
text
stringlengths 7
328k
| id
stringlengths 14
166
| metadata
dict | __index_level_0__
int64 0
459
|
|---|---|---|---|
[package]
name = "candle-wasm-example-whisper"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
num-traits = { workspace = true }
tokenizers = { workspace = true, features = ["unstable_wasm"] }
# App crates.
anyhow = { workspace = true }
log = { workspace = true }
rand = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
wav = { workspace = true }
safetensors = { workspace = true }
# Wasm specific crates.
getrandom = { version = "0.2", features = ["js"] }
gloo = "0.11"
js-sys = "0.3.64"
wasm-bindgen = "0.2.87"
wasm-bindgen-futures = "0.4.37"
wasm-logger = "0.2"
yew-agent = "0.2.0"
yew = { version = "0.20.0", features = ["csr"] }
[dependencies.web-sys]
version = "0.3.64"
features = [
'Blob',
'Document',
'Element',
'HtmlElement',
'Node',
'Window',
'Request',
'RequestCache',
'RequestInit',
'RequestMode',
'Response',
'Performance',
]
| candle/candle-wasm-examples/whisper/Cargo.toml/0 | {
"file_path": "candle/candle-wasm-examples/whisper/Cargo.toml",
"repo_id": "candle",
"token_count": 428
} | 46 |
## Running Yolo Examples
Here, we provide two examples of how to run YOLOv8 using a Candle-compiled WASM binary and runtimes.
### Pure Rust UI
To build and test the UI made in Rust you will need [Trunk](https://trunkrs.dev/#install)
From the `candle-wasm-examples/yolo` directory run:
Download assets:
```bash
wget -c https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/bike.jpeg
wget -c https://huggingface.co/lmz/candle-yolo-v8/resolve/main/yolov8s.safetensors
```
Run hot reload server:
```bash
trunk serve --release --public-url / --port 8080
```
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model, ModelPose } from "./build/m.js";
```
The full example can be found under `./lib-example.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/lib-example.html` in your browser.
| candle/candle-wasm-examples/yolo/README.md/0 | {
"file_path": "candle/candle-wasm-examples/yolo/README.md",
"repo_id": "candle",
"token_count": 412
} | 47 |
use candle::{
quantized::{self, k_quants, GgmlDType, GgmlType},
test_utils::to_vec2_round,
Device, Module, Result, Tensor,
};
use wasm_bindgen_test::*;
wasm_bindgen_test_configure!(run_in_browser);
#[wasm_bindgen_test]
fn quantized_matmul_neg() -> Result<()> {
let cpu = &Device::Cpu;
let (m, k, n) = (3, 64, 4);
let lhs = (0..(m * k))
.map(|v| v as f32 - (m * k) as f32 / 2.0)
.collect::<Vec<_>>();
let tensor_lhs = Tensor::from_slice(&lhs, (m, k), cpu)?;
let mut dst = vec![42.; 3 * 4];
let mut rhs_t = vec![k_quants::BlockQ4_0::zeros(); 8];
let rhs = (0..k * n)
.map(|v| v as f32 - (k * n) as f32 / 3.0)
.collect::<Vec<_>>();
let tensor_rhs = Tensor::from_slice(&rhs, (n, k), cpu)?.t()?;
k_quants::BlockQ4_0::from_float(&rhs, &mut rhs_t)?;
k_quants::matmul((m, k, n), &lhs, &rhs_t, &mut dst)?;
assert_eq!(
dst.iter().map(|x| x.round()).collect::<Vec<_>>(),
&[
243524.0, -19596.0, -285051.0, -549815.0, 23777.0, 21651.0, 19398.0, 18367.0,
-196472.0, 63012.0, 324585.0, 587902.0
]
);
let mm = tensor_lhs.matmul(&tensor_rhs)?;
assert_eq!(
to_vec2_round(&mm, 0)?,
&[
[244064.0, -20128.0, -284320.0, -548512.0],
[23563.0, 21515.0, 19467.0, 17419.0],
[-196939.0, 63157.0, 323253.0, 583349.0]
]
);
let qtensor = quantized::QTensor::new(quantized::QStorage::Cpu(Box::new(rhs_t)), (4, 64))?;
let matmul = quantized::QMatMul::from_qtensor(qtensor)?;
let res = matmul.forward(&tensor_lhs)?;
assert_eq!(
to_vec2_round(&res, 0)?,
&[
[243524.0, -19596.0, -285051.0, -549815.0],
[23777.0, 21651.0, 19398.0, 18367.0],
[-196472.0, 63012.0, 324585.0, 587902.0]
]
);
Ok(())
}
/// Creates a vector simillarly to the one used in GGML unit tests: https://github.com/ggerganov/llama.cpp/blob/master/tests/test-quantize-fns.cpp#L26-L30
fn create_ggml_like_vector(offset: f32) -> Vec<f32> {
const GGML_TEST_SIZE: usize = 32 * 128;
(0..GGML_TEST_SIZE)
.map(|i| 0.1 + 2.0 * (i as f32 + offset).cos())
.collect()
}
/// Very simple dot product implementation
fn vec_dot_reference(a: &[f32], b: &[f32]) -> f32 {
a.iter().zip(b).map(|(a, b)| a * b).sum()
}
/// Returns the error achieved by the GGML matmul unit test.
fn ggml_reference_matmul_error(dtype: GgmlDType) -> Result<f32> {
let err = match dtype {
GgmlDType::F16 => 0.000010,
GgmlDType::Q2K => 0.004086,
GgmlDType::Q3K => 0.016148,
GgmlDType::Q4K => 0.002425,
GgmlDType::Q5K => 0.000740,
GgmlDType::Q6K => 0.000952,
GgmlDType::Q4_0 => 0.001143,
GgmlDType::Q4_1 => 0.007784,
GgmlDType::Q5_0 => 0.001353,
GgmlDType::Q5_1 => 0.001363,
GgmlDType::Q8_0 => 0.000092,
// Not from the ggml repo.
GgmlDType::Q8K => 0.00065,
_ => candle::bail!("No GGML results for quantization type {dtype:?}",),
};
Ok(err)
}
/// Mirrores the GGML matmul unit test: https://github.com/ggerganov/llama.cpp/blob/master/tests/test-quantize-fns.cpp#L76-L91
fn ggml_matmul_error_test<T: GgmlType>() -> Result<()> {
const GGML_MAX_DOT_PRODUCT_ERROR: f32 = 0.02;
let a = create_ggml_like_vector(0.0);
let b = create_ggml_like_vector(1.0);
let length = a.len();
let mut a_quant = vec![T::zeros(); length / T::BLCK_SIZE];
let mut b_quant = vec![T::VecDotType::zeros(); length / T::VecDotType::BLCK_SIZE];
T::from_float(&a, &mut a_quant)?;
T::VecDotType::from_float(&b, &mut b_quant)?;
let result = T::vec_dot(length, &a_quant, &b_quant)?;
let result_unopt = T::vec_dot_unopt(length, &a_quant, &b_quant)?;
let reference_result = vec_dot_reference(&a, &b);
if (result - result_unopt).abs() / length as f32 > 1e-6 {
candle::bail!(
"the opt and unopt vec-dot returned different values, opt {result}, unopt {result_unopt}"
)
}
let error = (result - reference_result).abs() / length as f32;
let ggml_error = ggml_reference_matmul_error(T::DTYPE)?;
if !error.is_finite() || error > GGML_MAX_DOT_PRODUCT_ERROR {
candle::bail!(
"Dot product error {} exceeds max error {}",
error,
GGML_MAX_DOT_PRODUCT_ERROR
);
}
// We diverge slightly due to different rounding behavior / f16 to f32 conversions in GGML
// => we use a slightly higher error threshold
const ERROR_LENIENCY: f32 = 0.00001;
if error - ERROR_LENIENCY > ggml_error {
candle::bail!(
"Dot product error {} exceeds ggml reference error {}",
error,
ggml_error
);
}
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q40() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ4_0>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q50() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ5_0>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q80() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ8_0>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q2k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ2K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q3k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ3K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q4k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ4K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q5k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ5K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q6k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ6K>()?;
Ok(())
}
#[wasm_bindgen_test]
fn quantized_matmul_q8k() -> Result<()> {
ggml_matmul_error_test::<candle::quantized::k_quants::BlockQ8K>()?;
Ok(())
}
| candle/candle-wasm-tests/tests/quantized_tests.rs/0 | {
"file_path": "candle/candle-wasm-tests/tests/quantized_tests.rs",
"repo_id": "candle",
"token_count": 3145
} | 48 |
# Prompt templates
These are the templates used to format the conversation history for different models used in HuggingChat. Set them in your `.env.local` [like so](https://github.com/huggingface/chat-ui#chatprompttemplate).
## Llama 2
```env
<s>[INST] <<SYS>>\n{{preprompt}}\n<</SYS>>\n\n{{#each messages}}{{#ifUser}}{{content}} [/INST] {{/ifUser}}{{#ifAssistant}}{{content}} </s><s>[INST] {{/ifAssistant}}{{/each}}
```
## CodeLlama
```env
<s>[INST] <<SYS>>\n{{preprompt}}\n<</SYS>>\n\n{{#each messages}}{{#ifUser}}{{content}} [/INST] {{/ifUser}}{{#ifAssistant}}{{content}} </s><s>[INST] {{/ifAssistant}}{{/each}}
```
## Falcon
```env
System: {{preprompt}}\nUser:{{#each messages}}{{#ifUser}}{{content}}\nFalcon:{{/ifUser}}{{#ifAssistant}}{{content}}\nUser:{{/ifAssistant}}{{/each}}
```
## Mistral
```env
<s>{{#each messages}}{{#ifUser}}[INST] {{#if @first}}{{#if @root.preprompt}}{{@root.preprompt}}\n{{/if}}{{/if}} {{content}} [/INST]{{/ifUser}}{{#ifAssistant}}{{content}}</s> {{/ifAssistant}}{{/each}}
```
## Zephyr
```env
<|system|>\n{{preprompt}}</s>\n{{#each messages}}{{#ifUser}}<|user|>\n{{content}}</s>\n<|assistant|>\n{{/ifUser}}{{#ifAssistant}}{{content}}</s>\n{{/ifAssistant}}{{/each}}
```
## IDEFICS
```env
{{#each messages}}{{#ifUser}}User: {{content}}{{/ifUser}}<end_of_utterance>\nAssistant: {{#ifAssistant}}{{content}}\n{{/ifAssistant}}{{/each}}
```
## OpenChat
```env
<s>{{#each messages}}{{#ifUser}}GPT4 User: {{#if @first}}{{#if @root.preprompt}}{{@root.preprompt}}\n{{/if}}{{/if}}{{content}}<|end_of_turn|>GPT4 Assistant: {{/ifUser}}{{#ifAssistant}}{{content}}<|end_of_turn|>{{/ifAssistant}}{{/each}}
```
## Mixtral
```env
<s> {{#each messages}}{{#ifUser}}[INST]{{#if @first}}{{#if @root.preprompt}}{{@root.preprompt}}\n{{/if}}{{/if}} {{content}} [/INST]{{/ifUser}}{{#ifAssistant}} {{content}}</s> {{/ifAssistant}}{{/each}}
```
## ChatML
```env
{{#if @root.preprompt}}<|im_start|>system\n{{@root.preprompt}}<|im_end|>\n{{/if}}{{#each messages}}{{#ifUser}}<|im_start|>user\n{{content}}<|im_end|>\n<|im_start|>assistant\n{{/ifUser}}{{#ifAssistant}}{{content}}<|im_end|>\n{{/ifAssistant}}{{/each}}
```
## CodeLlama 70B
```env
<s>{{#if @root.preprompt}}Source: system\n\n {{@root.preprompt}} <step> {{/if}}{{#each messages}}{{#ifUser}}Source: user\n\n {{content}} <step> {{/ifUser}}{{#ifAssistant}}Source: assistant\n\n {{content}} <step> {{/ifAssistant}}{{/each}}Source: assistant\nDestination: user\n\n ``
```
## Gemma
```env
{{#each messages}}{{#ifUser}}<start_of_turn>user\n{{#if @first}}{{#if @root.preprompt}}{{@root.preprompt}}\n{{/if}}{{/if}}{{content}}<end_of_turn>\n<start_of_turn>model\n{{/ifUser}}{{#ifAssistant}}{{content}}<end_of_turn>\n{{/ifAssistant}}{{/each}}
```
| chat-ui/PROMPTS.md/0 | {
"file_path": "chat-ui/PROMPTS.md",
"repo_id": "chat-ui",
"token_count": 1133
} | 49 |
<script lang="ts">
export let title = "";
export let classNames = "";
</script>
<div class="flex items-center rounded-xl bg-gray-100 p-1 text-sm dark:bg-gray-800 {classNames}">
<span
class="mr-2 inline-flex items-center rounded-lg bg-gradient-to-br from-primary-300 px-2 py-1 text-xxs font-medium uppercase leading-3 text-primary-700 dark:from-primary-900 dark:text-primary-400"
>New</span
>
{title}
<div class="ml-auto shrink-0">
<slot />
</div>
</div>
| chat-ui/src/lib/components/AnnouncementBanner.svelte/0 | {
"file_path": "chat-ui/src/lib/components/AnnouncementBanner.svelte",
"repo_id": "chat-ui",
"token_count": 184
} | 50 |
<script lang="ts">
import { onMount, onDestroy } from "svelte";
let el: HTMLElement;
onMount(() => {
el.ownerDocument.body.appendChild(el);
});
onDestroy(() => {
if (el?.parentNode) {
el.parentNode.removeChild(el);
}
});
</script>
<div bind:this={el} class="contents" hidden>
<slot />
</div>
| chat-ui/src/lib/components/Portal.svelte/0 | {
"file_path": "chat-ui/src/lib/components/Portal.svelte",
"repo_id": "chat-ui",
"token_count": 130
} | 51 |
<script lang="ts">
export let classNames = "";
</script>
<svg
width="1em"
height="1em"
viewBox="0 0 15 6"
class={classNames}
fill="none"
xmlns="http://www.w3.org/2000/svg"
>
<path
d="M1.67236 1L7.67236 7L13.6724 1"
stroke="currentColor"
stroke-width="2"
stroke-linecap="round"
stroke-linejoin="round"
/>
</svg>
| chat-ui/src/lib/components/icons/IconChevron.svelte/0 | {
"file_path": "chat-ui/src/lib/components/icons/IconChevron.svelte",
"repo_id": "chat-ui",
"token_count": 156
} | 52 |
import { MONGODB_URL, MONGODB_DB_NAME, MONGODB_DIRECT_CONNECTION } from "$env/static/private";
import { GridFSBucket, MongoClient } from "mongodb";
import type { Conversation } from "$lib/types/Conversation";
import type { SharedConversation } from "$lib/types/SharedConversation";
import type { AbortedGeneration } from "$lib/types/AbortedGeneration";
import type { Settings } from "$lib/types/Settings";
import type { User } from "$lib/types/User";
import type { MessageEvent } from "$lib/types/MessageEvent";
import type { Session } from "$lib/types/Session";
import type { Assistant } from "$lib/types/Assistant";
import type { Report } from "$lib/types/Report";
import type { ConversationStats } from "$lib/types/ConversationStats";
import type { MigrationResult } from "$lib/types/MigrationResult";
import type { Semaphore } from "$lib/types/Semaphore";
if (!MONGODB_URL) {
throw new Error(
"Please specify the MONGODB_URL environment variable inside .env.local. Set it to mongodb://localhost:27017 if you are running MongoDB locally, or to a MongoDB Atlas free instance for example."
);
}
export const CONVERSATION_STATS_COLLECTION = "conversations.stats";
const client = new MongoClient(MONGODB_URL, {
directConnection: MONGODB_DIRECT_CONNECTION === "true",
});
export const connectPromise = client.connect().catch(console.error);
export function getCollections(mongoClient: MongoClient) {
const db = mongoClient.db(MONGODB_DB_NAME + (import.meta.env.MODE === "test" ? "-test" : ""));
const conversations = db.collection<Conversation>("conversations");
const conversationStats = db.collection<ConversationStats>(CONVERSATION_STATS_COLLECTION);
const assistants = db.collection<Assistant>("assistants");
const reports = db.collection<Report>("reports");
const sharedConversations = db.collection<SharedConversation>("sharedConversations");
const abortedGenerations = db.collection<AbortedGeneration>("abortedGenerations");
const settings = db.collection<Settings>("settings");
const users = db.collection<User>("users");
const sessions = db.collection<Session>("sessions");
const messageEvents = db.collection<MessageEvent>("messageEvents");
const bucket = new GridFSBucket(db, { bucketName: "files" });
const migrationResults = db.collection<MigrationResult>("migrationResults");
const semaphores = db.collection<Semaphore>("semaphores");
return {
conversations,
conversationStats,
assistants,
reports,
sharedConversations,
abortedGenerations,
settings,
users,
sessions,
messageEvents,
bucket,
migrationResults,
semaphores,
};
}
const db = client.db(MONGODB_DB_NAME + (import.meta.env.MODE === "test" ? "-test" : ""));
const collections = getCollections(client);
const {
conversations,
conversationStats,
assistants,
reports,
sharedConversations,
abortedGenerations,
settings,
users,
sessions,
messageEvents,
semaphores,
} = collections;
export { client, db, collections };
client.on("open", () => {
conversations
.createIndex(
{ sessionId: 1, updatedAt: -1 },
{ partialFilterExpression: { sessionId: { $exists: true } } }
)
.catch(console.error);
conversations
.createIndex(
{ userId: 1, updatedAt: -1 },
{ partialFilterExpression: { userId: { $exists: true } } }
)
.catch(console.error);
conversations
.createIndex(
{ "message.id": 1, "message.ancestors": 1 },
{ partialFilterExpression: { userId: { $exists: true } } }
)
.catch(console.error);
// To do stats on conversations
conversations.createIndex({ updatedAt: 1 }).catch(console.error);
// Not strictly necessary, could use _id, but more convenient. Also for stats
conversations.createIndex({ createdAt: 1 }).catch(console.error);
// To do stats on conversation messages
conversations.createIndex({ "messages.createdAt": 1 }, { sparse: true }).catch(console.error);
// Unique index for stats
conversationStats
.createIndex(
{
type: 1,
"date.field": 1,
"date.span": 1,
"date.at": 1,
distinct: 1,
},
{ unique: true }
)
.catch(console.error);
// Allow easy check of last computed stat for given type/dateField
conversationStats
.createIndex({
type: 1,
"date.field": 1,
"date.at": 1,
})
.catch(console.error);
abortedGenerations.createIndex({ updatedAt: 1 }, { expireAfterSeconds: 30 }).catch(console.error);
abortedGenerations.createIndex({ conversationId: 1 }, { unique: true }).catch(console.error);
sharedConversations.createIndex({ hash: 1 }, { unique: true }).catch(console.error);
settings.createIndex({ sessionId: 1 }, { unique: true, sparse: true }).catch(console.error);
settings.createIndex({ userId: 1 }, { unique: true, sparse: true }).catch(console.error);
settings.createIndex({ assistants: 1 }).catch(console.error);
users.createIndex({ hfUserId: 1 }, { unique: true }).catch(console.error);
users.createIndex({ sessionId: 1 }, { unique: true, sparse: true }).catch(console.error);
// No unicity because due to renames & outdated info from oauth provider, there may be the same username on different users
users.createIndex({ username: 1 }).catch(console.error);
messageEvents.createIndex({ createdAt: 1 }, { expireAfterSeconds: 60 }).catch(console.error);
sessions.createIndex({ expiresAt: 1 }, { expireAfterSeconds: 0 }).catch(console.error);
sessions.createIndex({ sessionId: 1 }, { unique: true }).catch(console.error);
assistants.createIndex({ createdById: 1, userCount: -1 }).catch(console.error);
assistants.createIndex({ userCount: 1 }).catch(console.error);
assistants.createIndex({ featured: 1, userCount: -1 }).catch(console.error);
assistants.createIndex({ modelId: 1, userCount: -1 }).catch(console.error);
assistants.createIndex({ searchTokens: 1 }).catch(console.error);
reports.createIndex({ assistantId: 1 }).catch(console.error);
reports.createIndex({ createdBy: 1, assistantId: 1 }).catch(console.error);
// Unique index for semaphore and migration results
semaphores.createIndex({ key: 1 }, { unique: true }).catch(console.error);
semaphores.createIndex({ createdAt: 1 }, { expireAfterSeconds: 60 }).catch(console.error);
});
| chat-ui/src/lib/server/database.ts/0 | {
"file_path": "chat-ui/src/lib/server/database.ts",
"repo_id": "chat-ui",
"token_count": 1994
} | 53 |
import type { Conversation } from "$lib/types/Conversation";
import { sha256 } from "$lib/utils/sha256";
import { collections } from "../database";
export async function uploadFile(file: Blob, conv: Conversation): Promise<string> {
const sha = await sha256(await file.text());
const upload = collections.bucket.openUploadStream(`${conv._id}-${sha}`, {
metadata: { conversation: conv._id.toString(), mime: "image/jpeg" },
});
upload.write((await file.arrayBuffer()) as unknown as Buffer);
upload.end();
// only return the filename when upload throws a finish event or a 10s time out occurs
return new Promise((resolve, reject) => {
upload.once("finish", () => resolve(sha));
upload.once("error", reject);
setTimeout(() => reject(new Error("Upload timed out")), 10000);
});
}
| chat-ui/src/lib/server/files/uploadFile.ts/0 | {
"file_path": "chat-ui/src/lib/server/files/uploadFile.ts",
"repo_id": "chat-ui",
"token_count": 244
} | 54 |
import type { Message } from "$lib/types/Message";
import { getContext, setContext } from "svelte";
import { writable, type Writable } from "svelte/store";
// used to store the id of the message that is the currently displayed leaf of the conversation tree
// (that is the last message in the current branch of the conversation tree)
interface ConvTreeStore {
leaf: Message["id"] | null;
editing: Message["id"] | null;
}
export function useConvTreeStore() {
return getContext<Writable<ConvTreeStore>>("convTreeStore");
}
export function createConvTreeStore() {
const convTreeStore = writable<ConvTreeStore>({
leaf: null,
editing: null,
});
setContext("convTreeStore", convTreeStore);
return convTreeStore;
}
| chat-ui/src/lib/stores/convTree.ts/0 | {
"file_path": "chat-ui/src/lib/stores/convTree.ts",
"repo_id": "chat-ui",
"token_count": 216
} | 55 |
import type { ObjectId } from "mongodb";
export interface MigrationResult {
_id: ObjectId;
name: string;
status: "success" | "failure" | "ongoing";
}
| chat-ui/src/lib/types/MigrationResult.ts/0 | {
"file_path": "chat-ui/src/lib/types/MigrationResult.ts",
"repo_id": "chat-ui",
"token_count": 53
} | 56 |
/**
* A debounce function that works in both browser and Nodejs.
* For pure Nodejs work, prefer the `Debouncer` class.
*/
export function debounce<T extends unknown[]>(
callback: (...rest: T) => unknown,
limit: number
): (...rest: T) => void {
let timer: ReturnType<typeof setTimeout>;
return function (...rest) {
clearTimeout(timer);
timer = setTimeout(() => {
callback(...rest);
}, limit);
};
}
| chat-ui/src/lib/utils/debounce.ts/0 | {
"file_path": "chat-ui/src/lib/utils/debounce.ts",
"repo_id": "chat-ui",
"token_count": 138
} | 57 |
// https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Statements/for-await...of#iterating_over_async_generators
export async function* streamToAsyncIterable(
stream: ReadableStream<Uint8Array>
): AsyncIterableIterator<Uint8Array> {
const reader = stream.getReader();
try {
while (true) {
const { done, value } = await reader.read();
if (done) return;
yield value;
}
} finally {
reader.releaseLock();
}
}
| chat-ui/src/lib/utils/streamToAsyncIterable.ts/0 | {
"file_path": "chat-ui/src/lib/utils/streamToAsyncIterable.ts",
"repo_id": "chat-ui",
"token_count": 161
} | 58 |
import type { LayoutServerLoad } from "./$types";
import { collections } from "$lib/server/database";
import type { Conversation } from "$lib/types/Conversation";
import { UrlDependency } from "$lib/types/UrlDependency";
import { defaultModel, models, oldModels, validateModel } from "$lib/server/models";
import { authCondition, requiresUser } from "$lib/server/auth";
import { DEFAULT_SETTINGS } from "$lib/types/Settings";
import {
SERPAPI_KEY,
SERPER_API_KEY,
SERPSTACK_API_KEY,
MESSAGES_BEFORE_LOGIN,
YDC_API_KEY,
USE_LOCAL_WEBSEARCH,
SEARXNG_QUERY_URL,
ENABLE_ASSISTANTS,
ENABLE_ASSISTANTS_RAG,
} from "$env/static/private";
import { ObjectId } from "mongodb";
import type { ConvSidebar } from "$lib/types/ConvSidebar";
export const load: LayoutServerLoad = async ({ locals, depends }) => {
depends(UrlDependency.ConversationList);
const settings = await collections.settings.findOne(authCondition(locals));
// If the active model in settings is not valid, set it to the default model. This can happen if model was disabled.
if (
settings &&
!validateModel(models).safeParse(settings?.activeModel).success &&
!settings.assistants?.map((el) => el.toString())?.includes(settings?.activeModel)
) {
settings.activeModel = defaultModel.id;
await collections.settings.updateOne(authCondition(locals), {
$set: { activeModel: defaultModel.id },
});
}
// if the model is unlisted, set the active model to the default model
if (
settings?.activeModel &&
models.find((m) => m.id === settings?.activeModel)?.unlisted === true
) {
settings.activeModel = defaultModel.id;
await collections.settings.updateOne(authCondition(locals), {
$set: { activeModel: defaultModel.id },
});
}
const enableAssistants = ENABLE_ASSISTANTS === "true";
const assistantActive = !models.map(({ id }) => id).includes(settings?.activeModel ?? "");
const assistant = assistantActive
? JSON.parse(
JSON.stringify(
await collections.assistants.findOne({
_id: new ObjectId(settings?.activeModel),
})
)
)
: null;
const conversations = await collections.conversations
.find(authCondition(locals))
.sort({ updatedAt: -1 })
.project<
Pick<Conversation, "title" | "model" | "_id" | "updatedAt" | "createdAt" | "assistantId">
>({
title: 1,
model: 1,
_id: 1,
updatedAt: 1,
createdAt: 1,
assistantId: 1,
})
.limit(300)
.toArray();
const userAssistants = settings?.assistants?.map((assistantId) => assistantId.toString()) ?? [];
const userAssistantsSet = new Set(userAssistants);
const assistantIds = [
...userAssistants.map((el) => new ObjectId(el)),
...(conversations.map((conv) => conv.assistantId).filter((el) => !!el) as ObjectId[]),
];
const assistants = await collections.assistants.find({ _id: { $in: assistantIds } }).toArray();
const messagesBeforeLogin = MESSAGES_BEFORE_LOGIN ? parseInt(MESSAGES_BEFORE_LOGIN) : 0;
let loginRequired = false;
if (requiresUser && !locals.user && messagesBeforeLogin) {
if (conversations.length > messagesBeforeLogin) {
loginRequired = true;
} else {
// get the number of messages where `from === "assistant"` across all conversations.
const totalMessages =
(
await collections.conversations
.aggregate([
{ $match: { ...authCondition(locals), "messages.from": "assistant" } },
{ $project: { messages: 1 } },
{ $limit: messagesBeforeLogin + 1 },
{ $unwind: "$messages" },
{ $match: { "messages.from": "assistant" } },
{ $count: "messages" },
])
.toArray()
)[0]?.messages ?? 0;
loginRequired = totalMessages > messagesBeforeLogin;
}
}
return {
conversations: conversations.map((conv) => {
if (settings?.hideEmojiOnSidebar) {
conv.title = conv.title.replace(/\p{Emoji}/gu, "");
}
// remove invalid unicode and trim whitespaces
conv.title = conv.title.replace(/\uFFFD/gu, "").trimStart();
return {
id: conv._id.toString(),
title: conv.title,
model: conv.model ?? defaultModel,
updatedAt: conv.updatedAt,
assistantId: conv.assistantId?.toString(),
avatarHash:
conv.assistantId &&
assistants.find((a) => a._id.toString() === conv.assistantId?.toString())?.avatar,
};
}) satisfies ConvSidebar[],
settings: {
searchEnabled: !!(
SERPAPI_KEY ||
SERPER_API_KEY ||
SERPSTACK_API_KEY ||
YDC_API_KEY ||
USE_LOCAL_WEBSEARCH ||
SEARXNG_QUERY_URL
),
ethicsModalAccepted: !!settings?.ethicsModalAcceptedAt,
ethicsModalAcceptedAt: settings?.ethicsModalAcceptedAt ?? null,
activeModel: settings?.activeModel ?? DEFAULT_SETTINGS.activeModel,
hideEmojiOnSidebar: settings?.hideEmojiOnSidebar ?? false,
shareConversationsWithModelAuthors:
settings?.shareConversationsWithModelAuthors ??
DEFAULT_SETTINGS.shareConversationsWithModelAuthors,
customPrompts: settings?.customPrompts ?? {},
assistants: userAssistants,
},
models: models.map((model) => ({
id: model.id,
name: model.name,
websiteUrl: model.websiteUrl,
modelUrl: model.modelUrl,
datasetName: model.datasetName,
datasetUrl: model.datasetUrl,
displayName: model.displayName,
description: model.description,
logoUrl: model.logoUrl,
promptExamples: model.promptExamples,
parameters: model.parameters,
preprompt: model.preprompt,
multimodal: model.multimodal,
unlisted: model.unlisted,
})),
oldModels,
assistants: assistants
.filter((el) => userAssistantsSet.has(el._id.toString()))
.map((el) => ({
...el,
_id: el._id.toString(),
createdById: undefined,
createdByMe:
el.createdById.toString() === (locals.user?._id ?? locals.sessionId).toString(),
})),
user: locals.user && {
id: locals.user._id.toString(),
username: locals.user.username,
avatarUrl: locals.user.avatarUrl,
email: locals.user.email,
},
assistant,
enableAssistants,
enableAssistantsRAG: ENABLE_ASSISTANTS_RAG === "true",
loginRequired,
loginEnabled: requiresUser,
guestMode: requiresUser && messagesBeforeLogin > 0,
};
};
| chat-ui/src/routes/+layout.server.ts/0 | {
"file_path": "chat-ui/src/routes/+layout.server.ts",
"repo_id": "chat-ui",
"token_count": 2362
} | 59 |
import { collections } from "$lib/server/database";
import { ObjectId } from "mongodb";
import { error } from "@sveltejs/kit";
import { authCondition } from "$lib/server/auth";
import { UrlDependency } from "$lib/types/UrlDependency";
import { convertLegacyConversation } from "$lib/utils/tree/convertLegacyConversation.js";
export const load = async ({ params, depends, locals }) => {
let conversation;
let shared = false;
// if the conver
if (params.id.length === 7) {
// shared link of length 7
conversation = await collections.sharedConversations.findOne({
_id: params.id,
});
shared = true;
if (!conversation) {
throw error(404, "Conversation not found");
}
} else {
// todo: add validation on params.id
conversation = await collections.conversations.findOne({
_id: new ObjectId(params.id),
...authCondition(locals),
});
depends(UrlDependency.Conversation);
if (!conversation) {
const conversationExists =
(await collections.conversations.countDocuments({
_id: new ObjectId(params.id),
})) !== 0;
if (conversationExists) {
throw error(
403,
"You don't have access to this conversation. If someone gave you this link, ask them to use the 'share' feature instead."
);
}
throw error(404, "Conversation not found.");
}
}
const convertedConv = { ...conversation, ...convertLegacyConversation(conversation) };
return {
messages: convertedConv.messages,
title: convertedConv.title,
model: convertedConv.model,
preprompt: convertedConv.preprompt,
rootMessageId: convertedConv.rootMessageId,
assistant: convertedConv.assistantId
? JSON.parse(
JSON.stringify(
await collections.assistants.findOne({
_id: new ObjectId(convertedConv.assistantId),
})
)
)
: null,
shared,
};
};
| chat-ui/src/routes/conversation/[id]/+page.server.ts/0 | {
"file_path": "chat-ui/src/routes/conversation/[id]/+page.server.ts",
"repo_id": "chat-ui",
"token_count": 678
} | 60 |
<script lang="ts">
import { page } from "$app/stores";
import { base } from "$app/paths";
import { goto } from "$app/navigation";
import { onMount } from "svelte";
import { PUBLIC_APP_NAME, PUBLIC_ORIGIN } from "$env/static/public";
import ChatWindow from "$lib/components/chat/ChatWindow.svelte";
import { findCurrentModel } from "$lib/utils/models";
import { useSettingsStore } from "$lib/stores/settings";
import { ERROR_MESSAGES, error } from "$lib/stores/errors";
import { pendingMessage } from "$lib/stores/pendingMessage";
export let data;
let loading = false;
let files: File[] = [];
const settings = useSettingsStore();
const modelId = $page.params.model;
async function createConversation(message: string) {
try {
loading = true;
// check if $settings.activeModel is a valid model
// else check if it's an assistant, and use that model
// else use the first model
const validModels = data.models.map((model) => model.id);
let model;
if (validModels.includes($settings.activeModel)) {
model = $settings.activeModel;
} else {
if (validModels.includes(data.assistant?.modelId)) {
model = data.assistant?.modelId;
} else {
model = data.models[0].id;
}
}
const res = await fetch(`${base}/conversation`, {
method: "POST",
headers: {
"Content-Type": "application/json",
},
body: JSON.stringify({
model,
preprompt: $settings.customPrompts[$settings.activeModel],
}),
});
if (!res.ok) {
error.set("Error while creating conversation, try again.");
console.error("Error while creating conversation: " + (await res.text()));
return;
}
const { conversationId } = await res.json();
// Ugly hack to use a store as temp storage, feel free to improve ^^
pendingMessage.set({
content: message,
files,
});
// invalidateAll to update list of conversations
await goto(`${base}/conversation/${conversationId}`, { invalidateAll: true });
} catch (err) {
error.set(ERROR_MESSAGES.default);
console.error(err);
} finally {
loading = false;
}
}
onMount(async () => {
settings.instantSet({
activeModel: modelId,
});
});
</script>
<svelte:head>
<meta property="og:title" content={modelId + " - " + PUBLIC_APP_NAME} />
<meta property="og:type" content="link" />
<meta property="og:description" content={`Use ${modelId} with ${PUBLIC_APP_NAME}`} />
<meta
property="og:image"
content="{PUBLIC_ORIGIN || $page.url.origin}{base}/models/{modelId}/thumbnail.png"
/>
<meta property="og:url" content={$page.url.href} />
<meta name="twitter:card" content="summary_large_image" />
</svelte:head>
<ChatWindow
on:message={(ev) => createConversation(ev.detail)}
{loading}
currentModel={findCurrentModel([...data.models, ...data.oldModels], modelId)}
models={data.models}
bind:files
/>
| chat-ui/src/routes/models/[...model]/+page.svelte/0 | {
"file_path": "chat-ui/src/routes/models/[...model]/+page.svelte",
"repo_id": "chat-ui",
"token_count": 1066
} | 61 |
<script lang="ts">
import type { PageData, ActionData } from "./$types";
import { page } from "$app/stores";
import AssistantSettings from "$lib/components/AssistantSettings.svelte";
export let data: PageData;
export let form: ActionData;
$: assistant = data.assistants.find((el) => el._id.toString() === $page.params.assistantId);
</script>
<AssistantSettings bind:form {assistant} models={data.models} />
| chat-ui/src/routes/settings/(nav)/assistants/[assistantId]/edit/[email protected]/0 | {
"file_path": "chat-ui/src/routes/settings/(nav)/assistants/[assistantId]/edit/[email protected]",
"repo_id": "chat-ui",
"token_count": 130
} | 62 |
# Security Policy
## Supported Versions
<!--
Use this section to tell people about which versions of your project are
currently being supported with security updates.
| Version | Supported |
| ------- | ------------------ |
| 5.1.x | :white_check_mark: |
| 5.0.x | :x: |
| 4.0.x | :white_check_mark: |
| < 4.0 | :x: |
-->
Each major version is currently being supported with security updates.
| Version | Supported |
|---------|--------------------|
| 1.x.x | :white_check_mark: |
| 2.x.x | :white_check_mark: |
## Reporting a Vulnerability
<!--
Use this section to tell people how to report a vulnerability.
Tell them where to go, how often they can expect to get an update on a
reported vulnerability, what to expect if the vulnerability is accepted or
declined, etc.
-->
To report a security vulnerability, please contact: [email protected]
| datasets/SECURITY.md/0 | {
"file_path": "datasets/SECURITY.md",
"repo_id": "datasets",
"token_count": 306
} | 63 |
# docstyle-ignore
INSTALL_CONTENT = """
# Datasets installation
! pip install datasets transformers
# To install from source instead of the last release, comment the command above and uncomment the following one.
# ! pip install git+https://github.com/huggingface/datasets.git
"""
notebook_first_cells = [{"type": "code", "content": INSTALL_CONTENT}]
default_branch_name = "main"
version_prefix = ""
| datasets/docs/source/_config.py/0 | {
"file_path": "datasets/docs/source/_config.py",
"repo_id": "datasets",
"token_count": 118
} | 64 |
# Create a dataset
Sometimes, you may need to create a dataset if you're working with your own data. Creating a dataset with 🤗 Datasets confers all the advantages of the library to your dataset: fast loading and processing, [stream enormous datasets](stream), [memory-mapping](https://huggingface.co/course/chapter5/4?fw=pt#the-magic-of-memory-mapping), and more. You can easily and rapidly create a dataset with 🤗 Datasets low-code approaches, reducing the time it takes to start training a model. In many cases, it is as easy as [dragging and dropping](upload_dataset#upload-with-the-hub-ui) your data files into a dataset repository on the Hub.
In this tutorial, you'll learn how to use 🤗 Datasets low-code methods for creating all types of datasets:
* Folder-based builders for quickly creating an image or audio dataset
* `from_` methods for creating datasets from local files
## Folder-based builders
There are two folder-based builders, [`ImageFolder`] and [`AudioFolder`]. These are low-code methods for quickly creating an image or speech and audio dataset with several thousand examples. They are great for rapidly prototyping computer vision and speech models before scaling to a larger dataset. Folder-based builders takes your data and automatically generates the dataset's features, splits, and labels. Under the hood:
* [`ImageFolder`] uses the [`~datasets.Image`] feature to decode an image file. Many image extension formats are supported, such as jpg and png, but other formats are also supported. You can check the complete [list](https://github.com/huggingface/datasets/blob/b5672a956d5de864e6f5550e493527d962d6ae55/src/datasets/packaged_modules/imagefolder/imagefolder.py#L39) of supported image extensions.
* [`AudioFolder`] uses the [`~datasets.Audio`] feature to decode an audio file. Audio extensions such as wav and mp3 are supported, and you can check the complete [list](https://github.com/huggingface/datasets/blob/b5672a956d5de864e6f5550e493527d962d6ae55/src/datasets/packaged_modules/audiofolder/audiofolder.py#L39) of supported audio extensions.
The dataset splits are generated from the repository structure, and the label names are automatically inferred from the directory name.
For example, if your image dataset (it is the same for an audio dataset) is stored like this:
```
pokemon/train/grass/bulbasaur.png
pokemon/train/fire/charmander.png
pokemon/train/water/squirtle.png
pokemon/test/grass/ivysaur.png
pokemon/test/fire/charmeleon.png
pokemon/test/water/wartortle.png
```
Then this is how the folder-based builder generates an example:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/folder-based-builder.png"/>
</div>
Create the image dataset by specifying `imagefolder` in [`load_dataset`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("imagefolder", data_dir="/path/to/pokemon")
```
An audio dataset is created in the same way, except you specify `audiofolder` in [`load_dataset`] instead:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("audiofolder", data_dir="/path/to/folder")
```
Any additional information about your dataset, such as text captions or transcriptions, can be included with a `metadata.csv` file in the folder containing your dataset. The metadata file needs to have a `file_name` column that links the image or audio file to its corresponding metadata:
```
file_name, text
bulbasaur.png, There is a plant seed on its back right from the day this Pokémon is born.
charmander.png, It has a preference for hot things.
squirtle.png, When it retracts its long neck into its shell, it squirts out water with vigorous force.
```
To learn more about each of these folder-based builders, check out the and <a href="https://huggingface.co/docs/datasets/image_dataset#imagefolder"><span class="underline decoration-yellow-400 decoration-2 font-semibold">ImageFolder</span></a> or <a href="https://huggingface.co/docs/datasets/audio_dataset#audiofolder"><span class="underline decoration-pink-400 decoration-2 font-semibold">AudioFolder</span></a> guides.
## From local files
You can also create a dataset from local files by specifying the path to the data files. There are two ways you can create a dataset using the `from_` methods:
* The [`~Dataset.from_generator`] method is the most memory-efficient way to create a dataset from a [generator](https://wiki.python.org/moin/Generators) due to a generators iterative behavior. This is especially useful when you're working with a really large dataset that may not fit in memory, since the dataset is generated on disk progressively and then memory-mapped.
```py
>>> from datasets import Dataset
>>> def gen():
... yield {"pokemon": "bulbasaur", "type": "grass"}
... yield {"pokemon": "squirtle", "type": "water"}
>>> ds = Dataset.from_generator(gen)
>>> ds[0]
{"pokemon": "bulbasaur", "type": "grass"}
```
A generator-based [`IterableDataset`] needs to be iterated over with a `for` loop for example:
```py
>>> from datasets import IterableDataset
>>> ds = IterableDataset.from_generator(gen)
>>> for example in ds:
... print(example)
{"pokemon": "bulbasaur", "type": "grass"}
{"pokemon": "squirtle", "type": "water"}
```
* The [`~Dataset.from_dict`] method is a straightforward way to create a dataset from a dictionary:
```py
>>> from datasets import Dataset
>>> ds = Dataset.from_dict({"pokemon": ["bulbasaur", "squirtle"], "type": ["grass", "water"]})
>>> ds[0]
{"pokemon": "bulbasaur", "type": "grass"}
```
To create an image or audio dataset, chain the [`~Dataset.cast_column`] method with [`~Dataset.from_dict`] and specify the column and feature type. For example, to create an audio dataset:
```py
>>> audio_dataset = Dataset.from_dict({"audio": ["path/to/audio_1", ..., "path/to/audio_n"]}).cast_column("audio", Audio())
```
## Next steps
We didn't mention this in the tutorial, but you can also create a dataset with a loading script. A loading script is a more manual and code-intensive method for creating a dataset, but it also gives you the most flexibility and control over how a dataset is generated. It lets you configure additional options such as creating multiple configurations within a dataset, or enabling your dataset to be streamed.
To learn more about how to write loading scripts, take a look at the <a href="https://huggingface.co/docs/datasets/main/en/image_dataset#loading-script"><span class="underline decoration-yellow-400 decoration-2 font-semibold">image loading script</span></a>, <a href="https://huggingface.co/docs/datasets/main/en/audio_dataset"><span class="underline decoration-pink-400 decoration-2 font-semibold">audio loading script</span></a>, and <a href="https://huggingface.co/docs/datasets/main/en/dataset_script"><span class="underline decoration-green-400 decoration-2 font-semibold">text loading script</span></a> guides.
Now that you know how to create a dataset, consider sharing it on the Hub so the community can also benefit from your work! Go on to the next section to learn how to share your dataset.
| datasets/docs/source/create_dataset.mdx/0 | {
"file_path": "datasets/docs/source/create_dataset.mdx",
"repo_id": "datasets",
"token_count": 2167
} | 65 |
# Load a dataset from the Hub
Finding high-quality datasets that are reproducible and accessible can be difficult. One of 🤗 Datasets main goals is to provide a simple way to load a dataset of any format or type. The easiest way to get started is to discover an existing dataset on the [Hugging Face Hub](https://huggingface.co/datasets) - a community-driven collection of datasets for tasks in NLP, computer vision, and audio - and use 🤗 Datasets to download and generate the dataset.
This tutorial uses the [rotten_tomatoes](https://huggingface.co/datasets/rotten_tomatoes) and [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) datasets, but feel free to load any dataset you want and follow along. Head over to the Hub now and find a dataset for your task!
## Load a dataset
Before you take the time to download a dataset, it's often helpful to quickly get some general information about a dataset. A dataset's information is stored inside [`DatasetInfo`] and can include information such as the dataset description, features, and dataset size.
Use the [`load_dataset_builder`] function to load a dataset builder and inspect a dataset's attributes without committing to downloading it:
```py
>>> from datasets import load_dataset_builder
>>> ds_builder = load_dataset_builder("rotten_tomatoes")
# Inspect dataset description
>>> ds_builder.info.description
Movie Review Dataset. This is a dataset of containing 5,331 positive and 5,331 negative processed sentences from Rotten Tomatoes movie reviews. This data was first used in Bo Pang and Lillian Lee, ``Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales.'', Proceedings of the ACL, 2005.
# Inspect dataset features
>>> ds_builder.info.features
{'label': ClassLabel(num_classes=2, names=['neg', 'pos'], id=None),
'text': Value(dtype='string', id=None)}
```
If you're happy with the dataset, then load it with [`load_dataset`]:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes", split="train")
```
## Splits
A split is a specific subset of a dataset like `train` and `test`. List a dataset's split names with the [`get_dataset_split_names`] function:
```py
>>> from datasets import get_dataset_split_names
>>> get_dataset_split_names("rotten_tomatoes")
['train', 'validation', 'test']
```
Then you can load a specific split with the `split` parameter. Loading a dataset `split` returns a [`Dataset`] object:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes", split="train")
>>> dataset
Dataset({
features: ['text', 'label'],
num_rows: 8530
})
```
If you don't specify a `split`, 🤗 Datasets returns a [`DatasetDict`] object instead:
```py
>>> from datasets import load_dataset
>>> dataset = load_dataset("rotten_tomatoes")
DatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 8530
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 1066
})
test: Dataset({
features: ['text', 'label'],
num_rows: 1066
})
})
```
## Configurations
Some datasets contain several sub-datasets. For example, the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset has several sub-datasets, each one containing audio data in a different language. These sub-datasets are known as *configurations*, and you must explicitly select one when loading the dataset. If you don't provide a configuration name, 🤗 Datasets will raise a `ValueError` and remind you to choose a configuration.
Use the [`get_dataset_config_names`] function to retrieve a list of all the possible configurations available to your dataset:
```py
>>> from datasets import get_dataset_config_names
>>> configs = get_dataset_config_names("PolyAI/minds14")
>>> print(configs)
['cs-CZ', 'de-DE', 'en-AU', 'en-GB', 'en-US', 'es-ES', 'fr-FR', 'it-IT', 'ko-KR', 'nl-NL', 'pl-PL', 'pt-PT', 'ru-RU', 'zh-CN', 'all']
```
Then load the configuration you want:
```py
>>> from datasets import load_dataset
>>> mindsFR = load_dataset("PolyAI/minds14", "fr-FR", split="train")
```
## Remote code
Certain datasets repositories contain a loading script with the Python code used to generate the dataset.
Those datasets are generally exported to Parquet by Hugging Face, so that 🤗 Datasets can load the dataset fast and without running a loading script.
Even if a Parquet export is not available, you can still use any dataset with Python code in its repository with `load_dataset`.
All files and code uploaded to the Hub are scanned for malware (refer to the Hub security documentation for more information), but you should still review the dataset loading scripts and authors to avoid executing malicious code on your machine. You should set `trust_remote_code=True` to use a dataset with a loading script, or you will get a warning:
```py
>>> from datasets import get_dataset_config_names, get_dataset_split_names, load_dataset
>>> c4 = load_dataset("c4", "en", split="train", trust_remote_code=True)
>>> get_dataset_config_names("c4", trust_remote_code=True)
['en', 'realnewslike', 'en.noblocklist', 'en.noclean']
>>> get_dataset_split_names("c4", "en", trust_remote_code=True)
['train', 'validation']
```
<Tip warning=true>
In the next major release, the new safety features of 🤗 Datasets will disable running dataset loading scripts by default, and you will have to pass `trust_remote_code=True` to load datasets that require running a dataset script.
</Tip>
| datasets/docs/source/load_hub.mdx/0 | {
"file_path": "datasets/docs/source/load_hub.mdx",
"repo_id": "datasets",
"token_count": 1685
} | 66 |
# Share a dataset using the CLI
At Hugging Face, we are on a mission to democratize good Machine Learning and we believe in the value of open source. That's why we designed 🤗 Datasets so that anyone can share a dataset with the greater ML community. There are currently thousands of datasets in over 100 languages in the Hugging Face Hub, and the Hugging Face team always welcomes new contributions!
Dataset repositories offer features such as:
- Free dataset hosting
- Dataset versioning
- Commit history and diffs
- Metadata for discoverability
- Dataset cards for documentation, licensing, limitations, etc.
- [Dataset Viewer](../hub/datasets-viewer)
This guide will show you how to share a dataset folder or repository that can be easily accessed by anyone.
<a id='upload_dataset_repo'></a>
## Add a dataset
You can share your dataset with the community with a dataset repository on the Hugging Face Hub.
It can also be a private dataset if you want to control who has access to it.
In a dataset repository, you can host all your data files and [configure your dataset](./repository_structure#define-your-splits-in-yaml) to define which file goes to which split.
The following formats are supported: CSV, TSV, JSON, JSON lines, text, Parquet, Arrow, SQLite, WebDataset.
Many kinds of compressed file types are also supported: GZ, BZ2, LZ4, LZMA or ZSTD.
For example, your dataset can be made of `.json.gz` files.
On the other hand, if your dataset is not in a supported format or if you want more control over how your dataset is loaded, you can write your own dataset script.
Note that some feature are not available for datasets defined using a loading scripts, such as the Dataset Viewer. Users also have to pass `trust_remote_code=True` to load the dataset. It is generally recommended for datasets to not rely on a loading script if possible, to benefit from all the Hub's features.
When loading a dataset from the Hub, all the files in the supported formats are loaded, following the [repository structure](./repository_structure).
However if there's a dataset script, it is downloaded and executed to download and prepare the dataset instead.
For more information on how to load a dataset from the Hub, take a look at the [load a dataset from the Hub](./load_hub) tutorial.
### Create the repository
Sharing a community dataset will require you to create an account on [hf.co](https://huggingface.co/join) if you don't have one yet.
You can directly create a [new dataset repository](https://huggingface.co/login?next=%2Fnew-dataset) from your account on the Hugging Face Hub, but this guide will show you how to upload a dataset from the terminal.
1. Make sure you are in the virtual environment where you installed Datasets, and run the following command:
```
huggingface-cli login
```
2. Login using your Hugging Face Hub credentials, and create a new dataset repository:
```
huggingface-cli repo create my-cool-dataset --type dataset
```
Add the `-organization` flag to create a repository under a specific organization:
```
huggingface-cli repo create my-cool-dataset --type dataset --organization your-org-name
```
## Prepare your files
Check your directory to ensure the only files you're uploading are:
- The data files of the dataset
- The dataset card `README.md`
- (optional) `your_dataset_name.py` is your dataset loading script (optional if your data files are already in the supported formats csv/jsonl/json/parquet/txt). To create a dataset script, see the [dataset script](dataset_script) page. Note that some feature are not available for datasets defined using a loading scripts, such as the Dataset Viewer. Users also have to pass `trust_remote_code=True` to load the dataset. It is generally recommended for datasets to not rely on a loading script if possible, to benefit from all the Hub's features.
## huggingface-cli upload
Use the `huggingface-cli upload` command to upload files to the Hub directly. Internally, it uses the same [`upload_file`] and [`upload_folder`] helpers described in the [Upload guide](../huggingface_hub/guides/upload). In the examples below, we will walk through the most common use cases. For a full list of available options, you can run:
```bash
>>> huggingface-cli upload --help
```
For more general information about `huggingface-cli` you can check the [CLI guide](../huggingface_hub/guides/cli).
### Upload an entire folder
The default usage for this command is:
```bash
# Usage: huggingface-cli upload [dataset_repo_id] --repo-type=dataset [local_path] [path_in_repo]
```
To upload the current directory at the root of the repo, use:
```bash
>>> huggingface-cli upload my-cool-dataset --repo-type=dataset . .
https://huggingface.co/datasets/Wauplin/my-cool-dataset/tree/main/
```
<Tip>
If the repo doesn't exist yet, it will be created automatically.
</Tip>
You can also upload a specific folder:
```bash
>>> huggingface-cli upload my-cool-dataset --repo-type=dataset ./data .
https://huggingface.co/datasetsWauplin/my-cool-dataset/tree/main/
```
Finally, you can upload a folder to a specific destination on the repo:
```bash
>>> huggingface-cli upload my-cool-dataset --repo-type=dataset ./path/to/curated/data /data/train
https://huggingface.co/datasetsWauplin/my-cool-dataset/tree/main/data/train
```
### Upload a single file
You can also upload a single file by setting `local_path` to point to a file on your machine. If that's the case, `path_in_repo` is optional and will default to the name of your local file:
```bash
>>> huggingface-cli upload Wauplin/my-cool-dataset --repo-type=dataset ./files/train.csv
https://huggingface.co/datasetsWauplin/my-cool-dataset/blob/main/train.csv
```
If you want to upload a single file to a specific directory, set `path_in_repo` accordingly:
```bash
>>> huggingface-cli upload Wauplin/my-cool-dataset --repo-type=dataset ./files/train.csv /data/train.csv
https://huggingface.co/datasetsWauplin/my-cool-dataset/blob/main/data/train.csv
```
### Upload multiple files
To upload multiple files from a folder at once without uploading the entire folder, use the `--include` and `--exclude` patterns. It can also be combined with the `--delete` option to delete files on the repo while uploading new ones. In the example below, we sync the local Space by deleting remote files and uploading all CSV files:
```bash
# Sync local Space with Hub (upload new CSV files, delete removed files)
>>> huggingface-cli upload Wauplin/my-cool-dataset --repo-type=dataset --include="/data/*.csv" --delete="*" --commit-message="Sync local dataset with Hub"
...
```
### Upload to an organization
To upload content to a repo owned by an organization instead of a personal repo, you must explicitly specify it in the `repo_id`:
```bash
>>> huggingface-cli upload MyCoolOrganization/my-cool-dataset --repo-type=dataset . .
https://huggingface.co/datasetsMyCoolOrganization/my-cool-dataset/tree/main/
```
### Upload to a specific revision
By default, files are uploaded to the `main` branch. If you want to upload files to another branch or reference, use the `--revision` option:
```bash
# Upload files to a PR
>>> huggingface-cli upload bigcode/the-stack --repo-type dataset -revision refs/pr/104 . .
...
```
**Note:** if `revision` does not exist and `--create-pr` is not set, a branch will be created automatically from the `main` branch.
### Upload and create a PR
If you don't have the permission to push to a repo, you must open a PR and let the authors know about the changes you want to make. This can be done by setting the `--create-pr` option:
```bash
# Create a PR and upload the files to it
>>> huggingface-cli upload bigcode/the-stack --repo-type dataset --revision refs/pr/104 --create-pr . .
https://huggingface.co/datasets/bigcode/the-stack/blob/refs%2Fpr%2F104/
```
### Upload at regular intervals
In some cases, you might want to push regular updates to a repo. For example, this is useful if your dataset is growing over time and you want to upload the data folder every 10 minutes. You can do this using the `--every` option:
```bash
# Upload new logs every 10 minutes
huggingface-cli upload my-cool-dynamic-dataset data/ --every=10
```
### Specify a commit message
Use the `--commit-message` and `--commit-description` to set a custom message and description for your commit instead of the default one
```bash
>>> huggingface-cli upload Wauplin/my-cool-dataset ./data . --repo-type dataset --commit-message="Version 2" --commit-description="Train size: 4321. Check Dataset Viewer for more details."
...
https://huggingface.co/datasetsWauplin/my-cool-dataset/tree/main
```
### Specify a token
To upload files, you must use a token. By default, the token saved locally (using `huggingface-cli login`) will be used. If you want to authenticate explicitly, use the `--token` option:
```bash
>>> huggingface-cli upload Wauplin/my-cool-dataset ./data . --token=hf_****
...
https://huggingface.co/datasetsWauplin/my-cool-data/tree/main
```
### Quiet mode
By default, the `huggingface-cli upload` command will be verbose. It will print details such as warning messages, information about the uploaded files, and progress bars. If you want to silence all of this, use the `--quiet` option. Only the last line (i.e. the URL to the uploaded files) is printed. This can prove useful if you want to pass the output to another command in a script.
```bash
>>> huggingface-cli upload Wauplin/my-cool-dataset ./data . --quiet
https://huggingface.co/datasets/Wauplin/my-cool-dataset/tree/main
```
## Enjoy !
Congratulations, your dataset has now been uploaded to the Hugging Face Hub where anyone can load it in a single line of code! 🥳
```
dataset = load_dataset("Wauplin/my-cool-dataset")
```
If your dataset is supported, it should also have a [Dataset Viewer](../hub/datasets-viewer) for everyone to explore the dataset content.
Finally, don't forget to enrich the dataset card to document your dataset and make it discoverable! Check out the [Create a dataset card](dataset_card) guide to learn more.
| datasets/docs/source/share.mdx/0 | {
"file_path": "datasets/docs/source/share.mdx",
"repo_id": "datasets",
"token_count": 2930
} | 67 |
# Metric Card for BLEU
## Metric Description
BLEU (Bilingual Evaluation Understudy) is an algorithm for evaluating the quality of text which has been machine-translated from one natural language to another. Quality is considered to be the correspondence between a machine's output and that of a human: "the closer a machine translation is to a professional human translation, the better it is" – this is the central idea behind BLEU. BLEU was one of the first metrics to claim a high correlation with human judgements of quality, and remains one of the most popular automated and inexpensive metrics.
Scores are calculated for individual translated segments—generally sentences—by comparing them with a set of good quality reference translations. Those scores are then averaged over the whole corpus to reach an estimate of the translation's overall quality. Neither intelligibility nor grammatical correctness are not taken into account.
## Intended Uses
BLEU and BLEU-derived metrics are most often used for machine translation.
## How to Use
This metric takes as input lists of predicted sentences and reference sentences:
```python
>>> predictions = [
... ["hello", "there", "general", "kenobi"],
... ["foo", "bar", "foobar"]
... ]
>>> references = [
... [["hello", "there", "general", "kenobi"]],
... [["foo", "bar", "foobar"]]
... ]
>>> bleu = datasets.load_metric("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 7, 'reference_length': 7}
```
### Inputs
- **predictions** (`list`): Translations to score. Each translation should be tokenized into a list of tokens.
- **references** (`list` of `list`s): references for each translation. Each reference should be tokenized into a list of tokens.
- **max_order** (`int`): Maximum n-gram order to use when computing BLEU score. Defaults to `4`.
- **smooth** (`boolean`): Whether or not to apply Lin et al. 2004 smoothing. Defaults to `False`.
### Output Values
- **bleu** (`float`): bleu score
- **precisions** (`list` of `float`s): geometric mean of n-gram precisions,
- **brevity_penalty** (`float`): brevity penalty,
- **length_ratio** (`float`): ratio of lengths,
- **translation_length** (`int`): translation_length,
- **reference_length** (`int`): reference_length
Output Example:
```python
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.167, 'translation_length': 7, 'reference_length': 6}
```
BLEU's output is always a number between 0 and 1. This value indicates how similar the candidate text is to the reference texts, with values closer to 1 representing more similar texts. Few human translations will attain a score of 1, since this would indicate that the candidate is identical to one of the reference translations. For this reason, it is not necessary to attain a score of 1. Because there are more opportunities to match, adding additional reference translations will increase the BLEU score.
#### Values from Popular Papers
The [original BLEU paper](https://aclanthology.org/P02-1040/) (Papineni et al. 2002) compares BLEU scores of five different models on the same 500-sentence corpus. These scores ranged from 0.0527 to 0.2571.
The [Attention is All you Need paper](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) (Vaswani et al. 2017) got a BLEU score of 0.284 on the WMT 2014 English-to-German translation task, and 0.41 on the WMT 2014 English-to-French translation task.
### Examples
Example where each sample has 1 reference:
```python
>>> predictions = [
... ["hello", "there", "general", "kenobi"],
... ["foo", "bar", "foobar"]
... ]
>>> references = [
... [["hello", "there", "general", "kenobi"]],
... [["foo", "bar", "foobar"]]
... ]
>>> bleu = datasets.load_metric("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.0, 'translation_length': 7, 'reference_length': 7}
```
Example where the first sample has 2 references:
```python
>>> predictions = [
... ["hello", "there", "general", "kenobi"],
... ["foo", "bar", "foobar"]
... ]
>>> references = [
... [["hello", "there", "general", "kenobi"], ["hello", "there", "!"]],
... [["foo", "bar", "foobar"]]
... ]
>>> bleu = datasets.load_metric("bleu")
>>> results = bleu.compute(predictions=predictions, references=references)
>>> print(results)
{'bleu': 1.0, 'precisions': [1.0, 1.0, 1.0, 1.0], 'brevity_penalty': 1.0, 'length_ratio': 1.1666666666666667, 'translation_length': 7, 'reference_length': 6}
```
## Limitations and Bias
This metric hase multiple known limitations and biases:
- BLEU compares overlap in tokens from the predictions and references, instead of comparing meaning. This can lead to discrepencies between BLEU scores and human ratings.
- BLEU scores are not comparable across different datasets, nor are they comparable across different languages.
- BLEU scores can vary greatly depending on which parameters are used to generate the scores, especially when different tokenization and normalization techniques are used. It is therefore not possible to compare BLEU scores generated using different parameters, or when these parameters are unknown.
- Shorter predicted translations achieve higher scores than longer ones, simply due to how the score is calculated. A brevity penalty is introduced to attempt to counteract this.
## Citation
```bibtex
@INPROCEEDINGS{Papineni02bleu:a,
author = {Kishore Papineni and Salim Roukos and Todd Ward and Wei-jing Zhu},
title = {BLEU: a Method for Automatic Evaluation of Machine Translation},
booktitle = {},
year = {2002},
pages = {311--318}
}
@inproceedings{lin-och-2004-orange,
title = "{ORANGE}: a Method for Evaluating Automatic Evaluation Metrics for Machine Translation",
author = "Lin, Chin-Yew and
Och, Franz Josef",
booktitle = "{COLING} 2004: Proceedings of the 20th International Conference on Computational Linguistics",
month = "aug 23{--}aug 27",
year = "2004",
address = "Geneva, Switzerland",
publisher = "COLING",
url = "https://www.aclweb.org/anthology/C04-1072",
pages = "501--507",
}
```
## Further References
- This Hugging Face implementation uses [this Tensorflow implementation](https://github.com/tensorflow/nmt/blob/master/nmt/scripts/bleu.py)
| datasets/metrics/bleu/README.md/0 | {
"file_path": "datasets/metrics/bleu/README.md",
"repo_id": "datasets",
"token_count": 1990
} | 68 |
# Copyright 2020 The HuggingFace Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""CoVal metric."""
import coval # From: git+https://github.com/ns-moosavi/coval.git # noqa: F401
from coval.conll import reader, util
from coval.eval import evaluator
import datasets
logger = datasets.logging.get_logger(__name__)
_CITATION = """\
@InProceedings{moosavi2019minimum,
author = { Nafise Sadat Moosavi, Leo Born, Massimo Poesio and Michael Strube},
title = {Using Automatically Extracted Minimum Spans to Disentangle Coreference Evaluation from Boundary Detection},
year = {2019},
booktitle = {Proceedings of the 57th Annual Meeting of
the Association for Computational Linguistics (Volume 1: Long Papers)},
publisher = {Association for Computational Linguistics},
address = {Florence, Italy},
}
@inproceedings{10.3115/1072399.1072405,
author = {Vilain, Marc and Burger, John and Aberdeen, John and Connolly, Dennis and Hirschman, Lynette},
title = {A Model-Theoretic Coreference Scoring Scheme},
year = {1995},
isbn = {1558604022},
publisher = {Association for Computational Linguistics},
address = {USA},
url = {https://doi.org/10.3115/1072399.1072405},
doi = {10.3115/1072399.1072405},
booktitle = {Proceedings of the 6th Conference on Message Understanding},
pages = {45–52},
numpages = {8},
location = {Columbia, Maryland},
series = {MUC6 ’95}
}
@INPROCEEDINGS{Bagga98algorithmsfor,
author = {Amit Bagga and Breck Baldwin},
title = {Algorithms for Scoring Coreference Chains},
booktitle = {In The First International Conference on Language Resources and Evaluation Workshop on Linguistics Coreference},
year = {1998},
pages = {563--566}
}
@INPROCEEDINGS{Luo05oncoreference,
author = {Xiaoqiang Luo},
title = {On coreference resolution performance metrics},
booktitle = {In Proc. of HLT/EMNLP},
year = {2005},
pages = {25--32},
publisher = {URL}
}
@inproceedings{moosavi-strube-2016-coreference,
title = "Which Coreference Evaluation Metric Do You Trust? A Proposal for a Link-based Entity Aware Metric",
author = "Moosavi, Nafise Sadat and
Strube, Michael",
booktitle = "Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
month = aug,
year = "2016",
address = "Berlin, Germany",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/P16-1060",
doi = "10.18653/v1/P16-1060",
pages = "632--642",
}
"""
_DESCRIPTION = """\
CoVal is a coreference evaluation tool for the CoNLL and ARRAU datasets which
implements of the common evaluation metrics including MUC [Vilain et al, 1995],
B-cubed [Bagga and Baldwin, 1998], CEAFe [Luo et al., 2005],
LEA [Moosavi and Strube, 2016] and the averaged CoNLL score
(the average of the F1 values of MUC, B-cubed and CEAFe)
[Denis and Baldridge, 2009a; Pradhan et al., 2011].
This wrapper of CoVal currently only work with CoNLL line format:
The CoNLL format has one word per line with all the annotation for this word in column separated by spaces:
Column Type Description
1 Document ID This is a variation on the document filename
2 Part number Some files are divided into multiple parts numbered as 000, 001, 002, ... etc.
3 Word number
4 Word itself This is the token as segmented/tokenized in the Treebank. Initially the *_skel file contain the placeholder [WORD] which gets replaced by the actual token from the Treebank which is part of the OntoNotes release.
5 Part-of-Speech
6 Parse bit This is the bracketed structure broken before the first open parenthesis in the parse, and the word/part-of-speech leaf replaced with a *. The full parse can be created by substituting the asterix with the "([pos] [word])" string (or leaf) and concatenating the items in the rows of that column.
7 Predicate lemma The predicate lemma is mentioned for the rows for which we have semantic role information. All other rows are marked with a "-"
8 Predicate Frameset ID This is the PropBank frameset ID of the predicate in Column 7.
9 Word sense This is the word sense of the word in Column 3.
10 Speaker/Author This is the speaker or author name where available. Mostly in Broadcast Conversation and Web Log data.
11 Named Entities These columns identifies the spans representing various named entities.
12:N Predicate Arguments There is one column each of predicate argument structure information for the predicate mentioned in Column 7.
N Coreference Coreference chain information encoded in a parenthesis structure.
More informations on the format can be found here (section "*_conll File Format"): http://www.conll.cemantix.org/2012/data.html
Details on the evaluation on CoNLL can be found here: https://github.com/ns-moosavi/coval/blob/master/conll/README.md
CoVal code was written by @ns-moosavi.
Some parts are borrowed from https://github.com/clarkkev/deep-coref/blob/master/evaluation.py
The test suite is taken from https://github.com/conll/reference-coreference-scorers/
Mention evaluation and the test suite are added by @andreasvc.
Parsing CoNLL files is developed by Leo Born.
"""
_KWARGS_DESCRIPTION = """
Calculates coreference evaluation metrics.
Args:
predictions: list of sentences. Each sentence is a list of word predictions to score in the CoNLL format.
Each prediction is a word with its annotations as a string made of columns joined with spaces.
Only columns 4, 5, 6 and the last column are used (word, POS, Pars and coreference annotation)
See the details on the format in the description of the metric.
references: list of sentences. Each sentence is a list of word reference to score in the CoNLL format.
Each reference is a word with its annotations as a string made of columns joined with spaces.
Only columns 4, 5, 6 and the last column are used (word, POS, Pars and coreference annotation)
See the details on the format in the description of the metric.
keep_singletons: After extracting all mentions of key or system files,
mentions whose corresponding coreference chain is of size one,
are considered as singletons. The default evaluation mode will include
singletons in evaluations if they are included in the key or the system files.
By setting 'keep_singletons=False', all singletons in the key and system files
will be excluded from the evaluation.
NP_only: Most of the recent coreference resolvers only resolve NP mentions and
leave out the resolution of VPs. By setting the 'NP_only' option, the scorer will only evaluate the resolution of NPs.
min_span: By setting 'min_span', the scorer reports the results based on automatically detected minimum spans.
Minimum spans are determined using the MINA algorithm.
Returns:
'mentions': mentions
'muc': MUC metric [Vilain et al, 1995]
'bcub': B-cubed [Bagga and Baldwin, 1998]
'ceafe': CEAFe [Luo et al., 2005]
'lea': LEA [Moosavi and Strube, 2016]
'conll_score': averaged CoNLL score (the average of the F1 values of MUC, B-cubed and CEAFe)
Examples:
>>> coval = datasets.load_metric('coval')
>>> words = ['bc/cctv/00/cctv_0005 0 0 Thank VBP (TOP(S(VP* thank 01 1 Xu_li * (V*) * -',
... 'bc/cctv/00/cctv_0005 0 1 you PRP (NP*) - - - Xu_li * (ARG1*) (ARG0*) (116)',
... 'bc/cctv/00/cctv_0005 0 2 everyone NN (NP*) - - - Xu_li * (ARGM-DIS*) * (116)',
... 'bc/cctv/00/cctv_0005 0 3 for IN (PP* - - - Xu_li * (ARG2* * -',
... 'bc/cctv/00/cctv_0005 0 4 watching VBG (S(VP*)))) watch 01 1 Xu_li * *) (V*) -',
... 'bc/cctv/00/cctv_0005 0 5 . . *)) - - - Xu_li * * * -']
>>> references = [words]
>>> predictions = [words]
>>> results = coval.compute(predictions=predictions, references=references)
>>> print(results) # doctest:+ELLIPSIS
{'mentions/recall': 1.0,[...] 'conll_score': 100.0}
"""
def get_coref_infos(
key_lines, sys_lines, NP_only=False, remove_nested=False, keep_singletons=True, min_span=False, doc="dummy_doc"
):
key_doc_lines = {doc: key_lines}
sys_doc_lines = {doc: sys_lines}
doc_coref_infos = {}
key_nested_coref_num = 0
sys_nested_coref_num = 0
key_removed_nested_clusters = 0
sys_removed_nested_clusters = 0
key_singletons_num = 0
sys_singletons_num = 0
key_clusters, singletons_num = reader.get_doc_mentions(doc, key_doc_lines[doc], keep_singletons)
key_singletons_num += singletons_num
if NP_only or min_span:
key_clusters = reader.set_annotated_parse_trees(key_clusters, key_doc_lines[doc], NP_only, min_span)
sys_clusters, singletons_num = reader.get_doc_mentions(doc, sys_doc_lines[doc], keep_singletons)
sys_singletons_num += singletons_num
if NP_only or min_span:
sys_clusters = reader.set_annotated_parse_trees(sys_clusters, key_doc_lines[doc], NP_only, min_span)
if remove_nested:
nested_mentions, removed_clusters = reader.remove_nested_coref_mentions(key_clusters, keep_singletons)
key_nested_coref_num += nested_mentions
key_removed_nested_clusters += removed_clusters
nested_mentions, removed_clusters = reader.remove_nested_coref_mentions(sys_clusters, keep_singletons)
sys_nested_coref_num += nested_mentions
sys_removed_nested_clusters += removed_clusters
sys_mention_key_cluster = reader.get_mention_assignments(sys_clusters, key_clusters)
key_mention_sys_cluster = reader.get_mention_assignments(key_clusters, sys_clusters)
doc_coref_infos[doc] = (key_clusters, sys_clusters, key_mention_sys_cluster, sys_mention_key_cluster)
if remove_nested:
logger.info(
"Number of removed nested coreferring mentions in the key "
f"annotation: {key_nested_coref_num}; and system annotation: {sys_nested_coref_num}"
)
logger.info(
"Number of resulting singleton clusters in the key "
f"annotation: {key_removed_nested_clusters}; and system annotation: {sys_removed_nested_clusters}"
)
if not keep_singletons:
logger.info(
f"{key_singletons_num:d} and {sys_singletons_num:d} singletons are removed from the key and system "
"files, respectively"
)
return doc_coref_infos
def evaluate(key_lines, sys_lines, metrics, NP_only, remove_nested, keep_singletons, min_span):
doc_coref_infos = get_coref_infos(key_lines, sys_lines, NP_only, remove_nested, keep_singletons, min_span)
output_scores = {}
conll = 0
conll_subparts_num = 0
for name, metric in metrics:
recall, precision, f1 = evaluator.evaluate_documents(doc_coref_infos, metric, beta=1)
if name in ["muc", "bcub", "ceafe"]:
conll += f1
conll_subparts_num += 1
output_scores.update({f"{name}/recall": recall, f"{name}/precision": precision, f"{name}/f1": f1})
logger.info(
name.ljust(10),
f"Recall: {recall * 100:.2f}",
f" Precision: {precision * 100:.2f}",
f" F1: {f1 * 100:.2f}",
)
if conll_subparts_num == 3:
conll = (conll / 3) * 100
logger.info(f"CoNLL score: {conll:.2f}")
output_scores.update({"conll_score": conll})
return output_scores
def check_gold_parse_annotation(key_lines):
has_gold_parse = False
for line in key_lines:
if not line.startswith("#"):
if len(line.split()) > 6:
parse_col = line.split()[5]
if not parse_col == "-":
has_gold_parse = True
break
else:
break
return has_gold_parse
@datasets.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class Coval(datasets.Metric):
def _info(self):
return datasets.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"predictions": datasets.Sequence(datasets.Value("string")),
"references": datasets.Sequence(datasets.Value("string")),
}
),
codebase_urls=["https://github.com/ns-moosavi/coval"],
reference_urls=[
"https://github.com/ns-moosavi/coval",
"https://www.aclweb.org/anthology/P16-1060",
"http://www.conll.cemantix.org/2012/data.html",
],
)
def _compute(
self, predictions, references, keep_singletons=True, NP_only=False, min_span=False, remove_nested=False
):
allmetrics = [
("mentions", evaluator.mentions),
("muc", evaluator.muc),
("bcub", evaluator.b_cubed),
("ceafe", evaluator.ceafe),
("lea", evaluator.lea),
]
if min_span:
has_gold_parse = util.check_gold_parse_annotation(references)
if not has_gold_parse:
raise NotImplementedError("References should have gold parse annotation to use 'min_span'.")
# util.parse_key_file(key_file)
# key_file = key_file + ".parsed"
score = evaluate(
key_lines=references,
sys_lines=predictions,
metrics=allmetrics,
NP_only=NP_only,
remove_nested=remove_nested,
keep_singletons=keep_singletons,
min_span=min_span,
)
return score
| datasets/metrics/coval/coval.py/0 | {
"file_path": "datasets/metrics/coval/coval.py",
"repo_id": "datasets",
"token_count": 5731
} | 69 |
# Metric Card for MAE
## Metric Description
Mean Absolute Error (MAE) is the mean of the magnitude of difference between the predicted and actual numeric values:
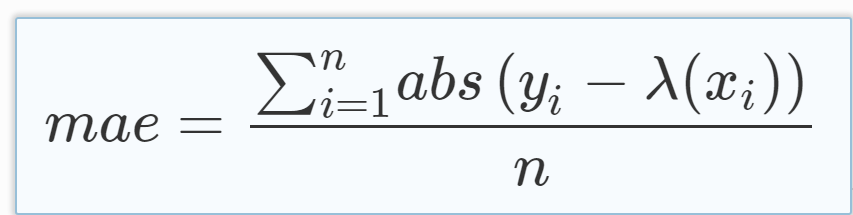
## How to Use
At minimum, this metric requires predictions and references as inputs.
```python
>>> mae_metric = datasets.load_metric("mae")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mae_metric.compute(predictions=predictions, references=references)
```
### Inputs
Mandatory inputs:
- `predictions`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the estimated target values.
- `references`: numeric array-like of shape (`n_samples,`) or (`n_samples`, `n_outputs`), representing the ground truth (correct) target values.
Optional arguments:
- `sample_weight`: numeric array-like of shape (`n_samples,`) representing sample weights. The default is `None`.
- `multioutput`: `raw_values`, `uniform_average` or numeric array-like of shape (`n_outputs,`), which defines the aggregation of multiple output values. The default value is `uniform_average`.
- `raw_values` returns a full set of errors in case of multioutput input.
- `uniform_average` means that the errors of all outputs are averaged with uniform weight.
- the array-like value defines weights used to average errors.
### Output Values
This metric outputs a dictionary, containing the mean absolute error score, which is of type:
- `float`: if multioutput is `uniform_average` or an ndarray of weights, then the weighted average of all output errors is returned.
- numeric array-like of shape (`n_outputs,`): if multioutput is `raw_values`, then the score is returned for each output separately.
Each MAE `float` value ranges from `0.0` to `1.0`, with the best value being 0.0.
Output Example(s):
```python
{'mae': 0.5}
```
If `multioutput="raw_values"`:
```python
{'mae': array([0.5, 1. ])}
```
#### Values from Popular Papers
### Examples
Example with the `uniform_average` config:
```python
>>> from datasets import load_metric
>>> mae_metric = load_metric("mae")
>>> predictions = [2.5, 0.0, 2, 8]
>>> references = [3, -0.5, 2, 7]
>>> results = mae_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mae': 0.5}
```
Example with multi-dimensional lists, and the `raw_values` config:
```python
>>> from datasets import load_metric
>>> mae_metric = datasets.load_metric("mae", "multilist")
>>> predictions = [[0.5, 1], [-1, 1], [7, -6]]
>>> references = [[0, 2], [-1, 2], [8, -5]]
>>> results = mae_metric.compute(predictions=predictions, references=references)
>>> print(results)
{'mae': 0.75}
>>> results = mae_metric.compute(predictions=predictions, references=references, multioutput='raw_values')
>>> print(results)
{'mae': array([0.5, 1. ])}
```
## Limitations and Bias
One limitation of MAE is that the relative size of the error is not always obvious, meaning that it can be difficult to tell a big error from a smaller one -- metrics such as Mean Absolute Percentage Error (MAPE) have been proposed to calculate MAE in percentage terms.
Also, since it calculates the mean, MAE may underestimate the impact of big, but infrequent, errors -- metrics such as the Root Mean Square Error (RMSE) compensate for this by taking the root of error values.
## Citation(s)
```bibtex
@article{scikit-learn,
title={Scikit-learn: Machine Learning in {P}ython},
author={Pedregosa, F. and Varoquaux, G. and Gramfort, A. and Michel, V.
and Thirion, B. and Grisel, O. and Blondel, M. and Prettenhofer, P.
and Weiss, R. and Dubourg, V. and Vanderplas, J. and Passos, A. and
Cournapeau, D. and Brucher, M. and Perrot, M. and Duchesnay, E.},
journal={Journal of Machine Learning Research},
volume={12},
pages={2825--2830},
year={2011}
}
```
```bibtex
@article{willmott2005advantages,
title={Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance},
author={Willmott, Cort J and Matsuura, Kenji},
journal={Climate research},
volume={30},
number={1},
pages={79--82},
year={2005}
}
```
## Further References
- [Mean Absolute Error - Wikipedia](https://en.wikipedia.org/wiki/Mean_absolute_error)
| datasets/metrics/mae/README.md/0 | {
"file_path": "datasets/metrics/mae/README.md",
"repo_id": "datasets",
"token_count": 1421
} | 70 |
# Metric Card for Perplexity
## Metric Description
Given a model and an input text sequence, perplexity measures how likely the model is to generate the input text sequence. This can be used in two main ways:
1. to evaluate how well the model has learned the distribution of the text it was trained on
- In this case, the model input should be the trained model to be evaluated, and the input texts should be the text that the model was trained on.
2. to evaluate how well a selection of text matches the distribution of text that the input model was trained on
- In this case, the model input should be a trained model, and the input texts should be the text to be evaluated.
## Intended Uses
Any language generation task.
## How to Use
The metric takes a list of text as input, as well as the name of the model used to compute the metric:
```python
from datasets import load_metric
perplexity = load_metric("perplexity")
results = perplexity.compute(input_texts=input_texts, model_id='gpt2')
```
### Inputs
- **model_id** (str): model used for calculating Perplexity. NOTE: Perplexity can only be calculated for causal language models.
- This includes models such as gpt2, causal variations of bert, causal versions of t5, and more (the full list can be found in the AutoModelForCausalLM documentation here: https://huggingface.co/docs/transformers/master/en/model_doc/auto#transformers.AutoModelForCausalLM )
- **input_texts** (list of str): input text, each separate text snippet is one list entry.
- **batch_size** (int): the batch size to run texts through the model. Defaults to 16.
- **add_start_token** (bool): whether to add the start token to the texts, so the perplexity can include the probability of the first word. Defaults to True.
- **device** (str): device to run on, defaults to 'cuda' when available
### Output Values
This metric outputs a dictionary with the perplexity scores for the text input in the list, and the average perplexity.
If one of the input texts is longer than the max input length of the model, then it is truncated to the max length for the perplexity computation.
```
{'perplexities': [8.182524681091309, 33.42122268676758, 27.012239456176758], 'mean_perplexity': 22.871995608011883}
```
This metric's range is 0 and up. A lower score is better.
#### Values from Popular Papers
### Examples
Calculating perplexity on input_texts defined here:
```python
perplexity = datasets.load_metric("perplexity")
input_texts = ["lorem ipsum", "Happy Birthday!", "Bienvenue"]
results = perplexity.compute(model_id='gpt2',
add_start_token=False,
input_texts=input_texts)
print(list(results.keys()))
>>>['perplexities', 'mean_perplexity']
print(round(results["mean_perplexity"], 2))
>>>78.22
print(round(results["perplexities"][0], 2))
>>>11.11
```
Calculating perplexity on input_texts loaded in from a dataset:
```python
perplexity = datasets.load_metric("perplexity")
input_texts = datasets.load_dataset("wikitext",
"wikitext-2-raw-v1",
split="test")["text"][:50]
input_texts = [s for s in input_texts if s!='']
results = perplexity.compute(model_id='gpt2',
input_texts=input_texts)
print(list(results.keys()))
>>>['perplexities', 'mean_perplexity']
print(round(results["mean_perplexity"], 2))
>>>60.35
print(round(results["perplexities"][0], 2))
>>>81.12
```
## Limitations and Bias
Note that the output value is based heavily on what text the model was trained on. This means that perplexity scores are not comparable between models or datasets.
## Citation
```bibtex
@article{jelinek1977perplexity,
title={Perplexity—a measure of the difficulty of speech recognition tasks},
author={Jelinek, Fred and Mercer, Robert L and Bahl, Lalit R and Baker, James K},
journal={The Journal of the Acoustical Society of America},
volume={62},
number={S1},
pages={S63--S63},
year={1977},
publisher={Acoustical Society of America}
}
```
## Further References
- [Hugging Face Perplexity Blog Post](https://huggingface.co/docs/transformers/perplexity)
| datasets/metrics/perplexity/README.md/0 | {
"file_path": "datasets/metrics/perplexity/README.md",
"repo_id": "datasets",
"token_count": 1345
} | 71 |
# Metric Card for Spearman Correlation Coefficient Metric (spearmanr)
## Metric Description
The Spearman rank-order correlation coefficient is a measure of the
relationship between two datasets. Like other correlation coefficients,
this one varies between -1 and +1 with 0 implying no correlation.
Positive correlations imply that as data in dataset x increases, so
does data in dataset y. Negative correlations imply that as x increases,
y decreases. Correlations of -1 or +1 imply an exact monotonic relationship.
Unlike the Pearson correlation, the Spearman correlation does not
assume that both datasets are normally distributed.
The p-value roughly indicates the probability of an uncorrelated system
producing datasets that have a Spearman correlation at least as extreme
as the one computed from these datasets. The p-values are not entirely
reliable but are probably reasonable for datasets larger than 500 or so.
## How to Use
At minimum, this metric only requires a `list` of predictions and a `list` of references:
```python
>>> spearmanr_metric = datasets.load_metric("spearmanr")
>>> results = spearmanr_metric.compute(references=[1, 2, 3, 4, 5], predictions=[10, 9, 2.5, 6, 4])
>>> print(results)
{'spearmanr': -0.7}
```
### Inputs
- **`predictions`** (`list` of `float`): Predicted labels, as returned by a model.
- **`references`** (`list` of `float`): Ground truth labels.
- **`return_pvalue`** (`bool`): If `True`, returns the p-value. If `False`, returns
only the spearmanr score. Defaults to `False`.
### Output Values
- **`spearmanr`** (`float`): Spearman correlation coefficient.
- **`p-value`** (`float`): p-value. **Note**: is only returned
if `return_pvalue=True` is input.
If `return_pvalue=False`, the output is a `dict` with one value, as below:
```python
{'spearmanr': -0.7}
```
Otherwise, if `return_pvalue=True`, the output is a `dict` containing a the `spearmanr` value as well as the corresponding `pvalue`:
```python
{'spearmanr': -0.7, 'spearmanr_pvalue': 0.1881204043741873}
```
Spearman rank-order correlations can take on any value from `-1` to `1`, inclusive.
The p-values can take on any value from `0` to `1`, inclusive.
#### Values from Popular Papers
### Examples
A basic example:
```python
>>> spearmanr_metric = datasets.load_metric("spearmanr")
>>> results = spearmanr_metric.compute(references=[1, 2, 3, 4, 5], predictions=[10, 9, 2.5, 6, 4])
>>> print(results)
{'spearmanr': -0.7}
```
The same example, but that also returns the pvalue:
```python
>>> spearmanr_metric = datasets.load_metric("spearmanr")
>>> results = spearmanr_metric.compute(references=[1, 2, 3, 4, 5], predictions=[10, 9, 2.5, 6, 4], return_pvalue=True)
>>> print(results)
{'spearmanr': -0.7, 'spearmanr_pvalue': 0.1881204043741873
>>> print(results['spearmanr'])
-0.7
>>> print(results['spearmanr_pvalue'])
0.1881204043741873
```
## Limitations and Bias
## Citation
```bibtex
@book{kokoska2000crc,
title={CRC standard probability and statistics tables and formulae},
author={Kokoska, Stephen and Zwillinger, Daniel},
year={2000},
publisher={Crc Press}
}
@article{2020SciPy-NMeth,
author = {Virtanen, Pauli and Gommers, Ralf and Oliphant, Travis E. and
Haberland, Matt and Reddy, Tyler and Cournapeau, David and
Burovski, Evgeni and Peterson, Pearu and Weckesser, Warren and
Bright, Jonathan and {van der Walt}, St{\'e}fan J. and
Brett, Matthew and Wilson, Joshua and Millman, K. Jarrod and
Mayorov, Nikolay and Nelson, Andrew R. J. and Jones, Eric and
Kern, Robert and Larson, Eric and Carey, C J and
Polat, {\.I}lhan and Feng, Yu and Moore, Eric W. and
{VanderPlas}, Jake and Laxalde, Denis and Perktold, Josef and
Cimrman, Robert and Henriksen, Ian and Quintero, E. A. and
Harris, Charles R. and Archibald, Anne M. and
Ribeiro, Ant{\^o}nio H. and Pedregosa, Fabian and
{van Mulbregt}, Paul and {SciPy 1.0 Contributors}},
title = {{{SciPy} 1.0: Fundamental Algorithms for Scientific
Computing in Python}},
journal = {Nature Methods},
year = {2020},
volume = {17},
pages = {261--272},
adsurl = {https://rdcu.be/b08Wh},
doi = {10.1038/s41592-019-0686-2},
}
```
## Further References
*Add any useful further references.*
| datasets/metrics/spearmanr/README.md/0 | {
"file_path": "datasets/metrics/spearmanr/README.md",
"repo_id": "datasets",
"token_count": 1585
} | 72 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""WIKI_SPLIT metric."""
import re
import string
from collections import Counter
import sacrebleu
import sacremoses
from packaging import version
import datasets
_CITATION = """
@inproceedings{xu-etal-2016-optimizing,
title = {Optimizing Statistical Machine Translation for Text Simplification},
authors={Xu, Wei and Napoles, Courtney and Pavlick, Ellie and Chen, Quanze and Callison-Burch, Chris},
journal = {Transactions of the Association for Computational Linguistics},
volume = {4},
year={2016},
url = {https://www.aclweb.org/anthology/Q16-1029},
pages = {401--415
},
@inproceedings{post-2018-call,
title = "A Call for Clarity in Reporting {BLEU} Scores",
author = "Post, Matt",
booktitle = "Proceedings of the Third Conference on Machine Translation: Research Papers",
month = oct,
year = "2018",
address = "Belgium, Brussels",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/W18-6319",
pages = "186--191",
}
"""
_DESCRIPTION = """\
WIKI_SPLIT is the combination of three metrics SARI, EXACT and SACREBLEU
It can be used to evaluate the quality of machine-generated texts.
"""
_KWARGS_DESCRIPTION = """
Calculates sari score (between 0 and 100) given a list of source and predicted
sentences, and a list of lists of reference sentences. It also computes the BLEU score as well as the exact match score.
Args:
sources: list of source sentences where each sentence should be a string.
predictions: list of predicted sentences where each sentence should be a string.
references: list of lists of reference sentences where each sentence should be a string.
Returns:
sari: sari score
sacrebleu: sacrebleu score
exact: exact score
Examples:
>>> sources=["About 95 species are currently accepted ."]
>>> predictions=["About 95 you now get in ."]
>>> references=[["About 95 species are currently known ."]]
>>> wiki_split = datasets.load_metric("wiki_split")
>>> results = wiki_split.compute(sources=sources, predictions=predictions, references=references)
>>> print(results)
{'sari': 21.805555555555557, 'sacrebleu': 14.535768424205482, 'exact': 0.0}
"""
def normalize_answer(s):
"""Lower text and remove punctuation, articles and extra whitespace."""
def remove_articles(text):
regex = re.compile(r"\b(a|an|the)\b", re.UNICODE)
return re.sub(regex, " ", text)
def white_space_fix(text):
return " ".join(text.split())
def remove_punc(text):
exclude = set(string.punctuation)
return "".join(ch for ch in text if ch not in exclude)
def lower(text):
return text.lower()
return white_space_fix(remove_articles(remove_punc(lower(s))))
def compute_exact(a_gold, a_pred):
return int(normalize_answer(a_gold) == normalize_answer(a_pred))
def compute_em(predictions, references):
scores = [any(compute_exact(ref, pred) for ref in refs) for pred, refs in zip(predictions, references)]
return (sum(scores) / len(scores)) * 100
def SARIngram(sgrams, cgrams, rgramslist, numref):
rgramsall = [rgram for rgrams in rgramslist for rgram in rgrams]
rgramcounter = Counter(rgramsall)
sgramcounter = Counter(sgrams)
sgramcounter_rep = Counter()
for sgram, scount in sgramcounter.items():
sgramcounter_rep[sgram] = scount * numref
cgramcounter = Counter(cgrams)
cgramcounter_rep = Counter()
for cgram, ccount in cgramcounter.items():
cgramcounter_rep[cgram] = ccount * numref
# KEEP
keepgramcounter_rep = sgramcounter_rep & cgramcounter_rep
keepgramcountergood_rep = keepgramcounter_rep & rgramcounter
keepgramcounterall_rep = sgramcounter_rep & rgramcounter
keeptmpscore1 = 0
keeptmpscore2 = 0
for keepgram in keepgramcountergood_rep:
keeptmpscore1 += keepgramcountergood_rep[keepgram] / keepgramcounter_rep[keepgram]
# Fix an alleged bug [2] in the keep score computation.
# keeptmpscore2 += keepgramcountergood_rep[keepgram] / keepgramcounterall_rep[keepgram]
keeptmpscore2 += keepgramcountergood_rep[keepgram]
# Define 0/0=1 instead of 0 to give higher scores for predictions that match
# a target exactly.
keepscore_precision = 1
keepscore_recall = 1
if len(keepgramcounter_rep) > 0:
keepscore_precision = keeptmpscore1 / len(keepgramcounter_rep)
if len(keepgramcounterall_rep) > 0:
# Fix an alleged bug [2] in the keep score computation.
# keepscore_recall = keeptmpscore2 / len(keepgramcounterall_rep)
keepscore_recall = keeptmpscore2 / sum(keepgramcounterall_rep.values())
keepscore = 0
if keepscore_precision > 0 or keepscore_recall > 0:
keepscore = 2 * keepscore_precision * keepscore_recall / (keepscore_precision + keepscore_recall)
# DELETION
delgramcounter_rep = sgramcounter_rep - cgramcounter_rep
delgramcountergood_rep = delgramcounter_rep - rgramcounter
delgramcounterall_rep = sgramcounter_rep - rgramcounter
deltmpscore1 = 0
deltmpscore2 = 0
for delgram in delgramcountergood_rep:
deltmpscore1 += delgramcountergood_rep[delgram] / delgramcounter_rep[delgram]
deltmpscore2 += delgramcountergood_rep[delgram] / delgramcounterall_rep[delgram]
# Define 0/0=1 instead of 0 to give higher scores for predictions that match
# a target exactly.
delscore_precision = 1
if len(delgramcounter_rep) > 0:
delscore_precision = deltmpscore1 / len(delgramcounter_rep)
# ADDITION
addgramcounter = set(cgramcounter) - set(sgramcounter)
addgramcountergood = set(addgramcounter) & set(rgramcounter)
addgramcounterall = set(rgramcounter) - set(sgramcounter)
addtmpscore = 0
for addgram in addgramcountergood:
addtmpscore += 1
# Define 0/0=1 instead of 0 to give higher scores for predictions that match
# a target exactly.
addscore_precision = 1
addscore_recall = 1
if len(addgramcounter) > 0:
addscore_precision = addtmpscore / len(addgramcounter)
if len(addgramcounterall) > 0:
addscore_recall = addtmpscore / len(addgramcounterall)
addscore = 0
if addscore_precision > 0 or addscore_recall > 0:
addscore = 2 * addscore_precision * addscore_recall / (addscore_precision + addscore_recall)
return (keepscore, delscore_precision, addscore)
def SARIsent(ssent, csent, rsents):
numref = len(rsents)
s1grams = ssent.split(" ")
c1grams = csent.split(" ")
s2grams = []
c2grams = []
s3grams = []
c3grams = []
s4grams = []
c4grams = []
r1gramslist = []
r2gramslist = []
r3gramslist = []
r4gramslist = []
for rsent in rsents:
r1grams = rsent.split(" ")
r2grams = []
r3grams = []
r4grams = []
r1gramslist.append(r1grams)
for i in range(0, len(r1grams) - 1):
if i < len(r1grams) - 1:
r2gram = r1grams[i] + " " + r1grams[i + 1]
r2grams.append(r2gram)
if i < len(r1grams) - 2:
r3gram = r1grams[i] + " " + r1grams[i + 1] + " " + r1grams[i + 2]
r3grams.append(r3gram)
if i < len(r1grams) - 3:
r4gram = r1grams[i] + " " + r1grams[i + 1] + " " + r1grams[i + 2] + " " + r1grams[i + 3]
r4grams.append(r4gram)
r2gramslist.append(r2grams)
r3gramslist.append(r3grams)
r4gramslist.append(r4grams)
for i in range(0, len(s1grams) - 1):
if i < len(s1grams) - 1:
s2gram = s1grams[i] + " " + s1grams[i + 1]
s2grams.append(s2gram)
if i < len(s1grams) - 2:
s3gram = s1grams[i] + " " + s1grams[i + 1] + " " + s1grams[i + 2]
s3grams.append(s3gram)
if i < len(s1grams) - 3:
s4gram = s1grams[i] + " " + s1grams[i + 1] + " " + s1grams[i + 2] + " " + s1grams[i + 3]
s4grams.append(s4gram)
for i in range(0, len(c1grams) - 1):
if i < len(c1grams) - 1:
c2gram = c1grams[i] + " " + c1grams[i + 1]
c2grams.append(c2gram)
if i < len(c1grams) - 2:
c3gram = c1grams[i] + " " + c1grams[i + 1] + " " + c1grams[i + 2]
c3grams.append(c3gram)
if i < len(c1grams) - 3:
c4gram = c1grams[i] + " " + c1grams[i + 1] + " " + c1grams[i + 2] + " " + c1grams[i + 3]
c4grams.append(c4gram)
(keep1score, del1score, add1score) = SARIngram(s1grams, c1grams, r1gramslist, numref)
(keep2score, del2score, add2score) = SARIngram(s2grams, c2grams, r2gramslist, numref)
(keep3score, del3score, add3score) = SARIngram(s3grams, c3grams, r3gramslist, numref)
(keep4score, del4score, add4score) = SARIngram(s4grams, c4grams, r4gramslist, numref)
avgkeepscore = sum([keep1score, keep2score, keep3score, keep4score]) / 4
avgdelscore = sum([del1score, del2score, del3score, del4score]) / 4
avgaddscore = sum([add1score, add2score, add3score, add4score]) / 4
finalscore = (avgkeepscore + avgdelscore + avgaddscore) / 3
return finalscore
def normalize(sentence, lowercase: bool = True, tokenizer: str = "13a", return_str: bool = True):
# Normalization is requried for the ASSET dataset (one of the primary
# datasets in sentence simplification) to allow using space
# to split the sentence. Even though Wiki-Auto and TURK datasets,
# do not require normalization, we do it for consistency.
# Code adapted from the EASSE library [1] written by the authors of the ASSET dataset.
# [1] https://github.com/feralvam/easse/blob/580bba7e1378fc8289c663f864e0487188fe8067/easse/utils/preprocessing.py#L7
if lowercase:
sentence = sentence.lower()
if tokenizer in ["13a", "intl"]:
if version.parse(sacrebleu.__version__).major >= 2:
normalized_sent = sacrebleu.metrics.bleu._get_tokenizer(tokenizer)()(sentence)
else:
normalized_sent = sacrebleu.TOKENIZERS[tokenizer]()(sentence)
elif tokenizer == "moses":
normalized_sent = sacremoses.MosesTokenizer().tokenize(sentence, return_str=True, escape=False)
elif tokenizer == "penn":
normalized_sent = sacremoses.MosesTokenizer().penn_tokenize(sentence, return_str=True)
else:
normalized_sent = sentence
if not return_str:
normalized_sent = normalized_sent.split()
return normalized_sent
def compute_sari(sources, predictions, references):
if not (len(sources) == len(predictions) == len(references)):
raise ValueError("Sources length must match predictions and references lengths.")
sari_score = 0
for src, pred, refs in zip(sources, predictions, references):
sari_score += SARIsent(normalize(src), normalize(pred), [normalize(sent) for sent in refs])
sari_score = sari_score / len(predictions)
return 100 * sari_score
def compute_sacrebleu(
predictions,
references,
smooth_method="exp",
smooth_value=None,
force=False,
lowercase=False,
use_effective_order=False,
):
references_per_prediction = len(references[0])
if any(len(refs) != references_per_prediction for refs in references):
raise ValueError("Sacrebleu requires the same number of references for each prediction")
transformed_references = [[refs[i] for refs in references] for i in range(references_per_prediction)]
output = sacrebleu.corpus_bleu(
predictions,
transformed_references,
smooth_method=smooth_method,
smooth_value=smooth_value,
force=force,
lowercase=lowercase,
use_effective_order=use_effective_order,
)
return output.score
@datasets.utils.file_utils.add_start_docstrings(_DESCRIPTION, _KWARGS_DESCRIPTION)
class WikiSplit(datasets.Metric):
def _info(self):
return datasets.MetricInfo(
description=_DESCRIPTION,
citation=_CITATION,
inputs_description=_KWARGS_DESCRIPTION,
features=datasets.Features(
{
"predictions": datasets.Value("string", id="sequence"),
"references": datasets.Sequence(datasets.Value("string", id="sequence"), id="references"),
}
),
codebase_urls=[
"https://github.com/huggingface/transformers/blob/master/src/transformers/data/metrics/squad_metrics.py",
"https://github.com/cocoxu/simplification/blob/master/SARI.py",
"https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/sari_hook.py",
"https://github.com/mjpost/sacreBLEU",
],
reference_urls=[
"https://www.aclweb.org/anthology/Q16-1029.pdf",
"https://github.com/mjpost/sacreBLEU",
"https://en.wikipedia.org/wiki/BLEU",
"https://towardsdatascience.com/evaluating-text-output-in-nlp-bleu-at-your-own-risk-e8609665a213",
],
)
def _compute(self, sources, predictions, references):
result = {}
result.update({"sari": compute_sari(sources=sources, predictions=predictions, references=references)})
result.update({"sacrebleu": compute_sacrebleu(predictions=predictions, references=references)})
result.update({"exact": compute_em(predictions=predictions, references=references)})
return result
| datasets/metrics/wiki_split/wiki_split.py/0 | {
"file_path": "datasets/metrics/wiki_split/wiki_split.py",
"repo_id": "datasets",
"token_count": 5827
} | 73 |
import os
import re
import shutil
from argparse import ArgumentParser, Namespace
from datasets.commands import BaseDatasetsCLICommand
from datasets.utils.logging import get_logger
HIGHLIGHT_MESSAGE_PRE = """<<<<<<< This should probably be modified because it mentions: """
HIGHLIGHT_MESSAGE_POST = """=======
>>>>>>>
"""
TO_HIGHLIGHT = [
"TextEncoderConfig",
"ByteTextEncoder",
"SubwordTextEncoder",
"encoder_config",
"maybe_build_from_corpus",
"manual_dir",
]
TO_CONVERT = [
# (pattern, replacement)
# Order is important here for some replacements
(r"tfds\.core", r"datasets"),
(r"tf\.io\.gfile\.GFile", r"open"),
(r"tf\.([\w\d]+)", r"datasets.Value('\1')"),
(r"tfds\.features\.Text\(\)", r"datasets.Value('string')"),
(r"tfds\.features\.Text\(", r"datasets.Value('string'),"),
(r"features\s*=\s*tfds.features.FeaturesDict\(", r"features=datasets.Features("),
(r"tfds\.features\.FeaturesDict\(", r"dict("),
(r"The TensorFlow Datasets Authors", r"The TensorFlow Datasets Authors and the HuggingFace Datasets Authors"),
(r"tfds\.", r"datasets."),
(r"dl_manager\.manual_dir", r"self.config.data_dir"),
(r"self\.builder_config", r"self.config"),
]
def convert_command_factory(args: Namespace):
"""
Factory function used to convert a model TF 1.0 checkpoint in a PyTorch checkpoint.
Returns: ConvertCommand
"""
return ConvertCommand(args.tfds_path, args.datasets_directory)
class ConvertCommand(BaseDatasetsCLICommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
"""
Register this command to argparse so it's available for the datasets-cli
Args:
parser: Root parser to register command-specific arguments
"""
train_parser = parser.add_parser(
"convert",
help="Convert a TensorFlow Datasets dataset to a HuggingFace Datasets dataset.",
)
train_parser.add_argument(
"--tfds_path",
type=str,
required=True,
help="Path to a TensorFlow Datasets folder to convert or a single tfds file to convert.",
)
train_parser.add_argument(
"--datasets_directory", type=str, required=True, help="Path to the HuggingFace Datasets folder."
)
train_parser.set_defaults(func=convert_command_factory)
def __init__(self, tfds_path: str, datasets_directory: str, *args):
self._logger = get_logger("datasets-cli/converting")
self._tfds_path = tfds_path
self._datasets_directory = datasets_directory
def run(self):
if os.path.isdir(self._tfds_path):
abs_tfds_path = os.path.abspath(self._tfds_path)
elif os.path.isfile(self._tfds_path):
abs_tfds_path = os.path.dirname(self._tfds_path)
else:
raise ValueError("--tfds_path is neither a directory nor a file. Please check path.")
abs_datasets_path = os.path.abspath(self._datasets_directory)
self._logger.info(f"Converting datasets from {abs_tfds_path} to {abs_datasets_path}")
utils_files = []
with_manual_update = []
imports_to_builder_map = {}
if os.path.isdir(self._tfds_path):
file_names = os.listdir(abs_tfds_path)
else:
file_names = [os.path.basename(self._tfds_path)]
for f_name in file_names:
self._logger.info(f"Looking at file {f_name}")
input_file = os.path.join(abs_tfds_path, f_name)
output_file = os.path.join(abs_datasets_path, f_name)
if not os.path.isfile(input_file) or "__init__" in f_name or "_test" in f_name or ".py" not in f_name:
self._logger.info("Skipping file")
continue
with open(input_file, encoding="utf-8") as f:
lines = f.readlines()
out_lines = []
is_builder = False
needs_manual_update = False
tfds_imports = []
for line in lines:
out_line = line
# Convert imports
if "import tensorflow.compat.v2 as tf" in out_line:
continue
elif "@tfds.core" in out_line:
continue
elif "builder=self" in out_line:
continue
elif "import tensorflow_datasets.public_api as tfds" in out_line:
out_line = "import datasets\n"
elif "import tensorflow" in out_line:
# order is important here
out_line = ""
continue
elif "from absl import logging" in out_line:
out_line = "from datasets import logging\n"
elif "getLogger" in out_line:
out_line = out_line.replace("getLogger", "get_logger")
elif any(expression in out_line for expression in TO_HIGHLIGHT):
needs_manual_update = True
to_remove = list(filter(lambda e: e in out_line, TO_HIGHLIGHT))
out_lines.append(HIGHLIGHT_MESSAGE_PRE + str(to_remove) + "\n")
out_lines.append(out_line)
out_lines.append(HIGHLIGHT_MESSAGE_POST)
continue
else:
for pattern, replacement in TO_CONVERT:
out_line = re.sub(pattern, replacement, out_line)
# Take care of saving utilities (to later move them together with main script)
if "tensorflow_datasets" in out_line:
match = re.match(r"from\stensorflow_datasets.*import\s([^\.\r\n]+)", out_line)
tfds_imports.extend(imp.strip() for imp in match.group(1).split(","))
out_line = "from . import " + match.group(1)
# Check we have not forget anything
if "tf." in out_line or "tfds." in out_line or "tensorflow_datasets" in out_line:
raise ValueError(f"Error converting {out_line.strip()}")
if "GeneratorBasedBuilder" in out_line or "BeamBasedBuilder" in out_line:
is_builder = True
out_lines.append(out_line)
if is_builder or "wmt" in f_name:
# We create a new directory for each dataset
dir_name = f_name.replace(".py", "")
output_dir = os.path.join(abs_datasets_path, dir_name)
output_file = os.path.join(output_dir, f_name)
os.makedirs(output_dir, exist_ok=True)
self._logger.info(f"Adding directory {output_dir}")
imports_to_builder_map.update({imp: output_dir for imp in tfds_imports})
else:
# Utilities will be moved at the end
utils_files.append(output_file)
if needs_manual_update:
with_manual_update.append(output_file)
with open(output_file, "w", encoding="utf-8") as f:
f.writelines(out_lines)
self._logger.info(f"Converted in {output_file}")
for utils_file in utils_files:
try:
f_name = os.path.basename(utils_file)
dest_folder = imports_to_builder_map[f_name.replace(".py", "")]
self._logger.info(f"Moving {dest_folder} to {utils_file}")
shutil.copy(utils_file, dest_folder)
except KeyError:
self._logger.error(f"Cannot find destination folder for {utils_file}. Please copy manually.")
if with_manual_update:
for file_path in with_manual_update:
self._logger.warning(
f"You need to manually update file {file_path} to remove configurations using 'TextEncoderConfig'."
)
| datasets/src/datasets/commands/convert.py/0 | {
"file_path": "datasets/src/datasets/commands/convert.py",
"repo_id": "datasets",
"token_count": 3822
} | 74 |
# ruff: noqa
__all__ = [
"Audio",
"Array2D",
"Array3D",
"Array4D",
"Array5D",
"ClassLabel",
"Features",
"Sequence",
"Value",
"Image",
"Translation",
"TranslationVariableLanguages",
]
from .audio import Audio
from .features import Array2D, Array3D, Array4D, Array5D, ClassLabel, Features, Sequence, Value
from .image import Image
from .translation import Translation, TranslationVariableLanguages
| datasets/src/datasets/features/__init__.py/0 | {
"file_path": "datasets/src/datasets/features/__init__.py",
"repo_id": "datasets",
"token_count": 165
} | 75 |
# Copyright 2020 The HuggingFace Datasets Authors and the TensorFlow Datasets Authors.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# Lint as: python3
"""DatasetInfo and MetricInfo record information we know about a dataset and a metric.
This includes things that we know about the dataset statically, i.e.:
- description
- canonical location
- does it have validation and tests splits
- size
- etc.
This also includes the things that can and should be computed once we've
processed the dataset as well:
- number of examples (in each split)
- etc.
"""
import copy
import dataclasses
import json
import os
import posixpath
import warnings
from dataclasses import dataclass
from pathlib import Path
from typing import ClassVar, Dict, List, Optional, Union
import fsspec
from fsspec.core import url_to_fs
from huggingface_hub import DatasetCard, DatasetCardData
from . import config
from .features import Features, Value
from .splits import SplitDict
from .tasks import TaskTemplate, task_template_from_dict
from .utils import Version
from .utils.logging import get_logger
from .utils.py_utils import asdict, unique_values
logger = get_logger(__name__)
@dataclass
class SupervisedKeysData:
input: str = ""
output: str = ""
@dataclass
class DownloadChecksumsEntryData:
key: str = ""
value: str = ""
class MissingCachedSizesConfigError(Exception):
"""The expected cached sizes of the download file are missing."""
class NonMatchingCachedSizesError(Exception):
"""The prepared split doesn't have expected sizes."""
@dataclass
class PostProcessedInfo:
features: Optional[Features] = None
resources_checksums: Optional[dict] = None
def __post_init__(self):
# Convert back to the correct classes when we reload from dict
if self.features is not None and not isinstance(self.features, Features):
self.features = Features.from_dict(self.features)
@classmethod
def from_dict(cls, post_processed_info_dict: dict) -> "PostProcessedInfo":
field_names = {f.name for f in dataclasses.fields(cls)}
return cls(**{k: v for k, v in post_processed_info_dict.items() if k in field_names})
@dataclass
class DatasetInfo:
"""Information about a dataset.
`DatasetInfo` documents datasets, including its name, version, and features.
See the constructor arguments and properties for a full list.
Not all fields are known on construction and may be updated later.
Attributes:
description (`str`):
A description of the dataset.
citation (`str`):
A BibTeX citation of the dataset.
homepage (`str`):
A URL to the official homepage for the dataset.
license (`str`):
The dataset's license. It can be the name of the license or a paragraph containing the terms of the license.
features ([`Features`], *optional*):
The features used to specify the dataset's column types.
post_processed (`PostProcessedInfo`, *optional*):
Information regarding the resources of a possible post-processing of a dataset. For example, it can contain the information of an index.
supervised_keys (`SupervisedKeysData`, *optional*):
Specifies the input feature and the label for supervised learning if applicable for the dataset (legacy from TFDS).
builder_name (`str`, *optional*):
The name of the `GeneratorBasedBuilder` subclass used to create the dataset. Usually matched to the corresponding script name. It is also the snake_case version of the dataset builder class name.
config_name (`str`, *optional*):
The name of the configuration derived from [`BuilderConfig`].
version (`str` or [`Version`], *optional*):
The version of the dataset.
splits (`dict`, *optional*):
The mapping between split name and metadata.
download_checksums (`dict`, *optional*):
The mapping between the URL to download the dataset's checksums and corresponding metadata.
download_size (`int`, *optional*):
The size of the files to download to generate the dataset, in bytes.
post_processing_size (`int`, *optional*):
Size of the dataset in bytes after post-processing, if any.
dataset_size (`int`, *optional*):
The combined size in bytes of the Arrow tables for all splits.
size_in_bytes (`int`, *optional*):
The combined size in bytes of all files associated with the dataset (downloaded files + Arrow files).
task_templates (`List[TaskTemplate]`, *optional*):
The task templates to prepare the dataset for during training and evaluation. Each template casts the dataset's [`Features`] to standardized column names and types as detailed in `datasets.tasks`.
**config_kwargs (additional keyword arguments):
Keyword arguments to be passed to the [`BuilderConfig`] and used in the [`DatasetBuilder`].
"""
# Set in the dataset scripts
description: str = dataclasses.field(default_factory=str)
citation: str = dataclasses.field(default_factory=str)
homepage: str = dataclasses.field(default_factory=str)
license: str = dataclasses.field(default_factory=str)
features: Optional[Features] = None
post_processed: Optional[PostProcessedInfo] = None
supervised_keys: Optional[SupervisedKeysData] = None
task_templates: Optional[List[TaskTemplate]] = None
# Set later by the builder
builder_name: Optional[str] = None
dataset_name: Optional[str] = None # for packaged builders, to be different from builder_name
config_name: Optional[str] = None
version: Optional[Union[str, Version]] = None
# Set later by `download_and_prepare`
splits: Optional[dict] = None
download_checksums: Optional[dict] = None
download_size: Optional[int] = None
post_processing_size: Optional[int] = None
dataset_size: Optional[int] = None
size_in_bytes: Optional[int] = None
_INCLUDED_INFO_IN_YAML: ClassVar[List[str]] = [
"config_name",
"download_size",
"dataset_size",
"features",
"splits",
]
def __post_init__(self):
# Convert back to the correct classes when we reload from dict
if self.features is not None and not isinstance(self.features, Features):
self.features = Features.from_dict(self.features)
if self.post_processed is not None and not isinstance(self.post_processed, PostProcessedInfo):
self.post_processed = PostProcessedInfo.from_dict(self.post_processed)
if self.version is not None and not isinstance(self.version, Version):
if isinstance(self.version, str):
self.version = Version(self.version)
else:
self.version = Version.from_dict(self.version)
if self.splits is not None and not isinstance(self.splits, SplitDict):
self.splits = SplitDict.from_split_dict(self.splits)
if self.supervised_keys is not None and not isinstance(self.supervised_keys, SupervisedKeysData):
if isinstance(self.supervised_keys, (tuple, list)):
self.supervised_keys = SupervisedKeysData(*self.supervised_keys)
else:
self.supervised_keys = SupervisedKeysData(**self.supervised_keys)
# Parse and make a list of templates
if self.task_templates is not None:
if isinstance(self.task_templates, (list, tuple)):
templates = [
template if isinstance(template, TaskTemplate) else task_template_from_dict(template)
for template in self.task_templates
]
self.task_templates = [template for template in templates if template is not None]
elif isinstance(self.task_templates, TaskTemplate):
self.task_templates = [self.task_templates]
else:
template = task_template_from_dict(self.task_templates)
self.task_templates = [template] if template is not None else []
# Align task templates with features
if self.task_templates is not None:
self.task_templates = list(self.task_templates)
if self.features is not None:
self.task_templates = [
template.align_with_features(self.features) for template in (self.task_templates)
]
def write_to_directory(
self, dataset_info_dir, pretty_print=False, fs="deprecated", storage_options: Optional[dict] = None
):
"""Write `DatasetInfo` and license (if present) as JSON files to `dataset_info_dir`.
Args:
dataset_info_dir (`str`):
Destination directory.
pretty_print (`bool`, defaults to `False`):
If `True`, the JSON will be pretty-printed with the indent level of 4.
fs (`fsspec.spec.AbstractFileSystem`, *optional*):
Instance of the remote filesystem used to download the files from.
<Deprecated version="2.9.0">
`fs` was deprecated in version 2.9.0 and will be removed in 3.0.0.
Please use `storage_options` instead, e.g. `storage_options=fs.storage_options`.
</Deprecated>
storage_options (`dict`, *optional*):
Key/value pairs to be passed on to the file-system backend, if any.
<Added version="2.9.0"/>
Example:
```py
>>> from datasets import load_dataset
>>> ds = load_dataset("rotten_tomatoes", split="validation")
>>> ds.info.write_to_directory("/path/to/directory/")
```
"""
if fs != "deprecated":
warnings.warn(
"'fs' was deprecated in favor of 'storage_options' in version 2.9.0 and will be removed in 3.0.0.\n"
"You can remove this warning by passing 'storage_options=fs.storage_options' instead.",
FutureWarning,
)
storage_options = fs.storage_options
fs: fsspec.AbstractFileSystem
fs, *_ = url_to_fs(dataset_info_dir, **(storage_options or {}))
with fs.open(posixpath.join(dataset_info_dir, config.DATASET_INFO_FILENAME), "wb") as f:
self._dump_info(f, pretty_print=pretty_print)
if self.license:
with fs.open(posixpath.join(dataset_info_dir, config.LICENSE_FILENAME), "wb") as f:
self._dump_license(f)
def _dump_info(self, file, pretty_print=False):
"""Dump info in `file` file-like object open in bytes mode (to support remote files)"""
file.write(json.dumps(asdict(self), indent=4 if pretty_print else None).encode("utf-8"))
def _dump_license(self, file):
"""Dump license in `file` file-like object open in bytes mode (to support remote files)"""
file.write(self.license.encode("utf-8"))
@classmethod
def from_merge(cls, dataset_infos: List["DatasetInfo"]):
dataset_infos = [dset_info.copy() for dset_info in dataset_infos if dset_info is not None]
if len(dataset_infos) > 0 and all(dataset_infos[0] == dset_info for dset_info in dataset_infos):
# if all dataset_infos are equal we don't need to merge. Just return the first.
return dataset_infos[0]
description = "\n\n".join(unique_values(info.description for info in dataset_infos)).strip()
citation = "\n\n".join(unique_values(info.citation for info in dataset_infos)).strip()
homepage = "\n\n".join(unique_values(info.homepage for info in dataset_infos)).strip()
license = "\n\n".join(unique_values(info.license for info in dataset_infos)).strip()
features = None
supervised_keys = None
task_templates = None
# Find common task templates across all dataset infos
all_task_templates = [info.task_templates for info in dataset_infos if info.task_templates is not None]
if len(all_task_templates) > 1:
task_templates = list(set(all_task_templates[0]).intersection(*all_task_templates[1:]))
elif len(all_task_templates):
task_templates = list(set(all_task_templates[0]))
# If no common task templates found, replace empty list with None
task_templates = task_templates if task_templates else None
return cls(
description=description,
citation=citation,
homepage=homepage,
license=license,
features=features,
supervised_keys=supervised_keys,
task_templates=task_templates,
)
@classmethod
def from_directory(
cls, dataset_info_dir: str, fs="deprecated", storage_options: Optional[dict] = None
) -> "DatasetInfo":
"""Create [`DatasetInfo`] from the JSON file in `dataset_info_dir`.
This function updates all the dynamically generated fields (num_examples,
hash, time of creation,...) of the [`DatasetInfo`].
This will overwrite all previous metadata.
Args:
dataset_info_dir (`str`):
The directory containing the metadata file. This
should be the root directory of a specific dataset version.
fs (`fsspec.spec.AbstractFileSystem`, *optional*):
Instance of the remote filesystem used to download the files from.
<Deprecated version="2.9.0">
`fs` was deprecated in version 2.9.0 and will be removed in 3.0.0.
Please use `storage_options` instead, e.g. `storage_options=fs.storage_options`.
</Deprecated>
storage_options (`dict`, *optional*):
Key/value pairs to be passed on to the file-system backend, if any.
<Added version="2.9.0"/>
Example:
```py
>>> from datasets import DatasetInfo
>>> ds_info = DatasetInfo.from_directory("/path/to/directory/")
```
"""
if fs != "deprecated":
warnings.warn(
"'fs' was deprecated in favor of 'storage_options' in version 2.9.0 and will be removed in 3.0.0.\n"
"You can remove this warning by passing 'storage_options=fs.storage_options' instead.",
FutureWarning,
)
storage_options = fs.storage_options
fs: fsspec.AbstractFileSystem
fs, *_ = url_to_fs(dataset_info_dir, **(storage_options or {}))
logger.info(f"Loading Dataset info from {dataset_info_dir}")
if not dataset_info_dir:
raise ValueError("Calling DatasetInfo.from_directory() with undefined dataset_info_dir.")
with fs.open(posixpath.join(dataset_info_dir, config.DATASET_INFO_FILENAME), "r", encoding="utf-8") as f:
dataset_info_dict = json.load(f)
return cls.from_dict(dataset_info_dict)
@classmethod
def from_dict(cls, dataset_info_dict: dict) -> "DatasetInfo":
field_names = {f.name for f in dataclasses.fields(cls)}
return cls(**{k: v for k, v in dataset_info_dict.items() if k in field_names})
def update(self, other_dataset_info: "DatasetInfo", ignore_none=True):
self_dict = self.__dict__
self_dict.update(
**{
k: copy.deepcopy(v)
for k, v in other_dataset_info.__dict__.items()
if (v is not None or not ignore_none)
}
)
def copy(self) -> "DatasetInfo":
return self.__class__(**{k: copy.deepcopy(v) for k, v in self.__dict__.items()})
def _to_yaml_dict(self) -> dict:
yaml_dict = {}
dataset_info_dict = asdict(self)
for key in dataset_info_dict:
if key in self._INCLUDED_INFO_IN_YAML:
value = getattr(self, key)
if hasattr(value, "_to_yaml_list"): # Features, SplitDict
yaml_dict[key] = value._to_yaml_list()
elif hasattr(value, "_to_yaml_string"): # Version
yaml_dict[key] = value._to_yaml_string()
else:
yaml_dict[key] = value
return yaml_dict
@classmethod
def _from_yaml_dict(cls, yaml_data: dict) -> "DatasetInfo":
yaml_data = copy.deepcopy(yaml_data)
if yaml_data.get("features") is not None:
yaml_data["features"] = Features._from_yaml_list(yaml_data["features"])
if yaml_data.get("splits") is not None:
yaml_data["splits"] = SplitDict._from_yaml_list(yaml_data["splits"])
field_names = {f.name for f in dataclasses.fields(cls)}
return cls(**{k: v for k, v in yaml_data.items() if k in field_names})
class DatasetInfosDict(Dict[str, DatasetInfo]):
def write_to_directory(self, dataset_infos_dir, overwrite=False, pretty_print=False) -> None:
total_dataset_infos = {}
dataset_infos_path = os.path.join(dataset_infos_dir, config.DATASETDICT_INFOS_FILENAME)
dataset_readme_path = os.path.join(dataset_infos_dir, config.REPOCARD_FILENAME)
if not overwrite:
total_dataset_infos = self.from_directory(dataset_infos_dir)
total_dataset_infos.update(self)
if os.path.exists(dataset_infos_path):
# for backward compatibility, let's update the JSON file if it exists
with open(dataset_infos_path, "w", encoding="utf-8") as f:
dataset_infos_dict = {
config_name: asdict(dset_info) for config_name, dset_info in total_dataset_infos.items()
}
json.dump(dataset_infos_dict, f, indent=4 if pretty_print else None)
# Dump the infos in the YAML part of the README.md file
if os.path.exists(dataset_readme_path):
dataset_card = DatasetCard.load(dataset_readme_path)
dataset_card_data = dataset_card.data
else:
dataset_card = None
dataset_card_data = DatasetCardData()
if total_dataset_infos:
total_dataset_infos.to_dataset_card_data(dataset_card_data)
dataset_card = (
DatasetCard("---\n" + str(dataset_card_data) + "\n---\n") if dataset_card is None else dataset_card
)
dataset_card.save(Path(dataset_readme_path))
@classmethod
def from_directory(cls, dataset_infos_dir) -> "DatasetInfosDict":
logger.info(f"Loading Dataset Infos from {dataset_infos_dir}")
# Load the info from the YAML part of README.md
if os.path.exists(os.path.join(dataset_infos_dir, config.REPOCARD_FILENAME)):
dataset_card_data = DatasetCard.load(Path(dataset_infos_dir) / config.REPOCARD_FILENAME).data
if "dataset_info" in dataset_card_data:
return cls.from_dataset_card_data(dataset_card_data)
if os.path.exists(os.path.join(dataset_infos_dir, config.DATASETDICT_INFOS_FILENAME)):
# this is just to have backward compatibility with dataset_infos.json files
with open(os.path.join(dataset_infos_dir, config.DATASETDICT_INFOS_FILENAME), encoding="utf-8") as f:
return cls(
{
config_name: DatasetInfo.from_dict(dataset_info_dict)
for config_name, dataset_info_dict in json.load(f).items()
}
)
else:
return cls()
@classmethod
def from_dataset_card_data(cls, dataset_card_data: DatasetCardData) -> "DatasetInfosDict":
if isinstance(dataset_card_data.get("dataset_info"), (list, dict)):
if isinstance(dataset_card_data["dataset_info"], list):
return cls(
{
dataset_info_yaml_dict.get("config_name", "default"): DatasetInfo._from_yaml_dict(
dataset_info_yaml_dict
)
for dataset_info_yaml_dict in dataset_card_data["dataset_info"]
}
)
else:
dataset_info = DatasetInfo._from_yaml_dict(dataset_card_data["dataset_info"])
dataset_info.config_name = dataset_card_data["dataset_info"].get("config_name", "default")
return cls({dataset_info.config_name: dataset_info})
else:
return cls()
def to_dataset_card_data(self, dataset_card_data: DatasetCardData) -> None:
if self:
# first get existing metadata info
if "dataset_info" in dataset_card_data and isinstance(dataset_card_data["dataset_info"], dict):
dataset_metadata_infos = {
dataset_card_data["dataset_info"].get("config_name", "default"): dataset_card_data["dataset_info"]
}
elif "dataset_info" in dataset_card_data and isinstance(dataset_card_data["dataset_info"], list):
dataset_metadata_infos = {
config_metadata["config_name"]: config_metadata
for config_metadata in dataset_card_data["dataset_info"]
}
else:
dataset_metadata_infos = {}
# update/rewrite existing metadata info with the one to dump
total_dataset_infos = {
**dataset_metadata_infos,
**{config_name: dset_info._to_yaml_dict() for config_name, dset_info in self.items()},
}
# the config_name from the dataset_infos_dict takes over the config_name of the DatasetInfo
for config_name, dset_info_yaml_dict in total_dataset_infos.items():
dset_info_yaml_dict["config_name"] = config_name
if len(total_dataset_infos) == 1:
# use a struct instead of a list of configurations, since there's only one
dataset_card_data["dataset_info"] = next(iter(total_dataset_infos.values()))
config_name = dataset_card_data["dataset_info"].pop("config_name", None)
if config_name != "default":
# if config_name is not "default" preserve it and put at the first position
dataset_card_data["dataset_info"] = {
"config_name": config_name,
**dataset_card_data["dataset_info"],
}
else:
dataset_card_data["dataset_info"] = []
for config_name, dataset_info_yaml_dict in sorted(total_dataset_infos.items()):
# add the config_name field in first position
dataset_info_yaml_dict.pop("config_name", None)
dataset_info_yaml_dict = {"config_name": config_name, **dataset_info_yaml_dict}
dataset_card_data["dataset_info"].append(dataset_info_yaml_dict)
@dataclass
class MetricInfo:
"""Information about a metric.
`MetricInfo` documents a metric, including its name, version, and features.
See the constructor arguments and properties for a full list.
Note: Not all fields are known on construction and may be updated later.
"""
# Set in the dataset scripts
description: str
citation: str
features: Features
inputs_description: str = dataclasses.field(default_factory=str)
homepage: str = dataclasses.field(default_factory=str)
license: str = dataclasses.field(default_factory=str)
codebase_urls: List[str] = dataclasses.field(default_factory=list)
reference_urls: List[str] = dataclasses.field(default_factory=list)
streamable: bool = False
format: Optional[str] = None
# Set later by the builder
metric_name: Optional[str] = None
config_name: Optional[str] = None
experiment_id: Optional[str] = None
def __post_init__(self):
if self.format is not None:
for key, value in self.features.items():
if not isinstance(value, Value):
raise ValueError(
f"When using 'numpy' format, all features should be a `datasets.Value` feature. "
f"Here {key} is an instance of {value.__class__.__name__}"
)
def write_to_directory(self, metric_info_dir, pretty_print=False):
"""Write `MetricInfo` as JSON to `metric_info_dir`.
Also save the license separately in LICENCE.
If `pretty_print` is True, the JSON will be pretty-printed with the indent level of 4.
Example:
```py
>>> from datasets import load_metric
>>> metric = load_metric("accuracy")
>>> metric.info.write_to_directory("/path/to/directory/")
```
"""
with open(os.path.join(metric_info_dir, config.METRIC_INFO_FILENAME), "w", encoding="utf-8") as f:
json.dump(asdict(self), f, indent=4 if pretty_print else None)
if self.license:
with open(os.path.join(metric_info_dir, config.LICENSE_FILENAME), "w", encoding="utf-8") as f:
f.write(self.license)
@classmethod
def from_directory(cls, metric_info_dir) -> "MetricInfo":
"""Create MetricInfo from the JSON file in `metric_info_dir`.
Args:
metric_info_dir: `str` The directory containing the metadata file. This
should be the root directory of a specific dataset version.
Example:
```py
>>> from datasets import MetricInfo
>>> metric_info = MetricInfo.from_directory("/path/to/directory/")
```
"""
logger.info(f"Loading Metric info from {metric_info_dir}")
if not metric_info_dir:
raise ValueError("Calling MetricInfo.from_directory() with undefined metric_info_dir.")
with open(os.path.join(metric_info_dir, config.METRIC_INFO_FILENAME), encoding="utf-8") as f:
metric_info_dict = json.load(f)
return cls.from_dict(metric_info_dict)
@classmethod
def from_dict(cls, metric_info_dict: dict) -> "MetricInfo":
field_names = {f.name for f in dataclasses.fields(cls)}
return cls(**{k: v for k, v in metric_info_dict.items() if k in field_names})
| datasets/src/datasets/info.py/0 | {
"file_path": "datasets/src/datasets/info.py",
"repo_id": "datasets",
"token_count": 11406
} | 76 |
import inspect
import re
from typing import Dict, List, Tuple
from huggingface_hub.utils import insecure_hashlib
from .arrow import arrow
from .audiofolder import audiofolder
from .cache import cache # noqa F401
from .csv import csv
from .imagefolder import imagefolder
from .json import json
from .pandas import pandas
from .parquet import parquet
from .sql import sql # noqa F401
from .text import text
from .webdataset import webdataset
def _hash_python_lines(lines: List[str]) -> str:
filtered_lines = []
for line in lines:
line = re.sub(r"#.*", "", line) # remove comments
if line:
filtered_lines.append(line)
full_str = "\n".join(filtered_lines)
# Make a hash from all this code
full_bytes = full_str.encode("utf-8")
return insecure_hashlib.sha256(full_bytes).hexdigest()
# get importable module names and hash for caching
_PACKAGED_DATASETS_MODULES = {
"csv": (csv.__name__, _hash_python_lines(inspect.getsource(csv).splitlines())),
"json": (json.__name__, _hash_python_lines(inspect.getsource(json).splitlines())),
"pandas": (pandas.__name__, _hash_python_lines(inspect.getsource(pandas).splitlines())),
"parquet": (parquet.__name__, _hash_python_lines(inspect.getsource(parquet).splitlines())),
"arrow": (arrow.__name__, _hash_python_lines(inspect.getsource(arrow).splitlines())),
"text": (text.__name__, _hash_python_lines(inspect.getsource(text).splitlines())),
"imagefolder": (imagefolder.__name__, _hash_python_lines(inspect.getsource(imagefolder).splitlines())),
"audiofolder": (audiofolder.__name__, _hash_python_lines(inspect.getsource(audiofolder).splitlines())),
"webdataset": (webdataset.__name__, _hash_python_lines(inspect.getsource(webdataset).splitlines())),
}
# Used to infer the module to use based on the data files extensions
_EXTENSION_TO_MODULE: Dict[str, Tuple[str, dict]] = {
".csv": ("csv", {}),
".tsv": ("csv", {"sep": "\t"}),
".json": ("json", {}),
".jsonl": ("json", {}),
".parquet": ("parquet", {}),
".geoparquet": ("parquet", {}),
".gpq": ("parquet", {}),
".arrow": ("arrow", {}),
".txt": ("text", {}),
".tar": ("webdataset", {}),
}
_EXTENSION_TO_MODULE.update({ext: ("imagefolder", {}) for ext in imagefolder.ImageFolder.EXTENSIONS})
_EXTENSION_TO_MODULE.update({ext.upper(): ("imagefolder", {}) for ext in imagefolder.ImageFolder.EXTENSIONS})
_EXTENSION_TO_MODULE.update({ext: ("audiofolder", {}) for ext in audiofolder.AudioFolder.EXTENSIONS})
_EXTENSION_TO_MODULE.update({ext.upper(): ("audiofolder", {}) for ext in audiofolder.AudioFolder.EXTENSIONS})
_MODULE_SUPPORTS_METADATA = {"imagefolder", "audiofolder"}
# Used to filter data files based on extensions given a module name
_MODULE_TO_EXTENSIONS: Dict[str, List[str]] = {}
for _ext, (_module, _) in _EXTENSION_TO_MODULE.items():
_MODULE_TO_EXTENSIONS.setdefault(_module, []).append(_ext)
for _module in _MODULE_TO_EXTENSIONS:
_MODULE_TO_EXTENSIONS[_module].append(".zip")
| datasets/src/datasets/packaged_modules/__init__.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/__init__.py",
"repo_id": "datasets",
"token_count": 1108
} | 77 |
import io
import itertools
import json
from dataclasses import dataclass
from typing import Optional
import pyarrow as pa
import pyarrow.json as paj
import datasets
from datasets.table import table_cast
from datasets.utils.file_utils import readline
logger = datasets.utils.logging.get_logger(__name__)
@dataclass
class JsonConfig(datasets.BuilderConfig):
"""BuilderConfig for JSON."""
features: Optional[datasets.Features] = None
encoding: str = "utf-8"
encoding_errors: Optional[str] = None
field: Optional[str] = None
use_threads: bool = True # deprecated
block_size: Optional[int] = None # deprecated
chunksize: int = 10 << 20 # 10MB
newlines_in_values: Optional[bool] = None
class Json(datasets.ArrowBasedBuilder):
BUILDER_CONFIG_CLASS = JsonConfig
def _info(self):
if self.config.block_size is not None:
logger.warning("The JSON loader parameter `block_size` is deprecated. Please use `chunksize` instead")
self.config.chunksize = self.config.block_size
if self.config.use_threads is not True:
logger.warning(
"The JSON loader parameter `use_threads` is deprecated and doesn't have any effect anymore."
)
if self.config.newlines_in_values is not None:
raise ValueError("The JSON loader parameter `newlines_in_values` is no longer supported")
return datasets.DatasetInfo(features=self.config.features)
def _split_generators(self, dl_manager):
"""We handle string, list and dicts in datafiles"""
if not self.config.data_files:
raise ValueError(f"At least one data file must be specified, but got data_files={self.config.data_files}")
data_files = dl_manager.download_and_extract(self.config.data_files)
if isinstance(data_files, (str, list, tuple)):
files = data_files
if isinstance(files, str):
files = [files]
files = [dl_manager.iter_files(file) for file in files]
return [datasets.SplitGenerator(name=datasets.Split.TRAIN, gen_kwargs={"files": files})]
splits = []
for split_name, files in data_files.items():
if isinstance(files, str):
files = [files]
files = [dl_manager.iter_files(file) for file in files]
splits.append(datasets.SplitGenerator(name=split_name, gen_kwargs={"files": files}))
return splits
def _cast_table(self, pa_table: pa.Table) -> pa.Table:
if self.config.features is not None:
# adding missing columns
for column_name in set(self.config.features) - set(pa_table.column_names):
type = self.config.features.arrow_schema.field(column_name).type
pa_table = pa_table.append_column(column_name, pa.array([None] * len(pa_table), type=type))
# more expensive cast to support nested structures with keys in a different order
# allows str <-> int/float or str to Audio for example
pa_table = table_cast(pa_table, self.config.features.arrow_schema)
return pa_table
def _generate_tables(self, files):
for file_idx, file in enumerate(itertools.chain.from_iterable(files)):
# If the file is one json object and if we need to look at the list of items in one specific field
if self.config.field is not None:
with open(file, encoding=self.config.encoding, errors=self.config.encoding_errors) as f:
dataset = json.load(f)
# We keep only the field we are interested in
dataset = dataset[self.config.field]
# We accept two format: a list of dicts or a dict of lists
if isinstance(dataset, (list, tuple)):
keys = set().union(*[row.keys() for row in dataset])
mapping = {col: [row.get(col) for row in dataset] for col in keys}
else:
mapping = dataset
pa_table = pa.Table.from_pydict(mapping)
yield file_idx, self._cast_table(pa_table)
# If the file has one json object per line
else:
with open(file, "rb") as f:
batch_idx = 0
# Use block_size equal to the chunk size divided by 32 to leverage multithreading
# Set a default minimum value of 16kB if the chunk size is really small
block_size = max(self.config.chunksize // 32, 16 << 10)
encoding_errors = (
self.config.encoding_errors if self.config.encoding_errors is not None else "strict"
)
while True:
batch = f.read(self.config.chunksize)
if not batch:
break
# Finish current line
try:
batch += f.readline()
except (AttributeError, io.UnsupportedOperation):
batch += readline(f)
# PyArrow only accepts utf-8 encoded bytes
if self.config.encoding != "utf-8":
batch = batch.decode(self.config.encoding, errors=encoding_errors).encode("utf-8")
try:
while True:
try:
pa_table = paj.read_json(
io.BytesIO(batch), read_options=paj.ReadOptions(block_size=block_size)
)
break
except (pa.ArrowInvalid, pa.ArrowNotImplementedError) as e:
if (
isinstance(e, pa.ArrowInvalid)
and "straddling" not in str(e)
or block_size > len(batch)
):
raise
else:
# Increase the block size in case it was too small.
# The block size will be reset for the next file.
logger.debug(
f"Batch of {len(batch)} bytes couldn't be parsed with block_size={block_size}. Retrying with block_size={block_size * 2}."
)
block_size *= 2
except pa.ArrowInvalid as e:
try:
with open(
file, encoding=self.config.encoding, errors=self.config.encoding_errors
) as f:
dataset = json.load(f)
except json.JSONDecodeError:
logger.error(f"Failed to read file '{file}' with error {type(e)}: {e}")
raise e
# If possible, parse the file as a list of json objects/strings and exit the loop
if isinstance(dataset, list): # list is the only sequence type supported in JSON
try:
if dataset and isinstance(dataset[0], str):
pa_table_names = (
list(self.config.features)
if self.config.features is not None
else ["text"]
)
pa_table = pa.Table.from_arrays([pa.array(dataset)], names=pa_table_names)
else:
keys = set().union(*[row.keys() for row in dataset])
mapping = {col: [row.get(col) for row in dataset] for col in keys}
pa_table = pa.Table.from_pydict(mapping)
except (pa.ArrowInvalid, AttributeError) as e:
logger.error(f"Failed to read file '{file}' with error {type(e)}: {e}")
raise ValueError(f"Not able to read records in the JSON file at {file}.") from None
yield file_idx, self._cast_table(pa_table)
break
else:
logger.error(f"Failed to read file '{file}' with error {type(e)}: {e}")
raise ValueError(
f"Not able to read records in the JSON file at {file}. "
f"You should probably indicate the field of the JSON file containing your records. "
f"This JSON file contain the following fields: {str(list(dataset.keys()))}. "
f"Select the correct one and provide it as `field='XXX'` to the dataset loading method. "
) from None
# Uncomment for debugging (will print the Arrow table size and elements)
# logger.warning(f"pa_table: {pa_table} num rows: {pa_table.num_rows}")
# logger.warning('\n'.join(str(pa_table.slice(i, 1).to_pydict()) for i in range(pa_table.num_rows)))
yield (file_idx, batch_idx), self._cast_table(pa_table)
batch_idx += 1
| datasets/src/datasets/packaged_modules/json/json.py/0 | {
"file_path": "datasets/src/datasets/packaged_modules/json/json.py",
"repo_id": "datasets",
"token_count": 5320
} | 78 |
import importlib.util
import os
import tempfile
from pathlib import PurePath
from typing import TYPE_CHECKING, Dict, List, NamedTuple, Optional, Union
import fsspec
import numpy as np
from .utils import logging
from .utils import tqdm as hf_tqdm
if TYPE_CHECKING:
from .arrow_dataset import Dataset # noqa: F401
try:
from elasticsearch import Elasticsearch # noqa: F401
except ImportError:
pass
try:
import faiss # noqa: F401
except ImportError:
pass
_has_elasticsearch = importlib.util.find_spec("elasticsearch") is not None
_has_faiss = importlib.util.find_spec("faiss") is not None
logger = logging.get_logger(__name__)
class MissingIndex(Exception):
pass
class SearchResults(NamedTuple):
scores: List[float]
indices: List[int]
class BatchedSearchResults(NamedTuple):
total_scores: List[List[float]]
total_indices: List[List[int]]
class NearestExamplesResults(NamedTuple):
scores: List[float]
examples: dict
class BatchedNearestExamplesResults(NamedTuple):
total_scores: List[List[float]]
total_examples: List[dict]
class BaseIndex:
"""Base class for indexing"""
def search(self, query, k: int = 10, **kwargs) -> SearchResults:
"""
To implement.
This method has to return the scores and the indices of the retrieved examples given a certain query.
"""
raise NotImplementedError
def search_batch(self, queries, k: int = 10, **kwargs) -> BatchedSearchResults:
"""Find the nearest examples indices to the query.
Args:
queries (`Union[List[str], np.ndarray]`): The queries as a list of strings if `column` is a text index or as a numpy array if `column` is a vector index.
k (`int`): The number of examples to retrieve per query.
Ouput:
total_scores (`List[List[float]`): The retrieval scores of the retrieved examples per query.
total_indices (`List[List[int]]`): The indices of the retrieved examples per query.
"""
total_scores, total_indices = [], []
for query in queries:
scores, indices = self.search(query, k)
total_scores.append(scores)
total_indices.append(indices)
return BatchedSearchResults(total_scores, total_indices)
def save(self, file: Union[str, PurePath]):
"""Serialize the index on disk"""
raise NotImplementedError
@classmethod
def load(cls, file: Union[str, PurePath]) -> "BaseIndex":
"""Deserialize the index from disk"""
raise NotImplementedError
class ElasticSearchIndex(BaseIndex):
"""
Sparse index using Elasticsearch. It is used to index text and run queries based on BM25 similarity.
An Elasticsearch server needs to be accessible, and a python client is declared with
```
es_client = Elasticsearch([{'host': 'localhost', 'port': '9200'}])
```
for example.
"""
def __init__(
self,
host: Optional[str] = None,
port: Optional[int] = None,
es_client: Optional["Elasticsearch"] = None,
es_index_name: Optional[str] = None,
es_index_config: Optional[dict] = None,
):
if not _has_elasticsearch:
raise ImportError(
"You must install ElasticSearch to use ElasticSearchIndex. To do so you can run `pip install elasticsearch==7.7.1 for example`"
)
if es_client is not None and (host is not None or port is not None):
raise ValueError("Please specify either `es_client` or `(host, port)`, but not both.")
host = host or "localhost"
port = port or 9200
import elasticsearch.helpers # noqa: F401 - need this to properly load all the es features
from elasticsearch import Elasticsearch # noqa: F811
self.es_client = es_client if es_client is not None else Elasticsearch([{"host": host, "port": str(port)}])
self.es_index_name = (
es_index_name
if es_index_name is not None
else "huggingface_datasets_" + os.path.basename(tempfile.NamedTemporaryFile().name)
)
self.es_index_config = (
es_index_config
if es_index_config is not None
else {
"settings": {
"number_of_shards": 1,
"analysis": {"analyzer": {"stop_standard": {"type": "standard", " stopwords": "_english_"}}},
},
"mappings": {"properties": {"text": {"type": "text", "analyzer": "standard", "similarity": "BM25"}}},
}
)
def add_documents(self, documents: Union[List[str], "Dataset"], column: Optional[str] = None):
"""
Add documents to the index.
If the documents are inside a certain column, you can specify it using the `column` argument.
"""
index_name = self.es_index_name
index_config = self.es_index_config
self.es_client.indices.create(index=index_name, body=index_config)
number_of_docs = len(documents)
progress = hf_tqdm(unit="docs", total=number_of_docs)
successes = 0
def passage_generator():
if column is not None:
for i, example in enumerate(documents):
yield {"text": example[column], "_id": i}
else:
for i, example in enumerate(documents):
yield {"text": example, "_id": i}
# create the ES index
import elasticsearch as es
for ok, action in es.helpers.streaming_bulk(
client=self.es_client,
index=index_name,
actions=passage_generator(),
):
progress.update(1)
successes += ok
if successes != len(documents):
logger.warning(
f"Some documents failed to be added to ElasticSearch. Failures: {len(documents)-successes}/{len(documents)}"
)
logger.info(f"Indexed {successes:d} documents")
def search(self, query: str, k=10, **kwargs) -> SearchResults:
"""Find the nearest examples indices to the query.
Args:
query (`str`): The query as a string.
k (`int`): The number of examples to retrieve.
Ouput:
scores (`List[List[float]`): The retrieval scores of the retrieved examples.
indices (`List[List[int]]`): The indices of the retrieved examples.
"""
response = self.es_client.search(
index=self.es_index_name,
body={"query": {"multi_match": {"query": query, "fields": ["text"], "type": "cross_fields"}}, "size": k},
**kwargs,
)
hits = response["hits"]["hits"]
return SearchResults([hit["_score"] for hit in hits], [int(hit["_id"]) for hit in hits])
def search_batch(self, queries, k: int = 10, max_workers=10, **kwargs) -> BatchedSearchResults:
import concurrent.futures
total_scores, total_indices = [None] * len(queries), [None] * len(queries)
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_index = {executor.submit(self.search, query, k, **kwargs): i for i, query in enumerate(queries)}
for future in concurrent.futures.as_completed(future_to_index):
index = future_to_index[future]
results: SearchResults = future.result()
total_scores[index] = results.scores
total_indices[index] = results.indices
return BatchedSearchResults(total_indices=total_indices, total_scores=total_scores)
class FaissIndex(BaseIndex):
"""
Dense index using Faiss. It is used to index vectors.
Faiss is a library for efficient similarity search and clustering of dense vectors.
It contains algorithms that search in sets of vectors of any size, up to ones that possibly do not fit in RAM.
You can find more information about Faiss here:
- For index types and the string factory: https://github.com/facebookresearch/faiss/wiki/The-index-factory
- For GPU settings: https://github.com/facebookresearch/faiss/wiki/Faiss-on-the-GPU
"""
def __init__(
self,
device: Optional[Union[int, List[int]]] = None,
string_factory: Optional[str] = None,
metric_type: Optional[int] = None,
custom_index: Optional["faiss.Index"] = None,
):
"""
Create a Dense index using Faiss. You can specify `device` if you want to run it on GPU (`device` must be the GPU index).
You can find more information about Faiss here:
- For `string factory`: https://github.com/facebookresearch/faiss/wiki/The-index-factory
"""
if string_factory is not None and custom_index is not None:
raise ValueError("Please specify either `string_factory` or `custom_index` but not both.")
if device is not None and custom_index is not None:
raise ValueError(
"Cannot pass both 'custom_index' and 'device'. "
"Pass 'custom_index' already transferred to the target device instead."
)
self.device = device
self.string_factory = string_factory
self.metric_type = metric_type
self.faiss_index = custom_index
if not _has_faiss:
raise ImportError(
"You must install Faiss to use FaissIndex. To do so you can run `conda install -c pytorch faiss-cpu` or `conda install -c pytorch faiss-gpu`. "
"A community supported package is also available on pypi: `pip install faiss-cpu` or `pip install faiss-gpu`. "
"Note that pip may not have the latest version of FAISS, and thus, some of the latest features and bug fixes may not be available."
)
def add_vectors(
self,
vectors: Union[np.array, "Dataset"],
column: Optional[str] = None,
batch_size: int = 1000,
train_size: Optional[int] = None,
faiss_verbose: Optional[bool] = None,
):
"""
Add vectors to the index.
If the arrays are inside a certain column, you can specify it using the `column` argument.
"""
import faiss # noqa: F811
# Create index
if self.faiss_index is None:
size = len(vectors[0]) if column is None else len(vectors[0][column])
if self.string_factory is not None:
if self.metric_type is None:
index = faiss.index_factory(size, self.string_factory)
else:
index = faiss.index_factory(size, self.string_factory, self.metric_type)
else:
if self.metric_type is None:
index = faiss.IndexFlat(size)
else:
index = faiss.IndexFlat(size, self.metric_type)
self.faiss_index = self._faiss_index_to_device(index, self.device)
logger.info(f"Created faiss index of type {type(self.faiss_index)}")
# Set verbosity level
if faiss_verbose is not None:
self.faiss_index.verbose = faiss_verbose
if hasattr(self.faiss_index, "index") and self.faiss_index.index is not None:
self.faiss_index.index.verbose = faiss_verbose
if hasattr(self.faiss_index, "quantizer") and self.faiss_index.quantizer is not None:
self.faiss_index.quantizer.verbose = faiss_verbose
if hasattr(self.faiss_index, "clustering_index") and self.faiss_index.clustering_index is not None:
self.faiss_index.clustering_index.verbose = faiss_verbose
# Train
if train_size is not None:
train_vecs = vectors[:train_size] if column is None else vectors[:train_size][column]
logger.info(f"Training the index with the first {len(train_vecs)} vectors")
self.faiss_index.train(train_vecs)
else:
logger.info("Ignored the training step of the faiss index as `train_size` is None.")
# Add vectors
logger.info(f"Adding {len(vectors)} vectors to the faiss index")
for i in hf_tqdm(range(0, len(vectors), batch_size)):
vecs = vectors[i : i + batch_size] if column is None else vectors[i : i + batch_size][column]
self.faiss_index.add(vecs)
@staticmethod
def _faiss_index_to_device(index: "faiss.Index", device: Optional[Union[int, List[int]]] = None) -> "faiss.Index":
"""
Sends a faiss index to a device.
A device can either be a positive integer (GPU id), a negative integer (all GPUs),
or a list of positive integers (select GPUs to use), or `None` for CPU.
"""
# If device is not specified, then it runs on CPU.
if device is None:
return index
import faiss # noqa: F811
# If the device id is given as an integer
if isinstance(device, int):
# Positive integers are directly mapped to GPU ids
if device > -1:
faiss_res = faiss.StandardGpuResources()
index = faiss.index_cpu_to_gpu(faiss_res, device, index)
# And negative integers mean using all GPUs
else:
index = faiss.index_cpu_to_all_gpus(index)
# Device ids given as a list mean mapping to those devices specified.
elif isinstance(device, (list, tuple)):
index = faiss.index_cpu_to_gpus_list(index, gpus=list(device))
else:
raise TypeError(
f"The argument type: {type(device)} is not expected. "
+ "Please pass in either nothing, a positive int, a negative int, or a list of positive ints."
)
return index
def search(self, query: np.array, k=10, **kwargs) -> SearchResults:
"""Find the nearest examples indices to the query.
Args:
query (`np.array`): The query as a numpy array.
k (`int`): The number of examples to retrieve.
Ouput:
scores (`List[List[float]`): The retrieval scores of the retrieved examples.
indices (`List[List[int]]`): The indices of the retrieved examples.
"""
if len(query.shape) != 1 and (len(query.shape) != 2 or query.shape[0] != 1):
raise ValueError("Shape of query is incorrect, it has to be either a 1D array or 2D (1, N)")
queries = query.reshape(1, -1)
if not queries.flags.c_contiguous:
queries = np.asarray(queries, order="C")
scores, indices = self.faiss_index.search(queries, k, **kwargs)
return SearchResults(scores[0], indices[0].astype(int))
def search_batch(self, queries: np.array, k=10, **kwargs) -> BatchedSearchResults:
"""Find the nearest examples indices to the queries.
Args:
queries (`np.array`): The queries as a numpy array.
k (`int`): The number of examples to retrieve.
Ouput:
total_scores (`List[List[float]`): The retrieval scores of the retrieved examples per query.
total_indices (`List[List[int]]`): The indices of the retrieved examples per query.
"""
if len(queries.shape) != 2:
raise ValueError("Shape of query must be 2D")
if not queries.flags.c_contiguous:
queries = np.asarray(queries, order="C")
scores, indices = self.faiss_index.search(queries, k, **kwargs)
return BatchedSearchResults(scores, indices.astype(int))
def save(self, file: Union[str, PurePath], storage_options: Optional[Dict] = None):
"""Serialize the FaissIndex on disk"""
import faiss # noqa: F811
if self.device is not None and isinstance(self.device, (int, list, tuple)):
index = faiss.index_gpu_to_cpu(self.faiss_index)
else:
index = self.faiss_index
with fsspec.open(str(file), "wb", **(storage_options or {})) as f:
faiss.write_index(index, faiss.BufferedIOWriter(faiss.PyCallbackIOWriter(f.write)))
@classmethod
def load(
cls,
file: Union[str, PurePath],
device: Optional[Union[int, List[int]]] = None,
storage_options: Optional[Dict] = None,
) -> "FaissIndex":
"""Deserialize the FaissIndex from disk"""
import faiss # noqa: F811
# Instances of FaissIndex is essentially just a wrapper for faiss indices.
faiss_index = cls(device=device)
with fsspec.open(str(file), "rb", **(storage_options or {})) as f:
index = faiss.read_index(faiss.BufferedIOReader(faiss.PyCallbackIOReader(f.read)))
faiss_index.faiss_index = faiss_index._faiss_index_to_device(index, faiss_index.device)
return faiss_index
class IndexableMixin:
"""Add indexing features to `datasets.Dataset`"""
def __init__(self):
self._indexes: Dict[str, BaseIndex] = {}
def __len__(self):
raise NotImplementedError
def __getitem__(self, key):
raise NotImplementedError
def is_index_initialized(self, index_name: str) -> bool:
return index_name in self._indexes
def _check_index_is_initialized(self, index_name: str):
if not self.is_index_initialized(index_name):
raise MissingIndex(
f"Index with index_name '{index_name}' not initialized yet. Please make sure that you call `add_faiss_index` or `add_elasticsearch_index` first."
)
def list_indexes(self) -> List[str]:
"""List the `colindex_nameumns`/identifiers of all the attached indexes."""
return list(self._indexes)
def get_index(self, index_name: str) -> BaseIndex:
"""List the `index_name`/identifiers of all the attached indexes.
Args:
index_name (`str`): Index name.
Returns:
[`BaseIndex`]
"""
self._check_index_is_initialized(index_name)
return self._indexes[index_name]
def add_faiss_index(
self,
column: str,
index_name: Optional[str] = None,
device: Optional[Union[int, List[int]]] = None,
string_factory: Optional[str] = None,
metric_type: Optional[int] = None,
custom_index: Optional["faiss.Index"] = None,
batch_size: int = 1000,
train_size: Optional[int] = None,
faiss_verbose: bool = False,
):
"""Add a dense index using Faiss for fast retrieval.
The index is created using the vectors of the specified column.
You can specify `device` if you want to run it on GPU (`device` must be the GPU index, see more below).
You can find more information about Faiss here:
- For `string factory`: https://github.com/facebookresearch/faiss/wiki/The-index-factory
Args:
column (`str`): The column of the vectors to add to the index.
index_name (Optional `str`): The index_name/identifier of the index. This is the index_name that is used to call `.get_nearest` or `.search`.
By default it corresponds to `column`.
device (Optional `Union[int, List[int]]`): If positive integer, this is the index of the GPU to use. If negative integer, use all GPUs.
If a list of positive integers is passed in, run only on those GPUs. By default it uses the CPU.
string_factory (Optional `str`): This is passed to the index factory of Faiss to create the index. Default index class is IndexFlatIP.
metric_type (Optional `int`): Type of metric. Ex: `faiss.METRIC_INNER_PRODUCT` or `faiss.METRIC_L2`.
custom_index (Optional `faiss.Index`): Custom Faiss index that you already have instantiated and configured for your needs.
batch_size (Optional `int`): Size of the batch to use while adding vectors to the FaissIndex. Default value is 1000.
<Added version="2.4.0"/>
train_size (Optional `int`): If the index needs a training step, specifies how many vectors will be used to train the index.
faiss_verbose (`bool`, defaults to False): Enable the verbosity of the Faiss index.
"""
index_name = index_name if index_name is not None else column
faiss_index = FaissIndex(
device=device, string_factory=string_factory, metric_type=metric_type, custom_index=custom_index
)
faiss_index.add_vectors(
self, column=column, batch_size=batch_size, train_size=train_size, faiss_verbose=faiss_verbose
)
self._indexes[index_name] = faiss_index
def add_faiss_index_from_external_arrays(
self,
external_arrays: np.array,
index_name: str,
device: Optional[Union[int, List[int]]] = None,
string_factory: Optional[str] = None,
metric_type: Optional[int] = None,
custom_index: Optional["faiss.Index"] = None,
batch_size: int = 1000,
train_size: Optional[int] = None,
faiss_verbose: bool = False,
):
"""Add a dense index using Faiss for fast retrieval.
The index is created using the vectors of `external_arrays`.
You can specify `device` if you want to run it on GPU (`device` must be the GPU index).
You can find more information about Faiss here:
- For `string factory`: https://github.com/facebookresearch/faiss/wiki/The-index-factory
Args:
external_arrays (`np.array`): If you want to use arrays from outside the lib for the index, you can set `external_arrays`.
It will use `external_arrays` to create the Faiss index instead of the arrays in the given `column`.
index_name (`str`): The index_name/identifier of the index. This is the index_name that is used to call `.get_nearest` or `.search`.
device (Optional `Union[int, List[int]]`): If positive integer, this is the index of the GPU to use. If negative integer, use all GPUs.
If a list of positive integers is passed in, run only on those GPUs. By default it uses the CPU.
string_factory (Optional `str`): This is passed to the index factory of Faiss to create the index. Default index class is IndexFlatIP.
metric_type (Optional `int`): Type of metric. Ex: `faiss.METRIC_INNER_PRODUCT` or `faiss.METRIC_L2`.
custom_index (Optional `faiss.Index`): Custom Faiss index that you already have instantiated and configured for your needs.
batch_size (Optional `int`): Size of the batch to use while adding vectors to the FaissIndex. Default value is 1000.
<Added version="2.4.0"/>
train_size (Optional `int`): If the index needs a training step, specifies how many vectors will be used to train the index.
faiss_verbose (`bool`, defaults to False): Enable the verbosity of the Faiss index.
"""
faiss_index = FaissIndex(
device=device, string_factory=string_factory, metric_type=metric_type, custom_index=custom_index
)
faiss_index.add_vectors(
external_arrays, column=None, batch_size=batch_size, train_size=train_size, faiss_verbose=faiss_verbose
)
self._indexes[index_name] = faiss_index
def save_faiss_index(self, index_name: str, file: Union[str, PurePath], storage_options: Optional[Dict] = None):
"""Save a FaissIndex on disk.
Args:
index_name (`str`): The index_name/identifier of the index. This is the index_name that is used to call `.get_nearest` or `.search`.
file (`str`): The path to the serialized faiss index on disk or remote URI (e.g. `"s3://my-bucket/index.faiss"`).
storage_options (`dict`, *optional*):
Key/value pairs to be passed on to the file-system backend, if any.
<Added version="2.11.0"/>
"""
index = self.get_index(index_name)
if not isinstance(index, FaissIndex):
raise ValueError(f"Index '{index_name}' is not a FaissIndex but a '{type(index)}'")
index.save(file, storage_options=storage_options)
logger.info(f"Saved FaissIndex {index_name} at {file}")
def load_faiss_index(
self,
index_name: str,
file: Union[str, PurePath],
device: Optional[Union[int, List[int]]] = None,
storage_options: Optional[Dict] = None,
):
"""Load a FaissIndex from disk.
If you want to do additional configurations, you can have access to the faiss index object by doing
`.get_index(index_name).faiss_index` to make it fit your needs.
Args:
index_name (`str`): The index_name/identifier of the index. This is the index_name that is used to
call `.get_nearest` or `.search`.
file (`str`): The path to the serialized faiss index on disk or remote URI (e.g. `"s3://my-bucket/index.faiss"`).
device (Optional `Union[int, List[int]]`): If positive integer, this is the index of the GPU to use. If negative integer, use all GPUs.
If a list of positive integers is passed in, run only on those GPUs. By default it uses the CPU.
storage_options (`dict`, *optional*):
Key/value pairs to be passed on to the file-system backend, if any.
<Added version="2.11.0"/>
"""
index = FaissIndex.load(file, device=device, storage_options=storage_options)
if index.faiss_index.ntotal != len(self):
raise ValueError(
f"Index size should match Dataset size, but Index '{index_name}' at {file} has {index.faiss_index.ntotal} elements while the dataset has {len(self)} examples."
)
self._indexes[index_name] = index
logger.info(f"Loaded FaissIndex {index_name} from {file}")
def add_elasticsearch_index(
self,
column: str,
index_name: Optional[str] = None,
host: Optional[str] = None,
port: Optional[int] = None,
es_client: Optional["Elasticsearch"] = None,
es_index_name: Optional[str] = None,
es_index_config: Optional[dict] = None,
):
"""Add a text index using ElasticSearch for fast retrieval.
Args:
column (`str`): The column of the documents to add to the index.
index_name (Optional `str`): The index_name/identifier of the index. This is the index name that is used to call `.get_nearest` or `.search`.
By default it corresponds to `column`.
host (Optional `str`, defaults to localhost):
host of where ElasticSearch is running
port (Optional `str`, defaults to 9200):
port of where ElasticSearch is running
es_client (Optional `elasticsearch.Elasticsearch`):
The elasticsearch client used to create the index if host and port are None.
es_index_name (Optional `str`): The elasticsearch index name used to create the index.
es_index_config (Optional `dict`):
The configuration of the elasticsearch index.
Default config is:
Config::
{
"settings": {
"number_of_shards": 1,
"analysis": {"analyzer": {"stop_standard": {"type": "standard", " stopwords": "_english_"}}},
},
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "standard",
"similarity": "BM25"
},
}
},
}
"""
index_name = index_name if index_name is not None else column
es_index = ElasticSearchIndex(
host=host, port=port, es_client=es_client, es_index_name=es_index_name, es_index_config=es_index_config
)
es_index.add_documents(self, column=column)
self._indexes[index_name] = es_index
def load_elasticsearch_index(
self,
index_name: str,
es_index_name: str,
host: Optional[str] = None,
port: Optional[int] = None,
es_client: Optional["Elasticsearch"] = None,
es_index_config: Optional[dict] = None,
):
"""Load an existing text index using ElasticSearch for fast retrieval.
Args:
index_name (`str`):
The `index_name`/identifier of the index. This is the index name that is used to call `get_nearest` or `search`.
es_index_name (`str`):
The name of elasticsearch index to load.
host (`str`, *optional*, defaults to `localhost`):
Host of where ElasticSearch is running.
port (`str`, *optional*, defaults to `9200`):
Port of where ElasticSearch is running.
es_client (`elasticsearch.Elasticsearch`, *optional*):
The elasticsearch client used to create the index if host and port are `None`.
es_index_config (`dict`, *optional*):
The configuration of the elasticsearch index.
Default config is:
```
{
"settings": {
"number_of_shards": 1,
"analysis": {"analyzer": {"stop_standard": {"type": "standard", " stopwords": "_english_"}}},
},
"mappings": {
"properties": {
"text": {
"type": "text",
"analyzer": "standard",
"similarity": "BM25"
},
}
},
}
```
"""
self._indexes[index_name] = ElasticSearchIndex(
host=host, port=port, es_client=es_client, es_index_name=es_index_name, es_index_config=es_index_config
)
def drop_index(self, index_name: str):
"""Drop the index with the specified column.
Args:
index_name (`str`):
The `index_name`/identifier of the index.
"""
del self._indexes[index_name]
def search(self, index_name: str, query: Union[str, np.array], k: int = 10, **kwargs) -> SearchResults:
"""Find the nearest examples indices in the dataset to the query.
Args:
index_name (`str`):
The name/identifier of the index.
query (`Union[str, np.ndarray]`):
The query as a string if `index_name` is a text index or as a numpy array if `index_name` is a vector index.
k (`int`):
The number of examples to retrieve.
Returns:
`(scores, indices)`:
A tuple of `(scores, indices)` where:
- **scores** (`List[List[float]`): the retrieval scores from either FAISS (`IndexFlatL2` by default) or ElasticSearch of the retrieved examples
- **indices** (`List[List[int]]`): the indices of the retrieved examples
"""
self._check_index_is_initialized(index_name)
return self._indexes[index_name].search(query, k, **kwargs)
def search_batch(
self, index_name: str, queries: Union[List[str], np.array], k: int = 10, **kwargs
) -> BatchedSearchResults:
"""Find the nearest examples indices in the dataset to the query.
Args:
index_name (`str`):
The `index_name`/identifier of the index.
queries (`Union[List[str], np.ndarray]`):
The queries as a list of strings if `index_name` is a text index or as a numpy array if `index_name` is a vector index.
k (`int`):
The number of examples to retrieve per query.
Returns:
`(total_scores, total_indices)`:
A tuple of `(total_scores, total_indices)` where:
- **total_scores** (`List[List[float]`): the retrieval scores from either FAISS (`IndexFlatL2` by default) or ElasticSearch of the retrieved examples per query
- **total_indices** (`List[List[int]]`): the indices of the retrieved examples per query
"""
self._check_index_is_initialized(index_name)
return self._indexes[index_name].search_batch(queries, k, **kwargs)
def get_nearest_examples(
self, index_name: str, query: Union[str, np.array], k: int = 10, **kwargs
) -> NearestExamplesResults:
"""Find the nearest examples in the dataset to the query.
Args:
index_name (`str`):
The index_name/identifier of the index.
query (`Union[str, np.ndarray]`):
The query as a string if `index_name` is a text index or as a numpy array if `index_name` is a vector index.
k (`int`):
The number of examples to retrieve.
Returns:
`(scores, examples)`:
A tuple of `(scores, examples)` where:
- **scores** (`List[float]`): the retrieval scores from either FAISS (`IndexFlatL2` by default) or ElasticSearch of the retrieved examples
- **examples** (`dict`): the retrieved examples
"""
self._check_index_is_initialized(index_name)
scores, indices = self.search(index_name, query, k, **kwargs)
top_indices = [i for i in indices if i >= 0]
return NearestExamplesResults(scores[: len(top_indices)], self[top_indices])
def get_nearest_examples_batch(
self, index_name: str, queries: Union[List[str], np.array], k: int = 10, **kwargs
) -> BatchedNearestExamplesResults:
"""Find the nearest examples in the dataset to the query.
Args:
index_name (`str`):
The `index_name`/identifier of the index.
queries (`Union[List[str], np.ndarray]`):
The queries as a list of strings if `index_name` is a text index or as a numpy array if `index_name` is a vector index.
k (`int`):
The number of examples to retrieve per query.
Returns:
`(total_scores, total_examples)`:
A tuple of `(total_scores, total_examples)` where:
- **total_scores** (`List[List[float]`): the retrieval scores from either FAISS (`IndexFlatL2` by default) or ElasticSearch of the retrieved examples per query
- **total_examples** (`List[dict]`): the retrieved examples per query
"""
self._check_index_is_initialized(index_name)
total_scores, total_indices = self.search_batch(index_name, queries, k, **kwargs)
total_scores = [
scores_i[: len([i for i in indices_i if i >= 0])]
for scores_i, indices_i in zip(total_scores, total_indices)
]
total_samples = [self[[i for i in indices if i >= 0]] for indices in total_indices]
return BatchedNearestExamplesResults(total_scores, total_samples)
| datasets/src/datasets/search.py/0 | {
"file_path": "datasets/src/datasets/search.py",
"repo_id": "datasets",
"token_count": 15237
} | 79 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License
"""Utilities to handle file locking in `datasets`."""
import os
from filelock import FileLock as FileLock_
from filelock import UnixFileLock
from filelock import __version__ as _filelock_version
from packaging import version
class FileLock(FileLock_):
"""
A `filelock.FileLock` initializer that handles long paths.
It also uses the current umask for lock files.
"""
MAX_FILENAME_LENGTH = 255
def __init__(self, lock_file, *args, **kwargs):
# The "mode" argument is required if we want to use the current umask in filelock >= 3.10
# In previous previous it was already using the current umask.
if "mode" not in kwargs and version.parse(_filelock_version) >= version.parse("3.10.0"):
umask = os.umask(0o666)
os.umask(umask)
kwargs["mode"] = 0o666 & ~umask
lock_file = self.hash_filename_if_too_long(lock_file)
super().__init__(lock_file, *args, **kwargs)
@classmethod
def hash_filename_if_too_long(cls, path: str) -> str:
path = os.path.abspath(os.path.expanduser(path))
filename = os.path.basename(path)
max_filename_length = cls.MAX_FILENAME_LENGTH
if issubclass(cls, UnixFileLock):
max_filename_length = min(max_filename_length, os.statvfs(os.path.dirname(path)).f_namemax)
if len(filename) > max_filename_length:
dirname = os.path.dirname(path)
hashed_filename = str(hash(filename))
new_filename = (
filename[: max_filename_length - len(hashed_filename) - 8] + "..." + hashed_filename + ".lock"
)
return os.path.join(dirname, new_filename)
else:
return path
| datasets/src/datasets/utils/_filelock.py/0 | {
"file_path": "datasets/src/datasets/utils/_filelock.py",
"repo_id": "datasets",
"token_count": 903
} | 80 |
# Copyright 2020 The HuggingFace Datasets Authors and the current dataset script contributor.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# TODO: Address all TODOs and remove all explanatory comments
"""TODO: Add a description here."""
import csv
import json
import os
import datasets
# TODO: Add BibTeX citation
# Find for instance the citation on arxiv or on the dataset repo/website
_CITATION = """\
@InProceedings{huggingface:dataset,
title = {A great new dataset},
author={huggingface, Inc.
},
year={2020}
}
"""
# TODO: Add description of the dataset here
# You can copy an official description
_DESCRIPTION = """\
This new dataset is designed to solve this great NLP task and is crafted with a lot of care.
"""
# TODO: Add a link to an official homepage for the dataset here
_HOMEPAGE = ""
# TODO: Add the licence for the dataset here if you can find it
_LICENSE = ""
# TODO: Add link to the official dataset URLs here
# The HuggingFace Datasets library doesn't host the datasets but only points to the original files.
# This can be an arbitrary nested dict/list of URLs (see below in `_split_generators` method)
_URLS = {
"first_domain": "https://huggingface.co/great-new-dataset-first_domain.zip",
"second_domain": "https://huggingface.co/great-new-dataset-second_domain.zip",
}
# TODO: Name of the dataset usually matches the script name with CamelCase instead of snake_case
class NewDataset(datasets.GeneratorBasedBuilder):
"""TODO: Short description of my dataset."""
VERSION = datasets.Version("1.1.0")
# This is an example of a dataset with multiple configurations.
# If you don't want/need to define several sub-sets in your dataset,
# just remove the BUILDER_CONFIG_CLASS and the BUILDER_CONFIGS attributes.
# If you need to make complex sub-parts in the datasets with configurable options
# You can create your own builder configuration class to store attribute, inheriting from datasets.BuilderConfig
# BUILDER_CONFIG_CLASS = MyBuilderConfig
# You will be able to load one or the other configurations in the following list with
# data = datasets.load_dataset('my_dataset', 'first_domain')
# data = datasets.load_dataset('my_dataset', 'second_domain')
BUILDER_CONFIGS = [
datasets.BuilderConfig(name="first_domain", version=VERSION, description="This part of my dataset covers a first domain"),
datasets.BuilderConfig(name="second_domain", version=VERSION, description="This part of my dataset covers a second domain"),
]
DEFAULT_CONFIG_NAME = "first_domain" # It's not mandatory to have a default configuration. Just use one if it make sense.
def _info(self):
# TODO: This method specifies the datasets.DatasetInfo object which contains informations and typings for the dataset
if self.config.name == "first_domain": # This is the name of the configuration selected in BUILDER_CONFIGS above
features = datasets.Features(
{
"sentence": datasets.Value("string"),
"option1": datasets.Value("string"),
"answer": datasets.Value("string")
# These are the features of your dataset like images, labels ...
}
)
else: # This is an example to show how to have different features for "first_domain" and "second_domain"
features = datasets.Features(
{
"sentence": datasets.Value("string"),
"option2": datasets.Value("string"),
"second_domain_answer": datasets.Value("string")
# These are the features of your dataset like images, labels ...
}
)
return datasets.DatasetInfo(
# This is the description that will appear on the datasets page.
description=_DESCRIPTION,
# This defines the different columns of the dataset and their types
features=features, # Here we define them above because they are different between the two configurations
# If there's a common (input, target) tuple from the features, uncomment supervised_keys line below and
# specify them. They'll be used if as_supervised=True in builder.as_dataset.
# supervised_keys=("sentence", "label"),
# Homepage of the dataset for documentation
homepage=_HOMEPAGE,
# License for the dataset if available
license=_LICENSE,
# Citation for the dataset
citation=_CITATION,
)
def _split_generators(self, dl_manager):
# TODO: This method is tasked with downloading/extracting the data and defining the splits depending on the configuration
# If several configurations are possible (listed in BUILDER_CONFIGS), the configuration selected by the user is in self.config.name
# dl_manager is a datasets.download.DownloadManager that can be used to download and extract URLS
# It can accept any type or nested list/dict and will give back the same structure with the url replaced with path to local files.
# By default the archives will be extracted and a path to a cached folder where they are extracted is returned instead of the archive
urls = _URLS[self.config.name]
data_dir = dl_manager.download_and_extract(urls)
return [
datasets.SplitGenerator(
name=datasets.Split.TRAIN,
# These kwargs will be passed to _generate_examples
gen_kwargs={
"filepath": os.path.join(data_dir, "train.jsonl"),
"split": "train",
},
),
datasets.SplitGenerator(
name=datasets.Split.VALIDATION,
# These kwargs will be passed to _generate_examples
gen_kwargs={
"filepath": os.path.join(data_dir, "dev.jsonl"),
"split": "dev",
},
),
datasets.SplitGenerator(
name=datasets.Split.TEST,
# These kwargs will be passed to _generate_examples
gen_kwargs={
"filepath": os.path.join(data_dir, "test.jsonl"),
"split": "test"
},
),
]
# method parameters are unpacked from `gen_kwargs` as given in `_split_generators`
def _generate_examples(self, filepath, split):
# TODO: This method handles input defined in _split_generators to yield (key, example) tuples from the dataset.
# The `key` is for legacy reasons (tfds) and is not important in itself, but must be unique for each example.
with open(filepath, encoding="utf-8") as f:
for key, row in enumerate(f):
data = json.loads(row)
if self.config.name == "first_domain":
# Yields examples as (key, example) tuples
yield key, {
"sentence": data["sentence"],
"option1": data["option1"],
"answer": "" if split == "test" else data["answer"],
}
else:
yield key, {
"sentence": data["sentence"],
"option2": data["option2"],
"second_domain_answer": "" if split == "test" else data["second_domain_answer"],
}
| datasets/templates/new_dataset_script.py/0 | {
"file_path": "datasets/templates/new_dataset_script.py",
"repo_id": "datasets",
"token_count": 3156
} | 81 |
import contextlib
import os
import sqlite3
import pytest
from datasets import Dataset, Features, Value
from datasets.io.sql import SqlDatasetReader, SqlDatasetWriter
from ..utils import assert_arrow_memory_doesnt_increase, assert_arrow_memory_increases, require_sqlalchemy
def _check_sql_dataset(dataset, expected_features):
assert isinstance(dataset, Dataset)
assert dataset.num_rows == 4
assert dataset.num_columns == 3
assert dataset.column_names == ["col_1", "col_2", "col_3"]
for feature, expected_dtype in expected_features.items():
assert dataset.features[feature].dtype == expected_dtype
@require_sqlalchemy
@pytest.mark.parametrize("keep_in_memory", [False, True])
def test_dataset_from_sql_keep_in_memory(keep_in_memory, sqlite_path, tmp_path, set_sqlalchemy_silence_uber_warning):
cache_dir = tmp_path / "cache"
expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
with assert_arrow_memory_increases() if keep_in_memory else assert_arrow_memory_doesnt_increase():
dataset = SqlDatasetReader(
"dataset", "sqlite:///" + sqlite_path, cache_dir=cache_dir, keep_in_memory=keep_in_memory
).read()
_check_sql_dataset(dataset, expected_features)
@require_sqlalchemy
@pytest.mark.parametrize(
"features",
[
None,
{"col_1": "string", "col_2": "int64", "col_3": "float64"},
{"col_1": "string", "col_2": "string", "col_3": "string"},
{"col_1": "int32", "col_2": "int32", "col_3": "int32"},
{"col_1": "float32", "col_2": "float32", "col_3": "float32"},
],
)
def test_dataset_from_sql_features(features, sqlite_path, tmp_path, set_sqlalchemy_silence_uber_warning):
cache_dir = tmp_path / "cache"
default_expected_features = {"col_1": "string", "col_2": "int64", "col_3": "float64"}
expected_features = features.copy() if features else default_expected_features
features = (
Features({feature: Value(dtype) for feature, dtype in features.items()}) if features is not None else None
)
dataset = SqlDatasetReader("dataset", "sqlite:///" + sqlite_path, features=features, cache_dir=cache_dir).read()
_check_sql_dataset(dataset, expected_features)
def iter_sql_file(sqlite_path):
with contextlib.closing(sqlite3.connect(sqlite_path)) as con:
cur = con.cursor()
cur.execute("SELECT * FROM dataset")
for row in cur:
yield row
@require_sqlalchemy
def test_dataset_to_sql(sqlite_path, tmp_path, set_sqlalchemy_silence_uber_warning):
cache_dir = tmp_path / "cache"
output_sqlite_path = os.path.join(cache_dir, "tmp.sql")
dataset = SqlDatasetReader("dataset", "sqlite:///" + sqlite_path, cache_dir=cache_dir).read()
SqlDatasetWriter(dataset, "dataset", "sqlite:///" + output_sqlite_path, num_proc=1).write()
original_sql = iter_sql_file(sqlite_path)
expected_sql = iter_sql_file(output_sqlite_path)
for row1, row2 in zip(original_sql, expected_sql):
assert row1 == row2
@require_sqlalchemy
def test_dataset_to_sql_multiproc(sqlite_path, tmp_path, set_sqlalchemy_silence_uber_warning):
cache_dir = tmp_path / "cache"
output_sqlite_path = os.path.join(cache_dir, "tmp.sql")
dataset = SqlDatasetReader("dataset", "sqlite:///" + sqlite_path, cache_dir=cache_dir).read()
SqlDatasetWriter(dataset, "dataset", "sqlite:///" + output_sqlite_path, num_proc=2).write()
original_sql = iter_sql_file(sqlite_path)
expected_sql = iter_sql_file(output_sqlite_path)
for row1, row2 in zip(original_sql, expected_sql):
assert row1 == row2
@require_sqlalchemy
def test_dataset_to_sql_invalidproc(sqlite_path, tmp_path, set_sqlalchemy_silence_uber_warning):
cache_dir = tmp_path / "cache"
output_sqlite_path = os.path.join(cache_dir, "tmp.sql")
dataset = SqlDatasetReader("dataset", "sqlite:///" + sqlite_path, cache_dir=cache_dir).read()
with pytest.raises(ValueError):
SqlDatasetWriter(dataset, "dataset", "sqlite:///" + output_sqlite_path, num_proc=0).write()
| datasets/tests/io/test_sql.py/0 | {
"file_path": "datasets/tests/io/test_sql.py",
"repo_id": "datasets",
"token_count": 1628
} | 82 |
import importlib
import os
import tempfile
import types
from contextlib import nullcontext as does_not_raise
from multiprocessing import Process
from pathlib import Path
from unittest import TestCase
from unittest.mock import patch
import numpy as np
import pyarrow as pa
import pyarrow.parquet as pq
import pytest
from multiprocess.pool import Pool
from datasets.arrow_dataset import Dataset
from datasets.arrow_reader import DatasetNotOnHfGcsError
from datasets.arrow_writer import ArrowWriter
from datasets.builder import ArrowBasedBuilder, BeamBasedBuilder, BuilderConfig, DatasetBuilder, GeneratorBasedBuilder
from datasets.dataset_dict import DatasetDict, IterableDatasetDict
from datasets.download.download_manager import DownloadMode
from datasets.features import Features, Value
from datasets.info import DatasetInfo, PostProcessedInfo
from datasets.iterable_dataset import IterableDataset
from datasets.load import configure_builder_class
from datasets.splits import Split, SplitDict, SplitGenerator, SplitInfo
from datasets.streaming import xjoin
from datasets.utils.file_utils import is_local_path
from datasets.utils.info_utils import VerificationMode
from datasets.utils.logging import INFO, get_logger
from .utils import (
assert_arrow_memory_doesnt_increase,
assert_arrow_memory_increases,
require_beam,
require_faiss,
set_current_working_directory_to_temp_dir,
)
class DummyBuilder(DatasetBuilder):
def _info(self):
return DatasetInfo(features=Features({"text": Value("string")}))
def _split_generators(self, dl_manager):
return [SplitGenerator(name=Split.TRAIN)]
def _prepare_split(self, split_generator, **kwargs):
fname = f"{self.dataset_name}-{split_generator.name}.arrow"
with ArrowWriter(features=self.info.features, path=os.path.join(self._output_dir, fname)) as writer:
writer.write_batch({"text": ["foo"] * 100})
num_examples, num_bytes = writer.finalize()
split_generator.split_info.num_examples = num_examples
split_generator.split_info.num_bytes = num_bytes
class DummyGeneratorBasedBuilder(GeneratorBasedBuilder):
def _info(self):
return DatasetInfo(features=Features({"text": Value("string")}))
def _split_generators(self, dl_manager):
return [SplitGenerator(name=Split.TRAIN)]
def _generate_examples(self):
for i in range(100):
yield i, {"text": "foo"}
class DummyArrowBasedBuilder(ArrowBasedBuilder):
def _info(self):
return DatasetInfo(features=Features({"text": Value("string")}))
def _split_generators(self, dl_manager):
return [SplitGenerator(name=Split.TRAIN)]
def _generate_tables(self):
for i in range(10):
yield i, pa.table({"text": ["foo"] * 10})
class DummyBeamBasedBuilder(BeamBasedBuilder):
def _info(self):
return DatasetInfo(features=Features({"text": Value("string")}))
def _split_generators(self, dl_manager):
return [SplitGenerator(name=Split.TRAIN)]
def _build_pcollection(self, pipeline):
import apache_beam as beam
def _process(item):
for i in range(10):
yield f"{i}_{item}", {"text": "foo"}
return pipeline | "Initialize" >> beam.Create(range(10)) | "Extract content" >> beam.FlatMap(_process)
class DummyGeneratorBasedBuilderWithIntegers(GeneratorBasedBuilder):
def _info(self):
return DatasetInfo(features=Features({"id": Value("int8")}))
def _split_generators(self, dl_manager):
return [SplitGenerator(name=Split.TRAIN)]
def _generate_examples(self):
for i in range(100):
yield i, {"id": i}
class DummyGeneratorBasedBuilderConfig(BuilderConfig):
def __init__(self, content="foo", times=2, *args, **kwargs):
super().__init__(*args, **kwargs)
self.content = content
self.times = times
class DummyGeneratorBasedBuilderWithConfig(GeneratorBasedBuilder):
BUILDER_CONFIG_CLASS = DummyGeneratorBasedBuilderConfig
def _info(self):
return DatasetInfo(features=Features({"text": Value("string")}))
def _split_generators(self, dl_manager):
return [SplitGenerator(name=Split.TRAIN)]
def _generate_examples(self):
for i in range(100):
yield i, {"text": self.config.content * self.config.times}
class DummyBuilderWithMultipleConfigs(DummyBuilder):
BUILDER_CONFIGS = [
DummyGeneratorBasedBuilderConfig(name="a"),
DummyGeneratorBasedBuilderConfig(name="b"),
]
class DummyBuilderWithDefaultConfig(DummyBuilderWithMultipleConfigs):
DEFAULT_CONFIG_NAME = "a"
class DummyBuilderWithDownload(DummyBuilder):
def __init__(self, *args, rel_path=None, abs_path=None, **kwargs):
super().__init__(*args, **kwargs)
self._rel_path = rel_path
self._abs_path = abs_path
def _split_generators(self, dl_manager):
if self._rel_path is not None:
assert os.path.exists(dl_manager.download(self._rel_path)), "dl_manager must support relative paths"
if self._abs_path is not None:
assert os.path.exists(dl_manager.download(self._abs_path)), "dl_manager must support absolute paths"
return [SplitGenerator(name=Split.TRAIN)]
class DummyBuilderWithManualDownload(DummyBuilderWithMultipleConfigs):
@property
def manual_download_instructions(self):
return "To use the dataset you have to download some stuff manually and pass the data path to data_dir"
def _split_generators(self, dl_manager):
if not os.path.exists(self.config.data_dir):
raise FileNotFoundError(f"data_dir {self.config.data_dir} doesn't exist.")
return [SplitGenerator(name=Split.TRAIN)]
class DummyArrowBasedBuilderWithShards(ArrowBasedBuilder):
def _info(self):
return DatasetInfo(features=Features({"id": Value("int8"), "filepath": Value("string")}))
def _split_generators(self, dl_manager):
return [SplitGenerator(name=Split.TRAIN, gen_kwargs={"filepaths": [f"data{i}.txt" for i in range(4)]})]
def _generate_tables(self, filepaths):
idx = 0
for filepath in filepaths:
for i in range(10):
yield idx, pa.table({"id": range(10 * i, 10 * (i + 1)), "filepath": [filepath] * 10})
idx += 1
class DummyGeneratorBasedBuilderWithShards(GeneratorBasedBuilder):
def _info(self):
return DatasetInfo(features=Features({"id": Value("int8"), "filepath": Value("string")}))
def _split_generators(self, dl_manager):
return [SplitGenerator(name=Split.TRAIN, gen_kwargs={"filepaths": [f"data{i}.txt" for i in range(4)]})]
def _generate_examples(self, filepaths):
idx = 0
for filepath in filepaths:
for i in range(100):
yield idx, {"id": i, "filepath": filepath}
idx += 1
class DummyArrowBasedBuilderWithAmbiguousShards(ArrowBasedBuilder):
def _info(self):
return DatasetInfo(features=Features({"id": Value("int8"), "filepath": Value("string")}))
def _split_generators(self, dl_manager):
return [
SplitGenerator(
name=Split.TRAIN,
gen_kwargs={
"filepaths": [f"data{i}.txt" for i in range(4)],
"dummy_kwarg_with_different_length": [f"dummy_data{i}.txt" for i in range(3)],
},
)
]
def _generate_tables(self, filepaths, dummy_kwarg_with_different_length):
idx = 0
for filepath in filepaths:
for i in range(10):
yield idx, pa.table({"id": range(10 * i, 10 * (i + 1)), "filepath": [filepath] * 10})
idx += 1
class DummyGeneratorBasedBuilderWithAmbiguousShards(GeneratorBasedBuilder):
def _info(self):
return DatasetInfo(features=Features({"id": Value("int8"), "filepath": Value("string")}))
def _split_generators(self, dl_manager):
return [
SplitGenerator(
name=Split.TRAIN,
gen_kwargs={
"filepaths": [f"data{i}.txt" for i in range(4)],
"dummy_kwarg_with_different_length": [f"dummy_data{i}.txt" for i in range(3)],
},
)
]
def _generate_examples(self, filepaths, dummy_kwarg_with_different_length):
idx = 0
for filepath in filepaths:
for i in range(100):
yield idx, {"id": i, "filepath": filepath}
idx += 1
def _run_concurrent_download_and_prepare(tmp_dir):
builder = DummyBuilder(cache_dir=tmp_dir)
builder.download_and_prepare(download_mode=DownloadMode.REUSE_DATASET_IF_EXISTS)
return builder
def check_streaming(builder):
builders_module = importlib.import_module(builder.__module__)
assert builders_module._patched_for_streaming
assert builders_module.os.path.join is xjoin
class BuilderTest(TestCase):
def test_download_and_prepare(self):
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyBuilder(cache_dir=tmp_dir)
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD)
self.assertTrue(
os.path.exists(
os.path.join(
tmp_dir, builder.dataset_name, "default", "0.0.0", f"{builder.dataset_name}-train.arrow"
)
)
)
self.assertDictEqual(builder.info.features, Features({"text": Value("string")}))
self.assertEqual(builder.info.splits["train"].num_examples, 100)
self.assertTrue(
os.path.exists(os.path.join(tmp_dir, builder.dataset_name, "default", "0.0.0", "dataset_info.json"))
)
def test_download_and_prepare_checksum_computation(self):
with tempfile.TemporaryDirectory() as tmp_dir:
builder_no_verification = DummyBuilder(cache_dir=tmp_dir)
builder_no_verification.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD)
self.assertTrue(
all(v["checksum"] is not None for _, v in builder_no_verification.info.download_checksums.items())
)
builder_with_verification = DummyBuilder(cache_dir=tmp_dir)
builder_with_verification.download_and_prepare(
download_mode=DownloadMode.FORCE_REDOWNLOAD,
verification_mode=VerificationMode.ALL_CHECKS,
)
self.assertTrue(
all(v["checksum"] is None for _, v in builder_with_verification.info.download_checksums.items())
)
def test_concurrent_download_and_prepare(self):
with tempfile.TemporaryDirectory() as tmp_dir:
processes = 2
with Pool(processes=processes) as pool:
jobs = [
pool.apply_async(_run_concurrent_download_and_prepare, kwds={"tmp_dir": tmp_dir})
for _ in range(processes)
]
builders = [job.get() for job in jobs]
for builder in builders:
self.assertTrue(
os.path.exists(
os.path.join(
tmp_dir,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train.arrow",
)
)
)
self.assertDictEqual(builder.info.features, Features({"text": Value("string")}))
self.assertEqual(builder.info.splits["train"].num_examples, 100)
self.assertTrue(
os.path.exists(
os.path.join(tmp_dir, builder.dataset_name, "default", "0.0.0", "dataset_info.json")
)
)
def test_download_and_prepare_with_base_path(self):
with tempfile.TemporaryDirectory() as tmp_dir:
rel_path = "dummy1.data"
abs_path = os.path.join(tmp_dir, "dummy2.data")
# test relative path is missing
builder = DummyBuilderWithDownload(cache_dir=tmp_dir, rel_path=rel_path)
with self.assertRaises(FileNotFoundError):
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD, base_path=tmp_dir)
# test absolute path is missing
builder = DummyBuilderWithDownload(cache_dir=tmp_dir, abs_path=abs_path)
with self.assertRaises(FileNotFoundError):
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD, base_path=tmp_dir)
# test that they are both properly loaded when they exist
open(os.path.join(tmp_dir, rel_path), "w")
open(abs_path, "w")
builder = DummyBuilderWithDownload(cache_dir=tmp_dir, rel_path=rel_path, abs_path=abs_path)
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD, base_path=tmp_dir)
self.assertTrue(
os.path.exists(
os.path.join(
tmp_dir,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train.arrow",
)
)
)
def test_as_dataset_with_post_process(self):
def _post_process(self, dataset, resources_paths):
def char_tokenize(example):
return {"tokens": list(example["text"])}
return dataset.map(char_tokenize, cache_file_name=resources_paths["tokenized_dataset"])
def _post_processing_resources(self, split):
return {"tokenized_dataset": f"tokenized_dataset-{split}.arrow"}
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyBuilder(cache_dir=tmp_dir)
builder.info.post_processed = PostProcessedInfo(
features=Features({"text": Value("string"), "tokens": [Value("string")]})
)
builder._post_process = types.MethodType(_post_process, builder)
builder._post_processing_resources = types.MethodType(_post_processing_resources, builder)
os.makedirs(builder.cache_dir)
builder.info.splits = SplitDict()
builder.info.splits.add(SplitInfo("train", num_examples=10))
builder.info.splits.add(SplitInfo("test", num_examples=10))
for split in builder.info.splits:
with ArrowWriter(
path=os.path.join(builder.cache_dir, f"{builder.dataset_name}-{split}.arrow"),
features=Features({"text": Value("string")}),
) as writer:
writer.write_batch({"text": ["foo"] * 10})
writer.finalize()
with ArrowWriter(
path=os.path.join(builder.cache_dir, f"tokenized_dataset-{split}.arrow"),
features=Features({"text": Value("string"), "tokens": [Value("string")]}),
) as writer:
writer.write_batch({"text": ["foo"] * 10, "tokens": [list("foo")] * 10})
writer.finalize()
dsets = builder.as_dataset()
self.assertIsInstance(dsets, DatasetDict)
self.assertListEqual(list(dsets.keys()), ["train", "test"])
self.assertEqual(len(dsets["train"]), 10)
self.assertEqual(len(dsets["test"]), 10)
self.assertDictEqual(
dsets["train"].features, Features({"text": Value("string"), "tokens": [Value("string")]})
)
self.assertDictEqual(
dsets["test"].features, Features({"text": Value("string"), "tokens": [Value("string")]})
)
self.assertListEqual(dsets["train"].column_names, ["text", "tokens"])
self.assertListEqual(dsets["test"].column_names, ["text", "tokens"])
del dsets
dset = builder.as_dataset("train")
self.assertIsInstance(dset, Dataset)
self.assertEqual(dset.split, "train")
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"text": Value("string"), "tokens": [Value("string")]}))
self.assertListEqual(dset.column_names, ["text", "tokens"])
self.assertGreater(builder.info.post_processing_size, 0)
self.assertGreater(
builder.info.post_processed.resources_checksums["train"]["tokenized_dataset"]["num_bytes"], 0
)
del dset
dset = builder.as_dataset("train+test[:30%]")
self.assertIsInstance(dset, Dataset)
self.assertEqual(dset.split, "train+test[:30%]")
self.assertEqual(len(dset), 13)
self.assertDictEqual(dset.features, Features({"text": Value("string"), "tokens": [Value("string")]}))
self.assertListEqual(dset.column_names, ["text", "tokens"])
del dset
dset = builder.as_dataset("all")
self.assertIsInstance(dset, Dataset)
self.assertEqual(dset.split, "train+test")
self.assertEqual(len(dset), 20)
self.assertDictEqual(dset.features, Features({"text": Value("string"), "tokens": [Value("string")]}))
self.assertListEqual(dset.column_names, ["text", "tokens"])
del dset
def _post_process(self, dataset, resources_paths):
return dataset.select([0, 1], keep_in_memory=True)
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyBuilder(cache_dir=tmp_dir)
builder._post_process = types.MethodType(_post_process, builder)
os.makedirs(builder.cache_dir)
builder.info.splits = SplitDict()
builder.info.splits.add(SplitInfo("train", num_examples=10))
builder.info.splits.add(SplitInfo("test", num_examples=10))
for split in builder.info.splits:
with ArrowWriter(
path=os.path.join(builder.cache_dir, f"{builder.dataset_name}-{split}.arrow"),
features=Features({"text": Value("string")}),
) as writer:
writer.write_batch({"text": ["foo"] * 10})
writer.finalize()
with ArrowWriter(
path=os.path.join(builder.cache_dir, f"small_dataset-{split}.arrow"),
features=Features({"text": Value("string")}),
) as writer:
writer.write_batch({"text": ["foo"] * 2})
writer.finalize()
dsets = builder.as_dataset()
self.assertIsInstance(dsets, DatasetDict)
self.assertListEqual(list(dsets.keys()), ["train", "test"])
self.assertEqual(len(dsets["train"]), 2)
self.assertEqual(len(dsets["test"]), 2)
self.assertDictEqual(dsets["train"].features, Features({"text": Value("string")}))
self.assertDictEqual(dsets["test"].features, Features({"text": Value("string")}))
self.assertListEqual(dsets["train"].column_names, ["text"])
self.assertListEqual(dsets["test"].column_names, ["text"])
del dsets
dset = builder.as_dataset("train")
self.assertIsInstance(dset, Dataset)
self.assertEqual(dset.split, "train")
self.assertEqual(len(dset), 2)
self.assertDictEqual(dset.features, Features({"text": Value("string")}))
self.assertListEqual(dset.column_names, ["text"])
del dset
dset = builder.as_dataset("train+test[:30%]")
self.assertIsInstance(dset, Dataset)
self.assertEqual(dset.split, "train+test[:30%]")
self.assertEqual(len(dset), 2)
self.assertDictEqual(dset.features, Features({"text": Value("string")}))
self.assertListEqual(dset.column_names, ["text"])
del dset
@require_faiss
def test_as_dataset_with_post_process_with_index(self):
def _post_process(self, dataset, resources_paths):
if os.path.exists(resources_paths["index"]):
dataset.load_faiss_index("my_index", resources_paths["index"])
return dataset
else:
dataset.add_faiss_index_from_external_arrays(
external_arrays=np.ones((len(dataset), 8)), string_factory="Flat", index_name="my_index"
)
dataset.save_faiss_index("my_index", resources_paths["index"])
return dataset
def _post_processing_resources(self, split):
return {"index": f"Flat-{split}.faiss"}
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyBuilder(cache_dir=tmp_dir)
builder._post_process = types.MethodType(_post_process, builder)
builder._post_processing_resources = types.MethodType(_post_processing_resources, builder)
os.makedirs(builder.cache_dir)
builder.info.splits = SplitDict()
builder.info.splits.add(SplitInfo("train", num_examples=10))
builder.info.splits.add(SplitInfo("test", num_examples=10))
for split in builder.info.splits:
with ArrowWriter(
path=os.path.join(builder.cache_dir, f"{builder.dataset_name}-{split}.arrow"),
features=Features({"text": Value("string")}),
) as writer:
writer.write_batch({"text": ["foo"] * 10})
writer.finalize()
with ArrowWriter(
path=os.path.join(builder.cache_dir, f"small_dataset-{split}.arrow"),
features=Features({"text": Value("string")}),
) as writer:
writer.write_batch({"text": ["foo"] * 2})
writer.finalize()
dsets = builder.as_dataset()
self.assertIsInstance(dsets, DatasetDict)
self.assertListEqual(list(dsets.keys()), ["train", "test"])
self.assertEqual(len(dsets["train"]), 10)
self.assertEqual(len(dsets["test"]), 10)
self.assertDictEqual(dsets["train"].features, Features({"text": Value("string")}))
self.assertDictEqual(dsets["test"].features, Features({"text": Value("string")}))
self.assertListEqual(dsets["train"].column_names, ["text"])
self.assertListEqual(dsets["test"].column_names, ["text"])
self.assertListEqual(dsets["train"].list_indexes(), ["my_index"])
self.assertListEqual(dsets["test"].list_indexes(), ["my_index"])
self.assertGreater(builder.info.post_processing_size, 0)
self.assertGreater(builder.info.post_processed.resources_checksums["train"]["index"]["num_bytes"], 0)
del dsets
dset = builder.as_dataset("train")
self.assertIsInstance(dset, Dataset)
self.assertEqual(dset.split, "train")
self.assertEqual(len(dset), 10)
self.assertDictEqual(dset.features, Features({"text": Value("string")}))
self.assertListEqual(dset.column_names, ["text"])
self.assertListEqual(dset.list_indexes(), ["my_index"])
del dset
dset = builder.as_dataset("train+test[:30%]")
self.assertIsInstance(dset, Dataset)
self.assertEqual(dset.split, "train+test[:30%]")
self.assertEqual(len(dset), 13)
self.assertDictEqual(dset.features, Features({"text": Value("string")}))
self.assertListEqual(dset.column_names, ["text"])
self.assertListEqual(dset.list_indexes(), ["my_index"])
del dset
def test_download_and_prepare_with_post_process(self):
def _post_process(self, dataset, resources_paths):
def char_tokenize(example):
return {"tokens": list(example["text"])}
return dataset.map(char_tokenize, cache_file_name=resources_paths["tokenized_dataset"])
def _post_processing_resources(self, split):
return {"tokenized_dataset": f"tokenized_dataset-{split}.arrow"}
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyBuilder(cache_dir=tmp_dir)
builder.info.post_processed = PostProcessedInfo(
features=Features({"text": Value("string"), "tokens": [Value("string")]})
)
builder._post_process = types.MethodType(_post_process, builder)
builder._post_processing_resources = types.MethodType(_post_processing_resources, builder)
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD)
self.assertTrue(
os.path.exists(
os.path.join(
tmp_dir, builder.dataset_name, "default", "0.0.0", f"{builder.dataset_name}-train.arrow"
)
)
)
self.assertDictEqual(builder.info.features, Features({"text": Value("string")}))
self.assertDictEqual(
builder.info.post_processed.features,
Features({"text": Value("string"), "tokens": [Value("string")]}),
)
self.assertEqual(builder.info.splits["train"].num_examples, 100)
self.assertTrue(
os.path.exists(os.path.join(tmp_dir, builder.dataset_name, "default", "0.0.0", "dataset_info.json"))
)
def _post_process(self, dataset, resources_paths):
return dataset.select([0, 1], keep_in_memory=True)
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyBuilder(cache_dir=tmp_dir)
builder._post_process = types.MethodType(_post_process, builder)
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD)
self.assertTrue(
os.path.exists(
os.path.join(
tmp_dir, builder.dataset_name, "default", "0.0.0", f"{builder.dataset_name}-train.arrow"
)
)
)
self.assertDictEqual(builder.info.features, Features({"text": Value("string")}))
self.assertIsNone(builder.info.post_processed)
self.assertEqual(builder.info.splits["train"].num_examples, 100)
self.assertTrue(
os.path.exists(os.path.join(tmp_dir, builder.dataset_name, "default", "0.0.0", "dataset_info.json"))
)
def _post_process(self, dataset, resources_paths):
if os.path.exists(resources_paths["index"]):
dataset.load_faiss_index("my_index", resources_paths["index"])
return dataset
else:
dataset = dataset.add_faiss_index_from_external_arrays(
external_arrays=np.ones((len(dataset), 8)), string_factory="Flat", index_name="my_index"
)
dataset.save_faiss_index("my_index", resources_paths["index"])
return dataset
def _post_processing_resources(self, split):
return {"index": f"Flat-{split}.faiss"}
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyBuilder(cache_dir=tmp_dir)
builder._post_process = types.MethodType(_post_process, builder)
builder._post_processing_resources = types.MethodType(_post_processing_resources, builder)
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD)
self.assertTrue(
os.path.exists(
os.path.join(
tmp_dir, builder.dataset_name, "default", "0.0.0", f"{builder.dataset_name}-train.arrow"
)
)
)
self.assertDictEqual(builder.info.features, Features({"text": Value("string")}))
self.assertIsNone(builder.info.post_processed)
self.assertEqual(builder.info.splits["train"].num_examples, 100)
self.assertTrue(
os.path.exists(os.path.join(tmp_dir, builder.dataset_name, "default", "0.0.0", "dataset_info.json"))
)
def test_error_download_and_prepare(self):
def _prepare_split(self, split_generator, **kwargs):
raise ValueError()
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyBuilder(cache_dir=tmp_dir)
builder._prepare_split = types.MethodType(_prepare_split, builder)
self.assertRaises(
ValueError,
builder.download_and_prepare,
download_mode=DownloadMode.FORCE_REDOWNLOAD,
)
self.assertRaises(FileNotFoundError, builder.as_dataset)
def test_generator_based_download_and_prepare(self):
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir)
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD)
self.assertTrue(
os.path.exists(
os.path.join(
tmp_dir,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train.arrow",
)
)
)
self.assertDictEqual(builder.info.features, Features({"text": Value("string")}))
self.assertEqual(builder.info.splits["train"].num_examples, 100)
self.assertTrue(
os.path.exists(os.path.join(tmp_dir, builder.dataset_name, "default", "0.0.0", "dataset_info.json"))
)
# Test that duplicated keys are ignored if verification_mode is "no_checks"
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir)
with patch("datasets.builder.ArrowWriter", side_effect=ArrowWriter) as mock_arrow_writer:
builder.download_and_prepare(
download_mode=DownloadMode.FORCE_REDOWNLOAD, verification_mode=VerificationMode.NO_CHECKS
)
mock_arrow_writer.assert_called_once()
args, kwargs = mock_arrow_writer.call_args_list[0]
self.assertFalse(kwargs["check_duplicates"])
mock_arrow_writer.reset_mock()
builder.download_and_prepare(
download_mode=DownloadMode.FORCE_REDOWNLOAD, verification_mode=VerificationMode.BASIC_CHECKS
)
mock_arrow_writer.assert_called_once()
args, kwargs = mock_arrow_writer.call_args_list[0]
self.assertTrue(kwargs["check_duplicates"])
def test_cache_dir_no_args(self):
with tempfile.TemporaryDirectory() as tmp_dir:
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_dir=None, data_files=None)
relative_cache_dir_parts = Path(builder._relative_data_dir()).parts
self.assertTupleEqual(relative_cache_dir_parts, (builder.dataset_name, "default", "0.0.0"))
def test_cache_dir_for_data_files(self):
with tempfile.TemporaryDirectory() as tmp_dir:
dummy_data1 = os.path.join(tmp_dir, "dummy_data1.txt")
with open(dummy_data1, "w", encoding="utf-8") as f:
f.writelines("foo bar")
dummy_data2 = os.path.join(tmp_dir, "dummy_data2.txt")
with open(dummy_data2, "w", encoding="utf-8") as f:
f.writelines("foo bar\n")
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=dummy_data1)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=dummy_data1)
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=[dummy_data1])
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files={"train": dummy_data1})
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files={Split.TRAIN: dummy_data1})
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files={"train": [dummy_data1]})
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files={"test": dummy_data1})
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=dummy_data2)
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=[dummy_data2])
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=[dummy_data1, dummy_data2])
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=[dummy_data1, dummy_data2])
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=[dummy_data1, dummy_data2])
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(cache_dir=tmp_dir, data_files=[dummy_data2, dummy_data1])
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
builder = DummyGeneratorBasedBuilder(
cache_dir=tmp_dir, data_files={"train": dummy_data1, "test": dummy_data2}
)
other_builder = DummyGeneratorBasedBuilder(
cache_dir=tmp_dir, data_files={"train": dummy_data1, "test": dummy_data2}
)
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(
cache_dir=tmp_dir, data_files={"train": [dummy_data1], "test": dummy_data2}
)
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(
cache_dir=tmp_dir, data_files={"train": dummy_data1, "validation": dummy_data2}
)
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilder(
cache_dir=tmp_dir,
data_files={"train": [dummy_data1, dummy_data2], "test": dummy_data2},
)
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
def test_cache_dir_for_features(self):
with tempfile.TemporaryDirectory() as tmp_dir:
f1 = Features({"id": Value("int8")})
f2 = Features({"id": Value("int32")})
builder = DummyGeneratorBasedBuilderWithIntegers(cache_dir=tmp_dir, features=f1)
other_builder = DummyGeneratorBasedBuilderWithIntegers(cache_dir=tmp_dir, features=f1)
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilderWithIntegers(cache_dir=tmp_dir, features=f2)
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
def test_cache_dir_for_config_kwargs(self):
with tempfile.TemporaryDirectory() as tmp_dir:
# create config on the fly
builder = DummyGeneratorBasedBuilderWithConfig(cache_dir=tmp_dir, content="foo", times=2)
other_builder = DummyGeneratorBasedBuilderWithConfig(cache_dir=tmp_dir, times=2, content="foo")
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
self.assertIn("content=foo", builder.cache_dir)
self.assertIn("times=2", builder.cache_dir)
other_builder = DummyGeneratorBasedBuilderWithConfig(cache_dir=tmp_dir, content="bar", times=2)
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyGeneratorBasedBuilderWithConfig(cache_dir=tmp_dir, content="foo")
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
with tempfile.TemporaryDirectory() as tmp_dir:
# overwrite an existing config
builder = DummyBuilderWithMultipleConfigs(cache_dir=tmp_dir, config_name="a", content="foo", times=2)
other_builder = DummyBuilderWithMultipleConfigs(cache_dir=tmp_dir, config_name="a", times=2, content="foo")
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
self.assertIn("content=foo", builder.cache_dir)
self.assertIn("times=2", builder.cache_dir)
other_builder = DummyBuilderWithMultipleConfigs(cache_dir=tmp_dir, config_name="a", content="bar", times=2)
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyBuilderWithMultipleConfigs(cache_dir=tmp_dir, config_name="a", content="foo")
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
def test_config_names(self):
with tempfile.TemporaryDirectory() as tmp_dir:
with self.assertRaises(ValueError) as error_context:
DummyBuilderWithMultipleConfigs(cache_dir=tmp_dir, data_files=None, data_dir=None)
self.assertIn("Please pick one among the available configs", str(error_context.exception))
builder = DummyBuilderWithMultipleConfigs(cache_dir=tmp_dir, config_name="a")
self.assertEqual(builder.config.name, "a")
builder = DummyBuilderWithMultipleConfigs(cache_dir=tmp_dir, config_name="b")
self.assertEqual(builder.config.name, "b")
with self.assertRaises(ValueError):
DummyBuilderWithMultipleConfigs(cache_dir=tmp_dir)
builder = DummyBuilderWithDefaultConfig(cache_dir=tmp_dir)
self.assertEqual(builder.config.name, "a")
def test_cache_dir_for_data_dir(self):
with tempfile.TemporaryDirectory() as tmp_dir, tempfile.TemporaryDirectory() as data_dir:
builder = DummyBuilderWithManualDownload(cache_dir=tmp_dir, config_name="a", data_dir=data_dir)
other_builder = DummyBuilderWithManualDownload(cache_dir=tmp_dir, config_name="a", data_dir=data_dir)
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = DummyBuilderWithManualDownload(cache_dir=tmp_dir, config_name="a", data_dir=tmp_dir)
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
def test_cache_dir_for_configured_builder(self):
with tempfile.TemporaryDirectory() as tmp_dir, tempfile.TemporaryDirectory() as data_dir:
builder_cls = configure_builder_class(
DummyBuilderWithManualDownload,
builder_configs=[BuilderConfig(data_dir=data_dir)],
default_config_name=None,
dataset_name="dummy",
)
builder = builder_cls(cache_dir=tmp_dir, hash="abc")
other_builder = builder_cls(cache_dir=tmp_dir, hash="abc")
self.assertEqual(builder.cache_dir, other_builder.cache_dir)
other_builder = builder_cls(cache_dir=tmp_dir, hash="def")
self.assertNotEqual(builder.cache_dir, other_builder.cache_dir)
def test_arrow_based_download_and_prepare(tmp_path):
builder = DummyArrowBasedBuilder(cache_dir=tmp_path)
builder.download_and_prepare()
assert os.path.exists(
os.path.join(
tmp_path,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train.arrow",
)
)
assert builder.info.features, Features({"text": Value("string")})
assert builder.info.splits["train"].num_examples == 100
assert os.path.exists(os.path.join(tmp_path, builder.dataset_name, "default", "0.0.0", "dataset_info.json"))
@require_beam
def test_beam_based_download_and_prepare(tmp_path):
builder = DummyBeamBasedBuilder(cache_dir=tmp_path, beam_runner="DirectRunner")
builder.download_and_prepare()
assert os.path.exists(
os.path.join(
tmp_path,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train.arrow",
)
)
assert builder.info.features, Features({"text": Value("string")})
assert builder.info.splits["train"].num_examples == 100
assert os.path.exists(os.path.join(tmp_path, builder.dataset_name, "default", "0.0.0", "dataset_info.json"))
@require_beam
def test_beam_based_as_dataset(tmp_path):
builder = DummyBeamBasedBuilder(cache_dir=tmp_path, beam_runner="DirectRunner")
builder.download_and_prepare()
dataset = builder.as_dataset()
assert dataset
assert isinstance(dataset["train"], Dataset)
assert len(dataset["train"]) > 0
@pytest.mark.parametrize(
"split, expected_dataset_class, expected_dataset_length",
[
(None, DatasetDict, 10),
("train", Dataset, 10),
("train+test[:30%]", Dataset, 13),
],
)
@pytest.mark.parametrize("in_memory", [False, True])
def test_builder_as_dataset(split, expected_dataset_class, expected_dataset_length, in_memory, tmp_path):
cache_dir = str(tmp_path)
builder = DummyBuilder(cache_dir=cache_dir)
os.makedirs(builder.cache_dir)
builder.info.splits = SplitDict()
builder.info.splits.add(SplitInfo("train", num_examples=10))
builder.info.splits.add(SplitInfo("test", num_examples=10))
for info_split in builder.info.splits:
with ArrowWriter(
path=os.path.join(builder.cache_dir, f"{builder.dataset_name}-{info_split}.arrow"),
features=Features({"text": Value("string")}),
) as writer:
writer.write_batch({"text": ["foo"] * 10})
writer.finalize()
with assert_arrow_memory_increases() if in_memory else assert_arrow_memory_doesnt_increase():
dataset = builder.as_dataset(split=split, in_memory=in_memory)
assert isinstance(dataset, expected_dataset_class)
if isinstance(dataset, DatasetDict):
assert list(dataset.keys()) == ["train", "test"]
datasets = dataset.values()
expected_splits = ["train", "test"]
elif isinstance(dataset, Dataset):
datasets = [dataset]
expected_splits = [split]
for dataset, expected_split in zip(datasets, expected_splits):
assert dataset.split == expected_split
assert len(dataset) == expected_dataset_length
assert dataset.features == Features({"text": Value("string")})
dataset.column_names == ["text"]
@pytest.mark.parametrize("in_memory", [False, True])
def test_generator_based_builder_as_dataset(in_memory, tmp_path):
cache_dir = tmp_path / "data"
cache_dir.mkdir()
cache_dir = str(cache_dir)
builder = DummyGeneratorBasedBuilder(cache_dir=cache_dir)
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD)
with assert_arrow_memory_increases() if in_memory else assert_arrow_memory_doesnt_increase():
dataset = builder.as_dataset("train", in_memory=in_memory)
assert dataset.data.to_pydict() == {"text": ["foo"] * 100}
@pytest.mark.parametrize(
"writer_batch_size, default_writer_batch_size, expected_chunks", [(None, None, 1), (None, 5, 20), (10, None, 10)]
)
def test_custom_writer_batch_size(tmp_path, writer_batch_size, default_writer_batch_size, expected_chunks):
cache_dir = str(tmp_path)
if default_writer_batch_size:
DummyGeneratorBasedBuilder.DEFAULT_WRITER_BATCH_SIZE = default_writer_batch_size
builder = DummyGeneratorBasedBuilder(cache_dir=cache_dir, writer_batch_size=writer_batch_size)
assert builder._writer_batch_size == (writer_batch_size or default_writer_batch_size)
builder.download_and_prepare(download_mode=DownloadMode.FORCE_REDOWNLOAD)
dataset = builder.as_dataset("train")
assert len(dataset.data[0].chunks) == expected_chunks
def test_builder_as_streaming_dataset(tmp_path):
dummy_builder = DummyGeneratorBasedBuilder(cache_dir=str(tmp_path))
check_streaming(dummy_builder)
dsets = dummy_builder.as_streaming_dataset()
assert isinstance(dsets, IterableDatasetDict)
assert isinstance(dsets["train"], IterableDataset)
assert len(list(dsets["train"])) == 100
dset = dummy_builder.as_streaming_dataset(split="train")
assert isinstance(dset, IterableDataset)
assert len(list(dset)) == 100
@require_beam
def test_beam_based_builder_as_streaming_dataset(tmp_path):
builder = DummyBeamBasedBuilder(cache_dir=tmp_path)
check_streaming(builder)
with pytest.raises(DatasetNotOnHfGcsError):
builder.as_streaming_dataset()
def _run_test_builder_streaming_works_in_subprocesses(builder):
check_streaming(builder)
dset = builder.as_streaming_dataset(split="train")
assert isinstance(dset, IterableDataset)
assert len(list(dset)) == 100
def test_builder_streaming_works_in_subprocess(tmp_path):
dummy_builder = DummyGeneratorBasedBuilder(cache_dir=str(tmp_path))
p = Process(target=_run_test_builder_streaming_works_in_subprocesses, args=(dummy_builder,))
p.start()
p.join()
class DummyBuilderWithVersion(GeneratorBasedBuilder):
VERSION = "2.0.0"
def _info(self):
return DatasetInfo(features=Features({"text": Value("string")}))
def _split_generators(self, dl_manager):
pass
def _generate_examples(self):
pass
class DummyBuilderWithBuilderConfigs(GeneratorBasedBuilder):
BUILDER_CONFIGS = [BuilderConfig(name="custom", version="2.0.0")]
def _info(self):
return DatasetInfo(features=Features({"text": Value("string")}))
def _split_generators(self, dl_manager):
pass
def _generate_examples(self):
pass
class CustomBuilderConfig(BuilderConfig):
def __init__(self, date=None, language=None, version="2.0.0", **kwargs):
name = f"{date}.{language}"
super().__init__(name=name, version=version, **kwargs)
self.date = date
self.language = language
class DummyBuilderWithCustomBuilderConfigs(GeneratorBasedBuilder):
BUILDER_CONFIGS = [CustomBuilderConfig(date="20220501", language="en")]
BUILDER_CONFIG_CLASS = CustomBuilderConfig
def _info(self):
return DatasetInfo(features=Features({"text": Value("string")}))
def _split_generators(self, dl_manager):
pass
def _generate_examples(self):
pass
@pytest.mark.parametrize(
"builder_class, kwargs",
[
(DummyBuilderWithVersion, {}),
(DummyBuilderWithBuilderConfigs, {"config_name": "custom"}),
(DummyBuilderWithCustomBuilderConfigs, {"config_name": "20220501.en"}),
(DummyBuilderWithCustomBuilderConfigs, {"date": "20220501", "language": "ca"}),
],
)
def test_builder_config_version(builder_class, kwargs, tmp_path):
cache_dir = str(tmp_path)
builder = builder_class(cache_dir=cache_dir, **kwargs)
assert builder.config.version == "2.0.0"
def test_builder_download_and_prepare_with_absolute_output_dir(tmp_path):
builder = DummyGeneratorBasedBuilder()
output_dir = str(tmp_path)
builder.download_and_prepare(output_dir)
assert builder._output_dir.startswith(tmp_path.resolve().as_posix())
assert os.path.exists(os.path.join(output_dir, "dataset_info.json"))
assert os.path.exists(os.path.join(output_dir, f"{builder.dataset_name}-train.arrow"))
assert not os.path.exists(os.path.join(output_dir + ".incomplete"))
def test_builder_download_and_prepare_with_relative_output_dir():
with set_current_working_directory_to_temp_dir():
builder = DummyGeneratorBasedBuilder()
output_dir = "test-out"
builder.download_and_prepare(output_dir)
assert Path(builder._output_dir).resolve().as_posix().startswith(Path(output_dir).resolve().as_posix())
assert os.path.exists(os.path.join(output_dir, "dataset_info.json"))
assert os.path.exists(os.path.join(output_dir, f"{builder.dataset_name}-train.arrow"))
assert not os.path.exists(os.path.join(output_dir + ".incomplete"))
def test_builder_with_filesystem_download_and_prepare(tmp_path, mockfs):
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_path)
builder.download_and_prepare("mock://my_dataset", storage_options=mockfs.storage_options)
assert builder._output_dir.startswith("mock://my_dataset")
assert is_local_path(builder._cache_downloaded_dir)
assert isinstance(builder._fs, type(mockfs))
assert builder._fs.storage_options == mockfs.storage_options
assert mockfs.exists("my_dataset/dataset_info.json")
assert mockfs.exists(f"my_dataset/{builder.dataset_name}-train.arrow")
assert not mockfs.exists("my_dataset.incomplete")
def test_builder_with_filesystem_download_and_prepare_reload(tmp_path, mockfs, caplog):
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_path)
mockfs.makedirs("my_dataset")
DatasetInfo().write_to_directory("mock://my_dataset", storage_options=mockfs.storage_options)
mockfs.touch(f"my_dataset/{builder.dataset_name}-train.arrow")
caplog.clear()
with caplog.at_level(INFO, logger=get_logger().name):
builder.download_and_prepare("mock://my_dataset", storage_options=mockfs.storage_options)
assert "Found cached dataset" in caplog.text
def test_generator_based_builder_download_and_prepare_as_parquet(tmp_path):
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_path)
builder.download_and_prepare(file_format="parquet")
assert builder.info.splits["train"].num_examples == 100
parquet_path = os.path.join(
tmp_path, builder.dataset_name, "default", "0.0.0", f"{builder.dataset_name}-train.parquet"
)
assert os.path.exists(parquet_path)
assert pq.ParquetFile(parquet_path) is not None
def test_generator_based_builder_download_and_prepare_sharded(tmp_path):
writer_batch_size = 25
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_path, writer_batch_size=writer_batch_size)
with patch("datasets.config.MAX_SHARD_SIZE", 1): # one batch per shard
builder.download_and_prepare(file_format="parquet")
expected_num_shards = 100 // writer_batch_size
assert builder.info.splits["train"].num_examples == 100
parquet_path = os.path.join(
tmp_path,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train-00000-of-{expected_num_shards:05d}.parquet",
)
assert os.path.exists(parquet_path)
parquet_files = [
pq.ParquetFile(parquet_path)
for parquet_path in Path(tmp_path).rglob(
f"{builder.dataset_name}-train-*-of-{expected_num_shards:05d}.parquet"
)
]
assert len(parquet_files) == expected_num_shards
assert sum(parquet_file.metadata.num_rows for parquet_file in parquet_files) == 100
def test_generator_based_builder_download_and_prepare_with_max_shard_size(tmp_path):
writer_batch_size = 25
builder = DummyGeneratorBasedBuilder(cache_dir=tmp_path, writer_batch_size=writer_batch_size)
builder.download_and_prepare(file_format="parquet", max_shard_size=1) # one batch per shard
expected_num_shards = 100 // writer_batch_size
assert builder.info.splits["train"].num_examples == 100
parquet_path = os.path.join(
tmp_path,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train-00000-of-{expected_num_shards:05d}.parquet",
)
assert os.path.exists(parquet_path)
parquet_files = [
pq.ParquetFile(parquet_path)
for parquet_path in Path(tmp_path).rglob(
f"{builder.dataset_name}-train-*-of-{expected_num_shards:05d}.parquet"
)
]
assert len(parquet_files) == expected_num_shards
assert sum(parquet_file.metadata.num_rows for parquet_file in parquet_files) == 100
def test_generator_based_builder_download_and_prepare_with_num_proc(tmp_path):
builder = DummyGeneratorBasedBuilderWithShards(cache_dir=tmp_path)
builder.download_and_prepare(num_proc=2)
expected_num_shards = 2
assert builder.info.splits["train"].num_examples == 400
assert builder.info.splits["train"].shard_lengths == [200, 200]
arrow_path = os.path.join(
tmp_path,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train-00000-of-{expected_num_shards:05d}.arrow",
)
assert os.path.exists(arrow_path)
ds = builder.as_dataset("train")
assert len(ds) == 400
assert ds.to_dict() == {
"id": [i for _ in range(4) for i in range(100)],
"filepath": [f"data{i}.txt" for i in range(4) for _ in range(100)],
}
@pytest.mark.parametrize(
"num_proc, expectation", [(None, does_not_raise()), (1, does_not_raise()), (2, pytest.raises(RuntimeError))]
)
def test_generator_based_builder_download_and_prepare_with_ambiguous_shards(num_proc, expectation, tmp_path):
builder = DummyGeneratorBasedBuilderWithAmbiguousShards(cache_dir=tmp_path)
with expectation:
builder.download_and_prepare(num_proc=num_proc)
def test_arrow_based_builder_download_and_prepare_as_parquet(tmp_path):
builder = DummyArrowBasedBuilder(cache_dir=tmp_path)
builder.download_and_prepare(file_format="parquet")
assert builder.info.splits["train"].num_examples == 100
parquet_path = os.path.join(
tmp_path, builder.dataset_name, "default", "0.0.0", f"{builder.dataset_name}-train.parquet"
)
assert os.path.exists(parquet_path)
assert pq.ParquetFile(parquet_path) is not None
def test_arrow_based_builder_download_and_prepare_sharded(tmp_path):
builder = DummyArrowBasedBuilder(cache_dir=tmp_path)
with patch("datasets.config.MAX_SHARD_SIZE", 1): # one batch per shard
builder.download_and_prepare(file_format="parquet")
expected_num_shards = 10
assert builder.info.splits["train"].num_examples == 100
parquet_path = os.path.join(
tmp_path,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train-00000-of-{expected_num_shards:05d}.parquet",
)
assert os.path.exists(parquet_path)
parquet_files = [
pq.ParquetFile(parquet_path)
for parquet_path in Path(tmp_path).rglob(
f"{builder.dataset_name}-train-*-of-{expected_num_shards:05d}.parquet"
)
]
assert len(parquet_files) == expected_num_shards
assert sum(parquet_file.metadata.num_rows for parquet_file in parquet_files) == 100
def test_arrow_based_builder_download_and_prepare_with_max_shard_size(tmp_path):
builder = DummyArrowBasedBuilder(cache_dir=tmp_path)
builder.download_and_prepare(file_format="parquet", max_shard_size=1) # one table per shard
expected_num_shards = 10
assert builder.info.splits["train"].num_examples == 100
parquet_path = os.path.join(
tmp_path,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train-00000-of-{expected_num_shards:05d}.parquet",
)
assert os.path.exists(parquet_path)
parquet_files = [
pq.ParquetFile(parquet_path)
for parquet_path in Path(tmp_path).rglob(
f"{builder.dataset_name}-train-*-of-{expected_num_shards:05d}.parquet"
)
]
assert len(parquet_files) == expected_num_shards
assert sum(parquet_file.metadata.num_rows for parquet_file in parquet_files) == 100
def test_arrow_based_builder_download_and_prepare_with_num_proc(tmp_path):
builder = DummyArrowBasedBuilderWithShards(cache_dir=tmp_path)
builder.download_and_prepare(num_proc=2)
expected_num_shards = 2
assert builder.info.splits["train"].num_examples == 400
assert builder.info.splits["train"].shard_lengths == [200, 200]
arrow_path = os.path.join(
tmp_path,
builder.dataset_name,
"default",
"0.0.0",
f"{builder.dataset_name}-train-00000-of-{expected_num_shards:05d}.arrow",
)
assert os.path.exists(arrow_path)
ds = builder.as_dataset("train")
assert len(ds) == 400
assert ds.to_dict() == {
"id": [i for _ in range(4) for i in range(100)],
"filepath": [f"data{i}.txt" for i in range(4) for _ in range(100)],
}
@pytest.mark.parametrize(
"num_proc, expectation", [(None, does_not_raise()), (1, does_not_raise()), (2, pytest.raises(RuntimeError))]
)
def test_arrow_based_builder_download_and_prepare_with_ambiguous_shards(num_proc, expectation, tmp_path):
builder = DummyArrowBasedBuilderWithAmbiguousShards(cache_dir=tmp_path)
with expectation:
builder.download_and_prepare(num_proc=num_proc)
@require_beam
def test_beam_based_builder_download_and_prepare_as_parquet(tmp_path):
builder = DummyBeamBasedBuilder(cache_dir=tmp_path, beam_runner="DirectRunner")
builder.download_and_prepare(file_format="parquet")
assert builder.info.splits["train"].num_examples == 100
parquet_path = os.path.join(
tmp_path, builder.dataset_name, "default", "0.0.0", f"{builder.dataset_name}-train.parquet"
)
assert os.path.exists(parquet_path)
assert pq.ParquetFile(parquet_path) is not None
| datasets/tests/test_builder.py/0 | {
"file_path": "datasets/tests/test_builder.py",
"repo_id": "datasets",
"token_count": 26111
} | 83 |
import pytest
import datasets.config
from datasets.utils.info_utils import is_small_dataset
@pytest.mark.parametrize("dataset_size", [None, 400 * 2**20, 600 * 2**20])
@pytest.mark.parametrize("input_in_memory_max_size", ["default", 0, 100 * 2**20, 900 * 2**20])
def test_is_small_dataset(dataset_size, input_in_memory_max_size, monkeypatch):
if input_in_memory_max_size != "default":
monkeypatch.setattr(datasets.config, "IN_MEMORY_MAX_SIZE", input_in_memory_max_size)
in_memory_max_size = datasets.config.IN_MEMORY_MAX_SIZE
if input_in_memory_max_size == "default":
assert in_memory_max_size == 0
else:
assert in_memory_max_size == input_in_memory_max_size
if dataset_size and in_memory_max_size:
expected = dataset_size < in_memory_max_size
else:
expected = False
result = is_small_dataset(dataset_size)
assert result == expected
| datasets/tests/test_info_utils.py/0 | {
"file_path": "datasets/tests/test_info_utils.py",
"repo_id": "datasets",
"token_count": 366
} | 84 |
import copy
import pickle
from typing import List, Union
import numpy as np
import pyarrow as pa
import pytest
from datasets import Sequence, Value
from datasets.features.features import Array2D, Array2DExtensionType, ClassLabel, Features, Image, get_nested_type
from datasets.table import (
ConcatenationTable,
InMemoryTable,
MemoryMappedTable,
Table,
TableBlock,
_in_memory_arrow_table_from_buffer,
_in_memory_arrow_table_from_file,
_interpolation_search,
_memory_mapped_arrow_table_from_file,
cast_array_to_feature,
concat_tables,
embed_array_storage,
embed_table_storage,
inject_arrow_table_documentation,
table_cast,
table_iter,
)
from .utils import assert_arrow_memory_doesnt_increase, assert_arrow_memory_increases, slow
@pytest.fixture(scope="session")
def in_memory_pa_table(arrow_file) -> pa.Table:
return pa.ipc.open_stream(arrow_file).read_all()
def _to_testing_blocks(table: TableBlock) -> List[List[TableBlock]]:
assert len(table) > 2
blocks = [
[table.slice(0, 2)],
[table.slice(2).drop([c for c in table.column_names if c != "tokens"]), table.slice(2).drop(["tokens"])],
]
return blocks
@pytest.fixture(scope="session")
def in_memory_blocks(in_memory_pa_table):
table = InMemoryTable(in_memory_pa_table)
return _to_testing_blocks(table)
@pytest.fixture(scope="session")
def memory_mapped_blocks(arrow_file):
table = MemoryMappedTable.from_file(arrow_file)
return _to_testing_blocks(table)
@pytest.fixture(scope="session")
def mixed_in_memory_and_memory_mapped_blocks(in_memory_blocks, memory_mapped_blocks):
return in_memory_blocks[:1] + memory_mapped_blocks[1:]
def assert_deepcopy_without_bringing_data_in_memory(table: MemoryMappedTable):
with assert_arrow_memory_doesnt_increase():
copied_table = copy.deepcopy(table)
assert isinstance(copied_table, MemoryMappedTable)
assert copied_table.table == table.table
def assert_deepcopy_does_bring_data_in_memory(table: MemoryMappedTable):
with assert_arrow_memory_increases():
copied_table = copy.deepcopy(table)
assert isinstance(copied_table, MemoryMappedTable)
assert copied_table.table == table.table
def assert_pickle_without_bringing_data_in_memory(table: MemoryMappedTable):
with assert_arrow_memory_doesnt_increase():
pickled_table = pickle.dumps(table)
unpickled_table = pickle.loads(pickled_table)
assert isinstance(unpickled_table, MemoryMappedTable)
assert unpickled_table.table == table.table
def assert_pickle_does_bring_data_in_memory(table: MemoryMappedTable):
with assert_arrow_memory_increases():
pickled_table = pickle.dumps(table)
unpickled_table = pickle.loads(pickled_table)
assert isinstance(unpickled_table, MemoryMappedTable)
assert unpickled_table.table == table.table
def assert_index_attributes_equal(table: Table, other: Table):
assert table._batches == other._batches
np.testing.assert_array_equal(table._offsets, other._offsets)
assert table._schema == other._schema
def add_suffix_to_column_names(table, suffix):
return table.rename_columns([f"{name}{suffix}" for name in table.column_names])
def test_inject_arrow_table_documentation(in_memory_pa_table):
method = pa.Table.slice
def function_to_wrap(*args):
return method(*args)
args = (0, 1)
wrapped_method = inject_arrow_table_documentation(method)(function_to_wrap)
assert method(in_memory_pa_table, *args) == wrapped_method(in_memory_pa_table, *args)
assert "pyarrow.Table" not in wrapped_method.__doc__
assert "Table" in wrapped_method.__doc__
def test_in_memory_arrow_table_from_file(arrow_file, in_memory_pa_table):
with assert_arrow_memory_increases():
pa_table = _in_memory_arrow_table_from_file(arrow_file)
assert in_memory_pa_table == pa_table
def test_in_memory_arrow_table_from_buffer(in_memory_pa_table):
with assert_arrow_memory_increases():
buf_writer = pa.BufferOutputStream()
writer = pa.RecordBatchStreamWriter(buf_writer, schema=in_memory_pa_table.schema)
writer.write_table(in_memory_pa_table)
writer.close()
buf_writer.close()
pa_table = _in_memory_arrow_table_from_buffer(buf_writer.getvalue())
assert in_memory_pa_table == pa_table
def test_memory_mapped_arrow_table_from_file(arrow_file, in_memory_pa_table):
with assert_arrow_memory_doesnt_increase():
pa_table = _memory_mapped_arrow_table_from_file(arrow_file)
assert in_memory_pa_table == pa_table
def test_table_init(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert table.table == in_memory_pa_table
def test_table_validate(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert table.validate() == in_memory_pa_table.validate()
def test_table_equals(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert table.equals(in_memory_pa_table)
def test_table_to_batches(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert table.to_batches() == in_memory_pa_table.to_batches()
def test_table_to_pydict(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert table.to_pydict() == in_memory_pa_table.to_pydict()
def test_table_to_string(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert table.to_string() == in_memory_pa_table.to_string()
def test_table_field(in_memory_pa_table):
assert "tokens" in in_memory_pa_table.column_names
table = Table(in_memory_pa_table)
assert table.field("tokens") == in_memory_pa_table.field("tokens")
def test_table_column(in_memory_pa_table):
assert "tokens" in in_memory_pa_table.column_names
table = Table(in_memory_pa_table)
assert table.column("tokens") == in_memory_pa_table.column("tokens")
def test_table_itercolumns(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert isinstance(table.itercolumns(), type(in_memory_pa_table.itercolumns()))
assert list(table.itercolumns()) == list(in_memory_pa_table.itercolumns())
def test_table_getitem(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert table[0] == in_memory_pa_table[0]
def test_table_len(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert len(table) == len(in_memory_pa_table)
def test_table_str(in_memory_pa_table):
table = Table(in_memory_pa_table)
assert str(table) == str(in_memory_pa_table).replace("pyarrow.Table", "Table")
assert repr(table) == repr(in_memory_pa_table).replace("pyarrow.Table", "Table")
@pytest.mark.parametrize(
"attribute", ["schema", "columns", "num_columns", "num_rows", "shape", "nbytes", "column_names"]
)
def test_table_attributes(in_memory_pa_table, attribute):
table = Table(in_memory_pa_table)
assert getattr(table, attribute) == getattr(in_memory_pa_table, attribute)
def test_in_memory_table_from_file(arrow_file, in_memory_pa_table):
with assert_arrow_memory_increases():
table = InMemoryTable.from_file(arrow_file)
assert table.table == in_memory_pa_table
assert isinstance(table, InMemoryTable)
def test_in_memory_table_from_buffer(in_memory_pa_table):
with assert_arrow_memory_increases():
buf_writer = pa.BufferOutputStream()
writer = pa.RecordBatchStreamWriter(buf_writer, schema=in_memory_pa_table.schema)
writer.write_table(in_memory_pa_table)
writer.close()
buf_writer.close()
table = InMemoryTable.from_buffer(buf_writer.getvalue())
assert table.table == in_memory_pa_table
assert isinstance(table, InMemoryTable)
def test_in_memory_table_from_pandas(in_memory_pa_table):
df = in_memory_pa_table.to_pandas()
with assert_arrow_memory_increases():
# with no schema it might infer another order of the fields in the schema
table = InMemoryTable.from_pandas(df)
assert isinstance(table, InMemoryTable)
# by specifying schema we get the same order of features, and so the exact same table
table = InMemoryTable.from_pandas(df, schema=in_memory_pa_table.schema)
assert table.table == in_memory_pa_table
assert isinstance(table, InMemoryTable)
def test_in_memory_table_from_arrays(in_memory_pa_table):
arrays = list(in_memory_pa_table.columns)
names = list(in_memory_pa_table.column_names)
table = InMemoryTable.from_arrays(arrays, names=names)
assert table.table == in_memory_pa_table
assert isinstance(table, InMemoryTable)
def test_in_memory_table_from_pydict(in_memory_pa_table):
pydict = in_memory_pa_table.to_pydict()
with assert_arrow_memory_increases():
table = InMemoryTable.from_pydict(pydict)
assert isinstance(table, InMemoryTable)
assert table.table == pa.Table.from_pydict(pydict)
def test_in_memory_table_from_pylist(in_memory_pa_table):
pylist = InMemoryTable(in_memory_pa_table).to_pylist()
table = InMemoryTable.from_pylist(pylist)
assert isinstance(table, InMemoryTable)
assert pylist == table.to_pylist()
def test_in_memory_table_from_batches(in_memory_pa_table):
batches = list(in_memory_pa_table.to_batches())
table = InMemoryTable.from_batches(batches)
assert table.table == in_memory_pa_table
assert isinstance(table, InMemoryTable)
def test_in_memory_table_deepcopy(in_memory_pa_table):
table = InMemoryTable(in_memory_pa_table)
copied_table = copy.deepcopy(table)
assert table.table == copied_table.table
assert_index_attributes_equal(table, copied_table)
# deepcopy must return the exact same arrow objects since they are immutable
assert table.table is copied_table.table
assert all(batch1 is batch2 for batch1, batch2 in zip(table._batches, copied_table._batches))
def test_in_memory_table_pickle(in_memory_pa_table):
table = InMemoryTable(in_memory_pa_table)
pickled_table = pickle.dumps(table)
unpickled_table = pickle.loads(pickled_table)
assert unpickled_table.table == table.table
assert_index_attributes_equal(table, unpickled_table)
@slow
def test_in_memory_table_pickle_big_table():
big_table_4GB = InMemoryTable.from_pydict({"col": [0] * ((4 * 8 << 30) // 64)})
length = len(big_table_4GB)
big_table_4GB = pickle.dumps(big_table_4GB)
big_table_4GB = pickle.loads(big_table_4GB)
assert len(big_table_4GB) == length
def test_in_memory_table_slice(in_memory_pa_table):
table = InMemoryTable(in_memory_pa_table).slice(1, 2)
assert table.table == in_memory_pa_table.slice(1, 2)
assert isinstance(table, InMemoryTable)
def test_in_memory_table_filter(in_memory_pa_table):
mask = pa.array([i % 2 == 0 for i in range(len(in_memory_pa_table))])
table = InMemoryTable(in_memory_pa_table).filter(mask)
assert table.table == in_memory_pa_table.filter(mask)
assert isinstance(table, InMemoryTable)
def test_in_memory_table_flatten(in_memory_pa_table):
table = InMemoryTable(in_memory_pa_table).flatten()
assert table.table == in_memory_pa_table.flatten()
assert isinstance(table, InMemoryTable)
def test_in_memory_table_combine_chunks(in_memory_pa_table):
table = InMemoryTable(in_memory_pa_table).combine_chunks()
assert table.table == in_memory_pa_table.combine_chunks()
assert isinstance(table, InMemoryTable)
def test_in_memory_table_cast(in_memory_pa_table):
assert pa.list_(pa.int64()) in in_memory_pa_table.schema.types
schema = pa.schema(
{
k: v if v != pa.list_(pa.int64()) else pa.list_(pa.int32())
for k, v in zip(in_memory_pa_table.schema.names, in_memory_pa_table.schema.types)
}
)
table = InMemoryTable(in_memory_pa_table).cast(schema)
assert table.table == in_memory_pa_table.cast(schema)
assert isinstance(table, InMemoryTable)
def test_in_memory_table_cast_reorder_struct():
table = InMemoryTable(
pa.Table.from_pydict(
{
"top": [
{
"foo": "a",
"bar": "b",
}
]
}
)
)
schema = pa.schema({"top": pa.struct({"bar": pa.string(), "foo": pa.string()})})
assert table.cast(schema).schema == schema
def test_in_memory_table_cast_with_hf_features():
table = InMemoryTable(pa.Table.from_pydict({"labels": [0, 1]}))
features = Features({"labels": ClassLabel(names=["neg", "pos"])})
schema = features.arrow_schema
assert table.cast(schema).schema == schema
assert Features.from_arrow_schema(table.cast(schema).schema) == features
def test_in_memory_table_replace_schema_metadata(in_memory_pa_table):
metadata = {"huggingface": "{}"}
table = InMemoryTable(in_memory_pa_table).replace_schema_metadata(metadata)
assert table.table.schema.metadata == in_memory_pa_table.replace_schema_metadata(metadata).schema.metadata
assert isinstance(table, InMemoryTable)
def test_in_memory_table_add_column(in_memory_pa_table):
i = len(in_memory_pa_table.column_names)
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
table = InMemoryTable(in_memory_pa_table).add_column(i, field_, column)
assert table.table == in_memory_pa_table.add_column(i, field_, column)
assert isinstance(table, InMemoryTable)
def test_in_memory_table_append_column(in_memory_pa_table):
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
table = InMemoryTable(in_memory_pa_table).append_column(field_, column)
assert table.table == in_memory_pa_table.append_column(field_, column)
assert isinstance(table, InMemoryTable)
def test_in_memory_table_remove_column(in_memory_pa_table):
table = InMemoryTable(in_memory_pa_table).remove_column(0)
assert table.table == in_memory_pa_table.remove_column(0)
assert isinstance(table, InMemoryTable)
def test_in_memory_table_set_column(in_memory_pa_table):
i = len(in_memory_pa_table.column_names)
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
table = InMemoryTable(in_memory_pa_table).set_column(i, field_, column)
assert table.table == in_memory_pa_table.set_column(i, field_, column)
assert isinstance(table, InMemoryTable)
def test_in_memory_table_rename_columns(in_memory_pa_table):
assert "tokens" in in_memory_pa_table.column_names
names = [name if name != "tokens" else "new_tokens" for name in in_memory_pa_table.column_names]
table = InMemoryTable(in_memory_pa_table).rename_columns(names)
assert table.table == in_memory_pa_table.rename_columns(names)
assert isinstance(table, InMemoryTable)
def test_in_memory_table_drop(in_memory_pa_table):
names = [in_memory_pa_table.column_names[0]]
table = InMemoryTable(in_memory_pa_table).drop(names)
assert table.table == in_memory_pa_table.drop(names)
assert isinstance(table, InMemoryTable)
def test_memory_mapped_table_init(arrow_file, in_memory_pa_table):
table = MemoryMappedTable(_memory_mapped_arrow_table_from_file(arrow_file), arrow_file)
assert table.table == in_memory_pa_table
assert isinstance(table, MemoryMappedTable)
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_from_file(arrow_file, in_memory_pa_table):
with assert_arrow_memory_doesnt_increase():
table = MemoryMappedTable.from_file(arrow_file)
assert table.table == in_memory_pa_table
assert isinstance(table, MemoryMappedTable)
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_from_file_with_replay(arrow_file, in_memory_pa_table):
replays = [("slice", (0, 1), {}), ("flatten", (), {})]
with assert_arrow_memory_doesnt_increase():
table = MemoryMappedTable.from_file(arrow_file, replays=replays)
assert len(table) == 1
for method, args, kwargs in replays:
in_memory_pa_table = getattr(in_memory_pa_table, method)(*args, **kwargs)
assert table.table == in_memory_pa_table
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_deepcopy(arrow_file):
table = MemoryMappedTable.from_file(arrow_file)
copied_table = copy.deepcopy(table)
assert table.table == copied_table.table
assert table.path == copied_table.path
assert_index_attributes_equal(table, copied_table)
# deepcopy must return the exact same arrow objects since they are immutable
assert table.table is copied_table.table
assert all(batch1 is batch2 for batch1, batch2 in zip(table._batches, copied_table._batches))
def test_memory_mapped_table_pickle(arrow_file):
table = MemoryMappedTable.from_file(arrow_file)
pickled_table = pickle.dumps(table)
unpickled_table = pickle.loads(pickled_table)
assert unpickled_table.table == table.table
assert unpickled_table.path == table.path
assert_index_attributes_equal(table, unpickled_table)
def test_memory_mapped_table_pickle_doesnt_fill_memory(arrow_file):
with assert_arrow_memory_doesnt_increase():
table = MemoryMappedTable.from_file(arrow_file)
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_pickle_applies_replay(arrow_file):
replays = [("slice", (0, 1), {}), ("flatten", (), {})]
with assert_arrow_memory_doesnt_increase():
table = MemoryMappedTable.from_file(arrow_file, replays=replays)
assert isinstance(table, MemoryMappedTable)
assert table.replays == replays
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_slice(arrow_file, in_memory_pa_table):
table = MemoryMappedTable.from_file(arrow_file).slice(1, 2)
assert table.table == in_memory_pa_table.slice(1, 2)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("slice", (1, 2), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_filter(arrow_file, in_memory_pa_table):
mask = pa.array([i % 2 == 0 for i in range(len(in_memory_pa_table))])
table = MemoryMappedTable.from_file(arrow_file).filter(mask)
assert table.table == in_memory_pa_table.filter(mask)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("filter", (mask,), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
# filter DOES increase memory
# assert_pickle_without_bringing_data_in_memory(table)
assert_pickle_does_bring_data_in_memory(table)
def test_memory_mapped_table_flatten(arrow_file, in_memory_pa_table):
table = MemoryMappedTable.from_file(arrow_file).flatten()
assert table.table == in_memory_pa_table.flatten()
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("flatten", (), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_combine_chunks(arrow_file, in_memory_pa_table):
table = MemoryMappedTable.from_file(arrow_file).combine_chunks()
assert table.table == in_memory_pa_table.combine_chunks()
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("combine_chunks", (), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_cast(arrow_file, in_memory_pa_table):
assert pa.list_(pa.int64()) in in_memory_pa_table.schema.types
schema = pa.schema(
{
k: v if v != pa.list_(pa.int64()) else pa.list_(pa.int32())
for k, v in zip(in_memory_pa_table.schema.names, in_memory_pa_table.schema.types)
}
)
table = MemoryMappedTable.from_file(arrow_file).cast(schema)
assert table.table == in_memory_pa_table.cast(schema)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("cast", (schema,), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
# cast DOES increase memory when converting integers precision for example
# assert_pickle_without_bringing_data_in_memory(table)
assert_pickle_does_bring_data_in_memory(table)
def test_memory_mapped_table_replace_schema_metadata(arrow_file, in_memory_pa_table):
metadata = {"huggingface": "{}"}
table = MemoryMappedTable.from_file(arrow_file).replace_schema_metadata(metadata)
assert table.table.schema.metadata == in_memory_pa_table.replace_schema_metadata(metadata).schema.metadata
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("replace_schema_metadata", (metadata,), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_add_column(arrow_file, in_memory_pa_table):
i = len(in_memory_pa_table.column_names)
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
table = MemoryMappedTable.from_file(arrow_file).add_column(i, field_, column)
assert table.table == in_memory_pa_table.add_column(i, field_, column)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("add_column", (i, field_, column), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_append_column(arrow_file, in_memory_pa_table):
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
table = MemoryMappedTable.from_file(arrow_file).append_column(field_, column)
assert table.table == in_memory_pa_table.append_column(field_, column)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("append_column", (field_, column), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_remove_column(arrow_file, in_memory_pa_table):
table = MemoryMappedTable.from_file(arrow_file).remove_column(0)
assert table.table == in_memory_pa_table.remove_column(0)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("remove_column", (0,), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_set_column(arrow_file, in_memory_pa_table):
i = len(in_memory_pa_table.column_names)
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
table = MemoryMappedTable.from_file(arrow_file).set_column(i, field_, column)
assert table.table == in_memory_pa_table.set_column(i, field_, column)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("set_column", (i, field_, column), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_rename_columns(arrow_file, in_memory_pa_table):
assert "tokens" in in_memory_pa_table.column_names
names = [name if name != "tokens" else "new_tokens" for name in in_memory_pa_table.column_names]
table = MemoryMappedTable.from_file(arrow_file).rename_columns(names)
assert table.table == in_memory_pa_table.rename_columns(names)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("rename_columns", (names,), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
def test_memory_mapped_table_drop(arrow_file, in_memory_pa_table):
names = [in_memory_pa_table.column_names[0]]
table = MemoryMappedTable.from_file(arrow_file).drop(names)
assert table.table == in_memory_pa_table.drop(names)
assert isinstance(table, MemoryMappedTable)
assert table.replays == [("drop", (names,), {})]
assert_deepcopy_without_bringing_data_in_memory(table)
assert_pickle_without_bringing_data_in_memory(table)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_init(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = (
in_memory_blocks
if blocks_type == "in_memory"
else memory_mapped_blocks
if blocks_type == "memory_mapped"
else mixed_in_memory_and_memory_mapped_blocks
)
table = ConcatenationTable(in_memory_pa_table, blocks)
assert table.table == in_memory_pa_table
assert table.blocks == blocks
def test_concatenation_table_from_blocks(in_memory_pa_table, in_memory_blocks):
assert len(in_memory_pa_table) > 2
in_memory_table = InMemoryTable(in_memory_pa_table)
t1, t2 = in_memory_table.slice(0, 2), in_memory_table.slice(2)
table = ConcatenationTable.from_blocks(in_memory_table)
assert isinstance(table, ConcatenationTable)
assert table.table == in_memory_pa_table
assert table.blocks == [[in_memory_table]]
table = ConcatenationTable.from_blocks([t1, t2])
assert isinstance(table, ConcatenationTable)
assert table.table == in_memory_pa_table
assert table.blocks == [[in_memory_table]]
table = ConcatenationTable.from_blocks([[t1], [t2]])
assert isinstance(table, ConcatenationTable)
assert table.table == in_memory_pa_table
assert table.blocks == [[in_memory_table]]
table = ConcatenationTable.from_blocks(in_memory_blocks)
assert isinstance(table, ConcatenationTable)
assert table.table == in_memory_pa_table
assert table.blocks == [[in_memory_table]]
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_from_blocks_doesnt_increase_memory(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
with assert_arrow_memory_doesnt_increase():
table = ConcatenationTable.from_blocks(blocks)
assert isinstance(table, ConcatenationTable)
assert table.table == in_memory_pa_table
if blocks_type == "in_memory":
assert table.blocks == [[InMemoryTable(in_memory_pa_table)]]
else:
assert table.blocks == blocks
@pytest.mark.parametrize("axis", [0, 1])
def test_concatenation_table_from_tables(axis, in_memory_pa_table, arrow_file):
in_memory_table = InMemoryTable(in_memory_pa_table)
concatenation_table = ConcatenationTable.from_blocks(in_memory_table)
memory_mapped_table = MemoryMappedTable.from_file(arrow_file)
tables = [in_memory_pa_table, in_memory_table, concatenation_table, memory_mapped_table]
if axis == 0:
expected_table = pa.concat_tables([in_memory_pa_table] * len(tables))
else:
# avoids error due to duplicate column names
tables[1:] = [add_suffix_to_column_names(table, i) for i, table in enumerate(tables[1:], 1)]
expected_table = in_memory_pa_table
for table in tables[1:]:
for name, col in zip(table.column_names, table.columns):
expected_table = expected_table.append_column(name, col)
with assert_arrow_memory_doesnt_increase():
table = ConcatenationTable.from_tables(tables, axis=axis)
assert isinstance(table, ConcatenationTable)
assert table.table == expected_table
# because of consolidation, we end up with 1 InMemoryTable and 1 MemoryMappedTable
assert len(table.blocks) == 1 if axis == 1 else 2
assert len(table.blocks[0]) == 1 if axis == 0 else 2
assert axis == 1 or len(table.blocks[1]) == 1
assert isinstance(table.blocks[0][0], InMemoryTable)
assert isinstance(table.blocks[1][0] if axis == 0 else table.blocks[0][1], MemoryMappedTable)
def test_concatenation_table_from_tables_axis1_misaligned_blocks(arrow_file):
table = MemoryMappedTable.from_file(arrow_file)
t1 = table.slice(0, 2)
t2 = table.slice(0, 3).rename_columns([col + "_1" for col in table.column_names])
concatenated = ConcatenationTable.from_tables(
[
ConcatenationTable.from_blocks([[t1], [t1], [t1]]),
ConcatenationTable.from_blocks([[t2], [t2]]),
],
axis=1,
)
assert len(concatenated) == 6
assert [len(row_blocks[0]) for row_blocks in concatenated.blocks] == [2, 1, 1, 2]
concatenated = ConcatenationTable.from_tables(
[
ConcatenationTable.from_blocks([[t2], [t2]]),
ConcatenationTable.from_blocks([[t1], [t1], [t1]]),
],
axis=1,
)
assert len(concatenated) == 6
assert [len(row_blocks[0]) for row_blocks in concatenated.blocks] == [2, 1, 1, 2]
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_deepcopy(
blocks_type, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
table = ConcatenationTable.from_blocks(blocks)
copied_table = copy.deepcopy(table)
assert table.table == copied_table.table
assert table.blocks == copied_table.blocks
assert_index_attributes_equal(table, copied_table)
# deepcopy must return the exact same arrow objects since they are immutable
assert table.table is copied_table.table
assert all(batch1 is batch2 for batch1, batch2 in zip(table._batches, copied_table._batches))
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_pickle(
blocks_type, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
table = ConcatenationTable.from_blocks(blocks)
pickled_table = pickle.dumps(table)
unpickled_table = pickle.loads(pickled_table)
assert unpickled_table.table == table.table
assert unpickled_table.blocks == table.blocks
assert_index_attributes_equal(table, unpickled_table)
def test_concat_tables_with_features_metadata(arrow_file, in_memory_pa_table):
input_features = Features.from_arrow_schema(in_memory_pa_table.schema)
input_features["id"] = Value("int64", id="my_id")
intput_schema = input_features.arrow_schema
t0 = in_memory_pa_table.replace_schema_metadata(intput_schema.metadata)
t1 = MemoryMappedTable.from_file(arrow_file)
tables = [t0, t1]
concatenated_table = concat_tables(tables, axis=0)
output_schema = concatenated_table.schema
output_features = Features.from_arrow_schema(output_schema)
assert output_schema == intput_schema
assert output_schema.metadata == intput_schema.metadata
assert output_features == input_features
assert output_features["id"].id == "my_id"
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_slice(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
table = ConcatenationTable.from_blocks(blocks).slice(1, 2)
assert table.table == in_memory_pa_table.slice(1, 2)
assert isinstance(table, ConcatenationTable)
def test_concatenation_table_slice_mixed_schemas_vertically(arrow_file):
t1 = MemoryMappedTable.from_file(arrow_file)
t2 = InMemoryTable.from_pydict({"additional_column": ["foo"]})
expected = pa.table(
{
**{column: values + [None] for column, values in t1.to_pydict().items()},
"additional_column": [None] * len(t1) + ["foo"],
}
)
blocks = [[t1], [t2]]
table = ConcatenationTable.from_blocks(blocks)
assert table.to_pydict() == expected.to_pydict()
assert isinstance(table, ConcatenationTable)
reloaded = pickle.loads(pickle.dumps(table))
assert reloaded.to_pydict() == expected.to_pydict()
assert isinstance(reloaded, ConcatenationTable)
reloaded = pickle.loads(pickle.dumps(table.slice(1, 2)))
assert reloaded.to_pydict() == expected.slice(1, 2).to_pydict()
assert isinstance(reloaded, ConcatenationTable)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_filter(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
mask = pa.array([i % 2 == 0 for i in range(len(in_memory_pa_table))])
table = ConcatenationTable.from_blocks(blocks).filter(mask)
assert table.table == in_memory_pa_table.filter(mask)
assert isinstance(table, ConcatenationTable)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_flatten(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
table = ConcatenationTable.from_blocks(blocks).flatten()
assert table.table == in_memory_pa_table.flatten()
assert isinstance(table, ConcatenationTable)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_combine_chunks(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
table = ConcatenationTable.from_blocks(blocks).combine_chunks()
assert table.table == in_memory_pa_table.combine_chunks()
assert isinstance(table, ConcatenationTable)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_cast(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
assert pa.list_(pa.int64()) in in_memory_pa_table.schema.types
assert pa.int64() in in_memory_pa_table.schema.types
schema = pa.schema(
{
k: v if v != pa.list_(pa.int64()) else pa.list_(pa.int32())
for k, v in zip(in_memory_pa_table.schema.names, in_memory_pa_table.schema.types)
}
)
table = ConcatenationTable.from_blocks(blocks).cast(schema)
assert table.table == in_memory_pa_table.cast(schema)
assert isinstance(table, ConcatenationTable)
schema = pa.schema(
{
k: v if v != pa.int64() else pa.int32()
for k, v in zip(in_memory_pa_table.schema.names, in_memory_pa_table.schema.types)
}
)
table = ConcatenationTable.from_blocks(blocks).cast(schema)
assert table.table == in_memory_pa_table.cast(schema)
assert isinstance(table, ConcatenationTable)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concat_tables_cast_with_features_metadata(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
input_features = Features.from_arrow_schema(in_memory_pa_table.schema)
input_features["id"] = Value("int64", id="my_id")
intput_schema = input_features.arrow_schema
concatenated_table = ConcatenationTable.from_blocks(blocks).cast(intput_schema)
output_schema = concatenated_table.schema
output_features = Features.from_arrow_schema(output_schema)
assert output_schema == intput_schema
assert output_schema.metadata == intput_schema.metadata
assert output_features == input_features
assert output_features["id"].id == "my_id"
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_replace_schema_metadata(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
metadata = {"huggingface": "{}"}
table = ConcatenationTable.from_blocks(blocks).replace_schema_metadata(metadata)
assert table.table.schema.metadata == in_memory_pa_table.replace_schema_metadata(metadata).schema.metadata
assert isinstance(table, ConcatenationTable)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_add_column(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
i = len(in_memory_pa_table.column_names)
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
with pytest.raises(NotImplementedError):
ConcatenationTable.from_blocks(blocks).add_column(i, field_, column)
# assert table.table == in_memory_pa_table.add_column(i, field_, column)
# unpickled_table = pickle.loads(pickle.dumps(table))
# assert unpickled_table.table == in_memory_pa_table.add_column(i, field_, column)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_append_column(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
with pytest.raises(NotImplementedError):
ConcatenationTable.from_blocks(blocks).append_column(field_, column)
# assert table.table == in_memory_pa_table.append_column(field_, column)
# unpickled_table = pickle.loads(pickle.dumps(table))
# assert unpickled_table.table == in_memory_pa_table.append_column(field_, column)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_remove_column(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
table = ConcatenationTable.from_blocks(blocks).remove_column(0)
assert table.table == in_memory_pa_table.remove_column(0)
assert isinstance(table, ConcatenationTable)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_set_column(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
i = len(in_memory_pa_table.column_names)
field_ = "new_field"
column = pa.array(list(range(len(in_memory_pa_table))))
with pytest.raises(NotImplementedError):
ConcatenationTable.from_blocks(blocks).set_column(i, field_, column)
# assert table.table == in_memory_pa_table.set_column(i, field_, column)
# unpickled_table = pickle.loads(pickle.dumps(table))
# assert unpickled_table.table == in_memory_pa_table.set_column(i, field_, column)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_rename_columns(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
assert "tokens" in in_memory_pa_table.column_names
names = [name if name != "tokens" else "new_tokens" for name in in_memory_pa_table.column_names]
table = ConcatenationTable.from_blocks(blocks).rename_columns(names)
assert isinstance(table, ConcatenationTable)
assert table.table == in_memory_pa_table.rename_columns(names)
@pytest.mark.parametrize("blocks_type", ["in_memory", "memory_mapped", "mixed"])
def test_concatenation_table_drop(
blocks_type, in_memory_pa_table, in_memory_blocks, memory_mapped_blocks, mixed_in_memory_and_memory_mapped_blocks
):
blocks = {
"in_memory": in_memory_blocks,
"memory_mapped": memory_mapped_blocks,
"mixed": mixed_in_memory_and_memory_mapped_blocks,
}[blocks_type]
names = [in_memory_pa_table.column_names[0]]
table = ConcatenationTable.from_blocks(blocks).drop(names)
assert table.table == in_memory_pa_table.drop(names)
assert isinstance(table, ConcatenationTable)
def test_concat_tables(arrow_file, in_memory_pa_table):
t0 = in_memory_pa_table
t1 = InMemoryTable(t0)
t2 = MemoryMappedTable.from_file(arrow_file)
t3 = ConcatenationTable.from_blocks(t1)
tables = [t0, t1, t2, t3]
concatenated_table = concat_tables(tables, axis=0)
assert concatenated_table.table == pa.concat_tables([t0] * 4)
assert concatenated_table.table.shape == (40, 4)
assert isinstance(concatenated_table, ConcatenationTable)
assert len(concatenated_table.blocks) == 3 # t0 and t1 are consolidated as a single InMemoryTable
assert isinstance(concatenated_table.blocks[0][0], InMemoryTable)
assert isinstance(concatenated_table.blocks[1][0], MemoryMappedTable)
assert isinstance(concatenated_table.blocks[2][0], InMemoryTable)
# add suffix to avoid error due to duplicate column names
concatenated_table = concat_tables(
[add_suffix_to_column_names(table, i) for i, table in enumerate(tables)], axis=1
)
assert concatenated_table.table.shape == (10, 16)
assert len(concatenated_table.blocks[0]) == 3 # t0 and t1 are consolidated as a single InMemoryTable
assert isinstance(concatenated_table.blocks[0][0], InMemoryTable)
assert isinstance(concatenated_table.blocks[0][1], MemoryMappedTable)
assert isinstance(concatenated_table.blocks[0][2], InMemoryTable)
def _interpolation_search_ground_truth(arr: List[int], x: int) -> Union[int, IndexError]:
for i in range(len(arr) - 1):
if arr[i] <= x < arr[i + 1]:
return i
return IndexError
class _ListWithGetitemCounter(list):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.unique_getitem_calls = set()
def __getitem__(self, i):
out = super().__getitem__(i)
self.unique_getitem_calls.add(i)
return out
@property
def getitem_unique_count(self):
return len(self.unique_getitem_calls)
@pytest.mark.parametrize(
"arr, x",
[(np.arange(0, 14, 3), x) for x in range(-1, 22)]
+ [(list(np.arange(-5, 5)), x) for x in range(-6, 6)]
+ [([0, 1_000, 1_001, 1_003], x) for x in [-1, 0, 2, 100, 999, 1_000, 1_001, 1_002, 1_003, 1_004]]
+ [(list(range(1_000)), x) for x in [-1, 0, 1, 10, 666, 999, 1_000, 1_0001]],
)
def test_interpolation_search(arr, x):
ground_truth = _interpolation_search_ground_truth(arr, x)
if isinstance(ground_truth, int):
arr = _ListWithGetitemCounter(arr)
output = _interpolation_search(arr, x)
assert ground_truth == output
# 4 maximum unique getitem calls is expected for the cases of this test
# but it can be bigger for large and messy arrays.
assert arr.getitem_unique_count <= 4
else:
with pytest.raises(ground_truth):
_interpolation_search(arr, x)
def test_indexed_table_mixin():
n_rows_per_chunk = 10
n_chunks = 4
pa_table = pa.Table.from_pydict({"col": [0] * n_rows_per_chunk})
pa_table = pa.concat_tables([pa_table] * n_chunks)
table = Table(pa_table)
assert all(table._offsets.tolist() == np.cumsum([0] + [n_rows_per_chunk] * n_chunks))
assert table.fast_slice(5) == pa_table.slice(5)
assert table.fast_slice(2, 13) == pa_table.slice(2, 13)
def test_cast_array_to_features():
arr = pa.array([[0, 1]])
assert cast_array_to_feature(arr, Sequence(Value("string"))).type == pa.list_(pa.string())
with pytest.raises(TypeError):
cast_array_to_feature(arr, Sequence(Value("string")), allow_number_to_str=False)
def test_cast_array_to_features_nested():
arr = pa.array([[{"foo": [0]}]])
assert cast_array_to_feature(arr, [{"foo": Sequence(Value("string"))}]).type == pa.list_(
pa.struct({"foo": pa.list_(pa.string())})
)
def test_cast_array_to_features_to_nested_with_no_fields():
arr = pa.array([{}])
assert cast_array_to_feature(arr, {}).type == pa.struct({})
assert cast_array_to_feature(arr, {}).to_pylist() == arr.to_pylist()
def test_cast_array_to_features_nested_with_nulls():
# same type
arr = pa.array([{"foo": [None, [0]]}], pa.struct({"foo": pa.list_(pa.list_(pa.int64()))}))
casted_array = cast_array_to_feature(arr, {"foo": [[Value("int64")]]})
assert casted_array.type == pa.struct({"foo": pa.list_(pa.list_(pa.int64()))})
assert casted_array.to_pylist() == arr.to_pylist()
# different type
arr = pa.array([{"foo": [None, [0]]}], pa.struct({"foo": pa.list_(pa.list_(pa.int64()))}))
casted_array = cast_array_to_feature(arr, {"foo": [[Value("int32")]]})
assert casted_array.type == pa.struct({"foo": pa.list_(pa.list_(pa.int32()))})
assert casted_array.to_pylist() == [{"foo": [None, [0]]}]
def test_cast_array_to_features_to_null_type():
# same type
arr = pa.array([[None, None]])
assert cast_array_to_feature(arr, Sequence(Value("null"))).type == pa.list_(pa.null())
# different type
arr = pa.array([[None, 1]])
with pytest.raises(TypeError):
cast_array_to_feature(arr, Sequence(Value("null")))
def test_cast_array_to_features_array_xd():
# same storage type
arr = pa.array([[[0, 1], [2, 3]], [[4, 5], [6, 7]]], pa.list_(pa.list_(pa.int32(), 2), 2))
casted_array = cast_array_to_feature(arr, Array2D(shape=(2, 2), dtype="int32"))
assert casted_array.type == Array2DExtensionType(shape=(2, 2), dtype="int32")
# different storage type
casted_array = cast_array_to_feature(arr, Array2D(shape=(2, 2), dtype="float32"))
assert casted_array.type == Array2DExtensionType(shape=(2, 2), dtype="float32")
def test_cast_array_to_features_sequence_classlabel():
arr = pa.array([[], [1], [0, 1]], pa.list_(pa.int64()))
assert cast_array_to_feature(arr, Sequence(ClassLabel(names=["foo", "bar"]))).type == pa.list_(pa.int64())
arr = pa.array([[], ["bar"], ["foo", "bar"]], pa.list_(pa.string()))
assert cast_array_to_feature(arr, Sequence(ClassLabel(names=["foo", "bar"]))).type == pa.list_(pa.int64())
# Test empty arrays
arr = pa.array([[], []], pa.list_(pa.int64()))
assert cast_array_to_feature(arr, Sequence(ClassLabel(names=["foo", "bar"]))).type == pa.list_(pa.int64())
arr = pa.array([[], []], pa.list_(pa.string()))
assert cast_array_to_feature(arr, Sequence(ClassLabel(names=["foo", "bar"]))).type == pa.list_(pa.int64())
# Test invalid class labels
arr = pa.array([[2]], pa.list_(pa.int64()))
with pytest.raises(ValueError):
assert cast_array_to_feature(arr, Sequence(ClassLabel(names=["foo", "bar"])))
arr = pa.array([["baz"]], pa.list_(pa.string()))
with pytest.raises(ValueError):
assert cast_array_to_feature(arr, Sequence(ClassLabel(names=["foo", "bar"])))
@pytest.mark.parametrize(
"arr",
[
pa.array([[0, 1, 2], [3, None, 5], None, [6, 7, 8], None], pa.list_(pa.int32(), 3)),
],
)
@pytest.mark.parametrize("slice", [None, slice(1, None), slice(-1), slice(1, 3), slice(2, 3), slice(1, 1)])
@pytest.mark.parametrize("target_value_feature", [Value("int64")])
def test_cast_fixed_size_list_array_to_features_sequence(arr, slice, target_value_feature):
arr = arr if slice is None else arr[slice]
# Fixed size list
casted_array = cast_array_to_feature(arr, Sequence(target_value_feature, length=arr.type.list_size))
assert casted_array.type == get_nested_type(Sequence(target_value_feature, length=arr.type.list_size))
assert casted_array.to_pylist() == arr.to_pylist()
with pytest.raises(TypeError):
cast_array_to_feature(arr, Sequence(target_value_feature, length=arr.type.list_size + 1))
# Variable size list
casted_array = cast_array_to_feature(arr, Sequence(target_value_feature))
assert casted_array.type == get_nested_type(Sequence(target_value_feature))
assert casted_array.to_pylist() == arr.to_pylist()
casted_array = cast_array_to_feature(arr, [target_value_feature])
assert casted_array.type == get_nested_type([target_value_feature])
assert casted_array.to_pylist() == arr.to_pylist()
@pytest.mark.parametrize(
"arr",
[
pa.array([[0, 1, 2], [3, None, 5], None, [6, 7, 8], None], pa.list_(pa.int32())),
],
)
@pytest.mark.parametrize("slice", [None, slice(1, None), slice(-1), slice(1, 3), slice(2, 3), slice(1, 1)])
@pytest.mark.parametrize("target_value_feature", [Value("int64")])
def test_cast_list_array_to_features_sequence(arr, slice, target_value_feature):
arr = arr if slice is None else arr[slice]
# Variable size list
casted_array = cast_array_to_feature(arr, Sequence(target_value_feature))
assert casted_array.type == get_nested_type(Sequence(target_value_feature))
assert casted_array.to_pylist() == arr.to_pylist()
casted_array = cast_array_to_feature(arr, [target_value_feature])
assert casted_array.type == get_nested_type([target_value_feature])
assert casted_array.to_pylist() == arr.to_pylist()
# Fixed size list
list_size = arr.value_lengths().drop_null()[0].as_py() if arr.value_lengths().drop_null() else 2
casted_array = cast_array_to_feature(arr, Sequence(target_value_feature, length=list_size))
assert casted_array.type == get_nested_type(Sequence(target_value_feature, length=list_size))
assert casted_array.to_pylist() == arr.to_pylist()
def test_cast_array_xd_to_features_sequence():
arr = np.random.randint(0, 10, size=(8, 2, 3)).tolist()
arr = Array2DExtensionType(shape=(2, 3), dtype="int64").wrap_array(pa.array(arr, pa.list_(pa.list_(pa.int64()))))
arr = pa.ListArray.from_arrays([0, None, 4, 8], arr)
# Variable size list
casted_array = cast_array_to_feature(arr, Sequence(Array2D(shape=(2, 3), dtype="int32")))
assert casted_array.type == get_nested_type(Sequence(Array2D(shape=(2, 3), dtype="int32")))
assert casted_array.to_pylist() == arr.to_pylist()
# Fixed size list
casted_array = cast_array_to_feature(arr, Sequence(Array2D(shape=(2, 3), dtype="int32"), length=4))
assert casted_array.type == get_nested_type(Sequence(Array2D(shape=(2, 3), dtype="int32"), length=4))
assert casted_array.to_pylist() == arr.to_pylist()
def test_embed_array_storage(image_file):
array = pa.array([{"bytes": None, "path": image_file}], type=Image.pa_type)
embedded_images_array = embed_array_storage(array, Image())
assert isinstance(embedded_images_array.to_pylist()[0]["path"], str)
assert embedded_images_array.to_pylist()[0]["path"] == "test_image_rgb.jpg"
assert isinstance(embedded_images_array.to_pylist()[0]["bytes"], bytes)
def test_embed_array_storage_nested(image_file):
array = pa.array([[{"bytes": None, "path": image_file}]], type=pa.list_(Image.pa_type))
embedded_images_array = embed_array_storage(array, [Image()])
assert isinstance(embedded_images_array.to_pylist()[0][0]["path"], str)
assert isinstance(embedded_images_array.to_pylist()[0][0]["bytes"], bytes)
array = pa.array([{"foo": {"bytes": None, "path": image_file}}], type=pa.struct({"foo": Image.pa_type}))
embedded_images_array = embed_array_storage(array, {"foo": Image()})
assert isinstance(embedded_images_array.to_pylist()[0]["foo"]["path"], str)
assert isinstance(embedded_images_array.to_pylist()[0]["foo"]["bytes"], bytes)
def test_embed_table_storage(image_file):
features = Features({"image": Image()})
table = table_cast(pa.table({"image": [image_file]}), features.arrow_schema)
embedded_images_table = embed_table_storage(table)
assert isinstance(embedded_images_table.to_pydict()["image"][0]["path"], str)
assert isinstance(embedded_images_table.to_pydict()["image"][0]["bytes"], bytes)
@pytest.mark.parametrize(
"table",
[
InMemoryTable(pa.table({"foo": range(10)})),
InMemoryTable(pa.concat_tables([pa.table({"foo": range(0, 5)}), pa.table({"foo": range(5, 10)})])),
InMemoryTable(pa.concat_tables([pa.table({"foo": [i]}) for i in range(10)])),
],
)
@pytest.mark.parametrize("batch_size", [1, 2, 3, 9, 10, 11, 20])
@pytest.mark.parametrize("drop_last_batch", [False, True])
def test_table_iter(table, batch_size, drop_last_batch):
num_rows = len(table) if not drop_last_batch else len(table) // batch_size * batch_size
num_batches = (num_rows // batch_size) + 1 if num_rows % batch_size else num_rows // batch_size
subtables = list(table_iter(table, batch_size=batch_size, drop_last_batch=drop_last_batch))
assert len(subtables) == num_batches
if drop_last_batch:
assert all(len(subtable) == batch_size for subtable in subtables)
else:
assert all(len(subtable) == batch_size for subtable in subtables[:-1])
assert len(subtables[-1]) <= batch_size
if num_rows > 0:
reloaded = pa.concat_tables(subtables)
assert table.slice(0, num_rows).to_pydict() == reloaded.to_pydict()
| datasets/tests/test_table.py/0 | {
"file_path": "datasets/tests/test_table.py",
"repo_id": "datasets",
"token_count": 21863
} | 85 |
<jupyter_start><jupyter_text>Unit 3: Deep Q-Learning with Atari Games 👾 using RL Baselines3 ZooIn this notebook, **you'll train a Deep Q-Learning agent** playing Space Invaders using [RL Baselines3 Zoo](https://github.com/DLR-RM/rl-baselines3-zoo), a training framework based on [Stable-Baselines3](https://stable-baselines3.readthedocs.io/en/master/) that provides scripts for training, evaluating agents, tuning hyperparameters, plotting results and recording videos.We're using the [RL-Baselines-3 Zoo integration, a vanilla version of Deep Q-Learning](https://stable-baselines3.readthedocs.io/en/master/modules/dqn.html) with no extensions such as Double-DQN, Dueling-DQN, and Prioritized Experience Replay.⬇️ Here is an example of what **you will achieve** ⬇️<jupyter_code>%%html
<video controls autoplay><source src="https://huggingface.co/ThomasSimonini/ppo-SpaceInvadersNoFrameskip-v4/resolve/main/replay.mp4" type="video/mp4"></video><jupyter_output><empty_output><jupyter_text>🎮 Environments: - [SpacesInvadersNoFrameskip-v4](https://gymnasium.farama.org/environments/atari/space_invaders/)You can see the difference between Space Invaders versions here 👉 https://gymnasium.farama.org/environments/atari/space_invaders/variants 📚 RL-Library: - [RL-Baselines3-Zoo](https://github.com/DLR-RM/rl-baselines3-zoo) Objectives of this notebook 🏆At the end of the notebook, you will:- Be able to understand deeper **how RL Baselines3 Zoo works**.- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥. This notebook is from Deep Reinforcement Learning Course In this free course, you will:- 📖 Study Deep Reinforcement Learning in **theory and practice**.- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.- 🤖 Train **agents in unique environments** And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-courseDon’t forget to **sign up to the course** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5 Prerequisites 🏗️Before diving into the notebook, you need to:🔲 📚 **[Study Deep Q-Learning by reading Unit 3](https://huggingface.co/deep-rl-course/unit3/introduction)** 🤗 We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the Github Repo](https://github.com/huggingface/deep-rl-class/issues). Let's train a Deep Q-Learning agent playing Atari' Space Invaders 👾 and upload it to the Hub.We strongly recommend students **to use Google Colab for the hands-on exercises instead of running them on their personal computers**.By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects of setting up your environments**.To validate this hands-on for the certification process, you need to push your trained model to the Hub and **get a result of >= 200**.To find your result, go to the leaderboard and find your model, **the result = mean_reward - std of reward**For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introductioncertification-process An advice 💡It's better to run this colab in a copy on your Google Drive, so that **if it timeouts** you still have the saved notebook on your Google Drive and do not need to fill everything from scratch.To do that you can either do `Ctrl + S` or `File > Save a copy in Google Drive.`Also, we're going to **train it for 90 minutes with 1M timesteps**. By typing `!nvidia-smi` will tell you what GPU you're using.And if you want to train more such 10 million steps, this will take about 9 hours, potentially resulting in Colab timing out. In that case, I recommend running this on your local computer (or somewhere else). Just click on: `File>Download`. Set the GPU 💪- To **accelerate the agent's training, we'll use a GPU**. To do that, go to `Runtime > Change Runtime type` - `Hardware Accelerator > GPU` Install RL-Baselines3 Zoo and its dependencies 📚If you see `ERROR: pip's dependency resolver does not currently take into account all the packages that are installed.` **this is normal and it's not a critical error** there's a conflict of version. But the packages we need are installed.<jupyter_code># For now we install this update of RL-Baselines3 Zoo
!pip install git+https://github.com/DLR-RM/rl-baselines3-zoo@update/hf<jupyter_output><empty_output><jupyter_text>IF AND ONLY IF THE VERSION ABOVE DOES NOT EXIST ANYMORE. UNCOMMENT AND INSTALL THE ONE BELOW<jupyter_code>#!pip install rl_zoo3==2.0.0a9
!apt-get install swig cmake ffmpeg<jupyter_output><empty_output><jupyter_text>To be able to use Atari games in Gymnasium we need to install atari package. And accept-rom-license to download the rom files (games files).<jupyter_code>!pip install gymnasium[atari]
!pip install gymnasium[accept-rom-license]<jupyter_output><empty_output><jupyter_text>Create a virtual display 🔽During the notebook, we'll need to generate a replay video. To do so, with colab, **we need to have a virtual screen to be able to render the environment** (and thus record the frames). Hence the following cell will install the librairies and create and run a virtual screen 🖥<jupyter_code>%%capture
!apt install python-opengl
!apt install xvfb
!pip3 install pyvirtualdisplay
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()<jupyter_output><empty_output><jupyter_text>Train our Deep Q-Learning Agent to Play Space Invaders 👾To train an agent with RL-Baselines3-Zoo, we just need to do two things:1. Create a hyperparameter config file that will contain our training hyperparameters called `dqn.yml`.This is a template example:```SpaceInvadersNoFrameskip-v4: env_wrapper: - stable_baselines3.common.atari_wrappers.AtariWrapper frame_stack: 4 policy: 'CnnPolicy' n_timesteps: !!float 1e6 buffer_size: 100000 learning_rate: !!float 1e-4 batch_size: 32 learning_starts: 100000 target_update_interval: 1000 train_freq: 4 gradient_steps: 1 exploration_fraction: 0.1 exploration_final_eps: 0.01 If True, you need to deactivate handle_timeout_termination in the replay_buffer_kwargs optimize_memory_usage: False``` Here we see that:- We use the `Atari Wrapper` that preprocess the input (Frame reduction ,grayscale, stack 4 frames)- We use `CnnPolicy`, since we use Convolutional layers to process the frames- We train it for 10 million `n_timesteps` - Memory (Experience Replay) size is 100000, aka the amount of experience steps you saved to train again your agent with.💡 My advice is to **reduce the training timesteps to 1M,** which will take about 90 minutes on a P100. `!nvidia-smi` will tell you what GPU you're using. At 10 million steps, this will take about 9 hours, which could likely result in Colab timing out. I recommend running this on your local computer (or somewhere else). Just click on: `File>Download`. In terms of hyperparameters optimization, my advice is to focus on these 3 hyperparameters:- `learning_rate`- `buffer_size (Experience Memory size)`- `batch_size`As a good practice, you need to **check the documentation to understand what each hyperparameters does**: https://stable-baselines3.readthedocs.io/en/master/modules/dqn.htmlparameters 2. We start the training and save the models on `logs` folder 📁- Define the algorithm after `--algo`, where we save the model after `-f` and where the hyperparameter config is after `-c`.<jupyter_code>!python -m rl_zoo3.train --algo ________ --env SpaceInvadersNoFrameskip-v4 -f _________ -c _________<jupyter_output><empty_output><jupyter_text>Solution<jupyter_code>!python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -c dqn.yml<jupyter_output><empty_output><jupyter_text>Let's evaluate our agent 👀- RL-Baselines3-Zoo provides `enjoy.py`, a python script to evaluate our agent. In most RL libraries, we call the evaluation script `enjoy.py`.- Let's evaluate it for 5000 timesteps 🔥<jupyter_code>!python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n-timesteps _________ --folder logs/<jupyter_output><empty_output><jupyter_text>Solution<jupyter_code>!python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 --no-render --n-timesteps 5000 --folder logs/<jupyter_output><empty_output><jupyter_text>Publish our trained model on the Hub 🚀Now that we saw we got good results after the training, we can publish our trained model on the hub 🤗 with one line of code. By using `rl_zoo3.push_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the hub**.This way:- You can **showcase our work** 🔥- You can **visualize your agent playing** 👀- You can **share with the community an agent that others can use** 💾- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard To be able to share your model with the community there are three more steps to follow:1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.- Create a new token (https://huggingface.co/settings/tokens) **with write role** - Copy the token - Run the cell below and past the token<jupyter_code>from huggingface_hub import notebook_login # To log to our Hugging Face account to be able to upload models to the Hub.
notebook_login()
!git config --global credential.helper store<jupyter_output><empty_output><jupyter_text>If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login` 3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 Let's run push_to_hub.py file to upload our trained agent to the Hub.`--repo-name `: The name of the repo`-orga`: Your Hugging Face username`-f`: Where the trained model folder is (in our case `logs`)<jupyter_code>!python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 --repo-name _____________________ -orga _____________________ -f logs/<jupyter_output><empty_output><jupyter_text>Solution<jupyter_code>!python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 --repo-name dqn-SpaceInvadersNoFrameskip-v4 -orga ThomasSimonini -f logs/<jupyter_output><empty_output><jupyter_text>. Congrats 🥳 you've just trained and uploaded your first Deep Q-Learning agent using RL-Baselines-3 Zoo. The script above should have displayed a link to a model repository such as https://huggingface.co/ThomasSimonini/dqn-SpaceInvadersNoFrameskip-v4. When you go to this link, you can:- See a **video preview of your agent** at the right. - Click "Files and versions" to see all the files in the repository.- Click "Use in stable-baselines3" to get a code snippet that shows how to load the model.- A model card (`README.md` file) which gives a description of the model and the hyperparameters you used.Under the hood, the Hub uses git-based repositories (don't worry if you don't know what git is), which means you can update the model with new versions as you experiment and improve your agent.**Compare the results of your agents with your classmates** using the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) 🏆 Load a powerful trained model 🔥- The Stable-Baselines3 team uploaded **more than 150 trained Deep Reinforcement Learning agents on the Hub**.You can find them here: 👉 https://huggingface.co/sb3Some examples:- Asteroids: https://huggingface.co/sb3/dqn-AsteroidsNoFrameskip-v4- Beam Rider: https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4- Breakout: https://huggingface.co/sb3/dqn-BreakoutNoFrameskip-v4- Road Runner: https://huggingface.co/sb3/dqn-RoadRunnerNoFrameskip-v4Let's load an agent playing Beam Rider: https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4<jupyter_code>%%html
<video controls autoplay><source src="https://huggingface.co/sb3/dqn-BeamRiderNoFrameskip-v4/resolve/main/replay.mp4" type="video/mp4"></video><jupyter_output><empty_output><jupyter_text>1. We download the model using `rl_zoo3.load_from_hub`, and place it in a new folder that we can call `rl_trained`<jupyter_code># Download model and save it into the logs/ folder
!python -m rl_zoo3.load_from_hub --algo dqn --env BeamRiderNoFrameskip-v4 -orga sb3 -f rl_trained/<jupyter_output><empty_output><jupyter_text>2. Let's evaluate if for 5000 timesteps<jupyter_code>!python -m rl_zoo3.enjoy --algo dqn --env BeamRiderNoFrameskip-v4 -n 5000 -f rl_trained/ --no-render<jupyter_output><empty_output> | deep-rl-class/notebooks/unit3/unit3.ipynb/0 | {
"file_path": "deep-rl-class/notebooks/unit3/unit3.ipynb",
"repo_id": "deep-rl-class",
"token_count": 3982
} | 86 |
# Conclusion [[conclusion]]
Congrats on finishing this unit! **That was the biggest one**, and there was a lot of information. And congrats on finishing the tutorial. You’ve just trained your first Deep RL agents and shared them with the community! 🥳
It's **normal if you still feel confused by some of these elements**. This was the same for me and for all people who studied RL.
**Take time to really grasp the material** before continuing. It’s important to master these elements and have a solid foundation before entering the fun part.
Naturally, during the course, we’re going to use and explain these terms again, but it’s better to understand them before diving into the next units.
In the next (bonus) unit, we’re going to reinforce what we just learned by **training Huggy the Dog to fetch a stick**.
You will then be able to play with him 🤗.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy.jpg" alt="Huggy"/>
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then, please 👉 [fill this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
| deep-rl-class/units/en/unit1/conclusion.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit1/conclusion.mdx",
"repo_id": "deep-rl-class",
"token_count": 349
} | 87 |
# Hands-on [[hands-on]]
<CourseFloatingBanner classNames="absolute z-10 right-0 top-0"
notebooks={[
{label: "Google Colab", value: "https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/notebooks/unit2/unit2.ipynb"}
]}
askForHelpUrl="http://hf.co/join/discord" />
Now that we studied the Q-Learning algorithm, let's implement it from scratch and train our Q-Learning agent in two environments:
1. [Frozen-Lake-v1 (non-slippery and slippery version)](https://gymnasium.farama.org/environments/toy_text/frozen_lake/) ☃️ : where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
2. [An autonomous taxi](https://gymnasium.farama.org/environments/toy_text/taxi/) 🚖 will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/envs.gif" alt="Environments"/>
Thanks to a [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard), you'll be able to compare your results with other classmates and exchange the best practices to improve your agent's scores. Who will win the challenge for Unit 2?
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
And you can check your progress here 👉 https://huggingface.co/spaces/ThomasSimonini/Check-my-progress-Deep-RL-Course
**To start the hands-on click on the Open In Colab button** 👇 :
[](https://colab.research.google.com/github/huggingface/deep-rl-class/blob/master/notebooks/unit2/unit2.ipynb)
We strongly **recommend students use Google Colab for the hands-on exercises** instead of running them on their personal computers.
By using Google Colab, **you can focus on learning and experimenting without worrying about the technical aspects** of setting up your environments.
# Unit 2: Q-Learning with FrozenLake-v1 ⛄ and Taxi-v3 🚕
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/thumbnail.jpg" alt="Unit 2 Thumbnail">
In this notebook, **you'll code your first Reinforcement Learning agent from scratch** to play FrozenLake ❄️ using Q-Learning, share it with the community, and experiment with different configurations.
⬇️ Here is an example of what **you will achieve in just a couple of minutes.** ⬇️
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/envs.gif" alt="Environments"/>
### 🎮 Environments:
- [FrozenLake-v1](https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
- [Taxi-v3](https://gymnasium.farama.org/environments/toy_text/taxi/)
### 📚 RL-Library:
- Python and NumPy
- [Gymnasium](https://gymnasium.farama.org/)
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
## Objectives of this notebook 🏆
At the end of the notebook, you will:
- Be able to use **Gymnasium**, the environment library.
- Be able to code a Q-Learning agent from scratch.
- Be able to **push your trained agent and the code to the Hub** with a nice video replay and an evaluation score 🔥.
## This notebook is from the Deep Reinforcement Learning Course
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/deep-rl-course-illustration.jpg" alt="Deep RL Course illustration"/>
In this free course, you will:
- 📖 Study Deep Reinforcement Learning in **theory and practice**.
- 🧑💻 Learn to **use famous Deep RL libraries** such as Stable Baselines3, RL Baselines3 Zoo, CleanRL and Sample Factory 2.0.
- 🤖 Train **agents in unique environments**
And more check 📚 the syllabus 👉 https://simoninithomas.github.io/deep-rl-course
Don’t forget to **<a href="http://eepurl.com/ic5ZUD">sign up to the course</a>** (we are collecting your email to be able to **send you the links when each Unit is published and give you information about the challenges and updates).**
The best way to keep in touch is to join our discord server to exchange with the community and with us 👉🏻 https://discord.gg/ydHrjt3WP5
## Prerequisites 🏗️
Before diving into the notebook, you need to:
🔲 📚 **Study [Q-Learning by reading Unit 2](https://huggingface.co/deep-rl-course/unit2/introduction)** 🤗
## A small recap of Q-Learning
*Q-Learning* **is the RL algorithm that**:
- Trains *Q-Function*, an **action-value function** that is encoded, in internal memory, by a *Q-table* **that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search the Q-table for the corresponding value.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-function-2.jpg" alt="Q function" width="100%"/>
- When the training is done, **we have an optimal Q-Function, so an optimal Q-Table.**
- And if we **have an optimal Q-function**, we
have an optimal policy, since we **know for each state, the best action to take.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/link-value-policy.jpg" alt="Link value policy" width="100%"/>
But, in the beginning, our **Q-Table is useless since it gives arbitrary value for each state-action pair (most of the time we initialize the Q-Table to 0 values)**. But, as we’ll explore the environment and update our Q-Table it will give us better and better approximations
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/q-learning.jpeg" alt="q-learning.jpeg" width="100%"/>
This is the Q-Learning pseudocode:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-2.jpg" alt="Q-Learning" width="100%"/>
# Let's code our first Reinforcement Learning algorithm 🚀
To validate this hands-on for the [certification process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process), you need to push your trained Taxi model to the Hub and **get a result of >= 4.5**.
To find your result, go to the [leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) and find your model, **the result = mean_reward - std of reward**
For more information about the certification process, check this section 👉 https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process
## Install dependencies and create a virtual display 🔽
In the notebook, we'll need to generate a replay video. To do so, with Colab, **we need to have a virtual screen to render the environment** (and thus record the frames).
Hence the following cell will install the libraries and create and run a virtual screen 🖥
We’ll install multiple ones:
- `gymnasium`: Contains the FrozenLake-v1 ⛄ and Taxi-v3 🚕 environments.
- `pygame`: Used for the FrozenLake-v1 and Taxi-v3 UI.
- `numpy`: Used for handling our Q-table.
The Hugging Face Hub 🤗 works as a central place where anyone can share and explore models and datasets. It has versioning, metrics, visualizations and other features that will allow you to easily collaborate with others.
You can see here all the Deep RL models available (if they use Q Learning) here 👉 https://huggingface.co/models?other=q-learning
```bash
pip install -r https://raw.githubusercontent.com/huggingface/deep-rl-class/main/notebooks/unit2/requirements-unit2.txt
```
```bash
sudo apt-get update
sudo apt-get install -y python3-opengl
apt install ffmpeg xvfb
pip3 install pyvirtualdisplay
```
To make sure the new installed libraries are used, **sometimes it's required to restart the notebook runtime**. The next cell will force the **runtime to crash, so you'll need to connect again and run the code starting from here**. Thanks to this trick, **we will be able to run our virtual screen.**
```python
import os
os.kill(os.getpid(), 9)
```
```python
# Virtual display
from pyvirtualdisplay import Display
virtual_display = Display(visible=0, size=(1400, 900))
virtual_display.start()
```
## Import the packages 📦
In addition to the installed libraries, we also use:
- `random`: To generate random numbers (that will be useful for epsilon-greedy policy).
- `imageio`: To generate a replay video.
```python
import numpy as np
import gymnasium as gym
import random
import imageio
import os
import tqdm
import pickle5 as pickle
from tqdm.notebook import tqdm
```
We're now ready to code our Q-Learning algorithm 🔥
# Part 1: Frozen Lake ⛄ (non slippery version)
## Create and understand [FrozenLake environment ⛄]((https://gymnasium.farama.org/environments/toy_text/frozen_lake/)
---
💡 A good habit when you start to use an environment is to check its documentation
👉 https://gymnasium.farama.org/environments/toy_text/frozen_lake/
---
We're going to train our Q-Learning agent **to navigate from the starting state (S) to the goal state (G) by walking only on frozen tiles (F) and avoid holes (H)**.
We can have two sizes of environment:
- `map_name="4x4"`: a 4x4 grid version
- `map_name="8x8"`: a 8x8 grid version
The environment has two modes:
- `is_slippery=False`: The agent always moves **in the intended direction** due to the non-slippery nature of the frozen lake (deterministic).
- `is_slippery=True`: The agent **may not always move in the intended direction** due to the slippery nature of the frozen lake (stochastic).
For now let's keep it simple with the 4x4 map and non-slippery.
We add a parameter called `render_mode` that specifies how the environment should be visualised. In our case because we **want to record a video of the environment at the end, we need to set render_mode to rgb_array**.
As [explained in the documentation](https://gymnasium.farama.org/api/env/#gymnasium.Env.render) “rgb_array”: Return a single frame representing the current state of the environment. A frame is a np.ndarray with shape (x, y, 3) representing RGB values for an x-by-y pixel image.
```python
# Create the FrozenLake-v1 environment using 4x4 map and non-slippery version and render_mode="rgb_array"
env = gym.make() # TODO use the correct parameters
```
### Solution
```python
env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False, render_mode="rgb_array")
```
You can create your own custom grid like this:
```python
desc=["SFFF", "FHFH", "FFFH", "HFFG"]
gym.make('FrozenLake-v1', desc=desc, is_slippery=True)
```
but we'll use the default environment for now.
### Let's see what the Environment looks like:
```python
# We create our environment with gym.make("<name_of_the_environment>")- `is_slippery=False`: The agent always moves in the intended direction due to the non-slippery nature of the frozen lake (deterministic).
print("_____OBSERVATION SPACE_____ \n")
print("Observation Space", env.observation_space)
print("Sample observation", env.observation_space.sample()) # Get a random observation
```
We see with `Observation Space Shape Discrete(16)` that the observation is an integer representing the **agent’s current position as current_row * ncols + current_col (where both the row and col start at 0)**.
For example, the goal position in the 4x4 map can be calculated as follows: 3 * 4 + 3 = 15. The number of possible observations is dependent on the size of the map. **For example, the 4x4 map has 16 possible observations.**
For instance, this is what state = 0 looks like:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/frozenlake.png" alt="FrozenLake">
```python
print("\n _____ACTION SPACE_____ \n")
print("Action Space Shape", env.action_space.n)
print("Action Space Sample", env.action_space.sample()) # Take a random action
```
The action space (the set of possible actions the agent can take) is discrete with 4 actions available 🎮:
- 0: GO LEFT
- 1: GO DOWN
- 2: GO RIGHT
- 3: GO UP
Reward function 💰:
- Reach goal: +1
- Reach hole: 0
- Reach frozen: 0
## Create and Initialize the Q-table 🗄️
(👀 Step 1 of the pseudocode)
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-2.jpg" alt="Q-Learning" width="100%"/>
It's time to initialize our Q-table! To know how many rows (states) and columns (actions) to use, we need to know the action and observation space. We already know their values from before, but we'll want to obtain them programmatically so that our algorithm generalizes for different environments. Gym provides us a way to do that: `env.action_space.n` and `env.observation_space.n`
```python
state_space =
print("There are ", state_space, " possible states")
action_space =
print("There are ", action_space, " possible actions")
```
```python
# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros. np.zeros needs a tuple (a,b)
def initialize_q_table(state_space, action_space):
Qtable =
return Qtable
```
```python
Qtable_frozenlake = initialize_q_table(state_space, action_space)
```
### Solution
```python
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
action_space = env.action_space.n
print("There are ", action_space, " possible actions")
```
```python
# Let's create our Qtable of size (state_space, action_space) and initialized each values at 0 using np.zeros
def initialize_q_table(state_space, action_space):
Qtable = np.zeros((state_space, action_space))
return Qtable
```
```python
Qtable_frozenlake = initialize_q_table(state_space, action_space)
```
## Define the greedy policy 🤖
Remember we have two policies since Q-Learning is an **off-policy** algorithm. This means we're using a **different policy for acting and updating the value function**.
- Epsilon-greedy policy (acting policy)
- Greedy-policy (updating policy)
The greedy policy will also be the final policy we'll have when the Q-learning agent completes training. The greedy policy is used to select an action using the Q-table.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/off-on-4.jpg" alt="Q-Learning" width="100%"/>
```python
def greedy_policy(Qtable, state):
# Exploitation: take the action with the highest state, action value
action =
return action
```
#### Solution
```python
def greedy_policy(Qtable, state):
# Exploitation: take the action with the highest state, action value
action = np.argmax(Qtable[state][:])
return action
```
## Define the epsilon-greedy policy 🤖
Epsilon-greedy is the training policy that handles the exploration/exploitation trade-off.
The idea with epsilon-greedy:
- With *probability 1 - ɛ* : **we do exploitation** (i.e. our agent selects the action with the highest state-action pair value).
- With *probability ɛ*: we do **exploration** (trying a random action).
As the training continues, we progressively **reduce the epsilon value since we will need less and less exploration and more exploitation.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-4.jpg" alt="Q-Learning" width="100%"/>
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# Randomly generate a number between 0 and 1
random_num =
# if random_num > greater than epsilon --> exploitation
if random_num > epsilon:
# Take the action with the highest value given a state
# np.argmax can be useful here
action =
# else --> exploration
else:
action = # Take a random action
return action
```
#### Solution
```python
def epsilon_greedy_policy(Qtable, state, epsilon):
# Randomly generate a number between 0 and 1
random_num = random.uniform(0, 1)
# if random_num > greater than epsilon --> exploitation
if random_num > epsilon:
# Take the action with the highest value given a state
# np.argmax can be useful here
action = greedy_policy(Qtable, state)
# else --> exploration
else:
action = env.action_space.sample()
return action
```
## Define the hyperparameters ⚙️
The exploration related hyperparamters are some of the most important ones.
- We need to make sure that our agent **explores enough of the state space** to learn a good value approximation. To do that, we need to have progressive decay of the epsilon.
- If you decrease epsilon too fast (too high decay_rate), **you take the risk that your agent will be stuck**, since your agent didn't explore enough of the state space and hence can't solve the problem.
```python
# Training parameters
n_training_episodes = 10000 # Total training episodes
learning_rate = 0.7 # Learning rate
# Evaluation parameters
n_eval_episodes = 100 # Total number of test episodes
# Environment parameters
env_id = "FrozenLake-v1" # Name of the environment
max_steps = 99 # Max steps per episode
gamma = 0.95 # Discounting rate
eval_seed = [] # The evaluation seed of the environment
# Exploration parameters
max_epsilon = 1.0 # Exploration probability at start
min_epsilon = 0.05 # Minimum exploration probability
decay_rate = 0.0005 # Exponential decay rate for exploration prob
```
## Create the training loop method
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit3/Q-learning-2.jpg" alt="Q-Learning" width="100%"/>
The training loop goes like this:
```
For episode in the total of training episodes:
Reduce epsilon (since we need less and less exploration)
Reset the environment
For step in max timesteps:
Choose the action At using epsilon greedy policy
Take the action (a) and observe the outcome state(s') and reward (r)
Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
If done, finish the episode
Our next state is the new state
```
```python
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in tqdm(range(n_training_episodes)):
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state, info = env.reset()
step = 0
terminated = False
truncated = False
# repeat
for step in range(max_steps):
# Choose the action At using epsilon greedy policy
action =
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
new_state, reward, terminated, truncated, info =
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
Qtable[state][action] =
# If terminated or truncated finish the episode
if terminated or truncated:
break
# Our next state is the new state
state = new_state
return Qtable
```
#### Solution
```python
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in tqdm(range(n_training_episodes)):
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon) * np.exp(-decay_rate * episode)
# Reset the environment
state, info = env.reset()
step = 0
terminated = False
truncated = False
# repeat
for step in range(max_steps):
# Choose the action At using epsilon greedy policy
action = epsilon_greedy_policy(Qtable, state, epsilon)
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
new_state, reward, terminated, truncated, info = env.step(action)
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
Qtable[state][action] = Qtable[state][action] + learning_rate * (
reward + gamma * np.max(Qtable[new_state]) - Qtable[state][action]
)
# If terminated or truncated finish the episode
if terminated or truncated:
break
# Our next state is the new state
state = new_state
return Qtable
```
## Train the Q-Learning agent 🏃
```python
Qtable_frozenlake = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_frozenlake)
```
## Let's see what our Q-Learning table looks like now 👀
```python
Qtable_frozenlake
```
## The evaluation method 📝
- We defined the evaluation method that we're going to use to test our Q-Learning agent.
```python
def evaluate_agent(env, max_steps, n_eval_episodes, Q, seed):
"""
Evaluate the agent for ``n_eval_episodes`` episodes and returns average reward and std of reward.
:param env: The evaluation environment
:param n_eval_episodes: Number of episode to evaluate the agent
:param Q: The Q-table
:param seed: The evaluation seed array (for taxi-v3)
"""
episode_rewards = []
for episode in tqdm(range(n_eval_episodes)):
if seed:
state, info = env.reset(seed=seed[episode])
else:
state, info = env.reset()
step = 0
truncated = False
terminated = False
total_rewards_ep = 0
for step in range(max_steps):
# Take the action (index) that have the maximum expected future reward given that state
action = greedy_policy(Q, state)
new_state, reward, terminated, truncated, info = env.step(action)
total_rewards_ep += reward
if terminated or truncated:
break
state = new_state
episode_rewards.append(total_rewards_ep)
mean_reward = np.mean(episode_rewards)
std_reward = np.std(episode_rewards)
return mean_reward, std_reward
```
## Evaluate our Q-Learning agent 📈
- Usually, you should have a mean reward of 1.0
- The **environment is relatively easy** since the state space is really small (16). What you can try to do is [to replace it with the slippery version](https://www.gymlibrary.dev/environments/toy_text/frozen_lake/), which introduces stochasticity, making the environment more complex.
```python
# Evaluate our Agent
mean_reward, std_reward = evaluate_agent(env, max_steps, n_eval_episodes, Qtable_frozenlake, eval_seed)
print(f"Mean_reward={mean_reward:.2f} +/- {std_reward:.2f}")
```
## Publish our trained model to the Hub 🔥
Now that we saw good results after the training, **we can publish our trained model to the Hub 🤗 with one line of code**.
Here's an example of a Model Card:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/modelcard.png" alt="Model card" width="100%"/>
Under the hood, the Hub uses git-based repositories (don't worry if you don't know what git is), which means you can update the model with new versions as you experiment and improve your agent.
#### Do not modify this code
```python
from huggingface_hub import HfApi, snapshot_download
from huggingface_hub.repocard import metadata_eval_result, metadata_save
from pathlib import Path
import datetime
import json
```
```python
def record_video(env, Qtable, out_directory, fps=1):
"""
Generate a replay video of the agent
:param env
:param Qtable: Qtable of our agent
:param out_directory
:param fps: how many frame per seconds (with taxi-v3 and frozenlake-v1 we use 1)
"""
images = []
terminated = False
truncated = False
state, info = env.reset(seed=random.randint(0, 500))
img = env.render()
images.append(img)
while not terminated or truncated:
# Take the action (index) that have the maximum expected future reward given that state
action = np.argmax(Qtable[state][:])
state, reward, terminated, truncated, info = env.step(
action
) # We directly put next_state = state for recording logic
img = env.render()
images.append(img)
imageio.mimsave(out_directory, [np.array(img) for i, img in enumerate(images)], fps=fps)
```
```python
def push_to_hub(repo_id, model, env, video_fps=1, local_repo_path="hub"):
"""
Evaluate, Generate a video and Upload a model to Hugging Face Hub.
This method does the complete pipeline:
- It evaluates the model
- It generates the model card
- It generates a replay video of the agent
- It pushes everything to the Hub
:param repo_id: repo_id: id of the model repository from the Hugging Face Hub
:param env
:param video_fps: how many frame per seconds to record our video replay
(with taxi-v3 and frozenlake-v1 we use 1)
:param local_repo_path: where the local repository is
"""
_, repo_name = repo_id.split("/")
eval_env = env
api = HfApi()
# Step 1: Create the repo
repo_url = api.create_repo(
repo_id=repo_id,
exist_ok=True,
)
# Step 2: Download files
repo_local_path = Path(snapshot_download(repo_id=repo_id))
# Step 3: Save the model
if env.spec.kwargs.get("map_name"):
model["map_name"] = env.spec.kwargs.get("map_name")
if env.spec.kwargs.get("is_slippery", "") == False:
model["slippery"] = False
# Pickle the model
with open((repo_local_path) / "q-learning.pkl", "wb") as f:
pickle.dump(model, f)
# Step 4: Evaluate the model and build JSON with evaluation metrics
mean_reward, std_reward = evaluate_agent(
eval_env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"]
)
evaluate_data = {
"env_id": model["env_id"],
"mean_reward": mean_reward,
"n_eval_episodes": model["n_eval_episodes"],
"eval_datetime": datetime.datetime.now().isoformat(),
}
# Write a JSON file called "results.json" that will contain the
# evaluation results
with open(repo_local_path / "results.json", "w") as outfile:
json.dump(evaluate_data, outfile)
# Step 5: Create the model card
env_name = model["env_id"]
if env.spec.kwargs.get("map_name"):
env_name += "-" + env.spec.kwargs.get("map_name")
if env.spec.kwargs.get("is_slippery", "") == False:
env_name += "-" + "no_slippery"
metadata = {}
metadata["tags"] = [env_name, "q-learning", "reinforcement-learning", "custom-implementation"]
# Add metrics
eval = metadata_eval_result(
model_pretty_name=repo_name,
task_pretty_name="reinforcement-learning",
task_id="reinforcement-learning",
metrics_pretty_name="mean_reward",
metrics_id="mean_reward",
metrics_value=f"{mean_reward:.2f} +/- {std_reward:.2f}",
dataset_pretty_name=env_name,
dataset_id=env_name,
)
# Merges both dictionaries
metadata = {**metadata, **eval}
model_card = f"""
# **Q-Learning** Agent playing1 **{env_id}**
This is a trained model of a **Q-Learning** agent playing **{env_id}** .
## Usage
model = load_from_hub(repo_id="{repo_id}", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
"""
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
readme_path = repo_local_path / "README.md"
readme = ""
print(readme_path.exists())
if readme_path.exists():
with readme_path.open("r", encoding="utf8") as f:
readme = f.read()
else:
readme = model_card
with readme_path.open("w", encoding="utf-8") as f:
f.write(readme)
# Save our metrics to Readme metadata
metadata_save(readme_path, metadata)
# Step 6: Record a video
video_path = repo_local_path / "replay.mp4"
record_video(env, model["qtable"], video_path, video_fps)
# Step 7. Push everything to the Hub
api.upload_folder(
repo_id=repo_id,
folder_path=repo_local_path,
path_in_repo=".",
)
print("Your model is pushed to the Hub. You can view your model here: ", repo_url)
```
### .
By using `push_to_hub` **you evaluate, record a replay, generate a model card of your agent and push it to the Hub**.
This way:
- You can **showcase our work** 🔥
- You can **visualize your agent playing** 👀
- You can **share an agent with the community that others can use** 💾
- You can **access a leaderboard 🏆 to see how well your agent is performing compared to your classmates** 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
To be able to share your model with the community there are three more steps to follow:
1️⃣ (If it's not already done) create an account to HF ➡ https://huggingface.co/join
2️⃣ Sign in and then, you need to store your authentication token from the Hugging Face website.
- Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
```python
from huggingface_hub import notebook_login
notebook_login()
```
If you don't want to use a Google Colab or a Jupyter Notebook, you need to use this command instead: `huggingface-cli login` (or `login`)
3️⃣ We're now ready to push our trained agent to the 🤗 Hub 🔥 using `push_to_hub()` function
- Let's create **the model dictionary that contains the hyperparameters and the Q_table**.
```python
model = {
"env_id": env_id,
"max_steps": max_steps,
"n_training_episodes": n_training_episodes,
"n_eval_episodes": n_eval_episodes,
"eval_seed": eval_seed,
"learning_rate": learning_rate,
"gamma": gamma,
"max_epsilon": max_epsilon,
"min_epsilon": min_epsilon,
"decay_rate": decay_rate,
"qtable": Qtable_frozenlake,
}
```
Let's fill the `push_to_hub` function:
- `repo_id`: the name of the Hugging Face Hub Repository that will be created/updated `
(repo_id = {username}/{repo_name})`
💡 A good `repo_id` is `{username}/q-{env_id}`
- `model`: our model dictionary containing the hyperparameters and the Qtable.
- `env`: the environment.
- `commit_message`: message of the commit
```python
model
```
```python
username = "" # FILL THIS
repo_name = "q-FrozenLake-v1-4x4-noSlippery"
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
```
Congrats 🥳 you've just implemented from scratch, trained, and uploaded your first Reinforcement Learning agent.
FrozenLake-v1 no_slippery is very simple environment, let's try a harder one 🔥.
# Part 2: Taxi-v3 🚖
## Create and understand [Taxi-v3 🚕](https://gymnasium.farama.org/environments/toy_text/taxi/)
---
💡 A good habit when you start to use an environment is to check its documentation
👉 https://gymnasium.farama.org/environments/toy_text/taxi/
---
In `Taxi-v3` 🚕, there are four designated locations in the grid world indicated by R(ed), G(reen), Y(ellow), and B(lue).
When the episode starts, **the taxi starts off at a random square** and the passenger is at a random location. The taxi drives to the passenger’s location, **picks up the passenger**, drives to the passenger’s destination (another one of the four specified locations), and then **drops off the passenger**. Once the passenger is dropped off, the episode ends.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/taxi.png" alt="Taxi">
```python
env = gym.make("Taxi-v3", render_mode="rgb_array")
```
There are **500 discrete states since there are 25 taxi positions, 5 possible locations of the passenger** (including the case when the passenger is in the taxi), and **4 destination locations.**
```python
state_space = env.observation_space.n
print("There are ", state_space, " possible states")
```
```python
action_space = env.action_space.n
print("There are ", action_space, " possible actions")
```
The action space (the set of possible actions the agent can take) is discrete with **6 actions available 🎮**:
- 0: move south
- 1: move north
- 2: move east
- 3: move west
- 4: pickup passenger
- 5: drop off passenger
Reward function 💰:
- -1 per step unless other reward is triggered.
- +20 delivering passenger.
- -10 executing “pickup” and “drop-off” actions illegally.
```python
# Create our Q table with state_size rows and action_size columns (500x6)
Qtable_taxi = initialize_q_table(state_space, action_space)
print(Qtable_taxi)
print("Q-table shape: ", Qtable_taxi.shape)
```
## Define the hyperparameters ⚙️
⚠ DO NOT MODIFY EVAL_SEED: the eval_seed array **allows us to evaluate your agent with the same taxi starting positions for every classmate**
```python
# Training parameters
n_training_episodes = 25000 # Total training episodes
learning_rate = 0.7 # Learning rate
# Evaluation parameters
n_eval_episodes = 100 # Total number of test episodes
# DO NOT MODIFY EVAL_SEED
eval_seed = [
16,
54,
165,
177,
191,
191,
120,
80,
149,
178,
48,
38,
6,
125,
174,
73,
50,
172,
100,
148,
146,
6,
25,
40,
68,
148,
49,
167,
9,
97,
164,
176,
61,
7,
54,
55,
161,
131,
184,
51,
170,
12,
120,
113,
95,
126,
51,
98,
36,
135,
54,
82,
45,
95,
89,
59,
95,
124,
9,
113,
58,
85,
51,
134,
121,
169,
105,
21,
30,
11,
50,
65,
12,
43,
82,
145,
152,
97,
106,
55,
31,
85,
38,
112,
102,
168,
123,
97,
21,
83,
158,
26,
80,
63,
5,
81,
32,
11,
28,
148,
] # Evaluation seed, this ensures that all classmates agents are trained on the same taxi starting position
# Each seed has a specific starting state
# Environment parameters
env_id = "Taxi-v3" # Name of the environment
max_steps = 99 # Max steps per episode
gamma = 0.95 # Discounting rate
# Exploration parameters
max_epsilon = 1.0 # Exploration probability at start
min_epsilon = 0.05 # Minimum exploration probability
decay_rate = 0.005 # Exponential decay rate for exploration prob
```
## Train our Q-Learning agent 🏃
```python
Qtable_taxi = train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable_taxi)
Qtable_taxi
```
## Create a model dictionary 💾 and publish our trained model to the Hub 🔥
- We create a model dictionary that will contain all the training hyperparameters for reproducibility and the Q-Table.
```python
model = {
"env_id": env_id,
"max_steps": max_steps,
"n_training_episodes": n_training_episodes,
"n_eval_episodes": n_eval_episodes,
"eval_seed": eval_seed,
"learning_rate": learning_rate,
"gamma": gamma,
"max_epsilon": max_epsilon,
"min_epsilon": min_epsilon,
"decay_rate": decay_rate,
"qtable": Qtable_taxi,
}
```
```python
username = "" # FILL THIS
repo_name = "" # FILL THIS
push_to_hub(repo_id=f"{username}/{repo_name}", model=model, env=env)
```
Now that it's on the Hub, you can compare the results of your Taxi-v3 with your classmates using the leaderboard 🏆 👉 https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/taxi-leaderboard.png" alt="Taxi Leaderboard">
# Part 3: Load from Hub 🔽
What's amazing with Hugging Face Hub 🤗 is that you can easily load powerful models from the community.
Loading a saved model from the Hub is really easy:
1. You go https://huggingface.co/models?other=q-learning to see the list of all the q-learning saved models.
2. You select one and copy its repo_id
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit2/copy-id.png" alt="Copy id">
3. Then we just need to use `load_from_hub` with:
- The repo_id
- The filename: the saved model inside the repo.
#### Do not modify this code
```python
from urllib.error import HTTPError
from huggingface_hub import hf_hub_download
def load_from_hub(repo_id: str, filename: str) -> str:
"""
Download a model from Hugging Face Hub.
:param repo_id: id of the model repository from the Hugging Face Hub
:param filename: name of the model zip file from the repository
"""
# Get the model from the Hub, download and cache the model on your local disk
pickle_model = hf_hub_download(repo_id=repo_id, filename=filename)
with open(pickle_model, "rb") as f:
downloaded_model_file = pickle.load(f)
return downloaded_model_file
```
### .
```python
model = load_from_hub(repo_id="ThomasSimonini/q-Taxi-v3", filename="q-learning.pkl") # Try to use another model
print(model)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
```python
model = load_from_hub(
repo_id="ThomasSimonini/q-FrozenLake-v1-no-slippery", filename="q-learning.pkl"
) # Try to use another model
env = gym.make(model["env_id"], is_slippery=False)
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
## Some additional challenges 🏆
The best way to learn **is to try things on your own**! As you saw, the current agent is not doing great. As a first suggestion, you can train for more steps. With 1,000,000 steps, we saw some great results!
In the [Leaderboard](https://huggingface.co/spaces/huggingface-projects/Deep-Reinforcement-Learning-Leaderboard) you will find your agents. Can you get to the top?
Here are some ideas to climb up the leaderboard:
* Train more steps
* Try different hyperparameters by looking at what your classmates have done.
* **Push your new trained model** on the Hub 🔥
Are walking on ice and driving taxis too boring to you? Try to **change the environment**, why not use FrozenLake-v1 slippery version? Check how they work [using the gymnasium documentation](https://gymnasium.farama.org/) and have fun 🎉.
_____________________________________________________________________
Congrats 🥳, you've just implemented, trained, and uploaded your first Reinforcement Learning agent.
Understanding Q-Learning is an **important step to understanding value-based methods.**
In the next Unit with Deep Q-Learning, we'll see that while creating and updating a Q-table was a good strategy — **however, it is not scalable.**
For instance, imagine you create an agent that learns to play Doom.
<img src="https://vizdoom.cs.put.edu.pl/user/pages/01.tutorial/basic.png" alt="Doom"/>
Doom is a large environment with a huge state space (millions of different states). Creating and updating a Q-table for that environment would not be efficient.
That's why we'll study Deep Q-Learning in the next unit, an algorithm **where we use a neural network that approximates, given a state, the different Q-values for each action.**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit4/atari-envs.gif" alt="Environments"/>
See you in Unit 3! 🔥
## Keep learning, stay awesome 🤗
| deep-rl-class/units/en/unit2/hands-on.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit2/hands-on.mdx",
"repo_id": "deep-rl-class",
"token_count": 13932
} | 88 |
# Glossary
This is a community-created glossary. Contributions are welcomed!
- **Tabular Method:** Type of problem in which the state and action spaces are small enough to approximate value functions to be represented as arrays and tables.
**Q-learning** is an example of tabular method since a table is used to represent the value for different state-action pairs.
- **Deep Q-Learning:** Method that trains a neural network to approximate, given a state, the different **Q-values** for each possible action at that state.
It is used to solve problems when observational space is too big to apply a tabular Q-Learning approach.
- **Temporal Limitation** is a difficulty presented when the environment state is represented by frames. A frame by itself does not provide temporal information.
In order to obtain temporal information, we need to **stack** a number of frames together.
- **Phases of Deep Q-Learning:**
- **Sampling:** Actions are performed, and observed experience tuples are stored in a **replay memory**.
- **Training:** Batches of tuples are selected randomly and the neural network updates its weights using gradient descent.
- **Solutions to stabilize Deep Q-Learning:**
- **Experience Replay:** A replay memory is created to save experiences samples that can be reused during training.
This allows the agent to learn from the same experiences multiple times. Also, it helps the agent avoid forgetting previous experiences as it gets new ones.
- **Random sampling** from replay buffer allows to remove correlation in the observation sequences and prevents action values from oscillating or diverging
catastrophically.
- **Fixed Q-Target:** In order to calculate the **Q-Target** we need to estimate the discounted optimal **Q-value** of the next state by using Bellman equation. The problem
is that the same network weights are used to calculate the **Q-Target** and the **Q-value**. This means that everytime we are modifying the **Q-value**, the **Q-Target** also moves with it.
To avoid this issue, a separate network with fixed parameters is used for estimating the Temporal Difference Target. The target network is updated by copying parameters from
our Deep Q-Network after certain **C steps**.
- **Double DQN:** Method to handle **overestimation** of **Q-Values**. This solution uses two networks to decouple the action selection from the target **Value generation**:
- **DQN Network** to select the best action to take for the next state (the action with the highest **Q-Value**)
- **Target Network** to calculate the target **Q-Value** of taking that action at the next state.
This approach reduces the **Q-Values** overestimation, it helps to train faster and have more stable learning.
If you want to improve the course, you can [open a Pull Request.](https://github.com/huggingface/deep-rl-class/pulls)
This glossary was made possible thanks to:
- [Dario Paez](https://github.com/dario248)
| deep-rl-class/units/en/unit3/glossary.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit3/glossary.mdx",
"repo_id": "deep-rl-class",
"token_count": 721
} | 89 |
# (Optional) What is Curiosity in Deep Reinforcement Learning?
This is an (optional) introduction to Curiosity. If you want to learn more, you can read two additional articles where we dive into the mathematical details:
- [Curiosity-Driven Learning through Next State Prediction](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-next-state-prediction-f7f4e2f592fa)
- [Random Network Distillation: a new take on Curiosity-Driven Learning](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938)
## Two Major Problems in Modern RL
To understand what Curiosity is, we first need to understand the two major problems with RL:
First, the *sparse rewards problem:* that is, **most rewards do not contain information, and hence are set to zero**.
Remember that RL is based on the *reward hypothesis*, which is the idea that each goal can be described as the maximization of the rewards. Therefore, rewards act as feedback for RL agents; **if they don’t receive any, their knowledge of which action is appropriate (or not) cannot change**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/curiosity1.png" alt="Curiosity"/>
<figcaption>Source: Thanks to the reward, our agent knows that this action at that state was good</figcaption>
</figure>
For instance, in [Vizdoom](https://vizdoom.cs.put.edu.pl/), a set of environments based on the game Doom “DoomMyWayHome,” your agent is only rewarded **if it finds the vest**.
However, the vest is far away from your starting point, so most of your rewards will be zero. Therefore, if our agent does not receive useful feedback (dense rewards), it will take much longer to learn an optimal policy, and **it can spend time turning around without finding the goal**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/curiosity2.png" alt="Curiosity"/>
The second big problem is that **the extrinsic reward function is handmade; in each environment, a human has to implement a reward function**. But how we can scale that in big and complex environments?
## So what is Curiosity?
A solution to these problems is **to develop a reward function intrinsic to the agent, i.e., generated by the agent itself**. The agent will act as a self-learner since it will be the student and its own feedback master.
**This intrinsic reward mechanism is known as Curiosity** because this reward pushes the agent to explore states that are novel/unfamiliar. To achieve that, our agent will receive a high reward when exploring new trajectories.
This reward is inspired by how humans act. ** We naturally have an intrinsic desire to explore environments and discover new things**.
There are different ways to calculate this intrinsic reward. The classical approach (Curiosity through next-state prediction) is to calculate Curiosity **as the error of our agent in predicting the next state, given the current state and action taken**.
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/curiosity3.png" alt="Curiosity"/>
Because the idea of Curiosity is to **encourage our agent to perform actions that reduce the uncertainty in the agent’s ability to predict the consequences of its actions** (uncertainty will be higher in areas where the agent has spent less time or in areas with complex dynamics).
If the agent spends a lot of time on these states, it will be good at predicting the next state (low Curiosity). On the other hand, if it’s in a new, unexplored state, it will be hard to predict the following state (high Curiosity).
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit5/curiosity4.png" alt="Curiosity"/>
Using Curiosity will push our agent to favor transitions with high prediction error (which will be higher in areas where the agent has spent less time, or in areas with complex dynamics) and **consequently better explore our environment**.
There’s also **other curiosity calculation methods**. ML-Agents uses a more advanced one called Curiosity through random network distillation. This is out of the scope of the tutorial but if you’re interested [I wrote an article explaining it in detail](https://medium.com/data-from-the-trenches/curiosity-driven-learning-through-random-network-distillation-488ffd8e5938).
| deep-rl-class/units/en/unit5/curiosity.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit5/curiosity.mdx",
"repo_id": "deep-rl-class",
"token_count": 1153
} | 90 |
# Hands-on
Now that you learned the basics of multi-agents, you're ready to train your first agents in a multi-agent system: **a 2vs2 soccer team that needs to beat the opponent team**.
And you’re going to participate in AI vs. AI challenges where your trained agent will compete against other classmates’ **agents every day and be ranked on a new leaderboard.**
To validate this hands-on for the certification process, you just need to push a trained model. There **are no minimal results to attain to validate it.**
For more information about the certification process, check this section 👉 [https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process](https://huggingface.co/deep-rl-course/en/unit0/introduction#certification-process)
This hands-on will be different since to get correct results **you need to train your agents from 4 hours to 8 hours**. And given the risk of timeout in Colab, we advise you to train on your computer. You don’t need a supercomputer: a simple laptop is good enough for this exercise.
Let's get started! 🔥
## What is AI vs. AI?
AI vs. AI is an open-source tool we developed at Hugging Face to compete agents on the Hub against one another in a multi-agent setting. These models are then ranked in a leaderboard.
The idea of this tool is to have a robust evaluation tool: **by evaluating your agent with a lot of others, you’ll get a good idea of the quality of your policy.**
More precisely, AI vs. AI is three tools:
- A *matchmaking process* defining the matches (which model against which) and running the model fights using a background task in the Space.
- A *leaderboard* getting the match history results and displaying the models’ ELO ratings: [https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos](https://huggingface.co/spaces/huggingface-projects/AIvsAI-SoccerTwos)
- A *Space demo* to visualize your agents playing against others: [https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos](https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos)
In addition to these three tools, your classmate cyllum created a 🤗 SoccerTwos Challenge Analytics where you can check the detailed match results of a model: [https://huggingface.co/spaces/cyllum/soccertwos-analytics](https://huggingface.co/spaces/cyllum/soccertwos-analytics)
We're [wrote a blog post to explain this AI vs. AI tool in detail](https://huggingface.co/blog/aivsai), but to give you the big picture it works this way:
- Every four hours, our algorithm **fetches all the available models for a given environment (in our case ML-Agents-SoccerTwos).**
- It creates a **queue of matches with the matchmaking algorithm.**
- We simulate the match in a Unity headless process and **gather the match result** (1 if the first model won, 0.5 if it’s a draw, 0 if the second model won) in a Dataset.
- Then, when all matches from the matches queue are done, **we update the ELO score for each model and update the leaderboard.**
### Competition Rules
This first AI vs. AI competition **is an experiment**: the goal is to improve the tool in the future with your feedback. So some **breakups can happen during the challenge**. But don't worry
**all the results are saved in a dataset so we can always restart the calculation correctly without losing information**.
In order for your model to get correctly evaluated against others you need to follow these rules:
1. **You can't change the observation space or action space of the agent.** By doing that your model will not work during evaluation.
2. You **can't use a custom trainer for now,** you need to use the Unity MLAgents ones.
3. We provide executables to train your agents. You can also use the Unity Editor if you prefer **, but to avoid bugs, we advise that you use our executables**.
What will make the difference during this challenge are **the hyperparameters you choose**.
We're constantly trying to improve our tutorials, so **if you find some issues in this notebook**, please [open an issue on the GitHub Repo](https://github.com/huggingface/deep-rl-class/issues).
### Chat with your classmates, share advice and ask questions on Discord
- We created a new channel called `ai-vs-ai-challenge` to exchange advice and ask questions.
- If you didn’t join the discord server yet, you can [join here](https://discord.gg/ydHrjt3WP5)
## Step 0: Install MLAgents and download the correct executable
We advise you to use [conda](https://docs.conda.io/en/latest/) as a package manager and create a new environment.
With conda, we create a new environment called rl with **Python 3.10.12**:
```bash
conda create --name rl python=3.10.12
conda activate rl
```
To be able to train our agents correctly and push to the Hub, we need to install ML-Agents
```bash
git clone https://github.com/Unity-Technologies/ml-agents
```
When the cloning is done (it takes 2.63 GB), we go inside the repository and install the package
```bash
cd ml-agents
pip install -e ./ml-agents-envs
pip install -e ./ml-agents
```
Finally, you need to install git-lfs: https://git-lfs.com/
Now that it’s installed, we need to add the environment training executable. Based on your operating system you need to download one of them, unzip it and place it in a new folder inside `ml-agents` that you call `training-envs-executables`
At the end your executable should be in `ml-agents/training-envs-executables/SoccerTwos`
Windows: Download [this executable](https://drive.google.com/file/d/1sqFxbEdTMubjVktnV4C6ICjp89wLhUcP/view?usp=sharing)
Linux (Ubuntu): Download [this executable](https://drive.google.com/file/d/1KuqBKYiXiIcU4kNMqEzhgypuFP5_45CL/view?usp=sharing)
Mac: Download [this executable](https://drive.google.com/drive/folders/1h7YB0qwjoxxghApQdEUQmk95ZwIDxrPG?usp=share_link)
⚠ For Mac you need also to call this `xattr -cr training-envs-executables/SoccerTwos/SoccerTwos.app` to be able to run SoccerTwos
## Step 1: Understand the environment
The environment is called `SoccerTwos`. The Unity MLAgents Team made it. You can find its documentation [here](https://github.com/Unity-Technologies/ml-agents/blob/develop/docs/Learning-Environment-Examples.md#soccer-twos)
The goal in this environment **is to get the ball into the opponent's goal while preventing the ball from entering your own goal.**
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/soccertwos.gif" alt="SoccerTwos"/>
<figcaption>This environment was made by the <a href="https://github.com/Unity-Technologies/ml-agents"> Unity MLAgents Team</a></figcaption>
</figure>
### The reward function
The reward function is:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/soccerreward.png" alt="SoccerTwos Reward"/>
### The observation space
The observation space is composed of vectors of size 336:
- 11 ray-casts forward distributed over 120 degrees (264 state dimensions)
- 3 ray-casts backward distributed over 90 degrees (72 state dimensions)
- Both of these ray-casts can detect 6 objects:
- Ball
- Blue Goal
- Purple Goal
- Wall
- Blue Agent
- Purple Agent
### The action space
The action space is three discrete branches:
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/socceraction.png" alt="SoccerTwos Action"/>
## Step 2: Understand MA-POCA
We know how to train agents to play against others: **we can use self-play.** This is a perfect technique for a 1vs1.
But in our case we’re 2vs2, and each team has 2 agents. How then can we **train cooperative behavior for groups of agents?**
As explained in the [Unity Blog](https://blog.unity.com/technology/ml-agents-v20-release-now-supports-training-complex-cooperative-behaviors), agents typically receive a reward as a group (+1 - penalty) when the team scores a goal. This implies that **every agent on the team is rewarded even if each agent didn’t contribute the same to the win**, which makes it difficult to learn what to do independently.
The Unity MLAgents team developed the solution in a new multi-agent trainer called *MA-POCA (Multi-Agent POsthumous Credit Assignment)*.
The idea is simple but powerful: a centralized critic **processes the states of all agents in the team to estimate how well each agent is doing**. Think of this critic as a coach.
This allows each agent to **make decisions based only on what it perceives locally**, and **simultaneously evaluate how good its behavior is in the context of the whole group**.
<figure>
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/mapoca.png" alt="MA POCA"/>
<figcaption>This illustrates MA-POCA’s centralized learning and decentralized execution. Source: <a href="https://blog.unity.com/technology/ml-agents-plays-dodgeball">MLAgents Plays Dodgeball</a>
</figcaption>
</figure>
The solution then is to use Self-Play with an MA-POCA trainer (called poca). The poca trainer will help us to train cooperative behavior and self-play to win against an opponent team.
If you want to dive deeper into this MA-POCA algorithm, you need to read the paper they published [here](https://arxiv.org/pdf/2111.05992.pdf) and the sources we put on the additional readings section.
## Step 3: Define the config file
We already learned in [Unit 5](https://huggingface.co/deep-rl-course/unit5/introduction) that in ML-Agents, you define **the training hyperparameters in `config.yaml` files.**
There are multiple hyperparameters. To understand them better, you should read the explanations for each of them in **[the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md)**
The config file we’re going to use here is in `./config/poca/SoccerTwos.yaml`. It looks like this:
```csharp
behaviors:
SoccerTwos:
trainer_type: poca
hyperparameters:
batch_size: 2048
buffer_size: 20480
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 5000000
time_horizon: 1000
summary_freq: 10000
self_play:
save_steps: 50000
team_change: 200000
swap_steps: 2000
window: 10
play_against_latest_model_ratio: 0.5
initial_elo: 1200.0
```
Compared to Pyramids or SnowballTarget, we have new hyperparameters with a self-play part. How you modify them can be critical in getting good results.
The advice I can give you here is to check the explanation and recommended value for each parameters (especially self-play ones) against **[the documentation](https://github.com/Unity-Technologies/ml-agents/blob/release_20_docs/docs/Training-Configuration-File.md).**
Now that you’ve modified our config file, you’re ready to train your agents.
## Step 4: Start the training
To train the agents, we need to **launch mlagents-learn and select the executable containing the environment.**
We define four parameters:
1. `mlagents-learn <config>`: the path where the hyperparameter config file is.
2. `-env`: where the environment executable is.
3. `-run_id`: the name you want to give to your training run id.
4. `-no-graphics`: to not launch the visualization during the training.
Depending on your hardware, 5M timesteps (the recommended value, but you can also try 10M) will take 5 to 8 hours of training. You can continue using your computer in the meantime, but I advise deactivating the computer standby mode to prevent the training from being stopped.
Depending on the executable you use (windows, ubuntu, mac) the training command will look like this (your executable path can be different so don’t hesitate to check before running).
```bash
mlagents-learn ./config/poca/SoccerTwos.yaml --env=./training-envs-executables/SoccerTwos.exe --run-id="SoccerTwos" --no-graphics
```
The executable contains 8 copies of SoccerTwos.
⚠️ It’s normal if you don’t see a big increase of ELO score (and even a decrease below 1200) before 2M timesteps, since your agents will spend most of their time moving randomly on the field before being able to goal.
⚠️ You can stop the training with Ctrl + C but beware of typing this command only once to stop the training since MLAgents needs to generate a final .onnx file before closing the run.
## Step 5: **Push the agent to the Hugging Face Hub**
Now that we trained our agents, we’re **ready to push them to the Hub to be able to participate in the AI vs. AI challenge and visualize them playing on your browser🔥.**
To be able to share your model with the community, there are three more steps to follow:
1️⃣ (If it’s not already done) create an account to HF ➡ [https://huggingface.co/join](https://huggingface.co/join)
2️⃣ Sign in and store your authentication token from the Hugging Face website.
Create a new token (https://huggingface.co/settings/tokens) **with write role**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/create-token.jpg" alt="Create HF Token">
Copy the token, run this, and paste the token
```bash
huggingface-cli login
```
Then, we need to run `mlagents-push-to-hf`.
And we define four parameters:
1. `-run-id`: the name of the training run id.
2. `-local-dir`: where the agent was saved, it’s results/<run_id name>, so in my case results/First Training.
3. `-repo-id`: the name of the Hugging Face repo you want to create or update. It’s always <your huggingface username>/<the repo name>
If the repo does not exist **it will be created automatically**
4. `--commit-message`: since HF repos are git repositories you need to give a commit message.
In my case
```bash
mlagents-push-to-hf --run-id="SoccerTwos" --local-dir="./results/SoccerTwos" --repo-id="ThomasSimonini/poca-SoccerTwos" --commit-message="First Push"`
```
```bash
mlagents-push-to-hf --run-id= # Add your run id --local-dir= # Your local dir --repo-id= # Your repo id --commit-message="First Push"
```
If everything worked you should see this at the end of the process (but with a different url 😆) :
Your model is pushed to the Hub. You can view your model here: https://huggingface.co/ThomasSimonini/poca-SoccerTwos
It's the link to your model. It contains a model card that explains how to use it, your Tensorboard, and your config file. **What's awesome is that it's a git repository, which means you can have different commits, update your repository with a new push, etc.**
## Step 6: Verify that your model is ready for AI vs AI Challenge
Now that your model is pushed to the Hub, **it’s going to be added automatically to the AI vs AI Challenge model pool.** It can take a little bit of time before your model is added to the leaderboard given we do a run of matches every 4h.
But to ensure that everything works perfectly you need to check:
1. That you have this tag in your model: ML-Agents-SoccerTwos. This is the tag we use to select models to be added to the challenge pool. To do that go to your model and check the tags
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/verify1.png" alt="Verify"/>
If it’s not the case you just need to modify the readme and add it
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/verify2.png" alt="Verify"/>
2. That you have a `SoccerTwos.onnx` file
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/unit10/verify3.png" alt="Verify"/>
We strongly suggest that you create a new model when you push to the Hub if you want to train it again or train a new version.
## Step 7: Visualize some match in our demo
Now that your model is part of AI vs AI Challenge, **you can visualize how good it is compared to others**: https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
In order to do that, you just need to go to this demo:
- Select your model as team blue (or team purple if you prefer) and another model to compete against. The best opponents to compare your model to are either whoever is on top of the leaderboard or the [baseline model](https://huggingface.co/unity/MLAgents-SoccerTwos)
The matches you see live are not used in the calculation of your result **but they are a good way to visualize how good your agent is**.
And don't hesitate to share the best score your agent gets on discord in the #rl-i-made-this channel 🔥
| deep-rl-class/units/en/unit7/hands-on.mdx/0 | {
"file_path": "deep-rl-class/units/en/unit7/hands-on.mdx",
"repo_id": "deep-rl-class",
"token_count": 5036
} | 91 |
# Conclusion [[conclusion]]
Congrats on finishing this bonus unit!
You can now sit and enjoy playing with your Huggy 🐶. And don't **forget to spread the love by sharing Huggy with your friends 🤗**. And if you share about it on social media, **please tag us @huggingface and me @simoninithomas**
<img src="https://huggingface.co/datasets/huggingface-deep-rl-course/course-images/resolve/main/en/notebooks/unit-bonus1/huggy-cover.jpeg" alt="Huggy cover" width="100%">
Finally, we would love **to hear what you think of the course and how we can improve it**. If you have some feedback then please 👉 [fill out this form](https://forms.gle/BzKXWzLAGZESGNaE9)
### Keep Learning, stay awesome 🤗
| deep-rl-class/units/en/unitbonus1/conclusion.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus1/conclusion.mdx",
"repo_id": "deep-rl-class",
"token_count": 227
} | 92 |
# Model Based Reinforcement Learning (MBRL)
Model-based reinforcement learning only differs from its model-free counterpart in learning a *dynamics model*, but that has substantial downstream effects on how the decisions are made.
The dynamics model usually models the environment transition dynamics, \\( s_{t+1} = f_\theta (s_t, a_t) \\), but things like inverse dynamics models (mapping from states to actions) or reward models (predicting rewards) can be used in this framework.
## Simple definition
- There is an agent that repeatedly tries to solve a problem, **accumulating state and action data**.
- With that data, the agent creates a structured learning tool, *a dynamics model*, to reason about the world.
- With the dynamics model, the agent **decides how to act by predicting the future**.
- With those actions, **the agent collects more data, improves said model, and hopefully improves future actions**.
## Academic definition
Model-based reinforcement learning (MBRL) follows the framework of an agent interacting in an environment, **learning a model of said environment**, and then **leveraging the model for control (making decisions).
Specifically, the agent acts in a Markov Decision Process (MDP) governed by a transition function \\( s_{t+1} = f (s_t , a_t) \\) and returns a reward at each step \\( r(s_t, a_t) \\). With a collected dataset \\( D :={ s_i, a_i, s_{i+1}, r_i} \\), the agent learns a model, \\( s_{t+1} = f_\theta (s_t , a_t) \\) **to minimize the negative log-likelihood of the transitions**.
We employ sample-based model-predictive control (MPC) using the learned dynamics model, which optimizes the expected reward over a finite, recursively predicted horizon, \\( \tau \\), from a set of actions sampled from a uniform distribution \\( U(a) \\), (see [paper](https://arxiv.org/pdf/2002.04523) or [paper](https://arxiv.org/pdf/2012.09156.pdf) or [paper](https://arxiv.org/pdf/2009.01221.pdf)).
## Further reading
For more information on MBRL, we recommend you check out the following resources:
- A [blog post on debugging MBRL](https://www.natolambert.com/writing/debugging-mbrl).
- A [recent review paper on MBRL](https://arxiv.org/abs/2006.16712),
## Author
This section was written by <a href="https://twitter.com/natolambert"> Nathan Lambert </a>
| deep-rl-class/units/en/unitbonus3/model-based.mdx/0 | {
"file_path": "deep-rl-class/units/en/unitbonus3/model-based.mdx",
"repo_id": "deep-rl-class",
"token_count": 641
} | 93 |
.PHONY: deps_table_update modified_only_fixup extra_style_checks quality style fixup fix-copies test test-examples
# make sure to test the local checkout in scripts and not the pre-installed one (don't use quotes!)
export PYTHONPATH = src
check_dirs := examples scripts src tests utils benchmarks
modified_only_fixup:
$(eval modified_py_files := $(shell python utils/get_modified_files.py $(check_dirs)))
@if test -n "$(modified_py_files)"; then \
echo "Checking/fixing $(modified_py_files)"; \
ruff check $(modified_py_files) --fix; \
ruff format $(modified_py_files);\
else \
echo "No library .py files were modified"; \
fi
# Update src/diffusers/dependency_versions_table.py
deps_table_update:
@python setup.py deps_table_update
deps_table_check_updated:
@md5sum src/diffusers/dependency_versions_table.py > md5sum.saved
@python setup.py deps_table_update
@md5sum -c --quiet md5sum.saved || (printf "\nError: the version dependency table is outdated.\nPlease run 'make fixup' or 'make style' and commit the changes.\n\n" && exit 1)
@rm md5sum.saved
# autogenerating code
autogenerate_code: deps_table_update
# Check that the repo is in a good state
repo-consistency:
python utils/check_dummies.py
python utils/check_repo.py
python utils/check_inits.py
# this target runs checks on all files
quality:
ruff check $(check_dirs) setup.py
ruff format --check $(check_dirs) setup.py
python utils/check_doc_toc.py
# Format source code automatically and check is there are any problems left that need manual fixing
extra_style_checks:
python utils/custom_init_isort.py
python utils/check_doc_toc.py --fix_and_overwrite
# this target runs checks on all files and potentially modifies some of them
style:
ruff check $(check_dirs) setup.py --fix
ruff format $(check_dirs) setup.py
${MAKE} autogenerate_code
${MAKE} extra_style_checks
# Super fast fix and check target that only works on relevant modified files since the branch was made
fixup: modified_only_fixup extra_style_checks autogenerate_code repo-consistency
# Make marked copies of snippets of codes conform to the original
fix-copies:
python utils/check_copies.py --fix_and_overwrite
python utils/check_dummies.py --fix_and_overwrite
# Run tests for the library
test:
python -m pytest -n auto --dist=loadfile -s -v ./tests/
# Run tests for examples
test-examples:
python -m pytest -n auto --dist=loadfile -s -v ./examples/
# Release stuff
pre-release:
python utils/release.py
pre-patch:
python utils/release.py --patch
post-release:
python utils/release.py --post_release
post-patch:
python utils/release.py --post_release --patch
| diffusers/Makefile/0 | {
"file_path": "diffusers/Makefile",
"repo_id": "diffusers",
"token_count": 889
} | 94 |
FROM ubuntu:20.04
LABEL maintainer="Hugging Face"
LABEL repository="diffusers"
ENV DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y bash \
build-essential \
git \
git-lfs \
curl \
ca-certificates \
libsndfile1-dev \
python3.8 \
python3-pip \
python3.8-venv && \
rm -rf /var/lib/apt/lists
# make sure to use venv
RUN python3 -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
# follow the instructions here: https://cloud.google.com/tpu/docs/run-in-container#train_a_jax_model_in_a_docker_container
RUN python3 -m pip install --no-cache-dir --upgrade pip uv==0.1.11 && \
python3 -m pip install --no-cache-dir \
"jax[tpu]>=0.2.16,!=0.3.2" \
-f https://storage.googleapis.com/jax-releases/libtpu_releases.html && \
python3 -m uv pip install --upgrade --no-cache-dir \
clu \
"flax>=0.4.1" \
"jaxlib>=0.1.65" && \
python3 -m uv pip install --no-cache-dir \
accelerate \
datasets \
hf-doc-builder \
huggingface-hub \
Jinja2 \
librosa \
numpy \
scipy \
tensorboard \
transformers
CMD ["/bin/bash"] | diffusers/docker/diffusers-flax-tpu/Dockerfile/0 | {
"file_path": "diffusers/docker/diffusers-flax-tpu/Dockerfile",
"repo_id": "diffusers",
"token_count": 740
} | 95 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# IP-Adapter
[IP-Adapter](https://hf.co/papers/2308.06721) is a lightweight adapter that enables prompting a diffusion model with an image. This method decouples the cross-attention layers of the image and text features. The image features are generated from an image encoder.
<Tip>
Learn how to load an IP-Adapter checkpoint and image in the IP-Adapter [loading](../../using-diffusers/loading_adapters#ip-adapter) guide, and you can see how to use it in the [usage](../../using-diffusers/ip_adapter) guide.
</Tip>
## IPAdapterMixin
[[autodoc]] loaders.ip_adapter.IPAdapterMixin
## IPAdapterMaskProcessor
[[autodoc]] image_processor.IPAdapterMaskProcessor | diffusers/docs/source/en/api/loaders/ip_adapter.md/0 | {
"file_path": "diffusers/docs/source/en/api/loaders/ip_adapter.md",
"repo_id": "diffusers",
"token_count": 339
} | 96 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Inpainting
The Stable Diffusion model can also be applied to inpainting which lets you edit specific parts of an image by providing a mask and a text prompt using Stable Diffusion.
## Tips
It is recommended to use this pipeline with checkpoints that have been specifically fine-tuned for inpainting, such
as [runwayml/stable-diffusion-inpainting](https://huggingface.co/runwayml/stable-diffusion-inpainting). Default
text-to-image Stable Diffusion checkpoints, such as
[runwayml/stable-diffusion-v1-5](https://huggingface.co/runwayml/stable-diffusion-v1-5) are also compatible but they might be less performant.
<Tip>
Make sure to check out the Stable Diffusion [Tips](overview#tips) section to learn how to explore the tradeoff between scheduler speed and quality, and how to reuse pipeline components efficiently!
If you're interested in using one of the official checkpoints for a task, explore the [CompVis](https://huggingface.co/CompVis), [Runway](https://huggingface.co/runwayml), and [Stability AI](https://huggingface.co/stabilityai) Hub organizations!
</Tip>
## StableDiffusionInpaintPipeline
[[autodoc]] StableDiffusionInpaintPipeline
- all
- __call__
- enable_attention_slicing
- disable_attention_slicing
- enable_xformers_memory_efficient_attention
- disable_xformers_memory_efficient_attention
- load_textual_inversion
- load_lora_weights
- save_lora_weights
## StableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.StableDiffusionPipelineOutput
## FlaxStableDiffusionInpaintPipeline
[[autodoc]] FlaxStableDiffusionInpaintPipeline
- all
- __call__
## FlaxStableDiffusionPipelineOutput
[[autodoc]] pipelines.stable_diffusion.FlaxStableDiffusionPipelineOutput
| diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.md/0 | {
"file_path": "diffusers/docs/source/en/api/pipelines/stable_diffusion/inpaint.md",
"repo_id": "diffusers",
"token_count": 680
} | 97 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# OpenVINO
🤗 [Optimum](https://github.com/huggingface/optimum-intel) provides Stable Diffusion pipelines compatible with OpenVINO to perform inference on a variety of Intel processors (see the [full list](https://docs.openvino.ai/latest/openvino_docs_OV_UG_supported_plugins_Supported_Devices.html) of supported devices).
You'll need to install 🤗 Optimum Intel with the `--upgrade-strategy eager` option to ensure [`optimum-intel`](https://github.com/huggingface/optimum-intel) is using the latest version:
```bash
pip install --upgrade-strategy eager optimum["openvino"]
```
This guide will show you how to use the Stable Diffusion and Stable Diffusion XL (SDXL) pipelines with OpenVINO.
## Stable Diffusion
To load and run inference, use the [`~optimum.intel.OVStableDiffusionPipeline`]. If you want to load a PyTorch model and convert it to the OpenVINO format on-the-fly, set `export=True`:
```python
from optimum.intel import OVStableDiffusionPipeline
model_id = "runwayml/stable-diffusion-v1-5"
pipeline = OVStableDiffusionPipeline.from_pretrained(model_id, export=True)
prompt = "sailing ship in storm by Rembrandt"
image = pipeline(prompt).images[0]
# Don't forget to save the exported model
pipeline.save_pretrained("openvino-sd-v1-5")
```
To further speed-up inference, statically reshape the model. If you change any parameters such as the outputs height or width, you’ll need to statically reshape your model again.
```python
# Define the shapes related to the inputs and desired outputs
batch_size, num_images, height, width = 1, 1, 512, 512
# Statically reshape the model
pipeline.reshape(batch_size, height, width, num_images)
# Compile the model before inference
pipeline.compile()
image = pipeline(
prompt,
height=height,
width=width,
num_images_per_prompt=num_images,
).images[0]
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/optimum/documentation-images/resolve/main/intel/openvino/stable_diffusion_v1_5_sail_boat_rembrandt.png">
</div>
You can find more examples in the 🤗 Optimum [documentation](https://huggingface.co/docs/optimum/intel/inference#stable-diffusion), and Stable Diffusion is supported for text-to-image, image-to-image, and inpainting.
## Stable Diffusion XL
To load and run inference with SDXL, use the [`~optimum.intel.OVStableDiffusionXLPipeline`]:
```python
from optimum.intel import OVStableDiffusionXLPipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipeline = OVStableDiffusionXLPipeline.from_pretrained(model_id)
prompt = "sailing ship in storm by Rembrandt"
image = pipeline(prompt).images[0]
```
To further speed-up inference, [statically reshape](#stable-diffusion) the model as shown in the Stable Diffusion section.
You can find more examples in the 🤗 Optimum [documentation](https://huggingface.co/docs/optimum/intel/inference#stable-diffusion-xl), and running SDXL in OpenVINO is supported for text-to-image and image-to-image.
| diffusers/docs/source/en/optimization/open_vino.md/0 | {
"file_path": "diffusers/docs/source/en/optimization/open_vino.md",
"repo_id": "diffusers",
"token_count": 1109
} | 98 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Latent Consistency Distillation
[Latent Consistency Models (LCMs)](https://hf.co/papers/2310.04378) are able to generate high-quality images in just a few steps, representing a big leap forward because many pipelines require at least 25+ steps. LCMs are produced by applying the latent consistency distillation method to any Stable Diffusion model. This method works by applying *one-stage guided distillation* to the latent space, and incorporating a *skipping-step* method to consistently skip timesteps to accelerate the distillation process (refer to section 4.1, 4.2, and 4.3 of the paper for more details).
If you're training on a GPU with limited vRAM, try enabling `gradient_checkpointing`, `gradient_accumulation_steps`, and `mixed_precision` to reduce memory-usage and speedup training. You can reduce your memory-usage even more by enabling memory-efficient attention with [xFormers](../optimization/xformers) and [bitsandbytes'](https://github.com/TimDettmers/bitsandbytes) 8-bit optimizer.
This guide will explore the [train_lcm_distill_sd_wds.py](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_sd_wds.py) script to help you become more familiar with it, and how you can adapt it for your own use-case.
Before running the script, make sure you install the library from source:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then navigate to the example folder containing the training script and install the required dependencies for the script you're using:
```bash
cd examples/consistency_distillation
pip install -r requirements.txt
```
<Tip>
🤗 Accelerate is a library for helping you train on multiple GPUs/TPUs or with mixed-precision. It'll automatically configure your training setup based on your hardware and environment. Take a look at the 🤗 Accelerate [Quick tour](https://huggingface.co/docs/accelerate/quicktour) to learn more.
</Tip>
Initialize an 🤗 Accelerate environment (try enabling `torch.compile` to significantly speedup training):
```bash
accelerate config
```
To setup a default 🤗 Accelerate environment without choosing any configurations:
```bash
accelerate config default
```
Or if your environment doesn't support an interactive shell, like a notebook, you can use:
```bash
from accelerate.utils import write_basic_config
write_basic_config()
```
Lastly, if you want to train a model on your own dataset, take a look at the [Create a dataset for training](create_dataset) guide to learn how to create a dataset that works with the training script.
## Script parameters
<Tip>
The following sections highlight parts of the training script that are important for understanding how to modify it, but it doesn't cover every aspect of the script in detail. If you're interested in learning more, feel free to read through the [script](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_sd_wds.py) and let us know if you have any questions or concerns.
</Tip>
The training script provides many parameters to help you customize your training run. All of the parameters and their descriptions are found in the [`parse_args()`](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L419) function. This function provides default values for each parameter, such as the training batch size and learning rate, but you can also set your own values in the training command if you'd like.
For example, to speedup training with mixed precision using the fp16 format, add the `--mixed_precision` parameter to the training command:
```bash
accelerate launch train_lcm_distill_sd_wds.py \
--mixed_precision="fp16"
```
Most of the parameters are identical to the parameters in the [Text-to-image](text2image#script-parameters) training guide, so you'll focus on the parameters that are relevant to latent consistency distillation in this guide.
- `--pretrained_teacher_model`: the path to a pretrained latent diffusion model to use as the teacher model
- `--pretrained_vae_model_name_or_path`: path to a pretrained VAE; the SDXL VAE is known to suffer from numerical instability, so this parameter allows you to specify an alternative VAE (like this [VAE]((https://huggingface.co/madebyollin/sdxl-vae-fp16-fix)) by madebyollin which works in fp16)
- `--w_min` and `--w_max`: the minimum and maximum guidance scale values for guidance scale sampling
- `--num_ddim_timesteps`: the number of timesteps for DDIM sampling
- `--loss_type`: the type of loss (L2 or Huber) to calculate for latent consistency distillation; Huber loss is generally preferred because it's more robust to outliers
- `--huber_c`: the Huber loss parameter
## Training script
The training script starts by creating a dataset class - [`Text2ImageDataset`](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L141) - for preprocessing the images and creating a training dataset.
```py
def transform(example):
image = example["image"]
image = TF.resize(image, resolution, interpolation=transforms.InterpolationMode.BILINEAR)
c_top, c_left, _, _ = transforms.RandomCrop.get_params(image, output_size=(resolution, resolution))
image = TF.crop(image, c_top, c_left, resolution, resolution)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
example["image"] = image
return example
```
For improved performance on reading and writing large datasets stored in the cloud, this script uses the [WebDataset](https://github.com/webdataset/webdataset) format to create a preprocessing pipeline to apply transforms and create a dataset and dataloader for training. Images are processed and fed to the training loop without having to download the full dataset first.
```py
processing_pipeline = [
wds.decode("pil", handler=wds.ignore_and_continue),
wds.rename(image="jpg;png;jpeg;webp", text="text;txt;caption", handler=wds.warn_and_continue),
wds.map(filter_keys({"image", "text"})),
wds.map(transform),
wds.to_tuple("image", "text"),
]
```
In the [`main()`](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L768) function, all the necessary components like the noise scheduler, tokenizers, text encoders, and VAE are loaded. The teacher UNet is also loaded here and then you can create a student UNet from the teacher UNet. The student UNet is updated by the optimizer during training.
```py
teacher_unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
unet = UNet2DConditionModel(**teacher_unet.config)
unet.load_state_dict(teacher_unet.state_dict(), strict=False)
unet.train()
```
Now you can create the [optimizer](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L979) to update the UNet parameters:
```py
optimizer = optimizer_class(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
```
Create the [dataset](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L994):
```py
dataset = Text2ImageDataset(
train_shards_path_or_url=args.train_shards_path_or_url,
num_train_examples=args.max_train_samples,
per_gpu_batch_size=args.train_batch_size,
global_batch_size=args.train_batch_size * accelerator.num_processes,
num_workers=args.dataloader_num_workers,
resolution=args.resolution,
shuffle_buffer_size=1000,
pin_memory=True,
persistent_workers=True,
)
train_dataloader = dataset.train_dataloader
```
Next, you're ready to setup the [training loop](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L1049) and implement the latent consistency distillation method (see Algorithm 1 in the paper for more details). This section of the script takes care of adding noise to the latents, sampling and creating a guidance scale embedding, and predicting the original image from the noise.
```py
pred_x_0 = predicted_origin(
noise_pred,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
```
It gets the [teacher model predictions](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L1172) and the [LCM predictions](https://github.com/huggingface/diffusers/blob/3b37488fa3280aed6a95de044d7a42ffdcb565ef/examples/consistency_distillation/train_lcm_distill_sd_wds.py#L1209) next, calculates the loss, and then backpropagates it to the LCM.
```py
if args.loss_type == "l2":
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
elif args.loss_type == "huber":
loss = torch.mean(
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
)
```
If you want to learn more about how the training loop works, check out the [Understanding pipelines, models and schedulers tutorial](../using-diffusers/write_own_pipeline) which breaks down the basic pattern of the denoising process.
## Launch the script
Now you're ready to launch the training script and start distilling!
For this guide, you'll use the `--train_shards_path_or_url` to specify the path to the [Conceptual Captions 12M](https://github.com/google-research-datasets/conceptual-12m) dataset stored on the Hub [here](https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset). Set the `MODEL_DIR` environment variable to the name of the teacher model and `OUTPUT_DIR` to where you want to save the model.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path/to/saved/model"
accelerate launch train_lcm_distill_sd_wds.py \
--pretrained_teacher_model=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--mixed_precision=fp16 \
--resolution=512 \
--learning_rate=1e-6 --loss_type="huber" --ema_decay=0.95 --adam_weight_decay=0.0 \
--max_train_steps=1000 \
--max_train_samples=4000000 \
--dataloader_num_workers=8 \
--train_shards_path_or_url="pipe:curl -L -s https://huggingface.co/datasets/laion/conceptual-captions-12m-webdataset/resolve/main/data/{00000..01099}.tar?download=true" \
--validation_steps=200 \
--checkpointing_steps=200 --checkpoints_total_limit=10 \
--train_batch_size=12 \
--gradient_checkpointing --enable_xformers_memory_efficient_attention \
--gradient_accumulation_steps=1 \
--use_8bit_adam \
--resume_from_checkpoint=latest \
--report_to=wandb \
--seed=453645634 \
--push_to_hub
```
Once training is complete, you can use your new LCM for inference.
```py
from diffusers import UNet2DConditionModel, DiffusionPipeline, LCMScheduler
import torch
unet = UNet2DConditionModel.from_pretrained("your-username/your-model", torch_dtype=torch.float16, variant="fp16")
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", unet=unet, torch_dtype=torch.float16, variant="fp16")
pipeline.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipeline.to("cuda")
prompt = "sushi rolls in the form of panda heads, sushi platter"
image = pipeline(prompt, num_inference_steps=4, guidance_scale=1.0).images[0]
```
## LoRA
LoRA is a training technique for significantly reducing the number of trainable parameters. As a result, training is faster and it is easier to store the resulting weights because they are a lot smaller (~100MBs). Use the [train_lcm_distill_lora_sd_wds.py](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py) or [train_lcm_distill_lora_sdxl.wds.py](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_lora_sdxl_wds.py) script to train with LoRA.
The LoRA training script is discussed in more detail in the [LoRA training](lora) guide.
## Stable Diffusion XL
Stable Diffusion XL (SDXL) is a powerful text-to-image model that generates high-resolution images, and it adds a second text-encoder to its architecture. Use the [train_lcm_distill_sdxl_wds.py](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/train_lcm_distill_sdxl_wds.py) script to train a SDXL model with LoRA.
The SDXL training script is discussed in more detail in the [SDXL training](sdxl) guide.
## Next steps
Congratulations on distilling a LCM model! To learn more about LCM, the following may be helpful:
- Learn how to use [LCMs for inference](../using-diffusers/lcm) for text-to-image, image-to-image, and with LoRA checkpoints.
- Read the [SDXL in 4 steps with Latent Consistency LoRAs](https://huggingface.co/blog/lcm_lora) blog post to learn more about SDXL LCM-LoRA's for super fast inference, quality comparisons, benchmarks, and more. | diffusers/docs/source/en/training/lcm_distill.md/0 | {
"file_path": "diffusers/docs/source/en/training/lcm_distill.md",
"repo_id": "diffusers",
"token_count": 4582
} | 99 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Contribute a community pipeline
<Tip>
💡 Take a look at GitHub Issue [#841](https://github.com/huggingface/diffusers/issues/841) for more context about why we're adding community pipelines to help everyone easily share their work without being slowed down.
</Tip>
Community pipelines allow you to add any additional features you'd like on top of the [`DiffusionPipeline`]. The main benefit of building on top of the `DiffusionPipeline` is anyone can load and use your pipeline by only adding one more argument, making it super easy for the community to access.
This guide will show you how to create a community pipeline and explain how they work. To keep things simple, you'll create a "one-step" pipeline where the `UNet` does a single forward pass and calls the scheduler once.
## Initialize the pipeline
You should start by creating a `one_step_unet.py` file for your community pipeline. In this file, create a pipeline class that inherits from the [`DiffusionPipeline`] to be able to load model weights and the scheduler configuration from the Hub. The one-step pipeline needs a `UNet` and a scheduler, so you'll need to add these as arguments to the `__init__` function:
```python
from diffusers import DiffusionPipeline
import torch
class UnetSchedulerOneForwardPipeline(DiffusionPipeline):
def __init__(self, unet, scheduler):
super().__init__()
```
To ensure your pipeline and its components (`unet` and `scheduler`) can be saved with [`~DiffusionPipeline.save_pretrained`], add them to the `register_modules` function:
```diff
from diffusers import DiffusionPipeline
import torch
class UnetSchedulerOneForwardPipeline(DiffusionPipeline):
def __init__(self, unet, scheduler):
super().__init__()
+ self.register_modules(unet=unet, scheduler=scheduler)
```
Cool, the `__init__` step is done and you can move to the forward pass now! 🔥
## Define the forward pass
In the forward pass, which we recommend defining as `__call__`, you have complete creative freedom to add whatever feature you'd like. For our amazing one-step pipeline, create a random image and only call the `unet` and `scheduler` once by setting `timestep=1`:
```diff
from diffusers import DiffusionPipeline
import torch
class UnetSchedulerOneForwardPipeline(DiffusionPipeline):
def __init__(self, unet, scheduler):
super().__init__()
self.register_modules(unet=unet, scheduler=scheduler)
+ def __call__(self):
+ image = torch.randn(
+ (1, self.unet.config.in_channels, self.unet.config.sample_size, self.unet.config.sample_size),
+ )
+ timestep = 1
+ model_output = self.unet(image, timestep).sample
+ scheduler_output = self.scheduler.step(model_output, timestep, image).prev_sample
+ return scheduler_output
```
That's it! 🚀 You can now run this pipeline by passing a `unet` and `scheduler` to it:
```python
from diffusers import DDPMScheduler, UNet2DModel
scheduler = DDPMScheduler()
unet = UNet2DModel()
pipeline = UnetSchedulerOneForwardPipeline(unet=unet, scheduler=scheduler)
output = pipeline()
```
But what's even better is you can load pre-existing weights into the pipeline if the pipeline structure is identical. For example, you can load the [`google/ddpm-cifar10-32`](https://huggingface.co/google/ddpm-cifar10-32) weights into the one-step pipeline:
```python
pipeline = UnetSchedulerOneForwardPipeline.from_pretrained("google/ddpm-cifar10-32", use_safetensors=True)
output = pipeline()
```
## Share your pipeline
Open a Pull Request on the 🧨 Diffusers [repository](https://github.com/huggingface/diffusers) to add your awesome pipeline in `one_step_unet.py` to the [examples/community](https://github.com/huggingface/diffusers/tree/main/examples/community) subfolder.
Once it is merged, anyone with `diffusers >= 0.4.0` installed can use this pipeline magically 🪄 by specifying it in the `custom_pipeline` argument:
```python
from diffusers import DiffusionPipeline
pipe = DiffusionPipeline.from_pretrained(
"google/ddpm-cifar10-32", custom_pipeline="one_step_unet", use_safetensors=True
)
pipe()
```
Another way to share your community pipeline is to upload the `one_step_unet.py` file directly to your preferred [model repository](https://huggingface.co/docs/hub/models-uploading) on the Hub. Instead of specifying the `one_step_unet.py` file, pass the model repository id to the `custom_pipeline` argument:
```python
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained(
"google/ddpm-cifar10-32", custom_pipeline="stevhliu/one_step_unet", use_safetensors=True
)
```
Take a look at the following table to compare the two sharing workflows to help you decide the best option for you:
| | GitHub community pipeline | HF Hub community pipeline |
|----------------|------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------|
| usage | same | same |
| review process | open a Pull Request on GitHub and undergo a review process from the Diffusers team before merging; may be slower | upload directly to a Hub repository without any review; this is the fastest workflow |
| visibility | included in the official Diffusers repository and documentation | included on your HF Hub profile and relies on your own usage/promotion to gain visibility |
<Tip>
💡 You can use whatever package you want in your community pipeline file - as long as the user has it installed, everything will work fine. Make sure you have one and only one pipeline class that inherits from `DiffusionPipeline` because this is automatically detected.
</Tip>
## How do community pipelines work?
A community pipeline is a class that inherits from [`DiffusionPipeline`] which means:
- It can be loaded with the [`custom_pipeline`] argument.
- The model weights and scheduler configuration are loaded from [`pretrained_model_name_or_path`].
- The code that implements a feature in the community pipeline is defined in a `pipeline.py` file.
Sometimes you can't load all the pipeline components weights from an official repository. In this case, the other components should be passed directly to the pipeline:
```python
from diffusers import DiffusionPipeline
from transformers import CLIPImageProcessor, CLIPModel
model_id = "CompVis/stable-diffusion-v1-4"
clip_model_id = "laion/CLIP-ViT-B-32-laion2B-s34B-b79K"
feature_extractor = CLIPImageProcessor.from_pretrained(clip_model_id)
clip_model = CLIPModel.from_pretrained(clip_model_id, torch_dtype=torch.float16)
pipeline = DiffusionPipeline.from_pretrained(
model_id,
custom_pipeline="clip_guided_stable_diffusion",
clip_model=clip_model,
feature_extractor=feature_extractor,
scheduler=scheduler,
torch_dtype=torch.float16,
use_safetensors=True,
)
```
The magic behind community pipelines is contained in the following code. It allows the community pipeline to be loaded from GitHub or the Hub, and it'll be available to all 🧨 Diffusers packages.
```python
# 2. Load the pipeline class, if using custom module then load it from the Hub
# if we load from explicit class, let's use it
if custom_pipeline is not None:
pipeline_class = get_class_from_dynamic_module(
custom_pipeline, module_file=CUSTOM_PIPELINE_FILE_NAME, cache_dir=custom_pipeline
)
elif cls != DiffusionPipeline:
pipeline_class = cls
else:
diffusers_module = importlib.import_module(cls.__module__.split(".")[0])
pipeline_class = getattr(diffusers_module, config_dict["_class_name"])
```
| diffusers/docs/source/en/using-diffusers/contribute_pipeline.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/contribute_pipeline.md",
"repo_id": "diffusers",
"token_count": 2939
} | 100 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Kandinsky
[[open-in-colab]]
The Kandinsky models are a series of multilingual text-to-image generation models. The Kandinsky 2.0 model uses two multilingual text encoders and concatenates those results for the UNet.
[Kandinsky 2.1](../api/pipelines/kandinsky) changes the architecture to include an image prior model ([`CLIP`](https://huggingface.co/docs/transformers/model_doc/clip)) to generate a mapping between text and image embeddings. The mapping provides better text-image alignment and it is used with the text embeddings during training, leading to higher quality results. Finally, Kandinsky 2.1 uses a [Modulating Quantized Vectors (MoVQ)](https://huggingface.co/papers/2209.09002) decoder - which adds a spatial conditional normalization layer to increase photorealism - to decode the latents into images.
[Kandinsky 2.2](../api/pipelines/kandinsky_v22) improves on the previous model by replacing the image encoder of the image prior model with a larger CLIP-ViT-G model to improve quality. The image prior model was also retrained on images with different resolutions and aspect ratios to generate higher-resolution images and different image sizes.
[Kandinsky 3](../api/pipelines/kandinsky3) simplifies the architecture and shifts away from the two-stage generation process involving the prior model and diffusion model. Instead, Kandinsky 3 uses [Flan-UL2](https://huggingface.co/google/flan-ul2) to encode text, a UNet with [BigGan-deep](https://hf.co/papers/1809.11096) blocks, and [Sber-MoVQGAN](https://github.com/ai-forever/MoVQGAN) to decode the latents into images. Text understanding and generated image quality are primarily achieved by using a larger text encoder and UNet.
This guide will show you how to use the Kandinsky models for text-to-image, image-to-image, inpainting, interpolation, and more.
Before you begin, make sure you have the following libraries installed:
```py
# uncomment to install the necessary libraries in Colab
#!pip install -q diffusers transformers accelerate
```
<Tip warning={true}>
Kandinsky 2.1 and 2.2 usage is very similar! The only difference is Kandinsky 2.2 doesn't accept `prompt` as an input when decoding the latents. Instead, Kandinsky 2.2 only accepts `image_embeds` during decoding.
<br>
Kandinsky 3 has a more concise architecture and it doesn't require a prior model. This means it's usage is identical to other diffusion models like [Stable Diffusion XL](sdxl).
</Tip>
## Text-to-image
To use the Kandinsky models for any task, you always start by setting up the prior pipeline to encode the prompt and generate the image embeddings. The prior pipeline also generates `negative_image_embeds` that correspond to the negative prompt `""`. For better results, you can pass an actual `negative_prompt` to the prior pipeline, but this'll increase the effective batch size of the prior pipeline by 2x.
<hfoptions id="text-to-image">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
import torch
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16).to("cuda")
pipeline = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16).to("cuda")
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality" # optional to include a negative prompt, but results are usually better
image_embeds, negative_image_embeds = prior_pipeline(prompt, negative_prompt, guidance_scale=1.0).to_tuple()
```
Now pass all the prompts and embeddings to the [`KandinskyPipeline`] to generate an image:
```py
image = pipeline(prompt, image_embeds=image_embeds, negative_prompt=negative_prompt, negative_image_embeds=negative_image_embeds, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-docs/cheeseburger.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import KandinskyV22PriorPipeline, KandinskyV22Pipeline
import torch
prior_pipeline = KandinskyV22PriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16).to("cuda")
pipeline = KandinskyV22Pipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16).to("cuda")
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality" # optional to include a negative prompt, but results are usually better
image_embeds, negative_image_embeds = prior_pipeline(prompt, guidance_scale=1.0).to_tuple()
```
Pass the `image_embeds` and `negative_image_embeds` to the [`KandinskyV22Pipeline`] to generate an image:
```py
image = pipeline(image_embeds=image_embeds, negative_image_embeds=negative_image_embeds, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-text-to-image.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 3">
Kandinsky 3 doesn't require a prior model so you can directly load the [`Kandinsky3Pipeline`] and pass a prompt to generate an image:
```py
from diffusers import Kandinsky3Pipeline
import torch
pipeline = Kandinsky3Pipeline.from_pretrained("kandinsky-community/kandinsky-3", variant="fp16", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
image = pipeline(prompt).images[0]
image
```
</hfoption>
</hfoptions>
🤗 Diffusers also provides an end-to-end API with the [`KandinskyCombinedPipeline`] and [`KandinskyV22CombinedPipeline`], meaning you don't have to separately load the prior and text-to-image pipeline. The combined pipeline automatically loads both the prior model and the decoder. You can still set different values for the prior pipeline with the `prior_guidance_scale` and `prior_num_inference_steps` parameters if you want.
Use the [`AutoPipelineForText2Image`] to automatically call the combined pipelines under the hood:
<hfoptions id="text-to-image">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, prior_guidance_scale=1.0, guidance_scale=4.0, height=768, width=768).images[0]
image
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt = "A alien cheeseburger creature eating itself, claymation, cinematic, moody lighting"
negative_prompt = "low quality, bad quality"
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, prior_guidance_scale=1.0, guidance_scale=4.0, height=768, width=768).images[0]
image
```
</hfoption>
</hfoptions>
## Image-to-image
For image-to-image, pass the initial image and text prompt to condition the image to the pipeline. Start by loading the prior pipeline:
<hfoptions id="image-to-image">
<hfoption id="Kandinsky 2.1">
```py
import torch
from diffusers import KandinskyImg2ImgPipeline, KandinskyPriorPipeline
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipeline = KandinskyImg2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
import torch
from diffusers import KandinskyV22Img2ImgPipeline, KandinskyPriorPipeline
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipeline = KandinskyV22Img2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
</hfoption>
<hfoption id="Kandinsky 3">
Kandinsky 3 doesn't require a prior model so you can directly load the image-to-image pipeline:
```py
from diffusers import Kandinsky3Img2ImgPipeline
from diffusers.utils import load_image
import torch
pipeline = Kandinsky3Img2ImgPipeline.from_pretrained("kandinsky-community/kandinsky-3", variant="fp16", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
```
</hfoption>
</hfoptions>
Download an image to condition on:
```py
from diffusers.utils import load_image
# download image
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
original_image = load_image(url)
original_image = original_image.resize((768, 512))
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"/>
</div>
Generate the `image_embeds` and `negative_image_embeds` with the prior pipeline:
```py
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
image_embeds, negative_image_embeds = prior_pipeline(prompt, negative_prompt).to_tuple()
```
Now pass the original image, and all the prompts and embeddings to the pipeline to generate an image:
<hfoptions id="image-to-image">
<hfoption id="Kandinsky 2.1">
```py
from diffusers.utils import make_image_grid
image = pipeline(prompt, negative_prompt=negative_prompt, image=original_image, image_embeds=image_embeds, negative_image_embeds=negative_image_embeds, height=768, width=768, strength=0.3).images[0]
make_image_grid([original_image.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-docs/img2img_fantasyland.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers.utils import make_image_grid
image = pipeline(image=original_image, image_embeds=image_embeds, negative_image_embeds=negative_image_embeds, height=768, width=768, strength=0.3).images[0]
make_image_grid([original_image.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-image-to-image.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 3">
```py
image = pipeline(prompt, negative_prompt=negative_prompt, image=image, strength=0.75, num_inference_steps=25).images[0]
image
```
</hfoption>
</hfoptions>
🤗 Diffusers also provides an end-to-end API with the [`KandinskyImg2ImgCombinedPipeline`] and [`KandinskyV22Img2ImgCombinedPipeline`], meaning you don't have to separately load the prior and image-to-image pipeline. The combined pipeline automatically loads both the prior model and the decoder. You can still set different values for the prior pipeline with the `prior_guidance_scale` and `prior_num_inference_steps` parameters if you want.
Use the [`AutoPipelineForImage2Image`] to automatically call the combined pipelines under the hood:
<hfoptions id="image-to-image">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
import torch
pipeline = AutoPipelineForImage2Image.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16, use_safetensors=True)
pipeline.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
original_image = load_image(url)
original_image.thumbnail((768, 768))
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, image=original_image, strength=0.3).images[0]
make_image_grid([original_image.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import AutoPipelineForImage2Image
from diffusers.utils import make_image_grid, load_image
import torch
pipeline = AutoPipelineForImage2Image.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16)
pipeline.enable_model_cpu_offload()
prompt = "A fantasy landscape, Cinematic lighting"
negative_prompt = "low quality, bad quality"
url = "https://raw.githubusercontent.com/CompVis/stable-diffusion/main/assets/stable-samples/img2img/sketch-mountains-input.jpg"
original_image = load_image(url)
original_image.thumbnail((768, 768))
image = pipeline(prompt=prompt, negative_prompt=negative_prompt, image=original_image, strength=0.3).images[0]
make_image_grid([original_image.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
</hfoption>
</hfoptions>
## Inpainting
<Tip warning={true}>
⚠️ The Kandinsky models use ⬜️ **white pixels** to represent the masked area now instead of black pixels. If you are using [`KandinskyInpaintPipeline`] in production, you need to change the mask to use white pixels:
```py
# For PIL input
import PIL.ImageOps
mask = PIL.ImageOps.invert(mask)
# For PyTorch and NumPy input
mask = 1 - mask
```
</Tip>
For inpainting, you'll need the original image, a mask of the area to replace in the original image, and a text prompt of what to inpaint. Load the prior pipeline:
<hfoptions id="inpaint">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import KandinskyInpaintPipeline, KandinskyPriorPipeline
from diffusers.utils import load_image, make_image_grid
import torch
import numpy as np
from PIL import Image
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipeline = KandinskyInpaintPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import KandinskyV22InpaintPipeline, KandinskyV22PriorPipeline
from diffusers.utils import load_image, make_image_grid
import torch
import numpy as np
from PIL import Image
prior_pipeline = KandinskyV22PriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
pipeline = KandinskyV22InpaintPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
</hfoption>
</hfoptions>
Load an initial image and create a mask:
```py
init_image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
mask = np.zeros((768, 768), dtype=np.float32)
# mask area above cat's head
mask[:250, 250:-250] = 1
```
Generate the embeddings with the prior pipeline:
```py
prompt = "a hat"
prior_output = prior_pipeline(prompt)
```
Now pass the initial image, mask, and prompt and embeddings to the pipeline to generate an image:
<hfoptions id="inpaint">
<hfoption id="Kandinsky 2.1">
```py
output_image = pipeline(prompt, image=init_image, mask_image=mask, **prior_output, height=768, width=768, num_inference_steps=150).images[0]
mask = Image.fromarray((mask*255).astype('uint8'), 'L')
make_image_grid([init_image, mask, output_image], rows=1, cols=3)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-docs/inpaint_cat_hat.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
output_image = pipeline(image=init_image, mask_image=mask, **prior_output, height=768, width=768, num_inference_steps=150).images[0]
mask = Image.fromarray((mask*255).astype('uint8'), 'L')
make_image_grid([init_image, mask, output_image], rows=1, cols=3)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinskyv22-inpaint.png"/>
</div>
</hfoption>
</hfoptions>
You can also use the end-to-end [`KandinskyInpaintCombinedPipeline`] and [`KandinskyV22InpaintCombinedPipeline`] to call the prior and decoder pipelines together under the hood. Use the [`AutoPipelineForInpainting`] for this:
<hfoptions id="inpaint">
<hfoption id="Kandinsky 2.1">
```py
import torch
import numpy as np
from PIL import Image
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipe = AutoPipelineForInpainting.from_pretrained("kandinsky-community/kandinsky-2-1-inpaint", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
init_image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
mask = np.zeros((768, 768), dtype=np.float32)
# mask area above cat's head
mask[:250, 250:-250] = 1
prompt = "a hat"
output_image = pipe(prompt=prompt, image=init_image, mask_image=mask).images[0]
mask = Image.fromarray((mask*255).astype('uint8'), 'L')
make_image_grid([init_image, mask, output_image], rows=1, cols=3)
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
import torch
import numpy as np
from PIL import Image
from diffusers import AutoPipelineForInpainting
from diffusers.utils import load_image, make_image_grid
pipe = AutoPipelineForInpainting.from_pretrained("kandinsky-community/kandinsky-2-2-decoder-inpaint", torch_dtype=torch.float16)
pipe.enable_model_cpu_offload()
init_image = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
mask = np.zeros((768, 768), dtype=np.float32)
# mask area above cat's head
mask[:250, 250:-250] = 1
prompt = "a hat"
output_image = pipe(prompt=prompt, image=original_image, mask_image=mask).images[0]
mask = Image.fromarray((mask*255).astype('uint8'), 'L')
make_image_grid([init_image, mask, output_image], rows=1, cols=3)
```
</hfoption>
</hfoptions>
## Interpolation
Interpolation allows you to explore the latent space between the image and text embeddings which is a cool way to see some of the prior model's intermediate outputs. Load the prior pipeline and two images you'd like to interpolate:
<hfoptions id="interpolate">
<hfoption id="Kandinsky 2.1">
```py
from diffusers import KandinskyPriorPipeline, KandinskyPipeline
from diffusers.utils import load_image, make_image_grid
import torch
prior_pipeline = KandinskyPriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-1-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
img_1 = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
img_2 = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/starry_night.jpeg")
make_image_grid([img_1.resize((512,512)), img_2.resize((512,512))], rows=1, cols=2)
```
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
from diffusers import KandinskyV22PriorPipeline, KandinskyV22Pipeline
from diffusers.utils import load_image, make_image_grid
import torch
prior_pipeline = KandinskyV22PriorPipeline.from_pretrained("kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
img_1 = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png")
img_2 = load_image("https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/starry_night.jpeg")
make_image_grid([img_1.resize((512,512)), img_2.resize((512,512))], rows=1, cols=2)
```
</hfoption>
</hfoptions>
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/cat.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">a cat</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinsky/starry_night.jpeg"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">Van Gogh's Starry Night painting</figcaption>
</div>
</div>
Specify the text or images to interpolate, and set the weights for each text or image. Experiment with the weights to see how they affect the interpolation!
```py
images_texts = ["a cat", img_1, img_2]
weights = [0.3, 0.3, 0.4]
```
Call the `interpolate` function to generate the embeddings, and then pass them to the pipeline to generate the image:
<hfoptions id="interpolate">
<hfoption id="Kandinsky 2.1">
```py
# prompt can be left empty
prompt = ""
prior_out = prior_pipeline.interpolate(images_texts, weights)
pipeline = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
image = pipeline(prompt, **prior_out, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinsky-docs/starry_cat.png"/>
</div>
</hfoption>
<hfoption id="Kandinsky 2.2">
```py
# prompt can be left empty
prompt = ""
prior_out = prior_pipeline.interpolate(images_texts, weights)
pipeline = KandinskyV22Pipeline.from_pretrained("kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16, use_safetensors=True).to("cuda")
image = pipeline(prompt, **prior_out, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/kandinskyv22-interpolate.png"/>
</div>
</hfoption>
</hfoptions>
## ControlNet
<Tip warning={true}>
⚠️ ControlNet is only supported for Kandinsky 2.2!
</Tip>
ControlNet enables conditioning large pretrained diffusion models with additional inputs such as a depth map or edge detection. For example, you can condition Kandinsky 2.2 with a depth map so the model understands and preserves the structure of the depth image.
Let's load an image and extract it's depth map:
```py
from diffusers.utils import load_image
img = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/cat.png"
).resize((768, 768))
img
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/cat.png"/>
</div>
Then you can use the `depth-estimation` [`~transformers.Pipeline`] from 🤗 Transformers to process the image and retrieve the depth map:
```py
import torch
import numpy as np
from transformers import pipeline
def make_hint(image, depth_estimator):
image = depth_estimator(image)["depth"]
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
detected_map = torch.from_numpy(image).float() / 255.0
hint = detected_map.permute(2, 0, 1)
return hint
depth_estimator = pipeline("depth-estimation")
hint = make_hint(img, depth_estimator).unsqueeze(0).half().to("cuda")
```
### Text-to-image [[controlnet-text-to-image]]
Load the prior pipeline and the [`KandinskyV22ControlnetPipeline`]:
```py
from diffusers import KandinskyV22PriorPipeline, KandinskyV22ControlnetPipeline
prior_pipeline = KandinskyV22PriorPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True
).to("cuda")
pipeline = KandinskyV22ControlnetPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-controlnet-depth", torch_dtype=torch.float16
).to("cuda")
```
Generate the image embeddings from a prompt and negative prompt:
```py
prompt = "A robot, 4k photo"
negative_prior_prompt = "lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature"
generator = torch.Generator(device="cuda").manual_seed(43)
image_emb, zero_image_emb = prior_pipeline(
prompt=prompt, negative_prompt=negative_prior_prompt, generator=generator
).to_tuple()
```
Finally, pass the image embeddings and the depth image to the [`KandinskyV22ControlnetPipeline`] to generate an image:
```py
image = pipeline(image_embeds=image_emb, negative_image_embeds=zero_image_emb, hint=hint, num_inference_steps=50, generator=generator, height=768, width=768).images[0]
image
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/robot_cat_text2img.png"/>
</div>
### Image-to-image [[controlnet-image-to-image]]
For image-to-image with ControlNet, you'll need to use the:
- [`KandinskyV22PriorEmb2EmbPipeline`] to generate the image embeddings from a text prompt and an image
- [`KandinskyV22ControlnetImg2ImgPipeline`] to generate an image from the initial image and the image embeddings
Process and extract a depth map of an initial image of a cat with the `depth-estimation` [`~transformers.Pipeline`] from 🤗 Transformers:
```py
import torch
import numpy as np
from diffusers import KandinskyV22PriorEmb2EmbPipeline, KandinskyV22ControlnetImg2ImgPipeline
from diffusers.utils import load_image
from transformers import pipeline
img = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/cat.png"
).resize((768, 768))
def make_hint(image, depth_estimator):
image = depth_estimator(image)["depth"]
image = np.array(image)
image = image[:, :, None]
image = np.concatenate([image, image, image], axis=2)
detected_map = torch.from_numpy(image).float() / 255.0
hint = detected_map.permute(2, 0, 1)
return hint
depth_estimator = pipeline("depth-estimation")
hint = make_hint(img, depth_estimator).unsqueeze(0).half().to("cuda")
```
Load the prior pipeline and the [`KandinskyV22ControlnetImg2ImgPipeline`]:
```py
prior_pipeline = KandinskyV22PriorEmb2EmbPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16, use_safetensors=True
).to("cuda")
pipeline = KandinskyV22ControlnetImg2ImgPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-controlnet-depth", torch_dtype=torch.float16
).to("cuda")
```
Pass a text prompt and the initial image to the prior pipeline to generate the image embeddings:
```py
prompt = "A robot, 4k photo"
negative_prior_prompt = "lowres, text, error, cropped, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, out of frame, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck, username, watermark, signature"
generator = torch.Generator(device="cuda").manual_seed(43)
img_emb = prior_pipeline(prompt=prompt, image=img, strength=0.85, generator=generator)
negative_emb = prior_pipeline(prompt=negative_prior_prompt, image=img, strength=1, generator=generator)
```
Now you can run the [`KandinskyV22ControlnetImg2ImgPipeline`] to generate an image from the initial image and the image embeddings:
```py
image = pipeline(image=img, strength=0.5, image_embeds=img_emb.image_embeds, negative_image_embeds=negative_emb.image_embeds, hint=hint, num_inference_steps=50, generator=generator, height=768, width=768).images[0]
make_image_grid([img.resize((512, 512)), image.resize((512, 512))], rows=1, cols=2)
```
<div class="flex justify-center">
<img class="rounded-xl" src="https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/kandinskyv22/robot_cat.png"/>
</div>
## Optimizations
Kandinsky is unique because it requires a prior pipeline to generate the mappings, and a second pipeline to decode the latents into an image. Optimization efforts should be focused on the second pipeline because that is where the bulk of the computation is done. Here are some tips to improve Kandinsky during inference.
1. Enable [xFormers](../optimization/xformers) if you're using PyTorch < 2.0:
```diff
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
+ pipe.enable_xformers_memory_efficient_attention()
```
2. Enable `torch.compile` if you're using PyTorch >= 2.0 to automatically use scaled dot-product attention (SDPA):
```diff
pipe.unet.to(memory_format=torch.channels_last)
+ pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
This is the same as explicitly setting the attention processor to use [`~models.attention_processor.AttnAddedKVProcessor2_0`]:
```py
from diffusers.models.attention_processor import AttnAddedKVProcessor2_0
pipe.unet.set_attn_processor(AttnAddedKVProcessor2_0())
```
3. Offload the model to the CPU with [`~KandinskyPriorPipeline.enable_model_cpu_offload`] to avoid out-of-memory errors:
```diff
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", torch_dtype=torch.float16)
+ pipe.enable_model_cpu_offload()
```
4. By default, the text-to-image pipeline uses the [`DDIMScheduler`] but you can replace it with another scheduler like [`DDPMScheduler`] to see how that affects the tradeoff between inference speed and image quality:
```py
from diffusers import DDPMScheduler
from diffusers import DiffusionPipeline
scheduler = DDPMScheduler.from_pretrained("kandinsky-community/kandinsky-2-1", subfolder="ddpm_scheduler")
pipe = DiffusionPipeline.from_pretrained("kandinsky-community/kandinsky-2-1", scheduler=scheduler, torch_dtype=torch.float16, use_safetensors=True).to("cuda")
```
| diffusers/docs/source/en/using-diffusers/kandinsky.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/kandinsky.md",
"repo_id": "diffusers",
"token_count": 10810
} | 101 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# Stable Video Diffusion
[[open-in-colab]]
[Stable Video Diffusion (SVD)](https://huggingface.co/papers/2311.15127) is a powerful image-to-video generation model that can generate 2-4 second high resolution (576x1024) videos conditioned on an input image.
This guide will show you how to use SVD to generate short videos from images.
Before you begin, make sure you have the following libraries installed:
```py
!pip install -q -U diffusers transformers accelerate
```
The are two variants of this model, [SVD](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid) and [SVD-XT](https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt). The SVD checkpoint is trained to generate 14 frames and the SVD-XT checkpoint is further finetuned to generate 25 frames.
You'll use the SVD-XT checkpoint for this guide.
```python
import torch
from diffusers import StableVideoDiffusionPipeline
from diffusers.utils import load_image, export_to_video
pipe = StableVideoDiffusionPipeline.from_pretrained(
"stabilityai/stable-video-diffusion-img2vid-xt", torch_dtype=torch.float16, variant="fp16"
)
pipe.enable_model_cpu_offload()
# Load the conditioning image
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png")
image = image.resize((1024, 576))
generator = torch.manual_seed(42)
frames = pipe(image, decode_chunk_size=8, generator=generator).frames[0]
export_to_video(frames, "generated.mp4", fps=7)
```
<div class="flex gap-4">
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">"source image of a rocket"</figcaption>
</div>
<div>
<img class="rounded-xl" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/output_rocket.gif"/>
<figcaption class="mt-2 text-center text-sm text-gray-500">"generated video from source image"</figcaption>
</div>
</div>
## torch.compile
You can gain a 20-25% speedup at the expense of slightly increased memory by [compiling](../optimization/torch2.0#torchcompile) the UNet.
```diff
- pipe.enable_model_cpu_offload()
+ pipe.to("cuda")
+ pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
## Reduce memory usage
Video generation is very memory intensive because you're essentially generating `num_frames` all at once, similar to text-to-image generation with a high batch size. To reduce the memory requirement, there are multiple options that trade-off inference speed for lower memory requirement:
- enable model offloading: each component of the pipeline is offloaded to the CPU once it's not needed anymore.
- enable feed-forward chunking: the feed-forward layer runs in a loop instead of running a single feed-forward with a huge batch size.
- reduce `decode_chunk_size`: the VAE decodes frames in chunks instead of decoding them all together. Setting `decode_chunk_size=1` decodes one frame at a time and uses the least amount of memory (we recommend adjusting this value based on your GPU memory) but the video might have some flickering.
```diff
- pipe.enable_model_cpu_offload()
- frames = pipe(image, decode_chunk_size=8, generator=generator).frames[0]
+ pipe.enable_model_cpu_offload()
+ pipe.unet.enable_forward_chunking()
+ frames = pipe(image, decode_chunk_size=2, generator=generator, num_frames=25).frames[0]
```
Using all these tricks together should lower the memory requirement to less than 8GB VRAM.
## Micro-conditioning
Stable Diffusion Video also accepts micro-conditioning, in addition to the conditioning image, which allows more control over the generated video:
- `fps`: the frames per second of the generated video.
- `motion_bucket_id`: the motion bucket id to use for the generated video. This can be used to control the motion of the generated video. Increasing the motion bucket id increases the motion of the generated video.
- `noise_aug_strength`: the amount of noise added to the conditioning image. The higher the values the less the video resembles the conditioning image. Increasing this value also increases the motion of the generated video.
For example, to generate a video with more motion, use the `motion_bucket_id` and `noise_aug_strength` micro-conditioning parameters:
```python
import torch
from diffusers import StableVideoDiffusionPipeline
from diffusers.utils import load_image, export_to_video
pipe = StableVideoDiffusionPipeline.from_pretrained(
"stabilityai/stable-video-diffusion-img2vid-xt", torch_dtype=torch.float16, variant="fp16"
)
pipe.enable_model_cpu_offload()
# Load the conditioning image
image = load_image("https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/svd/rocket.png")
image = image.resize((1024, 576))
generator = torch.manual_seed(42)
frames = pipe(image, decode_chunk_size=8, generator=generator, motion_bucket_id=180, noise_aug_strength=0.1).frames[0]
export_to_video(frames, "generated.mp4", fps=7)
```

| diffusers/docs/source/en/using-diffusers/svd.md/0 | {
"file_path": "diffusers/docs/source/en/using-diffusers/svd.md",
"repo_id": "diffusers",
"token_count": 1759
} | 102 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# ControlNet
[Adding Conditional Control to Text-to-Image Diffusion Models](https://arxiv.org/abs/2302.05543) (ControlNet)은 Lvmin Zhang과 Maneesh Agrawala에 의해 쓰여졌습니다.
이 예시는 [원본 ControlNet 리포지토리에서 예시 학습하기](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md)에 기반합니다. ControlNet은 원들을 채우기 위해 [small synthetic dataset](https://huggingface.co/datasets/fusing/fill50k)을 사용해서 학습됩니다.
## 의존성 설치하기
아래의 스크립트를 실행하기 전에, 라이브러리의 학습 의존성을 설치해야 합니다.
<Tip warning={true}>
가장 최신 버전의 예시 스크립트를 성공적으로 실행하기 위해서는, 소스에서 설치하고 최신 버전의 설치를 유지하는 것을 강력하게 추천합니다. 우리는 예시 스크립트들을 자주 업데이트하고 예시에 맞춘 특정한 요구사항을 설치합니다.
</Tip>
위 사항을 만족시키기 위해서, 새로운 가상환경에서 다음 일련의 스텝을 실행하세요:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install -e .
```
그 다음에는 [예시 폴더](https://github.com/huggingface/diffusers/tree/main/examples/controlnet)으로 이동합니다.
```bash
cd examples/controlnet
```
이제 실행하세요:
```bash
pip install -r requirements.txt
```
[🤗Accelerate](https://github.com/huggingface/accelerate/) 환경을 초기화 합니다:
```bash
accelerate config
```
혹은 여러분의 환경이 무엇인지 몰라도 기본적인 🤗Accelerate 구성으로 초기화할 수 있습니다:
```bash
accelerate config default
```
혹은 당신의 환경이 노트북 같은 상호작용하는 쉘을 지원하지 않는다면, 아래의 코드로 초기화 할 수 있습니다:
```python
from accelerate.utils import write_basic_config
write_basic_config()
```
## 원을 채우는 데이터셋
원본 데이터셋은 ControlNet [repo](https://huggingface.co/lllyasviel/ControlNet/blob/main/training/fill50k.zip)에 올라와있지만, 우리는 [여기](https://huggingface.co/datasets/fusing/fill50k)에 새롭게 다시 올려서 🤗 Datasets 과 호환가능합니다. 그래서 학습 스크립트 상에서 데이터 불러오기를 다룰 수 있습니다.
우리의 학습 예시는 원래 ControlNet의 학습에 쓰였던 [`runwayml/stable-diffusion-v1-5`](https://huggingface.co/runwayml/stable-diffusion-v1-5)을 사용합니다. 그렇지만 ControlNet은 대응되는 어느 Stable Diffusion 모델([`CompVis/stable-diffusion-v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4)) 혹은 [`stabilityai/stable-diffusion-2-1`](https://huggingface.co/stabilityai/stable-diffusion-2-1)의 증가를 위해 학습될 수 있습니다.
자체 데이터셋을 사용하기 위해서는 [학습을 위한 데이터셋 생성하기](create_dataset) 가이드를 확인하세요.
## 학습
이 학습에 사용될 다음 이미지들을 다운로드하세요:
```sh
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_1.png
wget https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/diffusers/controlnet_training/conditioning_image_2.png
```
`MODEL_NAME` 환경 변수 (Hub 모델 리포지토리 아이디 혹은 모델 가중치가 있는 디렉토리로 가는 주소)를 명시하고 [`pretrained_model_name_or_path`](https://huggingface.co/docs/diffusers/en/api/diffusion_pipeline#diffusers.DiffusionPipeline.from_pretrained.pretrained_model_name_or_path) 인자로 환경변수를 보냅니다.
학습 스크립트는 당신의 리포지토리에 `diffusion_pytorch_model.bin` 파일을 생성하고 저장합니다.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=4 \
--push_to_hub
```
이 기본적인 설정으로는 ~38GB VRAM이 필요합니다.
기본적으로 학습 스크립트는 결과를 텐서보드에 기록합니다. 가중치(weight)와 편향(bias)을 사용하기 위해 `--report_to wandb` 를 전달합니다.
더 작은 batch(배치) 크기로 gradient accumulation(기울기 누적)을 하면 학습 요구사항을 ~20 GB VRAM으로 줄일 수 있습니다.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--push_to_hub
```
## 여러개 GPU로 학습하기
`accelerate` 은 seamless multi-GPU 학습을 고려합니다. `accelerate`과 함께 분산된 학습을 실행하기 위해 [여기](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
의 설명을 확인하세요. 아래는 예시 명령어입니다:
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch --mixed_precision="fp16" --multi_gpu train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=4 \
--mixed_precision="fp16" \
--tracker_project_name="controlnet-demo" \
--report_to=wandb \
--push_to_hub
```
## 예시 결과
#### 배치 사이즈 8로 300 스텝 이후:
| | |
|-------------------|:-------------------------:|
| | 푸른 배경과 빨간 원 |
 |  |
| | 갈색 꽃 배경과 청록색 원 |
 |  |
#### 배치 사이즈 8로 6000 스텝 이후:
| | |
|-------------------|:-------------------------:|
| | 푸른 배경과 빨간 원 |
 |  |
| | 갈색 꽃 배경과 청록색 원 |
 |  |
## 16GB GPU에서 학습하기
16GB GPU에서 학습하기 위해 다음의 최적화를 진행하세요:
- 기울기 체크포인트 저장하기
- bitsandbyte의 [8-bit optimizer](https://github.com/TimDettmers/bitsandbytes#requirements--installation)가 설치되지 않았다면 링크에 연결된 설명서를 보세요.
이제 학습 스크립트를 시작할 수 있습니다:
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam \
--push_to_hub
```
## 12GB GPU에서 학습하기
12GB GPU에서 실행하기 위해 다음의 최적화를 진행하세요:
- 기울기 체크포인트 저장하기
- bitsandbyte의 8-bit [optimizer](https://github.com/TimDettmers/bitsandbytes#requirements--installation)(가 설치되지 않았다면 링크에 연결된 설명서를 보세요)
- [xFormers](https://huggingface.co/docs/diffusers/training/optimization/xformers)(가 설치되지 않았다면 링크에 연결된 설명서를 보세요)
- 기울기를 `None`으로 설정
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--learning_rate=1e-5 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--use_8bit_adam \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none \
--push_to_hub
```
`pip install xformers`으로 `xformers`을 확실히 설치하고 `enable_xformers_memory_efficient_attention`을 사용하세요.
## 8GB GPU에서 학습하기
우리는 ControlNet을 지원하기 위한 DeepSpeed를 철저하게 테스트하지 않았습니다. 환경설정이 메모리를 저장할 때,
그 환경이 성공적으로 학습했는지를 확정하지 않았습니다. 성공한 학습 실행을 위해 설정을 변경해야 할 가능성이 높습니다.
8GB GPU에서 실행하기 위해 다음의 최적화를 진행하세요:
- 기울기 체크포인트 저장하기
- bitsandbyte의 8-bit [optimizer](https://github.com/TimDettmers/bitsandbytes#requirements--installation)(가 설치되지 않았다면 링크에 연결된 설명서를 보세요)
- [xFormers](https://huggingface.co/docs/diffusers/training/optimization/xformers)(가 설치되지 않았다면 링크에 연결된 설명서를 보세요)
- 기울기를 `None`으로 설정
- DeepSpeed stage 2 변수와 optimizer 없에기
- fp16 혼합 정밀도(precision)
[DeepSpeed](https://www.deepspeed.ai/)는 CPU 또는 NVME로 텐서를 VRAM에서 오프로드할 수 있습니다.
이를 위해서 훨씬 더 많은 RAM(약 25 GB)가 필요합니다.
DeepSpeed stage 2를 활성화하기 위해서 `accelerate config`로 환경을 구성해야합니다.
구성(configuration) 파일은 이런 모습이어야 합니다:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config:
gradient_accumulation_steps: 4
offload_optimizer_device: cpu
offload_param_device: cpu
zero3_init_flag: false
zero_stage: 2
distributed_type: DEEPSPEED
```
<팁>
[문서](https://huggingface.co/docs/accelerate/usage_guides/deepspeed)를 더 많은 DeepSpeed 설정 옵션을 위해 보세요.
<팁>
기본 Adam optimizer를 DeepSpeed'의 Adam
`deepspeed.ops.adam.DeepSpeedCPUAdam` 으로 바꾸면 상당한 속도 향상을 이룰수 있지만,
Pytorch와 같은 버전의 CUDA toolchain이 필요합니다. 8-비트 optimizer는 현재 DeepSpeed와
호환되지 않는 것 같습니다.
```bash
export MODEL_DIR="runwayml/stable-diffusion-v1-5"
export OUTPUT_DIR="path to save model"
accelerate launch train_controlnet.py \
--pretrained_model_name_or_path=$MODEL_DIR \
--output_dir=$OUTPUT_DIR \
--dataset_name=fusing/fill50k \
--resolution=512 \
--validation_image "./conditioning_image_1.png" "./conditioning_image_2.png" \
--validation_prompt "red circle with blue background" "cyan circle with brown floral background" \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--enable_xformers_memory_efficient_attention \
--set_grads_to_none \
--mixed_precision fp16 \
--push_to_hub
```
## 추론
학습된 모델은 [`StableDiffusionControlNetPipeline`]과 함께 실행될 수 있습니다.
`base_model_path`와 `controlnet_path` 에 값을 지정하세요 `--pretrained_model_name_or_path` 와
`--output_dir` 는 학습 스크립트에 개별적으로 지정됩니다.
```py
from diffusers import StableDiffusionControlNetPipeline, ControlNetModel, UniPCMultistepScheduler
from diffusers.utils import load_image
import torch
base_model_path = "path to model"
controlnet_path = "path to controlnet"
controlnet = ControlNetModel.from_pretrained(controlnet_path, torch_dtype=torch.float16)
pipe = StableDiffusionControlNetPipeline.from_pretrained(
base_model_path, controlnet=controlnet, torch_dtype=torch.float16
)
# 더 빠른 스케줄러와 메모리 최적화로 diffusion 프로세스 속도 올리기
pipe.scheduler = UniPCMultistepScheduler.from_config(pipe.scheduler.config)
# xformers가 설치되지 않으면 아래 줄을 삭제하기
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_model_cpu_offload()
control_image = load_image("./conditioning_image_1.png")
prompt = "pale golden rod circle with old lace background"
# 이미지 생성하기
generator = torch.manual_seed(0)
image = pipe(prompt, num_inference_steps=20, generator=generator, image=control_image).images[0]
image.save("./output.png")
```
| diffusers/docs/source/ko/training/controlnet.md/0 | {
"file_path": "diffusers/docs/source/ko/training/controlnet.md",
"repo_id": "diffusers",
"token_count": 7782
} | 103 |
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
-->
# 제어된 생성
Diffusion 모델에 의해 생성된 출력을 제어하는 것은 커뮤니티에서 오랫동안 추구해 왔으며 현재 활발한 연구 주제입니다. 널리 사용되는 많은 diffusion 모델에서는 이미지와 텍스트 프롬프트 등 입력의 미묘한 변화로 인해 출력이 크게 달라질 수 있습니다. 이상적인 세계에서는 의미가 유지되고 변경되는 방식을 제어할 수 있기를 원합니다.
의미 보존의 대부분의 예는 입력의 변화를 출력의 변화에 정확하게 매핑하는 것으로 축소됩니다. 즉, 프롬프트에서 피사체에 형용사를 추가하면 전체 이미지가 보존되고 변경된 피사체만 수정됩니다. 또는 특정 피사체의 이미지를 변형하면 피사체의 포즈가 유지됩니다.
추가적으로 생성된 이미지의 품질에는 의미 보존 외에도 영향을 미치고자 하는 품질이 있습니다. 즉, 일반적으로 결과물의 품질이 좋거나 특정 스타일을 고수하거나 사실적이기를 원합니다.
diffusion 모델 생성을 제어하기 위해 `diffusers`가 지원하는 몇 가지 기술을 문서화합니다. 많은 부분이 최첨단 연구이며 미묘한 차이가 있을 수 있습니다. 명확한 설명이 필요하거나 제안 사항이 있으면 주저하지 마시고 [포럼](https://discuss.huggingface.co/) 또는 [GitHub 이슈](https://github.com/huggingface/diffusers/issues)에서 토론을 시작하세요.
생성 제어 방법에 대한 개략적인 설명과 기술 개요를 제공합니다. 기술에 대한 자세한 설명은 파이프라인에서 링크된 원본 논문을 참조하는 것이 가장 좋습니다.
사용 사례에 따라 적절한 기술을 선택해야 합니다. 많은 경우 이러한 기법을 결합할 수 있습니다. 예를 들어, 텍스트 반전과 SEGA를 결합하여 텍스트 반전을 사용하여 생성된 출력에 더 많은 의미적 지침을 제공할 수 있습니다.
별도의 언급이 없는 한, 이러한 기법은 기존 모델과 함께 작동하며 자체 가중치가 필요하지 않은 기법입니다.
1. [Instruct Pix2Pix](#instruct-pix2pix)
2. [Pix2Pix Zero](#pix2pixzero)
3. [Attend and Excite](#attend-and-excite)
4. [Semantic Guidance](#semantic-guidance)
5. [Self-attention Guidance](#self-attention-guidance)
6. [Depth2Image](#depth2image)
7. [MultiDiffusion Panorama](#multidiffusion-panorama)
8. [DreamBooth](#dreambooth)
9. [Textual Inversion](#textual-inversion)
10. [ControlNet](#controlnet)
11. [Prompt Weighting](#prompt-weighting)
12. [Custom Diffusion](#custom-diffusion)
13. [Model Editing](#model-editing)
14. [DiffEdit](#diffedit)
15. [T2I-Adapter](#t2i-adapter)
편의를 위해, 추론만 하거나 파인튜닝/학습하는 방법에 대한 표를 제공합니다.
| **Method** | **Inference only** | **Requires training /<br> fine-tuning** | **Comments** |
| :-------------------------------------------------: | :----------------: | :-------------------------------------: | :---------------------------------------------------------------------------------------------: |
| [Instruct Pix2Pix](#instruct-pix2pix) | ✅ | ❌ | Can additionally be<br>fine-tuned for better <br>performance on specific <br>edit instructions. |
| [Pix2Pix Zero](#pix2pixzero) | ✅ | ❌ | |
| [Attend and Excite](#attend-and-excite) | ✅ | ❌ | |
| [Semantic Guidance](#semantic-guidance) | ✅ | ❌ | |
| [Self-attention Guidance](#self-attention-guidance) | ✅ | ❌ | |
| [Depth2Image](#depth2image) | ✅ | ❌ | |
| [MultiDiffusion Panorama](#multidiffusion-panorama) | ✅ | ❌ | |
| [DreamBooth](#dreambooth) | ❌ | ✅ | |
| [Textual Inversion](#textual-inversion) | ❌ | ✅ | |
| [ControlNet](#controlnet) | ✅ | ❌ | A ControlNet can be <br>trained/fine-tuned on<br>a custom conditioning. |
| [Prompt Weighting](#prompt-weighting) | ✅ | ❌ | |
| [Custom Diffusion](#custom-diffusion) | ❌ | ✅ | |
| [Model Editing](#model-editing) | ✅ | ❌ | |
| [DiffEdit](#diffedit) | ✅ | ❌ | |
| [T2I-Adapter](#t2i-adapter) | ✅ | ❌ | |
## Pix2Pix Instruct
[Paper](https://arxiv.org/abs/2211.09800)
[Instruct Pix2Pix](../api/pipelines/stable_diffusion/pix2pix) 는 입력 이미지 편집을 지원하기 위해 stable diffusion에서 미세-조정되었습니다. 이미지와 편집을 설명하는 프롬프트를 입력으로 받아 편집된 이미지를 출력합니다.
Instruct Pix2Pix는 [InstructGPT](https://openai.com/blog/instruction-following/)와 같은 프롬프트와 잘 작동하도록 명시적으로 훈련되었습니다.
사용 방법에 대한 자세한 내용은 [여기](../api/pipelines/stable_diffusion/pix2pix)를 참조하세요.
## Pix2Pix Zero
[Paper](https://arxiv.org/abs/2302.03027)
[Pix2Pix Zero](../api/pipelines/stable_diffusion/pix2pix_zero)를 사용하면 일반적인 이미지 의미를 유지하면서 한 개념이나 피사체가 다른 개념이나 피사체로 변환되도록 이미지를 수정할 수 있습니다.
노이즈 제거 프로세스는 한 개념적 임베딩에서 다른 개념적 임베딩으로 안내됩니다. 중간 잠복(intermediate latents)은 디노이징(denoising?) 프로세스 중에 최적화되어 참조 주의 지도(reference attention maps)를 향해 나아갑니다. 참조 주의 지도(reference attention maps)는 입력 이미지의 노이즈 제거(?) 프로세스에서 나온 것으로 의미 보존을 장려하는 데 사용됩니다.
Pix2Pix Zero는 합성 이미지와 실제 이미지를 편집하는 데 모두 사용할 수 있습니다.
- 합성 이미지를 편집하려면 먼저 캡션이 지정된 이미지를 생성합니다.
다음으로 편집할 컨셉과 새로운 타겟 컨셉에 대한 이미지 캡션을 생성합니다. 이를 위해 [Flan-T5](https://huggingface.co/docs/transformers/model_doc/flan-t5)와 같은 모델을 사용할 수 있습니다. 그런 다음 텍스트 인코더를 통해 소스 개념과 대상 개념 모두에 대한 "평균" 프롬프트 임베딩을 생성합니다. 마지막으로, 합성 이미지를 편집하기 위해 pix2pix-zero 알고리즘을 사용합니다.
- 실제 이미지를 편집하려면 먼저 [BLIP](https://huggingface.co/docs/transformers/model_doc/blip)과 같은 모델을 사용하여 이미지 캡션을 생성합니다. 그런 다음 프롬프트와 이미지에 ddim 반전을 적용하여 "역(inverse)" latents을 생성합니다. 이전과 마찬가지로 소스 및 대상 개념 모두에 대한 "평균(mean)" 프롬프트 임베딩이 생성되고 마지막으로 "역(inverse)" latents와 결합된 pix2pix-zero 알고리즘이 이미지를 편집하는 데 사용됩니다.
<Tip>
Pix2Pix Zero는 '제로 샷(zero-shot)' 이미지 편집이 가능한 최초의 모델입니다.
즉, 이 모델은 다음과 같이 일반 소비자용 GPU에서 1분 이내에 이미지를 편집할 수 있습니다(../api/pipelines/stable_diffusion/pix2pix_zero#usage-example).
</Tip>
위에서 언급했듯이 Pix2Pix Zero에는 특정 개념으로 세대를 유도하기 위해 (UNet, VAE 또는 텍스트 인코더가 아닌) latents을 최적화하는 기능이 포함되어 있습니다.즉, 전체 파이프라인에 표준 [StableDiffusionPipeline](../api/pipelines/stable_diffusion/text2img)보다 더 많은 메모리가 필요할 수 있습니다.
사용 방법에 대한 자세한 내용은 [여기](../api/pipelines/stable_diffusion/pix2pix_zero)를 참조하세요.
## Attend and Excite
[Paper](https://arxiv.org/abs/2301.13826)
[Attend and Excite](../api/pipelines/stable_diffusion/attend_and_excite)를 사용하면 프롬프트의 피사체가 최종 이미지에 충실하게 표현되도록 할 수 있습니다.
이미지에 존재해야 하는 프롬프트의 피사체에 해당하는 일련의 토큰 인덱스가 입력으로 제공됩니다. 노이즈 제거 중에 각 토큰 인덱스는 이미지의 최소 한 패치 이상에 대해 최소 주의 임계값을 갖도록 보장됩니다. 모든 피사체 토큰에 대해 주의 임계값이 통과될 때까지 노이즈 제거 프로세스 중에 중간 잠복기가 반복적으로 최적화되어 가장 소홀히 취급되는 피사체 토큰의 주의력을 강화합니다.
Pix2Pix Zero와 마찬가지로 Attend and Excite 역시 파이프라인에 미니 최적화 루프(사전 학습된 가중치를 그대로 둔 채)가 포함되며, 일반적인 'StableDiffusionPipeline'보다 더 많은 메모리가 필요할 수 있습니다.
사용 방법에 대한 자세한 내용은 [여기](../api/pipelines/stable_diffusion/attend_and_excite)를 참조하세요.
## Semantic Guidance (SEGA)
[Paper](https://arxiv.org/abs/2301.12247)
의미유도(SEGA)를 사용하면 이미지에서 하나 이상의 컨셉을 적용하거나 제거할 수 있습니다. 컨셉의 강도도 조절할 수 있습니다. 즉, 스마일 컨셉을 사용하여 인물 사진의 스마일을 점진적으로 늘리거나 줄일 수 있습니다.
분류기 무료 안내(classifier free guidance)가 빈 프롬프트 입력을 통해 안내를 제공하는 방식과 유사하게, SEGA는 개념 프롬프트에 대한 안내를 제공합니다. 이러한 개념 프롬프트는 여러 개를 동시에 적용할 수 있습니다. 각 개념 프롬프트는 안내가 긍정적으로 적용되는지 또는 부정적으로 적용되는지에 따라 해당 개념을 추가하거나 제거할 수 있습니다.
Pix2Pix Zero 또는 Attend and Excite와 달리 SEGA는 명시적인 그라데이션 기반 최적화를 수행하는 대신 확산 프로세스와 직접 상호 작용합니다.
사용 방법에 대한 자세한 내용은 [여기](../api/pipelines/semantic_stable_diffusion)를 참조하세요.
## Self-attention Guidance (SAG)
[Paper](https://arxiv.org/abs/2210.00939)
[자기 주의 안내](../api/pipelines/stable_diffusion/self_attention_guidance)는 이미지의 전반적인 품질을 개선합니다.
SAG는 고빈도 세부 정보를 기반으로 하지 않은 예측에서 완전히 조건화된 이미지에 이르기까지 가이드를 제공합니다. 고빈도 디테일은 UNet 자기 주의 맵에서 추출됩니다.
사용 방법에 대한 자세한 내용은 [여기](../api/pipelines/stable_diffusion/self_attention_guidance)를 참조하세요.
## Depth2Image
[Project](https://huggingface.co/stabilityai/stable-diffusion-2-depth)
[Depth2Image](../pipelines/stable_diffusion_2#depthtoimage)는 텍스트 안내 이미지 변화에 대한 시맨틱을 더 잘 보존하도록 안정적 확산에서 미세 조정되었습니다.
원본 이미지의 단안(monocular) 깊이 추정치를 조건으로 합니다.
사용 방법에 대한 자세한 내용은 [여기](../api/pipelines/stable_diffusion_2#depthtoimage)를 참조하세요.
<Tip>
InstructPix2Pix와 Pix2Pix Zero와 같은 방법의 중요한 차이점은 전자의 경우
는 사전 학습된 가중치를 미세 조정하는 반면, 후자는 그렇지 않다는 것입니다. 즉, 다음을 수행할 수 있습니다.
사용 가능한 모든 안정적 확산 모델에 Pix2Pix Zero를 적용할 수 있습니다.
</Tip>
## MultiDiffusion Panorama
[Paper](https://arxiv.org/abs/2302.08113)
MultiDiffusion은 사전 학습된 diffusion model을 통해 새로운 생성 프로세스를 정의합니다. 이 프로세스는 고품질의 다양한 이미지를 생성하는 데 쉽게 적용할 수 있는 여러 diffusion 생성 방법을 하나로 묶습니다. 결과는 원하는 종횡비(예: 파노라마) 및 타이트한 분할 마스크에서 바운딩 박스에 이르는 공간 안내 신호와 같은 사용자가 제공한 제어를 준수합니다.
[MultiDiffusion 파노라마](../api/pipelines/stable_diffusion/panorama)를 사용하면 임의의 종횡비(예: 파노라마)로 고품질 이미지를 생성할 수 있습니다.
파노라마 이미지를 생성하는 데 사용하는 방법에 대한 자세한 내용은 [여기](../api/pipelines/stable_diffusion/panorama)를 참조하세요.
## 나만의 모델 파인튜닝
사전 학습된 모델 외에도 Diffusers는 사용자가 제공한 데이터에 대해 모델을 파인튜닝할 수 있는 학습 스크립트가 있습니다.
## DreamBooth
[DreamBooth](../training/dreambooth)는 모델을 파인튜닝하여 새로운 주제에 대해 가르칩니다. 즉, 한 사람의 사진 몇 장을 사용하여 다양한 스타일로 그 사람의 이미지를 생성할 수 있습니다.
사용 방법에 대한 자세한 내용은 [여기](../training/dreambooth)를 참조하세요.
## Textual Inversion
[Textual Inversion](../training/text_inversion)은 모델을 파인튜닝하여 새로운 개념에 대해 학습시킵니다. 즉, 특정 스타일의 아트웍 사진 몇 장을 사용하여 해당 스타일의 이미지를 생성할 수 있습니다.
사용 방법에 대한 자세한 내용은 [여기](../training/text_inversion)를 참조하세요.
## ControlNet
[Paper](https://arxiv.org/abs/2302.05543)
[ControlNet](../api/pipelines/stable_diffusion/controlnet)은 추가 조건을 추가하는 보조 네트워크입니다.
가장자리 감지, 낙서, 깊이 맵, 의미적 세그먼트와 같은 다양한 조건에 대해 훈련된 8개의 표준 사전 훈련된 ControlNet이 있습니다,
깊이 맵, 시맨틱 세그먼테이션과 같은 다양한 조건으로 훈련된 8개의 표준 제어망이 있습니다.
사용 방법에 대한 자세한 내용은 [여기](../api/pipelines/stable_diffusion/controlnet)를 참조하세요.
## Prompt Weighting
프롬프트 가중치는 텍스트의 특정 부분에 더 많은 관심 가중치를 부여하는 간단한 기법입니다.
입력에 가중치를 부여하는 간단한 기법입니다.
자세한 설명과 예시는 [여기](../using-diffusers/weighted_prompts)를 참조하세요.
## Custom Diffusion
[Custom Diffusion](../training/custom_diffusion)은 사전 학습된 text-to-image 간 확산 모델의 교차 관심도 맵만 미세 조정합니다.
또한 textual inversion을 추가로 수행할 수 있습니다. 설계상 다중 개념 훈련을 지원합니다.
DreamBooth 및 Textual Inversion 마찬가지로, 사용자 지정 확산은 사전학습된 text-to-image diffusion 모델에 새로운 개념을 학습시켜 관심 있는 개념과 관련된 출력을 생성하는 데에도 사용됩니다.
자세한 설명은 [공식 문서](../training/custom_diffusion)를 참조하세요.
## Model Editing
[Paper](https://arxiv.org/abs/2303.08084)
[텍스트-이미지 모델 편집 파이프라인](../api/pipelines/model_editing)을 사용하면 사전학습된 text-to-image diffusion 모델이 입력 프롬프트에 있는 피사체에 대해 내릴 수 있는 잘못된 암시적 가정을 완화하는 데 도움이 됩니다.
예를 들어, 안정적 확산에 "A pack of roses"에 대한 이미지를 생성하라는 메시지를 표시하면 생성된 이미지의 장미는 빨간색일 가능성이 높습니다. 이 파이프라인은 이러한 가정을 변경하는 데 도움이 됩니다.
자세한 설명은 [공식 문서](../api/pipelines/model_editing)를 참조하세요.
## DiffEdit
[Paper](https://arxiv.org/abs/2210.11427)
[DiffEdit](../api/pipelines/diffedit)를 사용하면 원본 입력 이미지를 최대한 보존하면서 입력 프롬프트와 함께 입력 이미지의 의미론적 편집이 가능합니다.
자세한 설명은 [공식 문서](../api/pipelines/diffedit)를 참조하세요.
## T2I-Adapter
[Paper](https://arxiv.org/abs/2302.08453)
[T2I-어댑터](../api/pipelines/stable_diffusion/adapter)는 추가적인 조건을 추가하는 auxiliary 네트워크입니다.
가장자리 감지, 스케치, depth maps, semantic segmentations와 같은 다양한 조건에 대해 훈련된 8개의 표준 사전훈련된 adapter가 있습니다,
[공식 문서](api/pipelines/stable_diffusion/adapter)에서 사용 방법에 대한 정보를 참조하세요. | diffusers/docs/source/ko/using-diffusers/controlling_generation.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/controlling_generation.md",
"repo_id": "diffusers",
"token_count": 14041
} | 104 |
# 세이프텐서 로드
[safetensors](https://github.com/huggingface/safetensors)는 텐서를 저장하고 로드하기 위한 안전하고 빠른 파일 형식입니다. 일반적으로 PyTorch 모델 가중치는 Python의 [`pickle`](https://docs.python.org/3/library/pickle.html) 유틸리티를 사용하여 `.bin` 파일에 저장되거나 `피클`됩니다. 그러나 `피클`은 안전하지 않으며 피클된 파일에는 실행될 수 있는 악성 코드가 포함될 수 있습니다. 세이프텐서는 `피클`의 안전한 대안으로 모델 가중치를 공유하는 데 이상적입니다.
이 가이드에서는 `.safetensor` 파일을 로드하는 방법과 다른 형식으로 저장된 안정적 확산 모델 가중치를 `.safetensor`로 변환하는 방법을 보여드리겠습니다. 시작하기 전에 세이프텐서가 설치되어 있는지 확인하세요:
```bash
!pip install safetensors
```
['runwayml/stable-diffusion-v1-5`] (https://huggingface.co/runwayml/stable-diffusion-v1-5/tree/main) 리포지토리를 보면 `text_encoder`, `unet` 및 `vae` 하위 폴더에 가중치가 `.safetensors` 형식으로 저장되어 있는 것을 볼 수 있습니다. 기본적으로 🤗 디퓨저는 모델 저장소에서 사용할 수 있는 경우 해당 하위 폴더에서 이러한 '.safetensors` 파일을 자동으로 로드합니다.
보다 명시적인 제어를 위해 선택적으로 `사용_세이프텐서=True`를 설정할 수 있습니다(`세이프텐서`가 설치되지 않은 경우 설치하라는 오류 메시지가 표시됨):
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", use_safetensors=True)
```
그러나 모델 가중치가 위의 예시처럼 반드시 별도의 하위 폴더에 저장되는 것은 아닙니다. 모든 가중치가 하나의 '.safetensors` 파일에 저장되는 경우도 있습니다. 이 경우 가중치가 Stable Diffusion 가중치인 경우 [`~diffusers.loaders.FromCkptMixin.from_ckpt`] 메서드를 사용하여 파일을 직접 로드할 수 있습니다:
```py
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_ckpt(
"https://huggingface.co/WarriorMama777/OrangeMixs/blob/main/Models/AbyssOrangeMix/AbyssOrangeMix.safetensors"
)
```
## 세이프텐서로 변환
허브의 모든 가중치를 '.safetensors` 형식으로 사용할 수 있는 것은 아니며, '.bin`으로 저장된 가중치가 있을 수 있습니다. 이 경우 [Convert Space](https://huggingface.co/spaces/diffusers/convert)을 사용하여 가중치를 '.safetensors'로 변환하세요. Convert Space는 피클된 가중치를 다운로드하여 변환한 후 풀 리퀘스트를 열어 허브에 새로 변환된 `.safetensors` 파일을 업로드합니다. 이렇게 하면 피클된 파일에 악성 코드가 포함되어 있는 경우, 안전하지 않은 파일과 의심스러운 피클 가져오기를 탐지하는 [보안 스캐너](https://huggingface.co/docs/hub/security-pickle#hubs-security-scanner)가 있는 허브로 업로드됩니다. - 개별 컴퓨터가 아닌.
개정` 매개변수에 풀 리퀘스트에 대한 참조를 지정하여 새로운 '.safetensors` 가중치가 적용된 모델을 사용할 수 있습니다(허브의 [Check PR](https://huggingface.co/spaces/diffusers/check_pr) 공간에서 테스트할 수도 있음)(예: `refs/pr/22`):
```py
from diffusers import DiffusionPipeline
pipeline = DiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1", revision="refs/pr/22")
```
## 세이프센서를 사용하는 이유는 무엇인가요?
세이프티 센서를 사용하는 데에는 여러 가지 이유가 있습니다:
- 세이프텐서를 사용하는 가장 큰 이유는 안전입니다.오픈 소스 및 모델 배포가 증가함에 따라 다운로드한 모델 가중치에 악성 코드가 포함되어 있지 않다는 것을 신뢰할 수 있는 것이 중요해졌습니다.세이프센서의 현재 헤더 크기는 매우 큰 JSON 파일을 구문 분석하지 못하게 합니다.
- 모델 전환 간의 로딩 속도는 텐서의 제로 카피를 수행하는 세이프텐서를 사용해야 하는 또 다른 이유입니다. 가중치를 CPU(기본값)로 로드하는 경우 '피클'에 비해 특히 빠르며, 가중치를 GPU로 직접 로드하는 경우에도 빠르지는 않더라도 비슷하게 빠릅니다. 모델이 이미 로드된 경우에만 성능 차이를 느낄 수 있으며, 가중치를 다운로드하거나 모델을 처음 로드하는 경우에는 성능 차이를 느끼지 못할 것입니다.
전체 파이프라인을 로드하는 데 걸리는 시간입니다:
```py
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained("stabilityai/stable-diffusion-2-1")
"Loaded in safetensors 0:00:02.033658"
"Loaded in PyTorch 0:00:02.663379"
```
하지만 실제로 500MB의 모델 가중치를 로드하는 데 걸리는 시간은 얼마 되지 않습니다:
```bash
safetensors: 3.4873ms
PyTorch: 172.7537ms
```
지연 로딩은 세이프텐서에서도 지원되며, 이는 분산 설정에서 일부 텐서만 로드하는 데 유용합니다. 이 형식을 사용하면 [BLOOM](https://huggingface.co/bigscience/bloom) 모델을 일반 PyTorch 가중치를 사용하여 10분이 걸리던 것을 8개의 GPU에서 45초 만에 로드할 수 있습니다.
| diffusers/docs/source/ko/using-diffusers/using_safetensors.md/0 | {
"file_path": "diffusers/docs/source/ko/using-diffusers/using_safetensors.md",
"repo_id": "diffusers",
"token_count": 4065
} | 105 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import contextlib
import gc
import hashlib
import itertools
import json
import logging
import math
import os
import random
import re
import shutil
import warnings
from pathlib import Path
from typing import List, Optional
import numpy as np
import torch
import torch.nn.functional as F
# imports of the TokenEmbeddingsHandler class
import torch.utils.checkpoint
import transformers
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import DistributedDataParallelKwargs, ProjectConfiguration, set_seed
from huggingface_hub import create_repo, hf_hub_download, upload_folder
from packaging import version
from peft import LoraConfig, set_peft_model_state_dict
from peft.utils import get_peft_model_state_dict
from PIL import Image
from PIL.ImageOps import exif_transpose
from safetensors.torch import load_file, save_file
from torch.utils.data import Dataset
from torchvision import transforms
from torchvision.transforms.functional import crop
from tqdm.auto import tqdm
from transformers import AutoTokenizer, PretrainedConfig
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
DPMSolverMultistepScheduler,
EDMEulerScheduler,
EulerDiscreteScheduler,
StableDiffusionXLPipeline,
UNet2DConditionModel,
)
from diffusers.loaders import LoraLoaderMixin
from diffusers.optimization import get_scheduler
from diffusers.training_utils import _set_state_dict_into_text_encoder, cast_training_params, compute_snr
from diffusers.utils import (
check_min_version,
convert_all_state_dict_to_peft,
convert_state_dict_to_diffusers,
convert_state_dict_to_kohya,
convert_unet_state_dict_to_peft,
is_wandb_available,
)
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.torch_utils import is_compiled_module
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.28.0.dev0")
logger = get_logger(__name__)
def determine_scheduler_type(pretrained_model_name_or_path, revision):
model_index_filename = "model_index.json"
if os.path.isdir(pretrained_model_name_or_path):
model_index = os.path.join(pretrained_model_name_or_path, model_index_filename)
else:
model_index = hf_hub_download(
repo_id=pretrained_model_name_or_path, filename=model_index_filename, revision=revision
)
with open(model_index, "r") as f:
scheduler_type = json.load(f)["scheduler"][1]
return scheduler_type
def save_model_card(
repo_id: str,
use_dora: bool,
images=None,
base_model=str,
train_text_encoder=False,
train_text_encoder_ti=False,
token_abstraction_dict=None,
instance_prompt=str,
validation_prompt=str,
repo_folder=None,
vae_path=None,
):
img_str = "widget:\n"
lora = "lora" if not use_dora else "dora"
for i, image in enumerate(images):
image.save(os.path.join(repo_folder, f"image_{i}.png"))
img_str += f"""
- text: '{validation_prompt if validation_prompt else ' ' }'
output:
url:
"image_{i}.png"
"""
if not images:
img_str += f"""
- text: '{instance_prompt}'
"""
embeddings_filename = f"{repo_folder}_emb"
instance_prompt_webui = re.sub(r"<s\d+>", "", re.sub(r"<s\d+>", embeddings_filename, instance_prompt, count=1))
ti_keys = ", ".join(f'"{match}"' for match in re.findall(r"<s\d+>", instance_prompt))
if instance_prompt_webui != embeddings_filename:
instance_prompt_sentence = f"For example, `{instance_prompt_webui}`"
else:
instance_prompt_sentence = ""
trigger_str = f"You should use {instance_prompt} to trigger the image generation."
diffusers_imports_pivotal = ""
diffusers_example_pivotal = ""
webui_example_pivotal = ""
if train_text_encoder_ti:
trigger_str = (
"To trigger image generation of trained concept(or concepts) replace each concept identifier "
"in you prompt with the new inserted tokens:\n"
)
diffusers_imports_pivotal = """from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
"""
diffusers_example_pivotal = f"""embedding_path = hf_hub_download(repo_id='{repo_id}', filename='{embeddings_filename}.safetensors', repo_type="model")
state_dict = load_file(embedding_path)
pipeline.load_textual_inversion(state_dict["clip_l"], token=[{ti_keys}], text_encoder=pipeline.text_encoder, tokenizer=pipeline.tokenizer)
pipeline.load_textual_inversion(state_dict["clip_g"], token=[{ti_keys}], text_encoder=pipeline.text_encoder_2, tokenizer=pipeline.tokenizer_2)
"""
webui_example_pivotal = f"""- *Embeddings*: download **[`{embeddings_filename}.safetensors` here 💾](/{repo_id}/blob/main/{embeddings_filename}.safetensors)**.
- Place it on it on your `embeddings` folder
- Use it by adding `{embeddings_filename}` to your prompt. {instance_prompt_sentence}
(you need both the LoRA and the embeddings as they were trained together for this LoRA)
"""
if token_abstraction_dict:
for key, value in token_abstraction_dict.items():
tokens = "".join(value)
trigger_str += f"""
to trigger concept `{key}` → use `{tokens}` in your prompt \n
"""
yaml = f"""---
tags:
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
- diffusers-training
- text-to-image
- diffusers
- {lora}
- template:sd-lora
{img_str}
base_model: {base_model}
instance_prompt: {instance_prompt}
license: openrail++
---
"""
model_card = f"""
# SDXL LoRA DreamBooth - {repo_id}
<Gallery />
## Model description
### These are {repo_id} LoRA adaption weights for {base_model}.
## Download model
### Use it with UIs such as AUTOMATIC1111, Comfy UI, SD.Next, Invoke
- **LoRA**: download **[`{repo_folder}.safetensors` here 💾](/{repo_id}/blob/main/{repo_folder}.safetensors)**.
- Place it on your `models/Lora` folder.
- On AUTOMATIC1111, load the LoRA by adding `<lora:{repo_folder}:1>` to your prompt. On ComfyUI just [load it as a regular LoRA](https://comfyanonymous.github.io/ComfyUI_examples/lora/).
{webui_example_pivotal}
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
{diffusers_imports_pivotal}
pipeline = AutoPipelineForText2Image.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('{repo_id}', weight_name='pytorch_lora_weights.safetensors')
{diffusers_example_pivotal}
image = pipeline('{validation_prompt if validation_prompt else instance_prompt}').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Trigger words
{trigger_str}
## Details
All [Files & versions](/{repo_id}/tree/main).
The weights were trained using [🧨 diffusers Advanced Dreambooth Training Script](https://github.com/huggingface/diffusers/blob/main/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py).
LoRA for the text encoder was enabled. {train_text_encoder}.
Pivotal tuning was enabled: {train_text_encoder_ti}.
Special VAE used for training: {vae_path}.
"""
with open(os.path.join(repo_folder, "README.md"), "w") as f:
f.write(yaml + model_card)
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args(input_args=None):
parser = argparse.ArgumentParser(description="Simple example of a training script.")
parser.add_argument(
"--pretrained_model_name_or_path",
type=str,
default=None,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained model identifier from huggingface.co/models.",
)
parser.add_argument(
"--variant",
type=str,
default=None,
help="Variant of the model files of the pretrained model identifier from huggingface.co/models, 'e.g.' fp16",
)
parser.add_argument(
"--dataset_name",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) containing the training data of instance images (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand.To load the custom captions, the training set directory needs to follow the structure of a "
"datasets ImageFolder, containing both the images and the corresponding caption for each image. see: "
"https://huggingface.co/docs/datasets/image_dataset for more information"
),
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The config of the Dataset. In some cases, a dataset may have more than one configuration (for example "
"if it contains different subsets of data within, and you only wish to load a specific subset - in that case specify the desired configuration using --dataset_config_name. Leave as "
"None if there's only one config.",
)
parser.add_argument(
"--instance_data_dir",
type=str,
default=None,
help="A path to local folder containing the training data of instance images. Specify this arg instead of "
"--dataset_name if you wish to train using a local folder without custom captions. If you wish to train with custom captions please specify "
"--dataset_name instead.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument(
"--image_column",
type=str,
default="image",
help="The column of the dataset containing the target image. By "
"default, the standard Image Dataset maps out 'file_name' "
"to 'image'.",
)
parser.add_argument(
"--caption_column",
type=str,
default=None,
help="The column of the dataset containing the instance prompt for each image",
)
parser.add_argument("--repeats", type=int, default=1, help="How many times to repeat the training data.")
parser.add_argument(
"--class_data_dir",
type=str,
default=None,
required=False,
help="A folder containing the training data of class images.",
)
parser.add_argument(
"--instance_prompt",
type=str,
default=None,
required=True,
help="The prompt with identifier specifying the instance, e.g. 'photo of a TOK dog', 'in the style of TOK'",
)
parser.add_argument(
"--token_abstraction",
type=str,
default="TOK",
help="identifier specifying the instance(or instances) as used in instance_prompt, validation prompt, "
"captions - e.g. TOK. To use multiple identifiers, please specify them in a comma seperated string - e.g. "
"'TOK,TOK2,TOK3' etc.",
)
parser.add_argument(
"--num_new_tokens_per_abstraction",
type=int,
default=2,
help="number of new tokens inserted to the tokenizers per token_abstraction identifier when "
"--train_text_encoder_ti = True. By default, each --token_abstraction (e.g. TOK) is mapped to 2 new "
"tokens - <si><si+1> ",
)
parser.add_argument(
"--class_prompt",
type=str,
default=None,
help="The prompt to specify images in the same class as provided instance images.",
)
parser.add_argument(
"--validation_prompt",
type=str,
default=None,
help="A prompt that is used during validation to verify that the model is learning.",
)
parser.add_argument(
"--num_validation_images",
type=int,
default=4,
help="Number of images that should be generated during validation with `validation_prompt`.",
)
parser.add_argument(
"--validation_epochs",
type=int,
default=50,
help=(
"Run dreambooth validation every X epochs. Dreambooth validation consists of running the prompt"
" `args.validation_prompt` multiple times: `args.num_validation_images`."
),
)
parser.add_argument(
"--do_edm_style_training",
action="store_true",
help="Flag to conduct training using the EDM formulation as introduced in https://arxiv.org/abs/2206.00364.",
)
parser.add_argument(
"--with_prior_preservation",
default=False,
action="store_true",
help="Flag to add prior preservation loss.",
)
parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
parser.add_argument(
"--num_class_images",
type=int,
default=100,
help=(
"Minimal class images for prior preservation loss. If there are not enough images already present in"
" class_data_dir, additional images will be sampled with class_prompt."
),
)
parser.add_argument(
"--output_dir",
type=str,
default="lora-dreambooth-model",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
parser.add_argument(
"--resolution",
type=int,
default=1024,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
parser.add_argument(
"--train_text_encoder",
action="store_true",
help="Whether to train the text encoder. If set, the text encoder should be float32 precision.",
)
parser.add_argument(
"--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
)
parser.add_argument(
"--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
)
parser.add_argument("--num_train_epochs", type=int, default=1)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints can be used both as final"
" checkpoints in case they are better than the last checkpoint, and are also suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--text_encoder_lr",
type=float,
default=5e-6,
help="Text encoder learning rate to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--snr_gamma",
type=float,
default=None,
help="SNR weighting gamma to be used if rebalancing the loss. Recommended value is 5.0. "
"More details here: https://arxiv.org/abs/2303.09556.",
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--lr_num_cycles",
type=int,
default=1,
help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
)
parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
parser.add_argument(
"--train_text_encoder_ti",
action="store_true",
help=("Whether to use textual inversion"),
)
parser.add_argument(
"--train_text_encoder_ti_frac",
type=float,
default=0.5,
help=("The percentage of epochs to perform textual inversion"),
)
parser.add_argument(
"--train_text_encoder_frac",
type=float,
default=1.0,
help=("The percentage of epochs to perform text encoder tuning"),
)
parser.add_argument(
"--optimizer",
type=str,
default="adamW",
help=('The optimizer type to use. Choose between ["AdamW", "prodigy"]'),
)
parser.add_argument(
"--use_8bit_adam",
action="store_true",
help="Whether or not to use 8-bit Adam from bitsandbytes. Ignored if optimizer is not set to AdamW",
)
parser.add_argument(
"--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam and Prodigy optimizers."
)
parser.add_argument(
"--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam and Prodigy optimizers."
)
parser.add_argument(
"--prodigy_beta3",
type=float,
default=None,
help="coefficients for computing the Prodidy stepsize using running averages. If set to None, "
"uses the value of square root of beta2. Ignored if optimizer is adamW",
)
parser.add_argument("--prodigy_decouple", type=bool, default=True, help="Use AdamW style decoupled weight decay")
parser.add_argument("--adam_weight_decay", type=float, default=1e-04, help="Weight decay to use for unet params")
parser.add_argument(
"--adam_weight_decay_text_encoder", type=float, default=None, help="Weight decay to use for text_encoder"
)
parser.add_argument(
"--adam_epsilon",
type=float,
default=1e-08,
help="Epsilon value for the Adam optimizer and Prodigy optimizers.",
)
parser.add_argument(
"--prodigy_use_bias_correction",
type=bool,
default=True,
help="Turn on Adam's bias correction. True by default. Ignored if optimizer is adamW",
)
parser.add_argument(
"--prodigy_safeguard_warmup",
type=bool,
default=True,
help="Remove lr from the denominator of D estimate to avoid issues during warm-up stage. True by default. "
"Ignored if optimizer is adamW",
)
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--prior_generation_precision",
type=str,
default=None,
choices=["no", "fp32", "fp16", "bf16"],
help=(
"Choose prior generation precision between fp32, fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to fp16 if a GPU is available else fp32."
),
)
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument("--noise_offset", type=float, default=0, help="The scale of noise offset.")
parser.add_argument(
"--rank",
type=int,
default=4,
help=("The dimension of the LoRA update matrices."),
)
parser.add_argument(
"--use_dora",
action="store_true",
default=False,
help=(
"Wether to train a DoRA as proposed in- DoRA: Weight-Decomposed Low-Rank Adaptation https://arxiv.org/abs/2402.09353. "
"Note: to use DoRA you need to install peft from main, `pip install git+https://github.com/huggingface/peft.git`"
),
)
parser.add_argument(
"--cache_latents",
action="store_true",
default=False,
help="Cache the VAE latents",
)
if input_args is not None:
args = parser.parse_args(input_args)
else:
args = parser.parse_args()
if args.dataset_name is None and args.instance_data_dir is None:
raise ValueError("Specify either `--dataset_name` or `--instance_data_dir`")
if args.dataset_name is not None and args.instance_data_dir is not None:
raise ValueError("Specify only one of `--dataset_name` or `--instance_data_dir`")
if args.train_text_encoder and args.train_text_encoder_ti:
raise ValueError(
"Specify only one of `--train_text_encoder` or `--train_text_encoder_ti. "
"For full LoRA text encoder training check --train_text_encoder, for textual "
"inversion training check `--train_text_encoder_ti`"
)
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.with_prior_preservation:
if args.class_data_dir is None:
raise ValueError("You must specify a data directory for class images.")
if args.class_prompt is None:
raise ValueError("You must specify prompt for class images.")
else:
# logger is not available yet
if args.class_data_dir is not None:
warnings.warn("You need not use --class_data_dir without --with_prior_preservation.")
if args.class_prompt is not None:
warnings.warn("You need not use --class_prompt without --with_prior_preservation.")
return args
# Taken from https://github.com/replicate/cog-sdxl/blob/main/dataset_and_utils.py
class TokenEmbeddingsHandler:
def __init__(self, text_encoders, tokenizers):
self.text_encoders = text_encoders
self.tokenizers = tokenizers
self.train_ids: Optional[torch.Tensor] = None
self.inserting_toks: Optional[List[str]] = None
self.embeddings_settings = {}
def initialize_new_tokens(self, inserting_toks: List[str]):
idx = 0
for tokenizer, text_encoder in zip(self.tokenizers, self.text_encoders):
assert isinstance(inserting_toks, list), "inserting_toks should be a list of strings."
assert all(
isinstance(tok, str) for tok in inserting_toks
), "All elements in inserting_toks should be strings."
self.inserting_toks = inserting_toks
special_tokens_dict = {"additional_special_tokens": self.inserting_toks}
tokenizer.add_special_tokens(special_tokens_dict)
text_encoder.resize_token_embeddings(len(tokenizer))
self.train_ids = tokenizer.convert_tokens_to_ids(self.inserting_toks)
# random initialization of new tokens
std_token_embedding = text_encoder.text_model.embeddings.token_embedding.weight.data.std()
print(f"{idx} text encodedr's std_token_embedding: {std_token_embedding}")
text_encoder.text_model.embeddings.token_embedding.weight.data[self.train_ids] = (
torch.randn(len(self.train_ids), text_encoder.text_model.config.hidden_size)
.to(device=self.device)
.to(dtype=self.dtype)
* std_token_embedding
)
self.embeddings_settings[
f"original_embeddings_{idx}"
] = text_encoder.text_model.embeddings.token_embedding.weight.data.clone()
self.embeddings_settings[f"std_token_embedding_{idx}"] = std_token_embedding
inu = torch.ones((len(tokenizer),), dtype=torch.bool)
inu[self.train_ids] = False
self.embeddings_settings[f"index_no_updates_{idx}"] = inu
print(self.embeddings_settings[f"index_no_updates_{idx}"].shape)
idx += 1
def save_embeddings(self, file_path: str):
assert self.train_ids is not None, "Initialize new tokens before saving embeddings."
tensors = {}
# text_encoder_0 - CLIP ViT-L/14, text_encoder_1 - CLIP ViT-G/14
idx_to_text_encoder_name = {0: "clip_l", 1: "clip_g"}
for idx, text_encoder in enumerate(self.text_encoders):
assert text_encoder.text_model.embeddings.token_embedding.weight.data.shape[0] == len(
self.tokenizers[0]
), "Tokenizers should be the same."
new_token_embeddings = text_encoder.text_model.embeddings.token_embedding.weight.data[self.train_ids]
# New tokens for each text encoder are saved under "clip_l" (for text_encoder 0), "clip_g" (for
# text_encoder 1) to keep compatible with the ecosystem.
# Note: When loading with diffusers, any name can work - simply specify in inference
tensors[idx_to_text_encoder_name[idx]] = new_token_embeddings
# tensors[f"text_encoders_{idx}"] = new_token_embeddings
save_file(tensors, file_path)
@property
def dtype(self):
return self.text_encoders[0].dtype
@property
def device(self):
return self.text_encoders[0].device
@torch.no_grad()
def retract_embeddings(self):
for idx, text_encoder in enumerate(self.text_encoders):
index_no_updates = self.embeddings_settings[f"index_no_updates_{idx}"]
text_encoder.text_model.embeddings.token_embedding.weight.data[index_no_updates] = (
self.embeddings_settings[f"original_embeddings_{idx}"][index_no_updates]
.to(device=text_encoder.device)
.to(dtype=text_encoder.dtype)
)
# for the parts that were updated, we need to normalize them
# to have the same std as before
std_token_embedding = self.embeddings_settings[f"std_token_embedding_{idx}"]
index_updates = ~index_no_updates
new_embeddings = text_encoder.text_model.embeddings.token_embedding.weight.data[index_updates]
off_ratio = std_token_embedding / new_embeddings.std()
new_embeddings = new_embeddings * (off_ratio**0.1)
text_encoder.text_model.embeddings.token_embedding.weight.data[index_updates] = new_embeddings
class DreamBoothDataset(Dataset):
"""
A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
It pre-processes the images.
"""
def __init__(
self,
instance_data_root,
instance_prompt,
class_prompt,
dataset_name,
dataset_config_name,
cache_dir,
image_column,
caption_column,
train_text_encoder_ti,
class_data_root=None,
class_num=None,
token_abstraction_dict=None, # token mapping for textual inversion
size=1024,
repeats=1,
center_crop=False,
):
self.size = size
self.center_crop = center_crop
self.instance_prompt = instance_prompt
self.custom_instance_prompts = None
self.class_prompt = class_prompt
self.token_abstraction_dict = token_abstraction_dict
self.train_text_encoder_ti = train_text_encoder_ti
# if --dataset_name is provided or a metadata jsonl file is provided in the local --instance_data directory,
# we load the training data using load_dataset
if dataset_name is not None:
try:
from datasets import load_dataset
except ImportError:
raise ImportError(
"You are trying to load your data using the datasets library. If you wish to train using custom "
"captions please install the datasets library: `pip install datasets`. If you wish to load a "
"local folder containing images only, specify --instance_data_dir instead."
)
# Downloading and loading a dataset from the hub.
# See more about loading custom images at
# https://huggingface.co/docs/datasets/v2.0.0/en/dataset_script
dataset = load_dataset(
dataset_name,
dataset_config_name,
cache_dir=cache_dir,
)
# Preprocessing the datasets.
column_names = dataset["train"].column_names
# 6. Get the column names for input/target.
if image_column is None:
image_column = column_names[0]
logger.info(f"image column defaulting to {image_column}")
else:
if image_column not in column_names:
raise ValueError(
f"`--image_column` value '{image_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
instance_images = dataset["train"][image_column]
if caption_column is None:
logger.info(
"No caption column provided, defaulting to instance_prompt for all images. If your dataset "
"contains captions/prompts for the images, make sure to specify the "
"column as --caption_column"
)
self.custom_instance_prompts = None
else:
if caption_column not in column_names:
raise ValueError(
f"`--caption_column` value '{caption_column}' not found in dataset columns. Dataset columns are: {', '.join(column_names)}"
)
custom_instance_prompts = dataset["train"][caption_column]
# create final list of captions according to --repeats
self.custom_instance_prompts = []
for caption in custom_instance_prompts:
self.custom_instance_prompts.extend(itertools.repeat(caption, repeats))
else:
self.instance_data_root = Path(instance_data_root)
if not self.instance_data_root.exists():
raise ValueError("Instance images root doesn't exists.")
instance_images = [Image.open(path) for path in list(Path(instance_data_root).iterdir())]
self.custom_instance_prompts = None
self.instance_images = []
for img in instance_images:
self.instance_images.extend(itertools.repeat(img, repeats))
# image processing to prepare for using SD-XL micro-conditioning
self.original_sizes = []
self.crop_top_lefts = []
self.pixel_values = []
train_resize = transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR)
train_crop = transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size)
train_flip = transforms.RandomHorizontalFlip(p=1.0)
train_transforms = transforms.Compose(
[
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
for image in self.instance_images:
image = exif_transpose(image)
if not image.mode == "RGB":
image = image.convert("RGB")
self.original_sizes.append((image.height, image.width))
image = train_resize(image)
if args.random_flip and random.random() < 0.5:
# flip
image = train_flip(image)
if args.center_crop:
y1 = max(0, int(round((image.height - args.resolution) / 2.0)))
x1 = max(0, int(round((image.width - args.resolution) / 2.0)))
image = train_crop(image)
else:
y1, x1, h, w = train_crop.get_params(image, (args.resolution, args.resolution))
image = crop(image, y1, x1, h, w)
crop_top_left = (y1, x1)
self.crop_top_lefts.append(crop_top_left)
image = train_transforms(image)
self.pixel_values.append(image)
self.num_instance_images = len(self.instance_images)
self._length = self.num_instance_images
if class_data_root is not None:
self.class_data_root = Path(class_data_root)
self.class_data_root.mkdir(parents=True, exist_ok=True)
self.class_images_path = list(self.class_data_root.iterdir())
self.original_sizes_class_imgs = []
self.crop_top_lefts_class_imgs = []
self.pixel_values_class_imgs = []
self.class_images = [Image.open(path) for path in self.class_images_path]
for image in self.class_images:
image = exif_transpose(image)
if not image.mode == "RGB":
image = image.convert("RGB")
self.original_sizes_class_imgs.append((image.height, image.width))
image = train_resize(image)
if args.random_flip and random.random() < 0.5:
# flip
image = train_flip(image)
if args.center_crop:
y1 = max(0, int(round((image.height - args.resolution) / 2.0)))
x1 = max(0, int(round((image.width - args.resolution) / 2.0)))
image = train_crop(image)
else:
y1, x1, h, w = train_crop.get_params(image, (args.resolution, args.resolution))
image = crop(image, y1, x1, h, w)
crop_top_left = (y1, x1)
self.crop_top_lefts_class_imgs.append(crop_top_left)
image = train_transforms(image)
self.pixel_values_class_imgs.append(image)
if class_num is not None:
self.num_class_images = min(len(self.class_images_path), class_num)
else:
self.num_class_images = len(self.class_images_path)
self._length = max(self.num_class_images, self.num_instance_images)
else:
self.class_data_root = None
self.image_transforms = transforms.Compose(
[
transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def __len__(self):
return self._length
def __getitem__(self, index):
example = {}
example["instance_images"] = self.pixel_values[index % self.num_instance_images]
example["original_size"] = self.original_sizes[index % self.num_instance_images]
example["crop_top_left"] = self.crop_top_lefts[index % self.num_instance_images]
if self.custom_instance_prompts:
caption = self.custom_instance_prompts[index % self.num_instance_images]
if caption:
if self.train_text_encoder_ti:
# replace instances of --token_abstraction in caption with the new tokens: "<si><si+1>" etc.
for token_abs, token_replacement in self.token_abstraction_dict.items():
caption = caption.replace(token_abs, "".join(token_replacement))
example["instance_prompt"] = caption
else:
example["instance_prompt"] = self.instance_prompt
else: # costum prompts were provided, but length does not match size of image dataset
example["instance_prompt"] = self.instance_prompt
if self.class_data_root:
example["class_prompt"] = self.class_prompt
example["class_images"] = self.pixel_values_class_imgs[index % self.num_class_images]
example["class_original_size"] = self.original_sizes_class_imgs[index % self.num_class_images]
example["class_crop_top_left"] = self.crop_top_lefts_class_imgs[index % self.num_class_images]
return example
def collate_fn(examples, with_prior_preservation=False):
pixel_values = [example["instance_images"] for example in examples]
prompts = [example["instance_prompt"] for example in examples]
original_sizes = [example["original_size"] for example in examples]
crop_top_lefts = [example["crop_top_left"] for example in examples]
# Concat class and instance examples for prior preservation.
# We do this to avoid doing two forward passes.
if with_prior_preservation:
pixel_values += [example["class_images"] for example in examples]
prompts += [example["class_prompt"] for example in examples]
original_sizes += [example["class_original_size"] for example in examples]
crop_top_lefts += [example["class_crop_top_left"] for example in examples]
pixel_values = torch.stack(pixel_values)
pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
batch = {
"pixel_values": pixel_values,
"prompts": prompts,
"original_sizes": original_sizes,
"crop_top_lefts": crop_top_lefts,
}
return batch
class PromptDataset(Dataset):
"A simple dataset to prepare the prompts to generate class images on multiple GPUs."
def __init__(self, prompt, num_samples):
self.prompt = prompt
self.num_samples = num_samples
def __len__(self):
return self.num_samples
def __getitem__(self, index):
example = {}
example["prompt"] = self.prompt
example["index"] = index
return example
def tokenize_prompt(tokenizer, prompt, add_special_tokens=False):
text_inputs = tokenizer(
prompt,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
add_special_tokens=add_special_tokens,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
return text_input_ids
# Adapted from pipelines.StableDiffusionXLPipeline.encode_prompt
def encode_prompt(text_encoders, tokenizers, prompt, text_input_ids_list=None):
prompt_embeds_list = []
for i, text_encoder in enumerate(text_encoders):
if tokenizers is not None:
tokenizer = tokenizers[i]
text_input_ids = tokenize_prompt(tokenizer, prompt)
else:
assert text_input_ids_list is not None
text_input_ids = text_input_ids_list[i]
prompt_embeds = text_encoder(
text_input_ids.to(text_encoder.device),
output_hidden_states=True,
)
# We are only ALWAYS interested in the pooled output of the final text encoder
pooled_prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.hidden_states[-2]
bs_embed, seq_len, _ = prompt_embeds.shape
prompt_embeds = prompt_embeds.view(bs_embed, seq_len, -1)
prompt_embeds_list.append(prompt_embeds)
prompt_embeds = torch.concat(prompt_embeds_list, dim=-1)
pooled_prompt_embeds = pooled_prompt_embeds.view(bs_embed, -1)
return prompt_embeds, pooled_prompt_embeds
def main(args):
if args.report_to == "wandb" and args.hub_token is not None:
raise ValueError(
"You cannot use both --report_to=wandb and --hub_token due to a security risk of exposing your token."
" Please use `huggingface-cli login` to authenticate with the Hub."
)
if args.do_edm_style_training and args.snr_gamma is not None:
raise ValueError("Min-SNR formulation is not supported when conducting EDM-style training.")
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
kwargs = DistributedDataParallelKwargs(find_unused_parameters=True)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
kwargs_handlers=[kwargs],
)
if args.report_to == "wandb":
if not is_wandb_available():
raise ImportError("Make sure to install wandb if you want to use it for logging during training.")
import wandb
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Generate class images if prior preservation is enabled.
if args.with_prior_preservation:
class_images_dir = Path(args.class_data_dir)
if not class_images_dir.exists():
class_images_dir.mkdir(parents=True)
cur_class_images = len(list(class_images_dir.iterdir()))
if cur_class_images < args.num_class_images:
torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
if args.prior_generation_precision == "fp32":
torch_dtype = torch.float32
elif args.prior_generation_precision == "fp16":
torch_dtype = torch.float16
elif args.prior_generation_precision == "bf16":
torch_dtype = torch.bfloat16
pipeline = StableDiffusionXLPipeline.from_pretrained(
args.pretrained_model_name_or_path,
torch_dtype=torch_dtype,
revision=args.revision,
variant=args.variant,
)
pipeline.set_progress_bar_config(disable=True)
num_new_images = args.num_class_images - cur_class_images
logger.info(f"Number of class images to sample: {num_new_images}.")
sample_dataset = PromptDataset(args.class_prompt, num_new_images)
sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
sample_dataloader = accelerator.prepare(sample_dataloader)
pipeline.to(accelerator.device)
for example in tqdm(
sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
):
images = pipeline(example["prompt"]).images
for i, image in enumerate(images):
hash_image = hashlib.sha1(image.tobytes()).hexdigest()
image_filename = class_images_dir / f"{example['index'][i] + cur_class_images}-{hash_image}.jpg"
image.save(image_filename)
del pipeline
if torch.cuda.is_available():
torch.cuda.empty_cache()
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
model_id = args.hub_model_id or Path(args.output_dir).name
repo_id = None
if args.push_to_hub:
repo_id = create_repo(repo_id=model_id, exist_ok=True, token=args.hub_token).repo_id
# Load the tokenizers
tokenizer_one = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer",
revision=args.revision,
variant=args.variant,
use_fast=False,
)
tokenizer_two = AutoTokenizer.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="tokenizer_2",
revision=args.revision,
variant=args.variant,
use_fast=False,
)
# import correct text encoder classes
text_encoder_cls_one = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision
)
text_encoder_cls_two = import_model_class_from_model_name_or_path(
args.pretrained_model_name_or_path, args.revision, subfolder="text_encoder_2"
)
# Load scheduler and models
scheduler_type = determine_scheduler_type(args.pretrained_model_name_or_path, args.revision)
if "EDM" in scheduler_type:
args.do_edm_style_training = True
noise_scheduler = EDMEulerScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
logger.info("Performing EDM-style training!")
elif args.do_edm_style_training:
noise_scheduler = EulerDiscreteScheduler.from_pretrained(
args.pretrained_model_name_or_path, subfolder="scheduler"
)
logger.info("Performing EDM-style training!")
else:
noise_scheduler = DDPMScheduler.from_pretrained(args.pretrained_model_name_or_path, subfolder="scheduler")
text_encoder_one = text_encoder_cls_one.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder", revision=args.revision, variant=args.variant
)
text_encoder_two = text_encoder_cls_two.from_pretrained(
args.pretrained_model_name_or_path, subfolder="text_encoder_2", revision=args.revision, variant=args.variant
)
vae_path = (
args.pretrained_model_name_or_path
if args.pretrained_vae_model_name_or_path is None
else args.pretrained_vae_model_name_or_path
)
vae = AutoencoderKL.from_pretrained(
vae_path,
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
revision=args.revision,
variant=args.variant,
)
latents_mean = latents_std = None
if hasattr(vae.config, "latents_mean") and vae.config.latents_mean is not None:
latents_mean = torch.tensor(vae.config.latents_mean).view(1, 4, 1, 1)
if hasattr(vae.config, "latents_std") and vae.config.latents_std is not None:
latents_std = torch.tensor(vae.config.latents_std).view(1, 4, 1, 1)
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_model_name_or_path, subfolder="unet", revision=args.revision, variant=args.variant
)
if args.train_text_encoder_ti:
# we parse the provided token identifier (or identifiers) into a list. s.t. - "TOK" -> ["TOK"], "TOK,
# TOK2" -> ["TOK", "TOK2"] etc.
token_abstraction_list = "".join(args.token_abstraction.split()).split(",")
logger.info(f"list of token identifiers: {token_abstraction_list}")
token_abstraction_dict = {}
token_idx = 0
for i, token in enumerate(token_abstraction_list):
token_abstraction_dict[token] = [
f"<s{token_idx + i + j}>" for j in range(args.num_new_tokens_per_abstraction)
]
token_idx += args.num_new_tokens_per_abstraction - 1
# replace instances of --token_abstraction in --instance_prompt with the new tokens: "<si><si+1>" etc.
for token_abs, token_replacement in token_abstraction_dict.items():
args.instance_prompt = args.instance_prompt.replace(token_abs, "".join(token_replacement))
if args.with_prior_preservation:
args.class_prompt = args.class_prompt.replace(token_abs, "".join(token_replacement))
if args.validation_prompt:
args.validation_prompt = args.validation_prompt.replace(token_abs, "".join(token_replacement))
print("validation prompt:", args.validation_prompt)
# initialize the new tokens for textual inversion
embedding_handler = TokenEmbeddingsHandler(
[text_encoder_one, text_encoder_two], [tokenizer_one, tokenizer_two]
)
inserting_toks = []
for new_tok in token_abstraction_dict.values():
inserting_toks.extend(new_tok)
embedding_handler.initialize_new_tokens(inserting_toks=inserting_toks)
# We only train the additional adapter LoRA layers
vae.requires_grad_(False)
text_encoder_one.requires_grad_(False)
text_encoder_two.requires_grad_(False)
unet.requires_grad_(False)
# For mixed precision training we cast all non-trainable weights (vae, non-lora text_encoder and non-lora unet) to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
unet.to(accelerator.device, dtype=weight_dtype)
# The VAE is always in float32 to avoid NaN losses.
vae.to(accelerator.device, dtype=torch.float32)
text_encoder_one.to(accelerator.device, dtype=weight_dtype)
text_encoder_two.to(accelerator.device, dtype=weight_dtype)
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warning(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, "
"please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
if args.train_text_encoder:
text_encoder_one.gradient_checkpointing_enable()
text_encoder_two.gradient_checkpointing_enable()
# now we will add new LoRA weights to the attention layers
unet_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
use_dora=args.use_dora,
init_lora_weights="gaussian",
target_modules=["to_k", "to_q", "to_v", "to_out.0"],
)
unet.add_adapter(unet_lora_config)
# The text encoder comes from 🤗 transformers, so we cannot directly modify it.
# So, instead, we monkey-patch the forward calls of its attention-blocks.
if args.train_text_encoder:
text_lora_config = LoraConfig(
r=args.rank,
lora_alpha=args.rank,
use_dora=args.use_dora,
init_lora_weights="gaussian",
target_modules=["q_proj", "k_proj", "v_proj", "out_proj"],
)
text_encoder_one.add_adapter(text_lora_config)
text_encoder_two.add_adapter(text_lora_config)
# if we use textual inversion, we freeze all parameters except for the token embeddings
# in text encoder
elif args.train_text_encoder_ti:
text_lora_parameters_one = []
for name, param in text_encoder_one.named_parameters():
if "token_embedding" in name:
# ensure that dtype is float32, even if rest of the model that isn't trained is loaded in fp16
param.data = param.to(dtype=torch.float32)
param.requires_grad = True
text_lora_parameters_one.append(param)
else:
param.requires_grad = False
text_lora_parameters_two = []
for name, param in text_encoder_two.named_parameters():
if "token_embedding" in name:
# ensure that dtype is float32, even if rest of the model that isn't trained is loaded in fp16
param.data = param.to(dtype=torch.float32)
param.requires_grad = True
text_lora_parameters_two.append(param)
else:
param.requires_grad = False
def unwrap_model(model):
model = accelerator.unwrap_model(model)
model = model._orig_mod if is_compiled_module(model) else model
return model
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
# there are only two options here. Either are just the unet attn processor layers
# or there are the unet and text encoder atten layers
unet_lora_layers_to_save = None
text_encoder_one_lora_layers_to_save = None
text_encoder_two_lora_layers_to_save = None
for model in models:
if isinstance(model, type(unwrap_model(unet))):
unet_lora_layers_to_save = convert_state_dict_to_diffusers(get_peft_model_state_dict(model))
elif isinstance(model, type(unwrap_model(text_encoder_one))):
if args.train_text_encoder:
text_encoder_one_lora_layers_to_save = convert_state_dict_to_diffusers(
get_peft_model_state_dict(model)
)
elif isinstance(model, type(unwrap_model(text_encoder_two))):
if args.train_text_encoder:
text_encoder_two_lora_layers_to_save = convert_state_dict_to_diffusers(
get_peft_model_state_dict(model)
)
else:
raise ValueError(f"unexpected save model: {model.__class__}")
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
StableDiffusionXLPipeline.save_lora_weights(
output_dir,
unet_lora_layers=unet_lora_layers_to_save,
text_encoder_lora_layers=text_encoder_one_lora_layers_to_save,
text_encoder_2_lora_layers=text_encoder_two_lora_layers_to_save,
)
if args.train_text_encoder_ti:
embedding_handler.save_embeddings(f"{output_dir}/{args.output_dir}_emb.safetensors")
def load_model_hook(models, input_dir):
unet_ = None
text_encoder_one_ = None
text_encoder_two_ = None
while len(models) > 0:
model = models.pop()
if isinstance(model, type(unwrap_model(unet))):
unet_ = model
elif isinstance(model, type(unwrap_model(text_encoder_one))):
text_encoder_one_ = model
elif isinstance(model, type(unwrap_model(text_encoder_two))):
text_encoder_two_ = model
else:
raise ValueError(f"unexpected save model: {model.__class__}")
lora_state_dict, network_alphas = LoraLoaderMixin.lora_state_dict(input_dir)
unet_state_dict = {f'{k.replace("unet.", "")}': v for k, v in lora_state_dict.items() if k.startswith("unet.")}
unet_state_dict = convert_unet_state_dict_to_peft(unet_state_dict)
incompatible_keys = set_peft_model_state_dict(unet_, unet_state_dict, adapter_name="default")
if incompatible_keys is not None:
# check only for unexpected keys
unexpected_keys = getattr(incompatible_keys, "unexpected_keys", None)
if unexpected_keys:
logger.warning(
f"Loading adapter weights from state_dict led to unexpected keys not found in the model: "
f" {unexpected_keys}. "
)
if args.train_text_encoder:
_set_state_dict_into_text_encoder(lora_state_dict, prefix="text_encoder.", text_encoder=text_encoder_one_)
_set_state_dict_into_text_encoder(
lora_state_dict, prefix="text_encoder_2.", text_encoder=text_encoder_two_
)
# Make sure the trainable params are in float32. This is again needed since the base models
# are in `weight_dtype`. More details:
# https://github.com/huggingface/diffusers/pull/6514#discussion_r1449796804
if args.mixed_precision == "fp16":
models = [unet_]
if args.train_text_encoder:
models.extend([text_encoder_one_, text_encoder_two_])
cast_training_params(models)
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.scale_lr:
args.learning_rate = (
args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
)
# Make sure the trainable params are in float32.
if args.mixed_precision == "fp16":
models = [unet]
if args.train_text_encoder:
models.extend([text_encoder_one, text_encoder_two])
cast_training_params(models, dtype=torch.float32)
unet_lora_parameters = list(filter(lambda p: p.requires_grad, unet.parameters()))
if args.train_text_encoder:
text_lora_parameters_one = list(filter(lambda p: p.requires_grad, text_encoder_one.parameters()))
text_lora_parameters_two = list(filter(lambda p: p.requires_grad, text_encoder_two.parameters()))
# If neither --train_text_encoder nor --train_text_encoder_ti, text_encoders remain frozen during training
freeze_text_encoder = not (args.train_text_encoder or args.train_text_encoder_ti)
# Optimization parameters
unet_lora_parameters_with_lr = {"params": unet_lora_parameters, "lr": args.learning_rate}
if not freeze_text_encoder:
# different learning rate for text encoder and unet
text_lora_parameters_one_with_lr = {
"params": text_lora_parameters_one,
"weight_decay": args.adam_weight_decay_text_encoder
if args.adam_weight_decay_text_encoder
else args.adam_weight_decay,
"lr": args.text_encoder_lr if args.text_encoder_lr else args.learning_rate,
}
text_lora_parameters_two_with_lr = {
"params": text_lora_parameters_two,
"weight_decay": args.adam_weight_decay_text_encoder
if args.adam_weight_decay_text_encoder
else args.adam_weight_decay,
"lr": args.text_encoder_lr if args.text_encoder_lr else args.learning_rate,
}
params_to_optimize = [
unet_lora_parameters_with_lr,
text_lora_parameters_one_with_lr,
text_lora_parameters_two_with_lr,
]
else:
params_to_optimize = [unet_lora_parameters_with_lr]
# Optimizer creation
if not (args.optimizer.lower() == "prodigy" or args.optimizer.lower() == "adamw"):
logger.warning(
f"Unsupported choice of optimizer: {args.optimizer}.Supported optimizers include [adamW, prodigy]."
"Defaulting to adamW"
)
args.optimizer = "adamw"
if args.use_8bit_adam and not args.optimizer.lower() == "adamw":
logger.warning(
f"use_8bit_adam is ignored when optimizer is not set to 'AdamW'. Optimizer was "
f"set to {args.optimizer.lower()}"
)
if args.optimizer.lower() == "adamw":
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
optimizer = optimizer_class(
params_to_optimize,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
if args.optimizer.lower() == "prodigy":
try:
import prodigyopt
except ImportError:
raise ImportError("To use Prodigy, please install the prodigyopt library: `pip install prodigyopt`")
optimizer_class = prodigyopt.Prodigy
if args.learning_rate <= 0.1:
logger.warning(
"Learning rate is too low. When using prodigy, it's generally better to set learning rate around 1.0"
)
if args.train_text_encoder and args.text_encoder_lr:
logger.warning(
f"Learning rates were provided both for the unet and the text encoder- e.g. text_encoder_lr:"
f" {args.text_encoder_lr} and learning_rate: {args.learning_rate}. "
f"When using prodigy only learning_rate is used as the initial learning rate."
)
# changes the learning rate of text_encoder_parameters_one and text_encoder_parameters_two to be
# --learning_rate
params_to_optimize[1]["lr"] = args.learning_rate
params_to_optimize[2]["lr"] = args.learning_rate
optimizer = optimizer_class(
params_to_optimize,
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
beta3=args.prodigy_beta3,
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
decouple=args.prodigy_decouple,
use_bias_correction=args.prodigy_use_bias_correction,
safeguard_warmup=args.prodigy_safeguard_warmup,
)
# Dataset and DataLoaders creation:
train_dataset = DreamBoothDataset(
instance_data_root=args.instance_data_dir,
instance_prompt=args.instance_prompt,
class_prompt=args.class_prompt,
dataset_name=args.dataset_name,
dataset_config_name=args.dataset_config_name,
cache_dir=args.cache_dir,
image_column=args.image_column,
train_text_encoder_ti=args.train_text_encoder_ti,
caption_column=args.caption_column,
class_data_root=args.class_data_dir if args.with_prior_preservation else None,
token_abstraction_dict=token_abstraction_dict if args.train_text_encoder_ti else None,
class_num=args.num_class_images,
size=args.resolution,
repeats=args.repeats,
center_crop=args.center_crop,
)
train_dataloader = torch.utils.data.DataLoader(
train_dataset,
batch_size=args.train_batch_size,
shuffle=True,
collate_fn=lambda examples: collate_fn(examples, args.with_prior_preservation),
num_workers=args.dataloader_num_workers,
)
# Computes additional embeddings/ids required by the SDXL UNet.
# regular text embeddings (when `train_text_encoder` is not True)
# pooled text embeddings
# time ids
def compute_time_ids(crops_coords_top_left, original_size=None):
# Adapted from pipeline.StableDiffusionXLPipeline._get_add_time_ids
if original_size is None:
original_size = (args.resolution, args.resolution)
target_size = (args.resolution, args.resolution)
add_time_ids = list(original_size + crops_coords_top_left + target_size)
add_time_ids = torch.tensor([add_time_ids])
add_time_ids = add_time_ids.to(accelerator.device, dtype=weight_dtype)
return add_time_ids
if not args.train_text_encoder:
tokenizers = [tokenizer_one, tokenizer_two]
text_encoders = [text_encoder_one, text_encoder_two]
def compute_text_embeddings(prompt, text_encoders, tokenizers):
with torch.no_grad():
prompt_embeds, pooled_prompt_embeds = encode_prompt(text_encoders, tokenizers, prompt)
prompt_embeds = prompt_embeds.to(accelerator.device)
pooled_prompt_embeds = pooled_prompt_embeds.to(accelerator.device)
return prompt_embeds, pooled_prompt_embeds
# If no type of tuning is done on the text_encoder and custom instance prompts are NOT
# provided (i.e. the --instance_prompt is used for all images), we encode the instance prompt once to avoid
# the redundant encoding.
if freeze_text_encoder and not train_dataset.custom_instance_prompts:
instance_prompt_hidden_states, instance_pooled_prompt_embeds = compute_text_embeddings(
args.instance_prompt, text_encoders, tokenizers
)
# Handle class prompt for prior-preservation.
if args.with_prior_preservation:
if freeze_text_encoder:
class_prompt_hidden_states, class_pooled_prompt_embeds = compute_text_embeddings(
args.class_prompt, text_encoders, tokenizers
)
# Clear the memory here
if freeze_text_encoder and not train_dataset.custom_instance_prompts:
del tokenizers, text_encoders
gc.collect()
torch.cuda.empty_cache()
# If custom instance prompts are NOT provided (i.e. the instance prompt is used for all images),
# pack the statically computed variables appropriately here. This is so that we don't
# have to pass them to the dataloader.
# if --train_text_encoder_ti we need add_special_tokens to be True fo textual inversion
add_special_tokens = True if args.train_text_encoder_ti else False
if not train_dataset.custom_instance_prompts:
if freeze_text_encoder:
prompt_embeds = instance_prompt_hidden_states
unet_add_text_embeds = instance_pooled_prompt_embeds
if args.with_prior_preservation:
prompt_embeds = torch.cat([prompt_embeds, class_prompt_hidden_states], dim=0)
unet_add_text_embeds = torch.cat([unet_add_text_embeds, class_pooled_prompt_embeds], dim=0)
# if we're optmizing the text encoder (both if instance prompt is used for all images or custom prompts) we need to tokenize and encode the
# batch prompts on all training steps
else:
tokens_one = tokenize_prompt(tokenizer_one, args.instance_prompt, add_special_tokens)
tokens_two = tokenize_prompt(tokenizer_two, args.instance_prompt, add_special_tokens)
if args.with_prior_preservation:
class_tokens_one = tokenize_prompt(tokenizer_one, args.class_prompt, add_special_tokens)
class_tokens_two = tokenize_prompt(tokenizer_two, args.class_prompt, add_special_tokens)
tokens_one = torch.cat([tokens_one, class_tokens_one], dim=0)
tokens_two = torch.cat([tokens_two, class_tokens_two], dim=0)
if args.cache_latents:
latents_cache = []
for batch in tqdm(train_dataloader, desc="Caching latents"):
with torch.no_grad():
batch["pixel_values"] = batch["pixel_values"].to(
accelerator.device, non_blocking=True, dtype=torch.float32
)
latents_cache.append(vae.encode(batch["pixel_values"]).latent_dist)
if args.validation_prompt is None:
del vae
if torch.cuda.is_available():
torch.cuda.empty_cache()
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps * accelerator.num_processes,
num_cycles=args.lr_num_cycles,
power=args.lr_power,
)
# Prepare everything with our `accelerator`.
if not freeze_text_encoder:
unet, text_encoder_one, text_encoder_two, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, text_encoder_one, text_encoder_two, optimizer, train_dataloader, lr_scheduler
)
else:
unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
unet, optimizer, train_dataloader, lr_scheduler
)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
accelerator.init_trackers("dreambooth-lora-sd-xl", config=vars(args))
# Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(train_dataset)}")
logger.info(f" Num batches each epoch = {len(train_dataloader)}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the mos recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
def get_sigmas(timesteps, n_dim=4, dtype=torch.float32):
# TODO: revisit other sampling algorithms
sigmas = noise_scheduler.sigmas.to(device=accelerator.device, dtype=dtype)
schedule_timesteps = noise_scheduler.timesteps.to(accelerator.device)
timesteps = timesteps.to(accelerator.device)
step_indices = [(schedule_timesteps == t).nonzero().item() for t in timesteps]
sigma = sigmas[step_indices].flatten()
while len(sigma.shape) < n_dim:
sigma = sigma.unsqueeze(-1)
return sigma
if args.train_text_encoder:
num_train_epochs_text_encoder = int(args.train_text_encoder_frac * args.num_train_epochs)
elif args.train_text_encoder_ti: # args.train_text_encoder_ti
num_train_epochs_text_encoder = int(args.train_text_encoder_ti_frac * args.num_train_epochs)
# flag used for textual inversion
pivoted = False
for epoch in range(first_epoch, args.num_train_epochs):
# if performing any kind of optimization of text_encoder params
if args.train_text_encoder or args.train_text_encoder_ti:
if epoch == num_train_epochs_text_encoder:
print("PIVOT HALFWAY", epoch)
# stopping optimization of text_encoder params
# this flag is used to reset the optimizer to optimize only on unet params
pivoted = True
else:
# still optimizing the text encoder
text_encoder_one.train()
text_encoder_two.train()
# set top parameter requires_grad = True for gradient checkpointing works
if args.train_text_encoder:
text_encoder_one.text_model.embeddings.requires_grad_(True)
text_encoder_two.text_model.embeddings.requires_grad_(True)
unet.train()
for step, batch in enumerate(train_dataloader):
if pivoted:
# stopping optimization of text_encoder params
# re setting the optimizer to optimize only on unet params
optimizer.param_groups[1]["lr"] = 0.0
optimizer.param_groups[2]["lr"] = 0.0
with accelerator.accumulate(unet):
prompts = batch["prompts"]
# encode batch prompts when custom prompts are provided for each image -
if train_dataset.custom_instance_prompts:
if freeze_text_encoder:
prompt_embeds, unet_add_text_embeds = compute_text_embeddings(
prompts, text_encoders, tokenizers
)
else:
tokens_one = tokenize_prompt(tokenizer_one, prompts, add_special_tokens)
tokens_two = tokenize_prompt(tokenizer_two, prompts, add_special_tokens)
if args.cache_latents:
model_input = latents_cache[step].sample()
else:
pixel_values = batch["pixel_values"].to(dtype=vae.dtype)
model_input = vae.encode(pixel_values).latent_dist.sample()
if latents_mean is None and latents_std is None:
model_input = model_input * vae.config.scaling_factor
if args.pretrained_vae_model_name_or_path is None:
model_input = model_input.to(weight_dtype)
else:
latents_mean = latents_mean.to(device=model_input.device, dtype=model_input.dtype)
latents_std = latents_std.to(device=model_input.device, dtype=model_input.dtype)
model_input = (model_input - latents_mean) * vae.config.scaling_factor / latents_std
model_input = model_input.to(dtype=weight_dtype)
# Sample noise that we'll add to the latents
noise = torch.randn_like(model_input)
if args.noise_offset:
# https://www.crosslabs.org//blog/diffusion-with-offset-noise
noise += args.noise_offset * torch.randn(
(model_input.shape[0], model_input.shape[1], 1, 1), device=model_input.device
)
bsz = model_input.shape[0]
# Sample a random timestep for each image
if not args.do_edm_style_training:
timesteps = torch.randint(
0, noise_scheduler.config.num_train_timesteps, (bsz,), device=model_input.device
)
timesteps = timesteps.long()
else:
# in EDM formulation, the model is conditioned on the pre-conditioned noise levels
# instead of discrete timesteps, so here we sample indices to get the noise levels
# from `scheduler.timesteps`
indices = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,))
timesteps = noise_scheduler.timesteps[indices].to(device=model_input.device)
# Add noise to the model input according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_model_input = noise_scheduler.add_noise(model_input, noise, timesteps)
# For EDM-style training, we first obtain the sigmas based on the continuous timesteps.
# We then precondition the final model inputs based on these sigmas instead of the timesteps.
# Follow: Section 5 of https://arxiv.org/abs/2206.00364.
if args.do_edm_style_training:
sigmas = get_sigmas(timesteps, len(noisy_model_input.shape), noisy_model_input.dtype)
if "EDM" in scheduler_type:
inp_noisy_latents = noise_scheduler.precondition_inputs(noisy_model_input, sigmas)
else:
inp_noisy_latents = noisy_model_input / ((sigmas**2 + 1) ** 0.5)
# time ids
add_time_ids = torch.cat(
[
compute_time_ids(original_size=s, crops_coords_top_left=c)
for s, c in zip(batch["original_sizes"], batch["crop_top_lefts"])
]
)
# Calculate the elements to repeat depending on the use of prior-preservation and custom captions.
if not train_dataset.custom_instance_prompts:
elems_to_repeat_text_embeds = bsz // 2 if args.with_prior_preservation else bsz
else:
elems_to_repeat_text_embeds = 1
# Predict the noise residual
if freeze_text_encoder:
unet_added_conditions = {
"time_ids": add_time_ids,
# "time_ids": add_time_ids.repeat(elems_to_repeat_time_ids, 1),
"text_embeds": unet_add_text_embeds.repeat(elems_to_repeat_text_embeds, 1),
}
prompt_embeds_input = prompt_embeds.repeat(elems_to_repeat_text_embeds, 1, 1)
model_pred = unet(
inp_noisy_latents if args.do_edm_style_training else noisy_model_input,
timesteps,
prompt_embeds_input,
added_cond_kwargs=unet_added_conditions,
).sample
else:
unet_added_conditions = {"time_ids": add_time_ids}
prompt_embeds, pooled_prompt_embeds = encode_prompt(
text_encoders=[text_encoder_one, text_encoder_two],
tokenizers=None,
prompt=None,
text_input_ids_list=[tokens_one, tokens_two],
)
unet_added_conditions.update(
{"text_embeds": pooled_prompt_embeds.repeat(elems_to_repeat_text_embeds, 1)}
)
prompt_embeds_input = prompt_embeds.repeat(elems_to_repeat_text_embeds, 1, 1)
model_pred = unet(
inp_noisy_latents if args.do_edm_style_training else noisy_model_input,
timesteps,
prompt_embeds_input,
added_cond_kwargs=unet_added_conditions,
).sample
weighting = None
if args.do_edm_style_training:
# Similar to the input preconditioning, the model predictions are also preconditioned
# on noised model inputs (before preconditioning) and the sigmas.
# Follow: Section 5 of https://arxiv.org/abs/2206.00364.
if "EDM" in scheduler_type:
model_pred = noise_scheduler.precondition_outputs(noisy_model_input, model_pred, sigmas)
else:
if noise_scheduler.config.prediction_type == "epsilon":
model_pred = model_pred * (-sigmas) + noisy_model_input
elif noise_scheduler.config.prediction_type == "v_prediction":
model_pred = model_pred * (-sigmas / (sigmas**2 + 1) ** 0.5) + (
noisy_model_input / (sigmas**2 + 1)
)
# We are not doing weighting here because it tends result in numerical problems.
# See: https://github.com/huggingface/diffusers/pull/7126#issuecomment-1968523051
# There might be other alternatives for weighting as well:
# https://github.com/huggingface/diffusers/pull/7126#discussion_r1505404686
if "EDM" not in scheduler_type:
weighting = (sigmas**-2.0).float()
# Get the target for loss depending on the prediction type
if noise_scheduler.config.prediction_type == "epsilon":
target = model_input if args.do_edm_style_training else noise
elif noise_scheduler.config.prediction_type == "v_prediction":
target = (
model_input
if args.do_edm_style_training
else noise_scheduler.get_velocity(model_input, noise, timesteps)
)
else:
raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
if args.with_prior_preservation:
# Chunk the noise and model_pred into two parts and compute the loss on each part separately.
model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
target, target_prior = torch.chunk(target, 2, dim=0)
# Compute prior loss
if weighting is not None:
prior_loss = torch.mean(
(weighting.float() * (model_pred_prior.float() - target_prior.float()) ** 2).reshape(
target_prior.shape[0], -1
),
1,
)
prior_loss = prior_loss.mean()
else:
prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
if args.snr_gamma is None:
if weighting is not None:
loss = torch.mean(
(weighting.float() * (model_pred.float() - target.float()) ** 2).reshape(
target.shape[0], -1
),
1,
)
loss = loss.mean()
else:
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
else:
# Compute loss-weights as per Section 3.4 of https://arxiv.org/abs/2303.09556.
# Since we predict the noise instead of x_0, the original formulation is slightly changed.
# This is discussed in Section 4.2 of the same paper.
if args.with_prior_preservation:
# if we're using prior preservation, we calc snr for instance loss only -
# and hence only need timesteps corresponding to instance images
snr_timesteps, _ = torch.chunk(timesteps, 2, dim=0)
else:
snr_timesteps = timesteps
snr = compute_snr(noise_scheduler, snr_timesteps)
base_weight = (
torch.stack([snr, args.snr_gamma * torch.ones_like(snr_timesteps)], dim=1).min(dim=1)[0] / snr
)
if noise_scheduler.config.prediction_type == "v_prediction":
# Velocity objective needs to be floored to an SNR weight of one.
mse_loss_weights = base_weight + 1
else:
# Epsilon and sample both use the same loss weights.
mse_loss_weights = base_weight
loss = F.mse_loss(model_pred.float(), target.float(), reduction="none")
loss = loss.mean(dim=list(range(1, len(loss.shape)))) * mse_loss_weights
loss = loss.mean()
if args.with_prior_preservation:
# Add the prior loss to the instance loss.
loss = loss + args.prior_loss_weight * prior_loss
accelerator.backward(loss)
if accelerator.sync_gradients:
params_to_clip = (
itertools.chain(unet_lora_parameters, text_lora_parameters_one, text_lora_parameters_two)
if (args.train_text_encoder or args.train_text_encoder_ti)
else unet_lora_parameters
)
accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# every step, we reset the embeddings to the original embeddings.
if args.train_text_encoder_ti:
embedding_handler.retract_embeddings()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
if accelerator.is_main_process:
if args.validation_prompt is not None and epoch % args.validation_epochs == 0:
logger.info(
f"Running validation... \n Generating {args.num_validation_images} images with prompt:"
f" {args.validation_prompt}."
)
# create pipeline
if freeze_text_encoder:
text_encoder_one = text_encoder_cls_one.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="text_encoder",
revision=args.revision,
variant=args.variant,
)
text_encoder_two = text_encoder_cls_two.from_pretrained(
args.pretrained_model_name_or_path,
subfolder="text_encoder_2",
revision=args.revision,
variant=args.variant,
)
pipeline = StableDiffusionXLPipeline.from_pretrained(
args.pretrained_model_name_or_path,
vae=vae,
tokenizer=tokenizer_one,
tokenizer_2=tokenizer_two,
text_encoder=accelerator.unwrap_model(text_encoder_one),
text_encoder_2=accelerator.unwrap_model(text_encoder_two),
unet=accelerator.unwrap_model(unet),
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
# We train on the simplified learning objective. If we were previously predicting a variance, we need the scheduler to ignore it
scheduler_args = {}
if not args.do_edm_style_training:
if "variance_type" in pipeline.scheduler.config:
variance_type = pipeline.scheduler.config.variance_type
if variance_type in ["learned", "learned_range"]:
variance_type = "fixed_small"
scheduler_args["variance_type"] = variance_type
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(
pipeline.scheduler.config, **scheduler_args
)
pipeline = pipeline.to(accelerator.device)
pipeline.set_progress_bar_config(disable=True)
# run inference
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
pipeline_args = {"prompt": args.validation_prompt}
inference_ctx = (
contextlib.nullcontext()
if "playground" in args.pretrained_model_name_or_path
else torch.cuda.amp.autocast()
)
with inference_ctx:
images = [
pipeline(**pipeline_args, generator=generator).images[0]
for _ in range(args.num_validation_images)
]
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("validation", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"validation": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
del pipeline
torch.cuda.empty_cache()
# Save the lora layers
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
unet = unet.to(torch.float32)
unet_lora_layers = convert_state_dict_to_diffusers(get_peft_model_state_dict(unet))
if args.train_text_encoder:
text_encoder_one = accelerator.unwrap_model(text_encoder_one)
text_encoder_lora_layers = convert_state_dict_to_diffusers(
get_peft_model_state_dict(text_encoder_one.to(torch.float32))
)
text_encoder_two = accelerator.unwrap_model(text_encoder_two)
text_encoder_2_lora_layers = convert_state_dict_to_diffusers(
get_peft_model_state_dict(text_encoder_two.to(torch.float32))
)
else:
text_encoder_lora_layers = None
text_encoder_2_lora_layers = None
StableDiffusionXLPipeline.save_lora_weights(
save_directory=args.output_dir,
unet_lora_layers=unet_lora_layers,
text_encoder_lora_layers=text_encoder_lora_layers,
text_encoder_2_lora_layers=text_encoder_2_lora_layers,
)
if args.train_text_encoder_ti:
embeddings_path = f"{args.output_dir}/{args.output_dir}_emb.safetensors"
embedding_handler.save_embeddings(embeddings_path)
images = []
if args.validation_prompt and args.num_validation_images > 0:
# Final inference
# Load previous pipeline
vae = AutoencoderKL.from_pretrained(
vae_path,
subfolder="vae" if args.pretrained_vae_model_name_or_path is None else None,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
pipeline = StableDiffusionXLPipeline.from_pretrained(
args.pretrained_model_name_or_path,
vae=vae,
revision=args.revision,
variant=args.variant,
torch_dtype=weight_dtype,
)
# We train on the simplified learning objective. If we were previously predicting a variance, we need the scheduler to ignore it
scheduler_args = {}
if not args.do_edm_style_training:
if "variance_type" in pipeline.scheduler.config:
variance_type = pipeline.scheduler.config.variance_type
if variance_type in ["learned", "learned_range"]:
variance_type = "fixed_small"
scheduler_args["variance_type"] = variance_type
pipeline.scheduler = DPMSolverMultistepScheduler.from_config(
pipeline.scheduler.config, **scheduler_args
)
# load attention processors
pipeline.load_lora_weights(args.output_dir)
# load new tokens
if args.train_text_encoder_ti:
state_dict = load_file(embeddings_path)
all_new_tokens = []
for key, value in token_abstraction_dict.items():
all_new_tokens.extend(value)
pipeline.load_textual_inversion(
state_dict["clip_l"],
token=all_new_tokens,
text_encoder=pipeline.text_encoder,
tokenizer=pipeline.tokenizer,
)
pipeline.load_textual_inversion(
state_dict["clip_g"],
token=all_new_tokens,
text_encoder=pipeline.text_encoder_2,
tokenizer=pipeline.tokenizer_2,
)
# run inference
pipeline = pipeline.to(accelerator.device)
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed) if args.seed else None
images = [
pipeline(args.validation_prompt, num_inference_steps=25, generator=generator).images[0]
for _ in range(args.num_validation_images)
]
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
np_images = np.stack([np.asarray(img) for img in images])
tracker.writer.add_images("test", np_images, epoch, dataformats="NHWC")
if tracker.name == "wandb":
tracker.log(
{
"test": [
wandb.Image(image, caption=f"{i}: {args.validation_prompt}")
for i, image in enumerate(images)
]
}
)
# Conver to WebUI format
lora_state_dict = load_file(f"{args.output_dir}/pytorch_lora_weights.safetensors")
peft_state_dict = convert_all_state_dict_to_peft(lora_state_dict)
kohya_state_dict = convert_state_dict_to_kohya(peft_state_dict)
save_file(kohya_state_dict, f"{args.output_dir}/{args.output_dir}.safetensors")
save_model_card(
model_id if not args.push_to_hub else repo_id,
use_dora=args.use_dora,
images=images,
base_model=args.pretrained_model_name_or_path,
train_text_encoder=args.train_text_encoder,
train_text_encoder_ti=args.train_text_encoder_ti,
token_abstraction_dict=train_dataset.token_abstraction_dict,
instance_prompt=args.instance_prompt,
validation_prompt=args.validation_prompt,
repo_folder=args.output_dir,
vae_path=args.pretrained_vae_model_name_or_path,
)
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py/0 | {
"file_path": "diffusers/examples/advanced_diffusion_training/train_dreambooth_lora_sdxl_advanced.py",
"repo_id": "diffusers",
"token_count": 47936
} | 106 |
import inspect
from typing import Callable, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import DiffusionPipeline
from diffusers.configuration_utils import FrozenDict
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import deprecate, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def prepare_mask_and_masked_image(image, mask):
image = np.array(image.convert("RGB"))
image = image[None].transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
mask = np.array(mask.convert("L"))
mask = mask.astype(np.float32) / 255.0
mask = mask[None, None]
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
mask = torch.from_numpy(mask)
masked_image = image * (mask < 0.5)
return mask, masked_image
def check_size(image, height, width):
if isinstance(image, PIL.Image.Image):
w, h = image.size
elif isinstance(image, torch.Tensor):
*_, h, w = image.shape
if h != height or w != width:
raise ValueError(f"Image size should be {height}x{width}, but got {h}x{w}")
def overlay_inner_image(image, inner_image, paste_offset: Tuple[int] = (0, 0)):
inner_image = inner_image.convert("RGBA")
image = image.convert("RGB")
image.paste(inner_image, paste_offset, inner_image)
image = image.convert("RGB")
return image
class ImageToImageInpaintingPipeline(DiffusionPipeline):
r"""
Pipeline for text-guided image-to-image inpainting using Stable Diffusion. *This is an experimental feature*.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latens. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
image: Union[torch.FloatTensor, PIL.Image.Image],
inner_image: Union[torch.FloatTensor, PIL.Image.Image],
mask_image: Union[torch.FloatTensor, PIL.Image.Image],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
inner_image (`torch.Tensor` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be overlayed onto `image`. Non-transparent
regions of `inner_image` must fit inside white pixels in `mask_image`. Expects four channels, with
the last channel representing the alpha channel, which will be used to blend `inner_image` with
`image`. If not provided, it will be forcibly cast to RGBA.
mask_image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
# check if input sizes are correct
check_size(image, height, width)
check_size(inner_image, height, width)
check_size(mask_image, height, width)
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""]
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(batch_size, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
num_channels_latents = self.vae.config.latent_channels
latents_shape = (batch_size * num_images_per_prompt, num_channels_latents, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not exist on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# overlay the inner image
image = overlay_inner_image(image, inner_image)
# prepare mask and masked_image
mask, masked_image = prepare_mask_and_masked_image(image, mask_image)
mask = mask.to(device=self.device, dtype=text_embeddings.dtype)
masked_image = masked_image.to(device=self.device, dtype=text_embeddings.dtype)
# resize the mask to latents shape as we concatenate the mask to the latents
mask = torch.nn.functional.interpolate(mask, size=(height // 8, width // 8))
# encode the mask image into latents space so we can concatenate it to the latents
masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
masked_image_latents = 0.18215 * masked_image_latents
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
mask = mask.repeat(batch_size * num_images_per_prompt, 1, 1, 1)
masked_image_latents = masked_image_latents.repeat(batch_size * num_images_per_prompt, 1, 1, 1)
mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
num_channels_mask = mask.shape[1]
num_channels_masked_image = masked_image_latents.shape[1]
if num_channels_latents + num_channels_mask + num_channels_masked_image != self.unet.config.in_channels:
raise ValueError(
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} +"
f" `num_channels_mask`: {num_channels_mask} + `num_channels_masked_image`: {num_channels_masked_image}"
f" = {num_channels_latents+num_channels_masked_image+num_channels_mask}. Please verify the config of"
" `pipeline.unet` or your `mask_image` or `image` input."
)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
self.device
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| diffusers/examples/community/img2img_inpainting.py/0 | {
"file_path": "diffusers/examples/community/img2img_inpainting.py",
"repo_id": "diffusers",
"token_count": 9677
} | 107 |
import inspect
from typing import Callable, List, Optional, Union
import torch
from transformers import (
CLIPImageProcessor,
CLIPTextModel,
CLIPTokenizer,
MBart50TokenizerFast,
MBartForConditionalGeneration,
pipeline,
)
from diffusers.configuration_utils import FrozenDict
from diffusers.models import AutoencoderKL, UNet2DConditionModel
from diffusers.pipelines.pipeline_utils import DiffusionPipeline, StableDiffusionMixin
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import DDIMScheduler, LMSDiscreteScheduler, PNDMScheduler
from diffusers.utils import deprecate, logging
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def detect_language(pipe, prompt, batch_size):
"""helper function to detect language(s) of prompt"""
if batch_size == 1:
preds = pipe(prompt, top_k=1, truncation=True, max_length=128)
return preds[0]["label"]
else:
detected_languages = []
for p in prompt:
preds = pipe(p, top_k=1, truncation=True, max_length=128)
detected_languages.append(preds[0]["label"])
return detected_languages
def translate_prompt(prompt, translation_tokenizer, translation_model, device):
"""helper function to translate prompt to English"""
encoded_prompt = translation_tokenizer(prompt, return_tensors="pt").to(device)
generated_tokens = translation_model.generate(**encoded_prompt, max_new_tokens=1000)
en_trans = translation_tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
return en_trans[0]
class MultilingualStableDiffusion(DiffusionPipeline, StableDiffusionMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion in different languages.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
detection_pipeline ([`pipeline`]):
Transformers pipeline to detect prompt's language.
translation_model ([`MBartForConditionalGeneration`]):
Model to translate prompt to English, if necessary. Please refer to the
[model card](https://huggingface.co/docs/transformers/model_doc/mbart) for details.
translation_tokenizer ([`MBart50TokenizerFast`]):
Tokenizer of the translation model.
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latens. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
def __init__(
self,
detection_pipeline: pipeline,
translation_model: MBartForConditionalGeneration,
translation_tokenizer: MBart50TokenizerFast,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, PNDMScheduler, LMSDiscreteScheduler],
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
self.register_modules(
detection_pipeline=detection_pipeline,
translation_model=translation_model,
translation_tokenizer=translation_tokenizer,
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]],
height: int = 512,
width: int = 512,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[torch.Generator] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
**kwargs,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation. Can be in different languages.
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
A [torch generator](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make generation
deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
# detect language and translate if necessary
prompt_language = detect_language(self.detection_pipeline, prompt, batch_size)
if batch_size == 1 and prompt_language != "en":
prompt = translate_prompt(prompt, self.translation_tokenizer, self.translation_model, self.device)
if isinstance(prompt, list):
for index in range(batch_size):
if prompt_language[index] != "en":
p = translate_prompt(
prompt[index], self.translation_tokenizer, self.translation_model, self.device
)
prompt[index] = p
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
if text_input_ids.shape[-1] > self.tokenizer.model_max_length:
removed_text = self.tokenizer.batch_decode(text_input_ids[:, self.tokenizer.model_max_length :])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids[:, : self.tokenizer.model_max_length]
text_embeddings = self.text_encoder(text_input_ids.to(self.device))[0]
# duplicate text embeddings for each generation per prompt, using mps friendly method
bs_embed, seq_len, _ = text_embeddings.shape
text_embeddings = text_embeddings.repeat(1, num_images_per_prompt, 1)
text_embeddings = text_embeddings.view(bs_embed * num_images_per_prompt, seq_len, -1)
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
# detect language and translate it if necessary
negative_prompt_language = detect_language(self.detection_pipeline, negative_prompt, batch_size)
if negative_prompt_language != "en":
negative_prompt = translate_prompt(
negative_prompt, self.translation_tokenizer, self.translation_model, self.device
)
if isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
# detect language and translate it if necessary
if isinstance(negative_prompt, list):
negative_prompt_languages = detect_language(self.detection_pipeline, negative_prompt, batch_size)
for index in range(batch_size):
if negative_prompt_languages[index] != "en":
p = translate_prompt(
negative_prompt[index], self.translation_tokenizer, self.translation_model, self.device
)
negative_prompt[index] = p
uncond_tokens = negative_prompt
max_length = text_input_ids.shape[-1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
uncond_embeddings = self.text_encoder(uncond_input.input_ids.to(self.device))[0]
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = uncond_embeddings.shape[1]
uncond_embeddings = uncond_embeddings.repeat(1, num_images_per_prompt, 1)
uncond_embeddings = uncond_embeddings.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
# get the initial random noise unless the user supplied it
# Unlike in other pipelines, latents need to be generated in the target device
# for 1-to-1 results reproducibility with the CompVis implementation.
# However this currently doesn't work in `mps`.
latents_shape = (batch_size * num_images_per_prompt, self.unet.config.in_channels, height // 8, width // 8)
latents_dtype = text_embeddings.dtype
if latents is None:
if self.device.type == "mps":
# randn does not work reproducibly on mps
latents = torch.randn(latents_shape, generator=generator, device="cpu", dtype=latents_dtype).to(
self.device
)
else:
latents = torch.randn(latents_shape, generator=generator, device=self.device, dtype=latents_dtype)
else:
if latents.shape != latents_shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {latents_shape}")
latents = latents.to(self.device)
# set timesteps
self.scheduler.set_timesteps(num_inference_steps)
# Some schedulers like PNDM have timesteps as arrays
# It's more optimized to move all timesteps to correct device beforehand
timesteps_tensor = self.scheduler.timesteps.to(self.device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
latents = 1 / 0.18215 * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(
self.device
)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(text_embeddings.dtype)
)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| diffusers/examples/community/multilingual_stable_diffusion.py/0 | {
"file_path": "diffusers/examples/community/multilingual_stable_diffusion.py",
"repo_id": "diffusers",
"token_count": 9168
} | 108 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import PIL.Image
import torch
import torch.nn.functional as F
import torchvision.transforms as T
from gmflow.gmflow import GMFlow
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers.image_processor import VaeImageProcessor
from diffusers.models import AutoencoderKL, ControlNetModel, UNet2DConditionModel
from diffusers.models.attention_processor import Attention, AttnProcessor
from diffusers.pipelines.controlnet.multicontrolnet import MultiControlNetModel
from diffusers.pipelines.controlnet.pipeline_controlnet_img2img import StableDiffusionControlNetImg2ImgPipeline
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import BaseOutput, deprecate, logging
from diffusers.utils.torch_utils import is_compiled_module, randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def coords_grid(b, h, w, homogeneous=False, device=None):
y, x = torch.meshgrid(torch.arange(h), torch.arange(w)) # [H, W]
stacks = [x, y]
if homogeneous:
ones = torch.ones_like(x) # [H, W]
stacks.append(ones)
grid = torch.stack(stacks, dim=0).float() # [2, H, W] or [3, H, W]
grid = grid[None].repeat(b, 1, 1, 1) # [B, 2, H, W] or [B, 3, H, W]
if device is not None:
grid = grid.to(device)
return grid
def bilinear_sample(img, sample_coords, mode="bilinear", padding_mode="zeros", return_mask=False):
# img: [B, C, H, W]
# sample_coords: [B, 2, H, W] in image scale
if sample_coords.size(1) != 2: # [B, H, W, 2]
sample_coords = sample_coords.permute(0, 3, 1, 2)
b, _, h, w = sample_coords.shape
# Normalize to [-1, 1]
x_grid = 2 * sample_coords[:, 0] / (w - 1) - 1
y_grid = 2 * sample_coords[:, 1] / (h - 1) - 1
grid = torch.stack([x_grid, y_grid], dim=-1) # [B, H, W, 2]
img = F.grid_sample(img, grid, mode=mode, padding_mode=padding_mode, align_corners=True)
if return_mask:
mask = (x_grid >= -1) & (y_grid >= -1) & (x_grid <= 1) & (y_grid <= 1) # [B, H, W]
return img, mask
return img
def flow_warp(feature, flow, mask=False, mode="bilinear", padding_mode="zeros"):
b, c, h, w = feature.size()
assert flow.size(1) == 2
grid = coords_grid(b, h, w).to(flow.device) + flow # [B, 2, H, W]
grid = grid.to(feature.dtype)
return bilinear_sample(feature, grid, mode=mode, padding_mode=padding_mode, return_mask=mask)
def forward_backward_consistency_check(fwd_flow, bwd_flow, alpha=0.01, beta=0.5):
# fwd_flow, bwd_flow: [B, 2, H, W]
# alpha and beta values are following UnFlow
# (https://arxiv.org/abs/1711.07837)
assert fwd_flow.dim() == 4 and bwd_flow.dim() == 4
assert fwd_flow.size(1) == 2 and bwd_flow.size(1) == 2
flow_mag = torch.norm(fwd_flow, dim=1) + torch.norm(bwd_flow, dim=1) # [B, H, W]
warped_bwd_flow = flow_warp(bwd_flow, fwd_flow) # [B, 2, H, W]
warped_fwd_flow = flow_warp(fwd_flow, bwd_flow) # [B, 2, H, W]
diff_fwd = torch.norm(fwd_flow + warped_bwd_flow, dim=1) # [B, H, W]
diff_bwd = torch.norm(bwd_flow + warped_fwd_flow, dim=1)
threshold = alpha * flow_mag + beta
fwd_occ = (diff_fwd > threshold).float() # [B, H, W]
bwd_occ = (diff_bwd > threshold).float()
return fwd_occ, bwd_occ
@torch.no_grad()
def get_warped_and_mask(flow_model, image1, image2, image3=None, pixel_consistency=False, device=None):
if image3 is None:
image3 = image1
padder = InputPadder(image1.shape, padding_factor=8)
image1, image2 = padder.pad(image1[None].to(device), image2[None].to(device))
results_dict = flow_model(
image1, image2, attn_splits_list=[2], corr_radius_list=[-1], prop_radius_list=[-1], pred_bidir_flow=True
)
flow_pr = results_dict["flow_preds"][-1] # [B, 2, H, W]
fwd_flow = padder.unpad(flow_pr[0]).unsqueeze(0) # [1, 2, H, W]
bwd_flow = padder.unpad(flow_pr[1]).unsqueeze(0) # [1, 2, H, W]
fwd_occ, bwd_occ = forward_backward_consistency_check(fwd_flow, bwd_flow) # [1, H, W] float
if pixel_consistency:
warped_image1 = flow_warp(image1, bwd_flow)
bwd_occ = torch.clamp(
bwd_occ + (abs(image2 - warped_image1).mean(dim=1) > 255 * 0.25).float(), 0, 1
).unsqueeze(0)
warped_results = flow_warp(image3, bwd_flow)
return warped_results, bwd_occ, bwd_flow
blur = T.GaussianBlur(kernel_size=(9, 9), sigma=(18, 18))
@dataclass
class TextToVideoSDPipelineOutput(BaseOutput):
"""
Output class for text-to-video pipelines.
Args:
frames (`List[np.ndarray]` or `torch.FloatTensor`)
List of denoised frames (essentially images) as NumPy arrays of shape `(height, width, num_channels)` or as
a `torch` tensor. The length of the list denotes the video length (the number of frames).
"""
frames: Union[List[np.ndarray], torch.FloatTensor]
@torch.no_grad()
def find_flat_region(mask):
device = mask.device
kernel_x = torch.Tensor([[-1, 0, 1], [-1, 0, 1], [-1, 0, 1]]).unsqueeze(0).unsqueeze(0).to(device)
kernel_y = torch.Tensor([[-1, -1, -1], [0, 0, 0], [1, 1, 1]]).unsqueeze(0).unsqueeze(0).to(device)
mask_ = F.pad(mask.unsqueeze(0), (1, 1, 1, 1), mode="replicate")
grad_x = torch.nn.functional.conv2d(mask_, kernel_x)
grad_y = torch.nn.functional.conv2d(mask_, kernel_y)
return ((abs(grad_x) + abs(grad_y)) == 0).float()[0]
class AttnState:
STORE = 0
LOAD = 1
LOAD_AND_STORE_PREV = 2
def __init__(self):
self.reset()
@property
def state(self):
return self.__state
@property
def timestep(self):
return self.__timestep
def set_timestep(self, t):
self.__timestep = t
def reset(self):
self.__state = AttnState.STORE
self.__timestep = 0
def to_load(self):
self.__state = AttnState.LOAD
def to_load_and_store_prev(self):
self.__state = AttnState.LOAD_AND_STORE_PREV
class CrossFrameAttnProcessor(AttnProcessor):
"""
Cross frame attention processor. Each frame attends the first frame and previous frame.
Args:
attn_state: Whether the model is processing the first frame or an intermediate frame
"""
def __init__(self, attn_state: AttnState):
super().__init__()
self.attn_state = attn_state
self.first_maps = {}
self.prev_maps = {}
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None, temb=None):
# Is self attention
if encoder_hidden_states is None:
t = self.attn_state.timestep
if self.attn_state.state == AttnState.STORE:
self.first_maps[t] = hidden_states.detach()
self.prev_maps[t] = hidden_states.detach()
res = super().__call__(attn, hidden_states, encoder_hidden_states, attention_mask, temb)
else:
if self.attn_state.state == AttnState.LOAD_AND_STORE_PREV:
tmp = hidden_states.detach()
cross_map = torch.cat((self.first_maps[t], self.prev_maps[t]), dim=1)
res = super().__call__(attn, hidden_states, cross_map, attention_mask, temb)
if self.attn_state.state == AttnState.LOAD_AND_STORE_PREV:
self.prev_maps[t] = tmp
else:
res = super().__call__(attn, hidden_states, encoder_hidden_states, attention_mask, temb)
return res
def prepare_image(image):
if isinstance(image, torch.Tensor):
# Batch single image
if image.ndim == 3:
image = image.unsqueeze(0)
image = image.to(dtype=torch.float32)
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
return image
class RerenderAVideoPipeline(StableDiffusionControlNetImg2ImgPipeline):
r"""
Pipeline for video-to-video translation using Stable Diffusion with Rerender Algorithm.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
controlnet ([`ControlNetModel`] or `List[ControlNetModel]`):
Provides additional conditioning to the unet during the denoising process. If you set multiple ControlNets
as a list, the outputs from each ControlNet are added together to create one combined additional
conditioning.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
controlnet: Union[ControlNetModel, List[ControlNetModel], Tuple[ControlNetModel], MultiControlNetModel],
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
image_encoder=None,
requires_safety_checker: bool = True,
device=None,
):
super().__init__(
vae,
text_encoder,
tokenizer,
unet,
controlnet,
scheduler,
safety_checker,
feature_extractor,
image_encoder,
requires_safety_checker,
)
self.to(device)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
if isinstance(controlnet, (list, tuple)):
controlnet = MultiControlNetModel(controlnet)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
controlnet=controlnet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True)
self.control_image_processor = VaeImageProcessor(
vae_scale_factor=self.vae_scale_factor, do_convert_rgb=True, do_normalize=False
)
self.register_to_config(requires_safety_checker=requires_safety_checker)
self.attn_state = AttnState()
attn_processor_dict = {}
for k in unet.attn_processors.keys():
if k.startswith("up"):
attn_processor_dict[k] = CrossFrameAttnProcessor(self.attn_state)
else:
attn_processor_dict[k] = AttnProcessor()
self.unet.set_attn_processor(attn_processor_dict)
flow_model = GMFlow(
feature_channels=128,
num_scales=1,
upsample_factor=8,
num_head=1,
attention_type="swin",
ffn_dim_expansion=4,
num_transformer_layers=6,
).to(self.device)
checkpoint = torch.utils.model_zoo.load_url(
"https://huggingface.co/Anonymous-sub/Rerender/resolve/main/models/gmflow_sintel-0c07dcb3.pth",
map_location=lambda storage, loc: storage,
)
weights = checkpoint["model"] if "model" in checkpoint else checkpoint
flow_model.load_state_dict(weights, strict=False)
flow_model.eval()
self.flow_model = flow_model
# Modified from src/diffusers/pipelines/controlnet/pipeline_controlnet.StableDiffusionControlNetImg2ImgPipeline.check_inputs
def check_inputs(
self,
prompt,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
controlnet_conditioning_scale=1.0,
control_guidance_start=0.0,
control_guidance_end=1.0,
):
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# `prompt` needs more sophisticated handling when there are multiple
# conditionings.
if isinstance(self.controlnet, MultiControlNetModel):
if isinstance(prompt, list):
logger.warning(
f"You have {len(self.controlnet.nets)} ControlNets and you have passed {len(prompt)}"
" prompts. The conditionings will be fixed across the prompts."
)
is_compiled = hasattr(F, "scaled_dot_product_attention") and isinstance(
self.controlnet, torch._dynamo.eval_frame.OptimizedModule
)
# Check `controlnet_conditioning_scale`
if (
isinstance(self.controlnet, ControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, ControlNetModel)
):
if not isinstance(controlnet_conditioning_scale, float):
raise TypeError("For single controlnet: `controlnet_conditioning_scale` must be type `float`.")
elif (
isinstance(self.controlnet, MultiControlNetModel)
or is_compiled
and isinstance(self.controlnet._orig_mod, MultiControlNetModel)
):
if isinstance(controlnet_conditioning_scale, list):
if any(isinstance(i, list) for i in controlnet_conditioning_scale):
raise ValueError("A single batch of multiple conditionings are supported at the moment.")
elif isinstance(controlnet_conditioning_scale, list) and len(controlnet_conditioning_scale) != len(
self.controlnet.nets
):
raise ValueError(
"For multiple controlnets: When `controlnet_conditioning_scale` is specified as `list`, it must have"
" the same length as the number of controlnets"
)
else:
assert False
if len(control_guidance_start) != len(control_guidance_end):
raise ValueError(
f"`control_guidance_start` has {len(control_guidance_start)} elements, but `control_guidance_end` has {len(control_guidance_end)} elements. Make sure to provide the same number of elements to each list."
)
if isinstance(self.controlnet, MultiControlNetModel):
if len(control_guidance_start) != len(self.controlnet.nets):
raise ValueError(
f"`control_guidance_start`: {control_guidance_start} has {len(control_guidance_start)} elements but there are {len(self.controlnet.nets)} controlnets available. Make sure to provide {len(self.controlnet.nets)}."
)
for start, end in zip(control_guidance_start, control_guidance_end):
if start >= end:
raise ValueError(
f"control guidance start: {start} cannot be larger or equal to control guidance end: {end}."
)
if start < 0.0:
raise ValueError(f"control guidance start: {start} can't be smaller than 0.")
if end > 1.0:
raise ValueError(f"control guidance end: {end} can't be larger than 1.0.")
# Copied from diffusers.pipelines.controlnet.pipeline_controlnet.StableDiffusionControlNetPipeline.prepare_image
def prepare_control_image(
self,
image,
width,
height,
batch_size,
num_images_per_prompt,
device,
dtype,
do_classifier_free_guidance=False,
guess_mode=False,
):
image = self.control_image_processor.preprocess(image, height=height, width=width).to(dtype=torch.float32)
image_batch_size = image.shape[0]
if image_batch_size == 1:
repeat_by = batch_size
else:
# image batch size is the same as prompt batch size
repeat_by = num_images_per_prompt
image = image.repeat_interleave(repeat_by, dim=0)
image = image.to(device=device, dtype=dtype)
if do_classifier_free_guidance and not guess_mode:
image = torch.cat([image] * 2)
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.get_timesteps
def get_timesteps(self, num_inference_steps, strength, device):
# get the original timestep using init_timestep
init_timestep = min(int(num_inference_steps * strength), num_inference_steps)
t_start = max(num_inference_steps - init_timestep, 0)
timesteps = self.scheduler.timesteps[t_start * self.scheduler.order :]
return timesteps, num_inference_steps - t_start
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion_img2img.StableDiffusionImg2ImgPipeline.prepare_latents
def prepare_latents(self, image, timestep, batch_size, num_images_per_prompt, dtype, device, generator=None):
if not isinstance(image, (torch.Tensor, PIL.Image.Image, list)):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `PIL.Image.Image` or list but is {type(image)}"
)
image = image.to(device=device, dtype=dtype)
batch_size = batch_size * num_images_per_prompt
if image.shape[1] == 4:
init_latents = image
else:
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
elif isinstance(generator, list):
init_latents = [
self.vae.encode(image[i : i + 1]).latent_dist.sample(generator[i]) for i in range(batch_size)
]
init_latents = torch.cat(init_latents, dim=0)
else:
init_latents = self.vae.encode(image).latent_dist.sample(generator)
init_latents = self.vae.config.scaling_factor * init_latents
if batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] == 0:
# expand init_latents for batch_size
deprecation_message = (
f"You have passed {batch_size} text prompts (`prompt`), but only {init_latents.shape[0]} initial"
" images (`image`). Initial images are now duplicating to match the number of text prompts. Note"
" that this behavior is deprecated and will be removed in a version 1.0.0. Please make sure to update"
" your script to pass as many initial images as text prompts to suppress this warning."
)
deprecate("len(prompt) != len(image)", "1.0.0", deprecation_message, standard_warn=False)
additional_image_per_prompt = batch_size // init_latents.shape[0]
init_latents = torch.cat([init_latents] * additional_image_per_prompt, dim=0)
elif batch_size > init_latents.shape[0] and batch_size % init_latents.shape[0] != 0:
raise ValueError(
f"Cannot duplicate `image` of batch size {init_latents.shape[0]} to {batch_size} text prompts."
)
else:
init_latents = torch.cat([init_latents], dim=0)
shape = init_latents.shape
noise = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
# get latents
init_latents = self.scheduler.add_noise(init_latents, noise, timestep)
latents = init_latents
return latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
frames: Union[List[np.ndarray], torch.FloatTensor] = None,
control_frames: Union[List[np.ndarray], torch.FloatTensor] = None,
strength: float = 0.8,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
controlnet_conditioning_scale: Union[float, List[float]] = 0.8,
guess_mode: bool = False,
control_guidance_start: Union[float, List[float]] = 0.0,
control_guidance_end: Union[float, List[float]] = 1.0,
warp_start: Union[float, List[float]] = 0.0,
warp_end: Union[float, List[float]] = 0.3,
mask_start: Union[float, List[float]] = 0.5,
mask_end: Union[float, List[float]] = 0.8,
smooth_boundary: bool = True,
mask_strength: Union[float, List[float]] = 0.5,
inner_strength: Union[float, List[float]] = 0.9,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
frames (`List[np.ndarray]` or `torch.FloatTensor`): The input images to be used as the starting point for the image generation process.
control_frames (`List[np.ndarray]` or `torch.FloatTensor`): The ControlNet input images condition to provide guidance to the `unet` for generation.
strength ('float'): SDEdit strength.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the `AttentionProcessor` as defined under
`self.processor` in
[diffusers.models.attention_processor](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
controlnet_conditioning_scale (`float` or `List[float]`, *optional*, defaults to 1.0):
The outputs of the controlnet are multiplied by `controlnet_conditioning_scale` before they are added
to the residual in the original unet. If multiple ControlNets are specified in init, you can set the
corresponding scale as a list. Note that by default, we use a smaller conditioning scale for inpainting
than for [`~StableDiffusionControlNetPipeline.__call__`].
guess_mode (`bool`, *optional*, defaults to `False`):
In this mode, the ControlNet encoder will try best to recognize the content of the input image even if
you remove all prompts. The `guidance_scale` between 3.0 and 5.0 is recommended.
control_guidance_start (`float` or `List[float]`, *optional*, defaults to 0.0):
The percentage of total steps at which the controlnet starts applying.
control_guidance_end (`float` or `List[float]`, *optional*, defaults to 1.0):
The percentage of total steps at which the controlnet stops applying.
warp_start (`float`): Shape-aware fusion start timestep.
warp_end (`float`): Shape-aware fusion end timestep.
mask_start (`float`): Pixel-aware fusion start timestep.
mask_end (`float`):Pixel-aware fusion end timestep.
smooth_boundary (`bool`): Smooth fusion boundary. Set `True` to prevent artifacts at boundary.
mask_strength (`float`): Pixel-aware fusion strength.
inner_strength (`float`): Pixel-aware fusion detail level.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
controlnet = self.controlnet._orig_mod if is_compiled_module(self.controlnet) else self.controlnet
# align format for control guidance
if not isinstance(control_guidance_start, list) and isinstance(control_guidance_end, list):
control_guidance_start = len(control_guidance_end) * [control_guidance_start]
elif not isinstance(control_guidance_end, list) and isinstance(control_guidance_start, list):
control_guidance_end = len(control_guidance_start) * [control_guidance_end]
elif not isinstance(control_guidance_start, list) and not isinstance(control_guidance_end, list):
mult = len(controlnet.nets) if isinstance(controlnet, MultiControlNetModel) else 1
control_guidance_start, control_guidance_end = (
mult * [control_guidance_start],
mult * [control_guidance_end],
)
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
controlnet_conditioning_scale,
control_guidance_start,
control_guidance_end,
)
# 2. Define call parameters
# Currently we only support 1 prompt
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
assert False
else:
assert False
num_images_per_prompt = 1
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
if isinstance(controlnet, MultiControlNetModel) and isinstance(controlnet_conditioning_scale, float):
controlnet_conditioning_scale = [controlnet_conditioning_scale] * len(controlnet.nets)
global_pool_conditions = (
controlnet.config.global_pool_conditions
if isinstance(controlnet, ControlNetModel)
else controlnet.nets[0].config.global_pool_conditions
)
guess_mode = guess_mode or global_pool_conditions
# 3. Encode input prompt
text_encoder_lora_scale = (
cross_attention_kwargs.get("scale", None) if cross_attention_kwargs is not None else None
)
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=text_encoder_lora_scale,
)
# 4. Process the first frame
height, width = None, None
output_frames = []
self.attn_state.reset()
# 4.1 prepare frames
image = self.image_processor.preprocess(frames[0]).to(dtype=torch.float32)
first_image = image[0] # C, H, W
# 4.2 Prepare controlnet_conditioning_image
# Currently we only support single control
if isinstance(controlnet, ControlNetModel):
control_image = self.prepare_control_image(
image=control_frames[0],
width=width,
height=height,
batch_size=batch_size,
num_images_per_prompt=1,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
else:
assert False
# 4.3 Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, cur_num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size)
# 4.4 Prepare latent variables
latents = self.prepare_latents(
image,
latent_timestep,
batch_size,
num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
)
# 4.5 Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 4.6 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
first_x0_list = []
# 4.7 Denoising loop
num_warmup_steps = len(timesteps) - cur_num_inference_steps * self.scheduler.order
with self.progress_bar(total=cur_num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
self.attn_state.set_timestep(t.item())
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# controlnet(s) inference
if guess_mode and do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=control_image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
return_dict=False,
)
if guess_mode and do_classifier_free_guidance:
# Infered ControlNet only for the conditional batch.
# To apply the output of ControlNet to both the unconditional and conditional batches,
# add 0 to the unconditional batch to keep it unchanged.
down_block_res_samples = [torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples]
mid_block_res_sample = torch.cat([torch.zeros_like(mid_block_res_sample), mid_block_res_sample])
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
alpha_prod_t = self.scheduler.alphas_cumprod[t]
beta_prod_t = 1 - alpha_prod_t
pred_x0 = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
first_x0 = pred_x0.detach()
first_x0_list.append(first_x0)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[0]
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
callback(i, t, latents)
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
else:
image = latents
first_result = image
prev_result = image
do_denormalize = [True] * image.shape[0]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
output_frames.append(image[0])
# 5. Process each frame
for idx in range(1, len(frames)):
image = frames[idx]
prev_image = frames[idx - 1]
control_image = control_frames[idx]
# 5.1 prepare frames
image = self.image_processor.preprocess(image).to(dtype=torch.float32)
prev_image = self.image_processor.preprocess(prev_image).to(dtype=torch.float32)
warped_0, bwd_occ_0, bwd_flow_0 = get_warped_and_mask(
self.flow_model, first_image, image[0], first_result, False, self.device
)
blend_mask_0 = blur(F.max_pool2d(bwd_occ_0, kernel_size=9, stride=1, padding=4))
blend_mask_0 = torch.clamp(blend_mask_0 + bwd_occ_0, 0, 1)
warped_pre, bwd_occ_pre, bwd_flow_pre = get_warped_and_mask(
self.flow_model, prev_image[0], image[0], prev_result, False, self.device
)
blend_mask_pre = blur(F.max_pool2d(bwd_occ_pre, kernel_size=9, stride=1, padding=4))
blend_mask_pre = torch.clamp(blend_mask_pre + bwd_occ_pre, 0, 1)
warp_mask = 1 - F.max_pool2d(blend_mask_0, kernel_size=8)
warp_flow = F.interpolate(bwd_flow_0 / 8.0, scale_factor=1.0 / 8, mode="bilinear")
# 5.2 Prepare controlnet_conditioning_image
# Currently we only support single control
if isinstance(controlnet, ControlNetModel):
control_image = self.prepare_control_image(
image=control_image,
width=width,
height=height,
batch_size=batch_size,
num_images_per_prompt=1,
device=device,
dtype=controlnet.dtype,
do_classifier_free_guidance=do_classifier_free_guidance,
guess_mode=guess_mode,
)
else:
assert False
# 5.3 Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, cur_num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
latent_timestep = timesteps[:1].repeat(batch_size)
skip_t = int(num_inference_steps * (1 - strength))
warp_start_t = int(warp_start * num_inference_steps)
warp_end_t = int(warp_end * num_inference_steps)
mask_start_t = int(mask_start * num_inference_steps)
mask_end_t = int(mask_end * num_inference_steps)
# 5.4 Prepare latent variables
init_latents = self.prepare_latents(
image,
latent_timestep,
batch_size,
num_images_per_prompt,
prompt_embeds.dtype,
device,
generator,
)
# 5.5 Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
# 5.6 Create tensor stating which controlnets to keep
controlnet_keep = []
for i in range(len(timesteps)):
keeps = [
1.0 - float(i / len(timesteps) < s or (i + 1) / len(timesteps) > e)
for s, e in zip(control_guidance_start, control_guidance_end)
]
controlnet_keep.append(keeps[0] if isinstance(controlnet, ControlNetModel) else keeps)
# 5.7 Denoising loop
num_warmup_steps = len(timesteps) - cur_num_inference_steps * self.scheduler.order
def denoising_loop(latents, mask=None, xtrg=None, noise_rescale=None):
dir_xt = 0
latents_dtype = latents.dtype
with self.progress_bar(total=cur_num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
self.attn_state.set_timestep(t.item())
if i + skip_t >= mask_start_t and i + skip_t <= mask_end_t and xtrg is not None:
rescale = torch.maximum(1.0 - mask, (1 - mask**2) ** 0.5 * inner_strength)
if noise_rescale is not None:
rescale = (1.0 - mask) * (1 - noise_rescale) + rescale * noise_rescale
noise = randn_tensor(xtrg.shape, generator=generator, device=device, dtype=xtrg.dtype)
latents_ref = self.scheduler.add_noise(xtrg, noise, t)
latents = latents_ref * mask + (1.0 - mask) * (latents - dir_xt) + rescale * dir_xt
latents = latents.to(latents_dtype)
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# controlnet(s) inference
if guess_mode and do_classifier_free_guidance:
# Infer ControlNet only for the conditional batch.
control_model_input = latents
control_model_input = self.scheduler.scale_model_input(control_model_input, t)
controlnet_prompt_embeds = prompt_embeds.chunk(2)[1]
else:
control_model_input = latent_model_input
controlnet_prompt_embeds = prompt_embeds
if isinstance(controlnet_keep[i], list):
cond_scale = [c * s for c, s in zip(controlnet_conditioning_scale, controlnet_keep[i])]
else:
controlnet_cond_scale = controlnet_conditioning_scale
if isinstance(controlnet_cond_scale, list):
controlnet_cond_scale = controlnet_cond_scale[0]
cond_scale = controlnet_cond_scale * controlnet_keep[i]
down_block_res_samples, mid_block_res_sample = self.controlnet(
control_model_input,
t,
encoder_hidden_states=controlnet_prompt_embeds,
controlnet_cond=control_image,
conditioning_scale=cond_scale,
guess_mode=guess_mode,
return_dict=False,
)
if guess_mode and do_classifier_free_guidance:
# Infered ControlNet only for the conditional batch.
# To apply the output of ControlNet to both the unconditional and conditional batches,
# add 0 to the unconditional batch to keep it unchanged.
down_block_res_samples = [
torch.cat([torch.zeros_like(d), d]) for d in down_block_res_samples
]
mid_block_res_sample = torch.cat(
[torch.zeros_like(mid_block_res_sample), mid_block_res_sample]
)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
return_dict=False,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# Get pred_x0 from scheduler
alpha_prod_t = self.scheduler.alphas_cumprod[t]
beta_prod_t = 1 - alpha_prod_t
pred_x0 = (latents - beta_prod_t ** (0.5) * noise_pred) / alpha_prod_t ** (0.5)
if i + skip_t >= warp_start_t and i + skip_t <= warp_end_t:
# warp x_0
pred_x0 = (
flow_warp(first_x0_list[i], warp_flow, mode="nearest") * warp_mask
+ (1 - warp_mask) * pred_x0
)
# get x_t from x_0
latents = self.scheduler.add_noise(pred_x0, noise_pred, t).to(latents_dtype)
prev_t = t - self.scheduler.config.num_train_timesteps // self.scheduler.num_inference_steps
if i == len(timesteps) - 1:
alpha_t_prev = 1.0
else:
alpha_t_prev = self.scheduler.alphas_cumprod[prev_t]
dir_xt = (1.0 - alpha_t_prev) ** 0.5 * noise_pred
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs, return_dict=False)[
0
]
# call the callback, if provided
if i == len(timesteps) - 1 or (
(i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0
):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
callback(i, t, latents)
return latents
if mask_start_t <= mask_end_t:
self.attn_state.to_load()
else:
self.attn_state.to_load_and_store_prev()
latents = denoising_loop(init_latents)
if mask_start_t <= mask_end_t:
direct_result = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
blend_results = (1 - blend_mask_pre) * warped_pre + blend_mask_pre * direct_result
blend_results = (1 - blend_mask_0) * warped_0 + blend_mask_0 * blend_results
bwd_occ = 1 - torch.clamp(1 - bwd_occ_pre + 1 - bwd_occ_0, 0, 1)
blend_mask = blur(F.max_pool2d(bwd_occ, kernel_size=9, stride=1, padding=4))
blend_mask = 1 - torch.clamp(blend_mask + bwd_occ, 0, 1)
blend_results = blend_results.to(latents.dtype)
xtrg = self.vae.encode(blend_results).latent_dist.sample(generator)
xtrg = self.vae.config.scaling_factor * xtrg
blend_results_rec = self.vae.decode(xtrg / self.vae.config.scaling_factor, return_dict=False)[0]
xtrg_rec = self.vae.encode(blend_results_rec).latent_dist.sample(generator)
xtrg_rec = self.vae.config.scaling_factor * xtrg_rec
xtrg_ = xtrg + (xtrg - xtrg_rec)
blend_results_rec_new = self.vae.decode(xtrg_ / self.vae.config.scaling_factor, return_dict=False)[0]
tmp = (abs(blend_results_rec_new - blend_results).mean(dim=1, keepdims=True) > 0.25).float()
mask_x = F.max_pool2d(
(F.interpolate(tmp, scale_factor=1 / 8.0, mode="bilinear") > 0).float(),
kernel_size=3,
stride=1,
padding=1,
)
mask = 1 - F.max_pool2d(1 - blend_mask, kernel_size=8) # * (1-mask_x)
if smooth_boundary:
noise_rescale = find_flat_region(mask)
else:
noise_rescale = torch.ones_like(mask)
xtrg = (xtrg + (1 - mask_x) * (xtrg - xtrg_rec)) * mask
xtrg = xtrg.to(latents.dtype)
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps, cur_num_inference_steps = self.get_timesteps(num_inference_steps, strength, device)
self.attn_state.to_load_and_store_prev()
latents = denoising_loop(init_latents, mask * mask_strength, xtrg, noise_rescale)
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
else:
image = latents
prev_result = image
do_denormalize = [True] * image.shape[0]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
output_frames.append(image[0])
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return output_frames
return TextToVideoSDPipelineOutput(frames=output_frames)
class InputPadder:
"""Pads images such that dimensions are divisible by 8"""
def __init__(self, dims, mode="sintel", padding_factor=8):
self.ht, self.wd = dims[-2:]
pad_ht = (((self.ht // padding_factor) + 1) * padding_factor - self.ht) % padding_factor
pad_wd = (((self.wd // padding_factor) + 1) * padding_factor - self.wd) % padding_factor
if mode == "sintel":
self._pad = [pad_wd // 2, pad_wd - pad_wd // 2, pad_ht // 2, pad_ht - pad_ht // 2]
else:
self._pad = [pad_wd // 2, pad_wd - pad_wd // 2, 0, pad_ht]
def pad(self, *inputs):
return [F.pad(x, self._pad, mode="replicate") for x in inputs]
def unpad(self, x):
ht, wd = x.shape[-2:]
c = [self._pad[2], ht - self._pad[3], self._pad[0], wd - self._pad[1]]
return x[..., c[0] : c[1], c[2] : c[3]]
| diffusers/examples/community/rerender_a_video.py/0 | {
"file_path": "diffusers/examples/community/rerender_a_video.py",
"repo_id": "diffusers",
"token_count": 27079
} | 109 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Callable, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from packaging import version
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, DiffusionPipeline, UNet2DConditionModel
from diffusers.configuration_utils import FrozenDict, deprecate
from diffusers.loaders import LoraLoaderMixin, TextualInversionLoaderMixin
from diffusers.pipelines.pipeline_utils import StableDiffusionMixin
from diffusers.pipelines.stable_diffusion import StableDiffusionPipelineOutput
from diffusers.pipelines.stable_diffusion.safety_checker import (
StableDiffusionSafetyChecker,
)
from diffusers.schedulers import KarrasDiffusionSchedulers
from diffusers.utils import (
logging,
)
from diffusers.utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def prepare_mask_and_masked_image(image, mask):
"""
Prepares a pair (image, mask) to be consumed by the Stable Diffusion pipeline. This means that those inputs will be
converted to ``torch.Tensor`` with shapes ``batch x channels x height x width`` where ``channels`` is ``3`` for the
``image`` and ``1`` for the ``mask``.
The ``image`` will be converted to ``torch.float32`` and normalized to be in ``[-1, 1]``. The ``mask`` will be
binarized (``mask > 0.5``) and cast to ``torch.float32`` too.
Args:
image (Union[np.array, PIL.Image, torch.Tensor]): The image to inpaint.
It can be a ``PIL.Image``, or a ``height x width x 3`` ``np.array`` or a ``channels x height x width``
``torch.Tensor`` or a ``batch x channels x height x width`` ``torch.Tensor``.
mask (_type_): The mask to apply to the image, i.e. regions to inpaint.
It can be a ``PIL.Image``, or a ``height x width`` ``np.array`` or a ``1 x height x width``
``torch.Tensor`` or a ``batch x 1 x height x width`` ``torch.Tensor``.
Raises:
ValueError: ``torch.Tensor`` images should be in the ``[-1, 1]`` range. ValueError: ``torch.Tensor`` mask
should be in the ``[0, 1]`` range. ValueError: ``mask`` and ``image`` should have the same spatial dimensions.
TypeError: ``mask`` is a ``torch.Tensor`` but ``image`` is not
(ot the other way around).
Returns:
tuple[torch.Tensor]: The pair (mask, masked_image) as ``torch.Tensor`` with 4
dimensions: ``batch x channels x height x width``.
"""
if isinstance(image, torch.Tensor):
if not isinstance(mask, torch.Tensor):
raise TypeError(f"`image` is a torch.Tensor but `mask` (type: {type(mask)} is not")
# Batch single image
if image.ndim == 3:
assert image.shape[0] == 3, "Image outside a batch should be of shape (3, H, W)"
image = image.unsqueeze(0)
# Batch and add channel dim for single mask
if mask.ndim == 2:
mask = mask.unsqueeze(0).unsqueeze(0)
# Batch single mask or add channel dim
if mask.ndim == 3:
# Single batched mask, no channel dim or single mask not batched but channel dim
if mask.shape[0] == 1:
mask = mask.unsqueeze(0)
# Batched masks no channel dim
else:
mask = mask.unsqueeze(1)
assert image.ndim == 4 and mask.ndim == 4, "Image and Mask must have 4 dimensions"
assert image.shape[-2:] == mask.shape[-2:], "Image and Mask must have the same spatial dimensions"
assert image.shape[0] == mask.shape[0], "Image and Mask must have the same batch size"
# Check image is in [-1, 1]
if image.min() < -1 or image.max() > 1:
raise ValueError("Image should be in [-1, 1] range")
# Check mask is in [0, 1]
if mask.min() < 0 or mask.max() > 1:
raise ValueError("Mask should be in [0, 1] range")
# Binarize mask
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
# Image as float32
image = image.to(dtype=torch.float32)
elif isinstance(mask, torch.Tensor):
raise TypeError(f"`mask` is a torch.Tensor but `image` (type: {type(image)} is not")
else:
# preprocess image
if isinstance(image, (PIL.Image.Image, np.ndarray)):
image = [image]
if isinstance(image, list) and isinstance(image[0], PIL.Image.Image):
image = [np.array(i.convert("RGB"))[None, :] for i in image]
image = np.concatenate(image, axis=0)
elif isinstance(image, list) and isinstance(image[0], np.ndarray):
image = np.concatenate([i[None, :] for i in image], axis=0)
image = image.transpose(0, 3, 1, 2)
image = torch.from_numpy(image).to(dtype=torch.float32) / 127.5 - 1.0
# preprocess mask
if isinstance(mask, (PIL.Image.Image, np.ndarray)):
mask = [mask]
if isinstance(mask, list) and isinstance(mask[0], PIL.Image.Image):
mask = np.concatenate([np.array(m.convert("L"))[None, None, :] for m in mask], axis=0)
mask = mask.astype(np.float32) / 255.0
elif isinstance(mask, list) and isinstance(mask[0], np.ndarray):
mask = np.concatenate([m[None, None, :] for m in mask], axis=0)
mask[mask < 0.5] = 0
mask[mask >= 0.5] = 1
mask = torch.from_numpy(mask)
# masked_image = image * (mask >= 0.5)
masked_image = image
return mask, masked_image
class StableDiffusionRepaintPipeline(
DiffusionPipeline, StableDiffusionMixin, TextualInversionLoaderMixin, LoraLoaderMixin
):
r"""
Pipeline for text-guided image inpainting using Stable Diffusion. *This is an experimental feature*.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
In addition the pipeline inherits the following loading methods:
- *Textual-Inversion*: [`loaders.TextualInversionLoaderMixin.load_textual_inversion`]
- *LoRA*: [`loaders.LoraLoaderMixin.load_lora_weights`]
as well as the following saving methods:
- *LoRA*: [`loaders.LoraLoaderMixin.save_lora_weights`]
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) Model to encode and decode images to and from latent representations.
text_encoder ([`CLIPTextModel`]):
Frozen text-encoder. Stable Diffusion uses the text portion of
[CLIP](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel), specifically
the [clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14) variant.
tokenizer (`CLIPTokenizer`):
Tokenizer of class
[CLIPTokenizer](https://huggingface.co/docs/transformers/v4.21.0/en/model_doc/clip#transformers.CLIPTokenizer).
unet ([`UNet2DConditionModel`]): Conditional U-Net architecture to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please, refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for details.
feature_extractor ([`CLIPImageProcessor`]):
Model that extracts features from generated images to be used as inputs for the `safety_checker`.
"""
_optional_components = ["safety_checker", "feature_extractor"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "skip_prk_steps") and scheduler.config.skip_prk_steps is False:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration"
" `skip_prk_steps`. `skip_prk_steps` should be set to True in the configuration file. Please make"
" sure to update the config accordingly as not setting `skip_prk_steps` in the config might lead to"
" incorrect results in future versions. If you have downloaded this checkpoint from the Hugging Face"
" Hub, it would be very nice if you could open a Pull request for the"
" `scheduler/scheduler_config.json` file"
)
deprecate(
"skip_prk_steps not set",
"1.0.0",
deprecation_message,
standard_warn=False,
)
new_config = dict(scheduler.config)
new_config["skip_prk_steps"] = True
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
is_unet_version_less_0_9_0 = hasattr(unet.config, "_diffusers_version") and version.parse(
version.parse(unet.config._diffusers_version).base_version
) < version.parse("0.9.0.dev0")
is_unet_sample_size_less_64 = hasattr(unet.config, "sample_size") and unet.config.sample_size < 64
if is_unet_version_less_0_9_0 and is_unet_sample_size_less_64:
deprecation_message = (
"The configuration file of the unet has set the default `sample_size` to smaller than"
" 64 which seems highly unlikely .If you're checkpoint is a fine-tuned version of any of the"
" following: \n- CompVis/stable-diffusion-v1-4 \n- CompVis/stable-diffusion-v1-3 \n-"
" CompVis/stable-diffusion-v1-2 \n- CompVis/stable-diffusion-v1-1 \n- runwayml/stable-diffusion-v1-5"
" \n- runwayml/stable-diffusion-inpainting \n you should change 'sample_size' to 64 in the"
" configuration file. Please make sure to update the config accordingly as leaving `sample_size=32`"
" in the config might lead to incorrect results in future versions. If you have downloaded this"
" checkpoint from the Hugging Face Hub, it would be very nice if you could open a Pull request for"
" the `unet/config.json` file"
)
deprecate("sample_size<64", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(unet.config)
new_config["sample_size"] = 64
unet._internal_dict = FrozenDict(new_config)
# Check shapes, assume num_channels_latents == 4, num_channels_mask == 1, num_channels_masked == 4
if unet.config.in_channels != 4:
logger.warning(
f"You have loaded a UNet with {unet.config.in_channels} input channels, whereas by default,"
f" {self.__class__} assumes that `pipeline.unet` has 4 input channels: 4 for `num_channels_latents`,"
". If you did not intend to modify"
" this behavior, please check whether you have loaded the right checkpoint."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
prompt_embeds = self.text_encoder(
text_input_ids.to(device),
attention_mask=attention_mask,
)
prompt_embeds = prompt_embeds[0]
prompt_embeds = prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=self.text_encoder.dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(self.numpy_to_pil(image), return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
else:
has_nsfw_concept = None
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.check_inputs
def check_inputs(
self,
prompt,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(
self,
batch_size,
num_channels_latents,
height,
width,
dtype,
device,
generator,
latents=None,
):
shape = (
batch_size,
num_channels_latents,
height // self.vae_scale_factor,
width // self.vae_scale_factor,
)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
def prepare_mask_latents(
self,
mask,
masked_image,
batch_size,
height,
width,
dtype,
device,
generator,
do_classifier_free_guidance,
):
# resize the mask to latents shape as we concatenate the mask to the latents
# we do that before converting to dtype to avoid breaking in case we're using cpu_offload
# and half precision
mask = torch.nn.functional.interpolate(
mask, size=(height // self.vae_scale_factor, width // self.vae_scale_factor)
)
mask = mask.to(device=device, dtype=dtype)
masked_image = masked_image.to(device=device, dtype=dtype)
# encode the mask image into latents space so we can concatenate it to the latents
if isinstance(generator, list):
masked_image_latents = [
self.vae.encode(masked_image[i : i + 1]).latent_dist.sample(generator=generator[i])
for i in range(batch_size)
]
masked_image_latents = torch.cat(masked_image_latents, dim=0)
else:
masked_image_latents = self.vae.encode(masked_image).latent_dist.sample(generator=generator)
masked_image_latents = self.vae.config.scaling_factor * masked_image_latents
# duplicate mask and masked_image_latents for each generation per prompt, using mps friendly method
if mask.shape[0] < batch_size:
if not batch_size % mask.shape[0] == 0:
raise ValueError(
"The passed mask and the required batch size don't match. Masks are supposed to be duplicated to"
f" a total batch size of {batch_size}, but {mask.shape[0]} masks were passed. Make sure the number"
" of masks that you pass is divisible by the total requested batch size."
)
mask = mask.repeat(batch_size // mask.shape[0], 1, 1, 1)
if masked_image_latents.shape[0] < batch_size:
if not batch_size % masked_image_latents.shape[0] == 0:
raise ValueError(
"The passed images and the required batch size don't match. Images are supposed to be duplicated"
f" to a total batch size of {batch_size}, but {masked_image_latents.shape[0]} images were passed."
" Make sure the number of images that you pass is divisible by the total requested batch size."
)
masked_image_latents = masked_image_latents.repeat(batch_size // masked_image_latents.shape[0], 1, 1, 1)
mask = torch.cat([mask] * 2) if do_classifier_free_guidance else mask
masked_image_latents = (
torch.cat([masked_image_latents] * 2) if do_classifier_free_guidance else masked_image_latents
)
# aligning device to prevent device errors when concating it with the latent model input
masked_image_latents = masked_image_latents.to(device=device, dtype=dtype)
return mask, masked_image_latents
@torch.no_grad()
def __call__(
self,
prompt: Union[str, List[str]] = None,
image: Union[torch.FloatTensor, PIL.Image.Image] = None,
mask_image: Union[torch.FloatTensor, PIL.Image.Image] = None,
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
jump_length: Optional[int] = 10,
jump_n_sample: Optional[int] = 10,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide the image generation. If not defined, one has to pass `prompt_embeds`.
instead.
image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch which will be inpainted, *i.e.* parts of the image will
be masked out with `mask_image` and repainted according to `prompt`.
mask_image (`PIL.Image.Image`):
`Image`, or tensor representing an image batch, to mask `image`. White pixels in the mask will be
repainted, while black pixels will be preserved. If `mask_image` is a PIL image, it will be converted
to a single channel (luminance) before use. If it's a tensor, it should contain one color channel (L)
instead of 3, so the expected shape would be `(B, H, W, 1)`.
height (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to self.unet.config.sample_size * self.vae_scale_factor):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
jump_length (`int`, *optional*, defaults to 10):
The number of steps taken forward in time before going backward in time for a single jump ("j" in
RePaint paper). Take a look at Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
jump_n_sample (`int`, *optional*, defaults to 10):
The number of times we will make forward time jump for a given chosen time sample. Take a look at
Figure 9 and 10 in https://arxiv.org/pdf/2201.09865.pdf.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds`. instead. Ignored when not using guidance (i.e., ignored if `guidance_scale`
is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`torch.Generator`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Examples:
```py
>>> import PIL
>>> import requests
>>> import torch
>>> from io import BytesIO
>>> from diffusers import StableDiffusionPipeline, RePaintScheduler
>>> def download_image(url):
... response = requests.get(url)
... return PIL.Image.open(BytesIO(response.content)).convert("RGB")
>>> base_url = "https://raw.githubusercontent.com/CompVis/latent-diffusion/main/data/inpainting_examples/"
>>> img_url = base_url + "overture-creations-5sI6fQgYIuo.png"
>>> mask_url = base_url + "overture-creations-5sI6fQgYIuo_mask.png "
>>> init_image = download_image(img_url).resize((512, 512))
>>> mask_image = download_image(mask_url).resize((512, 512))
>>> pipe = DiffusionPipeline.from_pretrained(
... "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16, custom_pipeline="stable_diffusion_repaint",
... )
>>> pipe.scheduler = RePaintScheduler.from_config(pipe.scheduler.config)
>>> pipe = pipe.to("cuda")
>>> prompt = "Face of a yellow cat, high resolution, sitting on a park bench"
>>> image = pipe(prompt=prompt, image=init_image, mask_image=mask_image).images[0]
```
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs
self.check_inputs(
prompt,
height,
width,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
)
if image is None:
raise ValueError("`image` input cannot be undefined.")
if mask_image is None:
raise ValueError("`mask_image` input cannot be undefined.")
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds = self._encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
# 4. Preprocess mask and image
mask, masked_image = prepare_mask_and_masked_image(image, mask_image)
# 5. set timesteps
self.scheduler.set_timesteps(num_inference_steps, jump_length, jump_n_sample, device)
self.scheduler.eta = eta
timesteps = self.scheduler.timesteps
# latent_timestep = timesteps[:1].repeat(batch_size * num_images_per_prompt)
# 6. Prepare latent variables
num_channels_latents = self.vae.config.latent_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 7. Prepare mask latent variables
mask, masked_image_latents = self.prepare_mask_latents(
mask,
masked_image,
batch_size * num_images_per_prompt,
height,
width,
prompt_embeds.dtype,
device,
generator,
do_classifier_free_guidance=False, # We do not need duplicate mask and image
)
# 8. Check that sizes of mask, masked image and latents match
# num_channels_mask = mask.shape[1]
# num_channels_masked_image = masked_image_latents.shape[1]
if num_channels_latents != self.unet.config.in_channels:
raise ValueError(
f"Incorrect configuration settings! The config of `pipeline.unet`: {self.unet.config} expects"
f" {self.unet.config.in_channels} but received `num_channels_latents`: {num_channels_latents} "
f" = Please verify the config of"
" `pipeline.unet` or your `mask_image` or `image` input."
)
# 9. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
t_last = timesteps[0] + 1
# 10. Denoising loop
with self.progress_bar(total=len(timesteps)) as progress_bar:
for i, t in enumerate(timesteps):
if t >= t_last:
# compute the reverse: x_t-1 -> x_t
latents = self.scheduler.undo_step(latents, t_last, generator)
progress_bar.update()
t_last = t
continue
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# latent_model_input = torch.cat([latent_model_input, mask, masked_image_latents], dim=1)
# predict the noise residual
noise_pred = self.unet(latent_model_input, t, encoder_hidden_states=prompt_embeds).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
noise_pred,
t,
latents,
masked_image_latents,
mask,
**extra_step_kwargs,
).prev_sample
# call the callback, if provided
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
t_last = t
# 11. Post-processing
image = self.decode_latents(latents)
# 12. Run safety checker
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
# 13. Convert to PIL
if output_type == "pil":
image = self.numpy_to_pil(image)
# Offload last model to CPU
if hasattr(self, "final_offload_hook") and self.final_offload_hook is not None:
self.final_offload_hook.offload()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| diffusers/examples/community/stable_diffusion_repaint.py/0 | {
"file_path": "diffusers/examples/community/stable_diffusion_repaint.py",
"repo_id": "diffusers",
"token_count": 19597
} | 110 |
#!/usr/bin/env python
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import functools
import gc
import itertools
import json
import logging
import math
import os
import random
import shutil
from pathlib import Path
from typing import List, Union
import accelerate
import numpy as np
import torch
import torch.nn.functional as F
import torch.utils.checkpoint
import torchvision.transforms.functional as TF
import transformers
import webdataset as wds
from accelerate import Accelerator
from accelerate.logging import get_logger
from accelerate.utils import ProjectConfiguration, set_seed
from braceexpand import braceexpand
from huggingface_hub import create_repo, upload_folder
from packaging import version
from peft import LoraConfig, get_peft_model, get_peft_model_state_dict
from torch.utils.data import default_collate
from torchvision import transforms
from tqdm.auto import tqdm
from transformers import AutoTokenizer, CLIPTextModel, PretrainedConfig
from webdataset.tariterators import (
base_plus_ext,
tar_file_expander,
url_opener,
valid_sample,
)
import diffusers
from diffusers import (
AutoencoderKL,
DDPMScheduler,
LCMScheduler,
StableDiffusionPipeline,
UNet2DConditionModel,
)
from diffusers.optimization import get_scheduler
from diffusers.training_utils import resolve_interpolation_mode
from diffusers.utils import check_min_version, is_wandb_available
from diffusers.utils.import_utils import is_xformers_available
MAX_SEQ_LENGTH = 77
if is_wandb_available():
import wandb
# Will error if the minimal version of diffusers is not installed. Remove at your own risks.
check_min_version("0.28.0.dev0")
logger = get_logger(__name__)
def get_module_kohya_state_dict(module, prefix: str, dtype: torch.dtype, adapter_name: str = "default"):
kohya_ss_state_dict = {}
for peft_key, weight in get_peft_model_state_dict(module, adapter_name=adapter_name).items():
kohya_key = peft_key.replace("base_model.model", prefix)
kohya_key = kohya_key.replace("lora_A", "lora_down")
kohya_key = kohya_key.replace("lora_B", "lora_up")
kohya_key = kohya_key.replace(".", "_", kohya_key.count(".") - 2)
kohya_ss_state_dict[kohya_key] = weight.to(dtype)
# Set alpha parameter
if "lora_down" in kohya_key:
alpha_key = f'{kohya_key.split(".")[0]}.alpha'
kohya_ss_state_dict[alpha_key] = torch.tensor(module.peft_config[adapter_name].lora_alpha).to(dtype)
return kohya_ss_state_dict
def filter_keys(key_set):
def _f(dictionary):
return {k: v for k, v in dictionary.items() if k in key_set}
return _f
def group_by_keys_nothrow(data, keys=base_plus_ext, lcase=True, suffixes=None, handler=None):
"""Return function over iterator that groups key, value pairs into samples.
:param keys: function that splits the key into key and extension (base_plus_ext) :param lcase: convert suffixes to
lower case (Default value = True)
"""
current_sample = None
for filesample in data:
assert isinstance(filesample, dict)
fname, value = filesample["fname"], filesample["data"]
prefix, suffix = keys(fname)
if prefix is None:
continue
if lcase:
suffix = suffix.lower()
# FIXME webdataset version throws if suffix in current_sample, but we have a potential for
# this happening in the current LAION400m dataset if a tar ends with same prefix as the next
# begins, rare, but can happen since prefix aren't unique across tar files in that dataset
if current_sample is None or prefix != current_sample["__key__"] or suffix in current_sample:
if valid_sample(current_sample):
yield current_sample
current_sample = {"__key__": prefix, "__url__": filesample["__url__"]}
if suffixes is None or suffix in suffixes:
current_sample[suffix] = value
if valid_sample(current_sample):
yield current_sample
def tarfile_to_samples_nothrow(src, handler=wds.warn_and_continue):
# NOTE this is a re-impl of the webdataset impl with group_by_keys that doesn't throw
streams = url_opener(src, handler=handler)
files = tar_file_expander(streams, handler=handler)
samples = group_by_keys_nothrow(files, handler=handler)
return samples
class WebdatasetFilter:
def __init__(self, min_size=1024, max_pwatermark=0.5):
self.min_size = min_size
self.max_pwatermark = max_pwatermark
def __call__(self, x):
try:
if "json" in x:
x_json = json.loads(x["json"])
filter_size = (x_json.get("original_width", 0.0) or 0.0) >= self.min_size and x_json.get(
"original_height", 0
) >= self.min_size
filter_watermark = (x_json.get("pwatermark", 1.0) or 1.0) <= self.max_pwatermark
return filter_size and filter_watermark
else:
return False
except Exception:
return False
class SDText2ImageDataset:
def __init__(
self,
train_shards_path_or_url: Union[str, List[str]],
num_train_examples: int,
per_gpu_batch_size: int,
global_batch_size: int,
num_workers: int,
resolution: int = 512,
interpolation_type: str = "bilinear",
shuffle_buffer_size: int = 1000,
pin_memory: bool = False,
persistent_workers: bool = False,
):
if not isinstance(train_shards_path_or_url, str):
train_shards_path_or_url = [list(braceexpand(urls)) for urls in train_shards_path_or_url]
# flatten list using itertools
train_shards_path_or_url = list(itertools.chain.from_iterable(train_shards_path_or_url))
interpolation_mode = resolve_interpolation_mode(interpolation_type)
def transform(example):
# resize image
image = example["image"]
image = TF.resize(image, resolution, interpolation=interpolation_mode)
# get crop coordinates and crop image
c_top, c_left, _, _ = transforms.RandomCrop.get_params(image, output_size=(resolution, resolution))
image = TF.crop(image, c_top, c_left, resolution, resolution)
image = TF.to_tensor(image)
image = TF.normalize(image, [0.5], [0.5])
example["image"] = image
return example
processing_pipeline = [
wds.decode("pil", handler=wds.ignore_and_continue),
wds.rename(image="jpg;png;jpeg;webp", text="text;txt;caption", handler=wds.warn_and_continue),
wds.map(filter_keys({"image", "text"})),
wds.map(transform),
wds.to_tuple("image", "text"),
]
# Create train dataset and loader
pipeline = [
wds.ResampledShards(train_shards_path_or_url),
tarfile_to_samples_nothrow,
wds.shuffle(shuffle_buffer_size),
*processing_pipeline,
wds.batched(per_gpu_batch_size, partial=False, collation_fn=default_collate),
]
num_worker_batches = math.ceil(num_train_examples / (global_batch_size * num_workers)) # per dataloader worker
num_batches = num_worker_batches * num_workers
num_samples = num_batches * global_batch_size
# each worker is iterating over this
self._train_dataset = wds.DataPipeline(*pipeline).with_epoch(num_worker_batches)
self._train_dataloader = wds.WebLoader(
self._train_dataset,
batch_size=None,
shuffle=False,
num_workers=num_workers,
pin_memory=pin_memory,
persistent_workers=persistent_workers,
)
# add meta-data to dataloader instance for convenience
self._train_dataloader.num_batches = num_batches
self._train_dataloader.num_samples = num_samples
@property
def train_dataset(self):
return self._train_dataset
@property
def train_dataloader(self):
return self._train_dataloader
def log_validation(vae, unet, args, accelerator, weight_dtype, step):
logger.info("Running validation... ")
unet = accelerator.unwrap_model(unet)
pipeline = StableDiffusionPipeline.from_pretrained(
args.pretrained_teacher_model,
vae=vae,
scheduler=LCMScheduler.from_pretrained(args.pretrained_teacher_model, subfolder="scheduler"),
revision=args.revision,
torch_dtype=weight_dtype,
safety_checker=None,
)
pipeline.set_progress_bar_config(disable=True)
lora_state_dict = get_module_kohya_state_dict(unet, "lora_unet", weight_dtype)
pipeline.load_lora_weights(lora_state_dict)
pipeline.fuse_lora()
pipeline = pipeline.to(accelerator.device, dtype=weight_dtype)
if args.enable_xformers_memory_efficient_attention:
pipeline.enable_xformers_memory_efficient_attention()
if args.seed is None:
generator = None
else:
generator = torch.Generator(device=accelerator.device).manual_seed(args.seed)
validation_prompts = [
"portrait photo of a girl, photograph, highly detailed face, depth of field, moody light, golden hour, style by Dan Winters, Russell James, Steve McCurry, centered, extremely detailed, Nikon D850, award winning photography",
"Self-portrait oil painting, a beautiful cyborg with golden hair, 8k",
"Astronaut in a jungle, cold color palette, muted colors, detailed, 8k",
"A photo of beautiful mountain with realistic sunset and blue lake, highly detailed, masterpiece",
]
image_logs = []
for _, prompt in enumerate(validation_prompts):
images = []
with torch.autocast("cuda", dtype=weight_dtype):
images = pipeline(
prompt=prompt,
num_inference_steps=4,
num_images_per_prompt=4,
generator=generator,
guidance_scale=1.0,
).images
image_logs.append({"validation_prompt": prompt, "images": images})
for tracker in accelerator.trackers:
if tracker.name == "tensorboard":
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
formatted_images = []
for image in images:
formatted_images.append(np.asarray(image))
formatted_images = np.stack(formatted_images)
tracker.writer.add_images(validation_prompt, formatted_images, step, dataformats="NHWC")
elif tracker.name == "wandb":
formatted_images = []
for log in image_logs:
images = log["images"]
validation_prompt = log["validation_prompt"]
for image in images:
image = wandb.Image(image, caption=validation_prompt)
formatted_images.append(image)
tracker.log({"validation": formatted_images})
else:
logger.warning(f"image logging not implemented for {tracker.name}")
del pipeline
gc.collect()
torch.cuda.empty_cache()
return image_logs
# From LatentConsistencyModel.get_guidance_scale_embedding
def guidance_scale_embedding(w, embedding_dim=512, dtype=torch.float32):
"""
See https://github.com/google-research/vdm/blob/dc27b98a554f65cdc654b800da5aa1846545d41b/model_vdm.py#L298
Args:
timesteps (`torch.Tensor`):
generate embedding vectors at these timesteps
embedding_dim (`int`, *optional*, defaults to 512):
dimension of the embeddings to generate
dtype:
data type of the generated embeddings
Returns:
`torch.FloatTensor`: Embedding vectors with shape `(len(timesteps), embedding_dim)`
"""
assert len(w.shape) == 1
w = w * 1000.0
half_dim = embedding_dim // 2
emb = torch.log(torch.tensor(10000.0)) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, dtype=dtype) * -emb)
emb = w.to(dtype)[:, None] * emb[None, :]
emb = torch.cat([torch.sin(emb), torch.cos(emb)], dim=1)
if embedding_dim % 2 == 1: # zero pad
emb = torch.nn.functional.pad(emb, (0, 1))
assert emb.shape == (w.shape[0], embedding_dim)
return emb
def append_dims(x, target_dims):
"""Appends dimensions to the end of a tensor until it has target_dims dimensions."""
dims_to_append = target_dims - x.ndim
if dims_to_append < 0:
raise ValueError(f"input has {x.ndim} dims but target_dims is {target_dims}, which is less")
return x[(...,) + (None,) * dims_to_append]
# From LCMScheduler.get_scalings_for_boundary_condition_discrete
def scalings_for_boundary_conditions(timestep, sigma_data=0.5, timestep_scaling=10.0):
scaled_timestep = timestep_scaling * timestep
c_skip = sigma_data**2 / (scaled_timestep**2 + sigma_data**2)
c_out = scaled_timestep / (scaled_timestep**2 + sigma_data**2) ** 0.5
return c_skip, c_out
# Compare LCMScheduler.step, Step 4
def get_predicted_original_sample(model_output, timesteps, sample, prediction_type, alphas, sigmas):
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
if prediction_type == "epsilon":
pred_x_0 = (sample - sigmas * model_output) / alphas
elif prediction_type == "sample":
pred_x_0 = model_output
elif prediction_type == "v_prediction":
pred_x_0 = alphas * sample - sigmas * model_output
else:
raise ValueError(
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
f" are supported."
)
return pred_x_0
# Based on step 4 in DDIMScheduler.step
def get_predicted_noise(model_output, timesteps, sample, prediction_type, alphas, sigmas):
alphas = extract_into_tensor(alphas, timesteps, sample.shape)
sigmas = extract_into_tensor(sigmas, timesteps, sample.shape)
if prediction_type == "epsilon":
pred_epsilon = model_output
elif prediction_type == "sample":
pred_epsilon = (sample - alphas * model_output) / sigmas
elif prediction_type == "v_prediction":
pred_epsilon = alphas * model_output + sigmas * sample
else:
raise ValueError(
f"Prediction type {prediction_type} is not supported; currently, `epsilon`, `sample`, and `v_prediction`"
f" are supported."
)
return pred_epsilon
def extract_into_tensor(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))
class DDIMSolver:
def __init__(self, alpha_cumprods, timesteps=1000, ddim_timesteps=50):
# DDIM sampling parameters
step_ratio = timesteps // ddim_timesteps
self.ddim_timesteps = (np.arange(1, ddim_timesteps + 1) * step_ratio).round().astype(np.int64) - 1
self.ddim_alpha_cumprods = alpha_cumprods[self.ddim_timesteps]
self.ddim_alpha_cumprods_prev = np.asarray(
[alpha_cumprods[0]] + alpha_cumprods[self.ddim_timesteps[:-1]].tolist()
)
# convert to torch tensors
self.ddim_timesteps = torch.from_numpy(self.ddim_timesteps).long()
self.ddim_alpha_cumprods = torch.from_numpy(self.ddim_alpha_cumprods)
self.ddim_alpha_cumprods_prev = torch.from_numpy(self.ddim_alpha_cumprods_prev)
def to(self, device):
self.ddim_timesteps = self.ddim_timesteps.to(device)
self.ddim_alpha_cumprods = self.ddim_alpha_cumprods.to(device)
self.ddim_alpha_cumprods_prev = self.ddim_alpha_cumprods_prev.to(device)
return self
def ddim_step(self, pred_x0, pred_noise, timestep_index):
alpha_cumprod_prev = extract_into_tensor(self.ddim_alpha_cumprods_prev, timestep_index, pred_x0.shape)
dir_xt = (1.0 - alpha_cumprod_prev).sqrt() * pred_noise
x_prev = alpha_cumprod_prev.sqrt() * pred_x0 + dir_xt
return x_prev
@torch.no_grad()
def update_ema(target_params, source_params, rate=0.99):
"""
Update target parameters to be closer to those of source parameters using
an exponential moving average.
:param target_params: the target parameter sequence.
:param source_params: the source parameter sequence.
:param rate: the EMA rate (closer to 1 means slower).
"""
for targ, src in zip(target_params, source_params):
targ.detach().mul_(rate).add_(src, alpha=1 - rate)
def import_model_class_from_model_name_or_path(
pretrained_model_name_or_path: str, revision: str, subfolder: str = "text_encoder"
):
text_encoder_config = PretrainedConfig.from_pretrained(
pretrained_model_name_or_path, subfolder=subfolder, revision=revision
)
model_class = text_encoder_config.architectures[0]
if model_class == "CLIPTextModel":
from transformers import CLIPTextModel
return CLIPTextModel
elif model_class == "CLIPTextModelWithProjection":
from transformers import CLIPTextModelWithProjection
return CLIPTextModelWithProjection
else:
raise ValueError(f"{model_class} is not supported.")
def parse_args():
parser = argparse.ArgumentParser(description="Simple example of a training script.")
# ----------Model Checkpoint Loading Arguments----------
parser.add_argument(
"--pretrained_teacher_model",
type=str,
default=None,
required=True,
help="Path to pretrained LDM teacher model or model identifier from huggingface.co/models.",
)
parser.add_argument(
"--pretrained_vae_model_name_or_path",
type=str,
default=None,
help="Path to pretrained VAE model with better numerical stability. More details: https://github.com/huggingface/diffusers/pull/4038.",
)
parser.add_argument(
"--teacher_revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM teacher model identifier from huggingface.co/models.",
)
parser.add_argument(
"--revision",
type=str,
default=None,
required=False,
help="Revision of pretrained LDM model identifier from huggingface.co/models.",
)
# ----------Training Arguments----------
# ----General Training Arguments----
parser.add_argument(
"--output_dir",
type=str,
default="lcm-xl-distilled",
help="The output directory where the model predictions and checkpoints will be written.",
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="The directory where the downloaded models and datasets will be stored.",
)
parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
# ----Logging----
parser.add_argument(
"--logging_dir",
type=str,
default="logs",
help=(
"[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
" *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
),
)
parser.add_argument(
"--report_to",
type=str,
default="tensorboard",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
),
)
# ----Checkpointing----
parser.add_argument(
"--checkpointing_steps",
type=int,
default=500,
help=(
"Save a checkpoint of the training state every X updates. These checkpoints are only suitable for resuming"
" training using `--resume_from_checkpoint`."
),
)
parser.add_argument(
"--checkpoints_total_limit",
type=int,
default=None,
help=("Max number of checkpoints to store."),
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help=(
"Whether training should be resumed from a previous checkpoint. Use a path saved by"
' `--checkpointing_steps`, or `"latest"` to automatically select the last available checkpoint.'
),
)
# ----Image Processing----
parser.add_argument(
"--train_shards_path_or_url",
type=str,
default=None,
help=(
"The name of the Dataset (from the HuggingFace hub) to train on (could be your own, possibly private,"
" dataset). It can also be a path pointing to a local copy of a dataset in your filesystem,"
" or to a folder containing files that 🤗 Datasets can understand."
),
)
parser.add_argument(
"--resolution",
type=int,
default=512,
help=(
"The resolution for input images, all the images in the train/validation dataset will be resized to this"
" resolution"
),
)
parser.add_argument(
"--interpolation_type",
type=str,
default="bilinear",
help=(
"The interpolation function used when resizing images to the desired resolution. Choose between `bilinear`,"
" `bicubic`, `box`, `nearest`, `nearest_exact`, `hamming`, and `lanczos`."
),
)
parser.add_argument(
"--center_crop",
default=False,
action="store_true",
help=(
"Whether to center crop the input images to the resolution. If not set, the images will be randomly"
" cropped. The images will be resized to the resolution first before cropping."
),
)
parser.add_argument(
"--random_flip",
action="store_true",
help="whether to randomly flip images horizontally",
)
# ----Dataloader----
parser.add_argument(
"--dataloader_num_workers",
type=int,
default=0,
help=(
"Number of subprocesses to use for data loading. 0 means that the data will be loaded in the main process."
),
)
# ----Batch Size and Training Steps----
parser.add_argument(
"--train_batch_size", type=int, default=16, help="Batch size (per device) for the training dataloader."
)
parser.add_argument("--num_train_epochs", type=int, default=100)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
# ----Learning Rate----
parser.add_argument(
"--learning_rate",
type=float,
default=1e-4,
help="Initial learning rate (after the potential warmup period) to use.",
)
parser.add_argument(
"--scale_lr",
action="store_true",
default=False,
help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
)
parser.add_argument(
"--lr_scheduler",
type=str,
default="constant",
help=(
'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
' "constant", "constant_with_warmup"]'
),
)
parser.add_argument(
"--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
# ----Optimizer (Adam)----
parser.add_argument(
"--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
)
parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
# ----Diffusion Training Arguments----
parser.add_argument(
"--proportion_empty_prompts",
type=float,
default=0,
help="Proportion of image prompts to be replaced with empty strings. Defaults to 0 (no prompt replacement).",
)
# ----Latent Consistency Distillation (LCD) Specific Arguments----
parser.add_argument(
"--w_min",
type=float,
default=5.0,
required=False,
help=(
"The minimum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--w_max",
type=float,
default=15.0,
required=False,
help=(
"The maximum guidance scale value for guidance scale sampling. Note that we are using the Imagen CFG"
" formulation rather than the LCM formulation, which means all guidance scales have 1 added to them as"
" compared to the original paper."
),
)
parser.add_argument(
"--num_ddim_timesteps",
type=int,
default=50,
help="The number of timesteps to use for DDIM sampling.",
)
parser.add_argument(
"--loss_type",
type=str,
default="l2",
choices=["l2", "huber"],
help="The type of loss to use for the LCD loss.",
)
parser.add_argument(
"--huber_c",
type=float,
default=0.001,
help="The huber loss parameter. Only used if `--loss_type=huber`.",
)
parser.add_argument(
"--lora_rank",
type=int,
default=64,
help="The rank of the LoRA projection matrix.",
)
parser.add_argument(
"--lora_alpha",
type=int,
default=64,
help=(
"The value of the LoRA alpha parameter, which controls the scaling factor in front of the LoRA weight"
" update delta_W. No scaling will be performed if this value is equal to `lora_rank`."
),
)
parser.add_argument(
"--lora_dropout",
type=float,
default=0.0,
help="The dropout probability for the dropout layer added before applying the LoRA to each layer input.",
)
parser.add_argument(
"--lora_target_modules",
type=str,
default=None,
help=(
"A comma-separated string of target module keys to add LoRA to. If not set, a default list of modules will"
" be used. By default, LoRA will be applied to all conv and linear layers."
),
)
parser.add_argument(
"--vae_encode_batch_size",
type=int,
default=32,
required=False,
help=(
"The batch size used when encoding (and decoding) images to latents (and vice versa) using the VAE."
" Encoding or decoding the whole batch at once may run into OOM issues."
),
)
parser.add_argument(
"--timestep_scaling_factor",
type=float,
default=10.0,
help=(
"The multiplicative timestep scaling factor used when calculating the boundary scalings for LCM. The"
" higher the scaling is, the lower the approximation error, but the default value of 10.0 should typically"
" suffice."
),
)
# ----Mixed Precision----
parser.add_argument(
"--mixed_precision",
type=str,
default=None,
choices=["no", "fp16", "bf16"],
help=(
"Whether to use mixed precision. Choose between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >="
" 1.10.and an Nvidia Ampere GPU. Default to the value of accelerate config of the current system or the"
" flag passed with the `accelerate.launch` command. Use this argument to override the accelerate config."
),
)
parser.add_argument(
"--allow_tf32",
action="store_true",
help=(
"Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
" https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
),
)
parser.add_argument(
"--cast_teacher_unet",
action="store_true",
help="Whether to cast the teacher U-Net to the precision specified by `--mixed_precision`.",
)
# ----Training Optimizations----
parser.add_argument(
"--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers."
)
parser.add_argument(
"--gradient_checkpointing",
action="store_true",
help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
)
# ----Distributed Training----
parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
# ----------Validation Arguments----------
parser.add_argument(
"--validation_steps",
type=int,
default=200,
help="Run validation every X steps.",
)
# ----------Huggingface Hub Arguments-----------
parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
parser.add_argument(
"--hub_model_id",
type=str,
default=None,
help="The name of the repository to keep in sync with the local `output_dir`.",
)
# ----------Accelerate Arguments----------
parser.add_argument(
"--tracker_project_name",
type=str,
default="text2image-fine-tune",
help=(
"The `project_name` argument passed to Accelerator.init_trackers for"
" more information see https://huggingface.co/docs/accelerate/v0.17.0/en/package_reference/accelerator#accelerate.Accelerator"
),
)
args = parser.parse_args()
env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
if env_local_rank != -1 and env_local_rank != args.local_rank:
args.local_rank = env_local_rank
if args.proportion_empty_prompts < 0 or args.proportion_empty_prompts > 1:
raise ValueError("`--proportion_empty_prompts` must be in the range [0, 1].")
return args
# Adapted from pipelines.StableDiffusionPipeline.encode_prompt
def encode_prompt(prompt_batch, text_encoder, tokenizer, proportion_empty_prompts, is_train=True):
captions = []
for caption in prompt_batch:
if random.random() < proportion_empty_prompts:
captions.append("")
elif isinstance(caption, str):
captions.append(caption)
elif isinstance(caption, (list, np.ndarray)):
# take a random caption if there are multiple
captions.append(random.choice(caption) if is_train else caption[0])
with torch.no_grad():
text_inputs = tokenizer(
captions,
padding="max_length",
max_length=tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
prompt_embeds = text_encoder(text_input_ids.to(text_encoder.device))[0]
return prompt_embeds
def main(args):
if args.report_to == "wandb" and args.hub_token is not None:
raise ValueError(
"You cannot use both --report_to=wandb and --hub_token due to a security risk of exposing your token."
" Please use `huggingface-cli login` to authenticate with the Hub."
)
logging_dir = Path(args.output_dir, args.logging_dir)
accelerator_project_config = ProjectConfiguration(project_dir=args.output_dir, logging_dir=logging_dir)
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
mixed_precision=args.mixed_precision,
log_with=args.report_to,
project_config=accelerator_project_config,
split_batches=True, # It's important to set this to True when using webdataset to get the right number of steps for lr scheduling. If set to False, the number of steps will be devide by the number of processes assuming batches are multiplied by the number of processes
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state, main_process_only=False)
if accelerator.is_local_main_process:
transformers.utils.logging.set_verbosity_warning()
diffusers.utils.logging.set_verbosity_info()
else:
transformers.utils.logging.set_verbosity_error()
diffusers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
if args.push_to_hub:
repo_id = create_repo(
repo_id=args.hub_model_id or Path(args.output_dir).name,
exist_ok=True,
token=args.hub_token,
private=True,
).repo_id
# 1. Create the noise scheduler and the desired noise schedule.
noise_scheduler = DDPMScheduler.from_pretrained(
args.pretrained_teacher_model, subfolder="scheduler", revision=args.teacher_revision
)
# DDPMScheduler calculates the alpha and sigma noise schedules (based on the alpha bars) for us
alpha_schedule = torch.sqrt(noise_scheduler.alphas_cumprod)
sigma_schedule = torch.sqrt(1 - noise_scheduler.alphas_cumprod)
# Initialize the DDIM ODE solver for distillation.
solver = DDIMSolver(
noise_scheduler.alphas_cumprod.numpy(),
timesteps=noise_scheduler.config.num_train_timesteps,
ddim_timesteps=args.num_ddim_timesteps,
)
# 2. Load tokenizers from SD 1.X/2.X checkpoint.
tokenizer = AutoTokenizer.from_pretrained(
args.pretrained_teacher_model, subfolder="tokenizer", revision=args.teacher_revision, use_fast=False
)
# 3. Load text encoders from SD 1.X/2.X checkpoint.
# import correct text encoder classes
text_encoder = CLIPTextModel.from_pretrained(
args.pretrained_teacher_model, subfolder="text_encoder", revision=args.teacher_revision
)
# 4. Load VAE from SD 1.X/2.X checkpoint
vae = AutoencoderKL.from_pretrained(
args.pretrained_teacher_model,
subfolder="vae",
revision=args.teacher_revision,
)
# 5. Load teacher U-Net from SD 1.X/2.X checkpoint
teacher_unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
# 6. Freeze teacher vae, text_encoder, and teacher_unet
vae.requires_grad_(False)
text_encoder.requires_grad_(False)
teacher_unet.requires_grad_(False)
# 7. Create online student U-Net.
unet = UNet2DConditionModel.from_pretrained(
args.pretrained_teacher_model, subfolder="unet", revision=args.teacher_revision
)
unet.train()
# Check that all trainable models are in full precision
low_precision_error_string = (
" Please make sure to always have all model weights in full float32 precision when starting training - even if"
" doing mixed precision training, copy of the weights should still be float32."
)
if accelerator.unwrap_model(unet).dtype != torch.float32:
raise ValueError(
f"Controlnet loaded as datatype {accelerator.unwrap_model(unet).dtype}. {low_precision_error_string}"
)
# 8. Add LoRA to the student U-Net, only the LoRA projection matrix will be updated by the optimizer.
if args.lora_target_modules is not None:
lora_target_modules = [module_key.strip() for module_key in args.lora_target_modules.split(",")]
else:
lora_target_modules = [
"to_q",
"to_k",
"to_v",
"to_out.0",
"proj_in",
"proj_out",
"ff.net.0.proj",
"ff.net.2",
"conv1",
"conv2",
"conv_shortcut",
"downsamplers.0.conv",
"upsamplers.0.conv",
"time_emb_proj",
]
lora_config = LoraConfig(
r=args.lora_rank,
target_modules=lora_target_modules,
lora_alpha=args.lora_alpha,
lora_dropout=args.lora_dropout,
)
unet = get_peft_model(unet, lora_config)
# 9. Handle mixed precision and device placement
# For mixed precision training we cast all non-trainable weigths to half-precision
# as these weights are only used for inference, keeping weights in full precision is not required.
weight_dtype = torch.float32
if accelerator.mixed_precision == "fp16":
weight_dtype = torch.float16
elif accelerator.mixed_precision == "bf16":
weight_dtype = torch.bfloat16
# Move unet, vae and text_encoder to device and cast to weight_dtype
# The VAE is in float32 to avoid NaN losses.
vae.to(accelerator.device)
if args.pretrained_vae_model_name_or_path is not None:
vae.to(dtype=weight_dtype)
text_encoder.to(accelerator.device, dtype=weight_dtype)
# Move teacher_unet to device, optionally cast to weight_dtype
teacher_unet.to(accelerator.device)
if args.cast_teacher_unet:
teacher_unet.to(dtype=weight_dtype)
# Also move the alpha and sigma noise schedules to accelerator.device.
alpha_schedule = alpha_schedule.to(accelerator.device)
sigma_schedule = sigma_schedule.to(accelerator.device)
# Move the ODE solver to accelerator.device.
solver = solver.to(accelerator.device)
# 10. Handle saving and loading of checkpoints
# `accelerate` 0.16.0 will have better support for customized saving
if version.parse(accelerate.__version__) >= version.parse("0.16.0"):
# create custom saving & loading hooks so that `accelerator.save_state(...)` serializes in a nice format
def save_model_hook(models, weights, output_dir):
if accelerator.is_main_process:
unet_ = accelerator.unwrap_model(unet)
lora_state_dict = get_peft_model_state_dict(unet_, adapter_name="default")
StableDiffusionPipeline.save_lora_weights(os.path.join(output_dir, "unet_lora"), lora_state_dict)
# save weights in peft format to be able to load them back
unet_.save_pretrained(output_dir)
for _, model in enumerate(models):
# make sure to pop weight so that corresponding model is not saved again
weights.pop()
def load_model_hook(models, input_dir):
# load the LoRA into the model
unet_ = accelerator.unwrap_model(unet)
unet_.load_adapter(input_dir, "default", is_trainable=True)
for _ in range(len(models)):
# pop models so that they are not loaded again
models.pop()
accelerator.register_save_state_pre_hook(save_model_hook)
accelerator.register_load_state_pre_hook(load_model_hook)
# 11. Enable optimizations
if args.enable_xformers_memory_efficient_attention:
if is_xformers_available():
import xformers
xformers_version = version.parse(xformers.__version__)
if xformers_version == version.parse("0.0.16"):
logger.warning(
"xFormers 0.0.16 cannot be used for training in some GPUs. If you observe problems during training, please update xFormers to at least 0.0.17. See https://huggingface.co/docs/diffusers/main/en/optimization/xformers for more details."
)
unet.enable_xformers_memory_efficient_attention()
teacher_unet.enable_xformers_memory_efficient_attention()
# target_unet.enable_xformers_memory_efficient_attention()
else:
raise ValueError("xformers is not available. Make sure it is installed correctly")
# Enable TF32 for faster training on Ampere GPUs,
# cf https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices
if args.allow_tf32:
torch.backends.cuda.matmul.allow_tf32 = True
if args.gradient_checkpointing:
unet.enable_gradient_checkpointing()
# Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
if args.use_8bit_adam:
try:
import bitsandbytes as bnb
except ImportError:
raise ImportError(
"To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
)
optimizer_class = bnb.optim.AdamW8bit
else:
optimizer_class = torch.optim.AdamW
# 12. Optimizer creation
optimizer = optimizer_class(
unet.parameters(),
lr=args.learning_rate,
betas=(args.adam_beta1, args.adam_beta2),
weight_decay=args.adam_weight_decay,
eps=args.adam_epsilon,
)
# 13. Dataset creation and data processing
# Here, we compute not just the text embeddings but also the additional embeddings
# needed for the SD XL UNet to operate.
def compute_embeddings(prompt_batch, proportion_empty_prompts, text_encoder, tokenizer, is_train=True):
prompt_embeds = encode_prompt(prompt_batch, text_encoder, tokenizer, proportion_empty_prompts, is_train)
return {"prompt_embeds": prompt_embeds}
dataset = SDText2ImageDataset(
train_shards_path_or_url=args.train_shards_path_or_url,
num_train_examples=args.max_train_samples,
per_gpu_batch_size=args.train_batch_size,
global_batch_size=args.train_batch_size * accelerator.num_processes,
num_workers=args.dataloader_num_workers,
resolution=args.resolution,
interpolation_type=args.interpolation_type,
shuffle_buffer_size=1000,
pin_memory=True,
persistent_workers=True,
)
train_dataloader = dataset.train_dataloader
compute_embeddings_fn = functools.partial(
compute_embeddings,
proportion_empty_prompts=0,
text_encoder=text_encoder,
tokenizer=tokenizer,
)
# 14. LR Scheduler creation
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
args.lr_scheduler,
optimizer=optimizer,
num_warmup_steps=args.lr_warmup_steps,
num_training_steps=args.max_train_steps,
)
# 15. Prepare for training
# Prepare everything with our `accelerator`.
unet, optimizer, lr_scheduler = accelerator.prepare(unet, optimizer, lr_scheduler)
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(train_dataloader.num_batches / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if accelerator.is_main_process:
tracker_config = dict(vars(args))
accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
uncond_input_ids = tokenizer(
[""] * args.train_batch_size, return_tensors="pt", padding="max_length", max_length=77
).input_ids.to(accelerator.device)
uncond_prompt_embeds = text_encoder(uncond_input_ids)[0]
# 16. Train!
total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num batches each epoch = {train_dataloader.num_batches}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
global_step = 0
first_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint != "latest":
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = os.listdir(args.output_dir)
dirs = [d for d in dirs if d.startswith("checkpoint")]
dirs = sorted(dirs, key=lambda x: int(x.split("-")[1]))
path = dirs[-1] if len(dirs) > 0 else None
if path is None:
accelerator.print(
f"Checkpoint '{args.resume_from_checkpoint}' does not exist. Starting a new training run."
)
args.resume_from_checkpoint = None
initial_global_step = 0
else:
accelerator.print(f"Resuming from checkpoint {path}")
accelerator.load_state(os.path.join(args.output_dir, path))
global_step = int(path.split("-")[1])
initial_global_step = global_step
first_epoch = global_step // num_update_steps_per_epoch
else:
initial_global_step = 0
progress_bar = tqdm(
range(0, args.max_train_steps),
initial=initial_global_step,
desc="Steps",
# Only show the progress bar once on each machine.
disable=not accelerator.is_local_main_process,
)
for epoch in range(first_epoch, args.num_train_epochs):
for step, batch in enumerate(train_dataloader):
with accelerator.accumulate(unet):
# 1. Load and process the image and text conditioning
image, text = batch
image = image.to(accelerator.device, non_blocking=True)
encoded_text = compute_embeddings_fn(text)
pixel_values = image.to(dtype=weight_dtype)
if vae.dtype != weight_dtype:
vae.to(dtype=weight_dtype)
# encode pixel values with batch size of at most args.vae_encode_batch_size
latents = []
for i in range(0, pixel_values.shape[0], args.vae_encode_batch_size):
latents.append(vae.encode(pixel_values[i : i + args.vae_encode_batch_size]).latent_dist.sample())
latents = torch.cat(latents, dim=0)
latents = latents * vae.config.scaling_factor
latents = latents.to(weight_dtype)
bsz = latents.shape[0]
# 2. Sample a random timestep for each image t_n from the ODE solver timesteps without bias.
# For the DDIM solver, the timestep schedule is [T - 1, T - k - 1, T - 2 * k - 1, ...]
topk = noise_scheduler.config.num_train_timesteps // args.num_ddim_timesteps
index = torch.randint(0, args.num_ddim_timesteps, (bsz,), device=latents.device).long()
start_timesteps = solver.ddim_timesteps[index]
timesteps = start_timesteps - topk
timesteps = torch.where(timesteps < 0, torch.zeros_like(timesteps), timesteps)
# 3. Get boundary scalings for start_timesteps and (end) timesteps.
c_skip_start, c_out_start = scalings_for_boundary_conditions(
start_timesteps, timestep_scaling=args.timestep_scaling_factor
)
c_skip_start, c_out_start = [append_dims(x, latents.ndim) for x in [c_skip_start, c_out_start]]
c_skip, c_out = scalings_for_boundary_conditions(
timesteps, timestep_scaling=args.timestep_scaling_factor
)
c_skip, c_out = [append_dims(x, latents.ndim) for x in [c_skip, c_out]]
# 4. Sample noise from the prior and add it to the latents according to the noise magnitude at each
# timestep (this is the forward diffusion process) [z_{t_{n + k}} in Algorithm 1]
noise = torch.randn_like(latents)
noisy_model_input = noise_scheduler.add_noise(latents, noise, start_timesteps)
# 5. Sample a random guidance scale w from U[w_min, w_max]
# Note that for LCM-LoRA distillation it is not necessary to use a guidance scale embedding
w = (args.w_max - args.w_min) * torch.rand((bsz,)) + args.w_min
w = w.reshape(bsz, 1, 1, 1)
w = w.to(device=latents.device, dtype=latents.dtype)
# 6. Prepare prompt embeds and unet_added_conditions
prompt_embeds = encoded_text.pop("prompt_embeds")
# 7. Get online LCM prediction on z_{t_{n + k}} (noisy_model_input), w, c, t_{n + k} (start_timesteps)
noise_pred = unet(
noisy_model_input,
start_timesteps,
timestep_cond=None,
encoder_hidden_states=prompt_embeds.float(),
added_cond_kwargs=encoded_text,
).sample
pred_x_0 = get_predicted_original_sample(
noise_pred,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
model_pred = c_skip_start * noisy_model_input + c_out_start * pred_x_0
# 8. Compute the conditional and unconditional teacher model predictions to get CFG estimates of the
# predicted noise eps_0 and predicted original sample x_0, then run the ODE solver using these
# estimates to predict the data point in the augmented PF-ODE trajectory corresponding to the next ODE
# solver timestep.
with torch.no_grad():
with torch.autocast("cuda"):
# 1. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and conditional embedding c
cond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=prompt_embeds.to(weight_dtype),
).sample
cond_pred_x0 = get_predicted_original_sample(
cond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
cond_pred_noise = get_predicted_noise(
cond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# 2. Get teacher model prediction on noisy_model_input z_{t_{n + k}} and unconditional embedding 0
uncond_teacher_output = teacher_unet(
noisy_model_input.to(weight_dtype),
start_timesteps,
encoder_hidden_states=uncond_prompt_embeds.to(weight_dtype),
).sample
uncond_pred_x0 = get_predicted_original_sample(
uncond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
uncond_pred_noise = get_predicted_noise(
uncond_teacher_output,
start_timesteps,
noisy_model_input,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
# 3. Calculate the CFG estimate of x_0 (pred_x0) and eps_0 (pred_noise)
# Note that this uses the LCM paper's CFG formulation rather than the Imagen CFG formulation
pred_x0 = cond_pred_x0 + w * (cond_pred_x0 - uncond_pred_x0)
pred_noise = cond_pred_noise + w * (cond_pred_noise - uncond_pred_noise)
# 4. Run one step of the ODE solver to estimate the next point x_prev on the
# augmented PF-ODE trajectory (solving backward in time)
# Note that the DDIM step depends on both the predicted x_0 and source noise eps_0.
x_prev = solver.ddim_step(pred_x0, pred_noise, index)
# 9. Get target LCM prediction on x_prev, w, c, t_n (timesteps)
# Note that we do not use a separate target network for LCM-LoRA distillation.
with torch.no_grad():
with torch.autocast("cuda", dtype=weight_dtype):
target_noise_pred = unet(
x_prev.float(),
timesteps,
timestep_cond=None,
encoder_hidden_states=prompt_embeds.float(),
).sample
pred_x_0 = get_predicted_original_sample(
target_noise_pred,
timesteps,
x_prev,
noise_scheduler.config.prediction_type,
alpha_schedule,
sigma_schedule,
)
target = c_skip * x_prev + c_out * pred_x_0
# 10. Calculate loss
if args.loss_type == "l2":
loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
elif args.loss_type == "huber":
loss = torch.mean(
torch.sqrt((model_pred.float() - target.float()) ** 2 + args.huber_c**2) - args.huber_c
)
# 11. Backpropagate on the online student model (`unet`)
accelerator.backward(loss)
if accelerator.sync_gradients:
accelerator.clip_grad_norm_(unet.parameters(), args.max_grad_norm)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad(set_to_none=True)
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
global_step += 1
if accelerator.is_main_process:
if global_step % args.checkpointing_steps == 0:
# _before_ saving state, check if this save would set us over the `checkpoints_total_limit`
if args.checkpoints_total_limit is not None:
checkpoints = os.listdir(args.output_dir)
checkpoints = [d for d in checkpoints if d.startswith("checkpoint")]
checkpoints = sorted(checkpoints, key=lambda x: int(x.split("-")[1]))
# before we save the new checkpoint, we need to have at _most_ `checkpoints_total_limit - 1` checkpoints
if len(checkpoints) >= args.checkpoints_total_limit:
num_to_remove = len(checkpoints) - args.checkpoints_total_limit + 1
removing_checkpoints = checkpoints[0:num_to_remove]
logger.info(
f"{len(checkpoints)} checkpoints already exist, removing {len(removing_checkpoints)} checkpoints"
)
logger.info(f"removing checkpoints: {', '.join(removing_checkpoints)}")
for removing_checkpoint in removing_checkpoints:
removing_checkpoint = os.path.join(args.output_dir, removing_checkpoint)
shutil.rmtree(removing_checkpoint)
save_path = os.path.join(args.output_dir, f"checkpoint-{global_step}")
accelerator.save_state(save_path)
logger.info(f"Saved state to {save_path}")
if global_step % args.validation_steps == 0:
log_validation(vae, unet, args, accelerator, weight_dtype, global_step)
logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
progress_bar.set_postfix(**logs)
accelerator.log(logs, step=global_step)
if global_step >= args.max_train_steps:
break
# Create the pipeline using using the trained modules and save it.
accelerator.wait_for_everyone()
if accelerator.is_main_process:
unet = accelerator.unwrap_model(unet)
unet.save_pretrained(args.output_dir)
lora_state_dict = get_peft_model_state_dict(unet, adapter_name="default")
StableDiffusionPipeline.save_lora_weights(os.path.join(args.output_dir, "unet_lora"), lora_state_dict)
if args.push_to_hub:
upload_folder(
repo_id=repo_id,
folder_path=args.output_dir,
commit_message="End of training",
ignore_patterns=["step_*", "epoch_*"],
)
accelerator.end_training()
if __name__ == "__main__":
args = parse_args()
main(args)
| diffusers/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py/0 | {
"file_path": "diffusers/examples/consistency_distillation/train_lcm_distill_lora_sd_wds.py",
"repo_id": "diffusers",
"token_count": 26899
} | 111 |
# Copyright 2024 Custom Diffusion authors. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import os
from io import BytesIO
from pathlib import Path
import requests
from clip_retrieval.clip_client import ClipClient
from PIL import Image
from tqdm import tqdm
def retrieve(class_prompt, class_data_dir, num_class_images):
factor = 1.5
num_images = int(factor * num_class_images)
client = ClipClient(
url="https://knn.laion.ai/knn-service", indice_name="laion_400m", num_images=num_images, aesthetic_weight=0.1
)
os.makedirs(f"{class_data_dir}/images", exist_ok=True)
if len(list(Path(f"{class_data_dir}/images").iterdir())) >= num_class_images:
return
while True:
class_images = client.query(text=class_prompt)
if len(class_images) >= factor * num_class_images or num_images > 1e4:
break
else:
num_images = int(factor * num_images)
client = ClipClient(
url="https://knn.laion.ai/knn-service",
indice_name="laion_400m",
num_images=num_images,
aesthetic_weight=0.1,
)
count = 0
total = 0
pbar = tqdm(desc="downloading real regularization images", total=num_class_images)
with open(f"{class_data_dir}/caption.txt", "w") as f1, open(f"{class_data_dir}/urls.txt", "w") as f2, open(
f"{class_data_dir}/images.txt", "w"
) as f3:
while total < num_class_images:
images = class_images[count]
count += 1
try:
img = requests.get(images["url"], timeout=30)
if img.status_code == 200:
_ = Image.open(BytesIO(img.content))
with open(f"{class_data_dir}/images/{total}.jpg", "wb") as f:
f.write(img.content)
f1.write(images["caption"] + "\n")
f2.write(images["url"] + "\n")
f3.write(f"{class_data_dir}/images/{total}.jpg" + "\n")
total += 1
pbar.update(1)
else:
continue
except Exception:
continue
return
def parse_args():
parser = argparse.ArgumentParser("", add_help=False)
parser.add_argument("--class_prompt", help="text prompt to retrieve images", required=True, type=str)
parser.add_argument("--class_data_dir", help="path to save images", required=True, type=str)
parser.add_argument("--num_class_images", help="number of images to download", default=200, type=int)
return parser.parse_args()
if __name__ == "__main__":
args = parse_args()
retrieve(args.class_prompt, args.class_data_dir, args.num_class_images)
| diffusers/examples/custom_diffusion/retrieve.py/0 | {
"file_path": "diffusers/examples/custom_diffusion/retrieve.py",
"repo_id": "diffusers",
"token_count": 1429
} | 112 |
import warnings
from diffusers import StableDiffusionImg2ImgPipeline # noqa F401
warnings.warn(
"The `image_to_image.py` script is outdated. Please use directly `from diffusers import"
" StableDiffusionImg2ImgPipeline` instead."
)
| diffusers/examples/inference/image_to_image.py/0 | {
"file_path": "diffusers/examples/inference/image_to_image.py",
"repo_id": "diffusers",
"token_count": 84
} | 113 |
# Research projects
This folder contains various research projects using 🧨 Diffusers.
They are not really maintained by the core maintainers of this library and often require a specific version of Diffusers that is indicated in the requirements file of each folder.
Updating them to the most recent version of the library will require some work.
To use any of them, just run the command
```
pip install -r requirements.txt
```
inside the folder of your choice.
If you need help with any of those, please open an issue where you directly ping the author(s), as indicated at the top of the README of each folder.
| diffusers/examples/research_projects/README.md/0 | {
"file_path": "diffusers/examples/research_projects/README.md",
"repo_id": "diffusers",
"token_count": 143
} | 114 |
# Diffusion Model Alignment Using Direct Preference Optimization
This directory provides LoRA implementations of Diffusion DPO proposed in [DiffusionModel Alignment Using Direct Preference Optimization](https://arxiv.org/abs/2311.12908) by Bram Wallace, Meihua Dang, Rafael Rafailov, Linqi Zhou, Aaron Lou, Senthil Purushwalkam, Stefano Ermon, Caiming Xiong, Shafiq Joty, and Nikhil Naik.
We provide implementations for both Stable Diffusion (SD) and Stable Diffusion XL (SDXL). The original checkpoints are available at the URLs below:
* [mhdang/dpo-sd1.5-text2image-v1](https://huggingface.co/mhdang/dpo-sd1.5-text2image-v1)
* [mhdang/dpo-sdxl-text2image-v1](https://huggingface.co/mhdang/dpo-sdxl-text2image-v1)
> 💡 Note: The scripts are highly experimental and were only tested on low-data regimes. Proceed with caution. Feel free to let us know about your findings via GitHub issues.
## SD training command
```bash
accelerate launch train_diffusion_dpo.py \
--pretrained_model_name_or_path=runwayml/stable-diffusion-v1-5 \
--output_dir="diffusion-dpo" \
--mixed_precision="fp16" \
--dataset_name=kashif/pickascore \
--resolution=512 \
--train_batch_size=16 \
--gradient_accumulation_steps=2 \
--gradient_checkpointing \
--use_8bit_adam \
--rank=8 \
--learning_rate=1e-5 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=10000 \
--checkpointing_steps=2000 \
--run_validation --validation_steps=200 \
--seed="0" \
--report_to="wandb" \
--push_to_hub
```
## SDXL training command
```bash
accelerate launch train_diffusion_dpo_sdxl.py \
--pretrained_model_name_or_path=stabilityai/stable-diffusion-xl-base-1.0 \
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix \
--output_dir="diffusion-sdxl-dpo" \
--mixed_precision="fp16" \
--dataset_name=kashif/pickascore \
--train_batch_size=8 \
--gradient_accumulation_steps=2 \
--gradient_checkpointing \
--use_8bit_adam \
--rank=8 \
--learning_rate=1e-5 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=2000 \
--checkpointing_steps=500 \
--run_validation --validation_steps=50 \
--seed="0" \
--report_to="wandb" \
--push_to_hub
```
## SDXL Turbo training command
```bash
accelerate launch train_diffusion_dpo_sdxl.py \
--pretrained_model_name_or_path=stabilityai/sdxl-turbo \
--pretrained_vae_model_name_or_path=madebyollin/sdxl-vae-fp16-fix \
--output_dir="diffusion-sdxl-turbo-dpo" \
--mixed_precision="fp16" \
--dataset_name=kashif/pickascore \
--train_batch_size=8 \
--gradient_accumulation_steps=2 \
--gradient_checkpointing \
--use_8bit_adam \
--rank=8 \
--learning_rate=1e-5 \
--report_to="wandb" \
--lr_scheduler="constant" \
--lr_warmup_steps=0 \
--max_train_steps=2000 \
--checkpointing_steps=500 \
--run_validation --validation_steps=50 \
--seed="0" \
--report_to="wandb" \
--is_turbo --resolution 512 \
--push_to_hub
```
## Acknowledgements
This is based on the amazing work done by [Bram](https://github.com/bram-w) here for Diffusion DPO: https://github.com/bram-w/trl/blob/dpo/.
| diffusers/examples/research_projects/diffusion_dpo/README.md/0 | {
"file_path": "diffusers/examples/research_projects/diffusion_dpo/README.md",
"repo_id": "diffusers",
"token_count": 1251
} | 115 |
## Diffusers examples with ONNXRuntime optimizations
**This research project is not actively maintained by the diffusers team. For any questions or comments, please contact Isamu Isozaki(isamu-isozaki) on github with any questions.**
The aim of this project is to provide retrieval augmented diffusion models to diffusers! | diffusers/examples/research_projects/rdm/README.md/0 | {
"file_path": "diffusers/examples/research_projects/rdm/README.md",
"repo_id": "diffusers",
"token_count": 75
} | 116 |
# Stable Diffusion text-to-image fine-tuning
The `train_text_to_image.py` script shows how to fine-tune stable diffusion model on your own dataset.
___Note___:
___This script is experimental. The script fine-tunes the whole model and often times the model overfits and runs into issues like catastrophic forgetting. It's recommended to try different hyperparameters to get the best result on your dataset.___
## Running locally with PyTorch
### Installing the dependencies
Before running the scripts, make sure to install the library's training dependencies:
**Important**
To make sure you can successfully run the latest versions of the example scripts, we highly recommend **installing from source** and keeping the install up to date as we update the example scripts frequently and install some example-specific requirements. To do this, execute the following steps in a new virtual environment:
```bash
git clone https://github.com/huggingface/diffusers
cd diffusers
pip install .
```
Then cd in the example folder and run
```bash
pip install -r requirements.txt
```
And initialize an [🤗Accelerate](https://github.com/huggingface/accelerate/) environment with:
```bash
accelerate config
```
Note also that we use PEFT library as backend for LoRA training, make sure to have `peft>=0.6.0` installed in your environment.
### Pokemon example
You need to accept the model license before downloading or using the weights. In this example we'll use model version `v1-4`, so you'll need to visit [its card](https://huggingface.co/CompVis/stable-diffusion-v1-4), read the license and tick the checkbox if you agree.
You have to be a registered user in 🤗 Hugging Face Hub, and you'll also need to use an access token for the code to work. For more information on access tokens, please refer to [this section of the documentation](https://huggingface.co/docs/hub/security-tokens).
Run the following command to authenticate your token
```bash
huggingface-cli login
```
If you have already cloned the repo, then you won't need to go through these steps.
<br>
#### Hardware
With `gradient_checkpointing` and `mixed_precision` it should be possible to fine tune the model on a single 24GB GPU. For higher `batch_size` and faster training it's better to use GPUs with >30GB memory.
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
<!-- accelerate_snippet_start -->
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
<!-- accelerate_snippet_end -->
To run on your own training files prepare the dataset according to the format required by `datasets`, you can find the instructions for how to do that in this [document](https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder-with-metadata).
If you wish to use custom loading logic, you should modify the script, we have left pointers for that in the training script.
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export TRAIN_DIR="path_to_your_dataset"
accelerate launch --mixed_precision="fp16" train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
Once the training is finished the model will be saved in the `output_dir` specified in the command. In this example it's `sd-pokemon-model`. To load the fine-tuned model for inference just pass that path to `StableDiffusionPipeline`
```python
import torch
from diffusers import StableDiffusionPipeline
model_path = "path_to_saved_model"
pipe = StableDiffusionPipeline.from_pretrained(model_path, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="yoda").images[0]
image.save("yoda-pokemon.png")
```
Checkpoints only save the unet, so to run inference from a checkpoint, just load the unet
```python
import torch
from diffusers import StableDiffusionPipeline, UNet2DConditionModel
model_path = "path_to_saved_model"
unet = UNet2DConditionModel.from_pretrained(model_path + "/checkpoint-<N>/unet", torch_dtype=torch.float16)
pipe = StableDiffusionPipeline.from_pretrained("<initial model>", unet=unet, torch_dtype=torch.float16)
pipe.to("cuda")
image = pipe(prompt="yoda").images[0]
image.save("yoda-pokemon.png")
```
#### Training with multiple GPUs
`accelerate` allows for seamless multi-GPU training. Follow the instructions [here](https://huggingface.co/docs/accelerate/basic_tutorials/launch)
for running distributed training with `accelerate`. Here is an example command:
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
accelerate launch --mixed_precision="fp16" --multi_gpu train_text_to_image.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--use_ema \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--gradient_accumulation_steps=4 \
--gradient_checkpointing \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--lr_scheduler="constant" --lr_warmup_steps=0 \
--output_dir="sd-pokemon-model"
```
#### Training with Min-SNR weighting
We support training with the Min-SNR weighting strategy proposed in [Efficient Diffusion Training via Min-SNR Weighting Strategy](https://arxiv.org/abs/2303.09556) which helps to achieve faster convergence
by rebalancing the loss. In order to use it, one needs to set the `--snr_gamma` argument. The recommended
value when using it is 5.0.
You can find [this project on Weights and Biases](https://wandb.ai/sayakpaul/text2image-finetune-minsnr) that compares the loss surfaces of the following setups:
* Training without the Min-SNR weighting strategy
* Training with the Min-SNR weighting strategy (`snr_gamma` set to 5.0)
* Training with the Min-SNR weighting strategy (`snr_gamma` set to 1.0)
For our small Pokemons dataset, the effects of Min-SNR weighting strategy might not appear to be pronounced, but for larger datasets, we believe the effects will be more pronounced.
Also, note that in this example, we either predict `epsilon` (i.e., the noise) or the `v_prediction`. For both of these cases, the formulation of the Min-SNR weighting strategy that we have used holds.
## Training with LoRA
Low-Rank Adaption of Large Language Models was first introduced by Microsoft in [LoRA: Low-Rank Adaptation of Large Language Models](https://arxiv.org/abs/2106.09685) by *Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen*.
In a nutshell, LoRA allows adapting pretrained models by adding pairs of rank-decomposition matrices to existing weights and **only** training those newly added weights. This has a couple of advantages:
- Previous pretrained weights are kept frozen so that model is not prone to [catastrophic forgetting](https://www.pnas.org/doi/10.1073/pnas.1611835114).
- Rank-decomposition matrices have significantly fewer parameters than original model, which means that trained LoRA weights are easily portable.
- LoRA attention layers allow to control to which extent the model is adapted toward new training images via a `scale` parameter.
[cloneofsimo](https://github.com/cloneofsimo) was the first to try out LoRA training for Stable Diffusion in the popular [lora](https://github.com/cloneofsimo/lora) GitHub repository.
With LoRA, it's possible to fine-tune Stable Diffusion on a custom image-caption pair dataset
on consumer GPUs like Tesla T4, Tesla V100.
### Training
First, you need to set up your development environment as is explained in the [installation section](#installing-the-dependencies). Make sure to set the `MODEL_NAME` and `DATASET_NAME` environment variables. Here, we will use [Stable Diffusion v1-4](https://hf.co/CompVis/stable-diffusion-v1-4) and the [Pokemons dataset](https://huggingface.co/datasets/lambdalabs/pokemon-blip-captions).
**___Note: Change the `resolution` to 768 if you are using the [stable-diffusion-2](https://huggingface.co/stabilityai/stable-diffusion-2) 768x768 model.___**
**___Note: It is quite useful to monitor the training progress by regularly generating sample images during training. [Weights and Biases](https://docs.wandb.ai/quickstart) is a nice solution to easily see generating images during training. All you need to do is to run `pip install wandb` before training to automatically log images.___**
```bash
export MODEL_NAME="CompVis/stable-diffusion-v1-4"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
```
For this example we want to directly store the trained LoRA embeddings on the Hub, so
we need to be logged in and add the `--push_to_hub` flag.
```bash
huggingface-cli login
```
Now we can start training!
```bash
accelerate launch --mixed_precision="fp16" train_text_to_image_lora.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME --caption_column="text" \
--resolution=512 --random_flip \
--train_batch_size=1 \
--num_train_epochs=100 --checkpointing_steps=5000 \
--learning_rate=1e-04 --lr_scheduler="constant" --lr_warmup_steps=0 \
--seed=42 \
--output_dir="sd-pokemon-model-lora" \
--validation_prompt="cute dragon creature" --report_to="wandb"
```
The above command will also run inference as fine-tuning progresses and log the results to Weights and Biases.
**___Note: When using LoRA we can use a much higher learning rate compared to non-LoRA fine-tuning. Here we use *1e-4* instead of the usual *1e-5*. Also, by using LoRA, it's possible to run `train_text_to_image_lora.py` in consumer GPUs like T4 or V100.___**
The final LoRA embedding weights have been uploaded to [sayakpaul/sd-model-finetuned-lora-t4](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4). **___Note: [The final weights](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/pytorch_lora_weights.bin) are only 3 MB in size, which is orders of magnitudes smaller than the original model.___**
You can check some inference samples that were logged during the course of the fine-tuning process [here](https://wandb.ai/sayakpaul/text2image-fine-tune/runs/q4lc0xsw).
### Inference
Once you have trained a model using above command, the inference can be done simply using the `StableDiffusionPipeline` after loading the trained LoRA weights. You
need to pass the `output_dir` for loading the LoRA weights which, in this case, is `sd-pokemon-model-lora`.
```python
from diffusers import StableDiffusionPipeline
import torch
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
prompt = "A pokemon with green eyes and red legs."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5).images[0]
image.save("pokemon.png")
```
If you are loading the LoRA parameters from the Hub and if the Hub repository has
a `base_model` tag (such as [this](https://huggingface.co/sayakpaul/sd-model-finetuned-lora-t4/blob/main/README.md?code=true#L4)), then
you can do:
```py
from huggingface_hub.repocard import RepoCard
lora_model_id = "sayakpaul/sd-model-finetuned-lora-t4"
card = RepoCard.load(lora_model_id)
base_model_id = card.data.to_dict()["base_model"]
pipe = StableDiffusionPipeline.from_pretrained(base_model_id, torch_dtype=torch.float16)
...
```
## Training with Flax/JAX
For faster training on TPUs and GPUs you can leverage the flax training example. Follow the instructions above to get the model and dataset before running the script.
**___Note: The flax example doesn't yet support features like gradient checkpoint, gradient accumulation etc, so to use flax for faster training we will need >30GB cards or TPU v3.___**
Before running the scripts, make sure to install the library's training dependencies:
```bash
pip install -U -r requirements_flax.txt
```
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export DATASET_NAME="lambdalabs/pokemon-blip-captions"
python train_text_to_image_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--dataset_name=$DATASET_NAME \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--mixed_precision="fp16" \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--output_dir="sd-pokemon-model"
```
To run on your own training files prepare the dataset according to the format required by `datasets`, you can find the instructions for how to do that in this [document](https://huggingface.co/docs/datasets/v2.4.0/en/image_load#imagefolder-with-metadata).
If you wish to use custom loading logic, you should modify the script, we have left pointers for that in the training script.
```bash
export MODEL_NAME="duongna/stable-diffusion-v1-4-flax"
export TRAIN_DIR="path_to_your_dataset"
python train_text_to_image_flax.py \
--pretrained_model_name_or_path=$MODEL_NAME \
--train_data_dir=$TRAIN_DIR \
--resolution=512 --center_crop --random_flip \
--train_batch_size=1 \
--mixed_precision="fp16" \
--max_train_steps=15000 \
--learning_rate=1e-05 \
--max_grad_norm=1 \
--output_dir="sd-pokemon-model"
```
### Training with xFormers:
You can enable memory efficient attention by [installing xFormers](https://huggingface.co/docs/diffusers/main/en/optimization/xformers) and passing the `--enable_xformers_memory_efficient_attention` argument to the script.
xFormers training is not available for Flax/JAX.
**Note**:
According to [this issue](https://github.com/huggingface/diffusers/issues/2234#issuecomment-1416931212), xFormers `v0.0.16` cannot be used for training in some GPUs. If you observe that problem, please install a development version as indicated in that comment.
## Stable Diffusion XL
* We support fine-tuning the UNet shipped in [Stable Diffusion XL](https://huggingface.co/papers/2307.01952) via the `train_text_to_image_sdxl.py` script. Please refer to the docs [here](./README_sdxl.md).
* We also support fine-tuning of the UNet and Text Encoder shipped in [Stable Diffusion XL](https://huggingface.co/papers/2307.01952) with LoRA via the `train_text_to_image_lora_sdxl.py` script. Please refer to the docs [here](./README_sdxl.md).
| diffusers/examples/text_to_image/README.md/0 | {
"file_path": "diffusers/examples/text_to_image/README.md",
"repo_id": "diffusers",
"token_count": 4855
} | 117 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import os
import sys
import tempfile
sys.path.append("..")
from test_examples_utils import ExamplesTestsAccelerate, run_command # noqa: E402
logging.basicConfig(level=logging.DEBUG)
logger = logging.getLogger()
stream_handler = logging.StreamHandler(sys.stdout)
logger.addHandler(stream_handler)
class TextualInversion(ExamplesTestsAccelerate):
def test_textual_inversion(self):
with tempfile.TemporaryDirectory() as tmpdir:
test_args = f"""
examples/textual_inversion/textual_inversion.py
--pretrained_model_name_or_path hf-internal-testing/tiny-stable-diffusion-pipe
--train_data_dir docs/source/en/imgs
--learnable_property object
--placeholder_token <cat-toy>
--initializer_token a
--save_steps 1
--num_vectors 2
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
--max_train_steps 2
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
""".split()
run_command(self._launch_args + test_args)
# save_pretrained smoke test
self.assertTrue(os.path.isfile(os.path.join(tmpdir, "learned_embeds.safetensors")))
def test_textual_inversion_checkpointing(self):
with tempfile.TemporaryDirectory() as tmpdir:
test_args = f"""
examples/textual_inversion/textual_inversion.py
--pretrained_model_name_or_path hf-internal-testing/tiny-stable-diffusion-pipe
--train_data_dir docs/source/en/imgs
--learnable_property object
--placeholder_token <cat-toy>
--initializer_token a
--save_steps 1
--num_vectors 2
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
--max_train_steps 3
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
--checkpointing_steps=1
--checkpoints_total_limit=2
""".split()
run_command(self._launch_args + test_args)
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
{"checkpoint-2", "checkpoint-3"},
)
def test_textual_inversion_checkpointing_checkpoints_total_limit_removes_multiple_checkpoints(self):
with tempfile.TemporaryDirectory() as tmpdir:
test_args = f"""
examples/textual_inversion/textual_inversion.py
--pretrained_model_name_or_path hf-internal-testing/tiny-stable-diffusion-pipe
--train_data_dir docs/source/en/imgs
--learnable_property object
--placeholder_token <cat-toy>
--initializer_token a
--save_steps 1
--num_vectors 2
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
--max_train_steps 2
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
--checkpointing_steps=1
""".split()
run_command(self._launch_args + test_args)
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
{"checkpoint-1", "checkpoint-2"},
)
resume_run_args = f"""
examples/textual_inversion/textual_inversion.py
--pretrained_model_name_or_path hf-internal-testing/tiny-stable-diffusion-pipe
--train_data_dir docs/source/en/imgs
--learnable_property object
--placeholder_token <cat-toy>
--initializer_token a
--save_steps 1
--num_vectors 2
--resolution 64
--train_batch_size 1
--gradient_accumulation_steps 1
--max_train_steps 2
--learning_rate 5.0e-04
--scale_lr
--lr_scheduler constant
--lr_warmup_steps 0
--output_dir {tmpdir}
--checkpointing_steps=1
--resume_from_checkpoint=checkpoint-2
--checkpoints_total_limit=2
""".split()
run_command(self._launch_args + resume_run_args)
# check checkpoint directories exist
self.assertEqual(
{x for x in os.listdir(tmpdir) if "checkpoint" in x},
{"checkpoint-2", "checkpoint-3"},
)
| diffusers/examples/textual_inversion/test_textual_inversion.py/0 | {
"file_path": "diffusers/examples/textual_inversion/test_textual_inversion.py",
"repo_id": "diffusers",
"token_count": 2914
} | 118 |
import argparse
import re
import torch
import yaml
from transformers import (
CLIPProcessor,
CLIPTextModel,
CLIPTokenizer,
CLIPVisionModelWithProjection,
)
from diffusers import (
AutoencoderKL,
DDIMScheduler,
StableDiffusionGLIGENPipeline,
StableDiffusionGLIGENTextImagePipeline,
UNet2DConditionModel,
)
from diffusers.pipelines.stable_diffusion.convert_from_ckpt import (
assign_to_checkpoint,
conv_attn_to_linear,
protected,
renew_attention_paths,
renew_resnet_paths,
renew_vae_attention_paths,
renew_vae_resnet_paths,
shave_segments,
textenc_conversion_map,
textenc_pattern,
)
def convert_open_clip_checkpoint(checkpoint):
checkpoint = checkpoint["text_encoder"]
text_model = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
keys = list(checkpoint.keys())
text_model_dict = {}
if "cond_stage_model.model.text_projection" in checkpoint:
d_model = int(checkpoint["cond_stage_model.model.text_projection"].shape[0])
else:
d_model = 1024
for key in keys:
if "resblocks.23" in key: # Diffusers drops the final layer and only uses the penultimate layer
continue
if key in textenc_conversion_map:
text_model_dict[textenc_conversion_map[key]] = checkpoint[key]
# if key.startswith("cond_stage_model.model.transformer."):
new_key = key[len("transformer.") :]
if new_key.endswith(".in_proj_weight"):
new_key = new_key[: -len(".in_proj_weight")]
new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
text_model_dict[new_key + ".q_proj.weight"] = checkpoint[key][:d_model, :]
text_model_dict[new_key + ".k_proj.weight"] = checkpoint[key][d_model : d_model * 2, :]
text_model_dict[new_key + ".v_proj.weight"] = checkpoint[key][d_model * 2 :, :]
elif new_key.endswith(".in_proj_bias"):
new_key = new_key[: -len(".in_proj_bias")]
new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
text_model_dict[new_key + ".q_proj.bias"] = checkpoint[key][:d_model]
text_model_dict[new_key + ".k_proj.bias"] = checkpoint[key][d_model : d_model * 2]
text_model_dict[new_key + ".v_proj.bias"] = checkpoint[key][d_model * 2 :]
else:
if key != "transformer.text_model.embeddings.position_ids":
new_key = textenc_pattern.sub(lambda m: protected[re.escape(m.group(0))], new_key)
text_model_dict[new_key] = checkpoint[key]
if key == "transformer.text_model.embeddings.token_embedding.weight":
text_model_dict["text_model.embeddings.token_embedding.weight"] = checkpoint[key]
text_model_dict.pop("text_model.embeddings.transformer.text_model.embeddings.token_embedding.weight")
text_model.load_state_dict(text_model_dict)
return text_model
def convert_gligen_vae_checkpoint(checkpoint, config):
checkpoint = checkpoint["autoencoder"]
vae_state_dict = {}
vae_key = "first_stage_model."
keys = list(checkpoint.keys())
for key in keys:
vae_state_dict[key.replace(vae_key, "")] = checkpoint.get(key)
new_checkpoint = {}
new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
# Retrieves the keys for the encoder down blocks only
num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer})
down_blocks = {
layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
}
# Retrieves the keys for the decoder up blocks only
num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
up_blocks = {
layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
}
for i in range(num_down_blocks):
resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
f"encoder.down.{i}.downsample.conv.weight"
)
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
f"encoder.down.{i}.downsample.conv.bias"
)
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
num_mid_res_blocks = 2
for i in range(1, num_mid_res_blocks + 1):
resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
paths = renew_vae_attention_paths(mid_attentions)
meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
conv_attn_to_linear(new_checkpoint)
for i in range(num_up_blocks):
block_id = num_up_blocks - 1 - i
resnets = [
key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
]
if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
f"decoder.up.{block_id}.upsample.conv.weight"
]
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
f"decoder.up.{block_id}.upsample.conv.bias"
]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
num_mid_res_blocks = 2
for i in range(1, num_mid_res_blocks + 1):
resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
paths = renew_vae_attention_paths(mid_attentions)
meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
conv_attn_to_linear(new_checkpoint)
for key in new_checkpoint.keys():
if "encoder.mid_block.attentions.0" in key or "decoder.mid_block.attentions.0" in key:
if "query" in key:
new_checkpoint[key.replace("query", "to_q")] = new_checkpoint.pop(key)
if "value" in key:
new_checkpoint[key.replace("value", "to_v")] = new_checkpoint.pop(key)
if "key" in key:
new_checkpoint[key.replace("key", "to_k")] = new_checkpoint.pop(key)
if "proj_attn" in key:
new_checkpoint[key.replace("proj_attn", "to_out.0")] = new_checkpoint.pop(key)
return new_checkpoint
def convert_gligen_unet_checkpoint(checkpoint, config, path=None, extract_ema=False):
unet_state_dict = {}
checkpoint = checkpoint["model"]
keys = list(checkpoint.keys())
unet_key = "model.diffusion_model."
if sum(k.startswith("model_ema") for k in keys) > 100 and extract_ema:
print(f"Checkpoint {path} has bot EMA and non-EMA weights.")
print(
"In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
" weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
)
for key in keys:
if key.startswith("model.diffusion_model"):
flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
else:
if sum(k.startswith("model_ema") for k in keys) > 100:
print(
"In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
" weights (usually better for inference), please make sure to add the `--extract_ema` flag."
)
for key in keys:
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
new_checkpoint = {}
new_checkpoint["time_embedding.linear_1.weight"] = unet_state_dict["time_embed.0.weight"]
new_checkpoint["time_embedding.linear_1.bias"] = unet_state_dict["time_embed.0.bias"]
new_checkpoint["time_embedding.linear_2.weight"] = unet_state_dict["time_embed.2.weight"]
new_checkpoint["time_embedding.linear_2.bias"] = unet_state_dict["time_embed.2.bias"]
new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
# Retrieves the keys for the input blocks only
num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
input_blocks = {
layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
for layer_id in range(num_input_blocks)
}
# Retrieves the keys for the middle blocks only
num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
middle_blocks = {
layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
for layer_id in range(num_middle_blocks)
}
# Retrieves the keys for the output blocks only
num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
output_blocks = {
layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
for layer_id in range(num_output_blocks)
}
for i in range(1, num_input_blocks):
block_id = (i - 1) // (config["layers_per_block"] + 1)
layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
resnets = [
key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
]
attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
f"input_blocks.{i}.0.op.weight"
)
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
f"input_blocks.{i}.0.op.bias"
)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
resnet_0 = middle_blocks[0]
attentions = middle_blocks[1]
resnet_1 = middle_blocks[2]
resnet_0_paths = renew_resnet_paths(resnet_0)
assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
resnet_1_paths = renew_resnet_paths(resnet_1)
assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
attentions_paths = renew_attention_paths(attentions)
meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(
attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
for i in range(num_output_blocks):
block_id = i // (config["layers_per_block"] + 1)
layer_in_block_id = i % (config["layers_per_block"] + 1)
output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
output_block_list = {}
for layer in output_block_layers:
layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
if layer_id in output_block_list:
output_block_list[layer_id].append(layer_name)
else:
output_block_list[layer_id] = [layer_name]
if len(output_block_list) > 1:
resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
resnet_0_paths = renew_resnet_paths(resnets)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
output_block_list = {k: sorted(v) for k, v in output_block_list.items()}
if ["conv.bias", "conv.weight"] in output_block_list.values():
index = list(output_block_list.values()).index(["conv.bias", "conv.weight"])
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.weight"
]
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.bias"
]
# Clear attentions as they have been attributed above.
if len(attentions) == 2:
attentions = []
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {
"old": f"output_blocks.{i}.1",
"new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
else:
resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
for path in resnet_0_paths:
old_path = ".".join(["output_blocks", str(i), path["old"]])
new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
new_checkpoint[new_path] = unet_state_dict[old_path]
for key in keys:
if "position_net" in key:
new_checkpoint[key] = unet_state_dict[key]
return new_checkpoint
def create_vae_config(original_config, image_size: int):
vae_params = original_config["autoencoder"]["params"]["ddconfig"]
_ = original_config["autoencoder"]["params"]["embed_dim"]
block_out_channels = [vae_params["ch"] * mult for mult in vae_params["ch_mult"]]
down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels)
up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels)
config = {
"sample_size": image_size,
"in_channels": vae_params["in_channels"],
"out_channels": vae_params["out_ch"],
"down_block_types": tuple(down_block_types),
"up_block_types": tuple(up_block_types),
"block_out_channels": tuple(block_out_channels),
"latent_channels": vae_params["z_channels"],
"layers_per_block": vae_params["num_res_blocks"],
}
return config
def create_unet_config(original_config, image_size: int, attention_type):
unet_params = original_config["model"]["params"]
vae_params = original_config["autoencoder"]["params"]["ddconfig"]
block_out_channels = [unet_params["model_channels"] * mult for mult in unet_params["channel_mult"]]
down_block_types = []
resolution = 1
for i in range(len(block_out_channels)):
block_type = "CrossAttnDownBlock2D" if resolution in unet_params["attention_resolutions"] else "DownBlock2D"
down_block_types.append(block_type)
if i != len(block_out_channels) - 1:
resolution *= 2
up_block_types = []
for i in range(len(block_out_channels)):
block_type = "CrossAttnUpBlock2D" if resolution in unet_params["attention_resolutions"] else "UpBlock2D"
up_block_types.append(block_type)
resolution //= 2
vae_scale_factor = 2 ** (len(vae_params["ch_mult"]) - 1)
head_dim = unet_params["num_heads"] if "num_heads" in unet_params else None
use_linear_projection = (
unet_params["use_linear_in_transformer"] if "use_linear_in_transformer" in unet_params else False
)
if use_linear_projection:
if head_dim is None:
head_dim = [5, 10, 20, 20]
config = {
"sample_size": image_size // vae_scale_factor,
"in_channels": unet_params["in_channels"],
"down_block_types": tuple(down_block_types),
"block_out_channels": tuple(block_out_channels),
"layers_per_block": unet_params["num_res_blocks"],
"cross_attention_dim": unet_params["context_dim"],
"attention_head_dim": head_dim,
"use_linear_projection": use_linear_projection,
"attention_type": attention_type,
}
return config
def convert_gligen_to_diffusers(
checkpoint_path: str,
original_config_file: str,
attention_type: str,
image_size: int = 512,
extract_ema: bool = False,
num_in_channels: int = None,
device: str = None,
):
if device is None:
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = torch.load(checkpoint_path, map_location=device)
else:
checkpoint = torch.load(checkpoint_path, map_location=device)
if "global_step" in checkpoint:
checkpoint["global_step"]
else:
print("global_step key not found in model")
original_config = yaml.safe_load(original_config_file)
if num_in_channels is not None:
original_config["model"]["params"]["in_channels"] = num_in_channels
num_train_timesteps = original_config["diffusion"]["params"]["timesteps"]
beta_start = original_config["diffusion"]["params"]["linear_start"]
beta_end = original_config["diffusion"]["params"]["linear_end"]
scheduler = DDIMScheduler(
beta_end=beta_end,
beta_schedule="scaled_linear",
beta_start=beta_start,
num_train_timesteps=num_train_timesteps,
steps_offset=1,
clip_sample=False,
set_alpha_to_one=False,
prediction_type="epsilon",
)
# Convert the UNet2DConditionalModel model
unet_config = create_unet_config(original_config, image_size, attention_type)
unet = UNet2DConditionModel(**unet_config)
converted_unet_checkpoint = convert_gligen_unet_checkpoint(
checkpoint, unet_config, path=checkpoint_path, extract_ema=extract_ema
)
unet.load_state_dict(converted_unet_checkpoint)
# Convert the VAE model
vae_config = create_vae_config(original_config, image_size)
converted_vae_checkpoint = convert_gligen_vae_checkpoint(checkpoint, vae_config)
vae = AutoencoderKL(**vae_config)
vae.load_state_dict(converted_vae_checkpoint)
# Convert the text model
text_encoder = convert_open_clip_checkpoint(checkpoint)
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
if attention_type == "gated-text-image":
image_encoder = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
processor = CLIPProcessor.from_pretrained("openai/clip-vit-large-patch14")
pipe = StableDiffusionGLIGENTextImagePipeline(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
image_encoder=image_encoder,
processor=processor,
unet=unet,
scheduler=scheduler,
safety_checker=None,
feature_extractor=None,
)
elif attention_type == "gated":
pipe = StableDiffusionGLIGENPipeline(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=None,
feature_extractor=None,
)
return pipe
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--checkpoint_path", default=None, type=str, required=True, help="Path to the checkpoint to convert."
)
parser.add_argument(
"--original_config_file",
default=None,
type=str,
required=True,
help="The YAML config file corresponding to the gligen architecture.",
)
parser.add_argument(
"--num_in_channels",
default=None,
type=int,
help="The number of input channels. If `None` number of input channels will be automatically inferred.",
)
parser.add_argument(
"--extract_ema",
action="store_true",
help=(
"Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
" or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
" higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
),
)
parser.add_argument(
"--attention_type",
default=None,
type=str,
required=True,
help="Type of attention ex: gated or gated-text-image",
)
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
parser.add_argument("--device", type=str, help="Device to use.")
parser.add_argument("--half", action="store_true", help="Save weights in half precision.")
args = parser.parse_args()
pipe = convert_gligen_to_diffusers(
checkpoint_path=args.checkpoint_path,
original_config_file=args.original_config_file,
attention_type=args.attention_type,
extract_ema=args.extract_ema,
num_in_channels=args.num_in_channels,
device=args.device,
)
if args.half:
pipe.to(dtype=torch.float16)
pipe.save_pretrained(args.dump_path)
| diffusers/scripts/convert_gligen_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_gligen_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 11150
} | 119 |
# coding=utf-8
# Copyright 2024 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Conversion script for the Versatile Stable Diffusion checkpoints."""
import argparse
from argparse import Namespace
import torch
from transformers import (
CLIPImageProcessor,
CLIPTextModelWithProjection,
CLIPTokenizer,
CLIPVisionModelWithProjection,
)
from diffusers import (
AutoencoderKL,
DDIMScheduler,
DPMSolverMultistepScheduler,
EulerAncestralDiscreteScheduler,
EulerDiscreteScheduler,
LMSDiscreteScheduler,
PNDMScheduler,
UNet2DConditionModel,
VersatileDiffusionPipeline,
)
from diffusers.pipelines.versatile_diffusion.modeling_text_unet import UNetFlatConditionModel
SCHEDULER_CONFIG = Namespace(
**{
"beta_linear_start": 0.00085,
"beta_linear_end": 0.012,
"timesteps": 1000,
"scale_factor": 0.18215,
}
)
IMAGE_UNET_CONFIG = Namespace(
**{
"input_channels": 4,
"model_channels": 320,
"output_channels": 4,
"num_noattn_blocks": [2, 2, 2, 2],
"channel_mult": [1, 2, 4, 4],
"with_attn": [True, True, True, False],
"num_heads": 8,
"context_dim": 768,
"use_checkpoint": True,
}
)
TEXT_UNET_CONFIG = Namespace(
**{
"input_channels": 768,
"model_channels": 320,
"output_channels": 768,
"num_noattn_blocks": [2, 2, 2, 2],
"channel_mult": [1, 2, 4, 4],
"second_dim": [4, 4, 4, 4],
"with_attn": [True, True, True, False],
"num_heads": 8,
"context_dim": 768,
"use_checkpoint": True,
}
)
AUTOENCODER_CONFIG = Namespace(
**{
"double_z": True,
"z_channels": 4,
"resolution": 256,
"in_channels": 3,
"out_ch": 3,
"ch": 128,
"ch_mult": [1, 2, 4, 4],
"num_res_blocks": 2,
"attn_resolutions": [],
"dropout": 0.0,
}
)
def shave_segments(path, n_shave_prefix_segments=1):
"""
Removes segments. Positive values shave the first segments, negative shave the last segments.
"""
if n_shave_prefix_segments >= 0:
return ".".join(path.split(".")[n_shave_prefix_segments:])
else:
return ".".join(path.split(".")[:n_shave_prefix_segments])
def renew_resnet_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside resnets to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item.replace("in_layers.0", "norm1")
new_item = new_item.replace("in_layers.2", "conv1")
new_item = new_item.replace("out_layers.0", "norm2")
new_item = new_item.replace("out_layers.3", "conv2")
new_item = new_item.replace("emb_layers.1", "time_emb_proj")
new_item = new_item.replace("skip_connection", "conv_shortcut")
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def renew_vae_resnet_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside resnets to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item
new_item = new_item.replace("nin_shortcut", "conv_shortcut")
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def renew_attention_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside attentions to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item
# new_item = new_item.replace('norm.weight', 'group_norm.weight')
# new_item = new_item.replace('norm.bias', 'group_norm.bias')
# new_item = new_item.replace('proj_out.weight', 'proj_attn.weight')
# new_item = new_item.replace('proj_out.bias', 'proj_attn.bias')
# new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def renew_vae_attention_paths(old_list, n_shave_prefix_segments=0):
"""
Updates paths inside attentions to the new naming scheme (local renaming)
"""
mapping = []
for old_item in old_list:
new_item = old_item
new_item = new_item.replace("norm.weight", "group_norm.weight")
new_item = new_item.replace("norm.bias", "group_norm.bias")
new_item = new_item.replace("q.weight", "query.weight")
new_item = new_item.replace("q.bias", "query.bias")
new_item = new_item.replace("k.weight", "key.weight")
new_item = new_item.replace("k.bias", "key.bias")
new_item = new_item.replace("v.weight", "value.weight")
new_item = new_item.replace("v.bias", "value.bias")
new_item = new_item.replace("proj_out.weight", "proj_attn.weight")
new_item = new_item.replace("proj_out.bias", "proj_attn.bias")
new_item = shave_segments(new_item, n_shave_prefix_segments=n_shave_prefix_segments)
mapping.append({"old": old_item, "new": new_item})
return mapping
def assign_to_checkpoint(
paths, checkpoint, old_checkpoint, attention_paths_to_split=None, additional_replacements=None, config=None
):
"""
This does the final conversion step: take locally converted weights and apply a global renaming
to them. It splits attention layers, and takes into account additional replacements
that may arise.
Assigns the weights to the new checkpoint.
"""
assert isinstance(paths, list), "Paths should be a list of dicts containing 'old' and 'new' keys."
# Splits the attention layers into three variables.
if attention_paths_to_split is not None:
for path, path_map in attention_paths_to_split.items():
old_tensor = old_checkpoint[path]
channels = old_tensor.shape[0] // 3
target_shape = (-1, channels) if len(old_tensor.shape) == 3 else (-1)
num_heads = old_tensor.shape[0] // config["num_head_channels"] // 3
old_tensor = old_tensor.reshape((num_heads, 3 * channels // num_heads) + old_tensor.shape[1:])
query, key, value = old_tensor.split(channels // num_heads, dim=1)
checkpoint[path_map["query"]] = query.reshape(target_shape)
checkpoint[path_map["key"]] = key.reshape(target_shape)
checkpoint[path_map["value"]] = value.reshape(target_shape)
for path in paths:
new_path = path["new"]
# These have already been assigned
if attention_paths_to_split is not None and new_path in attention_paths_to_split:
continue
# Global renaming happens here
new_path = new_path.replace("middle_block.0", "mid_block.resnets.0")
new_path = new_path.replace("middle_block.1", "mid_block.attentions.0")
new_path = new_path.replace("middle_block.2", "mid_block.resnets.1")
if additional_replacements is not None:
for replacement in additional_replacements:
new_path = new_path.replace(replacement["old"], replacement["new"])
# proj_attn.weight has to be converted from conv 1D to linear
if "proj_attn.weight" in new_path:
checkpoint[new_path] = old_checkpoint[path["old"]][:, :, 0]
elif path["old"] in old_checkpoint:
checkpoint[new_path] = old_checkpoint[path["old"]]
def conv_attn_to_linear(checkpoint):
keys = list(checkpoint.keys())
attn_keys = ["query.weight", "key.weight", "value.weight"]
for key in keys:
if ".".join(key.split(".")[-2:]) in attn_keys:
if checkpoint[key].ndim > 2:
checkpoint[key] = checkpoint[key][:, :, 0, 0]
elif "proj_attn.weight" in key:
if checkpoint[key].ndim > 2:
checkpoint[key] = checkpoint[key][:, :, 0]
def create_image_unet_diffusers_config(unet_params):
"""
Creates a config for the diffusers based on the config of the VD model.
"""
block_out_channels = [unet_params.model_channels * mult for mult in unet_params.channel_mult]
down_block_types = []
resolution = 1
for i in range(len(block_out_channels)):
block_type = "CrossAttnDownBlock2D" if unet_params.with_attn[i] else "DownBlock2D"
down_block_types.append(block_type)
if i != len(block_out_channels) - 1:
resolution *= 2
up_block_types = []
for i in range(len(block_out_channels)):
block_type = "CrossAttnUpBlock2D" if unet_params.with_attn[-i - 1] else "UpBlock2D"
up_block_types.append(block_type)
resolution //= 2
if not all(n == unet_params.num_noattn_blocks[0] for n in unet_params.num_noattn_blocks):
raise ValueError("Not all num_res_blocks are equal, which is not supported in this script.")
config = {
"sample_size": None,
"in_channels": unet_params.input_channels,
"out_channels": unet_params.output_channels,
"down_block_types": tuple(down_block_types),
"up_block_types": tuple(up_block_types),
"block_out_channels": tuple(block_out_channels),
"layers_per_block": unet_params.num_noattn_blocks[0],
"cross_attention_dim": unet_params.context_dim,
"attention_head_dim": unet_params.num_heads,
}
return config
def create_text_unet_diffusers_config(unet_params):
"""
Creates a config for the diffusers based on the config of the VD model.
"""
block_out_channels = [unet_params.model_channels * mult for mult in unet_params.channel_mult]
down_block_types = []
resolution = 1
for i in range(len(block_out_channels)):
block_type = "CrossAttnDownBlockFlat" if unet_params.with_attn[i] else "DownBlockFlat"
down_block_types.append(block_type)
if i != len(block_out_channels) - 1:
resolution *= 2
up_block_types = []
for i in range(len(block_out_channels)):
block_type = "CrossAttnUpBlockFlat" if unet_params.with_attn[-i - 1] else "UpBlockFlat"
up_block_types.append(block_type)
resolution //= 2
if not all(n == unet_params.num_noattn_blocks[0] for n in unet_params.num_noattn_blocks):
raise ValueError("Not all num_res_blocks are equal, which is not supported in this script.")
config = {
"sample_size": None,
"in_channels": (unet_params.input_channels, 1, 1),
"out_channels": (unet_params.output_channels, 1, 1),
"down_block_types": tuple(down_block_types),
"up_block_types": tuple(up_block_types),
"block_out_channels": tuple(block_out_channels),
"layers_per_block": unet_params.num_noattn_blocks[0],
"cross_attention_dim": unet_params.context_dim,
"attention_head_dim": unet_params.num_heads,
}
return config
def create_vae_diffusers_config(vae_params):
"""
Creates a config for the diffusers based on the config of the VD model.
"""
block_out_channels = [vae_params.ch * mult for mult in vae_params.ch_mult]
down_block_types = ["DownEncoderBlock2D"] * len(block_out_channels)
up_block_types = ["UpDecoderBlock2D"] * len(block_out_channels)
config = {
"sample_size": vae_params.resolution,
"in_channels": vae_params.in_channels,
"out_channels": vae_params.out_ch,
"down_block_types": tuple(down_block_types),
"up_block_types": tuple(up_block_types),
"block_out_channels": tuple(block_out_channels),
"latent_channels": vae_params.z_channels,
"layers_per_block": vae_params.num_res_blocks,
}
return config
def create_diffusers_scheduler(original_config):
schedular = DDIMScheduler(
num_train_timesteps=original_config.model.params.timesteps,
beta_start=original_config.model.params.linear_start,
beta_end=original_config.model.params.linear_end,
beta_schedule="scaled_linear",
)
return schedular
def convert_vd_unet_checkpoint(checkpoint, config, unet_key, extract_ema=False):
"""
Takes a state dict and a config, and returns a converted checkpoint.
"""
# extract state_dict for UNet
unet_state_dict = {}
keys = list(checkpoint.keys())
# at least a 100 parameters have to start with `model_ema` in order for the checkpoint to be EMA
if sum(k.startswith("model_ema") for k in keys) > 100:
print("Checkpoint has both EMA and non-EMA weights.")
if extract_ema:
print(
"In this conversion only the EMA weights are extracted. If you want to instead extract the non-EMA"
" weights (useful to continue fine-tuning), please make sure to remove the `--extract_ema` flag."
)
for key in keys:
if key.startswith("model.diffusion_model"):
flat_ema_key = "model_ema." + "".join(key.split(".")[1:])
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(flat_ema_key)
else:
print(
"In this conversion only the non-EMA weights are extracted. If you want to instead extract the EMA"
" weights (usually better for inference), please make sure to add the `--extract_ema` flag."
)
for key in keys:
if key.startswith(unet_key):
unet_state_dict[key.replace(unet_key, "")] = checkpoint.pop(key)
new_checkpoint = {}
new_checkpoint["time_embedding.linear_1.weight"] = checkpoint["model.diffusion_model.time_embed.0.weight"]
new_checkpoint["time_embedding.linear_1.bias"] = checkpoint["model.diffusion_model.time_embed.0.bias"]
new_checkpoint["time_embedding.linear_2.weight"] = checkpoint["model.diffusion_model.time_embed.2.weight"]
new_checkpoint["time_embedding.linear_2.bias"] = checkpoint["model.diffusion_model.time_embed.2.bias"]
new_checkpoint["conv_in.weight"] = unet_state_dict["input_blocks.0.0.weight"]
new_checkpoint["conv_in.bias"] = unet_state_dict["input_blocks.0.0.bias"]
new_checkpoint["conv_norm_out.weight"] = unet_state_dict["out.0.weight"]
new_checkpoint["conv_norm_out.bias"] = unet_state_dict["out.0.bias"]
new_checkpoint["conv_out.weight"] = unet_state_dict["out.2.weight"]
new_checkpoint["conv_out.bias"] = unet_state_dict["out.2.bias"]
# Retrieves the keys for the input blocks only
num_input_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "input_blocks" in layer})
input_blocks = {
layer_id: [key for key in unet_state_dict if f"input_blocks.{layer_id}" in key]
for layer_id in range(num_input_blocks)
}
# Retrieves the keys for the middle blocks only
num_middle_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "middle_block" in layer})
middle_blocks = {
layer_id: [key for key in unet_state_dict if f"middle_block.{layer_id}" in key]
for layer_id in range(num_middle_blocks)
}
# Retrieves the keys for the output blocks only
num_output_blocks = len({".".join(layer.split(".")[:2]) for layer in unet_state_dict if "output_blocks" in layer})
output_blocks = {
layer_id: [key for key in unet_state_dict if f"output_blocks.{layer_id}" in key]
for layer_id in range(num_output_blocks)
}
for i in range(1, num_input_blocks):
block_id = (i - 1) // (config["layers_per_block"] + 1)
layer_in_block_id = (i - 1) % (config["layers_per_block"] + 1)
resnets = [
key for key in input_blocks[i] if f"input_blocks.{i}.0" in key and f"input_blocks.{i}.0.op" not in key
]
attentions = [key for key in input_blocks[i] if f"input_blocks.{i}.1" in key]
if f"input_blocks.{i}.0.op.weight" in unet_state_dict:
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.weight"] = unet_state_dict.pop(
f"input_blocks.{i}.0.op.weight"
)
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.conv.bias"] = unet_state_dict.pop(
f"input_blocks.{i}.0.op.bias"
)
elif f"input_blocks.{i}.0.weight" in unet_state_dict:
# text_unet uses linear layers in place of downsamplers
shape = unet_state_dict[f"input_blocks.{i}.0.weight"].shape
if shape[0] != shape[1]:
continue
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.weight"] = unet_state_dict.pop(
f"input_blocks.{i}.0.weight"
)
new_checkpoint[f"down_blocks.{block_id}.downsamplers.0.bias"] = unet_state_dict.pop(
f"input_blocks.{i}.0.bias"
)
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"input_blocks.{i}.0", "new": f"down_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {"old": f"input_blocks.{i}.1", "new": f"down_blocks.{block_id}.attentions.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
resnet_0 = middle_blocks[0]
attentions = middle_blocks[1]
resnet_1 = middle_blocks[2]
resnet_0_paths = renew_resnet_paths(resnet_0)
assign_to_checkpoint(resnet_0_paths, new_checkpoint, unet_state_dict, config=config)
resnet_1_paths = renew_resnet_paths(resnet_1)
assign_to_checkpoint(resnet_1_paths, new_checkpoint, unet_state_dict, config=config)
attentions_paths = renew_attention_paths(attentions)
meta_path = {"old": "middle_block.1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(
attentions_paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
for i in range(num_output_blocks):
block_id = i // (config["layers_per_block"] + 1)
layer_in_block_id = i % (config["layers_per_block"] + 1)
output_block_layers = [shave_segments(name, 2) for name in output_blocks[i]]
output_block_list = {}
for layer in output_block_layers:
layer_id, layer_name = layer.split(".")[0], shave_segments(layer, 1)
if layer_id in output_block_list:
output_block_list[layer_id].append(layer_name)
else:
output_block_list[layer_id] = [layer_name]
if len(output_block_list) > 1:
resnets = [key for key in output_blocks[i] if f"output_blocks.{i}.0" in key]
attentions = [key for key in output_blocks[i] if f"output_blocks.{i}.1" in key]
paths = renew_resnet_paths(resnets)
meta_path = {"old": f"output_blocks.{i}.0", "new": f"up_blocks.{block_id}.resnets.{layer_in_block_id}"}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
if ["conv.weight", "conv.bias"] in output_block_list.values():
index = list(output_block_list.values()).index(["conv.weight", "conv.bias"])
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.weight"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.weight"
]
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.conv.bias"] = unet_state_dict[
f"output_blocks.{i}.{index}.conv.bias"
]
# Clear attentions as they have been attributed above.
if len(attentions) == 2:
attentions = []
elif f"output_blocks.{i}.1.weight" in unet_state_dict:
# text_unet uses linear layers in place of upsamplers
shape = unet_state_dict[f"output_blocks.{i}.1.weight"].shape
if shape[0] != shape[1]:
continue
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.weight"] = unet_state_dict.pop(
f"output_blocks.{i}.1.weight"
)
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.bias"] = unet_state_dict.pop(
f"output_blocks.{i}.1.bias"
)
# Clear attentions as they have been attributed above.
if len(attentions) == 2:
attentions = []
elif f"output_blocks.{i}.2.weight" in unet_state_dict:
# text_unet uses linear layers in place of upsamplers
shape = unet_state_dict[f"output_blocks.{i}.2.weight"].shape
if shape[0] != shape[1]:
continue
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.weight"] = unet_state_dict.pop(
f"output_blocks.{i}.2.weight"
)
new_checkpoint[f"up_blocks.{block_id}.upsamplers.0.bias"] = unet_state_dict.pop(
f"output_blocks.{i}.2.bias"
)
if len(attentions):
paths = renew_attention_paths(attentions)
meta_path = {
"old": f"output_blocks.{i}.1",
"new": f"up_blocks.{block_id}.attentions.{layer_in_block_id}",
}
assign_to_checkpoint(
paths, new_checkpoint, unet_state_dict, additional_replacements=[meta_path], config=config
)
else:
resnet_0_paths = renew_resnet_paths(output_block_layers, n_shave_prefix_segments=1)
for path in resnet_0_paths:
old_path = ".".join(["output_blocks", str(i), path["old"]])
new_path = ".".join(["up_blocks", str(block_id), "resnets", str(layer_in_block_id), path["new"]])
new_checkpoint[new_path] = unet_state_dict[old_path]
return new_checkpoint
def convert_vd_vae_checkpoint(checkpoint, config):
# extract state dict for VAE
vae_state_dict = {}
keys = list(checkpoint.keys())
for key in keys:
vae_state_dict[key] = checkpoint.get(key)
new_checkpoint = {}
new_checkpoint["encoder.conv_in.weight"] = vae_state_dict["encoder.conv_in.weight"]
new_checkpoint["encoder.conv_in.bias"] = vae_state_dict["encoder.conv_in.bias"]
new_checkpoint["encoder.conv_out.weight"] = vae_state_dict["encoder.conv_out.weight"]
new_checkpoint["encoder.conv_out.bias"] = vae_state_dict["encoder.conv_out.bias"]
new_checkpoint["encoder.conv_norm_out.weight"] = vae_state_dict["encoder.norm_out.weight"]
new_checkpoint["encoder.conv_norm_out.bias"] = vae_state_dict["encoder.norm_out.bias"]
new_checkpoint["decoder.conv_in.weight"] = vae_state_dict["decoder.conv_in.weight"]
new_checkpoint["decoder.conv_in.bias"] = vae_state_dict["decoder.conv_in.bias"]
new_checkpoint["decoder.conv_out.weight"] = vae_state_dict["decoder.conv_out.weight"]
new_checkpoint["decoder.conv_out.bias"] = vae_state_dict["decoder.conv_out.bias"]
new_checkpoint["decoder.conv_norm_out.weight"] = vae_state_dict["decoder.norm_out.weight"]
new_checkpoint["decoder.conv_norm_out.bias"] = vae_state_dict["decoder.norm_out.bias"]
new_checkpoint["quant_conv.weight"] = vae_state_dict["quant_conv.weight"]
new_checkpoint["quant_conv.bias"] = vae_state_dict["quant_conv.bias"]
new_checkpoint["post_quant_conv.weight"] = vae_state_dict["post_quant_conv.weight"]
new_checkpoint["post_quant_conv.bias"] = vae_state_dict["post_quant_conv.bias"]
# Retrieves the keys for the encoder down blocks only
num_down_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "encoder.down" in layer})
down_blocks = {
layer_id: [key for key in vae_state_dict if f"down.{layer_id}" in key] for layer_id in range(num_down_blocks)
}
# Retrieves the keys for the decoder up blocks only
num_up_blocks = len({".".join(layer.split(".")[:3]) for layer in vae_state_dict if "decoder.up" in layer})
up_blocks = {
layer_id: [key for key in vae_state_dict if f"up.{layer_id}" in key] for layer_id in range(num_up_blocks)
}
for i in range(num_down_blocks):
resnets = [key for key in down_blocks[i] if f"down.{i}" in key and f"down.{i}.downsample" not in key]
if f"encoder.down.{i}.downsample.conv.weight" in vae_state_dict:
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.weight"] = vae_state_dict.pop(
f"encoder.down.{i}.downsample.conv.weight"
)
new_checkpoint[f"encoder.down_blocks.{i}.downsamplers.0.conv.bias"] = vae_state_dict.pop(
f"encoder.down.{i}.downsample.conv.bias"
)
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"down.{i}.block", "new": f"down_blocks.{i}.resnets"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_resnets = [key for key in vae_state_dict if "encoder.mid.block" in key]
num_mid_res_blocks = 2
for i in range(1, num_mid_res_blocks + 1):
resnets = [key for key in mid_resnets if f"encoder.mid.block_{i}" in key]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_attentions = [key for key in vae_state_dict if "encoder.mid.attn" in key]
paths = renew_vae_attention_paths(mid_attentions)
meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
conv_attn_to_linear(new_checkpoint)
for i in range(num_up_blocks):
block_id = num_up_blocks - 1 - i
resnets = [
key for key in up_blocks[block_id] if f"up.{block_id}" in key and f"up.{block_id}.upsample" not in key
]
if f"decoder.up.{block_id}.upsample.conv.weight" in vae_state_dict:
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.weight"] = vae_state_dict[
f"decoder.up.{block_id}.upsample.conv.weight"
]
new_checkpoint[f"decoder.up_blocks.{i}.upsamplers.0.conv.bias"] = vae_state_dict[
f"decoder.up.{block_id}.upsample.conv.bias"
]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"up.{block_id}.block", "new": f"up_blocks.{i}.resnets"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_resnets = [key for key in vae_state_dict if "decoder.mid.block" in key]
num_mid_res_blocks = 2
for i in range(1, num_mid_res_blocks + 1):
resnets = [key for key in mid_resnets if f"decoder.mid.block_{i}" in key]
paths = renew_vae_resnet_paths(resnets)
meta_path = {"old": f"mid.block_{i}", "new": f"mid_block.resnets.{i - 1}"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
mid_attentions = [key for key in vae_state_dict if "decoder.mid.attn" in key]
paths = renew_vae_attention_paths(mid_attentions)
meta_path = {"old": "mid.attn_1", "new": "mid_block.attentions.0"}
assign_to_checkpoint(paths, new_checkpoint, vae_state_dict, additional_replacements=[meta_path], config=config)
conv_attn_to_linear(new_checkpoint)
return new_checkpoint
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument(
"--unet_checkpoint_path", default=None, type=str, required=False, help="Path to the checkpoint to convert."
)
parser.add_argument(
"--vae_checkpoint_path", default=None, type=str, required=False, help="Path to the checkpoint to convert."
)
parser.add_argument(
"--optimus_checkpoint_path", default=None, type=str, required=False, help="Path to the checkpoint to convert."
)
parser.add_argument(
"--scheduler_type",
default="pndm",
type=str,
help="Type of scheduler to use. Should be one of ['pndm', 'lms', 'ddim', 'euler', 'euler-ancestral', 'dpm']",
)
parser.add_argument(
"--extract_ema",
action="store_true",
help=(
"Only relevant for checkpoints that have both EMA and non-EMA weights. Whether to extract the EMA weights"
" or not. Defaults to `False`. Add `--extract_ema` to extract the EMA weights. EMA weights usually yield"
" higher quality images for inference. Non-EMA weights are usually better to continue fine-tuning."
),
)
parser.add_argument("--dump_path", default=None, type=str, required=True, help="Path to the output model.")
args = parser.parse_args()
scheduler_config = SCHEDULER_CONFIG
num_train_timesteps = scheduler_config.timesteps
beta_start = scheduler_config.beta_linear_start
beta_end = scheduler_config.beta_linear_end
if args.scheduler_type == "pndm":
scheduler = PNDMScheduler(
beta_end=beta_end,
beta_schedule="scaled_linear",
beta_start=beta_start,
num_train_timesteps=num_train_timesteps,
skip_prk_steps=True,
steps_offset=1,
)
elif args.scheduler_type == "lms":
scheduler = LMSDiscreteScheduler(beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear")
elif args.scheduler_type == "euler":
scheduler = EulerDiscreteScheduler(beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear")
elif args.scheduler_type == "euler-ancestral":
scheduler = EulerAncestralDiscreteScheduler(
beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear"
)
elif args.scheduler_type == "dpm":
scheduler = DPMSolverMultistepScheduler(
beta_start=beta_start, beta_end=beta_end, beta_schedule="scaled_linear"
)
elif args.scheduler_type == "ddim":
scheduler = DDIMScheduler(
beta_start=beta_start,
beta_end=beta_end,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
steps_offset=1,
)
else:
raise ValueError(f"Scheduler of type {args.scheduler_type} doesn't exist!")
# Convert the UNet2DConditionModel models.
if args.unet_checkpoint_path is not None:
# image UNet
image_unet_config = create_image_unet_diffusers_config(IMAGE_UNET_CONFIG)
checkpoint = torch.load(args.unet_checkpoint_path)
converted_image_unet_checkpoint = convert_vd_unet_checkpoint(
checkpoint, image_unet_config, unet_key="model.diffusion_model.unet_image.", extract_ema=args.extract_ema
)
image_unet = UNet2DConditionModel(**image_unet_config)
image_unet.load_state_dict(converted_image_unet_checkpoint)
# text UNet
text_unet_config = create_text_unet_diffusers_config(TEXT_UNET_CONFIG)
converted_text_unet_checkpoint = convert_vd_unet_checkpoint(
checkpoint, text_unet_config, unet_key="model.diffusion_model.unet_text.", extract_ema=args.extract_ema
)
text_unet = UNetFlatConditionModel(**text_unet_config)
text_unet.load_state_dict(converted_text_unet_checkpoint)
# Convert the VAE model.
if args.vae_checkpoint_path is not None:
vae_config = create_vae_diffusers_config(AUTOENCODER_CONFIG)
checkpoint = torch.load(args.vae_checkpoint_path)
converted_vae_checkpoint = convert_vd_vae_checkpoint(checkpoint, vae_config)
vae = AutoencoderKL(**vae_config)
vae.load_state_dict(converted_vae_checkpoint)
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
image_feature_extractor = CLIPImageProcessor.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
image_encoder = CLIPVisionModelWithProjection.from_pretrained("openai/clip-vit-large-patch14")
pipe = VersatileDiffusionPipeline(
scheduler=scheduler,
tokenizer=tokenizer,
image_feature_extractor=image_feature_extractor,
text_encoder=text_encoder,
image_encoder=image_encoder,
image_unet=image_unet,
text_unet=text_unet,
vae=vae,
)
pipe.save_pretrained(args.dump_path)
| diffusers/scripts/convert_versatile_diffusion_to_diffusers.py/0 | {
"file_path": "diffusers/scripts/convert_versatile_diffusion_to_diffusers.py",
"repo_id": "diffusers",
"token_count": 14926
} | 120 |
from .rl import ValueGuidedRLPipeline
| diffusers/src/diffusers/experimental/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/experimental/__init__.py",
"repo_id": "diffusers",
"token_count": 12
} | 121 |
# Models
For more detail on the models, please refer to the [docs](https://huggingface.co/docs/diffusers/api/models/overview). | diffusers/src/diffusers/models/README.md/0 | {
"file_path": "diffusers/src/diffusers/models/README.md",
"repo_id": "diffusers",
"token_count": 39
} | 122 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Optional, Tuple
import torch
import torch.nn as nn
import torch.nn.functional as F
from ..utils import deprecate
from .normalization import RMSNorm
from .upsampling import upfirdn2d_native
class Downsample1D(nn.Module):
"""A 1D downsampling layer with an optional convolution.
Parameters:
channels (`int`):
number of channels in the inputs and outputs.
use_conv (`bool`, default `False`):
option to use a convolution.
out_channels (`int`, optional):
number of output channels. Defaults to `channels`.
padding (`int`, default `1`):
padding for the convolution.
name (`str`, default `conv`):
name of the downsampling 1D layer.
"""
def __init__(
self,
channels: int,
use_conv: bool = False,
out_channels: Optional[int] = None,
padding: int = 1,
name: str = "conv",
):
super().__init__()
self.channels = channels
self.out_channels = out_channels or channels
self.use_conv = use_conv
self.padding = padding
stride = 2
self.name = name
if use_conv:
self.conv = nn.Conv1d(self.channels, self.out_channels, 3, stride=stride, padding=padding)
else:
assert self.channels == self.out_channels
self.conv = nn.AvgPool1d(kernel_size=stride, stride=stride)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
assert inputs.shape[1] == self.channels
return self.conv(inputs)
class Downsample2D(nn.Module):
"""A 2D downsampling layer with an optional convolution.
Parameters:
channels (`int`):
number of channels in the inputs and outputs.
use_conv (`bool`, default `False`):
option to use a convolution.
out_channels (`int`, optional):
number of output channels. Defaults to `channels`.
padding (`int`, default `1`):
padding for the convolution.
name (`str`, default `conv`):
name of the downsampling 2D layer.
"""
def __init__(
self,
channels: int,
use_conv: bool = False,
out_channels: Optional[int] = None,
padding: int = 1,
name: str = "conv",
kernel_size=3,
norm_type=None,
eps=None,
elementwise_affine=None,
bias=True,
):
super().__init__()
self.channels = channels
self.out_channels = out_channels or channels
self.use_conv = use_conv
self.padding = padding
stride = 2
self.name = name
conv_cls = nn.Conv2d
if norm_type == "ln_norm":
self.norm = nn.LayerNorm(channels, eps, elementwise_affine)
elif norm_type == "rms_norm":
self.norm = RMSNorm(channels, eps, elementwise_affine)
elif norm_type is None:
self.norm = None
else:
raise ValueError(f"unknown norm_type: {norm_type}")
if use_conv:
conv = conv_cls(
self.channels, self.out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias
)
else:
assert self.channels == self.out_channels
conv = nn.AvgPool2d(kernel_size=stride, stride=stride)
# TODO(Suraj, Patrick) - clean up after weight dicts are correctly renamed
if name == "conv":
self.Conv2d_0 = conv
self.conv = conv
elif name == "Conv2d_0":
self.conv = conv
else:
self.conv = conv
def forward(self, hidden_states: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
assert hidden_states.shape[1] == self.channels
if self.norm is not None:
hidden_states = self.norm(hidden_states.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
if self.use_conv and self.padding == 0:
pad = (0, 1, 0, 1)
hidden_states = F.pad(hidden_states, pad, mode="constant", value=0)
assert hidden_states.shape[1] == self.channels
hidden_states = self.conv(hidden_states)
return hidden_states
class FirDownsample2D(nn.Module):
"""A 2D FIR downsampling layer with an optional convolution.
Parameters:
channels (`int`):
number of channels in the inputs and outputs.
use_conv (`bool`, default `False`):
option to use a convolution.
out_channels (`int`, optional):
number of output channels. Defaults to `channels`.
fir_kernel (`tuple`, default `(1, 3, 3, 1)`):
kernel for the FIR filter.
"""
def __init__(
self,
channels: Optional[int] = None,
out_channels: Optional[int] = None,
use_conv: bool = False,
fir_kernel: Tuple[int, int, int, int] = (1, 3, 3, 1),
):
super().__init__()
out_channels = out_channels if out_channels else channels
if use_conv:
self.Conv2d_0 = nn.Conv2d(channels, out_channels, kernel_size=3, stride=1, padding=1)
self.fir_kernel = fir_kernel
self.use_conv = use_conv
self.out_channels = out_channels
def _downsample_2d(
self,
hidden_states: torch.FloatTensor,
weight: Optional[torch.FloatTensor] = None,
kernel: Optional[torch.FloatTensor] = None,
factor: int = 2,
gain: float = 1,
) -> torch.FloatTensor:
"""Fused `Conv2d()` followed by `downsample_2d()`.
Padding is performed only once at the beginning, not between the operations. The fused op is considerably more
efficient than performing the same calculation using standard TensorFlow ops. It supports gradients of
arbitrary order.
Args:
hidden_states (`torch.FloatTensor`):
Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
weight (`torch.FloatTensor`, *optional*):
Weight tensor of the shape `[filterH, filterW, inChannels, outChannels]`. Grouped convolution can be
performed by `inChannels = x.shape[0] // numGroups`.
kernel (`torch.FloatTensor`, *optional*):
FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] * factor`, which
corresponds to average pooling.
factor (`int`, *optional*, default to `2`):
Integer downsampling factor.
gain (`float`, *optional*, default to `1.0`):
Scaling factor for signal magnitude.
Returns:
output (`torch.FloatTensor`):
Tensor of the shape `[N, C, H // factor, W // factor]` or `[N, H // factor, W // factor, C]`, and same
datatype as `x`.
"""
assert isinstance(factor, int) and factor >= 1
if kernel is None:
kernel = [1] * factor
# setup kernel
kernel = torch.tensor(kernel, dtype=torch.float32)
if kernel.ndim == 1:
kernel = torch.outer(kernel, kernel)
kernel /= torch.sum(kernel)
kernel = kernel * gain
if self.use_conv:
_, _, convH, convW = weight.shape
pad_value = (kernel.shape[0] - factor) + (convW - 1)
stride_value = [factor, factor]
upfirdn_input = upfirdn2d_native(
hidden_states,
torch.tensor(kernel, device=hidden_states.device),
pad=((pad_value + 1) // 2, pad_value // 2),
)
output = F.conv2d(upfirdn_input, weight, stride=stride_value, padding=0)
else:
pad_value = kernel.shape[0] - factor
output = upfirdn2d_native(
hidden_states,
torch.tensor(kernel, device=hidden_states.device),
down=factor,
pad=((pad_value + 1) // 2, pad_value // 2),
)
return output
def forward(self, hidden_states: torch.FloatTensor) -> torch.FloatTensor:
if self.use_conv:
downsample_input = self._downsample_2d(hidden_states, weight=self.Conv2d_0.weight, kernel=self.fir_kernel)
hidden_states = downsample_input + self.Conv2d_0.bias.reshape(1, -1, 1, 1)
else:
hidden_states = self._downsample_2d(hidden_states, kernel=self.fir_kernel, factor=2)
return hidden_states
# downsample/upsample layer used in k-upscaler, might be able to use FirDownsample2D/DirUpsample2D instead
class KDownsample2D(nn.Module):
r"""A 2D K-downsampling layer.
Parameters:
pad_mode (`str`, *optional*, default to `"reflect"`): the padding mode to use.
"""
def __init__(self, pad_mode: str = "reflect"):
super().__init__()
self.pad_mode = pad_mode
kernel_1d = torch.tensor([[1 / 8, 3 / 8, 3 / 8, 1 / 8]])
self.pad = kernel_1d.shape[1] // 2 - 1
self.register_buffer("kernel", kernel_1d.T @ kernel_1d, persistent=False)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
inputs = F.pad(inputs, (self.pad,) * 4, self.pad_mode)
weight = inputs.new_zeros(
[
inputs.shape[1],
inputs.shape[1],
self.kernel.shape[0],
self.kernel.shape[1],
]
)
indices = torch.arange(inputs.shape[1], device=inputs.device)
kernel = self.kernel.to(weight)[None, :].expand(inputs.shape[1], -1, -1)
weight[indices, indices] = kernel
return F.conv2d(inputs, weight, stride=2)
def downsample_2d(
hidden_states: torch.FloatTensor,
kernel: Optional[torch.FloatTensor] = None,
factor: int = 2,
gain: float = 1,
) -> torch.FloatTensor:
r"""Downsample2D a batch of 2D images with the given filter.
Accepts a batch of 2D images of the shape `[N, C, H, W]` or `[N, H, W, C]` and downsamples each image with the
given filter. The filter is normalized so that if the input pixels are constant, they will be scaled by the
specified `gain`. Pixels outside the image are assumed to be zero, and the filter is padded with zeros so that its
shape is a multiple of the downsampling factor.
Args:
hidden_states (`torch.FloatTensor`)
Input tensor of the shape `[N, C, H, W]` or `[N, H, W, C]`.
kernel (`torch.FloatTensor`, *optional*):
FIR filter of the shape `[firH, firW]` or `[firN]` (separable). The default is `[1] * factor`, which
corresponds to average pooling.
factor (`int`, *optional*, default to `2`):
Integer downsampling factor.
gain (`float`, *optional*, default to `1.0`):
Scaling factor for signal magnitude.
Returns:
output (`torch.FloatTensor`):
Tensor of the shape `[N, C, H // factor, W // factor]`
"""
assert isinstance(factor, int) and factor >= 1
if kernel is None:
kernel = [1] * factor
kernel = torch.tensor(kernel, dtype=torch.float32)
if kernel.ndim == 1:
kernel = torch.outer(kernel, kernel)
kernel /= torch.sum(kernel)
kernel = kernel * gain
pad_value = kernel.shape[0] - factor
output = upfirdn2d_native(
hidden_states,
kernel.to(device=hidden_states.device),
down=factor,
pad=((pad_value + 1) // 2, pad_value // 2),
)
return output
| diffusers/src/diffusers/models/downsampling.py/0 | {
"file_path": "diffusers/src/diffusers/models/downsampling.py",
"repo_id": "diffusers",
"token_count": 5528
} | 123 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Any, Dict, Optional, Tuple, Union
import numpy as np
import torch
import torch.nn.functional as F
from torch import nn
from ...utils import deprecate, is_torch_version, logging
from ...utils.torch_utils import apply_freeu
from ..activations import get_activation
from ..attention_processor import Attention, AttnAddedKVProcessor, AttnAddedKVProcessor2_0
from ..normalization import AdaGroupNorm
from ..resnet import (
Downsample2D,
FirDownsample2D,
FirUpsample2D,
KDownsample2D,
KUpsample2D,
ResnetBlock2D,
ResnetBlockCondNorm2D,
Upsample2D,
)
from ..transformers.dual_transformer_2d import DualTransformer2DModel
from ..transformers.transformer_2d import Transformer2DModel
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
def get_down_block(
down_block_type: str,
num_layers: int,
in_channels: int,
out_channels: int,
temb_channels: int,
add_downsample: bool,
resnet_eps: float,
resnet_act_fn: str,
transformer_layers_per_block: int = 1,
num_attention_heads: Optional[int] = None,
resnet_groups: Optional[int] = None,
cross_attention_dim: Optional[int] = None,
downsample_padding: Optional[int] = None,
dual_cross_attention: bool = False,
use_linear_projection: bool = False,
only_cross_attention: bool = False,
upcast_attention: bool = False,
resnet_time_scale_shift: str = "default",
attention_type: str = "default",
resnet_skip_time_act: bool = False,
resnet_out_scale_factor: float = 1.0,
cross_attention_norm: Optional[str] = None,
attention_head_dim: Optional[int] = None,
downsample_type: Optional[str] = None,
dropout: float = 0.0,
):
# If attn head dim is not defined, we default it to the number of heads
if attention_head_dim is None:
logger.warning(
f"It is recommended to provide `attention_head_dim` when calling `get_down_block`. Defaulting `attention_head_dim` to {num_attention_heads}."
)
attention_head_dim = num_attention_heads
down_block_type = down_block_type[7:] if down_block_type.startswith("UNetRes") else down_block_type
if down_block_type == "DownBlock2D":
return DownBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
downsample_padding=downsample_padding,
resnet_time_scale_shift=resnet_time_scale_shift,
)
elif down_block_type == "ResnetDownsampleBlock2D":
return ResnetDownsampleBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
resnet_time_scale_shift=resnet_time_scale_shift,
skip_time_act=resnet_skip_time_act,
output_scale_factor=resnet_out_scale_factor,
)
elif down_block_type == "AttnDownBlock2D":
if add_downsample is False:
downsample_type = None
else:
downsample_type = downsample_type or "conv" # default to 'conv'
return AttnDownBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
downsample_padding=downsample_padding,
attention_head_dim=attention_head_dim,
resnet_time_scale_shift=resnet_time_scale_shift,
downsample_type=downsample_type,
)
elif down_block_type == "CrossAttnDownBlock2D":
if cross_attention_dim is None:
raise ValueError("cross_attention_dim must be specified for CrossAttnDownBlock2D")
return CrossAttnDownBlock2D(
num_layers=num_layers,
transformer_layers_per_block=transformer_layers_per_block,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
downsample_padding=downsample_padding,
cross_attention_dim=cross_attention_dim,
num_attention_heads=num_attention_heads,
dual_cross_attention=dual_cross_attention,
use_linear_projection=use_linear_projection,
only_cross_attention=only_cross_attention,
upcast_attention=upcast_attention,
resnet_time_scale_shift=resnet_time_scale_shift,
attention_type=attention_type,
)
elif down_block_type == "SimpleCrossAttnDownBlock2D":
if cross_attention_dim is None:
raise ValueError("cross_attention_dim must be specified for SimpleCrossAttnDownBlock2D")
return SimpleCrossAttnDownBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
cross_attention_dim=cross_attention_dim,
attention_head_dim=attention_head_dim,
resnet_time_scale_shift=resnet_time_scale_shift,
skip_time_act=resnet_skip_time_act,
output_scale_factor=resnet_out_scale_factor,
only_cross_attention=only_cross_attention,
cross_attention_norm=cross_attention_norm,
)
elif down_block_type == "SkipDownBlock2D":
return SkipDownBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
downsample_padding=downsample_padding,
resnet_time_scale_shift=resnet_time_scale_shift,
)
elif down_block_type == "AttnSkipDownBlock2D":
return AttnSkipDownBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
attention_head_dim=attention_head_dim,
resnet_time_scale_shift=resnet_time_scale_shift,
)
elif down_block_type == "DownEncoderBlock2D":
return DownEncoderBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
downsample_padding=downsample_padding,
resnet_time_scale_shift=resnet_time_scale_shift,
)
elif down_block_type == "AttnDownEncoderBlock2D":
return AttnDownEncoderBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
downsample_padding=downsample_padding,
attention_head_dim=attention_head_dim,
resnet_time_scale_shift=resnet_time_scale_shift,
)
elif down_block_type == "KDownBlock2D":
return KDownBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
)
elif down_block_type == "KCrossAttnDownBlock2D":
return KCrossAttnDownBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
dropout=dropout,
add_downsample=add_downsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
cross_attention_dim=cross_attention_dim,
attention_head_dim=attention_head_dim,
add_self_attention=True if not add_downsample else False,
)
raise ValueError(f"{down_block_type} does not exist.")
def get_mid_block(
mid_block_type: str,
temb_channels: int,
in_channels: int,
resnet_eps: float,
resnet_act_fn: str,
resnet_groups: int,
output_scale_factor: float = 1.0,
transformer_layers_per_block: int = 1,
num_attention_heads: Optional[int] = None,
cross_attention_dim: Optional[int] = None,
dual_cross_attention: bool = False,
use_linear_projection: bool = False,
mid_block_only_cross_attention: bool = False,
upcast_attention: bool = False,
resnet_time_scale_shift: str = "default",
attention_type: str = "default",
resnet_skip_time_act: bool = False,
cross_attention_norm: Optional[str] = None,
attention_head_dim: Optional[int] = 1,
dropout: float = 0.0,
):
if mid_block_type == "UNetMidBlock2DCrossAttn":
return UNetMidBlock2DCrossAttn(
transformer_layers_per_block=transformer_layers_per_block,
in_channels=in_channels,
temb_channels=temb_channels,
dropout=dropout,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
output_scale_factor=output_scale_factor,
resnet_time_scale_shift=resnet_time_scale_shift,
cross_attention_dim=cross_attention_dim,
num_attention_heads=num_attention_heads,
resnet_groups=resnet_groups,
dual_cross_attention=dual_cross_attention,
use_linear_projection=use_linear_projection,
upcast_attention=upcast_attention,
attention_type=attention_type,
)
elif mid_block_type == "UNetMidBlock2DSimpleCrossAttn":
return UNetMidBlock2DSimpleCrossAttn(
in_channels=in_channels,
temb_channels=temb_channels,
dropout=dropout,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
output_scale_factor=output_scale_factor,
cross_attention_dim=cross_attention_dim,
attention_head_dim=attention_head_dim,
resnet_groups=resnet_groups,
resnet_time_scale_shift=resnet_time_scale_shift,
skip_time_act=resnet_skip_time_act,
only_cross_attention=mid_block_only_cross_attention,
cross_attention_norm=cross_attention_norm,
)
elif mid_block_type == "UNetMidBlock2D":
return UNetMidBlock2D(
in_channels=in_channels,
temb_channels=temb_channels,
dropout=dropout,
num_layers=0,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
output_scale_factor=output_scale_factor,
resnet_groups=resnet_groups,
resnet_time_scale_shift=resnet_time_scale_shift,
add_attention=False,
)
elif mid_block_type is None:
return None
else:
raise ValueError(f"unknown mid_block_type : {mid_block_type}")
def get_up_block(
up_block_type: str,
num_layers: int,
in_channels: int,
out_channels: int,
prev_output_channel: int,
temb_channels: int,
add_upsample: bool,
resnet_eps: float,
resnet_act_fn: str,
resolution_idx: Optional[int] = None,
transformer_layers_per_block: int = 1,
num_attention_heads: Optional[int] = None,
resnet_groups: Optional[int] = None,
cross_attention_dim: Optional[int] = None,
dual_cross_attention: bool = False,
use_linear_projection: bool = False,
only_cross_attention: bool = False,
upcast_attention: bool = False,
resnet_time_scale_shift: str = "default",
attention_type: str = "default",
resnet_skip_time_act: bool = False,
resnet_out_scale_factor: float = 1.0,
cross_attention_norm: Optional[str] = None,
attention_head_dim: Optional[int] = None,
upsample_type: Optional[str] = None,
dropout: float = 0.0,
) -> nn.Module:
# If attn head dim is not defined, we default it to the number of heads
if attention_head_dim is None:
logger.warning(
f"It is recommended to provide `attention_head_dim` when calling `get_up_block`. Defaulting `attention_head_dim` to {num_attention_heads}."
)
attention_head_dim = num_attention_heads
up_block_type = up_block_type[7:] if up_block_type.startswith("UNetRes") else up_block_type
if up_block_type == "UpBlock2D":
return UpBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
prev_output_channel=prev_output_channel,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
resnet_time_scale_shift=resnet_time_scale_shift,
)
elif up_block_type == "ResnetUpsampleBlock2D":
return ResnetUpsampleBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
prev_output_channel=prev_output_channel,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
resnet_time_scale_shift=resnet_time_scale_shift,
skip_time_act=resnet_skip_time_act,
output_scale_factor=resnet_out_scale_factor,
)
elif up_block_type == "CrossAttnUpBlock2D":
if cross_attention_dim is None:
raise ValueError("cross_attention_dim must be specified for CrossAttnUpBlock2D")
return CrossAttnUpBlock2D(
num_layers=num_layers,
transformer_layers_per_block=transformer_layers_per_block,
in_channels=in_channels,
out_channels=out_channels,
prev_output_channel=prev_output_channel,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
cross_attention_dim=cross_attention_dim,
num_attention_heads=num_attention_heads,
dual_cross_attention=dual_cross_attention,
use_linear_projection=use_linear_projection,
only_cross_attention=only_cross_attention,
upcast_attention=upcast_attention,
resnet_time_scale_shift=resnet_time_scale_shift,
attention_type=attention_type,
)
elif up_block_type == "SimpleCrossAttnUpBlock2D":
if cross_attention_dim is None:
raise ValueError("cross_attention_dim must be specified for SimpleCrossAttnUpBlock2D")
return SimpleCrossAttnUpBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
prev_output_channel=prev_output_channel,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
cross_attention_dim=cross_attention_dim,
attention_head_dim=attention_head_dim,
resnet_time_scale_shift=resnet_time_scale_shift,
skip_time_act=resnet_skip_time_act,
output_scale_factor=resnet_out_scale_factor,
only_cross_attention=only_cross_attention,
cross_attention_norm=cross_attention_norm,
)
elif up_block_type == "AttnUpBlock2D":
if add_upsample is False:
upsample_type = None
else:
upsample_type = upsample_type or "conv" # default to 'conv'
return AttnUpBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
prev_output_channel=prev_output_channel,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
attention_head_dim=attention_head_dim,
resnet_time_scale_shift=resnet_time_scale_shift,
upsample_type=upsample_type,
)
elif up_block_type == "SkipUpBlock2D":
return SkipUpBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
prev_output_channel=prev_output_channel,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_time_scale_shift=resnet_time_scale_shift,
)
elif up_block_type == "AttnSkipUpBlock2D":
return AttnSkipUpBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
prev_output_channel=prev_output_channel,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
attention_head_dim=attention_head_dim,
resnet_time_scale_shift=resnet_time_scale_shift,
)
elif up_block_type == "UpDecoderBlock2D":
return UpDecoderBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
resnet_time_scale_shift=resnet_time_scale_shift,
temb_channels=temb_channels,
)
elif up_block_type == "AttnUpDecoderBlock2D":
return AttnUpDecoderBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
resnet_groups=resnet_groups,
attention_head_dim=attention_head_dim,
resnet_time_scale_shift=resnet_time_scale_shift,
temb_channels=temb_channels,
)
elif up_block_type == "KUpBlock2D":
return KUpBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
)
elif up_block_type == "KCrossAttnUpBlock2D":
return KCrossAttnUpBlock2D(
num_layers=num_layers,
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
resolution_idx=resolution_idx,
dropout=dropout,
add_upsample=add_upsample,
resnet_eps=resnet_eps,
resnet_act_fn=resnet_act_fn,
cross_attention_dim=cross_attention_dim,
attention_head_dim=attention_head_dim,
)
raise ValueError(f"{up_block_type} does not exist.")
class AutoencoderTinyBlock(nn.Module):
"""
Tiny Autoencoder block used in [`AutoencoderTiny`]. It is a mini residual module consisting of plain conv + ReLU
blocks.
Args:
in_channels (`int`): The number of input channels.
out_channels (`int`): The number of output channels.
act_fn (`str`):
` The activation function to use. Supported values are `"swish"`, `"mish"`, `"gelu"`, and `"relu"`.
Returns:
`torch.FloatTensor`: A tensor with the same shape as the input tensor, but with the number of channels equal to
`out_channels`.
"""
def __init__(self, in_channels: int, out_channels: int, act_fn: str):
super().__init__()
act_fn = get_activation(act_fn)
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),
act_fn,
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
act_fn,
nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),
)
self.skip = (
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
if in_channels != out_channels
else nn.Identity()
)
self.fuse = nn.ReLU()
def forward(self, x: torch.FloatTensor) -> torch.FloatTensor:
return self.fuse(self.conv(x) + self.skip(x))
class UNetMidBlock2D(nn.Module):
"""
A 2D UNet mid-block [`UNetMidBlock2D`] with multiple residual blocks and optional attention blocks.
Args:
in_channels (`int`): The number of input channels.
temb_channels (`int`): The number of temporal embedding channels.
dropout (`float`, *optional*, defaults to 0.0): The dropout rate.
num_layers (`int`, *optional*, defaults to 1): The number of residual blocks.
resnet_eps (`float`, *optional*, 1e-6 ): The epsilon value for the resnet blocks.
resnet_time_scale_shift (`str`, *optional*, defaults to `default`):
The type of normalization to apply to the time embeddings. This can help to improve the performance of the
model on tasks with long-range temporal dependencies.
resnet_act_fn (`str`, *optional*, defaults to `swish`): The activation function for the resnet blocks.
resnet_groups (`int`, *optional*, defaults to 32):
The number of groups to use in the group normalization layers of the resnet blocks.
attn_groups (`Optional[int]`, *optional*, defaults to None): The number of groups for the attention blocks.
resnet_pre_norm (`bool`, *optional*, defaults to `True`):
Whether to use pre-normalization for the resnet blocks.
add_attention (`bool`, *optional*, defaults to `True`): Whether to add attention blocks.
attention_head_dim (`int`, *optional*, defaults to 1):
Dimension of a single attention head. The number of attention heads is determined based on this value and
the number of input channels.
output_scale_factor (`float`, *optional*, defaults to 1.0): The output scale factor.
Returns:
`torch.FloatTensor`: The output of the last residual block, which is a tensor of shape `(batch_size,
in_channels, height, width)`.
"""
def __init__(
self,
in_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default", # default, spatial
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
attn_groups: Optional[int] = None,
resnet_pre_norm: bool = True,
add_attention: bool = True,
attention_head_dim: int = 1,
output_scale_factor: float = 1.0,
):
super().__init__()
resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
self.add_attention = add_attention
if attn_groups is None:
attn_groups = resnet_groups if resnet_time_scale_shift == "default" else None
# there is always at least one resnet
if resnet_time_scale_shift == "spatial":
resnets = [
ResnetBlockCondNorm2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm="spatial",
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
)
]
else:
resnets = [
ResnetBlock2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
]
attentions = []
if attention_head_dim is None:
logger.warning(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {in_channels}."
)
attention_head_dim = in_channels
for _ in range(num_layers):
if self.add_attention:
attentions.append(
Attention(
in_channels,
heads=in_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=attn_groups,
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
else:
attentions.append(None)
if resnet_time_scale_shift == "spatial":
resnets.append(
ResnetBlockCondNorm2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm="spatial",
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
)
)
else:
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
def forward(self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None) -> torch.FloatTensor:
hidden_states = self.resnets[0](hidden_states, temb)
for attn, resnet in zip(self.attentions, self.resnets[1:]):
if attn is not None:
hidden_states = attn(hidden_states, temb=temb)
hidden_states = resnet(hidden_states, temb)
return hidden_states
class UNetMidBlock2DCrossAttn(nn.Module):
def __init__(
self,
in_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
num_attention_heads: int = 1,
output_scale_factor: float = 1.0,
cross_attention_dim: int = 1280,
dual_cross_attention: bool = False,
use_linear_projection: bool = False,
upcast_attention: bool = False,
attention_type: str = "default",
):
super().__init__()
self.has_cross_attention = True
self.num_attention_heads = num_attention_heads
resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
# support for variable transformer layers per block
if isinstance(transformer_layers_per_block, int):
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
# there is always at least one resnet
resnets = [
ResnetBlock2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
]
attentions = []
for i in range(num_layers):
if not dual_cross_attention:
attentions.append(
Transformer2DModel(
num_attention_heads,
in_channels // num_attention_heads,
in_channels=in_channels,
num_layers=transformer_layers_per_block[i],
cross_attention_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
use_linear_projection=use_linear_projection,
upcast_attention=upcast_attention,
attention_type=attention_type,
)
)
else:
attentions.append(
DualTransformer2DModel(
num_attention_heads,
in_channels // num_attention_heads,
in_channels=in_channels,
num_layers=1,
cross_attention_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
)
)
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
) -> torch.FloatTensor:
if cross_attention_kwargs is not None:
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
hidden_states = self.resnets[0](hidden_states, temb)
for attn, resnet in zip(self.attentions, self.resnets[1:]):
if self.training and self.gradient_checkpointing:
def create_custom_forward(module, return_dict=None):
def custom_forward(*inputs):
if return_dict is not None:
return module(*inputs, return_dict=return_dict)
else:
return module(*inputs)
return custom_forward
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet),
hidden_states,
temb,
**ckpt_kwargs,
)
else:
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
hidden_states = resnet(hidden_states, temb)
return hidden_states
class UNetMidBlock2DSimpleCrossAttn(nn.Module):
def __init__(
self,
in_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
output_scale_factor: float = 1.0,
cross_attention_dim: int = 1280,
skip_time_act: bool = False,
only_cross_attention: bool = False,
cross_attention_norm: Optional[str] = None,
):
super().__init__()
self.has_cross_attention = True
self.attention_head_dim = attention_head_dim
resnet_groups = resnet_groups if resnet_groups is not None else min(in_channels // 4, 32)
self.num_heads = in_channels // self.attention_head_dim
# there is always at least one resnet
resnets = [
ResnetBlock2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
)
]
attentions = []
for _ in range(num_layers):
processor = (
AttnAddedKVProcessor2_0() if hasattr(F, "scaled_dot_product_attention") else AttnAddedKVProcessor()
)
attentions.append(
Attention(
query_dim=in_channels,
cross_attention_dim=in_channels,
heads=self.num_heads,
dim_head=self.attention_head_dim,
added_kv_proj_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
bias=True,
upcast_softmax=True,
only_cross_attention=only_cross_attention,
cross_attention_norm=cross_attention_norm,
processor=processor,
)
)
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=in_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
) -> torch.FloatTensor:
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
if attention_mask is None:
# if encoder_hidden_states is defined: we are doing cross-attn, so we should use cross-attn mask.
mask = None if encoder_hidden_states is None else encoder_attention_mask
else:
# when attention_mask is defined: we don't even check for encoder_attention_mask.
# this is to maintain compatibility with UnCLIP, which uses 'attention_mask' param for cross-attn masks.
# TODO: UnCLIP should express cross-attn mask via encoder_attention_mask param instead of via attention_mask.
# then we can simplify this whole if/else block to:
# mask = attention_mask if encoder_hidden_states is None else encoder_attention_mask
mask = attention_mask
hidden_states = self.resnets[0](hidden_states, temb)
for attn, resnet in zip(self.attentions, self.resnets[1:]):
# attn
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=mask,
**cross_attention_kwargs,
)
# resnet
hidden_states = resnet(hidden_states, temb)
return hidden_states
class AttnDownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
output_scale_factor: float = 1.0,
downsample_padding: int = 1,
downsample_type: str = "conv",
):
super().__init__()
resnets = []
attentions = []
self.downsample_type = downsample_type
if attention_head_dim is None:
logger.warning(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {out_channels}."
)
attention_head_dim = out_channels
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
attentions.append(
Attention(
out_channels,
heads=out_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=resnet_groups,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if downsample_type == "conv":
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
elif downsample_type == "resnet":
self.downsamplers = nn.ModuleList(
[
ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
down=True,
)
]
)
else:
self.downsamplers = None
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
upsample_size: Optional[int] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
output_states = ()
for resnet, attn in zip(self.resnets, self.attentions):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(hidden_states, **cross_attention_kwargs)
output_states = output_states + (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
if self.downsample_type == "resnet":
hidden_states = downsampler(hidden_states, temb=temb)
else:
hidden_states = downsampler(hidden_states)
output_states += (hidden_states,)
return hidden_states, output_states
class CrossAttnDownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
num_attention_heads: int = 1,
cross_attention_dim: int = 1280,
output_scale_factor: float = 1.0,
downsample_padding: int = 1,
add_downsample: bool = True,
dual_cross_attention: bool = False,
use_linear_projection: bool = False,
only_cross_attention: bool = False,
upcast_attention: bool = False,
attention_type: str = "default",
):
super().__init__()
resnets = []
attentions = []
self.has_cross_attention = True
self.num_attention_heads = num_attention_heads
if isinstance(transformer_layers_per_block, int):
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
if not dual_cross_attention:
attentions.append(
Transformer2DModel(
num_attention_heads,
out_channels // num_attention_heads,
in_channels=out_channels,
num_layers=transformer_layers_per_block[i],
cross_attention_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
use_linear_projection=use_linear_projection,
only_cross_attention=only_cross_attention,
upcast_attention=upcast_attention,
attention_type=attention_type,
)
)
else:
attentions.append(
DualTransformer2DModel(
num_attention_heads,
out_channels // num_attention_heads,
in_channels=out_channels,
num_layers=1,
cross_attention_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
else:
self.downsamplers = None
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
additional_residuals: Optional[torch.FloatTensor] = None,
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
if cross_attention_kwargs is not None:
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
output_states = ()
blocks = list(zip(self.resnets, self.attentions))
for i, (resnet, attn) in enumerate(blocks):
if self.training and self.gradient_checkpointing:
def create_custom_forward(module, return_dict=None):
def custom_forward(*inputs):
if return_dict is not None:
return module(*inputs, return_dict=return_dict)
else:
return module(*inputs)
return custom_forward
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet),
hidden_states,
temb,
**ckpt_kwargs,
)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
else:
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
# apply additional residuals to the output of the last pair of resnet and attention blocks
if i == len(blocks) - 1 and additional_residuals is not None:
hidden_states = hidden_states + additional_residuals
output_states = output_states + (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
class DownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
output_scale_factor: float = 1.0,
add_downsample: bool = True,
downsample_padding: int = 1,
):
super().__init__()
resnets = []
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
else:
self.downsamplers = None
self.gradient_checkpointing = False
def forward(
self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None, *args, **kwargs
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
output_states = ()
for resnet in self.resnets:
if self.training and self.gradient_checkpointing:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
if is_torch_version(">=", "1.11.0"):
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb, use_reentrant=False
)
else:
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb
)
else:
hidden_states = resnet(hidden_states, temb)
output_states = output_states + (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
class DownEncoderBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
output_scale_factor: float = 1.0,
add_downsample: bool = True,
downsample_padding: int = 1,
):
super().__init__()
resnets = []
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
if resnet_time_scale_shift == "spatial":
resnets.append(
ResnetBlockCondNorm2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=None,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm="spatial",
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
)
)
else:
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=None,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
else:
self.downsamplers = None
def forward(self, hidden_states: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
for resnet in self.resnets:
hidden_states = resnet(hidden_states, temb=None)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
return hidden_states
class AttnDownEncoderBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
output_scale_factor: float = 1.0,
add_downsample: bool = True,
downsample_padding: int = 1,
):
super().__init__()
resnets = []
attentions = []
if attention_head_dim is None:
logger.warning(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {out_channels}."
)
attention_head_dim = out_channels
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
if resnet_time_scale_shift == "spatial":
resnets.append(
ResnetBlockCondNorm2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=None,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm="spatial",
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
)
)
else:
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=None,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
attentions.append(
Attention(
out_channels,
heads=out_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=resnet_groups,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
Downsample2D(
out_channels, use_conv=True, out_channels=out_channels, padding=downsample_padding, name="op"
)
]
)
else:
self.downsamplers = None
def forward(self, hidden_states: torch.FloatTensor, *args, **kwargs) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
for resnet, attn in zip(self.resnets, self.attentions):
hidden_states = resnet(hidden_states, temb=None)
hidden_states = attn(hidden_states)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
return hidden_states
class AttnSkipDownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
output_scale_factor: float = np.sqrt(2.0),
add_downsample: bool = True,
):
super().__init__()
self.attentions = nn.ModuleList([])
self.resnets = nn.ModuleList([])
if attention_head_dim is None:
logger.warning(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {out_channels}."
)
attention_head_dim = out_channels
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
self.resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=min(in_channels // 4, 32),
groups_out=min(out_channels // 4, 32),
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.attentions.append(
Attention(
out_channels,
heads=out_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=32,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
if add_downsample:
self.resnet_down = ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=min(out_channels // 4, 32),
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
use_in_shortcut=True,
down=True,
kernel="fir",
)
self.downsamplers = nn.ModuleList([FirDownsample2D(out_channels, out_channels=out_channels)])
self.skip_conv = nn.Conv2d(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
else:
self.resnet_down = None
self.downsamplers = None
self.skip_conv = None
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
skip_sample: Optional[torch.FloatTensor] = None,
*args,
**kwargs,
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...], torch.FloatTensor]:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
output_states = ()
for resnet, attn in zip(self.resnets, self.attentions):
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(hidden_states)
output_states += (hidden_states,)
if self.downsamplers is not None:
hidden_states = self.resnet_down(hidden_states, temb)
for downsampler in self.downsamplers:
skip_sample = downsampler(skip_sample)
hidden_states = self.skip_conv(skip_sample) + hidden_states
output_states += (hidden_states,)
return hidden_states, output_states, skip_sample
class SkipDownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_pre_norm: bool = True,
output_scale_factor: float = np.sqrt(2.0),
add_downsample: bool = True,
downsample_padding: int = 1,
):
super().__init__()
self.resnets = nn.ModuleList([])
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
self.resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=min(in_channels // 4, 32),
groups_out=min(out_channels // 4, 32),
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
if add_downsample:
self.resnet_down = ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=min(out_channels // 4, 32),
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
use_in_shortcut=True,
down=True,
kernel="fir",
)
self.downsamplers = nn.ModuleList([FirDownsample2D(out_channels, out_channels=out_channels)])
self.skip_conv = nn.Conv2d(3, out_channels, kernel_size=(1, 1), stride=(1, 1))
else:
self.resnet_down = None
self.downsamplers = None
self.skip_conv = None
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
skip_sample: Optional[torch.FloatTensor] = None,
*args,
**kwargs,
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...], torch.FloatTensor]:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
output_states = ()
for resnet in self.resnets:
hidden_states = resnet(hidden_states, temb)
output_states += (hidden_states,)
if self.downsamplers is not None:
hidden_states = self.resnet_down(hidden_states, temb)
for downsampler in self.downsamplers:
skip_sample = downsampler(skip_sample)
hidden_states = self.skip_conv(skip_sample) + hidden_states
output_states += (hidden_states,)
return hidden_states, output_states, skip_sample
class ResnetDownsampleBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
output_scale_factor: float = 1.0,
add_downsample: bool = True,
skip_time_act: bool = False,
):
super().__init__()
resnets = []
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
)
)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
down=True,
)
]
)
else:
self.downsamplers = None
self.gradient_checkpointing = False
def forward(
self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None, *args, **kwargs
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
output_states = ()
for resnet in self.resnets:
if self.training and self.gradient_checkpointing:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
if is_torch_version(">=", "1.11.0"):
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb, use_reentrant=False
)
else:
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb
)
else:
hidden_states = resnet(hidden_states, temb)
output_states = output_states + (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states, temb)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
class SimpleCrossAttnDownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
cross_attention_dim: int = 1280,
output_scale_factor: float = 1.0,
add_downsample: bool = True,
skip_time_act: bool = False,
only_cross_attention: bool = False,
cross_attention_norm: Optional[str] = None,
):
super().__init__()
self.has_cross_attention = True
resnets = []
attentions = []
self.attention_head_dim = attention_head_dim
self.num_heads = out_channels // self.attention_head_dim
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=in_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
)
)
processor = (
AttnAddedKVProcessor2_0() if hasattr(F, "scaled_dot_product_attention") else AttnAddedKVProcessor()
)
attentions.append(
Attention(
query_dim=out_channels,
cross_attention_dim=out_channels,
heads=self.num_heads,
dim_head=attention_head_dim,
added_kv_proj_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
bias=True,
upcast_softmax=True,
only_cross_attention=only_cross_attention,
cross_attention_norm=cross_attention_norm,
processor=processor,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
self.downsamplers = nn.ModuleList(
[
ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
down=True,
)
]
)
else:
self.downsamplers = None
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
output_states = ()
if attention_mask is None:
# if encoder_hidden_states is defined: we are doing cross-attn, so we should use cross-attn mask.
mask = None if encoder_hidden_states is None else encoder_attention_mask
else:
# when attention_mask is defined: we don't even check for encoder_attention_mask.
# this is to maintain compatibility with UnCLIP, which uses 'attention_mask' param for cross-attn masks.
# TODO: UnCLIP should express cross-attn mask via encoder_attention_mask param instead of via attention_mask.
# then we can simplify this whole if/else block to:
# mask = attention_mask if encoder_hidden_states is None else encoder_attention_mask
mask = attention_mask
for resnet, attn in zip(self.resnets, self.attentions):
if self.training and self.gradient_checkpointing:
def create_custom_forward(module, return_dict=None):
def custom_forward(*inputs):
if return_dict is not None:
return module(*inputs, return_dict=return_dict)
else:
return module(*inputs)
return custom_forward
hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=mask,
**cross_attention_kwargs,
)
else:
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=mask,
**cross_attention_kwargs,
)
output_states = output_states + (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states, temb)
output_states = output_states + (hidden_states,)
return hidden_states, output_states
class KDownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
dropout: float = 0.0,
num_layers: int = 4,
resnet_eps: float = 1e-5,
resnet_act_fn: str = "gelu",
resnet_group_size: int = 32,
add_downsample: bool = False,
):
super().__init__()
resnets = []
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
groups = in_channels // resnet_group_size
groups_out = out_channels // resnet_group_size
resnets.append(
ResnetBlockCondNorm2D(
in_channels=in_channels,
out_channels=out_channels,
dropout=dropout,
temb_channels=temb_channels,
groups=groups,
groups_out=groups_out,
eps=resnet_eps,
non_linearity=resnet_act_fn,
time_embedding_norm="ada_group",
conv_shortcut_bias=False,
)
)
self.resnets = nn.ModuleList(resnets)
if add_downsample:
# YiYi's comments- might be able to use FirDownsample2D, look into details later
self.downsamplers = nn.ModuleList([KDownsample2D()])
else:
self.downsamplers = None
self.gradient_checkpointing = False
def forward(
self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None, *args, **kwargs
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
output_states = ()
for resnet in self.resnets:
if self.training and self.gradient_checkpointing:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
if is_torch_version(">=", "1.11.0"):
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb, use_reentrant=False
)
else:
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb
)
else:
hidden_states = resnet(hidden_states, temb)
output_states += (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
return hidden_states, output_states
class KCrossAttnDownBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
cross_attention_dim: int,
dropout: float = 0.0,
num_layers: int = 4,
resnet_group_size: int = 32,
add_downsample: bool = True,
attention_head_dim: int = 64,
add_self_attention: bool = False,
resnet_eps: float = 1e-5,
resnet_act_fn: str = "gelu",
):
super().__init__()
resnets = []
attentions = []
self.has_cross_attention = True
for i in range(num_layers):
in_channels = in_channels if i == 0 else out_channels
groups = in_channels // resnet_group_size
groups_out = out_channels // resnet_group_size
resnets.append(
ResnetBlockCondNorm2D(
in_channels=in_channels,
out_channels=out_channels,
dropout=dropout,
temb_channels=temb_channels,
groups=groups,
groups_out=groups_out,
eps=resnet_eps,
non_linearity=resnet_act_fn,
time_embedding_norm="ada_group",
conv_shortcut_bias=False,
)
)
attentions.append(
KAttentionBlock(
out_channels,
out_channels // attention_head_dim,
attention_head_dim,
cross_attention_dim=cross_attention_dim,
temb_channels=temb_channels,
attention_bias=True,
add_self_attention=add_self_attention,
cross_attention_norm="layer_norm",
group_size=resnet_group_size,
)
)
self.resnets = nn.ModuleList(resnets)
self.attentions = nn.ModuleList(attentions)
if add_downsample:
self.downsamplers = nn.ModuleList([KDownsample2D()])
else:
self.downsamplers = None
self.gradient_checkpointing = False
def forward(
self,
hidden_states: torch.FloatTensor,
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
) -> Tuple[torch.FloatTensor, Tuple[torch.FloatTensor, ...]]:
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
output_states = ()
for resnet, attn in zip(self.resnets, self.attentions):
if self.training and self.gradient_checkpointing:
def create_custom_forward(module, return_dict=None):
def custom_forward(*inputs):
if return_dict is not None:
return module(*inputs, return_dict=return_dict)
else:
return module(*inputs)
return custom_forward
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet),
hidden_states,
temb,
**ckpt_kwargs,
)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
emb=temb,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
)
else:
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
emb=temb,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
)
if self.downsamplers is None:
output_states += (None,)
else:
output_states += (hidden_states,)
if self.downsamplers is not None:
for downsampler in self.downsamplers:
hidden_states = downsampler(hidden_states)
return hidden_states, output_states
class AttnUpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
prev_output_channel: int,
out_channels: int,
temb_channels: int,
resolution_idx: int = None,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
output_scale_factor: float = 1.0,
upsample_type: str = "conv",
):
super().__init__()
resnets = []
attentions = []
self.upsample_type = upsample_type
if attention_head_dim is None:
logger.warning(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `in_channels`: {out_channels}."
)
attention_head_dim = out_channels
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
attentions.append(
Attention(
out_channels,
heads=out_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=resnet_groups,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if upsample_type == "conv":
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
elif upsample_type == "resnet":
self.upsamplers = nn.ModuleList(
[
ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
up=True,
)
]
)
else:
self.upsamplers = None
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
upsample_size: Optional[int] = None,
*args,
**kwargs,
) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
for resnet, attn in zip(self.resnets, self.attentions):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(hidden_states)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
if self.upsample_type == "resnet":
hidden_states = upsampler(hidden_states, temb=temb)
else:
hidden_states = upsampler(hidden_states)
return hidden_states
class CrossAttnUpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
prev_output_channel: int,
temb_channels: int,
resolution_idx: Optional[int] = None,
dropout: float = 0.0,
num_layers: int = 1,
transformer_layers_per_block: Union[int, Tuple[int]] = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
num_attention_heads: int = 1,
cross_attention_dim: int = 1280,
output_scale_factor: float = 1.0,
add_upsample: bool = True,
dual_cross_attention: bool = False,
use_linear_projection: bool = False,
only_cross_attention: bool = False,
upcast_attention: bool = False,
attention_type: str = "default",
):
super().__init__()
resnets = []
attentions = []
self.has_cross_attention = True
self.num_attention_heads = num_attention_heads
if isinstance(transformer_layers_per_block, int):
transformer_layers_per_block = [transformer_layers_per_block] * num_layers
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
if not dual_cross_attention:
attentions.append(
Transformer2DModel(
num_attention_heads,
out_channels // num_attention_heads,
in_channels=out_channels,
num_layers=transformer_layers_per_block[i],
cross_attention_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
use_linear_projection=use_linear_projection,
only_cross_attention=only_cross_attention,
upcast_attention=upcast_attention,
attention_type=attention_type,
)
)
else:
attentions.append(
DualTransformer2DModel(
num_attention_heads,
out_channels // num_attention_heads,
in_channels=out_channels,
num_layers=1,
cross_attention_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if add_upsample:
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
else:
self.upsamplers = None
self.gradient_checkpointing = False
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
upsample_size: Optional[int] = None,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
) -> torch.FloatTensor:
if cross_attention_kwargs is not None:
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
is_freeu_enabled = (
getattr(self, "s1", None)
and getattr(self, "s2", None)
and getattr(self, "b1", None)
and getattr(self, "b2", None)
)
for resnet, attn in zip(self.resnets, self.attentions):
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
# FreeU: Only operate on the first two stages
if is_freeu_enabled:
hidden_states, res_hidden_states = apply_freeu(
self.resolution_idx,
hidden_states,
res_hidden_states,
s1=self.s1,
s2=self.s2,
b1=self.b1,
b2=self.b2,
)
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
if self.training and self.gradient_checkpointing:
def create_custom_forward(module, return_dict=None):
def custom_forward(*inputs):
if return_dict is not None:
return module(*inputs, return_dict=return_dict)
else:
return module(*inputs)
return custom_forward
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet),
hidden_states,
temb,
**ckpt_kwargs,
)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
else:
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
cross_attention_kwargs=cross_attention_kwargs,
attention_mask=attention_mask,
encoder_attention_mask=encoder_attention_mask,
return_dict=False,
)[0]
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
class UpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
prev_output_channel: int,
out_channels: int,
temb_channels: int,
resolution_idx: Optional[int] = None,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
output_scale_factor: float = 1.0,
add_upsample: bool = True,
):
super().__init__()
resnets = []
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.resnets = nn.ModuleList(resnets)
if add_upsample:
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
else:
self.upsamplers = None
self.gradient_checkpointing = False
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
upsample_size: Optional[int] = None,
*args,
**kwargs,
) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
is_freeu_enabled = (
getattr(self, "s1", None)
and getattr(self, "s2", None)
and getattr(self, "b1", None)
and getattr(self, "b2", None)
)
for resnet in self.resnets:
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
# FreeU: Only operate on the first two stages
if is_freeu_enabled:
hidden_states, res_hidden_states = apply_freeu(
self.resolution_idx,
hidden_states,
res_hidden_states,
s1=self.s1,
s2=self.s2,
b1=self.b1,
b2=self.b2,
)
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
if self.training and self.gradient_checkpointing:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
if is_torch_version(">=", "1.11.0"):
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb, use_reentrant=False
)
else:
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb
)
else:
hidden_states = resnet(hidden_states, temb)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, upsample_size)
return hidden_states
class UpDecoderBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
resolution_idx: Optional[int] = None,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default", # default, spatial
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
output_scale_factor: float = 1.0,
add_upsample: bool = True,
temb_channels: Optional[int] = None,
):
super().__init__()
resnets = []
for i in range(num_layers):
input_channels = in_channels if i == 0 else out_channels
if resnet_time_scale_shift == "spatial":
resnets.append(
ResnetBlockCondNorm2D(
in_channels=input_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm="spatial",
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
)
)
else:
resnets.append(
ResnetBlock2D(
in_channels=input_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.resnets = nn.ModuleList(resnets)
if add_upsample:
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
else:
self.upsamplers = None
self.resolution_idx = resolution_idx
def forward(self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None) -> torch.FloatTensor:
for resnet in self.resnets:
hidden_states = resnet(hidden_states, temb=temb)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states)
return hidden_states
class AttnUpDecoderBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
resolution_idx: Optional[int] = None,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
output_scale_factor: float = 1.0,
add_upsample: bool = True,
temb_channels: Optional[int] = None,
):
super().__init__()
resnets = []
attentions = []
if attention_head_dim is None:
logger.warning(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `out_channels`: {out_channels}."
)
attention_head_dim = out_channels
for i in range(num_layers):
input_channels = in_channels if i == 0 else out_channels
if resnet_time_scale_shift == "spatial":
resnets.append(
ResnetBlockCondNorm2D(
in_channels=input_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm="spatial",
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
)
)
else:
resnets.append(
ResnetBlock2D(
in_channels=input_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
attentions.append(
Attention(
out_channels,
heads=out_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=resnet_groups if resnet_time_scale_shift != "spatial" else None,
spatial_norm_dim=temb_channels if resnet_time_scale_shift == "spatial" else None,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if add_upsample:
self.upsamplers = nn.ModuleList([Upsample2D(out_channels, use_conv=True, out_channels=out_channels)])
else:
self.upsamplers = None
self.resolution_idx = resolution_idx
def forward(self, hidden_states: torch.FloatTensor, temb: Optional[torch.FloatTensor] = None) -> torch.FloatTensor:
for resnet, attn in zip(self.resnets, self.attentions):
hidden_states = resnet(hidden_states, temb=temb)
hidden_states = attn(hidden_states, temb=temb)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states)
return hidden_states
class AttnSkipUpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
prev_output_channel: int,
out_channels: int,
temb_channels: int,
resolution_idx: Optional[int] = None,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
output_scale_factor: float = np.sqrt(2.0),
add_upsample: bool = True,
):
super().__init__()
self.attentions = nn.ModuleList([])
self.resnets = nn.ModuleList([])
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
self.resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=min(resnet_in_channels + res_skip_channels // 4, 32),
groups_out=min(out_channels // 4, 32),
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
if attention_head_dim is None:
logger.warning(
f"It is not recommend to pass `attention_head_dim=None`. Defaulting `attention_head_dim` to `out_channels`: {out_channels}."
)
attention_head_dim = out_channels
self.attentions.append(
Attention(
out_channels,
heads=out_channels // attention_head_dim,
dim_head=attention_head_dim,
rescale_output_factor=output_scale_factor,
eps=resnet_eps,
norm_num_groups=32,
residual_connection=True,
bias=True,
upcast_softmax=True,
_from_deprecated_attn_block=True,
)
)
self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
if add_upsample:
self.resnet_up = ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=min(out_channels // 4, 32),
groups_out=min(out_channels // 4, 32),
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
use_in_shortcut=True,
up=True,
kernel="fir",
)
self.skip_conv = nn.Conv2d(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.skip_norm = torch.nn.GroupNorm(
num_groups=min(out_channels // 4, 32), num_channels=out_channels, eps=resnet_eps, affine=True
)
self.act = nn.SiLU()
else:
self.resnet_up = None
self.skip_conv = None
self.skip_norm = None
self.act = None
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
skip_sample=None,
*args,
**kwargs,
) -> Tuple[torch.FloatTensor, torch.FloatTensor]:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
for resnet in self.resnets:
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
hidden_states = self.attentions[0](hidden_states)
if skip_sample is not None:
skip_sample = self.upsampler(skip_sample)
else:
skip_sample = 0
if self.resnet_up is not None:
skip_sample_states = self.skip_norm(hidden_states)
skip_sample_states = self.act(skip_sample_states)
skip_sample_states = self.skip_conv(skip_sample_states)
skip_sample = skip_sample + skip_sample_states
hidden_states = self.resnet_up(hidden_states, temb)
return hidden_states, skip_sample
class SkipUpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
prev_output_channel: int,
out_channels: int,
temb_channels: int,
resolution_idx: Optional[int] = None,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_pre_norm: bool = True,
output_scale_factor: float = np.sqrt(2.0),
add_upsample: bool = True,
upsample_padding: int = 1,
):
super().__init__()
self.resnets = nn.ModuleList([])
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
self.resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=min((resnet_in_channels + res_skip_channels) // 4, 32),
groups_out=min(out_channels // 4, 32),
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
)
)
self.upsampler = FirUpsample2D(in_channels, out_channels=out_channels)
if add_upsample:
self.resnet_up = ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=min(out_channels // 4, 32),
groups_out=min(out_channels // 4, 32),
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
use_in_shortcut=True,
up=True,
kernel="fir",
)
self.skip_conv = nn.Conv2d(out_channels, 3, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
self.skip_norm = torch.nn.GroupNorm(
num_groups=min(out_channels // 4, 32), num_channels=out_channels, eps=resnet_eps, affine=True
)
self.act = nn.SiLU()
else:
self.resnet_up = None
self.skip_conv = None
self.skip_norm = None
self.act = None
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
skip_sample=None,
*args,
**kwargs,
) -> Tuple[torch.FloatTensor, torch.FloatTensor]:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
for resnet in self.resnets:
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
hidden_states = resnet(hidden_states, temb)
if skip_sample is not None:
skip_sample = self.upsampler(skip_sample)
else:
skip_sample = 0
if self.resnet_up is not None:
skip_sample_states = self.skip_norm(hidden_states)
skip_sample_states = self.act(skip_sample_states)
skip_sample_states = self.skip_conv(skip_sample_states)
skip_sample = skip_sample + skip_sample_states
hidden_states = self.resnet_up(hidden_states, temb)
return hidden_states, skip_sample
class ResnetUpsampleBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
prev_output_channel: int,
out_channels: int,
temb_channels: int,
resolution_idx: Optional[int] = None,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
output_scale_factor: float = 1.0,
add_upsample: bool = True,
skip_time_act: bool = False,
):
super().__init__()
resnets = []
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
)
)
self.resnets = nn.ModuleList(resnets)
if add_upsample:
self.upsamplers = nn.ModuleList(
[
ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
up=True,
)
]
)
else:
self.upsamplers = None
self.gradient_checkpointing = False
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
upsample_size: Optional[int] = None,
*args,
**kwargs,
) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
for resnet in self.resnets:
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
if self.training and self.gradient_checkpointing:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
if is_torch_version(">=", "1.11.0"):
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb, use_reentrant=False
)
else:
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb
)
else:
hidden_states = resnet(hidden_states, temb)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, temb)
return hidden_states
class SimpleCrossAttnUpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
prev_output_channel: int,
temb_channels: int,
resolution_idx: Optional[int] = None,
dropout: float = 0.0,
num_layers: int = 1,
resnet_eps: float = 1e-6,
resnet_time_scale_shift: str = "default",
resnet_act_fn: str = "swish",
resnet_groups: int = 32,
resnet_pre_norm: bool = True,
attention_head_dim: int = 1,
cross_attention_dim: int = 1280,
output_scale_factor: float = 1.0,
add_upsample: bool = True,
skip_time_act: bool = False,
only_cross_attention: bool = False,
cross_attention_norm: Optional[str] = None,
):
super().__init__()
resnets = []
attentions = []
self.has_cross_attention = True
self.attention_head_dim = attention_head_dim
self.num_heads = out_channels // self.attention_head_dim
for i in range(num_layers):
res_skip_channels = in_channels if (i == num_layers - 1) else out_channels
resnet_in_channels = prev_output_channel if i == 0 else out_channels
resnets.append(
ResnetBlock2D(
in_channels=resnet_in_channels + res_skip_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
)
)
processor = (
AttnAddedKVProcessor2_0() if hasattr(F, "scaled_dot_product_attention") else AttnAddedKVProcessor()
)
attentions.append(
Attention(
query_dim=out_channels,
cross_attention_dim=out_channels,
heads=self.num_heads,
dim_head=self.attention_head_dim,
added_kv_proj_dim=cross_attention_dim,
norm_num_groups=resnet_groups,
bias=True,
upcast_softmax=True,
only_cross_attention=only_cross_attention,
cross_attention_norm=cross_attention_norm,
processor=processor,
)
)
self.attentions = nn.ModuleList(attentions)
self.resnets = nn.ModuleList(resnets)
if add_upsample:
self.upsamplers = nn.ModuleList(
[
ResnetBlock2D(
in_channels=out_channels,
out_channels=out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=resnet_groups,
dropout=dropout,
time_embedding_norm=resnet_time_scale_shift,
non_linearity=resnet_act_fn,
output_scale_factor=output_scale_factor,
pre_norm=resnet_pre_norm,
skip_time_act=skip_time_act,
up=True,
)
]
)
else:
self.upsamplers = None
self.gradient_checkpointing = False
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
upsample_size: Optional[int] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
) -> torch.FloatTensor:
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
if attention_mask is None:
# if encoder_hidden_states is defined: we are doing cross-attn, so we should use cross-attn mask.
mask = None if encoder_hidden_states is None else encoder_attention_mask
else:
# when attention_mask is defined: we don't even check for encoder_attention_mask.
# this is to maintain compatibility with UnCLIP, which uses 'attention_mask' param for cross-attn masks.
# TODO: UnCLIP should express cross-attn mask via encoder_attention_mask param instead of via attention_mask.
# then we can simplify this whole if/else block to:
# mask = attention_mask if encoder_hidden_states is None else encoder_attention_mask
mask = attention_mask
for resnet, attn in zip(self.resnets, self.attentions):
# resnet
# pop res hidden states
res_hidden_states = res_hidden_states_tuple[-1]
res_hidden_states_tuple = res_hidden_states_tuple[:-1]
hidden_states = torch.cat([hidden_states, res_hidden_states], dim=1)
if self.training and self.gradient_checkpointing:
def create_custom_forward(module, return_dict=None):
def custom_forward(*inputs):
if return_dict is not None:
return module(*inputs, return_dict=return_dict)
else:
return module(*inputs)
return custom_forward
hidden_states = torch.utils.checkpoint.checkpoint(create_custom_forward(resnet), hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=mask,
**cross_attention_kwargs,
)
else:
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=mask,
**cross_attention_kwargs,
)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states, temb)
return hidden_states
class KUpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
resolution_idx: int,
dropout: float = 0.0,
num_layers: int = 5,
resnet_eps: float = 1e-5,
resnet_act_fn: str = "gelu",
resnet_group_size: Optional[int] = 32,
add_upsample: bool = True,
):
super().__init__()
resnets = []
k_in_channels = 2 * out_channels
k_out_channels = in_channels
num_layers = num_layers - 1
for i in range(num_layers):
in_channels = k_in_channels if i == 0 else out_channels
groups = in_channels // resnet_group_size
groups_out = out_channels // resnet_group_size
resnets.append(
ResnetBlockCondNorm2D(
in_channels=in_channels,
out_channels=k_out_channels if (i == num_layers - 1) else out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=groups,
groups_out=groups_out,
dropout=dropout,
non_linearity=resnet_act_fn,
time_embedding_norm="ada_group",
conv_shortcut_bias=False,
)
)
self.resnets = nn.ModuleList(resnets)
if add_upsample:
self.upsamplers = nn.ModuleList([KUpsample2D()])
else:
self.upsamplers = None
self.gradient_checkpointing = False
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
upsample_size: Optional[int] = None,
*args,
**kwargs,
) -> torch.FloatTensor:
if len(args) > 0 or kwargs.get("scale", None) is not None:
deprecation_message = "The `scale` argument is deprecated and will be ignored. Please remove it, as passing it will raise an error in the future. `scale` should directly be passed while calling the underlying pipeline component i.e., via `cross_attention_kwargs`."
deprecate("scale", "1.0.0", deprecation_message)
res_hidden_states_tuple = res_hidden_states_tuple[-1]
if res_hidden_states_tuple is not None:
hidden_states = torch.cat([hidden_states, res_hidden_states_tuple], dim=1)
for resnet in self.resnets:
if self.training and self.gradient_checkpointing:
def create_custom_forward(module):
def custom_forward(*inputs):
return module(*inputs)
return custom_forward
if is_torch_version(">=", "1.11.0"):
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb, use_reentrant=False
)
else:
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet), hidden_states, temb
)
else:
hidden_states = resnet(hidden_states, temb)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states)
return hidden_states
class KCrossAttnUpBlock2D(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
temb_channels: int,
resolution_idx: int,
dropout: float = 0.0,
num_layers: int = 4,
resnet_eps: float = 1e-5,
resnet_act_fn: str = "gelu",
resnet_group_size: int = 32,
attention_head_dim: int = 1, # attention dim_head
cross_attention_dim: int = 768,
add_upsample: bool = True,
upcast_attention: bool = False,
):
super().__init__()
resnets = []
attentions = []
is_first_block = in_channels == out_channels == temb_channels
is_middle_block = in_channels != out_channels
add_self_attention = True if is_first_block else False
self.has_cross_attention = True
self.attention_head_dim = attention_head_dim
# in_channels, and out_channels for the block (k-unet)
k_in_channels = out_channels if is_first_block else 2 * out_channels
k_out_channels = in_channels
num_layers = num_layers - 1
for i in range(num_layers):
in_channels = k_in_channels if i == 0 else out_channels
groups = in_channels // resnet_group_size
groups_out = out_channels // resnet_group_size
if is_middle_block and (i == num_layers - 1):
conv_2d_out_channels = k_out_channels
else:
conv_2d_out_channels = None
resnets.append(
ResnetBlockCondNorm2D(
in_channels=in_channels,
out_channels=out_channels,
conv_2d_out_channels=conv_2d_out_channels,
temb_channels=temb_channels,
eps=resnet_eps,
groups=groups,
groups_out=groups_out,
dropout=dropout,
non_linearity=resnet_act_fn,
time_embedding_norm="ada_group",
conv_shortcut_bias=False,
)
)
attentions.append(
KAttentionBlock(
k_out_channels if (i == num_layers - 1) else out_channels,
k_out_channels // attention_head_dim
if (i == num_layers - 1)
else out_channels // attention_head_dim,
attention_head_dim,
cross_attention_dim=cross_attention_dim,
temb_channels=temb_channels,
attention_bias=True,
add_self_attention=add_self_attention,
cross_attention_norm="layer_norm",
upcast_attention=upcast_attention,
)
)
self.resnets = nn.ModuleList(resnets)
self.attentions = nn.ModuleList(attentions)
if add_upsample:
self.upsamplers = nn.ModuleList([KUpsample2D()])
else:
self.upsamplers = None
self.gradient_checkpointing = False
self.resolution_idx = resolution_idx
def forward(
self,
hidden_states: torch.FloatTensor,
res_hidden_states_tuple: Tuple[torch.FloatTensor, ...],
temb: Optional[torch.FloatTensor] = None,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
upsample_size: Optional[int] = None,
attention_mask: Optional[torch.FloatTensor] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
) -> torch.FloatTensor:
res_hidden_states_tuple = res_hidden_states_tuple[-1]
if res_hidden_states_tuple is not None:
hidden_states = torch.cat([hidden_states, res_hidden_states_tuple], dim=1)
for resnet, attn in zip(self.resnets, self.attentions):
if self.training and self.gradient_checkpointing:
def create_custom_forward(module, return_dict=None):
def custom_forward(*inputs):
if return_dict is not None:
return module(*inputs, return_dict=return_dict)
else:
return module(*inputs)
return custom_forward
ckpt_kwargs: Dict[str, Any] = {"use_reentrant": False} if is_torch_version(">=", "1.11.0") else {}
hidden_states = torch.utils.checkpoint.checkpoint(
create_custom_forward(resnet),
hidden_states,
temb,
**ckpt_kwargs,
)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
emb=temb,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
)
else:
hidden_states = resnet(hidden_states, temb)
hidden_states = attn(
hidden_states,
encoder_hidden_states=encoder_hidden_states,
emb=temb,
attention_mask=attention_mask,
cross_attention_kwargs=cross_attention_kwargs,
encoder_attention_mask=encoder_attention_mask,
)
if self.upsamplers is not None:
for upsampler in self.upsamplers:
hidden_states = upsampler(hidden_states)
return hidden_states
# can potentially later be renamed to `No-feed-forward` attention
class KAttentionBlock(nn.Module):
r"""
A basic Transformer block.
Parameters:
dim (`int`): The number of channels in the input and output.
num_attention_heads (`int`): The number of heads to use for multi-head attention.
attention_head_dim (`int`): The number of channels in each head.
dropout (`float`, *optional*, defaults to 0.0): The dropout probability to use.
cross_attention_dim (`int`, *optional*): The size of the encoder_hidden_states vector for cross attention.
attention_bias (`bool`, *optional*, defaults to `False`):
Configure if the attention layers should contain a bias parameter.
upcast_attention (`bool`, *optional*, defaults to `False`):
Set to `True` to upcast the attention computation to `float32`.
temb_channels (`int`, *optional*, defaults to 768):
The number of channels in the token embedding.
add_self_attention (`bool`, *optional*, defaults to `False`):
Set to `True` to add self-attention to the block.
cross_attention_norm (`str`, *optional*, defaults to `None`):
The type of normalization to use for the cross attention. Can be `None`, `layer_norm`, or `group_norm`.
group_size (`int`, *optional*, defaults to 32):
The number of groups to separate the channels into for group normalization.
"""
def __init__(
self,
dim: int,
num_attention_heads: int,
attention_head_dim: int,
dropout: float = 0.0,
cross_attention_dim: Optional[int] = None,
attention_bias: bool = False,
upcast_attention: bool = False,
temb_channels: int = 768, # for ada_group_norm
add_self_attention: bool = False,
cross_attention_norm: Optional[str] = None,
group_size: int = 32,
):
super().__init__()
self.add_self_attention = add_self_attention
# 1. Self-Attn
if add_self_attention:
self.norm1 = AdaGroupNorm(temb_channels, dim, max(1, dim // group_size))
self.attn1 = Attention(
query_dim=dim,
heads=num_attention_heads,
dim_head=attention_head_dim,
dropout=dropout,
bias=attention_bias,
cross_attention_dim=None,
cross_attention_norm=None,
)
# 2. Cross-Attn
self.norm2 = AdaGroupNorm(temb_channels, dim, max(1, dim // group_size))
self.attn2 = Attention(
query_dim=dim,
cross_attention_dim=cross_attention_dim,
heads=num_attention_heads,
dim_head=attention_head_dim,
dropout=dropout,
bias=attention_bias,
upcast_attention=upcast_attention,
cross_attention_norm=cross_attention_norm,
)
def _to_3d(self, hidden_states: torch.FloatTensor, height: int, weight: int) -> torch.FloatTensor:
return hidden_states.permute(0, 2, 3, 1).reshape(hidden_states.shape[0], height * weight, -1)
def _to_4d(self, hidden_states: torch.FloatTensor, height: int, weight: int) -> torch.FloatTensor:
return hidden_states.permute(0, 2, 1).reshape(hidden_states.shape[0], -1, height, weight)
def forward(
self,
hidden_states: torch.FloatTensor,
encoder_hidden_states: Optional[torch.FloatTensor] = None,
# TODO: mark emb as non-optional (self.norm2 requires it).
# requires assessing impact of change to positional param interface.
emb: Optional[torch.FloatTensor] = None,
attention_mask: Optional[torch.FloatTensor] = None,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
encoder_attention_mask: Optional[torch.FloatTensor] = None,
) -> torch.FloatTensor:
cross_attention_kwargs = cross_attention_kwargs if cross_attention_kwargs is not None else {}
if cross_attention_kwargs.get("scale", None) is not None:
logger.warning("Passing `scale` to `cross_attention_kwargs` is deprecated. `scale` will be ignored.")
# 1. Self-Attention
if self.add_self_attention:
norm_hidden_states = self.norm1(hidden_states, emb)
height, weight = norm_hidden_states.shape[2:]
norm_hidden_states = self._to_3d(norm_hidden_states, height, weight)
attn_output = self.attn1(
norm_hidden_states,
encoder_hidden_states=None,
attention_mask=attention_mask,
**cross_attention_kwargs,
)
attn_output = self._to_4d(attn_output, height, weight)
hidden_states = attn_output + hidden_states
# 2. Cross-Attention/None
norm_hidden_states = self.norm2(hidden_states, emb)
height, weight = norm_hidden_states.shape[2:]
norm_hidden_states = self._to_3d(norm_hidden_states, height, weight)
attn_output = self.attn2(
norm_hidden_states,
encoder_hidden_states=encoder_hidden_states,
attention_mask=attention_mask if encoder_hidden_states is None else encoder_attention_mask,
**cross_attention_kwargs,
)
attn_output = self._to_4d(attn_output, height, weight)
hidden_states = attn_output + hidden_states
return hidden_states
| diffusers/src/diffusers/models/unets/unet_2d_blocks.py/0 | {
"file_path": "diffusers/src/diffusers/models/unets/unet_2d_blocks.py",
"repo_id": "diffusers",
"token_count": 77898
} | 124 |
from dataclasses import dataclass
from typing import List, Optional, Union
import numpy as np
import PIL
from PIL import Image
from ...utils import OptionalDependencyNotAvailable, is_torch_available, is_transformers_available
try:
if not (is_transformers_available() and is_torch_available()):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils.dummy_torch_and_transformers_objects import ShapEPipeline
else:
from .blip_image_processing import BlipImageProcessor
from .modeling_blip2 import Blip2QFormerModel
from .modeling_ctx_clip import ContextCLIPTextModel
from .pipeline_blip_diffusion import BlipDiffusionPipeline
| diffusers/src/diffusers/pipelines/blip_diffusion/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/blip_diffusion/__init__.py",
"repo_id": "diffusers",
"token_count": 219
} | 125 |
fast27_timesteps = [
999,
800,
799,
600,
599,
500,
400,
399,
377,
355,
333,
311,
288,
266,
244,
222,
200,
199,
177,
155,
133,
111,
88,
66,
44,
22,
0,
]
smart27_timesteps = [
999,
976,
952,
928,
905,
882,
858,
857,
810,
762,
715,
714,
572,
429,
428,
286,
285,
238,
190,
143,
142,
118,
95,
71,
47,
24,
0,
]
smart50_timesteps = [
999,
988,
977,
966,
955,
944,
933,
922,
911,
900,
899,
879,
859,
840,
820,
800,
799,
766,
733,
700,
699,
650,
600,
599,
500,
499,
400,
399,
350,
300,
299,
266,
233,
200,
199,
179,
159,
140,
120,
100,
99,
88,
77,
66,
55,
44,
33,
22,
11,
0,
]
smart100_timesteps = [
999,
995,
992,
989,
985,
981,
978,
975,
971,
967,
964,
961,
957,
956,
951,
947,
942,
937,
933,
928,
923,
919,
914,
913,
908,
903,
897,
892,
887,
881,
876,
871,
870,
864,
858,
852,
846,
840,
834,
828,
827,
820,
813,
806,
799,
792,
785,
784,
777,
770,
763,
756,
749,
742,
741,
733,
724,
716,
707,
699,
698,
688,
677,
666,
656,
655,
645,
634,
623,
613,
612,
598,
584,
570,
569,
555,
541,
527,
526,
505,
484,
483,
462,
440,
439,
396,
395,
352,
351,
308,
307,
264,
263,
220,
219,
176,
132,
88,
44,
0,
]
smart185_timesteps = [
999,
997,
995,
992,
990,
988,
986,
984,
981,
979,
977,
975,
972,
970,
968,
966,
964,
961,
959,
957,
956,
954,
951,
949,
946,
944,
941,
939,
936,
934,
931,
929,
926,
924,
921,
919,
916,
914,
913,
910,
907,
905,
902,
899,
896,
893,
891,
888,
885,
882,
879,
877,
874,
871,
870,
867,
864,
861,
858,
855,
852,
849,
846,
843,
840,
837,
834,
831,
828,
827,
824,
821,
817,
814,
811,
808,
804,
801,
798,
795,
791,
788,
785,
784,
780,
777,
774,
770,
766,
763,
760,
756,
752,
749,
746,
742,
741,
737,
733,
730,
726,
722,
718,
714,
710,
707,
703,
699,
698,
694,
690,
685,
681,
677,
673,
669,
664,
660,
656,
655,
650,
646,
641,
636,
632,
627,
622,
618,
613,
612,
607,
602,
596,
591,
586,
580,
575,
570,
569,
563,
557,
551,
545,
539,
533,
527,
526,
519,
512,
505,
498,
491,
484,
483,
474,
466,
457,
449,
440,
439,
428,
418,
407,
396,
395,
381,
366,
352,
351,
330,
308,
307,
286,
264,
263,
242,
220,
219,
176,
175,
132,
131,
88,
44,
0,
]
super27_timesteps = [
999,
991,
982,
974,
966,
958,
950,
941,
933,
925,
916,
908,
900,
899,
874,
850,
825,
800,
799,
700,
600,
500,
400,
300,
200,
100,
0,
]
super40_timesteps = [
999,
992,
985,
978,
971,
964,
957,
949,
942,
935,
928,
921,
914,
907,
900,
899,
879,
859,
840,
820,
800,
799,
766,
733,
700,
699,
650,
600,
599,
500,
499,
400,
399,
300,
299,
200,
199,
100,
99,
0,
]
super100_timesteps = [
999,
996,
992,
989,
985,
982,
979,
975,
972,
968,
965,
961,
958,
955,
951,
948,
944,
941,
938,
934,
931,
927,
924,
920,
917,
914,
910,
907,
903,
900,
899,
891,
884,
876,
869,
861,
853,
846,
838,
830,
823,
815,
808,
800,
799,
788,
777,
766,
755,
744,
733,
722,
711,
700,
699,
688,
677,
666,
655,
644,
633,
622,
611,
600,
599,
585,
571,
557,
542,
528,
514,
500,
499,
485,
471,
457,
442,
428,
414,
400,
399,
379,
359,
340,
320,
300,
299,
279,
259,
240,
220,
200,
199,
166,
133,
100,
99,
66,
33,
0,
]
| diffusers/src/diffusers/pipelines/deepfloyd_if/timesteps.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deepfloyd_if/timesteps.py",
"repo_id": "diffusers",
"token_count": 3772
} | 126 |
from typing import TYPE_CHECKING
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
_import_structure = {"pipeline_repaint": ["RePaintPipeline"]}
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .pipeline_repaint import RePaintPipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
__name__,
globals()["__file__"],
_import_structure,
module_spec=__spec__,
)
| diffusers/src/diffusers/pipelines/deprecated/repaint/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/repaint/__init__.py",
"repo_id": "diffusers",
"token_count": 183
} | 127 |
from typing import TYPE_CHECKING
from ....utils import DIFFUSERS_SLOW_IMPORT, _LazyModule
_import_structure = {"pipeline_stochastic_karras_ve": ["KarrasVePipeline"]}
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
from .pipeline_stochastic_karras_ve import KarrasVePipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
__name__,
globals()["__file__"],
_import_structure,
module_spec=__spec__,
)
| diffusers/src/diffusers/pipelines/deprecated/stochastic_karras_ve/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/deprecated/stochastic_karras_ve/__init__.py",
"repo_id": "diffusers",
"token_count": 199
} | 128 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from typing import Callable, List, Optional, Union
import torch
from transformers import (
XLMRobertaTokenizer,
)
from ...models import UNet2DConditionModel, VQModel
from ...schedulers import DDIMScheduler, DDPMScheduler
from ...utils import (
logging,
replace_example_docstring,
)
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline, ImagePipelineOutput
from .text_encoder import MultilingualCLIP
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> from diffusers import KandinskyPipeline, KandinskyPriorPipeline
>>> import torch
>>> pipe_prior = KandinskyPriorPipeline.from_pretrained("kandinsky-community/Kandinsky-2-1-prior")
>>> pipe_prior.to("cuda")
>>> prompt = "red cat, 4k photo"
>>> out = pipe_prior(prompt)
>>> image_emb = out.image_embeds
>>> negative_image_emb = out.negative_image_embeds
>>> pipe = KandinskyPipeline.from_pretrained("kandinsky-community/kandinsky-2-1")
>>> pipe.to("cuda")
>>> image = pipe(
... prompt,
... image_embeds=image_emb,
... negative_image_embeds=negative_image_emb,
... height=768,
... width=768,
... num_inference_steps=100,
... ).images
>>> image[0].save("cat.png")
```
"""
def get_new_h_w(h, w, scale_factor=8):
new_h = h // scale_factor**2
if h % scale_factor**2 != 0:
new_h += 1
new_w = w // scale_factor**2
if w % scale_factor**2 != 0:
new_w += 1
return new_h * scale_factor, new_w * scale_factor
class KandinskyPipeline(DiffusionPipeline):
"""
Pipeline for text-to-image generation using Kandinsky
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods the
library implements for all the pipelines (such as downloading or saving, running on a particular device, etc.)
Args:
text_encoder ([`MultilingualCLIP`]):
Frozen text-encoder.
tokenizer ([`XLMRobertaTokenizer`]):
Tokenizer of class
scheduler (Union[`DDIMScheduler`,`DDPMScheduler`]):
A scheduler to be used in combination with `unet` to generate image latents.
unet ([`UNet2DConditionModel`]):
Conditional U-Net architecture to denoise the image embedding.
movq ([`VQModel`]):
MoVQ Decoder to generate the image from the latents.
"""
model_cpu_offload_seq = "text_encoder->unet->movq"
def __init__(
self,
text_encoder: MultilingualCLIP,
tokenizer: XLMRobertaTokenizer,
unet: UNet2DConditionModel,
scheduler: Union[DDIMScheduler, DDPMScheduler],
movq: VQModel,
):
super().__init__()
self.register_modules(
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
movq=movq,
)
self.movq_scale_factor = 2 ** (len(self.movq.config.block_out_channels) - 1)
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.prepare_latents
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
latents = latents * scheduler.init_noise_sigma
return latents
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
):
batch_size = len(prompt) if isinstance(prompt, list) else 1
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
truncation=True,
max_length=77,
return_attention_mask=True,
add_special_tokens=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1])
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
text_input_ids = text_input_ids.to(device)
text_mask = text_inputs.attention_mask.to(device)
prompt_embeds, text_encoder_hidden_states = self.text_encoder(
input_ids=text_input_ids, attention_mask=text_mask
)
prompt_embeds = prompt_embeds.repeat_interleave(num_images_per_prompt, dim=0)
text_encoder_hidden_states = text_encoder_hidden_states.repeat_interleave(num_images_per_prompt, dim=0)
text_mask = text_mask.repeat_interleave(num_images_per_prompt, dim=0)
if do_classifier_free_guidance:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=77,
truncation=True,
return_attention_mask=True,
add_special_tokens=True,
return_tensors="pt",
)
uncond_text_input_ids = uncond_input.input_ids.to(device)
uncond_text_mask = uncond_input.attention_mask.to(device)
negative_prompt_embeds, uncond_text_encoder_hidden_states = self.text_encoder(
input_ids=uncond_text_input_ids, attention_mask=uncond_text_mask
)
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len)
seq_len = uncond_text_encoder_hidden_states.shape[1]
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.repeat(1, num_images_per_prompt, 1)
uncond_text_encoder_hidden_states = uncond_text_encoder_hidden_states.view(
batch_size * num_images_per_prompt, seq_len, -1
)
uncond_text_mask = uncond_text_mask.repeat_interleave(num_images_per_prompt, dim=0)
# done duplicates
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
text_encoder_hidden_states = torch.cat([uncond_text_encoder_hidden_states, text_encoder_hidden_states])
text_mask = torch.cat([uncond_text_mask, text_mask])
return prompt_embeds, text_encoder_hidden_states, text_mask
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]],
image_embeds: Union[torch.FloatTensor, List[torch.FloatTensor]],
negative_image_embeds: Union[torch.FloatTensor, List[torch.FloatTensor]],
negative_prompt: Optional[Union[str, List[str]]] = None,
height: int = 512,
width: int = 512,
num_inference_steps: int = 100,
guidance_scale: float = 4.0,
num_images_per_prompt: int = 1,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
return_dict: bool = True,
):
"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
The clip image embeddings for text prompt, that will be used to condition the image generation.
negative_image_embeds (`torch.FloatTensor` or `List[torch.FloatTensor]`):
The clip image embeddings for negative text prompt, will be used to condition the image generation.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
height (`int`, *optional*, defaults to 512):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to 512):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 100):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 4.0):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
One or a list of [torch generator(s)](https://pytorch.org/docs/stable/generated/torch.Generator.html)
to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between: `"pil"` (`PIL.Image.Image`), `"np"`
(`np.array`) or `"pt"` (`torch.Tensor`).
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.ImagePipelineOutput`] instead of a plain tuple.
Examples:
Returns:
[`~pipelines.ImagePipelineOutput`] or `tuple`
"""
if isinstance(prompt, str):
batch_size = 1
elif isinstance(prompt, list):
batch_size = len(prompt)
else:
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
device = self._execution_device
batch_size = batch_size * num_images_per_prompt
do_classifier_free_guidance = guidance_scale > 1.0
prompt_embeds, text_encoder_hidden_states, _ = self._encode_prompt(
prompt, device, num_images_per_prompt, do_classifier_free_guidance, negative_prompt
)
if isinstance(image_embeds, list):
image_embeds = torch.cat(image_embeds, dim=0)
if isinstance(negative_image_embeds, list):
negative_image_embeds = torch.cat(negative_image_embeds, dim=0)
if do_classifier_free_guidance:
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
negative_image_embeds = negative_image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
image_embeds = torch.cat([negative_image_embeds, image_embeds], dim=0).to(
dtype=prompt_embeds.dtype, device=device
)
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps_tensor = self.scheduler.timesteps
num_channels_latents = self.unet.config.in_channels
height, width = get_new_h_w(height, width, self.movq_scale_factor)
# create initial latent
latents = self.prepare_latents(
(batch_size, num_channels_latents, height, width),
text_encoder_hidden_states.dtype,
device,
generator,
latents,
self.scheduler,
)
for i, t in enumerate(self.progress_bar(timesteps_tensor)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
added_cond_kwargs = {"text_embeds": prompt_embeds, "image_embeds": image_embeds}
noise_pred = self.unet(
sample=latent_model_input,
timestep=t,
encoder_hidden_states=text_encoder_hidden_states,
added_cond_kwargs=added_cond_kwargs,
return_dict=False,
)[0]
if do_classifier_free_guidance:
noise_pred, variance_pred = noise_pred.split(latents.shape[1], dim=1)
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
_, variance_pred_text = variance_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
noise_pred = torch.cat([noise_pred, variance_pred_text], dim=1)
if not (
hasattr(self.scheduler.config, "variance_type")
and self.scheduler.config.variance_type in ["learned", "learned_range"]
):
noise_pred, _ = noise_pred.split(latents.shape[1], dim=1)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
noise_pred,
t,
latents,
generator=generator,
).prev_sample
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# post-processing
image = self.movq.decode(latents, force_not_quantize=True)["sample"]
self.maybe_free_model_hooks()
if output_type not in ["pt", "np", "pil"]:
raise ValueError(f"Only the output types `pt`, `pil` and `np` are supported not output_type={output_type}")
if output_type in ["np", "pil"]:
image = image * 0.5 + 0.5
image = image.clamp(0, 1)
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image,)
return ImagePipelineOutput(images=image)
| diffusers/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky/pipeline_kandinsky.py",
"repo_id": "diffusers",
"token_count": 7949
} | 129 |
#!/usr/bin/env python3
import argparse
import fnmatch
from safetensors.torch import load_file
from diffusers import Kandinsky3UNet
MAPPING = {
"to_time_embed.1": "time_embedding.linear_1",
"to_time_embed.3": "time_embedding.linear_2",
"in_layer": "conv_in",
"out_layer.0": "conv_norm_out",
"out_layer.2": "conv_out",
"down_samples": "down_blocks",
"up_samples": "up_blocks",
"projection_lin": "encoder_hid_proj.projection_linear",
"projection_ln": "encoder_hid_proj.projection_norm",
"feature_pooling": "add_time_condition",
"to_query": "to_q",
"to_key": "to_k",
"to_value": "to_v",
"output_layer": "to_out.0",
"self_attention_block": "attentions.0",
}
DYNAMIC_MAP = {
"resnet_attn_blocks.*.0": "resnets_in.*",
"resnet_attn_blocks.*.1": ("attentions.*", 1),
"resnet_attn_blocks.*.2": "resnets_out.*",
}
# MAPPING = {}
def convert_state_dict(unet_state_dict):
"""
Convert the state dict of a U-Net model to match the key format expected by Kandinsky3UNet model.
Args:
unet_model (torch.nn.Module): The original U-Net model.
unet_kandi3_model (torch.nn.Module): The Kandinsky3UNet model to match keys with.
Returns:
OrderedDict: The converted state dictionary.
"""
# Example of renaming logic (this will vary based on your model's architecture)
converted_state_dict = {}
for key in unet_state_dict:
new_key = key
for pattern, new_pattern in MAPPING.items():
new_key = new_key.replace(pattern, new_pattern)
for dyn_pattern, dyn_new_pattern in DYNAMIC_MAP.items():
has_matched = False
if fnmatch.fnmatch(new_key, f"*.{dyn_pattern}.*") and not has_matched:
star = int(new_key.split(dyn_pattern.split(".")[0])[-1].split(".")[1])
if isinstance(dyn_new_pattern, tuple):
new_star = star + dyn_new_pattern[-1]
dyn_new_pattern = dyn_new_pattern[0]
else:
new_star = star
pattern = dyn_pattern.replace("*", str(star))
new_pattern = dyn_new_pattern.replace("*", str(new_star))
new_key = new_key.replace(pattern, new_pattern)
has_matched = True
converted_state_dict[new_key] = unet_state_dict[key]
return converted_state_dict
def main(model_path, output_path):
# Load your original U-Net model
unet_state_dict = load_file(model_path)
# Initialize your Kandinsky3UNet model
config = {}
# Convert the state dict
converted_state_dict = convert_state_dict(unet_state_dict)
unet = Kandinsky3UNet(config)
unet.load_state_dict(converted_state_dict)
unet.save_pretrained(output_path)
print(f"Converted model saved to {output_path}")
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="Convert U-Net PyTorch model to Kandinsky3UNet format")
parser.add_argument("--model_path", type=str, required=True, help="Path to the original U-Net PyTorch model")
parser.add_argument("--output_path", type=str, required=True, help="Path to save the converted model")
args = parser.parse_args()
main(args.model_path, args.output_path)
| diffusers/src/diffusers/pipelines/kandinsky3/convert_kandinsky3_unet.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/kandinsky3/convert_kandinsky3_unet.py",
"repo_id": "diffusers",
"token_count": 1403
} | 130 |
from dataclasses import dataclass
from typing import TYPE_CHECKING, List, Optional, Union
import numpy as np
import PIL
from PIL import Image
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is_torch_available()):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils import dummy_torch_and_transformers_objects # noqa F403
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
else:
_import_structure["image_encoder"] = ["PaintByExampleImageEncoder"]
_import_structure["pipeline_paint_by_example"] = ["PaintByExamplePipeline"]
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
try:
if not (is_transformers_available() and is_torch_available()):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils.dummy_torch_and_transformers_objects import *
else:
from .image_encoder import PaintByExampleImageEncoder
from .pipeline_paint_by_example import PaintByExamplePipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
__name__,
globals()["__file__"],
_import_structure,
module_spec=__spec__,
)
for name, value in _dummy_objects.items():
setattr(sys.modules[__name__], name, value)
| diffusers/src/diffusers/pipelines/paint_by_example/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/paint_by_example/__init__.py",
"repo_id": "diffusers",
"token_count": 599
} | 131 |
# Copyright 2024 Open AI and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from dataclasses import dataclass
from typing import List, Optional, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPVisionModel
from ...models import PriorTransformer
from ...schedulers import HeunDiscreteScheduler
from ...utils import (
BaseOutput,
logging,
replace_example_docstring,
)
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline
from .renderer import ShapERenderer
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> from PIL import Image
>>> import torch
>>> from diffusers import DiffusionPipeline
>>> from diffusers.utils import export_to_gif, load_image
>>> device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
>>> repo = "openai/shap-e-img2img"
>>> pipe = DiffusionPipeline.from_pretrained(repo, torch_dtype=torch.float16)
>>> pipe = pipe.to(device)
>>> guidance_scale = 3.0
>>> image_url = "https://hf.co/datasets/diffusers/docs-images/resolve/main/shap-e/corgi.png"
>>> image = load_image(image_url).convert("RGB")
>>> images = pipe(
... image,
... guidance_scale=guidance_scale,
... num_inference_steps=64,
... frame_size=256,
... ).images
>>> gif_path = export_to_gif(images[0], "corgi_3d.gif")
```
"""
@dataclass
class ShapEPipelineOutput(BaseOutput):
"""
Output class for [`ShapEPipeline`] and [`ShapEImg2ImgPipeline`].
Args:
images (`torch.FloatTensor`)
A list of images for 3D rendering.
"""
images: Union[PIL.Image.Image, np.ndarray]
class ShapEImg2ImgPipeline(DiffusionPipeline):
"""
Pipeline for generating latent representation of a 3D asset and rendering with the NeRF method from an image.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
Args:
prior ([`PriorTransformer`]):
The canonical unCLIP prior to approximate the image embedding from the text embedding.
image_encoder ([`~transformers.CLIPVisionModel`]):
Frozen image-encoder.
image_processor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to process images.
scheduler ([`HeunDiscreteScheduler`]):
A scheduler to be used in combination with the `prior` model to generate image embedding.
shap_e_renderer ([`ShapERenderer`]):
Shap-E renderer projects the generated latents into parameters of a MLP to create 3D objects with the NeRF
rendering method.
"""
model_cpu_offload_seq = "image_encoder->prior"
_exclude_from_cpu_offload = ["shap_e_renderer"]
def __init__(
self,
prior: PriorTransformer,
image_encoder: CLIPVisionModel,
image_processor: CLIPImageProcessor,
scheduler: HeunDiscreteScheduler,
shap_e_renderer: ShapERenderer,
):
super().__init__()
self.register_modules(
prior=prior,
image_encoder=image_encoder,
image_processor=image_processor,
scheduler=scheduler,
shap_e_renderer=shap_e_renderer,
)
# Copied from diffusers.pipelines.unclip.pipeline_unclip.UnCLIPPipeline.prepare_latents
def prepare_latents(self, shape, dtype, device, generator, latents, scheduler):
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
if latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
latents = latents.to(device)
latents = latents * scheduler.init_noise_sigma
return latents
def _encode_image(
self,
image,
device,
num_images_per_prompt,
do_classifier_free_guidance,
):
if isinstance(image, List) and isinstance(image[0], torch.Tensor):
image = torch.cat(image, axis=0) if image[0].ndim == 4 else torch.stack(image, axis=0)
if not isinstance(image, torch.Tensor):
image = self.image_processor(image, return_tensors="pt").pixel_values[0].unsqueeze(0)
image = image.to(dtype=self.image_encoder.dtype, device=device)
image_embeds = self.image_encoder(image)["last_hidden_state"]
image_embeds = image_embeds[:, 1:, :].contiguous() # batch_size, dim, 256
image_embeds = image_embeds.repeat_interleave(num_images_per_prompt, dim=0)
if do_classifier_free_guidance:
negative_image_embeds = torch.zeros_like(image_embeds)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
image_embeds = torch.cat([negative_image_embeds, image_embeds])
return image_embeds
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
image: Union[PIL.Image.Image, List[PIL.Image.Image]],
num_images_per_prompt: int = 1,
num_inference_steps: int = 25,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
guidance_scale: float = 4.0,
frame_size: int = 64,
output_type: Optional[str] = "pil", # pil, np, latent, mesh
return_dict: bool = True,
):
"""
The call function to the pipeline for generation.
Args:
image (`torch.FloatTensor`, `PIL.Image.Image`, `np.ndarray`, `List[torch.FloatTensor]`, `List[PIL.Image.Image]`, or `List[np.ndarray]`):
`Image` or tensor representing an image batch to be used as the starting point. Can also accept image
latents as image, but if passing latents directly it is not encoded again.
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
num_inference_steps (`int`, *optional*, defaults to 25):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
guidance_scale (`float`, *optional*, defaults to 4.0):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
frame_size (`int`, *optional*, default to 64):
The width and height of each image frame of the generated 3D output.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `"pil"` (`PIL.Image.Image`), `"np"`
(`np.array`), `"latent"` (`torch.Tensor`), or mesh ([`MeshDecoderOutput`]).
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.shap_e.pipeline_shap_e.ShapEPipelineOutput`] instead of a plain
tuple.
Examples:
Returns:
[`~pipelines.shap_e.pipeline_shap_e.ShapEPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.shap_e.pipeline_shap_e.ShapEPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images.
"""
if isinstance(image, PIL.Image.Image):
batch_size = 1
elif isinstance(image, torch.Tensor):
batch_size = image.shape[0]
elif isinstance(image, list) and isinstance(image[0], (torch.Tensor, PIL.Image.Image)):
batch_size = len(image)
else:
raise ValueError(
f"`image` has to be of type `PIL.Image.Image`, `torch.Tensor`, `List[PIL.Image.Image]` or `List[torch.Tensor]` but is {type(image)}"
)
device = self._execution_device
batch_size = batch_size * num_images_per_prompt
do_classifier_free_guidance = guidance_scale > 1.0
image_embeds = self._encode_image(image, device, num_images_per_prompt, do_classifier_free_guidance)
# prior
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
num_embeddings = self.prior.config.num_embeddings
embedding_dim = self.prior.config.embedding_dim
latents = self.prepare_latents(
(batch_size, num_embeddings * embedding_dim),
image_embeds.dtype,
device,
generator,
latents,
self.scheduler,
)
# YiYi notes: for testing only to match ldm, we can directly create a latents with desired shape: batch_size, num_embeddings, embedding_dim
latents = latents.reshape(latents.shape[0], num_embeddings, embedding_dim)
for i, t in enumerate(self.progress_bar(timesteps)):
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
scaled_model_input = self.scheduler.scale_model_input(latent_model_input, t)
noise_pred = self.prior(
scaled_model_input,
timestep=t,
proj_embedding=image_embeds,
).predicted_image_embedding
# remove the variance
noise_pred, _ = noise_pred.split(
scaled_model_input.shape[2], dim=2
) # batch_size, num_embeddings, embedding_dim
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred - noise_pred_uncond)
latents = self.scheduler.step(
noise_pred,
timestep=t,
sample=latents,
).prev_sample
if output_type not in ["np", "pil", "latent", "mesh"]:
raise ValueError(
f"Only the output types `pil`, `np`, `latent` and `mesh` are supported not output_type={output_type}"
)
# Offload all models
self.maybe_free_model_hooks()
if output_type == "latent":
return ShapEPipelineOutput(images=latents)
images = []
if output_type == "mesh":
for i, latent in enumerate(latents):
mesh = self.shap_e_renderer.decode_to_mesh(
latent[None, :],
device,
)
images.append(mesh)
else:
# np, pil
for i, latent in enumerate(latents):
image = self.shap_e_renderer.decode_to_image(
latent[None, :],
device,
size=frame_size,
)
images.append(image)
images = torch.stack(images)
images = images.cpu().numpy()
if output_type == "pil":
images = [self.numpy_to_pil(image) for image in images]
if not return_dict:
return (images,)
return ShapEPipelineOutput(images=images)
| diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e_img2img.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/shap_e/pipeline_shap_e_img2img.py",
"repo_id": "diffusers",
"token_count": 5663
} | 132 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
from typing import Any, Callable, List, Optional, Union
import numpy as np
import PIL.Image
import torch
from transformers import CLIPImageProcessor, CLIPTokenizer
from ...configuration_utils import FrozenDict
from ...schedulers import DDPMScheduler, KarrasDiffusionSchedulers
from ...utils import deprecate, logging
from ..onnx_utils import ORT_TO_NP_TYPE, OnnxRuntimeModel
from ..pipeline_utils import DiffusionPipeline
from . import StableDiffusionPipelineOutput
logger = logging.get_logger(__name__)
def preprocess(image):
if isinstance(image, torch.Tensor):
return image
elif isinstance(image, PIL.Image.Image):
image = [image]
if isinstance(image[0], PIL.Image.Image):
w, h = image[0].size
w, h = (x - x % 64 for x in (w, h)) # resize to integer multiple of 32
image = [np.array(i.resize((w, h)))[None, :] for i in image]
image = np.concatenate(image, axis=0)
image = np.array(image).astype(np.float32) / 255.0
image = image.transpose(0, 3, 1, 2)
image = 2.0 * image - 1.0
image = torch.from_numpy(image)
elif isinstance(image[0], torch.Tensor):
image = torch.cat(image, dim=0)
return image
class OnnxStableDiffusionUpscalePipeline(DiffusionPipeline):
vae: OnnxRuntimeModel
text_encoder: OnnxRuntimeModel
tokenizer: CLIPTokenizer
unet: OnnxRuntimeModel
low_res_scheduler: DDPMScheduler
scheduler: KarrasDiffusionSchedulers
safety_checker: OnnxRuntimeModel
feature_extractor: CLIPImageProcessor
_optional_components = ["safety_checker", "feature_extractor"]
_is_onnx = True
def __init__(
self,
vae: OnnxRuntimeModel,
text_encoder: OnnxRuntimeModel,
tokenizer: Any,
unet: OnnxRuntimeModel,
low_res_scheduler: DDPMScheduler,
scheduler: KarrasDiffusionSchedulers,
safety_checker: Optional[OnnxRuntimeModel] = None,
feature_extractor: Optional[CLIPImageProcessor] = None,
max_noise_level: int = 350,
num_latent_channels=4,
num_unet_input_channels=7,
requires_safety_checker: bool = True,
):
super().__init__()
if hasattr(scheduler.config, "steps_offset") and scheduler.config.steps_offset != 1:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} is outdated. `steps_offset`"
f" should be set to 1 instead of {scheduler.config.steps_offset}. Please make sure "
"to update the config accordingly as leaving `steps_offset` might led to incorrect results"
" in future versions. If you have downloaded this checkpoint from the Hugging Face Hub,"
" it would be very nice if you could open a Pull request for the `scheduler/scheduler_config.json`"
" file"
)
deprecate("steps_offset!=1", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["steps_offset"] = 1
scheduler._internal_dict = FrozenDict(new_config)
if hasattr(scheduler.config, "clip_sample") and scheduler.config.clip_sample is True:
deprecation_message = (
f"The configuration file of this scheduler: {scheduler} has not set the configuration `clip_sample`."
" `clip_sample` should be set to False in the configuration file. Please make sure to update the"
" config accordingly as not setting `clip_sample` in the config might lead to incorrect results in"
" future versions. If you have downloaded this checkpoint from the Hugging Face Hub, it would be very"
" nice if you could open a Pull request for the `scheduler/scheduler_config.json` file"
)
deprecate("clip_sample not set", "1.0.0", deprecation_message, standard_warn=False)
new_config = dict(scheduler.config)
new_config["clip_sample"] = False
scheduler._internal_dict = FrozenDict(new_config)
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
low_res_scheduler=low_res_scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.register_to_config(
max_noise_level=max_noise_level,
num_latent_channels=num_latent_channels,
num_unet_input_channels=num_unet_input_channels,
)
def check_inputs(
self,
prompt: Union[str, List[str]],
image,
noise_level,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
):
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
if (
not isinstance(image, torch.Tensor)
and not isinstance(image, PIL.Image.Image)
and not isinstance(image, np.ndarray)
and not isinstance(image, list)
):
raise ValueError(
f"`image` has to be of type `torch.Tensor`, `np.ndarray`, `PIL.Image.Image` or `list` but is {type(image)}"
)
# verify batch size of prompt and image are same if image is a list or tensor or numpy array
if isinstance(image, list) or isinstance(image, np.ndarray):
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if isinstance(image, list):
image_batch_size = len(image)
else:
image_batch_size = image.shape[0]
if batch_size != image_batch_size:
raise ValueError(
f"`prompt` has batch size {batch_size} and `image` has batch size {image_batch_size}."
" Please make sure that passed `prompt` matches the batch size of `image`."
)
# check noise level
if noise_level > self.config.max_noise_level:
raise ValueError(f"`noise_level` has to be <= {self.config.max_noise_level} but is {noise_level}")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, generator, latents=None):
shape = (batch_size, num_channels_latents, height, width)
if latents is None:
latents = generator.randn(*shape).astype(dtype)
elif latents.shape != shape:
raise ValueError(f"Unexpected latents shape, got {latents.shape}, expected {shape}")
return latents
def decode_latents(self, latents):
latents = 1 / 0.08333 * latents
image = self.vae(latent_sample=latents)[0]
image = np.clip(image / 2 + 0.5, 0, 1)
image = image.transpose((0, 2, 3, 1))
return image
def _encode_prompt(
self,
prompt: Union[str, List[str]],
num_images_per_prompt: Optional[int],
do_classifier_free_guidance: bool,
negative_prompt: Optional[str],
prompt_embeds: Optional[np.ndarray] = None,
negative_prompt_embeds: Optional[np.ndarray] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`):
prompt to be encoded
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
prompt_embeds (`np.ndarray`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`np.ndarray`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
"""
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# get prompt text embeddings
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="np",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="max_length", return_tensors="np").input_ids
if not np.array_equal(text_input_ids, untruncated_ids):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
prompt_embeds = self.text_encoder(input_ids=text_input_ids.astype(np.int32))[0]
prompt_embeds = np.repeat(prompt_embeds, num_images_per_prompt, axis=0)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt] * batch_size
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="np",
)
negative_prompt_embeds = self.text_encoder(input_ids=uncond_input.input_ids.astype(np.int32))[0]
if do_classifier_free_guidance:
negative_prompt_embeds = np.repeat(negative_prompt_embeds, num_images_per_prompt, axis=0)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
prompt_embeds = np.concatenate([negative_prompt_embeds, prompt_embeds])
return prompt_embeds
def __call__(
self,
prompt: Union[str, List[str]],
image: Union[np.ndarray, PIL.Image.Image, List[PIL.Image.Image]],
num_inference_steps: int = 75,
guidance_scale: float = 9.0,
noise_level: int = 20,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: Optional[int] = 1,
eta: float = 0.0,
generator: Optional[Union[np.random.RandomState, List[np.random.RandomState]]] = None,
latents: Optional[np.ndarray] = None,
prompt_embeds: Optional[np.ndarray] = None,
negative_prompt_embeds: Optional[np.ndarray] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, np.ndarray], None]] = None,
callback_steps: Optional[int] = 1,
):
r"""
Function invoked when calling the pipeline for generation.
Args:
prompt (`str` or `List[str]`):
The prompt or prompts to guide the image generation.
image (`np.ndarray` or `PIL.Image.Image`):
`Image`, or tensor representing an image batch, that will be used as the starting point for the
process.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference. This parameter will be modulated by `strength`.
guidance_scale (`float`, *optional*, defaults to 7.5):
Guidance scale as defined in [Classifier-Free Diffusion Guidance](https://arxiv.org/abs/2207.12598).
`guidance_scale` is defined as `w` of equation 2. of [Imagen
Paper](https://arxiv.org/pdf/2205.11487.pdf). Guidance scale is enabled by setting `guidance_scale >
1`. Higher guidance scale encourages to generate images that are closely linked to the text `prompt`,
usually at the expense of lower image quality.
noise_level (`float`, defaults to 0.2):
Deteremines the amount of noise to add to the initial image before performing upscaling.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. Ignored when not using guidance (i.e., ignored
if `guidance_scale` is less than `1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) in the DDIM paper: https://arxiv.org/abs/2010.02502. Only applies to
[`schedulers.DDIMScheduler`], will be ignored for others.
generator (`np.random.RandomState`, *optional*):
A np.random.RandomState to make generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents, sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor will ge generated by sampling using the supplied random `generator`.
prompt_embeds (`np.ndarray`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`np.ndarray`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generate image. Choose between
[PIL](https://pillow.readthedocs.io/en/stable/): `PIL.Image.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that will be called every `callback_steps` steps during inference. The function will be
called with the following arguments: `callback(step: int, timestep: int, latents: np.ndarray)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function will be called. If not specified, the callback will be
called at every step.
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] if `return_dict` is True, otherwise a `tuple.
When returning a tuple, the first element is a list with the generated images, and the second element is a
list of `bool`s denoting whether the corresponding generated image likely represents "not-safe-for-work"
(nsfw) content, according to the `safety_checker`.
"""
# 1. Check inputs
self.check_inputs(
prompt,
image,
noise_level,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if generator is None:
generator = np.random
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
prompt_embeds = self._encode_prompt(
prompt,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
)
latents_dtype = prompt_embeds.dtype
image = preprocess(image).cpu().numpy()
height, width = image.shape[2:]
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
self.config.num_latent_channels,
height,
width,
latents_dtype,
generator,
)
image = image.astype(latents_dtype)
self.scheduler.set_timesteps(num_inference_steps)
timesteps = self.scheduler.timesteps
# Scale the initial noise by the standard deviation required by the scheduler
latents = latents * np.float64(self.scheduler.init_noise_sigma)
# 5. Add noise to image
noise_level = np.array([noise_level]).astype(np.int64)
noise = generator.randn(*image.shape).astype(latents_dtype)
image = self.low_res_scheduler.add_noise(
torch.from_numpy(image), torch.from_numpy(noise), torch.from_numpy(noise_level)
)
image = image.numpy()
batch_multiplier = 2 if do_classifier_free_guidance else 1
image = np.concatenate([image] * batch_multiplier * num_images_per_prompt)
noise_level = np.concatenate([noise_level] * image.shape[0])
# 7. Check that sizes of image and latents match
num_channels_image = image.shape[1]
if self.config.num_latent_channels + num_channels_image != self.config.num_unet_input_channels:
raise ValueError(
"Incorrect configuration settings! The config of `pipeline.unet` expects"
f" {self.config.num_unet_input_channels} but received `num_channels_latents`: {self.config.num_latent_channels} +"
f" `num_channels_image`: {num_channels_image} "
f" = {self.config.num_latent_channels + num_channels_image}. Please verify the config of"
" `pipeline.unet` or your `image` input."
)
# 8. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
timestep_dtype = next(
(input.type for input in self.unet.model.get_inputs() if input.name == "timestep"), "tensor(float)"
)
timestep_dtype = ORT_TO_NP_TYPE[timestep_dtype]
# 9. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# expand the latents if we are doing classifier free guidance
latent_model_input = np.concatenate([latents] * 2) if do_classifier_free_guidance else latents
# concat latents, mask, masked_image_latents in the channel dimension
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
latent_model_input = np.concatenate([latent_model_input, image], axis=1)
# timestep to tensor
timestep = np.array([t], dtype=timestep_dtype)
# predict the noise residual
noise_pred = self.unet(
sample=latent_model_input,
timestep=timestep,
encoder_hidden_states=prompt_embeds,
class_labels=noise_level,
)[0]
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = np.split(noise_pred, 2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(
torch.from_numpy(noise_pred), t, torch.from_numpy(latents), **extra_step_kwargs
).prev_sample
latents = latents.numpy()
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# 10. Post-processing
image = self.decode_latents(latents)
if self.safety_checker is not None:
safety_checker_input = self.feature_extractor(
self.numpy_to_pil(image), return_tensors="np"
).pixel_values.astype(image.dtype)
images, has_nsfw_concept = [], []
for i in range(image.shape[0]):
image_i, has_nsfw_concept_i = self.safety_checker(
clip_input=safety_checker_input[i : i + 1], images=image[i : i + 1]
)
images.append(image_i)
has_nsfw_concept.append(has_nsfw_concept_i[0])
image = np.concatenate(images)
else:
has_nsfw_concept = None
if output_type == "pil":
image = self.numpy_to_pil(image)
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
| diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion/pipeline_onnx_stable_diffusion_upscale.py",
"repo_id": "diffusers",
"token_count": 12562
} | 133 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import inspect
import math
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import numpy as np
import torch
from torch.nn import functional as F
from transformers import CLIPImageProcessor, CLIPTextModel, CLIPTokenizer
from ...image_processor import VaeImageProcessor
from ...loaders import LoraLoaderMixin, TextualInversionLoaderMixin
from ...models import AutoencoderKL, UNet2DConditionModel
from ...models.attention_processor import Attention
from ...models.lora import adjust_lora_scale_text_encoder
from ...schedulers import KarrasDiffusionSchedulers
from ...utils import (
USE_PEFT_BACKEND,
deprecate,
logging,
replace_example_docstring,
scale_lora_layers,
unscale_lora_layers,
)
from ...utils.torch_utils import randn_tensor
from ..pipeline_utils import DiffusionPipeline, StableDiffusionMixin
from ..stable_diffusion import StableDiffusionPipelineOutput
from ..stable_diffusion.safety_checker import StableDiffusionSafetyChecker
logger = logging.get_logger(__name__)
EXAMPLE_DOC_STRING = """
Examples:
```py
>>> import torch
>>> from diffusers import StableDiffusionAttendAndExcitePipeline
>>> pipe = StableDiffusionAttendAndExcitePipeline.from_pretrained(
... "CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16
... ).to("cuda")
>>> prompt = "a cat and a frog"
>>> # use get_indices function to find out indices of the tokens you want to alter
>>> pipe.get_indices(prompt)
{0: '<|startoftext|>', 1: 'a</w>', 2: 'cat</w>', 3: 'and</w>', 4: 'a</w>', 5: 'frog</w>', 6: '<|endoftext|>'}
>>> token_indices = [2, 5]
>>> seed = 6141
>>> generator = torch.Generator("cuda").manual_seed(seed)
>>> images = pipe(
... prompt=prompt,
... token_indices=token_indices,
... guidance_scale=7.5,
... generator=generator,
... num_inference_steps=50,
... max_iter_to_alter=25,
... ).images
>>> image = images[0]
>>> image.save(f"../images/{prompt}_{seed}.png")
```
"""
class AttentionStore:
@staticmethod
def get_empty_store():
return {"down": [], "mid": [], "up": []}
def __call__(self, attn, is_cross: bool, place_in_unet: str):
if self.cur_att_layer >= 0 and is_cross:
if attn.shape[1] == np.prod(self.attn_res):
self.step_store[place_in_unet].append(attn)
self.cur_att_layer += 1
if self.cur_att_layer == self.num_att_layers:
self.cur_att_layer = 0
self.between_steps()
def between_steps(self):
self.attention_store = self.step_store
self.step_store = self.get_empty_store()
def get_average_attention(self):
average_attention = self.attention_store
return average_attention
def aggregate_attention(self, from_where: List[str]) -> torch.Tensor:
"""Aggregates the attention across the different layers and heads at the specified resolution."""
out = []
attention_maps = self.get_average_attention()
for location in from_where:
for item in attention_maps[location]:
cross_maps = item.reshape(-1, self.attn_res[0], self.attn_res[1], item.shape[-1])
out.append(cross_maps)
out = torch.cat(out, dim=0)
out = out.sum(0) / out.shape[0]
return out
def reset(self):
self.cur_att_layer = 0
self.step_store = self.get_empty_store()
self.attention_store = {}
def __init__(self, attn_res):
"""
Initialize an empty AttentionStore :param step_index: used to visualize only a specific step in the diffusion
process
"""
self.num_att_layers = -1
self.cur_att_layer = 0
self.step_store = self.get_empty_store()
self.attention_store = {}
self.curr_step_index = 0
self.attn_res = attn_res
class AttendExciteAttnProcessor:
def __init__(self, attnstore, place_in_unet):
super().__init__()
self.attnstore = attnstore
self.place_in_unet = place_in_unet
def __call__(self, attn: Attention, hidden_states, encoder_hidden_states=None, attention_mask=None):
batch_size, sequence_length, _ = hidden_states.shape
attention_mask = attn.prepare_attention_mask(attention_mask, sequence_length, batch_size)
query = attn.to_q(hidden_states)
is_cross = encoder_hidden_states is not None
encoder_hidden_states = encoder_hidden_states if encoder_hidden_states is not None else hidden_states
key = attn.to_k(encoder_hidden_states)
value = attn.to_v(encoder_hidden_states)
query = attn.head_to_batch_dim(query)
key = attn.head_to_batch_dim(key)
value = attn.head_to_batch_dim(value)
attention_probs = attn.get_attention_scores(query, key, attention_mask)
# only need to store attention maps during the Attend and Excite process
if attention_probs.requires_grad:
self.attnstore(attention_probs, is_cross, self.place_in_unet)
hidden_states = torch.bmm(attention_probs, value)
hidden_states = attn.batch_to_head_dim(hidden_states)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
return hidden_states
class StableDiffusionAttendAndExcitePipeline(DiffusionPipeline, StableDiffusionMixin, TextualInversionLoaderMixin):
r"""
Pipeline for text-to-image generation using Stable Diffusion and Attend-and-Excite.
This model inherits from [`DiffusionPipeline`]. Check the superclass documentation for the generic methods
implemented for all pipelines (downloading, saving, running on a particular device, etc.).
The pipeline also inherits the following loading methods:
- [`~loaders.TextualInversionLoaderMixin.load_textual_inversion`] for loading textual inversion embeddings
Args:
vae ([`AutoencoderKL`]):
Variational Auto-Encoder (VAE) model to encode and decode images to and from latent representations.
text_encoder ([`~transformers.CLIPTextModel`]):
Frozen text-encoder ([clip-vit-large-patch14](https://huggingface.co/openai/clip-vit-large-patch14)).
tokenizer ([`~transformers.CLIPTokenizer`]):
A `CLIPTokenizer` to tokenize text.
unet ([`UNet2DConditionModel`]):
A `UNet2DConditionModel` to denoise the encoded image latents.
scheduler ([`SchedulerMixin`]):
A scheduler to be used in combination with `unet` to denoise the encoded image latents. Can be one of
[`DDIMScheduler`], [`LMSDiscreteScheduler`], or [`PNDMScheduler`].
safety_checker ([`StableDiffusionSafetyChecker`]):
Classification module that estimates whether generated images could be considered offensive or harmful.
Please refer to the [model card](https://huggingface.co/runwayml/stable-diffusion-v1-5) for more details
about a model's potential harms.
feature_extractor ([`~transformers.CLIPImageProcessor`]):
A `CLIPImageProcessor` to extract features from generated images; used as inputs to the `safety_checker`.
"""
model_cpu_offload_seq = "text_encoder->unet->vae"
_optional_components = ["safety_checker", "feature_extractor"]
_exclude_from_cpu_offload = ["safety_checker"]
def __init__(
self,
vae: AutoencoderKL,
text_encoder: CLIPTextModel,
tokenizer: CLIPTokenizer,
unet: UNet2DConditionModel,
scheduler: KarrasDiffusionSchedulers,
safety_checker: StableDiffusionSafetyChecker,
feature_extractor: CLIPImageProcessor,
requires_safety_checker: bool = True,
):
super().__init__()
if safety_checker is None and requires_safety_checker:
logger.warning(
f"You have disabled the safety checker for {self.__class__} by passing `safety_checker=None`. Ensure"
" that you abide to the conditions of the Stable Diffusion license and do not expose unfiltered"
" results in services or applications open to the public. Both the diffusers team and Hugging Face"
" strongly recommend to keep the safety filter enabled in all public facing circumstances, disabling"
" it only for use-cases that involve analyzing network behavior or auditing its results. For more"
" information, please have a look at https://github.com/huggingface/diffusers/pull/254 ."
)
if safety_checker is not None and feature_extractor is None:
raise ValueError(
"Make sure to define a feature extractor when loading {self.__class__} if you want to use the safety"
" checker. If you do not want to use the safety checker, you can pass `'safety_checker=None'` instead."
)
self.register_modules(
vae=vae,
text_encoder=text_encoder,
tokenizer=tokenizer,
unet=unet,
scheduler=scheduler,
safety_checker=safety_checker,
feature_extractor=feature_extractor,
)
self.vae_scale_factor = 2 ** (len(self.vae.config.block_out_channels) - 1)
self.image_processor = VaeImageProcessor(vae_scale_factor=self.vae_scale_factor)
self.register_to_config(requires_safety_checker=requires_safety_checker)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline._encode_prompt
def _encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
**kwargs,
):
deprecation_message = "`_encode_prompt()` is deprecated and it will be removed in a future version. Use `encode_prompt()` instead. Also, be aware that the output format changed from a concatenated tensor to a tuple."
deprecate("_encode_prompt()", "1.0.0", deprecation_message, standard_warn=False)
prompt_embeds_tuple = self.encode_prompt(
prompt=prompt,
device=device,
num_images_per_prompt=num_images_per_prompt,
do_classifier_free_guidance=do_classifier_free_guidance,
negative_prompt=negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
lora_scale=lora_scale,
**kwargs,
)
# concatenate for backwards comp
prompt_embeds = torch.cat([prompt_embeds_tuple[1], prompt_embeds_tuple[0]])
return prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.encode_prompt
def encode_prompt(
self,
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt=None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
lora_scale: Optional[float] = None,
clip_skip: Optional[int] = None,
):
r"""
Encodes the prompt into text encoder hidden states.
Args:
prompt (`str` or `List[str]`, *optional*):
prompt to be encoded
device: (`torch.device`):
torch device
num_images_per_prompt (`int`):
number of images that should be generated per prompt
do_classifier_free_guidance (`bool`):
whether to use classifier free guidance or not
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts not to guide the image generation. If not defined, one has to pass
`negative_prompt_embeds` instead. Ignored when not using guidance (i.e., ignored if `guidance_scale` is
less than `1`).
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt weighting. If not
provided, text embeddings will be generated from `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs, *e.g.* prompt
weighting. If not provided, negative_prompt_embeds will be generated from `negative_prompt` input
argument.
lora_scale (`float`, *optional*):
A LoRA scale that will be applied to all LoRA layers of the text encoder if LoRA layers are loaded.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
"""
# set lora scale so that monkey patched LoRA
# function of text encoder can correctly access it
if lora_scale is not None and isinstance(self, LoraLoaderMixin):
self._lora_scale = lora_scale
# dynamically adjust the LoRA scale
if not USE_PEFT_BACKEND:
adjust_lora_scale_text_encoder(self.text_encoder, lora_scale)
else:
scale_lora_layers(self.text_encoder, lora_scale)
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
if prompt_embeds is None:
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
prompt = self.maybe_convert_prompt(prompt, self.tokenizer)
text_inputs = self.tokenizer(
prompt,
padding="max_length",
max_length=self.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
text_input_ids = text_inputs.input_ids
untruncated_ids = self.tokenizer(prompt, padding="longest", return_tensors="pt").input_ids
if untruncated_ids.shape[-1] >= text_input_ids.shape[-1] and not torch.equal(
text_input_ids, untruncated_ids
):
removed_text = self.tokenizer.batch_decode(
untruncated_ids[:, self.tokenizer.model_max_length - 1 : -1]
)
logger.warning(
"The following part of your input was truncated because CLIP can only handle sequences up to"
f" {self.tokenizer.model_max_length} tokens: {removed_text}"
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = text_inputs.attention_mask.to(device)
else:
attention_mask = None
if clip_skip is None:
prompt_embeds = self.text_encoder(text_input_ids.to(device), attention_mask=attention_mask)
prompt_embeds = prompt_embeds[0]
else:
prompt_embeds = self.text_encoder(
text_input_ids.to(device), attention_mask=attention_mask, output_hidden_states=True
)
# Access the `hidden_states` first, that contains a tuple of
# all the hidden states from the encoder layers. Then index into
# the tuple to access the hidden states from the desired layer.
prompt_embeds = prompt_embeds[-1][-(clip_skip + 1)]
# We also need to apply the final LayerNorm here to not mess with the
# representations. The `last_hidden_states` that we typically use for
# obtaining the final prompt representations passes through the LayerNorm
# layer.
prompt_embeds = self.text_encoder.text_model.final_layer_norm(prompt_embeds)
if self.text_encoder is not None:
prompt_embeds_dtype = self.text_encoder.dtype
elif self.unet is not None:
prompt_embeds_dtype = self.unet.dtype
else:
prompt_embeds_dtype = prompt_embeds.dtype
prompt_embeds = prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
bs_embed, seq_len, _ = prompt_embeds.shape
# duplicate text embeddings for each generation per prompt, using mps friendly method
prompt_embeds = prompt_embeds.repeat(1, num_images_per_prompt, 1)
prompt_embeds = prompt_embeds.view(bs_embed * num_images_per_prompt, seq_len, -1)
# get unconditional embeddings for classifier free guidance
if do_classifier_free_guidance and negative_prompt_embeds is None:
uncond_tokens: List[str]
if negative_prompt is None:
uncond_tokens = [""] * batch_size
elif prompt is not None and type(prompt) is not type(negative_prompt):
raise TypeError(
f"`negative_prompt` should be the same type to `prompt`, but got {type(negative_prompt)} !="
f" {type(prompt)}."
)
elif isinstance(negative_prompt, str):
uncond_tokens = [negative_prompt]
elif batch_size != len(negative_prompt):
raise ValueError(
f"`negative_prompt`: {negative_prompt} has batch size {len(negative_prompt)}, but `prompt`:"
f" {prompt} has batch size {batch_size}. Please make sure that passed `negative_prompt` matches"
" the batch size of `prompt`."
)
else:
uncond_tokens = negative_prompt
# textual inversion: process multi-vector tokens if necessary
if isinstance(self, TextualInversionLoaderMixin):
uncond_tokens = self.maybe_convert_prompt(uncond_tokens, self.tokenizer)
max_length = prompt_embeds.shape[1]
uncond_input = self.tokenizer(
uncond_tokens,
padding="max_length",
max_length=max_length,
truncation=True,
return_tensors="pt",
)
if hasattr(self.text_encoder.config, "use_attention_mask") and self.text_encoder.config.use_attention_mask:
attention_mask = uncond_input.attention_mask.to(device)
else:
attention_mask = None
negative_prompt_embeds = self.text_encoder(
uncond_input.input_ids.to(device),
attention_mask=attention_mask,
)
negative_prompt_embeds = negative_prompt_embeds[0]
if do_classifier_free_guidance:
# duplicate unconditional embeddings for each generation per prompt, using mps friendly method
seq_len = negative_prompt_embeds.shape[1]
negative_prompt_embeds = negative_prompt_embeds.to(dtype=prompt_embeds_dtype, device=device)
negative_prompt_embeds = negative_prompt_embeds.repeat(1, num_images_per_prompt, 1)
negative_prompt_embeds = negative_prompt_embeds.view(batch_size * num_images_per_prompt, seq_len, -1)
if isinstance(self, LoraLoaderMixin) and USE_PEFT_BACKEND:
# Retrieve the original scale by scaling back the LoRA layers
unscale_lora_layers(self.text_encoder, lora_scale)
return prompt_embeds, negative_prompt_embeds
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.run_safety_checker
def run_safety_checker(self, image, device, dtype):
if self.safety_checker is None:
has_nsfw_concept = None
else:
if torch.is_tensor(image):
feature_extractor_input = self.image_processor.postprocess(image, output_type="pil")
else:
feature_extractor_input = self.image_processor.numpy_to_pil(image)
safety_checker_input = self.feature_extractor(feature_extractor_input, return_tensors="pt").to(device)
image, has_nsfw_concept = self.safety_checker(
images=image, clip_input=safety_checker_input.pixel_values.to(dtype)
)
return image, has_nsfw_concept
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.decode_latents
def decode_latents(self, latents):
deprecation_message = "The decode_latents method is deprecated and will be removed in 1.0.0. Please use VaeImageProcessor.postprocess(...) instead"
deprecate("decode_latents", "1.0.0", deprecation_message, standard_warn=False)
latents = 1 / self.vae.config.scaling_factor * latents
image = self.vae.decode(latents, return_dict=False)[0]
image = (image / 2 + 0.5).clamp(0, 1)
# we always cast to float32 as this does not cause significant overhead and is compatible with bfloat16
image = image.cpu().permute(0, 2, 3, 1).float().numpy()
return image
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_extra_step_kwargs
def prepare_extra_step_kwargs(self, generator, eta):
# prepare extra kwargs for the scheduler step, since not all schedulers have the same signature
# eta (η) is only used with the DDIMScheduler, it will be ignored for other schedulers.
# eta corresponds to η in DDIM paper: https://arxiv.org/abs/2010.02502
# and should be between [0, 1]
accepts_eta = "eta" in set(inspect.signature(self.scheduler.step).parameters.keys())
extra_step_kwargs = {}
if accepts_eta:
extra_step_kwargs["eta"] = eta
# check if the scheduler accepts generator
accepts_generator = "generator" in set(inspect.signature(self.scheduler.step).parameters.keys())
if accepts_generator:
extra_step_kwargs["generator"] = generator
return extra_step_kwargs
def check_inputs(
self,
prompt,
indices,
height,
width,
callback_steps,
negative_prompt=None,
prompt_embeds=None,
negative_prompt_embeds=None,
):
if height % 8 != 0 or width % 8 != 0:
raise ValueError(f"`height` and `width` have to be divisible by 8 but are {height} and {width}.")
if (callback_steps is None) or (
callback_steps is not None and (not isinstance(callback_steps, int) or callback_steps <= 0)
):
raise ValueError(
f"`callback_steps` has to be a positive integer but is {callback_steps} of type"
f" {type(callback_steps)}."
)
if prompt is not None and prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `prompt`: {prompt} and `prompt_embeds`: {prompt_embeds}. Please make sure to"
" only forward one of the two."
)
elif prompt is None and prompt_embeds is None:
raise ValueError(
"Provide either `prompt` or `prompt_embeds`. Cannot leave both `prompt` and `prompt_embeds` undefined."
)
elif prompt is not None and (not isinstance(prompt, str) and not isinstance(prompt, list)):
raise ValueError(f"`prompt` has to be of type `str` or `list` but is {type(prompt)}")
if negative_prompt is not None and negative_prompt_embeds is not None:
raise ValueError(
f"Cannot forward both `negative_prompt`: {negative_prompt} and `negative_prompt_embeds`:"
f" {negative_prompt_embeds}. Please make sure to only forward one of the two."
)
if prompt_embeds is not None and negative_prompt_embeds is not None:
if prompt_embeds.shape != negative_prompt_embeds.shape:
raise ValueError(
"`prompt_embeds` and `negative_prompt_embeds` must have the same shape when passed directly, but"
f" got: `prompt_embeds` {prompt_embeds.shape} != `negative_prompt_embeds`"
f" {negative_prompt_embeds.shape}."
)
indices_is_list_ints = isinstance(indices, list) and isinstance(indices[0], int)
indices_is_list_list_ints = (
isinstance(indices, list) and isinstance(indices[0], list) and isinstance(indices[0][0], int)
)
if not indices_is_list_ints and not indices_is_list_list_ints:
raise TypeError("`indices` must be a list of ints or a list of a list of ints")
if indices_is_list_ints:
indices_batch_size = 1
elif indices_is_list_list_ints:
indices_batch_size = len(indices)
if prompt is not None and isinstance(prompt, str):
prompt_batch_size = 1
elif prompt is not None and isinstance(prompt, list):
prompt_batch_size = len(prompt)
elif prompt_embeds is not None:
prompt_batch_size = prompt_embeds.shape[0]
if indices_batch_size != prompt_batch_size:
raise ValueError(
f"indices batch size must be same as prompt batch size. indices batch size: {indices_batch_size}, prompt batch size: {prompt_batch_size}"
)
# Copied from diffusers.pipelines.stable_diffusion.pipeline_stable_diffusion.StableDiffusionPipeline.prepare_latents
def prepare_latents(self, batch_size, num_channels_latents, height, width, dtype, device, generator, latents=None):
shape = (batch_size, num_channels_latents, height // self.vae_scale_factor, width // self.vae_scale_factor)
if isinstance(generator, list) and len(generator) != batch_size:
raise ValueError(
f"You have passed a list of generators of length {len(generator)}, but requested an effective batch"
f" size of {batch_size}. Make sure the batch size matches the length of the generators."
)
if latents is None:
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
else:
latents = latents.to(device)
# scale the initial noise by the standard deviation required by the scheduler
latents = latents * self.scheduler.init_noise_sigma
return latents
@staticmethod
def _compute_max_attention_per_index(
attention_maps: torch.Tensor,
indices: List[int],
) -> List[torch.Tensor]:
"""Computes the maximum attention value for each of the tokens we wish to alter."""
attention_for_text = attention_maps[:, :, 1:-1]
attention_for_text *= 100
attention_for_text = torch.nn.functional.softmax(attention_for_text, dim=-1)
# Shift indices since we removed the first token
indices = [index - 1 for index in indices]
# Extract the maximum values
max_indices_list = []
for i in indices:
image = attention_for_text[:, :, i]
smoothing = GaussianSmoothing().to(attention_maps.device)
input = F.pad(image.unsqueeze(0).unsqueeze(0), (1, 1, 1, 1), mode="reflect")
image = smoothing(input).squeeze(0).squeeze(0)
max_indices_list.append(image.max())
return max_indices_list
def _aggregate_and_get_max_attention_per_token(
self,
indices: List[int],
):
"""Aggregates the attention for each token and computes the max activation value for each token to alter."""
attention_maps = self.attention_store.aggregate_attention(
from_where=("up", "down", "mid"),
)
max_attention_per_index = self._compute_max_attention_per_index(
attention_maps=attention_maps,
indices=indices,
)
return max_attention_per_index
@staticmethod
def _compute_loss(max_attention_per_index: List[torch.Tensor]) -> torch.Tensor:
"""Computes the attend-and-excite loss using the maximum attention value for each token."""
losses = [max(0, 1.0 - curr_max) for curr_max in max_attention_per_index]
loss = max(losses)
return loss
@staticmethod
def _update_latent(latents: torch.Tensor, loss: torch.Tensor, step_size: float) -> torch.Tensor:
"""Update the latent according to the computed loss."""
grad_cond = torch.autograd.grad(loss.requires_grad_(True), [latents], retain_graph=True)[0]
latents = latents - step_size * grad_cond
return latents
def _perform_iterative_refinement_step(
self,
latents: torch.Tensor,
indices: List[int],
loss: torch.Tensor,
threshold: float,
text_embeddings: torch.Tensor,
step_size: float,
t: int,
max_refinement_steps: int = 20,
):
"""
Performs the iterative latent refinement introduced in the paper. Here, we continuously update the latent code
according to our loss objective until the given threshold is reached for all tokens.
"""
iteration = 0
target_loss = max(0, 1.0 - threshold)
while loss > target_loss:
iteration += 1
latents = latents.clone().detach().requires_grad_(True)
self.unet(latents, t, encoder_hidden_states=text_embeddings).sample
self.unet.zero_grad()
# Get max activation value for each subject token
max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
indices=indices,
)
loss = self._compute_loss(max_attention_per_index)
if loss != 0:
latents = self._update_latent(latents, loss, step_size)
logger.info(f"\t Try {iteration}. loss: {loss}")
if iteration >= max_refinement_steps:
logger.info(f"\t Exceeded max number of iterations ({max_refinement_steps})! ")
break
# Run one more time but don't compute gradients and update the latents.
# We just need to compute the new loss - the grad update will occur below
latents = latents.clone().detach().requires_grad_(True)
_ = self.unet(latents, t, encoder_hidden_states=text_embeddings).sample
self.unet.zero_grad()
# Get max activation value for each subject token
max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
indices=indices,
)
loss = self._compute_loss(max_attention_per_index)
logger.info(f"\t Finished with loss of: {loss}")
return loss, latents, max_attention_per_index
def register_attention_control(self):
attn_procs = {}
cross_att_count = 0
for name in self.unet.attn_processors.keys():
if name.startswith("mid_block"):
place_in_unet = "mid"
elif name.startswith("up_blocks"):
place_in_unet = "up"
elif name.startswith("down_blocks"):
place_in_unet = "down"
else:
continue
cross_att_count += 1
attn_procs[name] = AttendExciteAttnProcessor(attnstore=self.attention_store, place_in_unet=place_in_unet)
self.unet.set_attn_processor(attn_procs)
self.attention_store.num_att_layers = cross_att_count
def get_indices(self, prompt: str) -> Dict[str, int]:
"""Utility function to list the indices of the tokens you wish to alte"""
ids = self.tokenizer(prompt).input_ids
indices = {i: tok for tok, i in zip(self.tokenizer.convert_ids_to_tokens(ids), range(len(ids)))}
return indices
@torch.no_grad()
@replace_example_docstring(EXAMPLE_DOC_STRING)
def __call__(
self,
prompt: Union[str, List[str]],
token_indices: Union[List[int], List[List[int]]],
height: Optional[int] = None,
width: Optional[int] = None,
num_inference_steps: int = 50,
guidance_scale: float = 7.5,
negative_prompt: Optional[Union[str, List[str]]] = None,
num_images_per_prompt: int = 1,
eta: float = 0.0,
generator: Optional[Union[torch.Generator, List[torch.Generator]]] = None,
latents: Optional[torch.FloatTensor] = None,
prompt_embeds: Optional[torch.FloatTensor] = None,
negative_prompt_embeds: Optional[torch.FloatTensor] = None,
output_type: Optional[str] = "pil",
return_dict: bool = True,
callback: Optional[Callable[[int, int, torch.FloatTensor], None]] = None,
callback_steps: int = 1,
cross_attention_kwargs: Optional[Dict[str, Any]] = None,
max_iter_to_alter: int = 25,
thresholds: dict = {0: 0.05, 10: 0.5, 20: 0.8},
scale_factor: int = 20,
attn_res: Optional[Tuple[int]] = (16, 16),
clip_skip: Optional[int] = None,
):
r"""
The call function to the pipeline for generation.
Args:
prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide image generation. If not defined, you need to pass `prompt_embeds`.
token_indices (`List[int]`):
The token indices to alter with attend-and-excite.
height (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The height in pixels of the generated image.
width (`int`, *optional*, defaults to `self.unet.config.sample_size * self.vae_scale_factor`):
The width in pixels of the generated image.
num_inference_steps (`int`, *optional*, defaults to 50):
The number of denoising steps. More denoising steps usually lead to a higher quality image at the
expense of slower inference.
guidance_scale (`float`, *optional*, defaults to 7.5):
A higher guidance scale value encourages the model to generate images closely linked to the text
`prompt` at the expense of lower image quality. Guidance scale is enabled when `guidance_scale > 1`.
negative_prompt (`str` or `List[str]`, *optional*):
The prompt or prompts to guide what to not include in image generation. If not defined, you need to
pass `negative_prompt_embeds` instead. Ignored when not using guidance (`guidance_scale < 1`).
num_images_per_prompt (`int`, *optional*, defaults to 1):
The number of images to generate per prompt.
eta (`float`, *optional*, defaults to 0.0):
Corresponds to parameter eta (η) from the [DDIM](https://arxiv.org/abs/2010.02502) paper. Only applies
to the [`~schedulers.DDIMScheduler`], and is ignored in other schedulers.
generator (`torch.Generator` or `List[torch.Generator]`, *optional*):
A [`torch.Generator`](https://pytorch.org/docs/stable/generated/torch.Generator.html) to make
generation deterministic.
latents (`torch.FloatTensor`, *optional*):
Pre-generated noisy latents sampled from a Gaussian distribution, to be used as inputs for image
generation. Can be used to tweak the same generation with different prompts. If not provided, a latents
tensor is generated by sampling using the supplied random `generator`.
prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated text embeddings. Can be used to easily tweak text inputs (prompt weighting). If not
provided, text embeddings are generated from the `prompt` input argument.
negative_prompt_embeds (`torch.FloatTensor`, *optional*):
Pre-generated negative text embeddings. Can be used to easily tweak text inputs (prompt weighting). If
not provided, `negative_prompt_embeds` are generated from the `negative_prompt` input argument.
output_type (`str`, *optional*, defaults to `"pil"`):
The output format of the generated image. Choose between `PIL.Image` or `np.array`.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] instead of a
plain tuple.
callback (`Callable`, *optional*):
A function that calls every `callback_steps` steps during inference. The function is called with the
following arguments: `callback(step: int, timestep: int, latents: torch.FloatTensor)`.
callback_steps (`int`, *optional*, defaults to 1):
The frequency at which the `callback` function is called. If not specified, the callback is called at
every step.
cross_attention_kwargs (`dict`, *optional*):
A kwargs dictionary that if specified is passed along to the [`AttentionProcessor`] as defined in
[`self.processor`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/models/attention_processor.py).
max_iter_to_alter (`int`, *optional*, defaults to `25`):
Number of denoising steps to apply attend-and-excite. The `max_iter_to_alter` denoising steps are when
attend-and-excite is applied. For example, if `max_iter_to_alter` is `25` and there are a total of `30`
denoising steps, the first `25` denoising steps applies attend-and-excite and the last `5` will not.
thresholds (`dict`, *optional*, defaults to `{0: 0.05, 10: 0.5, 20: 0.8}`):
Dictionary defining the iterations and desired thresholds to apply iterative latent refinement in.
scale_factor (`int`, *optional*, default to 20):
Scale factor to control the step size of each attend-and-excite update.
attn_res (`tuple`, *optional*, default computed from width and height):
The 2D resolution of the semantic attention map.
clip_skip (`int`, *optional*):
Number of layers to be skipped from CLIP while computing the prompt embeddings. A value of 1 means that
the output of the pre-final layer will be used for computing the prompt embeddings.
Examples:
Returns:
[`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] or `tuple`:
If `return_dict` is `True`, [`~pipelines.stable_diffusion.StableDiffusionPipelineOutput`] is returned,
otherwise a `tuple` is returned where the first element is a list with the generated images and the
second element is a list of `bool`s indicating whether the corresponding generated image contains
"not-safe-for-work" (nsfw) content.
"""
# 0. Default height and width to unet
height = height or self.unet.config.sample_size * self.vae_scale_factor
width = width or self.unet.config.sample_size * self.vae_scale_factor
# 1. Check inputs. Raise error if not correct
self.check_inputs(
prompt,
token_indices,
height,
width,
callback_steps,
negative_prompt,
prompt_embeds,
negative_prompt_embeds,
)
# 2. Define call parameters
if prompt is not None and isinstance(prompt, str):
batch_size = 1
elif prompt is not None and isinstance(prompt, list):
batch_size = len(prompt)
else:
batch_size = prompt_embeds.shape[0]
device = self._execution_device
# here `guidance_scale` is defined analog to the guidance weight `w` of equation (2)
# of the Imagen paper: https://arxiv.org/pdf/2205.11487.pdf . `guidance_scale = 1`
# corresponds to doing no classifier free guidance.
do_classifier_free_guidance = guidance_scale > 1.0
# 3. Encode input prompt
prompt_embeds, negative_prompt_embeds = self.encode_prompt(
prompt,
device,
num_images_per_prompt,
do_classifier_free_guidance,
negative_prompt,
prompt_embeds=prompt_embeds,
negative_prompt_embeds=negative_prompt_embeds,
clip_skip=clip_skip,
)
# For classifier free guidance, we need to do two forward passes.
# Here we concatenate the unconditional and text embeddings into a single batch
# to avoid doing two forward passes
if do_classifier_free_guidance:
prompt_embeds = torch.cat([negative_prompt_embeds, prompt_embeds])
# 4. Prepare timesteps
self.scheduler.set_timesteps(num_inference_steps, device=device)
timesteps = self.scheduler.timesteps
# 5. Prepare latent variables
num_channels_latents = self.unet.config.in_channels
latents = self.prepare_latents(
batch_size * num_images_per_prompt,
num_channels_latents,
height,
width,
prompt_embeds.dtype,
device,
generator,
latents,
)
# 6. Prepare extra step kwargs. TODO: Logic should ideally just be moved out of the pipeline
extra_step_kwargs = self.prepare_extra_step_kwargs(generator, eta)
if attn_res is None:
attn_res = int(np.ceil(width / 32)), int(np.ceil(height / 32))
self.attention_store = AttentionStore(attn_res)
self.register_attention_control()
# default config for step size from original repo
scale_range = np.linspace(1.0, 0.5, len(self.scheduler.timesteps))
step_size = scale_factor * np.sqrt(scale_range)
text_embeddings = (
prompt_embeds[batch_size * num_images_per_prompt :] if do_classifier_free_guidance else prompt_embeds
)
if isinstance(token_indices[0], int):
token_indices = [token_indices]
indices = []
for ind in token_indices:
indices = indices + [ind] * num_images_per_prompt
# 7. Denoising loop
num_warmup_steps = len(timesteps) - num_inference_steps * self.scheduler.order
with self.progress_bar(total=num_inference_steps) as progress_bar:
for i, t in enumerate(timesteps):
# Attend and excite process
with torch.enable_grad():
latents = latents.clone().detach().requires_grad_(True)
updated_latents = []
for latent, index, text_embedding in zip(latents, indices, text_embeddings):
# Forward pass of denoising with text conditioning
latent = latent.unsqueeze(0)
text_embedding = text_embedding.unsqueeze(0)
self.unet(
latent,
t,
encoder_hidden_states=text_embedding,
cross_attention_kwargs=cross_attention_kwargs,
).sample
self.unet.zero_grad()
# Get max activation value for each subject token
max_attention_per_index = self._aggregate_and_get_max_attention_per_token(
indices=index,
)
loss = self._compute_loss(max_attention_per_index=max_attention_per_index)
# If this is an iterative refinement step, verify we have reached the desired threshold for all
if i in thresholds.keys() and loss > 1.0 - thresholds[i]:
loss, latent, max_attention_per_index = self._perform_iterative_refinement_step(
latents=latent,
indices=index,
loss=loss,
threshold=thresholds[i],
text_embeddings=text_embedding,
step_size=step_size[i],
t=t,
)
# Perform gradient update
if i < max_iter_to_alter:
if loss != 0:
latent = self._update_latent(
latents=latent,
loss=loss,
step_size=step_size[i],
)
logger.info(f"Iteration {i} | Loss: {loss:0.4f}")
updated_latents.append(latent)
latents = torch.cat(updated_latents, dim=0)
# expand the latents if we are doing classifier free guidance
latent_model_input = torch.cat([latents] * 2) if do_classifier_free_guidance else latents
latent_model_input = self.scheduler.scale_model_input(latent_model_input, t)
# predict the noise residual
noise_pred = self.unet(
latent_model_input,
t,
encoder_hidden_states=prompt_embeds,
cross_attention_kwargs=cross_attention_kwargs,
).sample
# perform guidance
if do_classifier_free_guidance:
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = self.scheduler.step(noise_pred, t, latents, **extra_step_kwargs).prev_sample
# call the callback, if provided
if i == len(timesteps) - 1 or ((i + 1) > num_warmup_steps and (i + 1) % self.scheduler.order == 0):
progress_bar.update()
if callback is not None and i % callback_steps == 0:
step_idx = i // getattr(self.scheduler, "order", 1)
callback(step_idx, t, latents)
# 8. Post-processing
if not output_type == "latent":
image = self.vae.decode(latents / self.vae.config.scaling_factor, return_dict=False)[0]
image, has_nsfw_concept = self.run_safety_checker(image, device, prompt_embeds.dtype)
else:
image = latents
has_nsfw_concept = None
if has_nsfw_concept is None:
do_denormalize = [True] * image.shape[0]
else:
do_denormalize = [not has_nsfw for has_nsfw in has_nsfw_concept]
image = self.image_processor.postprocess(image, output_type=output_type, do_denormalize=do_denormalize)
self.maybe_free_model_hooks()
if not return_dict:
return (image, has_nsfw_concept)
return StableDiffusionPipelineOutput(images=image, nsfw_content_detected=has_nsfw_concept)
class GaussianSmoothing(torch.nn.Module):
"""
Arguments:
Apply gaussian smoothing on a 1d, 2d or 3d tensor. Filtering is performed seperately for each channel in the input
using a depthwise convolution.
channels (int, sequence): Number of channels of the input tensors. Output will
have this number of channels as well.
kernel_size (int, sequence): Size of the gaussian kernel. sigma (float, sequence): Standard deviation of the
gaussian kernel. dim (int, optional): The number of dimensions of the data.
Default value is 2 (spatial).
"""
# channels=1, kernel_size=kernel_size, sigma=sigma, dim=2
def __init__(
self,
channels: int = 1,
kernel_size: int = 3,
sigma: float = 0.5,
dim: int = 2,
):
super().__init__()
if isinstance(kernel_size, int):
kernel_size = [kernel_size] * dim
if isinstance(sigma, float):
sigma = [sigma] * dim
# The gaussian kernel is the product of the
# gaussian function of each dimension.
kernel = 1
meshgrids = torch.meshgrid([torch.arange(size, dtype=torch.float32) for size in kernel_size])
for size, std, mgrid in zip(kernel_size, sigma, meshgrids):
mean = (size - 1) / 2
kernel *= 1 / (std * math.sqrt(2 * math.pi)) * torch.exp(-(((mgrid - mean) / (2 * std)) ** 2))
# Make sure sum of values in gaussian kernel equals 1.
kernel = kernel / torch.sum(kernel)
# Reshape to depthwise convolutional weight
kernel = kernel.view(1, 1, *kernel.size())
kernel = kernel.repeat(channels, *[1] * (kernel.dim() - 1))
self.register_buffer("weight", kernel)
self.groups = channels
if dim == 1:
self.conv = F.conv1d
elif dim == 2:
self.conv = F.conv2d
elif dim == 3:
self.conv = F.conv3d
else:
raise RuntimeError("Only 1, 2 and 3 dimensions are supported. Received {}.".format(dim))
def forward(self, input):
"""
Arguments:
Apply gaussian filter to input.
input (torch.Tensor): Input to apply gaussian filter on.
Returns:
filtered (torch.Tensor): Filtered output.
"""
return self.conv(input, weight=self.weight.to(input.dtype), groups=self.groups)
| diffusers/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/stable_diffusion_attend_and_excite/pipeline_stable_diffusion_attend_and_excite.py",
"repo_id": "diffusers",
"token_count": 22599
} | 134 |
from typing import TYPE_CHECKING
from ...utils import (
DIFFUSERS_SLOW_IMPORT,
OptionalDependencyNotAvailable,
_LazyModule,
get_objects_from_module,
is_torch_available,
is_transformers_available,
)
_dummy_objects = {}
_import_structure = {}
try:
if not (is_transformers_available() and is_torch_available()):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils import dummy_torch_and_transformers_objects # noqa F403
_dummy_objects.update(get_objects_from_module(dummy_torch_and_transformers_objects))
else:
_import_structure["pipeline_output"] = ["TextToVideoSDPipelineOutput"]
_import_structure["pipeline_text_to_video_synth"] = ["TextToVideoSDPipeline"]
_import_structure["pipeline_text_to_video_synth_img2img"] = ["VideoToVideoSDPipeline"]
_import_structure["pipeline_text_to_video_zero"] = ["TextToVideoZeroPipeline"]
_import_structure["pipeline_text_to_video_zero_sdxl"] = ["TextToVideoZeroSDXLPipeline"]
if TYPE_CHECKING or DIFFUSERS_SLOW_IMPORT:
try:
if not (is_transformers_available() and is_torch_available()):
raise OptionalDependencyNotAvailable()
except OptionalDependencyNotAvailable:
from ...utils.dummy_torch_and_transformers_objects import * # noqa F403
else:
from .pipeline_output import TextToVideoSDPipelineOutput
from .pipeline_text_to_video_synth import TextToVideoSDPipeline
from .pipeline_text_to_video_synth_img2img import VideoToVideoSDPipeline
from .pipeline_text_to_video_zero import TextToVideoZeroPipeline
from .pipeline_text_to_video_zero_sdxl import TextToVideoZeroSDXLPipeline
else:
import sys
sys.modules[__name__] = _LazyModule(
__name__,
globals()["__file__"],
_import_structure,
module_spec=__spec__,
)
for name, value in _dummy_objects.items():
setattr(sys.modules[__name__], name, value)
| diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/text_to_video_synthesis/__init__.py",
"repo_id": "diffusers",
"token_count": 788
} | 135 |
import torch
import torch.nn as nn
from ...models.attention_processor import Attention
class WuerstchenLayerNorm(nn.LayerNorm):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
x = super().forward(x)
return x.permute(0, 3, 1, 2)
class TimestepBlock(nn.Module):
def __init__(self, c, c_timestep):
super().__init__()
linear_cls = nn.Linear
self.mapper = linear_cls(c_timestep, c * 2)
def forward(self, x, t):
a, b = self.mapper(t)[:, :, None, None].chunk(2, dim=1)
return x * (1 + a) + b
class ResBlock(nn.Module):
def __init__(self, c, c_skip=0, kernel_size=3, dropout=0.0):
super().__init__()
conv_cls = nn.Conv2d
linear_cls = nn.Linear
self.depthwise = conv_cls(c + c_skip, c, kernel_size=kernel_size, padding=kernel_size // 2, groups=c)
self.norm = WuerstchenLayerNorm(c, elementwise_affine=False, eps=1e-6)
self.channelwise = nn.Sequential(
linear_cls(c, c * 4), nn.GELU(), GlobalResponseNorm(c * 4), nn.Dropout(dropout), linear_cls(c * 4, c)
)
def forward(self, x, x_skip=None):
x_res = x
if x_skip is not None:
x = torch.cat([x, x_skip], dim=1)
x = self.norm(self.depthwise(x)).permute(0, 2, 3, 1)
x = self.channelwise(x).permute(0, 3, 1, 2)
return x + x_res
# from https://github.com/facebookresearch/ConvNeXt-V2/blob/3608f67cc1dae164790c5d0aead7bf2d73d9719b/models/utils.py#L105
class GlobalResponseNorm(nn.Module):
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
agg_norm = torch.norm(x, p=2, dim=(1, 2), keepdim=True)
stand_div_norm = agg_norm / (agg_norm.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * stand_div_norm) + self.beta + x
class AttnBlock(nn.Module):
def __init__(self, c, c_cond, nhead, self_attn=True, dropout=0.0):
super().__init__()
linear_cls = nn.Linear
self.self_attn = self_attn
self.norm = WuerstchenLayerNorm(c, elementwise_affine=False, eps=1e-6)
self.attention = Attention(query_dim=c, heads=nhead, dim_head=c // nhead, dropout=dropout, bias=True)
self.kv_mapper = nn.Sequential(nn.SiLU(), linear_cls(c_cond, c))
def forward(self, x, kv):
kv = self.kv_mapper(kv)
norm_x = self.norm(x)
if self.self_attn:
batch_size, channel, _, _ = x.shape
kv = torch.cat([norm_x.view(batch_size, channel, -1).transpose(1, 2), kv], dim=1)
x = x + self.attention(norm_x, encoder_hidden_states=kv)
return x
| diffusers/src/diffusers/pipelines/wuerstchen/modeling_wuerstchen_common.py/0 | {
"file_path": "diffusers/src/diffusers/pipelines/wuerstchen/modeling_wuerstchen_common.py",
"repo_id": "diffusers",
"token_count": 1389
} | 136 |
# Copyright 2024 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
# and https://github.com/hojonathanho/diffusion
from dataclasses import dataclass
from typing import Optional, Tuple, Union
import flax
import jax.numpy as jnp
from ..configuration_utils import ConfigMixin, register_to_config
from .scheduling_utils_flax import (
CommonSchedulerState,
FlaxKarrasDiffusionSchedulers,
FlaxSchedulerMixin,
FlaxSchedulerOutput,
add_noise_common,
get_velocity_common,
)
@flax.struct.dataclass
class DDIMSchedulerState:
common: CommonSchedulerState
final_alpha_cumprod: jnp.ndarray
# setable values
init_noise_sigma: jnp.ndarray
timesteps: jnp.ndarray
num_inference_steps: Optional[int] = None
@classmethod
def create(
cls,
common: CommonSchedulerState,
final_alpha_cumprod: jnp.ndarray,
init_noise_sigma: jnp.ndarray,
timesteps: jnp.ndarray,
):
return cls(
common=common,
final_alpha_cumprod=final_alpha_cumprod,
init_noise_sigma=init_noise_sigma,
timesteps=timesteps,
)
@dataclass
class FlaxDDIMSchedulerOutput(FlaxSchedulerOutput):
state: DDIMSchedulerState
class FlaxDDIMScheduler(FlaxSchedulerMixin, ConfigMixin):
"""
Denoising diffusion implicit models is a scheduler that extends the denoising procedure introduced in denoising
diffusion probabilistic models (DDPMs) with non-Markovian guidance.
[`~ConfigMixin`] takes care of storing all config attributes that are passed in the scheduler's `__init__`
function, such as `num_train_timesteps`. They can be accessed via `scheduler.config.num_train_timesteps`.
[`SchedulerMixin`] provides general loading and saving functionality via the [`SchedulerMixin.save_pretrained`] and
[`~SchedulerMixin.from_pretrained`] functions.
For more details, see the original paper: https://arxiv.org/abs/2010.02502
Args:
num_train_timesteps (`int`): number of diffusion steps used to train the model.
beta_start (`float`): the starting `beta` value of inference.
beta_end (`float`): the final `beta` value.
beta_schedule (`str`):
the beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear`, `scaled_linear`, or `squaredcos_cap_v2`.
trained_betas (`jnp.ndarray`, optional):
option to pass an array of betas directly to the constructor to bypass `beta_start`, `beta_end` etc.
clip_sample (`bool`, default `True`):
option to clip predicted sample between for numerical stability. The clip range is determined by `clip_sample_range`.
clip_sample_range (`float`, default `1.0`):
the maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
set_alpha_to_one (`bool`, default `True`):
each diffusion step uses the value of alphas product at that step and at the previous one. For the final
step there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
otherwise it uses the value of alpha at step 0.
steps_offset (`int`, default `0`):
An offset added to the inference steps, as required by some model families.
prediction_type (`str`, default `epsilon`):
indicates whether the model predicts the noise (epsilon), or the samples. One of `epsilon`, `sample`.
`v-prediction` is not supported for this scheduler.
dtype (`jnp.dtype`, *optional*, defaults to `jnp.float32`):
the `dtype` used for params and computation.
"""
_compatibles = [e.name for e in FlaxKarrasDiffusionSchedulers]
dtype: jnp.dtype
@property
def has_state(self):
return True
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.0001,
beta_end: float = 0.02,
beta_schedule: str = "linear",
trained_betas: Optional[jnp.ndarray] = None,
clip_sample: bool = True,
clip_sample_range: float = 1.0,
set_alpha_to_one: bool = True,
steps_offset: int = 0,
prediction_type: str = "epsilon",
dtype: jnp.dtype = jnp.float32,
):
self.dtype = dtype
def create_state(self, common: Optional[CommonSchedulerState] = None) -> DDIMSchedulerState:
if common is None:
common = CommonSchedulerState.create(self)
# At every step in ddim, we are looking into the previous alphas_cumprod
# For the final step, there is no previous alphas_cumprod because we are already at 0
# `set_alpha_to_one` decides whether we set this parameter simply to one or
# whether we use the final alpha of the "non-previous" one.
final_alpha_cumprod = (
jnp.array(1.0, dtype=self.dtype) if self.config.set_alpha_to_one else common.alphas_cumprod[0]
)
# standard deviation of the initial noise distribution
init_noise_sigma = jnp.array(1.0, dtype=self.dtype)
timesteps = jnp.arange(0, self.config.num_train_timesteps).round()[::-1]
return DDIMSchedulerState.create(
common=common,
final_alpha_cumprod=final_alpha_cumprod,
init_noise_sigma=init_noise_sigma,
timesteps=timesteps,
)
def scale_model_input(
self, state: DDIMSchedulerState, sample: jnp.ndarray, timestep: Optional[int] = None
) -> jnp.ndarray:
"""
Args:
state (`PNDMSchedulerState`): the `FlaxPNDMScheduler` state data class instance.
sample (`jnp.ndarray`): input sample
timestep (`int`, optional): current timestep
Returns:
`jnp.ndarray`: scaled input sample
"""
return sample
def set_timesteps(
self, state: DDIMSchedulerState, num_inference_steps: int, shape: Tuple = ()
) -> DDIMSchedulerState:
"""
Sets the discrete timesteps used for the diffusion chain. Supporting function to be run before inference.
Args:
state (`DDIMSchedulerState`):
the `FlaxDDIMScheduler` state data class instance.
num_inference_steps (`int`):
the number of diffusion steps used when generating samples with a pre-trained model.
"""
step_ratio = self.config.num_train_timesteps // num_inference_steps
# creates integer timesteps by multiplying by ratio
# rounding to avoid issues when num_inference_step is power of 3
timesteps = (jnp.arange(0, num_inference_steps) * step_ratio).round()[::-1] + self.config.steps_offset
return state.replace(
num_inference_steps=num_inference_steps,
timesteps=timesteps,
)
def _get_variance(self, state: DDIMSchedulerState, timestep, prev_timestep):
alpha_prod_t = state.common.alphas_cumprod[timestep]
alpha_prod_t_prev = jnp.where(
prev_timestep >= 0, state.common.alphas_cumprod[prev_timestep], state.final_alpha_cumprod
)
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
return variance
def step(
self,
state: DDIMSchedulerState,
model_output: jnp.ndarray,
timestep: int,
sample: jnp.ndarray,
eta: float = 0.0,
return_dict: bool = True,
) -> Union[FlaxDDIMSchedulerOutput, Tuple]:
"""
Predict the sample at the previous timestep by reversing the SDE. Core function to propagate the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
state (`DDIMSchedulerState`): the `FlaxDDIMScheduler` state data class instance.
model_output (`jnp.ndarray`): direct output from learned diffusion model.
timestep (`int`): current discrete timestep in the diffusion chain.
sample (`jnp.ndarray`):
current instance of sample being created by diffusion process.
return_dict (`bool`): option for returning tuple rather than FlaxDDIMSchedulerOutput class
Returns:
[`FlaxDDIMSchedulerOutput`] or `tuple`: [`FlaxDDIMSchedulerOutput`] if `return_dict` is True, otherwise a
`tuple`. When returning a tuple, the first element is the sample tensor.
"""
if state.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
# See formulas (12) and (16) of DDIM paper https://arxiv.org/pdf/2010.02502.pdf
# Ideally, read DDIM paper in-detail understanding
# Notation (<variable name> -> <name in paper>
# - pred_noise_t -> e_theta(x_t, t)
# - pred_original_sample -> f_theta(x_t, t) or x_0
# - std_dev_t -> sigma_t
# - eta -> η
# - pred_sample_direction -> "direction pointing to x_t"
# - pred_prev_sample -> "x_t-1"
# 1. get previous step value (=t-1)
prev_timestep = timestep - self.config.num_train_timesteps // state.num_inference_steps
alphas_cumprod = state.common.alphas_cumprod
final_alpha_cumprod = state.final_alpha_cumprod
# 2. compute alphas, betas
alpha_prod_t = alphas_cumprod[timestep]
alpha_prod_t_prev = jnp.where(prev_timestep >= 0, alphas_cumprod[prev_timestep], final_alpha_cumprod)
beta_prod_t = 1 - alpha_prod_t
# 3. compute predicted original sample from predicted noise also called
# "predicted x_0" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
if self.config.prediction_type == "epsilon":
pred_original_sample = (sample - beta_prod_t ** (0.5) * model_output) / alpha_prod_t ** (0.5)
pred_epsilon = model_output
elif self.config.prediction_type == "sample":
pred_original_sample = model_output
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
elif self.config.prediction_type == "v_prediction":
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
else:
raise ValueError(
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample`, or"
" `v_prediction`"
)
# 4. Clip or threshold "predicted x_0"
if self.config.clip_sample:
pred_original_sample = pred_original_sample.clip(
-self.config.clip_sample_range, self.config.clip_sample_range
)
# 4. compute variance: "sigma_t(η)" -> see formula (16)
# σ_t = sqrt((1 − α_t−1)/(1 − α_t)) * sqrt(1 − α_t/α_t−1)
variance = self._get_variance(state, timestep, prev_timestep)
std_dev_t = eta * variance ** (0.5)
# 5. compute "direction pointing to x_t" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
pred_sample_direction = (1 - alpha_prod_t_prev - std_dev_t**2) ** (0.5) * pred_epsilon
# 6. compute x_t without "random noise" of formula (12) from https://arxiv.org/pdf/2010.02502.pdf
prev_sample = alpha_prod_t_prev ** (0.5) * pred_original_sample + pred_sample_direction
if not return_dict:
return (prev_sample, state)
return FlaxDDIMSchedulerOutput(prev_sample=prev_sample, state=state)
def add_noise(
self,
state: DDIMSchedulerState,
original_samples: jnp.ndarray,
noise: jnp.ndarray,
timesteps: jnp.ndarray,
) -> jnp.ndarray:
return add_noise_common(state.common, original_samples, noise, timesteps)
def get_velocity(
self,
state: DDIMSchedulerState,
sample: jnp.ndarray,
noise: jnp.ndarray,
timesteps: jnp.ndarray,
) -> jnp.ndarray:
return get_velocity_common(state.common, sample, noise, timesteps)
def __len__(self):
return self.config.num_train_timesteps
| diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_ddim_flax.py",
"repo_id": "diffusers",
"token_count": 5525
} | 137 |
# Copyright 2024 Katherine Crowson and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import math
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import numpy as np
import torch
from ..configuration_utils import ConfigMixin, register_to_config
from ..utils import BaseOutput, logging
from ..utils.torch_utils import randn_tensor
from .scheduling_utils import KarrasDiffusionSchedulers, SchedulerMixin
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
@dataclass
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMSchedulerOutput with DDPM->EulerDiscrete
class EulerDiscreteSchedulerOutput(BaseOutput):
"""
Output class for the scheduler's `step` function output.
Args:
prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
denoising loop.
pred_original_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
The predicted denoised sample `(x_{0})` based on the model output from the current timestep.
`pred_original_sample` can be used to preview progress or for guidance.
"""
prev_sample: torch.FloatTensor
pred_original_sample: Optional[torch.FloatTensor] = None
# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
def betas_for_alpha_bar(
num_diffusion_timesteps,
max_beta=0.999,
alpha_transform_type="cosine",
):
"""
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
(1-beta) over time from t = [0,1].
Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
to that part of the diffusion process.
Args:
num_diffusion_timesteps (`int`): the number of betas to produce.
max_beta (`float`): the maximum beta to use; use values lower than 1 to
prevent singularities.
alpha_transform_type (`str`, *optional*, default to `cosine`): the type of noise schedule for alpha_bar.
Choose from `cosine` or `exp`
Returns:
betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
"""
if alpha_transform_type == "cosine":
def alpha_bar_fn(t):
return math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2
elif alpha_transform_type == "exp":
def alpha_bar_fn(t):
return math.exp(t * -12.0)
else:
raise ValueError(f"Unsupported alpha_transform_type: {alpha_transform_type}")
betas = []
for i in range(num_diffusion_timesteps):
t1 = i / num_diffusion_timesteps
t2 = (i + 1) / num_diffusion_timesteps
betas.append(min(1 - alpha_bar_fn(t2) / alpha_bar_fn(t1), max_beta))
return torch.tensor(betas, dtype=torch.float32)
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas):
"""
Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
Args:
betas (`torch.FloatTensor`):
the betas that the scheduler is being initialized with.
Returns:
`torch.FloatTensor`: rescaled betas with zero terminal SNR
"""
# Convert betas to alphas_bar_sqrt
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_bar_sqrt = alphas_cumprod.sqrt()
# Store old values.
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
# Shift so the last timestep is zero.
alphas_bar_sqrt -= alphas_bar_sqrt_T
# Scale so the first timestep is back to the old value.
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
# Convert alphas_bar_sqrt to betas
alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
alphas = torch.cat([alphas_bar[0:1], alphas])
betas = 1 - alphas
return betas
class EulerDiscreteScheduler(SchedulerMixin, ConfigMixin):
"""
Euler scheduler.
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. Check the superclass documentation for the generic
methods the library implements for all schedulers such as loading and saving.
Args:
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
beta_start (`float`, defaults to 0.0001):
The starting `beta` value of inference.
beta_end (`float`, defaults to 0.02):
The final `beta` value.
beta_schedule (`str`, defaults to `"linear"`):
The beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear` or `scaled_linear`.
trained_betas (`np.ndarray`, *optional*):
Pass an array of betas directly to the constructor to bypass `beta_start` and `beta_end`.
prediction_type (`str`, defaults to `epsilon`, *optional*):
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
Video](https://imagen.research.google/video/paper.pdf) paper).
interpolation_type(`str`, defaults to `"linear"`, *optional*):
The interpolation type to compute intermediate sigmas for the scheduler denoising steps. Should be on of
`"linear"` or `"log_linear"`.
use_karras_sigmas (`bool`, *optional*, defaults to `False`):
Whether to use Karras sigmas for step sizes in the noise schedule during the sampling process. If `True`,
the sigmas are determined according to a sequence of noise levels {σi}.
timestep_spacing (`str`, defaults to `"linspace"`):
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
steps_offset (`int`, defaults to 0):
An offset added to the inference steps, as required by some model families.
rescale_betas_zero_snr (`bool`, defaults to `False`):
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
dark samples instead of limiting it to samples with medium brightness. Loosely related to
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
_compatibles = [e.name for e in KarrasDiffusionSchedulers]
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.0001,
beta_end: float = 0.02,
beta_schedule: str = "linear",
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
prediction_type: str = "epsilon",
interpolation_type: str = "linear",
use_karras_sigmas: Optional[bool] = False,
sigma_min: Optional[float] = None,
sigma_max: Optional[float] = None,
timestep_spacing: str = "linspace",
timestep_type: str = "discrete", # can be "discrete" or "continuous"
steps_offset: int = 0,
rescale_betas_zero_snr: bool = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
elif beta_schedule == "linear":
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
elif beta_schedule == "scaled_linear":
# this schedule is very specific to the latent diffusion model.
self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
elif beta_schedule == "squaredcos_cap_v2":
# Glide cosine schedule
self.betas = betas_for_alpha_bar(num_train_timesteps)
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
if rescale_betas_zero_snr:
self.betas = rescale_zero_terminal_snr(self.betas)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
if rescale_betas_zero_snr:
# Close to 0 without being 0 so first sigma is not inf
# FP16 smallest positive subnormal works well here
self.alphas_cumprod[-1] = 2**-24
sigmas = (((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5).flip(0)
timesteps = np.linspace(0, num_train_timesteps - 1, num_train_timesteps, dtype=float)[::-1].copy()
timesteps = torch.from_numpy(timesteps).to(dtype=torch.float32)
# setable values
self.num_inference_steps = None
# TODO: Support the full EDM scalings for all prediction types and timestep types
if timestep_type == "continuous" and prediction_type == "v_prediction":
self.timesteps = torch.Tensor([0.25 * sigma.log() for sigma in sigmas])
else:
self.timesteps = timesteps
self.sigmas = torch.cat([sigmas, torch.zeros(1, device=sigmas.device)])
self.is_scale_input_called = False
self.use_karras_sigmas = use_karras_sigmas
self._step_index = None
self._begin_index = None
self.sigmas = self.sigmas.to("cpu") # to avoid too much CPU/GPU communication
@property
def init_noise_sigma(self):
# standard deviation of the initial noise distribution
max_sigma = max(self.sigmas) if isinstance(self.sigmas, list) else self.sigmas.max()
if self.config.timestep_spacing in ["linspace", "trailing"]:
return max_sigma
return (max_sigma**2 + 1) ** 0.5
@property
def step_index(self):
"""
The index counter for current timestep. It will increase 1 after each scheduler step.
"""
return self._step_index
@property
def begin_index(self):
"""
The index for the first timestep. It should be set from pipeline with `set_begin_index` method.
"""
return self._begin_index
# Copied from diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler.set_begin_index
def set_begin_index(self, begin_index: int = 0):
"""
Sets the begin index for the scheduler. This function should be run from pipeline before the inference.
Args:
begin_index (`int`):
The begin index for the scheduler.
"""
self._begin_index = begin_index
def scale_model_input(
self, sample: torch.FloatTensor, timestep: Union[float, torch.FloatTensor]
) -> torch.FloatTensor:
"""
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
current timestep. Scales the denoising model input by `(sigma**2 + 1) ** 0.5` to match the Euler algorithm.
Args:
sample (`torch.FloatTensor`):
The input sample.
timestep (`int`, *optional*):
The current timestep in the diffusion chain.
Returns:
`torch.FloatTensor`:
A scaled input sample.
"""
if self.step_index is None:
self._init_step_index(timestep)
sigma = self.sigmas[self.step_index]
sample = sample / ((sigma**2 + 1) ** 0.5)
self.is_scale_input_called = True
return sample
def set_timesteps(self, num_inference_steps: int, device: Union[str, torch.device] = None):
"""
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
Args:
num_inference_steps (`int`):
The number of diffusion steps used when generating samples with a pre-trained model.
device (`str` or `torch.device`, *optional*):
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
"""
self.num_inference_steps = num_inference_steps
# "linspace", "leading", "trailing" corresponds to annotation of Table 2. of https://arxiv.org/abs/2305.08891
if self.config.timestep_spacing == "linspace":
timesteps = np.linspace(0, self.config.num_train_timesteps - 1, num_inference_steps, dtype=np.float32)[
::-1
].copy()
elif self.config.timestep_spacing == "leading":
step_ratio = self.config.num_train_timesteps // self.num_inference_steps
# creates integer timesteps by multiplying by ratio
# casting to int to avoid issues when num_inference_step is power of 3
timesteps = (np.arange(0, num_inference_steps) * step_ratio).round()[::-1].copy().astype(np.float32)
timesteps += self.config.steps_offset
elif self.config.timestep_spacing == "trailing":
step_ratio = self.config.num_train_timesteps / self.num_inference_steps
# creates integer timesteps by multiplying by ratio
# casting to int to avoid issues when num_inference_step is power of 3
timesteps = (np.arange(self.config.num_train_timesteps, 0, -step_ratio)).round().copy().astype(np.float32)
timesteps -= 1
else:
raise ValueError(
f"{self.config.timestep_spacing} is not supported. Please make sure to choose one of 'linspace', 'leading' or 'trailing'."
)
sigmas = np.array(((1 - self.alphas_cumprod) / self.alphas_cumprod) ** 0.5)
log_sigmas = np.log(sigmas)
if self.config.interpolation_type == "linear":
sigmas = np.interp(timesteps, np.arange(0, len(sigmas)), sigmas)
elif self.config.interpolation_type == "log_linear":
sigmas = torch.linspace(np.log(sigmas[-1]), np.log(sigmas[0]), num_inference_steps + 1).exp().numpy()
else:
raise ValueError(
f"{self.config.interpolation_type} is not implemented. Please specify interpolation_type to either"
" 'linear' or 'log_linear'"
)
if self.config.use_karras_sigmas:
sigmas = self._convert_to_karras(in_sigmas=sigmas, num_inference_steps=self.num_inference_steps)
timesteps = np.array([self._sigma_to_t(sigma, log_sigmas) for sigma in sigmas])
sigmas = torch.from_numpy(sigmas).to(dtype=torch.float32, device=device)
# TODO: Support the full EDM scalings for all prediction types and timestep types
if self.config.timestep_type == "continuous" and self.config.prediction_type == "v_prediction":
self.timesteps = torch.Tensor([0.25 * sigma.log() for sigma in sigmas]).to(device=device)
else:
self.timesteps = torch.from_numpy(timesteps.astype(np.float32)).to(device=device)
self.sigmas = torch.cat([sigmas, torch.zeros(1, device=sigmas.device)])
self._step_index = None
self._begin_index = None
self.sigmas = self.sigmas.to("cpu") # to avoid too much CPU/GPU communication
def _sigma_to_t(self, sigma, log_sigmas):
# get log sigma
log_sigma = np.log(np.maximum(sigma, 1e-10))
# get distribution
dists = log_sigma - log_sigmas[:, np.newaxis]
# get sigmas range
low_idx = np.cumsum((dists >= 0), axis=0).argmax(axis=0).clip(max=log_sigmas.shape[0] - 2)
high_idx = low_idx + 1
low = log_sigmas[low_idx]
high = log_sigmas[high_idx]
# interpolate sigmas
w = (low - log_sigma) / (low - high)
w = np.clip(w, 0, 1)
# transform interpolation to time range
t = (1 - w) * low_idx + w * high_idx
t = t.reshape(sigma.shape)
return t
# Copied from https://github.com/crowsonkb/k-diffusion/blob/686dbad0f39640ea25c8a8c6a6e56bb40eacefa2/k_diffusion/sampling.py#L17
def _convert_to_karras(self, in_sigmas: torch.FloatTensor, num_inference_steps) -> torch.FloatTensor:
"""Constructs the noise schedule of Karras et al. (2022)."""
# Hack to make sure that other schedulers which copy this function don't break
# TODO: Add this logic to the other schedulers
if hasattr(self.config, "sigma_min"):
sigma_min = self.config.sigma_min
else:
sigma_min = None
if hasattr(self.config, "sigma_max"):
sigma_max = self.config.sigma_max
else:
sigma_max = None
sigma_min = sigma_min if sigma_min is not None else in_sigmas[-1].item()
sigma_max = sigma_max if sigma_max is not None else in_sigmas[0].item()
rho = 7.0 # 7.0 is the value used in the paper
ramp = np.linspace(0, 1, num_inference_steps)
min_inv_rho = sigma_min ** (1 / rho)
max_inv_rho = sigma_max ** (1 / rho)
sigmas = (max_inv_rho + ramp * (min_inv_rho - max_inv_rho)) ** rho
return sigmas
def index_for_timestep(self, timestep, schedule_timesteps=None):
if schedule_timesteps is None:
schedule_timesteps = self.timesteps
indices = (schedule_timesteps == timestep).nonzero()
# The sigma index that is taken for the **very** first `step`
# is always the second index (or the last index if there is only 1)
# This way we can ensure we don't accidentally skip a sigma in
# case we start in the middle of the denoising schedule (e.g. for image-to-image)
pos = 1 if len(indices) > 1 else 0
return indices[pos].item()
def _init_step_index(self, timestep):
if self.begin_index is None:
if isinstance(timestep, torch.Tensor):
timestep = timestep.to(self.timesteps.device)
self._step_index = self.index_for_timestep(timestep)
else:
self._step_index = self._begin_index
def step(
self,
model_output: torch.FloatTensor,
timestep: Union[float, torch.FloatTensor],
sample: torch.FloatTensor,
s_churn: float = 0.0,
s_tmin: float = 0.0,
s_tmax: float = float("inf"),
s_noise: float = 1.0,
generator: Optional[torch.Generator] = None,
return_dict: bool = True,
) -> Union[EulerDiscreteSchedulerOutput, Tuple]:
"""
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.FloatTensor`):
The direct output from learned diffusion model.
timestep (`float`):
The current discrete timestep in the diffusion chain.
sample (`torch.FloatTensor`):
A current instance of a sample created by the diffusion process.
s_churn (`float`):
s_tmin (`float`):
s_tmax (`float`):
s_noise (`float`, defaults to 1.0):
Scaling factor for noise added to the sample.
generator (`torch.Generator`, *optional*):
A random number generator.
return_dict (`bool`):
Whether or not to return a [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or
tuple.
Returns:
[`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] or `tuple`:
If return_dict is `True`, [`~schedulers.scheduling_euler_discrete.EulerDiscreteSchedulerOutput`] is
returned, otherwise a tuple is returned where the first element is the sample tensor.
"""
if (
isinstance(timestep, int)
or isinstance(timestep, torch.IntTensor)
or isinstance(timestep, torch.LongTensor)
):
raise ValueError(
(
"Passing integer indices (e.g. from `enumerate(timesteps)`) as timesteps to"
" `EulerDiscreteScheduler.step()` is not supported. Make sure to pass"
" one of the `scheduler.timesteps` as a timestep."
),
)
if not self.is_scale_input_called:
logger.warning(
"The `scale_model_input` function should be called before `step` to ensure correct denoising. "
"See `StableDiffusionPipeline` for a usage example."
)
if self.step_index is None:
self._init_step_index(timestep)
# Upcast to avoid precision issues when computing prev_sample
sample = sample.to(torch.float32)
sigma = self.sigmas[self.step_index]
gamma = min(s_churn / (len(self.sigmas) - 1), 2**0.5 - 1) if s_tmin <= sigma <= s_tmax else 0.0
noise = randn_tensor(
model_output.shape, dtype=model_output.dtype, device=model_output.device, generator=generator
)
eps = noise * s_noise
sigma_hat = sigma * (gamma + 1)
if gamma > 0:
sample = sample + eps * (sigma_hat**2 - sigma**2) ** 0.5
# 1. compute predicted original sample (x_0) from sigma-scaled predicted noise
# NOTE: "original_sample" should not be an expected prediction_type but is left in for
# backwards compatibility
if self.config.prediction_type == "original_sample" or self.config.prediction_type == "sample":
pred_original_sample = model_output
elif self.config.prediction_type == "epsilon":
pred_original_sample = sample - sigma_hat * model_output
elif self.config.prediction_type == "v_prediction":
# denoised = model_output * c_out + input * c_skip
pred_original_sample = model_output * (-sigma / (sigma**2 + 1) ** 0.5) + (sample / (sigma**2 + 1))
else:
raise ValueError(
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, or `v_prediction`"
)
# 2. Convert to an ODE derivative
derivative = (sample - pred_original_sample) / sigma_hat
dt = self.sigmas[self.step_index + 1] - sigma_hat
prev_sample = sample + derivative * dt
# Cast sample back to model compatible dtype
prev_sample = prev_sample.to(model_output.dtype)
# upon completion increase step index by one
self._step_index += 1
if not return_dict:
return (prev_sample,)
return EulerDiscreteSchedulerOutput(prev_sample=prev_sample, pred_original_sample=pred_original_sample)
def add_noise(
self,
original_samples: torch.FloatTensor,
noise: torch.FloatTensor,
timesteps: torch.FloatTensor,
) -> torch.FloatTensor:
# Make sure sigmas and timesteps have the same device and dtype as original_samples
sigmas = self.sigmas.to(device=original_samples.device, dtype=original_samples.dtype)
if original_samples.device.type == "mps" and torch.is_floating_point(timesteps):
# mps does not support float64
schedule_timesteps = self.timesteps.to(original_samples.device, dtype=torch.float32)
timesteps = timesteps.to(original_samples.device, dtype=torch.float32)
else:
schedule_timesteps = self.timesteps.to(original_samples.device)
timesteps = timesteps.to(original_samples.device)
# self.begin_index is None when scheduler is used for training, or pipeline does not implement set_begin_index
if self.begin_index is None:
step_indices = [self.index_for_timestep(t, schedule_timesteps) for t in timesteps]
elif self.step_index is not None:
# add_noise is called after first denoising step (for inpainting)
step_indices = [self.step_index] * timesteps.shape[0]
else:
# add noise is called before first denoising step to create initial latent(img2img)
step_indices = [self.begin_index] * timesteps.shape[0]
sigma = sigmas[step_indices].flatten()
while len(sigma.shape) < len(original_samples.shape):
sigma = sigma.unsqueeze(-1)
noisy_samples = original_samples + noise * sigma
return noisy_samples
def __len__(self):
return self.config.num_train_timesteps
| diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_euler_discrete.py",
"repo_id": "diffusers",
"token_count": 10879
} | 138 |
# Copyright 2024 Stanford University Team and The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# DISCLAIMER: This code is strongly influenced by https://github.com/pesser/pytorch_diffusion
# and https://github.com/hojonathanho/diffusion
import math
from dataclasses import dataclass
from typing import List, Optional, Tuple, Union
import numpy as np
import torch
from ..configuration_utils import ConfigMixin, register_to_config
from ..schedulers.scheduling_utils import SchedulerMixin
from ..utils import BaseOutput, logging
from ..utils.torch_utils import randn_tensor
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
@dataclass
class TCDSchedulerOutput(BaseOutput):
"""
Output class for the scheduler's `step` function output.
Args:
prev_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
Computed sample `(x_{t-1})` of previous timestep. `prev_sample` should be used as next model input in the
denoising loop.
pred_noised_sample (`torch.FloatTensor` of shape `(batch_size, num_channels, height, width)` for images):
The predicted noised sample `(x_{s})` based on the model output from the current timestep.
"""
prev_sample: torch.FloatTensor
pred_noised_sample: Optional[torch.FloatTensor] = None
# Copied from diffusers.schedulers.scheduling_ddpm.betas_for_alpha_bar
def betas_for_alpha_bar(
num_diffusion_timesteps,
max_beta=0.999,
alpha_transform_type="cosine",
):
"""
Create a beta schedule that discretizes the given alpha_t_bar function, which defines the cumulative product of
(1-beta) over time from t = [0,1].
Contains a function alpha_bar that takes an argument t and transforms it to the cumulative product of (1-beta) up
to that part of the diffusion process.
Args:
num_diffusion_timesteps (`int`): the number of betas to produce.
max_beta (`float`): the maximum beta to use; use values lower than 1 to
prevent singularities.
alpha_transform_type (`str`, *optional*, default to `cosine`): the type of noise schedule for alpha_bar.
Choose from `cosine` or `exp`
Returns:
betas (`np.ndarray`): the betas used by the scheduler to step the model outputs
"""
if alpha_transform_type == "cosine":
def alpha_bar_fn(t):
return math.cos((t + 0.008) / 1.008 * math.pi / 2) ** 2
elif alpha_transform_type == "exp":
def alpha_bar_fn(t):
return math.exp(t * -12.0)
else:
raise ValueError(f"Unsupported alpha_transform_type: {alpha_transform_type}")
betas = []
for i in range(num_diffusion_timesteps):
t1 = i / num_diffusion_timesteps
t2 = (i + 1) / num_diffusion_timesteps
betas.append(min(1 - alpha_bar_fn(t2) / alpha_bar_fn(t1), max_beta))
return torch.tensor(betas, dtype=torch.float32)
# Copied from diffusers.schedulers.scheduling_ddim.rescale_zero_terminal_snr
def rescale_zero_terminal_snr(betas: torch.FloatTensor) -> torch.FloatTensor:
"""
Rescales betas to have zero terminal SNR Based on https://arxiv.org/pdf/2305.08891.pdf (Algorithm 1)
Args:
betas (`torch.FloatTensor`):
the betas that the scheduler is being initialized with.
Returns:
`torch.FloatTensor`: rescaled betas with zero terminal SNR
"""
# Convert betas to alphas_bar_sqrt
alphas = 1.0 - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_bar_sqrt = alphas_cumprod.sqrt()
# Store old values.
alphas_bar_sqrt_0 = alphas_bar_sqrt[0].clone()
alphas_bar_sqrt_T = alphas_bar_sqrt[-1].clone()
# Shift so the last timestep is zero.
alphas_bar_sqrt -= alphas_bar_sqrt_T
# Scale so the first timestep is back to the old value.
alphas_bar_sqrt *= alphas_bar_sqrt_0 / (alphas_bar_sqrt_0 - alphas_bar_sqrt_T)
# Convert alphas_bar_sqrt to betas
alphas_bar = alphas_bar_sqrt**2 # Revert sqrt
alphas = alphas_bar[1:] / alphas_bar[:-1] # Revert cumprod
alphas = torch.cat([alphas_bar[0:1], alphas])
betas = 1 - alphas
return betas
class TCDScheduler(SchedulerMixin, ConfigMixin):
"""
`TCDScheduler` incorporates the `Strategic Stochastic Sampling` introduced by the paper `Trajectory Consistency Distillation`,
extending the original Multistep Consistency Sampling to enable unrestricted trajectory traversal.
This code is based on the official repo of TCD(https://github.com/jabir-zheng/TCD).
This model inherits from [`SchedulerMixin`] and [`ConfigMixin`]. [`~ConfigMixin`] takes care of storing all config
attributes that are passed in the scheduler's `__init__` function, such as `num_train_timesteps`. They can be
accessed via `scheduler.config.num_train_timesteps`. [`SchedulerMixin`] provides general loading and saving
functionality via the [`SchedulerMixin.save_pretrained`] and [`~SchedulerMixin.from_pretrained`] functions.
Args:
num_train_timesteps (`int`, defaults to 1000):
The number of diffusion steps to train the model.
beta_start (`float`, defaults to 0.0001):
The starting `beta` value of inference.
beta_end (`float`, defaults to 0.02):
The final `beta` value.
beta_schedule (`str`, defaults to `"linear"`):
The beta schedule, a mapping from a beta range to a sequence of betas for stepping the model. Choose from
`linear`, `scaled_linear`, or `squaredcos_cap_v2`.
trained_betas (`np.ndarray`, *optional*):
Pass an array of betas directly to the constructor to bypass `beta_start` and `beta_end`.
original_inference_steps (`int`, *optional*, defaults to 50):
The default number of inference steps used to generate a linearly-spaced timestep schedule, from which we
will ultimately take `num_inference_steps` evenly spaced timesteps to form the final timestep schedule.
clip_sample (`bool`, defaults to `True`):
Clip the predicted sample for numerical stability.
clip_sample_range (`float`, defaults to 1.0):
The maximum magnitude for sample clipping. Valid only when `clip_sample=True`.
set_alpha_to_one (`bool`, defaults to `True`):
Each diffusion step uses the alphas product value at that step and at the previous one. For the final step
there is no previous alpha. When this option is `True` the previous alpha product is fixed to `1`,
otherwise it uses the alpha value at step 0.
steps_offset (`int`, defaults to 0):
An offset added to the inference steps, as required by some model families.
prediction_type (`str`, defaults to `epsilon`, *optional*):
Prediction type of the scheduler function; can be `epsilon` (predicts the noise of the diffusion process),
`sample` (directly predicts the noisy sample`) or `v_prediction` (see section 2.4 of [Imagen
Video](https://imagen.research.google/video/paper.pdf) paper).
thresholding (`bool`, defaults to `False`):
Whether to use the "dynamic thresholding" method. This is unsuitable for latent-space diffusion models such
as Stable Diffusion.
dynamic_thresholding_ratio (`float`, defaults to 0.995):
The ratio for the dynamic thresholding method. Valid only when `thresholding=True`.
sample_max_value (`float`, defaults to 1.0):
The threshold value for dynamic thresholding. Valid only when `thresholding=True`.
timestep_spacing (`str`, defaults to `"leading"`):
The way the timesteps should be scaled. Refer to Table 2 of the [Common Diffusion Noise Schedules and
Sample Steps are Flawed](https://huggingface.co/papers/2305.08891) for more information.
timestep_scaling (`float`, defaults to 10.0):
The factor the timesteps will be multiplied by when calculating the consistency model boundary conditions
`c_skip` and `c_out`. Increasing this will decrease the approximation error (although the approximation
error at the default of `10.0` is already pretty small).
rescale_betas_zero_snr (`bool`, defaults to `False`):
Whether to rescale the betas to have zero terminal SNR. This enables the model to generate very bright and
dark samples instead of limiting it to samples with medium brightness. Loosely related to
[`--offset_noise`](https://github.com/huggingface/diffusers/blob/74fd735eb073eb1d774b1ab4154a0876eb82f055/examples/dreambooth/train_dreambooth.py#L506).
"""
order = 1
@register_to_config
def __init__(
self,
num_train_timesteps: int = 1000,
beta_start: float = 0.00085,
beta_end: float = 0.012,
beta_schedule: str = "scaled_linear",
trained_betas: Optional[Union[np.ndarray, List[float]]] = None,
original_inference_steps: int = 50,
clip_sample: bool = False,
clip_sample_range: float = 1.0,
set_alpha_to_one: bool = True,
steps_offset: int = 0,
prediction_type: str = "epsilon",
thresholding: bool = False,
dynamic_thresholding_ratio: float = 0.995,
sample_max_value: float = 1.0,
timestep_spacing: str = "leading",
timestep_scaling: float = 10.0,
rescale_betas_zero_snr: bool = False,
):
if trained_betas is not None:
self.betas = torch.tensor(trained_betas, dtype=torch.float32)
elif beta_schedule == "linear":
self.betas = torch.linspace(beta_start, beta_end, num_train_timesteps, dtype=torch.float32)
elif beta_schedule == "scaled_linear":
# this schedule is very specific to the latent diffusion model.
self.betas = torch.linspace(beta_start**0.5, beta_end**0.5, num_train_timesteps, dtype=torch.float32) ** 2
elif beta_schedule == "squaredcos_cap_v2":
# Glide cosine schedule
self.betas = betas_for_alpha_bar(num_train_timesteps)
else:
raise NotImplementedError(f"{beta_schedule} does is not implemented for {self.__class__}")
# Rescale for zero SNR
if rescale_betas_zero_snr:
self.betas = rescale_zero_terminal_snr(self.betas)
self.alphas = 1.0 - self.betas
self.alphas_cumprod = torch.cumprod(self.alphas, dim=0)
# At every step in ddim, we are looking into the previous alphas_cumprod
# For the final step, there is no previous alphas_cumprod because we are already at 0
# `set_alpha_to_one` decides whether we set this parameter simply to one or
# whether we use the final alpha of the "non-previous" one.
self.final_alpha_cumprod = torch.tensor(1.0) if set_alpha_to_one else self.alphas_cumprod[0]
# standard deviation of the initial noise distribution
self.init_noise_sigma = 1.0
# setable values
self.num_inference_steps = None
self.timesteps = torch.from_numpy(np.arange(0, num_train_timesteps)[::-1].copy().astype(np.int64))
self.custom_timesteps = False
self._step_index = None
self._begin_index = None
# Copied from diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler.index_for_timestep
def index_for_timestep(self, timestep, schedule_timesteps=None):
if schedule_timesteps is None:
schedule_timesteps = self.timesteps
indices = (schedule_timesteps == timestep).nonzero()
# The sigma index that is taken for the **very** first `step`
# is always the second index (or the last index if there is only 1)
# This way we can ensure we don't accidentally skip a sigma in
# case we start in the middle of the denoising schedule (e.g. for image-to-image)
pos = 1 if len(indices) > 1 else 0
return indices[pos].item()
# Copied from diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler._init_step_index
def _init_step_index(self, timestep):
if self.begin_index is None:
if isinstance(timestep, torch.Tensor):
timestep = timestep.to(self.timesteps.device)
self._step_index = self.index_for_timestep(timestep)
else:
self._step_index = self._begin_index
@property
def step_index(self):
return self._step_index
@property
def begin_index(self):
"""
The index for the first timestep. It should be set from pipeline with `set_begin_index` method.
"""
return self._begin_index
# Copied from diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler.set_begin_index
def set_begin_index(self, begin_index: int = 0):
"""
Sets the begin index for the scheduler. This function should be run from pipeline before the inference.
Args:
begin_index (`int`):
The begin index for the scheduler.
"""
self._begin_index = begin_index
def scale_model_input(self, sample: torch.FloatTensor, timestep: Optional[int] = None) -> torch.FloatTensor:
"""
Ensures interchangeability with schedulers that need to scale the denoising model input depending on the
current timestep.
Args:
sample (`torch.FloatTensor`):
The input sample.
timestep (`int`, *optional*):
The current timestep in the diffusion chain.
Returns:
`torch.FloatTensor`:
A scaled input sample.
"""
return sample
# Copied from diffusers.schedulers.scheduling_ddim.DDIMScheduler._get_variance
def _get_variance(self, timestep, prev_timestep):
alpha_prod_t = self.alphas_cumprod[timestep]
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
beta_prod_t = 1 - alpha_prod_t
beta_prod_t_prev = 1 - alpha_prod_t_prev
variance = (beta_prod_t_prev / beta_prod_t) * (1 - alpha_prod_t / alpha_prod_t_prev)
return variance
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler._threshold_sample
def _threshold_sample(self, sample: torch.FloatTensor) -> torch.FloatTensor:
"""
"Dynamic thresholding: At each sampling step we set s to a certain percentile absolute pixel value in xt0 (the
prediction of x_0 at timestep t), and if s > 1, then we threshold xt0 to the range [-s, s] and then divide by
s. Dynamic thresholding pushes saturated pixels (those near -1 and 1) inwards, thereby actively preventing
pixels from saturation at each step. We find that dynamic thresholding results in significantly better
photorealism as well as better image-text alignment, especially when using very large guidance weights."
https://arxiv.org/abs/2205.11487
"""
dtype = sample.dtype
batch_size, channels, *remaining_dims = sample.shape
if dtype not in (torch.float32, torch.float64):
sample = sample.float() # upcast for quantile calculation, and clamp not implemented for cpu half
# Flatten sample for doing quantile calculation along each image
sample = sample.reshape(batch_size, channels * np.prod(remaining_dims))
abs_sample = sample.abs() # "a certain percentile absolute pixel value"
s = torch.quantile(abs_sample, self.config.dynamic_thresholding_ratio, dim=1)
s = torch.clamp(
s, min=1, max=self.config.sample_max_value
) # When clamped to min=1, equivalent to standard clipping to [-1, 1]
s = s.unsqueeze(1) # (batch_size, 1) because clamp will broadcast along dim=0
sample = torch.clamp(sample, -s, s) / s # "we threshold xt0 to the range [-s, s] and then divide by s"
sample = sample.reshape(batch_size, channels, *remaining_dims)
sample = sample.to(dtype)
return sample
def set_timesteps(
self,
num_inference_steps: Optional[int] = None,
device: Union[str, torch.device] = None,
original_inference_steps: Optional[int] = None,
timesteps: Optional[List[int]] = None,
strength: float = 1.0,
):
"""
Sets the discrete timesteps used for the diffusion chain (to be run before inference).
Args:
num_inference_steps (`int`, *optional*):
The number of diffusion steps used when generating samples with a pre-trained model. If used,
`timesteps` must be `None`.
device (`str` or `torch.device`, *optional*):
The device to which the timesteps should be moved to. If `None`, the timesteps are not moved.
original_inference_steps (`int`, *optional*):
The original number of inference steps, which will be used to generate a linearly-spaced timestep
schedule (which is different from the standard `diffusers` implementation). We will then take
`num_inference_steps` timesteps from this schedule, evenly spaced in terms of indices, and use that as
our final timestep schedule. If not set, this will default to the `original_inference_steps` attribute.
timesteps (`List[int]`, *optional*):
Custom timesteps used to support arbitrary spacing between timesteps. If `None`, then the default
timestep spacing strategy of equal spacing between timesteps on the training/distillation timestep
schedule is used. If `timesteps` is passed, `num_inference_steps` must be `None`.
strength (`float`, *optional*, defaults to 1.0):
Used to determine the number of timesteps used for inference when using img2img, inpaint, etc.
"""
# 0. Check inputs
if num_inference_steps is None and timesteps is None:
raise ValueError("Must pass exactly one of `num_inference_steps` or `custom_timesteps`.")
if num_inference_steps is not None and timesteps is not None:
raise ValueError("Can only pass one of `num_inference_steps` or `custom_timesteps`.")
# 1. Calculate the TCD original training/distillation timestep schedule.
original_steps = (
original_inference_steps if original_inference_steps is not None else self.config.original_inference_steps
)
if original_inference_steps is None:
# default option, timesteps align with discrete inference steps
if original_steps > self.config.num_train_timesteps:
raise ValueError(
f"`original_steps`: {original_steps} cannot be larger than `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
f" maximal {self.config.num_train_timesteps} timesteps."
)
# TCD Timesteps Setting
# The skipping step parameter k from the paper.
k = self.config.num_train_timesteps // original_steps
# TCD Training/Distillation Steps Schedule
tcd_origin_timesteps = np.asarray(list(range(1, int(original_steps * strength) + 1))) * k - 1
else:
# customised option, sampled timesteps can be any arbitrary value
tcd_origin_timesteps = np.asarray(list(range(0, int(self.config.num_train_timesteps * strength))))
# 2. Calculate the TCD inference timestep schedule.
if timesteps is not None:
# 2.1 Handle custom timestep schedules.
train_timesteps = set(tcd_origin_timesteps)
non_train_timesteps = []
for i in range(1, len(timesteps)):
if timesteps[i] >= timesteps[i - 1]:
raise ValueError("`custom_timesteps` must be in descending order.")
if timesteps[i] not in train_timesteps:
non_train_timesteps.append(timesteps[i])
if timesteps[0] >= self.config.num_train_timesteps:
raise ValueError(
f"`timesteps` must start before `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps}."
)
# Raise warning if timestep schedule does not start with self.config.num_train_timesteps - 1
if strength == 1.0 and timesteps[0] != self.config.num_train_timesteps - 1:
logger.warning(
f"The first timestep on the custom timestep schedule is {timesteps[0]}, not"
f" `self.config.num_train_timesteps - 1`: {self.config.num_train_timesteps - 1}. You may get"
f" unexpected results when using this timestep schedule."
)
# Raise warning if custom timestep schedule contains timesteps not on original timestep schedule
if non_train_timesteps:
logger.warning(
f"The custom timestep schedule contains the following timesteps which are not on the original"
f" training/distillation timestep schedule: {non_train_timesteps}. You may get unexpected results"
f" when using this timestep schedule."
)
# Raise warning if custom timestep schedule is longer than original_steps
if original_steps is not None:
if len(timesteps) > original_steps:
logger.warning(
f"The number of timesteps in the custom timestep schedule is {len(timesteps)}, which exceeds the"
f" the length of the timestep schedule used for training: {original_steps}. You may get some"
f" unexpected results when using this timestep schedule."
)
else:
if len(timesteps) > self.config.num_train_timesteps:
logger.warning(
f"The number of timesteps in the custom timestep schedule is {len(timesteps)}, which exceeds the"
f" the length of the timestep schedule used for training: {self.config.num_train_timesteps}. You may get some"
f" unexpected results when using this timestep schedule."
)
timesteps = np.array(timesteps, dtype=np.int64)
self.num_inference_steps = len(timesteps)
self.custom_timesteps = True
# Apply strength (e.g. for img2img pipelines) (see StableDiffusionImg2ImgPipeline.get_timesteps)
init_timestep = min(int(self.num_inference_steps * strength), self.num_inference_steps)
t_start = max(self.num_inference_steps - init_timestep, 0)
timesteps = timesteps[t_start * self.order :]
# TODO: also reset self.num_inference_steps?
else:
# 2.2 Create the "standard" TCD inference timestep schedule.
if num_inference_steps > self.config.num_train_timesteps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `self.config.train_timesteps`:"
f" {self.config.num_train_timesteps} as the unet model trained with this scheduler can only handle"
f" maximal {self.config.num_train_timesteps} timesteps."
)
if original_steps is not None:
skipping_step = len(tcd_origin_timesteps) // num_inference_steps
if skipping_step < 1:
raise ValueError(
f"The combination of `original_steps x strength`: {original_steps} x {strength} is smaller than `num_inference_steps`: {num_inference_steps}. Make sure to either reduce `num_inference_steps` to a value smaller than {int(original_steps * strength)} or increase `strength` to a value higher than {float(num_inference_steps / original_steps)}."
)
self.num_inference_steps = num_inference_steps
if original_steps is not None:
if num_inference_steps > original_steps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `original_inference_steps`:"
f" {original_steps} because the final timestep schedule will be a subset of the"
f" `original_inference_steps`-sized initial timestep schedule."
)
else:
if num_inference_steps > self.config.num_train_timesteps:
raise ValueError(
f"`num_inference_steps`: {num_inference_steps} cannot be larger than `num_train_timesteps`:"
f" {self.config.num_train_timesteps} because the final timestep schedule will be a subset of the"
f" `num_train_timesteps`-sized initial timestep schedule."
)
# TCD Inference Steps Schedule
tcd_origin_timesteps = tcd_origin_timesteps[::-1].copy()
# Select (approximately) evenly spaced indices from tcd_origin_timesteps.
inference_indices = np.linspace(0, len(tcd_origin_timesteps), num=num_inference_steps, endpoint=False)
inference_indices = np.floor(inference_indices).astype(np.int64)
timesteps = tcd_origin_timesteps[inference_indices]
self.timesteps = torch.from_numpy(timesteps).to(device=device, dtype=torch.long)
self._step_index = None
self._begin_index = None
def step(
self,
model_output: torch.FloatTensor,
timestep: int,
sample: torch.FloatTensor,
eta: float = 0.3,
generator: Optional[torch.Generator] = None,
return_dict: bool = True,
) -> Union[TCDSchedulerOutput, Tuple]:
"""
Predict the sample from the previous timestep by reversing the SDE. This function propagates the diffusion
process from the learned model outputs (most often the predicted noise).
Args:
model_output (`torch.FloatTensor`):
The direct output from learned diffusion model.
timestep (`int`):
The current discrete timestep in the diffusion chain.
sample (`torch.FloatTensor`):
A current instance of a sample created by the diffusion process.
eta (`float`):
A stochastic parameter (referred to as `gamma` in the paper) used to control the stochasticity in every step.
When eta = 0, it represents deterministic sampling, whereas eta = 1 indicates full stochastic sampling.
generator (`torch.Generator`, *optional*):
A random number generator.
return_dict (`bool`, *optional*, defaults to `True`):
Whether or not to return a [`~schedulers.scheduling_tcd.TCDSchedulerOutput`] or `tuple`.
Returns:
[`~schedulers.scheduling_utils.TCDSchedulerOutput`] or `tuple`:
If return_dict is `True`, [`~schedulers.scheduling_tcd.TCDSchedulerOutput`] is returned, otherwise a
tuple is returned where the first element is the sample tensor.
"""
if self.num_inference_steps is None:
raise ValueError(
"Number of inference steps is 'None', you need to run 'set_timesteps' after creating the scheduler"
)
if self.step_index is None:
self._init_step_index(timestep)
assert 0 <= eta <= 1.0, "gamma must be less than or equal to 1.0"
# 1. get previous step value
prev_step_index = self.step_index + 1
if prev_step_index < len(self.timesteps):
prev_timestep = self.timesteps[prev_step_index]
else:
prev_timestep = torch.tensor(0)
timestep_s = torch.floor((1 - eta) * prev_timestep).to(dtype=torch.long)
# 2. compute alphas, betas
alpha_prod_t = self.alphas_cumprod[timestep]
beta_prod_t = 1 - alpha_prod_t
alpha_prod_t_prev = self.alphas_cumprod[prev_timestep] if prev_timestep >= 0 else self.final_alpha_cumprod
alpha_prod_s = self.alphas_cumprod[timestep_s]
beta_prod_s = 1 - alpha_prod_s
# 3. Compute the predicted noised sample x_s based on the model parameterization
if self.config.prediction_type == "epsilon": # noise-prediction
pred_original_sample = (sample - beta_prod_t.sqrt() * model_output) / alpha_prod_t.sqrt()
pred_epsilon = model_output
pred_noised_sample = alpha_prod_s.sqrt() * pred_original_sample + beta_prod_s.sqrt() * pred_epsilon
elif self.config.prediction_type == "sample": # x-prediction
pred_original_sample = model_output
pred_epsilon = (sample - alpha_prod_t ** (0.5) * pred_original_sample) / beta_prod_t ** (0.5)
pred_noised_sample = alpha_prod_s.sqrt() * pred_original_sample + beta_prod_s.sqrt() * pred_epsilon
elif self.config.prediction_type == "v_prediction": # v-prediction
pred_original_sample = (alpha_prod_t**0.5) * sample - (beta_prod_t**0.5) * model_output
pred_epsilon = (alpha_prod_t**0.5) * model_output + (beta_prod_t**0.5) * sample
pred_noised_sample = alpha_prod_s.sqrt() * pred_original_sample + beta_prod_s.sqrt() * pred_epsilon
else:
raise ValueError(
f"prediction_type given as {self.config.prediction_type} must be one of `epsilon`, `sample` or"
" `v_prediction` for `TCDScheduler`."
)
# 4. Sample and inject noise z ~ N(0, I) for MultiStep Inference
# Noise is not used on the final timestep of the timestep schedule.
# This also means that noise is not used for one-step sampling.
# Eta (referred to as "gamma" in the paper) was introduced to control the stochasticity in every step.
# When eta = 0, it represents deterministic sampling, whereas eta = 1 indicates full stochastic sampling.
if eta > 0:
if self.step_index != self.num_inference_steps - 1:
noise = randn_tensor(
model_output.shape, generator=generator, device=model_output.device, dtype=pred_noised_sample.dtype
)
prev_sample = (alpha_prod_t_prev / alpha_prod_s).sqrt() * pred_noised_sample + (
1 - alpha_prod_t_prev / alpha_prod_s
).sqrt() * noise
else:
prev_sample = pred_noised_sample
else:
prev_sample = pred_noised_sample
# upon completion increase step index by one
self._step_index += 1
if not return_dict:
return (prev_sample, pred_noised_sample)
return TCDSchedulerOutput(prev_sample=prev_sample, pred_noised_sample=pred_noised_sample)
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.add_noise
def add_noise(
self,
original_samples: torch.FloatTensor,
noise: torch.FloatTensor,
timesteps: torch.IntTensor,
) -> torch.FloatTensor:
# Make sure alphas_cumprod and timestep have same device and dtype as original_samples
# Move the self.alphas_cumprod to device to avoid redundant CPU to GPU data movement
# for the subsequent add_noise calls
self.alphas_cumprod = self.alphas_cumprod.to(device=original_samples.device)
alphas_cumprod = self.alphas_cumprod.to(dtype=original_samples.dtype)
timesteps = timesteps.to(original_samples.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(original_samples.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(original_samples.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
noisy_samples = sqrt_alpha_prod * original_samples + sqrt_one_minus_alpha_prod * noise
return noisy_samples
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.get_velocity
def get_velocity(
self, sample: torch.FloatTensor, noise: torch.FloatTensor, timesteps: torch.IntTensor
) -> torch.FloatTensor:
# Make sure alphas_cumprod and timestep have same device and dtype as sample
self.alphas_cumprod = self.alphas_cumprod.to(device=sample.device)
alphas_cumprod = self.alphas_cumprod.to(dtype=sample.dtype)
timesteps = timesteps.to(sample.device)
sqrt_alpha_prod = alphas_cumprod[timesteps] ** 0.5
sqrt_alpha_prod = sqrt_alpha_prod.flatten()
while len(sqrt_alpha_prod.shape) < len(sample.shape):
sqrt_alpha_prod = sqrt_alpha_prod.unsqueeze(-1)
sqrt_one_minus_alpha_prod = (1 - alphas_cumprod[timesteps]) ** 0.5
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.flatten()
while len(sqrt_one_minus_alpha_prod.shape) < len(sample.shape):
sqrt_one_minus_alpha_prod = sqrt_one_minus_alpha_prod.unsqueeze(-1)
velocity = sqrt_alpha_prod * noise - sqrt_one_minus_alpha_prod * sample
return velocity
def __len__(self):
return self.config.num_train_timesteps
# Copied from diffusers.schedulers.scheduling_ddpm.DDPMScheduler.previous_timestep
def previous_timestep(self, timestep):
if self.custom_timesteps:
index = (self.timesteps == timestep).nonzero(as_tuple=True)[0][0]
if index == self.timesteps.shape[0] - 1:
prev_t = torch.tensor(-1)
else:
prev_t = self.timesteps[index + 1]
else:
num_inference_steps = (
self.num_inference_steps if self.num_inference_steps else self.config.num_train_timesteps
)
prev_t = timestep - self.config.num_train_timesteps // num_inference_steps
return prev_t
| diffusers/src/diffusers/schedulers/scheduling_tcd.py/0 | {
"file_path": "diffusers/src/diffusers/schedulers/scheduling_tcd.py",
"repo_id": "diffusers",
"token_count": 14800
} | 139 |
# This file is autogenerated by the command `make fix-copies`, do not edit.
from ..utils import DummyObject, requires_backends
class AsymmetricAutoencoderKL(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoencoderKL(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoencoderKLTemporalDecoder(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoencoderTiny(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ConsistencyDecoderVAE(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ControlNetModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class I2VGenXLUNet(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class Kandinsky3UNet(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ModelMixin(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class MotionAdapter(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class MultiAdapter(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class PriorTransformer(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class T2IAdapter(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class T5FilmDecoder(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class Transformer2DModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNet1DModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNet2DConditionModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNet2DModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNet3DConditionModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNetMotionModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UNetSpatioTemporalConditionModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UVit2DModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class VQModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
def get_constant_schedule(*args, **kwargs):
requires_backends(get_constant_schedule, ["torch"])
def get_constant_schedule_with_warmup(*args, **kwargs):
requires_backends(get_constant_schedule_with_warmup, ["torch"])
def get_cosine_schedule_with_warmup(*args, **kwargs):
requires_backends(get_cosine_schedule_with_warmup, ["torch"])
def get_cosine_with_hard_restarts_schedule_with_warmup(*args, **kwargs):
requires_backends(get_cosine_with_hard_restarts_schedule_with_warmup, ["torch"])
def get_linear_schedule_with_warmup(*args, **kwargs):
requires_backends(get_linear_schedule_with_warmup, ["torch"])
def get_polynomial_decay_schedule_with_warmup(*args, **kwargs):
requires_backends(get_polynomial_decay_schedule_with_warmup, ["torch"])
def get_scheduler(*args, **kwargs):
requires_backends(get_scheduler, ["torch"])
class AudioPipelineOutput(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoPipelineForImage2Image(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoPipelineForInpainting(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AutoPipelineForText2Image(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class BlipDiffusionControlNetPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class BlipDiffusionPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class CLIPImageProjection(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ConsistencyModelPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DanceDiffusionPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDIMPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDPMPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DiffusionPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DiTPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ImagePipelineOutput(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class KarrasVePipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class LDMPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class LDMSuperResolutionPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class PNDMPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class RePaintPipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ScoreSdeVePipeline(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class StableDiffusionMixin(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class AmusedScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class CMStochasticIterativeScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDIMInverseScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDIMParallelScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDIMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDPMParallelScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDPMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DDPMWuerstchenScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DEISMultistepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DPMSolverMultistepInverseScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DPMSolverMultistepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class DPMSolverSinglestepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EDMDPMSolverMultistepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EDMEulerScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EulerAncestralDiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EulerDiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class HeunDiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class IPNDMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class KarrasVeScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class KDPM2AncestralDiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class KDPM2DiscreteScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class LCMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class PNDMScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class RePaintScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class SASolverScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class SchedulerMixin(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class ScoreSdeVeScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class TCDScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UnCLIPScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class UniPCMultistepScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class VQDiffusionScheduler(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
class EMAModel(metaclass=DummyObject):
_backends = ["torch"]
def __init__(self, *args, **kwargs):
requires_backends(self, ["torch"])
@classmethod
def from_config(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
@classmethod
def from_pretrained(cls, *args, **kwargs):
requires_backends(cls, ["torch"])
| diffusers/src/diffusers/utils/dummy_pt_objects.py/0 | {
"file_path": "diffusers/src/diffusers/utils/dummy_pt_objects.py",
"repo_id": "diffusers",
"token_count": 12780
} | 140 |
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
PEFT utilities: Utilities related to peft library
"""
import collections
import importlib
from typing import Optional
from packaging import version
from .import_utils import is_peft_available, is_torch_available
if is_torch_available():
import torch
def recurse_remove_peft_layers(model):
r"""
Recursively replace all instances of `LoraLayer` with corresponding new layers in `model`.
"""
from peft.tuners.tuners_utils import BaseTunerLayer
has_base_layer_pattern = False
for module in model.modules():
if isinstance(module, BaseTunerLayer):
has_base_layer_pattern = hasattr(module, "base_layer")
break
if has_base_layer_pattern:
from peft.utils import _get_submodules
key_list = [key for key, _ in model.named_modules() if "lora" not in key]
for key in key_list:
try:
parent, target, target_name = _get_submodules(model, key)
except AttributeError:
continue
if hasattr(target, "base_layer"):
setattr(parent, target_name, target.get_base_layer())
else:
# This is for backwards compatibility with PEFT <= 0.6.2.
# TODO can be removed once that PEFT version is no longer supported.
from peft.tuners.lora import LoraLayer
for name, module in model.named_children():
if len(list(module.children())) > 0:
## compound module, go inside it
recurse_remove_peft_layers(module)
module_replaced = False
if isinstance(module, LoraLayer) and isinstance(module, torch.nn.Linear):
new_module = torch.nn.Linear(module.in_features, module.out_features, bias=module.bias is not None).to(
module.weight.device
)
new_module.weight = module.weight
if module.bias is not None:
new_module.bias = module.bias
module_replaced = True
elif isinstance(module, LoraLayer) and isinstance(module, torch.nn.Conv2d):
new_module = torch.nn.Conv2d(
module.in_channels,
module.out_channels,
module.kernel_size,
module.stride,
module.padding,
module.dilation,
module.groups,
).to(module.weight.device)
new_module.weight = module.weight
if module.bias is not None:
new_module.bias = module.bias
module_replaced = True
if module_replaced:
setattr(model, name, new_module)
del module
if torch.cuda.is_available():
torch.cuda.empty_cache()
return model
def scale_lora_layers(model, weight):
"""
Adjust the weightage given to the LoRA layers of the model.
Args:
model (`torch.nn.Module`):
The model to scale.
weight (`float`):
The weight to be given to the LoRA layers.
"""
from peft.tuners.tuners_utils import BaseTunerLayer
for module in model.modules():
if isinstance(module, BaseTunerLayer):
module.scale_layer(weight)
def unscale_lora_layers(model, weight: Optional[float] = None):
"""
Removes the previously passed weight given to the LoRA layers of the model.
Args:
model (`torch.nn.Module`):
The model to scale.
weight (`float`, *optional*):
The weight to be given to the LoRA layers. If no scale is passed the scale of the lora layer will be
re-initialized to the correct value. If 0.0 is passed, we will re-initialize the scale with the correct
value.
"""
from peft.tuners.tuners_utils import BaseTunerLayer
for module in model.modules():
if isinstance(module, BaseTunerLayer):
if weight is not None and weight != 0:
module.unscale_layer(weight)
elif weight is not None and weight == 0:
for adapter_name in module.active_adapters:
# if weight == 0 unscale should re-set the scale to the original value.
module.set_scale(adapter_name, 1.0)
def get_peft_kwargs(rank_dict, network_alpha_dict, peft_state_dict, is_unet=True):
rank_pattern = {}
alpha_pattern = {}
r = lora_alpha = list(rank_dict.values())[0]
if len(set(rank_dict.values())) > 1:
# get the rank occuring the most number of times
r = collections.Counter(rank_dict.values()).most_common()[0][0]
# for modules with rank different from the most occuring rank, add it to the `rank_pattern`
rank_pattern = dict(filter(lambda x: x[1] != r, rank_dict.items()))
rank_pattern = {k.split(".lora_B.")[0]: v for k, v in rank_pattern.items()}
if network_alpha_dict is not None and len(network_alpha_dict) > 0:
if len(set(network_alpha_dict.values())) > 1:
# get the alpha occuring the most number of times
lora_alpha = collections.Counter(network_alpha_dict.values()).most_common()[0][0]
# for modules with alpha different from the most occuring alpha, add it to the `alpha_pattern`
alpha_pattern = dict(filter(lambda x: x[1] != lora_alpha, network_alpha_dict.items()))
if is_unet:
alpha_pattern = {
".".join(k.split(".lora_A.")[0].split(".")).replace(".alpha", ""): v
for k, v in alpha_pattern.items()
}
else:
alpha_pattern = {".".join(k.split(".down.")[0].split(".")[:-1]): v for k, v in alpha_pattern.items()}
else:
lora_alpha = set(network_alpha_dict.values()).pop()
# layer names without the Diffusers specific
target_modules = list({name.split(".lora")[0] for name in peft_state_dict.keys()})
lora_config_kwargs = {
"r": r,
"lora_alpha": lora_alpha,
"rank_pattern": rank_pattern,
"alpha_pattern": alpha_pattern,
"target_modules": target_modules,
}
return lora_config_kwargs
def get_adapter_name(model):
from peft.tuners.tuners_utils import BaseTunerLayer
for module in model.modules():
if isinstance(module, BaseTunerLayer):
return f"default_{len(module.r)}"
return "default_0"
def set_adapter_layers(model, enabled=True):
from peft.tuners.tuners_utils import BaseTunerLayer
for module in model.modules():
if isinstance(module, BaseTunerLayer):
# The recent version of PEFT needs to call `enable_adapters` instead
if hasattr(module, "enable_adapters"):
module.enable_adapters(enabled=enabled)
else:
module.disable_adapters = not enabled
def delete_adapter_layers(model, adapter_name):
from peft.tuners.tuners_utils import BaseTunerLayer
for module in model.modules():
if isinstance(module, BaseTunerLayer):
if hasattr(module, "delete_adapter"):
module.delete_adapter(adapter_name)
else:
raise ValueError(
"The version of PEFT you are using is not compatible, please use a version that is greater than 0.6.1"
)
# For transformers integration - we need to pop the adapter from the config
if getattr(model, "_hf_peft_config_loaded", False) and hasattr(model, "peft_config"):
model.peft_config.pop(adapter_name, None)
# In case all adapters are deleted, we need to delete the config
# and make sure to set the flag to False
if len(model.peft_config) == 0:
del model.peft_config
model._hf_peft_config_loaded = None
def set_weights_and_activate_adapters(model, adapter_names, weights):
from peft.tuners.tuners_utils import BaseTunerLayer
# iterate over each adapter, make it active and set the corresponding scaling weight
for adapter_name, weight in zip(adapter_names, weights):
for module in model.modules():
if isinstance(module, BaseTunerLayer):
# For backward compatbility with previous PEFT versions
if hasattr(module, "set_adapter"):
module.set_adapter(adapter_name)
else:
module.active_adapter = adapter_name
module.set_scale(adapter_name, weight)
# set multiple active adapters
for module in model.modules():
if isinstance(module, BaseTunerLayer):
# For backward compatbility with previous PEFT versions
if hasattr(module, "set_adapter"):
module.set_adapter(adapter_names)
else:
module.active_adapter = adapter_names
def check_peft_version(min_version: str) -> None:
r"""
Checks if the version of PEFT is compatible.
Args:
version (`str`):
The version of PEFT to check against.
"""
if not is_peft_available():
raise ValueError("PEFT is not installed. Please install it with `pip install peft`")
is_peft_version_compatible = version.parse(importlib.metadata.version("peft")) > version.parse(min_version)
if not is_peft_version_compatible:
raise ValueError(
f"The version of PEFT you are using is not compatible, please use a version that is greater"
f" than {min_version}"
)
| diffusers/src/diffusers/utils/peft_utils.py/0 | {
"file_path": "diffusers/src/diffusers/utils/peft_utils.py",
"repo_id": "diffusers",
"token_count": 4356
} | 141 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import unittest
import numpy as np
import torch
from parameterized import parameterized
from diffusers import (
AsymmetricAutoencoderKL,
AutoencoderKL,
AutoencoderKLTemporalDecoder,
AutoencoderTiny,
ConsistencyDecoderVAE,
StableDiffusionPipeline,
)
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.loading_utils import load_image
from diffusers.utils.testing_utils import (
backend_empty_cache,
enable_full_determinism,
floats_tensor,
load_hf_numpy,
require_torch_accelerator,
require_torch_accelerator_with_fp16,
require_torch_accelerator_with_training,
require_torch_gpu,
skip_mps,
slow,
torch_all_close,
torch_device,
)
from diffusers.utils.torch_utils import randn_tensor
from ..test_modeling_common import ModelTesterMixin, UNetTesterMixin
enable_full_determinism()
def get_autoencoder_kl_config(block_out_channels=None, norm_num_groups=None):
block_out_channels = block_out_channels or [32, 64]
norm_num_groups = norm_num_groups or 32
init_dict = {
"block_out_channels": block_out_channels,
"in_channels": 3,
"out_channels": 3,
"down_block_types": ["DownEncoderBlock2D"] * len(block_out_channels),
"up_block_types": ["UpDecoderBlock2D"] * len(block_out_channels),
"latent_channels": 4,
"norm_num_groups": norm_num_groups,
}
return init_dict
def get_asym_autoencoder_kl_config(block_out_channels=None, norm_num_groups=None):
block_out_channels = block_out_channels or [32, 64]
norm_num_groups = norm_num_groups or 32
init_dict = {
"in_channels": 3,
"out_channels": 3,
"down_block_types": ["DownEncoderBlock2D"] * len(block_out_channels),
"down_block_out_channels": block_out_channels,
"layers_per_down_block": 1,
"up_block_types": ["UpDecoderBlock2D"] * len(block_out_channels),
"up_block_out_channels": block_out_channels,
"layers_per_up_block": 1,
"act_fn": "silu",
"latent_channels": 4,
"norm_num_groups": norm_num_groups,
"sample_size": 32,
"scaling_factor": 0.18215,
}
return init_dict
def get_autoencoder_tiny_config(block_out_channels=None):
block_out_channels = (len(block_out_channels) * [32]) if block_out_channels is not None else [32, 32]
init_dict = {
"in_channels": 3,
"out_channels": 3,
"encoder_block_out_channels": block_out_channels,
"decoder_block_out_channels": block_out_channels,
"num_encoder_blocks": [b // min(block_out_channels) for b in block_out_channels],
"num_decoder_blocks": [b // min(block_out_channels) for b in reversed(block_out_channels)],
}
return init_dict
def get_consistency_vae_config(block_out_channels=None, norm_num_groups=None):
block_out_channels = block_out_channels or [32, 64]
norm_num_groups = norm_num_groups or 32
return {
"encoder_block_out_channels": block_out_channels,
"encoder_in_channels": 3,
"encoder_out_channels": 4,
"encoder_down_block_types": ["DownEncoderBlock2D"] * len(block_out_channels),
"decoder_add_attention": False,
"decoder_block_out_channels": block_out_channels,
"decoder_down_block_types": ["ResnetDownsampleBlock2D"] * len(block_out_channels),
"decoder_downsample_padding": 1,
"decoder_in_channels": 7,
"decoder_layers_per_block": 1,
"decoder_norm_eps": 1e-05,
"decoder_norm_num_groups": norm_num_groups,
"encoder_norm_num_groups": norm_num_groups,
"decoder_num_train_timesteps": 1024,
"decoder_out_channels": 6,
"decoder_resnet_time_scale_shift": "scale_shift",
"decoder_time_embedding_type": "learned",
"decoder_up_block_types": ["ResnetUpsampleBlock2D"] * len(block_out_channels),
"scaling_factor": 1,
"latent_channels": 4,
}
class AutoencoderKLTests(ModelTesterMixin, UNetTesterMixin, unittest.TestCase):
model_class = AutoencoderKL
main_input_name = "sample"
base_precision = 1e-2
@property
def dummy_input(self):
batch_size = 4
num_channels = 3
sizes = (32, 32)
image = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
return {"sample": image}
@property
def input_shape(self):
return (3, 32, 32)
@property
def output_shape(self):
return (3, 32, 32)
def prepare_init_args_and_inputs_for_common(self):
init_dict = get_autoencoder_kl_config()
inputs_dict = self.dummy_input
return init_dict, inputs_dict
def test_forward_signature(self):
pass
def test_training(self):
pass
@require_torch_accelerator_with_training
def test_gradient_checkpointing(self):
# enable deterministic behavior for gradient checkpointing
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict)
model.to(torch_device)
assert not model.is_gradient_checkpointing and model.training
out = model(**inputs_dict).sample
# run the backwards pass on the model. For backwards pass, for simplicity purpose,
# we won't calculate the loss and rather backprop on out.sum()
model.zero_grad()
labels = torch.randn_like(out)
loss = (out - labels).mean()
loss.backward()
# re-instantiate the model now enabling gradient checkpointing
model_2 = self.model_class(**init_dict)
# clone model
model_2.load_state_dict(model.state_dict())
model_2.to(torch_device)
model_2.enable_gradient_checkpointing()
assert model_2.is_gradient_checkpointing and model_2.training
out_2 = model_2(**inputs_dict).sample
# run the backwards pass on the model. For backwards pass, for simplicity purpose,
# we won't calculate the loss and rather backprop on out.sum()
model_2.zero_grad()
loss_2 = (out_2 - labels).mean()
loss_2.backward()
# compare the output and parameters gradients
self.assertTrue((loss - loss_2).abs() < 1e-5)
named_params = dict(model.named_parameters())
named_params_2 = dict(model_2.named_parameters())
for name, param in named_params.items():
self.assertTrue(torch_all_close(param.grad.data, named_params_2[name].grad.data, atol=5e-5))
def test_from_pretrained_hub(self):
model, loading_info = AutoencoderKL.from_pretrained("fusing/autoencoder-kl-dummy", output_loading_info=True)
self.assertIsNotNone(model)
self.assertEqual(len(loading_info["missing_keys"]), 0)
model.to(torch_device)
image = model(**self.dummy_input)
assert image is not None, "Make sure output is not None"
def test_output_pretrained(self):
model = AutoencoderKL.from_pretrained("fusing/autoencoder-kl-dummy")
model = model.to(torch_device)
model.eval()
# Keep generator on CPU for non-CUDA devices to compare outputs with CPU result tensors
generator_device = "cpu" if not torch_device.startswith("cuda") else "cuda"
if torch_device != "mps":
generator = torch.Generator(device=generator_device).manual_seed(0)
else:
generator = torch.manual_seed(0)
image = torch.randn(
1,
model.config.in_channels,
model.config.sample_size,
model.config.sample_size,
generator=torch.manual_seed(0),
)
image = image.to(torch_device)
with torch.no_grad():
output = model(image, sample_posterior=True, generator=generator).sample
output_slice = output[0, -1, -3:, -3:].flatten().cpu()
# Since the VAE Gaussian prior's generator is seeded on the appropriate device,
# the expected output slices are not the same for CPU and GPU.
if torch_device == "mps":
expected_output_slice = torch.tensor(
[
-4.0078e-01,
-3.8323e-04,
-1.2681e-01,
-1.1462e-01,
2.0095e-01,
1.0893e-01,
-8.8247e-02,
-3.0361e-01,
-9.8644e-03,
]
)
elif generator_device == "cpu":
expected_output_slice = torch.tensor(
[
-0.1352,
0.0878,
0.0419,
-0.0818,
-0.1069,
0.0688,
-0.1458,
-0.4446,
-0.0026,
]
)
else:
expected_output_slice = torch.tensor(
[
-0.2421,
0.4642,
0.2507,
-0.0438,
0.0682,
0.3160,
-0.2018,
-0.0727,
0.2485,
]
)
self.assertTrue(torch_all_close(output_slice, expected_output_slice, rtol=1e-2))
class AsymmetricAutoencoderKLTests(ModelTesterMixin, UNetTesterMixin, unittest.TestCase):
model_class = AsymmetricAutoencoderKL
main_input_name = "sample"
base_precision = 1e-2
@property
def dummy_input(self):
batch_size = 4
num_channels = 3
sizes = (32, 32)
image = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
mask = torch.ones((batch_size, 1) + sizes).to(torch_device)
return {"sample": image, "mask": mask}
@property
def input_shape(self):
return (3, 32, 32)
@property
def output_shape(self):
return (3, 32, 32)
def prepare_init_args_and_inputs_for_common(self):
init_dict = get_asym_autoencoder_kl_config()
inputs_dict = self.dummy_input
return init_dict, inputs_dict
def test_forward_signature(self):
pass
def test_forward_with_norm_groups(self):
pass
class AutoencoderTinyTests(ModelTesterMixin, unittest.TestCase):
model_class = AutoencoderTiny
main_input_name = "sample"
base_precision = 1e-2
@property
def dummy_input(self):
batch_size = 4
num_channels = 3
sizes = (32, 32)
image = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
return {"sample": image}
@property
def input_shape(self):
return (3, 32, 32)
@property
def output_shape(self):
return (3, 32, 32)
def prepare_init_args_and_inputs_for_common(self):
init_dict = get_autoencoder_tiny_config()
inputs_dict = self.dummy_input
return init_dict, inputs_dict
def test_outputs_equivalence(self):
pass
class ConsistencyDecoderVAETests(ModelTesterMixin, unittest.TestCase):
model_class = ConsistencyDecoderVAE
main_input_name = "sample"
base_precision = 1e-2
forward_requires_fresh_args = True
def inputs_dict(self, seed=None):
generator = torch.Generator("cpu")
if seed is not None:
generator.manual_seed(0)
image = randn_tensor((4, 3, 32, 32), generator=generator, device=torch.device(torch_device))
return {"sample": image, "generator": generator}
@property
def input_shape(self):
return (3, 32, 32)
@property
def output_shape(self):
return (3, 32, 32)
@property
def init_dict(self):
return get_consistency_vae_config()
def prepare_init_args_and_inputs_for_common(self):
return self.init_dict, self.inputs_dict()
@unittest.skip
def test_training(self):
...
@unittest.skip
def test_ema_training(self):
...
class AutoncoderKLTemporalDecoderFastTests(ModelTesterMixin, unittest.TestCase):
model_class = AutoencoderKLTemporalDecoder
main_input_name = "sample"
base_precision = 1e-2
@property
def dummy_input(self):
batch_size = 3
num_channels = 3
sizes = (32, 32)
image = floats_tensor((batch_size, num_channels) + sizes).to(torch_device)
num_frames = 3
return {"sample": image, "num_frames": num_frames}
@property
def input_shape(self):
return (3, 32, 32)
@property
def output_shape(self):
return (3, 32, 32)
def prepare_init_args_and_inputs_for_common(self):
init_dict = {
"block_out_channels": [32, 64],
"in_channels": 3,
"out_channels": 3,
"down_block_types": ["DownEncoderBlock2D", "DownEncoderBlock2D"],
"latent_channels": 4,
"layers_per_block": 2,
}
inputs_dict = self.dummy_input
return init_dict, inputs_dict
def test_forward_signature(self):
pass
def test_training(self):
pass
@unittest.skipIf(torch_device == "mps", "Gradient checkpointing skipped on MPS")
def test_gradient_checkpointing(self):
# enable deterministic behavior for gradient checkpointing
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict)
model.to(torch_device)
assert not model.is_gradient_checkpointing and model.training
out = model(**inputs_dict).sample
# run the backwards pass on the model. For backwards pass, for simplicity purpose,
# we won't calculate the loss and rather backprop on out.sum()
model.zero_grad()
labels = torch.randn_like(out)
loss = (out - labels).mean()
loss.backward()
# re-instantiate the model now enabling gradient checkpointing
model_2 = self.model_class(**init_dict)
# clone model
model_2.load_state_dict(model.state_dict())
model_2.to(torch_device)
model_2.enable_gradient_checkpointing()
assert model_2.is_gradient_checkpointing and model_2.training
out_2 = model_2(**inputs_dict).sample
# run the backwards pass on the model. For backwards pass, for simplicity purpose,
# we won't calculate the loss and rather backprop on out.sum()
model_2.zero_grad()
loss_2 = (out_2 - labels).mean()
loss_2.backward()
# compare the output and parameters gradients
self.assertTrue((loss - loss_2).abs() < 1e-5)
named_params = dict(model.named_parameters())
named_params_2 = dict(model_2.named_parameters())
for name, param in named_params.items():
if "post_quant_conv" in name:
continue
self.assertTrue(torch_all_close(param.grad.data, named_params_2[name].grad.data, atol=5e-5))
@slow
class AutoencoderTinyIntegrationTests(unittest.TestCase):
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
backend_empty_cache(torch_device)
def get_file_format(self, seed, shape):
return f"gaussian_noise_s={seed}_shape={'_'.join([str(s) for s in shape])}.npy"
def get_sd_image(self, seed=0, shape=(4, 3, 512, 512), fp16=False):
dtype = torch.float16 if fp16 else torch.float32
image = torch.from_numpy(load_hf_numpy(self.get_file_format(seed, shape))).to(torch_device).to(dtype)
return image
def get_sd_vae_model(self, model_id="hf-internal-testing/taesd-diffusers", fp16=False):
torch_dtype = torch.float16 if fp16 else torch.float32
model = AutoencoderTiny.from_pretrained(model_id, torch_dtype=torch_dtype)
model.to(torch_device).eval()
return model
@parameterized.expand(
[
[(1, 4, 73, 97), (1, 3, 584, 776)],
[(1, 4, 97, 73), (1, 3, 776, 584)],
[(1, 4, 49, 65), (1, 3, 392, 520)],
[(1, 4, 65, 49), (1, 3, 520, 392)],
[(1, 4, 49, 49), (1, 3, 392, 392)],
]
)
def test_tae_tiling(self, in_shape, out_shape):
model = self.get_sd_vae_model()
model.enable_tiling()
with torch.no_grad():
zeros = torch.zeros(in_shape).to(torch_device)
dec = model.decode(zeros).sample
assert dec.shape == out_shape
def test_stable_diffusion(self):
model = self.get_sd_vae_model()
image = self.get_sd_image(seed=33)
with torch.no_grad():
sample = model(image).sample
assert sample.shape == image.shape
output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
expected_output_slice = torch.tensor([0.0093, 0.6385, -0.1274, 0.1631, -0.1762, 0.5232, -0.3108, -0.0382])
assert torch_all_close(output_slice, expected_output_slice, atol=3e-3)
@parameterized.expand([(True,), (False,)])
def test_tae_roundtrip(self, enable_tiling):
# load the autoencoder
model = self.get_sd_vae_model()
if enable_tiling:
model.enable_tiling()
# make a black image with a white square in the middle,
# which is large enough to split across multiple tiles
image = -torch.ones(1, 3, 1024, 1024, device=torch_device)
image[..., 256:768, 256:768] = 1.0
# round-trip the image through the autoencoder
with torch.no_grad():
sample = model(image).sample
# the autoencoder reconstruction should match original image, sorta
def downscale(x):
return torch.nn.functional.avg_pool2d(x, model.spatial_scale_factor)
assert torch_all_close(downscale(sample), downscale(image), atol=0.125)
@slow
class AutoencoderKLIntegrationTests(unittest.TestCase):
def get_file_format(self, seed, shape):
return f"gaussian_noise_s={seed}_shape={'_'.join([str(s) for s in shape])}.npy"
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
backend_empty_cache(torch_device)
def get_sd_image(self, seed=0, shape=(4, 3, 512, 512), fp16=False):
dtype = torch.float16 if fp16 else torch.float32
image = torch.from_numpy(load_hf_numpy(self.get_file_format(seed, shape))).to(torch_device).to(dtype)
return image
def get_sd_vae_model(self, model_id="CompVis/stable-diffusion-v1-4", fp16=False):
revision = "fp16" if fp16 else None
torch_dtype = torch.float16 if fp16 else torch.float32
model = AutoencoderKL.from_pretrained(
model_id,
subfolder="vae",
torch_dtype=torch_dtype,
revision=revision,
)
model.to(torch_device)
return model
def get_generator(self, seed=0):
generator_device = "cpu" if not torch_device.startswith("cuda") else "cuda"
if torch_device != "mps":
return torch.Generator(device=generator_device).manual_seed(seed)
return torch.manual_seed(seed)
@parameterized.expand(
[
# fmt: off
[
33,
[-0.1603, 0.9878, -0.0495, -0.0790, -0.2709, 0.8375, -0.2060, -0.0824],
[-0.2395, 0.0098, 0.0102, -0.0709, -0.2840, -0.0274, -0.0718, -0.1824],
],
[
47,
[-0.2376, 0.1168, 0.1332, -0.4840, -0.2508, -0.0791, -0.0493, -0.4089],
[0.0350, 0.0847, 0.0467, 0.0344, -0.0842, -0.0547, -0.0633, -0.1131],
],
# fmt: on
]
)
def test_stable_diffusion(self, seed, expected_slice, expected_slice_mps):
model = self.get_sd_vae_model()
image = self.get_sd_image(seed)
generator = self.get_generator(seed)
with torch.no_grad():
sample = model(image, generator=generator, sample_posterior=True).sample
assert sample.shape == image.shape
output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
expected_output_slice = torch.tensor(expected_slice_mps if torch_device == "mps" else expected_slice)
assert torch_all_close(output_slice, expected_output_slice, atol=3e-3)
@parameterized.expand(
[
# fmt: off
[33, [-0.0513, 0.0289, 1.3799, 0.2166, -0.2573, -0.0871, 0.5103, -0.0999]],
[47, [-0.4128, -0.1320, -0.3704, 0.1965, -0.4116, -0.2332, -0.3340, 0.2247]],
# fmt: on
]
)
@require_torch_accelerator_with_fp16
def test_stable_diffusion_fp16(self, seed, expected_slice):
model = self.get_sd_vae_model(fp16=True)
image = self.get_sd_image(seed, fp16=True)
generator = self.get_generator(seed)
with torch.no_grad():
sample = model(image, generator=generator, sample_posterior=True).sample
assert sample.shape == image.shape
output_slice = sample[-1, -2:, :2, -2:].flatten().float().cpu()
expected_output_slice = torch.tensor(expected_slice)
assert torch_all_close(output_slice, expected_output_slice, atol=1e-2)
@parameterized.expand(
[
# fmt: off
[
33,
[-0.1609, 0.9866, -0.0487, -0.0777, -0.2716, 0.8368, -0.2055, -0.0814],
[-0.2395, 0.0098, 0.0102, -0.0709, -0.2840, -0.0274, -0.0718, -0.1824],
],
[
47,
[-0.2377, 0.1147, 0.1333, -0.4841, -0.2506, -0.0805, -0.0491, -0.4085],
[0.0350, 0.0847, 0.0467, 0.0344, -0.0842, -0.0547, -0.0633, -0.1131],
],
# fmt: on
]
)
def test_stable_diffusion_mode(self, seed, expected_slice, expected_slice_mps):
model = self.get_sd_vae_model()
image = self.get_sd_image(seed)
with torch.no_grad():
sample = model(image).sample
assert sample.shape == image.shape
output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
expected_output_slice = torch.tensor(expected_slice_mps if torch_device == "mps" else expected_slice)
assert torch_all_close(output_slice, expected_output_slice, atol=3e-3)
@parameterized.expand(
[
# fmt: off
[13, [-0.2051, -0.1803, -0.2311, -0.2114, -0.3292, -0.3574, -0.2953, -0.3323]],
[37, [-0.2632, -0.2625, -0.2199, -0.2741, -0.4539, -0.4990, -0.3720, -0.4925]],
# fmt: on
]
)
@require_torch_accelerator
@skip_mps
def test_stable_diffusion_decode(self, seed, expected_slice):
model = self.get_sd_vae_model()
encoding = self.get_sd_image(seed, shape=(3, 4, 64, 64))
with torch.no_grad():
sample = model.decode(encoding).sample
assert list(sample.shape) == [3, 3, 512, 512]
output_slice = sample[-1, -2:, :2, -2:].flatten().cpu()
expected_output_slice = torch.tensor(expected_slice)
assert torch_all_close(output_slice, expected_output_slice, atol=1e-3)
@parameterized.expand(
[
# fmt: off
[27, [-0.0369, 0.0207, -0.0776, -0.0682, -0.1747, -0.1930, -0.1465, -0.2039]],
[16, [-0.1628, -0.2134, -0.2747, -0.2642, -0.3774, -0.4404, -0.3687, -0.4277]],
# fmt: on
]
)
@require_torch_accelerator_with_fp16
def test_stable_diffusion_decode_fp16(self, seed, expected_slice):
model = self.get_sd_vae_model(fp16=True)
encoding = self.get_sd_image(seed, shape=(3, 4, 64, 64), fp16=True)
with torch.no_grad():
sample = model.decode(encoding).sample
assert list(sample.shape) == [3, 3, 512, 512]
output_slice = sample[-1, -2:, :2, -2:].flatten().float().cpu()
expected_output_slice = torch.tensor(expected_slice)
assert torch_all_close(output_slice, expected_output_slice, atol=5e-3)
@parameterized.expand([(13,), (16,), (27,)])
@require_torch_gpu
@unittest.skipIf(
not is_xformers_available(),
reason="xformers is not required when using PyTorch 2.0.",
)
def test_stable_diffusion_decode_xformers_vs_2_0_fp16(self, seed):
model = self.get_sd_vae_model(fp16=True)
encoding = self.get_sd_image(seed, shape=(3, 4, 64, 64), fp16=True)
with torch.no_grad():
sample = model.decode(encoding).sample
model.enable_xformers_memory_efficient_attention()
with torch.no_grad():
sample_2 = model.decode(encoding).sample
assert list(sample.shape) == [3, 3, 512, 512]
assert torch_all_close(sample, sample_2, atol=1e-1)
@parameterized.expand([(13,), (16,), (37,)])
@require_torch_gpu
@unittest.skipIf(
not is_xformers_available(),
reason="xformers is not required when using PyTorch 2.0.",
)
def test_stable_diffusion_decode_xformers_vs_2_0(self, seed):
model = self.get_sd_vae_model()
encoding = self.get_sd_image(seed, shape=(3, 4, 64, 64))
with torch.no_grad():
sample = model.decode(encoding).sample
model.enable_xformers_memory_efficient_attention()
with torch.no_grad():
sample_2 = model.decode(encoding).sample
assert list(sample.shape) == [3, 3, 512, 512]
assert torch_all_close(sample, sample_2, atol=1e-2)
@parameterized.expand(
[
# fmt: off
[33, [-0.3001, 0.0918, -2.6984, -3.9720, -3.2099, -5.0353, 1.7338, -0.2065, 3.4267]],
[47, [-1.5030, -4.3871, -6.0355, -9.1157, -1.6661, -2.7853, 2.1607, -5.0823, 2.5633]],
# fmt: on
]
)
def test_stable_diffusion_encode_sample(self, seed, expected_slice):
model = self.get_sd_vae_model()
image = self.get_sd_image(seed)
generator = self.get_generator(seed)
with torch.no_grad():
dist = model.encode(image).latent_dist
sample = dist.sample(generator=generator)
assert list(sample.shape) == [image.shape[0], 4] + [i // 8 for i in image.shape[2:]]
output_slice = sample[0, -1, -3:, -3:].flatten().cpu()
expected_output_slice = torch.tensor(expected_slice)
tolerance = 3e-3 if torch_device != "mps" else 1e-2
assert torch_all_close(output_slice, expected_output_slice, atol=tolerance)
def test_stable_diffusion_model_local(self):
model_id = "stabilityai/sd-vae-ft-mse"
model_1 = AutoencoderKL.from_pretrained(model_id).to(torch_device)
url = "https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors"
model_2 = AutoencoderKL.from_single_file(url).to(torch_device)
image = self.get_sd_image(33)
with torch.no_grad():
sample_1 = model_1(image).sample
sample_2 = model_2(image).sample
assert sample_1.shape == sample_2.shape
output_slice_1 = sample_1[-1, -2:, -2:, :2].flatten().float().cpu()
output_slice_2 = sample_2[-1, -2:, -2:, :2].flatten().float().cpu()
assert torch_all_close(output_slice_1, output_slice_2, atol=3e-3)
def test_single_file_component_configs(self):
vae_single_file = AutoencoderKL.from_single_file(
"https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors"
)
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
PARAMS_TO_IGNORE = ["torch_dtype", "_name_or_path", "_use_default_values"]
for param_name, param_value in vae_single_file.config.items():
if param_name in PARAMS_TO_IGNORE:
continue
assert (
vae.config[param_name] == param_value
), f"{param_name} differs between single file loading and pretrained loading"
def test_single_file_arguments(self):
vae_default = AutoencoderKL.from_single_file(
"https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors",
)
assert vae_default.config.scaling_factor == 0.18215
assert vae_default.config.sample_size == 512
assert vae_default.dtype == torch.float32
scaling_factor = 2.0
image_size = 256
torch_dtype = torch.float16
vae = AutoencoderKL.from_single_file(
"https://huggingface.co/stabilityai/sd-vae-ft-mse-original/blob/main/vae-ft-mse-840000-ema-pruned.safetensors",
image_size=image_size,
scaling_factor=scaling_factor,
torch_dtype=torch_dtype,
)
assert vae.config.scaling_factor == scaling_factor
assert vae.config.sample_size == image_size
assert vae.dtype == torch_dtype
@slow
class AsymmetricAutoencoderKLIntegrationTests(unittest.TestCase):
def get_file_format(self, seed, shape):
return f"gaussian_noise_s={seed}_shape={'_'.join([str(s) for s in shape])}.npy"
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
backend_empty_cache(torch_device)
def get_sd_image(self, seed=0, shape=(4, 3, 512, 512), fp16=False):
dtype = torch.float16 if fp16 else torch.float32
image = torch.from_numpy(load_hf_numpy(self.get_file_format(seed, shape))).to(torch_device).to(dtype)
return image
def get_sd_vae_model(self, model_id="cross-attention/asymmetric-autoencoder-kl-x-1-5", fp16=False):
revision = "main"
torch_dtype = torch.float32
model = AsymmetricAutoencoderKL.from_pretrained(
model_id,
torch_dtype=torch_dtype,
revision=revision,
)
model.to(torch_device).eval()
return model
def get_generator(self, seed=0):
generator_device = "cpu" if not torch_device.startswith("cuda") else "cuda"
if torch_device != "mps":
return torch.Generator(device=generator_device).manual_seed(seed)
return torch.manual_seed(seed)
@parameterized.expand(
[
# fmt: off
[
33,
[-0.0344, 0.2912, 0.1687, -0.0137, -0.3462, 0.3552, -0.1337, 0.1078],
[-0.1603, 0.9878, -0.0495, -0.0790, -0.2709, 0.8375, -0.2060, -0.0824],
],
[
47,
[0.4400, 0.0543, 0.2873, 0.2946, 0.0553, 0.0839, -0.1585, 0.2529],
[-0.2376, 0.1168, 0.1332, -0.4840, -0.2508, -0.0791, -0.0493, -0.4089],
],
# fmt: on
]
)
def test_stable_diffusion(self, seed, expected_slice, expected_slice_mps):
model = self.get_sd_vae_model()
image = self.get_sd_image(seed)
generator = self.get_generator(seed)
with torch.no_grad():
sample = model(image, generator=generator, sample_posterior=True).sample
assert sample.shape == image.shape
output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
expected_output_slice = torch.tensor(expected_slice_mps if torch_device == "mps" else expected_slice)
assert torch_all_close(output_slice, expected_output_slice, atol=5e-3)
@parameterized.expand(
[
# fmt: off
[
33,
[-0.0340, 0.2870, 0.1698, -0.0105, -0.3448, 0.3529, -0.1321, 0.1097],
[-0.0344, 0.2912, 0.1687, -0.0137, -0.3462, 0.3552, -0.1337, 0.1078],
],
[
47,
[0.4397, 0.0550, 0.2873, 0.2946, 0.0567, 0.0855, -0.1580, 0.2531],
[0.4397, 0.0550, 0.2873, 0.2946, 0.0567, 0.0855, -0.1580, 0.2531],
],
# fmt: on
]
)
def test_stable_diffusion_mode(self, seed, expected_slice, expected_slice_mps):
model = self.get_sd_vae_model()
image = self.get_sd_image(seed)
with torch.no_grad():
sample = model(image).sample
assert sample.shape == image.shape
output_slice = sample[-1, -2:, -2:, :2].flatten().float().cpu()
expected_output_slice = torch.tensor(expected_slice_mps if torch_device == "mps" else expected_slice)
assert torch_all_close(output_slice, expected_output_slice, atol=3e-3)
@parameterized.expand(
[
# fmt: off
[13, [-0.0521, -0.2939, 0.1540, -0.1855, -0.5936, -0.3138, -0.4579, -0.2275]],
[37, [-0.1820, -0.4345, -0.0455, -0.2923, -0.8035, -0.5089, -0.4795, -0.3106]],
# fmt: on
]
)
@require_torch_accelerator
@skip_mps
def test_stable_diffusion_decode(self, seed, expected_slice):
model = self.get_sd_vae_model()
encoding = self.get_sd_image(seed, shape=(3, 4, 64, 64))
with torch.no_grad():
sample = model.decode(encoding).sample
assert list(sample.shape) == [3, 3, 512, 512]
output_slice = sample[-1, -2:, :2, -2:].flatten().cpu()
expected_output_slice = torch.tensor(expected_slice)
assert torch_all_close(output_slice, expected_output_slice, atol=2e-3)
@parameterized.expand([(13,), (16,), (37,)])
@require_torch_gpu
@unittest.skipIf(
not is_xformers_available(),
reason="xformers is not required when using PyTorch 2.0.",
)
def test_stable_diffusion_decode_xformers_vs_2_0(self, seed):
model = self.get_sd_vae_model()
encoding = self.get_sd_image(seed, shape=(3, 4, 64, 64))
with torch.no_grad():
sample = model.decode(encoding).sample
model.enable_xformers_memory_efficient_attention()
with torch.no_grad():
sample_2 = model.decode(encoding).sample
assert list(sample.shape) == [3, 3, 512, 512]
assert torch_all_close(sample, sample_2, atol=5e-2)
@parameterized.expand(
[
# fmt: off
[33, [-0.3001, 0.0918, -2.6984, -3.9720, -3.2099, -5.0353, 1.7338, -0.2065, 3.4267]],
[47, [-1.5030, -4.3871, -6.0355, -9.1157, -1.6661, -2.7853, 2.1607, -5.0823, 2.5633]],
# fmt: on
]
)
def test_stable_diffusion_encode_sample(self, seed, expected_slice):
model = self.get_sd_vae_model()
image = self.get_sd_image(seed)
generator = self.get_generator(seed)
with torch.no_grad():
dist = model.encode(image).latent_dist
sample = dist.sample(generator=generator)
assert list(sample.shape) == [image.shape[0], 4] + [i // 8 for i in image.shape[2:]]
output_slice = sample[0, -1, -3:, -3:].flatten().cpu()
expected_output_slice = torch.tensor(expected_slice)
tolerance = 3e-3 if torch_device != "mps" else 1e-2
assert torch_all_close(output_slice, expected_output_slice, atol=tolerance)
@slow
class ConsistencyDecoderVAEIntegrationTests(unittest.TestCase):
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
@torch.no_grad()
def test_encode_decode(self):
vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder") # TODO - update
vae.to(torch_device)
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
"/img2img/sketch-mountains-input.jpg"
).resize((256, 256))
image = torch.from_numpy(np.array(image).transpose(2, 0, 1).astype(np.float32) / 127.5 - 1)[
None, :, :, :
].cuda()
latent = vae.encode(image).latent_dist.mean
sample = vae.decode(latent, generator=torch.Generator("cpu").manual_seed(0)).sample
actual_output = sample[0, :2, :2, :2].flatten().cpu()
expected_output = torch.tensor([-0.0141, -0.0014, 0.0115, 0.0086, 0.1051, 0.1053, 0.1031, 0.1024])
assert torch_all_close(actual_output, expected_output, atol=5e-3)
def test_sd(self):
vae = ConsistencyDecoderVAE.from_pretrained("openai/consistency-decoder") # TODO - update
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", vae=vae, safety_checker=None)
pipe.to(torch_device)
out = pipe(
"horse",
num_inference_steps=2,
output_type="pt",
generator=torch.Generator("cpu").manual_seed(0),
).images[0]
actual_output = out[:2, :2, :2].flatten().cpu()
expected_output = torch.tensor([0.7686, 0.8228, 0.6489, 0.7455, 0.8661, 0.8797, 0.8241, 0.8759])
assert torch_all_close(actual_output, expected_output, atol=5e-3)
def test_encode_decode_f16(self):
vae = ConsistencyDecoderVAE.from_pretrained(
"openai/consistency-decoder", torch_dtype=torch.float16
) # TODO - update
vae.to(torch_device)
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main"
"/img2img/sketch-mountains-input.jpg"
).resize((256, 256))
image = (
torch.from_numpy(np.array(image).transpose(2, 0, 1).astype(np.float32) / 127.5 - 1)[None, :, :, :]
.half()
.cuda()
)
latent = vae.encode(image).latent_dist.mean
sample = vae.decode(latent, generator=torch.Generator("cpu").manual_seed(0)).sample
actual_output = sample[0, :2, :2, :2].flatten().cpu()
expected_output = torch.tensor(
[-0.0111, -0.0125, -0.0017, -0.0007, 0.1257, 0.1465, 0.1450, 0.1471],
dtype=torch.float16,
)
assert torch_all_close(actual_output, expected_output, atol=5e-3)
def test_sd_f16(self):
vae = ConsistencyDecoderVAE.from_pretrained(
"openai/consistency-decoder", torch_dtype=torch.float16
) # TODO - update
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float16,
vae=vae,
safety_checker=None,
)
pipe.to(torch_device)
out = pipe(
"horse",
num_inference_steps=2,
output_type="pt",
generator=torch.Generator("cpu").manual_seed(0),
).images[0]
actual_output = out[:2, :2, :2].flatten().cpu()
expected_output = torch.tensor(
[0.0000, 0.0249, 0.0000, 0.0000, 0.1709, 0.2773, 0.0471, 0.1035],
dtype=torch.float16,
)
assert torch_all_close(actual_output, expected_output, atol=5e-3)
| diffusers/tests/models/autoencoders/test_models_vae.py/0 | {
"file_path": "diffusers/tests/models/autoencoders/test_models_vae.py",
"repo_id": "diffusers",
"token_count": 19066
} | 142 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import os
import tempfile
import unittest
import numpy as np
import torch
from diffusers import MotionAdapter, UNet2DConditionModel, UNetMotionModel
from diffusers.utils import logging
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.testing_utils import (
enable_full_determinism,
floats_tensor,
torch_device,
)
from ..test_modeling_common import ModelTesterMixin, UNetTesterMixin
logger = logging.get_logger(__name__)
enable_full_determinism()
class UNetMotionModelTests(ModelTesterMixin, UNetTesterMixin, unittest.TestCase):
model_class = UNetMotionModel
main_input_name = "sample"
@property
def dummy_input(self):
batch_size = 4
num_channels = 4
num_frames = 8
sizes = (32, 32)
noise = floats_tensor((batch_size, num_channels, num_frames) + sizes).to(torch_device)
time_step = torch.tensor([10]).to(torch_device)
encoder_hidden_states = floats_tensor((batch_size, 4, 32)).to(torch_device)
return {"sample": noise, "timestep": time_step, "encoder_hidden_states": encoder_hidden_states}
@property
def input_shape(self):
return (4, 8, 32, 32)
@property
def output_shape(self):
return (4, 8, 32, 32)
def prepare_init_args_and_inputs_for_common(self):
init_dict = {
"block_out_channels": (32, 64),
"down_block_types": ("CrossAttnDownBlockMotion", "DownBlockMotion"),
"up_block_types": ("UpBlockMotion", "CrossAttnUpBlockMotion"),
"cross_attention_dim": 32,
"num_attention_heads": 4,
"out_channels": 4,
"in_channels": 4,
"layers_per_block": 1,
"sample_size": 32,
}
inputs_dict = self.dummy_input
return init_dict, inputs_dict
def test_from_unet2d(self):
torch.manual_seed(0)
unet2d = UNet2DConditionModel()
torch.manual_seed(1)
model = self.model_class.from_unet2d(unet2d)
model_state_dict = model.state_dict()
for param_name, param_value in unet2d.named_parameters():
self.assertTrue(torch.equal(model_state_dict[param_name], param_value))
def test_freeze_unet2d(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict)
model.freeze_unet2d_params()
for param_name, param_value in model.named_parameters():
if "motion_modules" not in param_name:
self.assertFalse(param_value.requires_grad)
else:
self.assertTrue(param_value.requires_grad)
def test_loading_motion_adapter(self):
model = self.model_class()
adapter = MotionAdapter()
model.load_motion_modules(adapter)
for idx, down_block in enumerate(model.down_blocks):
adapter_state_dict = adapter.down_blocks[idx].motion_modules.state_dict()
for param_name, param_value in down_block.motion_modules.named_parameters():
self.assertTrue(torch.equal(adapter_state_dict[param_name], param_value))
for idx, up_block in enumerate(model.up_blocks):
adapter_state_dict = adapter.up_blocks[idx].motion_modules.state_dict()
for param_name, param_value in up_block.motion_modules.named_parameters():
self.assertTrue(torch.equal(adapter_state_dict[param_name], param_value))
mid_block_adapter_state_dict = adapter.mid_block.motion_modules.state_dict()
for param_name, param_value in model.mid_block.motion_modules.named_parameters():
self.assertTrue(torch.equal(mid_block_adapter_state_dict[param_name], param_value))
def test_saving_motion_modules(self):
torch.manual_seed(0)
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict)
model.to(torch_device)
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_motion_modules(tmpdirname)
self.assertTrue(os.path.isfile(os.path.join(tmpdirname, "diffusion_pytorch_model.safetensors")))
adapter_loaded = MotionAdapter.from_pretrained(tmpdirname)
torch.manual_seed(0)
model_loaded = self.model_class(**init_dict)
model_loaded.load_motion_modules(adapter_loaded)
model_loaded.to(torch_device)
with torch.no_grad():
output = model(**inputs_dict)[0]
output_loaded = model_loaded(**inputs_dict)[0]
max_diff = (output - output_loaded).abs().max().item()
self.assertLessEqual(max_diff, 1e-4, "Models give different forward passes")
@unittest.skipIf(
torch_device != "cuda" or not is_xformers_available(),
reason="XFormers attention is only available with CUDA and `xformers` installed",
)
def test_xformers_enable_works(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict)
model.enable_xformers_memory_efficient_attention()
assert (
model.mid_block.attentions[0].transformer_blocks[0].attn1.processor.__class__.__name__
== "XFormersAttnProcessor"
), "xformers is not enabled"
def test_gradient_checkpointing_is_applied(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model_class_copy = copy.copy(self.model_class)
modules_with_gc_enabled = {}
# now monkey patch the following function:
# def _set_gradient_checkpointing(self, module, value=False):
# if hasattr(module, "gradient_checkpointing"):
# module.gradient_checkpointing = value
def _set_gradient_checkpointing_new(self, module, value=False):
if hasattr(module, "gradient_checkpointing"):
module.gradient_checkpointing = value
modules_with_gc_enabled[module.__class__.__name__] = True
model_class_copy._set_gradient_checkpointing = _set_gradient_checkpointing_new
model = model_class_copy(**init_dict)
model.enable_gradient_checkpointing()
EXPECTED_SET = {
"CrossAttnUpBlockMotion",
"CrossAttnDownBlockMotion",
"UNetMidBlockCrossAttnMotion",
"UpBlockMotion",
"Transformer2DModel",
"DownBlockMotion",
}
assert set(modules_with_gc_enabled.keys()) == EXPECTED_SET
assert all(modules_with_gc_enabled.values()), "All modules should be enabled"
def test_feed_forward_chunking(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
init_dict["norm_num_groups"] = 32
model = self.model_class(**init_dict)
model.to(torch_device)
model.eval()
with torch.no_grad():
output = model(**inputs_dict)[0]
model.enable_forward_chunking()
with torch.no_grad():
output_2 = model(**inputs_dict)[0]
self.assertEqual(output.shape, output_2.shape, "Shape doesn't match")
assert np.abs(output.cpu() - output_2.cpu()).max() < 1e-2
def test_pickle(self):
# enable deterministic behavior for gradient checkpointing
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
model = self.model_class(**init_dict)
model.to(torch_device)
with torch.no_grad():
sample = model(**inputs_dict).sample
sample_copy = copy.copy(sample)
assert (sample - sample_copy).abs().max() < 1e-4
def test_from_save_pretrained(self, expected_max_diff=5e-5):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
torch.manual_seed(0)
model = self.model_class(**init_dict)
model.to(torch_device)
model.eval()
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname, safe_serialization=False)
torch.manual_seed(0)
new_model = self.model_class.from_pretrained(tmpdirname)
new_model.to(torch_device)
with torch.no_grad():
image = model(**inputs_dict)
if isinstance(image, dict):
image = image.to_tuple()[0]
new_image = new_model(**inputs_dict)
if isinstance(new_image, dict):
new_image = new_image.to_tuple()[0]
max_diff = (image - new_image).abs().max().item()
self.assertLessEqual(max_diff, expected_max_diff, "Models give different forward passes")
def test_from_save_pretrained_variant(self, expected_max_diff=5e-5):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
torch.manual_seed(0)
model = self.model_class(**init_dict)
model.to(torch_device)
model.eval()
with tempfile.TemporaryDirectory() as tmpdirname:
model.save_pretrained(tmpdirname, variant="fp16", safe_serialization=False)
torch.manual_seed(0)
new_model = self.model_class.from_pretrained(tmpdirname, variant="fp16")
# non-variant cannot be loaded
with self.assertRaises(OSError) as error_context:
self.model_class.from_pretrained(tmpdirname)
# make sure that error message states what keys are missing
assert "Error no file named diffusion_pytorch_model.bin found in directory" in str(error_context.exception)
new_model.to(torch_device)
with torch.no_grad():
image = model(**inputs_dict)
if isinstance(image, dict):
image = image.to_tuple()[0]
new_image = new_model(**inputs_dict)
if isinstance(new_image, dict):
new_image = new_image.to_tuple()[0]
max_diff = (image - new_image).abs().max().item()
self.assertLessEqual(max_diff, expected_max_diff, "Models give different forward passes")
def test_forward_with_norm_groups(self):
init_dict, inputs_dict = self.prepare_init_args_and_inputs_for_common()
init_dict["norm_num_groups"] = 16
init_dict["block_out_channels"] = (16, 32)
model = self.model_class(**init_dict)
model.to(torch_device)
model.eval()
with torch.no_grad():
output = model(**inputs_dict)
if isinstance(output, dict):
output = output.to_tuple()[0]
self.assertIsNotNone(output)
expected_shape = inputs_dict["sample"].shape
self.assertEqual(output.shape, expected_shape, "Input and output shapes do not match")
| diffusers/tests/models/unets/test_models_unet_motion.py/0 | {
"file_path": "diffusers/tests/models/unets/test_models_unet_motion.py",
"repo_id": "diffusers",
"token_count": 4946
} | 143 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import tempfile
import traceback
import unittest
import numpy as np
import torch
from transformers import CLIPTextConfig, CLIPTextModel, CLIPTokenizer
from diffusers import (
AutoencoderKL,
ControlNetModel,
DDIMScheduler,
EulerDiscreteScheduler,
LCMScheduler,
StableDiffusionControlNetPipeline,
UNet2DConditionModel,
)
from diffusers.pipelines.controlnet.pipeline_controlnet import MultiControlNetModel
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.testing_utils import (
enable_full_determinism,
load_image,
load_numpy,
numpy_cosine_similarity_distance,
require_python39_or_higher,
require_torch_2,
require_torch_gpu,
run_test_in_subprocess,
slow,
torch_device,
)
from diffusers.utils.torch_utils import randn_tensor
from ..pipeline_params import (
IMAGE_TO_IMAGE_IMAGE_PARAMS,
TEXT_TO_IMAGE_BATCH_PARAMS,
TEXT_TO_IMAGE_IMAGE_PARAMS,
TEXT_TO_IMAGE_PARAMS,
)
from ..test_pipelines_common import (
IPAdapterTesterMixin,
PipelineKarrasSchedulerTesterMixin,
PipelineLatentTesterMixin,
PipelineTesterMixin,
)
enable_full_determinism()
# Will be run via run_test_in_subprocess
def _test_stable_diffusion_compile(in_queue, out_queue, timeout):
error = None
try:
_ = in_queue.get(timeout=timeout)
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.to("cuda")
pipe.set_progress_bar_config(disable=None)
pipe.unet.to(memory_format=torch.channels_last)
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
pipe.controlnet.to(memory_format=torch.channels_last)
pipe.controlnet = torch.compile(pipe.controlnet, mode="reduce-overhead", fullgraph=True)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "bird"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
).resize((512, 512))
output = pipe(prompt, image, num_inference_steps=10, generator=generator, output_type="np")
image = output.images[0]
assert image.shape == (512, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny_out_full.npy"
)
expected_image = np.resize(expected_image, (512, 512, 3))
assert np.abs(expected_image - image).max() < 1.0
except Exception:
error = f"{traceback.format_exc()}"
results = {"error": error}
out_queue.put(results, timeout=timeout)
out_queue.join()
class ControlNetPipelineFastTests(
IPAdapterTesterMixin,
PipelineLatentTesterMixin,
PipelineKarrasSchedulerTesterMixin,
PipelineTesterMixin,
unittest.TestCase,
):
pipeline_class = StableDiffusionControlNetPipeline
params = TEXT_TO_IMAGE_PARAMS
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
image_params = IMAGE_TO_IMAGE_IMAGE_PARAMS
image_latents_params = TEXT_TO_IMAGE_IMAGE_PARAMS
def get_dummy_components(self, time_cond_proj_dim=None):
torch.manual_seed(0)
unet = UNet2DConditionModel(
block_out_channels=(4, 8),
layers_per_block=2,
sample_size=32,
in_channels=4,
out_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
cross_attention_dim=32,
norm_num_groups=1,
time_cond_proj_dim=time_cond_proj_dim,
)
torch.manual_seed(0)
controlnet = ControlNetModel(
block_out_channels=(4, 8),
layers_per_block=2,
in_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
cross_attention_dim=32,
conditioning_embedding_out_channels=(16, 32),
norm_num_groups=1,
)
torch.manual_seed(0)
scheduler = DDIMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
)
torch.manual_seed(0)
vae = AutoencoderKL(
block_out_channels=[4, 8],
in_channels=3,
out_channels=3,
down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
latent_channels=4,
norm_num_groups=2,
)
torch.manual_seed(0)
text_encoder_config = CLIPTextConfig(
bos_token_id=0,
eos_token_id=2,
hidden_size=32,
intermediate_size=37,
layer_norm_eps=1e-05,
num_attention_heads=4,
num_hidden_layers=5,
pad_token_id=1,
vocab_size=1000,
)
text_encoder = CLIPTextModel(text_encoder_config)
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
components = {
"unet": unet,
"controlnet": controlnet,
"scheduler": scheduler,
"vae": vae,
"text_encoder": text_encoder,
"tokenizer": tokenizer,
"safety_checker": None,
"feature_extractor": None,
"image_encoder": None,
}
return components
def get_dummy_inputs(self, device, seed=0):
if str(device).startswith("mps"):
generator = torch.manual_seed(seed)
else:
generator = torch.Generator(device=device).manual_seed(seed)
controlnet_embedder_scale_factor = 2
image = randn_tensor(
(1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
generator=generator,
device=torch.device(device),
)
inputs = {
"prompt": "A painting of a squirrel eating a burger",
"generator": generator,
"num_inference_steps": 2,
"guidance_scale": 6.0,
"output_type": "np",
"image": image,
}
return inputs
def test_attention_slicing_forward_pass(self):
return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
@unittest.skipIf(
torch_device != "cuda" or not is_xformers_available(),
reason="XFormers attention is only available with CUDA and `xformers` installed",
)
def test_xformers_attention_forwardGenerator_pass(self):
self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
def test_inference_batch_single_identical(self):
self._test_inference_batch_single_identical(expected_max_diff=2e-3)
def test_controlnet_lcm(self):
device = "cpu" # ensure determinism for the device-dependent torch.Generator
components = self.get_dummy_components(time_cond_proj_dim=256)
sd_pipe = StableDiffusionControlNetPipeline(**components)
sd_pipe.scheduler = LCMScheduler.from_config(sd_pipe.scheduler.config)
sd_pipe = sd_pipe.to(torch_device)
sd_pipe.set_progress_bar_config(disable=None)
inputs = self.get_dummy_inputs(device)
output = sd_pipe(**inputs)
image = output.images
image_slice = image[0, -3:, -3:, -1]
assert image.shape == (1, 64, 64, 3)
expected_slice = np.array(
[0.52700454, 0.3930534, 0.25509018, 0.7132304, 0.53696585, 0.46568912, 0.7095368, 0.7059624, 0.4744786]
)
assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
def test_controlnet_lcm_custom_timesteps(self):
device = "cpu" # ensure determinism for the device-dependent torch.Generator
components = self.get_dummy_components(time_cond_proj_dim=256)
sd_pipe = StableDiffusionControlNetPipeline(**components)
sd_pipe.scheduler = LCMScheduler.from_config(sd_pipe.scheduler.config)
sd_pipe = sd_pipe.to(torch_device)
sd_pipe.set_progress_bar_config(disable=None)
inputs = self.get_dummy_inputs(device)
del inputs["num_inference_steps"]
inputs["timesteps"] = [999, 499]
output = sd_pipe(**inputs)
image = output.images
image_slice = image[0, -3:, -3:, -1]
assert image.shape == (1, 64, 64, 3)
expected_slice = np.array(
[0.52700454, 0.3930534, 0.25509018, 0.7132304, 0.53696585, 0.46568912, 0.7095368, 0.7059624, 0.4744786]
)
assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
class StableDiffusionMultiControlNetPipelineFastTests(
IPAdapterTesterMixin, PipelineTesterMixin, PipelineKarrasSchedulerTesterMixin, unittest.TestCase
):
pipeline_class = StableDiffusionControlNetPipeline
params = TEXT_TO_IMAGE_PARAMS
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
image_params = frozenset([]) # TO_DO: add image_params once refactored VaeImageProcessor.preprocess
def get_dummy_components(self):
torch.manual_seed(0)
unet = UNet2DConditionModel(
block_out_channels=(4, 8),
layers_per_block=2,
sample_size=32,
in_channels=4,
out_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
cross_attention_dim=32,
norm_num_groups=1,
)
torch.manual_seed(0)
def init_weights(m):
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.normal_(m.weight)
m.bias.data.fill_(1.0)
controlnet1 = ControlNetModel(
block_out_channels=(4, 8),
layers_per_block=2,
in_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
cross_attention_dim=32,
conditioning_embedding_out_channels=(16, 32),
norm_num_groups=1,
)
controlnet1.controlnet_down_blocks.apply(init_weights)
torch.manual_seed(0)
controlnet2 = ControlNetModel(
block_out_channels=(4, 8),
layers_per_block=2,
in_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
cross_attention_dim=32,
conditioning_embedding_out_channels=(16, 32),
norm_num_groups=1,
)
controlnet2.controlnet_down_blocks.apply(init_weights)
torch.manual_seed(0)
scheduler = DDIMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
)
torch.manual_seed(0)
vae = AutoencoderKL(
block_out_channels=[4, 8],
in_channels=3,
out_channels=3,
down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
latent_channels=4,
norm_num_groups=2,
)
torch.manual_seed(0)
text_encoder_config = CLIPTextConfig(
bos_token_id=0,
eos_token_id=2,
hidden_size=32,
intermediate_size=37,
layer_norm_eps=1e-05,
num_attention_heads=4,
num_hidden_layers=5,
pad_token_id=1,
vocab_size=1000,
)
text_encoder = CLIPTextModel(text_encoder_config)
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
controlnet = MultiControlNetModel([controlnet1, controlnet2])
components = {
"unet": unet,
"controlnet": controlnet,
"scheduler": scheduler,
"vae": vae,
"text_encoder": text_encoder,
"tokenizer": tokenizer,
"safety_checker": None,
"feature_extractor": None,
"image_encoder": None,
}
return components
def get_dummy_inputs(self, device, seed=0):
if str(device).startswith("mps"):
generator = torch.manual_seed(seed)
else:
generator = torch.Generator(device=device).manual_seed(seed)
controlnet_embedder_scale_factor = 2
images = [
randn_tensor(
(1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
generator=generator,
device=torch.device(device),
),
randn_tensor(
(1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
generator=generator,
device=torch.device(device),
),
]
inputs = {
"prompt": "A painting of a squirrel eating a burger",
"generator": generator,
"num_inference_steps": 2,
"guidance_scale": 6.0,
"output_type": "np",
"image": images,
}
return inputs
def test_control_guidance_switch(self):
components = self.get_dummy_components()
pipe = self.pipeline_class(**components)
pipe.to(torch_device)
scale = 10.0
steps = 4
inputs = self.get_dummy_inputs(torch_device)
inputs["num_inference_steps"] = steps
inputs["controlnet_conditioning_scale"] = scale
output_1 = pipe(**inputs)[0]
inputs = self.get_dummy_inputs(torch_device)
inputs["num_inference_steps"] = steps
inputs["controlnet_conditioning_scale"] = scale
output_2 = pipe(**inputs, control_guidance_start=0.1, control_guidance_end=0.2)[0]
inputs = self.get_dummy_inputs(torch_device)
inputs["num_inference_steps"] = steps
inputs["controlnet_conditioning_scale"] = scale
output_3 = pipe(**inputs, control_guidance_start=[0.1, 0.3], control_guidance_end=[0.2, 0.7])[0]
inputs = self.get_dummy_inputs(torch_device)
inputs["num_inference_steps"] = steps
inputs["controlnet_conditioning_scale"] = scale
output_4 = pipe(**inputs, control_guidance_start=0.4, control_guidance_end=[0.5, 0.8])[0]
# make sure that all outputs are different
assert np.sum(np.abs(output_1 - output_2)) > 1e-3
assert np.sum(np.abs(output_1 - output_3)) > 1e-3
assert np.sum(np.abs(output_1 - output_4)) > 1e-3
def test_attention_slicing_forward_pass(self):
return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
@unittest.skipIf(
torch_device != "cuda" or not is_xformers_available(),
reason="XFormers attention is only available with CUDA and `xformers` installed",
)
def test_xformers_attention_forwardGenerator_pass(self):
self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
def test_inference_batch_single_identical(self):
self._test_inference_batch_single_identical(expected_max_diff=2e-3)
def test_save_pretrained_raise_not_implemented_exception(self):
components = self.get_dummy_components()
pipe = self.pipeline_class(**components)
pipe.to(torch_device)
pipe.set_progress_bar_config(disable=None)
with tempfile.TemporaryDirectory() as tmpdir:
try:
# save_pretrained is not implemented for Multi-ControlNet
pipe.save_pretrained(tmpdir)
except NotImplementedError:
pass
def test_inference_multiple_prompt_input(self):
device = "cpu"
components = self.get_dummy_components()
sd_pipe = StableDiffusionControlNetPipeline(**components)
sd_pipe = sd_pipe.to(torch_device)
sd_pipe.set_progress_bar_config(disable=None)
inputs = self.get_dummy_inputs(device)
inputs["prompt"] = [inputs["prompt"], inputs["prompt"]]
inputs["image"] = [inputs["image"], inputs["image"]]
output = sd_pipe(**inputs)
image = output.images
assert image.shape == (2, 64, 64, 3)
image_1, image_2 = image
# make sure that the outputs are different
assert np.sum(np.abs(image_1 - image_2)) > 1e-3
# multiple prompts, single image conditioning
inputs = self.get_dummy_inputs(device)
inputs["prompt"] = [inputs["prompt"], inputs["prompt"]]
output_1 = sd_pipe(**inputs)
assert np.abs(image - output_1.images).max() < 1e-3
class StableDiffusionMultiControlNetOneModelPipelineFastTests(
IPAdapterTesterMixin, PipelineTesterMixin, PipelineKarrasSchedulerTesterMixin, unittest.TestCase
):
pipeline_class = StableDiffusionControlNetPipeline
params = TEXT_TO_IMAGE_PARAMS
batch_params = TEXT_TO_IMAGE_BATCH_PARAMS
image_params = frozenset([]) # TO_DO: add image_params once refactored VaeImageProcessor.preprocess
def get_dummy_components(self):
torch.manual_seed(0)
unet = UNet2DConditionModel(
block_out_channels=(4, 8),
layers_per_block=2,
sample_size=32,
in_channels=4,
out_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
up_block_types=("CrossAttnUpBlock2D", "UpBlock2D"),
cross_attention_dim=32,
norm_num_groups=1,
)
torch.manual_seed(0)
def init_weights(m):
if isinstance(m, torch.nn.Conv2d):
torch.nn.init.normal_(m.weight)
m.bias.data.fill_(1.0)
controlnet = ControlNetModel(
block_out_channels=(4, 8),
layers_per_block=2,
in_channels=4,
down_block_types=("DownBlock2D", "CrossAttnDownBlock2D"),
cross_attention_dim=32,
conditioning_embedding_out_channels=(16, 32),
norm_num_groups=1,
)
controlnet.controlnet_down_blocks.apply(init_weights)
torch.manual_seed(0)
scheduler = DDIMScheduler(
beta_start=0.00085,
beta_end=0.012,
beta_schedule="scaled_linear",
clip_sample=False,
set_alpha_to_one=False,
)
torch.manual_seed(0)
vae = AutoencoderKL(
block_out_channels=[4, 8],
in_channels=3,
out_channels=3,
down_block_types=["DownEncoderBlock2D", "DownEncoderBlock2D"],
up_block_types=["UpDecoderBlock2D", "UpDecoderBlock2D"],
latent_channels=4,
norm_num_groups=2,
)
torch.manual_seed(0)
text_encoder_config = CLIPTextConfig(
bos_token_id=0,
eos_token_id=2,
hidden_size=32,
intermediate_size=37,
layer_norm_eps=1e-05,
num_attention_heads=4,
num_hidden_layers=5,
pad_token_id=1,
vocab_size=1000,
)
text_encoder = CLIPTextModel(text_encoder_config)
tokenizer = CLIPTokenizer.from_pretrained("hf-internal-testing/tiny-random-clip")
controlnet = MultiControlNetModel([controlnet])
components = {
"unet": unet,
"controlnet": controlnet,
"scheduler": scheduler,
"vae": vae,
"text_encoder": text_encoder,
"tokenizer": tokenizer,
"safety_checker": None,
"feature_extractor": None,
"image_encoder": None,
}
return components
def get_dummy_inputs(self, device, seed=0):
if str(device).startswith("mps"):
generator = torch.manual_seed(seed)
else:
generator = torch.Generator(device=device).manual_seed(seed)
controlnet_embedder_scale_factor = 2
images = [
randn_tensor(
(1, 3, 32 * controlnet_embedder_scale_factor, 32 * controlnet_embedder_scale_factor),
generator=generator,
device=torch.device(device),
),
]
inputs = {
"prompt": "A painting of a squirrel eating a burger",
"generator": generator,
"num_inference_steps": 2,
"guidance_scale": 6.0,
"output_type": "np",
"image": images,
}
return inputs
def test_control_guidance_switch(self):
components = self.get_dummy_components()
pipe = self.pipeline_class(**components)
pipe.to(torch_device)
scale = 10.0
steps = 4
inputs = self.get_dummy_inputs(torch_device)
inputs["num_inference_steps"] = steps
inputs["controlnet_conditioning_scale"] = scale
output_1 = pipe(**inputs)[0]
inputs = self.get_dummy_inputs(torch_device)
inputs["num_inference_steps"] = steps
inputs["controlnet_conditioning_scale"] = scale
output_2 = pipe(**inputs, control_guidance_start=0.1, control_guidance_end=0.2)[0]
inputs = self.get_dummy_inputs(torch_device)
inputs["num_inference_steps"] = steps
inputs["controlnet_conditioning_scale"] = scale
output_3 = pipe(
**inputs,
control_guidance_start=[0.1],
control_guidance_end=[0.2],
)[0]
inputs = self.get_dummy_inputs(torch_device)
inputs["num_inference_steps"] = steps
inputs["controlnet_conditioning_scale"] = scale
output_4 = pipe(**inputs, control_guidance_start=0.4, control_guidance_end=[0.5])[0]
# make sure that all outputs are different
assert np.sum(np.abs(output_1 - output_2)) > 1e-3
assert np.sum(np.abs(output_1 - output_3)) > 1e-3
assert np.sum(np.abs(output_1 - output_4)) > 1e-3
def test_attention_slicing_forward_pass(self):
return self._test_attention_slicing_forward_pass(expected_max_diff=2e-3)
@unittest.skipIf(
torch_device != "cuda" or not is_xformers_available(),
reason="XFormers attention is only available with CUDA and `xformers` installed",
)
def test_xformers_attention_forwardGenerator_pass(self):
self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=2e-3)
def test_inference_batch_single_identical(self):
self._test_inference_batch_single_identical(expected_max_diff=2e-3)
def test_save_pretrained_raise_not_implemented_exception(self):
components = self.get_dummy_components()
pipe = self.pipeline_class(**components)
pipe.to(torch_device)
pipe.set_progress_bar_config(disable=None)
with tempfile.TemporaryDirectory() as tmpdir:
try:
# save_pretrained is not implemented for Multi-ControlNet
pipe.save_pretrained(tmpdir)
except NotImplementedError:
pass
@slow
@require_torch_gpu
class ControlNetPipelineSlowTests(unittest.TestCase):
def tearDown(self):
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def test_canny(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "bird"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
)
output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (768, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny_out.npy"
)
assert np.abs(expected_image - image).max() < 9e-2
def test_depth(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-depth")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "Stormtrooper's lecture"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/stormtrooper_depth.png"
)
output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (512, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/stormtrooper_depth_out.npy"
)
assert np.abs(expected_image - image).max() < 8e-1
def test_hed(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-hed")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "oil painting of handsome old man, masterpiece"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/man_hed.png"
)
output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (704, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/man_hed_out.npy"
)
assert np.abs(expected_image - image).max() < 8e-2
def test_mlsd(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-mlsd")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "room"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/room_mlsd.png"
)
output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (704, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/room_mlsd_out.npy"
)
assert np.abs(expected_image - image).max() < 5e-2
def test_normal(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-normal")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "cute toy"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/cute_toy_normal.png"
)
output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (512, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/cute_toy_normal_out.npy"
)
assert np.abs(expected_image - image).max() < 5e-2
def test_openpose(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "Chef in the kitchen"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/pose.png"
)
output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (768, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/chef_pose_out.npy"
)
assert np.abs(expected_image - image).max() < 8e-2
def test_scribble(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-scribble")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(5)
prompt = "bag"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bag_scribble.png"
)
output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (640, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bag_scribble_out.npy"
)
assert np.abs(expected_image - image).max() < 8e-2
def test_seg(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-seg")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(5)
prompt = "house"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/house_seg.png"
)
output = pipe(prompt, image, generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (512, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/house_seg_out.npy"
)
assert np.abs(expected_image - image).max() < 8e-2
def test_sequential_cpu_offloading(self):
torch.cuda.empty_cache()
torch.cuda.reset_max_memory_allocated()
torch.cuda.reset_peak_memory_stats()
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-seg")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.set_progress_bar_config(disable=None)
pipe.enable_attention_slicing()
pipe.enable_sequential_cpu_offload()
prompt = "house"
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/house_seg.png"
)
_ = pipe(
prompt,
image,
num_inference_steps=2,
output_type="np",
)
mem_bytes = torch.cuda.max_memory_allocated()
# make sure that less than 7 GB is allocated
assert mem_bytes < 4 * 10**9
def test_canny_guess_mode(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = ""
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
)
output = pipe(
prompt,
image,
generator=generator,
output_type="np",
num_inference_steps=3,
guidance_scale=3.0,
guess_mode=True,
)
image = output.images[0]
assert image.shape == (768, 512, 3)
image_slice = image[-3:, -3:, -1]
expected_slice = np.array([0.2724, 0.2846, 0.2724, 0.3843, 0.3682, 0.2736, 0.4675, 0.3862, 0.2887])
assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
def test_canny_guess_mode_euler(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = ""
image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
)
output = pipe(
prompt,
image,
generator=generator,
output_type="np",
num_inference_steps=3,
guidance_scale=3.0,
guess_mode=True,
)
image = output.images[0]
assert image.shape == (768, 512, 3)
image_slice = image[-3:, -3:, -1]
expected_slice = np.array([0.1655, 0.1721, 0.1623, 0.1685, 0.1711, 0.1646, 0.1651, 0.1631, 0.1494])
assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
@require_python39_or_higher
@require_torch_2
def test_stable_diffusion_compile(self):
run_test_in_subprocess(test_case=self, target_func=_test_stable_diffusion_compile, inputs=None)
def test_v11_shuffle_global_pool_conditions(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11e_sd15_shuffle")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "New York"
image = load_image(
"https://huggingface.co/lllyasviel/control_v11e_sd15_shuffle/resolve/main/images/control.png"
)
output = pipe(
prompt,
image,
generator=generator,
output_type="np",
num_inference_steps=3,
guidance_scale=7.0,
)
image = output.images[0]
assert image.shape == (512, 640, 3)
image_slice = image[-3:, -3:, -1]
expected_slice = np.array([0.1338, 0.1597, 0.1202, 0.1687, 0.1377, 0.1017, 0.2070, 0.1574, 0.1348])
assert np.abs(image_slice.flatten() - expected_slice).max() < 1e-2
def test_load_local(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_canny")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=controlnet
)
pipe.unet.set_default_attn_processor()
pipe.enable_model_cpu_offload()
controlnet = ControlNetModel.from_single_file(
"https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11p_sd15_canny.pth"
)
pipe_sf = StableDiffusionControlNetPipeline.from_single_file(
"https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/v1-5-pruned-emaonly.safetensors",
safety_checker=None,
controlnet=controlnet,
scheduler_type="pndm",
)
pipe_sf.unet.set_default_attn_processor()
pipe_sf.enable_model_cpu_offload()
control_image = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
).resize((512, 512))
prompt = "bird"
generator = torch.Generator(device="cpu").manual_seed(0)
output = pipe(
prompt,
image=control_image,
generator=generator,
output_type="np",
num_inference_steps=3,
).images[0]
generator = torch.Generator(device="cpu").manual_seed(0)
output_sf = pipe_sf(
prompt,
image=control_image,
generator=generator,
output_type="np",
num_inference_steps=3,
).images[0]
max_diff = numpy_cosine_similarity_distance(output_sf.flatten(), output.flatten())
assert max_diff < 1e-3
def test_single_file_component_configs(self):
controlnet = ControlNetModel.from_pretrained("lllyasviel/control_v11p_sd15_canny", variant="fp16")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", variant="fp16", safety_checker=None, controlnet=controlnet
)
controlnet_single_file = ControlNetModel.from_single_file(
"https://huggingface.co/lllyasviel/ControlNet-v1-1/blob/main/control_v11p_sd15_canny.pth"
)
single_file_pipe = StableDiffusionControlNetPipeline.from_single_file(
"https://huggingface.co/runwayml/stable-diffusion-v1-5/blob/main/v1-5-pruned-emaonly.safetensors",
safety_checker=None,
controlnet=controlnet_single_file,
scheduler_type="pndm",
)
PARAMS_TO_IGNORE = ["torch_dtype", "_name_or_path", "architectures", "_use_default_values"]
for param_name, param_value in single_file_pipe.controlnet.config.items():
if param_name in PARAMS_TO_IGNORE:
continue
# This parameter doesn't appear to be loaded from the config.
# So when it is registered to config, it remains a tuple as this is the default in the class definition
# from_pretrained, does load from config and converts to a list when registering to config
if param_name == "conditioning_embedding_out_channels" and isinstance(param_value, tuple):
param_value = list(param_value)
assert (
pipe.controlnet.config[param_name] == param_value
), f"{param_name} differs between single file loading and pretrained loading"
for param_name, param_value in single_file_pipe.unet.config.items():
if param_name in PARAMS_TO_IGNORE:
continue
assert (
pipe.unet.config[param_name] == param_value
), f"{param_name} differs between single file loading and pretrained loading"
for param_name, param_value in single_file_pipe.vae.config.items():
if param_name in PARAMS_TO_IGNORE:
continue
assert (
pipe.vae.config[param_name] == param_value
), f"{param_name} differs between single file loading and pretrained loading"
@slow
@require_torch_gpu
class StableDiffusionMultiControlNetPipelineSlowTests(unittest.TestCase):
def tearDown(self):
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def test_pose_and_canny(self):
controlnet_canny = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-canny")
controlnet_pose = ControlNetModel.from_pretrained("lllyasviel/sd-controlnet-openpose")
pipe = StableDiffusionControlNetPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5", safety_checker=None, controlnet=[controlnet_pose, controlnet_canny]
)
pipe.enable_model_cpu_offload()
pipe.set_progress_bar_config(disable=None)
generator = torch.Generator(device="cpu").manual_seed(0)
prompt = "bird and Chef"
image_canny = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/bird_canny.png"
)
image_pose = load_image(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/pose.png"
)
output = pipe(prompt, [image_pose, image_canny], generator=generator, output_type="np", num_inference_steps=3)
image = output.images[0]
assert image.shape == (768, 512, 3)
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/sd_controlnet/pose_canny_out.npy"
)
assert np.abs(expected_image - image).max() < 5e-2
| diffusers/tests/pipelines/controlnet/test_controlnet.py/0 | {
"file_path": "diffusers/tests/pipelines/controlnet/test_controlnet.py",
"repo_id": "diffusers",
"token_count": 20126
} | 144 |
# coding=utf-8
# Copyright 2024 HuggingFace Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import gc
import random
import unittest
import torch
from diffusers import IFImg2ImgPipeline
from diffusers.models.attention_processor import AttnAddedKVProcessor
from diffusers.utils.import_utils import is_xformers_available
from diffusers.utils.testing_utils import floats_tensor, load_numpy, require_torch_gpu, skip_mps, slow, torch_device
from ..pipeline_params import (
TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS,
TEXT_GUIDED_IMAGE_VARIATION_PARAMS,
)
from ..test_pipelines_common import PipelineTesterMixin, assert_mean_pixel_difference
from . import IFPipelineTesterMixin
@skip_mps
class IFImg2ImgPipelineFastTests(PipelineTesterMixin, IFPipelineTesterMixin, unittest.TestCase):
pipeline_class = IFImg2ImgPipeline
params = TEXT_GUIDED_IMAGE_VARIATION_PARAMS - {"width", "height"}
batch_params = TEXT_GUIDED_IMAGE_VARIATION_BATCH_PARAMS
required_optional_params = PipelineTesterMixin.required_optional_params - {"latents"}
def get_dummy_components(self):
return self._get_dummy_components()
def get_dummy_inputs(self, device, seed=0):
if str(device).startswith("mps"):
generator = torch.manual_seed(seed)
else:
generator = torch.Generator(device=device).manual_seed(seed)
image = floats_tensor((1, 3, 32, 32), rng=random.Random(seed)).to(device)
inputs = {
"prompt": "A painting of a squirrel eating a burger",
"image": image,
"generator": generator,
"num_inference_steps": 2,
"output_type": "np",
}
return inputs
def test_save_load_optional_components(self):
self._test_save_load_optional_components()
@unittest.skipIf(
torch_device != "cuda" or not is_xformers_available(),
reason="XFormers attention is only available with CUDA and `xformers` installed",
)
def test_xformers_attention_forwardGenerator_pass(self):
self._test_xformers_attention_forwardGenerator_pass(expected_max_diff=1e-3)
@unittest.skipIf(torch_device != "cuda", reason="float16 requires CUDA")
def test_save_load_float16(self):
# Due to non-determinism in save load of the hf-internal-testing/tiny-random-t5 text encoder
super().test_save_load_float16(expected_max_diff=1e-1)
@unittest.skipIf(torch_device != "cuda", reason="float16 requires CUDA")
def test_float16_inference(self):
super().test_float16_inference(expected_max_diff=1e-1)
def test_attention_slicing_forward_pass(self):
self._test_attention_slicing_forward_pass(expected_max_diff=1e-2)
def test_save_load_local(self):
self._test_save_load_local()
def test_inference_batch_single_identical(self):
self._test_inference_batch_single_identical(
expected_max_diff=1e-2,
)
@slow
@require_torch_gpu
class IFImg2ImgPipelineSlowTests(unittest.TestCase):
def tearDown(self):
# clean up the VRAM after each test
super().tearDown()
gc.collect()
torch.cuda.empty_cache()
def test_if_img2img(self):
pipe = IFImg2ImgPipeline.from_pretrained(
"DeepFloyd/IF-I-L-v1.0",
variant="fp16",
torch_dtype=torch.float16,
)
pipe.unet.set_attn_processor(AttnAddedKVProcessor())
pipe.enable_model_cpu_offload()
image = floats_tensor((1, 3, 64, 64), rng=random.Random(0)).to(torch_device)
generator = torch.Generator(device="cpu").manual_seed(0)
output = pipe(
prompt="anime turtle",
image=image,
num_inference_steps=2,
generator=generator,
output_type="np",
)
image = output.images[0]
mem_bytes = torch.cuda.max_memory_allocated()
assert mem_bytes < 12 * 10**9
expected_image = load_numpy(
"https://huggingface.co/datasets/hf-internal-testing/diffusers-images/resolve/main/if/test_if_img2img.npy"
)
assert_mean_pixel_difference(image, expected_image)
pipe.remove_all_hooks()
| diffusers/tests/pipelines/deepfloyd_if/test_if_img2img.py/0 | {
"file_path": "diffusers/tests/pipelines/deepfloyd_if/test_if_img2img.py",
"repo_id": "diffusers",
"token_count": 1947
} | 145 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.