-base-960h/resolve/main/tokenizer_config.json"
),
},
}
# Wav2Vec2 has no max input length
PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES = {"facebook/wav2vec2-base-960h": sys.maxsize}
WAV2VEC2_KWARGS_DOCSTRING = r"""
padding (`bool`, `str` or [`~utils.PaddingStrategy`], *optional*, defaults to `False`):
Activates and controls padding. Accepts the following values:
- `True` or `'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
- `'max_length'`: Pad to a maximum length specified with the argument `max_length` or to the maximum
acceptable input length for the model if that argument is not provided.
- `False` or `'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of different
lengths).
max_length (`int`, *optional*):
Controls the maximum length to use by one of the truncation/padding parameters.
If left unset or set to `None`, this will use the predefined model maximum length if a maximum length
is required by one of the truncation/padding parameters. If the model has no specific maximum input
length (like XLNet) truncation/padding to a maximum length will be deactivated.
pad_to_multiple_of (`int`, *optional*):
If set will pad the sequence to a multiple of the provided value. This is especially useful to enable
the use of Tensor Cores on NVIDIA hardware with compute capability `>= 7.5` (Volta).
return_tensors (`str` or [`~utils.TensorType`], *optional*):
If set, will return tensors instead of list of python integers. Acceptable values are:
- `'tf'`: Return TensorFlow `tf.constant` objects.
- `'pt'`: Return PyTorch `torch.Tensor` objects.
- `'np'`: Return Numpy `np.ndarray` objects.
verbose (`bool`, *optional*, defaults to `True`):
Whether or not to print more information and warnings.
"""
ListOfDict = List[Dict[str, Union[int, str]]]
@dataclass
class Wav2Vec2CTCTokenizerOutput(ModelOutput):
"""
Output type of [` Wav2Vec2CTCTokenizer`], with transcription.
Args:
text (list of `str` or `str`):
Decoded logits in text from. Usually the speech transcription.
char_offsets (list of `List[Dict[str, Union[int, str]]]` or `List[Dict[str, Union[int, str]]]`):
Offsets of the decoded characters. In combination with sampling rate and model downsampling rate char
offsets can be used to compute time stamps for each charater. Total logit score of the beam associated with
produced text.
word_offsets (list of `List[Dict[str, Union[int, str]]]` or `List[Dict[str, Union[int, str]]]`):
Offsets of the decoded words. In combination with sampling rate and model downsampling rate word offsets
can be used to compute time stamps for each word.
"""
text: Union[List[str], str]
char_offsets: Union[List[ListOfDict], ListOfDict] = None
word_offsets: Union[List[ListOfDict], ListOfDict] = None
class Wav2Vec2CTCTokenizer(PreTrainedTokenizer):
"""
Constructs a Wav2Vec2CTC tokenizer.
This tokenizer inherits from [`PreTrainedTokenizer`] which contains some of the main methods. Users should refer to
the superclass for more information regarding such methods.
Args:
vocab_file (`str`):
File containing the vocabulary.
bos_token (`str`, *optional*, defaults to `"<s>"`):
The beginning of sentence token.
eos_token (`str`, *optional*, defaults to `"</s>"`):
The end of sentence token.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
word_delimiter_token (`str`, *optional*, defaults to `"|"`):
The token used for defining the end of a word.
do_lower_case (`bool`, *optional*, defaults to `False`):
Whether or not to accept lowercase input and lowercase the output when decoding.
target_lang (`str`, *optional*):
A target language the tokenizer should set by default. `target_lang` has to be defined for multi-lingual,
nested vocabulary such as [facebook/mms-1b-all](https://huggingface.co/facebook/mms-1b-all).
**kwargs
Additional keyword arguments passed along to [`PreTrainedTokenizer`]
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = PRETRAINED_VOCAB_FILES_MAP
max_model_input_sizes = PRETRAINED_POSITIONAL_EMBEDDINGS_SIZES
model_input_names = ["input_ids", "attention_mask"]
def __init__(
self,
vocab_file,
bos_token="<s>",
eos_token="</s>",
unk_token="<unk>",
pad_token="<pad>",
word_delimiter_token="|",
replace_word_delimiter_char=" ",
do_lower_case=False,
target_lang=None,
**kwargs,
):
self._word_delimiter_token = word_delimiter_token
self.do_lower_case = do_lower_case
self.replace_word_delimiter_char = replace_word_delimiter_char
self.target_lang = target_lang
with open(vocab_file, encoding="utf-8") as vocab_handle:
self.vocab = json.load(vocab_handle)
# if target lang is defined vocab must be a nested dict
# with each target lang being one vocabulary
if target_lang is not None:
self.encoder = self.vocab[target_lang]
else:
self.encoder = self.vocab
self.decoder = {v: k for k, v in self.encoder.items()}
super().__init__(
unk_token=unk_token,
bos_token=bos_token,
eos_token=eos_token,
pad_token=pad_token,
do_lower_case=do_lower_case,
word_delimiter_token=word_delimiter_token,
replace_word_delimiter_char=replace_word_delimiter_char,
target_lang=target_lang,
**kwargs,
)
# make sure that tokens made of several
# characters are not split at tokenization
for token in self.encoder.keys():
if len(token) > 1:
self.add_tokens(AddedToken(token, rstrip=True, lstrip=True, normalized=False))
def set_target_lang(self, target_lang: str):
"""
Set the target language of a nested multi-lingual dictionary
"""
if self.vocab == self.encoder:
raise ValueError(f"{self.vocab} is not a multi-lingual, nested tokenizer. Cannot set target language.")
if target_lang not in self.vocab:
raise ValueError(f"{target_lang} does not exist. Choose one of {', '.join(self.vocab.keys())}.")
self.target_lang = target_lang
self.init_kwargs["target_lang"] = target_lang
self.encoder = self.vocab[target_lang]
self.decoder = {v: k for k, v in self.encoder.items()}
# make sure that tokens made of several
# characters are not split at tokenization
for token in self.encoder.keys():
if len(token) > 1:
self.add_tokens(AddedToken(token, rstrip=True, lstrip=True, normalized=False))
@property
def word_delimiter_token(self) -> str:
"""
`str`: Word delimiter token. Log an error if used while not having been set.
"""
if self._word_delimiter_token is None and self.verbose:
logger.error("Using word_delimiter_token, but it is not set yet.")
return None
return str(self._word_delimiter_token)
@property
def word_delimiter_token_id(self) -> Optional[int]:
"""
`Optional[int]`: Id of the word_delimiter_token in the vocabulary. Returns `None` if the token has not been
set.
"""
if self._word_delimiter_token is None:
return None
return self.convert_tokens_to_ids(self.word_delimiter_token)
@word_delimiter_token.setter
def word_delimiter_token(self, value):
self._word_delimiter_token = value
@word_delimiter_token_id.setter
def word_delimiter_token_id(self, value):
self._word_delimiter_token = self.convert_tokens_to_ids(value)
@property
def vocab_size(self) -> int:
return len(self.decoder)
def get_vocab(self) -> Dict:
vocab = dict(self.encoder)
vocab.update(self.added_tokens_encoder)
return vocab
def _add_tokens(self, new_tokens: Union[List[str], List[AddedToken]], special_tokens: bool = False) -> int:
# Overwritten to never strip!
to_add = []
for token in new_tokens:
if isinstance(token, str):
to_add.append(AddedToken(token, rstrip=False, lstrip=False, normalized=False))
else:
to_add.append(token)
return super()._add_tokens(to_add, special_tokens)
def _tokenize(self, text, **kwargs):
"""
Converts a string into a sequence of tokens (string), using the tokenizer.
"""
if self.do_lower_case:
text = text.upper()
return list(text.replace(" ", self.word_delimiter_token))
def _convert_token_to_id(self, token: str) -> int:
"""Converts a token (str) in an index (integer) using the vocab."""
return self.encoder.get(token, self.encoder.get(self.unk_token))
def _convert_id_to_token(self, index: int) -> str:
"""Converts an index (integer) in a token (str) using the vocab."""
result = self.decoder.get(index, self.unk_token)
return result
def convert_tokens_to_string(
self,
tokens: List[str],
group_tokens: bool = True,
spaces_between_special_tokens: bool = False,
output_char_offsets: bool = False,
output_word_offsets: bool = False,
) -> Dict[str, Union[str, float]]:
"""
Converts a connectionist-temporal-classification (CTC) output tokens into a single string.
"""
if len(tokens) == 0:
return {"text": "", "char_offsets": [], "word_offsets": []}
# group same tokens into non-repeating tokens in CTC style decoding
if group_tokens:
chars, char_repetitions = zip(*((token, len(list(group_iter))) for token, group_iter in groupby(tokens)))
else:
chars = tokens
char_repetitions = len(tokens) * [1]
# filter self.pad_token which is used as CTC-blank token
processed_chars = list(filter(lambda char: char != self.pad_token, chars))
# replace delimiter token
processed_chars = [
self.replace_word_delimiter_char if char == self.word_delimiter_token else char for char in processed_chars
]
# retrieve offsets
char_offsets = word_offsets = None
if output_char_offsets or output_word_offsets:
char_offsets = self._compute_offsets(char_repetitions, chars, self.pad_token)
if len(char_offsets) != len(processed_chars):
raise ValueError(
f"`char_offsets`: {char_offsets} and `processed_tokens`: {processed_chars}"
" have to be of the same length, but are: "
f"`len(offsets)`: {len(char_offsets)} and `len(processed_tokens)`:"
f" {len(processed_chars)}"
)
# set tokens to correct processed token
for i, char in enumerate(processed_chars):
char_offsets[i]["char"] = char
# retrieve word offsets from character offsets
word_offsets = None
if output_word_offsets:
word_offsets = self._get_word_offsets(char_offsets, self.replace_word_delimiter_char)
# don't output chars if not set to True
if not output_char_offsets:
char_offsets = None
# join to string
join_char = " " if spaces_between_special_tokens else ""
string = join_char.join(processed_chars).strip()
if self.do_lower_case:
string = string.lower()
return {"text": string, "char_offsets": char_offsets, "word_offsets": word_offsets}
@staticmethod
def _compute_offsets(
char_repetitions: List[int], chars: List[str], ctc_token: int
) -> List[Dict[str, Union[str, int]]]:
end_indices = np.asarray(char_repetitions).cumsum()
start_indices = np.concatenate(([0], end_indices[:-1]))
offsets = [
{"char": t, "start_offset": s, "end_offset": e} for t, s, e in zip(chars, start_indices, end_indices)
]
# filter out CTC token
offsets = list(filter(lambda offsets: offsets["char"] != ctc_token, offsets))
return offsets
@staticmethod
def _get_word_offsets(
offsets: Dict[str, Union[str, float]], word_delimiter_char: str = " "
) -> Dict[str, Union[str, float]]:
word_offsets = []
last_state = "SPACE"
word = ""
start_offset = 0
end_offset = 0
for i, offset in enumerate(offsets):
char = offset["char"]
state = "SPACE" if char == word_delimiter_char else "WORD"
if state == last_state:
# If we are in the same state as before, we simply repeat what we've done before
end_offset = offset["end_offset"]
word += char
else:
# Switching state
if state == "SPACE":
# Finishing a word
word_offsets.append({"word": word, "start_offset": start_offset, "end_offset": end_offset})
else:
# Starting a new word
start_offset = offset["start_offset"]
end_offset = offset["end_offset"]
word = char
last_state = state
if last_state == "WORD":
word_offsets.append({"word": word, "start_offset": start_offset, "end_offset": end_offset})
return word_offsets
def prepare_for_tokenization(self, text, is_split_into_words=False, **kwargs):
if is_split_into_words:
text = " " + text
return (text, kwargs)
def _decode(
self,
token_ids: List[int],
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
group_tokens: bool = True,
spaces_between_special_tokens: bool = False,
output_word_offsets: Optional[bool] = False,
output_char_offsets: Optional[bool] = False,
) -> str:
"""
special _decode function is needed for Wav2Vec2Tokenizer because added tokens should be treated exactly the
same as tokens of the base vocabulary and therefore the function `convert_tokens_to_string` has to be called on
the whole token list and not individually on added tokens
"""
filtered_tokens = self.convert_ids_to_tokens(token_ids, skip_special_tokens=skip_special_tokens)
result = []
for token in filtered_tokens:
if skip_special_tokens and token in self.all_special_ids:
continue
result.append(token)
string_output = self.convert_tokens_to_string(
result,
group_tokens=group_tokens,
spaces_between_special_tokens=spaces_between_special_tokens,
output_word_offsets=output_word_offsets,
output_char_offsets=output_char_offsets,
)
text = string_output["text"]
clean_up_tokenization_spaces = (
clean_up_tokenization_spaces
if clean_up_tokenization_spaces is not None
else self.clean_up_tokenization_spaces
)
if clean_up_tokenization_spaces:
text = self.clean_up_tokenization(text)
if output_word_offsets or output_char_offsets:
return Wav2Vec2CTCTokenizerOutput(
text=text,
char_offsets=string_output["char_offsets"],
word_offsets=string_output["word_offsets"],
)
else:
return text
# overwritten from `tokenization_utils_base.py` because tokenizer can output
# `ModelOutput` which should not be a list for batched output and
# because we need docs for `output_char_offsets` here
def batch_decode(
self,
sequences: Union[List[int], List[List[int]], "np.ndarray", "torch.Tensor", "tf.Tensor"],
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
output_char_offsets: bool = False,
output_word_offsets: bool = False,
**kwargs,
) -> List[str]:
"""
Convert a list of lists of token ids into a list of strings by calling decode.
Args:
sequences (`Union[List[int], List[List[int]], np.ndarray, torch.Tensor, tf.Tensor]`):
List of tokenized input ids. Can be obtained using the `__call__` method.
skip_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not to remove special tokens in the decoding.
clean_up_tokenization_spaces (`bool`, *optional*):
Whether or not to clean up the tokenization spaces.
output_char_offsets (`bool`, *optional*, defaults to `False`):
Whether or not to output character offsets. Character offsets can be used in combination with the
sampling rate and model downsampling rate to compute the time-stamps of transcribed characters.
<Tip>
Please take a look at the Example of [`~Wav2Vec2CTCTokenizer.decode`] to better understand how to make
use of `output_char_offsets`. [`~Wav2Vec2CTCTokenizer.batch_decode`] works the same way with batched
output.
</Tip>
output_word_offsets (`bool`, *optional*, defaults to `False`):
Whether or not to output word offsets. Word offsets can be used in combination with the sampling rate
and model downsampling rate to compute the time-stamps of transcribed words.
<Tip>
Please take a look at the Example of [`~Wav2Vec2CTCTokenizer.decode`] to better understand how to make
use of `output_word_offsets`. [`~Wav2Vec2CTCTokenizer.batch_decode`] works the same way with batched
output.
</Tip>
kwargs (additional keyword arguments, *optional*):
Will be passed to the underlying model specific decode method.
Returns:
`List[str]` or [`~models.wav2vec2.tokenization_wav2vec2.Wav2Vec2CTCTokenizerOutput`]: The list of decoded
sentences. Will be a [`~models.wav2vec2.tokenization_wav2vec2.Wav2Vec2CTCTokenizerOutput`] when
`output_char_offsets == True` or `output_word_offsets == True`.
"""
batch_decoded = [
self.decode(
seq,
skip_special_tokens=skip_special_tokens,
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
output_char_offsets=output_char_offsets,
output_word_offsets=output_word_offsets,
**kwargs,
)
for seq in sequences
]
if output_char_offsets or output_word_offsets:
# transform list of dicts to dict of lists
return Wav2Vec2CTCTokenizerOutput({k: [d[k] for d in batch_decoded] for k in batch_decoded[0]})
return batch_decoded
# overwritten from `tokenization_utils_base.py` because we need docs for `output_char_offsets`
# and `output_word_offsets` here
def decode(
self,
token_ids: Union[int, List[int], "np.ndarray", "torch.Tensor", "tf.Tensor"],
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
output_char_offsets: bool = False,
output_word_offsets: bool = False,
**kwargs,
) -> str:
"""
Converts a sequence of ids in a string, using the tokenizer and vocabulary with options to remove special
tokens and clean up tokenization spaces.
Similar to doing `self.convert_tokens_to_string(self.convert_ids_to_tokens(token_ids))`.
Args:
token_ids (`Union[int, List[int], np.ndarray, torch.Tensor, tf.Tensor]`):
List of tokenized input ids. Can be obtained using the `__call__` method.
skip_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not to remove special tokens in the decoding.
clean_up_tokenization_spaces (`bool`, *optional*):
Whether or not to clean up the tokenization spaces.
output_char_offsets (`bool`, *optional*, defaults to `False`):
Whether or not to output character offsets. Character offsets can be used in combination with the
sampling rate and model downsampling rate to compute the time-stamps of transcribed characters.
<Tip>
Please take a look at the example below to better understand how to make use of `output_char_offsets`.
</Tip>
output_word_offsets (`bool`, *optional*, defaults to `False`):
Whether or not to output word offsets. Word offsets can be used in combination with the sampling rate
and model downsampling rate to compute the time-stamps of transcribed words.
<Tip>
Please take a look at the example below to better understand how to make use of `output_word_offsets`.
</Tip>
kwargs (additional keyword arguments, *optional*):
Will be passed to the underlying model specific decode method.
Returns:
`str` or [`~models.wav2vec2.tokenization_wav2vec2.Wav2Vec2CTCTokenizerOutput`]: The list of decoded
sentences. Will be a [`~models.wav2vec2.tokenization_wav2vec2.Wav2Vec2CTCTokenizerOutput`] when
`output_char_offsets == True` or `output_word_offsets == True`.
Example:
```python
>>> # Let's see how to retrieve time steps for a model
>>> from transformers import AutoTokenizer, AutoFeatureExtractor, AutoModelForCTC
>>> from datasets import load_dataset
>>> import datasets
>>> import torch
>>> # import model, feature extractor, tokenizer
>>> model = AutoModelForCTC.from_pretrained("facebook/wav2vec2-base-960h")
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/wav2vec2-base-960h")
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base-960h")
>>> # load first sample of English common_voice
>>> dataset = load_dataset("mozilla-foundation/common_voice_11_0", "en", split="train", streaming=True)
>>> dataset = dataset.cast_column("audio", datasets.Audio(sampling_rate=16_000))
>>> dataset_iter = iter(dataset)
>>> sample = next(dataset_iter)
>>> # forward sample through model to get greedily predicted transcription ids
>>> input_values = feature_extractor(sample["audio"]["array"], return_tensors="pt").input_values
>>> logits = model(input_values).logits[0]
>>> pred_ids = torch.argmax(logits, axis=-1)
>>> # retrieve word stamps (analogous commands for `output_char_offsets`)
>>> outputs = tokenizer.decode(pred_ids, output_word_offsets=True)
>>> # compute `time_offset` in seconds as product of downsampling ratio and sampling_rate
>>> time_offset = model.config.inputs_to_logits_ratio / feature_extractor.sampling_rate
>>> word_offsets = [
... {
... "word": d["word"],
... "start_time": round(d["start_offset"] * time_offset, 2),
... "end_time": round(d["end_offset"] * time_offset, 2),
... }
... for d in outputs.word_offsets
... ]
>>> # compare word offsets with audio `en_train_0/common_voice_en_19121553.mp3` online on the dataset viewer:
>>> # https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0/viewer/en
>>> word_offsets[:3]
[{'word': 'THE', 'start_time': 0.7, 'end_time': 0.78}, {'word': 'TRICK', 'start_time': 0.88, 'end_time': 1.08}, {'word': 'APPEARS', 'start_time': 1.2, 'end_time': 1.64}]
```"""
# Convert inputs to python lists
token_ids = to_py_obj(token_ids)
return self._decode(
token_ids=token_ids,
skip_special_tokens=skip_special_tokens,
clean_up_tokenization_spaces=clean_up_tokenization_spaces,
output_char_offsets=output_char_offsets,
output_word_offsets=output_word_offsets,
**kwargs,
)
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
with open(vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(self.vocab, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
return (vocab_file,)
class Wav2Vec2Tokenizer(PreTrainedTokenizer):
"""
Constructs a Wav2Vec2 tokenizer.
This tokenizer inherits from [`PreTrainedTokenizer`] which contains some of the main methods. Users should refer to
the superclass for more information regarding such methods.
Args:
vocab_file (`str`):
File containing the vocabulary.
bos_token (`str`, *optional*, defaults to `"<s>"`):
The beginning of sentence token.
eos_token (`str`, *optional*, defaults to `"</s>"`):
The end of sentence token.
unk_token (`str`, *optional*, defaults to `"<unk>"`):
The unknown token. A token that is not in the vocabulary cannot be converted to an ID and is set to be this
token instead.
pad_token (`str`, *optional*, defaults to `"<pad>"`):
The token used for padding, for example when batching sequences of different lengths.
word_delimiter_token (`str`, *optional*, defaults to `"|"`):
The token used for defining the end of a word.
do_lower_case (`bool`, *optional*, defaults to `False`):
Whether or not to lowercase the output when decoding.
do_normalize (`bool`, *optional*, defaults to `False`):
Whether or not to zero-mean unit-variance normalize the input. Normalizing can help to significantly
improve the performance for some models, *e.g.*,
[wav2vec2-lv60](https://huggingface.co/models?search=lv60).
return_attention_mask (`bool`, *optional*, defaults to `False`):
Whether or not [`~Wav2Vec2Tokenizer.__call__`] should return `attention_mask`.
<Tip>
Wav2Vec2 models that have set `config.feat_extract_norm == "group"`, such as
[wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base-960h), have **not** been trained using
`attention_mask`. For such models, `input_values` should simply be padded with 0 and no `attention_mask`
should be passed.
For Wav2Vec2 models that have set `config.feat_extract_norm == "layer"`, such as
[wav2vec2-lv60](https://huggingface.co/facebook/wav2vec2-large-960h-lv60-self), `attention_mask` should be
passed for batched inference.
</Tip>
**kwargs
Additional keyword arguments passed along to [`PreTrainedTokenizer`]
"""
vocab_files_names = VOCAB_FILES_NAMES
pretrained_vocab_files_map = {
"vocab_file": {
"facebook/wav2vec2-base-960h": "https://huggingface.co/facebook/wav2vec2-base-960h/resolve/main/vocab.json"
},
"tokenizer_config_file": {
"facebook/wav2vec2-base-960h": (
"https://huggingface.co/facebook/wav2vec2-base-960h/resolve/main/tokenizer.json"
),
},
}
model_input_names = ["input_values", "attention_mask"]
def __init__(
self,
vocab_file,
bos_token="<s>",
eos_token="</s>",
unk_token="<unk>",
pad_token="<pad>",
word_delimiter_token="|",
do_lower_case=False,
do_normalize=False,
return_attention_mask=False,
**kwargs,
):
warnings.warn(
"The class `Wav2Vec2Tokenizer` is deprecated and will be removed in version 5 of Transformers. Please use"
" `Wav2Vec2Processor` or `Wav2Vec2CTCTokenizer` instead.",
FutureWarning,
)
self._word_delimiter_token = word_delimiter_token
self.do_lower_case = do_lower_case
self.return_attention_mask = return_attention_mask
self.do_normalize = do_normalize
with open(vocab_file, encoding="utf-8") as vocab_handle:
self.encoder = json.load(vocab_handle)
self.decoder = {v: k for k, v in self.encoder.items()}
super().__init__(
unk_token=unk_token,
bos_token=bos_token,
eos_token=eos_token,
pad_token=pad_token,
do_lower_case=do_lower_case,
do_normalize=do_normalize,
return_attention_mask=return_attention_mask,
word_delimiter_token=word_delimiter_token,
**kwargs,
)
@property
def word_delimiter_token(self) -> str:
"""
`str`: Padding token. Log an error if used while not having been set.
"""
if self._word_delimiter_token is None and self.verbose:
logger.error("Using word_delimiter_token, but it is not set yet.")
return None
return str(self._word_delimiter_token)
@property
def word_delimiter_token_id(self) -> Optional[int]:
"""
`Optional[int]`: Id of the word_delimiter_token in the vocabulary. Returns `None` if the token has not been
set.
"""
if self._word_delimiter_token is None:
return None
return self.convert_tokens_to_ids(self.word_delimiter_token)
@word_delimiter_token.setter
def word_delimiter_token(self, value):
self._word_delimiter_token = value
@word_delimiter_token_id.setter
def word_delimiter_token_id(self, value):
self._word_delimiter_token = self.convert_tokens_to_ids(value)
@add_end_docstrings(WAV2VEC2_KWARGS_DOCSTRING)
def __call__(
self,
raw_speech: Union[np.ndarray, List[float], List[np.ndarray], List[List[float]]],
padding: Union[bool, str, PaddingStrategy] = False,
max_length: Optional[int] = None,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
"""
Main method to tokenize and prepare for the model one or several sequence(s) or one or several pair(s) of
sequences.
Args:
raw_speech (`np.ndarray`, `List[float]`, `List[np.ndarray]`, `List[List[float]]`):
The sequence or batch of sequences to be padded. Each sequence can be a numpy array, a list of float
values, a list of numpy array or a list of list of float values. Must be mono channel audio, not
stereo, i.e. single float per timestep.
"""
is_batched_numpy = isinstance(raw_speech, np.ndarray) and len(raw_speech.shape) > 1
if is_batched_numpy and len(raw_speech.shape) > 2:
raise ValueError(f"Only mono-channel audio is supported for input to {self}")
is_batched = is_batched_numpy or (
isinstance(raw_speech, (list, tuple)) and (isinstance(raw_speech[0], (np.ndarray, tuple, list)))
)
# make sure input is in list format
if is_batched and not isinstance(raw_speech[0], np.ndarray):
raw_speech = [np.asarray(speech) for speech in raw_speech]
elif not is_batched and not isinstance(raw_speech, np.ndarray):
raw_speech = np.asarray(raw_speech)
# always return batch
if not is_batched:
raw_speech = [raw_speech]
# zero-mean and unit-variance normalization
if self.do_normalize:
raw_speech = [(x - np.mean(x)) / np.sqrt(np.var(x) + 1e-5) for x in raw_speech]
# convert into correct format for padding
encoded_inputs = BatchEncoding({"input_values": raw_speech})
padded_inputs = self.pad(
encoded_inputs,
padding=padding,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_attention_mask=self.return_attention_mask,
return_tensors=return_tensors,
verbose=verbose,
)
return padded_inputs
@property
def vocab_size(self) -> int:
return len(self.decoder)
def get_vocab(self) -> Dict:
return dict(self.encoder, **self.added_tokens_encoder)
def _convert_token_to_id(self, token: str) -> int:
"""Converts a token (str) in an index (integer) using the vocab."""
return self.encoder.get(token, self.encoder.get(self.unk_token))
def _convert_id_to_token(self, index: int) -> str:
"""Converts an index (integer) in a token (str) using the vocab."""
result = self.decoder.get(index, self.unk_token)
return result
def convert_tokens_to_string(self, tokens: List[str]) -> str:
"""
Converts a connectionist-temporal-classification (CTC) output tokens into a single string.
"""
# group same tokens into non-repeating tokens in CTC style decoding
grouped_tokens = [token_group[0] for token_group in groupby(tokens)]
# filter self.pad_token which is used as CTC-blank token
filtered_tokens = list(filter(lambda token: token != self.pad_token, grouped_tokens))
# replace delimiter token
string = "".join([" " if token == self.word_delimiter_token else token for token in filtered_tokens]).strip()
if self.do_lower_case:
string = string.lower()
return string
def _decode(
self,
token_ids: List[int],
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
**kwargs,
) -> str:
"""
special _decode function is needed for Wav2Vec2Tokenizer because added tokens should be treated exactly the
same as tokens of the base vocabulary and therefore the function `convert_tokens_to_string` has to be called on
the whole token list and not individually on added tokens
"""
filtered_tokens = self.convert_ids_to_tokens(token_ids, skip_special_tokens=skip_special_tokens)
result = []
for token in filtered_tokens:
if skip_special_tokens and token in self.all_special_ids:
continue
result.append(token)
text = self.convert_tokens_to_string(result)
clean_up_tokenization_spaces = (
clean_up_tokenization_spaces
if clean_up_tokenization_spaces is not None
else self.clean_up_tokenization_spaces
)
if clean_up_tokenization_spaces:
clean_text = self.clean_up_tokenization(text)
return clean_text
else:
return text
def save_vocabulary(self, save_directory: str, filename_prefix: Optional[str] = None) -> Tuple[str]:
if not os.path.isdir(save_directory):
logger.error(f"Vocabulary path ({save_directory}) should be a directory")
return
vocab_file = os.path.join(
save_directory, (filename_prefix + "-" if filename_prefix else "") + VOCAB_FILES_NAMES["vocab_file"]
)
with open(vocab_file, "w", encoding="utf-8") as f:
f.write(json.dumps(self.encoder, indent=2, sort_keys=True, ensure_ascii=False) + "\n")
return (vocab_file,)
| transformers/src/transformers/models/wav2vec2/tokenization_wav2vec2.py/0 | {
"file_path": "transformers/src/transformers/models/wav2vec2/tokenization_wav2vec2.py",
"repo_id": "transformers",
"token_count": 16882
} | 340 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert WavLM checkpoint."""
import argparse
import torch
# Step 1. clone https://github.com/microsoft/unilm
# Step 2. git checkout to https://github.com/microsoft/unilm/commit/b94ec76c36f02fb2b0bf0dcb0b8554a2185173cd
# Step 3. cd unilm
# Step 4. ln -s $(realpath wavlm/modules.py) ./ # create simlink
# import classes
from unilm.wavlm.WavLM import WavLM as WavLMOrig
from unilm.wavlm.WavLM import WavLMConfig as WavLMConfigOrig
from transformers import WavLMConfig, WavLMModel, logging
logging.set_verbosity_info()
logger = logging.get_logger(__name__)
MAPPING = {
"post_extract_proj": "feature_projection.projection",
"encoder.pos_conv.0": "encoder.pos_conv_embed.conv",
"self_attn.k_proj": "encoder.layers.*.attention.k_proj",
"self_attn.v_proj": "encoder.layers.*.attention.v_proj",
"self_attn.q_proj": "encoder.layers.*.attention.q_proj",
"self_attn.out_proj": "encoder.layers.*.attention.out_proj",
"self_attn.grep_linear": "encoder.layers.*.attention.gru_rel_pos_linear",
"self_attn.relative_attention_bias": "encoder.layers.*.attention.rel_attn_embed",
"self_attn.grep_a": "encoder.layers.*.attention.gru_rel_pos_const",
"self_attn_layer_norm": "encoder.layers.*.layer_norm",
"fc1": "encoder.layers.*.feed_forward.intermediate_dense",
"fc2": "encoder.layers.*.feed_forward.output_dense",
"final_layer_norm": "encoder.layers.*.final_layer_norm",
"encoder.layer_norm": "encoder.layer_norm",
"w2v_model.layer_norm": "feature_projection.layer_norm",
"quantizer.weight_proj": "quantizer.weight_proj",
"quantizer.vars": "quantizer.codevectors",
"project_q": "project_q",
"final_proj": "project_hid",
"w2v_encoder.proj": "ctc_proj",
"mask_emb": "masked_spec_embed",
}
TOP_LEVEL_KEYS = [
"ctc_proj",
"quantizer.weight_proj",
"quantizer.codevectors",
"project_q",
"project_hid",
]
def set_recursively(hf_pointer, key, value, full_name, weight_type):
for attribute in key.split("."):
hf_pointer = getattr(hf_pointer, attribute)
if weight_type is not None:
hf_shape = getattr(hf_pointer, weight_type).shape
else:
hf_shape = hf_pointer.shape
assert hf_shape == value.shape, (
f"Shape of hf {key + '.' + weight_type if weight_type is not None else ''} is {hf_shape}, but should be"
f" {value.shape} for {full_name}"
)
if weight_type == "weight":
hf_pointer.weight.data = value
elif weight_type == "weight_g":
hf_pointer.weight_g.data = value
elif weight_type == "weight_v":
hf_pointer.weight_v.data = value
elif weight_type == "bias":
hf_pointer.bias.data = value
else:
hf_pointer.data = value
logger.info(f"{key + '.' + weight_type if weight_type is not None else ''} was initialized from {full_name}.")
def recursively_load_weights(fairseq_model, hf_model):
unused_weights = []
fairseq_dict = fairseq_model.state_dict()
feature_extractor = hf_model.feature_extractor
for name, value in fairseq_dict.items():
is_used = False
if "conv_layers" in name:
load_conv_layer(
name,
value,
feature_extractor,
unused_weights,
hf_model.config.feat_extract_norm == "group",
)
is_used = True
else:
for key, mapped_key in MAPPING.items():
if key in name or key.split("w2v_model.")[-1] == name.split(".")[0]:
is_used = True
if "*" in mapped_key:
layer_index = name.split(key)[0].split(".")[-2]
mapped_key = mapped_key.replace("*", layer_index)
if "weight_g" in name:
weight_type = "weight_g"
elif "weight_v" in name:
weight_type = "weight_v"
elif "bias" in name and "relative_attention_bias" not in name:
weight_type = "bias"
elif "weight" in name:
# TODO: don't match quantizer.weight_proj
weight_type = "weight"
else:
weight_type = None
set_recursively(hf_model, mapped_key, value, name, weight_type)
continue
if not is_used:
unused_weights.append(name)
logger.warning(f"Unused weights: {unused_weights}")
def load_conv_layer(full_name, value, feature_extractor, unused_weights, use_group_norm):
name = full_name.split("conv_layers.")[-1]
items = name.split(".")
layer_id = int(items[0])
type_id = int(items[1])
if type_id == 0:
if "bias" in name:
assert value.shape == feature_extractor.conv_layers[layer_id].conv.bias.data.shape, (
f"{full_name} has size {value.shape}, but"
f" {feature_extractor.conv_layers[layer_id].conv.bias.data.shape} was found."
)
feature_extractor.conv_layers[layer_id].conv.bias.data = value
logger.info(f"Feat extract conv layer {layer_id} was initialized from {full_name}.")
elif "weight" in name:
assert value.shape == feature_extractor.conv_layers[layer_id].conv.weight.data.shape, (
f"{full_name} has size {value.shape}, but"
f" {feature_extractor.conv_layers[layer_id].conv.weight.data.shape} was found."
)
feature_extractor.conv_layers[layer_id].conv.weight.data = value
logger.info(f"Feat extract conv layer {layer_id} was initialized from {full_name}.")
elif (type_id == 2 and not use_group_norm) or (type_id == 2 and layer_id == 0 and use_group_norm):
if "bias" in name:
assert value.shape == feature_extractor.conv_layers[layer_id].layer_norm.bias.data.shape, (
f"{full_name} has size {value.shape}, but {feature_extractor[layer_id].layer_norm.bias.data.shape} was"
" found."
)
feature_extractor.conv_layers[layer_id].layer_norm.bias.data = value
logger.info(f"Feat extract layer norm weight of layer {layer_id} was initialized from {full_name}.")
elif "weight" in name:
assert value.shape == feature_extractor.conv_layers[layer_id].layer_norm.weight.data.shape, (
f"{full_name} has size {value.shape}, but"
f" {feature_extractor[layer_id].layer_norm.weight.data.shape} was found."
)
feature_extractor.conv_layers[layer_id].layer_norm.weight.data = value
logger.info(f"Feat extract layer norm weight of layer {layer_id} was initialized from {full_name}.")
else:
unused_weights.append(full_name)
@torch.no_grad()
def convert_wavlm_checkpoint(checkpoint_path, pytorch_dump_folder_path, config_path=None):
# load the pre-trained checkpoints
checkpoint = torch.load(checkpoint_path)
cfg = WavLMConfigOrig(checkpoint["cfg"])
model = WavLMOrig(cfg)
model.load_state_dict(checkpoint["model"])
model.eval()
if config_path is not None:
config = WavLMConfig.from_pretrained(config_path)
else:
config = WavLMConfig()
hf_wavlm = WavLMModel(config)
recursively_load_weights(model, hf_wavlm)
hf_wavlm.save_pretrained(pytorch_dump_folder_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--pytorch_dump_folder_path", default=None, type=str, help="Path to the output PyTorch model.")
parser.add_argument("--checkpoint_path", default=None, type=str, help="Path to fairseq checkpoint")
parser.add_argument("--config_path", default=None, type=str, help="Path to hf config.json of model to convert")
args = parser.parse_args()
convert_wavlm_checkpoint(args.checkpoint_path, args.pytorch_dump_folder_path, args.config_path)
| transformers/src/transformers/models/wavlm/convert_wavlm_original_pytorch_checkpoint_to_pytorch.py/0 | {
"file_path": "transformers/src/transformers/models/wavlm/convert_wavlm_original_pytorch_checkpoint_to_pytorch.py",
"repo_id": "transformers",
"token_count": 3804
} | 341 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" X-CLIP model configuration"""
import os
from typing import Union
from ...configuration_utils import PretrainedConfig
from ...utils import logging
logger = logging.get_logger(__name__)
XCLIP_PRETRAINED_CONFIG_ARCHIVE_MAP = {
"microsoft/xclip-base-patch32": "https://huggingface.co/microsoft/xclip-base-patch32/resolve/main/config.json",
}
class XCLIPTextConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`XCLIPModel`]. It is used to instantiate an X-CLIP
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the X-CLIP
[microsoft/xclip-base-patch32](https://huggingface.co/microsoft/xclip-base-patch32) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
vocab_size (`int`, *optional*, defaults to 49408):
Vocabulary size of the X-CLIP text model. Defines the number of different tokens that can be represented by
the `inputs_ids` passed when calling [`XCLIPModel`].
hidden_size (`int`, *optional*, defaults to 512):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 2048):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 8):
Number of attention heads for each attention layer in the Transformer encoder.
max_position_embeddings (`int`, *optional*, defaults to 77):
The maximum sequence length that this model might ever be used with. Typically set this to something large
just in case (e.g., 512 or 1024 or 2048).
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
Example:
```python
>>> from transformers import XCLIPTextModel, XCLIPTextConfig
>>> # Initializing a XCLIPTextModel with microsoft/xclip-base-patch32 style configuration
>>> configuration = XCLIPTextConfig()
>>> # Initializing a XCLIPTextConfig from the microsoft/xclip-base-patch32 style configuration
>>> model = XCLIPTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "xclip_text_model"
def __init__(
self,
vocab_size=49408,
hidden_size=512,
intermediate_size=2048,
num_hidden_layers=12,
num_attention_heads=8,
max_position_embeddings=77,
hidden_act="quick_gelu",
layer_norm_eps=1e-5,
attention_dropout=0.0,
initializer_range=0.02,
initializer_factor=1.0,
pad_token_id=1,
bos_token_id=0,
eos_token_id=2,
**kwargs,
):
super().__init__(pad_token_id=pad_token_id, bos_token_id=bos_token_id, eos_token_id=eos_token_id, **kwargs)
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.max_position_embeddings = max_position_embeddings
self.layer_norm_eps = layer_norm_eps
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.attention_dropout = attention_dropout
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
cls._set_token_in_kwargs(kwargs)
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
# get the text config dict if we are loading from XCLIPConfig
if config_dict.get("model_type") == "xclip":
config_dict = config_dict["text_config"]
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
logger.warning(
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
)
return cls.from_dict(config_dict, **kwargs)
class XCLIPVisionConfig(PretrainedConfig):
r"""
This is the configuration class to store the configuration of a [`XCLIPModel`]. It is used to instantiate an X-CLIP
model according to the specified arguments, defining the model architecture. Instantiating a configuration with the
defaults will yield a similar configuration to that of the X-CLIP
[microsoft/xclip-base-patch32](https://huggingface.co/microsoft/xclip-base-patch32) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
hidden_size (`int`, *optional*, defaults to 768):
Dimensionality of the encoder layers and the pooler layer.
intermediate_size (`int`, *optional*, defaults to 3072):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Transformer encoder.
num_hidden_layers (`int`, *optional*, defaults to 12):
Number of hidden layers in the Transformer encoder.
num_attention_heads (`int`, *optional*, defaults to 12):
Number of attention heads for each attention layer in the Transformer encoder.
mit_hidden_size (`int`, *optional*, defaults to 512):
Dimensionality of the encoder layers of the Multiframe Integration Transformer (MIT).
mit_intermediate_size (`int`, *optional*, defaults to 2048):
Dimensionality of the "intermediate" (i.e., feed-forward) layer in the Multiframe Integration Transformer
(MIT).
mit_num_hidden_layers (`int`, *optional*, defaults to 1):
Number of hidden layers in the Multiframe Integration Transformer (MIT).
mit_num_attention_heads (`int`, *optional*, defaults to 8):
Number of attention heads for each attention layer in the Multiframe Integration Transformer (MIT).
image_size (`int`, *optional*, defaults to 224):
The size (resolution) of each image.
patch_size (`int`, *optional*, defaults to 32):
The size (resolution) of each patch.
hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the encoder and pooler. If string, `"gelu"`,
`"relu"`, `"selu"`, `"gelu_new"` and ``"quick_gelu"` are supported.
layer_norm_eps (`float`, *optional*, defaults to 1e-5):
The epsilon used by the layer normalization layers.
attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout ratio for the attention probabilities.
initializer_range (`float`, *optional*, defaults to 0.02):
The standard deviation of the truncated_normal_initializer for initializing all weight matrices.
initializer_factor (`float`, *optional*, defaults to 1):
A factor for initializing all weight matrices (should be kept to 1, used internally for initialization
testing).
drop_path_rate (`float`, *optional*, defaults to 0.0):
Stochastic depth rate.
Example:
```python
>>> from transformers import XCLIPVisionModel, XCLIPVisionConfig
>>> # Initializing a XCLIPVisionModel with microsoft/xclip-base-patch32 style configuration
>>> configuration = XCLIPVisionConfig()
>>> # Initializing a XCLIPVisionModel model from the microsoft/xclip-base-patch32 style configuration
>>> model = XCLIPVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```"""
model_type = "xclip_vision_model"
def __init__(
self,
hidden_size=768,
intermediate_size=3072,
num_hidden_layers=12,
num_attention_heads=12,
mit_hidden_size=512,
mit_intermediate_size=2048,
mit_num_hidden_layers=1,
mit_num_attention_heads=8,
num_channels=3,
image_size=224,
patch_size=32,
num_frames=8,
hidden_act="quick_gelu",
layer_norm_eps=1e-5,
attention_dropout=0.0,
initializer_range=0.02,
initializer_factor=1.0,
drop_path_rate=0.0,
**kwargs,
):
super().__init__(**kwargs)
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.mit_hidden_size = mit_hidden_size
self.mit_intermediate_size = mit_intermediate_size
self.mit_num_hidden_layers = mit_num_hidden_layers
self.mit_num_attention_heads = mit_num_attention_heads
self.num_channels = num_channels
self.patch_size = patch_size
self.num_frames = num_frames
self.image_size = image_size
self.initializer_range = initializer_range
self.initializer_factor = initializer_factor
self.attention_dropout = attention_dropout
self.layer_norm_eps = layer_norm_eps
self.hidden_act = hidden_act
self.drop_path_rate = drop_path_rate
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path: Union[str, os.PathLike], **kwargs) -> "PretrainedConfig":
cls._set_token_in_kwargs(kwargs)
config_dict, kwargs = cls.get_config_dict(pretrained_model_name_or_path, **kwargs)
# get the vision config dict if we are loading from XCLIPConfig
if config_dict.get("model_type") == "xclip":
config_dict = config_dict["vision_config"]
if "model_type" in config_dict and hasattr(cls, "model_type") and config_dict["model_type"] != cls.model_type:
logger.warning(
f"You are using a model of type {config_dict['model_type']} to instantiate a model of type "
f"{cls.model_type}. This is not supported for all configurations of models and can yield errors."
)
return cls.from_dict(config_dict, **kwargs)
class XCLIPConfig(PretrainedConfig):
r"""
[`XCLIPConfig`] is the configuration class to store the configuration of a [`XCLIPModel`]. It is used to
instantiate X-CLIP model according to the specified arguments, defining the text model and vision model configs.
Instantiating a configuration with the defaults will yield a similar configuration to that of the X-CLIP
[microsoft/xclip-base-patch32](https://huggingface.co/microsoft/xclip-base-patch32) architecture.
Configuration objects inherit from [`PretrainedConfig`] and can be used to control the model outputs. Read the
documentation from [`PretrainedConfig`] for more information.
Args:
text_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`XCLIPTextConfig`].
vision_config (`dict`, *optional*):
Dictionary of configuration options used to initialize [`XCLIPVisionConfig`].
projection_dim (`int`, *optional*, defaults to 512):
Dimentionality of text and vision projection layers.
prompt_layers (`int`, *optional*, defaults to 2):
Number of layers in the video specific prompt generator.
prompt_alpha (`float`, *optional*, defaults to 0.1):
Alpha value to use in the video specific prompt generator.
prompt_hidden_act (`str` or `function`, *optional*, defaults to `"quick_gelu"`):
The non-linear activation function (function or string) in the video specific prompt generator. If string,
`"gelu"`, `"relu"`, `"selu"` and `"gelu_new"` ``"quick_gelu"` are supported.
prompt_num_attention_heads (`int`, *optional*, defaults to 8):
Number of attention heads in the cross-attention of the video specific prompt generator.
prompt_attention_dropout (`float`, *optional*, defaults to 0.0):
The dropout probability for the attention layers in the video specific prompt generator.
prompt_projection_dropout (`float`, *optional*, defaults to 0.0):
The dropout probability for the projection layers in the video specific prompt generator.
logit_scale_init_value (`float`, *optional*, defaults to 2.6592):
The inital value of the *logit_scale* parameter. Default is used as per the original XCLIP implementation.
kwargs (*optional*):
Dictionary of keyword arguments.
"""
model_type = "xclip"
def __init__(
self,
text_config=None,
vision_config=None,
projection_dim=512,
prompt_layers=2,
prompt_alpha=0.1,
prompt_hidden_act="quick_gelu",
prompt_num_attention_heads=8,
prompt_attention_dropout=0.0,
prompt_projection_dropout=0.0,
logit_scale_init_value=2.6592,
**kwargs,
):
# If `_config_dict` exist, we use them for the backward compatibility.
# We pop out these 2 attributes before calling `super().__init__` to avoid them being saved (which causes a lot
# of confusion!).
text_config_dict = kwargs.pop("text_config_dict", None)
vision_config_dict = kwargs.pop("vision_config_dict", None)
super().__init__(**kwargs)
# Instead of simply assigning `[text|vision]_config_dict` to `[text|vision]_config`, we use the values in
# `[text|vision]_config_dict` to update the values in `[text|vision]_config`. The values should be same in most
# cases, but we don't want to break anything regarding `_config_dict` that existed before commit `8827e1b2`.
if text_config_dict is not None:
if text_config is None:
text_config = {}
# This is the complete result when using `text_config_dict`.
_text_config_dict = XCLIPTextConfig(**text_config_dict).to_dict()
# Give a warning if the values exist in both `_text_config_dict` and `text_config` but being different.
for key, value in _text_config_dict.items():
if key in text_config and value != text_config[key] and key not in ["transformers_version"]:
# If specified in `text_config_dict`
if key in text_config_dict:
message = (
f"`{key}` is found in both `text_config_dict` and `text_config` but with different values. "
f'The value `text_config_dict["{key}"]` will be used instead.'
)
# If inferred from default argument values (just to be super careful)
else:
message = (
f"`text_config_dict` is provided which will be used to initialize `XCLIPTextConfig`. The "
f'value `text_config["{key}"]` will be overriden.'
)
logger.info(message)
# Update all values in `text_config` with the ones in `_text_config_dict`.
text_config.update(_text_config_dict)
if vision_config_dict is not None:
if vision_config is None:
vision_config = {}
# This is the complete result when using `vision_config_dict`.
_vision_config_dict = XCLIPVisionConfig(**vision_config_dict).to_dict()
# convert keys to string instead of integer
if "id2label" in _vision_config_dict:
_vision_config_dict["id2label"] = {
str(key): value for key, value in _vision_config_dict["id2label"].items()
}
# Give a warning if the values exist in both `_vision_config_dict` and `vision_config` but being different.
for key, value in _vision_config_dict.items():
if key in vision_config and value != vision_config[key] and key not in ["transformers_version"]:
# If specified in `vision_config_dict`
if key in vision_config_dict:
message = (
f"`{key}` is found in both `vision_config_dict` and `vision_config` but with different "
f'values. The value `vision_config_dict["{key}"]` will be used instead.'
)
# If inferred from default argument values (just to be super careful)
else:
message = (
f"`vision_config_dict` is provided which will be used to initialize `XCLIPVisionConfig`. "
f'The value `vision_config["{key}"]` will be overriden.'
)
logger.info(message)
# Update all values in `vision_config` with the ones in `_vision_config_dict`.
vision_config.update(_vision_config_dict)
if text_config is None:
text_config = {}
logger.info("`text_config` is `None`. Initializing the `XCLIPTextConfig` with default values.")
if vision_config is None:
vision_config = {}
logger.info("`vision_config` is `None`. initializing the `XCLIPVisionConfig` with default values.")
self.text_config = XCLIPTextConfig(**text_config)
self.vision_config = XCLIPVisionConfig(**vision_config)
self.projection_dim = projection_dim
self.prompt_layers = prompt_layers
self.prompt_alpha = prompt_alpha
self.prompt_hidden_act = prompt_hidden_act
self.prompt_num_attention_heads = prompt_num_attention_heads
self.prompt_attention_dropout = prompt_attention_dropout
self.prompt_projection_dropout = prompt_projection_dropout
self.logit_scale_init_value = logit_scale_init_value
self.initializer_factor = 1.0
@classmethod
def from_text_vision_configs(cls, text_config: XCLIPTextConfig, vision_config: XCLIPVisionConfig, **kwargs):
r"""
Instantiate a [`XCLIPConfig`] (or a derived class) from xclip text model configuration and xclip vision model
configuration.
Returns:
[`XCLIPConfig`]: An instance of a configuration object
"""
return cls(text_config=text_config.to_dict(), vision_config=vision_config.to_dict(), **kwargs)
| transformers/src/transformers/models/x_clip/configuration_x_clip.py/0 | {
"file_path": "transformers/src/transformers/models/x_clip/configuration_x_clip.py",
"repo_id": "transformers",
"token_count": 8112
} | 342 |
# Copyright 2023 The HuggingFace Team. All rights reserved.
import datetime
import platform
import subprocess
from typing import Optional, Tuple, Union
import numpy as np
def ffmpeg_read(bpayload: bytes, sampling_rate: int) -> np.array:
"""
Helper function to read an audio file through ffmpeg.
"""
ar = f"{sampling_rate}"
ac = "1"
format_for_conversion = "f32le"
ffmpeg_command = [
"ffmpeg",
"-i",
"pipe:0",
"-ac",
ac,
"-ar",
ar,
"-f",
format_for_conversion,
"-hide_banner",
"-loglevel",
"quiet",
"pipe:1",
]
try:
with subprocess.Popen(ffmpeg_command, stdin=subprocess.PIPE, stdout=subprocess.PIPE) as ffmpeg_process:
output_stream = ffmpeg_process.communicate(bpayload)
except FileNotFoundError as error:
raise ValueError("ffmpeg was not found but is required to load audio files from filename") from error
out_bytes = output_stream[0]
audio = np.frombuffer(out_bytes, np.float32)
if audio.shape[0] == 0:
raise ValueError(
"Soundfile is either not in the correct format or is malformed. Ensure that the soundfile has "
"a valid audio file extension (e.g. wav, flac or mp3) and is not corrupted. If reading from a remote "
"URL, ensure that the URL is the full address to **download** the audio file."
)
return audio
def ffmpeg_microphone(
sampling_rate: int,
chunk_length_s: float,
format_for_conversion: str = "f32le",
):
"""
Helper function to read raw microphone data.
"""
ar = f"{sampling_rate}"
ac = "1"
if format_for_conversion == "s16le":
size_of_sample = 2
elif format_for_conversion == "f32le":
size_of_sample = 4
else:
raise ValueError(f"Unhandled format `{format_for_conversion}`. Please use `s16le` or `f32le`")
system = platform.system()
if system == "Linux":
format_ = "alsa"
input_ = "default"
elif system == "Darwin":
format_ = "avfoundation"
input_ = ":0"
elif system == "Windows":
format_ = "dshow"
input_ = _get_microphone_name()
ffmpeg_command = [
"ffmpeg",
"-f",
format_,
"-i",
input_,
"-ac",
ac,
"-ar",
ar,
"-f",
format_for_conversion,
"-fflags",
"nobuffer",
"-hide_banner",
"-loglevel",
"quiet",
"pipe:1",
]
chunk_len = int(round(sampling_rate * chunk_length_s)) * size_of_sample
iterator = _ffmpeg_stream(ffmpeg_command, chunk_len)
for item in iterator:
yield item
def ffmpeg_microphone_live(
sampling_rate: int,
chunk_length_s: float,
stream_chunk_s: Optional[int] = None,
stride_length_s: Optional[Union[Tuple[float, float], float]] = None,
format_for_conversion: str = "f32le",
):
"""
Helper function to read audio from the microphone file through ffmpeg. This will output `partial` overlapping
chunks starting from `stream_chunk_s` (if it is defined) until `chunk_length_s` is reached. It will make use of
striding to avoid errors on the "sides" of the various chunks.
Arguments:
sampling_rate (`int`):
The sampling_rate to use when reading the data from the microphone. Try using the model's sampling_rate to
avoid resampling later.
chunk_length_s (`float` or `int`):
The length of the maximum chunk of audio to be sent returned. This includes the eventual striding.
stream_chunk_s (`float` or `int`)
The length of the minimal temporary audio to be returned.
stride_length_s (`float` or `int` or `(float, float)`, *optional*, defaults to `None`)
The length of the striding to be used. Stride is used to provide context to a model on the (left, right) of
an audio sample but without using that part to actually make the prediction. Setting this does not change
the length of the chunk.
format_for_conversion (`str`, defalts to `f32le`)
The name of the format of the audio samples to be returned by ffmpeg. The standard is `f32le`, `s16le`
could also be used.
Return:
A generator yielding dictionaries of the following form
`{"sampling_rate": int, "raw": np.array(), "partial" bool}` With optionnally a `"stride" (int, int)` key if
`stride_length_s` is defined.
`stride` and `raw` are all expressed in `samples`, and `partial` is a boolean saying if the current yield item
is a whole chunk, or a partial temporary result to be later replaced by another larger chunk.
"""
if stream_chunk_s is not None:
chunk_s = stream_chunk_s
else:
chunk_s = chunk_length_s
microphone = ffmpeg_microphone(sampling_rate, chunk_s, format_for_conversion=format_for_conversion)
if format_for_conversion == "s16le":
dtype = np.int16
size_of_sample = 2
elif format_for_conversion == "f32le":
dtype = np.float32
size_of_sample = 4
else:
raise ValueError(f"Unhandled format `{format_for_conversion}`. Please use `s16le` or `f32le`")
if stride_length_s is None:
stride_length_s = chunk_length_s / 6
chunk_len = int(round(sampling_rate * chunk_length_s)) * size_of_sample
if isinstance(stride_length_s, (int, float)):
stride_length_s = [stride_length_s, stride_length_s]
stride_left = int(round(sampling_rate * stride_length_s[0])) * size_of_sample
stride_right = int(round(sampling_rate * stride_length_s[1])) * size_of_sample
audio_time = datetime.datetime.now()
delta = datetime.timedelta(seconds=chunk_s)
for item in chunk_bytes_iter(microphone, chunk_len, stride=(stride_left, stride_right), stream=True):
# Put everything back in numpy scale
item["raw"] = np.frombuffer(item["raw"], dtype=dtype)
item["stride"] = (
item["stride"][0] // size_of_sample,
item["stride"][1] // size_of_sample,
)
item["sampling_rate"] = sampling_rate
audio_time += delta
if datetime.datetime.now() > audio_time + 10 * delta:
# We're late !! SKIP
continue
yield item
def chunk_bytes_iter(iterator, chunk_len: int, stride: Tuple[int, int], stream: bool = False):
"""
Reads raw bytes from an iterator and does chunks of length `chunk_len`. Optionally adds `stride` to each chunks to
get overlaps. `stream` is used to return partial results even if a full `chunk_len` is not yet available.
"""
acc = b""
stride_left, stride_right = stride
if stride_left + stride_right >= chunk_len:
raise ValueError(
f"Stride needs to be strictly smaller than chunk_len: ({stride_left}, {stride_right}) vs {chunk_len}"
)
_stride_left = 0
for raw in iterator:
acc += raw
if stream and len(acc) < chunk_len:
stride = (_stride_left, 0)
yield {"raw": acc[:chunk_len], "stride": stride, "partial": True}
else:
while len(acc) >= chunk_len:
# We are flushing the accumulator
stride = (_stride_left, stride_right)
item = {"raw": acc[:chunk_len], "stride": stride}
if stream:
item["partial"] = False
yield item
_stride_left = stride_left
acc = acc[chunk_len - stride_left - stride_right :]
# Last chunk
if len(acc) > stride_left:
item = {"raw": acc, "stride": (_stride_left, 0)}
if stream:
item["partial"] = False
yield item
def _ffmpeg_stream(ffmpeg_command, buflen: int):
"""
Internal function to create the generator of data through ffmpeg
"""
bufsize = 2**24 # 16Mo
try:
with subprocess.Popen(ffmpeg_command, stdout=subprocess.PIPE, bufsize=bufsize) as ffmpeg_process:
while True:
raw = ffmpeg_process.stdout.read(buflen)
if raw == b"":
break
yield raw
except FileNotFoundError as error:
raise ValueError("ffmpeg was not found but is required to stream audio files from filename") from error
def _get_microphone_name():
"""
Retrieve the microphone name in Windows .
"""
command = ["ffmpeg", "-list_devices", "true", "-f", "dshow", "-i", ""]
try:
ffmpeg_devices = subprocess.run(command, text=True, stderr=subprocess.PIPE, encoding="utf-8")
microphone_lines = [line for line in ffmpeg_devices.stderr.splitlines() if "(audio)" in line]
if microphone_lines:
microphone_name = microphone_lines[0].split('"')[1]
print(f"Using microphone: {microphone_name}")
return f"audio={microphone_name}"
except FileNotFoundError:
print("ffmpeg was not found. Please install it or make sure it is in your system PATH.")
return "default"
| transformers/src/transformers/pipelines/audio_utils.py/0 | {
"file_path": "transformers/src/transformers/pipelines/audio_utils.py",
"repo_id": "transformers",
"token_count": 3857
} | 343 |
import inspect
import types
import warnings
from collections.abc import Iterable
from typing import TYPE_CHECKING, Dict, List, Optional, Tuple, Union
import numpy as np
from ..data import SquadExample, SquadFeatures, squad_convert_examples_to_features
from ..modelcard import ModelCard
from ..tokenization_utils import PreTrainedTokenizer
from ..utils import (
PaddingStrategy,
add_end_docstrings,
is_tf_available,
is_tokenizers_available,
is_torch_available,
logging,
)
from .base import ArgumentHandler, ChunkPipeline, build_pipeline_init_args
logger = logging.get_logger(__name__)
if TYPE_CHECKING:
from ..modeling_tf_utils import TFPreTrainedModel
from ..modeling_utils import PreTrainedModel
if is_tokenizers_available():
import tokenizers
if is_tf_available():
import tensorflow as tf
from ..models.auto.modeling_tf_auto import TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES
Dataset = None
if is_torch_available():
import torch
from torch.utils.data import Dataset
from ..models.auto.modeling_auto import MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES
def decode_spans(
start: np.ndarray, end: np.ndarray, topk: int, max_answer_len: int, undesired_tokens: np.ndarray
) -> Tuple:
"""
Take the output of any `ModelForQuestionAnswering` and will generate probabilities for each span to be the actual
answer.
In addition, it filters out some unwanted/impossible cases like answer len being greater than max_answer_len or
answer end position being before the starting position. The method supports output the k-best answer through the
topk argument.
Args:
start (`np.ndarray`): Individual start probabilities for each token.
end (`np.ndarray`): Individual end probabilities for each token.
topk (`int`): Indicates how many possible answer span(s) to extract from the model output.
max_answer_len (`int`): Maximum size of the answer to extract from the model's output.
undesired_tokens (`np.ndarray`): Mask determining tokens that can be part of the answer
"""
# Ensure we have batch axis
if start.ndim == 1:
start = start[None]
if end.ndim == 1:
end = end[None]
# Compute the score of each tuple(start, end) to be the real answer
outer = np.matmul(np.expand_dims(start, -1), np.expand_dims(end, 1))
# Remove candidate with end < start and end - start > max_answer_len
candidates = np.tril(np.triu(outer), max_answer_len - 1)
# Inspired by Chen & al. (https://github.com/facebookresearch/DrQA)
scores_flat = candidates.flatten()
if topk == 1:
idx_sort = [np.argmax(scores_flat)]
elif len(scores_flat) < topk:
idx_sort = np.argsort(-scores_flat)
else:
idx = np.argpartition(-scores_flat, topk)[0:topk]
idx_sort = idx[np.argsort(-scores_flat[idx])]
starts, ends = np.unravel_index(idx_sort, candidates.shape)[1:]
desired_spans = np.isin(starts, undesired_tokens.nonzero()) & np.isin(ends, undesired_tokens.nonzero())
starts = starts[desired_spans]
ends = ends[desired_spans]
scores = candidates[0, starts, ends]
return starts, ends, scores
def select_starts_ends(
start,
end,
p_mask,
attention_mask,
min_null_score=1000000,
top_k=1,
handle_impossible_answer=False,
max_answer_len=15,
):
"""
Takes the raw output of any `ModelForQuestionAnswering` and first normalizes its outputs and then uses
`decode_spans()` to generate probabilities for each span to be the actual answer.
Args:
start (`np.ndarray`): Individual start logits for each token.
end (`np.ndarray`): Individual end logits for each token.
p_mask (`np.ndarray`): A mask with 1 for values that cannot be in the answer
attention_mask (`np.ndarray`): The attention mask generated by the tokenizer
min_null_score(`float`): The minimum null (empty) answer score seen so far.
topk (`int`): Indicates how many possible answer span(s) to extract from the model output.
handle_impossible_answer(`bool`): Whether to allow null (empty) answers
max_answer_len (`int`): Maximum size of the answer to extract from the model's output.
"""
# Ensure padded tokens & question tokens cannot belong to the set of candidate answers.
undesired_tokens = np.abs(np.array(p_mask) - 1)
if attention_mask is not None:
undesired_tokens = undesired_tokens & attention_mask
# Generate mask
undesired_tokens_mask = undesired_tokens == 0.0
# Make sure non-context indexes in the tensor cannot contribute to the softmax
start = np.where(undesired_tokens_mask, -10000.0, start)
end = np.where(undesired_tokens_mask, -10000.0, end)
# Normalize logits and spans to retrieve the answer
start = np.exp(start - start.max(axis=-1, keepdims=True))
start = start / start.sum()
end = np.exp(end - end.max(axis=-1, keepdims=True))
end = end / end.sum()
if handle_impossible_answer:
min_null_score = min(min_null_score, (start[0, 0] * end[0, 0]).item())
# Mask CLS
start[0, 0] = end[0, 0] = 0.0
starts, ends, scores = decode_spans(start, end, top_k, max_answer_len, undesired_tokens)
return starts, ends, scores, min_null_score
class QuestionAnsweringArgumentHandler(ArgumentHandler):
"""
QuestionAnsweringPipeline requires the user to provide multiple arguments (i.e. question & context) to be mapped to
internal [`SquadExample`].
QuestionAnsweringArgumentHandler manages all the possible to create a [`SquadExample`] from the command-line
supplied arguments.
"""
def normalize(self, item):
if isinstance(item, SquadExample):
return item
elif isinstance(item, dict):
for k in ["question", "context"]:
if k not in item:
raise KeyError("You need to provide a dictionary with keys {question:..., context:...}")
elif item[k] is None:
raise ValueError(f"`{k}` cannot be None")
elif isinstance(item[k], str) and len(item[k]) == 0:
raise ValueError(f"`{k}` cannot be empty")
return QuestionAnsweringPipeline.create_sample(**item)
raise ValueError(f"{item} argument needs to be of type (SquadExample, dict)")
def __call__(self, *args, **kwargs):
# Detect where the actual inputs are
if args is not None and len(args) > 0:
if len(args) == 1:
inputs = args[0]
elif len(args) == 2 and {type(el) for el in args} == {str}:
inputs = [{"question": args[0], "context": args[1]}]
else:
inputs = list(args)
# Generic compatibility with sklearn and Keras
# Batched data
elif "X" in kwargs:
inputs = kwargs["X"]
elif "data" in kwargs:
inputs = kwargs["data"]
elif "question" in kwargs and "context" in kwargs:
if isinstance(kwargs["question"], list) and isinstance(kwargs["context"], str):
inputs = [{"question": Q, "context": kwargs["context"]} for Q in kwargs["question"]]
elif isinstance(kwargs["question"], list) and isinstance(kwargs["context"], list):
if len(kwargs["question"]) != len(kwargs["context"]):
raise ValueError("Questions and contexts don't have the same lengths")
inputs = [{"question": Q, "context": C} for Q, C in zip(kwargs["question"], kwargs["context"])]
elif isinstance(kwargs["question"], str) and isinstance(kwargs["context"], str):
inputs = [{"question": kwargs["question"], "context": kwargs["context"]}]
else:
raise ValueError("Arguments can't be understood")
else:
raise ValueError(f"Unknown arguments {kwargs}")
# When user is sending a generator we need to trust it's a valid example
generator_types = (types.GeneratorType, Dataset) if Dataset is not None else (types.GeneratorType,)
if isinstance(inputs, generator_types):
return inputs
# Normalize inputs
if isinstance(inputs, dict):
inputs = [inputs]
elif isinstance(inputs, Iterable):
# Copy to avoid overriding arguments
inputs = list(inputs)
else:
raise ValueError(f"Invalid arguments {kwargs}")
for i, item in enumerate(inputs):
inputs[i] = self.normalize(item)
return inputs
@add_end_docstrings(build_pipeline_init_args(has_tokenizer=True))
class QuestionAnsweringPipeline(ChunkPipeline):
"""
Question Answering pipeline using any `ModelForQuestionAnswering`. See the [question answering
examples](../task_summary#question-answering) for more information.
Example:
```python
>>> from transformers import pipeline
>>> oracle = pipeline(model="deepset/roberta-base-squad2")
>>> oracle(question="Where do I live?", context="My name is Wolfgang and I live in Berlin")
{'score': 0.9191, 'start': 34, 'end': 40, 'answer': 'Berlin'}
```
Learn more about the basics of using a pipeline in the [pipeline tutorial](../pipeline_tutorial)
This question answering pipeline can currently be loaded from [`pipeline`] using the following task identifier:
`"question-answering"`.
The models that this pipeline can use are models that have been fine-tuned on a question answering task. See the
up-to-date list of available models on
[huggingface.co/models](https://huggingface.co/models?filter=question-answering).
"""
default_input_names = "question,context"
handle_impossible_answer = False
def __init__(
self,
model: Union["PreTrainedModel", "TFPreTrainedModel"],
tokenizer: PreTrainedTokenizer,
modelcard: Optional[ModelCard] = None,
framework: Optional[str] = None,
task: str = "",
**kwargs,
):
super().__init__(
model=model,
tokenizer=tokenizer,
modelcard=modelcard,
framework=framework,
task=task,
**kwargs,
)
self._args_parser = QuestionAnsweringArgumentHandler()
self.check_model_type(
TF_MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES
if self.framework == "tf"
else MODEL_FOR_QUESTION_ANSWERING_MAPPING_NAMES
)
@staticmethod
def create_sample(
question: Union[str, List[str]], context: Union[str, List[str]]
) -> Union[SquadExample, List[SquadExample]]:
"""
QuestionAnsweringPipeline leverages the [`SquadExample`] internally. This helper method encapsulate all the
logic for converting question(s) and context(s) to [`SquadExample`].
We currently support extractive question answering.
Arguments:
question (`str` or `List[str]`): The question(s) asked.
context (`str` or `List[str]`): The context(s) in which we will look for the answer.
Returns:
One or a list of [`SquadExample`]: The corresponding [`SquadExample`] grouping question and context.
"""
if isinstance(question, list):
return [SquadExample(None, q, c, None, None, None) for q, c in zip(question, context)]
else:
return SquadExample(None, question, context, None, None, None)
def _sanitize_parameters(
self,
padding=None,
topk=None,
top_k=None,
doc_stride=None,
max_answer_len=None,
max_seq_len=None,
max_question_len=None,
handle_impossible_answer=None,
align_to_words=None,
**kwargs,
):
# Set defaults values
preprocess_params = {}
if padding is not None:
preprocess_params["padding"] = padding
if doc_stride is not None:
preprocess_params["doc_stride"] = doc_stride
if max_question_len is not None:
preprocess_params["max_question_len"] = max_question_len
if max_seq_len is not None:
preprocess_params["max_seq_len"] = max_seq_len
postprocess_params = {}
if topk is not None and top_k is None:
warnings.warn("topk parameter is deprecated, use top_k instead", UserWarning)
top_k = topk
if top_k is not None:
if top_k < 1:
raise ValueError(f"top_k parameter should be >= 1 (got {top_k})")
postprocess_params["top_k"] = top_k
if max_answer_len is not None:
if max_answer_len < 1:
raise ValueError(f"max_answer_len parameter should be >= 1 (got {max_answer_len}")
if max_answer_len is not None:
postprocess_params["max_answer_len"] = max_answer_len
if handle_impossible_answer is not None:
postprocess_params["handle_impossible_answer"] = handle_impossible_answer
if align_to_words is not None:
postprocess_params["align_to_words"] = align_to_words
return preprocess_params, {}, postprocess_params
def __call__(self, *args, **kwargs):
"""
Answer the question(s) given as inputs by using the context(s).
Args:
args ([`SquadExample`] or a list of [`SquadExample`]):
One or several [`SquadExample`] containing the question and context.
X ([`SquadExample`] or a list of [`SquadExample`], *optional*):
One or several [`SquadExample`] containing the question and context (will be treated the same way as if
passed as the first positional argument).
data ([`SquadExample`] or a list of [`SquadExample`], *optional*):
One or several [`SquadExample`] containing the question and context (will be treated the same way as if
passed as the first positional argument).
question (`str` or `List[str]`):
One or several question(s) (must be used in conjunction with the `context` argument).
context (`str` or `List[str]`):
One or several context(s) associated with the question(s) (must be used in conjunction with the
`question` argument).
topk (`int`, *optional*, defaults to 1):
The number of answers to return (will be chosen by order of likelihood). Note that we return less than
topk answers if there are not enough options available within the context.
doc_stride (`int`, *optional*, defaults to 128):
If the context is too long to fit with the question for the model, it will be split in several chunks
with some overlap. This argument controls the size of that overlap.
max_answer_len (`int`, *optional*, defaults to 15):
The maximum length of predicted answers (e.g., only answers with a shorter length are considered).
max_seq_len (`int`, *optional*, defaults to 384):
The maximum length of the total sentence (context + question) in tokens of each chunk passed to the
model. The context will be split in several chunks (using `doc_stride` as overlap) if needed.
max_question_len (`int`, *optional*, defaults to 64):
The maximum length of the question after tokenization. It will be truncated if needed.
handle_impossible_answer (`bool`, *optional*, defaults to `False`):
Whether or not we accept impossible as an answer.
align_to_words (`bool`, *optional*, defaults to `True`):
Attempts to align the answer to real words. Improves quality on space separated langages. Might hurt on
non-space-separated languages (like Japanese or Chinese)
Return:
A `dict` or a list of `dict`: Each result comes as a dictionary with the following keys:
- **score** (`float`) -- The probability associated to the answer.
- **start** (`int`) -- The character start index of the answer (in the tokenized version of the input).
- **end** (`int`) -- The character end index of the answer (in the tokenized version of the input).
- **answer** (`str`) -- The answer to the question.
"""
# Convert inputs to features
examples = self._args_parser(*args, **kwargs)
if isinstance(examples, (list, tuple)) and len(examples) == 1:
return super().__call__(examples[0], **kwargs)
return super().__call__(examples, **kwargs)
def preprocess(self, example, padding="do_not_pad", doc_stride=None, max_question_len=64, max_seq_len=None):
# XXX: This is specal, args_parser will not handle anything generator or dataset like
# For those we expect user to send a simple valid example either directly as a SquadExample or simple dict.
# So we still need a little sanitation here.
if isinstance(example, dict):
example = SquadExample(None, example["question"], example["context"], None, None, None)
if max_seq_len is None:
max_seq_len = min(self.tokenizer.model_max_length, 384)
if doc_stride is None:
doc_stride = min(max_seq_len // 2, 128)
if doc_stride > max_seq_len:
raise ValueError(f"`doc_stride` ({doc_stride}) is larger than `max_seq_len` ({max_seq_len})")
if not self.tokenizer.is_fast:
features = squad_convert_examples_to_features(
examples=[example],
tokenizer=self.tokenizer,
max_seq_length=max_seq_len,
doc_stride=doc_stride,
max_query_length=max_question_len,
padding_strategy=PaddingStrategy.MAX_LENGTH,
is_training=False,
tqdm_enabled=False,
)
else:
# Define the side we want to truncate / pad and the text/pair sorting
question_first = self.tokenizer.padding_side == "right"
encoded_inputs = self.tokenizer(
text=example.question_text if question_first else example.context_text,
text_pair=example.context_text if question_first else example.question_text,
padding=padding,
truncation="only_second" if question_first else "only_first",
max_length=max_seq_len,
stride=doc_stride,
return_token_type_ids=True,
return_overflowing_tokens=True,
return_offsets_mapping=True,
return_special_tokens_mask=True,
)
# When the input is too long, it's converted in a batch of inputs with overflowing tokens
# and a stride of overlap between the inputs. If a batch of inputs is given, a special output
# "overflow_to_sample_mapping" indicate which member of the encoded batch belong to which original batch sample.
# Here we tokenize examples one-by-one so we don't need to use "overflow_to_sample_mapping".
# "num_span" is the number of output samples generated from the overflowing tokens.
num_spans = len(encoded_inputs["input_ids"])
# p_mask: mask with 1 for token than cannot be in the answer (0 for token which can be in an answer)
# We put 0 on the tokens from the context and 1 everywhere else (question and special tokens)
p_mask = [
[tok != 1 if question_first else 0 for tok in encoded_inputs.sequence_ids(span_id)]
for span_id in range(num_spans)
]
features = []
for span_idx in range(num_spans):
input_ids_span_idx = encoded_inputs["input_ids"][span_idx]
attention_mask_span_idx = (
encoded_inputs["attention_mask"][span_idx] if "attention_mask" in encoded_inputs else None
)
token_type_ids_span_idx = (
encoded_inputs["token_type_ids"][span_idx] if "token_type_ids" in encoded_inputs else None
)
# keep the cls_token unmasked (some models use it to indicate unanswerable questions)
if self.tokenizer.cls_token_id is not None:
cls_indices = np.nonzero(np.array(input_ids_span_idx) == self.tokenizer.cls_token_id)[0]
for cls_index in cls_indices:
p_mask[span_idx][cls_index] = 0
submask = p_mask[span_idx]
features.append(
SquadFeatures(
input_ids=input_ids_span_idx,
attention_mask=attention_mask_span_idx,
token_type_ids=token_type_ids_span_idx,
p_mask=submask,
encoding=encoded_inputs[span_idx],
# We don't use the rest of the values - and actually
# for Fast tokenizer we could totally avoid using SquadFeatures and SquadExample
cls_index=None,
token_to_orig_map={},
example_index=0,
unique_id=0,
paragraph_len=0,
token_is_max_context=0,
tokens=[],
start_position=0,
end_position=0,
is_impossible=False,
qas_id=None,
)
)
for i, feature in enumerate(features):
fw_args = {}
others = {}
model_input_names = self.tokenizer.model_input_names + ["p_mask", "token_type_ids"]
for k, v in feature.__dict__.items():
if k in model_input_names:
if self.framework == "tf":
tensor = tf.constant(v)
if tensor.dtype == tf.int64:
tensor = tf.cast(tensor, tf.int32)
fw_args[k] = tf.expand_dims(tensor, 0)
elif self.framework == "pt":
tensor = torch.tensor(v)
if tensor.dtype == torch.int32:
tensor = tensor.long()
fw_args[k] = tensor.unsqueeze(0)
else:
others[k] = v
is_last = i == len(features) - 1
yield {"example": example, "is_last": is_last, **fw_args, **others}
def _forward(self, inputs):
example = inputs["example"]
model_inputs = {k: inputs[k] for k in self.tokenizer.model_input_names}
# `XXXForSequenceClassification` models should not use `use_cache=True` even if it's supported
model_forward = self.model.forward if self.framework == "pt" else self.model.call
if "use_cache" in inspect.signature(model_forward).parameters.keys():
model_inputs["use_cache"] = False
output = self.model(**model_inputs)
if isinstance(output, dict):
return {"start": output["start_logits"], "end": output["end_logits"], "example": example, **inputs}
else:
start, end = output[:2]
return {"start": start, "end": end, "example": example, **inputs}
def postprocess(
self,
model_outputs,
top_k=1,
handle_impossible_answer=False,
max_answer_len=15,
align_to_words=True,
):
min_null_score = 1000000 # large and positive
answers = []
for output in model_outputs:
start_ = output["start"]
end_ = output["end"]
example = output["example"]
p_mask = output["p_mask"]
attention_mask = (
output["attention_mask"].numpy() if output.get("attention_mask", None) is not None else None
)
starts, ends, scores, min_null_score = select_starts_ends(
start_, end_, p_mask, attention_mask, min_null_score, top_k, handle_impossible_answer, max_answer_len
)
if not self.tokenizer.is_fast:
char_to_word = np.array(example.char_to_word_offset)
# Convert the answer (tokens) back to the original text
# Score: score from the model
# Start: Index of the first character of the answer in the context string
# End: Index of the character following the last character of the answer in the context string
# Answer: Plain text of the answer
for s, e, score in zip(starts, ends, scores):
token_to_orig_map = output["token_to_orig_map"]
answers.append(
{
"score": score.item(),
"start": np.where(char_to_word == token_to_orig_map[s])[0][0].item(),
"end": np.where(char_to_word == token_to_orig_map[e])[0][-1].item(),
"answer": " ".join(example.doc_tokens[token_to_orig_map[s] : token_to_orig_map[e] + 1]),
}
)
else:
# Convert the answer (tokens) back to the original text
# Score: score from the model
# Start: Index of the first character of the answer in the context string
# End: Index of the character following the last character of the answer in the context string
# Answer: Plain text of the answer
question_first = bool(self.tokenizer.padding_side == "right")
enc = output["encoding"]
# Encoding was *not* padded, input_ids *might*.
# It doesn't make a difference unless we're padding on
# the left hand side, since now we have different offsets
# everywhere.
if self.tokenizer.padding_side == "left":
offset = (output["input_ids"] == self.tokenizer.pad_token_id).numpy().sum()
else:
offset = 0
# Sometimes the max probability token is in the middle of a word so:
# - we start by finding the right word containing the token with `token_to_word`
# - then we convert this word in a character span with `word_to_chars`
sequence_index = 1 if question_first else 0
for s, e, score in zip(starts, ends, scores):
s = s - offset
e = e - offset
start_index, end_index = self.get_indices(enc, s, e, sequence_index, align_to_words)
answers.append(
{
"score": score.item(),
"start": start_index,
"end": end_index,
"answer": example.context_text[start_index:end_index],
}
)
if handle_impossible_answer:
answers.append({"score": min_null_score, "start": 0, "end": 0, "answer": ""})
answers = sorted(answers, key=lambda x: x["score"], reverse=True)[:top_k]
if len(answers) == 1:
return answers[0]
return answers
def get_indices(
self, enc: "tokenizers.Encoding", s: int, e: int, sequence_index: int, align_to_words: bool
) -> Tuple[int, int]:
if align_to_words:
try:
start_word = enc.token_to_word(s)
end_word = enc.token_to_word(e)
start_index = enc.word_to_chars(start_word, sequence_index=sequence_index)[0]
end_index = enc.word_to_chars(end_word, sequence_index=sequence_index)[1]
except Exception:
# Some tokenizers don't really handle words. Keep to offsets then.
start_index = enc.offsets[s][0]
end_index = enc.offsets[e][1]
else:
start_index = enc.offsets[s][0]
end_index = enc.offsets[e][1]
return start_index, end_index
def span_to_answer(self, text: str, start: int, end: int) -> Dict[str, Union[str, int]]:
"""
When decoding from token probabilities, this method maps token indexes to actual word in the initial context.
Args:
text (`str`): The actual context to extract the answer from.
start (`int`): The answer starting token index.
end (`int`): The answer end token index.
Returns:
Dictionary like `{'answer': str, 'start': int, 'end': int}`
"""
words = []
token_idx = char_start_idx = char_end_idx = chars_idx = 0
for i, word in enumerate(text.split(" ")):
token = self.tokenizer.tokenize(word)
# Append words if they are in the span
if start <= token_idx <= end:
if token_idx == start:
char_start_idx = chars_idx
if token_idx == end:
char_end_idx = chars_idx + len(word)
words += [word]
# Stop if we went over the end of the answer
if token_idx > end:
break
# Append the subtokenization length to the running index
token_idx += len(token)
chars_idx += len(word) + 1
# Join text with spaces
return {
"answer": " ".join(words),
"start": max(0, char_start_idx),
"end": min(len(text), char_end_idx),
}
| transformers/src/transformers/pipelines/question_answering.py/0 | {
"file_path": "transformers/src/transformers/pipelines/question_answering.py",
"repo_id": "transformers",
"token_count": 13330
} | 344 |
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import warnings
from typing import Dict, Optional, Union
from ..models.auto.configuration_auto import AutoConfig
from ..utils.quantization_config import (
AqlmConfig,
AwqConfig,
BitsAndBytesConfig,
GPTQConfig,
QuantizationConfigMixin,
QuantizationMethod,
QuantoConfig,
)
from .quantizer_aqlm import AqlmHfQuantizer
from .quantizer_awq import AwqQuantizer
from .quantizer_bnb_4bit import Bnb4BitHfQuantizer
from .quantizer_bnb_8bit import Bnb8BitHfQuantizer
from .quantizer_gptq import GptqHfQuantizer
from .quantizer_quanto import QuantoHfQuantizer
AUTO_QUANTIZER_MAPPING = {
"awq": AwqQuantizer,
"bitsandbytes_4bit": Bnb4BitHfQuantizer,
"bitsandbytes_8bit": Bnb8BitHfQuantizer,
"gptq": GptqHfQuantizer,
"aqlm": AqlmHfQuantizer,
"quanto": QuantoHfQuantizer,
}
AUTO_QUANTIZATION_CONFIG_MAPPING = {
"awq": AwqConfig,
"bitsandbytes_4bit": BitsAndBytesConfig,
"bitsandbytes_8bit": BitsAndBytesConfig,
"gptq": GPTQConfig,
"aqlm": AqlmConfig,
"quanto": QuantoConfig,
}
class AutoQuantizationConfig:
"""
The Auto-HF quantization config class that takes care of automatically dispatching to the correct
quantization config given a quantization config stored in a dictionary.
"""
@classmethod
def from_dict(cls, quantization_config_dict: Dict):
quant_method = quantization_config_dict.get("quant_method", None)
# We need a special care for bnb models to make sure everything is BC ..
if quantization_config_dict.get("load_in_8bit", False) or quantization_config_dict.get("load_in_4bit", False):
suffix = "_4bit" if quantization_config_dict.get("load_in_4bit", False) else "_8bit"
quant_method = QuantizationMethod.BITS_AND_BYTES + suffix
elif quant_method is None:
raise ValueError(
"The model's quantization config from the arguments has no `quant_method` attribute. Make sure that the model has been correctly quantized"
)
if quant_method not in AUTO_QUANTIZATION_CONFIG_MAPPING.keys():
raise ValueError(
f"Unknown quantization type, got {quant_method} - supported types are:"
f" {list(AUTO_QUANTIZER_MAPPING.keys())}"
)
target_cls = AUTO_QUANTIZATION_CONFIG_MAPPING[quant_method]
return target_cls.from_dict(quantization_config_dict)
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
model_config = AutoConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
if getattr(model_config, "quantization_config", None) is None:
raise ValueError(
f"Did not found a `quantization_config` in {pretrained_model_name_or_path}. Make sure that the model is correctly quantized."
)
quantization_config_dict = model_config.quantization_config
quantization_config = cls.from_dict(quantization_config_dict)
# Update with potential kwargs that are passed through from_pretrained.
quantization_config.update(kwargs)
return quantization_config
class AutoHfQuantizer:
"""
The Auto-HF quantizer class that takes care of automatically instantiating to the correct
`HfQuantizer` given the `QuantizationConfig`.
"""
@classmethod
def from_config(cls, quantization_config: Union[QuantizationConfigMixin, Dict], **kwargs):
# Convert it to a QuantizationConfig if the q_config is a dict
if isinstance(quantization_config, dict):
quantization_config = AutoQuantizationConfig.from_dict(quantization_config)
quant_method = quantization_config.quant_method
# Again, we need a special care for bnb as we have a single quantization config
# class for both 4-bit and 8-bit quantization
if quant_method == QuantizationMethod.BITS_AND_BYTES:
if quantization_config.load_in_8bit:
quant_method += "_8bit"
else:
quant_method += "_4bit"
if quant_method not in AUTO_QUANTIZER_MAPPING.keys():
raise ValueError(
f"Unknown quantization type, got {quant_method} - supported types are:"
f" {list(AUTO_QUANTIZER_MAPPING.keys())}"
)
target_cls = AUTO_QUANTIZER_MAPPING[quant_method]
return target_cls(quantization_config, **kwargs)
@classmethod
def from_pretrained(cls, pretrained_model_name_or_path, **kwargs):
quantization_config = AutoQuantizationConfig.from_pretrained(pretrained_model_name_or_path, **kwargs)
return cls.from_config(quantization_config)
@classmethod
def merge_quantization_configs(
cls,
quantization_config: Union[dict, QuantizationConfigMixin],
quantization_config_from_args: Optional[QuantizationConfigMixin],
):
"""
handles situations where both quantization_config from args and quantization_config from model config are present.
"""
if quantization_config_from_args is not None:
warning_msg = (
"You passed `quantization_config` or equivalent parameters to `from_pretrained` but the model you're loading"
" already has a `quantization_config` attribute. The `quantization_config` from the model will be used."
)
else:
warning_msg = ""
if isinstance(quantization_config, dict):
quantization_config = AutoQuantizationConfig.from_dict(quantization_config)
if isinstance(quantization_config, (GPTQConfig, AwqConfig)) and quantization_config_from_args is not None:
# special case for GPTQ / AWQ config collision
loading_attr_dict = quantization_config_from_args.get_loading_attributes()
for attr, val in loading_attr_dict.items():
setattr(quantization_config, attr, val)
warning_msg += f"However, loading attributes (e.g. {list(loading_attr_dict.keys())}) will be overwritten with the one you passed to `from_pretrained`. The rest will be ignored."
if warning_msg != "":
warnings.warn(warning_msg)
return quantization_config
| transformers/src/transformers/quantizers/auto.py/0 | {
"file_path": "transformers/src/transformers/quantizers/auto.py",
"repo_id": "transformers",
"token_count": 2633
} | 345 |
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Tokenization classes for python tokenizers. For fast tokenizers (provided by HuggingFace's tokenizers library) see
tokenization_utils_fast.py
"""
import bisect
import itertools
import re
import unicodedata
from collections import OrderedDict
from typing import Any, Dict, List, Optional, Tuple, Union, overload
from .tokenization_utils_base import (
ENCODE_KWARGS_DOCSTRING,
ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING,
INIT_TOKENIZER_DOCSTRING,
AddedToken,
BatchEncoding,
EncodedInput,
EncodedInputPair,
PreTokenizedInput,
PreTokenizedInputPair,
PreTrainedTokenizerBase,
TextInput,
TextInputPair,
TruncationStrategy,
)
from .utils import PaddingStrategy, TensorType, add_end_docstrings, logging
logger = logging.get_logger(__name__)
# Slow tokenizers are saved in a vocabulary plus three separated files
SPECIAL_TOKENS_MAP_FILE = "special_tokens_map.json"
ADDED_TOKENS_FILE = "added_tokens.json"
TOKENIZER_CONFIG_FILE = "tokenizer_config.json"
class Trie:
"""
Trie in Python. Creates a Trie out of a list of words. The trie is used to split on `added_tokens` in one pass
Loose reference https://en.wikipedia.org/wiki/Trie
"""
def __init__(self):
self.data = {}
self._tokens = set()
def add(self, word: str):
"""
Passes over every char (utf-8 char) on word and recursively adds it to the internal `data` trie representation.
The special key `""` is used to represent termination.
This function is idempotent, adding twice the same word will leave the trie unchanged
Example:
```python
>>> trie = Trie()
>>> trie.add("Hello 友達")
>>> trie.data
{"H": {"e": {"l": {"l": {"o": {" ": {"友": {"達": {"": 1}}}}}}}}}
>>> trie.add("Hello")
>>> trie.data
{"H": {"e": {"l": {"l": {"o": {"": 1, " ": {"友": {"達": {"": 1}}}}}}}}}
```
"""
if not word:
# Prevent empty string
return
self._tokens.add(word)
ref = self.data
for char in word:
ref[char] = char in ref and ref[char] or {}
ref = ref[char]
ref[""] = 1
def split(self, text: str) -> List[str]:
"""
Will look for the words added to the trie within `text`. Output is the original string splitted along the
boundaries of the words found.
This trie will match the longest possible word first !
Example:
```python
>>> trie = Trie()
>>> trie.split("[CLS] This is a extra_id_100")
["[CLS] This is a extra_id_100"]
>>> trie.add("[CLS]")
>>> trie.add("extra_id_1")
>>> trie.add("extra_id_100")
>>> trie.split("[CLS] This is a extra_id_100")
["[CLS]", " This is a ", "extra_id_100"]
```
"""
# indexes are counted left of the chars index.
# "hello", index 0, is left of h, index 1 is between h and e.
# index 5 is right of the "o".
# States are going to capture every possible start (indexes as above)
# as keys, and have as values, a pointer to the position in the trie
# where we're at. This is a partial match for now.
# This enables to keep track of multiple matches while we're iterating
# the string
# If the trie contains, "blowing", and "lower" and we encounter the
# string "blower", we need to split into ["b", "lower"].
# This is where we need to keep track of multiple possible starts.
states = OrderedDict()
# This will contain every indices where we need
# to cut.
# We force to cut at offset 0 and len(text) (added later)
offsets = [0]
# This is used by the lookahead which needs to skip over
# some text where the full match exceeded the place in the initial
# for loop
skip = 0
# Main loop, Giving this algorithm O(n) complexity
for current, current_char in enumerate(text):
if skip and current < skip:
# Prevents the lookahead for matching twice
# like extra_id_100 and id_100
continue
# This will track every state
# that stop matching, we need to stop tracking them.
# If we look at "lowball", we're going to match "l" (add it to states), "o", "w", then
# fail on "b", we need to remove 0 from the valid states.
to_remove = set()
# Whenever we found a match, we need to drop everything
# this is a greedy algorithm, it will match on the first found token
reset = False
# In this case, we already have partial matches (But unfinished)
for start, trie_pointer in states.items():
if "" in trie_pointer:
# This is a final match, we need to reset and
# store the results in `offsets`.
# Lookahead to match longest first
# Important in case of extra_id_1 vs extra_id_100
# Here we are also actively looking for other earlier partial
# matches
# "[CLS]", "L", we need to match CLS even if L is special
for lookstart, looktrie_pointer in states.items():
if lookstart > start:
# This partial match is later, we can stop looking
break
elif lookstart < start:
# This partial match is earlier, the trie pointer
# was already updated, so index is + 1
lookahead_index = current + 1
end = current + 1
else:
# Here lookstart == start and
# looktrie_pointer == trie_pointer
# It wasn't updated yet so indices are current ones
lookahead_index = current
end = current
next_char = text[lookahead_index] if lookahead_index < len(text) else None
if "" in looktrie_pointer:
start = lookstart
end = lookahead_index
skip = lookahead_index
while next_char in looktrie_pointer:
looktrie_pointer = looktrie_pointer[next_char]
lookahead_index += 1
if "" in looktrie_pointer:
start = lookstart
end = lookahead_index
skip = lookahead_index
if lookahead_index == len(text):
# End of string
break
next_char = text[lookahead_index]
# End lookahead
# Storing and resetting
offsets.append(start)
offsets.append(end)
reset = True
break
elif current_char in trie_pointer:
# The current character being looked at has a match within the trie
# update the pointer (it will be stored back into states later).
trie_pointer = trie_pointer[current_char]
# Storing back the new pointer into the states.
# Partial matches got longer by one.
states[start] = trie_pointer
else:
# The new character has not match in the trie, we need
# to stop keeping track of this partial match.
# We can't do it directly within the loop because of how
# python iteration works
to_remove.add(start)
# Either clearing the full start (we found a real match)
# Or clearing only the partial matches that didn't work.
if reset:
states = {}
else:
for start in to_remove:
del states[start]
# If this character is a starting character within the trie
# start keeping track of this partial match.
if current >= skip and current_char in self.data:
states[current] = self.data[current_char]
# We have a cut at the end with states.
for start, trie_pointer in states.items():
if "" in trie_pointer:
# This is a final match, we need to reset and
# store the results in `offsets`.
end = len(text)
offsets.append(start)
offsets.append(end)
# Longest cut is always the one with lower start so the first
# item so we need to break.
break
return self.cut_text(text, offsets)
def cut_text(self, text, offsets):
# We have all the offsets now, we just need to do the actual splitting.
# We need to eventually add the first part of the string and the eventual
# last part.
offsets.append(len(text))
tokens = []
start = 0
for end in offsets:
if start > end:
logger.error(
"There was a bug in Trie algorithm in tokenization. Attempting to recover. Please report it"
" anyway."
)
continue
elif start == end:
# This might happen if there's a match at index 0
# we're also preventing zero-width cuts in case of two
# consecutive matches
continue
tokens.append(text[start:end])
start = end
return tokens
def _is_whitespace(char):
"""Checks whether `char` is a whitespace character."""
# \t, \n, and \r are technically control characters but we treat them
# as whitespace since they are generally considered as such.
if char == " " or char == "\t" or char == "\n" or char == "\r":
return True
cat = unicodedata.category(char)
if cat == "Zs":
return True
return False
def _is_control(char):
"""Checks whether `char` is a control character."""
# These are technically control characters but we count them as whitespace
# characters.
if char == "\t" or char == "\n" or char == "\r":
return False
cat = unicodedata.category(char)
if cat.startswith("C"):
return True
return False
def _is_punctuation(char):
"""Checks whether `char` is a punctuation character."""
cp = ord(char)
# We treat all non-letter/number ASCII as punctuation.
# Characters such as "^", "$", and "`" are not in the Unicode
# Punctuation class but we treat them as punctuation anyways, for
# consistency.
if (cp >= 33 and cp <= 47) or (cp >= 58 and cp <= 64) or (cp >= 91 and cp <= 96) or (cp >= 123 and cp <= 126):
return True
cat = unicodedata.category(char)
if cat.startswith("P"):
return True
return False
def _is_end_of_word(text):
"""Checks whether the last character in text is one of a punctuation, control or whitespace character."""
last_char = text[-1]
return bool(_is_control(last_char) | _is_punctuation(last_char) | _is_whitespace(last_char))
def _is_start_of_word(text):
"""Checks whether the first character in text is one of a punctuation, control or whitespace character."""
first_char = text[0]
return bool(_is_control(first_char) | _is_punctuation(first_char) | _is_whitespace(first_char))
def _insert_one_token_to_ordered_list(token_list: List[str], new_token: str):
"""
Inserts one token to an ordered list if it does not already exist. Note: token_list must be sorted.
"""
insertion_idx = bisect.bisect_left(token_list, new_token)
# Checks if new_token is already in the ordered token_list
if insertion_idx < len(token_list) and token_list[insertion_idx] == new_token:
# new_token is in token_list, don't add
return
else:
token_list.insert(insertion_idx, new_token)
@add_end_docstrings(INIT_TOKENIZER_DOCSTRING)
class PreTrainedTokenizer(PreTrainedTokenizerBase):
"""
Base class for all slow tokenizers.
Inherits from [`~tokenization_utils_base.PreTrainedTokenizerBase`].
Handle all the shared methods for tokenization and special tokens as well as methods downloading/caching/loading
pretrained tokenizers as well as adding tokens to the vocabulary.
This class also contain the added tokens in a unified way on top of all tokenizers so we don't have to handle the
specific vocabulary augmentation methods of the various underlying dictionary structures (BPE, sentencepiece...).
"""
def __init__(self, **kwargs):
# 1. Init the parent class
self.tokens_trie = Trie()
# 2. init `_added_tokens_decoder` if child class did not
if not hasattr(self, "_added_tokens_decoder"):
self._added_tokens_decoder: Dict[int, AddedToken] = {}
# 3. if a `added_tokens_decoder` is passed, we are loading from a saved tokenizer, we overwrite
self._added_tokens_decoder.update(kwargs.pop("added_tokens_decoder", {}))
self._added_tokens_encoder: Dict[str, int] = {k.content: v for v, k in self._added_tokens_decoder.items()}
# 4 init the parent class
super().__init__(**kwargs)
# 4. If some of the special tokens are not part of the vocab, we add them, at the end.
# the order of addition is the same as self.SPECIAL_TOKENS_ATTRIBUTES following `tokenizers`
self._add_tokens(
[token for token in self.all_special_tokens_extended if token not in self._added_tokens_encoder],
special_tokens=True,
)
self._decode_use_source_tokenizer = False
@property
def is_fast(self) -> bool:
return False
@property
def vocab_size(self) -> int:
"""
`int`: Size of the base vocabulary (without the added tokens).
"""
raise NotImplementedError
@property
def added_tokens_encoder(self) -> Dict[str, int]:
"""
Returns the sorted mapping from string to index. The added tokens encoder is cached for performance
optimisation in `self._added_tokens_encoder` for the slow tokenizers.
"""
return {k.content: v for v, k in sorted(self._added_tokens_decoder.items(), key=lambda item: item[0])}
@property
def added_tokens_decoder(self) -> Dict[int, AddedToken]:
"""
Returns the added tokens in the vocabulary as a dictionary of index to AddedToken.
Returns:
`Dict[str, int]`: The added tokens.
"""
return dict(sorted(self._added_tokens_decoder.items(), key=lambda item: item[0]))
@added_tokens_decoder.setter
def added_tokens_decoder(self, value: Dict[int, Union[AddedToken, str]]) -> Dict[int, AddedToken]:
# Always raise an error if string because users should define the behavior
for index, token in value.items():
if not isinstance(token, (str, AddedToken)) or not isinstance(index, int):
raise ValueError(
f"The provided `added_tokens_decoder` has an element of type {index.__class__, token.__class__}, should be a dict of {int, Union[AddedToken, str]}"
)
self._added_tokens_decoder[index] = AddedToken(token) if isinstance(token, str) else token
self._added_tokens_encoder[str(token)] = index
def get_added_vocab(self) -> Dict[str, int]:
"""
Returns the added tokens in the vocabulary as a dictionary of token to index. Results might be different from
the fast call because for now we always add the tokens even if they are already in the vocabulary. This is
something we should change.
Returns:
`Dict[str, int]`: The added tokens.
"""
return self._added_tokens_encoder
def __len__(self):
"""
Size of the full vocabulary with the added tokens. Counts the `keys` and not the `values` because otherwise if
there is a hole in the vocab, we will add tokenizers at a wrong index.
"""
return len(set(self.get_vocab().keys()))
def _add_tokens(self, new_tokens: Union[List[str], List[AddedToken]], special_tokens: bool = False) -> int:
"""
Add a list of new tokens to the tokenizer class. If the new tokens are not in the vocabulary, they are added to
it with indices starting from length of the current vocabulary. Special tokens are sometimes already in the
vocab which is why they have to be handled specifically.
Args:
new_tokens (`List[str]`or `List[tokenizers.AddedToken]`):
Token(s) to add in vocabulary. A token is counted as added if it's not already in the vocabulary
(tested by checking if the tokenizer assign the index of the `unk_token` to them). If a token is part
of the vocabulary then we simply mark this token as an `AddedToken` which allows to control the
stripping and normalization of this token. This is NOT possible in `tokenizers`.
special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the tokens should be added as special tokens.
Returns:
`int`: The number of tokens actually added to the vocabulary.
Examples:
```python
# Let's see how to increase the vocabulary of Bert model and tokenizer
tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
model = BertModel.from_pretrained("google-bert/bert-base-uncased")
num_added_toks = tokenizer.add_tokens(["new_tok1", "my_new-tok2"])
print("We have added", num_added_toks, "tokens")
# Note: resize_token_embeddings expects to receive the full size of the new vocabulary, i.e. the length of the tokenizer.
model.resize_token_embeddings(len(tokenizer))
```"""
added_tokens = 0
if new_tokens is None:
return added_tokens
# TODO this is fairly slow to improve!
current_vocab = self.get_vocab().copy()
new_idx = len(current_vocab) # only call this once, len gives the last index + 1
for token in new_tokens:
if not isinstance(token, (str, AddedToken)):
raise TypeError(f"Token {token} is not a string but a {type(token)}.")
if str(token) == "":
continue
if isinstance(token, str):
if token in self._added_tokens_encoder:
continue
else:
# very important for fast and slow equivalence!
is_special = token in self.all_special_tokens or special_tokens
token = AddedToken(
token, rstrip=False, lstrip=False, normalized=not is_special, special=is_special
)
elif special_tokens:
# doing token.special=True changes the normalization! will fix in rust
# this is important and the only reason why the AddedTokens in each class are normalized by default
token.__setstate__({"special": True, "normalized": token.normalized})
if token in self._added_tokens_decoder:
continue
if not token.special and token.normalized and getattr(self, "do_lower_case", False):
# Normalize if requested
token.content = token.content.lower()
if token.content not in current_vocab:
token_index = new_idx + added_tokens
current_vocab[token.content] = token_index
added_tokens += 1
else:
token_index = current_vocab[token.content]
if token.special and str(token) not in self.all_special_tokens:
self._additional_special_tokens.append(token)
# the setter automatically updates the reverse map
self._added_tokens_decoder[token_index] = token
self._added_tokens_encoder[token.content] = token_index
if self.verbose:
logger.info(f"Adding {token} to the vocabulary")
self._update_trie()
return added_tokens
def _update_trie(self, unique_no_split_tokens: Optional[str] = []):
for token in self._added_tokens_decoder.values():
if token not in self.tokens_trie._tokens:
self.tokens_trie.add(token.content)
for token in unique_no_split_tokens:
if token not in self.tokens_trie._tokens:
self.tokens_trie.add(token)
def num_special_tokens_to_add(self, pair: bool = False) -> int:
"""
Returns the number of added tokens when encoding a sequence with special tokens.
<Tip>
This encodes a dummy input and checks the number of added tokens, and is therefore not efficient. Do not put
this inside your training loop.
</Tip>
Args:
pair (`bool`, *optional*, defaults to `False`):
Whether the number of added tokens should be computed in the case of a sequence pair or a single
sequence.
Returns:
`int`: Number of special tokens added to sequences.
"""
token_ids_0 = []
token_ids_1 = []
return len(self.build_inputs_with_special_tokens(token_ids_0, token_ids_1 if pair else None))
def tokenize(self, text: TextInput, **kwargs) -> List[str]:
"""
Converts a string into a sequence of tokens, using the tokenizer.
Split in words for word-based vocabulary or sub-words for sub-word-based vocabularies
(BPE/SentencePieces/WordPieces). Takes care of added tokens.
Args:
text (`str`):
The sequence to be encoded.
**kwargs (additional keyword arguments):
Passed along to the model-specific `prepare_for_tokenization` preprocessing method.
Returns:
`List[str]`: The list of tokens.
"""
split_special_tokens = kwargs.pop("split_special_tokens", self.split_special_tokens)
text, kwargs = self.prepare_for_tokenization(text, **kwargs)
if kwargs:
logger.warning(f"Keyword arguments {kwargs} not recognized.")
if hasattr(self, "do_lower_case") and self.do_lower_case:
# convert non-special tokens to lowercase. Might be super slow as well?
escaped_special_toks = [re.escape(s_tok) for s_tok in (self.all_special_tokens)]
escaped_special_toks += [
re.escape(s_tok.content)
for s_tok in (self._added_tokens_decoder.values())
if not s_tok.special and s_tok.normalized
]
pattern = r"(" + r"|".join(escaped_special_toks) + r")|" + r"(.+?)"
text = re.sub(pattern, lambda m: m.groups()[0] or m.groups()[1].lower(), text)
if split_special_tokens:
no_split_token = []
tokens = [text]
else:
no_split_token = self._added_tokens_encoder.keys() # don't split on any of the added tokens
# "This is something<special_token_1> else"
tokens = self.tokens_trie.split(text)
# ["This is something", "<special_token_1>", " else"]
for i, token in enumerate(tokens):
if token in no_split_token:
tok_extended = self._added_tokens_decoder.get(self._added_tokens_encoder[token], None)
left = tokens[i - 1] if i > 0 else None
right = tokens[i + 1] if i < len(tokens) - 1 else None
if isinstance(tok_extended, AddedToken):
if tok_extended.rstrip and right:
# A bit counter-intuitive but we strip the left of the string
# since tok_extended.rstrip means the special token is eating all white spaces on its right
tokens[i + 1] = right.lstrip()
# Strip white spaces on the left
if tok_extended.lstrip and left:
tokens[i - 1] = left.rstrip() # Opposite here
if tok_extended.single_word and left and left[-1] != " ":
tokens[i - 1] += token
tokens[i] = ""
elif tok_extended.single_word and right and right[0] != " ":
tokens[i + 1] = token + tokens[i + 1]
tokens[i] = ""
else:
raise ValueError(
f"{tok_extended} cannot be tokenized because it was not properly added"
f" to the tokenizer. This means that it is not an `AddedToken` but a {type(tok_extended)}"
)
# ["This is something", "<special_token_1>", "else"]
tokenized_text = []
for token in tokens:
# Need to skip eventual empty (fully stripped) tokens
if not token:
continue
if token in no_split_token:
tokenized_text.append(token)
else:
tokenized_text.extend(self._tokenize(token))
# ["This", " is", " something", "<special_token_1>", "else"]
return tokenized_text
def _tokenize(self, text, **kwargs):
"""
Converts a string into a sequence of tokens (string), using the tokenizer. Split in words for word-based
vocabulary or sub-words for sub-word-based vocabularies (BPE/SentencePieces/WordPieces).
Do NOT take care of added tokens.
"""
raise NotImplementedError
def convert_tokens_to_ids(self, tokens: Union[str, List[str]]) -> Union[int, List[int]]:
"""
Converts a token string (or a sequence of tokens) in a single integer id (or a sequence of ids), using the
vocabulary.
Args:
tokens (`str` or `List[str]`): One or several token(s) to convert to token id(s).
Returns:
`int` or `List[int]`: The token id or list of token ids.
"""
if tokens is None:
return None
if isinstance(tokens, str):
return self._convert_token_to_id_with_added_voc(tokens)
ids = []
for token in tokens:
ids.append(self._convert_token_to_id_with_added_voc(token))
return ids
def _convert_token_to_id_with_added_voc(self, token):
if token is None:
return None
if token in self._added_tokens_encoder:
return self._added_tokens_encoder[token]
return self._convert_token_to_id(token)
def _convert_token_to_id(self, token):
raise NotImplementedError
def _encode_plus(
self,
text: Union[TextInput, PreTokenizedInput, EncodedInput],
text_pair: Optional[Union[TextInput, PreTokenizedInput, EncodedInput]] = None,
add_special_tokens: bool = True,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
max_length: Optional[int] = None,
stride: int = 0,
is_split_into_words: bool = False,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
def get_input_ids(text):
if isinstance(text, str):
tokens = self.tokenize(text, **kwargs)
return self.convert_tokens_to_ids(tokens)
elif isinstance(text, (list, tuple)) and len(text) > 0 and isinstance(text[0], str):
if is_split_into_words:
tokens = list(
itertools.chain(*(self.tokenize(t, is_split_into_words=True, **kwargs) for t in text))
)
return self.convert_tokens_to_ids(tokens)
else:
return self.convert_tokens_to_ids(text)
elif isinstance(text, (list, tuple)) and len(text) > 0 and isinstance(text[0], int):
return text
else:
if is_split_into_words:
raise ValueError(
f"Input {text} is not valid. Should be a string or a list/tuple of strings when"
" `is_split_into_words=True`."
)
else:
raise ValueError(
f"Input {text} is not valid. Should be a string, a list/tuple of strings or a list/tuple of"
" integers."
)
if return_offsets_mapping:
raise NotImplementedError(
"return_offset_mapping is not available when using Python tokenizers. "
"To use this feature, change your tokenizer to one deriving from "
"transformers.PreTrainedTokenizerFast. "
"More information on available tokenizers at "
"https://github.com/huggingface/transformers/pull/2674"
)
first_ids = get_input_ids(text)
second_ids = get_input_ids(text_pair) if text_pair is not None else None
return self.prepare_for_model(
first_ids,
pair_ids=second_ids,
add_special_tokens=add_special_tokens,
padding=padding_strategy.value,
truncation=truncation_strategy.value,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors=return_tensors,
prepend_batch_axis=True,
return_attention_mask=return_attention_mask,
return_token_type_ids=return_token_type_ids,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_length=return_length,
verbose=verbose,
)
def _batch_encode_plus(
self,
batch_text_or_text_pairs: Union[
List[TextInput],
List[TextInputPair],
List[PreTokenizedInput],
List[PreTokenizedInputPair],
List[EncodedInput],
List[EncodedInputPair],
],
add_special_tokens: bool = True,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
max_length: Optional[int] = None,
stride: int = 0,
is_split_into_words: bool = False,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[Union[str, TensorType]] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_offsets_mapping: bool = False,
return_length: bool = False,
verbose: bool = True,
**kwargs,
) -> BatchEncoding:
def get_input_ids(text):
if isinstance(text, str):
tokens = self.tokenize(text, **kwargs)
return self.convert_tokens_to_ids(tokens)
elif isinstance(text, (list, tuple)) and len(text) > 0 and isinstance(text[0], str):
if is_split_into_words:
tokens = list(
itertools.chain(*(self.tokenize(t, is_split_into_words=True, **kwargs) for t in text))
)
return self.convert_tokens_to_ids(tokens)
else:
return self.convert_tokens_to_ids(text)
elif isinstance(text, (list, tuple)) and len(text) > 0 and isinstance(text[0], int):
return text
else:
raise ValueError(
"Input is not valid. Should be a string, a list/tuple of strings or a list/tuple of integers."
)
if return_offsets_mapping:
raise NotImplementedError(
"return_offset_mapping is not available when using Python tokenizers. "
"To use this feature, change your tokenizer to one deriving from "
"transformers.PreTrainedTokenizerFast."
)
input_ids = []
for ids_or_pair_ids in batch_text_or_text_pairs:
if not isinstance(ids_or_pair_ids, (list, tuple)):
ids, pair_ids = ids_or_pair_ids, None
elif is_split_into_words and not isinstance(ids_or_pair_ids[0], (list, tuple)):
ids, pair_ids = ids_or_pair_ids, None
else:
ids, pair_ids = ids_or_pair_ids
first_ids = get_input_ids(ids)
second_ids = get_input_ids(pair_ids) if pair_ids is not None else None
input_ids.append((first_ids, second_ids))
batch_outputs = self._batch_prepare_for_model(
input_ids,
add_special_tokens=add_special_tokens,
padding_strategy=padding_strategy,
truncation_strategy=truncation_strategy,
max_length=max_length,
stride=stride,
pad_to_multiple_of=pad_to_multiple_of,
return_attention_mask=return_attention_mask,
return_token_type_ids=return_token_type_ids,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_length=return_length,
return_tensors=return_tensors,
verbose=verbose,
)
return BatchEncoding(batch_outputs)
@add_end_docstrings(ENCODE_KWARGS_DOCSTRING, ENCODE_PLUS_ADDITIONAL_KWARGS_DOCSTRING)
def _batch_prepare_for_model(
self,
batch_ids_pairs: List[Union[PreTokenizedInputPair, Tuple[List[int], None]]],
add_special_tokens: bool = True,
padding_strategy: PaddingStrategy = PaddingStrategy.DO_NOT_PAD,
truncation_strategy: TruncationStrategy = TruncationStrategy.DO_NOT_TRUNCATE,
max_length: Optional[int] = None,
stride: int = 0,
pad_to_multiple_of: Optional[int] = None,
return_tensors: Optional[str] = None,
return_token_type_ids: Optional[bool] = None,
return_attention_mask: Optional[bool] = None,
return_overflowing_tokens: bool = False,
return_special_tokens_mask: bool = False,
return_length: bool = False,
verbose: bool = True,
) -> BatchEncoding:
"""
Prepares a sequence of input id, or a pair of sequences of inputs ids so that it can be used by the model. It
adds special tokens, truncates sequences if overflowing while taking into account the special tokens and
manages a moving window (with user defined stride) for overflowing tokens
Args:
batch_ids_pairs: list of tokenized input ids or input ids pairs
"""
batch_outputs = {}
for first_ids, second_ids in batch_ids_pairs:
outputs = self.prepare_for_model(
first_ids,
second_ids,
add_special_tokens=add_special_tokens,
padding=PaddingStrategy.DO_NOT_PAD.value, # we pad in batch afterward
truncation=truncation_strategy.value,
max_length=max_length,
stride=stride,
pad_to_multiple_of=None, # we pad in batch afterward
return_attention_mask=False, # we pad in batch afterward
return_token_type_ids=return_token_type_ids,
return_overflowing_tokens=return_overflowing_tokens,
return_special_tokens_mask=return_special_tokens_mask,
return_length=return_length,
return_tensors=None, # We convert the whole batch to tensors at the end
prepend_batch_axis=False,
verbose=verbose,
)
for key, value in outputs.items():
if key not in batch_outputs:
batch_outputs[key] = []
batch_outputs[key].append(value)
batch_outputs = self.pad(
batch_outputs,
padding=padding_strategy.value,
max_length=max_length,
pad_to_multiple_of=pad_to_multiple_of,
return_attention_mask=return_attention_mask,
)
batch_outputs = BatchEncoding(batch_outputs, tensor_type=return_tensors)
return batch_outputs
def prepare_for_tokenization(
self, text: str, is_split_into_words: bool = False, **kwargs
) -> Tuple[str, Dict[str, Any]]:
"""
Performs any necessary transformations before tokenization.
This method should pop the arguments from kwargs and return the remaining `kwargs` as well. We test the
`kwargs` at the end of the encoding process to be sure all the arguments have been used.
Args:
text (`str`):
The text to prepare.
is_split_into_words (`bool`, *optional*, defaults to `False`):
Whether or not the input is already pre-tokenized (e.g., split into words). If set to `True`, the
tokenizer assumes the input is already split into words (for instance, by splitting it on whitespace)
which it will tokenize. This is useful for NER or token classification.
kwargs (`Dict[str, Any]`, *optional*):
Keyword arguments to use for the tokenization.
Returns:
`Tuple[str, Dict[str, Any]]`: The prepared text and the unused kwargs.
"""
return (text, kwargs)
def get_special_tokens_mask(
self, token_ids_0: List, token_ids_1: Optional[List] = None, already_has_special_tokens: bool = False
) -> List[int]:
"""
Retrieves sequence ids from a token list that has no special tokens added. This method is called when adding
special tokens using the tokenizer `prepare_for_model` or `encode_plus` methods.
Args:
token_ids_0 (`List[int]`):
List of ids of the first sequence.
token_ids_1 (`List[int]`, *optional*):
List of ids of the second sequence.
already_has_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not the token list is already formatted with special tokens for the model.
Returns:
A list of integers in the range [0, 1]: 1 for a special token, 0 for a sequence token.
"""
if already_has_special_tokens:
if token_ids_1 is not None:
raise ValueError(
"You should not supply a second sequence if the provided sequence of "
"ids is already formatted with special tokens for the model."
)
return super().get_special_tokens_mask(
token_ids_0=token_ids_0, token_ids_1=token_ids_1, already_has_special_tokens=True
)
return [0] * ((len(token_ids_1) if token_ids_1 else 0) + len(token_ids_0))
@overload
def convert_ids_to_tokens(self, ids: int, skip_special_tokens: bool = False) -> str:
...
@overload
def convert_ids_to_tokens(self, ids: List[int], skip_special_tokens: bool = False) -> List[str]:
...
def convert_ids_to_tokens(
self, ids: Union[int, List[int]], skip_special_tokens: bool = False
) -> Union[str, List[str]]:
"""
Converts a single index or a sequence of indices in a token or a sequence of tokens, using the vocabulary and
added tokens.
Args:
ids (`int` or `List[int]`):
The token id (or token ids) to convert to tokens.
skip_special_tokens (`bool`, *optional*, defaults to `False`):
Whether or not to remove special tokens in the decoding.
Returns:
`str` or `List[str]`: The decoded token(s).
"""
if isinstance(ids, int):
if ids in self._added_tokens_decoder:
return self._added_tokens_decoder[ids].content
else:
return self._convert_id_to_token(ids)
tokens = []
for index in ids:
index = int(index)
if skip_special_tokens and index in self.all_special_ids:
continue
if index in self._added_tokens_decoder:
tokens.append(self._added_tokens_decoder[index].content)
else:
tokens.append(self._convert_id_to_token(index))
return tokens
def _convert_id_to_token(self, index: int) -> str:
raise NotImplementedError
def convert_tokens_to_string(self, tokens: List[str]) -> str:
return " ".join(tokens)
def _decode(
self,
token_ids: List[int],
skip_special_tokens: bool = False,
clean_up_tokenization_spaces: bool = None,
spaces_between_special_tokens: bool = True,
**kwargs,
) -> str:
self._decode_use_source_tokenizer = kwargs.pop("use_source_tokenizer", False)
filtered_tokens = self.convert_ids_to_tokens(token_ids, skip_special_tokens=skip_special_tokens)
legacy_added_tokens = set(self._added_tokens_encoder.keys()) - set(self.all_special_tokens) | {
token for token in self.additional_special_tokens if self.convert_tokens_to_ids(token) >= self.vocab_size
}
# To avoid mixing byte-level and unicode for byte-level BPT
# we need to build string separately for added tokens and byte-level tokens
# cf. https://github.com/huggingface/transformers/issues/1133
sub_texts = []
current_sub_text = []
# TODO @ArthurZ in version 5, special tokens should be handled in convert_tokens_to_string, while _convert_tokens_to_string
for token in filtered_tokens:
if skip_special_tokens and token in self.all_special_ids:
continue
if token in legacy_added_tokens:
if current_sub_text:
string = self.convert_tokens_to_string(current_sub_text)
if len(string) > 0:
sub_texts.append(string)
current_sub_text = []
sub_texts.append(token)
else:
current_sub_text.append(token)
if current_sub_text:
sub_texts.append(self.convert_tokens_to_string(current_sub_text))
if spaces_between_special_tokens:
text = " ".join(sub_texts)
else:
text = "".join(sub_texts)
clean_up_tokenization_spaces = (
clean_up_tokenization_spaces
if clean_up_tokenization_spaces is not None
else self.clean_up_tokenization_spaces
)
if clean_up_tokenization_spaces:
clean_text = self.clean_up_tokenization(text)
return clean_text
else:
return text
| transformers/src/transformers/tokenization_utils.py/0 | {
"file_path": "transformers/src/transformers/tokenization_utils.py",
"repo_id": "transformers",
"token_count": 20391
} | 346 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from ..models.auto import AutoModelForSeq2SeqLM, AutoTokenizer
from .base import PipelineTool
QA_PROMPT = """Here is a text containing a lot of information: '''{text}'''.
Can you answer this question about the text: '{question}'"""
class TextQuestionAnsweringTool(PipelineTool):
default_checkpoint = "google/flan-t5-base"
description = (
"This is a tool that answers questions related to a text. It takes two arguments named `text`, which is the "
"text where to find the answer, and `question`, which is the question, and returns the answer to the question."
)
name = "text_qa"
pre_processor_class = AutoTokenizer
model_class = AutoModelForSeq2SeqLM
inputs = ["text", "text"]
outputs = ["text"]
def encode(self, text: str, question: str):
prompt = QA_PROMPT.format(text=text, question=question)
return self.pre_processor(prompt, return_tensors="pt")
def forward(self, inputs):
output_ids = self.model.generate(**inputs)
in_b, _ = inputs["input_ids"].shape
out_b = output_ids.shape[0]
return output_ids.reshape(in_b, out_b // in_b, *output_ids.shape[1:])[0][0]
def decode(self, outputs):
return self.pre_processor.decode(outputs, skip_special_tokens=True, clean_up_tokenization_spaces=True)
| transformers/src/transformers/tools/text_question_answering.py/0 | {
"file_path": "transformers/src/transformers/tools/text_question_answering.py",
"repo_id": "transformers",
"token_count": 665
} | 347 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Doc utilities: Utilities related to documentation
"""
import functools
import re
import types
def add_start_docstrings(*docstr):
def docstring_decorator(fn):
fn.__doc__ = "".join(docstr) + (fn.__doc__ if fn.__doc__ is not None else "")
return fn
return docstring_decorator
def add_start_docstrings_to_model_forward(*docstr):
def docstring_decorator(fn):
docstring = "".join(docstr) + (fn.__doc__ if fn.__doc__ is not None else "")
class_name = f"[`{fn.__qualname__.split('.')[0]}`]"
intro = f" The {class_name} forward method, overrides the `__call__` special method."
note = r"""
<Tip>
Although the recipe for forward pass needs to be defined within this function, one should call the [`Module`]
instance afterwards instead of this since the former takes care of running the pre and post processing steps while
the latter silently ignores them.
</Tip>
"""
fn.__doc__ = intro + note + docstring
return fn
return docstring_decorator
def add_end_docstrings(*docstr):
def docstring_decorator(fn):
fn.__doc__ = (fn.__doc__ if fn.__doc__ is not None else "") + "".join(docstr)
return fn
return docstring_decorator
PT_RETURN_INTRODUCTION = r"""
Returns:
[`{full_output_type}`] or `tuple(torch.FloatTensor)`: A [`{full_output_type}`] or a tuple of
`torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various
elements depending on the configuration ([`{config_class}`]) and inputs.
"""
TF_RETURN_INTRODUCTION = r"""
Returns:
[`{full_output_type}`] or `tuple(tf.Tensor)`: A [`{full_output_type}`] or a tuple of `tf.Tensor` (if
`return_dict=False` is passed or when `config.return_dict=False`) comprising various elements depending on the
configuration ([`{config_class}`]) and inputs.
"""
def _get_indent(t):
"""Returns the indentation in the first line of t"""
search = re.search(r"^(\s*)\S", t)
return "" if search is None else search.groups()[0]
def _convert_output_args_doc(output_args_doc):
"""Convert output_args_doc to display properly."""
# Split output_arg_doc in blocks argument/description
indent = _get_indent(output_args_doc)
blocks = []
current_block = ""
for line in output_args_doc.split("\n"):
# If the indent is the same as the beginning, the line is the name of new arg.
if _get_indent(line) == indent:
if len(current_block) > 0:
blocks.append(current_block[:-1])
current_block = f"{line}\n"
else:
# Otherwise it's part of the description of the current arg.
# We need to remove 2 spaces to the indentation.
current_block += f"{line[2:]}\n"
blocks.append(current_block[:-1])
# Format each block for proper rendering
for i in range(len(blocks)):
blocks[i] = re.sub(r"^(\s+)(\S+)(\s+)", r"\1- **\2**\3", blocks[i])
blocks[i] = re.sub(r":\s*\n\s*(\S)", r" -- \1", blocks[i])
return "\n".join(blocks)
def _prepare_output_docstrings(output_type, config_class, min_indent=None):
"""
Prepares the return part of the docstring using `output_type`.
"""
output_docstring = output_type.__doc__
# Remove the head of the docstring to keep the list of args only
lines = output_docstring.split("\n")
i = 0
while i < len(lines) and re.search(r"^\s*(Args|Parameters):\s*$", lines[i]) is None:
i += 1
if i < len(lines):
params_docstring = "\n".join(lines[(i + 1) :])
params_docstring = _convert_output_args_doc(params_docstring)
else:
raise ValueError(
f"No `Args` or `Parameters` section is found in the docstring of `{output_type.__name__}`. Make sure it has "
"docstring and contain either `Args` or `Parameters`."
)
# Add the return introduction
full_output_type = f"{output_type.__module__}.{output_type.__name__}"
intro = TF_RETURN_INTRODUCTION if output_type.__name__.startswith("TF") else PT_RETURN_INTRODUCTION
intro = intro.format(full_output_type=full_output_type, config_class=config_class)
result = intro + params_docstring
# Apply minimum indent if necessary
if min_indent is not None:
lines = result.split("\n")
# Find the indent of the first nonempty line
i = 0
while len(lines[i]) == 0:
i += 1
indent = len(_get_indent(lines[i]))
# If too small, add indentation to all nonempty lines
if indent < min_indent:
to_add = " " * (min_indent - indent)
lines = [(f"{to_add}{line}" if len(line) > 0 else line) for line in lines]
result = "\n".join(lines)
return result
FAKE_MODEL_DISCLAIMER = """
<Tip warning={true}>
This example uses a random model as the real ones are all very big. To get proper results, you should use
{real_checkpoint} instead of {fake_checkpoint}. If you get out-of-memory when loading that checkpoint, you can try
adding `device_map="auto"` in the `from_pretrained` call.
</Tip>
"""
PT_TOKEN_CLASSIFICATION_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> predicted_tokens_classes
{expected_output}
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
{expected_loss}
```
"""
PT_QUESTION_ANSWERING_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> tokenizer.decode(predict_answer_tokens, skip_special_tokens=True)
{expected_output}
>>> # target is "nice puppet"
>>> target_start_index = torch.tensor([{qa_target_start_index}])
>>> target_end_index = torch.tensor([{qa_target_end_index}])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = outputs.loss
>>> round(loss.item(), 2)
{expected_loss}
```
"""
PT_SEQUENCE_CLASSIFICATION_SAMPLE = r"""
Example of single-label classification:
```python
>>> import torch
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> model.config.id2label[predicted_class_id]
{expected_output}
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = {model_class}.from_pretrained("{checkpoint}", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
{expected_loss}
```
Example of multi-label classification:
```python
>>> import torch
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = {model_class}.from_pretrained(
... "{checkpoint}", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).loss
```
"""
PT_MASKED_LM_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("The capital of France is {mask}.", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # retrieve index of {mask}
>>> mask_token_index = (inputs.input_ids == tokenizer.mask_token_id)[0].nonzero(as_tuple=True)[0]
>>> predicted_token_id = logits[0, mask_token_index].argmax(axis=-1)
>>> tokenizer.decode(predicted_token_id)
{expected_output}
>>> labels = tokenizer("The capital of France is Paris.", return_tensors="pt")["input_ids"]
>>> # mask labels of non-{mask} tokens
>>> labels = torch.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
>>> outputs = model(**inputs, labels=labels)
>>> round(outputs.loss.item(), 2)
{expected_loss}
```
"""
PT_BASE_MODEL_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
"""
PT_MULTIPLE_CHOICE_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
>>> choice0 = "It is eaten with a fork and a knife."
>>> choice1 = "It is eaten while held in the hand."
>>> labels = torch.tensor(0).unsqueeze(0) # choice0 is correct (according to Wikipedia ;)), batch size 1
>>> encoding = tokenizer([prompt, prompt], [choice0, choice1], return_tensors="pt", padding=True)
>>> outputs = model(**{{k: v.unsqueeze(0) for k, v in encoding.items()}}, labels=labels) # batch size is 1
>>> # the linear classifier still needs to be trained
>>> loss = outputs.loss
>>> logits = outputs.logits
```
"""
PT_CAUSAL_LM_SAMPLE = r"""
Example:
```python
>>> import torch
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs, labels=inputs["input_ids"])
>>> loss = outputs.loss
>>> logits = outputs.logits
```
"""
PT_SPEECH_BASE_MODEL_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoProcessor, {model_class}
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
{expected_output}
```
"""
PT_SPEECH_CTC_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoProcessor, {model_class}
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_ids = torch.argmax(logits, dim=-1)
>>> # transcribe speech
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription[0]
{expected_output}
>>> inputs["labels"] = processor(text=dataset[0]["text"], return_tensors="pt").input_ids
>>> # compute loss
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
{expected_loss}
```
"""
PT_SPEECH_SEQ_CLASS_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoFeatureExtractor, {model_class}
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.argmax(logits, dim=-1).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
{expected_output}
>>> # compute loss - target_label is e.g. "down"
>>> target_label = model.config.id2label[0]
>>> inputs["labels"] = torch.tensor([model.config.label2id[target_label]])
>>> loss = model(**inputs).loss
>>> round(loss.item(), 2)
{expected_loss}
```
"""
PT_SPEECH_FRAME_CLASS_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoFeatureExtractor, {model_class}
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], return_tensors="pt", sampling_rate=sampling_rate)
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> probabilities = torch.sigmoid(logits[0])
>>> # labels is a one-hot array of shape (num_frames, num_speakers)
>>> labels = (probabilities > 0.5).long()
>>> labels[0].tolist()
{expected_output}
```
"""
PT_SPEECH_XVECTOR_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoFeatureExtractor, {model_class}
>>> from datasets import load_dataset
>>> import torch
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> # audio file is decoded on the fly
>>> inputs = feature_extractor(
... [d["array"] for d in dataset[:2]["audio"]], sampling_rate=sampling_rate, return_tensors="pt", padding=True
... )
>>> with torch.no_grad():
... embeddings = model(**inputs).embeddings
>>> embeddings = torch.nn.functional.normalize(embeddings, dim=-1).cpu()
>>> # the resulting embeddings can be used for cosine similarity-based retrieval
>>> cosine_sim = torch.nn.CosineSimilarity(dim=-1)
>>> similarity = cosine_sim(embeddings[0], embeddings[1])
>>> threshold = 0.7 # the optimal threshold is dataset-dependent
>>> if similarity < threshold:
... print("Speakers are not the same!")
>>> round(similarity.item(), 2)
{expected_output}
```
"""
PT_VISION_BASE_MODEL_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoImageProcessor, {model_class}
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
{expected_output}
```
"""
PT_VISION_SEQ_CLASS_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoImageProcessor, {model_class}
>>> import torch
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = image_processor(image, return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = logits.argmax(-1).item()
>>> print(model.config.id2label[predicted_label])
{expected_output}
```
"""
PT_SAMPLE_DOCSTRINGS = {
"SequenceClassification": PT_SEQUENCE_CLASSIFICATION_SAMPLE,
"QuestionAnswering": PT_QUESTION_ANSWERING_SAMPLE,
"TokenClassification": PT_TOKEN_CLASSIFICATION_SAMPLE,
"MultipleChoice": PT_MULTIPLE_CHOICE_SAMPLE,
"MaskedLM": PT_MASKED_LM_SAMPLE,
"LMHead": PT_CAUSAL_LM_SAMPLE,
"BaseModel": PT_BASE_MODEL_SAMPLE,
"SpeechBaseModel": PT_SPEECH_BASE_MODEL_SAMPLE,
"CTC": PT_SPEECH_CTC_SAMPLE,
"AudioClassification": PT_SPEECH_SEQ_CLASS_SAMPLE,
"AudioFrameClassification": PT_SPEECH_FRAME_CLASS_SAMPLE,
"AudioXVector": PT_SPEECH_XVECTOR_SAMPLE,
"VisionBaseModel": PT_VISION_BASE_MODEL_SAMPLE,
"ImageClassification": PT_VISION_SEQ_CLASS_SAMPLE,
}
TF_TOKEN_CLASSIFICATION_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="tf"
... )
>>> logits = model(**inputs).logits
>>> predicted_token_class_ids = tf.math.argmax(logits, axis=-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t] for t in predicted_token_class_ids[0].numpy().tolist()]
>>> predicted_tokens_classes
{expected_output}
```
```python
>>> labels = predicted_token_class_ids
>>> loss = tf.math.reduce_mean(model(**inputs, labels=labels).loss)
>>> round(float(loss), 2)
{expected_loss}
```
"""
TF_QUESTION_ANSWERING_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="tf")
>>> outputs = model(**inputs)
>>> answer_start_index = int(tf.math.argmax(outputs.start_logits, axis=-1)[0])
>>> answer_end_index = int(tf.math.argmax(outputs.end_logits, axis=-1)[0])
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> tokenizer.decode(predict_answer_tokens)
{expected_output}
```
```python
>>> # target is "nice puppet"
>>> target_start_index = tf.constant([{qa_target_start_index}])
>>> target_end_index = tf.constant([{qa_target_end_index}])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = tf.math.reduce_mean(outputs.loss)
>>> round(float(loss), 2)
{expected_loss}
```
"""
TF_SEQUENCE_CLASSIFICATION_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> logits = model(**inputs).logits
>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])
>>> model.config.id2label[predicted_class_id]
{expected_output}
```
```python
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = {model_class}.from_pretrained("{checkpoint}", num_labels=num_labels)
>>> labels = tf.constant(1)
>>> loss = model(**inputs, labels=labels).loss
>>> round(float(loss), 2)
{expected_loss}
```
"""
TF_MASKED_LM_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("The capital of France is {mask}.", return_tensors="tf")
>>> logits = model(**inputs).logits
>>> # retrieve index of {mask}
>>> mask_token_index = tf.where((inputs.input_ids == tokenizer.mask_token_id)[0])
>>> selected_logits = tf.gather_nd(logits[0], indices=mask_token_index)
>>> predicted_token_id = tf.math.argmax(selected_logits, axis=-1)
>>> tokenizer.decode(predicted_token_id)
{expected_output}
```
```python
>>> labels = tokenizer("The capital of France is Paris.", return_tensors="tf")["input_ids"]
>>> # mask labels of non-{mask} tokens
>>> labels = tf.where(inputs.input_ids == tokenizer.mask_token_id, labels, -100)
>>> outputs = model(**inputs, labels=labels)
>>> round(float(outputs.loss), 2)
{expected_loss}
```
"""
TF_BASE_MODEL_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
"""
TF_MULTIPLE_CHOICE_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
>>> choice0 = "It is eaten with a fork and a knife."
>>> choice1 = "It is eaten while held in the hand."
>>> encoding = tokenizer([prompt, prompt], [choice0, choice1], return_tensors="tf", padding=True)
>>> inputs = {{k: tf.expand_dims(v, 0) for k, v in encoding.items()}}
>>> outputs = model(inputs) # batch size is 1
>>> # the linear classifier still needs to be trained
>>> logits = outputs.logits
```
"""
TF_CAUSAL_LM_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> logits = outputs.logits
```
"""
TF_SPEECH_BASE_MODEL_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoProcessor, {model_class}
>>> from datasets import load_dataset
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
{expected_output}
```
"""
TF_SPEECH_CTC_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoProcessor, {model_class}
>>> from datasets import load_dataset
>>> import tensorflow as tf
>>> dataset = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> dataset = dataset.sort("id")
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> processor = AutoProcessor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> # audio file is decoded on the fly
>>> inputs = processor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="tf")
>>> logits = model(**inputs).logits
>>> predicted_ids = tf.math.argmax(logits, axis=-1)
>>> # transcribe speech
>>> transcription = processor.batch_decode(predicted_ids)
>>> transcription[0]
{expected_output}
```
```python
>>> inputs["labels"] = processor(text=dataset[0]["text"], return_tensors="tf").input_ids
>>> # compute loss
>>> loss = model(**inputs).loss
>>> round(float(loss), 2)
{expected_loss}
```
"""
TF_VISION_BASE_MODEL_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoImageProcessor, {model_class}
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = image_processor(image, return_tensors="tf")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
>>> list(last_hidden_states.shape)
{expected_output}
```
"""
TF_VISION_SEQ_CLASS_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoImageProcessor, {model_class}
>>> import tensorflow as tf
>>> from datasets import load_dataset
>>> dataset = load_dataset("huggingface/cats-image")
>>> image = dataset["test"]["image"][0]
>>> image_processor = AutoImageProcessor.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = image_processor(image, return_tensors="tf")
>>> logits = model(**inputs).logits
>>> # model predicts one of the 1000 ImageNet classes
>>> predicted_label = int(tf.math.argmax(logits, axis=-1))
>>> print(model.config.id2label[predicted_label])
{expected_output}
```
"""
TF_SAMPLE_DOCSTRINGS = {
"SequenceClassification": TF_SEQUENCE_CLASSIFICATION_SAMPLE,
"QuestionAnswering": TF_QUESTION_ANSWERING_SAMPLE,
"TokenClassification": TF_TOKEN_CLASSIFICATION_SAMPLE,
"MultipleChoice": TF_MULTIPLE_CHOICE_SAMPLE,
"MaskedLM": TF_MASKED_LM_SAMPLE,
"LMHead": TF_CAUSAL_LM_SAMPLE,
"BaseModel": TF_BASE_MODEL_SAMPLE,
"SpeechBaseModel": TF_SPEECH_BASE_MODEL_SAMPLE,
"CTC": TF_SPEECH_CTC_SAMPLE,
"VisionBaseModel": TF_VISION_BASE_MODEL_SAMPLE,
"ImageClassification": TF_VISION_SEQ_CLASS_SAMPLE,
}
FLAX_TOKEN_CLASSIFICATION_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```
"""
FLAX_QUESTION_ANSWERING_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="jax")
>>> outputs = model(**inputs)
>>> start_scores = outputs.start_logits
>>> end_scores = outputs.end_logits
```
"""
FLAX_SEQUENCE_CLASSIFICATION_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```
"""
FLAX_MASKED_LM_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("The capital of France is {mask}.", return_tensors="jax")
>>> outputs = model(**inputs)
>>> logits = outputs.logits
```
"""
FLAX_BASE_MODEL_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
"""
FLAX_MULTIPLE_CHOICE_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> prompt = "In Italy, pizza served in formal settings, such as at a restaurant, is presented unsliced."
>>> choice0 = "It is eaten with a fork and a knife."
>>> choice1 = "It is eaten while held in the hand."
>>> encoding = tokenizer([prompt, prompt], [choice0, choice1], return_tensors="jax", padding=True)
>>> outputs = model(**{{k: v[None, :] for k, v in encoding.items()}})
>>> logits = outputs.logits
```
"""
FLAX_CAUSAL_LM_SAMPLE = r"""
Example:
```python
>>> from transformers import AutoTokenizer, {model_class}
>>> tokenizer = AutoTokenizer.from_pretrained("{checkpoint}")
>>> model = {model_class}.from_pretrained("{checkpoint}")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]
```
"""
FLAX_SAMPLE_DOCSTRINGS = {
"SequenceClassification": FLAX_SEQUENCE_CLASSIFICATION_SAMPLE,
"QuestionAnswering": FLAX_QUESTION_ANSWERING_SAMPLE,
"TokenClassification": FLAX_TOKEN_CLASSIFICATION_SAMPLE,
"MultipleChoice": FLAX_MULTIPLE_CHOICE_SAMPLE,
"MaskedLM": FLAX_MASKED_LM_SAMPLE,
"BaseModel": FLAX_BASE_MODEL_SAMPLE,
"LMHead": FLAX_CAUSAL_LM_SAMPLE,
}
def filter_outputs_from_example(docstring, **kwargs):
"""
Removes the lines testing an output with the doctest syntax in a code sample when it's set to `None`.
"""
for key, value in kwargs.items():
if value is not None:
continue
doc_key = "{" + key + "}"
docstring = re.sub(rf"\n([^\n]+)\n\s+{doc_key}\n", "\n", docstring)
return docstring
def add_code_sample_docstrings(
*docstr,
processor_class=None,
checkpoint=None,
output_type=None,
config_class=None,
mask="[MASK]",
qa_target_start_index=14,
qa_target_end_index=15,
model_cls=None,
modality=None,
expected_output=None,
expected_loss=None,
real_checkpoint=None,
revision=None,
):
def docstring_decorator(fn):
# model_class defaults to function's class if not specified otherwise
model_class = fn.__qualname__.split(".")[0] if model_cls is None else model_cls
if model_class[:2] == "TF":
sample_docstrings = TF_SAMPLE_DOCSTRINGS
elif model_class[:4] == "Flax":
sample_docstrings = FLAX_SAMPLE_DOCSTRINGS
else:
sample_docstrings = PT_SAMPLE_DOCSTRINGS
# putting all kwargs for docstrings in a dict to be used
# with the `.format(**doc_kwargs)`. Note that string might
# be formatted with non-existing keys, which is fine.
doc_kwargs = {
"model_class": model_class,
"processor_class": processor_class,
"checkpoint": checkpoint,
"mask": mask,
"qa_target_start_index": qa_target_start_index,
"qa_target_end_index": qa_target_end_index,
"expected_output": expected_output,
"expected_loss": expected_loss,
"real_checkpoint": real_checkpoint,
"fake_checkpoint": checkpoint,
"true": "{true}", # For <Tip warning={true}> syntax that conflicts with formatting.
}
if ("SequenceClassification" in model_class or "AudioClassification" in model_class) and modality == "audio":
code_sample = sample_docstrings["AudioClassification"]
elif "SequenceClassification" in model_class:
code_sample = sample_docstrings["SequenceClassification"]
elif "QuestionAnswering" in model_class:
code_sample = sample_docstrings["QuestionAnswering"]
elif "TokenClassification" in model_class:
code_sample = sample_docstrings["TokenClassification"]
elif "MultipleChoice" in model_class:
code_sample = sample_docstrings["MultipleChoice"]
elif "MaskedLM" in model_class or model_class in ["FlaubertWithLMHeadModel", "XLMWithLMHeadModel"]:
code_sample = sample_docstrings["MaskedLM"]
elif "LMHead" in model_class or "CausalLM" in model_class:
code_sample = sample_docstrings["LMHead"]
elif "CTC" in model_class:
code_sample = sample_docstrings["CTC"]
elif "AudioFrameClassification" in model_class:
code_sample = sample_docstrings["AudioFrameClassification"]
elif "XVector" in model_class and modality == "audio":
code_sample = sample_docstrings["AudioXVector"]
elif "Model" in model_class and modality == "audio":
code_sample = sample_docstrings["SpeechBaseModel"]
elif "Model" in model_class and modality == "vision":
code_sample = sample_docstrings["VisionBaseModel"]
elif "Model" in model_class or "Encoder" in model_class:
code_sample = sample_docstrings["BaseModel"]
elif "ImageClassification" in model_class:
code_sample = sample_docstrings["ImageClassification"]
else:
raise ValueError(f"Docstring can't be built for model {model_class}")
code_sample = filter_outputs_from_example(
code_sample, expected_output=expected_output, expected_loss=expected_loss
)
if real_checkpoint is not None:
code_sample = FAKE_MODEL_DISCLAIMER + code_sample
func_doc = (fn.__doc__ or "") + "".join(docstr)
output_doc = "" if output_type is None else _prepare_output_docstrings(output_type, config_class)
built_doc = code_sample.format(**doc_kwargs)
if revision is not None:
if re.match(r"^refs/pr/\\d+", revision):
raise ValueError(
f"The provided revision '{revision}' is incorrect. It should point to"
" a pull request reference on the hub like 'refs/pr/6'"
)
built_doc = built_doc.replace(
f'from_pretrained("{checkpoint}")', f'from_pretrained("{checkpoint}", revision="{revision}")'
)
fn.__doc__ = func_doc + output_doc + built_doc
return fn
return docstring_decorator
def replace_return_docstrings(output_type=None, config_class=None):
def docstring_decorator(fn):
func_doc = fn.__doc__
lines = func_doc.split("\n")
i = 0
while i < len(lines) and re.search(r"^\s*Returns?:\s*$", lines[i]) is None:
i += 1
if i < len(lines):
indent = len(_get_indent(lines[i]))
lines[i] = _prepare_output_docstrings(output_type, config_class, min_indent=indent)
func_doc = "\n".join(lines)
else:
raise ValueError(
f"The function {fn} should have an empty 'Return:' or 'Returns:' in its docstring as placeholder, "
f"current docstring is:\n{func_doc}"
)
fn.__doc__ = func_doc
return fn
return docstring_decorator
def copy_func(f):
"""Returns a copy of a function f."""
# Based on http://stackoverflow.com/a/6528148/190597 (Glenn Maynard)
g = types.FunctionType(f.__code__, f.__globals__, name=f.__name__, argdefs=f.__defaults__, closure=f.__closure__)
g = functools.update_wrapper(g, f)
g.__kwdefaults__ = f.__kwdefaults__
return g
| transformers/src/transformers/utils/doc.py/0 | {
"file_path": "transformers/src/transformers/utils/doc.py",
"repo_id": "transformers",
"token_count": 15528
} | 348 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Generic utilities
"""
import inspect
import tempfile
from collections import OrderedDict, UserDict
from collections.abc import MutableMapping
from contextlib import ExitStack, contextmanager
from dataclasses import fields, is_dataclass
from enum import Enum
from functools import partial
from typing import Any, ContextManager, Iterable, List, Tuple
import numpy as np
from packaging import version
from .import_utils import (
get_torch_version,
is_flax_available,
is_mlx_available,
is_tf_available,
is_torch_available,
is_torch_fx_proxy,
)
if is_flax_available():
import jax.numpy as jnp
class cached_property(property):
"""
Descriptor that mimics @property but caches output in member variable.
From tensorflow_datasets
Built-in in functools from Python 3.8.
"""
def __get__(self, obj, objtype=None):
# See docs.python.org/3/howto/descriptor.html#properties
if obj is None:
return self
if self.fget is None:
raise AttributeError("unreadable attribute")
attr = "__cached_" + self.fget.__name__
cached = getattr(obj, attr, None)
if cached is None:
cached = self.fget(obj)
setattr(obj, attr, cached)
return cached
# vendored from distutils.util
def strtobool(val):
"""Convert a string representation of truth to true (1) or false (0).
True values are 'y', 'yes', 't', 'true', 'on', and '1'; false values are 'n', 'no', 'f', 'false', 'off', and '0'.
Raises ValueError if 'val' is anything else.
"""
val = val.lower()
if val in {"y", "yes", "t", "true", "on", "1"}:
return 1
if val in {"n", "no", "f", "false", "off", "0"}:
return 0
raise ValueError(f"invalid truth value {val!r}")
def infer_framework_from_repr(x):
"""
Tries to guess the framework of an object `x` from its repr (brittle but will help in `is_tensor` to try the
frameworks in a smart order, without the need to import the frameworks).
"""
representation = str(type(x))
if representation.startswith("<class 'torch."):
return "pt"
elif representation.startswith("<class 'tensorflow."):
return "tf"
elif representation.startswith("<class 'jax"):
return "jax"
elif representation.startswith("<class 'numpy."):
return "np"
elif representation.startswith("<class 'mlx."):
return "mlx"
def _get_frameworks_and_test_func(x):
"""
Returns an (ordered since we are in Python 3.7+) dictionary framework to test function, which places the framework
we can guess from the repr first, then Numpy, then the others.
"""
framework_to_test = {
"pt": is_torch_tensor,
"tf": is_tf_tensor,
"jax": is_jax_tensor,
"np": is_numpy_array,
"mlx": is_mlx_array,
}
preferred_framework = infer_framework_from_repr(x)
# We will test this one first, then numpy, then the others.
frameworks = [] if preferred_framework is None else [preferred_framework]
if preferred_framework != "np":
frameworks.append("np")
frameworks.extend([f for f in framework_to_test if f not in [preferred_framework, "np"]])
return {f: framework_to_test[f] for f in frameworks}
def is_tensor(x):
"""
Tests if `x` is a `torch.Tensor`, `tf.Tensor`, `jaxlib.xla_extension.DeviceArray`, `np.ndarray` or `mlx.array`
in the order defined by `infer_framework_from_repr`
"""
# This gives us a smart order to test the frameworks with the corresponding tests.
framework_to_test_func = _get_frameworks_and_test_func(x)
for test_func in framework_to_test_func.values():
if test_func(x):
return True
# Tracers
if is_torch_fx_proxy(x):
return True
if is_flax_available():
from jax.core import Tracer
if isinstance(x, Tracer):
return True
return False
def _is_numpy(x):
return isinstance(x, np.ndarray)
def is_numpy_array(x):
"""
Tests if `x` is a numpy array or not.
"""
return _is_numpy(x)
def _is_torch(x):
import torch
return isinstance(x, torch.Tensor)
def is_torch_tensor(x):
"""
Tests if `x` is a torch tensor or not. Safe to call even if torch is not installed.
"""
return False if not is_torch_available() else _is_torch(x)
def _is_torch_device(x):
import torch
return isinstance(x, torch.device)
def is_torch_device(x):
"""
Tests if `x` is a torch device or not. Safe to call even if torch is not installed.
"""
return False if not is_torch_available() else _is_torch_device(x)
def _is_torch_dtype(x):
import torch
if isinstance(x, str):
if hasattr(torch, x):
x = getattr(torch, x)
else:
return False
return isinstance(x, torch.dtype)
def is_torch_dtype(x):
"""
Tests if `x` is a torch dtype or not. Safe to call even if torch is not installed.
"""
return False if not is_torch_available() else _is_torch_dtype(x)
def _is_tensorflow(x):
import tensorflow as tf
return isinstance(x, tf.Tensor)
def is_tf_tensor(x):
"""
Tests if `x` is a tensorflow tensor or not. Safe to call even if tensorflow is not installed.
"""
return False if not is_tf_available() else _is_tensorflow(x)
def _is_tf_symbolic_tensor(x):
import tensorflow as tf
# the `is_symbolic_tensor` predicate is only available starting with TF 2.14
if hasattr(tf, "is_symbolic_tensor"):
return tf.is_symbolic_tensor(x)
return type(x) == tf.Tensor
def is_tf_symbolic_tensor(x):
"""
Tests if `x` is a tensorflow symbolic tensor or not (ie. not eager). Safe to call even if tensorflow is not
installed.
"""
return False if not is_tf_available() else _is_tf_symbolic_tensor(x)
def _is_jax(x):
import jax.numpy as jnp # noqa: F811
return isinstance(x, jnp.ndarray)
def is_jax_tensor(x):
"""
Tests if `x` is a Jax tensor or not. Safe to call even if jax is not installed.
"""
return False if not is_flax_available() else _is_jax(x)
def _is_mlx(x):
import mlx.core as mx
return isinstance(x, mx.array)
def is_mlx_array(x):
"""
Tests if `x` is a mlx array or not. Safe to call even when mlx is not installed.
"""
return False if not is_mlx_available() else _is_mlx(x)
def to_py_obj(obj):
"""
Convert a TensorFlow tensor, PyTorch tensor, Numpy array or python list to a python list.
"""
framework_to_py_obj = {
"pt": lambda obj: obj.detach().cpu().tolist(),
"tf": lambda obj: obj.numpy().tolist(),
"jax": lambda obj: np.asarray(obj).tolist(),
"np": lambda obj: obj.tolist(),
}
if isinstance(obj, (dict, UserDict)):
return {k: to_py_obj(v) for k, v in obj.items()}
elif isinstance(obj, (list, tuple)):
return [to_py_obj(o) for o in obj]
# This gives us a smart order to test the frameworks with the corresponding tests.
framework_to_test_func = _get_frameworks_and_test_func(obj)
for framework, test_func in framework_to_test_func.items():
if test_func(obj):
return framework_to_py_obj[framework](obj)
# tolist also works on 0d np arrays
if isinstance(obj, np.number):
return obj.tolist()
else:
return obj
def to_numpy(obj):
"""
Convert a TensorFlow tensor, PyTorch tensor, Numpy array or python list to a Numpy array.
"""
framework_to_numpy = {
"pt": lambda obj: obj.detach().cpu().numpy(),
"tf": lambda obj: obj.numpy(),
"jax": lambda obj: np.asarray(obj),
"np": lambda obj: obj,
}
if isinstance(obj, (dict, UserDict)):
return {k: to_numpy(v) for k, v in obj.items()}
elif isinstance(obj, (list, tuple)):
return np.array(obj)
# This gives us a smart order to test the frameworks with the corresponding tests.
framework_to_test_func = _get_frameworks_and_test_func(obj)
for framework, test_func in framework_to_test_func.items():
if test_func(obj):
return framework_to_numpy[framework](obj)
return obj
class ModelOutput(OrderedDict):
"""
Base class for all model outputs as dataclass. Has a `__getitem__` that allows indexing by integer or slice (like a
tuple) or strings (like a dictionary) that will ignore the `None` attributes. Otherwise behaves like a regular
python dictionary.
<Tip warning={true}>
You can't unpack a `ModelOutput` directly. Use the [`~utils.ModelOutput.to_tuple`] method to convert it to a tuple
before.
</Tip>
"""
def __init_subclass__(cls) -> None:
"""Register subclasses as pytree nodes.
This is necessary to synchronize gradients when using `torch.nn.parallel.DistributedDataParallel` with
`static_graph=True` with modules that output `ModelOutput` subclasses.
"""
if is_torch_available():
if version.parse(get_torch_version()) >= version.parse("2.2"):
_torch_pytree.register_pytree_node(
cls,
_model_output_flatten,
partial(_model_output_unflatten, output_type=cls),
serialized_type_name=f"{cls.__module__}.{cls.__name__}",
)
else:
_torch_pytree._register_pytree_node(
cls,
_model_output_flatten,
partial(_model_output_unflatten, output_type=cls),
)
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# Subclasses of ModelOutput must use the @dataclass decorator
# This check is done in __init__ because the @dataclass decorator operates after __init_subclass__
# issubclass() would return True for issubclass(ModelOutput, ModelOutput) when False is needed
# Just need to check that the current class is not ModelOutput
is_modeloutput_subclass = self.__class__ != ModelOutput
if is_modeloutput_subclass and not is_dataclass(self):
raise TypeError(
f"{self.__module__}.{self.__class__.__name__} is not a dataclasss."
" This is a subclass of ModelOutput and so must use the @dataclass decorator."
)
def __post_init__(self):
"""Check the ModelOutput dataclass.
Only occurs if @dataclass decorator has been used.
"""
class_fields = fields(self)
# Safety and consistency checks
if not len(class_fields):
raise ValueError(f"{self.__class__.__name__} has no fields.")
if not all(field.default is None for field in class_fields[1:]):
raise ValueError(f"{self.__class__.__name__} should not have more than one required field.")
first_field = getattr(self, class_fields[0].name)
other_fields_are_none = all(getattr(self, field.name) is None for field in class_fields[1:])
if other_fields_are_none and not is_tensor(first_field):
if isinstance(first_field, dict):
iterator = first_field.items()
first_field_iterator = True
else:
try:
iterator = iter(first_field)
first_field_iterator = True
except TypeError:
first_field_iterator = False
# if we provided an iterator as first field and the iterator is a (key, value) iterator
# set the associated fields
if first_field_iterator:
for idx, element in enumerate(iterator):
if (
not isinstance(element, (list, tuple))
or not len(element) == 2
or not isinstance(element[0], str)
):
if idx == 0:
# If we do not have an iterator of key/values, set it as attribute
self[class_fields[0].name] = first_field
else:
# If we have a mixed iterator, raise an error
raise ValueError(
f"Cannot set key/value for {element}. It needs to be a tuple (key, value)."
)
break
setattr(self, element[0], element[1])
if element[1] is not None:
self[element[0]] = element[1]
elif first_field is not None:
self[class_fields[0].name] = first_field
else:
for field in class_fields:
v = getattr(self, field.name)
if v is not None:
self[field.name] = v
def __delitem__(self, *args, **kwargs):
raise Exception(f"You cannot use ``__delitem__`` on a {self.__class__.__name__} instance.")
def setdefault(self, *args, **kwargs):
raise Exception(f"You cannot use ``setdefault`` on a {self.__class__.__name__} instance.")
def pop(self, *args, **kwargs):
raise Exception(f"You cannot use ``pop`` on a {self.__class__.__name__} instance.")
def update(self, *args, **kwargs):
raise Exception(f"You cannot use ``update`` on a {self.__class__.__name__} instance.")
def __getitem__(self, k):
if isinstance(k, str):
inner_dict = dict(self.items())
return inner_dict[k]
else:
return self.to_tuple()[k]
def __setattr__(self, name, value):
if name in self.keys() and value is not None:
# Don't call self.__setitem__ to avoid recursion errors
super().__setitem__(name, value)
super().__setattr__(name, value)
def __setitem__(self, key, value):
# Will raise a KeyException if needed
super().__setitem__(key, value)
# Don't call self.__setattr__ to avoid recursion errors
super().__setattr__(key, value)
def __reduce__(self):
if not is_dataclass(self):
return super().__reduce__()
callable, _args, *remaining = super().__reduce__()
args = tuple(getattr(self, field.name) for field in fields(self))
return callable, args, *remaining
def to_tuple(self) -> Tuple[Any]:
"""
Convert self to a tuple containing all the attributes/keys that are not `None`.
"""
return tuple(self[k] for k in self.keys())
if is_torch_available():
import torch.utils._pytree as _torch_pytree
def _model_output_flatten(output: ModelOutput) -> Tuple[List[Any], "_torch_pytree.Context"]:
return list(output.values()), list(output.keys())
def _model_output_unflatten(
values: Iterable[Any],
context: "_torch_pytree.Context",
output_type=None,
) -> ModelOutput:
return output_type(**dict(zip(context, values)))
if version.parse(get_torch_version()) >= version.parse("2.2"):
_torch_pytree.register_pytree_node(
ModelOutput,
_model_output_flatten,
partial(_model_output_unflatten, output_type=ModelOutput),
serialized_type_name=f"{ModelOutput.__module__}.{ModelOutput.__name__}",
)
else:
_torch_pytree._register_pytree_node(
ModelOutput,
_model_output_flatten,
partial(_model_output_unflatten, output_type=ModelOutput),
)
class ExplicitEnum(str, Enum):
"""
Enum with more explicit error message for missing values.
"""
@classmethod
def _missing_(cls, value):
raise ValueError(
f"{value} is not a valid {cls.__name__}, please select one of {list(cls._value2member_map_.keys())}"
)
class PaddingStrategy(ExplicitEnum):
"""
Possible values for the `padding` argument in [`PreTrainedTokenizerBase.__call__`]. Useful for tab-completion in an
IDE.
"""
LONGEST = "longest"
MAX_LENGTH = "max_length"
DO_NOT_PAD = "do_not_pad"
class TensorType(ExplicitEnum):
"""
Possible values for the `return_tensors` argument in [`PreTrainedTokenizerBase.__call__`]. Useful for
tab-completion in an IDE.
"""
PYTORCH = "pt"
TENSORFLOW = "tf"
NUMPY = "np"
JAX = "jax"
MLX = "mlx"
class ContextManagers:
"""
Wrapper for `contextlib.ExitStack` which enters a collection of context managers. Adaptation of `ContextManagers`
in the `fastcore` library.
"""
def __init__(self, context_managers: List[ContextManager]):
self.context_managers = context_managers
self.stack = ExitStack()
def __enter__(self):
for context_manager in self.context_managers:
self.stack.enter_context(context_manager)
def __exit__(self, *args, **kwargs):
self.stack.__exit__(*args, **kwargs)
def can_return_loss(model_class):
"""
Check if a given model can return loss.
Args:
model_class (`type`): The class of the model.
"""
framework = infer_framework(model_class)
if framework == "tf":
signature = inspect.signature(model_class.call) # TensorFlow models
elif framework == "pt":
signature = inspect.signature(model_class.forward) # PyTorch models
else:
signature = inspect.signature(model_class.__call__) # Flax models
for p in signature.parameters:
if p == "return_loss" and signature.parameters[p].default is True:
return True
return False
def find_labels(model_class):
"""
Find the labels used by a given model.
Args:
model_class (`type`): The class of the model.
"""
model_name = model_class.__name__
framework = infer_framework(model_class)
if framework == "tf":
signature = inspect.signature(model_class.call) # TensorFlow models
elif framework == "pt":
signature = inspect.signature(model_class.forward) # PyTorch models
else:
signature = inspect.signature(model_class.__call__) # Flax models
if "QuestionAnswering" in model_name:
return [p for p in signature.parameters if "label" in p or p in ("start_positions", "end_positions")]
else:
return [p for p in signature.parameters if "label" in p]
def flatten_dict(d: MutableMapping, parent_key: str = "", delimiter: str = "."):
"""Flatten a nested dict into a single level dict."""
def _flatten_dict(d, parent_key="", delimiter="."):
for k, v in d.items():
key = str(parent_key) + delimiter + str(k) if parent_key else k
if v and isinstance(v, MutableMapping):
yield from flatten_dict(v, key, delimiter=delimiter).items()
else:
yield key, v
return dict(_flatten_dict(d, parent_key, delimiter))
@contextmanager
def working_or_temp_dir(working_dir, use_temp_dir: bool = False):
if use_temp_dir:
with tempfile.TemporaryDirectory() as tmp_dir:
yield tmp_dir
else:
yield working_dir
def transpose(array, axes=None):
"""
Framework-agnostic version of `numpy.transpose` that will work on torch/TensorFlow/Jax tensors as well as NumPy
arrays.
"""
if is_numpy_array(array):
return np.transpose(array, axes=axes)
elif is_torch_tensor(array):
return array.T if axes is None else array.permute(*axes)
elif is_tf_tensor(array):
import tensorflow as tf
return tf.transpose(array, perm=axes)
elif is_jax_tensor(array):
return jnp.transpose(array, axes=axes)
else:
raise ValueError(f"Type not supported for transpose: {type(array)}.")
def reshape(array, newshape):
"""
Framework-agnostic version of `numpy.reshape` that will work on torch/TensorFlow/Jax tensors as well as NumPy
arrays.
"""
if is_numpy_array(array):
return np.reshape(array, newshape)
elif is_torch_tensor(array):
return array.reshape(*newshape)
elif is_tf_tensor(array):
import tensorflow as tf
return tf.reshape(array, newshape)
elif is_jax_tensor(array):
return jnp.reshape(array, newshape)
else:
raise ValueError(f"Type not supported for reshape: {type(array)}.")
def squeeze(array, axis=None):
"""
Framework-agnostic version of `numpy.squeeze` that will work on torch/TensorFlow/Jax tensors as well as NumPy
arrays.
"""
if is_numpy_array(array):
return np.squeeze(array, axis=axis)
elif is_torch_tensor(array):
return array.squeeze() if axis is None else array.squeeze(dim=axis)
elif is_tf_tensor(array):
import tensorflow as tf
return tf.squeeze(array, axis=axis)
elif is_jax_tensor(array):
return jnp.squeeze(array, axis=axis)
else:
raise ValueError(f"Type not supported for squeeze: {type(array)}.")
def expand_dims(array, axis):
"""
Framework-agnostic version of `numpy.expand_dims` that will work on torch/TensorFlow/Jax tensors as well as NumPy
arrays.
"""
if is_numpy_array(array):
return np.expand_dims(array, axis)
elif is_torch_tensor(array):
return array.unsqueeze(dim=axis)
elif is_tf_tensor(array):
import tensorflow as tf
return tf.expand_dims(array, axis=axis)
elif is_jax_tensor(array):
return jnp.expand_dims(array, axis=axis)
else:
raise ValueError(f"Type not supported for expand_dims: {type(array)}.")
def tensor_size(array):
"""
Framework-agnostic version of `numpy.size` that will work on torch/TensorFlow/Jax tensors as well as NumPy arrays.
"""
if is_numpy_array(array):
return np.size(array)
elif is_torch_tensor(array):
return array.numel()
elif is_tf_tensor(array):
import tensorflow as tf
return tf.size(array)
elif is_jax_tensor(array):
return array.size
else:
raise ValueError(f"Type not supported for tensor_size: {type(array)}.")
def add_model_info_to_auto_map(auto_map, repo_id):
"""
Adds the information of the repo_id to a given auto map.
"""
for key, value in auto_map.items():
if isinstance(value, (tuple, list)):
auto_map[key] = [f"{repo_id}--{v}" if (v is not None and "--" not in v) else v for v in value]
elif value is not None and "--" not in value:
auto_map[key] = f"{repo_id}--{value}"
return auto_map
def infer_framework(model_class):
"""
Infers the framework of a given model without using isinstance(), because we cannot guarantee that the relevant
classes are imported or available.
"""
for base_class in inspect.getmro(model_class):
module = base_class.__module__
name = base_class.__name__
if module.startswith("tensorflow") or module.startswith("keras") or name == "TFPreTrainedModel":
return "tf"
elif module.startswith("torch") or name == "PreTrainedModel":
return "pt"
elif module.startswith("flax") or module.startswith("jax") or name == "FlaxPreTrainedModel":
return "flax"
else:
raise TypeError(f"Could not infer framework from class {model_class}.")
| transformers/src/transformers/utils/generic.py/0 | {
"file_path": "transformers/src/transformers/utils/generic.py",
"repo_id": "transformers",
"token_count": 10103
} | 349 |
{
"example_name": "text classification",
"directory_name": "{{cookiecutter.example_name|lower|replace(' ', '-')}}",
"example_shortcut": "{{cookiecutter.directory_name}}",
"model_class": "AutoModel",
"authors": "The HuggingFace Team",
"can_train_from_scratch": ["True", "False"],
"with_trainer": ["True", "False"]
} | transformers/templates/adding_a_new_example_script/cookiecutter.json/0 | {
"file_path": "transformers/templates/adding_a_new_example_script/cookiecutter.json",
"repo_id": "transformers",
"token_count": 115
} | 350 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# {{cookiecutter.modelname}}
## Overview
The {{cookiecutter.modelname}} model was proposed in [<INSERT PAPER NAME HERE>](<INSERT PAPER LINK HERE>) by <INSERT AUTHORS HERE>. <INSERT SHORT SUMMARY HERE>
The abstract from the paper is the following:
*<INSERT PAPER ABSTRACT HERE>*
Tips:
<INSERT TIPS ABOUT MODEL HERE>
This model was contributed by [INSERT YOUR HF USERNAME HERE](<https://huggingface.co/<INSERT YOUR HF USERNAME HERE>). The original code can be found [here](<INSERT LINK TO GITHUB REPO HERE>).
## {{cookiecutter.camelcase_modelname}}Config
[[autodoc]] {{cookiecutter.camelcase_modelname}}Config
## {{cookiecutter.camelcase_modelname}}Tokenizer
[[autodoc]] {{cookiecutter.camelcase_modelname}}Tokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## {{cookiecutter.camelcase_modelname}}TokenizerFast
[[autodoc]] {{cookiecutter.camelcase_modelname}}TokenizerFast
{% if "PyTorch" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## {{cookiecutter.camelcase_modelname}}Model
[[autodoc]] {{cookiecutter.camelcase_modelname}}Model
- forward
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## {{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForCausalLM
- forward
## {{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForMaskedLM
- forward
## {{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- forward
## {{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] transformers.{{cookiecutter.camelcase_modelname}}ForTokenClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- forward
{%- else %}
## {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- forward
## {{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForSequenceClassification
- forward
## {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- forward
## {{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] {{cookiecutter.camelcase_modelname}}ForCausalLM
- forward
{% endif -%}
{% endif -%}
{% if "TensorFlow" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## TF{{cookiecutter.camelcase_modelname}}Model
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}Model
- call
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## TF{{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForMaskedLM
- call
## TF{{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForCausalLM
- call
## TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- call
## TF{{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForTokenClassification
- call
## TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
{%- else %}
## TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] TF{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- call
{% endif -%}
{% endif -%}
{% if "Flax" in cookiecutter.generate_tensorflow_pytorch_and_flax -%}
## Flax{{cookiecutter.camelcase_modelname}}Model
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}Model
- call
{% if cookiecutter.is_encoder_decoder_model == "False" %}
## Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForMaskedLM
- call
## Flax{{cookiecutter.camelcase_modelname}}ForCausalLM
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForCausalLM
- call
## Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForMultipleChoice
- call
## Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForTokenClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
{%- else %}
## Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForSequenceClassification
- call
## Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForQuestionAnswering
- call
## Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
[[autodoc]] Flax{{cookiecutter.camelcase_modelname}}ForConditionalGeneration
- call
{% endif -%}
{% endif -%}
| transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/{{cookiecutter.lowercase_modelname}}.md/0 | {
"file_path": "transformers/templates/adding_a_new_model/cookiecutter-template-{{cookiecutter.modelname}}/{{cookiecutter.lowercase_modelname}}.md",
"repo_id": "transformers",
"token_count": 2170
} | 351 |
# coding=utf-8
# Copyright 2021 the HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import sys
import tempfile
import unittest
from pathlib import Path
import transformers
from transformers import (
CONFIG_MAPPING,
FEATURE_EXTRACTOR_MAPPING,
AutoConfig,
AutoFeatureExtractor,
Wav2Vec2Config,
Wav2Vec2FeatureExtractor,
)
from transformers.testing_utils import DUMMY_UNKNOWN_IDENTIFIER, get_tests_dir
sys.path.append(str(Path(__file__).parent.parent.parent.parent / "utils"))
from test_module.custom_configuration import CustomConfig # noqa E402
from test_module.custom_feature_extraction import CustomFeatureExtractor # noqa E402
SAMPLE_FEATURE_EXTRACTION_CONFIG_DIR = get_tests_dir("fixtures")
SAMPLE_FEATURE_EXTRACTION_CONFIG = get_tests_dir("fixtures/dummy_feature_extractor_config.json")
SAMPLE_CONFIG = get_tests_dir("fixtures/dummy-config.json")
class AutoFeatureExtractorTest(unittest.TestCase):
def setUp(self):
transformers.dynamic_module_utils.TIME_OUT_REMOTE_CODE = 0
def test_feature_extractor_from_model_shortcut(self):
config = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base-960h")
self.assertIsInstance(config, Wav2Vec2FeatureExtractor)
def test_feature_extractor_from_local_directory_from_key(self):
config = AutoFeatureExtractor.from_pretrained(SAMPLE_FEATURE_EXTRACTION_CONFIG_DIR)
self.assertIsInstance(config, Wav2Vec2FeatureExtractor)
def test_feature_extractor_from_local_directory_from_config(self):
with tempfile.TemporaryDirectory() as tmpdirname:
model_config = Wav2Vec2Config()
# remove feature_extractor_type to make sure config.json alone is enough to load feature processor locally
config_dict = AutoFeatureExtractor.from_pretrained(SAMPLE_FEATURE_EXTRACTION_CONFIG_DIR).to_dict()
config_dict.pop("feature_extractor_type")
config = Wav2Vec2FeatureExtractor(**config_dict)
# save in new folder
model_config.save_pretrained(tmpdirname)
config.save_pretrained(tmpdirname)
config = AutoFeatureExtractor.from_pretrained(tmpdirname)
# make sure private variable is not incorrectly saved
dict_as_saved = json.loads(config.to_json_string())
self.assertTrue("_processor_class" not in dict_as_saved)
self.assertIsInstance(config, Wav2Vec2FeatureExtractor)
def test_feature_extractor_from_local_file(self):
config = AutoFeatureExtractor.from_pretrained(SAMPLE_FEATURE_EXTRACTION_CONFIG)
self.assertIsInstance(config, Wav2Vec2FeatureExtractor)
def test_repo_not_found(self):
with self.assertRaisesRegex(
EnvironmentError, "bert-base is not a local folder and is not a valid model identifier"
):
_ = AutoFeatureExtractor.from_pretrained("bert-base")
def test_revision_not_found(self):
with self.assertRaisesRegex(
EnvironmentError, r"aaaaaa is not a valid git identifier \(branch name, tag name or commit id\)"
):
_ = AutoFeatureExtractor.from_pretrained(DUMMY_UNKNOWN_IDENTIFIER, revision="aaaaaa")
def test_feature_extractor_not_found(self):
with self.assertRaisesRegex(
EnvironmentError,
"hf-internal-testing/config-no-model does not appear to have a file named preprocessor_config.json.",
):
_ = AutoFeatureExtractor.from_pretrained("hf-internal-testing/config-no-model")
def test_from_pretrained_dynamic_feature_extractor(self):
# If remote code is not set, we will time out when asking whether to load the model.
with self.assertRaises(ValueError):
feature_extractor = AutoFeatureExtractor.from_pretrained(
"hf-internal-testing/test_dynamic_feature_extractor"
)
# If remote code is disabled, we can't load this config.
with self.assertRaises(ValueError):
feature_extractor = AutoFeatureExtractor.from_pretrained(
"hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=False
)
feature_extractor = AutoFeatureExtractor.from_pretrained(
"hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=True
)
self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
# Test feature extractor can be reloaded.
with tempfile.TemporaryDirectory() as tmp_dir:
feature_extractor.save_pretrained(tmp_dir)
reloaded_feature_extractor = AutoFeatureExtractor.from_pretrained(tmp_dir, trust_remote_code=True)
self.assertEqual(reloaded_feature_extractor.__class__.__name__, "NewFeatureExtractor")
def test_new_feature_extractor_registration(self):
try:
AutoConfig.register("custom", CustomConfig)
AutoFeatureExtractor.register(CustomConfig, CustomFeatureExtractor)
# Trying to register something existing in the Transformers library will raise an error
with self.assertRaises(ValueError):
AutoFeatureExtractor.register(Wav2Vec2Config, Wav2Vec2FeatureExtractor)
# Now that the config is registered, it can be used as any other config with the auto-API
feature_extractor = CustomFeatureExtractor.from_pretrained(SAMPLE_FEATURE_EXTRACTION_CONFIG_DIR)
with tempfile.TemporaryDirectory() as tmp_dir:
feature_extractor.save_pretrained(tmp_dir)
new_feature_extractor = AutoFeatureExtractor.from_pretrained(tmp_dir)
self.assertIsInstance(new_feature_extractor, CustomFeatureExtractor)
finally:
if "custom" in CONFIG_MAPPING._extra_content:
del CONFIG_MAPPING._extra_content["custom"]
if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
def test_from_pretrained_dynamic_feature_extractor_conflict(self):
class NewFeatureExtractor(Wav2Vec2FeatureExtractor):
is_local = True
try:
AutoConfig.register("custom", CustomConfig)
AutoFeatureExtractor.register(CustomConfig, NewFeatureExtractor)
# If remote code is not set, the default is to use local
feature_extractor = AutoFeatureExtractor.from_pretrained(
"hf-internal-testing/test_dynamic_feature_extractor"
)
self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
self.assertTrue(feature_extractor.is_local)
# If remote code is disabled, we load the local one.
feature_extractor = AutoFeatureExtractor.from_pretrained(
"hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=False
)
self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
self.assertTrue(feature_extractor.is_local)
# If remote is enabled, we load from the Hub
feature_extractor = AutoFeatureExtractor.from_pretrained(
"hf-internal-testing/test_dynamic_feature_extractor", trust_remote_code=True
)
self.assertEqual(feature_extractor.__class__.__name__, "NewFeatureExtractor")
self.assertTrue(not hasattr(feature_extractor, "is_local"))
finally:
if "custom" in CONFIG_MAPPING._extra_content:
del CONFIG_MAPPING._extra_content["custom"]
if CustomConfig in FEATURE_EXTRACTOR_MAPPING._extra_content:
del FEATURE_EXTRACTOR_MAPPING._extra_content[CustomConfig]
| transformers/tests/models/auto/test_feature_extraction_auto.py/0 | {
"file_path": "transformers/tests/models/auto/test_feature_extraction_auto.py",
"repo_id": "transformers",
"token_count": 3275
} | 352 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import copy
import tempfile
import unittest
import numpy as np
from transformers import BartConfig, BartTokenizer, is_tf_available
from transformers.testing_utils import require_tf, slow
from transformers.utils import cached_property
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
from ...utils.test_modeling_tf_core import TFCoreModelTesterMixin
if is_tf_available():
import tensorflow as tf
from transformers import TFBartForConditionalGeneration, TFBartForSequenceClassification, TFBartModel
@require_tf
class TFBartModelTester:
config_cls = BartConfig
config_updates = {}
hidden_act = "gelu"
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs_for_common(self):
# Ids are clipped to avoid "beginng of sequence", "end of sequence", and "pad" tokens
input_ids = tf.clip_by_value(
ids_tensor([self.batch_size, self.seq_length - 1], self.vocab_size),
clip_value_min=self.eos_token_id + 1,
clip_value_max=self.vocab_size + 1,
)
# Explicity add "end of sequence" to the inputs
eos_tensor = tf.expand_dims(tf.constant([self.eos_token_id] * self.batch_size), 1)
input_ids = tf.concat([input_ids, eos_tensor], axis=1)
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.config_cls(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_ids=[2],
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.pad_token_id,
**self.config_updates,
)
inputs_dict = prepare_bart_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = TFBartModel(config=config).get_decoder()
input_ids = inputs_dict["input_ids"]
input_ids = input_ids[:1, :]
attention_mask = inputs_dict["attention_mask"][:1, :]
head_mask = inputs_dict["head_mask"]
self.batch_size = 1
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, head_mask=head_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = tf.cast(ids_tensor((self.batch_size, 3), 2), tf.int8)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([attention_mask, next_attn_mask], axis=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)
output_from_no_past = output_from_no_past[0]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)
output_from_past = output_from_past[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def prepare_bart_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
):
if attention_mask is None:
attention_mask = tf.cast(tf.math.not_equal(input_ids, config.pad_token_id), tf.int8)
if decoder_attention_mask is None:
decoder_attention_mask = tf.concat(
[
tf.ones(decoder_input_ids[:, :1].shape, dtype=tf.int8),
tf.cast(tf.math.not_equal(decoder_input_ids[:, 1:], config.pad_token_id), tf.int8),
],
axis=-1,
)
if head_mask is None:
head_mask = tf.ones((config.encoder_layers, config.encoder_attention_heads))
if decoder_head_mask is None:
decoder_head_mask = tf.ones((config.decoder_layers, config.decoder_attention_heads))
if cross_attn_head_mask is None:
cross_attn_head_mask = tf.ones((config.decoder_layers, config.decoder_attention_heads))
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": decoder_attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
}
@require_tf
class TFBartModelTest(TFModelTesterMixin, TFCoreModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(TFBartForConditionalGeneration, TFBartForSequenceClassification, TFBartModel) if is_tf_available() else ()
)
all_generative_model_classes = (TFBartForConditionalGeneration,) if is_tf_available() else ()
pipeline_model_mapping = (
{
"conversational": TFBartForConditionalGeneration,
"feature-extraction": TFBartModel,
"summarization": TFBartForConditionalGeneration,
"text-classification": TFBartForSequenceClassification,
"text2text-generation": TFBartForConditionalGeneration,
"translation": TFBartForConditionalGeneration,
"zero-shot": TFBartForSequenceClassification,
}
if is_tf_available()
else {}
)
is_encoder_decoder = True
test_pruning = False
test_onnx = True
onnx_min_opset = 10
def setUp(self):
self.model_tester = TFBartModelTester(self)
self.config_tester = ConfigTester(self, config_class=BartConfig)
def test_config(self):
self.config_tester.run_common_tests()
def test_decoder_model_past_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_decoder_model_past_large_inputs(*config_and_inputs)
# TODO (Joao): fix me
@unittest.skip("Onnx compliancy broke with TF 2.10")
def test_onnx_compliancy(self):
pass
# TFBartForSequenceClassification does not support inputs_embeds
def test_inputs_embeds(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in (TFBartForConditionalGeneration, TFBartModel):
model = model_class(config)
inputs = copy.deepcopy(inputs_dict)
if not self.is_encoder_decoder:
input_ids = inputs["input_ids"]
del inputs["input_ids"]
else:
encoder_input_ids = inputs["input_ids"]
decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids)
del inputs["input_ids"]
inputs.pop("decoder_input_ids", None)
if not self.is_encoder_decoder:
inputs["inputs_embeds"] = model.get_input_embeddings()(input_ids)
else:
inputs["inputs_embeds"] = model.get_input_embeddings()(encoder_input_ids)
inputs["decoder_inputs_embeds"] = model.get_input_embeddings()(decoder_input_ids)
inputs = self._prepare_for_class(inputs, model_class)
model(inputs)
# TFBartForSequenceClassification does not support inputs_embeds
@slow
def test_graph_mode_with_inputs_embeds(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in (TFBartForConditionalGeneration, TFBartModel):
model = model_class(config)
inputs = copy.deepcopy(inputs_dict)
if not self.is_encoder_decoder:
input_ids = inputs["input_ids"]
del inputs["input_ids"]
else:
encoder_input_ids = inputs["input_ids"]
decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids)
del inputs["input_ids"]
inputs.pop("decoder_input_ids", None)
if not self.is_encoder_decoder:
inputs["inputs_embeds"] = model.get_input_embeddings()(input_ids)
else:
inputs["inputs_embeds"] = model.get_input_embeddings()(encoder_input_ids)
inputs["decoder_inputs_embeds"] = model.get_input_embeddings()(decoder_input_ids)
inputs = self._prepare_for_class(inputs, model_class)
@tf.function
def run_in_graph_mode():
return model(inputs)
outputs = run_in_graph_mode()
self.assertIsNotNone(outputs)
@slow
def test_save_load_after_resize_token_embeddings(self):
# Custom version of this test to ensure "end of sequence" tokens are present throughout
if not self.test_resize_embeddings:
return
config, original_inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
# create a model with resized (expended) embeddings
new_tokens_size = 10
old_total_size = config.vocab_size
new_total_size = old_total_size + new_tokens_size
model = model_class(config=copy.deepcopy(config)) # `resize_token_embeddings` mutates `config`
model.build_in_name_scope()
model.resize_token_embeddings(new_total_size)
# fetch the output for an input exclusively made of new members of the vocabulary
inputs_dict = copy.deepcopy(original_inputs_dict)
ids_feat_name = None
if "input_ids" in inputs_dict:
ids_feat_name = "input_ids"
elif "decoder_input_ids" in inputs_dict:
ids_feat_name = "decoder_input_ids"
else:
assert False, "No input ids feature found in the inputs dict"
new_vocab_input_ids = ids_tensor(inputs_dict[ids_feat_name].shape, new_tokens_size)
new_vocab_input_ids += old_total_size
# Replace last id with EOS token
new_vocab_input_ids = new_vocab_input_ids[:, :-1]
new_vocab_input_ids = tf.concat(
[new_vocab_input_ids, tf.ones((tf.shape(new_vocab_input_ids)[0], 1), dtype=tf.int32) * 2], axis=1
)
inputs_dict[ids_feat_name] = new_vocab_input_ids
if "input_ids" in inputs_dict:
inputs_dict["input_ids"] = new_vocab_input_ids
if "decoder_input_ids" in inputs_dict:
inputs_dict["decoder_input_ids"] = new_vocab_input_ids
prepared_inputs = self._prepare_for_class(inputs_dict, model_class)
outputs = model(**prepared_inputs)
# save and load the model
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname, saved_model=False)
model = model_class.from_pretrained(tmpdirname)
restored_model_outputs = model(**prepared_inputs)
# check that the output for the restored model is the same
self.assert_outputs_same(restored_model_outputs, outputs)
@unittest.skip("Does not support conversations.")
def test_pipeline_conversational(self):
pass
def _long_tensor(tok_lst):
return tf.constant(tok_lst, dtype=tf.int32)
@require_tf
class TFBartHeadTests(unittest.TestCase):
vocab_size = 99
def _get_config_and_data(self):
eos_column_vector = tf.ones((4, 1), dtype=tf.int32) * 2
input_ids = tf.concat([ids_tensor((4, 6), self.vocab_size - 3) + 3, eos_column_vector], axis=1)
batch_size = input_ids.shape[0]
config = BartConfig(
vocab_size=self.vocab_size,
d_model=24,
encoder_layers=2,
decoder_layers=2,
encoder_attention_heads=2,
decoder_attention_heads=2,
encoder_ffn_dim=32,
decoder_ffn_dim=32,
max_position_embeddings=48,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
decoder_start_token_id=2,
)
return config, input_ids, batch_size
def test_lm_forward(self):
config, input_ids, batch_size = self._get_config_and_data()
decoder_lm_labels = ids_tensor([batch_size, input_ids.shape[1]], self.vocab_size)
lm_model = TFBartForConditionalGeneration(config)
outputs = lm_model(input_ids=input_ids, labels=decoder_lm_labels, decoder_input_ids=input_ids, use_cache=False)
expected_shape = (batch_size, input_ids.shape[1], config.vocab_size)
self.assertEqual(outputs.logits.shape, expected_shape)
def test_lm_uneven_forward(self):
config = BartConfig(
vocab_size=10,
d_model=24,
encoder_layers=2,
decoder_layers=2,
encoder_attention_heads=2,
decoder_attention_heads=2,
encoder_ffn_dim=32,
decoder_ffn_dim=32,
max_position_embeddings=48,
)
lm_model = TFBartForConditionalGeneration(config)
context = tf.fill((7, 2), 4)
summary = tf.fill((7, 7), 6)
outputs = lm_model(input_ids=context, decoder_input_ids=summary, use_cache=False)
expected_shape = (*summary.shape, config.vocab_size)
self.assertEqual(outputs.logits.shape, expected_shape)
@require_tf
class TFBartForSequenceClassificationTest(unittest.TestCase):
def test_model_fails_for_uneven_eos_tokens(self):
config = BartConfig(eos_token_id=2)
model = TFBartForSequenceClassification(config)
inputs = {
"input_ids": tf.constant([[1, 2, 2, 2], [1, 3, 2, 2], [2, 2, 3, 3]]),
"attention_mask": tf.constant([[1, 1, 1, 1], [1, 1, 1, 1], [1, 1, 1, 1]]),
}
with self.assertRaises(tf.errors.InvalidArgumentError):
model(inputs)
@slow
@require_tf
class TFBartModelIntegrationTest(unittest.TestCase):
def test_inference_no_head(self):
model = TFBartForConditionalGeneration.from_pretrained("facebook/bart-large").model
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
attention_mask = tf.cast(tf.math.not_equal(input_ids, model.config.pad_token_id), tf.int8)
output = model(input_ids=input_ids, attention_mask=attention_mask)[0]
expected_shape = (1, 11, 1024)
self.assertEqual(output.shape, expected_shape)
expected_slice = tf.convert_to_tensor(
[[0.7144, 0.8143, -1.2813], [0.7144, 0.8143, -1.2813], [-0.0467, 2.5911, -2.1845]],
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=1e-3)
def test_cnn_summarization_same_as_fairseq_hard(self):
hf = TFBartForConditionalGeneration.from_pretrained("facebook/bart-large-cnn")
tok = self.tok
FRANCE_ARTICLE = ( # @noqa
" Marseille, France (CNN)The French prosecutor leading an investigation into the crash of Germanwings"
" Flight 9525 insisted Wednesday that he was not aware of any video footage from on board the plane."
' Marseille prosecutor Brice Robin told CNN that "so far no videos were used in the crash investigation."'
' He added, "A person who has such a video needs to immediately give it to the investigators." Robin\'s'
" comments follow claims by two magazines, German daily Bild and French Paris Match, of a cell phone video"
" showing the harrowing final seconds from on board Germanwings Flight 9525 as it crashed into the French"
" Alps. All 150 on board were killed. Paris Match and Bild reported that the video was recovered from a"
" phone at the wreckage site. The two publications described the supposed video, but did not post it on"
" their websites. The publications said that they watched the video, which was found by a source close to"
" the investigation. \"One can hear cries of 'My God' in several languages,\" Paris Match reported."
' "Metallic banging can also be heard more than three times, perhaps of the pilot trying to open the'
" cockpit door with a heavy object. Towards the end, after a heavy shake, stronger than the others, the"
' screaming intensifies. Then nothing." "It is a very disturbing scene," said Julian Reichelt,'
" editor-in-chief of Bild online. An official with France's accident investigation agency, the BEA, said"
" the agency is not aware of any such video. Lt. Col. Jean-Marc Menichini, a French Gendarmerie spokesman"
" in charge of communications on rescue efforts around the Germanwings crash site, told CNN that the"
' reports were "completely wrong" and "unwarranted." Cell phones have been collected at the site, he said,'
' but that they "hadn\'t been exploited yet." Menichini said he believed the cell phones would need to be'
" sent to the Criminal Research Institute in Rosny sous-Bois, near Paris, in order to be analyzed by"
" specialized technicians working hand-in-hand with investigators. But none of the cell phones found so"
" far have been sent to the institute, Menichini said. Asked whether staff involved in the search could"
' have leaked a memory card to the media, Menichini answered with a categorical "no." Reichelt told "Erin'
' Burnett: Outfront" that he had watched the video and stood by the report, saying Bild and Paris Match'
' are "very confident" that the clip is real. He noted that investigators only revealed they\'d recovered'
' cell phones from the crash site after Bild and Paris Match published their reports. "That is something'
" we did not know before. ... Overall we can say many things of the investigation weren't revealed by the"
' investigation at the beginning," he said. What was mental state of Germanwings co-pilot? German airline'
" Lufthansa confirmed Tuesday that co-pilot Andreas Lubitz had battled depression years before he took the"
" controls of Germanwings Flight 9525, which he's accused of deliberately crashing last week in the"
' French Alps. Lubitz told his Lufthansa flight training school in 2009 that he had a "previous episode of'
' severe depression," the airline said Tuesday. Email correspondence between Lubitz and the school'
" discovered in an internal investigation, Lufthansa said, included medical documents he submitted in"
" connection with resuming his flight training. The announcement indicates that Lufthansa, the parent"
" company of Germanwings, knew of Lubitz's battle with depression, allowed him to continue training and"
" ultimately put him in the cockpit. Lufthansa, whose CEO Carsten Spohr previously said Lubitz was 100%"
' fit to fly, described its statement Tuesday as a "swift and seamless clarification" and said it was'
" sharing the information and documents -- including training and medical records -- with public"
" prosecutors. Spohr traveled to the crash site Wednesday, where recovery teams have been working for the"
" past week to recover human remains and plane debris scattered across a steep mountainside. He saw the"
" crisis center set up in Seyne-les-Alpes, laid a wreath in the village of Le Vernet, closer to the crash"
" site, where grieving families have left flowers at a simple stone memorial. Menichini told CNN late"
" Tuesday that no visible human remains were left at the site but recovery teams would keep searching."
" French President Francois Hollande, speaking Tuesday, said that it should be possible to identify all"
" the victims using DNA analysis by the end of the week, sooner than authorities had previously suggested."
" In the meantime, the recovery of the victims' personal belongings will start Wednesday, Menichini said."
" Among those personal belongings could be more cell phones belonging to the 144 passengers and six crew"
" on board. Check out the latest from our correspondents . The details about Lubitz's correspondence with"
" the flight school during his training were among several developments as investigators continued to"
" delve into what caused the crash and Lubitz's possible motive for downing the jet. A Lufthansa"
" spokesperson told CNN on Tuesday that Lubitz had a valid medical certificate, had passed all his"
' examinations and "held all the licenses required." Earlier, a spokesman for the prosecutor\'s office in'
" Dusseldorf, Christoph Kumpa, said medical records reveal Lubitz suffered from suicidal tendencies at"
" some point before his aviation career and underwent psychotherapy before he got his pilot's license."
" Kumpa emphasized there's no evidence suggesting Lubitz was suicidal or acting aggressively before the"
" crash. Investigators are looking into whether Lubitz feared his medical condition would cause him to"
" lose his pilot's license, a European government official briefed on the investigation told CNN on"
' Tuesday. While flying was "a big part of his life," the source said, it\'s only one theory being'
" considered. Another source, a law enforcement official briefed on the investigation, also told CNN that"
" authorities believe the primary motive for Lubitz to bring down the plane was that he feared he would"
" not be allowed to fly because of his medical problems. Lubitz's girlfriend told investigators he had"
" seen an eye doctor and a neuropsychologist, both of whom deemed him unfit to work recently and concluded"
" he had psychological issues, the European government official said. But no matter what details emerge"
" about his previous mental health struggles, there's more to the story, said Brian Russell, a forensic"
' psychologist. "Psychology can explain why somebody would turn rage inward on themselves about the fact'
" that maybe they weren't going to keep doing their job and they're upset about that and so they're"
' suicidal," he said. "But there is no mental illness that explains why somebody then feels entitled to'
" also take that rage and turn it outward on 149 other people who had nothing to do with the person's"
' problems." Germanwings crash compensation: What we know . Who was the captain of Germanwings Flight'
" 9525? CNN's Margot Haddad reported from Marseille and Pamela Brown from Dusseldorf, while Laura"
" Smith-Spark wrote from London. CNN's Frederik Pleitgen, Pamela Boykoff, Antonia Mortensen, Sandrine"
" Amiel and Anna-Maja Rappard contributed to this report."
)
EXPECTED_SUMMARY_FRANCE = (
"French prosecutor says he's not aware of any video footage from on board the plane. German daily Bild"
" and French Paris Match claim to have found a cell phone video of the crash. A French Gendarmerie"
' spokesman calls the reports "completely wrong" and "unwarranted" German airline Lufthansa confirms'
" co-pilot Andreas Lubitz had battled depression."
)
SHORTER_ARTICLE = (
" (CNN)The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
" Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories. The"
" formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is based."
" The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted its"
' jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including East'
' Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination into the'
" situation in Palestinian territories, paving the way for possible war crimes investigations against"
" Israelis. As members of the court, Palestinians may be subject to counter-charges as well. Israel and"
" the United States, neither of which is an ICC member, opposed the Palestinians' efforts to join the"
" body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony, said it was a"
' move toward greater justice. "As Palestine formally becomes a State Party to the Rome Statute today, the'
' world is also a step closer to ending a long era of impunity and injustice," he said, according to an'
' ICC news release. "Indeed, today brings us closer to our shared goals of justice and peace." Judge'
" Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was just the first step for the"
' Palestinians. "As the Rome Statute today enters into force for the State of Palestine, Palestine'
" acquires all the rights as well as responsibilities that come with being a State Party to the Statute."
' These are substantive commitments, which cannot be taken lightly," she said. Rights group Human Rights'
' Watch welcomed the development. "Governments seeking to penalize Palestine for joining the ICC should'
" immediately end their pressure, and countries that support universal acceptance of the court's treaty"
' should speak out to welcome its membership," said Balkees Jarrah, international justice counsel for the'
" group. \"What's objectionable is the attempts to undermine international justice, not Palestine's"
' decision to join a treaty to which over 100 countries around the world are members." In January, when'
" the preliminary ICC examination was opened, Israeli Prime Minister Benjamin Netanyahu described it as an"
' outrage, saying the court was overstepping its boundaries. The United States also said it "strongly"'
" disagreed with the court's decision. \"As we have said repeatedly, we do not believe that Palestine is a"
' state and therefore we do not believe that it is eligible to join the ICC," the State Department said in'
' a statement. It urged the warring sides to resolve their differences through direct negotiations. "We'
' will continue to oppose actions against Israel at the ICC as counterproductive to the cause of peace,"'
" it said. But the ICC begs to differ with the definition of a state for its purposes and refers to the"
' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows the'
" court to review evidence and determine whether to investigate suspects on both sides. Prosecutor Fatou"
' Bensouda said her office would "conduct its analysis in full independence and impartiality." The war'
" between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The inquiry"
" will include alleged war crimes committed since June. The International Criminal Court was set up in"
" 2002 to prosecute genocide, crimes against humanity and war crimes. CNN's Vasco Cotovio, Kareem Khadder"
" and Faith Karimi contributed to this report."
)
EXPECTED_SUMMARY_SHORTER = (
"The Palestinian Authority becomes the 123rd member of the International Criminal Court. The move gives"
" the court jurisdiction over alleged crimes in Palestinian territories. Israel and the United States"
" opposed the Palestinians' efforts to join the body. But Palestinian Foreign Minister Riad al-Malki said"
" it was a move toward greater justice."
)
# The below article tests that we don't add any hypotheses outside of the top n_beams
IRAN_ARTICLE = (
" (CNN)The United States and its negotiating partners reached a very strong framework agreement with Iran"
" in Lausanne, Switzerland, on Thursday that limits Iran's nuclear program in such a way as to effectively"
" block it from building a nuclear weapon. Expect pushback anyway, if the recent past is any harbinger."
" Just last month, in an attempt to head off such an agreement, House Speaker John Boehner invited Israeli"
" Prime Minister Benjamin Netanyahu to preemptively blast it before Congress, and 47 senators sent a"
" letter to the Iranian leadership warning them away from a deal. The debate that has already begun since"
" the announcement of the new framework will likely result in more heat than light. It will not be helped"
" by the gathering swirl of dubious assumptions and doubtful assertions. Let us address some of these: ."
" The most misleading assertion, despite universal rejection by experts, is that the negotiations'"
" objective at the outset was the total elimination of any nuclear program in Iran. That is the position"
" of Netanyahu and his acolytes in the U.S. Congress. But that is not and never was the objective. If it"
" had been, there would have been no Iranian team at the negotiating table. Rather, the objective has"
" always been to structure an agreement or series of agreements so that Iran could not covertly develop a"
" nuclear arsenal before the United States and its allies could respond. The new framework has exceeded"
" expectations in achieving that goal. It would reduce Iran's low-enriched uranium stockpile, cut by"
" two-thirds its number of installed centrifuges and implement a rigorous inspection regime. Another"
" dubious assumption of opponents is that the Iranian nuclear program is a covert weapons program. Despite"
" sharp accusations by some in the United States and its allies, Iran denies having such a program, and"
" U.S. intelligence contends that Iran has not yet made the decision to build a nuclear weapon. Iran's"
" continued cooperation with International Atomic Energy Agency inspections is further evidence on this"
" point, and we'll know even more about Iran's program in the coming months and years because of the deal."
" In fact, the inspections provisions that are part of this agreement are designed to protect against any"
" covert action by the Iranians. What's more, the rhetoric of some members of Congress has implied that"
" the negotiations have been between only the United States and Iran (i.e., the 47 senators' letter"
" warning that a deal might be killed by Congress or a future president). This of course is not the case."
" The talks were between Iran and the five permanent members of the U.N. Security Council (United States,"
" United Kingdom, France, China and Russia) plus Germany, dubbed the P5+1. While the United States has"
" played a leading role in the effort, it negotiated the terms alongside its partners. If the agreement"
" reached by the P5+1 is rejected by Congress, it could result in an unraveling of the sanctions on Iran"
" and threaten NATO cohesion in other areas. Another questionable assertion is that this agreement"
" contains a sunset clause, after which Iran will be free to do as it pleases. Again, this is not the"
" case. Some of the restrictions on Iran's nuclear activities, such as uranium enrichment, will be eased"
" or eliminated over time, as long as 15 years. But most importantly, the framework agreement includes"
" Iran's ratification of the Additional Protocol, which allows IAEA inspectors expanded access to nuclear"
" sites both declared and nondeclared. This provision will be permanent. It does not sunset. Thus, going"
" forward, if Iran decides to enrich uranium to weapons-grade levels, monitors will be able to detect such"
" a move in a matter of days and alert the U.N. Security Council. Many in Congress have said that the"
' agreement should be a formal treaty requiring the Senate to "advise and consent." But the issue is not'
" suited for a treaty. Treaties impose equivalent obligations on all signatories. For example, the New"
" START treaty limits Russia and the United States to 1,550 deployed strategic warheads. But any agreement"
" with Iran will not be so balanced. The restrictions and obligations in the final framework agreement"
" will be imposed almost exclusively on Iran. The P5+1 are obligated only to ease and eventually remove"
" most but not all economic sanctions, which were imposed as leverage to gain this final deal. Finally"
" some insist that any agreement must address Iranian missile programs, human rights violations or support"
" for Hamas or Hezbollah. As important as these issues are, and they must indeed be addressed, they are"
" unrelated to the most important aim of a nuclear deal: preventing a nuclear Iran. To include them in"
" the negotiations would be a poison pill. This agreement should be judged on its merits and on how it"
" affects the security of our negotiating partners and allies, including Israel. Those judgments should be"
" fact-based, not based on questionable assertions or dubious assumptions."
)
EXPECTED_SUMMARY_IRAN = (
"The U.S. and its negotiating partners reached a very strong framework agreement with Iran. Peter Bergen:"
" The debate that has already begun will likely result in more heat than light. He says the agreement"
" limits Iran's nuclear program in such a way as to effectively block it from building a nuclear weapon."
" Bergen says the most important aim of a nuclear deal is preventing a nuclear Iran."
)
ARTICLE_SUBWAY = (
" New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A"
" year later, she got married again in Westchester County, but to a different man and without divorcing"
" her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos"
' declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married'
" once more, this time in the Bronx. In an application for a marriage license, she stated it was her"
' "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false'
' instrument for filing in the first degree," referring to her false statements on the 2010 marriage'
" license application, according to court documents. Prosecutors said the marriages were part of an"
" immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to"
" her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was"
" arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New"
" York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total,"
" Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All"
" occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be"
" married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors"
" said the immigration scam involved some of her husbands, who filed for permanent residence status"
" shortly after the marriages. Any divorces happened only after such filings were approved. It was"
" unclear whether any of the men will be prosecuted. The case was referred to the Bronx District"
" Attorney's Office by Immigration and Customs Enforcement and the Department of Homeland Security's"
' Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt,'
" Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his"
" native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces"
" up to four years in prison. Her next court appearance is scheduled for May 18."
)
EXPECTED_SUMMARY_SUBWAY = (
"Liana Barrientos has been married 10 times, sometimes within two weeks of each other. Prosecutors say the"
" marriages were part of an immigration scam. On Friday, she pleaded not guilty at State Supreme Court in"
" the Bronx. She was arrested and charged with theft of service and criminal trespass for allegedly"
" sneaking into the subway."
)
dct = tok(
[FRANCE_ARTICLE, SHORTER_ARTICLE, IRAN_ARTICLE, ARTICLE_SUBWAY],
max_length=1024,
truncation_strategy="only_first",
padding="longest",
truncation=True,
return_tensors="tf",
)
self.assertEqual(1024, dct["input_ids"].shape[1])
hypotheses_batch = hf.generate(
input_ids=dct["input_ids"],
attention_mask=dct["attention_mask"],
)
assert hypotheses_batch[:, 1].numpy().tolist() == [0, 0, 0, 0] # test force_bos_token_to_be_generated
decoded = tok.batch_decode(hypotheses_batch, skip_special_tokens=True, clean_up_tokenization_spaces=False)
expected_batch = [
EXPECTED_SUMMARY_FRANCE,
EXPECTED_SUMMARY_SHORTER,
EXPECTED_SUMMARY_IRAN,
EXPECTED_SUMMARY_SUBWAY,
]
assert decoded == expected_batch
@cached_property
def tok(self):
return BartTokenizer.from_pretrained("facebook/bart-large")
@slow
def test_contrastive_search_bart(self):
article = (
" New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A"
" year later, she got married again in Westchester County, but to a different man and without divorcing"
" her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos"
' declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married'
" once more, this time in the Bronx. In an application for a marriage license, she stated it was her"
' "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false'
' instrument for filing in the first degree," referring to her false statements on the 2010 marriage'
" license application, according to court documents. Prosecutors said the marriages were part of an"
" immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to"
" her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was"
" arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New"
" York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total,"
" Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All"
" occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be"
" married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors"
" said the immigration scam involved some of her husbands, who filed for permanent residence status"
" shortly after the marriages. Any divorces happened only after such filings were approved. It was"
" unclear whether any of the men will be prosecuted. The case was referred to the Bronx District"
" Attorney's Office by Immigration and Customs Enforcement and the Department of Homeland Security's"
' Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt,'
" Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his"
" native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces"
" up to four years in prison. Her next court appearance is scheduled for May 18."
)
bart_tokenizer = BartTokenizer.from_pretrained("facebook/bart-large-cnn")
bart_model = TFBartForConditionalGeneration.from_pretrained("facebook/bart-large-cnn")
input_ids = bart_tokenizer(
article, add_special_tokens=False, truncation=True, max_length=512, return_tensors="tf"
).input_ids
outputs = bart_model.generate(input_ids, penalty_alpha=0.5, top_k=5, max_length=64)
generated_text = bart_tokenizer.batch_decode(outputs, skip_special_tokens=True)
self.assertListEqual(
generated_text,
[
"Liana Barrientos, 39, pleaded not guilty to charges related to false marriage statements. "
"Prosecutors say she married at least 10 times, sometimes within two weeks of each other. She is "
"accused of being part of an immigration scam to get permanent residency. If convicted, she faces up "
"to four years in"
],
)
@slow
def test_contrastive_search_bart_xla(self):
article = (
" New York (CNN)When Liana Barrientos was 23 years old, she got married in Westchester County, New York. A"
" year later, she got married again in Westchester County, but to a different man and without divorcing"
" her first husband. Only 18 days after that marriage, she got hitched yet again. Then, Barrientos"
' declared "I do" five more times, sometimes only within two weeks of each other. In 2010, she married'
" once more, this time in the Bronx. In an application for a marriage license, she stated it was her"
' "first and only" marriage. Barrientos, now 39, is facing two criminal counts of "offering a false'
' instrument for filing in the first degree," referring to her false statements on the 2010 marriage'
" license application, according to court documents. Prosecutors said the marriages were part of an"
" immigration scam. On Friday, she pleaded not guilty at State Supreme Court in the Bronx, according to"
" her attorney, Christopher Wright, who declined to comment further. After leaving court, Barrientos was"
" arrested and charged with theft of service and criminal trespass for allegedly sneaking into the New"
" York subway through an emergency exit, said Detective Annette Markowski, a police spokeswoman. In total,"
" Barrientos has been married 10 times, with nine of her marriages occurring between 1999 and 2002. All"
" occurred either in Westchester County, Long Island, New Jersey or the Bronx. She is believed to still be"
" married to four men, and at one time, she was married to eight men at once, prosecutors say. Prosecutors"
" said the immigration scam involved some of her husbands, who filed for permanent residence status"
" shortly after the marriages. Any divorces happened only after such filings were approved. It was"
" unclear whether any of the men will be prosecuted. The case was referred to the Bronx District"
" Attorney's Office by Immigration and Customs Enforcement and the Department of Homeland Security's"
' Investigation Division. Seven of the men are from so-called "red-flagged" countries, including Egypt,'
" Turkey, Georgia, Pakistan and Mali. Her eighth husband, Rashid Rajput, was deported in 2006 to his"
" native Pakistan after an investigation by the Joint Terrorism Task Force. If convicted, Barrientos faces"
" up to four years in prison. Her next court appearance is scheduled for May 18."
)
bart_tokenizer = BartTokenizer.from_pretrained("facebook/bart-large-cnn")
bart_model = TFBartForConditionalGeneration.from_pretrained("facebook/bart-large-cnn")
input_ids = bart_tokenizer(
article, add_special_tokens=False, truncation=True, max_length=512, return_tensors="tf"
).input_ids
xla_generate = tf.function(bart_model.generate, jit_compile=True)
# no_repeat_ngram_size set to 0 because it isn't compatible with XLA, but doesn't change the original output
outputs = xla_generate(input_ids, penalty_alpha=0.5, top_k=5, max_length=64, no_repeat_ngram_size=0)
generated_text = bart_tokenizer.batch_decode(outputs, skip_special_tokens=True)
self.assertListEqual(
generated_text,
[
"Liana Barrientos, 39, pleaded not guilty to charges related to false marriage statements. "
"Prosecutors say she married at least 10 times, sometimes within two weeks of each other. She is "
"accused of being part of an immigration scam to get permanent residency. If convicted, she faces up "
"to four years in"
],
)
@slow
@require_tf
class FasterTFBartModelIntegrationTests(unittest.TestCase):
"""These tests are useful for debugging since they operate on a model with 1 encoder layer and 1 decoder layer."""
@cached_property
def tok(self):
return BartTokenizer.from_pretrained("facebook/bart-large")
@cached_property
def xsum_1_1_model(self):
return TFBartForConditionalGeneration.from_pretrained("sshleifer/distilbart-xsum-1-1")
def test_xsum_1_1_generation(self):
model = self.xsum_1_1_model
assert model.model.decoder.embed_tokens == model.model.shared
ARTICLE = (
"The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
" Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories. The"
" formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is based."
" The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted its"
' jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including East'
' Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination into the'
" situation in Palestinian territories, paving the way for possible war crimes investigations against"
" Israelis. As members of the court, Palestinians may be subject to counter-charges as well. Israel and"
" the United States, neither of which is an ICC member, opposed the Palestinians' efforts to join the"
" body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony, said it was a"
' move toward greater justice. "As Palestine formally becomes a State Party to the Rome Statute today, the'
' world is also a step closer to ending a long era of impunity and injustice," he said, according to an'
' ICC news release. "Indeed, today brings us closer to our shared goals of justice and peace." Judge'
" Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was just the first step for the"
' Palestinians. "As the Rome Statute today enters into force for the State of Palestine, Palestine'
" acquires all the rights as well as responsibilities that come with being a State Party to the Statute."
' These are substantive commitments, which cannot be taken lightly," she said. Rights group Human Rights'
' Watch welcomed the development. "Governments seeking to penalize Palestine for joining the ICC should'
" immediately end their pressure, and countries that support universal acceptance of the court's treaty"
' should speak out to welcome its membership," said Balkees Jarrah, international justice counsel for the'
" group. \"What's objectionable is the attempts to undermine international justice, not Palestine's"
' decision to join a treaty to which over 100 countries around the world are members." In January, when'
" the preliminary ICC examination was opened, Israeli Prime Minister Benjamin Netanyahu described it as an"
' outrage, saying the court was overstepping its boundaries. The United States also said it "strongly"'
" disagreed with the court's decision. \"As we have said repeatedly, we do not believe that Palestine is a"
' state and therefore we do not believe that it is eligible to join the ICC," the State Department said in'
' a statement. It urged the warring sides to resolve their differences through direct negotiations. "We'
' will continue to oppose actions against Israel at the ICC as counterproductive to the cause of peace,"'
" it said. But the ICC begs to differ with the definition of a state for its purposes and refers to the"
' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows the'
" court to review evidence and determine whether to investigate suspects on both sides. Prosecutor Fatou"
' Bensouda said her office would "conduct its analysis in full independence and impartiality." The war'
" between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The inquiry"
" will include alleged war crimes committed since June. The International Criminal Court was set up in"
" 2002 to prosecute genocide, crimes against humanity and war crimes."
)
EXPECTED = (
" The International Criminal Court (ICC) has announced that it has been announced by the International"
" Criminal court."
)
dct = self.tok(ARTICLE, return_tensors="tf")
generated_ids = model.generate(**dct, num_beams=4)
result = self.tok.batch_decode(generated_ids, skip_special_tokens=True)[0]
assert result == EXPECTED
def test_xsum_1_1_xla_generation(self):
# same test as above, but with `no_repeat_ngram_size=0` (not compatible with XLA) and XLA comparison enabled
model = self.xsum_1_1_model
assert model.model.decoder.embed_tokens == model.model.shared
ARTICLE = (
"The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
" Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories. The"
" formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is based."
" The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted its"
' jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including East'
' Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination into the'
" situation in Palestinian territories, paving the way for possible war crimes investigations against"
" Israelis. As members of the court, Palestinians may be subject to counter-charges as well. Israel and"
" the United States, neither of which is an ICC member, opposed the Palestinians' efforts to join the"
" body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony, said it was a"
' move toward greater justice. "As Palestine formally becomes a State Party to the Rome Statute today, the'
' world is also a step closer to ending a long era of impunity and injustice," he said, according to an'
' ICC news release. "Indeed, today brings us closer to our shared goals of justice and peace." Judge'
" Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was just the first step for the"
' Palestinians. "As the Rome Statute today enters into force for the State of Palestine, Palestine'
" acquires all the rights as well as responsibilities that come with being a State Party to the Statute."
' These are substantive commitments, which cannot be taken lightly," she said. Rights group Human Rights'
' Watch welcomed the development. "Governments seeking to penalize Palestine for joining the ICC should'
" immediately end their pressure, and countries that support universal acceptance of the court's treaty"
' should speak out to welcome its membership," said Balkees Jarrah, international justice counsel for the'
" group. \"What's objectionable is the attempts to undermine international justice, not Palestine's"
' decision to join a treaty to which over 100 countries around the world are members." In January, when'
" the preliminary ICC examination was opened, Israeli Prime Minister Benjamin Netanyahu described it as an"
' outrage, saying the court was overstepping its boundaries. The United States also said it "strongly"'
" disagreed with the court's decision. \"As we have said repeatedly, we do not believe that Palestine is a"
' state and therefore we do not believe that it is eligible to join the ICC," the State Department said in'
' a statement. It urged the warring sides to resolve their differences through direct negotiations. "We'
' will continue to oppose actions against Israel at the ICC as counterproductive to the cause of peace,"'
" it said. But the ICC begs to differ with the definition of a state for its purposes and refers to the"
' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows the'
" court to review evidence and determine whether to investigate suspects on both sides. Prosecutor Fatou"
' Bensouda said her office would "conduct its analysis in full independence and impartiality." The war'
" between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The inquiry"
" will include alleged war crimes committed since June. The International Criminal Court was set up in"
" 2002 to prosecute genocide, crimes against humanity and war crimes."
)
EXPECTED = (
" The International Criminal Court (ICC) has announced that it is to be investigated by the International"
" Criminal Court (ICC) over allegations of war crimes."
)
dct = self.tok(ARTICLE, return_tensors="tf")
generated_ids = model.generate(**dct, num_beams=4, no_repeat_ngram_size=0)
result = self.tok.batch_decode(generated_ids, skip_special_tokens=True)[0]
assert result == EXPECTED
xla_generate = tf.function(model.generate, jit_compile=True)
generated_ids = xla_generate(**dct, num_beams=4, no_repeat_ngram_size=0)
result = self.tok.batch_decode(generated_ids, skip_special_tokens=True)[0]
assert result == EXPECTED
def test_xsum_1_1_batch_generation(self):
batch = self.tok(
[
"The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
" Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories."
" The formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is"
" based. The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted"
' its jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including'
' East Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination'
" into the situation in Palestinian territories, paving the way for possible war crimes investigations"
" against Israelis. As members of the court, Palestinians may be subject to counter-charges as well."
" Israel and the United States, neither of which is an ICC member, opposed the Palestinians' efforts"
" to join the body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony,"
' said it was a move toward greater justice. "As Palestine formally becomes a State Party to the Rome'
' Statute today, the world is also a step closer to ending a long era of impunity and injustice," he'
' said, according to an ICC news release. "Indeed, today brings us closer to our shared goals of'
' justice and peace." Judge Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was'
' just the first step for the Palestinians. "As the Rome Statute today enters into force for the State'
" of Palestine, Palestine acquires all the rights as well as responsibilities that come with being a"
' State Party to the Statute. These are substantive commitments, which cannot be taken lightly," she'
' said. Rights group Human Rights Watch welcomed the development. "Governments seeking to penalize'
" Palestine for joining the ICC should immediately end their pressure, and countries that support"
" universal acceptance of the court's treaty should speak out to welcome its membership,\" said"
" Balkees Jarrah, international justice counsel for the group. \"What's objectionable is the attempts"
" to undermine international justice, not Palestine's decision to join a treaty to which over 100"
' countries around the world are members." In January, when the preliminary ICC examination was'
" opened, Israeli Prime Minister Benjamin Netanyahu described it as an outrage, saying the court was"
' overstepping its boundaries. The United States also said it "strongly" disagreed with the court\'s'
' decision. "As we have said repeatedly, we do not believe that Palestine is a state and therefore we'
' do not believe that it is eligible to join the ICC," the State Department said in a statement. It'
' urged the warring sides to resolve their differences through direct negotiations. "We will continue'
' to oppose actions against Israel at the ICC as counterproductive to the cause of peace," it said.'
" But the ICC begs to differ with the definition of a state for its purposes and refers to the"
' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows'
" the court to review evidence and determine whether to investigate suspects on both sides. Prosecutor"
' Fatou Bensouda said her office would "conduct its analysis in full independence and impartiality."'
" The war between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The"
" inquiry will include alleged war crimes committed since June. The International Criminal Court was"
" set up in 2002 to prosecute genocide, crimes against humanity and war crimes.",
"The French prosecutor leading an investigation into the crash of Germanwings Flight 9525 insisted"
" Wednesday that he was not aware of any video footage from on board the plane. Marseille prosecutor"
' Brice Robin told CNN that "so far no videos were used in the crash investigation." He added, "A'
" person who has such a video needs to immediately give it to the investigators.\" Robin's comments"
" follow claims by two magazines, German daily Bild and French Paris Match, of a cell phone video"
" showing the harrowing final seconds from on board Germanwings Flight 9525 as it crashed into the"
" French Alps. All 150 on board were killed. Paris Match and Bild reported that the video was"
" recovered from a phone at the wreckage site. The two publications described the supposed video, but"
" did not post it on their websites. The publications said that they watched the video, which was"
" found by a source close to the investigation. \"One can hear cries of 'My God' in several"
' languages," Paris Match reported. "Metallic banging can also be heard more than three times, perhaps'
" of the pilot trying to open the cockpit door with a heavy object. Towards the end, after a heavy"
' shake, stronger than the others, the screaming intensifies. Then nothing." "It is a very disturbing'
" scene,\" said Julian Reichelt, editor-in-chief of Bild online. An official with France's accident"
" investigation agency, the BEA, said the agency is not aware of any such video. Lt. Col. Jean-Marc"
" Menichini, a French Gendarmerie spokesman in charge of communications on rescue efforts around the"
' Germanwings crash site, told CNN that the reports were "completely wrong" and "unwarranted." Cell'
' phones have been collected at the site, he said, but that they "hadn\'t been exploited yet."'
" Menichini said he believed the cell phones would need to be sent to the Criminal Research Institute"
" in Rosny sous-Bois, near Paris, in order to be analyzed by specialized technicians working"
" hand-in-hand with investigators. But none of the cell phones found so far have been sent to the"
" institute, Menichini said. Asked whether staff involved in the search could have leaked a memory"
' card to the media, Menichini answered with a categorical "no." Reichelt told "Erin Burnett:'
' Outfront" that he had watched the video and stood by the report, saying Bild and Paris Match are'
' "very confident" that the clip is real. He noted that investigators only revealed they\'d recovered'
' cell phones from the crash site after Bild and Paris Match published their reports. "That is'
" something we did not know before. ... Overall we can say many things of the investigation weren't"
' revealed by the investigation at the beginning," he said. What was mental state of Germanwings'
" co-pilot? German airline Lufthansa confirmed Tuesday that co-pilot Andreas Lubitz had battled"
" depression years before he took the controls of Germanwings Flight 9525, which he's accused of"
" deliberately crashing last week in the French Alps. Lubitz told his Lufthansa flight training school"
' in 2009 that he had a "previous episode of severe depression," the airline said Tuesday. Email'
" correspondence between Lubitz and the school discovered in an internal investigation, Lufthansa"
" said, included medical documents he submitted in connection with resuming his flight training. The"
" announcement indicates that Lufthansa, the parent company of Germanwings, knew of Lubitz's battle"
" with depression, allowed him to continue training and ultimately put him in the cockpit. Lufthansa,"
" whose CEO Carsten Spohr previously said Lubitz was 100% fit to fly, described its statement Tuesday"
' as a "swift and seamless clarification" and said it was sharing the information and documents --'
" including training and medical records -- with public prosecutors. Spohr traveled to the crash site"
" Wednesday, where recovery teams have been working for the past week to recover human remains and"
" plane debris scattered across a steep mountainside. He saw the crisis center set up in"
" Seyne-les-Alpes, laid a wreath in the village of Le Vernet, closer to the crash site, where grieving"
" families have left flowers at a simple stone memorial. Menichini told CNN late Tuesday that no"
" visible human remains were left at the site but recovery teams would keep searching. French"
" President Francois Hollande, speaking Tuesday, said that it should be possible to identify all the"
" victims using DNA analysis by the end of the week, sooner than authorities had previously suggested."
" In the meantime, the recovery of the victims' personal belongings will start Wednesday, Menichini"
" said. Among those personal belongings could be more cell phones belonging to the 144 passengers and"
" six crew on board. Check out the latest from our correspondents . The details about Lubitz's"
" correspondence with the flight school during his training were among several developments as"
" investigators continued to delve into what caused the crash and Lubitz's possible motive for"
" downing the jet. A Lufthansa spokesperson told CNN on Tuesday that Lubitz had a valid medical"
' certificate, had passed all his examinations and "held all the licenses required." Earlier, a'
" spokesman for the prosecutor's office in Dusseldorf, Christoph Kumpa, said medical records reveal"
" Lubitz suffered from suicidal tendencies at some point before his aviation career and underwent"
" psychotherapy before he got his pilot's license. Kumpa emphasized there's no evidence suggesting"
" Lubitz was suicidal or acting aggressively before the crash. Investigators are looking into whether"
" Lubitz feared his medical condition would cause him to lose his pilot's license, a European"
' government official briefed on the investigation told CNN on Tuesday. While flying was "a big part'
" of his life,\" the source said, it's only one theory being considered. Another source, a law"
" enforcement official briefed on the investigation, also told CNN that authorities believe the"
" primary motive for Lubitz to bring down the plane was that he feared he would not be allowed to fly"
" because of his medical problems. Lubitz's girlfriend told investigators he had seen an eye doctor"
" and a neuropsychologist, both of whom deemed him unfit to work recently and concluded he had"
" psychological issues, the European government official said. But no matter what details emerge about"
" his previous mental health struggles, there's more to the story, said Brian Russell, a forensic"
' psychologist. "Psychology can explain why somebody would turn rage inward on themselves about the'
" fact that maybe they weren't going to keep doing their job and they're upset about that and so"
' they\'re suicidal," he said. "But there is no mental illness that explains why somebody then feels'
" entitled to also take that rage and turn it outward on 149 other people who had nothing to do with"
" the person's problems.\" Germanwings crash compensation: What we know . Who was the captain of"
" Germanwings Flight 9525? CNN's Margot Haddad reported from Marseille and Pamela Brown from"
" Dusseldorf, while Laura Smith-Spark wrote from London. CNN's Frederik Pleitgen, Pamela Boykoff,"
" Antonia Mortensen, Sandrine Amiel and Anna-Maja Rappard contributed to this report.",
],
return_tensors="tf",
padding="longest",
truncation=True,
)
generated_ids = self.xsum_1_1_model.generate(**batch, num_beams=4)
result = self.tok.batch_decode(generated_ids, skip_special_tokens=True)
assert (
result[0]
== " The International Criminal Court (ICC) has announced that it has been announced by the International"
" Criminal court."
)
assert (
result[1]
== " An investigation into the crash that killed at least 10 people in the French capital has been"
" released by the French police investigating the crash."
)
def test_encoder_equiv(self):
batch = self.tok(
[
"The Palestinian Authority officially became the 123rd member of the International Criminal Court on"
" Wednesday, a step that gives the court jurisdiction over alleged crimes in Palestinian territories."
" The formal accession was marked with a ceremony at The Hague, in the Netherlands, where the court is"
" based. The Palestinians signed the ICC's founding Rome Statute in January, when they also accepted"
' its jurisdiction over alleged crimes committed "in the occupied Palestinian territory, including'
' East Jerusalem, since June 13, 2014." Later that month, the ICC opened a preliminary examination'
" into the situation in Palestinian territories, paving the way for possible war crimes investigations"
" against Israelis. As members of the court, Palestinians may be subject to counter-charges as well."
" Israel and the United States, neither of which is an ICC member, opposed the Palestinians' efforts"
" to join the body. But Palestinian Foreign Minister Riad al-Malki, speaking at Wednesday's ceremony,"
' said it was a move toward greater justice. "As Palestine formally becomes a State Party to the Rome'
' Statute today, the world is also a step closer to ending a long era of impunity and injustice," he'
' said, according to an ICC news release. "Indeed, today brings us closer to our shared goals of'
' justice and peace." Judge Kuniko Ozaki, a vice president of the ICC, said acceding to the treaty was'
' just the first step for the Palestinians. "As the Rome Statute today enters into force for the State'
" of Palestine, Palestine acquires all the rights as well as responsibilities that come with being a"
' State Party to the Statute. These are substantive commitments, which cannot be taken lightly," she'
' said. Rights group Human Rights Watch welcomed the development. "Governments seeking to penalize'
" Palestine for joining the ICC should immediately end their pressure, and countries that support"
" universal acceptance of the court's treaty should speak out to welcome its membership,\" said"
" Balkees Jarrah, international justice counsel for the group. \"What's objectionable is the attempts"
" to undermine international justice, not Palestine's decision to join a treaty to which over 100"
' countries around the world are members." In January, when the preliminary ICC examination was'
" opened, Israeli Prime Minister Benjamin Netanyahu described it as an outrage, saying the court was"
' overstepping its boundaries. The United States also said it "strongly" disagreed with the court\'s'
' decision. "As we have said repeatedly, we do not believe that Palestine is a state and therefore we'
' do not believe that it is eligible to join the ICC," the State Department said in a statement. It'
' urged the warring sides to resolve their differences through direct negotiations. "We will continue'
' to oppose actions against Israel at the ICC as counterproductive to the cause of peace," it said.'
" But the ICC begs to differ with the definition of a state for its purposes and refers to the"
' territories as "Palestine." While a preliminary examination is not a formal investigation, it allows'
" the court to review evidence and determine whether to investigate suspects on both sides. Prosecutor"
' Fatou Bensouda said her office would "conduct its analysis in full independence and impartiality."'
" The war between Israel and Hamas militants in Gaza last summer left more than 2,000 people dead. The"
" inquiry will include alleged war crimes committed since June. The International Criminal Court was"
" set up in 2002 to prosecute genocide, crimes against humanity and war crimes.",
"The French prosecutor leading an investigation into the crash of Germanwings Flight 9525 insisted"
" Wednesday that he was not aware of any video footage from on board the plane. Marseille prosecutor"
' Brice Robin told CNN that "so far no videos were used in the crash investigation." He added, "A'
" person who has such a video needs to immediately give it to the investigators.\" Robin's comments"
" follow claims by two magazines, German daily Bild and French Paris Match, of a cell phone video"
" showing the harrowing final seconds from on board Germanwings Flight 9525 as it crashed into the"
" French Alps. All 150 on board were killed. Paris Match and Bild reported that the video was"
" recovered from a phone at the wreckage site. The two publications described the supposed video, but"
" did not post it on their websites. The publications said that they watched the video, which was"
" found by a source close to the investigation. \"One can hear cries of 'My God' in several"
' languages," Paris Match reported. "Metallic banging can also be heard more than three times, perhaps'
" of the pilot trying to open the cockpit door with a heavy object. Towards the end, after a heavy"
' shake, stronger than the others, the screaming intensifies. Then nothing." "It is a very disturbing'
" scene,\" said Julian Reichelt, editor-in-chief of Bild online. An official with France's accident"
" investigation agency, the BEA, said the agency is not aware of any such video. Lt. Col. Jean-Marc"
" Menichini, a French Gendarmerie spokesman in charge of communications on rescue efforts around the"
' Germanwings crash site, told CNN that the reports were "completely wrong" and "unwarranted." Cell'
' phones have been collected at the site, he said, but that they "hadn\'t been exploited yet."'
" Menichini said he believed the cell phones would need to be sent to the Criminal Research Institute"
" in Rosny sous-Bois, near Paris, in order to be analyzed by specialized technicians working"
" hand-in-hand with investigators. But none of the cell phones found so far have been sent to the"
" institute, Menichini said. Asked whether staff involved in the search could have leaked a memory"
' card to the media, Menichini answered with a categorical "no." Reichelt told "Erin Burnett:'
' Outfront" that he had watched the video and stood by the report, saying Bild and Paris Match are'
' "very confident" that the clip is real. He noted that investigators only revealed they\'d recovered'
' cell phones from the crash site after Bild and Paris Match published their reports. "That is'
" something we did not know before. ... Overall we can say many things of the investigation weren't"
' revealed by the investigation at the beginning," he said. What was mental state of Germanwings'
" co-pilot? German airline Lufthansa confirmed Tuesday that co-pilot Andreas Lubitz had battled"
" depression years before he took the controls of Germanwings Flight 9525, which he's accused of"
" deliberately crashing last week in the French Alps. Lubitz told his Lufthansa flight training school"
' in 2009 that he had a "previous episode of severe depression," the airline said Tuesday. Email'
" correspondence between Lubitz and the school discovered in an internal investigation, Lufthansa"
" said, included medical documents he submitted in connection with resuming his flight training. The"
" announcement indicates that Lufthansa, the parent company of Germanwings, knew of Lubitz's battle"
" with depression, allowed him to continue training and ultimately put him in the cockpit. Lufthansa,"
" whose CEO Carsten Spohr previously said Lubitz was 100% fit to fly, described its statement Tuesday"
' as a "swift and seamless clarification" and said it was sharing the information and documents --'
" including training and medical records -- with public prosecutors. Spohr traveled to the crash site"
" Wednesday, where recovery teams have been working for the past week to recover human remains and"
" plane debris scattered across a steep mountainside. He saw the crisis center set up in"
" Seyne-les-Alpes, laid a wreath in the village of Le Vernet, closer to the crash site, where grieving"
" families have left flowers at a simple stone memorial. Menichini told CNN late Tuesday that no"
" visible human remains were left at the site but recovery teams would keep searching. French"
" President Francois Hollande, speaking Tuesday, said that it should be possible to identify all the"
" victims using DNA analysis by the end of the week, sooner than authorities had previously suggested."
" In the meantime, the recovery of the victims' personal belongings will start Wednesday, Menichini"
" said. Among those personal belongings could be more cell phones belonging to the 144 passengers and"
" six crew on board. Check out the latest from our correspondents . The details about Lubitz's"
" correspondence with the flight school during his training were among several developments as"
" investigators continued to delve into what caused the crash and Lubitz's possible motive for"
" downing the jet. A Lufthansa spokesperson told CNN on Tuesday that Lubitz had a valid medical"
' certificate, had passed all his examinations and "held all the licenses required." Earlier, a'
" spokesman for the prosecutor's office in Dusseldorf, Christoph Kumpa, said medical records reveal"
" Lubitz suffered from suicidal tendencies at some point before his aviation career and underwent"
" psychotherapy before he got his pilot's license. Kumpa emphasized there's no evidence suggesting"
" Lubitz was suicidal or acting aggressively before the crash. Investigators are looking into whether"
" Lubitz feared his medical condition would cause him to lose his pilot's license, a European"
' government official briefed on the investigation told CNN on Tuesday. While flying was "a big part'
" of his life,\" the source said, it's only one theory being considered. Another source, a law"
" enforcement official briefed on the investigation, also told CNN that authorities believe the"
" primary motive for Lubitz to bring down the plane was that he feared he would not be allowed to fly"
" because of his medical problems. Lubitz's girlfriend told investigators he had seen an eye doctor"
" and a neuropsychologist, both of whom deemed him unfit to work recently and concluded he had"
" psychological issues, the European government official said. But no matter what details emerge about"
" his previous mental health struggles, there's more to the story, said Brian Russell, a forensic"
' psychologist. "Psychology can explain why somebody would turn rage inward on themselves about the'
" fact that maybe they weren't going to keep doing their job and they're upset about that and so"
' they\'re suicidal," he said. "But there is no mental illness that explains why somebody then feels'
" entitled to also take that rage and turn it outward on 149 other people who had nothing to do with"
" the person's problems.\" Germanwings crash compensation: What we know . Who was the captain of"
" Germanwings Flight 9525? CNN's Margot Haddad reported from Marseille and Pamela Brown from"
" Dusseldorf, while Laura Smith-Spark wrote from London. CNN's Frederik Pleitgen, Pamela Boykoff,"
" Antonia Mortensen, Sandrine Amiel and Anna-Maja Rappard contributed to this report.",
],
return_tensors="tf",
padding="longest",
truncation=True,
)
features = self.xsum_1_1_model.get_encoder()(**batch).last_hidden_state
expected = np.array([[-0.0828, -0.0251, -0.0674], [0.1277, 0.3311, -0.0255], [0.2613, -0.0840, -0.2763]])
assert np.allclose(features[0, :3, :3].numpy(), expected, atol=1e-3)
| transformers/tests/models/bart/test_modeling_tf_bart.py/0 | {
"file_path": "transformers/tests/models/bart/test_modeling_tf_bart.py",
"repo_id": "transformers",
"token_count": 30096
} | 353 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the TensorFlow Blip model. """
from __future__ import annotations
import inspect
import tempfile
import unittest
import numpy as np
import requests
from transformers import BlipConfig, BlipTextConfig, BlipVisionConfig
from transformers.testing_utils import require_tf, require_vision, slow
from transformers.utils import is_tf_available, is_vision_available
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_tf_available():
import tensorflow as tf
from transformers import (
TFBlipForConditionalGeneration,
TFBlipForImageTextRetrieval,
TFBlipForQuestionAnswering,
TFBlipModel,
TFBlipTextModel,
TFBlipVisionModel,
)
from transformers.modeling_tf_utils import keras
from transformers.models.blip.modeling_tf_blip import TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
from transformers import BlipProcessor
class TFBlipVisionModelTester:
def __init__(
self,
parent,
batch_size=12,
image_size=30,
patch_size=2,
num_channels=3,
is_training=True,
hidden_size=32,
projection_dim=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
dropout=0.1,
attention_dropout=0.1,
initializer_range=1e-10,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.is_training = is_training
self.hidden_size = hidden_size
self.projection_dim = projection_dim
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.dropout = dropout
self.attention_dropout = attention_dropout
self.initializer_range = initializer_range
self.scope = scope
# in ViT, the seq length equals the number of patches + 1 (we add 1 for the [CLS] token)
num_patches = (image_size // patch_size) ** 2
self.seq_length = num_patches + 1
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
config = self.get_config()
return config, pixel_values
def get_config(self):
return BlipVisionConfig(
image_size=self.image_size,
patch_size=self.patch_size,
num_channels=self.num_channels,
hidden_size=self.hidden_size,
projection_dim=self.projection_dim,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
initializer_range=self.initializer_range,
)
def create_and_check_model(self, config, pixel_values):
model = TFBlipVisionModel(config=config)
result = model(pixel_values)
# expected sequence length = num_patches + 1 (we add 1 for the [CLS] token)
image_size = (self.image_size, self.image_size)
patch_size = (self.patch_size, self.patch_size)
num_patches = (image_size[1] // patch_size[1]) * (image_size[0] // patch_size[0])
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, num_patches + 1, self.hidden_size))
self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, pixel_values = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
@require_tf
class TFBlipVisionModelTest(TFModelTesterMixin, unittest.TestCase):
"""
Here we also overwrite some of the tests of test_modeling_common.py, as Blip does not use input_ids, inputs_embeds,
attention_mask and seq_length.
"""
all_model_classes = (TFBlipVisionModel,) if is_tf_available() else ()
fx_compatible = False
test_pruning = False
test_resize_embeddings = False
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TFBlipVisionModelTester(self)
self.config_tester = ConfigTester(self, config_class=BlipVisionConfig, has_text_modality=False, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
@unittest.skip(reason="Blip does not use inputs_embeds")
def test_inputs_embeds(self):
pass
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
signature = inspect.signature(model.call)
# signature.parameters is an OrderedDict => so arg_names order is deterministic
arg_names = [*signature.parameters.keys()]
expected_arg_names = ["pixel_values"]
self.assertListEqual(arg_names[:1], expected_arg_names)
def test_model_common_attributes(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
self.assertIsInstance(model.get_input_embeddings(), (keras.layers.Layer))
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, keras.layers.Layer))
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(reason="BlipVisionModel has no base class and is not available in MODEL_MAPPING")
def test_save_load_fast_init_from_base(self):
pass
@unittest.skip(reason="BlipVisionModel has no base class and is not available in MODEL_MAPPING")
def test_save_load_fast_init_to_base(self):
pass
@slow
def test_model_from_pretrained(self):
for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = TFBlipVisionModel.from_pretrained(model_name)
self.assertIsNotNone(model)
class TFBlipTextModelTester:
def __init__(
self,
parent,
batch_size=12,
seq_length=7,
is_training=True,
use_input_mask=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
projection_dim=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
dropout=0.1,
attention_dropout=0.1,
max_position_embeddings=512,
initializer_range=0.02,
bos_token_id=0,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.projection_dim = projection_dim
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.dropout = dropout
self.attention_dropout = attention_dropout
self.max_position_embeddings = max_position_embeddings
self.initializer_range = initializer_range
self.scope = scope
self.bos_token_id = bos_token_id
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
if input_mask is not None:
input_mask = input_mask.numpy()
batch_size, seq_length = input_mask.shape
rnd_start_indices = np.random.randint(1, seq_length - 1, size=(batch_size,))
for batch_idx, start_index in enumerate(rnd_start_indices):
input_mask[batch_idx, :start_index] = 1
input_mask[batch_idx, start_index:] = 0
input_mask = tf.convert_to_tensor(input_mask)
config = self.get_config()
return config, input_ids, input_mask
def get_config(self):
return BlipTextConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
projection_dim=self.projection_dim,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
dropout=self.dropout,
attention_dropout=self.attention_dropout,
max_position_embeddings=self.max_position_embeddings,
initializer_range=self.initializer_range,
bos_token_id=self.bos_token_id,
)
def create_and_check_model(self, config, input_ids, input_mask):
model = TFBlipTextModel(config=config)
result = model(input_ids, attention_mask=input_mask, training=False)
result = model(input_ids, training=False)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, input_ids, input_mask = config_and_inputs
inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_tf
class TFBlipTextModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (TFBlipTextModel,) if is_tf_available() else ()
fx_compatible = False
test_pruning = False
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TFBlipTextModelTester(self)
self.config_tester = ConfigTester(self, config_class=BlipTextConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(reason="Blip does not use inputs_embeds")
def test_inputs_embeds(self):
pass
@unittest.skip(reason="BlipTextModel has no base class and is not available in MODEL_MAPPING")
def test_save_load_fast_init_from_base(self):
pass
@unittest.skip(reason="BlipTextModel has no base class and is not available in MODEL_MAPPING")
def test_save_load_fast_init_to_base(self):
pass
@slow
def test_model_from_pretrained(self):
for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = TFBlipTextModel.from_pretrained(model_name)
self.assertIsNotNone(model)
def test_pt_tf_model_equivalence(self, allow_missing_keys=True):
super().test_pt_tf_model_equivalence(allow_missing_keys=allow_missing_keys)
class TFBlipModelTester:
def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
if text_kwargs is None:
text_kwargs = {}
if vision_kwargs is None:
vision_kwargs = {}
self.parent = parent
self.text_model_tester = TFBlipTextModelTester(parent, **text_kwargs)
self.vision_model_tester = TFBlipVisionModelTester(parent, **vision_kwargs)
self.is_training = is_training
def prepare_config_and_inputs(self):
text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
config = self.get_config()
return config, input_ids, attention_mask, pixel_values
def get_config(self):
return BlipConfig.from_text_vision_configs(
self.text_model_tester.get_config(), self.vision_model_tester.get_config(), projection_dim=64
)
def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
model = TFBlipModel(config)
result = model(input_ids, pixel_values, attention_mask, training=False)
self.parent.assertEqual(
result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
)
self.parent.assertEqual(
result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, input_ids, attention_mask, pixel_values = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"pixel_values": pixel_values,
"return_loss": True,
}
return config, inputs_dict
@require_tf
class TFBlipModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (TFBlipModel,) if is_tf_available() else ()
pipeline_model_mapping = (
{"feature-extraction": TFBlipModel, "image-to-text": TFBlipForConditionalGeneration}
if is_tf_available()
else {}
)
test_head_masking = False
test_pruning = False
test_resize_embeddings = False
test_attention_outputs = False
test_onnx = False
def setUp(self):
self.model_tester = TFBlipModelTester(self)
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(reason="Hidden_states is tested in individual model tests")
def test_hidden_states_output(self):
pass
@unittest.skip(reason="Inputs_embeds is tested in individual model tests")
def test_inputs_embeds(self):
pass
@unittest.skip(reason="Retain_grad is tested in individual model tests")
def test_retain_grad_hidden_states_attentions(self):
pass
@unittest.skip(reason="BlipModel does not have input/output embeddings")
def test_model_common_attributes(self):
pass
def test_load_vision_text_config(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
# Save BlipConfig and check if we can load BlipVisionConfig from it
with tempfile.TemporaryDirectory() as tmp_dir_name:
config.save_pretrained(tmp_dir_name)
vision_config = BlipVisionConfig.from_pretrained(tmp_dir_name)
self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
# Save BlipConfig and check if we can load BlipTextConfig from it
with tempfile.TemporaryDirectory() as tmp_dir_name:
config.save_pretrained(tmp_dir_name)
text_config = BlipTextConfig.from_pretrained(tmp_dir_name)
self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
@slow
def test_model_from_pretrained(self):
for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = TFBlipModel.from_pretrained(model_name)
self.assertIsNotNone(model)
def test_pt_tf_model_equivalence(self, allow_missing_keys=True):
super().test_pt_tf_model_equivalence(allow_missing_keys=allow_missing_keys)
@unittest.skip("Matt: Re-enable this test when we have a proper export function for TF models.")
def test_saved_model_creation(self):
# This fails because the if return_loss: conditional can return None or a Tensor and TF hates that.
# We could fix that by setting the bool to a constant when exporting, but that requires a dedicated export
# function that we don't have yet.
pass
class BlipTextRetrievalModelTester:
def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
if text_kwargs is None:
text_kwargs = {}
if vision_kwargs is None:
vision_kwargs = {}
self.parent = parent
self.text_model_tester = TFBlipTextModelTester(parent, **text_kwargs)
self.vision_model_tester = TFBlipVisionModelTester(parent, **vision_kwargs)
self.is_training = is_training
def prepare_config_and_inputs(self):
text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
config = self.get_config()
return config, input_ids, attention_mask, pixel_values
def get_config(self):
return BlipConfig.from_text_vision_configs(
self.text_model_tester.get_config(), self.vision_model_tester.get_config(), projection_dim=64
)
def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
model = TFBlipModel(config)
result = model(input_ids, pixel_values, attention_mask, training=False)
self.parent.assertEqual(
result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
)
self.parent.assertEqual(
result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, input_ids, attention_mask, pixel_values = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"pixel_values": pixel_values,
}
return config, inputs_dict
class BlipTextImageModelsModelTester:
def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
if text_kwargs is None:
text_kwargs = {}
if vision_kwargs is None:
vision_kwargs = {}
self.parent = parent
self.text_model_tester = TFBlipTextModelTester(parent, **text_kwargs)
self.vision_model_tester = TFBlipVisionModelTester(parent, **vision_kwargs)
self.is_training = is_training
def prepare_config_and_inputs(self):
text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
config = self.get_config()
return config, input_ids, attention_mask, pixel_values
def get_config(self):
return BlipConfig.from_text_vision_configs(
self.text_model_tester.get_config(), self.vision_model_tester.get_config(), projection_dim=64
)
def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
model = TFBlipModel(config)
result = model(input_ids, pixel_values, attention_mask, training=False)
self.parent.assertEqual(
result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
)
self.parent.assertEqual(
result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, input_ids, attention_mask, pixel_values = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"labels": input_ids,
"attention_mask": attention_mask,
"pixel_values": pixel_values,
}
return config, inputs_dict
class BlipVQAModelsModelTester:
def __init__(self, parent, text_kwargs=None, vision_kwargs=None, is_training=True):
if text_kwargs is None:
text_kwargs = {}
if vision_kwargs is None:
vision_kwargs = {}
self.parent = parent
self.text_model_tester = TFBlipTextModelTester(parent, **text_kwargs)
self.vision_model_tester = TFBlipVisionModelTester(parent, **vision_kwargs)
self.is_training = is_training
def prepare_config_and_inputs(self):
text_config, input_ids, attention_mask = self.text_model_tester.prepare_config_and_inputs()
vision_config, pixel_values = self.vision_model_tester.prepare_config_and_inputs()
config = self.get_config()
return config, input_ids, attention_mask, pixel_values
def get_config(self):
return BlipConfig.from_text_vision_configs(
self.text_model_tester.get_config(), self.vision_model_tester.get_config(), projection_dim=64
)
def create_and_check_model(self, config, input_ids, attention_mask, pixel_values):
model = TFBlipModel(config)
result = model(input_ids, pixel_values, attention_mask, training=False)
self.parent.assertEqual(
result.logits_per_image.shape, (self.vision_model_tester.batch_size, self.text_model_tester.batch_size)
)
self.parent.assertEqual(
result.logits_per_text.shape, (self.text_model_tester.batch_size, self.vision_model_tester.batch_size)
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, input_ids, attention_mask, pixel_values = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"decoder_input_ids": input_ids,
"labels": input_ids,
"attention_mask": attention_mask,
"pixel_values": pixel_values,
}
return config, inputs_dict
@require_tf
@require_vision
class TFBlipVQAModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (TFBlipForQuestionAnswering,) if is_tf_available() else ()
test_head_masking = False
test_pruning = False
test_resize_embeddings = False
test_attention_outputs = False
test_onnx = False
def setUp(self):
self.model_tester = BlipVQAModelsModelTester(self)
def _prepare_inputs_for_vqa(self):
_, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
inputs_dict["labels"] = inputs_dict["input_ids"]
inputs_dict["decoder_input_ids"] = inputs_dict["input_ids"]
inputs_dict.pop("return_loss")
return inputs_dict
def test_class_name_consistency(self):
"""
Tests that all VQA models have a class name that ends with "ForQuestionAnswering"
"""
for model_class in self.all_model_classes:
model = model_class(self.model_tester.get_config())
self.assertTrue(
model.__class__.__name__.endswith("ForQuestionAnswering"),
f"Class name should end with 'ForVisualQuestionAnswering' got {model.__class__.__name__}",
)
def test_training(self):
"""
Tests that all VQA models can be trained on a single batch
"""
for model_class in self.all_model_classes:
model = model_class(self.model_tester.get_config())
loss = model(**self.model_tester.prepare_config_and_inputs_for_common()[1], training=True).loss
self.assertIsNotNone(loss, "Loss should not be None")
@unittest.skip(reason="Hidden_states is tested in individual model tests")
def test_hidden_states_output(self):
pass
@unittest.skip(reason="Inputs_embeds is tested in individual model tests")
def test_inputs_embeds(self):
pass
@unittest.skip(reason="Retain_grad is tested in individual model tests")
def test_retain_grad_hidden_states_attentions(self):
pass
@unittest.skip(reason="BlipModel does not have input/output embeddings")
def test_model_common_attributes(self):
pass
@unittest.skip(reason="Tested in individual model tests")
def test_compile_tf_model(self):
pass
@unittest.skip("Model doesn't have a clean loss output.")
def test_keras_fit(self):
pass
@require_tf
class TFBlipTextRetrievalModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (TFBlipForImageTextRetrieval,) if is_tf_available() else ()
test_head_masking = False
test_pruning = False
test_resize_embeddings = False
test_attention_outputs = False
test_onnx = False
def setUp(self):
self.model_tester = BlipTextRetrievalModelTester(self)
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(reason="Hidden_states is tested in individual model tests")
def test_hidden_states_output(self):
pass
@unittest.skip(reason="Inputs_embeds is tested in individual model tests")
def test_inputs_embeds(self):
pass
@unittest.skip(reason="Retain_grad is tested in individual model tests")
def test_retain_grad_hidden_states_attentions(self):
pass
@unittest.skip(reason="BlipModel does not have input/output embeddings")
def test_model_common_attributes(self):
pass
def test_training(self):
if not self.model_tester.is_training:
return
for model_class in self.all_model_classes[:-1]:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
model = model_class(config)
inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
# hardcode labels to be the same as input_ids
inputs["labels"] = inputs["input_ids"]
loss = model(**inputs, training=True).loss
self.assertTrue(loss is not None)
def test_load_vision_text_config(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
# Save BlipConfig and check if we can load BlipVisionConfig from it
with tempfile.TemporaryDirectory() as tmp_dir_name:
config.save_pretrained(tmp_dir_name)
vision_config = BlipVisionConfig.from_pretrained(tmp_dir_name)
self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
# Save BlipConfig and check if we can load BlipTextConfig from it
with tempfile.TemporaryDirectory() as tmp_dir_name:
config.save_pretrained(tmp_dir_name)
text_config = BlipTextConfig.from_pretrained(tmp_dir_name)
self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
@slow
def test_model_from_pretrained(self):
for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = TFBlipModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@unittest.skip(reason="Tested in individual model tests")
def test_compile_tf_model(self):
pass
@unittest.skip("Model doesn't have a clean loss output.")
def test_keras_fit(self):
pass
@require_tf
class TFBlipTextImageModelTest(TFModelTesterMixin, unittest.TestCase):
all_model_classes = (TFBlipForConditionalGeneration,) if is_tf_available() else ()
test_head_masking = False
test_pruning = False
test_resize_embeddings = False
test_attention_outputs = False
test_onnx = False
def setUp(self):
self.model_tester = BlipTextImageModelsModelTester(self)
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(reason="Hidden_states is tested in individual model tests")
def test_hidden_states_output(self):
pass
@unittest.skip(reason="Inputs_embeds is tested in individual model tests")
def test_inputs_embeds(self):
pass
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
signature = inspect.signature(model.call)
# signature.parameters is an OrderedDict => so arg_names order is deterministic
arg_names = [*signature.parameters.keys()]
if model.config.is_encoder_decoder:
expected_arg_names = [
"input_ids",
"attention_mask",
"decoder_input_ids",
"decoder_attention_mask",
]
expected_arg_names.extend(
["head_mask", "decoder_head_mask", "cross_attn_head_mask", "encoder_outputs"]
if "head_mask" and "decoder_head_mask" and "cross_attn_head_mask" in arg_names
else ["encoder_outputs"]
)
self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
else:
expected_arg_names = (
["input_ids"] if model_class != TFBlipForConditionalGeneration else ["pixel_values"]
)
self.assertListEqual(arg_names[:1], expected_arg_names)
@unittest.skip(reason="Tested in individual model tests")
def test_compile_tf_model(self):
pass
@unittest.skip("Has some odd input names!")
def test_keras_fit(self):
pass
@unittest.skip(reason="Retain_grad is tested in individual model tests")
def test_retain_grad_hidden_states_attentions(self):
pass
@unittest.skip(reason="BlipModel does not have input/output embeddings")
def test_model_common_attributes(self):
pass
def test_training(self):
if not self.model_tester.is_training:
return
for model_class in self.all_model_classes[:-1]:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
model = model_class(config)
inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
# hardcode labels to be the same as input_ids
inputs["labels"] = inputs["input_ids"]
loss = model(**inputs, training=True).loss
self.assertIsNotNone(loss)
def test_load_vision_text_config(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
# Save BlipConfig and check if we can load BlipVisionConfig from it
with tempfile.TemporaryDirectory() as tmp_dir_name:
config.save_pretrained(tmp_dir_name)
vision_config = BlipVisionConfig.from_pretrained(tmp_dir_name)
self.assertDictEqual(config.vision_config.to_dict(), vision_config.to_dict())
# Save BlipConfig and check if we can load BlipTextConfig from it
with tempfile.TemporaryDirectory() as tmp_dir_name:
config.save_pretrained(tmp_dir_name)
text_config = BlipTextConfig.from_pretrained(tmp_dir_name)
self.assertDictEqual(config.text_config.to_dict(), text_config.to_dict())
@slow
def test_model_from_pretrained(self):
for model_name in TF_BLIP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = TFBlipModel.from_pretrained(model_name)
self.assertIsNotNone(model)
# We will verify our results on an image of cute cats
def prepare_img():
url = "https://huggingface.co/hf-internal-testing/blip-test-image/resolve/main/demo.jpg"
im = Image.open(requests.get(url, stream=True).raw)
return im
@require_vision
@require_tf
@slow
class TFBlipModelIntegrationTest(unittest.TestCase):
def test_inference_image_captioning(self):
model = TFBlipForConditionalGeneration.from_pretrained("Salesforce/blip-image-captioning-base")
processor = BlipProcessor.from_pretrained("Salesforce/blip-image-captioning-base")
image = prepare_img()
# image only
inputs = processor(images=image, return_tensors="tf")
predictions = model.generate(**inputs)
# Test output
self.assertEqual(
predictions[0].numpy().tolist(), [30522, 1037, 2450, 3564, 2006, 1996, 3509, 2007, 2014, 3899, 102]
)
# image and context
context = ["a picture of"]
inputs = processor(images=image, text=context, return_tensors="tf")
predictions = model.generate(**inputs)
# Test output
self.assertEqual(
predictions[0].numpy().tolist(),
[30522, 1037, 3861, 1997, 1037, 2450, 1998, 2014, 3899, 2006, 1996, 3509, 102],
)
def test_inference_vqa(self):
model = TFBlipForQuestionAnswering.from_pretrained("Salesforce/blip-vqa-base")
processor = BlipProcessor.from_pretrained("Salesforce/blip-vqa-base")
image = prepare_img()
text = "how many dogs are in the picture?"
inputs = processor(image, text=text, return_tensors="tf")
out = model.generate(**inputs)
# Test output
self.assertEqual(out[0].numpy().tolist(), [30522, 1015, 102])
def test_inference_itm(self):
model = TFBlipForImageTextRetrieval.from_pretrained("Salesforce/blip-itm-base-coco")
processor = BlipProcessor.from_pretrained("Salesforce/blip-itm-base-coco")
image = prepare_img()
text = "A woman and her dog sitting in a beach"
inputs = processor(image, text, return_tensors="tf")
out_itm = model(**inputs)
out = model(**inputs, use_itm_head=False, training=False)
expected_scores = tf.convert_to_tensor([[0.0029, 0.9971]])
self.assertTrue(np.allclose(tf.nn.softmax(out_itm[0]).numpy(), expected_scores, rtol=1e-3, atol=1e-3))
self.assertTrue(np.allclose(out[0], tf.convert_to_tensor([[0.5162]]), rtol=1e-3, atol=1e-3))
| transformers/tests/models/blip/test_modeling_tf_blip.py/0 | {
"file_path": "transformers/tests/models/blip/test_modeling_tf_blip.py",
"repo_id": "transformers",
"token_count": 14940
} | 354 |
# coding=utf-8
# Copyright 2020 Huggingface
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from transformers import (
DPRContextEncoderTokenizer,
DPRContextEncoderTokenizerFast,
DPRQuestionEncoderTokenizer,
DPRQuestionEncoderTokenizerFast,
DPRReaderOutput,
DPRReaderTokenizer,
DPRReaderTokenizerFast,
)
from transformers.testing_utils import require_tokenizers, slow
from transformers.tokenization_utils_base import BatchEncoding
from ..bert.test_tokenization_bert import BertTokenizationTest
@require_tokenizers
class DPRContextEncoderTokenizationTest(BertTokenizationTest):
tokenizer_class = DPRContextEncoderTokenizer
rust_tokenizer_class = DPRContextEncoderTokenizerFast
test_rust_tokenizer = True
from_pretrained_id = "facebook/dpr-ctx_encoder-single-nq-base"
@require_tokenizers
class DPRQuestionEncoderTokenizationTest(BertTokenizationTest):
tokenizer_class = DPRQuestionEncoderTokenizer
rust_tokenizer_class = DPRQuestionEncoderTokenizerFast
test_rust_tokenizer = True
from_pretrained_id = "facebook/dpr-ctx_encoder-single-nq-base"
@require_tokenizers
class DPRReaderTokenizationTest(BertTokenizationTest):
tokenizer_class = DPRReaderTokenizer
rust_tokenizer_class = DPRReaderTokenizerFast
test_rust_tokenizer = True
from_pretrained_id = "facebook/dpr-ctx_encoder-single-nq-base"
@slow
def test_decode_best_spans(self):
tokenizer = self.tokenizer_class.from_pretrained("google-bert/bert-base-uncased")
text_1 = tokenizer.encode("question sequence", add_special_tokens=False)
text_2 = tokenizer.encode("title sequence", add_special_tokens=False)
text_3 = tokenizer.encode("text sequence " * 4, add_special_tokens=False)
input_ids = [[101] + text_1 + [102] + text_2 + [102] + text_3]
reader_input = BatchEncoding({"input_ids": input_ids})
start_logits = [[0] * len(input_ids[0])]
end_logits = [[0] * len(input_ids[0])]
relevance_logits = [0]
reader_output = DPRReaderOutput(start_logits, end_logits, relevance_logits)
start_index, end_index = 8, 9
start_logits[0][start_index] = 10
end_logits[0][end_index] = 10
predicted_spans = tokenizer.decode_best_spans(reader_input, reader_output)
self.assertEqual(predicted_spans[0].start_index, start_index)
self.assertEqual(predicted_spans[0].end_index, end_index)
self.assertEqual(predicted_spans[0].doc_id, 0)
@slow
def test_call(self):
tokenizer = self.tokenizer_class.from_pretrained("google-bert/bert-base-uncased")
text_1 = tokenizer.encode("question sequence", add_special_tokens=False)
text_2 = tokenizer.encode("title sequence", add_special_tokens=False)
text_3 = tokenizer.encode("text sequence", add_special_tokens=False)
expected_input_ids = [101] + text_1 + [102] + text_2 + [102] + text_3
encoded_input = tokenizer(questions=["question sequence"], titles=["title sequence"], texts=["text sequence"])
self.assertIn("input_ids", encoded_input)
self.assertIn("attention_mask", encoded_input)
self.assertListEqual(encoded_input["input_ids"][0], expected_input_ids)
| transformers/tests/models/dpr/test_tokenization_dpr.py/0 | {
"file_path": "transformers/tests/models/dpr/test_tokenization_dpr.py",
"repo_id": "transformers",
"token_count": 1358
} | 355 |
# coding=utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import unittest
from transformers import ElectraConfig, is_tf_available
from transformers.testing_utils import require_tf, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_tf_available():
import tensorflow as tf
from transformers.models.electra.modeling_tf_electra import (
TFElectraForMaskedLM,
TFElectraForMultipleChoice,
TFElectraForPreTraining,
TFElectraForQuestionAnswering,
TFElectraForSequenceClassification,
TFElectraForTokenClassification,
TFElectraModel,
)
class TFElectraModelTester:
def __init__(
self,
parent,
):
self.parent = parent
self.batch_size = 13
self.seq_length = 7
self.is_training = True
self.use_input_mask = True
self.use_token_type_ids = True
self.use_labels = True
self.vocab_size = 99
self.hidden_size = 32
self.num_hidden_layers = 2
self.num_attention_heads = 4
self.intermediate_size = 37
self.hidden_act = "gelu"
self.hidden_dropout_prob = 0.1
self.attention_probs_dropout_prob = 0.1
self.max_position_embeddings = 512
self.type_vocab_size = 16
self.type_sequence_label_size = 2
self.initializer_range = 0.02
self.num_labels = 3
self.num_choices = 4
self.scope = None
self.embedding_size = 128
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = ElectraConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
)
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
config.is_decoder = True
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TFElectraModel(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_causal_lm_base_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.is_decoder = True
model = TFElectraModel(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = TFElectraModel(config=config)
inputs = {
"input_ids": input_ids,
"attention_mask": input_mask,
"token_type_ids": token_type_ids,
"encoder_hidden_states": encoder_hidden_states,
"encoder_attention_mask": encoder_attention_mask,
}
result = model(inputs)
inputs = [input_ids, input_mask]
result = model(inputs, token_type_ids=token_type_ids, encoder_hidden_states=encoder_hidden_states)
# Also check the case where encoder outputs are not passed
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_causal_lm_base_model_past(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TFElectraModel(config=config)
# first forward pass
outputs = model(input_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids)
outputs_no_past = model(input_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# append to next input_ids and attn_mask
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
output_from_no_past = model(next_input_ids, output_hidden_states=True).hidden_states[0]
output_from_past = model(
next_tokens, past_key_values=past_key_values, output_hidden_states=True
).hidden_states[0]
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx]
output_from_past_slice = output_from_past[:, 0, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-6)
def create_and_check_causal_lm_base_model_past_with_attn_mask(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TFElectraModel(config=config)
# create attention mask
half_seq_length = self.seq_length // 2
attn_mask_begin = tf.ones((self.batch_size, half_seq_length), dtype=tf.int32)
attn_mask_end = tf.zeros((self.batch_size, self.seq_length - half_seq_length), dtype=tf.int32)
attn_mask = tf.concat([attn_mask_begin, attn_mask_end], axis=1)
# first forward pass
outputs = model(input_ids, attention_mask=attn_mask, use_cache=True)
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
past_key_values = outputs.past_key_values
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).numpy() + 1
random_other_next_tokens = ids_tensor((self.batch_size, self.seq_length), config.vocab_size)
vector_condition = tf.range(self.seq_length) == (self.seq_length - random_seq_idx_to_change)
condition = tf.transpose(
tf.broadcast_to(tf.expand_dims(vector_condition, -1), (self.seq_length, self.batch_size))
)
input_ids = tf.where(condition, random_other_next_tokens, input_ids)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
attn_mask = tf.concat(
[attn_mask, tf.ones((attn_mask.shape[0], 1), dtype=tf.int32)],
axis=1,
)
output_from_no_past = model(
next_input_ids,
attention_mask=attn_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens, past_key_values=past_key_values, attention_mask=attn_mask, output_hidden_states=True
).hidden_states[0]
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx]
output_from_past_slice = output_from_past[:, 0, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-6)
def create_and_check_causal_lm_base_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
):
config.is_decoder = True
model = TFElectraModel(config=config)
input_ids = input_ids[:1, :]
input_mask = input_mask[:1, :]
self.batch_size = 1
# first forward pass
outputs = model(input_ids, attention_mask=input_mask, use_cache=True)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([input_mask, next_attn_mask], axis=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
).hidden_states[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def create_and_check_decoder_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = TFElectraModel(config=config)
input_ids = input_ids[:1, :]
input_mask = input_mask[:1, :]
encoder_hidden_states = encoder_hidden_states[:1, :, :]
encoder_attention_mask = encoder_attention_mask[:1, :]
self.batch_size = 1
# first forward pass
outputs = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=True,
)
past_key_values = outputs.past_key_values
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = tf.concat([input_ids, next_tokens], axis=-1)
next_attention_mask = tf.concat([input_mask, next_attn_mask], axis=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_hidden_states=True,
).hidden_states[0]
output_from_past = model(
next_tokens,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
).hidden_states[0]
self.parent.assertEqual(next_tokens.shape[1], output_from_past.shape[1])
# select random slice
random_slice_idx = int(ids_tensor((1,), output_from_past.shape[-1]))
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx]
output_from_past_slice = output_from_past[:, :, random_slice_idx]
# test that outputs are equal for slice
tf.debugging.assert_near(output_from_past_slice, output_from_no_past_slice, rtol=1e-3)
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TFElectraForMaskedLM(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_pretraining(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TFElectraForPreTraining(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = TFElectraForSequenceClassification(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = TFElectraForMultipleChoice(config=config)
multiple_choice_inputs_ids = tf.tile(tf.expand_dims(input_ids, 1), (1, self.num_choices, 1))
multiple_choice_input_mask = tf.tile(tf.expand_dims(input_mask, 1), (1, self.num_choices, 1))
multiple_choice_token_type_ids = tf.tile(tf.expand_dims(token_type_ids, 1), (1, self.num_choices, 1))
inputs = {
"input_ids": multiple_choice_inputs_ids,
"attention_mask": multiple_choice_input_mask,
"token_type_ids": multiple_choice_token_type_ids,
}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = TFElectraForQuestionAnswering(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = TFElectraForTokenClassification(config=config)
inputs = {"input_ids": input_ids, "attention_mask": input_mask, "token_type_ids": token_type_ids}
result = model(inputs)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_tf
class TFElectraModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
TFElectraModel,
TFElectraForMaskedLM,
TFElectraForPreTraining,
TFElectraForTokenClassification,
TFElectraForMultipleChoice,
TFElectraForSequenceClassification,
TFElectraForQuestionAnswering,
)
if is_tf_available()
else ()
)
pipeline_model_mapping = (
{
"feature-extraction": TFElectraModel,
"fill-mask": TFElectraForMaskedLM,
"question-answering": TFElectraForQuestionAnswering,
"text-classification": TFElectraForSequenceClassification,
"token-classification": TFElectraForTokenClassification,
"zero-shot": TFElectraForSequenceClassification,
}
if is_tf_available()
else {}
)
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TFElectraModelTester(self)
self.config_tester = ConfigTester(self, config_class=ElectraConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
"""Test the base model"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_causal_lm_base_model(self):
"""Test the base model of the causal LM model
is_deocder=True, no cross_attention, no encoder outputs
"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_base_model(*config_and_inputs)
def test_model_as_decoder(self):
"""Test the base model as a decoder (of an encoder-decoder architecture)
is_deocder=True + cross_attention + pass encoder outputs
"""
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
def test_causal_lm_base_model_past(self):
"""Test causal LM base model with `past_key_values`"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_base_model_past(*config_and_inputs)
def test_causal_lm_base_model_past_with_attn_mask(self):
"""Test the causal LM base model with `past_key_values` and `attention_mask`"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_base_model_past_with_attn_mask(*config_and_inputs)
def test_causal_lm_base_model_past_with_large_inputs(self):
"""Test the causal LM base model with `past_key_values` and a longer decoder sequence length"""
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causal_lm_base_model_past_large_inputs(*config_and_inputs)
def test_decoder_model_past_with_large_inputs(self):
"""Similar to `test_causal_lm_base_model_past_with_large_inputs` but with cross-attention"""
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_pretraining(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
# for model_name in TF_ELECTRA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
for model_name in ["google/electra-small-discriminator"]:
model = TFElectraModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_tf
class TFElectraModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_masked_lm(self):
model = TFElectraForPreTraining.from_pretrained("lysandre/tiny-electra-random")
input_ids = tf.constant([[0, 1, 2, 3, 4, 5]])
output = model(input_ids)[0]
expected_shape = [1, 6]
self.assertEqual(output.shape, expected_shape)
print(output[:, :3])
expected_slice = tf.constant([[-0.24651965, 0.8835437, 1.823782]])
tf.debugging.assert_near(output[:, :3], expected_slice, atol=1e-4)
| transformers/tests/models/electra/test_modeling_tf_electra.py/0 | {
"file_path": "transformers/tests/models/electra/test_modeling_tf_electra.py",
"repo_id": "transformers",
"token_count": 10994
} | 356 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch ESM model. """
import unittest
from transformers import EsmConfig, is_torch_available
from transformers.testing_utils import TestCasePlus, require_torch, slow, torch_device
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers.models.esm.modeling_esmfold import EsmForProteinFolding
class EsmFoldModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=False,
use_input_mask=True,
use_token_type_ids=False,
use_labels=False,
vocab_size=19,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config()
return config, input_ids, input_mask, sequence_labels, token_labels, choice_labels
def get_config(self):
esmfold_config = {
"trunk": {
"num_blocks": 2,
"sequence_state_dim": 64,
"pairwise_state_dim": 16,
"sequence_head_width": 4,
"pairwise_head_width": 4,
"position_bins": 4,
"chunk_size": 16,
"structure_module": {
"ipa_dim": 16,
"num_angles": 7,
"num_blocks": 2,
"num_heads_ipa": 4,
"pairwise_dim": 16,
"resnet_dim": 16,
"sequence_dim": 48,
},
},
"fp16_esm": False,
"lddt_head_hid_dim": 16,
}
config = EsmConfig(
vocab_size=33,
hidden_size=self.hidden_size,
pad_token_id=1,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
is_folding_model=True,
esmfold_config=esmfold_config,
)
return config
def create_and_check_model(self, config, input_ids, input_mask, sequence_labels, token_labels, choice_labels):
model = EsmForProteinFolding(config=config).float()
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask)
result = model(input_ids)
result = model(input_ids)
self.parent.assertEqual(result.positions.shape, (2, self.batch_size, self.seq_length, 14, 3))
self.parent.assertEqual(result.angles.shape, (2, self.batch_size, self.seq_length, 7, 2))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_torch
class EsmFoldModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
test_mismatched_shapes = False
all_model_classes = (EsmForProteinFolding,) if is_torch_available() else ()
all_generative_model_classes = ()
pipeline_model_mapping = {} if is_torch_available() else {}
test_sequence_classification_problem_types = False
def setUp(self):
self.model_tester = EsmFoldModelTester(self)
self.config_tester = ConfigTester(self, config_class=EsmConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip("Does not support attention outputs")
def test_attention_outputs(self):
pass
@unittest.skip
def test_correct_missing_keys(self):
pass
@unittest.skip("Esm does not support embedding resizing")
def test_resize_embeddings_untied(self):
pass
@unittest.skip("Esm does not support embedding resizing")
def test_resize_tokens_embeddings(self):
pass
@unittest.skip("ESMFold does not support passing input embeds!")
def test_inputs_embeds(self):
pass
@unittest.skip("ESMFold does not support head pruning.")
def test_head_pruning(self):
pass
@unittest.skip("ESMFold does not support head pruning.")
def test_head_pruning_integration(self):
pass
@unittest.skip("ESMFold does not support head pruning.")
def test_head_pruning_save_load_from_config_init(self):
pass
@unittest.skip("ESMFold does not support head pruning.")
def test_head_pruning_save_load_from_pretrained(self):
pass
@unittest.skip("ESMFold does not support head pruning.")
def test_headmasking(self):
pass
@unittest.skip("ESMFold does not output hidden states in the normal way.")
def test_hidden_states_output(self):
pass
@unittest.skip("ESMfold does not output hidden states in the normal way.")
def test_retain_grad_hidden_states_attentions(self):
pass
@unittest.skip("ESMFold only has one output format.")
def test_model_outputs_equivalence(self):
pass
@unittest.skip("This test doesn't work for ESMFold and doesn't test core functionality")
def test_save_load_fast_init_from_base(self):
pass
@unittest.skip("ESMFold does not support input chunking.")
def test_feed_forward_chunking(self):
pass
@unittest.skip("ESMFold doesn't respect you and it certainly doesn't respect your initialization arguments.")
def test_initialization(self):
pass
@unittest.skip("ESMFold doesn't support torchscript compilation.")
def test_torchscript_output_attentions(self):
pass
@unittest.skip("ESMFold doesn't support torchscript compilation.")
def test_torchscript_output_hidden_state(self):
pass
@unittest.skip("ESMFold doesn't support torchscript compilation.")
def test_torchscript_simple(self):
pass
@unittest.skip("ESMFold doesn't support data parallel.")
def test_multi_gpu_data_parallel_forward(self):
pass
@require_torch
class EsmModelIntegrationTest(TestCasePlus):
@slow
def test_inference_protein_folding(self):
model = EsmForProteinFolding.from_pretrained("facebook/esmfold_v1").float()
model.eval()
input_ids = torch.tensor([[0, 6, 4, 13, 5, 4, 16, 12, 11, 7, 2]])
position_outputs = model(input_ids)["positions"]
expected_slice = torch.tensor([2.5828, 0.7993, -10.9334], dtype=torch.float32)
self.assertTrue(torch.allclose(position_outputs[0, 0, 0, 0], expected_slice, atol=1e-4))
| transformers/tests/models/esm/test_modeling_esmfold.py/0 | {
"file_path": "transformers/tests/models/esm/test_modeling_esmfold.py",
"repo_id": "transformers",
"token_count": 4347
} | 357 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
from transformers import AutoTokenizer, GemmaConfig, is_flax_available
from transformers.testing_utils import require_flax, require_read_token, slow
from ...generation.test_flax_utils import FlaxGenerationTesterMixin
from ...test_modeling_flax_common import FlaxModelTesterMixin, ids_tensor
if is_flax_available():
import jax
import jax.numpy as jnp
from transformers.models.gemma.modeling_flax_gemma import (
FlaxGemmaForCausalLM,
FlaxGemmaModel,
)
class FlaxGemmaModelTester:
def __init__(
self,
parent,
batch_size=2,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=False,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
num_key_value_heads=2,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
initializer_range=0.02,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.num_key_value_heads = num_key_value_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.initializer_range = initializer_range
self.scope = None
self.bos_token_id = vocab_size - 1
self.eos_token_id = vocab_size - 1
self.pad_token_id = vocab_size - 1
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = np.tril(np.ones((self.batch_size, self.seq_length)))
config = GemmaConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
num_key_value_heads=self.num_key_value_heads,
head_dim=self.hidden_size // self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
use_cache=True,
is_decoder=False,
initializer_range=self.initializer_range,
)
return config, input_ids, input_mask
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, input_ids, attention_mask = config_and_inputs
inputs_dict = {"input_ids": input_ids, "attention_mask": attention_mask}
return config, inputs_dict
def check_use_cache_forward(self, model_class_name, config, input_ids, attention_mask):
max_decoder_length = 20
model = model_class_name(config)
past_key_values = model.init_cache(input_ids.shape[0], max_decoder_length)
attention_mask = jnp.ones((input_ids.shape[0], max_decoder_length), dtype="i4")
position_ids = jnp.broadcast_to(
jnp.arange(input_ids.shape[-1] - 1)[None, :], (input_ids.shape[0], input_ids.shape[-1] - 1)
)
outputs_cache = model(
input_ids[:, :-1],
attention_mask=attention_mask,
past_key_values=past_key_values,
position_ids=position_ids,
)
position_ids = jnp.array(input_ids.shape[0] * [[input_ids.shape[-1] - 1]], dtype="i4")
outputs_cache_next = model(
input_ids[:, -1:],
attention_mask=attention_mask,
past_key_values=outputs_cache.past_key_values,
position_ids=position_ids,
)
outputs = model(input_ids)
diff = np.max(np.abs((outputs_cache_next[0][:, -1, :5] - outputs[0][:, -1, :5])))
self.parent.assertTrue(diff < 1e-3, msg=f"Max diff is {diff}")
def check_use_cache_forward_with_attn_mask(self, model_class_name, config, input_ids, attention_mask):
max_decoder_length = 20
model = model_class_name(config)
attention_mask_cache = jnp.concatenate(
[attention_mask, jnp.zeros((attention_mask.shape[0], max_decoder_length - attention_mask.shape[1]))],
axis=-1,
)
past_key_values = model.init_cache(input_ids.shape[0], max_decoder_length)
position_ids = jnp.broadcast_to(
jnp.arange(input_ids.shape[-1] - 1)[None, :], (input_ids.shape[0], input_ids.shape[-1] - 1)
)
outputs_cache = model(
input_ids[:, :-1],
attention_mask=attention_mask_cache,
past_key_values=past_key_values,
position_ids=position_ids,
)
position_ids = jnp.array(input_ids.shape[0] * [[input_ids.shape[-1] - 1]], dtype="i4")
outputs_cache_next = model(
input_ids[:, -1:],
past_key_values=outputs_cache.past_key_values,
attention_mask=attention_mask_cache,
position_ids=position_ids,
)
outputs = model(input_ids, attention_mask=attention_mask)
diff = np.max(np.abs((outputs_cache_next[0][:, -1, :5] - outputs[0][:, -1, :5])))
self.parent.assertTrue(diff < 1e-3, msg=f"Max diff is {diff}")
@require_flax
class FlaxGemmaModelTest(FlaxModelTesterMixin, FlaxGenerationTesterMixin, unittest.TestCase):
all_model_classes = (FlaxGemmaModel, FlaxGemmaForCausalLM) if is_flax_available() else ()
all_generative_model_classes = (FlaxGemmaForCausalLM,) if is_flax_available() else ()
def setUp(self):
self.model_tester = FlaxGemmaModelTester(self)
def test_use_cache_forward(self):
for model_class_name in self.all_model_classes:
config, input_ids, attention_mask = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_use_cache_forward(model_class_name, config, input_ids, attention_mask)
def test_use_cache_forward_with_attn_mask(self):
for model_class_name in self.all_model_classes:
config, input_ids, attention_mask = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_use_cache_forward_with_attn_mask(
model_class_name, config, input_ids, attention_mask
)
@slow
def test_model_from_pretrained(self):
for model_class_name in self.all_model_classes:
model = model_class_name.from_pretrained("google/gemma-2b", from_pt=True)
outputs = model(np.ones((1, 1)))
self.assertIsNotNone(outputs)
@slow
@require_flax
@require_read_token
class FlaxGemmaIntegrationTest(unittest.TestCase):
input_text = ["The capital of France is", "To play the perfect cover drive"]
model_id = "google/gemma-2b"
revision = "flax"
def setUp(self):
self.model, self.params = FlaxGemmaForCausalLM.from_pretrained(
self.model_id, revision=self.revision, _do_init=False
)
self.tokenizer = AutoTokenizer.from_pretrained(self.model_id)
self.tokenizer.padding_side = "left"
def test_logits(self):
inputs = self.tokenizer(self.input_text, return_tensors="np", padding=True)
# fmt: off
EXPECTED_MEAN = [
[-16.427, -21.386, -35.491, -36.258, -31.401, -36.370, -37.598],
[-21.386, -32.150, -33.155, -34.344, -34.706, -34.678, -38.495],
]
EXPECTED_SLICE = [-33.462, -16.481, -30.837, -32.195, -33.113]
# fmt: on
logits = self.model(**inputs, params=self.params).logits
diff_mean = jnp.abs(logits.mean(-1) - np.array(EXPECTED_MEAN)).max()
diff_slice = jnp.abs(logits[0, -1, 475:480] - np.array(EXPECTED_SLICE)).max()
self.assertAlmostEqual(diff_mean, 0, places=3)
self.assertAlmostEqual(diff_slice, 0, places=3)
def test_generation(self):
EXPECTED_TEXTS = [
"The capital of France is a city of contrasts. It is a city of history, of art, of culture, of fashion",
"To play the perfect cover drive, you need to have a good technique and a good mindset.\n\nThe cover drive is a shot",
]
inputs = self.tokenizer(self.input_text, return_tensors="np", padding=True)
output = self.model.generate(**inputs, params=self.params, max_new_tokens=20, do_sample=False)
output_text = self.tokenizer.batch_decode(output.sequences, skip_special_tokens=True)
self.assertEqual(output_text, EXPECTED_TEXTS)
def test_jit_generation(self):
EXPECTED_TEXTS = [
"The capital of France is a city of contrasts. It is a city of history, culture, and art, but it is",
"To play the perfect cover drive, you need to have a good technique and a good mindset.\n\nThe cover drive is a shot",
]
inputs = self.tokenizer(self.input_text, return_tensors="np", padding=True)
def generate(input_ids, attention_mask):
outputs = self.model.generate(
input_ids, attention_mask=attention_mask, params=self.params, max_new_tokens=20, do_sample=False
)
return outputs
jit_generate = jax.jit(generate)
output_sequences = jit_generate(**inputs).sequences
output_text = self.tokenizer.batch_decode(output_sequences, skip_special_tokens=True)
self.assertEqual(output_text, EXPECTED_TEXTS)
| transformers/tests/models/gemma/test_modeling_flax_gemma.py/0 | {
"file_path": "transformers/tests/models/gemma/test_modeling_flax_gemma.py",
"repo_id": "transformers",
"token_count": 4825
} | 358 |
# coding=utf-8
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
import unittest
from parameterized import parameterized
from transformers import GPTBigCodeConfig, is_torch_available
from transformers.testing_utils import require_torch, slow, torch_device
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
GPT2TokenizerFast,
GPTBigCodeForCausalLM,
GPTBigCodeForSequenceClassification,
GPTBigCodeForTokenClassification,
GPTBigCodeModel,
)
from transformers.models.gpt_bigcode.modeling_gpt_bigcode import GPTBigCodeAttention
from transformers.pytorch_utils import is_torch_greater_or_equal_than_1_12
else:
is_torch_greater_or_equal_than_1_12 = False
class GPTBigCodeModelTester:
def __init__(
self,
parent,
batch_size=14,
seq_length=7,
is_training=True,
use_token_type_ids=True,
use_input_mask=True,
use_labels=True,
use_mc_token_ids=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="relu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
multi_query=True,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_token_type_ids = use_token_type_ids
self.use_input_mask = use_input_mask
self.use_labels = use_labels
self.use_mc_token_ids = use_mc_token_ids
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = None
self.bos_token_id = vocab_size - 1
self.eos_token_id = vocab_size - 2
self.pad_token_id = vocab_size - 3
self.multi_query = multi_query
def get_large_model_config(self):
return GPTBigCodeConfig.from_pretrained("bigcode/gpt_bigcode-santacoder")
def prepare_config_and_inputs(
self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
mc_token_ids = None
if self.use_mc_token_ids:
mc_token_ids = ids_tensor([self.batch_size, self.num_choices], self.seq_length)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config(
gradient_checkpointing=gradient_checkpointing,
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
reorder_and_upcast_attn=reorder_and_upcast_attn,
)
head_mask = ids_tensor([self.num_hidden_layers, self.num_attention_heads], 2)
return (
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
)
def get_config(
self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
):
return GPTBigCodeConfig(
vocab_size=self.vocab_size,
n_embd=self.hidden_size,
n_layer=self.num_hidden_layers,
n_head=self.num_attention_heads,
n_inner=self.intermediate_size,
activation_function=self.hidden_act,
resid_pdrop=self.hidden_dropout_prob,
attn_pdrop=self.attention_probs_dropout_prob,
n_positions=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
use_cache=True,
bos_token_id=self.bos_token_id,
eos_token_id=self.eos_token_id,
pad_token_id=self.pad_token_id,
gradient_checkpointing=gradient_checkpointing,
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
reorder_and_upcast_attn=reorder_and_upcast_attn,
attention_softmax_in_fp32=False,
scale_attention_softmax_in_fp32=False,
multi_query=self.multi_query,
)
def get_pipeline_config(self):
config = self.get_config()
config.vocab_size = 300
return config
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_gpt_bigcode_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = GPTBigCodeModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, token_type_ids=token_type_ids, head_mask=head_mask)
result = model(input_ids, token_type_ids=token_type_ids)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(len(result.past_key_values), config.n_layer)
def create_and_check_gpt_bigcode_model_past(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = GPTBigCodeModel(config=config)
model.to(torch_device)
model.eval()
# first forward pass
outputs = model(input_ids, token_type_ids=token_type_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids, token_type_ids=token_type_ids)
outputs_no_past = model(input_ids, token_type_ids=token_type_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
output, past = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
next_token_types = ids_tensor([self.batch_size, 1], self.type_vocab_size)
# append to next input_ids and token_type_ids
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
output_from_no_past = model(next_input_ids, token_type_ids=next_token_type_ids)["last_hidden_state"]
output_from_past = model(next_tokens, token_type_ids=next_token_types, past_key_values=past)[
"last_hidden_state"
]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_gpt_bigcode_model_attention_mask_past(
self, config, input_ids, input_mask, head_mask, token_type_ids, *args
):
model = GPTBigCodeModel(config=config)
model.to(torch_device)
model.eval()
# create attention mask
attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
half_seq_length = self.seq_length // 2
attn_mask[:, half_seq_length:] = 0
# first forward pass
output, past = model(input_ids, attention_mask=attn_mask).to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
# append to next input_ids and attn_mask
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
attn_mask = torch.cat(
[attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
dim=1,
)
# get two different outputs
output_from_no_past = model(next_input_ids, attention_mask=attn_mask)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past, attention_mask=attn_mask)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_gpt_bigcode_model_past_large_inputs(
self, config, input_ids, input_mask, head_mask, token_type_ids, *args
):
model = GPTBigCodeModel(config=config)
model.to(torch_device)
model.eval()
# first forward pass
outputs = model(input_ids, token_type_ids=token_type_ids, attention_mask=input_mask, use_cache=True)
output, past = outputs.to_tuple()
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_token_types = ids_tensor([self.batch_size, 3], self.type_vocab_size)
next_mask = ids_tensor((self.batch_size, 3), vocab_size=2)
# append to next input_ids and token_type_ids
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_token_type_ids = torch.cat([token_type_ids, next_token_types], dim=-1)
next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
output_from_no_past = model(
next_input_ids, token_type_ids=next_token_type_ids, attention_mask=next_attention_mask
)["last_hidden_state"]
output_from_past = model(
next_tokens, token_type_ids=next_token_types, attention_mask=next_attention_mask, past_key_values=past
)["last_hidden_state"]
self.parent.assertTrue(output_from_past.shape[1] == next_tokens.shape[1])
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_lm_head_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = GPTBigCodeForCausalLM(config)
model.to(torch_device)
model.eval()
result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_forward_and_backwards(
self, config, input_ids, input_mask, head_mask, token_type_ids, *args, gradient_checkpointing=False
):
model = GPTBigCodeForCausalLM(config)
model.to(torch_device)
if gradient_checkpointing:
model.gradient_checkpointing_enable()
result = model(input_ids, token_type_ids=token_type_ids, labels=input_ids)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
result.loss.backward()
def create_and_check_gpt_bigcode_for_sequence_classification(
self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, sequence_labels, *args
):
config.num_labels = self.num_labels
model = GPTBigCodeForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_gpt_bigcode_for_token_classification(
self, config, input_ids, input_mask, head_mask, token_type_ids, mc_token_ids, sequence_labels, *args
):
config.num_labels = self.num_labels
model = GPTBigCodeForTokenClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_gpt_bigcode_weight_initialization(self, config, *args):
model = GPTBigCodeModel(config)
model_std = model.config.initializer_range / math.sqrt(2 * model.config.n_layer)
for key in model.state_dict().keys():
if "c_proj" in key and "weight" in key:
self.parent.assertLessEqual(abs(torch.std(model.state_dict()[key]) - model_std), 0.001)
self.parent.assertLessEqual(abs(torch.mean(model.state_dict()[key]) - 0.0), 0.01)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"token_type_ids": token_type_ids,
"head_mask": head_mask,
}
return config, inputs_dict
@require_torch
class GPTBigCodeModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
# TODO: Update the tests to use valid pretrained models.
all_model_classes = (
(
GPTBigCodeModel,
GPTBigCodeForCausalLM,
GPTBigCodeForSequenceClassification,
GPTBigCodeForTokenClassification,
)
if is_torch_available()
else ()
)
all_generative_model_classes = (GPTBigCodeForCausalLM,) if is_torch_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": GPTBigCodeModel,
"text-classification": GPTBigCodeForSequenceClassification,
"text-generation": GPTBigCodeForCausalLM,
"token-classification": GPTBigCodeForTokenClassification,
"zero-shot": GPTBigCodeForSequenceClassification,
}
if is_torch_available()
else {}
)
fx_compatible = False
test_missing_keys = False
test_pruning = False
test_torchscript = False
multi_query = True
# special case for DoubleHeads model
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
return inputs_dict
def setUp(self):
self.model_tester = GPTBigCodeModelTester(self, multi_query=self.multi_query)
self.config_tester = ConfigTester(self, config_class=GPTBigCodeConfig, n_embd=37)
def tearDown(self):
import gc
gc.collect()
def test_config(self):
self.config_tester.run_common_tests()
@unittest.skip("MQA models does not support retain_grad")
def test_retain_grad_hidden_states_attentions(self):
pass
@unittest.skip("Contrastive search not supported due to non-standard caching mechanism")
def test_contrastive_generate(self):
pass
@unittest.skip("Contrastive search not supported due to non-standard caching mechanism")
def test_contrastive_generate_dict_outputs_use_cache(self):
pass
@unittest.skip("CPU offload seems to be broken for some reason - tiny models keep hitting corner cases")
def test_cpu_offload(self):
pass
@unittest.skip("Disk offload seems to be broken for some reason - tiny models keep hitting corner cases")
def test_disk_offload(self):
pass
@unittest.skip("BigCodeGPT has a non-standard KV cache format.")
def test_past_key_values_format(self):
pass
def test_gpt_bigcode_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt_bigcode_model(*config_and_inputs)
def test_gpt_bigcode_model_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt_bigcode_model_past(*config_and_inputs)
def test_gpt_bigcode_model_att_mask_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt_bigcode_model_attention_mask_past(*config_and_inputs)
def test_gpt_bigcode_model_past_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt_bigcode_model_past_large_inputs(*config_and_inputs)
def test_gpt_bigcode_lm_head_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_lm_head_model(*config_and_inputs)
def test_gpt_bigcode_sequence_classification_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt_bigcode_for_sequence_classification(*config_and_inputs)
def test_gpt_bigcode_token_classification_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt_bigcode_for_token_classification(*config_and_inputs)
def test_gpt_bigcode_gradient_checkpointing(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs, gradient_checkpointing=True)
def test_gpt_bigcode_scale_attn_by_inverse_layer_idx(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(scale_attn_by_inverse_layer_idx=True)
self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs)
def test_gpt_bigcode_reorder_and_upcast_attn(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(reorder_and_upcast_attn=True)
self.model_tester.create_and_check_forward_and_backwards(*config_and_inputs)
def test_gpt_bigcode_weight_initialization(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_gpt_bigcode_weight_initialization(*config_and_inputs)
@require_torch
class GPTBigCodeMHAModelTest(GPTBigCodeModelTest):
# `parameterized_class` breaks with mixins, so we use inheritance instead
multi_query = False
@unittest.skipIf(
not is_torch_greater_or_equal_than_1_12,
reason="`GPTBigCode` checkpoints use `PytorchGELUTanh` which requires `torch>=1.12.0`.",
)
@slow
@require_torch
class GPTBigCodeModelLanguageGenerationTest(unittest.TestCase):
def test_generate_simple(self):
model = GPTBigCodeForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder").to(torch_device)
tokenizer = GPT2TokenizerFast.from_pretrained("bigcode/gpt_bigcode-santacoder")
input_ids = tokenizer("def print_hello_world():", return_tensors="pt").input_ids.to(torch_device)
output_sequence = model.generate(input_ids)
output_sentence = tokenizer.decode(output_sequence[0], skip_special_tokens=True)
expected_output = """def print_hello_world():\n print("Hello World!")\n\n\ndef print_hello_"""
self.assertEqual(output_sentence, expected_output)
def test_generate_batched(self):
tokenizer = GPT2TokenizerFast.from_pretrained("bigcode/gpt_bigcode-santacoder")
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
model = GPTBigCodeForCausalLM.from_pretrained("bigcode/gpt_bigcode-santacoder").to(torch_device)
inputs = tokenizer(["def print_hello_world():", "def say_hello():"], return_tensors="pt", padding=True).to(
torch_device
)
outputs = model.generate(**inputs)
outputs = tokenizer.batch_decode(outputs, skip_special_tokens=True)
expected_output = [
'def print_hello_world():\n print("Hello World!")\n\n\ndef print_hello_',
'def say_hello():\n print("Hello, World!")\n\n\nsay_hello()',
]
self.assertListEqual(outputs, expected_output)
@require_torch
class GPTBigCodeMQATest(unittest.TestCase):
def get_attention(self, multi_query):
config = GPTBigCodeConfig.from_pretrained(
"bigcode/gpt_bigcode-santacoder",
multi_query=multi_query,
attn_pdrop=0,
resid_pdrop=0,
)
return GPTBigCodeAttention(config)
@parameterized.expand([(seed, is_train_mode) for seed in range(5) for is_train_mode in [True, False]])
def test_mqa_reduces_to_mha(self, seed, is_train_mode=True):
torch.manual_seed(seed)
# CREATE MQA AND MHA ATTENTIONS
attention_mqa = self.get_attention(True)
attention_mha = self.get_attention(False)
# ENFORCE MATCHING WEIGHTS
num_heads = attention_mqa.num_heads
embed_dim = attention_mqa.embed_dim
head_dim = attention_mqa.head_dim
with torch.no_grad():
mqa_q_weight = attention_mqa.c_attn.weight[:embed_dim, :].view(num_heads, 1, head_dim, embed_dim)
mqa_kv_weight = attention_mqa.c_attn.weight[embed_dim:, :].view(1, 2, head_dim, embed_dim)
mha_c_weight = torch.cat(
[mqa_q_weight, mqa_kv_weight.expand(num_heads, 2, head_dim, embed_dim)], dim=1
).view(3 * num_heads * head_dim, embed_dim)
mqa_q_bias = attention_mqa.c_attn.bias[:embed_dim].view(num_heads, 1, head_dim)
mqa_kv_bias = attention_mqa.c_attn.bias[embed_dim:].view(1, 2, head_dim)
mha_c_bias = torch.cat([mqa_q_bias, mqa_kv_bias.expand(num_heads, 2, head_dim)], dim=1).view(
3 * num_heads * head_dim
)
attention_mha.c_attn.weight.copy_(mha_c_weight)
attention_mha.c_attn.bias.copy_(mha_c_bias)
attention_mha.c_proj.weight.copy_(attention_mqa.c_proj.weight)
attention_mha.c_proj.bias.copy_(attention_mqa.c_proj.bias)
# PUT THE MODEL INTO THE CORRECT MODE
attention_mha.train(is_train_mode)
attention_mqa.train(is_train_mode)
# RUN AN INPUT THROUGH THE MODELS
num_tokens = 5
hidden_states = torch.randn(1, num_tokens, embed_dim)
attention_mha_result = attention_mha(hidden_states)[0]
attention_mqa_result = attention_mqa(hidden_states)[0]
# CHECK THAT ALL OUTPUTS ARE THE SAME
self.assertTrue(torch.allclose(attention_mha_result, attention_mqa_result, atol=1e-5))
| transformers/tests/models/gpt_bigcode/test_modeling_gpt_bigcode.py/0 | {
"file_path": "transformers/tests/models/gpt_bigcode/test_modeling_gpt_bigcode.py",
"repo_id": "transformers",
"token_count": 11767
} | 359 |
# coding=utf-8
# Copyright 2023 Toshiyuki Sakamoto(tanreinama) and HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
from transformers import (
GPTSanJapaneseConfig,
GPTSanJapaneseForConditionalGeneration,
GPTSanJapaneseModel,
GPTSanJapaneseTokenizer,
is_torch_available,
)
from transformers.generation import GenerationConfig
from transformers.testing_utils import require_torch, slow, tooslow, torch_device
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
class GPTSanJapaneseTester:
def __init__(
self,
parent,
vocab_size=99,
batch_size=13,
num_contexts=7,
# For common tests
is_training=True,
hidden_size=32,
ext_size=42,
num_hidden_layers=2,
num_ext_layers=2,
num_attention_heads=4,
num_experts=2,
d_ff=32,
d_ext=80,
d_spout=33,
dropout_rate=0.0,
layer_norm_epsilon=1e-6,
expert_capacity=100,
router_jitter_noise=0.0,
):
self.vocab_size = vocab_size
self.parent = parent
self.batch_size = batch_size
self.num_contexts = num_contexts
# For common tests
self.seq_length = self.num_contexts
self.is_training = is_training
self.hidden_size = hidden_size
self.num_ext_layers = num_ext_layers
self.ext_size = ext_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.num_experts = num_experts
self.d_ff = d_ff
self.d_ext = d_ext
self.d_spout = d_spout
self.dropout_rate = dropout_rate
self.layer_norm_epsilon = layer_norm_epsilon
self.expert_capacity = expert_capacity
self.router_jitter_noise = router_jitter_noise
def get_large_model_config(self):
return GPTSanJapaneseConfig.from_pretrained("Tanrei/GPTSAN-japanese")
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.get_config()
return (config, input_ids)
def prepare_config_and_inputs_for_common(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = self.get_config()
return (config, {"input_ids": input_ids})
def get_config(self):
return GPTSanJapaneseConfig(
vocab_size=self.vocab_size,
num_contexts=self.seq_length,
d_model=self.hidden_size,
d_ff=self.d_ff,
d_ext=self.d_ext,
d_spout=self.d_spout,
num_switch_layers=self.num_hidden_layers - self.num_ext_layers,
num_ext_layers=self.num_ext_layers,
num_heads=self.num_attention_heads,
num_experts=self.num_experts,
expert_capacity=self.expert_capacity,
dropout_rate=self.dropout_rate,
layer_norm_epsilon=self.layer_norm_epsilon,
router_jitter_noise=self.router_jitter_noise,
)
def create_and_check_model(
self,
config,
input_ids,
):
model = GPTSanJapaneseForConditionalGeneration(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids=input_ids,
)
self.parent.assertIsNotNone(result)
@require_torch
class GPTSanJapaneseTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (GPTSanJapaneseModel,) if is_torch_available() else ()
pipeline_model_mapping = (
{
"conversational": GPTSanJapaneseForConditionalGeneration,
"feature-extraction": GPTSanJapaneseForConditionalGeneration,
"summarization": GPTSanJapaneseForConditionalGeneration,
"text2text-generation": GPTSanJapaneseForConditionalGeneration,
"translation": GPTSanJapaneseForConditionalGeneration,
}
if is_torch_available()
else {}
)
fx_compatible = False
is_encoder_decoder = False
test_pruning = False
test_headmasking = False
test_cpu_offload = False
test_disk_offload = False
test_save_load_fast_init_to_base = False
test_training = False
# The small GPTSAN_JAPANESE model needs higher percentages for CPU/MP tests
model_split_percents = [0.8, 0.9]
# TODO: Fix the failed tests when this model gets more usage
def is_pipeline_test_to_skip(
self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
):
if pipeline_test_casse_name == "SummarizationPipelineTests":
# TODO: fix `_reorder_cache` is not implemented for this model
return True
elif pipeline_test_casse_name == "Text2TextGenerationPipelineTests":
# TODO: check this.
return True
return False
def setUp(self):
self.model_tester = GPTSanJapaneseTester(self)
self.config_tester = ConfigTester(self, config_class=GPTSanJapaneseConfig, d_model=37)
def test_config(self):
GPTSanJapaneseConfig()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(
reason="skip for now as the computed `max_memory` by `model_split_percents` in the test method will be changed inside `from_pretrained`"
)
def test_model_parallelism(self):
super().test_model_parallelism()
@require_torch
class GPTSanJapaneseForConditionalGenerationTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
all_model_classes = (GPTSanJapaneseForConditionalGeneration,) if is_torch_available() else ()
fx_compatible = False
is_encoder_decoder = False
test_pruning = False
test_headmasking = False
test_cpu_offload = False
test_disk_offload = False
# The small GPTSAN_JAPANESE model needs higher percentages for CPU/MP tests
model_split_percents = [0.8, 0.9]
def setUp(self):
self.model_tester = GPTSanJapaneseTester(self)
self.config_tester = ConfigTester(self, config_class=GPTSanJapaneseConfig, d_model=37)
def test_config(self):
GPTSanJapaneseConfig()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip(
reason="skip for now as the computed `max_memory` by `model_split_percents` in the test method will be changed inside `from_pretrained`"
)
def test_model_parallelism(self):
super().test_model_parallelism()
@slow
def test_logits(self):
model = GPTSanJapaneseForConditionalGeneration.from_pretrained("Tanrei/GPTSAN-japanese")
tokenizer = GPTSanJapaneseTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
input_ids = tokenizer.encode("武田信玄は", return_tensors="pt")
outputs = model(input_ids)
output_logits = outputs.logits.detach().cpu().numpy()
# Output of original model created with mesh-tensoflow
# fmt: off
target = [
[-12.037839889526367, -12.433061599731445, -14.333840370178223, -12.450345993041992, -11.1661376953125,
-11.930137634277344, -10.659740447998047, -12.909574508666992, -13.241043090820312, -13.398579597473145,
-11.107524871826172, -12.3685941696167, -22.97943115234375, -10.481067657470703, -12.484030723571777,
-12.807360649108887, -14.769700050354004, -12.233579635620117, -13.428145408630371, -22.624177932739258],
[-7.511149883270264, -8.281851768493652, -7.943127155303955, -7.55021333694458, -6.49869966506958,
-7.586796283721924, -6.978085994720459, -7.839145183563232, -8.21964168548584, -8.695091247558594,
-6.706910610198975, -6.6585798263549805, -19.565698623657227, -5.353842735290527, -8.350686073303223,
-8.039388656616211, -10.856569290161133, -7.75154447555542, -8.819022178649902, -19.51532745361328],
[-9.73066234588623, -10.223922729492188, -9.932981491088867, -11.857836723327637, -7.662626266479492,
-11.13529109954834, -7.765097618103027, -11.472923278808594, -9.543149948120117, -11.905633926391602,
-9.366164207458496, -11.5734281539917, -23.699003219604492, -9.429590225219727, -10.42839241027832,
-10.585240364074707, -10.94771957397461, -11.095416069030762, -10.390240669250488, -23.769372940063477],
[-9.728265762329102, -9.859712600708008, -10.09729290008545, -9.678522109985352, -6.879519939422607,
-9.68487548828125, -4.2803425788879395, -10.018914222717285, -9.308445930480957, -10.63394546508789,
-8.083646774291992, -9.06301498413086, -21.904266357421875, -8.90160846710205, -8.841876029968262,
-11.856719970703125, -12.079398155212402, -11.233753204345703, -10.177338600158691, -21.87256622314453],
[-9.669764518737793, -9.614198684692383, -9.814510345458984, -9.996501922607422, -11.375690460205078,
-10.113405227661133, -10.546867370605469, -10.04369068145752, -10.907809257507324, -10.504216194152832,
-11.129199028015137, -10.151124000549316, -21.96586799621582, -9.086349487304688, -11.730339050292969,
-10.460667610168457, -10.298049926757812, -10.784148216247559, -10.840693473815918, -22.03152847290039],
]
# fmt: on
target = np.array(target).flatten()
predict = output_logits[0, :, :20].flatten()
def check(a, b, epsilon=5e-4):
return abs(a - b) < epsilon * max(abs(a), abs(b))
self.assertTrue(np.all([check(target[i], predict[i]) for i in range(len(target))]))
@slow
def test_batch_generation(self):
model = GPTSanJapaneseForConditionalGeneration.from_pretrained("Tanrei/GPTSAN-japanese")
tokenizer = GPTSanJapaneseTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
model.to(torch_device)
# set deterministically
generation_config = GenerationConfig.from_pretrained("Tanrei/GPTSAN-japanese")
generation_config.top_k = 1
# use different length sentences to test batching
sentences = [
"甲斐なら武田と言うほど",
"織田信長は、",
]
tokenizer.padding_side = "left"
inputs = tokenizer(sentences, return_tensors="pt", padding=True)
input_ids = inputs["input_ids"].to(torch_device)
self.assertNotEqual(inputs["attention_mask"][0].numpy().tolist(), inputs["attention_mask"][1].numpy().tolist())
outputs = model.generate(
input_ids=input_ids,
attention_mask=inputs["attention_mask"].to(torch_device),
max_new_tokens=3,
generation_config=generation_config,
)
inputs_non_padded = tokenizer(sentences[0], return_tensors="pt").input_ids.to(torch_device)
output_non_padded = model.generate(
input_ids=inputs_non_padded, max_new_tokens=3, generation_config=generation_config
)
inputs_padded = tokenizer(sentences[1], return_tensors="pt").input_ids.to(torch_device)
output_padded = model.generate(input_ids=inputs_padded, max_new_tokens=3, generation_config=generation_config)
self.assertNotEqual(inputs_non_padded.shape, inputs_padded.shape)
batch_out_sentence = tokenizer.batch_decode(outputs, skip_special_tokens=True)
non_padded_sentence = tokenizer.decode(output_non_padded[0], skip_special_tokens=True)
padded_sentence = tokenizer.decode(output_padded[0], skip_special_tokens=True)
expected_output_sentence = [
"甲斐なら武田と言うほど甲斐の武田",
"織田信長は、このような",
]
self.assertListEqual(expected_output_sentence, batch_out_sentence)
self.assertListEqual(batch_out_sentence, [non_padded_sentence, padded_sentence])
@tooslow
def test_sample(self):
model = GPTSanJapaneseForConditionalGeneration.from_pretrained("Tanrei/GPTSAN-japanese")
tokenizer = GPTSanJapaneseTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
# Output of original model created with mesh-tensoflow
target = [
("武田信玄は", 35675),
("武田信玄は、", 45),
("武田信玄は、この", 29),
("武田信玄は、このよう", 30642),
("武田信玄は、このような", 35680),
("武田信玄は、このような「", 8640),
("武田信玄は、このような「武田", 31617),
("武田信玄は、このような「武田家", 30646),
("武田信玄は、このような「武田家の", 31617),
("武田信玄は、このような「武田家の家", 31381),
]
for input, output in target:
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model(input_ids)
output_logits = outputs.logits.detach().cpu().numpy()[0]
output_id = np.argmax(output_logits[-1])
self.assertEqual(output_id, output)
@slow
def test_spout_generation(self):
model = GPTSanJapaneseForConditionalGeneration.from_pretrained("Tanrei/GPTSAN-japanese")
tokenizer = GPTSanJapaneseTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
model.to(torch_device)
# set deterministically
generation_config = GenerationConfig.from_pretrained("Tanrei/GPTSAN-japanese")
generation_config.top_k = 1
input_text = "武田信玄は、"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to(torch_device)
input_ids_batch = tokenizer([input_text, input_text], return_tensors="pt").input_ids.to(torch_device)
# spout from uniform and one-hot
spouts = [
[0.87882208, 0.38426396, 0.33220248, 0.43890406, 0.16562252,
0.04803985, 0.211572 , 0.23188473, 0.37153068, 0.7836377 ,
0.02160172, 0.38761719, 0.75290772, 0.90198857, 0.34365777,
0.64168169, 0.44318471, 0.14575746, 0.92562881, 0.40812148,
0.29019122, 0.88861599, 0.65524846, 0.43563456, 0.38177187,
0.70832965, 0.81527892, 0.68832812, 0.38833192, 0.4561522 ,
0.14828817, 0.47248213, 0.54357335, 0.82009566, 0.1338884 ,
0.02755417, 0.19764677, 0.2422084 , 0.04757674, 0.65409606,
0.0824589 , 0.03304383, 0.94387689, 0.98764509, 0.82433901,
0.27646741, 0.64907493, 0.76009406, 0.30087915, 0.17904689,
0.41601714, 0.67046398, 0.10422822, 0.08447374, 0.07354344,
0.61423565, 0.70284866, 0.7532333 , 0.1972038 , 0.29575659,
0.90583886, 0.29265307, 0.50000175, 0.70407655, 0.889363 ,
0.81904418, 0.66829128, 0.64468815, 0.56563723, 0.85601875,
0.94924672, 0.00166762, 0.25220643, 0.74540219, 0.67993247,
0.1549675 , 0.39385352, 0.92153607, 0.63745931, 0.27759043,
0.84702295, 0.65904271, 0.58676614, 0.8666936 , 0.39607438,
0.79954983, 0.42220697, 0.39650381, 0.7849864 , 0.56150201,
0.15678925, 0.14746032, 0.34542114, 0.47026783, 0.11956489,
0.25421435, 0.33788901, 0.68934842, 0.36424685, 0.71737898,
0.38983449, 0.94393779, 0.39575588, 0.36616553, 0.87104665,
0.64630203, 0.22516905, 0.88270804, 0.15031338, 0.75144345,
0.46459025, 0.85396454, 0.86355643, 0.65139851, 0.70266061,
0.30241389, 0.81056497, 0.88865969, 0.38773807, 0.70635849,
0.90718459, 0.43245789, 0.28000654, 0.45935562, 0.08773519,
0.9552151 , 0.93901511, 0.22489288], # uniform
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0.],
] # fmt: skip
output1 = model.generate(
input_ids=input_ids,
spout=spouts[0],
max_new_tokens=20,
generation_config=generation_config,
)
output2 = model.generate(
input_ids=input_ids,
spout=spouts[1],
max_new_tokens=20,
generation_config=generation_config,
)
output3 = model.generate(
input_ids=input_ids_batch,
spout=spouts,
max_new_tokens=20,
generation_config=generation_config,
)
out1_sentence = tokenizer.decode(output1[0])
out2_sentence = tokenizer.decode(output2[0])
batch_out_sentence = tokenizer.batch_decode(output3)
expected_output_sentence = [
"武田信玄は、武田氏の滅亡後、武田氏の居城であった甲斐武田氏の居城である",
"武田信玄は、武田家の滅亡を防ぐため、武田家の家臣である武田信虎を討",
]
self.assertListEqual(expected_output_sentence, batch_out_sentence)
self.assertListEqual(batch_out_sentence, [out1_sentence, out2_sentence])
@slow
def test_prefix_lm_generation(self):
model = GPTSanJapaneseForConditionalGeneration.from_pretrained("Tanrei/GPTSAN-japanese")
tokenizer = GPTSanJapaneseTokenizer.from_pretrained("Tanrei/GPTSAN-japanese")
model.to(torch_device)
# set deterministically
generation_config = GenerationConfig.from_pretrained("Tanrei/GPTSAN-japanese")
generation_config.top_k = 1
prefix_text_1 = "武田信玄"
prefix_text_2 = "織田信長"
input_text_1 = "は、"
input_text_2 = "が、"
input_tok_1 = tokenizer(input_text_1, prefix_text=prefix_text_1, return_tensors="pt")
input_tok_2 = tokenizer(input_text_2, prefix_text=prefix_text_2, return_tensors="pt")
input_tok_3 = tokenizer([[prefix_text_1, input_text_1], [prefix_text_2, input_text_2]], return_tensors="pt")
output1 = model.generate(
input_ids=input_tok_1.input_ids.to(torch_device),
token_type_ids=input_tok_1.token_type_ids.to(torch_device),
max_new_tokens=20,
generation_config=generation_config,
)
output2 = model.generate(
input_ids=input_tok_2.input_ids.to(torch_device),
token_type_ids=input_tok_2.token_type_ids.to(torch_device),
max_new_tokens=20,
generation_config=generation_config,
)
output3 = model.generate(
input_ids=input_tok_3.input_ids.to(torch_device),
token_type_ids=input_tok_3.token_type_ids.to(torch_device),
attention_mask=input_tok_3.attention_mask.to(torch_device),
max_new_tokens=20,
generation_config=generation_config,
)
out1_sentence = tokenizer.decode(output1[0])
out2_sentence = tokenizer.decode(output2[0])
batch_out_sentence = tokenizer.batch_decode(output3)
expected_output_sentence = [
"武田信玄は、武田氏の祖である武田信虎を、その子・武田信友を擁して",
"織田信長が、織田信長の妻・お市の方を妻として迎えたという逸話が残",
]
self.assertListEqual(expected_output_sentence, batch_out_sentence)
self.assertListEqual(batch_out_sentence, [out1_sentence, out2_sentence])
| transformers/tests/models/gptsan_japanese/test_modeling_gptsan_japanese.py/0 | {
"file_path": "transformers/tests/models/gptsan_japanese/test_modeling_gptsan_japanese.py",
"repo_id": "transformers",
"token_count": 10015
} | 360 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch Idefics model. """
import unittest
from parameterized import parameterized
from transformers import BitsAndBytesConfig, IdeficsConfig, is_torch_available, is_vision_available
from transformers.testing_utils import (
TestCasePlus,
require_bitsandbytes,
require_torch,
require_torch_sdpa,
require_vision,
slow,
torch_device,
)
from transformers.utils import cached_property
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import IdeficsForVisionText2Text, IdeficsModel, IdeficsProcessor
from transformers.models.idefics.configuration_idefics import IdeficsPerceiverConfig, IdeficsVisionConfig
from transformers.models.idefics.modeling_idefics import IDEFICS_PRETRAINED_MODEL_ARCHIVE_LIST
from transformers.pytorch_utils import is_torch_greater_or_equal_than_2_0
else:
is_torch_greater_or_equal_than_2_0 = False
if is_vision_available():
from PIL import Image
class IdeficsModelTester:
def __init__(
self,
parent,
batch_size=1,
seq_length=7,
image_size=30,
patch_size=2,
num_channels=3,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
alpha_initializer="ones",
num_labels=3,
scope=None,
modality_type_vocab_size=2,
vision_embed_dim=32,
vision_patch_size=2,
vision_image_size=30,
vision_num_attention_heads=4,
vision_num_hidden_layers=5,
vision_intermediate_size=37,
perceiver_qk_layer_norms_perceiver=False,
perceiver_resampler_depth=2,
perceiver_resampler_head_dim=8,
perceiver_resampler_n_heads=2,
perceiver_resampler_n_latents=16,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.image_size = image_size
self.patch_size = patch_size
self.num_channels = num_channels
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.alpha_initializer = alpha_initializer
self.num_labels = num_labels
self.scope = scope
self.modality_type_vocab_size = modality_type_vocab_size
self.vision_embed_dim = vision_embed_dim
self.vision_patch_size = vision_patch_size
self.vision_image_size = vision_image_size
self.vision_num_attention_heads = vision_num_attention_heads
self.vision_num_hidden_layers = vision_num_hidden_layers
self.vision_intermediate_size = vision_intermediate_size
self.vision_config = IdeficsVisionConfig(
embed_dim=self.vision_embed_dim,
patch_size=self.vision_patch_size,
image_size=self.vision_image_size,
num_attention_heads=self.vision_num_attention_heads,
num_hidden_layers=self.vision_num_hidden_layers,
intermediate_size=self.vision_intermediate_size,
)
self.perceiver_qk_layer_norms_perceiver = perceiver_qk_layer_norms_perceiver
self.perceiver_resampler_depth = perceiver_resampler_depth
self.perceiver_resampler_head_dim = perceiver_resampler_head_dim
self.perceiver_resampler_n_heads = perceiver_resampler_n_heads
self.perceiver_resampler_n_latents = perceiver_resampler_n_latents
self.perceiver_config = IdeficsPerceiverConfig(
qk_layer_norms_perceiver=self.perceiver_qk_layer_norms_perceiver,
resampler_depth=self.perceiver_resampler_depth,
resampler_head_dim=self.perceiver_resampler_head_dim,
resampler_n_heads=self.perceiver_resampler_n_heads,
resampler_n_latents=self.perceiver_resampler_n_latents,
)
# we set the expected sequence length (which is used in several tests)
# this is equal to the seq length of the text tokens + number of image patches + 1 for the CLS token
self.expected_seq_len = self.seq_length + (self.image_size // self.patch_size) ** 2 + 1
def prepare_config_and_inputs(self, num_images=1, interpolate_pos_encoding=False, image_expansion=0):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
pixel_values = floats_tensor(
[
self.batch_size,
num_images,
self.num_channels,
self.image_size + image_expansion,
self.image_size + image_expansion,
]
)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
image_attention_mask = random_attention_mask([self.batch_size, self.seq_length, num_images])
config = self.get_config()
return (config, input_ids, input_mask, pixel_values, image_attention_mask, interpolate_pos_encoding)
def prepare_config_and_inputs_gate_tests(self):
# Create a list of configs and inputs, to test 2 things:
# 1. For the same image, the output should be different when image_attention_mask is filled with 0s vs filled with 1s.
# 2. For 2 different images, the output should be the same when image_attention_mask is filled with 0s.
interpolate_pos_encoding = False
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
pixel_values = floats_tensor(
[
self.batch_size,
1,
self.num_channels,
self.image_size,
self.image_size,
]
)
pixel_values_list = [
pixel_values.clone(),
pixel_values.clone(),
pixel_values.clone().fill_(0.6),
pixel_values.clone().fill_(0.3),
]
attention_mask = None
if self.use_input_mask:
attention_mask = random_attention_mask([self.batch_size, self.seq_length])
image_attention_mask = random_attention_mask([self.batch_size, self.seq_length, 1])
image_attention_mask_list = [
image_attention_mask.clone().fill_(0),
image_attention_mask.clone().fill_(1),
image_attention_mask.clone().fill_(0),
image_attention_mask.clone().fill_(0),
]
config = self.get_config()
inputs_list = []
for pixel_values, image_attention_mask in zip(pixel_values_list, image_attention_mask_list):
inputs_list.append(
{
"input_ids": input_ids,
"attention_mask": attention_mask,
"pixel_values": pixel_values,
"image_attention_mask": image_attention_mask,
"interpolate_pos_encoding": interpolate_pos_encoding,
}
)
inputs_w_same_img = inputs_list[:2]
inputs_w_0_img_attn = inputs_list[2:]
return config, inputs_w_same_img, inputs_w_0_img_attn
def get_config(self):
return IdeficsConfig(
image_size=self.image_size,
patch_size=self.patch_size,
num_channels=self.num_channels,
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
is_decoder=False,
initializer_range=self.initializer_range,
alpha_initializer=self.alpha_initializer,
num_labels=self.num_labels,
modality_type_vocab_size=self.modality_type_vocab_size,
vision_config=self.vision_config,
)
def create_and_check_model(
self,
config,
input_ids,
input_mask,
pixel_values,
image_attention_mask,
interpolate_pos_encoding,
):
model = IdeficsModel(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
pixel_values=pixel_values,
image_attention_mask=image_attention_mask,
interpolate_pos_encoding=interpolate_pos_encoding,
)
self.parent.assertEqual(
result.last_hidden_state.shape, (self.batch_size, input_ids.shape[1], self.hidden_size)
)
def create_and_check_model_gen(
self,
config,
input_ids,
input_mask,
pixel_values,
image_attention_mask,
interpolate_pos_encoding,
):
model = IdeficsForVisionText2Text(config)
model.to(torch_device)
model.eval()
model.generate(
input_ids,
attention_mask=input_mask,
pixel_values=pixel_values,
image_attention_mask=image_attention_mask,
interpolate_pos_encoding=interpolate_pos_encoding,
max_length=self.seq_length + 2,
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
input_mask,
pixel_values,
image_attention_mask,
interpolate_pos_encoding,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": input_mask,
"pixel_values": pixel_values,
"image_attention_mask": image_attention_mask,
"interpolate_pos_encoding": interpolate_pos_encoding,
}
return config, inputs_dict
def prepare_pixel_values(self):
return floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
@require_torch_sdpa
@slow
@parameterized.expand([("float16",), ("bfloat16",), ("float32",)])
def test_eager_matches_sdpa_inference(self, torch_dtype: str):
self.skipTest("Idefics has a hard requirement on SDPA, skipping this test")
@unittest.skipIf(not is_torch_greater_or_equal_than_2_0, reason="pytorch 2.0 or higher is required")
@require_torch
class IdeficsModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (IdeficsModel, IdeficsForVisionText2Text) if is_torch_available() else ()
pipeline_model_mapping = {"feature-extraction": IdeficsModel} if is_torch_available() else {}
test_pruning = False
test_headmasking = False
test_torchscript = False
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
inputs_dict = super()._prepare_for_class(inputs_dict, model_class, return_labels=return_labels)
# XXX: IdeficsForVisionText2TextTest has no MODEL_FOR group yet, but it should be the same
# as MODEL_FOR_CAUSAL_LM_MAPPING_NAMES, so for now manually changing to do the right thing
# as super won't do it
if return_labels:
inputs_dict["labels"] = torch.zeros(
(self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device
)
return inputs_dict
def test_model_outputs_equivalence(self):
try:
orig = self.all_model_classes
# IdeficsModel.forward doesn't have labels input arg - only IdeficsForVisionText2Text does
self.all_model_classes = (IdeficsForVisionText2Text,) if is_torch_available() else ()
super().test_model_outputs_equivalence()
finally:
self.all_model_classes = orig
def setUp(self):
self.model_tester = IdeficsModelTester(self)
self.config_tester = ConfigTester(self, config_class=IdeficsConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model_single_image(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(
num_images=1, interpolate_pos_encoding=False, image_expansion=0
)
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_multiple_images(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(
num_images=2, interpolate_pos_encoding=False, image_expansion=0
)
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_with_image_pos_embeddings_interpolation_single_image(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(
num_images=1, interpolate_pos_encoding=True, image_expansion=2
)
self.model_tester.create_and_check_model(*config_and_inputs)
config_and_inputs = self.model_tester.prepare_config_and_inputs(
num_images=1, interpolate_pos_encoding=True, image_expansion=0
)
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_with_image_pos_embeddings_interpolation_multiple_images(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(
num_images=2, interpolate_pos_encoding=True, image_expansion=2
)
self.model_tester.create_and_check_model(*config_and_inputs)
config_and_inputs = self.model_tester.prepare_config_and_inputs(
num_images=2, interpolate_pos_encoding=True, image_expansion=0
)
self.model_tester.create_and_check_model(*config_and_inputs)
def test_generate_with_image_pos_embeddings_interpolation_single_image(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(
num_images=1, interpolate_pos_encoding=True, image_expansion=2
)
self.model_tester.create_and_check_model_gen(*config_and_inputs)
def test_generate_with_image_pos_embeddings_interpolation_multiple_images(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(
num_images=2, interpolate_pos_encoding=True, image_expansion=2
)
self.model_tester.create_and_check_model_gen(*config_and_inputs)
def test_cross_attention_gates(self):
config, inputs_w_same_img, inputs_w_0_img_attn = self.model_tester.prepare_config_and_inputs_gate_tests()
model = IdeficsModel(config=config).to(torch_device)
model.eval()
test_1_results = []
for inputs in inputs_w_same_img:
with torch.no_grad():
last_hidden_states = model(**inputs).last_hidden_state
last_hidden_states = model(**inputs).last_hidden_state
test_1_results.append(last_hidden_states)
self.assertNotEqual(test_1_results[0].sum().item(), test_1_results[1].sum().item())
test_2_results = []
for inputs in inputs_w_0_img_attn:
with torch.no_grad():
last_hidden_states = model(**inputs).last_hidden_state
test_2_results.append(last_hidden_states)
self.assertEqual(test_2_results[0].sum().item(), test_2_results[1].sum().item())
def test_training(self):
if not self.model_tester.is_training:
return
for model_class in self.all_model_classes:
# IdeficsModel does not support training, users should use
# IdeficsForVisionText2Text for this purpose
if model_class == IdeficsModel:
return
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.train()
inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
loss = model(**inputs).loss
loss.backward()
def test_training_gradient_checkpointing(self):
if not self.model_tester.is_training:
return
for model_class in self.all_model_classes:
# IdeficsModel does not support training, users should use
# IdeficsForVisionText2Text for this purpose
if model_class == IdeficsModel:
return
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.use_cache = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.gradient_checkpointing_enable()
model.train()
inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
loss = model(**inputs).loss
loss.backward()
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
@unittest.skip(reason="""IDEFICS does not support retaining the gradients of the hidden states and attention""")
def test_retain_grad_hidden_states_attentions(self):
return
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.attentions
# IDEFICS does not support outputting attention score becuase it uses SDPA under the hood
self.assertTrue(attentions[0] is None)
out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
self.assertEqual(out_len + 1, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
# IDEFICS does not support outputting attention score becuase it uses SDPA under the hood
self.assertTrue(self_attentions[0] is None)
def test_hidden_states_output(self):
def check_hidden_states_output(inputs_dict, config, model_class):
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
expected_num_layers = getattr(
self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
)
self.assertEqual(len(hidden_states), expected_num_layers)
seq_length = self.model_tester.seq_length
self.assertListEqual(
list(hidden_states[0].shape[-2:]),
[seq_length, self.model_tester.hidden_size],
)
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
inputs_dict["output_hidden_states"] = True
check_hidden_states_output(inputs_dict, config, model_class)
# check that output_hidden_states also work using config
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
check_hidden_states_output(inputs_dict, config, model_class)
@slow
def test_model_from_pretrained(self):
for model_name in IDEFICS_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = IdeficsModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_torch_sdpa
@slow
@parameterized.expand([("float16",), ("bfloat16",), ("float32",)])
def test_eager_matches_sdpa_inference(self, torch_dtype: str):
self.skipTest("Idefics has a hard requirement on SDPA, skipping this test")
@unittest.skipIf(not is_torch_greater_or_equal_than_2_0, reason="pytorch 2.0 or higher is required")
@require_torch
class IdeficsForVisionText2TextTest(IdeficsModelTest, unittest.TestCase):
all_model_classes = (IdeficsForVisionText2Text,) if is_torch_available() else ()
def setUp(self):
self.model_tester = IdeficsModelTester(
self,
modality_type_vocab_size=3,
)
self.config_tester = ConfigTester(self, config_class=IdeficsConfig, hidden_size=37)
@unittest.skip("We only test the model that takes in multiple images")
def test_model(self):
pass
@unittest.skip("We only test the model that takes in multiple images")
def test_for_token_classification(self):
pass
@unittest.skip(reason="""IDEFICS does not support retaining the gradients of the hidden states and attention""")
def test_retain_grad_hidden_states_attentions(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
@unittest.skipIf(not is_torch_greater_or_equal_than_2_0, reason="pytorch 2.0 or higher is required")
@require_torch
@require_vision
class IdeficsModelIntegrationTest(TestCasePlus):
@cached_property
def default_processor(self):
return (
IdeficsProcessor.from_pretrained("HuggingFaceM4/idefics-9b", revision="refs/pr/11")
if is_vision_available()
else None
)
@require_bitsandbytes
@slow
def test_inference_natural_language_visual_reasoning(self):
cat_image_path = self.tests_dir / "fixtures/tests_samples/COCO/000000039769.png"
cats_image_obj = Image.open(cat_image_path) # 2 cats
dogs_image_url = "https://huggingface.co/datasets/hf-internal-testing/fixtures_nlvr2/raw/main/image1.jpeg"
prompts = [
[
"User:",
dogs_image_url,
"Describe this image.\nAssistant: An image of two dogs.\n",
"User:",
cats_image_obj,
"Describe this image.\nAssistant:",
],
[
"User:",
cats_image_obj,
"Describe this image.\nAssistant: An image of two kittens.\n",
"User:",
dogs_image_url,
"Describe this image.\nAssistant:",
],
]
# the CI gpu is small so using quantization to fit
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype="float16",
)
model = IdeficsForVisionText2Text.from_pretrained(
"HuggingFaceM4/idefics-9b", quantization_config=quantization_config, device_map="auto"
)
processor = self.default_processor
inputs = processor(prompts, return_tensors="pt").to(torch_device)
generated_ids = model.generate(**inputs, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
# keep for debugging
for i, t in enumerate(generated_text):
t = bytes(t, "utf-8").decode("unicode_escape")
print(f"{i}:\n{t}\n")
self.assertIn("image of two cats", generated_text[0])
self.assertIn("image of two dogs", generated_text[1])
| transformers/tests/models/idefics/test_modeling_idefics.py/0 | {
"file_path": "transformers/tests/models/idefics/test_modeling_idefics.py",
"repo_id": "transformers",
"token_count": 12287
} | 361 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch Llava model. """
import copy
import gc
import unittest
import requests
from transformers import (
AutoProcessor,
LlavaConfig,
LlavaForConditionalGeneration,
is_torch_available,
is_vision_available,
)
from transformers.testing_utils import require_bitsandbytes, require_torch, require_torch_gpu, slow, torch_device
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
if is_torch_available():
import torch
else:
is_torch_greater_or_equal_than_2_0 = False
if is_vision_available():
from PIL import Image
class LlavaVisionText2TextModelTester:
def __init__(
self,
parent,
ignore_index=-100,
image_token_index=0,
projector_hidden_act="gelu",
seq_length=7,
vision_feature_select_strategy="default",
vision_feature_layer=-1,
text_config={
"model_type": "llama",
"seq_length": 7,
"is_training": True,
"use_input_mask": True,
"use_token_type_ids": False,
"use_labels": True,
"vocab_size": 99,
"hidden_size": 32,
"num_hidden_layers": 2,
"num_attention_heads": 4,
"intermediate_size": 37,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"attention_probs_dropout_prob": 0.1,
"max_position_embeddings": 512,
"type_vocab_size": 16,
"type_sequence_label_size": 2,
"initializer_range": 0.02,
"num_labels": 3,
"num_choices": 4,
"pad_token_id": 0,
},
is_training=True,
vision_config={
"image_size": 30,
"patch_size": 2,
"num_channels": 3,
"is_training": True,
"hidden_size": 32,
"projection_dim": 32,
"num_hidden_layers": 2,
"num_attention_heads": 4,
"intermediate_size": 37,
"dropout": 0.1,
"attention_dropout": 0.1,
"initializer_range": 0.02,
},
):
self.parent = parent
self.ignore_index = ignore_index
self.image_token_index = image_token_index
self.projector_hidden_act = projector_hidden_act
self.vision_feature_select_strategy = vision_feature_select_strategy
self.vision_feature_layer = vision_feature_layer
self.text_config = text_config
self.vision_config = vision_config
self.seq_length = seq_length
self.num_hidden_layers = text_config["num_hidden_layers"]
self.vocab_size = text_config["vocab_size"]
self.hidden_size = text_config["hidden_size"]
self.num_attention_heads = text_config["num_attention_heads"]
self.is_training = is_training
self.batch_size = 3
self.num_channels = 3
self.image_size = 336
self.encoder_seq_length = 231
def get_config(self):
return LlavaConfig(
text_config=self.text_config,
vision_config=self.vision_config,
ignore_index=self.ignore_index,
image_token_index=self.image_token_index,
projector_hidden_act=self.projector_hidden_act,
vision_feature_select_strategy=self.vision_feature_select_strategy,
vision_feature_layer=self.vision_feature_layer,
)
def prepare_config_and_inputs(self):
pixel_values = floats_tensor(
[
self.batch_size,
self.vision_config["num_channels"],
self.vision_config["image_size"],
self.vision_config["image_size"],
]
)
config = self.get_config()
return config, pixel_values
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, pixel_values = config_and_inputs
input_ids = ids_tensor([self.batch_size, self.seq_length], config.text_config.vocab_size - 1) + 1
attention_mask = input_ids.ne(1).to(torch_device)
# we are giving 3 images let's make sure we pass in 3 image tokens
input_ids[:, 1] = config.image_token_index
inputs_dict = {
"pixel_values": pixel_values,
"input_ids": input_ids,
"attention_mask": attention_mask,
}
return config, inputs_dict
@require_torch
class LlavaForConditionalGenerationModelTest(ModelTesterMixin, unittest.TestCase):
"""
Model tester for `LlavaForConditionalGeneration`.
"""
all_model_classes = (LlavaForConditionalGeneration,) if is_torch_available() else ()
pipeline_model_mapping = {"image-to-text": LlavaForConditionalGeneration} if is_torch_available() else {}
test_pruning = False
test_head_masking = False
def setUp(self):
self.model_tester = LlavaVisionText2TextModelTester(self)
self.config_tester = ConfigTester(self, config_class=LlavaConfig, has_text_modality=False)
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
# Copied from tests.test_modeling_common.ModelTesterMixin.test_resize_tokens_embeddings with config.vocab_size->config.text_config.vocab_size
def test_resize_tokens_embeddings(self):
(
original_config,
inputs_dict,
) = self.model_tester.prepare_config_and_inputs_for_common()
if not self.test_resize_embeddings:
return
for model_class in self.all_model_classes:
config = copy.deepcopy(original_config)
model = model_class(config)
model.to(torch_device)
if self.model_tester.is_training is False:
model.eval()
model_vocab_size = config.text_config.vocab_size
# Retrieve the embeddings and clone theme
model_embed = model.resize_token_embeddings(model_vocab_size)
cloned_embeddings = model_embed.weight.clone()
# Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
model_embed = model.resize_token_embeddings(model_vocab_size + 10)
self.assertEqual(model.config.text_config.vocab_size, model_vocab_size + 10)
# Check that it actually resizes the embeddings matrix
self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] + 10)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
model(**self._prepare_for_class(inputs_dict, model_class))
# Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
model_embed = model.resize_token_embeddings(model_vocab_size - 15)
self.assertEqual(model.config.text_config.vocab_size, model_vocab_size - 15)
# Check that it actually resizes the embeddings matrix
self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] - 15)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
# Input ids should be clamped to the maximum size of the vocabulary
inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 1)
# make sure that decoder_input_ids are resized as well
if "decoder_input_ids" in inputs_dict:
inputs_dict["decoder_input_ids"].clamp_(max=model_vocab_size - 15 - 1)
model(**self._prepare_for_class(inputs_dict, model_class))
# Check that adding and removing tokens has not modified the first part of the embedding matrix.
models_equal = True
for p1, p2 in zip(cloned_embeddings, model_embed.weight):
if p1.data.ne(p2.data).sum() > 0:
models_equal = False
self.assertTrue(models_equal)
config = copy.deepcopy(original_config)
model = model_class(config)
model.to(torch_device)
model_vocab_size = config.text_config.vocab_size
model.resize_token_embeddings(model_vocab_size + 10, pad_to_multiple_of=1)
self.assertTrue(model.config.text_config.vocab_size + 10, model_vocab_size)
model_embed = model.resize_token_embeddings(model_vocab_size, pad_to_multiple_of=64)
self.assertTrue(model_embed.weight.shape[0] // 64, 0)
self.assertTrue(model_embed.weight.shape[0], model.config.text_config.vocab_size)
self.assertTrue(model.config.text_config.vocab_size, model.vocab_size)
model_embed = model.resize_token_embeddings(model_vocab_size + 13, pad_to_multiple_of=64)
self.assertTrue(model_embed.weight.shape[0] // 64, 0)
# Check that resizing a model to a multiple of pad_to_multiple leads to a model of exactly that size
target_dimension = 128
model_embed = model.resize_token_embeddings(target_dimension, pad_to_multiple_of=64)
self.assertTrue(model_embed.weight.shape[0], target_dimension)
with self.assertRaisesRegex(
ValueError,
"Asking to pad the embedding matrix to a multiple of `1.3`, which is not and integer. Please make sure to pass an integer",
):
model.resize_token_embeddings(model_vocab_size, pad_to_multiple_of=1.3)
# Copied from tests.test_modeling_common.ModelTesterMixin.test_resize_embeddings_untied with config.vocab_size->config.text_config.vocab_size
def test_resize_embeddings_untied(self):
(
original_config,
inputs_dict,
) = self.model_tester.prepare_config_and_inputs_for_common()
if not self.test_resize_embeddings:
return
original_config.tie_word_embeddings = False
# if model cannot untied embeddings -> leave test
if original_config.tie_word_embeddings:
return
for model_class in self.all_model_classes:
config = copy.deepcopy(original_config)
model = model_class(config).to(torch_device)
# if no output embeddings -> leave test
if model.get_output_embeddings() is None:
continue
# Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
model_vocab_size = config.text_config.vocab_size
model.resize_token_embeddings(model_vocab_size + 10)
self.assertEqual(model.config.text_config.vocab_size, model_vocab_size + 10)
output_embeds = model.get_output_embeddings()
self.assertEqual(output_embeds.weight.shape[0], model_vocab_size + 10)
# Check bias if present
if output_embeds.bias is not None:
self.assertEqual(output_embeds.bias.shape[0], model_vocab_size + 10)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
model(**self._prepare_for_class(inputs_dict, model_class))
# Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
model.resize_token_embeddings(model_vocab_size - 15)
self.assertEqual(model.config.text_config.vocab_size, model_vocab_size - 15)
# Check that it actually resizes the embeddings matrix
output_embeds = model.get_output_embeddings()
self.assertEqual(output_embeds.weight.shape[0], model_vocab_size - 15)
# Check bias if present
if output_embeds.bias is not None:
self.assertEqual(output_embeds.bias.shape[0], model_vocab_size - 15)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
# Input ids should be clamped to the maximum size of the vocabulary
inputs_dict["input_ids"].clamp_(max=model_vocab_size - 15 - 1)
if "decoder_input_ids" in inputs_dict:
inputs_dict["decoder_input_ids"].clamp_(max=model_vocab_size - 15 - 1)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
model(**self._prepare_for_class(inputs_dict, model_class))
# Copied from tests.test_modeling_common.ModelTesterMixin.test_tie_model_weights with config.vocab_size->config.text_config.vocab_size
def test_tie_model_weights(self):
if not self.test_torchscript:
return
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
def check_same_values(layer_1, layer_2):
equal = True
for p1, p2 in zip(layer_1.weight, layer_2.weight):
if p1.data.ne(p2.data).sum() > 0:
equal = False
return equal
for model_class in self.all_model_classes:
config.torchscript = True
model_not_tied = model_class(config)
if model_not_tied.get_output_embeddings() is None:
continue
config_tied = copy.deepcopy(config)
config_tied.torchscript = False
model_tied = model_class(config_tied)
params_tied = list(model_tied.parameters())
# Check that the embedding layer and decoding layer are the same in size and in value
# self.assertTrue(check_same_values(embeddings, decoding))
# Check that after resize they remain tied.
model_tied.resize_token_embeddings(config.text_config.vocab_size + 10)
params_tied_2 = list(model_tied.parameters())
self.assertEqual(len(params_tied_2), len(params_tied))
@require_torch
class LlavaForConditionalGenerationIntegrationTest(unittest.TestCase):
def setUp(self):
self.processor = AutoProcessor.from_pretrained("llava-hf/bakLlava-v1-hf")
def tearDown(self):
gc.collect()
torch.cuda.empty_cache()
@slow
@require_bitsandbytes
def test_small_model_integration_test(self):
# Let' s make sure we test the preprocessing to replace what is used
model = LlavaForConditionalGeneration.from_pretrained("llava-hf/bakLlava-v1-hf", load_in_4bit=True)
prompt = "<image>\nUSER: What are the things I should be cautious about when I visit this place?\nASSISTANT:"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = self.processor(prompt, raw_image, return_tensors="pt")
EXPECTED_INPUT_IDS = torch.tensor([[1, 32000, 28705, 13, 11123, 28747, 1824, 460, 272, 1722,315, 1023, 347, 13831, 925, 684, 739, 315, 3251, 456,1633, 28804, 13, 4816, 8048, 12738, 28747]]) # fmt: skip
self.assertTrue(torch.equal(inputs["input_ids"], EXPECTED_INPUT_IDS))
output = model.generate(**inputs, max_new_tokens=20)
EXPECTED_DECODED_TEXT = "\nUSER: What are the things I should be cautious about when I visit this place?\nASSISTANT: When visiting this place, there are a few things one should be cautious about. Firstly," # fmt: skip
self.assertEqual(
self.processor.decode(output[0], skip_special_tokens=True),
EXPECTED_DECODED_TEXT,
)
@slow
@require_bitsandbytes
def test_small_model_integration_test_llama(self):
# Let' s make sure we test the preprocessing to replace what is used
model_id = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf", load_in_4bit=True)
processor = AutoProcessor.from_pretrained(model_id)
prompt = "USER: <image>\nWhat are the things I should be cautious about when I visit this place?\nASSISTANT:"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(prompt, raw_image, return_tensors="pt").to(torch_device, torch.float16)
output = model.generate(**inputs, max_new_tokens=900, do_sample=False)
EXPECTED_DECODED_TEXT = "USER: \nWhat are the things I should be cautious about when I visit this place?\nASSISTANT: When visiting this place, which is a pier or dock extending over a body of water, there are a few things to be cautious about. First, be aware of the weather conditions, as sudden changes in weather can make the pier unsafe to walk on. Second, be mindful of the water depth and any potential hazards, such as submerged rocks or debris, that could cause accidents or injuries. Additionally, be cautious of the presence of wildlife, such as birds or fish, and avoid disturbing their natural habitats. Lastly, be aware of any local regulations or guidelines for the use of the pier, as some areas may be restricted or prohibited for certain activities." # fmt: skip
self.assertEqual(
processor.decode(output[0], skip_special_tokens=True),
EXPECTED_DECODED_TEXT,
)
@slow
@require_bitsandbytes
def test_small_model_integration_test_llama_batched(self):
# Let' s make sure we test the preprocessing to replace what is used
model_id = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained("llava-hf/llava-1.5-7b-hf", load_in_4bit=True)
processor = AutoProcessor.from_pretrained(model_id)
prompts = [
"USER: <image>\nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT:",
"USER: <image>\nWhat is this?\nASSISTANT:",
]
image1 = Image.open(requests.get("https://llava-vl.github.io/static/images/view.jpg", stream=True).raw)
image2 = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
inputs = processor(prompts, images=[image1, image2], return_tensors="pt", padding=True)
output = model.generate(**inputs, max_new_tokens=20)
EXPECTED_DECODED_TEXT = ['USER: \nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT: When visiting this place, which appears to be a dock or pier extending over a body of water', 'USER: \nWhat is this?\nASSISTANT: The image features two cats lying down on a pink couch. One cat is located on'] # fmt: skip
self.assertEqual(processor.batch_decode(output, skip_special_tokens=True), EXPECTED_DECODED_TEXT)
@slow
@require_bitsandbytes
def test_small_model_integration_test_batch(self):
# Let' s make sure we test the preprocessing to replace what is used
model = LlavaForConditionalGeneration.from_pretrained("llava-hf/bakLlava-v1-hf", load_in_4bit=True)
# The first batch is longer in terms of text, but only has 1 image. The second batch will be padded in text, but the first will be padded because images take more space!.
prompts = [
"USER: <image>\nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT:",
"USER: <image>\nWhat is this?\nASSISTANT:",
]
image1 = Image.open(requests.get("https://llava-vl.github.io/static/images/view.jpg", stream=True).raw)
image2 = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
inputs = self.processor(prompts, images=[image1, image2], return_tensors="pt", padding=True)
output = model.generate(**inputs, max_new_tokens=20)
EXPECTED_DECODED_TEXT = ['USER: \nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT: When visiting this place, there are a few things to be cautious about and items to bring along', 'USER: \nWhat is this?\nASSISTANT: Cats'] # fmt: skip
self.assertEqual(self.processor.batch_decode(output, skip_special_tokens=True), EXPECTED_DECODED_TEXT)
@slow
@require_bitsandbytes
def test_small_model_integration_test_llama_batched_regression(self):
# Let' s make sure we test the preprocessing to replace what is used
model_id = "llava-hf/llava-1.5-7b-hf"
# Multi-image & multi-prompt (e.g. 3 images and 2 prompts now fails with SDPA, this tests if "eager" works as before)
model = LlavaForConditionalGeneration.from_pretrained(
"llava-hf/llava-1.5-7b-hf", load_in_4bit=True, attn_implementation="eager"
)
processor = AutoProcessor.from_pretrained(model_id, pad_token="<pad>")
prompts = [
"USER: <image>\nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT:",
"USER: <image>\nWhat is this?\nASSISTANT: Two cats lying on a bed!\nUSER: <image>\nAnd this?\nASSISTANT:",
]
image1 = Image.open(requests.get("https://llava-vl.github.io/static/images/view.jpg", stream=True).raw)
image2 = Image.open(requests.get("http://images.cocodataset.org/val2017/000000039769.jpg", stream=True).raw)
inputs = processor(prompts, images=[image1, image2, image1], return_tensors="pt", padding=True)
output = model.generate(**inputs, max_new_tokens=20)
EXPECTED_DECODED_TEXT = ['USER: \nWhat are the things I should be cautious about when I visit this place? What should I bring with me?\nASSISTANT: When visiting this serene location, one should be cautious about the weather conditions and potential', 'USER: \nWhat is this?\nASSISTANT: Two cats lying on a bed!\nUSER: \nAnd this?\nASSISTANT: A cat sleeping on a bed.'] # fmt: skip
self.assertEqual(processor.batch_decode(output, skip_special_tokens=True), EXPECTED_DECODED_TEXT)
@slow
@require_bitsandbytes
def test_llava_index_error_bug(self):
# This is a reproducer of https://github.com/huggingface/transformers/pull/28032 and makes sure it does not happen anymore
# Please refer to that PR, or specifically https://github.com/huggingface/transformers/pull/28032#issuecomment-1860650043 for
# more details
model_id = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained(model_id, load_in_4bit=True)
processor = AutoProcessor.from_pretrained(model_id)
# Simulate a super long prompt
user_prompt = "Describe the image:?\n" * 200
prompt = f"USER: <image>\n{user_prompt}ASSISTANT:"
image_file = "http://images.cocodataset.org/val2017/000000039769.jpg"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(prompt, raw_image, return_tensors="pt").to(torch_device, torch.float16)
# Make sure that `generate` works
_ = model.generate(**inputs, max_new_tokens=20)
@slow
@require_torch_gpu
def test_llava_merge_inputs_error_bug(self):
# This is a reproducer of https://github.com/huggingface/transformers/pull/28333 and makes sure it does not happen anymore
model_id = "llava-hf/llava-1.5-7b-hf"
model = LlavaForConditionalGeneration.from_pretrained(
model_id, torch_dtype=torch.float16, low_cpu_mem_usage=True
).to(torch_device)
# Simulate some user inputs
pixel_values = torch.randn(
(2, 3, 336, 336),
dtype=torch.float,
device=torch_device,
)
input_ids = torch.tensor(
[
[32001, 32001, 1, 15043, 7084, 32000, 29871, 13, 7900],
[1, 15043, 7084, 29901, 29871, 32000, 29871, 13, 7900],
],
dtype=torch.long,
device=torch_device,
)
attention_mask = torch.tensor(
[[0, 0, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1, 1, 1, 1, 1]],
dtype=torch.long,
device=torch_device,
)
# Make sure that the loss is properly computed
loss = model(
pixel_values=pixel_values,
input_ids=input_ids,
attention_mask=attention_mask,
labels=input_ids,
).loss
loss.backward()
| transformers/tests/models/llava/test_modeling_llava.py/0 | {
"file_path": "transformers/tests/models/llava/test_modeling_llava.py",
"repo_id": "transformers",
"token_count": 10919
} | 362 |
# coding=utf-8
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import tempfile
import unittest
import numpy as np
from transformers import LxmertConfig, is_tf_available
from transformers.testing_utils import require_tf, slow
from ...test_configuration_common import ConfigTester
from ...test_modeling_tf_common import TFModelTesterMixin, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_tf_available():
import tensorflow as tf
from transformers.models.lxmert.modeling_tf_lxmert import TFLxmertForPreTraining, TFLxmertModel
class TFLxmertModelTester(object):
def __init__(
self,
parent,
vocab_size=300,
hidden_size=28,
num_attention_heads=2,
num_labels=2,
intermediate_size=64,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=2,
initializer_range=0.02,
layer_norm_eps=1e-12,
pad_token_id=0,
num_qa_labels=30,
num_object_labels=16,
num_attr_labels=4,
num_visual_features=10,
l_layers=2,
x_layers=1,
r_layers=1,
visual_feat_dim=128,
visual_pos_dim=4,
visual_loss_normalizer=6.67,
seq_length=20,
batch_size=8,
is_training=True,
task_matched=True,
task_mask_lm=True,
task_obj_predict=True,
task_qa=True,
visual_obj_loss=True,
visual_attr_loss=True,
visual_feat_loss=True,
use_token_type_ids=True,
use_lang_mask=True,
output_attentions=False,
output_hidden_states=False,
scope=None,
):
self.parent = parent
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_attention_heads = num_attention_heads
self.num_labels = num_labels
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.pad_token_id = pad_token_id
self.num_qa_labels = num_qa_labels
self.num_object_labels = num_object_labels
self.num_attr_labels = num_attr_labels
self.l_layers = l_layers
self.x_layers = x_layers
self.r_layers = r_layers
self.visual_feat_dim = visual_feat_dim
self.visual_pos_dim = visual_pos_dim
self.visual_loss_normalizer = visual_loss_normalizer
self.seq_length = seq_length
self.batch_size = batch_size
self.is_training = is_training
self.use_lang_mask = use_lang_mask
self.task_matched = task_matched
self.task_mask_lm = task_mask_lm
self.task_obj_predict = task_obj_predict
self.task_qa = task_qa
self.visual_obj_loss = visual_obj_loss
self.visual_attr_loss = visual_attr_loss
self.visual_feat_loss = visual_feat_loss
self.num_visual_features = num_visual_features
self.use_token_type_ids = use_token_type_ids
self.output_attentions = output_attentions
self.output_hidden_states = output_hidden_states
self.scope = scope
self.num_hidden_layers = {"vision": r_layers, "cross_encoder": x_layers, "language": l_layers}
def prepare_config_and_inputs(self):
output_attentions = self.output_attentions
input_ids = ids_tensor([self.batch_size, self.seq_length], vocab_size=self.vocab_size)
visual_feats = tf.random.uniform((self.batch_size, self.num_visual_features, self.visual_feat_dim))
bounding_boxes = tf.random.uniform((self.batch_size, self.num_visual_features, 4))
input_mask = None
if self.use_lang_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
obj_labels = None
if self.task_obj_predict:
obj_labels = {}
if self.visual_attr_loss and self.task_obj_predict:
obj_labels["attr"] = (
ids_tensor([self.batch_size, self.num_visual_features], self.num_attr_labels),
ids_tensor([self.batch_size, self.num_visual_features], self.num_attr_labels),
)
if self.visual_feat_loss and self.task_obj_predict:
obj_labels["feat"] = (
ids_tensor(
[self.batch_size, self.num_visual_features, self.visual_feat_dim], self.num_visual_features
),
ids_tensor([self.batch_size, self.num_visual_features], self.num_visual_features),
)
if self.visual_obj_loss and self.task_obj_predict:
obj_labels["obj"] = (
ids_tensor([self.batch_size, self.num_visual_features], self.num_object_labels),
ids_tensor([self.batch_size, self.num_visual_features], self.num_object_labels),
)
ans = None
if self.task_qa:
ans = ids_tensor([self.batch_size], self.num_qa_labels)
masked_lm_labels = None
if self.task_mask_lm:
masked_lm_labels = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
matched_label = None
if self.task_matched:
matched_label = ids_tensor([self.batch_size], self.num_labels)
config = LxmertConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_attention_heads=self.num_attention_heads,
num_labels=self.num_labels,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
layer_norm_eps=self.layer_norm_eps,
pad_token_id=self.pad_token_id,
num_qa_labels=self.num_qa_labels,
num_object_labels=self.num_object_labels,
num_attr_labels=self.num_attr_labels,
l_layers=self.l_layers,
x_layers=self.x_layers,
r_layers=self.r_layers,
visual_feat_dim=self.visual_feat_dim,
visual_pos_dim=self.visual_pos_dim,
visual_loss_normalizer=self.visual_loss_normalizer,
task_matched=self.task_matched,
task_mask_lm=self.task_mask_lm,
task_obj_predict=self.task_obj_predict,
task_qa=self.task_qa,
visual_obj_loss=self.visual_obj_loss,
visual_attr_loss=self.visual_attr_loss,
visual_feat_loss=self.visual_feat_loss,
output_attentions=self.output_attentions,
output_hidden_states=self.output_hidden_states,
)
return (
config,
input_ids,
visual_feats,
bounding_boxes,
token_type_ids,
input_mask,
obj_labels,
masked_lm_labels,
matched_label,
ans,
output_attentions,
)
def create_and_check_lxmert_model(
self,
config,
input_ids,
visual_feats,
bounding_boxes,
token_type_ids,
input_mask,
obj_labels,
masked_lm_labels,
matched_label,
ans,
output_attentions,
):
model = TFLxmertModel(config=config)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
output_attentions=output_attentions,
)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
output_attentions=not output_attentions,
)
result = model(input_ids, visual_feats, bounding_boxes, return_dict=False)
result = model(input_ids, visual_feats, bounding_boxes, return_dict=True)
self.parent.assertEqual(result.language_output.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(
result.vision_output.shape, (self.batch_size, self.num_visual_features, self.hidden_size)
)
self.parent.assertEqual(result.pooled_output.shape, (self.batch_size, self.hidden_size))
def prepare_config_and_inputs_for_common(self, return_obj_labels=False):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
visual_feats,
bounding_boxes,
token_type_ids,
input_mask,
obj_labels,
masked_lm_labels,
matched_label,
ans,
output_attentions,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"visual_feats": visual_feats,
"visual_pos": bounding_boxes,
"token_type_ids": token_type_ids,
"attention_mask": input_mask,
}
if return_obj_labels:
inputs_dict["obj_labels"] = obj_labels
else:
config.task_obj_predict = False
return config, inputs_dict
def create_and_check_lxmert_for_pretraining(
self,
config,
input_ids,
visual_feats,
bounding_boxes,
token_type_ids,
input_mask,
obj_labels,
masked_lm_labels,
matched_label,
ans,
output_attentions,
):
model = TFLxmertForPreTraining(config=config)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
masked_lm_labels=masked_lm_labels,
obj_labels=obj_labels,
matched_label=matched_label,
ans=ans,
output_attentions=output_attentions,
)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
masked_lm_labels=masked_lm_labels,
output_attentions=not output_attentions,
return_dict=False,
)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
masked_lm_labels=masked_lm_labels,
)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
obj_labels=obj_labels,
)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
matched_label=matched_label,
)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
ans=ans,
)
result = model(
input_ids,
visual_feats,
bounding_boxes,
token_type_ids=token_type_ids,
attention_mask=input_mask,
masked_lm_labels=masked_lm_labels,
obj_labels=obj_labels,
matched_label=matched_label,
ans=ans,
output_attentions=not output_attentions,
)
self.parent.assertEqual(result.prediction_logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
@require_tf
class TFLxmertModelTest(TFModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (TFLxmertModel, TFLxmertForPreTraining) if is_tf_available() else ()
pipeline_model_mapping = {"feature-extraction": TFLxmertModel} if is_tf_available() else {}
test_head_masking = False
test_onnx = False
def setUp(self):
self.model_tester = TFLxmertModelTester(self)
self.config_tester = ConfigTester(self, config_class=LxmertConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_lxmert_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_lxmert_model(*config_and_inputs)
def test_lxmert_for_pretraining(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_lxmert_for_pretraining(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
for model_name in ["unc-nlp/lxmert-base-uncased"]:
model = TFLxmertModel.from_pretrained(model_name)
self.assertIsNotNone(model)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
encoder_seq_length = (
self.model_tester.encoder_seq_length
if hasattr(self.model_tester, "encoder_seq_length")
else self.model_tester.seq_length
)
encoder_key_length = (
self.model_tester.key_length if hasattr(self.model_tester, "key_length") else encoder_seq_length
)
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
model = model_class(config)
outputs = model(self._prepare_for_class(inputs_dict, model_class))
language_attentions, vision_attentions, cross_encoder_attentions = (outputs[-3], outputs[-2], outputs[-1])
self.assertEqual(model.config.output_hidden_states, False)
self.assertEqual(len(language_attentions), self.model_tester.num_hidden_layers["language"])
self.assertEqual(len(vision_attentions), self.model_tester.num_hidden_layers["vision"])
self.assertEqual(len(cross_encoder_attentions), self.model_tester.num_hidden_layers["cross_encoder"])
attentions = [language_attentions, vision_attentions, cross_encoder_attentions]
attention_shapes = [
[self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
[
self.model_tester.num_attention_heads,
self.model_tester.num_visual_features,
self.model_tester.num_visual_features,
],
[self.model_tester.num_attention_heads, encoder_key_length, self.model_tester.num_visual_features],
]
for attention, attention_shape in zip(attentions, attention_shapes):
self.assertListEqual(list(attention[0].shape[-3:]), attention_shape)
out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
outputs = model(self._prepare_for_class(inputs_dict, model_class))
# 2 hidden states were added
self.assertEqual(out_len + 2, len(outputs))
language_attentions, vision_attentions, cross_encoder_attentions = (outputs[-3], outputs[-2], outputs[-1])
self.assertEqual(len(language_attentions), self.model_tester.num_hidden_layers["language"])
self.assertEqual(len(vision_attentions), self.model_tester.num_hidden_layers["vision"])
self.assertEqual(len(cross_encoder_attentions), self.model_tester.num_hidden_layers["cross_encoder"])
attentions = [language_attentions, vision_attentions, cross_encoder_attentions]
attention_shapes = [
[self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
[
self.model_tester.num_attention_heads,
self.model_tester.num_visual_features,
self.model_tester.num_visual_features,
],
[self.model_tester.num_attention_heads, encoder_key_length, self.model_tester.num_visual_features],
]
for attention, attention_shape in zip(attentions, attention_shapes):
self.assertListEqual(list(attention[0].shape[-3:]), attention_shape)
def test_hidden_states_output(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
def check_hidden_states_output(config, inputs_dict, model_class):
model = model_class(config)
outputs = model(self._prepare_for_class(inputs_dict, model_class))
language_hidden_states, vision_hidden_states = outputs[-2], outputs[-1]
self.assertEqual(len(language_hidden_states), self.model_tester.num_hidden_layers["language"] + 1)
self.assertEqual(len(vision_hidden_states), self.model_tester.num_hidden_layers["vision"] + 1)
seq_length = self.model_tester.seq_length
num_visual_features = self.model_tester.num_visual_features
self.assertListEqual(
list(language_hidden_states[0].shape[-2:]),
[seq_length, self.model_tester.hidden_size],
)
self.assertListEqual(
list(vision_hidden_states[0].shape[-2:]),
[num_visual_features, self.model_tester.hidden_size],
)
for model_class in self.all_model_classes:
inputs_dict["output_hidden_states"] = True
check_hidden_states_output(config, inputs_dict, model_class)
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
check_hidden_states_output(config, inputs_dict, model_class)
def prepare_pt_inputs_from_tf_inputs(self, tf_inputs_dict):
import torch
pt_inputs_dict = {}
for key, value in tf_inputs_dict.items():
if isinstance(value, dict):
pt_inputs_dict[key] = self.prepare_pt_inputs_from_tf_inputs(value)
elif isinstance(value, (list, tuple)):
pt_inputs_dict[key] = (self.prepare_pt_inputs_from_tf_inputs(iter_value) for iter_value in value)
elif isinstance(key, bool):
pt_inputs_dict[key] = value
elif key == "input_values":
pt_inputs_dict[key] = torch.from_numpy(value.numpy()).to(torch.float32)
elif key == "pixel_values":
pt_inputs_dict[key] = torch.from_numpy(value.numpy()).to(torch.float32)
elif key == "input_features":
pt_inputs_dict[key] = torch.from_numpy(value.numpy()).to(torch.float32)
# other general float inputs
elif tf_inputs_dict[key].dtype.is_floating:
pt_inputs_dict[key] = torch.from_numpy(value.numpy()).to(torch.float32)
else:
pt_inputs_dict[key] = torch.from_numpy(value.numpy()).to(torch.long)
return pt_inputs_dict
def test_save_load(self):
for model_class in self.all_model_classes:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common(
return_obj_labels="PreTraining" in model_class.__name__
)
model = model_class(config)
outputs = model(self._prepare_for_class(inputs_dict, model_class))
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model = model_class.from_pretrained(tmpdirname)
after_outputs = model(self._prepare_for_class(inputs_dict, model_class))
self.assert_outputs_same(after_outputs, outputs)
@require_tf
class TFLxmertModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_masked_lm(self):
model = TFLxmertModel.from_pretrained("unc-nlp/lxmert-base-uncased")
input_ids = tf.constant([[101, 345, 232, 328, 740, 140, 1695, 69, 6078, 1588, 102]])
num_visual_features = 10
_, visual_feats = np.random.seed(0), np.random.rand(1, num_visual_features, model.config.visual_feat_dim)
_, visual_pos = np.random.seed(0), np.random.rand(1, num_visual_features, 4)
visual_feats = tf.convert_to_tensor(visual_feats, dtype=tf.float32)
visual_pos = tf.convert_to_tensor(visual_pos, dtype=tf.float32)
output = model(input_ids, visual_feats=visual_feats, visual_pos=visual_pos)[0]
expected_shape = [1, 11, 768]
self.assertEqual(expected_shape, output.shape)
expected_slice = tf.constant(
[
[
[0.24170142, -0.98075, 0.14797261],
[1.2540525, -0.83198136, 0.5112344],
[1.4070463, -1.1051831, 0.6990401],
]
]
)
tf.debugging.assert_near(output[:, :3, :3], expected_slice, atol=1e-4)
| transformers/tests/models/lxmert/test_modeling_tf_lxmert.py/0 | {
"file_path": "transformers/tests/models/lxmert/test_modeling_tf_lxmert.py",
"repo_id": "transformers",
"token_count": 10963
} | 363 |
# coding=utf-8
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from transformers import MegaConfig, is_torch_available
from transformers.testing_utils import (
TestCasePlus,
is_flaky,
require_torch,
require_torch_fp16,
slow,
torch_device,
)
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
MegaForCausalLM,
MegaForMaskedLM,
MegaForMultipleChoice,
MegaForQuestionAnswering,
MegaForSequenceClassification,
MegaForTokenClassification,
MegaModel,
)
from transformers.models.mega.modeling_mega import MEGA_PRETRAINED_MODEL_ARCHIVE_LIST
class MegaModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
intermediate_size=37,
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_positions=1024,
bidirectional=False, # needed for decoding, and can't modify common generation tests; test separately by overriding
ema_projection_size=16,
shared_representation_size=64,
use_chunking=False,
chunk_size=32,
attention_activation="softmax",
use_normalized_ffn=True,
nffn_hidden_size=24,
add_token_type_embeddings=True,
type_vocab_size=2,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.add_token_type_embeddings = add_token_type_embeddings
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.intermediate_size = intermediate_size
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_positions = max_positions
self.bidirectional = bidirectional
self.ema_projection_size = ema_projection_size
self.shared_representation_size = shared_representation_size
self.use_chunking = use_chunking
self.chunk_size = chunk_size
self.attention_activation = attention_activation
self.use_normalized_ffn = use_normalized_ffn
self.nffn_hidden_size = nffn_hidden_size
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
self.num_attention_heads = 1
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.add_token_type_embeddings:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config()
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def get_config(self):
return MegaConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
intermediate_size=self.intermediate_size,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
type_vocab_size=self.type_vocab_size,
initializer_range=self.initializer_range,
# added args
add_token_type_embeddings=self.add_token_type_embeddings,
max_positions=self.max_positions,
bidirectional=self.bidirectional,
ema_projection_size=self.ema_projection_size,
shared_representation_size=self.shared_representation_size,
use_chunking=self.use_chunking,
chunk_size=self.chunk_size,
attention_activation=self.attention_activation,
use_normalized_ffn=self.use_normalized_ffn,
nffn_hidden_size=self.nffn_hidden_size,
)
def get_pipeline_config(self):
config = self.get_config()
config.vocab_size = 300
return config
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
config.is_decoder = True
config.bidirectional = False
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = MegaModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
result = model(input_ids, token_type_ids=token_type_ids)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
def create_and_check_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = MegaModel(config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
)
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
encoder_hidden_states=encoder_hidden_states,
)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(result.pooler_output.shape, (self.batch_size, self.hidden_size))
def create_and_check_for_causal_lm(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
model = MegaForCausalLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_decoder_model_past_large_inputs(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.is_decoder = True
config.bidirectional = False
config.add_cross_attention = True
model = MegaForCausalLM(config=config).to(torch_device).eval()
# make sure that ids don't start with pad token
mask = input_ids.ne(config.pad_token_id).long()
input_ids = input_ids * mask
# first forward pass
outputs = model(
input_ids,
attention_mask=input_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
use_cache=True,
)
past_key_values = outputs.past_key_values
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# make sure that ids don't start with pad token
mask = next_tokens.ne(config.pad_token_id).long()
next_tokens = next_tokens * mask
next_mask = ids_tensor((self.batch_size, 1), vocab_size=2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([input_mask, next_mask], dim=-1)
output_from_no_past = model(
next_input_ids,
attention_mask=next_attention_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_hidden_states=True,
)["hidden_states"][0]
output_from_past = model(
next_tokens,
attention_mask=next_mask,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
past_key_values=past_key_values,
output_hidden_states=True,
)["hidden_states"][0]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -1:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3))
def create_and_check_decoder_model_with_chunking(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.use_chunking = True
config.output_attentions = True
config.attention_activation = "laplace"
config.chunk_size = input_ids.size(1) * 2
model = MegaForCausalLM(config).to(torch_device).eval()
input_ids = input_ids.repeat(1, 8)
# multiply the sequence length by 8 since we repeat the same ids 8 times in input_ids
input_mask = random_attention_mask([self.batch_size, self.seq_length * 8])
result = model(input_ids, attention_mask=input_mask)
# test if the sequence length of attentions is same provided chunk_size
self.parent.assertEqual(result["attentions"][0].shape[-1], config.chunk_size)
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = MegaForMaskedLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = MegaForTokenClassification(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = MegaForMultipleChoice(config=config)
model.to(torch_device)
model.eval()
multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
result = model(
multiple_choice_inputs_ids,
attention_mask=multiple_choice_input_mask,
token_type_ids=multiple_choice_token_type_ids,
labels=choice_labels,
)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = MegaForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
start_positions=sequence_labels,
end_positions=sequence_labels,
)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
# extra checks for Mega-specific model functionality
def create_and_check_bidirectionality(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.bidirectional = True
model = MegaModel(config)
model.to(torch_device)
model.eval()
# no mask
result = model(input_ids)
# with mask & token types
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result[0].shape, (self.batch_size, self.seq_length, self.hidden_size))
def check_chunking_shorter_sequence(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.use_chunking = True
config.chunk_size = input_ids.size(1) + 25
model = MegaModel(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result[0].shape, (self.batch_size, self.seq_length, self.hidden_size))
def check_chunking_longer_sequence(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.use_chunking = True
# we want the chunk size to be < sequence length, and the sequence length to be a multiple of chunk size
config.chunk_size = input_ids.size(1) * 2
model = MegaModel(config)
model.to(torch_device)
model.eval()
result = model(
input_ids.repeat(1, 8),
)
self.parent.assertEqual(result[0].shape, (self.batch_size, self.seq_length * 8, self.hidden_size))
def check_laplace_self_attention(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.attention_activation = "laplace"
model = MegaModel(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result[0].shape, (self.batch_size, self.seq_length, self.hidden_size))
def check_relu2_self_attention(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.attention_activation = "relu2"
model = MegaModel(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result[0].shape, (self.batch_size, self.seq_length, self.hidden_size))
def check_sequence_length_beyond_max_positions(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.max_positions = self.seq_length - 2
model = MegaModel(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result[0].shape, (self.batch_size, self.seq_length, self.hidden_size))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_torch
class MegaModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
MegaForCausalLM,
MegaForMaskedLM,
MegaModel,
MegaForSequenceClassification,
MegaForTokenClassification,
MegaForMultipleChoice,
MegaForQuestionAnswering,
)
if is_torch_available()
else ()
)
all_generative_model_classes = (MegaForCausalLM,) if is_torch_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": MegaModel,
"fill-mask": MegaForMaskedLM,
"question-answering": MegaForQuestionAnswering,
"text-classification": MegaForSequenceClassification,
"text-generation": MegaForCausalLM,
"token-classification": MegaForTokenClassification,
"zero-shot": MegaForSequenceClassification,
}
if is_torch_available()
else {}
)
fx_compatible = False
test_head_masking = False
test_pruning = False
def setUp(self):
self.model_tester = MegaModelTester(self)
self.config_tester = ConfigTester(self, config_class=MegaConfig, hidden_size=37)
# TODO: @ydshieh
@is_flaky(description="Sometimes gives `AssertionError` on expected outputs")
def test_pipeline_fill_mask(self):
super().test_pipeline_fill_mask()
# TODO: @ydshieh
@is_flaky(
description="Sometimes gives `RuntimeError: probability tensor contains either `inf`, `nan` or element < 0`"
)
def test_pipeline_text_generation(self):
super().test_pipeline_text_generation()
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_as_decoder(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_model_as_decoder(*config_and_inputs)
def test_model_as_decoder_with_default_input_mask(self):
# This regression test was failing with PyTorch < 1.3
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
) = self.model_tester.prepare_config_and_inputs_for_decoder()
input_mask = None
self.model_tester.create_and_check_model_as_decoder(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def test_for_causal_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_for_causal_lm(*config_and_inputs)
def test_decoder_model_past_with_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_decoder_model_with_chunking(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_decoder()
self.model_tester.create_and_check_decoder_model_with_chunking(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_bidirectionality(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_bidirectionality(*config_and_inputs)
def test_for_chunking_shorter_sequence(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_chunking_shorter_sequence(*config_and_inputs)
def test_for_chunking_longer_sequence(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_chunking_longer_sequence(*config_and_inputs)
def test_for_laplace_attention(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_laplace_self_attention(*config_and_inputs)
def test_for_relu2_attention(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_relu2_self_attention(*config_and_inputs)
def test_for_sequence_length_beyond_max_positions(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_sequence_length_beyond_max_positions(*config_and_inputs)
@require_torch_fp16
def test_generate_fp16(self):
config, input_ids, _, attention_mask, *_ = self.model_tester.prepare_config_and_inputs_for_decoder()
# attention_mask = torch.LongTensor(input_ids.ne(1)).to(torch_device)
model = MegaForCausalLM(config).eval().to(torch_device)
model.half()
model.generate(input_ids, attention_mask=attention_mask)
model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
def test_sequence_classification_model(self):
config, input_ids, _, attention_mask, *_ = self.model_tester.prepare_config_and_inputs()
config.num_labels = self.model_tester.num_labels
sequence_labels = ids_tensor([self.model_tester.batch_size], self.model_tester.type_sequence_label_size)
model = MegaForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
def test_sequence_classification_model_for_multi_label(self):
config, input_ids, _, attention_mask, *_ = self.model_tester.prepare_config_and_inputs()
config.num_labels = self.model_tester.num_labels
config.problem_type = "multi_label_classification"
sequence_labels = ids_tensor(
[self.model_tester.batch_size, config.num_labels], self.model_tester.type_sequence_label_size
).to(torch.float)
model = MegaForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=attention_mask, labels=sequence_labels)
self.assertEqual(result.logits.shape, (self.model_tester.batch_size, self.model_tester.num_labels))
@slow
def test_model_from_pretrained(self):
for model_name in MEGA_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = MegaModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@unittest.skip(reason="Does not work on the tiny model as we keep hitting edge cases.")
def test_cpu_offload(self):
super().test_cpu_offload()
@unittest.skip(reason="Does not work on the tiny model as we keep hitting edge cases.")
def test_disk_offload(self):
super().test_disk_offload()
@unittest.skip(reason="Does not work on the tiny model as we keep hitting edge cases.")
def test_model_parallelism(self):
super().test_model_parallelism()
@unittest.skip(
reason=(
"Calling `self.attention_function` in `MegaMovingAverageGatedAttention.forward` changes the submodules on "
"device 1 to device 0 (also changes `requires_grad`). No idea how this could happen for now."
)
)
def test_multi_gpu_data_parallel_forward(self):
super().test_multi_gpu_data_parallel_forward()
@unittest.skip(reason="Tracing of the dynamically computed `MegaMultiDimensionDampedEma._kernel` doesn't work.")
def test_torchscript_simple(self):
super().test_torchscript_simple()
@unittest.skip(reason="Tracing of the dynamically computed `MegaMultiDimensionDampedEma._kernel` doesn't work.")
def test_torchscript_output_hidden_state(self):
super().test_torchscript_output_hidden_state()
@unittest.skip(reason="Tracing of the dynamically computed `MegaMultiDimensionDampedEma._kernel` doesn't work.")
def test_torchscript_output_attentions(self):
super().test_torchscript_output_attentions()
@require_torch
class MegaModelIntegrationTest(TestCasePlus):
@slow
def test_inference_masked_lm(self):
model = MegaForMaskedLM.from_pretrained("mnaylor/mega-base-wikitext")
input_ids = torch.tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
with torch.no_grad():
output = model(input_ids)[0]
expected_shape = torch.Size((1, 11, 50265))
self.assertEqual(output.shape, expected_shape)
# compare the actual values for a slice.
expected_slice = torch.tensor(
[[[67.8389, 10.1470, -32.7148], [-11.1655, 29.1152, 23.1304], [-3.8015, 66.0397, 29.6733]]]
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4))
@slow
def test_inference_no_head(self):
model = MegaModel.from_pretrained("mnaylor/mega-base-wikitext")
input_ids = torch.tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
with torch.no_grad():
output = model(input_ids)[0]
expected_shape = torch.Size((1, 11, 128))
self.assertEqual(output.shape, expected_shape)
# compare the actual values for a slice. taken from output[:, :3, :3]
expected_slice = torch.tensor(
[[[1.1767, -0.6349, 2.8494], [-0.5109, -0.7745, 1.9495], [-0.3287, -0.2111, 3.3367]]]
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4))
| transformers/tests/models/mega/test_modeling_mega.py/0 | {
"file_path": "transformers/tests/models/mega/test_modeling_mega.py",
"repo_id": "transformers",
"token_count": 13179
} | 364 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import itertools
import math
import os
import random
import tempfile
import unittest
import numpy as np
from transformers.testing_utils import (
check_json_file_has_correct_format,
require_torch,
require_torchaudio,
)
from transformers.utils.import_utils import is_torchaudio_available
from ...test_sequence_feature_extraction_common import SequenceFeatureExtractionTestMixin
if is_torchaudio_available():
import torch
from transformers import MusicgenMelodyFeatureExtractor
global_rng = random.Random()
# Copied from tests.models.whisper.test_feature_extraction_whisper.floats_list
def floats_list(shape, scale=1.0, rng=None, name=None):
"""Creates a random float32 tensor"""
if rng is None:
rng = global_rng
values = []
for batch_idx in range(shape[0]):
values.append([])
for _ in range(shape[1]):
values[-1].append(rng.random() * scale)
return values
# Copied from tests.models.musicgen.test_modeling_musicgen.get_bip_bip
def get_bip_bip(bip_duration=0.125, duration=0.5, sample_rate=32000):
"""Produces a series of 'bip bip' sounds at a given frequency."""
timesteps = np.arange(int(duration * sample_rate)) / sample_rate
wav = np.cos(2 * math.pi * 440 * timesteps)
time_period = (timesteps % (2 * bip_duration)) / (2 * bip_duration)
envelope = time_period >= 0.5
return wav * envelope
@require_torch
@require_torchaudio
class MusicgenMelodyFeatureExtractionTester(unittest.TestCase):
def __init__(
self,
parent,
batch_size=7,
min_seq_length=400,
max_seq_length=2000,
feature_size=12,
padding_value=0.0,
sampling_rate=4_000,
return_attention_mask=True,
):
self.parent = parent
self.batch_size = batch_size
self.min_seq_length = min_seq_length
self.max_seq_length = max_seq_length
self.seq_length_diff = (self.max_seq_length - self.min_seq_length) // (self.batch_size - 1)
self.padding_value = padding_value
self.sampling_rate = sampling_rate
self.return_attention_mask = return_attention_mask
self.feature_size = feature_size
self.num_chroma = feature_size
def prepare_feat_extract_dict(self):
return {
"feature_size": self.feature_size,
"padding_value": self.padding_value,
"sampling_rate": self.sampling_rate,
"return_attention_mask": self.return_attention_mask,
}
# Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTester.prepare_inputs_for_common
def prepare_inputs_for_common(self, equal_length=False, numpify=False):
def _flatten(list_of_lists):
return list(itertools.chain(*list_of_lists))
if equal_length:
speech_inputs = [floats_list((self.max_seq_length, self.feature_size)) for _ in range(self.batch_size)]
else:
# make sure that inputs increase in size
speech_inputs = [
floats_list((x, self.feature_size))
for x in range(self.min_seq_length, self.max_seq_length, self.seq_length_diff)
]
if numpify:
speech_inputs = [np.asarray(x) for x in speech_inputs]
return speech_inputs
@require_torchaudio
@require_torch
class MusicgenMelodyFeatureExtractionTest(SequenceFeatureExtractionTestMixin, unittest.TestCase):
feature_extraction_class = MusicgenMelodyFeatureExtractor if is_torchaudio_available() else None
def setUp(self):
self.feat_extract_tester = MusicgenMelodyFeatureExtractionTester(self)
# Copied from tests.models.seamless_m4t.test_feature_extraction_seamless_m4t.SeamlessM4TFeatureExtractionTest.test_feat_extract_from_and_save_pretrained
def test_feat_extract_from_and_save_pretrained(self):
feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
with tempfile.TemporaryDirectory() as tmpdirname:
saved_file = feat_extract_first.save_pretrained(tmpdirname)[0]
check_json_file_has_correct_format(saved_file)
feat_extract_second = self.feature_extraction_class.from_pretrained(tmpdirname)
dict_first = feat_extract_first.to_dict()
dict_second = feat_extract_second.to_dict()
self.assertDictEqual(dict_first, dict_second)
# Copied from tests.models.seamless_m4t.test_feature_extraction_seamless_m4t.SeamlessM4TFeatureExtractionTest.test_feat_extract_to_json_file
def test_feat_extract_to_json_file(self):
feat_extract_first = self.feature_extraction_class(**self.feat_extract_dict)
with tempfile.TemporaryDirectory() as tmpdirname:
json_file_path = os.path.join(tmpdirname, "feat_extract.json")
feat_extract_first.to_json_file(json_file_path)
feat_extract_second = self.feature_extraction_class.from_json_file(json_file_path)
dict_first = feat_extract_first.to_dict()
dict_second = feat_extract_second.to_dict()
self.assertEqual(dict_first, dict_second)
def test_call(self):
# Tests that all call wrap to encode_plus and batch_encode_plus
feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
# create three inputs of length 800, 1000, and 1200
speech_inputs = [floats_list((1, x))[0] for x in range(800, 1400, 200)]
np_speech_inputs = [np.asarray(speech_input) for speech_input in speech_inputs]
# Test feature size
input_features = feature_extractor(np_speech_inputs, padding=True, return_tensors="np").input_features
self.assertTrue(input_features.ndim == 3)
self.assertTrue(input_features.shape[0] == 3)
# Ignore copy
self.assertTrue(input_features.shape[-1] == feature_extractor.feature_size)
# Test not batched input
encoded_sequences_1 = feature_extractor(speech_inputs[0], return_tensors="np").input_features
encoded_sequences_2 = feature_extractor(np_speech_inputs[0], return_tensors="np").input_features
self.assertTrue(np.allclose(encoded_sequences_1, encoded_sequences_2, atol=1e-3))
# Test batched
encoded_sequences_1 = feature_extractor(speech_inputs, return_tensors="np").input_features
encoded_sequences_2 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
# Test 2-D numpy arrays are batched.
speech_inputs = [floats_list((1, x))[0] for x in (800, 800, 800)]
np_speech_inputs = np.asarray(speech_inputs)
encoded_sequences_1 = feature_extractor(speech_inputs, return_tensors="np").input_features
encoded_sequences_2 = feature_extractor(np_speech_inputs, return_tensors="np").input_features
for enc_seq_1, enc_seq_2 in zip(encoded_sequences_1, encoded_sequences_2):
self.assertTrue(np.allclose(enc_seq_1, enc_seq_2, atol=1e-3))
@require_torchaudio
def test_call_from_demucs(self):
# Tests that all call wrap to encode_plus and batch_encode_plus
feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
# (batch_size, num_stems, channel_size, audio_length)
inputs = torch.rand([4, 5, 2, 44000])
# Test feature size
input_features = feature_extractor(inputs, padding=True, return_tensors="np").input_features
self.assertTrue(input_features.ndim == 3)
self.assertTrue(input_features.shape[0] == 4)
self.assertTrue(input_features.shape[-1] == feature_extractor.feature_size)
# Test single input
encoded_sequences_1 = feature_extractor(inputs[[0]], return_tensors="np").input_features
self.assertTrue(np.allclose(encoded_sequences_1[0], input_features[0], atol=1e-3))
# Copied from tests.models.whisper.test_feature_extraction_whisper.WhisperFeatureExtractionTest.test_double_precision_pad with input_features->input_features
def test_double_precision_pad(self):
import torch
feature_extractor = self.feature_extraction_class(**self.feat_extract_tester.prepare_feat_extract_dict())
np_speech_inputs = np.random.rand(100, 32).astype(np.float64)
py_speech_inputs = np_speech_inputs.tolist()
for inputs in [py_speech_inputs, np_speech_inputs]:
np_processed = feature_extractor.pad([{"input_features": inputs}], return_tensors="np")
self.assertTrue(np_processed.input_features.dtype == np.float32)
pt_processed = feature_extractor.pad([{"input_features": inputs}], return_tensors="pt")
self.assertTrue(pt_processed.input_features.dtype == torch.float32)
def test_integration(self):
EXPECTED_INPUT_FEATURES = torch.zeros([2, 8, 12])
EXPECTED_INPUT_FEATURES[0, :6, 9] = 1
EXPECTED_INPUT_FEATURES[0, 6:, 0] = 1
EXPECTED_INPUT_FEATURES[1, :, 9] = 1
input_speech = [get_bip_bip(duration=0.5), get_bip_bip(duration=1.0)]
feature_extractor = MusicgenMelodyFeatureExtractor()
input_features = feature_extractor(input_speech, return_tensors="pt").input_features
self.assertEqual(input_features.shape, (2, 8, 12))
self.assertTrue((input_features == EXPECTED_INPUT_FEATURES).all())
| transformers/tests/models/musicgen_melody/test_feature_extraction_musicgen_melody.py/0 | {
"file_path": "transformers/tests/models/musicgen_melody/test_feature_extraction_musicgen_melody.py",
"repo_id": "transformers",
"token_count": 4129
} | 365 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch PEGASUS-X model. """
import copy
import math
import tempfile
import unittest
from transformers import is_torch_available
from transformers.testing_utils import (
require_sentencepiece,
require_tokenizers,
require_torch,
require_torch_fp16,
slow,
torch_device,
)
from transformers.utils import cached_property
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import PegasusTokenizer, PegasusXConfig, PegasusXForConditionalGeneration, PegasusXModel
from transformers.models.pegasus_x.modeling_pegasus_x import PegasusXDecoder, PegasusXEncoder
def prepare_pegasus_x_inputs_dict(
config,
input_ids,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
):
if attention_mask is None:
attention_mask = input_ids.ne(config.pad_token_id)
if decoder_attention_mask is None:
decoder_attention_mask = decoder_input_ids.ne(config.pad_token_id)
return {
"input_ids": input_ids,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": attention_mask,
}
@require_torch
class PegasusXModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=16,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=4,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(
3,
)
input_ids[:, -1] = self.eos_token_id # Eos Token
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
config = PegasusXConfig(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
eos_token_id=self.eos_token_id,
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
stagger_local_blocks=False,
)
inputs_dict = prepare_pegasus_x_inputs_dict(config, input_ids, decoder_input_ids)
return config, inputs_dict
def prepare_config_and_inputs_for_common(self):
config, inputs_dict = self.prepare_config_and_inputs()
return config, inputs_dict
def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = PegasusXModel(config=config).get_decoder().to(torch_device).eval()
input_ids = inputs_dict["input_ids"]
attention_mask = inputs_dict["attention_mask"]
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
"last_hidden_state"
]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-2))
def check_encoder_decoder_model_standalone(self, config, inputs_dict):
model = PegasusXModel(config=config).to(torch_device).eval()
outputs = model(**inputs_dict)
encoder_last_hidden_state = outputs.encoder_last_hidden_state
last_hidden_state = outputs.last_hidden_state
with tempfile.TemporaryDirectory() as tmpdirname:
encoder = model.get_encoder()
encoder.save_pretrained(tmpdirname)
encoder = PegasusXEncoder.from_pretrained(tmpdirname).to(torch_device)
encoder_last_hidden_state_2 = encoder(inputs_dict["input_ids"], attention_mask=inputs_dict["attention_mask"])[
0
]
self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
with tempfile.TemporaryDirectory() as tmpdirname:
decoder = model.get_decoder()
decoder.save_pretrained(tmpdirname)
decoder = PegasusXDecoder.from_pretrained(tmpdirname).to(torch_device)
last_hidden_state_2 = decoder(
input_ids=inputs_dict["decoder_input_ids"],
attention_mask=inputs_dict["decoder_attention_mask"],
encoder_hidden_states=encoder_last_hidden_state,
encoder_attention_mask=inputs_dict["attention_mask"],
)[0]
self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
@require_torch
class PegasusXModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (PegasusXModel, PegasusXForConditionalGeneration) if is_torch_available() else ()
all_generative_model_classes = (PegasusXForConditionalGeneration,) if is_torch_available() else ()
pipeline_model_mapping = (
{
"conversational": PegasusXForConditionalGeneration,
"feature-extraction": PegasusXModel,
"summarization": PegasusXForConditionalGeneration,
"text2text-generation": PegasusXForConditionalGeneration,
"translation": PegasusXForConditionalGeneration,
}
if is_torch_available()
else {}
)
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_missing_keys = False
def setUp(self):
self.model_tester = PegasusXModelTester(self)
self.config_tester = ConfigTester(self, config_class=PegasusXConfig)
@unittest.skip(
"`PegasusXGlobalLocalAttention` returns attentions as dictionary - not compatible with torchscript "
)
def test_torchscript_output_attentions(self):
pass
def test_config(self):
self.config_tester.run_common_tests()
def test_save_load_strict(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs()
for model_class in self.all_model_classes:
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
self.assertEqual(info["missing_keys"], [])
def test_decoder_model_past_with_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_encoder_decoder_model_standalone(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
def test_inputs_embeds(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in (PegasusXModel, PegasusXForConditionalGeneration):
model = model_class(config)
model.to(torch_device)
model.eval()
inputs = copy.deepcopy(self._prepare_for_class(inputs_dict, model_class))
if not self.is_encoder_decoder:
input_ids = inputs["input_ids"]
del inputs["input_ids"]
else:
encoder_input_ids = inputs["input_ids"]
decoder_input_ids = inputs.get("decoder_input_ids", encoder_input_ids)
del inputs["input_ids"]
inputs.pop("decoder_input_ids", None)
wte = model.get_input_embeddings()
if not self.is_encoder_decoder:
inputs["inputs_embeds"] = wte(input_ids)
else:
inputs["inputs_embeds"] = wte(encoder_input_ids)
inputs["decoder_inputs_embeds"] = wte(decoder_input_ids)
with torch.no_grad():
model(**inputs)[0]
@require_torch_fp16
def test_generate_fp16(self):
config, input_dict = self.model_tester.prepare_config_and_inputs()
input_ids = input_dict["input_ids"]
attention_mask = input_ids.ne(1).to(torch_device)
model = PegasusXForConditionalGeneration(config).eval().to(torch_device)
model.half()
model.generate(input_ids, attention_mask=attention_mask)
model.generate(num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
seq_len = getattr(self.model_tester, "seq_length", None)
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
decoder_key_length = getattr(self.model_tester, "decoder_key_length", decoder_seq_length)
encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
chunk_length = getattr(self.model_tester, "chunk_length", None)
if chunk_length is not None and hasattr(self.model_tester, "num_hashes"):
encoder_seq_length = encoder_seq_length * self.model_tester.num_hashes
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0]["local"].shape[-4:]),
[
self.model_tester.num_attention_heads,
math.ceil(encoder_seq_length / model.config.block_size),
model.config.block_size,
model.config.block_size + model.config.num_global_tokens,
],
)
out_len = len(outputs)
if self.is_encoder_decoder:
correct_outlen = 5
# loss is at first position
if "labels" in inputs_dict:
correct_outlen += 1 # loss is added to beginning
if "past_key_values" in outputs:
correct_outlen += 1 # past_key_values have been returned
self.assertEqual(out_len, correct_outlen)
# decoder attentions
decoder_attentions = outputs.decoder_attentions
self.assertIsInstance(decoder_attentions, (list, tuple))
self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(decoder_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
)
# cross attentions
cross_attentions = outputs.cross_attentions
self.assertIsInstance(cross_attentions, (list, tuple))
self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(cross_attentions[0].shape[-3:]),
[
self.model_tester.num_attention_heads,
decoder_seq_length,
encoder_key_length,
],
)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
if hasattr(self.model_tester, "num_hidden_states_types"):
added_hidden_states = self.model_tester.num_hidden_states_types
elif self.is_encoder_decoder:
added_hidden_states = 2
else:
added_hidden_states = 1
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0]["local"].shape[-4:]),
[
self.model_tester.num_attention_heads,
math.ceil(encoder_seq_length / model.config.block_size),
model.config.block_size,
model.config.block_size + model.config.num_global_tokens,
],
)
def _check_encoder_attention_for_generate(self, attentions, batch_size, config, seq_length):
encoder_expected_shape = (
batch_size,
config.num_attention_heads,
math.ceil(seq_length / config.block_size),
config.block_size,
config.block_size + config.num_global_tokens,
)
self.assertIsInstance(attentions, tuple)
self.assertListEqual(
[layer_attentions["local"].shape for layer_attentions in attentions],
[encoder_expected_shape] * len(attentions),
)
def _check_encoder_hidden_states_for_generate(self, hidden_states, batch_size, config, seq_length):
encoder_expected_shape = (batch_size, self.round_up(seq_length, config.block_size), config.hidden_size)
self.assertIsInstance(hidden_states, tuple)
# Only the last layer will have the hidden states truncated back to token level
self.assertListEqual(
[layer_hidden_states.shape for layer_hidden_states in hidden_states[:-1]],
[encoder_expected_shape] * (len(hidden_states) - 1),
)
# Only the last layer will have the hidden states truncated back to token level
self.assertEqual(
hidden_states[-1][0].shape,
(batch_size, seq_length, config.hidden_size),
)
def test_hidden_states_output(self):
def _check_hidden_states_output(inputs_dict, config, model_class):
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
expected_num_layers = getattr(
self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
)
self.assertEqual(len(hidden_states), expected_num_layers)
if hasattr(self.model_tester, "encoder_seq_length"):
seq_length = self.model_tester.encoder_seq_length
if hasattr(self.model_tester, "chunk_length") and self.model_tester.chunk_length > 1:
seq_length = seq_length * self.model_tester.chunk_length
else:
seq_length = self.model_tester.seq_length
self.assertListEqual(
list(hidden_states[0].shape[-2:]),
[self.round_up(seq_length, config.block_size), self.model_tester.hidden_size],
)
if config.is_encoder_decoder:
hidden_states = outputs.decoder_hidden_states
self.assertIsInstance(hidden_states, (list, tuple))
self.assertEqual(len(hidden_states), expected_num_layers)
seq_len = getattr(self.model_tester, "seq_length", None)
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
self.assertListEqual(
list(hidden_states[0].shape[-2:]),
[decoder_seq_length, self.model_tester.hidden_size],
)
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
inputs_dict["output_hidden_states"] = True
_check_hidden_states_output(inputs_dict, config, model_class)
# check that output_hidden_states also work using config
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
_check_hidden_states_output(inputs_dict, config, model_class)
def test_retain_grad_hidden_states_attentions(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.output_hidden_states = True
config.output_attentions = self.has_attentions
# no need to test all models as different heads yield the same functionality
model_class = self.all_model_classes[0]
model = model_class(config)
model.to(torch_device)
inputs = self._prepare_for_class(inputs_dict, model_class)
outputs = model(**inputs)
output = outputs[0]
if config.is_encoder_decoder:
# Seq2Seq models
encoder_hidden_states = outputs.encoder_hidden_states[0]
encoder_hidden_states.retain_grad()
decoder_hidden_states = outputs.decoder_hidden_states[0]
decoder_hidden_states.retain_grad()
if self.has_attentions:
encoder_attentions = outputs.encoder_attentions[0]
encoder_attentions["local"].retain_grad()
encoder_attentions["global"].retain_grad()
decoder_attentions = outputs.decoder_attentions[0]
decoder_attentions.retain_grad()
cross_attentions = outputs.cross_attentions[0]
cross_attentions.retain_grad()
output.flatten()[0].backward(retain_graph=True)
self.assertIsNotNone(encoder_hidden_states.grad)
self.assertIsNotNone(decoder_hidden_states.grad)
if self.has_attentions:
self.assertIsNotNone(encoder_attentions["local"].grad)
self.assertIsNotNone(encoder_attentions["global"].grad)
self.assertIsNotNone(decoder_attentions.grad)
self.assertIsNotNone(cross_attentions.grad)
else:
# Encoder-/Decoder-only models
hidden_states = outputs.hidden_states[0]
hidden_states.retain_grad()
if self.has_attentions:
attentions = outputs.attentions[0]
attentions.retain_grad()
output.flatten()[0].backward(retain_graph=True)
self.assertIsNotNone(hidden_states.grad)
if self.has_attentions:
self.assertIsNotNone(attentions.grad)
@classmethod
def round_up(cls, n, k):
return math.ceil(n / k) * k
def assert_tensors_close(a, b, atol=1e-12, prefix=""):
"""If tensors have different shapes, different values or a and b are not both tensors, raise a nice Assertion error."""
if a is None and b is None:
return True
try:
if torch.allclose(a, b, atol=atol):
return True
raise
except Exception:
pct_different = (torch.gt((a - b).abs(), atol)).float().mean().item()
if a.numel() > 100:
msg = f"tensor values are {pct_different:.1%} percent different."
else:
msg = f"{a} != {b}"
if prefix:
msg = prefix + ": " + msg
raise AssertionError(msg)
def _long_tensor(tok_lst):
return torch.tensor(tok_lst, dtype=torch.long, device=torch_device)
TOLERANCE = 1e-4
@require_torch
@require_sentencepiece
@require_tokenizers
@slow
class PegasusXModelIntegrationTests(unittest.TestCase):
@cached_property
def default_tokenizer(self):
return PegasusTokenizer.from_pretrained("google/pegasus-x-base")
def test_inference_no_head(self):
model = PegasusXModel.from_pretrained("google/pegasus-x-base").to(torch_device)
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[2, 0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588]])
inputs_dict = prepare_pegasus_x_inputs_dict(model.config, input_ids, decoder_input_ids)
with torch.no_grad():
output = model(**inputs_dict)[0]
expected_shape = torch.Size((1, 11, 768))
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = torch.tensor(
[[0.0702, -0.1552, 0.1192], [0.0836, -0.1848, 0.1304], [0.0673, -0.1686, 0.1045]], device=torch_device
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=TOLERANCE))
def test_inference_head(self):
model = PegasusXForConditionalGeneration.from_pretrained("google/pegasus-x-base").to(torch_device)
# change to intended input
input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
decoder_input_ids = _long_tensor([[0, 31414, 232, 328, 740, 1140, 12695, 69, 46078, 1588, 2]])
inputs_dict = prepare_pegasus_x_inputs_dict(model.config, input_ids, decoder_input_ids)
with torch.no_grad():
output = model(**inputs_dict)[0]
expected_shape = torch.Size((1, 11, model.config.vocab_size))
self.assertEqual(output.shape, expected_shape)
# change to expected output here
expected_slice = torch.tensor(
[[0.0, 9.5705185, 1.5897303], [0.0, 9.833374, 1.5828674], [0.0, 10.429961, 1.5643371]], device=torch_device
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=TOLERANCE))
def test_seq_to_seq_generation(self):
hf = PegasusXForConditionalGeneration.from_pretrained("google/pegasus-x-base-arxiv").to(torch_device)
tok = PegasusTokenizer.from_pretrained("google/pegasus-x-base")
batch_input = [
"While large pretrained Transformer models have proven highly capable at tackling natural language tasks,"
" handling long sequence inputs continues to be a significant challenge. One such task is long input"
" summarization, where inputs are longer than the maximum input context of most pretrained models. Through"
" an extensive set of experiments, we investigate what model architectural changes and pretraining"
" paradigms can most efficiently adapt a pretrained Transformer for long input summarization. We find that"
" a staggered, block-local Transformer with global encoder tokens strikes a good balance of performance"
" and efficiency, and that an additional pretraining phase on long sequences meaningfully improves"
" downstream summarization performance. Based on our findings, we introduce PEGASUS-X, an extension of the"
" PEGASUS model with additional long input pretraining to handle inputs of up to 16K tokens. PEGASUS-X"
" achieves strong performance on long input summarization tasks comparable with much larger models while"
" adding few additional parameters and not requiring model parallelism to train."
]
# The below article tests that we don't add any hypotheses outside of the top n_beams
dct = tok.batch_encode_plus(
batch_input,
max_length=512,
padding="max_length",
truncation_strategy="only_first",
truncation=True,
return_tensors="pt",
)
hypotheses_batch = hf.generate(
input_ids=dct["input_ids"].to(torch_device),
attention_mask=dct["attention_mask"].to(torch_device),
num_beams=2,
max_length=32,
)
EXPECTED = [
"we investigate the performance of a new pretrained model for long input summarization. <n> the model is a"
" superposition of two well -"
]
generated = tok.batch_decode(
hypotheses_batch.tolist(), clean_up_tokenization_spaces=True, skip_special_tokens=True
)
assert generated == EXPECTED
class PegasusXStandaloneDecoderModelTester:
def __init__(
self,
parent,
vocab_size=99,
batch_size=13,
d_model=16,
decoder_seq_length=7,
is_training=True,
is_decoder=True,
use_attention_mask=True,
use_cache=False,
use_labels=True,
decoder_start_token_id=2,
decoder_ffn_dim=32,
decoder_layers=2,
encoder_attention_heads=4,
decoder_attention_heads=4,
max_position_embeddings=30,
is_encoder_decoder=False,
pad_token_id=0,
bos_token_id=1,
eos_token_id=2,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.decoder_seq_length = decoder_seq_length
# For common tests
self.seq_length = self.decoder_seq_length
self.is_training = is_training
self.use_attention_mask = use_attention_mask
self.use_labels = use_labels
self.vocab_size = vocab_size
self.d_model = d_model
self.hidden_size = d_model
self.num_hidden_layers = decoder_layers
self.decoder_layers = decoder_layers
self.decoder_ffn_dim = decoder_ffn_dim
self.encoder_attention_heads = encoder_attention_heads
self.decoder_attention_heads = decoder_attention_heads
self.num_attention_heads = decoder_attention_heads
self.eos_token_id = eos_token_id
self.bos_token_id = bos_token_id
self.pad_token_id = pad_token_id
self.decoder_start_token_id = decoder_start_token_id
self.use_cache = use_cache
self.max_position_embeddings = max_position_embeddings
self.is_encoder_decoder = is_encoder_decoder
self.scope = None
self.decoder_key_length = decoder_seq_length
self.base_model_out_len = 2
self.decoder_attention_idx = 1
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
attention_mask = None
if self.use_attention_mask:
attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
lm_labels = None
if self.use_labels:
lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
config = PegasusXConfig(
vocab_size=self.vocab_size,
d_model=self.d_model,
decoder_layers=self.decoder_layers,
decoder_ffn_dim=self.decoder_ffn_dim,
encoder_attention_heads=self.encoder_attention_heads,
decoder_attention_heads=self.decoder_attention_heads,
eos_token_id=self.eos_token_id,
bos_token_id=self.bos_token_id,
use_cache=self.use_cache,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.decoder_start_token_id,
max_position_embeddings=self.max_position_embeddings,
is_encoder_decoder=self.is_encoder_decoder,
)
return (
config,
input_ids,
attention_mask,
lm_labels,
)
def create_and_check_decoder_model_past(
self,
config,
input_ids,
attention_mask,
lm_labels,
):
config.use_cache = True
model = PegasusXDecoder(config=config).to(torch_device).eval()
# first forward pass
outputs = model(input_ids, use_cache=True)
outputs_use_cache_conf = model(input_ids)
outputs_no_past = model(input_ids, use_cache=False)
self.parent.assertTrue(len(outputs) == len(outputs_use_cache_conf))
self.parent.assertTrue(len(outputs) == len(outputs_no_past) + 1)
past_key_values = outputs["past_key_values"]
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
output_from_no_past = model(next_input_ids)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-3)
def create_and_check_decoder_model_attention_mask_past(
self,
config,
input_ids,
attention_mask,
lm_labels,
):
model = PegasusXDecoder(config=config).to(torch_device).eval()
# create attention mask
attn_mask = torch.ones(input_ids.shape, dtype=torch.long, device=torch_device)
half_seq_length = input_ids.shape[-1] // 2
attn_mask[:, half_seq_length:] = 0
# first forward pass
past_key_values = model(input_ids, attention_mask=attn_mask, use_cache=True)["past_key_values"]
# create hypothetical next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size)
# change a random masked slice from input_ids
random_seq_idx_to_change = ids_tensor((1,), half_seq_length).item() + 1
random_other_next_tokens = ids_tensor((self.batch_size, 1), config.vocab_size).squeeze(-1)
input_ids[:, -random_seq_idx_to_change] = random_other_next_tokens
# append to next input_ids and attn_mask
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
attn_mask = torch.cat(
[attn_mask, torch.ones((attn_mask.shape[0], 1), dtype=torch.long, device=torch_device)],
dim=1,
)
# get two different outputs
output_from_no_past = model(next_input_ids)["last_hidden_state"]
output_from_past = model(next_tokens, past_key_values=past_key_values)["last_hidden_state"]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, next_input_ids.shape[-1] - 1, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, 0, random_slice_idx].detach()
# test that outputs are equal for slice
assert torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-2)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
attention_mask,
lm_labels,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": attention_mask,
}
return config, inputs_dict
@require_torch
class PegasusXStandaloneDecoderModelTest(ModelTesterMixin, GenerationTesterMixin, unittest.TestCase):
all_model_classes = (PegasusXDecoder,) if is_torch_available() else ()
all_generative_model_classes = ()
test_pruning = False
is_encoder_decoder = False
test_head_masking = False
def setUp(
self,
):
self.model_tester = PegasusXStandaloneDecoderModelTester(self, is_training=False)
self.config_tester = ConfigTester(self, config_class=PegasusXConfig)
def test_config(self):
self.config_tester.run_common_tests()
def test_decoder_model_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past(*config_and_inputs)
def test_decoder_model_attn_mask_past(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_attention_mask_past(*config_and_inputs)
def test_retain_grad_hidden_states_attentions(self):
# decoder cannot keep gradients
return
| transformers/tests/models/pegasus_x/test_modeling_pegasus_x.py/0 | {
"file_path": "transformers/tests/models/pegasus_x/test_modeling_pegasus_x.py",
"repo_id": "transformers",
"token_count": 16624
} | 366 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import tempfile
import unittest
from transformers import SPIECE_UNDERLINE, BatchEncoding, PLBartTokenizer, is_torch_available
from transformers.testing_utils import (
get_tests_dir,
nested_simplify,
require_sentencepiece,
require_tokenizers,
require_torch,
)
from ...test_tokenization_common import TokenizerTesterMixin
SAMPLE_VOCAB = get_tests_dir("fixtures/test_sentencepiece.model")
if is_torch_available():
from transformers.models.plbart.modeling_plbart import shift_tokens_right
EN_CODE = 50003
PYTHON_CODE = 50002
@require_sentencepiece
@require_tokenizers
class PLBartTokenizationTest(TokenizerTesterMixin, unittest.TestCase):
from_pretrained_id = "uclanlp/plbart-base"
tokenizer_class = PLBartTokenizer
rust_tokenizer_class = None
test_rust_tokenizer = False
def setUp(self):
super().setUp()
# We have a SentencePiece fixture for testing
tokenizer = PLBartTokenizer(SAMPLE_VOCAB, language_codes="base", keep_accents=True)
tokenizer.save_pretrained(self.tmpdirname)
def test_full_base_tokenizer(self):
tokenizer = PLBartTokenizer(SAMPLE_VOCAB, language_codes="base", keep_accents=True)
tokens = tokenizer.tokenize("This is a test")
self.assertListEqual(tokens, ["▁This", "▁is", "▁a", "▁t", "est"])
self.assertListEqual(
tokenizer.convert_tokens_to_ids(tokens),
[value + tokenizer.fairseq_offset for value in [285, 46, 10, 170, 382]],
)
tokens = tokenizer.tokenize("I was born in 92000, and this is falsé.")
self.assertListEqual(
tokens,
[
SPIECE_UNDERLINE + "I",
SPIECE_UNDERLINE + "was",
SPIECE_UNDERLINE + "b",
"or",
"n",
SPIECE_UNDERLINE + "in",
SPIECE_UNDERLINE + "",
"9",
"2",
"0",
"0",
"0",
",",
SPIECE_UNDERLINE + "and",
SPIECE_UNDERLINE + "this",
SPIECE_UNDERLINE + "is",
SPIECE_UNDERLINE + "f",
"al",
"s",
"é",
".",
],
)
ids = tokenizer.convert_tokens_to_ids(tokens)
self.assertListEqual(
ids,
[
value + tokenizer.fairseq_offset
for value in [8, 21, 84, 55, 24, 19, 7, 2, 602, 347, 347, 347, 3, 12, 66, 46, 72, 80, 6, 2, 4]
],
)
back_tokens = tokenizer.convert_ids_to_tokens(ids)
self.assertListEqual(
back_tokens,
[
SPIECE_UNDERLINE + "I",
SPIECE_UNDERLINE + "was",
SPIECE_UNDERLINE + "b",
"or",
"n",
SPIECE_UNDERLINE + "in",
SPIECE_UNDERLINE + "",
"<unk>",
"2",
"0",
"0",
"0",
",",
SPIECE_UNDERLINE + "and",
SPIECE_UNDERLINE + "this",
SPIECE_UNDERLINE + "is",
SPIECE_UNDERLINE + "f",
"al",
"s",
"<unk>",
".",
],
)
end = tokenizer.vocab_size
language_tokens = [tokenizer.convert_ids_to_tokens(x) for x in range(end - 4, end)]
self.assertListEqual(language_tokens, ["__java__", "__python__", "__en_XX__", "<mask>"])
code = "java.lang.Exception, python.lang.Exception, javascript, php, ruby, go"
input_ids = tokenizer(code).input_ids
self.assertEqual(
tokenizer.decode(input_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False),
code,
)
def test_full_multi_tokenizer(self):
tokenizer = PLBartTokenizer(SAMPLE_VOCAB, language_codes="multi", keep_accents=True)
tokens = tokenizer.tokenize("This is a test")
self.assertListEqual(tokens, ["▁This", "▁is", "▁a", "▁t", "est"])
self.assertListEqual(
tokenizer.convert_tokens_to_ids(tokens),
[value + tokenizer.fairseq_offset for value in [285, 46, 10, 170, 382]],
)
tokens = tokenizer.tokenize("I was born in 92000, and this is falsé.")
self.assertListEqual(
tokens,
[
SPIECE_UNDERLINE + "I",
SPIECE_UNDERLINE + "was",
SPIECE_UNDERLINE + "b",
"or",
"n",
SPIECE_UNDERLINE + "in",
SPIECE_UNDERLINE + "",
"9",
"2",
"0",
"0",
"0",
",",
SPIECE_UNDERLINE + "and",
SPIECE_UNDERLINE + "this",
SPIECE_UNDERLINE + "is",
SPIECE_UNDERLINE + "f",
"al",
"s",
"é",
".",
],
)
ids = tokenizer.convert_tokens_to_ids(tokens)
self.assertListEqual(
ids,
[
value + tokenizer.fairseq_offset
for value in [8, 21, 84, 55, 24, 19, 7, 2, 602, 347, 347, 347, 3, 12, 66, 46, 72, 80, 6, 2, 4]
],
)
back_tokens = tokenizer.convert_ids_to_tokens(ids)
self.assertListEqual(
back_tokens,
[
SPIECE_UNDERLINE + "I",
SPIECE_UNDERLINE + "was",
SPIECE_UNDERLINE + "b",
"or",
"n",
SPIECE_UNDERLINE + "in",
SPIECE_UNDERLINE + "",
"<unk>",
"2",
"0",
"0",
"0",
",",
SPIECE_UNDERLINE + "and",
SPIECE_UNDERLINE + "this",
SPIECE_UNDERLINE + "is",
SPIECE_UNDERLINE + "f",
"al",
"s",
"<unk>",
".",
],
)
end = tokenizer.vocab_size
language_tokens = [tokenizer.convert_ids_to_tokens(x) for x in range(end - 7, end)]
self.assertListEqual(
language_tokens, ["__java__", "__python__", "__en_XX__", "__javascript__", "__php__", "__ruby__", "__go__"]
)
code = "java.lang.Exception, python.lang.Exception, javascript, php, ruby, go"
input_ids = tokenizer(code).input_ids
self.assertEqual(
tokenizer.decode(input_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False),
code,
)
@require_torch
@require_sentencepiece
@require_tokenizers
class PLBartPythonEnIntegrationTest(unittest.TestCase):
checkpoint_name = "uclanlp/plbart-python-en_XX"
src_text = [
"def maximum(a,b,c):NEW_LINE_INDENTreturn max([a,b,c])",
"def sum(a,b,c):NEW_LINE_INDENTreturn sum([a,b,c])",
]
tgt_text = [
"Returns the maximum value of a b c.",
"Sums the values of a b c.",
]
expected_src_tokens = [
134,
5452,
33460,
33441,
33463,
33465,
33463,
33449,
988,
20,
33456,
19,
33456,
771,
39,
4258,
889,
3318,
33441,
33463,
33465,
33463,
33449,
2471,
2,
PYTHON_CODE,
]
@classmethod
def setUpClass(cls):
cls.tokenizer: PLBartTokenizer = PLBartTokenizer.from_pretrained(
cls.checkpoint_name, language_codes="base", src_lang="python", tgt_lang="en_XX"
)
cls.pad_token_id = 1
return cls
def check_language_codes(self):
self.assertEqual(self.tokenizer.fairseq_tokens_to_ids["__java__"], 50001)
self.assertEqual(self.tokenizer.fairseq_tokens_to_ids["__python__"], 50002)
self.assertEqual(self.tokenizer.fairseq_tokens_to_ids["__en_XX__"], 50003)
def test_python_en_tokenizer_batch_encode_plus(self):
ids = self.tokenizer.batch_encode_plus(self.src_text).input_ids[0]
self.assertListEqual(self.expected_src_tokens, ids)
def test_python_en_tokenizer_decode_ignores_language_codes(self):
self.assertIn(PYTHON_CODE, self.tokenizer.all_special_ids)
generated_ids = [EN_CODE, 9037, 33442, 57, 752, 153, 14, 56, 18, 9, 2]
result = self.tokenizer.decode(generated_ids, skip_special_tokens=True)
expected_english = self.tokenizer.decode(generated_ids[1:], skip_special_tokens=True)
self.assertEqual(result, expected_english)
self.assertNotIn(self.tokenizer.eos_token, result)
def test_python_en_tokenizer_truncation(self):
src_text = ["def sum(a,b,c):NEW_LINE_INDENTreturn sum([a,b,c])" * 20]
self.assertIsInstance(src_text[0], str)
desired_max_length = 10
ids = self.tokenizer(src_text, max_length=desired_max_length, truncation=True).input_ids[0]
self.assertEqual(ids[-2], 2)
self.assertEqual(ids[-1], PYTHON_CODE)
self.assertEqual(len(ids), desired_max_length)
def test_mask_token(self):
self.assertListEqual(self.tokenizer.convert_tokens_to_ids(["<mask>", "__java__"]), [50004, 50001])
def test_special_tokens_unaffacted_by_save_load(self):
tmpdirname = tempfile.mkdtemp()
original_special_tokens = self.tokenizer.fairseq_tokens_to_ids
self.tokenizer.save_pretrained(tmpdirname)
new_tok = PLBartTokenizer.from_pretrained(tmpdirname)
self.assertDictEqual(new_tok.fairseq_tokens_to_ids, original_special_tokens)
@require_torch
def test_batch_fairseq_parity(self):
batch = self.tokenizer(self.src_text, text_target=self.tgt_text, padding=True, return_tensors="pt")
batch["decoder_input_ids"] = shift_tokens_right(batch["labels"], self.tokenizer.pad_token_id)
# fairseq batch: https://gist.github.com/sshleifer/cba08bc2109361a74ac3760a7e30e4f4
self.assertEqual(batch.input_ids[1][-2:].tolist(), [2, PYTHON_CODE])
self.assertEqual(batch.decoder_input_ids[1][0], EN_CODE)
self.assertEqual(batch.decoder_input_ids[1][-1], 2)
self.assertEqual(batch.labels[1][-2:].tolist(), [2, EN_CODE])
@require_torch
def test_python_en_tokenizer_prepare_batch(self):
batch = self.tokenizer(
self.src_text,
text_target=self.tgt_text,
padding=True,
truncation=True,
max_length=len(self.expected_src_tokens),
return_tensors="pt",
)
batch["decoder_input_ids"] = shift_tokens_right(batch["labels"], self.tokenizer.pad_token_id)
self.assertIsInstance(batch, BatchEncoding)
self.assertEqual((2, 26), batch.input_ids.shape)
self.assertEqual((2, 26), batch.attention_mask.shape)
result = batch.input_ids.tolist()[0]
self.assertListEqual(self.expected_src_tokens, result)
self.assertEqual(2, batch.decoder_input_ids[0, -1]) # EOS
# Test that special tokens are reset
self.assertEqual(self.tokenizer.prefix_tokens, [])
self.assertEqual(self.tokenizer.suffix_tokens, [self.tokenizer.eos_token_id, PYTHON_CODE])
def test_seq2seq_max_length(self):
batch = self.tokenizer(self.src_text, padding=True, truncation=True, max_length=3, return_tensors="pt")
targets = self.tokenizer(
text_target=self.tgt_text, padding=True, truncation=True, max_length=10, return_tensors="pt"
)
labels = targets["input_ids"]
batch["decoder_input_ids"] = shift_tokens_right(labels, self.tokenizer.pad_token_id)
self.assertEqual(batch.input_ids.shape[1], 3)
self.assertEqual(batch.decoder_input_ids.shape[1], 10)
@require_torch
def test_tokenizer_translation(self):
inputs = self.tokenizer._build_translation_inputs(
"A test", return_tensors="pt", src_lang="en_XX", tgt_lang="java"
)
self.assertEqual(
nested_simplify(inputs),
{
# A, test, EOS, en_XX
"input_ids": [[150, 242, 2, 50003]],
"attention_mask": [[1, 1, 1, 1]],
# java
"forced_bos_token_id": 50001,
},
)
| transformers/tests/models/plbart/test_tokenization_plbart.py/0 | {
"file_path": "transformers/tests/models/plbart/test_tokenization_plbart.py",
"repo_id": "transformers",
"token_count": 6897
} | 367 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Testing suite for the PyTorch PvtV2 model."""
import inspect
import tempfile
import unittest
from transformers import PvtV2Backbone, PvtV2Config, is_torch_available, is_vision_available
from transformers.testing_utils import (
require_accelerate,
require_torch,
require_torch_accelerator,
require_torch_fp16,
slow,
torch_device,
)
from ...test_backbone_common import BackboneTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import AutoImageProcessor, PvtV2ForImageClassification, PvtV2Model
from transformers.models.auto.modeling_auto import MODEL_MAPPING_NAMES
from transformers.models.pvt_v2.modeling_pvt_v2 import PVT_V2_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
class PvtV2ConfigTester(ConfigTester):
def run_common_tests(self):
config = self.config_class(**self.inputs_dict)
self.parent.assertTrue(hasattr(config, "hidden_sizes"))
self.parent.assertTrue(hasattr(config, "num_encoder_blocks"))
class PvtV2ModelTester(ModelTesterMixin):
def __init__(
self,
parent,
batch_size=13,
image_size=None,
num_channels=3,
num_encoder_blocks=4,
depths=[2, 2, 2, 2],
sr_ratios=[8, 4, 2, 1],
hidden_sizes=[16, 32, 64, 128],
downsampling_rates=[1, 4, 8, 16],
num_attention_heads=[1, 2, 4, 8],
out_indices=[0, 1, 2, 3],
is_training=True,
use_labels=True,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
initializer_range=0.02,
num_labels=3,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.image_size = 64 if image_size is None else image_size
self.num_channels = num_channels
self.num_encoder_blocks = num_encoder_blocks
self.sr_ratios = sr_ratios
self.depths = depths
self.hidden_sizes = hidden_sizes
self.downsampling_rates = downsampling_rates
self.num_attention_heads = num_attention_heads
self.is_training = is_training
self.use_labels = use_labels
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.initializer_range = initializer_range
self.out_indices = out_indices
self.num_labels = num_labels
self.scope = scope
def prepare_config_and_inputs(self):
pixel_values = floats_tensor([self.batch_size, self.num_channels, self.image_size, self.image_size])
labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size, self.image_size, self.image_size], self.num_labels)
config = self.get_config()
return config, pixel_values, labels
def get_config(self):
return PvtV2Config(
image_size=self.image_size,
num_channels=self.num_channels,
num_encoder_blocks=self.num_encoder_blocks,
depths=self.depths,
sr_ratios=self.sr_ratios,
hidden_sizes=self.hidden_sizes,
num_attention_heads=self.num_attention_heads,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
initializer_range=self.initializer_range,
out_indices=self.out_indices,
)
def create_and_check_model(self, config, pixel_values, labels):
model = PvtV2Model(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
self.parent.assertIsNotNone(result.last_hidden_state)
def create_and_check_backbone(self, config, pixel_values, labels):
model = PvtV2Backbone(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
# verify feature maps
self.parent.assertEqual(len(result.feature_maps), len(config.out_features))
self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, self.hidden_sizes[1], 4, 4])
# verify channels
self.parent.assertEqual(len(model.channels), len(config.out_features))
self.parent.assertListEqual(model.channels, config.hidden_sizes[1:])
# verify backbone works with out_features=None
config.out_features = None
model = PvtV2Backbone(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
# verify feature maps
self.parent.assertEqual(len(result.feature_maps), 1)
self.parent.assertListEqual(list(result.feature_maps[0].shape), [self.batch_size, self.hidden_sizes[-1], 1, 1])
# verify channels
self.parent.assertEqual(len(model.channels), 1)
self.parent.assertListEqual(model.channels, [config.hidden_sizes[-1]])
def create_and_check_for_image_classification(self, config, pixel_values, labels):
config.num_labels = self.num_labels
model = PvtV2ForImageClassification(config)
model.to(torch_device)
model.eval()
result = model(pixel_values, labels=labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
# test greyscale images
config.num_channels = 1
model = PvtV2ForImageClassification(config)
model.to(torch_device)
model.eval()
pixel_values = floats_tensor([self.batch_size, 1, self.image_size, self.image_size])
result = model(pixel_values)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.type_sequence_label_size))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, pixel_values, labels = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
# We will verify our results on an image of cute cats
def prepare_img():
image = Image.open("./tests/fixtures/tests_samples/COCO/000000039769.png")
return image
@require_torch
class PvtV2ModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (PvtV2Model, PvtV2ForImageClassification) if is_torch_available() else ()
pipeline_model_mapping = (
{"feature-extraction": PvtV2Model, "image-classification": PvtV2ForImageClassification}
if is_torch_available()
else {}
)
test_head_masking = False
test_pruning = False
test_resize_embeddings = False
test_torchscript = False
has_attentions = False
def setUp(self):
self.model_tester = PvtV2ModelTester(self)
self.config_tester = PvtV2ConfigTester(self, config_class=PvtV2Config)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skip("Pvt-V2 does not use inputs_embeds")
def test_inputs_embeds(self):
pass
@unittest.skip("Pvt-V2 does not have get_input_embeddings method and get_output_embeddings methods")
def test_model_common_attributes(self):
pass
@unittest.skip(reason="This architecture does not work with using reentrant.")
def test_training_gradient_checkpointing(self):
# Scenario - 1 default behaviour
self.check_training_gradient_checkpointing()
@unittest.skip(reason="This architecture does not work with using reentrant.")
def test_training_gradient_checkpointing_use_reentrant(self):
# Scenario - 2 with `use_reentrant=True` - this is the default value that is used in pytorch's
# torch.utils.checkpoint.checkpoint
self.check_training_gradient_checkpointing(gradient_checkpointing_kwargs={"use_reentrant": True})
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config=config)
for name, param in model.named_parameters():
self.assertTrue(
-1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
msg=f"Parameter {name} of model {model_class} seems not properly initialized",
)
def test_hidden_states_output(self):
def check_hidden_states_output(inputs_dict, config, model_class):
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
hidden_states = outputs.hidden_states
expected_num_layers = len(self.model_tester.depths)
self.assertEqual(len(hidden_states), expected_num_layers)
# verify the first hidden states (first block)
self.assertListEqual(
list(hidden_states[0].shape[-3:]),
[
self.model_tester.hidden_sizes[self.model_tester.out_indices[0]],
self.model_tester.image_size // 2 ** (2 + self.model_tester.out_indices[0]),
self.model_tester.image_size // 2 ** (2 + self.model_tester.out_indices[0]),
],
)
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
inputs_dict["output_hidden_states"] = True
check_hidden_states_output(inputs_dict, config, model_class)
# check that output_hidden_states also work using config
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
check_hidden_states_output(inputs_dict, config, model_class)
def test_training(self):
if not self.model_tester.is_training:
return
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
for model_class in self.all_model_classes:
if model_class.__name__ in MODEL_MAPPING_NAMES.values():
continue
model = model_class(config)
model.to(torch_device)
model.train()
inputs = self._prepare_for_class(inputs_dict, model_class, return_labels=True)
loss = model(**inputs).loss
loss.backward()
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
signature = inspect.signature(model.forward)
# signature.parameters is an OrderedDict => so arg_names order is deterministic
arg_names = [*signature.parameters.keys()]
expected_arg_names = ["pixel_values"]
self.assertListEqual(arg_names[:1], expected_arg_names)
@slow
def test_model_from_pretrained(self):
for model_name in PVT_V2_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = PvtV2Model.from_pretrained(model_name)
self.assertIsNotNone(model)
@require_torch
class PvtV2ModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_image_classification(self):
# only resize + normalize
image_processor = AutoImageProcessor.from_pretrained("OpenGVLab/pvt_v2_b0")
model = PvtV2ForImageClassification.from_pretrained("OpenGVLab/pvt_v2_b0").to(torch_device).eval()
image = prepare_img()
encoded_inputs = image_processor(images=image, return_tensors="pt")
pixel_values = encoded_inputs.pixel_values.to(torch_device)
with torch.no_grad():
outputs = model(pixel_values)
expected_shape = torch.Size((1, model.config.num_labels))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = torch.tensor([-1.4192, -1.9158, -0.9702]).to(torch_device)
self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
@slow
def test_inference_model(self):
model = PvtV2Model.from_pretrained("OpenGVLab/pvt_v2_b0").to(torch_device).eval()
image_processor = AutoImageProcessor.from_pretrained("OpenGVLab/pvt_v2_b0")
image = prepare_img()
inputs = image_processor(images=image, return_tensors="pt")
pixel_values = inputs.pixel_values.to(torch_device)
# forward pass
with torch.no_grad():
outputs = model(pixel_values)
# verify the logits
expected_shape = torch.Size((1, 50, 512))
self.assertEqual(outputs.last_hidden_state.shape, expected_shape)
expected_slice = torch.tensor(
[[-0.3086, 1.0402, 1.1816], [-0.2880, 0.5781, 0.6124], [0.1480, 0.6129, -0.0590]]
).to(torch_device)
self.assertTrue(torch.allclose(outputs.last_hidden_state[0, :3, :3], expected_slice, atol=1e-4))
@slow
@require_accelerate
@require_torch_accelerator
@require_torch_fp16
def test_inference_fp16(self):
r"""
A small test to make sure that inference work in half precision without any problem.
"""
model = PvtV2ForImageClassification.from_pretrained("OpenGVLab/pvt_v2_b0", torch_dtype=torch.float16)
model.to(torch_device)
image_processor = AutoImageProcessor.from_pretrained("OpenGVLab/pvt_v2_b0")
image = prepare_img()
inputs = image_processor(images=image, return_tensors="pt")
pixel_values = inputs.pixel_values.to(torch_device, dtype=torch.float16)
# forward pass to make sure inference works in fp16
with torch.no_grad():
_ = model(pixel_values)
@require_torch
class PvtV2BackboneTest(BackboneTesterMixin, unittest.TestCase):
all_model_classes = (PvtV2Backbone,) if is_torch_available() else ()
has_attentions = False
config_class = PvtV2Config
def test_config(self):
config_class = self.config_class
# test default config
config = config_class()
self.assertIsNotNone(config)
num_stages = len(config.depths) if hasattr(config, "depths") else config.num_hidden_layers
expected_stage_names = [f"stage{idx}" for idx in range(1, num_stages + 1)]
self.assertEqual(config.stage_names, expected_stage_names)
self.assertTrue(set(config.out_features).issubset(set(config.stage_names)))
# Test out_features and out_indices are correctly set
# out_features and out_indices both None
config = config_class(out_features=None, out_indices=None)
self.assertEqual(config.out_features, [config.stage_names[-1]])
self.assertEqual(config.out_indices, [len(config.stage_names) - 1])
# out_features and out_indices both set
config = config_class(out_features=["stage1", "stage2"], out_indices=[0, 1])
self.assertEqual(config.out_features, ["stage1", "stage2"])
self.assertEqual(config.out_indices, [0, 1])
# Only out_features set
config = config_class(out_features=["stage2", "stage4"])
self.assertEqual(config.out_features, ["stage2", "stage4"])
self.assertEqual(config.out_indices, [1, 3])
# Only out_indices set
config = config_class(out_indices=[0, 2])
self.assertEqual(config.out_features, [config.stage_names[0], config.stage_names[2]])
self.assertEqual(config.out_indices, [0, 2])
# Error raised when out_indices do not correspond to out_features
with self.assertRaises(ValueError):
config = config_class(out_features=["stage1", "stage2"], out_indices=[0, 2])
def test_config_save_pretrained(self):
config_class = self.config_class
config_first = config_class(out_indices=[0, 1, 2, 3])
with tempfile.TemporaryDirectory() as tmpdirname:
config_first.save_pretrained(tmpdirname)
config_second = self.config_class.from_pretrained(tmpdirname)
# Fix issue where type switches in the saving process
if isinstance(config_second.image_size, list):
config_second.image_size = tuple(config_second.image_size)
self.assertEqual(config_second.to_dict(), config_first.to_dict())
def setUp(self):
self.model_tester = PvtV2ModelTester(self)
| transformers/tests/models/pvt_v2/test_modeling_pvt_v2.py/0 | {
"file_path": "transformers/tests/models/pvt_v2/test_modeling_pvt_v2.py",
"repo_id": "transformers",
"token_count": 7479
} | 368 |
# coding=utf-8 # Copyright 2020 Huggingface
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from transformers import ReformerConfig, is_torch_available
from transformers.testing_utils import (
require_sentencepiece,
require_tokenizers,
require_torch,
require_torch_fp16,
require_torch_multi_gpu,
slow,
torch_device,
)
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from torch import nn
from transformers import (
REFORMER_PRETRAINED_MODEL_ARCHIVE_LIST,
ReformerForMaskedLM,
ReformerForQuestionAnswering,
ReformerForSequenceClassification,
ReformerLayer,
ReformerModel,
ReformerModelWithLMHead,
ReformerTokenizer,
)
class ReformerModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=32,
is_training=True,
is_decoder=True,
use_input_mask=True,
use_labels=True,
vocab_size=32,
attention_head_size=16,
hidden_size=32,
num_attention_heads=2,
local_attn_chunk_length=4,
local_num_chunks_before=1,
local_num_chunks_after=0,
num_buckets=None,
num_hashes=1,
lsh_attn_chunk_length=None,
lsh_num_chunks_before=None,
lsh_num_chunks_after=None,
chunk_size_lm_head=0,
chunk_size_feed_forward=0,
feed_forward_size=32,
hidden_act="gelu",
hidden_dropout_prob=0.1,
local_attention_probs_dropout_prob=0.1,
lsh_attention_probs_dropout_prob=None,
max_position_embeddings=512,
initializer_range=0.02,
axial_norm_std=1.0,
layer_norm_eps=1e-12,
axial_pos_embds=True,
axial_pos_shape=[4, 8],
axial_pos_embds_dim=[16, 16],
attn_layers=["local", "local", "local", "local"],
pad_token_id=0,
eos_token_id=2,
scope=None,
hash_seed=0,
num_labels=2,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.is_decoder = is_decoder
self.use_input_mask = use_input_mask
self.use_labels = use_labels
self.vocab_size = vocab_size
self.attention_head_size = attention_head_size
self.hidden_size = hidden_size
self.num_attention_heads = num_attention_heads
self.num_hidden_layers = len(attn_layers) if attn_layers is not None else 0
self.local_attn_chunk_length = local_attn_chunk_length
self.local_num_chunks_after = local_num_chunks_after
self.local_num_chunks_before = local_num_chunks_before
self.num_hashes = num_hashes
self.num_buckets = tuple(num_buckets) if isinstance(num_buckets, list) else num_buckets
self.lsh_attn_chunk_length = lsh_attn_chunk_length
self.lsh_num_chunks_after = lsh_num_chunks_after
self.lsh_num_chunks_before = lsh_num_chunks_before
self.hidden_act = hidden_act
self.feed_forward_size = feed_forward_size
self.hidden_dropout_prob = hidden_dropout_prob
self.local_attention_probs_dropout_prob = local_attention_probs_dropout_prob
self.lsh_attention_probs_dropout_prob = lsh_attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.initializer_range = initializer_range
self.layer_norm_eps = layer_norm_eps
self.axial_pos_embds = axial_pos_embds
self.axial_pos_shape = tuple(axial_pos_shape)
self.axial_pos_embds_dim = tuple(axial_pos_embds_dim)
self.axial_norm_std = axial_norm_std
self.chunk_size_lm_head = chunk_size_lm_head
self.chunk_size_feed_forward = chunk_size_feed_forward
self.scope = scope
self.attn_layers = attn_layers
self.pad_token_id = pad_token_id
self.hash_seed = hash_seed
attn_chunk_length = local_attn_chunk_length if local_attn_chunk_length is not None else lsh_attn_chunk_length
num_chunks_after = local_num_chunks_after if local_num_chunks_after is not None else lsh_num_chunks_after
num_chunks_before = local_num_chunks_before if local_num_chunks_before is not None else lsh_num_chunks_before
self.encoder_seq_length = seq_length // attn_chunk_length + (self.seq_length % attn_chunk_length != 0)
self.key_length = (num_chunks_before + num_chunks_after + 1) * attn_chunk_length
self.chunk_length = attn_chunk_length
self.num_labels = num_labels
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
choice_labels = None
if self.use_labels:
choice_labels = ids_tensor([self.batch_size], 2)
config = self.get_config()
return (
config,
input_ids,
input_mask,
choice_labels,
)
def get_config(self):
return ReformerConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
feed_forward_size=self.feed_forward_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
local_attention_probs_dropout_prob=self.local_attention_probs_dropout_prob,
lsh_attention_probs_dropout_prob=self.lsh_attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
is_decoder=self.is_decoder,
axial_pos_embds=self.axial_pos_embds,
axial_pos_shape=self.axial_pos_shape,
axial_pos_embds_dim=self.axial_pos_embds_dim,
local_attn_chunk_length=self.local_attn_chunk_length,
local_num_chunks_after=self.local_num_chunks_after,
local_num_chunks_before=self.local_num_chunks_before,
num_hashes=self.num_hashes,
num_buckets=self.num_buckets,
lsh_attn_chunk_length=self.lsh_attn_chunk_length,
lsh_num_chunks_after=self.lsh_num_chunks_after,
lsh_num_chunks_before=self.lsh_num_chunks_before,
attn_layers=self.attn_layers,
pad_token_id=self.pad_token_id,
hash_seed=self.hash_seed,
)
def get_pipeline_config(self):
config = self.get_config()
config.vocab_size = 100
config.max_position_embeddings = 100
config.axial_pos_shape = (4, 25)
config.is_decoder = False
return config
def create_and_check_reformer_model(self, config, input_ids, input_mask, choice_labels):
model = ReformerModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask)
result = model(input_ids)
# 2 * hidden_size because we use reversible resnet layers
self.parent.assertEqual(
result.last_hidden_state.shape, (self.batch_size, self.seq_length, 2 * self.hidden_size)
)
def create_and_check_reformer_model_with_lm_backward(self, config, input_ids, input_mask, choice_labels):
if not self.is_training:
return
config.is_decoder = False
config.lsh_num_chunks_after = 1
model = ReformerForMaskedLM(config=config)
model.to(torch_device)
model.train()
loss = model(input_ids, attention_mask=input_mask, labels=input_ids)["loss"]
loss.backward()
def create_and_check_reformer_with_lm(self, config, input_ids, input_mask, choice_labels):
config.lsh_num_chunks_after = 0
config.is_decoder = True
model = ReformerModelWithLMHead(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, labels=input_ids)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_reformer_with_mlm(self, config, input_ids, input_mask, choice_labels):
config.is_decoder = False
model = ReformerForMaskedLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, labels=input_ids)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_reformer_model_with_attn_mask(
self, config, input_ids, input_mask, choice_labels, is_decoder=False
):
# no special position embeddings
config.axial_pos_embds = False
config.is_decoder = is_decoder
if self.lsh_attn_chunk_length is not None:
# need to set chunk length equal sequence length to be certain that chunking works
config.lsh_attn_chunk_length = self.seq_length
model = ReformerModel(config=config)
model.to(torch_device)
model.eval()
# set all position encodings to zero so that postions don't matter
with torch.no_grad():
embedding = model.embeddings.position_embeddings.embedding
embedding.weight = nn.Parameter(torch.zeros(embedding.weight.shape).to(torch_device))
embedding.weight.requires_grad = False
half_seq_len = self.seq_length // 2
roll = self.chunk_length
half_input_ids = input_ids[:, :half_seq_len]
# normal padded
attn_mask = torch.cat(
[torch.ones_like(half_input_ids), torch.zeros_like(half_input_ids)],
dim=-1,
)
input_ids_padded = torch.cat(
[half_input_ids, ids_tensor((self.batch_size, half_seq_len), self.vocab_size)],
dim=-1,
)
# shifted padded
input_ids_roll = torch.cat(
[half_input_ids, ids_tensor((self.batch_size, half_seq_len), self.vocab_size)],
dim=-1,
)
input_ids_roll = torch.roll(input_ids_roll, roll, dims=-1)
attn_mask_roll = torch.roll(attn_mask, roll, dims=-1)
output_padded = model(input_ids_padded, attention_mask=attn_mask)[0][:, :half_seq_len]
output_padded_rolled = model(input_ids_roll, attention_mask=attn_mask_roll)[0][:, roll : half_seq_len + roll]
self.parent.assertTrue(torch.allclose(output_padded, output_padded_rolled, atol=1e-3))
def create_and_check_reformer_layer_dropout_seed(
self, config, input_ids, input_mask, choice_labels, is_decoder=False
):
config.is_decoder = is_decoder
layer = ReformerLayer(config).to(torch_device)
layer.train()
shape = (
self.batch_size,
self.seq_length,
config.hidden_size,
) # Batch x SeqLen x hiddenSize
# get random tensors
hidden_states = floats_tensor(shape)
prev_attn_output = floats_tensor(shape)
# now the random seeds for attention and feed forward is initialized
# forward tensors with dropout
layer_outputs = layer(prev_attn_output, hidden_states, attention_mask=input_mask)
next_attn_output = layer_outputs.attn_output
next_hidden_states = layer_outputs.hidden_states
torch.manual_seed(layer.attention_seed)
attn_outputs = layer.attention(hidden_states, attention_mask=input_mask)
self.parent.assertTrue(
torch.allclose(
prev_attn_output + attn_outputs.hidden_states,
next_attn_output,
atol=1e-3,
)
)
torch.manual_seed(layer.feed_forward_seed)
feed_forward_hidden_states = layer.feed_forward(next_attn_output)
self.parent.assertTrue(
torch.allclose(
next_hidden_states,
hidden_states + feed_forward_hidden_states,
atol=1e-3,
)
)
def create_and_check_reformer_feed_backward_chunking(self, config, input_ids, input_mask, choice_labels):
if not self.is_training:
return
# disable dropout
config.hidden_dropout_prob = 0
config.local_attention_probs_dropout_prob = 0
config.lsh_attention_probs_dropout_prob = 0
config.lsh_num_chunks_after = 1
config.is_decoder = False
torch.manual_seed(0)
model = ReformerForMaskedLM(config=config)
model.to(torch_device)
model.train()
model.zero_grad()
loss_no_chunk, output_no_chunk = model(input_ids, labels=input_ids, attention_mask=input_mask)[:2]
loss_no_chunk.backward()
grad_slice_word_no_chunk = model.reformer.embeddings.word_embeddings.weight.grad[0, :5]
grad_slice_position_factor_1_no_chunk = model.reformer.embeddings.position_embeddings.weights[0][1, 0, -5:]
grad_slice_position_factor_2_no_chunk = model.reformer.embeddings.position_embeddings.weights[1][0, 1, :5]
config.chunk_size_lm_head = 1
config.chunk_size_feed_forward = 1
torch.manual_seed(0)
model = ReformerForMaskedLM(config=config)
model.to(torch_device)
model.train()
model.zero_grad()
loss_chunk, output_chunk = model(input_ids, labels=input_ids, attention_mask=input_mask)[:2]
loss_chunk.backward()
grad_slice_word_chunk = model.reformer.embeddings.word_embeddings.weight.grad[0, :5]
grad_slice_position_factor_1_chunk = model.reformer.embeddings.position_embeddings.weights[0][1, 0, -5:]
grad_slice_position_factor_2_chunk = model.reformer.embeddings.position_embeddings.weights[1][0, 1, :5]
self.parent.assertTrue(torch.allclose(loss_chunk, loss_no_chunk, atol=1e-3))
self.parent.assertTrue(torch.allclose(grad_slice_word_no_chunk, grad_slice_word_chunk, atol=1e-3))
self.parent.assertTrue(
torch.allclose(grad_slice_position_factor_1_chunk, grad_slice_position_factor_1_no_chunk, atol=1e-3)
)
self.parent.assertTrue(
torch.allclose(grad_slice_position_factor_2_chunk, grad_slice_position_factor_2_no_chunk, atol=1e-3)
)
def create_and_check_reformer_random_seed(self, config, input_ids, input_mask, choice_labels):
layer = ReformerLayer(config).to(torch_device)
layer.train()
shape = (
self.batch_size,
self.seq_length,
config.hidden_size,
) # Batch x SeqLen x hiddenSize
hidden_states = floats_tensor(shape)
attn_output = floats_tensor(shape)
seeds = []
for _ in range(100):
layer_outputs = layer(attn_output, hidden_states, attention_mask=input_mask)
attn_output = layer_outputs.attn_output
hidden_states = layer_outputs.hidden_states
torch.manual_seed(layer.attention_seed)
seeds.append(layer.attention_seed)
self.parent.assertGreater(len(set(seeds)), 70)
seeds = []
for _ in range(100):
layer_outputs = layer(attn_output, hidden_states, attention_mask=input_mask)
attn_output = layer_outputs.attn_output
hidden_states = layer_outputs.hidden_states
torch.manual_seed(layer.feed_forward_seed)
seeds.append(layer.feed_forward_seed)
self.parent.assertGreater(len(set(seeds)), 70)
def create_and_check_reformer_model_fp16_forward(self, config, input_ids, input_mask, choice_labels):
model = ReformerModel(config=config)
model.to(torch_device)
model.half()
model.eval()
output = model(input_ids, attention_mask=input_mask)["last_hidden_state"]
self.parent.assertFalse(torch.isnan(output).any().item())
def create_and_check_reformer_model_generate(self, config, input_ids, input_mask, choice_labels):
config.is_decoder = True
config.lsh_num_chunks_after = 0
config.bos_token_id = 0
config.eos_token_id = None
config.max_length = 20
model = ReformerModelWithLMHead(config=config)
model.to(torch_device)
model.eval()
output = model.generate()
self.parent.assertIsNotNone(output)
def create_and_check_reformer_model_fp16_generate(self, config, input_ids, input_mask, choice_labels):
config.is_decoder = True
config.lsh_num_chunks_after = 0
model = ReformerModelWithLMHead(config=config)
model.to(torch_device)
model.half()
model.eval()
# only use last 10 inputs for generation
output = model.generate(input_ids[:, -10:], attention_mask=input_mask, do_sample=False)
self.parent.assertFalse(torch.isnan(output).any().item())
def create_and_check_reformer_no_chunking(self, config, input_ids, input_mask, choice_labels):
# force chunk length to be bigger than input_ids
config.lsh_attn_chunk_length = 2 * input_ids.shape[-1]
config.local_attn_chunk_length = 2 * input_ids.shape[-1]
config.lsh_num_chunks_after = 1
config.is_decoder = False
model = ReformerForMaskedLM(config=config)
model.to(torch_device)
model.eval()
output_logits = model(input_ids, attention_mask=input_mask)["logits"]
self.parent.assertTrue(output_logits.shape[1] == input_ids.shape[-1])
def create_and_check_reformer_for_question_answering(self, config, input_ids, input_mask, choice_labels):
model = ReformerForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
start_positions=choice_labels,
end_positions=choice_labels,
)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_past_buckets_states(self, config, input_ids, input_mask, choice_labels):
config.is_decoder = True
config.lsh_num_chunks_before = 1
config.lsh_num_chunks_after = 0
model = ReformerModelWithLMHead(config=config)
model.to(torch_device)
model.eval()
input_ids_first = input_ids[:, :-1]
input_ids_second = input_ids[:, -1:]
# return saved cache
past_buckets_states = model(input_ids_first, use_cache=True)["past_buckets_states"]
# calculate last output with and without cache
outputs_with_cache = model(input_ids_second, past_buckets_states=past_buckets_states, use_cache=True)["logits"]
outputs_without_cache = model(input_ids)["logits"][:, -1]
# select random slice idx
random_slice_idx = torch.randint(outputs_without_cache.shape[-1], (1, 1), device=torch_device).item()
# outputs should be similar within range
self.parent.assertTrue(
torch.allclose(
outputs_with_cache[:, 0, random_slice_idx], outputs_without_cache[:, random_slice_idx], atol=1e-2
)
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(config, input_ids, input_mask, choice_labels) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "attention_mask": input_mask}
return config, inputs_dict
def create_and_check_reformer_for_sequence_classification(
self, config, input_ids, input_mask, choice_labels, is_decoder
):
config.is_decoder = is_decoder
sequence_labels = ids_tensor([self.batch_size], config.num_labels)
model = ReformerForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, labels=sequence_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
class ReformerTesterMixin:
"""
Reformer Local and Reformer LSH run essentially the same tests
"""
def test_config(self):
self.config_tester.run_common_tests()
def test_reformer_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_model(*config_and_inputs)
def test_reformer_lm_model_backward(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_model_with_lm_backward(*config_and_inputs)
def test_reformer_model_attn_masking(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_model_with_attn_mask(*config_and_inputs, is_decoder=True)
self.model_tester.create_and_check_reformer_model_with_attn_mask(*config_and_inputs, is_decoder=False)
def test_reformer_with_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_with_lm(*config_and_inputs)
def test_reformer_with_mlm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_with_mlm(*config_and_inputs)
def test_reformer_layer_training_dropout(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_layer_dropout_seed(*config_and_inputs, is_decoder=True)
self.model_tester.create_and_check_reformer_layer_dropout_seed(*config_and_inputs, is_decoder=False)
def test_reformer_chunking_backward_equality(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_feed_backward_chunking(*config_and_inputs)
def test_reformer_no_chunking(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_no_chunking(*config_and_inputs)
def test_reformer_qa_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_for_question_answering(*config_and_inputs)
def test_reformer_cached_inference(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_past_buckets_states(*config_and_inputs)
def test_reformer_cached_generate(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_model_generate(*config_and_inputs)
@slow
def test_dropout_random_seed_is_changing(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_random_seed(*config_and_inputs)
@require_torch_fp16
def test_reformer_model_fp16_forward(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_model_fp16_forward(*config_and_inputs)
@require_torch_fp16
def test_reformer_model_fp16_generate(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_model_fp16_generate(*config_and_inputs)
@require_torch_multi_gpu
@unittest.skip(
reason=(
"Reformer does not work with data parallel (DP) because of a bug in PyTorch:"
" https://github.com/pytorch/pytorch/issues/36035"
)
)
def test_multi_gpu_data_parallel_forward(self):
pass
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_reformer_for_sequence_classification(*config_and_inputs, is_decoder=False)
def test_retain_grad_hidden_states_attentions(self):
# reformer cannot keep gradients in attentions or hidden states
return
def test_resize_embeddings_untied(self):
# reformer cannot resize embeddings that easily
return
@require_torch
class ReformerLocalAttnModelTest(ReformerTesterMixin, GenerationTesterMixin, ModelTesterMixin, unittest.TestCase):
all_model_classes = (
(ReformerModel, ReformerModelWithLMHead, ReformerForSequenceClassification, ReformerForQuestionAnswering)
if is_torch_available()
else ()
)
all_generative_model_classes = (ReformerModelWithLMHead,) if is_torch_available() else ()
test_pruning = False
test_headmasking = False
test_torchscript = False
test_sequence_classification_problem_types = True
def setUp(self):
self.model_tester = ReformerModelTester(self)
self.config_tester = ConfigTester(self, config_class=ReformerConfig, hidden_size=37)
@slow
def test_model_from_pretrained(self):
for model_name in REFORMER_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = ReformerModelWithLMHead.from_pretrained(model_name)
self.assertIsNotNone(model)
def _check_attentions_for_generate(
self, batch_size, attentions, min_length, max_length, config, use_cache=False, num_beam_groups=1
):
self.assertIsInstance(attentions, tuple)
self.assertListEqual(
[isinstance(iter_attentions, list) for iter_attentions in attentions], [True] * len(attentions)
)
self.assertEqual(len(attentions), (max_length - min_length) * num_beam_groups)
for idx, iter_attentions in enumerate(attentions):
tgt_len = min_length + idx if not use_cache else 1
num_chunks = tgt_len // config.local_attn_chunk_length + (tgt_len % config.local_attn_chunk_length != 0)
tgt_chunk_len = config.local_attn_chunk_length
src_chunk_len = config.local_attn_chunk_length * (
1 + config.local_num_chunks_after + config.local_num_chunks_before
)
if use_cache:
expected_shape = (
batch_size * num_beam_groups,
config.num_attention_heads,
tgt_len,
min_length // config.local_attn_chunk_length + 1 + idx,
)
else:
expected_shape = (
batch_size * num_beam_groups,
config.num_attention_heads,
num_chunks,
tgt_chunk_len,
src_chunk_len,
)
# check attn size
self.assertListEqual(
[layer_attention.shape for layer_attention in iter_attentions], [expected_shape] * len(iter_attentions)
)
def _check_hidden_states_for_generate(
self, batch_size, hidden_states, min_length, max_length, config, use_cache=False, num_beam_groups=1
):
self.assertIsInstance(hidden_states, tuple)
self.assertListEqual(
[isinstance(iter_hidden_states, list) for iter_hidden_states in hidden_states],
[True] * len(hidden_states),
)
self.assertEqual(len(hidden_states), (max_length - min_length) * num_beam_groups)
for idx, iter_hidden_states in enumerate(hidden_states):
seq_len = min_length + idx
seq_len = config.local_attn_chunk_length * (
seq_len // config.local_attn_chunk_length + (seq_len % config.local_attn_chunk_length != 0)
)
if use_cache:
seq_len = 1
expected_shape = (batch_size * num_beam_groups, seq_len, config.hidden_size)
# check hidden size
self.assertListEqual(
[layer_hidden_states.shape for layer_hidden_states in iter_hidden_states],
[expected_shape] * len(iter_hidden_states),
)
@unittest.skip("The model doesn't support left padding") # and it's not used enough to be worth fixing :)
def test_left_padding_compatibility(self):
pass
@require_torch
class ReformerLSHAttnModelTest(
ReformerTesterMixin, ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase
):
all_model_classes = (
(ReformerModel, ReformerModelWithLMHead, ReformerForSequenceClassification, ReformerForQuestionAnswering)
if is_torch_available()
else ()
)
all_generative_model_classes = (ReformerModelWithLMHead,) if is_torch_available() else ()
pipeline_model_mapping = (
{
"feature-extraction": ReformerModel,
"fill-mask": ReformerForMaskedLM,
"question-answering": ReformerForQuestionAnswering,
"text-classification": ReformerForSequenceClassification,
"text-generation": ReformerModelWithLMHead,
"zero-shot": ReformerForSequenceClassification,
}
if is_torch_available()
else {}
)
test_pruning = False
test_headmasking = False
test_torchscript = False
# TODO: Fix the failed tests
def is_pipeline_test_to_skip(
self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
):
if (
pipeline_test_casse_name == "QAPipelineTests"
and tokenizer_name is not None
and not tokenizer_name.endswith("Fast")
):
# `QAPipelineTests` fails for a few models when the slower tokenizer are used.
# (The slower tokenizers were never used for pipeline tests before the pipeline testing rework)
# TODO: check (and possibly fix) the `QAPipelineTests` with slower tokenizer
return True
return False
def setUp(self):
self.model_tester = ReformerModelTester(
self,
batch_size=13,
seq_length=13,
use_input_mask=True,
use_labels=True,
is_training=False,
is_decoder=True,
vocab_size=32,
attention_head_size=16,
hidden_size=64,
num_attention_heads=2,
num_buckets=2,
num_hashes=4,
lsh_attn_chunk_length=4,
lsh_num_chunks_before=1,
lsh_num_chunks_after=0,
chunk_size_lm_head=5,
chunk_size_feed_forward=6,
feed_forward_size=32,
hidden_act="relu",
hidden_dropout_prob=0.1,
lsh_attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
initializer_range=0.02,
axial_norm_std=1.0,
layer_norm_eps=1e-12,
axial_pos_embds=True,
axial_pos_shape=[4, 8],
axial_pos_embds_dim=[16, 48],
# sanotheu
# attn_layers=[lsh,lsh,lsh,lsh],
attn_layers=["lsh"],
pad_token_id=0,
eos_token_id=2,
scope=None,
hash_seed=0,
num_labels=2,
)
self.config_tester = ConfigTester(self, config_class=ReformerConfig, hidden_size=37)
def _check_attentions_for_generate(
self, batch_size, attentions, min_length, max_length, config, use_cache=False, num_beam_groups=1
):
self.assertIsInstance(attentions, tuple)
self.assertListEqual(
[isinstance(iter_attentions, list) for iter_attentions in attentions], [True] * len(attentions)
)
self.assertEqual(len(attentions), (max_length - min_length) * num_beam_groups)
for idx, iter_attentions in enumerate(attentions):
tgt_len = min_length + idx if not use_cache else 1
num_chunks = tgt_len // config.lsh_attn_chunk_length + (tgt_len % config.lsh_attn_chunk_length != 0)
tgt_chunk_len = config.lsh_attn_chunk_length
src_chunk_len = config.lsh_attn_chunk_length * (
1 + config.lsh_num_chunks_after + config.lsh_num_chunks_before
)
if use_cache:
expected_shape = (
batch_size * num_beam_groups,
config.num_attention_heads,
config.num_hashes,
tgt_len,
config.num_hashes * (1 + config.lsh_num_chunks_after + config.lsh_num_chunks_before),
)
else:
expected_shape = (
batch_size * num_beam_groups,
config.num_attention_heads,
num_chunks * config.num_hashes,
tgt_chunk_len,
src_chunk_len,
)
# check attn size
self.assertListEqual(
[layer_attention.shape for layer_attention in iter_attentions], [expected_shape] * len(iter_attentions)
)
def _check_hidden_states_for_generate(
self, batch_size, hidden_states, min_length, max_length, config, use_cache=False, num_beam_groups=1
):
self.assertIsInstance(hidden_states, tuple)
self.assertListEqual(
[isinstance(iter_hidden_states, list) for iter_hidden_states in hidden_states],
[True] * len(hidden_states),
)
self.assertEqual(len(hidden_states), (max_length - min_length) * num_beam_groups)
for idx, iter_hidden_states in enumerate(hidden_states):
seq_len = min_length + idx if not use_cache else 1
seq_len = config.lsh_attn_chunk_length * (
seq_len // config.lsh_attn_chunk_length + (seq_len % config.lsh_attn_chunk_length != 0)
)
if use_cache:
seq_len = 1
expected_shape = (batch_size * num_beam_groups, seq_len, config.hidden_size)
# check hidden size
self.assertListEqual(
[layer_hidden_states.shape for layer_hidden_states in iter_hidden_states],
[expected_shape] * len(iter_hidden_states),
)
@unittest.skip("Fails because the sequence length is not a multiple of 4")
def test_problem_types(self):
pass
@unittest.skip("Fails because the sequence length is not a multiple of 4")
def test_past_key_values_format(self):
pass
@unittest.skip("The model doesn't support left padding") # and it's not used enough to be worth fixing :)
def test_left_padding_compatibility(self):
pass
@require_torch
@require_sentencepiece
@require_tokenizers
class ReformerIntegrationTests(unittest.TestCase):
"""
These integration tests test the current layer activations and gradients againts the output of the Hugging Face Reformer model at time of integration: 29/06/2020. During integration, the model was tested against the output of the official Trax ReformerLM model for various cases ("lsh" only, "lsh" only, masked / non-masked, different chunk length, ....). In order to recover the original trax integration tests, one should use patrickvonplaten's fork of trax and the code that lives on the branch `reformer_trax_tests`.
"""
def _get_basic_config_and_input(self):
config = {
"vocab_size": 320,
"attention_head_size": 8,
"hidden_size": 16,
"num_attention_heads": 2,
"num_buckets": 2,
"num_hashes": 4,
"lsh_attn_chunk_length": 4,
"local_attn_chunk_length": 4,
"lsh_num_chunks_before": 1,
"lsh_num_chunks_after": 0,
"local_num_chunks_before": 1,
"local_num_chunks_after": 0,
"chunk_size_lm_head": 0,
"chunk_size_feed_forward": 0,
"feed_forward_size": 32,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.0,
"lsh_attention_probs_dropout_prob": 0.0,
"local_attention_probs_dropout_prob": 0.0,
"max_position_embeddings": 32,
"initializer_range": 0.02,
"axial_norm_std": 1.0,
"layer_norm_eps": 1e-12,
"sinusoidal_pos_embds": False,
"axial_pos_embds": True,
"axial_pos_shape": [4, 8],
"axial_pos_embds_dim": [8, 8],
"hash_seed": 0,
"is_decoder": True,
}
return config
def _get_hidden_states(self):
return torch.tensor(
[
[
[
1.90826353e00,
-1.45999730e00,
-6.20405462e-01,
1.52503433e00,
-3.64464232e-01,
-8.27359235e-01,
8.39670803e-01,
2.44492178e-01,
4.98332758e-01,
2.69175139e00,
-7.08081422e-03,
1.04915401e00,
-1.83476661e00,
7.67220476e-01,
2.98580543e-01,
2.84803992e-02,
],
[
-2.66374286e-02,
4.33497576e-01,
3.10386309e-01,
5.46039944e-01,
-2.47292666e-04,
-7.52305019e-01,
2.39162103e-01,
7.25216186e-01,
-7.58357372e-01,
4.20635998e-01,
-4.04739919e-02,
1.59924145e-01,
2.05135748e00,
-1.15997978e00,
5.37166397e-01,
2.62873606e-01,
],
[
1.85247482e-01,
7.07046037e-01,
-6.77089715e-01,
-2.24209655e00,
-3.75307980e-02,
-8.59380874e-01,
-2.81027884e00,
1.01276376e00,
-1.69438001e00,
4.17574660e-01,
-1.49196962e00,
-1.76483717e00,
-1.94566312e-01,
-1.71183858e00,
7.72903565e-01,
-1.11557056e00,
],
[
9.46069193e-01,
1.53417623e-01,
-9.58686996e-01,
1.18126669e-01,
1.75967724e00,
1.62194590e00,
-5.74108159e-01,
6.79920443e-01,
5.44028163e-01,
2.05466114e-01,
-3.63045868e-01,
2.41865062e-01,
3.20348382e-01,
-9.05611176e-01,
-1.92690727e-01,
-1.19917547e00,
],
]
],
dtype=torch.float32,
device=torch_device,
)
def _get_attn_mask(self):
return torch.tensor([[0, 1, 0, 0]], dtype=torch.long, device=torch_device)
def _get_input_ids_and_mask(self):
mask = torch.tensor(
[
[1, 0, 0, 1, 1, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 1, 1],
[0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0],
],
dtype=torch.long,
device=torch_device,
)
input_ids = torch.tensor(
[
[
89,
279,
286,
84,
194,
316,
182,
28,
283,
37,
169,
7,
253,
267,
107,
250,
44,
7,
102,
62,
3,
243,
171,
265,
302,
48,
164,
264,
148,
229,
280,
150,
],
[
9,
192,
66,
112,
163,
83,
135,
70,
224,
96,
31,
80,
196,
80,
63,
22,
85,
100,
47,
283,
0,
163,
126,
143,
195,
82,
53,
82,
18,
27,
182,
52,
],
],
dtype=torch.long,
device=torch_device,
)
return input_ids, mask
def test_lsh_layer_forward(self):
config = self._get_basic_config_and_input()
config["lsh_num_chunks_before"] = 0
config["attn_layers"] = ["lsh"]
config["is_decoder"] = False
hidden_states = self._get_hidden_states()
torch.manual_seed(0)
layer = ReformerLayer(ReformerConfig(**config)).to(torch_device)
layer.eval()
reformer_output = layer(prev_attn_output=hidden_states.clone(), hidden_states=hidden_states)
output_slice = reformer_output.hidden_states[0, 0, :5]
expected_output_slice = torch.tensor(
[1.6879, -1.3083, -0.4708, 1.3555, -0.6292],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3))
def test_lsh_layer_forward_complex(self):
config = self._get_basic_config_and_input()
config["lsh_num_chunks_before"] = 0
config["attn_layers"] = ["lsh"]
config["num_buckets"] = [2, 4]
attn_mask = self._get_attn_mask()
hidden_states = self._get_hidden_states()
torch.manual_seed(0)
layer = ReformerLayer(ReformerConfig(**config)).to(torch_device)
layer.eval()
reformer_output = layer(
prev_attn_output=hidden_states.clone(),
hidden_states=hidden_states,
attention_mask=attn_mask,
)
output_slice = reformer_output.hidden_states[0, 0, :5]
expected_output_slice = torch.tensor(
[1.6439, -1.2306, -0.5108, 1.3006, -0.6537],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3))
def test_local_layer_forward(self):
config = self._get_basic_config_and_input()
config["local_num_chunks_before"] = 0
config["attn_layers"] = ["local"]
config["is_decoder"] = False
hidden_states = self._get_hidden_states()
torch.manual_seed(0)
layer = ReformerLayer(ReformerConfig(**config)).to(torch_device)
layer.eval()
reformer_output = layer(prev_attn_output=hidden_states, hidden_states=hidden_states)
output_slice = reformer_output.hidden_states[0, 0, :5]
expected_output_slice = torch.tensor(
[1.4212, -2.0576, -0.9688, 1.4599, -0.1344],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3))
def test_local_layer_forward_complex(self):
config = self._get_basic_config_and_input()
config["local_num_chunks_before"] = 0
config["attn_layers"] = ["local"]
attn_mask = self._get_attn_mask()
hidden_states = self._get_hidden_states()
torch.manual_seed(0)
layer = ReformerLayer(ReformerConfig(**config)).to(torch_device)
layer.eval()
reformer_output = layer(
prev_attn_output=hidden_states,
hidden_states=hidden_states,
attention_mask=attn_mask,
)
output_slice = reformer_output.hidden_states[0, 0, :5]
expected_output_slice = torch.tensor(
[1.4750, -2.0235, -0.9743, 1.4463, -0.1269],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3))
def test_lsh_model_forward(self):
config = self._get_basic_config_and_input()
config["attn_layers"] = ["lsh", "lsh", "lsh", "lsh"]
config["num_buckets"] = [2, 4]
torch.manual_seed(0)
model = ReformerModel(ReformerConfig(**config)).to(torch_device)
model.eval()
input_ids, attn_mask = self._get_input_ids_and_mask()
hidden_states = model(input_ids=input_ids, attention_mask=attn_mask)[0]
output_slice = hidden_states[0, 0, :5]
expected_output_slice = torch.tensor(
[-0.9896, -0.9396, -1.0831, -0.0597, 0.2456],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3))
def test_local_model_forward(self):
config = self._get_basic_config_and_input()
config["attn_layers"] = ["local", "local", "local", "local"]
torch.manual_seed(0)
model = ReformerModel(ReformerConfig(**config)).to(torch_device)
model.eval()
input_ids, attn_mask = self._get_input_ids_and_mask()
hidden_states = model(input_ids=input_ids, attention_mask=attn_mask)[0]
output_slice = hidden_states[0, 0, :5]
expected_output_slice = torch.tensor(
[-1.6791, 0.7171, 0.1594, 0.4063, 1.2584],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3))
def test_lm_model_forward(self):
config = self._get_basic_config_and_input()
config["attn_layers"] = ["local", "lsh", "local", "lsh", "local", "lsh"]
config["num_buckets"] = [2, 4]
config["is_decoder"] = False
torch.manual_seed(0)
model = ReformerForMaskedLM(ReformerConfig(**config)).to(torch_device)
model.eval()
input_ids, attn_mask = self._get_input_ids_and_mask()
hidden_states = model(input_ids=input_ids, attention_mask=attn_mask)[0]
output_slice = hidden_states[1, -1, :5]
expected_output_slice = torch.tensor(
[0.1018, -0.2026, 0.2116, 0.0270, -0.1233],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(output_slice, expected_output_slice, atol=1e-3))
def test_local_lm_model_grad(self):
config = self._get_basic_config_and_input()
config["attn_layers"] = ["local", "local", "local", "local"]
config["hidden_dropout_prob"] = 0.0
config["local_attention_probs_dropout_prob"] = 0.0
torch.manual_seed(0)
model = ReformerModelWithLMHead(ReformerConfig(**config)).to(torch_device)
model.train()
model.zero_grad()
input_ids, _ = self._get_input_ids_and_mask()
loss = model(input_ids=input_ids, labels=input_ids)[0]
self.assertTrue(torch.allclose(loss, torch.tensor(5.8019, dtype=torch.float, device=torch_device), atol=1e-3))
loss.backward()
# check last grads to cover all proable errors
grad_slice_word = model.reformer.embeddings.word_embeddings.weight.grad[0, :5]
expected_grad_slice_word = torch.tensor(
[-0.0005, -0.0001, -0.0002, -0.0006, -0.0006],
dtype=torch.float,
device=torch_device,
)
grad_slice_position_factor_1 = model.reformer.embeddings.position_embeddings.weights[0][1, 0, -5:]
expected_grad_slice_pos_fac_1 = torch.tensor(
[-0.5235, 0.5704, 0.0922, -0.3140, 0.9928],
dtype=torch.float,
device=torch_device,
)
grad_slice_position_factor_2 = model.reformer.embeddings.position_embeddings.weights[1][0, 1, :5]
expected_grad_slice_pos_fac_2 = torch.tensor(
[1.7960, 1.7668, 0.5593, 0.0907, 1.8342],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(grad_slice_word, expected_grad_slice_word, atol=1e-3))
self.assertTrue(torch.allclose(grad_slice_position_factor_1, expected_grad_slice_pos_fac_1, atol=1e-3))
self.assertTrue(torch.allclose(grad_slice_position_factor_2, expected_grad_slice_pos_fac_2, atol=1e-3))
def test_lsh_lm_model_grad(self):
config = self._get_basic_config_and_input()
config["attn_layers"] = ["lsh", "lsh", "lsh", "lsh"]
config["hidden_dropout_prob"] = 0.0
config["lsh_attention_probs_dropout_prob"] = 0.0
config["num_buckets"] = [2, 4]
config["num_hashes"] = 6
torch.manual_seed(0)
model = ReformerModelWithLMHead(ReformerConfig(**config)).to(torch_device)
model.train()
model.zero_grad()
input_ids, _ = self._get_input_ids_and_mask()
loss = model(input_ids=input_ids, labels=input_ids)[0]
self.assertTrue(torch.allclose(loss, torch.tensor(5.7854, dtype=torch.float, device=torch_device), atol=1e-3))
loss.backward()
# check last grads to cover all proable errors
grad_slice_word = model.reformer.embeddings.word_embeddings.weight.grad[0, :5]
expected_grad_slice_word = torch.tensor(
[0.0004, 0.0003, 0.0006, -0.0004, 0.0002],
dtype=torch.float,
device=torch_device,
)
grad_slice_position_factor_1 = model.reformer.embeddings.position_embeddings.weights[0][1, 0, -5:]
expected_grad_slice_pos_fac_1 = torch.tensor(
[-0.3792, 0.5593, -1.6993, 0.2033, 0.4131],
dtype=torch.float,
device=torch_device,
)
grad_slice_position_factor_2 = model.reformer.embeddings.position_embeddings.weights[1][0, 1, :5]
expected_grad_slice_pos_fac_2 = torch.tensor(
[-1.4212, -0.3201, -1.1944, 0.1258, 0.2856],
dtype=torch.float,
device=torch_device,
)
self.assertTrue(torch.allclose(grad_slice_word, expected_grad_slice_word, atol=1e-3))
self.assertTrue(torch.allclose(grad_slice_position_factor_1, expected_grad_slice_pos_fac_1, atol=1e-3))
self.assertTrue(torch.allclose(grad_slice_position_factor_2, expected_grad_slice_pos_fac_2, atol=1e-3))
@slow
def test_pretrained_generate_crime_and_punish(self):
model = ReformerModelWithLMHead.from_pretrained("google/reformer-crime-and-punishment").to(torch_device)
tokenizer = ReformerTokenizer.from_pretrained("google/reformer-crime-and-punishment")
model.eval()
input_ids = tokenizer.encode("A few months later", return_tensors="pt").to(torch_device)
output_ids = model.generate(
input_ids, max_length=50, num_beams=4, early_stopping=True, do_sample=False, num_hashes=8
)
output = tokenizer.decode(output_ids[0])
self.assertEqual(
output,
"A few months later state expression in his ideas, at the first entrance. He was positively for an inst",
)
@slow
def test_pretrained_generate_use_cache_equality(self):
model = ReformerModelWithLMHead.from_pretrained("google/reformer-crime-and-punishment").to(torch_device)
tokenizer = ReformerTokenizer.from_pretrained("google/reformer-crime-and-punishment")
model.eval()
input_ids = tokenizer.encode("A few months later", return_tensors="pt").to(torch_device)
output_ids_with_cache = model.generate(input_ids, max_length=130, num_hashes=8, use_cache=False)
output_ids_without_cache = model.generate(input_ids, max_length=130, num_hashes=8, use_cache=True)
output_with_cache = tokenizer.decode(output_ids_with_cache[0])
output_without_cache = tokenizer.decode(output_ids_without_cache[0])
self.assertEqual(output_with_cache, output_without_cache)
| transformers/tests/models/reformer/test_modeling_reformer.py/0 | {
"file_path": "transformers/tests/models/reformer/test_modeling_reformer.py",
"repo_id": "transformers",
"token_count": 26931
} | 369 |
# coding=utf-8
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from unittest.util import safe_repr
from transformers import AutoTokenizer, RwkvConfig, is_torch_available
from transformers.testing_utils import require_torch, slow, torch_device
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
RWKV_PRETRAINED_MODEL_ARCHIVE_LIST,
RwkvForCausalLM,
RwkvModel,
)
from transformers.pytorch_utils import is_torch_greater_or_equal_than_2_0
else:
is_torch_greater_or_equal_than_2_0 = False
class RwkvModelTester:
def __init__(
self,
parent,
batch_size=14,
seq_length=7,
is_training=True,
use_token_type_ids=False,
use_input_mask=True,
use_labels=True,
use_mc_token_ids=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_token_type_ids = use_token_type_ids
self.use_input_mask = use_input_mask
self.use_labels = use_labels
self.use_mc_token_ids = use_mc_token_ids
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
self.bos_token_id = vocab_size - 1
self.eos_token_id = vocab_size - 1
self.pad_token_id = vocab_size - 1
def get_large_model_config(self):
return RwkvConfig.from_pretrained("sgugger/rwkv-4-pile-7b")
def prepare_config_and_inputs(
self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
mc_token_ids = None
if self.use_mc_token_ids:
mc_token_ids = ids_tensor([self.batch_size, self.num_choices], self.seq_length)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config(
gradient_checkpointing=gradient_checkpointing,
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
reorder_and_upcast_attn=reorder_and_upcast_attn,
)
return (
config,
input_ids,
input_mask,
None,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
)
def get_config(
self, gradient_checkpointing=False, scale_attn_by_inverse_layer_idx=False, reorder_and_upcast_attn=False
):
return RwkvConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
intermediate_size=self.intermediate_size,
activation_function=self.hidden_act,
resid_pdrop=self.hidden_dropout_prob,
attn_pdrop=self.attention_probs_dropout_prob,
n_positions=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
use_cache=True,
bos_token_id=self.bos_token_id,
eos_token_id=self.eos_token_id,
pad_token_id=self.pad_token_id,
gradient_checkpointing=gradient_checkpointing,
scale_attn_by_inverse_layer_idx=scale_attn_by_inverse_layer_idx,
reorder_and_upcast_attn=reorder_and_upcast_attn,
)
def get_pipeline_config(self):
config = self.get_config()
config.vocab_size = 300
return config
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_rwkv_model(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
config.output_hidden_states = True
model = RwkvModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
self.parent.assertEqual(len(result.hidden_states), config.num_hidden_layers + 1)
def create_and_check_causl_lm(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = RwkvForCausalLM(config)
model.to(torch_device)
model.eval()
result = model(input_ids, labels=input_ids)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_state_equivalency(self, config, input_ids, input_mask, head_mask, token_type_ids, *args):
model = RwkvModel(config=config)
model.to(torch_device)
model.eval()
outputs = model(input_ids)
output_whole = outputs.last_hidden_state
outputs = model(input_ids[:, :2])
output_one = outputs.last_hidden_state
# Using the state computed on the first inputs, we will get the same output
outputs = model(input_ids[:, 2:], state=outputs.state)
output_two = outputs.last_hidden_state
self.parent.assertTrue(torch.allclose(torch.cat([output_one, output_two], dim=1), output_whole, atol=1e-5))
def create_and_check_forward_and_backwards(
self, config, input_ids, input_mask, head_mask, token_type_ids, *args, gradient_checkpointing=False
):
model = RwkvForCausalLM(config)
model.to(torch_device)
if gradient_checkpointing:
model.gradient_checkpointing_enable()
result = model(input_ids, labels=input_ids)
self.parent.assertEqual(result.loss.shape, ())
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
result.loss.backward()
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
input_mask,
head_mask,
token_type_ids,
mc_token_ids,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids}
return config, inputs_dict
@unittest.skipIf(
not is_torch_greater_or_equal_than_2_0, reason="See https://github.com/huggingface/transformers/pull/24204"
)
@require_torch
class RwkvModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (RwkvModel, RwkvForCausalLM) if is_torch_available() else ()
pipeline_model_mapping = (
{"feature-extraction": RwkvModel, "text-generation": RwkvForCausalLM} if is_torch_available() else {}
)
# all_generative_model_classes = (RwkvForCausalLM,) if is_torch_available() else ()
fx_compatible = False
test_missing_keys = False
test_model_parallel = False
test_pruning = False
test_head_masking = False # Rwkv does not support head masking
def setUp(self):
self.model_tester = RwkvModelTester(self)
self.config_tester = ConfigTester(
self, config_class=RwkvConfig, n_embd=37, common_properties=["hidden_size", "num_hidden_layers"]
)
def assertInterval(self, member, container, msg=None):
r"""
Simple utility function to check if a member is inside an interval.
"""
if isinstance(member, torch.Tensor):
max_value, min_value = member.max().item(), member.min().item()
elif isinstance(member, list) or isinstance(member, tuple):
max_value, min_value = max(member), min(member)
if not isinstance(container, list):
raise TypeError("container should be a list or tuple")
elif len(container) != 2:
raise ValueError("container should have 2 elements")
expected_min, expected_max = container
is_inside_interval = (min_value >= expected_min) and (max_value <= expected_max)
if not is_inside_interval:
standardMsg = "%s not found in %s" % (safe_repr(member), safe_repr(container))
self.fail(self._formatMessage(msg, standardMsg))
def test_config(self):
self.config_tester.run_common_tests()
def test_rwkv_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_rwkv_model(*config_and_inputs)
def test_rwkv_lm_head_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_causl_lm(*config_and_inputs)
def test_state_equivalency(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_state_equivalency(*config_and_inputs)
def test_initialization(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config=config)
for name, param in model.named_parameters():
if "time_decay" in name:
if param.requires_grad:
self.assertTrue(param.data.max().item() == 3.0)
self.assertTrue(param.data.min().item() == -5.0)
elif "time_first" in name:
if param.requires_grad:
# check if it's a ones like
self.assertTrue(torch.allclose(param.data, torch.ones_like(param.data), atol=1e-5, rtol=1e-5))
elif any(x in name for x in ["time_mix_key", "time_mix_receptance"]):
if param.requires_grad:
self.assertInterval(
param.data,
[0.0, 1.0],
msg=f"Parameter {name} of model {model_class} seems not properly initialized",
)
elif "time_mix_value" in name:
if param.requires_grad:
self.assertInterval(
param.data,
[0.0, 1.3],
msg=f"Parameter {name} of model {model_class} seems not properly initialized",
)
def test_attention_outputs(self):
r"""
Overriding the test_attention_outputs test as the attention outputs of Rwkv are different from other models
it has a shape `batch_size, seq_len, hidden_size`.
"""
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
seq_len = getattr(self.model_tester, "seq_length", None)
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
inputs = self._prepare_for_class(inputs_dict, model_class)
batch_size = inputs["input_ids"].shape[0]
with torch.no_grad():
outputs = model(**inputs)
attentions = outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
inputs = self._prepare_for_class(inputs_dict, model_class)
batch_size = inputs["input_ids"].shape[0]
with torch.no_grad():
outputs = model(**inputs)
attentions = outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[batch_size, seq_len, config.hidden_size],
)
out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
inputs = self._prepare_for_class(inputs_dict, model_class)
batch_size = inputs["input_ids"].shape[0]
with torch.no_grad():
outputs = model(**inputs)
added_hidden_states = 1
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[batch_size, seq_len, config.hidden_size],
)
@slow
def test_model_from_pretrained(self):
for model_name in RWKV_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = RwkvModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@unittest.skipIf(
not is_torch_greater_or_equal_than_2_0, reason="See https://github.com/huggingface/transformers/pull/24204"
)
@slow
class RWKVIntegrationTests(unittest.TestCase):
def setUp(self):
self.model_id = "RWKV/rwkv-4-169m-pile"
self.tokenizer = AutoTokenizer.from_pretrained(self.model_id)
def test_simple_generate(self):
expected_output = "Hello my name is Jasmine and I am a newbie to the"
model = RwkvForCausalLM.from_pretrained(self.model_id).to(torch_device)
input_ids = self.tokenizer("Hello my name is", return_tensors="pt").input_ids.to(torch_device)
output = model.generate(input_ids, max_new_tokens=10)
output_sentence = self.tokenizer.decode(output[0].tolist())
self.assertEqual(output_sentence, expected_output)
def test_simple_generate_bf16(self):
expected_output = "Hello my name is Jasmine and I am a newbie to the"
input_ids = self.tokenizer("Hello my name is", return_tensors="pt").input_ids.to(torch_device)
model = RwkvForCausalLM.from_pretrained(self.model_id, torch_dtype=torch.bfloat16).to(torch_device)
output = model.generate(input_ids, max_new_tokens=10)
output_sentence = self.tokenizer.decode(output[0].tolist())
self.assertEqual(output_sentence, expected_output)
| transformers/tests/models/rwkv/test_modeling_rwkv.py/0 | {
"file_path": "transformers/tests/models/rwkv/test_modeling_rwkv.py",
"repo_id": "transformers",
"token_count": 8254
} | 370 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch Speech2Text model. """
import copy
import inspect
import os
import tempfile
import unittest
from transformers import Speech2TextConfig
from transformers.testing_utils import (
is_torch_available,
require_sentencepiece,
require_tokenizers,
require_torch,
require_torch_fp16,
require_torchaudio,
slow,
torch_device,
)
from transformers.utils import cached_property
from ...generation.test_utils import GenerationTesterMixin
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, _config_zero_init, floats_tensor, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import Speech2TextForConditionalGeneration, Speech2TextModel, Speech2TextProcessor
from transformers.models.speech_to_text.modeling_speech_to_text import Speech2TextDecoder, Speech2TextEncoder
def prepare_speech_to_text_inputs_dict(
config,
input_features,
decoder_input_ids,
attention_mask=None,
decoder_attention_mask=None,
head_mask=None,
decoder_head_mask=None,
cross_attn_head_mask=None,
):
if attention_mask is None:
attention_mask = input_features.ne(0)
if decoder_attention_mask is None:
decoder_attention_mask = decoder_input_ids.ne(config.pad_token_id)
if head_mask is None:
head_mask = torch.ones(config.encoder_layers, config.encoder_attention_heads, device=torch_device)
if decoder_head_mask is None:
decoder_head_mask = torch.ones(config.decoder_layers, config.decoder_attention_heads, device=torch_device)
if cross_attn_head_mask is None:
cross_attn_head_mask = torch.ones(config.decoder_layers, config.decoder_attention_heads, device=torch_device)
return {
# "input_ids": input_features,
"input_features": input_features,
"decoder_input_ids": decoder_input_ids,
"attention_mask": attention_mask,
"decoder_attention_mask": attention_mask,
"head_mask": head_mask,
"decoder_head_mask": decoder_head_mask,
"cross_attn_head_mask": cross_attn_head_mask,
}
@require_torch
class Speech2TextModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_labels=False,
vocab_size=99,
hidden_size=16,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=4,
num_conv_layers=2,
conv_kernel_sizes=(5, 5),
conv_channels=32,
input_feat_per_channel=24,
input_channels=1,
hidden_act="relu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=20,
max_source_positions=20,
max_target_positions=20,
eos_token_id=2,
pad_token_id=1,
bos_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.num_conv_layers = num_conv_layers
self.conv_kernel_sizes = conv_kernel_sizes
self.conv_channels = conv_channels
self.input_feat_per_channel = input_feat_per_channel
self.input_channels = input_channels
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.max_source_positions = max_source_positions
self.max_target_positions = max_target_positions
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.bos_token_id = bos_token_id
def prepare_config_and_inputs(self):
input_features = floats_tensor(
[self.batch_size, self.seq_length, self.input_feat_per_channel], self.vocab_size
)
attention_mask = torch.ones([self.batch_size, self.seq_length], dtype=torch.long, device=torch_device)
decoder_input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size).clamp(2)
config = self.get_config()
inputs_dict = prepare_speech_to_text_inputs_dict(
config,
input_features=input_features,
decoder_input_ids=decoder_input_ids,
attention_mask=attention_mask,
)
return config, inputs_dict
def get_config(self):
return Speech2TextConfig(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
num_conv_layers=self.num_conv_layers,
conv_kernel_sizes=self.conv_kernel_sizes,
conv_channels=self.conv_channels,
input_feat_per_channel=self.input_feat_per_channel,
input_channels=self.input_channels,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
max_source_positions=self.max_source_positions,
max_target_positions=self.max_target_positions,
eos_token_id=self.eos_token_id,
bos_token_id=self.bos_token_id,
pad_token_id=self.pad_token_id,
)
def prepare_config_and_inputs_for_common(self):
config, inputs_dict = self.prepare_config_and_inputs()
return config, inputs_dict
def get_subsampled_output_lengths(self, input_lengths):
"""
Computes the output length of the convolutional layers
"""
for i in range(self.num_conv_layers):
input_lengths = (input_lengths - 1) // 2 + 1
return input_lengths
def create_and_check_model_forward(self, config, inputs_dict):
model = Speech2TextModel(config=config).to(torch_device).eval()
input_features = inputs_dict["input_features"]
decoder_input_ids = inputs_dict["decoder_input_ids"]
# first forward pass
last_hidden_state = model(input_features, decoder_input_ids=decoder_input_ids).last_hidden_state
self.parent.assertTrue(last_hidden_state.shape, (13, 7, 16))
def create_and_check_decoder_model_past_large_inputs(self, config, inputs_dict):
model = Speech2TextModel(config=config).get_decoder().to(torch_device).eval()
input_ids = inputs_dict["decoder_input_ids"]
attention_mask = inputs_dict["decoder_attention_mask"]
# first forward pass
outputs = model(input_ids, attention_mask=attention_mask, use_cache=True)
output, past_key_values = outputs.to_tuple()
# create hypothetical multiple next token and extent to next_input_ids
next_tokens = ids_tensor((self.batch_size, 3), config.vocab_size).clamp(2)
next_attn_mask = ids_tensor((self.batch_size, 3), 2)
# append to next input_ids and
next_input_ids = torch.cat([input_ids, next_tokens], dim=-1)
next_attention_mask = torch.cat([attention_mask, next_attn_mask], dim=-1)
output_from_no_past = model(next_input_ids, attention_mask=next_attention_mask)["last_hidden_state"]
output_from_past = model(next_tokens, attention_mask=next_attention_mask, past_key_values=past_key_values)[
"last_hidden_state"
]
# select random slice
random_slice_idx = ids_tensor((1,), output_from_past.shape[-1]).item()
output_from_no_past_slice = output_from_no_past[:, -3:, random_slice_idx].detach()
output_from_past_slice = output_from_past[:, :, random_slice_idx].detach()
self.parent.assertTrue(output_from_past_slice.shape[1] == next_tokens.shape[1])
# test that outputs are equal for slice
self.parent.assertTrue(torch.allclose(output_from_past_slice, output_from_no_past_slice, atol=1e-2))
def check_encoder_decoder_model_standalone(self, config, inputs_dict):
model = Speech2TextModel(config=config).to(torch_device).eval()
outputs = model(**inputs_dict)
encoder_last_hidden_state = outputs.encoder_last_hidden_state
last_hidden_state = outputs.last_hidden_state
with tempfile.TemporaryDirectory() as tmpdirname:
encoder = model.get_encoder()
encoder.save_pretrained(tmpdirname)
encoder = Speech2TextEncoder.from_pretrained(tmpdirname).to(torch_device)
encoder_last_hidden_state_2 = encoder(
inputs_dict["input_features"], attention_mask=inputs_dict["attention_mask"]
)[0]
self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
with tempfile.TemporaryDirectory() as tmpdirname:
decoder = model.get_decoder()
decoder.save_pretrained(tmpdirname)
decoder = Speech2TextDecoder.from_pretrained(tmpdirname).to(torch_device)
encoder_attention_mask = encoder._get_feature_vector_attention_mask(
encoder_last_hidden_state.shape[1], inputs_dict["attention_mask"]
)
last_hidden_state_2 = decoder(
input_ids=inputs_dict["decoder_input_ids"],
attention_mask=inputs_dict["decoder_attention_mask"],
encoder_hidden_states=encoder_last_hidden_state,
encoder_attention_mask=encoder_attention_mask,
)[0]
self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
@require_torch
class Speech2TextModelTest(ModelTesterMixin, GenerationTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (Speech2TextModel, Speech2TextForConditionalGeneration) if is_torch_available() else ()
all_generative_model_classes = (Speech2TextForConditionalGeneration,) if is_torch_available() else ()
pipeline_model_mapping = (
{"automatic-speech-recognition": Speech2TextForConditionalGeneration, "feature-extraction": Speech2TextModel}
if is_torch_available()
else {}
)
is_encoder_decoder = True
fx_compatible = True
test_pruning = False
test_missing_keys = False
input_name = "input_features"
def _get_input_ids_and_config(self, batch_size=2):
config, input_ids, attention_mask, max_length = GenerationTesterMixin._get_input_ids_and_config(self)
# `input_ids` is actually `input_features` which is a 3D tensor.
# We must overwrite the mask to make it 2D since the original `_get_input_ids_and_config` creates an
# attention mask of the same shape as `input_ids`.
if len(attention_mask.shape) > 2:
sequence_length = input_ids.shape[1]
attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=attention_mask.device)
return config, input_ids, attention_mask, max_length
def setUp(self):
self.model_tester = Speech2TextModelTester(self)
self.config_tester = ConfigTester(self, config_class=Speech2TextConfig)
self.maxDiff = 3000
def test_config(self):
self.config_tester.run_common_tests()
def test_save_load_strict(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs()
for model_class in self.all_model_classes:
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
self.assertEqual(info["missing_keys"], [])
def test_model_forward(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_forward(*config_and_inputs)
def test_decoder_model_past_with_large_inputs(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_decoder_model_past_large_inputs(*config_and_inputs)
def test_encoder_decoder_model_standalone(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
# not implemented currently
def test_inputs_embeds(self):
pass
# training is not supported yet
def test_training(self):
pass
def test_training_gradient_checkpointing(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
@require_torch_fp16
def test_generate_fp16(self):
config, input_dict = self.model_tester.prepare_config_and_inputs()
input_features = input_dict["input_features"]
attention_mask = input_dict["attention_mask"]
model = Speech2TextForConditionalGeneration(config).eval().to(torch_device)
input_features = input_features.half()
model.half()
model.generate(input_features, attention_mask=attention_mask)
model.generate(input_features, num_beams=4, do_sample=True, early_stopping=False, num_return_sequences=3)
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
signature = inspect.signature(model.forward)
# signature.parameters is an OrderedDict => so arg_names order is deterministic
arg_names = [*signature.parameters.keys()]
expected_arg_names = [
"input_features",
"attention_mask",
"decoder_input_ids",
"decoder_attention_mask",
]
expected_arg_names.extend(
["head_mask", "decoder_head_mask", "cross_attn_head_mask", "encoder_outputs"]
if "head_mask" and "decoder_head_mask" and "cross_attn_head_mask" in arg_names
else ["encoder_outputs"]
)
self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
def test_hidden_states_output(self):
def check_hidden_states_output(inputs_dict, config, model_class):
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
expected_num_layers = getattr(
self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
)
self.assertEqual(len(hidden_states), expected_num_layers)
if hasattr(self.model_tester, "encoder_seq_length"):
seq_length = self.model_tester.encoder_seq_length
else:
seq_length = self.model_tester.seq_length
subsampled_seq_length = model._get_feat_extract_output_lengths(seq_length)
self.assertListEqual(
list(hidden_states[0].shape[-2:]),
[subsampled_seq_length, self.model_tester.hidden_size],
)
if config.is_encoder_decoder:
hidden_states = outputs.decoder_hidden_states
self.assertIsInstance(hidden_states, (list, tuple))
self.assertEqual(len(hidden_states), expected_num_layers)
seq_len = getattr(self.model_tester, "seq_length", None)
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
self.assertListEqual(
list(hidden_states[0].shape[-2:]),
[decoder_seq_length, self.model_tester.hidden_size],
)
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
inputs_dict["output_hidden_states"] = True
check_hidden_states_output(inputs_dict, config, model_class)
# check that output_hidden_states also work using config
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
check_hidden_states_output(inputs_dict, config, model_class)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
seq_len = getattr(self.model_tester, "seq_length", None)
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
decoder_key_length = getattr(self.model_tester, "decoder_key_length", decoder_seq_length)
encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
subsampled_encoder_seq_length = model._get_feat_extract_output_lengths(encoder_seq_length)
subsampled_encoder_key_length = model._get_feat_extract_output_lengths(encoder_key_length)
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, subsampled_encoder_seq_length, subsampled_encoder_key_length],
)
out_len = len(outputs)
correct_outlen = 5
# loss is at first position
if "labels" in inputs_dict:
correct_outlen += 1 # loss is added to beginning
if "past_key_values" in outputs:
correct_outlen += 1 # past_key_values have been returned
self.assertEqual(out_len, correct_outlen)
# decoder attentions
decoder_attentions = outputs.decoder_attentions
self.assertIsInstance(decoder_attentions, (list, tuple))
self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(decoder_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, decoder_seq_length, decoder_key_length],
)
# cross attentions
cross_attentions = outputs.cross_attentions
self.assertIsInstance(cross_attentions, (list, tuple))
self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(cross_attentions[0].shape[-3:]),
[
self.model_tester.num_attention_heads,
decoder_seq_length,
subsampled_encoder_key_length,
],
)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
added_hidden_states = 2
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, subsampled_encoder_seq_length, subsampled_encoder_key_length],
)
def test_resize_tokens_embeddings(self):
(
original_config,
inputs_dict,
) = self.model_tester.prepare_config_and_inputs_for_common()
if not self.test_resize_embeddings:
return
for model_class in self.all_model_classes:
config = copy.deepcopy(original_config)
model = model_class(config)
model.to(torch_device)
if self.model_tester.is_training is False:
model.eval()
model_vocab_size = config.vocab_size
# Retrieve the embeddings and clone theme
model_embed = model.resize_token_embeddings(model_vocab_size)
cloned_embeddings = model_embed.weight.clone()
# Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
model_embed = model.resize_token_embeddings(model_vocab_size + 10)
self.assertEqual(model.config.vocab_size, model_vocab_size + 10)
# Check that it actually resizes the embeddings matrix
self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] + 10)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
model(**self._prepare_for_class(inputs_dict, model_class))
# Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
model_embed = model.resize_token_embeddings(model_vocab_size - 15)
self.assertEqual(model.config.vocab_size, model_vocab_size - 15)
# Check that it actually resizes the embeddings matrix
self.assertEqual(model_embed.weight.shape[0], cloned_embeddings.shape[0] - 15)
# make sure that decoder_input_ids are resized
if "decoder_input_ids" in inputs_dict:
inputs_dict["decoder_input_ids"].clamp_(max=model_vocab_size - 15 - 1)
model(**self._prepare_for_class(inputs_dict, model_class))
# Check that adding and removing tokens has not modified the first part of the embedding matrix.
models_equal = True
for p1, p2 in zip(cloned_embeddings, model_embed.weight):
if p1.data.ne(p2.data).sum() > 0:
models_equal = False
self.assertTrue(models_equal)
def test_resize_embeddings_untied(self):
(
original_config,
inputs_dict,
) = self.model_tester.prepare_config_and_inputs_for_common()
if not self.test_resize_embeddings:
return
original_config.tie_word_embeddings = False
# if model cannot untied embeddings -> leave test
if original_config.tie_word_embeddings:
return
for model_class in self.all_model_classes:
config = copy.deepcopy(original_config)
model = model_class(config).to(torch_device)
# if no output embeddings -> leave test
if model.get_output_embeddings() is None:
continue
# Check that resizing the token embeddings with a larger vocab size increases the model's vocab size
model_vocab_size = config.vocab_size
model.resize_token_embeddings(model_vocab_size + 10)
self.assertEqual(model.config.vocab_size, model_vocab_size + 10)
output_embeds = model.get_output_embeddings()
self.assertEqual(output_embeds.weight.shape[0], model_vocab_size + 10)
# Check bias if present
if output_embeds.bias is not None:
self.assertEqual(output_embeds.bias.shape[0], model_vocab_size + 10)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
model(**self._prepare_for_class(inputs_dict, model_class))
# Check that resizing the token embeddings with a smaller vocab size decreases the model's vocab size
model.resize_token_embeddings(model_vocab_size - 15)
self.assertEqual(model.config.vocab_size, model_vocab_size - 15)
# Check that it actually resizes the embeddings matrix
output_embeds = model.get_output_embeddings()
self.assertEqual(output_embeds.weight.shape[0], model_vocab_size - 15)
# Check bias if present
if output_embeds.bias is not None:
self.assertEqual(output_embeds.bias.shape[0], model_vocab_size - 15)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
if "decoder_input_ids" in inputs_dict:
inputs_dict["decoder_input_ids"].clamp_(max=model_vocab_size - 15 - 1)
# Check that the model can still do a forward pass successfully (every parameter should be resized)
model(**self._prepare_for_class(inputs_dict, model_class))
def test_generate_without_input_ids(self):
pass
@staticmethod
def _get_encoder_outputs(
model, input_ids, attention_mask, output_attentions=None, output_hidden_states=None, num_interleave=1
):
encoder = model.get_encoder()
encoder_outputs = encoder(
input_ids,
attention_mask=attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
encoder_outputs["last_hidden_state"] = encoder_outputs.last_hidden_state.repeat_interleave(
num_interleave, dim=0
)
input_ids = input_ids[:, :, 0]
input_ids = torch.zeros_like(input_ids[:, :1], dtype=torch.long) + model._get_decoder_start_token_id()
attention_mask = None
return encoder_outputs, input_ids, attention_mask
def _check_outputs(self, output, input_ids, config, use_cache=False, num_return_sequences=1):
batch_size, seq_length = input_ids.shape[:2]
subsampled_seq_length = self.model_tester.get_subsampled_output_lengths(seq_length)
num_sequences_in_output = batch_size * num_return_sequences
gen_len = (
output.sequences.shape[-1] - 1 if config.is_encoder_decoder else output.sequences.shape[-1] - seq_length
)
# scores
self._check_scores(num_sequences_in_output, output.scores, length=gen_len, config=config)
# Attentions
# encoder
self._check_encoder_attention_for_generate(
output.encoder_attentions, batch_size, config, subsampled_seq_length
)
# decoder
self._check_attentions_for_generate(
num_sequences_in_output,
output.decoder_attentions,
min_length=1,
max_length=output.sequences.shape[-1],
config=config,
use_cache=use_cache,
)
# Hidden States
# encoder
self._check_encoder_hidden_states_for_generate(
output.encoder_hidden_states, batch_size, config, subsampled_seq_length
)
# decoder
self._check_hidden_states_for_generate(
num_sequences_in_output,
output.decoder_hidden_states,
min_length=1,
max_length=output.sequences.shape[-1],
config=config,
use_cache=use_cache,
)
def _create_and_check_torchscript(self, config, inputs_dict):
if not self.test_torchscript:
return
configs_no_init = _config_zero_init(config) # To be sure we have no Nan
configs_no_init.torchscript = True
for model_class in self.all_model_classes:
model = model_class(config=configs_no_init)
model.to(torch_device)
model.eval()
inputs = self._prepare_for_class(inputs_dict, model_class)
try:
model.config.use_cache = False # FSTM still requires this hack -> FSTM should probably be refactored similar to BART afterward
input_features = inputs["input_features"]
attention_mask = inputs["attention_mask"]
decoder_input_ids = inputs["decoder_input_ids"]
decoder_attention_mask = inputs["decoder_attention_mask"]
traced_model = torch.jit.trace(
model, (input_features, attention_mask, decoder_input_ids, decoder_attention_mask)
)
except RuntimeError:
self.fail("Couldn't trace module.")
with tempfile.TemporaryDirectory() as tmp_dir_name:
pt_file_name = os.path.join(tmp_dir_name, "traced_model.pt")
try:
torch.jit.save(traced_model, pt_file_name)
except Exception:
self.fail("Couldn't save module.")
try:
loaded_model = torch.jit.load(pt_file_name)
except Exception:
self.fail("Couldn't load module.")
model.to(torch_device)
model.eval()
loaded_model.to(torch_device)
loaded_model.eval()
model_state_dict = model.state_dict()
loaded_model_state_dict = loaded_model.state_dict()
non_persistent_buffers = {}
for key in loaded_model_state_dict.keys():
if key not in model_state_dict.keys():
non_persistent_buffers[key] = loaded_model_state_dict[key]
loaded_model_state_dict = {
key: value for key, value in loaded_model_state_dict.items() if key not in non_persistent_buffers
}
self.assertEqual(set(model_state_dict.keys()), set(loaded_model_state_dict.keys()))
model_buffers = list(model.buffers())
for non_persistent_buffer in non_persistent_buffers.values():
found_buffer = False
for i, model_buffer in enumerate(model_buffers):
if torch.equal(non_persistent_buffer, model_buffer):
found_buffer = True
break
self.assertTrue(found_buffer)
model_buffers.pop(i)
models_equal = True
for layer_name, p1 in model_state_dict.items():
p2 = loaded_model_state_dict[layer_name]
if p1.data.ne(p2.data).sum() > 0:
models_equal = False
self.assertTrue(models_equal)
def test_pt_tf_model_equivalence(self, allow_missing_keys=True):
# Allow missing keys since TF doesn't cache the sinusoidal embeddings in an attribute
super().test_pt_tf_model_equivalence(allow_missing_keys=allow_missing_keys)
@unittest.skip("Test failing, @RocketNight is looking into it")
def test_tf_from_pt_safetensors(self):
pass
@require_torch
@require_torchaudio
@require_sentencepiece
@require_tokenizers
@slow
class Speech2TextModelIntegrationTests(unittest.TestCase):
@cached_property
def default_processor(self):
return Speech2TextProcessor.from_pretrained("facebook/s2t-small-librispeech-asr")
def _load_datasamples(self, num_samples):
from datasets import load_dataset
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
# automatic decoding with librispeech
speech_samples = ds.sort("id").select(range(num_samples))[:num_samples]["audio"]
return [x["array"] for x in speech_samples]
def test_generation_librispeech(self):
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
model.to(torch_device)
processor = self.default_processor
input_speech = self._load_datasamples(1)
input_features = processor(input_speech, return_tensors="pt").input_features.to(torch_device)
generated_ids = model.generate(input_features)
generated_transcript = processor.batch_decode(generated_ids, skip_special_tokens=True)
EXPECTED_TRANSCRIPTIONS = [
"mister quilter is the apostle of the middle classes and we are glad to welcome his gospel"
]
self.assertListEqual(generated_transcript, EXPECTED_TRANSCRIPTIONS)
def test_generation_librispeech_batched(self):
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-librispeech-asr")
model.to(torch_device)
processor = self.default_processor
input_speech = self._load_datasamples(4)
inputs = processor(input_speech, return_tensors="pt", padding=True)
input_features = inputs.input_features.to(torch_device)
attention_mask = inputs.attention_mask.to(torch_device)
generated_ids = model.generate(input_features, attention_mask=attention_mask)
generated_transcripts = processor.batch_decode(generated_ids, skip_special_tokens=True)
EXPECTED_TRANSCRIPTIONS = [
"mister quilter is the apostle of the middle classes and we are glad to welcome his gospel",
"nor is mister cultar's manner less interesting than his matter",
"he tells us that at this festive season of the year with christmas and roast beef looming before us"
" similes drawn from eating and its results occur most readily to the mind",
"he has grave doubts whether sir frederick leyton's work is really greek after all and can discover in it"
" but little of rocky ithaca",
]
self.assertListEqual(generated_transcripts, EXPECTED_TRANSCRIPTIONS)
| transformers/tests/models/speech_to_text/test_modeling_speech_to_text.py/0 | {
"file_path": "transformers/tests/models/speech_to_text/test_modeling_speech_to_text.py",
"repo_id": "transformers",
"token_count": 16001
} | 371 |
# coding=utf-8
# Copyright 2020 The SqueezeBert authors and The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from transformers import SqueezeBertTokenizer, SqueezeBertTokenizerFast
from transformers.testing_utils import require_tokenizers, slow
from ..bert.test_tokenization_bert import BertTokenizationTest
@require_tokenizers
class SqueezeBertTokenizationTest(BertTokenizationTest):
tokenizer_class = SqueezeBertTokenizer
rust_tokenizer_class = SqueezeBertTokenizerFast
test_rust_tokenizer = True
from_pretrained_id = "squeezebert/squeezebert-uncased"
def get_rust_tokenizer(self, **kwargs):
return SqueezeBertTokenizerFast.from_pretrained(self.tmpdirname, **kwargs)
@slow
def test_sequence_builders(self):
tokenizer = SqueezeBertTokenizer.from_pretrained("squeezebert/squeezebert-mnli-headless")
text = tokenizer.encode("sequence builders", add_special_tokens=False)
text_2 = tokenizer.encode("multi-sequence build", add_special_tokens=False)
encoded_sentence = tokenizer.build_inputs_with_special_tokens(text)
encoded_pair = tokenizer.build_inputs_with_special_tokens(text, text_2)
assert encoded_sentence == [tokenizer.cls_token_id] + text + [tokenizer.sep_token_id]
assert encoded_pair == [tokenizer.cls_token_id] + text + [tokenizer.sep_token_id] + text_2 + [
tokenizer.sep_token_id
]
| transformers/tests/models/squeezebert/test_tokenization_squeezebert.py/0 | {
"file_path": "transformers/tests/models/squeezebert/test_tokenization_squeezebert.py",
"repo_id": "transformers",
"token_count": 669
} | 372 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch TimeSeriesTransformer model. """
import inspect
import tempfile
import unittest
from huggingface_hub import hf_hub_download
from parameterized import parameterized
from transformers import is_torch_available
from transformers.testing_utils import is_flaky, require_torch, slow, torch_device
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
TOLERANCE = 1e-4
if is_torch_available():
import torch
from transformers import (
TimeSeriesTransformerConfig,
TimeSeriesTransformerForPrediction,
TimeSeriesTransformerModel,
)
from transformers.models.time_series_transformer.modeling_time_series_transformer import (
TimeSeriesTransformerDecoder,
TimeSeriesTransformerEncoder,
)
@require_torch
class TimeSeriesTransformerModelTester:
def __init__(
self,
parent,
batch_size=13,
prediction_length=7,
context_length=14,
cardinality=19,
embedding_dimension=5,
num_time_features=4,
is_training=True,
hidden_size=64,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=4,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
lags_sequence=[1, 2, 3, 4, 5],
):
self.parent = parent
self.batch_size = batch_size
self.prediction_length = prediction_length
self.context_length = context_length
self.cardinality = cardinality
self.num_time_features = num_time_features
self.lags_sequence = lags_sequence
self.embedding_dimension = embedding_dimension
self.is_training = is_training
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.encoder_seq_length = context_length
self.decoder_seq_length = prediction_length
def get_config(self):
return TimeSeriesTransformerConfig(
encoder_layers=self.num_hidden_layers,
decoder_layers=self.num_hidden_layers,
encoder_attention_heads=self.num_attention_heads,
decoder_attention_heads=self.num_attention_heads,
encoder_ffn_dim=self.intermediate_size,
decoder_ffn_dim=self.intermediate_size,
dropout=self.hidden_dropout_prob,
attention_dropout=self.attention_probs_dropout_prob,
prediction_length=self.prediction_length,
context_length=self.context_length,
lags_sequence=self.lags_sequence,
num_time_features=self.num_time_features,
num_static_real_features=1,
num_static_categorical_features=1,
cardinality=[self.cardinality],
embedding_dimension=[self.embedding_dimension],
scaling="std", # we need std to get non-zero `loc`
)
def prepare_time_series_transformer_inputs_dict(self, config):
_past_length = config.context_length + max(config.lags_sequence)
static_categorical_features = ids_tensor([self.batch_size, 1], config.cardinality[0])
static_real_features = floats_tensor([self.batch_size, 1])
past_time_features = floats_tensor([self.batch_size, _past_length, config.num_time_features])
past_values = floats_tensor([self.batch_size, _past_length])
past_observed_mask = floats_tensor([self.batch_size, _past_length]) > 0.5
# decoder inputs
future_time_features = floats_tensor([self.batch_size, config.prediction_length, config.num_time_features])
future_values = floats_tensor([self.batch_size, config.prediction_length])
inputs_dict = {
"past_values": past_values,
"static_categorical_features": static_categorical_features,
"static_real_features": static_real_features,
"past_time_features": past_time_features,
"past_observed_mask": past_observed_mask,
"future_time_features": future_time_features,
"future_values": future_values,
}
return inputs_dict
def prepare_config_and_inputs(self):
config = self.get_config()
inputs_dict = self.prepare_time_series_transformer_inputs_dict(config)
return config, inputs_dict
def prepare_config_and_inputs_for_common(self):
config, inputs_dict = self.prepare_config_and_inputs()
return config, inputs_dict
def check_encoder_decoder_model_standalone(self, config, inputs_dict):
model = TimeSeriesTransformerModel(config=config).to(torch_device).eval()
outputs = model(**inputs_dict)
encoder_last_hidden_state = outputs.encoder_last_hidden_state
last_hidden_state = outputs.last_hidden_state
with tempfile.TemporaryDirectory() as tmpdirname:
encoder = model.get_encoder()
encoder.save_pretrained(tmpdirname)
encoder = TimeSeriesTransformerEncoder.from_pretrained(tmpdirname).to(torch_device)
transformer_inputs, _, _, _ = model.create_network_inputs(**inputs_dict)
enc_input = transformer_inputs[:, : config.context_length, ...]
dec_input = transformer_inputs[:, config.context_length :, ...]
encoder_last_hidden_state_2 = encoder(inputs_embeds=enc_input)[0]
self.parent.assertTrue((encoder_last_hidden_state_2 - encoder_last_hidden_state).abs().max().item() < 1e-3)
with tempfile.TemporaryDirectory() as tmpdirname:
decoder = model.get_decoder()
decoder.save_pretrained(tmpdirname)
decoder = TimeSeriesTransformerDecoder.from_pretrained(tmpdirname).to(torch_device)
last_hidden_state_2 = decoder(
inputs_embeds=dec_input,
encoder_hidden_states=encoder_last_hidden_state,
)[0]
self.parent.assertTrue((last_hidden_state_2 - last_hidden_state).abs().max().item() < 1e-3)
@require_torch
class TimeSeriesTransformerModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(TimeSeriesTransformerModel, TimeSeriesTransformerForPrediction) if is_torch_available() else ()
)
all_generative_model_classes = (TimeSeriesTransformerForPrediction,) if is_torch_available() else ()
pipeline_model_mapping = {"feature-extraction": TimeSeriesTransformerModel} if is_torch_available() else {}
is_encoder_decoder = True
test_pruning = False
test_head_masking = False
test_missing_keys = False
test_torchscript = False
test_inputs_embeds = False
test_model_common_attributes = False
def setUp(self):
self.model_tester = TimeSeriesTransformerModelTester(self)
self.config_tester = ConfigTester(
self,
config_class=TimeSeriesTransformerConfig,
has_text_modality=False,
prediction_length=self.model_tester.prediction_length,
)
def test_config(self):
self.config_tester.run_common_tests()
def test_save_load_strict(self):
config, _ = self.model_tester.prepare_config_and_inputs()
for model_class in self.all_model_classes:
model = model_class(config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model2, info = model_class.from_pretrained(tmpdirname, output_loading_info=True)
self.assertEqual(info["missing_keys"], [])
def test_encoder_decoder_model_standalone(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.check_encoder_decoder_model_standalone(*config_and_inputs)
# Ignore since we have no tokens embeddings
def test_resize_tokens_embeddings(self):
pass
# # Input is 'static_categorical_features' not 'input_ids'
def test_model_main_input_name(self):
model_signature = inspect.signature(getattr(TimeSeriesTransformerModel, "forward"))
# The main input is the name of the argument after `self`
observed_main_input_name = list(model_signature.parameters.keys())[1]
self.assertEqual(TimeSeriesTransformerModel.main_input_name, observed_main_input_name)
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
signature = inspect.signature(model.forward)
# signature.parameters is an OrderedDict => so arg_names order is deterministic
arg_names = [*signature.parameters.keys()]
expected_arg_names = [
"past_values",
"past_time_features",
"past_observed_mask",
"static_categorical_features",
"static_real_features",
"future_values",
"future_time_features",
]
expected_arg_names.extend(
[
"future_observed_mask",
"decoder_attention_mask",
"head_mask",
"decoder_head_mask",
"cross_attn_head_mask",
"encoder_outputs",
"past_key_values",
"output_hidden_states",
"output_attentions",
"use_cache",
"return_dict",
]
if "future_observed_mask" in arg_names
else [
"decoder_attention_mask",
"head_mask",
"decoder_head_mask",
"cross_attn_head_mask",
"encoder_outputs",
"past_key_values",
"output_hidden_states",
"output_attentions",
"use_cache",
"return_dict",
]
)
self.assertListEqual(arg_names[: len(expected_arg_names)], expected_arg_names)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
seq_len = getattr(self.model_tester, "seq_length", None)
decoder_seq_length = getattr(self.model_tester, "decoder_seq_length", seq_len)
encoder_seq_length = getattr(self.model_tester, "encoder_seq_length", seq_len)
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, encoder_seq_length, encoder_seq_length],
)
out_len = len(outputs)
correct_outlen = 7
if "last_hidden_state" in outputs:
correct_outlen += 1
if "past_key_values" in outputs:
correct_outlen += 1 # past_key_values have been returned
if "loss" in outputs:
correct_outlen += 1
if "params" in outputs:
correct_outlen += 1
self.assertEqual(out_len, correct_outlen)
# decoder attentions
decoder_attentions = outputs.decoder_attentions
self.assertIsInstance(decoder_attentions, (list, tuple))
self.assertEqual(len(decoder_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(decoder_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, decoder_seq_length, decoder_seq_length],
)
# cross attentions
cross_attentions = outputs.cross_attentions
self.assertIsInstance(cross_attentions, (list, tuple))
self.assertEqual(len(cross_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(cross_attentions[0].shape[-3:]),
[
self.model_tester.num_attention_heads,
decoder_seq_length,
encoder_seq_length,
],
)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
self.assertEqual(out_len + 2, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, encoder_seq_length, encoder_seq_length],
)
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
@parameterized.expand(
[
(1, 5, [1]),
(1, 5, [1, 10, 15]),
(1, 5, [3, 6, 9, 10]),
(2, 5, [1, 2, 7]),
(2, 5, [2, 3, 4, 6]),
(4, 5, [1, 5, 9, 11]),
(4, 5, [7, 8, 13, 14]),
],
)
def test_create_network_inputs(self, prediction_length, context_length, lags_sequence):
history_length = max(lags_sequence) + context_length
config = TimeSeriesTransformerConfig(
prediction_length=prediction_length,
context_length=context_length,
lags_sequence=lags_sequence,
scaling=False,
num_parallel_samples=10,
num_static_categorical_features=1,
cardinality=[1],
embedding_dimension=[2],
num_static_real_features=1,
)
model = TimeSeriesTransformerModel(config)
batch = {
"static_categorical_features": torch.tensor([[0]], dtype=torch.int64),
"static_real_features": torch.tensor([[0.0]], dtype=torch.float32),
"past_time_features": torch.arange(history_length, dtype=torch.float32).view(1, history_length, 1),
"past_values": torch.arange(history_length, dtype=torch.float32).view(1, history_length),
"past_observed_mask": torch.arange(history_length, dtype=torch.float32).view(1, history_length),
}
# test with no future_target (only one step prediction)
batch["future_time_features"] = torch.arange(history_length, history_length + 1, dtype=torch.float32).view(
1, 1, 1
)
transformer_inputs, loc, scale, _ = model.create_network_inputs(**batch)
self.assertTrue((scale == 1.0).all())
assert (loc == 0.0).all()
ref = torch.arange(max(lags_sequence), history_length, dtype=torch.float32)
for idx, lag in enumerate(lags_sequence):
assert torch.isclose(ref - lag, transformer_inputs[0, :, idx]).all()
# test with all future data
batch["future_time_features"] = torch.arange(
history_length, history_length + prediction_length, dtype=torch.float32
).view(1, prediction_length, 1)
batch["future_values"] = torch.arange(
history_length, history_length + prediction_length, dtype=torch.float32
).view(1, prediction_length)
transformer_inputs, loc, scale, _ = model.create_network_inputs(**batch)
assert (scale == 1.0).all()
assert (loc == 0.0).all()
ref = torch.arange(max(lags_sequence), history_length + prediction_length, dtype=torch.float32)
for idx, lag in enumerate(lags_sequence):
assert torch.isclose(ref - lag, transformer_inputs[0, :, idx]).all()
# test for generation
batch.pop("future_values")
transformer_inputs, loc, scale, _ = model.create_network_inputs(**batch)
lagged_sequence = model.get_lagged_subsequences(
sequence=batch["past_values"],
subsequences_length=1,
shift=1,
)
# assert that the last element of the lagged sequence is the one after the encoders input
assert transformer_inputs[0, ..., 0][-1] + 1 == lagged_sequence[0, ..., 0][-1]
future_values = torch.arange(history_length, history_length + prediction_length, dtype=torch.float32).view(
1, prediction_length
)
# assert that the first element of the future_values is offset by lag after the decoders input
assert lagged_sequence[0, ..., 0][-1] + lags_sequence[0] == future_values[0, ..., 0]
@is_flaky()
def test_retain_grad_hidden_states_attentions(self):
super().test_retain_grad_hidden_states_attentions()
def prepare_batch(filename="train-batch.pt"):
file = hf_hub_download(repo_id="hf-internal-testing/tourism-monthly-batch", filename=filename, repo_type="dataset")
batch = torch.load(file, map_location=torch_device)
return batch
@require_torch
@slow
class TimeSeriesTransformerModelIntegrationTests(unittest.TestCase):
def test_inference_no_head(self):
model = TimeSeriesTransformerModel.from_pretrained("huggingface/time-series-transformer-tourism-monthly").to(
torch_device
)
batch = prepare_batch()
with torch.no_grad():
output = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"],
static_real_features=batch["static_real_features"],
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
).last_hidden_state
expected_shape = torch.Size((64, model.config.context_length, model.config.d_model))
self.assertEqual(output.shape, expected_shape)
expected_slice = torch.tensor(
[[0.8196, -1.5131, 1.4620], [1.1268, -1.3238, 1.5997], [1.5098, -1.0715, 1.7359]], device=torch_device
)
self.assertTrue(torch.allclose(output[0, :3, :3], expected_slice, atol=TOLERANCE))
def test_inference_head(self):
model = TimeSeriesTransformerForPrediction.from_pretrained(
"huggingface/time-series-transformer-tourism-monthly"
).to(torch_device)
batch = prepare_batch("val-batch.pt")
with torch.no_grad():
output = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"],
static_real_features=batch["static_real_features"],
future_time_features=batch["future_time_features"],
).encoder_last_hidden_state
expected_shape = torch.Size((64, model.config.context_length, model.config.d_model))
self.assertEqual(output.shape, expected_shape)
expected_slice = torch.tensor(
[[-1.2957, -1.0280, -0.6045], [-0.7017, -0.8193, -0.3717], [-1.0449, -0.8149, 0.1405]], device=torch_device
)
self.assertTrue(torch.allclose(output[0, :3, :3], expected_slice, atol=TOLERANCE))
def test_seq_to_seq_generation(self):
model = TimeSeriesTransformerForPrediction.from_pretrained(
"huggingface/time-series-transformer-tourism-monthly"
).to(torch_device)
batch = prepare_batch("val-batch.pt")
with torch.no_grad():
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"],
static_real_features=batch["static_real_features"],
past_time_features=batch["past_time_features"],
past_values=batch["past_values"],
future_time_features=batch["future_time_features"],
past_observed_mask=batch["past_observed_mask"],
)
expected_shape = torch.Size((64, model.config.num_parallel_samples, model.config.prediction_length))
self.assertEqual(outputs.sequences.shape, expected_shape)
expected_slice = torch.tensor([2825.2749, 3584.9207, 6763.9951], device=torch_device)
mean_prediction = outputs.sequences.mean(dim=1)
self.assertTrue(torch.allclose(mean_prediction[0, -3:], expected_slice, rtol=1e-1))
| transformers/tests/models/time_series_transformer/test_modeling_time_series_transformer.py/0 | {
"file_path": "transformers/tests/models/time_series_transformer/test_modeling_time_series_transformer.py",
"repo_id": "transformers",
"token_count": 10453
} | 373 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import inspect
import unittest
from huggingface_hub import hf_hub_download
from transformers import UdopConfig, is_torch_available, is_vision_available
from transformers.testing_utils import (
require_sentencepiece,
require_tokenizers,
require_torch,
require_vision,
slow,
torch_device,
)
from transformers.utils import cached_property
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import UdopEncoderModel, UdopForConditionalGeneration, UdopModel, UdopProcessor
from transformers.models.udop.modeling_udop import UDOP_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from PIL import Image
class UdopModelTester:
def __init__(
self,
parent,
vocab_size=99,
batch_size=13,
encoder_seq_length=7,
decoder_seq_length=9,
# For common tests
is_training=True,
use_attention_mask=True,
use_labels=True,
hidden_size=32,
num_hidden_layers=5,
num_attention_heads=4,
d_ff=37,
relative_attention_num_buckets=32,
dropout_rate=0.1,
initializer_factor=0.002,
eos_token_id=1,
pad_token_id=0,
scope=None,
decoder_layers=None,
range_bbox=1000,
decoder_start_token_id=0,
):
self.parent = parent
self.batch_size = batch_size
self.encoder_seq_length = encoder_seq_length
self.decoder_seq_length = decoder_seq_length
# For common tests
self.seq_length = self.decoder_seq_length
self.is_training = is_training
self.use_attention_mask = use_attention_mask
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.d_ff = d_ff
self.relative_attention_num_buckets = relative_attention_num_buckets
self.dropout_rate = dropout_rate
self.initializer_factor = initializer_factor
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.scope = None
self.decoder_layers = decoder_layers
self.range_bbox = range_bbox
self.decoder_start_token_id = decoder_start_token_id
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.encoder_seq_length], self.vocab_size)
bbox = ids_tensor([self.batch_size, self.encoder_seq_length, 4], self.range_bbox).float()
# Ensure that bbox is legal
for i in range(bbox.shape[0]):
for j in range(bbox.shape[1]):
if bbox[i, j, 3] < bbox[i, j, 1]:
t = bbox[i, j, 3]
bbox[i, j, 3] = bbox[i, j, 1]
bbox[i, j, 1] = t
if bbox[i, j, 2] < bbox[i, j, 0]:
t = bbox[i, j, 2]
bbox[i, j, 2] = bbox[i, j, 0]
bbox[i, j, 0] = t
decoder_input_ids = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
attention_mask = None
decoder_attention_mask = None
if self.use_attention_mask:
attention_mask = ids_tensor([self.batch_size, self.encoder_seq_length], vocab_size=2)
decoder_attention_mask = ids_tensor([self.batch_size, self.decoder_seq_length], vocab_size=2)
lm_labels = None
if self.use_labels:
lm_labels = ids_tensor([self.batch_size, self.decoder_seq_length], self.vocab_size)
config = self.get_config()
return (
config,
input_ids,
bbox,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
)
def get_config(self):
return UdopConfig(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
d_ff=self.d_ff,
d_kv=self.hidden_size // self.num_attention_heads,
num_layers=self.num_hidden_layers,
num_decoder_layers=self.decoder_layers,
num_heads=self.num_attention_heads,
relative_attention_num_buckets=self.relative_attention_num_buckets,
dropout_rate=self.dropout_rate,
initializer_factor=self.initializer_factor,
eos_token_id=self.eos_token_id,
bos_token_id=self.pad_token_id,
pad_token_id=self.pad_token_id,
decoder_start_token_id=self.decoder_start_token_id,
)
def create_and_check_model(
self,
config,
input_ids,
bbox,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = UdopModel(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids=input_ids,
bbox=bbox,
decoder_input_ids=decoder_input_ids,
attention_mask=attention_mask,
decoder_attention_mask=decoder_attention_mask,
)
result = model(input_ids=input_ids, bbox=bbox, decoder_input_ids=decoder_input_ids)
decoder_output = result.last_hidden_state
decoder_past = result.past_key_values
encoder_output = result.encoder_last_hidden_state
self.parent.assertEqual(encoder_output.size(), (self.batch_size, self.encoder_seq_length, self.hidden_size))
self.parent.assertEqual(decoder_output.size(), (self.batch_size, self.decoder_seq_length, self.hidden_size))
# There should be `num_layers` key value embeddings stored in decoder_past
self.parent.assertEqual(len(decoder_past), config.num_layers)
# There should be a self attn key, a self attn value, a cross attn key and a cross attn value stored in each decoder_past tuple
self.parent.assertEqual(len(decoder_past[0]), 4)
def create_and_check_with_lm_head(
self,
config,
input_ids,
bbox,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = UdopForConditionalGeneration(config=config).to(torch_device).eval()
outputs = model(
input_ids=input_ids,
bbox=bbox,
decoder_input_ids=decoder_input_ids,
decoder_attention_mask=decoder_attention_mask,
labels=lm_labels,
)
self.parent.assertEqual(len(outputs), 4)
self.parent.assertEqual(outputs["logits"].size(), (self.batch_size, self.decoder_seq_length, self.vocab_size))
self.parent.assertEqual(outputs["loss"].size(), ())
def create_and_check_generate_with_past_key_values(
self,
config,
input_ids,
bbox,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
):
model = UdopForConditionalGeneration(config=config).to(torch_device).eval()
torch.manual_seed(0)
output_without_past_cache = model.generate(
input_ids[:1], bbox=bbox[:1, :, :], num_beams=2, max_length=5, do_sample=True, use_cache=False
)
torch.manual_seed(0)
output_with_past_cache = model.generate(
input_ids[:1], bbox=bbox[:1, :, :], num_beams=2, max_length=5, do_sample=True
)
self.parent.assertTrue(torch.all(output_with_past_cache == output_without_past_cache))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
bbox,
decoder_input_ids,
attention_mask,
decoder_attention_mask,
lm_labels,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"attention_mask": attention_mask,
"bbox": bbox,
"decoder_input_ids": decoder_input_ids,
"decoder_attention_mask": decoder_attention_mask,
"use_cache": False,
}
return config, inputs_dict
@require_torch
class UdopModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
UdopModel,
UdopForConditionalGeneration,
)
if is_torch_available()
else ()
)
all_generative_model_classes = (UdopForConditionalGeneration,) if is_torch_available() else ()
pipeline_model_mapping = {"feature-extraction": UdopModel} if is_torch_available() else {}
fx_compatible = False
test_pruning = False
test_torchscript = False
test_head_masking = False
test_resize_embeddings = True
test_model_parallel = False
is_encoder_decoder = True
# The small UDOP model needs higher percentages for CPU/MP tests
model_split_percents = [0.8, 0.9]
def setUp(self):
self.model_tester = UdopModelTester(self)
self.config_tester = ConfigTester(self, config_class=UdopConfig, d_model=37)
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
inputs_dict = copy.deepcopy(inputs_dict)
if model_class.__name__ == "UdopForConditionalGeneration":
if return_labels:
inputs_dict["labels"] = torch.zeros(
(self.model_tester.batch_size, self.model_tester.seq_length), dtype=torch.long, device=torch_device
)
return inputs_dict
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_with_lm_head(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_with_lm_head(*config_and_inputs)
def test_generate_with_past_key_values(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_generate_with_past_key_values(*config_and_inputs)
@unittest.skipIf(torch_device == "cpu", "Cant do half precision")
def test_model_fp16_forward(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_fp16_forward(*config_and_inputs)
@unittest.skip("Gradient checkpointing is not supported by this model")
def test_training_gradient_checkpointing(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
def test_forward_signature(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
signature = inspect.signature(model.forward)
# signature.parameters is an OrderedDict => so arg_names order is deterministic
arg_names = sorted([*signature.parameters.keys()])
expected_arg_names = [
"attention_mask",
"bbox",
"cross_attn_head_mask",
"decoder_attention_mask",
"decoder_head_mask",
"decoder_input_ids",
"decoder_inputs_embeds",
"encoder_outputs",
"head_mask",
"input_ids",
"inputs_embeds",
]
if model_class in self.all_generative_model_classes:
expected_arg_names.append(
"labels",
)
expected_arg_names = sorted(expected_arg_names)
self.assertListEqual(sorted(arg_names[: len(expected_arg_names)]), expected_arg_names)
@unittest.skip(
"Not currently compatible. Fails with - NotImplementedError: Cannot copy out of meta tensor; no data!"
)
def test_save_load_low_cpu_mem_usage(self):
pass
@slow
def test_model_from_pretrained(self):
for model_name in UDOP_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = UdopForConditionalGeneration.from_pretrained(model_name)
self.assertIsNotNone(model)
class UdopEncoderOnlyModelTester:
def __init__(
self,
parent,
vocab_size=99,
batch_size=13,
seq_length=7,
# For common tests
is_training=False,
use_attention_mask=True,
hidden_size=32,
num_hidden_layers=5,
decoder_layers=2,
num_attention_heads=4,
d_ff=37,
relative_attention_num_buckets=32,
dropout_rate=0.1,
initializer_factor=0.002,
eos_token_id=1,
pad_token_id=0,
scope=None,
range_bbox=1000,
):
self.parent = parent
self.batch_size = batch_size
# For common tests
self.seq_length = seq_length
self.is_training = is_training
self.use_attention_mask = use_attention_mask
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.decoder_layers = decoder_layers
self.num_attention_heads = num_attention_heads
self.d_ff = d_ff
self.relative_attention_num_buckets = relative_attention_num_buckets
self.dropout_rate = dropout_rate
self.initializer_factor = initializer_factor
self.eos_token_id = eos_token_id
self.pad_token_id = pad_token_id
self.scope = None
self.range_bbox = range_bbox
def get_config(self):
return UdopConfig(
vocab_size=self.vocab_size,
d_model=self.hidden_size,
d_ff=self.d_ff,
d_kv=self.hidden_size // self.num_attention_heads,
num_layers=self.num_hidden_layers,
num_decoder_layers=self.decoder_layers,
num_heads=self.num_attention_heads,
relative_attention_num_buckets=self.relative_attention_num_buckets,
dropout_rate=self.dropout_rate,
initializer_factor=self.initializer_factor,
eos_token_id=self.eos_token_id,
bos_token_id=self.pad_token_id,
pad_token_id=self.pad_token_id,
is_encoder_decoder=False,
)
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
bbox = ids_tensor([self.batch_size, self.seq_length, 4], self.range_bbox).float()
# Ensure that bbox is legal
for i in range(bbox.shape[0]):
for j in range(bbox.shape[1]):
if bbox[i, j, 3] < bbox[i, j, 1]:
t = bbox[i, j, 3]
bbox[i, j, 3] = bbox[i, j, 1]
bbox[i, j, 1] = t
if bbox[i, j, 2] < bbox[i, j, 0]:
t = bbox[i, j, 2]
bbox[i, j, 2] = bbox[i, j, 0]
bbox[i, j, 0] = t
attention_mask = None
if self.use_attention_mask:
attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
config = self.get_config()
return (
config,
input_ids,
bbox,
attention_mask,
)
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
bbox,
attention_mask,
) = config_and_inputs
inputs_dict = {
"input_ids": input_ids,
"bbox": bbox,
"attention_mask": attention_mask,
}
return config, inputs_dict
def create_and_check_model(
self,
config,
input_ids,
bbox,
attention_mask,
):
model = UdopEncoderModel(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids=input_ids,
bbox=bbox,
attention_mask=attention_mask,
)
encoder_output = result.last_hidden_state
self.parent.assertEqual(encoder_output.size(), (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_model_fp16_forward(
self,
config,
input_ids,
attention_mask,
):
model = UdopEncoderModel(config=config).to(torch_device).half().eval()
output = model(input_ids, attention_mask=attention_mask)["last_hidden_state"]
self.parent.assertFalse(torch.isnan(output).any().item())
class UdopEncoderOnlyModelTest(ModelTesterMixin, unittest.TestCase):
all_model_classes = (UdopEncoderModel,) if is_torch_available() else ()
test_pruning = False
test_torchscript = False
test_head_masking = False
test_resize_embeddings = False
test_model_parallel = True
all_parallelizable_model_classes = (UdopEncoderModel,) if is_torch_available() else ()
def setUp(self):
self.model_tester = UdopEncoderOnlyModelTester(self)
self.config_tester = ConfigTester(self, config_class=UdopConfig, d_model=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
@unittest.skipIf(torch_device == "cpu", "Cant do half precision")
def test_model_fp16_forward(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_fp16_forward(*config_and_inputs)
@unittest.skip(
"Not currently compatible. Fails with - NotImplementedError: Cannot copy out of meta tensor; no data!"
)
def test_save_load_low_cpu_mem_usage(self):
pass
@require_torch
@require_sentencepiece
@require_tokenizers
@require_vision
@slow
class UdopModelIntegrationTests(unittest.TestCase):
@cached_property
def image(self):
filepath = hf_hub_download(
repo_id="hf-internal-testing/fixtures_docvqa", filename="document_2.png", repo_type="dataset"
)
image = Image.open(filepath).convert("RGB")
return image
@cached_property
def processor(self):
return UdopProcessor.from_pretrained("microsoft/udop-large")
@cached_property
def model(self):
return UdopForConditionalGeneration.from_pretrained("microsoft/udop-large").to(torch_device)
def test_conditional_generation(self):
processor = self.processor
model = self.model
prompt = "Question answering. In which year is the report made?"
encoding = processor(images=self.image, text=prompt, return_tensors="pt")
predicted_ids = model.generate(**encoding)
predicted_text = processor.batch_decode(predicted_ids, skip_special_tokens=True)[0]
self.assertEquals(predicted_text, "2013")
| transformers/tests/models/udop/test_modeling_udop.py/0 | {
"file_path": "transformers/tests/models/udop/test_modeling_udop.py",
"repo_id": "transformers",
"token_count": 9592
} | 374 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch VideoMAE model. """
import copy
import unittest
import numpy as np
from huggingface_hub import hf_hub_download
from transformers import VideoMAEConfig
from transformers.models.auto import get_values
from transformers.testing_utils import require_torch, require_vision, slow, torch_device
from transformers.utils import cached_property, is_torch_available, is_vision_available
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from torch import nn
from transformers import (
MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING,
VideoMAEForPreTraining,
VideoMAEForVideoClassification,
VideoMAEModel,
)
from transformers.models.videomae.modeling_videomae import VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST
if is_vision_available():
from transformers import VideoMAEImageProcessor
class VideoMAEModelTester:
def __init__(
self,
parent,
batch_size=13,
image_size=10,
num_channels=3,
patch_size=2,
tubelet_size=2,
num_frames=2,
is_training=True,
use_labels=True,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
type_sequence_label_size=10,
initializer_range=0.02,
mask_ratio=0.9,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.image_size = image_size
self.num_channels = num_channels
self.patch_size = patch_size
self.tubelet_size = tubelet_size
self.num_frames = num_frames
self.is_training = is_training
self.use_labels = use_labels
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.mask_ratio = mask_ratio
self.scope = scope
# in VideoMAE, the number of tokens equals num_frames/tubelet_size * num_patches per frame
self.num_patches_per_frame = (image_size // patch_size) ** 2
self.seq_length = (num_frames // tubelet_size) * self.num_patches_per_frame
# use this variable to define bool_masked_pos
self.num_masks = int(mask_ratio * self.seq_length)
def prepare_config_and_inputs(self):
pixel_values = floats_tensor(
[self.batch_size, self.num_frames, self.num_channels, self.image_size, self.image_size]
)
labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
config = self.get_config()
return config, pixel_values, labels
def get_config(self):
return VideoMAEConfig(
image_size=self.image_size,
patch_size=self.patch_size,
num_channels=self.num_channels,
num_frames=self.num_frames,
tubelet_size=self.tubelet_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
is_decoder=False,
initializer_range=self.initializer_range,
decoder_hidden_size=self.hidden_size,
decoder_intermediate_size=self.intermediate_size,
decoder_num_attention_heads=self.num_attention_heads,
decoder_num_hidden_layers=self.num_hidden_layers,
)
def create_and_check_model(self, config, pixel_values, labels):
model = VideoMAEModel(config=config)
model.to(torch_device)
model.eval()
result = model(pixel_values)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_for_pretraining(self, config, pixel_values, labels):
model = VideoMAEForPreTraining(config)
model.to(torch_device)
model.eval()
# important: each video needs to have the same number of masked patches
# hence we define a single mask, which we then repeat for each example in the batch
mask = torch.ones((self.num_masks,))
mask = torch.cat([mask, torch.zeros(self.seq_length - mask.size(0))])
bool_masked_pos = mask.expand(self.batch_size, -1).bool()
result = model(pixel_values, bool_masked_pos)
# model only returns predictions for masked patches
num_masked_patches = mask.sum().item()
decoder_num_labels = 3 * self.tubelet_size * self.patch_size**2
self.parent.assertEqual(result.logits.shape, (self.batch_size, num_masked_patches, decoder_num_labels))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
config, pixel_values, labels = config_and_inputs
inputs_dict = {"pixel_values": pixel_values}
return config, inputs_dict
@require_torch
class VideoMAEModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
"""
Here we also overwrite some of the tests of test_modeling_common.py, as VideoMAE does not use input_ids, inputs_embeds,
attention_mask and seq_length.
"""
all_model_classes = (
(VideoMAEModel, VideoMAEForPreTraining, VideoMAEForVideoClassification) if is_torch_available() else ()
)
pipeline_model_mapping = (
{"feature-extraction": VideoMAEModel, "video-classification": VideoMAEForVideoClassification}
if is_torch_available()
else {}
)
test_pruning = False
test_torchscript = False
test_resize_embeddings = False
test_head_masking = False
def setUp(self):
self.model_tester = VideoMAEModelTester(self)
self.config_tester = ConfigTester(self, config_class=VideoMAEConfig, has_text_modality=False, hidden_size=37)
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
inputs_dict = copy.deepcopy(inputs_dict)
if model_class == VideoMAEForPreTraining:
# important: each video needs to have the same number of masked patches
# hence we define a single mask, which we then repeat for each example in the batch
mask = torch.ones((self.model_tester.num_masks,))
mask = torch.cat([mask, torch.zeros(self.model_tester.seq_length - mask.size(0))])
bool_masked_pos = mask.expand(self.model_tester.batch_size, -1).bool()
inputs_dict["bool_masked_pos"] = bool_masked_pos.to(torch_device)
if return_labels:
if model_class in [
*get_values(MODEL_FOR_VIDEO_CLASSIFICATION_MAPPING),
]:
inputs_dict["labels"] = torch.zeros(
self.model_tester.batch_size, dtype=torch.long, device=torch_device
)
return inputs_dict
def test_config(self):
self.config_tester.run_common_tests()
@unittest.skip(reason="VideoMAE does not use inputs_embeds")
def test_inputs_embeds(self):
pass
def test_model_common_attributes(self):
config, _ = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
model = model_class(config)
self.assertIsInstance(model.get_input_embeddings(), (nn.Module))
x = model.get_output_embeddings()
self.assertTrue(x is None or isinstance(x, nn.Linear))
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_pretraining(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
for model_name in VIDEOMAE_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = VideoMAEModel.from_pretrained(model_name)
self.assertIsNotNone(model)
def test_attention_outputs(self):
if not self.has_attentions:
pass
else:
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
for model_class in self.all_model_classes:
num_visible_patches = self.model_tester.seq_length - self.model_tester.num_masks
seq_len = (
num_visible_patches if model_class == VideoMAEForPreTraining else self.model_tester.seq_length
)
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, seq_len, seq_len],
)
out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
self.assertEqual(out_len + 1, len(outputs))
self_attentions = outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, seq_len, seq_len],
)
def test_hidden_states_output(self):
def check_hidden_states_output(inputs_dict, config, model_class):
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
hidden_states = outputs.hidden_states
expected_num_layers = self.model_tester.num_hidden_layers + 1
self.assertEqual(len(hidden_states), expected_num_layers)
num_visible_patches = self.model_tester.seq_length - self.model_tester.num_masks
seq_length = num_visible_patches if model_class == VideoMAEForPreTraining else self.model_tester.seq_length
self.assertListEqual(
list(hidden_states[0].shape[-2:]),
[seq_length, self.model_tester.hidden_size],
)
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
inputs_dict["output_hidden_states"] = True
check_hidden_states_output(inputs_dict, config, model_class)
# check that output_hidden_states also work using config
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
check_hidden_states_output(inputs_dict, config, model_class)
# We will verify our results on a video of eating spaghetti
# Frame indices used: [164 168 172 176 181 185 189 193 198 202 206 210 215 219 223 227]
def prepare_video():
file = hf_hub_download(
repo_id="hf-internal-testing/spaghetti-video", filename="eating_spaghetti.npy", repo_type="dataset"
)
video = np.load(file)
return list(video)
@require_torch
@require_vision
class VideoMAEModelIntegrationTest(unittest.TestCase):
@cached_property
def default_image_processor(self):
# logits were tested with a different mean and std, so we use the same here
return (
VideoMAEImageProcessor(image_mean=[0.5, 0.5, 0.5], image_std=[0.5, 0.5, 0.5])
if is_vision_available()
else None
)
@slow
def test_inference_for_video_classification(self):
model = VideoMAEForVideoClassification.from_pretrained("MCG-NJU/videomae-base-finetuned-kinetics").to(
torch_device
)
image_processor = self.default_image_processor
video = prepare_video()
inputs = image_processor(video, return_tensors="pt").to(torch_device)
# forward pass
with torch.no_grad():
outputs = model(**inputs)
# verify the logits
expected_shape = torch.Size((1, 400))
self.assertEqual(outputs.logits.shape, expected_shape)
expected_slice = torch.tensor([0.3669, -0.0688, -0.2421]).to(torch_device)
self.assertTrue(torch.allclose(outputs.logits[0, :3], expected_slice, atol=1e-4))
@slow
def test_inference_for_pretraining(self):
model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base-short").to(torch_device)
image_processor = self.default_image_processor
video = prepare_video()
inputs = image_processor(video, return_tensors="pt").to(torch_device)
# add boolean mask, indicating which patches to mask
local_path = hf_hub_download(repo_id="hf-internal-testing/bool-masked-pos", filename="bool_masked_pos.pt")
inputs["bool_masked_pos"] = torch.load(local_path)
# forward pass
with torch.no_grad():
outputs = model(**inputs)
# verify the logits
expected_shape = torch.Size([1, 1408, 1536])
expected_slice = torch.tensor(
[[0.7994, 0.9612, 0.8508], [0.7401, 0.8958, 0.8302], [0.5862, 0.7468, 0.7325]], device=torch_device
)
self.assertEqual(outputs.logits.shape, expected_shape)
self.assertTrue(torch.allclose(outputs.logits[0, :3, :3], expected_slice, atol=1e-4))
# verify the loss (`config.norm_pix_loss` = `True`)
expected_loss = torch.tensor([0.5142], device=torch_device)
self.assertTrue(torch.allclose(outputs.loss, expected_loss, atol=1e-4))
# verify the loss (`config.norm_pix_loss` = `False`)
model = VideoMAEForPreTraining.from_pretrained("MCG-NJU/videomae-base-short", norm_pix_loss=False).to(
torch_device
)
with torch.no_grad():
outputs = model(**inputs)
expected_loss = torch.tensor(torch.tensor([0.6469]), device=torch_device)
self.assertTrue(torch.allclose(outputs.loss, expected_loss, atol=1e-4))
| transformers/tests/models/videomae/test_modeling_videomae.py/0 | {
"file_path": "transformers/tests/models/videomae/test_modeling_videomae.py",
"repo_id": "transformers",
"token_count": 7450
} | 375 |
# coding=utf-8
# Copyright 2021 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch VisualBERT model. """
import copy
import unittest
from transformers import VisualBertConfig, is_torch_available
from transformers.testing_utils import require_torch, slow, torch_device
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
VisualBertForMultipleChoice,
VisualBertForPreTraining,
VisualBertForQuestionAnswering,
VisualBertForRegionToPhraseAlignment,
VisualBertForVisualReasoning,
VisualBertModel,
)
from transformers.models.visual_bert.modeling_visual_bert import VISUAL_BERT_PRETRAINED_MODEL_ARCHIVE_LIST
class VisualBertModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
visual_seq_length=5,
is_training=True,
use_attention_mask=True,
use_visual_attention_mask=True,
use_token_type_ids=True,
use_visual_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
visual_embedding_dim=20,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.visual_seq_length = visual_seq_length
self.is_training = is_training
self.use_attention_mask = use_attention_mask
self.use_visual_attention_mask = use_visual_attention_mask
self.use_token_type_ids = use_token_type_ids
self.use_visual_token_type_ids = use_visual_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.visual_embedding_dim = visual_embedding_dim
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
def get_config(self):
return VisualBertConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
visual_embedding_dim=self.visual_embedding_dim,
num_labels=self.num_labels,
is_decoder=False,
initializer_range=self.initializer_range,
)
def prepare_config_and_inputs_for_common(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
visual_embeds = floats_tensor([self.batch_size, self.visual_seq_length, self.visual_embedding_dim])
attention_mask = None
if self.use_attention_mask:
attention_mask = torch.ones((self.batch_size, self.seq_length), dtype=torch.long, device=torch_device)
visual_attention_mask = None
if self.use_visual_attention_mask:
visual_attention_mask = torch.ones(
(self.batch_size, self.visual_seq_length), dtype=torch.long, device=torch_device
)
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
visual_token_type_ids = None
if self.use_visual_token_type_ids:
visual_token_type_ids = ids_tensor([self.batch_size, self.visual_seq_length], self.type_vocab_size)
config = self.get_config()
return config, {
"input_ids": input_ids,
"token_type_ids": token_type_ids,
"attention_mask": attention_mask,
"visual_embeds": visual_embeds,
"visual_token_type_ids": visual_token_type_ids,
"visual_attention_mask": visual_attention_mask,
}
def prepare_config_and_inputs_for_pretraining(self):
masked_lm_labels = None
sentence_image_labels = None
if self.use_labels:
masked_lm_labels = ids_tensor([self.batch_size, self.seq_length + self.visual_seq_length], self.vocab_size)
sentence_image_labels = ids_tensor(
[self.batch_size],
self.type_sequence_label_size,
)
config, input_dict = self.prepare_config_and_inputs_for_common()
input_dict.update({"labels": masked_lm_labels, "sentence_image_labels": sentence_image_labels})
return config, input_dict
def prepare_config_and_inputs_for_multiple_choice(self):
input_ids = ids_tensor([self.batch_size, self.num_choices, self.seq_length], self.vocab_size)
visual_embeds = floats_tensor(
[self.batch_size, self.num_choices, self.visual_seq_length, self.visual_embedding_dim]
)
attention_mask = None
if self.use_attention_mask:
attention_mask = torch.ones(
(self.batch_size, self.num_choices, self.seq_length), dtype=torch.long, device=torch_device
)
visual_attention_mask = None
if self.use_visual_attention_mask:
visual_attention_mask = torch.ones(
(self.batch_size, self.num_choices, self.visual_seq_length), dtype=torch.long, device=torch_device
)
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.num_choices, self.seq_length], self.type_vocab_size)
visual_token_type_ids = None
if self.use_visual_token_type_ids:
visual_token_type_ids = ids_tensor(
[self.batch_size, self.num_choices, self.visual_seq_length], self.type_vocab_size
)
labels = None
if self.use_labels:
labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config()
return config, {
"input_ids": input_ids,
"token_type_ids": token_type_ids,
"attention_mask": attention_mask,
"visual_embeds": visual_embeds,
"visual_token_type_ids": visual_token_type_ids,
"visual_attention_mask": visual_attention_mask,
"labels": labels,
}
def prepare_config_and_inputs_for_vqa(self):
vqa_labels = None
if self.use_labels:
vqa_labels = floats_tensor([self.batch_size, self.num_labels])
config, input_dict = self.prepare_config_and_inputs_for_common()
input_dict.update({"labels": vqa_labels})
return config, input_dict
def prepare_config_and_inputs_for_nlvr(self):
nlvr_labels = None
if self.use_labels:
nlvr_labels = ids_tensor([self.batch_size], self.num_labels)
config, input_dict = self.prepare_config_and_inputs_for_common()
input_dict.update({"labels": nlvr_labels})
return config, input_dict
def prepare_config_and_inputs_for_flickr(self):
region_to_phrase_position = torch.cat(
(
ids_tensor([self.batch_size, self.seq_length], self.visual_seq_length),
torch.ones(self.batch_size, self.visual_seq_length, dtype=torch.long, device=torch_device) * -1,
),
dim=-1,
)
flickr_labels = None
if self.use_labels:
flickr_labels = floats_tensor(
[self.batch_size, self.seq_length + self.visual_seq_length, self.visual_seq_length]
)
config, input_dict = self.prepare_config_and_inputs_for_common()
input_dict.update({"region_to_phrase_position": region_to_phrase_position, "labels": flickr_labels})
return config, input_dict
def create_and_check_model(self, config, input_dict):
model = VisualBertModel(config=config)
model.to(torch_device)
model.eval()
result = model(**input_dict)
self.parent.assertEqual(
result.last_hidden_state.shape,
(self.batch_size, self.seq_length + self.visual_seq_length, self.hidden_size),
)
def create_and_check_for_pretraining(self, config, input_dict):
model = VisualBertForPreTraining(config=config)
model.to(torch_device)
model.eval()
result = model(**input_dict)
self.parent.assertEqual(
result.prediction_logits.shape,
(self.batch_size, self.seq_length + self.visual_seq_length, self.vocab_size),
)
def create_and_check_for_vqa(self, config, input_dict):
model = VisualBertForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(**input_dict)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_multiple_choice(self, config, input_dict):
model = VisualBertForMultipleChoice(config=config)
model.to(torch_device)
model.eval()
result = model(**input_dict)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def create_and_check_for_nlvr(self, config, input_dict):
model = VisualBertForVisualReasoning(config=config)
model.to(torch_device)
model.eval()
result = model(**input_dict)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_flickr(self, config, input_dict):
model = VisualBertForRegionToPhraseAlignment(config=config)
model.to(torch_device)
model.eval()
result = model(**input_dict)
self.parent.assertEqual(
result.logits.shape, (self.batch_size, self.seq_length + self.visual_seq_length, self.visual_seq_length)
)
@require_torch
class VisualBertModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
VisualBertModel,
VisualBertForMultipleChoice,
VisualBertForVisualReasoning,
VisualBertForRegionToPhraseAlignment,
VisualBertForQuestionAnswering,
VisualBertForPreTraining,
)
if is_torch_available()
else ()
)
pipeline_model_mapping = {"feature-extraction": VisualBertModel} if is_torch_available() else {}
test_torchscript = False
test_pruning = False
def _prepare_for_class(self, inputs_dict, model_class, return_labels=False):
inputs_dict = copy.deepcopy(inputs_dict)
if model_class == VisualBertForMultipleChoice:
for key in inputs_dict.keys():
value = inputs_dict[key]
if isinstance(value, torch.Tensor) and value.ndim > 1:
if key != "visual_embeds":
inputs_dict[key] = (
inputs_dict[key].unsqueeze(1).expand(-1, self.model_tester.num_choices, -1).contiguous()
)
else:
inputs_dict[key] = (
inputs_dict[key]
.unsqueeze(1)
.expand(-1, self.model_tester.num_choices, -1, self.model_tester.visual_embedding_dim)
.contiguous()
)
elif model_class == VisualBertForRegionToPhraseAlignment:
total_length = self.model_tester.seq_length + self.model_tester.visual_seq_length
batch_size = self.model_tester.batch_size
inputs_dict["region_to_phrase_position"] = torch.zeros(
(batch_size, total_length),
dtype=torch.long,
device=torch_device,
)
if return_labels:
if model_class == VisualBertForMultipleChoice:
inputs_dict["labels"] = torch.zeros(
self.model_tester.batch_size, dtype=torch.long, device=torch_device
)
elif model_class == VisualBertForPreTraining:
total_length = self.model_tester.seq_length + self.model_tester.visual_seq_length
batch_size = self.model_tester.batch_size
inputs_dict["labels"] = torch.zeros(
(batch_size, total_length),
dtype=torch.long,
device=torch_device,
)
inputs_dict["sentence_image_labels"] = torch.zeros(
self.model_tester.batch_size, dtype=torch.long, device=torch_device
)
# Flickr expects float labels
elif model_class == VisualBertForRegionToPhraseAlignment:
batch_size = self.model_tester.batch_size
total_length = self.model_tester.seq_length + self.model_tester.visual_seq_length
inputs_dict["labels"] = torch.ones(
(
batch_size,
total_length,
self.model_tester.visual_seq_length,
),
dtype=torch.float,
device=torch_device,
)
# VQA expects float labels
elif model_class == VisualBertForQuestionAnswering:
inputs_dict["labels"] = torch.ones(
(self.model_tester.batch_size, self.model_tester.num_labels),
dtype=torch.float,
device=torch_device,
)
elif model_class == VisualBertForVisualReasoning:
inputs_dict["labels"] = torch.zeros(
(self.model_tester.batch_size), dtype=torch.long, device=torch_device
)
return inputs_dict
def setUp(self):
self.model_tester = VisualBertModelTester(self)
self.config_tester = ConfigTester(self, config_class=VisualBertConfig, hidden_size=37)
def test_attention_outputs(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.return_dict = True
seq_len = getattr(self.model_tester, "seq_length", None)
visual_seq_len = getattr(self.model_tester, "visual_seq_length", None)
encoder_seq_length = (seq_len if seq_len is not None else 0) + (
visual_seq_len if visual_seq_len is not None else 0
)
encoder_key_length = getattr(self.model_tester, "key_length", encoder_seq_length)
chunk_length = getattr(self.model_tester, "chunk_length", None)
if chunk_length is not None and hasattr(self.model_tester, "num_hashes"):
encoder_seq_length = encoder_seq_length * self.model_tester.num_hashes
for model_class in self.all_model_classes:
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = False
config.return_dict = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
# check that output_attentions also work using config
del inputs_dict["output_attentions"]
config.output_attentions = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(attentions), self.model_tester.num_hidden_layers)
if chunk_length is not None:
self.assertListEqual(
list(attentions[0].shape[-4:]),
[self.model_tester.num_attention_heads, encoder_seq_length, chunk_length, encoder_key_length],
)
else:
self.assertListEqual(
list(attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
)
out_len = len(outputs)
# Check attention is always last and order is fine
inputs_dict["output_attentions"] = True
inputs_dict["output_hidden_states"] = True
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
if hasattr(self.model_tester, "num_hidden_states_types"):
added_hidden_states = self.model_tester.num_hidden_states_types
elif self.is_encoder_decoder:
added_hidden_states = 2
else:
added_hidden_states = 1
self.assertEqual(out_len + added_hidden_states, len(outputs))
self_attentions = outputs.encoder_attentions if config.is_encoder_decoder else outputs.attentions
self.assertEqual(len(self_attentions), self.model_tester.num_hidden_layers)
if chunk_length is not None:
self.assertListEqual(
list(self_attentions[0].shape[-4:]),
[self.model_tester.num_attention_heads, encoder_seq_length, chunk_length, encoder_key_length],
)
else:
self.assertListEqual(
list(self_attentions[0].shape[-3:]),
[self.model_tester.num_attention_heads, encoder_seq_length, encoder_key_length],
)
def test_hidden_states_output(self):
def check_hidden_states_output(inputs_dict, config, model_class):
model = model_class(config)
model.to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**self._prepare_for_class(inputs_dict, model_class))
hidden_states = outputs.encoder_hidden_states if config.is_encoder_decoder else outputs.hidden_states
expected_num_layers = getattr(
self.model_tester, "expected_num_hidden_layers", self.model_tester.num_hidden_layers + 1
)
self.assertEqual(len(hidden_states), expected_num_layers)
if hasattr(self.model_tester, "encoder_seq_length"):
seq_length = self.model_tester.encoder_seq_length
if hasattr(self.model_tester, "chunk_length") and self.model_tester.chunk_length > 1:
seq_length = seq_length * self.model_tester.chunk_length
else:
seq_length = self.model_tester.seq_length + self.model_tester.visual_seq_length
self.assertListEqual(
list(hidden_states[0].shape[-2:]),
[seq_length, self.model_tester.hidden_size],
)
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
for model_class in self.all_model_classes:
inputs_dict["output_hidden_states"] = True
check_hidden_states_output(inputs_dict, config, model_class)
# check that output_hidden_states also work using config
del inputs_dict["output_hidden_states"]
config.output_hidden_states = True
check_hidden_states_output(inputs_dict, config, model_class)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_various_embeddings(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_common()
for type in ["absolute", "relative_key", "relative_key_query"]:
config_and_inputs[0].position_embedding_type = type
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_for_pretraining(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_pretraining()
self.model_tester.create_and_check_for_pretraining(*config_and_inputs)
def test_model_for_vqa(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_vqa()
self.model_tester.create_and_check_for_vqa(*config_and_inputs)
def test_model_for_nlvr(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_nlvr()
self.model_tester.create_and_check_for_nlvr(*config_and_inputs)
def test_model_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_multiple_choice()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_model_for_flickr(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs_for_flickr()
self.model_tester.create_and_check_for_flickr(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
for model_name in VISUAL_BERT_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = VisualBertModel.from_pretrained(model_name)
self.assertIsNotNone(model)
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant(self):
pass
@unittest.skip(
reason="This architecure seem to not compute gradients properly when using GC, check: https://github.com/huggingface/transformers/pull/27124"
)
def test_training_gradient_checkpointing_use_reentrant_false(self):
pass
@require_torch
class VisualBertModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_vqa_coco_pre(self):
model = VisualBertForPreTraining.from_pretrained("uclanlp/visualbert-vqa-coco-pre")
input_ids = torch.tensor([1, 2, 3, 4, 5, 6], dtype=torch.long).reshape(1, -1)
token_type_ids = torch.tensor([0, 0, 0, 1, 1, 1], dtype=torch.long).reshape(1, -1)
visual_embeds = torch.ones(size=(1, 10, 2048), dtype=torch.float32) * 0.5
visual_token_type_ids = torch.ones(size=(1, 10), dtype=torch.long)
attention_mask = torch.tensor([1] * 6).reshape(1, -1)
visual_attention_mask = torch.tensor([1] * 10).reshape(1, -1)
with torch.no_grad():
output = model(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
visual_embeds=visual_embeds,
visual_attention_mask=visual_attention_mask,
visual_token_type_ids=visual_token_type_ids,
)
vocab_size = 30522
expected_shape = torch.Size((1, 16, vocab_size))
self.assertEqual(output.prediction_logits.shape, expected_shape)
expected_slice = torch.tensor(
[[[-5.1858, -5.1903, -4.9142], [-6.2214, -5.9238, -5.8381], [-6.3027, -5.9939, -5.9297]]]
)
self.assertTrue(torch.allclose(output.prediction_logits[:, :3, :3], expected_slice, atol=1e-4))
expected_shape_2 = torch.Size((1, 2))
self.assertEqual(output.seq_relationship_logits.shape, expected_shape_2)
expected_slice_2 = torch.tensor([[0.7393, 0.1754]])
self.assertTrue(torch.allclose(output.seq_relationship_logits, expected_slice_2, atol=1e-4))
@slow
def test_inference_vqa(self):
model = VisualBertForQuestionAnswering.from_pretrained("uclanlp/visualbert-vqa")
input_ids = torch.tensor([1, 2, 3, 4, 5, 6], dtype=torch.long).reshape(1, -1)
token_type_ids = torch.tensor([0, 0, 0, 1, 1, 1], dtype=torch.long).reshape(1, -1)
visual_embeds = torch.ones(size=(1, 10, 2048), dtype=torch.float32) * 0.5
visual_token_type_ids = torch.ones(size=(1, 10), dtype=torch.long)
attention_mask = torch.tensor([1] * 6).reshape(1, -1)
visual_attention_mask = torch.tensor([1] * 10).reshape(1, -1)
with torch.no_grad():
output = model(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
visual_embeds=visual_embeds,
visual_attention_mask=visual_attention_mask,
visual_token_type_ids=visual_token_type_ids,
)
# vocab_size = 30522
expected_shape = torch.Size((1, 3129))
self.assertEqual(output.logits.shape, expected_shape)
expected_slice = torch.tensor(
[[-8.9898, 3.0803, -1.8016, 2.4542, -8.3420, -2.0224, -3.3124, -4.4139, -3.1491, -3.8997]]
)
self.assertTrue(torch.allclose(output.logits[:, :10], expected_slice, atol=1e-4))
@slow
def test_inference_nlvr(self):
model = VisualBertForVisualReasoning.from_pretrained("uclanlp/visualbert-nlvr2")
input_ids = torch.tensor([1, 2, 3, 4, 5, 6], dtype=torch.long).reshape(1, -1)
token_type_ids = torch.tensor([0, 0, 0, 1, 1, 1], dtype=torch.long).reshape(1, -1)
visual_embeds = torch.ones(size=(1, 10, 1024), dtype=torch.float32) * 0.5
visual_token_type_ids = torch.ones(size=(1, 10), dtype=torch.long)
attention_mask = torch.tensor([1] * 6).reshape(1, -1)
visual_attention_mask = torch.tensor([1] * 10).reshape(1, -1)
with torch.no_grad():
output = model(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
visual_embeds=visual_embeds,
visual_attention_mask=visual_attention_mask,
visual_token_type_ids=visual_token_type_ids,
)
# vocab_size = 30522
expected_shape = torch.Size((1, 2))
self.assertEqual(output.logits.shape, expected_shape)
expected_slice = torch.tensor([[-1.1436, 0.8900]])
self.assertTrue(torch.allclose(output.logits, expected_slice, atol=1e-4))
@slow
def test_inference_vcr(self):
model = VisualBertForMultipleChoice.from_pretrained("uclanlp/visualbert-vcr")
input_ids = torch.tensor([[[1, 2, 3, 4, 5, 6] for i in range(4)]], dtype=torch.long)
attention_mask = torch.ones_like(input_ids)
token_type_ids = torch.ones_like(input_ids)
visual_embeds = torch.ones(size=(1, 4, 10, 512), dtype=torch.float32) * 0.5
visual_token_type_ids = torch.ones(size=(1, 4, 10), dtype=torch.long)
visual_attention_mask = torch.ones_like(visual_token_type_ids)
with torch.no_grad():
output = model(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
visual_embeds=visual_embeds,
visual_attention_mask=visual_attention_mask,
visual_token_type_ids=visual_token_type_ids,
)
# vocab_size = 30522
expected_shape = torch.Size((1, 4))
self.assertEqual(output.logits.shape, expected_shape)
expected_slice = torch.tensor([[-7.7697, -7.7697, -7.7697, -7.7697]])
self.assertTrue(torch.allclose(output.logits, expected_slice, atol=1e-4))
| transformers/tests/models/visual_bert/test_modeling_visual_bert.py/0 | {
"file_path": "transformers/tests/models/visual_bert/test_modeling_visual_bert.py",
"repo_id": "transformers",
"token_count": 14046
} | 376 |
# coding=utf-8
# Copyright 2023 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import numpy as np
from transformers.testing_utils import require_torch, require_vision
from transformers.utils import is_torch_available, is_vision_available
from ...test_image_processing_common import ImageProcessingTestMixin, prepare_image_inputs
if is_torch_available():
import torch
if is_vision_available():
from PIL import Image
from transformers import VitMatteImageProcessor
class VitMatteImageProcessingTester(unittest.TestCase):
def __init__(
self,
parent,
batch_size=7,
num_channels=3,
image_size=18,
min_resolution=30,
max_resolution=400,
do_rescale=True,
rescale_factor=0.5,
do_pad=True,
size_divisibility=10,
do_normalize=True,
image_mean=[0.5, 0.5, 0.5],
image_std=[0.5, 0.5, 0.5],
):
self.parent = parent
self.batch_size = batch_size
self.num_channels = num_channels
self.image_size = image_size
self.min_resolution = min_resolution
self.max_resolution = max_resolution
self.do_rescale = do_rescale
self.rescale_factor = rescale_factor
self.do_pad = do_pad
self.size_divisibility = size_divisibility
self.do_normalize = do_normalize
self.image_mean = image_mean
self.image_std = image_std
def prepare_image_processor_dict(self):
return {
"image_mean": self.image_mean,
"image_std": self.image_std,
"do_normalize": self.do_normalize,
"do_rescale": self.do_rescale,
"rescale_factor": self.rescale_factor,
"do_pad": self.do_pad,
"size_divisibility": self.size_divisibility,
}
def prepare_image_inputs(self, equal_resolution=False, numpify=False, torchify=False):
return prepare_image_inputs(
batch_size=self.batch_size,
num_channels=self.num_channels,
min_resolution=self.min_resolution,
max_resolution=self.max_resolution,
equal_resolution=equal_resolution,
numpify=numpify,
torchify=torchify,
)
@require_torch
@require_vision
class VitMatteImageProcessingTest(ImageProcessingTestMixin, unittest.TestCase):
image_processing_class = VitMatteImageProcessor if is_vision_available() else None
def setUp(self):
self.image_processor_tester = VitMatteImageProcessingTester(self)
@property
def image_processor_dict(self):
return self.image_processor_tester.prepare_image_processor_dict()
def test_image_processor_properties(self):
image_processing = self.image_processing_class(**self.image_processor_dict)
self.assertTrue(hasattr(image_processing, "image_mean"))
self.assertTrue(hasattr(image_processing, "image_std"))
self.assertTrue(hasattr(image_processing, "do_normalize"))
self.assertTrue(hasattr(image_processing, "do_rescale"))
self.assertTrue(hasattr(image_processing, "rescale_factor"))
self.assertTrue(hasattr(image_processing, "do_pad"))
self.assertTrue(hasattr(image_processing, "size_divisibility"))
def test_call_numpy(self):
# Initialize image_processing
image_processing = self.image_processing_class(**self.image_processor_dict)
# create random numpy tensors
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
for image in image_inputs:
self.assertIsInstance(image, np.ndarray)
# Test not batched input (image processor does not support batched inputs)
image = image_inputs[0]
trimap = np.random.randint(0, 3, size=image.shape[:2])
encoded_images = image_processing(images=image, trimaps=trimap, return_tensors="pt").pixel_values
# Verify that width and height can be divided by size_divisibility
self.assertTrue(encoded_images.shape[-1] % self.image_processor_tester.size_divisibility == 0)
self.assertTrue(encoded_images.shape[-2] % self.image_processor_tester.size_divisibility == 0)
def test_call_pytorch(self):
# Initialize image_processing
image_processing = self.image_processing_class(**self.image_processor_dict)
# create random PyTorch tensors
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, torchify=True)
for image in image_inputs:
self.assertIsInstance(image, torch.Tensor)
# Test not batched input (image processor does not support batched inputs)
image = image_inputs[0]
trimap = np.random.randint(0, 3, size=image.shape[:2])
encoded_images = image_processing(images=image, trimaps=trimap, return_tensors="pt").pixel_values
# Verify that width and height can be divided by size_divisibility
self.assertTrue(encoded_images.shape[-1] % self.image_processor_tester.size_divisibility == 0)
self.assertTrue(encoded_images.shape[-2] % self.image_processor_tester.size_divisibility == 0)
def test_call_pil(self):
# Initialize image_processing
image_processing = self.image_processing_class(**self.image_processor_dict)
# create random PIL images
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False)
for image in image_inputs:
self.assertIsInstance(image, Image.Image)
# Test not batched input (image processor does not support batched inputs)
image = image_inputs[0]
trimap = np.random.randint(0, 3, size=image.size[::-1])
encoded_images = image_processing(images=image, trimaps=trimap, return_tensors="pt").pixel_values
# Verify that width and height can be divided by size_divisibility
self.assertTrue(encoded_images.shape[-1] % self.image_processor_tester.size_divisibility == 0)
self.assertTrue(encoded_images.shape[-2] % self.image_processor_tester.size_divisibility == 0)
def test_call_numpy_4_channels(self):
# Test that can process images which have an arbitrary number of channels
# Initialize image_processing
image_processor = self.image_processing_class(**self.image_processor_dict)
# create random numpy tensors
self.image_processor_tester.num_channels = 4
image_inputs = self.image_processor_tester.prepare_image_inputs(equal_resolution=False, numpify=True)
# Test not batched input (image processor does not support batched inputs)
image = image_inputs[0]
trimap = np.random.randint(0, 3, size=image.shape[:2])
encoded_images = image_processor(
images=image,
trimaps=trimap,
input_data_format="channels_first",
image_mean=0,
image_std=1,
return_tensors="pt",
).pixel_values
# Verify that width and height can be divided by size_divisibility
self.assertTrue(encoded_images.shape[-1] % self.image_processor_tester.size_divisibility == 0)
self.assertTrue(encoded_images.shape[-2] % self.image_processor_tester.size_divisibility == 0)
def test_padding(self):
image_processing = self.image_processing_class(**self.image_processor_dict)
image = np.random.randn(3, 249, 491)
images = image_processing.pad_image(image)
assert images.shape == (3, 256, 512)
| transformers/tests/models/vitmatte/test_image_processing_vitmatte.py/0 | {
"file_path": "transformers/tests/models/vitmatte/test_image_processing_vitmatte.py",
"repo_id": "transformers",
"token_count": 3229
} | 377 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch Wav2Vec2-BERT model. """
import tempfile
import unittest
from datasets import load_dataset
from transformers import Wav2Vec2BertConfig, is_torch_available
from transformers.testing_utils import (
is_pt_flax_cross_test,
require_torch,
require_torch_accelerator,
require_torch_fp16,
slow,
torch_device,
)
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import (
ModelTesterMixin,
_config_zero_init,
floats_tensor,
ids_tensor,
random_attention_mask,
)
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
AutoFeatureExtractor,
Wav2Vec2BertForAudioFrameClassification,
Wav2Vec2BertForCTC,
Wav2Vec2BertForSequenceClassification,
Wav2Vec2BertForXVector,
Wav2Vec2BertModel,
)
from transformers.models.wav2vec2_bert.modeling_wav2vec2_bert import (
_compute_mask_indices,
_sample_negative_indices,
)
# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerModelTester with Conformer->Bert, input_values->input_features
class Wav2Vec2BertModelTester:
# Ignore copy
def __init__(
self,
parent,
batch_size=13,
seq_length=200, # speech is longer
is_training=False,
hidden_size=16,
feature_projection_input_dim=16,
num_conv_pos_embeddings=16,
num_conv_pos_embedding_groups=2,
num_hidden_layers=2,
num_attention_heads=2,
hidden_dropout_prob=0.1,
intermediate_size=20,
layer_norm_eps=1e-5,
hidden_act="gelu",
initializer_range=0.02,
mask_time_prob=0.5,
mask_time_length=2,
vocab_size=32,
do_stable_layer_norm=False,
num_adapter_layers=2,
adapter_stride=2,
tdnn_dim=(32, 32),
tdnn_kernel=(5, 3),
tdnn_dilation=(1, 2),
xvector_output_dim=32,
position_embeddings_type="relative",
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.hidden_size = hidden_size
self.feature_projection_input_dim = feature_projection_input_dim
self.num_conv_pos_embeddings = num_conv_pos_embeddings
self.num_conv_pos_embedding_groups = num_conv_pos_embedding_groups
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.hidden_dropout_prob = hidden_dropout_prob
self.intermediate_size = intermediate_size
self.layer_norm_eps = layer_norm_eps
self.hidden_act = hidden_act
self.initializer_range = initializer_range
self.vocab_size = vocab_size
self.do_stable_layer_norm = do_stable_layer_norm
self.num_adapter_layers = num_adapter_layers
self.adapter_stride = adapter_stride
self.mask_time_prob = mask_time_prob
self.mask_time_length = mask_time_length
self.scope = scope
self.tdnn_dim = tdnn_dim
self.tdnn_kernel = tdnn_kernel
self.tdnn_dilation = tdnn_dilation
self.xvector_output_dim = xvector_output_dim
self.position_embeddings_type = position_embeddings_type
self.output_seq_length = self.seq_length
self.encoder_seq_length = self.output_seq_length
self.adapter_output_seq_length = self.output_seq_length
for _ in range(num_adapter_layers):
self.adapter_output_seq_length = (self.adapter_output_seq_length - 1) // adapter_stride + 1
# Ignore copy
def prepare_config_and_inputs(self, position_embeddings_type="relative"):
input_shape = [self.batch_size, self.seq_length, self.feature_projection_input_dim]
input_features = floats_tensor(input_shape, self.vocab_size)
attention_mask = random_attention_mask([self.batch_size, self.seq_length])
config = self.get_config(position_embeddings_type=position_embeddings_type)
return config, input_features, attention_mask
# Ignore copy
def get_config(self, position_embeddings_type="relative"):
return Wav2Vec2BertConfig(
hidden_size=self.hidden_size,
feature_projection_input_dim=self.feature_projection_input_dim,
mask_time_prob=self.mask_time_prob,
mask_time_length=self.mask_time_length,
num_conv_pos_embeddings=self.num_conv_pos_embeddings,
num_conv_pos_embedding_groups=self.num_conv_pos_embedding_groups,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
hidden_dropout_prob=self.hidden_dropout_prob,
intermediate_size=self.intermediate_size,
layer_norm_eps=self.layer_norm_eps,
do_stable_layer_norm=self.do_stable_layer_norm,
hidden_act=self.hidden_act,
initializer_range=self.initializer_range,
vocab_size=self.vocab_size,
num_adapter_layers=self.num_adapter_layers,
adapter_stride=self.adapter_stride,
tdnn_dim=self.tdnn_dim,
tdnn_kernel=self.tdnn_kernel,
tdnn_dilation=self.tdnn_dilation,
xvector_output_dim=self.xvector_output_dim,
position_embeddings_type=position_embeddings_type,
)
def create_and_check_model(self, config, input_features, attention_mask):
model = Wav2Vec2BertModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_features, attention_mask=attention_mask)
self.parent.assertEqual(
result.last_hidden_state.shape, (self.batch_size, self.output_seq_length, self.hidden_size)
)
def create_and_check_model_with_adapter(self, config, input_features, attention_mask):
config.add_adapter = True
model = Wav2Vec2BertModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_features, attention_mask=attention_mask)
self.parent.assertEqual(
result.last_hidden_state.shape, (self.batch_size, self.adapter_output_seq_length, self.hidden_size)
)
def create_and_check_model_with_adapter_for_ctc(self, config, input_features, attention_mask):
config.add_adapter = True
config.output_hidden_size = 2 * config.hidden_size
model = Wav2Vec2BertForCTC(config=config)
model.to(torch_device)
model.eval()
result = model(input_features, attention_mask=attention_mask)
self.parent.assertEqual(
result.logits.shape, (self.batch_size, self.adapter_output_seq_length, self.vocab_size)
)
# Ignore copy
def create_and_check_model_with_intermediate_ffn_before_adapter(self, config, input_features, attention_mask):
config.add_adapter = True
config.use_intermediate_ffn_before_adapter = True
model = Wav2Vec2BertModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_features, attention_mask=attention_mask)
self.parent.assertEqual(
result.last_hidden_state.shape,
(self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
)
# also try with different adapter proj dim
config.output_hidden_size = 8
model = Wav2Vec2BertModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_features, attention_mask=attention_mask)
self.parent.assertEqual(
result.last_hidden_state.shape,
(self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
)
def create_and_check_model_with_adapter_proj_dim(self, config, input_features, attention_mask):
config.add_adapter = True
config.output_hidden_size = 8
model = Wav2Vec2BertModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_features, attention_mask=attention_mask)
self.parent.assertEqual(
result.last_hidden_state.shape,
(self.batch_size, self.adapter_output_seq_length, config.output_hidden_size),
)
def create_and_check_model_float16(self, config, input_features, attention_mask):
model = Wav2Vec2BertModel(config=config)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname)
model = Wav2Vec2BertModel.from_pretrained(tmpdirname, torch_dtype=torch.float16)
model.to(torch_device)
model.eval()
with torch.no_grad():
result = model(input_features.type(dtype=torch.float16), attention_mask=attention_mask)
self.parent.assertEqual(
result.last_hidden_state.shape, (self.batch_size, self.output_seq_length, self.hidden_size)
)
def create_and_check_batch_inference(self, config, input_features, *args):
# test does not pass for models making use of `group_norm`
# check: https://github.com/pytorch/fairseq/issues/3227
model = Wav2Vec2BertModel(config=config)
model.to(torch_device)
model.eval()
input_features = input_features[:3]
attention_mask = torch.ones(input_features.shape, device=torch_device, dtype=torch.bool)
input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
# pad input
for i in range(len(input_lengths)):
input_features[i, input_lengths[i] :] = 0.0
attention_mask[i, input_lengths[i] :] = 0.0
batch_outputs = model(input_features, attention_mask=attention_mask).last_hidden_state
for i in range(input_features.shape[0]):
input_slice = input_features[i : i + 1, : input_lengths[i]]
output = model(input_slice).last_hidden_state
batch_output = batch_outputs[i : i + 1, : output.shape[1]]
self.parent.assertTrue(torch.allclose(output, batch_output, atol=1e-3))
def check_ctc_loss(self, config, input_features, *args):
model = Wav2Vec2BertForCTC(config=config)
model.to(torch_device)
# make sure that dropout is disabled
model.eval()
input_features = input_features[:3]
# Ignore copy
attention_mask = torch.ones(input_features.shape[:2], device=torch_device, dtype=torch.long)
input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
labels = ids_tensor((input_features.shape[0], min(max_length_labels) - 1), model.config.vocab_size)
# pad input
for i in range(len(input_lengths)):
input_features[i, input_lengths[i] :] = 0.0
attention_mask[i, input_lengths[i] :] = 0
model.config.ctc_loss_reduction = "sum"
sum_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
model.config.ctc_loss_reduction = "mean"
mean_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
self.parent.assertTrue(isinstance(sum_loss, float))
self.parent.assertTrue(isinstance(mean_loss, float))
def check_seq_classifier_loss(self, config, input_features, *args):
model = Wav2Vec2BertForSequenceClassification(config=config)
model.to(torch_device)
# make sure that dropout is disabled
model.eval()
input_features = input_features[:3]
# Ignore copy
attention_mask = torch.ones(input_features.shape[:2], device=torch_device, dtype=torch.long)
input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
# pad input
for i in range(len(input_lengths)):
input_features[i, input_lengths[i] :] = 0.0
attention_mask[i, input_lengths[i] :] = 0
masked_loss = model(input_features, attention_mask=attention_mask, labels=labels).loss.item()
unmasked_loss = model(input_features, labels=labels).loss.item()
self.parent.assertTrue(isinstance(masked_loss, float))
self.parent.assertTrue(isinstance(unmasked_loss, float))
self.parent.assertTrue(masked_loss != unmasked_loss)
def check_ctc_training(self, config, input_features, *args):
config.ctc_zero_infinity = True
model = Wav2Vec2BertForCTC(config=config)
model.to(torch_device)
model.train()
# Ignore copy
input_features = input_features[:3]
input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
labels = ids_tensor((input_features.shape[0], max(max_length_labels) - 2), model.config.vocab_size)
# pad input
for i in range(len(input_lengths)):
input_features[i, input_lengths[i] :] = 0.0
if max_length_labels[i] < labels.shape[-1]:
# it's important that we make sure that target lengths are at least
# one shorter than logit lengths to prevent -inf
labels[i, max_length_labels[i] - 1 :] = -100
loss = model(input_features, labels=labels).loss
self.parent.assertFalse(torch.isinf(loss).item())
loss.backward()
def check_seq_classifier_training(self, config, input_features, *args):
config.ctc_zero_infinity = True
model = Wav2Vec2BertForSequenceClassification(config=config)
model.to(torch_device)
model.train()
# freeze everything but the classification head
model.freeze_base_model()
input_features = input_features[:3]
# Ignore copy
input_lengths = [input_features.shape[1] // i for i in [4, 2, 1]]
labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
# pad input
for i in range(len(input_lengths)):
input_features[i, input_lengths[i] :] = 0.0
loss = model(input_features, labels=labels).loss
self.parent.assertFalse(torch.isinf(loss).item())
loss.backward()
def check_xvector_training(self, config, input_features, *args):
config.ctc_zero_infinity = True
model = Wav2Vec2BertForXVector(config=config)
model.to(torch_device)
model.train()
# freeze everything but the classification head
model.freeze_base_model()
input_features = input_features[:3]
input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
labels = ids_tensor((input_features.shape[0], 1), len(model.config.id2label))
# pad input
for i in range(len(input_lengths)):
input_features[i, input_lengths[i] :] = 0.0
loss = model(input_features, labels=labels).loss
self.parent.assertFalse(torch.isinf(loss).item())
loss.backward()
def check_labels_out_of_vocab(self, config, input_features, *args):
model = Wav2Vec2BertForCTC(config)
model.to(torch_device)
model.train()
input_features = input_features[:3]
input_lengths = [input_features.shape[-1] // i for i in [4, 2, 1]]
max_length_labels = model._get_feat_extract_output_lengths(torch.tensor(input_lengths))
labels = ids_tensor((input_features.shape[0], max(max_length_labels) - 2), model.config.vocab_size + 100)
with self.parent.assertRaises(ValueError):
model(input_features, labels=labels)
def prepare_config_and_inputs_for_common(self):
config, input_features, attention_mask = self.prepare_config_and_inputs()
inputs_dict = {"input_features": input_features, "attention_mask": attention_mask}
return config, inputs_dict
@require_torch
# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerModelTest with Conformer->Bert, input_values->input_features
class Wav2Vec2BertModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
# Ignore copy
all_model_classes = (
(
Wav2Vec2BertForCTC,
Wav2Vec2BertModel,
Wav2Vec2BertForSequenceClassification,
Wav2Vec2BertForAudioFrameClassification,
Wav2Vec2BertForXVector,
)
if is_torch_available()
else ()
)
pipeline_model_mapping = (
{
"audio-classification": Wav2Vec2BertForSequenceClassification,
"automatic-speech-recognition": Wav2Vec2BertForCTC,
"feature-extraction": Wav2Vec2BertModel,
}
if is_torch_available()
else {}
)
test_pruning = False
test_headmasking = False
test_torchscript = False
def setUp(self):
self.model_tester = Wav2Vec2BertModelTester(self)
self.config_tester = ConfigTester(self, config_class=Wav2Vec2BertConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_with_relative(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative")
self.model_tester.create_and_check_model(*config_and_inputs)
# Ignore copy
def test_model_with_relative_key(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative_key")
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_with_rotary(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="rotary")
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_with_no_rel_pos(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type=None)
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_with_adapter(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_adapter(*config_and_inputs)
def test_model_with_adapter_for_ctc(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_adapter_for_ctc(*config_and_inputs)
# Ignore copy
def test_model_with_intermediate_ffn_before_adapter(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_intermediate_ffn_before_adapter(*config_and_inputs)
def test_model_with_adapter_proj_dim(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model_with_adapter_proj_dim(*config_and_inputs)
@require_torch_accelerator
@require_torch_fp16
def test_model_float16_with_relative(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative")
self.model_tester.create_and_check_model_float16(*config_and_inputs)
# Ignore copy
@require_torch_accelerator
@require_torch_fp16
def test_model_float16_with_relative_key(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="relative_key")
self.model_tester.create_and_check_model_float16(*config_and_inputs)
@require_torch_accelerator
@require_torch_fp16
def test_model_float16_with_rotary(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs(position_embeddings_type="rotary")
self.model_tester.create_and_check_model_float16(*config_and_inputs)
def test_ctc_loss_inference(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_ctc_loss(*config_and_inputs)
def test_seq_classifier_loss_inference(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_seq_classifier_loss(*config_and_inputs)
def test_ctc_train(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_ctc_training(*config_and_inputs)
def test_seq_classifier_train(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_seq_classifier_training(*config_and_inputs)
def test_xvector_train(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_xvector_training(*config_and_inputs)
def test_labels_out_of_vocab(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.check_labels_out_of_vocab(*config_and_inputs)
# Ignore copy
@unittest.skip(reason="Wav2Vec2Bert has no inputs_embeds")
def test_inputs_embeds(self):
pass
# Ignore copy
@unittest.skip(reason="`input_ids` is renamed to `input_features`")
def test_forward_signature(self):
pass
# Ignore copy
@unittest.skip(reason="Wav2Vec2Bert has no tokens embeddings")
def test_resize_tokens_embeddings(self):
pass
# Ignore copy
@unittest.skip(reason="Wav2Vec2Bert has no inputs_embeds")
def test_model_common_attributes(self):
pass
# Ignore copy
@unittest.skip(reason="non-robust architecture does not exist in Flax")
@is_pt_flax_cross_test
def test_equivalence_flax_to_pt(self):
pass
# Ignore copy
@unittest.skip(reason="non-robust architecture does not exist in Flax")
@is_pt_flax_cross_test
def test_equivalence_pt_to_flax(self):
pass
def test_retain_grad_hidden_states_attentions(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
config.output_hidden_states = True
config.output_attentions = True
# no need to test all models as different heads yield the same functionality
model_class = self.all_model_classes[0]
model = model_class(config)
model.to(torch_device)
# set layer drop to 0
model.config.layerdrop = 0.0
input_features = inputs_dict["input_features"]
input_lengths = torch.tensor(
[input_features.shape[1] for _ in range(input_features.shape[0])], dtype=torch.long, device=torch_device
)
output_lengths = model._get_feat_extract_output_lengths(input_lengths)
labels = ids_tensor((input_features.shape[0], output_lengths[0] - 2), self.model_tester.vocab_size)
inputs_dict["attention_mask"] = torch.ones_like(inputs_dict["attention_mask"])
inputs_dict["labels"] = labels
outputs = model(**inputs_dict)
output = outputs[0]
# Encoder-/Decoder-only models
hidden_states = outputs.hidden_states[0]
attentions = outputs.attentions[0]
hidden_states.retain_grad()
attentions.retain_grad()
output.flatten()[0].backward(retain_graph=True)
self.assertIsNotNone(hidden_states.grad)
self.assertIsNotNone(attentions.grad)
def test_initialization(self):
config, inputs_dict = self.model_tester.prepare_config_and_inputs_for_common()
configs_no_init = _config_zero_init(config)
for model_class in self.all_model_classes:
model = model_class(config=configs_no_init)
for name, param in model.named_parameters():
uniform_init_parms = [
"conv.weight",
"conv.parametrizations.weight",
"masked_spec_embed",
"codevectors",
"quantizer.weight_proj.weight",
"project_hid.weight",
"project_hid.bias",
"project_q.weight",
"project_q.bias",
"pos_bias_v",
"pos_bias_u",
"pointwise_conv1",
"pointwise_conv2",
"feature_projection.projection.weight",
"feature_projection.projection.bias",
"objective.weight",
]
if param.requires_grad:
if any(x in name for x in uniform_init_parms):
self.assertTrue(
-1.0 <= ((param.data.mean() * 1e9).round() / 1e9).item() <= 1.0,
msg=f"Parameter {name} of model {model_class} seems not properly initialized",
)
else:
self.assertIn(
((param.data.mean() * 1e9).round() / 1e9).item(),
[0.0, 1.0],
msg=f"Parameter {name} of model {model_class} seems not properly initialized",
)
# overwrite from test_modeling_common
def _mock_init_weights(self, module):
if hasattr(module, "weight") and module.weight is not None:
module.weight.data.fill_(3)
if hasattr(module, "weight_g") and module.weight_g is not None:
module.weight_g.data.fill_(3)
if hasattr(module, "weight_v") and module.weight_v is not None:
module.weight_v.data.fill_(3)
if hasattr(module, "bias") and module.bias is not None:
module.bias.data.fill_(3)
if hasattr(module, "pos_bias_u") and module.pos_bias_u is not None:
module.pos_bias_u.data.fill_(3)
if hasattr(module, "pos_bias_v") and module.pos_bias_v is not None:
module.pos_bias_v.data.fill_(3)
if hasattr(module, "codevectors") and module.codevectors is not None:
module.codevectors.data.fill_(3)
if hasattr(module, "masked_spec_embed") and module.masked_spec_embed is not None:
module.masked_spec_embed.data.fill_(3)
# Ignore copy
@unittest.skip(reason="Kept to make #Copied from working")
def test_mask_feature_prob_ctc(self):
pass
# Ignore copy
@unittest.skip(reason="Kept to make #Copied from working")
def test_mask_time_prob_ctc(self):
pass
@unittest.skip(reason="Feed forward chunking is not implemented")
def test_feed_forward_chunking(self):
pass
@slow
def test_model_from_pretrained(self):
# Ignore copy
model = Wav2Vec2BertModel.from_pretrained("facebook/w2v-bert-2.0")
self.assertIsNotNone(model)
@require_torch
# Copied from tests.models.wav2vec2_conformer.test_modeling_wav2vec2_conformer.Wav2Vec2ConformerUtilsTest with Conformer->Bert, input_values->input_features
class Wav2Vec2BertUtilsTest(unittest.TestCase):
def test_compute_mask_indices(self):
batch_size = 4
sequence_length = 60
mask_prob = 0.5
mask_length = 1
mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
mask = torch.from_numpy(mask).to(torch_device)
self.assertListEqual(mask.sum(axis=-1).tolist(), [mask_prob * sequence_length for _ in range(batch_size)])
def test_compute_mask_indices_low_prob(self):
# with these settings num_masked_spans=0.5, which means probabilistic rounding
# ensures that in 5 out of 10 method calls, num_masked_spans=0, and in
# the other 5 out of 10, cases num_masked_spans=1
n_trials = 100
batch_size = 4
sequence_length = 100
mask_prob = 0.05
mask_length = 10
count_dimensions_masked = 0
count_dimensions_not_masked = 0
for _ in range(n_trials):
mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
mask = torch.from_numpy(mask).to(torch_device)
num_masks = torch.sum(mask).item()
if num_masks > 0:
count_dimensions_masked += 1
else:
count_dimensions_not_masked += 1
# as we test for at least 10 masked dimension and at least
# 10 non-masked dimension, this test could fail with probability:
# P(100 coin flips, at most 9 heads) = 1.66e-18
self.assertGreater(count_dimensions_masked, int(n_trials * 0.1))
self.assertGreater(count_dimensions_not_masked, int(n_trials * 0.1))
def test_compute_mask_indices_overlap(self):
batch_size = 4
sequence_length = 80
mask_prob = 0.5
mask_length = 4
mask = _compute_mask_indices((batch_size, sequence_length), mask_prob, mask_length)
mask = torch.from_numpy(mask).to(torch_device)
# because of overlap mask don't have to add up exactly to `mask_prob * sequence_length`, but have to be smaller or equal
for batch_sum in mask.sum(axis=-1):
self.assertTrue(int(batch_sum) <= mask_prob * sequence_length)
def test_compute_mask_indices_attn_mask_overlap(self):
batch_size = 4
sequence_length = 80
mask_prob = 0.5
mask_length = 4
attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
attention_mask[:2, sequence_length // 2 :] = 0
mask = _compute_mask_indices(
(batch_size, sequence_length), mask_prob, mask_length, attention_mask=attention_mask
)
mask = torch.from_numpy(mask).to(torch_device)
for batch_sum in mask.sum(axis=-1):
self.assertTrue(int(batch_sum) <= mask_prob * sequence_length)
self.assertTrue(mask[:2, sequence_length // 2 :].sum() == 0)
def test_compute_mask_indices_short_audio(self):
batch_size = 4
sequence_length = 100
mask_prob = 0.05
mask_length = 10
attention_mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
# force one example to be heavily padded
attention_mask[0, 5:] = 0
mask = _compute_mask_indices(
(batch_size, sequence_length), mask_prob, mask_length, attention_mask=attention_mask, min_masks=2
)
# make sure that non-padded examples cannot be padded
self.assertFalse(mask[0][attention_mask[0].to(torch.bool).cpu()].any())
# Ignore copy
@unittest.skip(reason="Kept to make #Copied from working. Test a class used for pretraining, not yet supported.")
def test_compute_perplexity(self):
pass
def test_sample_negatives(self):
batch_size = 2
sequence_length = 10
hidden_size = 4
num_negatives = 3
features = (torch.arange(sequence_length * hidden_size, device=torch_device) // hidden_size).view(
sequence_length, hidden_size
) # each value in vector consits of same value
features = features[None, :].expand(batch_size, sequence_length, hidden_size).contiguous()
# sample negative indices
sampled_negative_indices = _sample_negative_indices((batch_size, sequence_length), num_negatives, None)
sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device)
negatives = features.view(-1, hidden_size)[sampled_negative_indices.long().view(-1)]
negatives = negatives.view(batch_size, sequence_length, -1, hidden_size).permute(2, 0, 1, 3)
self.assertTrue(negatives.shape == (num_negatives, batch_size, sequence_length, hidden_size))
# make sure no negatively sampled vector is actually a positive one
for negative in negatives:
self.assertTrue(((negative - features) == 0).sum() == 0.0)
# make sure that full vectors are sampled and not values of vectors => this means that `unique()` yields a single value for `hidden_size` dim
self.assertTrue(negatives.unique(dim=-1).shape, (num_negatives, batch_size, sequence_length, 1))
def test_sample_negatives_with_mask(self):
batch_size = 2
sequence_length = 10
hidden_size = 4
num_negatives = 3
# second half of last input tensor is padded
mask = torch.ones((batch_size, sequence_length), dtype=torch.long, device=torch_device)
mask[-1, sequence_length // 2 :] = 0
features = (torch.arange(sequence_length * hidden_size, device=torch_device) // hidden_size).view(
sequence_length, hidden_size
) # each value in vector consits of same value
features = features[None, :].expand(batch_size, sequence_length, hidden_size).contiguous()
# replace masked feature vectors with -100 to test that those are not sampled
features = torch.where(mask[:, :, None].expand(features.shape).bool(), features, -100)
# sample negative indices
sampled_negative_indices = _sample_negative_indices(
(batch_size, sequence_length), num_negatives, mask.cpu().numpy()
)
sampled_negative_indices = torch.from_numpy(sampled_negative_indices).to(torch_device)
negatives = features.view(-1, hidden_size)[sampled_negative_indices.long().view(-1)]
negatives = negatives.view(batch_size, sequence_length, -1, hidden_size).permute(2, 0, 1, 3)
self.assertTrue((negatives >= 0).all().item())
self.assertTrue(negatives.shape == (num_negatives, batch_size, sequence_length, hidden_size))
# make sure no negatively sampled vector is actually a positive one
for negative in negatives:
self.assertTrue(((negative - features) == 0).sum() == 0.0)
# make sure that full vectors are sampled and not values of vectors => this means that `unique()` yields a single value for `hidden_size` dim
self.assertTrue(negatives.unique(dim=-1).shape, (num_negatives, batch_size, sequence_length, 1))
@require_torch
@slow
class Wav2Vec2BertModelIntegrationTest(unittest.TestCase):
def _load_datasamples(self, num_samples):
ds = load_dataset("hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")
# automatic decoding with librispeech
speech_samples = ds.sort("id").filter(lambda x: x["id"] in [f"1272-141231-000{i}" for i in range(num_samples)])
speech_samples = speech_samples[:num_samples]["audio"]
return [x["array"] for x in speech_samples]
def test_inference_w2v2_bert(self):
model = Wav2Vec2BertModel.from_pretrained("facebook/w2v-bert-2.0")
model.to(torch_device)
feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/w2v-bert-2.0")
input_speech = self._load_datasamples(2)
inputs = feature_extractor(input_speech, return_tensors="pt", padding=True).to(torch_device)
model.eval()
with torch.no_grad():
outputs = model(**inputs, output_attentions=True)
# fmt: off
expected_slice_0 = torch.tensor(
[[-0.0098, -0.0570, -0.1286, 0.0439, -0.1037, -0.0235],
[-0.0767, 0.0574, -0.3224, 0.0482, 0.0440, -0.0193],
[ 0.0220, -0.0878, -0.2027, -0.0028, -0.0666, 0.0721],
[ 0.0307, -0.1099, 0.0273, -0.0416, -0.0715, 0.0094],
[ 0.0758, -0.0291, 0.1084, 0.0004, -0.0751, -0.0116],
[ 0.0349, -0.0343, -0.0098, 0.0415, -0.0617, 0.0241],
[-0.0193, -0.0171, 0.1965, 0.0797, -0.0308, 0.2033],
[-0.0323, -0.0315, 0.0948, 0.0944, -0.0254, 0.1241],
[-0.0493, 0.0010, -0.1762, 0.0034, -0.0787, 0.0832],
[ 0.0043, -0.1228, -0.0739, 0.0266, -0.0337, -0.0068]]
).to(torch_device)
# fmt: on
# fmt: off
expected_slice_1 = torch.tensor(
[[-0.0348, -0.0521, -0.3036, 0.0285, -0.0715, -0.0453],
[-0.0102, 0.0114, -0.3266, 0.0027, -0.0558, 0.0038],
[ 0.0454, 0.0148, -0.2418, -0.0392, -0.0455, 0.0478],
[-0.0013, 0.0825, -0.1730, -0.0091, -0.0426, 0.0360],
[-0.0227, 0.0687, -0.1168, 0.0569, -0.0160, 0.0759],
[-0.0318, 0.0562, -0.0508, 0.0605, 0.0150, 0.0953],
[-0.0415, 0.0438, 0.0233, 0.0336, 0.0262, 0.0860],
[-0.0163, 0.0048, 0.0807, 0.0119, 0.0712, 0.0158],
[ 0.0244, -0.0145, 0.0262, -0.0237, 0.0283, -0.0125],
[-0.0587, -0.0516, -0.0368, -0.0196, 0.0307, -0.1434]]
).to(torch_device)
# fmt: on
self.assertTrue((outputs.last_hidden_state[0, 25:35, 4:10] - expected_slice_0).abs().max() <= 1e-4)
self.assertTrue((outputs.last_hidden_state[1, 25:35, 4:10] - expected_slice_1).abs().max() <= 1e-4)
self.assertAlmostEqual(outputs.last_hidden_state[1].mean().item(), 3.3123e-05)
self.assertAlmostEqual(outputs.last_hidden_state[1].std().item(), 0.1545, delta=2e-5)
self.assertListEqual(list(outputs.last_hidden_state.shape), [2, 326, 1024])
| transformers/tests/models/wav2vec2_bert/test_modeling_wav2vec2_bert.py/0 | {
"file_path": "transformers/tests/models/wav2vec2_bert/test_modeling_wav2vec2_bert.py",
"repo_id": "transformers",
"token_count": 17010
} | 378 |
# coding=utf-8
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from transformers import AutoTokenizer, is_flax_available
from transformers.testing_utils import require_flax, require_sentencepiece, require_tokenizers, slow
if is_flax_available():
import jax.numpy as jnp
from transformers import FlaxXLMRobertaModel
@require_sentencepiece
@require_tokenizers
@require_flax
class FlaxXLMRobertaModelIntegrationTest(unittest.TestCase):
@slow
def test_flax_xlm_roberta_base(self):
model = FlaxXLMRobertaModel.from_pretrained("FacebookAI/xlm-roberta-base")
tokenizer = AutoTokenizer.from_pretrained("FacebookAI/xlm-roberta-base")
text = "The dog is cute and lives in the garden house"
input_ids = jnp.array([tokenizer.encode(text)])
expected_output_shape = (1, 12, 768) # batch_size, sequence_length, embedding_vector_dim
expected_output_values_last_dim = jnp.array(
[[-0.0101, 0.1218, -0.0803, 0.0801, 0.1327, 0.0776, -0.1215, 0.2383, 0.3338, 0.3106, 0.0300, 0.0252]]
)
output = model(input_ids)["last_hidden_state"]
self.assertEqual(output.shape, expected_output_shape)
# compare the actual values for a slice of last dim
self.assertTrue(jnp.allclose(output[:, :, -1], expected_output_values_last_dim, atol=1e-3))
| transformers/tests/models/xlm_roberta/test_modeling_flax_xlm_roberta.py/0 | {
"file_path": "transformers/tests/models/xlm_roberta/test_modeling_flax_xlm_roberta.py",
"repo_id": "transformers",
"token_count": 690
} | 379 |
# coding=utf-8
# Copyright 2022 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
""" Testing suite for the PyTorch YOSO model. """
import unittest
from transformers import YosoConfig, is_torch_available
from transformers.testing_utils import require_torch, slow, torch_device
from ...test_configuration_common import ConfigTester
from ...test_modeling_common import ModelTesterMixin, floats_tensor, ids_tensor, random_attention_mask
from ...test_pipeline_mixin import PipelineTesterMixin
if is_torch_available():
import torch
from transformers import (
YosoForMaskedLM,
YosoForMultipleChoice,
YosoForQuestionAnswering,
YosoForSequenceClassification,
YosoForTokenClassification,
YosoModel,
)
from transformers.models.yoso.modeling_yoso import YOSO_PRETRAINED_MODEL_ARCHIVE_LIST
class YosoModelTester:
def __init__(
self,
parent,
batch_size=13,
seq_length=7,
is_training=True,
use_input_mask=True,
use_token_type_ids=True,
use_labels=True,
vocab_size=99,
hidden_size=32,
num_hidden_layers=2,
num_attention_heads=4,
intermediate_size=37,
hidden_act="gelu",
hidden_dropout_prob=0.1,
attention_probs_dropout_prob=0.1,
max_position_embeddings=512,
type_vocab_size=16,
type_sequence_label_size=2,
initializer_range=0.02,
num_labels=3,
num_choices=4,
scope=None,
):
self.parent = parent
self.batch_size = batch_size
self.seq_length = seq_length
self.is_training = is_training
self.use_input_mask = use_input_mask
self.use_token_type_ids = use_token_type_ids
self.use_labels = use_labels
self.vocab_size = vocab_size
self.hidden_size = hidden_size
self.num_hidden_layers = num_hidden_layers
self.num_attention_heads = num_attention_heads
self.intermediate_size = intermediate_size
self.hidden_act = hidden_act
self.hidden_dropout_prob = hidden_dropout_prob
self.attention_probs_dropout_prob = attention_probs_dropout_prob
self.max_position_embeddings = max_position_embeddings
self.type_vocab_size = type_vocab_size
self.type_sequence_label_size = type_sequence_label_size
self.initializer_range = initializer_range
self.num_labels = num_labels
self.num_choices = num_choices
self.scope = scope
def prepare_config_and_inputs(self):
input_ids = ids_tensor([self.batch_size, self.seq_length], self.vocab_size)
input_mask = None
if self.use_input_mask:
input_mask = random_attention_mask([self.batch_size, self.seq_length])
token_type_ids = None
if self.use_token_type_ids:
token_type_ids = ids_tensor([self.batch_size, self.seq_length], self.type_vocab_size)
sequence_labels = None
token_labels = None
choice_labels = None
if self.use_labels:
sequence_labels = ids_tensor([self.batch_size], self.type_sequence_label_size)
token_labels = ids_tensor([self.batch_size, self.seq_length], self.num_labels)
choice_labels = ids_tensor([self.batch_size], self.num_choices)
config = self.get_config()
return config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
def get_config(self):
return YosoConfig(
vocab_size=self.vocab_size,
hidden_size=self.hidden_size,
num_hidden_layers=self.num_hidden_layers,
num_attention_heads=self.num_attention_heads,
intermediate_size=self.intermediate_size,
hidden_act=self.hidden_act,
hidden_dropout_prob=self.hidden_dropout_prob,
attention_probs_dropout_prob=self.attention_probs_dropout_prob,
max_position_embeddings=self.max_position_embeddings,
type_vocab_size=self.type_vocab_size,
is_decoder=False,
initializer_range=self.initializer_range,
)
def get_pipeline_config(self):
config = self.get_config()
config.vocab_size = 300
return config
def prepare_config_and_inputs_for_decoder(self):
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = self.prepare_config_and_inputs()
config.is_decoder = True
encoder_hidden_states = floats_tensor([self.batch_size, self.seq_length, self.hidden_size])
encoder_attention_mask = ids_tensor([self.batch_size, self.seq_length], vocab_size=2)
return (
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
)
def create_and_check_model(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = YosoModel(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
result = model(input_ids, token_type_ids=token_type_ids)
result = model(input_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_model_as_decoder(
self,
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
encoder_hidden_states,
encoder_attention_mask,
):
config.add_cross_attention = True
model = YosoModel(config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
)
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
encoder_hidden_states=encoder_hidden_states,
)
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids)
self.parent.assertEqual(result.last_hidden_state.shape, (self.batch_size, self.seq_length, self.hidden_size))
def create_and_check_for_masked_lm(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = YosoForMaskedLM(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.vocab_size))
def create_and_check_for_question_answering(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
model = YosoForQuestionAnswering(config=config)
model.to(torch_device)
model.eval()
result = model(
input_ids,
attention_mask=input_mask,
token_type_ids=token_type_ids,
start_positions=sequence_labels,
end_positions=sequence_labels,
)
self.parent.assertEqual(result.start_logits.shape, (self.batch_size, self.seq_length))
self.parent.assertEqual(result.end_logits.shape, (self.batch_size, self.seq_length))
def create_and_check_for_sequence_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = YosoForSequenceClassification(config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=sequence_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_labels))
def create_and_check_for_token_classification(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_labels = self.num_labels
model = YosoForTokenClassification(config=config)
model.to(torch_device)
model.eval()
result = model(input_ids, attention_mask=input_mask, token_type_ids=token_type_ids, labels=token_labels)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.seq_length, self.num_labels))
def create_and_check_for_multiple_choice(
self, config, input_ids, token_type_ids, input_mask, sequence_labels, token_labels, choice_labels
):
config.num_choices = self.num_choices
model = YosoForMultipleChoice(config=config)
model.to(torch_device)
model.eval()
multiple_choice_inputs_ids = input_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_token_type_ids = token_type_ids.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
multiple_choice_input_mask = input_mask.unsqueeze(1).expand(-1, self.num_choices, -1).contiguous()
result = model(
multiple_choice_inputs_ids,
attention_mask=multiple_choice_input_mask,
token_type_ids=multiple_choice_token_type_ids,
labels=choice_labels,
)
self.parent.assertEqual(result.logits.shape, (self.batch_size, self.num_choices))
def prepare_config_and_inputs_for_common(self):
config_and_inputs = self.prepare_config_and_inputs()
(
config,
input_ids,
token_type_ids,
input_mask,
sequence_labels,
token_labels,
choice_labels,
) = config_and_inputs
inputs_dict = {"input_ids": input_ids, "token_type_ids": token_type_ids, "attention_mask": input_mask}
return config, inputs_dict
@require_torch
class YosoModelTest(ModelTesterMixin, PipelineTesterMixin, unittest.TestCase):
all_model_classes = (
(
YosoModel,
YosoForMaskedLM,
YosoForMultipleChoice,
YosoForQuestionAnswering,
YosoForSequenceClassification,
YosoForTokenClassification,
)
if is_torch_available()
else ()
)
test_pruning = False
test_headmasking = False
test_torchscript = False
all_generative_model_classes = ()
pipeline_model_mapping = (
{
"feature-extraction": YosoModel,
"fill-mask": YosoForMaskedLM,
"question-answering": YosoForQuestionAnswering,
"text-classification": YosoForSequenceClassification,
"token-classification": YosoForTokenClassification,
"zero-shot": YosoForSequenceClassification,
}
if is_torch_available()
else {}
)
def setUp(self):
self.model_tester = YosoModelTester(self)
self.config_tester = ConfigTester(self, config_class=YosoConfig, hidden_size=37)
def test_config(self):
self.config_tester.run_common_tests()
def test_model(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_model(*config_and_inputs)
def test_model_various_embeddings(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
for type in ["absolute", "relative_key", "relative_key_query"]:
config_and_inputs[0].position_embedding_type = type
self.model_tester.create_and_check_model(*config_and_inputs)
def test_for_masked_lm(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_masked_lm(*config_and_inputs)
def test_for_multiple_choice(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_multiple_choice(*config_and_inputs)
def test_for_question_answering(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_question_answering(*config_and_inputs)
def test_for_sequence_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_sequence_classification(*config_and_inputs)
def test_for_token_classification(self):
config_and_inputs = self.model_tester.prepare_config_and_inputs()
self.model_tester.create_and_check_for_token_classification(*config_and_inputs)
@slow
def test_model_from_pretrained(self):
for model_name in YOSO_PRETRAINED_MODEL_ARCHIVE_LIST[:1]:
model = YosoModel.from_pretrained(model_name)
self.assertIsNotNone(model)
def test_attention_outputs(self):
return
@require_torch
class YosoModelIntegrationTest(unittest.TestCase):
@slow
def test_inference_no_head(self):
model = YosoModel.from_pretrained("uw-madison/yoso-4096")
input_ids = torch.tensor([[0, 1, 2, 3, 4, 5]])
with torch.no_grad():
output = model(input_ids)[0]
expected_shape = torch.Size((1, 6, 768))
self.assertEqual(output.shape, expected_shape)
expected_slice = torch.tensor(
[[[-0.0611, 0.1242, 0.0840], [0.0280, -0.0048, 0.1125], [0.0106, 0.0226, 0.0751]]]
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4))
@slow
def test_inference_masked_lm(self):
model = YosoForMaskedLM.from_pretrained("uw-madison/yoso-4096")
input_ids = torch.tensor([[0, 1, 2, 3, 4, 5]])
with torch.no_grad():
output = model(input_ids)[0]
vocab_size = 50265
expected_shape = torch.Size((1, 6, vocab_size))
self.assertEqual(output.shape, expected_shape)
expected_slice = torch.tensor(
[[[-2.1313, -3.7285, -2.2407], [-2.7047, -3.3314, -2.6408], [0.0629, -2.5166, -0.3356]]]
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4))
@slow
def test_inference_masked_lm_long_input(self):
model = YosoForMaskedLM.from_pretrained("uw-madison/yoso-4096")
input_ids = torch.arange(4096).unsqueeze(0)
with torch.no_grad():
output = model(input_ids)[0]
vocab_size = 50265
expected_shape = torch.Size((1, 4096, vocab_size))
self.assertEqual(output.shape, expected_shape)
expected_slice = torch.tensor(
[[[-2.3914, -4.3742, -5.0956], [-4.0988, -4.2384, -7.0406], [-3.1427, -3.7192, -6.6800]]]
)
self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4))
| transformers/tests/models/yoso/test_modeling_yoso.py/0 | {
"file_path": "transformers/tests/models/yoso/test_modeling_yoso.py",
"repo_id": "transformers",
"token_count": 7199
} | 380 |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import tempfile
import unittest
from typing import Dict
import datasets
import numpy as np
import requests
from datasets import load_dataset
from huggingface_hub.utils import insecure_hashlib
from transformers import (
MODEL_FOR_IMAGE_SEGMENTATION_MAPPING,
MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING,
MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING,
AutoImageProcessor,
AutoModelForImageSegmentation,
AutoModelForInstanceSegmentation,
DetrForSegmentation,
ImageSegmentationPipeline,
MaskFormerForInstanceSegmentation,
is_vision_available,
pipeline,
)
from transformers.testing_utils import (
is_pipeline_test,
nested_simplify,
require_tf,
require_timm,
require_torch,
require_vision,
slow,
)
from .test_pipelines_common import ANY
if is_vision_available():
from PIL import Image
else:
class Image:
@staticmethod
def open(*args, **kwargs):
pass
def hashimage(image: Image) -> str:
m = insecure_hashlib.md5(image.tobytes())
return m.hexdigest()[:10]
def mask_to_test_readable(mask: Image) -> Dict:
npimg = np.array(mask)
white_pixels = (npimg == 255).sum()
shape = npimg.shape
return {"hash": hashimage(mask), "white_pixels": white_pixels, "shape": shape}
def mask_to_test_readable_only_shape(mask: Image) -> Dict:
npimg = np.array(mask)
shape = npimg.shape
return {"shape": shape}
@is_pipeline_test
@require_vision
@require_timm
@require_torch
class ImageSegmentationPipelineTests(unittest.TestCase):
model_mapping = dict(
(list(MODEL_FOR_IMAGE_SEGMENTATION_MAPPING.items()) if MODEL_FOR_IMAGE_SEGMENTATION_MAPPING else [])
+ (MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING.items() if MODEL_FOR_SEMANTIC_SEGMENTATION_MAPPING else [])
+ (MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING.items() if MODEL_FOR_INSTANCE_SEGMENTATION_MAPPING else [])
)
def get_test_pipeline(self, model, tokenizer, processor):
image_segmenter = ImageSegmentationPipeline(model=model, image_processor=processor)
return image_segmenter, [
"./tests/fixtures/tests_samples/COCO/000000039769.png",
"./tests/fixtures/tests_samples/COCO/000000039769.png",
]
def run_pipeline_test(self, image_segmenter, examples):
outputs = image_segmenter(
"./tests/fixtures/tests_samples/COCO/000000039769.png",
threshold=0.0,
mask_threshold=0,
overlap_mask_area_threshold=0,
)
self.assertIsInstance(outputs, list)
n = len(outputs)
if isinstance(image_segmenter.model, (MaskFormerForInstanceSegmentation, DetrForSegmentation)):
# Instance segmentation (maskformer, and detr) have a slot for null class
# and can output nothing even with a low threshold
self.assertGreaterEqual(n, 0)
else:
self.assertGreaterEqual(n, 1)
# XXX: PIL.Image implements __eq__ which bypasses ANY, so we inverse the comparison
# to make it work
self.assertEqual([{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * n, outputs)
# we use revision="refs/pr/1" until the PR is merged
# https://hf.co/datasets/hf-internal-testing/fixtures_image_utils/discussions/1
dataset = datasets.load_dataset("hf-internal-testing/fixtures_image_utils", split="test", revision="refs/pr/1")
# RGBA
outputs = image_segmenter(dataset[0]["image"], threshold=0.0, mask_threshold=0, overlap_mask_area_threshold=0)
m = len(outputs)
self.assertEqual([{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * m, outputs)
# LA
outputs = image_segmenter(dataset[1]["image"], threshold=0.0, mask_threshold=0, overlap_mask_area_threshold=0)
m = len(outputs)
self.assertEqual([{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * m, outputs)
# L
outputs = image_segmenter(dataset[2]["image"], threshold=0.0, mask_threshold=0, overlap_mask_area_threshold=0)
m = len(outputs)
self.assertEqual([{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * m, outputs)
if isinstance(image_segmenter.model, DetrForSegmentation):
# We need to test batch_size with images with the same size.
# Detr doesn't normalize the size of the images, meaning we can have
# 800x800 or 800x1200, meaning we cannot batch simply.
# We simply bail on this
batch_size = 1
else:
batch_size = 2
# 5 times the same image so the output shape is predictable
batch = [
"./tests/fixtures/tests_samples/COCO/000000039769.png",
"./tests/fixtures/tests_samples/COCO/000000039769.png",
"./tests/fixtures/tests_samples/COCO/000000039769.png",
"./tests/fixtures/tests_samples/COCO/000000039769.png",
"./tests/fixtures/tests_samples/COCO/000000039769.png",
]
outputs = image_segmenter(
batch,
threshold=0.0,
mask_threshold=0,
overlap_mask_area_threshold=0,
batch_size=batch_size,
)
self.assertEqual(len(batch), len(outputs))
self.assertEqual(len(outputs[0]), n)
self.assertEqual(
[
[{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * n,
[{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * n,
[{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * n,
[{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * n,
[{"score": ANY(float, type(None)), "label": ANY(str), "mask": ANY(Image.Image)}] * n,
],
outputs,
f"Expected [{n}, {n}, {n}, {n}, {n}], got {[len(item) for item in outputs]}",
)
@require_tf
@unittest.skip("Image segmentation not implemented in TF")
def test_small_model_tf(self):
pass
@require_torch
def test_small_model_pt_no_panoptic(self):
model_id = "hf-internal-testing/tiny-random-mobilevit"
# The default task is `image-classification` we need to override
pipe = pipeline(task="image-segmentation", model=model_id)
# This model does NOT support neither `instance` nor `panoptic`
# We should error out
with self.assertRaises(ValueError) as e:
pipe("http://images.cocodataset.org/val2017/000000039769.jpg", subtask="panoptic")
self.assertEqual(
str(e.exception),
"Subtask panoptic is not supported for model <class"
" 'transformers.models.mobilevit.modeling_mobilevit.MobileViTForSemanticSegmentation'>",
)
with self.assertRaises(ValueError) as e:
pipe("http://images.cocodataset.org/val2017/000000039769.jpg", subtask="instance")
self.assertEqual(
str(e.exception),
"Subtask instance is not supported for model <class"
" 'transformers.models.mobilevit.modeling_mobilevit.MobileViTForSemanticSegmentation'>",
)
@require_torch
def test_small_model_pt(self):
model_id = "hf-internal-testing/tiny-detr-mobilenetsv3-panoptic"
model = AutoModelForImageSegmentation.from_pretrained(model_id)
image_processor = AutoImageProcessor.from_pretrained(model_id)
image_segmenter = ImageSegmentationPipeline(
model=model,
image_processor=image_processor,
subtask="panoptic",
threshold=0.0,
mask_threshold=0.0,
overlap_mask_area_threshold=0.0,
)
outputs = image_segmenter(
"http://images.cocodataset.org/val2017/000000039769.jpg",
)
# Shortening by hashing
for o in outputs:
o["mask"] = mask_to_test_readable(o["mask"])
# This is extremely brittle, and those values are made specific for the CI.
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": 0.004,
"label": "LABEL_215",
"mask": {"hash": "a01498ca7c", "shape": (480, 640), "white_pixels": 307200},
},
],
)
outputs = image_segmenter(
[
"http://images.cocodataset.org/val2017/000000039769.jpg",
"http://images.cocodataset.org/val2017/000000039769.jpg",
],
)
for output in outputs:
for o in output:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
[
{
"score": 0.004,
"label": "LABEL_215",
"mask": {"hash": "a01498ca7c", "shape": (480, 640), "white_pixels": 307200},
},
],
[
{
"score": 0.004,
"label": "LABEL_215",
"mask": {"hash": "a01498ca7c", "shape": (480, 640), "white_pixels": 307200},
},
],
],
)
output = image_segmenter("http://images.cocodataset.org/val2017/000000039769.jpg", subtask="instance")
for o in output:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(output, decimals=4),
[
{
"score": 0.004,
"label": "LABEL_215",
"mask": {"hash": "a01498ca7c", "shape": (480, 640), "white_pixels": 307200},
},
],
)
# This must be surprising to the reader.
# The `panoptic` returns only LABEL_215, and this returns 3 labels.
#
output = image_segmenter("http://images.cocodataset.org/val2017/000000039769.jpg", subtask="semantic")
output_masks = [o["mask"] for o in output]
# page links (to visualize)
expected_masks = [
"https://huggingface.co/datasets/hf-internal-testing/mask-for-image-segmentation-tests/blob/main/mask_0.png",
"https://huggingface.co/datasets/hf-internal-testing/mask-for-image-segmentation-tests/blob/main/mask_1.png",
"https://huggingface.co/datasets/hf-internal-testing/mask-for-image-segmentation-tests/blob/main/mask_2.png",
]
# actual links to get files
expected_masks = [x.replace("/blob/", "/resolve/") for x in expected_masks]
expected_masks = [Image.open(requests.get(image, stream=True).raw) for image in expected_masks]
# Convert masks to numpy array
output_masks = [np.array(x) for x in output_masks]
expected_masks = [np.array(x) for x in expected_masks]
self.assertEqual(output_masks[0].shape, expected_masks[0].shape)
self.assertEqual(output_masks[1].shape, expected_masks[1].shape)
self.assertEqual(output_masks[2].shape, expected_masks[2].shape)
# With un-trained tiny random models, the output `logits` tensor is very likely to contain many values
# close to each other, which cause `argmax` to give quite different results when running the test on 2
# environments. We use a lower threshold `0.9` here to avoid flakiness.
self.assertGreaterEqual(np.mean(output_masks[0] == expected_masks[0]), 0.9)
self.assertGreaterEqual(np.mean(output_masks[1] == expected_masks[1]), 0.9)
self.assertGreaterEqual(np.mean(output_masks[2] == expected_masks[2]), 0.9)
for o in output:
o["mask"] = mask_to_test_readable_only_shape(o["mask"])
self.maxDiff = None
self.assertEqual(
nested_simplify(output, decimals=4),
[
{
"label": "LABEL_88",
"mask": {"shape": (480, 640)},
"score": None,
},
{
"label": "LABEL_101",
"mask": {"shape": (480, 640)},
"score": None,
},
{
"label": "LABEL_215",
"mask": {"shape": (480, 640)},
"score": None,
},
],
)
@require_torch
def test_small_model_pt_semantic(self):
model_id = "hf-internal-testing/tiny-random-beit-pipeline"
image_segmenter = pipeline(model=model_id)
outputs = image_segmenter("http://images.cocodataset.org/val2017/000000039769.jpg")
for o in outputs:
# shortening by hashing
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": None,
"label": "LABEL_0",
"mask": {"hash": "42d0907228", "shape": (480, 640), "white_pixels": 10714},
},
{
"score": None,
"label": "LABEL_1",
"mask": {"hash": "46b8cc3976", "shape": (480, 640), "white_pixels": 296486},
},
],
)
@require_torch
@slow
def test_integration_torch_image_segmentation(self):
model_id = "facebook/detr-resnet-50-panoptic"
image_segmenter = pipeline(
"image-segmentation",
model=model_id,
threshold=0.0,
overlap_mask_area_threshold=0.0,
)
outputs = image_segmenter(
"http://images.cocodataset.org/val2017/000000039769.jpg",
)
# Shortening by hashing
for o in outputs:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": 0.9094,
"label": "blanket",
"mask": {"hash": "dcff19a97a", "shape": (480, 640), "white_pixels": 16617},
},
{
"score": 0.9941,
"label": "cat",
"mask": {"hash": "9c0af87bd0", "shape": (480, 640), "white_pixels": 59185},
},
{
"score": 0.9987,
"label": "remote",
"mask": {"hash": "c7870600d6", "shape": (480, 640), "white_pixels": 4182},
},
{
"score": 0.9995,
"label": "remote",
"mask": {"hash": "ef899a25fd", "shape": (480, 640), "white_pixels": 2275},
},
{
"score": 0.9722,
"label": "couch",
"mask": {"hash": "37b8446ac5", "shape": (480, 640), "white_pixels": 172380},
},
{
"score": 0.9994,
"label": "cat",
"mask": {"hash": "6a09d3655e", "shape": (480, 640), "white_pixels": 52561},
},
],
)
outputs = image_segmenter(
[
"http://images.cocodataset.org/val2017/000000039769.jpg",
"http://images.cocodataset.org/val2017/000000039769.jpg",
],
)
# Shortening by hashing
for output in outputs:
for o in output:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
[
{
"score": 0.9094,
"label": "blanket",
"mask": {"hash": "dcff19a97a", "shape": (480, 640), "white_pixels": 16617},
},
{
"score": 0.9941,
"label": "cat",
"mask": {"hash": "9c0af87bd0", "shape": (480, 640), "white_pixels": 59185},
},
{
"score": 0.9987,
"label": "remote",
"mask": {"hash": "c7870600d6", "shape": (480, 640), "white_pixels": 4182},
},
{
"score": 0.9995,
"label": "remote",
"mask": {"hash": "ef899a25fd", "shape": (480, 640), "white_pixels": 2275},
},
{
"score": 0.9722,
"label": "couch",
"mask": {"hash": "37b8446ac5", "shape": (480, 640), "white_pixels": 172380},
},
{
"score": 0.9994,
"label": "cat",
"mask": {"hash": "6a09d3655e", "shape": (480, 640), "white_pixels": 52561},
},
],
[
{
"score": 0.9094,
"label": "blanket",
"mask": {"hash": "dcff19a97a", "shape": (480, 640), "white_pixels": 16617},
},
{
"score": 0.9941,
"label": "cat",
"mask": {"hash": "9c0af87bd0", "shape": (480, 640), "white_pixels": 59185},
},
{
"score": 0.9987,
"label": "remote",
"mask": {"hash": "c7870600d6", "shape": (480, 640), "white_pixels": 4182},
},
{
"score": 0.9995,
"label": "remote",
"mask": {"hash": "ef899a25fd", "shape": (480, 640), "white_pixels": 2275},
},
{
"score": 0.9722,
"label": "couch",
"mask": {"hash": "37b8446ac5", "shape": (480, 640), "white_pixels": 172380},
},
{
"score": 0.9994,
"label": "cat",
"mask": {"hash": "6a09d3655e", "shape": (480, 640), "white_pixels": 52561},
},
],
],
)
@require_torch
@slow
def test_threshold(self):
model_id = "facebook/detr-resnet-50-panoptic"
image_segmenter = pipeline("image-segmentation", model=model_id)
outputs = image_segmenter("http://images.cocodataset.org/val2017/000000039769.jpg", threshold=0.999)
# Shortening by hashing
for o in outputs:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": 0.9995,
"label": "remote",
"mask": {"hash": "d02404f578", "shape": (480, 640), "white_pixels": 2789},
},
{
"score": 0.9994,
"label": "cat",
"mask": {"hash": "eaa115b40c", "shape": (480, 640), "white_pixels": 304411},
},
],
)
outputs = image_segmenter("http://images.cocodataset.org/val2017/000000039769.jpg", threshold=0.5)
for o in outputs:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": 0.9941,
"label": "cat",
"mask": {"hash": "9c0af87bd0", "shape": (480, 640), "white_pixels": 59185},
},
{
"score": 0.9987,
"label": "remote",
"mask": {"hash": "c7870600d6", "shape": (480, 640), "white_pixels": 4182},
},
{
"score": 0.9995,
"label": "remote",
"mask": {"hash": "ef899a25fd", "shape": (480, 640), "white_pixels": 2275},
},
{
"score": 0.9722,
"label": "couch",
"mask": {"hash": "37b8446ac5", "shape": (480, 640), "white_pixels": 172380},
},
{
"score": 0.9994,
"label": "cat",
"mask": {"hash": "6a09d3655e", "shape": (480, 640), "white_pixels": 52561},
},
],
)
@require_torch
@slow
def test_maskformer(self):
threshold = 0.8
model_id = "facebook/maskformer-swin-base-ade"
model = AutoModelForInstanceSegmentation.from_pretrained(model_id)
image_processor = AutoImageProcessor.from_pretrained(model_id)
image_segmenter = pipeline("image-segmentation", model=model, image_processor=image_processor)
image = load_dataset("hf-internal-testing/fixtures_ade20k", split="test")
file = image[0]["file"]
outputs = image_segmenter(file, threshold=threshold)
# Shortening by hashing
for o in outputs:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": 0.9974,
"label": "wall",
"mask": {"hash": "a547b7c062", "shape": (512, 683), "white_pixels": 14252},
},
{
"score": 0.949,
"label": "house",
"mask": {"hash": "0da9b7b38f", "shape": (512, 683), "white_pixels": 132177},
},
{
"score": 0.9995,
"label": "grass",
"mask": {"hash": "1d07ea0a26", "shape": (512, 683), "white_pixels": 53444},
},
{
"score": 0.9976,
"label": "tree",
"mask": {"hash": "6cdc97c7da", "shape": (512, 683), "white_pixels": 7944},
},
{
"score": 0.8239,
"label": "plant",
"mask": {"hash": "1ab4ce378f", "shape": (512, 683), "white_pixels": 4136},
},
{
"score": 0.9942,
"label": "road, route",
"mask": {"hash": "39c5d17be5", "shape": (512, 683), "white_pixels": 1941},
},
{
"score": 1.0,
"label": "sky",
"mask": {"hash": "a3756324a6", "shape": (512, 683), "white_pixels": 135802},
},
],
)
@require_torch
@slow
def test_oneformer(self):
image_segmenter = pipeline(model="shi-labs/oneformer_ade20k_swin_tiny")
image = load_dataset("hf-internal-testing/fixtures_ade20k", split="test")
file = image[0]["file"]
outputs = image_segmenter(file, threshold=0.99)
# Shortening by hashing
for o in outputs:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": 0.9981,
"label": "grass",
"mask": {"hash": "3a92904d4c", "white_pixels": 118131, "shape": (512, 683)},
},
{
"score": 0.9992,
"label": "sky",
"mask": {"hash": "fa2300cc9a", "white_pixels": 231565, "shape": (512, 683)},
},
],
)
# Different task
outputs = image_segmenter(file, threshold=0.99, subtask="instance")
# Shortening by hashing
for o in outputs:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": 0.9991,
"label": "sky",
"mask": {"hash": "8b1ffad016", "white_pixels": 230566, "shape": (512, 683)},
},
{
"score": 0.9981,
"label": "grass",
"mask": {"hash": "9bbdf83d3d", "white_pixels": 119130, "shape": (512, 683)},
},
],
)
# Different task
outputs = image_segmenter(file, subtask="semantic")
# Shortening by hashing
for o in outputs:
o["mask"] = mask_to_test_readable(o["mask"])
self.assertEqual(
nested_simplify(outputs, decimals=4),
[
{
"score": None,
"label": "wall",
"mask": {"hash": "897fb20b7f", "white_pixels": 14506, "shape": (512, 683)},
},
{
"score": None,
"label": "building",
"mask": {"hash": "f2a68c63e4", "white_pixels": 125019, "shape": (512, 683)},
},
{
"score": None,
"label": "sky",
"mask": {"hash": "e0ca3a548e", "white_pixels": 135330, "shape": (512, 683)},
},
{
"score": None,
"label": "tree",
"mask": {"hash": "7c9544bcac", "white_pixels": 16263, "shape": (512, 683)},
},
{
"score": None,
"label": "road, route",
"mask": {"hash": "2c7704e491", "white_pixels": 2143, "shape": (512, 683)},
},
{
"score": None,
"label": "grass",
"mask": {"hash": "bf6c2867e0", "white_pixels": 53040, "shape": (512, 683)},
},
{
"score": None,
"label": "plant",
"mask": {"hash": "93c4b7199e", "white_pixels": 3335, "shape": (512, 683)},
},
{
"score": None,
"label": "house",
"mask": {"hash": "93ec419ad5", "white_pixels": 60, "shape": (512, 683)},
},
],
)
def test_save_load(self):
model_id = "hf-internal-testing/tiny-detr-mobilenetsv3-panoptic"
model = AutoModelForImageSegmentation.from_pretrained(model_id)
image_processor = AutoImageProcessor.from_pretrained(model_id)
image_segmenter = pipeline(
task="image-segmentation",
model=model,
image_processor=image_processor,
)
with tempfile.TemporaryDirectory() as tmpdirname:
image_segmenter.save_pretrained(tmpdirname)
pipeline(task="image-segmentation", model=tmpdirname)
| transformers/tests/pipelines/test_pipelines_image_segmentation.py/0 | {
"file_path": "transformers/tests/pipelines/test_pipelines_image_segmentation.py",
"repo_id": "transformers",
"token_count": 15529
} | 381 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
from transformers import (
MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING,
Pipeline,
ZeroShotClassificationPipeline,
pipeline,
)
from transformers.testing_utils import is_pipeline_test, nested_simplify, require_tf, require_torch, slow
from .test_pipelines_common import ANY
# These 2 model types require different inputs than those of the usual text models.
_TO_SKIP = {"LayoutLMv2Config", "LayoutLMv3Config"}
@is_pipeline_test
class ZeroShotClassificationPipelineTests(unittest.TestCase):
model_mapping = MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING
tf_model_mapping = TF_MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING
if model_mapping is not None:
model_mapping = {config: model for config, model in model_mapping.items() if config.__name__ not in _TO_SKIP}
if tf_model_mapping is not None:
tf_model_mapping = {
config: model for config, model in tf_model_mapping.items() if config.__name__ not in _TO_SKIP
}
def get_test_pipeline(self, model, tokenizer, processor):
classifier = ZeroShotClassificationPipeline(
model=model, tokenizer=tokenizer, candidate_labels=["polics", "health"]
)
return classifier, ["Who are you voting for in 2020?", "My stomach hurts."]
def run_pipeline_test(self, classifier, _):
outputs = classifier("Who are you voting for in 2020?", candidate_labels="politics")
self.assertEqual(outputs, {"sequence": ANY(str), "labels": [ANY(str)], "scores": [ANY(float)]})
# No kwarg
outputs = classifier("Who are you voting for in 2020?", ["politics"])
self.assertEqual(outputs, {"sequence": ANY(str), "labels": [ANY(str)], "scores": [ANY(float)]})
outputs = classifier("Who are you voting for in 2020?", candidate_labels=["politics"])
self.assertEqual(outputs, {"sequence": ANY(str), "labels": [ANY(str)], "scores": [ANY(float)]})
outputs = classifier("Who are you voting for in 2020?", candidate_labels="politics, public health")
self.assertEqual(
outputs, {"sequence": ANY(str), "labels": [ANY(str), ANY(str)], "scores": [ANY(float), ANY(float)]}
)
self.assertAlmostEqual(sum(nested_simplify(outputs["scores"])), 1.0)
outputs = classifier("Who are you voting for in 2020?", candidate_labels=["politics", "public health"])
self.assertEqual(
outputs, {"sequence": ANY(str), "labels": [ANY(str), ANY(str)], "scores": [ANY(float), ANY(float)]}
)
self.assertAlmostEqual(sum(nested_simplify(outputs["scores"])), 1.0)
outputs = classifier(
"Who are you voting for in 2020?", candidate_labels="politics", hypothesis_template="This text is about {}"
)
self.assertEqual(outputs, {"sequence": ANY(str), "labels": [ANY(str)], "scores": [ANY(float)]})
# https://github.com/huggingface/transformers/issues/13846
outputs = classifier(["I am happy"], ["positive", "negative"])
self.assertEqual(
outputs,
[
{"sequence": ANY(str), "labels": [ANY(str), ANY(str)], "scores": [ANY(float), ANY(float)]}
for i in range(1)
],
)
outputs = classifier(["I am happy", "I am sad"], ["positive", "negative"])
self.assertEqual(
outputs,
[
{"sequence": ANY(str), "labels": [ANY(str), ANY(str)], "scores": [ANY(float), ANY(float)]}
for i in range(2)
],
)
with self.assertRaises(ValueError):
classifier("", candidate_labels="politics")
with self.assertRaises(TypeError):
classifier(None, candidate_labels="politics")
with self.assertRaises(ValueError):
classifier("Who are you voting for in 2020?", candidate_labels="")
with self.assertRaises(TypeError):
classifier("Who are you voting for in 2020?", candidate_labels=None)
with self.assertRaises(ValueError):
classifier(
"Who are you voting for in 2020?",
candidate_labels="politics",
hypothesis_template="Not formatting template",
)
with self.assertRaises(AttributeError):
classifier(
"Who are you voting for in 2020?",
candidate_labels="politics",
hypothesis_template=None,
)
self.run_entailment_id(classifier)
def run_entailment_id(self, zero_shot_classifier: Pipeline):
config = zero_shot_classifier.model.config
original_label2id = config.label2id
original_entailment = zero_shot_classifier.entailment_id
config.label2id = {"LABEL_0": 0, "LABEL_1": 1, "LABEL_2": 2}
self.assertEqual(zero_shot_classifier.entailment_id, -1)
config.label2id = {"entailment": 0, "neutral": 1, "contradiction": 2}
self.assertEqual(zero_shot_classifier.entailment_id, 0)
config.label2id = {"ENTAIL": 0, "NON-ENTAIL": 1}
self.assertEqual(zero_shot_classifier.entailment_id, 0)
config.label2id = {"ENTAIL": 2, "NEUTRAL": 1, "CONTR": 0}
self.assertEqual(zero_shot_classifier.entailment_id, 2)
zero_shot_classifier.model.config.label2id = original_label2id
self.assertEqual(original_entailment, zero_shot_classifier.entailment_id)
@require_torch
def test_truncation(self):
zero_shot_classifier = pipeline(
"zero-shot-classification",
model="sshleifer/tiny-distilbert-base-cased-distilled-squad",
framework="pt",
)
# There was a regression in 4.10 for this
# Adding a test so we don't make the mistake again.
# https://github.com/huggingface/transformers/issues/13381#issuecomment-912343499
zero_shot_classifier(
"Who are you voting for in 2020?" * 100, candidate_labels=["politics", "public health", "science"]
)
@require_torch
def test_small_model_pt(self):
zero_shot_classifier = pipeline(
"zero-shot-classification",
model="sshleifer/tiny-distilbert-base-cased-distilled-squad",
framework="pt",
)
outputs = zero_shot_classifier(
"Who are you voting for in 2020?", candidate_labels=["politics", "public health", "science"]
)
self.assertEqual(
nested_simplify(outputs),
{
"sequence": "Who are you voting for in 2020?",
"labels": ["science", "public health", "politics"],
"scores": [0.333, 0.333, 0.333],
},
)
@require_tf
def test_small_model_tf(self):
zero_shot_classifier = pipeline(
"zero-shot-classification",
model="sshleifer/tiny-distilbert-base-cased-distilled-squad",
framework="tf",
)
outputs = zero_shot_classifier(
"Who are you voting for in 2020?", candidate_labels=["politics", "public health", "science"]
)
self.assertEqual(
nested_simplify(outputs),
{
"sequence": "Who are you voting for in 2020?",
"labels": ["science", "public health", "politics"],
"scores": [0.333, 0.333, 0.333],
},
)
@slow
@require_torch
def test_large_model_pt(self):
zero_shot_classifier = pipeline(
"zero-shot-classification", model="FacebookAI/roberta-large-mnli", framework="pt"
)
outputs = zero_shot_classifier(
"Who are you voting for in 2020?", candidate_labels=["politics", "public health", "science"]
)
self.assertEqual(
nested_simplify(outputs),
{
"sequence": "Who are you voting for in 2020?",
"labels": ["politics", "public health", "science"],
"scores": [0.976, 0.015, 0.009],
},
)
outputs = zero_shot_classifier(
"The dominant sequence transduction models are based on complex recurrent or convolutional neural networks"
" in an encoder-decoder configuration. The best performing models also connect the encoder and decoder"
" through an attention mechanism. We propose a new simple network architecture, the Transformer, based"
" solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two"
" machine translation tasks show these models to be superior in quality while being more parallelizable"
" and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014"
" English-to-German translation task, improving over the existing best results, including ensembles by"
" over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new"
" single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small"
" fraction of the training costs of the best models from the literature. We show that the Transformer"
" generalizes well to other tasks by applying it successfully to English constituency parsing both with"
" large and limited training data.",
candidate_labels=["machine learning", "statistics", "translation", "vision"],
multi_label=True,
)
self.assertEqual(
nested_simplify(outputs),
{
"sequence": (
"The dominant sequence transduction models are based on complex recurrent or convolutional neural"
" networks in an encoder-decoder configuration. The best performing models also connect the"
" encoder and decoder through an attention mechanism. We propose a new simple network"
" architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence"
" and convolutions entirely. Experiments on two machine translation tasks show these models to be"
" superior in quality while being more parallelizable and requiring significantly less time to"
" train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task,"
" improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014"
" English-to-French translation task, our model establishes a new single-model state-of-the-art"
" BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training"
" costs of the best models from the literature. We show that the Transformer generalizes well to"
" other tasks by applying it successfully to English constituency parsing both with large and"
" limited training data."
),
"labels": ["translation", "machine learning", "vision", "statistics"],
"scores": [0.817, 0.713, 0.018, 0.018],
},
)
@slow
@require_tf
def test_large_model_tf(self):
zero_shot_classifier = pipeline(
"zero-shot-classification", model="FacebookAI/roberta-large-mnli", framework="tf"
)
outputs = zero_shot_classifier(
"Who are you voting for in 2020?", candidate_labels=["politics", "public health", "science"]
)
self.assertEqual(
nested_simplify(outputs),
{
"sequence": "Who are you voting for in 2020?",
"labels": ["politics", "public health", "science"],
"scores": [0.976, 0.015, 0.009],
},
)
outputs = zero_shot_classifier(
"The dominant sequence transduction models are based on complex recurrent or convolutional neural networks"
" in an encoder-decoder configuration. The best performing models also connect the encoder and decoder"
" through an attention mechanism. We propose a new simple network architecture, the Transformer, based"
" solely on attention mechanisms, dispensing with recurrence and convolutions entirely. Experiments on two"
" machine translation tasks show these models to be superior in quality while being more parallelizable"
" and requiring significantly less time to train. Our model achieves 28.4 BLEU on the WMT 2014"
" English-to-German translation task, improving over the existing best results, including ensembles by"
" over 2 BLEU. On the WMT 2014 English-to-French translation task, our model establishes a new"
" single-model state-of-the-art BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small"
" fraction of the training costs of the best models from the literature. We show that the Transformer"
" generalizes well to other tasks by applying it successfully to English constituency parsing both with"
" large and limited training data.",
candidate_labels=["machine learning", "statistics", "translation", "vision"],
multi_label=True,
)
self.assertEqual(
nested_simplify(outputs),
{
"sequence": (
"The dominant sequence transduction models are based on complex recurrent or convolutional neural"
" networks in an encoder-decoder configuration. The best performing models also connect the"
" encoder and decoder through an attention mechanism. We propose a new simple network"
" architecture, the Transformer, based solely on attention mechanisms, dispensing with recurrence"
" and convolutions entirely. Experiments on two machine translation tasks show these models to be"
" superior in quality while being more parallelizable and requiring significantly less time to"
" train. Our model achieves 28.4 BLEU on the WMT 2014 English-to-German translation task,"
" improving over the existing best results, including ensembles by over 2 BLEU. On the WMT 2014"
" English-to-French translation task, our model establishes a new single-model state-of-the-art"
" BLEU score of 41.8 after training for 3.5 days on eight GPUs, a small fraction of the training"
" costs of the best models from the literature. We show that the Transformer generalizes well to"
" other tasks by applying it successfully to English constituency parsing both with large and"
" limited training data."
),
"labels": ["translation", "machine learning", "vision", "statistics"],
"scores": [0.817, 0.713, 0.018, 0.018],
},
)
| transformers/tests/pipelines/test_pipelines_zero_shot.py/0 | {
"file_path": "transformers/tests/pipelines/test_pipelines_zero_shot.py",
"repo_id": "transformers",
"token_count": 6385
} | 382 |
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import os
import shutil
import sys
import tempfile
import unittest
from contextlib import contextmanager
from pathlib import Path
git_repo_path = os.path.abspath(os.path.dirname(os.path.dirname(os.path.dirname(__file__))))
sys.path.append(os.path.join(git_repo_path, "utils"))
import check_copies # noqa: E402
from check_copies import convert_to_localized_md, find_code_in_transformers, is_copy_consistent # noqa: E402
# This is the reference code that will be used in the tests.
# If BertLMPredictionHead is changed in modeling_bert.py, this code needs to be manually updated.
REFERENCE_CODE = """ def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
"""
MOCK_BERT_CODE = """from ...modeling_utils import PreTrainedModel
def bert_function(x):
return x
class BertAttention(nn.Module):
def __init__(self, config):
super().__init__()
class BertModel(BertPreTrainedModel):
def __init__(self, config):
super().__init__()
self.bert = BertEncoder(config)
@add_docstring(BERT_DOCSTRING)
def forward(self, x):
return self.bert(x)
"""
MOCK_BERT_COPY_CODE = """from ...modeling_utils import PreTrainedModel
# Copied from transformers.models.bert.modeling_bert.bert_function
def bert_copy_function(x):
return x
# Copied from transformers.models.bert.modeling_bert.BertAttention
class BertCopyAttention(nn.Module):
def __init__(self, config):
super().__init__()
# Copied from transformers.models.bert.modeling_bert.BertModel with Bert->BertCopy all-casing
class BertCopyModel(BertCopyPreTrainedModel):
def __init__(self, config):
super().__init__()
self.bertcopy = BertCopyEncoder(config)
@add_docstring(BERTCOPY_DOCSTRING)
def forward(self, x):
return self.bertcopy(x)
"""
MOCK_DUMMY_BERT_CODE_MATCH = """
class BertDummyModel:
attr_1 = 1
attr_2 = 2
def __init__(self, a=1, b=2):
self.a = a
self.b = b
# Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
def forward(self, c):
return 1
def existing_common(self, c):
return 4
def existing_diff_to_be_ignored(self, c):
return 9
"""
MOCK_DUMMY_ROBERTA_CODE_MATCH = """
# Copied from transformers.models.dummy_bert_match.modeling_dummy_bert_match.BertDummyModel with BertDummy->RobertaBertDummy
class RobertaBertDummyModel:
attr_1 = 1
attr_2 = 2
def __init__(self, a=1, b=2):
self.a = a
self.b = b
# Ignore copy
def only_in_roberta_to_be_ignored(self, c):
return 3
# Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
def forward(self, c):
return 1
def existing_common(self, c):
return 4
# Ignore copy
def existing_diff_to_be_ignored(self, c):
return 6
"""
MOCK_DUMMY_BERT_CODE_NO_MATCH = """
class BertDummyModel:
attr_1 = 1
attr_2 = 2
def __init__(self, a=1, b=2):
self.a = a
self.b = b
# Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
def forward(self, c):
return 1
def only_in_bert(self, c):
return 7
def existing_common(self, c):
return 4
def existing_diff_not_ignored(self, c):
return 8
def existing_diff_to_be_ignored(self, c):
return 9
"""
MOCK_DUMMY_ROBERTA_CODE_NO_MATCH = """
# Copied from transformers.models.dummy_bert_no_match.modeling_dummy_bert_no_match.BertDummyModel with BertDummy->RobertaBertDummy
class RobertaBertDummyModel:
attr_1 = 1
attr_2 = 3
def __init__(self, a=1, b=2):
self.a = a
self.b = b
# Ignore copy
def only_in_roberta_to_be_ignored(self, c):
return 3
# Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
def forward(self, c):
return 1
def only_in_roberta_not_ignored(self, c):
return 2
def existing_common(self, c):
return 4
def existing_diff_not_ignored(self, c):
return 5
# Ignore copy
def existing_diff_to_be_ignored(self, c):
return 6
"""
EXPECTED_REPLACED_CODE = """
# Copied from transformers.models.dummy_bert_no_match.modeling_dummy_bert_no_match.BertDummyModel with BertDummy->RobertaBertDummy
class RobertaBertDummyModel:
attr_1 = 1
attr_2 = 2
def __init__(self, a=1, b=2):
self.a = a
self.b = b
# Copied from transformers.models.dummy_gpt2.modeling_dummy_gpt2.GPT2DummyModel.forward
def forward(self, c):
return 1
def only_in_bert(self, c):
return 7
def existing_common(self, c):
return 4
def existing_diff_not_ignored(self, c):
return 8
# Ignore copy
def existing_diff_to_be_ignored(self, c):
return 6
# Ignore copy
def only_in_roberta_to_be_ignored(self, c):
return 3
"""
def replace_in_file(filename, old, new):
with open(filename, "r", encoding="utf-8") as f:
content = f.read()
content = content.replace(old, new)
with open(filename, "w", encoding="utf-8", newline="\n") as f:
f.write(content)
def create_tmp_repo(tmp_dir):
"""
Creates a mock repository in a temporary folder for testing.
"""
tmp_dir = Path(tmp_dir)
if tmp_dir.exists():
shutil.rmtree(tmp_dir)
tmp_dir.mkdir(exist_ok=True)
model_dir = tmp_dir / "src" / "transformers" / "models"
model_dir.mkdir(parents=True, exist_ok=True)
models = {
"bert": MOCK_BERT_CODE,
"bertcopy": MOCK_BERT_COPY_CODE,
"dummy_bert_match": MOCK_DUMMY_BERT_CODE_MATCH,
"dummy_roberta_match": MOCK_DUMMY_ROBERTA_CODE_MATCH,
"dummy_bert_no_match": MOCK_DUMMY_BERT_CODE_NO_MATCH,
"dummy_roberta_no_match": MOCK_DUMMY_ROBERTA_CODE_NO_MATCH,
}
for model, code in models.items():
model_subdir = model_dir / model
model_subdir.mkdir(exist_ok=True)
with open(model_subdir / f"modeling_{model}.py", "w", encoding="utf-8", newline="\n") as f:
f.write(code)
@contextmanager
def patch_transformer_repo_path(new_folder):
"""
Temporarily patches the variables defines in `check_copies` to use a different location for the repo.
"""
old_repo_path = check_copies.REPO_PATH
old_doc_path = check_copies.PATH_TO_DOCS
old_transformer_path = check_copies.TRANSFORMERS_PATH
repo_path = Path(new_folder).resolve()
check_copies.REPO_PATH = str(repo_path)
check_copies.PATH_TO_DOCS = str(repo_path / "docs" / "source" / "en")
check_copies.TRANSFORMERS_PATH = str(repo_path / "src" / "transformers")
try:
yield
finally:
check_copies.REPO_PATH = old_repo_path
check_copies.PATH_TO_DOCS = old_doc_path
check_copies.TRANSFORMERS_PATH = old_transformer_path
class CopyCheckTester(unittest.TestCase):
def test_find_code_in_transformers(self):
with tempfile.TemporaryDirectory() as tmp_folder:
create_tmp_repo(tmp_folder)
with patch_transformer_repo_path(tmp_folder):
code = find_code_in_transformers("models.bert.modeling_bert.BertAttention")
reference_code = (
"class BertAttention(nn.Module):\n def __init__(self, config):\n super().__init__()\n"
)
self.assertEqual(code, reference_code)
def test_is_copy_consistent(self):
path_to_check = ["src", "transformers", "models", "bertcopy", "modeling_bertcopy.py"]
with tempfile.TemporaryDirectory() as tmp_folder:
# Base check
create_tmp_repo(tmp_folder)
with patch_transformer_repo_path(tmp_folder):
file_to_check = os.path.join(tmp_folder, *path_to_check)
diffs = is_copy_consistent(file_to_check)
self.assertEqual(diffs, [])
# Base check with an inconsistency
create_tmp_repo(tmp_folder)
with patch_transformer_repo_path(tmp_folder):
file_to_check = os.path.join(tmp_folder, *path_to_check)
replace_in_file(file_to_check, "self.bertcopy(x)", "self.bert(x)")
diffs = is_copy_consistent(file_to_check)
self.assertEqual(diffs, [["models.bert.modeling_bert.BertModel", 22]])
_ = is_copy_consistent(file_to_check, overwrite=True)
with open(file_to_check, "r", encoding="utf-8") as f:
self.assertEqual(f.read(), MOCK_BERT_COPY_CODE)
def test_is_copy_consistent_with_ignored_match(self):
path_to_check = ["src", "transformers", "models", "dummy_roberta_match", "modeling_dummy_roberta_match.py"]
with tempfile.TemporaryDirectory() as tmp_folder:
# Base check
create_tmp_repo(tmp_folder)
with patch_transformer_repo_path(tmp_folder):
file_to_check = os.path.join(tmp_folder, *path_to_check)
diffs = is_copy_consistent(file_to_check)
self.assertEqual(diffs, [])
def test_is_copy_consistent_with_ignored_no_match(self):
path_to_check = [
"src",
"transformers",
"models",
"dummy_roberta_no_match",
"modeling_dummy_roberta_no_match.py",
]
with tempfile.TemporaryDirectory() as tmp_folder:
# Base check with an inconsistency
create_tmp_repo(tmp_folder)
with patch_transformer_repo_path(tmp_folder):
file_to_check = os.path.join(tmp_folder, *path_to_check)
diffs = is_copy_consistent(file_to_check)
# line 6: `attr_2 = 3` in `MOCK_DUMMY_ROBERTA_CODE_NO_MATCH`.
# (which has a leading `\n`.)
self.assertEqual(
diffs, [["models.dummy_bert_no_match.modeling_dummy_bert_no_match.BertDummyModel", 6]]
)
_ = is_copy_consistent(file_to_check, overwrite=True)
with open(file_to_check, "r", encoding="utf-8") as f:
self.assertEqual(f.read(), EXPECTED_REPLACED_CODE)
def test_convert_to_localized_md(self):
localized_readme = check_copies.LOCALIZED_READMES["README_zh-hans.md"]
md_list = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (from Google Research and the"
" Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for"
" Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong"
" Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut.\n1."
" **[DistilBERT](https://huggingface.co/transformers/model_doc/distilbert.html)** (from HuggingFace),"
" released together with the paper [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and"
" lighter](https://arxiv.org/abs/1910.01108) by Victor Sanh, Lysandre Debut and Thomas Wolf. The same"
" method has been applied to compress GPT2 into"
" [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into"
" [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation),"
" Multilingual BERT into"
" [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German"
" version of DistilBERT.\n1. **[ELECTRA](https://huggingface.co/transformers/model_doc/electra.html)**"
" (from Google Research/Stanford University) released with the paper [ELECTRA: Pre-training text encoders"
" as discriminators rather than generators](https://arxiv.org/abs/2003.10555) by Kevin Clark, Minh-Thang"
" Luong, Quoc V. Le, Christopher D. Manning."
)
localized_md_list = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (来自 Google Research and the"
" Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of"
" Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
" Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。\n"
)
converted_md_list_sample = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (来自 Google Research and the"
" Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of"
" Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
" Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。\n1."
" **[DistilBERT](https://huggingface.co/transformers/model_doc/distilbert.html)** (来自 HuggingFace) 伴随论文"
" [DistilBERT, a distilled version of BERT: smaller, faster, cheaper and"
" lighter](https://arxiv.org/abs/1910.01108) 由 Victor Sanh, Lysandre Debut and Thomas Wolf 发布。 The same"
" method has been applied to compress GPT2 into"
" [DistilGPT2](https://github.com/huggingface/transformers/tree/main/examples/distillation), RoBERTa into"
" [DistilRoBERTa](https://github.com/huggingface/transformers/tree/main/examples/distillation),"
" Multilingual BERT into"
" [DistilmBERT](https://github.com/huggingface/transformers/tree/main/examples/distillation) and a German"
" version of DistilBERT.\n1. **[ELECTRA](https://huggingface.co/transformers/model_doc/electra.html)** (来自"
" Google Research/Stanford University) 伴随论文 [ELECTRA: Pre-training text encoders as discriminators rather"
" than generators](https://arxiv.org/abs/2003.10555) 由 Kevin Clark, Minh-Thang Luong, Quoc V. Le,"
" Christopher D. Manning 发布。\n"
)
num_models_equal, converted_md_list = convert_to_localized_md(
md_list, localized_md_list, localized_readme["format_model_list"]
)
self.assertFalse(num_models_equal)
self.assertEqual(converted_md_list, converted_md_list_sample)
num_models_equal, converted_md_list = convert_to_localized_md(
md_list, converted_md_list, localized_readme["format_model_list"]
)
# Check whether the number of models is equal to README.md after conversion.
self.assertTrue(num_models_equal)
link_changed_md_list = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (from Google Research and the"
" Toyota Technological Institute at Chicago) released with the paper [ALBERT: A Lite BERT for"
" Self-supervised Learning of Language Representations](https://arxiv.org/abs/1909.11942), by Zhenzhong"
" Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut."
)
link_unchanged_md_list = (
"1. **[ALBERT](https://huggingface.co/transformers/main/model_doc/albert.html)** (来自 Google Research and"
" the Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of"
" Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
" Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。\n"
)
converted_md_list_sample = (
"1. **[ALBERT](https://huggingface.co/transformers/model_doc/albert.html)** (来自 Google Research and the"
" Toyota Technological Institute at Chicago) 伴随论文 [ALBERT: A Lite BERT for Self-supervised Learning of"
" Language Representations](https://arxiv.org/abs/1909.11942), 由 Zhenzhong Lan, Mingda Chen, Sebastian"
" Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut 发布。\n"
)
num_models_equal, converted_md_list = convert_to_localized_md(
link_changed_md_list, link_unchanged_md_list, localized_readme["format_model_list"]
)
# Check if the model link is synchronized.
self.assertEqual(converted_md_list, converted_md_list_sample)
| transformers/tests/repo_utils/test_check_copies.py/0 | {
"file_path": "transformers/tests/repo_utils/test_check_copies.py",
"repo_id": "transformers",
"token_count": 7781
} | 383 |
import json
import os
import subprocess
import unittest
from ast import literal_eval
import pytest
from parameterized import parameterized_class
from . import is_sagemaker_available
if is_sagemaker_available():
from sagemaker import Session, TrainingJobAnalytics
from sagemaker.huggingface import HuggingFace
@pytest.mark.skipif(
literal_eval(os.getenv("TEST_SAGEMAKER", "False")) is not True,
reason="Skipping test because should only be run when releasing minor transformers version",
)
@pytest.mark.usefixtures("sm_env")
@parameterized_class(
[
{
"framework": "pytorch",
"script": "run_glue.py",
"model_name_or_path": "distilbert/distilbert-base-cased",
"instance_type": "ml.g4dn.xlarge",
"results": {"train_runtime": 650, "eval_accuracy": 0.6, "eval_loss": 0.9},
},
{
"framework": "tensorflow",
"script": "run_tf.py",
"model_name_or_path": "distilbert/distilbert-base-cased",
"instance_type": "ml.g4dn.xlarge",
"results": {"train_runtime": 600, "eval_accuracy": 0.3, "eval_loss": 0.9},
},
]
)
class SingleNodeTest(unittest.TestCase):
def setUp(self):
if self.framework == "pytorch":
subprocess.run(
f"cp ./examples/pytorch/text-classification/run_glue.py {self.env.test_path}/run_glue.py".split(),
encoding="utf-8",
check=True,
)
assert hasattr(self, "env")
def create_estimator(self, instance_count=1):
# creates estimator
return HuggingFace(
entry_point=self.script,
source_dir=self.env.test_path,
role=self.env.role,
image_uri=self.env.image_uri,
base_job_name=f"{self.env.base_job_name}-single",
instance_count=instance_count,
instance_type=self.instance_type,
debugger_hook_config=False,
hyperparameters={**self.env.hyperparameters, "model_name_or_path": self.model_name_or_path},
metric_definitions=self.env.metric_definitions,
py_version="py36",
)
def save_results_as_csv(self, job_name):
TrainingJobAnalytics(job_name).export_csv(f"{self.env.test_path}/{job_name}_metrics.csv")
def test_glue(self):
# create estimator
estimator = self.create_estimator()
# run training
estimator.fit()
# result dataframe
result_metrics_df = TrainingJobAnalytics(estimator.latest_training_job.name).dataframe()
# extract kpis
eval_accuracy = list(result_metrics_df[result_metrics_df.metric_name == "eval_accuracy"]["value"])
eval_loss = list(result_metrics_df[result_metrics_df.metric_name == "eval_loss"]["value"])
# get train time from SageMaker job, this includes starting, preprocessing, stopping
train_runtime = (
Session().describe_training_job(estimator.latest_training_job.name).get("TrainingTimeInSeconds", 999999)
)
# assert kpis
assert train_runtime <= self.results["train_runtime"]
assert all(t >= self.results["eval_accuracy"] for t in eval_accuracy)
assert all(t <= self.results["eval_loss"] for t in eval_loss)
# dump tests result into json file to share in PR
with open(f"{estimator.latest_training_job.name}.json", "w") as outfile:
json.dump({"train_time": train_runtime, "eval_accuracy": eval_accuracy, "eval_loss": eval_loss}, outfile)
| transformers/tests/sagemaker/test_single_node_gpu.py/0 | {
"file_path": "transformers/tests/sagemaker/test_single_node_gpu.py",
"repo_id": "transformers",
"token_count": 1592
} | 384 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import json
import os
import random
import unittest
from pathlib import Path
from transformers.testing_utils import (
is_pipeline_test,
require_decord,
require_pytesseract,
require_timm,
require_torch,
require_torch_or_tf,
require_vision,
)
from transformers.utils import direct_transformers_import, logging
from .pipelines.test_pipelines_audio_classification import AudioClassificationPipelineTests
from .pipelines.test_pipelines_automatic_speech_recognition import AutomaticSpeechRecognitionPipelineTests
from .pipelines.test_pipelines_conversational import ConversationalPipelineTests
from .pipelines.test_pipelines_depth_estimation import DepthEstimationPipelineTests
from .pipelines.test_pipelines_document_question_answering import DocumentQuestionAnsweringPipelineTests
from .pipelines.test_pipelines_feature_extraction import FeatureExtractionPipelineTests
from .pipelines.test_pipelines_fill_mask import FillMaskPipelineTests
from .pipelines.test_pipelines_image_classification import ImageClassificationPipelineTests
from .pipelines.test_pipelines_image_feature_extraction import ImageFeatureExtractionPipelineTests
from .pipelines.test_pipelines_image_segmentation import ImageSegmentationPipelineTests
from .pipelines.test_pipelines_image_to_image import ImageToImagePipelineTests
from .pipelines.test_pipelines_image_to_text import ImageToTextPipelineTests
from .pipelines.test_pipelines_mask_generation import MaskGenerationPipelineTests
from .pipelines.test_pipelines_object_detection import ObjectDetectionPipelineTests
from .pipelines.test_pipelines_question_answering import QAPipelineTests
from .pipelines.test_pipelines_summarization import SummarizationPipelineTests
from .pipelines.test_pipelines_table_question_answering import TQAPipelineTests
from .pipelines.test_pipelines_text2text_generation import Text2TextGenerationPipelineTests
from .pipelines.test_pipelines_text_classification import TextClassificationPipelineTests
from .pipelines.test_pipelines_text_generation import TextGenerationPipelineTests
from .pipelines.test_pipelines_text_to_audio import TextToAudioPipelineTests
from .pipelines.test_pipelines_token_classification import TokenClassificationPipelineTests
from .pipelines.test_pipelines_translation import TranslationPipelineTests
from .pipelines.test_pipelines_video_classification import VideoClassificationPipelineTests
from .pipelines.test_pipelines_visual_question_answering import VisualQuestionAnsweringPipelineTests
from .pipelines.test_pipelines_zero_shot import ZeroShotClassificationPipelineTests
from .pipelines.test_pipelines_zero_shot_audio_classification import ZeroShotAudioClassificationPipelineTests
from .pipelines.test_pipelines_zero_shot_image_classification import ZeroShotImageClassificationPipelineTests
from .pipelines.test_pipelines_zero_shot_object_detection import ZeroShotObjectDetectionPipelineTests
pipeline_test_mapping = {
"audio-classification": {"test": AudioClassificationPipelineTests},
"automatic-speech-recognition": {"test": AutomaticSpeechRecognitionPipelineTests},
"conversational": {"test": ConversationalPipelineTests},
"depth-estimation": {"test": DepthEstimationPipelineTests},
"document-question-answering": {"test": DocumentQuestionAnsweringPipelineTests},
"feature-extraction": {"test": FeatureExtractionPipelineTests},
"fill-mask": {"test": FillMaskPipelineTests},
"image-classification": {"test": ImageClassificationPipelineTests},
"image-feature-extraction": {"test": ImageFeatureExtractionPipelineTests},
"image-segmentation": {"test": ImageSegmentationPipelineTests},
"image-to-image": {"test": ImageToImagePipelineTests},
"image-to-text": {"test": ImageToTextPipelineTests},
"mask-generation": {"test": MaskGenerationPipelineTests},
"object-detection": {"test": ObjectDetectionPipelineTests},
"question-answering": {"test": QAPipelineTests},
"summarization": {"test": SummarizationPipelineTests},
"table-question-answering": {"test": TQAPipelineTests},
"text2text-generation": {"test": Text2TextGenerationPipelineTests},
"text-classification": {"test": TextClassificationPipelineTests},
"text-generation": {"test": TextGenerationPipelineTests},
"text-to-audio": {"test": TextToAudioPipelineTests},
"token-classification": {"test": TokenClassificationPipelineTests},
"translation": {"test": TranslationPipelineTests},
"video-classification": {"test": VideoClassificationPipelineTests},
"visual-question-answering": {"test": VisualQuestionAnsweringPipelineTests},
"zero-shot": {"test": ZeroShotClassificationPipelineTests},
"zero-shot-audio-classification": {"test": ZeroShotAudioClassificationPipelineTests},
"zero-shot-image-classification": {"test": ZeroShotImageClassificationPipelineTests},
"zero-shot-object-detection": {"test": ZeroShotObjectDetectionPipelineTests},
}
for task, task_info in pipeline_test_mapping.items():
test = task_info["test"]
task_info["mapping"] = {
"pt": getattr(test, "model_mapping", None),
"tf": getattr(test, "tf_model_mapping", None),
}
# The default value `hf-internal-testing` is for running the pipeline testing against the tiny models on the Hub.
# For debugging purpose, we can specify a local path which is the `output_path` argument of a previous run of
# `utils/create_dummy_models.py`.
TRANSFORMERS_TINY_MODEL_PATH = os.environ.get("TRANSFORMERS_TINY_MODEL_PATH", "hf-internal-testing")
if TRANSFORMERS_TINY_MODEL_PATH == "hf-internal-testing":
TINY_MODEL_SUMMARY_FILE_PATH = os.path.join(Path(__file__).parent.parent, "tests/utils/tiny_model_summary.json")
else:
TINY_MODEL_SUMMARY_FILE_PATH = os.path.join(TRANSFORMERS_TINY_MODEL_PATH, "reports", "tiny_model_summary.json")
with open(TINY_MODEL_SUMMARY_FILE_PATH) as fp:
tiny_model_summary = json.load(fp)
PATH_TO_TRANSFORMERS = os.path.join(Path(__file__).parent.parent, "src/transformers")
# Dynamically import the Transformers module to grab the attribute classes of the processor form their names.
transformers_module = direct_transformers_import(PATH_TO_TRANSFORMERS)
logger = logging.get_logger(__name__)
class PipelineTesterMixin:
model_tester = None
pipeline_model_mapping = None
supported_frameworks = ["pt", "tf"]
def run_task_tests(self, task):
"""Run pipeline tests for a specific `task`
Args:
task (`str`):
A task name. This should be a key in the mapping `pipeline_test_mapping`.
"""
if task not in self.pipeline_model_mapping:
self.skipTest(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')} is skipped: `{task}` is not in "
f"`self.pipeline_model_mapping` for `{self.__class__.__name__}`."
)
model_architectures = self.pipeline_model_mapping[task]
if not isinstance(model_architectures, tuple):
model_architectures = (model_architectures,)
if not isinstance(model_architectures, tuple):
raise ValueError(f"`model_architectures` must be a tuple. Got {type(model_architectures)} instead.")
for model_architecture in model_architectures:
model_arch_name = model_architecture.__name__
# Get the canonical name
for _prefix in ["Flax", "TF"]:
if model_arch_name.startswith(_prefix):
model_arch_name = model_arch_name[len(_prefix) :]
break
tokenizer_names = []
processor_names = []
commit = None
if model_arch_name in tiny_model_summary:
tokenizer_names = tiny_model_summary[model_arch_name]["tokenizer_classes"]
processor_names = tiny_model_summary[model_arch_name]["processor_classes"]
if "sha" in tiny_model_summary[model_arch_name]:
commit = tiny_model_summary[model_arch_name]["sha"]
# Adding `None` (if empty) so we can generate tests
tokenizer_names = [None] if len(tokenizer_names) == 0 else tokenizer_names
processor_names = [None] if len(processor_names) == 0 else processor_names
repo_name = f"tiny-random-{model_arch_name}"
if TRANSFORMERS_TINY_MODEL_PATH != "hf-internal-testing":
repo_name = model_arch_name
self.run_model_pipeline_tests(
task, repo_name, model_architecture, tokenizer_names, processor_names, commit
)
def run_model_pipeline_tests(self, task, repo_name, model_architecture, tokenizer_names, processor_names, commit):
"""Run pipeline tests for a specific `task` with the give model class and tokenizer/processor class names
Args:
task (`str`):
A task name. This should be a key in the mapping `pipeline_test_mapping`.
repo_name (`str`):
A model repository id on the Hub.
model_architecture (`type`):
A subclass of `PretrainedModel` or `PretrainedModel`.
tokenizer_names (`List[str]`):
A list of names of a subclasses of `PreTrainedTokenizerFast` or `PreTrainedTokenizer`.
processor_names (`List[str]`):
A list of names of subclasses of `BaseImageProcessor` or `FeatureExtractionMixin`.
"""
# Get an instance of the corresponding class `XXXPipelineTests` in order to use `get_test_pipeline` and
# `run_pipeline_test`.
pipeline_test_class_name = pipeline_test_mapping[task]["test"].__name__
for tokenizer_name in tokenizer_names:
for processor_name in processor_names:
if self.is_pipeline_test_to_skip(
pipeline_test_class_name,
model_architecture.config_class,
model_architecture,
tokenizer_name,
processor_name,
):
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')} is skipped: test is "
f"currently known to fail for: model `{model_architecture.__name__}` | tokenizer "
f"`{tokenizer_name}` | processor `{processor_name}`."
)
continue
self.run_pipeline_test(task, repo_name, model_architecture, tokenizer_name, processor_name, commit)
def run_pipeline_test(self, task, repo_name, model_architecture, tokenizer_name, processor_name, commit):
"""Run pipeline tests for a specific `task` with the give model class and tokenizer/processor class name
The model will be loaded from a model repository on the Hub.
Args:
task (`str`):
A task name. This should be a key in the mapping `pipeline_test_mapping`.
repo_name (`str`):
A model repository id on the Hub.
model_architecture (`type`):
A subclass of `PretrainedModel` or `PretrainedModel`.
tokenizer_name (`str`):
The name of a subclass of `PreTrainedTokenizerFast` or `PreTrainedTokenizer`.
processor_name (`str`):
The name of a subclass of `BaseImageProcessor` or `FeatureExtractionMixin`.
"""
repo_id = f"{TRANSFORMERS_TINY_MODEL_PATH}/{repo_name}"
if TRANSFORMERS_TINY_MODEL_PATH != "hf-internal-testing":
model_type = model_architecture.config_class.model_type
repo_id = os.path.join(TRANSFORMERS_TINY_MODEL_PATH, model_type, repo_name)
tokenizer = None
if tokenizer_name is not None:
tokenizer_class = getattr(transformers_module, tokenizer_name)
tokenizer = tokenizer_class.from_pretrained(repo_id, revision=commit)
processor = None
if processor_name is not None:
processor_class = getattr(transformers_module, processor_name)
# If the required packages (like `Pillow` or `torchaudio`) are not installed, this will fail.
try:
processor = processor_class.from_pretrained(repo_id, revision=commit)
except Exception:
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')} is skipped: Could not load the "
f"processor from `{repo_id}` with `{processor_name}`."
)
return
# TODO: Maybe not upload such problematic tiny models to Hub.
if tokenizer is None and processor is None:
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')} is skipped: Could not find or load "
f"any tokenizer / processor from `{repo_id}`."
)
return
# TODO: We should check if a model file is on the Hub repo. instead.
try:
model = model_architecture.from_pretrained(repo_id, revision=commit)
except Exception:
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')} is skipped: Could not find or load "
f"the model from `{repo_id}` with `{model_architecture}`."
)
return
pipeline_test_class_name = pipeline_test_mapping[task]["test"].__name__
if self.is_pipeline_test_to_skip_more(pipeline_test_class_name, model.config, model, tokenizer, processor):
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')} is skipped: test is "
f"currently known to fail for: model `{model_architecture.__name__}` | tokenizer "
f"`{tokenizer_name}` | processor `{processor_name}`."
)
return
# validate
validate_test_components(self, task, model, tokenizer, processor)
if hasattr(model, "eval"):
model = model.eval()
# Get an instance of the corresponding class `XXXPipelineTests` in order to use `get_test_pipeline` and
# `run_pipeline_test`.
task_test = pipeline_test_mapping[task]["test"]()
pipeline, examples = task_test.get_test_pipeline(model, tokenizer, processor)
if pipeline is None:
# The test can disable itself, but it should be very marginal
# Concerns: Wav2Vec2ForCTC without tokenizer test (FastTokenizer don't exist)
logger.warning(
f"{self.__class__.__name__}::test_pipeline_{task.replace('-', '_')} is skipped: Could not get the "
"pipeline for testing."
)
return
task_test.run_pipeline_test(pipeline, examples)
def run_batch_test(pipeline, examples):
# Need to copy because `Conversation` are stateful
if pipeline.tokenizer is not None and pipeline.tokenizer.pad_token_id is None:
return # No batching for this and it's OK
# 10 examples with batch size 4 means there needs to be a unfinished batch
# which is important for the unbatcher
def data(n):
for _ in range(n):
# Need to copy because Conversation object is mutated
yield copy.deepcopy(random.choice(examples))
out = []
if task == "conversational":
for item in pipeline(data(10), batch_size=4, max_new_tokens=5):
out.append(item)
else:
for item in pipeline(data(10), batch_size=4):
out.append(item)
self.assertEqual(len(out), 10)
run_batch_test(pipeline, examples)
@is_pipeline_test
def test_pipeline_audio_classification(self):
self.run_task_tests(task="audio-classification")
@is_pipeline_test
def test_pipeline_automatic_speech_recognition(self):
self.run_task_tests(task="automatic-speech-recognition")
@is_pipeline_test
def test_pipeline_conversational(self):
self.run_task_tests(task="conversational")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_depth_estimation(self):
self.run_task_tests(task="depth-estimation")
@is_pipeline_test
@require_pytesseract
@require_torch
@require_vision
def test_pipeline_document_question_answering(self):
self.run_task_tests(task="document-question-answering")
@is_pipeline_test
def test_pipeline_feature_extraction(self):
self.run_task_tests(task="feature-extraction")
@is_pipeline_test
def test_pipeline_fill_mask(self):
self.run_task_tests(task="fill-mask")
@is_pipeline_test
@require_torch_or_tf
@require_vision
def test_pipeline_image_classification(self):
self.run_task_tests(task="image-classification")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_image_segmentation(self):
self.run_task_tests(task="image-segmentation")
@is_pipeline_test
@require_vision
def test_pipeline_image_to_text(self):
self.run_task_tests(task="image-to-text")
@is_pipeline_test
@require_timm
@require_vision
@require_torch
def test_pipeline_image_feature_extraction(self):
self.run_task_tests(task="image-feature-extraction")
@unittest.skip(reason="`run_pipeline_test` is currently not implemented.")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_mask_generation(self):
self.run_task_tests(task="mask-generation")
@is_pipeline_test
@require_vision
@require_timm
@require_torch
def test_pipeline_object_detection(self):
self.run_task_tests(task="object-detection")
@is_pipeline_test
def test_pipeline_question_answering(self):
self.run_task_tests(task="question-answering")
@is_pipeline_test
def test_pipeline_summarization(self):
self.run_task_tests(task="summarization")
@is_pipeline_test
def test_pipeline_table_question_answering(self):
self.run_task_tests(task="table-question-answering")
@is_pipeline_test
def test_pipeline_text2text_generation(self):
self.run_task_tests(task="text2text-generation")
@is_pipeline_test
def test_pipeline_text_classification(self):
self.run_task_tests(task="text-classification")
@is_pipeline_test
@require_torch_or_tf
def test_pipeline_text_generation(self):
self.run_task_tests(task="text-generation")
@is_pipeline_test
@require_torch
def test_pipeline_text_to_audio(self):
self.run_task_tests(task="text-to-audio")
@is_pipeline_test
def test_pipeline_token_classification(self):
self.run_task_tests(task="token-classification")
@is_pipeline_test
def test_pipeline_translation(self):
self.run_task_tests(task="translation")
@is_pipeline_test
@require_torch_or_tf
@require_vision
@require_decord
def test_pipeline_video_classification(self):
self.run_task_tests(task="video-classification")
@is_pipeline_test
@require_torch
@require_vision
def test_pipeline_visual_question_answering(self):
self.run_task_tests(task="visual-question-answering")
@is_pipeline_test
def test_pipeline_zero_shot(self):
self.run_task_tests(task="zero-shot")
@is_pipeline_test
@require_torch
def test_pipeline_zero_shot_audio_classification(self):
self.run_task_tests(task="zero-shot-audio-classification")
@is_pipeline_test
@require_vision
def test_pipeline_zero_shot_image_classification(self):
self.run_task_tests(task="zero-shot-image-classification")
@is_pipeline_test
@require_vision
@require_torch
def test_pipeline_zero_shot_object_detection(self):
self.run_task_tests(task="zero-shot-object-detection")
# This contains the test cases to be skipped without model architecture being involved.
def is_pipeline_test_to_skip(
self, pipeline_test_casse_name, config_class, model_architecture, tokenizer_name, processor_name
):
"""Skip some tests based on the classes or their names without the instantiated objects.
This is to avoid calling `from_pretrained` (so reducing the runtime) if we already know the tests will fail.
"""
# No fix is required for this case.
if (
pipeline_test_casse_name == "DocumentQuestionAnsweringPipelineTests"
and tokenizer_name is not None
and not tokenizer_name.endswith("Fast")
):
# `DocumentQuestionAnsweringPipelineTests` requires a fast tokenizer.
return True
return False
def is_pipeline_test_to_skip_more(self, pipeline_test_casse_name, config, model, tokenizer, processor): # noqa
"""Skip some more tests based on the information from the instantiated objects."""
# No fix is required for this case.
if (
pipeline_test_casse_name == "QAPipelineTests"
and tokenizer is not None
and getattr(tokenizer, "pad_token", None) is None
and not tokenizer.__class__.__name__.endswith("Fast")
):
# `QAPipelineTests` doesn't work with a slow tokenizer that has no pad token.
return True
return False
def validate_test_components(test_case, task, model, tokenizer, processor):
# TODO: Move this to tiny model creation script
# head-specific (within a model type) necessary changes to the config
# 1. for `BlenderbotForCausalLM`
if model.__class__.__name__ == "BlenderbotForCausalLM":
model.config.encoder_no_repeat_ngram_size = 0
# TODO: Change the tiny model creation script: don't create models with problematic tokenizers
# Avoid `IndexError` in embedding layers
CONFIG_WITHOUT_VOCAB_SIZE = ["CanineConfig"]
if tokenizer is not None:
config_vocab_size = getattr(model.config, "vocab_size", None)
# For CLIP-like models
if config_vocab_size is None:
if hasattr(model.config, "text_config"):
config_vocab_size = getattr(model.config.text_config, "vocab_size", None)
elif hasattr(model.config, "text_encoder"):
config_vocab_size = getattr(model.config.text_encoder, "vocab_size", None)
if config_vocab_size is None and model.config.__class__.__name__ not in CONFIG_WITHOUT_VOCAB_SIZE:
raise ValueError(
"Could not determine `vocab_size` from model configuration while `tokenizer` is not `None`."
)
| transformers/tests/test_pipeline_mixin.py/0 | {
"file_path": "transformers/tests/test_pipeline_mixin.py",
"repo_id": "transformers",
"token_count": 9643
} | 385 |
# coding=utf-8
# Copyright 2020 The Hugging Face Team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import io
import unittest
from dataclasses import dataclass
from typing import Optional
from transformers import AlbertForMaskedLM
from transformers.testing_utils import require_torch
from transformers.utils import ModelOutput, is_torch_available
if is_torch_available():
import torch
from transformers.pytorch_utils import is_torch_greater_or_equal_than_2_2
@dataclass
class ModelOutputTest(ModelOutput):
a: float
b: Optional[float] = None
c: Optional[float] = None
class ModelOutputTester(unittest.TestCase):
def test_get_attributes(self):
x = ModelOutputTest(a=30)
self.assertEqual(x.a, 30)
self.assertIsNone(x.b)
self.assertIsNone(x.c)
with self.assertRaises(AttributeError):
_ = x.d
def test_index_with_ints_and_slices(self):
x = ModelOutputTest(a=30, b=10)
self.assertEqual(x[0], 30)
self.assertEqual(x[1], 10)
self.assertEqual(x[:2], (30, 10))
self.assertEqual(x[:], (30, 10))
x = ModelOutputTest(a=30, c=10)
self.assertEqual(x[0], 30)
self.assertEqual(x[1], 10)
self.assertEqual(x[:2], (30, 10))
self.assertEqual(x[:], (30, 10))
def test_index_with_strings(self):
x = ModelOutputTest(a=30, b=10)
self.assertEqual(x["a"], 30)
self.assertEqual(x["b"], 10)
with self.assertRaises(KeyError):
_ = x["c"]
x = ModelOutputTest(a=30, c=10)
self.assertEqual(x["a"], 30)
self.assertEqual(x["c"], 10)
with self.assertRaises(KeyError):
_ = x["b"]
def test_dict_like_properties(self):
x = ModelOutputTest(a=30)
self.assertEqual(list(x.keys()), ["a"])
self.assertEqual(list(x.values()), [30])
self.assertEqual(list(x.items()), [("a", 30)])
self.assertEqual(list(x), ["a"])
x = ModelOutputTest(a=30, b=10)
self.assertEqual(list(x.keys()), ["a", "b"])
self.assertEqual(list(x.values()), [30, 10])
self.assertEqual(list(x.items()), [("a", 30), ("b", 10)])
self.assertEqual(list(x), ["a", "b"])
x = ModelOutputTest(a=30, c=10)
self.assertEqual(list(x.keys()), ["a", "c"])
self.assertEqual(list(x.values()), [30, 10])
self.assertEqual(list(x.items()), [("a", 30), ("c", 10)])
self.assertEqual(list(x), ["a", "c"])
with self.assertRaises(Exception):
x = x.update({"d": 20})
with self.assertRaises(Exception):
del x["a"]
with self.assertRaises(Exception):
_ = x.pop("a")
with self.assertRaises(Exception):
_ = x.setdefault("d", 32)
def test_set_attributes(self):
x = ModelOutputTest(a=30)
x.a = 10
self.assertEqual(x.a, 10)
self.assertEqual(x["a"], 10)
def test_set_keys(self):
x = ModelOutputTest(a=30)
x["a"] = 10
self.assertEqual(x.a, 10)
self.assertEqual(x["a"], 10)
def test_instantiate_from_dict(self):
x = ModelOutputTest({"a": 30, "b": 10})
self.assertEqual(list(x.keys()), ["a", "b"])
self.assertEqual(x.a, 30)
self.assertEqual(x.b, 10)
def test_instantiate_from_iterator(self):
x = ModelOutputTest([("a", 30), ("b", 10)])
self.assertEqual(list(x.keys()), ["a", "b"])
self.assertEqual(x.a, 30)
self.assertEqual(x.b, 10)
with self.assertRaises(ValueError):
_ = ModelOutputTest([("a", 30), (10, 10)])
x = ModelOutputTest(a=(30, 30))
self.assertEqual(list(x.keys()), ["a"])
self.assertEqual(x.a, (30, 30))
@require_torch
def test_torch_pytree(self):
# ensure torch.utils._pytree treats ModelOutput subclasses as nodes (and not leaves)
# this is important for DistributedDataParallel gradient synchronization with static_graph=True
import torch.utils._pytree as pytree
x = ModelOutput({"a": 1.0, "c": 2.0})
self.assertFalse(pytree._is_leaf(x))
x = ModelOutputTest(a=1.0, c=2.0)
self.assertFalse(pytree._is_leaf(x))
expected_flat_outs = [1.0, 2.0]
expected_tree_spec = pytree.TreeSpec(ModelOutputTest, ["a", "c"], [pytree.LeafSpec(), pytree.LeafSpec()])
actual_flat_outs, actual_tree_spec = pytree.tree_flatten(x)
self.assertEqual(expected_flat_outs, actual_flat_outs)
self.assertEqual(expected_tree_spec, actual_tree_spec)
unflattened_x = pytree.tree_unflatten(actual_flat_outs, actual_tree_spec)
self.assertEqual(x, unflattened_x)
if is_torch_greater_or_equal_than_2_2:
self.assertEqual(
pytree.treespec_dumps(actual_tree_spec),
'[1, {"type": "tests.utils.test_model_output.ModelOutputTest", "context": "[\\"a\\", \\"c\\"]", "children_spec": [{"type": null, "context": null, "children_spec": []}, {"type": null, "context": null, "children_spec": []}]}]',
)
# TODO: @ydshieh
@unittest.skip("CPU OOM")
@require_torch
def test_export_serialization(self):
if not is_torch_greater_or_equal_than_2_2:
return
model_cls = AlbertForMaskedLM
model_config = model_cls.config_class()
model = model_cls(model_config)
input_dict = {"input_ids": torch.randint(0, 30000, (1, 512), dtype=torch.int64, requires_grad=False)}
ep = torch.export.export(model, (), input_dict)
buffer = io.BytesIO()
torch.export.save(ep, buffer)
buffer.seek(0)
loaded_ep = torch.export.load(buffer)
input_dict = {"input_ids": torch.randint(0, 30000, (1, 512), dtype=torch.int64, requires_grad=False)}
assert torch.allclose(model(**input_dict).logits, loaded_ep(**input_dict).logits)
class ModelOutputTestNoDataclass(ModelOutput):
"""Invalid test subclass of ModelOutput where @dataclass decorator is not used"""
a: float
b: Optional[float] = None
c: Optional[float] = None
class ModelOutputSubclassTester(unittest.TestCase):
def test_direct_model_output(self):
# Check that direct usage of ModelOutput instantiates without errors
ModelOutput({"a": 1.1})
def test_subclass_no_dataclass(self):
# Check that a subclass of ModelOutput without @dataclass is invalid
# A valid subclass is inherently tested other unit tests above.
with self.assertRaises(TypeError):
ModelOutputTestNoDataclass(a=1.1, b=2.2, c=3.3)
| transformers/tests/utils/test_model_output.py/0 | {
"file_path": "transformers/tests/utils/test_model_output.py",
"repo_id": "transformers",
"token_count": 3168
} | 386 |
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import glob
import os
from get_test_info import get_tester_classes
if __name__ == "__main__":
failures = []
pattern = os.path.join("tests", "models", "**", "test_modeling_*.py")
test_files = glob.glob(pattern)
# TODO: deal with TF/Flax too
test_files = [
x for x in test_files if not (x.startswith("test_modeling_tf_") or x.startswith("test_modeling_flax_"))
]
for test_file in test_files:
tester_classes = get_tester_classes(test_file)
for tester_class in tester_classes:
# A few tester classes don't have `parent` parameter in `__init__`.
# TODO: deal this better
try:
tester = tester_class(parent=None)
except Exception:
continue
if hasattr(tester, "get_config"):
config = tester.get_config()
for k, v in config.to_dict().items():
if isinstance(v, int):
target = None
if k in ["vocab_size"]:
target = 100
elif k in ["max_position_embeddings"]:
target = 128
elif k in ["hidden_size", "d_model"]:
target = 40
elif k == ["num_layers", "num_hidden_layers", "num_encoder_layers", "num_decoder_layers"]:
target = 5
if target is not None and v > target:
failures.append(
f"{tester_class.__name__} will produce a `config` of type `{config.__class__.__name__}`"
f' with config["{k}"] = {v} which is too large for testing! Set its value to be smaller'
f" than {target}."
)
if len(failures) > 0:
raise Exception(f"There were {len(failures)} failures:\n" + "\n".join(failures))
| transformers/utils/check_model_tester.py/0 | {
"file_path": "transformers/utils/check_model_tester.py",
"repo_id": "transformers",
"token_count": 1240
} | 387 |
from transformers import BertTokenizer
class CustomTokenizer(BertTokenizer):
pass
| transformers/utils/test_module/custom_tokenization.py/0 | {
"file_path": "transformers/utils/test_module/custom_tokenization.py",
"repo_id": "transformers",
"token_count": 25
} | 388 |
.PHONY: test precommit benchmark_core benchmark_aux common_tests slow_tests test_examples tests_gpu
check_dirs := examples tests trl
ACCELERATE_CONFIG_PATH = `pwd`/examples/accelerate_configs
COMMAND_FILES_PATH = `pwd`/commands
dev:
[ -L "$(pwd)/trl/commands/scripts" ] && unlink "$(pwd)/trl/commands/scripts" || true
pip install -e ".[dev]"
ln -s `pwd`/examples/scripts/ `pwd`/trl/commands
test:
python -m pytest -n auto --dist=loadfile -s -v ./tests/
precommit:
pre-commit run --all-files
benchmark_core:
bash ./benchmark/benchmark_core.sh
benchmark_aux:
bash ./benchmark/benchmark_aux.sh
tests_gpu:
python -m pytest tests/test_* $(if $(IS_GITHUB_CI),--report-log "common_tests.log",)
slow_tests:
python -m pytest tests/slow/test_* $(if $(IS_GITHUB_CI),--report-log "slow_tests.log",)
test_examples:
touch temp_results_sft_tests.txt
for file in $(ACCELERATE_CONFIG_PATH)/*.yaml; do \
TRL_ACCELERATE_CONFIG=$${file} bash $(COMMAND_FILES_PATH)/run_sft.sh; \
echo $$?','$${file} >> temp_results_sft_tests.txt; \
done
touch temp_results_dpo_tests.txt
for file in $(ACCELERATE_CONFIG_PATH)/*.yaml; do \
TRL_ACCELERATE_CONFIG=$${file} bash $(COMMAND_FILES_PATH)/run_dpo.sh; \
echo $$?','$${file} >> temp_results_dpo_tests.txt; \
done | trl/Makefile/0 | {
"file_path": "trl/Makefile",
"repo_id": "trl",
"token_count": 526
} | 389 |
#!/bin/bash
# This script runs an SFT example end-to-end on a tiny model using different possible configurations
# but defaults to QLoRA + PEFT
OUTPUT_DIR="test_sft/"
MODEL_NAME="HuggingFaceM4/tiny-random-LlamaForCausalLM"
DATASET_NAME="imdb"
MAX_STEPS=5
BATCH_SIZE=2
SEQ_LEN=128
# Handle extra arguments in case one passes accelerate configs.
EXTRA_ACCELERATE_ARGS=""
EXTRA_TRAINING_ARGS="""--use_peft \
--load_in_4bit
"""
# Set your number of GPUs here
NUM_GPUS=2
if [[ "${TRL_ACCELERATE_CONFIG}" == "" ]]; then
EXTRA_ACCELERATE_ARGS=""
else
EXTRA_ACCELERATE_ARGS="--config_file $TRL_ACCELERATE_CONFIG"
# For DeepSpeed configs we need to set the `--fp16` flag to comply with our configs exposed
# on `examples/accelerate_configs` and our runners do not support bf16 mixed precision training.
if [[ $TRL_ACCELERATE_CONFIG == *"deepspeed"* ]]; then
EXTRA_TRAINING_ARGS="--fp16"
else
echo "Keeping QLoRA + PEFT"
fi
fi
CMD="""
accelerate launch $EXTRA_ACCELERATE_ARGS \
--num_processes $NUM_GPUS \
--mixed_precision 'fp16' \
`pwd`/examples/scripts/sft.py \
--model_name $MODEL_NAME \
--dataset_name $DATASET_NAME \
--output_dir $OUTPUT_DIR \
--max_steps $MAX_STEPS \
--per_device_train_batch_size $BATCH_SIZE \
--max_seq_length $SEQ_LEN \
$EXTRA_TRAINING_ARGS
"""
echo "Starting program..."
{ # try
echo $CMD
eval "$CMD"
} || { # catch
# save log for exception
echo "Operation Failed!"
exit 1
}
exit 0 | trl/commands/run_sft.sh/0 | {
"file_path": "trl/commands/run_sft.sh",
"repo_id": "trl",
"token_count": 619
} | 390 |
# Learning Tools (Experimental 🧪)
Using Large Language Models (LLMs) with tools has been a popular topic recently with awesome works such as [ToolFormer](https://arxiv.org/abs/2302.04761) and [ToolBench](https://arxiv.org/pdf/2305.16504.pdf). In TRL, we provide a simple example of how to teach LLM to use tools with reinforcement learning.
Here's an overview of the scripts in the [trl repository](https://github.com/lvwerra/trl/tree/main/examples/research_projects/tools):
| File | Description |
|---|---|
| [`calculator.py`](https://github.com/lvwerra/trl/blob/main/examples/research_projects/tools/calculator.py) | Script to train LLM to use a calculator with reinforcement learning. |
| [`triviaqa.py`](https://github.com/lvwerra/trl/blob/main/examples/research_projects/tools/triviaqa.py) | Script to train LLM to use a wiki tool to answer questions. |
| [`python_interpreter.py`](https://github.com/lvwerra/trl/blob/main/examples/research_projects/tools/python_interpreter.py) | Script to train LLM to use python interpreter to solve math puzzles. |
<Tip warning={true}>
Note that the scripts above rely heavily on the `TextEnvironment` API which is still under active development. The API may change in the future. Please see [`TextEnvironment`](text_environment) for the related docs.
</Tip>
## Learning to Use a Calculator
The rough idea is as follows:
1. Load a tool such as [ybelkada/simple-calculator](https://huggingface.co/spaces/ybelkada/simple-calculator) that parse a text calculation like `"14 + 34"` and return the calulated number:
```python
from transformers import AutoTokenizer, load_tool
tool = load_tool("ybelkada/simple-calculator")
tool_fn = lambda text: str(round(float(tool(text)), 2)) # rounding to 2 decimal places
```
1. Define a reward function that returns a positive reward if the tool returns the correct answer. In the script we create a dummy reward function like `reward_fn = lambda x: 1`, but we override the rewards directly later.
1. Create a prompt on how to use the tools
```python
# system prompt
prompt = """\
What is 13.1-3?
<request><SimpleCalculatorTool>13.1-3<call>10.1<response>
Result=10.1<submit>
What is 4*3?
<request><SimpleCalculatorTool>4*3<call>12<response>
Result=12<submit>
What is 12.1+1?
<request><SimpleCalculatorTool>12.1+1<call>13.1<response>
Result=13.1<submit>
What is 12.1-20?
<request><SimpleCalculatorTool>12.1-20<call>-7.9<response>
Result=-7.9<submit>"""
```
3. Create a `trl.TextEnvironment` with the model
```python
env = TextEnvironment(
model,
tokenizer,
{"SimpleCalculatorTool": tool_fn},
reward_fn,
prompt,
generation_kwargs=generation_kwargs,
)
```
4. Then generate some data such as `tasks = ["\n\nWhat is 13.1-3?", "\n\nWhat is 4*3?"]` and run the environment with `queries, responses, masks, rewards, histories = env.run(tasks)`. The environment will look for the `<call>` token in the prompt and append the tool output to the response; it will also return the mask associated with the response. You can further use the `histories` to visualize the interaction between the model and the tool; `histories[0].show_text()` will show the text with color-coded tool output and `histories[0].show_tokens(tokenizer)` will show visualize the tokens.

1. Finally, we can train the model with `train_stats = ppo_trainer.step(queries, responses, rewards, masks)`. The trainer will use the mask to ignore the tool output when computing the loss, make sure to pass that argument to `step`.
## Experiment results
We trained a model with the above script for 10 random seeds. You can reproduce the run with the following command. Feel free to remove the `--slurm-*` arguments if you don't have access to a slurm cluster.
```
WANDB_TAGS="calculator_final" python benchmark/benchmark.py \
--command "python examples/research_projects/tools/calculator.py" \
--num-seeds 10 \
--start-seed 1 \
--workers 10 \
--slurm-gpus-per-task 1 \
--slurm-ntasks 1 \
--slurm-total-cpus 8 \
--slurm-template-path benchmark/trl.slurm_template
```
We can then use [`openrlbenchmark`](https://github.com/openrlbenchmark/openrlbenchmark) which generates the following plot.
```
python -m openrlbenchmark.rlops_multi_metrics \
--filters '?we=openrlbenchmark&wpn=trl&xaxis=_step&ceik=trl_ppo_trainer_config.value.tracker_project_name&cen=trl_ppo_trainer_config.value.log_with&metrics=env/reward_mean&metrics=objective/kl' \
'wandb?tag=calculator_final&cl=calculator_mask' \
--env-ids trl \
--check-empty-runs \
--pc.ncols 2 \
--pc.ncols-legend 1 \
--output-filename static/0compare \
--scan-history
```
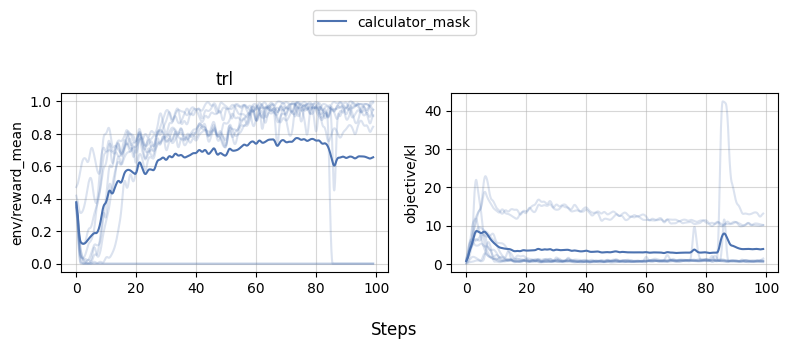
As we can see, while 1-2 experiments crashed for some reason, most of the runs obtained near perfect proficiency in the calculator task.
## (Early Experiments 🧪): learning to use a wiki tool for question answering
In the [ToolFormer](https://arxiv.org/abs/2302.04761) paper, it shows an interesting use case that utilizes a Wikipedia Search tool to help answer questions. In this section, we attempt to perform similar experiments but uses RL instead to teach the model to use a wiki tool on the [TriviaQA](https://nlp.cs.washington.edu/triviaqa/) dataset.
<Tip warning={true}>
**Note that many settings are different so the results are not directly comparable.**
</Tip>
### Building a search index
Since [ToolFormer](https://arxiv.org/abs/2302.04761) did not open source, we needed to first replicate the search index. It is mentioned in their paper that the authors built the search index using a BM25 retriever that indexes the Wikipedia dump from [KILT](https://github.com/facebookresearch/KILT)
Fortunately, [`pyserini`](https://github.com/castorini/pyserini) already implements the BM25 retriever and provides a prebuilt index for the KILT Wikipedia dump. We can use the following code to search the index.
```python
from pyserini.search.lucene import LuceneSearcher
import json
searcher = LuceneSearcher.from_prebuilt_index('wikipedia-kilt-doc')
def search(query):
hits = searcher.search(query, k=1)
hit = hits[0]
contents = json.loads(hit.raw)['contents']
return contents
print(search("tennis racket"))
```
```
Racket (sports equipment)
A racket or racquet is a sports implement consisting of a handled frame with an open hoop across which a network of strings or catgut is stretched tightly. It is used for striking a ball or shuttlecock in games such as squash, tennis, racquetball, and badminton. Collectively, these games are known as racket sports. Racket design and manufacturing has changed considerably over the centuries.
The frame of rackets for all sports was traditionally made of solid wood (later laminated wood) and the strings of animal intestine known as catgut. The traditional racket size was limited by the strength and weight of the wooden frame which had to be strong enough to hold the strings and stiff enough to hit the ball or shuttle. Manufacturers started adding non-wood laminates to wood rackets to improve stiffness. Non-wood rackets were made first of steel, then of aluminum, and then carbon fiber composites. Wood is still used for real tennis, rackets, and xare. Most rackets are now made of composite materials including carbon fiber or fiberglass, metals such as titanium alloys, or ceramics.
...
```
We then basically deployed this snippet as a Hugging Face space [here](https://huggingface.co/spaces/vwxyzjn/pyserini-wikipedia-kilt-doc), so that we can use the space as a `transformers.Tool` later.
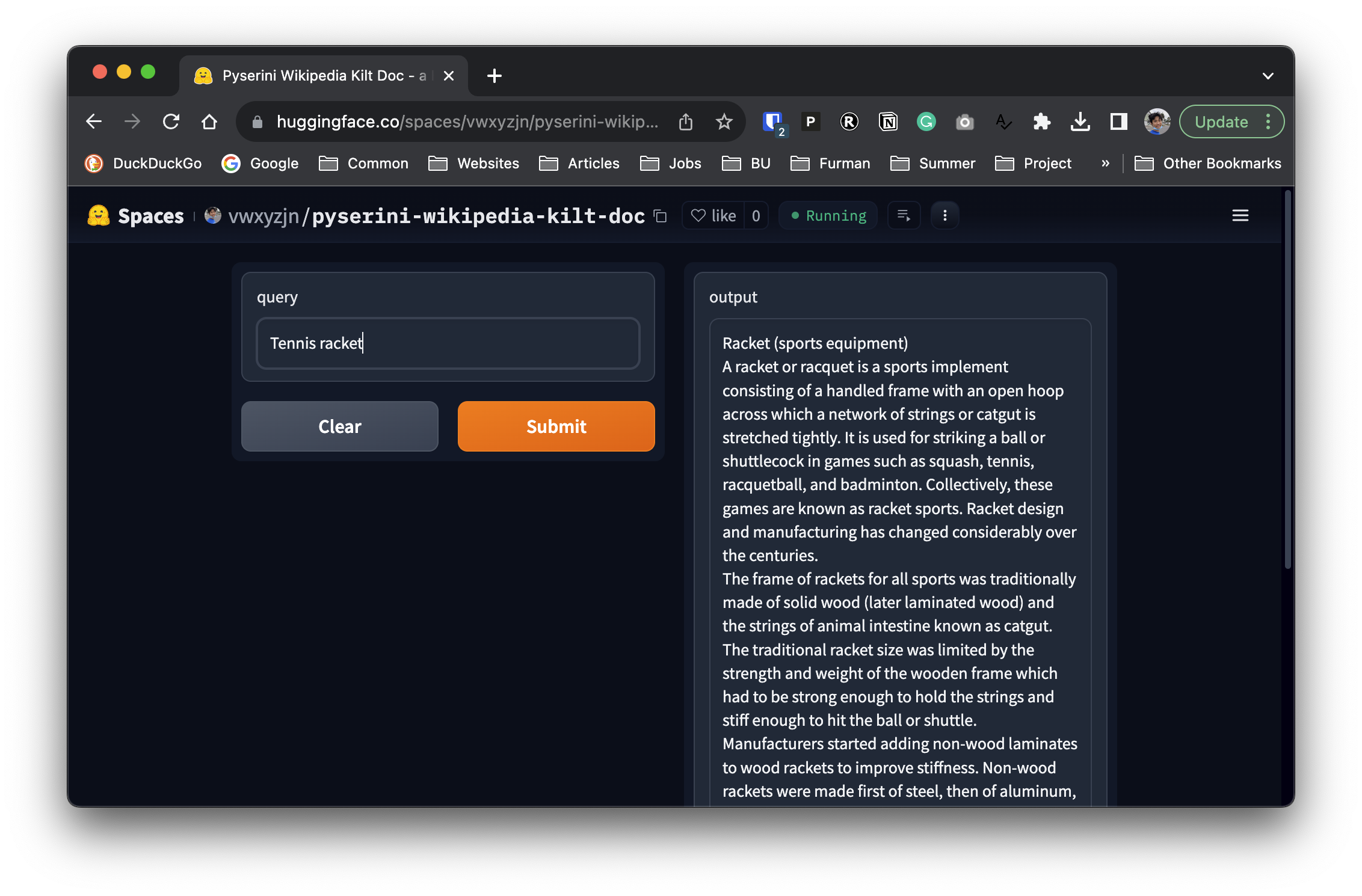
### Experiment settings
We use the following settings:
* use the `bigcode/starcoderbase` model as the base model
* use the `pyserini-wikipedia-kilt-doc` space as the wiki tool and only uses the first paragrahs of the search result, allowing the `TextEnvironment` to obtain at most `max_tool_reponse=400` response tokens from the tool.
* test if the response contain the answer string, if so, give a reward of 1, otherwise, give a reward of 0.
* notice this is a simplified evaluation criteria. In [ToolFormer](https://arxiv.org/abs/2302.04761), the authors checks if the first 20 words of the response contain the correct answer.
* used the following prompt that demonstrates the usage of the wiki tool.
```python
prompt = """\
Answer the following question:
Q: In which branch of the arts is Patricia Neary famous?
A: Ballets
A2: <request><Wiki>Patricia Neary<call>Patricia Neary (born October 27, 1942) is an American ballerina, choreographer and ballet director, who has been particularly active in Switzerland. She has also been a highly successful ambassador for the Balanchine Trust, bringing George Balanchine's ballets to 60 cities around the globe.<response>
Result=Ballets<submit>
Q: Who won Super Bowl XX?
A: Chicago Bears
A2: <request><Wiki>Super Bowl XX<call>Super Bowl XX was an American football game between the National Football Conference (NFC) champion Chicago Bears and the American Football Conference (AFC) champion New England Patriots to decide the National Football League (NFL) champion for the 1985 season. The Bears defeated the Patriots by the score of 46–10, capturing their first NFL championship (and Chicago's first overall sports victory) since 1963, three years prior to the birth of the Super Bowl. Super Bowl XX was played on January 26, 1986 at the Louisiana Superdome in New Orleans.<response>
Result=Chicago Bears<submit>
Q: """
```
### Result and Discussion
Our experiments show that the agent can learn to use the wiki tool to answer questions. The learning curves would go up mostly, but one of the experiment did crash.
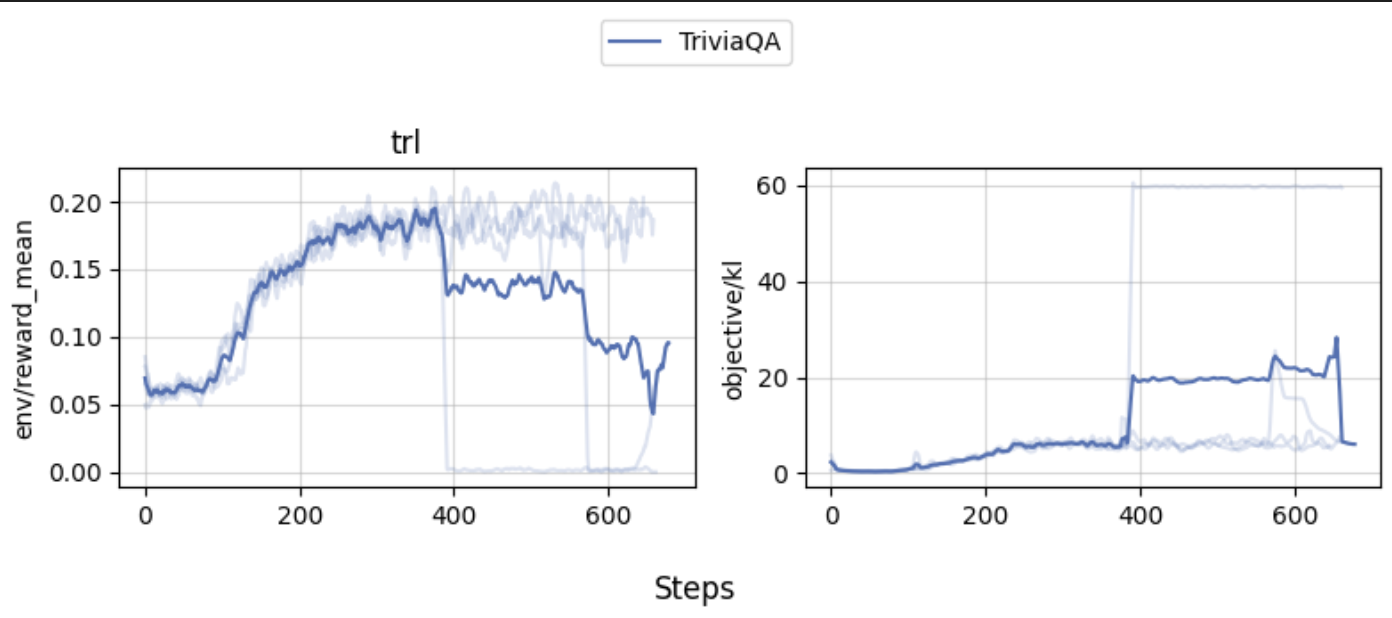
Wandb report is [here](https://wandb.ai/costa-huang/cleanRL/reports/TriviaQA-Final-Experiments--Vmlldzo1MjY0ODk5) for further inspection.
Note that the correct rate of the trained model is on the low end, which could be due to the following reasons:
* **incorrect searches:** When given the question `"What is Bruce Willis' real first name?"` if the model searches for `Bruce Willis`, our wiki tool returns "Patrick Poivey (born 18 February 1948) is a French actor. He is especially known for his voice: he is the French dub voice of Bruce Willis since 1988.` But a correct search should be `Walter Bruce Willis (born March 19, 1955) is an American former actor. He achieved fame with a leading role on the comedy-drama series Moonlighting (1985–1989) and appeared in over a hundred films, gaining recognition as an action hero after his portrayal of John McClane in the Die Hard franchise (1988–2013) and other roles.[1][2]"
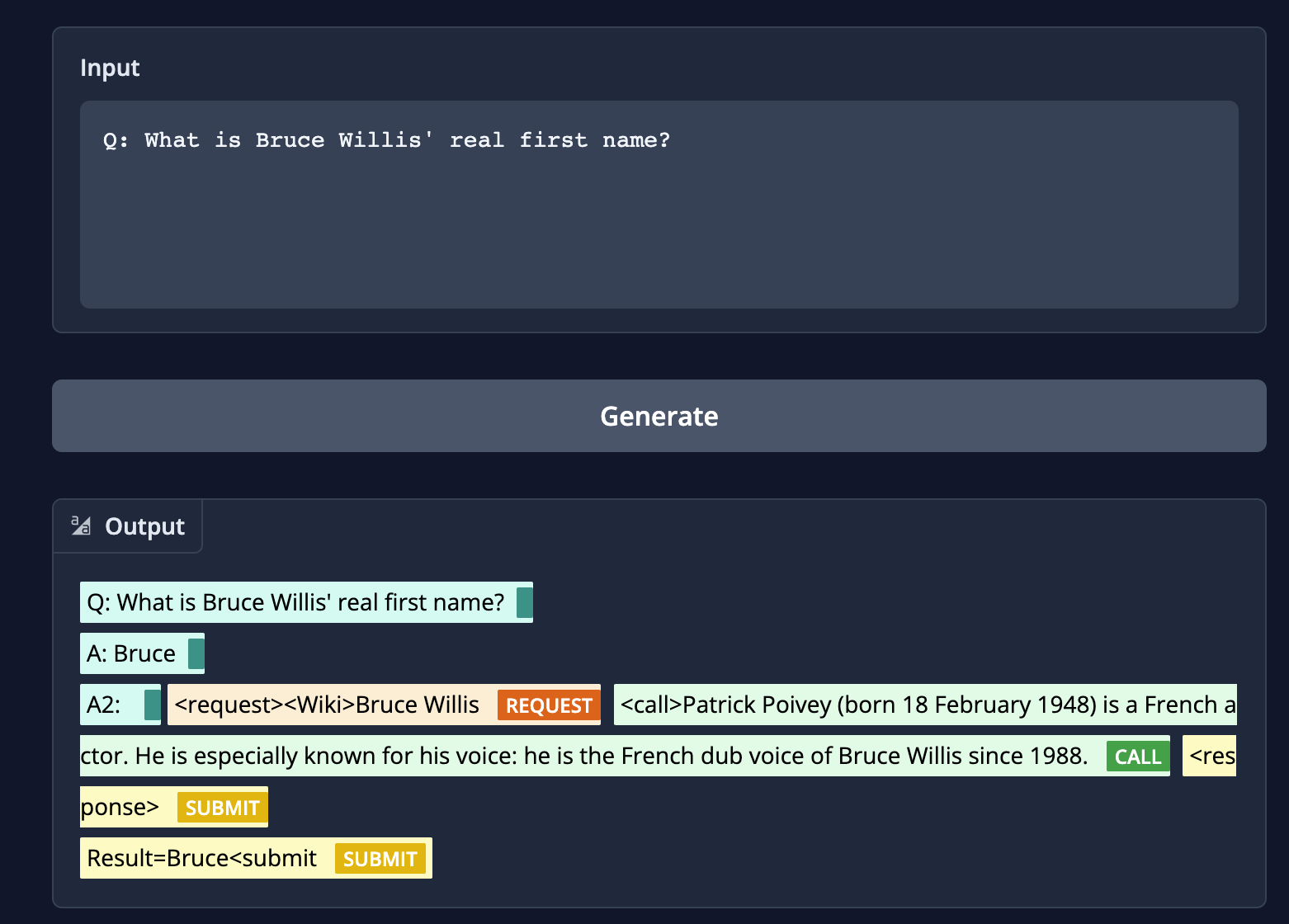
* **unnecessarily long response**: The wiki tool by default sometimes output very long sequences. E.g., when the wiki tool searches for "Brown Act"
* Our wiki tool returns "The Ralph M. Brown Act, located at California Government Code 54950 "et seq.", is an act of the California State Legislature, authored by Assemblymember Ralph M. Brown and passed in 1953, that guarantees the public's right to attend and participate in meetings of local legislative bodies."
* [ToolFormer](https://arxiv.org/abs/2302.04761)'s wiki tool returns "The Ralph M. Brown Act is an act of the California State Legislature that guarantees the public's right to attend and participate in meetings of local legislative bodies." which is more succinct.

## (Early Experiments 🧪): solving math puzzles with python interpreter
In this section, we attempt to teach the model to use a python interpreter to solve math puzzles. The rough idea is to give the agent a prompt like the following:
```python
prompt = """\
Example of using a Python API to solve math questions.
Q: Olivia has $23. She bought five bagels for $3 each. How much money does she have left?
<request><PythonInterpreter>
def solution():
money_initial = 23
bagels = 5
bagel_cost = 3
money_spent = bagels * bagel_cost
money_left = money_initial - money_spent
result = money_left
return result
print(solution())
<call>72<response>
Result = 72 <submit>
Q: """
```
Training experiment can be found at https://wandb.ai/lvwerra/trl-gsm8k/runs/a5odv01y
| trl/docs/source/learning_tools.mdx/0 | {
"file_path": "trl/docs/source/learning_tools.mdx",
"repo_id": "trl",
"token_count": 3876
} | 391 |
compute_environment: LOCAL_MACHINE
debug: false
deepspeed_config:
deepspeed_multinode_launcher: standard
gradient_accumulation_steps: 1
zero3_init_flag: false
zero_stage: 1
distributed_type: DEEPSPEED
downcast_bf16: 'no'
machine_rank: 0
main_training_function: main
mixed_precision: 'bf16'
num_machines: 1
num_processes: 8
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
| trl/examples/accelerate_configs/deepspeed_zero1.yaml/0 | {
"file_path": "trl/examples/accelerate_configs/deepspeed_zero1.yaml",
"repo_id": "trl",
"token_count": 171
} | 392 |
from dataclasses import dataclass, field
from typing import Any, Dict, List, Optional, Union
import evaluate
import numpy as np
import torch
import torch.nn as nn
from datasets import load_dataset
from peft import LoraConfig, TaskType, get_peft_model
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
HfArgumentParser,
PreTrainedTokenizerBase,
Trainer,
TrainerCallback,
TrainingArguments,
set_seed,
)
from transformers.utils import PaddingStrategy
# Define and parse arguments.
@dataclass
class ScriptArguments:
"""
These arguments vary depending on how many GPUs you have, what their capacity and features are, and what size model you want to train.
"""
local_rank: Optional[int] = field(default=-1, metadata={"help": "Used for multi-gpu"})
resume_from_checkpoint: Optional[bool] = field(
default=False,
metadata={"help": "If you want to resume training where it left off."},
)
deepspeed: Optional[str] = field(
default=None,
metadata={
"help": "Path to deepspeed config if using deepspeed. You may need this if the model that you want to train doesn't fit on a single GPU."
},
)
per_device_train_batch_size: Optional[int] = field(default=4)
per_device_eval_batch_size: Optional[int] = field(default=1)
gradient_accumulation_steps: Optional[int] = field(default=1)
learning_rate: Optional[float] = field(default=2e-5)
weight_decay: Optional[float] = field(default=0.001)
model_name: Optional[str] = field(
default="gpt2",
metadata={
"help": "The model that you want to train from the Hugging Face hub. E.g. gpt2, gpt2-xl, bert, etc."
},
)
tokenizer_name: Optional[str] = field(
default=None,
metadata={
"help": "The tokenizer for your model, if left empty will use the default for your model",
},
)
bf16: Optional[bool] = field(
default=True,
metadata={
"help": "This essentially cuts the training time in half if you want to sacrifice a little precision and have a supported GPU."
},
)
num_train_epochs: Optional[int] = field(
default=1,
metadata={"help": "The number of training epochs for the reward model."},
)
train_subset: Optional[int] = field(
default=100000,
metadata={"help": "The size of the subset of the training data to use"},
)
eval_subset: Optional[int] = field(
default=50000,
metadata={"help": "The size of the subset of the eval data to use"},
)
gradient_checkpointing: Optional[bool] = field(
default=False,
metadata={"help": "Enables gradient checkpointing."},
)
optim: Optional[str] = field(
default="adamw_hf",
metadata={"help": "The optimizer to use."},
)
lr_scheduler_type: Optional[str] = field(
default="linear",
metadata={"help": "The lr scheduler"},
)
max_length: Optional[int] = field(default=512)
eval_first_step: Optional[bool] = field(
default=False,
metadata={"help": "Whether to run eval after the first step"},
)
seed: Optional[int] = field(
default=0, metadata={"help": "Random seed that will be set at the beginning of training."}
)
parser = HfArgumentParser(ScriptArguments)
script_args = parser.parse_args_into_dataclasses()[0]
set_seed(script_args.seed)
# Load the human stack-exchange-paired dataset for tuning the reward model.
train_dataset = load_dataset("lvwerra/stack-exchange-paired", data_dir="data/reward", split="train")
if script_args.train_subset > 0:
train_dataset = train_dataset.select(range(script_args.train_subset))
eval_dataset = load_dataset("lvwerra/stack-exchange-paired", data_dir="data/evaluation", split="train")
if script_args.eval_subset > 0:
eval_dataset = eval_dataset.select(range(script_args.eval_subset))
# Define the training args. Needs to be done before the model is loaded if you are using deepspeed.
model_name_split = script_args.model_name.split("/")[-1]
output_name = (
f"{model_name_split}_peft_stack-exchange-paired_rmts__{script_args.train_subset}_{script_args.learning_rate}"
)
training_args = TrainingArguments(
output_dir=output_name,
learning_rate=script_args.learning_rate,
per_device_train_batch_size=script_args.per_device_train_batch_size,
per_device_eval_batch_size=script_args.per_device_eval_batch_size,
num_train_epochs=script_args.num_train_epochs,
weight_decay=script_args.weight_decay,
evaluation_strategy="steps",
eval_steps=500,
save_strategy="steps",
save_steps=500,
gradient_accumulation_steps=script_args.gradient_accumulation_steps,
gradient_checkpointing=script_args.gradient_checkpointing,
deepspeed=script_args.deepspeed,
local_rank=script_args.local_rank,
remove_unused_columns=False,
label_names=[],
bf16=script_args.bf16,
logging_strategy="steps",
logging_steps=10,
optim=script_args.optim,
lr_scheduler_type=script_args.lr_scheduler_type,
seed=script_args.seed,
)
# Load the value-head model and tokenizer.
tokenizer_name = script_args.tokenizer_name if script_args.tokenizer_name is not None else script_args.model_name
tokenizer = AutoTokenizer.from_pretrained(tokenizer_name, use_auth_token=True)
tokenizer.pad_token = tokenizer.eos_token
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
)
model = AutoModelForSequenceClassification.from_pretrained(
script_args.model_name, num_labels=1, torch_dtype=torch.bfloat16
)
model = get_peft_model(model, peft_config)
model.print_trainable_parameters()
# Need to do this for gpt2, because it doesn't have an official pad token.
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = tokenizer.eos_token_id
model.config.use_cache = not script_args.gradient_checkpointing
num_proc = 24 # Can adjust to be higher if you have more processors.
original_columns = train_dataset.column_names
# Turn the dataset into pairs of post + summaries, where text_j is the preferred question + answer and text_k is the other.
# Then tokenize the dataset.
def preprocess_function(examples):
new_examples = {
"input_ids_j": [],
"attention_mask_j": [],
"input_ids_k": [],
"attention_mask_k": [],
}
for question, response_j, response_k in zip(examples["question"], examples["response_j"], examples["response_k"]):
tokenized_j = tokenizer("Question: " + question + "\n\nAnswer: " + response_j, truncation=True)
tokenized_k = tokenizer("Question: " + question + "\n\nAnswer: " + response_k, truncation=True)
new_examples["input_ids_j"].append(tokenized_j["input_ids"])
new_examples["attention_mask_j"].append(tokenized_j["attention_mask"])
new_examples["input_ids_k"].append(tokenized_k["input_ids"])
new_examples["attention_mask_k"].append(tokenized_k["attention_mask"])
return new_examples
# preprocess the dataset and filter out QAs that are longer than script_args.max_length
train_dataset = train_dataset.map(
preprocess_function,
batched=True,
num_proc=num_proc,
remove_columns=original_columns,
)
train_dataset = train_dataset.filter(
lambda x: len(x["input_ids_j"]) <= script_args.max_length and len(x["input_ids_k"]) <= script_args.max_length
)
eval_dataset = eval_dataset.map(
preprocess_function,
batched=True,
num_proc=num_proc,
remove_columns=original_columns,
)
eval_dataset = eval_dataset.filter(
lambda x: len(x["input_ids_j"]) <= script_args.max_length and len(x["input_ids_k"]) <= script_args.max_length
)
# We need to define a special data collator that batches the data in our j vs k format.
@dataclass
class RewardDataCollatorWithPadding:
tokenizer: PreTrainedTokenizerBase
padding: Union[bool, str, PaddingStrategy] = True
max_length: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
return_tensors: str = "pt"
def __call__(self, features: List[Dict[str, Any]]) -> Dict[str, Any]:
features_j = []
features_k = []
for feature in features:
features_j.append(
{
"input_ids": feature["input_ids_j"],
"attention_mask": feature["attention_mask_j"],
}
)
features_k.append(
{
"input_ids": feature["input_ids_k"],
"attention_mask": feature["attention_mask_k"],
}
)
batch_j = self.tokenizer.pad(
features_j,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors=self.return_tensors,
)
batch_k = self.tokenizer.pad(
features_k,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors=self.return_tensors,
)
batch = {
"input_ids_j": batch_j["input_ids"],
"attention_mask_j": batch_j["attention_mask"],
"input_ids_k": batch_k["input_ids"],
"attention_mask_k": batch_k["attention_mask"],
"return_loss": True,
}
return batch
# Define the metric that we'll use for validation.
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions, _ = eval_pred
# Here, predictions is rewards_j and rewards_k.
# We want to see how much of the time rewards_j > rewards_k.
predictions = np.argmax(predictions, axis=0)
labels = np.zeros(predictions.shape)
return accuracy.compute(predictions=predictions, references=labels)
class RewardTrainer(Trainer):
# Define how to compute the reward loss. We use the InstructGPT pairwise logloss: https://arxiv.org/abs/2203.02155
def compute_loss(self, model, inputs, return_outputs=False):
rewards_j = model(input_ids=inputs["input_ids_j"], attention_mask=inputs["attention_mask_j"])[0]
rewards_k = model(input_ids=inputs["input_ids_k"], attention_mask=inputs["attention_mask_k"])[0]
loss = -nn.functional.logsigmoid(rewards_j - rewards_k).mean()
if return_outputs:
return loss, {"rewards_j": rewards_j, "rewards_k": rewards_k}
return loss
# Train the model, woohoo.
trainer = RewardTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
compute_metrics=compute_metrics,
data_collator=RewardDataCollatorWithPadding(tokenizer=tokenizer, max_length=script_args.max_length),
)
if script_args.eval_first_step:
class EvaluateFirstStepCallback(TrainerCallback):
def on_step_end(self, args, state, control, **kwargs):
if state.global_step == 1:
control.should_evaluate = True
trainer.add_callback(EvaluateFirstStepCallback())
trainer.train(script_args.resume_from_checkpoint)
print("Saving last checkpoint of the model")
model.save_pretrained(output_name + "_peft_last_checkpoint")
| trl/examples/research_projects/stack_llama/scripts/reward_modeling.py/0 | {
"file_path": "trl/examples/research_projects/stack_llama/scripts/reward_modeling.py",
"repo_id": "trl",
"token_count": 4554
} | 393 |
# flake8: noqa
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
# regular:
python examples/scripts/dpo.py \
--dataset_name=trl-internal-testing/hh-rlhf-trl-style \
--model_name_or_path=gpt2 \
--per_device_train_batch_size 4 \
--learning_rate 1e-3 \
--gradient_accumulation_steps 1 \
--logging_steps 10 \
--eval_steps 500 \
--output_dir="dpo_anthropic_hh" \
--warmup_steps 150 \
--report_to wandb \
--bf16 \
--logging_first_step \
--no_remove_unused_columns
# peft:
python examples/scripts/dpo.py \
--dataset_name=trl-internal-testing/hh-rlhf-trl-style \
--model_name_or_path=gpt2 \
--per_device_train_batch_size 4 \
--learning_rate 1e-3 \
--gradient_accumulation_steps 1 \
--logging_steps 10 \
--eval_steps 500 \
--output_dir="dpo_anthropic_hh" \
--optim rmsprop \
--warmup_steps 150 \
--report_to wandb \
--bf16 \
--logging_first_step \
--no_remove_unused_columns \
--use_peft \
--lora_r=16 \
--lora_alpha=16
"""
import logging
import multiprocessing
import os
from contextlib import nullcontext
TRL_USE_RICH = os.environ.get("TRL_USE_RICH", False)
from trl.commands.cli_utils import DpoScriptArguments, init_zero_verbose, TrlParser
if TRL_USE_RICH:
init_zero_verbose()
FORMAT = "%(message)s"
from rich.console import Console
from rich.logging import RichHandler
import torch
from datasets import load_dataset
from transformers import AutoModelForCausalLM, AutoTokenizer, TrainingArguments
from trl import (
DPOTrainer,
ModelConfig,
RichProgressCallback,
get_kbit_device_map,
get_peft_config,
get_quantization_config,
)
if TRL_USE_RICH:
logging.basicConfig(format=FORMAT, datefmt="[%X]", handlers=[RichHandler()], level=logging.INFO)
if __name__ == "__main__":
parser = TrlParser((DpoScriptArguments, TrainingArguments, ModelConfig))
args, training_args, model_config = parser.parse_args_and_config()
# Force use our print callback
if TRL_USE_RICH:
training_args.disable_tqdm = True
console = Console()
################
# Model & Tokenizer
################
torch_dtype = (
model_config.torch_dtype
if model_config.torch_dtype in ["auto", None]
else getattr(torch, model_config.torch_dtype)
)
quantization_config = get_quantization_config(model_config)
model_kwargs = dict(
revision=model_config.model_revision,
trust_remote_code=model_config.trust_remote_code,
attn_implementation=model_config.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
model = AutoModelForCausalLM.from_pretrained(model_config.model_name_or_path, **model_kwargs)
peft_config = get_peft_config(model_config)
if peft_config is None:
model_ref = AutoModelForCausalLM.from_pretrained(model_config.model_name_or_path, **model_kwargs)
else:
model_ref = None
tokenizer = AutoTokenizer.from_pretrained(model_config.model_name_or_path)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
if tokenizer.chat_template is None:
tokenizer.chat_template = "{% for message in messages %}{{message['role'] + ': ' + message['content'] + '\n\n'}}{% endfor %}{{ eos_token }}"
if args.ignore_bias_buffers:
# torch distributed hack
model._ddp_params_and_buffers_to_ignore = [
name for name, buffer in model.named_buffers() if buffer.dtype == torch.bool
]
################
# Optional rich context managers
###############
init_context = nullcontext() if not TRL_USE_RICH else console.status("[bold green]Initializing the DPOTrainer...")
save_context = (
nullcontext()
if not TRL_USE_RICH
else console.status(f"[bold green]Training completed! Saving the model to {training_args.output_dir}")
)
################
# Dataset
################
ds = load_dataset(args.dataset_name)
if args.sanity_check:
for key in ds:
ds[key] = ds[key].select(range(50))
def process(row):
row["chosen"] = tokenizer.apply_chat_template(row["chosen"], tokenize=False)
row["rejected"] = tokenizer.apply_chat_template(row["rejected"], tokenize=False)
return row
ds = ds.map(
process,
num_proc=multiprocessing.cpu_count(),
load_from_cache_file=False,
)
train_dataset = ds["train"]
eval_dataset = ds["test"]
################
# Training
################
with init_context:
trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=args.beta,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
max_length=args.max_length,
max_target_length=args.max_target_length,
max_prompt_length=args.max_prompt_length,
generate_during_eval=args.generate_during_eval,
peft_config=get_peft_config(model_config),
callbacks=[RichProgressCallback] if TRL_USE_RICH else None,
)
trainer.train()
with save_context:
trainer.save_model(training_args.output_dir)
| trl/examples/scripts/dpo.py/0 | {
"file_path": "trl/examples/scripts/dpo.py",
"repo_id": "trl",
"token_count": 2476
} | 394 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import itertools
import tempfile
import unittest
import torch
from accelerate.utils.memory import release_memory
from datasets import load_dataset
from parameterized import parameterized
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, TrainingArguments
from trl import SFTTrainer, is_peft_available
from trl.models.utils import setup_chat_format
from ..testing_utils import require_bitsandbytes, require_peft, require_torch_gpu, require_torch_multi_gpu
from .testing_constants import DEVICE_MAP_OPTIONS, GRADIENT_CHECKPOINTING_KWARGS, MODELS_TO_TEST, PACKING_OPTIONS
if is_peft_available():
from peft import LoraConfig, PeftModel
@require_torch_gpu
class SFTTrainerSlowTester(unittest.TestCase):
@classmethod
def setUpClass(cls):
cls.train_dataset = load_dataset("imdb", split="train[:10%]")
cls.eval_dataset = load_dataset("imdb", split="test[:10%]")
cls.dataset_text_field = "text"
cls.max_seq_length = 128
cls.peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=8,
bias="none",
task_type="CAUSAL_LM",
)
def tearDown(self):
gc.collect()
torch.cuda.empty_cache()
gc.collect()
@parameterized.expand(list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS)))
def test_sft_trainer_str(self, model_name, packing):
"""
Simply tests if passing a simple str to `SFTTrainer` loads and runs the trainer
as expected.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
)
trainer = SFTTrainer(
model_name,
args=args,
train_dataset=self.train_dataset,
eval_dataset=self.eval_dataset,
packing=packing,
dataset_text_field=self.dataset_text_field,
max_seq_length=self.max_seq_length,
)
trainer.train()
@parameterized.expand(list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS)))
def test_sft_trainer_transformers(self, model_name, packing):
"""
Simply tests if passing a transformers model to `SFTTrainer` loads and runs the trainer
as expected.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
)
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
trainer = SFTTrainer(
model,
args=args,
tokenizer=tokenizer,
train_dataset=self.train_dataset,
eval_dataset=self.eval_dataset,
packing=packing,
dataset_text_field=self.dataset_text_field,
max_seq_length=self.max_seq_length,
)
trainer.train()
release_memory(model, trainer)
@parameterized.expand(list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS)))
@require_peft
def test_sft_trainer_peft(self, model_name, packing):
"""
Simply tests if passing a transformers model + peft config to `SFTTrainer` loads and runs the trainer
as expected.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
fp16=True,
)
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
trainer = SFTTrainer(
model,
args=args,
tokenizer=tokenizer,
train_dataset=self.train_dataset,
eval_dataset=self.eval_dataset,
packing=packing,
dataset_text_field=self.dataset_text_field,
max_seq_length=self.max_seq_length,
peft_config=self.peft_config,
)
assert isinstance(trainer.model, PeftModel)
trainer.train()
release_memory(model, trainer)
@parameterized.expand(list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS)))
def test_sft_trainer_transformers_mp(self, model_name, packing):
"""
Simply tests if passing a transformers model to `SFTTrainer` loads and runs the trainer
as expected in mixed precision.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
fp16=True, # this is sufficient to enable amp
)
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
trainer = SFTTrainer(
model,
args=args,
tokenizer=tokenizer,
train_dataset=self.train_dataset,
eval_dataset=self.eval_dataset,
packing=packing,
dataset_text_field=self.dataset_text_field,
max_seq_length=self.max_seq_length,
)
trainer.train()
release_memory(model, trainer)
@parameterized.expand(list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS, GRADIENT_CHECKPOINTING_KWARGS)))
def test_sft_trainer_transformers_mp_gc(self, model_name, packing, gradient_checkpointing_kwargs):
"""
Simply tests if passing a transformers model to `SFTTrainer` loads and runs the trainer
as expected in mixed precision + different scenarios of gradient_checkpointing.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
fp16=True, # this is sufficient to enable amp
gradient_checkpointing=True,
gradient_checkpointing_kwargs=gradient_checkpointing_kwargs,
)
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
trainer = SFTTrainer(
model,
args=args,
tokenizer=tokenizer,
train_dataset=self.train_dataset,
eval_dataset=self.eval_dataset,
packing=packing,
dataset_text_field=self.dataset_text_field,
max_seq_length=self.max_seq_length,
)
trainer.train()
release_memory(model, trainer)
@parameterized.expand(list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS, GRADIENT_CHECKPOINTING_KWARGS)))
@require_peft
def test_sft_trainer_transformers_mp_gc_peft(self, model_name, packing, gradient_checkpointing_kwargs):
"""
Simply tests if passing a transformers model + PEFT to `SFTTrainer` loads and runs the trainer
as expected in mixed precision + different scenarios of gradient_checkpointing.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
fp16=True, # this is sufficient to enable amp
gradient_checkpointing=True,
gradient_checkpointing_kwargs=gradient_checkpointing_kwargs,
)
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
trainer = SFTTrainer(
model,
args=args,
tokenizer=tokenizer,
train_dataset=self.train_dataset,
eval_dataset=self.eval_dataset,
packing=packing,
dataset_text_field=self.dataset_text_field,
max_seq_length=self.max_seq_length,
peft_config=self.peft_config,
)
assert isinstance(trainer.model, PeftModel)
trainer.train()
release_memory(model, trainer)
@parameterized.expand(
list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS, GRADIENT_CHECKPOINTING_KWARGS, DEVICE_MAP_OPTIONS))
)
@require_torch_multi_gpu
def test_sft_trainer_transformers_mp_gc_device_map(
self, model_name, packing, gradient_checkpointing_kwargs, device_map
):
"""
Simply tests if passing a transformers model to `SFTTrainer` loads and runs the trainer
as expected in mixed precision + different scenarios of gradient_checkpointing (single, multi-gpu, etc).
"""
with tempfile.TemporaryDirectory() as tmp_dir:
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
fp16=True, # this is sufficient to enable amp
gradient_checkpointing=True,
gradient_checkpointing_kwargs=gradient_checkpointing_kwargs,
)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map=device_map)
tokenizer = AutoTokenizer.from_pretrained(model_name)
trainer = SFTTrainer(
model,
args=args,
tokenizer=tokenizer,
train_dataset=self.train_dataset,
eval_dataset=self.eval_dataset,
packing=packing,
dataset_text_field=self.dataset_text_field,
max_seq_length=self.max_seq_length,
)
trainer.train()
release_memory(model, trainer)
@parameterized.expand(list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS, GRADIENT_CHECKPOINTING_KWARGS)))
@require_peft
@require_bitsandbytes
def test_sft_trainer_transformers_mp_gc_peft_qlora(self, model_name, packing, gradient_checkpointing_kwargs):
"""
Simply tests if passing a transformers model + PEFT + bnb to `SFTTrainer` loads and runs the trainer
as expected in mixed precision + different scenarios of gradient_checkpointing.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
fp16=True, # this is sufficient to enable amp
gradient_checkpointing=True,
gradient_checkpointing_kwargs=gradient_checkpointing_kwargs,
)
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_name)
trainer = SFTTrainer(
model,
args=args,
tokenizer=tokenizer,
train_dataset=self.train_dataset,
eval_dataset=self.eval_dataset,
packing=packing,
dataset_text_field=self.dataset_text_field,
max_seq_length=self.max_seq_length,
peft_config=self.peft_config,
)
assert isinstance(trainer.model, PeftModel)
trainer.train()
release_memory(model, trainer)
@parameterized.expand(list(itertools.product(MODELS_TO_TEST, PACKING_OPTIONS)))
@require_peft
@require_bitsandbytes
def test_sft_trainer_with_chat_format_qlora(self, model_name, packing):
"""
Simply tests if using setup_chat_format with a transformers model + peft + bnb config to `SFTTrainer` loads and runs the trainer
as expected.
"""
with tempfile.TemporaryDirectory() as tmp_dir:
train_dataset = load_dataset("trl-internal-testing/dolly-chatml-sft", split="train")
args = TrainingArguments(
output_dir=tmp_dir,
logging_strategy="no",
report_to="none",
per_device_train_batch_size=2,
max_steps=10,
fp16=True,
)
quantization_config = BitsAndBytesConfig(load_in_4bit=True, bnb_4bit_compute_dtype=torch.float16)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quantization_config)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model, tokenizer = setup_chat_format(model, tokenizer)
trainer = SFTTrainer(
model,
args=args,
tokenizer=tokenizer,
train_dataset=train_dataset,
packing=packing,
max_seq_length=self.max_seq_length,
peft_config=self.peft_config,
)
assert isinstance(trainer.model, PeftModel)
trainer.train()
release_memory(model, trainer)
| trl/tests/slow/test_sft_slow.py/0 | {
"file_path": "trl/tests/slow/test_sft_slow.py",
"repo_id": "trl",
"token_count": 7186
} | 395 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import fnmatch
import gc
import re
import tempfile
import unittest
from functools import partial
import pytest
import torch
from huggingface_hub import HfApi, HfFolder, delete_repo
from parameterized import parameterized
from pytest import mark
from requests.exceptions import HTTPError
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead, AutoModelForSeq2SeqLMWithValueHead, PPOConfig, PPOTrainer, set_seed
from trl.core import respond_to_batch
from .testing_constants import CI_HUB_ENDPOINT, CI_HUB_USER, CI_HUB_USER_TOKEN
from .testing_utils import require_peft, require_torch_multi_gpu
EXPECTED_STATS = [
"objective/kl",
"objective/kl_dist",
"objective/logprobs",
"objective/ref_logprobs",
"objective/kl_coef",
"objective/entropy",
"ppo/mean_non_score_reward",
"ppo/loss/policy",
"ppo/loss/value",
"ppo/loss/total",
"ppo/policy/entropy",
"ppo/policy/approxkl",
"ppo/policy/policykl",
"ppo/policy/clipfrac",
"ppo/policy/advantages",
"ppo/policy/advantages_mean",
"ppo/policy/ratio",
"ppo/returns/mean",
"ppo/returns/var",
"ppo/val/vpred",
"ppo/val/error",
"ppo/val/clipfrac",
"ppo/val/mean",
"ppo/val/var",
"ppo/val/var_explained",
"time/ppo/forward_pass",
"time/ppo/compute_rewards",
"time/ppo/optimize_step",
"time/ppo/calc_stats",
"time/ppo/total",
"ppo/learning_rate",
]
class DummyDataset(torch.utils.data.Dataset):
def __init__(self, query_data, response_data):
self.query_data = query_data
self.response_data = response_data
def __len__(self):
return len(self.query_data)
def __getitem__(self, idx):
return self.query_data[idx], self.response_data[idx]
def apply_mask(values, mask):
unmasked_values = []
for v, m in zip(values, mask):
if m == 1:
unmasked_values.append(v)
return torch.Tensor(unmasked_values)
def abs_diff_masked_tensors(tensor_1, tensor_2, mask_1, mask_2):
diffs = []
for l1, l2, m1, m2 in zip(tensor_1, tensor_2, mask_1, mask_2):
diff = apply_mask(l1, m1) - apply_mask(l2, m2)
diffs.append(diff.sum())
return abs(sum(diffs))
class PPOTrainerTester(unittest.TestCase):
"""
A wrapper class for testing PPOTrainer
"""
@classmethod
def setUpClass(cls):
set_seed(42)
cls._token = CI_HUB_USER_TOKEN
cls._api = HfApi(endpoint=CI_HUB_ENDPOINT)
HfFolder.save_token(CI_HUB_USER_TOKEN)
# model_id
cls.model_id = "trl-internal-testing/dummy-GPT2-correct-vocab"
# get models and tokenizer
cls.gpt2_model = AutoModelForCausalLMWithValueHead.from_pretrained(cls.model_id)
cls.gpt2_model_ref = AutoModelForCausalLMWithValueHead.from_pretrained(cls.model_id)
cls.gpt2_tokenizer = AutoTokenizer.from_pretrained(cls.model_id)
cls.gpt2_tokenizer.pad_token = cls.gpt2_tokenizer.eos_token
# get bloom as right padding examples:
model_id = "trl-internal-testing/tiny-BloomForCausalLM-correct-vocab"
cls.bloom_model = AutoModelForCausalLMWithValueHead.from_pretrained(model_id)
cls.bloom_tokenizer = AutoTokenizer.from_pretrained(model_id)
model_id = "trl-internal-testing/tiny-T5ForConditionalGeneration-correct-vocab"
cls.t5_model = AutoModelForSeq2SeqLMWithValueHead.from_pretrained(model_id)
cls.t5_tokenizer = AutoTokenizer.from_pretrained(model_id)
# initialize trainer
cls.ppo_config = PPOConfig(batch_size=2, mini_batch_size=1, log_with=None)
@classmethod
def tearDownClass(cls):
for model in [f"{CI_HUB_USER}/test-ppo-trainer"]:
try:
delete_repo(token=cls._token, repo_id=model)
except HTTPError:
pass
def setUp(self):
# initialize trainer
self.ppo_config = PPOConfig(batch_size=2, mini_batch_size=1, log_with=None)
self.gpt2_model.train()
return super().setUp()
def tearDown(self):
# free memory
gc.collect()
def _init_dummy_dataset(self):
# encode a query
query_txt = "This morning I went to the "
query_tensor = self.gpt2_tokenizer.encode(query_txt, return_tensors="pt")
assert query_tensor.shape == (1, 7)
# get model response
response_tensor = respond_to_batch(self.gpt2_model, query_tensor)
assert response_tensor.shape == (1, 20)
# create a dummy dataset
min_length = min(len(query_tensor[0]), len(response_tensor[0]))
dummy_dataset = DummyDataset(
[query_tensor[:, :min_length].squeeze(0) for _ in range(2)],
[response_tensor[:, :min_length].squeeze(0) for _ in range(2)],
)
return dummy_dataset
def test_drop_last_dataloader(self):
self.ppo_config = PPOConfig(batch_size=3, mini_batch_size=1, log_with=None)
dummy_dataset = self._init_dummy_dataset()
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=self.gpt2_model_ref,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
dummy_dataloader = ppo_trainer.dataloader
assert len(dummy_dataloader) == 0
def test_ppo_step(self):
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=self.gpt2_model_ref,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model
train_stats = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
for param in ppo_trainer.model.parameters():
assert param.grad is not None
for stat in EXPECTED_STATS:
assert stat in train_stats.keys()
def test_ppo_step_with_masks(self):
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=self.gpt2_model_ref,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
response_mask = [torch.ones_like(r) for r in response_tensor]
# train model
train_stats = ppo_trainer.step(list(query_tensor), list(response_tensor), reward, response_mask)
break
for param in ppo_trainer.model.parameters():
assert param.grad is not None
for stat in EXPECTED_STATS:
assert stat in train_stats.keys()
def test_ppo_step_with_no_ref_sgd(self):
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
optimizer = torch.optim.SGD(self.gpt2_model.parameters(), lr=0.01)
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
optimizer=optimizer,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
assert isinstance(ppo_trainer.optimizer.optimizer, torch.optim.SGD)
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model
train_stats = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
for name, param in ppo_trainer.model.named_parameters():
assert param.grad is not None, f"Parameter {name} has no gradient"
# ref model should not be trained
for name, param in ppo_trainer.ref_model.named_parameters():
assert param.grad is None, f"Parameter {name} has a gradient"
# Finally check stats
for stat in EXPECTED_STATS:
assert stat in train_stats.keys()
def test_ppo_step_with_no_ref_sgd_lr_scheduler(self):
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
optimizer = torch.optim.SGD(self.gpt2_model.parameters(), lr=0.01)
lr_scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma=0.9)
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
optimizer=optimizer,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
lr_scheduler=lr_scheduler,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
assert isinstance(ppo_trainer.optimizer.optimizer, torch.optim.SGD)
assert isinstance(ppo_trainer.lr_scheduler.scheduler, torch.optim.lr_scheduler.ExponentialLR)
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
train_stats = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
for name, param in ppo_trainer.model.named_parameters():
assert param.grad is not None, f"Parameter {name} has no gradient"
# ref model should not be trained
for name, param in ppo_trainer.ref_model.named_parameters():
assert param.grad is None, f"Parameter {name} has a gradient"
# Finally check stats
for stat in EXPECTED_STATS:
assert stat in train_stats.keys()
# assert that the LR has increased for exponential decay
assert train_stats["ppo/learning_rate"] > self.ppo_config.learning_rate
def test_ppo_step_with_no_ref(self):
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
self.gpt2_model = AutoModelForCausalLMWithValueHead.from_pretrained(self.model_id)
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model
train_stats = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
for name, param in ppo_trainer.model.named_parameters():
assert param.grad is not None, f"Parameter {name} has no gradient"
# ref model should not be trained
for name, param in ppo_trainer.ref_model.named_parameters():
assert param.grad is None, f"Parameter {name} has a gradient"
# initialize a new gpt2 model:
model = AutoModelForCausalLMWithValueHead.from_pretrained(self.model_id)
for name, param in ppo_trainer.ref_model.named_parameters():
if "v_head" not in name:
name = name.replace("pretrained_model.", "")
assert torch.allclose(
param.cpu(), model.state_dict()[name].cpu()
), f"Parameter {name} has changed from the original model"
# Finally check stats
for stat in EXPECTED_STATS:
assert stat in train_stats.keys()
def test_ppo_step_with_no_ref_custom_layers(self):
"""
Test PPO step with no reference model and custom layers
For shared layers configuration, all the layers after the `num_shared_layers` are considered as custom layers
therefore the gradients should be computed for these layers only.
"""
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
self.gpt2_model = AutoModelForCausalLMWithValueHead.from_pretrained(self.model_id)
num_shared_layers = 1
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
num_shared_layers=num_shared_layers,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model
train_stats = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
pattern = r".*transformer\.h\.(\d+)\..*"
final_layers = ["ln_f", "v_head", "lm_head"]
for name, param in ppo_trainer.model.named_parameters():
if re.match(pattern, name):
layer_number = int(re.match(pattern, name).groups(0)[0])
if layer_number < num_shared_layers:
assert param.grad is None, f"Parameter {name} has a gradient"
else:
assert param.grad is not None, f"Parameter {name} has no gradient"
elif any(layer in name for layer in final_layers):
assert param.grad is not None, f"Parameter {name} has no gradient"
# ref model should not be trained
for name, param in ppo_trainer.ref_model.named_parameters():
assert param.grad is None, f"Parameter {name} has a gradient"
for stat in EXPECTED_STATS:
assert stat in train_stats.keys()
def test_ppo_step_with_ref_and_custom_layers_warning(self):
"""
Test PPO step with a reference model and custom layers
The trainer should raise a warning if the argument `num_shared_layers` is set
together with a reference model.
"""
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
num_shared_layers = 6
with self.assertWarns(UserWarning):
_ = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=self.gpt2_model_ref,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
num_shared_layers=num_shared_layers,
)
def test_ppo_step_rewards_shape(self):
"""
Test if the rewards shape is correct by asserting that if a wrong reward shape is passed, we get
a value error.
"""
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor([[1.0]]), torch.tensor([[0.0]])]
# train model - this should raise an error
with pytest.raises(ValueError):
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
reward = [torch.tensor([1.0]), torch.tensor([0.0])]
# train model - this should work
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
# check if the gradients are computed for the model
for name, param in ppo_trainer.model.named_parameters():
assert param.grad is not None, f"Parameter {name} has no gradient"
# ref model should not be trained
for name, param in ppo_trainer.ref_model.named_parameters():
assert param.grad is None, f"Parameter {name} has a gradient"
def test_ppo_step_input_shape(self):
"""
Test if the shape of the expected inputs are correct
"""
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor([1.0]), torch.tensor([0.0])]
# train model - this should raise an error
bs = ppo_trainer.config.batch_size
queries, responses, _, _ = ppo_trainer._step_safety_checker(
bs, list(query_tensor), list(response_tensor), reward
)
assert isinstance(queries, list), f"queries should be a list, got {type(queries)}"
assert isinstance(responses, list), f"responses should be a list, got {type(responses)}"
# check the shapes
for i in range(bs):
assert queries[i].shape == torch.Size([7])
assert responses[i].size() == torch.Size([7])
break
def test_ppo_step_no_dataset(self):
"""
Test if the training loop works fine without passing a dataset
"""
query_txt = "This morning I went to the "
query_tensor = self.gpt2_tokenizer.encode(query_txt, return_tensors="pt")
self.ppo_config.batch_size = 1
response_tensor = respond_to_batch(self.gpt2_model, query_tensor)
# Check that this warns the user about batch size
with self.assertWarns(UserWarning):
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=self.gpt2_model_ref,
tokenizer=self.gpt2_tokenizer,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
# train model with ppo
reward = [torch.tensor([1.0])]
# train model - this should work fine
train_stats = ppo_trainer.step([query_tensor[0]], [response_tensor[0]], reward)
# check gradients
for name, param in ppo_trainer.model.named_parameters():
assert param.grad is not None, f"Parameter {name} has no gradient"
# ref model should not be trained
for name, param in ppo_trainer.ref_model.named_parameters():
assert param.grad is None, f"Parameter {name} has a gradient"
# check train stats
for stat in EXPECTED_STATS:
assert stat in train_stats, f"Train stats should contain {stat}"
def test_loss_trainer(self):
"""
Test if the loss trainer works fine
"""
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
self.gpt2_model.eval()
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
dummy_queries = [torch.tensor([1, 2, 3, 4]), torch.tensor([1, 2, 3, 4, 5, 6, 7])]
dummy_responses = [torch.tensor([5, 6, 7, 8, 9]), torch.tensor([8, 9, 10, 11, 12, 13])]
dummy_scores = torch.Tensor([1, 2])
ppo_trainer.config.mini_batch_size = 1
ppo_trainer.config.batch_size = 1
model_inputs = ppo_trainer.prepare_model_inputs(dummy_queries, dummy_responses)
all_logprobs, _, values, mask = ppo_trainer.batched_forward_pass(
self.gpt2_model, dummy_queries, dummy_responses, model_inputs
)
# dummy values
ref_logprobs = all_logprobs + 1
logits = torch.exp(all_logprobs)
vpreds = values + 0.1
score, non_score, kls = ppo_trainer.compute_rewards(dummy_scores, all_logprobs, ref_logprobs, mask)
values, advantages, returns = ppo_trainer.compute_advantages(values, score, mask)
# just make sure a dummy loss is computed
idx = 0
pg_loss, v_loss, _ = ppo_trainer.loss(
all_logprobs[idx].unsqueeze(0),
values[idx].unsqueeze(0),
logits[idx].unsqueeze(0),
vpreds[idx].unsqueeze(0),
ref_logprobs[idx].unsqueeze(0),
mask[idx].unsqueeze(0),
advantages[idx].unsqueeze(0),
returns[idx].unsqueeze(0),
)
assert abs(pg_loss.item() - 2.0494) < 0.0001
assert abs(v_loss.item() - 0.0711) < 0.0001
# check if we get same results with masked parts removed
pg_loss_unmasked, v_loss_unmasked, _ = ppo_trainer.loss(
apply_mask(all_logprobs[idx], mask[idx]).unsqueeze(0),
apply_mask(values[idx], mask[idx]).unsqueeze(0),
apply_mask(logits[idx], mask[idx]).unsqueeze(0),
apply_mask(vpreds[idx], mask[idx]).unsqueeze(0),
apply_mask(ref_logprobs[idx], mask[idx]).unsqueeze(0),
apply_mask(mask[idx], mask[idx]).unsqueeze(0),
apply_mask(advantages[idx], mask[idx]).unsqueeze(0),
apply_mask(returns[idx], mask[idx]).unsqueeze(0),
)
assert abs(pg_loss_unmasked.item() - 2.0494) < 0.0001
assert abs(v_loss_unmasked.item() - 0.0711) < 0.0001
@parameterized.expand(
[
["gpt2"],
["bloom"],
["t5"],
]
)
def test_batched_forward_pass(self, name):
"""
Test if the loss trainer works fine
"""
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
dummy_queries = [torch.tensor([1, 2, 3, 4]), torch.tensor([1, 2, 3, 4, 5, 6, 7])]
dummy_responses = [torch.tensor([5, 6, 7, 8, 9]), torch.tensor([8, 9, 10, 11, 12, 13])]
if name == "gpt2":
model = self.gpt2_model
tokenizer = self.gpt2_tokenizer
elif name == "bloom":
model = self.bloom_model
tokenizer = self.bloom_tokenizer
elif name == "t5":
model = self.t5_model
tokenizer = self.t5_tokenizer
model.eval()
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=model,
ref_model=None,
tokenizer=tokenizer,
dataset=dummy_dataset,
)
# we test all combinations of fwd_bs and bs:
# if fwd_bs=bs=1: no padding is applied and only one forward pass
# if fwd_bs=1/bs=2: padding is applied and results computed in two fwd passes
# if fwd_bs=bs=2: padding is applied and results computed in one fwd pass
ppo_trainer.config.mini_batch_size = 1
ppo_trainer.config.batch_size = 1
model_inputs = ppo_trainer.prepare_model_inputs([dummy_queries[0]], [dummy_responses[0]])
logprobs_0, logits_0, values_0, mask_0 = ppo_trainer.batched_forward_pass(
model, [dummy_queries[0]], [dummy_responses[0]], model_inputs
)
ppo_trainer.config.batch_size = 2
model_inputs = ppo_trainer.prepare_model_inputs(dummy_queries, dummy_responses)
logprobs_1, logits_1, values_1, mask_1 = ppo_trainer.batched_forward_pass(
model, dummy_queries, dummy_responses, model_inputs
)
ppo_trainer.config.mini_batch_size = 2
model_inputs = ppo_trainer.prepare_model_inputs(dummy_queries, dummy_responses)
logprobs_2, logits_2, values_2, mask_2 = ppo_trainer.batched_forward_pass(
model, dummy_queries, dummy_responses, model_inputs
)
assert abs_diff_masked_tensors(logprobs_1, logprobs_2, mask_1, mask_2) <= 0.0001
assert abs_diff_masked_tensors(values_1, values_2, mask_1, mask_2) <= 0.0001
assert abs_diff_masked_tensors(logprobs_0, logprobs_2[:1], mask_0, mask_2[:1]) <= 0.0001
assert abs_diff_masked_tensors(values_0, values_2[:1], mask_0, mask_2[:1]) <= 0.0001
def test_ppo_trainer_max_grad_norm(self):
"""
Test if the `max_grad_norm` feature works as expected
"""
# initialize dataset
dummy_dataset = self._init_dummy_dataset()
self.ppo_config.max_grad_norm = 0.00001
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
# check gradients
for name, param in ppo_trainer.model.named_parameters():
assert param.grad is not None, f"Parameter {name} has no gradient"
assert torch.all(
param.grad.abs() <= self.ppo_config.max_grad_norm
), f"Parameter {name} has a gradient larger than max_grad_norm"
def test_ppo_trainer_kl_penalty(self):
dummy_dataset = self._init_dummy_dataset()
log_probs = torch.Tensor([[0.5, 0.2, 0.1], [0.6, 0.2, 0.1]])
ref_log_probs = torch.Tensor([[0.4, 0.3, 0.0], [0.7, 0.1, 0.3]])
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
expected_output = torch.Tensor([[0.1000, -0.1000, 0.1000], [-0.1000, 0.1000, -0.2000]])
assert torch.allclose(ppo_trainer._kl_penalty(log_probs, ref_log_probs), expected_output)
self.ppo_config.kl_penalty = "abs"
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
expected_output = torch.Tensor([[0.1000, 0.1000, 0.1000], [0.1000, 0.1000, 0.2000]])
assert torch.allclose(ppo_trainer._kl_penalty(log_probs, ref_log_probs), expected_output)
self.ppo_config.kl_penalty = "mse"
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
expected_output = torch.Tensor([[0.0050, 0.0050, 0.0050], [0.0050, 0.0050, 0.0200]])
assert torch.allclose(ppo_trainer._kl_penalty(log_probs, ref_log_probs), expected_output)
def test_ppo_trainer_full_kl_penalty(self):
# a few more extensive tests for the full kl option as it is more involved
dummy_dataset = self._init_dummy_dataset()
self.ppo_config.kl_penalty = "full"
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
# Test on tensors for size B,S,T = (1,2,3)
# test for when the two dists are the same
log_probs = torch.Tensor(
[
[
[0.1, 0.2, 0.7],
[0.3, 0.4, 0.3],
]
]
).exp()
ref_log_probs = torch.Tensor(
[
[
[0.1, 0.2, 0.7],
[0.3, 0.4, 0.3],
]
]
).exp()
expected_output = torch.Tensor(
[[0.0, 0.0]],
)
output = ppo_trainer._kl_penalty(log_probs, ref_log_probs)
assert output.shape == (1, 2)
assert torch.allclose(output, expected_output)
# test for when the two dists are almost not overlapping
log_probs = torch.Tensor(
[
[
[0.98, 0.01, 0.01],
[0.01, 0.98, 0.01],
]
]
).log()
ref_log_probs = torch.Tensor(
[
[
[0.01, 0.01, 0.98],
[0.01, 0.01, 0.98],
]
]
).log()
expected_output = torch.Tensor(
[[4.4474, 4.4474]],
)
output = ppo_trainer._kl_penalty(log_probs, ref_log_probs)
assert output.shape == (1, 2)
assert torch.allclose(output, expected_output)
# test for when the two dists are almost not overlapping
log_probs = torch.Tensor(
[
[
[0.49, 0.02, 0.49],
[0.49, 0.02, 0.49],
]
]
).log()
ref_log_probs = torch.Tensor(
[
[
[0.01, 0.98, 0.01],
[0.49, 0.02, 0.49],
]
]
).log()
expected_output = torch.Tensor(
[[3.7361, 0.0]],
)
output = ppo_trainer._kl_penalty(log_probs, ref_log_probs)
assert output.shape == (1, 2)
assert torch.allclose(output, expected_output, atol=0.0001)
@require_peft
@mark.peft_test
def test_peft_model_ppo_trainer(self):
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
gpt2_model = AutoModelForCausalLM.from_pretrained(self.model_id)
# this line is very important
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
gpt2_model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
peft_model = get_peft_model(gpt2_model, lora_config)
model = AutoModelForCausalLMWithValueHead.from_pretrained(peft_model)
dummy_dataset = self._init_dummy_dataset()
self.ppo_config.batch_size = 2
self.ppo_config.mini_batch_size = 1
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
assert ppo_trainer.ref_model is None
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model by running a step twice
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
ppo_trainer.model.train()
ppo_trainer.model.gradient_checkpointing_enable()
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
# check gradients
for name, param in model.named_parameters():
if "lora" in name or "v_head" in name:
assert param.grad is not None, f"Parameter {name} has a no gradient"
else:
assert param.grad is None, f"Parameter {name} has a gradient"
@require_peft
@mark.peft_test
def test_peft_model_ppo_adapter_rm_trainer(self):
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM, AutoModelForSequenceClassification
dummy_inputs = torch.LongTensor([[1, 2, 3, 4, 5], [1, 2, 3, 4, 5]])
rm_lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="SEQ_CLS",
)
reward_model = AutoModelForSequenceClassification.from_pretrained(self.model_id)
reward_model = get_peft_model(reward_model, rm_lora_config)
dummy_optim = torch.optim.Adam(filter(lambda p: p.requires_grad, reward_model.parameters()), lr=1e-3)
previous_rm_logits = reward_model(dummy_inputs).logits
loss = previous_rm_logits.mean()
loss.backward()
dummy_optim.step()
reward_model.eval()
original_rm_logits = reward_model(dummy_inputs).logits
with tempfile.TemporaryDirectory() as tmpdirname:
reward_model.save_pretrained(tmpdirname)
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
gpt2_model = AutoModelForCausalLM.from_pretrained(self.model_id)
# this line is very important
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
gpt2_model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
peft_model = get_peft_model(gpt2_model, lora_config)
model = AutoModelForCausalLMWithValueHead.from_pretrained(
peft_model,
reward_adapter=tmpdirname,
)
dummy_dataset = self._init_dummy_dataset()
self.ppo_config.batch_size = 2
self.ppo_config.mini_batch_size = 1
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
assert ppo_trainer.ref_model is None
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model by running a step twice
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
ppo_trainer.model.train()
ppo_trainer.model.gradient_checkpointing_enable()
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
new_logits = ppo_trainer.model.compute_reward_score(dummy_inputs)
assert not torch.allclose(previous_rm_logits, new_logits[:, -1, :])
assert torch.allclose(original_rm_logits, new_logits[:, -1, :])
# check gradients
for name, param in model.named_parameters():
if ("lora" in name or "v_head" in name) and ("reward" not in name):
assert param.grad is not None, f"Parameter {name} has a no gradient"
else:
assert param.grad is None, f"Parameter {name} has a gradient"
@unittest.skip("Fix by either patching `whomai()` to work in the staging endpoint or use a dummy prod user.")
def test_push_to_hub(self):
REPO_NAME = "test-ppo-trainer"
repo_id = f"{CI_HUB_USER}/{REPO_NAME}"
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=self.gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=self._init_dummy_dataset(),
)
with tempfile.TemporaryDirectory():
url = ppo_trainer.push_to_hub(repo_id=repo_id, token=self._token, api_endpoint=CI_HUB_ENDPOINT)
# Extract repo_name from the url
re_search = re.search(CI_HUB_ENDPOINT + r"/([^/]+/[^/]+)/", url)
assert re_search is not None
hub_repo_id = re_search.groups()[0]
# Check we created a Hub repo
assert hub_repo_id == repo_id
# Ensure all files are present
files = sorted(self._api.list_repo_files(hub_repo_id))
assert all(
fnmatch.fnmatch(file, expected_file)
for file, expected_file in zip(
files,
[
".gitattributes",
"README.md",
"config.json",
"merges.txt",
"pytorch_model.bin",
"special_tokens_map.json",
"tokenizer_config.json",
"vocab.json",
],
)
)
@require_peft
@require_torch_multi_gpu
@mark.peft_test
def test_peft_model_ppo_trainer_multi_gpu(self):
from peft import LoraConfig, get_peft_model
from transformers import AutoModelForCausalLM
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
)
gpt2_model = AutoModelForCausalLM.from_pretrained(
"gpt2", device_map="balanced", max_memory={0: "500MB", 1: "500MB"}
)
assert set(gpt2_model.hf_device_map.values()) == {0, 1}
# this line is very important
def make_inputs_require_grad(module, input, output):
output.requires_grad_(True)
gpt2_model.get_input_embeddings().register_forward_hook(make_inputs_require_grad)
peft_model = get_peft_model(gpt2_model, lora_config)
model = AutoModelForCausalLMWithValueHead.from_pretrained(peft_model)
assert model.is_sequential_parallel
dummy_dataset = self._init_dummy_dataset()
self.ppo_config.batch_size = 2
self.ppo_config.mini_batch_size = 1
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
assert ppo_trainer.ref_model is None
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model by running a step twice
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
ppo_trainer.model.train()
ppo_trainer.model.gradient_checkpointing_enable()
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
# check gradients
for name, param in model.named_parameters():
if "lora" in name or "v_head" in name:
assert param.grad is not None, f"Parameter {name} has a no gradient"
else:
assert param.grad is None, f"Parameter {name} has a gradient"
def test_generation(self):
dummy_dataset = self._init_dummy_dataset()
model = AutoModelForCausalLMWithValueHead.from_pretrained("gpt2")
tokenizer = AutoTokenizer.from_pretrained("gpt2")
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=model,
ref_model=None,
tokenizer=tokenizer,
dataset=dummy_dataset,
)
input_texts = ["this is a test", "this is another, longer test"]
generation_kwargs = {"do_sample": False, "max_new_tokens": 4, "pad_token_id": tokenizer.eos_token_id}
tokenizer.pad_token = tokenizer.eos_token
model_inputs = [tokenizer(txt, return_tensors="pt").input_ids.squeeze() for txt in input_texts]
generations_batched = ppo_trainer.generate(model_inputs, batch_size=2, **generation_kwargs)
generations_batched = tokenizer.batch_decode(generations_batched)
generations_single = [ppo_trainer.generate(inputs, **generation_kwargs).squeeze() for inputs in model_inputs]
generations_single = tokenizer.batch_decode(generations_single)
assert generations_single == generations_batched
def test_grad_accumulation(self):
dummy_dataset = self._init_dummy_dataset()
torch.manual_seed(0)
gpt2_model = AutoModelForCausalLMWithValueHead.from_pretrained(self.model_id, summary_dropout_prob=0.0)
gpt2_model_clone = copy.deepcopy(gpt2_model)
self.ppo_config.mini_batch_size = 2
self.ppo_config.ppo_epochs = 1
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=gpt2_model,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(1.0)]
# train model by running a step twice
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
model_grad = gpt2_model.v_head.summary.weight
self.ppo_config.mini_batch_size = 1
self.ppo_config.gradient_accumulation_steps = 2
ppo_trainer = PPOTrainer(
config=self.ppo_config,
model=gpt2_model_clone,
ref_model=None,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(1.0)]
# train model by running a step twice
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
model_grad_acc = gpt2_model_clone.v_head.summary.weight
assert torch.allclose(model_grad_acc, model_grad, rtol=0.001, atol=0.001)
@unittest.skip("Fix by either patching `whomai()` to work in the staging endpoint or use a dummy prod user.")
def test_push_to_hub_if_best_reward(self):
REPO_NAME = "test-ppo-trainer"
repo_id = f"{CI_HUB_USER}/{REPO_NAME}"
dummy_dataset = self._init_dummy_dataset()
push_to_hub_if_best_kwargs = {"repo_id": repo_id}
ppo_config = PPOConfig(
batch_size=2,
mini_batch_size=1,
log_with=None,
push_to_hub_if_best_kwargs=push_to_hub_if_best_kwargs,
compare_steps=1,
)
ppo_trainer = PPOTrainer(
config=ppo_config,
model=self.gpt2_model,
ref_model=self.gpt2_model_ref,
tokenizer=self.gpt2_tokenizer,
dataset=dummy_dataset,
)
ppo_trainer.optimizer.zero_grad = partial(ppo_trainer.optimizer.zero_grad, set_to_none=False)
dummy_dataloader = ppo_trainer.dataloader
# train model with ppo
for query_tensor, response_tensor in dummy_dataloader:
# define a reward for response
# (this could be any reward such as human feedback or output from another model)
reward = [torch.tensor(1.0), torch.tensor(0.0)]
# train model
_ = ppo_trainer.step(list(query_tensor), list(response_tensor), reward)
break
def test_batch_size_check(self):
with pytest.raises(ValueError):
PPOConfig(batch_size=2, mini_batch_size=2, gradient_accumulation_steps=2)
| trl/tests/test_ppo_trainer.py/0 | {
"file_path": "trl/tests/test_ppo_trainer.py",
"repo_id": "trl",
"token_count": 22933
} | 396 |
# flake8: noqa
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# flake8: noqa
from typing import TYPE_CHECKING
from ..import_utils import _LazyModule, is_diffusers_available, OptionalDependencyNotAvailable
_import_structure = {
"modeling_base": ["PreTrainedModelWrapper", "create_reference_model"],
"modeling_value_head": [
"AutoModelForCausalLMWithValueHead",
"AutoModelForSeq2SeqLMWithValueHead",
],
"utils": ["setup_chat_format", "SUPPORTED_ARCHITECTURES"],
}
try:
if not is_diffusers_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
_import_structure["modeling_sd_base"] = [
"DDPOPipelineOutput",
"DDPOSchedulerOutput",
"DDPOStableDiffusionPipeline",
"DefaultDDPOStableDiffusionPipeline",
]
if TYPE_CHECKING:
from .modeling_base import PreTrainedModelWrapper, create_reference_model
from .modeling_value_head import AutoModelForCausalLMWithValueHead, AutoModelForSeq2SeqLMWithValueHead
from .utils import setup_chat_format, SUPPORTED_ARCHITECTURES
try:
if not is_diffusers_available():
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
pass
else:
from .modeling_sd_base import (
DDPOPipelineOutput,
DDPOSchedulerOutput,
DDPOStableDiffusionPipeline,
DefaultDDPOStableDiffusionPipeline,
)
else:
import sys
sys.modules[__name__] = _LazyModule(__name__, globals()["__file__"], _import_structure, module_spec=__spec__)
| trl/trl/models/__init__.py/0 | {
"file_path": "trl/trl/models/__init__.py",
"repo_id": "trl",
"token_count": 795
} | 397 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import math
import os
import time
import typing
import warnings
from contextlib import nullcontext
from typing import Callable, List, Optional, Union
import datasets
import numpy as np
import torch
import torch.nn.functional as F
from accelerate import Accelerator
from accelerate.utils import ProjectConfiguration, gather_object, is_deepspeed_available
from datasets import Dataset
from huggingface_hub import whoami
from packaging import version
from torch.optim import Adam
from transformers import (
DataCollatorForLanguageModeling,
PreTrainedTokenizer,
PreTrainedTokenizerBase,
PreTrainedTokenizerFast,
)
from ..core import (
WANDB_PADDING,
PPODecorators,
clip_by_value,
convert_to_scalar,
entropy_from_logits,
flatten_dict,
logprobs_from_logits,
masked_mean,
masked_var,
masked_whiten,
set_seed,
stack_dicts,
stats_to_np,
)
from ..import_utils import is_npu_available, is_torch_greater_2_0, is_xpu_available
from ..models import SUPPORTED_ARCHITECTURES, PreTrainedModelWrapper, create_reference_model
from . import AdaptiveKLController, BaseTrainer, FixedKLController, PPOConfig, RunningMoments
if is_deepspeed_available():
import deepspeed
MODEL_CARD_TEMPLATE = """---
license: apache-2.0
tags:
- trl
- ppo
- transformers
- reinforcement-learning
---
# {model_name}
This is a [TRL language model](https://github.com/huggingface/trl) that has been fine-tuned with reinforcement learning to
guide the model outputs according to a value, function, or human feedback. The model can be used for text generation.
## Usage
To use this model for inference, first install the TRL library:
```bash
python -m pip install trl
```
You can then generate text as follows:
```python
from transformers import pipeline
generator = pipeline("text-generation", model="{model_id}")
outputs = generator("Hello, my llama is cute")
```
If you want to use the model for training or to obtain the outputs from the value head, load the model as follows:
```python
from transformers import AutoTokenizer
from trl import AutoModelForCausalLMWithValueHead
tokenizer = AutoTokenizer.from_pretrained("{model_id}")
model = AutoModelForCausalLMWithValueHead.from_pretrained("{model_id}")
inputs = tokenizer("Hello, my llama is cute", return_tensors="pt")
outputs = model(**inputs, labels=inputs["input_ids"])
```
"""
class PPOTrainer(BaseTrainer):
"""
The PPOTrainer uses Proximal Policy Optimization to optimise language models.
Note, this trainer is heavily inspired by the original OpenAI learning to summarize work here:
https://github.com/openai/summarize-from-feedback
Attributes:
**config** (`PPOConfig`) -- Configuration object for PPOTrainer. Check the documentation of `PPOConfig` for more
details.
**model** (`PreTrainedModelWrapper`) -- Model to be optimized, Hugging Face transformer model with a value head.
Check the documentation of `PreTrainedModelWrapper` for more details.
**ref_model** (`PreTrainedModelWrapper`, *optional*) -- Reference model to be used for KL penalty, Hugging Face
transformer model with a casual language modelling head. Check the documentation of `PreTrainedModelWrapper`
for more details. If no reference model is provided, the trainer will create a reference model with the same
architecture as the model to be optimized with shared layers.
**tokenizer** (`PreTrainedTokenizerBase`) -- Tokenizer to be used for encoding the
data. Check the documentation of `transformers.PreTrainedTokenizer` and
`transformers.PreTrainedTokenizerFast` for more details.
**dataset** (Union[`torch.utils.data.Dataset`, `datasets.Dataset`], *optional*) -- PyTorch dataset or Hugging
Face dataset. This is used to create a PyTorch dataloader. If no dataset is provided, the dataloader must be
created outside the trainer users needs to design their own dataloader and make sure the batch
size that is used is the same as the one specified in the configuration object.
**optimizer** (`torch.optim.Optimizer`, *optional*) -- Optimizer to be used for training. If no optimizer is
provided, the trainer will create an Adam optimizer with the learning rate specified in the configuration
object.
**data_collator** (DataCollatorForLanguageModeling, *optional*) -- Data collator to be used for training and
passed along the dataloader
**num_shared_layers** (int, *optional*) -- Number of layers to be shared between the model and the reference
model, if no reference model is passed. If no number is provided, all the layers will be shared.
**lr_scheduler** (`torch.optim.lr_scheduler`, *optional*) -- Learning rate scheduler to be used for training.
"""
_tag_names = ["trl", "ppo"]
def __init__(
self,
config: Optional[PPOConfig] = None,
model: Optional[PreTrainedModelWrapper] = None,
ref_model: Optional[PreTrainedModelWrapper] = None,
tokenizer: Optional[PreTrainedTokenizerBase] = None,
dataset: Optional[Union[torch.utils.data.Dataset, Dataset]] = None,
optimizer: Optional[torch.optim.Optimizer] = None,
data_collator: Optional[typing.Callable] = None,
num_shared_layers: Optional[int] = None,
lr_scheduler: Optional[torch.optim.lr_scheduler._LRScheduler] = None,
):
"""
Initialize PPOTrainer.
Args:
config (`PPOConfig`):
Configuration object for PPOTrainer. Check the documentation of `PPOConfig` for more details.
model (`PreTrainedModelWrapper`):
Hugging Face transformer model with a value head.
ref_model (`PreTrainedModelWrapper`):
Hugging Face transformer model with a casual language modelling head. Used for KL penalty
tokenizer (`transformers.PreTrainedTokenizerBase`):
Hugging Face tokenizer
dataset (Optional[Union[`torch.utils.data.Dataset`, `datasets.Dataset`]]):
PyTorch dataset or Hugging Face dataset. If a Hugging Face dataset is passed, the dataset
will be preprocessed by removing the columns that are not used by the model. If none is passed,
a warning will be raised in a multi-GPU setting.
optimizer (Optional[`torch.optim.Optimizer`]):
Optimizer used for training. If `None`, the `Adam` is used as default.
data_collator (Optional[function]):
Data collator function.
num_shared_layers (Optional[int]):
Number of shared layers between the model and the reference model. If `None`, all layers are shared.
used only if `ref_model` is `None`.
lr_scheduler (Optional[`torch.optim.lr_scheduler`]):
Learning rate scheduler used for training.
"""
super().__init__(config)
# initial seed for reproducible experiments
set_seed(config.seed)
# Step 0: check positional arguments validity
if not isinstance(config, PPOConfig):
raise ValueError(f"config must be a PPOConfig, got {type(config)}")
if not isinstance(tokenizer, (PreTrainedTokenizerBase)):
raise ValueError(
f"tokenizer must be a PreTrainedTokenizerBase like a PreTrainedTokenizer or a PreTrainedTokenizerFast, got {type(tokenizer)}"
)
if not isinstance(model, (SUPPORTED_ARCHITECTURES)):
raise ValueError(
f"model must be a PreTrainedModelWrapper, got {type(model)} - supported architectures are: {SUPPORTED_ARCHITECTURES}"
)
# Step 1: Initialize Accelerator
self.accelerator = Accelerator(
log_with=config.log_with,
gradient_accumulation_steps=config.gradient_accumulation_steps,
project_config=ProjectConfiguration(**config.project_kwargs),
**config.accelerator_kwargs,
)
# Step 1.1 Runtime variables filled by the accelerator
config.world_size = self.accelerator.num_processes
config.global_backward_batch_size = config.backward_batch_size * config.world_size
config.global_batch_size = config.batch_size * config.world_size
self.model = model
self.model_params = filter(lambda p: p.requires_grad, self.model.parameters())
self.is_encoder_decoder = hasattr(self.model, "is_encoder_decoder")
self.is_peft_model = getattr(self.model, "is_peft_model", False)
config.is_encoder_decoder = self.is_encoder_decoder
config.is_peft_model = self.is_peft_model
is_using_tensorboard = config.log_with is not None and config.log_with == "tensorboard"
self.accelerator.init_trackers(
config.tracker_project_name,
config=dict(trl_ppo_trainer_config=config.to_dict()) if not is_using_tensorboard else config.to_dict(),
init_kwargs=config.tracker_kwargs,
)
self.is_using_text_environment = getattr(config, "use_text_environment", False)
if isinstance(ref_model, SUPPORTED_ARCHITECTURES):
self.ref_model = ref_model
if num_shared_layers is not None:
warnings.warn(
"num_shared_layers is ignored when ref_model is provided. Two different models are used for the "
"model and the reference model and no layers are shared.",
UserWarning,
)
elif ref_model is None and not self.is_peft_model:
self.ref_model = create_reference_model(self.model, num_shared_layers=num_shared_layers)
elif self.is_peft_model:
self.ref_model = None
else:
raise ValueError(
f"ref_model must be a PreTrainedModelWrapper or `None`, got {type(ref_model)} - supported "
f"architectures are: {SUPPORTED_ARCHITECTURES} "
)
self.optional_peft_ctx = (
self.accelerator.unwrap_model(self.model).pretrained_model.disable_adapter
if self.is_peft_model
else nullcontext
)
if not (isinstance(tokenizer, PreTrainedTokenizer) or isinstance(tokenizer, PreTrainedTokenizerFast)):
raise ValueError(
"tokenizer must be a transformers.PreTrainedTokenizer or transformers.PreTrainedTokenizerFast"
)
self.tokenizer = tokenizer
if dataset is not None and not (isinstance(dataset, torch.utils.data.Dataset) or isinstance(dataset, Dataset)):
raise ValueError("dataset must be a torch.utils.data.Dataset or datasets.Dataset")
elif dataset is None:
warnings.warn(
"No dataset is provided. Make sure to set config.batch_size to the correct value before training.",
UserWarning,
)
self.dataset = dataset
self._signature_columns = None
if self.dataset is not None:
self.dataloader = self.prepare_dataloader(self.dataset, data_collator)
elif self.dataset is None and self.accelerator.num_processes > 1:
warnings.warn(
"No dataset is provided. In a multi-GPU setting, this will lead to an error. You should"
" prepare your dataloader yourself with `dataloader = ppo_trainer.accelerator.prepare(dataloader)`"
" and using `torch.utils.data.DataLoader`, or pass a dataset to the `PPOTrainer`. Please "
" refer to the documentation for more details.",
UserWarning,
)
self.dataloader = None
else:
self.dataloader = None
# Step 3: Initialize optimizer and data collator
self.data_collator = DataCollatorForLanguageModeling(self.tokenizer, mlm=False)
if optimizer is None:
self.optimizer = Adam(
filter(lambda p: p.requires_grad, self.model.parameters()),
lr=self.config.learning_rate,
)
else:
self.optimizer = optimizer
self.lr_scheduler = lr_scheduler
if self.lr_scheduler is not None:
lr_scheduler_class = (
torch.optim.lr_scheduler._LRScheduler
if not is_torch_greater_2_0()
else torch.optim.lr_scheduler.LRScheduler
)
if not isinstance(self.lr_scheduler, lr_scheduler_class):
raise ValueError(
"lr_scheduler must be a torch.optim.lr_scheduler._LRScheduler or torch.optim.lr_scheduler.LRScheduler (for torch >= 2.0)"
)
if self.config.adap_kl_ctrl:
self.kl_ctl = AdaptiveKLController(self.config.init_kl_coef, self.config.target, self.config.horizon)
else:
self.kl_ctl = FixedKLController(self.config.init_kl_coef)
# Safety checkers for DS integration
is_deepspeed_used = self.accelerator.distributed_type == "DEEPSPEED" and hasattr(
self.accelerator.state, "deepspeed_plugin"
)
(
self.model,
self.optimizer,
self.data_collator,
self.dataloader,
self.lr_scheduler,
) = self.accelerator.prepare(
self.model,
self.optimizer,
self.data_collator,
self.dataloader,
self.lr_scheduler,
)
if is_deepspeed_used:
# Quantized models are already set on the correct device
if not self.is_peft_model and not (
getattr(self.ref_model.pretrained_model, "is_loaded_in_8bit", False)
or getattr(self.ref_model.pretrained_model, "is_loaded_in_4bit", False)
):
self.ref_model = self._prepare_deepspeed(self.ref_model)
else:
self.ref_model = self.accelerator.prepare(self.ref_model)
# In a distributed setup, only logging needs to be performed on the main process
# check: https://pytorch.org/docs/stable/generated/torch.nn.parallel.DistributedDataParallel.html
# or: https://discuss.pytorch.org/t/use-distributed-data-parallel-correctly/82500/11
self.is_distributed = self.accelerator.num_processes > 1
# init the current step
self.current_step = 0
# init variables for pushing model to hub
if config.push_to_hub_if_best_kwargs:
if "repo_id" not in config.push_to_hub_if_best_kwargs:
raise ValueError("You have to specify repo_id in order to push the model to the hub!")
self.push_to_hub_kwargs = config.push_to_hub_if_best_kwargs
self.compare_step = 0
self.highest_reward = torch.tensor(-float("inf"))
# post process for PP
if not getattr(self.model, "is_sequential_parallel", False):
self.current_device = self.accelerator.device
else:
if is_xpu_available():
self.current_device = torch.device("xpu:0")
elif is_npu_available():
self.current_device = torch.device("npu:0")
else:
self.current_device = torch.device("cuda:0")
PPODecorators.optimize_device_cache = self.config.optimize_device_cache
self.running = RunningMoments(self.accelerator)
def _filter_kwargs(self, kwargs, target_func):
"""
filter the keyword arguments that are supported by the target function.
Args:
kwargs (dict):
Keyword arguments
target_func (function):
Target function
"""
return {k: v for k, v in kwargs.items() if k in inspect.signature(target_func).parameters.keys()}
def prepare_dataloader(self, dataset: Union[torch.utils.data.Dataset, Dataset], data_collator=None):
"""
Prepare the dataloader for training.
Args:
dataset (Union[`torch.utils.data.Dataset`, `datasets.Dataset`]):
PyTorch dataset or Hugging Face dataset. If a Hugging Face dataset is passed, the dataset
will be preprocessed by removing the columns that are not used by the model.
data_collator (Optional[function]):
Data collator function.
Returns:
`torch.utils.data.DataLoader`: PyTorch dataloader
"""
if isinstance(dataset, Dataset):
dataset = self._remove_unused_columns(dataset)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=self.config.batch_size,
collate_fn=data_collator,
shuffle=True,
drop_last=True,
)
return dataloader
# Adapted from transformers.Trainer._set_signature_columns_if_needed
def _set_signature_columns_if_needed(self):
if self._signature_columns is None:
# Inspect model forward signature to keep only the arguments it accepts.
signature = inspect.signature(self.model.forward)
self._signature_columns = list(signature.parameters.keys())
# label => sentiment | we need query and response for logging purpose
self._signature_columns += ["label", "query", "response"]
# Adapted from transformers.Trainer._remove_unused_columns
def _remove_unused_columns(self, dataset: "Dataset"):
if not self.config.remove_unused_columns:
return dataset
self._set_signature_columns_if_needed()
signature_columns = self._signature_columns
ignored_columns = list(set(dataset.column_names) - set(signature_columns))
columns = [k for k in signature_columns if k in dataset.column_names]
if version.parse(datasets.__version__) < version.parse("1.4.0"):
dataset.set_format(
type=dataset.format["type"],
columns=columns,
format_kwargs=dataset.format["format_kwargs"],
)
return dataset
else:
return dataset.remove_columns(ignored_columns)
def generate(
self,
query_tensor: Union[torch.Tensor, List[torch.Tensor]],
length_sampler: Optional[Callable] = None,
batch_size: int = 4,
return_prompt: bool = True,
generate_ref_response: bool = False,
**generation_kwargs,
):
"""
Generate response with the model given the query tensor.
call the `generate` method of the model.
Args:
query_tensor (`torch.LongTensor`):
A tensor of shape (`seq_len`) containing query tokens or a list of tensors of shape (`seq_len`).
length_sampler (`Callable`, *optional*):
Callable that returns the number of newly generated tokens.
batch_size (`int`, *optional):
Batch size used for generation, defaults to `4`.
return_prompt (`bool`, *optional*):
If set to `False` the prompt is not returned but only the newly generated tokens, defaults to `True`.
generate_ref_response (`bool`, *optional*):
If set to `True` the reference response is also generated, defaults to `False`.
generation_kwargs (dict[str, Any]):
Keyword arguments for generation.
Returns:
`torch.LongTensor`: A tensor of shape (`batch_size`, `gen_len`) containing response tokens.
"""
if generate_ref_response:
ref_model = self.model if self.is_peft_model else self.ref_model
if isinstance(query_tensor, List):
response = self._generate_batched(
self.model,
query_tensor,
length_sampler=length_sampler,
batch_size=batch_size,
return_prompt=return_prompt,
**generation_kwargs,
)
if generate_ref_response:
with self.optional_peft_ctx():
ref_response = self._generate_batched(
ref_model,
query_tensor,
length_sampler=length_sampler,
batch_size=batch_size,
return_prompt=return_prompt,
**generation_kwargs,
)
else:
if len(query_tensor.shape) == 2:
raise ValueError(
"query_tensor must be a tensor of shape (`seq_len`) or a list of tensors of shape (`seq_len`)"
)
if length_sampler is not None:
generation_kwargs["max_new_tokens"] = length_sampler()
response = self.accelerator.unwrap_model(self.model).generate(
input_ids=query_tensor.unsqueeze(dim=0), **generation_kwargs
)
if generate_ref_response:
with self.optional_peft_ctx():
ref_response = ref_model.generate(input_ids=query_tensor.unsqueeze(dim=0), **generation_kwargs)
if not return_prompt and not self.is_encoder_decoder:
response = response[:, query_tensor.shape[0] :]
if generate_ref_response:
ref_response = ref_response[:, query_tensor.shape[0] :]
if generate_ref_response:
return response, ref_response
return response
def _generate_batched(
self,
model: PreTrainedModelWrapper,
query_tensors: List[torch.Tensor],
length_sampler: Optional[Callable] = None,
batch_size: int = 4,
return_prompt: bool = True,
pad_to_multiple_of: Optional[int] = None,
remove_padding: bool = True,
**generation_kwargs,
):
outputs = []
padding_side_default = self.tokenizer.padding_side
if not self.is_encoder_decoder:
self.tokenizer.padding_side = "left"
# in case we have fewer examples than bs
batch_size = min(len(query_tensors), batch_size)
for i in range(0, len(query_tensors), batch_size):
if length_sampler is not None:
generation_kwargs["max_new_tokens"] = length_sampler()
# prevent overflow if query tensors are not even multiple of bs
end_index = min(len(query_tensors), i + batch_size)
batch = query_tensors[i:end_index]
batch_mask = [torch.ones_like(element) for element in batch]
inputs = {"input_ids": batch, "attention_mask": batch_mask}
padded_inputs = self.tokenizer.pad(
inputs,
padding=True,
max_length=None,
pad_to_multiple_of=pad_to_multiple_of,
return_tensors="pt",
).to(self.current_device)
generations = self.accelerator.unwrap_model(model).generate(**padded_inputs, **generation_kwargs)
for generation, mask in zip(generations, padded_inputs["attention_mask"]):
if not self.is_encoder_decoder:
output = generation[(1 - mask).sum() :] # remove padding
else:
output = generation
if not return_prompt and not self.is_encoder_decoder:
output = output[(mask).sum() :] # remove prompt
if remove_padding and self.tokenizer.eos_token_id in output:
pad_mask = output == self.tokenizer.eos_token_id
pad_start = torch.nonzero(pad_mask, as_tuple=False)[0, 0].item()
output = output[: pad_start + 1] # keep the eos token at the end
outputs.append(output)
self.tokenizer.padding_side = padding_side_default
return outputs
def _step_safety_checker(
self,
batch_size: int,
queries: List[torch.LongTensor],
responses: List[torch.LongTensor],
scores: List[torch.FloatTensor],
masks: Optional[List[torch.LongTensor]] = None,
):
"""
Check if the input data is valid for training.
Args:
batch_size (int):
Batch size from the config file.
queries (List[`torch.LongTensor`]):
List of tensors containing the encoded queries of shape (`query_length`)
responses (List[`torch.LongTensor`]):
List of tensors containing the encoded responses of shape (`response_length`)
scores (List[`torch.FloatTensor`]):
List of tensors containing the scores.
masks (List[`torch.LongTensor`], *optional*):
list of optional tensors containing the masks of shape (`query_length` + `response_length`)
Returns:
`tuple`: The input processed data.
"""
for name, tensor_list in zip(["queries", "responses", "scores"], [queries, responses, scores]):
if not isinstance(tensor_list, list):
raise ValueError(f"{name} must be a list of tensors - got {type(tensor_list)}")
if not isinstance(tensor_list[0], torch.Tensor):
raise ValueError(f"Elements in {name} must be tensors - got {type(tensor_list[0])}")
if batch_size is not None and len(tensor_list) != batch_size:
raise ValueError(
f"Batch size ({batch_size}) does not match number of examples - but got {len(tensor_list)} for: {name}"
)
# add queries, scores and responses on the correct device
queries = [tensor.to(self.current_device) for tensor in queries]
responses = [tensor.to(self.current_device) for tensor in responses]
scores = [tensor.to(self.current_device) for tensor in scores]
masks = [tensor.to(self.current_device) for tensor in masks] if masks is not None else None
# squeeze scores if needed
for i, score in enumerate(scores):
if score.dim() > 1:
raise ValueError(f"Scores must be 1-dimensional - got {score.dim()} for {score}")
elif score.dim() == 1:
scores[i] = score.squeeze()
return queries, responses, scores, masks
@PPODecorators.empty_device_cache()
def step(
self,
queries: List[torch.LongTensor],
responses: List[torch.LongTensor],
scores: List[torch.FloatTensor],
response_masks: Optional[List[torch.LongTensor]] = None,
):
"""
Run a PPO optimisation step given a list of queries, model responses, and rewards.
Args:
queries (List[`torch.LongTensor`]):
List of tensors containing the encoded queries of shape (`query_length`)
responses (List[`torch.LongTensor`]):
List of tensors containing the encoded responses of shape (`response_length`)
scores (List[`torch.FloatTensor`]):
List of tensors containing the scores.
response_masks (List[`torch.FloatTensor`], *optional*)):
List of tensors containing masks of the response tokens.
Returns:
`dict[str, Any]`: A summary of the training statistics
"""
bs = self.config.batch_size
queries, responses, scores, response_masks = self._step_safety_checker(
bs, queries, responses, scores, response_masks
)
scores = torch.tensor(scores, device=self.current_device)
if self.config.use_score_scaling:
# Score scaling
scores_mean, scores_std = self.running.update(scores)
tensor_to_kwargs = dict(dtype=scores.dtype, device=scores.device)
score_scaling_factor = self.running.std.to(**tensor_to_kwargs) + torch.finfo(scores.dtype).eps
if self.config.use_score_norm:
scores = (scores - self.running.mean.to(**tensor_to_kwargs)) / score_scaling_factor
else:
scores /= score_scaling_factor
if self.config.score_clip is not None:
# Score clipping
scores_dtype = scores.dtype
scores = torch.clip(scores.float(), -self.config.score_clip, self.config.score_clip).to(dtype=scores_dtype)
# if we want to push best model to the hub
if hasattr(self, "highest_reward"):
if self.compare_step % self.config.compare_steps == 0:
curr_mean_reward = scores.mean()
# if the best reward ever seen
if curr_mean_reward > self.highest_reward:
self.highest_reward = curr_mean_reward
# push model to hub
self.push_to_hub(**self.push_to_hub_kwargs)
self.compare_step += 1
timing = dict()
t0 = time.time()
t = time.time()
model_inputs = self.prepare_model_inputs(queries, responses)
if self.is_distributed:
pad_first = self.tokenizer.padding_side == "left"
model_inputs["input_ids"] = self.accelerator.pad_across_processes(
model_inputs["input_ids"],
dim=1,
pad_index=self.tokenizer.pad_token_id,
pad_first=pad_first,
)
model_inputs["attention_mask"] = self.accelerator.pad_across_processes(
model_inputs["attention_mask"], dim=1, pad_index=0, pad_first=pad_first
)
if self.is_encoder_decoder:
model_inputs["decoder_input_ids"] = self.accelerator.pad_across_processes(
model_inputs["decoder_input_ids"],
dim=1,
pad_index=self.tokenizer.pad_token_id,
pad_first=pad_first,
)
model_inputs["decoder_attention_mask"] = self.accelerator.pad_across_processes(
model_inputs["decoder_attention_mask"],
dim=1,
pad_index=0,
pad_first=pad_first,
)
model_inputs_names = list(model_inputs.keys())
full_kl_penalty = self.config.kl_penalty == "full"
with torch.no_grad():
all_logprobs, logits_or_none, values, masks = self.batched_forward_pass(
self.model,
queries,
responses,
model_inputs,
response_masks=response_masks,
return_logits=full_kl_penalty,
)
with self.optional_peft_ctx():
ref_logprobs, ref_logits_or_none, _, _ = self.batched_forward_pass(
self.model if self.is_peft_model else self.ref_model,
queries,
responses,
model_inputs,
return_logits=full_kl_penalty,
)
timing["time/ppo/forward_pass"] = time.time() - t
with torch.no_grad():
t = time.time()
if full_kl_penalty:
active_full_logprobs = logprobs_from_logits(logits_or_none, None, gather=False)
ref_full_logprobs = logprobs_from_logits(ref_logits_or_none, None, gather=False)
rewards, non_score_reward, kls = self.compute_rewards(
scores, active_full_logprobs, ref_full_logprobs, masks
)
else:
rewards, non_score_reward, kls = self.compute_rewards(scores, all_logprobs, ref_logprobs, masks)
timing["time/ppo/compute_rewards"] = time.time() - t
t = time.time()
values, advantages, returns = self.compute_advantages(values, rewards, masks)
timing["time/ppo/compute_advantages"] = time.time() - t
# upcast to float32 to avoid dataset issues
batch_dict = {
"queries": queries,
"responses": responses,
"logprobs": all_logprobs.to(torch.float32),
"values": values.to(torch.float32),
"masks": masks,
"advantages": advantages,
"returns": returns,
}
batch_dict.update(model_inputs)
t = time.time()
all_stats = []
early_stop = False
for _ in range(self.config.ppo_epochs):
if early_stop:
break
b_inds = np.random.permutation(bs)
for backward_batch_start in range(0, bs, self.config.backward_batch_size):
backward_batch_end = backward_batch_start + self.config.backward_batch_size
backward_batch_inds = b_inds[backward_batch_start:backward_batch_end]
for mini_batch_start in range(0, self.config.backward_batch_size, self.config.mini_batch_size):
mini_batch_end = mini_batch_start + self.config.mini_batch_size
mini_batch_inds = backward_batch_inds[mini_batch_start:mini_batch_end]
mini_batch_dict = {
"logprobs": batch_dict["logprobs"][mini_batch_inds],
"values": batch_dict["values"][mini_batch_inds],
"masks": batch_dict["masks"][mini_batch_inds],
# hacks: the queries and responses are ragged.
"queries": [batch_dict["queries"][i] for i in mini_batch_inds],
"responses": [batch_dict["responses"][i] for i in mini_batch_inds],
"advantages": batch_dict["advantages"][mini_batch_inds],
"returns": batch_dict["returns"][mini_batch_inds],
}
for k in model_inputs_names:
mini_batch_dict[k] = batch_dict[k][mini_batch_inds]
with self.accelerator.accumulate(self.model):
model_inputs = {k: mini_batch_dict[k] for k in model_inputs_names}
logprobs, logits, vpreds, _ = self.batched_forward_pass(
self.model,
mini_batch_dict["queries"],
mini_batch_dict["responses"],
model_inputs,
return_logits=True,
)
train_stats = self.train_minibatch(
mini_batch_dict["logprobs"],
mini_batch_dict["values"],
logprobs,
logits,
vpreds,
mini_batch_dict["masks"],
mini_batch_dict["advantages"],
mini_batch_dict["returns"],
)
all_stats.append(train_stats)
# typically, early stopping is done at the epoch level
if self.config.early_stopping:
policykl = train_stats["policy/policykl"]
early_stop = self._early_stop(policykl)
if early_stop:
break
timing["time/ppo/optimize_step"] = time.time() - t
t = time.time()
train_stats = stack_dicts(all_stats)
# reshape advantages/ratios such that they are not averaged.
train_stats["policy/advantages"] = torch.flatten(train_stats["policy/advantages"]).unsqueeze(0)
train_stats["policy/advantages"] = torch.nan_to_num(train_stats["policy/advantages"], WANDB_PADDING)
train_stats["policy/ratio"] = torch.flatten(train_stats["policy/ratio"]).unsqueeze(0)
stats = self.record_step_stats(
scores=scores,
logprobs=all_logprobs,
ref_logprobs=ref_logprobs,
non_score_reward=non_score_reward,
train_stats=train_stats,
kl_coef=self.kl_ctl.value,
masks=masks,
queries=queries,
responses=responses,
kls=kls,
)
# Gather/Reduce stats from all processes
if self.is_distributed:
stats = self.gather_stats(stats)
stats = stats_to_np(stats)
timing["time/ppo/calc_stats"] = time.time() - t
stats["ppo/learning_rate"] = self.optimizer.param_groups[0]["lr"]
# Update the KL control - multiply the batch_size by the number of processes
self.kl_ctl.update(
stats["objective/kl"],
self.config.batch_size * self.accelerator.num_processes,
)
# Log the total ppo time
timing["time/ppo/total"] = time.time() - t0
stats.update(timing)
# post-process stats for tensorboard and other loggers
if self.config.log_with != "wandb":
stats = convert_to_scalar(stats)
if self.lr_scheduler is not None:
self.lr_scheduler.step()
return stats
def _early_stop(self, policykl):
r"""
Handles the early stopping logic. If the policy KL is greater than the target KL, then the gradient is zeroed and
the optimization step is skipped.
This also handles the multi-gpu case where the policy KL is averaged across all processes.
Args:
policy_kl (torch.Tensor):
the policy KL
Returns:
`bool`: whether to early stop or not
"""
early_stop = False
if not self.config.early_stopping:
return early_stop
if not self.is_distributed and policykl > 1.5 * self.config.target_kl:
self.optimizer.zero_grad()
early_stop = True
elif self.is_distributed:
import torch.distributed as dist
# Wait for all processes to finish
dist.barrier()
# all gather the policykl
dist.all_reduce(policykl, dist.ReduceOp.SUM)
policykl /= self.accelerator.num_processes
if policykl > 1.5 * self.config.target_kl:
self.optimizer.zero_grad()
early_stop = True
return early_stop
def gather_stats(self, stats):
"""
Gather stats from all processes. Useful in the context of distributed training.
Args:
stats (dict[str, Any]):
a dictionary of stats to be gathered. The stats should contain torch tensors.
Returns:
`dict[str, Any]`: A dictionary of stats with the tensors gathered.
"""
import torch.distributed as dist
# Wait for all processes to finish
dist.barrier()
for k, v in stats.items():
if isinstance(v, torch.Tensor):
dist.all_reduce(v.to(self.accelerator.device), dist.ReduceOp.SUM)
v /= self.accelerator.num_processes
stats[k] = v
return stats
def prepare_model_inputs(self, queries: torch.Tensor, responses: torch.Tensor):
if self.is_encoder_decoder:
input_data = self.data_collator(
[{"input_ids": q, "attention_mask": torch.ones_like(q)} for q in queries]
).to(self.current_device)
decoder_inputs = self.data_collator(
[{"input_ids": r, "attention_mask": torch.ones_like(r)} for r in responses]
).to(self.current_device)
input_data["decoder_input_ids"] = decoder_inputs["input_ids"]
input_data["decoder_attention_mask"] = decoder_inputs["attention_mask"]
else:
input_ids = [torch.cat([q, r]) for q, r in zip(queries, responses)]
input_data = self.data_collator(
[{"input_ids": ids, "attention_mask": torch.ones_like(ids)} for ids in input_ids]
).to(self.current_device)
input_data.pop("labels", None) # we don't want to compute LM losses
return input_data
@PPODecorators.empty_device_cache()
def batched_forward_pass(
self,
model: PreTrainedModelWrapper,
queries: torch.Tensor,
responses: torch.Tensor,
model_inputs: dict,
return_logits: bool = False,
response_masks: Optional[torch.Tensor] = None,
):
"""
Calculate model outputs in multiple batches.
Args:
queries (`torch.LongTensor`):
List of tensors containing the encoded queries, shape (`batch_size`, `query_length`)
responses (`torch.LongTensor`):
List of tensors containing the encoded responses, shape (`batch_size`, `response_length`)
return_logits (`bool`, *optional*, defaults to `False`):
Whether to return all_logits. Set to `False` if logits are not needed to reduce memory consumption.
Returns:
(tuple):
- all_logprobs (`torch.FloatTensor`): Log probabilities of the responses,
shape (`batch_size`, `response_length`)
- all_ref_logprobs (`torch.FloatTensor`): Log probabilities of the responses,
shape (`batch_size`, `response_length`)
- all_values (`torch.FloatTensor`): Values of the responses, shape (`batch_size`, `response_length`)
"""
bs = len(queries)
fbs = self.config.mini_batch_size
all_logprobs = []
all_logits = []
all_masks = []
all_values = []
model.eval()
for i in range(math.ceil(bs / fbs)):
input_kwargs = {key: value[i * fbs : (i + 1) * fbs] for key, value in model_inputs.items()}
query_batch = queries[i * fbs : (i + 1) * fbs]
response_batch = responses[i * fbs : (i + 1) * fbs]
if response_masks is not None:
response_masks_batch = response_masks[i * fbs : (i + 1) * fbs]
logits, _, values = model(**input_kwargs)
if self.is_encoder_decoder:
input_ids = input_kwargs["decoder_input_ids"]
attention_mask = input_kwargs["decoder_attention_mask"]
else:
input_ids = input_kwargs["input_ids"]
attention_mask = input_kwargs["attention_mask"]
logprobs = logprobs_from_logits(logits[:, :-1, :], input_ids[:, 1:])
masks = torch.zeros_like(attention_mask)
masks[:, :-1] = attention_mask[:, 1:]
for j in range(len(query_batch)):
if self.is_encoder_decoder:
# Decoder sentence starts always in the index 1 after padding in the Enc-Dec Models
start = 1
end = attention_mask[j, :].sum() - 1
else:
start = len(query_batch[j]) - 1 # logprobs starts from the second query token
if attention_mask[j, 0] == 0: # offset left padding
start += attention_mask[j, :].nonzero()[0]
end = start + len(response_batch[j])
if response_masks is not None:
response_masks_batch[j] = torch.cat(
(torch.zeros_like(query_batch[j]), response_masks_batch[j])
)[1:]
masks[j, :start] = 0
masks[j, end:] = 0
if response_masks is not None:
masks[j, start:end] = masks[j, start:end] * response_masks_batch[j][start:end]
if return_logits:
all_logits.append(logits)
else:
del logits
all_values.append(values)
all_logprobs.append(logprobs)
all_masks.append(masks)
return (
torch.cat(all_logprobs),
torch.cat(all_logits)[:, :-1] if return_logits else None,
torch.cat(all_values)[:, :-1],
torch.cat(all_masks)[:, :-1],
)
@PPODecorators.empty_device_cache()
def train_minibatch(
self,
old_logprobs: torch.FloatTensor,
values: torch.FloatTensor,
logprobs: torch.FloatTensor,
logits: torch.FloatTensor,
vpreds: torch.FloatTensor,
mask: torch.LongTensor,
advantages: torch.FloatTensor,
returns: torch.FloatTensor,
):
"""
Train one PPO minibatch
Args:
logprobs (`torch.FloatTensor`):
Log probabilities of the model, shape [mini_batch_size, response_length]
values (`torch.FloatTensor`):
Values of the value head, shape [mini_batch_size, response_length]
query (`torch.LongTensor`):
Encoded queries, shape [mini_batch_size, query_length]
response (`torch.LongTensor`):
Encoded responses, shape [mini_batch_size, response_length]
model_input (`torch.LongTensor`):
Concatenated queries and responses, shape [mini_batch_size, query_length+response_length]
Returns:
train_stats (dict[str, `torch.Tensor`]):
Dictionary of training statistics
"""
self.model.train()
loss_p, loss_v, train_stats = self.loss(
old_logprobs, values, logits, vpreds, logprobs, mask, advantages, returns
)
loss = loss_p + loss_v
self.accelerator.backward(loss)
if self.config.max_grad_norm is not None:
if self.accelerator.sync_gradients:
self.accelerator.clip_grad_norm_(self.model_params, self.config.max_grad_norm)
self.optimizer.step()
# we call optimizer.zero_grad() every time and let `accelerator` handle accumulation
# see https://huggingface.co/docs/accelerate/usage_guides/gradient_accumulation#the-finished-code
self.optimizer.zero_grad()
return train_stats
def compute_rewards(
self,
scores: torch.FloatTensor,
logprobs: torch.FloatTensor,
ref_logprobs: torch.FloatTensor,
masks: torch.LongTensor,
):
"""
Compute per token rewards from scores and KL-penalty.
Args:
scores (`torch.FloatTensor`):
Scores from the reward model, shape (`batch_size`)
logprobs (`torch.FloatTensor`):
Log probabilities of the model, shape (`batch_size`, `response_length`)
ref_logprobs (`torch.FloatTensor`):
Log probabilities of the reference model, shape (`batch_size`, `response_length`)
Returns:
`torch.FloatTensor`: Per token rewards, shape (`batch_size`, `response_length`)
`torch.FloatTensor`: Non score rewards, shape (`batch_size`, `response_length`)
`torch.FloatTensor`: KL penalty, shape (`batch_size`, `response_length`)
"""
rewards, non_score_rewards, kls = [], [], []
for score, logprob, ref_logprob, mask in zip(scores, logprobs, ref_logprobs, masks):
# compute KL penalty (from difference in logprobs)
kl = self._kl_penalty(logprob, ref_logprob)
kls.append(kl)
non_score_reward = -self.kl_ctl.value * kl
non_score_rewards.append(non_score_reward)
reward = non_score_reward.clone()
last_non_masked_index = mask.nonzero()[-1]
# reward is preference model score + KL penalty
reward[last_non_masked_index] += score
rewards.append(reward)
return torch.stack(rewards), torch.stack(non_score_rewards), torch.stack(kls)
def _kl_penalty(self, logprob: torch.FloatTensor, ref_logprob: torch.FloatTensor) -> torch.FloatTensor:
if self.config.kl_penalty == "kl":
return logprob - ref_logprob
if self.config.kl_penalty == "abs":
return (logprob - ref_logprob).abs()
if self.config.kl_penalty == "mse":
return 0.5 * (logprob - ref_logprob).square()
if self.config.kl_penalty == "full":
# Flip is required due to this issue? :https://github.com/pytorch/pytorch/issues/57459
return F.kl_div(ref_logprob, logprob, log_target=True, reduction="none").sum(-1)
raise NotImplementedError
def compute_advantages(
self,
values: torch.FloatTensor,
rewards: torch.FloatTensor,
mask: torch.FloatTensor,
):
lastgaelam = 0
advantages_reversed = []
gen_len = rewards.shape[-1]
values = values * mask
rewards = rewards * mask
if self.config.whiten_rewards:
rewards = masked_whiten(rewards, mask, shift_mean=False)
for t in reversed(range(gen_len)):
nextvalues = values[:, t + 1] if t < gen_len - 1 else 0.0
delta = rewards[:, t] + self.config.gamma * nextvalues - values[:, t]
lastgaelam = delta + self.config.gamma * self.config.lam * lastgaelam
advantages_reversed.append(lastgaelam)
advantages = torch.stack(advantages_reversed[::-1]).transpose(0, 1)
returns = advantages + values
advantages = masked_whiten(advantages, mask)
advantages = advantages.detach()
return values, advantages, returns
def loss(
self,
old_logprobs: torch.FloatTensor,
values: torch.FloatTensor,
logits: torch.FloatTensor,
vpreds: torch.FloatTensor,
logprobs: torch.FloatTensor,
mask: torch.LongTensor,
advantages: torch.FloatTensor,
returns: torch.FloatTensor,
):
"""
Calculate policy and value losses.
Args:
old_logprobs (`torch.FloatTensor`):
Log probabilities of the model, shape (`batch_size`, `response_length`)
values (`torch.FloatTensor`):
Values of the value head, shape (`batch_size`, `response_length`)
rewards (`torch.FloatTensor`):
Rewards from the reward model, shape (`batch_size`, `response_length`)
logits (`torch.FloatTensor`):
Logits of the model, shape (`batch_size`, `response_length`, `vocab_size`)
v_pred (`torch.FloatTensor`):
Values of the value head, shape (`batch_size`, `response_length`)
logprobs (`torch.FloatTensor`):
Log probabilities of the model, shape (`batch_size`, `response_length`)
"""
vpredclipped = clip_by_value(
vpreds,
values - self.config.cliprange_value,
values + self.config.cliprange_value,
)
vf_losses1 = (vpreds - returns) ** 2
vf_losses2 = (vpredclipped - returns) ** 2
vf_loss = 0.5 * masked_mean(torch.max(vf_losses1, vf_losses2), mask)
vf_clipfrac = masked_mean(torch.gt(vf_losses2, vf_losses1).float(), mask)
ratio = torch.exp(logprobs - old_logprobs)
pg_losses = -advantages * ratio
pg_losses2 = -advantages * torch.clamp(ratio, 1.0 - self.config.cliprange, 1.0 + self.config.cliprange)
pg_loss = masked_mean(torch.max(pg_losses, pg_losses2), mask)
pg_clipfrac = masked_mean(torch.gt(pg_losses2, pg_losses).float(), mask)
loss = pg_loss + self.config.vf_coef * vf_loss
avg_ratio = masked_mean(ratio, mask).item()
if avg_ratio > self.config.ratio_threshold:
warnings.warn(
f"The average ratio of batch ({avg_ratio:.2f}) exceeds threshold {self.config.ratio_threshold:.2f}. Skipping batch."
)
pg_loss = pg_loss * 0.0
vf_loss = vf_loss * 0.0
loss = loss * 0.0
entropy = masked_mean(entropy_from_logits(logits), mask)
approxkl = 0.5 * masked_mean((logprobs - old_logprobs) ** 2, mask)
policykl = masked_mean(old_logprobs - logprobs, mask)
return_mean, return_var = masked_mean(returns, mask), masked_var(returns, mask)
value_mean, value_var = masked_mean(values, mask), masked_var(values, mask)
stats = dict(
loss=dict(policy=pg_loss.detach(), value=vf_loss.detach(), total=loss.detach()),
policy=dict(
entropy=entropy.detach(),
approxkl=approxkl.detach(),
policykl=policykl.detach(),
clipfrac=pg_clipfrac.detach(),
advantages=advantages.detach(),
advantages_mean=masked_mean(advantages, mask).detach(),
ratio=ratio.detach(),
),
returns=dict(mean=return_mean.detach(), var=return_var.detach()),
val=dict(
vpred=masked_mean(vpreds, mask).detach(),
error=masked_mean((vpreds - returns) ** 2, mask).detach(),
clipfrac=vf_clipfrac.detach(),
mean=value_mean.detach(),
var=value_var.detach(),
),
)
return pg_loss, self.config.vf_coef * vf_loss, flatten_dict(stats)
def record_step_stats(self, kl_coef: float, **data):
"""
Record training step statistics.
Args:
kl_coef (`float`):
KL coefficient
data (`dict`):
Dictionary of training step data
Returns:
stats (`dict`):
Dictionary of training step statistics
"""
mask = data.pop("masks")
kls = data.pop("kls")
kl_list = ((kls) * mask).sum(axis=-1)
mean_kl = kl_list.mean()
mean_entropy = (-data["logprobs"] * mask).sum(axis=-1).mean()
mean_non_score_reward = masked_mean(
data["non_score_reward"], mask
) # non_score_reward is size `batch_size`, `response_length`
mean_scores = data["scores"].mean() # scores is size `batch_size`
std_scores = data["scores"].std()
if mean_kl.item() < -1.0:
# warn users
warnings.warn(
f"KL divergence is starting to become negative: {mean_kl.item():.2f} - this might be a precursor for failed training."
" sometimes this happens because the generation kwargs are not correctly set. Please make sure"
" that the generation kwargs are set correctly, or review your training hyperparameters."
)
stats = {
"objective/kl": mean_kl,
"objective/kl_dist": kl_list,
"objective/logprobs": data["logprobs"],
"objective/ref_logprobs": data["ref_logprobs"],
"objective/kl_coef": kl_coef,
"objective/entropy": mean_entropy,
"ppo/mean_non_score_reward": mean_non_score_reward,
"ppo/mean_scores": mean_scores,
"ppo/std_scores": std_scores,
}
# Log text properties
query_lens = torch.tensor([len(query) for query in data["queries"]], dtype=torch.float)
response_lens = torch.tensor([len(response) for response in data["responses"]], dtype=torch.float)
stats["tokens/queries_len_mean"] = torch.mean(query_lens).cpu().numpy().item()
stats["tokens/queries_len_std"] = torch.std(query_lens).cpu().numpy().item()
stats["tokens/queries_dist"] = query_lens.cpu().numpy()
stats["tokens/responses_len_mean"] = torch.mean(response_lens).cpu().numpy().item()
stats["tokens/responses_len_std"] = torch.std(response_lens).cpu().numpy().item()
stats["tokens/responses_dist"] = response_lens.cpu().numpy()
for k, v in data["train_stats"].items():
stats[f"ppo/{k}"] = torch.mean(v, axis=0)
stats["ppo/val/var_explained"] = 1 - stats["ppo/val/error"] / stats["ppo/returns/var"]
return stats
def log_stats(
self,
stats: dict,
batch: dict,
rewards: List[torch.FloatTensor],
columns_to_log: typing.Iterable[str] = ("query", "response"),
):
"""
A function that logs all the training stats. Call it at the end of each epoch.
Args:
stats (dict[str, Any]):
A dictionary of training stats.
batch (dict[str, Any]):
A dictionary of batch data, this contains the queries and responses.
rewards (`List[torch.FloatTensor]`):
A tensor of rewards.
"""
# all gather stats
if not isinstance(rewards, torch.Tensor):
rewards = torch.tensor(rewards).to(self.current_device)
rewards = self.accelerator.gather(rewards).flatten()
if self.config.log_with == "wandb":
import wandb
if any(column_to_log not in batch.keys() for column_to_log in columns_to_log):
raise ValueError(f"Columns to log {columns_to_log} are not present in the batch {batch.keys()}.")
batch_list = [batch[column_to_log] for column_to_log in columns_to_log]
if self.is_distributed:
gathered_batch_list = []
for b in batch_list:
flattened = gather_object(b)
gathered_batch_list.append(flattened)
batch_list = gathered_batch_list
# Log only if we are in the main process
if self.accelerator.is_main_process:
logs = {}
# Log stats
if "query" not in batch.keys() and "response" not in batch.keys():
# warn the user that the game logs will not be logged
warnings.warn(
"The game logs will not be logged because the batch does not contain the keys 'query' and "
"'response'. "
)
elif self.config.log_with == "wandb":
table_rows = [list(r) for r in zip(*batch_list, rewards.cpu().tolist())]
logs.update({"game_log": wandb.Table(columns=[*columns_to_log, "reward"], rows=table_rows)})
logs.update(stats)
# manually cast in fp32 for bf16 torch tensors
for k, v in logs.items():
if isinstance(v, torch.Tensor) and v.dtype == torch.bfloat16:
logs[k] = v.float()
logs["env/reward_mean"] = torch.mean(rewards).cpu().numpy().item()
logs["env/reward_std"] = torch.std(rewards).cpu().numpy().item()
logs["env/reward_dist"] = rewards.cpu().numpy()
if self.config.log_with == "tensorboard":
# update the current step
self.current_step += 1
self.accelerator.log(
logs,
step=self.current_step if self.config.log_with == "tensorboard" else None,
)
def create_model_card(self, path: str, model_name: Optional[str] = "TRL Model") -> None:
"""Creates and saves a model card for a TRL model.
Args:
path (`str`): The path to save the model card to.
model_name (`str`, *optional*): The name of the model, defaults to `TRL Model`.
"""
try:
user = whoami()["name"]
# handle the offline case
except Exception:
warnings.warn("Cannot retrieve user information assuming you are running in offline mode.")
return
if not os.path.exists(path):
os.makedirs(path)
model_card_content = MODEL_CARD_TEMPLATE.format(model_name=model_name, model_id=f"{user}/{path}")
with open(os.path.join(path, "README.md"), "w", encoding="utf-8") as f:
f.write(model_card_content)
def _save_pretrained(self, save_directory: str) -> None:
self.accelerator.unwrap_model(self.model).save_pretrained(save_directory)
self.tokenizer.save_pretrained(save_directory)
self.create_model_card(save_directory)
def _show_tokens(self, tokens, masks):
from rich import print
from rich.text import Text
text = Text()
for _i, (token, mask) in enumerate(zip(tokens, masks)):
if mask == 1:
text.append(self.tokenizer.decode(token.item()), style="black on deep_sky_blue1")
text.append(" ")
else:
text.append(self.tokenizer.decode(token.item()), style="black on cyan3")
text.append(" ")
print(text)
def _prepare_deepspeed(self, model: PreTrainedModelWrapper):
# Adapted from accelerate: https://github.com/huggingface/accelerate/blob/739b135f8367becb67ffaada12fe76e3aa60fefd/src/accelerate/accelerator.py#L1473
deepspeed_plugin = self.accelerator.state.deepspeed_plugin
config_kwargs = deepspeed_plugin.deepspeed_config
if model is not None:
if hasattr(model, "config"):
hidden_size = (
max(model.config.hidden_sizes)
if getattr(model.config, "hidden_sizes", None)
else getattr(model.config, "hidden_size", None)
)
if hidden_size is not None and config_kwargs["zero_optimization"]["stage"] == 3:
# Note that `stage3_prefetch_bucket_size` can produce DeepSpeed messages like: `Invalidate trace cache @ step 0: expected module 1, but got module 0`
# This is expected and is not an error, see: https://github.com/microsoft/DeepSpeed/discussions/4081
config_kwargs.update(
{
"zero_optimization.reduce_bucket_size": hidden_size * hidden_size,
"zero_optimization.stage3_param_persistence_threshold": 10 * hidden_size,
"zero_optimization.stage3_prefetch_bucket_size": 0.9 * hidden_size * hidden_size,
}
)
# If ZeRO-3 is used, we shard both the active and reference model.
# Otherwise, we assume the reference model fits in memory and is initialized on each device with ZeRO disabled (stage 0)
if config_kwargs["zero_optimization"]["stage"] != 3:
config_kwargs["zero_optimization"]["stage"] = 0
model, *_ = deepspeed.initialize(model=model, config=config_kwargs)
model.eval()
return model
| trl/trl/trainer/ppo_trainer.py/0 | {
"file_path": "trl/trl/trainer/ppo_trainer.py",
"repo_id": "trl",
"token_count": 29303
} | 398 |
# Minimal makefile for Sphinx documentation
#
# You can set these variables from the command line.
SPHINXOPTS =
SPHINXBUILD = sphinx-build
SOURCEDIR = source
BUILDDIR = _build
# Put it first so that "make" without argument is like "make help".
help:
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
.PHONY: help Makefile
# Catch-all target: route all unknown targets to Sphinx using the new
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
%: Makefile
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O) | accelerate/docs/Makefile/0 | {
"file_path": "accelerate/docs/Makefile",
"repo_id": "accelerate",
"token_count": 237
} | 0 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Comparing performance between different device setups
Evaluating and comparing the performance from different setups can be quite tricky if you don't know what to look for.
For example, you cannot run the same script with the same batch size across TPU, multi-GPU, and single-GPU with Accelerate
and expect your results to line up.
But why?
There are three reasons for this that this tutorial will cover:
1. **Setting the right seeds**
2. **Observed Batch Sizes**
3. **Learning Rates**
## Setting the Seed
While this issue has not come up as much, make sure to use [`utils.set_seed`] to fully set the seed in all distributed cases so training will be reproducible:
```python
from accelerate.utils import set_seed
set_seed(42)
```
Why is this important? Under the hood this will set **5** different seed settings:
```python
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
# ^^ safe to call this function even if cuda is not available
if is_torch_xla_available():
xm.set_rng_state(seed)
```
The random state, numpy's state, torch, torch's cuda state, and if TPUs are available torch_xla's cuda state.
## Observed Batch Sizes
When training with Accelerate, the batch size passed to the dataloader is the **batch size per GPU**. What this entails is
a batch size of 64 on two GPUs is truly a batch size of 128. As a result, when testing on a single GPU this needs to be accounted for,
as well as similarly for TPUs.
The below table can be used as a quick reference to try out different batch sizes:
<Tip>
In this example, there are two GPUs for "Multi-GPU" and a TPU pod with 8 workers
</Tip>
| Single GPU Batch Size | Multi-GPU Equivalent Batch Size | TPU Equivalent Batch Size |
|-----------------------|---------------------------------|---------------------------|
| 256 | 128 | 32 |
| 128 | 64 | 16 |
| 64 | 32 | 8 |
| 32 | 16 | 4 |
## Learning Rates
As noted in multiple sources[[1](https://aws.amazon.com/blogs/machine-learning/scalable-multi-node-deep-learning-training-using-gpus-in-the-aws-cloud/)][[2](https://docs.nvidia.com/clara/clara-train-sdk/pt/model.html#classification-models-multi-gpu-training)], the learning rate should be scaled *linearly* based on the number of devices present. The below
snippet shows doing so with Accelerate:
<Tip>
Since users can have their own learning rate schedulers defined, we leave this up to the user to decide if they wish to scale their
learning rate or not.
</Tip>
```python
learning_rate = 1e-3
accelerator = Accelerator()
learning_rate *= accelerator.num_processes
optimizer = AdamW(params=model.parameters(), lr=learning_rate)
```
You will also find that `accelerate` will step the learning rate based on the number of processes being trained on. This is because
of the observed batch size noted earlier. So in the case of 2 GPUs, the learning rate will be stepped twice as often as a single GPU
to account for the batch size being twice as large (if no changes to the batch size on the single GPU instance are made).
## Gradient Accumulation and Mixed Precision
When using gradient accumulation and mixed precision, due to how gradient averaging works (accumulation) and the precision loss (mixed precision),
some degradation in performance is expected. This will be explicitly seen when comparing the batch-wise loss between different compute
setups. However, the overall loss, metric, and general performance at the end of training should be _roughly_ the same.
| accelerate/docs/source/concept_guides/performance.md/0 | {
"file_path": "accelerate/docs/source/concept_guides/performance.md",
"repo_id": "accelerate",
"token_count": 1463
} | 1 |
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Wrapper classes for torch Dataloaders, Optimizers, and Schedulers
The internal classes Accelerate uses to prepare objects for distributed training
when calling [`~Accelerator.prepare`].
## Datasets and DataLoaders
[[autodoc]] data_loader.prepare_data_loader
[[autodoc]] data_loader.skip_first_batches
[[autodoc]] data_loader.BatchSamplerShard
[[autodoc]] data_loader.IterableDatasetShard
[[autodoc]] data_loader.DataLoaderShard
[[autodoc]] data_loader.DataLoaderDispatcher
## Optimizers
[[autodoc]] optimizer.AcceleratedOptimizer
## Schedulers
[[autodoc]] scheduler.AcceleratedScheduler | accelerate/docs/source/package_reference/torch_wrappers.md/0 | {
"file_path": "accelerate/docs/source/package_reference/torch_wrappers.md",
"repo_id": "accelerate",
"token_count": 381
} | 2 |
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Accelerated PyTorch Training on Mac
With PyTorch v1.12 release, developers and researchers can take advantage of Apple silicon GPUs for significantly faster model training.
This unlocks the ability to perform machine learning workflows like prototyping and fine-tuning locally, right on Mac.
Apple's Metal Performance Shaders (MPS) as a backend for PyTorch enables this and can be used via the new `"mps"` device.
This will map computational graphs and primitives on the MPS Graph framework and tuned kernels provided by MPS.
For more information please refer official documents [Introducing Accelerated PyTorch Training on Mac](https://pytorch.org/blog/introducing-accelerated-pytorch-training-on-mac/)
and [MPS BACKEND](https://pytorch.org/docs/stable/notes/mps.html).
### Benefits of Training and Inference using Apple Silicon Chips
1. Enables users to train larger networks or batch sizes locally
2. Reduces data retrieval latency and provides the GPU with direct access to the full memory store due to unified memory architecture.
Therefore, improving end-to-end performance.
3. Reduces costs associated with cloud-based development or the need for additional local GPUs.
**Pre-requisites**: To install torch with mps support,
please follow this nice medium article [GPU-Acceleration Comes to PyTorch on M1 Macs](https://medium.com/towards-data-science/gpu-acceleration-comes-to-pytorch-on-m1-macs-195c399efcc1).
## How it works out of the box
It is enabled by default on MacOs machines with MPS enabled Apple Silicon GPUs.
To disable it, pass `--cpu` flag to `accelerate launch` command or answer the corresponding question when answering the `accelerate config` questionnaire.
You can directly run the following script to test it out on MPS enabled Apple Silicon machines:
```bash
accelerate launch /examples/cv_example.py --data_dir images
```
## A few caveats to be aware of
1. We strongly recommend to install PyTorch >= 1.13 (nightly version at the time of writing) on your MacOS machine.
It has major fixes related to model correctness and performance improvements for transformer based models.
Please refer to https://github.com/pytorch/pytorch/issues/82707 for more details.
2. Distributed setups `gloo` and `nccl` are not working with `mps` device.
This means that currently only single GPU of `mps` device type can be used.
Finally, please, remember that, 🤗 `Accelerate` only integrates MPS backend, therefore if you
have any problems or questions with regards to MPS backend usage, please, file an issue with [PyTorch GitHub](https://github.com/pytorch/pytorch/issues). | accelerate/docs/source/usage_guides/mps.md/0 | {
"file_path": "accelerate/docs/source/usage_guides/mps.md",
"repo_id": "accelerate",
"token_count": 861
} | 3 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import random
from pathlib import Path
from typing import List
import numpy as np
import torch
from safetensors.torch import load_file
from torch.cuda.amp import GradScaler
from .utils import (
MODEL_NAME,
OPTIMIZER_NAME,
RNG_STATE_NAME,
SAFE_MODEL_NAME,
SAFE_WEIGHTS_NAME,
SAMPLER_NAME,
SCALER_NAME,
SCHEDULER_NAME,
WEIGHTS_NAME,
get_pretty_name,
is_torch_xla_available,
is_xpu_available,
save,
)
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
from .logging import get_logger
from .state import PartialState
logger = get_logger(__name__)
def save_accelerator_state(
output_dir: str,
model_states: List[dict],
optimizers: list,
schedulers: list,
dataloaders: list,
process_index: int,
scaler: GradScaler = None,
save_on_each_node: bool = False,
safe_serialization: bool = True,
):
"""
Saves the current states of the models, optimizers, scaler, and RNG generators to a given directory.
<Tip>
If `safe_serialization` is `True`, models will be saved with `safetensors` while the rest are saved using native
`pickle`.
</Tip>
Args:
output_dir (`str` or `os.PathLike`):
The name of the folder to save all relevant weights and states.
model_states (`List[torch.nn.Module]`):
A list of model states
optimizers (`List[torch.optim.Optimizer]`):
A list of optimizer instances
schedulers (`List[torch.optim.lr_scheduler._LRScheduler]`):
A list of learning rate schedulers
dataloaders (`List[torch.utils.data.DataLoader]`):
A list of dataloader instances to save their sampler states
process_index (`int`):
The current process index in the Accelerator state
scaler (`torch.cuda.amp.GradScaler`, *optional*):
An optional gradient scaler instance to save
save_on_each_node (`bool`, *optional*):
Whether to save on every node, or only the main node.
safe_serialization (`bool`, *optional*, defaults to `True`):
Whether to save the model using `safetensors` or the traditional PyTorch way (that uses `pickle`).
"""
output_dir = Path(output_dir)
# Model states
for i, state in enumerate(model_states):
weights_name = WEIGHTS_NAME if not safe_serialization else SAFE_WEIGHTS_NAME
if i > 0:
weights_name = weights_name.replace(".", f"_{i}.")
output_model_file = output_dir.joinpath(weights_name)
save(state, output_model_file, save_on_each_node=save_on_each_node, safe_serialization=safe_serialization)
logger.info(f"Model weights saved in {output_model_file}")
# Optimizer states
for i, opt in enumerate(optimizers):
state = opt.state_dict()
optimizer_name = f"{OPTIMIZER_NAME}.bin" if i == 0 else f"{OPTIMIZER_NAME}_{i}.bin"
output_optimizer_file = output_dir.joinpath(optimizer_name)
save(state, output_optimizer_file, save_on_each_node=save_on_each_node, safe_serialization=False)
logger.info(f"Optimizer state saved in {output_optimizer_file}")
# Scheduler states
for i, scheduler in enumerate(schedulers):
state = scheduler.state_dict()
scheduler_name = f"{SCHEDULER_NAME}.bin" if i == 0 else f"{SCHEDULER_NAME}_{i}.bin"
output_scheduler_file = output_dir.joinpath(scheduler_name)
save(state, output_scheduler_file, save_on_each_node=save_on_each_node, safe_serialization=False)
logger.info(f"Scheduler state saved in {output_scheduler_file}")
# DataLoader states
for i, dataloader in enumerate(dataloaders):
sampler_name = f"{SAMPLER_NAME}.bin" if i == 0 else f"{SAMPLER_NAME}_{i}.bin"
output_sampler_file = output_dir.joinpath(sampler_name)
# Only save if we have our custom sampler
from .data_loader import IterableDatasetShard, SeedableRandomSampler
if isinstance(dataloader.dataset, IterableDatasetShard):
sampler = dataloader.sampler.sampler
if isinstance(sampler, SeedableRandomSampler):
save(sampler, output_sampler_file, save_on_each_node=save_on_each_node, safe_serialization=False)
logger.info(f"Sampler state for dataloader {i} saved in {output_sampler_file}")
# GradScaler state
if scaler is not None:
state = scaler.state_dict()
output_scaler_file = output_dir.joinpath(SCALER_NAME)
torch.save(state, output_scaler_file)
logger.info(f"Gradient scaler state saved in {output_scaler_file}")
# Random number generator states
states = {}
states_name = f"{RNG_STATE_NAME}_{process_index}.pkl"
states["random_state"] = random.getstate()
states["numpy_random_seed"] = np.random.get_state()
states["torch_manual_seed"] = torch.get_rng_state()
if is_xpu_available():
states["torch_xpu_manual_seed"] = torch.xpu.get_rng_state_all()
else:
states["torch_cuda_manual_seed"] = torch.cuda.get_rng_state_all()
if is_torch_xla_available():
states["xm_seed"] = xm.get_rng_state()
output_states_file = output_dir.joinpath(states_name)
torch.save(states, output_states_file)
logger.info(f"Random states saved in {output_states_file}")
return output_dir
def load_accelerator_state(
input_dir,
models,
optimizers,
schedulers,
dataloaders,
process_index,
scaler=None,
map_location=None,
**load_model_func_kwargs,
):
"""
Loads states of the models, optimizers, scaler, and RNG generators from a given directory.
Args:
input_dir (`str` or `os.PathLike`):
The name of the folder to load all relevant weights and states.
models (`List[torch.nn.Module]`):
A list of model instances
optimizers (`List[torch.optim.Optimizer]`):
A list of optimizer instances
schedulers (`List[torch.optim.lr_scheduler._LRScheduler]`):
A list of learning rate schedulers
process_index (`int`):
The current process index in the Accelerator state
scaler (`torch.cuda.amp.GradScaler`, *optional*):
An optional *GradScaler* instance to load
map_location (`str`, *optional*):
What device to load the optimizer state onto. Should be one of either "cpu" or "on_device".
load_model_func_kwargs (`dict`, *optional*):
Additional arguments that can be passed to the model's `load_state_dict` method.
"""
if map_location not in [None, "cpu", "on_device"]:
raise TypeError(
"Unsupported optimizer map location passed, please choose one of `None`, `'cpu'`, or `'on_device'`"
)
if map_location is None:
map_location = "cpu"
elif map_location == "on_device":
map_location = PartialState().device
input_dir = Path(input_dir)
# Model states
for i, model in enumerate(models):
ending = f"_{i}" if i > 0 else ""
input_model_file = input_dir.joinpath(f"{SAFE_MODEL_NAME}{ending}.safetensors")
if input_model_file.exists():
state_dict = load_file(input_model_file, device=str(map_location))
else:
# Load with torch
input_model_file = input_dir.joinpath(f"{MODEL_NAME}{ending}.bin")
state_dict = torch.load(input_model_file, map_location=map_location)
models[i].load_state_dict(state_dict, **load_model_func_kwargs)
logger.info("All model weights loaded successfully")
# Optimizer states
for i, opt in enumerate(optimizers):
optimizer_name = f"{OPTIMIZER_NAME}.bin" if i == 0 else f"{OPTIMIZER_NAME}_{i}.bin"
input_optimizer_file = input_dir.joinpath(optimizer_name)
optimizer_state = torch.load(input_optimizer_file, map_location=map_location)
optimizers[i].load_state_dict(optimizer_state)
logger.info("All optimizer states loaded successfully")
# Scheduler states
for i, scheduler in enumerate(schedulers):
scheduler_name = f"{SCHEDULER_NAME}.bin" if i == 0 else f"{SCHEDULER_NAME}_{i}.bin"
input_scheduler_file = input_dir.joinpath(scheduler_name)
scheduler.load_state_dict(torch.load(input_scheduler_file))
logger.info("All scheduler states loaded successfully")
for i, dataloader in enumerate(dataloaders):
sampler_name = f"{SAMPLER_NAME}.bin" if i == 0 else f"{SAMPLER_NAME}_{i}.bin"
input_sampler_file = input_dir.joinpath(sampler_name)
# Only load if we have our custom sampler
from .data_loader import IterableDatasetShard, SeedableRandomSampler
if isinstance(dataloader.dataset, IterableDatasetShard):
sampler = dataloader.sampler.sampler
if isinstance(sampler, SeedableRandomSampler):
dataloader.sampler.sampler = torch.load(input_sampler_file)
logger.info("All dataloader sampler states loaded successfully")
# GradScaler state
if scaler is not None:
input_scaler_file = input_dir.joinpath(SCALER_NAME)
scaler.load_state_dict(torch.load(input_scaler_file))
logger.info("GradScaler state loaded successfully")
# Random states
try:
states = torch.load(input_dir.joinpath(f"{RNG_STATE_NAME}_{process_index}.pkl"))
random.setstate(states["random_state"])
np.random.set_state(states["numpy_random_seed"])
torch.set_rng_state(states["torch_manual_seed"])
if is_xpu_available():
torch.xpu.set_rng_state_all(states["torch_xpu_manual_seed"])
else:
torch.cuda.set_rng_state_all(states["torch_cuda_manual_seed"])
if is_torch_xla_available():
xm.set_rng_state(states["xm_seed"])
logger.info("All random states loaded successfully")
except Exception:
logger.info("Could not load random states")
def save_custom_state(obj, path, index: int = 0, save_on_each_node: bool = False):
"""
Saves the state of `obj` to `{path}/custom_checkpoint_{index}.pkl`
"""
# Should this be the right way to get a qual_name type value from `obj`?
save_location = Path(path) / f"custom_checkpoint_{index}.pkl"
logger.info(f"Saving the state of {get_pretty_name(obj)} to {save_location}")
save(obj.state_dict(), save_location, save_on_each_node=save_on_each_node)
def load_custom_state(obj, path, index: int = 0):
"""
Loads the state of `obj` at `{path}/custom_checkpoint_{index}.pkl`
"""
load_location = f"{path}/custom_checkpoint_{index}.pkl"
logger.info(f"Loading the state of {get_pretty_name(obj)} from {load_location}")
obj.load_state_dict(torch.load(load_location, map_location="cpu"))
| accelerate/src/accelerate/checkpointing.py/0 | {
"file_path": "accelerate/src/accelerate/checkpointing.py",
"repo_id": "accelerate",
"token_count": 4647
} | 4 |
# Copyright 2022 The HuggingFace Team and Brian Chao. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
A variety of helper functions and constants when dealing with terminal menu choices, based on
https://github.com/bchao1/bullet
"""
import enum
import shutil
import sys
TERMINAL_WIDTH, _ = shutil.get_terminal_size()
CURSOR_TO_CHAR = {"UP": "A", "DOWN": "B", "RIGHT": "C", "LEFT": "D"}
class Direction(enum.Enum):
UP = 0
DOWN = 1
def forceWrite(content, end=""):
sys.stdout.write(str(content) + end)
sys.stdout.flush()
def writeColor(content, color, end=""):
forceWrite(f"\u001b[{color}m{content}\u001b[0m", end)
def reset_cursor():
forceWrite("\r")
def move_cursor(num_lines: int, direction: str):
forceWrite(f"\033[{num_lines}{CURSOR_TO_CHAR[direction.upper()]}")
def clear_line():
forceWrite(" " * TERMINAL_WIDTH)
reset_cursor()
def linebreak():
reset_cursor()
forceWrite("-" * TERMINAL_WIDTH)
| accelerate/src/accelerate/commands/menu/helpers.py/0 | {
"file_path": "accelerate/src/accelerate/commands/menu/helpers.py",
"repo_id": "accelerate",
"token_count": 505
} | 5 |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from __future__ import annotations
import logging
import math
import os
import threading
import warnings
from contextlib import contextmanager
from functools import partial
from typing import Any, Callable, Optional
import torch
from .utils import (
DistributedType,
DynamoBackend,
GradientAccumulationPlugin,
check_cuda_p2p_ib_support,
check_fp8_capability,
get_ccl_version,
get_int_from_env,
is_ccl_available,
is_datasets_available,
is_deepspeed_available,
is_fp8_available,
is_ipex_available,
is_mlu_available,
is_mps_available,
is_npu_available,
is_pynvml_available,
is_torch_xla_available,
is_xpu_available,
parse_choice_from_env,
parse_flag_from_env,
)
from .utils.dataclasses import SageMakerDistributedType
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
if is_mlu_available(check_device=False):
import torch_mlu # noqa: F401
if is_npu_available(check_device=False):
import torch_npu # noqa: F401
if is_pynvml_available():
import pynvml as nvml
logger = logging.getLogger(__name__)
def is_initialized() -> bool:
"""
Checks if the `AcceleratorState` has been initialized from `Accelerator`. Same as `AcceleratorState.initialized`,
but works as a module method.
"""
return AcceleratorState._shared_state != {}
# Lambda function that does nothing
def do_nothing(*args, **kwargs):
return None
class ThreadLocalSharedDict(threading.local):
"""
Descriptor that holds a dict shared between instances of a class in the same thread.
Note: Descriptors have slightly different semantics than just a dict field on its own.
`PartialState(...)._shared_state` and `PartialState._shared_state` (instance vs class) give the same value: the
underlying _storage dict. Likewise, `PartialState(...)._shared_state = {...}` overrides the _storage dict inside
the descriptor as you would expect. However, `PartialState._shared_state = {}` actually replaces the descriptor
object with a dict instead Thus, you should modify the _storage dict in-place (e.g. `_shared_state.clear()`).
See Python documentation for an explanation of descriptors: https://docs.python.org/3/howto/descriptor.html
This is required for using PyTorch/XLA with PJRT in multithreaded mode (required for TPU v2 and v3).
See https://github.com/pytorch/xla/blob/r2.0/docs/pjrt.md#multithreading-on-tpu-v2v3
"""
def __init__(self, thread_local: bool = False):
self._storage = {}
def __get__(self, obj, objtype=None):
return self._storage
def __set__(self, obj, value):
self._storage = value
# Prefer global shared dictionary, except when using TPU.
SharedDict = dict if not is_torch_xla_available() else ThreadLocalSharedDict
# Inspired by Alex Martelli's 'Borg'.
class PartialState:
"""
Singleton class that has information about the current training environment and functions to help with process
control. Designed to be used when only process control and device execution states are needed. Does *not* need to
be initialized from `Accelerator`.
**Available attributes:**
- **device** (`torch.device`) -- The device to use.
- **distributed_type** ([`~accelerate.state.DistributedType`]) -- The type of distributed environment currently
in use.
- **local_process_index** (`int`) -- The index of the current process on the current server.
- **mixed_precision** (`str`) -- Whether or not the current script will use mixed precision, and if so the type
of mixed precision being performed. (Choose from 'no','fp16','bf16 or 'fp8').
- **num_processes** (`int`) -- The number of processes currently launched in parallel.
- **process_index** (`int`) -- The index of the current process.
- **is_last_process** (`bool`) -- Whether or not the current process is the last one.
- **is_main_process** (`bool`) -- Whether or not the current process is the main one.
- **is_local_main_process** (`bool`) -- Whether or not the current process is the main one on the local node.
- **debug** (`bool`) -- Whether or not the current script is being run in debug mode.
"""
_shared_state = SharedDict()
def __init__(self, cpu: bool = False, **kwargs):
self.__dict__ = self._shared_state
if not self.initialized:
self._cpu = cpu
self.backend = None
env_device = os.environ.get("ACCELERATE_TORCH_DEVICE", None)
self.device = torch.device(env_device) if env_device is not None else None
self.debug = parse_flag_from_env("ACCELERATE_DEBUG_MODE")
use_sagemaker_dp = kwargs.pop("_use_sagemaker_dp", None)
if use_sagemaker_dp is None:
use_sagemaker_dp = (
os.environ.get("ACCELERATE_USE_SAGEMAKER", "false") == "true"
and os.environ.get("ACCELERATE_SAGEMAKER_DISTRIBUTED_TYPE") != SageMakerDistributedType.NO
)
if use_sagemaker_dp and not cpu:
if (
os.environ.get("ACCELERATE_SAGEMAKER_DISTRIBUTED_TYPE") == SageMakerDistributedType.DATA_PARALLEL
) or use_sagemaker_dp:
self.distributed_type = DistributedType.MULTI_GPU
import smdistributed.dataparallel.torch.torch_smddp # noqa
if not torch.distributed.is_initialized():
torch.distributed.init_process_group(backend="smddp")
self.backend = "smddp"
self.num_processes = torch.distributed.get_world_size()
self.process_index = torch.distributed.get_rank()
self.local_process_index = int(os.environ.get("LOCAL_RANK", -1))
if self.device is None:
self.device = torch.device("cuda", self.local_process_index)
torch.cuda.set_device(self.device)
elif is_torch_xla_available() and not cpu:
self.distributed_type = DistributedType.XLA
self.device = xm.xla_device()
xm.set_replication(self.device, xm.get_xla_supported_devices())
self.num_processes = xm.xrt_world_size()
self.process_index = xm.get_ordinal()
if is_torch_xla_available(check_is_tpu=True):
self.local_process_index = xm.get_local_ordinal()
else:
self.local_process_index = int(os.environ.get("LOCAL_RANK", -1))
elif (
os.environ.get("ACCELERATE_USE_DEEPSPEED", "false") == "true"
and int(os.environ.get("LOCAL_RANK", -1)) != -1
and not cpu
):
assert (
is_deepspeed_available()
), "DeepSpeed is not available => install it using `pip3 install deepspeed` or build it from source"
self.distributed_type = DistributedType.DEEPSPEED
if not torch.distributed.is_initialized():
from deepspeed import comm as dist
# DeepSpeed always uses nccl
kwargs.pop("backend", None)
if is_xpu_available and is_ccl_available():
# Set DeepSpeed backend to ccl for xpu
self.backend = "ccl"
os.environ["CCL_PROCESS_LAUNCHER"] = "none"
os.environ["CCL_LOCAL_SIZE"] = os.environ.get("LOCAL_WORLD_SIZE", "1")
os.environ["CCL_LOCAL_RANK"] = os.environ.get("LOCAL_RANK", "0")
elif is_mlu_available():
self.backend = "cncl"
elif is_npu_available():
self.backend = "hccl"
else:
self.backend = "nccl"
dist.init_distributed(dist_backend=self.backend, auto_mpi_discovery=False, **kwargs)
self.num_processes = torch.distributed.get_world_size()
self.process_index = torch.distributed.get_rank()
self.local_process_index = int(os.environ.get("LOCAL_RANK", -1))
if self.device is None:
if is_xpu_available():
self.device = torch.device("xpu", self.local_process_index)
if self.device is not None:
torch.xpu.set_device(self.device)
elif is_mlu_available():
self.device = torch.device("mlu", self.local_process_index)
if self.device is not None:
torch.mlu.set_device(self.device)
elif is_npu_available():
self.device = torch.device("npu", self.local_process_index)
if self.device is not None:
torch.npu.set_device(self.device)
else:
self.device = torch.device("cuda", self.local_process_index)
if self.device is not None:
torch.cuda.set_device(self.device)
if self.device.type == "cuda" and not check_cuda_p2p_ib_support():
if "NCCL_P2P_DISABLE" not in os.environ or "NCCL_IB_DISABLE" not in os.environ:
raise NotImplementedError(
"Using RTX 4000 series doesn't support faster communication broadband via P2P or IB. "
'Please set `NCCL_P2P_DISABLE="1"` and `NCCL_IB_DISABLE="1" or use `accelerate launch` which '
"will do this automatically."
)
self._mixed_precision = "no" # deepspeed handles mixed_precision using deepspeed_config
elif is_mlu_available() and not cpu and int(os.environ.get("LOCAL_RANK", -1)) != -1:
self.distributed_type = DistributedType.MULTI_MLU
if not torch.distributed.is_initialized():
# Backend is not set by the user, we set it here
kwargs.pop("backend", None)
self.backend = "cncl"
torch.distributed.init_process_group(backend=self.backend, **kwargs)
self.num_processes = torch.distributed.get_world_size()
self.process_index = torch.distributed.get_rank()
self.local_process_index = int(os.environ.get("LOCAL_RANK", -1))
if self.device is None:
self.device = torch.device("mlu", self.local_process_index)
torch.mlu.set_device(self.device)
elif int(os.environ.get("LOCAL_RANK", -1)) != -1 and not cpu and torch.cuda.is_available():
self.distributed_type = DistributedType.MULTI_GPU
if not torch.distributed.is_initialized():
self.backend = kwargs.pop("backend", "nccl")
# Special case for `TrainingArguments`, where `backend` will be `None`
if self.backend is None:
self.backend = "nccl"
torch.distributed.init_process_group(backend=self.backend, **kwargs)
if not check_cuda_p2p_ib_support():
if "NCCL_P2P_DISABLE" not in os.environ or "NCCL_IB_DISABLE" not in os.environ:
raise NotImplementedError(
"Using RTX 4000 series doesn't support faster communication broadband via P2P or IB. "
'Please set `NCCL_P2P_DISABLE="1"` and `NCCL_IB_DISABLE="1" or use `accelerate launch` which '
"will do this automatically."
)
self.num_processes = torch.distributed.get_world_size()
self.process_index = torch.distributed.get_rank()
self.local_process_index = int(os.environ.get("LOCAL_RANK", -1))
if self.device is None:
self.device = torch.device("cuda", self.local_process_index)
torch.cuda.set_device(self.device)
elif is_npu_available() and not cpu and int(os.environ.get("LOCAL_RANK", -1)) != -1:
self.distributed_type = DistributedType.MULTI_NPU
if not torch.distributed.is_initialized():
# Backend is not set by the user, we set it here
kwargs.pop("backend", None)
self.backend = "hccl"
torch.distributed.init_process_group(backend=self.backend, **kwargs)
self.num_processes = torch.distributed.get_world_size()
self.process_index = torch.distributed.get_rank()
self.local_process_index = int(os.environ.get("LOCAL_RANK", -1))
if self.device is None:
self.device = torch.device("npu", self.local_process_index)
torch.npu.set_device(self.device)
elif (
get_int_from_env(["PMI_SIZE", "OMPI_COMM_WORLD_SIZE", "MV2_COMM_WORLD_SIZE", "WORLD_SIZE"], 1) > 1
or int(os.environ.get("LOCAL_RANK", -1)) != -1
):
if not cpu and is_xpu_available():
self.distributed_type = DistributedType.MULTI_XPU
else:
self.distributed_type = DistributedType.MULTI_CPU
# Actually, CCL_WORKER_COUNT is a CPU only env var in CCL, no need to set it for XPU.
if is_ccl_available() and (
get_int_from_env(["CCL_WORKER_COUNT"], 0) > 0 or self.distributed_type == DistributedType.MULTI_XPU
):
if get_ccl_version() >= "1.12":
import oneccl_bindings_for_pytorch # noqa: F401
else:
import torch_ccl # noqa: F401
backend = "ccl"
elif torch.distributed.is_mpi_available():
backend = "mpi"
else:
backend = "gloo"
# Try to get launch configuration from environment variables set by MPI launcher - works for Intel MPI, OpenMPI and MVAPICH
rank = get_int_from_env(["RANK", "PMI_RANK", "OMPI_COMM_WORLD_RANK", "MV2_COMM_WORLD_RANK"], 0)
size = get_int_from_env(["WORLD_SIZE", "PMI_SIZE", "OMPI_COMM_WORLD_SIZE", "MV2_COMM_WORLD_SIZE"], 1)
local_rank = get_int_from_env(
["LOCAL_RANK", "MPI_LOCALRANKID", "OMPI_COMM_WORLD_LOCAL_RANK", "MV2_COMM_WORLD_LOCAL_RANK"], 0
)
local_size = get_int_from_env(
["LOCAL_WORLD_SIZE", "MPI_LOCALNRANKS", "OMPI_COMM_WORLD_LOCAL_SIZE", "MV2_COMM_WORLD_LOCAL_SIZE"],
1,
)
self.local_process_index = local_rank
os.environ["RANK"] = str(rank)
os.environ["WORLD_SIZE"] = str(size)
os.environ["LOCAL_RANK"] = str(local_rank)
os.environ["LOCAL_WORLD_SIZE"] = str(local_size)
if backend == "ccl" and self.distributed_type == DistributedType.MULTI_XPU:
os.environ["CCL_PROCESS_LAUNCHER"] = "none"
os.environ["CCL_LOCAL_SIZE"] = str(local_size)
os.environ["CCL_LOCAL_RANK"] = str(local_rank)
if not os.environ.get("MASTER_PORT", None):
os.environ["MASTER_PORT"] = "29500"
if not os.environ.get("MASTER_ADDR", None):
if local_size != size and backend != "mpi":
raise ValueError(
"Looks like distributed multinode run but MASTER_ADDR env not set, "
"please try exporting rank 0's hostname as MASTER_ADDR"
)
if (
self.distributed_type == DistributedType.MULTI_CPU
and get_int_from_env(["OMP_NUM_THREADS", "MKL_NUM_THREADS"], 0) == 0
):
import psutil
num_cpu_threads_per_process = int(psutil.cpu_count(logical=False) / local_size)
if num_cpu_threads_per_process == 0:
num_cpu_threads_per_process = 1
torch.set_num_threads(num_cpu_threads_per_process)
warnings.warn(
f"OMP_NUM_THREADS/MKL_NUM_THREADS unset, we set it at {num_cpu_threads_per_process} to improve oob"
" performance."
)
if not torch.distributed.is_initialized():
# Backend is not set by the user, we set it here
kwargs.pop("backend", None)
self.backend = backend
torch.distributed.init_process_group(self.backend, rank=rank, world_size=size, **kwargs)
self.num_processes = torch.distributed.get_world_size()
self.process_index = torch.distributed.get_rank()
if cpu:
self.device = torch.device("cpu")
elif is_xpu_available():
self.device = torch.device("xpu", self.local_process_index)
torch.xpu.set_device(self.device)
else:
self.device = self.default_device
else:
self.distributed_type = (
DistributedType.NO
if os.environ.get("ACCELERATE_USE_DEEPSPEED", "false") == "false"
else DistributedType.DEEPSPEED
)
self.num_processes = 1
self.process_index = self.local_process_index = 0
if self.device is None:
self.device = torch.device("cpu") if cpu else self.default_device
self.fork_launched = parse_flag_from_env("FORK_LAUNCHED", 0)
# Set CPU affinity if enabled
if parse_flag_from_env("ACCELERATE_CPU_AFFINITY", False):
# Eventually follow syntax here and update for other backends
if self.device.type == "cuda":
if not is_pynvml_available():
raise ImportError("To set CPU affinity on CUDA GPUs the pynvml package must be installed.")
# The below code is based on https://github.com/NVIDIA/DeepLearningExamples/blob/master/TensorFlow2/LanguageModeling/BERT/gpu_affinity.py
nvml.nvmlInit()
num_elements = math.ceil(os.cpu_count() / 64)
handle = nvml.nvmlDeviceGetHandleByIndex(self.local_process_index)
affinity_string = ""
for j in nvml.nvmlDeviceGetCpuAffinity(handle, num_elements):
# assume nvml returns list of 64 bit ints
affinity_string = f"{j:064b}{affinity_string}"
affinity_list = [int(x) for x in affinity_string]
affinity_list.reverse() # so core 0 is the 0th element
affinity_to_set = [i for i, e in enumerate(affinity_list) if e != 0]
os.sched_setaffinity(0, affinity_to_set)
def __repr__(self) -> str:
return (
f"Distributed environment: {self.distributed_type}{(' Backend: ' + self.backend) if self.backend else ''}\n"
f"Num processes: {self.num_processes}\n"
f"Process index: {self.process_index}\n"
f"Local process index: {self.local_process_index}\n"
f"Device: {self.device}\n"
)
@staticmethod
def _reset_state():
"Resets `_shared_state`, is used internally and should not be called"
PartialState._shared_state.clear()
@property
def initialized(self) -> bool:
"Returns whether the `PartialState` has been initialized"
return self._shared_state != {}
@property
def use_distributed(self):
"""
Whether the Accelerator is configured for distributed training
"""
return self.distributed_type != DistributedType.NO and self.num_processes > 1
@property
def is_last_process(self) -> bool:
"Returns whether the current process is the last one"
return self.process_index == self.num_processes - 1
@property
def is_main_process(self) -> bool:
"Returns whether the current process is the main process"
return (
self.process_index == 0 if self.distributed_type != DistributedType.MEGATRON_LM else self.is_last_process
)
@property
def is_local_main_process(self) -> bool:
"Returns whether the current process is the main process on the local node"
return (
self.local_process_index == 0
if self.distributed_type != DistributedType.MEGATRON_LM
else self.is_last_process
)
def wait_for_everyone(self):
"""
Will stop the execution of the current process until every other process has reached that point (so this does
nothing when the script is only run in one process). Useful to do before saving a model.
Example:
```python
>>> # Assuming two GPU processes
>>> import time
>>> from accelerate.state import PartialState
>>> state = PartialState()
>>> if state.is_main_process:
... time.sleep(2)
>>> else:
... print("I'm waiting for the main process to finish its sleep...")
>>> state.wait_for_everyone()
>>> # Should print on every process at the same time
>>> print("Everyone is here")
```
"""
if self.distributed_type in (
DistributedType.MULTI_GPU,
DistributedType.MULTI_MLU,
DistributedType.MULTI_NPU,
DistributedType.MULTI_XPU,
DistributedType.MULTI_CPU,
DistributedType.DEEPSPEED,
DistributedType.FSDP,
):
torch.distributed.barrier()
elif self.distributed_type == DistributedType.XLA:
xm.rendezvous("accelerate.utils.wait_for_everyone")
def _goes_first(self, is_main: bool):
if not is_main:
self.wait_for_everyone()
yield
if is_main:
self.wait_for_everyone()
@contextmanager
def split_between_processes(self, inputs: list | tuple | dict | torch.Tensor, apply_padding: bool = False):
"""
Splits `input` between `self.num_processes` quickly and can be then used on that process. Useful when doing
distributed inference, such as with different prompts.
Note that when using a `dict`, all keys need to have the same number of elements.
Args:
inputs (`list`, `tuple`, `torch.Tensor`, `dict` of `list`/`tuple`/`torch.Tensor`, or `datasets.Dataset`):
The input to split between processes.
apply_padding (`bool`, `optional`, defaults to `False`):
Whether to apply padding by repeating the last element of the input so that all processes have the same
number of elements. Useful when trying to perform actions such as `gather()` on the outputs or passing
in less inputs than there are processes. If so, just remember to drop the padded elements afterwards.
Example:
```python
# Assume there are two processes
from accelerate import PartialState
state = PartialState()
with state.split_between_processes(["A", "B", "C"]) as inputs:
print(inputs)
# Process 0
["A", "B"]
# Process 1
["C"]
with state.split_between_processes(["A", "B", "C"], apply_padding=True) as inputs:
print(inputs)
# Process 0
["A", "B"]
# Process 1
["C", "C"]
```
"""
if self.num_processes == 1:
yield inputs
return
length = len(inputs)
# Nested dictionary of any types
if isinstance(inputs, dict):
length = len(inputs[list(inputs.keys())[0]])
if not all(len(v) == length for v in inputs.values()):
raise ValueError("All values in the dictionary must have the same length")
num_samples_per_process = math.ceil(length / self.num_processes)
start_index = self.process_index * num_samples_per_process
end_index = start_index + num_samples_per_process
if (len(inputs) % self.num_processes != 0) and (self.process_index == self.num_processes - 1):
end_index = length
def _split_values(inputs, start_index, end_index):
if isinstance(inputs, (list, tuple, torch.Tensor)):
if start_index >= len(inputs):
result = inputs[-1:]
else:
result = inputs[start_index:end_index]
if apply_padding:
if isinstance(result, torch.Tensor):
from accelerate.utils import pad_across_processes, send_to_device
# The tensor needs to be on the device before we can pad it
tensorized_result = send_to_device(result, self.device)
result = pad_across_processes(tensorized_result, pad_index=inputs[-1])
else:
result += [result[-1]] * (num_samples_per_process - len(result))
return result
elif isinstance(inputs, dict):
for key in inputs.keys():
inputs[key] = _split_values(inputs[key], start_index, end_index)
return inputs
else:
if is_datasets_available():
from datasets import Dataset
if isinstance(inputs, Dataset):
if start_index >= len(inputs):
start_index = len(inputs) - 1
if end_index > len(inputs):
end_index = len(inputs)
result_idcs = list(range(start_index, end_index))
if apply_padding:
result_idcs += [end_index - 1] * (num_samples_per_process - len(result_idcs))
return inputs.select(result_idcs)
return inputs
yield _split_values(inputs, start_index, end_index)
@contextmanager
def main_process_first(self):
"""
Lets the main process go first inside a with block.
The other processes will enter the with block after the main process exits.
Example:
```python
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
>>> with accelerator.main_process_first():
... # This will be printed first by process 0 then in a seemingly
... # random order by the other processes.
... print(f"This will be printed by process {accelerator.process_index}")
```
"""
yield from self._goes_first(self.is_main_process)
@contextmanager
def local_main_process_first(self):
"""
Lets the local main process go inside a with block.
The other processes will enter the with block after the main process exits.
Example:
```python
>>> from accelerate.state import PartialState
>>> state = PartialState()
>>> with state.local_main_process_first():
... # This will be printed first by local process 0 then in a seemingly
... # random order by the other processes.
... print(f"This will be printed by process {state.local_process_index}")
```
"""
yield from self._goes_first(self.is_local_main_process)
def on_main_process(self, function: Callable[..., Any] = None):
"""
Decorator that only runs the decorated function on the main process.
Args:
function (`Callable`): The function to decorate.
Example:
```python
>>> from accelerate.state import PartialState
>>> state = PartialState()
>>> @state.on_main_process
... def print_something():
... print("This will be printed by process 0 only.")
>>> print_something()
"This will be printed by process 0 only"
```
"""
if not self.initialized:
raise ValueError("The `PartialState` or `Accelerator` must be initialized before calling this function.")
if self.is_main_process or not self.use_distributed:
return function
return do_nothing
def on_local_main_process(self, function: Callable[..., Any] = None):
"""
Decorator that only runs the decorated function on the local main process.
Args:
function (`Callable`): The function to decorate.
Example:
```python
# Assume we have 2 servers with 4 processes each.
from accelerate.state import PartialState
state = PartialState()
@state.on_local_main_process
def print_something():
print("This will be printed by process 0 only on each server.")
print_something()
# On server 1:
"This will be printed by process 0 only"
# On server 2:
"This will be printed by process 0 only"
```
"""
if self.is_local_main_process or not self.use_distributed:
return function
return do_nothing
def on_last_process(self, function: Callable[..., Any]):
"""
Decorator that only runs the decorated function on the last process.
Args:
function (`Callable`): The function to decorate.
Example:
```python
# Assume we have 4 processes.
from accelerate.state import PartialState
state = PartialState()
@state.on_last_process
def print_something():
print(f"Printed on process {state.process_index}")
print_something()
"Printed on process 3"
```
"""
if self.is_last_process or not self.use_distributed:
return function
return do_nothing
def on_process(self, function: Callable[..., Any] = None, process_index: int = None):
"""
Decorator that only runs the decorated function on the process with the given index.
Args:
function (`Callable`, `optional`):
The function to decorate.
process_index (`int`, `optional`):
The index of the process on which to run the function.
Example:
```python
# Assume we have 4 processes.
from accelerate.state import PartialState
state = PartialState()
@state.on_process(process_index=2)
def print_something():
print(f"Printed on process {state.process_index}")
print_something()
"Printed on process 2"
```
"""
if function is None:
return partial(self.on_process, process_index=process_index)
if (self.process_index == process_index) or (not self.use_distributed):
return function
return do_nothing
def on_local_process(self, function: Callable[..., Any] = None, local_process_index: int = None):
"""
Decorator that only runs the decorated function on the process with the given index on the current node.
Args:
function (`Callable`, *optional*):
The function to decorate.
local_process_index (`int`, *optional*):
The index of the local process on which to run the function.
Example:
```python
# Assume we have 2 servers with 4 processes each.
from accelerate import Accelerator
accelerator = Accelerator()
@accelerator.on_local_process(local_process_index=2)
def print_something():
print(f"Printed on process {accelerator.local_process_index}")
print_something()
# On server 1:
"Printed on process 2"
# On server 2:
"Printed on process 2"
```
"""
if function is None:
return partial(self.on_local_process, local_process_index=local_process_index)
if (self.local_process_index == local_process_index) or (not self.use_distributed):
return function
return do_nothing
def print(self, *args, **kwargs):
if self.is_local_main_process:
print(*args, **kwargs)
@property
def default_device(self) -> torch.device:
"""
Returns the default device which is:
- MPS if `torch.backends.mps.is_available()` and `torch.backends.mps.is_built()` both return True.
- CUDA if `torch.cuda.is_available()`
- MLU if `is_mlu_available()`
- NPU if `is_npu_available()`
- CPU otherwise
"""
if is_mps_available():
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
return torch.device("mps")
elif is_mlu_available():
return torch.device("mlu")
elif torch.cuda.is_available():
return torch.device("cuda")
elif is_xpu_available():
return torch.device("xpu:0")
elif is_npu_available():
return torch.device("npu")
else:
return torch.device("cpu")
class AcceleratorState:
"""
Singleton class that has information about the current training environment.
**Available attributes:**
- **device** (`torch.device`) -- The device to use.
- **distributed_type** ([`~accelerate.state.DistributedType`]) -- The type of distributed environment currently
in use.
- **initialized** (`bool`) -- Whether or not the `AcceleratorState` has been initialized from `Accelerator`.
- **local_process_index** (`int`) -- The index of the current process on the current server.
- **mixed_precision** (`str`) -- Whether or not the current script will use mixed precision, and if so the type
of mixed precision being performed. (Choose from 'no','fp16','bf16 or 'fp8').
- **num_processes** (`int`) -- The number of processes currently launched in parallel.
- **process_index** (`int`) -- The index of the current process.
- **is_last_process** (`bool`) -- Whether or not the current process is the last one.
- **is_main_process** (`bool`) -- Whether or not the current process is the main one.
- **is_local_main_process** (`bool`) -- Whether or not the current process is the main one on the local node.
- **debug** (`bool`) -- Whether or not the current script is being run in debug mode.
"""
_shared_state = SharedDict()
def __init__(
self,
mixed_precision: str = None,
cpu: bool = False,
dynamo_plugin=None,
deepspeed_plugin=None,
fsdp_plugin=None,
megatron_lm_plugin=None,
_from_accelerator: bool = False,
**kwargs,
):
self.__dict__ = self._shared_state
if parse_flag_from_env("ACCELERATE_USE_CPU"):
cpu = True
if PartialState._shared_state == {}:
PartialState(cpu, **kwargs)
self.__dict__.update(PartialState._shared_state)
self._check_initialized(mixed_precision, cpu)
if not self.initialized:
self.deepspeed_plugin = None
self.use_ipex = None
mixed_precision = (
parse_choice_from_env("ACCELERATE_MIXED_PRECISION", "no")
if mixed_precision is None
else mixed_precision.lower()
)
if mixed_precision == "fp8":
if not is_fp8_available():
raise ValueError(
"Using `fp8` precision requires `transformer_engine` or `MS-AMP` to be installed."
)
elif not check_fp8_capability():
logger.warning(
f"The current device has compute capability of {torch.cuda.get_device_capability()} which is "
"insufficient for FP8 mixed precision training (requires a GPU Hopper/Ada Lovelace "
"or higher, compute capability of 8.9 or higher). Will use FP16 instead."
)
mixed_precision = "fp16"
self.dynamo_plugin = dynamo_plugin
if not _from_accelerator:
raise ValueError(
"Please make sure to properly initialize your accelerator via `accelerator = Accelerator()` "
"before using any functionality from the `accelerate` library."
)
# deepspeed handles mixed_precision using deepspeed_config
self._mixed_precision = "no" if self.distributed_type == DistributedType.DEEPSPEED else mixed_precision
if self.distributed_type == DistributedType.XLA and is_torch_xla_available(check_is_tpu=True):
if mixed_precision == "bf16":
if os.environ.get("ACCELERATE_DOWNCAST_BF16"):
os.environ["XLA_USE_BF16"] = str(0)
os.environ["XLA_DOWNCAST_BF16"] = str(1)
self.downcast_bfloat = True
else:
os.environ["XLA_USE_BF16"] = str(1)
os.environ["XLA_DOWNCAST_BF16"] = str(0)
self.downcast_bfloat = False
elif os.environ.get("ACCELERATE_USE_DEEPSPEED", "false") == "true" and not cpu:
self.deepspeed_plugin = deepspeed_plugin
elif self.distributed_type in [DistributedType.MULTI_GPU, DistributedType.MULTI_MLU]:
if os.environ.get("ACCELERATE_USE_FSDP", "false") == "true":
self.distributed_type = DistributedType.FSDP
if self._mixed_precision != "no":
fsdp_plugin.set_mixed_precision(self._mixed_precision)
self.fsdp_plugin = fsdp_plugin
if os.environ.get("ACCELERATE_USE_MEGATRON_LM", "false") == "true":
self.distributed_type = DistributedType.MEGATRON_LM
megatron_lm_plugin.set_mixed_precision(self._mixed_precision)
self.megatron_lm_plugin = megatron_lm_plugin
elif self.distributed_type == DistributedType.MULTI_NPU:
if os.environ.get("ACCELERATE_USE_FSDP", "false") == "true":
self.distributed_type = DistributedType.FSDP
if self._mixed_precision != "no":
fsdp_plugin.set_mixed_precision(self._mixed_precision)
self.fsdp_plugin = fsdp_plugin
elif self.distributed_type in [DistributedType.MULTI_CPU, DistributedType.MULTI_XPU, DistributedType.NO]:
if is_ipex_available():
"check if user disables it explicitly"
self.use_ipex = parse_flag_from_env("ACCELERATE_USE_IPEX", default=True)
else:
self.use_ipex = False
if self.distributed_type == DistributedType.MULTI_XPU:
if os.environ.get("ACCELERATE_USE_FSDP", "false") == "true":
self.distributed_type = DistributedType.FSDP
if self._mixed_precision != "no":
fsdp_plugin.set_mixed_precision(self._mixed_precision)
self.fsdp_plugin = fsdp_plugin
if (
self.dynamo_plugin.backend != DynamoBackend.NO
and self._mixed_precision == "no"
and self.device.type == "cuda"
):
torch.backends.cuda.matmul.allow_tf32 = True
PartialState._shared_state["distributed_type"] = self.distributed_type
@property
def initialized(self) -> bool:
return self._shared_state != PartialState._shared_state
def __repr__(self):
repr = PartialState().__repr__() + f"\nMixed precision type: {self.mixed_precision}\n"
if self.distributed_type == DistributedType.DEEPSPEED:
repr += f"ds_config: {self.deepspeed_plugin.deepspeed_config}\n"
return repr
def _check_initialized(self, mixed_precision=None, cpu=None):
"Checks if a modification is trying to be made and the `AcceleratorState` has already been initialized"
if self.initialized:
err = "AcceleratorState has already been initialized and cannot be changed, restart your runtime completely and pass `{flag}` to `Accelerator()`."
if cpu and self.device.type != "cpu":
raise ValueError(err.format(flag="cpu=True"))
if (
mixed_precision is not None
and mixed_precision != self._mixed_precision
and self.distributed_type != DistributedType.DEEPSPEED
):
raise ValueError(err.format(flag=f"mixed_precision='{mixed_precision}'"))
# For backward compatibility
@property
def use_fp16(self):
warnings.warn(
"The `use_fp16` property is deprecated and will be removed in version 1.0 of Accelerate use "
"`AcceleratorState.mixed_precision == 'fp16'` instead.",
FutureWarning,
)
return self._mixed_precision != "no"
@property
def mixed_precision(self):
if self.distributed_type == DistributedType.DEEPSPEED:
config = self.deepspeed_plugin.deepspeed_config
if config.get("fp16", {}).get("enabled", False):
mixed_precision = "fp16"
elif config.get("bf16", {}).get("enabled", False):
mixed_precision = "bf16"
else:
mixed_precision = "no"
else:
mixed_precision = self._mixed_precision
return mixed_precision
@staticmethod
def _reset_state(reset_partial_state: bool = False):
"Resets `_shared_state`, is used internally and should not be called"
AcceleratorState._shared_state.clear()
if reset_partial_state:
PartialState._reset_state()
@property
def use_distributed(self):
"""
Whether the Accelerator is configured for distributed training
"""
return PartialState().use_distributed
@property
def is_last_process(self) -> bool:
"Returns whether the current process is the last one"
return PartialState().is_last_process
@property
def is_main_process(self) -> bool:
"Returns whether the current process is the main process"
return PartialState().is_main_process
@property
def is_local_main_process(self) -> bool:
"Returns whether the current process is the main process on the local node"
return PartialState().is_local_main_process
def wait_for_everyone(self):
PartialState().wait_for_everyone()
@contextmanager
def split_between_processes(self, inputs: list | tuple | dict | torch.Tensor, apply_padding: bool = False):
"""
Splits `input` between `self.num_processes` quickly and can be then used on that process. Useful when doing
distributed inference, such as with different prompts.
Note that when using a `dict`, all keys need to have the same number of elements.
Args:
inputs (`list`, `tuple`, `torch.Tensor`, or `dict` of `list`/`tuple`/`torch.Tensor`):
The input to split between processes.
apply_padding (`bool`, `optional`, defaults to `False`):
Whether to apply padding by repeating the last element of the input so that all processes have the same
number of elements. Useful when trying to perform actions such as `gather()` on the outputs or passing
in less inputs than there are processes. If so, just remember to drop the padded elements afterwards.
Example:
```python
# Assume there are two processes
from accelerate.state import AcceleratorState
state = AcceleratorState()
with state.split_between_processes(["A", "B", "C"]) as inputs:
print(inputs)
# Process 0
["A", "B"]
# Process 1
["C"]
with state.split_between_processes(["A", "B", "C"], apply_padding=True) as inputs:
print(inputs)
# Process 0
["A", "B"]
# Process 1
["C", "C"]
```
"""
with PartialState().split_between_processes(inputs, apply_padding=apply_padding) as inputs:
yield inputs
@contextmanager
def main_process_first(self):
"""
Lets the main process go first inside a with block.
The other processes will enter the with block after the main process exits.
"""
with PartialState().main_process_first():
yield
@contextmanager
def local_main_process_first(self):
"""
Lets the local main process go inside a with block.
The other processes will enter the with block after the main process exits.
"""
with PartialState().local_main_process_first():
yield
def print(self, *args, **kwargs):
PartialState().print(*args, **kwargs)
class GradientState:
"""
Singleton class that has information related to gradient synchronization for gradient accumulation
**Available attributes:**
- **end_of_dataloader** (`bool`) -- Whether we have reached the end the current dataloader
- **remainder** (`int`) -- The number of extra samples that were added from padding the dataloader
- **sync_gradients** (`bool`) -- Whether the gradients should be synced across all devices
- **active_dataloader** (`Optional[DataLoader]`) -- The dataloader that is currently being iterated over
- **dataloader_references** (`List[Optional[DataLoader]]`) -- A list of references to the dataloaders that are
being iterated over
- **num_steps** (`int`) -- The number of steps to accumulate over
- **adjust_scheduler** (`bool`) -- Whether the scheduler should be adjusted to account for the gradient
accumulation
- **sync_with_dataloader** (`bool`) -- Whether the gradients should be synced at the end of the dataloader
iteration and the number of total steps reset
- **is_xla_gradients_synced** (`bool`) -- Whether the XLA gradients have been synchronized. It is initialized
as false. Once gradients have been reduced before the optimizer step, this flag is set to true. Subsequently,
after each step, the flag is reset to false. FSDP will always synchronize the gradients, hence
is_xla_gradients_synced is always true.
"""
_shared_state = SharedDict()
def __init__(self, gradient_accumulation_plugin: Optional[GradientAccumulationPlugin] = None):
self.__dict__ = self._shared_state
if not self.initialized:
self.sync_gradients = True
self.active_dataloader = None
self.dataloader_references = [None]
self.plugin_kwargs = (
gradient_accumulation_plugin.to_kwargs() if gradient_accumulation_plugin is not None else {}
)
self._is_xla_gradients_synced = False
# Plugin args are different and can be updated
if gradient_accumulation_plugin is not None and self.plugin_kwargs != gradient_accumulation_plugin.to_kwargs():
self.plugin_kwargs = gradient_accumulation_plugin.to_kwargs()
@property
def num_steps(self) -> int:
"Returns the number of steps to accumulate over"
return self.plugin_kwargs.get("num_steps", 1)
@property
def adjust_scheduler(self) -> bool:
"Returns whether the scheduler should be adjusted"
return self.plugin_kwargs.get("adjust_scheduler", False)
@property
def sync_with_dataloader(self) -> bool:
"Returns whether the gradients should be synced at the end of the dataloader iteration and the number of total steps reset"
return self.plugin_kwargs.get("sync_with_dataloader", True)
@property
def initialized(self) -> bool:
"Returns whether the `GradientState` has been initialized"
return GradientState._shared_state != {}
@property
def end_of_dataloader(self) -> bool:
"Returns whether we have reached the end of the current dataloader"
if not self.in_dataloader:
return False
return self.active_dataloader.end_of_dataloader
@property
def remainder(self) -> int:
"Returns the number of extra samples that were added from padding the dataloader"
if not self.in_dataloader:
return -1
return self.active_dataloader.remainder
def __repr__(self):
return (
f"Sync Gradients: {self.sync_gradients}\n"
f"At end of current dataloader: {self.end_of_dataloader}\n"
f"Extra samples added: {self.remainder}\n"
f"Gradient accumulation plugin: {self.plugin_kwargs}\n"
)
@property
def is_xla_gradients_synced(self):
"Returns the value of is_xla_gradients_synced. FSDP will always synchronize the gradients, hence is_xla_gradients_synced is always true."
if parse_flag_from_env("ACCELERATE_USE_FSDP", default=False):
return True
return self._is_xla_gradients_synced
@is_xla_gradients_synced.setter
def is_xla_gradients_synced(self, is_synced):
"Set the _is_xla_gradients_synced attribute."
self._is_xla_gradients_synced = is_synced
def _set_sync_gradients(self, sync_gradients):
"Private function that sets whether gradients should be synchronized. Users should not have to call this."
self.sync_gradients = sync_gradients
# Allow grad-sync to automatically work on TPUs
if (
self.sync_gradients
and is_torch_xla_available(check_is_tpu=True)
and PartialState().distributed_type == DistributedType.XLA
):
xm.mark_step()
def _add_dataloader(self, dataloader):
"Private function that adds a dataloader to `self.dataloader_references` and sets `in_dataloader` to `True`. Users should not have to call this."
self.active_dataloader = dataloader
self.dataloader_references.append(self.active_dataloader)
def _remove_dataloader(self, dataloader):
"Private function that removes a dataloader from `self.dataloader_references` and sets `in_dataloader` to `False` if there are no more dataloaders. Users should not have to call this."
self.dataloader_references.remove(dataloader)
self.active_dataloader = self.dataloader_references[-1]
@property
def in_dataloader(self) -> bool:
"Returns whether the current process is in a dataloader"
return self.active_dataloader is not None
@staticmethod
def _reset_state():
"Resets `_shared_state`, is used internally and should not be called"
GradientState._shared_state.clear()
| accelerate/src/accelerate/state.py/0 | {
"file_path": "accelerate/src/accelerate/state.py",
"repo_id": "accelerate",
"token_count": 23959
} | 6 |
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import asyncio
import inspect
import os
import shutil
import subprocess
import sys
import tempfile
import unittest
from contextlib import contextmanager
from functools import partial
from pathlib import Path
from typing import List, Union
from unittest import mock
import torch
import accelerate
from ..state import AcceleratorState, PartialState
from ..utils import (
gather,
is_bnb_available,
is_clearml_available,
is_comet_ml_available,
is_cuda_available,
is_datasets_available,
is_deepspeed_available,
is_dvclive_available,
is_mlu_available,
is_mps_available,
is_npu_available,
is_pandas_available,
is_pippy_available,
is_tensorboard_available,
is_timm_available,
is_torch_version,
is_torch_xla_available,
is_transformers_available,
is_wandb_available,
is_xpu_available,
str_to_bool,
)
def get_backend():
if is_torch_xla_available():
return "xla", torch.cuda.device_count(), torch.cuda.memory_allocated
elif is_cuda_available():
return "cuda", torch.cuda.device_count(), torch.cuda.memory_allocated
elif is_mps_available():
return "mps", 1, torch.mps.current_allocated_memory()
elif is_mlu_available():
return "mlu", torch.mlu.device_count(), torch.mlu.memory_allocated
elif is_npu_available():
return "npu", torch.npu.device_count(), torch.npu.memory_allocated
elif is_xpu_available():
return "xpu", torch.xpu.device_count(), torch.xpu.memory_allocated
else:
return "cpu", 1, 0
torch_device, device_count, memory_allocated_func = get_backend()
def get_launch_command(**kwargs) -> list:
"""
Wraps around `kwargs` to help simplify launching from `subprocess`.
Example:
```python
# returns ['accelerate', 'launch', '--num_processes=2', '--device_count=2']
get_launch_command(num_processes=2, device_count=2)
```
"""
command = ["accelerate", "launch"]
for k, v in kwargs.items():
if isinstance(v, bool) and v:
command.append(f"--{k}")
elif v is not None:
command.append(f"--{k}={v}")
return command
DEFAULT_LAUNCH_COMMAND = get_launch_command(num_processes=device_count)
def parse_flag_from_env(key, default=False):
try:
value = os.environ[key]
except KeyError:
# KEY isn't set, default to `default`.
_value = default
else:
# KEY is set, convert it to True or False.
try:
_value = str_to_bool(value)
except ValueError:
# More values are supported, but let's keep the message simple.
raise ValueError(f"If set, {key} must be yes or no.")
return _value
_run_slow_tests = parse_flag_from_env("RUN_SLOW", default=False)
def skip(test_case):
"Decorator that skips a test unconditionally"
return unittest.skip("Test was skipped")(test_case)
def slow(test_case):
"""
Decorator marking a test as slow. Slow tests are skipped by default. Set the RUN_SLOW environment variable to a
truthy value to run them.
"""
return unittest.skipUnless(_run_slow_tests, "test is slow")(test_case)
def require_cpu(test_case):
"""
Decorator marking a test that must be only ran on the CPU. These tests are skipped when a GPU is available.
"""
return unittest.skipUnless(torch_device == "cpu", "test requires only a CPU")(test_case)
def require_non_cpu(test_case):
"""
Decorator marking a test that requires a hardware accelerator backend. These tests are skipped when there are no
hardware accelerator available.
"""
return unittest.skipUnless(torch_device != "cpu", "test requires a GPU")(test_case)
def require_cuda(test_case):
"""
Decorator marking a test that requires CUDA. These tests are skipped when there are no GPU available or when
TorchXLA is available.
"""
return unittest.skipUnless(is_cuda_available() and not is_torch_xla_available(), "test requires a GPU")(test_case)
def require_xpu(test_case):
"""
Decorator marking a test that requires XPU. These tests are skipped when there are no XPU available.
"""
return unittest.skipUnless(is_xpu_available(), "test requires a XPU")(test_case)
def require_non_xpu(test_case):
"""
Decorator marking a test that should be skipped for XPU.
"""
return unittest.skipUnless(torch_device != "xpu", "test requires a non-XPU")(test_case)
def require_mlu(test_case):
"""
Decorator marking a test that requires MLU. These tests are skipped when there are no MLU available.
"""
return unittest.skipUnless(is_mlu_available(), "test require a MLU")(test_case)
def require_npu(test_case):
"""
Decorator marking a test that requires NPU. These tests are skipped when there are no NPU available.
"""
return unittest.skipUnless(is_npu_available(), "test require a NPU")(test_case)
def require_mps(test_case):
"""
Decorator marking a test that requires MPS backend. These tests are skipped when torch doesn't support `mps`
backend.
"""
return unittest.skipUnless(is_mps_available(), "test requires a `mps` backend support in `torch`")(test_case)
def require_huggingface_suite(test_case):
"""
Decorator marking a test that requires transformers and datasets. These tests are skipped when they are not.
"""
return unittest.skipUnless(
is_transformers_available() and is_datasets_available(),
"test requires the Hugging Face suite",
)(test_case)
def require_transformers(test_case):
"""
Decorator marking a test that requires transformers. These tests are skipped when they are not.
"""
return unittest.skipUnless(is_transformers_available(), "test requires the transformers library")(test_case)
def require_timm(test_case):
"""
Decorator marking a test that requires transformers. These tests are skipped when they are not.
"""
return unittest.skipUnless(is_timm_available(), "test requires the timm library")(test_case)
def require_bnb(test_case):
"""
Decorator marking a test that requires bitsandbytes. These tests are skipped when they are not.
"""
return unittest.skipUnless(is_bnb_available(), "test requires the bitsandbytes library")(test_case)
def require_tpu(test_case):
"""
Decorator marking a test that requires TPUs. These tests are skipped when there are no TPUs available.
"""
return unittest.skipUnless(is_torch_xla_available(check_is_tpu=True), "test requires TPU")(test_case)
def require_non_torch_xla(test_case):
"""
Decorator marking a test as requiring an environment without TorchXLA. These tests are skipped when TorchXLA is
available.
"""
return unittest.skipUnless(not is_torch_xla_available(), "test requires an env without TorchXLA")(test_case)
def require_single_device(test_case):
"""
Decorator marking a test that requires a single device. These tests are skipped when there is no hardware
accelerator available or number of devices is more than one.
"""
return unittest.skipUnless(torch_device != "cpu" and device_count == 1, "test requires a hardware accelerator")(
test_case
)
def require_single_gpu(test_case):
"""
Decorator marking a test that requires CUDA on a single GPU. These tests are skipped when there are no GPU
available or number of GPUs is more than one.
"""
return unittest.skipUnless(torch.cuda.device_count() == 1, "test requires a GPU")(test_case)
def require_single_xpu(test_case):
"""
Decorator marking a test that requires CUDA on a single XPU. These tests are skipped when there are no XPU
available or number of xPUs is more than one.
"""
return unittest.skipUnless(torch.xpu.device_count() == 1, "test requires a XPU")(test_case)
def require_multi_device(test_case):
"""
Decorator marking a test that requires a multi-device setup. These tests are skipped on a machine without multiple
devices.
"""
return unittest.skipUnless(device_count > 1, "test requires multiple hardware accelerators")(test_case)
def require_multi_gpu(test_case):
"""
Decorator marking a test that requires a multi-GPU setup. These tests are skipped on a machine without multiple
GPUs.
"""
return unittest.skipUnless(torch.cuda.device_count() > 1, "test requires multiple GPUs")(test_case)
def require_multi_xpu(test_case):
"""
Decorator marking a test that requires a multi-XPU setup. These tests are skipped on a machine without multiple
XPUs.
"""
return unittest.skipUnless(torch.xpu.device_count() > 1, "test requires multiple XPUs")(test_case)
def require_deepspeed(test_case):
"""
Decorator marking a test that requires DeepSpeed installed. These tests are skipped when DeepSpeed isn't installed
"""
return unittest.skipUnless(is_deepspeed_available(), "test requires DeepSpeed")(test_case)
def require_fsdp(test_case):
"""
Decorator marking a test that requires FSDP installed. These tests are skipped when FSDP isn't installed
"""
return unittest.skipUnless(is_torch_version(">=", "1.12.0"), "test requires torch version >= 1.12.0")(test_case)
def require_torch_min_version(test_case=None, version=None):
"""
Decorator marking that a test requires a particular torch version to be tested. These tests are skipped when an
installed torch version is less than the required one.
"""
if test_case is None:
return partial(require_torch_min_version, version=version)
return unittest.skipUnless(is_torch_version(">=", version), f"test requires torch version >= {version}")(test_case)
def require_tensorboard(test_case):
"""
Decorator marking a test that requires tensorboard installed. These tests are skipped when tensorboard isn't
installed
"""
return unittest.skipUnless(is_tensorboard_available(), "test requires Tensorboard")(test_case)
def require_wandb(test_case):
"""
Decorator marking a test that requires wandb installed. These tests are skipped when wandb isn't installed
"""
return unittest.skipUnless(is_wandb_available(), "test requires wandb")(test_case)
def require_comet_ml(test_case):
"""
Decorator marking a test that requires comet_ml installed. These tests are skipped when comet_ml isn't installed
"""
return unittest.skipUnless(is_comet_ml_available(), "test requires comet_ml")(test_case)
def require_clearml(test_case):
"""
Decorator marking a test that requires clearml installed. These tests are skipped when clearml isn't installed
"""
return unittest.skipUnless(is_clearml_available(), "test requires clearml")(test_case)
def require_dvclive(test_case):
"""
Decorator marking a test that requires dvclive installed. These tests are skipped when dvclive isn't installed
"""
return unittest.skipUnless(is_dvclive_available(), "test requires dvclive")(test_case)
def require_pandas(test_case):
"""
Decorator marking a test that requires pandas installed. These tests are skipped when pandas isn't installed
"""
return unittest.skipUnless(is_pandas_available(), "test requires pandas")(test_case)
def require_pippy(test_case):
"""
Decorator marking a test that requires pippy installed. These tests are skipped when pippy isn't installed
"""
return unittest.skipUnless(is_pippy_available(), "test requires pippy")(test_case)
_atleast_one_tracker_available = (
any([is_wandb_available(), is_tensorboard_available()]) and not is_comet_ml_available()
)
def require_trackers(test_case):
"""
Decorator marking that a test requires at least one tracking library installed. These tests are skipped when none
are installed
"""
return unittest.skipUnless(
_atleast_one_tracker_available,
"test requires at least one tracker to be available and for `comet_ml` to not be installed",
)(test_case)
class TempDirTestCase(unittest.TestCase):
"""
A TestCase class that keeps a single `tempfile.TemporaryDirectory` open for the duration of the class, wipes its
data at the start of a test, and then destroyes it at the end of the TestCase.
Useful for when a class or API requires a single constant folder throughout it's use, such as Weights and Biases
The temporary directory location will be stored in `self.tmpdir`
"""
clear_on_setup = True
@classmethod
def setUpClass(cls):
"Creates a `tempfile.TemporaryDirectory` and stores it in `cls.tmpdir`"
cls.tmpdir = Path(tempfile.mkdtemp())
@classmethod
def tearDownClass(cls):
"Remove `cls.tmpdir` after test suite has finished"
if os.path.exists(cls.tmpdir):
shutil.rmtree(cls.tmpdir)
def setUp(self):
"Destroy all contents in `self.tmpdir`, but not `self.tmpdir`"
if self.clear_on_setup:
for path in self.tmpdir.glob("**/*"):
if path.is_file():
path.unlink()
elif path.is_dir():
shutil.rmtree(path)
class AccelerateTestCase(unittest.TestCase):
"""
A TestCase class that will reset the accelerator state at the end of every test. Every test that checks or utilizes
the `AcceleratorState` class should inherit from this to avoid silent failures due to state being shared between
tests.
"""
def tearDown(self):
super().tearDown()
# Reset the state of the AcceleratorState singleton.
AcceleratorState._reset_state()
PartialState._reset_state()
class MockingTestCase(unittest.TestCase):
"""
A TestCase class designed to dynamically add various mockers that should be used in every test, mimicking the
behavior of a class-wide mock when defining one normally will not do.
Useful when a mock requires specific information available only initialized after `TestCase.setUpClass`, such as
setting an environment variable with that information.
The `add_mocks` function should be ran at the end of a `TestCase`'s `setUp` function, after a call to
`super().setUp()` such as:
```python
def setUp(self):
super().setUp()
mocks = mock.patch.dict(os.environ, {"SOME_ENV_VAR", "SOME_VALUE"})
self.add_mocks(mocks)
```
"""
def add_mocks(self, mocks: Union[mock.Mock, List[mock.Mock]]):
"""
Add custom mocks for tests that should be repeated on each test. Should be called during
`MockingTestCase.setUp`, after `super().setUp()`.
Args:
mocks (`mock.Mock` or list of `mock.Mock`):
Mocks that should be added to the `TestCase` after `TestCase.setUpClass` has been run
"""
self.mocks = mocks if isinstance(mocks, (tuple, list)) else [mocks]
for m in self.mocks:
m.start()
self.addCleanup(m.stop)
def are_the_same_tensors(tensor):
state = AcceleratorState()
tensor = tensor[None].clone().to(state.device)
tensors = gather(tensor).cpu()
tensor = tensor[0].cpu()
for i in range(tensors.shape[0]):
if not torch.equal(tensors[i], tensor):
return False
return True
class _RunOutput:
def __init__(self, returncode, stdout, stderr):
self.returncode = returncode
self.stdout = stdout
self.stderr = stderr
async def _read_stream(stream, callback):
while True:
line = await stream.readline()
if line:
callback(line)
else:
break
async def _stream_subprocess(cmd, env=None, stdin=None, timeout=None, quiet=False, echo=False) -> _RunOutput:
if echo:
print("\nRunning: ", " ".join(cmd))
p = await asyncio.create_subprocess_exec(
cmd[0],
*cmd[1:],
stdin=stdin,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
env=env,
)
# note: there is a warning for a possible deadlock when using `wait` with huge amounts of data in the pipe
# https://docs.python.org/3/library/asyncio-subprocess.html#asyncio.asyncio.subprocess.Process.wait
#
# If it starts hanging, will need to switch to the following code. The problem is that no data
# will be seen until it's done and if it hangs for example there will be no debug info.
# out, err = await p.communicate()
# return _RunOutput(p.returncode, out, err)
out = []
err = []
def tee(line, sink, pipe, label=""):
line = line.decode("utf-8").rstrip()
sink.append(line)
if not quiet:
print(label, line, file=pipe)
# XXX: the timeout doesn't seem to make any difference here
await asyncio.wait(
[
asyncio.create_task(_read_stream(p.stdout, lambda l: tee(l, out, sys.stdout, label="stdout:"))),
asyncio.create_task(_read_stream(p.stderr, lambda l: tee(l, err, sys.stderr, label="stderr:"))),
],
timeout=timeout,
)
return _RunOutput(await p.wait(), out, err)
def execute_subprocess_async(cmd: list, env=None, stdin=None, timeout=180, quiet=False, echo=True) -> _RunOutput:
# Cast every path in `cmd` to a string
for i, c in enumerate(cmd):
if isinstance(c, Path):
cmd[i] = str(c)
loop = asyncio.get_event_loop()
result = loop.run_until_complete(
_stream_subprocess(cmd, env=env, stdin=stdin, timeout=timeout, quiet=quiet, echo=echo)
)
cmd_str = " ".join(cmd)
if result.returncode > 0:
stderr = "\n".join(result.stderr)
raise RuntimeError(
f"'{cmd_str}' failed with returncode {result.returncode}\n\n"
f"The combined stderr from workers follows:\n{stderr}"
)
return result
class SubprocessCallException(Exception):
pass
def run_command(command: List[str], return_stdout=False, env=None):
"""
Runs `command` with `subprocess.check_output` and will potentially return the `stdout`. Will also properly capture
if an error occured while running `command`
"""
# Cast every path in `command` to a string
for i, c in enumerate(command):
if isinstance(c, Path):
command[i] = str(c)
if env is None:
env = os.environ.copy()
try:
output = subprocess.check_output(command, stderr=subprocess.STDOUT, env=env)
if return_stdout:
if hasattr(output, "decode"):
output = output.decode("utf-8")
return output
except subprocess.CalledProcessError as e:
raise SubprocessCallException(
f"Command `{' '.join(command)}` failed with the following error:\n\n{e.output.decode()}"
) from e
def path_in_accelerate_package(*components: str) -> Path:
"""
Get a path within the `accelerate` package's directory.
Args:
*components: Components of the path to join after the package directory.
Returns:
`Path`: The path to the requested file or directory.
"""
accelerate_package_dir = Path(inspect.getfile(accelerate)).parent
return accelerate_package_dir.joinpath(*components)
@contextmanager
def assert_exception(exception_class: Exception, msg: str = None) -> bool:
"""
Context manager to assert that the right `Exception` class was raised.
If `msg` is provided, will check that the message is contained in the raised exception.
"""
was_ran = False
try:
yield
was_ran = True
except Exception as e:
assert isinstance(e, exception_class), f"Expected exception of type {exception_class} but got {type(e)}"
if msg is not None:
assert msg in str(e), f"Expected message '{msg}' to be in exception but got '{str(e)}'"
if was_ran:
raise AssertionError(f"Expected exception of type {exception_class} but ran without issue.")
| accelerate/src/accelerate/test_utils/testing.py/0 | {
"file_path": "accelerate/src/accelerate/test_utils/testing.py",
"repo_id": "accelerate",
"token_count": 7530
} | 7 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
A set of basic tensor ops compatible with tpu, gpu, and multigpu
"""
import pickle
import warnings
from functools import update_wrapper, wraps
from typing import Any, Mapping
import torch
from ..state import PartialState
from .constants import TORCH_DISTRIBUTED_OPERATION_TYPES
from .dataclasses import DistributedType, TensorInformation
from .imports import (
is_npu_available,
is_torch_distributed_available,
is_torch_version,
is_torch_xla_available,
is_xpu_available,
)
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
if is_torch_distributed_available():
from torch.distributed import ReduceOp
def is_torch_tensor(tensor):
return isinstance(tensor, torch.Tensor)
def is_torch_xpu_tensor(tensor):
return isinstance(
tensor,
torch.xpu.FloatTensor,
torch.xpu.ByteTensor,
torch.xpu.IntTensor,
torch.xpu.LongTensor,
torch.xpu.HalfTensor,
torch.xpu.DoubleTensor,
torch.xpu.BFloat16Tensor,
)
def is_tensor_information(tensor_info):
return isinstance(tensor_info, TensorInformation)
def is_namedtuple(data):
"""
Checks if `data` is a `namedtuple` or not. Can have false positives, but only if a user is trying to mimic a
`namedtuple` perfectly.
"""
return isinstance(data, tuple) and hasattr(data, "_asdict") and hasattr(data, "_fields")
def honor_type(obj, generator):
"""
Cast a generator to the same type as obj (list, tuple, or namedtuple)
"""
# Some objects may not be able to instantiate from a generator directly
if is_namedtuple(obj):
return type(obj)(*list(generator))
else:
return type(obj)(generator)
def recursively_apply(func, data, *args, test_type=is_torch_tensor, error_on_other_type=False, **kwargs):
"""
Recursively apply a function on a data structure that is a nested list/tuple/dictionary of a given base type.
Args:
func (`callable`):
The function to recursively apply.
data (nested list/tuple/dictionary of `main_type`):
The data on which to apply `func`
*args:
Positional arguments that will be passed to `func` when applied on the unpacked data.
main_type (`type`, *optional*, defaults to `torch.Tensor`):
The base type of the objects to which apply `func`.
error_on_other_type (`bool`, *optional*, defaults to `False`):
Whether to return an error or not if after unpacking `data`, we get on an object that is not of type
`main_type`. If `False`, the function will leave objects of types different than `main_type` unchanged.
**kwargs:
Keyword arguments that will be passed to `func` when applied on the unpacked data.
Returns:
The same data structure as `data` with `func` applied to every object of type `main_type`.
"""
if isinstance(data, (tuple, list)):
return honor_type(
data,
(
recursively_apply(
func, o, *args, test_type=test_type, error_on_other_type=error_on_other_type, **kwargs
)
for o in data
),
)
elif isinstance(data, Mapping):
return type(data)(
{
k: recursively_apply(
func, v, *args, test_type=test_type, error_on_other_type=error_on_other_type, **kwargs
)
for k, v in data.items()
}
)
elif test_type(data):
return func(data, *args, **kwargs)
elif error_on_other_type:
raise TypeError(
f"Unsupported types ({type(data)}) passed to `{func.__name__}`. Only nested list/tuple/dicts of "
f"objects that are valid for `{test_type.__name__}` should be passed."
)
return data
def send_to_device(tensor, device, non_blocking=False, skip_keys=None):
"""
Recursively sends the elements in a nested list/tuple/dictionary of tensors to a given device.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to send to a given device.
device (`torch.device`):
The device to send the data to.
Returns:
The same data structure as `tensor` with all tensors sent to the proper device.
"""
if is_torch_tensor(tensor) or hasattr(tensor, "to"):
# `torch.Tensor.to("npu")` could not find context when called for the first time (see this [issue](https://gitee.com/ascend/pytorch/issues/I8KECW?from=project-issue)).
if device == "npu":
device = "npu:0"
if device == "xpu":
device = "xpu:0"
# TODO: torch_mlu LongTensor.to(<int num>) has bugs, we will fix this later.
if is_torch_tensor(tensor) and tensor.device.type in ["mlu"] and tensor.dtype in [torch.int64]:
tensor = tensor.cpu()
try:
return tensor.to(device, non_blocking=non_blocking)
except TypeError: # .to() doesn't accept non_blocking as kwarg
return tensor.to(device)
except AssertionError as error:
# `torch.Tensor.to(<int num>)` is not supported by `torch_npu` (see this [issue](https://github.com/Ascend/pytorch/issues/16)).
# This call is inside the try-block since is_npu_available is not supported by torch.compile.
if is_npu_available():
if isinstance(device, int):
device = f"npu:{device}"
else:
raise error
except Exception as error:
if is_xpu_available():
if isinstance(device, int):
device = f"xpu:{device}"
else:
raise error
try:
return tensor.to(device, non_blocking=non_blocking)
except TypeError: # .to() doesn't accept non_blocking as kwarg
return tensor.to(device)
elif isinstance(tensor, (tuple, list)):
return honor_type(
tensor, (send_to_device(t, device, non_blocking=non_blocking, skip_keys=skip_keys) for t in tensor)
)
elif isinstance(tensor, Mapping):
if isinstance(skip_keys, str):
skip_keys = [skip_keys]
elif skip_keys is None:
skip_keys = []
return type(tensor)(
{
k: t if k in skip_keys else send_to_device(t, device, non_blocking=non_blocking, skip_keys=skip_keys)
for k, t in tensor.items()
}
)
else:
return tensor
def get_data_structure(data):
"""
Recursively gathers the information needed to rebuild a nested list/tuple/dictionary of tensors.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`):
The data to send to analyze.
Returns:
The same data structure as `data` with [`~utils.TensorInformation`] instead of tensors.
"""
def _get_data_structure(tensor):
return TensorInformation(shape=tensor.shape, dtype=tensor.dtype)
return recursively_apply(_get_data_structure, data)
def get_shape(data):
"""
Recursively gathers the shape of a nested list/tuple/dictionary of tensors as a list.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`):
The data to send to analyze.
Returns:
The same data structure as `data` with lists of tensor shapes instead of tensors.
"""
def _get_shape(tensor):
return list(tensor.shape)
return recursively_apply(_get_shape, data)
def initialize_tensors(data_structure):
"""
Recursively initializes tensors from a nested list/tuple/dictionary of [`~utils.TensorInformation`].
Returns:
The same data structure as `data` with tensors instead of [`~utils.TensorInformation`].
"""
def _initialize_tensor(tensor_info):
return torch.empty(*tensor_info.shape, dtype=tensor_info.dtype)
return recursively_apply(_initialize_tensor, data_structure, test_type=is_tensor_information)
def find_batch_size(data):
"""
Recursively finds the batch size in a nested list/tuple/dictionary of lists of tensors.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`): The data from which to find the batch size.
Returns:
`int`: The batch size.
"""
if isinstance(data, (tuple, list, Mapping)) and (len(data) == 0):
raise ValueError(f"Cannot find the batch size from empty {type(data)}.")
if isinstance(data, (tuple, list)):
return find_batch_size(data[0])
elif isinstance(data, Mapping):
for k in data.keys():
return find_batch_size(data[k])
elif not isinstance(data, torch.Tensor):
raise TypeError(f"Can only find the batch size of tensors but got {type(data)}.")
return data.shape[0]
def ignorant_find_batch_size(data):
"""
Same as [`utils.operations.find_batch_size`] except will ignore if `ValueError` and `TypeErrors` are raised
Args:
data (nested list/tuple/dictionary of `torch.Tensor`): The data from which to find the batch size.
Returns:
`int`: The batch size.
"""
try:
return find_batch_size(data)
except (ValueError, TypeError):
pass
return None
def listify(data):
"""
Recursively finds tensors in a nested list/tuple/dictionary and converts them to a list of numbers.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`): The data from which to convert to regular numbers.
Returns:
The same data structure as `data` with lists of numbers instead of `torch.Tensor`.
"""
def _convert_to_list(tensor):
tensor = tensor.detach().cpu()
if tensor.dtype == torch.bfloat16:
# As of Numpy 1.21.4, NumPy does not support bfloat16 (see
# https://github.com/numpy/numpy/blob/a47ecdea856986cd60eabbd53265c2ca5916ad5d/doc/source/user/basics.types.rst ).
# Until Numpy adds bfloat16, we must convert float32.
tensor = tensor.to(torch.float32)
return tensor.tolist()
return recursively_apply(_convert_to_list, data)
def _tpu_gather(tensor):
def _tpu_gather_one(tensor):
if tensor.ndim == 0:
tensor = tensor.clone()[None]
# Can only gather contiguous tensors
if not tensor.is_contiguous():
tensor = tensor.contiguous()
return xm.all_gather(tensor)
res = recursively_apply(_tpu_gather_one, tensor, error_on_other_type=True)
xm.mark_step()
return res
def _gpu_gather(tensor):
state = PartialState()
if is_torch_version(">=", "1.13"):
gather_op = torch.distributed.all_gather_into_tensor
else:
gather_op = torch.distributed._all_gather_base
def _gpu_gather_one(tensor):
if tensor.ndim == 0:
tensor = tensor.clone()[None]
# Can only gather contiguous tensors
if not tensor.is_contiguous():
tensor = tensor.contiguous()
if state.backend is not None and state.backend != "gloo":
# We use `empty` as `all_gather_into_tensor` slightly
# differs from `all_gather` for better efficiency,
# and we rely on the number of items in the tensor
# rather than its direct shape
output_tensors = torch.empty(
state.num_processes * tensor.numel(),
dtype=tensor.dtype,
device=state.device,
)
gather_op(output_tensors, tensor)
return output_tensors.view(-1, *tensor.size()[1:])
else:
# a backend of `None` is always CPU
# also gloo does not support `all_gather_into_tensor`,
# which will result in a larger memory overhead for the op
output_tensors = [torch.empty_like(tensor) for _ in range(state.num_processes)]
torch.distributed.all_gather(output_tensors, tensor)
return torch.cat(output_tensors, dim=0)
return recursively_apply(_gpu_gather_one, tensor, error_on_other_type=True)
class DistributedOperationException(Exception):
"""
An exception class for distributed operations. Raised if the operation cannot be performed due to the shape of the
tensors.
"""
pass
def verify_operation(function):
"""
Verifies that `tensor` is the same shape across all processes. Only ran if `PartialState().debug` is `True`.
"""
@wraps(function)
def wrapper(*args, **kwargs):
if PartialState().distributed_type == DistributedType.NO or not PartialState().debug:
return function(*args, **kwargs)
operation = f"{function.__module__}.{function.__name__}"
if "tensor" in kwargs:
tensor = kwargs["tensor"]
else:
tensor = args[0]
if PartialState().device.type != find_device(tensor).type:
raise DistributedOperationException(
f"One or more of the tensors passed to {operation} were not on the {tensor.device.type} while the `Accelerator` is configured for {PartialState().device.type}. "
f"Please move it to the {PartialState().device.type} before calling {operation}."
)
shapes = get_shape(tensor)
output = gather_object([shapes])
if output[0] is not None:
are_same = output.count(output[0]) == len(output)
if not are_same:
process_shape_str = "\n - ".join([f"Process {i}: {shape}" for i, shape in enumerate(output)])
raise DistributedOperationException(
f"Cannot apply desired operation due to shape mismatches. "
"All shapes across devices must be valid."
f"\n\nOperation: `{operation}`\nInput shapes:\n - {process_shape_str}"
)
return function(*args, **kwargs)
return wrapper
def chained_operation(function):
"""
Checks that `verify_operation` failed and if so reports a more helpful error chaining the existing
`DistributedOperationException`.
"""
@wraps(function)
def wrapper(*args, **kwargs):
try:
return function(*args, **kwargs)
except DistributedOperationException as e:
operation = f"{function.__module__}.{function.__name__}"
raise DistributedOperationException(
f"Error found while calling `{operation}`. Please see the earlier error for more details."
) from e
return wrapper
@verify_operation
def gather(tensor):
"""
Recursively gather tensor in a nested list/tuple/dictionary of tensors from all devices.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to gather.
Returns:
The same data structure as `tensor` with all tensors sent to the proper device.
"""
if PartialState().distributed_type == DistributedType.XLA:
return _tpu_gather(tensor)
elif PartialState().distributed_type in TORCH_DISTRIBUTED_OPERATION_TYPES:
return _gpu_gather(tensor)
else:
return tensor
def _gpu_gather_object(object: Any):
output_objects = [None for _ in range(PartialState().num_processes)]
torch.distributed.all_gather_object(output_objects, object)
# all_gather_object returns a list of lists, so we need to flatten it
return [x for y in output_objects for x in y]
def gather_object(object: Any):
"""
Recursively gather object in a nested list/tuple/dictionary of objects from all devices.
Args:
object (nested list/tuple/dictionary of picklable object):
The data to gather.
Returns:
The same data structure as `object` with all the objects sent to every device.
"""
if PartialState().distributed_type == DistributedType.XLA:
raise NotImplementedError("gather objects in TPU is not supported")
elif PartialState().distributed_type in TORCH_DISTRIBUTED_OPERATION_TYPES:
return _gpu_gather_object(object)
else:
return object
def _gpu_broadcast(data, src=0):
def _gpu_broadcast_one(tensor, src=0):
torch.distributed.broadcast(tensor, src=src)
return tensor
return recursively_apply(_gpu_broadcast_one, data, error_on_other_type=True, src=src)
def _tpu_broadcast(tensor, src=0, name="broadcast tensor"):
if isinstance(tensor, (list, tuple)):
return honor_type(tensor, (_tpu_broadcast(t, name=f"{name}_{i}") for i, t in enumerate(tensor)))
elif isinstance(tensor, Mapping):
return type(tensor)({k: _tpu_broadcast(v, name=f"{name}_{k}") for k, v in tensor.items()})
return xm.mesh_reduce(name, tensor, lambda x: x[src])
TENSOR_TYPE_TO_INT = {
torch.float: 1,
torch.double: 2,
torch.half: 3,
torch.bfloat16: 4,
torch.uint8: 5,
torch.int8: 6,
torch.int16: 7,
torch.int32: 8,
torch.int64: 9,
torch.bool: 10,
}
TENSOR_INT_TO_DTYPE = {v: k for k, v in TENSOR_TYPE_TO_INT.items()}
def gather_tensor_shape(tensor):
"""
Grabs the shape of `tensor` only available on one process and returns a tensor of its shape
"""
# Allocate 80 bytes to store the shape
max_tensor_dimension = 2**20
state = PartialState()
base_tensor = torch.empty(max_tensor_dimension, dtype=torch.int, device=state.device)
# Since PyTorch can't just send a tensor to another GPU without
# knowing its size, we store the size of the tensor with data
# in an allocation
if tensor is not None:
shape = tensor.shape
tensor_dtype = TENSOR_TYPE_TO_INT[tensor.dtype]
base_tensor[: len(shape) + 1] = torch.tensor(list(shape) + [tensor_dtype], dtype=int)
# Perform a reduction to copy the size data onto all GPUs
base_tensor = reduce(base_tensor, reduction="sum")
base_tensor = base_tensor[base_tensor.nonzero()]
# The last non-zero data contains the coded dtype the source tensor is
dtype = int(base_tensor[-1:][0])
base_tensor = base_tensor[:-1]
return base_tensor, dtype
def copy_tensor_to_devices(tensor=None) -> torch.Tensor:
"""
Copys a tensor that only exists on a single device and broadcasts it to other devices. Differs from `broadcast` as
each worker doesn't need to know its shape when used (and tensor can be `None`)
Args:
tensor (`torch.tensor`):
The tensor that should be sent to all devices. Must only have it be defined on a single device, the rest
should be `None`.
"""
state = PartialState()
shape, dtype = gather_tensor_shape(tensor)
if tensor is None:
tensor = torch.zeros(shape, dtype=TENSOR_INT_TO_DTYPE[dtype]).to(state.device)
return reduce(tensor, reduction="sum")
@verify_operation
def broadcast(tensor, from_process: int = 0):
"""
Recursively broadcast tensor in a nested list/tuple/dictionary of tensors to all devices.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to gather.
from_process (`int`, *optional*, defaults to 0):
The process from which to send the data
Returns:
The same data structure as `tensor` with all tensors broadcasted to the proper device.
"""
if PartialState().distributed_type == DistributedType.XLA:
return _tpu_broadcast(tensor, src=from_process, name="accelerate.utils.broadcast")
elif PartialState().distributed_type in TORCH_DISTRIBUTED_OPERATION_TYPES:
return _gpu_broadcast(tensor, src=from_process)
else:
return tensor
def broadcast_object_list(object_list, from_process: int = 0):
"""
Broadcast a list of picklable objects form one process to the others.
Args:
object_list (list of picklable objects):
The list of objects to broadcast. This list will be modified inplace.
from_process (`int`, *optional*, defaults to 0):
The process from which to send the data.
Returns:
The same list containing the objects from process 0.
"""
if PartialState().distributed_type == DistributedType.XLA:
for i, obj in enumerate(object_list):
object_list[i] = xm.mesh_reduce("accelerate.utils.broadcast_object_list", obj, lambda x: x[from_process])
elif PartialState().distributed_type in TORCH_DISTRIBUTED_OPERATION_TYPES:
torch.distributed.broadcast_object_list(object_list, src=from_process)
return object_list
def slice_tensors(data, tensor_slice, process_index=None, num_processes=None):
"""
Recursively takes a slice in a nested list/tuple/dictionary of tensors.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`):
The data to slice.
tensor_slice (`slice`):
The slice to take.
Returns:
The same data structure as `data` with all the tensors slices.
"""
def _slice_tensor(tensor, tensor_slice):
return tensor[tensor_slice]
return recursively_apply(_slice_tensor, data, tensor_slice)
def concatenate(data, dim=0):
"""
Recursively concatenate the tensors in a nested list/tuple/dictionary of lists of tensors with the same shape.
Args:
data (nested list/tuple/dictionary of lists of tensors `torch.Tensor`):
The data to concatenate.
dim (`int`, *optional*, defaults to 0):
The dimension on which to concatenate.
Returns:
The same data structure as `data` with all the tensors concatenated.
"""
if isinstance(data[0], (tuple, list)):
return honor_type(data[0], (concatenate([d[i] for d in data], dim=dim) for i in range(len(data[0]))))
elif isinstance(data[0], Mapping):
return type(data[0])({k: concatenate([d[k] for d in data], dim=dim) for k in data[0].keys()})
elif not isinstance(data[0], torch.Tensor):
raise TypeError(f"Can only concatenate tensors but got {type(data[0])}")
return torch.cat(data, dim=dim)
class CannotPadNestedTensorWarning(UserWarning):
pass
@chained_operation
def pad_across_processes(tensor, dim=0, pad_index=0, pad_first=False):
"""
Recursively pad the tensors in a nested list/tuple/dictionary of tensors from all devices to the same size so they
can safely be gathered.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to gather.
dim (`int`, *optional*, defaults to 0):
The dimension on which to pad.
pad_index (`int`, *optional*, defaults to 0):
The value with which to pad.
pad_first (`bool`, *optional*, defaults to `False`):
Whether to pad at the beginning or the end.
"""
def _pad_across_processes(tensor, dim=0, pad_index=0, pad_first=False):
if getattr(tensor, "is_nested", False):
warnings.warn(
"Cannot pad nested tensors without more information. Leaving unprocessed.",
CannotPadNestedTensorWarning,
)
return tensor
if dim >= len(tensor.shape):
return tensor
# Gather all sizes
size = torch.tensor(tensor.shape, device=tensor.device)[None]
sizes = gather(size).cpu()
# Then pad to the maximum size
max_size = max(s[dim] for s in sizes)
if max_size == tensor.shape[dim]:
return tensor
old_size = tensor.shape
new_size = list(old_size)
new_size[dim] = max_size
new_tensor = tensor.new_zeros(tuple(new_size)) + pad_index
if pad_first:
indices = tuple(
slice(max_size - old_size[dim], max_size) if i == dim else slice(None) for i in range(len(new_size))
)
else:
indices = tuple(slice(0, old_size[dim]) if i == dim else slice(None) for i in range(len(new_size)))
new_tensor[indices] = tensor
return new_tensor
return recursively_apply(
_pad_across_processes, tensor, error_on_other_type=True, dim=dim, pad_index=pad_index, pad_first=pad_first
)
def pad_input_tensors(tensor, batch_size, num_processes, dim=0):
"""
Takes a `tensor` of arbitrary size and pads it so that it can work given `num_processes` needed dimensions.
New tensors are just the last input repeated.
E.g.:
Tensor: ([3,4,4]) Num processes: 4 Expected result shape: ([4,4,4])
"""
def _pad_input_tensors(tensor, batch_size, num_processes, dim=0):
remainder = batch_size // num_processes
last_inputs = batch_size - (remainder * num_processes)
if batch_size // num_processes == 0:
to_pad = num_processes - batch_size
else:
to_pad = num_processes - (batch_size // num_processes)
# In the rare case that `to_pad` is negative,
# we need to pad the last inputs - the found `to_pad`
if last_inputs > to_pad & to_pad < 1:
to_pad = last_inputs - to_pad
old_size = tensor.shape
new_size = list(old_size)
new_size[0] = batch_size + to_pad
new_tensor = tensor.new_zeros(tuple(new_size))
indices = tuple(slice(0, old_size[dim]) if i == dim else slice(None) for i in range(len(new_size)))
new_tensor[indices] = tensor
return new_tensor
return recursively_apply(
_pad_input_tensors,
tensor,
error_on_other_type=True,
batch_size=batch_size,
num_processes=num_processes,
dim=dim,
)
@verify_operation
def reduce(tensor, reduction="mean", scale=1.0):
"""
Recursively reduce the tensors in a nested list/tuple/dictionary of lists of tensors across all processes by the
mean of a given operation.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to reduce.
reduction (`str`, *optional*, defaults to `"mean"`):
A reduction method. Can be of "mean", "sum", or "none"
scale (`float`, *optional*):
A default scaling value to be applied after the reduce, only valied on XLA.
Returns:
The same data structure as `data` with all the tensors reduced.
"""
def _reduce_across_processes(tensor, reduction="mean", scale=1.0):
state = PartialState()
cloned_tensor = tensor.clone()
if state.distributed_type == DistributedType.NO:
return cloned_tensor
if state.distributed_type == DistributedType.XLA:
# Some processes may have different HLO graphs than other
# processes, for example in the breakpoint API
# accelerator.set_trigger(). Use mark_step to make HLOs
# the same on all processes.
xm.mark_step()
xm.all_reduce(xm.REDUCE_SUM, [cloned_tensor], scale)
xm.mark_step()
elif state.distributed_type.value in TORCH_DISTRIBUTED_OPERATION_TYPES:
torch.distributed.all_reduce(cloned_tensor, ReduceOp.SUM)
if reduction == "mean":
cloned_tensor /= state.num_processes
return cloned_tensor
return recursively_apply(
_reduce_across_processes, tensor, error_on_other_type=True, reduction=reduction, scale=scale
)
def convert_to_fp32(tensor):
"""
Recursively converts the elements nested list/tuple/dictionary of tensors in FP16/BF16 precision to FP32.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to convert from FP16/BF16 to FP32.
Returns:
The same data structure as `tensor` with all tensors that were in FP16/BF16 precision converted to FP32.
"""
def _convert_to_fp32(tensor):
return tensor.float()
def _is_fp16_bf16_tensor(tensor):
return (is_torch_tensor(tensor) or hasattr(tensor, "dtype")) and tensor.dtype in (
torch.float16,
torch.bfloat16,
)
return recursively_apply(_convert_to_fp32, tensor, test_type=_is_fp16_bf16_tensor)
class ConvertOutputsToFp32:
"""
Decorator to apply to a function outputing tensors (like a model forward pass) that ensures the outputs in FP16
precision will be convert back to FP32.
Args:
model_forward (`Callable`):
The function which outputs we want to treat.
Returns:
The same function as `model_forward` but with converted outputs.
"""
def __init__(self, model_forward):
self.model_forward = model_forward
update_wrapper(self, model_forward)
def __call__(self, *args, **kwargs):
return convert_to_fp32(self.model_forward(*args, **kwargs))
def __getstate__(self):
raise pickle.PicklingError(
"Cannot pickle a prepared model with automatic mixed precision, please unwrap the model with `Accelerator.unwrap_model(model)` before pickling it."
)
def convert_outputs_to_fp32(model_forward):
model_forward = ConvertOutputsToFp32(model_forward)
def forward(*args, **kwargs):
return model_forward(*args, **kwargs)
# To act like a decorator so that it can be popped when doing `extract_model_from_parallel`
forward.__wrapped__ = model_forward
return forward
def find_device(data):
"""
Finds the device on which a nested dict/list/tuple of tensors lies (assuming they are all on the same device).
Args:
(nested list/tuple/dictionary of `torch.Tensor`): The data we want to know the device of.
"""
if isinstance(data, Mapping):
for obj in data.values():
device = find_device(obj)
if device is not None:
return device
elif isinstance(data, (tuple, list)):
for obj in data:
device = find_device(obj)
if device is not None:
return device
elif isinstance(data, torch.Tensor):
return data.device
| accelerate/src/accelerate/utils/operations.py/0 | {
"file_path": "accelerate/src/accelerate/utils/operations.py",
"repo_id": "accelerate",
"token_count": 12695
} | 8 |
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: 'NO'
downcast_bf16: 'no'
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 1
use_cpu: false | accelerate/tests/test_configs/0_12_0.yaml/0 | {
"file_path": "accelerate/tests/test_configs/0_12_0.yaml",
"repo_id": "accelerate",
"token_count": 105
} | 9 |
# Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import pickle
import unittest
import torch
from accelerate import Accelerator
from accelerate.state import AcceleratorState
from accelerate.test_utils import require_cpu, require_non_cpu, require_non_xpu
@require_cpu
class CPUOptimizerTester(unittest.TestCase):
def test_accelerated_optimizer_pickling(self):
model = torch.nn.Linear(10, 10)
optimizer = torch.optim.SGD(model.parameters(), 0.1)
accelerator = Accelerator()
optimizer = accelerator.prepare(optimizer)
try:
pickle.loads(pickle.dumps(optimizer))
except Exception as e:
self.fail(f"Accelerated optimizer pickling failed with {e}")
AcceleratorState._reset_state()
@require_non_cpu
@require_non_xpu
class OptimizerTester(unittest.TestCase):
def test_accelerated_optimizer_step_was_skipped(self):
model = torch.nn.Linear(5, 5)
optimizer = torch.optim.SGD(model.parameters(), 0.1)
accelerator = Accelerator(mixed_precision="fp16")
model, optimizer = accelerator.prepare(model, optimizer)
loss = model(torch.randn(2, 5, device=accelerator.device)).sum()
accelerator.backward(loss)
for p in model.parameters():
# Fake the gradients, as if there's no overflow
p.grad.fill_(0.01)
optimizer.step()
assert optimizer.step_was_skipped is False
loss = model(torch.randn(2, 5, device=accelerator.device)).sum()
accelerator.backward(loss)
for p in model.parameters():
p.grad.fill_(0.01)
# Manually set the gradients to be NaN, as if there's an overflow
p.grad[0] = torch.tensor(float("nan"))
optimizer.step()
assert optimizer.step_was_skipped is True
loss = model(torch.randn(2, 5, device=accelerator.device)).sum()
accelerator.backward(loss)
for p in model.parameters():
p.grad.fill_(0.01)
# Manually set the gradients to be NaN, as if there's an overflow
p.grad[0] = torch.tensor(float("nan"))
optimizer.step()
assert optimizer.step_was_skipped is True
loss = model(torch.randn(2, 5, device=accelerator.device)).sum()
accelerator.backward(loss)
for p in model.parameters():
# Fake the gradients, as if there's no overflow
p.grad.fill_(0.01)
optimizer.step()
assert optimizer.step_was_skipped is False
AcceleratorState._reset_state()
| accelerate/tests/test_optimizer.py/0 | {
"file_path": "accelerate/tests/test_optimizer.py",
"repo_id": "accelerate",
"token_count": 1209
} | 10 |
<p align="center">
<img src="https://raw.githubusercontent.com/huggingface/alignment-handbook/main/assets/handbook.png">
</p>
<p align="center">
🤗 <a href="https://huggingface.co/collections/alignment-handbook/handbook-v01-models-and-datasets-654e424d22e6880da5ebc015" target="_blank">Models & Datasets</a> | 📃 <a href="https://arxiv.org/abs/2310.16944" target="_blank">Technical Report</a>
</p>
# The Alignment Handbook
Robust recipes to continue pretraining and to align language models with human and AI preferences.
## What is this?
Just one year ago, chatbots were out of fashion and most people hadn't heard about techniques like Reinforcement Learning from Human Feedback (RLHF) to align language models with human preferences. Then, OpenAI broke the internet with ChatGPT and Meta followed suit by releasing the Llama series of language models which enabled the ML community to build their very own capable chatbots. This has led to a rich ecosystem of datasets and models that have mostly focused on teaching language models to follow instructions through supervised fine-tuning (SFT).
However, we know from the [InstructGPT](https://huggingface.co/papers/2203.02155) and [Llama2](https://huggingface.co/papers/2307.09288) papers that significant gains in helpfulness and safety can be had by augmenting SFT with human (or AI) preferences. At the same time, aligning language models to a set of preferences is a fairly novel idea and there are few public resources available on how to train these models, what data to collect, and what metrics to measure for best downstream performance.
The Alignment Handbook aims to fill that gap by providing the community with a series of robust training recipes that span the whole pipeline.
## News 🗞️
* **March 12, 2024:** We release StarChat2 15B, along with the recipe to train capable coding assistants 🌟
* **March 1, 2024:** We release Zephyr 7B Gemma, which is a new recipe to align Gemma 7B with RLAIF 🔥
* **February 1, 2024:** We release a recipe to align open LLMs with Constitutional AI 📜! See the [recipe](https://github.com/huggingface/alignment-handbook/tree/main/recipes/constitutional-ai) and the [blog post](https://huggingface.co/blog/constitutional_ai) for details.
* **January 18, 2024:** We release a suite of evaluations of DPO vs KTO vs IPO, see the [recipe](recipes/pref_align_scan/README.md) and the [blog post](https://huggingface.co/blog/pref-tuning) for details.
* **November 10, 2023:** We release all the training code to replicate Zephyr-7b-β 🪁! We also release [No Robots](https://huggingface.co/datasets/HuggingFaceH4/no_robots), a brand new dataset of 10,000 instructions and demonstrations written entirely by skilled human annotators.
## Links 🔗
* [Zephyr 7B models, datasets, and demos](https://huggingface.co/collections/HuggingFaceH4/zephyr-7b-6538c6d6d5ddd1cbb1744a66)
## How to navigate this project 🧭
This project is simple by design and mostly consists of:
* [`scripts`](./scripts/) to train and evaluate models. Three steps are included: continued pretraining, supervised-finetuning (SFT) for chat, and preference alignment with DPO. Each script supports distributed training of the full model weights with DeepSpeed ZeRO-3, or LoRA/QLoRA for parameter-efficient fine-tuning.
* [`recipes`](./recipes/) to reproduce models like Zephyr 7B. Each recipe takes the form of a YAML file which contains all the parameters associated with a single training run. A `gpt2-nl` recipe is also given to illustrate how this handbook can be used for language or domain adaptation, e.g. by continuing to pretrain on a different language, and then SFT and DPO tuning the result.
We are also working on a series of guides to explain how methods like direct preference optimization (DPO) work, along with lessons learned from gathering human preferences in practice. To get started, we recommend the following:
1. Follow the [installation instructions](#installation-instructions) to set up your environment etc.
2. Replicate Zephyr-7b-β by following the [recipe instructions](./recipes/zephyr-7b-beta/README.md).
If you would like to train chat models on your own datasets, we recommend following the dataset formatting instructions [here](./scripts/README.md#fine-tuning-on-your-datasets).
## Contents
The initial release of the handbook will focus on the following techniques:
* **Continued pretraining:** adapt language models to a new language or domain, or simply improve it by continue pretraning (causal language modeling) on a new dataset.
* **Supervised fine-tuning:** teach language models to follow instructions and tips on how to collect and curate your own training dataset.
* **Reward modeling:** teach language models to distinguish model responses according to human or AI preferences.
* **Rejection sampling:** a simple, but powerful technique to boost the performance of your SFT model.
* **Direct preference optimisation (DPO):** a powerful and promising alternative to PPO.
## Installation instructions
To run the code in this project, first, create a Python virtual environment using e.g. Conda:
```shell
conda create -n handbook python=3.10 && conda activate handbook
```
Next, install PyTorch `v2.1.2` - the precise version is important for reproducibility! Since this is hardware-dependent, we
direct you to the [PyTorch Installation Page](https://pytorch.org/get-started/locally/).
You can then install the remaining package dependencies as follows:
```shell
git clone https://github.com/huggingface/alignment-handbook.git
cd ./alignment-handbook/
python -m pip install .
```
You will also need Flash Attention 2 installed, which can be done by running:
```shell
python -m pip install flash-attn==2.3.6 --no-build-isolation
```
> **Note**
> If your machine has less than 96GB of RAM and many CPU cores, reduce the `MAX_JOBS` arguments, e.g. `MAX_JOBS=4 pip install flash-attn==2.3.6 --no-build-isolation`
Next, log into your Hugging Face account as follows:
```shell
huggingface-cli login
```
Finally, install Git LFS so that you can push models to the Hugging Face Hub:
```shell
sudo apt-get install git-lfs
```
You can now check out the `scripts` and `recipes` directories for instructions on how to train some models 🪁!
## Project structure
```
├── LICENSE
├── Makefile <- Makefile with commands like `make style`
├── README.md <- The top-level README for developers using this project
├── chapters <- Educational content to render on hf.co/learn
├── recipes <- Recipe configs, accelerate configs, slurm scripts
├── scripts <- Scripts to train and evaluate chat models
├── setup.cfg <- Installation config (mostly used for configuring code quality & tests)
├── setup.py <- Makes project pip installable (pip install -e .) so `alignment` can be imported
├── src <- Source code for use in this project
└── tests <- Unit tests
```
## Citation
If you find the content of this repo useful in your work, please cite it as follows:
```bibtex
@misc{alignment_handbook2023,
author = {Lewis Tunstall and Edward Beeching and Nathan Lambert and Nazneen Rajani and Shengyi Huang and Kashif Rasul and Alexander M. Rush and Thomas Wolf},
title = {The Alignment Handbook},
year = {2023},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/huggingface/alignment-handbook}}
}
```
| alignment-handbook/README.md/0 | {
"file_path": "alignment-handbook/README.md",
"repo_id": "alignment-handbook",
"token_count": 2243
} | 11 |
# Model arguments
model_name_or_path: teknium/OpenHermes-2.5-Mistral-7B
torch_dtype: null
# Data training arguments
dataset_mixer:
HuggingFaceH4/orca_dpo_pairs: 1.0
dataset_splits:
- train_prefs
- test_prefs
preprocessing_num_workers: 12
# Training arguments with sensible defaults
bf16: true
beta: 0.01
loss_type: sigmoid
do_eval: true
do_train: true
evaluation_strategy: steps
eval_steps: 100
gradient_accumulation_steps: 2
gradient_checkpointing: true
gradient_checkpointing_kwargs:
use_reentrant: False
hub_model_id: HuggingFaceH4/openhermes-2.5-mistral-7b-dpo
hub_model_revision: v1.0
learning_rate: 5.0e-7
logging_steps: 10
lr_scheduler_type: cosine
max_prompt_length: 512
num_train_epochs: 1
optim: adamw_torch
output_dir: data/openhermes-2.5-mistral-7b-dpo-v1.0
per_device_train_batch_size: 8
per_device_eval_batch_size: 8
save_strategy: "steps"
save_steps: 100
save_total_limit: 1
seed: 42
warmup_ratio: 0.1 | alignment-handbook/recipes/pref_align_scan/dpo/config_openhermes.yaml/0 | {
"file_path": "alignment-handbook/recipes/pref_align_scan/dpo/config_openhermes.yaml",
"repo_id": "alignment-handbook",
"token_count": 377
} | 12 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import random
import sys
import torch
import transformers
from transformers import AutoModelForCausalLM, set_seed
from alignment import (
DataArguments,
DPOConfig,
H4ArgumentParser,
ModelArguments,
apply_chat_template,
decontaminate_humaneval,
get_checkpoint,
get_datasets,
get_kbit_device_map,
get_peft_config,
get_quantization_config,
get_tokenizer,
is_adapter_model,
)
from peft import PeftConfig, PeftModel
from trl import DPOTrainer
logger = logging.getLogger(__name__)
def main():
parser = H4ArgumentParser((ModelArguments, DataArguments, DPOConfig))
model_args, data_args, training_args = parser.parse()
#######
# Setup
#######
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.info(f"Model parameters {model_args}")
logger.info(f"Data parameters {data_args}")
logger.info(f"Training/evaluation parameters {training_args}")
# Check for last checkpoint
last_checkpoint = get_checkpoint(training_args)
if last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(f"Checkpoint detected, resuming training at {last_checkpoint=}.")
# Set seed for reproducibility
set_seed(training_args.seed)
###############
# Load datasets
###############
raw_datasets = get_datasets(data_args, splits=data_args.dataset_splits, configs=data_args.dataset_configs)
logger.info(
f"Training on the following splits: {[split + ' : ' + str(dset.num_rows) for split, dset in raw_datasets.items()]}"
)
column_names = list(raw_datasets["train"].features)
#####################################
# Load tokenizer and process datasets
#####################################
data_args.truncation_side = "left" # Truncate from left to ensure we don't lose labels in final turn
tokenizer = get_tokenizer(model_args, data_args)
#####################
# Apply chat template
#####################
raw_datasets = raw_datasets.map(
apply_chat_template,
fn_kwargs={
"tokenizer": tokenizer,
"task": "dpo",
"auto_insert_empty_system_msg": data_args.auto_insert_empty_system_msg,
},
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
desc="Formatting comparisons with prompt template",
)
##########################
# Decontaminate benchmarks
##########################
num_raw_train_samples = len(raw_datasets["train"])
raw_datasets = raw_datasets.filter(
decontaminate_humaneval,
fn_kwargs={"text_column": "text_chosen"},
batched=True,
batch_size=10_000,
num_proc=1,
desc="Decontaminating HumanEval samples",
)
num_filtered_train_samples = num_raw_train_samples - len(raw_datasets["train"])
logger.info(
f"Decontaminated {num_filtered_train_samples} ({num_filtered_train_samples/num_raw_train_samples * 100:.2f}%) samples from the training set."
)
# Replace column names with what TRL needs, text_chosen -> chosen and text_rejected -> rejected
for split in ["train", "test"]:
raw_datasets[split] = raw_datasets[split].rename_columns(
{"text_prompt": "prompt", "text_chosen": "chosen", "text_rejected": "rejected"}
)
# Log a few random samples from the training set:
for index in random.sample(range(len(raw_datasets["train"])), 3):
logger.info(f"Prompt sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['prompt']}")
logger.info(f"Chosen sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['chosen']}")
logger.info(f"Rejected sample {index} of the raw training set:\n\n{raw_datasets['train'][index]['rejected']}")
torch_dtype = (
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
)
quantization_config = get_quantization_config(model_args)
model_kwargs = dict(
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
use_flash_attention_2=model_args.use_flash_attention_2,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
model = model_args.model_name_or_path
if is_adapter_model(model, model_args.model_revision) is True:
logger.info(f"Loading SFT adapter for {model_args.model_name_or_path=}")
peft_config = PeftConfig.from_pretrained(model_args.model_name_or_path, revision=model_args.model_revision)
model_kwargs = dict(
revision=model_args.base_model_revision,
trust_remote_code=model_args.trust_remote_code,
use_flash_attention_2=model_args.use_flash_attention_2,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
base_model = AutoModelForCausalLM.from_pretrained(
peft_config.base_model_name_or_path,
**model_kwargs,
)
model = PeftModel.from_pretrained(
base_model,
model_args.model_name_or_path,
revision=model_args.model_revision,
)
model_kwargs = None
ref_model = model
ref_model_kwargs = model_kwargs
if model_args.use_peft is True:
ref_model = None
ref_model_kwargs = None
#########################
# Instantiate DPO trainer
#########################
trainer = DPOTrainer(
model,
ref_model,
model_init_kwargs=model_kwargs,
ref_model_init_kwargs=ref_model_kwargs,
args=training_args,
beta=training_args.beta,
train_dataset=raw_datasets["train"],
eval_dataset=raw_datasets["test"],
tokenizer=tokenizer,
max_length=training_args.max_length,
max_prompt_length=training_args.max_prompt_length,
peft_config=get_peft_config(model_args),
loss_type=training_args.loss_type,
)
###############
# Training loop
###############
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
metrics = train_result.metrics
metrics["train_samples"] = len(raw_datasets["train"])
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
logger.info("*** Training complete ***")
##################################
# Save model and create model card
##################################
logger.info("*** Save model ***")
trainer.save_model(training_args.output_dir)
logger.info(f"Model saved to {training_args.output_dir}")
# Save everything else on main process
kwargs = {
"finetuned_from": model_args.model_name_or_path,
"dataset": list(data_args.dataset_mixer.keys()),
"dataset_tags": list(data_args.dataset_mixer.keys()),
"tags": ["alignment-handbook"],
}
if trainer.accelerator.is_main_process:
trainer.create_model_card(**kwargs)
# Restore k,v cache for fast inference
trainer.model.config.use_cache = True
trainer.model.config.save_pretrained(training_args.output_dir)
##########
# Evaluate
##########
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
metrics["eval_samples"] = len(raw_datasets["test"])
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if training_args.push_to_hub is True:
logger.info("Pushing to hub...")
trainer.push_to_hub(**kwargs)
logger.info("*** Training complete! ***")
if __name__ == "__main__":
main()
| alignment-handbook/scripts/run_dpo.py/0 | {
"file_path": "alignment-handbook/scripts/run_dpo.py",
"repo_id": "alignment-handbook",
"token_count": 3735
} | 13 |
# coding=utf-8
# Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import unittest
import torch
from transformers import AutoTokenizer
from alignment import (
DataArguments,
ModelArguments,
get_peft_config,
get_quantization_config,
get_tokenizer,
is_adapter_model,
)
from alignment.data import DEFAULT_CHAT_TEMPLATE
class GetQuantizationConfigTest(unittest.TestCase):
def test_4bit(self):
model_args = ModelArguments(load_in_4bit=True)
quantization_config = get_quantization_config(model_args)
self.assertTrue(quantization_config.load_in_4bit)
self.assertEqual(quantization_config.bnb_4bit_compute_dtype, torch.float16)
self.assertEqual(quantization_config.bnb_4bit_quant_type, "nf4")
self.assertFalse(quantization_config.bnb_4bit_use_double_quant)
def test_8bit(self):
model_args = ModelArguments(load_in_8bit=True)
quantization_config = get_quantization_config(model_args)
self.assertTrue(quantization_config.load_in_8bit)
def test_no_quantization(self):
model_args = ModelArguments()
quantization_config = get_quantization_config(model_args)
self.assertIsNone(quantization_config)
class GetTokenizerTest(unittest.TestCase):
def setUp(self) -> None:
self.model_args = ModelArguments(model_name_or_path="HuggingFaceH4/zephyr-7b-alpha")
def test_right_truncation_side(self):
tokenizer = get_tokenizer(self.model_args, DataArguments(truncation_side="right"))
self.assertEqual(tokenizer.truncation_side, "right")
def test_left_truncation_side(self):
tokenizer = get_tokenizer(self.model_args, DataArguments(truncation_side="left"))
self.assertEqual(tokenizer.truncation_side, "left")
def test_default_chat_template(self):
tokenizer = get_tokenizer(self.model_args, DataArguments())
self.assertEqual(tokenizer.chat_template, DEFAULT_CHAT_TEMPLATE)
def test_default_chat_template_no_overwrite(self):
"""
If no chat template is passed explicitly in the config, then for models with a
`default_chat_template` but no `chat_template` we do not set a `chat_template`,
and that we do not change `default_chat_template`
"""
model_args = ModelArguments(model_name_or_path="m-a-p/OpenCodeInterpreter-SC2-7B")
base_tokenizer = AutoTokenizer.from_pretrained("m-a-p/OpenCodeInterpreter-SC2-7B")
processed_tokenizer = get_tokenizer(model_args, DataArguments())
assert getattr(processed_tokenizer, "chat_template") is None
self.assertEqual(base_tokenizer.default_chat_template, processed_tokenizer.default_chat_template)
def test_chatml_chat_template(self):
chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
tokenizer = get_tokenizer(self.model_args, DataArguments(chat_template=chat_template))
self.assertEqual(tokenizer.chat_template, chat_template)
class GetPeftConfigTest(unittest.TestCase):
def test_peft_config(self):
model_args = ModelArguments(use_peft=True, lora_r=42, lora_alpha=0.66, lora_dropout=0.99)
peft_config = get_peft_config(model_args)
self.assertEqual(peft_config.r, 42)
self.assertEqual(peft_config.lora_alpha, 0.66)
self.assertEqual(peft_config.lora_dropout, 0.99)
def test_no_peft_config(self):
model_args = ModelArguments(use_peft=False)
peft_config = get_peft_config(model_args)
self.assertIsNone(peft_config)
class IsAdapterModelTest(unittest.TestCase):
def test_is_adapter_model_calls_listdir(self):
# Assert that for an invalid repo name it gets to the point where it calls os.listdir,
# which is expected to raise a FileNotFoundError
self.assertRaises(FileNotFoundError, is_adapter_model, "nonexistent/model")
| alignment-handbook/tests/test_model_utils.py/0 | {
"file_path": "alignment-handbook/tests/test_model_utils.py",
"repo_id": "alignment-handbook",
"token_count": 1784
} | 14 |
# Introduction
{{#include ../../README.md:features}}
This book will introduce step by step how to use `candle`.
| candle/candle-book/src/README.md/0 | {
"file_path": "candle/candle-book/src/README.md",
"repo_id": "candle",
"token_count": 34
} | 15 |
# Porting a custom kernel
| candle/candle-book/src/inference/cuda/porting.md/0 | {
"file_path": "candle/candle-book/src/inference/cuda/porting.md",
"repo_id": "candle",
"token_count": 7
} | 16 |
use crate::benchmarks::{BenchDevice, BenchDeviceHandler};
use candle_core::{DType, Device, Tensor};
use criterion::{black_box, criterion_group, Criterion, Throughput};
use std::time::Instant;
fn run(a: &Tensor, b: &Tensor) {
a.matmul(&b.t().unwrap()).unwrap();
}
fn run_bench(c: &mut Criterion, device: &Device) {
let b = 1;
let m = 1;
let n = 2048;
let k = 2048;
let dtype = DType::F32;
let lhs = Tensor::zeros((b, m, k), dtype, device).unwrap();
let rhs = Tensor::zeros((b, n, k), dtype, device).unwrap();
let flops = b * m * n * k;
let mut group = c.benchmark_group(device.bench_name("matmul"));
group.throughput(Throughput::Bytes(flops as u64));
group.bench_function("iter", move |b| {
b.iter_custom(|iters| {
let start = Instant::now();
for _i in 0..iters {
run(black_box(&lhs), black_box(&rhs));
}
device.sync().unwrap();
start.elapsed()
})
});
group.finish();
}
fn criterion_benchmark(c: &mut Criterion) {
let handler = BenchDeviceHandler::new().unwrap();
for device in handler.devices {
run_bench(c, &device);
}
}
criterion_group!(benches, criterion_benchmark);
| candle/candle-core/benches/benchmarks/matmul.rs/0 | {
"file_path": "candle/candle-core/benches/benchmarks/matmul.rs",
"repo_id": "candle",
"token_count": 551
} | 17 |
pub mod erf;
pub mod kernels;
trait Cpu<const ARR: usize> {
type Unit;
type Array;
const STEP: usize;
const EPR: usize;
fn n() -> usize;
unsafe fn zero() -> Self::Unit;
unsafe fn zero_array() -> Self::Array;
unsafe fn load(mem_addr: *const f32) -> Self::Unit;
unsafe fn vec_add(a: Self::Unit, b: Self::Unit) -> Self::Unit;
unsafe fn vec_fma(a: Self::Unit, b: Self::Unit, c: Self::Unit) -> Self::Unit;
unsafe fn vec_reduce(x: Self::Array, y: *mut f32);
unsafe fn from_f32(v: f32) -> Self::Unit;
unsafe fn vec_store(mem_addr: *mut f32, a: Self::Unit);
}
trait CpuF16<const ARR: usize> {
type Unit;
type Array;
const STEP: usize;
const EPR: usize;
fn n() -> usize;
unsafe fn zero() -> Self::Unit;
unsafe fn zero_array() -> Self::Array;
unsafe fn load(mem_addr: *const f16) -> Self::Unit;
unsafe fn vec_add(a: Self::Unit, b: Self::Unit) -> Self::Unit;
unsafe fn vec_fma(a: Self::Unit, b: Self::Unit, c: Self::Unit) -> Self::Unit;
unsafe fn vec_reduce(x: Self::Array, y: *mut f32);
unsafe fn from_f32(v: f32) -> Self::Unit;
unsafe fn vec_store(mem_addr: *mut f16, a: Self::Unit);
}
use half::f16;
#[cfg(any(target_arch = "x86", target_arch = "x86_64"))]
#[cfg(target_feature = "avx")]
pub mod avx;
#[cfg(any(target_arch = "x86", target_arch = "x86_64"))]
#[cfg(target_feature = "avx")]
pub use avx::{CurrentCpu, CurrentCpuF16};
#[cfg(target_arch = "wasm32")]
#[cfg(target_feature = "simd128")]
pub mod simd128;
#[cfg(target_arch = "wasm32")]
#[cfg(target_feature = "simd128")]
pub use simd128::CurrentCpu;
#[cfg(any(target_arch = "arm", target_arch = "aarch64"))]
#[cfg(target_feature = "neon")]
pub mod neon;
#[cfg(any(target_arch = "arm", target_arch = "aarch64"))]
#[cfg(target_feature = "neon")]
pub use neon::CurrentCpu;
#[cfg(any(
target_feature = "neon",
target_feature = "avx",
target_feature = "simd128"
))]
#[inline(always)]
pub(crate) unsafe fn vec_dot_f32(a_row: *const f32, b_row: *const f32, c: *mut f32, k: usize) {
let np = k & !(CurrentCpu::STEP - 1);
let mut sum = CurrentCpu::zero_array();
let mut ax = CurrentCpu::zero_array();
let mut ay = CurrentCpu::zero_array();
for i in (0..np).step_by(CurrentCpu::STEP) {
for j in 0..CurrentCpu::n() {
ax[j] = CurrentCpu::load(a_row.add(i + j * CurrentCpu::EPR));
ay[j] = CurrentCpu::load(b_row.add(i + j * CurrentCpu::EPR));
sum[j] = CurrentCpu::vec_fma(sum[j], ax[j], ay[j]);
}
}
CurrentCpu::vec_reduce(sum, c);
// leftovers
for i in np..k {
*c += *a_row.add(i) * (*b_row.add(i));
}
}
#[cfg(not(any(
target_feature = "neon",
target_feature = "avx",
target_feature = "simd128"
)))]
#[inline(always)]
pub(crate) unsafe fn vec_dot_f32(a_row: *const f32, b_row: *const f32, c: *mut f32, k: usize) {
// leftovers
for i in 0..k {
*c += *a_row.add(i) * (*b_row.add(i));
}
}
#[cfg(any(
target_feature = "neon",
target_feature = "avx",
target_feature = "simd128"
))]
#[inline(always)]
pub(crate) unsafe fn vec_sum(row: *const f32, b: *mut f32, k: usize) {
let np = k & !(CurrentCpu::STEP - 1);
let mut sum = CurrentCpu::zero_array();
let mut x = CurrentCpu::zero_array();
for i in (0..np).step_by(CurrentCpu::STEP) {
for j in 0..CurrentCpu::n() {
x[j] = CurrentCpu::load(row.add(i + j * CurrentCpu::EPR));
sum[j] = CurrentCpu::vec_add(sum[j], x[j]);
}
}
CurrentCpu::vec_reduce(sum, b);
// leftovers
for i in np..k {
*b += *row.add(i)
}
}
#[cfg(not(any(
target_feature = "neon",
target_feature = "avx",
target_feature = "simd128"
)))]
#[inline(always)]
pub(crate) unsafe fn vec_sum(row: *const f32, b: *mut f32, k: usize) {
*b = 0f32;
for i in 0..k {
*b += *row.add(i)
}
}
#[cfg(target_feature = "avx")]
#[inline(always)]
pub(crate) unsafe fn vec_dot_f16(a_row: *const f16, b_row: *const f16, c: *mut f32, k: usize) {
let mut sumf = 0.0f32;
let np = k & !(CurrentCpuF16::STEP - 1);
let mut sum = CurrentCpuF16::zero_array();
let mut ax = CurrentCpuF16::zero_array();
let mut ay = CurrentCpuF16::zero_array();
for i in (0..np).step_by(CurrentCpuF16::STEP) {
for j in 0..CurrentCpuF16::n() {
ax[j] = CurrentCpuF16::load(a_row.add(i + j * CurrentCpuF16::EPR));
ay[j] = CurrentCpuF16::load(b_row.add(i + j * CurrentCpuF16::EPR));
sum[j] = CurrentCpuF16::vec_fma(sum[j], ax[j], ay[j]);
}
}
CurrentCpuF16::vec_reduce(sum, &mut sumf);
// leftovers
for i in np..k {
sumf += (*a_row.add(i)).to_f32() * (*b_row.add(i)).to_f32();
}
*c = sumf;
}
#[cfg(not(target_feature = "avx"))]
#[inline(always)]
pub(crate) unsafe fn vec_dot_f16(a_row: *const f16, b_row: *const f16, c: *mut f32, k: usize) {
// leftovers
let mut sum = 0.0;
for i in 0..k {
sum += (*a_row.add(i)).to_f32() * (*b_row.add(i)).to_f32();
}
*c = sum;
}
| candle/candle-core/src/cpu/mod.rs/0 | {
"file_path": "candle/candle-core/src/cpu/mod.rs",
"repo_id": "candle",
"token_count": 2416
} | 18 |
#![allow(dead_code)]
use libc::{c_char, c_double, c_float, c_int};
mod ffi {
use super::*;
extern "C" {
pub fn vsTanh(n: c_int, a: *const c_float, y: *mut c_float);
pub fn vdTanh(n: c_int, a: *const c_double, y: *mut c_double);
pub fn vsExp(n: c_int, a: *const c_float, y: *mut c_float);
pub fn vdExp(n: c_int, a: *const c_double, y: *mut c_double);
pub fn vsLn(n: c_int, a: *const c_float, y: *mut c_float);
pub fn vdLn(n: c_int, a: *const c_double, y: *mut c_double);
pub fn vsSin(n: c_int, a: *const c_float, y: *mut c_float);
pub fn vdSin(n: c_int, a: *const c_double, y: *mut c_double);
pub fn vsCos(n: c_int, a: *const c_float, y: *mut c_float);
pub fn vdCos(n: c_int, a: *const c_double, y: *mut c_double);
pub fn vsSqrt(n: c_int, a: *const c_float, y: *mut c_float);
pub fn vdSqrt(n: c_int, a: *const c_double, y: *mut c_double);
pub fn vsAdd(n: c_int, a: *const c_float, b: *const c_float, y: *mut c_float);
pub fn vdAdd(n: c_int, a: *const c_double, b: *const c_double, y: *mut c_double);
pub fn vsSub(n: c_int, a: *const c_float, b: *const c_float, y: *mut c_float);
pub fn vdSub(n: c_int, a: *const c_double, b: *const c_double, y: *mut c_double);
pub fn vsMul(n: c_int, a: *const c_float, b: *const c_float, y: *mut c_float);
pub fn vdMul(n: c_int, a: *const c_double, b: *const c_double, y: *mut c_double);
pub fn vsDiv(n: c_int, a: *const c_float, b: *const c_float, y: *mut c_float);
pub fn vdDiv(n: c_int, a: *const c_double, b: *const c_double, y: *mut c_double);
pub fn vsFmax(n: c_int, a: *const c_float, b: *const c_float, y: *mut c_float);
pub fn vdFmax(n: c_int, a: *const c_double, b: *const c_double, y: *mut c_double);
pub fn vsFmin(n: c_int, a: *const c_float, b: *const c_float, y: *mut c_float);
pub fn vdFmin(n: c_int, a: *const c_double, b: *const c_double, y: *mut c_double);
pub fn sgemm_(
transa: *const c_char,
transb: *const c_char,
m: *const c_int,
n: *const c_int,
k: *const c_int,
alpha: *const c_float,
a: *const c_float,
lda: *const c_int,
b: *const c_float,
ldb: *const c_int,
beta: *const c_float,
c: *mut c_float,
ldc: *const c_int,
);
pub fn dgemm_(
transa: *const c_char,
transb: *const c_char,
m: *const c_int,
n: *const c_int,
k: *const c_int,
alpha: *const c_double,
a: *const c_double,
lda: *const c_int,
b: *const c_double,
ldb: *const c_int,
beta: *const c_double,
c: *mut c_double,
ldc: *const c_int,
);
pub fn hgemm_(
transa: *const c_char,
transb: *const c_char,
m: *const c_int,
n: *const c_int,
k: *const c_int,
alpha: *const half::f16,
a: *const half::f16,
lda: *const c_int,
b: *const half::f16,
ldb: *const c_int,
beta: *const half::f16,
c: *mut half::f16,
ldc: *const c_int,
);
}
}
#[allow(clippy::too_many_arguments)]
#[inline]
pub unsafe fn sgemm(
transa: u8,
transb: u8,
m: i32,
n: i32,
k: i32,
alpha: f32,
a: &[f32],
lda: i32,
b: &[f32],
ldb: i32,
beta: f32,
c: &mut [f32],
ldc: i32,
) {
ffi::sgemm_(
&(transa as c_char),
&(transb as c_char),
&m,
&n,
&k,
&alpha,
a.as_ptr(),
&lda,
b.as_ptr(),
&ldb,
&beta,
c.as_mut_ptr(),
&ldc,
)
}
#[allow(clippy::too_many_arguments)]
#[inline]
pub unsafe fn dgemm(
transa: u8,
transb: u8,
m: i32,
n: i32,
k: i32,
alpha: f64,
a: &[f64],
lda: i32,
b: &[f64],
ldb: i32,
beta: f64,
c: &mut [f64],
ldc: i32,
) {
ffi::dgemm_(
&(transa as c_char),
&(transb as c_char),
&m,
&n,
&k,
&alpha,
a.as_ptr(),
&lda,
b.as_ptr(),
&ldb,
&beta,
c.as_mut_ptr(),
&ldc,
)
}
#[allow(clippy::too_many_arguments)]
#[inline]
pub unsafe fn hgemm(
transa: u8,
transb: u8,
m: i32,
n: i32,
k: i32,
alpha: half::f16,
a: &[half::f16],
lda: i32,
b: &[half::f16],
ldb: i32,
beta: half::f16,
c: &mut [half::f16],
ldc: i32,
) {
ffi::hgemm_(
&(transa as c_char),
&(transb as c_char),
&m,
&n,
&k,
&alpha,
a.as_ptr(),
&lda,
b.as_ptr(),
&ldb,
&beta,
c.as_mut_ptr(),
&ldc,
)
}
#[inline]
pub fn vs_exp(a: &[f32], y: &mut [f32]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vsExp(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_exp(a: &[f64], y: &mut [f64]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vdExp(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vs_ln(a: &[f32], y: &mut [f32]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vsLn(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_ln(a: &[f64], y: &mut [f64]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vdLn(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vs_sin(a: &[f32], y: &mut [f32]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vsSin(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_sin(a: &[f64], y: &mut [f64]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vdSin(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vs_cos(a: &[f32], y: &mut [f32]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vsCos(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_cos(a: &[f64], y: &mut [f64]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vdCos(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vs_sqrt(a: &[f32], y: &mut [f32]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vsSqrt(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_sqrt(a: &[f64], y: &mut [f64]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vdSqrt(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vs_sqr(a: &[f32], y: &mut [f32]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vsMul(a_len as i32, a.as_ptr(), a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_sqr(a: &[f64], y: &mut [f64]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vdMul(a_len as i32, a.as_ptr(), a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vs_tanh(a: &[f32], y: &mut [f32]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vsTanh(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_tanh(a: &[f64], y: &mut [f64]) {
let a_len = a.len();
let y_len = y.len();
if a_len != y_len {
panic!("a and y have different lengths {a_len} <> {y_len}")
}
unsafe { ffi::vdTanh(a_len as i32, a.as_ptr(), y.as_mut_ptr()) }
}
// The vector functions from mkl can be performed in place by using the same array for input and
// output.
// https://www.intel.com/content/www/us/en/docs/onemkl/developer-reference-c/2023-2/vector-mathematical-functions.html
#[inline]
pub fn vs_tanh_inplace(y: &mut [f32]) {
unsafe { ffi::vsTanh(y.len() as i32, y.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_tanh_inplace(y: &mut [f64]) {
unsafe { ffi::vdTanh(y.len() as i32, y.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vs_exp_inplace(y: &mut [f32]) {
unsafe { ffi::vsExp(y.len() as i32, y.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vd_exp_inplace(y: &mut [f64]) {
unsafe { ffi::vdExp(y.len() as i32, y.as_ptr(), y.as_mut_ptr()) }
}
#[inline]
pub fn vs_gelu(vs: &[f32], ys: &mut [f32]) {
for (&v, y) in vs.iter().zip(ys.iter_mut()) {
*y = (2.0f32 / std::f32::consts::PI).sqrt() * v * (1.0 + 0.044715 * v * v)
}
vs_tanh_inplace(ys);
for (&v, y) in vs.iter().zip(ys.iter_mut()) {
*y = 0.5 * v * (1.0 + *y)
}
}
#[inline]
pub fn vd_gelu(vs: &[f64], ys: &mut [f64]) {
for (&v, y) in vs.iter().zip(ys.iter_mut()) {
*y = (2.0f64 / std::f64::consts::PI).sqrt() * v * (1.0 + 0.044715 * v * v)
}
vd_tanh_inplace(ys);
for (&v, y) in vs.iter().zip(ys.iter_mut()) {
*y = 0.5 * v * (1.0 + *y)
}
}
#[inline]
pub fn vs_silu(vs: &[f32], ys: &mut [f32]) {
for (&v, y) in vs.iter().zip(ys.iter_mut()) {
*y = -v
}
vs_exp_inplace(ys);
for (&v, y) in vs.iter().zip(ys.iter_mut()) {
*y = v / (1.0 + *y)
}
}
#[inline]
pub fn vd_silu(vs: &[f64], ys: &mut [f64]) {
for (&v, y) in vs.iter().zip(ys.iter_mut()) {
*y = -v
}
vd_exp_inplace(ys);
for (&v, y) in vs.iter().zip(ys.iter_mut()) {
*y = v / (1.0 + *y)
}
}
macro_rules! binary_op {
($fn_name:ident, $ty:ty, $mkl_name:ident) => {
#[inline]
pub fn $fn_name(a: &[$ty], b: &[$ty], y: &mut [$ty]) {
let a_len = a.len();
let b_len = b.len();
let y_len = y.len();
if a_len != y_len || b_len != y_len {
panic!(
"{} a,b,y len mismatch {a_len} {b_len} {y_len}",
stringify!($fn_name)
);
}
unsafe { ffi::$mkl_name(a_len as i32, a.as_ptr(), b.as_ptr(), y.as_mut_ptr()) }
}
};
}
binary_op!(vs_add, f32, vsAdd);
binary_op!(vd_add, f64, vdAdd);
binary_op!(vs_sub, f32, vsSub);
binary_op!(vd_sub, f64, vdSub);
binary_op!(vs_mul, f32, vsMul);
binary_op!(vd_mul, f64, vdMul);
binary_op!(vs_div, f32, vsDiv);
binary_op!(vd_div, f64, vdDiv);
binary_op!(vs_max, f32, vsFmax);
binary_op!(vd_max, f64, vdFmax);
binary_op!(vs_min, f32, vsFmin);
binary_op!(vd_min, f64, vdFmin);
| candle/candle-core/src/mkl.rs/0 | {
"file_path": "candle/candle-core/src/mkl.rs",
"repo_id": "candle",
"token_count": 6463
} | 19 |
use crate::{DType, Device, Error, Result, Tensor, WithDType};
use safetensors::tensor as st;
use safetensors::tensor::SafeTensors;
use std::borrow::Cow;
use std::collections::HashMap;
use std::path::Path;
impl From<DType> for st::Dtype {
fn from(value: DType) -> Self {
match value {
DType::U8 => st::Dtype::U8,
DType::U32 => st::Dtype::U32,
DType::I64 => st::Dtype::I64,
DType::BF16 => st::Dtype::BF16,
DType::F16 => st::Dtype::F16,
DType::F32 => st::Dtype::F32,
DType::F64 => st::Dtype::F64,
}
}
}
impl TryFrom<st::Dtype> for DType {
type Error = Error;
fn try_from(value: st::Dtype) -> Result<Self> {
match value {
st::Dtype::U8 => Ok(DType::U8),
st::Dtype::U32 => Ok(DType::U32),
st::Dtype::I64 => Ok(DType::I64),
st::Dtype::BF16 => Ok(DType::BF16),
st::Dtype::F16 => Ok(DType::F16),
st::Dtype::F32 => Ok(DType::F32),
st::Dtype::F64 => Ok(DType::F64),
dtype => Err(Error::UnsupportedSafeTensorDtype(dtype)),
}
}
}
impl st::View for Tensor {
fn dtype(&self) -> st::Dtype {
self.dtype().into()
}
fn shape(&self) -> &[usize] {
self.shape().dims()
}
fn data(&self) -> Cow<[u8]> {
// This copies data from GPU to CPU.
// TODO: Avoid the unwrap here.
Cow::Owned(convert_back(self).unwrap())
}
fn data_len(&self) -> usize {
let n: usize = self.shape().elem_count();
let bytes_per_element = self.dtype().size_in_bytes();
n * bytes_per_element
}
}
impl st::View for &Tensor {
fn dtype(&self) -> st::Dtype {
(*self).dtype().into()
}
fn shape(&self) -> &[usize] {
self.dims()
}
fn data(&self) -> Cow<[u8]> {
// This copies data from GPU to CPU.
// TODO: Avoid the unwrap here.
Cow::Owned(convert_back(self).unwrap())
}
fn data_len(&self) -> usize {
let n: usize = self.dims().iter().product();
let bytes_per_element = (*self).dtype().size_in_bytes();
n * bytes_per_element
}
}
impl Tensor {
pub fn save_safetensors<P: AsRef<Path>>(&self, name: &str, filename: P) -> Result<()> {
let data = [(name, self.clone())];
Ok(st::serialize_to_file(data, &None, filename.as_ref())?)
}
}
fn convert_slice<T: WithDType>(data: &[u8], shape: &[usize], device: &Device) -> Result<Tensor> {
let size_in_bytes = T::DTYPE.size_in_bytes();
let elem_count = data.len() / size_in_bytes;
if (data.as_ptr() as usize) % size_in_bytes == 0 {
// SAFETY This is safe because we just checked that this
// was correctly aligned.
let data: &[T] =
unsafe { std::slice::from_raw_parts(data.as_ptr() as *const T, elem_count) };
Tensor::from_slice(data, shape, device)
} else {
// XXX: We need to specify `T` here, otherwise the compiler will infer u8 because of the following cast
// Making this vector too small to fit a full f16/f32/f64 weights, resulting in out-of-bounds access
let mut c: Vec<T> = Vec::with_capacity(elem_count);
// SAFETY: We just created c, so the allocated memory is necessarily
// contiguous and non overlapping with the view's data.
// We're downgrading the `c` pointer from T to u8, which removes alignment
// constraints.
unsafe {
std::ptr::copy_nonoverlapping(data.as_ptr(), c.as_mut_ptr() as *mut u8, data.len());
c.set_len(elem_count)
}
Tensor::from_slice(&c, shape, device)
}
}
fn convert_slice_with_cast<T: Sized + Copy, U: WithDType, F: Fn(T) -> Result<U>>(
data: &[u8],
shape: &[usize],
device: &Device,
conv: F,
) -> Result<Tensor> {
let size_in_bytes = std::mem::size_of::<T>();
let elem_count = data.len() / size_in_bytes;
if (data.as_ptr() as usize) % size_in_bytes == 0 {
// SAFETY This is safe because we just checked that this
// was correctly aligned.
let data: &[T] =
unsafe { std::slice::from_raw_parts(data.as_ptr() as *const T, elem_count) };
let data = data.iter().map(|t| conv(*t)).collect::<Result<Vec<_>>>()?;
Tensor::from_vec(data, shape, device)
} else {
// XXX: We need to specify `T` here, otherwise the compiler will infer u8 because of the following cast
// Making this vector too small to fit a full f16/f32/f64 weights, resulting in out-of-bounds access
let mut c: Vec<T> = Vec::with_capacity(elem_count);
// SAFETY: We just created c, so the allocated memory is necessarily
// contiguous and non overlapping with the view's data.
// We're downgrading the `c` pointer from T to u8, which removes alignment
// constraints.
unsafe {
std::ptr::copy_nonoverlapping(data.as_ptr(), c.as_mut_ptr() as *mut u8, data.len());
c.set_len(elem_count)
}
let c = c.into_iter().map(conv).collect::<Result<Vec<_>>>()?;
Tensor::from_vec(c, shape, device)
}
}
fn convert_with_cast_<T: Sized + Copy, U: WithDType, F: Fn(T) -> Result<U>>(
view: &st::TensorView<'_>,
device: &Device,
conv: F,
) -> Result<Tensor> {
convert_slice_with_cast::<T, U, F>(view.data(), view.shape(), device, conv)
}
fn convert_<T: WithDType>(view: &st::TensorView<'_>, device: &Device) -> Result<Tensor> {
convert_slice::<T>(view.data(), view.shape(), device)
}
fn convert_back_<T: WithDType>(mut vs: Vec<T>) -> Vec<u8> {
let size_in_bytes = T::DTYPE.size_in_bytes();
let length = vs.len() * size_in_bytes;
let capacity = vs.capacity() * size_in_bytes;
let ptr = vs.as_mut_ptr() as *mut u8;
// Don't run the destructor for Vec<T>
std::mem::forget(vs);
// SAFETY:
//
// Every T is larger than u8, so there is no issue regarding alignment.
// This re-interpret the Vec<T> as a Vec<u8>.
unsafe { Vec::from_raw_parts(ptr, length, capacity) }
}
pub trait Load {
fn load(&self, device: &Device) -> Result<Tensor>;
}
impl<'a> Load for st::TensorView<'a> {
fn load(&self, device: &Device) -> Result<Tensor> {
convert(self, device)
}
}
impl Tensor {
pub fn from_raw_buffer(
data: &[u8],
dtype: DType,
shape: &[usize],
device: &Device,
) -> Result<Self> {
match dtype {
DType::U8 => convert_slice::<u8>(data, shape, device),
DType::U32 => convert_slice::<u32>(data, shape, device),
DType::I64 => convert_slice::<i64>(data, shape, device),
DType::BF16 => convert_slice::<half::bf16>(data, shape, device),
DType::F16 => convert_slice::<half::f16>(data, shape, device),
DType::F32 => convert_slice::<f32>(data, shape, device),
DType::F64 => convert_slice::<f64>(data, shape, device),
}
}
}
fn convert(view: &st::TensorView<'_>, device: &Device) -> Result<Tensor> {
match view.dtype() {
st::Dtype::U8 => convert_::<u8>(view, device),
st::Dtype::U16 => {
let conv = |x| Ok(u32::from(x));
convert_with_cast_::<u16, u32, _>(view, device, conv)
}
st::Dtype::U32 => convert_::<u32>(view, device),
st::Dtype::I32 => {
let conv = |x| Ok(i64::from(x));
convert_with_cast_::<i32, i64, _>(view, device, conv)
}
st::Dtype::I64 => convert_::<i64>(view, device),
st::Dtype::BF16 => convert_::<half::bf16>(view, device),
st::Dtype::F16 => convert_::<half::f16>(view, device),
st::Dtype::F32 => convert_::<f32>(view, device),
st::Dtype::F64 => convert_::<f64>(view, device),
dtype => Err(Error::UnsupportedSafeTensorDtype(dtype)),
}
}
fn convert_back(tensor: &Tensor) -> Result<Vec<u8>> {
// TODO: This makes an unnecessary copy when the tensor is on the cpu.
let tensor = tensor.flatten_all()?;
match tensor.dtype() {
DType::U8 => Ok(convert_back_::<u8>(tensor.to_vec1()?)),
DType::U32 => Ok(convert_back_::<u32>(tensor.to_vec1()?)),
DType::I64 => Ok(convert_back_::<i64>(tensor.to_vec1()?)),
DType::F16 => Ok(convert_back_::<half::f16>(tensor.to_vec1()?)),
DType::BF16 => Ok(convert_back_::<half::bf16>(tensor.to_vec1()?)),
DType::F32 => Ok(convert_back_::<f32>(tensor.to_vec1()?)),
DType::F64 => Ok(convert_back_::<f64>(tensor.to_vec1()?)),
}
}
pub fn load<P: AsRef<Path>>(filename: P, device: &Device) -> Result<HashMap<String, Tensor>> {
let data = std::fs::read(filename.as_ref())?;
load_buffer(&data[..], device)
}
pub fn load_buffer(data: &[u8], device: &Device) -> Result<HashMap<String, Tensor>> {
let st = safetensors::SafeTensors::deserialize(data)?;
st.tensors()
.into_iter()
.map(|(name, view)| Ok((name, view.load(device)?)))
.collect()
}
pub fn save<K: AsRef<str> + Ord + std::fmt::Display, P: AsRef<Path>>(
tensors: &HashMap<K, Tensor>,
filename: P,
) -> Result<()> {
Ok(st::serialize_to_file(tensors, &None, filename.as_ref())?)
}
#[derive(yoke::Yokeable)]
struct SafeTensors_<'a>(SafeTensors<'a>);
pub struct MmapedSafetensors {
safetensors: Vec<yoke::Yoke<SafeTensors_<'static>, memmap2::Mmap>>,
routing: Option<HashMap<String, usize>>,
}
impl MmapedSafetensors {
/// Creates a wrapper around a memory mapped file and deserialize the safetensors header.
///
/// # Safety
///
/// The unsafe is inherited from [`memmap2::MmapOptions`].
pub unsafe fn new<P: AsRef<Path>>(p: P) -> Result<Self> {
let p = p.as_ref();
let file = std::fs::File::open(p).map_err(|e| Error::from(e).with_path(p))?;
let file = memmap2::MmapOptions::new()
.map(&file)
.map_err(|e| Error::from(e).with_path(p))?;
let safetensors = yoke::Yoke::<SafeTensors_<'static>, memmap2::Mmap>::try_attach_to_cart(
file,
|data: &[u8]| {
let st = safetensors::SafeTensors::deserialize(data)
.map_err(|e| Error::from(e).with_path(p))?;
Ok::<_, Error>(SafeTensors_(st))
},
)?;
Ok(Self {
safetensors: vec![safetensors],
routing: None,
})
}
/// Creates a wrapper around multiple memory mapped file and deserialize the safetensors headers.
///
/// If a tensor name appears in multiple files, the last entry is returned.
///
/// # Safety
///
/// The unsafe is inherited from [`memmap2::MmapOptions`].
pub unsafe fn multi<P: AsRef<Path>>(paths: &[P]) -> Result<Self> {
let mut routing = HashMap::new();
let mut safetensors = vec![];
for (index, p) in paths.iter().enumerate() {
let p = p.as_ref();
let file = std::fs::File::open(p).map_err(|e| Error::from(e).with_path(p))?;
let file = memmap2::MmapOptions::new()
.map(&file)
.map_err(|e| Error::from(e).with_path(p))?;
let data = yoke::Yoke::<SafeTensors_<'static>, memmap2::Mmap>::try_attach_to_cart(
file,
|data: &[u8]| {
let st = safetensors::SafeTensors::deserialize(data)
.map_err(|e| Error::from(e).with_path(p))?;
Ok::<_, Error>(SafeTensors_(st))
},
)?;
for k in data.get().0.names() {
routing.insert(k.to_string(), index);
}
safetensors.push(data)
}
Ok(Self {
safetensors,
routing: Some(routing),
})
}
pub fn load(&self, name: &str, dev: &Device) -> Result<Tensor> {
self.get(name)?.load(dev)
}
pub fn tensors(&self) -> Vec<(String, st::TensorView<'_>)> {
let mut tensors = vec![];
for safetensors in self.safetensors.iter() {
tensors.push(safetensors.get().0.tensors())
}
tensors.into_iter().flatten().collect()
}
pub fn get(&self, name: &str) -> Result<st::TensorView<'_>> {
let index = match &self.routing {
None => 0,
Some(routing) => {
let index = routing.get(name).ok_or_else(|| {
Error::CannotFindTensor {
path: name.to_string(),
}
.bt()
})?;
*index
}
};
Ok(self.safetensors[index].get().0.tensor(name)?)
}
}
pub struct BufferedSafetensors {
safetensors: yoke::Yoke<SafeTensors_<'static>, Vec<u8>>,
}
impl BufferedSafetensors {
/// Creates a wrapper around a binary buffer and deserialize the safetensors header.
pub fn new(buffer: Vec<u8>) -> Result<Self> {
let safetensors = yoke::Yoke::<SafeTensors_<'static>, Vec<u8>>::try_attach_to_cart(
buffer,
|data: &[u8]| {
let st = safetensors::SafeTensors::deserialize(data)?;
Ok::<_, Error>(SafeTensors_(st))
},
)?;
Ok(Self { safetensors })
}
pub fn load(&self, name: &str, dev: &Device) -> Result<Tensor> {
self.get(name)?.load(dev)
}
pub fn tensors(&self) -> Vec<(String, st::TensorView<'_>)> {
self.safetensors.get().0.tensors()
}
pub fn get(&self, name: &str) -> Result<st::TensorView<'_>> {
Ok(self.safetensors.get().0.tensor(name)?)
}
}
pub struct MmapedFile {
path: std::path::PathBuf,
inner: memmap2::Mmap,
}
impl MmapedFile {
/// Creates a wrapper around a memory mapped file from which you can retrieve
/// tensors using [`MmapedFile::deserialize`]
///
/// # Safety
///
/// The unsafe is inherited from [`memmap2::MmapOptions`].
pub unsafe fn new<P: AsRef<Path>>(p: P) -> Result<Self> {
let p = p.as_ref();
let file = std::fs::File::open(p).map_err(|e| Error::from(e).with_path(p))?;
let inner = memmap2::MmapOptions::new()
.map(&file)
.map_err(|e| Error::from(e).with_path(p))?;
Ok(Self {
inner,
path: p.to_path_buf(),
})
}
pub fn deserialize(&self) -> Result<SafeTensors<'_>> {
let st = safetensors::SafeTensors::deserialize(&self.inner)
.map_err(|e| Error::from(e).with_path(&self.path))?;
Ok(st)
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::collections::HashMap;
#[test]
fn save_single_tensor() {
let t = Tensor::zeros((2, 2), DType::F32, &Device::Cpu).unwrap();
t.save_safetensors("t", "t.safetensors").unwrap();
let bytes = std::fs::read("t.safetensors").unwrap();
assert_eq!(bytes, b"@\0\0\0\0\0\0\0{\"t\":{\"dtype\":\"F32\",\"shape\":[2,2],\"data_offsets\":[0,16]}} \0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0");
std::fs::remove_file("t.safetensors").unwrap();
}
#[test]
fn save_load_multiple_tensors() {
let t = Tensor::zeros((2, 2), DType::F32, &Device::Cpu).unwrap();
let u = Tensor::zeros((1, 2), DType::F32, &Device::Cpu).unwrap();
let map: HashMap<_, _> = [("t", t), ("u", u)].into_iter().collect();
save(&map, "multi.safetensors").unwrap();
let weights = load("multi.safetensors", &Device::Cpu).unwrap();
assert_eq!(weights.get("t").unwrap().dims(), &[2, 2]);
assert_eq!(weights.get("u").unwrap().dims(), &[1, 2]);
let bytes = std::fs::read("multi.safetensors").unwrap();
assert_eq!(bytes, b"x\0\0\0\0\0\0\0{\"t\":{\"dtype\":\"F32\",\"shape\":[2,2],\"data_offsets\":[0,16]},\"u\":{\"dtype\":\"F32\",\"shape\":[1,2],\"data_offsets\":[16,24]}} \0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0");
std::fs::remove_file("multi.safetensors").unwrap();
}
}
| candle/candle-core/src/safetensors.rs/0 | {
"file_path": "candle/candle-core/src/safetensors.rs",
"repo_id": "candle",
"token_count": 7743
} | 20 |
use candle::{test_device, Device, IndexOp, Result, Tensor};
use candle_core as candle;
fn contiguous(device: &Device) -> Result<()> {
let tensor = Tensor::arange(0u32, 24u32, device)?.reshape((2, 3, 4))?;
assert_eq!(
tensor.to_vec3::<u32>()?,
&[
[[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11]],
[[12, 13, 14, 15], [16, 17, 18, 19], [20, 21, 22, 23]]
]
);
assert_eq!(
tensor.t()?.contiguous()?.to_vec3::<u32>()?,
&[
[[0, 4, 8], [1, 5, 9], [2, 6, 10], [3, 7, 11]],
[[12, 16, 20], [13, 17, 21], [14, 18, 22], [15, 19, 23]]
]
);
assert_eq!(
tensor.transpose(0, 1)?.contiguous()?.to_vec3::<u32>()?,
&[
[[0, 1, 2, 3], [12, 13, 14, 15]],
[[4, 5, 6, 7], [16, 17, 18, 19]],
[[8, 9, 10, 11], [20, 21, 22, 23]]
]
);
assert_eq!(
tensor.transpose(0, 1)?.flatten_all()?.to_vec1::<u32>()?,
&[0, 1, 2, 3, 12, 13, 14, 15, 4, 5, 6, 7, 16, 17, 18, 19, 8, 9, 10, 11, 20, 21, 22, 23]
);
assert_eq!(
tensor
.i(1..)?
.transpose(0, 1)?
.contiguous()?
.to_vec3::<u32>()?,
&[[[12, 13, 14, 15]], [[16, 17, 18, 19]], [[20, 21, 22, 23]]]
);
assert_eq!(
tensor.transpose(0, 2)?.contiguous()?.to_vec3::<u32>()?,
&[
[[0, 12], [4, 16], [8, 20]],
[[1, 13], [5, 17], [9, 21]],
[[2, 14], [6, 18], [10, 22]],
[[3, 15], [7, 19], [11, 23]]
]
);
Ok(())
}
test_device!(contiguous, contiguous_cpu, contiguous_gpu, contiguous_metal);
#[test]
fn strided_blocks() -> Result<()> {
use candle::Device::Cpu;
let tensor = Tensor::arange(0u32, 24u32, &Cpu)?.reshape((2, 3, 4))?;
match tensor.strided_blocks() {
candle::StridedBlocks::SingleBlock { start_offset, len } => {
assert_eq!(start_offset, 0);
assert_eq!(len, 24);
}
candle::StridedBlocks::MultipleBlocks { .. } => {
panic!("unexpected block structure")
}
};
let tensor = Tensor::arange(0u32, 26u32, &Cpu)?
.i(2..)?
.reshape((2, 3, 4))?;
match tensor.strided_blocks() {
candle::StridedBlocks::SingleBlock { start_offset, len } => {
assert_eq!(start_offset, 2);
assert_eq!(len, 24);
}
candle::StridedBlocks::MultipleBlocks { .. } => {
panic!("unexpected block structure")
}
};
let tensor = Tensor::arange(0u32, 24u32, &Cpu)?.reshape((2, 3, 4))?;
let tensor = tensor.i(1)?;
match tensor.strided_blocks() {
candle::StridedBlocks::SingleBlock { start_offset, len } => {
assert_eq!(start_offset, 12);
assert_eq!(len, 12);
}
candle::StridedBlocks::MultipleBlocks { .. } => {
panic!("unexpected block structure")
}
};
let tensor = Tensor::arange(0u32, 24u32, &Cpu)?.reshape((2, 3, 4))?;
let tensor = tensor.i((.., 1))?.contiguous()?;
match tensor.strided_blocks() {
candle::StridedBlocks::SingleBlock { start_offset, len } => {
assert_eq!(start_offset, 0);
assert_eq!(len, 8);
assert_eq!(tensor.to_vec2::<u32>()?, &[[4, 5, 6, 7], [16, 17, 18, 19]]);
}
candle::StridedBlocks::MultipleBlocks { .. } => {
panic!("unexpected block structure")
}
};
let tensor = Tensor::arange(0u32, 24u32, &Cpu)?.reshape((2, 3, 4))?;
let tensor = tensor.i((.., 1))?;
match tensor.strided_blocks() {
candle::StridedBlocks::SingleBlock { .. } => {
panic!("unexpected block structure")
}
candle::StridedBlocks::MultipleBlocks {
block_len,
block_start_index,
} => {
assert_eq!(block_len, 4);
assert_eq!(block_start_index.collect::<Vec<_>>(), &[4, 16])
}
};
let tensor = Tensor::arange(0u32, 24u32, &Cpu)?.reshape((2, 3, 4))?;
match tensor.t()?.strided_blocks() {
candle::StridedBlocks::SingleBlock { .. } => {
panic!("unexpected block structure")
}
candle::StridedBlocks::MultipleBlocks {
block_start_index,
block_len,
} => {
assert_eq!(block_len, 1);
assert_eq!(
block_start_index.collect::<Vec<_>>(),
&[
0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11, 12, 16, 20, 13, 17, 21, 14, 18, 22, 15,
19, 23
]
)
}
};
let tensor = Tensor::arange(0u32, 24u32, &Cpu)?.reshape((2, 3, 4))?;
match tensor.transpose(0, 1)?.strided_blocks() {
candle::StridedBlocks::SingleBlock { .. } => {
panic!("unexpected block structure")
}
candle::StridedBlocks::MultipleBlocks {
block_start_index,
block_len,
} => {
assert_eq!(block_len, 4);
assert_eq!(
block_start_index.collect::<Vec<_>>(),
&[0, 12, 4, 16, 8, 20]
)
}
};
Ok(())
}
| candle/candle-core/tests/layout_tests.rs/0 | {
"file_path": "candle/candle-core/tests/layout_tests.rs",
"repo_id": "candle",
"token_count": 2819
} | 21 |
//! Datasets & Dataloaders for Candle
pub mod batcher;
pub mod hub;
pub mod nlp;
pub mod vision;
pub use batcher::Batcher;
| candle/candle-datasets/src/lib.rs/0 | {
"file_path": "candle/candle-datasets/src/lib.rs",
"repo_id": "candle",
"token_count": 45
} | 22 |
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::Parser;
use candle::{DType, IndexOp, D};
use candle_nn::{Module, VarBuilder};
use candle_transformers::models::convmixer;
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.model("lmz/candle-convmixer".into());
api.get("convmixer_1024_20_ks9_p14.safetensors")?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let model = convmixer::c1024_20(1000, vb)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| candle/candle-examples/examples/convmixer/main.rs/0 | {
"file_path": "candle/candle-examples/examples/convmixer/main.rs",
"repo_id": "candle",
"token_count": 768
} | 23 |
# candle-mamba: Mamba implementation
Candle implementation of *Mamba* [1] inference only. Mamba is an alternative to
the transformer architecture. It leverages State Space Models (SSMs) with the
goal of being computationally efficient on long sequences. The implementation is
based on [mamba.rs](https://github.com/LaurentMazare/mamba.rs).
- [1]. [Mamba: Linear-Time Sequence Modeling with Selective State Spaces](https://arxiv.org/abs/2312.00752).
Compared to the mamba-minimal example, this version is far more efficient but
would only work for inference.
## Running the example
```bash
$ cargo run --example mamba-minimal --release -- --prompt "Mamba is the"
```
| candle/candle-examples/examples/mamba/README.md/0 | {
"file_path": "candle/candle-examples/examples/mamba/README.md",
"repo_id": "candle",
"token_count": 190
} | 24 |
## Using ONNX models in Candle
This example demonstrates how to run [ONNX](https://github.com/onnx/onnx) based models in Candle.
It contains small variants of two models, [SqueezeNet](https://arxiv.org/pdf/1602.07360.pdf) (default) and [EfficientNet](https://arxiv.org/pdf/1905.11946.pdf).
You can run the examples with following commands:
```bash
cargo run --example onnx --features=onnx --release -- --image candle-examples/examples/yolo-v8/assets/bike.jpg
```
Use the `--which` flag to specify explicitly which network to use, i.e.
```bash
$ cargo run --example onnx --features=onnx --release -- --which squeeze-net --image candle-examples/examples/yolo-v8/assets/bike.jpg
Finished release [optimized] target(s) in 0.21s
Running `target/release/examples/onnx --which squeeze-net --image candle-examples/examples/yolo-v8/assets/bike.jpg`
loaded image Tensor[dims 3, 224, 224; f32]
unicycle, monocycle : 83.23%
ballplayer, baseball player : 3.68%
bearskin, busby, shako : 1.54%
military uniform : 0.78%
cowboy hat, ten-gallon hat : 0.76%
```
```bash
$ cargo run --example onnx --features=onnx --release -- --which efficient-net --image candle-examples/examples/yolo-v8/assets/bike.jpg
Finished release [optimized] target(s) in 0.20s
Running `target/release/examples/onnx --which efficient-net --image candle-examples/examples/yolo-v8/assets/bike.jpg`
loaded image Tensor[dims 224, 224, 3; f32]
bicycle-built-for-two, tandem bicycle, tandem : 99.16%
mountain bike, all-terrain bike, off-roader : 0.60%
unicycle, monocycle : 0.17%
crash helmet : 0.02%
alp : 0.02%
```
| candle/candle-examples/examples/onnx/README.md/0 | {
"file_path": "candle/candle-examples/examples/onnx/README.md",
"repo_id": "candle",
"token_count": 832
} | 25 |
#![allow(unused)]
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use candle::Result;
use clap::{Parser, Subcommand};
mod gym_env;
mod vec_gym_env;
mod ddpg;
mod dqn;
mod policy_gradient;
#[derive(Parser)]
struct Args {
#[command(subcommand)]
command: Command,
}
#[derive(Subcommand)]
enum Command {
Pg,
Ddpg,
Dqn,
}
fn main() -> Result<()> {
let args = Args::parse();
match args.command {
Command::Pg => policy_gradient::run()?,
Command::Ddpg => ddpg::run()?,
Command::Dqn => dqn::run()?,
}
Ok(())
}
| candle/candle-examples/examples/reinforcement-learning/main.rs/0 | {
"file_path": "candle/candle-examples/examples/reinforcement-learning/main.rs",
"repo_id": "candle",
"token_count": 287
} | 26 |
# candle-trocr
`TrOCR` is a transformer OCR Model. In this example it is used to
transcribe image text. See the associated [model
card](https://huggingface.co/microsoft/trocr-base-printed) for details on
the model itself.
Supported models include:
- `--which base`: small handwritten OCR model.
- `--which large`: large handwritten OCR model.
- `--which base-printed`: small printed OCR model.
- `--which large-printed`: large printed OCR model.
## Running an example
```bash
cargo run --example trocr --release -- --image candle-examples/examples/trocr/assets/trocr.png
cargo run --example trocr --release -- --which large --image candle-examples/examples/trocr/assets/trocr.png
cargo run --example trocr --release -- --which base-printed --image candle-examples/examples/trocr/assets/noto.png
cargo run --example trocr --release -- --which large-printed --image candle-examples/examples/trocr/assets/noto.png
```
### Outputs
```
industry , Mr. Brown commented icily . " Let us have a
industry , " Mr. Brown commented icily . " Let us have a
THE QUICK BROWN FOR JUMPS OVER THE LAY DOG
THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG
```
| candle/candle-examples/examples/trocr/readme.md/0 | {
"file_path": "candle/candle-examples/examples/trocr/readme.md",
"repo_id": "candle",
"token_count": 360
} | 27 |
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
use candle_transformers::models::stable_diffusion;
use candle_transformers::models::wuerstchen;
use anyhow::{Error as E, Result};
use candle::{DType, Device, IndexOp, Tensor};
use clap::Parser;
use tokenizers::Tokenizer;
const PRIOR_GUIDANCE_SCALE: f64 = 4.0;
const RESOLUTION_MULTIPLE: f64 = 42.67;
const LATENT_DIM_SCALE: f64 = 10.67;
const PRIOR_CIN: usize = 16;
const DECODER_CIN: usize = 4;
#[derive(Parser)]
#[command(author, version, about, long_about = None)]
struct Args {
/// The prompt to be used for image generation.
#[arg(
long,
default_value = "A very realistic photo of a rusty robot walking on a sandy beach"
)]
prompt: String,
#[arg(long, default_value = "")]
uncond_prompt: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
#[arg(long)]
use_flash_attn: bool,
/// The height in pixels of the generated image.
#[arg(long)]
height: Option<usize>,
/// The width in pixels of the generated image.
#[arg(long)]
width: Option<usize>,
/// The decoder weight file, in .safetensors format.
#[arg(long, value_name = "FILE")]
decoder_weights: Option<String>,
/// The CLIP weight file, in .safetensors format.
#[arg(long, value_name = "FILE")]
clip_weights: Option<String>,
/// The CLIP weight file used by the prior model, in .safetensors format.
#[arg(long, value_name = "FILE")]
prior_clip_weights: Option<String>,
/// The prior weight file, in .safetensors format.
#[arg(long, value_name = "FILE")]
prior_weights: Option<String>,
/// The VQGAN weight file, in .safetensors format.
#[arg(long, value_name = "FILE")]
vqgan_weights: Option<String>,
#[arg(long, value_name = "FILE")]
/// The file specifying the tokenizer to used for tokenization.
tokenizer: Option<String>,
#[arg(long, value_name = "FILE")]
/// The file specifying the tokenizer to used for prior tokenization.
prior_tokenizer: Option<String>,
/// The number of samples to generate.
#[arg(long, default_value_t = 1)]
num_samples: i64,
/// The name of the final image to generate.
#[arg(long, value_name = "FILE", default_value = "sd_final.png")]
final_image: String,
}
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
enum ModelFile {
Tokenizer,
PriorTokenizer,
Clip,
PriorClip,
Decoder,
VqGan,
Prior,
}
impl ModelFile {
fn get(&self, filename: Option<String>) -> Result<std::path::PathBuf> {
use hf_hub::api::sync::Api;
match filename {
Some(filename) => Ok(std::path::PathBuf::from(filename)),
None => {
let repo_main = "warp-ai/wuerstchen";
let repo_prior = "warp-ai/wuerstchen-prior";
let (repo, path) = match self {
Self::Tokenizer => (repo_main, "tokenizer/tokenizer.json"),
Self::PriorTokenizer => (repo_prior, "tokenizer/tokenizer.json"),
Self::Clip => (repo_main, "text_encoder/model.safetensors"),
Self::PriorClip => (repo_prior, "text_encoder/model.safetensors"),
Self::Decoder => (repo_main, "decoder/diffusion_pytorch_model.safetensors"),
Self::VqGan => (repo_main, "vqgan/diffusion_pytorch_model.safetensors"),
Self::Prior => (repo_prior, "prior/diffusion_pytorch_model.safetensors"),
};
let filename = Api::new()?.model(repo.to_string()).get(path)?;
Ok(filename)
}
}
}
}
fn output_filename(
basename: &str,
sample_idx: i64,
num_samples: i64,
timestep_idx: Option<usize>,
) -> String {
let filename = if num_samples > 1 {
match basename.rsplit_once('.') {
None => format!("{basename}.{sample_idx}.png"),
Some((filename_no_extension, extension)) => {
format!("{filename_no_extension}.{sample_idx}.{extension}")
}
}
} else {
basename.to_string()
};
match timestep_idx {
None => filename,
Some(timestep_idx) => match filename.rsplit_once('.') {
None => format!("{filename}-{timestep_idx}.png"),
Some((filename_no_extension, extension)) => {
format!("{filename_no_extension}-{timestep_idx}.{extension}")
}
},
}
}
fn encode_prompt(
prompt: &str,
uncond_prompt: Option<&str>,
tokenizer: std::path::PathBuf,
clip_weights: std::path::PathBuf,
clip_config: stable_diffusion::clip::Config,
device: &Device,
) -> Result<Tensor> {
let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;
let pad_id = match &clip_config.pad_with {
Some(padding) => *tokenizer.get_vocab(true).get(padding.as_str()).unwrap(),
None => *tokenizer.get_vocab(true).get("<|endoftext|>").unwrap(),
};
println!("Running with prompt \"{prompt}\".");
let mut tokens = tokenizer
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
let tokens_len = tokens.len();
while tokens.len() < clip_config.max_position_embeddings {
tokens.push(pad_id)
}
let tokens = Tensor::new(tokens.as_slice(), device)?.unsqueeze(0)?;
println!("Building the clip transformer.");
let text_model =
stable_diffusion::build_clip_transformer(&clip_config, clip_weights, device, DType::F32)?;
let text_embeddings = text_model.forward_with_mask(&tokens, tokens_len - 1)?;
match uncond_prompt {
None => Ok(text_embeddings),
Some(uncond_prompt) => {
let mut uncond_tokens = tokenizer
.encode(uncond_prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
let uncond_tokens_len = uncond_tokens.len();
while uncond_tokens.len() < clip_config.max_position_embeddings {
uncond_tokens.push(pad_id)
}
let uncond_tokens = Tensor::new(uncond_tokens.as_slice(), device)?.unsqueeze(0)?;
let uncond_embeddings =
text_model.forward_with_mask(&uncond_tokens, uncond_tokens_len - 1)?;
let text_embeddings = Tensor::cat(&[text_embeddings, uncond_embeddings], 0)?;
Ok(text_embeddings)
}
}
}
fn run(args: Args) -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let Args {
prompt,
uncond_prompt,
cpu,
height,
width,
tokenizer,
final_image,
num_samples,
clip_weights,
prior_weights,
vqgan_weights,
decoder_weights,
tracing,
..
} = args;
let _guard = if tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
let device = candle_examples::device(cpu)?;
let height = height.unwrap_or(1024);
let width = width.unwrap_or(1024);
let prior_text_embeddings = {
let tokenizer = ModelFile::PriorTokenizer.get(args.prior_tokenizer)?;
let weights = ModelFile::PriorClip.get(args.prior_clip_weights)?;
encode_prompt(
&prompt,
Some(&uncond_prompt),
tokenizer.clone(),
weights,
stable_diffusion::clip::Config::wuerstchen_prior(),
&device,
)?
};
println!("generated prior text embeddings {prior_text_embeddings:?}");
let text_embeddings = {
let tokenizer = ModelFile::Tokenizer.get(tokenizer)?;
let weights = ModelFile::Clip.get(clip_weights)?;
encode_prompt(
&prompt,
None,
tokenizer.clone(),
weights,
stable_diffusion::clip::Config::wuerstchen(),
&device,
)?
};
println!("generated text embeddings {text_embeddings:?}");
println!("Building the prior.");
let b_size = 1;
let image_embeddings = {
// https://huggingface.co/warp-ai/wuerstchen-prior/blob/main/prior/config.json
let latent_height = (height as f64 / RESOLUTION_MULTIPLE).ceil() as usize;
let latent_width = (width as f64 / RESOLUTION_MULTIPLE).ceil() as usize;
let mut latents = Tensor::randn(
0f32,
1f32,
(b_size, PRIOR_CIN, latent_height, latent_width),
&device,
)?;
let prior = {
let file = ModelFile::Prior.get(prior_weights)?;
let vb = unsafe {
candle_nn::VarBuilder::from_mmaped_safetensors(&[file], DType::F32, &device)?
};
wuerstchen::prior::WPrior::new(
/* c_in */ PRIOR_CIN,
/* c */ 1536,
/* c_cond */ 1280,
/* c_r */ 64,
/* depth */ 32,
/* nhead */ 24,
args.use_flash_attn,
vb,
)?
};
let prior_scheduler = wuerstchen::ddpm::DDPMWScheduler::new(60, Default::default())?;
let timesteps = prior_scheduler.timesteps();
let timesteps = ×teps[..timesteps.len() - 1];
println!("prior denoising");
for (index, &t) in timesteps.iter().enumerate() {
let start_time = std::time::Instant::now();
let latent_model_input = Tensor::cat(&[&latents, &latents], 0)?;
let ratio = (Tensor::ones(2, DType::F32, &device)? * t)?;
let noise_pred = prior.forward(&latent_model_input, &ratio, &prior_text_embeddings)?;
let noise_pred = noise_pred.chunk(2, 0)?;
let (noise_pred_text, noise_pred_uncond) = (&noise_pred[0], &noise_pred[1]);
let noise_pred = (noise_pred_uncond
+ ((noise_pred_text - noise_pred_uncond)? * PRIOR_GUIDANCE_SCALE)?)?;
latents = prior_scheduler.step(&noise_pred, t, &latents)?;
let dt = start_time.elapsed().as_secs_f32();
println!("step {}/{} done, {:.2}s", index + 1, timesteps.len(), dt);
}
((latents * 42.)? - 1.)?
};
println!("Building the vqgan.");
let vqgan = {
let file = ModelFile::VqGan.get(vqgan_weights)?;
let vb = unsafe {
candle_nn::VarBuilder::from_mmaped_safetensors(&[file], DType::F32, &device)?
};
wuerstchen::paella_vq::PaellaVQ::new(vb)?
};
println!("Building the decoder.");
// https://huggingface.co/warp-ai/wuerstchen/blob/main/decoder/config.json
let decoder = {
let file = ModelFile::Decoder.get(decoder_weights)?;
let vb = unsafe {
candle_nn::VarBuilder::from_mmaped_safetensors(&[file], DType::F32, &device)?
};
wuerstchen::diffnext::WDiffNeXt::new(
/* c_in */ DECODER_CIN,
/* c_out */ DECODER_CIN,
/* c_r */ 64,
/* c_cond */ 1024,
/* clip_embd */ 1024,
/* patch_size */ 2,
args.use_flash_attn,
vb,
)?
};
for idx in 0..num_samples {
// https://huggingface.co/warp-ai/wuerstchen/blob/main/model_index.json
let latent_height = (image_embeddings.dim(2)? as f64 * LATENT_DIM_SCALE) as usize;
let latent_width = (image_embeddings.dim(3)? as f64 * LATENT_DIM_SCALE) as usize;
let mut latents = Tensor::randn(
0f32,
1f32,
(b_size, DECODER_CIN, latent_height, latent_width),
&device,
)?;
println!("diffusion process with prior {image_embeddings:?}");
let scheduler = wuerstchen::ddpm::DDPMWScheduler::new(12, Default::default())?;
let timesteps = scheduler.timesteps();
let timesteps = ×teps[..timesteps.len() - 1];
for (index, &t) in timesteps.iter().enumerate() {
let start_time = std::time::Instant::now();
let ratio = (Tensor::ones(1, DType::F32, &device)? * t)?;
let noise_pred =
decoder.forward(&latents, &ratio, &image_embeddings, Some(&text_embeddings))?;
latents = scheduler.step(&noise_pred, t, &latents)?;
let dt = start_time.elapsed().as_secs_f32();
println!("step {}/{} done, {:.2}s", index + 1, timesteps.len(), dt);
}
println!(
"Generating the final image for sample {}/{}.",
idx + 1,
num_samples
);
let image = vqgan.decode(&(&latents * 0.3764)?)?;
let image = (image.clamp(0f32, 1f32)? * 255.)?
.to_dtype(DType::U8)?
.i(0)?;
let image_filename = output_filename(&final_image, idx + 1, num_samples, None);
candle_examples::save_image(&image, image_filename)?
}
Ok(())
}
fn main() -> Result<()> {
let args = Args::parse();
run(args)
}
| candle/candle-examples/examples/wuerstchen/main.rs/0 | {
"file_path": "candle/candle-examples/examples/wuerstchen/main.rs",
"repo_id": "candle",
"token_count": 6372
} | 28 |
use candle::{Device, Result, Tensor};
/// Loads an image from disk using the image crate, this returns a tensor with shape
/// (3, 224, 224). imagenet normalization is applied.
pub fn load_image224<P: AsRef<std::path::Path>>(p: P) -> Result<Tensor> {
let img = image::io::Reader::open(p)?
.decode()
.map_err(candle::Error::wrap)?
.resize_to_fill(224, 224, image::imageops::FilterType::Triangle);
let img = img.to_rgb8();
let data = img.into_raw();
let data = Tensor::from_vec(data, (224, 224, 3), &Device::Cpu)?.permute((2, 0, 1))?;
let mean = Tensor::new(&[0.485f32, 0.456, 0.406], &Device::Cpu)?.reshape((3, 1, 1))?;
let std = Tensor::new(&[0.229f32, 0.224, 0.225], &Device::Cpu)?.reshape((3, 1, 1))?;
(data.to_dtype(candle::DType::F32)? / 255.)?
.broadcast_sub(&mean)?
.broadcast_div(&std)
}
pub const CLASS_COUNT: i64 = 1000;
pub const CLASSES: [&str; 1000] = [
"tench, Tinca tinca",
"goldfish, Carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias",
"tiger shark, Galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, Struthio camelus",
"brambling, Fringilla montifringilla",
"goldfinch, Carduelis carduelis",
"house finch, linnet, Carpodacus mexicanus",
"junco, snowbird",
"indigo bunting, indigo finch, indigo bird, Passerina cyanea",
"robin, American robin, Turdus migratorius",
"bulbul",
"jay",
"magpie",
"chickadee",
"water ouzel, dipper",
"kite",
"bald eagle, American eagle, Haliaeetus leucocephalus",
"vulture",
"great grey owl, great gray owl, Strix nebulosa",
"European fire salamander, Salamandra salamandra",
"common newt, Triturus vulgaris",
"eft",
"spotted salamander, Ambystoma maculatum",
"axolotl, mud puppy, Ambystoma mexicanum",
"bullfrog, Rana catesbeiana",
"tree frog, tree-frog",
"tailed frog, bell toad, ribbed toad, tailed toad, Ascaphus trui",
"loggerhead, loggerhead turtle, Caretta caretta",
"leatherback turtle, leatherback, leathery turtle, Dermochelys coriacea",
"mud turtle",
"terrapin",
"box turtle, box tortoise",
"banded gecko",
"common iguana, iguana, Iguana iguana",
"American chameleon, anole, Anolis carolinensis",
"whiptail, whiptail lizard",
"agama",
"frilled lizard, Chlamydosaurus kingi",
"alligator lizard",
"Gila monster, Heloderma suspectum",
"green lizard, Lacerta viridis",
"African chameleon, Chamaeleo chamaeleon",
"Komodo dragon, Komodo lizard, dragon lizard, giant lizard, Varanus komodoensis",
"African crocodile, Nile crocodile, Crocodylus niloticus",
"American alligator, Alligator mississipiensis",
"triceratops",
"thunder snake, worm snake, Carphophis amoenus",
"ringneck snake, ring-necked snake, ring snake",
"hognose snake, puff adder, sand viper",
"green snake, grass snake",
"king snake, kingsnake",
"garter snake, grass snake",
"water snake",
"vine snake",
"night snake, Hypsiglena torquata",
"boa constrictor, Constrictor constrictor",
"rock python, rock snake, Python sebae",
"Indian cobra, Naja naja",
"green mamba",
"sea snake",
"horned viper, cerastes, sand viper, horned asp, Cerastes cornutus",
"diamondback, diamondback rattlesnake, Crotalus adamanteus",
"sidewinder, horned rattlesnake, Crotalus cerastes",
"trilobite",
"harvestman, daddy longlegs, Phalangium opilio",
"scorpion",
"black and gold garden spider, Argiope aurantia",
"barn spider, Araneus cavaticus",
"garden spider, Aranea diademata",
"black widow, Latrodectus mactans",
"tarantula",
"wolf spider, hunting spider",
"tick",
"centipede",
"black grouse",
"ptarmigan",
"ruffed grouse, partridge, Bonasa umbellus",
"prairie chicken, prairie grouse, prairie fowl",
"peacock",
"quail",
"partridge",
"African grey, African gray, Psittacus erithacus",
"macaw",
"sulphur-crested cockatoo, Kakatoe galerita, Cacatua galerita",
"lorikeet",
"coucal",
"bee eater",
"hornbill",
"hummingbird",
"jacamar",
"toucan",
"drake",
"red-breasted merganser, Mergus serrator",
"goose",
"black swan, Cygnus atratus",
"tusker",
"echidna, spiny anteater, anteater",
"platypus, duckbill, duckbilled platypus, duck-billed platypus, Ornithorhynchus anatinus",
"wallaby, brush kangaroo",
"koala, koala bear, kangaroo bear, native bear, Phascolarctos cinereus",
"wombat",
"jellyfish",
"sea anemone, anemone",
"brain coral",
"flatworm, platyhelminth",
"nematode, nematode worm, roundworm",
"conch",
"snail",
"slug",
"sea slug, nudibranch",
"chiton, coat-of-mail shell, sea cradle, polyplacophore",
"chambered nautilus, pearly nautilus, nautilus",
"Dungeness crab, Cancer magister",
"rock crab, Cancer irroratus",
"fiddler crab",
"king crab, Alaska crab, Alaskan king crab, Alaska king crab, Paralithodes camtschatica",
"American lobster, Northern lobster, Maine lobster, Homarus americanus",
"spiny lobster, langouste, rock lobster, crawfish, crayfish, sea crawfish",
"crayfish, crawfish, crawdad, crawdaddy",
"hermit crab",
"isopod",
"white stork, Ciconia ciconia",
"black stork, Ciconia nigra",
"spoonbill",
"flamingo",
"little blue heron, Egretta caerulea",
"American egret, great white heron, Egretta albus",
"bittern",
"crane",
"limpkin, Aramus pictus",
"European gallinule, Porphyrio porphyrio",
"American coot, marsh hen, mud hen, water hen, Fulica americana",
"bustard",
"ruddy turnstone, Arenaria interpres",
"red-backed sandpiper, dunlin, Erolia alpina",
"redshank, Tringa totanus",
"dowitcher",
"oystercatcher, oyster catcher",
"pelican",
"king penguin, Aptenodytes patagonica",
"albatross, mollymawk",
"grey whale, gray whale, devilfish, Eschrichtius gibbosus, Eschrichtius robustus",
"killer whale, killer, orca, grampus, sea wolf, Orcinus orca",
"dugong, Dugong dugon",
"sea lion",
"Chihuahua",
"Japanese spaniel",
"Maltese dog, Maltese terrier, Maltese",
"Pekinese, Pekingese, Peke",
"Shih-Tzu",
"Blenheim spaniel",
"papillon",
"toy terrier",
"Rhodesian ridgeback",
"Afghan hound, Afghan",
"basset, basset hound",
"beagle",
"bloodhound, sleuthhound",
"bluetick",
"black-and-tan coonhound",
"Walker hound, Walker foxhound",
"English foxhound",
"redbone",
"borzoi, Russian wolfhound",
"Irish wolfhound",
"Italian greyhound",
"whippet",
"Ibizan hound, Ibizan Podenco",
"Norwegian elkhound, elkhound",
"otterhound, otter hound",
"Saluki, gazelle hound",
"Scottish deerhound, deerhound",
"Weimaraner",
"Staffordshire bullterrier, Staffordshire bull terrier",
"American Staffordshire terrier, Staffordshire terrier, American pit bull terrier, pit bull terrier",
"Bedlington terrier",
"Border terrier",
"Kerry blue terrier",
"Irish terrier",
"Norfolk terrier",
"Norwich terrier",
"Yorkshire terrier",
"wire-haired fox terrier",
"Lakeland terrier",
"Sealyham terrier, Sealyham",
"Airedale, Airedale terrier",
"cairn, cairn terrier",
"Australian terrier",
"Dandie Dinmont, Dandie Dinmont terrier",
"Boston bull, Boston terrier",
"miniature schnauzer",
"giant schnauzer",
"standard schnauzer",
"Scotch terrier, Scottish terrier, Scottie",
"Tibetan terrier, chrysanthemum dog",
"silky terrier, Sydney silky",
"soft-coated wheaten terrier",
"West Highland white terrier",
"Lhasa, Lhasa apso",
"flat-coated retriever",
"curly-coated retriever",
"golden retriever",
"Labrador retriever",
"Chesapeake Bay retriever",
"German short-haired pointer",
"vizsla, Hungarian pointer",
"English setter",
"Irish setter, red setter",
"Gordon setter",
"Brittany spaniel",
"clumber, clumber spaniel",
"English springer, English springer spaniel",
"Welsh springer spaniel",
"cocker spaniel, English cocker spaniel, cocker",
"Sussex spaniel",
"Irish water spaniel",
"kuvasz",
"schipperke",
"groenendael",
"malinois",
"briard",
"kelpie",
"komondor",
"Old English sheepdog, bobtail",
"Shetland sheepdog, Shetland sheep dog, Shetland",
"collie",
"Border collie",
"Bouvier des Flandres, Bouviers des Flandres",
"Rottweiler",
"German shepherd, German shepherd dog, German police dog, alsatian",
"Doberman, Doberman pinscher",
"miniature pinscher",
"Greater Swiss Mountain dog",
"Bernese mountain dog",
"Appenzeller",
"EntleBucher",
"boxer",
"bull mastiff",
"Tibetan mastiff",
"French bulldog",
"Great Dane",
"Saint Bernard, St Bernard",
"Eskimo dog, husky",
"malamute, malemute, Alaskan malamute",
"Siberian husky",
"dalmatian, coach dog, carriage dog",
"affenpinscher, monkey pinscher, monkey dog",
"basenji",
"pug, pug-dog",
"Leonberg",
"Newfoundland, Newfoundland dog",
"Great Pyrenees",
"Samoyed, Samoyede",
"Pomeranian",
"chow, chow chow",
"keeshond",
"Brabancon griffon",
"Pembroke, Pembroke Welsh corgi",
"Cardigan, Cardigan Welsh corgi",
"toy poodle",
"miniature poodle",
"standard poodle",
"Mexican hairless",
"timber wolf, grey wolf, gray wolf, Canis lupus",
"white wolf, Arctic wolf, Canis lupus tundrarum",
"red wolf, maned wolf, Canis rufus, Canis niger",
"coyote, prairie wolf, brush wolf, Canis latrans",
"dingo, warrigal, warragal, Canis dingo",
"dhole, Cuon alpinus",
"African hunting dog, hyena dog, Cape hunting dog, Lycaon pictus",
"hyena, hyaena",
"red fox, Vulpes vulpes",
"kit fox, Vulpes macrotis",
"Arctic fox, white fox, Alopex lagopus",
"grey fox, gray fox, Urocyon cinereoargenteus",
"tabby, tabby cat",
"tiger cat",
"Persian cat",
"Siamese cat, Siamese",
"Egyptian cat",
"cougar, puma, catamount, mountain lion, painter, panther, Felis concolor",
"lynx, catamount",
"leopard, Panthera pardus",
"snow leopard, ounce, Panthera uncia",
"jaguar, panther, Panthera onca, Felis onca",
"lion, king of beasts, Panthera leo",
"tiger, Panthera tigris",
"cheetah, chetah, Acinonyx jubatus",
"brown bear, bruin, Ursus arctos",
"American black bear, black bear, Ursus americanus, Euarctos americanus",
"ice bear, polar bear, Ursus Maritimus, Thalarctos maritimus",
"sloth bear, Melursus ursinus, Ursus ursinus",
"mongoose",
"meerkat, mierkat",
"tiger beetle",
"ladybug, ladybeetle, lady beetle, ladybird, ladybird beetle",
"ground beetle, carabid beetle",
"long-horned beetle, longicorn, longicorn beetle",
"leaf beetle, chrysomelid",
"dung beetle",
"rhinoceros beetle",
"weevil",
"fly",
"bee",
"ant, emmet, pismire",
"grasshopper, hopper",
"cricket",
"walking stick, walkingstick, stick insect",
"cockroach, roach",
"mantis, mantid",
"cicada, cicala",
"leafhopper",
"lacewing, lacewing fly",
"dragonfly, darning needle, devil's darning needle, sewing needle, snake feeder, snake doctor, mosquito hawk, skeeter hawk",
"damselfly",
"admiral",
"ringlet, ringlet butterfly",
"monarch, monarch butterfly, milkweed butterfly, Danaus plexippus",
"cabbage butterfly",
"sulphur butterfly, sulfur butterfly",
"lycaenid, lycaenid butterfly",
"starfish, sea star",
"sea urchin",
"sea cucumber, holothurian",
"wood rabbit, cottontail, cottontail rabbit",
"hare",
"Angora, Angora rabbit",
"hamster",
"porcupine, hedgehog",
"fox squirrel, eastern fox squirrel, Sciurus niger",
"marmot",
"beaver",
"guinea pig, Cavia cobaya",
"sorrel",
"zebra",
"hog, pig, grunter, squealer, Sus scrofa",
"wild boar, boar, Sus scrofa",
"warthog",
"hippopotamus, hippo, river horse, Hippopotamus amphibius",
"ox",
"water buffalo, water ox, Asiatic buffalo, Bubalus bubalis",
"bison",
"ram, tup",
"bighorn, bighorn sheep, cimarron, Rocky Mountain bighorn, Rocky Mountain sheep, Ovis canadensis",
"ibex, Capra ibex",
"hartebeest",
"impala, Aepyceros melampus",
"gazelle",
"Arabian camel, dromedary, Camelus dromedarius",
"llama",
"weasel",
"mink",
"polecat, fitch, foulmart, foumart, Mustela putorius",
"black-footed ferret, ferret, Mustela nigripes",
"otter",
"skunk, polecat, wood pussy",
"badger",
"armadillo",
"three-toed sloth, ai, Bradypus tridactylus",
"orangutan, orang, orangutang, Pongo pygmaeus",
"gorilla, Gorilla gorilla",
"chimpanzee, chimp, Pan troglodytes",
"gibbon, Hylobates lar",
"siamang, Hylobates syndactylus, Symphalangus syndactylus",
"guenon, guenon monkey",
"patas, hussar monkey, Erythrocebus patas",
"baboon",
"macaque",
"langur",
"colobus, colobus monkey",
"proboscis monkey, Nasalis larvatus",
"marmoset",
"capuchin, ringtail, Cebus capucinus",
"howler monkey, howler",
"titi, titi monkey",
"spider monkey, Ateles geoffroyi",
"squirrel monkey, Saimiri sciureus",
"Madagascar cat, ring-tailed lemur, Lemur catta",
"indri, indris, Indri indri, Indri brevicaudatus",
"Indian elephant, Elephas maximus",
"African elephant, Loxodonta africana",
"lesser panda, red panda, panda, bear cat, cat bear, Ailurus fulgens",
"giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca",
"barracouta, snoek",
"eel",
"coho, cohoe, coho salmon, blue jack, silver salmon, Oncorhynchus kisutch",
"rock beauty, Holocanthus tricolor",
"anemone fish",
"sturgeon",
"gar, garfish, garpike, billfish, Lepisosteus osseus",
"lionfish",
"puffer, pufferfish, blowfish, globefish",
"abacus",
"abaya",
"academic gown, academic robe, judge's robe",
"accordion, piano accordion, squeeze box",
"acoustic guitar",
"aircraft carrier, carrier, flattop, attack aircraft carrier",
"airliner",
"airship, dirigible",
"altar",
"ambulance",
"amphibian, amphibious vehicle",
"analog clock",
"apiary, bee house",
"apron",
"ashcan, trash can, garbage can, wastebin, ash bin, ash-bin, ashbin, dustbin, trash barrel, trash bin",
"assault rifle, assault gun",
"backpack, back pack, knapsack, packsack, rucksack, haversack",
"bakery, bakeshop, bakehouse",
"balance beam, beam",
"balloon",
"ballpoint, ballpoint pen, ballpen, Biro",
"Band Aid",
"banjo",
"bannister, banister, balustrade, balusters, handrail",
"barbell",
"barber chair",
"barbershop",
"barn",
"barometer",
"barrel, cask",
"barrow, garden cart, lawn cart, wheelbarrow",
"baseball",
"basketball",
"bassinet",
"bassoon",
"bathing cap, swimming cap",
"bath towel",
"bathtub, bathing tub, bath, tub",
"beach wagon, station wagon, wagon, estate car, beach waggon, station waggon, waggon",
"beacon, lighthouse, beacon light, pharos",
"beaker",
"bearskin, busby, shako",
"beer bottle",
"beer glass",
"bell cote, bell cot",
"bib",
"bicycle-built-for-two, tandem bicycle, tandem",
"bikini, two-piece",
"binder, ring-binder",
"binoculars, field glasses, opera glasses",
"birdhouse",
"boathouse",
"bobsled, bobsleigh, bob",
"bolo tie, bolo, bola tie, bola",
"bonnet, poke bonnet",
"bookcase",
"bookshop, bookstore, bookstall",
"bottlecap",
"bow",
"bow tie, bow-tie, bowtie",
"brass, memorial tablet, plaque",
"brassiere, bra, bandeau",
"breakwater, groin, groyne, mole, bulwark, seawall, jetty",
"breastplate, aegis, egis",
"broom",
"bucket, pail",
"buckle",
"bulletproof vest",
"bullet train, bullet",
"butcher shop, meat market",
"cab, hack, taxi, taxicab",
"caldron, cauldron",
"candle, taper, wax light",
"cannon",
"canoe",
"can opener, tin opener",
"cardigan",
"car mirror",
"carousel, carrousel, merry-go-round, roundabout, whirligig",
"carpenter's kit, tool kit",
"carton",
"car wheel",
"cash machine, cash dispenser, automated teller machine, automatic teller machine, automated teller, automatic teller, ATM",
"cassette",
"cassette player",
"castle",
"catamaran",
"CD player",
"cello, violoncello",
"cellular telephone, cellular phone, cellphone, cell, mobile phone",
"chain",
"chainlink fence",
"chain mail, ring mail, mail, chain armor, chain armour, ring armor, ring armour",
"chain saw, chainsaw",
"chest",
"chiffonier, commode",
"chime, bell, gong",
"china cabinet, china closet",
"Christmas stocking",
"church, church building",
"cinema, movie theater, movie theatre, movie house, picture palace",
"cleaver, meat cleaver, chopper",
"cliff dwelling",
"cloak",
"clog, geta, patten, sabot",
"cocktail shaker",
"coffee mug",
"coffeepot",
"coil, spiral, volute, whorl, helix",
"combination lock",
"computer keyboard, keypad",
"confectionery, confectionary, candy store",
"container ship, containership, container vessel",
"convertible",
"corkscrew, bottle screw",
"cornet, horn, trumpet, trump",
"cowboy boot",
"cowboy hat, ten-gallon hat",
"cradle",
"crane",
"crash helmet",
"crate",
"crib, cot",
"Crock Pot",
"croquet ball",
"crutch",
"cuirass",
"dam, dike, dyke",
"desk",
"desktop computer",
"dial telephone, dial phone",
"diaper, nappy, napkin",
"digital clock",
"digital watch",
"dining table, board",
"dishrag, dishcloth",
"dishwasher, dish washer, dishwashing machine",
"disk brake, disc brake",
"dock, dockage, docking facility",
"dogsled, dog sled, dog sleigh",
"dome",
"doormat, welcome mat",
"drilling platform, offshore rig",
"drum, membranophone, tympan",
"drumstick",
"dumbbell",
"Dutch oven",
"electric fan, blower",
"electric guitar",
"electric locomotive",
"entertainment center",
"envelope",
"espresso maker",
"face powder",
"feather boa, boa",
"file, file cabinet, filing cabinet",
"fireboat",
"fire engine, fire truck",
"fire screen, fireguard",
"flagpole, flagstaff",
"flute, transverse flute",
"folding chair",
"football helmet",
"forklift",
"fountain",
"fountain pen",
"four-poster",
"freight car",
"French horn, horn",
"frying pan, frypan, skillet",
"fur coat",
"garbage truck, dustcart",
"gasmask, respirator, gas helmet",
"gas pump, gasoline pump, petrol pump, island dispenser",
"goblet",
"go-kart",
"golf ball",
"golfcart, golf cart",
"gondola",
"gong, tam-tam",
"gown",
"grand piano, grand",
"greenhouse, nursery, glasshouse",
"grille, radiator grille",
"grocery store, grocery, food market, market",
"guillotine",
"hair slide",
"hair spray",
"half track",
"hammer",
"hamper",
"hand blower, blow dryer, blow drier, hair dryer, hair drier",
"hand-held computer, hand-held microcomputer",
"handkerchief, hankie, hanky, hankey",
"hard disc, hard disk, fixed disk",
"harmonica, mouth organ, harp, mouth harp",
"harp",
"harvester, reaper",
"hatchet",
"holster",
"home theater, home theatre",
"honeycomb",
"hook, claw",
"hoopskirt, crinoline",
"horizontal bar, high bar",
"horse cart, horse-cart",
"hourglass",
"iPod",
"iron, smoothing iron",
"jack-o'-lantern",
"jean, blue jean, denim",
"jeep, landrover",
"jersey, T-shirt, tee shirt",
"jigsaw puzzle",
"jinrikisha, ricksha, rickshaw",
"joystick",
"kimono",
"knee pad",
"knot",
"lab coat, laboratory coat",
"ladle",
"lampshade, lamp shade",
"laptop, laptop computer",
"lawn mower, mower",
"lens cap, lens cover",
"letter opener, paper knife, paperknife",
"library",
"lifeboat",
"lighter, light, igniter, ignitor",
"limousine, limo",
"liner, ocean liner",
"lipstick, lip rouge",
"Loafer",
"lotion",
"loudspeaker, speaker, speaker unit, loudspeaker system, speaker system",
"loupe, jeweler's loupe",
"lumbermill, sawmill",
"magnetic compass",
"mailbag, postbag",
"mailbox, letter box",
"maillot",
"maillot, tank suit",
"manhole cover",
"maraca",
"marimba, xylophone",
"mask",
"matchstick",
"maypole",
"maze, labyrinth",
"measuring cup",
"medicine chest, medicine cabinet",
"megalith, megalithic structure",
"microphone, mike",
"microwave, microwave oven",
"military uniform",
"milk can",
"minibus",
"miniskirt, mini",
"minivan",
"missile",
"mitten",
"mixing bowl",
"mobile home, manufactured home",
"Model T",
"modem",
"monastery",
"monitor",
"moped",
"mortar",
"mortarboard",
"mosque",
"mosquito net",
"motor scooter, scooter",
"mountain bike, all-terrain bike, off-roader",
"mountain tent",
"mouse, computer mouse",
"mousetrap",
"moving van",
"muzzle",
"nail",
"neck brace",
"necklace",
"nipple",
"notebook, notebook computer",
"obelisk",
"oboe, hautboy, hautbois",
"ocarina, sweet potato",
"odometer, hodometer, mileometer, milometer",
"oil filter",
"organ, pipe organ",
"oscilloscope, scope, cathode-ray oscilloscope, CRO",
"overskirt",
"oxcart",
"oxygen mask",
"packet",
"paddle, boat paddle",
"paddlewheel, paddle wheel",
"padlock",
"paintbrush",
"pajama, pyjama, pj's, jammies",
"palace",
"panpipe, pandean pipe, syrinx",
"paper towel",
"parachute, chute",
"parallel bars, bars",
"park bench",
"parking meter",
"passenger car, coach, carriage",
"patio, terrace",
"pay-phone, pay-station",
"pedestal, plinth, footstall",
"pencil box, pencil case",
"pencil sharpener",
"perfume, essence",
"Petri dish",
"photocopier",
"pick, plectrum, plectron",
"pickelhaube",
"picket fence, paling",
"pickup, pickup truck",
"pier",
"piggy bank, penny bank",
"pill bottle",
"pillow",
"ping-pong ball",
"pinwheel",
"pirate, pirate ship",
"pitcher, ewer",
"plane, carpenter's plane, woodworking plane",
"planetarium",
"plastic bag",
"plate rack",
"plow, plough",
"plunger, plumber's helper",
"Polaroid camera, Polaroid Land camera",
"pole",
"police van, police wagon, paddy wagon, patrol wagon, wagon, black Maria",
"poncho",
"pool table, billiard table, snooker table",
"pop bottle, soda bottle",
"pot, flowerpot",
"potter's wheel",
"power drill",
"prayer rug, prayer mat",
"printer",
"prison, prison house",
"projectile, missile",
"projector",
"puck, hockey puck",
"punching bag, punch bag, punching ball, punchball",
"purse",
"quill, quill pen",
"quilt, comforter, comfort, puff",
"racer, race car, racing car",
"racket, racquet",
"radiator",
"radio, wireless",
"radio telescope, radio reflector",
"rain barrel",
"recreational vehicle, RV, R.V.",
"reel",
"reflex camera",
"refrigerator, icebox",
"remote control, remote",
"restaurant, eating house, eating place, eatery",
"revolver, six-gun, six-shooter",
"rifle",
"rocking chair, rocker",
"rotisserie",
"rubber eraser, rubber, pencil eraser",
"rugby ball",
"rule, ruler",
"running shoe",
"safe",
"safety pin",
"saltshaker, salt shaker",
"sandal",
"sarong",
"sax, saxophone",
"scabbard",
"scale, weighing machine",
"school bus",
"schooner",
"scoreboard",
"screen, CRT screen",
"screw",
"screwdriver",
"seat belt, seatbelt",
"sewing machine",
"shield, buckler",
"shoe shop, shoe-shop, shoe store",
"shoji",
"shopping basket",
"shopping cart",
"shovel",
"shower cap",
"shower curtain",
"ski",
"ski mask",
"sleeping bag",
"slide rule, slipstick",
"sliding door",
"slot, one-armed bandit",
"snorkel",
"snowmobile",
"snowplow, snowplough",
"soap dispenser",
"soccer ball",
"sock",
"solar dish, solar collector, solar furnace",
"sombrero",
"soup bowl",
"space bar",
"space heater",
"space shuttle",
"spatula",
"speedboat",
"spider web, spider's web",
"spindle",
"sports car, sport car",
"spotlight, spot",
"stage",
"steam locomotive",
"steel arch bridge",
"steel drum",
"stethoscope",
"stole",
"stone wall",
"stopwatch, stop watch",
"stove",
"strainer",
"streetcar, tram, tramcar, trolley, trolley car",
"stretcher",
"studio couch, day bed",
"stupa, tope",
"submarine, pigboat, sub, U-boat",
"suit, suit of clothes",
"sundial",
"sunglass",
"sunglasses, dark glasses, shades",
"sunscreen, sunblock, sun blocker",
"suspension bridge",
"swab, swob, mop",
"sweatshirt",
"swimming trunks, bathing trunks",
"swing",
"switch, electric switch, electrical switch",
"syringe",
"table lamp",
"tank, army tank, armored combat vehicle, armoured combat vehicle",
"tape player",
"teapot",
"teddy, teddy bear",
"television, television system",
"tennis ball",
"thatch, thatched roof",
"theater curtain, theatre curtain",
"thimble",
"thresher, thrasher, threshing machine",
"throne",
"tile roof",
"toaster",
"tobacco shop, tobacconist shop, tobacconist",
"toilet seat",
"torch",
"totem pole",
"tow truck, tow car, wrecker",
"toyshop",
"tractor",
"trailer truck, tractor trailer, trucking rig, rig, articulated lorry, semi",
"tray",
"trench coat",
"tricycle, trike, velocipede",
"trimaran",
"tripod",
"triumphal arch",
"trolleybus, trolley coach, trackless trolley",
"trombone",
"tub, vat",
"turnstile",
"typewriter keyboard",
"umbrella",
"unicycle, monocycle",
"upright, upright piano",
"vacuum, vacuum cleaner",
"vase",
"vault",
"velvet",
"vending machine",
"vestment",
"viaduct",
"violin, fiddle",
"volleyball",
"waffle iron",
"wall clock",
"wallet, billfold, notecase, pocketbook",
"wardrobe, closet, press",
"warplane, military plane",
"washbasin, handbasin, washbowl, lavabo, wash-hand basin",
"washer, automatic washer, washing machine",
"water bottle",
"water jug",
"water tower",
"whiskey jug",
"whistle",
"wig",
"window screen",
"window shade",
"Windsor tie",
"wine bottle",
"wing",
"wok",
"wooden spoon",
"wool, woolen, woollen",
"worm fence, snake fence, snake-rail fence, Virginia fence",
"wreck",
"yawl",
"yurt",
"web site, website, internet site, site",
"comic book",
"crossword puzzle, crossword",
"street sign",
"traffic light, traffic signal, stoplight",
"book jacket, dust cover, dust jacket, dust wrapper",
"menu",
"plate",
"guacamole",
"consomme",
"hot pot, hotpot",
"trifle",
"ice cream, icecream",
"ice lolly, lolly, lollipop, popsicle",
"French loaf",
"bagel, beigel",
"pretzel",
"cheeseburger",
"hotdog, hot dog, red hot",
"mashed potato",
"head cabbage",
"broccoli",
"cauliflower",
"zucchini, courgette",
"spaghetti squash",
"acorn squash",
"butternut squash",
"cucumber, cuke",
"artichoke, globe artichoke",
"bell pepper",
"cardoon",
"mushroom",
"Granny Smith",
"strawberry",
"orange",
"lemon",
"fig",
"pineapple, ananas",
"banana",
"jackfruit, jak, jack",
"custard apple",
"pomegranate",
"hay",
"carbonara",
"chocolate sauce, chocolate syrup",
"dough",
"meat loaf, meatloaf",
"pizza, pizza pie",
"potpie",
"burrito",
"red wine",
"espresso",
"cup",
"eggnog",
"alp",
"bubble",
"cliff, drop, drop-off",
"coral reef",
"geyser",
"lakeside, lakeshore",
"promontory, headland, head, foreland",
"sandbar, sand bar",
"seashore, coast, seacoast, sea-coast",
"valley, vale",
"volcano",
"ballplayer, baseball player",
"groom, bridegroom",
"scuba diver",
"rapeseed",
"daisy",
"yellow lady's slipper, yellow lady-slipper, Cypripedium calceolus, Cypripedium parviflorum",
"corn",
"acorn",
"hip, rose hip, rosehip",
"buckeye, horse chestnut, conker",
"coral fungus",
"agaric",
"gyromitra",
"stinkhorn, carrion fungus",
"earthstar",
"hen-of-the-woods, hen of the woods, Polyporus frondosus, Grifola frondosa",
"bolete",
"ear, spike, capitulum",
"toilet tissue, toilet paper, bathroom tissue",
];
| candle/candle-examples/src/imagenet.rs/0 | {
"file_path": "candle/candle-examples/src/imagenet.rs",
"repo_id": "candle",
"token_count": 12586
} | 29 |
/******************************************************************************
* Copyright (c) 2023, Tri Dao.
******************************************************************************/
#pragma once
#include <cmath>
#include <cute/tensor.hpp>
#include <cutlass/numeric_types.h>
#include "philox.cuh"
#include "utils.h"
namespace flash {
using namespace cute;
////////////////////////////////////////////////////////////////////////////////////////////////////
template<bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1, typename Operator>
__device__ inline void thread_reduce_(Tensor<Engine0, Layout0> const &tensor, Tensor<Engine1, Layout1> &summary, Operator &op) {
static_assert(Layout0::rank == 2, "Only support 2D Tensor");
static_assert(Layout1::rank == 1, "Only support 1D Tensor");
CUTE_STATIC_ASSERT_V(size<0>(summary) == size<0>(tensor));
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); mi++) {
summary(mi) = zero_init ? tensor(mi, 0) : op(summary(mi), tensor(mi, 0));
#pragma unroll
for (int ni = 1; ni < size<1>(tensor); ni++) {
summary(mi) = op(summary(mi), tensor(mi, ni));
}
}
}
template<typename Engine0, typename Layout0, typename Engine1, typename Layout1, typename Operator>
__device__ inline void quad_allreduce_(Tensor<Engine0, Layout0> &dst, Tensor<Engine1, Layout1> &src, Operator &op) {
CUTE_STATIC_ASSERT_V(size(dst) == size(src));
#pragma unroll
for (int i = 0; i < size(dst); i++){
dst(i) = Allreduce<4>::run(src(i), op);
}
}
template<bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1, typename Operator>
__device__ inline void reduce_(Tensor<Engine0, Layout0> const& tensor, Tensor<Engine1, Layout1> &summary, Operator &op) {
thread_reduce_<zero_init>(tensor, summary, op);
quad_allreduce_(summary, summary, op);
}
template<bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1>
__device__ inline void reduce_max(Tensor<Engine0, Layout0> const& tensor, Tensor<Engine1, Layout1> &max){
MaxOp<float> max_op;
reduce_<zero_init>(tensor, max, max_op);
}
template<typename Engine0, typename Layout0, typename Engine1, typename Layout1>
__device__ inline void reduce_sum(Tensor<Engine0, Layout0> const& tensor, Tensor<Engine1, Layout1> &sum){
SumOp<float> sum_op;
reduce_(tensor, sum, sum_op);
}
// Apply the exp to all the elements.
template <bool Scale_max=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1>
inline __device__ void scale_apply_exp2(Tensor<Engine0, Layout0> &tensor, Tensor<Engine1, Layout1> const &max, const float scale) {
static_assert(Layout0::rank == 2, "Only support 2D Tensor");
static_assert(Layout1::rank == 1, "Only support 1D Tensor");
CUTE_STATIC_ASSERT_V(size<0>(max) == size<0>(tensor));
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
// If max is -inf, then all elements must have been -inf (possibly due to masking).
// We don't want (-inf - (-inf)) since that would give NaN.
// If we don't have float around M_LOG2E the multiplication is done in fp64.
const float max_scaled = max(mi) == -INFINITY ? 0.f : max(mi) * (Scale_max ? scale : float(M_LOG2E));
#pragma unroll
for (int ni = 0; ni < size<1>(tensor); ++ni) {
// Instead of computing exp(x - max), we compute exp2(x * log_2(e) -
// max * log_2(e)) This allows the compiler to use the ffma
// instruction instead of fadd and fmul separately.
tensor(mi, ni) = exp2f(tensor(mi, ni) * scale - max_scaled);
}
}
}
// Apply the exp to all the elements.
template <bool zero_init=true, typename Engine0, typename Layout0, typename Engine1, typename Layout1>
inline __device__ void max_scale_exp2_sum(Tensor<Engine0, Layout0> &tensor, Tensor<Engine1, Layout1> &max, Tensor<Engine1, Layout1> &sum, const float scale) {
static_assert(Layout0::rank == 2, "Only support 2D Tensor");
static_assert(Layout1::rank == 1, "Only support 1D Tensor");
CUTE_STATIC_ASSERT_V(size<0>(max) == size<0>(tensor));
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
MaxOp<float> max_op;
max(mi) = zero_init ? tensor(mi, 0) : max_op(max(mi), tensor(mi, 0));
#pragma unroll
for (int ni = 1; ni < size<1>(tensor); ni++) {
max(mi) = max_op(max(mi), tensor(mi, ni));
}
max(mi) = Allreduce<4>::run(max(mi), max_op);
// If max is -inf, then all elements must have been -inf (possibly due to masking).
// We don't want (-inf - (-inf)) since that would give NaN.
const float max_scaled = max(mi) == -INFINITY ? 0.f : max(mi) * scale;
sum(mi) = 0;
#pragma unroll
for (int ni = 0; ni < size<1>(tensor); ++ni) {
// Instead of computing exp(x - max), we compute exp2(x * log_2(e) -
// max * log_2(e)) This allows the compiler to use the ffma
// instruction instead of fadd and fmul separately.
tensor(mi, ni) = exp2f(tensor(mi, ni) * scale - max_scaled);
sum(mi) += tensor(mi, ni);
}
SumOp<float> sum_op;
sum(mi) = Allreduce<4>::run(sum(mi), sum_op);
}
}
template <typename Engine, typename Layout>
inline __device__ void apply_mask(Tensor<Engine, Layout> &tensor, const int max_seqlen_k,
const int col_idx_offset_ = 0) {
// tensor has shape (ncol=(2, MMA_M), nrow=(2, MMA_N))
static_assert(Layout::rank == 2, "Only support 2D Tensor");
const int lane_id = threadIdx.x % 32;
const int col_idx_offset = col_idx_offset_ + (lane_id % 4) * 2;
#pragma unroll
for (int nj = 0; nj < size<1, 1>(tensor); ++nj) {
const int col_idx_base = col_idx_offset + nj * 8;
#pragma unroll
for (int j = 0; j < size<1, 0>(tensor); ++j) {
const int col_idx = col_idx_base + j;
if (col_idx >= max_seqlen_k) {
// Without the "make_coord" we get wrong results
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
tensor(mi, make_coord(j, nj)) = -INFINITY;
}
}
}
}
}
template <bool HasWSLeft=true, typename Engine, typename Layout>
inline __device__ void apply_mask_local(Tensor<Engine, Layout> &tensor, const int col_idx_offset_,
const int max_seqlen_k, const int row_idx_offset,
const int max_seqlen_q, const int warp_row_stride,
const int window_size_left, const int window_size_right) {
// tensor has shape (ncol=(2, MMA_M), nrow=(2, MMA_N))
static_assert(Layout::rank == 2, "Only support 2D Tensor");
const int lane_id = threadIdx.x % 32;
const int col_idx_offset = col_idx_offset_ + (lane_id % 4) * 2;
#pragma unroll
for (int mi = 0; mi < size<0, 1>(tensor); ++mi) {
const int row_idx_base = row_idx_offset + mi * warp_row_stride;
#pragma unroll
for (int i = 0; i < size<0, 0>(tensor); ++i) {
const int row_idx = row_idx_base + i * 8;
const int col_idx_limit_left = std::max(0, row_idx + max_seqlen_k - max_seqlen_q - window_size_left);
const int col_idx_limit_right = std::min(max_seqlen_k, row_idx + 1 + max_seqlen_k - max_seqlen_q + window_size_right);
#pragma unroll
for (int nj = 0; nj < size<1, 1>(tensor); ++nj) {
const int col_idx_base = col_idx_offset + nj * 8;
#pragma unroll
for (int j = 0; j < size<1, 0>(tensor); ++j) {
const int col_idx = col_idx_base + j;
if (col_idx >= col_idx_limit_right || (HasWSLeft && col_idx < col_idx_limit_left)) {
tensor(make_coord(i, mi), make_coord(j, nj)) = -INFINITY;
}
}
}
// if (cute::thread0()) {
// printf("mi = %d, i = %d, row_idx = %d, max_seqlen_k = %d\n", mi, i, row_idx, max_seqlen_k);
// print(tensor(make_coord(i, mi), _));
// // print(tensor(_, j + nj * size<1, 0>(tensor)));
// }
}
}
}
template <typename Engine, typename Layout>
inline __device__ void apply_mask_causal(Tensor<Engine, Layout> &tensor, const int col_idx_offset_,
const int max_seqlen_k, const int row_idx_offset,
const int max_seqlen_q, const int warp_row_stride) {
// Causal masking is equivalent to local masking with window_size_left = infinity and window_size_right = 0
apply_mask_local</*HasWSLeft=*/false>(tensor, col_idx_offset_, max_seqlen_k, row_idx_offset,
max_seqlen_q, warp_row_stride, -1, 0);
}
template <typename Engine0, typename Layout0, typename Engine1, typename Layout1>
inline __device__ void apply_mask_causal_w_idx(
Tensor<Engine0, Layout0> &tensor, Tensor<Engine1, Layout1> const &idx_rowcol,
const int col_idx_offset_, const int max_seqlen_k, const int row_idx_offset)
{
// tensor has shape (ncol=(2, MMA_M), nrow=(2, MMA_N))
static_assert(Layout0::rank == 2, "Only support 2D Tensor");
static_assert(Layout1::rank == 2, "Only support 2D Tensor");
CUTE_STATIC_ASSERT_V(size<0>(tensor) == size<0>(idx_rowcol));
CUTE_STATIC_ASSERT_V(size<1>(tensor) == size<1>(idx_rowcol));
#pragma unroll
for (int mi = 0; mi < size<0>(tensor); ++mi) {
const int col_idx_limit = std::min(max_seqlen_k, 1 + row_idx_offset + get<0>(idx_rowcol(mi, 0)));
#pragma unroll
for (int ni = 0; ni < size<1, 1>(tensor); ++ni) {
if (col_idx_offset_ + get<1>(idx_rowcol(0, ni)) >= col_idx_limit) {
tensor(mi, ni) = -INFINITY;
}
}
// if (cute::thread0()) {
// printf("ni = %d, j = %d, col_idx = %d, max_seqlen_k = %d\n", ni, j, col_idx, max_seqlen_k);
// print(tensor(_, make_coord(j, ni)));
// // print(tensor(_, j + ni * size<1, 0>(tensor)));
// }
}
}
template <bool encode_dropout_in_sign_bit=false, typename Engine, typename Layout>
inline __device__ void apply_dropout(Tensor<Engine, Layout> &tensor, uint8_t p_dropout_in_uint8_t,
unsigned long long seed, unsigned long long offset,
int block_row_start, int block_col_start,
int block_row_stride) {
// tensor has shape (8, MMA_M, MMA_N / 2)
using T = typename Engine::value_type;
auto encode_dropout = [](bool keep, T val) {
return keep ? val : (encode_dropout_in_sign_bit ? -val : T(0));
};
static_assert(decltype(size<2>(tensor))::value % 2 == 0);
const uint16_t p_dropout_8bit_in_uint16_t = uint16_t(p_dropout_in_uint8_t);
const uint32_t p_dropout_8bit_in_uint32_t = (uint32_t(p_dropout_8bit_in_uint16_t) << 16) | uint32_t(p_dropout_8bit_in_uint16_t);
// if (cute::thread0()) { printf("threshold2 = 0x%x\n", p_dropout_8bit_in_uint32_t); }
#pragma unroll
for (int m = 0; m < size<1>(tensor); ++m, block_row_start += block_row_stride) {
uint2 rowcol = make_uint2(block_row_start, block_col_start);
#pragma unroll
for (int n = 0; n < size<2>(tensor) / 2; ++n, ++rowcol.y) {
// if (cute::thread(32, 0)) { printf("m = %d, n = %d, row = %d, col = %d\n", m, n, int(rowcol.x), int(rowcol.y));}
uint4 random_uint4 = flash::philox(seed, reinterpret_cast<unsigned long long&>(rowcol), offset);
// if (cute::thread0()) { printf("philox = %u, %d, %d, %d\n", random_uint4.x, random_uint4.y, random_uint4.z, random_uint4.w);}
uint8_t (&rnd_8)[16] = reinterpret_cast<uint8_t (&)[16]>(random_uint4);
// Special implementation for 16-bit types: we duplicate the threshold to the
// low and high 16 bits of a 32-bit value, then use the f16x2 comparison instruction
// to get a mask. The low 16 bits of the mask will be either 0xffff or 0x0000,
// and the high 16 bits will be either 0xffff or 0x0000, depending on whether
// the random value is less than the threshold.
// We then do a bit-wise AND between the mask and the original value (in 32-bit).
// We're exploiting the fact that floating point comparison is equivalent to integer
// comparison, since we're comparing unsigned integers whose top 8-bits are zero.
if (!encode_dropout_in_sign_bit
&& (std::is_same<T, cutlass::half_t>::value || std::is_same<T, cutlass::bfloat16_t>::value)) {
uint16_t rnd_16[16];
#pragma unroll
for (int i = 0; i < 16; i++) { rnd_16[i] = uint16_t(rnd_8[i]); }
uint32_t (&rnd_32)[8] = reinterpret_cast<uint32_t (&)[8]>(rnd_16);
#pragma unroll
for (int j = 0; j < 2; j++) {
Tensor tensor_uint32 = recast<uint32_t>(tensor(_, m, n * 2 + j));
// if (cute::thread0()) { printf("random = 0x%x, 0x%x, 0x%x, 0x%x\n", rnd_32[j * 4 + 0], rnd_32[j * 4 + 1], rnd_32[j * 4 + 2], rnd_32[j * 4 + 3]); }
// if (cute::thread0()) { printf("tensor_uint32 = 0x%x, 0x%x, 0x%x, 0x%x\n", tensor_uint32(0), tensor_uint32(1), tensor_uint32(2), tensor_uint32(3)); }
#pragma unroll
for (int i = 0; i < 4; i++) {
uint32_t mask;
asm volatile("set.le.u32.f16x2 %0, %1, %2;\n" : "=r"(mask) : "r"(rnd_32[j * 4 + i]), "r"(p_dropout_8bit_in_uint32_t));
tensor_uint32(i) &= mask;
}
// if (cute::thread0()) { printf("tensor_uint32 = 0x%x, 0x%x, 0x%x, 0x%x\n", tensor_uint32(0), tensor_uint32(1), tensor_uint32(2), tensor_uint32(3)); }
}
} else {
#pragma unroll
for (int j = 0; j < 2; j++) {
#pragma unroll
for (int i = 0; i < 8; i++) {
tensor(i, m, n * 2 + j) = encode_dropout(rnd_8[j * 8 + i] <= p_dropout_in_uint8_t, tensor(i, m, n * 2 + j));
}
Tensor tensor_uint32 = recast<uint32_t>(tensor(_, m, n * 2 + j));
// if (cute::thread0()) { printf("tensor_uint32 = 0x%x, 0x%x, 0x%x, 0x%x\n", tensor_uint32(0), tensor_uint32(1), tensor_uint32(2), tensor_uint32(3)); }
}
}
// // if ((threadIdx.x == 0) && (blockIdx.x == 0) && (blockIdx.y == 0)) {
// // printf("n = %d, ph Philox: %u, %u, %u, %u\n", n, rnd_8.x, rnd_8.y, rnd_8.z, rnd_8.w);
// // }
}
}
}
} // namespace flash
| candle/candle-flash-attn/kernels/softmax.h/0 | {
"file_path": "candle/candle-flash-attn/kernels/softmax.h",
"repo_id": "candle",
"token_count": 7224
} | 30 |
#include<stdint.h>
#include "cuda_fp16.h"
template<typename T>
__device__ void fill_with(T *buf, T value, const size_t numel) {
for (unsigned int i = blockIdx.x * blockDim.x + threadIdx.x; i < numel; i += blockDim.x * gridDim.x) {
buf[i] = value;
}
}
extern "C" __global__ void fill_u8(uint8_t *buf, uint8_t value, const size_t numel) { fill_with(buf, value, numel); }
extern "C" __global__ void fill_u32(uint32_t *buf, uint32_t value, const size_t numel) { fill_with(buf, value, numel); }
extern "C" __global__ void fill_i64(int64_t *buf, int64_t value, const size_t numel) { fill_with(buf, value, numel); }
extern "C" __global__ void fill_f32(float *buf, float value, const size_t numel) { fill_with(buf, value, numel); }
extern "C" __global__ void fill_f64(double *buf, double value, const size_t numel) { fill_with(buf, value, numel); }
template<typename T>
__device__ void copy2d(const T *src, T *dst, uint32_t d1, uint32_t d2, uint32_t src_s, uint32_t dst_s) {
uint32_t idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx >= d1 * d2) {
return;
}
uint32_t idx1 = idx / d2;
uint32_t idx2 = idx - d2 * idx1;
dst[idx1 * dst_s + idx2] = src[idx1 * src_s + idx2];
}
#define COPY2D_OP(TYPENAME, FNNAME) \
extern "C" __global__ \
void FNNAME(const TYPENAME *src, TYPENAME *dst, uint32_t d1, uint32_t d2, uint32_t src_s, uint32_t dst_s) { \
copy2d(src, dst, d1, d2, src_s, dst_s); \
} \
COPY2D_OP(float, copy2d_f32)
COPY2D_OP(double, copy2d_f64)
COPY2D_OP(uint8_t, copy2d_u8)
COPY2D_OP(uint32_t, copy2d_u32)
COPY2D_OP(int64_t, copy2d_i64)
#if __CUDA_ARCH__ >= 530
extern "C" __global__ void fill_f16(__half *buf, __half value, const size_t numel) { fill_with(buf, value, numel); }
COPY2D_OP(__half, copy2d_f16)
#endif
#if __CUDA_ARCH__ >= 800
#include <cuda_bf16.h>
extern "C" __global__ void fill_bf16(__nv_bfloat16 *buf, __nv_bfloat16 value, const size_t numel) { fill_with(buf, value, numel); }
COPY2D_OP(__nv_bfloat16, copy2d_bf16)
#endif
| candle/candle-kernels/src/fill.cu/0 | {
"file_path": "candle/candle-kernels/src/fill.cu",
"repo_id": "candle",
"token_count": 919
} | 31 |
#include <metal_stdlib>
using namespace metal;
#define MAX(x, y) ((x) > (y) ? (x) : (y))
#define MIN(x, y) ((x) < (y) ? (x) : (y))
#define SWAP(x, y) { auto tmp = (x); (x) = (y); (y) = tmp; }
#define QK4_0 32
#define QR4_0 2
typedef struct {
half d; // delta
uint8_t qs[QK4_0 / 2]; // nibbles / quants
} block_q4_0;
#define QK4_1 32
typedef struct {
half d; // delta
half m; // min
uint8_t qs[QK4_1 / 2]; // nibbles / quants
} block_q4_1;
#define QK5_0 32
typedef struct {
half d; // delta
uint8_t qh[4]; // 5-th bit of quants
uint8_t qs[QK5_0 / 2]; // nibbles / quants
} block_q5_0;
#define QK5_1 32
typedef struct {
half d; // delta
half m; // min
uint8_t qh[4]; // 5-th bit of quants
uint8_t qs[QK5_1 / 2]; // nibbles / quants
} block_q5_1;
#define QK8_0 32
typedef struct {
half d; // delta
int8_t qs[QK8_0]; // quants
} block_q8_0;
#define N_SIMDWIDTH 32 // assuming SIMD group size is 32
enum ggml_sort_order {
GGML_SORT_ASC,
GGML_SORT_DESC,
};
// general-purpose kernel for addition, multiplication and division of two tensors
// pros: works for non-contiguous tensors, supports broadcast across all dims
// cons: not very efficient
kernel void kernel_add(
device const char * src0,
device const char * src1,
device char * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant uint64_t & nb13,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
constant int64_t & offs,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig.z;
const int64_t i02 = tgpig.y;
const int64_t i01 = tgpig.x;
const int64_t i13 = i03 % ne13;
const int64_t i12 = i02 % ne12;
const int64_t i11 = i01 % ne11;
device const char * src0_ptr = src0 + i03*nb03 + i02*nb02 + i01*nb01 + offs;
device const char * src1_ptr = src1 + i13*nb13 + i12*nb12 + i11*nb11;
device char * dst_ptr = dst + i03*nb3 + i02*nb2 + i01*nb1 + offs;
for (int i0 = tpitg.x; i0 < ne0; i0 += ntg.x) {
const int i10 = i0 % ne10;
*((device float *)(dst_ptr + i0*nb0)) = *((device float *)(src0_ptr + i0*nb00)) + *((device float *)(src1_ptr + i10*nb10));
}
}
kernel void kernel_mul(
device const char * src0,
device const char * src1,
device char * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant uint64_t & nb13,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig.z;
const int64_t i02 = tgpig.y;
const int64_t i01 = tgpig.x;
const int64_t i13 = i03 % ne13;
const int64_t i12 = i02 % ne12;
const int64_t i11 = i01 % ne11;
device const char * src0_ptr = src0 + i03*nb03 + i02*nb02 + i01*nb01;
device const char * src1_ptr = src1 + i13*nb13 + i12*nb12 + i11*nb11;
device char * dst_ptr = dst + i03*nb3 + i02*nb2 + i01*nb1;
for (int i0 = tpitg.x; i0 < ne0; i0 += ntg.x) {
const int i10 = i0 % ne10;
*((device float *)(dst_ptr + i0*nb0)) = *((device float *)(src0_ptr + i0*nb00)) * *((device float *)(src1_ptr + i10*nb10));
}
}
kernel void kernel_div(
device const char * src0,
device const char * src1,
device char * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant uint64_t & nb13,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig.z;
const int64_t i02 = tgpig.y;
const int64_t i01 = tgpig.x;
const int64_t i13 = i03 % ne13;
const int64_t i12 = i02 % ne12;
const int64_t i11 = i01 % ne11;
device const char * src0_ptr = src0 + i03*nb03 + i02*nb02 + i01*nb01;
device const char * src1_ptr = src1 + i13*nb13 + i12*nb12 + i11*nb11;
device char * dst_ptr = dst + i03*nb3 + i02*nb2 + i01*nb1;
for (int i0 = tpitg.x; i0 < ne0; i0 += ntg.x) {
const int i10 = i0 % ne10;
*((device float *)(dst_ptr + i0*nb0)) = *((device float *)(src0_ptr + i0*nb00)) / *((device float *)(src1_ptr + i10*nb10));
}
}
// assumption: src1 is a row
// broadcast src1 into src0
kernel void kernel_add_row(
device const float4 * src0,
device const float4 * src1,
device float4 * dst,
constant uint64_t & nb [[buffer(28)]],
uint tpig[[thread_position_in_grid]]) {
dst[tpig] = src0[tpig] + src1[tpig % nb];
}
kernel void kernel_mul_row(
device const float4 * src0,
device const float4 * src1,
device float4 * dst,
constant uint64_t & nb [[buffer(28)]],
uint tpig[[thread_position_in_grid]]) {
dst[tpig] = src0[tpig] * src1[tpig % nb];
}
kernel void kernel_div_row(
device const float4 * src0,
device const float4 * src1,
device float4 * dst,
constant uint64_t & nb [[buffer(28)]],
uint tpig[[thread_position_in_grid]]) {
dst[tpig] = src0[tpig] / src1[tpig % nb];
}
kernel void kernel_scale(
device const float * src0,
device float * dst,
constant float & scale,
uint tpig[[thread_position_in_grid]]) {
dst[tpig] = src0[tpig] * scale;
}
kernel void kernel_scale_4(
device const float4 * src0,
device float4 * dst,
constant float & scale,
uint tpig[[thread_position_in_grid]]) {
dst[tpig] = src0[tpig] * scale;
}
kernel void kernel_relu(
device const float * src0,
device float * dst,
uint tpig[[thread_position_in_grid]]) {
dst[tpig] = max(0.0f, src0[tpig]);
}
kernel void kernel_tanh(
device const float * src0,
device float * dst,
uint tpig[[thread_position_in_grid]]) {
device const float & x = src0[tpig];
dst[tpig] = precise::tanh(x);
}
constant float GELU_COEF_A = 0.044715f;
constant float GELU_QUICK_COEF = -1.702f;
constant float SQRT_2_OVER_PI = 0.79788456080286535587989211986876f;
kernel void kernel_gelu(
device const float4 * src0,
device float4 * dst,
uint tpig[[thread_position_in_grid]]) {
device const float4 & x = src0[tpig];
// BEWARE !!!
// Simply using "tanh" instead of "precise::tanh" will sometimes results in NaNs!
// This was observed with Falcon 7B and 40B models
//
dst[tpig] = 0.5f*x*(1.0f + precise::tanh(SQRT_2_OVER_PI*x*(1.0f + GELU_COEF_A*x*x)));
}
kernel void kernel_gelu_quick(
device const float4 * src0,
device float4 * dst,
uint tpig[[thread_position_in_grid]]) {
device const float4 & x = src0[tpig];
dst[tpig] = x*(1.0f/(1.0f+exp(GELU_QUICK_COEF*x)));
}
kernel void kernel_silu(
device const float4 * src0,
device float4 * dst,
uint tpig[[thread_position_in_grid]]) {
device const float4 & x = src0[tpig];
dst[tpig] = x / (1.0f + exp(-x));
}
kernel void kernel_sqr(
device const float * src0,
device float * dst,
uint tpig[[thread_position_in_grid]]) {
dst[tpig] = src0[tpig] * src0[tpig];
}
kernel void kernel_sum_rows(
device const float * src0,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant uint64_t & nb13,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tpig[[thread_position_in_grid]]) {
int64_t i3 = tpig.z;
int64_t i2 = tpig.y;
int64_t i1 = tpig.x;
if (i3 >= ne03 || i2 >= ne02 || i1 >= ne01) {
return;
}
device const float * src_row = (device const float *) ((device const char *) src0 + i1*nb01 + i2*nb02 + i3*nb03);
device float * dst_row = (device float *) ((device char *) dst + i1*nb1 + i2*nb2 + i3*nb3);
float row_sum = 0;
for (int64_t i0 = 0; i0 < ne00; i0++) {
row_sum += src_row[i0];
}
dst_row[0] = row_sum;
}
kernel void kernel_soft_max(
device const float * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant float & scale,
threadgroup float * buf [[threadgroup(0)]],
uint tgpig[[threadgroup_position_in_grid]],
uint tpitg[[thread_position_in_threadgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint ntg[[threads_per_threadgroup]]) {
const int64_t i03 = (tgpig) / (ne02*ne01);
const int64_t i02 = (tgpig - i03*ne02*ne01) / ne01;
const int64_t i01 = (tgpig - i03*ne02*ne01 - i02*ne01);
device const float * psrc0 = src0 + i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
device const float * pmask = src1 != src0 ? src1 + i01*ne00 : nullptr;
device float * pdst = dst + i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
// parallel max
float lmax = -INFINITY;
for (int i00 = tpitg; i00 < ne00; i00 += ntg) {
lmax = MAX(lmax, psrc0[i00]*scale + (pmask ? pmask[i00] : 0.0f));
}
// find the max value in the block
float max_val = simd_max(lmax);
if (ntg > N_SIMDWIDTH) {
if (sgitg == 0) {
buf[tiisg] = -INFINITY;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
if (tiisg == 0) {
buf[sgitg] = max_val;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
max_val = buf[tiisg];
max_val = simd_max(max_val);
}
// parallel sum
float lsum = 0.0f;
for (int i00 = tpitg; i00 < ne00; i00 += ntg) {
const float exp_psrc0 = exp((psrc0[i00]*scale + (pmask ? pmask[i00] : 0.0f)) - max_val);
lsum += exp_psrc0;
pdst[i00] = exp_psrc0;
}
// This barrier fixes a failing test
// ref: https://github.com/ggerganov/ggml/pull/621#discussion_r1425156335
threadgroup_barrier(mem_flags::mem_none);
float sum = simd_sum(lsum);
if (ntg > N_SIMDWIDTH) {
if (sgitg == 0) {
buf[tiisg] = 0.0f;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
if (tiisg == 0) {
buf[sgitg] = sum;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
sum = buf[tiisg];
sum = simd_sum(sum);
}
const float inv_sum = 1.0f/sum;
for (int i00 = tpitg; i00 < ne00; i00 += ntg) {
pdst[i00] *= inv_sum;
}
}
kernel void kernel_soft_max_4(
device const float * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant float & scale,
threadgroup float * buf [[threadgroup(0)]],
uint tgpig[[threadgroup_position_in_grid]],
uint tpitg[[thread_position_in_threadgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint ntg[[threads_per_threadgroup]]) {
const int64_t i03 = (tgpig) / (ne02*ne01);
const int64_t i02 = (tgpig - i03*ne02*ne01) / ne01;
const int64_t i01 = (tgpig - i03*ne02*ne01 - i02*ne01);
device const float4 * psrc4 = (device const float4 *)(src0 + i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00);
device const float4 * pmask = src1 != src0 ? (device const float4 *)(src1 + i01*ne00) : nullptr;
device float4 * pdst4 = (device float4 *)(dst + i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00);
// parallel max
float4 lmax4 = -INFINITY;
for (int i00 = tpitg; i00 < ne00/4; i00 += ntg) {
lmax4 = fmax(lmax4, psrc4[i00]*scale + (pmask ? pmask[i00] : 0.0f));
}
const float lmax = MAX(MAX(lmax4[0], lmax4[1]), MAX(lmax4[2], lmax4[3]));
float max_val = simd_max(lmax);
if (ntg > N_SIMDWIDTH) {
if (sgitg == 0) {
buf[tiisg] = -INFINITY;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
if (tiisg == 0) {
buf[sgitg] = max_val;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
max_val = buf[tiisg];
max_val = simd_max(max_val);
}
// parallel sum
float4 lsum4 = 0.0f;
for (int i00 = tpitg; i00 < ne00/4; i00 += ntg) {
const float4 exp_psrc4 = exp((psrc4[i00]*scale + (pmask ? pmask[i00] : 0.0f)) - max_val);
lsum4 += exp_psrc4;
pdst4[i00] = exp_psrc4;
}
const float lsum = lsum4[0] + lsum4[1] + lsum4[2] + lsum4[3];
// This barrier fixes a failing test
// ref: https://github.com/ggerganov/ggml/pull/621#discussion_r1425156335
threadgroup_barrier(mem_flags::mem_none);
float sum = simd_sum(lsum);
if (ntg > N_SIMDWIDTH) {
if (sgitg == 0) {
buf[tiisg] = 0.0f;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
if (tiisg == 0) {
buf[sgitg] = sum;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
sum = buf[tiisg];
sum = simd_sum(sum);
}
const float inv_sum = 1.0f/sum;
for (int i00 = tpitg; i00 < ne00/4; i00 += ntg) {
pdst4[i00] *= inv_sum;
}
}
kernel void kernel_diag_mask_inf(
device const float * src0,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int & n_past,
uint3 tpig[[thread_position_in_grid]]) {
const int64_t i02 = tpig[2];
const int64_t i01 = tpig[1];
const int64_t i00 = tpig[0];
if (i00 > n_past + i01) {
dst[i02*ne01*ne00 + i01*ne00 + i00] = -INFINITY;
} else {
dst[i02*ne01*ne00 + i01*ne00 + i00] = src0[i02*ne01*ne00 + i01*ne00 + i00];
}
}
kernel void kernel_diag_mask_inf_8(
device const float4 * src0,
device float4 * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int & n_past,
uint3 tpig[[thread_position_in_grid]]) {
const int64_t i = 2*tpig[0];
dst[i+0] = src0[i+0];
dst[i+1] = src0[i+1];
int64_t i4 = 4*i;
const int64_t i02 = i4/(ne00*ne01); i4 -= i02*ne00*ne01;
const int64_t i01 = i4/(ne00); i4 -= i01*ne00;
const int64_t i00 = i4;
for (int k = 3; k >= 0; --k) {
if (i00 + 4 + k <= n_past + i01) {
break;
}
dst[i+1][k] = -INFINITY;
if (i00 + k > n_past + i01) {
dst[i][k] = -INFINITY;
}
}
}
kernel void kernel_norm(
device const void * src0,
device float * dst,
constant int64_t & ne00,
constant uint64_t & nb01,
constant float & eps,
threadgroup float * sum [[threadgroup(0)]],
uint tgpig[[threadgroup_position_in_grid]],
uint tpitg[[thread_position_in_threadgroup]],
uint ntg[[threads_per_threadgroup]]) {
device const float * x = (device const float *) ((device const char *) src0 + tgpig*nb01);
// MEAN
// parallel sum
sum[tpitg] = 0.0f;
for (int i00 = tpitg; i00 < ne00; i00 += ntg) {
sum[tpitg] += x[i00];
}
// reduce
threadgroup_barrier(mem_flags::mem_threadgroup);
for (uint i = ntg/2; i > 0; i /= 2) {
if (tpitg < i) {
sum[tpitg] += sum[tpitg + i];
}
threadgroup_barrier(mem_flags::mem_threadgroup);
}
const float mean = sum[0] / ne00;
// recenter and VARIANCE
threadgroup_barrier(mem_flags::mem_threadgroup);
device float * y = dst + tgpig*ne00;
sum[tpitg] = 0.0f;
for (int i00 = tpitg; i00 < ne00; i00 += ntg) {
y[i00] = x[i00] - mean;
sum[tpitg] += y[i00] * y[i00];
}
// reduce
threadgroup_barrier(mem_flags::mem_threadgroup);
for (uint i = ntg/2; i > 0; i /= 2) {
if (tpitg < i) {
sum[tpitg] += sum[tpitg + i];
}
threadgroup_barrier(mem_flags::mem_threadgroup);
}
const float variance = sum[0] / ne00;
const float scale = 1.0f/sqrt(variance + eps);
for (int i00 = tpitg; i00 < ne00; i00 += ntg) {
y[i00] = y[i00] * scale;
}
}
kernel void kernel_rms_norm(
device const void * src0,
device float * dst,
constant int64_t & ne00,
constant uint64_t & nb01,
constant float & eps,
threadgroup float * buf [[threadgroup(0)]],
uint tgpig[[threadgroup_position_in_grid]],
uint tpitg[[thread_position_in_threadgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint ntg[[threads_per_threadgroup]]) {
device const float4 * x = (device const float4 *) ((device const char *) src0 + tgpig*nb01);
float4 sumf = 0;
float all_sum = 0;
// parallel sum
for (int i00 = tpitg; i00 < ne00/4; i00 += ntg) {
sumf += x[i00] * x[i00];
}
all_sum = sumf[0] + sumf[1] + sumf[2] + sumf[3];
all_sum = simd_sum(all_sum);
if (ntg > N_SIMDWIDTH) {
if (sgitg == 0) {
buf[tiisg] = 0.0f;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
if (tiisg == 0) {
buf[sgitg] = all_sum;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
all_sum = buf[tiisg];
all_sum = simd_sum(all_sum);
}
const float mean = all_sum/ne00;
const float scale = 1.0f/sqrt(mean + eps);
device float4 * y = (device float4 *) (dst + tgpig*ne00);
for (int i00 = tpitg; i00 < ne00/4; i00 += ntg) {
y[i00] = x[i00] * scale;
}
}
kernel void kernel_group_norm(
device const float * src0,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int32_t & n_groups,
constant float & eps,
threadgroup float * buf [[threadgroup(0)]],
uint tgpig[[threadgroup_position_in_grid]],
uint tpitg[[thread_position_in_threadgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint ntg[[threads_per_threadgroup]]) {
const int64_t ne = ne00*ne01*ne02;
const int64_t gs = ne00*ne01*((ne02 + n_groups - 1) / n_groups);
int start = tgpig * gs;
int end = start + gs;
start += tpitg;
if (end >= ne) {
end = ne;
}
float tmp = 0.0f; // partial sum for thread in warp
for (int j = start; j < end; j += ntg) {
tmp += src0[j];
}
threadgroup_barrier(mem_flags::mem_threadgroup);
tmp = simd_sum(tmp);
if (ntg > N_SIMDWIDTH) {
if (sgitg == 0) {
buf[tiisg] = 0.0f;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
if (tiisg == 0) {
buf[sgitg] = tmp;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
tmp = buf[tiisg];
tmp = simd_sum(tmp);
}
const float mean = tmp / gs;
tmp = 0.0f;
for (int j = start; j < end; j += ntg) {
float xi = src0[j] - mean;
dst[j] = xi;
tmp += xi * xi;
}
tmp = simd_sum(tmp);
if (ntg > N_SIMDWIDTH) {
if (sgitg == 0) {
buf[tiisg] = 0.0f;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
if (tiisg == 0) {
buf[sgitg] = tmp;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
tmp = buf[tiisg];
tmp = simd_sum(tmp);
}
const float variance = tmp / gs;
const float scale = 1.0f/sqrt(variance + eps);
for (int j = start; j < end; j += ntg) {
dst[j] *= scale;
}
}
// function for calculate inner product between half a q4_0 block and 16 floats (yl), sumy is SUM(yl[i])
// il indicates where the q4 quants begin (0 or QK4_0/4)
// we assume that the yl's have been multiplied with the appropriate scale factor
// that corresponds to the missing bit shifts (1, 1/16, 1/256, 1/4096)
inline float block_q_n_dot_y(device const block_q4_0 * qb_curr, float sumy, thread float * yl, int il) {
float d = qb_curr->d;
float2 acc = 0.f;
device const uint16_t * qs = ((device const uint16_t *)qb_curr + 1 + il/2);
for (int i = 0; i < 8; i+=2) {
acc[0] += yl[i + 0] * (qs[i / 2] & 0x000F)
+ yl[i + 1] * (qs[i / 2] & 0x0F00);
acc[1] += yl[i + 8] * (qs[i / 2] & 0x00F0)
+ yl[i + 9] * (qs[i / 2] & 0xF000);
}
return d * (sumy * -8.f + acc[0] + acc[1]);
}
// function for calculate inner product between half a q4_1 block and 16 floats (yl), sumy is SUM(yl[i])
// il indicates where the q4 quants begin (0 or QK4_0/4)
// we assume that the yl's have been multiplied with the appropriate scale factor
// that corresponds to the missing bit shifts (1, 1/16, 1/256, 1/4096)
inline float block_q_n_dot_y(device const block_q4_1 * qb_curr, float sumy, thread float * yl, int il) {
float d = qb_curr->d;
float m = qb_curr->m;
float2 acc = 0.f;
device const uint16_t * qs = ((device const uint16_t *)qb_curr + 2 + il/2);
for (int i = 0; i < 8; i+=2) {
acc[0] += yl[i + 0] * (qs[i / 2] & 0x000F)
+ yl[i + 1] * (qs[i / 2] & 0x0F00);
acc[1] += yl[i + 8] * (qs[i / 2] & 0x00F0)
+ yl[i + 9] * (qs[i / 2] & 0xF000);
}
return d * (acc[0] + acc[1]) + sumy * m;
}
// function for calculate inner product between half a q5_0 block and 16 floats (yl), sumy is SUM(yl[i])
// il indicates where the q5 quants begin (0 or QK5_0/4)
// we assume that the yl's have been multiplied with the appropriate scale factor
// that corresponds to the missing bit shifts (1, 1/16, 1/256, 1/4096)
inline float block_q_n_dot_y(device const block_q5_0 * qb_curr, float sumy, thread float * yl, int il) {
float d = qb_curr->d;
float2 acc = 0.f;
device const uint16_t * qs = ((device const uint16_t *)qb_curr + 3 + il/2);
const uint32_t qh = *((device const uint32_t *)qb_curr->qh);
for (int i = 0; i < 8; i+=2) {
acc[0] += yl[i + 0] * ((qs[i / 2] & 0x000F) | ((qh >> (i+0+il ) << 4 ) & 0x00010))
+ yl[i + 1] * ((qs[i / 2] & 0x0F00) | ((qh >> (i+1+il ) << 12) & 0x01000));
acc[1] += yl[i + 8] * ((qs[i / 2] & 0x00F0) | ((qh >> (i+0+il+QK5_0/2) << 8 ) & 0x00100))
+ yl[i + 9] * ((qs[i / 2] & 0xF000) | ((qh >> (i+1+il+QK5_0/2) << 16) & 0x10000));
}
return d * (sumy * -16.f + acc[0] + acc[1]);
}
// function for calculate inner product between half a q5_1 block and 16 floats (yl), sumy is SUM(yl[i])
// il indicates where the q5 quants begin (0 or QK5_1/4)
// we assume that the yl's have been multiplied with the appropriate scale factor
// that corresponds to the missing bit shifts (1, 1/16, 1/256, 1/4096)
inline float block_q_n_dot_y(device const block_q5_1 * qb_curr, float sumy, thread float * yl, int il) {
float d = qb_curr->d;
float m = qb_curr->m;
float2 acc = 0.f;
device const uint16_t * qs = ((device const uint16_t *)qb_curr + 4 + il/2);
const uint32_t qh = *((device const uint32_t *)qb_curr->qh);
for (int i = 0; i < 8; i+=2) {
acc[0] += yl[i + 0] * ((qs[i / 2] & 0x000F) | ((qh >> (i+0+il ) << 4 ) & 0x00010))
+ yl[i + 1] * ((qs[i / 2] & 0x0F00) | ((qh >> (i+1+il ) << 12) & 0x01000));
acc[1] += yl[i + 8] * ((qs[i / 2] & 0x00F0) | ((qh >> (i+0+il+QK5_0/2) << 8 ) & 0x00100))
+ yl[i + 9] * ((qs[i / 2] & 0xF000) | ((qh >> (i+1+il+QK5_0/2) << 16) & 0x10000));
}
return d * (acc[0] + acc[1]) + sumy * m;
}
// putting them in the kernel cause a significant performance penalty
#define N_DST 4 // each SIMD group works on 4 rows
#define N_SIMDGROUP 2 // number of SIMD groups in a thread group
//Note: This is a template, but strictly speaking it only applies to
// quantizations where the block size is 32. It also does not
// guard against the number of rows not being divisible by
// N_DST, so this is another explicit assumption of the implementation.
template<typename block_q_type, int nr, int nsg, int nw>
void mul_vec_q_n_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
int64_t ne00,
int64_t ne01,
int64_t ne02,
int64_t ne10,
int64_t ne12,
int64_t ne0,
int64_t ne1,
uint r2,
uint r3,
uint3 tgpig, uint tiisg, uint sgitg) {
const int nb = ne00/QK4_0;
const int r0 = tgpig.x;
const int r1 = tgpig.y;
const int im = tgpig.z;
const int first_row = (r0 * nsg + sgitg) * nr;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = first_row * nb + (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q_type * x = (device const block_q_type *) src0 + offset0;
device const float * y = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
float yl[16]; // src1 vector cache
float sumf[nr] = {0.f};
const int ix = (tiisg/2);
const int il = (tiisg%2)*8;
device const float * yb = y + ix * QK4_0 + il;
// each thread in a SIMD group deals with half a block.
for (int ib = ix; ib < nb; ib += nw/2) {
float sumy = 0;
for (int i = 0; i < 8; i += 2) {
sumy += yb[i] + yb[i+1];
yl[i+0] = yb[i+ 0];
yl[i+1] = yb[i+ 1]/256.f;
sumy += yb[i+16] + yb[i+17];
yl[i+8] = yb[i+16]/16.f;
yl[i+9] = yb[i+17]/4096.f;
}
for (int row = 0; row < nr; row++) {
sumf[row] += block_q_n_dot_y(x+ib+row*nb, sumy, yl, il);
}
yb += QK4_0 * 16;
}
for (int row = 0; row < nr; ++row) {
const float tot = simd_sum(sumf[row]);
if (tiisg == 0 && first_row + row < ne01) {
dst[im*ne0*ne1 + r1*ne0 + first_row + row] = tot;
}
}
}
kernel void kernel_mul_mv_q4_0_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
mul_vec_q_n_f32_impl<block_q4_0, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(src0,src1,dst,ne00,ne01,ne02,ne10,ne12,ne0,ne1,r2,r3,tgpig,tiisg,sgitg);
}
kernel void kernel_mul_mv_q4_1_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
mul_vec_q_n_f32_impl<block_q4_1, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(src0,src1,dst,ne00,ne01,ne02,ne10,ne12,ne0,ne1,r2,r3,tgpig,tiisg,sgitg);
}
kernel void kernel_mul_mv_q5_0_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
mul_vec_q_n_f32_impl<block_q5_0, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(src0,src1,dst,ne00,ne01,ne02,ne10,ne12,ne0,ne1,r2,r3,tgpig,tiisg,sgitg);
}
kernel void kernel_mul_mv_q5_1_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
mul_vec_q_n_f32_impl<block_q5_1, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(src0,src1,dst,ne00,ne01,ne02,ne10,ne12,ne0,ne1,r2,r3,tgpig,tiisg,sgitg);
}
#define NB_Q8_0 8
void kernel_mul_mv_q8_0_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne10,
constant int64_t & ne12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
const int nr = N_DST;
const int nsg = N_SIMDGROUP;
const int nw = N_SIMDWIDTH;
const int nb = ne00/QK8_0;
const int r0 = tgpig.x;
const int r1 = tgpig.y;
const int im = tgpig.z;
const int first_row = (r0 * nsg + sgitg) * nr;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = first_row * nb + (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q8_0 * x = (device const block_q8_0 *) src0 + offset0;
device const float * y = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
float yl[NB_Q8_0];
float sumf[nr]={0.f};
const int ix = tiisg/4;
const int il = tiisg%4;
device const float * yb = y + ix * QK8_0 + NB_Q8_0*il;
// each thread in a SIMD group deals with NB_Q8_0 quants at a time
for (int ib = ix; ib < nb; ib += nw/4) {
for (int i = 0; i < NB_Q8_0; ++i) {
yl[i] = yb[i];
}
for (int row = 0; row < nr; row++) {
device const int8_t * qs = x[ib+row*nb].qs + NB_Q8_0*il;
float sumq = 0.f;
for (int iq = 0; iq < NB_Q8_0; ++iq) {
sumq += qs[iq] * yl[iq];
}
sumf[row] += sumq*x[ib+row*nb].d;
}
yb += NB_Q8_0 * nw;
}
for (int row = 0; row < nr; ++row) {
const float tot = simd_sum(sumf[row]);
if (tiisg == 0 && first_row + row < ne01) {
dst[r1*ne0 + im*ne0*ne1 + first_row + row] = tot;
}
}
}
[[host_name("kernel_mul_mv_q8_0_f32")]]
kernel void kernel_mul_mv_q8_0_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
kernel_mul_mv_q8_0_f32_impl(src0,src1,dst,ne00,ne01,ne02,ne10,ne12,ne0,ne1,r2,r3,tgpig,tiisg,sgitg);
}
#define N_F32_F32 4
void kernel_mul_mv_f32_f32_impl(
device const char * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]]) {
const int64_t r0 = tgpig.x;
const int64_t rb = tgpig.y*N_F32_F32;
const int64_t im = tgpig.z;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = r0*nb01 + (i12/r2)*nb02 + (i13/r3)*nb02*ne02;
device const float * x = (device const float *) (src0 + offset0);
if (ne00 < 128) {
for (int row = 0; row < N_F32_F32; ++row) {
int r1 = rb + row;
if (r1 >= ne11) {
break;
}
device const float * y = (device const float *) (src1 + r1*nb11 + im*nb12);
float sumf = 0;
for (int i = tiisg; i < ne00; i += 32) {
sumf += (float) x[i] * (float) y[i];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
}
} else {
device const float4 * x4 = (device const float4 *)x;
for (int row = 0; row < N_F32_F32; ++row) {
int r1 = rb + row;
if (r1 >= ne11) {
break;
}
device const float * y = (device const float *) (src1 + r1*nb11 + im*nb12);
device const float4 * y4 = (device const float4 *) y;
float sumf = 0;
for (int i = tiisg; i < ne00/4; i += 32) {
for (int k = 0; k < 4; ++k) sumf += (float) x4[i][k] * y4[i][k];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
for (int i = 4*(ne00/4); i < ne00; ++i) all_sum += (float) x[i] * y[i];
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
}
}
}
[[host_name("kernel_mul_mv_f32_f32")]]
kernel void kernel_mul_mv_f32_f32(
device const char * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]]) {
kernel_mul_mv_f32_f32_impl(src0, src1, dst, ne00, ne01, ne02, nb00, nb01, nb02, ne10, ne11, ne12, nb10, nb11, nb12, ne0, ne1, r2, r3, tgpig, tiisg);
}
#define N_F16_F16 4
kernel void kernel_mul_mv_f16_f16(
device const char * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]]) {
const int64_t r0 = tgpig.x;
const int64_t rb = tgpig.y*N_F16_F16;
const int64_t im = tgpig.z;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = r0*nb01 + (i12/r2)*nb02 + (i13/r3)*nb02*ne02;
device const half * x = (device const half *) (src0 + offset0);
if (ne00 < 128) {
for (int row = 0; row < N_F16_F16; ++row) {
int r1 = rb + row;
if (r1 >= ne11) {
break;
}
device const half * y = (device const half *) (src1 + r1*nb11 + im*nb12);
float sumf = 0;
for (int i = tiisg; i < ne00; i += 32) {
sumf += (half) x[i] * (half) y[i];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
}
} else {
device const half4 * x4 = (device const half4 *)x;
for (int row = 0; row < N_F16_F16; ++row) {
int r1 = rb + row;
if (r1 >= ne11) {
break;
}
device const half * y = (device const half *) (src1 + r1*nb11 + im*nb12);
device const half4 * y4 = (device const half4 *) y;
float sumf = 0;
for (int i = tiisg; i < ne00/4; i += 32) {
for (int k = 0; k < 4; ++k) sumf += (half) x4[i][k] * y4[i][k];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
for (int i = 4*(ne00/4); i < ne00; ++i) all_sum += (half) x[i] * y[i];
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
}
}
}
void kernel_mul_mv_f16_f32_1row_impl(
device const char * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]]) {
const int64_t r0 = tgpig.x;
const int64_t r1 = tgpig.y;
const int64_t im = tgpig.z;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = r0*nb01 + (i12/r2)*nb02 + (i13/r3)*nb02*ne02;
device const half * x = (device const half *) (src0 + offset0);
device const float * y = (device const float *) (src1 + r1*nb11 + im*nb12);
float sumf = 0;
if (ne00 < 128) {
for (int i = tiisg; i < ne00; i += 32) {
sumf += (float) x[i] * (float) y[i];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
} else {
device const half4 * x4 = (device const half4 *) x;
device const float4 * y4 = (device const float4 *) y;
for (int i = tiisg; i < ne00/4; i += 32) {
for (int k = 0; k < 4; ++k) sumf += (float)x4[i][k] * y4[i][k];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
for (int i = 4*(ne00/4); i < ne00; ++i) all_sum += (float) x[i] * y[i];
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
}
}
[[host_name("kernel_mul_mv_f16_f32_1row")]]
kernel void kernel_mul_mv_f16_f32_1row(
device const char * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]]) {
kernel_mul_mv_f16_f32_1row_impl(src0, src1, dst, ne00, ne01, ne02, nb00, nb01, nb02, ne10, ne11, ne12, nb10, nb11, nb12, ne0, ne1, r2, r3, tgpig, tiisg);
}
#define N_F16_F32 4
void kernel_mul_mv_f16_f32_impl(
device const char * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]]) {
const int64_t r0 = tgpig.x;
const int64_t rb = tgpig.y*N_F16_F32;
const int64_t im = tgpig.z;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = r0*nb01 + (i12/r2)*nb02 + (i13/r3)*nb02*ne02;
device const half * x = (device const half *) (src0 + offset0);
if (ne00 < 128) {
for (int row = 0; row < N_F16_F32; ++row) {
int r1 = rb + row;
if (r1 >= ne11) {
break;
}
device const float * y = (device const float *) (src1 + r1*nb11 + im*nb12);
float sumf = 0;
for (int i = tiisg; i < ne00; i += 32) {
sumf += (float) x[i] * (float) y[i];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
}
} else {
device const half4 * x4 = (device const half4 *)x;
for (int row = 0; row < N_F16_F32; ++row) {
int r1 = rb + row;
if (r1 >= ne11) {
break;
}
device const float * y = (device const float *) (src1 + r1*nb11 + im*nb12);
device const float4 * y4 = (device const float4 *) y;
float sumf = 0;
for (int i = tiisg; i < ne00/4; i += 32) {
for (int k = 0; k < 4; ++k) sumf += (float) x4[i][k] * y4[i][k];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
for (int i = 4*(ne00/4); i < ne00; ++i) all_sum += (float) x[i] * y[i];
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
}
}
}
[[host_name("kernel_mul_mv_f16_f32")]]
kernel void kernel_mul_mv_f16_f32(
device const char * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]]) {
kernel_mul_mv_f16_f32_impl(src0, src1, dst, ne00, ne01, ne02, nb00, nb01, nb02, ne10, ne11, ne12, nb10, nb11, nb12, ne0, ne1, r2, r3, tgpig, tiisg);
}
// Assumes row size (ne00) is a multiple of 4
kernel void kernel_mul_mv_f16_f32_l4(
device const char * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]]) {
const int nrows = ne11;
const int64_t r0 = tgpig.x;
const int64_t im = tgpig.z;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = r0*nb01 + (i12/r2)*nb02 + (i13/r3)*nb02*ne02;
device const half4 * x4 = (device const half4 *) (src0 + offset0);
for (int r1 = 0; r1 < nrows; ++r1) {
device const float4 * y4 = (device const float4 *) (src1 + r1*nb11 + im*nb12);
float sumf = 0;
for (int i = tiisg; i < ne00/4; i += 32) {
for (int k = 0; k < 4; ++k) sumf += (float) x4[i][k] * y4[i][k];
}
float all_sum = simd_sum(sumf);
if (tiisg == 0) {
dst[im*ne1*ne0 + r1*ne0 + r0] = all_sum;
}
}
}
kernel void kernel_alibi_f32(
device const float * src0,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
constant float & m0,
constant float & m1,
constant int & n_heads_log2_floor,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig[2];
const int64_t i02 = tgpig[1];
const int64_t i01 = tgpig[0];
const int64_t n = i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
const int64_t i3 = n / (ne2*ne1*ne0);
const int64_t i2 = (n - i3*ne2*ne1*ne0) / (ne1*ne0);
const int64_t i1 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0) / ne0;
//const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0);
const int64_t k = i3*ne3 + i2;
float m_k;
if (k < n_heads_log2_floor) {
m_k = pow(m0, k + 1);
} else {
m_k = pow(m1, 2 * (k - n_heads_log2_floor) + 1);
}
device char * dst_row = (device char *) dst + i3*nb3 + i2*nb2 + i1*nb1;
device const char * src_row = (device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01;
for (int64_t i00 = tpitg.x; i00 < ne00; i00 += ntg.x) {
const float src_v = *(device float *)(src_row + i00*nb00);
device float * dst_v = (device float *)(dst_row + i00*nb0);
*dst_v = i00 * m_k + src_v;
}
}
static float rope_yarn_ramp(const float low, const float high, const int i0) {
const float y = (i0 / 2 - low) / max(0.001f, high - low);
return 1.0f - min(1.0f, max(0.0f, y));
}
// YaRN algorithm based on LlamaYaRNScaledRotaryEmbedding.py from https://github.com/jquesnelle/yarn
// MIT licensed. Copyright (c) 2023 Jeffrey Quesnelle and Bowen Peng.
static void rope_yarn(
float theta_extrap, float freq_scale, float corr_dims[2], int64_t i0, float ext_factor, float mscale,
thread float * cos_theta, thread float * sin_theta
) {
// Get n-d rotational scaling corrected for extrapolation
float theta_interp = freq_scale * theta_extrap;
float theta = theta_interp;
if (ext_factor != 0.0f) {
float ramp_mix = rope_yarn_ramp(corr_dims[0], corr_dims[1], i0) * ext_factor;
theta = theta_interp * (1 - ramp_mix) + theta_extrap * ramp_mix;
// Get n-d magnitude scaling corrected for interpolation
mscale *= 1.0f + 0.1f * log(1.0f / freq_scale);
}
*cos_theta = cos(theta) * mscale;
*sin_theta = sin(theta) * mscale;
}
// Apparently solving `n_rot = 2pi * x * base^((2 * max_pos_emb) / n_dims)` for x, we get
// `corr_fac(n_rot) = n_dims * log(max_pos_emb / (n_rot * 2pi)) / (2 * log(base))`
static float rope_yarn_corr_factor(int n_dims, int n_orig_ctx, float n_rot, float base) {
return n_dims * log(n_orig_ctx / (n_rot * 2 * M_PI_F)) / (2 * log(base));
}
static void rope_yarn_corr_dims(
int n_dims, int n_orig_ctx, float freq_base, float beta_fast, float beta_slow, float dims[2]
) {
// start and end correction dims
dims[0] = max(0.0f, floor(rope_yarn_corr_factor(n_dims, n_orig_ctx, beta_fast, freq_base)));
dims[1] = min(n_dims - 1.0f, ceil(rope_yarn_corr_factor(n_dims, n_orig_ctx, beta_slow, freq_base)));
}
typedef void (rope_t)(
device const void * src0,
device const int32_t * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
constant int & n_past,
constant int & n_dims,
constant int & mode,
constant int & n_orig_ctx,
constant float & freq_base,
constant float & freq_scale,
constant float & ext_factor,
constant float & attn_factor,
constant float & beta_fast,
constant float & beta_slow,
uint tiitg[[thread_index_in_threadgroup]],
uint3 tptg[[threads_per_threadgroup]],
uint3 tgpig[[threadgroup_position_in_grid]]);
template<typename T>
kernel void kernel_rope(
device const void * src0,
device const int32_t * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
constant int & n_past,
constant int & n_dims,
constant int & mode,
constant int & n_orig_ctx,
constant float & freq_base,
constant float & freq_scale,
constant float & ext_factor,
constant float & attn_factor,
constant float & beta_fast,
constant float & beta_slow,
uint tiitg[[thread_index_in_threadgroup]],
uint3 tptg[[threads_per_threadgroup]],
uint3 tgpig[[threadgroup_position_in_grid]]) {
const int64_t i3 = tgpig[2];
const int64_t i2 = tgpig[1];
const int64_t i1 = tgpig[0];
const bool is_neox = mode & 2;
float corr_dims[2];
rope_yarn_corr_dims(n_dims, n_orig_ctx, freq_base, beta_fast, beta_slow, corr_dims);
device const int32_t * pos = src1;
const int64_t p = pos[i2];
const float theta_0 = (float)p;
const float inv_ndims = -1.f/n_dims;
if (!is_neox) {
for (int64_t i0 = 2*tiitg; i0 < ne0; i0 += 2*tptg.x) {
const float theta = theta_0 * pow(freq_base, inv_ndims*i0);
float cos_theta, sin_theta;
rope_yarn(theta, freq_scale, corr_dims, i0, ext_factor, attn_factor, &cos_theta, &sin_theta);
device const T * const src = (device T *)((device char *) src0 + i3*nb03 + i2*nb02 + i1*nb01 + i0*nb00);
device T * dst_data = (device T *)((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
const T x0 = src[0];
const T x1 = src[1];
dst_data[0] = x0*cos_theta - x1*sin_theta;
dst_data[1] = x0*sin_theta + x1*cos_theta;
}
} else {
for (int64_t ic = 2*tiitg; ic < ne0; ic += 2*tptg.x) {
if (ic < n_dims) {
const int64_t ib = 0;
// simplified from `(ib * n_dims + ic) * inv_ndims`
const float cur_rot = inv_ndims*ic - ib;
const float theta = theta_0 * pow(freq_base, cur_rot);
float cos_theta, sin_theta;
rope_yarn(theta, freq_scale, corr_dims, cur_rot, ext_factor, attn_factor, &cos_theta, &sin_theta);
const int64_t i0 = ib*n_dims + ic/2;
device const T * const src = (device T *)((device char *) src0 + i3*nb03 + i2*nb02 + i1*nb01 + i0*nb00);
device T * dst_data = (device T *)((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
const float x0 = src[0];
const float x1 = src[n_dims/2];
dst_data[0] = x0*cos_theta - x1*sin_theta;
dst_data[n_dims/2] = x0*sin_theta + x1*cos_theta;
} else {
const int64_t i0 = ic;
device const T * const src = (device T *)((device char *) src0 + i3*nb03 + i2*nb02 + i1*nb01 + i0*nb00);
device T * dst_data = (device T *)((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
dst_data[0] = src[0];
dst_data[1] = src[1];
}
}
}
}
template [[host_name("kernel_rope_f32")]] kernel rope_t kernel_rope<float>;
template [[host_name("kernel_rope_f16")]] kernel rope_t kernel_rope<half>;
kernel void kernel_im2col_f16(
device const float * x,
device half * dst,
constant int32_t & ofs0,
constant int32_t & ofs1,
constant int32_t & IW,
constant int32_t & IH,
constant int32_t & CHW,
constant int32_t & s0,
constant int32_t & s1,
constant int32_t & p0,
constant int32_t & p1,
constant int32_t & d0,
constant int32_t & d1,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tgpg[[threadgroups_per_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int32_t iiw = tgpig[2] * s0 + tpitg[2] * d0 - p0;
const int32_t iih = tgpig[1] * s1 + tpitg[1] * d1 - p1;
const int32_t offset_dst =
(tpitg[0] * tgpg[1] * tgpg[2] + tgpig[1] * tgpg[2] + tgpig[2]) * CHW +
(tgpig[0] * (ntg[1] * ntg[2]) + tpitg[1] * ntg[2] + tpitg[2]);
if (iih < 0 || iih >= IH || iiw < 0 || iiw >= IW) {
dst[offset_dst] = 0.0f;
} else {
const int32_t offset_src = tpitg[0] * ofs0 + tgpig[0] * ofs1;
dst[offset_dst] = x[offset_src + iih * IW + iiw];
}
}
kernel void kernel_upscale_f32(
device const char * src0,
device char * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
constant int32_t & sf,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i3 = tgpig.z;
const int64_t i2 = tgpig.y;
const int64_t i1 = tgpig.x;
const int64_t i03 = i3;
const int64_t i02 = i2;
const int64_t i01 = i1/sf;
device const float * src0_ptr = (device const float *) (src0 + i03*nb03 + i02*nb02 + i01*nb01);
device float * dst_ptr = (device float *) (dst + i3*nb3 + i2*nb2 + i1*nb1);
for (int i0 = tpitg.x; i0 < ne0; i0 += ntg.x) {
dst_ptr[i0] = src0_ptr[i0/sf];
}
}
kernel void kernel_pad_f32(
device const char * src0,
device char * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i3 = tgpig.z;
const int64_t i2 = tgpig.y;
const int64_t i1 = tgpig.x;
const int64_t i03 = i3;
const int64_t i02 = i2;
const int64_t i01 = i1;
device const float * src0_ptr = (device const float *) (src0 + i03*nb03 + i02*nb02 + i01*nb01);
device float * dst_ptr = (device float *) (dst + i3*nb3 + i2*nb2 + i1*nb1);
if (i1 < ne01 && i2 < ne02 && i3 < ne03) {
for (int i0 = tpitg.x; i0 < ne0; i0 += ntg.x) {
if (i0 < ne00) {
dst_ptr[i0] = src0_ptr[i0];
} else {
dst_ptr[i0] = 0.0f;
}
}
return;
}
for (int i0 = tpitg.x; i0 < ne0; i0 += ntg.x) {
dst_ptr[i0] = 0.0f;
}
}
// bitonic sort implementation following the CUDA kernels as reference
typedef void (argsort_t)(
device const float * x,
device int32_t * dst,
constant int64_t & ncols,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]]);
template<ggml_sort_order order>
kernel void kernel_argsort_f32_i32(
device const float * x,
device int32_t * dst,
constant int64_t & ncols,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]]) {
// bitonic sort
int col = tpitg[0];
int row = tgpig[1];
if (col >= ncols) return;
device const float * x_row = x + row * ncols;
device int32_t * dst_row = dst + row * ncols;
// initialize indices
if (col < ncols) {
dst_row[col] = col;
}
threadgroup_barrier(mem_flags::mem_threadgroup);
for (int k = 2; k <= ncols; k *= 2) {
for (int j = k / 2; j > 0; j /= 2) {
int ixj = col ^ j;
if (ixj > col) {
if ((col & k) == 0) {
if (order == GGML_SORT_ASC ? x_row[dst_row[col]] > x_row[dst_row[ixj]] : x_row[dst_row[col]] < x_row[dst_row[ixj]]) {
SWAP(dst_row[col], dst_row[ixj]);
}
} else {
if (order == GGML_SORT_ASC ? x_row[dst_row[col]] < x_row[dst_row[ixj]] : x_row[dst_row[col]] > x_row[dst_row[ixj]]) {
SWAP(dst_row[col], dst_row[ixj]);
}
}
}
threadgroup_barrier(mem_flags::mem_threadgroup);
}
}
}
template [[host_name("kernel_argsort_f32_i32_asc")]] kernel argsort_t kernel_argsort_f32_i32<GGML_SORT_ASC>;
template [[host_name("kernel_argsort_f32_i32_desc")]] kernel argsort_t kernel_argsort_f32_i32<GGML_SORT_DESC>;
kernel void kernel_leaky_relu_f32(
device const float * src0,
device float * dst,
constant float & slope,
uint tpig[[thread_position_in_grid]]) {
dst[tpig] = src0[tpig] > 0.0f ? src0[tpig] : src0[tpig] * slope;
}
kernel void kernel_cpy_f16_f16(
device const half * src0,
device half * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig[2];
const int64_t i02 = tgpig[1];
const int64_t i01 = tgpig[0];
const int64_t n = i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
const int64_t i3 = n / (ne2*ne1*ne0);
const int64_t i2 = (n - i3*ne2*ne1*ne0) / (ne1*ne0);
const int64_t i1 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0) / ne0;
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0);
device half * dst_data = (device half *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
for (int64_t i00 = tpitg.x; i00 < ne00; i00 += ntg.x) {
device const half * src = (device half *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
dst_data[i00] = src[0];
}
}
kernel void kernel_cpy_f16_f32(
device const half * src0,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig[2];
const int64_t i02 = tgpig[1];
const int64_t i01 = tgpig[0];
const int64_t n = i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
const int64_t i3 = n / (ne2*ne1*ne0);
const int64_t i2 = (n - i3*ne2*ne1*ne0) / (ne1*ne0);
const int64_t i1 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0) / ne0;
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0);
device float * dst_data = (device float *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
for (int64_t i00 = tpitg.x; i00 < ne00; i00 += ntg.x) {
device const half * src = (device half *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
dst_data[i00] = src[0];
}
}
kernel void kernel_cpy_f32_f16(
device const float * src0,
device half * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig[2];
const int64_t i02 = tgpig[1];
const int64_t i01 = tgpig[0];
const int64_t n = i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
const int64_t i3 = n / (ne2*ne1*ne0);
const int64_t i2 = (n - i3*ne2*ne1*ne0) / (ne1*ne0);
const int64_t i1 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0) / ne0;
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0);
device half * dst_data = (device half *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
for (int64_t i00 = tpitg.x; i00 < ne00; i00 += ntg.x) {
device const float * src = (device float *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
dst_data[i00] = src[0];
}
}
kernel void kernel_cpy_f32_f32(
device const float * src0,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig[2];
const int64_t i02 = tgpig[1];
const int64_t i01 = tgpig[0];
const int64_t n = i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
const int64_t i3 = n / (ne2*ne1*ne0);
const int64_t i2 = (n - i3*ne2*ne1*ne0) / (ne1*ne0);
const int64_t i1 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0) / ne0;
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0);
device float * dst_data = (device float *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
for (int64_t i00 = tpitg.x; i00 < ne00; i00 += ntg.x) {
device const float * src = (device float *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
dst_data[i00] = src[0];
}
}
kernel void kernel_cpy_f32_q8_0(
device const float * src0,
device void * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig[2];
const int64_t i02 = tgpig[1];
const int64_t i01 = tgpig[0];
const int64_t n = i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
const int64_t i3 = n / (ne2*ne1*ne0);
const int64_t i2 = (n - i3*ne2*ne1*ne0) / (ne1*ne0);
const int64_t i1 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0) / ne0;
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0)/QK8_0;
device block_q8_0 * dst_data = (device block_q8_0 *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
for (int64_t i00 = tpitg.x*QK8_0; i00 < ne00; i00 += ntg.x*QK8_0) {
device const float * src = (device float *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
float amax = 0.0f; // absolute max
for (int j = 0; j < QK8_0; j++) {
const float v = src[j];
amax = MAX(amax, fabs(v));
}
const float d = amax / ((1 << 7) - 1);
const float id = d ? 1.0f/d : 0.0f;
dst_data[i00/QK8_0].d = d;
for (int j = 0; j < QK8_0; ++j) {
const float x0 = src[j]*id;
dst_data[i00/QK8_0].qs[j] = round(x0);
}
}
}
kernel void kernel_cpy_f32_q4_0(
device const float * src0,
device void * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig[2];
const int64_t i02 = tgpig[1];
const int64_t i01 = tgpig[0];
const int64_t n = i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
const int64_t i3 = n / (ne2*ne1*ne0);
const int64_t i2 = (n - i3*ne2*ne1*ne0) / (ne1*ne0);
const int64_t i1 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0) / ne0;
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0)/QK4_0;
device block_q4_0 * dst_data = (device block_q4_0 *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
for (int64_t i00 = tpitg.x*QK4_0; i00 < ne00; i00 += ntg.x*QK4_0) {
device const float * src = (device float *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
float amax = 0.0f; // absolute max
float max = 0.0f;
for (int j = 0; j < QK4_0; j++) {
const float v = src[j];
if (amax < fabs(v)) {
amax = fabs(v);
max = v;
}
}
const float d = max / -8;
const float id = d ? 1.0f/d : 0.0f;
dst_data[i00/QK4_0].d = d;
for (int j = 0; j < QK4_0/2; ++j) {
const float x0 = src[0 + j]*id;
const float x1 = src[QK4_0/2 + j]*id;
const uint8_t xi0 = MIN(15, (int8_t)(x0 + 8.5f));
const uint8_t xi1 = MIN(15, (int8_t)(x1 + 8.5f));
dst_data[i00/QK4_0].qs[j] = xi0;
dst_data[i00/QK4_0].qs[j] |= xi1 << 4;
}
}
}
kernel void kernel_cpy_f32_q4_1(
device const float * src0,
device void * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig[2];
const int64_t i02 = tgpig[1];
const int64_t i01 = tgpig[0];
const int64_t n = i03*ne02*ne01*ne00 + i02*ne01*ne00 + i01*ne00;
const int64_t i3 = n / (ne2*ne1*ne0);
const int64_t i2 = (n - i3*ne2*ne1*ne0) / (ne1*ne0);
const int64_t i1 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0) / ne0;
const int64_t i0 = (n - i3*ne2*ne1*ne0 - i2*ne1*ne0 - i1*ne0)/QK4_1;
device block_q4_1 * dst_data = (device block_q4_1 *) ((device char *) dst + i3*nb3 + i2*nb2 + i1*nb1 + i0*nb0);
for (int64_t i00 = tpitg.x*QK4_1; i00 < ne00; i00 += ntg.x*QK4_1) {
device const float * src = (device float *)((device char *) src0 + i03*nb03 + i02*nb02 + i01*nb01 + i00*nb00);
float min = FLT_MAX;
float max = -FLT_MAX;
for (int j = 0; j < QK4_1; j++) {
const float v = src[j];
if (min > v) min = v;
if (max < v) max = v;
}
const float d = (max - min) / ((1 << 4) - 1);
const float id = d ? 1.0f/d : 0.0f;
dst_data[i00/QK4_1].d = d;
dst_data[i00/QK4_1].m = min;
for (int j = 0; j < QK4_1/2; ++j) {
const float x0 = (src[0 + j] - min)*id;
const float x1 = (src[QK4_1/2 + j] - min)*id;
const uint8_t xi0 = MIN(15, (int8_t)(x0 + 0.5f));
const uint8_t xi1 = MIN(15, (int8_t)(x1 + 0.5f));
dst_data[i00/QK4_1].qs[j] = xi0;
dst_data[i00/QK4_1].qs[j] |= xi1 << 4;
}
}
}
kernel void kernel_concat(
device const char * src0,
device const char * src1,
device char * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne03,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant uint64_t & nb03,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant uint64_t & nb13,
constant int64_t & ne0,
constant int64_t & ne1,
constant int64_t & ne2,
constant int64_t & ne3,
constant uint64_t & nb0,
constant uint64_t & nb1,
constant uint64_t & nb2,
constant uint64_t & nb3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint3 tpitg[[thread_position_in_threadgroup]],
uint3 ntg[[threads_per_threadgroup]]) {
const int64_t i03 = tgpig.z;
const int64_t i02 = tgpig.y;
const int64_t i01 = tgpig.x;
const int64_t i13 = i03 % ne13;
const int64_t i12 = i02 % ne12;
const int64_t i11 = i01 % ne11;
device const char * src0_ptr = src0 + i03*nb03 + i02*nb02 + i01*nb01 + tpitg.x*nb00;
device const char * src1_ptr = src1 + i13*nb13 + i12*nb12 + i11*nb11 + tpitg.x*nb10;
device char * dst_ptr = dst + i03*nb3 + i02*nb2 + i01*nb1 + tpitg.x*nb0;
for (int i0 = tpitg.x; i0 < ne0; i0 += ntg.x) {
if (i02 < ne02) {
((device float *)dst_ptr)[0] = ((device float *)src0_ptr)[0];
src0_ptr += ntg.x*nb00;
} else {
((device float *)dst_ptr)[0] = ((device float *)src1_ptr)[0];
src1_ptr += ntg.x*nb10;
}
dst_ptr += ntg.x*nb0;
}
}
//============================================ k-quants ======================================================
#ifndef QK_K
#define QK_K 256
#else
static_assert(QK_K == 256 || QK_K == 64, "QK_K must be 256 or 64");
#endif
#if QK_K == 256
#define K_SCALE_SIZE 12
#else
#define K_SCALE_SIZE 4
#endif
typedef struct {
uint8_t scales[QK_K/16]; // scales and mins, quantized with 4 bits
uint8_t qs[QK_K/4]; // quants
half d; // super-block scale for quantized scales
half dmin; // super-block scale for quantized mins
} block_q2_K;
// 84 bytes / block
typedef struct {
uint8_t hmask[QK_K/8]; // quants - high bit
uint8_t qs[QK_K/4]; // quants - low 2 bits
#if QK_K == 64
uint8_t scales[2];
#else
uint8_t scales[K_SCALE_SIZE]; // scales, quantized with 6 bits
#endif
half d; // super-block scale
} block_q3_K;
#if QK_K == 64
typedef struct {
half d[2]; // super-block scales/mins
uint8_t scales[2];
uint8_t qs[QK_K/2]; // 4-bit quants
} block_q4_K;
#else
typedef struct {
half d; // super-block scale for quantized scales
half dmin; // super-block scale for quantized mins
uint8_t scales[K_SCALE_SIZE]; // scales and mins, quantized with 6 bits
uint8_t qs[QK_K/2]; // 4--bit quants
} block_q4_K;
#endif
#if QK_K == 64
typedef struct {
half d; // super-block scales/mins
int8_t scales[QK_K/16]; // 8-bit block scales
uint8_t qh[QK_K/8]; // quants, high bit
uint8_t qs[QK_K/2]; // quants, low 4 bits
} block_q5_K;
#else
typedef struct {
half d; // super-block scale for quantized scales
half dmin; // super-block scale for quantized mins
uint8_t scales[3*QK_K/64]; // scales and mins, quantized with 6 bits
uint8_t qh[QK_K/8]; // quants, high bit
uint8_t qs[QK_K/2]; // quants, low 4 bits
} block_q5_K;
// 176 bytes / block
#endif
typedef struct {
uint8_t ql[QK_K/2]; // quants, lower 4 bits
uint8_t qh[QK_K/4]; // quants, upper 2 bits
int8_t scales[QK_K/16]; // scales, quantized with 8 bits
half d; // super-block scale
} block_q6_K;
// 210 bytes / block
//====================================== dot products =========================
void kernel_mul_mv_q2_K_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne10,
constant int64_t & ne12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
const int nb = ne00/QK_K;
const int r0 = tgpig.x;
const int r1 = tgpig.y;
const int im = tgpig.z;
const int first_row = (r0 * N_SIMDGROUP + sgitg) * N_DST;
const int ib_row = first_row * nb;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q2_K * x = (device const block_q2_K *) src0 + ib_row + offset0;
device const float * y = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
float yl[32];
float sumf[N_DST]={0.f}, all_sum;
const int step = sizeof(block_q2_K) * nb;
#if QK_K == 256
const int ix = tiisg/8; // 0...3
const int it = tiisg%8; // 0...7
const int iq = it/4; // 0 or 1
const int ir = it%4; // 0...3
const int is = (8*ir)/16;// 0 or 1
device const float * y4 = y + ix * QK_K + 128 * iq + 8 * ir;
for (int ib = ix; ib < nb; ib += 4) {
float4 sumy = {0.f, 0.f, 0.f, 0.f};
for (int i = 0; i < 8; ++i) {
yl[i+ 0] = y4[i+ 0]; sumy[0] += yl[i+ 0];
yl[i+ 8] = y4[i+32]; sumy[1] += yl[i+ 8];
yl[i+16] = y4[i+64]; sumy[2] += yl[i+16];
yl[i+24] = y4[i+96]; sumy[3] += yl[i+24];
}
device const uint8_t * sc = (device const uint8_t *)x[ib].scales + 8*iq + is;
device const uint16_t * qs = (device const uint16_t *)x[ib].qs + 16 * iq + 4 * ir;
device const half * dh = &x[ib].d;
for (int row = 0; row < N_DST; row++) {
float4 acc1 = {0.f, 0.f, 0.f, 0.f};
float4 acc2 = {0.f, 0.f, 0.f, 0.f};
for (int i = 0; i < 8; i += 2) {
acc1[0] += yl[i+ 0] * (qs[i/2] & 0x0003);
acc2[0] += yl[i+ 1] * (qs[i/2] & 0x0300);
acc1[1] += yl[i+ 8] * (qs[i/2] & 0x000c);
acc2[1] += yl[i+ 9] * (qs[i/2] & 0x0c00);
acc1[2] += yl[i+16] * (qs[i/2] & 0x0030);
acc2[2] += yl[i+17] * (qs[i/2] & 0x3000);
acc1[3] += yl[i+24] * (qs[i/2] & 0x00c0);
acc2[3] += yl[i+25] * (qs[i/2] & 0xc000);
}
float dall = dh[0];
float dmin = dh[1] * 1.f/16.f;
sumf[row] += dall * ((acc1[0] + 1.f/256.f * acc2[0]) * (sc[0] & 0xF) * 1.f/ 1.f +
(acc1[1] + 1.f/256.f * acc2[1]) * (sc[2] & 0xF) * 1.f/ 4.f +
(acc1[2] + 1.f/256.f * acc2[2]) * (sc[4] & 0xF) * 1.f/16.f +
(acc1[3] + 1.f/256.f * acc2[3]) * (sc[6] & 0xF) * 1.f/64.f) -
dmin * (sumy[0] * (sc[0] & 0xF0) + sumy[1] * (sc[2] & 0xF0) + sumy[2] * (sc[4] & 0xF0) + sumy[3] * (sc[6] & 0xF0));
qs += step/2;
sc += step;
dh += step/2;
}
y4 += 4 * QK_K;
}
#else
const int ix = tiisg/2; // 0...15
const int it = tiisg%2; // 0...1
device const float * y4 = y + ix * QK_K + 8 * it;
for (int ib = ix; ib < nb; ib += 16) {
float4 sumy = {0.f, 0.f, 0.f, 0.f};
for (int i = 0; i < 8; ++i) {
yl[i+ 0] = y4[i+ 0]; sumy[0] += yl[i+ 0];
yl[i+ 8] = y4[i+16]; sumy[1] += yl[i+ 8];
yl[i+16] = y4[i+32]; sumy[2] += yl[i+16];
yl[i+24] = y4[i+48]; sumy[3] += yl[i+24];
}
device const uint8_t * sc = (device const uint8_t *)x[ib].scales;
device const uint16_t * qs = (device const uint16_t *)x[ib].qs + 4 * it;
device const half * dh = &x[ib].d;
for (int row = 0; row < N_DST; row++) {
float4 acc1 = {0.f, 0.f, 0.f, 0.f};
float4 acc2 = {0.f, 0.f, 0.f, 0.f};
for (int i = 0; i < 8; i += 2) {
acc1[0] += yl[i+ 0] * (qs[i/2] & 0x0003);
acc2[0] += yl[i+ 1] * (qs[i/2] & 0x0300);
acc1[1] += yl[i+ 8] * (qs[i/2] & 0x000c);
acc2[1] += yl[i+ 9] * (qs[i/2] & 0x0c00);
acc1[2] += yl[i+16] * (qs[i/2] & 0x0030);
acc2[2] += yl[i+17] * (qs[i/2] & 0x3000);
acc1[3] += yl[i+24] * (qs[i/2] & 0x00c0);
acc2[3] += yl[i+25] * (qs[i/2] & 0xc000);
}
float dall = dh[0];
float dmin = dh[1];
sumf[row] += dall * ((acc1[0] + 1.f/256.f * acc2[0]) * (sc[0] & 0xF) * 1.f/ 1.f +
(acc1[1] + 1.f/256.f * acc2[1]) * (sc[1] & 0xF) * 1.f/ 4.f +
(acc1[2] + 1.f/256.f * acc2[2]) * (sc[2] & 0xF) * 1.f/16.f +
(acc1[3] + 1.f/256.f * acc2[3]) * (sc[3] & 0xF) * 1.f/64.f) -
dmin * (sumy[0] * (sc[0] >> 4) + sumy[1] * (sc[1] >> 4) + sumy[2] * (sc[2] >> 4) + sumy[3] * (sc[3] >> 4));
qs += step/2;
sc += step;
dh += step/2;
}
y4 += 16 * QK_K;
}
#endif
for (int row = 0; row < N_DST; ++row) {
all_sum = simd_sum(sumf[row]);
if (tiisg == 0) {
dst[r1*ne0 + im*ne0*ne1 + first_row + row] = all_sum;
}
}
}
[[host_name("kernel_mul_mv_q2_K_f32")]]
kernel void kernel_mul_mv_q2_K_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
kernel_mul_mv_q2_K_f32_impl(src0, src1, dst, ne00, ne01, ne02, ne10, ne12, ne0, ne1, r2, r3, tgpig, tiisg, sgitg);
}
#if QK_K == 256
void kernel_mul_mv_q3_K_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne10,
constant int64_t & ne12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
const int nb = ne00/QK_K;
const int64_t r0 = tgpig.x;
const int64_t r1 = tgpig.y;
const int64_t im = tgpig.z;
const int first_row = (r0 * N_SIMDGROUP + sgitg) * 2;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q3_K * x = (device const block_q3_K *) src0 + first_row*nb + offset0;
device const float * yy = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
float yl[32];
//const uint16_t kmask1 = 0x3030;
//const uint16_t kmask2 = 0x0f0f;
const int tid = tiisg/4;
const int ix = tiisg%4;
const int ip = tid/4; // 0 or 1
const int il = 2*((tid%4)/2); // 0 or 2
const int ir = tid%2;
const int n = 8;
const int l0 = n*ir;
// One would think that the Metal compiler would figure out that ip and il can only have
// 4 possible states, and optimize accordingly. Well, no. It needs help, and we do it
// with these two tales.
//
// Possible masks for the high bit
const ushort4 mm[4] = {{0x0001, 0x0100, 0x0002, 0x0200}, // ip = 0, il = 0
{0x0004, 0x0400, 0x0008, 0x0800}, // ip = 0, il = 2
{0x0010, 0x1000, 0x0020, 0x2000}, // ip = 1, il = 0
{0x0040, 0x4000, 0x0080, 0x8000}}; // ip = 1, il = 2
// Possible masks for the low 2 bits
const int4 qm[2] = {{0x0003, 0x0300, 0x000c, 0x0c00}, {0x0030, 0x3000, 0x00c0, 0xc000}};
const ushort4 hm = mm[2*ip + il/2];
const int shift = 2*il;
const float v1 = il == 0 ? 4.f : 64.f;
const float v2 = 4.f * v1;
const uint16_t s_shift1 = 4*ip;
const uint16_t s_shift2 = s_shift1 + il;
const int q_offset = 32*ip + l0;
const int y_offset = 128*ip + 32*il + l0;
const int step = sizeof(block_q3_K) * nb / 2;
device const float * y1 = yy + ix*QK_K + y_offset;
uint32_t scales32, aux32;
thread uint16_t * scales16 = (thread uint16_t *)&scales32;
thread const int8_t * scales = (thread const int8_t *)&scales32;
float sumf1[2] = {0.f};
float sumf2[2] = {0.f};
for (int i = ix; i < nb; i += 4) {
for (int l = 0; l < 8; ++l) {
yl[l+ 0] = y1[l+ 0];
yl[l+ 8] = y1[l+16];
yl[l+16] = y1[l+32];
yl[l+24] = y1[l+48];
}
device const uint16_t * q = (device const uint16_t *)(x[i].qs + q_offset);
device const uint16_t * h = (device const uint16_t *)(x[i].hmask + l0);
device const uint16_t * a = (device const uint16_t *)(x[i].scales);
device const half * dh = &x[i].d;
for (int row = 0; row < 2; ++row) {
const float d_all = (float)dh[0];
scales16[0] = a[4];
scales16[1] = a[5];
aux32 = ((scales32 >> s_shift2) << 4) & 0x30303030;
scales16[0] = a[il+0];
scales16[1] = a[il+1];
scales32 = ((scales32 >> s_shift1) & 0x0f0f0f0f) | aux32;
float s1 = 0, s2 = 0, s3 = 0, s4 = 0, s5 = 0, s6 = 0;
for (int l = 0; l < n; l += 2) {
const int32_t qs = q[l/2];
s1 += yl[l+0] * (qs & qm[il/2][0]);
s2 += yl[l+1] * (qs & qm[il/2][1]);
s3 += ((h[l/2] & hm[0]) ? 0.f : yl[l+0]) + ((h[l/2] & hm[1]) ? 0.f : yl[l+1]);
s4 += yl[l+16] * (qs & qm[il/2][2]);
s5 += yl[l+17] * (qs & qm[il/2][3]);
s6 += ((h[l/2] & hm[2]) ? 0.f : yl[l+16]) + ((h[l/2] & hm[3]) ? 0.f : yl[l+17]);
}
float d1 = d_all * (s1 + 1.f/256.f * s2 - s3*v1);
float d2 = d_all * (s4 + 1.f/256.f * s5 - s6*v2);
sumf1[row] += d1 * (scales[0] - 32);
sumf2[row] += d2 * (scales[2] - 32);
s1 = s2 = s3 = s4 = s5 = s6 = 0;
for (int l = 0; l < n; l += 2) {
const int32_t qs = q[l/2+8];
s1 += yl[l+8] * (qs & qm[il/2][0]);
s2 += yl[l+9] * (qs & qm[il/2][1]);
s3 += ((h[l/2+8] & hm[0]) ? 0.f : yl[l+8]) + ((h[l/2+8] & hm[1]) ? 0.f : yl[l+9]);
s4 += yl[l+24] * (qs & qm[il/2][2]);
s5 += yl[l+25] * (qs & qm[il/2][3]);
s6 += ((h[l/2+8] & hm[2]) ? 0.f : yl[l+24]) + ((h[l/2+8] & hm[3]) ? 0.f : yl[l+25]);
}
d1 = d_all * (s1 + 1.f/256.f * s2 - s3*v1);
d2 = d_all * (s4 + 1.f/256.f * s5 - s6*v2);
sumf1[row] += d1 * (scales[1] - 32);
sumf2[row] += d2 * (scales[3] - 32);
q += step;
h += step;
a += step;
dh += step;
}
y1 += 4 * QK_K;
}
for (int row = 0; row < 2; ++row) {
const float sumf = (sumf1[row] + 0.25f * sumf2[row]) / (1 << shift);
sumf1[row] = simd_sum(sumf);
}
if (tiisg == 0) {
for (int row = 0; row < 2; ++row) {
dst[r1*ne0 + im*ne0*ne1 + first_row + row] = sumf1[row];
}
}
}
#else
void kernel_mul_mv_q3_K_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne10,
constant int64_t & ne12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
const int nb = ne00/QK_K;
const int64_t r0 = tgpig.x;
const int64_t r1 = tgpig.y;
const int64_t im = tgpig.z;
const int row = 2 * r0 + sgitg;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q3_K * x = (device const block_q3_K *) src0 + row*nb + offset0;
device const float * yy = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
const int ix = tiisg/4;
const int il = 4 * (tiisg%4);// 0, 4, 8, 12
const int iq = il/8; // 0, 0, 1, 1
const int in = il%8; // 0, 4, 0, 4
float2 sum = {0.f, 0.f};
for (int i = ix; i < nb; i += 8) {
const float d_all = (float)(x[i].d);
device const uint16_t * q = (device const uint16_t *)(x[i].qs + il);
device const uint16_t * h = (device const uint16_t *)(x[i].hmask + in);
device const uint16_t * s = (device const uint16_t *)(x[i].scales);
device const float * y = yy + i * QK_K + il;
const float d1 = d_all * ((int32_t)(s[0] & 0x000F) - 8);
const float d2 = d_all * ((int32_t)(s[0] & 0x00F0) - 128) * 1.f/64.f;
const float d3 = d_all * ((int32_t)(s[0] & 0x0F00) - 2048) * 1.f/4096.f;
const float d4 = d_all * ((int32_t)(s[0] & 0xF000) - 32768) * 1.f/262144.f;
for (int l = 0; l < 4; l += 2) {
const uint16_t hm = h[l/2] >> iq;
sum[0] += y[l+ 0] * d1 * ((int32_t)(q[l/2] & 0x0003) - ((hm & 0x0001) ? 0 : 4))
+ y[l+16] * d2 * ((int32_t)(q[l/2] & 0x000c) - ((hm & 0x0004) ? 0 : 16))
+ y[l+32] * d3 * ((int32_t)(q[l/2] & 0x0030) - ((hm & 0x0010) ? 0 : 64))
+ y[l+48] * d4 * ((int32_t)(q[l/2] & 0x00c0) - ((hm & 0x0040) ? 0 : 256));
sum[1] += y[l+ 1] * d1 * ((int32_t)(q[l/2] & 0x0300) - ((hm & 0x0100) ? 0 : 1024))
+ y[l+17] * d2 * ((int32_t)(q[l/2] & 0x0c00) - ((hm & 0x0400) ? 0 : 4096))
+ y[l+33] * d3 * ((int32_t)(q[l/2] & 0x3000) - ((hm & 0x1000) ? 0 : 16384))
+ y[l+49] * d4 * ((int32_t)(q[l/2] & 0xc000) - ((hm & 0x4000) ? 0 : 65536));
}
}
const float sumf = sum[0] + sum[1] * 1.f/256.f;
const float tot = simd_sum(sumf);
if (tiisg == 0) {
dst[r1*ne0 + im*ne0*ne1 + row] = tot;
}
}
#endif
[[host_name("kernel_mul_mv_q3_K_f32")]]
kernel void kernel_mul_mv_q3_K_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
kernel_mul_mv_q3_K_f32_impl(src0, src1, dst, ne00, ne01, ne02, ne10, ne12, ne0, ne1, r2, r3, tgpig, tiisg, sgitg);
}
#if QK_K == 256
void kernel_mul_mv_q4_K_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne10,
constant int64_t & ne12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
const uint16_t kmask1 = 0x3f3f;
const uint16_t kmask2 = 0x0f0f;
const uint16_t kmask3 = 0xc0c0;
const int ix = tiisg/8; // 0...3
const int it = tiisg%8; // 0...7
const int iq = it/4; // 0 or 1
const int ir = it%4; // 0...3
const int nb = ne00/QK_K;
const int r0 = tgpig.x;
const int r1 = tgpig.y;
const int im = tgpig.z;
//const int first_row = (r0 * N_SIMDGROUP + sgitg) * N_DST;
const int first_row = r0 * N_DST;
const int ib_row = first_row * nb;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q4_K * x = (device const block_q4_K *) src0 + ib_row + offset0;
device const float * y = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
float yl[16];
float yh[16];
float sumf[N_DST]={0.f}, all_sum;
const int step = sizeof(block_q4_K) * nb / 2;
device const float * y4 = y + ix * QK_K + 64 * iq + 8 * ir;
uint16_t sc16[4];
thread const uint8_t * sc8 = (thread const uint8_t *)sc16;
for (int ib = ix; ib < nb; ib += 4) {
float4 sumy = {0.f, 0.f, 0.f, 0.f};
for (int i = 0; i < 8; ++i) {
yl[i+0] = y4[i+ 0]; sumy[0] += yl[i+0];
yl[i+8] = y4[i+ 32]; sumy[1] += yl[i+8];
yh[i+0] = y4[i+128]; sumy[2] += yh[i+0];
yh[i+8] = y4[i+160]; sumy[3] += yh[i+8];
}
device const uint16_t * sc = (device const uint16_t *)x[ib].scales + iq;
device const uint16_t * q1 = (device const uint16_t *)x[ib].qs + 16 * iq + 4 * ir;
device const half * dh = &x[ib].d;
for (int row = 0; row < N_DST; row++) {
sc16[0] = sc[0] & kmask1;
sc16[1] = sc[2] & kmask1;
sc16[2] = ((sc[4] >> 0) & kmask2) | ((sc[0] & kmask3) >> 2);
sc16[3] = ((sc[4] >> 4) & kmask2) | ((sc[2] & kmask3) >> 2);
device const uint16_t * q2 = q1 + 32;
float4 acc1 = {0.f, 0.f, 0.f, 0.f};
float4 acc2 = {0.f, 0.f, 0.f, 0.f};
for (int i = 0; i < 8; i += 2) {
acc1[0] += yl[i+0] * (q1[i/2] & 0x000F);
acc1[1] += yl[i+1] * (q1[i/2] & 0x0F00);
acc1[2] += yl[i+8] * (q1[i/2] & 0x00F0);
acc1[3] += yl[i+9] * (q1[i/2] & 0xF000);
acc2[0] += yh[i+0] * (q2[i/2] & 0x000F);
acc2[1] += yh[i+1] * (q2[i/2] & 0x0F00);
acc2[2] += yh[i+8] * (q2[i/2] & 0x00F0);
acc2[3] += yh[i+9] * (q2[i/2] & 0xF000);
}
float dall = dh[0];
float dmin = dh[1];
sumf[row] += dall * ((acc1[0] + 1.f/256.f * acc1[1]) * sc8[0] +
(acc1[2] + 1.f/256.f * acc1[3]) * sc8[1] * 1.f/16.f +
(acc2[0] + 1.f/256.f * acc2[1]) * sc8[4] +
(acc2[2] + 1.f/256.f * acc2[3]) * sc8[5] * 1.f/16.f) -
dmin * (sumy[0] * sc8[2] + sumy[1] * sc8[3] + sumy[2] * sc8[6] + sumy[3] * sc8[7]);
q1 += step;
sc += step;
dh += step;
}
y4 += 4 * QK_K;
}
for (int row = 0; row < N_DST; ++row) {
all_sum = simd_sum(sumf[row]);
if (tiisg == 0) {
dst[r1*ne0 + im*ne0*ne1 + first_row + row] = all_sum;
}
}
}
#else
void kernel_mul_mv_q4_K_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne10,
constant int64_t & ne12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
const int ix = tiisg/4; // 0...7
const int it = tiisg%4; // 0...3
const int nb = ne00/QK_K;
const int r0 = tgpig.x;
const int r1 = tgpig.y;
const int im = tgpig.z;
const int first_row = r0 * N_DST;
const int ib_row = first_row * nb;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q4_K * x = (device const block_q4_K *) src0 + ib_row + offset0;
device const float * y = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
float yl[8];
float yh[8];
float sumf[N_DST]={0.f}, all_sum;
const int step = sizeof(block_q4_K) * nb / 2;
device const float * y4 = y + ix * QK_K + 8 * it;
uint16_t sc16[4];
for (int ib = ix; ib < nb; ib += 8) {
float2 sumy = {0.f, 0.f};
for (int i = 0; i < 8; ++i) {
yl[i] = y4[i+ 0]; sumy[0] += yl[i];
yh[i] = y4[i+32]; sumy[1] += yh[i];
}
device const uint16_t * sc = (device const uint16_t *)x[ib].scales;
device const uint16_t * qs = (device const uint16_t *)x[ib].qs + 4 * it;
device const half * dh = x[ib].d;
for (int row = 0; row < N_DST; row++) {
sc16[0] = sc[0] & 0x000f;
sc16[1] = sc[0] & 0x0f00;
sc16[2] = sc[0] & 0x00f0;
sc16[3] = sc[0] & 0xf000;
float2 acc1 = {0.f, 0.f};
float2 acc2 = {0.f, 0.f};
for (int i = 0; i < 8; i += 2) {
acc1[0] += yl[i+0] * (qs[i/2] & 0x000F);
acc1[1] += yl[i+1] * (qs[i/2] & 0x0F00);
acc2[0] += yh[i+0] * (qs[i/2] & 0x00F0);
acc2[1] += yh[i+1] * (qs[i/2] & 0xF000);
}
float dall = dh[0];
float dmin = dh[1];
sumf[row] += dall * ((acc1[0] + 1.f/256.f * acc1[1]) * sc16[0] +
(acc2[0] + 1.f/256.f * acc2[1]) * sc16[1] * 1.f/4096.f) -
dmin * 1.f/16.f * (sumy[0] * sc16[2] + sumy[1] * sc16[3] * 1.f/256.f);
qs += step;
sc += step;
dh += step;
}
y4 += 8 * QK_K;
}
for (int row = 0; row < N_DST; ++row) {
all_sum = simd_sum(sumf[row]);
if (tiisg == 0) {
dst[r1*ne0 + im*ne0*ne1 + first_row + row] = all_sum;
}
}
}
#endif
[[host_name("kernel_mul_mv_q4_K_f32")]]
kernel void kernel_mul_mv_q4_K_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
kernel_mul_mv_q4_K_f32_impl(src0, src1, dst, ne00, ne01, ne02, ne10, ne12, ne0, ne1, r2, r3, tgpig, tiisg, sgitg);
}
void kernel_mul_mv_q5_K_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne10,
constant int64_t & ne12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
const int nb = ne00/QK_K;
const int64_t r0 = tgpig.x;
const int64_t r1 = tgpig.y;
const int im = tgpig.z;
const int first_row = (r0 * N_SIMDGROUP + sgitg) * 2;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q5_K * x = (device const block_q5_K *) src0 + first_row*nb + offset0;
device const float * yy = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
float sumf[2]={0.f};
const int step = sizeof(block_q5_K) * nb;
#if QK_K == 256
#
float yl[16], yh[16];
const uint16_t kmask1 = 0x3f3f;
const uint16_t kmask2 = 0x0f0f;
const uint16_t kmask3 = 0xc0c0;
const int tid = tiisg/4;
const int ix = tiisg%4;
const int iq = tid/4;
const int ir = tid%4;
const int n = 8;
const int l0 = n*ir;
const int q_offset = 32*iq + l0;
const int y_offset = 64*iq + l0;
const uint8_t hm1 = 1u << (2*iq);
const uint8_t hm2 = hm1 << 1;
const uint8_t hm3 = hm1 << 4;
const uint8_t hm4 = hm2 << 4;
uint16_t sc16[4];
thread const uint8_t * sc8 = (thread const uint8_t *)sc16;
device const float * y1 = yy + ix*QK_K + y_offset;
for (int i = ix; i < nb; i += 4) {
device const uint8_t * q1 = x[i].qs + q_offset;
device const uint8_t * qh = x[i].qh + l0;
device const half * dh = &x[i].d;
device const uint16_t * a = (device const uint16_t *)x[i].scales + iq;
device const float * y2 = y1 + 128;
float4 sumy = {0.f, 0.f, 0.f, 0.f};
for (int l = 0; l < 8; ++l) {
yl[l+0] = y1[l+ 0]; sumy[0] += yl[l+0];
yl[l+8] = y1[l+32]; sumy[1] += yl[l+8];
yh[l+0] = y2[l+ 0]; sumy[2] += yh[l+0];
yh[l+8] = y2[l+32]; sumy[3] += yh[l+8];
}
for (int row = 0; row < 2; ++row) {
device const uint8_t * q2 = q1 + 64;
sc16[0] = a[0] & kmask1;
sc16[1] = a[2] & kmask1;
sc16[2] = ((a[4] >> 0) & kmask2) | ((a[0] & kmask3) >> 2);
sc16[3] = ((a[4] >> 4) & kmask2) | ((a[2] & kmask3) >> 2);
float4 acc1 = {0.f};
float4 acc2 = {0.f};
for (int l = 0; l < n; ++l) {
uint8_t h = qh[l];
acc1[0] += yl[l+0] * (q1[l] & 0x0F);
acc1[1] += yl[l+8] * (q1[l] & 0xF0);
acc1[2] += yh[l+0] * (q2[l] & 0x0F);
acc1[3] += yh[l+8] * (q2[l] & 0xF0);
acc2[0] += h & hm1 ? yl[l+0] : 0.f;
acc2[1] += h & hm2 ? yl[l+8] : 0.f;
acc2[2] += h & hm3 ? yh[l+0] : 0.f;
acc2[3] += h & hm4 ? yh[l+8] : 0.f;
}
const float dall = dh[0];
const float dmin = dh[1];
sumf[row] += dall * (sc8[0] * (acc1[0] + 16.f*acc2[0]) +
sc8[1] * (acc1[1]/16.f + 16.f*acc2[1]) +
sc8[4] * (acc1[2] + 16.f*acc2[2]) +
sc8[5] * (acc1[3]/16.f + 16.f*acc2[3])) -
dmin * (sumy[0] * sc8[2] + sumy[1] * sc8[3] + sumy[2] * sc8[6] + sumy[3] * sc8[7]);
q1 += step;
qh += step;
dh += step/2;
a += step/2;
}
y1 += 4 * QK_K;
}
#else
float yl[8], yh[8];
const int il = 4 * (tiisg/8); // 0, 4, 8, 12
const int ix = tiisg%8;
const int iq = il/8; // 0, 0, 1, 1
const int in = il%8; // 0, 4, 0, 4
device const float * y = yy + ix*QK_K + il;
for (int i = ix; i < nb; i += 8) {
for (int l = 0; l < 4; ++l) {
yl[l+0] = y[l+ 0];
yl[l+4] = y[l+16];
yh[l+0] = y[l+32];
yh[l+4] = y[l+48];
}
device const half * dh = &x[i].d;
device const uint8_t * q = x[i].qs + il;
device const uint8_t * h = x[i].qh + in;
device const int8_t * s = x[i].scales;
for (int row = 0; row < 2; ++row) {
const float d = dh[0];
float2 acc = {0.f, 0.f};
for (int l = 0; l < 4; ++l) {
const uint8_t hl = h[l] >> iq;
acc[0] += yl[l+0] * s[0] * ((int16_t)(q[l+ 0] & 0x0F) - (hl & 0x01 ? 0 : 16))
+ yl[l+4] * s[1] * ((int16_t)(q[l+16] & 0x0F) - (hl & 0x04 ? 0 : 16));
acc[1] += yh[l+0] * s[2] * ((int16_t)(q[l+ 0] & 0xF0) - (hl & 0x10 ? 0 : 256))
+ yh[l+4] * s[3] * ((int16_t)(q[l+16] & 0xF0) - (hl & 0x40 ? 0 : 256));
}
sumf[row] += d * (acc[0] + 1.f/16.f * acc[1]);
q += step;
h += step;
s += step;
dh += step/2;
}
y += 8 * QK_K;
}
#endif
for (int row = 0; row < 2; ++row) {
const float tot = simd_sum(sumf[row]);
if (tiisg == 0) {
dst[r1*ne0 + im*ne0*ne1 + first_row + row] = tot;
}
}
}
[[host_name("kernel_mul_mv_q5_K_f32")]]
kernel void kernel_mul_mv_q5_K_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
kernel_mul_mv_q5_K_f32_impl(src0, src1, dst, ne00, ne01, ne02, ne10, ne12, ne0, ne1, r2, r3, tgpig, tiisg, sgitg);
}
void kernel_mul_mv_q6_K_f32_impl(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant int64_t & ne10,
constant int64_t & ne12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
const uint8_t kmask1 = 0x03;
const uint8_t kmask2 = 0x0C;
const uint8_t kmask3 = 0x30;
const uint8_t kmask4 = 0xC0;
const int nb = ne00/QK_K;
const int64_t r0 = tgpig.x;
const int64_t r1 = tgpig.y;
const int im = tgpig.z;
const int row = 2 * r0 + sgitg;
const uint i12 = im%ne12;
const uint i13 = im/ne12;
const uint offset0 = (i12/r2)*(nb*ne01) + (i13/r3)*(nb*ne01*ne02);
device const block_q6_K * x = (device const block_q6_K *) src0 + row * nb + offset0;
device const float * yy = (device const float *) src1 + r1*ne10 + im*ne00*ne1;
float sumf = 0;
#if QK_K == 256
const int tid = tiisg/2;
const int ix = tiisg%2;
const int ip = tid/8; // 0 or 1
const int il = tid%8;
const int n = 4;
const int l0 = n*il;
const int is = 8*ip + l0/16;
const int y_offset = 128*ip + l0;
const int q_offset_l = 64*ip + l0;
const int q_offset_h = 32*ip + l0;
for (int i = ix; i < nb; i += 2) {
device const uint8_t * q1 = x[i].ql + q_offset_l;
device const uint8_t * q2 = q1 + 32;
device const uint8_t * qh = x[i].qh + q_offset_h;
device const int8_t * sc = x[i].scales + is;
device const float * y = yy + i * QK_K + y_offset;
const float dall = x[i].d;
float4 sums = {0.f, 0.f, 0.f, 0.f};
for (int l = 0; l < n; ++l) {
sums[0] += y[l+ 0] * ((int8_t)((q1[l] & 0xF) | ((qh[l] & kmask1) << 4)) - 32);
sums[1] += y[l+32] * ((int8_t)((q2[l] & 0xF) | ((qh[l] & kmask2) << 2)) - 32);
sums[2] += y[l+64] * ((int8_t)((q1[l] >> 4) | ((qh[l] & kmask3) << 0)) - 32);
sums[3] += y[l+96] * ((int8_t)((q2[l] >> 4) | ((qh[l] & kmask4) >> 2)) - 32);
}
sumf += dall * (sums[0] * sc[0] + sums[1] * sc[2] + sums[2] * sc[4] + sums[3] * sc[6]);
}
#else
const int ix = tiisg/4;
const int il = 4*(tiisg%4);
for (int i = ix; i < nb; i += 8) {
device const float * y = yy + i * QK_K + il;
device const uint8_t * ql = x[i].ql + il;
device const uint8_t * qh = x[i].qh + il;
device const int8_t * s = x[i].scales;
const float d = x[i].d;
float4 sums = {0.f, 0.f, 0.f, 0.f};
for (int l = 0; l < 4; ++l) {
sums[0] += y[l+ 0] * ((int8_t)((ql[l+ 0] & 0xF) | ((qh[l] & kmask1) << 4)) - 32);
sums[1] += y[l+16] * ((int8_t)((ql[l+16] & 0xF) | ((qh[l] & kmask2) << 2)) - 32);
sums[2] += y[l+32] * ((int8_t)((ql[l+ 0] >> 4) | ((qh[l] & kmask3) >> 0)) - 32);
sums[3] += y[l+48] * ((int8_t)((ql[l+16] >> 4) | ((qh[l] & kmask4) >> 2)) - 32);
}
sumf += d * (sums[0] * s[0] + sums[1] * s[1] + sums[2] * s[2] + sums[3] * s[3]);
}
#endif
const float tot = simd_sum(sumf);
if (tiisg == 0) {
dst[r1*ne0 + im*ne0*ne1 + row] = tot;
}
}
[[host_name("kernel_mul_mv_q6_K_f32")]]
kernel void kernel_mul_mv_q6_K_f32(
device const void * src0,
device const float * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
kernel_mul_mv_q6_K_f32_impl(src0, src1, dst, ne00, ne01, ne02, ne10, ne12, ne0, ne1, r2, r3, tgpig, tiisg, sgitg);
}
//============================= templates and their specializations =============================
// NOTE: this is not dequantizing - we are simply fitting the template
template <typename type4x4>
void dequantize_f32(device const float4x4 * src, short il, thread type4x4 & reg) {
float4x4 temp = *(((device float4x4 *)src));
for (int i = 0; i < 16; i++){
reg[i/4][i%4] = temp[i/4][i%4];
}
}
template <typename type4x4>
void dequantize_f16(device const half4x4 * src, short il, thread type4x4 & reg) {
half4x4 temp = *(((device half4x4 *)src));
for (int i = 0; i < 16; i++){
reg[i/4][i%4] = temp[i/4][i%4];
}
}
template <typename type4x4>
void dequantize_q4_0(device const block_q4_0 *xb, short il, thread type4x4 & reg) {
device const uint16_t * qs = ((device const uint16_t *)xb + 1);
const float d1 = il ? (xb->d / 16.h) : xb->d;
const float d2 = d1 / 256.f;
const float md = -8.h * xb->d;
const ushort mask0 = il ? 0x00F0 : 0x000F;
const ushort mask1 = mask0 << 8;
for (int i=0;i<8;i++) {
reg[i/2][2*(i%2)+0] = d1 * (qs[i] & mask0) + md;
reg[i/2][2*(i%2)+1] = d2 * (qs[i] & mask1) + md;
}
}
template <typename type4x4>
void dequantize_q4_1(device const block_q4_1 *xb, short il, thread type4x4 & reg) {
device const uint16_t * qs = ((device const uint16_t *)xb + 2);
const float d1 = il ? (xb->d / 16.h) : xb->d;
const float d2 = d1 / 256.f;
const float m = xb->m;
const ushort mask0 = il ? 0x00F0 : 0x000F;
const ushort mask1 = mask0 << 8;
for (int i=0;i<8;i++) {
reg[i/2][2*(i%2)+0] = ((qs[i] & mask0) * d1) + m;
reg[i/2][2*(i%2)+1] = ((qs[i] & mask1) * d2) + m;
}
}
template <typename type4x4>
void dequantize_q5_0(device const block_q5_0 *xb, short il, thread type4x4 & reg) {
device const uint16_t * qs = ((device const uint16_t *)xb + 3);
const float d = xb->d;
const float md = -16.h * xb->d;
const ushort mask = il ? 0x00F0 : 0x000F;
const uint32_t qh = *((device const uint32_t *)xb->qh);
const int x_mv = il ? 4 : 0;
const int gh_mv = il ? 12 : 0;
const int gh_bk = il ? 0 : 4;
for (int i = 0; i < 8; i++) {
// extract the 5-th bits for x0 and x1
const uint8_t xh_0 = ((qh >> (gh_mv + 2*i )) << gh_bk) & 0x10;
const uint8_t xh_1 = ((qh >> (gh_mv + 2*i+1)) << gh_bk) & 0x10;
// combine the 4-bits from qs with the 5th bit
const int32_t x0 = ((((qs[i] ) & mask) >> x_mv) | xh_0);
const int32_t x1 = ((((qs[i] >> 8) & mask) >> x_mv) | xh_1);
reg[i/2][2*(i%2)+0] = d * x0 + md;
reg[i/2][2*(i%2)+1] = d * x1 + md;
}
}
template <typename type4x4>
void dequantize_q5_1(device const block_q5_1 *xb, short il, thread type4x4 & reg) {
device const uint16_t * qs = ((device const uint16_t *)xb + 4);
const float d = xb->d;
const float m = xb->m;
const ushort mask = il ? 0x00F0 : 0x000F;
const uint32_t qh = *((device const uint32_t *)xb->qh);
const int x_mv = il ? 4 : 0;
const int gh_mv = il ? 12 : 0;
const int gh_bk = il ? 0 : 4;
for (int i = 0; i < 8; i++) {
// extract the 5-th bits for x0 and x1
const uint8_t xh_0 = ((qh >> (gh_mv + 2*i )) << gh_bk) & 0x10;
const uint8_t xh_1 = ((qh >> (gh_mv + 2*i+1)) << gh_bk) & 0x10;
// combine the 4-bits from qs with the 5th bit
const int32_t x0 = ((((qs[i] ) & mask) >> x_mv) | xh_0);
const int32_t x1 = ((((qs[i] >> 8) & mask) >> x_mv) | xh_1);
reg[i/2][2*(i%2)+0] = d * x0 + m;
reg[i/2][2*(i%2)+1] = d * x1 + m;
}
}
template <typename type4x4>
void dequantize_q8_0(device const block_q8_0 *xb, short il, thread type4x4 & reg) {
device const int8_t * qs = ((device const int8_t *)xb->qs);
const half d = xb->d;
for (int i = 0; i < 16; i++) {
reg[i/4][i%4] = (qs[i + 16*il] * d);
}
}
template <typename type4x4>
void dequantize_q2_K(device const block_q2_K *xb, short il, thread type4x4 & reg) {
const float d = xb->d;
const float min = xb->dmin;
device const uint8_t * q = (device const uint8_t *)xb->qs;
float dl, ml;
uint8_t sc = xb->scales[il];
#if QK_K == 256
q = q + 32*(il/8) + 16*(il&1);
il = (il/2)%4;
#endif
half coef = il>1 ? (il>2 ? 1/64.h : 1/16.h) : (il>0 ? 1/4.h : 1.h);
uchar mask = il>1 ? (il>2 ? 192 : 48) : (il>0 ? 12 : 3);
dl = d * (sc & 0xF) * coef, ml = min * (sc >> 4);
for (int i = 0; i < 16; ++i) {
reg[i/4][i%4] = dl * (q[i] & mask) - ml;
}
}
template <typename type4x4>
void dequantize_q3_K(device const block_q3_K *xb, short il, thread type4x4 & reg) {
const half d_all = xb->d;
device const uint8_t * q = (device const uint8_t *)xb->qs;
device const uint8_t * h = (device const uint8_t *)xb->hmask;
device const int8_t * scales = (device const int8_t *)xb->scales;
#if QK_K == 256
q = q + 32 * (il/8) + 16 * (il&1);
h = h + 16 * (il&1);
uint8_t m = 1 << (il/2);
uint16_t kmask1 = (il/4)>1 ? ((il/4)>2 ? 192 : 48) : \
((il/4)>0 ? 12 : 3);
uint16_t kmask2 = il/8 ? 0xF0 : 0x0F;
uint16_t scale_2 = scales[il%8], scale_1 = scales[8 + il%4];
int16_t dl_int = (il/4)&1 ? (scale_2&kmask2) | ((scale_1&kmask1) << 2)
: (scale_2&kmask2) | ((scale_1&kmask1) << 4);
half dl = il<8 ? d_all * (dl_int - 32.h) : d_all * (dl_int / 16.h - 32.h);
const half ml = 4.h * dl;
il = (il/2) & 3;
const half coef = il>1 ? (il>2 ? 1/64.h : 1/16.h) : (il>0 ? 1/4.h : 1.h);
const uint8_t mask = il>1 ? (il>2 ? 192 : 48) : (il>0 ? 12 : 3);
dl *= coef;
for (int i = 0; i < 16; ++i) {
reg[i/4][i%4] = dl * (q[i] & mask) - (h[i] & m ? 0 : ml);
}
#else
float kcoef = il&1 ? 1.f/16.f : 1.f;
uint16_t kmask = il&1 ? 0xF0 : 0x0F;
float dl = d_all * ((scales[il/2] & kmask) * kcoef - 8);
float coef = il>1 ? (il>2 ? 1/64.h : 1/16.h) : (il>0 ? 1/4.h : 1.h);
uint8_t mask = il>1 ? (il>2 ? 192 : 48) : (il>0 ? 12 : 3);
uint8_t m = 1<<(il*2);
for (int i = 0; i < 16; ++i) {
reg[i/4][i%4] = coef * dl * ((q[i] & mask) - ((h[i%8] & (m * (1 + i/8))) ? 0 : 4.f/coef));
}
#endif
}
static inline uchar2 get_scale_min_k4_just2(int j, int k, device const uchar * q) {
return j < 4 ? uchar2{uchar(q[j+0+k] & 63), uchar(q[j+4+k] & 63)}
: uchar2{uchar((q[j+4+k] & 0xF) | ((q[j-4+k] & 0xc0) >> 2)), uchar((q[j+4+k] >> 4) | ((q[j-0+k] & 0xc0) >> 2))};
}
template <typename type4x4>
void dequantize_q4_K(device const block_q4_K *xb, short il, thread type4x4 & reg) {
device const uchar * q = xb->qs;
#if QK_K == 256
short is = (il/4) * 2;
q = q + (il/4) * 32 + 16 * (il&1);
il = il & 3;
const uchar2 sc = get_scale_min_k4_just2(is, il/2, xb->scales);
const float d = il < 2 ? xb->d : xb->d / 16.h;
const float min = xb->dmin;
const float dl = d * sc[0];
const float ml = min * sc[1];
#else
q = q + 16 * (il&1);
device const uint8_t * s = xb->scales;
device const half2 * dh = (device const half2 *)xb->d;
const float2 d = (float2)dh[0];
const float dl = il<2 ? d[0] * (s[0]&0xF) : d[0] * (s[1]&0xF)/16.h;
const float ml = il<2 ? d[1] * (s[0]>>4) : d[1] * (s[1]>>4);
#endif
const ushort mask = il<2 ? 0x0F : 0xF0;
for (int i = 0; i < 16; ++i) {
reg[i/4][i%4] = dl * (q[i] & mask) - ml;
}
}
template <typename type4x4>
void dequantize_q5_K(device const block_q5_K *xb, short il, thread type4x4 & reg) {
device const uint8_t * q = xb->qs;
device const uint8_t * qh = xb->qh;
#if QK_K == 256
short is = (il/4) * 2;
q = q + 32 * (il/4) + 16 * (il&1);
qh = qh + 16 * (il&1);
uint8_t ul = 1 << (il/2);
il = il & 3;
const uchar2 sc = get_scale_min_k4_just2(is, il/2, xb->scales);
const float d = il < 2 ? xb->d : xb->d / 16.h;
const float min = xb->dmin;
const float dl = d * sc[0];
const float ml = min * sc[1];
const ushort mask = il<2 ? 0x0F : 0xF0;
const float qh_val = il<2 ? 16.f : 256.f;
for (int i = 0; i < 16; ++i) {
reg[i/4][i%4] = dl * ((q[i] & mask) + (qh[i] & ul ? qh_val : 0)) - ml;
}
#else
q = q + 16 * (il&1);
device const int8_t * s = xb->scales;
const float dl = xb->d * s[il];
uint8_t m = 1<<(il*2);
const float coef = il<2 ? 1.f : 1.f/16.f;
const ushort mask = il<2 ? 0x0F : 0xF0;
for (int i = 0; i < 16; ++i) {
reg[i/4][i%4] = coef * dl * ((q[i] & mask) - (qh[i%8] & (m*(1+i/8)) ? 0.f : 16.f/coef));
}
#endif
}
template <typename type4x4>
void dequantize_q6_K(device const block_q6_K *xb, short il, thread type4x4 & reg) {
const half d_all = xb->d;
device const uint8_t * ql = (device const uint8_t *)xb->ql;
device const uint8_t * qh = (device const uint8_t *)xb->qh;
device const int8_t * scales = (device const int8_t *)xb->scales;
#if QK_K == 256
ql = ql + 64*(il/8) + 32*((il/2)&1) + 16*(il&1);
qh = qh + 32*(il/8) + 16*(il&1);
half sc = scales[(il%2) + 2 * ((il/2))];
il = (il/2) & 3;
#else
ql = ql + 16 * (il&1);
half sc = scales[il];
#endif
const uint16_t kmask1 = il>1 ? (il>2 ? 192 : 48) : (il>0 ? 12 : 3);
const uint16_t kmask2 = il>1 ? 0xF0 : 0x0F;
const half coef = il>1 ? 1.f/16.h : 1.h;
const half ml = d_all * sc * 32.h;
const half dl = d_all * sc * coef;
for (int i = 0; i < 16; ++i) {
const half q = il&1 ? ((ql[i] & kmask2) | ((qh[i] & kmask1) << 2))
: ((ql[i] & kmask2) | ((qh[i] & kmask1) << 4));
reg[i/4][i%4] = dl * q - ml;
}
}
template<typename block_q, short nl, void (*dequantize_func)(device const block_q *, short, thread float4x4 &)>
kernel void kernel_get_rows(
device const void * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb1,
constant uint64_t & nb2,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint3 tptg [[threads_per_threadgroup]]) {
//const int64_t i = tgpig;
//const int64_t r = ((device int32_t *) src1)[i];
const int64_t i10 = tgpig.x;
const int64_t i11 = tgpig.y;
const int64_t r = ((device int32_t *) ((device char *) src1 + i11*nb11 + i10*nb10))[0];
const int64_t i02 = i11;
for (int64_t ind = tiitg; ind < ne00/16; ind += tptg.x) {
float4x4 temp;
dequantize_func(
((device const block_q *) ((device char *) src0 + r*nb01 + i02*nb02)) + ind/nl, ind%nl, temp);
*(((device float4x4 *) ((device char *) dst + i11*nb2 + i10*nb1)) + ind) = temp;
}
}
kernel void kernel_get_rows_f32(
device const void * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb1,
constant uint64_t & nb2,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint3 tptg [[threads_per_threadgroup]]) {
const int64_t i10 = tgpig.x;
const int64_t i11 = tgpig.y;
const int64_t r = ((device int32_t *) ((device char *) src1 + i11*nb11 + i10*nb10))[0];
const int64_t i02 = i11;
for (int ind = tiitg; ind < ne00; ind += tptg.x) {
((device float *) ((device char *) dst + i11*nb2 + i10*nb1))[ind] =
((device float *) ((device char *) src0 + r*nb01 + i02*nb02))[ind];
}
}
kernel void kernel_get_rows_f16(
device const void * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb1,
constant uint64_t & nb2,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint3 tptg [[threads_per_threadgroup]]) {
const int64_t i10 = tgpig.x;
const int64_t i11 = tgpig.y;
const int64_t r = ((device int32_t *) ((device char *) src1 + i11*nb11 + i10*nb10))[0];
const int64_t i02 = i11;
for (int ind = tiitg; ind < ne00; ind += tptg.x) {
((device float *) ((device char *) dst + i11*nb2 + i10*nb1))[ind] =
((device half *) ((device char *) src0 + r*nb01 + i02*nb02))[ind];
}
}
#define BLOCK_SIZE_M 64 // 8 simdgroup matrices from matrix A
#define BLOCK_SIZE_N 32 // 4 simdgroup matrices from matrix B
#define BLOCK_SIZE_K 32
#define THREAD_MAT_M 4 // each thread take 4 simdgroup matrices from matrix A
#define THREAD_MAT_N 2 // each thread take 2 simdgroup matrices from matrix B
#define THREAD_PER_BLOCK 128
#define THREAD_PER_ROW 2 // 2 thread for each row in matrix A to load numbers
#define THREAD_PER_COL 4 // 4 thread for each row in matrix B to load numbers
#define SG_MAT_SIZE 64 // simdgroup matrix is of shape 8x8
#define SG_MAT_ROW 8
// each block_q contains 16*nl weights
template<typename block_q, short nl, void (*dequantize_func)(device const block_q *, short, thread half4x4 &)>
void kernel_mul_mm_impl(device const uchar * src0,
device const uchar * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne02,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
threadgroup uchar * shared_memory [[threadgroup(0)]],
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
threadgroup half * sa = (threadgroup half *)(shared_memory);
threadgroup float * sb = (threadgroup float *)(shared_memory + 4096);
const uint r0 = tgpig.y;
const uint r1 = tgpig.x;
const uint im = tgpig.z;
// if this block is of 64x32 shape or smaller
short n_rows = (ne0 - r0 * BLOCK_SIZE_M < BLOCK_SIZE_M) ? (ne0 - r0 * BLOCK_SIZE_M) : BLOCK_SIZE_M;
short n_cols = (ne1 - r1 * BLOCK_SIZE_N < BLOCK_SIZE_N) ? (ne1 - r1 * BLOCK_SIZE_N) : BLOCK_SIZE_N;
// a thread shouldn't load data outside of the matrix
short thread_row = ((short)tiitg/THREAD_PER_ROW) < n_rows ? ((short)tiitg/THREAD_PER_ROW) : n_rows - 1;
short thread_col = ((short)tiitg/THREAD_PER_COL) < n_cols ? ((short)tiitg/THREAD_PER_COL) : n_cols - 1;
simdgroup_half8x8 ma[4];
simdgroup_float8x8 mb[2];
simdgroup_float8x8 c_res[8];
for (int i = 0; i < 8; i++){
c_res[i] = make_filled_simdgroup_matrix<float, 8>(0.f);
}
short il = (tiitg % THREAD_PER_ROW);
const uint i12 = im%ne12;
const uint i13 = im/ne12;
uint offset0 = (i12/r2)*nb02 + (i13/r3)*(nb02*ne02);
ushort offset1 = il/nl;
device const block_q * x = (device const block_q *)(src0 + (r0 * BLOCK_SIZE_M + thread_row) * nb01 + offset0) + offset1;
device const float * y = (device const float *)(src1
+ nb12 * im
+ nb11 * (r1 * BLOCK_SIZE_N + thread_col)
+ nb10 * (BLOCK_SIZE_K / THREAD_PER_COL * (tiitg % THREAD_PER_COL)));
for (int loop_k = 0; loop_k < ne00; loop_k += BLOCK_SIZE_K) {
// load data and store to threadgroup memory
half4x4 temp_a;
dequantize_func(x, il, temp_a);
threadgroup_barrier(mem_flags::mem_threadgroup);
#pragma unroll(16)
for (int i = 0; i < 16; i++) {
*(sa + SG_MAT_SIZE * ((tiitg / THREAD_PER_ROW / 8) \
+ (tiitg % THREAD_PER_ROW) * 16 + (i / 8) * 8) \
+ (tiitg / THREAD_PER_ROW) % 8 + (i & 7) * 8) = temp_a[i/4][i%4];
}
*(threadgroup float2x4 *)(sb + (tiitg % THREAD_PER_COL) * 8 * 32 + 8 * (tiitg / THREAD_PER_COL)) = *((device float2x4 *)y);
il = (il + 2 < nl) ? il + 2 : il % 2;
x = (il < 2) ? x + (2+nl-1)/nl : x;
y += BLOCK_SIZE_K;
threadgroup_barrier(mem_flags::mem_threadgroup);
// load matrices from threadgroup memory and conduct outer products
threadgroup half * lsma = (sa + THREAD_MAT_M * SG_MAT_SIZE * (sgitg % 2));
threadgroup float * lsmb = (sb + THREAD_MAT_N * SG_MAT_SIZE * (sgitg / 2));
#pragma unroll(4)
for (int ik = 0; ik < BLOCK_SIZE_K / 8; ik++) {
#pragma unroll(4)
for (int i = 0; i < 4; i++) {
simdgroup_load(ma[i],lsma + SG_MAT_SIZE * i);
}
simdgroup_barrier(mem_flags::mem_none);
#pragma unroll(2)
for (int i = 0; i < 2; i++) {
simdgroup_load(mb[i],lsmb + SG_MAT_SIZE * i);
}
lsma += BLOCK_SIZE_M / SG_MAT_ROW * SG_MAT_SIZE;
lsmb += BLOCK_SIZE_N / SG_MAT_ROW * SG_MAT_SIZE;
#pragma unroll(8)
for (int i = 0; i < 8; i++){
simdgroup_multiply_accumulate(c_res[i], mb[i/4], ma[i%4], c_res[i]);
}
}
}
if ((r0 + 1) * BLOCK_SIZE_M <= ne0 && (r1 + 1) * BLOCK_SIZE_N <= ne1) {
device float * C = dst + (BLOCK_SIZE_M * r0 + 32 * (sgitg & 1)) \
+ (BLOCK_SIZE_N * r1 + 16 * (sgitg >> 1)) * ne0 + im*ne1*ne0;
for (int i = 0; i < 8; i++) {
simdgroup_store(c_res[i], C + 8 * (i%4) + 8 * ne0 * (i/4), ne0);
}
} else {
// block is smaller than 64x32, we should avoid writing data outside of the matrix
threadgroup_barrier(mem_flags::mem_threadgroup);
threadgroup float * temp_str = ((threadgroup float *)shared_memory) \
+ 32 * (sgitg&1) + (16 * (sgitg>>1)) * BLOCK_SIZE_M;
for (int i = 0; i < 8; i++) {
simdgroup_store(c_res[i], temp_str + 8 * (i%4) + 8 * BLOCK_SIZE_M * (i/4), BLOCK_SIZE_M);
}
threadgroup_barrier(mem_flags::mem_threadgroup);
device float * C = dst + (BLOCK_SIZE_M * r0) + (BLOCK_SIZE_N * r1) * ne0 + im*ne1*ne0;
if (sgitg == 0) {
for (int i = 0; i < n_rows; i++) {
for (int j = tiitg; j < n_cols; j += BLOCK_SIZE_N) {
*(C + i + j * ne0) = *(temp_str + i + j * BLOCK_SIZE_M);
}
}
}
}
}
// same as kernel_mul_mm_impl, but src1 and dst are accessed via indices stored in src1ids
template<typename block_q, short nl, void (*dequantize_func)(device const block_q *, short, thread half4x4 &)>
void kernel_mul_mm_id_impl(
device const uchar * src0,
device const uchar * src1,
thread short * src1ids,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne02,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
int64_t ne1,
constant uint & r2,
constant uint & r3,
threadgroup uchar * shared_memory,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
threadgroup half * sa = (threadgroup half *)(shared_memory);
threadgroup float * sb = (threadgroup float *)(shared_memory + 4096);
const uint r0 = tgpig.y;
const uint r1 = tgpig.x;
const uint im = tgpig.z;
if (r1 * BLOCK_SIZE_N >= ne1) return;
// if this block is of 64x32 shape or smaller
short n_rows = (ne0 - r0 * BLOCK_SIZE_M < BLOCK_SIZE_M) ? (ne0 - r0 * BLOCK_SIZE_M) : BLOCK_SIZE_M;
short n_cols = (ne1 - r1 * BLOCK_SIZE_N < BLOCK_SIZE_N) ? (ne1 - r1 * BLOCK_SIZE_N) : BLOCK_SIZE_N;
// a thread shouldn't load data outside of the matrix
short thread_row = ((short)tiitg/THREAD_PER_ROW) < n_rows ? ((short)tiitg/THREAD_PER_ROW) : n_rows - 1;
short thread_col = ((short)tiitg/THREAD_PER_COL) < n_cols ? ((short)tiitg/THREAD_PER_COL) : n_cols - 1;
simdgroup_half8x8 ma[4];
simdgroup_float8x8 mb[2];
simdgroup_float8x8 c_res[8];
for (int i = 0; i < 8; i++){
c_res[i] = make_filled_simdgroup_matrix<float, 8>(0.f);
}
short il = (tiitg % THREAD_PER_ROW);
const uint i12 = im%ne12;
const uint i13 = im/ne12;
uint offset0 = (i12/r2)*nb02 + (i13/r3)*(nb02*ne02);
ushort offset1 = il/nl;
device const block_q * x = (device const block_q *)(src0 + (r0 * BLOCK_SIZE_M + thread_row) * nb01 + offset0) + offset1;
device const float * y = (device const float *)(src1
+ nb12 * im
+ nb11 * src1ids[r1 * BLOCK_SIZE_N + thread_col]
+ nb10 * (BLOCK_SIZE_K / THREAD_PER_COL * (tiitg % THREAD_PER_COL)));
for (int loop_k = 0; loop_k < ne00; loop_k += BLOCK_SIZE_K) {
// load data and store to threadgroup memory
half4x4 temp_a;
dequantize_func(x, il, temp_a);
threadgroup_barrier(mem_flags::mem_threadgroup);
for (int i = 0; i < 16; i++) {
*(sa + SG_MAT_SIZE * ((tiitg / THREAD_PER_ROW / 8) \
+ (tiitg % THREAD_PER_ROW) * 16 + (i / 8) * 8) \
+ (tiitg / THREAD_PER_ROW) % 8 + (i & 7) * 8) = temp_a[i/4][i%4];
}
*(threadgroup float2x4 *)(sb + (tiitg % THREAD_PER_COL) * 8 * 32 + 8 * (tiitg / THREAD_PER_COL)) = *((device float2x4 *)y);
il = (il + 2 < nl) ? il + 2 : il % 2;
x = (il < 2) ? x + (2+nl-1)/nl : x;
y += BLOCK_SIZE_K;
threadgroup_barrier(mem_flags::mem_threadgroup);
// load matrices from threadgroup memory and conduct outer products
threadgroup half * lsma = (sa + THREAD_MAT_M * SG_MAT_SIZE * (sgitg % 2));
threadgroup float * lsmb = (sb + THREAD_MAT_N * SG_MAT_SIZE * (sgitg / 2));
for (int ik = 0; ik < BLOCK_SIZE_K / 8; ik++) {
for (int i = 0; i < 4; i++) {
simdgroup_load(ma[i],lsma + SG_MAT_SIZE * i);
}
simdgroup_barrier(mem_flags::mem_none);
for (int i = 0; i < 2; i++) {
simdgroup_load(mb[i],lsmb + SG_MAT_SIZE * i);
}
lsma += BLOCK_SIZE_M / SG_MAT_ROW * SG_MAT_SIZE;
lsmb += BLOCK_SIZE_N / SG_MAT_ROW * SG_MAT_SIZE;
for (int i = 0; i < 8; i++){
simdgroup_multiply_accumulate(c_res[i], mb[i/4], ma[i%4], c_res[i]);
}
}
}
{
threadgroup_barrier(mem_flags::mem_threadgroup);
threadgroup float * temp_str = ((threadgroup float *)shared_memory) \
+ 32 * (sgitg&1) + (16 * (sgitg>>1)) * BLOCK_SIZE_M;
for (int i = 0; i < 8; i++) {
simdgroup_store(c_res[i], temp_str + 8 * (i%4) + 8 * BLOCK_SIZE_M * (i/4), BLOCK_SIZE_M);
}
threadgroup_barrier(mem_flags::mem_threadgroup);
device float * C = dst + (BLOCK_SIZE_M * r0) + im*ne1*ne0;
if (sgitg == 0) {
for (int i = 0; i < n_rows; i++) {
for (int j = tiitg; j < n_cols; j += BLOCK_SIZE_N) {
*(C + i + src1ids[j + r1*BLOCK_SIZE_N] * ne0) = *(temp_str + i + j * BLOCK_SIZE_M);
}
}
}
}
}
template<typename block_q, short nl, void (*dequantize_func)(device const block_q *, short, thread half4x4 &)>
kernel void kernel_mul_mm(device const uchar * src0,
device const uchar * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne02,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
threadgroup uchar * shared_memory [[threadgroup(0)]],
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
kernel_mul_mm_impl<block_q, nl, dequantize_func>(
src0,
src1,
dst,
ne00,
ne02,
nb01,
nb02,
ne12,
nb10,
nb11,
nb12,
ne0,
ne1,
r2,
r3,
shared_memory,
tgpig,
tiitg,
sgitg);
}
template<typename block_q, short nl, void (*dequantize_func)(device const block_q *, short, thread half4x4 &)>
kernel void kernel_mul_mm_id(
device const uchar * ids,
device const uchar * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne02,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const uchar * src00,
device const uchar * src01,
device const uchar * src02,
device const uchar * src03,
device const uchar * src04,
device const uchar * src05,
device const uchar * src06,
device const uchar * src07,
threadgroup uchar * shared_memory [[threadgroup(0)]],
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const uchar * src0s[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
// expert id
const int32_t id = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
// row indices of src1 for expert id
int64_t _ne1 = 0;
short src1ids[512];
for (int64_t i1 = 0; i1 < ne1; i1++) {
if (((device int32_t *) (ids + i1*nbi1))[idx] == id) {
src1ids[_ne1++] = i1;
}
}
kernel_mul_mm_id_impl<block_q, nl, dequantize_func>(
src0s[id],
src1,
src1ids,
dst,
ne00,
ne02,
nb01,
nb02,
ne12,
nb10,
nb11,
nb12,
ne0,
_ne1,
r2,
r3,
shared_memory,
tgpig,
tiitg,
sgitg);
}
#if QK_K == 256
#define QK_NL 16
#else
#define QK_NL 4
#endif
//
// get rows
//
typedef void (get_rows_t)(
device const void * src0,
device const char * src1,
device float * dst,
constant int64_t & ne00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb1,
constant uint64_t & nb2,
uint3, uint, uint3);
//template [[host_name("kernel_get_rows_f32")]] kernel get_rows_t kernel_get_rows<float4x4, 1, dequantize_f32>;
//template [[host_name("kernel_get_rows_f16")]] kernel get_rows_t kernel_get_rows<half4x4, 1, dequantize_f16>;
template [[host_name("kernel_get_rows_q4_0")]] kernel get_rows_t kernel_get_rows<block_q4_0, 2, dequantize_q4_0>;
template [[host_name("kernel_get_rows_q4_1")]] kernel get_rows_t kernel_get_rows<block_q4_1, 2, dequantize_q4_1>;
template [[host_name("kernel_get_rows_q5_0")]] kernel get_rows_t kernel_get_rows<block_q5_0, 2, dequantize_q5_0>;
template [[host_name("kernel_get_rows_q5_1")]] kernel get_rows_t kernel_get_rows<block_q5_1, 2, dequantize_q5_1>;
template [[host_name("kernel_get_rows_q8_0")]] kernel get_rows_t kernel_get_rows<block_q8_0, 2, dequantize_q8_0>;
template [[host_name("kernel_get_rows_q2_K")]] kernel get_rows_t kernel_get_rows<block_q2_K, QK_NL, dequantize_q2_K>;
template [[host_name("kernel_get_rows_q3_K")]] kernel get_rows_t kernel_get_rows<block_q3_K, QK_NL, dequantize_q3_K>;
template [[host_name("kernel_get_rows_q4_K")]] kernel get_rows_t kernel_get_rows<block_q4_K, QK_NL, dequantize_q4_K>;
template [[host_name("kernel_get_rows_q5_K")]] kernel get_rows_t kernel_get_rows<block_q5_K, QK_NL, dequantize_q5_K>;
template [[host_name("kernel_get_rows_q6_K")]] kernel get_rows_t kernel_get_rows<block_q6_K, QK_NL, dequantize_q6_K>;
//
// matrix-matrix multiplication
//
typedef void (mat_mm_t)(
device const uchar * src0,
device const uchar * src1,
device float * dst,
constant int64_t & ne00,
constant int64_t & ne02,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne12,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint & r2,
constant uint & r3,
threadgroup uchar *,
uint3, uint, uint);
template [[host_name("kernel_mul_mm_f32_f32")]] kernel mat_mm_t kernel_mul_mm<float4x4, 1, dequantize_f32>;
template [[host_name("kernel_mul_mm_f16_f32")]] kernel mat_mm_t kernel_mul_mm<half4x4, 1, dequantize_f16>;
template [[host_name("kernel_mul_mm_q4_0_f32")]] kernel mat_mm_t kernel_mul_mm<block_q4_0, 2, dequantize_q4_0>;
template [[host_name("kernel_mul_mm_q4_1_f32")]] kernel mat_mm_t kernel_mul_mm<block_q4_1, 2, dequantize_q4_1>;
template [[host_name("kernel_mul_mm_q5_0_f32")]] kernel mat_mm_t kernel_mul_mm<block_q5_0, 2, dequantize_q5_0>;
template [[host_name("kernel_mul_mm_q5_1_f32")]] kernel mat_mm_t kernel_mul_mm<block_q5_1, 2, dequantize_q5_1>;
template [[host_name("kernel_mul_mm_q8_0_f32")]] kernel mat_mm_t kernel_mul_mm<block_q8_0, 2, dequantize_q8_0>;
template [[host_name("kernel_mul_mm_q2_K_f32")]] kernel mat_mm_t kernel_mul_mm<block_q2_K, QK_NL, dequantize_q2_K>;
template [[host_name("kernel_mul_mm_q3_K_f32")]] kernel mat_mm_t kernel_mul_mm<block_q3_K, QK_NL, dequantize_q3_K>;
template [[host_name("kernel_mul_mm_q4_K_f32")]] kernel mat_mm_t kernel_mul_mm<block_q4_K, QK_NL, dequantize_q4_K>;
template [[host_name("kernel_mul_mm_q5_K_f32")]] kernel mat_mm_t kernel_mul_mm<block_q5_K, QK_NL, dequantize_q5_K>;
template [[host_name("kernel_mul_mm_q6_K_f32")]] kernel mat_mm_t kernel_mul_mm<block_q6_K, QK_NL, dequantize_q6_K>;
//
// indirect matrix-matrix multiplication
//
typedef void (mat_mm_id_t)(
device const uchar * ids,
device const uchar * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne02,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const uchar * src00,
device const uchar * src01,
device const uchar * src02,
device const uchar * src03,
device const uchar * src04,
device const uchar * src05,
device const uchar * src06,
device const uchar * src07,
threadgroup uchar *,
uint3, uint, uint);
template [[host_name("kernel_mul_mm_id_f32_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<float4x4, 1, dequantize_f32>;
template [[host_name("kernel_mul_mm_id_f16_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<half4x4, 1, dequantize_f16>;
template [[host_name("kernel_mul_mm_id_q4_0_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q4_0, 2, dequantize_q4_0>;
template [[host_name("kernel_mul_mm_id_q4_1_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q4_1, 2, dequantize_q4_1>;
template [[host_name("kernel_mul_mm_id_q5_0_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q5_0, 2, dequantize_q5_0>;
template [[host_name("kernel_mul_mm_id_q5_1_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q5_1, 2, dequantize_q5_1>;
template [[host_name("kernel_mul_mm_id_q8_0_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q8_0, 2, dequantize_q8_0>;
template [[host_name("kernel_mul_mm_id_q2_K_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q2_K, QK_NL, dequantize_q2_K>;
template [[host_name("kernel_mul_mm_id_q3_K_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q3_K, QK_NL, dequantize_q3_K>;
template [[host_name("kernel_mul_mm_id_q4_K_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q4_K, QK_NL, dequantize_q4_K>;
template [[host_name("kernel_mul_mm_id_q5_K_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q5_K, QK_NL, dequantize_q5_K>;
template [[host_name("kernel_mul_mm_id_q6_K_f32")]] kernel mat_mm_id_t kernel_mul_mm_id<block_q6_K, QK_NL, dequantize_q6_K>;
//
// matrix-vector multiplication
//
[[host_name("kernel_mul_mv_id_f32_f32")]]
kernel void kernel_mul_mv_id_f32_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
kernel_mul_mv_f32_f32_impl(
src0[id],
src1 + bid*nb11,
dst + bid*ne0,
ne00,
ne01,
ne02,
nb00,
nb01,
nb02,
ne10,
ne11,
ne12,
nb10,
nb11,
nb12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg);
}
[[host_name("kernel_mul_mv_id_f16_f32")]]
kernel void kernel_mul_mv_id_f16_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
kernel_mul_mv_f16_f32_impl(
src0[id],
src1 + bid*nb11,
dst + bid*ne0,
ne00,
ne01,
ne02,
nb00,
nb01,
nb02,
ne10,
ne11,
ne12,
nb10,
nb11,
nb12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg);
}
[[host_name("kernel_mul_mv_id_q8_0_f32")]]
kernel void kernel_mul_mv_id_q8_0_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
kernel_mul_mv_q8_0_f32_impl(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q4_0_f32")]]
kernel void kernel_mul_mv_id_q4_0_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
mul_vec_q_n_f32_impl<block_q4_0, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q4_1_f32")]]
kernel void kernel_mul_mv_id_q4_1_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
mul_vec_q_n_f32_impl<block_q4_1, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q5_0_f32")]]
kernel void kernel_mul_mv_id_q5_0_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
mul_vec_q_n_f32_impl<block_q5_0, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q5_1_f32")]]
kernel void kernel_mul_mv_id_q5_1_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
mul_vec_q_n_f32_impl<block_q5_1, N_DST, N_SIMDGROUP, N_SIMDWIDTH>(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q2_K_f32")]]
kernel void kernel_mul_mv_id_q2_K_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
kernel_mul_mv_q2_K_f32_impl(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q3_K_f32")]]
kernel void kernel_mul_mv_id_q3_K_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
kernel_mul_mv_q3_K_f32_impl(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q4_K_f32")]]
kernel void kernel_mul_mv_id_q4_K_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
kernel_mul_mv_q4_K_f32_impl(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q5_K_f32")]]
kernel void kernel_mul_mv_id_q5_K_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
kernel_mul_mv_q5_K_f32_impl(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
[[host_name("kernel_mul_mv_id_q6_K_f32")]]
kernel void kernel_mul_mv_id_q6_K_f32(
device const char * ids,
device const char * src1,
device float * dst,
constant uint64_t & nbi1,
constant int64_t & ne00,
constant int64_t & ne01,
constant int64_t & ne02,
constant uint64_t & nb00,
constant uint64_t & nb01,
constant uint64_t & nb02,
constant int64_t & ne10,
constant int64_t & ne11,
constant int64_t & ne12,
constant int64_t & ne13,
constant uint64_t & nb10,
constant uint64_t & nb11,
constant uint64_t & nb12,
constant int64_t & ne0,
constant int64_t & ne1,
constant uint64_t & nb1,
constant uint & r2,
constant uint & r3,
constant int & idx,
device const char * src00,
device const char * src01,
device const char * src02,
device const char * src03,
device const char * src04,
device const char * src05,
device const char * src06,
device const char * src07,
uint3 tgpig[[threadgroup_position_in_grid]],
uint tiitg[[thread_index_in_threadgroup]],
uint tiisg[[thread_index_in_simdgroup]],
uint sgitg[[simdgroup_index_in_threadgroup]]) {
device const char * src0[8] = {src00, src01, src02, src03, src04, src05, src06, src07};
const int64_t bid = tgpig.z/(ne12*ne13);
tgpig.z = tgpig.z%(ne12*ne13);
const int32_t id = ((device int32_t *) (ids + bid*nbi1))[idx];
kernel_mul_mv_q6_K_f32_impl(
src0[id],
(device const float *) (src1 + bid*nb11),
dst + bid*ne0,
ne00,
ne01,
ne02,
ne10,
ne12,
ne0,
ne1,
r2,
r3,
tgpig,
tiisg,
sgitg);
}
| candle/candle-metal-kernels/src/quantized.metal/0 | {
"file_path": "candle/candle-metal-kernels/src/quantized.metal",
"repo_id": "candle",
"token_count": 97268
} | 32 |
//! Convolution Layers.
use crate::BatchNorm;
use candle::{Result, Tensor};
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub struct Conv1dConfig {
pub padding: usize,
pub stride: usize,
pub dilation: usize,
pub groups: usize,
}
impl Default for Conv1dConfig {
fn default() -> Self {
Self {
padding: 0,
stride: 1,
dilation: 1,
groups: 1,
}
}
}
#[derive(Clone, Debug)]
pub struct Conv1d {
weight: Tensor,
bias: Option<Tensor>,
config: Conv1dConfig,
}
impl Conv1d {
pub fn new(weight: Tensor, bias: Option<Tensor>, config: Conv1dConfig) -> Self {
Self {
weight,
bias,
config,
}
}
pub fn config(&self) -> &Conv1dConfig {
&self.config
}
pub fn weight(&self) -> &Tensor {
&self.weight
}
pub fn bias(&self) -> Option<&Tensor> {
self.bias.as_ref()
}
}
impl crate::Module for Conv1d {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = x.conv1d(
&self.weight,
self.config.padding,
self.config.stride,
self.config.dilation,
self.config.groups,
)?;
match &self.bias {
None => Ok(x),
Some(bias) => {
let b = bias.dims1()?;
let bias = bias.reshape((1, b, 1))?;
Ok(x.broadcast_add(&bias)?)
}
}
}
}
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub struct ConvTranspose1dConfig {
pub padding: usize,
pub output_padding: usize,
pub stride: usize,
pub dilation: usize,
pub groups: usize,
}
impl Default for ConvTranspose1dConfig {
fn default() -> Self {
Self {
padding: 0,
output_padding: 0,
stride: 1,
dilation: 1,
groups: 1,
}
}
}
#[derive(Clone, Debug)]
pub struct ConvTranspose1d {
weight: Tensor,
bias: Option<Tensor>,
config: ConvTranspose1dConfig,
}
impl ConvTranspose1d {
pub fn new(weight: Tensor, bias: Option<Tensor>, config: ConvTranspose1dConfig) -> Self {
Self {
weight,
bias,
config,
}
}
pub fn config(&self) -> &ConvTranspose1dConfig {
&self.config
}
pub fn weight(&self) -> &Tensor {
&self.weight
}
pub fn bias(&self) -> Option<&Tensor> {
self.bias.as_ref()
}
}
impl crate::Module for ConvTranspose1d {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = x.conv_transpose1d(
&self.weight,
self.config.padding,
self.config.output_padding,
self.config.stride,
self.config.dilation,
self.config.groups,
)?;
match &self.bias {
None => Ok(x),
Some(bias) => {
let b = bias.dims1()?;
let bias = bias.reshape((1, b, 1))?;
Ok(x.broadcast_add(&bias)?)
}
}
}
}
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub struct Conv2dConfig {
pub padding: usize,
pub stride: usize,
pub dilation: usize,
pub groups: usize,
}
impl Default for Conv2dConfig {
fn default() -> Self {
Self {
padding: 0,
stride: 1,
dilation: 1,
groups: 1,
}
}
}
#[derive(Clone, Debug)]
pub struct Conv2d {
weight: Tensor,
bias: Option<Tensor>,
config: Conv2dConfig,
}
impl Conv2d {
pub fn new(weight: Tensor, bias: Option<Tensor>, config: Conv2dConfig) -> Self {
Self {
weight,
bias,
config,
}
}
pub fn config(&self) -> &Conv2dConfig {
&self.config
}
pub fn weight(&self) -> &Tensor {
&self.weight
}
pub fn bias(&self) -> Option<&Tensor> {
self.bias.as_ref()
}
pub fn absorb_bn(&self, bn: &BatchNorm) -> Result<Self> {
if let Some((w_bn, b_bn)) = bn.weight_and_bias() {
let std_ = w_bn.div(&((bn.running_var() + bn.eps())?.sqrt()?))?;
let weight = self
.weight()
.broadcast_mul(&(std_.reshape((self.weight().dims4()?.0, 1, 1, 1))?))?;
let bias = match &self.bias {
None => b_bn.sub(&(std_.mul(bn.running_mean())?))?,
Some(bias) => b_bn.add(&(std_.mul(&bias.sub(bn.running_mean())?)?))?,
};
Ok(Self {
weight,
bias: Some(bias),
config: self.config,
})
} else {
candle::bail!("batch norm does not have weight_and_bias")
}
}
}
impl crate::Module for Conv2d {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = x.conv2d(
&self.weight,
self.config.padding,
self.config.stride,
self.config.dilation,
self.config.groups,
)?;
match &self.bias {
None => Ok(x),
Some(bias) => {
let b = bias.dims1()?;
let bias = bias.reshape((1, b, 1, 1))?;
Ok(x.broadcast_add(&bias)?)
}
}
}
}
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
pub struct ConvTranspose2dConfig {
pub padding: usize,
pub output_padding: usize,
pub stride: usize,
pub dilation: usize,
// TODO: support groups.
}
impl Default for ConvTranspose2dConfig {
fn default() -> Self {
Self {
padding: 0,
output_padding: 0,
stride: 1,
dilation: 1,
}
}
}
#[derive(Clone, Debug)]
pub struct ConvTranspose2d {
weight: Tensor,
bias: Option<Tensor>,
config: ConvTranspose2dConfig,
}
impl ConvTranspose2d {
pub fn new(weight: Tensor, bias: Option<Tensor>, config: ConvTranspose2dConfig) -> Self {
Self {
weight,
bias,
config,
}
}
pub fn config(&self) -> &ConvTranspose2dConfig {
&self.config
}
pub fn weight(&self) -> &Tensor {
&self.weight
}
pub fn bias(&self) -> Option<&Tensor> {
self.bias.as_ref()
}
}
impl crate::Module for ConvTranspose2d {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = x.conv_transpose2d(
&self.weight,
self.config.padding,
self.config.output_padding,
self.config.stride,
self.config.dilation,
)?;
match &self.bias {
None => Ok(x),
Some(bias) => {
let b = bias.dims1()?;
let bias = bias.reshape((1, b, 1, 1))?;
Ok(x.broadcast_add(&bias)?)
}
}
}
}
pub fn conv1d(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
cfg: Conv1dConfig,
vb: crate::VarBuilder,
) -> Result<Conv1d> {
let init_ws = crate::init::DEFAULT_KAIMING_NORMAL;
let ws = vb.get_with_hints(
(out_channels, in_channels / cfg.groups, kernel_size),
"weight",
init_ws,
)?;
let bound = 1. / (in_channels as f64).sqrt();
let init_bs = crate::Init::Uniform {
lo: -bound,
up: bound,
};
let bs = vb.get_with_hints(out_channels, "bias", init_bs)?;
Ok(Conv1d::new(ws, Some(bs), cfg))
}
pub fn conv1d_no_bias(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
cfg: Conv1dConfig,
vb: crate::VarBuilder,
) -> Result<Conv1d> {
let init_ws = crate::init::DEFAULT_KAIMING_NORMAL;
let ws = vb.get_with_hints(
(out_channels, in_channels / cfg.groups, kernel_size),
"weight",
init_ws,
)?;
Ok(Conv1d::new(ws, None, cfg))
}
pub fn conv_transpose1d(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
cfg: ConvTranspose1dConfig,
vb: crate::VarBuilder,
) -> Result<ConvTranspose1d> {
let bound = 1. / (out_channels as f64 * kernel_size as f64).sqrt();
let init = crate::Init::Uniform {
lo: -bound,
up: bound,
};
let ws = vb.get_with_hints(
(in_channels, out_channels / cfg.groups, kernel_size),
"weight",
init,
)?;
let bs = vb.get_with_hints(out_channels, "bias", init)?;
Ok(ConvTranspose1d::new(ws, Some(bs), cfg))
}
pub fn conv_transpose1d_no_bias(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
cfg: ConvTranspose1dConfig,
vb: crate::VarBuilder,
) -> Result<ConvTranspose1d> {
let bound = 1. / (out_channels as f64 * kernel_size as f64).sqrt();
let init = crate::Init::Uniform {
lo: -bound,
up: bound,
};
let ws = vb.get_with_hints(
(in_channels, out_channels / cfg.groups, kernel_size),
"weight",
init,
)?;
Ok(ConvTranspose1d::new(ws, None, cfg))
}
pub fn conv2d(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
cfg: Conv2dConfig,
vb: crate::VarBuilder,
) -> Result<Conv2d> {
let init_ws = crate::init::DEFAULT_KAIMING_NORMAL;
let ws = vb.get_with_hints(
(
out_channels,
in_channels / cfg.groups,
kernel_size,
kernel_size,
),
"weight",
init_ws,
)?;
let bound = 1. / (in_channels as f64).sqrt();
let init_bs = crate::Init::Uniform {
lo: -bound,
up: bound,
};
let bs = vb.get_with_hints(out_channels, "bias", init_bs)?;
Ok(Conv2d::new(ws, Some(bs), cfg))
}
pub fn conv2d_no_bias(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
cfg: Conv2dConfig,
vb: crate::VarBuilder,
) -> Result<Conv2d> {
let init_ws = crate::init::DEFAULT_KAIMING_NORMAL;
let ws = vb.get_with_hints(
(
out_channels,
in_channels / cfg.groups,
kernel_size,
kernel_size,
),
"weight",
init_ws,
)?;
Ok(Conv2d::new(ws, None, cfg))
}
pub fn conv_transpose2d(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
cfg: ConvTranspose2dConfig,
vb: crate::VarBuilder,
) -> Result<ConvTranspose2d> {
let bound = 1. / (out_channels as f64).sqrt() / kernel_size as f64;
let init = crate::Init::Uniform {
lo: -bound,
up: bound,
};
let ws = vb.get_with_hints(
(in_channels, out_channels, kernel_size, kernel_size),
"weight",
init,
)?;
let bs = vb.get_with_hints(out_channels, "bias", init)?;
Ok(ConvTranspose2d::new(ws, Some(bs), cfg))
}
pub fn conv_transpose2d_no_bias(
in_channels: usize,
out_channels: usize,
kernel_size: usize,
cfg: ConvTranspose2dConfig,
vb: crate::VarBuilder,
) -> Result<ConvTranspose2d> {
let bound = 1. / (out_channels as f64).sqrt() / kernel_size as f64;
let init = crate::Init::Uniform {
lo: -bound,
up: bound,
};
let ws = vb.get_with_hints(
(in_channels, out_channels, kernel_size, kernel_size),
"weight",
init,
)?;
Ok(ConvTranspose2d::new(ws, None, cfg))
}
| candle/candle-nn/src/conv.rs/0 | {
"file_path": "candle/candle-nn/src/conv.rs",
"repo_id": "candle",
"token_count": 5891
} | 33 |
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::Result;
use candle::{test_utils, DType, Device, Tensor};
use candle_nn::BatchNorm;
/* The test below has been generated using the following PyTorch code:
import torch
torch.manual_seed(19551105)
m = torch.nn.BatchNorm2d(5, affine=False)
input = torch.randn(2, 5, 3, 4)
output = m(input)
print(input.flatten())
print(output.flatten())
print(m.running_mean)
print(m.running_var)
*/
#[test]
fn batch_norm() -> Result<()> {
let running_mean = Tensor::zeros(5, DType::F32, &Device::Cpu)?;
let running_var = Tensor::ones(5, DType::F32, &Device::Cpu)?;
let bn = BatchNorm::new_no_bias(5, running_mean.clone(), running_var.clone(), 1e-8)?;
let input: [f32; 120] = [
-0.7493, -1.0410, 1.6977, -0.6579, 1.7982, -0.0087, 0.2812, -0.1190, 0.2908, -0.5975,
-0.0278, -0.2138, -1.3130, -1.6048, -2.2028, 0.9452, 0.4002, 0.0831, 1.0004, 0.1860,
0.5004, 0.5539, 0.9991, -0.2540, -0.0703, -0.3752, -0.1096, -0.2374, 1.0258, -2.2208,
-0.0257, 0.6073, -1.1627, -0.0964, -1.9718, 1.6577, 0.1931, -0.3692, -0.8011, 0.9059,
0.4797, 0.6521, -0.0165, -0.6683, -0.4148, 2.0649, -0.8276, 1.7947, -0.2061, 0.5812,
-1.3598, 1.6192, 1.0466, -0.4423, 0.4202, 0.1749, 0.6969, 0.2616, -0.0369, -1.4951,
-0.0814, -0.1877, 0.0267, 0.6150, 0.2402, -1.1440, -2.0068, 0.6032, -2.6639, 0.8260,
0.1085, -0.1693, 1.2805, 0.7654, -0.4930, 0.3770, 1.1309, 0.2303, 0.2949, -0.2634, -0.5225,
0.4269, 0.6341, 1.5736, 0.9827, -1.2499, 0.3509, -1.6243, -0.8123, 0.7634, -0.3047, 0.0143,
-0.4032, 0.0537, 0.7022, 0.8405, -1.2221, -1.6847, -0.0714, -0.1608, 0.5579, -1.5858,
0.4617, -0.6480, 0.1332, 0.0419, -0.9784, 0.4173, 1.2313, -1.9046, -0.1656, 0.1259, 0.0763,
1.4252, -0.9115, -0.1093, -0.3100, -0.6734, -1.4357, 0.9205,
];
let input = Tensor::new(&input, &Device::Cpu)?.reshape((2, 5, 3, 4))?;
let output = bn.forward_train(&input)?;
assert_eq!(output.dims(), &[2, 5, 3, 4]);
let output = output.flatten_all()?;
assert_eq!(
test_utils::to_vec1_round(&output, 4)?,
&[
-0.6391, -0.9414, 1.8965, -0.5444, 2.0007, 0.1283, 0.4287, 0.014, 0.4387, -0.4818,
0.1085, -0.0842, -1.6809, -2.0057, -2.6714, 0.8328, 0.2262, -0.1268, 0.8943, -0.0123,
0.3377, 0.3973, 0.8928, -0.5021, 0.0861, -0.2324, 0.0451, -0.0884, 1.2311, -2.1603,
0.1327, 0.7939, -1.055, 0.0589, -1.9002, 1.8912, 0.2918, -0.3253, -0.7993, 1.0741,
0.6063, 0.7955, 0.0617, -0.6536, -0.3754, 2.3461, -0.8284, 2.0495, -0.201, 0.6476,
-1.4446, 1.7665, 1.1493, -0.4556, 0.4741, 0.2097, 0.7723, 0.3031, -0.0186, -1.5905,
0.053, -0.0572, 0.165, 0.7746, 0.3862, -1.0481, -1.9422, 0.7624, -2.6231, 0.9933,
0.2498, -0.0381, 1.2061, 0.6327, -0.7681, 0.2004, 1.0396, 0.037, 0.109, -0.5125,
-0.8009, 0.2559, 0.4865, 1.5324, 1.1861, -1.1461, 0.5261, -1.5372, -0.689, 0.957,
-0.1587, 0.1745, -0.2616, 0.2156, 0.8931, 1.0375, -1.2614, -1.7691, 0.0015, -0.0966,
0.6921, -1.6605, 0.5866, -0.6313, 0.226, 0.1258, -0.9939, 0.5378, 1.3484, -2.0319,
-0.1574, 0.1568, 0.1034, 1.5574, -0.9614, -0.0967, -0.313, -0.7047, -1.5264, 1.0134
]
);
let bn2 = BatchNorm::new(
5,
running_mean,
running_var,
Tensor::new(&[0.5f32], &Device::Cpu)?.broadcast_as(5)?,
Tensor::new(&[-1.5f32], &Device::Cpu)?.broadcast_as(5)?,
1e-8,
)?;
let output2 = bn2.forward_train(&input)?;
assert_eq!(output2.dims(), &[2, 5, 3, 4]);
let output2 = output2.flatten_all()?;
let diff2 = ((output2 - (output * 0.5)?)? + 1.5)?.sqr()?;
let sum_diff2 = diff2.sum_keepdim(0)?;
assert_eq!(test_utils::to_vec1_round(&sum_diff2, 4)?, &[0f32]);
assert_eq!(
test_utils::to_vec1_round(bn.running_mean(), 4)?,
&[-0.0133, 0.0197, -0.0153, -0.0073, -0.0020]
);
assert_eq!(
test_utils::to_vec1_round(bn.running_var(), 4)?,
&[0.9972, 0.9842, 0.9956, 0.9866, 0.9898]
);
Ok(())
}
| candle/candle-nn/tests/batch_norm.rs/0 | {
"file_path": "candle/candle-nn/tests/batch_norm.rs",
"repo_id": "candle",
"token_count": 2474
} | 34 |
[package]
name = "candle-pyo3"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
readme = "README.md"
[lib]
name = "candle"
crate-type = ["cdylib"]
[dependencies]
accelerate-src = { workspace = true, optional = true }
candle = { workspace = true }
candle-nn = { workspace = true }
candle-onnx = { workspace = true, optional = true }
half = { workspace = true }
intel-mkl-src = { workspace = true, optional = true }
pyo3 = { version = "0.20.0", features = ["extension-module", "abi3-py38"] }
[build-dependencies]
pyo3-build-config = "0.20"
[features]
default = []
accelerate = ["dep:accelerate-src", "candle/accelerate"]
cuda = ["candle/cuda"]
mkl = ["dep:intel-mkl-src","candle/mkl"]
onnx = ["dep:candle-onnx"]
| candle/candle-pyo3/Cargo.toml/0 | {
"file_path": "candle/candle-pyo3/Cargo.toml",
"repo_id": "candle",
"token_count": 315
} | 35 |
import candle
from candle import Tensor
from .module import Module
from typing import Union, List, Tuple, Optional, Any
_shape_t = Union[int, List[int]]
import numbers
class LayerNorm(Module):
r"""Applies Layer Normalization over a mini-batch of inputs as described in
the paper `Layer Normalization <https://arxiv.org/abs/1607.06450>`
math::
y = \frac{x - \mathrm{E}[x]}{ \sqrt{\mathrm{Var}[x] + \epsilon}} * \gamma + \beta
"""
__constants__ = ["normalized_shape", "eps"]
normalized_shape: Tuple[int, ...]
eps: float
def __init__(
self,
normalized_shape: _shape_t,
eps: float = 1e-5,
bias: bool = True,
device=None,
dtype=None,
) -> None:
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
self.normalized_shape = tuple(normalized_shape)
self.eps = eps
self.weight = candle.ones(normalized_shape, **factory_kwargs)
if bias:
self.bias = candle.zeros(normalized_shape, **factory_kwargs)
else:
self.bias = None
def forward(self, input: Tensor) -> Tensor:
mean_x = input.sum_keepdim(2) / float(self.normalized_shape[-1])
x = input.broadcast_sub(mean_x)
norm_x = x.sqr().sum_keepdim(2) / float(self.normalized_shape[-1])
x_normed = x.broadcast_div((norm_x + self.eps).sqrt())
x = x_normed.broadcast_mul(self.weight)
if self.bias:
x = x.broadcast_add(self.bias)
return x
def extra_repr(self) -> str:
return "{normalized_shape}, eps={eps}, " "elementwise_affine={elementwise_affine}".format(**self.__dict__)
| candle/candle-pyo3/py_src/candle/nn/normalization.py/0 | {
"file_path": "candle/candle-pyo3/py_src/candle/nn/normalization.py",
"repo_id": "candle",
"token_count": 803
} | 36 |
import candle
import torch
# convert from candle tensor to torch tensor
t = candle.randn((3, 512, 512))
torch_tensor = t.to_torch()
print(torch_tensor)
print(type(torch_tensor))
# convert from torch tensor to candle tensor
t = torch.randn((3, 512, 512))
candle_tensor = candle.Tensor(t)
print(candle_tensor)
print(type(candle_tensor))
| candle/candle-pyo3/test_pytorch.py/0 | {
"file_path": "candle/candle-pyo3/test_pytorch.py",
"repo_id": "candle",
"token_count": 126
} | 37 |
use crate::models::with_tracing::{linear_b as linear, Linear};
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
use candle_nn::VarBuilder;
#[derive(Debug, Clone)]
pub struct Config {
pub num_layers: usize,
pub padded_vocab_size: usize,
pub hidden_size: usize,
pub ffn_hidden_size: usize,
pub kv_channels: usize,
pub num_attention_heads: usize,
pub seq_length: usize,
pub layernorm_epsilon: f64,
pub rmsnorm: bool,
pub apply_residual_connection_post_layernorm: bool,
pub post_layer_norm: bool,
pub add_bias_linear: bool,
pub add_qkv_bias: bool,
pub bias_dropout_fusion: bool,
pub multi_query_attention: bool,
pub multi_query_group_num: usize,
pub apply_query_key_layer_scaling: bool,
pub attention_softmax_in_fp32: bool,
pub fp32_residual_connection: bool,
}
impl Config {
pub fn glm3_6b() -> Self {
Self {
num_layers: 28,
padded_vocab_size: 65024,
hidden_size: 4096,
ffn_hidden_size: 13696,
kv_channels: 128,
num_attention_heads: 32,
seq_length: 8192,
layernorm_epsilon: 1e-5,
rmsnorm: true,
apply_residual_connection_post_layernorm: false,
post_layer_norm: true,
add_bias_linear: false,
add_qkv_bias: true,
bias_dropout_fusion: true,
multi_query_attention: true,
multi_query_group_num: 2,
apply_query_key_layer_scaling: true,
attention_softmax_in_fp32: true,
fp32_residual_connection: false,
}
}
}
#[derive(Debug, Clone)]
struct RotaryEmbedding {
cache: Tensor,
}
impl RotaryEmbedding {
fn new(cfg: &Config, dtype: DType, dev: &Device) -> Result<Self> {
let rotary_dim = cfg.kv_channels;
let n_elem = rotary_dim / 2;
let inv_freq: Vec<_> = (0..n_elem)
.step_by(2)
.map(|i| 1f32 / 10_000f64.powf(i as f64 / n_elem as f64) as f32)
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?.to_dtype(dtype)?;
let t = Tensor::arange(0u32, cfg.seq_length as u32, dev)?
.to_dtype(dtype)?
.reshape((cfg.seq_length, 1))?;
let freqs = t.matmul(&inv_freq)?;
let cache = Tensor::stack(&[&freqs.cos()?, &freqs.sin()?], D::Minus1)?;
Ok(Self { cache })
}
fn apply(&self, xs: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let (seqlen, _b, np, _hn) = xs.dims4()?;
let cache = self.cache.narrow(0, seqlen_offset, seqlen)?;
let rot_dim = cache.dim(D::Minus2)? * 2;
let (xs, xs_pass) = (
xs.narrow(D::Minus1, 0, rot_dim)?,
xs.narrow(D::Minus1, rot_dim, rot_dim)?,
);
let xshaped = xs.reshape((seqlen, (), np, rot_dim / 2, 2))?;
let cache = cache.reshape((seqlen, (), 1, rot_dim / 2, 2))?;
let (xshaped0, xshaped1) = (
xshaped.i((.., .., .., .., 0))?,
xshaped.i((.., .., .., .., 1))?,
);
let (cache0, cache1) = (cache.i((.., .., .., .., 0))?, cache.i((.., .., .., .., 1))?);
let xs_out = Tensor::stack(
&[
(xshaped0.broadcast_mul(&cache0)? - xshaped1.broadcast_mul(&cache1)?)?,
(xshaped1.broadcast_mul(&cache0)? + xshaped0.broadcast_mul(&cache1)?)?,
],
D::Minus1,
)?;
let xs_out = xs_out.flatten_from(3)?;
Tensor::cat(&[xs_out, xs_pass], D::Minus1)
}
}
#[derive(Debug, Clone)]
struct CoreAttention {
coeff: Option<f64>,
norm_factor: f64,
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
impl CoreAttention {
fn new(layer_number: usize, cfg: &Config) -> Result<Self> {
let norm_factor = (cfg.kv_channels as f64).sqrt();
let (norm_factor, coeff) = if cfg.apply_query_key_layer_scaling {
let coeff = f64::max(1.0, layer_number as f64);
(norm_factor * coeff, Some(coeff))
} else {
(norm_factor, None)
};
Ok(Self { coeff, norm_factor })
}
fn forward(
&self,
query_layer: &Tensor,
key_layer: &Tensor,
value_layer: &Tensor,
attention_mask: &Option<Tensor>,
) -> Result<Tensor> {
let output_size = (
query_layer.dim(1)?, // b
query_layer.dim(2)?, // np
query_layer.dim(0)?, // sq
key_layer.dim(0)?, // sk
);
let query_layer =
query_layer.reshape((output_size.2, output_size.0 * output_size.1, ()))?;
let key_layer = key_layer.reshape((output_size.3, output_size.0 * output_size.1, ()))?;
let matmul_result = Tensor::matmul(
&query_layer.transpose(0, 1)?,
&key_layer.transpose(0, 1)?.transpose(1, 2)?,
)?;
let matmul_result = (matmul_result / self.norm_factor)?.reshape(output_size)?;
let matmul_result = match self.coeff {
None => matmul_result,
Some(coeff) => (matmul_result * coeff)?,
};
let attention_scores = match attention_mask {
Some(mask) => masked_fill(
&matmul_result,
&mask.broadcast_left((matmul_result.dim(0)?, matmul_result.dim(1)?))?,
f32::NEG_INFINITY,
)?,
None => matmul_result,
};
let attention_probs = candle_nn::ops::softmax_last_dim(&attention_scores)?;
let output_size = (
value_layer.dim(1)?,
value_layer.dim(2)?,
query_layer.dim(0)?,
value_layer.dim(3)?,
);
let value_layer =
value_layer.reshape((value_layer.dim(0)?, output_size.0 * output_size.1, ()))?;
let attention_probs =
attention_probs.reshape((output_size.0 * output_size.1, output_size.2, ()))?;
let context_layer = Tensor::matmul(&attention_probs, &value_layer.transpose(0, 1)?)?;
let context_layer = context_layer.reshape(output_size)?;
let context_layer = context_layer.permute((2, 0, 1, 3))?.contiguous()?;
context_layer.flatten_from(D::Minus2)
}
}
#[derive(Debug, Clone)]
struct SelfAttention {
query_key_value: Linear,
core_attention: CoreAttention,
dense: Linear,
multi_query_attention: bool,
num_attention_heads_per_partition: usize,
num_multi_query_groups_per_partition: usize,
hidden_size_per_attention_head: usize,
kv_cache: Option<(Tensor, Tensor)>,
}
impl SelfAttention {
fn new(layer_number: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let projection_size = cfg.kv_channels * cfg.num_attention_heads;
let hidden_size_per_attention_head = projection_size / cfg.num_attention_heads;
let qkv_hidden_size = if cfg.multi_query_attention {
projection_size + 2 * hidden_size_per_attention_head * cfg.multi_query_group_num
} else {
3 * projection_size
};
let query_key_value = linear(
cfg.hidden_size,
qkv_hidden_size,
cfg.add_bias_linear || cfg.add_qkv_bias,
vb.pp("query_key_value"),
)?;
let core_attention = CoreAttention::new(layer_number, cfg)?;
let dense = linear(
cfg.hidden_size,
cfg.hidden_size,
cfg.add_bias_linear,
vb.pp("dense"),
)?;
Ok(Self {
query_key_value,
core_attention,
dense,
multi_query_attention: cfg.multi_query_attention,
num_attention_heads_per_partition: cfg.num_attention_heads,
num_multi_query_groups_per_partition: cfg.multi_query_group_num,
hidden_size_per_attention_head: cfg.kv_channels,
kv_cache: None,
})
}
fn reset_kv_cache(&mut self) {
self.kv_cache = None
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: &Option<Tensor>,
rotary_emb: &RotaryEmbedding,
) -> Result<Tensor> {
let mixed_x_layer = xs.apply(&self.query_key_value)?;
if !self.multi_query_attention {
candle::bail!("only multi_query_attention=true is supported")
}
let hpa = self.hidden_size_per_attention_head;
let query_layer =
mixed_x_layer.narrow(D::Minus1, 0, self.num_attention_heads_per_partition * hpa)?;
let key_layer = mixed_x_layer.narrow(
D::Minus1,
self.num_attention_heads_per_partition * hpa,
self.num_multi_query_groups_per_partition * hpa,
)?;
let value_layer = mixed_x_layer.narrow(
D::Minus1,
self.num_attention_heads_per_partition * hpa
+ self.num_multi_query_groups_per_partition * hpa,
self.num_multi_query_groups_per_partition * hpa,
)?;
let query_layer = query_layer.reshape((
query_layer.dim(0)?,
query_layer.dim(1)?,
self.num_attention_heads_per_partition,
hpa,
))?;
let key_layer = key_layer.reshape((
key_layer.dim(0)?,
key_layer.dim(1)?,
self.num_multi_query_groups_per_partition,
hpa,
))?;
let value_layer = value_layer.reshape((
value_layer.dim(0)?,
value_layer.dim(1)?,
self.num_multi_query_groups_per_partition,
hpa,
))?;
// Rotary embeddings.
let seqlen_offset = match &self.kv_cache {
None => 0,
Some((prev_k, _)) => prev_k.dim(0)?,
};
let query_layer = rotary_emb.apply(&query_layer, seqlen_offset)?;
let key_layer = rotary_emb.apply(&key_layer, seqlen_offset)?;
// KV cache.
let (key_layer, value_layer) = match &self.kv_cache {
None => (key_layer, value_layer),
Some((prev_k, prev_v)) => {
let k = Tensor::cat(&[prev_k, &key_layer], 0)?;
let v = Tensor::cat(&[prev_v, &value_layer], 0)?;
(k, v)
}
};
self.kv_cache = Some((key_layer.clone(), value_layer.clone()));
// Repeat KV.
let ratio =
self.num_attention_heads_per_partition / self.num_multi_query_groups_per_partition;
let key_layer = {
let (d0, d1, d2, d3) = key_layer.dims4()?;
key_layer
.unsqueeze(D::Minus2)?
.expand((d0, d1, d2, ratio, d3))?
.reshape((
d0,
d1,
self.num_attention_heads_per_partition,
self.hidden_size_per_attention_head,
))?
};
let value_layer = {
let (d0, d1, d2, d3) = value_layer.dims4()?;
value_layer
.unsqueeze(D::Minus2)?
.expand((d0, d1, d2, ratio, d3))?
.reshape((
d0,
d1,
self.num_attention_heads_per_partition,
self.hidden_size_per_attention_head,
))?
};
let context_layer =
self.core_attention
.forward(&query_layer, &key_layer, &value_layer, attention_mask)?;
let output = context_layer.apply(&self.dense)?;
Ok(output)
}
}
#[allow(clippy::upper_case_acronyms)]
#[derive(Debug, Clone)]
struct MLP {
dense_h_to_4h: Linear,
dense_4h_to_h: Linear,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense_h_to_4h = linear(
cfg.hidden_size,
cfg.ffn_hidden_size * 2,
cfg.add_bias_linear,
vb.pp("dense_h_to_4h"),
)?;
let dense_4h_to_h = linear(
cfg.ffn_hidden_size,
cfg.hidden_size,
cfg.add_bias_linear,
vb.pp("dense_4h_to_h"),
)?;
Ok(Self {
dense_4h_to_h,
dense_h_to_4h,
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.dense_h_to_4h)?
.apply(&candle_nn::Activation::Swiglu)?
.apply(&self.dense_4h_to_h)
}
}
#[derive(Debug, Clone)]
struct Block {
input_layernorm: candle_nn::LayerNorm,
self_attention: SelfAttention,
post_attention_layernorm: candle_nn::LayerNorm,
mlp: MLP,
apply_residual_connection_post_layernorm: bool,
}
impl Block {
fn new(layer_number: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let input_layernorm = if cfg.rmsnorm {
candle_nn::rms_norm(
cfg.hidden_size,
cfg.layernorm_epsilon,
vb.pp("input_layernorm"),
)?
.into_inner()
} else {
candle_nn::layer_norm(
cfg.hidden_size,
cfg.layernorm_epsilon,
vb.pp("input_layernorm"),
)?
};
let post_attention_layernorm = if cfg.rmsnorm {
candle_nn::rms_norm(
cfg.hidden_size,
cfg.layernorm_epsilon,
vb.pp("post_attention_layernorm"),
)?
.into_inner()
} else {
candle_nn::layer_norm(
cfg.hidden_size,
cfg.layernorm_epsilon,
vb.pp("post_attention_layernorm"),
)?
};
let self_attention = SelfAttention::new(layer_number, cfg, vb.pp("self_attention"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
Ok(Self {
input_layernorm,
self_attention,
post_attention_layernorm,
mlp,
apply_residual_connection_post_layernorm: cfg.apply_residual_connection_post_layernorm,
})
}
fn reset_kv_cache(&mut self) {
self.self_attention.reset_kv_cache()
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: &Option<Tensor>,
rotary_emb: &RotaryEmbedding,
) -> Result<Tensor> {
let layernorm_output = xs.apply(&self.input_layernorm)?;
let attention_output =
self.self_attention
.forward(&layernorm_output, attention_mask, rotary_emb)?;
let residual = if self.apply_residual_connection_post_layernorm {
&layernorm_output
} else {
xs
};
let layernorm_input = (residual + attention_output)?;
let layernorm_output = layernorm_input.apply(&self.post_attention_layernorm)?;
let mlp_output = layernorm_output.apply(&self.mlp)?;
let residual = if self.apply_residual_connection_post_layernorm {
&layernorm_output
} else {
&layernorm_input
};
mlp_output + residual
}
}
#[derive(Debug, Clone)]
struct Transformer {
layers: Vec<Block>,
final_layernorm: Option<candle_nn::LayerNorm>,
rotary_emb: RotaryEmbedding,
}
impl Transformer {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_l = vb.pp("layers");
let mut layers = Vec::with_capacity(cfg.num_layers);
for layer_index in 0..cfg.num_layers {
let block = Block::new(layer_index + 1, cfg, vb_l.pp(layer_index))?;
layers.push(block)
}
let final_layernorm = if cfg.post_layer_norm {
let ln = if cfg.rmsnorm {
candle_nn::rms_norm(
cfg.hidden_size,
cfg.layernorm_epsilon,
vb.pp("final_layernorm"),
)?
.into_inner()
} else {
candle_nn::layer_norm(
cfg.hidden_size,
cfg.layernorm_epsilon,
vb.pp("final_layernorm"),
)?
};
Some(ln)
} else {
None
};
let rotary_emb = RotaryEmbedding::new(cfg, vb.dtype(), vb.device())?;
Ok(Self {
layers,
final_layernorm,
rotary_emb,
})
}
fn reset_kv_cache(&mut self) {
for block in self.layers.iter_mut() {
block.reset_kv_cache()
}
}
fn forward(&mut self, xs: &Tensor, attention_mask: &Option<Tensor>) -> Result<Tensor> {
let mut xs = xs.clone();
for block in self.layers.iter_mut() {
xs = block.forward(&xs, attention_mask, &self.rotary_emb)?
}
match self.final_layernorm.as_ref() {
None => Ok(xs),
Some(ln) => xs.apply(ln),
}
}
}
#[derive(Debug, Clone)]
struct Embedding {
word_embeddings: candle_nn::Embedding,
fp32_residual_connection: bool,
}
impl Embedding {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let word_embeddings = candle_nn::embedding(
cfg.padded_vocab_size,
cfg.hidden_size,
vb.pp("word_embeddings"),
)?;
Ok(Self {
word_embeddings,
fp32_residual_connection: cfg.fp32_residual_connection,
})
}
}
impl Module for Embedding {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.word_embeddings.forward(xs)?.transpose(0, 1)?; // b,s,h -> s,b,h
if self.fp32_residual_connection {
xs.to_dtype(candle::DType::F32)
} else {
xs.contiguous()
}
}
}
#[derive(Debug, Clone)]
pub struct Model {
embedding: Embedding,
encoder: Transformer,
output_layer: Linear,
}
fn get_mask(size: usize, device: &Device) -> Result<Tensor> {
let mask: Vec<_> = (0..size)
.flat_map(|i| (0..size).map(move |j| u8::from(j > i)))
.collect();
Tensor::from_slice(&mask, (size, size), device)
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb = vb.pp("transformer");
let embedding = Embedding::new(cfg, vb.pp("embedding"))?;
let encoder = Transformer::new(cfg, vb.pp("encoder"))?;
let output_layer = linear(
cfg.hidden_size,
cfg.padded_vocab_size,
false,
vb.pp("output_layer"),
)?;
Ok(Self {
embedding,
encoder,
output_layer,
})
}
pub fn reset_kv_cache(&mut self) {
self.encoder.reset_kv_cache()
}
pub fn forward(&mut self, xs: &Tensor) -> Result<Tensor> {
let (_b_size, seq_len) = xs.dims2()?;
let input_embeds = xs.apply(&self.embedding)?;
let attention_mask = if seq_len <= 1 {
None
} else {
Some(get_mask(seq_len, xs.device())?)
};
let xs = self.encoder.forward(&input_embeds, &attention_mask)?;
let lm_logits = xs.i(seq_len - 1)?.apply(&self.output_layer)?;
Ok(lm_logits)
}
}
| candle/candle-transformers/src/models/chatglm.rs/0 | {
"file_path": "candle/candle-transformers/src/models/chatglm.rs",
"repo_id": "candle",
"token_count": 10342
} | 38 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.